KR20220045980A - 체외 감마 델타 t 세포 집단 - Google Patents
체외 감마 델타 t 세포 집단 Download PDFInfo
- Publication number
- KR20220045980A KR20220045980A KR1020227008249A KR20227008249A KR20220045980A KR 20220045980 A KR20220045980 A KR 20220045980A KR 1020227008249 A KR1020227008249 A KR 1020227008249A KR 20227008249 A KR20227008249 A KR 20227008249A KR 20220045980 A KR20220045980 A KR 20220045980A
- Authority
- KR
- South Korea
- Prior art keywords
- cells
- seq
- antibody
- sequence
- fragment
- Prior art date
Links
- 238000000338 in vitro Methods 0.000 title claims abstract description 23
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 title description 8
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 404
- 239000012634 fragment Substances 0.000 claims abstract description 299
- 238000000034 method Methods 0.000 claims abstract description 172
- 210000004027 cell Anatomy 0.000 claims description 505
- 241000282414 Homo sapiens Species 0.000 claims description 202
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 147
- 108091008874 T cell receptors Proteins 0.000 claims description 100
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 100
- 230000027455 binding Effects 0.000 claims description 96
- 238000009739 binding Methods 0.000 claims description 96
- 125000000539 amino acid group Chemical group 0.000 claims description 72
- 210000001519 tissue Anatomy 0.000 claims description 69
- 238000012258 culturing Methods 0.000 claims description 60
- 206010028980 Neoplasm Diseases 0.000 claims description 58
- 102000004127 Cytokines Human genes 0.000 claims description 46
- 108090000695 Cytokines Proteins 0.000 claims description 46
- 230000003394 haemopoietic effect Effects 0.000 claims description 43
- 102000003812 Interleukin-15 Human genes 0.000 claims description 40
- 108090000172 Interleukin-15 Proteins 0.000 claims description 40
- 201000011510 cancer Diseases 0.000 claims description 35
- 230000035755 proliferation Effects 0.000 claims description 35
- 210000003491 skin Anatomy 0.000 claims description 29
- 108010002350 Interleukin-2 Proteins 0.000 claims description 25
- 102000000588 Interleukin-2 Human genes 0.000 claims description 25
- 239000003814 drug Substances 0.000 claims description 25
- 239000001963 growth medium Substances 0.000 claims description 22
- 102000004388 Interleukin-4 Human genes 0.000 claims description 20
- 108090000978 Interleukin-4 Proteins 0.000 claims description 20
- 229940028885 interleukin-4 Drugs 0.000 claims description 20
- 239000000203 mixture Substances 0.000 claims description 19
- 239000008194 pharmaceutical composition Substances 0.000 claims description 17
- 238000011282 treatment Methods 0.000 claims description 17
- 102100030704 Interleukin-21 Human genes 0.000 claims description 16
- 108010074108 interleukin-21 Proteins 0.000 claims description 16
- 108010002335 Interleukin-9 Proteins 0.000 claims description 14
- 102000000585 Interleukin-9 Human genes 0.000 claims description 14
- 229940118526 interleukin-9 Drugs 0.000 claims description 14
- 108010002586 Interleukin-7 Proteins 0.000 claims description 12
- 102000000704 Interleukin-7 Human genes 0.000 claims description 12
- 229940100994 interleukin-7 Drugs 0.000 claims description 12
- 108010074328 Interferon-gamma Proteins 0.000 claims description 11
- 239000012679 serum free medium Substances 0.000 claims description 11
- 102100037850 Interferon gamma Human genes 0.000 claims description 10
- 208000015181 infectious disease Diseases 0.000 claims description 9
- 210000000822 natural killer cell Anatomy 0.000 claims description 9
- 208000035473 Communicable disease Diseases 0.000 claims description 7
- 230000003213 activating effect Effects 0.000 claims description 7
- 108700041286 delta Proteins 0.000 claims description 7
- 210000002950 fibroblast Anatomy 0.000 claims description 7
- 208000027866 inflammatory disease Diseases 0.000 claims description 7
- 210000005259 peripheral blood Anatomy 0.000 claims description 7
- 239000011886 peripheral blood Substances 0.000 claims description 7
- 210000002536 stromal cell Anatomy 0.000 claims description 7
- 210000004881 tumor cell Anatomy 0.000 claims description 7
- 108010065805 Interleukin-12 Proteins 0.000 claims description 6
- 102000013462 Interleukin-12 Human genes 0.000 claims description 6
- 229940117681 interleukin-12 Drugs 0.000 claims description 6
- 210000000936 intestine Anatomy 0.000 claims description 6
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 claims description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 claims description 6
- 210000002307 prostate Anatomy 0.000 claims description 5
- 210000001165 lymph node Anatomy 0.000 claims description 4
- 210000001185 bone marrow Anatomy 0.000 claims description 3
- 210000001072 colon Anatomy 0.000 claims description 3
- 210000002919 epithelial cell Anatomy 0.000 claims description 3
- 210000004700 fetal blood Anatomy 0.000 claims description 3
- 210000004185 liver Anatomy 0.000 claims description 3
- 210000004072 lung Anatomy 0.000 claims description 3
- 210000003563 lymphoid tissue Anatomy 0.000 claims description 3
- 210000005087 mononuclear cell Anatomy 0.000 claims description 3
- 210000000496 pancreas Anatomy 0.000 claims description 3
- 210000001541 thymus gland Anatomy 0.000 claims description 3
- 210000004291 uterus Anatomy 0.000 claims description 3
- 210000005075 mammary gland Anatomy 0.000 claims description 2
- 210000002151 serous membrane Anatomy 0.000 claims description 2
- 210000000952 spleen Anatomy 0.000 claims description 2
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 133
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 110
- 239000000523 sample Substances 0.000 description 101
- 102000036639 antigens Human genes 0.000 description 71
- 108091007433 antigens Proteins 0.000 description 71
- 239000000427 antigen Substances 0.000 description 70
- 235000001014 amino acid Nutrition 0.000 description 67
- 108090000765 processed proteins & peptides Proteins 0.000 description 54
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 53
- 102000004196 processed proteins & peptides Human genes 0.000 description 49
- 102000040430 polynucleotide Human genes 0.000 description 44
- 108091033319 polynucleotide Proteins 0.000 description 44
- 239000002157 polynucleotide Substances 0.000 description 44
- 108090000623 proteins and genes Proteins 0.000 description 43
- 229920001184 polypeptide Polymers 0.000 description 40
- 241000880493 Leptailurus serval Species 0.000 description 38
- 239000002609 medium Substances 0.000 description 36
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 33
- 238000004458 analytical method Methods 0.000 description 33
- 150000001413 amino acids Chemical class 0.000 description 32
- 108010089804 glycyl-threonine Proteins 0.000 description 32
- 235000018102 proteins Nutrition 0.000 description 32
- 238000003556 assay Methods 0.000 description 31
- 239000013604 expression vector Substances 0.000 description 31
- 102000004169 proteins and genes Human genes 0.000 description 31
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 29
- 238000002955 isolation Methods 0.000 description 29
- 229940027941 immunoglobulin g Drugs 0.000 description 26
- 239000013598 vector Substances 0.000 description 26
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 25
- 108010073969 valyllysine Proteins 0.000 description 25
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 23
- 108010068265 aspartyltyrosine Proteins 0.000 description 23
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 22
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 22
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 22
- 108010081404 acein-2 Proteins 0.000 description 22
- 238000002474 experimental method Methods 0.000 description 22
- 238000006467 substitution reaction Methods 0.000 description 22
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 21
- 108020004414 DNA Proteins 0.000 description 21
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 21
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 20
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 20
- 210000004698 lymphocyte Anatomy 0.000 description 20
- 108010026333 seryl-proline Proteins 0.000 description 20
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 19
- 108010065920 Insulin Lispro Proteins 0.000 description 19
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 19
- 238000000684 flow cytometry Methods 0.000 description 19
- 230000006870 function Effects 0.000 description 19
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 18
- 108060003951 Immunoglobulin Proteins 0.000 description 18
- 102000018358 immunoglobulin Human genes 0.000 description 18
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 17
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 17
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 17
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 17
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 17
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 17
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 17
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 17
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 17
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 17
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 17
- 239000003102 growth factor Substances 0.000 description 17
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 17
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 16
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 16
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 16
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 16
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 16
- 108010008355 arginyl-glutamine Proteins 0.000 description 16
- 230000000694 effects Effects 0.000 description 16
- 238000002703 mutagenesis Methods 0.000 description 16
- 231100000350 mutagenesis Toxicity 0.000 description 16
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 16
- 210000002966 serum Anatomy 0.000 description 16
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 15
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 15
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 15
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 15
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 15
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 15
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 15
- 238000007792 addition Methods 0.000 description 15
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 15
- 210000004369 blood Anatomy 0.000 description 15
- 239000008280 blood Substances 0.000 description 15
- 239000012636 effector Substances 0.000 description 15
- 108010017391 lysylvaline Proteins 0.000 description 15
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 14
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 14
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 14
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 14
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 14
- 230000008859 change Effects 0.000 description 14
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 13
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 13
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 13
- 241001465754 Metazoa Species 0.000 description 13
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 13
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 13
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 13
- 230000004048 modification Effects 0.000 description 13
- 238000012986 modification Methods 0.000 description 13
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 13
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 12
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 12
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 12
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 12
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 12
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 12
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 12
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 12
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 12
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 12
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 12
- 201000010099 disease Diseases 0.000 description 12
- 230000002998 immunogenetic effect Effects 0.000 description 12
- 238000011534 incubation Methods 0.000 description 12
- 108010003137 tyrosyltyrosine Proteins 0.000 description 12
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 11
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 11
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 11
- -1 IL 4 Proteins 0.000 description 11
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 11
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 11
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 11
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 11
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 11
- 238000001514 detection method Methods 0.000 description 11
- 238000005516 engineering process Methods 0.000 description 11
- 230000002147 killing effect Effects 0.000 description 11
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 10
- 102100027207 CD27 antigen Human genes 0.000 description 10
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 10
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 10
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 10
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 10
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 10
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 10
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 10
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 10
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 10
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 10
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 10
- UBTNVMGPMYDYIU-HJPIBITLSA-N Ser-Tyr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UBTNVMGPMYDYIU-HJPIBITLSA-N 0.000 description 10
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 10
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 10
- 230000000052 comparative effect Effects 0.000 description 10
- 238000012217 deletion Methods 0.000 description 10
- 230000037430 deletion Effects 0.000 description 10
- 230000003828 downregulation Effects 0.000 description 10
- 239000000975 dye Substances 0.000 description 10
- 210000004602 germ cell Anatomy 0.000 description 10
- 238000013507 mapping Methods 0.000 description 10
- 238000002823 phage display Methods 0.000 description 10
- 230000002062 proliferating effect Effects 0.000 description 10
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 9
- OGZBJJLRKQZRHL-KJEVXHAQSA-N Arg-Thr-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OGZBJJLRKQZRHL-KJEVXHAQSA-N 0.000 description 9
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 9
- 102000019034 Chemokines Human genes 0.000 description 9
- 108010012236 Chemokines Proteins 0.000 description 9
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 9
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 9
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 9
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 9
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 9
- HYLNRGXEQACDKG-NYVOZVTQSA-N Trp-Asn-Trp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HYLNRGXEQACDKG-NYVOZVTQSA-N 0.000 description 9
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 9
- 238000010367 cloning Methods 0.000 description 9
- 230000001965 increasing effect Effects 0.000 description 9
- 239000013641 positive control Substances 0.000 description 9
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 9
- KVWLTGNCJYDJET-LSJOCFKGSA-N Ala-Arg-His Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KVWLTGNCJYDJET-LSJOCFKGSA-N 0.000 description 8
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 8
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 8
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 8
- NJIKKGUVGUBICV-ZLUOBGJFSA-N Asp-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O NJIKKGUVGUBICV-ZLUOBGJFSA-N 0.000 description 8
- 238000002965 ELISA Methods 0.000 description 8
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 8
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 8
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 8
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 8
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 8
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 8
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 8
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 8
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 8
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 8
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 8
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 8
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 8
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 8
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 8
- 230000004913 activation Effects 0.000 description 8
- 108010011559 alanylphenylalanine Proteins 0.000 description 8
- 239000002299 complementary DNA Substances 0.000 description 8
- 108010010147 glycylglutamine Proteins 0.000 description 8
- 210000004408 hybridoma Anatomy 0.000 description 8
- 239000003226 mitogen Substances 0.000 description 8
- 102000039446 nucleic acids Human genes 0.000 description 8
- 108020004707 nucleic acids Proteins 0.000 description 8
- 150000007523 nucleic acids Chemical class 0.000 description 8
- 238000002360 preparation method Methods 0.000 description 8
- 108010038745 tryptophylglycine Proteins 0.000 description 8
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 7
- NECWUSYTYSIFNC-DLOVCJGASA-N Asp-Ala-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 NECWUSYTYSIFNC-DLOVCJGASA-N 0.000 description 7
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 7
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 7
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 7
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 7
- OQCXTUQTKQFDCX-HTUGSXCWSA-N Thr-Glu-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O OQCXTUQTKQFDCX-HTUGSXCWSA-N 0.000 description 7
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 7
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 7
- 230000000890 antigenic effect Effects 0.000 description 7
- 239000011230 binding agent Substances 0.000 description 7
- 210000004899 c-terminal region Anatomy 0.000 description 7
- 230000030833 cell death Effects 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 7
- 238000010494 dissociation reaction Methods 0.000 description 7
- 230000005593 dissociations Effects 0.000 description 7
- 239000012091 fetal bovine serum Substances 0.000 description 7
- 239000000833 heterodimer Substances 0.000 description 7
- 230000002401 inhibitory effect Effects 0.000 description 7
- 239000013642 negative control Substances 0.000 description 7
- 108010051242 phenylalanylserine Proteins 0.000 description 7
- 239000013612 plasmid Substances 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 230000004083 survival effect Effects 0.000 description 7
- 238000012360 testing method Methods 0.000 description 7
- 238000013519 translation Methods 0.000 description 7
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 6
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 6
- QDGMZAOSMNGBLP-MRFFXTKBSA-N Ala-Trp-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N QDGMZAOSMNGBLP-MRFFXTKBSA-N 0.000 description 6
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 6
- DATSKXOXPUAOLK-KKUMJFAQSA-N Asn-Tyr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DATSKXOXPUAOLK-KKUMJFAQSA-N 0.000 description 6
- UZNSWMFLKVKJLI-VHWLVUOQSA-N Asp-Ile-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O UZNSWMFLKVKJLI-VHWLVUOQSA-N 0.000 description 6
- 108090000317 Chymotrypsin Proteins 0.000 description 6
- YZCKVEUIGOORGS-OUBTZVSYSA-N Deuterium Chemical group [2H] YZCKVEUIGOORGS-OUBTZVSYSA-N 0.000 description 6
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 6
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 6
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 6
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 6
- WKSHBPRUIRGWRZ-KCTSRDHCSA-N Ile-Trp-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N WKSHBPRUIRGWRZ-KCTSRDHCSA-N 0.000 description 6
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 6
- NROQVSYLPRLJIP-PMVMPFDFSA-N Lys-Trp-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NROQVSYLPRLJIP-PMVMPFDFSA-N 0.000 description 6
- 108010067372 Pancreatic elastase Proteins 0.000 description 6
- 102000016387 Pancreatic elastase Human genes 0.000 description 6
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 6
- 108010076504 Protein Sorting Signals Proteins 0.000 description 6
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 6
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 6
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 6
- 101150006914 TRP1 gene Proteins 0.000 description 6
- 108090001109 Thermolysin Proteins 0.000 description 6
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 6
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 6
- 108090000631 Trypsin Proteins 0.000 description 6
- 102000004142 Trypsin Human genes 0.000 description 6
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 6
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 6
- 108010087924 alanylproline Proteins 0.000 description 6
- 108010092854 aspartyllysine Proteins 0.000 description 6
- 230000037396 body weight Effects 0.000 description 6
- 230000003833 cell viability Effects 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 229960002376 chymotrypsin Drugs 0.000 description 6
- 230000034994 death Effects 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 229910052805 deuterium Inorganic materials 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 229940088598 enzyme Drugs 0.000 description 6
- 230000012010 growth Effects 0.000 description 6
- 108010018006 histidylserine Proteins 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 239000002773 nucleotide Substances 0.000 description 6
- 125000003729 nucleotide group Chemical group 0.000 description 6
- 108010031719 prolyl-serine Proteins 0.000 description 6
- 230000017854 proteolysis Effects 0.000 description 6
- 238000000746 purification Methods 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- 239000012588 trypsin Substances 0.000 description 6
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 5
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 5
- 102000004190 Enzymes Human genes 0.000 description 5
- 108090000790 Enzymes Proteins 0.000 description 5
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 5
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 5
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 5
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 5
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 5
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 5
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 5
- 241000282412 Homo Species 0.000 description 5
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 5
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 5
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 5
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 5
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 5
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 5
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 5
- 108010085220 Multiprotein Complexes Proteins 0.000 description 5
- 102000007474 Multiprotein Complexes Human genes 0.000 description 5
- 241000699666 Mus <mouse, genus> Species 0.000 description 5
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 5
- BKWJQWJPZMUWEG-LFSVMHDDSA-N Phe-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BKWJQWJPZMUWEG-LFSVMHDDSA-N 0.000 description 5
- 206010035226 Plasma cell myeloma Diseases 0.000 description 5
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 5
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 5
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 5
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 5
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 5
- NRUPKQSXTJNQGD-XGEHTFHBSA-N Thr-Cys-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NRUPKQSXTJNQGD-XGEHTFHBSA-N 0.000 description 5
- CXPJPTFWKXNDKV-NUTKFTJISA-N Trp-Leu-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CXPJPTFWKXNDKV-NUTKFTJISA-N 0.000 description 5
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 5
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 5
- 235000004279 alanine Nutrition 0.000 description 5
- 230000000735 allogeneic effect Effects 0.000 description 5
- 230000006907 apoptotic process Effects 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000000903 blocking effect Effects 0.000 description 5
- 208000035475 disorder Diseases 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 5
- 238000002372 labelling Methods 0.000 description 5
- 239000003446 ligand Substances 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 201000000050 myeloid neoplasm Diseases 0.000 description 5
- 239000002953 phosphate buffered saline Substances 0.000 description 5
- 230000001766 physiological effect Effects 0.000 description 5
- 230000000644 propagated effect Effects 0.000 description 5
- 238000000159 protein binding assay Methods 0.000 description 5
- 230000028327 secretion Effects 0.000 description 5
- 238000001542 size-exclusion chromatography Methods 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 238000004885 tandem mass spectrometry Methods 0.000 description 5
- 229940124597 therapeutic agent Drugs 0.000 description 5
- 239000004474 valine Substances 0.000 description 5
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 4
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 4
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 4
- PAXHINASXXXILC-SRVKXCTJSA-N Asn-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)O PAXHINASXXXILC-SRVKXCTJSA-N 0.000 description 4
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 4
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 4
- 108010008951 Chemokine CXCL12 Proteins 0.000 description 4
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 4
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 4
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 4
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 4
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 4
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 4
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- 102000015696 Interleukins Human genes 0.000 description 4
- 108010063738 Interleukins Proteins 0.000 description 4
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 4
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 4
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 4
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 4
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 4
- 208000006265 Renal cell carcinoma Diseases 0.000 description 4
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 4
- KJKQUQXDEKMPDK-FXQIFTODSA-N Ser-Met-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O KJKQUQXDEKMPDK-FXQIFTODSA-N 0.000 description 4
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 4
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 4
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 4
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 4
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 4
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 4
- BURPTJBFWIOHEY-UWJYBYFXSA-N Tyr-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BURPTJBFWIOHEY-UWJYBYFXSA-N 0.000 description 4
- RMRFSFXLFWWAJZ-HJOGWXRNSA-N Tyr-Tyr-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 RMRFSFXLFWWAJZ-HJOGWXRNSA-N 0.000 description 4
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 238000001574 biopsy Methods 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 210000000481 breast Anatomy 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 238000002659 cell therapy Methods 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 239000007850 fluorescent dye Substances 0.000 description 4
- 238000007710 freezing Methods 0.000 description 4
- 230000008014 freezing Effects 0.000 description 4
- 108010078144 glutaminyl-glycine Proteins 0.000 description 4
- 210000002865 immune cell Anatomy 0.000 description 4
- 210000000987 immune system Anatomy 0.000 description 4
- 238000003018 immunoassay Methods 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 108010029020 prolylglycine Proteins 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 108010009962 valyltyrosine Proteins 0.000 description 4
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 3
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 3
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 3
- IPWKGIFRRBGCJO-IMJSIDKUSA-N Ala-Ser Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](CO)C([O-])=O IPWKGIFRRBGCJO-IMJSIDKUSA-N 0.000 description 3
- QTAIIXQCOPUNBQ-QXEWZRGKSA-N Arg-Val-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QTAIIXQCOPUNBQ-QXEWZRGKSA-N 0.000 description 3
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 3
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 3
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 3
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 3
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 3
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 3
- ROHVCXBMIAAASL-HJGDQZAQSA-N Gln-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)N)N)O ROHVCXBMIAAASL-HJGDQZAQSA-N 0.000 description 3
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 3
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 3
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 3
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 3
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 3
- RXKFKJVJVHLRIE-XIRDDKMYSA-N His-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC3=CN=CN3)N RXKFKJVJVHLRIE-XIRDDKMYSA-N 0.000 description 3
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 3
- CISBRYJZMFWOHJ-JBDRJPRFSA-N Ile-Ala-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N CISBRYJZMFWOHJ-JBDRJPRFSA-N 0.000 description 3
- UWBDLNOCIDGPQE-GUBZILKMSA-N Ile-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN UWBDLNOCIDGPQE-GUBZILKMSA-N 0.000 description 3
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 3
- 108090000171 Interleukin-18 Proteins 0.000 description 3
- 102000003810 Interleukin-18 Human genes 0.000 description 3
- 108010067003 Interleukin-33 Proteins 0.000 description 3
- 102000017761 Interleukin-33 Human genes 0.000 description 3
- 102000004889 Interleukin-6 Human genes 0.000 description 3
- 108090001005 Interleukin-6 Proteins 0.000 description 3
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 3
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 3
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 3
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- RFEXGCASCQGGHZ-STQMWFEESA-N Phe-Gly-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O RFEXGCASCQGGHZ-STQMWFEESA-N 0.000 description 3
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 3
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 3
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 3
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 3
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 3
- YXHYJEPDKSYPSQ-AVGNSLFASA-N Pro-Leu-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 YXHYJEPDKSYPSQ-AVGNSLFASA-N 0.000 description 3
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 3
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 3
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 3
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 3
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 3
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- 230000006044 T cell activation Effects 0.000 description 3
- 230000006052 T cell proliferation Effects 0.000 description 3
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 3
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 3
- NLWDSYKZUPRMBJ-IEGACIPQSA-N Thr-Trp-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O NLWDSYKZUPRMBJ-IEGACIPQSA-N 0.000 description 3
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 3
- SGQSAIFDESQBRA-IHPCNDPISA-N Trp-Tyr-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SGQSAIFDESQBRA-IHPCNDPISA-N 0.000 description 3
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 3
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 3
- 239000013543 active substance Substances 0.000 description 3
- 150000001412 amines Chemical class 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 239000011324 bead Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 108010054813 diprotin B Proteins 0.000 description 3
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 3
- 239000012737 fresh medium Substances 0.000 description 3
- 230000033581 fucosylation Effects 0.000 description 3
- 238000002825 functional assay Methods 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 230000013595 glycosylation Effects 0.000 description 3
- 238000006206 glycosylation reaction Methods 0.000 description 3
- 239000000710 homodimer Substances 0.000 description 3
- 229910052739 hydrogen Inorganic materials 0.000 description 3
- 239000001257 hydrogen Substances 0.000 description 3
- 230000028993 immune response Effects 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 229940100601 interleukin-6 Drugs 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 238000003127 radioimmunoassay Methods 0.000 description 3
- 238000003259 recombinant expression Methods 0.000 description 3
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 3
- 238000002741 site-directed mutagenesis Methods 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 3
- 230000035899 viability Effects 0.000 description 3
- 239000013603 viral vector Substances 0.000 description 3
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 2
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 2
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 2
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 2
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 2
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 2
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 2
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 2
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 2
- APKFDSVGJQXUKY-KKGHZKTASA-N Amphotericin-B Natural products O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1C=CC=CC=CC=CC=CC=CC=C[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-KKGHZKTASA-N 0.000 description 2
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 2
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 2
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 2
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 2
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 2
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 2
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 2
- IOTKDTZEEBZNCM-UGYAYLCHSA-N Asn-Asn-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOTKDTZEEBZNCM-UGYAYLCHSA-N 0.000 description 2
- KXEGPPNPXOKKHK-ZLUOBGJFSA-N Asn-Asp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KXEGPPNPXOKKHK-ZLUOBGJFSA-N 0.000 description 2
- JZDZLBJVYWIIQU-AVGNSLFASA-N Asn-Glu-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JZDZLBJVYWIIQU-AVGNSLFASA-N 0.000 description 2
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 2
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 2
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 2
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 2
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 2
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 2
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 2
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- PHEDXBVPIONUQT-UHFFFAOYSA-N Cocarcinogen A1 Natural products CCCCCCCCCCCCCC(=O)OC1C(C)C2(O)C3C=C(C)C(=O)C3(O)CC(CO)=CC2C2C1(OC(C)=O)C2(C)C PHEDXBVPIONUQT-UHFFFAOYSA-N 0.000 description 2
- 108010035532 Collagen Proteins 0.000 description 2
- 102000008186 Collagen Human genes 0.000 description 2
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 2
- 241000699800 Cricetinae Species 0.000 description 2
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 2
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 2
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 108010087819 Fc receptors Proteins 0.000 description 2
- 102000009109 Fc receptors Human genes 0.000 description 2
- 241000724791 Filamentous phage Species 0.000 description 2
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 2
- WMOMPXKOKASNBK-PEFMBERDSA-N Gln-Asn-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WMOMPXKOKASNBK-PEFMBERDSA-N 0.000 description 2
- LVNILKSSFHCSJZ-IHRRRGAJSA-N Gln-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LVNILKSSFHCSJZ-IHRRRGAJSA-N 0.000 description 2
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 2
- NNXIQPMZGZUFJJ-AVGNSLFASA-N Gln-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N NNXIQPMZGZUFJJ-AVGNSLFASA-N 0.000 description 2
- LVRKAFPPFJRIOF-GARJFASQSA-N Gln-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N LVRKAFPPFJRIOF-GARJFASQSA-N 0.000 description 2
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 2
- VDMABHYXBULDGN-LAEOZQHASA-N Gln-Val-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O VDMABHYXBULDGN-LAEOZQHASA-N 0.000 description 2
- FTMLQFPULNGION-ZVZYQTTQSA-N Gln-Val-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O FTMLQFPULNGION-ZVZYQTTQSA-N 0.000 description 2
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 2
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 2
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 2
- ATVYZJGOZLVXDK-IUCAKERBSA-N Glu-Leu-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O ATVYZJGOZLVXDK-IUCAKERBSA-N 0.000 description 2
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 2
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 2
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 2
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 2
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 2
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 2
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 2
- BXDLTKLPPKBVEL-FJXKBIBVSA-N Gly-Thr-Met Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O BXDLTKLPPKBVEL-FJXKBIBVSA-N 0.000 description 2
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 2
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 2
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 2
- 102000001398 Granzyme Human genes 0.000 description 2
- 108060005986 Granzyme Proteins 0.000 description 2
- ALPXXNRQBMRCPZ-MEYUZBJRSA-N His-Thr-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ALPXXNRQBMRCPZ-MEYUZBJRSA-N 0.000 description 2
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 description 2
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 2
- 101000939740 Homo sapiens Probable non-functional T cell receptor gamma variable 11 Proteins 0.000 description 2
- 101000649128 Homo sapiens T cell receptor delta variable 1 Proteins 0.000 description 2
- 101000649129 Homo sapiens T cell receptor delta variable 2 Proteins 0.000 description 2
- 101000680678 Homo sapiens T cell receptor gamma variable 4 Proteins 0.000 description 2
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 2
- KFVUBLZRFSVDGO-BYULHYEWSA-N Ile-Gly-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O KFVUBLZRFSVDGO-BYULHYEWSA-N 0.000 description 2
- BBQABUDWDUKJMB-LZXPERKUSA-N Ile-Ile-Ile Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C([O-])=O BBQABUDWDUKJMB-LZXPERKUSA-N 0.000 description 2
- QQFSKBMCAKWHLG-UHFFFAOYSA-N Ile-Phe-Pro-Pro Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(NC(=O)C(N)C(C)CC)CC1=CC=CC=C1 QQFSKBMCAKWHLG-UHFFFAOYSA-N 0.000 description 2
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 2
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 2
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 102100037852 Insulin-like growth factor I Human genes 0.000 description 2
- 108090001007 Interleukin-8 Proteins 0.000 description 2
- 102000004890 Interleukin-8 Human genes 0.000 description 2
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- 102000007330 LDL Lipoproteins Human genes 0.000 description 2
- 108010007622 LDL Lipoproteins Proteins 0.000 description 2
- YSKSXVKQLLBVEX-SZMVWBNQSA-N Leu-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 YSKSXVKQLLBVEX-SZMVWBNQSA-N 0.000 description 2
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 2
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 2
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 2
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 2
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 2
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 2
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 2
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 2
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- JOSAKOKSPXROGQ-BJDJZHNGSA-N Lys-Ser-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JOSAKOKSPXROGQ-BJDJZHNGSA-N 0.000 description 2
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 2
- GVKINWYYLOLEFQ-XIRDDKMYSA-N Lys-Trp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O GVKINWYYLOLEFQ-XIRDDKMYSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- GHQFLTYXGUETFD-UFYCRDLUSA-N Met-Tyr-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N GHQFLTYXGUETFD-UFYCRDLUSA-N 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 2
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 2
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 2
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 2
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 2
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 2
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 2
- 108010047620 Phytohemagglutinins Proteins 0.000 description 2
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 2
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 2
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 2
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 2
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 2
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 2
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 2
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 2
- 102100029686 Probable non-functional T cell receptor gamma variable 11 Human genes 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 2
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 2
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 2
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 2
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 2
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 2
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 2
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 2
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 2
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 2
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 2
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 2
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 2
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 2
- GZGFSPWOMUKKCV-NAKRPEOUSA-N Ser-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO GZGFSPWOMUKKCV-NAKRPEOUSA-N 0.000 description 2
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 2
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 2
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 2
- OJFFAQFRCVPHNN-JYBASQMISA-N Ser-Thr-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OJFFAQFRCVPHNN-JYBASQMISA-N 0.000 description 2
- ZWSZBWAFDZRBNM-UBHSHLNASA-N Ser-Trp-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O ZWSZBWAFDZRBNM-UBHSHLNASA-N 0.000 description 2
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 2
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 2
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 2
- 108700005078 Synthetic Genes Proteins 0.000 description 2
- 102100027949 T cell receptor delta variable 1 Human genes 0.000 description 2
- 102100027948 T cell receptor delta variable 2 Human genes 0.000 description 2
- 102100022392 T cell receptor gamma variable 4 Human genes 0.000 description 2
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 2
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 2
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 2
- UNURFMVMXLENAZ-KJEVXHAQSA-N Thr-Arg-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UNURFMVMXLENAZ-KJEVXHAQSA-N 0.000 description 2
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 2
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 2
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 2
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 2
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 2
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 2
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 2
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 2
- 101710120037 Toxin CcdB Proteins 0.000 description 2
- DXDMNBJJEXYMLA-UBHSHLNASA-N Trp-Asn-Asp Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 DXDMNBJJEXYMLA-UBHSHLNASA-N 0.000 description 2
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 2
- KIMOCKLJBXHFIN-YLVFBTJISA-N Trp-Ile-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O)=CNC2=C1 KIMOCKLJBXHFIN-YLVFBTJISA-N 0.000 description 2
- LVTKHGUGBGNBPL-UHFFFAOYSA-N Trp-P-1 Chemical compound N1C2=CC=CC=C2C2=C1C(C)=C(N)N=C2C LVTKHGUGBGNBPL-UHFFFAOYSA-N 0.000 description 2
- UJGDFQRPYGJBEH-AAEUAGOBSA-N Trp-Ser-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N UJGDFQRPYGJBEH-AAEUAGOBSA-N 0.000 description 2
- GSCPHMSPGQSZJT-JYBASQMISA-N Trp-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O GSCPHMSPGQSZJT-JYBASQMISA-N 0.000 description 2
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 2
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 2
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 2
- XYBNMHRFAUKPAW-IHRRRGAJSA-N Tyr-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XYBNMHRFAUKPAW-IHRRRGAJSA-N 0.000 description 2
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 2
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 2
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 2
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 2
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 2
- 230000001594 aberrant effect Effects 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 238000003314 affinity selection Methods 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- APKFDSVGJQXUKY-INPOYWNPSA-N amphotericin B Chemical compound O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 APKFDSVGJQXUKY-INPOYWNPSA-N 0.000 description 2
- 229960003942 amphotericin b Drugs 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 2
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 2
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 239000007640 basal medium Substances 0.000 description 2
- 108091006004 biotinylated proteins Proteins 0.000 description 2
- 210000001772 blood platelet Anatomy 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 150000001720 carbohydrates Chemical group 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 230000022534 cell killing Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 229920001436 collagen Polymers 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 239000003431 cross linking reagent Substances 0.000 description 2
- 230000003013 cytotoxicity Effects 0.000 description 2
- 231100000135 cytotoxicity Toxicity 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 231100000655 enterotoxin Toxicity 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 239000003797 essential amino acid Substances 0.000 description 2
- 235000020776 essential amino acid Nutrition 0.000 description 2
- 210000001035 gastrointestinal tract Anatomy 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 2
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 2
- 108010084389 glycyltryptophan Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 238000003306 harvesting Methods 0.000 description 2
- 238000004896 high resolution mass spectrometry Methods 0.000 description 2
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 239000002955 immunomodulating agent Substances 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000002757 inflammatory effect Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 102000006495 integrins Human genes 0.000 description 2
- 108010044426 integrins Proteins 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 210000000214 mouth Anatomy 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 2
- 230000001885 phytohemagglutinin Effects 0.000 description 2
- 229910052697 platinum Inorganic materials 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 230000035752 proliferative phase Effects 0.000 description 2
- 238000002818 protein evolution Methods 0.000 description 2
- 229940043131 pyroglutamate Drugs 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000002702 ribosome display Methods 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000010186 staining Methods 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 238000010254 subcutaneous injection Methods 0.000 description 2
- 239000007929 subcutaneous injection Substances 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 238000010257 thawing Methods 0.000 description 2
- 231100001274 therapeutic index Toxicity 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 229910052721 tungsten Inorganic materials 0.000 description 2
- 108010020532 tyrosyl-proline Proteins 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 238000010200 validation analysis Methods 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 1
- LOGFVTREOLYCPF-KXNHARMFSA-N (2s,3r)-2-[[(2r)-1-[(2s)-2,6-diaminohexanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxybutanoic acid Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-KXNHARMFSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- IUVCFHHAEHNCFT-INIZCTEOSA-N 2-[(1s)-1-[4-amino-3-(3-fluoro-4-propan-2-yloxyphenyl)pyrazolo[3,4-d]pyrimidin-1-yl]ethyl]-6-fluoro-3-(3-fluorophenyl)chromen-4-one Chemical compound C1=C(F)C(OC(C)C)=CC=C1C(C1=C(N)N=CN=C11)=NN1[C@@H](C)C1=C(C=2C=C(F)C=CC=2)C(=O)C2=CC(F)=CC=C2O1 IUVCFHHAEHNCFT-INIZCTEOSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- LSLIRHLIUDVNBN-CIUDSAMLSA-N Ala-Asp-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LSLIRHLIUDVNBN-CIUDSAMLSA-N 0.000 description 1
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 1
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- KQESEZXHYOUIIM-CQDKDKBSSA-N Ala-Lys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KQESEZXHYOUIIM-CQDKDKBSSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- BEXGZLUHRXTZCC-CIUDSAMLSA-N Arg-Gln-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N BEXGZLUHRXTZCC-CIUDSAMLSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- ADPACBMPYWJJCE-FXQIFTODSA-N Arg-Ser-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O ADPACBMPYWJJCE-FXQIFTODSA-N 0.000 description 1
- WTFIFQWLQXZLIZ-UMPQAUOISA-N Arg-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O WTFIFQWLQXZLIZ-UMPQAUOISA-N 0.000 description 1
- QCTOLCVIGRLMQS-HRCADAONSA-N Arg-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O QCTOLCVIGRLMQS-HRCADAONSA-N 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 1
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 1
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- FANGHKQYFPYDNB-UBHSHLNASA-N Asn-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N FANGHKQYFPYDNB-UBHSHLNASA-N 0.000 description 1
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 1
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 1
- NVWJMQNYLYWVNQ-BYULHYEWSA-N Asn-Ile-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O NVWJMQNYLYWVNQ-BYULHYEWSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- SONUFGRSSMFHFN-IMJSIDKUSA-N Asn-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(O)=O SONUFGRSSMFHFN-IMJSIDKUSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- DPSUVAPLRQDWAO-YDHLFZDLSA-N Asn-Tyr-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)N)N DPSUVAPLRQDWAO-YDHLFZDLSA-N 0.000 description 1
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 1
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- YRBGRUOSJROZEI-NHCYSSNCSA-N Asp-His-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O YRBGRUOSJROZEI-NHCYSSNCSA-N 0.000 description 1
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 1
- KLYPOCBLKMPBIQ-GHCJXIJMSA-N Asp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N KLYPOCBLKMPBIQ-GHCJXIJMSA-N 0.000 description 1
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- MJJIHRWNWSQTOI-VEVYYDQMSA-N Asp-Thr-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MJJIHRWNWSQTOI-VEVYYDQMSA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- 102000012422 Collagen Type I Human genes 0.000 description 1
- 108010022452 Collagen Type I Proteins 0.000 description 1
- 102000007644 Colony-Stimulating Factors Human genes 0.000 description 1
- 108010071942 Colony-Stimulating Factors Proteins 0.000 description 1
- 241000022841 Concana Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 1
- KCPOQGRVVXYLAC-KKUMJFAQSA-N Cys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CS)N KCPOQGRVVXYLAC-KKUMJFAQSA-N 0.000 description 1
- JXVFJOMFOLFPMP-KKUMJFAQSA-N Cys-Leu-Tyr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JXVFJOMFOLFPMP-KKUMJFAQSA-N 0.000 description 1
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102000016359 Fibronectins Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 1
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 1
- GFLNKSQHOBOMNM-AVGNSLFASA-N Gln-His-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GFLNKSQHOBOMNM-AVGNSLFASA-N 0.000 description 1
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 1
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 1
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 1
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- ZJICFHQSPWFBKP-AVGNSLFASA-N Glu-Asn-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZJICFHQSPWFBKP-AVGNSLFASA-N 0.000 description 1
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 1
- LSTFYPOGBGFIPP-FXQIFTODSA-N Glu-Cys-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O LSTFYPOGBGFIPP-FXQIFTODSA-N 0.000 description 1
- ALCAUWPAMLVUDB-FXQIFTODSA-N Glu-Gln-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ALCAUWPAMLVUDB-FXQIFTODSA-N 0.000 description 1
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 1
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 1
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- MXJYXYDREQWUMS-XKBZYTNZSA-N Glu-Thr-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O MXJYXYDREQWUMS-XKBZYTNZSA-N 0.000 description 1
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- QSTLUOIOYLYLLF-WDSKDSINSA-N Gly-Asp-Glu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QSTLUOIOYLYLLF-WDSKDSINSA-N 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 1
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 1
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 1
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 1
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 1
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 1
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 1
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 229920002683 Glycosaminoglycan Polymers 0.000 description 1
- 208000009329 Graft vs Host Disease Diseases 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 102100021186 Granulysin Human genes 0.000 description 1
- 101710168479 Granulysin Proteins 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 1
- IIVZNQCUUMBBKF-GVXVVHGQSA-N His-Gln-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 IIVZNQCUUMBBKF-GVXVVHGQSA-N 0.000 description 1
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 1
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 1
- DGLAHESNTJWGDO-SRVKXCTJSA-N His-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N DGLAHESNTJWGDO-SRVKXCTJSA-N 0.000 description 1
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101000939741 Homo sapiens Probable non-functional T cell receptor gamma variable 10 Proteins 0.000 description 1
- 101000679304 Homo sapiens T cell receptor gamma variable 2 Proteins 0.000 description 1
- 101000679305 Homo sapiens T cell receptor gamma variable 3 Proteins 0.000 description 1
- 101000680679 Homo sapiens T cell receptor gamma variable 5 Proteins 0.000 description 1
- 101000680680 Homo sapiens T cell receptor gamma variable 8 Proteins 0.000 description 1
- 101000680681 Homo sapiens T cell receptor gamma variable 9 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 101150088952 IGF1 gene Proteins 0.000 description 1
- QTUSJASXLGLJSR-OSUNSFLBSA-N Ile-Arg-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N QTUSJASXLGLJSR-OSUNSFLBSA-N 0.000 description 1
- HZMLFETXHFHGBB-UGYAYLCHSA-N Ile-Asn-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HZMLFETXHFHGBB-UGYAYLCHSA-N 0.000 description 1
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 1
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- RMJWFINHACYKJI-SIUGBPQLSA-N Ile-Tyr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RMJWFINHACYKJI-SIUGBPQLSA-N 0.000 description 1
- NSPNUMNLZNOPAQ-SJWGOKEGSA-N Ile-Tyr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N NSPNUMNLZNOPAQ-SJWGOKEGSA-N 0.000 description 1
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 102000012745 Immunoglobulin Subunits Human genes 0.000 description 1
- 108010079585 Immunoglobulin Subunits Proteins 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 108020005350 Initiator Codon Proteins 0.000 description 1
- 102100022297 Integrin alpha-X Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 102000003777 Interleukin-1 beta Human genes 0.000 description 1
- 108090000193 Interleukin-1 beta Proteins 0.000 description 1
- 102000003816 Interleukin-13 Human genes 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 1
- 102000007547 Laminin Human genes 0.000 description 1
- 108010085895 Laminin Proteins 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- WUFYAPWIHCUMLL-CIUDSAMLSA-N Leu-Asn-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O WUFYAPWIHCUMLL-CIUDSAMLSA-N 0.000 description 1
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 1
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 1
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 1
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 1
- QLDHBYRUNQZIJQ-DKIMLUQUSA-N Leu-Ile-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QLDHBYRUNQZIJQ-DKIMLUQUSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- ODRREERHVHMIPT-OEAJRASXSA-N Leu-Thr-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ODRREERHVHMIPT-OEAJRASXSA-N 0.000 description 1
- RIHIGSWBLHSGLV-CQDKDKBSSA-N Leu-Tyr-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O RIHIGSWBLHSGLV-CQDKDKBSSA-N 0.000 description 1
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 1
- FMFNIDICDKEMOE-XUXIUFHCSA-N Leu-Val-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMFNIDICDKEMOE-XUXIUFHCSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 102000008072 Lymphokines Human genes 0.000 description 1
- 108010074338 Lymphokines Proteins 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- GGAPIOORBXHMNY-ULQDDVLXSA-N Lys-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)O GGAPIOORBXHMNY-ULQDDVLXSA-N 0.000 description 1
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 1
- DGWXCIORNLWGGG-CIUDSAMLSA-N Lys-Asn-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O DGWXCIORNLWGGG-CIUDSAMLSA-N 0.000 description 1
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 1
- ORVFEGYUJITPGI-IHRRRGAJSA-N Lys-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN ORVFEGYUJITPGI-IHRRRGAJSA-N 0.000 description 1
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 1
- VUTWYNQUSJWBHO-BZSNNMDCSA-N Lys-Leu-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VUTWYNQUSJWBHO-BZSNNMDCSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 1
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 1
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 1
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 1
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 1
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 1
- XOMXAVJBLRROMC-IHRRRGAJSA-N Met-Asp-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOMXAVJBLRROMC-IHRRRGAJSA-N 0.000 description 1
- 108010072489 Met-Ile-Phe-Leu Proteins 0.000 description 1
- AFVOKRHYSSFPHC-STECZYCISA-N Met-Ile-Tyr Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFVOKRHYSSFPHC-STECZYCISA-N 0.000 description 1
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 1
- MNGBICITWAPGAS-BPUTZDHNSA-N Met-Ser-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MNGBICITWAPGAS-BPUTZDHNSA-N 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 241000204031 Mycoplasma Species 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- KHGNFPUMBJSZSM-UHFFFAOYSA-N Perforine Natural products COC1=C2CCC(O)C(CCC(C)(C)O)(OC)C2=NC2=C1C=CO2 KHGNFPUMBJSZSM-UHFFFAOYSA-N 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- FRPVPGRXUKFEQE-YDHLFZDLSA-N Phe-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FRPVPGRXUKFEQE-YDHLFZDLSA-N 0.000 description 1
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 1
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 1
- NPLGQVKZFGJWAI-QWHCGFSZSA-N Phe-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O NPLGQVKZFGJWAI-QWHCGFSZSA-N 0.000 description 1
- DMEYUTSDVRCWRS-ULQDDVLXSA-N Phe-Lys-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DMEYUTSDVRCWRS-ULQDDVLXSA-N 0.000 description 1
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 1
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 1
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 1
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 1
- 108010089814 Plant Lectins Proteins 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 1
- RPLMFKUKFZOTER-AVGNSLFASA-N Pro-Met-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 RPLMFKUKFZOTER-AVGNSLFASA-N 0.000 description 1
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 1
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 1
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 1
- QKDIHFHGHBYTKB-IHRRRGAJSA-N Pro-Ser-Phe Chemical compound N([C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 QKDIHFHGHBYTKB-IHRRRGAJSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 1
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 1
- SFZKGGOGCNQPJY-CIUDSAMLSA-N Ser-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N SFZKGGOGCNQPJY-CIUDSAMLSA-N 0.000 description 1
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 1
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 1
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 1
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 1
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- MLSQXWSRHURDMF-GARJFASQSA-N Ser-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N)C(=O)O MLSQXWSRHURDMF-GARJFASQSA-N 0.000 description 1
- CAOYHZOWXFFAIR-CIUDSAMLSA-N Ser-His-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CAOYHZOWXFFAIR-CIUDSAMLSA-N 0.000 description 1
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 1
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 1
- GVMUJUPXFQFBBZ-GUBZILKMSA-N Ser-Lys-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GVMUJUPXFQFBBZ-GUBZILKMSA-N 0.000 description 1
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- UPLYXVPQLJVWMM-KKUMJFAQSA-N Ser-Phe-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UPLYXVPQLJVWMM-KKUMJFAQSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- FVFUOQIYDPAIJR-XIRDDKMYSA-N Ser-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FVFUOQIYDPAIJR-XIRDDKMYSA-N 0.000 description 1
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 1
- SYCFMSYTIFXWAJ-DCAQKATOSA-N Ser-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N SYCFMSYTIFXWAJ-DCAQKATOSA-N 0.000 description 1
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 1
- 108010088160 Staphylococcal Protein A Proteins 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 230000010782 T cell mediated cytotoxicity Effects 0.000 description 1
- 102100022581 T cell receptor gamma variable 2 Human genes 0.000 description 1
- 102100022591 T cell receptor gamma variable 3 Human genes 0.000 description 1
- 102100022391 T cell receptor gamma variable 5 Human genes 0.000 description 1
- 102100022394 T cell receptor gamma variable 8 Human genes 0.000 description 1
- 102100022393 T cell receptor gamma variable 9 Human genes 0.000 description 1
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- JNQZPAWOPBZGIX-RCWTZXSCSA-N Thr-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N JNQZPAWOPBZGIX-RCWTZXSCSA-N 0.000 description 1
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 1
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 1
- IHAPJUHCZXBPHR-WZLNRYEVSA-N Thr-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N IHAPJUHCZXBPHR-WZLNRYEVSA-N 0.000 description 1
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 1
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- IJKNKFJZOJCKRR-GBALPHGKSA-N Thr-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 IJKNKFJZOJCKRR-GBALPHGKSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 1
- 101000980463 Treponema pallidum (strain Nichols) Chaperonin GroEL Proteins 0.000 description 1
- 241000209140 Triticum Species 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 1
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 1
- YCEHCFIOIYNQTR-NYVOZVTQSA-N Trp-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)N[C@@H](CO)C(=O)O)N YCEHCFIOIYNQTR-NYVOZVTQSA-N 0.000 description 1
- YCQKQFKXBPJXRY-PMVMPFDFSA-N Trp-Tyr-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CCCCN)C(=O)O)N YCQKQFKXBPJXRY-PMVMPFDFSA-N 0.000 description 1
- BABINGWMZBWXIX-BPUTZDHNSA-N Trp-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BABINGWMZBWXIX-BPUTZDHNSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 1
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 1
- NZFCWALTLNFHHC-JYJNAYRXSA-N Tyr-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NZFCWALTLNFHHC-JYJNAYRXSA-N 0.000 description 1
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 1
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 1
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 1
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 1
- RVGVIWNHABGIFH-IHRRRGAJSA-N Tyr-Val-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O RVGVIWNHABGIFH-IHRRRGAJSA-N 0.000 description 1
- JFAWZADYPRMRCO-UBHSHLNASA-N Val-Ala-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JFAWZADYPRMRCO-UBHSHLNASA-N 0.000 description 1
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 1
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 1
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- COSLEEOIYRPTHD-YDHLFZDLSA-N Val-Asp-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 COSLEEOIYRPTHD-YDHLFZDLSA-N 0.000 description 1
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 1
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 1
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- AGXGCFSECFQMKB-NHCYSSNCSA-N Val-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N AGXGCFSECFQMKB-NHCYSSNCSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- CXWJFWAZIVWBOS-XQQFMLRXSA-N Val-Lys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CXWJFWAZIVWBOS-XQQFMLRXSA-N 0.000 description 1
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 1
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 1
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 1
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 1
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 1
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 1
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 1
- PDDJTOSAVNRJRH-UNQGMJICSA-N Val-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](C(C)C)N)O PDDJTOSAVNRJRH-UNQGMJICSA-N 0.000 description 1
- SUGRIIAOLCDLBD-ZOBUZTSGSA-N Val-Trp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SUGRIIAOLCDLBD-ZOBUZTSGSA-N 0.000 description 1
- GTACFKZDQFTVAI-STECZYCISA-N Val-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 GTACFKZDQFTVAI-STECZYCISA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 108010006886 Vitrogen Proteins 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 229910045601 alloy Inorganic materials 0.000 description 1
- 239000000956 alloy Substances 0.000 description 1
- 210000002203 alpha-beta t lymphocyte Anatomy 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 239000002870 angiogenesis inducing agent Substances 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 239000012805 animal sample Substances 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 238000011091 antibody purification Methods 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 230000001640 apoptogenic effect Effects 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- 239000012131 assay buffer Substances 0.000 description 1
- 238000007845 assembly PCR Methods 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 210000000270 basal cell Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 210000000013 bile duct Anatomy 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000003181 biological factor Substances 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 238000013378 biophysical characterization Methods 0.000 description 1
- 210000000988 bone and bone Anatomy 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 210000000621 bronchi Anatomy 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- CGOBLNWOMVGLOY-UHFFFAOYSA-N but-2-enyl hydroxymethyl phosphono phosphate Chemical compound CC=CCOP(=O)(OCO)OP(=O)(O)O CGOBLNWOMVGLOY-UHFFFAOYSA-N 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 229910000394 calcium triphosphate Inorganic materials 0.000 description 1
- XFWJKVMFIVXPKK-UHFFFAOYSA-N calcium;oxido(oxo)alumane Chemical compound [Ca+2].[O-][Al]=O.[O-][Al]=O XFWJKVMFIVXPKK-UHFFFAOYSA-N 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000012219 cassette mutagenesis Methods 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 239000000919 ceramic Substances 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 238000013377 clone selection method Methods 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 229940047120 colony stimulating factors Drugs 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000005138 cryopreservation Methods 0.000 description 1
- 238000012866 crystallographic experiment Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 125000000151 cysteine group Chemical class N[C@@H](CS)C(=O)* 0.000 description 1
- 108010057085 cytokine receptors Proteins 0.000 description 1
- 102000003675 cytokine receptors Human genes 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 238000010908 decantation Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- 210000002249 digestive system Anatomy 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 238000012137 double-staining Methods 0.000 description 1
- 230000002222 downregulating effect Effects 0.000 description 1
- 230000002500 effect on skin Effects 0.000 description 1
- 210000003162 effector t lymphocyte Anatomy 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000007184 endocrine pathway Effects 0.000 description 1
- 210000000750 endocrine system Anatomy 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 235000020774 essential nutrients Nutrition 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical group O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000012921 fluorescence analysis Methods 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 238000010230 functional analysis Methods 0.000 description 1
- 238000007306 functionalization reaction Methods 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 210000000232 gallbladder Anatomy 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 1
- 108010050848 glycylleucine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 229910052735 hafnium Inorganic materials 0.000 description 1
- VBJZVLUMGGDVMO-UHFFFAOYSA-N hafnium atom Chemical group [Hf] VBJZVLUMGGDVMO-UHFFFAOYSA-N 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000036074 healthy skin Effects 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 1
- 210000000777 hematopoietic system Anatomy 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 235000003642 hunger Nutrition 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000004968 inflammatory condition Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 229940096397 interleukin-8 Drugs 0.000 description 1
- XKTZWUACRZHVAN-VADRZIEHSA-N interleukin-8 Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@@H](NC(C)=O)CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(=O)N1[C@H](CCC1)C(=O)N1[C@H](CCC1)C(=O)N[C@@H](C)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC(O)=CC=1)C(=O)N[C@H](CO)C(=O)N1[C@H](CCC1)C(N)=O)C1=CC=CC=C1 XKTZWUACRZHVAN-VADRZIEHSA-N 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 108010027338 isoleucylcysteine Proteins 0.000 description 1
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 1
- 150000002540 isothiocyanates Chemical group 0.000 description 1
- 210000002510 keratinocyte Anatomy 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- 210000000867 larynx Anatomy 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 150000002617 leukotrienes Chemical class 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 238000007885 magnetic separation Methods 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000000816 matrix-assisted laser desorption--ionisation Methods 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 206010027191 meningioma Diseases 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 235000010981 methylcellulose Nutrition 0.000 description 1
- DLEDLHFNQDHEOJ-UDTOXTEMSA-N mezerein Chemical compound O([C@@H]1[C@H]([C@@]23[C@H]4[C@](C(C(C)=C4)=O)(O)[C@H](O)[C@@]4(CO)O[C@H]4[C@H]3[C@H]3O[C@@](O2)(O[C@]31C(C)=C)C=1C=CC=CC=1)C)C(=O)\C=C\C=C\C1=CC=CC=C1 DLEDLHFNQDHEOJ-UDTOXTEMSA-N 0.000 description 1
- DLEDLHFNQDHEOJ-KVZAMRGJSA-N mezerein Natural products CC1C(OC(=O)C=C/C=C/c2ccccc2)C3(OC4(OC3C5C6OC6(CO)C(O)C7(O)C(C=C(C)C7=O)C15O4)c8ccccc8)C(=C)C DLEDLHFNQDHEOJ-KVZAMRGJSA-N 0.000 description 1
- 239000010445 mica Substances 0.000 description 1
- 229910052618 mica group Inorganic materials 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- 230000000897 modulatory effect Effects 0.000 description 1
- 238000007479 molecular analysis Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 210000004400 mucous membrane Anatomy 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 229920005615 natural polymer Polymers 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 210000000653 nervous system Anatomy 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229910052758 niobium Inorganic materials 0.000 description 1
- 239000010955 niobium Chemical group 0.000 description 1
- GUCVJGMIXFAOAE-UHFFFAOYSA-N niobium atom Chemical group [Nb] GUCVJGMIXFAOAE-UHFFFAOYSA-N 0.000 description 1
- 239000013631 noncovalent dimer Substances 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- RFWLACFDYFIVMC-UHFFFAOYSA-D pentacalcium;[oxido(phosphonatooxy)phosphoryl] phosphate Chemical compound [Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O.[O-]P([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O RFWLACFDYFIVMC-UHFFFAOYSA-D 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 230000007030 peptide scission Effects 0.000 description 1
- 229930192851 perforin Natural products 0.000 description 1
- 210000003668 pericyte Anatomy 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 210000003800 pharynx Anatomy 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 1
- PHEDXBVPIONUQT-RGYGYFBISA-N phorbol 13-acetate 12-myristate Chemical compound C([C@]1(O)C(=O)C(C)=C[C@H]1[C@@]1(O)[C@H](C)[C@H]2OC(=O)CCCCCCCCCCCCC)C(CO)=C[C@H]1[C@H]1[C@]2(OC(C)=O)C1(C)C PHEDXBVPIONUQT-RGYGYFBISA-N 0.000 description 1
- 239000003726 plant lectin Substances 0.000 description 1
- 210000004180 plasmocyte Anatomy 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 239000004926 polymethyl methacrylate Substances 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000004814 polyurethane Substances 0.000 description 1
- 229920002635 polyurethane Polymers 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 208000023958 prostate neoplasm Diseases 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 210000000664 rectum Anatomy 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 210000004994 reproductive system Anatomy 0.000 description 1
- 210000002345 respiratory system Anatomy 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical group [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000012146 running buffer Substances 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 238000009738 saturating Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 230000009131 signaling function Effects 0.000 description 1
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 230000037351 starvation Effects 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 210000004003 subcutaneous fat Anatomy 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 210000001179 synovial fluid Anatomy 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229910052715 tantalum Inorganic materials 0.000 description 1
- GUVRBAGPIYLISA-UHFFFAOYSA-N tantalum atom Chemical compound [Ta] GUVRBAGPIYLISA-UHFFFAOYSA-N 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 238000011191 terminal modification Methods 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 229910052719 titanium Inorganic materials 0.000 description 1
- 239000010936 titanium Substances 0.000 description 1
- 210000002105 tongue Anatomy 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- WFKWXMTUELFFGS-UHFFFAOYSA-N tungsten Chemical group [W] WFKWXMTUELFFGS-UHFFFAOYSA-N 0.000 description 1
- 239000010937 tungsten Chemical group 0.000 description 1
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- 210000000626 ureter Anatomy 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 230000002485 urinary effect Effects 0.000 description 1
- 210000001215 vagina Anatomy 0.000 description 1
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 1
- 229910052720 vanadium Inorganic materials 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images








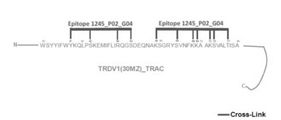

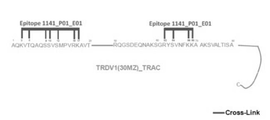








Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/74—Inducing cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/75—Agonist effect on antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2500/00—Specific components of cell culture medium
- C12N2500/90—Serum-free medium, which may still contain naturally-sourced components
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2301—Interleukin-1 (IL-1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2302—Interleukin-2 (IL-2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2304—Interleukin-4 (IL-4)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2307—Interleukin-7 (IL-7)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2309—Interleukin-9 (IL-9)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2312—Interleukin-12 (IL-12)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2315—Interleukin-15 (IL-15)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2321—Interleukin-21 (IL-21)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/25—Tumour necrosing factors [TNF]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/998—Proteins not provided for elsewhere
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Biomedical Technology (AREA)
- Genetics & Genomics (AREA)
- Cell Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Microbiology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Epidemiology (AREA)
- Mycology (AREA)
- Hematology (AREA)
- Oncology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Rheumatology (AREA)
- Pain & Pain Management (AREA)
- Communicable Diseases (AREA)
- Virology (AREA)
- Developmental Biology & Embryology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
본 발명은 항-Vδ1 항체 또는 이의 단편을 사용하여 Vδ1 T 세포를 조절하는 체외 방법에 관한 것이다.
Description
본 발명은 항-TCR 델타 가변 1(항-V`δ1) 항체와 접촉된 감마 델타 T 세포 집단에 관한 것이다.
암에 대한 T 세포 면역요법에 대해 증가하는 관심은 특히 PD-1, CTLA-4 및 기타 수용체에 의해 발휘되는 억제 경로의 임상적으로 매개되는 길항작용에 의해 탈-억제될 때 암세포를 인식하고 숙주를 보호하는 기능적 잠재력을 매개하는 CD8+ 및 CD4+ αβ T 세포 서브세트의 명백한 능력에 초점이 맞춰져 왔다. 그러나, αβ T 세포는 MHC-제한적이며, 이는 이식편대숙주질환(graft versus host disease)을 야기할 수 있다.
감마 델타 T 세포(γδ T 세포)는 표면에 독특하고, 뚜렷한 γδ T 세포 수용체(TCR)를 발현하는 T 세포의 서브세트이다. TCR은 하나의 감마(γ)와 하나의 델타(δ) 사슬로 구성되며, 이들 각각은 사슬 재배열을 거치지만 αβ T 세포에 비해 제한된 수의 V 유전자를 갖는다. Vγ를 암호화하는 주된 TGRV 유전자 절편은 TRGV2, TRGV3, TRGV4, TRGV5, TRGV8, TRGV9 및 TRGV11와 비-기능성 유전자 TRGV10, TRGV11, TRGVA 및 TRGVB이다. 가장 빈번한 TRDV 유전자 절편은 Vδ1, Vδ2 및 Vδ3과 함께, Vδ와 Vα 식별을 모두 갖는 여러 V 절편을 암호화한다(Adams et al., 296:30-40 (2015) Cell Immunol.). 인간 γδ T 세포는 특정 γ 및 δ 유형이 하나 이상의 조직 유형에서 배타적이지는 않더라도 더 우세하게 발견되기 때문에, TCR 사슬을 기준으로 대략적으로 분류될 수 있다. 예를 들어, 대부분의 혈액 상주 γδ T 세포는 Vδ2 TCR, 일반적으로 Vγ9Vδ2를 발현하는 반면, 이는 감마 사슬과 쌍을 이루는 Vδ1 TCR을 더 자주 사용하는 피부에서와 같은 조직-상재 γδ T 세포에서는 덜 일반적이며, 예를 들어 장에서는 종종 Vγ4와 쌍을 이룬다.
면역요법을 위해 γδ T 세포를 활용하려면 원래의 위치에서 세포를 증식하거나, 세포를 수집하고 재주입하기에 앞서 체외에서 증식하는 방법이 필요하다. 후자의 접근법은 종래 외인성 사이토카인의 첨가를 이용하여 기술되었으며, 예를 들어 WO2017/072367 및 WO2018/212808을 참조할 수 있다. 환자 자신의 γδ T 세포를 증식하는 방법은 약리학적으로 변형된 형태의 HMBPP(hydroxy-methyl but-2-enyl pyrophosphate) 또는 임상적으로 승인된 아미노비스포스포네이트(aminobisphosphonate)를 사용하여 설명되었다. 이러한 접근 방식을 통해 250명 이상의 암 환자가 겉보기에는 안전하게 치료를 받았으나, 완전한 관해가 된 경우는 극히 드물었다. 그러나, 많은 수의 γδ T 세포를 증식시키는 입증된 능력을 갖는 활성화제가 여전히 요구된다.
본 발명의 첫 번째 양태에 따르면, Vδ1 T 세포를 포함하는 세포 집단에,
(i) 서열번호: 1의 3-20 ; 및/또는
(ii) 서열번호: 1의 37-77
의 아미노산 영역 내에 하나 이상의 아미노산 잔기를 포함하는,
γδ T 세포 수용체(TCR)의 가변 델타 1(Vδ1) 사슬의 에피토프에 결합하는 인간 항-TCR 델타 가변 1(항-Vδ1) 항체 또는 이의 단편을 투여하는 것을 포함하는 Vδ1 T 세포를 조절하는 체외 방법이 제공된다.
본 발명의 다른 양태에 따르면, Vδ1 T 세포를 포함하는 세포 집단에,
서열 번호: 2-25 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR3;
서열 번호: 26-37 및 표 2의 서열 A1-A12 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 38-61 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR1,
중 하나 이상을 포함하는 항-Vδ1 항체 또는 이의 단편을 투여하는 것을 포함하는 Vδ1 T 세포를 조절하는 체외 방법이 제공된다.
본 발명의 다른 양태에 따르면, 본 명세서에 정의된 체외 방법에 의해 수득되는 Vδ1 T 세포 집단이 제공된다.
본 발명의 다른 양태에 따르면, 본 명세서에 정의된 Vδ1 T 세포 집단을 포함하는 조성물이 제공된다.
본 발명의 다른 양태에 따르면, 본 명세서에 정의된 Vδ1 T 세포 집단을 포함하는 약학 조성물이 제공된다.
본 발명의 다른 양태에 따르면, 이를 필요로 하는 대상에서 치료적 유효량의 Vδ1 T 세포 집단 또는 본 명세서에 정의된 약학 조성물을 투여하는 것을 포함하는 암, 감염성 질환 또는 염증성 질환의 치료 방법이 제공된다.
도 1: 항-Vδ1Ab(REA173, Miltenyi Biotec)로 직접 코팅된 항원의 ELISA 검출. Vδ1 도메인을 포함하는 항원에서만 검출이 보여졌다. 류신 지퍼(LZ, Leucine zipper) 형태는 세포-기반 플로우 경쟁 분석과 부합하는 Fc 형태보다 더 강력한 것으로 보인다(데이터 미도시).
도 2: DV1 선택을 위한 다클론 파지 DELFIA 데이터. A) 이종이량체 선택: 라운드 1 및 2에서 이종이량체인 LZ TCR 형태와, 두 라운드 모두에서 이종이량체인 LZ TCR에 대한 선택 해제 B) 동종이량체 선택: 인간 IgG1 Fc에 대한 선택 해제와 함께 동종이량체인 Fc 융합 TCR을 사용하여 라운드 1을 수행한 후 이종이량체인 LZ TCR에 대한 선택 해제와 함께 이종이량체인 LZ TCR에 대해 라운드 2를 수행하였다. 각 그래프는 다른 라이브러리로부터의 선택을 나타내는 각 타겟에 대한 두 개의 막대를 포함한다.
도 3: IgG 캡처: 좌) 항-L1 IgG와 L1의 상호작용의 센서그램, 우) 정상 상태 핏(가능한 경우). 모든 실험은 MASS-2 기기에서 상온에서 수행되었다. 정상 상태의 핏은 랭뮤어(Langmuir) 1:1 결합을 따른다.
도 4 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09, 1251_P02_G10 및 1252_P01_C08에 대한 TCR 하향 조절 분석 결과.
도 5 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09 및 1251_P02_G10에 대한 T 세포 탈과립 분석 결과.
도 6 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09 및 1251_P02_G10에 대한 사멸 분석(THP-1 플로우 기반 분석) 결과.
도 7: 1245_P01_E07에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1245_P01_E07의 에피토프 결합 부위를 나타낸 도면.
도 8: 1252_P01_C08에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1252_P01_C08의 에피토프 결합 부위를 나타낸 도면.
도 9: 1245_P02_G04에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1245_P02_G04의 에피토프 결합 부위를 나타낸 도면.
도 10: 1251_P02_C05에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1251_P02_C05의 에피토프 결합 부위를 나타낸 도면.
도 11: 1141_P01_E01에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1141_P01_E01의 에피토프 결합 부위를 나타낸 도면.
도 12: 실시예 10의 실험 1 동안의 총 세포 수. 시료를 본 명세서에 기재된 다양한 농도의 항-Vδ1 항체와 함께 배양하고 비교 항체와 함께 배양한 시료 또는 대조군과 비교하였다. 그래프는 (A) 7일, (B) 14일 및 (C) 18일에서 총 세포 수를 보여준다.
도 13: 실시예 10의 실험 1 동안의 Vδ1 T 세포의 분석. 그래프는 18일째 시료에서 (A) Vδ1 T 세포의 백분율, (B) Vδ1 T 세포 수 및 (C) Vδ1 배수 변화를 보여준다.
도 14: 실시예 10의 실험 2 동안의 총 세포 수. 시료를 본 명세서에 기재된 다양한 농도의 항-Vδ1 항체와 함께 배양하고 비교 항체와 함께 배양한 시료 또는 대조군과 비교하였다. 그래프는 (A) 7일, (B) 14일 및 (C) 17일에서 총 세포 수를 보여준다.
도 15: 실시예 10의 실험 2 동안의 Vδ1 T 세포의 분석. 그래프는 17일째 시료에서 (A) Vδ1 T 세포의 백분율, (B) Vδ1 T 세포 수 및 (C) Vδ1 배수 변화를 보여준다.
도 16: 세포 조성 분석. 시료에 존재하는 세포 유형(비-Vδ1 세포 포함)을 실험 2의 17일째에 측정하였다. 세포를 수집하고 Vδ1, Vδ2 및 αβTCR의 표면 발현에 대해 유세포 분석에 의해 분석하였다. 백분율 값 또한 표 6에 기재하였다.
도 17: SYTOX-플로우 사멸 분석 결과. SYTOX-플로우 사멸 분석을 사용하여 세포의 기능성을 검사하고, 결과를 (A) 작동체 대 표적(E:T) 비율이 10:1인 세포를 사용한 14일째의 실험 1 및 (B) E:T 비율이 1:1 및 10:1인 세포를 사용한 17일째(동결-해동 후) 실험 2에 대해 나타내었다.
도 18: 동결-해동 후 총 세포 수. 그래프는 동결 전에 B07, C08, E07, G04 또는 OKT-3 항체와 접촉된 배양물에 대해, 동결-해동 후 세포 배양 7일 후의 총 세포 수를 보여준다.
도 19: 세포 증식 모니터링. 동결-해동 후 배양된 세포에 대해 42일까지 총 세포 수를 모니터링하였다.
도 20: 항-Vδ1 항체는 인간 종양에서 종양-침윤-림프구(TIL, tumour-infilterating-lymphocyte)가 조절 및 증식되도록 하였다. 신장 세포 암종(RCC, renal cell carcinoma) +/- 항체에 대한 연구 A) TIL Vδ1+ 세포에서의 배수 증가. B) TIL Vδ1+ 세포의 총 수. C) 게이팅 전략의 예. D) TIL Vδ1+ 세포의 상대적인 세포-표면 표현형 프로파일. E) TIL Vδ1-음성 게이트 분획의 분석.
도 2: DV1 선택을 위한 다클론 파지 DELFIA 데이터. A) 이종이량체 선택: 라운드 1 및 2에서 이종이량체인 LZ TCR 형태와, 두 라운드 모두에서 이종이량체인 LZ TCR에 대한 선택 해제 B) 동종이량체 선택: 인간 IgG1 Fc에 대한 선택 해제와 함께 동종이량체인 Fc 융합 TCR을 사용하여 라운드 1을 수행한 후 이종이량체인 LZ TCR에 대한 선택 해제와 함께 이종이량체인 LZ TCR에 대해 라운드 2를 수행하였다. 각 그래프는 다른 라이브러리로부터의 선택을 나타내는 각 타겟에 대한 두 개의 막대를 포함한다.
도 3: IgG 캡처: 좌) 항-L1 IgG와 L1의 상호작용의 센서그램, 우) 정상 상태 핏(가능한 경우). 모든 실험은 MASS-2 기기에서 상온에서 수행되었다. 정상 상태의 핏은 랭뮤어(Langmuir) 1:1 결합을 따른다.
도 4 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09, 1251_P02_G10 및 1252_P01_C08에 대한 TCR 하향 조절 분석 결과.
도 5 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09 및 1251_P02_G10에 대한 T 세포 탈과립 분석 결과.
도 6 : (A) 클론 1245_P01_E07, 1252_P01_C08, 1245_P02_G04, 1245_P01_B07 및 1251_P02_C05 또는 (B) 클론 1139_P01_E04, 1245_P02_F07, 1245_P01_G06, 1245_P01_G09, 1138_P01_B09 및 1251_P02_G10에 대한 사멸 분석(THP-1 플로우 기반 분석) 결과.
도 7: 1245_P01_E07에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1245_P01_E07의 에피토프 결합 부위를 나타낸 도면.
도 8: 1252_P01_C08에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1252_P01_C08의 에피토프 결합 부위를 나타낸 도면.
도 9: 1245_P02_G04에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1245_P02_G04의 에피토프 결합 부위를 나타낸 도면.
도 10: 1251_P02_C05에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1251_P02_C05의 에피토프 결합 부위를 나타낸 도면.
도 11: 1141_P01_E01에 대한 에피토프 매핑 데이터. 서열번호: 1에서 1141_P01_E01의 에피토프 결합 부위를 나타낸 도면.
도 12: 실시예 10의 실험 1 동안의 총 세포 수. 시료를 본 명세서에 기재된 다양한 농도의 항-Vδ1 항체와 함께 배양하고 비교 항체와 함께 배양한 시료 또는 대조군과 비교하였다. 그래프는 (A) 7일, (B) 14일 및 (C) 18일에서 총 세포 수를 보여준다.
도 13: 실시예 10의 실험 1 동안의 Vδ1 T 세포의 분석. 그래프는 18일째 시료에서 (A) Vδ1 T 세포의 백분율, (B) Vδ1 T 세포 수 및 (C) Vδ1 배수 변화를 보여준다.
도 14: 실시예 10의 실험 2 동안의 총 세포 수. 시료를 본 명세서에 기재된 다양한 농도의 항-Vδ1 항체와 함께 배양하고 비교 항체와 함께 배양한 시료 또는 대조군과 비교하였다. 그래프는 (A) 7일, (B) 14일 및 (C) 17일에서 총 세포 수를 보여준다.
도 15: 실시예 10의 실험 2 동안의 Vδ1 T 세포의 분석. 그래프는 17일째 시료에서 (A) Vδ1 T 세포의 백분율, (B) Vδ1 T 세포 수 및 (C) Vδ1 배수 변화를 보여준다.
도 16: 세포 조성 분석. 시료에 존재하는 세포 유형(비-Vδ1 세포 포함)을 실험 2의 17일째에 측정하였다. 세포를 수집하고 Vδ1, Vδ2 및 αβTCR의 표면 발현에 대해 유세포 분석에 의해 분석하였다. 백분율 값 또한 표 6에 기재하였다.
도 17: SYTOX-플로우 사멸 분석 결과. SYTOX-플로우 사멸 분석을 사용하여 세포의 기능성을 검사하고, 결과를 (A) 작동체 대 표적(E:T) 비율이 10:1인 세포를 사용한 14일째의 실험 1 및 (B) E:T 비율이 1:1 및 10:1인 세포를 사용한 17일째(동결-해동 후) 실험 2에 대해 나타내었다.
도 18: 동결-해동 후 총 세포 수. 그래프는 동결 전에 B07, C08, E07, G04 또는 OKT-3 항체와 접촉된 배양물에 대해, 동결-해동 후 세포 배양 7일 후의 총 세포 수를 보여준다.
도 19: 세포 증식 모니터링. 동결-해동 후 배양된 세포에 대해 42일까지 총 세포 수를 모니터링하였다.
도 20: 항-Vδ1 항체는 인간 종양에서 종양-침윤-림프구(TIL, tumour-infilterating-lymphocyte)가 조절 및 증식되도록 하였다. 신장 세포 암종(RCC, renal cell carcinoma) +/- 항체에 대한 연구 A) TIL Vδ1+ 세포에서의 배수 증가. B) TIL Vδ1+ 세포의 총 수. C) 게이팅 전략의 예. D) TIL Vδ1+ 세포의 상대적인 세포-표면 표현형 프로파일. E) TIL Vδ1-음성 게이트 분획의 분석.
정의
별도로 정의되지 않는 한, 본 명세서에서 사용된 모든 기술 및 과학 용어는 본 발명이 속하는 기술 분야에서 당업자에 의해 일반적으로 이해되는 의미를 갖는다. 본 명세서에 사용된 바와 같이, 다음 용어는 하기에 부여된 의미를 갖는다.
감마 델타 T 세포(γδ T 세포)는 표면에 독특하고, 뚜렷한 γδ T 세포 수용체(TCR)를 발현하는 T 세포의 서브세트이다. TCR은 하나의 감마(γ)와 하나의 델타(δ) 사슬로 구성된다. 각 사슬은 가변(V) 영역, 불변(C) 영역, 막횡단 영역 및 세포질 미부(cytoplasmic tail)을 포함한다. V 영역은 항원 결합 부위를 포함한다. 인간 γδ T 세포에는 두 가지 주요 하위-유형이 있다: 하나는 말초혈액에서 우세하고 다른 하나는 비-조혈조직에서 우세하다. 두 가지 하위-유형은 세포에 존재하는 δ 및/또는 γ의 유형에 의해 정의될 수 있다. 예를 들어, 말초혈액에서 우세한 γδ T 세포는 주로 델타 가변 2 사슬(Vδ2)을 발현한다. 비-조혈조직에서 우세한(즉, 조직에 상재하는) γδ T 세포는 주로 델타 가변 1(Vδ1) 사슬을 발현한다. "Vδ1 T 세포"라고 하는 것은 Vδ1 사슬을 갖는 γδ T 세포, 즉 Vδ1+ T 세포를 의미한다.
"델타 가변 1"이라 함은 또한 Vδ1 또는 Vd1로도 지칭될 수 있는 한편, 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드는 "TRDV1"으로 지칭될 수 있다. γδ TCR의 Vδ1 사슬과 상호작용하는 항체 또는 이의 단편은 모두 Vδ1에 결합하는 효과적인 항체 또는 이의 단편이며 "항-TCR 델타 가변 1 항체 또는 이의 단편" 또는 "항-Vδ1 항체 또는 그 단편"을 지칭한다.
본 명세서에서 추가적인 지칭이 "델타 가변 2" 사슬과 같은 다른 델타 사슬에도 적용된다. 유사한 방식으로 지칭될 수 있다. 예를 들어, 델타 가변 2 사슬은 Vδ2로 지칭될 수 있는 한편, 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드는 "TRDV2"로 지칭될 수 있다. 바람직한 실시예에서 γδ TCR의 Vδ1 사슬과 상호작용하는 항체 또는 이의 단편은 Vδ2와 같은 다른 델타 사슬과 상호작용하지 않는다.
'감마 가변 사슬'에 대한 언급도 본 명세서에서 이루어진다. 이들은 γ-사슬 또는 Vγ로 지칭될 수 있는 한편, 이 영역을 포함하는 TCR 사슬을 암호화하는 뉴클레오티드는 TRGV로 지칭될 수 있다. 예를 들어, TRGV4는 Vγ4 사슬을 지칭한다. 바람직한 실시예에서, γδ TCR의 Vδ1 사슬과 상호작용하는 항체 또는 이의 단편은 Vγ4와 같은 감마 사슬과 상호작용하지 않는다.
용어 "항체"는 하나 이상의 항원 결합 부위(ABS)를 포함하는 하나 이상의 항체 가변 도메인을 포함하는 모든 항체 단백질 구조물을 포함한다. 항체는 IgA, IgG, IgE, IgD, IgM 유형(및 이들의 하위유형)의 면역글로불린을 포함하지만 이에 한정되지 않는다. 두 개의 동일한 중(H)-사슬 및 두 개의 동일한 경(L)-사슬 폴리펩타이드로부터 조립된 면역글로불린 G(IgG) 항체의 전체 구조는 포유동물에서 잘 확립되어 있고 고도로 보존되어 있다(Padlan (1994) Mol. Immunol. 31:169 -217).
통상적인 항체 또는 면역글로불린(Ig)은 네 개의 폴리펩타이드 사슬, 즉 두 개의 중(H) 사슬 및 두 개의 경(L) 사슬을 포함하는 단백질이다. 각 사슬은 불변 영역과 가변 영역으로 나뉘어진다. 중(H) 사슬 가변 도메인은 본 명세서에서 VH로 약칭되며, 경(L) 사슬 가변 도메인은 본 명세서에서 VL로 약칭된다. 이들 도메인, 이와 관련된 도메인 및 이로부터 유래된 도메인은 본 명세서에서 면역글로불린 사슬 가변 도메인으로 지칭될 수 있다. VH 및 VL 도메인(VH 및 VL 영역으로도 지칭됨)은 "프레임워크 영역"("FR")이라고 하는 더 보존된 영역이 산재되어 있는 "상보성 결정 영역"("CDR")이라고 하는 영역으로 더욱 세분화될 수 있다. 프레임워크 및 상보성 결정 영역은 명확하게 정의되어져 있다(Kabat et al. Sequences of Proteins of Immunological Interest, Fifth Edition U.S. Department of Health and Human Services, (1991) NIH Publication Number 91-3242). 예를 들어 Chothia et al. (1989) Nature 342: 877-883에 발표된 것과 같이 CDR 서열에 대한 대체 넘버링 규칙도 있다. 통상적인 항체에서, 각각의 VH 및 VL은 아미노 말단에서 카르복시 말단까지 FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4의 순서로 배열된 세 개의 CDR과 네 개의 FR로 구성된다. 두 개의 면역글로불린 중 사슬 및 두 개의 면역글로불린 경 사슬의 통상적인 항체 사량체(tetramer)는 면역글로불린 중 사슬과 경 사슬이 예를 들어 다이설파이드 결합에 의해 상호 연결되어 형성되며, 중 사슬도 유사하게 연결된다. 중 사슬 불변 영역은 CH1, CH2 및 CH3의 세 가지 도메인을 포함한다. 경 사슬 불변 영역은 하나의 도메인 CL로 구성된다. 중 사슬의 가변 도메인과 경 사슬의 가변 도메인은 항원과 상호작용하는 결합 도메인이다. 항체의 불변 영역은 일반적으로 면역계의 다양한 세포(예를 들어, 작동체 세포) 및 고전적인 보체계(complement system)의 첫 번째 성분(C1q)을 포함하는 숙주 조직 또는 인자에 대한 항체의 결합을 매개한다.
본 명세서에 사용된 항체의 단편("항체 단편", "면역글로불린 단편", "항원-결합 단편" 또는 "항원-결합 폴리펩타이드"로도 지칭될 수 있음)은 표적인 γδ T 세포 수용체의 델타 가변 1(Vδ1) 사슬에 특이적으로 결합하는 항체의 일부(또는 상기 부분을 포함하는 구조물)를 지칭한다(예를 들어, 하나 이상의 면역글로불린 사슬이 전장이 아니지만 표적에 특이적으로 결합하는 분자). 항체 단편이라는 용어에 포함되는 결합 단편의 예는 다음을 포함한다:
(i) Fab 단편 (VL, VH, CL 및 CH1 도메인으로 구성된 1가(monovalent) 단편);
(ii) F(ab')2 단편 (힌지 영역에서 다이설파이드 다리에 의해 연결된 두 개의 Fab 단편으로 구성된 2가(bivalent) 단편);
(iii) Fd 단편 (VH 및 CH1 도메인으로 구성됨);
(iv) Fv 단편 (항체의 단일 암(arm)의 VL 및 VH 도메인으로 구성됨);
(v) 단일 사슬 가변 단편, scFv (재조합 방법을 사용하여 VL 및 VH 영역이 쌍을 이루어 1가 분자를 형성하는 단일 단백질 사슬로 만들 수 있게 하는 합성 링커에 의해 연결된 VL 및 VH 도메인으로 구성됨);
(vi) VH (VH 도메인으로 구성된 면역글로불린 사슬 가변 도메인);
(vii) VL (VL 도메인으로 구성된 면역글로불린 사슬 가변 도메인);
(viii) 도메인 항체 (dAb, VH 또는 VL 도메인으로 구성됨);
(ix) 미니바디(minibody)(CH3 도메인을 통해 연결된 한 쌍의 scFv 단편으로 구성됨); 및
(x) 디아바디(diabody)(작은 펩타이드 링커에 의해 다른 항체로부터의 VL 도메인과 연결된 하나의 항체로부터의 VH 도메인으로 구성되는 scFv 단편의 비공유(noncovalent) 이량체로 구성됨).
"인간 항체"는 인간 생식계열 면역글로불린 서열로부터 유래된 가변 및 불변 영역을 갖는 항체를 지칭한다. 상기 인간 항체가 투여된 인간 대상체는 종-간(cross species) 항체 반응(예를 들어, HAMA(human-anti-mouse antibody) 반응으로 지칭되는)을 일으키지 않는다. 상기 인간 항체는 예를 들어 CDRs, 특히 CDR3에, 인간 생식계열 면역글로불린 서열에 의해 암호화되지 않는 아미노산 잔기(예를 들어, 무작위 또는 부위-특이적 돌연변이유발에 의하거나 또는 체세포 돌연변이에 의해 도입된 돌연변이)를 포함할 수 있다. 그러나 이 용어가 마우스와 같은 다른 포유동물 종의 생식계열에서 유래된 CDR 서열이 인간 프레임워크 서열에 이식된 항체를 포함하는 것을 의도하는 것은 아니다. 숙주세포에 형질감염된 재조합 발현 백터를 사용하여 발현된 항체, 재조합체(recombinant)로부터 단리된 항체, 조합 인간 항체 라이브러리, 인간 면역글로불린 유전제에 대해 유전자이식된 동물(예를 들면, 마우스)로부터 단리된 항체 또는 다른 DNA 서열에 대한 인간 면역글로불린 유전자 서열의 스플라이싱을 포함하는 임의의 다른 수단에 의해 제조, 발현, 생성 또는 단리된 항체와 같이, 재조합 수단에 의해 제조, 발현, 생성 또는 단리된 인간 항체 또한 "재조합 인간 항체"로 지칭될 수 있다.
비-인간 면역글로불린 가변 도메인의 프레임워크 영역에서 하나 이상의 아미노산 잔기를 인간 가변 도메인의 상응하는 잔기로 치환하는 것은 "인간화(humanisation)"로 지칭된다. 가변 도메인의 인간화는 인간의 면역원성을 감소시킬 수 있다.
"특이성"은 특정 항체 또는 그 단편이 결합할 수 있는 상이한 유형의 항원 또는 항원 결정기의 수를 지칭한다. 항체의 특이성은 특정 항원을 고유한 분자 실체로 인식하고 다른 항원과 구별하는 항체의 능력이다. 항원 또는 에피토프에 "특이적으로 결합하는" 항체는 당업계에서 공지된 용어이다. 분자가 다른 표적보다 특정 표적 항원 또는 에피토프와 더 자주, 더 빠르게, 더 오랫동안 및/또는 더 큰 친화도로 반응하는 경우, 분자는 "특이적 결합"을 나타낸다고 일컫는다. 항체가 다른 기질에 결합하는 것보다 더 큰 친화도, 결합력으로 더 빠르게 및/또는 더 오랫동안 결합하는 경우 항체는 표적 항원 또는 에피토프에 "특이적으로 결합"한다.
항원과 항원-결합 폴리펩타이드의 해리에 대한 평형 상수(KD)로 표시되는 "친화도(affinity)"는 항원 결정기와 항체(또는 그 단편) 상의 항원 결합 부위 사이의 결합 강도의 척도이다: KD 값이 작을수록 항원 결정기와 항원 결합 폴리펩타이드 간의 결합력이 강하다. 또는, 친화도는 1/KD인 친화도 상수(KA)로 표현될 수도 있다. 친화도는 관심 대상인 특정 항원에 따라 알려진 방법으로 결정할 수 있다.
10-6보다 작은 모든 KD 값은 결합을 나타내는 것으로 간주한다. 항원 또는 항원 결정기에 대한 항체 또는 이의 단편의 특이적 결합은, 예를 들어 스캐차드(Scatchard) 분석 및/또는 방사선면역분석(RIA), 효소 면역분석(EIA), 샌드위치 경쟁 분석과 같은 경쟁적 결합 분석, 평형 투석, 평형 결합, 겔 여과, ELISA, 표면 플라즈몬 공명 또는 분광법(예를 들면, 형광 분석을 사용하여) 및 당업계에 공지된 다른 변형법을 포함하는 임의의 적합한 공지된 방식으로 결정할 수 있다.
"결합력"은 항체 또는 이의 단편과 관련 항원 사이의 결합 강도의 척도이다. 결합력은 항원 결정기와 항체 상의 항원 결합 부위 사이의 친화도와 항체에 존재하는 관련 결합 부위의 수 모두와 관련이 있다.
"인간 조직 Vδ1+ 세포"와 "조혈 및 혈액 Vδ1+ 세포" 및 "종양 침윤 림프구(TIL) Vδ1+ 세포"는 각각 인간 조직 또는 조혈 혈액계 또는 인간 종양에 포함되거나 그로부터 유래된 Vδ1+ 세포로 정의된다. 상기 모든 세포 유형은 (i) 위치 또는 유래된 곳 및 (ii) Vδ1+ TCR의 발현에 의해 식별될 수 있다.
"조절 항체"는 항체가 결합하는 표적을 발현하는 세포와 접촉하거나 결합 시 측정 가능한 변화를 부여하는 항체로, 세포 주기 및/또는 세포 수, 및/또는 세포 생존율, 및/또는 하나 이상의 세포 표면 마커 및/또는 하나 이상의 분비 분자(예를 들어, 사이토카인, 케모카인, 류코트리엔 등)의 분비 및/또는 기능(예를 들어, 표적 세포 또는 병든 세포에 대한 세포독성)의 측정 가능한 변화를 포함하지만 이에 한정되지 않는다.
세포 또는 이의 집단을 "조절"하는 방법은 상기 세포 또는 세포들에서 하나 이상의 측정가능한 변화, 또는 이로부터의 분비가 유발되어 하나 이상의 "조절된 세포"가 생성되는 방법을 지칭한다.
"면역 반응"은 조절 항체의 첨가 시, 면역계의 하나 이상의 세포 또는 하나의 세포 유형 또는 하나의 내분비 경로 또는 하나의 외분비 경로에서 측정 가능한 변화이다(세포 매개 반응, 체액성 반응, 사이토카인 반응, 케모카인 반응을 포함하지만 이에 한정되지 않음).
"면역 세포"는 면역계의 세포로 정의되며, CD34+ 세포, B-세포, CD45+ (림프구 공통 항원) 세포, 알파-베타 T-세포, 세포독성 T-세포, 헬퍼 T-세포, 형질 세포, 호중구, 단핵구, 대식세포, 적혈구 세포, 혈소판, 수지상 세포, 식세포, 과립구, 선천 림프구 세포, 자연 살해(NK) 세포 및 감마 델타 T-세포를 포함하지만 이에 한정되지 않는다. 일반적으로 면역 세포는 면역 세포를 하위 집단으로 분화하기 위해 식별하거나 그룹화 또는 클러스터링하기 위해 조합 세포 표면 분자 분석(예를 들어, 유세포 분석을 통하여)에 의해 분류된다. 이후 추가 분석을 통해 더 세분화할 수 있다. 예를 들어, CD45+ 림프구는 vδ 양성 집단과 vδ 음성 집단으로 더 세분화될 수 있다.
"모델 시스템"은 항체 또는 이의 단편과 같은 의약품이 어떻게 질병의 징후 또는 증상을 개선하는 의약으로 기능 지에 대한 이해를 돕기 위해 설계된 생물학적 모델 또는 생물학적 재현(representions)이다. 이러한 모델은 일반적으로 시험관내, 체외 및 체내에서 병든 세포, 병들지 않은 세포, 건강한 세포, 작동체 세포 및 조직 등의 사용을 포함하며, 여기서 상기 약제의 성능이 연구되고 비교된다.
"병든 세포(diseased cells)"는 암과 같은 질병, 바이러스 감염과 같은 감염, 또는 염증성 상태 또는 염증성 질환과 같은 질병의 진행과 관련된 표현형을 나타낸다. 예를 들어, 병든 세포는 종양 세포, 자가면역 조직 세포 또는 바이러스에 감염된 세포일 수 있다. 따라서 상기 병든 세포는 종양성, 또는 바이러스 감염된 또는 염증성으로 정의될 수 있다.
"건강한 세포"는 병들지 않은 정상 세포를 의미한다. "정상" 또는 "병들지 않은" 세포로도 지칭될 수 있다. 병들지 않은 세포는 암이 아닌, 감염되지 않은 또는 염증성이 아닌 세포를 포함한다. 상기 세포는 약물에 의해 부여된 병든 세포 특이성을 결정하고/하거나 약물의 치료 지수를 더 잘 이해하기 위하여 관련 질병 세포와 함께 종종 사용된다.
"병든-세포-특이성"은 작동체 세포 또는 그 집단(예를 들어, Vδ1+ 세포 집단과 같은)이 병들지 않은 세포 또는 건강한 세포에는 해를 끼치지 않으면서 암 세포와 같은 병든 세포를 구별하고 사멸시키는 데 얼마나 효과적인지를 측정한 것이다. 이 잠재력은 모델 시스템에서 측정될 수 있으며, 병든 세포를 선택적으로 사멸시키거나 용해하는 작동체 세포 또는 작동체 세포 집단의 경향 대 병들지 않은 세포 또는 건강한 세포를 사멸시키거나 용해하는 상기 작동체 세포(들)의 경향을 비교하는 것을 포함할 수 있다. 상기 병든-세포-특이성은 약제의 잠재적인 치료 지수에 대한 정보를 제공할 수 있다.
"향상된 병든-세포 특이성"은 예를 들면 Vδ1+ 세포 또는 그의 집단과 같은 작동체 세포의 표현형을 나타내며, 이는 병든 세포를 특이적으로 사멸시키는 능력을 더욱 증가시키도록 조절되었다. 이 향상은 병든-세포 사멸 특이성 또는 선택성에서의 배수-변화 또는 백분율 증가를 포함하는 다양한 방식으로 측정될 수 있다.
적절하게는, 본 발명의 항체 또는 이의 단편(즉, 폴리펩타이드)이 단리된다. "단리된" 폴리펩타이드는 원래의 환경으로부터 제거된 것이다. 용어 "단리된"은 상이한 항원 특이성을 갖는 다른 항체가 실질적으로 없는 항체를 지칭하기 위하여 사용될 수 있다(예를 들어, Vδ1에 특이적으로 결합하는 단리된 항체 또는 그의 단편은 Vδ1 이외의 항원에 특이적으로 결합하는 항체가 실질적으로 없는 것이다). 용어 "단리된"은 또한 단리된 항체가 약학 조성물의 활성 성분으로 제형화될 때 치료적으로 투여하기에 충분히 순수하거나, 또는 70-80%(w/w) 이상 순수, 더욱 바람직하게는 80-90%(w/w) 이상 순수, 더욱 더 바람직하게는 90-95% 순수; 가장 바람직하게는 95%, 96%, 97%, 98%, 99% 이상 순수하거나 또는 100%(w/w) 순수한 제제를 지칭하기 위해 사용될 수 있다.
적절하게는, 본 발명에 사용된 폴리뉴클레오티드는 단리된다. "단리된" 폴리뉴클레오티드는 원래의 환경으로부터 제거된 것이다. 예를 들어, 자연 발생 폴리뉴클레오티드는 자연계에 공존하는 물질의 일부 또는 전체로부터 분리되는 경우 단리된다. 예를 들어 폴리뉴클레오티드가 자연 환경의 일부가 아닌 벡터에 클로닝되거나 cDNA 내에 포함되는 경우 폴리뉴클레오티드는 단리된 것으로 간주된다.
항체 또는 이의 단편은 천연 발생 대립유전자 변이체 뿐만 아니라 돌연변이체 또는 임의의 다른 비-자연으로 발생하는 변이체 역시 포함하는 "기능적 활성 변이체"일 수 있다. 당업계에 공지된 바와 같이, 대립유전자 변이체는 본질적으로 폴리펩타이드의 생물학적 기능을 변경하지 않는 하나 이상의 아미노산이 치환, 결실 또는 부가된 것을 특징으로 하는 (폴리)펩파이드의 대체 형태이다. 예를 들어, CDRs를 함유하는 프레임워크가 변형될 때, CDRs 자체가 변형될 때, 상기 CDRs가 대체 프레임워크에 이식될 때, 또는 N- 또는 C-말단 연장부가 포함될 때, 상기 기능적 활성 변이체는 여전히 기능할 수 있으며 이에 한정되지 않는다. 추가로, 결합 도메인을 함유하는 CDR은 다른 항체와 공유되는 것과 같은 상이한 파트너 사슬과 쌍을 이룰 수 있다. 소위 '공통' 경 사슬 또는 '공통' 중 사슬과 공유 시, 상기 결합 도메인은 여전히 기능할 수 있다. 추가로, 상기 결합 도메인은 다량체화될 때 기능할 수 있다. 추가로, '항체 또는 이의 단편'은 또한 VH 또는 VL 또는 불변 도메인이 다른 기준 서열(예를 들어, IMGT.org에 나열됨) 쪽으로 혹은 다른 쪽으로 변형되어 여전히 기능하는 기능적 변이체를 포함할 수 있다.
두 개의 밀접하게 관련된 폴리펩타이드 서열을 비교하기 위해, 제1 폴리펩타이드 서열과 제2 폴리펩타이드 서열 사이의 "% 상동성"은 폴리펩타이드 서열에 대한 표준 설정(BLASTP)으로 NCBI BLAST v2.0을 사용하여 계산될 수 있다. 두 개의 밀접하게 관련된 폴리뉴클레오티드 서열을 비교하기 위해, 제1 폴리뉴클레오티드 서열과 제2 폴리뉴클레오티드 서열 사이의 "% 상동성"은 뉴클레오티드 서열에 대한 표준 설정(BLASTN)으로 NCBI BLAST v2.0을 사용하여 계산될 수 있다.
폴리펩타이드 또는 폴리뉴클레오티드 서열은 전체 길이에 걸쳐 다른 폴리펩타이드 또는 폴리뉴클레오티드 서열과 100% 상동성을 갖는 경우 같거나 "동일하다"고 한다. 서열의 잔기는 왼쪽에서 오른쪽으로, 즉 폴리펩타이드에 대해서는 N-말단에서 C-말단으로, 폴리뉴클레오티드에 대해서는 5'에서 3' 말단으로 번호가 매겨진다.
서열 간의 "차이"는 제1 서열과 비교하여 제2 서열의 위치에서 단일 아미노산 잔기의 삽입, 결실 또는 치환을 지칭한다. 두 폴리펩타이드 서열은 하나, 둘 또는 그 이상의 아미노산 차이를 포함할 수 있다. 제1 서열과 동일(100% 상동성)하지 않은 제2 서열의 삽입, 결실 또는 치환은 % 상동성을 감소시킨다. 예를 들어, 동일한 서열이 9개의 아미노산 잔기 길이인 경우, 제2 서열에서 하나의 치환은 88.9%의 상동성을 초래한다. 제1 및 제2 폴리펩타이드 서열이 9개의 아미노산 잔기 길이이고 6개의 동일한 잔기를 공유한다면, 제1 및 제2 폴리펩타이드 서열은 66% 초과의 상동성을 갖는다(제1 및 제2 폴리펩타이드 서열은 66.7% 상동성을 갖는다).
또는, 제1, 기준 폴리펩타이드 서열을 제2, 비교 폴리펩타이드 서열과 비교하기 위하여, 제2 서열을 생성하기 위해 제1 서열에 이루어진 부가, 치환 및/또는 결실의 수를 확인할 수 있다. "부가"는 하나의 아미노산 잔기를 (제1 폴리펩타이의 양쪽 말단에 추가하는 것을 포함하여) 제1 폴리펩타이드의 서열에 추가하는 것이다. "치환"은 제1 폴리펩타이드의 서열에서 하나의 아미노산 잔기를 다른 하나의 아미노산 잔기로 대체하는 것이다. 상기 치환은 보존적이거나 비-보존적일 수 있다. "결실"은 제1 폴리펩타이드의 서열에서 하나의 아미노산 잔기를 (제1 폴리펩타이의 양쪽 말단에서 제거하는 것을 포함하여) 제거하는 것이다.
"보존적" 아미노산 치환은 아미노산 잔기가 화학 구조가 유사한 다른 아미노산 잔기로 대체되어, 폴리펩타이드의 기능, 활성 또는 다른 생물학적 특성에 거의 영향을 미치지 않을 것으로 예상되는 아미노산 치환이다. 이러한 보존적 치환은 적절하게는 하기 그룹 내의 하나의 아미노산이 동일한 그룹 내의 다른 아미노산 잔기로 치환되는 치환이다:

적절하게는, 소수성 아미노산 잔기는 비극성 아미노산이다. 더욱 적절하게는, 소수성 아미노산 잔기는 V, I, L, M, F, W 또는 C로부터 선택된다.
본 명세서에 사용된 바와 같이, 폴리펩타이드 서열의 넘버링 및 CDRs 및 FRs의 정의는 Kabat 시스템에 따라 정의된 바와 같다(Kabat et al., 1991, 그 전문이 본 명세서에 참고로 포함됨). 제1 및 제2 폴리펩타이드 서열 사이의 "상응하는" 아미노산 잔기는 Kabat 시스템에 따라 제2 서열의 아미노산 잔기와 동일한 위치를 공유하는 제1 서열의 아미노산 잔기이고, 제2 서열에서의 아미노산 잔기는 제1 서열과 동일성이 다를 수 있다. 적절하게는 Kabat 정의에 따라 프레임워크와 CDRs가 동일한 길이라면, 상응하는 잔기는 동일한 숫자(및 문자)를 공유한다. 배열은 수동으로 또는 예를 들어 표준 설정을 사용하는 NCBI BLAST v2.0(BLASTP 또는 BLASTN)과 같은 서열 배열에 대해 알려진 컴퓨터 알고리즘을 사용하여 수행될 수 있다.
본 명세서에서 "에피토프"라 함은 항체 또는 이의 단편에 의해 특이적으로 결합되는 표적의 부분을 지칭한다. 에피토프는 또한 "항원 결정기"로도 지칭될 수 있다. 두 항체 모두가 동일하거나 입체적으로 중첩되는 에피토프를 인식한다면 항체는 다른 항체와 "본질적으로 동일한 에피토프"에 결합한다. 두 항체가 동일하거나 중복되는 에피토프에 결합하는지 여부를 결정하기 위해 일반적으로 사용되는 방법은 경쟁 분석이며, 이는 표지된 항원이나 표지된 항체 중 하나를 사용하여 다양한 형태(예를 들어, 방사성 또는 효소 표지를 사용하는 웰 플레이트 또는 항원 발현 세포에 대한 유세포 분석)으로 구성될 수 있다.
단백질 표적에서 발견되는 에피토프는 "선형 에피토프" 또는 "입체 에피토프"로 정의될 수 있습니다. 선형 에피토프는 단백질 항원에서 연속적인 아미노산 서열에 의해 형성된다. 입체 에피토프는 단백질 서열에서는 불연속적이지만 단백질이 3차원 구조로 접힐 때 서로 접하는 아미노산으로 형성된다.
본 명세서에서 사용되는 용어 "벡터"는 연결된 또 다른 핵산을 수송할 수 있는 핵산 분자를 지칭하고자 하는 것이다. 벡터의 한 유형은 "플라스미드"로, 이는 추가적인 DNA 세그먼트가 연결(ligate)될 수 있는 원형의 이중 가닥 DNA 루프를 지칭한다. 다른 유형의 벡터는 바이러스 벡터이며, 그 안에서 추가의 DNA 세그먼트가 바이러스 게놈에 연결될 수 있다. 특정 벡터는 이들이 도입된 숙주 세포에서 자발적으로 복제할 수 있다(예를 들어, 박테리아 복제 기점을 갖는 박테리아 벡터 및 에피솜 포유동물 및 효모 벡터). 다른 벡터(예를 들어, 비-에피솜 포유동물 벡터)는 숙주 세포 내로 도입 시 숙주 세포의 게놈 내로 통합될 수 있으며, 이에 의해 숙주의 게놈과 함께 복제된다. 더 나아가 특정 벡터는 작동가능하게 연결된 유전자의 발현을 지시할 수 있다. 본 명세서에서 상기 벡터는 "재조합 발현 벡터"(또는 간단히 "발현 벡터")로 지칭된다. 일반적으로 재조합 DNA 기술에서 유용한 발현 벡터는 종종 플라스미드의 형태이다. 플라스미드는 가장 일반적으로 사용되는 벡터의 형태이므로, 본 명세서에서 "플라스미드"와 "벡터"는 혼용될 수 있다. 그러나, 본 발명은 동등한 기능을 제공하는 바이러스 벡터(예를 들어, 복제 결함 레트로바이러스, 아데노바이러스 및 아데노-관련 바이러스)와 박테리오파지 및 파지미드 시스템과 같은 다른 형태의 발현 벡터를 포함하고자 한다. 본 명세서에서 사용되는 용어 "재조합 숙주 세포"(또는 간단히 "숙주 세포")는 재조합 발현 벡터가 도입된 세포를 지칭하고자 하는 것이다. 상기 용어는 특정 대상 세포뿐만 아니라 상기 세포의 자손(progeny)도 지칭하려는 것으로, 예를 들어, 상기 자손이 세포주 또는 세포 은행을 만드는 데 사용되면, 이후 선택적으로 저장, 제공, 판매, 이전 또는 사용되어 본 명세서에 기재된 바와 같이 항체 또는 이의 단편을 제조한다.
"대상", "환자" 또는 "개인"이라 함은 치료될 대상, 특히 포유동물 대상을 지칭한다. 포유류 대상은 인간, 비-인간 영장류, 농장 동물(소와 같은), 스포츠 동물, 또는 개, 고양이, 기니피그, 토끼, 쥐 또는 생쥐와 같은 애완 동물을 포함합니다. 일부 실시예에서, 대상은 인간이다. 다른 실시예에서, 대상은 마우스와 같은 비-인간 포유동물이다.
용어 "충분한 양"은 원하는 효과를 나타내기에 충분한 양을 의미한다. 용어 "치료적 유효량"은 질병 또는 장애의 증상을 개선하는데 효과적인 양이다. 예방은 치료로 간주될 수 있기 때문에 치료적 유효량은 "예방적 유효량"일 수 있다.
본 명세서에서 사용되는 용어 "약"은 특정된 값보다 최대 10% 이상 및 최대 10% 이하를 포함하며, 적절하게는 특정된 값보다 최대 5% 이상 및 최대 5% 이하를 포함하고, 특히 특정된 값을 포함한다. 용어 "내지"는 특정된 경계 값을 포함한다.
질병 또는 장애의 징후 또는 증상의 중증도, 대상이 경험하는 상기 징후 또는 증상의 빈도, 또는 둘 모두가 감소되면 질병 또는 장애는 "개선"된 것이다.
본 명세서에서 사용되는 "질병 또는 장애의 치료"는 대상이 경험하는 질병 또는 장애의 적어도 하나의 징후 또는 증상의 빈도 및/또는 중증도를 감소시키는 것을 의미한다.
본 명세서에 사용되는 "암"은 세포의 비정상적인 성장 또는 분열을 의미한다. 일반적으로 암세포의 성장 및/또는 수명은 정상 세포 및 주변 조직의 성장 및/또는 수명을 초과하며 이와 조화를 이루지 않는다. 암은 양성, 전암성 또는 악성일 수 있다. 암은 다양한 세포 및 조직에서 발생하며, 구강(예를 들어, 입, 혀, 인두 등), 소화기계(예를 들어, 식도, 위, 소장, 결장, 직장, 간, 담관, 담낭, 췌장 등), 호흡기계(예를 들어, 후두, 폐, 기관지 등), 뼈, 관절, 피부(예를 들어, 기저 세포, 편평 세포, 수막종 등), 유방, 생식기 계통(예를 들어, 자궁, 난소, 전립선, 고환 등), 비뇨기계(예를 들어, 방광, 신장, 요관 등), 눈, 신경계(예를 들어, 뇌 등), 내분비계(예를 들어, 갑상선 등) 및 조혈계(예를 들어, 림프종, 골수종, 백혈병, 급성 림프구성 백혈병, 만성 림프구성 백혈병, 급성 골수성 백혈병, 만성 골수성 백혈병 등)을 포함한다.
γδ
T 세포를 조절하는 방법
본 발명의 첫 번째 양태에 따르면, Vδ1 T 세포를 포함하는 세포 집단에 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 투여하는 것을 포함하는, 델타 가변 1 사슬(Vδ1) T 세포를 조절하는 체외 방법이 제공된다. 항체 또는 이의 단편을 "투여"하는 것은 Vδ1 T 세포를 "접촉시키는" 것을 포함하는 것으로 이해될 것이다.
Vδ1 T 세포의 조절은 다음을 포함할 수 있다:
- 예를 들어, Vδ1 T 세포의 수를 선택적으로 증가시키거나 Vδ1 T 세포의 생존을 증진시키는 것에 의한, Vδ1 T 세포의 증식;
- 예를 들어, Vδ1 T 세포 효능을 증가시키는, 즉 표적 세포의 사멸을 증가시키는 것에 의한, Vδ1 T 세포의 자극;
- 예를 들어, Vδ1 T 세포의 지속성 증가시키는 것에 의한, Vδ1 T 세포 고갈 방지;
- Vδ1 T 세포의 탈과립화;
- 예를 들어, Vδ1 TCR 세포 표면의 발현을 하향조절, 즉 Vδ1 TCR 내재화 또는 Vδ1 TCR 단백질 발현 감소 또는 Vδ1 TCR의 결합 차단을 야기하는 것에 의한, Vδ1 T 세포의 면역억제;
- 예를 들어, Vδ1 T 세포 증식을 억제하거나 또는 Vδ1 T 세포 사멸을 유도(즉, Vδ1 T 세포를 사멸시킴)하는 것에 의한, Vδ1 T 세포 수 감소.
상기 Vδ1 T 세포의 조절은, 예를 들어 Vδ1 T 세포 활성화 또는 Vδ1 T 세포 억제를 포함할 수 있다. 일 실시예에서, Vδ1 T 세포는 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 투여함으로써 활성화된다. 다른 실시예에서, Vδ1 T 세포는 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 투여함으로써 억제된다. 다른 실시예에서, Vδ1 T 세포는 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 환자에게 투여할 때 억제되지 않는다.
일 실시예에서, Vδ1 T 세포의 조절은 배양물(즉, 시험관내 또는 체외)에서 항-TCR 델타 1 가변 항체 또는 이의 단편을 Vδ1 T 세포에 투여하는 것을 포함한다. Vδ1 T 세포는, 예를 들어, 다른 림프구 세포 유형(예를 들어, αβ T 세포 또는 NK 세포)을 포함하는 세포 집단과 같은, 혼합 세포 집단에 존재할 수 있다.
일 실시예에서, Vδ1 T 세포를 포함하는 세포 집단은 항-Vδ1 항체 또는 이의 단편의 투여 전에 (즉, 본 명세서에 기재된 바와 같이 시료로부터) 단리된다. 추가의 실시예에서, 세포 집단은 항-Vδ1 항체 또는 이의 단편의 투여 전에 T 세포에 대해 농축된다. 또 다른 실시예에서, 세포 집단은 항-Vδ1 항체 또는 이의 단편의 투여 전에 γδ T 세포에 대해 농축된다.
방법은 또한 γδ T 세포의 정제된 분획을 포함하는 세포 집단에 대해 수행될 수 있다. 상기 실시예에서, 세포 집단은 항-Vδ1 항체 또는 이의 단편의 투여 전에 시료에 존재하는 αβ T 세포 및/또는 NK 세포와 같은 γδ T 세포 이외의 세포 유형이 격감된다. 세포 집단은 부가적으로 또는 대안적으로 항-Vδ1 항체 또는 이의 단편의 투여 전에 T 세포 및/또는 γδ 세포와 같은 Vδ1을 함유할 수 있는 세포 유형이 농축될 수 있다. 예를 들어, 시료를 배양하기 전에, 시료는 T 세포가 농축되거나 γδ T 세포가 농축되거나 αβ T 세포가 격감되거나 비-γδ T 세포가 격감될 수 있다. 일 실시예에서, 시료는 먼저 αβ T 세포가 격감된 뒤 CD3+ 세포가 농축된다. 농축 또는 고갈은 농축/고갈될 표현형과 관련된 세포 표면 상의 분자에 결합하는 항체로 코팅된 자기 비드를 사용하는 것과 같은 당업계에 공지된 기술을 사용하여 수행될 수 있다.
세포 배양물에서 림프구 이외의 세포 유형의 존재는 Vδ1 세포 증식을 억제할 수 있다. 예를 들어 기질, 상피, 종양 및/또는 영양 세포와 같은 상기 세포는 배양 전에 제거될 수 있다. 따라서, 일 실시예에서, 세포 집단은 배양 동안 기질 세포와 직접 접촉하지 않는다. 기질 세포의 예로는 섬유아세포, 혈관주위세포, 중간엽 세포, 각질세포, 내피 세포 및 비-혈액학적 종양 세포를 포함한다. 바람직하게는, 림프구는 배양 동안 섬유아세포와 직접 접촉하지 않는다. 일 실시예에서, 세포 집단은 배양 동안 상피 세포와 직접 접촉하지 않는다. 일 실시예에서, 세포 집단은 배양 동안 종양 세포 및/또는 영양 세포와 직접 접촉하지 않는다.
일 실시예에서, 방법은 실질적으로 기질 세포와의 접촉이 없는 상태에서 Vδ1 T 세포를 배양하는 것을 포함한다. 추가 실시예에서, 방법은 실질적으로 섬유아세포와의 접촉이 없는 상태에서 Vδ1 T 세포를 배양하는 것을 포함한다.
일 실시예에서, 상기 방법은 실질적으로 혈청이 없는 배지(예를 들어, 무혈청(serum-free) 배지 또는 혈청 대체제(SR, serum-replacement)를 함유하는 배지)에서 Vδ1 T 세포를 배양하는 것을 포함한다. 따라서, 일 실시예에서, 방법은 무혈청 배지에서 배양하는 것을 포함한다. 상기 무혈청 배지는 또한 혈청 대체제 배지를 포함할 수 있으며, 혈청 대체제는 인간 또는 동물 유래 혈청의 사용을 피하기 위하여 화학적으로 정의된 성분을 기반으로 한다. 다른 실시예에서, 상기 방법은 혈청(예를 들어, 인간 AB 혈청 또는 소태아혈청(FBS))을 함유하는 배지에서 배양하는 것을 포함한다. 일 실시예에서, 상기 배지는 혈청 대체제를 함유한다. 일 실시예에서, 상기 배지는 동물 유래의 제품을 함유하지 않는다.
무혈청 배지에서 배양된 시료는 혈청의 여과, 침전, 오염 및 공급과 관련된 문제를 피할 수 있다는 이점이 있음은 당연하다. 또한, 동물 유래 제품은 인간 치료제의 임상 등급으로 제조하는데 사용하기에는 적당하지 않다. 세포, 특히 Vδ1 T 세포에 대해 무혈청 배지를 사용하면 AB 혈청을 함유하는 배지를 사용하는 것에 비해 시료로부터 수득된 세포의 수가 실질적으로 증가된다.
일 실시예에서, 항-Vδ1 항체 또는 이의 단편은 가용성 또는 고정화된 형태이다. 예를 들어, 항체 또는 이의 단편은 가용성 형태로 Vδ1 T 세포에 투여될 수 있다. 또는, 항체 또는 이의 단편은 항체 또는 이의 단편이 비드 또는 플레이트와 같은 표면에 부착되거나 공유 결합된 후 (즉, 고정화된 형태로) Vδ1 T 세포에 투여될 수 있다. 일 실시예에서, 항체는 Fc-코팅된 웰과 같은 표면 상에 고정화된다. 또는 항체 또는 이의 단편은 세포의 표면에 부착된다(예를 들어, 항원제시세포(APC, antigen presenting cell)의 표면에 고정된다). 또 다른 실시예에서, 항체는 세포 집단이 항체와 접촉될 때 표면에 고정되지 않는다.
항-Vδ1 항체 또는 이의 단편에 의해 접촉된 세포 집단은 다양한 시료 유형으로부터 수득될 수 있다(단리 방법은 하기에 추가로 기재됨). 일 실시예에서, 시료는 비-조혈조직 시료이다. 본 명세서에서 "비-조혈조직" 또는 "비-조혈조직 시료"라 함은 피부(예를 들어, 인간 피부) 및 장(예를 들어, 인간 장)을 포함한다. 비-조혈조직은 혈액, 골수, 림프 조직, 림프절 조직 또는 흉선 조직 이외의 조직이다. 일 실시예에서, 비-조혈조직 시료는 피부(예를 들어, 인간 피부)이다. 일부 실시예에서, 세포 집단(예를 들어, γδ T 세포)는 혈액 또는 활액(synovial fluid)과 같은 특정 유형의 생물학적 유체 시료로부터는 수득되지 않는다. 일부 실시예에서, 세포 집단(예를 들어, γδ T 세포)은 피부(예를 들어, 인간 피부)로부터 수득되며, 이는 당업계에 공지된 방법에 의해 수득될 수 있다. 예를 들어, 비-조혈조직 시료로부터의 세포 배출을 촉진하도록 구성된 합성 스캐폴드 상에서 비-조혈조직 시료를 배양하는 것에 의해, 세포 집단은 비-조혈조직 시료로부터 수득될 수 있다. 또는 상기 방법은 위장관(예를 들어, 결장 또는 장), 유선, 폐, 전립선, 간, 비장, 췌장, 자궁, 질 및 기타 피부, 점막 또는 장액막에서 얻은 세포 집단(예를 들어, γδ T 세포)에 적용될 수 있다.
다른 실시예에서, 시료는 조혈 시료 또는 그의 분획이다(즉, 세포 집단은 조혈 시료 또는 그의 분획으로부터 수득된다). 본 명세서에서 "조혈 시료" 또는 "조혈조직 시료"라 함은 혈액(예를 들어, 말초혈 또는 제대혈), 골수, 림프 조직, 림프절 조직, 흉선 조직, 및 이들의 분획 또는 농축 부분을 포함한다. 시료는 바람직하게는 버피 코트(buffy coat) 세포, 백혈구채집(leukapheresis) 생성물, 말초혈액 단핵세포(PBMC) 및 저밀도 단핵세포(LDMC)를 포함하는, 말초혈 또는 제대혈 또는 이의 분획을 포함하는 혈액이다. 일부 실시예에서 시료는 인간 혈액 또는 이의 분획이다. 세포는 밀도구배 원심분리와 같은 당업계에 공지된 기술을 사용하여 혈액 시료로부터 수득될 수 있다. 예를 들어, 동일 부피의 FICOLL-HYPAQUE 상에 전혈 층을 이루고, 상온에서 15-30분 동안 400xg에서 원심분리할 수 있다. 계면 물질은 배양 배지에서 수집 및 세척할 수 있는 저밀도 단핵세포를 포함하고, 상온에서 10분 동안 200xg에서 원심분리할 수 있다.
세포 집단은 예를 들어, 유방 또는 전립선 종양같은 암 조직 시료로부터 수득될 수 있다(즉, γδ T 세포는 암 조직 시료에도 상재할 수 있다). 일부 실시예에서, 세포 집단은 인간 암 조직 시료(예를 들어, 고형 종양 조직)로부터 유래할 수 있다. 다른 실시예에서, 세포 집단은 인간 암 조직 이외의 시료(예를 들어, 상당한 수의 종양 세포가 없는 조직)로부터 유래할 수 있다. 예를 들어, 세포 집단은 주변 또는 인접한 암 조직과 분리된 피부 영역(예를 들면, 건강한 피부)에서 유래할 수 있다. 따라서, 일부 실시예에서, 세포 집단은 인간 암 조직(예를 들어, 인간 암 조직)으로부터 수득되지 않는다.
세포 집단은 인간 또는 비-인간 동물 조직으로부터 수득될 수 있다. 따라서, 상기 방법은 인간 또는 비-인간 동물 조직으로부터 세포 집단을 수득하는 단계를 추가로 포함할 수 있다. 일 실시예에서 시료는 인간으로부터 수득되었다. 다른 실시예에서, 시료는 인간이 아닌 동물 대상으로부터 수득되었다.
γδ
T 세포의 증식
일 실시예에서, 조절은 Vδ1 T 세포의 활성화, 특히 Vδ1 T 세포의 증식을 포함한다. 따라서, 본 발명의 일 양태에 따르면, Vδ1 T 세포를 포함하는 세포 집단에 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 투여하는 것을 포함하는, Vδ1 T 세포를 증식하는 체외 방법이 제공된다. Vδ1 T 세포의 상기 증식은 Vδ1 T 세포의 수의 선택적으로 증가시키는 것 및/또는 Vδ1 T 세포의 생존 증진시키는 것을 통해 달성될 수 있다. 일 실시예에서, Vδ1 T 세포의 증식은 배양물(즉, 시험관내 또는 체외)에서 항-TCR 델타 1 가변 항체 또는 이의 단편을 Vδ1 T 세포에 투여하는 것을 포함한다. Vδ1 T 세포는, 예를 들어, 다른 림프구 세포 유형(예를 들어, αβ T 세포 또는 NK 세포)을 포함하는 세포 집단과 같은, 혼합 세포 집단에 존재할 수 있다.
따라서, 본 발명은 농축된 γδ T 세포(예를 들어, Vδ1 T 세포) 집단을 생성하기 위한 체외 방법을 제공한다. 농축된 집단은 혼합된 세포 집단 또는 이의 정제된 분획을 항체 또는 이의 단편과 접촉시키는 것을 포함하는 방법에 의해 혼합된 세포 집단(예를 들어, 환자/공여자로부터 채취한 시료에서 수득됨)으로부터 생성될 수 있다. 상기 항체(또는 이의 단편)는 γδ TCR의 Vδ1 사슬에 특이적인 에피토프에 결합함으로써 Vδ1 T 세포를 선택적으로 증식시킨다.
또한, 본 명세서에 정의된 방법에 따라 수득된 증식된 Vδ1 T 세포 집단이 제공된다. 본 발명의 이러한 양태에 따르면, 상기 증식된 Vδ1 T 세포 집단은 시험관내 또는 체외에서 수득 및/또는 증식될 수 있음은 당연할 것이다. 일 양태에서, 본 명세서에 정의된 방법에 따라 수득된 증식된 Vδ1 집단이 제공되며, 여기서 Vδ1 집단은 시험관내 또는 체외에서 단리되고 증식된다.
본 명세서에 기재된 바와 같은 항체 또는 이의 단편은 γδ T 세포(예를 들어, Vδ1 T 세포)를 증식하는 방법에 사용될 수 있다. 상기 방법은 시험관내에서 수행될 수 있다. 증식 방법이 시험관내에서 수행되는 경우, 항체(또는 이의 단편)는 전술한 바와 같이 수득된 단리된 γδ T 세포(예를 들어, Vδ1 T 세포)에 적용될 수 있다. 일부 실시예에서, γδ T 세포는 비-조혈조직 시료로부터 단리된 세포 집단으로부터 증식된다. 다른 실시예에서, γδ T 세포는 혈액 시료와 같은 조혈조직 시료로부터 단리된 세포 집단으로부터 증식된다.
γδ T 세포(예를 들어, Vδ1 T 세포)의 증식은 본 명세서에 기재된 바와 같이 항체 또는 이의 단편, 및 사이토카인의 존재 하에 시료를 배양하는 것을 포함할 수 있다. 사이토카인에는 인터루킨, 림포카인, 인터페론, 집락 자극 인자 및 케모카인이 포함될 수 있다. 일 실시예에서, 사이토카인은 인터루킨-2(IL-2), 인터루킨-4(IL-4), 인터루킨-6(IL-6), 인터루킨-7(IL-7), 인터루킨-8(IL-8), 인터루킨-9(IL-9), 인터루킨-12(IL-12), 인터루킨-18(IL-18), 인터루킨-21(IL-21), 인터루킨-33(IL-33), 인슐린 유사 성장 인자 1(IGF-1), 인터루킨-1β(IL-1β), 인터페론-γ(IFN-γ) 및 기질 세포-유래 인자-1(SDF-1)으로부터 선택된다. 본 명세서에 기재된 사이토카인에 대한 언급은 배양물에서 Vδ1 T 세포에 대한 유사한 생리학적 효과를 촉진하는 능력과 관련하여 상기 사이토카인과 동일한 활성을 갖는 모든 화합물을 포함할 수 있음은 당연하며, 모사체 또는 이의 기능적 등가물을 포함하지만 이에 한정되지 않는다.
일 실시예에서, 상기 사이토카인은 사이토카인의 공통 사이토카인 수용체 감마-사슬(γc) 패밀리이다. 추가 실시예에서, γc-사이토카인은 IL-2, IL 4, IL-7, IL-9, IL-12, IL-15, IL-21 또는 이들의 혼합물로부터 선택된다.
사용된 사이토카인(예를 들면, 인터루킨)은 인간 또는 동물 기원일 수 있으며, 바람직하게는 인간 기원이다. 이는 야생형 단백질 또는 그의 수용체에 결합할 수 있는 생물학적 활성 단편 또는 변이체일 수 있다. 상기 결합은 본 발명에 따른 방법의 조건에서 γδ T 세포의 활성화를 유도할 수 있다. 더욱 바람직하게는, 사이토카인은 예를 들어 펩타이드, 폴리펩타이드 또는 생물학적 활성 단백질과 같은 다른 분자와 융합되거나 복합된 가용성 형태일 수 있다. 바람직하게는, 인간 재조합 사이토카인이 사용된다. 보다 바람직하게는, 인터루킨 농도의 범위는 1-10000 U/ml, 훨씬 더 바람직하게는 100-1000 U/ml 사이에서 변할 수 있다.
추가 실시예에서, 사이토카인은 케모카인이다. 케모카인은 γδ T 세포를 수득하기 위해 사용되는 시료에 따라 달라지며, 선택될 것이라는 것은 당연하다.
한 실시예에서, 상기 방법은 IL-2, IL-9 및/또는 IL-15의 존재 하에 세포 집단을 배양하는 것을 포함한다. 추가 실시예에서, 상기 방법은 IL-2 및/또는 IL-15(즉, IL 2, IL-15 또는 이들의 조합)의 존재 하에 세포 집단을 배양하는 것을 포함한다. 다른 실시예에서, 상기 방법은 IL-9 및/또는 IL-15(즉, IL 9, IL-15 또는 이들의 조합)의 존재 하에 세포 집단을 배양하는 것을 포함한다. 일 실시예에서, 상기 방법은 IL-2, IL-9 및/또는 IL-15, 및 추가의 성장 인자(예를 들어, IL-21)의 존재 하의 세포 집단을 포함한다. 다른 실시예에서, 상기 방법은 IL-2 및/또는 IL-15 이외의 성장 인자가 없는 배지에서 세포 집단을 배양하는 것을 포함한다. 다른 실시예에서, 상기 방법은 IL-9 및/또는 IL-15 이외의 성장 인자가 없는 배지에서 세포 집단을 배양하는 것을 포함한다. 추가 실시예에서, 상기 방법은 IL-2, IL-9 및/또는 IL-15가 보충된 기본 배지로 구성된 배지에서 세포 집단을 배양하는 것을 포함한다. 추가 실시예에서, 상기 방법은 IL-2 및/또는 IL-15가 보충된 기본 배지로 구성된 배지에서 세포 집단을 배양하는 것을 포함한다.
일 실시예에서, 상기 방법은 IL 21의 존재 하에 세포 집단을 배양하는 것을 포함한다.
일 실시예에서, 상기 방법은 IL 4의 존재 하에 세포 집단을 배양하는 것을 포함한다. Vδ1 T 세포에 대한 IL-4에 의해 촉진되는 생리학적 효과(WO2016/198480에 기재된 바와 같은)는 NKG2D 및 NCR 발현 수준의 감소와 세포독성 기능의 억제 및 향상된 선택적 생존을 포함한다. 또한 배양 후기 동안 IL-4가 없으면 항종양 또는 항바이러스 치료제로 사용하기에 보다 적절한 표현형으로 세포의 생리학적 특성을 변화시킬 수 있다는 것은 공지되어 있다. 따라서, 일 실시예에서, 상기 증식 방법은 IL-4와 같은 IL-4-유사 활성을 갖는 성장 인자의 부재 하에 시료를 추가로 배양하는 것을 포함한다. 일 실시예에서, 상기 증식 방법은 IL-4의 부재 하에 시료를 배양하는 것을 포함한다.
일 실시예에서, 사이토카인은 인터루킨-15-유사 활성을 갖는 성장 인자, 즉 배양물에서 Vδ1 T 세포에 대해 유사한 생리학적 효과를 촉진하는 능력과 관련하여 IL-15와 동일한 활성을 갖는 화합물이지만, IL-15 및 IL-15 모사체 또는 IL-2 및 IL-7을 포함한 IL-15의 기능적 등가물에 한정되는 것은 아니다. 배양된 Vδ1 T 세포에 대한 IL-15, IL-2 및 IL-7에 의해 촉진되는 생리학적 효과(WO2016/198480에 기재된 바와 같은)는 본질적으로 동등하며, 즉, 세포독성이 큰 표현형으로 세포 분화를 유도한다. 또한, 배양 초기 기간 동안 IL-2, IL-7 및 IL-15가 없으면, 생존이 상기 사이토카인에 결정적으로 의존되는 (TCRαβ+ T 및 Vδ2+ T 세포를 포함한) 오염 세포의 기아(starvation) 및 아포토시스(apoptosis)에 기여한다는 것이 공지되어 있다. 따라서, 일 실시예에서, 상기 증식 방법은 IL-15-유사 활성을 갖는 성장 인자의 부재 하에 시료를 먼저 배양하는 것을 포함한다.
따라서, 일 실시예에서, 상기 방법은 세포 집단을 IL-4를 포함하는 제1 배양 배지에서 배양한 후, IL-15를 포함하는 제2 배양 배지에서 세포 집단을 배양하는 것을 포함한다.
일 실시예에서, 제1 배양 배지에는 IL-15, IL-2 및/또는 IL-7가 없다. 일 실시예에서, 제2 배양 배지에는 IL-4가 없다.
따라서, 일 실시예에서, 상기 증식 방법은 다음을 포함한다:
(1) 시료에서 세포를, 본 명세서에 기술된 항체 또는 이의 단편 및 IL-4를 포함하는 제1 배양 배지에서, IL-15, IL-2 및 IL-7의 부재 하에, 배양하는 단계; 및
(2) 단계 (1)에서 얻은 세포를, 본 명세서에 기술된 항체 또는 이의 단편 및 IL-15를 포함하는 제2 배양 배지에서, IL-4의 부재 하에, 배양하는 단계.
본 명세서에 기재된 바와 같이, 배양 배지는 또한 Vδ1 T 세포의 증식을 추가로 향상시킬 수 있는 사이토카인을 비롯한 다른 성장 인자를 함유할 수 있다. 상기 사이토카인의 예로는 (i) IFN-γ 및 IFN-γ-유사 활성을 갖는 임의의 성장 인자, (ii) IL-21 및 IL-21-유사 활성을 갖는 임의의 성장 인자 및 (iii) IL-1β 및 IL-1β 유사 활성을 갖는 임의의 성장 인자를 포함하지만 이에 한정되지 않는다. 추가될 수 있는 다른 성장 인자의 예로는 인간 항-SLAM 항체, CD27의 임의의 가용성 리간드 또는 CD7의 임의의 가용성 리간드와 같은 공동자극분자(co-simulatory molecules)를 포함한다. 상기 성장인자의 임의의 조합물은 배지에 포함될 수 있다
일 실시예에서, 제1 또는 제2 배양 배지, 또는 두 배양 배지 모두는 하나 이상의 추가 사이토카인을 포함한다. 제1 및/또는 제2 배양 배지는 제2, 제3 및/또는 제4 사이토카인을 포함할 수 있다. 추가 실시예에서, 추가 사이토카인은 IL-21, IFN-γ 및 IL-1β로부터 선택된다.
일 실시예에서, 상기 방법은 IL-2, IL-4, IL-21, IL-6, IL-7, IL-8, IL-9, IL-12, IL-18, IL-33, IGF-1, IL-1β, IFN-γ, 인간 혈소판 용해물(HPL, human platelet lysate) 및 기질세포-유래인자-1(SDF-1)로 이루어진 군으로부터 선택된 인자와 IL-15의 존재 하에 세포 집단을 배양하는 것을 포함한다. .
γδ T 세포의 증식은 하나 이상의 추가 T 세포 미토겐(mitogen)의 존재 하에 시료를 배양하는 것을 포함할 수 있다. 용어 "T 세포 미토겐"("γδ TCR 작용제"로도 지칭될 수 있음)은 TCR 신호전달을 통하여 T 세포를 자극할 수 있는 임의의 제제를 의미하며, 파이토헤마글루티닌(PHA) 및 콘카나발린 A(ConA)과 같은 식물 렉틴 및 비식물 기원의 렉틴을 포함하지만 이에 한정되지 않는다. 일 실시예에서, T 세포 미토겐은 항-CD3 단일클론 항체(mAb)이다. 다른 미토겐으로는 포르볼 12-미리스테이트-13-아세테이트(TPA, phorbol 12-myristate-13-acetate) 및 메제레인(mezerein) 같은 관련 화합물 또는 박테리아 화합물(예를 들어, 포도상구균 장독소 A(SEA, Staphylococcal enterotoxin A) 및 포도상구균 단백질 A)이 있다. T 세포 미토겐은 가용성이거나 고정화될 수 있고, 하나 이상의 T 세포 미토겐이 증식 방법에 사용될 수 있다.
본 명세서에 사용된 "증식된" 또는 "γδ T 세포의 증식된 집단"이라 함은 비-증식된 집단보다 더 크거나 더 많은 수의 세포를 함유하는 세포 집단을 포함한다. 상기 집단은 수가 많거나, 수가 적거나 혹은 집단 내 일부 또는 특정 세포 유형이 증식된 혼합 집단일 수 있다. 용어 "증식 방법"은 증식 또는 증식된 집단을 초래하는 과정을 의미하는 것으로 이해될 것이다. 따라서, 증식 또는 증식된 집단은 증식 단계가 수행되지 않았거나 증식 단계 이전인 집단에 비해 수가 더 많거나 더 많은 수의 세포를 포함할 수 있다. 증식(예를 들어, 배수-증가 또는 배수-증식)을 나타내기 위해 본 명세서에 지칭되는 모든 숫자는 세포 집단의 수 또는 크기 또는 세포 수의 증가를 예시하며. 증식의 양을 나타내는 것으로 추가로 이해될 것이다.
일 실시예에서, 상기 방법은 세포 집단을 5일 이상 동안(예를 들어, 6일 이상, 7일 이상, 8일 이상, 9일 이상, 10일 이상, 11일 이상, 12일 이상, 13일 이상, 14일 이상, 18일 이상, 21일 이상, 28일 이상, 또는 그 이상, 예를 들어 5일 내지 40일, 7일 내지 35일, 14일 내지 28일 또는 약 21일) 배양하는 것을 포함한다. 추가 실시예예에서, 상기 방법은 7일 이상 동안, 예를 들면 11일 이상 또는 14일 이상, 세포 집단을 배양하는 것을 포함한다.
추가 실시예에서, 상기 방법은 γδ T 세포의 증식된 집단을 생성하기에 효과적인 기간동안(예를 들어, 5일 이상, 6일 이상, 7일 이상, 8일 이상, 9일 이상, 10일 이상, 11일 이상, 12일 이상, 13일 이상, 14일 이상, 18일 이상, 21일 이상, 28일 이상, 또는 그 이상, 예를 들어 5일 내지 40일, 7일 내지 35일, 14일 내지 28일 또는 약 21일) 세포 집단을 배양하는 것을 포함한다.
일 실시예에서, 세포 집단은 5 내지 60일, 예들 들면 적어도 7 내지 45일, 7 내지 21일, 또는 7 내지 18일의 기간 동안 배양된다. 상기 방법이 단리 배양 기간(예를 들어, 1 내지 40일로 예를 들어 14 내지 21일)을 포함하는 경우, 단리 및 증식 단계는 일부 실시예에서 21 내지 39일 동안 지속될 수 있다.
상기 방법은 배양 동안 항-Vδ1 항체 또는 이의 단편 및/또는 성장 인자의 규칙적인 첨가를 포함할 수 있다. 예를 들어, 항-Vδ1 항체 또는 이의 단편 및/또는 성장 인자는 2 내지 5일마다, 더욱 바람직하게는 3 내지 4일마다 첨가될 수 있다. 일 실시예에서, 항-Vδ1 항체 또는 이의 단편 및/또는 성장 인자는 배양 7일 후 및 이후 3 내지 4일마다 첨가된다.
증식 방법은 참조 집단보다 더 많은 수의 γδ T 세포의 증식된 집단을 제공한다. 일부 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 증식 단계 이전의 γδ T 세포의 단리된 집단보다 수가 더 많다(예를 들어, 증식 단계 이전의 γδ T 세포의 단리된 집단에 비해 2배 이상의 수, 5배 이상의 수, 10배 이상의 수, 25배 이상의 수, 50배 이상의 수, 60배 이상의 수, 70배 이상의 수, 80배 이상의 수, 90배 이상의 수, 100배 이상의 수, 200배 이상의 수, 300배 이상의 수, 400배 이상의 수, 500배 이상의 수, 600배 이상의 수, 1,000배 이상의 수 또는 그 이상). 일 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 항체 또는 이의 단편이 없이 동일한 기간 동안 배양된 집단보다 수가 더 많다. 일 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 TS8.2 또는 TS 1의 존재 하에 동일한 기간 동안 배양된 집단보다 수가 더 많다.
증식 방법은 참조 집단보다 더 높은 비율의 Vδ1 T 세포를 갖는 γδ T 세포의 증식된 집단을 제공한다. 일부 실시예에서, Vδ1 T 세포의 증식된 집단은 약 50% 초과, 예를 들어 약 55%, 60%, 65%, 70%, 75%, 80%, 85%, 87%, 90%, 91%, 92%, 93%, 94% 또는 95% 초과의 vδ1 T 세포를 포함한다. 추가 실시예에서, Vδ1 T 세포의 증식된 집단은 약 85% 초과의 Vδ1 T 세포, 예를 들어 약 90% 초과의 Vδ1 T 세포를 함유한다.
일부 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 약 10% 미만, 예를 들어 약 5%, 4%, 3%, 2%, 1.5%, 1%, 0.5%, 0.2%, 0.1% 또는 0.05% 미만의 αβ T 세포를 함유한다. 추가 실시예에서, Vδ1 T 세포의 증식된 집단은 약 1% 미만의 αβ T 세포를 함유한다. αβ 수용체를 갖는 T 세포는 반응성이 높기 때문에, 본 발명의 맥락에서 환자에게 투여하기에 적절한 세포 집단은 낮은 수준의 αβ T 세포만을 함유할 수 있다. 본 명세서에 기재된 항체는, αβ T 세포를 제거하기 위해 증식 후 광범위한 정제 방법에 대한 필요성을 감소시키는 Vδ1 T 세포 집단을 선택적으로 증식하는 데 사용될 수 있다.
일부 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 약 10% 미만, 예를 들어 약 5%, 4%, 3%, 2%, 1.5%, 1%, 0.5%, 0.2%, 0.1% 또는 0.05% 미만의 Vδ2 T 세포를 함유한다. 추가 실시예에서, Vδ1 T 세포의 증식된 집단은 약 0.5% 미만의 Vδ2 T 세포를 함유한다.
일부 실시예에서, γδ T 세포(예를 들어, Vδ1 T 세포)의 증식된 집단은 약 10% 미만, 예를 들어 약 5%, 4%, 3%, 2.5%, 2%, 1.5% 또는 1% NK(Natural Killer) 세포(CD56+CD3- 세포라고도 칭한다)를 함유한다. 추가 실시예에서, Vδ1 T 세포의 증식된 집단은 약 2% 미만의 NK 세포를 함유한다.
세포 표면 마커의 발현 증가 또는 감소는 Vδ1 T 세포의 하나 이상의 증식된 집단을 특징짓기 위해 부가적으로 또는 대안적으로 사용될 수 있으며, CD27, CD69, TIGIT, PD-1 및 TIM-3을 포함한다. 일부 실시예에서, Vδ1 T 세포의 확장된 집단은 높은 수준의 CD27(CD27high)을 발현한다. 예를 들어, 약 70% 초과, 예를 들어 약 80%, 85%, 90% 초과의 Vδ1 T 세포의 증식된 집단이 CD27(즉, CD27+)을 발현한다. 일부 실시예에서, Vδ1 T 세포의 증식된 집단은, 예를 들어 증식 전의, Vδ1 T 세포의 단리된 집단에 비해 평균 CD27의 발현이 더 크다. 일부 실시예에서, Vδ1 T 세포의 증식된 집단은 낮은 수준의 CD69, TIGIT, PD 1 및/또는 TIM-3을 발현한다. 예를 들어, 약 40% 미만, 예를 들어 약 30% 미만의 Vδ1 T 세포의 확장된 집단이 CD69, TIGIT, PD 1 및/또는 TIM-3를 발현한다. 일부 실시예에서, Vδ1 T 세포의 증식된 집단은 Vδ1 T 세포의 단리된 집단에 비해 CD69, TIGIT, PD 1 및 TIM-3으로 이루어진 군으로부터 선택된 마커 중 하나 이상의 평균 발현이 더 낮다.
γδ T 세포의 증식에 사용하기에 적합한 수많은 기본 배양 배지, 특히 AIM-V, Iscoves 배지 및 RPMI-1640(Life Technologies), EXVIVO-10, EXVIVO-15 또는 EXVIVO-20(Lonza)와 같은 배지가 혈청 또는 혈장 존재 하에 이용 가능하다. 배지에는 혈청, 혈청 단백질 및 항생제와 같은 선택적 제제와 같은 본 명세서에 정의된 다른 배지 인자를 보충할 수 있다. 예를 들어, 일부 실시예에서, RPMI-1640 배지는 2mM 글루타민, 10% FBS, 10mM HEPES, pH 7.2, 1% 페니실린-스트렙토마이신, 피루브산나트륨(1mM; Life Technologies), 비필수 아미노산(예를 들어, 100 μM Gly, Ala, Asn, Asp, Glu, Pro 및 Ser, 1X MEM 비필수 아미노산(Life Technologies)) 및 10 μl/L β-메르캅토에탄올을 포함한다. 다른 실시예에서, AIM-V 배지는 CTS 면역 혈청 대체제 및 암포테리신 B로 보충될 수 있다. 특정 실시예에서, 배지는 본 명세서에 기재된 바와 같이 IL-2, IL-4, IL-9 및/또는 IL-15로 추가로 보충될 수 있다. 간편하게, 세포는 단리 및/또는 증식 동안 적절한 배양 배지에서 5% CO2를 함유하는 가습 분위기의 37℃에서 배양된다.
γδ T 세포의 증식 배양물에 다른 인자를 추가하는 것도 사용될 수 있다. 일 실시예에서, 상기 인자는 γδ T 세포의 증식을 선택적으로 촉진하는 증식에 사용된다. 예를 들어, 증식은 증식 배양물에 인터루킨과 같은 외인성 사이토카인의 첨가를 추가로 포함할 수 있다. 상기 증식은 IL-2 및 IL-15의 존재 하에 γδ T 세포를 배양하는 것을 포함할 수 있다. 또는, 증식은 IL-9 및 IL-15의 존재 하에 γδ T 세포를 배양하는 것을 포함할 수 있다. 모든 증식 단계는 γδ T 세포의 증식된 집단을 생성하는 데 효과적인 기간 동안 수행되는 것은 당연하다.
γδ T 세포를 증식하는 방법은 5일 미만(예를 들어, 4.5일 미만, 4.0일 미만, 3.9일 미만, 3.8일 미만, 3.7일 미만, 3.6일 미만, 3.5일 미만, 3.4일 미만, 3.3일 미만, 3.2일 미만, 3.1일 미만, 3.0일 미만, 2.9일 미만, 2.8일 미만, 2.7일 미만, 2.6일 미만, 2.5일 미만, 2.4일 미만, 2.3일 미만, 2.2일 미만, 2.1일 미만, 2.0일 미만, 46시간 미만, 42시간 미만, 38시간 미만, 35시간 미만, 32시간 미만)의 기간 동안 세포 집단을 배양하는 것을 포함한다.
γδ
T 세포를
단리하는
방법
본 명세서에 기재된 바와 같이, 항체(또는 이의 단편)는 배양물 중의 γδ T 세포, 즉 시료로부터 수득된 γδ T 세포에 적용될 수 있다. 일 실시예에서, 세포 집단은 항-Vδ1 항체 또는 이의 단편을 투여하기 전에 시료로부터 단리된다. 따라서 시료로부터 단리된 γδ T 세포 집단(예를 들어, Vδ1 T 세포를 포함하는 세포 집단)에 본 명세서에 정의된 항-Vδ1 항체 또는 이의 단편을 투여하는 것을 포함하는 Vδ1 T를 변형(특히, 증식)하는 방법이 제공된다.
비-조혈조직에 우세한(즉, 조직 상새) γδ T 세포는 주로 델타 가변 1 사슬을 함유하므로, 본 명세서에 기재된 항-Vδ1 항체는 특히 비-조혈조직으로부터 단리된 γδ T 세포에서 사용된다. 따라서, 일 실시예에서, 시료는 피부와 같은 비-조혈조직 시료이다. 또는, 본 발명의 방법은 예를 들어 혈액 시료와 같이 Vδ1 사슬 주로 함유하지 않는 시료에서 Vδ1 T 세포의 집단을 증식하는데 사용될 수 있다. 따라서, 상기 방법은 시료에서 Vδ1 T 세포의 수를 증가시키는 데 사용될 수 있다.
본 명세서에서 세포, 특히 γδ T 세포의 "단리" 또는 "단리하는 것"이라 함은 세포가 제거, 분리, 정제, 농축 또는 다른 방법으로 조직 또는 세포의 풀로부터 꺼내어지는 방법 또는 공정을 지칭한다. 상기 지칭은 "분리된", "제거된", "정제된", "농축된" 등의 용어를 포함하는 것으로 이해되어야 한다. γδ T 세포의 단리는 온전한 비-조혈조직 시료 또는 비-조혈조직의 기질세포(예를 들어, 섬유아세포 또는 상피세포)로부터 세포를 단리 또는 분리하는 것을 포함한다. 상기 단리는 대안적으로 또는 부가적으로 다른 조혈 세포(예를 들어, αβ T 세포 또는 다른 림프구)로부터의 γδ T 세포의 단리 또는 분리를 포함할 수 있다. 단리는 정의된 기간 동안 수행될 수 있으며, 예를 들어 조직 외식편(explant) 또는 생검을 단리 배양물에 넣을 때 시작하여 단리된 세포집단을 증식 배양물로 옮기거나 다른 목적으로 사용하기 위하여 원심분리 또는 다른 수단에 의해 세포가 배양액으로부터 수집되거나, 혹은 원래의 조직 외식편 또는 생검이 배양액에서 제거될 때 종료된다. 단리 단계는 최소 약 3일 내지 약 45일 동안일 수 있다. 일 실시예에서, 단리 단계는 약 10일 이상 내지 28 일 이상 동안이다. 추가 실시예에서, 단리 단계는 14일 이상 내지 21일 이상 동안이다. 따라서 단리 단계는 최소 3일, 4일, 5일, 6일, 7일, 8일, 9일, 10일, 11일, 12일, 13일, 14일, 15일, 16일, 17일, 18일, 19일, 20일, 21일, 22일, 23일, 24일, 25일, 26일, 27일, 28일, 29일, 30일, 31일, 32일, 약 35일, 약 40일 또는 약 45일 동안일 수 있다. 세포 증식이 상기 단리 단계동안 큰 규모로 일어나는 것은 아니지만, 전혀 일어나지 않아야 하는 것이 아님은 당연하다. 실제로 당업자에게는 단리된 세포가 또한 분열을 시작하여 시료를 포함하는 단리 용기 내에서 다수의 상기 세포를 생성 할 수 있다는 것이 인정된다.
따라서, 본 명세서에서 "단리된 γδ T 세포", "단리된 γδ T 세포 집단", 또는 "γδ T 세포의 단리된 집단"이라 함은 세포가 온전한 (비-조혈조직) 시료 내에 함유된 세포와 실질적으로 접촉하지 않도록 원래의 비-조혈조직 시료와 같은 시료로부터 단리, 분리, 제거, 정제 또는 농축된 γδ 세포를 지칭한다. 본 명세서에서 "단리된 Vδ1 T 세포", "단리된 Vδ1 T 세포 집단", "Vδ1 T 세포의 단리된 집단", "분리된 Vδ1 T 세포", "분리된 Vδ1 T 세포 집단" 또는 "Vδ1 T 세포의 분리된 집단"이라 함은 세포가 온전한 (비-조혈조직) 시료 내에 함유된 세포와 실질적으로 접촉하지 않도록 원래의 비-조혈조직 시료와 같은 시료로부터 단리, 분리, 제거, 정제 또는 농축된 Vδ1 T 세포를 지칭한다.
세포 집단은 비-조혈조직 시료와 같은 인간 또는 비-인간 동물 시료로부터 림프구, 특히 Vδ1 T 세포의 단리를 허용하는 임의의 적벙한 방법에 의해 수득될 수 있다. 이러한 방법 중 하나는 Clark et al. (2006) J. Invest. Dermatol . 126(5): 1059-70에 공개되었으며, 이는 인간 피부에서 림프구를 단리하기 위한 3차원 피부 이식 프로토콜을 기술한다. 외식편에서 스캐폴드로 림프구가 용이하게 유출되도록 외식편은 합성 스캐폴드에 부착될 수 있다. 합성 스캐폴드는 세포 성장을 지지하기에 적절한 비천연 3차원 구조를 지칭한다. 합성 스캐폴드는 고분자(예를 들어, 천연 또는 합성 폴리머, 예를 들어, 폴리 비닐 피롤리돈, 폴리메틸메타크릴레이트, 메틸 셀룰로스, 폴리스티렌, 폴리프로필렌, 폴리우레탄), 세라믹(예를 들어, 제삼인산칼슘, 알루미늄산 칼슘, 수산화인회석 칼슘(calcium hydroxyapatite)) 또는 금속(예를 들어, 탄탈, 티타늄, 백금 및 백금과 같은 족의 금속, 니오븀, 하프늄, 텅스텐 및 이들 조합의 합금)과 같은 물질로 구성될 수 있다. 생물학적 인자(예를 들어, 콜라겐 (예를 들어, 콜라겐 I 또는 콜라겐 II), 피브로넥틴, 라미닌, 인테그린, 혈관형성 인자, 항염증 인자, 글리코사미노글리칸, 비트로겐, 항체 및 이의 단편, 사이토카인(예를 들어, IL-2 또는 IL-15, 및 이들의 조합)이 당업계에 공지된 방법에 따라 스캐폴드 표면에 코팅되거나, 스캐폴드 소재 내에 캡슐화되어 세포 부착, 이동, 생존 또는 증식을 증진시킬 수 있다. 이 방법 및 다른 방법은 예를 들어 장, 전립선 및 유방과 같은 다수의 다른 비-조혈조직 유형으로부터 세포 집단을 단리하는데 사용할 수 있다. 적절한 단리 방법의 다른 예는 다른 비-조혈조직 유형, 예를 들어, 장, 전립선 및 유방 적절한 분리 방법의 다른 예는 Vδ T 세포, 특히 Vδ1 T 세포의 단리 또는 분리를 유도하기에 충분한 사이토카인 및/또는 케모카인의 존재 하에 세포 집단 및/또는 시료를 배양하는 것을 포함할 수 있는 "크롤아웃(crawl-out)" 방법을 활용한다. 시료(예를 들어, 비-조혈조직 시료)로부터 γδ T 세포의 단리는 IL-2 및 IL-15의 존재 하에 시료를 배양하는 것을 포함할 수 있다.
비-조혈조직 상재 림프구는 진피 섬유아세포와 같은 기질 세포로부터 예를 들어 능숙한 피펫팅에 의해 수집 및 분리할 수 있다. 림프구 수집물은 공정 동안 느슨해질 수 있는 섬유아세포 응집체를 유지하기 위해 40μm 나일론 메쉬를 통해 추가로 세척될 수 있다. 림프구는 또한 예를 들어 CD45 항체를 사용한 형광 또는 자기 관련 세포 분류를 사용하여 단리될 수 있다.
또는 시료(예를 들어, 조혈조직 시료)로부터 γδ T 세포의 단리는 WO2012/156958에 기술된 바와 같이 T 세포 미토겐(예를 들어, γδ TCR 작용제) 및 사이토카인(특히 사이토카인의 공통 사이토카인 수용체 감마-사슬(γc) 패밀리)의 존재 하에 시료를 배양하는 것을 포함할 수 있다. 또 다른 대안으로서, 시료(예를 들어, 조혈조직 시료)로부터 γδ T 세포의 단리는 WO2016/198480에 기술된 바와 같이 T 세포 미토겐 및 사이토카인의 존재 하에 시료를 배양하는 것을 포함할 수 있다.
γδ T 세포의 단리는 적어도 하나의 사이토카인의 존재 하에 시료를 배양하는 것을 포함할 수 있다. 예를 들어, 상기 방법은 케모카인과 같은 적어도 하나의 물질의 존재 하에 시료를 배양하는 것을 포함할 수 있다. 케모카인은 단리되는 γδ T 세포에 따라 선택되는 것은 당연하다. 또한, 케모카인은 γδ T 세포의 단리에 사용되는 시료에 따라 변화하고, 선택되어 진다.
γδ T 세포의 단리는 적어도 하나의 사이토카인의 존재 하에 시료를 추가로 배양하는 것을 포함할 수 있다. 상기 사이토카인은 초기 배양에 사용된 사이토카인과 상이할 수 있다.
단리 방법은 시료를 배양하는 것을 포함할 수 있다. 본 명세서에서 "배양"이라 함은 시료로부터 단리, 분리, 제거, 정제 또는 농축된 세포를 포함하는 시료를 세포 및/또는 시료에 필요하거나 유리한 성장 인자 및/또는 필수 영양소를 포함하는 배지에 첨가하는 것을 포함한다. 상기 배양 조건은 시료로부터 단리될 세포 또는 세포 집단에 따라 변경될 수 있거나, 시료로부터 단리 및 증식될 세포 또는 세포 집단에 따라 변경될 수 있음은 당연하다.
특정 실시예에서, 시료의 배양은 시료로부터 γδ T 세포를 단리하기에 충분한 기간 동안 이루어진다. 특정 실시예에서, 배양 기간은 14일 이상이다. 특정 실시예에서, 배양 기간은 45일 미만으로, 예들 들어 30일 미만, 예를 들어 25일 미만이다. 추가 실시예에서, 배양 기간은 14일 내지 35일, 예를 들어 14일 내지 21일이다. 또 다른 실시예에서, 배양 기간은 약 21일이다.
특정 실시예에서, γδ T는 시료의 배양 후에 배양물로부터 수집된다. γδ T 세포의 수집은 배양물로부터 γδ T 세포의 물리적 수집, 다른 림프구(예를 들어, αβ T 세포 및/또는 NK 세포)로부터 γδ T 세포의 단리 또는시료에 존재하는 다른 세포, 예를 들어 섬유아세포와 같은 기질 세포로부터 γδ T 세포의 단리 및/또는 분리가 포함될 수 있다. 일 실시예에서, γδ T 세포는 기계적 수단(예를 들어, 피펫팅)에 의해 수집된다. 추가 실시예에서, γδ T 세포는 자기 분리 및/또는 표지에 의해 수집된다. 또 다른 실시예에서, γδ T 세포는 FACS와 같은 유세포 분석 기술에 의해 수집된다. 따라서, 특정 실시예에서, γδ T 세포는 γδ T 세포를 특이적 표지하는 것에 의해 수집된다. γδ T 세포의 상기 수집은 시료의 배양물로부터의 물리적 제거, 별도의 배양 용기로의 이동, 또는 별개의 또는 상이한 배양 조건으로의 이동을 포함할 수 있음은 당연하다.
γδ T 세포의 상기 수집은 시료로부터 γδ T 세포의 단리된 집단을 획득하기에 충분한 기간 후에 수행되는 것은 당연하다. 특정 실시예에서, γδ T 세포는 시료의 배양의 1주 이상, 10일 이상, 11일 이상, 12일 이상, 13일 이상 또는 14일 이상 후에 수집된다. 적절하게는, γδ T 세포는 40일 이하, 예들 들어 38일 이하, 36일 이하, 34일 이하, 32일 이하, 30일 이하, 28일 이하, 26일 이하 또는 24일 이하 후에 수집된다. 일 실시예에서, γδ T 세포는 시료 배양의 14일 이상 후에 수집된다. 추가 실시예에서, γδ T 세포는 시료의 배양 14 내지 21일 후에 수집된다.
일 실시예에서, 시료는 실질적으로 없는 혈청이 배지(예를 들어, 무혈청 배지 또는 혈청-대체제(SR)를 함유하는 배지)에서 배양된다. 따라서, 일 실시예에서, 시료는 무혈청 배지에서 배양된다. 상기 무혈청 배지는 또한 혈청 대체제 배지를 포함할 수 있으며, 여기서 혈청 대체제는 인간 또는 동물 유래 혈청의 사용을 피하기 위하여 화학적으로 정의된 성분을 기반으로 한다. 일 실시예양태에서, 배지는 동물 유래 제품을 함유하지 않는다. 다른 실시예에서, 시료는 혈청(예를 들어, 인간 AB 혈청 또는 소태야혈청(FBS))을 함유하는 배지에서 배양된다.
배양 배지는 γδ T 세포의 성장 및 증식을 도울 수 있는 다른 성분을 추가로 포함할 수 있다. 추가될 수 있는 다른 성분의 예로는 혈장 또는 혈청, 알부민과 같은 정제된 단백질, 저밀도 지단백질(LDL)과 같은 지질원(lipid source), 비타민, 아미노산, 스테로이드 및 세포 성장 및/또는 생존을 지원하거나 촉진하는 모든 기타 보충제를 포함하나, 이에 한정되지 않는다.
혈액에 우세한 γδ T 세포는 주로 Vδ2 T 세포인 반면, 비-조혈조직에서 우세한 γδ T 세포는 주로 Vδ1 T 세포로, Vδ1 T 세포는 비-조혈조직-상재 γδ T 세포 집단의 약 70-80%를 차지한다. 바람직한 일 실시예에서, 단리된 γδ T 세포는 Vδ1 T 세포의 집단을 포함한다.
항체 또는 이의 단편
본 명세서에서는 Vδ1 T 세포 수용체(TCR)의 델타 가변 1 사슬(Vδ1)에 특이적으로 결합하는 항체 또는 이의 단편이 제공된다.
일 실시예에서, 항체 또는 이의 단편은 scFv, Fab, Fab', F(ab')2, Fv, 가변 도메인(예를 들어, VH 또는 VL), 디아바디, 미니바디 또는 단일클론 항체이다. 추가 실시예에서, 항체 또는 이의 단편은 scFv이다.
본 명세서에 기재된 항체는 임의의 부류, 예를 들어, IgG, IgA, IgM, IgE, IgD, 또는 이의 이소타입과 같은 항체일 수 있으며, 카파(kappa) 또는 람다(lambda) 경 사슬을 포함할 수 있다. 일 실시예에서, 항체는 IgG 항체, 예를 들어, 아이소타입, IgG1, IgG2, IgG3 또는 IgG4 중 적어도 하나이다. 추가 실시예에서, 항체는 Fc를 돌연변이시켜 작동체 기능을 감소시키거나 반감기를 연장하거나 ADCC를 변경하거나 또는 힌지 안정성을 개선하키는 것과 같이 원하는 특성을 부여하도록 변형된 IgG 형태과 같은 형태일 수 있다. . 이러한 변형은 당업계에 공지되어 있다.
일 실시예에서, 항체 또는 이의 단편은 인간이다. 따라서, 항체 또는 이의 단편은 인간 면역글로불린(Ig) 서열로부터 유래될 수 있다. 항체(또는 이의 단편)의 CDR, 프레임워크 및/또는 불변 영역은 인간 Ig 서열, 특히 인간 IgG 서열로부터 유래될 수 있다. CDR, 프레임워크 및/또는 불변 영역은 인간 Ig 서열, 특히 인간 IgG 서열에 대해 실질적으로 동일할 수 있다. 인간 항체를 사용하는 이점은 인간에게 면역원성이 낮거나 없다는 것이다.
항체 또는 그의 단편은 또한 키메라, 예를 들어 마우스-인간 항체 키메라일 수 있다.
또는, 항체 또는 이의 단편은 마우스와 같은 비-인간 종으로부터 유래된다. 상기 비-인간 항체는 인간에서 자연적으로 생성된 항체 변이체에 대한 유사성을 증가시키도록 변형될 수 있으며, 따라서 항체 또는 이의 단편은 부분적으로 또는 완전히 인간화될 수 있다. 따라서, 일 실시예에서, 항체 또는 이의 단편은 인간화된다.
에피토프를
표적으로 하는 항체
본 명세서에서 γδ TCR의 Vδ1 사슬의 에피토프에 결합하는 항체(또는 이의 단편)가 제공된다. 상기 결합은 γδ TCR 활성에 대한 활성화 또는 억제와 같은 영향을 선택적으로 가질 수 있다.
일 실시예에서, 에피토프는 γδ T 세포의 활성화 에피토프일 수 있다. "활성화" 에피토프는 예를 들어 탈과립화, TCR 하향조절, 세포독성, 증식, 동원(mobilisation), 생존 또는 피로에 대한 저항의 증가, 세포내 신호전달, 사이토카인 또는 성장인자 분비, 표현형 변화 또는 유전자 발현의 변화와 같은 TCR 기능의 자극을 포함할 수 있다. 예를 들어, 활성화 에피토프의 결합은 γδ T 세포 집단, 바람직하게는 Vδ1+ T 세포 집단의 증식을 자극할 수 있다. 따라서, 이들 항체는 γδ T 세포 활성화를 조절하고, 그에 의해 면역 반응을 조절하는데 사용될 수 있다. 따라서, 일 실시예에서, 활성화 에피토프의 결합은 γδ TCR을 하향조절한다. 부가적 또는 대안적 실시예에서, 활성화 에피토프의 결합은 γδ T 세포의 탈과립을 활성화시킨다. 추가의 부가적 또는 대안적 실시예에서, 활성화 에피토프의 결합은 γδ T 세포 사멸을 활성화시킨다.
또는, 항체(또는 이의 단편)는 다른 항체 또는 분자의 결합 또는 상호작용을 방해함으로써 차단 효과를 가질 수 있다. 일 실시예에서, 본 발명은 Vδ1을 차단하고 TCR 결합을 방해하는 (예를 들어, 입체 장애를 통해) 단리된 항체 또는 이의 단편을 제공한다. Vδ1을 차단하는 것에 의해 항체는 TCR 활성화 및/또는 신호전달을 방해할 수 있다. 에피토프는 γδ T 세포의 억제 에피토프일 수 있다. "억제" 에피토프는 예를 들어 TCR 기능을 차단하는 것에 의해 TCR 활성화를 억제하는 것을 포함할 수 있다.
에피토프는 바람직하게는 γδ TCR의 Vδ1 사슬의 적어도 하나의 세포외, 가용성, 친수성, 외부 또는 세포질 부분으로 구성된다.
특히, 에피토프는 γδ TCR의 Vδ1 사슬, 특히 Vδ1 사슬의 CDR3의 초가변(hypervariable) 영역에서 발견되는 에피토프를 포함하지 않는다. 바람직한 실시예에서, 에피토프는 γδ TCR의 Vδ1 사슬의 비-가변 영역 내에 있다. 상기 결합은 고도로 가변적인 TCR(특히 CDR3)의 서열에 제약없이 Vδ1 사슬의 고유한 인식을 허용하는 것은 당연하다. MHC-유사 펩타이드 또는 항원을 인식하는 다양한 γδ TCR 복합체는 Vδ1 사슬의 존재만으로 이러한 방식으로 인식될 수 있다. 이와 같이, 모든 Vδ1 사슬-포함 γδ TCR은 γδ TCR의 특이성과 무관하게 본 명세서에 정의된 바와 같은 항체 또는 이의 단편을 사용하여 인식될 수 있음은 당연하다. 일 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 1-24 및/또는 35-90, 예를 들어 CDR1 및/또는 CDR3 서열의 일부가 아닌 Vδ1 사슬의 일부 내의 하나 이상의 아미노산 잔기를 포함한다. 일 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 91-105(CDR3) 내의 아미노산 잔기를 포함하지 않는다.
잘 특성화된 αβ T 세포와 유사한 방식으로, γδ T 세포는 αβ T 세포보다 더 적은 수의 V, D 및 J 세그먼트를 함유하기는 하지만 γδ T 세포는 체세포적으로 재배열된 가변(V), 다양성(D), 연결(J) 및 불변(C) 유전자의 고유한 세트를 활용한다. 일 실시예에서, 항체(또는 이의 단편)에 의해 결합된 에피토프는 Vδ1 사슬의 J 영역(예를 들어, 인간 델타 1 사슬 생식계에 암호화된 4개의 J 영역 중 하나: 서열 번호: 131(J1*0) 또는 132(J2*0) 또는 133(J3*0) 또는 134(J4*0))에서 발견되는 에피토프를 포함하지 않는다. 일 실시예에서, 항체(또는 이의 단편)에 의해 결합된 에피토프는 Vδ1 사슬의 C-영역(예를 들어, C-말단 막옆/막 횡단 영역을 함유하는 서열번호: 135(C1*0)에서 발견되는 에피토프를 포함하지 않는다. 일 실시예에서, 항체(또는 이의 단편)에 의해 결합된 에피토프는 Vδ1 사슬의 N-말단 리더 서열(예를 들어, 서열번호: 129)에서 발견되는 에피토프를 포함하지 않는다. 따라서 항체 또는 단편은 Vδ1 사슬의 V 영역(예를 들어, 서열번호: 130)에서만 결합할 수 있다. 따라서, 일 실시예에서, 에피토프는 γδ TCR의 V 영역 내의 에피토프(예를 들어, 서열번호: 1의 아미노산 잔기 1-90)로 이루어진다.
에피토프라 함은 서열번호: 1로 표시되는 Luoma et al. (2013) Immunity 39: 1032-1042, 및 RCSB Protein Data Bank 항목: 4MNH 및 3OM에 기재된 서열로부터 유래된 Vδ1 서열과 관련하여 만들어진다: 1:
AQKVTQAQSSVSMPVRKAVTLNCLYETSWWSYYIFWYKQLPSKEMIFLIRQGSDEQNAKSGRYSVNFKKAAKSVALTISALQLEDSAKYFCALGESLTRADKLIFGKGTRVTVEPNIQNPDPAVYQLRDSKSSDKSVCLFTDFDSQTNVSQSKDSDVYITDKTVLDMRSMDFKSNSAVAWSNKSDFACANAFNNSIIPEDTFFPSPESS (서열번호: 1)
서열번호: 1은 V 영역(가변 도메인이라고도 지칭함), D 영역, J 영역 및 TCR 불변 영역을 포함하는 가용성 TCR을 나타낸다. V 영역은 아미노산 잔기 1-90을 포함하고, D 영역은 아미노산 잔기 91-104를 포함하고, J 영역은 아미노산 잔기 105-115를 포함하고, 불변 영역은 아미노산 잔기 116-209를 포함한다. V 영역 내에서, CDR1은 서열번호: 1의 아미노산 잔기 25-34로 정의되고, CDR2는 서열번호: 1의 아미노산 잔기 50-54로 정의되고, CDR3은 서열번호: 1의 아미노산 잔기 93-104로 정의된다 (Xu et al., PNAS USA 108(6):2414-2419 (2011)).
따라서, 일 실시예에서, 단리된 항체 또는 이의 단편은
(i) 서열번호: 1의 3-20 ; 및/또는
(ii) 서열번호: 1의 37-77
의 아미노산 영역 내에 하나 이상의 아미노산 잔기를 포함하는 γδ T 세포 수용체(TCR)의 가변 델타 1(Vδ1) 사슬의 에피토프에 결합한다.
추가 실시예에서, 항체 또는 이의 단편은 서열번호: 128의 아미노산 잔기 1-90 에피토프를 포함하는 다형성 V 영역을 추가로 인식한다. 따라서, 서열번호: 1의 아미노산 1-90 및 다형성 생식계 변이체 서열(서열번호: 128의 아미노산 1-90)은 본 명세서에 기재된 에피토프를 정의할 때 상호교환가능한 것으로 간주될 수 있다. 본 발명의 항체는 상기 생식계 서열의 두 변이체를 모두 인식할 수 있다. 예를 들어, 본 명세서에 정의된 항체 또는 이의 단편은 서열번호: 1의 아미노산 영역 1-24 및/또는 35-90 내에서 하나 이상의 아미노산 잔기를 포함하는 에피토프를 인식한다고 하는 경우, 이는 또한 서열번호: 128의 동일한 영역; 구체적으로 서열번호: 128의 아미노산 영역 1-24 및/또는 35-90을 지칭한다.
일 실시예에서, 항체 또는 이의 단편은 서열번호: 1의 아미노산 영역 1-90 내의 하나 이상의 아미노산 잔기 및 서열번호: 128의 아미노산 영역 1-90의 동등하게 위치된 아미노산을 인식한다. 보다 구체적으로, 일 실시예에서 본 명세서에 정의된 바와 같은 항체 또는 이의 단편은 인간 생식계 에피토프를 인식하며, 여기서 상기 생식계는 서열번호: 1의 위치 71에서 알라닌(A) 또는 발린(V)을 암호화한다.
일 실시예에서, 에피토프는 상기 기재된 영역 내에서 1개 이상, 예를 들어 2, 3, 4, 5, 6, 7, 8, 9, 10개 이상의 아미노산 잔기를 포함한다.
추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 3-20 내에 하나 이상(예를 들어, 5개 이상, 예를 들어 10개 이상)의 아미노산 잔기를 포함한다. 다른 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 37-77(예를 들어, 아미노산 영역 50-54) 내에서 하나 이상(예를 들어, 5개 이상, 예를 들어 10개 이상)의 아미노산 잔기를 포함한다. 또 다른 추가 실시예에서, 에피토프는 아미노산 영역 3-20(예를 들어, 5-20 또는 3-17) 내의 하나 이상(예를 들어, 5개 이상, 예를 들어 10개 이상)의 아미노산 잔기와 서열번호: 1의 아미노산 영역 37-77(예를 들어, 62-77 또는 62-69) 내의 하나 이상(예를 들어, 5개 이상, 예를 들어 10개 이상)의 아미노산 잔기를 포함한다.
상기 항체(또는 이의 단편)는 정의된 범위 내의 모든 아미노산에 결합할 필요는 없음은 당연하다. 상기 에피토프는 선형 에피토프라고 지칭할 수 있다. 예를 들어, 서열번호: 1의 아미노산 영역 5-20 내의 아미노산 잔기를 포함하는 에피토프에 결합하는 항체는 예를 들어 상기 범위의 각 말단의 아미노산 잔기(즉, 아미노산 3 및 20), 선택적으로 범위 내의 아미노산(즉, 아미노산 5, 9, 16 및 20)을 포함하는, 상기 범위 내의 하나 이상의 아미노산 잔기와만 결합할 수 있다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 잔기 3, 5, 9, 10, 12, 16, 17, 20, 37, 42, 50, 53, 59, 62, 64, 68, 69, 72 중 하나 이상을 포함한다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 잔기 3, 5, 9, 10, 12, 16, 17, 20, 37, 42, 50, 53, 59, 62, 64, 68, 69, 72 또는 77로부터 선택된 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개의 아미노산을 포함한다.
일 실시예에서, 상기 에피토프는 서열번호: 1(또는 상기 기재된 서열번호: 128)의 하기 아미노산 영역 내의 하나 이상의 아미노산 잔기를 포함한다:
(i) 3-17;
(ii) 5-20;
(iii) 37-53;
(iv) 50-64;
(v) 59-72;
(vi) 59-77;
(vii) 62-69; 및/또는
(viii) 62-77.
추가 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역: 5-20 및 62-77; 50-64; 37-53 및 59-72; 59-77; 또는 3-17 및 62-69 내의 하나 이상의 아미노산 잔기를 포함한다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역: 5-20 및 62-77; 50-64; 37-53 및 59-72; 59-77; 또는 3-17 및 62-69 내의 하나 이상의 아미노산 잔기로 구성된다.
추가 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 잔기: 3, 5, 9, 10, 12, 16, 17, 62, 64, 68 및 69를 포함하거나, 적절하게는 서열번호: 1의 아미노산 잔기 3, 5, 9, 10, 12, 16, 17, 62, 64, 68 및 69으로 구성된다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 잔기: 5, 9, 16, 20, 62, 64, 72 및 77을 포함하거나, 적절하게는 서열번호: 1의 아미노산 잔기: 5, 9, 16, 20, 62, 64, 72 및 77로 구성된다. 또 다른 실시예에서, 에피토프는 서열번호: 1의 아미노산 잔기: 37, 42, 50, 53, 59, 64, 68, 69, 72, 73 및 77을 포함하거나, 또는 적절하게는 서열번호: 1의 아미노산 잔기: 37, 42, 50, 53, 59, 64, 68, 69, 72, 73 및 77로 구성된다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 잔기: 50, 53, 59, 62 및 64를 포함하거나, 또는 적절하게는 서열번호: 1의 아미노산 잔기: 50, 53, 59, 62 및 64로 구성된다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 잔기: 59, 60, 68 및 72를 포함하거나, 또는 적절하게는 서열번호: 1의 아미노산 잔기: 59, 60, 68 및 72로 구성된다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 5-20 및/또는 62-77 내의 하나 이상의 아미노산 잔기를 포함한다. 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 5-20 및 62-77 내의 하나 이상의 아미노산 잔기로 구성된다. 다른 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 5-20 또는 62-77 내의 하나 이상의 아미노산 잔기를 포함한다. 상기 에피토프를 갖는 항체 또는 이의 단편은 1245_P01_E07의 서열의 일부 또는 전부를 가질 수 있거나, 상기 항체 또는 이의 단편은 1245_P01_E07로부터 유래될 수 있다. 예를 들어, 1245_P01_E07의 하나 이상의 CDR 서열 또는 1245_P01_E07의 VH 및 VL 서열 중 하나 또는 둘 모두를 갖는 항체 또는 이의 단편은 상기 에피토프에 결합할 수 있다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 50-64 내의 하나 이상의 아미노산 잔기를 포함한다. 추가 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 50-64 내의 하나 이상의 아미노산 잔기로 구성된다. 상기 에피토프를 갖는 항체 또는 이의 단편은 1252_P01_C08의 서열의 일부 또는 전부를 가질 수 있거나, 상기 항체 또는 이의 단편은 1252_P01_C08로부터 유래될 수 있다. 예를 들어, 1252_P01_C08의 하나 이상의 CDR 서열 또는 1252_P01_C08의 VH 및 VL 서열 중 하나 또는 둘 모두를 갖는 항체 또는 이의 단편은 상기 에피토프에 결합할 수 있다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 37-53 및/또는 59-77 내의 하나 이상의 아미노산 잔기를 포함한다. 추가 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 37-53 및/또는 59-77 내의 하나 이상의 아미노산 잔기로 구성된다. 다른 추가 실시예에서, 에피토프는 서열번호: 1의 아미노산 영역 37-53 및/또는 59-77 내의 하나 이상의 아미노산 잔기를 포함한다. 상기 에피토프를 갖는 항체 또는 이의 단편은 1245_P02_G04의 서열의 일부 또는 전부를 가질 수 있거나, 상기 항체 또는 이의 단편은 1245_P02_G04로부터 유래될 수 있다. 예를 들어, 1245_P02_G04의 하나 이상의 CDR 서열 또는 1245_P02_G04의 VH 및 VL 서열 중 하나 또는 둘 모두를 갖는 항체 또는 이의 단편은 상기 에피토프에 결합할 수 있다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 59-72 내의 하나 이상의 아미노산 잔기를 포함한다. 추가 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 59-72 내의 하나 이상의 아미노산 잔기로 구성된다. 상기 에피토프를 갖는 항체 또는 이의 단편은 1251_P02_C05의 서열의 일부 또는 전부를 가질 수 있거나, 상기 항체 또는 이의 단편은 1251_P02_C05로부터 유래될 수 있다. 예를 들어, 1251_P02_C05의 하나 이상의 CDR 서열 또는 1251_P02_C05의 VH 및 VL 서열 중 하나 또는 둘 모두를 갖는 항체 또는 이의 단편은 상기 에피토프에 결합할 수 있다.
일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 11-21 내의 하나 이상의 아미노산 잔기를 포함한다. 일 실시예에서, 상기 에피토프는 서열번호: 1의 아미노산 영역 21-28 내의 아미노산 잔기를 포함하지 않는다. 일 실시예에서 상기 에피토프는 서열번호: 1의 아미노산 영역 59 및 60 내의 아미노산 잔기를 포함하지 않는다. 일 실시예에서 상기 에피토프는 서열번호: 1의 아미노산 영역 67-82 내의 아미노산 잔기를 포함하지 않는다.
일 실시예에서, 상기 에피토프는 TS-1 또는 TS8.2와 같이 시판되는 항-Vδ1 항체에 의해 결합된 동일한 에피토프가 아니다. WO2017197347에 기재된 바와 같이, 가용성 TCR에 대한 TS-1 및 TS8.2의 결합은 δ1 사슬이 Vδ1 J1 및 Vδ1 J2 서열을 포함하는 경우에 검출되지만 Vδ1 J3 사슬에는 결합하지 않아, TS-1 및 TS8.2의 결합은 델타 J1 및 델타 J2 영역에 매우 중요한 잔기가 포함되어 있음을 나타내었다.
본 명세서에서 "내(within)"이라 함은 정의된 영역의 말단을 포함한다. 예를 들어, "아미노산 영역 5-20 내"는 잔기 5를 포함하는 것으로부터 잔기 20을 포함하는 것까지의 모든 아미노산 잔기를 지칭한다.
항체에 어떤 항체가 결합되어 있는 지를 입증하기 위한 다양한 기술이 당업계에 공지되어 있다. 예시적인 기술은 예를 들어 일상적인 교차 차단 분석(routine cross-blocking assays), 알라닌 스캐닝 돌연변이 분석(alanine scanning mutational anaylsis), 펩다이드 블랏 분석(peptide blot analysis), 펩티드 절단 분석 결정학 연구(peptide cleavage analysis crystallographic studies) 및 NMR 분석을 포함한다. 또한 에피토프 절제, 에피토프 추출 및 항원의 화학적 변형과 같은 방법을 사용할 수 있다. 항체가 상호작용하는 폴리펩파이드 내의 아미노산을 확인하는 데 사용할 수 있는 다른 방법은 (실시예 9에 기술되는 바와 같은) 질량 분석법에 의해 검출된 수소/중수소 교환이다. 일반적으로 수소/중수소 교환법은 관심 단백질을 중수소로 표지한 후 항체를 중수소가 표지된 단백질에 결합시키는 것을 포함한다. 다음, 단백질/항체 복합체는 물로 옮겨지고 항체 복합체에 의해 보호된 아미노산 내의 교환 가능한 양성자는 계면의 일부가 아닌 아미노산 내의 교환 가능한 양성자보다 느린 속도로 중수소에서 수소로 역교환을 진행한다. 그 결과, 단백질/항체 계면의 일부를 형성하는 아미노산은 중수소를 보유할 수 있으므로, 계면에 포함되지 않은 아미노산에 비해 상대적으로 더 높은 질량을 나타낸다. 항체의 해리 후, 표적 단백질은 프로테아제 절단 및 질량 분석 분석의 대상이 되며, 그에 의해 항체와 상호작용하는 특정 아미노산에 해당하는 중수소 표지된 잔기를 드러낸다.
항체 서열
단리된 항-Vδ1 항체 또는 이의 단편은 그의 CDR 서열을 참조하여 기재될 수 있다.
일 실시예에서, 상기 항-Vδ1 항체 또는 이의 단편은 다음 중 하나 이상을 포함한다:
서열번호: 2-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3;
서열번호: 26-37 및 서열: A1-A12 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2; 및/또는
서열번호: 38-61 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1.
일 실시예에서, 상기 단리된 항-Vδ1 항체 또는 이의 단편은 서열번호: 2-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 26-37 및 (표 2의) 서열 A1-A12 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 38-61 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-25 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열식호: 26-37 및 (표 2의) 서열: A1-A12 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 38-61 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-25 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 26-37 및 (표 2의) 서열: A1-A12 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR2를 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 38-61 중 어느 하나와 85%, 90%, 95%, 97%, 98% 또는 99% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR1을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 공유하는 CDR3 서열을 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역으로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 90% 이상의 서열 상동성을 갖는 CR3를 VL 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역으로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 95% 이상의 서열 상동성을 갖는 CR3를 VL 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-25 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역으로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 CR3를 VL 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역으로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 2-7, 특히 2-6, 예를 들어 2, 3, 또는 4 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 14-19, 특히 14-18, 예를 들어 14, 15 또는 16 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 90% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다. 일 실시예에서, 서열번호: 8-13, 특히 8, 9, 10 또는 11 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VH 영역 및/또는 서열번호: 20-25, 특히 20, 21, 22 또는 23 중 어느 하나와 95% 이상의 서열 상동성을 갖는 서열로 이루어진 CDR3를 포함하는 VL 영역을 포함한다.
본 명세서에서 "적어도 80%" 또는 "80% 이상"을 언급하는 실시예는 85%, 90%, 95%, 97%, 98%, 99% 또는 100% 서열 상동성과 같이 80% 이상의 모든 값을 포함하는 것으로 이해될 것이다. 일 실시예에서, 항체 또는 그의 단편은 특정 서열에 대해 90% 이상, 95% 이상, 97% 이상, 98% 이상 또는 99% 이상의 서열 상동성과 같이 85% 이상을 포함한다.
백분율 서열 상동성 대신에, 상기 실시예는 또한 하나 이상의 아미노산 변화, 예를 들어 하나 이상의 추가, 치환 및/또는 결실로 정의될 수 있다. 일 실시예에서, 상기 서열은 5개 이하의 아미노산의 변화, 예를 들어 3개 이하의 아미노산의 변화, 특히 2개 이하의 아미노산의 변화를 포함할 수 있다. 추가 실시예에서, 상기 서열은 5개 이하의 아미노산의 치환, 예를 들어 3개 이하의 아미노산의 치환, 특히 1 또는 2개의 아미노산의 치환을 포함할 수 있다. 예를 들어, 상기 항체 또는 이의 단편의 CDR3는 서열번호: 2-25 중 어느 하나 또는 더욱 적절하게는 이와 비교하여 2개 이하, 보다 적절하게는 1개 이하의 치환(들)을 갖는 서열을 포함할 수 있다.
적절하게는 서열번호: 2-61 및 서열: A1-A12에서의 상응하는 잔기와 상이한 CDR1, CDR2 또는 CDR3의 모든 잔기는 상응하는 잔기에 대한 보존적 치환이다. 예를 들어, 서열번호: 2-25에서의 상응하는 잔기와 상이한 CDR3의 모든 잔기는 상응하는 잔기에 대한 보존적 치환이다.
일 실시예에서, 상기 항체 또는 이의 단편은 다음을 포함한다:
(i) 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역;
(ii) 서열번호: 26-37 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역;
(iii) 서열번호: 38-49 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역;
(iv) 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역;
(v) 서열: A1-A12 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역; 및/또는
(vi) 서열번호: 50-61 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역.
일 실시예에서, 상기 항체 또는 이의 단편은 다음을 갖는 중 사슬을 포함한다:
(i) 서열번호: 2-13 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역;
(ii) 서열번호: 26-37 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역; 및
(iii) 서열번호: 38-49 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역.
일 실시예에서, 상기 항체 또는 이의 단편은 다음을 갖는 경 사슬을 포함한다:
(i) 서열번호: 14-25 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3을 포함하는 VL 영역;
(ii) 서열: A1-A12 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VL 영역; 및
(iii) 서열번호: 50-61 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VL 영역.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 2, 3, 4, 5 또는 6, 예를 들어 2, 3, 4 또는 5, 특히 2, 3, 또는 4 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3을 포함하는 VH 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 26, 27, 28, 29 또는 30, 예를 들어 26, 27, 28 또는 29, 특히 26, 27 또는 28중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 38, 39, 40, 41 또는 42, 예를 들어, 38, 39, 40 또는 41, 특히 38, 39 또는 40 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함한다(또는 이로 이루어진다).
일 실시예에서, 상기 항체 또는 그의 단편은 서열번호: 8, 9, 10 또는 11 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VH 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 32, 33, 34 또는 35 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR2를 포함하는 VH 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 44, 45, 46 또는 47 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR1을 포함하는 VH 영역을 포함한다(또는 이로 이루어진다).
일 실시예에서, 상기 VH 영역은 서열번호: 2의 서열을 포함하는 CDR3, 서열번호: 26의 서열을 포함하는 CDR2, 및 서열번호: 38의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3는 서열번호: 2의 서열로 이루어지고, CDR2는 서열번호: 26의 서열로 이루어지며, CDR1은 서열번호: 38의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 3의 서열을 포함하는 CDR3, 서열번호: 27의 서열을 포함하는 CDR2, 및 서열번호: 39의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 3의 서열로 이루어지고, CDR2는 서열번호: 27의 서열로 이루어지며, CDR1은 서열번호: 39의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 4의 서열을 포함하는 CDR3, 서열번호: 28의 서열을 포함하는 CDR2, 및 서열번호: 40의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 4의 서열로 이루어지고, CDR2는 서열번호: 28의 서열로 이루어지며, CDR1은 서열번호: 40의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 5의 서열을 포함하는 CDR3, 서열번호: 29의 서열을 포함하는 CDR2, 및 서열번호: 41의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 5의 서열로 이루어지고, CDR2는 서열번호: 29의 서열로 이루어지며, CDR1은 서열번호: 41의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 6의 서열을 포함하는 CDR3, 서열번호: 30의 서열을 포함하는 CDR2, 및 서열번호: 42의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 6의 서열로 이루어지고, CDR2는 서열번호: 30의 서열로 이루어지며, CDR1은 서열번호: 42의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 8의 서열을 포함하는 CDR3, 서열번호: 32의 서열을 포함하는 CDR2, 및 서열번호: 44의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 8의 서열로 이루어지고, CDR2는 서열번호: 32의 서열로 이루어지며, CDR1은 서열번호: 44의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 9의 서열을 포함하는 CDR3, 서열번호: 33의 서열을 포함하는 CDR2, 및 서열번호: 45의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 9의 서열로 이루어지고, CDR2는 서열번호: 33의 서열로 이루어지며, CDR1은 서열번호: 45의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 10의 서열을 포함하는 CDR3, 서열번호: 34의 서열을 포함하는 CDR2, 및 서열번호: 46의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 10의 서열로 이루어지고, CDR2는 서열번호: 34의 서열로 이루어지며, CDR1은 서열번호: 46의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 11의 서열을 포함하는 CDR3, 서열번호: 35의 서열을 포함하는 CDR2, 및 서열번호: 47의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 11의 서열로 이루어지고, CDR2는 서열번호: 35의 서열로 이루어지며, CDR1은 서열번호: 47의 서열로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 14-25, 예를 들어 14, 15, 16 또는 17과 같이 14, 15, 16, 17 또는 18, 특히 14, 15 또는 16 중 어느 하나와 80% 이상의 서열 상동성을 갖는 서열을 포함하는 CDR3를 포함하는 VL 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 (표 2의) 서열: A1-A12, 예를 들어 A1, A2, A3 또는 A4와 같이 서열: A1, A2, A3, A4 또는 A5, 특히 A1, A2 또는 A3 중 어느 하나와 80% 이상의 서열 상동성을 갖는 CDR2를 포함하는 VL 영역을 포함한다(또는 이로 이루어진다). 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 50-61, 예를 들어 50, 51, 52 또는 53과 같이 서열번호: 50, 51, 52, 53 또는 54, 특히 50, 51 또는 52 중 어느 하나와 80% 이상의 서열 상동성을 갖는 CDR1를 포함하는 VL 영역을 포함한다(또는 이로 이루어진다).
일 실시예에서, 상기 VL 영역은 서열번호: 14의 서열을 포함하는 CDR3, 서열: A1의 서열을 포함하는 CDR2, 및 서열번호: 50의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 14의 서열로 이루어지고, CDR2는 서열: A1의 서열로 이루어지고, CDR1은 서열번호: 50의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 15의 서열을 포함하는 CDR3, 서열: A2의 서열을 포함하는 CDR2, 및 서열번호: 51의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 15의 서열로 이루어지고, CDR2는 서열: A2의 서열로 이루어지고, CDR1은 서열번호: 51의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 16의 서열을 포함하는 CDR3, 서열: A3의 서열을 포함하는 CDR2, 및 서열번호: 52의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 16의 서열로 이루어지고, CDR2는 서열: A3의 서열로 이루어지고, CDR1은 서열번호: 52의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 17의 서열을 포함하는 CDR3, 서열: A4의 서열을 포함하는 CDR2, 및 서열번호: 53의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 17의 서열로 이루어지고, CDR2는 서열: A4의 서열로 이루어지고, CDR1은 서열번호: 53의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 18의 서열을 포함하는 CDR3, 서열: A5의 서열을 포함하는 CDR2, 및 서열번호: 54의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 18의 서열로 이루어지고, CDR2는 서열: A5의 서열로 이루어지고, CDR1은 서열번호: 54의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 20의 서열을 포함하는 CDR3, 서열: A7의 서열을 포함하는 CDR2, 및 서열번호: 56의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 20의 서열로 이루어지고, CDR2는 서열: A7의 서열로 이루어지고, CDR1은 서열번호: 56의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 21의 서열을 포함하는 CDR3, 서열: A8의 서열을 포함하는 CDR2, 및 서열번호: 57의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 21의 서열로 이루어지고, CDR2는 서열: A8의 서열로 이루어지고, CDR1은 서열번호: 57의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 22의 서열을 포함하는 CDR3, 서열: A9의 서열을 포함하는 CDR2, 및 서열번호: 58의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 22의 서열로 이루어지고, CDR2는 서열: A9의 서열로 이루어지고, CDR1은 서열번호: 58의 서열로 이루어진다.
일 실시예에서, 상기 VL 영역은 서열번호: 23의 서열을 포함하는 CDR3, 서열: A10의 서열을 포함하는 CDR2, 및 서열번호: 59의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, CDR3은 서열번호: 23의 서열로 이루어지고, CDR2는 서열: A10의 서열로 이루어지고, CDR1은 서열번호: 59의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 2의 서열을 포함하는 CDR3, 서열번호: 26의 서열을 포함하는 CDR2, 서열번호: 38의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 14의 서열을 포함하는 CDR3, 서열: A1의 서열을 포함하는 CDR2, 및 서열번호: 50의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 2의 서열로 이루어지고, HCDR2는 서열번호: 26의 서열로 이루어지며, HCDR1은 서열번호: 38의 서열로 이루어지고, LCDR3는 서열번호: 14의 서열로 이루어지고, LCDR2는 서열: A1의 서열로 이루어지며, LCDR1은 서열번호: 50의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 3의 서열을 포함하는 CDR3, 서열번호: 27의 서열을 포함하는 CDR2, 서열번호: 39의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 15의 서열을 포함하는 CDR3, 서열: A2의 서열을 포함하는 CDR2, 및 서열번호: 51의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 3의 서열로 이루어지고, HCDR2는 서열번호: 27의 서열로 이루어지며, HCDR1은 서열번호: 39의 서열로 이루어지고, LCDR3는 서열번호: 15의 서열로 이루어지고, LCDR2는 서열: A2의 서열로 이루어지며, LCDR1은 서열번호: 51의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 4의 서열을 포함하는 CDR3, 서열번호: 28의 서열을 포함하는 CDR2, 서열번호: 40의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 16의 서열을 포함하는 CDR3, 서열: A3의 서열을 포함하는 CDR2, 및 서열번호: 52의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 4의 서열로 이루어지고, HCDR2는 서열번호: 28의 서열로 이루어지며, HCDR1은 서열번호: 40의 서열로 이루어지고, LCDR3는 서열번호: 16의 서열로 이루어지고, LCDR2는 서열: A3의 서열로 이루어지며, LCDR1은 서열번호: 52의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 5의 서열을 포함하는 CDR3, 서열번호: 29의 서열을 포함하는 CDR2, 서열번호: 41의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 17의 서열을 포함하는 CDR3, 서열: A4의 서열을 포함하는 CDR2, 및 서열번호: 53의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 5의 서열로 이루어지고, HCDR2는 서열번호: 29의 서열로 이루어지며, HCDR1은 서열번호: 41의 서열로 이루어지고, LCDR3는 서열번호: 17의 서열로 이루어지고, LCDR2는 서열: A4의 서열로 이루어지며, LCDR1은 서열번호: 53의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 6의 서열을 포함하는 CDR3, 서열번호: 30의 서열을 포함하는 CDR2, 서열번호: 42의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 18의 서열을 포함하는 CDR3, 서열: A5의 서열을 포함하는 CDR2, 및 서열번호: 54의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 6의 서열로 이루어지고, HCDR2는 서열번호: 30의 서열로 이루어지며, HCDR1은 서열번호: 42의 서열로 이루어지고, LCDR3는 서열번호: 18의 서열로 이루어지고, LCDR2는 서열: A5의 서열로 이루어지며, LCDR1은 서열번호: 54의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 7의 서열을 포함하는 CDR3, 서열번호: 31의 서열을 포함하는 CDR2, 서열번호: 43의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 19의 서열을 포함하는 CDR3, 서열: A6의 서열을 포함하는 CDR2, 및 서열번호: 55의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 7의 서열로 이루어지고, HCDR2는 서열번호: 31의 서열로 이루어지며, HCDR1은 서열번호: 43의 서열로 이루어지고, LCDR3는 서열번호: 19의 서열로 이루어지고, LCDR2는 서열: A6의 서열로 이루어지며, LCDR1은 서열번호: 55의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 8의 서열을 포함하는 CDR3, 서열번호: 32의 서열을 포함하는 CDR2, 서열번호: 44의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 20의 서열을 포함하는 CDR3, 서열: A7의 서열을 포함하는 CDR2, 및 서열번호: 56의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 8의 서열로 이루어지고, HCDR2는 서열번호: 32의 서열로 이루어지며, HCDR1은 서열번호: 44의 서열로 이루어지고, LCDR3는 서열번호: 20의 서열로 이루어지고, LCDR2는 서열: A7의 서열로 이루어지며, LCDR1은 서열번호: 56의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 9의 서열을 포함하는 CDR3, 서열번호: 33의 서열을 포함하는 CDR2, 서열번호: 45의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 21의 서열을 포함하는 CDR3, 서열: A8의 서열을 포함하는 CDR2, 및 서열번호: 57의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 9의 서열로 이루어지고, HCDR2는 서열번호: 33의 서열로 이루어지며, HCDR1은 서열번호: 45의 서열로 이루어지고, LCDR3는 서열번호: 21의 서열로 이루어지고, LCDR2는 서열: A8의 서열로 이루어지며, LCDR1은 서열번호: 57의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 10의 서열을 포함하는 CDR3, 서열번호: 34의 서열을 포함하는 CDR2, 서열번호: 46의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 22의 서열을 포함하는 CDR3, 서열: A9의 서열을 포함하는 CDR2, 및 서열번호: 58의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 10의 서열로 이루어지고, HCDR2는 서열번호: 34의 서열로 이루어지며, HCDR1은 서열번호: 46의 서열로 이루어지고, LCDR3는 서열번호: 22의 서열로 이루어지고, LCDR2는 서열: A9의 서열로 이루어지며, LCDR1은 서열번호: 58의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 11의 서열을 포함하는 CDR3, 서열번호: 35의 서열을 포함하는 CDR2, 서열번호: 47의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 23의 서열을 포함하는 CDR3, 서열: A10의 서열을 포함하는 CDR2, 및 서열번호: 59의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 11의 서열로 이루어지고, HCDR2는 서열번호: 35의 서열로 이루어지며, HCDR1은 서열번호: 47의 서열로 이루어지고, LCDR3는 서열번호: 23의 서열로 이루어지고, LCDR2는 서열: A10의 서열로 이루어지며, LCDR1은 서열번호: 59의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 12의 서열을 포함하는 CDR3, 서열번호: 36의 서열을 포함하는 CDR2, 서열번호: 48의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 24의 서열을 포함하는 CDR3, 서열: A11의 서열을 포함하는 CDR2, 및 서열번호: 60의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 12의 서열로 이루어지고, HCDR2는 서열번호: 36의 서열로 이루어지며, HCDR1은 서열번호: 48의 서열로 이루어지고, LCDR3는 서열번호: 24의 서열로 이루어지고, LCDR2는 서열: A11의 서열로 이루어지며, LCDR1은 서열번호: 60의 서열로 이루어진다.
일 실시예에서, 상기 VH 영역은 서열번호: 13의 서열을 포함하는 CDR3, 서열번호: 37의 서열을 포함하는 CDR2, 서열번호: 49의 서열을 포함하는 CDR1을 포함하고, 상기 VL 영역은 서열번호: 25의 서열을 포함하는 CDR3, 서열: A12의 서열을 포함하는 CDR2, 및 서열번호: 61의 서열을 포함하는 CDR1을 포함한다. 일 실시예에서, HCDR3는 서열번호: 13의 서열로 이루어지고, HCDR2는 서열번호: 37의 서열로 이루어지며, HCDR1은 서열번호: 49의 서열로 이루어지고, LCDR3는 서열번호: 25의 서열로 이루어지고, LCDR2는 서열: A12의 서열로 이루어지며, LCDR1은 서열번호: 61의 서열로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 하나 이상의 CDR 서열을 포함한다. 추가의 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1252_P01_C08의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P01_E07의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P02_G04의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P02_B07의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1251_P02_C05의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1139_P01_E04의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P02_F07의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P01_G06의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1245_P01_G09의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1138_P01_B09의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 표 2에 기재된 클론 1251_P02_G10의 하나 이상의 (예를 들어, 모든) CDR 서열을 포함한다.
적절하게는 전술한 VH 및 VL 영역은 각각 4개의 프레임워크 영역(FR1-FR4)을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나의 프레임워크 영역과 80% 이상의 서열 상동성을 갖는 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나의 프레임워크 영역과 90% 이상, 예를 들어 95%, 97% 또는 99% 이상의 서열 상동성을 갖는 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나의 서열을 포함하는 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나의 서열로 이루어진 프레임워크 영역(예를 들어, FR1, FR2, FR3 및/또는 FR4)을 포함한다.
본 명세서에 기재된 상기 항체는 그의 전체 경 사슬 및/또는 중 사슬 가변 서열에 의해 정의될 수 있다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-73 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VH 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-73 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진 VH 영역을 포함한다. 추가 실시예에서, 상기 VH 영역은 서열번호: 62, 63, 64, 65 또는 66, 예를 들어 62, 63, 64 또는 65, 특히 62, 63 또는 65 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 VH 영역은 서열번호: 62, 63, 64, 65 또는 66, 예를 들어 62, 63, 64 또는 65, 특히 62, 63 또는 65 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다. 추가 실시예에서, 상기 VH 영역은 서열번호: 68, 69, 70, 71, 72 또는 73, 예를 들어 68, 69, 70 또는 71 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 VH 영역은 서열번호: 68, 69, 70, 71, 72 또는 73, 예를 들어 68, 69, 70 또는 71 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 74-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함한다. 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 74-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진 VL 영역을 포함한다. 추가 실시예에서, 상기 VL 영역은 서열번호: 74, 75, 76, 77 또는 78, 예를 들어 74, 75, 76 또는 77, 특히 74, 75 또는 76 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 VL 영역은 서열번호: 74, 75, 76, 77 또는 78, 예를 들어 74, 75, 76 또는 77, 특히 74, 75 또는 76 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다. 추가 실시예에서, 상기 VL 영역은 서열번호: 80, 81, 82, 83, 84 또는 85, 예를 들어 80, 81, 82 또는 83 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 VL 영역은 서열번호: 80, 81, 82, 83, 84 또는 85, 예를 들어 80, 81, 82 또는 83 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다.
추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-73 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VH 영역 및 서열번호: 74-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함한다. 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62-73 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진 VH 영역 및 서열번호: 74-85 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 63(1252_P01_C08)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62(1245_P01_E07)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 64(1245_P02_G04)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 68(1139_P01_E04)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 69(1245_P02_F07)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 70(1245_P01_G06)의 아미노산 서열을 포함하는 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 71(1245_P01_G09)의 아미노산 서열을 포함하는 VH 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 63(1252_P01_C08)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62(1245_P01_E07)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 64(1245_P02_G04)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 68(1139_P01_E04)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 69(1245_P02_F07)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 70(1245_P01_G06)의 아미노산 서열로 이루어진 VH 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 71(1245_P01_G09)의 아미노산 서열로 이루어진 VH 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 75(1252_P01_C08)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 74(1245_P01_E07)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 76(1245_P02_G04)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 80(1139_P01_E04)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 81(1245_P02_F07)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 82(1245_P01_G06)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 83(1245_P01_G09)의 아미노산 서열을 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 75(1252_P01_C08)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 74(1245_P01_E07)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 76(1245_P02_G04)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 80(1139_P01_E04)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 81(1245_P02_F07)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 82(1245_P01_G06)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 83(1245_P01_G09)의 아미노산 서열로 이루어진 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 63(1252_P01_C08)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 75(1252_P01_C08)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62(1245_P01_E07)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 74(1245_P01_E07)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 64(1245_P02_G04)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 76(1245_P02_G04)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 68(1139_P01_E04)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 80(1139_P01_E04)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 69(1245_P02_F07)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 81(1245_P02_F07)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 70(1245_P01_G06)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 82(1245_P01_G06)의 아미노산 서열을 포함하는 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 71(1245_P01_G06)의 아미노산 서열을 포함하는 VH 영역 및 서열번호: 83(1245_P01_G09)의 아미노산 서열을 포함하는 VL 영역을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 63(1252_P01_C08)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 75(1252_P01_C08)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 62(1245_P01_E07)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 74(1245_P01_E07)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 64(1245_P02_G04)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 76(1245_P02_G04)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 68(1139_P01_E04)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 80(1139_P01_E04)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 69(1245_P02_F07)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 81(1245_P02_F07)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 70(1245_P01_G06)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 82(1245_P01_G06)의 아미노산 서열로 이루어진 VL 영역을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 71(1245_P01_G09)의 아미노산 서열로 이루어진 VH 영역 및 서열번호: 83(1245_P01_G09)의 아미노산 서열로 이루어진 VL 영역을 포함한다.
VH 및 VL 영역을 모두 포함하는 단편의 경우, 이들은 공유 결합(예를 들어, 다이설파이드 결합 또는 링커를 통해) 또는 비공유 결합될 수 있다. 본 명세서에 기재된 항체 단편은 scFv, 즉 링커에 의해 연결된 VH 영역 및 VL 영역을 포함하는 단편을 포함할 수 있다. 일 실시예에서, 상기 VH 및 VL 영역은 (예를 들어, 합성) 폴리펩타이드 링커에 의해 연결된다. 상기 폴리펩타이드 링커는 (Gly4Ser)n 링커를 포함할 수 있으며, 여기서 n은 1 내지 8, 예를 들어 2, 3, 4, 5 또는 7이다. 상기 폴리펩타이드 링커는 [(Gly4Ser)n(Gly3AlaSer)m]p 링커를 포함할 수 있으며, 여기서 n = 1 내지 8, 예를 들어 2, 3, 4, 5 또는 7이고, m = 1 내지 8, 예를 들어 0, 1, 2 또는 3이며, p = 1 내지 8, 예를 들어 1, 2 또는 3이다. 추가 실시예에서, 상기 링커는 서열번호: 98을 포함한다. 추가 실시예에서, 상기 링커는 서열 98로 이루어진다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86-97 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86-97 중 어느 하나의 아미노산 서열을 포함한다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 87(1252_P01_C08)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86(1245_P01_E07)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 88(1245_P02_G04)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 92(1139_P01_E04)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 93(1245_P02_F07)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 94(1245_P01_G06)의 아미노산 서열을 포함한다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 95(1245_P01_G09)의 아미노산 서열을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86-97 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다. 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86-97 중 어느 하나의 아미노산 서열로 이루어진다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 87(1252_P01_C08)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 86(1245_P01_E07)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 88(1245_P02_G04)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 92(1139_P01_E04)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 93(1245_P02_F07)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 94(1245_P01_G06)의 아미노산 서열로 이루어진다. 다른 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 95(1245_P01_G09)의 아미노산 서열로 이루어진다.
당업자에게는 scFv 구조물이 번역, 정제 및 검출을 돕기 위해 N-말단 및 C-말단의 변형을 포함하도록 설계 및 제조될 수 있음은 당연하다. 예를 들어, scFv 서열의 N-말단에서, 부가 메티오닌 및/또는 알라닌 아미노산 잔기가 기준 VH 서열(예를 들어, QVQ 또는 EVQ로 시작하는)의 앞에 포함될 수 있다. C-말단(즉, IMGT 정의에 따라 끝나는 기준 VL 도메인 서열의 C-말단)에서, (i) 불변 도메인의 부분 서열 및/또는 (ii) 정제 및 검출을 돕는 His-태그 밀 Flag-태그와 같은 태그를 포함하는 부가 합성 서열과 같은 부가 서열이 포함될 수 있다. 일 실시예에서, 서열번호: 124는 서열번호: 86, 88-90, 92-97 중 어느 하나의 C-말단에 부가된다. 일 실시예에서, 서열번호: 125는 서열번호: 86, 88-90, 92-97 중 어느 하나의 C-말단에 부가된다. 일 실시예에서, 서열번호: 126은 서열번호: 87 또는 91 중 어느 하나의 C-말단에 부가된다. 일 실시예에서, 서열번호: 127은 서열번호: 87 또는 91 중 어느 하나의 C-말단에 부가된다. 상기 scFv N- 또는 C-말단 서열은 선택 사항이며, 다른 scFv 설계, 번역, 정제 또는 검출 전략이 채택되는 경우 제거, 수정 또는 대체될 수 있음은 당연하다.
본 명세서에 기재된 바와 같이, 상기 항체는 임의의 형태일 수 있다. 바람직한 실시예에서, 상기 항체는 IgG1 형태이다. 따라서, 일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-122 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함한다. 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-122 중 어느 하나의 아미노산 서열을 포함한다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-116, 예를 들어 서열번호: 111-113 및 116의 아미노산 서열을 포함한다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 117-122의 아미노산 서열, 예를 들어 서열번호: 117-120의 아미노산 서열을 포함한다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111, 112, 116-120, 예를 들어 서열번호: 111, 112 또는 116, 또는 서열번호: 117-120의 아미노산 서열을 포함한다.
일 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-122 중 어느 하나와 80% 이상의 서열 상동성을 갖는 아미노산 서열로 이루어진다. 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-122 중 어느 하나의 아미노산 서열로 이루어진다. 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111-116, 예를 들어 111-113 및 116의 아미노산 서열로 이루어진다. 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 117-122, 예를 들어 서열번호: 117-120의 아미노산 서열로 이루어진다, 또 다른 추가 실시예에서, 상기 항체 또는 이의 단편은 서열번호: 111, 112, 116-120, 예를 들어 서열번호: 111, 112 또는 116, 또는 서열번호: 117-120의 아미노산 서열로 이루어진다.
일 실시예에서, 상기 항체는 본 명세서에 정의된 항체 또는 이의 단편과 동일하거나 본질적으로 동일한 에피토프에 결합하거나 상기 항체 또는 이의 단편과 경쟁한다. 상기 항체가 참조 항-Vδ1 항체와 동일한 에피토프에 결합하는지 또는 결합에 대해 경쟁하는지 여부는 당업계에 공지된 통상적인 방법을 사용하여 용이하게 결정할 수 있다. 예를 들어, 시험 항체가 참조 항-Vδ1 항체와 동일한 에피토프에 결합하는지 결정하기 위하여, 참조 항체가 포화 조건 하에 Vδ1 단백질 또는 펩티드에 결합되도록 한다. 이후, Vδ1 사슬에 결합하는 시험 항체의 능력이 평가된다. 만일 참조 항-Vδ1 항체가 포화 결합된 후 시험 항체가 Vδ1에 결합할 수 있다면, 시험 항체는 참조 항-Vδ1 항체와 상이한 에피토프에 결합한다고 결론지을 수 있다. 반면에, 참조 항-Vδ1 항체가 포화 결합된 후 시험 항체가 Vδ1 사슬에 결합할 수 없다면, 시험 항체는 참조 항-Vδ1 항체에 의해 결합된 에피토프와 동일한 에피토프에 결합할 것이다.
본 발명은 또한 Vδ1에 대한 결합에 대해 본 명세서에 정의된 상기 항체 또는 이의 단편, 또는 본 명세서에 기재된 임의의 예시적인 항체의 CDR 서열을 갖는 항체와 경쟁하는 항-Vδ1 항체를 포함한다. 예를 들어, 어떤 단백질, 항체 및 기타 길항제가 상기 항체와 Vδ1 사슬에 결합하기 위해 경쟁하고/거나 에피토프를 공유하는지 결정하기 위해 항체와의 경쟁 분석을 수행할 수 있다. 상기 분석은 당업자에게 이미 공지되어 있다; 이들은 단백질, 예를 들어 Vδ1의 제한된 수의 결합 부위에 대한 길항제 또는 리간드 간의 경쟁을 평가한다. 상기 항체(또는 이의 단편)는 경쟁 전 또는 후에 고정되거나 불용화되어, 예를 들어 경사분리(항체가 사전에 불용화 된 경우) 또는 원심분리(항체가 경쟁 반응 후 침전된 경우)에 의해 Vδ1 사슬에 결합된 시료는 결합되지 않은 시료로부터 분리된다. 또한, 경쟁적 결합은 기능이 단백질에 대한 항체의 결합 또는 결합의 결여에 의해 변경되는지 여부, 예를 들어 항체 분자가, 예를 들어 표지의, 효소 활성을 억제하거나 강화하는지 여부에 의해 결정될 수 있다. ELISA 및 기타 기능적 분석이 당업계에 공지되고 본원에 기술된 바와 같이 사용될 수 있다.
각각의 항체가 표적 항원에 대한 다른 항체의 결합을 경쟁적으로 저해(차단)한다면, 두 개의 항체는 동일하거나 중첩되는 에피토프에 결합한다. 즉, 1-, 5-, 10-, 20- 또는 100-배 과량인 하나의 항체는 경쟁 결합 분석에서 측정할 때 다른 항체의 결합을 적어도 50%, 바람직하게는 75%, 90% 또는 심지어 99%까지 억제한다. 또는 본질적으로 하나의 항체의 결합을 감소 또는 제거하는 표적 항원에서의 모든 아미노산의 돌연변이가 다른 항체의 결합을 감소 또는 제거하는 경우, 두 개의 항체는 동일한 에피토프를 갖는다.
관측된 시험 항체의 결합 부족이 실제로 참조 항체와 동일한 에피토프에 대한 결합 때문인지 또는 입체적 차단(또는 다른 현상)이 관측된 결합의 부족에 대한 원인인지 확인하기 위하여 추가의 통상적인 실험작업(예를 들어, 펩타이드 돌연변이 및 결합 분석)이 수행될 수 있다. 이러한 종류의 실험은 ELISA, RIA, 표면 플라즈몬 공명, 유세포 분석 또는 당업계에서 이용 가능한 임의의 다른 정량적 또는 정성적 항체-결합 분석을 사용하여 수행될 수 있다.
일부 실시예에서, 상기 항체 또는 이의 단편은 Asn 297(EU 넘버링 방식)에 연결된 당에 대한 변경을 통해 변형된 작동체 기능을 포함한다. 추가의 상기 변형에서, Asn 297은 푸코실화되지 않거나 감소된 푸코실화를 나타낸다(즉, 디푸코실화된 항체 또는 푸코실화되지 않은 항체). 푸코실화(fucosylation)는 분자에 푸코오스 당의 첨가, 예를 들어 N-글리칸, O-글리칸 및 당지질에 대한 푸코오스의 부착을 포함한다. 따라서, 탈푸코실화된 항체에서 푸코스는 불변영역의 탄수화물 사슬에 부착되어 있지 않다. 상기 항체는 항체의 푸코실화를 방지하거나 억제하도록 변형될 수 있다. 전형적으로, 글리코실화 변형은 표적화된 조작을 통해 또는 표적화된 또는 우연한 숙주 또는 클론 선택을 통해 대체된 글리코실화 처리 능력을 함유하는 숙주 세포에서 상기 항체 또는 이의 단편을 발현시키는 것을 포함한다. 이들 및 다른 작동체 변형은 예를 들어 Xinhua Wang et al. (2018) Protein & Cell 9: 63-73과 Pereira et al. (2018) mAbs 10(5): 693-711 및 여기에 포함된 최근 리뷰에서 추가로 논의되어 있다.
항체 서열 변형
상기 항체 및 이의 단편은 공지된 방법을 사용하여 변형될 수 있다. 본 명세서에 기재된 항체 분자에 대한 서열 변형은 당업자에 의해 용이하게 통합될 수 있다. 하기 예는 비제한적이다.
항체 발견 및 파지 라이브러리로부터의 서열의 취득 동안, 원하는 항체 가변 도메인은 서브-클로닝에 의해 전장 IgG로 재-형태화될 수 있다. 상기 과정을 가속화하기 위해 가변 도메인은 종종 제한 효소를 사용하여 전달된다. 상기 고유한 제한 부위는 추가/대체 아미노산을 도입할 수 있고 기준 서열에서 벗어날 수 있다(상기 기준 서열은 예를 들어 국제 ImMunoGeneTics[IMGT] 정보 시스템에서 찾을 수 있음, http://www.imgt.org 참조). 이들은 카파(Kappa) 또는 람다(Lamda) 경 사슬 서열 변형으로 도입될 수 있다.
카파
경 사슬 변형
가변 카파 경 사슬 가변 서열은 전장 IgG로 재-형태화(re-formatting)하는 동안 제한 부위(예를 들어, Nhe1-Not1)를 사용하여 클로닝될 수 있다. 보다 구체적으로, 카파 경 사슬 N-말단에서 클로닝을 지원하기 위해 추가의 Ala-Ser 서열이 도입되었다. 바람직하게는, 상기 추가의 AS 서열은 이후 기준 N-말단 서열을 생성하도록 추가 개발 동안 제거된다. 따라서, 일 실시예에서, 본 명세서에 기재된 카파 경 사슬 함유 항체는 이의 N-말단에 AS 서열을 함유하지 않으며, 즉 서열번호: 74, 76-78 및 80-85는 초기 AS 서열을 포함하지 않는다. 추가 실시예에서, 서열번호: 74 및 76-78은 초기 AS 서열을 포함하지 않는다. 상기 실시예는 또한 상기 서열을 함유하는 본 명세서에 포함된 다른 서열(예를 들어, 서열 번호: 86, 88-90 및 92-97)에도 적용되는 것은 당연하다.
클로닝 지원하기 위해 추가적인 아미노산 변경이 이루어질 수 있다. 예를 들어, 본 명세서에 기술된 항체에 대해, 카파 경 사슬 가변 도메인/불변 도메인 경계에서 클로닝를 지원하기 위해 발린에서 알라닌으로의 변경이 도입되었다. 그 결과 카파 불변 도메인 변형이 발생하였다. 구체적으로 RTAAAPS(NotI 제한 사이트에서)로 시작하는 불변 도메인을 초래한다. 바람직하게는, 상기 서열은 RTVAAPS로 시작하는 기준 카파 경 사슬 불변영역을 생성하도록 추가 개발 동안 변형될 수 있다. 따라서, 일 실시예에서 본 명세서에 기재된 카파 경 사슬을 함유하는 항체는 서열 RTV로 시작하는 불변 도메인을 함유한다. 따라서, 일 실시예에서, 서열번호: 111-114 및 117-122에서의 서열 RTAAAPS는 서열 RTVAAPS로 대체된다.
람다
경 사슬 변형
상기 카파 예와 유사하게, 람다 경 사슬 가변 도메인은 전장 IgG로 재-형태화하는 동안 제한 부위(예를 들어, Nhe1-Not1)를 도입하여 클로닝될 수도 있다. 보다 구체적으로, 람다 경 사슬 N-말단에서 클로닝을 지원하기 위해 추가의 Ala-Ser 서열이 도입될 수 있다. 바람직하게는, 상기 추가의 AS 서열은 이후 기준 N-말단 서열을 생성하도록 추가 개발 동안 제거된다. 따라서, 일 실시예에서, 본 명세서에 기재된 람다 경 사슬 함유 항체는 이의 N-말단에 AS 서열을 함유하지 않으며, 즉 서열번호: 75 및 79는 초기 AS 서열을 포함하지 않는다. 상기 실시예는 또한 상기 서열을 함유하는 본 명세서에 포함된 다른 서열(예를 들어, 서열 번호: 87, 91, 115 및 116)에도 적용되는 것은 당연하다. 일 실시예에서, 서열번호: 75는 초기 6개 잔기를 함유하지 않으며, 즉 ASSYEL 서열이 제거된다.
또 다른 예로서, 본 명세서에 기술된 항체에 대해, 람다 경 사슬 가변 도메인/불변 도메인 경계에서 클로닝을 지원하기 위해 라이신에서 알라닌으로의 서열 변경이 도입되었다. 그 결과 람다 불변 도메인 변형이 발생하였다. 구체적으로 GQPAAAPS(NotI 제한 사이트에서)로 시작하는 불변 도메인을 초래한다. 바람직하게는, 상기 서열은 GQPKAAPS로 시작하는 기준 람다 경 사슬 불변 영역을 생성하도록 추가 개발 동안 변형될 수 있다. 따라서, 일 실시예에서, 본 명세서에 기재된 람다 경 사슬을 함유하는 항체는 서열 GQPK로 시작하는 불변 도메인을 함유한다. 따라서, 일 실시예에서, 서열번호: 115 또는 116에서의 서열 GQPAAAPS는 서열 GQPKAAPS로 대체된다.
중 사슬 변형
일반적으로 인간 가변 중 사슬 서열은 염기성 글루타민(Q) 또는 산성 글루타메이트(E)로 시작한다. 그러나 상기 두 서열 모두는 산성 아미노산 잔기인 피로-글루타메이트(pE, pyro-glutamate)로 전환되는 것으로 알려져 있다. Q에서 pE로의 전환은 항체에 전하 변화를 초래하는 반면, E에서 pE로의 전환은 항체의 전하를 변화시키지 않는다. 따라서 시간 경과에 따른 가변 전하-변화를 피하기 위한 한 가지 선택안은 우선적으로 Q로 시작하는 중 사슬 서열을 E로 변형하는 것이다. 따라서 일 실시예에서, 본 명세서에 기재된 항체의 중 사슬은 N-말단에서 Q에서 E로의 변형을 함유한다. 특히, 서열번호: 62, 64 및/또는 67-71의 초기 잔기는 Q에서 E로 변형될 수 있다. 상기 실시예는 또한 상기 서열을 함유하는 본 명세서에 포함된 다른 서열(예를 들어, 서열번호: 86, 88, 91-97 및 111, 112, 115, 117-120)에도 적용되는 것은 당연하다.
추가로, IgG1 불변 도메인의 C-말단은 PGK로 끝난다. 그러나 말단 염기성 라이신(K)은 이후 종종 발현 동안 절단된다(예를 들어, CHO 세포에서). 이는 뒤 이은 C-말단 라이신 잔기의 다양한 손실을 통해 항체에 전하 변화를 초래한다. 따라서 한 가지 선택안은 우선적으로 라이신을 제거하여 PG로 끝나는 균일하고 일관된 중 사슬 C-말단 서열을 생성하는 것이다. 따라서, 일 실시예에서, 본 명세서에 기재된 항체의 중 사슬은 그의 C-말단으로부터 K가 제거된 말단을 갖는다. 특히, 본 발명의 항체는 말단 라이신 잔기가 제거된 서열번호: 111-122 중 어느 하나를 포함할 수 있다.
선택적
동종이형
변형
항체 발견 동안, 특정 인간 동종이형(allotype)이 사용될 수 있다. 선택적으로, 상기 항체는 개발 동안 다른 인간 동종이형으로 전환될 수 있다. 비제한적인 예로서, 카파 사슬에 대해 (동종이형 넘버링 사용하여) 3개의 Km 대립유전자를 정의하는 Km1, Km1,2 및 Km3으로 지칭되는 3개의 인간 동종이형이 있다: Km1은 발린 153(IMGT V45.1) 및 류신 191(IMGT L101)과 관련되어 있고; Km1,2는 알라닌 153(IMGT A45.1) 및 류신 191(IMGT L101)과 관련되어 있으며; Km3는 알라닌 153(IMGT A45.1) 및 발린 191(IMGT V101)과 관련되어 있다. 선택적으로, 따라서 표준 클로닝 접근법에 의해 하나의 동종이형에서 다른 동종이형으로 서열을 변형할 수 있다. 예를 들어, L191V(IMGT L101V) 변경은 Km1,2 동종이형을 Km3 동종이형으로 전환한다. 상기 동종이형에 대한 추가 참조는 본 명세서에 참조문헌으로 포함된 Jefferis and Lefranc (2009) MAbs 1(4):332-8을 참조한다.
따라서 일 실시예에서 본 명세서에 기재된 항체는 동일한 유전자의 또 다른 인간 동종이형으로부터 유래된 아미노산 치환체를 함유한다. 추가 실시예에서, 상기 항체는 c-도메인을 km1,2에서 km3 동종이형으로 전환시키기 위한 카파 사슬에 대한 L191V(IMGT L101V) 치환을 함유한다.
항체 결합
상기 항체 또는 이의 단편은 표면 플라즈몬 공명에 의해 측정된 1.5 x 10-7 M(즉, 150 nM) 미만의 결합 친화도(KD)로 γδ TCR의 Vδ1 사슬에 결합할 수 있다. 바람직한 실시예에서, KD는 1.5 x 10-7 M(즉, 150 nM) 미만이다. 추가 실시예에서, KD는 1.3 x 10-7 M(즉, 130 nM) 이하, 예를 들어 1.0 x 10-7 M(즉, 100 nM) 이하이다. 또 다른 실시예에서, KD는 5.0 x 10-8 M(즉, 50 nM) 미만, 예를 들어 4.0 x 10-8 M(즉, 40 nM) 미만, 3.0 x 10-8 M(즉, 30 nM) 이하, 또는 2.0 x 10-8 M(즉, 20 nM) 미만이다. 예를 들어, 일 양태에 따르면, 표면 플라스몬 공명에 의해 측정된 1.5 x 10-7 M(즉, 150 nM) 미만의 결합 친화도(KD)로 γδ TCR의 Vδ1 사슬에 결합하는 인간 항-Vδ1 항체가 제공된다.
일 실시예에서, 상기 항체 또는 이의 단편은 표면 플라스몬 공명에 의해 측정된 4.0 x 10-8 M(즉, 40 nM) 미만, 3.0 x 10-8 M 미만(즉, 30nM) 또는 2.0 x 10-8 M(즉, 20 nM) 미만의 결합 친화도(KD)로 γδ TCR의 Vδ1 사슬에 결합한다.
일 실시예에서, 상기 항체 또는 이의 단편의 결합 친화도는, 센서(예를 들어, 아민 고용량 칩 또는 등가물)의 표면에 상기 항체 또는 이의 단편을 직접 또는 간접적으로 코팅함으로(예를 들어, 항-인간 IgG Fc로 포획하는 것에 의해) 입증되며, 여기서 상기 항체 또는 이의 단편에 의해 결합되는 표적(즉, γδ TCR의 Vδ1 사슬)은 결합을 검출하기 위해 칩 위로 흐른다. 적절하게는 MASS-2 기기(Sierra SPR-32로도 지칭될 수 있음)는 25℃, 30 μl/min 유속의 PBS + 0.02% Tween 20 버퍼에서 사용된다.
항체 기능을 정의하는 데 사용될 수 있는 다른 분석법이 본 명세서에 설명된다. 예를 들어, 본 명세서에 기재된 항체 또는 이의 단편은 γδ TCR 결합에 의해, 예를 들어 항체 결합 시 γδ TCR의 하향조절을 측정하는 것으로 평가될 수 있다. 상기 항체 또는 이의 단편(선택적으로 세포 표면에 제공됨)의 적용 후 γδ TCR의 표면 발현이 예를 들어, 유세포 분석에 의해 측정될 수 있다. 본 명세서에 기재된 항체 또는 이의 단편은 또한 γδ T 세포 탈과립을 측정하는 것에 의해 평가될 수 있다. 예를 들어, 세포 탈과립에 대한 마커인 CD107a의 발현은 γδ T 세포에 상기 항체 또는 이의 단편(선택적으로 세포 표면에 제공됨)을 적용한 후, 예를 들어 유세포 분석에 의해 측정할 수 있다. 본 명세서에 기재된 항체 또는 이의 단편은 또한 (항체가 γδ T 세포의 사멸 활성에 영향을 미치는지 검정하기 위해) γδ T 세포 사멸 활성을 측정함으로써 평가될 수 있다. 예를 들어, 표적 세포는 (선택적으로, 세포 표면에 존재하는) 상기 항체 또는 이의 단편의 존재 하에 γδ T 세포와 함께 배양될 수 있다. 배양 후, 배양물은 살아있는 표적 세포와 죽은 표적 세포를 구별하기 위해 세포 생존성 염료로 염색될 수 있다. 이후 죽은 세포의 비율을 예를 들어, 유세포 분석에 의해 측정할 수 있다.
본 명세서에 기재된 바와 같이, 분석에 사용된 항체 또는 이의 단편은 표면, 예를 들어 Fc 수용체를 포함하는 세포와 같이 세포의 표면 상에 존재할 수 있다. 예를 들어, 상기 항체 또는 이의 단편은 TIB 202™세포(American Type Culture Collection(ATCC)에서 입수 가능)와 같은 THP-1 세포의 표면에 존재할 수 있다. 또는, 상기 항체 또는 이의 단편은 분석에 직접 사용될 수 있다.
상기 기능 분석에서 출력은 "EC50" 또는 "50%의 유효 농도"로 지칭되기도 하는 최대 농도의 절반을 계산하여 측정할 수 있다. 용어 "IC50"은 억제 농도를 지칭한다. EC50 및 IC50 모두는 유세포 분석법과 같이 당업계에 공지된 방법을 사용하여 측정할 수 있다. 의심의 여지를 피하기 위해, 본 출원에서 EC50 값은 IgG1 형식태화된 항체를 사용하여 제공된다. 상기 값은 다음과 같이 등가 값에 대한 항체 형식의 분자량을 기반으로 용이하게 변환될 수 있다.
(μg/ml) / (kDa 단위의 MW) = μM
상기 항체(또는 단편)의 결합 시, γδ TCR의 하향조절에 대한 EC50은 0.50 ㎍/ml 미만, 예를 들어 0.40 ㎍/ml, 0.30 ㎍/ml, 0.20 ㎍/ml, 0.15 ㎍/ml, 0.10 ㎍/ml 또는 0.05μg/ml 미만일 수 있다. 바람직한 실시예에서, 상기 항체(또는 단편)의 결합 시, γδ TCR의 하향조절에 대한 EC50은 0.10 ㎍/ml 미만이다. 특히, 상기 항체(또는 단편)의 결합 시, γδ TCR의 하향조절에 대한 EC50은 0.06 ㎍/ml 미만, 예를 들어 0.05 ㎍/ml, 0.04 ㎍/ml 또는 0.03 ㎍/ml 미만일 수 있다. 특히, 상기 EC50 값은 항체가 IgG1 형태로 측정될 때의 값이다. 예를 들어, EC50 γδ TCR 하향조절 값은(예를 들어, 실시예 6의 분석에 기재된 바와 같이) 유세포 분석을 사용하여 측정될 수 있다.
상기 항체(또는 단편)의 결합 시, γδ T 세포 탈과립에 대한 EC50은 0.050 ㎍/ml 미만, 예를 들어 0.040 ㎍/ml, 0.030 ㎍/ml, 0.020 ㎍/ml, 0.015 ㎍/ml, 0.010 ㎍/ml 미만 또는 0.008 μg/ml일 수 있다. 특히, 상기 항체(또는 단편)의 결합 시, γδ T 세포 탈과립에 대한 EC50은 0.005 ㎍/ml 미만, 예를 들어 0.002 ㎍/ml 미만일 수 있다. 바람직한 실시예에서, 상기 항체(또는 단편)의 결합 시, γδ T 세포 탈과립에 대한 EC50은 0.007 ㎍/ml 미만이다. 특히, 상기 EC50 값은 항체가 IgG1 형태로 측정될 때의 값이다. 예를 들어, γδ T 세포 탈과립 EC50 값은 (예를 들어, 실시예 7의 분석에 기재된 바와 같이) 유세포 분석을 사용하여 CD107a 발현(즉, 세포 탈과립의 마커)을 검출함으로써 측정될 수 있다. 일 실시예에서, CD107a 발현은 항-인간 CD107a BV421(클론 H4A3)(BD Biosciences)과 같은 항-CD107a 항체를 사용하여 측정된다.
상기 항체(또는 단편)의 결합 시, γδ T 세포 사멸에 대한 EC50은 0.50 ㎍/ml 미만, 예를 들어 0.40 ㎍/ml, 0.30 ㎍/ml, 0.20 ㎍/ml, 0.15 ㎍/ml, 0.10 ㎍/ml 또는 0.07 μg/ml 미만일 수 있다. 바람직한 실시예에서, 상기 항체(또는 단편)의 결합 시, γδ T 세포 사멸에 대한 EC50은 0.10 ㎍/ml 미만이다. 특히, 상기 항체(또는 단편)의 결합 시, γδ T 세포 사멸에 대한 EC50은 0.060 ㎍/ml 미만, 예를 들어 0.055 ㎍/ml 미만, 특히 0.020 ㎍/ml 또는 0.010 ㎍/ml 미만일 수 있다. 특히, 상기 EC50 값은 항체가 IgG1 형태로 측정될 때의 값이다. 예를 들어, EC50 γδ T 세포 사멸 값은 (예를 들어, 실시예 8의 분석에 기재된 바와 같이) 항체, γδ T 세포 및 표적 세포의 배양 후 유세포 분석을 사용하여 죽은 세포의 비율을 검출함으로써(즉, 세포 생존성 염료를 사용하여) 측정할 수 있다. 일 실시예에서, 표적 세포의 사멸은 세포 생존성 염료인 Viability Dye eFluor™ 520(ThermoFisher)을 사용하여 측정된다.
상기 양태에 기재된 분석에서, 상기 항체 또는 이의 단편은 세포, 예를 들어 TIB-202™(ATCC)와 같은 THP-1 세포의 표면 상에 존재할 수 있다. THP-1 세포는 선택적으로 CellTracker™ Orange CMTMR(ThermoFisher)과 같은 염료로 표지된다.
항체(또는 단편)는 예를 들어 Green and Sambrook, Molecular Cloning: A Laboratory Manual (2012) 4th Edition Cold Spring Harbor Laboratory Press에 개시된 기술을 사용하여 수득 및 조작될 수 있다.
단일클론 항체는 하이브리도마 기술을 사용하여 조직 배양에서 성장하는 능력 및 항체 사슬 합성의 부재로 인해 선택된 골수종(B 세포 암) 세포와 특정 항체를 생산하는 B 세포를 융합함으로써 생산할 수 있다.
결정된 항원에 대한 단일클론 항체는 예를 들어;
a) 하이브리도마를 형성하기 위해 결정된 항원, 불멸 세포 및 바람직하게는 골수종 세포로 미리 면역화된 동물의 말초 혈액으로부터 얻은 림프구를 불멸화하고,
b) 형성된 불멸화 세포(하이브리도마)를 배양하고 원하는 특이성을 갖는 항체를 생산하는 세포를 회수하는 것에 의해 수득될 수 있다.
또는 하이브리도마 세포를 사용할 필요가 없다. 본 명세서에 기재된 표적 항원에 결합할 수 있는 항체는 적절한 항체 라이브러리로부터 당업계에 공지된 통상의 방법, 예를 들어, 파지 디스플레이, 효모 디스플레이, 리보솜 디스플레이 또는 포유동물 디스플레이 기술을 사용하여 단리될 수 있다. 따라서, 단일클론 항체는 예를 들어 다음 단계를 포함하는 방법에 의해 수득될 수 있다:
a) 림프구, 특히 (결정된 항원으로 적절하게 미리 면역화된) 동물의 말초 혈액 림프구로부터 얻은 DNA 또는 cDNA 서열을 벡터, 특히 파지 및 보다 상세하게는 사상 박테리오파지로 클로닝하는 단계,
b) 항체의 생산을 허용하는 조건에서 상기 벡터로 원핵 세포를 형질전환시키는 단계,
c) 항체를 항원-친화성 선택에 적용하여 항체를 선택하는 단계,
d) 원하는 특이성을 갖는 항체를 회수하는 단계.
약학 조성물
본 발명의 추가 양태에 따르면, 본 명세서에 정의된 방법에 의해 수득된 Vδ1 T 세포 집단을 포함하는 조성물이 제공된다. 일 실시예에서 Vδ1 T 세포 집단은 증식된 Vδ1 T 세포 집단이다. 이러한 실시예에서, 상기 조성물은 세포를 포함할 수 있으며, 선택적으로 다른 부형제와 조합될 수 있다. 또한 하나 이상의 추가 활성제(예를 들어, 본 명세서에 언급된 질병을 치료하기에 적절한 활성제)를 포함하는 조성물이 포함된다.
약학 조성물은 하나 이상의 약학적 또는 생리학적으로 허용되는 담체, 희석제 또는 부형제와 조합된 본 명세서에 기재된 γδ T 세포를 포함할 수 있다. 상기 조성물은 중성 완충 식염수, 인산 완충 식염수 등과 같은 완충액; 포도당, 만노스, 수크로스 또는 덱스트란과 같은 탄수화물, 만니톨; 단백질; 폴리펩티드 또는 글리신과 같은 아미노산; 항산화제; EDTA 또는 글루타치온과 같은 킬레이팅제; 보조제(aduvants, 예를 들어, 수산화 알루미늄); 및 방부제를 포함할 수 있다. 본 발명의 약학 조성물에 사용될 수 있는 동결보존 용액은 예를 들어 DMSO를 포함한다. 조성물은 예를 들어 정맥 내 투여를 위해 제형화될 수 있다.
일 실시예에서, 제약 조성물은 예를 들어, 내독소 또는 마이코플라스마와 같은 검출가능한 수준의 오염물이 실질적으로 없다.
바람직한 투여 방식은 비경구(예를 들어, 정맥내, 피하, 복강내, 근육내, 척추강내)이다. 바람직한 실시예에서, 상기 조성물은 정맥내 주입 또는 주사에 의해 투여된다. 또 다른 바람직한 실시예에서, 상기 조성물은 근육내 또는 피하 주사에 의해 투여된다.
본 명세서에 기재된 질병의 치료를 위한 치료 방법에서 본 발명의 약학 조성물을 상기 질병의 치료에 일반적으로 사용되는 다른 확립된 요법에 대한 보조로서 또는 이와 함께 사용하는 것은 본 발명의 범주 내에 있다.
본 발명의 추가 양태에서, 세포 집단, 조성물 또는 제약 조성물은 하나 이상의 활성제와 순차적으로, 동시에 또는 별도로 투여된다.
세포 집단을 이용한 치료 방법
본 발명의 추가 양태에 따르면, 약제로 사용하기 위해 본 명세서에 정의된 방법에 의해 수득된 세포 집단이 제공된다. 본 발명의 추가 양태에 따르면, 약제로 사용하기 위해 본 명세서에 정의된 증식된 세포 집단이 제공된다. 본 명세서에서 약제로서 또는 요법에서 "사용하기 위한" 세포 집단이라 함은 대상 세포 집단을 투여하는 것으로 제한된다. 상기 용도는 상기 항체 또는 이의 단편을 환자에게 직접 투여하는 것을 포함하지 않는다. 여기서 상기 항체는 치료제로 사용된다.
일 실시예에서, 세포 집단은 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 것이다. 추가 실시예에서, 세포 집단은 암 치료에 사용하기 위한 것이다.
일 실시예에서, 약제로 사용하기 위한 세포 집단은 50% 초과의 Vδ1 T 세포, 예를 들어 60% 초과, 70% 초과, 80% 초과, 90% 초과, 95% 초과 또는 99%% 초과의 Vδ1 T 세포를 포함한다. 추가 실시예에서, 약제로 사용하기 위한 세포 집단은 Vδ1 T 세포로 이루어진다.
일 실시예에서, 약제로 사용하기 위한 세포 집단은 10% 미만의 αβ T 세포, 예를 들어 8% 미만, 7% 미만, 6% 미만, 5% 미만, 4% 미만 또는 3% 미만의 αβ T 세포를 포함한다. 일 실시예에서, 약제로 사용하기 위한 세포 집단은 10% 미만의 Vδ2 T 세포, 예를 들어 8% 미만, 7% 미만, 6% 미만, 5% 미만, 4% 미만 또는 3% 미만의 Vδ2 T 세포를 포함한다. 일 실시예에서, 약제로 사용하기 위한 세포 집단은 50% 미만의 NK 세포, 예를 들어 40% 미만, 30% 미만, 20% 미만, 10% 미만 또는 5% 미만의 NK 세포를 포함한다. 일 실시예에서, 약제서 사용하기 위한 세포 집단에 존재하는 세포의 50% 미만이 CD56을 발현하며, 예를 들어 40% 미만, 30% 미만, 20% 미만, 10% 미만 또는 5% 미만이 CD56을 발현한다.
본 발명의 추가 양태에 따르면, 약제로 사용하기 위한 본 명세서에 정의된 세포 집단을 포함하는 제약 조성물이 제공된다. 일 실시예에서, 세포 집단을 포함하는 제약 조성물은 암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 것이다. 추가 실시예에서, 세포 집단을 포함하는 제약 조성물은 암 치료에 사용하기 위한 것이다.
본 발명의 추가 양태에 따르면, 본 명세서에 정의된 세포 집단의 치료적 유효량을 투여하는 것을 포함하는, 이를 필요로 하는 대상에서 면역 반응을 조절하는 방법이 제공된다.
본 발명의 추가 양태에 따르면, 본 명세서에 정의된 세포 집단의 치료적 유효량을 투여하는 것을 포함하는, 이를 필요로 하는 대상에서 암, 감염성 질환 또는 염증성 질환을 치료하는 방법이 제공된다. 또는, 세포 집단을 포함하는 약학 조성물의 치료학적 유효량이 투여된다.
본 발명의 추가 양태에 따르면, 예를 들어 암, 감염성 질환 또는 염증성 질환의 치료에서 약제의 제조를 위한 본 명세서에 정의된 세포 집단의 용도가 제공된다.
입양 T 세포 요법
본 발명의 증식 방법에 의해 수득된 감마 델타 T 세포는 예를 들어 입양 T 세포 요법을 위한 약제로 사용될 수 있다. 이는 γδ T 세포를 환자에게 전달하는 것을 포함한다. 요법은 γδ T 자가유래(autologous), 즉 세포가 수득된 동일 환자에게 다시 전달하는 것일 수 있으며, 또는 동종이계(allogenic), 즉 한 사람으로부터 수득한 γδ T 세포를 다른 환자에게 전달하는 것일 수도 있다. 동종이계 전달을 포함하는 경우, γδ T 세포에는 αβ T 세포가 실질적으로 없을 수 있다. 예를 들어, αβ T 세포는, 예를 들어 증식 후, 당업계에 공지된 임의의 적절한 수단을 사용하여 (예를 들어, 예를 들어 자기 비드를 사용한 음성 선택에 의해) γδ T 세포 집단으로부터 고갈될 수 있다. 치료 방법은 공여자 개체로부터 수득된 시료(예를 들어, 비-조혈조직 시료)를 제공하고; 본 명세서에 기재된 바와 같이 시료로부터 수득된 γδ T 세포를 배양하고, 예를 들어 증식된 집단을 생성하며; γδ T 세포 집단을 수용자 개체에게 투여하는 것을 포함할 수 있다.
치료될 환자 또는 대상은 바람직하게는 인간 암 환자(예를 들어, 고형 종양에 대해 치료될 인간 암 환자) 또는 바이러스 감염 환자(예를 들어, CMV-감염 또는 HIV 감염 환자)이다. 일부 예에서, 상기 환자는 고형 종양을 갖고 있으며/있거나 고형 종양을 치료 중이다. 그들은 평상시 일반적으로 비-조혈조직에 상재하기 때문에 조직-상재 Vδ1 T는 또한 전신적인 혈액-상재 대응물보다 종양 덩어리로 향하여 그 안에 머물 가능성이 더 높으며, 이러한 세포의 입양 전이는 고형 종양 및 잠재적으로 다른 비-조혈조직-관련 면역병리를 표적화하는 것이 더 효과적일 가능성이 있다.
γδ T 세포는 비-MHC 제한성이므로, 외래물질로서 전이되는 숙주를 인식하지 못하며, 이는 이식편대숙질환을 일으킬 가능성이 적음을 의미한다. 이는 이들이 "기성품(off the shelf)"으로 사용될 수 있고, 예를 들어 동종이계 입양 T 세포 치료를 위해, 모든 수용자에게 전달될 수 있음을 의미한다.
본 명세서에 기재된 방법에 의해 수득된 γδ T 세포는 NKG2D를 발현하고 악성 종양과 밀접하게 연관된 NKG2D 리간드(예를 들어, MICA)에 반응한다. 그들은 또한 임의의 활성화 부재 하에 세포독성 프로파일을 발현하므로, 종양 세포를 사멸시키는 데 효과적일 가능성이 있다. 예를 들어, 본 명세서에 기재된 바와 같이 수득된 γδ T 세포는 IFN-γ, TNF-α, GM-CSF, CCL4, IL-13, 그라눌리신(Granulysin), 그랜자임(Granzyme) A와 B, 및 퍼포린(Perforin) 중 하나 이상, 바람직하게는 모두를 발현할 수 있다. IL-17A는 발현되지 않을 수 있다.
일부 실시예에서, 종양이 있는 개체의 치료 방법은; 공여자 개체로부터 수득된 비-조혈조직 시료를 제공하고, 상기 기재된 바와 같이 시료로부터 γδ T 세포를 배양하여 증식된 집단을 생성하며; 증식된 γδ T 세포 집단을 종양이 있는 개체에게 투여하는 것을 포함할 수 있다.
일부 실시예에서, 종양이 있는 개체의 치료 방법은 공여자 개체로부터 수득된 상기 종양 시료를 제공하고, 상기 기재된 바와 같이 시료로부터 수득된 γδ T 세포를 배양하고, γδ T 세포 집단을 종양이 있는 개체에게 투여하는 것을 포함할 수 있다. 추가 실시예에서, 비-조혈 조직에 종양이 있는 개체를 치료하는 방법은 공여자 개체로부터 수득된 상기 비-조혈 조직 시료를 제공하고, 상기 기재된 바와 같이 시료로부터 수득된 γδ T 세포를 배양하고, γδ T 세포 집단을 종양이 있는 개체에게 투여하는 것을 포함할 수 있다.
일부 예에서, 상기 기재된 임의의 방법에 의해 수득된 γδ T 세포의 치료적 유효량은 대상에게 (예를 들어, 암 치료, 예를 들어 고형 종양 치료를 위해) 치료적 유효량으로 투여될 수 있다. 일부 경우에, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 치료적 유효량은 용량 당 10 x 1012 세포 미만(예를 들어, 용량 당 9 x 1012 세포 미만, 용량 당 8 x 1012 세포 미만, 용량 당 7 x 1012 세포 미만, 용량 당 6 x 1012 세포 미만, 용량 당 5 x 1012 세포 미만, 용량 당 4 x 1012 세포 미만, 용량 당 3 x 1012 세포 미만, 용량 당 2 x 1012 세포 미만, 용량 당 1 x 1012 세포 미만, 용량 당 9 x 1011 세포 미만, 용량 당 8 x 1011 미만 세포, 용량 당 7 x 1011 세포 미만, 용량 당 6 x 1011 세포 미만, 용량 당 5 x 1011 세포 미만, 용량 당 4 x 1011 세포 미만, 용량 당 3 x 1011 세포 미만, 용량 당 2 x 1011 세포 미만, 용량 당 1 x 1011 세포 미만, 용량 당 9 x 1010 세포 미만, 용량 당 7.5 x 1010 세포 미만, 용량 당 5 x 1010 세포 미만, 용량 당 2.5 x 1010 세포 미만, 용량 당 세포 1 x 1010 개, 용량 당 7.5 x 109 세포 미만, 용량 당 5 x 109 세포 미만, 용량 당 2.5 x 109 세포 미만, 용량 당 1 x 109 세포 미만, 용량 당 7.5 x 108 세포 미만, 용량 당 5 x 108 세포 미만, 용량 당 2.5 x 108 세포 미만, 용량 당 1 x 108 세포 미만, 용량 당 7.5 x 107 세포 미만, 용량 당 5 x 107 세포 미만, 용량 당 2.5 x 107 세포, 용량 당 1 x 107 세포 미만, 용량 당 7.5 x 106 세포 미만, 용량 당 5 x 106 세포 미만, 용량 당 2.5 x 106 세포 미만, 용량 당 1 x 106 세포, 용량 당 7.5 x 105 세포 미만, 용량 당 5 x 105 세포 미만, 용량 당 2,5 x 105 세포 미만, 또는 용량 당 1 x 105 세포 미만)이다.
일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 치료적 유효량은 치료 과정동안 10 x 1012 세포 미만(예를 들어, 치료 과정동안 9 x 1012 세포 미만, 8 x 1012 세포 미만, 7 x 1012 세포 미만, 6 x 1012 세포 미만, 5 x 1012 세포 미만, 4 x 1012 세포 미만, 3 x 1012 세포 미만, 2 x 1012 세포 미만, 1 x 1012 세포 미만, 9 x 1011 세포 미만, 8 x 1011 세포 미만, 7 x 1011 세포 미만, 6 x 1011 세포 미만, 미만 5 x 1011 세포 미만, 4 x 1011 세포 미만, 3 x 1011 세포 미만, 2 x 1011 세포 미만, 1 x 1011 세포 미만, 9 x 1010 세포 미만, 7.5 x 1010 세포 미만, 5 x 1010 세포 미만, 2.5 x 1010 세포 미만, 1 x 1010 세포 미만, 7.5 x 109 세포 미만, 5 x 109 세포 미만, 2.5 x 109 세포 미만, 1 x 109 세포 미만, 7.5 미만 x 108 세포, 5 x 108 세포 미만, 2,5 x 108 세포 미만, 1 x 108 세포 미만, 7.5 x 107 세포 미만, 5 x 107 세포 미만, 2,5 x 107 세포 미만, 1 x 107 세포 미만, 7.5 x 106 미만 세포, 5 x 106 세포 미만, 2,5 x 106 세포 미만, 1 x 106 세포 미만, 7.5 x 105 세포 미만, 5 x 105 세포 미만, 2,5 x 105 세포 미만 또는 1 x 105 세포 미만)이다.
일부 실시예에서, 본 명세서에 기재된 γδ T 세포의 용량은 약 1 x 106, 1.1 x 106, 2 x 106, 3.6 x 106, 5 x 106, 1 x 107, 1.8 x 107, 2 x 107, 5 x 107, 1 x 108, 2 x 108 또는 5 x 108 세포/kg을 포함한다. 일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 용량은 최대 약 1 x 106, 1.1 x 106, 2 x 106, 3.6 x 106, 5 x 106, 1 x 107, 1.8 x 107, 2 x 107, 5 x 107, 1 x 108, 2 x 108 또는 5 x 108 세포/kg을 포함한다. 일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 용량은 약 1.1 x 106 - 1.8 x 107 세포/kg을 포함한다. 일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 용량은 약 1 x 107, 2 x 107, 5 x 107, 1 x 108, 2 x 108, 5 x 108, 1 x 109, 2 x 109 또는 5 x 109 세포를 포함한다. 일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 용량은 최소 약 1 x 107, 2 x 107, 5 x 107, 1 x 108, 2 x 108, 5 x 108, 1 x 109, 2 x 109 또는 5 x 109 세포를 포함한다. 일부 실시예에서, γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)의 용량은 최대 1 x 107, 2 x 107, 5 x 107, 1 x 108, 2 x 108, 5 x 108, 1 x 109, 2 x 109 또는 5 x 109 세포를 포함한다.
일 실시예에서, 대상은 대상의 체중 kg 당 104 내지 106 개의 γδ T 세포(예를 들어, 피부-유래 γδ T 세포 및/또는, Vδ1 T 세포)를 투여 받는다. 일 실시예에서, 대상은 γδ T 세포 집단의 개시 투여(예를 들어, 대상의 체중 kg 당 104 내지 106 γδ T 세포, 예를 들어, 대상의 체중 kg 당 104 내지 105 γδ T 세포의 개시 투여)와 γδ T 세포의 1회 이상(예를 들어, 2, 3, 4 또는 5)의 후속 투여(예를 들어, 대상의 체중 kg 당 104 내지 106 γδ T 세포, 예를 들어 대상 체중 kg 당 104 내지 105 γδ T 세포의 1회 이상의 후속 투여)를 받는다. 일 실시예에서, 1회 이상의 후속 투여는 이전 투여 후 15일 미만, 예를 들어 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3 또는 2 일 후, 예를 들어, 이전 투여 후 4, 3, 또는 2일 미만에 투여된다. 일 실시예에서, 대상은 최소 3회의 γδ T 세포 집단의 투여 과정에 걸쳐 대상의 체중 kg 당 총 약 106 γδ T 세포를 투여받으며, 예를 들어 대상은 1 x 105 γδ T 세포의 개시 용량, 3 x 105 γδ T 세포의 2차 투여 및 6 x 105 γδ T 세포의 3차 투여를 받으며, 예를 들어, 각 투여는 이전 투여 후 4, 3 또는 2 일 이내에 투여된다.
일부 실시예에서, 하나 이상의 추가 치료제가 대상에게 투여될 수 있다. 추가 치료제는 면역 치료제, 세포독성제, 성장억제제, 방사선 치료제, 항-혈관신생제, 또는 이들의 2개 이상의 제제의 조합으로 이루어진 군으로부터 선택될 수 있다. 추가 치료제는 γδ T 세포의 투여와 동시에, 이전에 또는 이후에 투여될 수 있다. 추가 치료제는 면역 치료제일 수 있으며, 이는 대상의 신체 내 표적(예를 들어, 대상 자신의 면역계) 및/또는 전달된 γδ T 세포에 작용할 수 있다.
조성물의 투여는 임의의 편리한 방식으로 수행될 수 있다. 본 명세서에 기재된 조성물은 경동맥으로, 피하로, 피내로, 종양 내로, 비강 내로, 골수 내로, 근육 내로, 정맥 내 주사에 의해, 또는 복강 내로, 예를 들어 피내 또는 피하 주사에 의해 환자에게 투여될 수 있다. γδ T 세포의 조성물은 종양, 림프절 또는 감염 부위에 직접 주사될 수 있다.
유전자 공학
본 발명의 방법에 의해 수득된 γδ T 세포는 또한 CAR-T(Chimeric Antigen Receptor T cell) 요법과 같이 향상된 치료 특성을 위해 유전자 조작될 수 있다. 이것은 새로운 특이성, 예를 들어 단일클론 항체의 특이성을 갖는 T 세포를 재프로그래밍하기 위해 조작된 T 세포 수용체(TCR)의 생성을 포함한다. 조작된 TCR은 T 세포를 악성 종양 세포에 특이적으로 만들 수 있으므로 암 면역요법에 유용하다. 예를 들어, T 세포는 대상 조직의 정상 체세포에 의해 발현되지 않는 종양관련 항원과 같은 종양 항원을 발현하는 암 세포를 인식할 수 있다. 따라서, CAR-변형된 T 세포는, 예를 들어 암 환자의, 입양 T 세포 치료에 사용될 수 있다.
항체 또는 이의 단편의 기타 용도
본 발명의 추가 양태에 따르면, γδ T 세포(특히 Vδ1 T 세포)의 항원 인식, 활성화, 신호 전달 또는 기능을 연구하기 위한 본 명세서에 기재된 항-Vδ1 항체 또는 이의 단편의 용도가 제공된다. 본 명세서에 기재된 바와 같이, 상기 항체는 γδ T 세포 기능을 조사하는 데 사용될 수 있는 분석에서 활성임을 보여주었다. 상기 항체는 또한 γδ T 세포의 증식을 유도하는 데 유용할 수 있으므로, γδ T 세포(예를 들어, Vδ1 T 세포)를 증식하는 방법에 사용될 수 있다.
Vδ1 사슬에 결합하는 항체는 γδ T 세포를 검출하는 데 사용될 수 있다(즉, 표지로서). 바람직하게는, 표지로 사용된 항체는 세포 증식을 자극하지 않아 표적 Vδ1 T 세포는 항체 결합에 영향을 받지 않는다. 예를 들어, 상기 항체는 검출 가능한 표지 또는 리포터 분자로 표지되거나 시료에서 Vδ1 T 세포를 선택적으로 검출 및/또는 단리하기 위한 포획 리간드로 사용될 수 있다. 표지된 항체는 당업계에 공지된 많은 방법, 예를 들어 면역 조직 화학 및 ELISA에서 사용된다.
3H, 14C, 32P, 35S 또는 125l와 같은 방사성 동위원소; 플루오레세인, 이소티오시아네이트 또는 로다민과 같은 형광성 또는 화학 발광성 잔기; 또는 알칼리성 포스파타제, β-갈락토시다제, 양고추냉이 퍼옥시다제(horseradish peroxidase) 또는 루시페라제와 같은효소일 수 있다. 본발명의 항체에 적용된 형광 표지는 이후 형광-활성화 세포 분류(FACS) 방법에 사용될 수 있다.
폴리뉴클레오티드 및 발현 벡터
또한 본 발명의 항-Vδ1 항체 또는 단편을 암호화하는 폴리뉴클레오티드가 제공된다. 일 실시예에서, 상기 항-Vδ1 항체 또는 단편은 서열번호: 99-110과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 항-Vδ1 항체 또는 단편은 서열번호: 99-110의 VH 영역을 포함하는 발현 벡터에 의해 암호화 된다. 다른 실시예에서, 항-Vδ1 항체 또는 단편은 서열번호: 99-110의 VL 영역을 포함하는 발현 벡터에 의해 암호화된다. 추가 실시예에서 폴리뉴클레오티드는 서열번호: 99-110을 포함하거나, 이로 이루어진다. 추가 양태에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
일 실시예에서, 상기 폴리뉴클레오티드는 서열번호: 99-110과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 발현 벡터는 서열번호: 99-110의 VH 영역을 포함한다. 다른 실시예에서, 상기 발현 벡터는 서열번호: 99-110의 VL 영역을 포함한다. 추가 실시예에서 상기 폴리뉴클레오티드는 서열번호: 99-110을 포함하거나, 이로 이루어진다. 추가 양태에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
일 실시예에서, 상기 폴리뉴클레오티드는 서열번호: 99-101 또는 105-108과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 발현 벡터는 서열번호: 99-101 또는 105-108의 VH 영역을 포함한다. 다른 실시예에서, 상기 발현 벡터는 서열번호: 99-101 또는 105-108의 VL 영역을 포함한다. 추가 실시예에서 상기 폴리뉴클레오티드는 서열번호: 99-101 또는 105-108을 포함하거나, 이로 이루어진다. 추가 양태에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
일 실시예에서, 상기 폴리뉴클레오티드는 서열번호: 99-101과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 발현 벡터는 서열번호: 99-101의 VH 영역을 포함한다. 다른 실시예에서, 상기 발현 벡터는 서열번호: 99-101의 VL 영역을 포함한다. 추가 실시예에서 상기 폴리뉴클레오티드는 서열번호: 99-101을 포함하거나, 이로 이루어진다. 추가 양태에서, 상기 폴리뉴클레오티드를 포함하는 cDNA가 제공된다.
일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 CDR1, CDR2 및/또는 CDR3를 암호화하는 서열번호: 99-110과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 CDR1, CDR2 및/또는 CDR3를 암호화하는 서열번호: 99-101 또는 105-108과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 CDR1, CDR2 및/또는 CDR3를 암호화하는 서열번호: 99-101과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다.
일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 FR1, FR2, FR3 및/또는 FR4를 암호화하는 서열번호: 99-110과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 FR1, FR2, FR3 및/또는 FR4를 암호화하는 서열번호: 99-101 또는 105-108과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다. 일 실시예에서, 상기 폴리뉴클레오티드는 암호화된 면역글로불린 사슬 가변 도메인의 FR1, FR2, FR3 및/또는 FR4를 암호화하는 서열번호: 99-101과 70% 이상, 예를 들어 80% 이상, 예를 들어 90% 이상, 예를 들어 95% 이상, 예를 들어 99% 이상 서열 상동성을 갖는 서열을 포함하거나, 이로 이루어진다.
본 발명의 폴리뉴클레오티드 및 발현 벡터는 또한 암호화된 아미노산 서열을 참조하여 기재될 수 있다. 따라서, 일 실시예에서, 상기 폴리뉴클레오티드는 서열번호: 62 내지 85 중 어느 하나의 아미노산 서열을 암호화하는 서열을 포함하거나 이로 이루어진다. 일 실시예에서, 상기 발현 벡터는 서열번호: 62 내지 73 중 어느 하나의 아미노산 서열을 암호화하는 서열을 포함한다. 다른 실시예에서, 상기 발현 벡터는 서열번호: 74 내지 85 중 어느 하나의 아미노산 서열을 암호화하는 서열을 포함한다.
상기 항체 또는 이의 단편을 발현하기 위해, 본 명세서에 기재된 바와 같이, 유전자가 전사 및 번역 제어 서열에 작동가능하게 연결되도록 일부 또는 전장 경 사슬 및 중 사슬을 암호화하는 폴리뉴클레오티드를 발현 벡터에 삽입하였다. 따라서, 본 발명의 일 양태에서 본 명세서에 정의된 폴리뉴클레오티드 서열을 포함하는 발현 벡터가 제공된다. 일 실시예에서, 상기 발현 벡터는 서열번호: 99-110, 예를 들어, 99, 100, 101, 105, 106, 107 또는 108의 VH 영역을 포함한다. 다른 실시예에서, 상기 발현 벡터는 서열번호: 99-110, 예를 들어, 99, 100, 101, 105, 106, 107 또는 108의 VL 영역을 포함한다.
본 명세서에 기재된 뉴클레오티드 서열은 번역, 정제 및 검출을 돕기 위한 아미노산 잔기를 암호화하는 추가 서열을 포함하지만, 사용된 발현 시스템에 따라 다른 서열이 사용될 수 있음은 당연하다. 예를 들어, 서열번호: 99-110의 초기(5'-말단) 9개 뉴클레오티드 및 서열번호: 99-100, 102-103, 105-110의 최종(3'-말단) 36개 뉴클레오티드, 또는 서열번호: 101 및 104의 최종(3'-말단) 39개 뉴클레오티드는 선택적 서열이다. 상기 선택적 서열은 대체 설계, 번역, 정제 또는 검출 전략이 채택되는 경우 제거, 수정 또는 대체될 수 있다.
폴리펩타이드의 아미노산 서열에 관해서는 언급되지 않으나 특정 숙주에서 번역을 위한 바람직한 코돈을 제공하는 폴리펩타이드를 암호화하는 DNA 또는 cDNA에 돌연변이가 만들어질 수 있다. 예를 들어, 포유동물, 특히 인간뿐 아니라 E. coli 및 S. cerevisiae 에서도 핵산의 번역을 위한 바람직한 코돈은 공지되어 있다.
폴리펩타이드의 돌연변이는 예를 들어 폴리펩타이드를 암호화하는 핵산에 대한 치환, 부가 또는 결실에 의해 달성될 수 있다. 상기 폴리펩타이드를 암호화하는 핵산에 대한 치환, 부가 또는 결실은 예를 들어 실수유발 PCR(error-prone PCR), 셔플링(shuffling), 올리고뉴클레오티드-지정 돌연변이유발, 어셈블리 PCR, PCR 돌연변이유발, 생체 내 돌연변이유발, 카세트 돌연변이유발, 반복적 앙상블 돌연변이유발, 지수 앙상블 돌연변이 유발, 부위 특이적 돌연변이 유발, 유전자 재조립, 인공 유전자 합성, 유전자 부위 포화 돌연변이유발(GSSM, Gene Site Saturation Mutagenesis), 합성 결찰 재조립(SLR, Synthetic Ligation Reassembly) 또는 이들 방법의 조합을 포함하는 많은 방법에 의해 도입될 수 있다. 핵산에 대한 변형, 추가 또는 결실은 또한 재조합, 반복적 서열 재조합, 포스포티오에이트-변형된 DNA 돌연변이유발, 우라실-함유 주형 돌연변이유발, 갭 이중 돌연변이유발(gapped duplex mutagenesis), 점 불일치 수선 돌연변이유발, 수선-결핍 숙주 균주 돌연변이유발, 화학적 돌연변이유발, 방사성 돌연변이유발, 결실 돌연변이유발, 제한-선택 돌연변이유발, 제한-정제 돌연변이유발, 앙상블 돌연변이유발, 키메라 핵산 다량체 생성, 또는 이들의 조합을 포함하는 방법에 의해 도입될 수 있다.
특히 인공 유전자 합성이 사용될 수 있다. 본 발명의 폴리펩타이드를 암호화하는 유전자는 예를 들어 고체-상 DNA 합성에 의해 합성적으로 생성될 수 있다. 전체 유전자는 전구체 주형 DNA가 필요 없이 새롭게 합성될 수 있다. 원하는 올리고뉴클레오티드를 얻기 위해, 빌딩 블록은 생성물의 서열이 요구하는 순서대로 성장하는 올리고뉴클레오티드 사슬에 순차적으로 결합된다. 사슬 조립이 완료되면 생성물을 고체 상으로부터 용액으로 방출하고, 보호를 해제하고 수집한다. 고성능 액체 크로마토그래피(HPLC)로 생성물을 분리하여 원하는 올리고뉴클레오티드를 고순도로 단리할 수 있다.
발현 벡터는 예를 들어 플라스미드, 레트로바이러스, 코스미드, 효모 인공 염색체(YACs, yeast artificial chromosomes) 및 엡스타인-바 바이러스(EBV) 유래 에피솜을 포함 한다. 상기 폴리뉴클레오티드는 벡터 내의 전사 및 번역 제어 서열이 폴리뉴클레오티드의 전사 및 번역을 제어하는 의도된 기능을 수행하도록 벡터에 결찰된다. 발현 및/또는 제어 서열은 프로모터, 인핸서, 전사 종결자, 암호화 서열에 대한 개시 코돈(즉, ATG) 5', 인트론 및 정지 코돈에 대한 스플라이싱 신호를 포함할 수 있다. 상기 발현 벡터 및 발현 제어 서열은 사용된 발현 숙주 세포와 호환되도록 선택된다. 서열 번호: 99-110은 (예를 들어, 서열 번호: 98을 암호화하는) 합성 링커에 의해 연결된 VH 영역 및 VL 영역을 포함하는 본 발명의 단일 사슬 가변 단편을 암호화하는 뉴클레오티드 서열을 포함한다. 본 발명의 폴리뉴클레오티드 또는 발현 벡터는 VH 영역, VL 영역 또는 둘 모두(선택적으로 링커를 포함함)를 포함할 수 있음은 당연하다. 따라서, VH 및 VL 영역을 암호화하는 폴리뉴클레오티드는 별도의 벡터에 삽입될 수 있으며, 또는 두 영역을 암호화하는 서열은 동일한 발현 벡터에 삽입된다. 상기 폴리뉴클레오티드는 표준 방법(예를 들어, 상기 폴리뉴클레오티드 및 벡터 상의 상보적 제한 부위의 결찰, 또는 제한 부위가 존재하지 않는 경우 평활 말단 결찰)에 의해 발현 벡터 내로 삽입된다 .
편리한 벡터는 본 명세서에 기술된 바와 같이 임의의 VH 또는 VL 서열이 용이하게 삽입 및 발현될 수 있도록 조작된 적절한 제한 부위와 함께, 기능적으로 완전한 인간 CH 또는 CL 면역글로불린 서열을 암호화하는 벡터이다. 상기 발현 벡터는 또한 숙주 세포로부터 상기 항체(또는 이의 단편)의 분비를 촉진하는 신호 펩타이드를 암호화할 수 있다. 상기 폴리뉴클레오티드는 상기 신호 펩티드가 항체의 아미노 말단에 프레임-내 연결되도록 벡터 내로 클로닝될 수 있다. 상기 신호 펩티드는 면역글로불린 신호 펩티드 또는 이종 신호 펩티드(즉, 비-면역글로불린 단백질 유래의 신호 펩티드)일 수 있다.
숙주 세포는 상기 항체 또는 이의 단편의 경 사슬을 암호화하는 제1 벡터, 및 상기 항체 또는 이의 단편의 중 사슬을 암호화하는 제2 벡터를 포함할 수 있다. 또는, 중 사슬 및 경 사슬은 모두 숙주 세포에 도입되는 동일한 발현 벡터 상에 암호화된다. 일 실시예에서, 상기 폴리뉴클레오티드 또는 발현 벡터는 상기 항체 또는 이의 단편에 융합된 막 앵커 또는 막횡단 도메인을 암호화하고, 여기서 상기 항체 또는 이의 단편은 숙주 세포의 세포외 표면 상에 존재한다.
형질전환은 폴리뉴클레오티드를 숙주 세포 내로 도입하기 위한 임의의 공지된 방법에 의해 수행될 수 있다. 포유동물 세포에 이종 폴리뉴클레오티드를 도입하는 방법은 당업계에 공지되어 있으며 덱스트란-매개 형질감염, 인산칼슘 침전, 폴리브렌(polybrene)-매개 형질감염, 원형질체 융합, 전기천공, 리포솜 내 폴리뉴클레오티드의 캡슐화, 유전자총 주입(biolistic injection) 및 DNA를 핵에 직접 미세 주입하는 것을 포함한다. 또한, 핵산 분자는 바이러스 벡터에 의해 포유동물 세포에 도입될 수 있다.
발현을 위한 숙주로서 이용가능한 포유동물 세포주는 당업계에 공지되어 있으며, ATCC(American Type Culture Collection)으로부터 입수가능한 많은 불멸화 세포주를 포함한다. 여기에는 특히 중국 햄스터 난소(CHO) 세포, NSO, SP2 세포, HeLa 세포, 아기 햄스터 신장(BHK) 세포, 원숭이 신장 세포(COS), 인간 간세포 암종 세포(예를 들어, Hep G2), A549 세포, 3T3 세포 및 다수의 기타 세포주가 포함된다. 포유동물 숙주 세포는 인간, 마우스, 생쥐, 개, 원숭이, 돼지, 염소, 소, 말 및 햄스터 세포를 포함한다. 특히 바람직한 세포주는 어떤 세포주가 높은 발현 수준을 갖는 지를 결정하는 것을 통해 선택된다. 사용될 수 있는 다른 세포주는 Sf9 세포와 같은 곤충 세포주, 양서류 세포, 박테리아 세포, 식물 세포 및 진균 세포이다. scFv 및 Fv 단편과 같은 항체의 항원-결합 단편은 당업계에 공지된 방법을 사용하여 E. coli에서 단리 및 발현될 수 있다.
항체는 숙주 세포에서 항체의 발현되거나, 또는 보다 바람직하게는 숙주 세포가 성장하는 배양 배지로 항체가 분비되기에 충분한 기간 동안 숙주 세포를 배양함으로써 생산된다. 상기 항체는 표준 단백질 정제 방법을 사용하여 배양 배지에서 회수할 수 있다.
본 발명의 항체(또는 단편)는 예를 들어 Green and Sambrook, Molecular Cloning: A Laboratory Manual (2012) 4th Edition Cold Spring Harbor Laboratory Press에 개시된 기술을 사용하여 수득 및 조작할 수 있다.
단일클론 항체는 하이브리도마 기술을 사용하여 조직 배양에서 성장하는 능력 및 항체 사슬 합성의 부재로 인해 선택된 골수종(B 세포 암) 세포와 특정 항체를 생산하는 B 세포를 융합함으로써 생산할 수 있다.
결정된 항원에 대한 단일클론 항체는 예를 들어;
a) 하이브리도마를 형성하기 위해 결정된 항원, 불멸 세포 및 바람직하게는 골수종 세포로 미리 면역화된 동물의 말초 혈액으로부터 얻은 림프구를 불멸화하고,
b) 형성된 불멸화 세포(하이브리도마)를 배양하고 원하는 특이성을 갖는 항체를 생산하는 세포를 회수하는 것에 의해 수득될 수 있다.
또는 하이브리도마 세포를 사용할 필요가 없다. 본 명세서에 기재된 표적 항원에 결합할 수 있는 항체는 적절한 항체 라이브러리로부터 당업계에 공지된 통상의 방법, 예를 들어, 파지 디스플레이, 효모 디스플레이, 리보솜 디스플레이 또는 포유동물 디스플레이 기술을 사용하여 단리될 수 있다. 따라서, 단일클론 항체는 예를 들어 다음 단계를 포함하는 방법에 의해 수득될 수 있다:
a) 림프구, 특히 (결정된 항원으로 적절하게 미리 면역화된) 동물의 말초 혈액 림프구로부터 얻은 DNA 또는 cDNA 서열을 벡터, 특히 파지 및 보다 상세하게는 사상 박테리오파지로 클로닝하는 단계,
b) 항체의 생산을 허용하는 조건에서 상기 벡터로 원핵 세포를 형질전환시키는 단계,
c) 항체를 항원-친화성 선택에 적용하여 항체를 선택하는 단계,
d) 원하는 특이성을 갖는 항체를 회수하는 단계.
본 명세서에 설명된 모든 실시예는 본 발명의 모든 양태에 적용될 수 있음은 당연하다.
본 발명의 다른 특징 및 장점은 본 명세서에 제공된 설명으로부터 자명할 것이다. 그러나, 다양한 변경 및 변형이 당업자에게 자명할 것이기 때문에, 설명 및 특정 실시예는 본 발명의 바람직한 실시예를 나타내면서 단지 예시의 방식으로 제공되는 것으로 이해되어야 한다. 이제 하기의 비제한적인 실시예를 사용하여 본 발명을 설명한다.
실시예
실시예
1. 재료 및 방법
인간 항체 발견
인간 파지 디스플레이를 사용하여 본 명세서에 기재된 인간 항-인간 가변 Vδ1+ 도메인 항체를 생성하였다. 라이브러리는 Schofield et al.(Genome Biology 2007, 8 (11): R254)에 기재된 대로 구축되었으며, ~400억 인간 클론의 라이브러리를 표시하는 단일 사슬 단편 가변(scFv)을 포함한다. 상기 라이브러리를 본 명세서에 기술된 항원, 방법, 선택, 선택 해제, 스크리닝 및 특징화 전략을 사용하여 스크리닝하였다.
항원 준비
하기 실시예에서 사용된 TCRα 및 TCR β 불변 영역을 포함하는 가용성 yδ TCR 이종이량체의 설계는 Xu et al. (2011) PNAS 108: 2414-2419에 따라 생성되었다. Vγ 또는 Vδ 도메인은, 막횡단 도메인이 결여되고, 류신 지퍼 서열 또는 Fc 서열, 및 히스티딘 태그/링커가 뒤따르는 TCRα 또는 TCRβ 불변 영역에 프레임 내 융합되었다.
발현 구조물을 포유동물 EXPI HEK293 현탁 세포에 (이종이량체에 대한 단일 또는 공동-형질감염으로서) 일시적으로 형질감염하였다. 분비된 재조합 단백질을 회수하고 친화성 크로마토그래피에 의해 배양 상등액으로부터 정제하였다. 단량체 항원의 확실한 회수를 보장하기 위해 시료를 제조용 크기 배제 크로마토그래피(SEC)를 사용하여 추가로 정제하였다. 정제된 항원은 SDS-PAGE로 순도 분석을 실시하고, 분석 SEC에 의해 응집 상태를 분석하였다.
항원 기능 검증
델타 가변 1(Vδ1) 사슬을 함유하는 항원의 특이성은 REA173-Miltenyi Biotec 항-Vδ1 항체를 사용하여 γδ T 세포와 경쟁적인 DELFIA 면역분석(Perkin Elmer) 및 유동 기반 분석으로 확인하였다.
해리 강화
란탄족
형광 면역분석법(
DELFIA
)
항원 특이성을 확인하기 위하여, 플레이트에 직접 코팅된 항원(50 μL PBS 중 3 μg/mL 농도의 항원(Nunc #437111)으로 4℃에서 밤새)과 300nM에서 시작하는 1차 항체의 연속 희석으로 DELFIA 면역분석을 수행하였다. 검출을 위해 DELFIA Eu-N1 항-인간 IgG(Perkin Elmer #1244-330)를 3% MPBS(PBS + 3%(w/V) 탈지분유) 50μL에 1/500 희석하여 이차 항체로 사용하였다. 50 μL의 DELFIA 강화 용액(Perkin Elmer #4001-0010)을 사용하여 현상하였다.
관심 항체의 친화도 순위는 항체를 플레이트에 코팅된 단백질 G를 통해 포획하고 가용성 비오틴화 L1 (DV1-GV4) 항원을 5nM에서 50 μL으로 (3MPBS) 첨가하는 DELFIA 면역분석을 사용하여 정하였다. 검출을 위해 50 μL의 streptavidin-Eu (1:500 in assay buffer, Perkin Elmer)를 사용하고 DELFIA 강화 용액으로 신호를 현상하였다. D1.3 hIgG1(England et al . (1999) J. Immunol . 162: 2129-2136에 기재됨)을 음성 대조군으로 사용하였다.
파지 디스플레이 선택 출력은 scFv 발현 벡터 pSANG10(Martin et al. (2006) BMC Biotechnol . 6: 46)으로 서브클로닝하였다. 가용성 scFv를 발현시키고 직접 고정된 표적에서 DELFIA에서의 결합에 대해 스크리닝하였다. 히트(Hits)는 3000 형광 단위 이상의 DELFIA 신호로 정의하였다.
항체 준비
선택된 scFv는 시판되는 플라스미드를 사용하여 IgG1 프레임워크로 서브클로닝하였다. 항체 발현을 위해 expi293F 현탁 세포를 상기 플라스미드로 형질감염시켰다. 편의상, 별도로 언급되지 않는 한, 상기 실시예에서 특징화된 항체는 scFv로서 파지 디스플레이로부터 선택된 IgG1 형태화된 항체를 지칭한다. 그러나, 본 발명의 항체는 전술한 바와 같이 임의의 항체 형태일 수 있다.
항체 정제
IgG 항체는 단백질 A 크로마토그래피를 사용하여 상등액으로부터 배치 정제하였다. 농축된 단백질 A 용출액을 크기 배제 크로마토그래피(SEC)를 사용하여 정제하였다. 정제된 IgG의 품질은 ELISA, SDS-PAGE 및 SEC-HPLC를 사용하여 분석하였다.
γδ
T 세포 준비
농축된 γδ T 세포의 집단은 WO2016/198480(즉, 혈액-유래 γδ T 세포) 또는 WO2020/095059(즉, 피부-유래 γδ T 세포)에 기재된 방법에 따라 제조하였다. 간단하게는, 혈액-유래 γδ T 세포의 경우 PBMC를 혈액에서 수득하고 αβ T 세포의 자기 고갈을 실시하였다. 이후 αβ-고갈된 PBMC를 OKT-3(또는 각각의 항-Vδ1 항체), IL-4, IFN-γ, IL-21 및 IL-1β의 존재 하에 CTS OpTmiser 배지(ThermoFisher)에서 7일 동안 배양하였다. 배양 7일째, 배지에 OKT-3(또는 각각의 항-Vδ1 항체), IL-21 및 IL-15를 추가 4일 동안 보충하였다. 배양 11일째, 배지에 OKT-3(또는 각각의 항-Vδ1 항체) 및 IL-15를 추가 3일 동안 보충하였다. 배양 14일째, 배지의 절반을 신선한완전 OpTmiser 배지로 교체하고 OKT-3(또는 각각의 항-Vδ1 항체), IL-15 및 IFN-γ로 보충하였다. 배양 17일째부터 배양물에 OKT-3(또는 각각의 항-V δ1 항체) 및 IL-15를 3-4일마다 보충하고; 배지의 절반을 7일마다 새 배지로 교체하였다.
피부-유래 γδ T 세포의 경우, 피하 지방을 제거하여 피부 시료를 준비하고 3mm 생검 펀치를 사용하여 복수의 펀치를 만들었다. 펀치를 탄소 매트릭스 그리드에 놓고 G-REX6(Wilson Wolf)의 웰에 배치하였다. 각 웰은 AIM-V 배지(Gibco, Life Technologies), CTS 면역 혈청 대체제(Life Technologies), IL-2 및 IL-15를 포함하는 완전 단리 배지로 충진하였다. 배양의 처음 7일 동안, Amphotericin B(Life Technologies)를 포함하는 완전 단리 배지("+AMP")를 사용하였다. 배지는 플레이트 또는 생물반응기의 바닥에 있는 세포를 교란하지 않도록 주의하면서 상층 배지를 부드럽게 흡인하고 2X 완전 단리 배지(AMP가 없는)로 교체하는 것에 의해 7일마다 교체하였다. 배양 3주를 초과하여, 수득 전에 생성된 유출 세포를 새로운 조직 배양 용기 및 재조합 IL-2, IL-4, IL-15 및 IL- 21가 추가된 새로운 배지(예를 들어, AIM-V 배지 또는 TexMAX 배지(Miltenyi))로 계대배양하였다. 선택적으로, 배양물 내에도 존재하는 αβ T 세포는 Miltenyi에서 제공하는 것과 같은 αβ T 세포 고갈 키트 및 관련 프로토콜의 도움으로 제거하였다. 추가 참조는 WO2020/095059를 참조할 수 있다.
γδ
T 세포 결합 분석
γδ T 세포에 대한 항체의 결합은 250000개의 γδ T 세포와 함께 고정된 농도의 정제된 항체를 배양함으로써 검정하였다. 상기 배양은 Fc 수용체를 통한 항체의 비특이적 결합을 방지하기 위해 차단 조건에서 수행하였다. 인간 IgG1에 대한 2차 형광 염료-접합 항체를 첨가하여 검출을 수행하였다. 음성 대조군의 경우, 세포는 a) 이소형 항체 단독(재조합 인간 IgG), b) 형광 염료-접합 항-인간 IgG 항체 단독 및 c) a) 및 b)의 조합으로 제조하였다. 완전히 염색되지 않은 세포의 대조군 웰도 준비하고 분석하였다. 양성 대조군으로, 정제된 뮤린 단일클론 IgG2 항-인간 CD3 항체 및 정제된 뮤린 단일클론 IgG1 항-인간 TCR Vδ1 항체를 2가지 상이한 농도로 사용하고, 형광 염료-접합 염소 항-마우스 2차 항체로 염색하였다. FITC 채널에서 농도가 더 낮은 양성 대조군의 평균 형광 강도가 최고 음성 대조군보다 10배 이상 높은 경우 분석을 승인하였다.
SPR
분석
아민 고용량 칩을 갖는 MASS-2 기기(모두 Sierra Sensors, 독일)를 사용하여 SPR 분석을 수행하였다. 15nM IgG는 단백질 G를 통해 아민 고용량 칩(TS8.2의 경우, 100nM)으로 포획하였다. L1(DV1-GV4) 항원은 다음 매개변수를 사용하여 2000nM 에서 15.625nM 까지의 1:2 연속 희석으로 세포 위로 흘려보냈다: 180초 회합, 600초 해리, 유속 30μL/분, 러닝 완충액 PBS + 0.02%. 모든 실험은 MASS-2 기기에서 상온에서 수행하였다. 정상 상태 피팅은 소프트웨어 Sierra Analyzer 3.2를 사용하여 Langmuir 1:1 결합에 따라 결정하였다.
비교 항체
항체는 기재된 바와 같이 검정 분석에서 시판되는 항체와 비교하였다.

γδ
TCR
하향조절 및
탈과립
분석
검정 항체가 로딩되거나 로딩되지 않은 THP-1(TIB-202™, ATCC) 표적 세포는 CellTracker™ Orange CMTMR(ThermoFisher, C2927)로 표지하고, CD107a 항체 (항-인간 CD107a BV421(클론 H4A3) BD Biosciences 562623)의 존재 하에 2:1의 비율로 γδ T 세포와 함께 배양하였다. 2시간 배양 후, γδ T 세포에서의 γδ TCR의 표면 발현(TCR 하향조절을 측정하기 위함) 및 CD107a의 발현(탈과립을 측정하기 위함)을 유세포 분석을 사용하여 평가하였다.
사멸 분석
감마 델타 T 세포 사멸 활성 및 γδ T 세포의 사멸 활성에 대한 검정 항체의 영향을 유세포 분석에 의해 평가하였다. γδ T 세포와 CellTracker™ Orange CMTMR(ThermoFisher, C2927)로 표지된 (검정 항체가 로딩되거나 로딩되지 않은) THP-1 세포를 20:1 비율로 시험관 내에서 4시간 동안 공동-배양한 후, 살아있는 표적 THP-1 세포와 죽은 표적 THP-1 세포를 구별하기 위해 생존성 염료 eFluor™ 520(ThermoFisher , 520 65-0867-14)로 염색하였다. 시료를 수집하는 동안 표적 세포는 CellTracker™ Orange CMTMR 양성에 대해 게이팅하였고, 생존성 염료의 흡수를 기반으로 세포 사멸에을 조사하였다. CMTMR 및 eFluor™ 520 이중 양성 세포는 죽은 표적 세포로 인정하였다. γδ T 세포의 사멸 활성은 죽은 표적 세포의 %로 나타내었다.
에피토프
매핑
고-질량 MALDI를 사용하여 단백질 에피토프 매핑에 사용된 모든 단백질 시료(항원 L1(DV1-GV4) 및 항체 1245_P01_E07, 1245_P02_G04, 1252_P01_C08, 1251_P02_C05 및 1141_P01_E01)를 단백질 무결성 및 응집 수준에 대해 분석하였다.
L1(DV1-GV4)/1245_P01_E07, L1(DV1-GV4)/1245_P02_G04, L1(DV1-GV4)/1252_P01_C08, L1(DV1-GV4)/1251_P02_C05, 및 L1(DV1-GV4)/1141_P01_E01 복합체의 에피토프를 고분해능으로 결정하기 위하여, 단백질 복합체를 중수소화된 가교결합제와 함께 배양하고 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신(thermolysin)을 사용하여 다중-효소 단백질분해를 실시하였다. 가교된 펩타이드를 농축한 후 시료를 고분해능 질량분석기(nLC -LTQ-Orbitrap MS)로 분석하고, 생성된 데이터를 XQuest 및 Stavrox 소프트웨어를 사용하여 분석하였다.
SYTOX
-흐름 사멸 분석
SYTOX 분석은 유세포 분석을 사용하여 표적 세포의 T 세포 매개 세포용해를 정량화 할 수 있다. 죽은/죽어가는 세포는 건강한 세포의 온전한 세포막은 통과할 수 없으며 손상된 원형질막이 있는 세포에만 침투하는 사멸 세포 염색(SYTOXㄾ AADvanced™, Life Technologies, S10274)에 의해 검출된다. NALM-6 표적 세포는 CTV 염료(Cell Trace Violet™, Life Technologies, C34557)로 표지하였으며, 따라서 표지되지 않은 작동체 T 세포와 구별될 수 있었다. 죽은/죽어가는 표적 세포는 죽은 세포 염료와 세포 추적 염료의 이중 염색을 통해 식별하였다.
표시된 작동체 대 표적 세포 비율로(E:T, 1:1 또는 10:1) 작동체 및 CTV-표지된 표적 세포를 16시간 동안 시험관 내 공동 배양한 후, 세포를 SYTOXㄾ AADvanced™로 염색하고 FACSLyric™(BD)에서 수집하였다. 사멸 결과는 작동체 세포가 추가되지 않은 대조군 웰의 살아있는 표적 세포(최대 카운트)에 대한 검정 시료에서의 살아있는 표적 세포의 수(시료 카운트)를 고려하여 계산된 % 표적 세포 감소로 나타내었다:

실시예
2. 항원 설계
감마 델타(γδ) T 세포는 CDR3 다클론성을 갖는 다클론성이다. 생성된 항체가 CDR3 서열에 대해 선택되는 상황을 피하기 위해(CDR3 서열은 TCR 클론마다 다를 것이기 때문에), 항원 설계는 상이한 형태에서 일관된 CDR3를 유지하는 것을 포함하였다. 상기 설계는 가변 도메인 내의 서열을 인식하는 항체를 생성하는 것을 목표로 했으며, 이는 생식계로 암호화되며 따라서 모든 클론에서 동일하므로 γδ T 세포의 더 넓은 서브세트를 인식하는 항체를 제공한다.
항원 준비 과정의 다른 중요한 양태는 단백질로 발현하기에 적절한 항원을 설계하는 것이었다. γδ TCR은 사슬간 및 사슬내 다이설파이드 결합이 있는 이종이량체를 포함하는 복잡한 단백질이다. 파지 디스플레이 선택에서 사용할 가용성 TCR 항원을 생성하기 위하여 류신 지퍼(LZ) 형태 및 Fc 형태를 사용하였다. LZ 및 Fc 형태는 모두 잘 발현되었으며, TCR(특히 이종이량체 TCRs, 예를 들어 Vδ1Vγ4)을 성공적으로 표시하였다.
γδ TCR에 대한 공개 데이터베이스 항목 유래의 CDR3 서열은 단백질(RCSB Protein Data Bank 항목: 3OMZ)처럼 잘 발현되는 것으로 알려졌다. 따라서 항원 준비를 위해 이를 선택하였다.
델타 가변 1 사슬을 함유하는 항원은 이종이량체(즉, 다른 감마 가변 사슬 - "L1", "L2", "L3"와 조합된)로서 LZ 형태 및 이종이량체("F1", "F2", "F3") 또는 동종이량체(즉, 다른 델타 가변 1 사슬 "Fc1/1"과 조합된)로서 Fc 형태로 발현되었다. 항원의 모든 델타 가변 1 사슬은 3OMZ CDR3을 함유하였다. 유사한 형태를 사용하는 다른 일련의 γδ TCR 항원은 상이한 델타 가변 사슬(예를 들어, 델타 가변 2 및 델타 가변 3)을 포함하도록 설계되었으며, 비-특이적 또는 표적외 결합을 갖는 항체("L4", "F9", "Fc4/4", "Fc8/8")를 선택 해제하는 데 사용되었다. 이러한 항원은 또한 3OMZ CDR3을 포함하도록 설계되어 CDR3 영역에서 결합하는 항체도 선택 해제되도록 하였다.
설계된 항원이 항-TRDV1(TCR 델타 가변 1) 항체를 생성하는 데 적절함을 확인하기 위하여 항원 기능 검증을 수행하였다. δ1 도메인을 함유하는 항원에서만 검출이 나타났다(도 1).
실시예
3. 파지 디스플레이
파지 디스플레이 선택은 라운드 1 및 2에서 이종이량체 LZ TCR 형태를 사용하여 인간 scFv 의 라이브러리에 대해 수행하였으며, 양 라운드 모두에서 이종이량체 LZ TCR에 대한 선택 해제를 수행하였다. 또는 동종이량체 Fc 융합 TCR을 사용하여 인간 IgG1 Fc에 대한 선택 해제를 하며 라운드 1을 수행한 후, 이종이량체 LZ TCR에 대해 이종이량체 LZ TCR에 대한 선택 해제를 하며 라운드 2를 수행하였다( 표 1 참조).
표 1. 파지 디스플레이 선택 개요

선택은 100 nM 비오틴화된 단백질을 사용하여 용액상에서 수행하였다. 선택 해제는 1μM 비오틴화 되지 않은 단백질을 사용하여 수행하였다.
파지 디스플레이 선택의 성공은 다클론 파지 ELISA(DELFIA)에 의해 분석하였다. 모든 DV1 선택 출력은 표적 Fc 1/1, L1, L2, L3, F1 및 F3에 원하는 결합을 보여주었다. 비-표적 L4, F9, Fc 4/4, Fc 8/8 및 Fc에 대한 다양한 결합도가 검출되었다(도 2A 및 B 참조).
실시예
4. 항체 선택
실시예 3에서 얻은 히트를 (당업계에 공지된 표준 방법을 사용하여) 시퀀싱하였다. VH 및 VL CDR3의 독특한 조합을 나타내는 130개의 고유한 클론이 확인되었다. 상기 130개의 고유한 클론 중, 125개는 고유한 VH CDR3을 나타내고 109개는 고유한 VL CDR3을 나타내었다.
고유한 클론을 재배열하고 특이성을 ELISA(DELFIA)로 분석하였다. TRDV1(L1, L2, L3, F1, F2, F3)에 결합하지만 TRDV2(L4)에는 결합하지 않는 94개의 독특한 인간 scFv 결합제의 패널이 선택에서 확인되었다.
앞으로 클론을 선택하는 데 도움이 되도록 선택한 바인더의 친화도 순위가 포함되었다. 많은 수의 결합제가 25~100 nM 비오티닐화 항원과 반응하여 나노몰 범위의 친화성을 보였다. 소수의 결합제는 5 nM 항원과 강한 반응을 보였으며, 이는 한 자리 나노몰 친화도가 가능함을 나타낸다. 일부 결합제는 100 nM 항원과 반응하지 않았으며 이는 마이크로몰 범위의 친화성을 나타낸다.
IgG 전환을 진행하기 위한 클론을 선택하기 위하여, 가능한 한 많은 생식계 계통(gemline lineages)과 다양한 CDR3을 포함하는 것을 목표로 하였다. 또한, 글리코실화, 인테그린 결합 부위, CD11c/CD18 결합 부위, 짝을 이루지 않은 시스테인과 같은 서열 가능성을 피했다. 이 밖에도 다양한 친화력을 포함하였다.
다른 공여자로부터 얻은 피부 유래 γδ T 세포를 사용하여 선택된 클론을 자연적인 세포-표면 발현 γδTCR에 대한 결합에 대해 스크리닝하였다. IgG로 전환되어지도록 선택된 클론을 표 2 에 나타내었다.
표 2.
IgG
전환을 위한 DV1 결합제

실시예
5: 항체
SPR
분석
준비된 IgG 항체를 γδ 세포 결합 분석을 통해, 추가적인 기능적 및 생물리학적 특징화를 위한 5개의 최상의 결합제를 선택하였다. 평형 해리 상수(KD)를 결정하기 위하여 SPR 분석을 실시하였다. 검정 항체와 분석물의 상호작용의 센서그램을 (가능한 경우) 정상 상태 핏(fit)과 함께 도 3에 도시하였다. TS8.2에 대해서는 칩에 포획된 80RU의 IgG와의 결합이 검출되지 않았다. 결과는 표 3에 요약하였다.
표 3.
IgG
포획 결과

실시예
6:
TCR
결합 분석
본 발명자들은 선택된 항체의 기능적 특징화에 사용되는 여러 분석법을 설계하였다. 첫 번째 분석은 항체 결합 시 γδ TCR의 하향조절을 측정함으로써 γδ TCR 결합을 평가하였다. 선택된 항체를 양성 대조군으로 사용된 상용의 항-CD3 및 항-Vδ1 항체에 대해 검정하거나, (1139_P01_E04, 1245_P02_F07, 1245_P01_G06 및 1245_P01_에 대해서는) 양성 대조군으로 1252_P01_C08에 대해 검정하였다. 상용의항-panγδ는 가변 사슬에 관계없이 모든 γδ T 세포를 인식하는 panγδ 항체이기 때문에 다른 작용 방식을 가질 가능성이 있으므로, 음성 대조군으로 사용하였다.
세 개의 다른 공여자 시료(94%, 80% 및 57% 순도의 시료)에서 수득한 피부-유래 γδ T 세포를 사용하여 분석을 수행하였다. 결과는 도 4에 나타내었다. EC50 값은 하기 표 4에 요약하였다.
실시예
7: T 세포
탈과립
분석
두 번째 분석은 γδ T 세포의 탈과립을 평가하였다. γδ T 세포는 퍼포린-그랜자임 매개 활성화에 의한 세포자멸사(apoptosis)에 의해 표적 세포 사멸을 매개할 것으로 생각된다. γδ T 세포의 세포질 내의 용해 과립(lytic granule)은 T 세포 활성화 시 표적 세포로 방출될 수 있다. 따라서 CD107a에 대한 항체로 표적 세포를 표지하고, 유세포 분석에 의한 발현을 측정하여 탈과립된 γδ T 세포를 식별할 수 있다.
실시예 6에서와 같이, 선택된 항체를 양성 대조군으로 상용의 항-CD3 및 항-Vδ1 항체에 대해 검정하거나 또는 (1139_P01_E04, 1245_P02_F07, 1245_P01_G06 및 1245_P01_에 대해서는) 양성 대조군으로 1252_P01_C08에 대해 검정하였다. IgG2a, IgG1 및 D1.3 항체를 음성 대조군으로 사용하였다. 세 개의 다른 공여자 시료(94%, 80% 및 57% 순도의 시료)에서 수득한 피부-유래 γδ T 세포를 사용하여 분석을 수행하였다. 결과는 도 5에 나타내었다. EC50 값은 하기 표 4에 요약하였다.
실시예
8: 사멸 분석
세 번째 분석은 선택된 항체로 활성화된 γδ T 세포의 표적 세포 사멸 능력을 평가하였다.
실시예 6에서와 같이, 선택된 항체를 양성 대조군으로 상용의 항-CD3 및 항-Vδ1 항체에 대해 검정하거나 또는 (1139_P01_E04, 1245_P02_F07, 1245_P01_G06 및 1245_P01_에 대해서는) 양성 대조군으로 1252_P01_C08에 대해 검정하였으며, 항-panγδ를 음성 대조군으로, IgG2a, IgG1 및 D1.3 항체를 이소형 대조군으로 사용하였다. 두명의 공여자로부터 얻은 피부-유래 γδ T 세포(94% 및 80% 순도)를 사용하여 분석을 실시하였으며, 결과는 도 6에 나타내었다.
실시예 6-8에서 검정된 3가지 기능적 분석의 결과를 표 4에 요약하였다.
표 4. 기능 분석에서 얻은 결과 요약

실시예
9:
에피토프
매핑
고분해능으로 항원/항체 복합체의 에피토프를 결정하기 위하여, 단백질 복합체를 중수소화된 가교결합제와 함께 배양하고 다중 효소 절단을 수행하였다. 가교된 펩타이드를 농축한 후 시료를 고분해능 질량분석기(nLC -LTQ-Orbitrap MS)로 분석하고, 생성된 데이터를 XQuest(버전 2.0) 및 Stavrox(버전 3.6) 소프트웨어를 사용하여 분석하였다.
중수소화된 d0d12와 L1(DV1-GV4)/1245_P01_E07 단백질 복합체의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신 단백질 분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4)와 항체 1245_P01_E07 사이에 가교된 13개의 펩타이드를 검출하였다. 결과는 도 7에 도시하였다.
중수소화된 d0d12와 L1(DV1-GV4)/1252_P01_C08 단백질 복합체의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신 단백질 분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4)와 항체 1252_P01_C08 사이에 가교된 5개의 펩타이드를 검출하였다. 결과는 도 8에 도시하였다.
중수소화된 d0d12와 L1(DV1-GV4)/1245_P02_G04 단백질 복합체의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신 단백질 분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4)와 항체 1245_P02_G04 사이에 가교된 20개의 펩타이드를 검출하였다. 결과는 도 9에 도시하였다.
중수소화된 d0d12와 L1(DV1-GV4)/1251_P02_C05 단백질 복합체의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신 단백질 분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4)와 항체 1251_P02_C05 사이에 가교된 5개의 펩타이드를 검출하였다. 결과는 도 10에 도시하였다.
다른 항체인 클론 ID 1141_P01_E01과의 에피토프 결합도 검정하였다. 중수소화된 d0d12와 L1(DV1-GV4)/1141_P01_E01 단백질 복합체의 트립신, 키모트립신, Asp-N, 엘라스타제 및 써모리신 단백질 분해 후, nLC-orbitrap MS/MS 분석으로 L1(DV1-GV4)와 항체 1141_P01_E01 사이에 가교된 20개의 펩타이드를 검출하였다. 결과는 도 11에 도시하였다.
에피토프 매핑 결과의 요약은 표 5에 제시하였다.
표 5. 항원/항체 복합체에 대한
에피토프
맵핑
결과

실시예
10:
Vδ1
T 세포의 증식
단리된 γδ T 세포의 증식을 선택된 항체 및 비교 항체의 존재 하에 조사하였다. 비교 항체는 다음으로부터 선택하였다: 양성 대조군으로 OKT3 항-CD3 항체, 음성 대조군으로 항체 없음 또는 이소형 대조군으로 IgG1 항체. 시판되는 항-Vδ1 항체인 TS-1 및 TS8.2 역시 비교를 위해 검정하였다.
실험 1:
실시예 1의 혈액-유래 γδ T 세포에 대한 "γδ T 세포 준비"에 기재한 바와 같이, 초기 조사는 완전 Optimizer 배지 및 사이토카인과 함께 70,000개 세포/웰로 접종하여 수행하였다. 선택된 항체와 비교 항체를 4.2 ng/ml 내지 420 ng/ml 범위의 다양한 농도에서 검정하였다. 본 실험은 플라스틱에 대한 항체의 결합/고정이 허용되는 조직 배양 플레이트를 사용하여 수행하였다.
7, 14 및 18일째에 세포를 수집하고, 세포 계수기(NC250, ChemoMetec)를 사용하여 총 세포 수를 결정하였다. 결과를 도 12에 도시하였다. Vδ1 T 세포의 세포 생존성 또한 각 수집물에서 측정하였으며, 모든 항체는 실험 전반에 걸쳐 세포 생존성을 유지하는 것으로 나타났다(데이터 미도시). 18일째에, Vδ1 T 세포의 백분율, 세포 수 및 배수 변화 역시 분석하였다. 결과를 도 13에 도시하였다.
도 12에서 확인할 수 있듯이, 항체가 있는 배양물에서 생산된 세포의 총 수는 배양기간 전체에 걸쳐 점차 증가하였으며 상용 항-Vδ1 항체와 비슷하거나 더 우수하였다. 18일째에, 검정된 최대 농도에서 1245_P02_G04("G04"), 1245_P01_E07("E07"), 1245_P01_B07("B07") 및 1252_P01_C08("C08") 항체의 존재하에 Vδ1 양성 세포의 백분율은 OKT3, TS-1 또는 TS8.2 대조군 항체가 존재하는 배양물에서보다 더 높았다(도 13A 참조).
실험 2:
실시예 1의 "γδ T 세포 준비"에 기재된 바와 같이 사이토카인이 있는 배양 용기에서 단리된 세포에 대한 후속 실험을 수행하였다. 실험 1과 비교하여, 표면이 항체 결합/고정화를 용이하지 않는 상이한 배양 용기를 사용하였다. 선택된 항체와 비교 항체를 42 pg/ml 내지 42 ng/ml 범위의 다양한 농도에서 검정하였다. 실험 2 동안, 3회 반복실험에서 결과를 얻었다.
7, 11, 14 및 17일째에 세포를 수집하고 이전과 마찬가지로 세포 계수기를 사용하여 총 세포 수를 결정하였다. 상기 결과를 도 14에 도시하였다. 17일째, Vδ1 T 세포의 백분율, 세포 수 및 배수 변화 역시 분석하였다. 결과를 도 15 에 도시하였다.
비-Vδ1 세포를 포함하는 세포 조성 또한 실험 2 동안 측정하였다. 17일째 세포를 수집하고 Vδ1, Vδ2 및 αβTCR의 표면 발현에 대해 유세포 분석에 의해 분석하였다. 각 배양물에서 각 세포 유형의 비율을 도 16에 그래프로 도시하고 백분율 값은 표 6에 제시하였다.
표 6. 17일째의 세포 조성 - 각 서브세트의 살아있는 세포의 백분율

이들 결과로부터 알 수 있는 바와 같이, OKT3, TS-1 또는 TS8.2 대조군과 비교하여 B07, C08, E07 및 G04가 존재하는 배양물에서 Vδ1 양성 세포의 비율이 더 컸다. 따라서, 검정된 항체는 배양물에 낮은 농도로 존재하는 경우에도 시판되는 항체보다 더 효율적으로 Vδ1 양성 세포를 생산 및 증식하였다.
자연 살해(NK) 세포의 존재를 확인하기 위한 CD3-CD56+ 및 CD27을 발현하는 Vδ1 T 세포(즉, CD27+)를 비롯한 추가 세포 마커에 대해서도 실험 2의 17일째의 세포를 분석하였다. 결과는 표 7에 요약하였다.
표 7. 17일째의 세포 조성 -
NK
및 CD27+ 세포의 백분율

실시예
11:
Vδ1
T 세포의 기능성
선택된 항체의 존재 하에 증식된 Vδ1 T 세포는 CDR3 영역의 다클론성 레퍼토리를 보유하며, SYTOX-유동 사멸 분석을 사용하여 기능성에 대해 검정하였다. 상기 결과는 10:1 작동체 대 표적(E:T) 비율의 세포를 사용하여 실험 1 동안 14일째에 수득한 세포(도 17A ) 및 1:1 및 10:1 E:T 비율의 세포를 사용하여 실험 2 동안 17일째에 수득한 세포(동결-해동 후)에 대해 나타내었다(도 17B).
도 17 에서 확인할 수 있듯이, 모든 항체의 존재 하에 증식된 Vδ1 양성 세포는 표적 세포를 효과적으로 용해시켜, 세포를 동결 및 해동한 후에도 기능적임을 나타내었다.
실시예
12: 저장 후 세포의 기능성
동결 및 이후 해동의 저장 단계 후 세포의 기능성도 조사하였다. 실험 2의 17일째 배양물로부터 세포의 일부를 제거하고 동결시켰다. 이후 세포를 해동하고 IL-15와 함께 배양액에서 추가로 증식시켰다. 도 18은 동결 전에 B07, C08, E07, G04 또는 OKT-3 항체와 접촉된 배양물에 대해, 동결-해동 후 세포를 배양한 7일 후의 총 세포 수를 나타낸다. 모든 배양물은 저장 후 증식할 수 있음을 보여주었다. 배양은 42일까지 계속되었고 이 기간 동안 총 세포 수를 모니터링하였다(결과는 도 19에 도시됨). 총 세포 수는 선택된 항체에 미리 노출된 배양물에서 유지되거나 또는 증가하였다.
실시예
13:
TIL에
면역 세포의 조절 및 증식을 부여하는 항-
Vδ1
항체
인간 종양 침윤 림프구(TIL)의 조절 및 증식을 부여하는 항-Vδ1 항체를 조사하기 위한 연구가 수행되었다. 이러한 연구를 위해, 인간 신세포 암종(RCC) 종양 생검을 신선하게 배송하여 수령 즉시 처리하였다. 구체적으로, 상기 조직을 ~2 mm2으로 잘게 썰었다. 최대 1g의 조직을 4.7 mL RPMI 및 관련 세포 표면 분자의 절단을 방지하기 위해 효소 R을 0.2x의 농도로 사용한 것을 제외하고는 제조업체에서 권장하는 농도의 Miltenyi's Tumor Dissociation Kit의 효소와 함께 각각 Miltenyi C 튜브에 넣었다. C-튜브를 히터가 있는 gentleMACS™ Octo Dissociator에 위치시켰다. 연성 종양의 해리를 위해 프로그램 37C_h_TDK_1이 선택하였다. 이후 소화물을 70 mM 필터를 통해 여과하여 단일 세포 현탁액을 생성하였다. 효소 활성을 잃게 하기 위해 10% FBS를 함유하는 RPMI를 소화물에 첨가하였다. 상기 세포를 RPMI/10% FBS로 2회 세척하고, 계수를 위해 재현탁하였다. 유래된 세포를 TC 웰(24-웰 G-REX, Wilson Wolf)에 웰당 2.5x10e6으로 접종하였다. 이후 세포를 사이토카인과 함께 또는 없이, 또는 항체와 함께 또는 없이 18일 동안 배양하였다. 연구에 포함된 항체를 도 20에 요약하였다. 본 명세서에서 여기에는 OKT3(최대 50 ng/ml) 및 1252_P01_C08, 약칭 "C08"(최대 500 ng/ml)이 포함된다. 포함될 때, 이들 항체의 일시 첨가는 0, 7, 11 및 14일에 추가하였다. 상기 배양동안, 배지는 11일 및 14일째에 신선한 배지로 교체하였다. 0일 및 18일째에 유세포 분석을 실시하여 세포 수의 배수 변화 뿐 아니라 림플구의 표현형을 결정하였다. 세포는 먼저 살아있는 CD45+ 세포에 대해 게이팅하였다. 재조합 사이토카인이 포함된 암에는 하기와 같이 추가하였다. 0일: IL-4, IFN-γ, IL-21, IL-1β. 7, 11, 14일째에 추가의 IL-15가 포함되었다. 7 및 14일째에 각각 추가의 IL-21 및 IFN-γ가 포함되었다. 도 20(A)는 표시된 사이토카인 지지체(CK)가 있거나 없는 상태에서 C08 또는 OKT3의 존재 하에 18일 배양 이후 TIL Vδ1+ 세포의 배수 증가를 나타낸다. 상기 결과는 항체 또는 사이토카인 단독과 비교하여 사이토카인의 존재 하에 C08 또는 비교 OKT3 항체의 적용에 따른 TIL Vδ1+ 세포의 실질적인 배수 증가를 나타낸다. 도 20(B)는 수집 후 총 Vδ1 세포 수의 증가를 보여준다. 상기 결과는 항체 또는 사이토카인 단독과 비교하여 사이토카인의 존재 하에 C08 또는 비교 OKT3 항체와의 배양 후 TIL Vδ1+ 세포 수의 실질적인 증가를 보여준다. 도 20(C)는 세포의 유세포 분석에 사용되는 게이팅 전략의 예를 나타낸다. 살아있는 CD45+ 세포 집단으로부터 세포를 전방 및 측방 산란 특성(미도시)을 기반으로 림프구에 게이팅하였고, 이후γδ T 세포를 T 세포 수용체에 대한 염색에 의해 αβ T 세포로부터 분리하였다. 마지막으로, 전체 γδ T 세포 집단 내 Vδ1 세포의 비율을 결정하였다. 18일째에 대한 예시 데이터는 제시된 2가지 조건에 대해 나타내었다(+/-1252_P01_C08): 64.3% 세포가 CD45+이었으며, 이들 CD45% 세포 중 53.1%가 γδ+이고, γδ 세포 중 89.7이 Vδ1+였다. 도 20(D)는 수집물에서 TIL Vδ1+ 세포의 세포-표면 표현형 프로파일을 나타낸다. C08 항체로 배양한 후 더 높은 수준의 CD69가 관찰되었다. 도 20(E)는 수집물에서 살아있는 CD45-양성 게이트 내의 TIL γδ-음성, CD8-양성 림프구 분획의 분석을 나태낸다. 요약하면, 조합된 결과는 TIL 집단에 대해 본 명세서에 기재된 본 발명의 항-Vδ1 항체에 의해 부여된 조절 효과를 부각시킨다.
<110> GammaDelta Therapeutics Limited
<120> EX VIVO GAMMA DELTA T CELL POPULATIONS
<130> IP22-302/GDT/GB
<150> GB1911799.3
<151> 2019-08-16
<150> GB2010760.3
<151> 2020-07-13
<150> GB2012172.9
<151> 2020-08-05
<160> 135
<170> PatentIn version 3.5
<210> 1
<211> 209
<212> PRT
<213> Homo sapiens
<400> 1
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Ala Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Glu Ser
85 90 95
Leu Thr Arg Ala Asp Lys Leu Ile Phe Gly Lys Gly Thr Arg Val Thr
100 105 110
Val Glu Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
115 120 125
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
130 135 140
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
145 150 155 160
Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
165 170 175
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
180 185 190
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
195 200 205
Ser
<210> 2
<211> 9
<212> PRT
<213> Homo sapiens
<400> 2
Val Asp Tyr Ala Asp Ala Phe Asp Ile
1 5
<210> 3
<211> 9
<212> PRT
<213> Homo sapiens
<400> 3
Pro Ile Glu Leu Gly Ala Phe Asp Ile
1 5
<210> 4
<211> 8
<212> PRT
<213> Homo sapiens
<400> 4
Thr Trp Ser Gly Tyr Val Asp Val
1 5
<210> 5
<211> 9
<212> PRT
<213> Homo sapiens
<400> 5
Glu Asn Tyr Leu Asn Ala Phe Asp Ile
1 5
<210> 6
<211> 8
<212> PRT
<213> Homo sapiens
<400> 6
Asp Ser Gly Val Ala Phe Asp Ile
1 5
<210> 7
<211> 10
<212> PRT
<213> Homo sapiens
<400> 7
His Gln Val Asp Thr Arg Thr Ala Asp Tyr
1 5 10
<210> 8
<211> 8
<212> PRT
<213> Homo sapiens
<400> 8
Ser Trp Asn Asp Ala Phe Asp Ile
1 5
<210> 9
<211> 8
<212> PRT
<213> Homo sapiens
<400> 9
Asp Tyr Tyr Tyr Ser Met Asp Val
1 5
<210> 10
<211> 9
<212> PRT
<213> Homo sapiens
<400> 10
His Ser Trp Asn Asp Ala Phe Asp Val
1 5
<210> 11
<211> 8
<212> PRT
<213> Homo sapiens
<400> 11
Asp Tyr Tyr Tyr Ser Met Asp Val
1 5
<210> 12
<211> 9
<212> PRT
<213> Homo sapiens
<400> 12
His Ser Trp Ser Asp Ala Phe Asp Ile
1 5
<210> 13
<211> 9
<212> PRT
<213> Homo sapiens
<400> 13
His Ser Trp Asn Asp Ala Phe Asp Ile
1 5
<210> 14
<211> 9
<212> PRT
<213> Homo sapiens
<400> 14
Gln Gln Ser Tyr Ser Thr Leu Leu Thr
1 5
<210> 15
<211> 11
<212> PRT
<213> Homo sapiens
<400> 15
Gln Val Trp Asp Ser Ser Ser Asp His Val Val
1 5 10
<210> 16
<211> 10
<212> PRT
<213> Homo sapiens
<400> 16
Gln Gln Ser Tyr Ser Thr Pro Gln Val Thr
1 5 10
<210> 17
<211> 9
<212> PRT
<213> Homo sapiens
<400> 17
Gln Gln Ser Tyr Ser Thr Pro Leu Thr
1 5
<210> 18
<211> 9
<212> PRT
<213> Homo sapiens
<400> 18
Gln Gln Phe Lys Arg Tyr Pro Pro Thr
1 5
<210> 19
<211> 10
<212> PRT
<213> Homo sapiens
<400> 19
Ser Ser Tyr Thr Ser Thr Ser Thr Leu Val
1 5 10
<210> 20
<211> 9
<212> PRT
<213> Homo sapiens
<400> 20
Gln Gln Ser Tyr Ser Thr Pro Leu Thr
1 5
<210> 21
<211> 9
<212> PRT
<213> Homo sapiens
<400> 21
Gln Gln Ser His Ser His Pro Pro Thr
1 5
<210> 22
<211> 9
<212> PRT
<213> Homo sapiens
<400> 22
Gln Gln Ser Tyr Ser Thr Pro Asp Thr
1 5
<210> 23
<211> 9
<212> PRT
<213> Homo sapiens
<400> 23
Gln Gln Ser Tyr Ser Thr Pro Val Thr
1 5
<210> 24
<211> 9
<212> PRT
<213> Homo sapiens
<400> 24
Gln Gln Ser Tyr Ser Thr Pro Leu Thr
1 5
<210> 25
<211> 9
<212> PRT
<213> Homo sapiens
<400> 25
Gln Gln Ser Tyr Ser Thr Leu Leu Thr
1 5
<210> 26
<211> 8
<212> PRT
<213> Homo sapiens
<400> 26
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 27
<211> 7
<212> PRT
<213> Homo sapiens
<400> 27
Ile Tyr Ser Gly Gly Ser Thr
1 5
<210> 28
<211> 9
<212> PRT
<213> Homo sapiens
<400> 28
Thr Tyr Tyr Arg Ser Lys Trp Ser Thr
1 5
<210> 29
<211> 8
<212> PRT
<213> Homo sapiens
<400> 29
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 30
<211> 8
<212> PRT
<213> Homo sapiens
<400> 30
Ile Ser Gly Gly Gly Gly Thr Thr
1 5
<210> 31
<211> 8
<212> PRT
<213> Homo sapiens
<400> 31
Ile Tyr Pro Gly Asp Ser Asp Thr
1 5
<210> 32
<211> 9
<212> PRT
<213> Homo sapiens
<400> 32
Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn
1 5
<210> 33
<211> 9
<212> PRT
<213> Homo sapiens
<400> 33
Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn
1 5
<210> 34
<211> 8
<212> PRT
<213> Homo sapiens
<400> 34
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 35
<211> 9
<212> PRT
<213> Homo sapiens
<400> 35
Thr Tyr Tyr Gly Ser Lys Trp Tyr Asn
1 5
<210> 36
<211> 8
<212> PRT
<213> Homo sapiens
<400> 36
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 37
<211> 8
<212> PRT
<213> Homo sapiens
<400> 37
Ile Ser Ser Ser Gly Ser Thr Ile
1 5
<210> 38
<211> 8
<212> PRT
<213> Homo sapiens
<400> 38
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 39
<211> 8
<212> PRT
<213> Homo sapiens
<400> 39
Gly Phe Thr Val Ser Ser Asn Tyr
1 5
<210> 40
<211> 10
<212> PRT
<213> Homo sapiens
<400> 40
Gly Asp Ser Val Ser Ser Lys Ser Ala Ala
1 5 10
<210> 41
<211> 8
<212> PRT
<213> Homo sapiens
<400> 41
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 42
<211> 8
<212> PRT
<213> Homo sapiens
<400> 42
Gly Phe Thr Phe Ser Ser Tyr Ala
1 5
<210> 43
<211> 8
<212> PRT
<213> Homo sapiens
<400> 43
Gly Tyr Ser Phe Thr Ser Tyr Trp
1 5
<210> 44
<211> 10
<212> PRT
<213> Homo sapiens
<400> 44
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala
1 5 10
<210> 45
<211> 10
<212> PRT
<213> Homo sapiens
<400> 45
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala
1 5 10
<210> 46
<211> 8
<212> PRT
<213> Homo sapiens
<400> 46
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 47
<211> 10
<212> PRT
<213> Homo sapiens
<400> 47
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala
1 5 10
<210> 48
<211> 8
<212> PRT
<213> Homo sapiens
<400> 48
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 49
<211> 8
<212> PRT
<213> Homo sapiens
<400> 49
Gly Phe Thr Phe Ser Asp Tyr Tyr
1 5
<210> 50
<211> 6
<212> PRT
<213> Homo sapiens
<400> 50
Gln Ser Ile Gly Thr Tyr
1 5
<210> 51
<211> 6
<212> PRT
<213> Homo sapiens
<400> 51
Asn Ile Gly Ser Gln Ser
1 5
<210> 52
<211> 6
<212> PRT
<213> Homo sapiens
<400> 52
Gln Asp Ile Asn Asp Trp
1 5
<210> 53
<211> 6
<212> PRT
<213> Homo sapiens
<400> 53
Gln Ser Leu Ser Asn Tyr
1 5
<210> 54
<211> 6
<212> PRT
<213> Homo sapiens
<400> 54
Gln Asn Ile Arg Thr Trp
1 5
<210> 55
<211> 9
<212> PRT
<213> Homo sapiens
<400> 55
Arg Ser Asp Val Gly Gly Tyr Asn Tyr
1 5
<210> 56
<211> 6
<212> PRT
<213> Homo sapiens
<400> 56
Gln Ser Ile Ser Thr Trp
1 5
<210> 57
<211> 6
<212> PRT
<213> Homo sapiens
<400> 57
Gln Ser Ile Ser Ser Trp
1 5
<210> 58
<211> 6
<212> PRT
<213> Homo sapiens
<400> 58
Gln Ser Ile Ser Ser Tyr
1 5
<210> 59
<211> 6
<212> PRT
<213> Homo sapiens
<400> 59
Gln Ser Ile Ser Thr Trp
1 5
<210> 60
<211> 6
<212> PRT
<213> Homo sapiens
<400> 60
Gln Asp Ile Ser Asn Tyr
1 5
<210> 61
<211> 6
<212> PRT
<213> Homo sapiens
<400> 61
Gln Ser Ile Ser Ser His
1 5
<210> 62
<211> 118
<212> PRT
<213> Homo sapiens
<400> 62
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Asp Tyr Ala Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 63
<211> 117
<212> PRT
<213> Homo sapiens
<400> 63
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Ser Pro Ile Glu Leu Gly Ala Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 64
<211> 120
<212> PRT
<213> Homo sapiens
<400> 64
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Lys
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Ser Thr Asp Tyr Ala
50 55 60
Ala Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Leu Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Thr Trp Ser Gly Tyr Val Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 65
<211> 118
<212> PRT
<213> Homo sapiens
<400> 65
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Asn Tyr Leu Asn Ala Phe Asp Ile Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 66
<211> 117
<212> PRT
<213> Homo sapiens
<400> 66
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Thr Thr Tyr Ser Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ser Gly Val Ala Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 67
<211> 119
<212> PRT
<213> Homo sapiens
<400> 67
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Tyr Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg His Gln Val Asp Thr Arg Thr Ala Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 68
<211> 120
<212> PRT
<213> Homo sapiens
<400> 68
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Arg Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ser Trp Asn Asp Ala Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 69
<211> 120
<212> PRT
<213> Homo sapiens
<400> 69
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Val Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Tyr Tyr Tyr Ser Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 70
<211> 118
<212> PRT
<213> Homo sapiens
<400> 70
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Asn Asp Ala Phe Asp Val Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 71
<211> 120
<212> PRT
<213> Homo sapiens
<400> 71
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Gly Ser Lys Trp Tyr Asn Glu Tyr Ala
50 55 60
Leu Ser Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Tyr Tyr Tyr Ser Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 72
<211> 118
<212> PRT
<213> Homo sapiens
<400> 72
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Ser Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 73
<211> 118
<212> PRT
<213> Homo sapiens
<400> 73
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Asn Asp Ala Phe Asp Ile Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 74
<211> 109
<212> PRT
<213> Homo sapiens
<400> 74
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Ala Cys Arg Ala Gly Gln Ser Ile Gly
20 25 30
Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Leu Leu Thr Phe Gly Arg Gly Thr Lys Val Glu Ile Lys
100 105
<210> 75
<211> 110
<212> PRT
<213> Homo sapiens
<400> 75
Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ala Pro
1 5 10 15
Gly Lys Thr Ala Arg Ile Thr Cys Gly Gly Asn Asn Ile Gly Ser Gln
20 25 30
Ser Val His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Met Leu Val
35 40 45
Ile Tyr Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg Val Glu
65 70 75 80
Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser Ser Ser
85 90 95
Asp His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 76
<211> 110
<212> PRT
<213> Homo sapiens
<400> 76
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Pro Ala Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Asn
20 25 30
Asp Trp Leu Ala Trp Tyr Gln His Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Gln Val Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105 110
<210> 77
<211> 109
<212> PRT
<213> Homo sapiens
<400> 77
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Ser Leu Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 78
<211> 109
<212> PRT
<213> Homo sapiens
<400> 78
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Arg
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Arg Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Lys Arg Tyr
85 90 95
Pro Pro Thr Phe Gly Leu Gly Thr Lys Val Glu Ile Lys
100 105
<210> 79
<211> 112
<212> PRT
<213> Homo sapiens
<400> 79
Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Arg Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln His His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr
85 90 95
Ser Thr Ser Thr Leu Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 80
<211> 109
<212> PRT
<213> Homo sapiens
<400> 80
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Gly Gln Ser Ile Ser
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 81
<211> 109
<212> PRT
<213> Homo sapiens
<400> 81
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His Ser His
85 90 95
Pro Pro Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys
100 105
<210> 82
<211> 109
<212> PRT
<213> Homo sapiens
<400> 82
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Ser Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Asp Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 83
<211> 109
<212> PRT
<213> Homo sapiens
<400> 83
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Gly Gln Ser Ile Ser
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Ala Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Val Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 84
<211> 109
<212> PRT
<213> Homo sapiens
<400> 84
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 85
<211> 109
<212> PRT
<213> Homo sapiens
<400> 85
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser His Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Ala Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Leu Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 86
<211> 240
<212> PRT
<213> Homo sapiens
<400> 86
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Val Asp Tyr Ala Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Ala Cys Arg Ala Gly Gln
145 150 155 160
Ser Ile Gly Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Leu Leu Ile Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser
210 215 220
Tyr Ser Thr Leu Leu Thr Phe Gly Arg Gly Thr Lys Val Glu Ile Lys
225 230 235 240
<210> 87
<211> 240
<212> PRT
<213> Homo sapiens
<400> 87
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Asn
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Val Ile Tyr Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Ser Pro Ile Glu Leu Gly Ala Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val
130 135 140
Ala Pro Gly Lys Thr Ala Arg Ile Thr Cys Gly Gly Asn Asn Ile Gly
145 150 155 160
Ser Gln Ser Val His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Met
165 170 175
Leu Val Ile Tyr Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg
180 185 190
Phe Ser Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg
195 200 205
Val Glu Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser
210 215 220
Ser Ser Asp His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
225 230 235 240
<210> 88
<211> 243
<212> PRT
<213> Homo sapiens
<400> 88
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Lys
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Ser Thr Asp Tyr Ala
50 55 60
Ala Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Leu Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Thr Trp Ser Gly Tyr Val Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Pro
130 135 140
Ala Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Ser Gln Asp Ile Asn Asp Trp Leu Ala Trp Tyr Gln His Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly
180 185 190
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Thr Pro Gln Val Thr Phe Gly Gln Gly Thr Arg Leu
225 230 235 240
Glu Ile Lys
<210> 89
<211> 240
<212> PRT
<213> Homo sapiens
<400> 89
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Asn Tyr Leu Asn Ala Phe Asp Ile Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln
145 150 155 160
Ser Leu Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser
210 215 220
Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
225 230 235 240
<210> 90
<211> 239
<212> PRT
<213> Homo sapiens
<400> 90
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ala Ile Ser Gly Gly Gly Gly Thr Thr Tyr Ser Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Ser Gly Val Ala Phe Asp Ile Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser
130 135 140
Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn
145 150 155 160
Ile Arg Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Arg Ala Pro
165 170 175
Lys Leu Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser
180 185 190
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
195 200 205
Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Lys
210 215 220
Arg Tyr Pro Pro Thr Phe Gly Leu Gly Thr Lys Val Glu Ile Lys
225 230 235
<210> 91
<211> 244
<212> PRT
<213> Homo sapiens
<400> 91
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr
20 25 30
Trp Ile Gly Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Tyr Pro Gly Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe
50 55 60
Gln Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg His Gln Val Asp Thr Arg Thr Ala Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val
130 135 140
Ser Gly Ser Pro Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Arg
145 150 155 160
Ser Asp Val Gly Gly Tyr Asn Tyr Val Ser Trp Tyr Gln His His Pro
165 170 175
Gly Lys Ala Pro Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser
180 185 190
Gly Val Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser
195 200 205
Leu Thr Ile Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys
210 215 220
Ser Ser Tyr Thr Ser Thr Ser Thr Leu Val Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Val Leu
<210> 92
<211> 242
<212> PRT
<213> Homo sapiens
<400> 92
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Arg Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ser Trp Asn Asp Ala Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Gly Gln Ser Ile Ser Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly
180 185 190
Val Pro Leu Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu
225 230 235 240
Ile Lys
<210> 93
<211> 242
<212> PRT
<213> Homo sapiens
<400> 93
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Val Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Tyr Tyr Tyr Ser Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Ser Gln Ser Ile Ser Ser Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly
180 185 190
Val Pro Leu Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu
195 200 205
Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser His Ser His Pro Pro Thr Phe Gly Pro Gly Thr Lys Val Asp
225 230 235 240
Ile Lys
<210> 94
<211> 240
<212> PRT
<213> Homo sapiens
<400> 94
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Asn Asp Ala Phe Asp Val Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Ser Ile Thr Cys Arg Ala Ser Gln
145 150 155 160
Ser Ile Ser Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser
210 215 220
Tyr Ser Thr Pro Asp Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
225 230 235 240
<210> 95
<211> 242
<212> PRT
<213> Homo sapiens
<400> 95
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Gly Ser Lys Trp Tyr Asn Glu Tyr Ala
50 55 60
Leu Ser Val Lys Ser Arg Ile Ile Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Asp Tyr Tyr Tyr Ser Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser
130 135 140
Thr Leu Ser Ala Ser Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
145 150 155 160
Gly Gln Ser Ile Ser Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Lys Ala Pro Lys Leu Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly
180 185 190
Val Pro Leu Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu
195 200 205
Ala Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln
210 215 220
Gln Ser Tyr Ser Thr Pro Val Thr Phe Gly Gln Gly Thr Lys Val Glu
225 230 235 240
Ile Lys
<210> 96
<211> 240
<212> PRT
<213> Homo sapiens
<400> 96
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Ser Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln
145 150 155 160
Asp Ile Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Leu Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro
180 185 190
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser
210 215 220
Tyr Ser Thr Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
225 230 235 240
<210> 97
<211> 240
<212> PRT
<213> Homo sapiens
<400> 97
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ser Trp Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Tyr Ile Ser Ser Ser Gly Ser Thr Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg His Ser Trp Asn Asp Ala Phe Asp Ile Trp Gly Arg Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln
145 150 155 160
Ser Ile Ser Ser His Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala
165 170 175
Pro Lys Leu Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro
180 185 190
Ser Arg Phe Ser Ala Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
195 200 205
Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser
210 215 220
Tyr Ser Thr Leu Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
225 230 235 240
<210> 98
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic linker
<400> 98
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
1 5 10
<210> 99
<211> 765
<212> DNA
<213> Homo sapiens
<400> 99
gccatggccc aggtgcagct ggtggagtct gggggaggct tggtcaagcc tggagggtcc 60
ctgagactct cctgtgcagc ctctggattc accttcagtg actactacat gagctggatc 120
cgccaggctc cagggaaggg gctggagtgg gtttcataca ttagtagtag tggtagtacc 180
atatactacg cagactctgt gaagggccga ttcaccatct ccagggacaa cgccaagaac 240
tcactgtatc tgcaaatgaa cagcctgaga gccgaggaca cggctgtgta ttactgtgca 300
agggtggact acgctgatgc atttgatatc tggggccagg gcaccctggt caccgtctcg 360
agtggtggag gcggttcagg cggaggtggc tctggcggtg gcgctagcga catccagatg 420
acccagtctc catcctccct gtctgcatct gtaggagaca gagtcaccat cgcttgccgg 480
gcaggtcaga gcattggcac ctatttaaat tggtatcagc agaaaccagg gaaagcccct 540
aaactcctga tctatgttgc atccagtttg caaagtgggg tcccgtcacg gttcagtggc 600
agtggatctg ggacagaatt cactctcacc atcagcagtc tgcaacctga agattttgca 660
acttactact gtcaacagag ttacagtacc ctcctcactt tcggcagagg gaccaaggtg 720
gaaatcaaac gtaccgcggc cgcatccgca catcatcatc accat 765
<210> 100
<211> 768
<212> DNA
<213> Homo sapiens
<400> 100
gccatggccg aggtgcagct gttggagtct gggggaggct tggtacagcc tggcaggtcc 60
ctgagactct cctgtgcagc ctctgggttc accgtcagta gcaactacat gagctgggtc 120
cgccaggctc cagggaaggg gctggagtgg gtctcagtta tttatagcgg tggtagcaca 180
tactacgcag actccgtgaa gggccgattc accatctcca gagacaattc caagaacacg 240
ctgtatcttc aaatgaacag cctgagagcc gaggacacgg ctgtgtatta ctgtgcgagc 300
cccatagagc tgggtgcttt tgatatctgg ggccaaggaa ccctggtcac cgtctcgagt 360
ggtggaggcg gttcaggcgg aggtggctct ggcggtggcg ctagctccta tgagctgact 420
cagccaccct cagtgtcagt ggccccagga aagacggcca ggattacctg tgggggaaac 480
aacattggaa gtcaaagtgt gcactggtac cagcagaagc caggccaggc ccctatgctg 540
gtcatctatt atgatagcga ccggccctca gggatccctg agcgattctc tggctccaac 600
tctgggaaca cggccaccct gaccatcagc agggtcgaag ccggggatga ggccgactat 660
tactgtcagg tgtgggatag tagtagtgat catgtggtat tcggcggcgg gaccaagctg 720
accgtcctag gtcagcccgc ggccgcatcc gcacatcatc atcaccat 768
<210> 101
<211> 774
<212> DNA
<213> Homo sapiens
<400> 101
gccatggccc aggtacagct gcagcagtca ggtccaggac tggtgaagcc ctcgcagacc 60
ctctcactca cctgtgccat ctccggggac agtgtctcca gcaaaagtgc tgcttggaac 120
tggatcaggc agtccccatc gagaggcctt gagtggctgg gaaggacata ctacaggtcc 180
aagtggtcta ctgattatgc agcatctgtg aaaagtcgaa taaccatcaa cccagacaca 240
tccaagaacc agctctccct gcagttaaac tctgtgactc ccgaggacac ggctgtgtat 300
tactgtgcaa gaacgtggag tggttatgtg gacgtctggg gccaaggaac cctggtcacc 360
gtctcgagtg gtggaggcgg ttcaggcgga ggtggctctg gcggtggcgc tagcgacatc 420
cagatgaccc agtcccctcc cgccctgtct gcatctgtgg gagacagagt caccatcact 480
tgccgggcca gtcaagatat taatgactgg ttggcctggt atcagcataa acctgggaaa 540
gcccctaagc tcctgatcta tgatgcctcc agtttggaaa gtggggtccc atcaaggttc 600
agcggcagtg gatctgggac agaattcact ctcaccatca gcagcctgca gcctgatgat 660
tttgcaactt actactgtca acagagttac agtacccctc aggtcacttt tggccagggg 720
acacgactgg agatcaaacg taccgcggcc gcatccgcac atcatcatca ccat 774
<210> 102
<211> 765
<212> DNA
<213> Homo sapiens
<400> 102
gccatggccg aggtgcagct gttggagtct gggggaggct tggtcaagcc tggagggtcc 60
ctgagactct cctgtgcggc ctctggattc accttcagtg actactacat gagctggatc 120
cgccaggctc cagggaaggg gctggagtgg gtttcataca ttagtagtag tggtagtacc 180
atatactacg cagactctgt gaagggccga ttcaccatct ccagggacaa cgccaagaac 240
tcactgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtgta ttactgtgcg 300
agagaaaact atctaaatgc ttttgatatc tggggccgtg gcaccctggt caccgtctcg 360
agtggtggag gcggttcagg cggaggtggc tctggcggtg gcgctagcga catccagatg 420
acccagtctc catcctccct gtctgcatct gtaggagaca gagtcaccat cacttgccgg 480
acaagtcaga gccttagtaa ttacttaaat tggtatcagc agaaaccagg gaaagcccct 540
aagctcctga tctatgctgc atccagtttg caaagtgggg tcccatcaag gttcagtggc 600
agtggatctg ggacagattt cactctcacc atcagcagtc tgcaacctga agattttgcg 660
acttactact gtcaacagag ttacagtacc cctctcactt tcggcggagg gaccaagcta 720
gagatcaaac gtaccgcggc cgcatccgca catcatcatc accat 765
<210> 103
<211> 762
<212> DNA
<213> Homo sapiens
<400> 103
gccatggccg aggtgcagct gttggagtct gggggaggct tggtacagcc tggggggtcc 60
ctgagactct cctgtgcagc ctctggattc acctttagca gctatgccat gagctgggtc 120
cgccaggctc cagggaaggg gctggagtgg gtctcagcta ttagtggtgg tggtggtacc 180
acatactcct cagactccgt gaagggccgg ttcaccatct ccagagacaa ttccaagaac 240
acgctgtatc tgcaaatgaa cagcctgaga gccgaggaca cggctgtgta ttactgtgcg 300
agagattcag gggttgcttt tgatatctgg ggccaaggaa ccctggtcac cgtctcgagt 360
ggtggaggcg gttcaggcgg aggtggctct ggcggtggcg ctagcgacat ccagatgacc 420
cagtctccat ccttcctgtc tgcatctgta ggagacagag tcaccatcac ttgccgggcc 480
agtcagaata tacgtacctg gttggcctgg tatcagcaga aaccagggag agcccctaag 540
ctcctgatct atgatgcctc cagtttggaa agtggggtcc catcaaggtt cagcggcagt 600
ggatctggga ctgatttcac tctcaccatc agcagcctgc agcctgaaga ttttgcaact 660
tattactgtc aacagtttaa acgttaccct ccgacgtttg gcctggggac caaggtggag 720
atcaaacgta ccgcggccgc atccgcacat catcatcacc at 762
<210> 104
<211> 780
<212> DNA
<213> Homo sapiens
<400> 104
gccatggccc aggtccagct ggtacagtct ggagcagagg tgaaaaagcc cggggagtct 60
ctgaagatct cctgtaaggg ttctggatac agctttacca gctactggat cggctgggtg 120
cgccagatgc ccgggaaagg cctggagtgg atggggatca tctatcctgg tgactctgat 180
accagataca gcccgtcctt ccaaggccag gtcaccatct cagccgacaa gtccatcagc 240
accgcctacc tgcagtggag cagcctgaag gcctcggaca ccgccatgta ttattgtgcg 300
agacatcagg ttgatacacg gacggctgat tactggggcc agggaaccct ggtcaccgtc 360
tcgagtggtg gaggcggttc aggcggaggt ggctctggcg gtggcgctag ccagtctgcg 420
ctgactcagc ctgcctccgt gtctgggtct cctggacagt cggtcaccat ctcctgcact 480
ggaaccagga gtgacgttgg tggttataac tatgtctcct ggtaccaaca ccacccaggc 540
aaagccccca aactcatgat ttatgaggtc agtaatcggc cctcaggggt ttctaatcgc 600
ttctctggct ccaagtctgg caacacggcc tccctgacca tctctgggct ccaggctgag 660
gacgaggctg attattactg cagctcatat acaagcacca gcactctggt attcggcgga 720
gggaccaagc tgaccgtcct aggtcagccc gcggccgcat ccgcacatca tcatcaccat 780
780
<210> 105
<211> 771
<212> DNA
<213> Homo sapiens
<400> 105
gccatggccc aggtacagct gcagcagtca ggtccaggac tggtgaagcc ctcgcagacc 60
ctctcactca cctgtgccat ctccggggac agtgtctcta gcaacagtgc tgcttggaac 120
tggatcaggc agtccccatc gagaggcctt gagtggctgg gaaggacata ctacaggtcc 180
aagtggtata atgattatgc agtatctgtg agaagtcgaa taaccatcaa cccagacaca 240
tccaagaacc agttctccct gcagctgaac tctgtgactc ccgaggacac ggctgtgtat 300
tactgtgcaa gaagctggaa tgatgctttt gatatctggg ggcaagggac cacggtcacc 360
gtctcgagtg gtggaggcgg ttcaggcgga ggtggctctg gcggtggcgc tagcgatatt 420
gtgatgacac agtctccttc caccctgtct gcatctatag gagacagagt caccatcact 480
tgccgggccg gtcagagtat tagtacctgg ttggcctggt atcagcagaa accagggaaa 540
gcccctaagc tcctgatcta tgatgcctcc agtttggaaa gtggggtccc attaaggttc 600
agcggcagtg gatctgggac agatttcact ctcaccatca gcagtctgca acctgaagat 660
tttgcaactt actactgtca acagagttac agtaccccgc tcactttcgg cggagggacc 720
aaggtggaga tcaaacgtac cgcggccgca tccgcacatc atcatcacca t 771
<210> 106
<211> 771
<212> DNA
<213> Homo sapiens
<400> 106
gccatggccc aggtacagct gcagcagtca ggtccaggcc tggtgaagcc ctcgcagacc 60
ctctcactca cctgtgtcat ctccggggac agtgtctcta gcaacagtgc tgcttggaac 120
tggatcaggc agtccccatc gcgaggcctt gagtggctgg gaaggacata ctacaggtcc 180
aagtggtata atgattatgc agtatctgtg aaaagtcgaa taaccatcaa cccagacaca 240
tccaagaacc agttctccct gcagctgaac tctgtgactc ccgaggacac ggctgtctat 300
tattgtgcaa gagactacta ctacagtatg gacgtctggg gccaagggac aatggtcacc 360
gtctcgagtg gtggaggcgg ttcaggcgga ggtggctctg gcggtggcgc tagcgacatc 420
cagatgaccc agtctccctc caccctgtct gcatctgtag gagacagagt caccatcact 480
tgccgggcca gtcagagtat tagtagctgg ttggcctggt atcagcagaa accagggaaa 540
gcccctaagc tcctgatcta tgatgcctcc agtttggaaa gtggggtccc attaaggttc 600
agcggcagtg gatctgggac agaattcact ctcaccatca gcagcctgca gcctgatgat 660
tttgcaactt attactgtca acagagtcac agtcaccccc ctactttcgg ccctgggacc 720
aaagtggata tcaaacgtac cgcggccgca tccgcacatc atcatcacca t 771
<210> 107
<211> 765
<212> DNA
<213> Homo sapiens
<400> 107
gccatggccc aggtgcagct ggtggagtct gggggaggct tggtcaagcc tggagggtcc 60
ctgagactct cctgtgcagc ctctggattc accttcagtg actactacat gagctggatc 120
cgccaggctc cagggaaggg gctggagtgg gtttcataca ttagtagtag tggtagtacc 180
atatactacg cagactctgt gaagggccga ttcaccatct ccagggacaa cgccaagaac 240
tcactgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtgta ttactgtgcg 300
agacatagct ggaatgatgc ttttgatgtc tggggccagg gaaccctggt caccgtctcg 360
agtggtggag gcggttcagg cggaggtggc tctggcggtg gcgctagcga catccagatg 420
acccagtctc catcctccct gtctgcatct gtaggagaca gagtctccat cacctgccgg 480
gcaagtcaga gcattagcag ctatttaaat tggtatcagc agaaaccagg gaaagcccct 540
aagctcctga tctatgctgc atccagtttg caaagtgggg tcccatcaag gttcagtggc 600
agtggatctg ggacagattt cactctcacc atcagcagtc tgcaacctga agattttgca 660
acttactact gtcagcagag ttacagtacc cccgacactt tcggcggagg gaccaaggtg 720
gaaatcaaac gtaccgcggc cgcatccgca catcatcatc accat 765
<210> 108
<211> 771
<212> DNA
<213> Homo sapiens
<400> 108
gccatggccc aggtacagct gcagcagtca ggtccaggac tggtgaagcc ctcgcagacc 60
ctctcactca cctgtgccat ctccggggac agtgtctcta gcaacagtgc tgcttggaac 120
tggatcaggc agtccccatc gagaggcctt gagtggctgg gaaggacata ctacgggtcc 180
aagtggtata atgagtatgc actatctgtg aaaagtcgaa taatcatcaa cccagacaca 240
tccaagaacc agttctccct gcagctgaac tctgtgactc ccgaggacac ggctgtctat 300
tattgtgcaa gagactacta ctacagtatg gacgtctggg gccagggaac cctggtcacc 360
gtctcgagtg gtggaggcgg ttcaggcgga ggtggctctg gcggtggcgc tagcgatatt 420
gtgatgactc agtctccttc caccctgtct gcatctatag gagacagagt caccatcact 480
tgccgggccg gtcagagtat tagtacctgg ttggcctggt atcagcagaa accagggaaa 540
gcccctaagc tcctgatcta tgatgcctcc agtttggaaa gtggggtccc attaaggttc 600
agcggcagtg gatctgggac agaattcact ctcgccatca gcagcctgca gcctgatgat 660
tttgcaactt actactgtca acagagttac agtaccccgg taacttttgg ccaggggacc 720
aaggtggaga tcaaacgtac cgcggccgca tccgcacatc atcatcacca t 771
<210> 109
<211> 765
<212> DNA
<213> Homo sapiens
<400> 109
gccatggccg aggtgcagct gttggagtct gggggaggct tggtcaagcc tggagggtcc 60
ctgagactct cctgtgcagc ctctggattc accttcagtg actactacat gagctggatc 120
cgccaggctc cagggaaggg gctggagtgg gtttcataca ttagtagtag tggtagtacc 180
atatactacg cagactctgt gaagggccga ttcaccatct ccagggacaa cgccaagaac 240
tcactgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtgta ttactgtgcg 300
agacatagct ggagtgatgc ttttgatatc tggggccaag gaaccctggt caccgtctcg 360
agtggtggag gcggttcagg cggaggtggc tctggcggtg gcgctagcga catccagatg 420
acccagtctc catcctccct gtctgcatct gtaggagaca gagtcaccat cacttgccag 480
gcgagtcagg acattagcaa ctatttaaat tggtatcagc agaaaccagg gaaagcccct 540
aagctcctga tctacgatgc atccaatttg gaaacagggg tcccatcaag gttcagtgga 600
agtggatctg ggacagattt cactctcacc atcagcagtc tgcaacctga agattttgca 660
acttactact gtcaacagag ttacagtact cctctcactt tcggcggagg gaccaaggtg 720
gagatcaaac gtaccgcggc cgcatccgca catcatcatc accat 765
<210> 110
<211> 765
<212> DNA
<213> Homo sapiens
<400> 110
gccatggccg aagtgcagct ggtggagtcc gggggaggct tagttcagcc tggggggtcc 60
ctgagactct cctgtgcagc ctctggattc accttcagtg actactacat gagctggatc 120
cgccaggctc cagggaaggg gctggagtgg gtttcataca ttagtagtag tggtagtacc 180
atatactacg cagactctgt gaagggccga ttcaccatct ccagggacaa cgccaagaac 240
tcactgtatc tgcaaatgaa cagcctgaga gccgaggaca cggccgtgta ttactgtgcg 300
agacatagct ggaatgatgc ttttgatatc tggggccgtg gcaccctggt caccgtctcg 360
agtggtggag gcggttcagg cggaggtggc tctggcggtg gcgctagcga catccagatg 420
acccagtctc catcctccct gtctgcatct gtaggagaca gagtcaccat cacttgccgg 480
gcaagtcaga gcattagcag ccatttaaat tggtatcagc agaaaccagg gaaagcccct 540
aagctcctga tctatgctgc atccagtttg caaagtgggg tcccatccag gttcagtgcc 600
agtggatctg ggacagattt cactctcacc atcagcagcc tgcagcctga agattttgca 660
acttactact gtcaacagag ttacagtacc ctgctcactt tcggcggagg gaccaaggtg 720
gaaatcaaac gtaccgcggc cgcatccgca catcatcatc accat 765
<210> 111
<211> 664
<212> PRT
<213> Homo sapiens
<400> 111
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Ala Cys Arg Ala Gly Gln Ser Ile Gly
20 25 30
Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Val Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Leu Leu Thr Phe Gly Arg Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Lys Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Ser Trp Ile Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr Ile Ser Ser Ser Gly Ser
260 265 270
Thr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Val Asp Tyr Ala Asp Ala
305 310 315 320
Phe Asp Ile Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 112
<211> 667
<212> PRT
<213> Homo sapiens
<400> 112
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Pro Ala Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Asn
20 25 30
Asp Trp Leu Ala Trp Tyr Gln His Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Gln Val Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Thr
100 105 110
Ala Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
130 135 140
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
145 150 155 160
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
165 170 175
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
180 185 190
Lys Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
195 200 205
Thr Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Gln Gln Ser
210 215 220
Gly Pro Gly Leu Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala
225 230 235 240
Ile Ser Gly Asp Ser Val Ser Ser Lys Ser Ala Ala Trp Asn Trp Ile
245 250 255
Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr
260 265 270
Arg Ser Lys Trp Ser Thr Asp Tyr Ala Ala Ser Val Lys Ser Arg Ile
275 280 285
Thr Ile Asn Pro Asp Thr Ser Lys Asn Gln Leu Ser Leu Gln Leu Asn
290 295 300
Ser Val Thr Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Thr Trp
305 310 315 320
Ser Gly Tyr Val Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
450 455 460
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
485 490 495
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
500 505 510
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
515 520 525
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
530 535 540
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
545 550 555 560
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
565 570 575
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
580 585 590
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
595 600 605
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
610 615 620
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
625 630 635 640
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
645 650 655
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 113
<211> 664
<212> PRT
<213> Homo sapiens
<400> 113
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Thr Ser Gln Ser Leu Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Leu Val Lys Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Ser Trp Ile Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr Ile Ser Ser Ser Gly Ser
260 265 270
Thr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Glu Asn Tyr Leu Asn Ala
305 310 315 320
Phe Asp Ile Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 114
<211> 663
<212> PRT
<213> Homo sapiens
<400> 114
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Phe Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asn Ile Arg
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Arg Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Phe Lys Arg Tyr
85 90 95
Pro Pro Thr Phe Gly Leu Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Ser Tyr Ala Met Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Ala Ile Ser Gly Gly Gly Gly
260 265 270
Thr Thr Tyr Ser Ser Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Ser Gly Val Ala Phe
305 310 315 320
Asp Ile Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 115
<211> 667
<212> PRT
<213> Homo sapiens
<400> 115
Ala Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
1 5 10 15
Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Arg Ser Asp Val Gly
20 25 30
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln His His Pro Gly Lys Ala Pro
35 40 45
Lys Leu Met Ile Tyr Glu Val Ser Asn Arg Pro Ser Gly Val Ser Asn
50 55 60
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
65 70 75 80
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr
85 90 95
Ser Thr Ser Thr Leu Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
Gly Gln Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
115 120 125
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
130 135 140
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
145 150 155 160
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
165 170 175
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
180 185 190
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
195 200 205
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser Gln Val Gln Leu Val Gln
210 215 220
Ser Gly Ala Glu Val Lys Lys Pro Gly Glu Ser Leu Lys Ile Ser Cys
225 230 235 240
Lys Gly Ser Gly Tyr Ser Phe Thr Ser Tyr Trp Ile Gly Trp Val Arg
245 250 255
Gln Met Pro Gly Lys Gly Leu Glu Trp Met Gly Ile Ile Tyr Pro Gly
260 265 270
Asp Ser Asp Thr Arg Tyr Ser Pro Ser Phe Gln Gly Gln Val Thr Ile
275 280 285
Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr Leu Gln Trp Ser Ser Leu
290 295 300
Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys Ala Arg His Gln Val Asp
305 310 315 320
Thr Arg Thr Ala Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
325 330 335
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser
340 345 350
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
355 360 365
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
370 375 380
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
385 390 395 400
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
405 410 415
Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp
420 425 430
Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
435 440 445
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
450 455 460
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
465 470 475 480
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
485 490 495
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
500 505 510
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
515 520 525
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
530 535 540
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
545 550 555 560
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
565 570 575
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
580 585 590
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
595 600 605
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
610 615 620
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
625 630 635 640
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
645 650 655
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 116
<211> 663
<212> PRT
<213> Homo sapiens
<400> 116
Ala Ser Ser Tyr Glu Leu Thr Gln Pro Pro Ser Val Ser Val Ala Pro
1 5 10 15
Gly Lys Thr Ala Arg Ile Thr Cys Gly Gly Asn Asn Ile Gly Ser Gln
20 25 30
Ser Val His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Met Leu Val
35 40 45
Ile Tyr Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser
50 55 60
Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg Val Glu
65 70 75 80
Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Gln Val Trp Asp Ser Ser Ser
85 90 95
Asp His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln
100 105 110
Pro Ala Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu
115 120 125
Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr
130 135 140
Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys
145 150 155 160
Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr
165 170 175
Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His
180 185 190
Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val Glu Lys
195 200 205
Thr Val Ala Pro Thr Glu Cys Ser Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Arg Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Val Ser Ser Asn Tyr Met Ser Trp Val Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Val Ile Tyr Ser Gly Gly Ser
260 265 270
Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
275 280 285
Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu
290 295 300
Asp Thr Ala Val Tyr Tyr Cys Ala Ser Pro Ile Glu Leu Gly Ala Phe
305 310 315 320
Asp Ile Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
325 330 335
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
340 345 350
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
355 360 365
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
370 375 380
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
385 390 395 400
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
405 410 415
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu
420 425 430
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
435 440 445
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
450 455 460
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
465 470 475 480
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
485 490 495
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
500 505 510
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
515 520 525
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
530 535 540
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
545 550 555 560
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
565 570 575
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
580 585 590
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
595 600 605
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
610 615 620
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
625 630 635 640
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
645 650 655
Leu Ser Leu Ser Pro Gly Lys
660
<210> 117
<211> 666
<212> PRT
<213> Homo sapiens
<400> 117
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Gly Gln Ser Ile Ser
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Gln Gln Ser Gly
210 215 220
Pro Gly Leu Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile
225 230 235 240
Ser Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn Trp Ile Arg
245 250 255
Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg
260 265 270
Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser Val Arg Ser Arg Ile Thr
275 280 285
Ile Asn Pro Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser
290 295 300
Val Thr Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Ser Trp Asn
305 310 315 320
Asp Ala Phe Asp Ile Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 118
<211> 666
<212> PRT
<213> Homo sapiens
<400> 118
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser His Ser His
85 90 95
Pro Pro Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Gln Gln Ser Gly
210 215 220
Pro Gly Leu Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Val Ile
225 230 235 240
Ser Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn Trp Ile Arg
245 250 255
Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Arg
260 265 270
Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser Val Lys Ser Arg Ile Thr
275 280 285
Ile Asn Pro Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser
290 295 300
Val Thr Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Tyr
305 310 315 320
Tyr Ser Met Asp Val Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 119
<211> 664
<212> PRT
<213> Homo sapiens
<400> 119
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Ser Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Asp Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Lys Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Ser Trp Ile Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr Ile Ser Ser Ser Gly Ser
260 265 270
Thr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg His Ser Trp Asn Asp Ala
305 310 315 320
Phe Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 120
<211> 666
<212> PRT
<213> Homo sapiens
<400> 120
Ala Ser Asp Ile Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser
1 5 10 15
Ile Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Gly Gln Ser Ile Ser
20 25 30
Thr Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Ser Leu Glu Ser Gly Val Pro Leu Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Ala Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Val Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Gln Val Gln Leu Gln Gln Ser Gly
210 215 220
Pro Gly Leu Val Lys Pro Ser Gln Thr Leu Ser Leu Thr Cys Ala Ile
225 230 235 240
Ser Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn Trp Ile Arg
245 250 255
Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu Gly Arg Thr Tyr Tyr Gly
260 265 270
Ser Lys Trp Tyr Asn Glu Tyr Ala Leu Ser Val Lys Ser Arg Ile Ile
275 280 285
Ile Asn Pro Asp Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser
290 295 300
Val Thr Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Tyr
305 310 315 320
Tyr Ser Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
325 330 335
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
340 345 350
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
355 360 365
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
370 375 380
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
385 390 395 400
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
405 410 415
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
420 425 430
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
435 440 445
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
450 455 460
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
465 470 475 480
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
485 490 495
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
500 505 510
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
515 520 525
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
530 535 540
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
545 550 555 560
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
565 570 575
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
580 585 590
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
595 600 605
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
610 615 620
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
625 630 635 640
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
645 650 655
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
660 665
<210> 121
<211> 664
<212> PRT
<213> Homo sapiens
<400> 121
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asp Ile Ser
20 25 30
Asn Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Ala Ser Asn Leu Glu Thr Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Leu Glu Ser Gly
210 215 220
Gly Gly Leu Val Lys Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Ser Trp Ile Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr Ile Ser Ser Ser Gly Ser
260 265 270
Thr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg His Ser Trp Ser Asp Ala
305 310 315 320
Phe Asp Ile Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 122
<211> 664
<212> PRT
<213> Homo sapiens
<400> 122
Ala Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
1 5 10 15
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Ser His Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Ala Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Ser Thr
85 90 95
Leu Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr Ala
100 105 110
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
115 120 125
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
130 135 140
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
145 150 155 160
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
165 170 175
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
180 185 190
Leu Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
195 200 205
Lys Ser Phe Asn Arg Gly Glu Cys Glu Val Gln Leu Val Glu Ser Gly
210 215 220
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
225 230 235 240
Ser Gly Phe Thr Phe Ser Asp Tyr Tyr Met Ser Trp Ile Arg Gln Ala
245 250 255
Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr Ile Ser Ser Ser Gly Ser
260 265 270
Thr Ile Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
275 280 285
Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala
290 295 300
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg His Ser Trp Asn Asp Ala
305 310 315 320
Phe Asp Ile Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser Ala Ser
325 330 335
Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
340 345 350
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
355 360 365
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val
370 375 380
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
385 390 395 400
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
405 410 415
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val
420 425 430
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
435 440 445
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
450 455 460
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
465 470 475 480
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
485 490 495
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
500 505 510
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
515 520 525
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
530 535 540
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
545 550 555 560
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
565 570 575
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
580 585 590
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
595 600 605
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
610 615 620
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
625 630 635 640
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
645 650 655
Ser Leu Ser Leu Ser Pro Gly Lys
660
<210> 123
<211> 254
<212> PRT
<213> Artificial Sequence
<220>
<223> TRDV1(3OMZ) TRAC antigen sequence
<400> 123
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Ala Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Glu Ser
85 90 95
Leu Thr Arg Ala Asp Lys Leu Ile Phe Gly Lys Gly Thr Arg Val Thr
100 105 110
Val Glu Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
115 120 125
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
130 135 140
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
145 150 155 160
Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
165 170 175
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
180 185 190
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
195 200 205
Ser Cys Thr Thr Ala Pro Ser Ala Gln Leu Lys Lys Lys Leu Gln Ala
210 215 220
Leu Lys Lys Lys Asn Ala Gln Leu Lys Trp Lys Leu Gln Ala Leu Lys
225 230 235 240
Lys Lys Leu Ala Gln Gly Ser Gly His His His His His His
245 250
<210> 124
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Optional scFv tag sequence (kappa sequence + His tag)
<400> 124
Arg Thr Ala Ala Ala Ser Ala His His His His His
1 5 10
<210> 125
<211> 37
<212> PRT
<213> Artificial Sequence
<220>
<223> Optional scFv tag sequence (kappa sequence + His and FLAG tag)
<400> 125
Arg Thr Ala Ala Ala Ser Ala His His His His His His Lys Leu Asp
1 5 10 15
Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys
20 25 30
Asp Asp Asp Asp Lys
35
<210> 126
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Optional scFv tag sequence (lambda sequence + His tag)
<400> 126
Gly Gln Pro Ala Ala Ala Ser Ala His His His His His
1 5 10
<210> 127
<211> 38
<212> PRT
<213> Artificial Sequence
<220>
<223> Optional scFv tag sequence (lambda sequence + His and FLAG tag)
<400> 127
Gly Gln Pro Ala Ala Ala Ser Ala His His His His His His Lys Leu
1 5 10 15
Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr
20 25 30
Lys Asp Asp Asp Asp Lys
35
<210> 128
<211> 254
<212> PRT
<213> Homo sapiens
<400> 128
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Val Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Glu Ser
85 90 95
Leu Thr Arg Ala Asp Lys Leu Ile Phe Gly Lys Gly Thr Arg Val Thr
100 105 110
Val Glu Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
115 120 125
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
130 135 140
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
145 150 155 160
Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
165 170 175
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
180 185 190
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
195 200 205
Ser Cys Thr Thr Ala Pro Ser Ala Gln Leu Lys Lys Lys Leu Gln Ala
210 215 220
Leu Lys Lys Lys Asn Ala Gln Leu Lys Trp Lys Leu Gln Ala Leu Lys
225 230 235 240
Lys Lys Leu Ala Gln Gly Ser Gly His His His His His His
245 250
<210> 129
<211> 20
<212> PRT
<213> Homo sapiens
<400> 129
Met Leu Phe Ser Ser Leu Leu Cys Val Phe Val Ala Phe Ser Tyr Ser
1 5 10 15
Gly Ser Ser Val
20
<210> 130
<211> 95
<212> PRT
<213> Homo sapiens
<400> 130
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Ala Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Glu
85 90 95
<210> 131
<211> 16
<212> PRT
<213> Homo sapiens
<400> 131
Thr Asp Lys Leu Ile Phe Gly Lys Gly Thr Arg Val Thr Val Glu Pro
1 5 10 15
<210> 132
<211> 17
<212> PRT
<213> Homo sapiens
<400> 132
Leu Thr Ala Gln Leu Phe Phe Gly Lys Gly Thr Gln Leu Ile Val Glu
1 5 10 15
Pro
<210> 133
<211> 19
<212> PRT
<213> Homo sapiens
<400> 133
Ser Trp Asp Thr Arg Gln Met Phe Phe Gly Thr Gly Ile Lys Leu Phe
1 5 10 15
Val Glu Pro
<210> 134
<211> 15
<212> PRT
<213> Homo sapiens
<400> 134
Arg Pro Leu Ile Phe Gly Lys Gly Thr Tyr Leu Glu Val Gln Gln
1 5 10 15
<210> 135
<211> 153
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<222> (1)
<223> Xaa can be any naturally occurring amino acid
<400> 135
Xaa Ser Gln Pro His Thr Lys Pro Ser Val Phe Val Met Lys Asn Gly
1 5 10 15
Thr Asn Val Ala Cys Leu Val Lys Glu Phe Tyr Pro Lys Asp Ile Arg
20 25 30
Ile Asn Leu Val Ser Ser Lys Lys Ile Thr Glu Phe Asp Pro Ala Ile
35 40 45
Val Ile Ser Pro Ser Gly Lys Tyr Asn Ala Val Lys Leu Gly Lys Tyr
50 55 60
Glu Ser Asn Ser Val Thr Cys Ser Val Gln His Asp Asn Lys Thr Val
65 70 75 80
His Ser Thr Asp Phe Glu Val Lys Thr Asp Ser Thr Asp His Val Lys
85 90 95
Pro Lys Glu Thr Glu Asn Thr Lys Gln Pro Ser Lys Ser Cys His Lys
100 105 110
Pro Lys Ala Ile Val His Thr Glu Lys Val Asn Met Met Ser Leu Thr
115 120 125
Val Leu Gly Leu Arg Met Leu Phe Ala Lys Thr Val Ala Val Asn Phe
130 135 140
Leu Leu Thr Ala Lys Leu Phe Phe Leu
145 150
Claims (46)
- Vδ1 T 세포를 포함하는 세포 집단에,
(i) 서열번호: 1의 3-20 ; 및/또는
(ii) 서열번호: 1의 37-77
의 아미노산 영역 내에 하나 이상의 아미노산 잔기를 포함하는,
γδ T 세포 수용체(TCR)의 가변 델타 1(Vδ1) 사슬의 에피토프에 결합하는 인간 항-TCR 델타 가변 1(항-Vδ1) 항체 또는 이의 단편을 투여하는 것을 포함하는 Vδ1 T 세포를 조절하는 체외 방법.
- 제 1 항에 있어서,
상기 에피토프는 서열번호: 1의 아미노산 영역: 5-20 및 62-77; 50-64; 37-53 및 59-72; 59-77; 또는 3-17 및 62-69를 포함하는 방법.
- 제 1 항 또는 제 2 항에 있어서,
상기 에피토프는 γδ T 세포의 활성화 에피토프인 방법 .
- 제 1 항 내지 제 3 항 중 어느 한 항에 있어서,
γδ TCR의 Vδ1 사슬의 V 영역의 에피토프에만 결합하는 방법.
- 제 1 항 내지 제 4 항 중 어느 한 항에 있어서,
γδ TCR의 Vδ1 사슬의 CDR3에서 발견되는 에피토프에 결합하지 않는 방법.
- Vδ1 T 세포를 포함하는 세포 집단에,
서열 번호: 2-25 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR3;
서열 번호: 26-37 및 표 2의 서열 A1-A12 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR2; 및/또는
서열 번호 38-61 중 어느 하나와 80% 이상의 상동성을 갖는 서열을 포함하는 CDR1,
중 하나 이상을 포함하는 항-Vδ1 항체 또는 이의 단편을 투여하는 것을 포함하는 Vδ1 T 세포를 조절하는 체외 방법.
- 제 6 항 에 있어서,
상기 항체 또는 이의 단편은 서열번호: 62-73 중 어느 하나, 예를 들어 서열번호: 63, 62 또는 64와 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VH 영역을 포함하는 방법.
- 제 6 항에 있어서,
상기 항체 또는 이의 단편은 서열번호: 74-85 중 어느 하나, 예를 들어 서열번호: 75, 74 또는 76과 80% 이상의 서열 상동성을 갖는 아미노산 서열을 포함하는 VL 영역을 포함하는 방법.
- 제 6 항 내지 제 8 항 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편은 서열번호: 86-97 중 어느 하나, 예를 들어 서열 87, 86 또는 88의 아미노산 서열을 포함하는 방법.
- 제 6 항 내지 제 9 항 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편은 제 6 항 내지 제 9 항 중 어느 한 항에서 정의된 항체 또는 이의 단편과 동일하거나 또는 본질적으로 동일한 에피토프에 결합하거나 이와 경쟁하는 것인 방법.
- 제 1 항 내지 제 10 항 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편은 표면 플라즈몬 공명에 의해 측정된 1.5 x 10-7 M 미만의 결합 친화도(KD)로 γδ T 세포 수용체(TCR)의 가변 델타 1(Vδ1) 사슬에 결합하는 방법.
- 제 1 항 내지 제 11 항 중 어느 한 항에 있어서,
상기 항체 또는 이의 단편은 scFv, Fab, Fab', F(ab')2, Fv, 가변 도메인(예를 들어, VH 또는 VL), 디아바디, 미니바디 또는 전장 항체인 방법.
- 제 1 항 내지 제 12 항 중 어느 한 항에 있어서,
상기 조절은 Vδ1 T 세포의 증식을 포함하는 방법.
- 제 13 항에 있어서,
상기 방법은 약 85% 초과의 Vδ1 T 세포, 예를 들어 약 90% 초과의 Vδ1 T 세포를 함유하는 Vδ1 T 세포의 증식된 집단을 제공하는 방법.
- 제 1 항 내지 제 14 항 중 어느 한 항 에 있어서,
상기 방법은 세포 집단을 5일 이상 동안 배양하는 것을 포함하는 방법.
- 제 1 항 내지 제 15 항 중 어느 한 항에 있어서,
상기 방법은 하나 이상의 사이토카인의 존재 하에 세포 집단을 배양하는 것을 포함하는 방법 .
- 제 16 항에 있어서,
상기 사이토카인이 인터루킨-2 (IL-2), 인터루킨-4 (IL-4), 인터루킨-7 (IL-7), 인터루킨-9 (IL-9), 인터루킨-12 (IL-12), 인터루킨-15 (IL-15), 인터루킨-21 (IL-21) 또는 이들의 혼합물로부터 선택되는 방법.
- 제 1 항 내지 제 17 항 중 어느 한 항에 있어서,
상기 방법은 IL-2, IL-9 및/또는 IL-15의 존재 하에 세포 집단을 배양하는 것을 포함하는 방법 .
- 제 1 항 내지 제 18 항 중 어느 한 항에 있어서,
상기 방법은 IL-21의 존재 하에 세포 집단을 배양하는 것을 포함하는 방법.
- 제 1 항 내지 제 19 항 중 어느 한 항에 있어서,
상기 방법은 IL-4의 존재 하에 세포 집단을 배양하는 것을 포함하는 방법.
- 제 1 항 내지 제 17 항 중 어느 한 항에 있어서,
상기 방법은 IL-4를 포함하는 제1 배양 배지에서 세포 집단을 배양한 후, IL-15를 포함하는 제2 배양 배지에서 세포 집단을 배양하는 것을 포함하는 방법.
- 제 21 항에 있어서,
상기 제1 배양 배지에는 IL-15, IL-2 및/또는 IL-7가 없는 방법.
- 제 21 항에 있어서,
상기 제2 배양 배지에는 IL-4가 없는 방법.
- 제 21 항 내지 제 23항 중 어느 한 항에 있어서,
상기 제1 또는 제2 배양 배지, 또는 두 배양 배지 모두는 하나 이상의 추가 사이토카인을 포함하는 방법.
- 제 24 항에 있어서,
상기 추가 사이토카인이 IL-21, IFN-γ 및 IL-1β로 이루어진 군으로부터 선택되는 방법.
- 제 15 항 내지 제 25 항 중 어느 한 항에 있어서,
상기 세포 집단은 배양 동안 기질 및/또는 상피 세포와 직접 접촉하지 않는 방법.
- 제 26 항에 있어서,
상기 세포 집단은 배양 동안 섬유아세포와 직접 접촉하지 않는 방법.
- 제 15 항 내지 제 27항 중 어느 한 항에 있어서,
상기 세포 집단은 배양 동안 종양 세포 및/또는 영양 세포와 직접 접촉하지 않는 방법.
- 제 1 항 내지 제 28 항 중 어느 한 항에 있어서,
상기 방법은 무혈청 배지에서 세포 집단을 배양하는 것을 포함하는 방법.
- 제 1 항 내지 제 29 항 중 어느 한 항에 있어서,
상기 세포 집단은 상기 항체 또는 이의 단편의 투여 전에 T 세포에 대해 농축되는 방법.
- 제 1 항 내지 제 30 항 중 어느 한 항에 있어서,
상기 세포 집단은 상기 항체 또는 이의 단편의 투여 전에 γδ T 세포에 대해 농축되는 방법 .
- 제 1 항 내지 제 31 항 중 어느 한 항에 있어서,
상기 세포 집단은 상기 항체 또는 이의 단편의 투여 전에 αβ T 세포 또는 NK 세포가 고갈되는 방법.
- 제 1 항 내지 제 32 항 중 어느 한 항에 있어서,
상기 세포 집단은 조혈 시료 또는 그의 분획으로부터 수득되는 방법.
- 제 33 항에 있어서,
상기 조혈 시료는 말초 혈액, 제대혈, 림프 조직, 흉선, 골수, 림프절 조직 또는 이의 분획으로부터 선택되는 방법.
- 제 33 항 또는 제 34 항에 있어서,
상기 조혈 시료는 저밀도 단핵 세포(LDMC) 또는 말초 혈액 단핵 세포(PBMC)로 이루어지는 방법.
- 제 1 항 내지 제 32 항 중 어느 한 항에 있어서,
상기 세포 집단은 비-조혈 조직 시료, 예를 들어 피부, 결장, 장, 유선, 폐, 전립선, 간, 비장, 췌장, 자궁, 질 또는 기타 피부, 점막 또는 장액막 시료로부터 수득되는 방법.
- 제 36 항에 있어서,
상기 세포 집단은 비-조혈 조직 시료로부터의 세포 배출을 촉진하도록 구성된 합성 스캐폴드 상에서 비-조혈 조직 시료를 배양하는 것에 의해 비-조혈 조직 시료로부터 수득되는 방법.
- 제 1 항 내지 제 37 항 중 어느 한 항에 있어서,
상기 세포 집단은 암 조직 시료로부터 수득되는 방법.
- 제 1 항 내지 제 38 항 중 어느 한 항에 있어서,
상기 세포 집단은 인간 또는 비인간 동물 조직으로부터 수득되는 방법.
- 제 39 항 중 어느 한 항에 있어서,
상기 세포 집단은 항-Vδ1 항체 또는 이의 단편을 투여하기 전에 시료로부터 단리되는 방법.
- 제 1 항 내지 제 40 항 중 어느 한 항에 정의된 체외 방법에 의해 수득된 Vδ1 T 세포 집단 .
- 제 41 항에 정의된 Vδ1 T 세포 집단을 포함하는 조성물.
- 제 41 항에 정의된 Vδ1 T 세포 집단을 포함하는 약학 조성물.
- 제 43 항에 있어서,
약제로서 사용하기 위한 약학 조성물.
- 제 43 항에 있어서,
암, 감염성 질환 또는 염증성 질환의 치료에 사용하기 위한 약학 조성물.
- 제 41 항에 정의된 Vδ1 T 세포 집단 또는 제 43 항에 정의된 약학 조성물의 치료학적 유효량을 투여하는 것을 포함하는, 이를 필요로 하는 대상에서 암, 감염성 질환 또는 염증성 질환을 치료하는 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB1911799.3A GB201911799D0 (en) | 2019-08-16 | 2019-08-16 | Novel Antibodies |
| GB1911799.3 | 2019-08-16 | ||
| GB2010760.3 | 2020-07-13 | ||
| GBGB2010760.3A GB202010760D0 (en) | 2020-07-13 | 2020-07-13 | Novel antibodies |
| GB2012172.9 | 2020-08-05 | ||
| GBGB2012172.9A GB202012172D0 (en) | 2020-08-05 | 2020-08-05 | Gamma delta cell populations |
| PCT/GB2020/051956 WO2021032961A1 (en) | 2019-08-16 | 2020-08-14 | Ex vivo gamma delta t cell populations |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220045980A true KR20220045980A (ko) | 2022-04-13 |
Family
ID=72148175
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227008249A KR20220045980A (ko) | 2019-08-16 | 2020-08-14 | 체외 감마 델타 t 세포 집단 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20220290101A1 (ko) |
| EP (1) | EP4013787A1 (ko) |
| JP (1) | JP2022544964A (ko) |
| KR (1) | KR20220045980A (ko) |
| CN (1) | CN114599783A (ko) |
| AU (1) | AU2020334287A1 (ko) |
| BR (1) | BR112022001416A2 (ko) |
| CA (1) | CA3148588A1 (ko) |
| IL (1) | IL290538A (ko) |
| MX (1) | MX2022001977A (ko) |
| WO (1) | WO2021032961A1 (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10501541B2 (en) | 2015-01-27 | 2019-12-10 | Lava Therapeutics B.V. | Single domain antibodies targeting CD1d |
| US12077586B2 (en) | 2018-09-19 | 2024-09-03 | LAVA Therapeutics N.V. | Bispecific antibodies for use in the treatment of hematological malignancies |
| WO2021178890A1 (en) | 2020-03-06 | 2021-09-10 | Sorrento Therapeutics, Inc. | Innate immunity killer cells targeting psma positive tumor cells |
| EP4265643B1 (en) | 2020-08-14 | 2024-06-26 | GammaDelta Therapeutics Limited | Multispecific anti-tcr delta variable 1 antibodies |
| GB202013962D0 (en) | 2020-09-04 | 2020-10-21 | Gammadelta Therapeutics Ltd | Immunotherapy composition |
| CA3207265A1 (en) * | 2021-02-17 | 2022-08-25 | Mihriban Tuna | Anti-tcr delta variable 1 antibodies |
| EP4419118A1 (en) * | 2021-10-20 | 2024-08-28 | University of Pittsburgh - Of the Commonwealth System of Higher Education | Methods and materials for expanding tumor infiltrating gamma-delta t cells |
| EP4433068A1 (en) * | 2021-11-18 | 2024-09-25 | Regents of the University of Minnesota | Large-scale expansion of engineered human gamma delta t cells |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| PT2710123T (pt) | 2011-05-19 | 2017-10-13 | Inst De Medicina Molecular | Linha celular de linfócitos compreendendo células t gama-delta, método de composição e produção resultante dos mesmos |
| GB201506423D0 (en) * | 2015-04-15 | 2015-05-27 | Tc Biopharm Ltd | Gamma delta T cells and uses thereof |
| AU2016274633B2 (en) | 2015-06-09 | 2022-04-21 | Gammadelta Therapeutics Ltd | Methods for the production of TCR gamma delta+ T cells |
| BR112018008293A2 (pt) | 2015-10-30 | 2018-10-30 | Cancer Research Tech Ltd | expansão de células t gama delta não hematopoiéticas residentes no tecido e o uso dessas células |
| CN118421557A (zh) | 2016-05-12 | 2024-08-02 | 阿迪塞特治疗公司 | 选择性扩增γδT细胞群的方法及其组合物 |
| US10546518B2 (en) | 2017-05-15 | 2020-01-28 | Google Llc | Near-eye display with extended effective eyebox via eye tracking |
| US10519236B2 (en) * | 2018-01-23 | 2019-12-31 | New York University | Antibodies specific to delta 1 chain of T cell receptor |
| GB201818243D0 (en) | 2018-11-08 | 2018-12-26 | Gammadelta Therapeutics Ltd | Methods for isolating and expanding cells |
-
2020
- 2020-08-14 WO PCT/GB2020/051956 patent/WO2021032961A1/en unknown
- 2020-08-14 AU AU2020334287A patent/AU2020334287A1/en active Pending
- 2020-08-14 KR KR1020227008249A patent/KR20220045980A/ko active Search and Examination
- 2020-08-14 CA CA3148588A patent/CA3148588A1/en active Pending
- 2020-08-14 CN CN202080073438.6A patent/CN114599783A/zh active Pending
- 2020-08-14 BR BR112022001416A patent/BR112022001416A2/pt unknown
- 2020-08-14 MX MX2022001977A patent/MX2022001977A/es unknown
- 2020-08-14 EP EP20758306.3A patent/EP4013787A1/en active Pending
- 2020-08-14 JP JP2022509630A patent/JP2022544964A/ja active Pending
- 2020-08-14 US US17/635,479 patent/US20220290101A1/en active Pending
-
2022
- 2022-02-10 IL IL290538A patent/IL290538A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| IL290538A (en) | 2022-04-01 |
| JP2022544964A (ja) | 2022-10-24 |
| CA3148588A1 (en) | 2021-02-25 |
| MX2022001977A (es) | 2022-03-11 |
| CN114599783A (zh) | 2022-06-07 |
| BR112022001416A2 (pt) | 2022-06-21 |
| WO2021032961A1 (en) | 2021-02-25 |
| EP4013787A1 (en) | 2022-06-22 |
| AU2020334287A1 (en) | 2022-02-24 |
| US20220290101A1 (en) | 2022-09-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220290101A1 (en) | Ex vivo gamma delta t cell populations | |
| CA3145517A1 (en) | Novel anti-tcr delta variable 1 antibodies | |
| WO2020083406A1 (zh) | 靶向cll1的抗体及其应用 | |
| JP2022523781A (ja) | Dll3標的化キメラ抗原受容体および結合剤 | |
| JP2022513778A (ja) | キメラ抗原受容体及びt細胞受容体並びに使用方法 | |
| KR20210142638A (ko) | Cd3 항원 결합 단편 및 이의 응용 | |
| JP2019512207A (ja) | Foxp3由来のペプチドに特異的なt細胞受容体様抗体 | |
| US20080305121A1 (en) | Agents for Regulating the Activity of Interferon-Producing Cells | |
| US20230330143A1 (en) | Immunotherapy composition | |
| WO2024140816A1 (zh) | 抗cd33/cll1双特异性抗体-自然杀伤细胞偶联物及其用途 | |
| US20230159638A1 (en) | Ex vivo gamma delta t cell populations | |
| WO2024090458A1 (ja) | 抑制型kirに対するアゴニストを用いた免疫拒絶の回避方法 | |
| CN118580356A (zh) | 抗Claudin18.2的纳米抗体、嵌合抗原受体及其应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |