KR20210041593A - 암의 예방 또는 치료의 방법에 사용하기 위한 암/고환 항원을 암호화하는 바이러스 벡터 - Google Patents
암의 예방 또는 치료의 방법에 사용하기 위한 암/고환 항원을 암호화하는 바이러스 벡터 Download PDFInfo
- Publication number
- KR20210041593A KR20210041593A KR1020217006575A KR20217006575A KR20210041593A KR 20210041593 A KR20210041593 A KR 20210041593A KR 1020217006575 A KR1020217006575 A KR 1020217006575A KR 20217006575 A KR20217006575 A KR 20217006575A KR 20210041593 A KR20210041593 A KR 20210041593A
- Authority
- KR
- South Korea
- Prior art keywords
- gly
- ala
- cancer
- thr
- cys
- Prior art date
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 238
- 201000011510 cancer Diseases 0.000 title claims abstract description 161
- 239000000427 antigen Substances 0.000 title claims abstract description 149
- 108091007433 antigens Proteins 0.000 title claims abstract description 149
- 102000036639 antigens Human genes 0.000 title claims abstract description 149
- 238000000034 method Methods 0.000 title claims description 80
- 239000013603 viral vector Substances 0.000 title abstract description 48
- 210000001550 testis Anatomy 0.000 title description 2
- 239000013598 vector Substances 0.000 claims abstract description 175
- 241001217856 Chimpanzee adenovirus Species 0.000 claims abstract description 87
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 claims abstract description 73
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 claims abstract description 73
- 238000011282 treatment Methods 0.000 claims abstract description 68
- 210000004027 cell Anatomy 0.000 claims abstract description 58
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 53
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 53
- 239000002157 polynucleotide Substances 0.000 claims abstract description 53
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 claims abstract description 48
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 claims abstract description 48
- 239000002671 adjuvant Substances 0.000 claims abstract description 16
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 16
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 16
- 239000002246 antineoplastic agent Substances 0.000 claims abstract description 9
- 229940127089 cytotoxic agent Drugs 0.000 claims abstract description 9
- 239000012634 fragment Substances 0.000 claims description 68
- 230000002163 immunogen Effects 0.000 claims description 53
- 241001183012 Modified Vaccinia Ankara virus Species 0.000 claims description 45
- 150000001413 amino acids Chemical class 0.000 claims description 41
- 102000000440 Melanoma-associated antigen Human genes 0.000 claims description 32
- 108050008953 Melanoma-associated antigen Proteins 0.000 claims description 32
- 238000012737 microarray-based gene expression Methods 0.000 claims description 32
- 238000012243 multiplex automated genomic engineering Methods 0.000 claims description 32
- 241000282414 Homo sapiens Species 0.000 claims description 24
- 150000007523 nucleic acids Chemical class 0.000 claims description 24
- 230000002265 prevention Effects 0.000 claims description 24
- 230000028993 immune response Effects 0.000 claims description 21
- 230000004927 fusion Effects 0.000 claims description 20
- 102100039510 Cancer/testis antigen 2 Human genes 0.000 claims description 19
- 101000889345 Homo sapiens Cancer/testis antigen 2 Proteins 0.000 claims description 19
- 239000000203 mixture Substances 0.000 claims description 17
- 241000701161 unidentified adenovirus Species 0.000 claims description 16
- 102100040678 Programmed cell death protein 1 Human genes 0.000 claims description 14
- 238000002512 chemotherapy Methods 0.000 claims description 14
- 208000006593 Urologic Neoplasms Diseases 0.000 claims description 12
- 210000004102 animal cell Anatomy 0.000 claims description 12
- 201000001441 melanoma Diseases 0.000 claims description 12
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 12
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 12
- 102000039446 nucleic acids Human genes 0.000 claims description 11
- 108020004707 nucleic acids Proteins 0.000 claims description 11
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 10
- 238000002560 therapeutic procedure Methods 0.000 claims description 10
- 210000000987 immune system Anatomy 0.000 claims description 9
- 206010041067 Small cell lung cancer Diseases 0.000 claims description 7
- 208000000587 small cell lung carcinoma Diseases 0.000 claims description 7
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 6
- 206010005003 Bladder cancer Diseases 0.000 claims description 6
- 206010006187 Breast cancer Diseases 0.000 claims description 6
- 208000026310 Breast neoplasm Diseases 0.000 claims description 6
- 208000017604 Hodgkin disease Diseases 0.000 claims description 6
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 6
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 6
- 229930012538 Paclitaxel Natural products 0.000 claims description 6
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 6
- 229960003301 nivolumab Drugs 0.000 claims description 6
- 229960001592 paclitaxel Drugs 0.000 claims description 6
- 229960002621 pembrolizumab Drugs 0.000 claims description 6
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 claims description 6
- 238000013519 translation Methods 0.000 claims description 6
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 6
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 5
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims description 5
- 206010038389 Renal cancer Diseases 0.000 claims description 5
- 210000004436 artificial bacterial chromosome Anatomy 0.000 claims description 5
- 201000010982 kidney cancer Diseases 0.000 claims description 5
- 239000000126 substance Substances 0.000 claims description 5
- 238000013518 transcription Methods 0.000 claims description 5
- 230000035897 transcription Effects 0.000 claims description 5
- 108020004705 Codon Proteins 0.000 claims description 4
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 claims description 4
- 206010039491 Sarcoma Diseases 0.000 claims description 4
- 229960003852 atezolizumab Drugs 0.000 claims description 4
- 229960004562 carboplatin Drugs 0.000 claims description 4
- 190000008236 carboplatin Chemical compound 0.000 claims description 4
- 229950009791 durvalumab Drugs 0.000 claims description 4
- 201000010536 head and neck cancer Diseases 0.000 claims description 4
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 4
- 229960005386 ipilimumab Drugs 0.000 claims description 4
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 3
- 125000000539 amino acid group Chemical group 0.000 claims description 3
- 230000001093 anti-cancer Effects 0.000 claims description 3
- 229950002916 avelumab Drugs 0.000 claims description 3
- 229950007217 tremelimumab Drugs 0.000 claims description 3
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 claims description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 claims description 2
- 229960004316 cisplatin Drugs 0.000 claims description 2
- 229960003668 docetaxel Drugs 0.000 claims description 2
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 claims description 2
- 229960005420 etoposide Drugs 0.000 claims description 2
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 claims description 2
- 229960005277 gemcitabine Drugs 0.000 claims description 2
- 238000004806 packaging method and process Methods 0.000 claims description 2
- 238000001959 radiotherapy Methods 0.000 claims description 2
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 claims description 2
- 229960002066 vinorelbine Drugs 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 7
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims 2
- 102000008096 B7-H1 Antigen Human genes 0.000 claims 2
- 102000008203 CTLA-4 Antigen Human genes 0.000 claims 2
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims 2
- 238000011321 prophylaxis Methods 0.000 claims 2
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 claims 1
- 229910052698 phosphorus Inorganic materials 0.000 claims 1
- 239000011574 phosphorus Substances 0.000 claims 1
- 101001005719 Homo sapiens Melanoma-associated antigen 3 Proteins 0.000 abstract description 24
- 102100025082 Melanoma-associated antigen 3 Human genes 0.000 abstract description 24
- 230000004083 survival effect Effects 0.000 abstract description 19
- 230000000694 effects Effects 0.000 abstract description 16
- 230000005867 T cell response Effects 0.000 abstract description 13
- 238000013459 approach Methods 0.000 abstract description 13
- 230000002195 synergetic effect Effects 0.000 abstract description 5
- 230000001976 improved effect Effects 0.000 abstract description 4
- 238000001565 modulated differential scanning calorimetry Methods 0.000 abstract description 4
- 210000004985 myeloid-derived suppressor cell Anatomy 0.000 abstract description 4
- 210000001185 bone marrow Anatomy 0.000 abstract description 3
- 230000002401 inhibitory effect Effects 0.000 abstract description 3
- 238000010172 mouse model Methods 0.000 abstract description 3
- 238000011065 in-situ storage Methods 0.000 abstract 1
- 241000699670 Mus sp. Species 0.000 description 80
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 69
- 108090000623 proteins and genes Proteins 0.000 description 56
- 229960005486 vaccine Drugs 0.000 description 54
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 53
- 108010061238 threonyl-glycine Proteins 0.000 description 51
- 101800001318 Capsid protein VP4 Proteins 0.000 description 48
- 206010072219 Mevalonic aciduria Diseases 0.000 description 45
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 44
- 238000002255 vaccination Methods 0.000 description 41
- 108010047495 alanylglycine Proteins 0.000 description 39
- 102000004169 proteins and genes Human genes 0.000 description 39
- 108010004073 cysteinylcysteine Proteins 0.000 description 38
- 235000018102 proteins Nutrition 0.000 description 38
- 230000004044 response Effects 0.000 description 37
- 210000001744 T-lymphocyte Anatomy 0.000 description 36
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 35
- 108010079364 N-glycylalanine Proteins 0.000 description 33
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 27
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 27
- 229960000187 tissue plasminogen activator Drugs 0.000 description 27
- SSOORFWOBGFTHL-OTEJMHTDSA-N (4S)-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-5-carbamimidamido-1-[[(2S)-5-carbamimidamido-1-[[(1S)-4-carbamimidamido-1-carboxybutyl]amino]-1-oxopentan-2-yl]amino]-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-1-oxohexan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-[[(2S)-2-[[(2S)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SSOORFWOBGFTHL-OTEJMHTDSA-N 0.000 description 24
- 108020004414 DNA Proteins 0.000 description 23
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 23
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 22
- 108090000765 processed proteins & peptides Proteins 0.000 description 22
- 235000001014 amino acid Nutrition 0.000 description 21
- 229940024606 amino acid Drugs 0.000 description 21
- 108010016616 cysteinylglycine Proteins 0.000 description 21
- 108010050848 glycylleucine Proteins 0.000 description 21
- 238000002649 immunization Methods 0.000 description 20
- 230000003053 immunization Effects 0.000 description 20
- 238000011765 DBA/2 mouse Methods 0.000 description 18
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 18
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 17
- 230000005847 immunogenicity Effects 0.000 description 17
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 16
- ALNKNYKSZPSLBD-ZDLURKLDSA-N Cys-Thr-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ALNKNYKSZPSLBD-ZDLURKLDSA-N 0.000 description 16
- 241000699666 Mus <mouse, genus> Species 0.000 description 16
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 16
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 15
- KOHBWQDSVCARMI-BWBBJGPYSA-N Cys-Cys-Thr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KOHBWQDSVCARMI-BWBBJGPYSA-N 0.000 description 15
- NAPULYCVEVVFRB-HEIBUPTGSA-N Cys-Thr-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CS NAPULYCVEVVFRB-HEIBUPTGSA-N 0.000 description 15
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 15
- NMROINAYXCACKF-WHFBIAKZSA-N Gly-Cys-Cys Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(O)=O NMROINAYXCACKF-WHFBIAKZSA-N 0.000 description 15
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 15
- HYKFOHGZGLOCAY-ZLUOBGJFSA-N Cys-Cys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O HYKFOHGZGLOCAY-ZLUOBGJFSA-N 0.000 description 14
- FTTZLFIEUQHLHH-BWBBJGPYSA-N Cys-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O FTTZLFIEUQHLHH-BWBBJGPYSA-N 0.000 description 14
- DGOJNGCGEYOBKN-BWBBJGPYSA-N Thr-Cys-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N)O DGOJNGCGEYOBKN-BWBBJGPYSA-N 0.000 description 14
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 14
- 230000004614 tumor growth Effects 0.000 description 14
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 14
- LJFNNUBZSZCZFN-WHFBIAKZSA-N Ala-Gly-Cys Chemical compound N[C@@H](C)C(=O)NCC(=O)N[C@@H](CS)C(=O)O LJFNNUBZSZCZFN-WHFBIAKZSA-N 0.000 description 13
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 13
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 13
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 13
- 108010093581 aspartyl-proline Proteins 0.000 description 13
- 102000004196 processed proteins & peptides Human genes 0.000 description 13
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 12
- 239000007924 injection Substances 0.000 description 12
- 238000002347 injection Methods 0.000 description 12
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 12
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 11
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 11
- TZQWJCGVCIJDMU-HEIBUPTGSA-N Thr-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N)O TZQWJCGVCIJDMU-HEIBUPTGSA-N 0.000 description 11
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 11
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 11
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 11
- 108010089804 glycyl-threonine Proteins 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 239000002953 phosphate buffered saline Substances 0.000 description 11
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 11
- 108010029020 prolylglycine Proteins 0.000 description 11
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 10
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 10
- KUFVXLQLDHJVOG-SHGPDSBTSA-N Ala-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C)N)O KUFVXLQLDHJVOG-SHGPDSBTSA-N 0.000 description 10
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 10
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 10
- UZJDBCHMIQXLOQ-HEIBUPTGSA-N Thr-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O UZJDBCHMIQXLOQ-HEIBUPTGSA-N 0.000 description 10
- 230000000890 antigenic effect Effects 0.000 description 10
- 229940022399 cancer vaccine Drugs 0.000 description 10
- 238000009566 cancer vaccine Methods 0.000 description 10
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 10
- PEZMQPADLFXCJJ-ZETCQYMHSA-N 2-[[2-[[(2s)-1-(2-aminoacetyl)pyrrolidine-2-carbonyl]amino]acetyl]amino]acetic acid Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(=O)NCC(O)=O PEZMQPADLFXCJJ-ZETCQYMHSA-N 0.000 description 9
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 9
- CVOZXIPULQQFNY-ZLUOBGJFSA-N Cys-Ala-Cys Chemical compound C[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CS)C(O)=O CVOZXIPULQQFNY-ZLUOBGJFSA-N 0.000 description 9
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 9
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 9
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 9
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 9
- 241000764238 Isis Species 0.000 description 9
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 9
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 9
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 9
- QWMPARMKIDVBLV-VZFHVOOUSA-N Thr-Cys-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O QWMPARMKIDVBLV-VZFHVOOUSA-N 0.000 description 9
- WYKJENSCCRJLRC-ZDLURKLDSA-N Thr-Gly-Cys Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)O WYKJENSCCRJLRC-ZDLURKLDSA-N 0.000 description 9
- 108010005233 alanylglutamic acid Proteins 0.000 description 9
- 108010021908 aspartyl-aspartyl-glutamyl-aspartic acid Proteins 0.000 description 9
- 108010047857 aspartylglycine Proteins 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 9
- 108010057821 leucylproline Proteins 0.000 description 9
- 229920001184 polypeptide Polymers 0.000 description 9
- 230000003612 virological effect Effects 0.000 description 9
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 8
- RCQRKPUXJAGEEC-ZLUOBGJFSA-N Ala-Cys-Cys Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(O)=O RCQRKPUXJAGEEC-ZLUOBGJFSA-N 0.000 description 8
- 102000004127 Cytokines Human genes 0.000 description 8
- 108090000695 Cytokines Proteins 0.000 description 8
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 8
- VNBNZUAPOYGRDB-ZDLURKLDSA-N Gly-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN)O VNBNZUAPOYGRDB-ZDLURKLDSA-N 0.000 description 8
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 8
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 8
- 108010038633 aspartylglutamate Proteins 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 210000004881 tumor cell Anatomy 0.000 description 8
- PQFMROVJTOPVDF-JBDRJPRFSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-carboxypropanoyl]amino]-3-carboxypropanoyl]amino]-4-carboxybutanoyl]amino]butanedioic acid Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PQFMROVJTOPVDF-JBDRJPRFSA-N 0.000 description 7
- SBGXWWCLHIOABR-UHFFFAOYSA-N Ala Ala Gly Ala Chemical compound CC(N)C(=O)NC(C)C(=O)NCC(=O)NC(C)C(O)=O SBGXWWCLHIOABR-UHFFFAOYSA-N 0.000 description 7
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 7
- ZATRYQNPUHGXCU-DTWKUNHWSA-N Arg-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZATRYQNPUHGXCU-DTWKUNHWSA-N 0.000 description 7
- SMYXEYRYCLIPIL-ZLUOBGJFSA-N Cys-Cys-Cys Chemical compound SC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(O)=O SMYXEYRYCLIPIL-ZLUOBGJFSA-N 0.000 description 7
- GVVKYKCOFMMTKZ-WHFBIAKZSA-N Gly-Cys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)CN GVVKYKCOFMMTKZ-WHFBIAKZSA-N 0.000 description 7
- 241000282412 Homo Species 0.000 description 7
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- 108010044940 alanylglutamine Proteins 0.000 description 7
- 108010068380 arginylarginine Proteins 0.000 description 7
- 108010062796 arginyllysine Proteins 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 7
- 230000037452 priming Effects 0.000 description 7
- 108010090894 prolylleucine Proteins 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 6
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 6
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 6
- QKHWNPQNOHEFST-VZFHVOOUSA-N Ala-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N)O QKHWNPQNOHEFST-VZFHVOOUSA-N 0.000 description 6
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 6
- GQGAFTPXAPKSCF-WHFBIAKZSA-N Gly-Ala-Cys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O GQGAFTPXAPKSCF-WHFBIAKZSA-N 0.000 description 6
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 6
- JYPCXBJRLBHWME-IUCAKERBSA-N Gly-Pro-Arg Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JYPCXBJRLBHWME-IUCAKERBSA-N 0.000 description 6
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 6
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 6
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 6
- 108010074328 Interferon-gamma Proteins 0.000 description 6
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 6
- 241000880493 Leptailurus serval Species 0.000 description 6
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 6
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 6
- YRNBANYVJJBGDI-VZFHVOOUSA-N Thr-Ala-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N)O YRNBANYVJJBGDI-VZFHVOOUSA-N 0.000 description 6
- LYGKYFKSZTUXGZ-ZDLURKLDSA-N Thr-Cys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)NCC(O)=O LYGKYFKSZTUXGZ-ZDLURKLDSA-N 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 108010013835 arginine glutamate Proteins 0.000 description 6
- 108010008355 arginyl-glutamine Proteins 0.000 description 6
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 6
- 108010069495 cysteinyltyrosine Proteins 0.000 description 6
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 6
- 108010043293 glycyl-prolyl-glycyl-glycine Proteins 0.000 description 6
- 108010092114 histidylphenylalanine Proteins 0.000 description 6
- 230000006698 induction Effects 0.000 description 6
- 108010053725 prolylvaline Proteins 0.000 description 6
- 108010073969 valyllysine Proteins 0.000 description 6
- WOJJIRYPFAZEPF-YFKPBYRVSA-N 2-[[(2s)-2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]propanoyl]amino]acetate Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)CNC(=O)CN WOJJIRYPFAZEPF-YFKPBYRVSA-N 0.000 description 5
- UWQJHXKARZWDIJ-ZLUOBGJFSA-N Ala-Ala-Cys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(O)=O UWQJHXKARZWDIJ-ZLUOBGJFSA-N 0.000 description 5
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 5
- DEWWPUNXRNGMQN-LPEHRKFASA-N Ala-Met-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N DEWWPUNXRNGMQN-LPEHRKFASA-N 0.000 description 5
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 5
- XLWSGICNBZGYTA-CIUDSAMLSA-N Arg-Glu-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XLWSGICNBZGYTA-CIUDSAMLSA-N 0.000 description 5
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 5
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 5
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 5
- PXXGVUVQWQGGIG-YUMQZZPRSA-N Glu-Gly-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N PXXGVUVQWQGGIG-YUMQZZPRSA-N 0.000 description 5
- SUDUYJOBLHQAMI-WHFBIAKZSA-N Gly-Asp-Cys Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(O)=O SUDUYJOBLHQAMI-WHFBIAKZSA-N 0.000 description 5
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 5
- 108010065920 Insulin Lispro Proteins 0.000 description 5
- 102100037850 Interferon gamma Human genes 0.000 description 5
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 5
- IFMPDNRWZZEZSL-SRVKXCTJSA-N Leu-Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O IFMPDNRWZZEZSL-SRVKXCTJSA-N 0.000 description 5
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 5
- BKWJQWJPZMUWEG-LFSVMHDDSA-N Phe-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BKWJQWJPZMUWEG-LFSVMHDDSA-N 0.000 description 5
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 5
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 5
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 5
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 5
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 5
- VPGCVZRRBYOGCD-AVGNSLFASA-N Val-Lys-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O VPGCVZRRBYOGCD-AVGNSLFASA-N 0.000 description 5
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 5
- 238000011284 combination treatment Methods 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 5
- 108010049041 glutamylalanine Proteins 0.000 description 5
- 230000036039 immunity Effects 0.000 description 5
- 108010056582 methionylglutamic acid Proteins 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 5
- 229940023147 viral vector vaccine Drugs 0.000 description 5
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 4
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 4
- LZRNYBIJOSKKRJ-XVYDVKMFSA-N Ala-Asp-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LZRNYBIJOSKKRJ-XVYDVKMFSA-N 0.000 description 4
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 4
- UQJUGHFKNKGHFQ-VZFHVOOUSA-N Ala-Cys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UQJUGHFKNKGHFQ-VZFHVOOUSA-N 0.000 description 4
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 4
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 4
- YMIYZAOBQDRCPP-UHFFFAOYSA-N Ala-Thr-Cys-Cys Chemical compound CC(N)C(=O)NC(C(O)C)C(=O)NC(CS)C(=O)NC(CS)C(O)=O YMIYZAOBQDRCPP-UHFFFAOYSA-N 0.000 description 4
- DHONNEYAZPNGSG-UBHSHLNASA-N Ala-Val-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DHONNEYAZPNGSG-UBHSHLNASA-N 0.000 description 4
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 4
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 4
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 4
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 4
- POTCZYQVVNXUIG-BQBZGAKWSA-N Asp-Gly-Pro Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O POTCZYQVVNXUIG-BQBZGAKWSA-N 0.000 description 4
- MVRGBQGZSDJBSM-GMOBBJLQSA-N Asp-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N MVRGBQGZSDJBSM-GMOBBJLQSA-N 0.000 description 4
- -1 CD86 Proteins 0.000 description 4
- XMVZMBGFIOQONW-GARJFASQSA-N Cys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N)C(=O)O XMVZMBGFIOQONW-GARJFASQSA-N 0.000 description 4
- KZZYVYWSXMFYEC-DCAQKATOSA-N Cys-Val-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KZZYVYWSXMFYEC-DCAQKATOSA-N 0.000 description 4
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 4
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 4
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 4
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 4
- ZJICFHQSPWFBKP-AVGNSLFASA-N Glu-Asn-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZJICFHQSPWFBKP-AVGNSLFASA-N 0.000 description 4
- OGNJZUXUTPQVBR-BQBZGAKWSA-N Glu-Gly-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OGNJZUXUTPQVBR-BQBZGAKWSA-N 0.000 description 4
- OPAINBJQDQTGJY-JGVFFNPUSA-N Glu-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)O)N)C(=O)O OPAINBJQDQTGJY-JGVFFNPUSA-N 0.000 description 4
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 4
- GNBMOZPQUXTCRW-STQMWFEESA-N Gly-Asn-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)CN)C(O)=O)=CNC2=C1 GNBMOZPQUXTCRW-STQMWFEESA-N 0.000 description 4
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 4
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 4
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 4
- YIFUFYZELCMPJP-YUMQZZPRSA-N Gly-Leu-Cys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O YIFUFYZELCMPJP-YUMQZZPRSA-N 0.000 description 4
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 4
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 4
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 4
- ZZJVYSAQQMDIRD-UWVGGRQHSA-N Gly-Pro-His Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O ZZJVYSAQQMDIRD-UWVGGRQHSA-N 0.000 description 4
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 4
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 4
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- FDQYIRHBVVUTJF-ZETCQYMHSA-N His-Gly-Gly Chemical compound [O-]C(=O)CNC(=O)CNC(=O)[C@@H]([NH3+])CC1=CN=CN1 FDQYIRHBVVUTJF-ZETCQYMHSA-N 0.000 description 4
- ORERHHPZDDEMSC-VGDYDELISA-N His-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N ORERHHPZDDEMSC-VGDYDELISA-N 0.000 description 4
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 4
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 4
- LPXHYGGZJOCAFR-MNXVOIDGSA-N Ile-Glu-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N LPXHYGGZJOCAFR-MNXVOIDGSA-N 0.000 description 4
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 4
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 4
- 102100022338 Integrin alpha-M Human genes 0.000 description 4
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 4
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 4
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 4
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 4
- ONPJGOIVICHWBW-BZSNNMDCSA-N Leu-Lys-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 ONPJGOIVICHWBW-BZSNNMDCSA-N 0.000 description 4
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 4
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 4
- UZVWDRPUTHXQAM-FXQIFTODSA-N Met-Asp-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O UZVWDRPUTHXQAM-FXQIFTODSA-N 0.000 description 4
- YLLWCSDBVGZLOW-CIUDSAMLSA-N Met-Gln-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O YLLWCSDBVGZLOW-CIUDSAMLSA-N 0.000 description 4
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 4
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 4
- HZVXPUHLTZRQEL-UWVGGRQHSA-N Met-Leu-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O HZVXPUHLTZRQEL-UWVGGRQHSA-N 0.000 description 4
- BEZJTLKUMFMITF-AVGNSLFASA-N Met-Lys-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCNC(N)=N BEZJTLKUMFMITF-AVGNSLFASA-N 0.000 description 4
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 4
- FIRWJEJVFFGXSH-RYUDHWBXSA-N Phe-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FIRWJEJVFFGXSH-RYUDHWBXSA-N 0.000 description 4
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 4
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 4
- ZYNBEWGJFXTBDU-ACRUOGEOSA-N Phe-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N ZYNBEWGJFXTBDU-ACRUOGEOSA-N 0.000 description 4
- KUSYCSMTTHSZOA-DZKIICNBSA-N Phe-Val-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N KUSYCSMTTHSZOA-DZKIICNBSA-N 0.000 description 4
- ALJGSKMBIUEJOB-FXQIFTODSA-N Pro-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 ALJGSKMBIUEJOB-FXQIFTODSA-N 0.000 description 4
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 4
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 4
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 4
- XZBYTHCRAVAXQQ-DCAQKATOSA-N Pro-Met-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XZBYTHCRAVAXQQ-DCAQKATOSA-N 0.000 description 4
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 4
- DGHFNYXVIXNNMC-GUBZILKMSA-N Ser-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N DGHFNYXVIXNNMC-GUBZILKMSA-N 0.000 description 4
- DSGYZICNAMEJOC-AVGNSLFASA-N Ser-Glu-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DSGYZICNAMEJOC-AVGNSLFASA-N 0.000 description 4
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 4
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 4
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 4
- PJIQEIFXZPCWOJ-FXQIFTODSA-N Ser-Pro-Asp Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O PJIQEIFXZPCWOJ-FXQIFTODSA-N 0.000 description 4
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 4
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 4
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 4
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 4
- GUZGCDIZVGODML-NKIYYHGXSA-N Thr-Gln-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O GUZGCDIZVGODML-NKIYYHGXSA-N 0.000 description 4
- PCMDGXKXVMBIFP-VEVYYDQMSA-N Thr-Met-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMDGXKXVMBIFP-VEVYYDQMSA-N 0.000 description 4
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 4
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 4
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 4
- HDSKHCBAVVWPCQ-FHWLQOOXSA-N Tyr-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HDSKHCBAVVWPCQ-FHWLQOOXSA-N 0.000 description 4
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 4
- VXFXIBCCVLJCJT-JYJNAYRXSA-N Tyr-Pro-Pro Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(O)=O VXFXIBCCVLJCJT-JYJNAYRXSA-N 0.000 description 4
- 206010046865 Vaccinia virus infection Diseases 0.000 description 4
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 4
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 4
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 4
- 108010087924 alanylproline Proteins 0.000 description 4
- 230000002238 attenuated effect Effects 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 4
- 108010009298 lysylglutamic acid Proteins 0.000 description 4
- 108010054155 lysyllysine Proteins 0.000 description 4
- 108010073101 phenylalanylleucine Proteins 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 108010077112 prolyl-proline Proteins 0.000 description 4
- 108010004914 prolylarginine Proteins 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- 208000007089 vaccinia Diseases 0.000 description 4
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 3
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 3
- SDMAQFGBPOJFOM-GUBZILKMSA-N Ala-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SDMAQFGBPOJFOM-GUBZILKMSA-N 0.000 description 3
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 3
- KRHRBKYBJXMYBB-WHFBIAKZSA-N Ala-Cys-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O KRHRBKYBJXMYBB-WHFBIAKZSA-N 0.000 description 3
- MIPWEZAIMPYQST-FXQIFTODSA-N Ala-Cys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O MIPWEZAIMPYQST-FXQIFTODSA-N 0.000 description 3
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 3
- VWEWCZSUWOEEFM-WDSKDSINSA-N Ala-Gly-Ala-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(O)=O VWEWCZSUWOEEFM-WDSKDSINSA-N 0.000 description 3
- CBCCCLMNOBLBSC-XVYDVKMFSA-N Ala-His-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CBCCCLMNOBLBSC-XVYDVKMFSA-N 0.000 description 3
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 3
- DWYROCSXOOMOEU-CIUDSAMLSA-N Ala-Met-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N DWYROCSXOOMOEU-CIUDSAMLSA-N 0.000 description 3
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 3
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 3
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 3
- VNFWDYWTSHFRRG-SRVKXCTJSA-N Arg-Gln-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O VNFWDYWTSHFRRG-SRVKXCTJSA-N 0.000 description 3
- BEXGZLUHRXTZCC-CIUDSAMLSA-N Arg-Gln-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N BEXGZLUHRXTZCC-CIUDSAMLSA-N 0.000 description 3
- UPALZCBCKAMGIY-PEFMBERDSA-N Asn-Gln-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UPALZCBCKAMGIY-PEFMBERDSA-N 0.000 description 3
- UBGGJTMETLEXJD-DCAQKATOSA-N Asn-Leu-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O UBGGJTMETLEXJD-DCAQKATOSA-N 0.000 description 3
- AWXDRZJQCVHCIT-DCAQKATOSA-N Asn-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O AWXDRZJQCVHCIT-DCAQKATOSA-N 0.000 description 3
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 3
- WCFCYFDBMNFSPA-ACZMJKKPSA-N Asp-Asp-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O WCFCYFDBMNFSPA-ACZMJKKPSA-N 0.000 description 3
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 3
- KPNUCOPMVSGRCR-DCAQKATOSA-N Asp-His-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O KPNUCOPMVSGRCR-DCAQKATOSA-N 0.000 description 3
- DWOGMPWRQQWPPF-GUBZILKMSA-N Asp-Leu-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O DWOGMPWRQQWPPF-GUBZILKMSA-N 0.000 description 3
- BWJZSLQJNBSUPM-FXQIFTODSA-N Asp-Pro-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O BWJZSLQJNBSUPM-FXQIFTODSA-N 0.000 description 3
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 3
- 102100021277 Beta-secretase 2 Human genes 0.000 description 3
- 101710150190 Beta-secretase 2 Proteins 0.000 description 3
- 208000035473 Communicable disease Diseases 0.000 description 3
- OCEHKDFAWQIBHH-FXQIFTODSA-N Cys-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N OCEHKDFAWQIBHH-FXQIFTODSA-N 0.000 description 3
- UPJGYXRAPJWIHD-CIUDSAMLSA-N Cys-Asn-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UPJGYXRAPJWIHD-CIUDSAMLSA-N 0.000 description 3
- ZJBWJHQDOIMVLM-WHFBIAKZSA-N Cys-Cys-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O ZJBWJHQDOIMVLM-WHFBIAKZSA-N 0.000 description 3
- CVLIHKBUPSFRQP-WHFBIAKZSA-N Cys-Gly-Ala Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](C)C(O)=O CVLIHKBUPSFRQP-WHFBIAKZSA-N 0.000 description 3
- URDUGPGPLNXXES-WHFBIAKZSA-N Cys-Gly-Cys Chemical compound SC[C@H](N)C(=O)NCC(=O)N[C@@H](CS)C(O)=O URDUGPGPLNXXES-WHFBIAKZSA-N 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- LPJVZYMINRLCQA-AVGNSLFASA-N Gln-Cys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N LPJVZYMINRLCQA-AVGNSLFASA-N 0.000 description 3
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 3
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 3
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 3
- FHPXTPQBODWBIY-CIUDSAMLSA-N Glu-Ala-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FHPXTPQBODWBIY-CIUDSAMLSA-N 0.000 description 3
- FLQAKQOBSPFGKG-CIUDSAMLSA-N Glu-Cys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FLQAKQOBSPFGKG-CIUDSAMLSA-N 0.000 description 3
- GFLQTABMFBXRIY-GUBZILKMSA-N Glu-Gln-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GFLQTABMFBXRIY-GUBZILKMSA-N 0.000 description 3
- GYCPQVFKCPPRQB-GUBZILKMSA-N Glu-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N GYCPQVFKCPPRQB-GUBZILKMSA-N 0.000 description 3
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 3
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 3
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 3
- YKBUCXNNBYZYAY-MNXVOIDGSA-N Glu-Lys-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YKBUCXNNBYZYAY-MNXVOIDGSA-N 0.000 description 3
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 3
- WIKMTDVSCUJIPJ-CIUDSAMLSA-N Glu-Ser-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WIKMTDVSCUJIPJ-CIUDSAMLSA-N 0.000 description 3
- NTHIHAUEXVTXQG-KKUMJFAQSA-N Glu-Tyr-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O NTHIHAUEXVTXQG-KKUMJFAQSA-N 0.000 description 3
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 3
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 3
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 3
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 3
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 3
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 3
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 3
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 3
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 3
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 3
- SFOXOSKVTLDEDM-HOTGVXAUSA-N Gly-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CN)=CNC2=C1 SFOXOSKVTLDEDM-HOTGVXAUSA-N 0.000 description 3
- DGYNAJNQMBFYIF-SZMVWBNQSA-N His-Glu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 DGYNAJNQMBFYIF-SZMVWBNQSA-N 0.000 description 3
- SKYULSWNBYAQMG-IHRRRGAJSA-N His-Leu-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SKYULSWNBYAQMG-IHRRRGAJSA-N 0.000 description 3
- WYSJPCTWSBJFCO-AVGNSLFASA-N His-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CN=CN1)N WYSJPCTWSBJFCO-AVGNSLFASA-N 0.000 description 3
- 241000598171 Human adenovirus sp. Species 0.000 description 3
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 3
- HQEPKOFULQTSFV-JURCDPSOSA-N Ile-Phe-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)O)N HQEPKOFULQTSFV-JURCDPSOSA-N 0.000 description 3
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 3
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 3
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 3
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 3
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 3
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 3
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 3
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 3
- GSSMYQHXZNERFX-WDSOQIARSA-N Leu-Met-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N GSSMYQHXZNERFX-WDSOQIARSA-N 0.000 description 3
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 3
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 3
- BGGTYDNTOYRTTR-MEYUZBJRSA-N Leu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(C)C)N)O BGGTYDNTOYRTTR-MEYUZBJRSA-N 0.000 description 3
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 3
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 3
- CKSXSQUVEYCDIW-AVGNSLFASA-N Lys-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N CKSXSQUVEYCDIW-AVGNSLFASA-N 0.000 description 3
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 3
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 3
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 3
- AFVOKRHYSSFPHC-STECZYCISA-N Met-Ile-Tyr Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFVOKRHYSSFPHC-STECZYCISA-N 0.000 description 3
- RSOMVHWMIAZNLE-HJWJTTGWSA-N Met-Phe-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSOMVHWMIAZNLE-HJWJTTGWSA-N 0.000 description 3
- YLDSJJOGQNEQJK-AVGNSLFASA-N Met-Pro-Leu Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YLDSJJOGQNEQJK-AVGNSLFASA-N 0.000 description 3
- WXXNVZMWHOLNRJ-AVGNSLFASA-N Met-Pro-Lys Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O WXXNVZMWHOLNRJ-AVGNSLFASA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 3
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 3
- TXJJXEXCZBHDNA-ACRUOGEOSA-N Phe-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N TXJJXEXCZBHDNA-ACRUOGEOSA-N 0.000 description 3
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 3
- XKHCJJPNXFBADI-DCAQKATOSA-N Pro-Asp-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O XKHCJJPNXFBADI-DCAQKATOSA-N 0.000 description 3
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 3
- WSRWHZRUOCACLJ-UWVGGRQHSA-N Pro-Gly-His Chemical compound C([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H]1NCCC1)C1=CN=CN1 WSRWHZRUOCACLJ-UWVGGRQHSA-N 0.000 description 3
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 3
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 3
- 108010079005 RDV peptide Proteins 0.000 description 3
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 3
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 3
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 3
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 3
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 3
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 3
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 3
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 3
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 3
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 3
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 3
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 3
- CZWIHKFGHICAJX-BPUTZDHNSA-N Trp-Glu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 CZWIHKFGHICAJX-BPUTZDHNSA-N 0.000 description 3
- YYXIWHBHTARPOG-HJXMPXNTSA-N Trp-Ile-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YYXIWHBHTARPOG-HJXMPXNTSA-N 0.000 description 3
- YDTKYBHPRULROG-LTHWPDAASA-N Trp-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YDTKYBHPRULROG-LTHWPDAASA-N 0.000 description 3
- HKYTWJOWZTWBQB-AVGNSLFASA-N Tyr-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HKYTWJOWZTWBQB-AVGNSLFASA-N 0.000 description 3
- WVRUKYLYMFGKAN-IHRRRGAJSA-N Tyr-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 WVRUKYLYMFGKAN-IHRRRGAJSA-N 0.000 description 3
- JXGUUJMPCRXMSO-HJOGWXRNSA-N Tyr-Phe-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 JXGUUJMPCRXMSO-HJOGWXRNSA-N 0.000 description 3
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 3
- 241000700618 Vaccinia virus Species 0.000 description 3
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 3
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 3
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 3
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 3
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 3
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 239000012620 biological material Substances 0.000 description 3
- 230000000740 bleeding effect Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 230000036755 cellular response Effects 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 108010078144 glutaminyl-glycine Proteins 0.000 description 3
- 108010077515 glycylproline Proteins 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 108010028295 histidylhistidine Proteins 0.000 description 3
- 238000002513 implantation Methods 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 108010078274 isoleucylvaline Proteins 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 230000003211 malignant effect Effects 0.000 description 3
- 230000000174 oncolytic effect Effects 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 230000003389 potentiating effect Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 230000001681 protective effect Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 239000007929 subcutaneous injection Substances 0.000 description 3
- 238000010254 subcutaneous injection Methods 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- ABEXEQSGABRUHS-UHFFFAOYSA-N 16-methylheptadecyl 16-methylheptadecanoate Chemical compound CC(C)CCCCCCCCCCCCCCCOC(=O)CCCCCCCCCCCCCCC(C)C ABEXEQSGABRUHS-UHFFFAOYSA-N 0.000 description 2
- YEJQWBFDKKTPNO-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-3-methylbutanoyl)pyrrolidine-2-carbonyl]amino]acetyl]amino]-3-methylbutanoic acid Chemical compound CC(C)C(N)C(=O)N1CCCC1C(=O)NCC(=O)NC(C(C)C)C(O)=O YEJQWBFDKKTPNO-UHFFFAOYSA-N 0.000 description 2
- OZRFYUJEXYKQDV-UHFFFAOYSA-N 2-[[2-[[2-[(2-amino-3-carboxypropanoyl)amino]-3-carboxypropanoyl]amino]-3-carboxypropanoyl]amino]butanedioic acid Chemical compound OC(=O)CC(N)C(=O)NC(CC(O)=O)C(=O)NC(CC(O)=O)C(=O)NC(CC(O)=O)C(O)=O OZRFYUJEXYKQDV-UHFFFAOYSA-N 0.000 description 2
- 108010042708 Acetylmuramyl-Alanyl-Isoglutamine Proteins 0.000 description 2
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 2
- YBPLKDWJFYCZSV-ZLUOBGJFSA-N Ala-Asn-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N YBPLKDWJFYCZSV-ZLUOBGJFSA-N 0.000 description 2
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 2
- LGFCAXJBAZESCF-ACZMJKKPSA-N Ala-Gln-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O LGFCAXJBAZESCF-ACZMJKKPSA-N 0.000 description 2
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 2
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 2
- UHMQKOBNPRAZGB-CIUDSAMLSA-N Ala-Glu-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N UHMQKOBNPRAZGB-CIUDSAMLSA-N 0.000 description 2
- PUBLUECXJRHTBK-ACZMJKKPSA-N Ala-Glu-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O PUBLUECXJRHTBK-ACZMJKKPSA-N 0.000 description 2
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 2
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 2
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 2
- YUGFLWBWAJFGKY-BQBZGAKWSA-N Arg-Cys-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O YUGFLWBWAJFGKY-BQBZGAKWSA-N 0.000 description 2
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 2
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 2
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 2
- PAPSMOYMQDWIOR-AVGNSLFASA-N Arg-Lys-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PAPSMOYMQDWIOR-AVGNSLFASA-N 0.000 description 2
- DMLSCRJBWUEALP-LAEOZQHASA-N Asn-Glu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O DMLSCRJBWUEALP-LAEOZQHASA-N 0.000 description 2
- PLVAAIPKSGUXDV-WHFBIAKZSA-N Asn-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)N PLVAAIPKSGUXDV-WHFBIAKZSA-N 0.000 description 2
- GQRDIVQPSMPQME-ZPFDUUQYSA-N Asn-Ile-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O GQRDIVQPSMPQME-ZPFDUUQYSA-N 0.000 description 2
- ZYPWIUFLYMQZBS-SRVKXCTJSA-N Asn-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ZYPWIUFLYMQZBS-SRVKXCTJSA-N 0.000 description 2
- DATSKXOXPUAOLK-KKUMJFAQSA-N Asn-Tyr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DATSKXOXPUAOLK-KKUMJFAQSA-N 0.000 description 2
- DXHINQUXBZNUCF-MELADBBJSA-N Asn-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O DXHINQUXBZNUCF-MELADBBJSA-N 0.000 description 2
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 2
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 2
- DRCOAZZDQRCGGP-GHCJXIJMSA-N Asp-Ser-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DRCOAZZDQRCGGP-GHCJXIJMSA-N 0.000 description 2
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 2
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 2
- 238000011740 C57BL/6 mouse Methods 0.000 description 2
- 102100032912 CD44 antigen Human genes 0.000 description 2
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 2
- HKALUUKHYNEDRS-GUBZILKMSA-N Cys-Leu-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HKALUUKHYNEDRS-GUBZILKMSA-N 0.000 description 2
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 2
- RESAHOSBQHMOKH-KKUMJFAQSA-N Cys-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CS)N RESAHOSBQHMOKH-KKUMJFAQSA-N 0.000 description 2
- OEDPLIBVQGRKGZ-AVGNSLFASA-N Cys-Tyr-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O OEDPLIBVQGRKGZ-AVGNSLFASA-N 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- KWUSGAIFNHQCBY-DCAQKATOSA-N Gln-Arg-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O KWUSGAIFNHQCBY-DCAQKATOSA-N 0.000 description 2
- JESJDAAGXULQOP-CIUDSAMLSA-N Gln-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)CN=C(N)N JESJDAAGXULQOP-CIUDSAMLSA-N 0.000 description 2
- CYTSBCIIEHUPDU-ACZMJKKPSA-N Gln-Asp-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O CYTSBCIIEHUPDU-ACZMJKKPSA-N 0.000 description 2
- LWDGZZGWDMHBOF-FXQIFTODSA-N Gln-Glu-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O LWDGZZGWDMHBOF-FXQIFTODSA-N 0.000 description 2
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 2
- JNEITCMDYWKPIW-GUBZILKMSA-N Gln-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)N)N JNEITCMDYWKPIW-GUBZILKMSA-N 0.000 description 2
- LKVCNGLNTAPMSZ-JYJNAYRXSA-N Gln-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N LKVCNGLNTAPMSZ-JYJNAYRXSA-N 0.000 description 2
- FYAULIGIFPPOAA-ZPFDUUQYSA-N Gln-Ile-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCSC)C(O)=O FYAULIGIFPPOAA-ZPFDUUQYSA-N 0.000 description 2
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 2
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 2
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 2
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 2
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 2
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 2
- AKJRHDMTEJXTPV-ACZMJKKPSA-N Glu-Asn-Ala Chemical compound C[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AKJRHDMTEJXTPV-ACZMJKKPSA-N 0.000 description 2
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 2
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 2
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 2
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 2
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 2
- DWBBKNPKDHXIAC-SRVKXCTJSA-N Glu-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCC(O)=O DWBBKNPKDHXIAC-SRVKXCTJSA-N 0.000 description 2
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 2
- HQOGXFLBAKJUMH-CIUDSAMLSA-N Glu-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N HQOGXFLBAKJUMH-CIUDSAMLSA-N 0.000 description 2
- FQFWFZWOHOEVMZ-IHRRRGAJSA-N Glu-Phe-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FQFWFZWOHOEVMZ-IHRRRGAJSA-N 0.000 description 2
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 2
- MIWJDJAMMKHUAR-ZVZYQTTQSA-N Glu-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N MIWJDJAMMKHUAR-ZVZYQTTQSA-N 0.000 description 2
- YPHPEHMXOYTEQG-LAEOZQHASA-N Glu-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O YPHPEHMXOYTEQG-LAEOZQHASA-N 0.000 description 2
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 2
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 2
- XQHSBNVACKQWAV-WHFBIAKZSA-N Gly-Asp-Asn Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XQHSBNVACKQWAV-WHFBIAKZSA-N 0.000 description 2
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 2
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- IFHJOBKVXBESRE-YUMQZZPRSA-N Gly-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN IFHJOBKVXBESRE-YUMQZZPRSA-N 0.000 description 2
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 2
- ZKJZBRHRWKLVSJ-ZDLURKLDSA-N Gly-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O ZKJZBRHRWKLVSJ-ZDLURKLDSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 2
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 2
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 2
- 241000725303 Human immunodeficiency virus Species 0.000 description 2
- KIAOPHMUNPPGEN-PEXQALLHSA-N Ile-Gly-His Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KIAOPHMUNPPGEN-PEXQALLHSA-N 0.000 description 2
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 2
- MLSUZXHSNRBDCI-CYDGBPFRSA-N Ile-Pro-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)O)N MLSUZXHSNRBDCI-CYDGBPFRSA-N 0.000 description 2
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 2
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 2
- 102100022297 Integrin alpha-X Human genes 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- 102100033467 L-selectin Human genes 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 2
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 2
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 2
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 2
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 2
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 2
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 2
- AOFYPTOHESIBFZ-KKUMJFAQSA-N Leu-His-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O AOFYPTOHESIBFZ-KKUMJFAQSA-N 0.000 description 2
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 2
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 2
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 2
- SQUFDMCWMFOEBA-KKUMJFAQSA-N Leu-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SQUFDMCWMFOEBA-KKUMJFAQSA-N 0.000 description 2
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 2
- WBRJVRXEGQIDRK-XIRDDKMYSA-N Leu-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 WBRJVRXEGQIDRK-XIRDDKMYSA-N 0.000 description 2
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 2
- AXVIGSRGTMNSJU-YESZJQIVSA-N Leu-Tyr-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N AXVIGSRGTMNSJU-YESZJQIVSA-N 0.000 description 2
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- SVJRVFPSHPGWFF-DCAQKATOSA-N Lys-Cys-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SVJRVFPSHPGWFF-DCAQKATOSA-N 0.000 description 2
- GFWLIJDQILOEPP-HSCHXYMDSA-N Lys-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N GFWLIJDQILOEPP-HSCHXYMDSA-N 0.000 description 2
- RDLSEGZJMYGFNS-FXQIFTODSA-N Met-Ser-Asp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RDLSEGZJMYGFNS-FXQIFTODSA-N 0.000 description 2
- LPNWWHBFXPNHJG-AVGNSLFASA-N Met-Val-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN LPNWWHBFXPNHJG-AVGNSLFASA-N 0.000 description 2
- 108010006519 Molecular Chaperones Proteins 0.000 description 2
- 102000005431 Molecular Chaperones Human genes 0.000 description 2
- 108010008707 Mucin-1 Proteins 0.000 description 2
- 102000007298 Mucin-1 Human genes 0.000 description 2
- 241001467552 Mycobacterium bovis BCG Species 0.000 description 2
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 2
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 2
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- HGNGAMWHGGANAU-WHOFXGATSA-N Phe-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HGNGAMWHGGANAU-WHOFXGATSA-N 0.000 description 2
- OSBADCBXAMSPQD-YESZJQIVSA-N Phe-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N OSBADCBXAMSPQD-YESZJQIVSA-N 0.000 description 2
- HQPWNHXERZCIHP-PMVMPFDFSA-N Phe-Leu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 HQPWNHXERZCIHP-PMVMPFDFSA-N 0.000 description 2
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 2
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 2
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 2
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 2
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 2
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 2
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 2
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 2
- OFGUOWQVEGTVNU-DCAQKATOSA-N Pro-Lys-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OFGUOWQVEGTVNU-DCAQKATOSA-N 0.000 description 2
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 2
- CGSOWZUPLOKYOR-AVGNSLFASA-N Pro-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 CGSOWZUPLOKYOR-AVGNSLFASA-N 0.000 description 2
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 2
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 2
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 2
- YHUBAXGAAYULJY-ULQDDVLXSA-N Pro-Tyr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O YHUBAXGAAYULJY-ULQDDVLXSA-N 0.000 description 2
- VDHGTOHMHHQSKG-JYJNAYRXSA-N Pro-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O VDHGTOHMHHQSKG-JYJNAYRXSA-N 0.000 description 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 2
- BCKYYTVFBXHPOG-ACZMJKKPSA-N Ser-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N BCKYYTVFBXHPOG-ACZMJKKPSA-N 0.000 description 2
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 2
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 2
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 2
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 2
- UPLYXVPQLJVWMM-KKUMJFAQSA-N Ser-Phe-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UPLYXVPQLJVWMM-KKUMJFAQSA-N 0.000 description 2
- VFWQQZMRKFOGLE-ZLUOBGJFSA-N Ser-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O VFWQQZMRKFOGLE-ZLUOBGJFSA-N 0.000 description 2
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 2
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 2
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 2
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 2
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 2
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 2
- WPAKPLPGQNUXGN-OSUNSFLBSA-N Thr-Ile-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WPAKPLPGQNUXGN-OSUNSFLBSA-N 0.000 description 2
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 2
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 2
- ZJKZLNAECPIUTL-JBACZVJFSA-N Trp-Gln-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 ZJKZLNAECPIUTL-JBACZVJFSA-N 0.000 description 2
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 2
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 2
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 2
- XQYHLZNPOTXRMQ-KKUMJFAQSA-N Tyr-Glu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XQYHLZNPOTXRMQ-KKUMJFAQSA-N 0.000 description 2
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 2
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 2
- ZTKGDWOUYRRAOQ-ULQDDVLXSA-N Val-His-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N ZTKGDWOUYRRAOQ-ULQDDVLXSA-N 0.000 description 2
- APEBUJBRGCMMHP-HJWJTTGWSA-N Val-Ile-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 APEBUJBRGCMMHP-HJWJTTGWSA-N 0.000 description 2
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 2
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 229940037003 alum Drugs 0.000 description 2
- 230000005875 antibody response Effects 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 108010060035 arginylproline Proteins 0.000 description 2
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 229960000190 bacillus calmette–guérin vaccine Drugs 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 238000002619 cancer immunotherapy Methods 0.000 description 2
- 230000004709 cell invasion Effects 0.000 description 2
- 238000002659 cell therapy Methods 0.000 description 2
- 229940030156 cell vaccine Drugs 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000007812 deficiency Effects 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 210000002950 fibroblast Anatomy 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 2
- 238000001415 gene therapy Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 108010036413 histidylglycine Proteins 0.000 description 2
- 108010018006 histidylserine Proteins 0.000 description 2
- 238000005417 image-selected in vivo spectroscopy Methods 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 238000012739 integrated shape imaging system Methods 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 201000004792 malaria Diseases 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- BSOQXXWZTUDTEL-ZUYCGGNHSA-N muramyl dipeptide Chemical compound OC(=O)CC[C@H](C(N)=O)NC(=O)[C@H](C)NC(=O)[C@@H](C)O[C@H]1[C@H](O)[C@@H](CO)O[C@@H](O)[C@@H]1NC(C)=O BSOQXXWZTUDTEL-ZUYCGGNHSA-N 0.000 description 2
- 239000002773 nucleotide Substances 0.000 description 2
- 125000003729 nucleotide group Chemical group 0.000 description 2
- MXHCPCSDRGLRER-UHFFFAOYSA-N pentaglycine Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)NCC(O)=O MXHCPCSDRGLRER-UHFFFAOYSA-N 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 239000013605 shuttle vector Substances 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 229940066453 tecentriq Drugs 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 238000011269 treatment regimen Methods 0.000 description 2
- 108010038745 tryptophylglycine Proteins 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 229940126580 vector vaccine Drugs 0.000 description 2
- 108010027345 wheylin-1 peptide Proteins 0.000 description 2
- 229940055760 yervoy Drugs 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- GZCWLCBFPRFLKL-UHFFFAOYSA-N 1-prop-2-ynoxypropan-2-ol Chemical compound CC(O)COCC#C GZCWLCBFPRFLKL-UHFFFAOYSA-N 0.000 description 1
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 208000010370 Adenoviridae Infections Diseases 0.000 description 1
- 206010060931 Adenovirus infection Diseases 0.000 description 1
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 1
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 1
- NXSFUECZFORGOG-CIUDSAMLSA-N Ala-Asn-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXSFUECZFORGOG-CIUDSAMLSA-N 0.000 description 1
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 1
- GWFSQQNGMPGBEF-GHCJXIJMSA-N Ala-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N GWFSQQNGMPGBEF-GHCJXIJMSA-N 0.000 description 1
- ZODMADSIQZZBSQ-FXQIFTODSA-N Ala-Gln-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZODMADSIQZZBSQ-FXQIFTODSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- ANGAOPNEPIDLPO-XVYDVKMFSA-N Ala-His-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CS)C(=O)O)N ANGAOPNEPIDLPO-XVYDVKMFSA-N 0.000 description 1
- QCTFKEJEIMPOLW-JURCDPSOSA-N Ala-Ile-Phe Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QCTFKEJEIMPOLW-JURCDPSOSA-N 0.000 description 1
- 108010068139 Ala-Leu-Pro-Met Proteins 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- OQWQTGBOFPJOIF-DLOVCJGASA-N Ala-Lys-His Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N OQWQTGBOFPJOIF-DLOVCJGASA-N 0.000 description 1
- AUFACLFHBAGZEN-ZLUOBGJFSA-N Ala-Ser-Cys Chemical compound N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O AUFACLFHBAGZEN-ZLUOBGJFSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- 241000272525 Anas platyrhynchos Species 0.000 description 1
- GHNDBBVSWOWYII-LPEHRKFASA-N Arg-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GHNDBBVSWOWYII-LPEHRKFASA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- OZNSCVPYWZRQPY-CIUDSAMLSA-N Arg-Asp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OZNSCVPYWZRQPY-CIUDSAMLSA-N 0.000 description 1
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 1
- BBYTXXRNSFUOOX-IHRRRGAJSA-N Arg-Cys-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BBYTXXRNSFUOOX-IHRRRGAJSA-N 0.000 description 1
- LMPKCSXZJSXBBL-NHCYSSNCSA-N Arg-Gln-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O LMPKCSXZJSXBBL-NHCYSSNCSA-N 0.000 description 1
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- QKSAZKCRVQYYGS-UWVGGRQHSA-N Arg-Gly-His Chemical compound N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O QKSAZKCRVQYYGS-UWVGGRQHSA-N 0.000 description 1
- NVCIXQYNWYTLDO-IHRRRGAJSA-N Arg-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N NVCIXQYNWYTLDO-IHRRRGAJSA-N 0.000 description 1
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 1
- NYDIVDKTULRINZ-AVGNSLFASA-N Arg-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NYDIVDKTULRINZ-AVGNSLFASA-N 0.000 description 1
- INXWADWANGLMPJ-JYJNAYRXSA-N Arg-Phe-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CC1=CC=CC=C1 INXWADWANGLMPJ-JYJNAYRXSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- LQJAALCCPOTJGB-YUMQZZPRSA-N Arg-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O LQJAALCCPOTJGB-YUMQZZPRSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- AUIJUTGLPVHIRT-FXQIFTODSA-N Arg-Ser-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N AUIJUTGLPVHIRT-FXQIFTODSA-N 0.000 description 1
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 1
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- RZVVKNIACROXRM-ZLUOBGJFSA-N Asn-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N RZVVKNIACROXRM-ZLUOBGJFSA-N 0.000 description 1
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 1
- LJUOLNXOWSWGKF-ACZMJKKPSA-N Asn-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N LJUOLNXOWSWGKF-ACZMJKKPSA-N 0.000 description 1
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 1
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 1
- VWADICJNCPFKJS-ZLUOBGJFSA-N Asn-Ser-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O VWADICJNCPFKJS-ZLUOBGJFSA-N 0.000 description 1
- YNQMEIJEWSHOEO-SRVKXCTJSA-N Asn-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O YNQMEIJEWSHOEO-SRVKXCTJSA-N 0.000 description 1
- WSWYMRLTJVKRCE-ZLUOBGJFSA-N Asp-Ala-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O WSWYMRLTJVKRCE-ZLUOBGJFSA-N 0.000 description 1
- XBQSLMACWDXWLJ-GHCJXIJMSA-N Asp-Ala-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XBQSLMACWDXWLJ-GHCJXIJMSA-N 0.000 description 1
- VPPXTHJNTYDNFJ-CIUDSAMLSA-N Asp-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N VPPXTHJNTYDNFJ-CIUDSAMLSA-N 0.000 description 1
- CXBOKJPLEYUPGB-FXQIFTODSA-N Asp-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N CXBOKJPLEYUPGB-FXQIFTODSA-N 0.000 description 1
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 1
- ZLGKHJHFYSRUBH-FXQIFTODSA-N Asp-Arg-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLGKHJHFYSRUBH-FXQIFTODSA-N 0.000 description 1
- QRULNKJGYQQZMW-ZLUOBGJFSA-N Asp-Asn-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QRULNKJGYQQZMW-ZLUOBGJFSA-N 0.000 description 1
- ATYWBXGNXZYZGI-ACZMJKKPSA-N Asp-Asn-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ATYWBXGNXZYZGI-ACZMJKKPSA-N 0.000 description 1
- JDHOJQJMWBKHDB-CIUDSAMLSA-N Asp-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N JDHOJQJMWBKHDB-CIUDSAMLSA-N 0.000 description 1
- NAPNAGZWHQHZLG-ZLUOBGJFSA-N Asp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N NAPNAGZWHQHZLG-ZLUOBGJFSA-N 0.000 description 1
- XAJRHVUUVUPFQL-ACZMJKKPSA-N Asp-Glu-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XAJRHVUUVUPFQL-ACZMJKKPSA-N 0.000 description 1
- YNCHFVRXEQFPBY-BQBZGAKWSA-N Asp-Gly-Arg Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N YNCHFVRXEQFPBY-BQBZGAKWSA-N 0.000 description 1
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 1
- FOXXZZGDIAQPQI-XKNYDFJKSA-N Asp-Pro-Ser-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FOXXZZGDIAQPQI-XKNYDFJKSA-N 0.000 description 1
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 1
- MJJIHRWNWSQTOI-VEVYYDQMSA-N Asp-Thr-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MJJIHRWNWSQTOI-VEVYYDQMSA-N 0.000 description 1
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 1
- KACWACLNYLSVCA-VHWLVUOQSA-N Asp-Trp-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KACWACLNYLSVCA-VHWLVUOQSA-N 0.000 description 1
- FIRWLDUOFOULCA-XIRDDKMYSA-N Asp-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N FIRWLDUOFOULCA-XIRDDKMYSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 241000588832 Bordetella pertussis Species 0.000 description 1
- 102100025429 Butyrophilin-like protein 2 Human genes 0.000 description 1
- 108010017533 Butyrophilins Proteins 0.000 description 1
- 102000004555 Butyrophilins Human genes 0.000 description 1
- 102100031151 C-C chemokine receptor type 2 Human genes 0.000 description 1
- 101710149815 C-C chemokine receptor type 2 Proteins 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 108010056102 CD100 antigen Proteins 0.000 description 1
- 102100024263 CD160 antigen Human genes 0.000 description 1
- 102100038077 CD226 antigen Human genes 0.000 description 1
- 102100027207 CD27 antigen Human genes 0.000 description 1
- 102100038078 CD276 antigen Human genes 0.000 description 1
- 101710185679 CD276 antigen Proteins 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 102100036008 CD48 antigen Human genes 0.000 description 1
- 102100025221 CD70 antigen Human genes 0.000 description 1
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 102100038449 Claudin-6 Human genes 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- PKNIZMPLMSKROD-BIIVOSGPSA-N Cys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N PKNIZMPLMSKROD-BIIVOSGPSA-N 0.000 description 1
- CPTUXCUWQIBZIF-ZLUOBGJFSA-N Cys-Asn-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CPTUXCUWQIBZIF-ZLUOBGJFSA-N 0.000 description 1
- LDIKUWLAMDFHPU-FXQIFTODSA-N Cys-Cys-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LDIKUWLAMDFHPU-FXQIFTODSA-N 0.000 description 1
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 1
- KEBJBKIASQVRJS-WDSKDSINSA-N Cys-Gln-Gly Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N KEBJBKIASQVRJS-WDSKDSINSA-N 0.000 description 1
- RWGDABDXVXRLLH-ACZMJKKPSA-N Cys-Glu-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N RWGDABDXVXRLLH-ACZMJKKPSA-N 0.000 description 1
- CFQVGYWKSLKWFX-KBIXCLLPSA-N Cys-Glu-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CFQVGYWKSLKWFX-KBIXCLLPSA-N 0.000 description 1
- OXOQBEVULIBOSH-ZDLURKLDSA-N Cys-Gly-Thr Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O OXOQBEVULIBOSH-ZDLURKLDSA-N 0.000 description 1
- SSNJZBGOMNLSLA-CIUDSAMLSA-N Cys-Leu-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O SSNJZBGOMNLSLA-CIUDSAMLSA-N 0.000 description 1
- NRVQLLDIJJEIIZ-VZFHVOOUSA-N Cys-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CS)N)O NRVQLLDIJJEIIZ-VZFHVOOUSA-N 0.000 description 1
- JIVJQYNNAYFXDG-LKXGYXEUSA-N Cys-Thr-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JIVJQYNNAYFXDG-LKXGYXEUSA-N 0.000 description 1
- WTXCNOPZMQRTNN-BWBBJGPYSA-N Cys-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)O WTXCNOPZMQRTNN-BWBBJGPYSA-N 0.000 description 1
- QNNYDGBKNFDYOD-UBHSHLNASA-N Cys-Trp-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N QNNYDGBKNFDYOD-UBHSHLNASA-N 0.000 description 1
- HPZAJRPYUIHDIN-BZSNNMDCSA-N Cys-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CS)N HPZAJRPYUIHDIN-BZSNNMDCSA-N 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- 108010041986 DNA Vaccines Proteins 0.000 description 1
- 229940021995 DNA vaccine Drugs 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 101150029662 E1 gene Proteins 0.000 description 1
- 238000011510 Elispot assay Methods 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- 241000700662 Fowlpox virus Species 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- YNNXQZDEOCYJJL-CIUDSAMLSA-N Gln-Arg-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)CN=C(N)N YNNXQZDEOCYJJL-CIUDSAMLSA-N 0.000 description 1
- INFBPLSHYFALDE-ACZMJKKPSA-N Gln-Asn-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O INFBPLSHYFALDE-ACZMJKKPSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- ZRXBYKAOFHLTDN-GUBZILKMSA-N Gln-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N ZRXBYKAOFHLTDN-GUBZILKMSA-N 0.000 description 1
- QFTRCUPCARNIPZ-XHNCKOQMSA-N Gln-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N)C(=O)O QFTRCUPCARNIPZ-XHNCKOQMSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- PODFFOWWLUPNMN-DCAQKATOSA-N Gln-His-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PODFFOWWLUPNMN-DCAQKATOSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- SFAFZYYMAWOCIC-KKUMJFAQSA-N Gln-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SFAFZYYMAWOCIC-KKUMJFAQSA-N 0.000 description 1
- WIMVKDYAKRAUCG-IHRRRGAJSA-N Gln-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WIMVKDYAKRAUCG-IHRRRGAJSA-N 0.000 description 1
- QXQDADBVIBLBHN-FHWLQOOXSA-N Gln-Tyr-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QXQDADBVIBLBHN-FHWLQOOXSA-N 0.000 description 1
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 1
- BPDVTFBJZNBHEU-HGNGGELXSA-N Glu-Ala-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 BPDVTFBJZNBHEU-HGNGGELXSA-N 0.000 description 1
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 1
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 1
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 1
- VAIWPXWHWAPYDF-FXQIFTODSA-N Glu-Asp-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O VAIWPXWHWAPYDF-FXQIFTODSA-N 0.000 description 1
- XHUCVVHRLNPZSZ-CIUDSAMLSA-N Glu-Gln-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XHUCVVHRLNPZSZ-CIUDSAMLSA-N 0.000 description 1
- LVCHEMOPBORRLB-DCAQKATOSA-N Glu-Gln-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O LVCHEMOPBORRLB-DCAQKATOSA-N 0.000 description 1
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 1
- LGYZYFFDELZWRS-DCAQKATOSA-N Glu-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O LGYZYFFDELZWRS-DCAQKATOSA-N 0.000 description 1
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 1
- QJCKNLPMTPXXEM-AUTRQRHGSA-N Glu-Glu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O QJCKNLPMTPXXEM-AUTRQRHGSA-N 0.000 description 1
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- LHIPZASLKPYDPI-AVGNSLFASA-N Glu-Phe-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LHIPZASLKPYDPI-AVGNSLFASA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 1
- QOOFKCCZZWTCEP-AVGNSLFASA-N Glu-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O QOOFKCCZZWTCEP-AVGNSLFASA-N 0.000 description 1
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 1
- BRFJMRSRMOMIMU-WHFBIAKZSA-N Gly-Ala-Asn Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O BRFJMRSRMOMIMU-WHFBIAKZSA-N 0.000 description 1
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- PYUCNHJQQVSPGN-BQBZGAKWSA-N Gly-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)CN=C(N)N PYUCNHJQQVSPGN-BQBZGAKWSA-N 0.000 description 1
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 1
- BGVYNAQWHSTTSP-BYULHYEWSA-N Gly-Asn-Ile Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BGVYNAQWHSTTSP-BYULHYEWSA-N 0.000 description 1
- FMVLWTYYODVFRG-BQBZGAKWSA-N Gly-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN FMVLWTYYODVFRG-BQBZGAKWSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- AQLHORCVPGXDJW-IUCAKERBSA-N Gly-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)CN AQLHORCVPGXDJW-IUCAKERBSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 1
- HAXARWKYFIIHKD-ZKWXMUAHSA-N Gly-Ile-Ser Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HAXARWKYFIIHKD-ZKWXMUAHSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 1
- CVFOYJJOZYYEPE-KBPBESRZSA-N Gly-Lys-Tyr Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CVFOYJJOZYYEPE-KBPBESRZSA-N 0.000 description 1
- WMGHDYWNHNLGBV-ONGXEEELSA-N Gly-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 WMGHDYWNHNLGBV-ONGXEEELSA-N 0.000 description 1
- HJARVELKOSZUEW-YUMQZZPRSA-N Gly-Pro-Gln Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJARVELKOSZUEW-YUMQZZPRSA-N 0.000 description 1
- OCPPBNKYGYSLOE-IUCAKERBSA-N Gly-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN OCPPBNKYGYSLOE-IUCAKERBSA-N 0.000 description 1
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 1
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 1
- RHRLHXQWHCNJKR-PMVVWTBXSA-N Gly-Thr-His Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 RHRLHXQWHCNJKR-PMVVWTBXSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- 108010078321 Guanylate Cyclase Proteins 0.000 description 1
- 102000014469 Guanylate cyclase Human genes 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 102100035943 HERV-H LTR-associating protein 2 Human genes 0.000 description 1
- 229940033330 HIV vaccine Drugs 0.000 description 1
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- WJUYPBBCSSLVJE-CIUDSAMLSA-N His-Asn-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N WJUYPBBCSSLVJE-CIUDSAMLSA-N 0.000 description 1
- VOEGKUNRHYKYSU-XVYDVKMFSA-N His-Asp-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O VOEGKUNRHYKYSU-XVYDVKMFSA-N 0.000 description 1
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 1
- STOOMQFEJUVAKR-KKUMJFAQSA-N His-His-His Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(O)=O)C1=CNC=N1 STOOMQFEJUVAKR-KKUMJFAQSA-N 0.000 description 1
- GHAFKUCRIVBLDJ-IHRRRGAJSA-N His-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CN=CN2)N GHAFKUCRIVBLDJ-IHRRRGAJSA-N 0.000 description 1
- PZAJPILZRFPYJJ-SRVKXCTJSA-N His-Ser-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O PZAJPILZRFPYJJ-SRVKXCTJSA-N 0.000 description 1
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 1
- MCGOGXFMKHPMSQ-AVGNSLFASA-N His-Val-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 MCGOGXFMKHPMSQ-AVGNSLFASA-N 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000934738 Homo sapiens Butyrophilin-like protein 2 Proteins 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 1
- 101000884298 Homo sapiens CD226 antigen Proteins 0.000 description 1
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 1
- 101000716130 Homo sapiens CD48 antigen Proteins 0.000 description 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 1
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 1
- 101000882898 Homo sapiens Claudin-6 Proteins 0.000 description 1
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 1
- 101001021491 Homo sapiens HERV-H LTR-associating protein 2 Proteins 0.000 description 1
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 1
- 101100232351 Homo sapiens IL12RB1 gene Proteins 0.000 description 1
- 101000959820 Homo sapiens Interferon alpha-1/13 Proteins 0.000 description 1
- 101001002634 Homo sapiens Interleukin-1 alpha Proteins 0.000 description 1
- 101000960952 Homo sapiens Interleukin-1 receptor accessory protein Proteins 0.000 description 1
- 101001076418 Homo sapiens Interleukin-1 receptor type 1 Proteins 0.000 description 1
- 101000599048 Homo sapiens Interleukin-6 receptor subunit alpha Proteins 0.000 description 1
- 101001043809 Homo sapiens Interleukin-7 receptor subunit alpha Proteins 0.000 description 1
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 description 1
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 1
- 101001005728 Homo sapiens Melanoma-associated antigen 1 Proteins 0.000 description 1
- 101001005725 Homo sapiens Melanoma-associated antigen 10 Proteins 0.000 description 1
- 101001005716 Homo sapiens Melanoma-associated antigen 11 Proteins 0.000 description 1
- 101001005717 Homo sapiens Melanoma-associated antigen 12 Proteins 0.000 description 1
- 101001005718 Homo sapiens Melanoma-associated antigen 2 Proteins 0.000 description 1
- 101001005720 Homo sapiens Melanoma-associated antigen 4 Proteins 0.000 description 1
- 101001005722 Homo sapiens Melanoma-associated antigen 6 Proteins 0.000 description 1
- 101001005723 Homo sapiens Melanoma-associated antigen 8 Proteins 0.000 description 1
- 101001005724 Homo sapiens Melanoma-associated antigen 9 Proteins 0.000 description 1
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 1
- 101000884270 Homo sapiens Natural killer cell receptor 2B4 Proteins 0.000 description 1
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 1
- 101001117312 Homo sapiens Programmed cell death 1 ligand 2 Proteins 0.000 description 1
- 101001005721 Homo sapiens Putative melanoma-associated antigen 5P Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 101000801481 Homo sapiens Tissue-type plasminogen activator Proteins 0.000 description 1
- 101000764622 Homo sapiens Transmembrane and immunoglobulin domain-containing protein 2 Proteins 0.000 description 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 1
- 101000863873 Homo sapiens Tyrosine-protein phosphatase non-receptor type substrate 1 Proteins 0.000 description 1
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 1
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 1
- 241000886703 Human mastadenovirus E Species 0.000 description 1
- 241000701806 Human papillomavirus Species 0.000 description 1
- 102100034980 ICOS ligand Human genes 0.000 description 1
- 101710093458 ICOS ligand Proteins 0.000 description 1
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 1
- UAQSZXGJGLHMNV-XEGUGMAKSA-N Ile-Gly-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N UAQSZXGJGLHMNV-XEGUGMAKSA-N 0.000 description 1
- JLWLMGADIQFKRD-QSFUFRPTSA-N Ile-His-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CN=CN1 JLWLMGADIQFKRD-QSFUFRPTSA-N 0.000 description 1
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 1
- PARSHQDZROHERM-NHCYSSNCSA-N Ile-Lys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N PARSHQDZROHERM-NHCYSSNCSA-N 0.000 description 1
- FTUZWJVSNZMLPI-RVMXOQNASA-N Ile-Met-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N FTUZWJVSNZMLPI-RVMXOQNASA-N 0.000 description 1
- RWHRUZORDWZESH-ZQINRCPSSA-N Ile-Trp-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RWHRUZORDWZESH-ZQINRCPSSA-N 0.000 description 1
- GNXGAVNTVNOCLL-SIUGBPQLSA-N Ile-Tyr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GNXGAVNTVNOCLL-SIUGBPQLSA-N 0.000 description 1
- 229940123309 Immune checkpoint modulator Drugs 0.000 description 1
- 102100040019 Interferon alpha-1/13 Human genes 0.000 description 1
- 102100020881 Interleukin-1 alpha Human genes 0.000 description 1
- 102100039880 Interleukin-1 receptor accessory protein Human genes 0.000 description 1
- 102100026016 Interleukin-1 receptor type 1 Human genes 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 102100020790 Interleukin-12 receptor subunit beta-1 Human genes 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 102000003812 Interleukin-15 Human genes 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 description 1
- 102000000704 Interleukin-7 Human genes 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 102100021593 Interleukin-7 receptor subunit alpha Human genes 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 1
- 101150069255 KLRC1 gene Proteins 0.000 description 1
- 108010062028 L-BLP25 Proteins 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 102000017578 LAG3 Human genes 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- GZAUZBUKDXYPEH-CIUDSAMLSA-N Leu-Cys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N GZAUZBUKDXYPEH-CIUDSAMLSA-N 0.000 description 1
- DXYBNWJZJVSZAE-GUBZILKMSA-N Leu-Gln-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N DXYBNWJZJVSZAE-GUBZILKMSA-N 0.000 description 1
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 1
- YVKSMSDXKMSIRX-GUBZILKMSA-N Leu-Glu-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O YVKSMSDXKMSIRX-GUBZILKMSA-N 0.000 description 1
- KVMULWOHPPMHHE-DCAQKATOSA-N Leu-Glu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KVMULWOHPPMHHE-DCAQKATOSA-N 0.000 description 1
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 1
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 1
- FMEICTQWUKNAGC-YUMQZZPRSA-N Leu-Gly-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O FMEICTQWUKNAGC-YUMQZZPRSA-N 0.000 description 1
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 1
- KXODZBLFVFSLAI-AVGNSLFASA-N Leu-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KXODZBLFVFSLAI-AVGNSLFASA-N 0.000 description 1
- XQXGNBFMAXWIGI-MXAVVETBSA-N Leu-His-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 XQXGNBFMAXWIGI-MXAVVETBSA-N 0.000 description 1
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- KXCMQWMNYQOAKA-SRVKXCTJSA-N Leu-Met-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N KXCMQWMNYQOAKA-SRVKXCTJSA-N 0.000 description 1
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 1
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- JLYUZRKPDKHUTC-WDSOQIARSA-N Leu-Pro-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JLYUZRKPDKHUTC-WDSOQIARSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 1
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 1
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 1
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 1
- 102100032352 Leukemia inhibitory factor Human genes 0.000 description 1
- 108090000581 Leukemia inhibitory factor Proteins 0.000 description 1
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 description 1
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 1
- DNEJSAIMVANNPA-DCAQKATOSA-N Lys-Asn-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DNEJSAIMVANNPA-DCAQKATOSA-N 0.000 description 1
- QYOXSYXPHUHOJR-GUBZILKMSA-N Lys-Asn-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYOXSYXPHUHOJR-GUBZILKMSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- RDIILCRAWOSDOQ-CIUDSAMLSA-N Lys-Cys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RDIILCRAWOSDOQ-CIUDSAMLSA-N 0.000 description 1
- MLLKLNYPZRDIQG-GUBZILKMSA-N Lys-Cys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N MLLKLNYPZRDIQG-GUBZILKMSA-N 0.000 description 1
- DUTMKEAPLLUGNO-JYJNAYRXSA-N Lys-Glu-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DUTMKEAPLLUGNO-JYJNAYRXSA-N 0.000 description 1
- SQJSXOQXJYAVRV-SRVKXCTJSA-N Lys-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N SQJSXOQXJYAVRV-SRVKXCTJSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- URBJRJKWSUFCKS-AVGNSLFASA-N Lys-Met-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCCCN)N URBJRJKWSUFCKS-AVGNSLFASA-N 0.000 description 1
- MGKFCQFVPKOWOL-CIUDSAMLSA-N Lys-Ser-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N MGKFCQFVPKOWOL-CIUDSAMLSA-N 0.000 description 1
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 1
- UWHCKWNPWKTMBM-WDCWCFNPSA-N Lys-Thr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWHCKWNPWKTMBM-WDCWCFNPSA-N 0.000 description 1
- IMDJSVBFQKDDEQ-MGHWNKPDSA-N Lys-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCCN)N IMDJSVBFQKDDEQ-MGHWNKPDSA-N 0.000 description 1
- VWPJQIHBBOJWDN-DCAQKATOSA-N Lys-Val-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O VWPJQIHBBOJWDN-DCAQKATOSA-N 0.000 description 1
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 1
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 1
- HMZPYMSEAALNAE-ULQDDVLXSA-N Lys-Val-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMZPYMSEAALNAE-ULQDDVLXSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 101100404845 Macaca mulatta NKG2A gene Proteins 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 102100025050 Melanoma-associated antigen 1 Human genes 0.000 description 1
- 102100025049 Melanoma-associated antigen 10 Human genes 0.000 description 1
- 102100025083 Melanoma-associated antigen 11 Human genes 0.000 description 1
- 102100025084 Melanoma-associated antigen 12 Human genes 0.000 description 1
- 102100025081 Melanoma-associated antigen 2 Human genes 0.000 description 1
- 102100025077 Melanoma-associated antigen 4 Human genes 0.000 description 1
- 102100025075 Melanoma-associated antigen 6 Human genes 0.000 description 1
- 102100025076 Melanoma-associated antigen 8 Human genes 0.000 description 1
- 102100025079 Melanoma-associated antigen 9 Human genes 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- HUKLXYYPZWPXCC-KZVJFYERSA-N Met-Ala-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HUKLXYYPZWPXCC-KZVJFYERSA-N 0.000 description 1
- TUSOIZOVPJCMFC-FXQIFTODSA-N Met-Asp-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O TUSOIZOVPJCMFC-FXQIFTODSA-N 0.000 description 1
- JPCHYAUKOUGOIB-HJGDQZAQSA-N Met-Glu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPCHYAUKOUGOIB-HJGDQZAQSA-N 0.000 description 1
- JZNGSNMTXAHMSV-AVGNSLFASA-N Met-His-Arg Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JZNGSNMTXAHMSV-AVGNSLFASA-N 0.000 description 1
- RBGLBUDVQVPTEG-DCAQKATOSA-N Met-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N RBGLBUDVQVPTEG-DCAQKATOSA-N 0.000 description 1
- MQASRXPTQJJNFM-JYJNAYRXSA-N Met-Pro-Phe Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MQASRXPTQJJNFM-JYJNAYRXSA-N 0.000 description 1
- XPVCDCMPKCERFT-GUBZILKMSA-N Met-Ser-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XPVCDCMPKCERFT-GUBZILKMSA-N 0.000 description 1
- QQPMHUCGDRJFQK-RHYQMDGZSA-N Met-Thr-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QQPMHUCGDRJFQK-RHYQMDGZSA-N 0.000 description 1
- FAKYXUOUQCRGMO-FDARSICLSA-N Met-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCSC)N FAKYXUOUQCRGMO-FDARSICLSA-N 0.000 description 1
- 101100167320 Monascus purpureus mpl4 gene Proteins 0.000 description 1
- 102100023123 Mucin-16 Human genes 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 102100022682 NKG2-A/NKG2-B type II integral membrane protein Human genes 0.000 description 1
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 1
- 102000004473 OX40 Ligand Human genes 0.000 description 1
- 108010042215 OX40 Ligand Proteins 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 239000012270 PD-1 inhibitor Substances 0.000 description 1
- 239000012668 PD-1-inhibitor Substances 0.000 description 1
- BRDYYVQTEJVRQT-HRCADAONSA-N Phe-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O BRDYYVQTEJVRQT-HRCADAONSA-N 0.000 description 1
- WFDAEEUZPZSMOG-SRVKXCTJSA-N Phe-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O WFDAEEUZPZSMOG-SRVKXCTJSA-N 0.000 description 1
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 1
- TXKWKTWYTIAZSV-KKUMJFAQSA-N Phe-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N TXKWKTWYTIAZSV-KKUMJFAQSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- DNAXXTQSTKOHFO-QEJZJMRPSA-N Phe-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DNAXXTQSTKOHFO-QEJZJMRPSA-N 0.000 description 1
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 1
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 1
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 1
- BAONJAHBAUDJKA-BZSNNMDCSA-N Phe-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=CC=C1 BAONJAHBAUDJKA-BZSNNMDCSA-N 0.000 description 1
- APMXLWHMIVWLLR-BZSNNMDCSA-N Phe-Tyr-Ser Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(O)=O)C1=CC=CC=C1 APMXLWHMIVWLLR-BZSNNMDCSA-N 0.000 description 1
- DXWNFNOPBYAFRM-IHRRRGAJSA-N Phe-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N DXWNFNOPBYAFRM-IHRRRGAJSA-N 0.000 description 1
- 108010010677 Phosphodiesterase I Proteins 0.000 description 1
- 102100029740 Poliovirus receptor Human genes 0.000 description 1
- 101150096292 Ppme1 gene Proteins 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 1
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 1
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- ZYBUKTMPPFQSHL-JYJNAYRXSA-N Pro-Asp-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ZYBUKTMPPFQSHL-JYJNAYRXSA-N 0.000 description 1
- SZZBUDVXWZZPDH-BQBZGAKWSA-N Pro-Cys-Gly Chemical compound OC(=O)CNC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 SZZBUDVXWZZPDH-BQBZGAKWSA-N 0.000 description 1
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- VWXGFAIZUQBBBG-UWVGGRQHSA-N Pro-His-Gly Chemical compound C([C@@H](C(=O)NCC(=O)[O-])NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 VWXGFAIZUQBBBG-UWVGGRQHSA-N 0.000 description 1
- JUJGNDZIKKQMDJ-IHRRRGAJSA-N Pro-His-His Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O JUJGNDZIKKQMDJ-IHRRRGAJSA-N 0.000 description 1
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 1
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- QUBVFEANYYWBTM-VEVYYDQMSA-N Pro-Thr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUBVFEANYYWBTM-VEVYYDQMSA-N 0.000 description 1
- JRBWMRUPXWPEID-JYJNAYRXSA-N Pro-Trp-Cys Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CS)C(=O)O)C(=O)[C@@H]1CCCN1 JRBWMRUPXWPEID-JYJNAYRXSA-N 0.000 description 1
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 1
- 102100025078 Putative melanoma-associated antigen 5P Human genes 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 208000011767 Sarcoma of cervix uteri Diseases 0.000 description 1
- 102100027744 Semaphorin-4D Human genes 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- PZZJMBYSYAKYPK-UWJYBYFXSA-N Ser-Ala-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PZZJMBYSYAKYPK-UWJYBYFXSA-N 0.000 description 1
- JJKSSJVYOVRJMZ-FXQIFTODSA-N Ser-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)CN=C(N)N JJKSSJVYOVRJMZ-FXQIFTODSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 1
- GRRAECZXRONTEE-UBHSHLNASA-N Ser-Cys-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GRRAECZXRONTEE-UBHSHLNASA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- UGHCUDLCCVVIJR-VGDYDELISA-N Ser-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N UGHCUDLCCVVIJR-VGDYDELISA-N 0.000 description 1
- MLSQXWSRHURDMF-GARJFASQSA-N Ser-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N)C(=O)O MLSQXWSRHURDMF-GARJFASQSA-N 0.000 description 1
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- JLPMFVAIQHCBDC-CIUDSAMLSA-N Ser-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N JLPMFVAIQHCBDC-CIUDSAMLSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- JUTGONBTALQWMK-NAKRPEOUSA-N Ser-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CO)N JUTGONBTALQWMK-NAKRPEOUSA-N 0.000 description 1
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 1
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 1
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 1
- BCAVNDNYOGTQMQ-AAEUAGOBSA-N Ser-Trp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O BCAVNDNYOGTQMQ-AAEUAGOBSA-N 0.000 description 1
- FVFUOQIYDPAIJR-XIRDDKMYSA-N Ser-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FVFUOQIYDPAIJR-XIRDDKMYSA-N 0.000 description 1
- FRPNVPKQVFHSQY-BPUTZDHNSA-N Ser-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FRPNVPKQVFHSQY-BPUTZDHNSA-N 0.000 description 1
- VEVYMLNYMULSMS-AVGNSLFASA-N Ser-Tyr-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEVYMLNYMULSMS-AVGNSLFASA-N 0.000 description 1
- QYBRQMLZDDJBSW-AVGNSLFASA-N Ser-Tyr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYBRQMLZDDJBSW-AVGNSLFASA-N 0.000 description 1
- HAYADTTXNZFUDM-IHRRRGAJSA-N Ser-Tyr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HAYADTTXNZFUDM-IHRRRGAJSA-N 0.000 description 1
- 102000007073 Sialic Acid Binding Immunoglobulin-like Lectins Human genes 0.000 description 1
- 108010047827 Sialic Acid Binding Immunoglobulin-like Lectins Proteins 0.000 description 1
- 101710196623 Stimulator of interferon genes protein Proteins 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 102000043168 TGF-beta family Human genes 0.000 description 1
- 108091085018 TGF-beta family Proteins 0.000 description 1
- DDPVJPIGACCMEH-XQXXSGGOSA-N Thr-Ala-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DDPVJPIGACCMEH-XQXXSGGOSA-N 0.000 description 1
- FQPQPTHMHZKGFM-XQXXSGGOSA-N Thr-Ala-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O FQPQPTHMHZKGFM-XQXXSGGOSA-N 0.000 description 1
- CEXFELBFVHLYDZ-XGEHTFHBSA-N Thr-Arg-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CEXFELBFVHLYDZ-XGEHTFHBSA-N 0.000 description 1
- MFEBUIFJVPNZLO-OLHMAJIHSA-N Thr-Asp-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MFEBUIFJVPNZLO-OLHMAJIHSA-N 0.000 description 1
- RJBFAHKSFNNHAI-XKBZYTNZSA-N Thr-Gln-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O RJBFAHKSFNNHAI-XKBZYTNZSA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- VOHWDZNIESHTFW-XKBZYTNZSA-N Thr-Glu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O VOHWDZNIESHTFW-XKBZYTNZSA-N 0.000 description 1
- KRDSCBLRHORMRK-JXUBOQSCSA-N Thr-Lys-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O KRDSCBLRHORMRK-JXUBOQSCSA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- SIEZEMFJLYRUMK-YTWAJWBKSA-N Thr-Met-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N)O SIEZEMFJLYRUMK-YTWAJWBKSA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- DOBIBIXIHJKVJF-XKBZYTNZSA-N Thr-Ser-Gln Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O DOBIBIXIHJKVJF-XKBZYTNZSA-N 0.000 description 1
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 1
- IJKNKFJZOJCKRR-GBALPHGKSA-N Thr-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 IJKNKFJZOJCKRR-GBALPHGKSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- ILUOMMDDGREELW-OSUNSFLBSA-N Thr-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O ILUOMMDDGREELW-OSUNSFLBSA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 102100026224 Transmembrane and immunoglobulin domain-containing protein 2 Human genes 0.000 description 1
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 1
- HXMJXDNSFVNSEH-IHPCNDPISA-N Trp-Cys-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N HXMJXDNSFVNSEH-IHPCNDPISA-N 0.000 description 1
- CZSMNLQMRWPGQF-XEGUGMAKSA-N Trp-Gln-Ala Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CZSMNLQMRWPGQF-XEGUGMAKSA-N 0.000 description 1
- CCZXBOFIBYQLEV-IHPCNDPISA-N Trp-Leu-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O CCZXBOFIBYQLEV-IHPCNDPISA-N 0.000 description 1
- KXFYAQUYJKOQMI-QEJZJMRPSA-N Trp-Ser-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 KXFYAQUYJKOQMI-QEJZJMRPSA-N 0.000 description 1
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 1
- 102100024587 Tumor necrosis factor ligand superfamily member 15 Human genes 0.000 description 1
- 108090000138 Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 1
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 1
- AKXBNSZMYAOGLS-STQMWFEESA-N Tyr-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AKXBNSZMYAOGLS-STQMWFEESA-N 0.000 description 1
- KLGFILUOTCBNLJ-IHRRRGAJSA-N Tyr-Cys-Arg Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O KLGFILUOTCBNLJ-IHRRRGAJSA-N 0.000 description 1
- YWXMGBUGMLJMIP-IHPCNDPISA-N Tyr-Cys-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC3=CC=C(C=C3)O)N YWXMGBUGMLJMIP-IHPCNDPISA-N 0.000 description 1
- JKUZFODWJGEQAP-KBPBESRZSA-N Tyr-Gly-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O JKUZFODWJGEQAP-KBPBESRZSA-N 0.000 description 1
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 1
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 1
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 1
- SCZJKZLFSSPJDP-ACRUOGEOSA-N Tyr-Phe-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O SCZJKZLFSSPJDP-ACRUOGEOSA-N 0.000 description 1
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 1
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 1
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 1
- 102100029948 Tyrosine-protein phosphatase non-receptor type substrate 1 Human genes 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 description 1
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 description 1
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 1
- 241000587120 Vaccinia virus Ankara Species 0.000 description 1
- WGHVMKFREWGCGR-SRVKXCTJSA-N Val-Arg-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WGHVMKFREWGCGR-SRVKXCTJSA-N 0.000 description 1
- DNOOLPROHJWCSQ-RCWTZXSCSA-N Val-Arg-Thr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DNOOLPROHJWCSQ-RCWTZXSCSA-N 0.000 description 1
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 1
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 1
- CHWRZUGUMAMTFC-IHRRRGAJSA-N Val-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CNC=N1 CHWRZUGUMAMTFC-IHRRRGAJSA-N 0.000 description 1
- PYPZMFDMCCWNST-NAKRPEOUSA-N Val-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N PYPZMFDMCCWNST-NAKRPEOUSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- SJLVYVZBFDTRCG-DCAQKATOSA-N Val-Lys-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N SJLVYVZBFDTRCG-DCAQKATOSA-N 0.000 description 1
- QRVPEKJBBRYISE-XUXIUFHCSA-N Val-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N QRVPEKJBBRYISE-XUXIUFHCSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- MJOUSKQHAIARKI-JYJNAYRXSA-N Val-Phe-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 MJOUSKQHAIARKI-JYJNAYRXSA-N 0.000 description 1
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- PMKQKNBISAOSRI-XHSDSOJGSA-N Val-Tyr-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N PMKQKNBISAOSRI-XHSDSOJGSA-N 0.000 description 1
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 1
- JSOXWWFKRJKTMT-WOPDTQHZSA-N Val-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N JSOXWWFKRJKTMT-WOPDTQHZSA-N 0.000 description 1
- 241000700647 Variola virus Species 0.000 description 1
- 108010067390 Viral Proteins Proteins 0.000 description 1
- UZQJVUCHXGYFLQ-AYDHOLPZSA-N [(2s,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-4-[(2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-6-(hydroxymethyl)-4-[(2s,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-6-(hy Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@]([C@@]3(CC[C@H]2[C@@]1(C=O)C)C)(C)CC(O)[C@]1(CCC(CC14)(C)C)C(=O)O[C@H]1[C@@H]([C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O[C@H]4[C@@H]([C@@H](O[C@H]5[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O5)O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO)O1)O)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O UZQJVUCHXGYFLQ-AYDHOLPZSA-N 0.000 description 1
- 230000035508 accumulation Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 208000011589 adenoviridae infectious disease Diseases 0.000 description 1
- 229940021704 adenovirus vaccine Drugs 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 150000001408 amides Chemical group 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 230000005975 antitumor immune response Effects 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 230000005812 autoimmune toxicity Effects 0.000 description 1
- 231100001152 autoimmune toxicity Toxicity 0.000 description 1
- 230000010310 bacterial transformation Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000007969 cellular immunity Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000011260 co-administration Methods 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 150000001875 compounds Chemical group 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000007402 cytotoxic response Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 210000003162 effector t lymphocyte Anatomy 0.000 description 1
- 210000002308 embryonic cell Anatomy 0.000 description 1
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 1
- 230000008029 eradication Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 238000002695 general anesthesia Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 1
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010066198 glycyl-leucyl-phenylalanine Proteins 0.000 description 1
- 108010025801 glycyl-prolyl-arginine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010037850 glycylvaline Proteins 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 201000003911 head and neck carcinoma Diseases 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000004727 humoral immunity Effects 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000007944 immunity cancer cycle Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000008595 infiltration Effects 0.000 description 1
- 238000001764 infiltration Methods 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000010212 intracellular staining Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 238000001325 log-rank test Methods 0.000 description 1
- 230000005923 long-lasting effect Effects 0.000 description 1
- 238000011866 long-term treatment Methods 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 201000006512 mast cell neoplasm Diseases 0.000 description 1
- 208000006971 mastocytoma Diseases 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 238000012316 non-parametric ANOVA Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 229940121655 pd-1 inhibitor Drugs 0.000 description 1
- 230000010412 perfusion Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010074082 phenylalanyl-alanyl-lysine Proteins 0.000 description 1
- 108010082795 phenylalanyl-arginyl-arginine Proteins 0.000 description 1
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 108010048507 poliovirus receptor Proteins 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 229940023867 prime-boost vaccine Drugs 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 230000012743 protein tagging Effects 0.000 description 1
- 229940034080 provenge Drugs 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 229940083538 smallpox vaccine Drugs 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 108010068698 spleen exonuclease Proteins 0.000 description 1
- 210000004988 splenocyte Anatomy 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000000528 statistical test Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000012353 t test Methods 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 229940022511 therapeutic cancer vaccine Drugs 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 206010044412 transitional cell carcinoma Diseases 0.000 description 1
- 108700004896 tripeptide FEG Proteins 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 230000005740 tumor formation Effects 0.000 description 1
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 241000990167 unclassified Simian adenoviruses Species 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 208000023747 urothelial carcinoma Diseases 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 229960004854 viral vaccine Drugs 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
Images

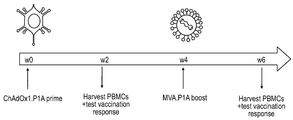






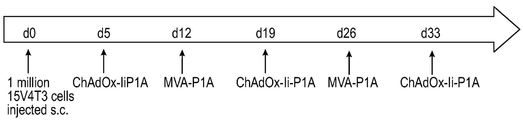


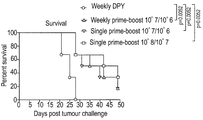


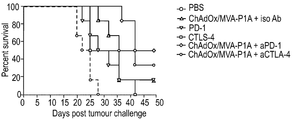

















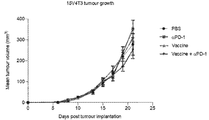
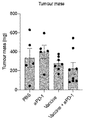




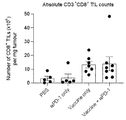
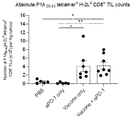
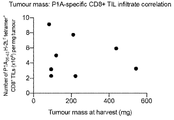





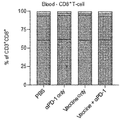



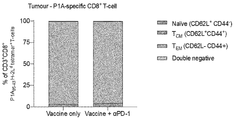






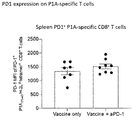

Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/00118—Cancer antigens from embryonic or fetal origin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001184—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/001186—MAGE
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001184—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/001188—NY-ESO
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70539—MHC-molecules, e.g. HLA-molecules
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/58—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation
- A61K2039/585—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation wherein the target is cancer
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
- A61K2039/605—MHC molecules or ligands thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10041—Use of virus, viral particle or viral elements as a vector
- C12N2710/10043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10311—Mastadenovirus, e.g. human or simian adenoviruses
- C12N2710/10341—Use of virus, viral particle or viral elements as a vector
- C12N2710/10343—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/24011—Poxviridae
- C12N2710/24041—Use of virus, viral particle or viral elements as a vector
- C12N2710/24043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/24011—Poxviridae
- C12N2710/24111—Orthopoxvirus, e.g. vaccinia virus, variola
- C12N2710/24141—Use of virus, viral particle or viral elements as a vector
- C12N2710/24143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Zoology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Oncology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Virology (AREA)
- Reproductive Health (AREA)
- Developmental Biology & Embryology (AREA)
- Gynecology & Obstetrics (AREA)
- Pregnancy & Childbirth (AREA)
- Cell Biology (AREA)
Abstract
암 항원을 암호화하는 폴리뉴클레오티드 서열을 함유하는 침팬지 아데노바이러스(ChAd) 및 MVA 바이러스 벡터들은, 프라임 부스트 효과를 달성하기 위해 적절한 보조제 하에 피험자에게 순차적으로 투여된다. 폴리뉴클레오티드는, MAGEA3/링커/NY-ESO-1 융합 단백질 및 이의 변이체, 또한, hli/MAGEA3/링커/NY-ESO-1 융합 단백질 및 이의 변이체를 제공하기 위해 투여 후에 인시튜 발현된다. 개선된 T 세포 반응은 확인된다. 특정 시너지 치료 접근법에서, ChAdOx 및 MVA 벡터와 함께 화학요법제 및 관문 억제제의 삼중 조합은, 암의 마우스 모델에서 골수 유래 억제 세포(MDSC)를 고갈시키고, 생존 시간을 극적으로 개선시킨다.
Description
본 발명은, 암의 예방 또는 치료를 위한 바이러스 벡터-기반 백신(viral vector-based vaccines), 특히, 포유류에 투여하기 위한, 관심의 암 백신 항원을 포함하는 복제-결함 아데노바이러스(replication-defective adenovirus: Ad) 및 변형된 우두 바이러스 앙카라(Modified Vaccinia Virus Ankara: MVA) 벡터들에 관한 것이다. 따라서, 본 발명은, 바이러스 입자(viral particles), 상기 바이러스 입자를 포함하는 면역원성 조성물(immunogenic compositions), 및 바이러스 벡터를 함유하는 숙주 세포와 관련된다. 바이러스 벡터 백신은, 암으로부터 고통받는 피험자를 치료하거나 또는 피험자가 암에 걸리는 것을 예방하는데 사용된다. 바람직한 요법(regime)에서, 본 발명은 Ad 벡터를 사용한 프라임 투여(prime administration), 이후에 MVA 벡터를 사용한 부스트 투여(boost administration)를 포함한다. 본 발명은, 본 발명의 새로운 복제-결함 아데노바이러스 벡터를 포함하는 백신 조성물을 더욱 제공한다.
매년 160만명 이상의 미국인이 암으로 진단되고 있으며, 2018년 미국에서만 대략 60만명이 이 질병으로 사망할 것으로 예상된다. 지난 수십 년 동안, 암의 발견, 진단, 및 치료에서 상당한 진전이 있었다. 그러나, 여전히 67%의 인간들 만이 치료의 시작 후 5년 동안 생존한다(Siegel, R. L. et al. (2017) Cancer J. Clin. 67 (1): 7-30, 참조).
현재 치료적 옵션은, 수술 절차, 방사선, 고주파, 화학요법, 단일클론 항체, 등을 포함한다. 대부분의 이들 접근법은, 심각한 위험, 독성 부작용, 고비용, 및 의심스러운 효능과 관련된다.
그러나, 암 면역요법은, 최근 몇 년 동안 상당한 진전을 보이고 있으며, 발전하는 관심 분야로서 지속되고 있다. 건강한 정상적인 인간 면역계(immune system)는, 종양-관련 항원(TA)을 인식하는 세포 용해성 T 림프구(cytolytic T lymphocytes: CTLs)의 능력에 기초하여 종양 세포를 식별하고 거부하는 타고난 역량(innate capacity)을 가지고 있다. 암 세포는 보통, 세포 및 체액 모두에서, 통합된 면역 반응(integrated immune response)을 활성화시켜야 한다. 세포 반응은 면역 반응에 참여하는 CD8+ 및 CD4+ T 세포를 포함한다. 그러나, 암 및 악성 암의 발생에서, 종양 세포에 대한 정상적인 CTL 활성(activity)은, 손상되거나 또는 상실된다. 따라서, 암 면역요법은, 종양 세포에 대한 인간 면역계의 CTL 활성을 회복하거나 또는 재생시키기 위한 다양한 접근법을 채택한다. 인간 암 환자의 면역계는, 종양-관련 항원(TA)을 발현하는 악성 세포를 박멸시키는 목표로 활용될 수 있다.
세포독성 T 세포는, CD8을 발현시키고 암 세포를 특이적으로 사멸시킬 수 있다. CD4+ T 세포 또는 T 헬퍼 세포(helper cells)는, 세포독성 반응의 발달을 지원하고, 사이토카인을 생성하며, 또한 B 세포의 성숙(maturation) 및 증식을 돕는다. 체액 반응 동안, B 세포는 활성화되고, 복제되며, 분화되고, TA-특이적 항체를 생성한다. 더 많은 정보는, Murphy, K. & Weaver, C. "Janeway's Immunobiology" 9th Edition (2016): Garland Science/Taylor & Francis: New York, NY을 참조.
입양(Adoptive) T 세포 치료법 및 면역 관문 조절제(immune checkpoint modulators)는, 종양을 거부하는 인간 면역계의 능력을 높이기 위한 임상 접근법이다. 그러나, 상기 접근법 모두는 제한을 갖는다. 입양 T 세포 치료법은, 요구된 특이성의 효과기 T 세포(effector T cells)의 확장 및 형질도입을 필요로 한다(Baruch E. N. et al. (2017) Cancer 123 (S11): 2154-62, 참조). 이러한 복잡성은 현재 이러한 접근법의 적용가능성을 제한한다. 면역 관문 조절제의 한 부분인, 관문 억제제 치료는, 효과기 기능을 개선하기 위해 T 세포에 대한 제동기(brakes)를 해제하는 단일클론 항체에 기초한다. 관문 억제제가 진행된 암 환자의 일부에서 장기적인 임상 반응을 유도할 수 있지만, 모든 T 세포의 이러한 자극에 의해 유발된 자가면역 독성의 부작용은 여전히 문제이다. 또한, 기존의 관문 억제제 치료는, T 세포에 의해 침투되지 않는 "불응성" 종양("cold" tumours)과 관련하여 효능이 부족하다.
이에 대한 유망한 대안을 대표하는 또 다른 접근법은, 종양 세포에 대한 면역 반응을 유도하는데 사용되는 암 백신 또는 좀 더 구체적으로 암 치료용 백신이다. 이것은 종양 세포가 본질적으로 면역원성이 낮고, 백신이 이러한 결핍을 극복하는데 도움이 되어야 한다는 개념에 기초한다. 많은 다른 타입의 암 백신은 연구되었으며, 몇몇은 유망한 결과를 나타냈다. Sahin U. et al. (2017) Nature 547 (7662): 222-226은, 암에 대하여 다중특이적 치료 면역을 동원하는 맞춤형 RNA 돌연변이 백신을 시도했다. 또한, Ott P. A. et al. (2017) Nature 547 (7662): 217-221은, 흑색종 환자에 대해 맞춤형 면역원성 신생항원 백신을 시도했다.
그러나, 암 백신의 잠재력은, GlaxoSmithKline(GSK)에 의한 2개의 대규모 Ⅲ 상(phase Ⅲ) 시험을 포함하여, 여러 대규모 임상 시험의 실패 후, 의심스러워졌다. 이들 시험들은, 보조제와 조합된 재조합 종양-관련 단백질에 기초한 백신접종 접근법을 사용한다. 이러한 백신 플랫폼(vaccine platform)은, 다른 많은 플랫폼과 마찬가지로, 우수한 항체 및 CD4+ T-헬퍼 반응을 유도할 수 있는 것으로 입증되었지만, 일관된 CTL 반응을 증가시킬 수 없었다. CTLs이 항-종양 면역 반응의 주요 효과기인 점을 감안할 때, 이는 이들 백신의 임상 실패를 적절히 설명한다. 따라서, 기술적 과제는, 인간에게 양호한 CD8 반응을 유도하는 새로운 암 백신 플랫폼을 제공하는 것이다.
일부 효능을 달성하기 위해, 암 백신은: ⅰ) 암 세포에 대해 잠재적으로 발현되거나 또는 단독으로 발현되고, 통합된 면역 반응을 유도할 수 있는 항원을 표적화하는 능력; 및 ⅱ) 항원-특이적 T 세포의 강력한 클론 확장 및 효과기 및 기억 분화를 유도하는 능력을 가져야 하는 것으로 믿어진다(Coulie, P.G. (2014) Nat. Rev. Cancer, 14 (2): 135-146, 참조).
전통적으로, 치료용 암 백신은 종양 항원(TA) 단백질 및 보조제를 포함한다. 예를 들어, (이전에 BLP25 리포솜 백신(L-BLP25)으로 알려진) Stimuvax로 불리든 백신은, 뮤신(mucin) 1(MUC1) 항원 및 보조제인 MPL4로부터 파생된 합성 펩티드를 캡슐화시킨 리포솜으로, US 6,600,012(B1) BIOMIRA INC.와 관련된다. 또한, 절개된 MAGE-A3-양성 비-소-세포 폐암 환자에서 3상 시험에서 평가된 MAGRIT 백신(Vansteenkiste, JF et al Lancet Oncol. 17 (6): 822-835, 참조)은, 재조합 흑색종-관련 항원 MAGE-A3 단백질과 조합된 AS15 보조제를 함유한다. 그러나, 위에서 일반적으로 나타낸 바와 같이, 이들 Stimuvax 및 MAGRIT 백신은, 대규모 Ⅲ 상 시험에서 효능을 나타내지 못했다.
미국과 유럽에서 승인된 최초의 "암 백신"은, 환자의 항원 제시 세포(APC)가 전립선 산성 인산효소(prostate acid phosphatase: PAP) 항원과 함께 배양되는 자가(autologous) 세포 백신인, PROVENGE이다. 적절한 T 세포 반응을 활성화시키는 능력 및 효능에도 불구하고, 이러한 백신은, 각 환자에 대해 개별적으로 만드는 것이 요구되며, 이에 의해 복잡하고 값비싼 제작 공정을 포함한다. 결과적으로, 백신은 제한된 실용성을 갖는다(US2004/141991 (A1) LAUS et al., 참조).
벡터-기반 암 백신은, 임상에서 시험된 여러 벡터 기술들, 보조제들 및 조합들로 큰 가능성을 보였고 강력한 치료적 관심을 불러 일으켰다. 이러한 전략의 토대는, 재조합 바이러스 벡터를 사용하여 종양 항원을 전달하는 것이다. 바이러스 벡터 자체는, 복제-결함이 있도록 변경되어, 더 이상 환자에게 해롭지 않다. 벡터는 보조제로서 작용하고 면역 반응의 유도를 가능하게 하는 다른 바이러스 항원뿐만 아니라 TA를 모두 발현한다. 이상적인 바이러스 벡터는: ⅰ) 안전하고; ⅱ) 효율적인 항원 제시를 가능하게 하며; ⅲ) 통합된 면역 반응을 유도하고; ⅳ) 대규모로 생산이 가능한, 몇 가지 특성을 가져야 한다(Melief, C. J. M. et al. (2015) J. Clin. Invest. 125 (9): 3401-3412, 참조).
임상 사용을 위해 여러 바이러스 벡터는 제안되었다. 예를 들어, 복제-결함 아데노바이러스(Ad)는, 인간 면역결핍 바이러스(HIV)-1에 대한 EP 2,130,921 B1 GLAXOSMITHKLINE BIOLOGALS SA 또는 말라리아에 대한 US2012/082694(A1) CRUCELL에 개시된 것과 같은 감염성 질병에 대한 백신 벡터로서 연구되었다.
백신접종의 분야에서, 백신 투여는 통상적으로 1차 주사와 동일한 방식으로, 그러나 나중에, 또는 후에 투여되는 하나 이상의 부스팅 주사(boosting injections)가 수반된다. 1차(프라이밍)와 후속(부스팅) 투여 사이에 간격 동안에, 면역계는 세포 및 체액 반응 모두를 유도하여 반응한다(Woodland, D.L. (2004) Trends Immunol. 25 (2): 98-104, 참조).
그러나, 동일한 벡터를 사용한 반복 투여(상동 부스팅(homologous boosting))는, 바이러스 항원에 대해 경쟁 면역원성(competing immunogenicity)이 발생되어, 바이러스 캡시드(capsid)의 표면 항원을 인식하고, 재조합 벡터에 의한 항원-제시 세포의 추가 감염을 방지하는 항체를 생성을 결과하기 때문에, 종양 항원-특이적 T 세포 반응을 높이는데 실패했다. 특히, 상동 부스팅은 삽입된 종양 항원에 대하여 CD8 T 세포를 유도하지 않는다. 이러한 문제를 피해가는 잠재적인 접근법은, 2개의 다른 바이러스 벡터와 같은 다른 항원-전달 시스템(이종 부스팅)을 사용하는 백신의 순차적 투여를 포함한다. EP 2,631,290 (A1) NATIONAL UNIVERSITY CORPORATION은, 우두 바이러스 벡터 및 센다이 바이러스 벡터를 포함하는 프라임/부스트 백신용 바이러스 벡터를 개시한다. Chen, J.-L. et al. (2015) Int. J. Cancer 136 (6): E590-601은, ISCOMATRIX에 NY-ESO-1 단백질로 프라이밍되고, 재조합 NY-ESO-1 계두 바이러스(fowlpox virus)로 부스팅된 흑색종 환자에서 NY-ESO-1 특이적 항체 및 세포 반응을 기재한다.
DNA 백신 및 다양한 바이러스 벡터로 구성된 많은 프라임/부스트 백신은, 시도되고 있다. 예를 들어, WO2006/057454 (A1) JAPAN SCIENCE AND TECHNOLOGY AGENCY는, 프라이밍용 Bacillus Calmette-Guerin(BCG) 벡터 및 부스팅용, 약독화된 우두 바이러스 균주 DIs를 사용하여 HIV-1 gag E 항원에 대해 개발된 이종 프라임/부스트 HIV 백신을 개시한다. Odunsi, K. et al. (2012) Proc. Natl. Acad. Sci. USA 109 (15): 5797-5802는, 2개의 다른 오르토폭스(orthopox) 벡터(우두 및 계두) 및 항원 NY-ESO-1을 이용한 프라임-부스트 접근법을 사용한 제한된 크기의 Ⅰ상 연구를 기재하고, 흑색종 및 난소 암 환자들 중에서 가능한 임상적 이점을 나타낸다.
인간 아데노바이러스는, 이의 특성들(예를 들어, 복제-결핍, 안정성, 높은 면역원성, 수많은 세포 타입을 형질도입하는 능력, 등) 때문에, 암 백신의 개발을 위해 과학자들에 의해 널리 사용된다. 자연적인 아데노바이러스 감염은, 인간 집단에서 만연하며, 대부분의 인간은 생후 5년 이내에 혈청전환된다. 따라서, 인간 아데노바이러스에서 파생된 암 백신은, 이의 효능을 제한할 선재성(pre-existing) 체액 및 세포 면역과 충돌할 것이다(Coughlan, L. (2015) et al. J. Pharm. Pharmacol. 67(3): 382-399 및 US 6,140,087 ADVEC INC entitled "Adenovirus Vectors for Gene Therapy", 참조).
명칭이 "Simian Adenovirus and hybrid Adenoviral vector"인, US 9,714,435 (B2) ISIS INNOVATION 및 명칭이 "Chimpanzee Adenovirus Vaccine Carriers"인, EP 2,163,260 (A2) ISTITUTO RICHERCHE DI BIOLOGICA MOLECULARE는, 과학자들이 어떻게 인간에서 임의의 선재성 면역을 피하는, 비-인간 영장류로부터 유래된 복제-결함 아데노바이러스를 개발했는지를 설명한다. 침팬지 아데노바이러스(ChAd)는 몇 가지 특질들: ⅰ) 강력한 면역원성; ⅱ) 인간에서 낮은 혈청유병률; ⅲ) 표준화된 제조 생산을 나타낸다.
또한, 약독화된 비-복제 우두 바이러스 앙카라 균주(MVA)는 알려져 있다. 이러한 바이러스 벡터는 우수한 안전성 프로파일(safety profile)로 면역 반응을 유도하는 것으로 나타났다. MVA는, 닭 배아 섬유아세포에서 570 초과의 계대(passages)에 의해 이의 게놈의 대략 15%의 결과 손실(consequent loss)로 약화되었다. 따라서, MVA는, 많은 포유류 세포에서 비리온(virions)을 성숙시키는 능력이 부족하고, 강력한 면역원성 및 감소된 증폭의 위험과 관련이 있다. Isis Innovation Limited의 WO2011/128704호는, 이식유전자가 폭스바이러스 게놈(poxvirus genome)에 삽입되고, 따라서, 폭스바이러스 벡터를 제공하는, MVA를 포함하는, 폭스바이러스 발현 시스템 및 감염, 암 치료 및 유전자 치료에 대한 백신의 목적을 위해 관심 유전자를 표적 세포로 전달하기 위한 이의 용도를 개시한다. 또한, Isis Innovation Limited의 EP 2044947 A1은, 면역 반응, 특히, 인플루엔자 바이러스에 대한 T 세포 면역 반응을 유도하는데 사용되는 MVA 바이러스 벡터를 기재한다.
감염성 질병에 대한 치유법을 목표로 하여, 이종 프라임-부스트 요법에서 바이러스 벡터-기반 백신은 개발되고 최적화되어, 강력한 CTL 반응을 유도한다. 이러한 백신 전략은, 프라임용 침팬지 아데노바이러스(ChAd) 및 부스트로 동일한 면역원을 전달하는 변형된 바이러스 앙카라(MVA)를 사용한다. Coughlan L. et al. (2015) J. Pharm. Pharmacol. 67 (3): 382-99 및 Hui E. P. et al. (2013) Cancer Res. 73 (6): 1676-88은, 감염성 질병 설정에서 전임상 및 임상 연구에서 2개의 바이러스 벡터들의 개별 시험 및 이들이 매우 높은 안전성 프로파일을 어떻게 갖는지에 대해 보고한다.
EP 2,044,947 (A1) ISIS INNOVATION은, 인플루엔자의 예방에서 프라이밍을 위한 아데노바이러스 벡터 및 그 다음 부스팅을 위한 MVA을 이용한 백신을 개시한다.
Ewer K. J. et al. (2013) Nat. Commun. 4: 2836 및 Ogwang, C. et al. (2015) Sci. Transl. Med. 7(286): 286re5는, 말라리아에 대해 프라이밍으로 ChAd 및 부스팅으로 MVA를 이용하는 백신을 개시한다.
동일한 프라임-부스트 접근법은, 암 마우스 모델에서 5T4 항원을 발현시키는 Cappuccini, F. et al. (2017) Oncotarget 8 (29): 47474-47489, 및 암 마우스 모델이 전립선 암 항원인 STEAP1을 발현시키는 Cappuccini, F. et al. (2016) Cancer Immunol. Immunother. CII 65 (6): 701-713에 기재되어 있다. 이들 모든 연구에서, 이종 프라임-부스트 백신은, TA에 대한 강력한 면역 반응 및 항원-특이적 CD8+ T 세포의 활성화를 유도한다.
또한, 임상적으로 관련된 암 모델에서 복제성 종양용해 랍도바이러스(oncolytic rhabdovirus) 및 면역 관문 억제제의 공동-투여를 기재하는 WO2017/120670 A1 (Lichty, B. & Bell, J.)은, 상당한 생존 및 항원-특이적 T 림프구의 자극을 결과한다. 종양용해 랍도바이러스는, 악성 세포를 특이적으로 감염시키고, 복제하며, 사멸하여 영향받지 않은 정상 조직을 남긴다. 종양용해 랍도바이러스(예를 들어, VSVdelta5 Ⅰ 또는 Mamba MG 1)는, 시험 동물이 MAGEA3, 인간 유두종 바이러스 E6/E7 융합 단백질, 전립선 단백질의 인간 6-막관통 상피 항원, 또는 암 고환 항원으로부터 선택된 선재성 면역을 갖는 종양 항원을 발현시킨다.
성공적인 암 치료용 백신은, 정상 조직이 아닌 종양에서 발현되는 종양 항원을 표적으로 삼을 필요가 있을 것이다. 암-생식계 항원은, 여러 타입의 암에서 생리학적으로 발현되지만, MHC I 분자의 결핍에 기인하여 면역계에 항원을 제시할 수 없는 생식계 세포를 제외하고는, 분화된, 정상 조직에서는 발현되지 않는 단백질의 이종 그룹이다. 이들 항원은 암-생식계 유전자에 의해 암호화된다. NY-ESO-1 및 MAGE-A3는, Gnjatic, S. et al. (2006) Cancer Res. 95: 1-30에 기재된 바와 같은 가장 대표하는 그룹 중 2개의 원형 MAGE-타입 항원들이다. 또한, 상기 Coulie P. G. et al. (2014)는, 다수의 환자에서 발생하는 것으로 나타난 반응을 기재한다.
본 개시는, 암의 예방 또는 치료를 위한 방법들 및 바이러스 벡터들을 제공한다.
본 발명에 따르면, 핵산 분자를 캡슐화하는 침팬지 아데노바이러스(ChAd) 벡터가 제공되며, 상기 핵산 분자는, 동물 세포에서 암 항원 또는 이의 단편의 번역, 전사 및/또는 발현을 지시하는 발현 조절 서열, 및 아데노바이러스 패키징 신호 서열(packaging signal sequence)에 작동 가능하게 연결된, (ⅰ) MAGE 암 항원 및/또는 NY-ESO-1 암 항원, 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 및/또는 LAGE1 암 항원, 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레오티드 서열을 포함한다. 유리하게는, 이러한 ChAd 바이러스 벡터는 안정하고, 잘-연구되어 있으며, 인간 아데노바이러스에 대한 항체에 의해 중화되지 않고, 복제 결핍인 것으로 유전자조작된다. 이들은 관심의 삽입된 항원에 대한 높은 용량(high capacity)을 가지고 있으며, 아데노바이러스 E1 유전자를 함유하는 HEK293 세포에서 생성될 수 있다.
MAGE-타입 항원은, 암 환자에서 CD8 T 세포를 유도하는 것으로 알려진 종양-특이적 공유 인간 종양 항원이다. 이들은, 많은 암 타입에서 발현되며, MHC-1 분자가 없는 수컷 생식계 세포를 제외하고는, 정상 조직에서는 발현되지 않는다.
NY-ESO-1(유전자명 CTAG1)은, 많은 암 환자에서 강력한 CD8 반응을 유도하고, 다수의 CD8 에피토프(epitopes)는, 다수의 HLA 클래스 I 특이성에 의해 제시된 바와 같이, 식별될 수 있다.
특정 형태에서, ChAd 벡터는, (a) WO2012/172277호에 개시된 바와 같은 ChAdOx1; 바람직하게는 WO2012/172277호에 개시된 바와 같은 SEQ ID NO: 38의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx1; 또는 (b) WO2017/221031호에 개시된 바와 같은 ChAdOx2; 바람직하게는 WO2017/221031호에 개시된 바와 같은 SEQ ID NO: 10의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx2일 수 있다.
본 발명은 또한 핵산 분자를 캡슐화하는 변형된 우두 바이러스 앙카라(MVA) 벡터를 제공하며, 상기 핵산 분자는, 동물 세포에서 암 항원 또는 이의 단편의 번역, 전사 및/또는 발현을 지시하는 발현 조절 서열에 작동 가능하게 연결된, (ⅰ) MAGE 암 항원 및/또는 NY-ESO-1 암 항원, 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 및/또는 LAGE1 암 항원, 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레오티드 서열을 포함한다. 유리하게는, 이러한 MVA 벡터는 인간에서 복제할 수 없으며, 천연두 백신과 같은 긴 안전성 추적 기록(safety track record)을 갖는다. MVA는 ChAd로 프라이밍 후 우수한 부스팅을 제공한다. MVA는 독성 및 면역계 회피 인자가 없고, 면역원성이 높으며, 닭 배아 섬유아세포 또는 불멸화된 오리 배아 세포주에서 쉽게 생성된다.
좀 더 특별한 형태의 MVA 벡터는, WO2011/128704호 또는 EP 2044947 A1에 개시된 바와 같은 것일 수 있다.
여기에서 기재된 바와 같은 본 발명의 ChAd 및/또는 MVA 벡터의 경우, MAGE 항원은 바람직하게는 MAGE3A이고, SEQ ID NO: 1의 아미노산 서열 또는 이와 적어도 46%; 바람직하게는 적어도 69%; 좀 더 바람직하게는 적어도 95% 동일성의 서열; 또는 이의 임의의 면역원성 단편을 갖는다.
여기에서 기재된 바와 같은 본 발명의 ChAd 및/또는 MVA 벡터의 경우, NY-ESO-1 암 항원은, SEQ ID NO: 3의 아미노산 서열 또는 이와 적어도 75%; 바람직하게는 적어도 76.7% 동일성의 서열; 또는 이의 임의의 면역원성 단편을 갖는다.
여기에서 기재된 바와 같은 본 발명의 ChAd 및/또는 MVA 벡터의 경우, LAGE1 항원은, SEQ ID NO: 5의 아미노산 서열, 또는 이와 적어도 78%; 바람직하게는 적어도 97% 동일성의 서열; 또는 이의 임의의 면역원성 단편을 갖는다.
본 발명의 바람직한 ChAd 및/또는 MVA 벡터에서, 폴리뉴클레오티드 서열은, 인간 HLA 클래스 Ⅱ 조직적합성 항원 감마 사슬(hli 또는 li)을 더욱 암호화할 수 있으며, li은 SEQ ID NO:6의 아미노산 서열 또는 이와 적어도 79% 동일성의 서열, 또는 이의 단편을 가질 수 있어서, 암 항원이 li 또는 이의 단편과의 융합으로서 동물 세포에서 발현되며; 더욱 바람직하게는, 여기서 상기 단편은 막관통 도메인(transmembrane domain)이고; 더욱 더 바람직하게는, 여기서 상기 막관통 도메인은 아미노산 잔기 30 내지 55 또는 30 내지 61을 포함한다. 특히 바람직한 구현 예에서, 상기 막관통 도메인은 SEQ ID NO: 7의 아미노산 서열을 갖는다.
본 발명의 선택적으로 바람직한 ChAd 및/또는 MVA 벡터에서, 폴리뉴클레오티드 서열은, SEQ ID NO: 8의 아미노산 서열 또는 이와 적어도 81% 동일성의 서열, 또는 이의 단편을 갖는 tPA를 더욱 암호화할 수 있어, 암 항원이 tPA 또는 이의 단편과 융합으로 동물 세포에서 발현되며; 좀 더 바람직하게는, 여기서, 상기 단편은 21개 아미노산 리더 서열(leader sequence)을 포함하고; 더욱 더 바람직하게는, 상기 21개 아미노산 리더 서열은 SEQ ID NO: 9이다.
유리하게는, li 또는 tPA의 포함은, 바이러스 벡터 생성 항원의 면역원성을 증가시킨다. 이는 항원-특이적 T 세포 반응의 크기, 폭 및 기간을 증가시킨다.
본 발명의 ChAd 벡터는, 융합 단백질로서 동물 세포에서 발현되는, (ⅰ) 여기에서 각각 정의된 바와 같은, MAGE 암 항원 또는 이의 면역원성 단편 및 NY-ESO-1 암 항원 또는 이의 면역원성 단편; 또는 (ⅱ) 여기에서 각각 정의된 바와 같은, MAGE 암 항원 또는 이의 면역원성 단편 및 LAGE1 암 항원 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레어타이드 서열을 갖도록 구축될 수 있다.
본 발명의 MVA 벡터는, 융합 단백질로서 동물 세포에서 발현되는, (ⅰ) 여기에서 각각 정의된 바와 같은, MAGE 암 항원 또는 이의 면역원성 단편 및/또는 NY-ESO-1 암 항원 또는 이의 면역원성 단편; 또는 (ⅱ) 여기에서 각각 정의된 바와 같은, MAGE 암 항원 또는 이의 면역원성 단편 및/또는 LAGE1 암 항원 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레오티드 서열을 갖도록 구축될 수 있고, 여기서, MAGE 암 항원, NY-ESO-1 암 항원 또는 LAGE1 암 항원 중 적어도 하나는 단편이다.
본 발명자들은, NYESO-1이 인간에서 MAGEA3보다 좀 더 면역원성일 수 있는 것으로 믿는다. 또한, 암 환자에서, 이들의 특정 그룹에서, 종양은 NY-ESO-1이 아닌 MAGEA3를 더 자주 발현시키는 것으로 확인된다. 따라서, 가능한 문제는, MAGEA3에 대해 효과 없는 면역화 및 NY-ESO-1에 대한 면역우성(immunodominant) 면역 반응으로 이어지는 MAGEA3 및 NY-ESO-1 항원들 모두를 포함하는, 본 발명의 프라임-부스트 요법에서 MVA 부스트 벡터를 갖는 것일 수 있다. 따라서, 적어도 이러한 특정 환자 그룹, 또는 NY-ESO-1에 비해 MAGEA3의 더 높은 발현을 갖는 그룹의 경우, 단지 MAGEA3 암 항원 또는 이의 면역원성 단편을 포함하는 MVA 벡터는, 프라임-부스트 요법에 바람직하다. 즉, 특정 구현 예에서, 본 발명은, 임의의 NY-ESO-1 암 항원 또는 이의 면역원성 단편을 포함하는 MVA 벡터를 포함하지 않는다. 유사한 방식으로, 특정 구현 예에서, 본 발명은, 임의의 LAGE1 암 항원 또는 이의 면역원성 단편을 포함하는 MVA 벡터를 포함하지 않는다.
바람직한 구현 예에서, 각각의 MVA 벡터, 각각의 MAGE 암 항원 및 NY-ESO-1, 또는 MAGE 암 항원 및 LAGE1은 면역원성 단편이다.
본 발명의 ChAd 및/또는 MVA 벡터가 발현시 항원의 융합을 산출하도록 구축되는 경우, 폴리뉴클레오티드 서열은 바람직하게는 또한, 발현시, 융합 단백질로서, 임의의 순서로, MAGE 및 NY-ESO-1 또는 LAGE1 암 항원들 또는 이의 단편들을 연결하는, 5 내지 9개의 아미노산의 적합한 폴리펩티드 링커; 좀 더 바람직하게는, 아미노산 서열 GGGPGGG를 갖는 링커를 암호화한다.
따라서, 본 발명은 또한 위에서 및 여기에서 기재된 바와 같은 ChAd 또는 MVA 벡터를 포함하는 면역원성 조성물을 제공한다. 이러한 조성물은 적합한 보조제를 더욱 포함할 수 있다.
본 발명은 여기에서 기재된 바와 같은 ChAd 벡터 또는 MVA 벡터에 함유된 융합 단백질을 암호화하는 서열을 포함하는 단리된 폴리뉴클레오티드를 더욱 제공한다.
바람직한 폴리뉴클레오티드는, MAGEA3/링커/NY-ESO-1 융합 단백질을 암호화하는 핵산 서열 SEQ ID NO: 10을 포함한다. 또한, SEQ ID NO: 10과 적어도 70% 동일성의 서열을 갖는 폴리뉴클레오티드는 가능하다. 501개 아미노산의 번역된 단백질 서열은, SEQ ID NO: 11에 제시된 바와 같거나 또는 이와 적어도 70% 동일성의 서열이다.
또 다른 바람직한 폴리뉴클레오티드는, hli/MAGEA3/링커/NY-ESO-1 융합 단백질을 암호화하는 핵산 서열 SEQ ID NO: 12를 갖는다. 또한, SEQ ID NO: 12와 적어도 70% 동일성의 서열을 갖는 폴리뉴클레오티드는 가능하다. 번역된 단백질 서열은, SEQ ID NO: 13에 제시된 서열 또는 이와 적어도 70% 동일성의 서열이다.
또 다른 바람직한 폴리뉴클레오티드는, tPA/MAGEA3/링커/NY-ESO-1 융합 단백질을 암호화하는 핵산 서열 SEQ ID NO: 14를 갖는다. 또한, SEQ ID NO: 14와 적어도 70% 동일성을 갖는 서열을 갖는 폴리뉴클레오티드는 가능하다. 번역된 단백질 서열은, SEQ ID NO: 15에 제시된 서열 또는 이와 적어도 70% 동일성의 서열이다.
특정 구현 예에서, 단리된 폴리뉴클레오티드는, 전술된 서열 중 어느 하나 또는 이의 변이체로 이루어진다.
본 발명의 모든 관점에서, 항원을 암호화하는 폴리뉴클레오티드는 바람직하게는 인간에서 발현을 위해 최적화된 코돈(codon)이다. 당업자는, 예를 들어, Puigbo, P. et al. (2007) OPTIMIZER: A web server for optimizing the codon usage of DNA sequences: Nucleic Acids Research, 35:W126-W131, 또는 미국 특허 제8,326,547호에 기재된 것들을 포함하는, 다수의 이용가능한 소프트웨어 패키지에 익숙할 것이다. 또한, 이와 같은 상업적으로 이용가능한 서비스 및 소프트웨어는, Integrated DNA Technologies 또는 GenScript에 의해 제공된다.
본 발명은 또한 여기에서 기재된 바와 같은 폴리뉴클레오티드를 포함하는 박테리아 인공 염색체(BAC) 클론을 포함한다. 바이러스 게놈의 BAC 클론을 바이러스로 전환("구제(rescue)")은, 여기에서 참조로서 병합된, Isis Innovation Limited의 WO2012/172277호에 기재된 바와 같은, 잘 알려진 공정에 의해 수행될 수 있다.
본 발명은 여기에서 기재된 바와 같은 ChAd 및/또는 MVA 벡터를 포함하는 단리된 숙주 세포를 더욱 포함한다.
또한, 본 발명은, 유효량의 여기에서 기재된 바와 같은 ChAd 벡터를 투여하는 단계, 및 유효량의 여기에서 기재된 바와 같은 MVA 벡터를 투여하는 단계를 포함하고, 이에 의해 개체의 후천성 면역계가 자극되어 항-암 면역 반응을 제공하는, 개체에서 암을 예방 또는 치료하는 방법을 제공한다. 유리하게는, 본 발명의 방법은, 강한 T 세포 면역 반응, 특히, 오래 지속되는 보호 면역으로 이어지는 강한 CD8+ 면역 반응을 발생시킨다.
본 발명에 따른 바람직한 암 예방 또는 치료 방법에서, ChAd 및 MVA 벡터의 투여는, 개별적으로, 순차적으로 또는 동시에 수행된다.
본 발명에 따른 암을 예방 또는 치료하는 특정 방법에서, 유효량의 하나 이상의 면역 관문 조절제는 추가 투여된다. 이러한 관문 조절제는, ChAd 및 MVA 벡터와 동시에, 개별적으로 또는 함께 투여될 수 있다.
본 발명에 따른 암을 예방 또는 치료하는 방법에서, 치료 중인 개체는, 화학요법 및/또는 방사선요법 치료를 받았거나, 받고 있거나, 또는 받을 예정인 개체일 수 있다.
본 발명에 따른 암 예방 또는 치료 방법에서, ChAd 벡터는 바람직하게는 맨 먼저 투여된다.
본 발명의 암 예방 또는 치료 방법에서, ChAd 및 MVA 벡터는 각각 1회 이상 투여될 수 있다. 바람직한 관점에서, ChAd가 프라이밍 면역화로 사용되는 경우, 이들 중 오직 1회 면역화가 있고, 뒤이어, 2회의 MVA 부스터 면역화가 수반된다. 또한, ChAd 및 MVA 벡터가 교대로 투여되는, 암 치료 또는 예방의 방법은 가능하다.
본 발명의 벡터의 각 투여 사이에 기간은, 5일 내지 8주 범위일 수 있고; 바람직하게는, 프라임과 후속 부스트 또는 부스트들 사이에 약 1주의 기간일 수 있다.
관문 조절제가 투여되고 또한 치료 요법의 일부를 형성하는 본 발명의 암 예방 또는 치료 방법에서, 관문 조절제는 PD-1, CTLA-4 또는 PD-L1을 차단하는 억제제일 수 있다. 유리하게는, 본 발명의 벡터 및 면역원성 조성물과 함께 하나 이상의 관문 조절제의 사용은, 등가 효과에 필요한 관문 조절제의 복용량을 감소시키는데 도움이 될 수 있다 (즉, 단독으로 사용되는 경우). 효과는 단순히 부가된 것이 아니라 본 발명의 바이러스 벡터 치료 요법과 관문 조절제 사이에서 상승 효과이다.
특히 바람직한 관문 조절제는, 니볼루맙(Opdivo®), 펨브롤리주맙(Keytruda®), 이필리무맙(Yervoy®), 트레멜리무맙 또는 아테졸리주맙(Tecentriq®), 두르발루맙(Imfinzi®) 또는 아벨루맙(Bavencio®)으로부터 선택될 수 있다.
본 발명에 따른 암을 예방 또는 치료하는 방법은, 암-생식계 유전자, 바람직하게는 MAGE-타입, NYESO, 및 LAGE 항원을 암호화하는 유전자를 발현하는 암과 관련되고: 바람직하게는 특정 암 타입들과 관련되며, 예를 들어, 여기서 상기 암은 비-소세포 폐암(NSCLC), 흑색종, 호지킨 림프종, 비-호지킨 림프종, 요로암(요로상피암), 식도암, 방광암, 소세포 폐암, 신장암, 두경부암, 육종, 또는 유방암이다.
따라서, 본 발명은 암의 예방 또는 치료에 사용하기 위한 본 발명의 ChAd 벡터를 포함한다. 또한, 본 발명은 암의 예방 또는 치료에 사용하기 위한 본 발명의 MVA 벡터를 포함한다. 이러한 사용과 관련하여, 본 발명의 방법의 각각의 다양한 관점은, 동일하게 적용된다.
더욱이, 본 발명은, 암의 예방 또는 치료를 위해 환자에게 개별적, 순차적 또는 동시 투여를 위한, 여기에 정의된 바와 같은 본 발명의 ChAd 벡터, 및 여기에 정의된 바와 같은 본 발명의 MVA 벡터를 포함한다.
여기에 정의된 바와 같은 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터는, Chen, DS 및 Mellman, I. (2013) Immunity 39(1):1-10, 및 Chen, D.S. and Mellman, I. (2017) Nature 541(7637):321-330에 기재된 바와 같은 암-면역 주기 또는 암-면역 설정-지점(cancer-immunity set-points)의 하나 이상의 조절제; 바람직하게는, 암의 치료를 위해 ChAd 및 MVA 벡터와 함께 투여하기 위한 관문 억제제를 더욱 포함할 수 있다.
현재 진행성 암 환자의 상당수는 관문 조절제에 기초한 면역치료에 반응하지 않는다. 예를 들어, 항-PD1 억제제가 흑색종, 신세포(renal cell) 암종, 두경부 암종 및 폐 암종에서 사용되는 경우이다. 하나의 관점에서, 본 발명은 항-PD1 및 화학요법과 조합하여 MAGE-A3 및 NY-ESO-1에 대하여 CD8 T 세포를 유도하기 위해 ChAd/MVA 백신을 사용한다. 어떤 특정 이론에 의해 구속되는 것을 원하지는 않지만, 본 발명자들은, 그렇게 하지 않으면, "불응성" 종양이 항-PD1에 의해 부스팅될 종양-특이적 CD8 T 세포에 의해 침투될 것으로 예상한다.
본 발명자들은 또한 본 발명에 따른 백신, 화학요법제에 더하여 관문 억제제의 삼중 조합이 백신 단독 또는 백신에 더하여 화학요법제 또는 백신에 더하여 관문 억제제와 비교할 때, 마우스 모델에서 현저하게 개선된 항-종양 효과, 및 마우스의 상당한 생존 시간을 제공한다. 실제로, 삼중 조합의 효과는 상승 효과가 있다. 골수 유래 억제 세포(MDSC)의 상당한 고갈은, 삼중 조합으로 달성된다. 따라서, 본 발명은 또한 이러한 삼중 조합 치료의 방법 및 상응하는 의학적 용도를 제공한다. 또한, 본 발명은, 암의 예방 또는 치료를 위해 환자에게 개별적, 순차적 또는 동시 투여를 위한, 위에서 정의된 바와 같은 ChAd 벡터, 위에서 정의된 바와 같은 MVA 벡터, 화학요법제, 및 관문 억제제를 제공한다.
화학요법제는, (a) 카보플라틴 또는 시스플라틴과 (b) 파클리탁셀, 도세탁셀, 비노렐빈, 젬시타빈, 에토포시드 또는 페메트렉시드 중 하나의 조합으로부터 선택될 수 있으나, 이에 제한되는 것은 아니다. 관문 억제제의 경우, PD-1일 수 있다. 이러한 특정 삼중 조합은, 비-소세포 폐암(NSCLC) 또는 소세포 폐암(SCLC), 흑색종, 호지킨 림프종, 비-호지킨 림프종, 요로암(요로상피암), 방광암, 신장암, 두경부암, 육종 또는 유방암에 대한 유용한 치료를 제공할 수 있다.
또한, 본 발명의 일부로서, 암의 예방 또는 치료를 위해 여기에서 기재된 바와 같은 ChAd 및/또는 MVA 벡터를 포함하는 키트는 제공된다. 이러한 키트는, 본 발명의 ChAd 및/또는 MVA 벡터 중 하나를 보유하는 적어도 하나의 용기를 포함한다. 키트는 본 발명의 다른 바이러스 벡터를 각각 갖는 둘 이상의, 즉, 다수의 용기를 포함할 수 있다. 키트는, 사용될 백신 요법에 대한 필수적 정보, 예를 들어, 프라임-부스트, 및 투여들 사이에 기간을 포함하는, 백신으로 벡터의 사용에서 일련의 사용 설명서를 포함할 수 있다. 더 복잡한 구현 예에서, 키트는, 여기서 기재된 발명에 따라, 추가 치료 요소 중 어느 하나, 예를 들어, 관문 조절제를 포함할 수 있다.
이하, 본 발명의 구현 예는 수반되는 도면을 참조하여 더욱 설명된다.
도 1a는, 마우스 P1A 항원(mouse P1A antigen)을 암호화하여 제조된 ChAdOx1 벡터를 개략적으로 나타낸다.
도 1b는, 말초 혈액 단핵 세포(PBMCs)를 취하고 면역 반응을 위해 시험된 마우스의 ChAdOx1-P1A/MVA-P1A 프라임-부스트 면역화의 개략적인 개요를 나타낸다.
도 2는, 도 1에 나타낸 바와 같이, P1A를 암호화하는 ChAdOx1/MVA 바이러스 벡터로 면역화된 마우스에서 CD8+ T 세포 반응의 결과를 나타낸다.
도 3은, 동계(syngeneic) P1A-발현 암 세포주, P815 및 15V4T3에 의한 공격에 대한 DBA/2 마우스의 ChAdOx1-P1A/MVA-P1A 프라임-부스트 예방 백신접종의 개략적인 개요를 나타낸다.
도 4는, 3개의 P1A 항원 대 인산 완충 식염수(PBS) 대조군에 대해 도 3에 나타낸 바와 같이 마우스의 프라임-부스트 백신접종 후 시간에 따른 평균 P815 종양 성장을 나타낸다.
도 5는, 도 4에 나타낸 백신접종된 마우스에 대한 카플란-마이어(K aplan-Meier) 생존 곡선을 나타낸다.
도 6a는, ChAdOx1-liP1A/MVA-P1A의 프라임-부스트 백신접종 후 시간에 따른 평균 15V4T3 종양 성장, 또는 인산 완충 식염수(PBS) 대조군에 대해 도 3에 나타낸 바와 같은 마우스의 세포주 L1210.P1A.B7.1을 이용한 면역화를 나타낸다.
도 6b는, 도 6a에 나타낸 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 7은, 확립된 종양(established tumours)의 거부를 포함하는, 치료 환경에서 마우스에 프라임-부스트 PIA 백신을 시험하기 위한 백신접종 계획을 개략적으로 나타낸다.
도 8a는, P1A-발현 동계 암주 15V4T3에 의한 공격에 대한 치료 환경에서 DBA/2 마우스에 다른 ChAdOx1-P1A/MVA-P1A 프라임-부스트 백신접종 요법으로 백신접종-후 시간에 따른 종양 부피 성장을 나타낸다.
도 8b는, 프라임 부스트 백신접종 계획(단일 프라임-부스트, 고용량(108 ChadOx/107MVA)) 후 25일까지 평균 종양 성장을 나타낸다.
도 8c는, 도 8에 나타낸 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 9는, 마우스의 치료 환경에서 ChAdOx1-liP1A/MVA-P1A의 프라임-부스트 백신접종과 항-PD1 관문 억제제 치료를 조합한 효과를 보여주기 위해 실험에 사용된 백신접종 계획을 나타낸다.
도 10은, P1A-발현 동계 암주(cancer line) 15V4T3에 의한 공격에 대한 DBA/2 마우스에서, 면역 관문 억제제와 조합한 ChAdOx1-liP1A/MVA-P1A 프라임-부스트 백신접종 요법에 대한 시간에 따른 종양 부피 성장을 나타낸다.
도 11은, 도 10에서 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 12는, 비근교계 CD1 마우스(outbred CD1 mice)가 MAGE-A3 (M) 및 NY-ESO-1 (NY) 단백질을 암호화하는 바이러스 벡터로 백신접종된 다음, CD8+ T 세포 반응이 결정되는 실험에 대한 개략적인 개요를 나타낸다.
도 13은, 불변 사슬 li 또는 tPA를 갖거나 갖지 않는, ChAdOx-MAGEA3/NY-ESO-1 융합을 이용한 비근교계 CD1 마우스의 면역화의 결과로서 (IFNγ 생산에 의해 측정된 것으로) CD8 T 세포의 유도를 나타낸다. 면역화 후 단리된 PBMCs는 중첩 MAGEA3 또는 중첩 NY-ESO-1 펩티드로 생체 외 자극된다.
도 14는, 도 13에서와 동일하고 tPA를 갖거나 갖지 않는 MVA-MAGEA3의 부스트를 이용한 면역화의 결과를 나타낸다.
도 15는, 도 13에서와 동일하고 tPA를 갖거나 갖지 않는 MVA-NY-ESO-1의 부스트를 이용한 면역화의 결과를 나타낸다.
도 16에서 A)는, ChAdOx-M-NY, ChAdOx-tPA-M-NY 또는 ChAdOx-li-M-NY를 이용한 프라임, 및 MVA-M, MVA-NY MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 부스트 후 PBMCs에서 MAGE-A3 및 NYESO 특이적 반응을 나타낸다.
도 16에서 B)는, MVA-M, MVA-NY MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 2차 부스트 후 PBMCs에서 MAGE-A3 및 NYESO 특이적 반응을 나타낸다.
도 17a는, ChAdOx-li-MAGEA3/NY-ESO-1 융합으로 면역화, 및 MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터로 부스트한 후 비근교계 CD1 마우스에서 MAGE-A3 및 NYESO에 대한 CD8 T 세포 반응의 유도를 나타낸다.
도 17b는, MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 2차 부스트 후 MAGE-A3 및 NYESO-특이적 반응을 나타낸다.
도 18은, 마우스 내로 15V4T3 세포 주사의 시각표(time lines) 및 마우스의 8개의 실험 그룹 각각에서 후속 처리 지점을 나타낸다.
도 19는, 도 18에 나타낸 실험의 평균 종양 성장 결과의 그래프를 나타낸다. 결과는 2-원(way) ANOVA에 의해 분석된다. * = p < 0.05. ** = p < 0.01. *** = p < 0.001. **** = p < 0.0001.
도 20a 및 도 20b는, 마우스의 8개의 실험 그룹 각각에 대해, 이식-후 종양의 시간에 따른 종양 부피의 그래프를 나타낸다.
도 21은, 마우스의 8개의 실험 그룹 각각에 대한 카플란-마이어 생존 플롯을 나타낸다. 데이터는 로그-순위(Mantel-Cox)법으로 분석된다. * = p < 0.05. ** = p < 0.01.
도 22는, 마우스의 8개의 실험 그룹 중 27일째 출혈에 대한 CD8 세포의 IFNγ 반응을 보여주는 차트이다.
도 23은, 마우스 내로 15V4T3 세포 주사의 반복된 실험의 시각표 및 마우스의 8개 실험 그룹 각각에서 후속 처리 지점를 나타낸다.
도 24는, 특정 실험 처리 및 대조군에 대한, (a) CD11b, (b) CD11b+ 및 GR1hi+; 또는 (c) CD11b 및 GR1int+인 CD45+ 세포의 비율의 그래프를 나타낸다.
도 25는, 특정 실험 처리 및 대조군에 대한, (a) CD11c, 및 (b) CD11b+ 및 CD11c+인 CD45+ 세포의 비율의 그래프를 나타낸다.
도 26은, PBS 대조군, αPD1 단독, 및 마우스의 2개의 시험 그룹 (1) 저 복용량 1주 간격의 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) 및 (2) 저 복용량 1주 간격의 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) + αPD1에 대한 백신접종의 시각표을 나타낸다.
도 27은, 도 26에 나타낸 각각의 실험 마우스 및 대조군에 대한 시간에 따른 평균 종양 부피를 나타낸다.
도 28은, 도 26에 나타낸 각각의 실험 마우스 및 대조군에 대한 종양 질량을 나타내는 차트이다.
도 29는, 도 25 내지 28에 나타낸 바와 같은 대조군 및 실험 그룹 각각에 대한 각 개별 동물에 대한 종양 성장 속도 데이터의 그래프이다.
도 30은, 마우스의 각 실험 그룹 및 대조군에서 종양에 총 세포의 비율로서 종양 침윤 림프구(TILs)의 비율을 나타내는 차트이다.
도 31은, 마우스의 실험 그룹 및 대조군 각각에서 CD4:CD8 T 세포의 비를 나타내는 차트이다.
도 32는, 마우스의 실험 그룹 및 대조군 각각에서 종양에 CD4+:CD8+ TILs의 비(좌측 차트) 및 CD8+ 세포인 T 세포의 퍼센트(우측 차트)의 비의 차트를 나타낸다.
도 33은, 대조군 및 실험 마우스 그룹 각각에서 CD3+ CD8+ TIL 카운트(counts)의 절대 수를 나타내는 차트이다.
도 34는, 대조군 및 실험 마우스 그룹 각각에서 절대 P1A35-43 테트라머+ H-2Ld CD8+ TIL 카운트를 나타내는 차트이다.
도 35는, 수확시 종양 질량과 P1A-특이적 CD8+ TIL 침윤 사이에 상관관계를 나타내는 다이어그램이다.
도 36-37은, 마우스의 혈액에서 CD8 반응을 나타내는 차트이다.
도 38-40은, 마우스의 비장에서 CD8 반응을 나타내는 데이터의 차트이다.
도 41-43은, T 세포 서브세트 분석을 나타내는 데이터의 막대 차트이다. 도 43의 범례는 도 41 및 42에 적용된다.
도 44 및 45는, 추가 T 세포 서브세트 분석을 나타내는 데이터의 막대 차트이다. 도 45의 범례는 도 44에 적용된다.
도 46은, T 세포-서브세트 분석의 추가 데이터를 나타낸다.
도 47은, T 세포 상에 PD1 발현에 대한 데이터의 차트를 나타낸다.
도 48은, T 세포 상에 PD1 발현에 대한 추가 데이터를 나타낸다.
도 49는, T 세포 상에 PD1 발현에 대한 추가 데이터를 나타낸다.
도 50은, P1A-특이적 T 세포 상에 PD1 발현에 대한 데이터의 차트를 나타낸다.
도 51-53은, P1A-특이적 T 세포 상에 PD1 발현에 대한 추가 데이터의 차트를 나타낸다.
도 1a는, 마우스 P1A 항원(mouse P1A antigen)을 암호화하여 제조된 ChAdOx1 벡터를 개략적으로 나타낸다.
도 1b는, 말초 혈액 단핵 세포(PBMCs)를 취하고 면역 반응을 위해 시험된 마우스의 ChAdOx1-P1A/MVA-P1A 프라임-부스트 면역화의 개략적인 개요를 나타낸다.
도 2는, 도 1에 나타낸 바와 같이, P1A를 암호화하는 ChAdOx1/MVA 바이러스 벡터로 면역화된 마우스에서 CD8+ T 세포 반응의 결과를 나타낸다.
도 3은, 동계(syngeneic) P1A-발현 암 세포주, P815 및 15V4T3에 의한 공격에 대한 DBA/2 마우스의 ChAdOx1-P1A/MVA-P1A 프라임-부스트 예방 백신접종의 개략적인 개요를 나타낸다.
도 4는, 3개의 P1A 항원 대 인산 완충 식염수(PBS) 대조군에 대해 도 3에 나타낸 바와 같이 마우스의 프라임-부스트 백신접종 후 시간에 따른 평균 P815 종양 성장을 나타낸다.
도 5는, 도 4에 나타낸 백신접종된 마우스에 대한 카플란-마이어(K aplan-Meier) 생존 곡선을 나타낸다.
도 6a는, ChAdOx1-liP1A/MVA-P1A의 프라임-부스트 백신접종 후 시간에 따른 평균 15V4T3 종양 성장, 또는 인산 완충 식염수(PBS) 대조군에 대해 도 3에 나타낸 바와 같은 마우스의 세포주 L1210.P1A.B7.1을 이용한 면역화를 나타낸다.
도 6b는, 도 6a에 나타낸 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 7은, 확립된 종양(established tumours)의 거부를 포함하는, 치료 환경에서 마우스에 프라임-부스트 PIA 백신을 시험하기 위한 백신접종 계획을 개략적으로 나타낸다.
도 8a는, P1A-발현 동계 암주 15V4T3에 의한 공격에 대한 치료 환경에서 DBA/2 마우스에 다른 ChAdOx1-P1A/MVA-P1A 프라임-부스트 백신접종 요법으로 백신접종-후 시간에 따른 종양 부피 성장을 나타낸다.
도 8b는, 프라임 부스트 백신접종 계획(단일 프라임-부스트, 고용량(108 ChadOx/107MVA)) 후 25일까지 평균 종양 성장을 나타낸다.
도 8c는, 도 8에 나타낸 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 9는, 마우스의 치료 환경에서 ChAdOx1-liP1A/MVA-P1A의 프라임-부스트 백신접종과 항-PD1 관문 억제제 치료를 조합한 효과를 보여주기 위해 실험에 사용된 백신접종 계획을 나타낸다.
도 10은, P1A-발현 동계 암주(cancer line) 15V4T3에 의한 공격에 대한 DBA/2 마우스에서, 면역 관문 억제제와 조합한 ChAdOx1-liP1A/MVA-P1A 프라임-부스트 백신접종 요법에 대한 시간에 따른 종양 부피 성장을 나타낸다.
도 11은, 도 10에서 백신접종된 마우스에 대한 카플란-마이어 생존 곡선을 나타낸다.
도 12는, 비근교계 CD1 마우스(outbred CD1 mice)가 MAGE-A3 (M) 및 NY-ESO-1 (NY) 단백질을 암호화하는 바이러스 벡터로 백신접종된 다음, CD8+ T 세포 반응이 결정되는 실험에 대한 개략적인 개요를 나타낸다.
도 13은, 불변 사슬 li 또는 tPA를 갖거나 갖지 않는, ChAdOx-MAGEA3/NY-ESO-1 융합을 이용한 비근교계 CD1 마우스의 면역화의 결과로서 (IFNγ 생산에 의해 측정된 것으로) CD8 T 세포의 유도를 나타낸다. 면역화 후 단리된 PBMCs는 중첩 MAGEA3 또는 중첩 NY-ESO-1 펩티드로 생체 외 자극된다.
도 14는, 도 13에서와 동일하고 tPA를 갖거나 갖지 않는 MVA-MAGEA3의 부스트를 이용한 면역화의 결과를 나타낸다.
도 15는, 도 13에서와 동일하고 tPA를 갖거나 갖지 않는 MVA-NY-ESO-1의 부스트를 이용한 면역화의 결과를 나타낸다.
도 16에서 A)는, ChAdOx-M-NY, ChAdOx-tPA-M-NY 또는 ChAdOx-li-M-NY를 이용한 프라임, 및 MVA-M, MVA-NY MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 부스트 후 PBMCs에서 MAGE-A3 및 NYESO 특이적 반응을 나타낸다.
도 16에서 B)는, MVA-M, MVA-NY MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 2차 부스트 후 PBMCs에서 MAGE-A3 및 NYESO 특이적 반응을 나타낸다.
도 17a는, ChAdOx-li-MAGEA3/NY-ESO-1 융합으로 면역화, 및 MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터로 부스트한 후 비근교계 CD1 마우스에서 MAGE-A3 및 NYESO에 대한 CD8 T 세포 반응의 유도를 나타낸다.
도 17b는, MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터를 이용한 2차 부스트 후 MAGE-A3 및 NYESO-특이적 반응을 나타낸다.
도 18은, 마우스 내로 15V4T3 세포 주사의 시각표(time lines) 및 마우스의 8개의 실험 그룹 각각에서 후속 처리 지점을 나타낸다.
도 19는, 도 18에 나타낸 실험의 평균 종양 성장 결과의 그래프를 나타낸다. 결과는 2-원(way) ANOVA에 의해 분석된다. * = p < 0.05. ** = p < 0.01. *** = p < 0.001. **** = p < 0.0001.
도 20a 및 도 20b는, 마우스의 8개의 실험 그룹 각각에 대해, 이식-후 종양의 시간에 따른 종양 부피의 그래프를 나타낸다.
도 21은, 마우스의 8개의 실험 그룹 각각에 대한 카플란-마이어 생존 플롯을 나타낸다. 데이터는 로그-순위(Mantel-Cox)법으로 분석된다. * = p < 0.05. ** = p < 0.01.
도 22는, 마우스의 8개의 실험 그룹 중 27일째 출혈에 대한 CD8 세포의 IFNγ 반응을 보여주는 차트이다.
도 23은, 마우스 내로 15V4T3 세포 주사의 반복된 실험의 시각표 및 마우스의 8개 실험 그룹 각각에서 후속 처리 지점를 나타낸다.
도 24는, 특정 실험 처리 및 대조군에 대한, (a) CD11b, (b) CD11b+ 및 GR1hi+; 또는 (c) CD11b 및 GR1int+인 CD45+ 세포의 비율의 그래프를 나타낸다.
도 25는, 특정 실험 처리 및 대조군에 대한, (a) CD11c, 및 (b) CD11b+ 및 CD11c+인 CD45+ 세포의 비율의 그래프를 나타낸다.
도 26은, PBS 대조군, αPD1 단독, 및 마우스의 2개의 시험 그룹 (1) 저 복용량 1주 간격의 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) 및 (2) 저 복용량 1주 간격의 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) + αPD1에 대한 백신접종의 시각표을 나타낸다.
도 27은, 도 26에 나타낸 각각의 실험 마우스 및 대조군에 대한 시간에 따른 평균 종양 부피를 나타낸다.
도 28은, 도 26에 나타낸 각각의 실험 마우스 및 대조군에 대한 종양 질량을 나타내는 차트이다.
도 29는, 도 25 내지 28에 나타낸 바와 같은 대조군 및 실험 그룹 각각에 대한 각 개별 동물에 대한 종양 성장 속도 데이터의 그래프이다.
도 30은, 마우스의 각 실험 그룹 및 대조군에서 종양에 총 세포의 비율로서 종양 침윤 림프구(TILs)의 비율을 나타내는 차트이다.
도 31은, 마우스의 실험 그룹 및 대조군 각각에서 CD4:CD8 T 세포의 비를 나타내는 차트이다.
도 32는, 마우스의 실험 그룹 및 대조군 각각에서 종양에 CD4+:CD8+ TILs의 비(좌측 차트) 및 CD8+ 세포인 T 세포의 퍼센트(우측 차트)의 비의 차트를 나타낸다.
도 33은, 대조군 및 실험 마우스 그룹 각각에서 CD3+ CD8+ TIL 카운트(counts)의 절대 수를 나타내는 차트이다.
도 34는, 대조군 및 실험 마우스 그룹 각각에서 절대 P1A35-43 테트라머+ H-2Ld CD8+ TIL 카운트를 나타내는 차트이다.
도 35는, 수확시 종양 질량과 P1A-특이적 CD8+ TIL 침윤 사이에 상관관계를 나타내는 다이어그램이다.
도 36-37은, 마우스의 혈액에서 CD8 반응을 나타내는 차트이다.
도 38-40은, 마우스의 비장에서 CD8 반응을 나타내는 데이터의 차트이다.
도 41-43은, T 세포 서브세트 분석을 나타내는 데이터의 막대 차트이다. 도 43의 범례는 도 41 및 42에 적용된다.
도 44 및 45는, 추가 T 세포 서브세트 분석을 나타내는 데이터의 막대 차트이다. 도 45의 범례는 도 44에 적용된다.
도 46은, T 세포-서브세트 분석의 추가 데이터를 나타낸다.
도 47은, T 세포 상에 PD1 발현에 대한 데이터의 차트를 나타낸다.
도 48은, T 세포 상에 PD1 발현에 대한 추가 데이터를 나타낸다.
도 49는, T 세포 상에 PD1 발현에 대한 추가 데이터를 나타낸다.
도 50은, P1A-특이적 T 세포 상에 PD1 발현에 대한 데이터의 차트를 나타낸다.
도 51-53은, P1A-특이적 T 세포 상에 PD1 발현에 대한 추가 데이터의 차트를 나타낸다.
본 발명에 따라 사용하기에 적합한 침팬지 아데노바이러스 벡터는, WO2012/17277호 Isis Innovations Limited, 또는 WO2005/071093호 Istituto di Ricerche di Biologia Molecolare P. Angeletti SpA, 또는 Oxford University Innovation Limited의 WO2017/221031호에 상세히 기재되어 있고, 이들 모두는 참조로서 여기에 병합된다.
특히 바람직한 아데노바이러스 벡터는, 옥스포드에 있는, Vaccitech Ltd의 침팬지 아데노바이러스 Oxford 1 및 2(ChAdOx1 및 ChAdOx2)이다. ChAdOx1은, 야생-형 분리물 Y25(인간 아데노바이러스 E 종) 유래의 복제 결함 E1/E3 침팬지 아데노바이러스 벡터이며, Dicks M.D. et al. (2012) PLoS ONE 7: e40385이다. ChAdOx2는, HEK293 세포에서 바이러스 수율을 높이기 위해 변형된 E4 영역을 갖는 ChAd68에서 파생된 E1/E3-결손 백신 벡터이다.
본 발명의 ChAd 벡터는, (a) WO2012/172277호에 개시된 ChAdOx1; 바람직하게는 WO2012/172277호에 개시된 바와 같은 SEQ ID NO:38의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx1; 또는 (b) WO2017/221031호에 개시된 바와 같은 ChAdOx2; 바람직하게는 WO2017/221031호에 개시된 바와 같은 SEQ ID NO: 10의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx2일 수 있다. 당업자는, 본 발명에 사용된 ChAd 벡터가, 여기에서 더욱 기재된 바와 같은, 모든 핵산 서열의 상동체, 등가물 및 유도체를 포함할 수 있는 것으로 이해할 것이다.
본 발명에 따라 사용하기에 적합한 변형된 우두 앙카라(MVA) 벡터는, WO2011/128704호 또는 EP 2044947 A1에 상세하게 기재되어 있으며, 이들 각각은 여기에 참조로서 병합된다.
본 발명의 바이러스 벡터 중 어느 하나에 의해 암호화되고 발현되는 바와 같은, 개별적으로 또는 서로 및 선택적으로 다른 폴리펩티드와 융합 형태로, 암 항원들은, 바람직하게는 여기에 정의된 바와 같은 면역원성이고, 이는 암 항원의 단편 및 서로 및 다른 폴리펩티드와 이들의 융합을 포함한다.
여기에서 사용된 바와 같은, "항원"은 일반적으로 이의 융합 및 단편 및 변이체를 포함하는, 단백질 또는 폴리펩티드의 하나 이상의 에피토프와 동일하다. 이러한 단편 및 변이체는 본질적으로 모 항원(parent antigen)과 동일한 생물학적 활성 또는 기능을 보유할 수 있다. "항원"은 보통 단백질 또는 폴리펩티드 또는 단편이 항체 또는 T 세포를 증대시키는데 사용될 수 있고, 따라서 피험자에게서 항체 또는 T 세포 반응을 유도할 수 있음을 의미한다. "면역원성"은, 단백질 또는 폴리펩티드 또는 단편이 피험자에게서 강력한, 바람직하게는 보호 면역 반응을 유도할 수 있음을 의미한다. 따라서, 후자의 경우에서, 단백질 또는 폴리펩티드 또는 단편은 항체 반응 및 비-항체 기반 면역 반응을 발생시킬 수 있다.
여기 사용된 바와 같은, 참조 서열(reference sequence)과 동일성을 갖는 핵산 서열에 대한 언급이 있을 때마다, 동일성의 정도는 다음 중 어느 하나로부터 선택될 수 있으며, 여기서, "적어도"는 여기에 나열된 각 퍼센트 수치에 적용된다: 적어도 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 98.1%, 98.2%, 98.3%, 98.4%, 98.5%, 98.6%, 98.7%, 98.8%, 98.9%, 99%, 99.1%, 99.2%, 99.3%, 99.4% 99.5%, 99.6%, 99.7%, 99.8% 또는 99.9%. 상동성 또는 동일성의 정도를 결정할 목적을 위해 핵산 서열을 비교하는 경우, 사람들은 BESTFIT 및 GAP(모두 Wisconsin Genetics Computer Group(GCG) 소프트웨어 패키지에서 제공)와 같은 프로그램을 사용할 수 있다. 예를 들어, BESTFIT는, 두 서열을 비교하고, 가장 유사한 세그먼트(segments)의 최적 정렬을 생성한다. GAP은, 서열이 이들의 전체 길이에 따라 정렬되는 것을 가능하게 하고, 적절하게 서열에 간격을 삽입하여 최적 정렬을 찾는다. 적합하게, 본 발명의 맥락에서, 핵산 서열의 동일성을 논의할 때, 비교는 서열의 전체 길이를 따라 서열의 정렬에 의해 이루어진다. 상기 내용은 본 출원에 개시된 모든 핵산 서열에 대해 준용하여 적용된다.
부가적으로, 당업자는 또한 여기에서 대표화된 특정 핵산 분자 유래의 변이가 유전 암호(genetic code)의 퇴화(degeneracy)의 측면에서 가능한 것으로 인식할 것이다. 바람직하게는, 이러한 변이체는 여기에 기재된 핵산 서열과 이의 전체 길이에 걸쳐 실질적인 동일성을 갖는다.
본 발명과 관련하여 기재된 임의의 아미노산 서열과 관련하여, 이는 이들 아미노산 서열의 변이체를 포함한다. 당업자에게 잘 알려진 바와 같이, 여기에 개시된 주어진 출발 또는 참조 서열의 경우, 하나 이상의 아미노산 잔기는 임의의 조합으로 치환, 결실 또는 첨가될 수 있다. 변화로서 바람직한 것은 본 발명의 단백질의 특성 및 활성을 변경시키지 않는 침묵 치환(silent substitutions), 첨가 및 결실이다. 다양한 아미노산은, 유사한 특성을 가지며, 하나 이상의 이러한 아미노산은, 그 물질의 원하는 면역원성 또는 다른 활성을 제거하지 않고 하나 이상의 다른 이러한 아미노산에 의해 치환될 수 있다. 따라서, 아미노산 글리신, 알라닌, 발린, 류신 및 이소류신은 종종 서로 치환될 수 있다 - 이들은 지방족 측쇄를 갖는다. 이들 중 글리신 및 알라닌은 바람직하게는 서로 치환을 위해 사용된다. 또한, 발린, 류신 및 이소류신은, 서로를 치환하는데 사용될 수 있고 - 이들은 소수성인 더 큰 지방족 측쇄를 갖는다. 방향족 측쇄를 가진 아미노산인 - 페닐알라닌, 티로신 및 트립토판은, 서로를 치환할 수 있다. 염기성 측쇄를 갖는 아미노산인 - 리신, 아르기닌 및 히스티딘은, 서로를 치환할 수 있다. 산성 측쇄를 갖는, 아스파르테이트 및 글루타메이트는 서로를 치환할 수 있다. 아미드 측쇄를 갖는 - 아스파라긴 및 글루타민은 서로를 치환할 수 있다. 황-함유 측쇄를 갖는 - 시스테인 및 메티오닌은 서로를 치환할 수 있다.
여기에서 기재된 바와 같은 "변이체"는, 자연 발생 또는 인공 변이체를 포함한다. 인공 변이체는, 핵산 분자, 세포 또는 유기체에 적용되는 것을 포함하여, 돌연변이 유발 또는 유전자 공학 또는 유전자 편집 기술을 사용하여 발생될 수 있다. 여기에 사용된 바와 같은, 참조 서열과 동일성을 갖는 아미노산 서열에 대한 언급이 있을 때마다, 동일성의 정도는 다음 중 어느 하나로부터 선택될 수 있으며: 여기서 "적어도"는, 여기에 나열된 각 퍼센트 수치에 적용된다: 적어도 46%, 47%, 48%, 49%, 50%, 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95% 96%, 97%, 98%, 98.1%, 98.2%, 98.3%, 98.4%, 98.5%, 98.6%, 98.7%, 98.8%, 98.9%, 99%, 99.1%, 99.2%, 99.3%, 99.4% 99.5%, 99.6%, 99.7%, 99.8% 또는 99.9%. 당업자는, 아미노산 서열을 비교하기 위해 CLUSTAL 프로그램과 같은 프로그램을 사용할 수 있다. 이러한 프로그램은 아미노산 서열을 비교하고 적절하게 서열에 간격을 삽입하여 최적의 정렬을 찾는다. 최적의 정렬을 위해 아미노산 동일성 또는 유사성(아미노산 타입의 동일성 + 보존)을 계산하는 것은 가능하다. BLASTx와 같은 프로그램은, 유사한 서열의 가장 긴 스트레치(stretch)를 정렬하고 값을 적합도(fit)로 할당한다. 따라서, 다른 스코어를 각각 갖는, 유사성의 여러 영역이 발견되는 비교를 얻는 것은 가능하다. 상기 내용은 본 출원에 개시된 모든 아미노산 서열에 대해 준용하여 적용된다.
특히 바람직한 MVA 벡터는, 당업계에서 가장 일반적으로 사용되는 대로 CEF에서 570 계대 후에 안톤 마이어(Anton Mayr)에 의해 생성된 표준 MVA이다. 이것은 천연두 박멸과 관련하여 개발된 우두 바이러스의 고도로 약독화된 균주이다. MVA는 우두 게놈의 약 10%를 잃었고, 영장류 세포에서 효율적으로 복제하는 능력을 갖추고 있다.
MAGE 인간 암 항원과 관련하여, MAGE 패밀리(family)는 대략 40개의 구성원으로 이루어진다. MAGE-A 단백질은, 적어도 46%의 서열 동일성, 정의된 생화학적 구조 및 특성을 공유한다. MAGE-A3는, 주요 형태의 암에서 현저하게 발현되며 이의 발현은 부정적인 결과와 관련이 있다. MAGE-A3 아미노산 서열과 다른 MAGE-A 페밀리 구성원의 정렬은 다음의 % 동일성 값을 제공한다:
| MAGEA3와 동일성 | |
| MAGEA1 | 66.9% |
| MAGEA2 | 84.4% |
| MAGEA4 | 69.3% |
| MAGEA5 | 71.8% |
| MAGEA6 | 95.9% |
| MAGEA8 | 63.7% |
| MAGEA9 | 59.6% |
| MAGEA10 | 47.8% |
| MAGEA11 | 59.6% |
| MAGEA12 | 85.4% |
위에서 언급된 각각의 MAGE 항원은, SEQ ID NO: 1의 MAGEA3 참조 서열과의 임의의 퍼센트 동일성의 측면에서 정의될 수 있는 바와 같이, 본 발명을 수행하는데 사용될 수 있다.
NY-ESO-1과 관련하여, 이것은 알려진 180개 아미노산의 암 항원이다. 상기 서열은 LAGE-1과 76.6% 동일성을 갖는다. 서열의 면역원성을 정의하기 위해 여러 연구는 시도되었다. 주요 영역은 NY-ESO-1의 aa 79로부터 173까지이다. Gnjatic S, et al. (2006) Adv. Cancer Res. vol 95: 1-30; Sabbatini P, et al. (2012) Clin. Cancer Res. Vol 18 (23): 6497-508; 및 Baumgaertner P, et al. (2016) Oncoimmunology vol 9:5(10)는, 흑색종 또는 난소암이 관심의 특이적 단편을 어떻게 강조했는지 보고한다. 이들은 본 발명의 임의의 관점에 사용하기 위한 각각의 옵션이다:
· NY-ESO-1 79-173
· NY-ESO-1 79-108
· NY-ESO-1 100-129
· NY-ESO-1 121-150
· NY-ESO-1 42-173
LAGE1은 또한 공지된 암 항원이고, 이것 또는 이의 단편도 본 발명의 바이러스 벡터 및 방법 및 용도에서 MAGEA3와 함께 사용될 수 있다.
보조제는, 여기에 기재된 본 발명의 AdCh 및/또는 MVA 벡터의 전달을 위한 조성물에 사용될 수 있다. 유리하게는, 이들 바이러스 벡터는, 이들이 암 항원 또는 단편과 CD74인, MHC 클래스 Ⅱ 불변 사슬(li) 사이에 융합 단백질을 암호화하는 폴리뉴클레오티드 구축물을 포함하도록 유전자 조작될 수 있다. 이것은 강화된 CD8+ T 세포 면역원성으로 이어질 것으로 예상된다. 이러한 단백질 융합 및 바람직한 li 서열을 만드는 방법에 대한 더 자세한 정보는, 여기에 참조로서 병합된, Isis Innovation Limited의 WO2015/082922호에서 제공된다.
본 발명의 바이러스 벡터는, 에피토프 스트링(epitope string)으로서 하나 이상의 항원 유전자를 발현하도록 설계될 수 있다. 바람직하게는, 다중 에피토프의 스트링에서 에피토프는, 불필요한 핵산 및/또는 아미노산 물질이 회피되도록 개재 서열(intervening sequences)없이 함께 연결된다. 에피토프 스트링의 생성은 바람직하게는 동일한 리딩 프레임(reading frame)에서 하나 이상의 에피토프를 암호화하는 DNA와 함께, 에피토프 스트링의 아미노산 서열을 암호화하는 재조합 DNA 구축물을 사용하여 달성된다. 선택적으로, 항원은 개별의 폴리펩티드로 발현될 수 있다.
기재된 바와 같은 에피토프 스트링에서 또는 개별적으로, 항원의 임의의 단편은, 바람직하게는 모 항원의 서열로부터 적어도 n개의 연속적인 아미노산을 포함하며, 여기서, n은 바람직하게는 적어도, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, 45, 46, 47, 48, 49, 50, 51 , 52, 53, 54, 55, 56, 57, 57, 58, 59, 60, 70, 80, 90 또는 100개의 아미노산이다. 단편은 바람직하게는 모 항원의 하나 이상의 에피토프를 포함한다. 단편은 몇몇 상황에서 모 항원의 단일 에피토프를 포함하거나 또는 단일 에피토프 만으로 이루어질 수 있다. 보통, 단편은 항원성/면역원성 특성이 유지되도록 모 영역 또는 에피토프(들)와 충분히 유사할 것이다.
본 발명에 사용되는 하나 이상의 항원 또는 항원 유전자는, C-말단 및/또는 N-말단에서 절단될 수 있다. 이는 벡터화된 백신의 클로닝 및 구축을 촉진하고 및/또는 항원의 면역원성 또는 항원성을 향상시킬 수 있다. 절단 방법은 당업자에게 알려져 있다. 예를 들어, 다양한 잘 알려진 유전 공학의 기술은, 항원 유전자의 한쪽 말단에서 암호화 핵산 서열을 선택적으로 삭제한 다음, 원하는 암호화 서열을 바이러스 벡터 내로 삽입하는데 사용될 수 있다. 예를 들어, 후보 단백질의 절단은, 각각, 암호화 핵산의 3' 및/또는 5' 말단을 침식(erode)시키기 위해 선택적으로 3' 및/또는 5' 엑소뉴클레아제 전략(exonuclease strategies)을 사용하여 생성된다. 야생형 유전자 서열은, 발현된 항원이 모 항원에 대해 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 이상의 아미노산 만큼 절단될 수 있다. 몇몇 사례에서, 항원 유전자는, 야생형 항원에 비해 C-말단에서 (발현시) 10-20개의 아미노산 만큼 절단된다. 다른 사례에서, 항원 유전자는 야생형 항원에 비해 C-말단에서 (발현시) 13-18개의 아미노산, 바람직하게는 (발현시) 15개의 아미노산 만큼 절단된다.
몇몇 상황에서, 항원 유전자는 리더 서열(leader sequence)을 포함할 수 있으며, 이는 mRNA로 1차 전사의 처리, 번역 효율, mRNA 안정성에 영향을 미칠 수 있으며, 항원의 발현 및/또는 면역원성을 향상시킬 수 있다. 본 발명과 관련하여, 보조 능력(adjuvanting capacity)으로도 역할을 할 수 있는 몇몇 바람직한 리더 서열은, 조직 플라스미노겐 활성인자(tPA) 또는 MHC Ⅱ 샤페론(chaperone) 단백질 불변 사슬(li)이다. 바람직하게는, 리더 서열은 하나 이상의 항원에 대해 N-말단에 위치된다.
본 발명은, 본 발명의 바이러스 벡터 또는 벡터들을 포함하는; 선택적으로 하나 이상의 부가적인 활성 성분, 약제학적으로 허용가능한 담체, 희석제, 부형제 또는 보조제와 조합한 약제학적 또는 면역원성 조성물을 포함한다. 바람직하게는, 조성물은 면역원성 및/또는 항원성 조성물이다.
적합한 보조제는, 당업계에 잘 알려져 있으며, 불완전 프로인트 보조제(incomplete Freund's adjuvant), 완전 프로인트 보조제, MDP를 갖는 프로인트 보조제(무라밀디펩티드), 명반(수산화 알루미늄), 명반과 보르데텔라 백일해 및 면역 자극 복합체(ISCOMs, 통상적으로 바이러스성 단백질을 포함하는 Quil A의 매트릭스(matrix))를 포함한다.
본 발명의 면역원성 및/또는 항원성 조성물은, 예방적(이에 의해 이들은 암 형성을 방지하는 면역 반응을 유도함) 또는 치료적(이에 의해 이들은 항-암 활성을 갖는 면역 반응을 유도함)일 수 있다.
본 발명의 벡터 또는 조성물은, 단일 면역화 또는 다중 면역화로서 개별 피험자에게 투여된다. 바람직하게는, 바이러스 벡터 또는 이의 면역원성 조성물은, 단일, 이중 또는 삼중 면역화 요법의 일부로 투여된다. 이들은 또한 상동 또는 이종 프라임-부스트 면역화 요법의 일부로 투여될 수 있다.
면역화 요법은, 본 발명의 바이러스 벡터 또는 면역원성 조성물의 2차 또는 후속 투여를 포함할 수 있다. 2차 투여는 단기간 또는 장기간에 걸쳐 투여될 수 있다. 1회 복용량은, 1차 투여 후 수 시간, 수 일, 수 주일, 수 개월 또는 수 년에 걸쳐, 예를 들어, 적어도 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10주 이상 또는 0.25, 0.5, 0.75, 1, 5, 10, 15, 20, 25, 30, 35 또는 40년 이상까지 투여될 수 있다. 바람직하게는, 2차 투여는 1차 투여 후 적어도 2개월에서 발생한다. 바람직하게는, 2차 투여는 1차 투여 후 10년까지 발생한다. 이러한 시간 간격은 바람직하게는 임의의 후속 복용량들 사이에 기간에 준용하여 적용된다.
투여의 측면에서, 본 발명의 바이러스 벡터는, 10, 100, 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012, 1013, 1014 이상의 바이러스 입자(vp)의 하나 이상 복용량의 양으로 투여될 수 있다.
투여는, 복강 내, 정맥내, 동맥-내, 근육내, 피내, 피하, 또는 비강내 투여에 의해 이루어질 수 있다. 바람직한 구현 예에서, 바이러스 벡터는, 특히 주사, 관류 및 이와 유사한 것을 포함하는, 혈관내 투여에 의해 전신 투여된다.
면역 관문 조절제(작용제(agonists) 또는 억제제)는, 암의 치료에 사용된 면역요법이다. 이들은 암 세포를 공격하는 T 세포를 조정하는 것으로 알려진 단백질인, 관문 단백질을 조절한다. 본 발명에 따라 사용하기 위한, 관문 조절제의 한 부분인, 관문 억제제는, CTLA-4(세포독성 T 림프구 관련 단백질 4), PD-1(프로그래밍된 세포 사멸 단백질 1) 또는 PD-L1(프로그래밍된 사멸 리간드 1)을 포함하는, 다른 관문 단백질을 차단한다. CTLA-4 및 PD-1은 T 세포에서 발견되는 반면, PD-L1은 암 세포에서 발견된다. PD-1을 차단하는데 적합한 관문 억제제는, 니볼루맙(Opdivo®), 펨브롤리주맙(Keytruda®)을 포함하며, 흑색종, 호지킨 림프종, 비소세포 폐암, 요로암(요로상피암), 방광암과 같은, 암을 앓고 있는 환자를 치료하기 위해 본 발명의 백신접종 접근법과 함께 사용될 수 있다. CTLA-4를 차단하는데 적합한 관문 억제제는, 이필리무맙(Yervoy®)을 포함하며, 흑색종의 치료를 위해 본 발명과 함께 사용될 수 있다. PD-L1을 차단하는데 적합한 관문 억제제는, 아테졸리주맙(Tecentriq®)을 포함하며, 폐암, 유방암 및 요로상피암을 포함하는 암의 치료를 위해 본 발명과 함께 사용될 수 있다.
본 발명의 방법 및 용도의 작동에 유용한 면역 관문 조절제에 대한 기타 적합한 표적은, 예를 들어, AMHRIl, B7-H3, B7-H4, BTLA, BTNL2, 부티로필린 페밀리, CD27, CD28, CD30, CD40, CD40L, CD47, CD48, CD70, CD80, CD86, CD155, CD160, CD226, CD244, CEACAM6, CLDN6, CCR2, CTLA4, CXCR4, GD2, GGG(구아닐일 사이클라아제 G), GIRT, GIRT 리간드, HHLA2, HVEM, ICOS, ICOS 리간드, IFN, IL1, IL1R, IL1RAP, IL6, IL6R, IL7, IL7R, IL12, IL12R, IL15, IL15R, LAG3, LIGHT, LIF, MUC16, NKG2A 페밀리, OX40, OX40 리간드, PD1, PDL1, PDL2, 레소킨, SEMA4D, Siglec 페밀리, SIRP알파, STING, TGF베타 페밀리, TIGIT, TIM3, TL1A, TMIGD2, TNFRSF, VISTA, 4-1BB 및 4-1BB 리간드로부터 선택된 임의의 것을 포함한다.
관문 조절제에 대한 더 충분한 검토는, Mahoney, A. M. et al., (2015) Nature Reviews Drug Discovery vol 14: 561-584 (특히 도 1 참조)에 의해 제공된다.
관문 조절제의 투여는, 본 발명의 프라임 또는 하나 이상의 부스트 면역화와 동시에 함께 수행될 수 있다. 따라서, 이것은 예방 또는 치료 목적을 위해, 병용 치료(combination treatment)를 제공한다. 동시 투여의 변형으로서, 관문 조절제는 프라임 및/또는 부스트 투여 후에 사실상 동시에 실질적으로 투여될 수 있다. 또는, 프라임 및/또는 부스트 투여로부터 시간이 지연된 순차적 투여가 있을 수 있다. 지연은, 프라임 및 부스트 투여에 대하여 다를 수 있으며, 관문 조절제가 백신 투여들 사이에 시간에 개별적으로 투여되도록 충분히 길 수 있다. 본 발명의 면역원성 조성물로부터 관문 조절제의 개별 투여는, 각 투여 사이에 동일 기간을 결과할 수 있다. 몇몇 사례에서, 관문 조절제는, 본 발명의 ChAd-기반 면역원성 조성물을 사용하여 프라임 백신접종 전에 투여될 수 있다.
하나 이상의 관문 조절제의 맥락에서 "병용 치료"는 병용의 성분의 동시, 순차적 또는 개별 투여를 고려한다. 예를 들어, 본 발명의 바이러스 벡터 및 관문 억제제는 동시 투여된다. 또한, 예를 들어, 본 발명의 바이러스 벡터 및 하나 이상의 관문 억제제의 순차적 투여는 가능하다. 더욱이, 본 발명의 바이러스 벡터 및 하나 이상의 관문 억제제를 개별 투여하는 예가 있다. 바이러스 벡터 및 관문 억제제의 투여가 순차적이거나 개별적인 경우, 바이러스 및 관문 억제제는 치료제가 협력적, 예를 들어, 상승 효과를 나타낼 수 있도록하는 시간 간격 내에 투여될 수 있다. 바람직한 구현 예에서, 본 발명의 바이러스 벡터 및 하나 이상의 관문 억제제는, 서로 1, 2, 3, 6, 12, 24, 48, 72시간 이내, 또는 4, 5, 6 또는 7일 이내 또는 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 또는 31일 이내에서 투여된다. 몇몇 구현 예에서, 본 발명의 바이러스 벡터의 제1 복용량은, 관문 억제제의 1차 복용량 전에 또는 그 반대의 경우로 투여되고, 바이러스 벡터와 관문 억제제를 이용한 치료가 중첩되는 단계를 포함할 수 있다. 다른 구현 예에서, 본 발명의 바이러스 벡터의 1차 복용량은 관문 억제제의 1차 복용량과 거의 동시간에 투여될 수 있다. 다른 구현 예에서, 본 발명의 바이러스 벡터의 1차 복용량은, 관문 억제제의 1차 복용량(또는 제2, 제3 또는 후속 복용량) 후에 투여되고, 바이러스 벡터 및 관문 억제제를 이용한 치료가 중첩되는 단계를 포함할 수 있다.
실시 예
물질 및 방법
바이러스 벡터 구축
바이러스 벡터에 삽입하기 위한 유전자 서열, 번역 효율을 위해 최적화된 코돈은, GeneArt(ThermoFisher Scientific)에 의해 DNA 스트링 또는 플라스미드로 합성된다. 침팬지 아데노바이러스 벡터(ChAdOx)의 구축을 위해, DNA 스트링 삽입물 및 p1990 백본(Gateway® 엔트리 벡터(entry vector))은, 제한 효소 KpnI/NotI로 분해된 다음, 밤새 배양을 통해 연결된다. 관심의 유전자 서열을 암호화하는 플라스미드 p1990은, DH5α™ 수용성(competent) E. coli로 형질전환된 다음, PCR 방법을 통해 양성 클론에 대해 스크리닝된다. 양성 클로닝된 DNA는, 미디프렙(midiprep)을 통해 증폭된 다음, Gateway® 클로닝(ThermoFisher Scientific)은, LR 클로나제(LR clonase)를 사용하여, ChAdOx 목표 벡터(destination vector)인, p2563 [SEQ ID NO:24]과 유전자 삽입물을 함유하는 p1990 사이에서 수행된다. p2563 목표 벡터 DNA는, 박테리아 형질전환, 미디프렙 및 중력 컬럼 정제(gravity column purification)를 통해 증폭된다. p2563 목표 벡터는, 바이러스 생산을 위해 보내기 전에 DNA를 선형화하기 위해 Pme1로 분해된다.
ChAdOx1 벡터를 발생시키기 위한 기탁된 생물학적 물질의 공급원 및 핵산 서열을 포함하는, 보다 포괄적인 기술 정보는, 여기에 참조로서 병합된, Isis Innovation Limited의 WO2012/172277호에 개시되어 있다. ChAdOx2 벡터를 발생시키기 위한 생물학적 물질의 공급원 및 핵산 서열을 포함하는, 보다 포괄적인 기술 정보는, 여기에 참조로서 병합된, Oxford University Innovation Limited의 WO2017/221031호에 개시되어 있다.
여기에 참조로 병합되고 본 발명의 ChAdOx 바이러스 벡터의 생산을 위한 더 많은 물질 및 방법 정보를 제공하는 다른 관련 개시는, Dicks, M.D.J., et al. (2012) "A Novel Chimpanzee Adenovirus Vector with Low Human Seroprevalence: Improved Systems for Vector Derivation and Comparative Immunogenicity" PlosOne e40385이다.
변형된 우두 앙카라(MVA) 벡터를 발생시키기 위해, GeneArt DNA 스트링 또는 플라스미드는, 주입 반응(InFusion reaction)에 대한 정확한 오버행(overhangs)을 보장하기 위해 Phusion® 중합효소(ThermoFisher Scientific)를 사용하여 PCR을 통해 증폭된다. 유전자 삽입물 및 p4719 [SEQ ID NO: 25]인, MVA 목표 벡터는, 그 다음 제한 효소 Ale I로 분해된다. 증폭된 삽입물 및 p4719는 그 다음 주입 방법을 사용하여 연결된다. 결찰된 플라스미드는 DH5α™ 수용성 E. coli.로 형질전환된다. 양성 클론은 스크리닝되고, 미디프렙을 통해 DNA를 증폭했다. DNA를 선형화하기 위한 Xho1 + Acc651을 이용한 최종 분해는, 바이러스 생산 전에 수행된다.
본 발명에 필요한 MVA 벡터를 발생 및 재생하기 위한 기탁된 생물학적 물질의 공급원 및 핵산 서열을 포함하는, 보다 포괄적인 기술 정보는, Isis Innovation Limited의 WO2011/128704호 및 EP 2044947 A1에 개시되어 있으며, 이들 각각의 전체적인 내용은 여기에 참조로서 병합된다. 여기에 참조로서 병합되고, 본 발명의 MVA 바이러스 벡터의 생산을 위한 더 많은 물질 및 방법 정보를 제공하는 기타 관련 개시는, Pavot V., Sebastian S., Turner A. V., Matthews J., Gilbert S.C. (2017) "Generation and Production of Modified Vaccinia Virus Ankara (MVA) as a Vaccine Vector" Ferran M., Skuse G. (eds) Recombinant Virus Vaccines, Methods in Molecular Biology, vol 1581 Humana Press, New York, NY이다.
펩티드 생산
P1A, MAGE-A3 및 NY-ESO-1 단백질의 전체를 커버하는 15개 아미노산 길이의 짧은 펩티드의 중첩 풀(Overlapping pools)은, Mimotopes of Mulgrave, Victoria, Australia에 의해 주문 생산된다.
마우스
6-8 주-령의 C57BL/6, DBA/2 및 CD1 마우스는, 영국 Envigo에서 구입하여, 영국 옥스퍼드 대학의 Functional Genomics Facility에 보관했다. 마우스 관리 및 실험 절차는, UK Animals Scientific Procedures Act Project License 30/2947의 조건에 따라 수행되었다.
생체 내 연구
백신 면역원성을 평가하기 위해, 마우스는, 생성된 ChAdOx1 및 MVA 바이러스 벡터를 전신마취 하에 총 부피 50㎕의 근육 내(i.m.) 주사를 통해 도면에 표시된 복용량으로 투여된다. 백신접종은 각 실험에 대해 자세히 설명된 계획에 따른 시점에서 투여된다. 살아있는 L1210.P1A.B7-1 세포를 이용한 면역화는 복강-내 주사를 통해 이루어졌다. 생체 외 분석을 위한 PBMCs를 얻기 위해, 혈액은 꼬리 정맥 출혈을 통해 샘플링되고, ACK 용해 완충액으로 적혈구를 제거하기 위해 처리된다.
10개의 다른 재조합 바이러스 백신(하기 표 2 참조)은 발생되고, 감염된 세포에서 항원 발현은 확인되었다.
| 바이러스 벡터 | 폴리뉴클레오티드 서열 삽입 | 항원 아미노산 서열 |
| ChAdOx_MAGEA3_NYESO | SEQ ID NO: 10 | SEQ ID NO: 11 |
| ChAdOx_li_MAGEA3_NYESO | SEQ ID NO: 12 | SEQ ID NO: 13 |
| ChAdOx_tPA_MAGEA3_NYESO | SEQ ID NO: 14 | SEQ ID NO: 15 |
| ChAdOx_P1A | SEQ ID NO: 26 | SEQ ID NO: 27 |
| ChAdOx_li_P1A | SEQ ID NO: 28 | SEQ ID NO: 29 |
| MVA_MAGEA3 | SEQ ID NO: 16 | SEQ ID NO: 17 |
| MVA_NYESO | SEQ ID NO: 18 | SEQ ID NO: 19 |
| MVA_tPA_MAGEA3 | SEQ ID NO: 20 | SEQ ID NO: 21 |
| MVA_tPA_NYESO | SEQ ID NO: 22 | SEQ ID NO: 23 |
| MVA_P1A | SEQ ID NO: 30 | SEQ ID NO: 31 |
P1A 항원을 발현하는 이들 바이러스 벡터 백신의 면역원성은, DBA/2, C57BL/6 및 CD1 비근교계 마우스를 포함하는 마우스의 3개의 다른 균주에서 시험된다.
생체 외 펩티드 자극
단리된 마우스 PBMCs 또는 비장세포는, 10% FCS로 보충된 RPMI 1640 배지에서 현탁되고, V-버텀 96-웰 플레이트에 첨가된다. 세포들은, P1A, MAGE-A3 또는 NY-ESO-1 펩티드 또는 DMSO 대조군을 항-CD28 항체(2㎍/㎖) 및 DNase(20㎍/㎖)와 함께 4㎎/㎖의 작용 농도(working concentration)로 배양 배지에 첨가하여 자극된다. 펩티드 자극 세포는, 세포내 사이토카인 축적을 촉진하기 위해 1시간 후 Brefaldin A의 첨가와 함께, 5% CO2로 37℃에서 5시간 동안 배양된다.
유세포 분석(flow cytometry) - 세포내 사이토카인 염색
펩티드 자극 후, PBMCs는 PBS로 세척되고, 4℃에서 20분 동안 PBS에서 Aqua 생/사 고정 염료(Aqua live/dead fixable dye)(Invitrogen) 및 항-CD8/항-CD4 항체와 함께 배양하여 표면 마커/생존율에 대해 염색된다. 사이토카인을 생성하는 활성화된 세포의 퍼센트를 평가하기 위해, 세포는 그 다음 고정되고, CytoFix/CytoPerm(BD Biosciences)으로 투과되며, 4℃에서 20분 동안 1x perm 완충액에서 항-IFN-γ, 항-TNF-α 및 항-IL-2 항체와 함께 배양된다. 샘플은, BD Fortessa에서 획득되고, FlowJo 소프트웨어(Tree Star, Inc.)를 사용하여 분석을 수행했다.
통계 분석
모든 통계 시험 및 분석은 GraphPad Prism 소프트웨어를 사용하여 수행된다. 다중 그룹들 사이에 차이는, Kruskal-Wallis 비-모수(non-parametric) ANOVA 및 Mann-Whitney 비-모수 t-검정으로 개별 그룹 사이에서 결정된다.
실시 예 1: ChAdOx/MVA로 면역화에 의한 P1A에 대한 CD8 T 세포의 유도
P1A는, 동계 숙주에서 돌연변이되지 않은 MAGE-타입 항원에 대한 CD8 반응의 유도를 확인하고, P1A-발현 종양 P815에 대한 보호를 유도하는데 사용될 수 있는 쥣과(murine) MAGE-타입 항원이다. 이것은 MAGE-A3 및 NY-ESO-1에 대한 대용물(surrogate)이다.
도 1b는, 말초 혈액 단핵 세포(PBMCs)를 취하고 백신접종 반응에 대해 시험된 마우스의 프라임-부스트 면역화의 개략적인 개요를 나타낸다. 도 2는, P1A를 암호화하는 ChAdOx1/MVA 바이러스 벡터로 백신접종된 마우스에서 CD8+ T 세포 반응을 나타낸다. 백신접종 계획 시각표(도 1)에 따르면 - BL/6, DBA/2 및 CD1 마우스는, ChAdOx1.P1A 또는 ChAdOx1.P1A-li(프라임)에 이어 4주 후 MVA.P1A(부스트)로 백신접종된다. P1A-특이적 T-세포 반응을 시험하기 위해, PMBCs는 유세포 분석에 의해 분석된 타입 I 사이토카인을 생산하는 퍼센트 세포 및 P1A 펩티드 풀로 생체 외에서 자극된다. 사이토카인 IFN-γ(A) 및 TNF-α(B)를 생성하는 CD8+ 세포의 퍼센트(그룹당 n = 6)는 측정된다. 이종 프라임-부스트 백신접종은, IFN-γ 및 TNF-α의 세포내 염색에 의해 예시된 바와 같이 마우스의 3개의 균주 모두에서 P1A에 대한 강한 CD8 반응을 유도했다(도 2). 반응은, P1A가 MHC Ⅱ 샤페론 단백질 불변 사슬(li)에 융합된 경우 더욱 향상되었다. 이들 결과는 DBA/2 마우스에서 IFN-γ ELISPOT 검정(assay) 및 P1A-특이적 사량체 염색에 의해 확인된다(결과는 나타내지 않음).
종합하면, 관찰된 반응은 DBA/2, B6 및 비근교계된 CD1 마우스에서 매우 강한 CD8 반응이다. CD8 반응은 ChAdOx 벡터에 li를 첨가하여 증가된다. CD8 T 세포가 중첩 펩티드에 의해 유도된 경우 확인된 것은 이들이 IFNγ, IL2, 및 TNFα를 분비하는 것이다. P1A에 대한 CD4 반응의 방식은 거의 없다(알려진 CD4 에피토프는 없음).
실시 예 2: 종양 발달에 대한 P1A를 운반하는 ChAdOx1 및 MVA 바이러스 벡터의 보호 효능의 평가
종양 공격에 대한 백신 보호 효능의 평가의 일부로서, 마우스는, 옆구리에 무-혈청 세포 배양 배지에서 종양 세포로 피하(s.c.) 주사된다. 촉지성 종양(palpable tumour)의 발달에 따라, 성장은 기록되고, 종양 크기가 어느 방향으로든 10㎜에 도달하면, 마우스는 안락사된다. 종양 부피는 식 길이(㎜) x 너비2(㎜) x 0.5를 사용하여 측정된다. 생존 곡선은 카플란-마이어 방법에 따라 만들어지고, 생존에서 차이는, 로그-순위 시험을 사용하여 시험된다. 0.05 미만의 P 값은 중요한 것으로 간주된다.
좀 더 상세하게는, DBA/2 마우스는, PBS, 살아있는 L1210.P1A.B7-1 세포 또는 4주 간격으로 제공된 ChAdOx1-P1A(±li)/MVA-P1A 프라임-부스트로 면역화된 다음, 옆구리에 피하 주사를 통한 1.5x106 P815 세포 또는 1x106 15V4T3 세포로 공격받는다. P815 및 15V4T3은 동계 P1A-양성 비만세포종 세포주이다. 15V4T3 세포는, Boon T, Van den Eynde B, Hirsch H, Moroni C, De Plaen E, van der Bruggen P, De Smet C, Lurquin C, Szikora JP, De Backer O (1994) "Genes coding for tumor-specific rejection antigens" Cold Spring Harb Symp Quant Biol. 59: 617-22에 기재되어 있다.
P815(도 4) 및 15V4T3(도 8a) 공격 후 각 처리 그룹에 대한 평균 종양 성장. 카플란-마이어 생존 곡선은, 그룹 당 P815(도 5), 15V4T3(도 8b) n = 10에 대해 나타낸다.
도 4 및 5에 나타낸 바와 같이, P1A를 이용한 아데노바이러스 프라임 및 MVA 부스트 백신접종은, PBS 대조군에 비해 백신접종된 마우스에서 종양 성장을 상당히 감소시키고 생존을 개선시켰다. 흥미롭게도, li_P1A로 백신접종된 그룹은 L1210.P1A B7.1 세포로 면역화된 양성 대조군에 비해 종양 부피가 더 작고 생존율이 더 좋았다. 이러한 세포주는, 이전에 매우 강력한 P1A-특이적 세포독성 활성 및 P1A 양성 종양 공격에 대한 보호를 유도하는 것으로 나타났다(Brandle D. et al. (1998) Eur. J. Immunol. 28 (12): 4010-4019 및 Naslund TI et al. (2007) J. Immunol. 178 (11): 6761-6769 참조). 이것은 백신접종으로 인한 자극된 면역 반응이 P815 종양으로부터 마우스를 보호하는데 효과적이라는 것을 나타낸다. 도 6a 및 6b는, 다른 P1A 양성 종양 세포주 15V4T3를 사용하여 관찰된 동일한 결과를 나타낸다.
종합하면, 관찰된 반응은 다른 P1A-발현 종양 모델 P815 및 15V4T3 (또한 V4D6 - 데이터는 나타내지 않음)에서 증가된 생존 및 종양 공격에 대한 보호와 관련된 CD8 반응이다. 프라임-부스트 요법은, 양성 대조군 세포 백신보다 우수한 보호를 제공한다. 또한, 어떻게 불변 사슬(li)-P1A 융합이 벡터에서 P1A 단독보다 더 우수하게 나타나는지는 관찰된다. 임의의 종양이 장기간 치료로 성장 감소 효과에서 벗어나면, 이들은 P1A 발현을 상실했다 (데이터는 나타내지 않음).
실시 예 3: P1A를 운반하는 ChAdOx1 및 MVA 바이러스 벡터의 백신 치료 효능의 평가
실험은 백신 치료 효능을 평가하기 위해 수행된다. 15V4T3 종양의 확립시, 마우스는, 5일 후 ChAdOx 벡터로 프라이밍된 다음, 26일에 MVA 벡터로 부스팅된다. 백신접종 계획은 도 7에 나타낸다. 3개의 다른 백신접종 계획은 시험된다. DBA/2 마우스는, 옆구리에 피하 주사를 통해 1x106 15V4T3 세포로 공격받은 다음, 공격 5일 후 3주 간격으로 단일 표준 복용량 ChAdOx-P1A (108 IU)/MVA-P1A (107 PFU) 프라임-부스트 백신접종, 3주 간격으로 단일 저 복용량 프라임-부스트 백신접종(ChAdOx-107 IU, MVA-106 PFU), 매주 교대로 저 복용량 ChAdOx-P1A/MVA-P1A 백신접종 또는 매주 대조 항원인, DPY를 암호화하는 ChAdOx/MVA 백신접종을 받는다. 그 다음, 각 치료 그룹에서 15V4T3 종양 성장 및 생존은 모니터링된다.
도 8에 나타낸 바와 같이, 종양 성장은, 관계없는 단백질 DPY를 발현하는 바이러스 벡터로 백신접종된 대조군에 비해 백신접종된 마우스에서 현저하게 지연된다. 게다가, 단일 표준 복용량의 프라임-부스트는, 종양 공격에 대한 최상의 보호와 생존을 입증했다. 그러나, 백신접종된 마우스는, 후기 단계(6 주)에서 종양 성장을 제어하는 능력을 잃기 시작했다.
따라서, 치료 효능은 15V4T3 모델에서 관찰된다.
실시 예 4: 면역 관문 억제제와 조합하여 ChAdOx1-P1A/MVA-P1A 프라임-부스트 백신접종 요법의 치료 효능을 평가
더 우수한 종양 보호를 달성하고, 백신 효능을 증가시키기 위해, 백신은, 동일한 15V4T3 종양 모델을 사용하여, 관문 억제제 차단과 조합되고, DBA/2 마우스는, P1A-발현 동계 15V4T3 종양 세포로 접종된다. DBA/2 마우스는, 옆구리에 피하 주사를 통해 1x106 15V4T3 세포로 공격받은 다음, 종양 크기에 기초하여 공격 후 8일에 다른 처리 그룹으로 무작위화된다. 마우스는, PBS(sham) 백신접종, 매주 ChAdOx/MVA 백신접종 - 단독으로 또는 항-PD1 또는 항-CTLA-4 항체과 조합하여 (3일 간격으로 3회분), 또는 항-PD1 또는 항-CTLA-4 항체 단독을 받는다. 각 치료 그룹에서 15V4T3 종양 성장(도 10) 및 생존(도 11)은, 기간 내내 모니터링되고 기록된다. 촉지성 종양의 확립한 후, 종양 크기는 측정되고 마우스는 다른 그룹으로 무작위화된다. 도 10(좌측 그래프)에 나타난 바와 같이, 병용 치료를 받은 마우스의 종양 성장은, 대조군 및 단일 치료 그룹에 마우스에 비해 훨씬 지연되었다. 또한, 항-PD1 및 백신의 병용 치료를 받은 마우스의 100%는, 종양 공격 후 36 일까지 생존했으며, 50%의 마우스는, 항-CTLA4 및 백신 처치의 그룹에서 생존한 반면, 다른 마우스는 모두 생존이 어려웠다.
백신 + 항-PD1의 상승 효과는, 15V4T3 모델의 치료 환경에서 관찰된다.
실시 예 5: CD1 비근교계 마우스에서 MAGE-A3 및 NY-ESO-1의 면역원성을 평가
마우스 P1A 유전자를 암호화하는 벡터로부터 반응을 확립한 후, 인간 MAGE-타입 항원을 암호화하는 벡터 구축물은 생성하고 시험된다. 인간 MAGE-타입 항원, MAGE-A3 및 NY-ESO-1의 다른 형태의 면역원성은 CD1 비근교계 마우스에서 조사된다. MAGE-A3 및 NY-ESO-1은, 침팬지 아데노바이러스 벡터에서 융합 단백질로 클로닝되고, 이들은 MVA에서 개별적으로 클로닝된다. 이는 2가지 주된 이유 때문이다. 먼저, 아데노바이러스 벡터 백신의 생성은 MVA보다 훨씬 고가이다. 임상 환경을 준비하기 위해, 목표는, MAGE-A3 및 NY-ESO-1의 융합을 발현하는 단일 아데노바이러스 벡터 백신을 포함하는 비용을 최소화하는 것이다. 둘째, 몇몇 인간 종양은, MAGE-A3 또는 NY-ESO-1을 발현시킨다. 종양에 대해 좀 더 특이적 반응을 유도하기 위해, 종양에 의해 발현되는 특정 항원은 부스팅용으로 표적화된다. 좀 더 상세하게는, 마우스는 시각표(도 12)에 따라 백신접종을 받는다 - MAGE-A3-NY-ESO-1을 암호화하는 ChAdOx1 ± li 또는 tPA로 프라임, 그 다음, MAGE-A3 또는 NY-ESO-1을 암호화하는 MVA ± tPA로 2번의 부스트(1차 MVA 부스트에 대해 대체 항원(alternate antigen)을 함유하는 2차 MVA 부스트)가 수반된다. 항원 특이적 T-세포 반응은, 지정된 시점에 각 백신접종 후 평가된다 - PBMCs는 수확되고, 유세포 분석에 의해 분석된 세포에 반응하는 IFN-γ+ 의 퍼센트 및 MAGE-A3(청색 원) 또는 NY-ESO-1(적색 사각형) 펩티드로 생체 외에서 자극받는다.
도 13은, ChAdOx1-MAGE-A3/NY-ESO-1 융합(M-NY), tPA와 ChAdOx1-MAGE-A3/NY-ESO-1 융합(tPA-M-NY) 및 불변 사슬과 ChAdOx1-MAGE-A3/NY-ESO-1 융합(li-M-NY)으로 비근교계 CD1 마우스의 프라이밍 주사 후 MAGE-A3/NY-ESO-1에 대한 CD8 T 세포의 유도를 나타낸다. 2주 후, PBMCs는 단리되고, MAGE-A3 중첩 펩티드(적색 원) 및 NY-ESO-1 중첩 펩티드(청색 사각형)에 대한 반응은 생체 외 세포내 사이토카인 염색에 의해 시험된다. 프라임 후 CD8 IFNγ 반응은, 융합 단백질을 함유하는 ChAdOx 프라임이 항원 모두에 대해 특이적 CD8 T 세포를 유도할 수 있음을 나타낸다.
그 다음, ChAdOx 프라이밍된 마우스는, (ⅰ) tPA에 융합되거나 융합되지 않은 MAGEA3를 함유하는 MVA; 및 (ⅱ) tPA에 융합되거나 융합되지 않은 NY-ESO-1을 함유하는 MVA로 부스터 주사를 맞는다. PBMCs는 그 다음 이들 마우스로부터 다시 단리되고, 중첩 펩티드로 자극 후 생체 외 세포내 사이토카인 염색을 사용하여 MAGEA3 및 NY-ESO-1 반응에 대해 시험된다. 도 14는, MVA-MAGEA3 + tPA 부스트의 효과를 나타내고, 도 15는, MVA-NY-ESO-1 + tPA 부스트의 효과를 나타낸다. 도 14 및 15 각각에서, 도 13은 부스트 결과와 프라임 결과 만의 편리한 비교를 위해 좌측 부분으로 포함된다. 알 수 있듯이, 초기 프라임 반응은, MVA를 사용하여 선택한 항원에 대해 훨씬 더 높은 크기로 부스팅된다.
프라임으로서 ChAdOx-불변 사슬(li) 및 MVA-tPA는, 샘플 크기 및 어느 정도의 가변성을 갖는 비근교계 마우스의 사용을 조건으로, 가장 면역원성 요법인 것으로 보인다.
이중 부스트에서, 초기 프라임 반응은, 동시에 더 높은 크기로 증가된다(데이터는 나타내지 않음). 관찰된 반응은, 다른 타입 I 사이토카인에 의해 광범위하게 일치된다(데이터는 나타내지 않음).
어떻게 항원-특이적 T-세포의 빈도가 훨씬 더 높은 수준으로 부스트되는 것처럼 보이고, 반응이 선택된 항원에 대해 향하는지 고려하면, 본 발명은 문제의 개별 종양의 특정 발현 패턴 후에 예방 또는 치료에 대한 좀 더 개인화된 접근법을 가능하게 할 수 있다.
도 16에서 A)는 MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터로 부스팅 후 CD8+ 세포에서 IFN-γ+ 세포의 퍼센트를 나타낸다. 도 16에서 B)는, MVA-M, MVA-NY, MVA-tPA-M, 또는 MVA-tPA-NY 벡터로 2차 부스팅 후 CD8+ 세포에서 IFN-γ+ 세포의 퍼센트를 나타낸다.
마우스가 융합 MAGE-A3 및 NY-ESO-1을 발현하는 아데노바이러스로 프라이밍되고, MAGE-A3 또는 NY-ESO-1을 발현하는 MVA로 부스팅된 경우, 증가된 CD8 반응은, MVA에 의해 발현된 항원을 향하게 된다(도 14 및 15). 또한, 두 MVAs(MVA_MAGEA3 및 MVA_NYESO)로 마우스의 부스팅은, 이들 두 항원에 대해 비슷한 수준의 CD8 반응을 유도했다.
항원의 면역원성은, Bolhassani A. et al. (2011) Mol. Cancer. 10:3에 기재된 바와 같이 유전자를 몇몇 분자 보조제에 융합시켜 향상될 수 있다. 이들 중에서, 인간 조직 플라스미노겐 활성인자(tPA) 신호 펩티드(Delogu G. et al. (2002) Infect. Immun.70(1): 292-302, 참조)는, 감염된 세포 내에서 단백질 발현을 증가시킬 수 있고, 따라서, T 세포 반응을 향상시킬 수 있다(예를 들어, Biswas S. et al. (2011) PLoS One 6(6): e20977). 또한, 항원을 MHC Ⅱ 관련 li에 융합은, CD8 반응을 강화시킬 수 있다(Mikkelsen M. et al. (2011) Journal of Immunology 186(4): 2355-2364; 및 Sorensen M. R. et al. (2009) European Journal of Immunology 39(10): 2725-2736).
상기 다양한 실시 예로부터 요약하면, P1A에 대한 CD8 반응은, 항원을 li에 융합시킬 때 향상된다(도 2). 또한, 더 잘 자극된 CD8 반응이 마우스에서 더 나은 종양 보호로 어떻게 번역되는지 나타낸다(도 4 및 5). tPA 융합의 효과는, 지금까지 바이러스 벡터 백신에서 연구되지 않았다. 실시 예는, li와 달리, MAGE 항원에 tPA 융합이 아데노바이러스를 이용한 단일 백신접종에서 CD8+ T 세포 반응을 향상시킬 수 없음을 나타낸다. 또한, CD8 반응의 증가는, 단일 프라임 부스트 백신접종에서, li에 융합된 항원을 발현하는 아데노바이러스로 프라이밍되고, tPA에 융합된 항원을 암호화하는 MVA로 부스팅된 경우 관찰된다(도 16의 A) 및 도 16의 B) 참조). 그러나, 추가 분석은, MVA 부스트에서 MAGE 항원에 대한 tPA 융합이 CD8 반응을 향상시킬 수 없음을 나타낸다.
실시 예 6: DBA/2 마우스에서 15V4T3 종양에 유효한 백신, 관문 억제제 및 화학요법의 삼중 조합
도 18은, 화학요법 및 관문 억제제 치료뿐만 아니라, 관련 대조군 치료와 함께 시험 마우스의 백신접종에 대한 실험 연대표(chronologies)를 나타낸다. 간단히 말해, 1 백만 개의 15V4T3 세포는 각각의 DBA/2 마우스 내로 피하 주사된다. 마우스는, 6일째에 종양 크기에 기초하여 무작위로 그룹으로 나누어진다. 마우스의 임의의 백신접종을 포함하는 치료는, 종양 이식 후 8일에 시작된다. 투여된 경우, 20㎎/㎏의 파클리탁셀 및 40㎎/㎏의 카보플라틴은, 8일째에 I.P로 마우스에 제공되고, 20㎎/㎏의 파클리탁셀은 I.P로 9일째 제공된다. 투여된 경우, 3회 복용량의 aPD1 100㎍은 I.P로 18일, 21일, 및 24일에 제공된다. 그룹당 마우스 수는 6 또는 7 또는 8 마리이다.
도 19는, 각각의 실험 및 대조군 처리에 대한 마우스에서 평균 종양 부피의 시간 경과를 나타낸다.
도 20a 및 20b는, 각 실험 그룹 또는 대조군에서 개별 마우스의 종양 부피에 대한 시간 경과를 나타낸다. 백신접종 및/또는 화학요법 및/또는 관문 억제제와 관계없이, 치료 시간은 나타낸다. 또한, 종양이 없는 것으로 밝혀진 각 그룹에서 마우스의 48일 종점 수(end-point numbers)는 표시된다. 백신접종, 화학요법 및 관문 억제제의 삼중 조합은, 다양한 치료 중 가장 효과적으로 종양의 형성을 명확히 억제한다.
도 21은, 각각의 실험 및 대조군에서 시간에 따른 마우스의 생존을 나타낸다. 백신접종, 화학요법 및 관문 억제제의 삼중 조합은, 명확히 다른 치료 및 대조군에 비해 마우스의 최상의 생존을 제공한다.
백신과 aPD1 및 화학요법의 삼중 조합은, 다른 그룹에 비해 종양 성장을 유의하게 억제했다. 종양 주사 후 23일째에 종양이 없는 마우스는 8 마리 중 6 마리가 있었고, 이들 마우스는 48일까지 종양이 없는 상태를 유지했다. 또한, 도 22에 나타낸 바와 같이, 삼중 조합 그룹은 또한 종양 주사 후 27일에 가장 높은 말초 P1A-특이적 CD8 반응을 갖는다.
실시 예 7: DBA/2 마우스에서 15V4T3 종양에 유효한 백신, 관문 억제제 및 화학요법의 삼중 조합
도 23은, 마우스 및 대조군의 각 실험 그룹에 대한 시각표를 나타낸다. 1 백만 개의 15V4T3 세포(초기 계대)는, DBA/2 마우스 내로 동시에 주사된다. 마우스는, 종양 이식 후 11일에 시작된 마우스의 백신접종 및 11일에 종양 크기에 기초한 그룹으로 무작위로 나누어진다. 투여된 경우, 20㎎/㎏의 파클리탁셀 및 40㎎/㎏의 카보플라틴은, 11일째에 I.P로 마우스에 제공되고, 20㎎/㎏의 파클리탁셀은 I.P로 12일째 제공된다. 투여된 경우, 3회 복용량의 aPD1 100㎍은 I.P로 21일, 24일, 및 27일에 제공된다. 그룹당 마우스 수는 6 또는 7 마리이다. 종양 공격이 없는 미경험 그룹(naive group)은 또한 본 실험에 포함된다. 출혈은 14일에 수행되었으며, 샘플은 골수 유래 억제 세포(MDSC) 고갈을 확인하기 위해 사용된다.
도 24 및 25는, 화학요법 단독 또는 화학요법과 백신으로 처치된 마우스가 더 낮은 MDSC 빈도(MDSC frequency)를 갖는 방법을 나타낸다.
실시 예 8: DBA/2 마우스에서 15V4T3 종양 - CPI를 이용한 백신접종은 종양 T 세포 침윤을 증가시킨다
1 백만 개의 15V4T3 세포는, DBA/2 마우스에 피하 주사된다. 백신접종 일정은, PBS 대조군, aPD1 단독, 및 마우스의 두 시험 그룹 (1) 1주 간격으로 저 복용량 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) 및 (2) 1주 간격의 저 복용량 프라임 부스트(ChAdOx1-li-P1A + MVA-tPA-P1A) + aPD1에 대해 도 26에 나타낸다. 마우스의 백신접종은, 종양 이식 후 10일째 시작된다. CPI(αPD1)는 프라임 후 3일, 종양 주입 후 13일, 16일, 19일에 100㎍을 3회 복용량으로, 제공된다. 모든 마우스는 20일에 채혈하고 21일에 희생된다. 종양 미세환경의 면역 프로파일은, FACS에 의해 연구되었다. 결과는 도 27-53에 제시되어 있다.
보다 상세하게는, 도 27은, 희생시 모든 마우스 그룹에서 종양 크기의 균일한 확산을 나타낸다. 도 28은, 이들 마우스에서 종양 제거의 시작을 나타내는, 백신 + 항-PD-1 병용 그룹의 마우스 서브세트에서 종양 질량의 감소를 나타낸다.
도 29는, 각 그룹에서 각각의 마우스에 대한 개별 종양 성장 곡선을 나타낸다.
도 30은, 마우스의 대조군 및 백신의 종양에서 CD8+ 종양 침윤 림프구(TILs)의 퍼센트를 나타낸다. 백신접종은 종양에서 총 세포의 비율로서 CD3+CD8+ TILs을 증가시킨다.
도 33 및 34는, 세포 수 및 종양 중량에 대해 계산되고 정규화된 절대 TIL 수를 나타낸다.
도 36 및 37은, αPD-1 처리의 부가가 ChAdOx 프라임 후 11일의 초기 시-점에서 평가될 때 ChAdOx/MVA 백신접종에 의해 프라이밍된 P1A-특이적 반응을 어떻게 부스팅시키는지를 나타낸다.
도 46은, 종양에서 P1A-특이적 TEM CD8+s의 침윤이 어떻게 P1A-특이적 CD8s와 동일한 패턴을 따르는지를 나타낸다.
종합적으로, 도 27-53의 결과는, 백신이 대조군과 비교한 마우스의 백신 그룹에서 CD3+CD8+ TIL의 증가 및 P1A-특이적 TIL의 증가와 함께, 종양의 T 세포 침윤을 어떻게 증가시키는지를 나타낸다.
또한, CD3+CD8+ TIL은, 주로 효과기 메모리 세포들 TEM(CD62L-CD44+) 및 TCM(CD62L+CD44+)이다.
더욱이, P1A-특이적 TILs은 백신 그룹에서 PD-1을 발현하지만, αPD1 차단에 따라 발현은 감소한다.
여기에서 언급된 뉴클레오티드 및 아미노산 서열
특정 단백질 또는 폴리펩티드는 여기에서 언급되고, 이들에 대한 참조 뉴클레오티드 및/또는 아미노산 서열은, 본 상세한 설명의 일부로서 제출된 수반되는 서열 목록에 제공된다. 몇몇의 서열은, 다음과 같은 추가 정보를 제공하기 위해 주석이 달린다:
인간 HLA 클래스 Ⅱ 조직적합성 항원 감마 사슬(li) UniProtKB/Swiss-Prot: P04233.3. 밑줄친 서열 부분은 벡터에 사용되는 막관통 도메인을 나타낸다:
MHRRRSRSCR EDQKPVMDDQ RDLISNNEQL PMLGRRPGAP ESKCSRGALY TGFSILVTLL LAGQATTAYF LYQQQGRLDK LTVTSQNLQL ENLRMKLPKP PKPVSKMRMA TPLLMQALPM GALPQGPMQN ATKYGNMTED HVMHLLQNAD PLKVYPPLKG SFPENLRHLK NTMETIDWKV FESWMHHWLL FEMSRHSLEQ KPTDAPPKVL TKCQEEVSHI PAVHPGSFRP KCDENGNYLP LQCYGSIGYC WCVFPNGTEV PNTRSRGHHN CSESLELEDP SSGLGVTKQD LGPVPM [SEQ ID NO: 6]
인간 조직-형 플라스미노겐 활성인자(tPA). 나타낸 밑줄친 서열 부분은 벡터에 사용되는 리더 서열이다.
MDAMKRGLCCVLLLCGAVFVSPSQEIHARFRRGARSYQVICRDEKTQMIYQQHQSWLRPVLRSNRVEYCWCNSGRAQCHSVPVKSCSEPRCFNGGTCQQALYFSDFVCQCPEGFAGKCCEIDTRATCYEDQGISYRGTWSTAESGAECTNWNSSALAQKPYSGRRPDAIRLGLGNHNYCRNPDRDSKPWCYVFKAGKYSSEFCSTPACSEGNSDCYFGNGSAYRGTHSLTESGASCLPWNSMILIGKVYTAQNPSAQALGLGKHNYCRNPDGDAKPWCHVLKNRRLTWEYCDVPSCSTCGLRQYSQPQFRIKGGLFADIASHPWQAAIFAKHRRSPGERFLCGGILISSCWILSAAHCFQERFPPHHLTVILGRTYRVVPGEEEQKFEVEKYIVHKEFDDDTYDNDIALLQLKSDSSRCAQESSVVRTVCLPPADLQLPDWTECELSGYGKHEALSPFYSERLKEAHVRLYPSSRCTSQHLLNRTVTDNMLCAGDTRSGGPQANLHDACQGDSGGPLVCLNDGRMTLVGIISWGLGCGQKDVPGVYTKVTNYLDWIRDNMRP [SEQ ID NO: 8]
벡터 ChAdOx1_MAGE_NYESO에 대한 폴리뉴클레오티드 구축물. 밑줄친 MAGEA3. 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체(italics)이다.
ATGCCCCTGGAACAGCGGAGCCAGCACTGCAAGCCTGAGGAAGGCCTGGAAGCCAGAGGCGAAGCTCTGGGACTCGTGGGAGCACAGGCTCCAGCCACCGAAGAACAGGAAGCCGCCAGCAGCAGCTCCACCCTGGTGGAAGTGACACTGGGCGAAGTGCCTGCCGCCGAGTCTCCTGATCCTCCTCAGTCTCCTCAGGGCGCCAGCTCTCTGCCCACCACCATGAACTACCCCCTGTGGTCCCAGTCCTACGAGGACAGCAGCAACCAGGAAGAAGAGGGCCCCAGCACCTTCCCCGACCTGGAATCTGAATTCCAGGCCGCCCTGAGCCGGAAGGTGGCCGAACTGGTGCACTTCCTGCTGCTGAAGTACCGGGCCAGAGAACCCGTGACCAAGGCCGAGATGCTGGGCAGCGTCGTGGGCAACTGGCAGTACTTCTTCCCCGTGATCTTCTCCAAGGCCAGCTCCAGCCTGCAGCTGGTGTTCGGCATCGAGCTGATGGAAGTGGACCCCATCGGACACCTGTACATCTTCGCCACCTGTCTGGGCCTGAGCTACGATGGCCTGCTGGGCGACAACCAGATCATGCCCAAAGCCGGCCTGCTGATCATCGTGCTGGCCATCATTGCCCGCGAGGGCGATTGTGCCCCCGAGGAAAAGATCTGGGAGGAACTGAGCGTGCTGGAAGTGTTCGAGGGAAGAGAGGACTCCATCCTGGGCGACCCCAAGAAGCTGCTGACCCAGCACTTCGTGCAGGAAAACTACCTGGAGTATAGACAGGTGCCCGGCAGCGACCCTGCCTGCTACGAATTTCTGTGGGGCCCTAGAGCACTGGTGGAAACCAGCTACGTGAAAGTGCTGCACCACATGGTCAAGATCAGCGGCGGACCCCACATCAGCTACCCCCCTCTGCATGAATGGGTGCTGAGAGAGGGCGAGGAA GGCGGAGGACCTGGCGGAGGA ATGCAGGCTGAAGGCAGAGGCACAGGCGGCTCTACAGGCGACGCTGATGGACCAGGCGGACCCGGAATTCCAGATGGCCCTGGCGGAAATGCTGGCGGGCCTGGCGAAGCTGGCGCTACAGGCGGAAGAGGACCTAGAGGCGCTGGCGCCGCTAGAGCTTCTGGACCAGGGGGAGGCGCTCCTAGAGGACCTCATGGCGGAGCTGCCTCTGGCCTGAACGGCTGCTGTAGATGTGGCGCCAGAGGCCCCGAAAGCAGACTGCTGGAATTCTACCTGGCCATGCCTTTCGCCACCCCCATGGAAGCTGAGCTGGCCAGAAGAAGCCTGGCCCAGGACGCTCCTCCACTGCCTGTGCCAGGCGTGCTGCTGAAAGAATTCACCGTGTCCGGCAACATCCTGACCATCCGGCTGACAGCCGCCGACCACAGACAGCTGCAGCTGAGCATCAGCAGCTGCCTGCAGCAGCTGTCCCTGCTGATGTGGATCACCCAGTGCTTTCTGCCCGTGTTTCTGGCCCAGCCTCCTAGCGGACAGCGGAGATGA [SEQ ID NO: 10]
ChAdOx1_MAGE_NYESO의 번역된 단백질. 밑줄친 MAGEA3. 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체이다:
MPLEQRSQHCKPEEGLEARGEALGLVGAQAPATEEQEAASSSSTLVEVTLGEVPAAESPDPPQSPQGASSLPTTMNYPLWSQSYEDSSNQEEEGPSTFPDLESEFQAALSRKVAELVHFLLLKYRAREPVTKAEMLGSVVGNWQYFFPVIFSKASSSLQLVFGIELMEVDPIGHLYIFATCLGLSYDGLLGDNQIMPKAGLLIIVLAIIAREGDCAPEEKIWEELSVLEVFEGREDSILGDPKKLLTQHFVQENYLEYRQVPGSDPACYEFLWGPRALVETSYVKVLHHMVKISGGPHISYPPLHEWVLREGEEGGGPGGG MQAEGRGTGGSTGDADGPGGPGIPDGPGGNAGGPGEAGATGGRGPRGAGAARASGPGGGAPRGPHGGAASGLNGCCRCGARGPESRLLEFYLAMPFATPMEAELARRSLAQDAPPLPVPGVLLKEFTVSGNILTIRLTAADHRQLQLSISSCLQQLSLLMWITQCFLPVFLAQPPSGQRR [SEQ ID NO: 11]
벡터 ChAdOx1_hli_MAGE_NY-ESO-1에 대한 폴리뉴클레오티드 구축물. 굵은 이탤릭체의 li 서열. MAGEA3은 밑줄쳐 있다. 서열 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체이다:
ATG GGCGCCCTGTACACCGGCTTTAGCATCCTCGTGACCCTGCTGCTGGCCGGACAGGCTACCACCGCCTACTTTCTGTAC CCCCTGGAACAGCGGAGCCAGCACTGCAAGCCTGAGGAAGGCCTGGAAGCCAGAGGCGAAGCTCTGGGACTCGTGGGAGCACAGGCTCCAGCCACCGAAGAACAGGAAGCCGCCAGCAGCTCTAGCACCCTGGTGGAAGTGACACTGGGCGAAGTGCCTGCCGCCGAGTCTCCTGATCCTCCTCAGTCTCCTCAGGGCGCCAGCTCTCTGCCCACCACCATGAACTACCCCCTGTGGTCCCAGTCCTACGAGGACAGCAGCAACCAGGAAGAAGAGGGCCCCAGCACCTTCCCCGACCTGGAATCTGAATTCCAGGCCGCCCTGAGCCGGAAGGTGGCCGAACTGGTGCACTTTCTGCTGCTGAAGTACCGGGCCAGAGAACCCGTGACCAAGGCCGAGATGCTGGGCAGCGTCGTGGGCAACTGGCAGTACTTCTTCCCCGTGATCTTCTCCAAGGCCAGCTCCAGCCTGCAGCTGGTGTTCGGCATCGAGCTGATGGAAGTGGACCCCATCGGACACCTGTACATCTTCGCCACCTGTCTGGGCCTGAGCTACGATGGCCTGCTGGGCGACAACCAGATCATGCCCAAAGCCGGCCTGCTGATCATCGTGCTGGCCATCATTGCCCGCGAGGGCGATTGTGCCCCCGAGGAAAAGATCTGGGAGGAACTGAGCGTGCTGGAAGTGTTCGAGGGAAGAGAGGACTCCATCCTGGGCGACCCCAAGAAGCTGCTGACCCAGCACTTCGTGCAGGAAAACTACCTGGAGTATAGACAGGTGCCCGGCAGCGACCCTGCCTGCTACGAATTTCTGTGGGGCCCTAGAGCACTGGTGGAAACCAGCTACGTGAAAGTGCTGCACCACATGGTCAAGATCAGCGGCGGACCCCACATCAGCTACCCCCCTCTGCATGAATGGGTGCTGAGAGAGGGCGAGGAA GGCGGAGGACCTGGCGGAGGA ATGCAGGCTGAAGGCAGAGGCACAGGCGGCTCTACAGGCGACGCTGATGGACCAGGCGGACCCGGAATTCCAGATGGCCCTGGCGGAAATGCTGGCGGGCCTGGCGAAGCTGGCGCTACAGGCGGAAGAGGACCTAGAGGCGCTGGCGCCGCTAGAGCATCTGGACCAGGGGGAGGCGCTCCTAGAGGACCTCATGGCGGAGCTGCCTCTGGCCTGAACGGCTGCTGTAGATGTGGCGCCAGAGGCCCCGAAAGCAGACTGCTGGAATTCTACCTGGCCATGCCTTTCGCCACCCCCATGGAAGCTGAGCTGGCCAGAAGAAGCCTGGCCCAGGACGCTCCTCCACTGCCTGTGCCAGGCGTGCTGCTGAAAGAATTCACCGTGTCCGGCAACATCCTGACCATCCGGCTGACAGCCGCCGACCACAGACAGCTGCAGCTGAGCATCAGCAGCTGCCTGCAGCAGCTGTCCCTGCTGATGTGGATCACCCAGTGCTTTCTGCCCGTGTTTCTGGCCCAGCCTCCTAGCGGACAGCGGAGATGA [SEQ ID NO: 12]
ChAdOx1_hli_MAGE_NY-ESO-1의 번역된 단백질 서열. 굵은 이탤릭체의 li 서열. MAGEA3은 밑줄쳐 있다. 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체이다:
M GALYTGFSILVTLLLAGQATTAYFLY PLEQRSQHCKPEEGLEARGEALGLVGAQAPATEEQEAASSSSTLVEVTLGEVPAAESPDPPQSPQGASSLPTTMNYPLWSQSYEDSSNQEEEGPSTFPDLESEFQAALSRKVAELVHFLLLKYRAREPVTKAEMLGSVVGNWQYFFPVIFSKASSSLQLVFGIELMEVDPIGHLYIFATCLGLSYDGLLGDNQIMPKAGLLIIVLAIIAREGDCAPEEKIWEELSVLEVFEGREDSILGDPKKLLTQHFVQENYLEYRQVPGSDPACYEFLWGPRALVETSYVKVLHHMVKISGGPHISYPPLHEWVLREGEE GGGPGGG MQAEGRGTGGSTGDADGPGGPGIPDGPGGNAGGPGEAGATGGRGPRGAGAARASGPGGGAPRGPHGGAASGLNGCCRCGARGPESRLLEFYLAMPFATPMEAELARRSLAQDAPPLPVPGVLLKEFTVSGNILTIRLTAADHRQLQLSISSCLQQLSLLMWITQCFLPVFLAQPPSGQRR* [SEQ ID NO: 13]
벡터 ChAdOx1_tPA_MAGE_NY-ESO-1에 대한 폴리뉴클레오티드 구축물. 굵은 이탤릭체로된 tPA 서열. MAGEA3은 밑줄쳐 있다. 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체이다:
ATG GACGCCATGAAGCGGGGCCTGTGTTGCGTGCTGCTGCTGTGTGGCGCTGTGTTCGTGTCCCCC CCACTGGAACAGAGAAGCCAGCACTGCAAGCCCGAGGAAGGCCTGGAAGCCAGAGGCGAAGCTCTGGGACTCGTGGGAGCACAGGCTCCAGCCACCGAAGAACAGGAAGCCGCCAGCAGCTCTAGCACCCTGGTGGAAGTGACACTGGGCGAAGTGCCTGCCGCCGAGTCTCCTGATCCTCCTCAGTCTCCTCAGGGCGCCAGCTCTCTGCCCACCACCATGAACTACCCCCTGTGGTCCCAGTCCTACGAGGACAGCAGCAACCAGGAAGAAGAGGGCCCCAGCACCTTCCCCGACCTGGAATCTGAATTCCAGGCCGCCCTGAGCCGGAAGGTGGCCGAACTGGTGCACTTCCTGCTGCTGAAGTACCGGGCCAGAGAACCCGTGACCAAGGCCGAGATGCTGGGCAGCGTCGTGGGCAACTGGCAGTACTTCTTCCCCGTGATCTTCTCCAAGGCCAGCTCCAGCCTGCAGCTGGTGTTCGGCATCGAGCTGATGGAAGTGGACCCCATCGGACACCTGTACATCTTCGCCACCTGTCTGGGCCTGAGCTACGATGGCCTGCTGGGCGACAACCAGATCATGCCCAAAGCCGGCCTGCTGATCATCGTGCTGGCCATCATTGCCCGCGAGGGCGATTGTGCCCCCGAGGAAAAGATCTGGGAGGAACTGAGCGTGCTGGAAGTGTTCGAGGGAAGAGAGGACTCCATCCTGGGCGACCCCAAGAAGCTGCTGACCCAGCACTTCGTGCAGGAAAACTACCTGGAGTATAGACAGGTGCCCGGCAGCGACCCTGCCTGCTACGAATTTCTGTGGGGCCCTAGAGCACTGGTGGAAACCAGCTACGTGAAAGTGCTGCACCACATGGTCAAGATCAGCGGCGGACCCCACATCAGCTACCCACCTCTGCACGAATGGGTGCTGAGAGAGGGCGAAGAA GGCGGAGGACCTGGCGGAGGA ATGCAGGCTGAAGGCAGAGGCACAGGCGGCTCTACAGGCGACGCTGATGGACCAGGCGGACCCGGAATTCCAGATGGCCCTGGCGGAAATGCTGGCGGGCCTGGCGAAGCTGGCGCTACAGGCGGAAGAGGACCTAGAGGCGCTGGCGCCGCTAGAGCATCTGGACCAGGGGGAGGCGCTCCTAGAGGACCTCATGGCGGAGCTGCCTCTGGCCTGAATGGCTGCTGTAGATGTGGCGCCAGAGGCCCCGAAAGCAGACTGCTGGAATTCTACCTGGCCATGCCTTTCGCCACCCCCATGGAAGCTGAGCTGGCCAGAAGAAGCCTGGCCCAGGACGCTCCTCCACTGCCTGTGCCAGGGGTGCTGCTGAAAGAATTCACCGTGTCCGGCAACATCCTGACCATCCGGCTGACAGCCGCCGACCACAGACAGCTGCAGCTGAGCATCAGCAGCTGCCTGCAGCAGCTGTCCCTGCTGATGTGGATCACCCAGTGCTTTCTGCCCGTGTTTCTGGCCCAGCCTCCTAGCGGACAGCGGAGATGA [SEQ ID NO: 14]
ChAdOx1_tPA_MAGE_NY-ESO-1의 번역된 단백질. 굵은 이탤릭체로된 tPA 서열. MAGEA3은 밑줄쳐 있다. 링커는 굵게 표시된다. NY-ESO-1은 이탤릭체이다:
M DAMKRGLCCVLLLCGAVFVSP PLEQRSQHCKPEEGLEARGEALGLVGAQAPATEEQEAASSSSTLVEVTLGEVPAAESPDPPQSPQGASSLPTTMNYPLWSQSYEDSSNQEEEGPSTFPDLESEFQAALSRKVAELVHFLLLKYRAREPVTKAEMLGSVVGNWQYFFPVIFSKASSSLQLVFGIELMEVDPIGHLYIFATCLGLSYDGLLGDNQIMPKAGLLIlVLAIIAREGDCAPEEKIWEELSVLEVFEGREDSILGDPKKLLTQHFVQENYLEYRQVPGSDPACYEFLWGPRALVETSYVKVLHHMVKISGGPHISYPPLHEWVLREGEE GGGPGGG MQAEGRGTGGSTGDADGPGGPGIPDGPGGNAGGPGEAGATGGRGPRGAGAARASGPGGGAPRGPHGGAASGLNGCCRCGARGPESRLLEFYLAMPFATPMEAELARRSLAQDAPPLPVPGVLLKEFTVSGNILTIRLTAADHRQLQLSISSCLQQLSLLMWITQCFLPVFLAQPPSGQRR [SEQ ID NO: 15]
벡터 MVA_tPA_MAGEA3에 대한 폴리뉴클레오티드 구축물. tPA는 밑줄쳐 있다:
ATGGACGCCATGAAGCGGGGCCTGTGCTGCGTGCTGCTGCTGTGTGGCGCTGTGTTCGTGTCCCCCCCACTGGAACAGAGAAGCCAGCACTGCAAGCCCGAGGAAGGCCTGGAAGCCAGAGGCGAAGCTCTGGGACTCGTGGGAGCACAGGCTCCAGCCACCGAAGAACAGGAAGCCGCCAGCAGCTCTAGCACCCTGGTGGAAGTGACACTGGGCGAAGTGCCTGCCGCCGAGTCTCCTGATCCTCCTCAGTCTCCTCAGGGCGCCAGCTCTCTGCCCACCACCATGAACTACCCCCTGTGGTCCCAGTCCTACGAGGACAGCAGCAACCAGGAAGAAGAGGGCCCCAGCACCTTCCCCGACCTGGAATCTGAATTCCAGGCCGCCCTGAGCCGGAAGGTGGCCGAACTGGTGCACTTCCTGCTGCTGAAGTACCGGGCCAGAGAACCCGTGACCAAGGCCGAGATGCTGGGCAGCGTCGTGGGCAACTGGCAGTACTTCTTCCCCGTGATCTTCTCCAAGGCCAGCTCCAGCCTGCAGCTGGTGTTCGGCATCGAGCTGATGGAAGTGGACCCCATCGGACACCTGTACATCTTCGCCACCTGTCTGGGCCTGAGCTACGATGGCCTGCTGGGCGACAACCAGATCATGCCCAAAGCCGGCCTGCTGATCATCGTGCTGGCCATCATTGCCCGCGAGGGCGATTGTGCCCCCGAGGAAAAGATCTGGGAGGAACTGAGCGTGCTGGAAGTGTTCGAGGGAAGAGAGGACTCCATCCTGGGCGACCCCAAGAAGCTGCTGACCCAGCACTTCGTGCAGGAAAACTACCTGGAGTATAGACAGGTGCCCGGCAGCGACCCTGCCTGCTACGAATTTCTGTGGGGCCCTAGAGCACTGGTGGAAACCAGCTACGTGAAAGTGCTGCACCACATGGTCAAGATCAGCGGCGGACCCCACATCAGCTACCCACCTCTGCACGAATGGGTGCTGCGGGAAGGCGAAGAGTGA [SEQ ID NO: 20]
MVA_tPA_MAGEA3의 번역된 단백질. tPA는 밑줄쳐 있다:
MDAMKRGLCCVLLLCGAVFVSPPLEQRSQHCKPEEGLEARGEALGLVGAQAPATEEQEAASSSSTLVEVTLGEVPAAESPDPPQSPQGASSLPTTMNYPLWSQSYEDSSNQEEEGPSTFPDLESEFQAALSRKVAELVHFLLLKYRAREPVTKAEMLGSVVGNWQYFFPVIFSKASSSLQLVFGIELMEVDPIGHLYIFATCLGLSYDGLLGDNQIMPKAGLLIlVLAIIAREGDCAPEEKIWEELSVLEVFEGREDSILGDPKKLLTQHFVQENYLEYRQVPGSDPACYEFLWGPRALVETSYVKVLHHMVKISGGPHISYPPLHEWVLREGEE [SEQ ID NO: 21]
벡터 MVA_tPA_NYESO에 대한 폴리뉴클레오티드 구축물. tPA는 밑줄쳐 있다:
ATGGACGCCATGAAGCGGGGCCTGTGCTGCGTGCTGCTGCTGTGTGGCGCTGTGTTCGTGAGCCCTCAGGCCGAGGGAAGAGGCACAGGCGGATCTACAGGCGACGCTGATGGACCTGGCGGCCCTGGAATTCCTGATGGCCCAGGCGGAAATGCTGGCGGACCAGGCGAAGCTGGCGCTACAGGCGGAAGAGGACCTAGAGGCGCTGGCGCCGCTAGAGCTTCTGGACCTGGGGGAGGCGCTCCTAGAGGACCTCATGGCGGAGCTGCCTCTGGCCTGAATGGCTGCTGTAGATGTGGCGCCAGAGGCCCCGAAAGCCGGCTGCTGGAATTCTACCTGGCCATGCCCTTCGCCACCCCCATGGAAGCTGAGCTGGCCAGAAGAAGCCTGGCCCAGGACGCTCCTCCACTGCCTGTGCCAGGGGTGCTGCTGAAAGAATTCACCGTGTCCGGCAACATCCTGACCATCCGGCTGACAGCCGCCGACCACAGACAGCTGCAGCTGAGCATCAGCAGCTGCCTGCAGCAGCTGTCCCTGCTGATGTGGATCACCCAGTGCTTTCTGCCCGTGTTTCTGGCCCAGCCTCCTAGCGGCCAGCGGCGCTAA [SEQ ID NO: 22]
MVA_tPA_NYESO의 번역된 단백질. tPA는 밑줄쳐 있다:
MDAMKRGLCCVLLLCGAVFVSPQAEGRGTGGSTGDADGPGGPGIPDGPGGNAGGPGEAGATGGRGPRGAGAARASGPGGGAPRGPHGGAASGLNGCCRCGARGPESRLLEFYLAMPFATPMEAELARRSLAQDAPPLPVPGVLLKEFTVSGNILTIRLTAADHRQLQLSISSCLQQLSLLMWITQCFLPVFLAQPPSGQRR [SEQ ID NO: 23]
벡터 ChAdOx1_mli_P1A에 대한 폴리뉴클레오티드 구축물. li 서열은 밑줄쳐 있다:
ATGGGCGCTCTGTATACTGGCGTGTCCGTGCTGGTGGCCCTGCTGCTGGCTGGACAGGCTACAACCGCCTACTTCCTGTACAGCGACAACAAGAAGCCCGACAAGGCCCACTCTGGCAGCGGCGGAGATGGCGACGGCAACAGATGTAACCTGCTGCACAGATACAGCCTGGAAGAGATCCTGCCCTACCTGGGCTGGCTGGTGTTCGCCGTCGTGACAACAAGCTTCCTGGCCCTGCAGATGTTCATCGACGCCCTGTACGAGGAACAGTACGAGAGGGACGTGGCCTGGATCGCCAGACAGAGCAAGAGAATGAGCAGCGTGGACGAGGACGAGGATGATGAGGACGACGAAGATGACTACTACGACGATGAGGATGACGACGACGACGCCTTCTACGATGACGAGGACGATGAAGAGGAAGAACTGGAAAACCTGATGGACGACGAGTCCGAGGATGAGGCCGAGGAAGAGATGAGCGTGGAAATGGGCGCTGGCGCCGAAGAGATGGGAGCCGGCGCTAACTGTGCTTGCGTGCCAGGACACCACCTGAGAAAGAACGAAGTGAAGTGCCGGATGATCTACTTCTTCCACGACCCCAACTTTCTGGTGTCCATCCCCGTGAACCCCAAAGAACAGATGGAATGCAGATGCGAGAACGCCGACGAAGAGGTGGCCATGGAAGAAGAAGAGGAAGAGGAAGAAGAAGAAGAAGAGGAAGAAATGGGCAACCCCGACGGCTTCAGCCCCTGA [SEQ ID NO: 28]
번역된 단백질 ChAdOx1_mli_P1A. li 서열은 밑줄쳐 있다:
MGALYTGVSVLVALLLAGQATTAYFLYSDNKKPDKAHSGSGGDGDGNRCNLLHRYSLEEILPYLGWLVFAVVTTSFLALQMFIDALYEEQYERDVAWIARQSKRMSSVDEDEDDEDDEDDYYDDEDDDDDAFYDDEDDEEEELENLMDDESEDEAEEEMSVEMGAGAEEMGAGANCACVPGHHLRKNEVKCRMIYFFHDPNFLVSIPVNPKEQMECRCENADEEVAMEEEEEEEEEEEEEEMGNPDGFSP [SEQ ID NO: 29]
본 명세서의 상세한 설명 및 청구범위 전체에 걸쳐, 단어 "포함한다" 및 "함유한다" 및 이들의 변형은, "포함하지만 이에 제한되지 않음"을 의미하고, 기타 모이어티(moieties), 첨가제, 구성요소, 정수 또는 단계들을 배제하는 것으로 의도되지 않는다(즉, 배제하지 않는다). 본 명세서의 상세한 설명 및 청구범위 전체에 걸쳐, 단어의 단수 형태는, 문맥상 별도로 명시되지 않는 한, 복수 형태를 포괄한다. 예를 들어, 용어 "항원"은, 문맥상 별도로 명시되지 않는 한, "항원들"을 포괄한다.
본 발명의 특정 관점, 구현 예 또는 실시 예와 관련하여 기재된 특색, 정수, 특징, 화합물, 화학적 모이어티 또는 그룹은, 이와 양립할 수 없는 경우를 제외하고 여기에 기재된 임의의 다른 관점, 구현 예 또는 실시 예에 적용 가능한 것으로 이해되어야 한다. (수반되는 청구범위, 요약서 및 도면을 포함하는) 본 명세서에 개시된 모든 특색, 및/또는 그렇게 개시된 임의의 방법 또는 공정의 모든 단계는, 이러한 특색 및/또는 단계들 중 적어도 몇몇이 상호 배타적인 경우의 조합을 제외하고, 임의의 조합으로 조합될 수 있다. 본 발명은 임의의 전술한 구현 예의 세부사항으로 제한되지 않는다. 본 발명은, (수반되는 청구범위, 요약서 및 도면을 포함하는) 본 명세서에 개시된 특색의, 임의의 신규의 하나, 또는 임의의 신규 조합, 또는 그렇게 개시된 임의의 방법 또는 공정의 단계들의, 임의의 신규의 하나, 또는 임의의 신규 조합으로 확장된다.
독자의 주의는, 본 출원과 관련하여 본 명세서와 동시에 또는 이전에 제출되고, 본 명세서와 함께 공람을 위해 오픈된 모든 논문 및 문서와 관련되며, 이러한 모든 논문 및 문서의 내용은 여기에 참조로서 병합된다.
SEQUENCE LISTING
<110> Ludwig Institute for Cancer Research Ltd.
<120> Viral vectors and methods for the prevention or treatment of
cancer
<130> P257619WO
<150> 1812647.4
<151> 2018-08-03
<160> 31
<170> PatentIn version 3.5
<210> 1
<211> 314
<212> PRT
<213> Homo sapiens
<400> 1
Met Pro Leu Glu Gln Arg Ser Gln His Cys Lys Pro Glu Glu Gly Leu
1 5 10 15
Glu Ala Arg Gly Glu Ala Leu Gly Leu Val Gly Ala Gln Ala Pro Ala
20 25 30
Thr Glu Glu Gln Glu Ala Ala Ser Ser Ser Ser Thr Leu Val Glu Val
35 40 45
Thr Leu Gly Glu Val Pro Ala Ala Glu Ser Pro Asp Pro Pro Gln Ser
50 55 60
Pro Gln Gly Ala Ser Ser Leu Pro Thr Thr Met Asn Tyr Pro Leu Trp
65 70 75 80
Ser Gln Ser Tyr Glu Asp Ser Ser Asn Gln Glu Glu Glu Gly Pro Ser
85 90 95
Thr Phe Pro Asp Leu Glu Ser Glu Phe Gln Ala Ala Leu Ser Arg Lys
100 105 110
Val Ala Glu Leu Val His Phe Leu Leu Leu Lys Tyr Arg Ala Arg Glu
115 120 125
Pro Val Thr Lys Ala Glu Met Leu Gly Ser Val Val Gly Asn Trp Gln
130 135 140
Tyr Phe Phe Pro Val Ile Phe Ser Lys Ala Ser Ser Ser Leu Gln Leu
145 150 155 160
Val Phe Gly Ile Glu Leu Met Glu Val Asp Pro Ile Gly His Leu Tyr
165 170 175
Ile Phe Ala Thr Cys Leu Gly Leu Ser Tyr Asp Gly Leu Leu Gly Asp
180 185 190
Asn Gln Ile Met Pro Lys Ala Gly Leu Leu Ile Ile Val Leu Ala Ile
195 200 205
Ile Ala Arg Glu Gly Asp Cys Ala Pro Glu Glu Lys Ile Trp Glu Glu
210 215 220
Leu Ser Val Leu Glu Val Phe Glu Gly Arg Glu Asp Ser Ile Leu Gly
225 230 235 240
Asp Pro Lys Lys Leu Leu Thr Gln His Phe Val Gln Glu Asn Tyr Leu
245 250 255
Glu Tyr Arg Gln Val Pro Gly Ser Asp Pro Ala Cys Tyr Glu Phe Leu
260 265 270
Trp Gly Pro Arg Ala Leu Val Glu Thr Ser Tyr Val Lys Val Leu His
275 280 285
His Met Val Lys Ile Ser Gly Gly Pro His Ile Ser Tyr Pro Pro Leu
290 295 300
His Glu Trp Val Leu Arg Glu Gly Glu Glu
305 310
<210> 2
<211> 1753
<212> PRT
<213> Homo sapiens
<400> 2
Gly Ala Gly Ala Thr Thr Cys Thr Cys Gly Cys Cys Cys Thr Gly Ala
1 5 10 15
Gly Cys Ala Ala Cys Gly Ala Gly Cys Gly Ala Cys Gly Gly Cys Cys
20 25 30
Thr Gly Ala Cys Gly Thr Cys Gly Gly Cys Gly Gly Ala Gly Gly Gly
35 40 45
Ala Ala Gly Cys Cys Gly Gly Cys Cys Cys Ala Gly Gly Cys Thr Cys
50 55 60
Gly Gly Thr Gly Ala Gly Gly Ala Gly Gly Cys Ala Ala Gly Gly Thr
65 70 75 80
Thr Cys Thr Gly Ala Gly Gly Gly Gly Ala Cys Ala Gly Gly Cys Thr
85 90 95
Gly Ala Cys Cys Thr Gly Gly Ala Gly Gly Ala Cys Cys Ala Gly Ala
100 105 110
Gly Gly Cys Cys Cys Cys Cys Gly Gly Ala Gly Gly Ala Gly Cys Ala
115 120 125
Cys Thr Gly Ala Ala Gly Gly Ala Gly Ala Ala Gly Ala Thr Cys Thr
130 135 140
Gly Cys Cys Ala Gly Thr Gly Gly Gly Thr Cys Thr Cys Cys Ala Thr
145 150 155 160
Thr Gly Cys Cys Cys Ala Gly Cys Thr Cys Cys Thr Gly Cys Cys Cys
165 170 175
Ala Cys Ala Cys Thr Cys Cys Cys Gly Cys Cys Thr Gly Thr Thr Gly
180 185 190
Cys Cys Cys Thr Gly Ala Cys Cys Ala Gly Ala Gly Thr Cys Ala Thr
195 200 205
Cys Ala Thr Gly Cys Cys Thr Cys Thr Thr Gly Ala Gly Cys Ala Gly
210 215 220
Ala Gly Gly Ala Gly Thr Cys Ala Gly Cys Ala Cys Thr Gly Cys Ala
225 230 235 240
Ala Gly Cys Cys Thr Gly Ala Ala Gly Ala Ala Gly Gly Cys Cys Thr
245 250 255
Thr Gly Ala Gly Gly Cys Cys Cys Gly Ala Gly Gly Ala Gly Ala Gly
260 265 270
Gly Cys Cys Cys Thr Gly Gly Gly Cys Cys Thr Gly Gly Thr Gly Gly
275 280 285
Gly Thr Gly Cys Gly Cys Ala Gly Gly Cys Thr Cys Cys Thr Gly Cys
290 295 300
Thr Ala Cys Thr Gly Ala Gly Gly Ala Gly Cys Ala Gly Gly Ala Gly
305 310 315 320
Gly Cys Thr Gly Cys Cys Thr Cys Cys Thr Cys Cys Thr Cys Thr Thr
325 330 335
Cys Thr Ala Cys Thr Cys Thr Ala Gly Thr Thr Gly Ala Ala Gly Thr
340 345 350
Cys Ala Cys Cys Cys Thr Gly Gly Gly Gly Gly Ala Gly Gly Thr Gly
355 360 365
Cys Cys Thr Gly Cys Thr Gly Cys Cys Gly Ala Gly Thr Cys Ala Cys
370 375 380
Cys Ala Gly Ala Thr Cys Cys Thr Cys Cys Cys Cys Ala Gly Ala Gly
385 390 395 400
Thr Cys Cys Thr Cys Ala Gly Gly Gly Ala Gly Cys Cys Thr Cys Cys
405 410 415
Ala Gly Cys Cys Thr Cys Cys Cys Cys Ala Cys Thr Ala Cys Cys Ala
420 425 430
Thr Gly Ala Ala Cys Thr Ala Cys Cys Cys Thr Cys Thr Cys Thr Gly
435 440 445
Gly Ala Gly Cys Cys Ala Ala Thr Cys Cys Thr Ala Thr Gly Ala Gly
450 455 460
Gly Ala Cys Thr Cys Cys Ala Gly Cys Ala Ala Cys Cys Ala Ala Gly
465 470 475 480
Ala Ala Gly Ala Gly Gly Ala Gly Gly Gly Gly Cys Cys Ala Ala Gly
485 490 495
Cys Ala Cys Cys Thr Thr Cys Cys Cys Thr Gly Ala Cys Cys Thr Gly
500 505 510
Gly Ala Gly Thr Cys Cys Gly Ala Gly Thr Thr Cys Cys Ala Ala Gly
515 520 525
Cys Ala Gly Cys Ala Cys Thr Cys Ala Gly Thr Ala Gly Gly Ala Ala
530 535 540
Gly Gly Thr Gly Gly Cys Cys Gly Ala Gly Thr Thr Gly Gly Thr Thr
545 550 555 560
Cys Ala Thr Thr Thr Thr Cys Thr Gly Cys Thr Cys Cys Thr Cys Ala
565 570 575
Ala Gly Thr Ala Thr Cys Gly Ala Gly Cys Cys Ala Gly Gly Gly Ala
580 585 590
Gly Cys Cys Gly Gly Thr Cys Ala Cys Ala Ala Ala Gly Gly Cys Ala
595 600 605
Gly Ala Ala Ala Thr Gly Cys Thr Gly Gly Gly Gly Ala Gly Thr Gly
610 615 620
Thr Cys Gly Thr Cys Gly Gly Ala Ala Ala Thr Thr Gly Gly Cys Ala
625 630 635 640
Gly Thr Ala Thr Thr Thr Cys Thr Thr Thr Cys Cys Thr Gly Thr Gly
645 650 655
Ala Thr Cys Thr Thr Cys Ala Gly Cys Ala Ala Ala Gly Cys Thr Thr
660 665 670
Cys Cys Ala Gly Thr Thr Cys Cys Thr Thr Gly Cys Ala Gly Cys Thr
675 680 685
Gly Gly Thr Cys Thr Thr Thr Gly Gly Cys Ala Thr Cys Gly Ala Gly
690 695 700
Cys Thr Gly Ala Thr Gly Gly Ala Ala Gly Thr Gly Gly Ala Cys Cys
705 710 715 720
Cys Cys Ala Thr Cys Gly Gly Cys Cys Ala Cys Thr Thr Gly Thr Ala
725 730 735
Cys Ala Thr Cys Thr Thr Thr Gly Cys Cys Ala Cys Cys Thr Gly Cys
740 745 750
Cys Thr Gly Gly Gly Cys Cys Thr Cys Thr Cys Cys Thr Ala Cys Gly
755 760 765
Ala Thr Gly Gly Cys Cys Thr Gly Cys Thr Gly Gly Gly Thr Gly Ala
770 775 780
Cys Ala Ala Thr Cys Ala Gly Ala Thr Cys Ala Thr Gly Cys Cys Cys
785 790 795 800
Ala Ala Gly Gly Cys Ala Gly Gly Cys Cys Thr Cys Cys Thr Gly Ala
805 810 815
Thr Ala Ala Thr Cys Gly Thr Cys Cys Thr Gly Gly Cys Cys Ala Thr
820 825 830
Ala Ala Thr Cys Gly Cys Ala Ala Gly Ala Gly Ala Gly Gly Gly Cys
835 840 845
Gly Ala Cys Thr Gly Thr Gly Cys Cys Cys Cys Thr Gly Ala Gly Gly
850 855 860
Ala Gly Ala Ala Ala Ala Thr Cys Thr Gly Gly Gly Ala Gly Gly Ala
865 870 875 880
Gly Cys Thr Gly Ala Gly Thr Gly Thr Gly Thr Thr Ala Gly Ala Gly
885 890 895
Gly Thr Gly Thr Thr Thr Gly Ala Gly Gly Gly Gly Ala Gly Gly Gly
900 905 910
Ala Ala Gly Ala Cys Ala Gly Thr Ala Thr Cys Thr Thr Gly Gly Gly
915 920 925
Gly Gly Ala Thr Cys Cys Cys Ala Ala Gly Ala Ala Gly Cys Thr Gly
930 935 940
Cys Thr Cys Ala Cys Cys Cys Ala Ala Cys Ala Thr Thr Thr Cys Gly
945 950 955 960
Thr Gly Cys Ala Gly Gly Ala Ala Ala Ala Cys Thr Ala Cys Cys Thr
965 970 975
Gly Gly Ala Gly Thr Ala Cys Cys Gly Gly Cys Ala Gly Gly Thr Cys
980 985 990
Cys Cys Cys Gly Gly Cys Ala Gly Thr Gly Ala Thr Cys Cys Thr Gly
995 1000 1005
Cys Ala Thr Gly Thr Thr Ala Thr Gly Ala Ala Thr Thr Cys Cys
1010 1015 1020
Thr Gly Thr Gly Gly Gly Gly Thr Cys Cys Ala Ala Gly Gly Gly
1025 1030 1035
Cys Cys Cys Thr Cys Gly Thr Thr Gly Ala Ala Ala Cys Cys Ala
1040 1045 1050
Gly Cys Thr Ala Thr Gly Thr Gly Ala Ala Ala Gly Thr Cys Cys
1055 1060 1065
Thr Gly Cys Ala Cys Cys Ala Thr Ala Thr Gly Gly Thr Ala Ala
1070 1075 1080
Ala Gly Ala Thr Cys Ala Gly Thr Gly Gly Ala Gly Gly Ala Cys
1085 1090 1095
Cys Thr Cys Ala Cys Ala Thr Thr Thr Cys Cys Thr Ala Cys Cys
1100 1105 1110
Cys Ala Cys Cys Cys Cys Thr Gly Cys Ala Thr Gly Ala Gly Thr
1115 1120 1125
Gly Gly Gly Thr Thr Thr Thr Gly Ala Gly Ala Gly Ala Gly Gly
1130 1135 1140
Gly Gly Gly Ala Ala Gly Ala Gly Thr Gly Ala Gly Thr Cys Thr
1145 1150 1155
Gly Ala Gly Cys Ala Cys Gly Ala Gly Thr Thr Gly Cys Ala Gly
1160 1165 1170
Cys Cys Ala Gly Gly Gly Cys Cys Ala Gly Thr Gly Gly Gly Ala
1175 1180 1185
Gly Gly Gly Gly Gly Thr Cys Thr Gly Gly Gly Cys Cys Ala Gly
1190 1195 1200
Thr Gly Cys Ala Cys Cys Thr Thr Cys Cys Gly Gly Gly Gly Cys
1205 1210 1215
Cys Gly Cys Ala Thr Cys Cys Cys Thr Thr Ala Gly Thr Thr Thr
1220 1225 1230
Cys Cys Ala Cys Thr Gly Cys Cys Thr Cys Cys Thr Gly Thr Gly
1235 1240 1245
Ala Cys Gly Thr Gly Ala Gly Gly Cys Cys Cys Ala Thr Thr Cys
1250 1255 1260
Thr Thr Cys Ala Cys Thr Cys Thr Thr Thr Gly Ala Ala Gly Cys
1265 1270 1275
Gly Ala Gly Cys Ala Gly Thr Cys Ala Gly Cys Ala Thr Thr Cys
1280 1285 1290
Thr Thr Ala Gly Thr Ala Gly Thr Gly Gly Gly Thr Thr Thr Cys
1295 1300 1305
Thr Gly Thr Thr Cys Thr Gly Thr Thr Gly Gly Ala Thr Gly Ala
1310 1315 1320
Cys Thr Thr Thr Gly Ala Gly Ala Thr Thr Ala Thr Thr Cys Thr
1325 1330 1335
Thr Thr Gly Thr Thr Thr Cys Cys Thr Gly Thr Thr Gly Gly Ala
1340 1345 1350
Gly Thr Thr Gly Thr Thr Cys Ala Ala Ala Thr Gly Thr Thr Cys
1355 1360 1365
Cys Thr Thr Thr Thr Ala Ala Cys Gly Gly Ala Thr Gly Gly Thr
1370 1375 1380
Thr Gly Ala Ala Thr Gly Ala Gly Cys Gly Thr Cys Ala Gly Cys
1385 1390 1395
Ala Thr Cys Cys Ala Gly Gly Thr Thr Thr Ala Thr Gly Ala Ala
1400 1405 1410
Thr Gly Ala Cys Ala Gly Thr Ala Gly Thr Cys Ala Cys Ala Cys
1415 1420 1425
Ala Thr Ala Gly Thr Gly Cys Thr Gly Thr Thr Thr Ala Thr Ala
1430 1435 1440
Thr Ala Gly Thr Thr Thr Ala Gly Gly Ala Gly Thr Ala Ala Gly
1445 1450 1455
Ala Gly Thr Cys Thr Thr Gly Thr Thr Thr Thr Thr Thr Ala Cys
1460 1465 1470
Thr Cys Ala Ala Ala Thr Thr Gly Gly Gly Ala Ala Ala Thr Cys
1475 1480 1485
Cys Ala Thr Thr Cys Cys Ala Thr Thr Thr Thr Gly Thr Gly Ala
1490 1495 1500
Ala Thr Thr Gly Thr Gly Ala Cys Ala Thr Ala Ala Thr Ala Ala
1505 1510 1515
Thr Ala Gly Cys Ala Gly Thr Gly Gly Thr Ala Ala Ala Ala Gly
1520 1525 1530
Thr Ala Thr Thr Thr Gly Cys Thr Thr Ala Ala Ala Ala Thr Thr
1535 1540 1545
Gly Thr Gly Ala Gly Cys Gly Ala Ala Thr Thr Ala Gly Cys Ala
1550 1555 1560
Ala Thr Ala Ala Cys Ala Thr Ala Cys Ala Thr Gly Ala Gly Ala
1565 1570 1575
Thr Ala Ala Cys Thr Cys Ala Ala Gly Ala Ala Ala Thr Cys Ala
1580 1585 1590
Ala Ala Ala Gly Ala Thr Ala Gly Thr Thr Gly Ala Thr Thr Cys
1595 1600 1605
Thr Thr Gly Cys Cys Thr Thr Gly Thr Ala Cys Cys Thr Cys Ala
1610 1615 1620
Ala Thr Cys Thr Ala Thr Thr Cys Thr Gly Thr Ala Ala Ala Ala
1625 1630 1635
Thr Thr Ala Ala Ala Cys Ala Ala Ala Thr Ala Thr Gly Cys Ala
1640 1645 1650
Ala Ala Cys Cys Ala Gly Gly Ala Thr Thr Thr Cys Cys Thr Thr
1655 1660 1665
Gly Ala Cys Thr Thr Cys Thr Thr Thr Gly Ala Gly Ala Ala Thr
1670 1675 1680
Gly Cys Ala Ala Gly Cys Gly Ala Ala Ala Thr Thr Ala Ala Ala
1685 1690 1695
Thr Cys Thr Gly Ala Ala Thr Ala Ala Ala Thr Ala Ala Thr Thr
1700 1705 1710
Cys Thr Thr Cys Cys Thr Cys Thr Thr Cys Ala Ala Ala Ala Ala
1715 1720 1725
Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala
1730 1735 1740
Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala
1745 1750
<210> 3
<211> 180
<212> PRT
<213> Homo sapiens
<400> 3
Met Gln Ala Glu Gly Arg Gly Thr Gly Gly Ser Thr Gly Asp Ala Asp
1 5 10 15
Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly Pro Gly Gly Asn Ala Gly
20 25 30
Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly Arg Gly Pro Arg Gly Ala
35 40 45
Gly Ala Ala Arg Ala Ser Gly Pro Gly Gly Gly Ala Pro Arg Gly Pro
50 55 60
His Gly Gly Ala Ala Ser Gly Leu Asn Gly Cys Cys Arg Cys Gly Ala
65 70 75 80
Arg Gly Pro Glu Ser Arg Leu Leu Glu Phe Tyr Leu Ala Met Pro Phe
85 90 95
Ala Thr Pro Met Glu Ala Glu Leu Ala Arg Arg Ser Leu Ala Gln Asp
100 105 110
Ala Pro Pro Leu Pro Val Pro Gly Val Leu Leu Lys Glu Phe Thr Val
115 120 125
Ser Gly Asn Ile Leu Thr Ile Arg Leu Thr Ala Ala Asp His Arg Gln
130 135 140
Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln Gln Leu Ser Leu Leu Met
145 150 155 160
Trp Ile Thr Gln Cys Phe Leu Pro Val Phe Leu Ala Gln Pro Pro Ser
165 170 175
Gly Gln Arg Arg
180
<210> 4
<211> 752
<212> DNA
<213> Homo sapiens
<400> 4
atcctcgtgg gccctgacct tctctctgag agccgggcag aggctccgga gccatgcagg 60
ccgaaggccg gggcacaggg ggttcgacgg gcgatgctga tggcccagga ggccctggca 120
ttcctgatgg cccagggggc aatgctggcg gcccaggaga ggcgggtgcc acgggcggca 180
gaggtccccg gggcgcaggg gcagcaaggg cctcggggcc gggaggaggc gccccgcggg 240
gtccgcatgg cggcgcggct tcagggctga atggatgctg cagatgcggg gccagggggc 300
cggagagccg cctgcttgag ttctacctcg ccatgccttt cgcgacaccc atggaagcag 360
agctggcccg caggagcctg gcccaggatg ccccaccgct tcccgtgcca ggggtgcttc 420
tgaaggagtt cactgtgtcc ggcaacatac tgactatccg actgactgct gcagaccacc 480
gccaactgca gctctccatc agctcctgtc tccagcagct ttccctgttg atgtggatca 540
cgcagtgctt tctgcccgtg tttttggctc agcctccctc agggcagagg cgctaagccc 600
agcctggcgc cccttcctag gtcatgcctc ctcccctagg gaatggtccc agcacgagtg 660
gccagttcat tgtgggggcc tgattgtttg tcgctggagg aggacggctt acatgtttgt 720
ttctgtagaa aataaaactg agctacgaaa aa 752
<210> 5
<211> 180
<212> PRT
<213> Homo sapiens
<400> 5
Met Gln Ala Glu Gly Gln Gly Thr Gly Gly Ser Thr Gly Asp Ala Asp
1 5 10 15
Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly Pro Gly Gly Asn Ala Gly
20 25 30
Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly Arg Gly Pro Arg Gly Ala
35 40 45
Gly Ala Ala Arg Ala Ser Gly Pro Arg Gly Gly Ala Pro Arg Gly Pro
50 55 60
His Gly Gly Ala Ala Ser Ala Gln Asp Gly Arg Cys Pro Cys Gly Ala
65 70 75 80
Arg Arg Pro Asp Ser Arg Leu Leu Gln Leu His Ile Thr Met Pro Phe
85 90 95
Ser Ser Pro Met Glu Ala Glu Leu Val Arg Arg Ile Leu Ser Arg Asp
100 105 110
Ala Ala Pro Leu Pro Arg Pro Gly Ala Val Leu Lys Asp Phe Thr Val
115 120 125
Ser Gly Asn Leu Leu Phe Ile Arg Leu Thr Ala Ala Asp His Arg Gln
130 135 140
Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln Gln Leu Ser Leu Leu Met
145 150 155 160
Trp Ile Thr Gln Cys Phe Leu Pro Val Phe Leu Ala Gln Ala Pro Ser
165 170 175
Gly Gln Arg Arg
180
<210> 6
<211> 296
<212> PRT
<213> Homo sapiens
<400> 6
Met His Arg Arg Arg Ser Arg Ser Cys Arg Glu Asp Gln Lys Pro Val
1 5 10 15
Met Asp Asp Gln Arg Asp Leu Ile Ser Asn Asn Glu Gln Leu Pro Met
20 25 30
Leu Gly Arg Arg Pro Gly Ala Pro Glu Ser Lys Cys Ser Arg Gly Ala
35 40 45
Leu Tyr Thr Gly Phe Ser Ile Leu Val Thr Leu Leu Leu Ala Gly Gln
50 55 60
Ala Thr Thr Ala Tyr Phe Leu Tyr Gln Gln Gln Gly Arg Leu Asp Lys
65 70 75 80
Leu Thr Val Thr Ser Gln Asn Leu Gln Leu Glu Asn Leu Arg Met Lys
85 90 95
Leu Pro Lys Pro Pro Lys Pro Val Ser Lys Met Arg Met Ala Thr Pro
100 105 110
Leu Leu Met Gln Ala Leu Pro Met Gly Ala Leu Pro Gln Gly Pro Met
115 120 125
Gln Asn Ala Thr Lys Tyr Gly Asn Met Thr Glu Asp His Val Met His
130 135 140
Leu Leu Gln Asn Ala Asp Pro Leu Lys Val Tyr Pro Pro Leu Lys Gly
145 150 155 160
Ser Phe Pro Glu Asn Leu Arg His Leu Lys Asn Thr Met Glu Thr Ile
165 170 175
Asp Trp Lys Val Phe Glu Ser Trp Met His His Trp Leu Leu Phe Glu
180 185 190
Met Ser Arg His Ser Leu Glu Gln Lys Pro Thr Asp Ala Pro Pro Lys
195 200 205
Val Leu Thr Lys Cys Gln Glu Glu Val Ser His Ile Pro Ala Val His
210 215 220
Pro Gly Ser Phe Arg Pro Lys Cys Asp Glu Asn Gly Asn Tyr Leu Pro
225 230 235 240
Leu Gln Cys Tyr Gly Ser Ile Gly Tyr Cys Trp Cys Val Phe Pro Asn
245 250 255
Gly Thr Glu Val Pro Asn Thr Arg Ser Arg Gly His His Asn Cys Ser
260 265 270
Glu Ser Leu Glu Leu Glu Asp Pro Ser Ser Gly Leu Gly Val Thr Lys
275 280 285
Gln Asp Leu Gly Pro Val Pro Met
290 295
<210> 7
<211> 26
<212> PRT
<213> Homo sapiens
<400> 7
Gly Ala Leu Tyr Thr Gly Phe Ser Ile Leu Val Thr Leu Leu Leu Ala
1 5 10 15
Gly Gln Ala Thr Thr Ala Tyr Phe Leu Tyr
20 25
<210> 8
<211> 562
<212> PRT
<213> Homo sapiens
<400> 8
Met Asp Ala Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Ser Gln Glu Ile His Ala Arg Phe Arg Arg
20 25 30
Gly Ala Arg Ser Tyr Gln Val Ile Cys Arg Asp Glu Lys Thr Gln Met
35 40 45
Ile Tyr Gln Gln His Gln Ser Trp Leu Arg Pro Val Leu Arg Ser Asn
50 55 60
Arg Val Glu Tyr Cys Trp Cys Asn Ser Gly Arg Ala Gln Cys His Ser
65 70 75 80
Val Pro Val Lys Ser Cys Ser Glu Pro Arg Cys Phe Asn Gly Gly Thr
85 90 95
Cys Gln Gln Ala Leu Tyr Phe Ser Asp Phe Val Cys Gln Cys Pro Glu
100 105 110
Gly Phe Ala Gly Lys Cys Cys Glu Ile Asp Thr Arg Ala Thr Cys Tyr
115 120 125
Glu Asp Gln Gly Ile Ser Tyr Arg Gly Thr Trp Ser Thr Ala Glu Ser
130 135 140
Gly Ala Glu Cys Thr Asn Trp Asn Ser Ser Ala Leu Ala Gln Lys Pro
145 150 155 160
Tyr Ser Gly Arg Arg Pro Asp Ala Ile Arg Leu Gly Leu Gly Asn His
165 170 175
Asn Tyr Cys Arg Asn Pro Asp Arg Asp Ser Lys Pro Trp Cys Tyr Val
180 185 190
Phe Lys Ala Gly Lys Tyr Ser Ser Glu Phe Cys Ser Thr Pro Ala Cys
195 200 205
Ser Glu Gly Asn Ser Asp Cys Tyr Phe Gly Asn Gly Ser Ala Tyr Arg
210 215 220
Gly Thr His Ser Leu Thr Glu Ser Gly Ala Ser Cys Leu Pro Trp Asn
225 230 235 240
Ser Met Ile Leu Ile Gly Lys Val Tyr Thr Ala Gln Asn Pro Ser Ala
245 250 255
Gln Ala Leu Gly Leu Gly Lys His Asn Tyr Cys Arg Asn Pro Asp Gly
260 265 270
Asp Ala Lys Pro Trp Cys His Val Leu Lys Asn Arg Arg Leu Thr Trp
275 280 285
Glu Tyr Cys Asp Val Pro Ser Cys Ser Thr Cys Gly Leu Arg Gln Tyr
290 295 300
Ser Gln Pro Gln Phe Arg Ile Lys Gly Gly Leu Phe Ala Asp Ile Ala
305 310 315 320
Ser His Pro Trp Gln Ala Ala Ile Phe Ala Lys His Arg Arg Ser Pro
325 330 335
Gly Glu Arg Phe Leu Cys Gly Gly Ile Leu Ile Ser Ser Cys Trp Ile
340 345 350
Leu Ser Ala Ala His Cys Phe Gln Glu Arg Phe Pro Pro His His Leu
355 360 365
Thr Val Ile Leu Gly Arg Thr Tyr Arg Val Val Pro Gly Glu Glu Glu
370 375 380
Gln Lys Phe Glu Val Glu Lys Tyr Ile Val His Lys Glu Phe Asp Asp
385 390 395 400
Asp Thr Tyr Asp Asn Asp Ile Ala Leu Leu Gln Leu Lys Ser Asp Ser
405 410 415
Ser Arg Cys Ala Gln Glu Ser Ser Val Val Arg Thr Val Cys Leu Pro
420 425 430
Pro Ala Asp Leu Gln Leu Pro Asp Trp Thr Glu Cys Glu Leu Ser Gly
435 440 445
Tyr Gly Lys His Glu Ala Leu Ser Pro Phe Tyr Ser Glu Arg Leu Lys
450 455 460
Glu Ala His Val Arg Leu Tyr Pro Ser Ser Arg Cys Thr Ser Gln His
465 470 475 480
Leu Leu Asn Arg Thr Val Thr Asp Asn Met Leu Cys Ala Gly Asp Thr
485 490 495
Arg Ser Gly Gly Pro Gln Ala Asn Leu His Asp Ala Cys Gln Gly Asp
500 505 510
Ser Gly Gly Pro Leu Val Cys Leu Asn Asp Gly Arg Met Thr Leu Val
515 520 525
Gly Ile Ile Ser Trp Gly Leu Gly Cys Gly Gln Lys Asp Val Pro Gly
530 535 540
Val Tyr Thr Lys Val Thr Asn Tyr Leu Asp Trp Ile Arg Asp Asn Met
545 550 555 560
Arg Pro
<210> 9
<211> 21
<212> PRT
<213> Homo sapiens
<400> 9
Asp Ala Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly Ala
1 5 10 15
Val Phe Val Ser Pro
20
<210> 10
<211> 1506
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector ChAdOx1_MAGE_NYESO
<400> 10
atgcccctgg aacagcggag ccagcactgc aagcctgagg aaggcctgga agccagaggc 60
gaagctctgg gactcgtggg agcacaggct ccagccaccg aagaacagga agccgccagc 120
agcagctcca ccctggtgga agtgacactg ggcgaagtgc ctgccgccga gtctcctgat 180
cctcctcagt ctcctcaggg cgccagctct ctgcccacca ccatgaacta ccccctgtgg 240
tcccagtcct acgaggacag cagcaaccag gaagaagagg gccccagcac cttccccgac 300
ctggaatctg aattccaggc cgccctgagc cggaaggtgg ccgaactggt gcacttcctg 360
ctgctgaagt accgggccag agaacccgtg accaaggccg agatgctggg cagcgtcgtg 420
ggcaactggc agtacttctt ccccgtgatc ttctccaagg ccagctccag cctgcagctg 480
gtgttcggca tcgagctgat ggaagtggac cccatcggac acctgtacat cttcgccacc 540
tgtctgggcc tgagctacga tggcctgctg ggcgacaacc agatcatgcc caaagccggc 600
ctgctgatca tcgtgctggc catcattgcc cgcgagggcg attgtgcccc cgaggaaaag 660
atctgggagg aactgagcgt gctggaagtg ttcgagggaa gagaggactc catcctgggc 720
gaccccaaga agctgctgac ccagcacttc gtgcaggaaa actacctgga gtatagacag 780
gtgcccggca gcgaccctgc ctgctacgaa tttctgtggg gccctagagc actggtggaa 840
accagctacg tgaaagtgct gcaccacatg gtcaagatca gcggcggacc ccacatcagc 900
tacccccctc tgcatgaatg ggtgctgaga gagggcgagg aaggcggagg acctggcgga 960
ggaatgcagg ctgaaggcag aggcacaggc ggctctacag gcgacgctga tggaccaggc 1020
ggacccggaa ttccagatgg ccctggcgga aatgctggcg ggcctggcga agctggcgct 1080
acaggcggaa gaggacctag aggcgctggc gccgctagag cttctggacc agggggaggc 1140
gctcctagag gacctcatgg cggagctgcc tctggcctga acggctgctg tagatgtggc 1200
gccagaggcc ccgaaagcag actgctggaa ttctacctgg ccatgccttt cgccaccccc 1260
atggaagctg agctggccag aagaagcctg gcccaggacg ctcctccact gcctgtgcca 1320
ggcgtgctgc tgaaagaatt caccgtgtcc ggcaacatcc tgaccatccg gctgacagcc 1380
gccgaccaca gacagctgca gctgagcatc agcagctgcc tgcagcagct gtccctgctg 1440
atgtggatca cccagtgctt tctgcccgtg tttctggccc agcctcctag cggacagcgg 1500
agatga 1506
<210> 11
<211> 501
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of ChAdOx1_MAGE_NYESO
<400> 11
Met Pro Leu Glu Gln Arg Ser Gln His Cys Lys Pro Glu Glu Gly Leu
1 5 10 15
Glu Ala Arg Gly Glu Ala Leu Gly Leu Val Gly Ala Gln Ala Pro Ala
20 25 30
Thr Glu Glu Gln Glu Ala Ala Ser Ser Ser Ser Thr Leu Val Glu Val
35 40 45
Thr Leu Gly Glu Val Pro Ala Ala Glu Ser Pro Asp Pro Pro Gln Ser
50 55 60
Pro Gln Gly Ala Ser Ser Leu Pro Thr Thr Met Asn Tyr Pro Leu Trp
65 70 75 80
Ser Gln Ser Tyr Glu Asp Ser Ser Asn Gln Glu Glu Glu Gly Pro Ser
85 90 95
Thr Phe Pro Asp Leu Glu Ser Glu Phe Gln Ala Ala Leu Ser Arg Lys
100 105 110
Val Ala Glu Leu Val His Phe Leu Leu Leu Lys Tyr Arg Ala Arg Glu
115 120 125
Pro Val Thr Lys Ala Glu Met Leu Gly Ser Val Val Gly Asn Trp Gln
130 135 140
Tyr Phe Phe Pro Val Ile Phe Ser Lys Ala Ser Ser Ser Leu Gln Leu
145 150 155 160
Val Phe Gly Ile Glu Leu Met Glu Val Asp Pro Ile Gly His Leu Tyr
165 170 175
Ile Phe Ala Thr Cys Leu Gly Leu Ser Tyr Asp Gly Leu Leu Gly Asp
180 185 190
Asn Gln Ile Met Pro Lys Ala Gly Leu Leu Ile Ile Val Leu Ala Ile
195 200 205
Ile Ala Arg Glu Gly Asp Cys Ala Pro Glu Glu Lys Ile Trp Glu Glu
210 215 220
Leu Ser Val Leu Glu Val Phe Glu Gly Arg Glu Asp Ser Ile Leu Gly
225 230 235 240
Asp Pro Lys Lys Leu Leu Thr Gln His Phe Val Gln Glu Asn Tyr Leu
245 250 255
Glu Tyr Arg Gln Val Pro Gly Ser Asp Pro Ala Cys Tyr Glu Phe Leu
260 265 270
Trp Gly Pro Arg Ala Leu Val Glu Thr Ser Tyr Val Lys Val Leu His
275 280 285
His Met Val Lys Ile Ser Gly Gly Pro His Ile Ser Tyr Pro Pro Leu
290 295 300
His Glu Trp Val Leu Arg Glu Gly Glu Glu Gly Gly Gly Pro Gly Gly
305 310 315 320
Gly Met Gln Ala Glu Gly Arg Gly Thr Gly Gly Ser Thr Gly Asp Ala
325 330 335
Asp Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly Pro Gly Gly Asn Ala
340 345 350
Gly Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly Arg Gly Pro Arg Gly
355 360 365
Ala Gly Ala Ala Arg Ala Ser Gly Pro Gly Gly Gly Ala Pro Arg Gly
370 375 380
Pro His Gly Gly Ala Ala Ser Gly Leu Asn Gly Cys Cys Arg Cys Gly
385 390 395 400
Ala Arg Gly Pro Glu Ser Arg Leu Leu Glu Phe Tyr Leu Ala Met Pro
405 410 415
Phe Ala Thr Pro Met Glu Ala Glu Leu Ala Arg Arg Ser Leu Ala Gln
420 425 430
Asp Ala Pro Pro Leu Pro Val Pro Gly Val Leu Leu Lys Glu Phe Thr
435 440 445
Val Ser Gly Asn Ile Leu Thr Ile Arg Leu Thr Ala Ala Asp His Arg
450 455 460
Gln Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln Gln Leu Ser Leu Leu
465 470 475 480
Met Trp Ile Thr Gln Cys Phe Leu Pro Val Phe Leu Ala Gln Pro Pro
485 490 495
Ser Gly Gln Arg Arg
500
<210> 12
<211> 1584
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector ChAdOx1_hIi_MAGE_NY-ESO-1
<400> 12
atgggcgccc tgtacaccgg ctttagcatc ctcgtgaccc tgctgctggc cggacaggct 60
accaccgcct actttctgta ccccctggaa cagcggagcc agcactgcaa gcctgaggaa 120
ggcctggaag ccagaggcga agctctggga ctcgtgggag cacaggctcc agccaccgaa 180
gaacaggaag ccgccagcag ctctagcacc ctggtggaag tgacactggg cgaagtgcct 240
gccgccgagt ctcctgatcc tcctcagtct cctcagggcg ccagctctct gcccaccacc 300
atgaactacc ccctgtggtc ccagtcctac gaggacagca gcaaccagga agaagagggc 360
cccagcacct tccccgacct ggaatctgaa ttccaggccg ccctgagccg gaaggtggcc 420
gaactggtgc actttctgct gctgaagtac cgggccagag aacccgtgac caaggccgag 480
atgctgggca gcgtcgtggg caactggcag tacttcttcc ccgtgatctt ctccaaggcc 540
agctccagcc tgcagctggt gttcggcatc gagctgatgg aagtggaccc catcggacac 600
ctgtacatct tcgccacctg tctgggcctg agctacgatg gcctgctggg cgacaaccag 660
atcatgccca aagccggcct gctgatcatc gtgctggcca tcattgcccg cgagggcgat 720
tgtgcccccg aggaaaagat ctgggaggaa ctgagcgtgc tggaagtgtt cgagggaaga 780
gaggactcca tcctgggcga ccccaagaag ctgctgaccc agcacttcgt gcaggaaaac 840
tacctggagt atagacaggt gcccggcagc gaccctgcct gctacgaatt tctgtggggc 900
cctagagcac tggtggaaac cagctacgtg aaagtgctgc accacatggt caagatcagc 960
ggcggacccc acatcagcta cccccctctg catgaatggg tgctgagaga gggcgaggaa 1020
ggcggaggac ctggcggagg aatgcaggct gaaggcagag gcacaggcgg ctctacaggc 1080
gacgctgatg gaccaggcgg acccggaatt ccagatggcc ctggcggaaa tgctggcggg 1140
cctggcgaag ctggcgctac aggcggaaga ggacctagag gcgctggcgc cgctagagca 1200
tctggaccag ggggaggcgc tcctagagga cctcatggcg gagctgcctc tggcctgaac 1260
ggctgctgta gatgtggcgc cagaggcccc gaaagcagac tgctggaatt ctacctggcc 1320
atgcctttcg ccacccccat ggaagctgag ctggccagaa gaagcctggc ccaggacgct 1380
cctccactgc ctgtgccagg cgtgctgctg aaagaattca ccgtgtccgg caacatcctg 1440
accatccggc tgacagccgc cgaccacaga cagctgcagc tgagcatcag cagctgcctg 1500
cagcagctgt ccctgctgat gtggatcacc cagtgctttc tgcccgtgtt tctggcccag 1560
cctcctagcg gacagcggag atga 1584
<210> 13
<211> 527
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein sequence of ChAdOx1_hIi_MAGE_NY-ESO-1
<400> 13
Met Gly Ala Leu Tyr Thr Gly Phe Ser Ile Leu Val Thr Leu Leu Leu
1 5 10 15
Ala Gly Gln Ala Thr Thr Ala Tyr Phe Leu Tyr Pro Leu Glu Gln Arg
20 25 30
Ser Gln His Cys Lys Pro Glu Glu Gly Leu Glu Ala Arg Gly Glu Ala
35 40 45
Leu Gly Leu Val Gly Ala Gln Ala Pro Ala Thr Glu Glu Gln Glu Ala
50 55 60
Ala Ser Ser Ser Ser Thr Leu Val Glu Val Thr Leu Gly Glu Val Pro
65 70 75 80
Ala Ala Glu Ser Pro Asp Pro Pro Gln Ser Pro Gln Gly Ala Ser Ser
85 90 95
Leu Pro Thr Thr Met Asn Tyr Pro Leu Trp Ser Gln Ser Tyr Glu Asp
100 105 110
Ser Ser Asn Gln Glu Glu Glu Gly Pro Ser Thr Phe Pro Asp Leu Glu
115 120 125
Ser Glu Phe Gln Ala Ala Leu Ser Arg Lys Val Ala Glu Leu Val His
130 135 140
Phe Leu Leu Leu Lys Tyr Arg Ala Arg Glu Pro Val Thr Lys Ala Glu
145 150 155 160
Met Leu Gly Ser Val Val Gly Asn Trp Gln Tyr Phe Phe Pro Val Ile
165 170 175
Phe Ser Lys Ala Ser Ser Ser Leu Gln Leu Val Phe Gly Ile Glu Leu
180 185 190
Met Glu Val Asp Pro Ile Gly His Leu Tyr Ile Phe Ala Thr Cys Leu
195 200 205
Gly Leu Ser Tyr Asp Gly Leu Leu Gly Asp Asn Gln Ile Met Pro Lys
210 215 220
Ala Gly Leu Leu Ile Ile Val Leu Ala Ile Ile Ala Arg Glu Gly Asp
225 230 235 240
Cys Ala Pro Glu Glu Lys Ile Trp Glu Glu Leu Ser Val Leu Glu Val
245 250 255
Phe Glu Gly Arg Glu Asp Ser Ile Leu Gly Asp Pro Lys Lys Leu Leu
260 265 270
Thr Gln His Phe Val Gln Glu Asn Tyr Leu Glu Tyr Arg Gln Val Pro
275 280 285
Gly Ser Asp Pro Ala Cys Tyr Glu Phe Leu Trp Gly Pro Arg Ala Leu
290 295 300
Val Glu Thr Ser Tyr Val Lys Val Leu His His Met Val Lys Ile Ser
305 310 315 320
Gly Gly Pro His Ile Ser Tyr Pro Pro Leu His Glu Trp Val Leu Arg
325 330 335
Glu Gly Glu Glu Gly Gly Gly Pro Gly Gly Gly Met Gln Ala Glu Gly
340 345 350
Arg Gly Thr Gly Gly Ser Thr Gly Asp Ala Asp Gly Pro Gly Gly Pro
355 360 365
Gly Ile Pro Asp Gly Pro Gly Gly Asn Ala Gly Gly Pro Gly Glu Ala
370 375 380
Gly Ala Thr Gly Gly Arg Gly Pro Arg Gly Ala Gly Ala Ala Arg Ala
385 390 395 400
Ser Gly Pro Gly Gly Gly Ala Pro Arg Gly Pro His Gly Gly Ala Ala
405 410 415
Ser Gly Leu Asn Gly Cys Cys Arg Cys Gly Ala Arg Gly Pro Glu Ser
420 425 430
Arg Leu Leu Glu Phe Tyr Leu Ala Met Pro Phe Ala Thr Pro Met Glu
435 440 445
Ala Glu Leu Ala Arg Arg Ser Leu Ala Gln Asp Ala Pro Pro Leu Pro
450 455 460
Val Pro Gly Val Leu Leu Lys Glu Phe Thr Val Ser Gly Asn Ile Leu
465 470 475 480
Thr Ile Arg Leu Thr Ala Ala Asp His Arg Gln Leu Gln Leu Ser Ile
485 490 495
Ser Ser Cys Leu Gln Gln Leu Ser Leu Leu Met Trp Ile Thr Gln Cys
500 505 510
Phe Leu Pro Val Phe Leu Ala Gln Pro Pro Ser Gly Gln Arg Arg
515 520 525
<210> 14
<211> 1569
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector ChAdOx1_tPA_MAGE_NY-ESO-1
<400> 14
atggacgcca tgaagcgggg cctgtgttgc gtgctgctgc tgtgtggcgc tgtgttcgtg 60
tcccccccac tggaacagag aagccagcac tgcaagcccg aggaaggcct ggaagccaga 120
ggcgaagctc tgggactcgt gggagcacag gctccagcca ccgaagaaca ggaagccgcc 180
agcagctcta gcaccctggt ggaagtgaca ctgggcgaag tgcctgccgc cgagtctcct 240
gatcctcctc agtctcctca gggcgccagc tctctgccca ccaccatgaa ctaccccctg 300
tggtcccagt cctacgagga cagcagcaac caggaagaag agggccccag caccttcccc 360
gacctggaat ctgaattcca ggccgccctg agccggaagg tggccgaact ggtgcacttc 420
ctgctgctga agtaccgggc cagagaaccc gtgaccaagg ccgagatgct gggcagcgtc 480
gtgggcaact ggcagtactt cttccccgtg atcttctcca aggccagctc cagcctgcag 540
ctggtgttcg gcatcgagct gatggaagtg gaccccatcg gacacctgta catcttcgcc 600
acctgtctgg gcctgagcta cgatggcctg ctgggcgaca accagatcat gcccaaagcc 660
ggcctgctga tcatcgtgct ggccatcatt gcccgcgagg gcgattgtgc ccccgaggaa 720
aagatctggg aggaactgag cgtgctggaa gtgttcgagg gaagagagga ctccatcctg 780
ggcgacccca agaagctgct gacccagcac ttcgtgcagg aaaactacct ggagtataga 840
caggtgcccg gcagcgaccc tgcctgctac gaatttctgt ggggccctag agcactggtg 900
gaaaccagct acgtgaaagt gctgcaccac atggtcaaga tcagcggcgg accccacatc 960
agctacccac ctctgcacga atgggtgctg agagagggcg aagaaggcgg aggacctggc 1020
ggaggaatgc aggctgaagg cagaggcaca ggcggctcta caggcgacgc tgatggacca 1080
ggcggacccg gaattccaga tggccctggc ggaaatgctg gcgggcctgg cgaagctggc 1140
gctacaggcg gaagaggacc tagaggcgct ggcgccgcta gagcatctgg accaggggga 1200
ggcgctccta gaggacctca tggcggagct gcctctggcc tgaatggctg ctgtagatgt 1260
ggcgccagag gccccgaaag cagactgctg gaattctacc tggccatgcc tttcgccacc 1320
cccatggaag ctgagctggc cagaagaagc ctggcccagg acgctcctcc actgcctgtg 1380
ccaggggtgc tgctgaaaga attcaccgtg tccggcaaca tcctgaccat ccggctgaca 1440
gccgccgacc acagacagct gcagctgagc atcagcagct gcctgcagca gctgtccctg 1500
ctgatgtgga tcacccagtg ctttctgccc gtgtttctgg cccagcctcc tagcggacag 1560
cggagatga 1569
<210> 15
<211> 522
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of ChAdOx1_tPA_MAGE_NY-ESO-1
<400> 15
Met Asp Ala Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Pro Leu Glu Gln Arg Ser Gln His Cys Lys
20 25 30
Pro Glu Glu Gly Leu Glu Ala Arg Gly Glu Ala Leu Gly Leu Val Gly
35 40 45
Ala Gln Ala Pro Ala Thr Glu Glu Gln Glu Ala Ala Ser Ser Ser Ser
50 55 60
Thr Leu Val Glu Val Thr Leu Gly Glu Val Pro Ala Ala Glu Ser Pro
65 70 75 80
Asp Pro Pro Gln Ser Pro Gln Gly Ala Ser Ser Leu Pro Thr Thr Met
85 90 95
Asn Tyr Pro Leu Trp Ser Gln Ser Tyr Glu Asp Ser Ser Asn Gln Glu
100 105 110
Glu Glu Gly Pro Ser Thr Phe Pro Asp Leu Glu Ser Glu Phe Gln Ala
115 120 125
Ala Leu Ser Arg Lys Val Ala Glu Leu Val His Phe Leu Leu Leu Lys
130 135 140
Tyr Arg Ala Arg Glu Pro Val Thr Lys Ala Glu Met Leu Gly Ser Val
145 150 155 160
Val Gly Asn Trp Gln Tyr Phe Phe Pro Val Ile Phe Ser Lys Ala Ser
165 170 175
Ser Ser Leu Gln Leu Val Phe Gly Ile Glu Leu Met Glu Val Asp Pro
180 185 190
Ile Gly His Leu Tyr Ile Phe Ala Thr Cys Leu Gly Leu Ser Tyr Asp
195 200 205
Gly Leu Leu Gly Asp Asn Gln Ile Met Pro Lys Ala Gly Leu Leu Ile
210 215 220
Ile Val Leu Ala Ile Ile Ala Arg Glu Gly Asp Cys Ala Pro Glu Glu
225 230 235 240
Lys Ile Trp Glu Glu Leu Ser Val Leu Glu Val Phe Glu Gly Arg Glu
245 250 255
Asp Ser Ile Leu Gly Asp Pro Lys Lys Leu Leu Thr Gln His Phe Val
260 265 270
Gln Glu Asn Tyr Leu Glu Tyr Arg Gln Val Pro Gly Ser Asp Pro Ala
275 280 285
Cys Tyr Glu Phe Leu Trp Gly Pro Arg Ala Leu Val Glu Thr Ser Tyr
290 295 300
Val Lys Val Leu His His Met Val Lys Ile Ser Gly Gly Pro His Ile
305 310 315 320
Ser Tyr Pro Pro Leu His Glu Trp Val Leu Arg Glu Gly Glu Glu Gly
325 330 335
Gly Gly Pro Gly Gly Gly Met Gln Ala Glu Gly Arg Gly Thr Gly Gly
340 345 350
Ser Thr Gly Asp Ala Asp Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly
355 360 365
Pro Gly Gly Asn Ala Gly Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly
370 375 380
Arg Gly Pro Arg Gly Ala Gly Ala Ala Arg Ala Ser Gly Pro Gly Gly
385 390 395 400
Gly Ala Pro Arg Gly Pro His Gly Gly Ala Ala Ser Gly Leu Asn Gly
405 410 415
Cys Cys Arg Cys Gly Ala Arg Gly Pro Glu Ser Arg Leu Leu Glu Phe
420 425 430
Tyr Leu Ala Met Pro Phe Ala Thr Pro Met Glu Ala Glu Leu Ala Arg
435 440 445
Arg Ser Leu Ala Gln Asp Ala Pro Pro Leu Pro Val Pro Gly Val Leu
450 455 460
Leu Lys Glu Phe Thr Val Ser Gly Asn Ile Leu Thr Ile Arg Leu Thr
465 470 475 480
Ala Ala Asp His Arg Gln Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln
485 490 495
Gln Leu Ser Leu Leu Met Trp Ile Thr Gln Cys Phe Leu Pro Val Phe
500 505 510
Leu Ala Gln Pro Pro Ser Gly Gln Arg Arg
515 520
<210> 16
<211> 945
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector MVA_MAGEA3
<400> 16
atgcccctgg aacagcggag ccagcactgc aagcctgagg aaggcctgga agccagaggc 60
gaagctctgg gactcgtggg agcacaggct ccagccaccg aagaacagga agccgccagc 120
agcagctcca ccctggtgga agtgacactg ggcgaagtgc ctgccgccga gtctcctgat 180
cctcctcagt ctcctcaggg cgccagctct ctgcccacca ccatgaacta ccccctgtgg 240
tcccagtcct acgaggacag cagcaaccag gaagaagagg gccccagcac cttccccgac 300
ctggaatctg aattccaggc cgccctgagc cggaaggtgg ccgaactggt gcacttcctg 360
ctgctgaagt accgggccag agaacccgtg accaaggccg agatgctggg cagcgtcgtg 420
ggcaactggc agtacttctt ccccgtgatc ttctccaagg ccagctccag cctgcagctg 480
gtgttcggca tcgagctgat ggaagtggac cccatcggac acctgtacat cttcgccacc 540
tgtctgggcc tgagctacga tggcctgctg ggcgacaacc agatcatgcc caaagccggc 600
ctgctgatca tcgtgctggc catcattgcc cgcgagggcg attgtgcccc cgaggaaaag 660
atctgggagg aactgagcgt gctggaagtg ttcgagggaa gagaggactc catcctgggc 720
gaccccaaga agctgctgac ccagcacttc gtgcaggaaa actacctgga gtatagacag 780
gtgcccggca gcgaccctgc ctgctacgaa tttctgtggg gccctagagc actggtggaa 840
accagctacg tgaaagtgct gcaccacatg gtcaagatca gcggcggacc ccacatcagc 900
tacccccctc tgcatgaatg ggtgctgcgg gaaggcgaag agtga 945
<210> 17
<211> 314
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of MVA_MAGEA3
<400> 17
Met Pro Leu Glu Gln Arg Ser Gln His Cys Lys Pro Glu Glu Gly Leu
1 5 10 15
Glu Ala Arg Gly Glu Ala Leu Gly Leu Val Gly Ala Gln Ala Pro Ala
20 25 30
Thr Glu Glu Gln Glu Ala Ala Ser Ser Ser Ser Thr Leu Val Glu Val
35 40 45
Thr Leu Gly Glu Val Pro Ala Ala Glu Ser Pro Asp Pro Pro Gln Ser
50 55 60
Pro Gln Gly Ala Ser Ser Leu Pro Thr Thr Met Asn Tyr Pro Leu Trp
65 70 75 80
Ser Gln Ser Tyr Glu Asp Ser Ser Asn Gln Glu Glu Glu Gly Pro Ser
85 90 95
Thr Phe Pro Asp Leu Glu Ser Glu Phe Gln Ala Ala Leu Ser Arg Lys
100 105 110
Val Ala Glu Leu Val His Phe Leu Leu Leu Lys Tyr Arg Ala Arg Glu
115 120 125
Pro Val Thr Lys Ala Glu Met Leu Gly Ser Val Val Gly Asn Trp Gln
130 135 140
Tyr Phe Phe Pro Val Ile Phe Ser Lys Ala Ser Ser Ser Leu Gln Leu
145 150 155 160
Val Phe Gly Ile Glu Leu Met Glu Val Asp Pro Ile Gly His Leu Tyr
165 170 175
Ile Phe Ala Thr Cys Leu Gly Leu Ser Tyr Asp Gly Leu Leu Gly Asp
180 185 190
Asn Gln Ile Met Pro Lys Ala Gly Leu Leu Ile Ile Val Leu Ala Ile
195 200 205
Ile Ala Arg Glu Gly Asp Cys Ala Pro Glu Glu Lys Ile Trp Glu Glu
210 215 220
Leu Ser Val Leu Glu Val Phe Glu Gly Arg Glu Asp Ser Ile Leu Gly
225 230 235 240
Asp Pro Lys Lys Leu Leu Thr Gln His Phe Val Gln Glu Asn Tyr Leu
245 250 255
Glu Tyr Arg Gln Val Pro Gly Ser Asp Pro Ala Cys Tyr Glu Phe Leu
260 265 270
Trp Gly Pro Arg Ala Leu Val Glu Thr Ser Tyr Val Lys Val Leu His
275 280 285
His Met Val Lys Ile Ser Gly Gly Pro His Ile Ser Tyr Pro Pro Leu
290 295 300
His Glu Trp Val Leu Arg Glu Gly Glu Glu
305 310
<210> 18
<211> 543
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector MVA_NYESO
<400> 18
atgcaggccg agggcagagg caccggcgga tctactgggg atgctgatgg acctggcggc 60
cctggcattc cagatggccc aggcggaaat gctggcggac caggcgaagc tggcgctaca 120
ggcggaagag gacctagagg cgctggcgcc gctagagctt ctggacctgg gggaggcgct 180
cctagaggac ctcatggcgg agctgcctct ggcctgaatg gctgctgtag atgtggcgcc 240
agaggccccg aaagccggct gctggaattc tacctggcca tgcccttcgc cacccccatg 300
gaagctgagc tggccagaag aagcctggcc caggacgctc ctcctctgcc tgtgcctggc 360
gtgctgctga aagaattcac cgtgtccggc aacatcctga ccatccggct gacagccgcc 420
gaccacagac agctgcagct gagcatcagc agctgcctgc agcagctgtc cctgctgatg 480
tggatcaccc agtgctttct gcccgtgttt ctggcccagc ctcctagcgg ccagcggcgc 540
taa 543
<210> 19
<211> 180
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of MVA_NYESO
<400> 19
Met Gln Ala Glu Gly Arg Gly Thr Gly Gly Ser Thr Gly Asp Ala Asp
1 5 10 15
Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly Pro Gly Gly Asn Ala Gly
20 25 30
Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly Arg Gly Pro Arg Gly Ala
35 40 45
Gly Ala Ala Arg Ala Ser Gly Pro Gly Gly Gly Ala Pro Arg Gly Pro
50 55 60
His Gly Gly Ala Ala Ser Gly Leu Asn Gly Cys Cys Arg Cys Gly Ala
65 70 75 80
Arg Gly Pro Glu Ser Arg Leu Leu Glu Phe Tyr Leu Ala Met Pro Phe
85 90 95
Ala Thr Pro Met Glu Ala Glu Leu Ala Arg Arg Ser Leu Ala Gln Asp
100 105 110
Ala Pro Pro Leu Pro Val Pro Gly Val Leu Leu Lys Glu Phe Thr Val
115 120 125
Ser Gly Asn Ile Leu Thr Ile Arg Leu Thr Ala Ala Asp His Arg Gln
130 135 140
Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln Gln Leu Ser Leu Leu Met
145 150 155 160
Trp Ile Thr Gln Cys Phe Leu Pro Val Phe Leu Ala Gln Pro Pro Ser
165 170 175
Gly Gln Arg Arg
180
<210> 20
<211> 1008
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector MVA_tPA_MAGEA3
<400> 20
atggacgcca tgaagcgggg cctgtgctgc gtgctgctgc tgtgtggcgc tgtgttcgtg 60
tcccccccac tggaacagag aagccagcac tgcaagcccg aggaaggcct ggaagccaga 120
ggcgaagctc tgggactcgt gggagcacag gctccagcca ccgaagaaca ggaagccgcc 180
agcagctcta gcaccctggt ggaagtgaca ctgggcgaag tgcctgccgc cgagtctcct 240
gatcctcctc agtctcctca gggcgccagc tctctgccca ccaccatgaa ctaccccctg 300
tggtcccagt cctacgagga cagcagcaac caggaagaag agggccccag caccttcccc 360
gacctggaat ctgaattcca ggccgccctg agccggaagg tggccgaact ggtgcacttc 420
ctgctgctga agtaccgggc cagagaaccc gtgaccaagg ccgagatgct gggcagcgtc 480
gtgggcaact ggcagtactt cttccccgtg atcttctcca aggccagctc cagcctgcag 540
ctggtgttcg gcatcgagct gatggaagtg gaccccatcg gacacctgta catcttcgcc 600
acctgtctgg gcctgagcta cgatggcctg ctgggcgaca accagatcat gcccaaagcc 660
ggcctgctga tcatcgtgct ggccatcatt gcccgcgagg gcgattgtgc ccccgaggaa 720
aagatctggg aggaactgag cgtgctggaa gtgttcgagg gaagagagga ctccatcctg 780
ggcgacccca agaagctgct gacccagcac ttcgtgcagg aaaactacct ggagtataga 840
caggtgcccg gcagcgaccc tgcctgctac gaatttctgt ggggccctag agcactggtg 900
gaaaccagct acgtgaaagt gctgcaccac atggtcaaga tcagcggcgg accccacatc 960
agctacccac ctctgcacga atgggtgctg cgggaaggcg aagagtga 1008
<210> 21
<211> 335
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of MVA_tPA_MAGEA3
<400> 21
Met Asp Ala Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Pro Leu Glu Gln Arg Ser Gln His Cys Lys
20 25 30
Pro Glu Glu Gly Leu Glu Ala Arg Gly Glu Ala Leu Gly Leu Val Gly
35 40 45
Ala Gln Ala Pro Ala Thr Glu Glu Gln Glu Ala Ala Ser Ser Ser Ser
50 55 60
Thr Leu Val Glu Val Thr Leu Gly Glu Val Pro Ala Ala Glu Ser Pro
65 70 75 80
Asp Pro Pro Gln Ser Pro Gln Gly Ala Ser Ser Leu Pro Thr Thr Met
85 90 95
Asn Tyr Pro Leu Trp Ser Gln Ser Tyr Glu Asp Ser Ser Asn Gln Glu
100 105 110
Glu Glu Gly Pro Ser Thr Phe Pro Asp Leu Glu Ser Glu Phe Gln Ala
115 120 125
Ala Leu Ser Arg Lys Val Ala Glu Leu Val His Phe Leu Leu Leu Lys
130 135 140
Tyr Arg Ala Arg Glu Pro Val Thr Lys Ala Glu Met Leu Gly Ser Val
145 150 155 160
Val Gly Asn Trp Gln Tyr Phe Phe Pro Val Ile Phe Ser Lys Ala Ser
165 170 175
Ser Ser Leu Gln Leu Val Phe Gly Ile Glu Leu Met Glu Val Asp Pro
180 185 190
Ile Gly His Leu Tyr Ile Phe Ala Thr Cys Leu Gly Leu Ser Tyr Asp
195 200 205
Gly Leu Leu Gly Asp Asn Gln Ile Met Pro Lys Ala Gly Leu Leu Ile
210 215 220
Ile Val Leu Ala Ile Ile Ala Arg Glu Gly Asp Cys Ala Pro Glu Glu
225 230 235 240
Lys Ile Trp Glu Glu Leu Ser Val Leu Glu Val Phe Glu Gly Arg Glu
245 250 255
Asp Ser Ile Leu Gly Asp Pro Lys Lys Leu Leu Thr Gln His Phe Val
260 265 270
Gln Glu Asn Tyr Leu Glu Tyr Arg Gln Val Pro Gly Ser Asp Pro Ala
275 280 285
Cys Tyr Glu Phe Leu Trp Gly Pro Arg Ala Leu Val Glu Thr Ser Tyr
290 295 300
Val Lys Val Leu His His Met Val Lys Ile Ser Gly Gly Pro His Ile
305 310 315 320
Ser Tyr Pro Pro Leu His Glu Trp Val Leu Arg Glu Gly Glu Glu
325 330 335
<210> 22
<211> 606
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector MVA_tPA_NYESO
<400> 22
atggacgcca tgaagcgggg cctgtgctgc gtgctgctgc tgtgtggcgc tgtgttcgtg 60
agccctcagg ccgagggaag aggcacaggc ggatctacag gcgacgctga tggacctggc 120
ggccctggaa ttcctgatgg cccaggcgga aatgctggcg gaccaggcga agctggcgct 180
acaggcggaa gaggacctag aggcgctggc gccgctagag cttctggacc tgggggaggc 240
gctcctagag gacctcatgg cggagctgcc tctggcctga atggctgctg tagatgtggc 300
gccagaggcc ccgaaagccg gctgctggaa ttctacctgg ccatgccctt cgccaccccc 360
atggaagctg agctggccag aagaagcctg gcccaggacg ctcctccact gcctgtgcca 420
ggggtgctgc tgaaagaatt caccgtgtcc ggcaacatcc tgaccatccg gctgacagcc 480
gccgaccaca gacagctgca gctgagcatc agcagctgcc tgcagcagct gtccctgctg 540
atgtggatca cccagtgctt tctgcccgtg tttctggccc agcctcctag cggccagcgg 600
cgctaa 606
<210> 23
<211> 201
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of MVA_tPA_NYESO
<400> 23
Met Asp Ala Met Lys Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Gln Ala Glu Gly Arg Gly Thr Gly Gly Ser
20 25 30
Thr Gly Asp Ala Asp Gly Pro Gly Gly Pro Gly Ile Pro Asp Gly Pro
35 40 45
Gly Gly Asn Ala Gly Gly Pro Gly Glu Ala Gly Ala Thr Gly Gly Arg
50 55 60
Gly Pro Arg Gly Ala Gly Ala Ala Arg Ala Ser Gly Pro Gly Gly Gly
65 70 75 80
Ala Pro Arg Gly Pro His Gly Gly Ala Ala Ser Gly Leu Asn Gly Cys
85 90 95
Cys Arg Cys Gly Ala Arg Gly Pro Glu Ser Arg Leu Leu Glu Phe Tyr
100 105 110
Leu Ala Met Pro Phe Ala Thr Pro Met Glu Ala Glu Leu Ala Arg Arg
115 120 125
Ser Leu Ala Gln Asp Ala Pro Pro Leu Pro Val Pro Gly Val Leu Leu
130 135 140
Lys Glu Phe Thr Val Ser Gly Asn Ile Leu Thr Ile Arg Leu Thr Ala
145 150 155 160
Ala Asp His Arg Gln Leu Gln Leu Ser Ile Ser Ser Cys Leu Gln Gln
165 170 175
Leu Ser Leu Leu Met Trp Ile Thr Gln Cys Phe Leu Pro Val Phe Leu
180 185 190
Ala Gln Pro Pro Ser Gly Gln Arg Arg
195 200
<210> 24
<211> 39593
<212> DNA
<213> Artificial Sequence
<220>
<223> ChAdOx1 shuttle vector p2563
<400> 24
gtttaaacgc ggccgccagg cctacccact agtcaattcg ggaggatcga aacggcagat 60
cgcaaaaaac agtacataca gaaggagaca tgaacatgaa catcaaaaaa attgtaaaac 120
aagccacagt tctgactttt acgactgcac ttctggcagg aggagcgact caagccttcg 180
cgaaagaaaa taaccaaaaa gcatacaaag aaacgtacgg cgtctctcat attacacgcc 240
atgatatgct gcagatccct aaacagcagc aaaacgaaaa ataccaagtg cctcaattcg 300
atcaatcaac gattaaaaat attgagtctg caaaaggact tgatgtgtgg gacagctggc 360
cgctgcaaaa cgctgacgga acagtagctg aatacaacgg ctatcacgtt gtgtttgctc 420
ttgcgggaag cccgaaagac gctgatgaca catcaatcta catgttttat caaaaggtcg 480
gcgacaactc aatcgacagc tggaaaaacg cgggccgtgt ctttaaagac agcgataagt 540
tcgacgccaa cgatccgatc ctgaaagatc agacgcaaga atggtccggt tctgcaacct 600
ttacatctga cggaaaaatc cgtttattct acactgacta ttccggtaaa cattacggca 660
aacaaagcct gacaacagcg caggtaaatg tgtcaaaatc tgatgacaca ctcaaaatca 720
acggagtgga agatcacaaa acgatttttg acggagacgg aaaaacatat cagaacgttc 780
agcagtttat cgatgaaggc aattatacat ccggcgacaa ccatacgctg agagaccctc 840
actacgttga agacaaaggc cataaatacc ttgtattcga agccaacacg ggaacagaaa 900
acggatacca aggcgaagaa tctttattta acaaagcgta ctacggcggc ggcacgaact 960
tcttccgtaa agaaagccag aagcttcagc agagcgctaa aaaacgcgat gctgagttag 1020
cgaacggcgc cctcggtatc atagagttaa ataatgatta cacattgaaa aaagtaatga 1080
agccgctgat cacttcaaac acggtaactg atgaaatcga gcgcgcgaat gttttcaaaa 1140
tgaacggcaa atggtacttg ttcactgatt cacgcggttc aaaaatgacg atcgatggta 1200
ttaactcaaa cgatatttac atgcttggtt atgtatcaaa ctctttaacc ggcccttaca 1260
agccgctgaa caaaacaggg cttgtgctgc aaatgggtct tgatccaaac gatgtgacat 1320
tcacttactc tcacttcgca gtgccgcaag ccaaaggcaa caatgtggtt atcacaagct 1380
acatgacaaa cagaggcttc ttcgaggata aaaaggcaac atttgcgcca agcttcttaa 1440
tgaacatcaa aggcaataaa acatccgttg tcaaaaacag catcctggag caaggacagc 1500
tgacagtcaa ctaataacag caaaaagaaa atgccgatac ttcattggca ttttctttta 1560
tttctcaaca agatggtgaa ttgactagtg ggtagatcca caggacgggt gtggtcgcca 1620
tgatcgcgta gtcgatagtg gctccaagta gcgaagcgag caggactggg cggcggccaa 1680
agcggtcgga cagtgctccg agaacgggtg cgcatagaaa ttgcatcaac gcatatagcg 1740
ctagcagcac gccatagtga ctggcgatgc tgtcggaatg gacgatatcc cgcaagaggc 1800
ccggcagtac cggcataacc aagcctatgc ctacagcatc cagggtgacg gtgccgagga 1860
tgacgatgag cgcattgtta gatttcatac acggtgcctg actgcgttag caatttaact 1920
gtgataaact accgcattaa agcttatcga tgataagctg tcaaacatga gaattgatcc 1980
ggaaccctta atataacttc gtataatgta tgctatacga agttattagg tccctcgact 2040
atagggtcac cgtcgacagc gacacacttg catcggatgc agcccggtta acgtgccggc 2100
acggcctggg taaccaggta ttttgtccac ataaccgtgc gcaaaatgtt gtggataagc 2160
aggacacagc agcaatccac agcaggcata caaccgcaca ccgaggttac tccgttctac 2220
aggttacgac gacatgtcaa tacttgccct tgacaggcat tgatggaatc gtagtctcac 2280
gctgatagtc tgatcgacaa tacaagtggg accgtggtcc cagaccgata atcagaccga 2340
crayacgagt gggaycgtgg tcccagacta ataatcagac cgacgatacg agtgggaccg 2400
tggtcccaga ctaataatca gaccgacgat acgagtggga ccgtggtycc agwctratwa 2460
tcagaccgac gatacragtg gracmgtggk cccagasaka atawtcagrc cgagwtaygc 2520
wktckggcct gtaacaaagg acattaagta aagacagata mrmgtgrgac taaaacgtgg 2580
tcccagtctg attatcagac cgacgatacg agtgggaccg tggtcccaga ctaataatca 2640
gaccgacgat acgagtggga ccgtggtccc agactaataa tcagaccgac gatacgagtg 2700
ggaccgtggt cccagtctga ttatcagacc gacgatacaa gtggaacagt gggcccagag 2760
agaatattca ggccagttat gctttctggc ctgtaacaaa ggacattaag taaagacaga 2820
taaacgtaga ctaaaacgtg gtcgcatcag ggtgctggct tttcaagttc cttaagaatg 2880
gcctcaattt tctctataca ctcagttgga acacgagacc tgtccaggtt aagcaccatt 2940
ttatcgccct tatacaatac tgtcgctcca ggagcaaact gatgtcgtga gcttaaacta 3000
gttcttgatg cagatgacgt tttaagcaca gaagttaaaa gagtgataac ttcttcagct 3060
tcaaatatca ccccagcttt tttctgctca tgaaggttag atgcctgctg cttaagtaat 3120
tcctctttat ctgtaaaggc tttttgaagt gcatcacctg accgggcaga tagttcaccg 3180
gggtgagaaa aaagagcaac aactgattta ggcaatttgg cggtgttgat acagcgggta 3240
ataatcttac gtgaaatatt ttccgcatca gccagcgcag aaatatttcc agcaaattca 3300
ttctgcaatc ggcttgcata acgctgacca cgttcataag cacttgttgg gcgataatcg 3360
ttacccaatc tggataatgc agccatctgc tcatcatcca gctcgccaac cagaacacga 3420
taatcacttt cggtaagtgc agcagcttta cgacggcgac tcccatcggc aatttctatg 3480
acaccagata ctcttcgacc gaacgccggt gtctgttgac cagtcagtag aaaagaaggg 3540
atgagatcat ccagtgcgtc ctcagtaagc agctcctggt cacgttcatt acctgaccat 3600
acccgagagg tcttctcaac actatcaccc cggagcactt caagagtaaa cttcacatcc 3660
cgaccacata caggcaaagt aatggcatta ccgcgagcca ttactcctac gcgcgcaatt 3720
aacgaatcca ccatcggggc agctggtgtc gataacgaag tatcttcaac cggttgagta 3780
ttgagcgtat gttttggaat aacaggcgca cgcttcatta tctaatctcc cagcgtggtt 3840
taatcagacg atcgaaaatt tcattgcaga caggttccca aatagaaaga gcatttctcc 3900
aggcaccagt tgaagagcgt tgatcaatgg cctgttcaaa aacagttctc atccggatct 3960
gacctttacc aacttcatcc gtttcacgta caacattttt tagaaccatg cttccccagg 4020
catcccgaat ttgctcctcc atccacgggg actgagagcc attactattg ctgtatttgg 4080
taagcaaaat acgtacatca ggctcgaacc ctttaagatc aacgttcttg agcagatcac 4140
gaagcatatc gaaaaactgc agtgcggagg tgtagtcaaa caactcagca ggcgtgggaa 4200
caatcagcac atcagcagca catacgacat taatcgtgcc gatacccagg ttaggcgcgc 4260
tgtcaataac tatgacatca tagtcatgag caacagtttc aatggccagt cggagcatca 4320
ggtgtggatc ggtgggcagt ttaccttcat caaatttgcc cattaactca gtttcaatac 4380
ggtgcagagc cagacaggaa ggaataatgt caagccccgg ccagcaagtg ggctttattg 4440
cataagtgac atcgtccttt tccccaagat agaaaggcag gagagtgtct tctgcatgaa 4500
tatgaagatc tggtacccat ccgtgataca ttgaggctgt tccctggggg tcgttacctt 4560
ccacgagcaa aacacgtagc cccttcagag ccagatcctg agcaagatga acagaaactg 4620
aggttttgta aacgccacct ttatgggcag caaccccgat caccggtgga aatacgtctt 4680
cagcacgtcg caatcgcgta ccaaacacat cacgcatatg attaatttgt tcaattgtat 4740
aaccaacacg ttgctcaacc cgtcctcgaa tttccatatc cgggtgcggt agtcgccctg 4800
ctttctcggc atctctgata gcctgagaag aaaccccaac taaatccgct gcttcaccta 4860
ttctccagcg ccgggttatt ttcctcgctt ccgggctgtc atcattaaac tgtgcaatgg 4920
cgatagcctt cgtcatttca tgaccagcgt ttatgcactg gttaagtgtt tccatgagtt 4980
tcattctgaa catcctttaa tcattgcttt gcgttttttt attaaatctt gcaatttact 5040
gcaaagcaac aacaaaatcg caaagtcatc aaaaaaccgc aaagttgttt aaaataagag 5100
caacactaca aaaggagata agaagagcac atacctcagt cacttattat cactagcgct 5160
cgccgcagcc gtgtaaccga gcatagcgag cgaactggcg aggaagcaaa gaagaactgt 5220
tctgtcagat agctcttacg ctcagcgcaa gaagaaatat ccaccgtggg aaaaactcca 5280
ggtagaggta cacacgcgga tagccaattc agagtaataa actgtgataa tcaaccctca 5340
tcaatgatga cgaactaacc cccgatatca ggtcacatga cgaagggaaa gagaaggaaa 5400
tcaactgtga caaactgccc tcaaatttgg cttccttaaa aattacagtt caaaaagtat 5460
gagaaaatcc atgcaggctg aaggaaacag caaaactgtg acaaattacc ctcagtaggt 5520
cagaacaaat gtgacgaacc accctcaaat ctgtgacaga taaccctcag actatcctgt 5580
cgtcatggaa gtgatatcgc ggaaggaaaa tacgatatga gtcgtctggc ggcctttctt 5640
tttctcaatg tatgagaggc gcattggagt tctgctgttg atctcattaa cacagacctg 5700
caggaagcgg cggcggaagt caggcatacg ctggtaactt tgaggcagct ggtaacgctc 5760
tatgatccag tcgattttca gagagacgat gcctgagcca tccggcttac gatactgaca 5820
cagggattcg tataaacgca tggcatacgg attggtgatt tcttttgttt cactaagccg 5880
aaactgcgta aaccggttct gtaacccgat aaagaaggga atgagatatg ggttgatatg 5940
tacactgtaa agccctctgg atggactgtg cgcacgtttg ataaaccaag gaaaagattc 6000
atagcctttt tcatcgccgg catcctcttc agggcgataa aaaaccactt ccttccccgc 6060
gaaactcttc aatgcctgcc gtatatcctt actggcttcc gcagaggtca atccgaatat 6120
ttcagcatat ttagcaacat ggatctcgca gataccgtca tgttcctgta gggtgccatc 6180
agattttctg atctggtcaa cgaacagata cagcatacgt ttttgatccc gggagagact 6240
atatgccgcc tcagtgaggt cgtttgactg gacgattcgc gggctatttt tacgtttctt 6300
gtgattgata accgctgttt ccgccatgac agatccatgt gaagtgtgac aagtttttag 6360
attgtcacac taaataaaaa agagtcaata agcagggata actttgtgaa aaaacagctt 6420
cttctgaggg caatttgtca cagggttaag ggcaatttgt cacagacagg actgtcattt 6480
gagggtgatt tgtcacactg aaagggcaat ttgtcacaac accttctcta gaaccagcat 6540
ggataaaggc ctacaaggcg ctctaaaaaa gaagatctaa aaactataaa aaaaataatt 6600
ataaaaatat ccccgtggat aagtggataa ccccaaggga agttttttca ggcatcgtgt 6660
gtaagcagaa tatataagtg ctgttccctg gtgcttcctc gctcactcga gggcttcgcc 6720
ctgtcgctca actgcggcga gcactactgg ctgtaaaagg acagaccaca tcatggttct 6780
gtgttcatta ggttgttctg tccattgctg acataatccg ctccacttca acgtaacacc 6840
gcacgaagat ttctattgtt cctgaaggca tattcaaatc gttttcgtta ccgcttgcag 6900
gcatcatgac agaacactac ttcctataaa cgctacacag gctcctgaga ttaataatgc 6960
ggatctctac gataatggga gattttcccg actgtttcgt tcgcttctca gtggataaca 7020
gccagcttct ctgtttaaca gacaaaaaca gcatatccac tcagttccac atttccatat 7080
aaaggccaag gcatttattc tcaggataat tgtttcagca tcgcaaccgc atcagactcc 7140
ggcatcgcaa actgcacccg gtgccgggca gccacatcca gcgcaaaaac cttcgtgtag 7200
acttccgttg aactgatgga cttatgtccc atcaggcttt gcagaacttt cagcggtata 7260
ccggcataca gcatgtgcat cgcataggaa tggcggaacg tatgtggtgt gaccggaaca 7320
gagaacgtca caccgtcagc agcagcggcg gcaaccgcct ccccaatcca ggtcctgacc 7380
gttctgtccg tcacttccca gatccgcgct ttctctgtcc ttcctgtgcg acggttacgc 7440
cgctccatga gcttatcgcg aataaatacc tgtgacggaa gatcacttcg cagaataaat 7500
aaatcctggt gtccctgttg ataccgggaa gccctgggcc aacttttggc gaaaatgaga 7560
cgttgatcgg cacgtaagag gttccaactt tcaccataat gaaataagat cactaccggg 7620
cgtatttttt gagttatcga gattttcagg agctaaggaa gctaaaatgg agaaaaaaat 7680
cactggatat accaccgttg atatatccca atggcatcgt aaagaacatt ttgaggcatt 7740
tcagtcagtt gctcaatgta cctataacca gaccgttcag ctggatatta cggccttttt 7800
aaagaccgta aagaaaaata agcacaagtt ttatccggcc tttattcaca ttcttgcccg 7860
cctgatgaat gctcatccgg agttccgtat ggcaatgaaa gacggtgagc tggtgatatg 7920
ggatagtgtt cacccttgtt acaccgtttt ccatgagcaa actgaaacgt tttcatcgct 7980
ctggagtgaa taccacgacg atttccggca gtttctacac atatattcgc aagatgtggc 8040
gtgttacggt gaaaacctgg cctatttccc taaagggttt attgagaata tgtttttcgt 8100
ctcagccaat ccctgggtga gtttcaccag ttttgattta aacgtggcca atatggacaa 8160
cttcttcgcc cccgttttca ccatgggcaa atattatacg caaggcgaca aggtgctgat 8220
gccgctggcg attcaggttc atcatgccgt ttgtgatggc ttccatgtcg gcagaatgct 8280
taatgaatta caacagtact gcgatgagtg gcagggcggg gcgtaatttt tttaaggcag 8340
ttattggtgc ccttaaacgc ctggttgcta cgcctgaata agtgataata agcggatgaa 8400
tggcagaaat tcgatgataa gctgtcaaac atgagaattg gtcgacggcg cgccaaagct 8460
tgcatgcctg cagccgcgta acctggcaaa atcggttacg gttgagtaat aaatggatgc 8520
cctgcgtaag cggggcacat ttcattacct ctttctccgc acccgacata gataataact 8580
tcgtatagta tacattatac gaagttatct agtagactta atcgcgttta aacccatcat 8640
caataatata cctcaaactt tttgtgcgcg ttaatatgca aatgaggcgt ttgaatttgg 8700
gaagggagga aggtgattgg ccgagagaag ggcgaccgtt aggggcgggg cgagtgacgt 8760
tttgatgacg tgaccgcgag gaggagccag tttgcaagtt ctcgtgggaa aagtgacgtc 8820
aaacgaggtg tggtttgaac acggaaatac tcaattttcc cgcgctctct gacaggaaat 8880
gaggtgtttc taggcggatg caagtgaaaa cgggccattt tcgcgcgaaa actgaatgag 8940
gaagtgaaaa tctgagtaat ttcgcgttta tgacagggag gagtatttgc cgagggccga 9000
gtagactttg accgattacg tgggggtttc gattaccgtg tttttcacct aaatttccgc 9060
gtacggtgtc aaagtccggt gtttttacgt aggtgtcagc tgatcgccag ggtatttaaa 9120
cctgcgctct ccagtcaaga ggccactctt gagtgccagc gagaagagtt ttctcctccg 9180
cgcgcgagtc agatctacac tttgaaaggc gatcgctagc gacatcgatc acaagtttgt 9240
acaaaaaagc tgaacgagaa acgtaaaatg atataaatat caatatatta aattagattt 9300
tgcataaaaa acagactaca taatactgta aaacacaaca tatccagtca ctatggcggc 9360
cgccgattta ttcaacaaag ccacgttgtg tctcaaaatc tctgatgtta cattgcacaa 9420
gataaaaata tatcatcatg aacaataaaa ctgtctgctt acataaacag taatacaagg 9480
ggtgttatga gccatattca acgggaaacg tcttgctcga ggccgcgatt aaattccaac 9540
atggatgctg atttatatgg gtataaatgg gctcgtgata atgtcgggca atcaggtgcg 9600
acaatctatc gattgtatgg gaagcccgat gcgccagagt tgtttctgaa acatggcaaa 9660
ggtagcgttg ccaatgatgt tacagatgag atggtcagac taaactggct gacggaattt 9720
atgcctcttc cgaccatcaa gcattttatc cgtactcctg atgatgcatg gttactcacc 9780
actgcgatcc ccgggaaaac agcattccag gtattagaag aatatcctga ttcaggtgaa 9840
aatattgttg atgcgctggc agtgttcctg cgccggttgc attcgattcc tgtttgtaat 9900
tgtcctttta acagcgatcg cgtatttcgt ctcgctcagg cgcaatcacg aatgaataac 9960
ggtttggttg atgcgagtga ttttgatgac gagcgtaatg gctggcctgt tgaacaagtc 10020
tggaaagaaa tgcataagct tttgccattc tcaccggatt cagtcgtcac tcatggtgat 10080
ttctcacttg ataaccttat ttttgacgag gggaaattaa taggttgtat tgatgttgga 10140
cgagtcggaa tcgcagaccg ataccaggat cttgccatcc tatggaactg cctcggtgag 10200
ttttctcctt cattacagaa acggcttttt caaaaatatg gtattgataa tcctgatatg 10260
aataaattgc agtttcattt gatgctcgat gagtttttct aatcagaatt ggttaattgg 10320
ttgtaacact ggcacgcgtg gatccggctt actaaaagcc agataacagt atgcgtattt 10380
gcgcgctgat ttttgcggta taagaatata tactgatatg tatacccgaa gtatgtcaaa 10440
aagaggtatg ctatgaagca gcgtattaca gtgacagttg acagcgacag ctatcagttg 10500
ctcaaggcat atatgatgtc aatatctccg gtctggtaag cacaaccatg cagaatgaag 10560
cccgtcgtct gcgtgccgaa cgctggaaag cggaaaatca ggaagggatg gctgaggtcg 10620
cccggtttat tgaaatgaac ggctcttttg ctgacgagaa caggggctgg tgaaatgcag 10680
tttaaggttt acacctataa aagagagagc cgttatcgtc tgtttgtgga tgtacagagt 10740
gatattattg acacgcccgg gcgacggatg gtgatccccc tggccagtgc acgtctgctg 10800
tcagataaag tctcccgtga actttacccg gtggtgcata tcggggatga aagctggcgc 10860
atgatgacca ccgatatggc cagtgtgccg gtctccgtta tcggggaaga agtggctgat 10920
ctcagccacc gcgaaaatga catcaaaaac gccattaacc tgatgttctg gggaatataa 10980
atgtcaggct cccttataca cagccagtct gcaggtcgac catagtgact ggatatgttg 11040
tgttttacag tattatgtag tctgtttttt atgcaaaatc taatttaata tattgatatt 11100
tatatcattt tacgtttctc gttcagcttt cttgtacaaa gtggtgatcg attcgacaga 11160
tcgcgatcgc agtgagtagt gttctggggc gggggaggac ctgcatgagg gccagaatga 11220
ctgaaatctg tgcttttctg tgtgttgcag catcatgagc ggaagcggct cctttgaggg 11280
aggggtattc agcccttatc tgacggggcg tctcccctcc tgggcgggag tgcgtcagaa 11340
tgtgatggga tccacggtgg acggccggcc cgtgcagccc gcgaactctt caaccctgac 11400
ctatgcaacc ctgagctctt cgtcggtgga cgcagctgcc gccgcagctg ctgcatccgc 11460
cgccagcgcc gtgcgcggaa tggccatggg cgccggctac tacggcactc tggtggccaa 11520
ctcgagttcc accaataatc ccgccagcct gaacgaggag aagctgctgc tgctgatggc 11580
ccagcttgag gccttgaccc agcgcctggg cgagctgacc cagcaggtgg ctcagctgca 11640
ggagcagacg cgggccgcgg ttgccacggt gaaatccaaa taaaaaatga atcaataaat 11700
aaacggagac ggttgttgat tttaacacag agtctgaatc tttatttgat ttttcgcgcg 11760
cggtaggccc tggaccaccg gtctcgatca ttgagcaccc ggtggatctt ttccaggacc 11820
cggtagaggt gggcttggat gttgaggtac atgggcatga gcccgtcccg ggggtggagg 11880
tagctccatt gcagggcctc gtgctcgggg gtggtgttgt aaatcaccca gtcatagcag 11940
gggcgcaggg cgtggtgttg cacaatatct ttgaggagga gactgatggc cacgggcagc 12000
cctttggtgt aggtgtttac aaatctgttg agctgggagg gatgcatgcg gggggagatg 12060
aggtgcatct tggcctggat cttgagattg gcgatgttac cgcccagatc ccgcctgggg 12120
ttcatgttgt gcaggaccac cagcacggtg tatccggtgc acttggggaa tttatcatgc 12180
aacttggaag ggaaggcgtg aaagaatttg gcgacgccct tgtgtccgcc caggttttcc 12240
atgcactcat ccatgatgat ggcaatgggc ccgtgggcgg cggcctgggc aaagacgttt 12300
cgggggtcgg acacatcata gttgtggtcc tgggtgaggt catcataggc cattttaatg 12360
aatttggggc ggagggtgcc ggactggggg acaaaggtac cctcgatccc gggggcgtag 12420
ttcccctcac agatctgcat ctcccaggct ttgagctcag agggggggat catgtccacc 12480
tgcggggcga taaagaacac ggtttccggg gcgggggaga tgagctgggc cgaaagcaag 12540
ttccggagca gctgggactt gccgcagccg gtggggccgt aaatgacccc gatgaccggc 12600
tgcaggtggt agttgaggga gagacagctg ccgtcctccc ggaggagggg ggccacctcg 12660
ttcatcatct cgcgcacgtg catgttctcg cgcaccagtt ccgccaggag gcgctctccc 12720
cccagagata ggagctcctg gagcgaggcg aagtttttca gcggcttgag tccgtcggcc 12780
atgggcattt tggagagggt ctgttgcaag agttccaagc ggtcccagag ctcggtgatg 12840
tgctctacgg catctcgatc cagcagacct cctcgtttcg cgggttggga cgactgcggg 12900
agtagggcac cagacgatgg gcgtccagcg cagccagggt ccggtccttc cagggccgca 12960
gcgtccgcgt cagggtggtc tccgtcacgg tgaaggggtg cgcgccgggc tgggcgcttg 13020
cgagggtgcg cttcaggctc atccggctgg tcgaaaaccg ctcccgatcg gcgccctgcg 13080
cgtcggccag gtagcaattg accatgagtt cgtagttgag cgcctcggcc gcgtggcctt 13140
tggcgcggag cttacctttg gaagtctgcc cgcaggcggg acagaggagg gacttgaggg 13200
cgtagagctt gggggcgagg aagacggaat cgggggcgta ggcgtccgcg ccgcagtggg 13260
cgcagacggt ctcgcactcc acgagccagg tgaggtcggg ctggtcgggg tcaaaaacca 13320
gtttcccgcc gttctttttg atgcgtttct tacctttggt ctccatgagc tcgtgtcccc 13380
gctgggtgac aaagaggctg tccgtgtccc cgtagaccga ctttatgggc cggtcctcga 13440
gcggtgtgcc gcggtcctcc tcgtagagga accccgccca ctccgagacg aaagcccggg 13500
tccaggccag cacgaaggag gccacgtggg acgggtagcg gtcgttgtcc accagcgggt 13560
ccactttttc cagggtatgc aaacacatgt ccccctcgtc cacatccagg aaggtgattg 13620
gcttgtaagt gtaggccacg tgaccggggg tcccggccgg gggggtataa aagggggcgg 13680
gcccctgctc gtcctcactg tcttccggat cgctgtccag gagcgccagc tgttggggta 13740
ggtattccct ctcgaaggcg ggcatgacct cggcactcag gttgtcagtt tctagaaacg 13800
aggaggattt gatattgacg gtgccagcgg agatgccttt caagagcccc tcgtccatct 13860
ggtcagaaaa gacgattttt ttgttgtcga gcttggtggc gaaggagccg tagagggcgt 13920
tggaaaggag cttggcgatg gagcgcatgg tctggttttt ttccttgtcg gcgcgctcct 13980
tggccgcgat gttgagctgc acgtactcgc gcgccacgca cttccattcg gggaagacgg 14040
tggtcatctc gtcgggcacg attctgacct gccaacctcg attatgcagg gtgatgaggt 14100
ccacactggt ggccacctcg ccgcgcaggg gctcgttggt ccagcagagg cggccgccct 14160
tgcgcgagca gaaggggggc agagggtcca gcatgacctc gtcggggggg tcggcatcga 14220
tggtgaagat gccgggcagg agatcggggt cgaagtagct gatggaagtg gccagatcgt 14280
ccagggaagc ttgccattcg cgcacggcca gcgcgcgctc gtagggactg aggggcgtgc 14340
cccagggcat ggggtgggtg agcgcggagg cgtacatgcc gcagatgtcg tagacgtaga 14400
ggggctcctc gaggatgccg atgtaggtgg ggtagcagcg ccccccgcgg atgctggcgc 14460
gcacgtagtc atacagctcg tgcgagggcg cgaggagccc cgggcccagg ttggtgcgac 14520
tgggcttttc ggcgcggtag acgatctggc gaaagatggc atgcgagttg gaggagatgg 14580
tgggcctttg gaagatgttg aagtgggcgt gggggaggcc gaccgagtcg cggatgaagt 14640
gggcgtagga gtcttgcagt ttggcgacga gctcggcggt gacgaggacg tccagagcgc 14700
agtagtcgag ggtctcctgg atgatgtcat acttgagctg gcccttttgt ttccacagct 14760
cgcggttgag aaggaactct tcgcggtcct tccagtactc ttcgaggggg aacccgtcct 14820
gatctgcacg gtaagagcct agcatgtaga actggttgac ggccttgtag gcgcagcagc 14880
ccttctccac ggggagggcg taggcctggg cggccttgcg cagggaggtg tgcgtgaggg 14940
cgaaggtgtc cctgaccatg accttgagga actggtgctt gaaatcgata tcgtcgcagc 15000
ccccctgctc ccagagctgg aagtccgtgc gcttcttgta ggcggggttg ggcaaagcga 15060
aagtaacatc gttgaaaagg atcttgcccg cgcggggcat aaagttgcga gtgatgcgga 15120
aaggctgggg cacctcggcc cggttgttga tgacctgggc ggcgagcacg atctcgtcga 15180
aaccgttgat gttgtggccc acgatgtaga gttccacgaa tcgcgggcgg cccttgacgt 15240
ggggcagctt cttgagctcc tcgtaggtga gctcgtcggg gtcgctgaga ccgtgctgct 15300
cgagcgccca gtcggcgaga tgggggttgg cgcggaggaa ggaagtccag agatccacgg 15360
ccagggcggt ttgcagacgg tcccggtact gacggaactg ctgcccgacg gccatttttt 15420
cgggggtgac gcagtagaag gtgcgggggt ccccgtgcca gcggtcccat ttgagctgga 15480
gggcgagatc gagggcgagc tcgacgaggc ggtcgtcccc tgagagtttc atgaccagca 15540
tgaaggggac gagctgcttg ccgaaggacc ccatccaggt gtaggtttcc acatcgtagg 15600
tgaggaagag cctttcggtg cgaggatgcg agccgatggg gaagaactgg atctcctgcc 15660
accaattgga ggaatggctg ttgatgtgat ggaagtagaa atgccgacgg cgcgccgaac 15720
actcgtgctt gtgtttatac aagcggccac agtgctcgca acgctgcacg ggatgcacgt 15780
gctgcacgag ctgtacctga gttcctttga cgaggaattt cagtgggaag tggagtcgtg 15840
gcgcctgcat ctcgtgctgt actacgtcgt ggtggtcggc ctggccctct tctgcctcga 15900
tggtggtcat gctgacgagc ccgcgcggga ggcaggtcca gacctcggcg cgagcgggtc 15960
ggagagcgag gacgagggcg cgcaggccgg agctgtccag ggtcctgaga cgctgcggag 16020
tcaggtcagt gggcagcggc ggcgcgcggt tgacttgcag gagtttttcc agggcgcgcg 16080
ggaggtccag atggtacttg atctccaccg cgccgttggt ggcgacgtcg atggcttgca 16140
gggtcccgtg cccctggggt gtgaccaccg tcccccgttt cttcttgggc ggctggggcg 16200
acgggggcgg tgcctcttcc atggttagaa gcggcggcga ggacgcgcgc cgggcggcag 16260
aggcggctcg gggcccggag gcaggggcgg caggggcacg tcggcgccgc gcgcgggtag 16320
gttctggtac tgcgcccgga gaagactggc gtgagcgacg acgcgacggt tgacgtcctg 16380
gatctgacgc ctctgggtga aggccacggg acccgtgagt ttgaacctga aagagagttc 16440
gacagaatca atctcggtat cgttgacggc ggcctgccgc aggatctctt gcacgtcgcc 16500
cgagttgtcc tggtaggcga tctcggtcat gaactgctcg atctcctcct cctgaaggtc 16560
tccgcgaccg gcgcgctcca cggtggccgc gaggtcgttg gagatgcggc ccatgagctg 16620
cgagaaggcg ttcatgcccg cctcgttcca gacgcggctg tagaccacga cgccctcggg 16680
atcgcgggcg cgcatgacca cctgggcgag gttgagctcc acgtggcgcg tgaagaccgc 16740
gtagttgcag aggcgctggt agaggtagtt gagcgtggtg gcgatgtgct cggtgacgaa 16800
gaaatacatg atccagcggc ggagcggcat ctcgctgacg tcgcccagcg cctccaagcg 16860
ttccatggcc tcgtaaaagt ccacggcgaa gttgaaaaac tgggagttgc gcgccgagac 16920
ggtcaactcc tcctccagaa gacggatgag ctcggcgatg gtggcgcgca cctcgcgctc 16980
gaaggccccc gggagttcct ccacttcctc ctcttcttcc tcctccacta acatctcttc 17040
tacttcctcc tcaggcggtg gtggtggcgg gggagggggc ctgcgtcgcc ggcggcgcac 17100
gggcagacgg tcgatgaagc gctcgatggt ctcgccgcgc cggcgtcgca tggtctcggt 17160
gacggcgcgc ccgtcctcgc ggggccgcag cgtgaagacg ccgccgcgca tctccaggtg 17220
gccggggggg tccccgttgg gcagggagag ggcgctgacg atgcatctta tcaattgccc 17280
cgtagggact ccgcgcaagg acctgagcgt ctcgagatcc acgggatctg aaaaccgttg 17340
aacgaaggct tcgagccagt cgcagtcgca aggtaggctg agcacggttt cttctgccgg 17400
gtcatgttgg ggagcggggc gggcgatgct gctggtgatg aagttgaaat aggcggttct 17460
gagacggcgg atggtggcga ggagcaccag gtctttgggc ccggcttgct ggatgcgcag 17520
acggtcggcc atgccccagg cgtggtcctg acacctggcc aggtccttgt agtagtcctg 17580
catgagccgc tccacgggca cctcctcctc gcccgcgcgg ccgtgcatgc gcgtgagccc 17640
gaagccgcgc tggggctgga cgagcgccag gtcggcgacg acgcgctcgg cgaggatggc 17700
ctgctggatc tgggtgaggg tggtctggaa gtcgtcaaag tcgacgaagc ggtggtaggc 17760
tccggtgttg atggtgtagg agcagttggc catgacggac cagttgacgg tctggtggcc 17820
cggacgcacg agctcgtggt acttgaggcg cgagtaggcg cgcgtgtcga agatgtagtc 17880
gttgcaggtg cgcaccaggt actggtagcc gatgaggaag tgcggcggcg gctggcggta 17940
gagcggccat cgctcggtgg cgggggcgcc gggcgcgagg tcctcgagca tggtgcggtg 18000
gtagccgtag atgtacctgg acatccaggt gatgccggcg gcggtggtgg aggcgcgcgg 18060
gaactcgcgg acgcggttcc agatgttgcg cagcggcagg aagtagttca tggtgggcac 18120
ggtctggccc gtgaggcgcg cgcagtcgtg gatgctctat acgggcaaaa acgaaagcgg 18180
tcagcggctc gactccgtgg cctggaggct aagcgaacgg gttgggctgc gcgtgtaccc 18240
cggttcgaat ctcgaatcag gctggagccg cagctaacgt ggtactggca ctcccgtctc 18300
gacccaagcc tgcaccaacc ctccaggata cggaggcggg tcgttttgca actttttttg 18360
gaggccggaa atgaaactag taagcgcgga aagcggccga ccgcgatggc tcgctgccgt 18420
agtctggaga agaatcgcca gggttgcgtt gcggtgtgcc ccggttcgag gccggccgga 18480
ttccgcggct aacgagggcg tggctgcccc gtcgtttcca agaccccata gccagccgac 18540
ttctccagtt acggagcgag cccctctttt gttttgtttg tttttgccag atgcatcccg 18600
tactgcggca gatgcgcccc caccaccctc caccgcaaca acagccccct cctccacagc 18660
cggcgcttct gcccccgccc cagcagcagc agcaacttcc agccacgacc gccgcggccg 18720
ccgtgagcgg ggctggacag acttctcagt atgatcacct ggccttggaa gagggcgagg 18780
ggctggcgcg cctgggggcg tcgtcgccgg agcggcaccc gcgcgtgcag atgaaaaggg 18840
acgctcgcga ggcctacgtg cccaagcaga acctgttcag agacaggagc ggcgaggagc 18900
ccgaggagat gcgcgcggcc cggttccacg cggggcggga gctgcggcgc ggcctggacc 18960
gaaagagggt gctgagggac gaggatttcg aggcggacga gctgacgggg atcagccccg 19020
cgcgcgcgca cgtggccgcg gccaacctgg tcacggcgta cgagcagacc gtgaaggagg 19080
agagcaactt ccaaaaatcc ttcaacaacc acgtgcgcac cctgatcgcg cgcgaggagg 19140
tgaccctggg cctgatgcac ctgtgggacc tgctggaggc catcgtgcag aaccccacca 19200
gcaagccgct gacggcgcag ctgttcctgg tggtgcagca tagtcgggac aacgaggcgt 19260
tcagggaggc gctgctgaat atcaccgagc ccgagggccg ctggctcctg gacctggtga 19320
acattctgca gagcatcgtg gtgcaggagc gcgggctgcc gctgtccgag aagctggcgg 19380
ccatcaactt ctcggtgctg agtctgggca agtactacgc taggaagatc tacaagaccc 19440
cgtacgtgcc catagacaag gaggtgaaga tcgacgggtt ttacatgcgc atgaccctga 19500
aagtgctgac cctgagcgac gatctggggg tgtaccgcaa cgacaggatg caccgcgcgg 19560
tgagcgccag caggcggcgc gagctgagcg accaggagct gatgcacagc ctgcagcggg 19620
ccctgaccgg ggccgggacc gagggggaga gctactttga catgggcgcg gacctgcact 19680
ggcagcccag ccgccgggcc ttggaggcgg caggcggtcc cccctacata gaagaggtgg 19740
acgatgaggt ggacgaggag ggcgagtacc tggaagactg atggcgcgac cgtatttttg 19800
ctagatgcaa caacagccac ctcctgatcc cgcgatgcgg gcggcgctgc agagccagcc 19860
gtccggcatt aactcctcgg acgattggac ccaggccatg caacgcatca tggcgctgac 19920
gacccgcaac cccgaagcct ttagacagca gccccaggcc aaccggctct cggccatcct 19980
ggaggccgtg gtgccctcgc gctccaaccc cacgcacgag aaggtcctgg ccatcgtgaa 20040
cgcgctggtg gagaacaagg ccatccgcgg cgacgaggcc ggcctggtgt acaacgcgct 20100
gctggagcgc gtggcccgct acaacagcac caacgtgcag accaacctgg accgcatggt 20160
gaccgacgtg cgcgaggccg tggcccagcg cgagcggttc caccgcgagt ccaacctggg 20220
atccatggtg gcgctgaacg ccttcctcag cacccagccc gccaacgtgc cccggggcca 20280
ggaggactac accaacttca tcagcgccct gcgcctgatg gtgaccgagg tgccccagag 20340
cgaggtgtac cagtccgggc cggactactt cttccagacc agtcgccagg gcttgcagac 20400
cgtgaacctg agccaggcgt tcaagaactt gcagggcctg tggggcgtgc aggccccggt 20460
cggggaccgc gcgacggtgt cgagcctgct gacgccgaac tcgcgcctgc tgctgctgct 20520
ggtggccccc ttcacggaca gcggcagcat caaccgcaac tcgtacctgg gctacctgat 20580
taacctgtac cgcgaggcca tcggccaggc gcacgtggac gagcagacct accaggagat 20640
cacccacgtg agccgcgccc tgggccagga cgacccgggc aatctggaag ccaccctgaa 20700
ctttttgctg accaaccggt cgcagaagat cccgccccag tacacgctca gcgccgagga 20760
ggagcgcatc ctgcgatacg tgcagcagag cgtgggcctg ttcctgatgc aggagggggc 20820
cacccccagc gccgcgctcg acatgaccgc gcgcaacatg gagcccagca tgtacgccag 20880
caaccgcccg ttcatcaata aactgatgga ctacttgcat cgggcggccg ccatgaactc 20940
tgactatttc accaacgcca tcctgaatcc ccactggctc ccgccgccgg ggttctacac 21000
gggcgagtac gacatgcccg accccaatga cgggttcctg tgggacgatg tggacagcag 21060
cgtgttctcc ccccgaccgg gtgctaacga gcgccccttg tggaagaagg aaggcagcga 21120
ccgacgcccg tcctcggcgc tgtccggccg cgagggtgct gccgcggcgg tgcccgaggc 21180
cgccagtcct ttcccgagct tgcccttctc gctgaacagt attcgcagca gcgagctggg 21240
caggatcacg cgcccgcgct tgctgggcga ggaggagtac ttgaatgact cgctgttgag 21300
acccgagcgg gagaagaact tccccaataa cgggatagag agcctggtgg acaagatgag 21360
ccgctggaag acgtatgcgc aggagcacag ggacgatccg tcgcaggggg ccacgagccg 21420
gggcagcgcc gcccgtaaac gccggtggca cgacaggcag cggggactga tgtgggacga 21480
tgaggattcc gccgacgaca gcagcgtgtt ggacttgggt gggagtggta acccgttcgc 21540
tcacctgcgc ccccgcatcg ggcgcatgat gtaagagaaa ccgaaaataa atgatactca 21600
ccaaggccat ggcgaccagc gtgcgttcgt ttcttctctg ttgttgtatc tagtatgatg 21660
aggcgtgcgt acccggaggg tcctcctccc tcgtacgaga gcgtgatgca gcaggcgatg 21720
gcggcggcgg cggcgatgca gcccccgctg gaggctcctt acgtgccccc gcggtacctg 21780
gcgcctacgg aggggcggaa cagcattcgt tactcggagc tggcaccctt gtacgatacc 21840
acccggttgt acctggtgga caacaagtcg gcggacatcg cctcgctgaa ctaccagaac 21900
gaccacagca acttcctgac caccgtggtg cagaacaatg acttcacccc cacggaggcc 21960
agcacccaga ccatcaactt tgacgagcgc tcgcggtggg gcggtcagct gaaaaccatc 22020
atgcacacca acatgcccaa cgtgaacgag ttcatgtaca gcaacaagtt caaggcgcgg 22080
gtgatggtct cccgcaagac ccccaacggg gtgacagtga cagatggtag tcaggatatc 22140
ttggagtatg aatgggtgga gtttgagctg cccgaaggca acttctcggt gaccatgacc 22200
atcgacctga tgaacaacgc catcatcgac aattacttgg cggtggggcg gcagaacggg 22260
gtcctggaga gcgatatcgg cgtgaagttc gacactagga acttcaggct gggctgggac 22320
cccgtgaccg agctggtcat gcccggggtg tacaccaacg aggccttcca ccccgatatt 22380
gtcttgctgc ccggctgcgg ggtggacttc accgagagcc gcctcagcaa cctgctgggc 22440
attcgcaaga ggcagccctt ccaggagggc ttccagatca tgtacgagga tctggagggg 22500
ggcaacatcc ccgcgctcct ggatgtcgac gcctatgaga aaagcaagga ggagagcgcc 22560
gccgcggcga ctgcagctgt agccaccgcc tctaccgagg tcaggggcga taattttgcc 22620
agccctgcag cagtggcagc ggccgaggcg gctgaaaccg aaagtaagat agtcattcag 22680
ccggtggaga aggatagcaa ggacaggagc tacaacgtgc tgccggacaa gataaacacc 22740
gcctaccgca gctggtacct ggcctacaac tatggcgacc ccgagaaggg cgtgcgctcc 22800
tggacgctgc tcaccacctc ggacgtcacc tgcggcgtgg agcaagtcta ctggtcgctg 22860
cccgacatga tgcaagaccc ggtcaccttc cgctccacgc gtcaagttag caactacccg 22920
gtggtgggcg ccgagctcct gcccgtctac tccaagagct tcttcaacga gcaggccgtc 22980
tactcgcagc agctgcgcgc cttcacctcg ctcacgcacg tcttcaaccg cttccccgag 23040
aaccagatcc tcgtccgccc gcccgcgccc accattacca ccgtcagtga aaacgttcct 23100
gctctcacag atcacgggac cctgccgctg cgcagcagta tccggggagt ccagcgcgtg 23160
accgttactg acgccagacg ccgcacctgc ccctacgtct acaaggccct gggcatagtc 23220
gcgccgcgcg tcctctcgag ccgcaccttc taaaaaatgt ccattctcat ctcgcccagt 23280
aataacaccg gttggggcct gcgcgcgccc agcaagatgt acggaggcgc tcgccaacgc 23340
tccacgcaac accccgtgcg cgtgcgcggg cacttccgcg ctccctgggg cgccctcaag 23400
ggccgcgtgc ggtcgcgcac caccgtcgac gacgtgatcg accaggtggt ggccgacgcg 23460
cgcaactaca cccccgccgc cgcgcccgtc tccaccgtgg acgccgtcat cgacagcgtg 23520
gtggccgacg cgcgccggta cgcccgcgcc aagagccggc ggcggcgcat cgcccggcgg 23580
caccggagca cccccgccat gcgcgcggcg cgagccttgc tgcgcagggc caggcgcacg 23640
ggacgcaggg ccatgctcag ggcggccaga cgcgcggctt caggcgccag cgccggcagg 23700
acccggagac gcgcggccac ggcggcggca gcggccatcg ccagcatgtc ccgcccgcgg 23760
cgagggaacg tgtactgggt gcgcgacgcc gccaccggtg tgcgcgtgcc cgtgcgcacc 23820
cgcccccctc gcacttgaag atgttcactt cgcgatgttg atgtgtccca gcggcgagga 23880
ggatgtccaa gcgcaaattc aaggaagaga tgctccaggt catcgcgcct gagatctacg 23940
gccccgcggt ggtgaaggag gaaagaaagc cccgcaaaat caagcgggtc aaaaaggaca 24000
aaaaggaaga agatgacgat ctggtggagt ttgtgcgcga gttcgccccc cggcggcgcg 24060
tgcagtggcg cgggcggaaa gtgcacccgg tgctgagacc cggcaccacc gtggtcttca 24120
cgcccggcga gcgctccggc agcgcttcca agcgctccta cgacgaggtg tacggggacg 24180
aggacatcct cgagcaggcg gccgagcgcc tgggcgagtt tgcttacggc aagcgcagcc 24240
gccccgccct gaaggaagag gcggtgtcca tcccgctgga ccacggcaac cccacgccga 24300
gcctcaagcc cgtgaccctg cagcaggtgc tgccgagcgc agcgccgcgc cgggggttca 24360
agcgcgaggg cgaggatctg taccccacca tgcagctgat ggtgcccaag cgccagaagc 24420
tggaagacgt gctggagacc atgaaggtgg acccggacgt gcagcccgag gtcaaggtgc 24480
ggcccatcaa gcaggtggcc ccgggcctgg gcgtgcagac cgtggacatc aagatcccca 24540
cggagcccat ggaaacgcag accgagccca tgatcaagcc cagcaccagc accatggagg 24600
tgcagacgga tccctggatg ccatcggctc ctagccgaag accccggcgc aagtacggcg 24660
cggccagcct gctgatgccc aactacgcgc tgcatccttc catcatcccc acgccgggct 24720
accgcggcac gcgcttctac cgcggtcata caaccagccg ccgccgcaag accaccaccc 24780
gccgccgccg tcgccgcaca gccgctgcat ctacccctgc cgccctggtg cggagagtgt 24840
accgccgcgg ccgcgcgcct ctgaccctac cgcgcgcgcg ctaccacccg agcatcgcca 24900
tttaaacttt cgcctgcttt gcagatggcc ctcacatgcc gcctccgcgt tcccattacg 24960
ggctaccgag gaagaaaacc gcgccgtaga aggctggcgg ggaacgggat gcgtcgccac 25020
caccatcggc ggcggcgcgc catcagcaag cggttggggg gaggcttcct gcccgcgctg 25080
atccccatca tcgccgcggc gatcggggcg atccccggca ttgcttccgt ggcggtgcag 25140
gcctctcagc gccactgaga cacttggaaa acatcttgta ataaaccaat ggactctgac 25200
gctcctggtc ctgtgatgtg ttttcgtaga cagatggaag acatcaattt ttcgtccctg 25260
gctccgcgac acggcacgcg gccgttcatg ggcacctgga gcgacatcgg caccagccaa 25320
ctgaacgggg gcgccttcaa ttggagcagt ctctggagcg ggcttaagaa tttcgggtcc 25380
acgcttaaaa cctatggcag caaggcgtgg aacagcacca cagggcaggc gctgagggat 25440
aagctgaaag agcagaactt ccagcagaag gtggtcgatg ggctcgcctc gggcatcaac 25500
ggggtggtgg acctggccaa ccaggccgtg cagcggcaga tcaacagccg cctggacccg 25560
gtgccgcccg ccggctccgt ggagatgccg caggtggagg aggagctgcc tcccctggac 25620
aagcggggcg agaagcgacc ccgccccgac gcggaggaga cgctgctgac gcacacggac 25680
gagccgcccc cgtacgagga ggcggtgaaa ctgggtctgc ccaccacgcg gcccatcgcg 25740
cccctggcca ccggggtgct gaaacccgaa agtaataagc ccgcgaccct ggacttgcct 25800
cctcccgctt cccgcccctc tacagtggct aagcccctgc cgccggtggc cgtggcccgc 25860
gcgcgacccg ggggctccgc ccgccctcat gcgaactggc agagcactct gaacagcatc 25920
gtgggtctgg gagtgcagag tgtgaagcgc cgccgctgct attaaaccta ccgtagcgct 25980
taacttgctt gtctgtgtgt gtatgtatta tgtcgccgct gtccgccaga aggaggagtg 26040
aagaggcgcg tcgccgagtt gcaagatggc caccccatcg atgctgcccc agtgggcgta 26100
catgcacatc gccggacagg acgcttcgga gtacctgagt ccgggtctgg tgcagttcgc 26160
ccgcgccaca gacacctact tcagtctggg gaacaagttt aggaacccca cggtggcgcc 26220
cacgcacgat gtgaccaccg accgcagcca gcggctgacg ctgcgcttcg tgcccgtgga 26280
ccgcgaggac aacacctact cgtacaaagt gcgctacacg ctggccgtgg gcgacaaccg 26340
cgtgctggac atggccagca cctactttga catccgcggc gtgctggatc ggggccctag 26400
cttcaaaccc tactccggca ccgcctacaa cagcctggct cccaagggag cgcccaattc 26460
cagccagtgg gagcaaaaaa aggcaggcaa tggtgacact atggaaacac acacatttgg 26520
tgtggcccca atgggcggtg agaatattac aatcgacgga ttacaaattg gaactgacgc 26580
tacagctgat caggataaac caatttatgc tgacaaaaca ttccagcctg aacctcaagt 26640
aggagaagaa aattggcaag aaactgaaag cttttatggc ggtagggctc ttaaaaaaga 26700
cacaagcatg aaaccttgct atggctccta tgctagaccc accaatgtaa agggaggtca 26760
agctaaactt aaagttggag ctgatggagt tcctaccaaa gaatttgaca tagacctggc 26820
tttctttgat actcccggtg gcacagtgaa tggacaagat gagtataaag cagacattgt 26880
catgtatacc gaaaacacgt atctggaaac tccagacacg catgtggtat acaaaccagg 26940
caaggatgat gcaagttctg aaattaacct ggttcagcag tccatgccca atagacccaa 27000
ctatattggg ttcagagaca actttattgg gctcatgtat tacaacagta ctggcaatat 27060
gggggtgctg gctggtcagg cctcacagct gaatgctgtg gtcgacttgc aagacagaaa 27120
caccgagctg tcataccagc tcttgcttga ctctttgggt gacagaaccc ggtatttcag 27180
tatgtggaat caggcggtgg acagttatga tcctgatgtg cgcattattg aaaaccatgg 27240
tgtggaagac gaacttccca actattgctt ccccctggat gggtctggca ctaatgccgc 27300
ttaccaaggt gtgaaagtaa aaaatggtaa cgatggtgat gttgagagcg aatgggaaaa 27360
tgatgatact gtcgcagctc gaaatcaatt atgcaagggc aacatttttg ccatggaaat 27420
taacctccaa gccaacctgt ggagaagttt cctctactcg aacgtggccc tgtacctgcc 27480
cgactcttac aagtacacgc cagccaacat caccctgccc accaacacca acacttatga 27540
ttacatgaac gggagagtgg tgcctccctc gctggtggac gcctacatca acatcggggc 27600
gcgctggtcg ctggacccca tggacaacgt caatcccttc aaccaccacc gcaacgcggg 27660
cctgcgctac cgctccatgc tcctgggcaa cgggcgctac gtgcccttcc acatccaggt 27720
gccccagaaa tttttcgcca tcaagagcct cctgctcctg cccgggtcct acacctacga 27780
gtggaacttc cgcaaggacg tcaacatgat cctgcagagc tccctcggca acgacctgcg 27840
cacggacggg gcctccatct ccttcaccag catcaacctc tacgccacct tcttccccat 27900
ggcgcacaac acggcctcca cgctcgaggc catgctgcgc aacgacacca acgaccagtc 27960
cttcaacgac tacctctcgg cggccaacat gctctacccc atcccggcca acgccaccaa 28020
cgtgcccatc tccatcccct cgcgcaactg ggccgccttc cgcggctggt ccttcacgcg 28080
cctcaagacc aaggagacgc cctcgctggg ctccgggttc gacccctact tcgtctactc 28140
gggctccatc ccctacctcg acggcacctt ctacctcaac cacaccttca agaaggtctc 28200
catcaccttc gactcctccg tcagctggcc cggcaacgac cggctcctga cgcccaacga 28260
gttcgaaatc aagcgcaccg tcgacggcga gggatacaac gtggcccagt gcaacatgac 28320
caaggactgg ttcctggtcc agatgctggc ccactacaac atcggctacc agggcttcta 28380
cgtgcccgag ggctacaagg accgcatgta ctccttcttc cgcaacttcc agcccatgag 28440
ccgccaggtg gtggacgagg tcaactacaa ggactaccag gccgtcaccc tggcctacca 28500
gcacaacaac tcgggcttcg tcggctacct cgcgcccacc atgcgccagg gccagcccta 28560
ccccgccaac tacccgtacc cgctcatcgg caagagcgcc gtcaccagcg tcacccagaa 28620
aaagttcctc tgcgacaggg tcatgtggcg catccccttc tccagcaact tcatgtccat 28680
gggcgcgctc accgacctcg gccagaacat gctctatgcc aactccgccc acgcgctaga 28740
catgaatttc gaagtcgacc ccatggatga gtccaccctt ctctatgttg tcttcgaagt 28800
cttcgacgtc gtccgagtgc accagcccca ccgcggcgtc atcgaggccg tctacctgcg 28860
cacccccttc tcggccggta acgccaccac ctaaattgct acttgcatga tggctgagcc 28920
cacaggctcc ggcgagcagg agctcagggc catcatccgc gacctgggct gcgggcccta 28980
cttcctgggc accttcgata agcgcttccc gggattcatg gccccgcaca agctggcctg 29040
cgccatcgtc aacacggccg gccgcgagac cgggggcgag cactggctgg ccttcgcctg 29100
gaacccgcgc tcgaacacct gctacctctt cgaccccttc gggttctcgg acgagcgcct 29160
caagcagatc taccagttcg agtacgaggg cctgctgcgc cgtagcgccc tggccaccga 29220
ggaccgctgc gtcaccctgg aaaagtccac ccagaccgtg cagggtccgc gctcggccgc 29280
ctgcgggctc ttctgctgca tgttcctgca cgccttcgtg cactggcccg accgccccat 29340
ggacaagaac cccaccatga acttgctgac gggggtgccc aacggcatgc tccagtcgcc 29400
ccaggtggaa cccaccctgc gccgcaacca ggaggcgctc taccgcttcc tcaactccca 29460
ctccgcctac tttcgctccc accgcgcgcg catcgagaag gccaccgcct tcgaccgcat 29520
gaacaatcaa gacatgtaaa ccgtgtgtgt atgtttaaaa tatcttttaa taaacagcac 29580
tttaatgtta cacatgcatc tgagatgatt ttattttaga aatcgaaagg gttctgccgg 29640
gtctcggcat ggcccgcggg cagggacacg ttgcggaact ggtacttggc cagccacttg 29700
aactcgggga tcagcagttt gggcagcggg gtgtcgggga aggagtcggt ccacagcttc 29760
cgcgtcagct gcagggcgcc cagcaggtcg ggcgcggaga tcttgaaatc gcagttggga 29820
cccgcgttct gcgcgcgaga gttgcggtac acggggttgc agcactggaa caccatcagg 29880
gccgggtgct tcacgctcgc cagcaccgcc gcgtcggtga tgctctccac gtcgaggtcc 29940
tcggcgttgg ccatcccgaa gggggtcatc ttgcaggtct gccttcccat ggtgggcacg 30000
cacccgggct tgtggttgca atcgcagtgc agggggatca gcatcatctg ggcctggtcg 30060
gcgttcatcc ccgggtacat ggccttcatg aaagcctcca attgcctgaa cgcctgctgg 30120
gccttggctc cctcggtgaa gaagaccccg caggacttgc tagagaactg gttggtggca 30180
cagccggcat cgtgcacgca gcagcgcgcg tcgttgttgg ccagctgcac cacgctgcgc 30240
ccccagcggt tctgggtgat cttggcccgg tcggggttct ccttcagcgc gcgctgcccg 30300
ttctcgctcg ccacatccat ctcgatcatg tgctccttct ggatcatggt ggtcccgtgc 30360
aggcaccgca gtttgccctc ggcctcggtg cacccgtgca gccacagcgc gcacccggtg 30420
cactcccagt tcttgtgggc gatctgggaa tgcgcgtgca cgaacccttg caggaagcgg 30480
cccatcatgg tcgtcagggt cttgttgcta gtgaaggtca acgggatgcc gcggtgctcc 30540
tcgttgatgt acaggtggca gatgcggcgg tacacctcgc cctgctcggg catcagttgg 30600
aagttggctt tcaggtcggt ctccacgcgg tagcggtcca tcagcatagt catgatttcc 30660
atgcccttct cccaggccga gacgatgggc aggctcatag ggttcttcac catcatctta 30720
gcactagcag ccgcggccag ggggtcgctc tcatccaggg tctcaaagct ccgcttgccg 30780
tccttctcgg tgatccgcac cggggggtag ctgaagccca cggccgccag ctcctcctcg 30840
gcctgtcttt cgtcctcgct gtcctggctg acgtcctgca tgaccacatg cttggtcttg 30900
cggggtttct tcttgggcgg cagtggcggc ggagatgctt gtggcgaggg ggagcgcgag 30960
ttctcgctca ccactactat ctcttcctct tcttggtccg aggccacgcg gcggtaggta 31020
tgtctcttcg ggggcagagg cggaggcgac gggctctcgc cgccgcgact tggcggatgg 31080
ctggcagagc cccttccgcg ttcgggggtg cgctcccggc ggcgctctga ctgacttcct 31140
ccgcggccgg ccattgtgtt ctcctaggga ggaacaacaa gcatggagac tcagccatcg 31200
ccaacctcgc catctgcccc caccgccggc gacgagaagc agcagcagca gaatgaaagc 31260
ttaaccgccc cgccgcccag ccccgcctcc gacgcagccg cggtcccaga catgcaagag 31320
atggaggaat ccatcgagat tgacctgggc tatgtgacgc ccgcggagca tgaggaggag 31380
ctggcagtgc gctttcaatc gtcaagccag gaagataaag aacagccaga gcaggaagca 31440
gagaacgagc agagtcaggc tgggctcgag catggcgact acctccacct gagcggggag 31500
gaggacgcgc tcatcaagca tctggcccgg caggccacca tcgtcaagga cgcgctgctc 31560
gaccgcaccg aggtgcccct cagcgtggag gagctcagcc gcgcctacga gctcaacctc 31620
ttctcgccgc gcgtgccccc caagcgccag cccaacggca cctgcgagcc caacccccgc 31680
ctcaacttct acccggtctt cgcggtgccc gaggccctgg ccacctacca catctttttc 31740
aagaaccaaa agatccccgt ctcctgccgc gccaaccgca cccgcgccga cgccctcttc 31800
aacctgggtc ccggcgcccg cctacctgat atcgcctcct tggaagaggt tcccaagatc 31860
ttcgagggtc tgggcagcga cgagactcgg gccgcgaacg ctctgcaagg agaaggagga 31920
ggagagcatg agcaccacag cgccctggtc gagttggaag gcgacaacgc gcggctggcg 31980
gtgctcaaac gcacggtcga gctgacccat ttcgcctacc cggctctgaa cctgcccccg 32040
aaagtcatga gcgcggtcat ggaccaggtg ctcatcaagc gcgcgtcgcc catctccgag 32100
gacgagggca tgcaagactc cgaggagggc aagcccgtgg tcagcgacga gcagctggcc 32160
cggtggctgg gtcctaatgc tacccctcaa agtttggaag agcggcgcaa gctcatgatg 32220
gccgtggtcc tggtgaccgt ggagctggag tgcctgcgcc gcttcttcgc cgacgcggag 32280
accctgcgca aggtcgagga gaacctgcac tacctcttca ggcacgggtt cgtgcgccag 32340
gcctgcaaga tctccaacgt ggagctgacc aacctggtct cctacatggg catcttgcac 32400
gagaaccgcc tggggcagaa cgtgctgcac accaccctgc gcggggaggc ccgccgcgac 32460
tacatccgcg actgcgtcta cctctacctc tgccacacct ggcagacggg catgggcgtg 32520
tggcagcagt gtctggagga gcagaacctg aaagagctct gcaagctcct gcaaaagaac 32580
ctcaagggtc tgtggaccgg gttcgacgag cggaccaccg cctcggacct ggccgacctc 32640
atcttccccg agcgcctcag gctgacgctg cgcaacggcc tgcccgactt tatgagccaa 32700
agcatgttgc aaaactttcg ctctttcatc ctcgaacgct ccggaatcct gcccgccacc 32760
tgctccgcgc tgccctcgga cttcgtgccg ctgaccttcc gcgagtgccc cccgccgctg 32820
tggagccact gctacctgct gcgcctggcc aactacctgg cctaccactc ggacgtgatc 32880
gaggacgtca gcggcgaggg cctgctcgag tgccactgcc gctgcaacct ctgcacgccg 32940
caccgctccc tggcctgcaa cccccagctg ctgagcgaga cccagatcat cggcaccttc 33000
gagttgcaag ggcccagcga gggcgaggga gccaaggggg gtctgaaact caccccgggg 33060
ctgtggacct cggcctactt gcgcaagttc gtgcccgagg attaccatcc cttcgagatc 33120
aggttctacg aggaccaatc ccagccgccc aaggccgagc tgtcggcctg cgtcatcacc 33180
cagggggcga tcctggccca attgcaagcc atccagaaat cccgccaaga attcttgctg 33240
aaaaagggcc gcggggtcta cctcgacccc cagaccggtg aggagctcaa ccccggcttc 33300
ccccaggatg ccccgaggaa acaagaagct gaaagtggag ctgccgcccg tggaggattt 33360
ggaggaagac tgggagaaca gcagtcaggc agaggagatg gaggaagact gggacagcac 33420
tcaggcagag gaggacagcc tgcaagacag tctggaggaa gacgaggagg aggcagagga 33480
ggaggtggaa gaagcagccg ccgccagacc gtcgtcctcg gcgggggaga aagcaagcag 33540
cacggatacc atctccgctc cgggtcgggg tcccgctcgg ccccacagta gatgggacga 33600
gaccgggcga ttcccgaacc ccaccaccca gaccggtaag aaggagcggc agggatacaa 33660
gtcctggcgg gggcacaaaa acgccatcgt ctcctgcttg caggcctgcg ggggcaacat 33720
ctccttcacc cggcgctacc tgctcttcca ccgcggggtg aacttccccc gcaacatctt 33780
gcattactac cgtcacctcc acagccccta ctacttccaa gaagaggcag cagcagcaga 33840
aaaagaccag aaaaccagct agaaaatcca cagcggcggc agcggcaggt ggactgagga 33900
tcgcggcgaa cgagccggcg cagacccggg agctgaggaa ccggatcttt cccaccctct 33960
atgccatctt ccagcagagt cgggggcagg agcaggaact gaaagtcaag aaccgttctc 34020
tgcgctcgct cacccgcagt tgtctgtatc acaagagcga agaccaactt cagcgcactc 34080
tcgaggacgc cgaggctctc ttcaacaagt actgcgcgct cactcttaaa gagtagcccg 34140
cgcccgccca gtcgcagaaa aaggcgggaa ttacgtcacc tgtgcccttc gccctagccg 34200
cctccaccca gcaccgccat gagcaaagag attcccacgc cttacatgtg gagctaccag 34260
ccccagatgg gcctggccgc cggcgccgcc caggactact ccacccgcat gaattggctc 34320
agcgccgggc ccgcgatgat ctcacgggtg aatgacatcc gcgcccaccg aaaccagata 34380
ctcctagaac agtcagcgct caccgccacg ccccgcaatc acctcaatcc gcgtaattgg 34440
cccgccgccc tggtgtacca ggaaattccc cagcccacga ccgtactact tccgcgagac 34500
gcccaggccg aagtccagct gactaactca ggtgtccagc tggcgggcgg cgccaccctg 34560
tgtcgtcacc gccccgctca gggtataaag cggctggtga tccggggcag aggcacacag 34620
ctcaacgacg aggtggtgag ctcttcgctg ggtctgcgac ctgacggagt cttccaactc 34680
gccggatcgg ggagatcttc cttcacgcct cgtcaggcgg tcctgacttt ggagagttcg 34740
tcctcgcagc cccgctcggg cggcatcggc actctccagt tcgtggagga gttcactccc 34800
tcggtctact tcaacccctt ctccggctcc cccggccact acccggacga gttcatcccg 34860
aactttgacg ccatcagcga gtcggtggac ggctacgatt gattaattaa tcaactaacc 34920
ccttacccct ttaccctcca gtaaaaataa agattaaaaa tgattgaatt gatcaataaa 34980
gaatcactta cttgaaatct gaaaccaggt ctctgtccat gttttctgtc agcagcactt 35040
cactcccctc ttcccaactc tggtactgca ggccccggcg ggctgcaaac ttcctccaca 35100
ctctgaaggg gatgtcaaat tcctcctgtc cctcaatctt catttttatc ttctatcaga 35160
tgtccaaaaa gcgcgcgcgg gtggatgatg gcttcgaccc cgtgtacccc tacgatgcag 35220
acaacgcacc gactgtgccc ttcatcaacc ctcccttcgt ctcttcagat ggattccaag 35280
aaaagcccct gggggtgttg tccctgcgac tggccgaccc cgtcaccacc aagaatgggg 35340
ctgtcaccct caagctgggg gagggggtgg acctcgacga ctcgggaaaa ctcatctcca 35400
aaaatgccac caaggccact gcccctctca gtatttccaa cggcaccatt tcccttaaca 35460
tggctgcccc tttttacaac aacaatggaa cgttaagtct caatgtttct acaccattag 35520
cagtatttcc cacttttaac actttaggta tcagtcttgg aaacggtctt caaacttcta 35580
ataagttgct gactgtacag ttaactcatc ctcttacatt cagctcaaat agcatcacag 35640
taaaaacaga caaaggactc tatattaatt ctagtggaaa cagagggctt gaggctaaca 35700
taagcctaaa aagaggactg atttttgatg gtaatgctat tgcaacatac cttggaagtg 35760
gtttagacta tggatcctat gatagcgatg ggaaaacaag acccatcatc accaaaattg 35820
gagcaggttt gaattttgat gctaataatg ccatggctgt gaagctaggc acaggtttaa 35880
gttttgactc tgccggtgcc ttaacagctg gaaacaaaga ggatgacaag ctaacacttt 35940
ggactacacc tgacccaagc cctaattgtc aattactttc agacagagat gccaaattta 36000
ccctatgtct tacaaaatgc ggtagtcaaa tactaggcac tgttgcagta gctgctgtta 36060
ctgtaggttc agcactaaat ccaattaatg acacagtaaa aagcgccata gtattcctta 36120
gatttgactc tgacggtgtg ctcatgtcaa actcatcaat ggtaggtgat tactggaact 36180
ttagggaagg acagaccacc caaagtgtgg cctatacaaa tgctgtggga ttcatgccca 36240
atctaggtgc atatcctaaa acccaaagca aaacaccaaa aaatagtata gtaagtcagg 36300
tatatttaaa tggagaaact actatgccaa tgacactgac aataactttc aatggcactg 36360
atgaaaaaga cacaacacct gtgagcactt actccatgac ttttacatgg cagtggactg 36420
gagactataa ggacaagaat attacctttg ctaccaactc ctttactttc tcctacatgg 36480
cccaagaata aaccctgcat gccaacccca ttgttcccac cactatggaa aactctgaag 36540
cagaaaaaaa taaagttcaa gtgttttatt gattcaacag ttttctcaca gaaccctagt 36600
attcaacctg ccacctccct cccaacacac agagtacaca gtcctttctc cccggctggc 36660
cttaaaaagc atcatatcat gggtaacaga catattctta ggtgttatat tccacacggt 36720
ttcctgtcga gccaaacgct catcagtgat attaataaac tccccgggca gctcacttaa 36780
gttcatgtcg ctgtccagct gctgagccac aggctgctgt ccaacttgcg gttgcttaac 36840
gggcggcgaa ggagaagtcc acgcctacat gggggtagag tcataatcgt gcatcaggat 36900
agggcggtgg tgctgcagca gcgcgcgaat aaactgctgc cgccgccgct ccgtcctgca 36960
ggaatacaac atggcagtgg tctcctcagc gatgattcgc accgcccgca gcataaggcg 37020
ccttgtcctc cgggcacagc agcgcaccct gatctcactt aaatcagcac agtaactgca 37080
gcacagcacc acaatattgt tcaaaatccc acagtgcaag gcgctgtatc caaagctcat 37140
ggcggggacc acagaaccca cgtggccatc ataccacaag cgcaggtaga ttaagtggcg 37200
acccctcata aacacgctgg acataaacat tacctctttt ggcatgttgt aattcaccac 37260
ctcccggtac catataaacc tctgattaaa catggcgcca tccaccacca tcctaaacca 37320
gctggccaaa acctgcccgc cggctataca ctgcagggaa ccgggactgg aacaatgaca 37380
gtggagagcc caggactcgt aaccatggat catcatgctc gtcatgatat caatgttggc 37440
acaacacagg cacacgtgca tacacttcct caggattaca agctcctccc gcgttagaac 37500
catatcccag ggaacaaccc attcctgaat cagcgtaaat cccacactgc agggaagacc 37560
tcgcacgtaa ctcacgttgt gcattgtcaa agtgttacat tcgggcagca gcggatgatc 37620
ctccagtatg gtagcgcggg tttctgtctc aaaaggaggt agacgatccc tactgtacgg 37680
agtgcgccga gacaaccgag atcgtgttgg tcgtagtgtc atgccaaatg gaacgccgga 37740
cgtagtcata tttcctgaag caaaaccagg tgcgggcgtg acaaacagat ctgcgtctcc 37800
ggtctcgccg cttagatcgc tctgtgtagt agttgtagta tatccactct ctcaaagcat 37860
ccaggcgccc cctggcttcg ggttctatgt aaactccttc atgcgccgct gccctgataa 37920
catccaccac cgcagaataa gccacaccca gccaacctac acattcgttc tgcgagtcac 37980
acacgggagg agcgggaaga gctggaagaa ccatgattaa ctttattcca aacggtctcg 38040
gagcacttca aaatgcaggt cccggaggtg gcacctctcg cccccactgt gttggtggaa 38100
aataacagcc aggtcaaagg tgacacggtt ctcgagatgt tccacggtgg cttccagcaa 38160
agcctccacg cgcacatcca gaaacaagag gacagcgaaa gcgggagcgt tttctaattc 38220
ctcaatcatc atattacact cctgcaccat ccccagataa ttttcatttt tccagccttg 38280
aatgattcgt attagttcct gaggtaaatc caagccagcc atgataaaaa gctcgcgcag 38340
agcgccctcc accggcattc ttaagcacac cctcataatt ccaagagatt ctgctcctgg 38400
ttcacctgca gcagattaac aatgggaata tcaaaatctc tgccgcgatc cctaagctcc 38460
tccctcaaca ataactgtat gtaatctttc atatcatctc cgaaattttt agccataggg 38520
ccgccaggaa taagagcagg gcaagccaca ttacagataa agcgaagtcc tccccagtgw 38580
gcattgccaa atgtaagatt gaaataagca tgctggctag accctgtgat atcttccaga 38640
taactggaca gaaaatcagg caagcaattt ttaagaaaat caacaaaaga aaagtcgtcc 38700
aggtgcaggt ttagagcctc aggaacaacg atggaataag tgcaaggagt gcgttccagc 38760
atggttagtg tttttttggt gatctgtaga acaaaaaata aacatgcaat attaaaccat 38820
gctagcctgg cgaacaggtg ggtaaatcac tctttccagc accaggcagg ctacggggtc 38880
tccggcgcga ccctcgtaga agctgtcgcc atgattgaaa agcatcaccg agagaccttc 38940
ccggtggccg gcatggatga ttcgagaaga agcatacact ccgggaacat tggcatccgt 39000
gagtgaaaaa aagcgaccta taaagcctcg gggcactaca atgctcaatc tcaattccag 39060
caaagccacc ccatgcggat ggagcacaaa attggcaggt gcgtaaaaaa tgtaattact 39120
cccctcctgc acaggcagca aagcccccgc tccctccaga aacacataca aagcctcagc 39180
gtccatagct taccgagcac ggcaggcgca agagtcagag aaaaggctga gctctaacct 39240
gactgcccgc tcctgtgctc aatatatagc cctaacctac actgacgtaa aggccaaagt 39300
ctaaaaatac ccgccaaaat gacacacacg cccagcacac gcccagaaac cggtgacaca 39360
ctcaaaaaaa tacgtgcgct tcctcaaacg cccaaaccgg cgtcatttcc gggttcccac 39420
gctacgtcac cgctcagcga ctttcaaatt ccgtcgaccg ttaaaaacgt cactcgcccc 39480
gcccctaacg gtcgcccttc tctcggccaa tcaccttcct cccttcccaa attcaaacgc 39540
ctcatttgca tattaacgcg cacaaaaagt ttgaggtata tatttgaatg atg 39593
<210> 25
<211> 39593
<212> DNA
<213> Artificial Sequence
<220>
<223> MVA shuttle vector p4719
<400> 25
gtttaaacgc ggccgccagg cctacccact agtcaattcg ggaggatcga aacggcagat 60
cgcaaaaaac agtacataca gaaggagaca tgaacatgaa catcaaaaaa attgtaaaac 120
aagccacagt tctgactttt acgactgcac ttctggcagg aggagcgact caagccttcg 180
cgaaagaaaa taaccaaaaa gcatacaaag aaacgtacgg cgtctctcat attacacgcc 240
atgatatgct gcagatccct aaacagcagc aaaacgaaaa ataccaagtg cctcaattcg 300
atcaatcaac gattaaaaat attgagtctg caaaaggact tgatgtgtgg gacagctggc 360
cgctgcaaaa cgctgacgga acagtagctg aatacaacgg ctatcacgtt gtgtttgctc 420
ttgcgggaag cccgaaagac gctgatgaca catcaatcta catgttttat caaaaggtcg 480
gcgacaactc aatcgacagc tggaaaaacg cgggccgtgt ctttaaagac agcgataagt 540
tcgacgccaa cgatccgatc ctgaaagatc agacgcaaga atggtccggt tctgcaacct 600
ttacatctga cggaaaaatc cgtttattct acactgacta ttccggtaaa cattacggca 660
aacaaagcct gacaacagcg caggtaaatg tgtcaaaatc tgatgacaca ctcaaaatca 720
acggagtgga agatcacaaa acgatttttg acggagacgg aaaaacatat cagaacgttc 780
agcagtttat cgatgaaggc aattatacat ccggcgacaa ccatacgctg agagaccctc 840
actacgttga agacaaaggc cataaatacc ttgtattcga agccaacacg ggaacagaaa 900
acggatacca aggcgaagaa tctttattta acaaagcgta ctacggcggc ggcacgaact 960
tcttccgtaa agaaagccag aagcttcagc agagcgctaa aaaacgcgat gctgagttag 1020
cgaacggcgc cctcggtatc atagagttaa ataatgatta cacattgaaa aaagtaatga 1080
agccgctgat cacttcaaac acggtaactg atgaaatcga gcgcgcgaat gttttcaaaa 1140
tgaacggcaa atggtacttg ttcactgatt cacgcggttc aaaaatgacg atcgatggta 1200
ttaactcaaa cgatatttac atgcttggtt atgtatcaaa ctctttaacc ggcccttaca 1260
agccgctgaa caaaacaggg cttgtgctgc aaatgggtct tgatccaaac gatgtgacat 1320
tcacttactc tcacttcgca gtgccgcaag ccaaaggcaa caatgtggtt atcacaagct 1380
acatgacaaa cagaggcttc ttcgaggata aaaaggcaac atttgcgcca agcttcttaa 1440
tgaacatcaa aggcaataaa acatccgttg tcaaaaacag catcctggag caaggacagc 1500
tgacagtcaa ctaataacag caaaaagaaa atgccgatac ttcattggca ttttctttta 1560
tttctcaaca agatggtgaa ttgactagtg ggtagatcca caggacgggt gtggtcgcca 1620
tgatcgcgta gtcgatagtg gctccaagta gcgaagcgag caggactggg cggcggccaa 1680
agcggtcgga cagtgctccg agaacgggtg cgcatagaaa ttgcatcaac gcatatagcg 1740
ctagcagcac gccatagtga ctggcgatgc tgtcggaatg gacgatatcc cgcaagaggc 1800
ccggcagtac cggcataacc aagcctatgc ctacagcatc cagggtgacg gtgccgagga 1860
tgacgatgag cgcattgtta gatttcatac acggtgcctg actgcgttag caatttaact 1920
gtgataaact accgcattaa agcttatcga tgataagctg tcaaacatga gaattgatcc 1980
ggaaccctta atataacttc gtataatgta tgctatacga agttattagg tccctcgact 2040
atagggtcac cgtcgacagc gacacacttg catcggatgc agcccggtta acgtgccggc 2100
acggcctggg taaccaggta ttttgtccac ataaccgtgc gcaaaatgtt gtggataagc 2160
aggacacagc agcaatccac agcaggcata caaccgcaca ccgaggttac tccgttctac 2220
aggttacgac gacatgtcaa tacttgccct tgacaggcat tgatggaatc gtagtctcac 2280
gctgatagtc tgatcgacaa tacaagtggg accgtggtcc cagaccgata atcagaccga 2340
crayacgagt gggaycgtgg tcccagacta ataatcagac cgacgatacg agtgggaccg 2400
tggtcccaga ctaataatca gaccgacgat acgagtggga ccgtggtycc agwctratwa 2460
tcagaccgac gatacragtg gracmgtggk cccagasaka atawtcagrc cgagwtaygc 2520
wktckggcct gtaacaaagg acattaagta aagacagata mrmgtgrgac taaaacgtgg 2580
tcccagtctg attatcagac cgacgatacg agtgggaccg tggtcccaga ctaataatca 2640
gaccgacgat acgagtggga ccgtggtccc agactaataa tcagaccgac gatacgagtg 2700
ggaccgtggt cccagtctga ttatcagacc gacgatacaa gtggaacagt gggcccagag 2760
agaatattca ggccagttat gctttctggc ctgtaacaaa ggacattaag taaagacaga 2820
taaacgtaga ctaaaacgtg gtcgcatcag ggtgctggct tttcaagttc cttaagaatg 2880
gcctcaattt tctctataca ctcagttgga acacgagacc tgtccaggtt aagcaccatt 2940
ttatcgccct tatacaatac tgtcgctcca ggagcaaact gatgtcgtga gcttaaacta 3000
gttcttgatg cagatgacgt tttaagcaca gaagttaaaa gagtgataac ttcttcagct 3060
tcaaatatca ccccagcttt tttctgctca tgaaggttag atgcctgctg cttaagtaat 3120
tcctctttat ctgtaaaggc tttttgaagt gcatcacctg accgggcaga tagttcaccg 3180
gggtgagaaa aaagagcaac aactgattta ggcaatttgg cggtgttgat acagcgggta 3240
ataatcttac gtgaaatatt ttccgcatca gccagcgcag aaatatttcc agcaaattca 3300
ttctgcaatc ggcttgcata acgctgacca cgttcataag cacttgttgg gcgataatcg 3360
ttacccaatc tggataatgc agccatctgc tcatcatcca gctcgccaac cagaacacga 3420
taatcacttt cggtaagtgc agcagcttta cgacggcgac tcccatcggc aatttctatg 3480
acaccagata ctcttcgacc gaacgccggt gtctgttgac cagtcagtag aaaagaaggg 3540
atgagatcat ccagtgcgtc ctcagtaagc agctcctggt cacgttcatt acctgaccat 3600
acccgagagg tcttctcaac actatcaccc cggagcactt caagagtaaa cttcacatcc 3660
cgaccacata caggcaaagt aatggcatta ccgcgagcca ttactcctac gcgcgcaatt 3720
aacgaatcca ccatcggggc agctggtgtc gataacgaag tatcttcaac cggttgagta 3780
ttgagcgtat gttttggaat aacaggcgca cgcttcatta tctaatctcc cagcgtggtt 3840
taatcagacg atcgaaaatt tcattgcaga caggttccca aatagaaaga gcatttctcc 3900
aggcaccagt tgaagagcgt tgatcaatgg cctgttcaaa aacagttctc atccggatct 3960
gacctttacc aacttcatcc gtttcacgta caacattttt tagaaccatg cttccccagg 4020
catcccgaat ttgctcctcc atccacgggg actgagagcc attactattg ctgtatttgg 4080
taagcaaaat acgtacatca ggctcgaacc ctttaagatc aacgttcttg agcagatcac 4140
gaagcatatc gaaaaactgc agtgcggagg tgtagtcaaa caactcagca ggcgtgggaa 4200
caatcagcac atcagcagca catacgacat taatcgtgcc gatacccagg ttaggcgcgc 4260
tgtcaataac tatgacatca tagtcatgag caacagtttc aatggccagt cggagcatca 4320
ggtgtggatc ggtgggcagt ttaccttcat caaatttgcc cattaactca gtttcaatac 4380
ggtgcagagc cagacaggaa ggaataatgt caagccccgg ccagcaagtg ggctttattg 4440
cataagtgac atcgtccttt tccccaagat agaaaggcag gagagtgtct tctgcatgaa 4500
tatgaagatc tggtacccat ccgtgataca ttgaggctgt tccctggggg tcgttacctt 4560
ccacgagcaa aacacgtagc cccttcagag ccagatcctg agcaagatga acagaaactg 4620
aggttttgta aacgccacct ttatgggcag caaccccgat caccggtgga aatacgtctt 4680
cagcacgtcg caatcgcgta ccaaacacat cacgcatatg attaatttgt tcaattgtat 4740
aaccaacacg ttgctcaacc cgtcctcgaa tttccatatc cgggtgcggt agtcgccctg 4800
ctttctcggc atctctgata gcctgagaag aaaccccaac taaatccgct gcttcaccta 4860
ttctccagcg ccgggttatt ttcctcgctt ccgggctgtc atcattaaac tgtgcaatgg 4920
cgatagcctt cgtcatttca tgaccagcgt ttatgcactg gttaagtgtt tccatgagtt 4980
tcattctgaa catcctttaa tcattgcttt gcgttttttt attaaatctt gcaatttact 5040
gcaaagcaac aacaaaatcg caaagtcatc aaaaaaccgc aaagttgttt aaaataagag 5100
caacactaca aaaggagata agaagagcac atacctcagt cacttattat cactagcgct 5160
cgccgcagcc gtgtaaccga gcatagcgag cgaactggcg aggaagcaaa gaagaactgt 5220
tctgtcagat agctcttacg ctcagcgcaa gaagaaatat ccaccgtggg aaaaactcca 5280
ggtagaggta cacacgcgga tagccaattc agagtaataa actgtgataa tcaaccctca 5340
tcaatgatga cgaactaacc cccgatatca ggtcacatga cgaagggaaa gagaaggaaa 5400
tcaactgtga caaactgccc tcaaatttgg cttccttaaa aattacagtt caaaaagtat 5460
gagaaaatcc atgcaggctg aaggaaacag caaaactgtg acaaattacc ctcagtaggt 5520
cagaacaaat gtgacgaacc accctcaaat ctgtgacaga taaccctcag actatcctgt 5580
cgtcatggaa gtgatatcgc ggaaggaaaa tacgatatga gtcgtctggc ggcctttctt 5640
tttctcaatg tatgagaggc gcattggagt tctgctgttg atctcattaa cacagacctg 5700
caggaagcgg cggcggaagt caggcatacg ctggtaactt tgaggcagct ggtaacgctc 5760
tatgatccag tcgattttca gagagacgat gcctgagcca tccggcttac gatactgaca 5820
cagggattcg tataaacgca tggcatacgg attggtgatt tcttttgttt cactaagccg 5880
aaactgcgta aaccggttct gtaacccgat aaagaaggga atgagatatg ggttgatatg 5940
tacactgtaa agccctctgg atggactgtg cgcacgtttg ataaaccaag gaaaagattc 6000
atagcctttt tcatcgccgg catcctcttc agggcgataa aaaaccactt ccttccccgc 6060
gaaactcttc aatgcctgcc gtatatcctt actggcttcc gcagaggtca atccgaatat 6120
ttcagcatat ttagcaacat ggatctcgca gataccgtca tgttcctgta gggtgccatc 6180
agattttctg atctggtcaa cgaacagata cagcatacgt ttttgatccc gggagagact 6240
atatgccgcc tcagtgaggt cgtttgactg gacgattcgc gggctatttt tacgtttctt 6300
gtgattgata accgctgttt ccgccatgac agatccatgt gaagtgtgac aagtttttag 6360
attgtcacac taaataaaaa agagtcaata agcagggata actttgtgaa aaaacagctt 6420
cttctgaggg caatttgtca cagggttaag ggcaatttgt cacagacagg actgtcattt 6480
gagggtgatt tgtcacactg aaagggcaat ttgtcacaac accttctcta gaaccagcat 6540
ggataaaggc ctacaaggcg ctctaaaaaa gaagatctaa aaactataaa aaaaataatt 6600
ataaaaatat ccccgtggat aagtggataa ccccaaggga agttttttca ggcatcgtgt 6660
gtaagcagaa tatataagtg ctgttccctg gtgcttcctc gctcactcga gggcttcgcc 6720
ctgtcgctca actgcggcga gcactactgg ctgtaaaagg acagaccaca tcatggttct 6780
gtgttcatta ggttgttctg tccattgctg acataatccg ctccacttca acgtaacacc 6840
gcacgaagat ttctattgtt cctgaaggca tattcaaatc gttttcgtta ccgcttgcag 6900
gcatcatgac agaacactac ttcctataaa cgctacacag gctcctgaga ttaataatgc 6960
ggatctctac gataatggga gattttcccg actgtttcgt tcgcttctca gtggataaca 7020
gccagcttct ctgtttaaca gacaaaaaca gcatatccac tcagttccac atttccatat 7080
aaaggccaag gcatttattc tcaggataat tgtttcagca tcgcaaccgc atcagactcc 7140
ggcatcgcaa actgcacccg gtgccgggca gccacatcca gcgcaaaaac cttcgtgtag 7200
acttccgttg aactgatgga cttatgtccc atcaggcttt gcagaacttt cagcggtata 7260
ccggcataca gcatgtgcat cgcataggaa tggcggaacg tatgtggtgt gaccggaaca 7320
gagaacgtca caccgtcagc agcagcggcg gcaaccgcct ccccaatcca ggtcctgacc 7380
gttctgtccg tcacttccca gatccgcgct ttctctgtcc ttcctgtgcg acggttacgc 7440
cgctccatga gcttatcgcg aataaatacc tgtgacggaa gatcacttcg cagaataaat 7500
aaatcctggt gtccctgttg ataccgggaa gccctgggcc aacttttggc gaaaatgaga 7560
cgttgatcgg cacgtaagag gttccaactt tcaccataat gaaataagat cactaccggg 7620
cgtatttttt gagttatcga gattttcagg agctaaggaa gctaaaatgg agaaaaaaat 7680
cactggatat accaccgttg atatatccca atggcatcgt aaagaacatt ttgaggcatt 7740
tcagtcagtt gctcaatgta cctataacca gaccgttcag ctggatatta cggccttttt 7800
aaagaccgta aagaaaaata agcacaagtt ttatccggcc tttattcaca ttcttgcccg 7860
cctgatgaat gctcatccgg agttccgtat ggcaatgaaa gacggtgagc tggtgatatg 7920
ggatagtgtt cacccttgtt acaccgtttt ccatgagcaa actgaaacgt tttcatcgct 7980
ctggagtgaa taccacgacg atttccggca gtttctacac atatattcgc aagatgtggc 8040
gtgttacggt gaaaacctgg cctatttccc taaagggttt attgagaata tgtttttcgt 8100
ctcagccaat ccctgggtga gtttcaccag ttttgattta aacgtggcca atatggacaa 8160
cttcttcgcc cccgttttca ccatgggcaa atattatacg caaggcgaca aggtgctgat 8220
gccgctggcg attcaggttc atcatgccgt ttgtgatggc ttccatgtcg gcagaatgct 8280
taatgaatta caacagtact gcgatgagtg gcagggcggg gcgtaatttt tttaaggcag 8340
ttattggtgc ccttaaacgc ctggttgcta cgcctgaata agtgataata agcggatgaa 8400
tggcagaaat tcgatgataa gctgtcaaac atgagaattg gtcgacggcg cgccaaagct 8460
tgcatgcctg cagccgcgta acctggcaaa atcggttacg gttgagtaat aaatggatgc 8520
cctgcgtaag cggggcacat ttcattacct ctttctccgc acccgacata gataataact 8580
tcgtatagta tacattatac gaagttatct agtagactta atcgcgttta aacccatcat 8640
caataatata cctcaaactt tttgtgcgcg ttaatatgca aatgaggcgt ttgaatttgg 8700
gaagggagga aggtgattgg ccgagagaag ggcgaccgtt aggggcgggg cgagtgacgt 8760
tttgatgacg tgaccgcgag gaggagccag tttgcaagtt ctcgtgggaa aagtgacgtc 8820
aaacgaggtg tggtttgaac acggaaatac tcaattttcc cgcgctctct gacaggaaat 8880
gaggtgtttc taggcggatg caagtgaaaa cgggccattt tcgcgcgaaa actgaatgag 8940
gaagtgaaaa tctgagtaat ttcgcgttta tgacagggag gagtatttgc cgagggccga 9000
gtagactttg accgattacg tgggggtttc gattaccgtg tttttcacct aaatttccgc 9060
gtacggtgtc aaagtccggt gtttttacgt aggtgtcagc tgatcgccag ggtatttaaa 9120
cctgcgctct ccagtcaaga ggccactctt gagtgccagc gagaagagtt ttctcctccg 9180
cgcgcgagtc agatctacac tttgaaaggc gatcgctagc gacatcgatc acaagtttgt 9240
acaaaaaagc tgaacgagaa acgtaaaatg atataaatat caatatatta aattagattt 9300
tgcataaaaa acagactaca taatactgta aaacacaaca tatccagtca ctatggcggc 9360
cgccgattta ttcaacaaag ccacgttgtg tctcaaaatc tctgatgtta cattgcacaa 9420
gataaaaata tatcatcatg aacaataaaa ctgtctgctt acataaacag taatacaagg 9480
ggtgttatga gccatattca acgggaaacg tcttgctcga ggccgcgatt aaattccaac 9540
atggatgctg atttatatgg gtataaatgg gctcgtgata atgtcgggca atcaggtgcg 9600
acaatctatc gattgtatgg gaagcccgat gcgccagagt tgtttctgaa acatggcaaa 9660
ggtagcgttg ccaatgatgt tacagatgag atggtcagac taaactggct gacggaattt 9720
atgcctcttc cgaccatcaa gcattttatc cgtactcctg atgatgcatg gttactcacc 9780
actgcgatcc ccgggaaaac agcattccag gtattagaag aatatcctga ttcaggtgaa 9840
aatattgttg atgcgctggc agtgttcctg cgccggttgc attcgattcc tgtttgtaat 9900
tgtcctttta acagcgatcg cgtatttcgt ctcgctcagg cgcaatcacg aatgaataac 9960
ggtttggttg atgcgagtga ttttgatgac gagcgtaatg gctggcctgt tgaacaagtc 10020
tggaaagaaa tgcataagct tttgccattc tcaccggatt cagtcgtcac tcatggtgat 10080
ttctcacttg ataaccttat ttttgacgag gggaaattaa taggttgtat tgatgttgga 10140
cgagtcggaa tcgcagaccg ataccaggat cttgccatcc tatggaactg cctcggtgag 10200
ttttctcctt cattacagaa acggcttttt caaaaatatg gtattgataa tcctgatatg 10260
aataaattgc agtttcattt gatgctcgat gagtttttct aatcagaatt ggttaattgg 10320
ttgtaacact ggcacgcgtg gatccggctt actaaaagcc agataacagt atgcgtattt 10380
gcgcgctgat ttttgcggta taagaatata tactgatatg tatacccgaa gtatgtcaaa 10440
aagaggtatg ctatgaagca gcgtattaca gtgacagttg acagcgacag ctatcagttg 10500
ctcaaggcat atatgatgtc aatatctccg gtctggtaag cacaaccatg cagaatgaag 10560
cccgtcgtct gcgtgccgaa cgctggaaag cggaaaatca ggaagggatg gctgaggtcg 10620
cccggtttat tgaaatgaac ggctcttttg ctgacgagaa caggggctgg tgaaatgcag 10680
tttaaggttt acacctataa aagagagagc cgttatcgtc tgtttgtgga tgtacagagt 10740
gatattattg acacgcccgg gcgacggatg gtgatccccc tggccagtgc acgtctgctg 10800
tcagataaag tctcccgtga actttacccg gtggtgcata tcggggatga aagctggcgc 10860
atgatgacca ccgatatggc cagtgtgccg gtctccgtta tcggggaaga agtggctgat 10920
ctcagccacc gcgaaaatga catcaaaaac gccattaacc tgatgttctg gggaatataa 10980
atgtcaggct cccttataca cagccagtct gcaggtcgac catagtgact ggatatgttg 11040
tgttttacag tattatgtag tctgtttttt atgcaaaatc taatttaata tattgatatt 11100
tatatcattt tacgtttctc gttcagcttt cttgtacaaa gtggtgatcg attcgacaga 11160
tcgcgatcgc agtgagtagt gttctggggc gggggaggac ctgcatgagg gccagaatga 11220
ctgaaatctg tgcttttctg tgtgttgcag catcatgagc ggaagcggct cctttgaggg 11280
aggggtattc agcccttatc tgacggggcg tctcccctcc tgggcgggag tgcgtcagaa 11340
tgtgatggga tccacggtgg acggccggcc cgtgcagccc gcgaactctt caaccctgac 11400
ctatgcaacc ctgagctctt cgtcggtgga cgcagctgcc gccgcagctg ctgcatccgc 11460
cgccagcgcc gtgcgcggaa tggccatggg cgccggctac tacggcactc tggtggccaa 11520
ctcgagttcc accaataatc ccgccagcct gaacgaggag aagctgctgc tgctgatggc 11580
ccagcttgag gccttgaccc agcgcctggg cgagctgacc cagcaggtgg ctcagctgca 11640
ggagcagacg cgggccgcgg ttgccacggt gaaatccaaa taaaaaatga atcaataaat 11700
aaacggagac ggttgttgat tttaacacag agtctgaatc tttatttgat ttttcgcgcg 11760
cggtaggccc tggaccaccg gtctcgatca ttgagcaccc ggtggatctt ttccaggacc 11820
cggtagaggt gggcttggat gttgaggtac atgggcatga gcccgtcccg ggggtggagg 11880
tagctccatt gcagggcctc gtgctcgggg gtggtgttgt aaatcaccca gtcatagcag 11940
gggcgcaggg cgtggtgttg cacaatatct ttgaggagga gactgatggc cacgggcagc 12000
cctttggtgt aggtgtttac aaatctgttg agctgggagg gatgcatgcg gggggagatg 12060
aggtgcatct tggcctggat cttgagattg gcgatgttac cgcccagatc ccgcctgggg 12120
ttcatgttgt gcaggaccac cagcacggtg tatccggtgc acttggggaa tttatcatgc 12180
aacttggaag ggaaggcgtg aaagaatttg gcgacgccct tgtgtccgcc caggttttcc 12240
atgcactcat ccatgatgat ggcaatgggc ccgtgggcgg cggcctgggc aaagacgttt 12300
cgggggtcgg acacatcata gttgtggtcc tgggtgaggt catcataggc cattttaatg 12360
aatttggggc ggagggtgcc ggactggggg acaaaggtac cctcgatccc gggggcgtag 12420
ttcccctcac agatctgcat ctcccaggct ttgagctcag agggggggat catgtccacc 12480
tgcggggcga taaagaacac ggtttccggg gcgggggaga tgagctgggc cgaaagcaag 12540
ttccggagca gctgggactt gccgcagccg gtggggccgt aaatgacccc gatgaccggc 12600
tgcaggtggt agttgaggga gagacagctg ccgtcctccc ggaggagggg ggccacctcg 12660
ttcatcatct cgcgcacgtg catgttctcg cgcaccagtt ccgccaggag gcgctctccc 12720
cccagagata ggagctcctg gagcgaggcg aagtttttca gcggcttgag tccgtcggcc 12780
atgggcattt tggagagggt ctgttgcaag agttccaagc ggtcccagag ctcggtgatg 12840
tgctctacgg catctcgatc cagcagacct cctcgtttcg cgggttggga cgactgcggg 12900
agtagggcac cagacgatgg gcgtccagcg cagccagggt ccggtccttc cagggccgca 12960
gcgtccgcgt cagggtggtc tccgtcacgg tgaaggggtg cgcgccgggc tgggcgcttg 13020
cgagggtgcg cttcaggctc atccggctgg tcgaaaaccg ctcccgatcg gcgccctgcg 13080
cgtcggccag gtagcaattg accatgagtt cgtagttgag cgcctcggcc gcgtggcctt 13140
tggcgcggag cttacctttg gaagtctgcc cgcaggcggg acagaggagg gacttgaggg 13200
cgtagagctt gggggcgagg aagacggaat cgggggcgta ggcgtccgcg ccgcagtggg 13260
cgcagacggt ctcgcactcc acgagccagg tgaggtcggg ctggtcgggg tcaaaaacca 13320
gtttcccgcc gttctttttg atgcgtttct tacctttggt ctccatgagc tcgtgtcccc 13380
gctgggtgac aaagaggctg tccgtgtccc cgtagaccga ctttatgggc cggtcctcga 13440
gcggtgtgcc gcggtcctcc tcgtagagga accccgccca ctccgagacg aaagcccggg 13500
tccaggccag cacgaaggag gccacgtggg acgggtagcg gtcgttgtcc accagcgggt 13560
ccactttttc cagggtatgc aaacacatgt ccccctcgtc cacatccagg aaggtgattg 13620
gcttgtaagt gtaggccacg tgaccggggg tcccggccgg gggggtataa aagggggcgg 13680
gcccctgctc gtcctcactg tcttccggat cgctgtccag gagcgccagc tgttggggta 13740
ggtattccct ctcgaaggcg ggcatgacct cggcactcag gttgtcagtt tctagaaacg 13800
aggaggattt gatattgacg gtgccagcgg agatgccttt caagagcccc tcgtccatct 13860
ggtcagaaaa gacgattttt ttgttgtcga gcttggtggc gaaggagccg tagagggcgt 13920
tggaaaggag cttggcgatg gagcgcatgg tctggttttt ttccttgtcg gcgcgctcct 13980
tggccgcgat gttgagctgc acgtactcgc gcgccacgca cttccattcg gggaagacgg 14040
tggtcatctc gtcgggcacg attctgacct gccaacctcg attatgcagg gtgatgaggt 14100
ccacactggt ggccacctcg ccgcgcaggg gctcgttggt ccagcagagg cggccgccct 14160
tgcgcgagca gaaggggggc agagggtcca gcatgacctc gtcggggggg tcggcatcga 14220
tggtgaagat gccgggcagg agatcggggt cgaagtagct gatggaagtg gccagatcgt 14280
ccagggaagc ttgccattcg cgcacggcca gcgcgcgctc gtagggactg aggggcgtgc 14340
cccagggcat ggggtgggtg agcgcggagg cgtacatgcc gcagatgtcg tagacgtaga 14400
ggggctcctc gaggatgccg atgtaggtgg ggtagcagcg ccccccgcgg atgctggcgc 14460
gcacgtagtc atacagctcg tgcgagggcg cgaggagccc cgggcccagg ttggtgcgac 14520
tgggcttttc ggcgcggtag acgatctggc gaaagatggc atgcgagttg gaggagatgg 14580
tgggcctttg gaagatgttg aagtgggcgt gggggaggcc gaccgagtcg cggatgaagt 14640
gggcgtagga gtcttgcagt ttggcgacga gctcggcggt gacgaggacg tccagagcgc 14700
agtagtcgag ggtctcctgg atgatgtcat acttgagctg gcccttttgt ttccacagct 14760
cgcggttgag aaggaactct tcgcggtcct tccagtactc ttcgaggggg aacccgtcct 14820
gatctgcacg gtaagagcct agcatgtaga actggttgac ggccttgtag gcgcagcagc 14880
ccttctccac ggggagggcg taggcctggg cggccttgcg cagggaggtg tgcgtgaggg 14940
cgaaggtgtc cctgaccatg accttgagga actggtgctt gaaatcgata tcgtcgcagc 15000
ccccctgctc ccagagctgg aagtccgtgc gcttcttgta ggcggggttg ggcaaagcga 15060
aagtaacatc gttgaaaagg atcttgcccg cgcggggcat aaagttgcga gtgatgcgga 15120
aaggctgggg cacctcggcc cggttgttga tgacctgggc ggcgagcacg atctcgtcga 15180
aaccgttgat gttgtggccc acgatgtaga gttccacgaa tcgcgggcgg cccttgacgt 15240
ggggcagctt cttgagctcc tcgtaggtga gctcgtcggg gtcgctgaga ccgtgctgct 15300
cgagcgccca gtcggcgaga tgggggttgg cgcggaggaa ggaagtccag agatccacgg 15360
ccagggcggt ttgcagacgg tcccggtact gacggaactg ctgcccgacg gccatttttt 15420
cgggggtgac gcagtagaag gtgcgggggt ccccgtgcca gcggtcccat ttgagctgga 15480
gggcgagatc gagggcgagc tcgacgaggc ggtcgtcccc tgagagtttc atgaccagca 15540
tgaaggggac gagctgcttg ccgaaggacc ccatccaggt gtaggtttcc acatcgtagg 15600
tgaggaagag cctttcggtg cgaggatgcg agccgatggg gaagaactgg atctcctgcc 15660
accaattgga ggaatggctg ttgatgtgat ggaagtagaa atgccgacgg cgcgccgaac 15720
actcgtgctt gtgtttatac aagcggccac agtgctcgca acgctgcacg ggatgcacgt 15780
gctgcacgag ctgtacctga gttcctttga cgaggaattt cagtgggaag tggagtcgtg 15840
gcgcctgcat ctcgtgctgt actacgtcgt ggtggtcggc ctggccctct tctgcctcga 15900
tggtggtcat gctgacgagc ccgcgcggga ggcaggtcca gacctcggcg cgagcgggtc 15960
ggagagcgag gacgagggcg cgcaggccgg agctgtccag ggtcctgaga cgctgcggag 16020
tcaggtcagt gggcagcggc ggcgcgcggt tgacttgcag gagtttttcc agggcgcgcg 16080
ggaggtccag atggtacttg atctccaccg cgccgttggt ggcgacgtcg atggcttgca 16140
gggtcccgtg cccctggggt gtgaccaccg tcccccgttt cttcttgggc ggctggggcg 16200
acgggggcgg tgcctcttcc atggttagaa gcggcggcga ggacgcgcgc cgggcggcag 16260
aggcggctcg gggcccggag gcaggggcgg caggggcacg tcggcgccgc gcgcgggtag 16320
gttctggtac tgcgcccgga gaagactggc gtgagcgacg acgcgacggt tgacgtcctg 16380
gatctgacgc ctctgggtga aggccacggg acccgtgagt ttgaacctga aagagagttc 16440
gacagaatca atctcggtat cgttgacggc ggcctgccgc aggatctctt gcacgtcgcc 16500
cgagttgtcc tggtaggcga tctcggtcat gaactgctcg atctcctcct cctgaaggtc 16560
tccgcgaccg gcgcgctcca cggtggccgc gaggtcgttg gagatgcggc ccatgagctg 16620
cgagaaggcg ttcatgcccg cctcgttcca gacgcggctg tagaccacga cgccctcggg 16680
atcgcgggcg cgcatgacca cctgggcgag gttgagctcc acgtggcgcg tgaagaccgc 16740
gtagttgcag aggcgctggt agaggtagtt gagcgtggtg gcgatgtgct cggtgacgaa 16800
gaaatacatg atccagcggc ggagcggcat ctcgctgacg tcgcccagcg cctccaagcg 16860
ttccatggcc tcgtaaaagt ccacggcgaa gttgaaaaac tgggagttgc gcgccgagac 16920
ggtcaactcc tcctccagaa gacggatgag ctcggcgatg gtggcgcgca cctcgcgctc 16980
gaaggccccc gggagttcct ccacttcctc ctcttcttcc tcctccacta acatctcttc 17040
tacttcctcc tcaggcggtg gtggtggcgg gggagggggc ctgcgtcgcc ggcggcgcac 17100
gggcagacgg tcgatgaagc gctcgatggt ctcgccgcgc cggcgtcgca tggtctcggt 17160
gacggcgcgc ccgtcctcgc ggggccgcag cgtgaagacg ccgccgcgca tctccaggtg 17220
gccggggggg tccccgttgg gcagggagag ggcgctgacg atgcatctta tcaattgccc 17280
cgtagggact ccgcgcaagg acctgagcgt ctcgagatcc acgggatctg aaaaccgttg 17340
aacgaaggct tcgagccagt cgcagtcgca aggtaggctg agcacggttt cttctgccgg 17400
gtcatgttgg ggagcggggc gggcgatgct gctggtgatg aagttgaaat aggcggttct 17460
gagacggcgg atggtggcga ggagcaccag gtctttgggc ccggcttgct ggatgcgcag 17520
acggtcggcc atgccccagg cgtggtcctg acacctggcc aggtccttgt agtagtcctg 17580
catgagccgc tccacgggca cctcctcctc gcccgcgcgg ccgtgcatgc gcgtgagccc 17640
gaagccgcgc tggggctgga cgagcgccag gtcggcgacg acgcgctcgg cgaggatggc 17700
ctgctggatc tgggtgaggg tggtctggaa gtcgtcaaag tcgacgaagc ggtggtaggc 17760
tccggtgttg atggtgtagg agcagttggc catgacggac cagttgacgg tctggtggcc 17820
cggacgcacg agctcgtggt acttgaggcg cgagtaggcg cgcgtgtcga agatgtagtc 17880
gttgcaggtg cgcaccaggt actggtagcc gatgaggaag tgcggcggcg gctggcggta 17940
gagcggccat cgctcggtgg cgggggcgcc gggcgcgagg tcctcgagca tggtgcggtg 18000
gtagccgtag atgtacctgg acatccaggt gatgccggcg gcggtggtgg aggcgcgcgg 18060
gaactcgcgg acgcggttcc agatgttgcg cagcggcagg aagtagttca tggtgggcac 18120
ggtctggccc gtgaggcgcg cgcagtcgtg gatgctctat acgggcaaaa acgaaagcgg 18180
tcagcggctc gactccgtgg cctggaggct aagcgaacgg gttgggctgc gcgtgtaccc 18240
cggttcgaat ctcgaatcag gctggagccg cagctaacgt ggtactggca ctcccgtctc 18300
gacccaagcc tgcaccaacc ctccaggata cggaggcggg tcgttttgca actttttttg 18360
gaggccggaa atgaaactag taagcgcgga aagcggccga ccgcgatggc tcgctgccgt 18420
agtctggaga agaatcgcca gggttgcgtt gcggtgtgcc ccggttcgag gccggccgga 18480
ttccgcggct aacgagggcg tggctgcccc gtcgtttcca agaccccata gccagccgac 18540
ttctccagtt acggagcgag cccctctttt gttttgtttg tttttgccag atgcatcccg 18600
tactgcggca gatgcgcccc caccaccctc caccgcaaca acagccccct cctccacagc 18660
cggcgcttct gcccccgccc cagcagcagc agcaacttcc agccacgacc gccgcggccg 18720
ccgtgagcgg ggctggacag acttctcagt atgatcacct ggccttggaa gagggcgagg 18780
ggctggcgcg cctgggggcg tcgtcgccgg agcggcaccc gcgcgtgcag atgaaaaggg 18840
acgctcgcga ggcctacgtg cccaagcaga acctgttcag agacaggagc ggcgaggagc 18900
ccgaggagat gcgcgcggcc cggttccacg cggggcggga gctgcggcgc ggcctggacc 18960
gaaagagggt gctgagggac gaggatttcg aggcggacga gctgacgggg atcagccccg 19020
cgcgcgcgca cgtggccgcg gccaacctgg tcacggcgta cgagcagacc gtgaaggagg 19080
agagcaactt ccaaaaatcc ttcaacaacc acgtgcgcac cctgatcgcg cgcgaggagg 19140
tgaccctggg cctgatgcac ctgtgggacc tgctggaggc catcgtgcag aaccccacca 19200
gcaagccgct gacggcgcag ctgttcctgg tggtgcagca tagtcgggac aacgaggcgt 19260
tcagggaggc gctgctgaat atcaccgagc ccgagggccg ctggctcctg gacctggtga 19320
acattctgca gagcatcgtg gtgcaggagc gcgggctgcc gctgtccgag aagctggcgg 19380
ccatcaactt ctcggtgctg agtctgggca agtactacgc taggaagatc tacaagaccc 19440
cgtacgtgcc catagacaag gaggtgaaga tcgacgggtt ttacatgcgc atgaccctga 19500
aagtgctgac cctgagcgac gatctggggg tgtaccgcaa cgacaggatg caccgcgcgg 19560
tgagcgccag caggcggcgc gagctgagcg accaggagct gatgcacagc ctgcagcggg 19620
ccctgaccgg ggccgggacc gagggggaga gctactttga catgggcgcg gacctgcact 19680
ggcagcccag ccgccgggcc ttggaggcgg caggcggtcc cccctacata gaagaggtgg 19740
acgatgaggt ggacgaggag ggcgagtacc tggaagactg atggcgcgac cgtatttttg 19800
ctagatgcaa caacagccac ctcctgatcc cgcgatgcgg gcggcgctgc agagccagcc 19860
gtccggcatt aactcctcgg acgattggac ccaggccatg caacgcatca tggcgctgac 19920
gacccgcaac cccgaagcct ttagacagca gccccaggcc aaccggctct cggccatcct 19980
ggaggccgtg gtgccctcgc gctccaaccc cacgcacgag aaggtcctgg ccatcgtgaa 20040
cgcgctggtg gagaacaagg ccatccgcgg cgacgaggcc ggcctggtgt acaacgcgct 20100
gctggagcgc gtggcccgct acaacagcac caacgtgcag accaacctgg accgcatggt 20160
gaccgacgtg cgcgaggccg tggcccagcg cgagcggttc caccgcgagt ccaacctggg 20220
atccatggtg gcgctgaacg ccttcctcag cacccagccc gccaacgtgc cccggggcca 20280
ggaggactac accaacttca tcagcgccct gcgcctgatg gtgaccgagg tgccccagag 20340
cgaggtgtac cagtccgggc cggactactt cttccagacc agtcgccagg gcttgcagac 20400
cgtgaacctg agccaggcgt tcaagaactt gcagggcctg tggggcgtgc aggccccggt 20460
cggggaccgc gcgacggtgt cgagcctgct gacgccgaac tcgcgcctgc tgctgctgct 20520
ggtggccccc ttcacggaca gcggcagcat caaccgcaac tcgtacctgg gctacctgat 20580
taacctgtac cgcgaggcca tcggccaggc gcacgtggac gagcagacct accaggagat 20640
cacccacgtg agccgcgccc tgggccagga cgacccgggc aatctggaag ccaccctgaa 20700
ctttttgctg accaaccggt cgcagaagat cccgccccag tacacgctca gcgccgagga 20760
ggagcgcatc ctgcgatacg tgcagcagag cgtgggcctg ttcctgatgc aggagggggc 20820
cacccccagc gccgcgctcg acatgaccgc gcgcaacatg gagcccagca tgtacgccag 20880
caaccgcccg ttcatcaata aactgatgga ctacttgcat cgggcggccg ccatgaactc 20940
tgactatttc accaacgcca tcctgaatcc ccactggctc ccgccgccgg ggttctacac 21000
gggcgagtac gacatgcccg accccaatga cgggttcctg tgggacgatg tggacagcag 21060
cgtgttctcc ccccgaccgg gtgctaacga gcgccccttg tggaagaagg aaggcagcga 21120
ccgacgcccg tcctcggcgc tgtccggccg cgagggtgct gccgcggcgg tgcccgaggc 21180
cgccagtcct ttcccgagct tgcccttctc gctgaacagt attcgcagca gcgagctggg 21240
caggatcacg cgcccgcgct tgctgggcga ggaggagtac ttgaatgact cgctgttgag 21300
acccgagcgg gagaagaact tccccaataa cgggatagag agcctggtgg acaagatgag 21360
ccgctggaag acgtatgcgc aggagcacag ggacgatccg tcgcaggggg ccacgagccg 21420
gggcagcgcc gcccgtaaac gccggtggca cgacaggcag cggggactga tgtgggacga 21480
tgaggattcc gccgacgaca gcagcgtgtt ggacttgggt gggagtggta acccgttcgc 21540
tcacctgcgc ccccgcatcg ggcgcatgat gtaagagaaa ccgaaaataa atgatactca 21600
ccaaggccat ggcgaccagc gtgcgttcgt ttcttctctg ttgttgtatc tagtatgatg 21660
aggcgtgcgt acccggaggg tcctcctccc tcgtacgaga gcgtgatgca gcaggcgatg 21720
gcggcggcgg cggcgatgca gcccccgctg gaggctcctt acgtgccccc gcggtacctg 21780
gcgcctacgg aggggcggaa cagcattcgt tactcggagc tggcaccctt gtacgatacc 21840
acccggttgt acctggtgga caacaagtcg gcggacatcg cctcgctgaa ctaccagaac 21900
gaccacagca acttcctgac caccgtggtg cagaacaatg acttcacccc cacggaggcc 21960
agcacccaga ccatcaactt tgacgagcgc tcgcggtggg gcggtcagct gaaaaccatc 22020
atgcacacca acatgcccaa cgtgaacgag ttcatgtaca gcaacaagtt caaggcgcgg 22080
gtgatggtct cccgcaagac ccccaacggg gtgacagtga cagatggtag tcaggatatc 22140
ttggagtatg aatgggtgga gtttgagctg cccgaaggca acttctcggt gaccatgacc 22200
atcgacctga tgaacaacgc catcatcgac aattacttgg cggtggggcg gcagaacggg 22260
gtcctggaga gcgatatcgg cgtgaagttc gacactagga acttcaggct gggctgggac 22320
cccgtgaccg agctggtcat gcccggggtg tacaccaacg aggccttcca ccccgatatt 22380
gtcttgctgc ccggctgcgg ggtggacttc accgagagcc gcctcagcaa cctgctgggc 22440
attcgcaaga ggcagccctt ccaggagggc ttccagatca tgtacgagga tctggagggg 22500
ggcaacatcc ccgcgctcct ggatgtcgac gcctatgaga aaagcaagga ggagagcgcc 22560
gccgcggcga ctgcagctgt agccaccgcc tctaccgagg tcaggggcga taattttgcc 22620
agccctgcag cagtggcagc ggccgaggcg gctgaaaccg aaagtaagat agtcattcag 22680
ccggtggaga aggatagcaa ggacaggagc tacaacgtgc tgccggacaa gataaacacc 22740
gcctaccgca gctggtacct ggcctacaac tatggcgacc ccgagaaggg cgtgcgctcc 22800
tggacgctgc tcaccacctc ggacgtcacc tgcggcgtgg agcaagtcta ctggtcgctg 22860
cccgacatga tgcaagaccc ggtcaccttc cgctccacgc gtcaagttag caactacccg 22920
gtggtgggcg ccgagctcct gcccgtctac tccaagagct tcttcaacga gcaggccgtc 22980
tactcgcagc agctgcgcgc cttcacctcg ctcacgcacg tcttcaaccg cttccccgag 23040
aaccagatcc tcgtccgccc gcccgcgccc accattacca ccgtcagtga aaacgttcct 23100
gctctcacag atcacgggac cctgccgctg cgcagcagta tccggggagt ccagcgcgtg 23160
accgttactg acgccagacg ccgcacctgc ccctacgtct acaaggccct gggcatagtc 23220
gcgccgcgcg tcctctcgag ccgcaccttc taaaaaatgt ccattctcat ctcgcccagt 23280
aataacaccg gttggggcct gcgcgcgccc agcaagatgt acggaggcgc tcgccaacgc 23340
tccacgcaac accccgtgcg cgtgcgcggg cacttccgcg ctccctgggg cgccctcaag 23400
ggccgcgtgc ggtcgcgcac caccgtcgac gacgtgatcg accaggtggt ggccgacgcg 23460
cgcaactaca cccccgccgc cgcgcccgtc tccaccgtgg acgccgtcat cgacagcgtg 23520
gtggccgacg cgcgccggta cgcccgcgcc aagagccggc ggcggcgcat cgcccggcgg 23580
caccggagca cccccgccat gcgcgcggcg cgagccttgc tgcgcagggc caggcgcacg 23640
ggacgcaggg ccatgctcag ggcggccaga cgcgcggctt caggcgccag cgccggcagg 23700
acccggagac gcgcggccac ggcggcggca gcggccatcg ccagcatgtc ccgcccgcgg 23760
cgagggaacg tgtactgggt gcgcgacgcc gccaccggtg tgcgcgtgcc cgtgcgcacc 23820
cgcccccctc gcacttgaag atgttcactt cgcgatgttg atgtgtccca gcggcgagga 23880
ggatgtccaa gcgcaaattc aaggaagaga tgctccaggt catcgcgcct gagatctacg 23940
gccccgcggt ggtgaaggag gaaagaaagc cccgcaaaat caagcgggtc aaaaaggaca 24000
aaaaggaaga agatgacgat ctggtggagt ttgtgcgcga gttcgccccc cggcggcgcg 24060
tgcagtggcg cgggcggaaa gtgcacccgg tgctgagacc cggcaccacc gtggtcttca 24120
cgcccggcga gcgctccggc agcgcttcca agcgctccta cgacgaggtg tacggggacg 24180
aggacatcct cgagcaggcg gccgagcgcc tgggcgagtt tgcttacggc aagcgcagcc 24240
gccccgccct gaaggaagag gcggtgtcca tcccgctgga ccacggcaac cccacgccga 24300
gcctcaagcc cgtgaccctg cagcaggtgc tgccgagcgc agcgccgcgc cgggggttca 24360
agcgcgaggg cgaggatctg taccccacca tgcagctgat ggtgcccaag cgccagaagc 24420
tggaagacgt gctggagacc atgaaggtgg acccggacgt gcagcccgag gtcaaggtgc 24480
ggcccatcaa gcaggtggcc ccgggcctgg gcgtgcagac cgtggacatc aagatcccca 24540
cggagcccat ggaaacgcag accgagccca tgatcaagcc cagcaccagc accatggagg 24600
tgcagacgga tccctggatg ccatcggctc ctagccgaag accccggcgc aagtacggcg 24660
cggccagcct gctgatgccc aactacgcgc tgcatccttc catcatcccc acgccgggct 24720
accgcggcac gcgcttctac cgcggtcata caaccagccg ccgccgcaag accaccaccc 24780
gccgccgccg tcgccgcaca gccgctgcat ctacccctgc cgccctggtg cggagagtgt 24840
accgccgcgg ccgcgcgcct ctgaccctac cgcgcgcgcg ctaccacccg agcatcgcca 24900
tttaaacttt cgcctgcttt gcagatggcc ctcacatgcc gcctccgcgt tcccattacg 24960
ggctaccgag gaagaaaacc gcgccgtaga aggctggcgg ggaacgggat gcgtcgccac 25020
caccatcggc ggcggcgcgc catcagcaag cggttggggg gaggcttcct gcccgcgctg 25080
atccccatca tcgccgcggc gatcggggcg atccccggca ttgcttccgt ggcggtgcag 25140
gcctctcagc gccactgaga cacttggaaa acatcttgta ataaaccaat ggactctgac 25200
gctcctggtc ctgtgatgtg ttttcgtaga cagatggaag acatcaattt ttcgtccctg 25260
gctccgcgac acggcacgcg gccgttcatg ggcacctgga gcgacatcgg caccagccaa 25320
ctgaacgggg gcgccttcaa ttggagcagt ctctggagcg ggcttaagaa tttcgggtcc 25380
acgcttaaaa cctatggcag caaggcgtgg aacagcacca cagggcaggc gctgagggat 25440
aagctgaaag agcagaactt ccagcagaag gtggtcgatg ggctcgcctc gggcatcaac 25500
ggggtggtgg acctggccaa ccaggccgtg cagcggcaga tcaacagccg cctggacccg 25560
gtgccgcccg ccggctccgt ggagatgccg caggtggagg aggagctgcc tcccctggac 25620
aagcggggcg agaagcgacc ccgccccgac gcggaggaga cgctgctgac gcacacggac 25680
gagccgcccc cgtacgagga ggcggtgaaa ctgggtctgc ccaccacgcg gcccatcgcg 25740
cccctggcca ccggggtgct gaaacccgaa agtaataagc ccgcgaccct ggacttgcct 25800
cctcccgctt cccgcccctc tacagtggct aagcccctgc cgccggtggc cgtggcccgc 25860
gcgcgacccg ggggctccgc ccgccctcat gcgaactggc agagcactct gaacagcatc 25920
gtgggtctgg gagtgcagag tgtgaagcgc cgccgctgct attaaaccta ccgtagcgct 25980
taacttgctt gtctgtgtgt gtatgtatta tgtcgccgct gtccgccaga aggaggagtg 26040
aagaggcgcg tcgccgagtt gcaagatggc caccccatcg atgctgcccc agtgggcgta 26100
catgcacatc gccggacagg acgcttcgga gtacctgagt ccgggtctgg tgcagttcgc 26160
ccgcgccaca gacacctact tcagtctggg gaacaagttt aggaacccca cggtggcgcc 26220
cacgcacgat gtgaccaccg accgcagcca gcggctgacg ctgcgcttcg tgcccgtgga 26280
ccgcgaggac aacacctact cgtacaaagt gcgctacacg ctggccgtgg gcgacaaccg 26340
cgtgctggac atggccagca cctactttga catccgcggc gtgctggatc ggggccctag 26400
cttcaaaccc tactccggca ccgcctacaa cagcctggct cccaagggag cgcccaattc 26460
cagccagtgg gagcaaaaaa aggcaggcaa tggtgacact atggaaacac acacatttgg 26520
tgtggcccca atgggcggtg agaatattac aatcgacgga ttacaaattg gaactgacgc 26580
tacagctgat caggataaac caatttatgc tgacaaaaca ttccagcctg aacctcaagt 26640
aggagaagaa aattggcaag aaactgaaag cttttatggc ggtagggctc ttaaaaaaga 26700
cacaagcatg aaaccttgct atggctccta tgctagaccc accaatgtaa agggaggtca 26760
agctaaactt aaagttggag ctgatggagt tcctaccaaa gaatttgaca tagacctggc 26820
tttctttgat actcccggtg gcacagtgaa tggacaagat gagtataaag cagacattgt 26880
catgtatacc gaaaacacgt atctggaaac tccagacacg catgtggtat acaaaccagg 26940
caaggatgat gcaagttctg aaattaacct ggttcagcag tccatgccca atagacccaa 27000
ctatattggg ttcagagaca actttattgg gctcatgtat tacaacagta ctggcaatat 27060
gggggtgctg gctggtcagg cctcacagct gaatgctgtg gtcgacttgc aagacagaaa 27120
caccgagctg tcataccagc tcttgcttga ctctttgggt gacagaaccc ggtatttcag 27180
tatgtggaat caggcggtgg acagttatga tcctgatgtg cgcattattg aaaaccatgg 27240
tgtggaagac gaacttccca actattgctt ccccctggat gggtctggca ctaatgccgc 27300
ttaccaaggt gtgaaagtaa aaaatggtaa cgatggtgat gttgagagcg aatgggaaaa 27360
tgatgatact gtcgcagctc gaaatcaatt atgcaagggc aacatttttg ccatggaaat 27420
taacctccaa gccaacctgt ggagaagttt cctctactcg aacgtggccc tgtacctgcc 27480
cgactcttac aagtacacgc cagccaacat caccctgccc accaacacca acacttatga 27540
ttacatgaac gggagagtgg tgcctccctc gctggtggac gcctacatca acatcggggc 27600
gcgctggtcg ctggacccca tggacaacgt caatcccttc aaccaccacc gcaacgcggg 27660
cctgcgctac cgctccatgc tcctgggcaa cgggcgctac gtgcccttcc acatccaggt 27720
gccccagaaa tttttcgcca tcaagagcct cctgctcctg cccgggtcct acacctacga 27780
gtggaacttc cgcaaggacg tcaacatgat cctgcagagc tccctcggca acgacctgcg 27840
cacggacggg gcctccatct ccttcaccag catcaacctc tacgccacct tcttccccat 27900
ggcgcacaac acggcctcca cgctcgaggc catgctgcgc aacgacacca acgaccagtc 27960
cttcaacgac tacctctcgg cggccaacat gctctacccc atcccggcca acgccaccaa 28020
cgtgcccatc tccatcccct cgcgcaactg ggccgccttc cgcggctggt ccttcacgcg 28080
cctcaagacc aaggagacgc cctcgctggg ctccgggttc gacccctact tcgtctactc 28140
gggctccatc ccctacctcg acggcacctt ctacctcaac cacaccttca agaaggtctc 28200
catcaccttc gactcctccg tcagctggcc cggcaacgac cggctcctga cgcccaacga 28260
gttcgaaatc aagcgcaccg tcgacggcga gggatacaac gtggcccagt gcaacatgac 28320
caaggactgg ttcctggtcc agatgctggc ccactacaac atcggctacc agggcttcta 28380
cgtgcccgag ggctacaagg accgcatgta ctccttcttc cgcaacttcc agcccatgag 28440
ccgccaggtg gtggacgagg tcaactacaa ggactaccag gccgtcaccc tggcctacca 28500
gcacaacaac tcgggcttcg tcggctacct cgcgcccacc atgcgccagg gccagcccta 28560
ccccgccaac tacccgtacc cgctcatcgg caagagcgcc gtcaccagcg tcacccagaa 28620
aaagttcctc tgcgacaggg tcatgtggcg catccccttc tccagcaact tcatgtccat 28680
gggcgcgctc accgacctcg gccagaacat gctctatgcc aactccgccc acgcgctaga 28740
catgaatttc gaagtcgacc ccatggatga gtccaccctt ctctatgttg tcttcgaagt 28800
cttcgacgtc gtccgagtgc accagcccca ccgcggcgtc atcgaggccg tctacctgcg 28860
cacccccttc tcggccggta acgccaccac ctaaattgct acttgcatga tggctgagcc 28920
cacaggctcc ggcgagcagg agctcagggc catcatccgc gacctgggct gcgggcccta 28980
cttcctgggc accttcgata agcgcttccc gggattcatg gccccgcaca agctggcctg 29040
cgccatcgtc aacacggccg gccgcgagac cgggggcgag cactggctgg ccttcgcctg 29100
gaacccgcgc tcgaacacct gctacctctt cgaccccttc gggttctcgg acgagcgcct 29160
caagcagatc taccagttcg agtacgaggg cctgctgcgc cgtagcgccc tggccaccga 29220
ggaccgctgc gtcaccctgg aaaagtccac ccagaccgtg cagggtccgc gctcggccgc 29280
ctgcgggctc ttctgctgca tgttcctgca cgccttcgtg cactggcccg accgccccat 29340
ggacaagaac cccaccatga acttgctgac gggggtgccc aacggcatgc tccagtcgcc 29400
ccaggtggaa cccaccctgc gccgcaacca ggaggcgctc taccgcttcc tcaactccca 29460
ctccgcctac tttcgctccc accgcgcgcg catcgagaag gccaccgcct tcgaccgcat 29520
gaacaatcaa gacatgtaaa ccgtgtgtgt atgtttaaaa tatcttttaa taaacagcac 29580
tttaatgtta cacatgcatc tgagatgatt ttattttaga aatcgaaagg gttctgccgg 29640
gtctcggcat ggcccgcggg cagggacacg ttgcggaact ggtacttggc cagccacttg 29700
aactcgggga tcagcagttt gggcagcggg gtgtcgggga aggagtcggt ccacagcttc 29760
cgcgtcagct gcagggcgcc cagcaggtcg ggcgcggaga tcttgaaatc gcagttggga 29820
cccgcgttct gcgcgcgaga gttgcggtac acggggttgc agcactggaa caccatcagg 29880
gccgggtgct tcacgctcgc cagcaccgcc gcgtcggtga tgctctccac gtcgaggtcc 29940
tcggcgttgg ccatcccgaa gggggtcatc ttgcaggtct gccttcccat ggtgggcacg 30000
cacccgggct tgtggttgca atcgcagtgc agggggatca gcatcatctg ggcctggtcg 30060
gcgttcatcc ccgggtacat ggccttcatg aaagcctcca attgcctgaa cgcctgctgg 30120
gccttggctc cctcggtgaa gaagaccccg caggacttgc tagagaactg gttggtggca 30180
cagccggcat cgtgcacgca gcagcgcgcg tcgttgttgg ccagctgcac cacgctgcgc 30240
ccccagcggt tctgggtgat cttggcccgg tcggggttct ccttcagcgc gcgctgcccg 30300
ttctcgctcg ccacatccat ctcgatcatg tgctccttct ggatcatggt ggtcccgtgc 30360
aggcaccgca gtttgccctc ggcctcggtg cacccgtgca gccacagcgc gcacccggtg 30420
cactcccagt tcttgtgggc gatctgggaa tgcgcgtgca cgaacccttg caggaagcgg 30480
cccatcatgg tcgtcagggt cttgttgcta gtgaaggtca acgggatgcc gcggtgctcc 30540
tcgttgatgt acaggtggca gatgcggcgg tacacctcgc cctgctcggg catcagttgg 30600
aagttggctt tcaggtcggt ctccacgcgg tagcggtcca tcagcatagt catgatttcc 30660
atgcccttct cccaggccga gacgatgggc aggctcatag ggttcttcac catcatctta 30720
gcactagcag ccgcggccag ggggtcgctc tcatccaggg tctcaaagct ccgcttgccg 30780
tccttctcgg tgatccgcac cggggggtag ctgaagccca cggccgccag ctcctcctcg 30840
gcctgtcttt cgtcctcgct gtcctggctg acgtcctgca tgaccacatg cttggtcttg 30900
cggggtttct tcttgggcgg cagtggcggc ggagatgctt gtggcgaggg ggagcgcgag 30960
ttctcgctca ccactactat ctcttcctct tcttggtccg aggccacgcg gcggtaggta 31020
tgtctcttcg ggggcagagg cggaggcgac gggctctcgc cgccgcgact tggcggatgg 31080
ctggcagagc cccttccgcg ttcgggggtg cgctcccggc ggcgctctga ctgacttcct 31140
ccgcggccgg ccattgtgtt ctcctaggga ggaacaacaa gcatggagac tcagccatcg 31200
ccaacctcgc catctgcccc caccgccggc gacgagaagc agcagcagca gaatgaaagc 31260
ttaaccgccc cgccgcccag ccccgcctcc gacgcagccg cggtcccaga catgcaagag 31320
atggaggaat ccatcgagat tgacctgggc tatgtgacgc ccgcggagca tgaggaggag 31380
ctggcagtgc gctttcaatc gtcaagccag gaagataaag aacagccaga gcaggaagca 31440
gagaacgagc agagtcaggc tgggctcgag catggcgact acctccacct gagcggggag 31500
gaggacgcgc tcatcaagca tctggcccgg caggccacca tcgtcaagga cgcgctgctc 31560
gaccgcaccg aggtgcccct cagcgtggag gagctcagcc gcgcctacga gctcaacctc 31620
ttctcgccgc gcgtgccccc caagcgccag cccaacggca cctgcgagcc caacccccgc 31680
ctcaacttct acccggtctt cgcggtgccc gaggccctgg ccacctacca catctttttc 31740
aagaaccaaa agatccccgt ctcctgccgc gccaaccgca cccgcgccga cgccctcttc 31800
aacctgggtc ccggcgcccg cctacctgat atcgcctcct tggaagaggt tcccaagatc 31860
ttcgagggtc tgggcagcga cgagactcgg gccgcgaacg ctctgcaagg agaaggagga 31920
ggagagcatg agcaccacag cgccctggtc gagttggaag gcgacaacgc gcggctggcg 31980
gtgctcaaac gcacggtcga gctgacccat ttcgcctacc cggctctgaa cctgcccccg 32040
aaagtcatga gcgcggtcat ggaccaggtg ctcatcaagc gcgcgtcgcc catctccgag 32100
gacgagggca tgcaagactc cgaggagggc aagcccgtgg tcagcgacga gcagctggcc 32160
cggtggctgg gtcctaatgc tacccctcaa agtttggaag agcggcgcaa gctcatgatg 32220
gccgtggtcc tggtgaccgt ggagctggag tgcctgcgcc gcttcttcgc cgacgcggag 32280
accctgcgca aggtcgagga gaacctgcac tacctcttca ggcacgggtt cgtgcgccag 32340
gcctgcaaga tctccaacgt ggagctgacc aacctggtct cctacatggg catcttgcac 32400
gagaaccgcc tggggcagaa cgtgctgcac accaccctgc gcggggaggc ccgccgcgac 32460
tacatccgcg actgcgtcta cctctacctc tgccacacct ggcagacggg catgggcgtg 32520
tggcagcagt gtctggagga gcagaacctg aaagagctct gcaagctcct gcaaaagaac 32580
ctcaagggtc tgtggaccgg gttcgacgag cggaccaccg cctcggacct ggccgacctc 32640
atcttccccg agcgcctcag gctgacgctg cgcaacggcc tgcccgactt tatgagccaa 32700
agcatgttgc aaaactttcg ctctttcatc ctcgaacgct ccggaatcct gcccgccacc 32760
tgctccgcgc tgccctcgga cttcgtgccg ctgaccttcc gcgagtgccc cccgccgctg 32820
tggagccact gctacctgct gcgcctggcc aactacctgg cctaccactc ggacgtgatc 32880
gaggacgtca gcggcgaggg cctgctcgag tgccactgcc gctgcaacct ctgcacgccg 32940
caccgctccc tggcctgcaa cccccagctg ctgagcgaga cccagatcat cggcaccttc 33000
gagttgcaag ggcccagcga gggcgaggga gccaaggggg gtctgaaact caccccgggg 33060
ctgtggacct cggcctactt gcgcaagttc gtgcccgagg attaccatcc cttcgagatc 33120
aggttctacg aggaccaatc ccagccgccc aaggccgagc tgtcggcctg cgtcatcacc 33180
cagggggcga tcctggccca attgcaagcc atccagaaat cccgccaaga attcttgctg 33240
aaaaagggcc gcggggtcta cctcgacccc cagaccggtg aggagctcaa ccccggcttc 33300
ccccaggatg ccccgaggaa acaagaagct gaaagtggag ctgccgcccg tggaggattt 33360
ggaggaagac tgggagaaca gcagtcaggc agaggagatg gaggaagact gggacagcac 33420
tcaggcagag gaggacagcc tgcaagacag tctggaggaa gacgaggagg aggcagagga 33480
ggaggtggaa gaagcagccg ccgccagacc gtcgtcctcg gcgggggaga aagcaagcag 33540
cacggatacc atctccgctc cgggtcgggg tcccgctcgg ccccacagta gatgggacga 33600
gaccgggcga ttcccgaacc ccaccaccca gaccggtaag aaggagcggc agggatacaa 33660
gtcctggcgg gggcacaaaa acgccatcgt ctcctgcttg caggcctgcg ggggcaacat 33720
ctccttcacc cggcgctacc tgctcttcca ccgcggggtg aacttccccc gcaacatctt 33780
gcattactac cgtcacctcc acagccccta ctacttccaa gaagaggcag cagcagcaga 33840
aaaagaccag aaaaccagct agaaaatcca cagcggcggc agcggcaggt ggactgagga 33900
tcgcggcgaa cgagccggcg cagacccggg agctgaggaa ccggatcttt cccaccctct 33960
atgccatctt ccagcagagt cgggggcagg agcaggaact gaaagtcaag aaccgttctc 34020
tgcgctcgct cacccgcagt tgtctgtatc acaagagcga agaccaactt cagcgcactc 34080
tcgaggacgc cgaggctctc ttcaacaagt actgcgcgct cactcttaaa gagtagcccg 34140
cgcccgccca gtcgcagaaa aaggcgggaa ttacgtcacc tgtgcccttc gccctagccg 34200
cctccaccca gcaccgccat gagcaaagag attcccacgc cttacatgtg gagctaccag 34260
ccccagatgg gcctggccgc cggcgccgcc caggactact ccacccgcat gaattggctc 34320
agcgccgggc ccgcgatgat ctcacgggtg aatgacatcc gcgcccaccg aaaccagata 34380
ctcctagaac agtcagcgct caccgccacg ccccgcaatc acctcaatcc gcgtaattgg 34440
cccgccgccc tggtgtacca ggaaattccc cagcccacga ccgtactact tccgcgagac 34500
gcccaggccg aagtccagct gactaactca ggtgtccagc tggcgggcgg cgccaccctg 34560
tgtcgtcacc gccccgctca gggtataaag cggctggtga tccggggcag aggcacacag 34620
ctcaacgacg aggtggtgag ctcttcgctg ggtctgcgac ctgacggagt cttccaactc 34680
gccggatcgg ggagatcttc cttcacgcct cgtcaggcgg tcctgacttt ggagagttcg 34740
tcctcgcagc cccgctcggg cggcatcggc actctccagt tcgtggagga gttcactccc 34800
tcggtctact tcaacccctt ctccggctcc cccggccact acccggacga gttcatcccg 34860
aactttgacg ccatcagcga gtcggtggac ggctacgatt gattaattaa tcaactaacc 34920
ccttacccct ttaccctcca gtaaaaataa agattaaaaa tgattgaatt gatcaataaa 34980
gaatcactta cttgaaatct gaaaccaggt ctctgtccat gttttctgtc agcagcactt 35040
cactcccctc ttcccaactc tggtactgca ggccccggcg ggctgcaaac ttcctccaca 35100
ctctgaaggg gatgtcaaat tcctcctgtc cctcaatctt catttttatc ttctatcaga 35160
tgtccaaaaa gcgcgcgcgg gtggatgatg gcttcgaccc cgtgtacccc tacgatgcag 35220
acaacgcacc gactgtgccc ttcatcaacc ctcccttcgt ctcttcagat ggattccaag 35280
aaaagcccct gggggtgttg tccctgcgac tggccgaccc cgtcaccacc aagaatgggg 35340
ctgtcaccct caagctgggg gagggggtgg acctcgacga ctcgggaaaa ctcatctcca 35400
aaaatgccac caaggccact gcccctctca gtatttccaa cggcaccatt tcccttaaca 35460
tggctgcccc tttttacaac aacaatggaa cgttaagtct caatgtttct acaccattag 35520
cagtatttcc cacttttaac actttaggta tcagtcttgg aaacggtctt caaacttcta 35580
ataagttgct gactgtacag ttaactcatc ctcttacatt cagctcaaat agcatcacag 35640
taaaaacaga caaaggactc tatattaatt ctagtggaaa cagagggctt gaggctaaca 35700
taagcctaaa aagaggactg atttttgatg gtaatgctat tgcaacatac cttggaagtg 35760
gtttagacta tggatcctat gatagcgatg ggaaaacaag acccatcatc accaaaattg 35820
gagcaggttt gaattttgat gctaataatg ccatggctgt gaagctaggc acaggtttaa 35880
gttttgactc tgccggtgcc ttaacagctg gaaacaaaga ggatgacaag ctaacacttt 35940
ggactacacc tgacccaagc cctaattgtc aattactttc agacagagat gccaaattta 36000
ccctatgtct tacaaaatgc ggtagtcaaa tactaggcac tgttgcagta gctgctgtta 36060
ctgtaggttc agcactaaat ccaattaatg acacagtaaa aagcgccata gtattcctta 36120
gatttgactc tgacggtgtg ctcatgtcaa actcatcaat ggtaggtgat tactggaact 36180
ttagggaagg acagaccacc caaagtgtgg cctatacaaa tgctgtggga ttcatgccca 36240
atctaggtgc atatcctaaa acccaaagca aaacaccaaa aaatagtata gtaagtcagg 36300
tatatttaaa tggagaaact actatgccaa tgacactgac aataactttc aatggcactg 36360
atgaaaaaga cacaacacct gtgagcactt actccatgac ttttacatgg cagtggactg 36420
gagactataa ggacaagaat attacctttg ctaccaactc ctttactttc tcctacatgg 36480
cccaagaata aaccctgcat gccaacccca ttgttcccac cactatggaa aactctgaag 36540
cagaaaaaaa taaagttcaa gtgttttatt gattcaacag ttttctcaca gaaccctagt 36600
attcaacctg ccacctccct cccaacacac agagtacaca gtcctttctc cccggctggc 36660
cttaaaaagc atcatatcat gggtaacaga catattctta ggtgttatat tccacacggt 36720
ttcctgtcga gccaaacgct catcagtgat attaataaac tccccgggca gctcacttaa 36780
gttcatgtcg ctgtccagct gctgagccac aggctgctgt ccaacttgcg gttgcttaac 36840
gggcggcgaa ggagaagtcc acgcctacat gggggtagag tcataatcgt gcatcaggat 36900
agggcggtgg tgctgcagca gcgcgcgaat aaactgctgc cgccgccgct ccgtcctgca 36960
ggaatacaac atggcagtgg tctcctcagc gatgattcgc accgcccgca gcataaggcg 37020
ccttgtcctc cgggcacagc agcgcaccct gatctcactt aaatcagcac agtaactgca 37080
gcacagcacc acaatattgt tcaaaatccc acagtgcaag gcgctgtatc caaagctcat 37140
ggcggggacc acagaaccca cgtggccatc ataccacaag cgcaggtaga ttaagtggcg 37200
acccctcata aacacgctgg acataaacat tacctctttt ggcatgttgt aattcaccac 37260
ctcccggtac catataaacc tctgattaaa catggcgcca tccaccacca tcctaaacca 37320
gctggccaaa acctgcccgc cggctataca ctgcagggaa ccgggactgg aacaatgaca 37380
gtggagagcc caggactcgt aaccatggat catcatgctc gtcatgatat caatgttggc 37440
acaacacagg cacacgtgca tacacttcct caggattaca agctcctccc gcgttagaac 37500
catatcccag ggaacaaccc attcctgaat cagcgtaaat cccacactgc agggaagacc 37560
tcgcacgtaa ctcacgttgt gcattgtcaa agtgttacat tcgggcagca gcggatgatc 37620
ctccagtatg gtagcgcggg tttctgtctc aaaaggaggt agacgatccc tactgtacgg 37680
agtgcgccga gacaaccgag atcgtgttgg tcgtagtgtc atgccaaatg gaacgccgga 37740
cgtagtcata tttcctgaag caaaaccagg tgcgggcgtg acaaacagat ctgcgtctcc 37800
ggtctcgccg cttagatcgc tctgtgtagt agttgtagta tatccactct ctcaaagcat 37860
ccaggcgccc cctggcttcg ggttctatgt aaactccttc atgcgccgct gccctgataa 37920
catccaccac cgcagaataa gccacaccca gccaacctac acattcgttc tgcgagtcac 37980
acacgggagg agcgggaaga gctggaagaa ccatgattaa ctttattcca aacggtctcg 38040
gagcacttca aaatgcaggt cccggaggtg gcacctctcg cccccactgt gttggtggaa 38100
aataacagcc aggtcaaagg tgacacggtt ctcgagatgt tccacggtgg cttccagcaa 38160
agcctccacg cgcacatcca gaaacaagag gacagcgaaa gcgggagcgt tttctaattc 38220
ctcaatcatc atattacact cctgcaccat ccccagataa ttttcatttt tccagccttg 38280
aatgattcgt attagttcct gaggtaaatc caagccagcc atgataaaaa gctcgcgcag 38340
agcgccctcc accggcattc ttaagcacac cctcataatt ccaagagatt ctgctcctgg 38400
ttcacctgca gcagattaac aatgggaata tcaaaatctc tgccgcgatc cctaagctcc 38460
tccctcaaca ataactgtat gtaatctttc atatcatctc cgaaattttt agccataggg 38520
ccgccaggaa taagagcagg gcaagccaca ttacagataa agcgaagtcc tccccagtgw 38580
gcattgccaa atgtaagatt gaaataagca tgctggctag accctgtgat atcttccaga 38640
taactggaca gaaaatcagg caagcaattt ttaagaaaat caacaaaaga aaagtcgtcc 38700
aggtgcaggt ttagagcctc aggaacaacg atggaataag tgcaaggagt gcgttccagc 38760
atggttagtg tttttttggt gatctgtaga acaaaaaata aacatgcaat attaaaccat 38820
gctagcctgg cgaacaggtg ggtaaatcac tctttccagc accaggcagg ctacggggtc 38880
tccggcgcga ccctcgtaga agctgtcgcc atgattgaaa agcatcaccg agagaccttc 38940
ccggtggccg gcatggatga ttcgagaaga agcatacact ccgggaacat tggcatccgt 39000
gagtgaaaaa aagcgaccta taaagcctcg gggcactaca atgctcaatc tcaattccag 39060
caaagccacc ccatgcggat ggagcacaaa attggcaggt gcgtaaaaaa tgtaattact 39120
cccctcctgc acaggcagca aagcccccgc tccctccaga aacacataca aagcctcagc 39180
gtccatagct taccgagcac ggcaggcgca agagtcagag aaaaggctga gctctaacct 39240
gactgcccgc tcctgtgctc aatatatagc cctaacctac actgacgtaa aggccaaagt 39300
ctaaaaatac ccgccaaaat gacacacacg cccagcacac gcccagaaac cggtgacaca 39360
ctcaaaaaaa tacgtgcgct tcctcaaacg cccaaaccgg cgtcatttcc gggttcccac 39420
gctacgtcac cgctcagcga ctttcaaatt ccgtcgaccg ttaaaaacgt cactcgcccc 39480
gcccctaacg gtcgcccttc tctcggccaa tcaccttcct cccttcccaa attcaaacgc 39540
ctcatttgca tattaacgcg cacaaaaagt ttgaggtata tatttgaatg atg 39593
<210> 26
<211> 675
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector ChAdOx1_P1A
<400> 26
atgagcgaca acaagaagcc cgacaaggcc cactctggca gcggcggaga tggcgacggc 60
aacagatgta acctgctgca cagatacagc ctggaagaga tcctgcccta cctgggctgg 120
ctggtgttcg ccgtcgtgac aacaagcttc ctggccctgc agatgttcat cgacgccctg 180
tacgaggaac agtacgagag ggacgtggcc tggatcgcca gacagagcaa gagaatgagc 240
agcgtggacg aggacgagga tgatgaggac gacgaagatg actactacga cgatgaggat 300
gacgacgacg acgccttcta cgatgacgag gacgatgaag aggaagaact ggaaaacctg 360
atggacgacg agtccgagga tgaggccgag gaagagatga gcgtggaaat gggcgctggc 420
gccgaagaga tgggagccgg cgctaactgt gcttgcgtgc caggacacca cctgagaaag 480
aacgaagtga agtgccggat gatctacttc ttccacgacc ccaactttct ggtgtccatc 540
cccgtgaacc ccaaagaaca gatggaatgc agatgcgaga acgccgacga agaggtggcc 600
atggaagaag aagaggaaga ggaagaagaa gaagaagagg aagaaatggg caaccccgac 660
ggcttcagcc cctga 675
<210> 27
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of ChAdOx1_P1A
<400> 27
Met Ser Asp Asn Lys Lys Pro Asp Lys Ala His Ser Gly Ser Gly Gly
1 5 10 15
Asp Gly Asp Gly Asn Arg Cys Asn Leu Leu His Arg Tyr Ser Leu Glu
20 25 30
Glu Ile Leu Pro Tyr Leu Gly Trp Leu Val Phe Ala Val Val Thr Thr
35 40 45
Ser Phe Leu Ala Leu Gln Met Phe Ile Asp Ala Leu Tyr Glu Glu Gln
50 55 60
Tyr Glu Arg Asp Val Ala Trp Ile Ala Arg Gln Ser Lys Arg Met Ser
65 70 75 80
Ser Val Asp Glu Asp Glu Asp Asp Glu Asp Asp Glu Asp Asp Tyr Tyr
85 90 95
Asp Asp Glu Asp Asp Asp Asp Asp Ala Phe Tyr Asp Asp Glu Asp Asp
100 105 110
Glu Glu Glu Glu Leu Glu Asn Leu Met Asp Asp Glu Ser Glu Asp Glu
115 120 125
Ala Glu Glu Glu Met Ser Val Glu Met Gly Ala Gly Ala Glu Glu Met
130 135 140
Gly Ala Gly Ala Asn Cys Ala Cys Val Pro Gly His His Leu Arg Lys
145 150 155 160
Asn Glu Val Lys Cys Arg Met Ile Tyr Phe Phe His Asp Pro Asn Phe
165 170 175
Leu Val Ser Ile Pro Val Asn Pro Lys Glu Gln Met Glu Cys Arg Cys
180 185 190
Glu Asn Ala Asp Glu Glu Val Ala Met Glu Glu Glu Glu Glu Glu Glu
195 200 205
Glu Glu Glu Glu Glu Glu Glu Met Gly Asn Pro Asp Gly Phe Ser Pro
210 215 220
<210> 28
<211> 753
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector ChAdOx1_mIi_P1A
<400> 28
atgggcgctc tgtatactgg cgtgtccgtg ctggtggccc tgctgctggc tggacaggct 60
acaaccgcct acttcctgta cagcgacaac aagaagcccg acaaggccca ctctggcagc 120
ggcggagatg gcgacggcaa cagatgtaac ctgctgcaca gatacagcct ggaagagatc 180
ctgccctacc tgggctggct ggtgttcgcc gtcgtgacaa caagcttcct ggccctgcag 240
atgttcatcg acgccctgta cgaggaacag tacgagaggg acgtggcctg gatcgccaga 300
cagagcaaga gaatgagcag cgtggacgag gacgaggatg atgaggacga cgaagatgac 360
tactacgacg atgaggatga cgacgacgac gccttctacg atgacgagga cgatgaagag 420
gaagaactgg aaaacctgat ggacgacgag tccgaggatg aggccgagga agagatgagc 480
gtggaaatgg gcgctggcgc cgaagagatg ggagccggcg ctaactgtgc ttgcgtgcca 540
ggacaccacc tgagaaagaa cgaagtgaag tgccggatga tctacttctt ccacgacccc 600
aactttctgg tgtccatccc cgtgaacccc aaagaacaga tggaatgcag atgcgagaac 660
gccgacgaag aggtggccat ggaagaagaa gaggaagagg aagaagaaga agaagaggaa 720
gaaatgggca accccgacgg cttcagcccc tga 753
<210> 29
<211> 250
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein ChAdOx1_mIi_P1A
<400> 29
Met Gly Ala Leu Tyr Thr Gly Val Ser Val Leu Val Ala Leu Leu Leu
1 5 10 15
Ala Gly Gln Ala Thr Thr Ala Tyr Phe Leu Tyr Ser Asp Asn Lys Lys
20 25 30
Pro Asp Lys Ala His Ser Gly Ser Gly Gly Asp Gly Asp Gly Asn Arg
35 40 45
Cys Asn Leu Leu His Arg Tyr Ser Leu Glu Glu Ile Leu Pro Tyr Leu
50 55 60
Gly Trp Leu Val Phe Ala Val Val Thr Thr Ser Phe Leu Ala Leu Gln
65 70 75 80
Met Phe Ile Asp Ala Leu Tyr Glu Glu Gln Tyr Glu Arg Asp Val Ala
85 90 95
Trp Ile Ala Arg Gln Ser Lys Arg Met Ser Ser Val Asp Glu Asp Glu
100 105 110
Asp Asp Glu Asp Asp Glu Asp Asp Tyr Tyr Asp Asp Glu Asp Asp Asp
115 120 125
Asp Asp Ala Phe Tyr Asp Asp Glu Asp Asp Glu Glu Glu Glu Leu Glu
130 135 140
Asn Leu Met Asp Asp Glu Ser Glu Asp Glu Ala Glu Glu Glu Met Ser
145 150 155 160
Val Glu Met Gly Ala Gly Ala Glu Glu Met Gly Ala Gly Ala Asn Cys
165 170 175
Ala Cys Val Pro Gly His His Leu Arg Lys Asn Glu Val Lys Cys Arg
180 185 190
Met Ile Tyr Phe Phe His Asp Pro Asn Phe Leu Val Ser Ile Pro Val
195 200 205
Asn Pro Lys Glu Gln Met Glu Cys Arg Cys Glu Asn Ala Asp Glu Glu
210 215 220
Val Ala Met Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu
225 230 235 240
Glu Met Gly Asn Pro Asp Gly Phe Ser Pro
245 250
<210> 30
<211> 675
<212> DNA
<213> Artificial Sequence
<220>
<223> Polynucleotide construct for vector MVA_P1A
<400> 30
atgagcgaca acaagaagcc cgacaaggcc cactctggca gcggcggaga tggcgacggc 60
aacagatgta acctgctgca cagatacagc ctggaagaga tcctgcccta cctgggctgg 120
ctggtgttcg ccgtcgtgac aacaagcttc ctggccctgc agatgttcat cgacgccctg 180
tacgaggaac agtacgagag ggacgtggcc tggatcgcca gacagagcaa gagaatgagc 240
agcgtggacg aggacgagga tgatgaggac gacgaagatg actactacga cgatgaggat 300
gacgacgacg acgccttcta cgatgacgag gacgatgaag aggaagaact ggaaaacctg 360
atggacgacg agtccgagga tgaggccgag gaagagatga gcgtggaaat gggcgctggc 420
gccgaagaga tgggagccgg cgctaactgt gcttgcgtgc caggacacca cctgagaaag 480
aacgaagtga agtgccggat gatctacttc ttccacgacc ccaactttct ggtgtccatc 540
cccgtgaacc ccaaagaaca gatggaatgc agatgcgaga acgccgacga agaggtggcc 600
atggaagaag aagaggaaga ggaagaagaa gaagaagagg aagaaatggg caaccccgac 660
ggcttcagcc cctga 675
<210> 31
<211> 224
<212> PRT
<213> Artificial Sequence
<220>
<223> Translated protein of MVA_P1A
<400> 31
Met Ser Asp Asn Lys Lys Pro Asp Lys Ala His Ser Gly Ser Gly Gly
1 5 10 15
Asp Gly Asp Gly Asn Arg Cys Asn Leu Leu His Arg Tyr Ser Leu Glu
20 25 30
Glu Ile Leu Pro Tyr Leu Gly Trp Leu Val Phe Ala Val Val Thr Thr
35 40 45
Ser Phe Leu Ala Leu Gln Met Phe Ile Asp Ala Leu Tyr Glu Glu Gln
50 55 60
Tyr Glu Arg Asp Val Ala Trp Ile Ala Arg Gln Ser Lys Arg Met Ser
65 70 75 80
Ser Val Asp Glu Asp Glu Asp Asp Glu Asp Asp Glu Asp Asp Tyr Tyr
85 90 95
Asp Asp Glu Asp Asp Asp Asp Asp Ala Phe Tyr Asp Asp Glu Asp Asp
100 105 110
Glu Glu Glu Glu Leu Glu Asn Leu Met Asp Asp Glu Ser Glu Asp Glu
115 120 125
Ala Glu Glu Glu Met Ser Val Glu Met Gly Ala Gly Ala Glu Glu Met
130 135 140
Gly Ala Gly Ala Asn Cys Ala Cys Val Pro Gly His His Leu Arg Lys
145 150 155 160
Asn Glu Val Lys Cys Arg Met Ile Tyr Phe Phe His Asp Pro Asn Phe
165 170 175
Leu Val Ser Ile Pro Val Asn Pro Lys Glu Gln Met Glu Cys Arg Cys
180 185 190
Glu Asn Ala Asp Glu Glu Val Ala Met Glu Glu Glu Glu Glu Glu Glu
195 200 205
Glu Glu Glu Glu Glu Glu Glu Met Gly Asn Pro Asp Gly Phe Ser Pro
210 215 220
Claims (48)
- 동물 세포에서 암 항원 또는 이의 단편의 번역, 전사 및/또는 발현을 지시하는 발현 조절 서열, 및 아데노바이러스 패키징 신호 서열에 작동 가능하게 연결된, (ⅰ) MAGE 암 항원 및/또는 NY-ESO-1 암 항원, 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 및/또는 LAGE1 암 항원, 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레오티드 서열을 포함하는 핵산 분자를 캡슐화하는 침팬지 아데노바이러스(ChAd) 벡터.
- 청구항 1에 있어서,
상기 ChAd 벡터는, (a) WO2012/172277호에 개시된 바와 같은 ChAdOx1; 바람직하게는 WO2012/172277호에 개시된 바와 같은 SEQ ID NO: 38의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx1; 또는 (b) WO2017/221031호에 개시된 바와 같은 ChAdOx2; 바람직하게는 WO2017/221031호에 개시된 바와 같은 SEQ ID NO: 10의 폴리뉴클레오티드 또는 이와 적어도 80% 동일성의 서열에 의해 암호화된 ChAdOx2인, ChAd 벡터. - 동물 세포에서 암 항원 또는 이의 단편의 번역, 전사 및/또는 발현을 지시하는 발현 조절 서열에 작동 가능하게 연결된, (ⅰ) MAGE 암 항원 및/또는 NY-ESO-1 암 항원, 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 및/또는 LAGE1 암 항원, 또는 이의 면역원성 단편을 암호화하는 폴리뉴클레오티드 서열을 포함하는 핵산 분자를 캡슐화하는 변형된 우두 바이러스 앙카라(MVA) 벡터.
- 청구항 3에 있어서,
상기 MVA 벡터는 WO2011/128704호 또는 EP 2044947 A1에 개시된 바와 같은, MVA 벡터. - 청구항 1 내지 4 중 어느 한 항에 있어서,
상기 MAGE 항원은, SEQ ID NO: 1의 아미노산 서열 또는 이와 적어도 46%; 바람직하게는 적어도 69%; 좀 더 바람직하게는 적어도 95% 동일성의 서열을 갖는 MAGE 3A; 또는 이의 임의의 면역원성 단편인, ChAd 또는 MVA 벡터. - 청구항 1 내지 5 중 어느 한 항에 있어서,
상기 NY-ESO-1 암 항원은, SEQ ID NO: 3의 아미노산 서열 또는 이와 적어도 75%; 바람직하게는 적어도 76.7% 동일성의 서열; 또는 이의 임의의 면역원성 단편을 갖는, ChAd 또는 MVA 벡터. - 청구항 1 내지 5 중 어느 한 항에 있어서,
상기 LAGE1 암 항원은, SEQ ID NO: 5의 아미노산 서열, 또는 이와 적어도 78%; 바람직하게는 적어도 97% 동일성의 서열; 또는 이의 임의의 면역원성 단편을 갖는, ChAd 또는 MVA 벡터. - 전술한 청구항 중 어느 한 항에 있어서,
상기 폴리뉴클레오티드 서열은, SEQ ID NO: 6의 아미노산 서열 또는 이와 적어도 79% 동일성의 서열, 또는 이의 단편을 갖는 인간 HLA 클래스 Ⅱ 조직적합성 항원 감마 사슬(li)을 더욱 암호화하여, 암 항원이 li 또는 이의 단편과의 융합으로서 동물 세포에서 발현되며; 바람직하게는, 여기서, 상기 단편은 막관통 도메인이고; 좀 더 바람직하게는, 상기 막관통 도메인은 아미노산 잔기 30 내지 55 또는 30 내지 61을 포함하며, 더욱 더 바람직하게는, 상기 막관통 도메인은 SEQ ID NO: 7의 아미노산 서열을 갖는, ChAd 또는 MVA 벡터. - 전술한 청구항 중 어느 한 항에 있어서,
상기 폴리뉴클레오티드 서열은, SEQ ID NO: 8의 아미노산 서열 또는 이와 적어도 81% 동일성의 서열, 또는 이의 단편을 갖는 tPA를 더욱 암호화하여; 암 항원이 tPA 또는 이의 단편과 융합으로 동물 세포에서 발현되며; 바람직하게는, 여기서, 상기 단편은 21개 아미노산 리더 서열을 포함하고; 좀 더 바람직하게는, 상기 21개 아미노산 리더 서열은 SEQ ID NO: 9인, ChAd 또는 MVA 벡터. - 전술한 청구항 중 어느 한 항에 있어서,
상기 폴리뉴클레오티드 서열은, 융합 단백질로서 동물 세포에서 발현되는, (ⅰ) MAGE 암 항원 또는 이의 면역원성 단편 및 NY-ESO-1 암 항원 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 또는 이의 면역원성 단편 및 LAGE1 암 항원 또는 이의 면역원성 단편을 암호화하는, ChAd 벡터. - 청구항 1 내지 9 중 어느 한 항에 있어서,
상기 폴리뉴클레오티드 서열은, 융합 단백질로서 동물 세포에서 발현되는, (ⅰ) MAGE 암 항원 또는 이의 면역원성 단편 및/또는 NY-ESO-1 암 항원 또는 이의 면역원성 단편; 또는 (ⅱ) MAGE 암 항원 또는 이의 면역원성 단편 및/또는 LAGE1 암 항원 또는 이의 면역원성 단편을 암호화하고, 여기서, 상기 MAGE 암 항원, NY-ESO-1 암 항원 또는 LAGE1 암 항원 중 적어도 하나는 단편인, MVA 벡터. - 청구항 11에 있어서,
상기 MAGE 암 항원 및 NY-ESO-1 또는 MAGE 암 항원 및 LAGE1은, 면역원성 단편인, MVA 벡터. - 청구항 10 내지 12 중 어느 한 항에 있어서,
상기 폴리뉴클레오티드 서열은, 발현시 융합 단백질로서, 임의의 순서로, MAGE 및 NY-ESO-1 또는 LAGE1 암 항원 또는 이의 단편을 연결하는, 5 내지 9개의 아미노산의 링커; 바람직하게는, 아미노산 서열 GGGPGGG를 갖는 링커를 암호화하는, ChAd 또는 MVA 벡터. - 전술한 청구항 중 어느 한 항에 청구된 ChAd 또는 MVA 벡터를 포함하는, 면역원성 조성물.
- 청구항 14에있어서,
보조제를 더욱 포함하는, 조성물. - 청구항 1 내지 10 또는 13 중 어느 한 항의 ChAd 벡터, 또는 청구항 3 내지 9 또는 11 내지 13 중 어느 한 항의 MVA 벡터를 암호화하는 서열을 포함하는, 단리된 폴리뉴클레오티드.
- 청구항 16에 있어서,
인간 코돈 사용을 위해 최적화된 코돈인, 단리된 폴리뉴클레오티드. - 청구항 16 또는 17의 폴리뉴클레오티드를 포함하는 박테리아 인공 염색체(BAC) 클론.
- 청구항 1 내지 13 중 어느 한 항에 기재된 ChAd 및/또는 MVA 벡터를 포함하는 단리된 숙주 세포.
- 청구항 1 내지 10 또는 13 중 어느 한 항에 기재된 유효량의 ChAd 벡터를 투여하는 단계, 및 청구항 3 내지 9 또는 11 내지 13 중 어느 한 항에 기재된 유효량의 MVA 벡터를 투여하는 단계를 포함하고, 이에 의해 개체의 후천성 면역계가 자극되어 항-암 면역 반응을 제공하는, 개체에서 암을 예방 또는 치료하는 방법.
- 청구항 20에 있어서,
상기 ChAd 및 MVA 벡터의 투여는, 개별적으로, 순차적으로 또는 동시에 수행되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 또는 21에 있어서,
유효량의 하나 이상의 관문 억제제의 투여를 더욱 포함하는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 22 중 어느 한 항에 있어서,
상기 관문 억제제는, ChAd 및 MVA 벡터와 동시에, 개별적으로 또는 함께 투여되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 23 중 어느 한 항에 있어서,
상기 개체는, 화학요법 및/또는 방사선요법 치료를 받았거나, 받고 있거나, 또는 받을 예정인, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 24 중 어느 한 항에 있어서,
상기 ChAd 벡터는 맨 먼저 투여되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 25 중 어느 한 항에 있어서,
상기 ChAd 및 MVA 벡터는, 각각 1회 이상 투여되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 26 중 어느 한 항에 있어서,
상기 ChAd 및 MVA 벡터는 교대로 투여되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 20 내지 27 중 어느 한 항에 있어서,
벡터의 각 투여 사이에 기간은 5일 내지 8주의 범위; 바람직하게는 1주인, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 22 내지 28 중 어느 한 항에 있어서,
상기 관문 억제제는, PD-1, CTLA-4 또는 PD-L1을 차단하는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 22 내지 28 중 어느 한 항에 있어서,
상기 관문 억제제는, 니볼루맙, 펨브롤리주맙, 이필리무맙, 트레멜리무맙 또는 아테졸리주맙, 두르발루맙 또는 아벨루맙으로부터 선택되는, 개체에서 암을 예방 또는 치료하는 방법. - 청구항 22 내지 28 중 어느 한 항에 있어서,
상기 암은, 비-소세포 폐암(NSCLC), 흑색종, 호지킨 림프종, 비-호지킨 림프종, 요로암(요로상피암), 방광암, 소세포 폐암, 신장암, 두경부암, 육종, 또는 유방암인, 개체에서 암을 예방 또는 치료하는 방법. - 암의 예방 또는 치료에 사용하기 위한 청구항 1, 2, 5 내지 10 또는 13 중 어느 한 항에 따른 ChAd 벡터.
- 암의 예방 또는 치료에 사용하기 위한 청구항 3 내지 9 또는 11 내지 13 중 어느 한 항에 따른 MVA 벡터.
- 암의 예방 또는 치료를 위해 환자에게 개별적, 순차적 또는 동시에 투여하기 위한, 청구항 1, 2, 5 내지 10 또는 13 중 어느 한 항에 기재된 ChAd 벡터 및 청구항 3 내지 9 또는 11 내지 13 중 어느 한 항에 기재된 MVA 벡터.
- 청구항 34에 있어서,
암의 치료를 위해 ChAd 및 MVA 벡터와 함께 투여하기 위한 하나 이상의 관문 억제제를 더욱 포함하는, 암 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 35에 있어서,
상기 관문 억제제는, 벡터와 동시에, 개별적으로 또는 함께 투여되는, 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 31 내지 33 중 어느 한 항에 있어서,
상기 환자는, 화학요법을 받았거나, 받고 있거나, 또는 받을 예정인, 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 34 내지 36 중 어느 한 항에 있어서,
상기 ChAd 벡터는 맨 먼저 투여되는, 암 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 34 내지 38 중 어느 한 항에 있어서,
상기 ChAd 및 MVA 벡터는 각각 1회 이상 투여되는, 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 34 내지 39 중 어느 한 항에 있어서,
상기 ChAd 및 MVA 벡터는 교대로 투여되는, 암 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 34 내지 40 중 어느 한 항에 있어서,
상기 벡터의 각 투여 사이에 기간은, 5일 내지 8주의 범위, 바람직하게는 1주인, 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 35 내지 41 중 어느 한 항에 있어서,
상기 관문 억제제는, PD-1, CTLA-4 또는 PD-L1을 차단하는, 암 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 35 내지 41 중 어느 한 항에 있어서,
상기 관문 억제제는, 니볼루맙, 펨브롤리주맙, 이필리무맙, 트레멜리무맙 또는 아테졸리주맙, 두르발루맙 또는 아벨루맙으로부터 선택되는, 암 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 청구항 35 내지 41 중 어느 한 항에 있어서,
상기 암은, 비-소세포 폐암(NSCLC), 흑색종, 호지킨 림프종, 비-호지킨 림프종, 요로암(요로상피암), 방광암, 소세포 폐암, 신장암, 두경부암, 육종, 또는 유방암인, 암의 예방 또는 치료에 사용하기 위한 ChAd 및 MVA 벡터. - 암의 예방 또는 치료를 위해 환자에게 개별적, 순차적 또는 동시에 투여하기 위한, 청구항 1, 2, 5 내지 10 또는 13 중 어느 한 항에 기재된 ChAd 벡터, 청구항 3 내지 9 또는 11 내지 13 중 어느 한 항에 기재된 MVA 벡터, 화학요법제, 및 관문 억제제.
- 청구항 45에 있어서,
상기 화학요법제는, (a) 카보플라틴 또는 시스플라틴과 (b) 파클리탁셀, 도세탁셀, 비노렐빈, 젬시타빈, 에토포시드 또는 페메트렉시드 중 하나의 조합으로부터 선택되는, ChAd 벡터, MVA 벡터, 화학요법제 및 관문 억제제. - 청구항 45 또는 46에 있어서,
상기 관문 억제제는 PD-1인, ChAd 벡터, MVA 벡터, 화학요법제 및 관문 억제제. - 청구항 45 내지 47 중 어느 한 항에 있어서,
상기 암은, 비-소세포 폐암(NSCLC) 또는 소세포 폐암(SCLC), 흑색종, 호지킨 림프종, 비-호지킨 림프종, 요로암(요로상피암), 방광암, 신장암, 두경부암, 육종 또는 유방암으로부터 선택되는, ChAd 벡터, MVA 벡터, 화학요법제 및 관문 억제제.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1812647.4 | 2018-08-03 | ||
| GBGB1812647.4A GB201812647D0 (en) | 2018-08-03 | 2018-08-03 | Viral vectors and methods for the prevention or treatment of cancer |
| PCT/EP2019/070555 WO2020025642A1 (en) | 2018-08-03 | 2019-07-30 | Viral vectors encoding cancer/testis antigens for use in a method of prevention or treatment of cancer |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210041593A true KR20210041593A (ko) | 2021-04-15 |
Family
ID=63518408
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217006575A KR20210041593A (ko) | 2018-08-03 | 2019-07-30 | 암의 예방 또는 치료의 방법에 사용하기 위한 암/고환 항원을 암호화하는 바이러스 벡터 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US20210171981A1 (ko) |
| EP (1) | EP3829627A1 (ko) |
| JP (1) | JP2021532791A (ko) |
| KR (1) | KR20210041593A (ko) |
| CN (1) | CN112789054A (ko) |
| AU (1) | AU2019315700A1 (ko) |
| CA (1) | CA3108350A1 (ko) |
| GB (1) | GB201812647D0 (ko) |
| SG (1) | SG11202101139XA (ko) |
| WO (1) | WO2020025642A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TW202043256A (zh) | 2019-01-10 | 2020-12-01 | 美商健生生物科技公司 | 前列腺新抗原及其用途 |
| WO2022099543A1 (zh) * | 2020-11-12 | 2022-05-19 | 深圳先进技术研究院 | Ny-eso-1基因抑制剂作为抗肿瘤化疗药物增敏剂的应用 |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6140087A (en) | 1993-06-24 | 2000-10-31 | Advec, Inc. | Adenovirus vectors for gene therapy |
| WO1998046769A1 (en) | 1997-04-11 | 1998-10-22 | Dendreon Corporation | Composition and method for inducing an immune response against tumour-related antigens |
| DE69839443D1 (de) | 1997-05-08 | 2008-06-19 | Biomira Inc | Verfahren zur gewinnung von aktivierten t-zellen und mit antigen inkubierten antigenpräsentierenden zellen |
| US20030138454A1 (en) * | 1997-06-09 | 2003-07-24 | Oxxon Pharmaccines, Ltd. | Vaccination method |
| DE60124899T2 (de) * | 2000-05-10 | 2007-08-16 | Sanofi Pasteur Ltd., Toronto | Durch mage minigene kodierte immunogene polypeptide und ihre verwendungen |
| WO2004055187A1 (en) | 2002-12-17 | 2004-07-01 | Crucell Holland B.V. | Recombinant viral-based malaria vaccines |
| CN102719478A (zh) | 2004-01-23 | 2012-10-10 | P.安杰莱蒂分子生物学研究所 | 黑猩猩腺病毒疫苗载运体 |
| GB0417494D0 (en) | 2004-08-05 | 2004-09-08 | Glaxosmithkline Biolog Sa | Vaccine |
| JP2006149234A (ja) | 2004-11-25 | 2006-06-15 | Japan Science & Technology Agency | プライム−ブーストワクチン接種法 |
| WO2006120474A2 (en) * | 2005-05-13 | 2006-11-16 | Oxxon Therapeutics Ltd | Compositions for inducing an immune response against tumor antigens |
| GB0719526D0 (en) | 2007-10-05 | 2007-11-14 | Isis Innovation | Compositions and methods |
| US8326547B2 (en) | 2009-10-07 | 2012-12-04 | Nanjingjinsirui Science & Technology Biology Corp. | Method of sequence optimization for improved recombinant protein expression using a particle swarm optimization algorithm |
| GB201006405D0 (en) * | 2010-04-16 | 2010-06-02 | Isis Innovation | Poxvirus expression system |
| ES2528369T3 (es) | 2010-08-06 | 2015-02-09 | Re.Le.Vi. S.P.A. | Agente sanitario |
| US20130302367A1 (en) | 2010-10-22 | 2013-11-14 | Hisatoshi Shida | Virus vector for prime/boost vaccines, which comprises vaccinia virus vector and sendai virus vector |
| GB201108879D0 (en) | 2011-05-25 | 2011-07-06 | Isis Innovation | Vector |
| WO2014139587A1 (en) * | 2013-03-15 | 2014-09-18 | Okairòs Ag | Improved poxviral vaccines |
| GB201321384D0 (en) | 2013-12-04 | 2014-01-15 | Isis Innovation | Molecular adjuvant |
| WO2015092710A1 (en) * | 2013-12-19 | 2015-06-25 | Glaxosmithkline Biologicals, S.A. | Contralateral co-administration of vaccines |
| EP3402500A4 (en) | 2016-01-11 | 2019-06-12 | Turnstone Limited Partnership | COMBINATION THERAPY OF ONCOLYTIC VIRUS AND CHECKPOINT INHIBITOR |
| GB2549809C (en) * | 2016-06-23 | 2022-11-30 | Univ Oxford Innovation Ltd | Vector |
-
2018
- 2018-08-03 GB GBGB1812647.4A patent/GB201812647D0/en not_active Ceased
-
2019
- 2019-07-30 WO PCT/EP2019/070555 patent/WO2020025642A1/en unknown
- 2019-07-30 AU AU2019315700A patent/AU2019315700A1/en active Pending
- 2019-07-30 CN CN201980065216.7A patent/CN112789054A/zh active Pending
- 2019-07-30 SG SG11202101139XA patent/SG11202101139XA/en unknown
- 2019-07-30 JP JP2021505666A patent/JP2021532791A/ja active Pending
- 2019-07-30 EP EP19749300.0A patent/EP3829627A1/en active Pending
- 2019-07-30 US US17/250,561 patent/US20210171981A1/en active Pending
- 2019-07-30 CA CA3108350A patent/CA3108350A1/en active Pending
- 2019-07-30 KR KR1020217006575A patent/KR20210041593A/ko unknown
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019315700A1 (en) | 2021-03-18 |
| JP2021532791A (ja) | 2021-12-02 |
| US20210171981A1 (en) | 2021-06-10 |
| CA3108350A1 (en) | 2020-02-06 |
| CN112789054A (zh) | 2021-05-11 |
| WO2020025642A1 (en) | 2020-02-06 |
| EP3829627A1 (en) | 2021-06-09 |
| GB201812647D0 (en) | 2018-09-19 |
| SG11202101139XA (en) | 2021-03-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220056473A1 (en) | Chimeric nucleic acid molecules with non-aug translation initiation sequences and uses thereof | |
| EP1931375B1 (en) | Chemo-immunotherapy method | |
| JP2023123609A (ja) | 個別化ワクチン | |
| CN112930394B (zh) | 表达ii类主要组织相容性复合物的癌细胞疫苗和用于产生整合免疫应答的使用方法 | |
| CN114929264A (zh) | 多结构域蛋白疫苗 | |
| KR20210041593A (ko) | 암의 예방 또는 치료의 방법에 사용하기 위한 암/고환 항원을 암호화하는 바이러스 벡터 | |
| CN114867491A (zh) | 用于肿瘤内和/或静脉内施用以治疗癌症的重组mva病毒 | |
| KR20210081325A (ko) | 경골어류 불변 사슬 암 백신 | |
| WO2023118508A1 (en) | Recombinant mva viruses for intraperitoneal administration for treating cancer | |
| US20230059344A1 (en) | Medical Uses of 4-1BBL Adjuvanted Recombinant Modified Vaccinia Virus Ankara (MVA) |