KR20210093933A - 개선된 산화환원 효소 모티프를 갖는 면역원성 펩티드 - Google Patents
개선된 산화환원 효소 모티프를 갖는 면역원성 펩티드 Download PDFInfo
- Publication number
- KR20210093933A KR20210093933A KR1020217017332A KR20217017332A KR20210093933A KR 20210093933 A KR20210093933 A KR 20210093933A KR 1020217017332 A KR1020217017332 A KR 1020217017332A KR 20217017332 A KR20217017332 A KR 20217017332A KR 20210093933 A KR20210093933 A KR 20210093933A
- Authority
- KR
- South Korea
- Prior art keywords
- amino acid
- peptide
- cst
- motif
- basic amino
- Prior art date
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 1091
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 168
- 230000002163 immunogen Effects 0.000 title claims abstract description 96
- 102000004190 Enzymes Human genes 0.000 title claims description 72
- 108090000790 Enzymes Proteins 0.000 title claims description 72
- 230000001976 improved effect Effects 0.000 title description 7
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 238
- 102000004316 Oxidoreductases Human genes 0.000 claims abstract description 121
- 108090000854 Oxidoreductases Proteins 0.000 claims abstract description 121
- 230000028993 immune response Effects 0.000 claims abstract description 24
- 150000001413 amino acids Chemical class 0.000 claims description 775
- 108090000623 proteins and genes Proteins 0.000 claims description 79
- 239000000427 antigen Substances 0.000 claims description 73
- 102000036639 antigens Human genes 0.000 claims description 71
- 108091007433 antigens Proteins 0.000 claims description 71
- 210000000581 natural killer T-cell Anatomy 0.000 claims description 66
- 102000004169 proteins and genes Human genes 0.000 claims description 65
- 210000004027 cell Anatomy 0.000 claims description 60
- 238000000034 method Methods 0.000 claims description 56
- 230000001461 cytolytic effect Effects 0.000 claims description 49
- 230000000890 antigenic effect Effects 0.000 claims description 39
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 claims description 32
- 102000043131 MHC class II family Human genes 0.000 claims description 27
- 108091054438 MHC class II family Proteins 0.000 claims description 27
- 238000011282 treatment Methods 0.000 claims description 23
- 229910052727 yttrium Inorganic materials 0.000 claims description 18
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 claims description 17
- 229960003104 ornithine Drugs 0.000 claims description 17
- 229910052700 potassium Inorganic materials 0.000 claims description 16
- 210000004899 c-terminal region Anatomy 0.000 claims description 15
- 238000004519 manufacturing process Methods 0.000 claims description 15
- 208000023275 Autoimmune disease Diseases 0.000 claims description 14
- 239000013566 allergen Substances 0.000 claims description 13
- 239000003814 drug Substances 0.000 claims description 13
- 230000003834 intracellular effect Effects 0.000 claims description 12
- 238000001415 gene therapy Methods 0.000 claims description 10
- 244000052769 pathogen Species 0.000 claims description 10
- 108010002350 Interleukin-2 Proteins 0.000 claims description 9
- 206010028980 Neoplasm Diseases 0.000 claims description 9
- 238000002255 vaccination Methods 0.000 claims description 9
- 239000013603 viral vector Substances 0.000 claims description 9
- 230000001717 pathogenic effect Effects 0.000 claims description 8
- 238000011321 prophylaxis Methods 0.000 claims description 7
- 230000000735 allogeneic effect Effects 0.000 claims description 6
- 108010050235 allogenic effect factor Proteins 0.000 claims description 6
- 208000015181 infectious disease Diseases 0.000 claims description 6
- 210000004976 peripheral blood cell Anatomy 0.000 claims description 6
- 229910052698 phosphorus Inorganic materials 0.000 claims description 4
- 210000000987 immune system Anatomy 0.000 claims description 3
- 241000700605 Viruses Species 0.000 claims 2
- 239000013598 vector Substances 0.000 claims 1
- 230000000694 effects Effects 0.000 abstract description 63
- 230000001965 increasing effect Effects 0.000 abstract description 10
- 229940024606 amino acid Drugs 0.000 description 715
- 235000001014 amino acid Nutrition 0.000 description 714
- 229910052799 carbon Inorganic materials 0.000 description 166
- 229910052717 sulfur Inorganic materials 0.000 description 159
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 63
- 238000012360 testing method Methods 0.000 description 59
- 235000018102 proteins Nutrition 0.000 description 56
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 52
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 47
- 125000005647 linker group Chemical group 0.000 description 37
- 239000000203 mixture Substances 0.000 description 33
- 229910052739 hydrogen Inorganic materials 0.000 description 30
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 29
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 28
- 101000873676 Homo sapiens Secretogranin-2 Proteins 0.000 description 26
- 102100035835 Secretogranin-2 Human genes 0.000 description 26
- 125000003275 alpha amino acid group Chemical group 0.000 description 26
- 102000004877 Insulin Human genes 0.000 description 24
- 108090001061 Insulin Proteins 0.000 description 24
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 24
- 229940125396 insulin Drugs 0.000 description 24
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 23
- JUNZLDGUJZIUCO-IHRRRGAJSA-N Cys-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O JUNZLDGUJZIUCO-IHRRRGAJSA-N 0.000 description 23
- SBDVXRYCOIEYNV-YUMQZZPRSA-N Cys-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N SBDVXRYCOIEYNV-YUMQZZPRSA-N 0.000 description 22
- -1 2 to 7 amino acids Chemical class 0.000 description 21
- 230000001603 reducing effect Effects 0.000 description 20
- 229910052721 tungsten Inorganic materials 0.000 description 20
- QBGPXOGXCVKULO-BQBZGAKWSA-N Lys-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(O)=O QBGPXOGXCVKULO-BQBZGAKWSA-N 0.000 description 18
- OSASDIVHOSJVII-WDSKDSINSA-N Arg-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCNC(N)=N OSASDIVHOSJVII-WDSKDSINSA-N 0.000 description 17
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 17
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 17
- 229910052731 fluorine Inorganic materials 0.000 description 17
- CZXKZMQKXQZDEX-YUMQZZPRSA-N His-Gly-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N CZXKZMQKXQZDEX-YUMQZZPRSA-N 0.000 description 16
- 201000010099 disease Diseases 0.000 description 16
- 239000008194 pharmaceutical composition Substances 0.000 description 16
- HAYVLBZZBDCKRA-SRVKXCTJSA-N Cys-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N HAYVLBZZBDCKRA-SRVKXCTJSA-N 0.000 description 15
- 241000124008 Mammalia Species 0.000 description 15
- 102100036013 Antigen-presenting glycoprotein CD1d Human genes 0.000 description 14
- RWAZRMXTVSIVJR-YUMQZZPRSA-N Cys-Gly-His Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC1=CNC=N1)C(O)=O RWAZRMXTVSIVJR-YUMQZZPRSA-N 0.000 description 14
- GGRDJANMZPGMNS-CIUDSAMLSA-N Cys-Ser-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O GGRDJANMZPGMNS-CIUDSAMLSA-N 0.000 description 14
- 101000716121 Homo sapiens Antigen-presenting glycoprotein CD1d Proteins 0.000 description 14
- BVTYXOFTHDXSNI-IHRRRGAJSA-N Pro-Tyr-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 BVTYXOFTHDXSNI-IHRRRGAJSA-N 0.000 description 14
- 239000004480 active ingredient Substances 0.000 description 14
- 108010038088 glutamyl-glycyl-seryl-leucyl-glutamine Proteins 0.000 description 14
- 208000026278 immune system disease Diseases 0.000 description 14
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 13
- 108010000123 Myelin-Oligodendrocyte Glycoprotein Proteins 0.000 description 13
- 102100023302 Myelin-oligodendrocyte glycoprotein Human genes 0.000 description 13
- 210000000612 antigen-presenting cell Anatomy 0.000 description 13
- 238000009472 formulation Methods 0.000 description 13
- 238000002347 injection Methods 0.000 description 13
- 239000007924 injection Substances 0.000 description 13
- 108010053037 kyotorphin Proteins 0.000 description 13
- 239000000126 substance Substances 0.000 description 12
- ANPADMNVVOOYKW-DCAQKATOSA-N Cys-His-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ANPADMNVVOOYKW-DCAQKATOSA-N 0.000 description 11
- KSFQPRLZAUXXPT-GARJFASQSA-N Lys-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)C(=O)O KSFQPRLZAUXXPT-GARJFASQSA-N 0.000 description 11
- 108020003175 receptors Proteins 0.000 description 11
- 102000005962 receptors Human genes 0.000 description 11
- 230000008685 targeting Effects 0.000 description 11
- MBPKYKSYUAPLMY-DCAQKATOSA-N Cys-Arg-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MBPKYKSYUAPLMY-DCAQKATOSA-N 0.000 description 10
- IVSWQHKONQIOHA-YUMQZZPRSA-N Gly-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN IVSWQHKONQIOHA-YUMQZZPRSA-N 0.000 description 10
- CAVGLNOOIFHJOF-SRVKXCTJSA-N Lys-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N CAVGLNOOIFHJOF-SRVKXCTJSA-N 0.000 description 10
- 238000000338 in vitro Methods 0.000 description 10
- 230000000638 stimulation Effects 0.000 description 10
- 206010020751 Hypersensitivity Diseases 0.000 description 9
- QQYRCUXKLDGCQN-SRVKXCTJSA-N Lys-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N QQYRCUXKLDGCQN-SRVKXCTJSA-N 0.000 description 9
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 9
- 150000001875 compounds Chemical class 0.000 description 9
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 9
- 235000014304 histidine Nutrition 0.000 description 9
- 108020004707 nucleic acids Proteins 0.000 description 9
- 102000039446 nucleic acids Human genes 0.000 description 9
- 150000007523 nucleic acids Chemical class 0.000 description 9
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 8
- NIUDXSFNLBIWOB-DCAQKATOSA-N Arg-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NIUDXSFNLBIWOB-DCAQKATOSA-N 0.000 description 8
- RGTVXXNMOGHRAY-WDSKDSINSA-N Cys-Arg Chemical compound SC[C@H](N)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RGTVXXNMOGHRAY-WDSKDSINSA-N 0.000 description 8
- PQHYZJPCYRDYNE-QWRGUYRKSA-N Cys-Gly-Phe Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PQHYZJPCYRDYNE-QWRGUYRKSA-N 0.000 description 8
- SKSJPIBFNFPTJB-NKWVEPMBSA-N Cys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CS)N)C(=O)O SKSJPIBFNFPTJB-NKWVEPMBSA-N 0.000 description 8
- WTNLLMQAFPOCTJ-GARJFASQSA-N Cys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N)C(=O)O WTNLLMQAFPOCTJ-GARJFASQSA-N 0.000 description 8
- QVDGHDFFYHKJPN-QWRGUYRKSA-N Gly-Phe-Cys Chemical compound NCC(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CS)C(O)=O QVDGHDFFYHKJPN-QWRGUYRKSA-N 0.000 description 8
- QSQXZZCGPXQBPP-BQBZGAKWSA-N Gly-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)CN)C(=O)N[C@@H](CS)C(=O)O QSQXZZCGPXQBPP-BQBZGAKWSA-N 0.000 description 8
- 102000001398 Granzyme Human genes 0.000 description 8
- 108060005986 Granzyme Proteins 0.000 description 8
- KHUFDBQXGLEIHC-BZSNNMDCSA-N His-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 KHUFDBQXGLEIHC-BZSNNMDCSA-N 0.000 description 8
- HBGKOLSGLYMWSW-DCAQKATOSA-N His-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CS)C(=O)O HBGKOLSGLYMWSW-DCAQKATOSA-N 0.000 description 8
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 8
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 8
- QUGRFWPMPVIAPW-IHRRRGAJSA-N Ser-Pro-Phe Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QUGRFWPMPVIAPW-IHRRRGAJSA-N 0.000 description 8
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 8
- FQNUWOHNGJWNLM-QWRGUYRKSA-N Tyr-Cys-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)NCC(O)=O FQNUWOHNGJWNLM-QWRGUYRKSA-N 0.000 description 8
- 108010016616 cysteinylglycine Proteins 0.000 description 8
- 208000035475 disorder Diseases 0.000 description 8
- 239000012634 fragment Substances 0.000 description 8
- 108091005601 modified peptides Proteins 0.000 description 8
- 238000010647 peptide synthesis reaction Methods 0.000 description 8
- 108010051242 phenylalanylserine Proteins 0.000 description 8
- 239000000523 sample Substances 0.000 description 8
- HJAICMSAKODKRF-GUBZILKMSA-N Arg-Cys-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O HJAICMSAKODKRF-GUBZILKMSA-N 0.000 description 7
- SVHRPCMZTWZROG-DCAQKATOSA-N Arg-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N SVHRPCMZTWZROG-DCAQKATOSA-N 0.000 description 7
- WXOFKRKAHJQKLT-BQBZGAKWSA-N Cys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CS WXOFKRKAHJQKLT-BQBZGAKWSA-N 0.000 description 7
- 102000000588 Interleukin-2 Human genes 0.000 description 7
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 7
- SVJRVFPSHPGWFF-DCAQKATOSA-N Lys-Cys-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SVJRVFPSHPGWFF-DCAQKATOSA-N 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- 108010055044 Tetanus Toxin Proteins 0.000 description 7
- 230000004913 activation Effects 0.000 description 7
- 235000018417 cysteine Nutrition 0.000 description 7
- 108010060199 cysteinylproline Proteins 0.000 description 7
- 238000001727 in vivo Methods 0.000 description 7
- 239000004615 ingredient Substances 0.000 description 7
- 238000005259 measurement Methods 0.000 description 7
- 229940118376 tetanus toxin Drugs 0.000 description 7
- OANWAFQRNQEDSY-DCAQKATOSA-N Arg-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N OANWAFQRNQEDSY-DCAQKATOSA-N 0.000 description 6
- 239000004475 Arginine Substances 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 6
- GURIQZQSTBBHRV-SRVKXCTJSA-N Gln-Lys-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GURIQZQSTBBHRV-SRVKXCTJSA-N 0.000 description 6
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 241000282412 Homo Species 0.000 description 6
- 102100037850 Interferon gamma Human genes 0.000 description 6
- 108010074328 Interferon-gamma Proteins 0.000 description 6
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 6
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 6
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 6
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 6
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 6
- 108010033276 Peptide Fragments Proteins 0.000 description 6
- 102000007079 Peptide Fragments Human genes 0.000 description 6
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 6
- GFHXZNVJIKMAGO-IHRRRGAJSA-N Pro-Phe-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GFHXZNVJIKMAGO-IHRRRGAJSA-N 0.000 description 6
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 6
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 6
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 6
- 208000026935 allergic disease Diseases 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 6
- 125000004432 carbon atom Chemical group C* 0.000 description 6
- 239000003937 drug carrier Substances 0.000 description 6
- 210000001163 endosome Anatomy 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 230000002265 prevention Effects 0.000 description 6
- 108010090894 prolylleucine Proteins 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 108010026333 seryl-proline Proteins 0.000 description 6
- 230000004936 stimulating effect Effects 0.000 description 6
- 239000004094 surface-active agent Substances 0.000 description 6
- 108010044292 tryptophyltyrosine Proteins 0.000 description 6
- PZVMBNFTBWQWQL-DCAQKATOSA-N Arg-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N PZVMBNFTBWQWQL-DCAQKATOSA-N 0.000 description 5
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 5
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 5
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 5
- IROABALAWGJQGM-OALUTQOASA-N Gly-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)CN IROABALAWGJQGM-OALUTQOASA-N 0.000 description 5
- WYWBYSPRCFADBM-GARJFASQSA-N His-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O WYWBYSPRCFADBM-GARJFASQSA-N 0.000 description 5
- UCRJTSIIAYHOHE-ULQDDVLXSA-N Leu-Tyr-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UCRJTSIIAYHOHE-ULQDDVLXSA-N 0.000 description 5
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 5
- 239000004472 Lysine Substances 0.000 description 5
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 5
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 5
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 5
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 5
- 230000005867 T cell response Effects 0.000 description 5
- KVRLNEILGGVBJX-IHRRRGAJSA-N Val-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CN=CN1 KVRLNEILGGVBJX-IHRRRGAJSA-N 0.000 description 5
- 230000007815 allergy Effects 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 238000003501 co-culture Methods 0.000 description 5
- 238000013270 controlled release Methods 0.000 description 5
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 5
- 150000001945 cysteines Chemical class 0.000 description 5
- 230000009089 cytolysis Effects 0.000 description 5
- 235000014113 dietary fatty acids Nutrition 0.000 description 5
- 229930195729 fatty acid Natural products 0.000 description 5
- 239000000194 fatty acid Substances 0.000 description 5
- 108010036413 histidylglycine Proteins 0.000 description 5
- 239000001257 hydrogen Substances 0.000 description 5
- 125000001165 hydrophobic group Chemical group 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 5
- 230000009467 reduction Effects 0.000 description 5
- 230000001225 therapeutic effect Effects 0.000 description 5
- PKAUMAVONPSDRW-IBGZPJMESA-N (2s)-2-(9h-fluoren-9-ylmethoxycarbonylamino)-3-[(2-methylpropan-2-yl)oxycarbonylamino]propanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@@H](CNC(=O)OC(C)(C)C)C(O)=O)C3=CC=CC=C3C2=C1 PKAUMAVONPSDRW-IBGZPJMESA-N 0.000 description 4
- KVUAOWDVYMUKPE-VWLOTQADSA-N (2s)-2-(9h-fluoren-9-ylmethoxycarbonylamino)-3-[4-[(2-methylpropan-2-yl)oxycarbonylamino]phenyl]propanoic acid Chemical compound C1=CC(NC(=O)OC(C)(C)C)=CC=C1C[C@@H](C(O)=O)NC(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21 KVUAOWDVYMUKPE-VWLOTQADSA-N 0.000 description 4
- JOOIZTMAHNLNHE-NRFANRHFSA-N (2s)-2-(9h-fluoren-9-ylmethoxycarbonylamino)-5-[(2-methylpropan-2-yl)oxycarbonylamino]pentanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@@H](CCCNC(=O)OC(C)(C)C)C(O)=O)C3=CC=CC=C3C2=C1 JOOIZTMAHNLNHE-NRFANRHFSA-N 0.000 description 4
- WPBXBYOKQUEIDW-VFNWGFHPSA-N (2s,4r)-1-(9h-fluoren-9-ylmethoxycarbonyl)-4-[(2-methylpropan-2-yl)oxy]pyrrolidine-2-carboxylic acid Chemical compound C1[C@H](OC(C)(C)C)C[C@@H](C(O)=O)N1C(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21 WPBXBYOKQUEIDW-VFNWGFHPSA-N 0.000 description 4
- SETTXXCZEDLMRX-KRWDZBQOSA-N (3s)-3-(9h-fluoren-9-ylmethoxycarbonylamino)-6-[(2-methylpropan-2-yl)oxycarbonylamino]hexanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@H](CC(O)=O)CCCNC(=O)OC(C)(C)C)C3=CC=CC=C3C2=C1 SETTXXCZEDLMRX-KRWDZBQOSA-N 0.000 description 4
- SDBUQLGECIYUDT-SFHVURJKSA-N (3s)-3-(9h-fluoren-9-ylmethoxycarbonylamino)-7-[(2-methylpropan-2-yl)oxycarbonylamino]heptanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@H](CC(O)=O)CCCCNC(=O)OC(C)(C)C)C3=CC=CC=C3C2=C1 SDBUQLGECIYUDT-SFHVURJKSA-N 0.000 description 4
- JDHMXPSXWMPYQZ-AAEUAGOBSA-N Cys-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N JDHMXPSXWMPYQZ-AAEUAGOBSA-N 0.000 description 4
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 4
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 4
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 4
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical group CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 125000000217 alkyl group Chemical group 0.000 description 4
- 230000000172 allergic effect Effects 0.000 description 4
- 208000010668 atopic eczema Diseases 0.000 description 4
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 4
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 4
- 239000013256 coordination polymer Substances 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 150000004665 fatty acids Chemical class 0.000 description 4
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 4
- 238000007918 intramuscular administration Methods 0.000 description 4
- 150000002632 lipids Chemical group 0.000 description 4
- 239000002736 nonionic surfactant Substances 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 150000003904 phospholipids Chemical class 0.000 description 4
- 108010066381 preproinsulin Proteins 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 229910052708 sodium Inorganic materials 0.000 description 4
- 239000011734 sodium Substances 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 241000894006 Bacteria Species 0.000 description 3
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 3
- 102100032937 CD40 ligand Human genes 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 102000015212 Fas Ligand Protein Human genes 0.000 description 3
- 108010039471 Fas Ligand Protein Proteins 0.000 description 3
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 3
- AKDOUBMVLRCHBD-SIUGBPQLSA-N Gln-Tyr-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AKDOUBMVLRCHBD-SIUGBPQLSA-N 0.000 description 3
- QCTLGOYODITHPQ-WHFBIAKZSA-N Gly-Cys-Ser Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O QCTLGOYODITHPQ-WHFBIAKZSA-N 0.000 description 3
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 3
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 3
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 description 3
- UIEZQYNXCYHMQS-BJDJZHNGSA-N Ile-Lys-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)O)N UIEZQYNXCYHMQS-BJDJZHNGSA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 3
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 3
- 108091054437 MHC class I family Proteins 0.000 description 3
- 241001529936 Murinae Species 0.000 description 3
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 3
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 description 3
- WGDYNRCOQRERLZ-KKUMJFAQSA-N Ser-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N WGDYNRCOQRERLZ-KKUMJFAQSA-N 0.000 description 3
- 108091008874 T cell receptors Proteins 0.000 description 3
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 239000003513 alkali Substances 0.000 description 3
- 229940037003 alum Drugs 0.000 description 3
- 150000003863 ammonium salts Chemical class 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 230000000981 bystander Effects 0.000 description 3
- 238000010366 cell biology technique Methods 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000012636 effector Substances 0.000 description 3
- 239000003995 emulsifying agent Substances 0.000 description 3
- 238000000684 flow cytometry Methods 0.000 description 3
- 235000013305 food Nutrition 0.000 description 3
- 230000003053 immunization Effects 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 230000002101 lytic effect Effects 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 108091033319 polynucleotide Proteins 0.000 description 3
- 102000040430 polynucleotide Human genes 0.000 description 3
- 239000002157 polynucleotide Substances 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 3
- 210000003289 regulatory T cell Anatomy 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 230000000087 stabilizing effect Effects 0.000 description 3
- 150000003871 sulfonates Chemical class 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 125000003396 thiol group Chemical group [H]S* 0.000 description 3
- 230000000699 topical effect Effects 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- JNYAEWCLZODPBN-JGWLITMVSA-N (2r,3r,4s)-2-[(1r)-1,2-dihydroxyethyl]oxolane-3,4-diol Chemical compound OC[C@@H](O)[C@H]1OC[C@H](O)[C@H]1O JNYAEWCLZODPBN-JGWLITMVSA-N 0.000 description 2
- UMRUUWFGLGNQLI-QFIPXVFZSA-N (2s)-2-(9h-fluoren-9-ylmethoxycarbonylamino)-6-[(2-methylpropan-2-yl)oxycarbonylamino]hexanoic acid Chemical compound C1=CC=C2C(COC(=O)N[C@@H](CCCCNC(=O)OC(C)(C)C)C(O)=O)C3=CC=CC=C3C2=C1 UMRUUWFGLGNQLI-QFIPXVFZSA-N 0.000 description 2
- ZPGDWQNBZYOZTI-UHFFFAOYSA-N 1-(9h-fluoren-9-ylmethoxycarbonyl)pyrrolidine-2-carboxylic acid Chemical compound OC(=O)C1CCCN1C(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21 ZPGDWQNBZYOZTI-UHFFFAOYSA-N 0.000 description 2
- 125000000339 4-pyridyl group Chemical group N1=C([H])C([H])=C([*])C([H])=C1[H] 0.000 description 2
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 2
- YWENWUYXQUWRHQ-LPEHRKFASA-N Arg-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O YWENWUYXQUWRHQ-LPEHRKFASA-N 0.000 description 2
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 2
- 206010003645 Atopy Diseases 0.000 description 2
- 102100027314 Beta-2-microglobulin Human genes 0.000 description 2
- 102100027207 CD27 antigen Human genes 0.000 description 2
- 210000004366 CD4-positive T-lymphocyte Anatomy 0.000 description 2
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 2
- 229940045513 CTLA4 antagonist Drugs 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 101100439675 Cucumis sativus CHRC gene Proteins 0.000 description 2
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 2
- HQZGVYJBRSISDT-BQBZGAKWSA-N Cys-Gly-Arg Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQZGVYJBRSISDT-BQBZGAKWSA-N 0.000 description 2
- DZSICRGTVPDCRN-YUMQZZPRSA-N Cys-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N DZSICRGTVPDCRN-YUMQZZPRSA-N 0.000 description 2
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 2
- HMWBPUDETPKSSS-DCAQKATOSA-N Cys-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CCCCN)C(=O)O HMWBPUDETPKSSS-DCAQKATOSA-N 0.000 description 2
- IOLWXFWVYYCVTJ-NRPADANISA-N Cys-Val-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N IOLWXFWVYYCVTJ-NRPADANISA-N 0.000 description 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- 101150059401 EGR2 gene Proteins 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 229930186217 Glycolipid Natural products 0.000 description 2
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 2
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 2
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 2
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 2
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 2
- MQFGXJNSUJTXDT-QSFUFRPTSA-N Ile-Gly-Ile Chemical compound N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)O MQFGXJNSUJTXDT-QSFUFRPTSA-N 0.000 description 2
- COWHUQXTSYTKQC-RWRJDSDZSA-N Ile-Thr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N COWHUQXTSYTKQC-RWRJDSDZSA-N 0.000 description 2
- 102000003814 Interleukin-10 Human genes 0.000 description 2
- 108090000174 Interleukin-10 Proteins 0.000 description 2
- 108090000978 Interleukin-4 Proteins 0.000 description 2
- 102000004388 Interleukin-4 Human genes 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- ZASPELYMPSACER-HOCLYGCPSA-N Lys-Gly-Trp Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ZASPELYMPSACER-HOCLYGCPSA-N 0.000 description 2
- LMGNWHDWJDIOPK-DKIMLUQUSA-N Lys-Phe-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LMGNWHDWJDIOPK-DKIMLUQUSA-N 0.000 description 2
- HONVOXINDBETTI-KKUMJFAQSA-N Lys-Tyr-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CS)C(O)=O)CC1=CC=C(O)C=C1 HONVOXINDBETTI-KKUMJFAQSA-N 0.000 description 2
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 101100077708 Mus musculus Mog gene Proteins 0.000 description 2
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 2
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 2
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- HXNYBZQLBWIADP-WDSKDSINSA-N Pro-Cys Chemical compound OC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 HXNYBZQLBWIADP-WDSKDSINSA-N 0.000 description 2
- 102000006010 Protein Disulfide-Isomerase Human genes 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 101001069703 Streptomyces griseus Streptogrisin-C Proteins 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical class OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- LHEZGZQRLDBSRR-WDCWCFNPSA-N Thr-Glu-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LHEZGZQRLDBSRR-WDCWCFNPSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 2
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 2
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 2
- BVOCLAPFOBSJHR-KKUMJFAQSA-N Tyr-Cys-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O BVOCLAPFOBSJHR-KKUMJFAQSA-N 0.000 description 2
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 2
- QOEZFICGUZTRFX-IHRRRGAJSA-N Tyr-Cys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O QOEZFICGUZTRFX-IHRRRGAJSA-N 0.000 description 2
- WSFXJLFSJSXGMQ-MGHWNKPDSA-N Tyr-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N WSFXJLFSJSXGMQ-MGHWNKPDSA-N 0.000 description 2
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 239000000443 aerosol Substances 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 150000008055 alkyl aryl sulfonates Chemical class 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 125000003785 benzimidazolyl group Chemical class N1=C(NC2=C1C=CC=C2)* 0.000 description 2
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 159000000007 calcium salts Chemical class 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 229960004926 chlorobutanol Drugs 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 210000005220 cytoplasmic tail Anatomy 0.000 description 2
- 210000004443 dendritic cell Anatomy 0.000 description 2
- 238000002405 diagnostic procedure Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 150000002191 fatty alcohols Chemical class 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 208000016755 gingival fibromatosis-hypertrichosis syndrome Diseases 0.000 description 2
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 238000000099 in vitro assay Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 238000001361 intraarterial administration Methods 0.000 description 2
- 238000007913 intrathecal administration Methods 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 108010038320 lysylphenylalanine Proteins 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000010534 mechanism of action Effects 0.000 description 2
- 239000003094 microcapsule Substances 0.000 description 2
- 239000004005 microsphere Substances 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 150000002894 organic compounds Chemical class 0.000 description 2
- 125000000913 palmityl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 2
- 229960003742 phenol Drugs 0.000 description 2
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 229920000151 polyglycol Polymers 0.000 description 2
- 239000010695 polyglycol Substances 0.000 description 2
- 229920001451 polypropylene glycol Polymers 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 108020003519 protein disulfide isomerase Proteins 0.000 description 2
- 150000003242 quaternary ammonium salts Chemical class 0.000 description 2
- 238000010791 quenching Methods 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 230000002468 redox effect Effects 0.000 description 2
- 239000000344 soap Substances 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000004334 sorbic acid Substances 0.000 description 2
- 229940075582 sorbic acid Drugs 0.000 description 2
- 235000010199 sorbic acid Nutrition 0.000 description 2
- 150000003467 sulfuric acid derivatives Chemical class 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 239000003826 tablet Substances 0.000 description 2
- 125000005931 tert-butyloxycarbonyl group Chemical group [H]C([H])([H])C(OC(*)=O)(C([H])([H])[H])C([H])([H])[H] 0.000 description 2
- AKXUUJCMWZFYMV-UHFFFAOYSA-M tetrakis(hydroxymethyl)phosphanium;chloride Chemical compound [Cl-].OC[P+](CO)(CO)CO AKXUUJCMWZFYMV-UHFFFAOYSA-M 0.000 description 2
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 2
- 239000002562 thickening agent Substances 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 238000011830 transgenic mouse model Methods 0.000 description 2
- 229960005486 vaccine Drugs 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- VZQHRKZCAZCACO-PYJNHQTQSA-N (2s)-2-[[(2s)-2-[2-[[(2s)-2-[[(2s)-2-amino-5-(diaminomethylideneamino)pentanoyl]amino]propanoyl]amino]prop-2-enoylamino]-3-methylbutanoyl]amino]propanoic acid Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)C(=C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VZQHRKZCAZCACO-PYJNHQTQSA-N 0.000 description 1
- DVQCNGKZAMNXCR-BYPYZUCNSA-N (2s)-3-methyl-2-(sulfanylamino)butanoic acid Chemical compound CC(C)[C@H](NS)C(O)=O DVQCNGKZAMNXCR-BYPYZUCNSA-N 0.000 description 1
- ASWBNKHCZGQVJV-UHFFFAOYSA-N (3-hexadecanoyloxy-2-hydroxypropyl) 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(O)COP([O-])(=O)OCC[N+](C)(C)C ASWBNKHCZGQVJV-UHFFFAOYSA-N 0.000 description 1
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- KILNVBDSWZSGLL-KXQOOQHDSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCC KILNVBDSWZSGLL-KXQOOQHDSA-N 0.000 description 1
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 1
- VQFKFAKEUMHBLV-BYSUZVQFSA-N 1-O-(alpha-D-galactosyl)-N-hexacosanoylphytosphingosine Chemical compound CCCCCCCCCCCCCCCCCCCCCCCCCC(=O)N[C@H]([C@H](O)[C@H](O)CCCCCCCCCCCCCC)CO[C@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O VQFKFAKEUMHBLV-BYSUZVQFSA-N 0.000 description 1
- IQFYYKKMVGJFEH-OFKYTIFKSA-N 1-[(2r,4s,5r)-4-hydroxy-5-(tritiooxymethyl)oxolan-2-yl]-5-methylpyrimidine-2,4-dione Chemical compound C1[C@H](O)[C@@H](CO[3H])O[C@H]1N1C(=O)NC(=O)C(C)=C1 IQFYYKKMVGJFEH-OFKYTIFKSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- QZEDXQFZACVDJE-UHFFFAOYSA-N 2,3-dibutylnaphthalene-1-sulfonic acid Chemical class C1=CC=C2C(S(O)(=O)=O)=C(CCCC)C(CCCC)=CC2=C1 QZEDXQFZACVDJE-UHFFFAOYSA-N 0.000 description 1
- JDSQBDGCMUXRBM-UHFFFAOYSA-N 2-[2-(2-butoxypropoxy)propoxy]propan-1-ol Chemical group CCCCOC(C)COC(C)COC(C)CO JDSQBDGCMUXRBM-UHFFFAOYSA-N 0.000 description 1
- CFWRDBDJAOHXSH-SECBINFHSA-N 2-azaniumylethyl [(2r)-2,3-diacetyloxypropyl] phosphate Chemical compound CC(=O)OC[C@@H](OC(C)=O)COP(O)(=O)OCCN CFWRDBDJAOHXSH-SECBINFHSA-N 0.000 description 1
- WBIQQQGBSDOWNP-UHFFFAOYSA-N 2-dodecylbenzenesulfonic acid Chemical class CCCCCCCCCCCCC1=CC=CC=C1S(O)(=O)=O WBIQQQGBSDOWNP-UHFFFAOYSA-N 0.000 description 1
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 1
- VOUAQYXWVJDEQY-QENPJCQMSA-N 33017-11-7 Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)NCC(=O)NCC(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)CCC1 VOUAQYXWVJDEQY-QENPJCQMSA-N 0.000 description 1
- IGFHQQFPSIBGKE-UHFFFAOYSA-N 4-nonylphenol Chemical compound CCCCCCCCCC1=CC=C(O)C=C1 IGFHQQFPSIBGKE-UHFFFAOYSA-N 0.000 description 1
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 1
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 1
- YUGFLWBWAJFGKY-BQBZGAKWSA-N Arg-Cys-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O YUGFLWBWAJFGKY-BQBZGAKWSA-N 0.000 description 1
- ZRNWJUAQKFUUKV-SRVKXCTJSA-N Arg-Met-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(O)=O ZRNWJUAQKFUUKV-SRVKXCTJSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 1
- 101100284398 Bos taurus BoLA-DQB gene Proteins 0.000 description 1
- 102100036301 C-C chemokine receptor type 7 Human genes 0.000 description 1
- 108010075254 C-Peptide Proteins 0.000 description 1
- 238000011740 C57BL/6 mouse Methods 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- LVNMAAGSAUGNIC-BQBZGAKWSA-N Cys-His Chemical compound SC[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 LVNMAAGSAUGNIC-BQBZGAKWSA-N 0.000 description 1
- CIVXDCMSSFGWAL-YUMQZZPRSA-N Cys-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N CIVXDCMSSFGWAL-YUMQZZPRSA-N 0.000 description 1
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 1
- JUUMIGUJJRFQQR-KKUMJFAQSA-N Cys-Lys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N)O JUUMIGUJJRFQQR-KKUMJFAQSA-N 0.000 description 1
- ZSRSLWKGWFFVCM-WDSKDSINSA-N Cys-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O ZSRSLWKGWFFVCM-WDSKDSINSA-N 0.000 description 1
- ZOKPRHVIFAUJPV-GUBZILKMSA-N Cys-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O ZOKPRHVIFAUJPV-GUBZILKMSA-N 0.000 description 1
- 150000008574 D-amino acids Chemical class 0.000 description 1
- 108010030351 DEC-205 receptor Proteins 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 101710106383 Disulfide bond formation protein B Proteins 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical class C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 208000004262 Food Hypersensitivity Diseases 0.000 description 1
- 102000017278 Glutaredoxin Human genes 0.000 description 1
- 108050005205 Glutaredoxin Proteins 0.000 description 1
- MFBYPDKTAJXHNI-VKHMYHEASA-N Gly-Cys Chemical compound [NH3+]CC(=O)N[C@@H](CS)C([O-])=O MFBYPDKTAJXHNI-VKHMYHEASA-N 0.000 description 1
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 102100028971 HLA class I histocompatibility antigen, C alpha chain Human genes 0.000 description 1
- 102100029966 HLA class II histocompatibility antigen, DP alpha 1 chain Human genes 0.000 description 1
- 102100031618 HLA class II histocompatibility antigen, DP beta 1 chain Human genes 0.000 description 1
- 102100036242 HLA class II histocompatibility antigen, DQ alpha 2 chain Human genes 0.000 description 1
- 102100040505 HLA class II histocompatibility antigen, DR alpha chain Human genes 0.000 description 1
- 102100040485 HLA class II histocompatibility antigen, DRB1 beta chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108010058607 HLA-B Antigens Proteins 0.000 description 1
- 108010052199 HLA-C Antigens Proteins 0.000 description 1
- 108010093061 HLA-DPA1 antigen Proteins 0.000 description 1
- 108010045483 HLA-DPB1 antigen Proteins 0.000 description 1
- 108010086786 HLA-DQA1 antigen Proteins 0.000 description 1
- 108010067802 HLA-DR alpha-Chains Proteins 0.000 description 1
- 108010039343 HLA-DRB1 Chains Proteins 0.000 description 1
- 101000691214 Haloarcula marismortui (strain ATCC 43049 / DSM 3752 / JCM 8966 / VKM B-1809) 50S ribosomal protein L44e Proteins 0.000 description 1
- VJLLLMIZEJJZTE-VNQXHBPZSA-N HexCer(d18:1/16:0) Chemical compound CCCCCCCCCCCCCCCC(=O)N[C@H]([C@H](O)\C=C\CCCCCCCCCCCCC)COC1OC(CO)C(O)C(O)C1O VJLLLMIZEJJZTE-VNQXHBPZSA-N 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- MAJYPBAJPNUFPV-BQBZGAKWSA-N His-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 MAJYPBAJPNUFPV-BQBZGAKWSA-N 0.000 description 1
- AASLOGQZZKZWKH-SRVKXCTJSA-N His-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N AASLOGQZZKZWKH-SRVKXCTJSA-N 0.000 description 1
- 101000716065 Homo sapiens C-C chemokine receptor type 7 Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101000713602 Homo sapiens T-box transcription factor TBX21 Proteins 0.000 description 1
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 1
- 208000001718 Immediate Hypersensitivity Diseases 0.000 description 1
- 102000003816 Interleukin-13 Human genes 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 102000000743 Interleukin-5 Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- ZUKPVRWZDMRIEO-VKHMYHEASA-N L-cysteinylglycine Chemical compound SC[C@H]([NH3+])C(=O)NCC([O-])=O ZUKPVRWZDMRIEO-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- FFFHZYDWPBMWHY-VKHMYHEASA-N L-homocysteine Chemical compound OC(=O)[C@@H](N)CCS FFFHZYDWPBMWHY-VKHMYHEASA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- HIZYETOZLYFUFF-BQBZGAKWSA-N Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(O)=O HIZYETOZLYFUFF-BQBZGAKWSA-N 0.000 description 1
- 239000002879 Lewis base Substances 0.000 description 1
- ZTPWXNOOKAXPPE-DCAQKATOSA-N Lys-Arg-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N ZTPWXNOOKAXPPE-DCAQKATOSA-N 0.000 description 1
- RLZDUFRBMQNYIJ-YUMQZZPRSA-N Lys-Cys-Gly Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N RLZDUFRBMQNYIJ-YUMQZZPRSA-N 0.000 description 1
- BYEBKXRNDLTGFW-CIUDSAMLSA-N Lys-Cys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O BYEBKXRNDLTGFW-CIUDSAMLSA-N 0.000 description 1
- 102000043129 MHC class I family Human genes 0.000 description 1
- 101150076359 Mhc gene Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101100101250 Mus musculus Th gene Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 102000006386 Myelin Proteins Human genes 0.000 description 1
- 108010083674 Myelin Proteins Proteins 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- 239000005642 Oleic acid Substances 0.000 description 1
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- KNPVDQMEHSCAGX-UWVGGRQHSA-N Phe-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KNPVDQMEHSCAGX-UWVGGRQHSA-N 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- 101710116318 Probable disulfide formation protein Proteins 0.000 description 1
- 108010076181 Proinsulin Proteins 0.000 description 1
- GOOHAUXETOMSMM-UHFFFAOYSA-N Propylene oxide Chemical compound CC1CO1 GOOHAUXETOMSMM-UHFFFAOYSA-N 0.000 description 1
- 102000007327 Protamines Human genes 0.000 description 1
- 108010007568 Protamines Proteins 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 229920002125 Sokalan® Polymers 0.000 description 1
- PRXRUNOAOLTIEF-ADSICKODSA-N Sorbitan trioleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@@H](OC(=O)CCCCCCC\C=C/CCCCCCCC)[C@H]1OC[C@H](O)[C@H]1OC(=O)CCCCCCC\C=C/CCCCCCCC PRXRUNOAOLTIEF-ADSICKODSA-N 0.000 description 1
- 239000004147 Sorbitan trioleate Substances 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- 101710167005 Thiol:disulfide interchange protein DsbD Proteins 0.000 description 1
- 108060008225 Thiolase Proteins 0.000 description 1
- 102100036407 Thioredoxin Human genes 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- 101800000859 Tumor necrosis factor ligand superfamily member 6, soluble form Proteins 0.000 description 1
- 102400000084 Tumor necrosis factor ligand superfamily member 6, soluble form Human genes 0.000 description 1
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- 102000014384 Type C Phospholipases Human genes 0.000 description 1
- 108010079194 Type C Phospholipases Proteins 0.000 description 1
- 206010045240 Type I hypersensitivity Diseases 0.000 description 1
- WJKJJGXZRHDNTN-UWVGGRQHSA-N Tyr-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 WJKJJGXZRHDNTN-UWVGGRQHSA-N 0.000 description 1
- ZAGPDPNPWYPEIR-SRVKXCTJSA-N Tyr-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ZAGPDPNPWYPEIR-SRVKXCTJSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 1
- 108010067390 Viral Proteins Proteins 0.000 description 1
- JCABVIFDXFFRMT-DIPNUNPCSA-N [(2r)-1-[ethoxy(hydroxy)phosphoryl]oxy-3-hexadecanoyloxypropan-2-yl] octadec-9-enoate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OCC)OC(=O)CCCCCCCC=CCCCCCCCC JCABVIFDXFFRMT-DIPNUNPCSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 210000005006 adaptive immune system Anatomy 0.000 description 1
- 239000000853 adhesive Substances 0.000 description 1
- 230000001070 adhesive effect Effects 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 230000000961 alloantigen Effects 0.000 description 1
- 102000006707 alpha-beta T-Cell Antigen Receptors Human genes 0.000 description 1
- 108010087408 alpha-beta T-Cell Antigen Receptors Proteins 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 235000021120 animal protein Nutrition 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 239000003945 anionic surfactant Substances 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 230000005775 apoptotic pathway Effects 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 208000010216 atopic IgE responsiveness Diseases 0.000 description 1
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 150000007528 brønsted-lowry bases Chemical class 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 210000001217 buttock Anatomy 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 125000006297 carbonyl amino group Chemical group [H]N([*:2])C([*:1])=O 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 239000003093 cationic surfactant Substances 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000004700 cellular uptake Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 210000001228 classical NK T cell Anatomy 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 239000003240 coconut oil Substances 0.000 description 1
- 235000019864 coconut oil Nutrition 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000007859 condensation product Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000006071 cream Substances 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 229960003067 cystine Drugs 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- MTHSVFCYNBDYFN-UHFFFAOYSA-N diethylene glycol Chemical group OCCOCCO MTHSVFCYNBDYFN-UHFFFAOYSA-N 0.000 description 1
- ZGSPNIOCEDOHGS-UHFFFAOYSA-L disodium [3-[2,3-di(octadeca-9,12-dienoyloxy)propoxy-oxidophosphoryl]oxy-2-hydroxypropyl] 2,3-di(octadeca-9,12-dienoyloxy)propyl phosphate Chemical compound [Na+].[Na+].CCCCCC=CCC=CCCCCCCCC(=O)OCC(OC(=O)CCCCCCCC=CCC=CCCCCC)COP([O-])(=O)OCC(O)COP([O-])(=O)OCC(OC(=O)CCCCCCCC=CCC=CCCCCC)COC(=O)CCCCCCCC=CCC=CCCCCC ZGSPNIOCEDOHGS-UHFFFAOYSA-L 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 125000003438 dodecyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 229940060296 dodecylbenzenesulfonic acid Drugs 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000009144 enzymatic modification Effects 0.000 description 1
- 235000019441 ethanol Nutrition 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000020932 food allergy Nutrition 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 235000004554 glutamine Nutrition 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 125000001475 halogen functional group Chemical group 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical group 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 229920003063 hydroxymethyl cellulose Polymers 0.000 description 1
- 229940031574 hydroxymethyl cellulose Drugs 0.000 description 1
- 230000009610 hypersensitivity Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 230000006882 induction of apoptosis Effects 0.000 description 1
- 208000030603 inherited susceptibility to asthma Diseases 0.000 description 1
- 210000005007 innate immune system Anatomy 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 230000014725 late viral mRNA transcription Effects 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 150000007527 lewis bases Chemical class 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 150000008146 mannosides Chemical class 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- CSHFHJNMIMPJST-HOTGVXAUSA-N methyl (2s)-2-[[(2s)-2-[[2-[(2-aminoacetyl)amino]acetyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoate Chemical compound NCC(=O)NCC(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(=O)OC)CC1=CC=CC=C1 CSHFHJNMIMPJST-HOTGVXAUSA-N 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 238000007837 multiplex assay Methods 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 210000005012 myelin Anatomy 0.000 description 1
- 125000001421 myristyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- PSZYNBSKGUBXEH-UHFFFAOYSA-N naphthalene-1-sulfonic acid Chemical class C1=CC=C2C(S(=O)(=O)O)=CC=CC2=C1 PSZYNBSKGUBXEH-UHFFFAOYSA-N 0.000 description 1
- 108010087904 neutravidin Proteins 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical class CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Chemical class CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- UYDLBVPAAFVANX-UHFFFAOYSA-N octylphenoxy polyethoxyethanol Chemical compound CC(C)(C)CC(C)(C)C1=CC=C(OCCOCCOCCOCCO)C=C1 UYDLBVPAAFVANX-UHFFFAOYSA-N 0.000 description 1
- 239000002674 ointment Substances 0.000 description 1
- 150000002888 oleic acid derivatives Chemical class 0.000 description 1
- 125000001117 oleyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])/C([H])=C([H])\C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 239000006186 oral dosage form Substances 0.000 description 1
- 239000007800 oxidant agent Substances 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 101800002712 p27 Proteins 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 239000006201 parenteral dosage form Substances 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- WXZMFSXDPGVJKK-UHFFFAOYSA-N pentaerythritol Chemical compound OCC(CO)(CO)CO WXZMFSXDPGVJKK-UHFFFAOYSA-N 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 229940127557 pharmaceutical product Drugs 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 150000003014 phosphoric acid esters Chemical class 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 229920001308 poly(aminoacid) Polymers 0.000 description 1
- 229920001483 poly(ethyl methacrylate) polymer Polymers 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 239000004584 polyacrylic acid Substances 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 239000004626 polylactic acid Substances 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 159000000001 potassium salts Chemical class 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 229950008679 protamine sulfate Drugs 0.000 description 1
- 239000011253 protective coating Substances 0.000 description 1
- 238000001243 protein synthesis Methods 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000009256 replacement therapy Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 208000023504 respiratory system disease Diseases 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 150000004671 saturated fatty acids Chemical class 0.000 description 1
- 235000003441 saturated fatty acids Nutrition 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 1
- 238000007921 solubility assay Methods 0.000 description 1
- 235000019337 sorbitan trioleate Nutrition 0.000 description 1
- 229960000391 sorbitan trioleate Drugs 0.000 description 1
- 239000007921 spray Substances 0.000 description 1
- 239000008117 stearic acid Chemical class 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000003459 sulfonic acid esters Chemical class 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 239000003760 tallow Substances 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 229940094937 thioredoxin Drugs 0.000 description 1
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 231100000440 toxicity profile Toxicity 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 125000002221 trityl group Chemical group [H]C1=C([H])C([H])=C([H])C([H])=C1C([*])(C1=C(C(=C(C(=C1[H])[H])[H])[H])[H])C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 1
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images




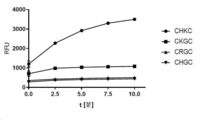








Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4713—Autoimmune diseases, e.g. Insulin-dependent diabetes mellitus, multiple sclerosis, rheumathoid arthritis, systemic lupus erythematosus; Autoantigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/43—Enzymes; Proenzymes; Derivatives thereof
- A61K38/44—Oxidoreductases (1)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0008—Antigens related to auto-immune diseases; Preparations to induce self-tolerance
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/001—Preparations to induce tolerance to non-self, e.g. prior to transplantation
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/02—Bacterial antigens
- A61K39/08—Clostridium, e.g. Clostridium tetani
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/35—Allergens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/385—Haptens or antigens, bound to carriers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/08—Antiallergic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
- C07K14/33—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria from Clostridium (G)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/62—Insulins
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/06—Linear peptides containing only normal peptide links having 5 to 11 amino acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/08—Linear peptides containing only normal peptide links having 12 to 20 amino acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0646—Natural killers cells [NK], NKT cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/515—Animal cells
- A61K2039/5158—Antigen-pulsed cells, e.g. T-cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/57—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2
- A61K2039/577—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2 tolerising response
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/62—Medicinal preparations containing antigens or antibodies characterised by the link between antigen and carrier
- A61K2039/627—Medicinal preparations containing antigens or antibodies characterised by the link between antigen and carrier characterised by the linker
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2302—Interleukin-2 (IL-2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/998—Proteins not provided for elsewhere
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- Genetics & Genomics (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Microbiology (AREA)
- Zoology (AREA)
- Epidemiology (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Mycology (AREA)
- Biochemistry (AREA)
- Cell Biology (AREA)
- General Engineering & Computer Science (AREA)
- Hematology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Transplantation (AREA)
- Virology (AREA)
- Rheumatology (AREA)
- Gastroenterology & Hepatology (AREA)
- Developmental Biology & Embryology (AREA)
- Oncology (AREA)
- Pulmonology (AREA)
- Diabetes (AREA)
- Toxicology (AREA)
Abstract
본 발명은 활성이 증가된, T-세포 에피토프 및 산화환원 효소 모티프를 포함하는 면역원성 펩티드, 및 대상체에서 면역 반응의 조절에서 이의 용도에 관한 것이다.
Description
본 발명은 개선된 산화환원 효소 모티프를 갖는 면역원성 펩티드에 관한 것이다.
항원에 대한 원치않는 면역 반응의 생성을 방지하기 위한 몇 가지 전략이 설명되었다. WO2008/017517호는 주어진 항원 단백질의 MHC 클래스 II 항원 및 산화환원 효소 모티프를 포함하는 펩티드를 사용한 새로운 전략을 기술한다. 이들 펩티드는 CD4+ T 세포를 세포용해성 CD4+ T 세포라고 하는 세포용해 특성을 가진 세포형으로 전환시킨다. 이들 세포는 펩티드가 유래된 항원을 제시하는 항원 제시 세포 (APC)를 아폽토시스 유발을 통해 사멸시킬 수 있다. WO2008/017517호는 알레르기 및 I 형 당뇨병과 같은 자가면역 질환에 대한 이러한 개념을 입증한다. 여기서, 인슐린은 자가 항원으로 작용할 수 있다.
WO2009101207호 및 Carlier et al. (2012) Plos one 7,10 e45366에서는 항원 특이적 세포용해 세포를 더 자세히 추가로 설명한다.
WO2009101206호는 대체 요법에 사용되는 경우 이러한 항원에 대한 면역 반응 (예를 들어, 당뇨병 환자에 주입된 인슐린에 대한 원치않는 면역 반응)을 방지하기 위해 가용성 동종 항원의 MCH 클래스 II 에피토프 및 산화환원 효소 모티프를 갖는 펩티드의 사용을 설명한다.
WO2016059236호는 추가 히스티딘이 산화환원 효소 모티프에 인접하여 존재하는 추가 변형된 펩티드를 개시한다.
I 형 당뇨병에 대한 펩티드의 설계에서는 자가 항원의 유형 (인슐린, GAD 65,…), 자가 항원의 특이적 도메인 및 에피토프, 산화환원 효소 모티프, 에피토프 서열과 산화환원 효소 모티프 사이의 아미노산 서열 및 길이와 같은 많은 요인이 고려될 수 있다.
알레르겐 또는 항원의 MHC 클래스 II 에피토프를 포함하는 펩티드 외에도, WO2012069568A2호는 CD1d 수용체에 결합하는 NKT 세포 에피토프의 사용으로 세포용해성 항원 특이적 NKT 세포의 활성화로 이어질 가능성을 추가로 공개하고, 항원-특이적 방식으로, 상기 특정 항원을 제시하는 APC를 제거하는 것을 입증하였다.
두 전략 모두 [CST]X2C 또는 CX2[CST] 유형의 산화환원 효소 모티프 사용을 기반으로 한다. 이러한 면역원성 펩티드를 사용하는 치료 효능을 개선하기 위해, 더 활성인 펩티드 및/또는 더 강력한 산화환원 효소 모티프에 대한 조사가 계속되고 있다.
발명의 요약
본 발명은 항원의 T-세포 에피토프 및 산화환원 효소 모티프를 포함하는 신규 면역원성 펩티드를 제공한다.
본 발명자들은 전통적으로 사용된 CXX[CST] 또는 [CST]XXC 산화환원 효소 모티프 앞, 내 또는 뒤에 염기성 (하전) 아미노산의 다양한 조합을 추가하는 효과를 시험하였다.
이를 수행함으로써 본 발명자들은 주장한 특정 조합을 사용하였을 때 많은 경우 산화환원 효소 활성이 변한다는 것을 발견하였다. 이것은 모티프에서 특정 염기성 아미노산의 선택이 임의적인 것이 아니고 모티프의 개선된 효과로 이어진다는 것을 의미한다. 특히, 본 발명자들은 염기성 아미노산 K (라이신) 또는 R (아르기닌)의 사용이 H (히스티딘)의 사용보다 더 나은 결과를 제공한다 것을 보여주었다. 일부 특정 위치에서, K 및 R 잔기는 또한 서로 더 나은 결과를 제공하며 모티프의 여러 염기성 아미노산 잔기의 조합은 이러한 효과를 더욱 증가시키는 것으로 보여진다. 이러한 효과는 도면에 표시되고 실시예 섹션에 설명되어 있다. 또한 모델 시스템에서 세포 수준에 대한 효과가 시험되었으며 본 발명의 면역원성 펩티드의 개선된 활성이 확인되었다.
본 발명은 다음 측면에 관한 것이다:
측면 1: 다음을 포함하는 면역원성 펩티드:
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커;
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R, 바람직하게는 K이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+ 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산이고,
바람직하게는 T 세포 에피토프가 NKT 세포 에피토프인 경우 H가 아니고, 보다 바람직하게는 R 또는 K이고,
바람직하게는 H, K 또는 R 또는 T-세포 에피토프가 MHC 클래스 II 에피토프인 경우 L-오르니틴과 같은 비천연 염기성 아미노산, 보다 바람직하게는 R 또는 K이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1이다.
측면 2: (Z1)+는 K 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이고/거나, (Z2)+ 및/또는 (Z3)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산을 포함하는 군으로부터 선택되는, 측면 1에 따른 면역원성 펩티드.
측면 3: X는 C, S 또는 T를 제외한 임의의 아미노산인, 측면 1 또는 2에 따른 면역원성 펩티드.
측면 4: X는 염기성 아미노산을 제외한 임의의 아미노산인, 측면 1 내지 3 중 어느 하나에 따른 면역원성 펩티드.
측면 5: (Z1)+, (Z2)+ 및/또는 (Z3)+ 중 하나는 K 또는 L-오르니틴인, 측면 1 내지 4 중 어느 하나에 따른 면역원성 펩티드.
측면 6: 항원 단백질의 상기 T 세포 에피토프는 NKT 세포 에피토프 또는 MHC 클래스 II T 세포 에피토프인, 측면 1 내지 5 중 어느 하나에 따른 면역원성 펩티드.
측면 7: 상기 에피토프는 7 내지 30 개 아미노산, 바람직하게는 7 내지 25 개 아미노산, 보다 바람직하게는 7 내지 20 개 아미노산의 길이를 갖는, 측면 1 내지 6 중 어느 하나에 따른 면역원성 펩티드.
측면 8: 11 내지 50 개 아미노산, 바람직하게는 11 내지 40 개 아미노산, 보다 바람직하게는 11 내지 30 개 아미노산의 길이를 갖는, 측면 1 내지 7 중 어느 하나에 따른 면역원성 펩티드.
측면 9: 상기 항원 단백질은 자가-항원, 가용성 동종 인자, 이식편에 의해 발산된 동종 항원, 세포 내 병원체의 항원, 유전자 치료 또는 유전자 백신 접종에 사용되는 바이러스 벡터의 항원, 종양 관련 항원 또는 알레르겐인, 측면 1 내지 8 중 어느 하나에 따른 면역원성 펩티드.
측면 10: 모티프에서 적어도 하나의 X가 P 또는 Y인, 측면 1 내지 9 중 어느 하나에 따른 면역원성 펩티드.
측면 11: 링커는 0 내지 4 개의 아미노산을 가진, 측면 1 내지 10 중 어느 하나에 따른 면역원성 펩티드.
측면 12: 상기 산화환원 효소 모티프는 상기 항원 단백질에서 T-세포 에피토프의 N-말단 또는 C-말단의 11 개 아미노산 영역 내에서 자연적으로 발생하지 않는, 측면 1 내지 11 중 어느 하나에 따른 면역원성 펩티드.
측면 14: T-세포 에피토프는 자연적으로 상기 산화환원 효소 모티프를 포함하지 않는, 측면 1 내지 13 중 어느 하나에 따른 면역원성 펩티드.
측면 15: 의학에서, 더욱 특히 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응의 치료 및/또는 예방에 사용하기 위한, 측면 1 내지 14 중 어느 하나에 따른 면역원성 펩티드.
측면 16: 다음 단계를 포함하는, 측면 1 내지 13 중 어느 하나에 따른 면역원성 펩티드의 제조 방법:
(a) 항원 단백질의 T-세포 에피토프로 이루어진 펩티드 서열을 제공하는 단계, 및
(b) 상기 모티프와 상기 에피토프가 서로 인접하거나 최대 7 개 아미노산의 링커에 의해 분리되도록 상기 펩티드 서열에 산화환원 효소 모티프를 연결하는 단계.
측면 17: 다음 단계를 포함하는, 상기 항원을 제시하는 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 집단을 수득하는 방법:
-
말초 혈액 세포를 제공하는 단계;
-
상기 세포를 보다 특히 다음을 포함하는 측면 1 내지 14 중 어느 하나에 따른 면역원성 펩티드와 접촉시키는 단계:
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커;
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R, 바람직하게는 K이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산이고,
바람직하게는 T 세포 에피토프가 NKT 세포 에피토프인 경우 H가 아니고, 보다 바람직하게는 R 또는 K이고,
바람직하게는 H, K 또는 R 또는 T-세포 에피토프가 MHC 클래스 II 에피토프인 경우 L-오르니틴과 같은 비천연 염기성 아미노산, 보다 바람직하게는 R 또는 K이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1임;
-
상기 세포를 IL-2의 존재하에 확장시키는 단계.
측면 18: 다음 단계를 포함하는, 항원-특이적 NKT 세포 집단을 수득하는 방법:
-
말초 혈액 세포를 제공하는 단계;
-
상기 세포를, 보다 특히 다음을 포함하는 측면 1 내지 14 중 어느 하나에 따른 면역원성 펩티드와 접촉시키는 단계:
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R, 바람직하게는 K이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산이고,
바람직하게는 T 세포 에피토프가 NKT 세포 에피토프인 경우 H가 아니고, 보다 바람직하게는 R 또는 K이고,
바람직하게는 H, K 또는 R 또는 T-세포 에피토프가 MHC 클래스 II 에피토프인 경우 L-오르니틴과 같은 비천연 염기성 아미노산, 보다 바람직하게는 R 또는 K이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1임;
-
상기 세포를 IL-2의 존재하에 확장시키는 단계.
측면 19: 다음 단계를 포함하는, 상기 항원을 제시하는 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 집단을 수득하는 방법:
-
보다 특히 다음을 포함하는 측면 1 내지 14 중 어느 하나에 따른 면역원성 펩티드를 제공하는 단계:
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R, 바람직하게는 K이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산이고,
바람직하게는 T 세포 에피토프가 NKT 세포 에피토프인 경우 H가 아니고, 보다 바람직하게는 R 또는 K이고,
바람직하게는 H, K 또는 R 또는 T-세포 에피토프가 MHC 클래스 II 에피토프인 경우 L-오르니틴과 같은 비천연 염기성 아미노산, 보다 바람직하게는 R 또는 K이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1임;
-
상기 펩티드를 대상체에 투여하는 단계; 및
-
상기 대상체로부터 상기 항원-특이적 세포용해성 CD4+ T 세포 집단을 수득하는 단계.
측면 20: 다음 단계를 포함하는, 항원-특이적 NKT 세포 집단을 수득하는 방법:
-
보다 특히 다음을 포함하는 측면 1 내지 14 중 어느 하나에 따른 면역원성 펩티드를 제공하는 단계:
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R, 바람직하게는 K이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산이고,
바람직하게는 T 세포 에피토프가 NKT 세포 에피토프인 경우 H가 아니고, 보다 바람직하게는 R 또는 K이고,
바람직하게는 H, K 또는 R 또는 T-세포 에피토프가 MHC 클래스 II 에피토프인 경우 L-오르니틴과 같은 비천연 염기성 아미노산, 보다 바람직하게는 R 또는 K이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1임;
-
상기 펩티드를 대상체에게 투여하는 단계; 및
-
상기 대상체로부터 상기 항원-특이적 NKT 세포 집단을 수득하는 단계.
측면 21: 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응의 치료 및/또는 예방에 사용하기 위한, 측면 17 내지 20의 방법에 의해 수득 가능한 항원 특이적 세포용해성 CD4+ T 세포 또는 NKT 세포 집단.
측면 22: 개체에게 측면 1 내지 13 중 어느 하나에 따른 면역원성 펩티드 또는 측면 17 내지 20 중 어느 하나에 따른 세포 집단을 투여하는 단계를 포함하는, 상기 개체에서 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응을 치료 및/또는 예방하는 방법.
측면 23: 다음 단계를 포함하는, 개체에서 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응을 치료 및/또는 예방하는 방법:
-
상기 개체의 말초 혈액 세포를 제공하는 단계,
-
상기 세포를 측면 1 내지 13 중 어느 하나에 따른 항원성 펩티드와 접촉시키는 단계,
-
상기 세포를 확장하는 단계 및
-
상기 확장된 세포를 상기 개체에게 투여하는 단계.
상기 측면 중 어느 하나의 상기 산화환원 효소 모티프의 바람직한 구체예에서, 존재하는 경우, B1 및/또는 B2는 각각 독립적으로 H, K 또는 R, 바람직하게는 H로부터 선택된다.
이 측면의 특히 바람직한 예는 다음 산화환원 효소 모티프 중 하나를 포함한다:
KCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 RCPYC, RCGHC, 또는 RCHGC;
KCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 KCPYC, KCGHC, 또는 KCHGC;
KHCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 RHCPYC, RHCGHC, 또는 RHCHGC;
KRCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 KHCPYC, KHCGHC, 또는 KHCHGC;
CXRC, 여기서, X는 임의의 아미노산, 바람직하게는 CGRC, CPRC, CHRC;
CXKC, 여기서, X는 임의의 아미노산, 바람직하게는 CGKC, CPKC, CHKC;
CXXCK, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCK, CPYCK, CGHCK;
CXXCHK, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCHK, CPYCHK, CGHCHK;
CXXCR, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCR, CPYCR, CGHCR;
CXXCHR, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCHR, CPYCHR, CGHCHR;
KCKXC, RCKXC, KCRXC, 또는 RCRXC, 여기서, X는 임의의 아미노산
KCXKC, RCXKC, KCXRC, 또는 RCXRC, 여기서, X는 임의의 아미노산
KCKXCK, RCKXCK, KCRXCK, KCKXCR, RCRXCK, RCKXCR, KCRXCR, 또는 RCRXCR, 여기서, X는 임의의 아미노산
KCKXCHK, RCKXCHK, KCRXCHK, KCKXCHR, RCRXCHK, RCKXCHR, KCRXCHR 또는 RCRXCHR, 여기서, X는 임의의 아미노산
KCXXCK, KCXXCR, RCXXCK 또는 RCXXCR, 여기서, X는 임의의 아미노산
KCXXCHK, KCXXCHR, RCXXCHK, RCXXCHR, 여기서, X는 임의의 아미노산
KCXKCK, RCXKCK, KCXRCK, KCXKCR, RCXRCK, RCXKCR, KCXRCR, 또는 RCXRCR, 여기서, X는 임의의 아미노산
KCXKCHK, RCXKCHK, KCXRCHK, KCXKCHR, RCXRCHK, RCXKCHR, KCXRCHR, 또는 RCXRCHR, 여기서, X는 임의의 아미노산임.
상기 측면 중 어느 하나에서, 에피토프가 설계되는 항원은 프로-인슐린, 인슐린, C-펩티드, MOG 및 파상풍 독소를 포함하는 군으로부터 선택될 수 있다.
상기 측면 중 어느 하나의 바람직한 구체예에서, 링커는 적어도 1 개의 아미노산, 적어도 2 개의 아미노산, 적어도 3 개의 아미노산, 또는 적어도 4 개의 아미노산을 포함한다. 바람직하게는, 상기 링커는 1 내지 7 개의 아미노산, 예컨대 2 내지 7 개의 아미노산, 3 내지 7 개의 아미노산, 또는 4 내지 7 개의 아미노산을 포함한다.
상기 측면 중 어느 하나의 바람직한 구체예에서, 특히 산화환원 효소 모티프가 [CST](Z1)+XC 또는 C(Z1)+X[CST]인 측면에서, 상기 산화환원 효소 모티프는 CRLC가 아니고/거나, 면역원성 펩티드는 CRLC-KVAPVIKAR-MM이 아니다.
상기 측면 중 어느 하나의 또 다른 바람직한 구체예에서, T-세포 에피토프는 그의 N-말단에 염기성 아미노산을 포함하지 않으며, 즉 링커 또는 산화환원 효소 모티프에 바로 인접하며, 더욱 특히 링커가 없거나, 1 개 또는 2 개의 아미노산만을 포함한다. 보다 바람직하게는, 산화환원 효소 모티프가 [CST]XXC(B2)m(Z2)+ 또는 CXX[CST](B2)m(Z2)+인 모든 측면에서, T-세포 에피토프는 그의 N-말단에 염기성 아미노산을 포함하지 않으며, 즉 링커 또는 산화환원 효소 모티프에 바로 인접하며, 더욱 특히 링커가 없거나 1 개 또는 2 개의 아미노산만을 포함한다.
상기 측면 중 어느 하나의 추가 구체예에서, T-세포 에피토프는 N-말단으로부터 세어진 위치 1, 2 및/또는 3에 염기성 아미노산을 포함하지 않으며, 즉 링커 또는 산화환원 효소 모티프에 바로 인접하고, 보다 특히 링커가 없거나 1 개 또는 2 개의 아미노산만을 포함한다.
상기 측면 중 어느 하나의 추가 구체예에서, X, (B1) 및/또는 (B2) 중 하나는 염기성 아미노산일 수 있다. 또 다른 구체예에서, X, (B1) 및/또는 (B2) 중 하나는 C, S 또는 T를 제외한 임의의 아미노산이다. 또 다른 구체예에서, X, (B1) 및/또는 (B2)는 염기성 아미노산을 제외한 임의의 아미노산이다.
본 발명의 펩티드는 이들 펩티드를 사용하여 생성된 세포용해성 CD4+ T 세포가 종래 기술의 펩티드에 비해 증가된 IFN-감마 및 sFasL 생산을 갖는다는 이점이 있다. 또한 상기 CD4+ T 세포에서 그랜자임 B의 생산이 증가되는 것으로 여겨진다.
이들 마커의 증가된 발현 수준은 종래 기술의 펩티드와 비교하여 본 발명의 펩티드가 세포용해성 CD4+ T 세포를 생산하는 능력이 더 크다는 것을 나타낸다.
도 1: CHGC 모티프 및 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 N-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. 전하를 띤 아미노산이 없거나 N-말단에 H가 있는 산화환원 효소 모티프를 가진 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 1을 참조한다.
도 2: CPYC 모티프 및 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 N-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. N-말단에 전하를 띤 아미노산이 없거나 H가 있는 산화환원 효소 모티프를 가진 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 2를 참조한다.
도 3: CPYC 모티프 및 MOG T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 N-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. N-말단에 전하를 띤 아미노산이 없거나 H가 있는 산화환원 효소 모티프를 가진 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 3을 참조한다.
도 4: 인슐린 T 세포 에피토프를 가지고 있고 P 또는 Y가 K로 치환된 CPYC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 4를 참조한다.
도 5: 인슐린 T 세포 에피토프를 가지고 있고 H 또는 G가 K로 치환된 CHGC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CHGC 및 CRGC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 5를 참조한다.
도 6: 인슐린 T 세포 에피토프를 가지고 있고 H가 K 또는 R로 치환된 CGHC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. CHKC 모티프도 시험하였다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CGHC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 6을 참조한다.
도 7: CHGC 모티프 및 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 C-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. C-말단에 염기성 아미노산이 없는 CHGC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 7을 참조한다.
도 8: CPYC 모티프 및 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 C-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. C-말단에 염기성 아미노산이 없는 CPYC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 8을 참조한다.
도 9: CPYC 모티프 및 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 활성 동역학을 나타낸다. 염기성 아미노산을 산화환원 효소 모티프 내와 N-/C-말단에 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYCSLQPLALEGSLQKRG 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 9를 참조한다.
도 10: CPYC 모티프 및 MOG T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 활성 동역학을 나타낸다. 염기성 아미노산을 산화환원 효소 모티프 내와 N-/C-말단에 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYCGWYRSPFSRVVHL 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 10을 참조한다.
도 11: MOG T 세포 에피토프 및 산화환원 효소 모티프를 포함하는 시험 및 참조 펩티드의 부재 및 존재하에 APC와 16 시간 공배양한 후 Ag-특이적 CD4 T 세포의 백분율을 나타낸다. 점선은 모든 시험 및 대조 펩티드 (흰색 컬럼)와 비교하여 HCPYC 모티프 (검은색 컬럼)가 있는 참조 펩티드에 대한 Ag-특이적 CD4+ T 세포의 백분율 차이를 보여준다. 제어 조건은 펩티드 비첨가 또는 산화환원 효소 모티프를 포함하는 DBY로부터의 펩티드 또는 산화환원 효소 모티프를 포함하는 뮤린 PPI로부터의 펩티드의 첨가를 포함한다. 생물학적 중복의 FACS 측정을 위한 SD가 모든 조건에 대해 표시된다. 자세한 내용은 표 11을 참조한다.
도 12: MOG T 세포 에피토프 및 산화환원 효소 모티프를 포함하는 시험 및 참조 펩티드의 부재 및 존재하에 APC와 24 시간 공배양한 후 2D2-전체 CD4 T 세포에 의해 분비된 sIL2를 나타낸다. 점선은 모든 실험 및 대조군 조건 (흰색 컬럼)에 대한 HCPYC 모티프 (검은색 컬럼)가 있는 참조 펩티드에 대한 sIL2 (pg/ml)의 양 간의 차이를 보여준다. 대조군 조건은 펩티드가 없는 APC, T 세포가 없는 APC 단독, 배지 단독 또는 산화환원 효소 모티프를 포함하는 DBY로부터의 펩티드 또는 산화환원 효소 모티프를 포함하는 뮤린 PPI로부터의 펩티드의 첨가를 포함한다. 생물학적 중복의 FACS 측정을 위한 SD가 모든 조건에 대해 표시된다. 자세한 내용은 표 11을 참조한다.
도 13: MOG T 세포 에피토프 및 산화환원 효소를 포함하는 시험 펩티드의 부재 및 존재하에 APC로 자극 16 시간 후 그랜자임 A, 그랜자임 B, CD107a/b를 단독으로 또는 조합하여 발현하는 Ag-특이적 CD4 T 세포의 백분율을 나타낸다. 용해 마커의 유도에 대한 산화환원 효소 모티프의 효과를 확인하기 위해 어떤 티오레독스 활성도 없는 야생형 펩티드에 대한 측정은 변형된 펩티드에 대한 다른 모든 측정에서 제거되었다. 점선은 모든 실험적 변형 펩티드와 비교하여 HCPYC 모티프가 있는 참조 펩티드에 대한 CD4+ T 세포에서 용해 마커의 발현 백분율 간의 차이를 보여준다. KHCPYC-MOG 펩티드의 결과는 기술적 어려움 (이벤트 수가 충분하지 않음)으로 인해 결정적이지 않다. 자세한 내용은 표 11을 참조한다.
도 2: CPYC 모티프 및 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 N-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. N-말단에 전하를 띤 아미노산이 없거나 H가 있는 산화환원 효소 모티프를 가진 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 2를 참조한다.
도 3: CPYC 모티프 및 MOG T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 N-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. N-말단에 전하를 띤 아미노산이 없거나 H가 있는 산화환원 효소 모티프를 가진 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 3을 참조한다.
도 4: 인슐린 T 세포 에피토프를 가지고 있고 P 또는 Y가 K로 치환된 CPYC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 4를 참조한다.
도 5: 인슐린 T 세포 에피토프를 가지고 있고 H 또는 G가 K로 치환된 CHGC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CHGC 및 CRGC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 5를 참조한다.
도 6: 인슐린 T 세포 에피토프를 가지고 있고 H가 K 또는 R로 치환된 CGHC 모티프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. CHKC 모티프도 시험하였다. 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CGHC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 6을 참조한다.
도 7: CHGC 모티프 및 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 C-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. C-말단에 염기성 아미노산이 없는 CHGC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 7을 참조한다.
도 8: CPYC 모티프 및 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 활성 동역학을 나타낸다. 산화환원 효소 모티프의 C-말단에 염기성 아미노산을 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. C-말단에 염기성 아미노산이 없는 CPYC 모티프가 대조 펩티드로 사용되었다. 자세한 내용은 표 8을 참조한다.
도 9: CPYC 모티프 및 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 활성 동역학을 나타낸다. 염기성 아미노산을 산화환원 효소 모티프 내와 N-/C-말단에 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYCSLQPLALEGSLQKRG 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 9를 참조한다.
도 10: CPYC 모티프 및 MOG T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 활성 동역학을 나타낸다. 염기성 아미노산을 산화환원 효소 모티프 내와 N-/C-말단에 삽입하고 산화환원 활성의 초기 속도를 10 분 동안 추적한다. CPYCGWYRSPFSRVVHL 펩티드가 대조 펩티드로 사용되었다. 자세한 내용은 표 10을 참조한다.
도 11: MOG T 세포 에피토프 및 산화환원 효소 모티프를 포함하는 시험 및 참조 펩티드의 부재 및 존재하에 APC와 16 시간 공배양한 후 Ag-특이적 CD4 T 세포의 백분율을 나타낸다. 점선은 모든 시험 및 대조 펩티드 (흰색 컬럼)와 비교하여 HCPYC 모티프 (검은색 컬럼)가 있는 참조 펩티드에 대한 Ag-특이적 CD4+ T 세포의 백분율 차이를 보여준다. 제어 조건은 펩티드 비첨가 또는 산화환원 효소 모티프를 포함하는 DBY로부터의 펩티드 또는 산화환원 효소 모티프를 포함하는 뮤린 PPI로부터의 펩티드의 첨가를 포함한다. 생물학적 중복의 FACS 측정을 위한 SD가 모든 조건에 대해 표시된다. 자세한 내용은 표 11을 참조한다.
도 12: MOG T 세포 에피토프 및 산화환원 효소 모티프를 포함하는 시험 및 참조 펩티드의 부재 및 존재하에 APC와 24 시간 공배양한 후 2D2-전체 CD4 T 세포에 의해 분비된 sIL2를 나타낸다. 점선은 모든 실험 및 대조군 조건 (흰색 컬럼)에 대한 HCPYC 모티프 (검은색 컬럼)가 있는 참조 펩티드에 대한 sIL2 (pg/ml)의 양 간의 차이를 보여준다. 대조군 조건은 펩티드가 없는 APC, T 세포가 없는 APC 단독, 배지 단독 또는 산화환원 효소 모티프를 포함하는 DBY로부터의 펩티드 또는 산화환원 효소 모티프를 포함하는 뮤린 PPI로부터의 펩티드의 첨가를 포함한다. 생물학적 중복의 FACS 측정을 위한 SD가 모든 조건에 대해 표시된다. 자세한 내용은 표 11을 참조한다.
도 13: MOG T 세포 에피토프 및 산화환원 효소를 포함하는 시험 펩티드의 부재 및 존재하에 APC로 자극 16 시간 후 그랜자임 A, 그랜자임 B, CD107a/b를 단독으로 또는 조합하여 발현하는 Ag-특이적 CD4 T 세포의 백분율을 나타낸다. 용해 마커의 유도에 대한 산화환원 효소 모티프의 효과를 확인하기 위해 어떤 티오레독스 활성도 없는 야생형 펩티드에 대한 측정은 변형된 펩티드에 대한 다른 모든 측정에서 제거되었다. 점선은 모든 실험적 변형 펩티드와 비교하여 HCPYC 모티프가 있는 참조 펩티드에 대한 CD4+ T 세포에서 용해 마커의 발현 백분율 간의 차이를 보여준다. KHCPYC-MOG 펩티드의 결과는 기술적 어려움 (이벤트 수가 충분하지 않음)으로 인해 결정적이지 않다. 자세한 내용은 표 11을 참조한다.
발명의 상세한 설명
본 발명이 특정 구체예에 대해 설명될 것이지만, 본 발명은 이에 제한되지 않고 청구범위에 의해서만 제한된다. 청구범위에서 인용 부호는 범위를 제한하는 것으로 해석되어서는 안된다. 다음 용어 또는 정의들은 단지 본 발명의 이해를 돕기 위해서만 제공되는 것이다. 본원에서 구체적으로 정의되지 않는 한, 본원에서 사용되는 모든 용어는 본 발명의 기술 분야에서 통상의 지식을 가진 자가 이해하는 것과 동일한 의미를 갖는다. 본원에 제공된 정의는 당업자가 이해하는 범위보다 좁은 범위를 갖는 것으로 해석되어서는 안된다.
달리 지시되지 않는 한, 상세하게 설명되지 않은 모든 방법, 단계, 기술 및 조작은 당업자에게 명백한 바와 같이 그 자체로 알려진 방식으로 수행될 수 있고 수행된다. 예를 들어 표준 핸드북, 위에서 언급한 일반적인 배경 기술 및 그 안에 인용된 추가 문헌이 참조된다.
본원에서 사용된 단수 형태는 문맥이 달리 명시하지 않는 한 단수 및 복수 지시 대상을 모두 포함한다. 본원에서 사용되는 측면, 청구항 또는 구체예와 관련하여 사용되는 경우 용어 "임의의"는 언급된 상기 측면, 청구 범위 또는 구체예의 임의의 단일의 것 (즉, 어느 하나)뿐만 아니라 모든 조합을 지칭한다.
본원에서 사용되는 용어 '포함하는', '포함한다' 및 '구성된'은 '포함한', '포함하다' 또는 '함유하는', '함유한다'와 동의어이고, 포괄적이거나 개방적이며 추가적인 비-인용된 구성원, 요소 또는 방법 단계를 배제하지 않는다. 상기 용어는 또한 "본질적으로 구성되는" 및 "구성되는" 구체예를 포함한다.
끝점에 의한 수치 범위의 열거는 인용된 끝점뿐만 아니라 각 범위 내에 포함된 모든 숫자와 분수를 포함한다.
매개 변수, 양, 시간적 기간 등과 같은 측정 가능한 값을 언급할 때 본원에서 사용되는 용어 '약'은 개시된 발명에서 수행하기에 적절하다면 특정 값으로부터 +/-10% 이하, 바람직하게는 +/-5% 이하, 보다 바람직하게는 +/-1% 이하, 보다 더 바람직하게는 +/-0.1% 이하의 변동을 포함하는 것을 의미한다. 수식어 '약'이 지칭하는 값은 그 자체가 또한 구체적이고 바람직하게는 개시되는 것으로 이해되어야 한다.
본원에서 사용되는 "질환 치료에 사용하기 위한 조성물"에 사용된 용어 "사용하기 위한"은 또한 상응하는 치료 방법 및 질환 치료용 약제의 제조를 위한 제제의 상응하는 용도를 나타낼 것이다.
본원에서 사용되는 용어 "펩티드"는 펩티드 결합에 의해 연결되지만 비-아미노산 구조를 포함할 수 있는 12 개 내지 200 개 아미노산의 아미노산 서열을 포함하는 분자를 지칭한다.
본원에 사용된 용어 "면역원성 펩티드"는 면역원성인, 즉 면역 반응을 유도할 수 있는 T-세포 에피토프를 포함하는 펩티드를 지칭한다.
본 발명에 따른 펩티드는 임의의 통상적인 20 개 아미노산 또는 이의 변형된 버전을 함유할 수 있거나, 화학적 펩티드 합성 또는 화학적 또는 효소적 변형에 의해 혼입된 비천연 아미노산을 함유할 수 있다.
본원에서 사용된 "항원"이라는 용어는, 거대분자 구조, 전형적으로 (폴리사카라이드를 포함하거나 포함하지 않는) 단백질로 이루어지거나, 또는 하나 이상의 합텐(들)을 포함하고 T 또는 NKT 세포 에피토프를 포함하는 단백질 조성물을 지칭한다.
본원에서 사용된 "항원 단백질"이라는 용어는 하나 이상의 T 또는 NKT 세포 에피토프를 포함하는 단백질을 지칭한다. 본원에서 사용된 자가항원 또는 자가항원 단백질이란 동일 인간 또는 동물 체내에서 면역 반응을 유도하는, 체내에 존재하는 인간 또는 동물 단백질 또는 그의 단편을 지칭한다.
"식품 또는 약학 항원 단백질"이라는 용어는 식품 또는 약학 제품, 예컨대 백신에 존재하는 항원 단백질을 지칭한다.
"에피토프"라는 용어는, 항체 또는 그의 일부 (Fab', Fab2' 등), 또는 B-, T- 또는 NKT 세포의 세포 표면에 존재하는 수용체에 의해 특이적으로 인식되고 결합되며, 상기 결합에 의해 면역 반응을 유도할 수 있는, 항원 단백질의 (입체형태적 에피토프를 정의할 수 있는) 한 부분 또는 여러 부분을 지칭한다.
본 발명과 관련하여 "T 세포 에피토프"라는 용어는 우세, 준우세 (sub-dominant) 또는 열세 (minor) T 세포 에피토프, 즉, T 림프구의 세포 표면에서 수용체에 의해 특이적으로 인식되고 결합되는 항원 단백질의 일부를 지칭한다. 에피토프가 우세 에피토프인지, 준우세 에피토프인지, 또는 열세 에피토프인지의 여부는 에피토프에 대해 유도되는 면역 반응에 좌우된다. 우세 정도는 상기 에피토프가 단백질의 모든 가능한 T 세포 에티토프들 중에서 T 세포에 의해 인식되고, 그를 활성화시킬 수 있는 빈도에 의존한다.
T 세포 에피토프는 MHC II 분자의 그루브에 맞는 (fit) +/- 9 개의 아미노산 서열로 이루어진, MHC 클래스 II 분자에 의해 인식되는 에피토프이다. T 세포 에피토프를 나타내는 펩티드 서열 내에서 에피토프 중의 아미노산은 P1 내지 P9로 번호가 매겨지는데, 에피토프의 아미노산 N-말단은 P-1, P-2 등으로 번호가 매겨지고, 에피토프의 아미노산 C-말단은 P+1, P+2 등으로 번호가 매겨진다. MHC 클래스 II 분자에 의해 인식되지만 MHC 클래스 I 분자에 의해 인식되지 않는 펩티드는 MHC 클래스 II 제한 T 세포 에피토프로 지칭된다.
항원 단백질로부터 T-세포 에피토프의 확인 및 선택은 당업자에게 알려져있다.
본 발명의 맥락에서 적합한 에피토프를 확인하기 위해, 항원 단백질의 단리된 펩티드 서열을 예를 들어 T 세포 생물학 기술로 시험하여 펩티드 서열이 T 세포 반응을 유도하는지 여부를 결정한다. T 세포 반응을 유도하는 것으로 밝혀진 펩티드 서열은 T 세포 자극 활성을 갖는 것으로 정의된다.
인간 T 세포 자극 활성은 예를 들어 T1D를 갖는 개체로부터 수득한 T 세포를 T1D에 관여하는 자가-항원으로부터 유래된 펩티드/에피토프와 함께 배양하고, 예를 들어 삼중수소화된 티미딘의 세포 흡수에 의해 측정되어 펩티드/에피토프에 대한 반응으로 T 세포의 증식이 일어나는지를 결정함으로써 추가로 시험될 수 있다. 펩티드/에피토프에 대한 T 세포의 반응에 대한 자극 지수는 대조 CPM으로 나눈 펩티드/에피토프에 대한 반응의 최대 CPM으로 계산할 수 있다. 배경 수준의 2 배 이상인 T 세포 자극 지수 (S.I.)를 "양성"으로 간주한다. 양성 결과가 시험된 펩티드/에피토프 그룹에 대한 각 펩티드/에피토프의 평균 자극 지수를 계산하는 데 사용된다.
비천연 (또는 변형된) T-세포 에피토프를 MHC 클래스 II 분자에 대한 결합 친화성에 대해 임의로 추가 시험될 수 있다. 이것은 상이한 방법으로 수행될 수 있다. 예를 들어, 주어진 클래스 II 분자에 대해 동형 접합 세포의 용해에 의해 가용성 HLA 클래스 II 분자를 수득한다. 이를 친화성 크로마토그래피로 정제한다. 가용성 클래스 II 분자를 해당 클래스 II 분자에 대한 강력한 결합 친화성에 따라 생성된 비오틴 표지된 참조 펩티드와 함께 배양한다. 클래스 II 결합에 대해 평가할 펩티드를 상이한 농도에서 인큐베이션하고 뉴트라비딘을 첨가하여 클래스 II 결합으로부터 참조 펩티드를 대체하는 능력을 계산한다.
예를 들어, 미세 매핑 기술에 의해 최적의 T 세포 에피토프를 결정하기 위해, T 세포 자극 활성을 갖고 따라서 T 세포 생물학 기술에 의해 결정된 적어도 하나의 T 세포 에피토프를 포함하는 펩티드를 펩티드의 아미노 말단 또는 카복시 말단에서 아미노산 잔기의 첨가 또는 결실에 의해 변형시켜 변형된 펩티드에 대한 T 세포 반응성의 변화를 확인하기 위한 시험을 하였다. T 세포 생물학 기술에 의해 결정된 바와 같이, 천연 단백질 서열에서 중첩 영역을 공유하는 2 개 이상의 펩티드가 인간 T 세포 자극 활성을 갖는 것으로 밝혀지면, 이러한 펩티드의 전부 또는 일부를 포함하는 추가 펩티드를 생산하고 이들 추가 펩티드를 유사한 절차로 시험할 수 있다. 이 기술에 따라, 펩티드가 재조합적으로 또는 합성적으로 선택되고 생산된다. 펩티드/에피토프에 대한 T 세포 반응의 강도 (예를 들어, 자극 지수) 및 개체 집단에서 펩티드에 대한 T 세포 반응의 빈도를 포함한 다양한 인자를 기반으로 T 세포 에피토프 또는 펩티드가 선택된다.
추가적으로 및/또는 대안적으로, 하나 이상의 시험관 내 알고리즘을 사용하여 항원 단백질 내 T 세포 에피토프 서열을 확인할 수 있다. 적합한 알고리즘은 [Zhang et al. (2005) Nucleic Acids Res 33, W180-W183 (PREDBALB); Salomon & Flower (2006) BMC Bioinformatics 7, 501 (MHCBN); Schuler et al. (2007) Methods Mol. Biol.409, 75-93 (SYFPEITHI); Donnes & Kohlbacher (2006) Nucleic Acids Res. 34, W194-W197 (SVMHC); Kolaskar & Tongaonkar (1990) FEBS Lett. 276, 172-174, Guan et al. (2003) Appl. Bioinformatics 2, 63-66 (MHCPred) 및 Singh and Raghava (2001) Bioinformatics 17, 1236-1237 (Propred)]에 기술된 것을 포함하지만 이에 한정되지 않는다. 더욱 특히, 이러한 알고리즘은 항원 단백질 내에서 MHC II 분자의 그루브에 맞을 하나 이상의 옥타- 또는 노나펩티드 서열 및 이의 상이한 HLA 유형의 예측을 가능케 한다.
용어 "MHC"는 "주요 조직적합성 항원"을 지칭한다. 인간에서, MHC 유전자는 HLA ("인간 백혈구 항원") 유전자로 알려져 있다. 일관되게 따르는 관례는 없지만, 일부 문헌은 HLA 단백질 분자를 지칭하기 위해 HLA를 사용하고, MHC는 HLA 단백질을 코딩하는 유전자를 지칭하기 위해 사용된다. 이와 같이 "MHC" 및 "HLA"라는 용어는 본원에서 사용되는 경우 등가적이다. 인간의 HLA 시스템은 마우스, 즉 H2 시스템에 해당하는 시스템을 가지고 있다. 가장 심도있게 연구된 HLA 유전자는 다음 9 개의 소위 고전적인 MHC 유전자이다: HLA-A, HLA-B, HLA-C, HLA-DPA1, HLA-DPB1, HLA-DQA1, HLAs DQB1, HLA-DRA, 및 HLA-DRB1. 인간에서는 MHC가 클래스 I, II 및 III의 세 영역으로 구분된다. A, B 및 C 유전자는 MHC 클래스 I에 속하며, 6 개의 D 유전자는 클래스 II에 속한다. MHC 클래스 I 분자는 세포 표면에서 베타 2 마이크로글로불린과 결합하는 3 개의 도메인 (알파 1, 2 및 3)을 포함하는 단일 다형쇄로 구성된다. 클래스 II 분자는 2 개의 다형쇄로 이루어져 있으며 이들은 각각 2 개의 사슬 (알파 1과 2, 및 베타 1과 2)을 포함한다.
클래스 I MHC 분자는 실질적으로 모든 핵생성 세포에서 발현된다.
클래스 I MHC 분자와 관련하여 제시된 펩티드 단편은 CD8+ T 림프구 (세포용해성 T 림프구 또는 CTL)에 의해 인식된다. CD8+ T 림프구는 종종 자극 항원을 갖는 세포를 용해시킬 수 있는 세포용해 이펙터로 성숙한다. 클래스 II MHC 분자는 주로 활성화된 림프구 및 항원 제시 세포에서 발현된다. CD4+ T 림프구 (헬퍼 T 림프구 또는 Th)는 대식세포 또는 수지상 세포와 같은 항원 제시 세포에서 보통 발견되는 클래스 II MHC 분자에 의해 제시된 독특한 펩티드 단편의 인식으로 활성화된다. CD4+ T 림프구는 항체 매개 및 세포 매개 반응을 지원하는 IL-2, IFN-γ 및 IL-4와 같은 사이토카인을 증식 및 분비한다.
기능성 HLA는 내인성 및 외래성의 잠재적 항원성 펩티드가 결합하는 깊은 결합 그루브를 특징으로 한다. 그루브는 잘 정의된 모양과 물리화학적 특성으로 추가 특정된다. 펩티드 말단이 그루브의 말단에 고정되어 있기 때문에 HLA 클래스 I 결합 부위는 닫혀 있다. 그들은 또한 보존 HLA 잔기가 있는 수소 결합의 네트워크에 관여한다. 이러한 제약의 관점에서, 결합된 펩티드의 길이는 8, 9 또는 10 잔기로 제한된다. 그러나, 12 개 까지의 아미노산 잔기의 펩티드가 또한 HLA 클래스 I에 결합할 수 있음이 입증되었다. 상이한 HLA 복합체의 구조 비교로 펩티드가 비교적 선형의 확장된 형태를 채택하는 일반적인 결합 방식이거나, 중앙 잔기가 그루브 밖으로 튀어나오게 포함할 수 있음을 확인하였다. HLA 클래스 I 결합 부위와 달리, 클래스 II 부위는 양단이 개방되어 있다. 이것은 펩티드가 실제 결합 영역으로부터 확장되어 양쪽 단부에서 "유지되는 (hanging out)" 것을 허용한다. 따라서 클래스 II HLA는 9 개에서 25개 초과의 아미노산 잔기에 이르는 가변 길이의 펩티드 리간드에 결합할 수 있다. HLA 클래스 I와 유사하게, 클래스 II 리간드의 친화성은 "불변" 및 "가변" 성분에 의해 결정된다. 불변 부분은 다시 HLA 클래스 II 그루브의 보존된 잔기와 결합된 펩티드의 주 사슬간에 형성된 수소 결합의 네트워크에 기인한다. 그러나, 이러한 수소 결합 패턴은 펩티드의 N- 및 C-말단 잔기에 국한되지 않고 전체 사슬에 분포된다. 후자는 복합화된 펩티드의 구조를 엄격하게 선형 결합 방식으로 제한하기 때문에 중요하다. 이것은 모든 클래스 II 알로타입에 공통적이다. 펩티드의 결합 친화성을 결정하는 제2 성분은 클래스 II 결합 부위 내 다형성의 특정 위치로 인해 가변적이다. 상이한 알로타입은 그루브 내에서 상이한 상보적 포켓을 형성함으로써, 펩티드의 아형 의존성 선택 또는 특이성을 설명한다. 중요하게, 클래스 II 포켓 내에서 유지되는 아미노산 잔기에 대한 제약은 일반적으로 클래스 I에 대한 것보다 "약하다". 상이한 HLA 클래스 II 알로타입 중에서 펩티드의 교차 반응이 훨씬 더 많다. MHC II 분자의 그루브에 들어 맞는 MHC 클래스 II T 세포 에피토프의 +/-9 (즉, 8, 9 또는 10) 아미노산 서열은 일반적으로 P1 내지 P9로 번호가 매겨진다. 에피토프의 추가 아미노산 N-말단은 P-1, P-2 등으로 번호가 매겨지고, 에피토프의 아미노산 C 말단은 P+1, P+2 등으로 번호가 매겨진다.
"NKT 세포 에피토프"라는 용어는 NKT 세포의 세포 표면에서 수용체에 의해 특이적으로 인식되고 결합되는 항원 단백질의 일부를 지칭한다. 특히, NKT 세포 에피토프는 CD1d 분자에 의해 결합된 에피토프이다. NKT 세포 에피토프는 일반 모티프 [FWYHT]-X(2)-[VILM]-X(2)-[FWYHT]를 가지고 있다. 이 일반 모티프의 대체 버전은 위치 1 및/또는 위치 7에 대체 [FWYH]를 가지며, 따라서 [FWYH]-X(2)-[VILM]-X(2)-[FWYH]를 가진다.
이 일반 모티프의 대체 버전은 위치 1 및/또는 위치 7에 대체 [FWYT], [FWYT]-X(2)-[VILM]-X(2)-[FWYT]를 가진다. 이 일반 모티프의 대체 버전은 위치 1 및/또는 위치 7에 대체 [FWY], [FWY]-X(2)-[VILM]-X(2)-[FWY]를 가진다.
위치 1 및/또는 7의 아미노산에 관계없이, 일반 모티프의 대체 버전은 위치 4에 대체 [ILM], 예를 들어 [FWYH]-X(2)-[ILM]-X(2)-[FWYH] 또는 [FWYHT]-X(2)-[ILM]-X(2)-[FWYHT] 또는 [FWY]-X(2)-[ILM]-X(2)-[FWY]를 가진다.
단백질에서 CD1d 결합 모티프는 ScanProsite De Castro E. et al. (2006) Nucleic Acids Res. 34(Web Server issue):W362-W365와 같은 알고리즘을 사용하여 수동으로 위의 서열 모티프에 대한 서열을 스캔하여 확인할 수 있다.
"자연 살해 T" 또는 "NKT" 세포는 비고전적인 MHC 복합체 분자 CD1d에 의해 제시된 항원을 인식하는 비-통상적 T 림프구의 상이한 서브세트를 구성한다. NKT 세포의 두 서브세트가 현재 설명되어 있다. 불변 NKT 세포 (iNKT)라고도 하는 I 형 NKT 세포가 가장 풍부하다. 이들은 불변 알파 사슬, 마우스에서 Valphal4 및 인간에서 Valpha24로 구성된 알파-베타 T 세포 수용체 (TCR)의 존재를 특징으로 한다. 이 알파 사슬은 제한된 수의 베타 사슬이지만 가변성과 관련된다. 2 형 NKT 세포는 알파-베타 TCR을 가지고 있지만 다형성 알파 사슬이 있다. 그러나 NKT 세포의 다른 서브세트가 존재하고 그 표현형은 아직 완전하게 정의되어 있지 않지만 CD1d 분자의 맥락에서 제시된 당지질에 의해 활성화되는 특성을 공유하는 것은 분명하다.
NKT 세포는 전형적으로 NKG2D 및 NK1.1을 포함한 자연 살해 (NK) 세포 수용체의 조합을 발현한다. NKT 세포는 선천 면역 체계의 일부이며, 완전한 이펙터 용량을 얻기 전에 확장이 필요하지 않다는 점에서 적응 면역 체계와 구별될 수 있다. 이들의 대부분의 매개자는 미리 형성되어 있으며 전사가 필요치 않다. NKT 세포는 세포 내 병원체 및 종양 거부에 대한 면역 반응의 주요 참여자인 것으로 나타났다. 자가면역 질환 및 이식 거부 제어에서의 이들의 역할이 또한 지지된다.
인식 단위인 CD1d 분자는 베타-2 마이크로글로불린의 존재를 포함하여 MHC 클래스 I 분자와 매우 유사한 구조를 가지고 있다. 그것은 두 개의 알파 사슬로 경계를 이루고 지질 사슬을 수용하는 고 소수성 잔기를 포함하는 깊은 틈이 특징이다. 상기 틈은 양단에서 열려 있어 더 긴 사슬을 수용할 수 있다. CD1d의 표준 리간드는 합성 알파 갈락토실세라마이드 (알파 GalCer)이다. 그러나, 당지질, 인지질, 미엘린에서 발견되는 천연 지질 설파타이드, 미생물 포스포이노시톨 만노사이드 및 알파-글루쿠로노실세라마이드를 포함하여 많은 천연 대체 리간드가 기술되었다. 당 업계에서 현재 일치를 이루고 있는 것 (Matsuda et al (2008), Curr. Opinion Immunol., 20 358-368; Godfrey et al (2010), Nature rev. Immunol 11, 197-206)은 여전히 CD1d가 일반적으로 CD1d에 묻혀 있는 지질 꼬리와 CD1d 밖으로 튀어 나온 당 잔기 헤드 그룹으로 이루어진 일반적인 구조 또는 지질 사슬을 포함하는 리간드에만 결합한다는 것이다.
에피토프와 관련하여 본원에서 사용된 "상동체"라는 용어는 자연적으로 발생된 에피토프와 적어도 50%, 적어도 70%, 적어도 80%, 적어도 90%, 적어도 95% 또는 적어도 98%의 아미노산 서열 동일성을 가지며, 이로써 B 및/또는 T 세포의 세포 표면 수용체 또는 항체에 결합할 수 있는 에피토프의 능력을 유지하는 분자를 지칭한다. 에피토프의 특정 상동체는 최대 3개, 더욱 특히, 최대 2 개, 가장 특히 1 개의 아미노산에서 변형된 천연 에피토프에 상응한다.
펩티드와 관련하여 본원에서 사용된 "유도체"라는 용어는 적어도 펩티드 활성 부분 (즉, 세포용해성 CD4+ T 세포 활성을 유도할 수 있는 산화환원 모티프 및 MHC 클래스 II 에피토프)를 함유하고, 그 이외에도, 다른 목적을 가질 수 있는, 예컨대 펩티드를 안정화시키거나 또는 펩티드의 약동학적 또는 약력학적 특성을 변경시키고자 하는 목적을 가진 상보적인 부분을 포함하는 분자를 지칭한다.
본원에서 사용되는 두 서열의 "서열 동일성"이라는 용어는 두 서열이 정렬될 때 동일한 뉴클레오티드 또는 아미노산을 갖는 위치의 수를 더 짧은 서열에서의 뉴클레오티드 또는 아미노산 수로 나눈 것을 가리킨다. 특히, 서열 동일성은 70% 내지 80%, 81% 내지 85%, 86% 내지 90%, 91% 내지 95%, 96% 내지 100% 또는 100%이다.
본원에 사용된 용어 "펩티드-코딩 폴리뉴클레오티드 (또는 핵산)" 및 "폴리뉴클레오티드 (또는 핵산) 코딩 펩티드"는 적절한 환경에서 발현될 때 관련 펩티드 서열 또는 그의 유도체 또는 상동체를 생성하는 뉴클레오티드 서열을 지칭한다. 이러한 폴리뉴클레오티드 또는 핵산은 펩티드를 코딩하는 정상 서열뿐만 아니라 요구되는 활성을 갖는 펩티드를 발현할 수 있는 이들 핵산의 유도체 및 단편을 포함한다. 본 발명에 따른 펩티드 또는 이의 단편을 코딩하는 핵산은 포유동물 유래 또는 포유동물에 상응하는 펩티드 또는 그 단편, 가장 특히 인간 펩티드 단편을 코딩하는 서열이다.
"산화환원 효소 모티프", "티올-산화환원 효소 모티프", "티오환원 효소 모티프", "티오레독스 모티프" 또는 "레독스 모티프"라는 용어는 본원에서 동의어로 사용되며, 한 분자 (환원제, 수소 또는 전자 공여체라고도 함)로부터 다른 분자 (산화제, 수소 또는 전자 수용체라고도 함)의 전자 전달에 관여하는 모티프를 지칭한다. 특히, 용어 "산화환원 효소 모티프"는 서열 모티프 [CST]-X-X-C 또는 C-X-X-[CST]를 지칭하며, 여기서, C는 시스테인, S는 세린, T는 트레오닌, X는 임의의 아미노산을 지칭한다.
"염기성 아미노산"이라는 용어는 브론스테드-로리 (Bronsted-Lowry) 및 루이스 (Lewis) 염기처럼 작용하는 모든 아미노산을 지칭하며 아르기닌 (R), 라이신 (K) 또는 히스티딘 (H)과 같은 천연 염기성 아미노산 또는 다음을 예로 들 수 있으나 이에 한정되지 않는 비천연 염기성 아미노산을 포함한다:
· Fmoc-β-Lys(Boc)-OH (CAS Number 219967-68-7), Fmoc-Orn(Boc)-OH (L-오르니틴 또는 오르니틴이라고도 함) (CAS Number 109425-55-0), Fmoc-β-Homolys(Boc)-OH (CAS Number 203854-47-1), Fmoc-Dap(Boc)-OH (CAS Number 162558-25-0) 또는 Fmoc-Lys(Boc)OH(DiMe)-OH (CAS Number 441020-33-3) 등의 라이신 변이체;
· Fmoc-L-3Pal-OH (CAS Number 175453-07-3), Fmoc-β-HomoPhe(CN)-OH (CAS Number 270065-87-7), Fmoc-L-β-HomoAla(4-피리딜)-OH (CAS Number 270065-69-5) 또는 Fmoc-L-Phe(4-NHBoc)-OH (CAS Number 174132-31-1)등의 티로신/페닐알라닌 변이체;
· Fmoc-Pro(4-NHBoc)-OH (CAS Number 221352-74-5) 또는 Fmoc-Hyp(tBu)-OH (CAS Number 122996-47-8)등의 프롤린 변이체;
· Fmoc-β-Homoarg(Pmc)-OH (CAS Number 700377-76-0) 등의 아르기닌 변이체.
"면역 장애" 또는 "면역 질환"이라는 용어는 면역계의 반응이 유기체에서 기능장애 또는 비생리학적인 상황의 원인이 되거나, 또는 그를 지속시키는 질환을 지칭한다. 그 중에서도 특히, 알레르기성 장애 및 자가면역 질환이 면역 질환에 포함된다.
본원에서 사용된 "알레르기성 질환" 또는 "알레르기성 장애"라는 용어는 알레르겐 (예컨대, 꽃가루, 쏘임, 약물, 또는 식품)이라 불리는 특이 물질에 대한 면역계의 과민성 반응을 특징으로 하는 질환을 의미한다. 알레르기는 개인 아토피성 환자를 감작화시켰던 알레르겐이 상기 환자와 접하게 될 때에는 언제든지 관찰되는 징후 및 증상의 집합체 (ensemble)로서, 이를 통해 각종 질환, 특히 호흡기 질환 및 증상, 예컨대 기관지 천식이 발병될 수 있는 것이다. 다양한 유형의 분류가 존재하며, 대개 알레르기성 장애는 그가 발생된 포유동물 모체의 위치에 따라 다른 명칭을 가진다. "과민성"은 개체가 감작화되었었던 항원에 노출되었을 때 개체에서 발생되는 바람직하지 못한 (손상성, 불쾌감 초래, 및 때로 치명적인) 반응이다; "즉시형 과민증"은 IgE 항체 생성에 의존하고, 따라서, 알레르기와 등가이다.
"자가면역 질환" 또는 "자가면역 장애"라는 용어는 유기체가 (분자 수준 이하에 이르기까지의) 그 자신의 구성 성분을 "자가"인 것으로 인식하지 못함에 따라 발생되는 그 자신의 세포 및 조직에 대한 비정상적인 면역 반응으로부터 유발되는 질환을 지칭한다. 상기 질환 군은 2 개의 카테고리, 기관-특이적 질환 및 전신 질환으로 분류될 수 있다.
"알레르겐"은 소인을 가진, 특히 유전적으로 소인을 가진 개인 (아토피) 환자에서 IgE 항체의 생성을 유도하는 물질, 일반적으로 거대분자 또는 단백질성 조성물로 정의된다. 유사한 정의는 문헌 [Liebers et al., (1996) Clin. Exp. Allergy 26, 494-516]에 제시되어 있다.
"치료적 유효량"이라는 용어는 환자에서 원하는 치료적 또는 예방적 효과를 일으키는 본 발명의 펩티드 또는 그의 유도체의 양을 의미한다. 이는 예를 들어, 질환 또는 장애와 관련하여, 질환 또는 장애의 하나 이상의 증상을 어느 정도 감소시키는 양, 및 더욱 특히, 질환 또는 장애와 관련되거나, 또는 그의 원인이 되는 생리학적 또는 생화학적 파라미터를 부분적으로 또는 완전하게 정상 수준으로 회복시키는 양이다. 전형적으로, 치료적 유효량은 정상적인 생리학적 상황으로 개선 또는 회복될 수 있도록 하는 본 발명의 펩티드 또는 그의 유도체의 양이다. 예를 들어, 면역 장애를 앓는 포유동물을 치료학적으로 치료하는 데 사용될 때, 이는 포유동물 체중 1 kg당 1일 펩티드 양이다. 대안적으로, 투여가 유전자 요법을 통해 이루어지는 경우, 나 (naked) DNA 또는 바이러스 벡터의 양은 본 발명의 펩티드, 이의 유도체 또는 상동체의 관련 투여량의 국부적인 생성을 보장하도록 조정된다.
본원에서 펩티드를 언급할 때, "천연"이라는 용어는 서열이 자연적으로 발생된 단백질 (야생형 또는 돌연변이)의 단편과 동일하다는 것과 관련된다. 상기와 달리, "인공"이라는 용어는 자연상에는 존재하지 않는 서열을 의미한다. 인공 서열은 자연 발생 서열 내 하나 이상의 아미노산을 변경/결실/삽입하거나, 자연 발생 서열의 아미노산 N- 또는 C-말단을 첨가/제거하는 것과 같은 제한된 변형에 의해 천연 서열로부터 얻어진다.
이러한 맥락에서, 펩티드 단편은 전형적으로 에피토프 스캐닝과 관련하여 항원으로부터 생성된다는 것이 인식된다. 우연히 그러한 펩티드는 그들의 서열에 T 세포 에피토프 (MHC 클래스 II 에피토프 또는 CD1d 결합 에피토프)를 포함할 수 있고, 이와 근접하여 본원에 정의된 바와 같은 변형된 산화환원 모티프를 갖는 서열을 포함할 수 있다. 대안적으로, 상기 에피토프와 상기 산화환원 효소 모티프 사이에 최대 11 개 아미노산, 최대 7 개 아미노산, 최대 4 개 아미노산, 최대 2 개 아미노산, 또는 심지어 0 개 아미노산 (즉, 에피토프와 산화환원 효소 모티프 서열은 서로 바로 인접한다)이 있을 수 있다. 바람직한 구체예에서, 이러한 자연 발생 펩티드는 주장되지 않는다.
아미노산은 본원에서 이들의 전체 이름, 3 자 약어 또는 1 자 약어로 지칭된다.
아미노산 서열의 모티프는 Prosite의 형식에 따라 본원에 쓰여진다. 모티프는 서열의 특정 부분에서 특정 서열 다양성을 설명하는 데 사용된다. 기호 X 또는 B는 아미노산이 허용되는 위치에 대해 사용된다. 기호 (Z1)+, (Z2)+ 및 (Z3)+는 임의의 염기성 아미노산이 본원의 다른 곳에서 정의된 바와 같이 허용되는 위치에 사용된다. 대체 아미노산은 대괄호 ('[]') 사이에 주어진 위치에 허용되는 아미노산을 나열하여 표시할 수 있다. 예를 들어, [CST]는 Cys, Ser 또는 Thr로부터 선택된 아미노산을 나타낸다. 대안으로 제외되는 아미노산은 중괄호 ('{}') 사이에 나열하여 표시할 수 있다. 예를 들어, {AM}은 Ala 및 Met를 제외한 모든 아미노산을 나타낸다. 모티프의 다른 요소는 임의로 하이픈 (-)으로 서로 분리된다. 아미노산을 구별하기 위해 산화환원 효소 모티프 외부의 아미노산을 외부 아미노산이라고 하고 산화환원 모티프 내의 아미노산을 내부 아미노산이라고 할 수 있다.
T 세포 에피토프를 포함하는 펩티드, 예를 들어, 환원 활성을 갖는 MHC 클래스 II T-세포 에피토프 또는 NKT-세포 에피토프 (또는 CD1d 결합 펩티드 에피토프) 및 변형된 펩티드 모티프 서열은 각각 항원 제시 세포를 향한 세포용해성 NKT-세포인 항원-특이적 세포용해성 CD4+ T-세포 집단을 생성할 수 있다.
따라서, 가장 넓은 의미에서, 본 발명은 면역 반응을 유발할 가능성이 있는 항원 (자기 또는 비-자기)의 적어도 하나의 T-세포 에피토프 (MHC 클래스 II T-세포 에피토프 또는 NKT-세포 에피토프) 및 펩티드 디설파이드 결합에 대한 환원 활성을 갖는 변형된 티오환원효소 서열 모티프를 포함하는 펩티드에 관한 것이다. T 세포 에피토프 및 변형된 산화환원 모티프 서열은 펩티드에서 서로 바로 인접하거나 임의로 하나 이상의 아미노산 (소위 링커 서열)에 의해 분리될 수 있다. 임의로 펩티드는 엔도솜 표적화 서열 및/또는 추가 "플랭킹" 서열을 더 포함한다.
본 발명의 펩티드는 면역 반응을 유발할 가능성이 있는 항원 (자기 또는 비 자기)의 T-세포 에피토프 및 변형된 산화환원 모티프를 포함한다. 펩티드에서 모티프 서열의 환원 활성은 환원에 따라 인슐린의 용해도가 달라지는 인슐린 용해도 분석, 또는 인슐린과 같은 형광 표지된 기질의 사용과 같이 설프히드릴 그룹을 환원시키는 능력에 대해 분석될 수 있다. 그러한 분석의 일례는 형광 펩티드를 사용하며 [Tomazzolli et al. (2006) Anal. Biochem. 350, 105-112]에 기술되어 있다. FITC 표지가 있는 두 개의 펩티드는 디설파이드 브릿지를 통해 서로 공유 결합되는 경우 자가 소광된다. 본 발명에 따른 펩티드에 의해 환원되면, 환원된 개별 펩티드는 다시 형광성으로 된다.
변형된 산화환원 모티프는 T-세포 에피토프의 아미노-말단 측 또는 T-세포 에피토프의 카복시-말단에 위치할 수 있다.
환원 활성을 갖는 펩티드 단편은 글루타레독신, 뉴클레오레독신, 티오레독신 및 기타 티올/디설파이드 산화환원 효소를 포함하는 작은 디설파이드 환원 효소인 티오환원 효소에서 접한다 (Holmgren (2000) Antioxid. Redox Signal. 2, 811-820; Jacquot et al. (2002) Biochem. Pharm. 64, 1065-1069). 이들은 다기능성이며 유비쿼터스적이고 많은 원핵생물 및 진핵생물에서 발견된다. 이들은 예를 들어 [Fomenko et al. ((2003) Biochemistry 42, 11214-11225; Fomenko et al. (2002) Prot. Science 11, 2285-2296)] (여기서, X는 임의의 아미노산을 나타냄) 및 위치 1 및/또는 4에 시스테인을 포함하는 WO2008/017517호로부터 알려진, 보존된 활성 도메인 공통 서열 내에서 산화환원 활성 시스테인을 통해 단백질 (예컨대 효소) 상의 디설파이드 결합에 대해 환원 활성을 발휘하는 것으로 알려져 있다. 따라서 모티프는 CXX[CST] 또는 [CST]XXC이다. 이러한 도메인은 또한 단백질 디설파이드 이소머라제 (PDI) 및 포스포이노사이티드 특이적 포스포리파제 C와 같은 더 큰 단백질에서도 발견된다. 본 발명은 더 많은 효능과 활성을 찾기 위해 상기 모티프를 재설계하였다.
이후에 상세히 설명하는 바와 같이, 본 발명의 펩티드는 비천연 아미노산의 도입을 허용하는 화학적 합성에 의해 제조될 수 있다. 따라서, 상기 언급된 산화환원 변형된 산화환원 모티프에서의 "C"는 시스테인 또는 티올기를 갖는 다른 아미노산, 예컨대 머캅토발린, 호모시스테인 또는 티올 작용기를 갖는 다른 천연 또는 비 천연 아미노산을 나타낸다. 환원 활성을 갖기 위해, 변형된 산화환원 모티프에 존재하는 시스테인은 시스틴 디설파이드 브릿지의 일부로서 발생하여서는 안된다. 그렇지만, 변형된 산화환원 모티프는 생체 내에서 자유 티올기를 갖는 시스테인으로 전환되는 메틸화된 시스테인과 같은 변형된 시스테인을 포함할 수 있다.
펩티드는 N 말단 NH2 기 또는 C 말단 COOH 기의 변형 (예를 들어, COOH가 CONH2기로 변형)과 같이, 안정성 또는 용해도를 증가시키기 위한 변형을 추가로 포함할 수 있다.
변형된 산화환원 모티프를 포함하는 본 발명의 펩티드에서, 모티프는 에피토프가 MHC 그루브에 맞거나 CD1d 수용체에 결합하는 경우 모티프가 MHC 또는 CD1d 수용체 결합 그루브의 외부에 남아 있도록 위치한다. 변형된 산화환원 모티프는 펩티드 내의 에피토프 서열에 바로 인접하여 위치 [다시 말해, 모티프와 에피토프 사이에 0 개의 아미노산으로 이루어진 링커 서열]에 위치하거나, 또는 7 개 이하의 아미노산으로 이루어진 아미노산 서열을 포함하는 링커에 의해 T 세포 에피토프로부터 분리된다. 보다 구체적으로, 링커는 1, 2, 3, 4, 5, 6 또는 7 개의 아미노산을 포함한다. 특정 구체예는 에피토프 서열과 변형된 산화환원 모티프 서열 사이에 0, 1 또는 2 개의 아미노산 링커를 갖는 펩티드이다. 펩티드 링커와 별도로, 다른 유기 화합물이 펩티드의 부분을 서로 연결시키는 (예를 들어, T 세포 에피토프 서열에 변형된 산화환원 모티프 서열) 링커로서 사용될 수 있다.
본 발명의 펩티드는 T 세포 에피토프 및 변형된 산화환원 모티프를 포함하는 서열의 N- 또는 C-말단에 추가의 짧은 아미노산 서열을 추가로 포함할 수 있다. 이러한 아미노산 서열은 일반적으로 본원에서 '플랭킹 서열'이라 칭한다. 플랭킹 서열은 에피토프와 엔도솜 표적 서열 사이 및/또는 변형된 산화환원 모티프와 엔도솜 표적 서열 사이에 위치할 수 있다. 엔도솜 표적화 서열을 포함하지 않는 특정 펩티드에서, 짧은 아미노산 서열은 펩티드 내에 N- 및/또는 C-말단에 변형된 산화환원 모티프 및/또는 에피토프 서열을 제공할 수 있다. 특히, 플랭킹 서열은 1 내지 7 개의 아미노산 서열, 특히 2 개의 아미노산 서열이다.
변형된 산화환원 모티프는 에피토프로부터 N-말단에 위치할 수 있다. 대안적으로, 변형된 산화환원 모티프는 에피토프로부터 C-말단에 위치할 수 있다.
본 발명의 특정 구체예에서, 하나의 에피토프 서열 및 변형된 산화환원 모티프 서열을 포함하는 펩티드가 제공된다. 추가의 특정 구체예에서, 변형된 산화환원 모티프는 펩티드에서 수회 (1, 2, 3, 4 회 또는 심지어 그 이상), 예를 들어, 하나 이상의 아미노에 의해 서로 이격될 수 있는 변형된 산화환원 모티프의 반복체 또는 서로 인접한 반복체로서 존재할 수 있다. 대안적으로, 하나 이상의 변형된 산화환원 모티프가 T 세포 에피토프 서열의 N 및 C 말단 모두에 제공된다.
본 발명의 펩티드에 대해 예상되는 다른 변형은 T 세포 에피토프 서열의 반복을 포함하는 펩티드를 포함하며, 여기서 각 에피토프 서열은 변형된 산화환원 모티프가 선행되고/되거나 이어진다 (예를 들어, "변형된 산화환원 모티프-에피토프"의 반복체 또는 "변형된 산화환원 모티프-에피토프-변형된 산화환원 모티프"의 반복체). 여기서, 변형된 산화환원 모티프는 모두 동일한 서열을 가질 수 있지만, 반드시 그러해야 하는 것은 아니다. 자체로 변형된 산화환원 모티프를 가지는 에피토프를 포함하는 펩티드의 반복 서열은 또한 '에피토프' 및 '변형된 산화환원 모티프'를 모두 가지는 서열로 이어질 것이라는 점에 유의바란다. 이러한 펩티드에서, 제1 에피토프 서열 내의 변형된 산화환원 모티프는 제2 에피토프 서열 외부의 변형된 산화환원 모티프로서 기능한다.
전형적으로, 본 발명의 펩티드는 단 하나의 T 세포 에피토프만을 포함한다. 하기 기술된 바와 같이, 단백질 서열에서의 T 세포 에피토프는 기능 분석 및/또는 실리카 예측 분석에서 하나 이상으로 동정될 수 있다. T 세포 에피토프 서열의 아미노산은 MHC 단백질의 결합 그루브 내에서 그들의 위치에 따라 번호가 매겨진다. 펩티드 내에 존재하는 T-세포 에피토프는 7 내지 30 개의 아미노산, 예컨대 8 내지 25 개의 아미노산, 보다 특히 8 내지 16 개의 아미노산, 가장 특히 8, 9, 10, 11, 12, 13, 14, 15 또는 16 개의 아미노산으로 구성된다.
보다 특정한 구체예에서, T 세포 에피토프는 7, 8, 또는 9 개의 아미노산 서열로 구성된다. 추가의 특정 구체예에서, T-세포 에피토프는 MHC-클래스 II 분자 [MHC 클래스 II 제한 T 세포 에피토프]에 의해 T 세포에 제시되는 에피토프이다. 전형적으로 T 세포 에피토프 서열은 MHC II 단백질의 틈새에 맞는 옥타펩티드 또는보다 구체적으로 노나펩티드 서열을 지칭한다.
보다 특정한 구체예에서, T 세포 에피토프는 7, 8, 또는 9 개의 아미노산 서열로 구성된다. 추가의 특정 구체예에서, T-세포 에피토프는 CD1d 분자에 의해 제시되는 에피토프 [NKT 세포 에피토프]이다. 전형적으로 NKT 세포 에피토프 서열은 CD1d 단백질에 결합하고 이에 의해 제시되는 7 개 아미노산 펩티드 서열을 의미한다.
본 발명의 펩티드의 T 세포 에피토프는 단백질의 천연 에피토프 서열 중 어느 하나에 상응할 수 있거나, 그의 변형된 버전일 수 있지만, 단 변형된 T 세포 에피토프는 천연 T 세포 에피토프 서열과 유사하게 MHC 틈새 내에서 결합하거나 CD1d에 결합하는 능력을 보유하여야 한다. 변형된 T 세포 에피토프는 천연 에피토프와 동일한 MHC 단백질 또는 CD1d 수용체에 대한 결합 친화력을 가질 수 있지만, 감소된 친화성을 가질 수도 있다. 특히, 변형된 펩티드의 결합 친화성은 원래의 펩티드보다 10배 이상 작지 않고, 특히 5배 이상 작지 않다. 본 발명의 펩티드는 단백질 복합체에 대해 안정화 효과를 갖는다. 따라서, 펩티드-MHC 또는 CD1d 복합체의 안정화 효과는 MHC 또는 CD1d 분자에 대한 변형된 에피토프의 저하된 친화성을 보상한다.
펩티드 내에 환원성 화합물 및 T 세포 에피토프를 포함하는 서열은 MHC 클래스 II 결정기 내에서 프로세싱 및 제시를 위해 후기 엔도솜으로의 펩티드의 흡수를 용이하게 하는 아미노산 서열 (또는 다른 유기 화합물)에 추가로 연결될 수 있다. 후기 엔도솜 표적화는 단백질의 세포질 꼬리에 존재하는 신호에 의해 매개되며, 잘 규명된 펩티드 모티프에 상응한다. 후기 엔도솜 표적화 서열은 MHC-클래스 II 분자에 의한 항원 유래 T-세포 에피토프의 프로세싱 및 효율적인 제시를 허용한다. 이러한 엔도솜 표적화 서열은 예를 들어, gp75 단백질 (Vijayasaradhi et al. (1995) J. Cell. Biol. 130, 807-820), 인간 CD3 감마 단백질, HLA-BM 11 (Copier et al. (1996) J. lmmunol. 157, 1017-1027), DEC205 수용체의 세포질 꼬리 (Mahnke et al. (2000) J. Cell Biol. 151, 673-683) 내에 함유된다. 엔도솜으로의 선별 신호로서 기능하는 펩티드의 다른 예는 [Bonifacio and Traub (2003) Annu. Rev. Biochem. 72, 395-447]의 리뷰편에 기재되었다. 대안적으로, 서열은 항원에 대한 T 세포 반응의 압도 없이 후기 엔도솜에서의 흡수를 용이하게 하는, 단백질로부터의 준우세 또는 열세 T 세포 에피토프의 것일 수 있다. 후기 엔도솜 표적화 서열은 효율적인 흡수 및 프로세싱을 위해 항원 유래 펩티드의 아미노 말단부 또는 카복시 말단부에 위치할 수 있으며, 또한 10 개 이하의 아미노산으로 이루어진 펩티드 서열과 같은 프랭킹 서열을 통해 결합될 수 있다. 표적화 목적을 위한 열세 T 세포 에피토프를 사용하는 경우, 후자는 전형적으로 항원 유래 펩티드의 아미노 말단부에 위치한다.
대안적으로, 본 발명은 CD1d 분자에 결합하는 능력을 부여하는 소수성 잔기를 함유하는 펩티드의 생산에 관한 것이다. 투여시, 이러한 펩티드는 APC에 의해 흡수되고, CD1d에 로딩되고 APC의 표면에 제시되는 후기 엔도솜으로 향한다. 상기 소수성 펩티드는 일반 서열 [FW]-xx-[ILM]-xx[FWTH] 또는 [FWTH]-xx-[ILM]-xx-[FW,]에 상응하는 모티프를 특징으로 하며, 여기서, 위치 P1 및 P7은 페닐알라닌 (F) 또는 트립토판 (W)과 같은 소수성 잔기가 차지한다. 그러나 P7은 트레오닌 (T) 또는 히스티딘 (H)과 같은 페닐알라닌 또는 트립토판에 대한 대체 소수성 잔기를 수용한다는 점에서 허용적이다. P4 위치는 이소류신 (I), 류신 (L) 또는 메티오닌 (M)과 같은 지방족 잔기가 차지한다. 본 발명은 자연적으로 CD1d 결합 모티프를 구성하는 소수성 잔기로 이루어진 펩티드에 관한 것이다. 일부 구체예에서, 상기 모티프의 아미노산 잔기는 일반적으로 CD1d에 결합하는 능력을 증가시키는 잔기로의 치환에 의해 변형된다. 특정 구체예에서, 모티프는 일반 모티프 [FW]-xx-[ILM]-xx-[FWTH]와 더 밀접하게 맞도록 변형된다. 보다 구체적으로, 펩티드는 위치 7에 F 또는 W를 포함하도록 생산된다.
따라서, 본 발명은 항원 단백질의 펩티드 및 특이적 면역 반응을 유도하는데 그의 용도를 구상한다. 이들 펩티드는 그 서열 내에, 최대 10 개, 바람직하게는 7 개 이하의 아미노산에 의해 분리된 T 세포 에피토프 및 환원성 화합물을 포함하는 단백질 단편에 상응할 수 있다. 대안적으로, 대부분의 항원 단백질에 대해, 본 발명의 펩티드는 환원성 화합물, 보다 구체적으로는 본원에 기재된 바와 같은 환원성 변형 산화환원 모티프를 항원 단백질의 T 세포 에피토프 (그에 직접 인접하거나 또는 10 개 이하, 보다 특히 7 개 이하의 아미노산 링커를 가지는)에 N-말단 또는 C-말단에 커플링함으로써 생성된다. 또한, 자연 발생 서열과 비교하여 단백질 및/또는 변형된 산화환원 모티프의 T 세포 에피토프 서열이 변형될 수 있고/있거나, 하나 이상의 플랭킹 서열 및/또는 표적화 서열이 도입 (또는 변형)될 수 있다. 따라서, 본 발명의 특징이 대상 항원 단백질의 서열 내에서 발견될 수 있는지의 여부에 따라, 본 발명의 펩티드는 '인공' 또는 '자연적으로 존재하는' 서열을 포함할 수 있다.
본 발명의 펩티드는 실질적으로 다양한 길이를 가질 수 있다. 펩티드의 길이는 13 또는 14 개의 아미노산 (즉, 8 내지 9 개 아미노산의 에피토프, 그에 인접하여 히스티딘을 가지는 5개 아미노산의 변형된 산화환원 모티프로 이루어짐)에서부터 20, 25, 30, 40 또는 50 개 이하의 아미노산까지로 변할 수 있다. 예를 들어, 펩티드는 40 개 아미노산의 엔도솜 표적화 서열, 약 2 개의 아미노산의 플랭킹 서열, 5 개 아미노산의 본원에 기재된 모티프, 4 개 아미노산의 링커 및 9 개 아미노산의 T 세포 에피토프 펩티드를 포함할 수 있다.
따라서, 특정 구체예에서, 완전한 펩티드는 13 개 아미노산 내지 20, 25, 30, 40, 50, 75 또는 100 개 까지의 아미노산으로 이루어진다. 더욱 특히, 환원성 화합물이 본원에 기재된 바와 같은 변형된 산화환원 모티프인 경우, 엔도솜 표적화 서열없이 링커에 의해 임의로 연결된 에피토프 및 변형된 산화환원 모티프를 포함하는 (인공 또는 천연) 서열 (본원에서 '에피토프-변형된 산화환원 모티프' 서열로 칭해짐)의 길이가 중요하다. '에피토프-변형된 산화환원 모티프'는 특히 13, 14, 15, 16, 17, 18 또는 19 개의 아미노산 길이를 갖는다. 이러한 13 또는 14 내지 19 개의 아미노산으로 이루어진 펩티드는 임의로 크기가 덜 중요한 엔도솜 표적화 신호에 결합될 수 있다.
상술한 바와 같이, 특정 구체예에서, 본 발명의 펩티드는 T 세포 에피토프 서열에 연결된 본원에 기재된 바와 같은 환원성 변형 산화환원 모티프를 포함한다.
추가의 특정 구체예에서, 본 발명의 펩티드는 그들의 천연 서열 내에 산화환원 특성을 갖는 아미노산 서열을 포함하지 않는 T 세포 에피토프를 포함하는 펩티드이다.
그러나, 대안적인 구체예에서, T 세포 에피토프는 MHC 틈새 또는 CD1d 분자에 에피토프의 결합을 보장하는 아미노산의 임의의 서열을 포함할 수 있다. 항원 단백질의 관심 에피토프가 그의 에피토프 서열 내에 본원에 기재된 바와 같은 변형된 산화환원 모티프를 포함하는 경우, 본 발명에 따른 면역원성 펩티드는 (틈새 내에 묻힌 에피토프 내에 존재하는 변형된 산화환원 모티프와 달리) 부착된 변형된 산화환원 모티프가 환원 활성을 보장할 수 있도록 본원에 기재된 바와 같은 변형된 산화환원 모티프의 서열 및/또는 에피토프 서열에 N-말단 또는 C-말단에 커플링된 다른 환원성 서열을 포함한다.
따라서, T 세포 에피토프 및 모티프는 서로 인접하거나 또는 서로 분리되어 중첩되지 않는다. "바로 인접한" 또는 "분리된"의 개념을 평가하기 위해, MHC 틈새 또는 CD1d 분자에 맞는 8 또는 9 개 아미노산 서열을 결정하고, 이 옥타펩티드 또는 노나펩티드와 산화환원 모티프 테트라펩티드 또는 히스티딘을 포함한 변형된 산화환원 모티프 펜타펩티드 사이의 거리를 결정한다.
일반적으로, 본 발명의 펩티드는 천연의 것이 아니라 (따라서 그러한 단백질 단편이 없음), T 세포 에피토프 이외에, 본원에 기재된 바와 같은 변형된 산화환원 모티프를 함유함으로써 변형된 산화환원 모티프가 7 개 이하, 가장 특히 4 개 또는 2 개 이하의 아미노산으로 이루어진 링커에 의해 T 세포 에피토프로부터 바로 분리되는 인공 펩티드이다.
산화환원 효소 모티프 및 MHC 클래스 II T-세포 에피토프를 포함하는 펩티드 (또는 이러한 펩티드를 포함하는 조성물)를 포유동물에게 투여 (즉, 주사)한 경우, 펩티드는 항원 유래 T 세포 에피토프를 인식하는 T 세포의 활성화를 유도하고 표면 수용체의 감소를 통해 T 세포에 추가 신호를 제공하는 것으로 나타났다. 이러한 최적의 활성화는 T 세포가 T 세포 에피토프를 제시하는 세포에 대한 세포용해 특성뿐만 아니라 방관자 T 세포에 대한 억제 특성을 획득하게 한다.
추가로, 산화환원 효소 모티프 및 NKT-세포 에피토프를 포함하는 펩티드 (또는 이러한 펩티드를 포함하는 조성물)를 포유동물에게 투여 (즉, 주사)한 경우 펩티드가 항원 유래 T 세포 에피토프를 인식하는 T 세포의 활성화를 유도하고 CD1d 표면 수용체에 대한 결합을 통해 T 세포에 추가 신호를 제공하는 것으로 나타났다. 이 활성화는 NKT 세포가 T 세포 에피토프를 제시하는 세포에 대한 세포용해 특성을 획득하게 한다.
이러한 방식으로, 항원 유래 T 세포 에피토프 및 에피토프 외부에 변형된 산화환원 모티프를 함유하는 펩티드 또는 본 발명에 기재된 펩티드를 포함하는 조성물이 인간을 비롯한 포유동물의 직접 면역화에 사용될 수 있다. 이에 따라, 본 발명은 의약으로서 사용하기 위한, 본 발명의 펩티드 또는 그의 유도체를 제공한다. 따라서, 본 발명은 본 발명에 따른 하나 이상의 펩티드를 이를 필요로 하는 환자에게 투여하는 것을 포함하는 치료 방법을 제공한다.
본 발명은 소형 펩티드로 면역화하여 세포용해 특성이 유도될 수 있는 항원 특이적 T 세포를 유도할 수 있는 방법을 제공한다. (i) 항원으로부터 T 세포 에피토프를 코딩하는 서열 및 (ii) 산화환원 특성을 갖는 공통 서열을 포함하고, 또한 임의로 효율적인 MHC-클래스 II 제시 또는 CD1d 수용체 결합을 위해 펩티드의 후기 엔도솜으로의 흡수를 용이하게 하는 서열을 포함하는 펩티드는 각각 세포용해성 CD4+ T-세포 또는 NKT 세포를 유도한다는 것이 발견되었다.
본 발명의 펩티드의 면역원성은 면역 반응의 치료 및 예방에 특히 중요하다.
본원에 기재된 펩티드는 약제로 사용되며, 보다 특히 포유동물, 특히 인간에서 면역 장애의 예방 또는 치료용 약제의 제조에 사용된다.
본 발명은 본 발명의 펩티드, 그의 상동체 또는 유도체를 사용하여 치료 또는 예방을 필요로 하는 포유동물의 면역 장애를 치료 또는 예방하는 방법을 기술하며, 이 방법은 면역 장애로 고통받거나 그의 위험이 있는 상기 포유동물에게 예컨대 면역 장애의 증상을 감소시키기에 치료적 유효량의 본 발명의 펩티드, 상동체 또는 이의 유도체를 투여하는 단계를 포함한다. 인간과 애완 동물 및 농장 동물과 같은 동물 모두의 치료가 고려된다. 일 구체예에서, 치료될 포유동물은 인간이다. 특정 구체예에서 상기 언급된 면역 장애는 알레르기 질환 및 자가면역 질환 중에서 선택된다.
본 발명의 펩티드 또는 본원에 정의된 바와 같은 펩티드를 포함하는 약학 조성물은 바람직하게는 피하 또는 근육 내 투여를 통해 투여된다. 바람직하게는, 이를 펩티드 또는 이를 포함하는 약학 조성물은 팔꿈치와 어깨 사이의 중간인 상완의 측면 부분 영역에 피하 (SC) 주사될 수 있다. 두 번 이상의 개별 주사가 필요한 경우 두 팔에 동시에 투여될 수 있다.
본 발명에 따른 펩티드 또는 이를 포함하는 약학 조성물은 치료적 유효 용량으로 투여된다. 예시적이지만 비제한적인 투여 요법은 50 내지 1500 ㎍, 바람직하게는 100 내지 1200 ㎍이다. 보다 구체적인 투여 계획은 환자의 상태와 질환의 중증도에 따라 50 내지 250 ㎍, 250 내지 450 ㎍ 또는 850 내지 1300 ㎍일 수 있다. 투약 요법은 단일 용량으로 또는 2, 3, 4, 5 또는 그 이상의 용량으로 동시에 또는 연속적으로 투여하는 것을 포함할 수 있다. 예시적인 비제한적 투여 계획은 다음과 같다:
- 각각 25 ㎍ (각각 100 μL)의 두 번의 개별 주사로 50 ㎍의 펩티드를 SC 투여 한 다음 각각 12.5 ㎍ (각각 50 μL)의 두 번의 개별 주사로 25 ㎍의 펩티드를 3 회 연속 주사하는 저용량 계획.
- 각각 75 ㎍ (각각 300 μL)의 두 번의 개별 주사로 150 ㎍의 펩티드를 SC 투여한 후 각각 37.5 ㎍ (각각 150 μL)의 두 번의 개별 주사로 75 ㎍의 펩티드를 3 회 연속 투여하는 중간 용량 계획.
- 각각 225 ㎍ (각각 900 μL)의 두 번의 개별 주사로 450 ㎍의 펩티드를 SC 투여한 후 각각 112.5 ㎍ (각각 450 μL)의 두 번의 개별 주사로 225 ㎍의 펩티드를 3 회 연속 투여하는 고용량 계획.
공지 산화환원 효소 모티프 및 T-세포 에피토프를 포함하는 면역원성 펩티드의 예시적인 용량 계획은 ClinicalTrials.gov에서 식별자 NCT03272269로 찾을 수 있다.
본 발명은 0 내지 7 개 아미노산의 링커에 의해 임의로 분리된, 개선된 산화환원 효소 모티프 및 항원 단백질의 T-세포 에피토프를 포함하는 면역원성 펩티드를 제공한다.
상기 개선된 산화환원 효소 모티프는 다음을 포함하는 군으로부터 선택된다:
(i)
[CST](Z1)+XC; 또는 C(Z1)+X[CST],
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이고;
(ii)
[CST]X(Z2)+C; CX(Z2)+[CST]; (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST];
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii)
[CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+,
여기서, (Z3)+는 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1이다.
바람직하게는 상기 X는 G, A, V, L, I, M, F, W, P, S, T, C, Y, N, Q, D, E, K 및 R, H, 또는 다음으로 구성된 군 중에서 선택되는 비천연 염기성 아미노산으로 구성된 군으로부터 선택된다:
· Fmoc-β-Lys(Boc)-OH (CAS Number 219967-68-7), Fmoc-Orn(Boc)-OH (L-오르니틴 또는 오르니틴이라고도 함) (CAS Number 109425-55-0), Fmoc-β-Homolys(Boc)-OH (CAS Number 203854-47-1), Fmoc-Dap(Boc)-OH (CAS Number 162558-25-0) 또는 Fmoc-Lys(Boc)OH(DiMe)-OH (CAS Number 441020-33-3) 등의 라이신 변이체;
· Fmoc-L-3Pal-OH (CAS Number 175453-07-3), Fmoc-β-HomoPhe(CN)-OH (CAS Number 270065-87-7), Fmoc-L-β-HomoAla(4-피리딜)-OH (CAS Number 270065-69-5) 또는 Fmoc-L-Phe(4-NHBoc)-OH (CAS Number 174132-31-1)등의 티로신/페닐알라닌 변이체;
· Fmoc-Pro(4-NHBoc)-OH (CAS Number 221352-74-5) 또는 Fmoc-Hyp(tBu)-OH (CAS Number 122996-47-8)등의 프롤린 변이체;
· Fmoc-β-Homoarg(Pmc)-OH (CAS Number 700377-76-0) 등의 아르기닌 변이체.
바람직한 구체예에서, (Z1)+는 K, R 또는 비천연 염기성 아미노산을 포함하는 군으로부터 선택되고/거나, (Z2)+ 및/또는 (Z3)+는 각각 개별적으로 K, H, R 또는 본원에 정의된 비천연 염기성 아미노산을 포함하는 군으로부터 선택된다. 바람직한 구체예에서, (Z1)+, (Z2)+ 및/또는 (Z3)+는 각각 개별적으로 K 또는 L-오르니틴일 수 있다.
바람직한 구체예에서, X는 C, S 또는 T를 제외한 임의의 아미노산이다.
일부 구체예에서 B1 및/또는 B2는 H이다.
일부 구체예에서, X는 염기성 아미노산을 제외한 임의의 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 티로신 (Y)임), 예컨대 C(Z1)+YC, S(Z1)+YC, T(Z1)+YC, C(Z1)+YC, C(Z1)+YS, C(Z1)+YT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST] (여기서, X는 프롤린 (P)임), 예컨대 CP(Z2)+C, SP(Z2)+C, TP(Z2)+C, CP(Z2)+C, CP(Z2)+S, CP(Z2)+T이다. 상기 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 글리신 (G)임), 예컨대 C(Z1)+GC, S(Z1)+GC, T(Z1)+GC, C(Z1)+GC, C(Z1)+GS, C(Z1)+GT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST] (여기서, X는 히스티딘 (H)임), 예컨대 CH(Z2)+C, SH(Z2)+C, TH(Z2)+C, CH(Z2)+C, CH(Z2)+S, CH(Z2)+T이다. 상기 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 프롤린 (P)임), 예컨대 C(Z1)+PC, S(Z1)+PC, T(Z1)+PC, C(Z1)+PC, C(Z1)+PS, C(Z1)+PT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST] (여기서, X는 글리신 (G)임), 예컨대 CG(Z2)+C, SG(Z2)+C, TG(Z2)+C, CG(Z2)+C, CG(Z2)+S, CG(Z2)+T이다. 상기 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 프롤린 (P)임), 예컨대 C(Z1)+PC, S(Z1)+PC, T(Z1)+PC, C(Z1)+PC, C(Z1)+PS, C(Z1)+PT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 페닐알라닌 (F)임), 예컨대 C(Z1)+FC, S(Z1)+FC, T(Z1)+FC, C(Z1)+FC, C(Z1)+FS, C(Z1)+FT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 히스티딘 (H)임), 예컨대 C(Z1)+HC, S(Z1)+HC, T(Z1)+HC, C(Z1)+HC, C(Z1)+HS, C(Z1)+HT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z1)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST] (여기서, X는 아르기닌 (R)임), 예컨대 CR(Z2)+C, SR(Z2)+C, TR(Z2)+C, CR(Z2)+C, CR(Z2)+S, CR(Z2)+T이다. 상기 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST](Z1)+XC 또는 C(Z1)+X[CST] (여기서, X는 류신 (L)임), 예컨대 C(Z1)+LC, S(Z1)+LC, T(Z1)+LC, C(Z1)+LC, C(Z1)+LS, C(Z1)+LT이다. 상기 모티프 중 어느 하나에서, (Z1)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있고/거나, 바람직하게는 R이 아니다. 특정 예에서, (Z1)+는 K 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]PYC 또는 (Z2)+(B1)nCPY[CST], 예컨대 (Z2)+(B1)nCPYC, (Z2)+(B1)nSPYC, (Z2)+(B1)nTPYC, (Z2)+(B1)nCPYC (Z2)+(B1)nCPYS, 또는 (Z2)+(B1)nCPYT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]HGC 또는 (Z2)+(B1)nCHG[CST], 예컨대 (Z2)+(B1)nCHGC, (Z2)+(B1)nSHGC, (Z2)+(B1)nTHGC, (Z2)+(B1)nCHGC (Z2)+(B1)nCHGS, 또는 (Z2)+(B1)nCHGT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]GPC 또는 (Z2)+(B1)nCGP[CST], 예컨대 (Z2)+(B1)nCGPC, (Z2)+(B1)nSGPC, (Z2)+(B1)nTGPC, (Z2)+(B1)nCGPC, (Z2)+(B1)nCGPS, 또는 (Z2)+(B1)nCGPT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]GHC 또는 (Z2)+(B1)nCGH[CST], 예컨대 (Z2)+(B1)nCGHC, (Z2)+(B1)nSGHC, (Z2)+(B1)nTGHC, (Z2)+(B1)nCGHC, (Z2)+(B1)nCGHS, 또는 (Z2)+(B1)nCGHT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]GFC 또는 (Z2)+(B1)nCGF[CST], 예컨대 (Z2)+(B1)nCGFC, (Z2)+(B1)nSGFC, (Z2)+(B1)nTGFC, (Z2)+(B1)nCGFC, (Z2)+(B1)nCGFS, 또는 (Z2)+(B1)nCGFT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]RLC 또는 (Z2)+(B1)nCRL[CST], 예컨대 (Z2)+(B1)nCRLC, (Z2)+(B1)nSRLC, (Z2)+(B1)nTRLC, (Z2)+(B1)nCRLC, (Z2)+(B1)nCRLS, 또는 (Z2)+(B1)nCRLT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]HPC 또는 (Z2)+(B1)nCHP[CST], 예컨대 (Z2)+(B1)nCHPC, (Z2)+(B1)nSHPC, (Z2)+(B1)nTHPC, (Z2)+(B1)nCHPC, (Z2)+(B1)nCHPS, 또는 (Z2)+(B1)nCHPT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]HGC 또는 (Z2)+(B1)nCHG[CST], 예컨대 (Z2)+(B1)nCHGC, (Z2)+(B1)nSHGC, (Z2)+(B1)nTHGC, (Z2)+(B1)nCHGCS, (Z2)+(B1)nCHGS, 또는 (Z2)+(B1)nCHGT이다. 이들 모티프 중 어느 하나에서, (Z2)+는 바람직하게는 H가 아닌 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z2)+는 K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B1)은 임의의 아미노산, 바람직하게는 H일 수 있고, 대안적으로 염기성 아미노산이 아닐 수 있으며, n은 0 내지 3의 정수이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]PYC(B2)m(Z3)+, 또는 CPY[CST](B2)m(Z3)+, 예컨대 CPYC(B2)m(Z3)+, SPYC(B2)m(Z3)+, TPYC(B2)m(Z3)+, CPYC(B2)m(Z3)+, CPYS(B2)m(Z3)+, 또는 CPYT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]HGC(B2)m(Z3)+, 또는 CHG[CST](B2)m(Z3)+, 예컨대 CHGC(B2)m(Z3)+, SHGC(B2)m(Z3)+, THGC(B2)m(Z3)+, CHGC(B2)m(Z3)+, CHGS(B2)m(Z3)+, 또는 CHGT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]GPC(B2)m(Z3)+, 또는 CGP[CST](B2)m(Z3)+, 예컨대 CGPC(B2)m(Z3)+, SGPC(B2)m(Z3)+, TGPC(B2)m(Z3)+, CGPC(B2)m(Z3)+, CGPS(B2)m(Z3)+, 또는 CGPT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]GHC(B2)m(Z3)+, 또는 CGH[CST](B2)m(Z3)+, 예컨대 CGHC(B2)m(Z3)+, SGHC(B2)m(Z3)+, TGHC(B2)m(Z3)+, CGHC(B2)m(Z3)+, CGHS(B2)m(Z3)+, 또는 CGHT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]GFC(B2)m(Z3)+, 또는 CGF[CST](B2)m(Z3)+, 예컨대 CGFC(B2)m(Z3)+, SGFC(B2)m(Z3)+, TGFC(B2)m(Z3)+, CGFC(B2)m(Z3)+, CGFS(B2)m(Z3)+, 또는 CGFT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]RLC(B2)m(Z3)+, 또는 CRL[CST](B2)m(Z3)+, 예컨대 CRLC(B2)m(Z3)+, SRLC(B2)m(Z3)+, TRLC(B2)m(Z3)+, CRLC(B2)m(Z3)+, CRLS(B2)m(Z3)+, 또는 CRLT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
바람직한 구체예에서, 상기 산화환원 효소 모티프는 [CST]HPC(B2)m(Z3)+, 또는 CHP[CST](B2)m(Z3)+, 예컨대 CHPC(B2)m(Z3)+, SHPC(B2)m(Z3)+, THPC(B2)m(Z3)+, CHPC(B2)m(Z3)+, CHPS(B2)m(Z3)+, 또는 CHPT(B2)m(Z3)+이다. 이들 모티프 중 어느 하나에서, (Z3)+는 임의의 염기성 아미노산일 수 있다. 특정 예에서, (Z3)+는 H, K, R 또는 본원에 정의된 바와 같은 비천연 염기성 아미노산이다. 이들 모티프 중 어느 하나에서, (B2)는 임의의 아미노산, 바람직하게는 H이고, 대안적으로 염기성 아미노산이 아니며, m 0 내지 3의 정수이되, (Z3)+가 R이면, m은 0이고, (Z3)+가 H이면, m은 0 또는 1이다.
위에 개시된 상기 예시적인 산화환원 효소 모티프의 바람직한 구체예에서, B1 및/또는 B2는 H이다.
이 측면의 특히 바람직한 예는 다음 산화환원 효소 모티프 중 하나를 포함한다:
KCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 RCPYC, RCGHC, 또는 RCHGC;
KCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 KCPYC, KCGHC, 또는 KCHGC;
KHCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 RHCPYC, RHCGHC, 또는 RHCHGC;
KRCXXC, 여기서, X는 임의의 아미노산, 바람직하게는 KHCPYC, KHCGHC, 또는 KHCHGC;
CXRC, 여기서, X는 임의의 아미노산, 바람직하게는 CGRC, CPRC, CHRC;
CXKC, 여기서, X는 임의의 아미노산, 바람직하게는 CGKC, CPKC, CHKC;
CXXCK, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCK, CPYCK, CGHCK;
CXXCHK, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCHK, CPYCHK, CGHCHK;
CXXCR, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCR, CPYCR, CGHCR;
CXXCHR, 여기서, X는 임의의 아미노산, 바람직하게는 CHGCHR, CPYCHR, CGHCHR;
KCKXC, RCKXC, KCRXC, 또는 RCRXC 여기서, X는 임의의 아미노산
KCXKC, RCXKC, KCXRC, 또는 RCXRC 여기서, X는 임의의 아미노산
KCKXCK, RCKXCK, KCRXCK, KCKXCR, RCRXCK, RCKXCR, KCRXCR, 또는 RCRXCR 여기서, X는 임의의 아미노산
KCKXCHK, RCKXCHK, KCRXCHK, KCKXCHR, RCRXCHK, RCKXCHR, KCRXCHR 또는 RCRXCHR 여기서, X는 임의의 아미노산
KCXXCK, KCXXCR, RCXXCK 또는 RCXXCR 여기서, X는 임의의 아미노산
KCXXCHK, KCXXCHR, RCXXCHK, RCXXCHR 여기서, X는 임의의 아미노산
KCXKCK, RCXKCK, KCXRCK, KCXKCR, RCXRCK, RCXKCR, KCXRCR, 또는 RCXRCR 여기서, X는 임의의 아미노산
KCXKCHK, RCXKCHK, KCXRCHK, KCXKCHR, RCXRCHK, RCXKCHR, KCXRCHR, 또는 RCXRCHR 여기서, X는 임의의 아미노산.
본 발명의 펩티드는 또한 샘플에서 클래스 II 제한 CD4+ T 세포를 검출하기 위한 시험관 내 진단 방법에 사용될 수 있다. 이 방법에서, 샘플은 MHC 클래스 II 분자 및 본 발명에 따른 펩티드의 복합체와 접촉된다. CD4+ T 세포는 샘플에서 복합체와 세포와의 결합을 측정함으로써 검출되며, 여기서, 세포에 대한 복합체의 결합은 샘플 중 CD4+ T 세포의 존재를 나타낸다. 상기 복합체는 펩티드와 MHC 클래스 II 분자의 융합 단백질일 수 있다. 대안적으로, 복합체 내의 MHC 분자는 테트라머이다. 복합체는 가용성 분자로서 제공될 수 있거나, 담체에 부착될 수 있다.
본 발명의 펩티드는 또한 샘플에서 NKT 세포를 검출하기 위한 시험관 내 진단 방법에 사용될 수 있다. 이 방법에서 샘플은 본 발명에 따른 CD1d 분자 및 펩티드의 복합체와 접촉된다. NKT 세포는 샘플에서 세포와 복합체와의 결합을 측정하여 검출되며, 여기서, 세포에 대한 복합체의 결합은 샘플 중 NKT 세포의 존재를 나타낸다. 복합체는 펩티드와 CD1d 분자의 융합 단백질일 수 있다.
따라서, 특정 구체예에서, 본 발명의 치료 및 예방 방법은 치료하고자 하는 질환 (예를 들면, 상술한 바와 같은 것)에서 작용을 하는 항원 단백질의 T 세포 에피토프를 포함하는 본원에 기재된 바와 같은 면역원성 펩티드의 투여를 포함한다. 추가의 특정 구체예에서, 사용된 에피토프는 우세한 에피토프이다.
본 발명에 따른 펩티드는 T 세포 에피토프 및 변형된 산화환원 모티프가 0 내지 5 개의 아미노산에 의해 분리된 펩티드를 합성함으로써 제조될 것이다. 특정 구체예에서, 변형된 산화환원 모티프는 에피토프 서열 외부에 1, 2 또는 3 개의 돌연변이를 도입하여 단백질에서 발생하는 서열 컨텍스트를 보존함으로써 수득될 수 있다. 전형적으로, 천연 서열의 일부인 노나펩티드에 대해 P-2 및 P-1뿐만 아니라 P+10 및 P+11에서의 아미노산이 펩티드 서열에서 보존된다. 이들 플랭킹 잔기는 일반적으로 MHC 클래스 II 또는 CD1d 분자에 대한 결합을 안정화시킨다. 다른 구체예에서, 에피토프의 서열 N 말단 또는 C 말단은 T 세포 에피토프 서열을 함유하는 항원 단백질의 서열과 무관할 것이다.
따라서, 펩티드를 설계하기 위한 상기 방법에 기초하여, 펩티드는 화학 펩티드 합성, 재조합 발현 방법 또는 보다 예외적인 경우 단백질의 단백질 분해 또는 화학적 단편화에 의해 생성된다.
상기 방법으로 제조된 펩티드는 시험관 내 및 생체 내 방법에서 T 세포 에피토프의 존재에 대해 시험될 수 있고, 시험관 내 분석에서 이들의 환원 활성에 대해 시험될 수 있다. 최종 품질 관리로서, 펩티드는 펩티드가 변형된 산화환원 모티프를 갖는 펩티드에 또한 존재하는 에피토프 서열을 가지는 항원을 제시하는 항원 제시 세포에 대한 세포자멸 경로를 통해 세포용해성인 CD4+ T 또는 NKT 세포를 생성할 수 있는지의 여부를 확인하기 위해 시험관 내 분석법으로 시험될 수 있다.
본 발명의 펩티드는 박테리아, 효모, 곤충 세포, 식물 세포 또는 포유동물 세포에서 재조합 DNA 기술을 사용하여 생성될 수 있다. 제한된 길이의 펩티드를 고려해, 이들은 화학적 펩티드 합성에 의해 제조될 수 있으며, 여기서, 펩티드는 상이한 아미노산을 서로 커플링시켜 제조된다. 화학적 합성은 예를 들어, D-아미노산, 자연적으로 발생하지 않는 측쇄를 갖는 아미노산 또는 메틸화된 시스테인과 같은 변형된 측쇄를 갖는 천연 아미노산을 포함시키는데 특히 적합하다.
화학적 펩티드 합성 방법은 잘 설명되어 있으며, 펩티드는 Applied Biosystems와 같은 회사 및 다른 회사에서 주문할 수 있다.
펩티드 합성은 고상 펩티드 합성 (SPPS)으로 또는 반대로 용액상 펩티드 합성으로 수행될 수 있다. 가장 잘 알려진 SPPS 방법은 t-Boc 및 Fmoc 고상 화학법이다:
펩티드 합성 동안 몇몇 보호기가 사용된다. 예를 들어, 하이드록실 및 카복실 작용기는 t-부틸기에 의해 보호되고, 리신 및 트립토판은 t-Boc기에 의해 보호되며, 아스파라긴, 글루타민, 시스테인 및 히스티딘은 트리틸기에 의해 보호되고, 아르기닌은 pbf기에 의해 보호된다. 적절한 경우, 이러한 보호기는 합성 후 펩티드 상에 남아있을 수 있다. 펩티드는 켄트 (Kent) (Schnelzer & Kent (1992), J. Pept. Protein Res. 40, 180-193)에 의해 최초 기술되고, 예를 들어 [Tam et al. (2001) Biopolymers 60, 194-205]에서 검토된 바와 같이, 결찰 전략 (두 개의 비보호된 펩티드 단편의 화학선택적 커플링)을 이용하여 더 긴 펩티드를 형성하도록 서로 연결될 수 있으며, SPPS의 범위를 벗어나는 단백질 합성을 달성할 엄청난 잠재력을 제공한다. 100-300 잔기의 크기를 갖는 많은 단백질이 이 방법으로 성공적으로 합성되었다. 합성 펩티드는 SPPS의 엄청난 발전으로 인해 생화학, 약리학, 신경생물학, 효소학 및 분자 생물학 분야의 연구 분야에서 끊임없이 중요한 역할을 계속해 왔다.
대안적으로, 펩티드는 코딩 뉴클레오티드 서열을 포함하는 적절한 발현 벡터에서 본 발명의 펩티드를 코딩하는 핵산 분자를 사용하여 합성될 수 있다. 그러한 DNA 분자는 자동화 DNA 합성기 및 유전자 코드의 잘 알려진 코돈-아미노산 관계를 이용하여 용이하게 제조할 수 있다. 이러한 DNA 분자는 또한 올리고뉴클레오티드 프로브 및 통상적인 혼성화 방법을 사용하여 게놈 DNA 또는 cDNA로서 수득될 수 있다. 이러한 DNA 분자는 박테리아, 예를 들어 대장균 (Escherichia coli), 효모 세포, 동물 세포 또는 식물 세포와 같은 적합한 숙주에서 DNA의 발현 및 폴리펩티드의 생성에 적합한 플라스미드를 포함하는 발현 벡터에 도입될 수 있다.
펩티드가 치료 조성물에 사용하기에 적합한지의 여부를 결정하기 위해 대상 펩티드의 물리적 및 화학적 성질 (예를 들어 용해도, 안정성)이 조사된다. 전형적으로 이는 펩티드의 서열을 조절함으로써 최적화된다. 임의로, 펩티드는 당 업계에 공지된 기술을 사용하여 합성 후에 변형 (화학적 변형, 예를 들어, 작용기의 첨가/제거)될 수 있다.
표준 산화환원 효소 모티프 및 MHC 클래스 II T-세포 에피토프를 포함하는 면역원성 펩티드의 작용 메커니즘은 상기 인용된 PCT 출원 WO2008/017517 및 본 발명자들의 공개물에 개시된 실험 데이터로 입증된다. 표준 산화환원 효소 모티프 및 CD1d 결합 NKT-세포 에피토프를 포함하는 면역원성 펩티드의 작용 메커니즘은 상기 인용된 PCT 출원 WO2012/069568 및 본 발명자들의 공개물에 개시된 실험 데이터로 입증된다.
본 발명은 생체 내 또는 시험관 내에서 항원-특이적 세포용해성 CD4+ T-세포 (MHC 클래스 II 에피토프를 포함하는 본원에 개시된 바와 같은 면역원성 펩티드를 사용하는 경우) 또는 항원-특이적 세포용해성 NKT-세포 (CD1d 분자에 결합하는 NKT 세포 에피토프를 포함하는 본원에 개시된 바와 같은 면역원성 펩티드를 사용하는 경우)를 생성하는 방법을 제공한다.
본 발명은 항원 특이적인 CD4+ T 세포 또는 NKT 세포의 생성을 위한 생체 내 방법을 기술한다. 특정 구체예는 동물 (인간 포함)을 본원에 기술된 바와 같은 본 발명의 펩티드로 면역화시킨 후, 면역화된 동물로부터 CD4+ T 세포 또는 NKT 세포를 단리함으로써 CD4+ T 세포 또는 NKT 세포를 생성 또는 단리하는 방법에 관한 것이다. 본 발명은 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 또는 NKT 세포의 생성을 위한 시험관 내 방법을 기술한다. 본 발명은 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 또는 NKT 세포를 생성하는 방법을 제공한다.
일 구체예에서, 말초 혈액 세포의 단리, 본 발명에 따른 면역원성 펩티드에 의한 시험관 내 세포 집단의 자극 및 자극된 세포 집단의 확장 (보다 특히는 IL-2의 존재하에서)을 포함하는 방법이 제공된다. 본 발명에 따른 방법은 많은 수의 CD4+ T 세포가 생성되고 (항원 특이적 에피토프를 포함하는 펩티드를 사용함으로써) 항원 단백질에 특이적인 CD4+ T 세포가 생성될 수 있다는 이점을 갖는다.
대안적인 구체예에서, CD4+ T 세포는 생체 내에서, 즉 본원에 기술된 면역원성 펩티드를 대상으로 주입하고 생체 내에서 생성된 세포용해성 CD4+ T 세포를 수집하여 생성할 수 있다.
본 발명의 방법에 의해 얻을 수 있는 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포는 알레르기 반응의 예방 및 자가면역 질환의 치료에서 면역 요법을 위해 포유동물에 투여하는데 특히 중요하다. 동종 및 자가생성 세포의 사용이 모두 고려된다.
세포용해성 CD4+ T 세포 집단은 본원에서 하기에 기술된 바와 같이 수득된다.
하나의 구체예에서, 본 발명은 특이적 NKT 세포를 확장한 결과 다음을 포함하지만 이에 제한되지 않는 활성을 증가시키기 위한 방법을 제공한다:
(i) 사이토카인 생산 증가
(ii) 항원 제시 세포의 증가된 접촉- 및 가용성 인자-의존성 제거. 이에 따른 결과 세포 내 병원체, 자가 항원, 동종 인자, 알레르겐, 종양 세포에 대한 보다 효율적인 반응이 가능하며 유전자 치료/유전자 백신 접종에 사용되는 이식편 및 바이러스 단백질에 대한 면역 반응을 보다 효율적으로 억제할 수 있다.
본 발명은 또한 체액 또는 기관에서 필요한 특성을 갖는 NKT 세포의 확인에 관한 것이다. 이 방법은 NK1.1, CD4, NKG2D 및 CD244의 발현을 비롯해, 표면 표현형에 의한 NKT 세포의 확인을 포함한다. 이어 세포를 CD1d 분자에 의해 제시될 수 있는 펩티드로서 정의되는 NKT 세포 에피토프와 접촉시킨다. 세포는 IL-2 또는 IL-15 또는 IL-7의 존재하에 시험관 내에서 확장된다.
본원에 기재된 바와 같은 항원 특이적 세포용해성 CD4+ T 세포 또는 NKT 세포는 약제로서, 특히 양자 세포 요법, 보다 특히 급성 알레르기 반응 및 다발성 경화증과 같은 자가면역 질환의 치료에 사용하기 위한 약제로서 사용될 수 있다. 단리된 세포용해성 CD4+ T 세포 또는 NKT 세포 또는 세포 집단, 보다 특히 기술된 바와 같이 생성된 항원 특이적 세포용해성 CD4+ T 세포 또는 NKT 세포 집단은 면역 질환의 예방 또는 치료용 약제의 제조에 사용된다. 단리되거나 생성된 세포용해성 CD4+ T 세포 또는 NKT 세포를 사용한 치료 방법이 개시된다.
WO2008/017517호에 설명된 바와 같이, APC에 대한 세포용해성 CD4+ T 세포는 세포의 발현 특성에 기초하여 천연 Treg 세포와 구별될 수 있다. 보다 구체적으로, 세포용해성 CD4+ T 세포 집단은 천연 Treg 세포 집단과 비교하여 하기 특성 중 하나 이상을 나타낸다:
활성화 시 CD103, CTLA-4, FasI 및 ICOS를 포함하는 표면 마커의 증가된 발현, CD25의 중간 발현, CD4, ICOS, CTLA-4, GITR의 발현 및 CD127 (IL7-R)의 저발현 또는 비발현, CD27의 비발현, 전사 인자 T-bet 및 egr-2 (Krox-20)는 발현하나 전사 억제 인자 Foxp3은 발현하지 않음, IFN-감마의 고 생산 및 IL-10, IL-4, IL-5, IL-13 또는 TGF-β는 비생산 또는 단지 미량 생산.
또한 세포용해성 T 세포는 CD45RO 및/또는 CD45RA를 발현하고 CCR7, CD27을 발현하지 않으며, 높은 수준의 그랜자임 B 및 기타 그랜자임뿐만 아니라 Fas 리간드를 제시한다.
WO2008/017517호에 설명된 바와 같이 APC에 대한 세포용해 NKT 세포는 세포의 발현 특성에 기초하여 비-세포용해 NKT 세포와 구별될 수 있다. 보다 구체적으로, 세포용해성 CD4+ NKT 세포 집단은 비-세포용해성 NKT 세포 집단과 비교하여 NK1.I, CD4, NKG2D 및 CD244의 발현 중 하나 이상을 보여준다.
본 발명의 펩티드는 살아있는 동물, 전형적으로 인간에게 투여 시, 방관자 T 세포에 억제 활성을 발휘하는 특이적 T 세포를 유도할 것이다.
특정 구체예에서, 본 발명의 세포용해 세포 집단은 FasL 및/또는 인터페론 감마의 발현을 특징으로 한다. 특정 구체예에서 본 발명의 세포용해 세포 집단은 추가로 그랜자임 B의 발현을 특징으로 한다.
이러한 메카니즘은 또한 특정 항원의 특이적 T 또는 NKT 세포 에피토프를 포함함에도 불구하고 본 발명의 펩티드가 동일 항원의 다른 T 세포 에피토프에 대한 면역 반응에 의해 유발되는 장애의 예방 또는 치료에 사용될 수 있거나, 또는 특정 상황에서 이들이 본 발명의 펩티드에 의해 활성화되는 T 세포 근처에서 MHC 클래스 II 분자에 의해 동일한 메커니즘을 통해 제시될 수 있다면, 심지어 다른 상이한 항원의 다른 T 세포 에피토프에 대한 면역 반응에 의해 유발되는 장애의 치료에 사용될 수 있음을 함축하고 실험 결과는 이를 보여준다.
또한 항원 특이적인, 즉 항원 특이적 면역 반응을 억제할 수 있는, 전술한 특성을 갖는 세포 유형의 단리된 세포 집단이 개시된다.
본 발명은 본 발명에 따른 하나 이상의 펩티드를 포함하고 약학적으로 허용 가능한 담체를 추가로 포함하는 약학 조성물을 제공한다. 상기에서 상세히 설명한 바와 같이, 본 발명은 또한 의약으로서 사용하기 위한 조성물 및 상기 조성물을 사용한 면역 장애 포유동물의 치료 방법, 및 면역 장애의 예방 또는 치료용 약제의 제조를 위한 상기 조성물의 용도에 관한 것이다. 약학 조성물은, 예를 들어 면역 장애, 특히 공기로 운반되는 알레르기 및 식인성 알레르기뿐만 아니라 알레르기 기원의 질환을 치료 또는 예방하기에 적합한 백신일 수 있다. 본원에서 약학 조성물로 기술된 예로서, 본 발명에 따른 펩티드는 수산화알루미늄 (알룸)과 같은 포유동물에 투여하기에 적합한 애쥬번트에 흡착된다. 전형적으로, 알룸에 흡착된 50 ㎍의 펩티드가 2 주 간격으로 3 회 피하 경로로 주입된다. 구강, 비강 내 또는 근육 내를 포함하는 다른 투여 경로가 가능하다는 것이 당업자에게 명백하다. 또한, 주입 횟수 및 주입량은 치료 상태에 따라 달라질 수 있다. 또한, MHC-클래스 II 제시 및 T 세포 활성화에서 펩티드 제시를 촉진한다면, 알룸 이외의 다른 보조제가 사용될 수 있다. 따라서, 활성 성분을 단독으로 투여하는 것이 가능하지만, 전형적으로는 약학적 제형으로서 제공된다. 본 발명의 수의학적 용도 및 인간 용도 모두를 위한 제형은 하나 이상의 약학적으로 허용 가능한 담체와 함께 상기한 바와 같은 적어도 하나의 활성 성분을 포함한다. 본 발명은 약학적으로 허용 가능한 담체와 함께, 활성 성분으로서 본 발명에 따른 하나 이상의 펩티드를 포함하는 약학 조성물에 관한 것이다. 본 발명의 약학 조성물은 치료 또는 예방의 방법과 관련하여 이후에 나타낸 바와 같은 치료적 유효량의 활성 성분을 포함해야 한다. 임의로, 조성물은 다른 치료 성분을 추가로 포함한다. 적합한 다른 치료 성분뿐만 아니라 이들이 속한 부류에 따른 그들의 일반적인 투여량은 당업자에게 잘 알려져 있으며, 면역 장애의 치료에 사용되는 다른 공지된 약물로부터 선택될 수 있다.
본원에서 사용된 "약학적으로 허용 가능한 담체"라는 용어는 활성 성분이 예를 들어 조성물을 용해, 분산 또는 확산시킴으로써 치료할 장소로의 적용 또는 전파을 용이하게 하고/하거나, 효과를 저해하지 않고 그의 저장, 운반 또는 취급을 용이하게 하도록 제형화하는 임의의 재료 또는 물질을 의미한다. 이들은 임의의 모든 용매, 분산 매질, 코팅제, 항균 및 항진균제 (예를 들어, 페놀, 소르브산, 클로로부탄올), 등장제 (예를 들어 당 또는 염화나트륨) 등을 포함한다. 조성물 중 면역원성 펩티드의 작용 지속 시간을 조절하기 위해 추가 성분이 포함될 수 있다. 약학적으로 허용 가능한 담체는 고체 또는 액체 또는 액체를 형성하도록 압축된 기체일 수 있으며, 즉 본 발명의 조성물은 농축물, 에멀젼, 용액, 과립제, 더스트, 스프레이, 에어로졸, 현탁액, 연고, 크림, 정제, 알약 또는 분말로서 적절히 사용될 수 있다. 약학 조성물 및 그의 제형에 사용하기에 적합한 약학적 담체는 당업자에게 공지되어 있으며, 본 발명의 범위 내에서 이들의 선택에 특별한 제한은 없다. 이들은 또한 습윤제, 분산제, 증점제, 접착제, 유화제, 용매, 코팅, 항균 및 항진균제 (예를 들어 페놀, 소르브산, 클로로부탄올), 등장제 (예를 들어 당 또는 염화나트륨) 등과 같은 첨가제를 포함할 수도 있으며, 단 이들은 제약 관행에 따라야 하며, 즉 담체 및 첨가제는 포유동물에 영구적인 손상을 주지 않아야 한다. 본 발명의 약학 조성물은 임의의 공지된 방식으로, 예를 들면, 활성 성분을 선택된 담체 물질 및 적절한 경우, 계면활성제와 같은 다른 첨가제와 함께 단일 단계 또는 복수 단계의 절차로 균질하게 혼합, 코팅 및/또는 분쇄하여 제조할 수 있다. 이들은 또한 예를 들어 일반적으로 약 1 내지 10 ㎛의 직경을 갖는 미소구 형태를 수득하기 위한 관점에서, 즉 활성 성분의 조절 방출 또는 지속 방출을 위한 마이크로캡슐의 제조를 위해 미소화에 의해 제조될 수 있다.
본 발명의 약학 조성물에 사용하기에 적합한, 에멀젼 또는 유화제로도 알려진 적합한 계면활성제는 양호한 유화, 분산 및/또는 습윤성을 갖는 비이온성, 양이온성 및/또는 음이온성 물질이다. 적합한 음이온성 계면활성제는 수용성 비누 및 수용성 합성 계면활성제 모두를 포함한다. 적합한 비누는 알칼리 또는 알칼리 토금속염, 비치환되거나 치환된 고급 지방산 (C10-C22)의 암모늄염, 예를 들면, 올레산 또는 스테아르산의 나트륨 또는 칼륨염, 또는 코코넛오일 또는 우지로부터 수득할 수 있는 천연 지방산 혼합물이다. 합성 계면활성제는 폴리아크릴산의 나트륨 또는 칼슘 염; 지방 설포네이트 및 설페이트; 설폰화 벤즈이미다졸 유도체 및 알킬아릴설포네이트를 포함한다. 지방 설포네이트 또는 설페이트는 통상 알칼리 또는 알칼리 토금속 염, 비치환 암모늄 염 또는 8 내지 22 개의 탄소 원자를 갖는 알킬 또는 아실 라디칼로 치환된 암모늄 염, 예를 들어, 리그노설폰산 또는 도데실설폰산의 나트륨 또는 칼슘 염 또는 천연 지방산으로부터 수득된 지방 알콜 설페이트의 혼합물, 황산 또는 설폰산 에스테르 (예컨대 나트륨 라우릴 설페이트) 및 지방 알콜의 설폰산/에틸렌 옥사이드 부가물의 알칼리 또는 알칼리 토금속 염의 형태이다. 적합한 설폰화 벤즈이미다졸 유도체는 전형적으로 8 내지 22 개의 탄소 원자를 함유한다. 알킬아릴설포네이트의 예로는 도데실벤젠 설폰산 또는 디부틸-나프탈렌설폰산 또는 나프탈렌-설폰산/포름알데히드 축합 생성물의 나트륨, 칼슘 또는 알칸올아민 염이 있다. 또한, 상응하는 포스페이트, 예를 들어 인산 에스테르 및 p-노닐페놀과 에틸렌 및/또는 프로필렌 옥사이드의 부가물, 또는 인지질의 염이 적합하다. 이러한 목적에 적합한 인지질은 천연 (동물 또는 식물 세포 유래) 또는 예를 들어, 세팔린 또는 레시틴 유형의 합성 인지질, 예컨대 포스파티딜-에탄올, 포스파티딜세린, 포스파티딜글리세린, 리소레시틴, 카디오리핀, 디옥타닐포스파티딜콜린, 디팔미토일포스파티딜콜린 및 이들의 혼합물을 포함한다.
적합한 비이온성 계면활성제는 분자 내에 적어도 12 개의 탄소 원자를 함유하는 알킬 페놀, 지방 알콜, 지방산, 지방족 아민 또는 아미드의 폴리에톡실화 및 폴리프로폭실화 유도체, 알킬아렌 설포네이트 및 디알킬설포숙시네이트, 예컨대 지방족 및 지환식 알콜의 폴리글리콜 에테르 유도체, 포화 및 불포화 지방산 및 알킬 페놀을 포함하며, 유도체는 전형적으로 (지방족) 탄화수소 잔기에 3 내지 10 개의 글리콜 에테르기 및 8 내지 20 개의 탄소 원자와 알킬 페놀의 알킬 잔기에 6 내지 18 개의 탄소 원자를 함유한다. 추가의 적합한 비이온성 계면활성제는 폴리에틸렌 옥사이드와 폴리프로필렌 글리콜, 알킬 사슬에 1 내지 10 개의 탄소 원자를 함유하는 에틸렌디아미노폴리프로필렌 글리콜의 수용성 부가물이며, 부가물은 20 내지 250 개의 에틸렌글리콜 에테르기 및/또는 10 내지 100 개의 프로필렌글리콜 에테르기를 함유한다. 이러한 화합물은 일반적으로 프로필렌글리콜 단위당 1 내지 5 개의 에틸렌글리콜 단위를 함유한다. 비이온성 계면활성제의 대표적인 예로는 노닐페놀-폴리에톡시에탄올, 피마자유 폴리글리콜 에테르, 폴리프로필렌/폴리에틸렌 옥사이드 부가물, 트리부틸페녹시폴리에톡시에탄올, 폴리에틸렌글리콜 및 옥틸페녹시폴리에톡시에탄올이 있다. 폴리에틸렌 소르비탄의 지방산 에스테르 (예컨대 폴리옥시에틸렌 소르비탄 트리올레에이트), 글리세롤, 소르비탄, 수크로스 및 펜타에리트리톨이 또한 적합한 비이온성 계면활성제이다. 적합한 양이온성 계면활성제는 할로, 페닐, 치환된 페닐 또는 하이드록시로 임의로 치환된 4 개의 탄화수소 라디칼을 갖는 4급 암모늄 염, 특히 할로겐화물; 예를 들어 N-치환체로서 적어도 하나의 C8-C22 알킬 라디칼 (예를 들어, 세틸, 라우릴, 팔미틸, 미리스틸, 올레일 등) 및 추가의 치환체로서 비치환 또는 할로겐화 저급 알킬, 벤질 및/하이드록시-저급 알킬 라디칼을 가지는 4급 암모늄 염을 포함한다.
이 목적에 적합한 계면활성제의 보다 상세한 설명은 예를 들어 "McCutcheon's Detergents and Emulsifiers Annual" (MC Publishing Crop., Ridgewood, New Jersey, 1981), "Tensid-Taschenbucw', 2d ed. (Hanser Verlag, Vienna, 1981) 및 "Encyclopaedia of Surfactants, (Chemical Publishing Co., New York, 1981)에 기술되어 있다. 본 발명에 따른 펩티드, 그의 상동체 또는 유도체 (및 이들의 생리학적으로 허용 가능한 염 또는 약학 조성물 - 모두 용어 "활성 성분"에 포함됨)는 치료할 상태에 적절하고 화합물, 여기에서는 투여되는 단백질 및 단편에 적절한 임의의 경로에 의해 투여될 수 있다. 가능한 경로는 국부, 전신, 구강 (고체 형태 또는 흡입), 직장, 비강, 국소 (안구, 협측 및 설하 포함), 질 및 비경구 (피하, 근육 내, 정맥 내, 피 내, 동맥 내, 척수강 내 및 경막 외 포함)를 포함한다. 바람직한 투여 경로는 예를 들어 수용자의 상태 또는 치료할 질환에 따라 달라질 수 있다. 본원에 기재된 바와 같이, 담체(들)는 최적으로는 제형의 다른 성분과 양립할 수 있고 수용자에게 유해하지 않다는 의미에서 "허용 가능하다". 제형은 경구, 직장, 비강, 국소 (협측 및 설하 포함), 질 또는 비경구 (피하, 근육 내, 정맥 내, 피 내, 동맥 내, 경 막내 및 경막 외 포함) 투여에 적합한 것들을 포함한다.
비경구 투여에 적합한 제형은 항산화제, 완충액, 정균제 및 제형을 의도된 수용자의 혈액과 등장성으로 만드는 용질을 함유할 수 있는 수성 및 비수성 멸균 주사 용액; 및 현탁제 및 증점제를 포함할 수 있는 수성 및 비수성 멸균 현탁액을 포함한다. 제형은 단위 용량 또는 다회 용량 용기, 예를 들어 밀봉 앰플 및 바이알에 제공될 수 있으며, 사용 직전 멸균 액체 담체, 예를 들어 주사용수의 첨가만을 필요로 하는 냉동 건조 (동결 건조) 상태로 저장될 수 있다. 전술한 종류의 멸균 분말, 과립 및 정제로부터 즉석 주사 용액 및 현탁액이 제조될 수 있다.
전형적인 단위 용량 제형은 활성 성분을 상기 언급된 바와 같이 1일 용량 또는 단위 1일 아용량 또는 이의 적절한 소부분을 함유하는 제형이다. 특히 상기 언급된 성분 이외에, 본 발명의 제형은 해당 제형의 타입을 고려하여 당 업계에서 통상적인 다른 제제를 포함할 수 있으며, 예를 들어 경구 투여에 적합한 것은 향미제를 포함할 수 있는 것으로 이해하여야 한다. 본 발명에 따른 펩티드, 그의 상동체 또는 유도체는 보다 적은 투여 빈도를 허용하거나 주어진 본 발명 화합물의 약동학 또는 독성 프로파일을 개선하도록 활성 성분의 방출을 제어 및 조절할 수 있는 하나 이상의 본 발명의 화합물을 활성 성분으로 함유하는 방출 조절 약학 제형 ("방출 조절 제형")을 제공하기 위해 사용될 수 있다. 본 발명의 하나 이상의 화합물을 포함하는 개별 단위인 경구 투여에 적합한 조절 방출 제형은 통상적인 방법에 따라 제조될 수 있다. 조성물 중의 활성 성분의 작용 지속 시간을 조절하기 위해 추가의 성분이 포함될 수 있다. 따라서, 예를 들어 폴리에스테르, 폴리아미노산, 폴리비닐 피롤리돈, 에틸렌-비닐 아세테이트 공중합체, 메틸셀룰로오스, 카복시메틸셀룰로오스, 프로타민 황산염 등과 같은 적당한 중합체 담체를 선택함으로써 방출 조절 조성물을 수득할 수 있다. 약물 방출 속도 및 작용 지속 시간은 또한 활성 성분을 하이드로겔, 폴리락트산, 하이드록시메틸셀룰로오스, 폴리에틸 메타크릴레이트 및 기타 상기 기재된 폴리머와 같은 폴리머 물질의 입자, 예를 들어 마이크로캡슐에 도입시킴으로써 제어할 수 있다. 그러한 방법은 리포솜, 마이크로스피어, 마이크로에멀젼, 나노입자, 나노캡슐 등과 같은 콜로이드 약물 전달 시스템을 포함한다. 투여 경로에 따라, 약학 조성물은 보호 코팅을 필요로 할 수 있다. 주사에 적합한 약학 형태는 멸균 수용액 또는 분산액 및 그의 즉석 제조를 위한 멸균 분말을 포함한다. 따라서, 이러한 목적에 전형적인 담체는 생체적합성 수성 완충액, 에탄올, 글리세롤, 프로필렌 글리콜, 폴리에틸렌 글리콜 등 및 이들의 혼합물을 포함한다. 다수의 활성 성분을 조합하여 사용하는 경우, 이들은 치료하고자 하는 포유동물에서 동시에 공동 치료 효과를 직접적으로 발휘할 필요가 없다는 사실에 비추어 볼 때, 해당 조성물은 또한 분리되었지만 인접한 저장소 또는 구획에 두 가지 성분이 들어 있는 의학적 키트 또는 패키지의 형태일 수 있다. 따라서, 후자와 관련하여, 각 활성 성분은 다른 성분의 것과 상이한 투여 경로에 적합한 방식으로 제형화될 수 있으며, 예를 들어 그 중 하나는 경구 또는 비경구 제형의 형태일 수 있고, 다른 하나는 정맥 내 주사용 앰풀 또는 에어로졸 형태이다.
본 발명에서 수득된 세포용해성 CD+ T 세포는 시험관 내 및 생체 내에서 입증된 바와 같이, 수지상 세포 및 B 세포 모두에 영향을 미치는 MHC-클래스 II 의존성 동족 활성화 후 APC 세포자멸을 유도하며, (2) IL-10 및/또는 TGF-β의 부재하에서 접촉 의존성 메카니즘에 의해 방관자 T 세포를 억제한다. 세포용해성 CD4+ T 세포는 WO2008/017517호에 상세히 논의된 바와 같이, 천연 및 입양성 Tregs 양자와 구별될 수 있다.
본 발명의 면역원성 펩티드는 CD1d 분자에 결합하는 능력을 부여하는 소수성 잔기를 함유한다. 투여시, APC에 의해 흡수되고, CD1d에 로딩되고 APC의 표면에 제시되는 후기 엔도솜으로 향한다. 일단 CD1d 분자에 의해 제시되면, 펩티드의 티오 환원 효소 모티프는 NKT 세포를 활성화하는 능력을 향상시켜 세포용해성 NKT 세포로 된다. 상기 면역원성 펩티드는 CD4+ T 세포 및 nCD8+ T 세포를 포함하는 다른 이펙터 세포를 활성화할 1FN-감마와 같은 사이토카인의 생산을 활성화시킨다. CD4+ 및 CD8+ T 세포 모두 WO2012/069568에서 상세히 논의된 바와 같이 항원을 제시하는 세포의 제거에 참여할 수 있다.
인터페론 감마는 세포용해성 CD4+ T 세포를 특성화하는 중요한 마커이다. 특정 CD4+ T 세포주는 면역원성 펩티드로 T1D 환자 (T1D07)로부터의 나이브 CD4+ T 세포를 프라이밍하고 자극하여 얻을 수 있다. 여러 번, (예를 들어) 12 회 자극 후, 세포를 상기 면역원성 펩티드가 로딩된 자가 LCL B 세포 (2 μM)와 함께 배양할 수 있다. 24 시간 후, 상등액을 수집하고 다중 분석법으로 IFN-감마를 측정한다.
또한, 세포용해성 CD4+ T 세포주에 의한 FasL 방출을 시험하여 본 발명의 면역원성 펩티드의 효과를 평가할 수 있다. 상기 설명된 바와 같이 원래 면역원성 펩티드로 생성된 T 세포주를 APC로서 자가 LCL B 세포주를 사용하여 4 회 연속 시험관 내 자극에 걸쳐 상기 면역원성 펩티드로 분할하고 자극시킬 수 있다. 11 일의 매 자극 (총 4 일) 시에 세포를 자가 B 세포에 의해 제시된 해당 펩티드로 재자극한 후 FasL에 대해 시험한다. 상등액을 공배양 24 시간 (자극 1 및 2) 또는 72 시간 (자극 3 및 4) 후에 수집한다.
본 발명은 이제 어떤 제한의 의도도 없이 제공되는 하기 실시예에 의해 예시될 것이다. 또한, 여기에 기술된 모든 참조문헌은 본원에 참조로서 명시적으로 포함된다.
실시예
실시예 1: 면역원성 펩티드의 감소된 활성을 평가하기 위한 방법.
면역원성 펩티드의 산화환원 효소 활성을 문헌[Tomazzolli et al. (2006) Anal. Biochem. 350, 105-112]에 기술된 형광체 분석법을 사용하여 결정하였다. FITC 표지된 두 개의 펩티드는 디설파이드 브릿지를 통해 서로 공유결합하는 경우 자가 소광된다. 본 발명에 따른 펩티드에 의한 환원 시, 환원된 개별 펩티드는 다시 형광성으로 된다. 대조군 실험은 디티오트레이톨 (100% 환원 활성)과 물 (0% 환원 활성)으로 수행할 수 있다.
실시예 2: 면역원성 펩티드의 환원 활성에 대한 산화환원 효소 모티프의 N-말단에 염기성 아미노산 첨가의 효과.
하기 표 1 내지 3은 T 세포 에피토프를 포함하는 다양한 면역원성 펩티드의 산화환원 효소 모티프의 N-말단에서 염기성 아미노산 증가의 영향을 시험하기 위해 사용된 펩티드 서열을 나타낸다. 이 펩티드를 사용한 모든 시험은 중복으로 수행되었으며 각 시험은 2 회 수행되었다. 도 1, 2 및 3은 일 반복의 초기 속도를 나타낸다. 활성은 중복의 평균으로 표현된다. 결과를 RFU (상대 형광 단위)로 표시하였다. 인슐린 T 세포 에피토프에 연결된 CHGC 산화환원 효소 모티프의 N-말단에 K, KH, R 또는 RH 아미노산을 포함하는 펩티드는 H가 있거나 추가 N-말단 아미노산이 없는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 1 및 도 1 참조). 동일한 방식으로, 파상풍 독소 T 세포 에피토프에 연결된 CPYC 산화환원 효소 모티프의 N-말단에 K 또는 KH 아미노산을 포함하는 펩티드는 H가 있거나 추가 N-말단 아미노산이 없는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 2 및 도 2 참조). MOG T 세포 에피토프에 연결된 CPYC 산화환원 효소 모티프의 N-말단에 K 또는 KH 아미노산을 포함하는 펩티드는 H가 있거나 추가 N-말단 아미노산이 없는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 3 및 도 3 참조).
| 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CHGC)의 N-말단에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 1 | K | CHGC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 2 | KH | CHGC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 3 | R | CHGC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 4 | RH | CHGC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 5 | CHGC | SLQP | LALEGSLQK | RG | 대조군 | |
| 6 | H | CHGC | SLQP | LALEGSLQK | RG | 대조군 |
| 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CPYC)의 N-말단에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 7 | K | CPYC | V | QYIKANSKFIGIT | EL | 시험 펩티드 |
| 8 | KH | CPYC | V | QYIKANSKFIGIT | EL | 시험 펩티드 |
| 9 | CPYC | V | QYIKANSKFIGIT | EL | 대조군 | |
| 10 | H | CPYC | V | QYIKANSKFIGIT | EL | 대조군 |
| MOG T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CPYC)의 N-말단에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 11 | K | CPYC | GW | YRSPFSRVVHL | YR | 시험 펩티드 |
| 12 | KH | CPYC | GW | YRSPFSRVVHL | YR | 시험 펩티드 |
| 13 | CPYC | GW | YRSPFSRVVHL | YR | 대조군 | |
| 14 | H | CPYC | GW | YRSPFSRVVHL | YR | 대조군 |
실시예 3: 면역원성 펩티드의 환원 활성에 대한 산화환원 효소 모티프 내 염기성 아미노산 첨가의 효과.
하기 표 4 내지 6은 T 세포 에피토프를 포함하는 다양한 면역원성 펩티드의 산화환원 효소 모티프 내 염기성 아미노산 첨가의 영향을 시험하기 위해 사용된 펩티드 서열을 나타낸다. 이 펩티드를 사용한 모든 시험은 중복으로 수행되었으며 각 시험은 2 회 수행되었다. 도 4, 5 및 6은 일 반복의 초기 속도를 나타낸다. 활성은 중복의 평균으로 표현된다. 결과를 RFU (상대 형광 단위)로 표시하였다. 인슐린 T 세포 에피토프가 있고 모티프 내에 K가 있는 산화환원 효소 모티프를 포함하는 펩티드는 고전적인 CPYC 산화환원 효소 모티프가 있는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 4 및 도 4 참조). 동일한 방식으로, 인슐린 T 세포 에피토프가 있고 모티프 내에 K가 있는 산화환원 효소 모티프를 포함하는 펩티드는 CHGC 또는 CRGC 고전적 산화환원 효소 모티프를 가진 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 5 및 도 5 참조). CGHC 산화환원 효소 모티프를 사용하여 동일한 결과를 얻었다 (표 6 및 도 6 참조).
| 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CPYC) 내에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 15 | - | CPKC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 16 | - | CKYC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 17 | - | CPYC | SLQP | LALEGSLQK | RG | 대조군 |
| 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CHGC) 내에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 18 | - | CHKC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 19 | - | CKGC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 20 | - | CRGC | SLQP | LALEGSLQK | RG | 대조군 |
| 21 | - | CHGC | SLQP | LALEGSLQK | RG | 대조군 |
| 인슐린 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CGHC) 내에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 22 | - | CHKC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 23 | - | CGRC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 24 | CGHC | SLQP | LALEGSLQK | RG | 대조군 | |
| 25 | CGKC | SLQP | LALEGSLQK | RG | 시험 펩티드 | |
실시예 4: 면역원성 펩티드의 환원 활성에 대한 산화환원 효소 모티프의 C-말단에 염기성 아미노산 첨가의 효과.
다음 표 7 및 8은 T 세포 에피토프를 포함하는 다양한 면역원성 펩티드의 산화환원 효소 모티프의 C-말단에서 염기성 아미노산 증가의 영향을 시험하는 데 사용된 펩티드 서열을 나타낸다. 이 펩티드를 사용한 모든 시험은 중복으로 수행되었으며 각 시험은 2 회 수행되었다. 도 7 및 8은 일 반복의 초기 속도를 나타낸다. 활성은 중복의 평균으로 표현된다. 결과를 RFU (상대 형광 단위)로 표시하였다. 인슐린 T 세포 에피토프에 연결된 CHGC 산화환원 효소 모티프의 C-말단에 K 또는 HK 아미노산을 포함하는 펩티드는 추가 염기성 C-말단 아미노산이 없는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 7 및 도 7 참조). 파상풍 독소 T 세포 에피토프에 연결된 CPYC 산화환원 효소 모티프의 C-말단에 K 또는 HK 아미노산을 포함하는 펩티드는 추가 염기성 C-말단 아미노산이 없는 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 8 및 도 8 참조).
| 인슐린 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CHGC)의 C-말단에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 26 | - | CHGC | KSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 27 | - | CHGC | HKSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 28 | - | CHGC | SLQP | LALEGSLQK | RG | 대조군 |
| 파상풍 독소 T 세포 에피토프를 포함하는 면역원성 펩티드의 산화환원 효소 모티프 (CPYC)의 C-말단에 염기성 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 29 | - | CPYC | KV | QYIKANSKFIGIT | EL | 시험 펩티드 |
| 30 | - | CPYC | HKV | QYIKANSKFIGIT | EL | 시험 펩티드 |
| 31 | - | CPYC | V | QYIKANSKFIGIT | EL | 대조군 |
실시예 5: 면역원성 펩티드의 환원 활성에 대한 산화환원 효소 모티프 내 및/또는 옆에 다중 염기성 아미노산 삽입의 효과.
다음 표 9 및 10은 산화환원 효소 모티프 내 및 N-/C-말단에서 면역원성 펩티드의 환원 활성에 대한 다중 염기성 아미노산 (K) 삽입의 영향을 시험하는 데 사용된 펩티드 서열을 나타낸다. 이 펩티드를 사용한 모든 시험은 중복으로 수행되었으며 각 시험은 2 회 수행되었다. 도 9 및 10은 일 반복의 초기 속도를 나타낸다. 활성은 중복의 평균으로 표현된다. 결과를 RFU (상대 형광 단위)로 표시하였다. 다중 염기성 아미노산을 갖는 산화환원 효소 모티프를 포함하는 펩티드는 인슐린 T 세포 에피토프를 포함하는 CPYCSLQPLALEGSLQKRG 대조 펩티드보다 더 높은 산화환원 효소 활성을 나타내었다 (표 9 및 도 9 참조). MOG T 세포 에피토프를 포함하는 CPYCGWYRSPFSRVVHL 펩티드의 변이체를 사용하여 동일한 결과를 얻었다 (표 10, 도 10 참조).
| 인슐린 T 세포 에피토프를 함유하는 이모토프의 산화환원 모티프 (CPYC)에서 다중 하전 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 32 | K | CKYC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 33 | K | CPKC | SLQP | LALEGSLQK | RG | 시험 펩티드 |
| 34 | K | CPKC | KSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 35 | K | CKYC | KSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 36 | K | CPYC | KSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 37 | K | CPKC | HKSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 38 | K | CKYC | HKSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 39 | K | CPYC | HKSLQP | LALEGSLQK | RG | 시험 펩티드 |
| 40 | CPYC | SLQP | LALEGSLQK | RG | 대조군 | |
| MOG T 세포 에피토프를 함유하는 이모토프의 산화환원 모티프 (CPYC)에서 다중 하전 아미노산. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 41 | KH | CKYC | GW | YRSPFSRVVHL | YR | 시험 펩티드 |
| 42 | K | CKYC | GW | YRSPFSRVVHL | YR | 시험 펩티드 |
| 43 | K | CPKC | HKGW | YRSPFSRVVHL | YR | 시험 펩티드 |
| 44 | H | CPYC | GW | YRSPFSRVVHL | YR | 대조군 |
| 45 | CPYC | GW | YRSPFSRVVHL | YR | 대조군 | |
실시예 6: 염기성 아미노산을 갖는 산화환원 효소 모티프를 포함하는 면역원성 펩티드의 생물학적 효과.
염기성 아미노산을 갖는 산화환원 효소 모티프를 포함하는 면역원성 펩티드의 생물학적 효과를 조사하기 위해, 마우스 MOG T 세포 에피토프 및 CPYC 산화환원 효소 모티프를 포함하는 서열 CPYCGWYRSPFSRVVHLYR을 갖는 펩티드의 상이한 변이체를 설계하고 합성하였다 (표 11). 이어서 각 펩티드에 대한 산화환원 효소 활성을 측정하고 염기성 아미노산에 의해 변형된 펩티드의 최고 산화환원 효소 활성을 확인하였다 (데이터 미표시).
| 마우스 MOG T 세포 에피토프 및 CPYC 산화환원 효소 모티프를 포함하는 펩티드 CPYCGWYRSPFSRVVHLYR 및 염기성 아미노산을 포함하는 산화환원 효소 모티프를 갖는 이의 변이체. | ||||||
| 서열 번호 | N-말단 | 모티프 | 링커 | T-에피토프 | C-말단 | 목적 |
| 46 | H | CPYC | GW | YRSPFSRVV | HLYR | 대조군 |
| 47 | KH | CPYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 48 | K | CPYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 49 | KH | CKYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 50 | K | CKYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 51 | K | CPKC | HKGW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 52 | RH | CPYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 53 | R | CPYC | GW | YRSPFSRVV | HLYR | 시험 펩티드 |
| 54 | CPYC | GW | YRSPFSRVV | HLYR | 대조군 | |
표 11에 나타낸 펩티드의 생물학적 효과를 비교하기 위해 2D2 형질전환 마우스 (Jackson Laboratory)를 CD4+ 세포의 공급원으로 사용하였다. 이 마우스는 미엘린 희소돌기 아교세포 당단백질 (MOG) 특이적 자기 반응성 T 세포 레퍼토리를 포함함으로써 표 11의 펩티드에 대한 CD4+의 동종 집단의 반응성을 연구하기에 적합한 후보인 것으로 나타났다. 이 연구에서, 2D2-전체 CD4+ 세포를 제조 지침 (Miltenyi Biotec, 130-104-454)을 사용하여 정제하고 항원 제시 세포를 C57BL6 마우스 (2D2-형질전환 마우스 적합성)로부터의 T 세포 레퍼토리 (CD90.2 depletion, Miltenyi Biotec, 130-104-454)에 대해 고갈시켰다.
모든 연구에 대한 대조군 조건은 펩티드 비첨가 또는 산화환원 효소 모티프를 포함하는 DBY (인간 남성 염색체)로부터의 펩티드 또는 산화환원 효소 모티프를 포함하는 뮤린 PPI (프리프로인슐린)로부터의 펩티드 (이들 펩티드는 나중에 C57BL6-APC로부터의 MHCII에 효율적으로 결합할 수 있지만 2D2-형질전환 CD4+ T 세포로부터의 TCR을 활성화할 수 없었음)의 추가하였다.
우리는 먼저 CD154+ 마커 (CD40L)를 사용한 Ag-특이적 T 세포의 관여를 측정함으로써 산화환원 효소 모티프 내 및 N-/C-말단에서 염기성 아미노산의 삽입에 의한 펩티드의 산화환원 효소 모티프의 변형이 이러한 펩티드의 CD4+ T 세포 활성화 능력에 영향을 미치는지의 여부를 조사하였다. 이 목표를 이루기 위해 2D2-Total CD4+ 및 C57BL6 APC (1:1 비율)의 공배양물을 CD40 차단 항체의 존재하에 최종 농도 5 μM의 각 시험 펩티드 및 대조 펩티드에 16 시간 동안 노출시켰다. 인큐베이션 시간 후, 모든 실험 및 제어 조건에 대해 Ag-특이적 세포의 빈도를 유세포 분석법에 의해 결정하였다 (Pro-19-004-v00) (도 11).
결과는 염기성 아미노산을 포함하는 산화환원 효소 모티프를 가지는 펩티드 변이체가 CPYC 또는 HCPYC 모티프를 가지는 대조군에 비해 더 높은 비율의 Ag-특이적 세포 (CD4+ CD154+)의 관여를 유도할 수 있음을 나타내었다 (도 11; 점선).
우리는 다음으로 염기성 아미노산으로 인해 더 높은 산화환원 효소 활성을 갖는 것이 활성화된 Ag-특이적 CD4 T 세포에 의해 IL-2의 유도를 증가시키는지를 결정하기 위한 시도를 하였다. 이를 위해, 2D2-Total CD4+ 및 미토마이신 C-처리 C57BL6 APC (1:1 비율)의 공배양물을 최종 농도 5 μM의 각 시험 펩티드 및 대조 펩티드에 24 시간 동안 노출시켰다. 인큐베이션 시간 후, 정지 프로테아제 억제제 칵테일 (Thermo Scientific; 78430)을 첨가하여 상등액 (SN)을 수집하고 유세포 분석법 (LEGENDplex 마우스 Th 사이토카인 패널 (13-플렉스); Cat No. 740005; Pro-19-007-v00)을 사용하여 모든 실험 및 대조군 조건에 대해 분비된 IL2 (sIL2)의 양을 측정할 때까지 -80 ℃ 냉동고에 보관하였다. FACS 결과는 염기성 아미노산을 포함하는 산화환원 효소 모티프를 가진 펩티드 변이체가 CPYC 또는 HCPYC 모티프를 가지는 대조군과 비교하여 더 많은 양의 sIL2를 유도할 수 있음을 나타내었다 (도 12; 점선).
T 세포 에피토프 및 산화환원 효소 모티프를 포함하는 변형된 펩티드가 CD4+ 세포가 용해 마커를 획득하고 세포용해성 CD4+ T 세포로 분화할 수 있도록 하는 경로를 유도할 수 있다는 것은 당 업계에 알려져 있다.
이에 따라 우리는 염기성 아미노산으로 인해 더 높은 산화환원 효소 활성을 갖는 면역원성 펩티드가 활성화된 Ag-특이적 CD4 T 세포에서 조기 및/또는 더 강한 (백분율 또는 강도) 용해 특성을 유발하는지를 결정하기 위한 시도를 하였다. 이 실험 세트에서, 2D2-Total CD4+를 미토마이신 C-처리 C57BL6 APC (1:1 비율)와 최종 농도 5 μM의 각 시험 펩티드 및 대조 펩티드로 자극하였다 (자극 1). 10-14 일 간격 후, 모든 시험 및 대조군 조건으로부터의 모든 세포 배양물을 관련 펩티드의 부재 및 존재하에 다시 자극하였다 (자극 2, 0 일). 제2 자극 (S2D1) 16 시간 후, 세포를 수집하고 세포 내 (IC) 용해 마커 측정 (그랜자임 A 및 B, CD107a 및 유세포 분석법 (Pro-19-014-v00)에 의한 b)를 위해 염색하였다. 예상대로 대조 펩티드 조건은 배양물이 S2에서 측정에 포함되지 못하였음을 주목해야 한다.
그런 다음 모든 펩티드 변이체에 대해 FACS 결과를 결정하고 티오레독스 활성이 없는 MOG T 세포 에피토프를 포함하는 야생형 펩티드에 대한 측정을 다른 모든 측정에서 제거하여 전적으로 모든 변형된 산화환원 효소 모티프가 용해 특성의 유도에 미치는 영향만을 결정하였다. 이 결과는 지금까지 염기성 아미노산을 포함하는 산화환원 효소 모티프를 가진 변형된 펩티드가 KHCPYC 펩티드를 제외하고는 CPYC 또는 HCPYC 모티프를 사용하는 대조군 (도 13; 점선)에 비해 더 높은 비율의 용해 마커를 유도할 수 있음을 나타내었다. 기술적인 어려움 (1000 개 미만의 이벤트 포함)으로 인해 이 특정 펩티드에 대한 결과를 얻지 못하였다.
SEQUENCE LISTING
<110> Imcyse SA
<120> IMMUNOGENIC PEPTIDES WITH IMPROVED OXIDOREDUCTASE MOTIFS
<130> IMCY-023-PCT
<150> 18205615.0
<151> 2018-11-12
<150> 18205611.9
<151> 2018-11-12
<160> 321
<170> PatentIn version 3.5
<210> 1
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 1
Lys Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 2
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 2
Lys His Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 3
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 3
Arg Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 4
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 4
Arg His Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 5
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 5
Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 6
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 6
His Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 7
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 7
Lys Cys Pro Tyr Cys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe Ile
1 5 10 15
Gly Ile Thr Glu Leu
20
<210> 8
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 8
Lys His Cys Pro Tyr Cys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe
1 5 10 15
Ile Gly Ile Thr Glu Leu
20
<210> 9
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 9
Cys Pro Tyr Cys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe Ile Gly
1 5 10 15
Ile Thr Glu Leu
20
<210> 10
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 10
His Cys Pro Tyr Cys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe Ile
1 5 10 15
Gly Ile Thr Glu Leu
20
<210> 11
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 11
Lys Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 12
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 12
Lys His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val
1 5 10 15
Val His Leu Tyr Arg
20
<210> 13
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 13
Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val His
1 5 10 15
Leu Tyr Arg
<210> 14
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 14
His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 15
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 15
Cys Pro Lys Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 16
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 16
Cys Lys Tyr Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 17
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 17
Cys Pro Tyr Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 18
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 18
Cys His Lys Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 19
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 19
Cys Lys Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 20
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 20
Cys Arg Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 21
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 21
Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 22
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 22
Cys His Lys Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 23
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 23
Cys Gly Arg Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 24
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 24
Cys Gly His Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 25
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 25
Cys Gly Lys Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 26
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 26
Cys His Gly Cys Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 27
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 27
Cys His Gly Cys His Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 28
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 28
Cys His Gly Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 29
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 29
Cys Pro Tyr Cys Lys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe Ile
1 5 10 15
Gly Ile Thr Glu Leu
20
<210> 30
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 30
Cys Pro Tyr Cys His Lys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe
1 5 10 15
Ile Gly Ile Thr Glu Leu
20
<210> 31
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 31
Cys Pro Tyr Cys Val Gln Tyr Ile Lys Ala Asn Ser Lys Phe Ile Gly
1 5 10 15
Ile Thr Glu Leu
20
<210> 32
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 32
Lys Cys Lys Tyr Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 33
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 33
Lys Cys Pro Lys Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu
1 5 10 15
Gln Lys Arg Gly
20
<210> 34
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 34
Lys Cys Pro Lys Cys Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 35
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 35
Lys Cys Lys Tyr Cys Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 36
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 36
Lys Cys Pro Tyr Cys Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser
1 5 10 15
Leu Gln Lys Arg Gly
20
<210> 37
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 37
Lys Cys Pro Lys Cys His Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly
1 5 10 15
Ser Leu Gln Lys Arg Gly
20
<210> 38
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 38
Lys Cys Lys Tyr Cys His Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly
1 5 10 15
Ser Leu Gln Lys Arg Gly
20
<210> 39
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 39
Lys Cys Pro Tyr Cys His Lys Ser Leu Gln Pro Leu Ala Leu Glu Gly
1 5 10 15
Ser Leu Gln Lys Arg Gly
20
<210> 40
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 40
Cys Pro Tyr Cys Ser Leu Gln Pro Leu Ala Leu Glu Gly Ser Leu Gln
1 5 10 15
Lys Arg Gly
<210> 41
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 41
Lys His Cys Lys Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val
1 5 10 15
Val His Leu Tyr Arg
20
<210> 42
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 42
Lys Cys Lys Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 43
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 43
Lys Cys Pro Lys Cys His Lys Gly Trp Tyr Arg Ser Pro Phe Ser Arg
1 5 10 15
Val Val His Leu Tyr Arg
20
<210> 44
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 44
His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 45
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 45
Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val His
1 5 10 15
Leu Tyr Arg
<210> 46
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 46
His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 47
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 47
Lys His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val
1 5 10 15
Val His Leu Tyr Arg
20
<210> 48
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 48
Lys Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 49
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 49
Lys His Cys Lys Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val
1 5 10 15
Val His Leu Tyr Arg
20
<210> 50
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 50
Lys Cys Lys Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 51
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 51
Lys Cys Pro Lys Cys His Lys Gly Trp Tyr Arg Ser Pro Phe Ser Arg
1 5 10 15
Val Val His Leu Tyr Arg
20
<210> 52
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 52
Arg His Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val
1 5 10 15
Val His Leu Tyr Arg
20
<210> 53
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 53
Arg Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val
1 5 10 15
His Leu Tyr Arg
20
<210> 54
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 54
Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val His
1 5 10 15
Leu Tyr Arg
<210> 55
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid which is not H or R
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 55
Xaa Xaa Xaa Cys
1
<210> 56
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid which is not H or R
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 56
Cys Xaa Xaa Xaa
1
<210> 57
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid which is not H
<400> 57
Xaa Xaa Xaa Cys
1
<210> 58
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid which is not H
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 58
Cys Xaa Xaa Xaa
1
<210> 59
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 59
Xaa Xaa Xaa Xaa Cys
1 5
<210> 60
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<220>
<221> misc_feature
<222> (4)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 60
Xaa Xaa Xaa Xaa Xaa Cys
1 5
<210> 61
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<400> 61
Xaa Xaa Xaa Xaa Xaa Xaa Cys
1 5
<210> 62
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<400> 62
Xaa Xaa Xaa Xaa Xaa Xaa Xaa Cys
1 5
<210> 63
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 63
Xaa Cys Xaa Xaa Xaa
1 5
<210> 64
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (4)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 64
Xaa Xaa Cys Xaa Xaa Xaa
1 5
<210> 65
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 65
Xaa Xaa Xaa Cys Xaa Xaa Xaa
1 5
<210> 66
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid which is not H
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (6)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 66
Xaa Xaa Xaa Xaa Cys Xaa Xaa Xaa
1 5
<210> 67
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 67
Xaa Xaa Xaa Cys Xaa
1 5
<210> 68
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 68
Xaa Xaa Xaa Cys Xaa Xaa
1 5
<210> 69
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 69
Xaa Xaa Xaa Cys Xaa Xaa Xaa
1 5
<210> 70
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 70
Xaa Xaa Xaa Cys Xaa Xaa Xaa Xaa
1 5
<210> 71
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 71
Cys Xaa Xaa Xaa Xaa
1 5
<210> 72
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 72
Cys Xaa Xaa Xaa Xaa Xaa
1 5
<210> 73
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 73
Cys Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 74
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 74
Cys Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 75
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 75
Cys Arg Leu Cys
1
<210> 76
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 76
Cys Arg Leu Cys Lys Val Ala Pro Val Ile Lys Ala Arg Met Met
1 5 10 15
<210> 77
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptdie
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,Y,H or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> V,I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,Y,H or T
<400> 77
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 78
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,Y or H
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> V,I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,Y or H
<400> 78
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 79
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,Y or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> V,I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,Y or T
<400> 79
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 80
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W or Y
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> V,I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W or Y
<400> 80
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 81
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,Y or H
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,Y or H
<400> 81
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 82
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,Y,H or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,Y, H or T
<400> 82
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 83
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W or Y
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W or Y
<400> 83
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 84
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 84
Xaa Xaa Xaa Cys
1
<210> 85
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 85
Cys Xaa Xaa Xaa
1
<210> 86
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F or W
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F,W,T or H
<400> 86
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 87
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> F,W,T or H
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> I,L or M
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> F or W
<400> 87
Xaa Xaa Xaa Xaa Xaa Xaa Xaa
1 5
<210> 88
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 88
Xaa Xaa Tyr Cys
1
<210> 89
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 89
Cys Xaa Tyr Xaa
1
<210> 90
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<400> 90
Xaa Pro Xaa Cys
1
<210> 91
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 91
Cys Pro Xaa Xaa
1
<210> 92
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 92
Xaa Xaa Gly Cys
1
<210> 93
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 93
Cys Xaa Gly Xaa
1
<210> 94
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<400> 94
Xaa His Xaa Cys
1
<210> 95
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 95
Cys His Xaa Xaa
1
<210> 96
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 96
Xaa Xaa Pro Cys
1
<210> 97
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 97
Cys Xaa Pro Cys
1
<210> 98
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<400> 98
Xaa Gly Xaa Cys
1
<210> 99
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 99
Cys Gly Xaa Xaa
1
<210> 100
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 100
Xaa Xaa Phe Cys
1
<210> 101
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 101
Cys Xaa Phe Xaa
1
<210> 102
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 102
Xaa Xaa His Cys
1
<210> 103
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 103
Cys Xaa His Xaa
1
<210> 104
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<400> 104
Xaa Arg Xaa Cys
1
<210> 105
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 105
Cys Arg Xaa Xaa
1
<210> 106
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<400> 106
Xaa Xaa Leu Cys
1
<210> 107
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 107
Cys Xaa Leu Xaa
1
<210> 108
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 108
Xaa Xaa Pro Tyr Cys
1 5
<210> 109
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 109
Xaa Xaa Xaa Pro Tyr Cys
1 5
<210> 110
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 110
Xaa Xaa Xaa Xaa Pro Tyr Cys
1 5
<210> 111
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 111
Xaa Xaa Xaa Xaa Xaa Pro Tyr Cys
1 5
<210> 112
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 112
Xaa Cys Pro Tyr Xaa
1 5
<210> 113
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 113
Xaa Xaa Cys Pro Tyr Xaa
1 5
<210> 114
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 114
Xaa Xaa Xaa Cys Pro Tyr Xaa
1 5
<210> 115
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 115
Xaa Xaa Xaa Xaa Cys Pro Tyr Xaa
1 5
<210> 116
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 116
Xaa Xaa His Gly Cys
1 5
<210> 117
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 117
Xaa Xaa Xaa His Gly Cys
1 5
<210> 118
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 118
Xaa Xaa Xaa Xaa His Gly Cys
1 5
<210> 119
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 119
Xaa Xaa Xaa Xaa Xaa His Gly Cys
1 5
<210> 120
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 120
Xaa Cys His Gly Xaa
1 5
<210> 121
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 121
Xaa Xaa Cys His Gly Xaa
1 5
<210> 122
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 122
Xaa Xaa Xaa Cys His Gly Xaa
1 5
<210> 123
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 123
Xaa Xaa Xaa Xaa Cys His Gly Xaa
1 5
<210> 124
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 124
Xaa Xaa Gly Pro Cys
1 5
<210> 125
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 125
Xaa Xaa Xaa Gly Pro Cys
1 5
<210> 126
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 126
Xaa Xaa Xaa Xaa Gly Pro Cys
1 5
<210> 127
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 127
Xaa Xaa Xaa Xaa Xaa Gly Pro Cys
1 5
<210> 128
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 128
Xaa Cys Gly Pro Xaa
1 5
<210> 129
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 129
Xaa Xaa Cys Gly Pro Xaa
1 5
<210> 130
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 130
Xaa Xaa Xaa Cys Gly Pro Xaa
1 5
<210> 131
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 131
Xaa Xaa Xaa Xaa Cys Gly Pro Xaa
1 5
<210> 132
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 132
Xaa Xaa Gly His Cys
1 5
<210> 133
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 133
Xaa Xaa Xaa Gly His Cys
1 5
<210> 134
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 134
Xaa Xaa Xaa Xaa Gly His Cys
1 5
<210> 135
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 135
Xaa Xaa Xaa Xaa Xaa Gly His Cys
1 5
<210> 136
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 136
Xaa Cys Gly His Xaa
1 5
<210> 137
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 137
Xaa Xaa Cys Gly His Xaa
1 5
<210> 138
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 138
Xaa Xaa Xaa Cys Gly His Xaa
1 5
<210> 139
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 139
Xaa Xaa Xaa Xaa Cys Gly His Xaa
1 5
<210> 140
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 140
Xaa Xaa Gly Phe Cys
1 5
<210> 141
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 141
Xaa Xaa Xaa Gly Phe Cys
1 5
<210> 142
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 142
Xaa Xaa Xaa Xaa Gly Phe Cys
1 5
<210> 143
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 143
Xaa Xaa Xaa Xaa Xaa Gly Phe Cys
1 5
<210> 144
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 144
Xaa Cys Gly Phe Xaa
1 5
<210> 145
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 145
Xaa Xaa Cys Gly Phe Xaa
1 5
<210> 146
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 146
Xaa Xaa Xaa Cys Gly Phe Xaa
1 5
<210> 147
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 147
Xaa Xaa Xaa Xaa Cys Gly Phe Xaa
1 5
<210> 148
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 148
Xaa Xaa Arg Leu Cys
1 5
<210> 149
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 149
Xaa Xaa Xaa Arg Leu Cys
1 5
<210> 150
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 150
Xaa Xaa Xaa Xaa Arg Leu Cys
1 5
<210> 151
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 151
Xaa Xaa Xaa Xaa Xaa Arg Leu Cys
1 5
<210> 152
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 152
Xaa Cys Arg Leu Xaa
1 5
<210> 153
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 153
Xaa Xaa Cys Arg Leu Xaa
1 5
<210> 154
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 154
Xaa Xaa Xaa Cys Arg Leu Xaa
1 5
<210> 155
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 155
Xaa Xaa Xaa Xaa Cys Arg Leu Xaa
1 5
<210> 156
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 156
Xaa Xaa His Pro Cys
1 5
<210> 157
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 157
Xaa Xaa Xaa His Pro Cys
1 5
<210> 158
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 158
Xaa Xaa Xaa Xaa His Pro Cys
1 5
<210> 159
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 159
Xaa Xaa Xaa Xaa Xaa His Pro Cys
1 5
<210> 160
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 160
Xaa Cys His Pro Xaa
1 5
<210> 161
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 161
Xaa Xaa Cys His Pro Xaa
1 5
<210> 162
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 162
Xaa Xaa Xaa Cys His Pro Xaa
1 5
<210> 163
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 163
Xaa Xaa Xaa Xaa Cys His Pro Xaa
1 5
<210> 164
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (2)..(2)
<223> C, S or T
<400> 164
Xaa Xaa His Gly Cys
1 5
<210> 165
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (3)..(3)
<223> C, S or T
<400> 165
Xaa Xaa Xaa His Gly Cys
1 5
<210> 166
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<400> 166
Xaa Xaa Xaa Xaa His Gly Cys
1 5
<210> 167
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 167
Xaa Xaa Xaa Xaa Xaa His Gly Cys
1 5
<210> 168
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> C, S or T
<400> 168
Xaa Cys His Gly Xaa
1 5
<210> 169
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> C, S or T
<400> 169
Xaa Xaa Cys His Gly Xaa
1 5
<210> 170
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> C, S or T
<400> 170
Xaa Xaa Xaa Cys His Gly Xaa
1 5
<210> 171
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> basic amino acid
<220>
<221> misc_feature
<222> (2)..(4)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> C, S or T
<400> 171
Xaa Xaa Xaa Xaa Cys His Gly Xaa
1 5
<210> 172
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 172
Xaa Pro Tyr Cys Xaa
1 5
<210> 173
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 173
Xaa Pro Tyr Cys Xaa Xaa
1 5
<210> 174
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 174
Xaa Pro Tyr Cys Xaa Xaa Xaa
1 5
<210> 175
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 175
Xaa Pro Tyr Cys Xaa Xaa Xaa Xaa
1 5
<210> 176
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 176
Cys Pro Tyr Xaa Xaa
1 5
<210> 177
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 177
Cys Pro Tyr Xaa Xaa Xaa
1 5
<210> 178
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 178
Cys Pro Tyr Xaa Xaa Xaa Xaa
1 5
<210> 179
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 179
Cys Pro Tyr Xaa Xaa Xaa Xaa Xaa
1 5
<210> 180
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 180
Xaa His Gly Cys Xaa
1 5
<210> 181
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 181
Xaa His Gly Cys Xaa Xaa
1 5
<210> 182
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 182
Xaa His Gly Cys Xaa Xaa Xaa
1 5
<210> 183
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 183
Xaa His Gly Cys Xaa Xaa Xaa Xaa
1 5
<210> 184
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 184
Cys His Gly Xaa Xaa
1 5
<210> 185
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 185
Cys His Gly Xaa Xaa Xaa
1 5
<210> 186
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 186
Cys His Gly Xaa Xaa Xaa Xaa
1 5
<210> 187
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 187
Cys His Gly Xaa Xaa Xaa Xaa Xaa
1 5
<210> 188
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 188
Xaa Gly Pro Cys Xaa
1 5
<210> 189
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 189
Xaa Gly Pro Cys Xaa Xaa
1 5
<210> 190
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 190
Xaa Gly Pro Cys Xaa Xaa Xaa
1 5
<210> 191
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 191
Xaa Gly Pro Cys Xaa Xaa Xaa Xaa
1 5
<210> 192
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 192
Cys Gly Pro Xaa Xaa
1 5
<210> 193
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 193
Cys Gly Pro Xaa Xaa Xaa
1 5
<210> 194
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 194
Cys Gly Pro Xaa Xaa Xaa Xaa
1 5
<210> 195
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 195
Cys Gly Pro Xaa Xaa Xaa Xaa Xaa
1 5
<210> 196
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 196
Xaa Gly His Cys Xaa
1 5
<210> 197
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 197
Xaa Gly His Cys Xaa Xaa
1 5
<210> 198
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 198
Xaa Gly His Cys Xaa Xaa Xaa
1 5
<210> 199
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 199
Xaa Gly His Cys Xaa Xaa Xaa Xaa
1 5
<210> 200
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 200
Cys Gly His Xaa Xaa
1 5
<210> 201
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 201
Cys Gly His Xaa Xaa Xaa
1 5
<210> 202
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 202
Cys Gly His Xaa Xaa Xaa Xaa
1 5
<210> 203
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 203
Cys Gly His Xaa Xaa Xaa Xaa Xaa
1 5
<210> 204
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 204
Xaa Gly Phe Cys Xaa
1 5
<210> 205
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 205
Xaa Gly Phe Cys Xaa Xaa
1 5
<210> 206
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 206
Xaa Gly Phe Cys Xaa Xaa Xaa
1 5
<210> 207
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 207
Xaa Gly Phe Cys Xaa Xaa Xaa Xaa
1 5
<210> 208
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 208
Cys Gly Phe Xaa Xaa
1 5
<210> 209
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 209
Cys Gly Phe Xaa Xaa Xaa
1 5
<210> 210
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 210
Cys Gly Phe Xaa Xaa Xaa Xaa
1 5
<210> 211
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 211
Cys Gly Phe Xaa Xaa Xaa Xaa Xaa
1 5
<210> 212
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 212
Xaa Arg Leu Cys Xaa
1 5
<210> 213
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 213
Xaa Arg Leu Cys Xaa Xaa
1 5
<210> 214
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 214
Xaa Arg Leu Cys Xaa Xaa Xaa
1 5
<210> 215
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 215
Xaa Arg Leu Cys Xaa Xaa Xaa Xaa
1 5
<210> 216
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 216
Cys Arg Leu Xaa Xaa
1 5
<210> 217
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 217
Cys Arg Leu Xaa Xaa Xaa
1 5
<210> 218
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 218
Cys Arg Leu Xaa Xaa Xaa Xaa
1 5
<210> 219
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 219
Cys Arg Leu Xaa Xaa Xaa Xaa Xaa
1 5
<210> 220
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 220
Xaa His Pro Cys Xaa
1 5
<210> 221
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 221
Xaa His Pro Cys Xaa Xaa
1 5
<210> 222
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 222
Xaa His Pro Cys Xaa Xaa Xaa
1 5
<210> 223
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (1)..(1)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 223
Xaa His Pro Cys Xaa Xaa Xaa Xaa
1 5
<210> 224
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> PEPTIDE
<222> (5)..(5)
<223> basic amino acid
<400> 224
Cys His Pro Xaa Xaa
1 5
<210> 225
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(5)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (6)..(6)
<223> basic amino acid which is not R
<400> 225
Cys His Pro Xaa Xaa Xaa
1 5
<210> 226
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(6)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (7)..(7)
<223> basic amino acid which is not R or H
<400> 226
Cys His Pro Xaa Xaa Xaa Xaa
1 5
<210> 227
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> PEPTIDE
<222> (4)..(4)
<223> C, S or T
<220>
<221> misc_feature
<222> (5)..(7)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> PEPTIDE
<222> (8)..(8)
<223> basic amino acid which is not R or H
<400> 227
Cys His Pro Xaa Xaa Xaa Xaa Xaa
1 5
<210> 228
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 228
Arg Cys Xaa Xaa Cys
1 5
<210> 229
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 229
Arg Cys Pro Tyr Cys
1 5
<210> 230
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 230
Arg Cys Gly His Cys
1 5
<210> 231
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 231
Arg Cys His Gly Cys
1 5
<210> 232
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 232
Lys Cys Xaa Xaa Cys
1 5
<210> 233
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 233
Lys Cys Pro Tyr Cys
1 5
<210> 234
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 234
Lys Cys Gly His Cys
1 5
<210> 235
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 235
Lys Cys His Gly Cys
1 5
<210> 236
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 236
Lys His Cys Xaa Xaa Cys
1 5
<210> 237
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 237
Arg His Cys Pro Tyr Cys
1 5
<210> 238
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 238
Arg His Cys Gly His Cys
1 5
<210> 239
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 239
Arg His Cys His Gly Cys
1 5
<210> 240
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(5)
<223> Xaa can be any naturally occurring amino acid
<400> 240
Lys Arg Cys Xaa Xaa Cys
1 5
<210> 241
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 241
Lys His Cys Pro Tyr Cys
1 5
<210> 242
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 242
Lys His Cys Gly His Cys
1 5
<210> 243
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 243
Lys His Cys His Gly Cys
1 5
<210> 244
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<400> 244
Cys Xaa Arg Cys
1
<210> 245
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 245
Cys Gly Arg Cys
1
<210> 246
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 246
Cys Pro Arg Cys
1
<210> 247
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 247
Cys His Arg Cys
1
<210> 248
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<400> 248
Cys Xaa Lys Cys
1
<210> 249
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 249
Cys Gly Lys Cys
1
<210> 250
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 250
Cys Pro Lys Cys
1
<210> 251
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 251
Cys His Lys Cys
1
<210> 252
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 252
Cys Xaa Xaa Cys Lys
1 5
<210> 253
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 253
Cys His Gly Cys Lys
1 5
<210> 254
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 254
Cys Pro Tyr Cys Lys
1 5
<210> 255
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 255
Cys Gly His Cys Lys
1 5
<210> 256
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 256
Cys Xaa Xaa Cys His Lys
1 5
<210> 257
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 257
Cys His Gly Cys His Lys
1 5
<210> 258
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 258
Cys Pro Tyr Cys His Lys
1 5
<210> 259
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> CGHCHK
<400> 259
Cys Gly His Cys His Lys
1 5
<210> 260
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 260
Cys Xaa Xaa Cys Arg
1 5
<210> 261
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 261
Cys His Gly Cys Arg
1 5
<210> 262
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 262
Cys Pro Tyr Cys Arg
1 5
<210> 263
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 263
Cys Gly His Cys Arg
1 5
<210> 264
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 264
Cys Xaa Xaa Cys His Arg
1 5
<210> 265
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 265
Cys His Gly Cys His Arg
1 5
<210> 266
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 266
Cys Pro Tyr Cys His Arg
1 5
<210> 267
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 267
Cys Gly His Cys His Arg
1 5
<210> 268
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 268
Lys Cys Lys Xaa Cys
1 5
<210> 269
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 269
Arg Cys Lys Xaa Cys
1 5
<210> 270
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 270
Lys Cys Arg Xaa Cys
1 5
<210> 271
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 271
Arg Cys Arg Xaa Cys
1 5
<210> 272
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 272
Lys Cys Xaa Lys Cys
1 5
<210> 273
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 273
Arg Cys Xaa Lys Cys
1 5
<210> 274
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 274
Lys Cys Xaa Arg Cys
1 5
<210> 275
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 275
Arg Cys Xaa Arg Cys
1 5
<210> 276
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 276
Lys Cys Lys Xaa Cys Lys
1 5
<210> 277
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 277
Arg Cys Lys Xaa Cys Lys
1 5
<210> 278
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 278
Lys Cys Arg Xaa Cys Lys
1 5
<210> 279
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 279
Lys Cys Lys Xaa Cys Arg
1 5
<210> 280
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 280
Arg Cys Arg Xaa Cys Lys
1 5
<210> 281
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 281
Arg Cys Lys Xaa Cys Arg
1 5
<210> 282
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 282
Lys Cys Arg Xaa Cys Arg
1 5
<210> 283
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 283
Arg Cys Arg Xaa Cys Arg
1 5
<210> 284
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 284
Lys Cys Lys Xaa Cys His Lys
1 5
<210> 285
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 285
Arg Cys Lys Xaa Cys His Lys
1 5
<210> 286
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 286
Lys Cys Arg Xaa Cys His Lys
1 5
<210> 287
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 287
Lys Cys Lys Xaa Cys His Arg
1 5
<210> 288
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 288
Arg Cys Arg Xaa Cys His Lys
1 5
<210> 289
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 289
Arg Cys Lys Xaa Cys His Arg
1 5
<210> 290
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 290
Lys Cys Arg Xaa Cys His Arg
1 5
<210> 291
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (4)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 291
Arg Cys Arg Xaa Cys His Arg
1 5
<210> 292
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 292
Lys Cys Xaa Xaa Cys Lys
1 5
<210> 293
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 293
Lys Cys Xaa Xaa Cys Arg
1 5
<210> 294
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 294
Arg Cys Xaa Xaa Cys Lys
1 5
<210> 295
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 295
Arg Cys Xaa Xaa Cys Arg
1 5
<210> 296
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 296
Lys Cys Xaa Xaa Cys His Lys
1 5
<210> 297
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 297
Lys Cys Xaa Xaa Cys His Arg
1 5
<210> 298
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 298
Arg Cys Xaa Xaa Cys His Lys
1 5
<210> 299
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(4)
<223> Xaa can be any naturally occurring amino acid
<400> 299
Arg Cys Xaa Xaa Cys His Arg
1 5
<210> 300
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 300
Lys Cys Xaa Lys Cys Lys
1 5
<210> 301
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 301
Arg Cys Xaa Lys Cys Lys
1 5
<210> 302
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 302
Lys Cys Xaa Arg Cys Lys
1 5
<210> 303
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 303
Lys Cys Xaa Lys Cys Arg
1 5
<210> 304
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (2)..(2)
<223> Xaa can be any naturally occurring amino acid
<400> 304
Cys Xaa Arg Cys Lys
1 5
<210> 305
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 305
Arg Cys Xaa Lys Cys Arg
1 5
<210> 306
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 306
Lys Cys Xaa Arg Cys Arg
1 5
<210> 307
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 307
Arg Cys Xaa Arg Cys Arg
1 5
<210> 308
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 308
Lys Cys Xaa Lys Cys His Lys
1 5
<210> 309
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 309
Arg Cys Xaa Lys Cys His Lys
1 5
<210> 310
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 310
Lys Cys Xaa Arg Cys His Lys
1 5
<210> 311
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 311
Lys Cys Xaa Lys Cys His Arg
1 5
<210> 312
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 312
Arg Cys Xaa Arg Cys His Lys
1 5
<210> 313
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 313
Arg Cys Xaa Lys Cys His Arg
1 5
<210> 314
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 314
Lys Cys Xaa Arg Cys His Arg
1 5
<210> 315
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<220>
<221> misc_feature
<222> (3)..(3)
<223> Xaa can be any naturally occurring amino acid
<400> 315
Arg Cys Xaa Arg Cys His Arg
1 5
<210> 316
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 316
Cys His Gly Cys
1
<210> 317
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 317
Cys Pro Tyr Cys
1
<210> 318
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 318
Cys Arg Gly Cys
1
<210> 319
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 319
Cys Gly His Cys
1
<210> 320
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 320
Cys Pro Tyr Cys Gly Trp Tyr Arg Ser Pro Phe Ser Arg Val Val His
1 5 10 15
Leu
<210> 321
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic peptide
<400> 321
His Cys Pro Tyr Cys
1 5
Claims (19)
- 면역원성 펩티드로서,
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커를 포함하고,
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산, 바람직하게는 K 또는 R 또는 L-오르니틴과 같은 비천연 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1인,
면역원성 펩티드. - 제1항에 있어서, (Z1)+는 K 또는 비천연 염기성 아미노산을 포함하는 군으로부터 선택되고/거나, 각 (Z2)+ 및/또는 (Z3)+ 중 어느 하나는 각각 개별적으로 K, R 또는 비천연 염기성 아미노산을 포함하는 군으로부터 선택되는, 면역원성 펩티드.
- 제1항 또는 제2항에 있어서, (Z1)+, (Z2)+ 및/또는 (Z3)+ 중 어느 하나는 K 또는 L-오르니틴인, 면역원성 펩티드.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 항원 단백질의 상기 T 세포 에피토프는 NKT 세포 에피토프 또는 MHC 클래스 II T 세포 에피토프인, 면역원성 펩티드.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 에피토프는 7 내지 30 개 아미노산, 바람직하게는 7 내지 25 개 아미노산, 보다 바람직하게는 7 내지 20 개 아미노산의 길이를 갖는, 면역원성 펩티드.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 11 내지 50 개 아미노산, 바람직하게는 11 내지 40 개 아미노산, 보다 바람직하게는 11 내지 30 개 아미노산의 길이를 갖는, 면역원성 펩티드.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 항원 단백질은 자가 항원, 가용성 동종 인자, 이식편에 의해 발산된 동종 항원, 세포 내 병원체의 항원, 유전자 치료 또는 유전자 백신 접종을 위해 사용된 바이러스 벡터의 항원, 종양 관련 항원 또는 알레르겐인, 면역원성 펩티드.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 의약에 사용하기 위한 면역원성 펩티드.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응의 치료 및/또는 예방에 사용하기 위한 면역원성 펩티드.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 모티프에서 적어도 하나의 X는 P 또는 Y인, 면역원성 펩티드.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 링커는 0 내지 4 개의 아미노산의 것인, 면역원성 펩티드.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 산화환원 효소 모티프는 상기 항원 단백질에서 T-세포 에피토프의 N-말단 또는 C-말단의 11 개 아미노산 영역 내에서 자연적으로 발생하지 않는, 면역원성 펩티드.
- 제1항 내지 제12항 중 어느 한 항에 있어서, T-세포 에피토프는 자연적으로는 상기 산화환원 효소 모티프를 포함하지 않는, 면역원성 펩티드.
- (a) 항원 단백질의 T-세포 에피토프로 이루어진 펩티드 서열을 제공하는 단계, 및
(b) 모티프와 에피토프가 서로 인접하거나 최대 7 개 아미노산의 링커에 의해 분리되도록 펩티드 서열에 산화환원 효소 모티프를 연결하는 단계를 포함하는,
제1항 내지 제13항 중 어느 한 항에 따른 면역원성 펩티드의 제조 방법. - - 말초 혈액 세포를 제공하는 단계;
- 상기 세포를
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커를 포함하는 면역원성 펩티드와 접촉시키는 단계, 및
- 상기 세포를 IL-2의 존재하에 확장시키는 단계를 포함하는,
상기 항원을 제시하는 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 집단을 수득하는 방법으로서,
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산, 바람직하게는 K 또는 R 또는 L-오르니틴과 같은 비천연 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1인,
방법. - - 말초 혈액 세포를 제공하는 단계;
- 상기 세포를
a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커를 포함하는 면역원성 펩티드와 접촉시키는 단계, 및
- 상기 세포를 IL-2의 존재하에 확장시키는 단계를 포함하는,
항원 특이적 NKT 세포 집단을 수득하는 방법으로서,
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산, 바람직하게는 K 또는 R 또는 L-오르니틴과 같은 비천연 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1인,
방법. - - a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커를 포함하는 면역원성 펩티드를 제공하는 단계,
- 상기 펩티드를 대상체에게 투여하는 단계; 및
- 상기 대상체로부터 상기 항원-특이적 세포용해성 CD4+ T 세포 집단을 수득하는 단계를 포함하는,
상기 항원을 제시하는 APC에 대한 항원 특이적 세포용해성 CD4+ T 세포 집단을 수득하는 방법으로서,
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고,
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산, 바람직하게는 K 또는 R 또는 L-오르니틴과 같은 비천연 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1인,
방법. - - a) 산화환원 효소 모티프,
b) 항원 단백질의 T-세포 에피토프, 및
c) a)와 b) 사이에 0 내지 7 개 아미노산의 링커를 포함하는 면역원성 펩티드를 제공하는 단계;
- 상기 펩티드를 대상체에게 투여하는 단계; 및
- 상기 대상체로부터 상기 항원-특이적 NKT 세포 집단을 수득하는 단계를 포함하는,
항원 특이적 NKT 세포 집단을 수득하는 방법으로서,
여기서,
(i) 상기 산화환원 효소 모티프는 (Z2)+(B1)n[CST]XXC 또는 (Z2)+(B1)nCXX[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(ii) 상기 산화환원 효소 모티프는 [CST]X(Z2)+C 또는 CX(Z2)+[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z2)+는 H가 아닌 염기성 아미노산이고;
X는 임의의 아미노산이고;
(B1)은 임의의 아미노산이고, n은 0 내지 3의 정수이거나; 또는
(iii) 상기 산화환원 효소 모티프는 [CST](Z1)+XC; 또는 C(Z1)+X[CST]를 포함하는 군으로부터 선택되고;
여기서, (Z1)+는 H가 아닌 염기성 아미노산 또는 R이고;
X는 임의의 아미노산이거나; 또는
(iv) 상기 산화환원 효소 모티프는 [CST]XXC(B2)m(Z3)+, 또는 CXX[CST](B2)m(Z3)+를 포함하는 군으로부터 선택되고,
여기서, (Z3)+는 염기성 아미노산, 바람직하게는 K 또는 R 또는 L-오르니틴과 같은 비천연 염기성 아미노산이고,
X는 임의의 아미노산이고;
(B2)는 임의의 아미노산이고 m은 0 내지 3의 정수이되, 단, (Z3)+가 R인 경우 m은 0이고 (Z3)+가 H인 경우 m은 0 또는 1인,
방법. - 자가면역 질환, 세포 내 병원체 감염, 종양, 동종 이식 거부 반응, 또는 가용성 동종 인자, 알레르겐 노출 또는 유전자 치료 또는 유전자 백신 접종에 사용된 바이러스 벡터에 대한 면역 반응의 치료 및/또는 예방에 사용하기 위한, 제15항 내지 제18항 중 어느 한 항의 방법에 의해 수득 가능한 항원-특이적 세포용해성 CD4+ T 세포 또는 NKT 세포 집단.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18205615.0 | 2018-11-12 | ||
| EP18205611 | 2018-11-12 | ||
| EP18205611.9 | 2018-11-12 | ||
| EP18205615 | 2018-11-12 | ||
| PCT/EP2019/080929 WO2020099356A2 (en) | 2018-11-12 | 2019-11-12 | Immunogenic peptides with improved oxidoreductase motifs |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210093933A true KR20210093933A (ko) | 2021-07-28 |
Family
ID=68655497
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217017332A KR20210093933A (ko) | 2018-11-12 | 2019-11-12 | 개선된 산화환원 효소 모티프를 갖는 면역원성 펩티드 |
Country Status (18)
| Country | Link |
|---|---|
| US (2) | US20210401976A1 (ko) |
| EP (2) | EP3880237A2 (ko) |
| JP (2) | JP2022513019A (ko) |
| KR (1) | KR20210093933A (ko) |
| CN (2) | CN113015542A (ko) |
| AU (2) | AU2019377983A1 (ko) |
| BR (1) | BR112021009210A2 (ko) |
| CA (2) | CA3118620A1 (ko) |
| CO (1) | CO2021007060A2 (ko) |
| CU (1) | CU20210041A7 (ko) |
| IL (1) | IL282849A (ko) |
| MX (1) | MX2021005540A (ko) |
| PE (1) | PE20211494A1 (ko) |
| PH (1) | PH12021551101A1 (ko) |
| SG (1) | SG11202104875XA (ko) |
| TW (1) | TW202043255A (ko) |
| WO (2) | WO2020099352A2 (ko) |
| ZA (1) | ZA202102909B (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DK2476436T3 (en) | 2006-08-11 | 2018-02-05 | Life Sciences Res Partners Vzw | Immunogenic peptides and their use in immune disorders |
| GB201418433D0 (en) | 2014-10-17 | 2014-12-03 | Imcyse Sa | Novel immunogenic peptides |
| CA3051518A1 (en) * | 2017-03-09 | 2018-09-13 | Imcyse Sa | Peptides and methods for the treatment of diabetes |
| US20210401976A1 (en) * | 2018-11-12 | 2021-12-30 | Imcyse Sa | Immunogenic peptides with improved oxidoreductase motifs |
| EP4146254A1 (en) * | 2020-05-06 | 2023-03-15 | Imcyse SA | Immunogenic peptides with extended oxidoreductase motifs |
| WO2021224403A1 (en) * | 2020-05-06 | 2021-11-11 | Imcyse Sa | Immunogenic peptides with new oxidoreductase motifs |
| IL308571A (en) | 2021-05-26 | 2024-01-01 | Imcyse Sa | Methods for the treatment or prevention of autoimmune diseases |
| AR126654A1 (es) * | 2021-06-29 | 2023-11-01 | Imcyse Sa | Péptidos y métodos para el tratamiento de neuromielitis óptica |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2407352A1 (en) * | 2000-04-21 | 2001-11-01 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of acne vulgaris |
| EP1501922A4 (en) * | 2001-12-21 | 2005-07-27 | Univ Rochester | METHODS OF MODULATING EXPRESSION OF HEME OXYGENASE-1 AND TREATMENT OF HEME OXYGENASE-1 MEDIATED CONDITIONS |
| EP1523557A2 (en) * | 2002-07-24 | 2005-04-20 | Intercell AG | Antigens encoded by alternative reading frame from pathogenic viruses |
| DK2476436T3 (en) * | 2006-08-11 | 2018-02-05 | Life Sciences Res Partners Vzw | Immunogenic peptides and their use in immune disorders |
| EP3075391A1 (en) | 2008-02-14 | 2016-10-05 | Life Sciences Research Partners VZW | Strategies to prevent and/or treat immune responses to soluble allofactors |
| ES2650236T3 (es) | 2008-02-14 | 2018-01-17 | Life Sciences Research Partners Vzw | Linfocitos T CD4+ con propiedades citolíticas |
| EP2106803A1 (en) * | 2008-04-04 | 2009-10-07 | Fondazione Centro San Raffaele del Monte Tabor | Method to design and uses of overlapping peptides for monitoring T-cell responses in HIV patients |
| DK2643345T5 (da) * | 2010-11-25 | 2021-05-17 | Imnate Sarl | Immunogene peptider til anvendelse til forebyggelse og/eller behandling af infektionssygdomme, autoimmune sygdomme, immunresponser på allofaktorer, allergisygdomme, tumorer, transplantatafstødning og immunresponser på virusvektorer anvendt til genterapi eller genvaccination |
| GB201201511D0 (en) * | 2012-01-30 | 2012-03-14 | Univ Leuven Kath | Modified epitopes for boosting CD4+ T-cell responses |
| GB201309469D0 (en) * | 2013-05-28 | 2013-07-10 | Imcyse Sa | Detection of CD4+ T lymphocytes |
| GB201418433D0 (en) * | 2014-10-17 | 2014-12-03 | Imcyse Sa | Novel immunogenic peptides |
| WO2017182528A1 (en) * | 2016-04-19 | 2017-10-26 | Imcyse Sa | Novel immunogenic cd1d binding peptides |
| EP3388447A1 (en) * | 2017-04-14 | 2018-10-17 | Imnate Sarl | Methods to produce peptides, polypeptides or cells for modulating immunity |
| US20210401976A1 (en) * | 2018-11-12 | 2021-12-30 | Imcyse Sa | Immunogenic peptides with improved oxidoreductase motifs |
| EP4146254A1 (en) * | 2020-05-06 | 2023-03-15 | Imcyse SA | Immunogenic peptides with extended oxidoreductase motifs |
-
2018
- 2018-11-12 US US17/292,893 patent/US20210401976A1/en active Pending
-
2019
- 2019-11-12 KR KR1020217017332A patent/KR20210093933A/ko not_active Application Discontinuation
- 2019-11-12 CN CN201980074481.1A patent/CN113015542A/zh active Pending
- 2019-11-12 WO PCT/EP2019/080925 patent/WO2020099352A2/en unknown
- 2019-11-12 CN CN201980074437.0A patent/CN113015541A/zh active Pending
- 2019-11-12 CA CA3118620A patent/CA3118620A1/en active Pending
- 2019-11-12 CU CU2021000041A patent/CU20210041A7/es unknown
- 2019-11-12 MX MX2021005540A patent/MX2021005540A/es unknown
- 2019-11-12 JP JP2021525806A patent/JP2022513019A/ja active Pending
- 2019-11-12 WO PCT/EP2019/080929 patent/WO2020099356A2/en unknown
- 2019-11-12 PE PE2021000701A patent/PE20211494A1/es unknown
- 2019-11-12 AU AU2019377983A patent/AU2019377983A1/en active Pending
- 2019-11-12 SG SG11202104875XA patent/SG11202104875XA/en unknown
- 2019-11-12 EP EP19797967.7A patent/EP3880237A2/en active Pending
- 2019-11-12 JP JP2021525809A patent/JP2022513021A/ja active Pending
- 2019-11-12 AU AU2019379760A patent/AU2019379760A1/en active Pending
- 2019-11-12 CA CA3118981A patent/CA3118981A1/en active Pending
- 2019-11-12 EP EP19797966.9A patent/EP3880236A2/en active Pending
- 2019-11-12 TW TW108141034A patent/TW202043255A/zh unknown
- 2019-11-12 US US17/292,888 patent/US20220288179A1/en active Pending
- 2019-11-12 BR BR112021009210-2A patent/BR112021009210A2/pt unknown
-
2021
- 2021-04-30 ZA ZA2021/02909A patent/ZA202102909B/en unknown
- 2021-05-02 IL IL282849A patent/IL282849A/en unknown
- 2021-05-12 PH PH12021551101A patent/PH12021551101A1/en unknown
- 2021-05-28 CO CONC2021/0007060A patent/CO2021007060A2/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019379760A1 (en) | 2021-05-27 |
| CN113015542A (zh) | 2021-06-22 |
| BR112021009210A2 (pt) | 2021-08-10 |
| ZA202102909B (en) | 2022-09-28 |
| CU20210041A7 (es) | 2021-12-08 |
| WO2020099356A2 (en) | 2020-05-22 |
| WO2020099352A3 (en) | 2020-07-09 |
| US20210401976A1 (en) | 2021-12-30 |
| CA3118981A1 (en) | 2020-05-22 |
| WO2020099356A3 (en) | 2020-07-23 |
| CA3118620A1 (en) | 2020-05-22 |
| TW202043255A (zh) | 2020-12-01 |
| IL282849A (en) | 2021-06-30 |
| CO2021007060A2 (es) | 2021-06-10 |
| EP3880236A2 (en) | 2021-09-22 |
| AU2019377983A1 (en) | 2021-05-27 |
| JP2022513021A (ja) | 2022-02-07 |
| PH12021551101A1 (en) | 2021-12-13 |
| US20220288179A1 (en) | 2022-09-15 |
| WO2020099352A2 (en) | 2020-05-22 |
| JP2022513019A (ja) | 2022-02-07 |
| SG11202104875XA (en) | 2021-06-29 |
| MX2021005540A (es) | 2021-06-18 |
| PE20211494A1 (es) | 2021-08-11 |
| EP3880237A2 (en) | 2021-09-22 |
| CN113015541A (zh) | 2021-06-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107148427B (zh) | 新型免疫原性肽 | |
| KR20210093933A (ko) | 개선된 산화환원 효소 모티프를 갖는 면역원성 펩티드 | |
| JP7320947B2 (ja) | 新規な免疫原性CD1d結合ペプチド | |
| RU2761653C2 (ru) | Пептиды и способы для лечения диабета | |
| US20240189404A1 (en) | Immunogenic peptides with extended oxidoreductase motifs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| WITB | Written withdrawal of application |