KR20200085776A - 신규한 감마 델타 t-세포 수용체 및 이의 리간드 - Google Patents
신규한 감마 델타 t-세포 수용체 및 이의 리간드 Download PDFInfo
- Publication number
- KR20200085776A KR20200085776A KR1020207014073A KR20207014073A KR20200085776A KR 20200085776 A KR20200085776 A KR 20200085776A KR 1020207014073 A KR1020207014073 A KR 1020207014073A KR 20207014073 A KR20207014073 A KR 20207014073A KR 20200085776 A KR20200085776 A KR 20200085776A
- Authority
- KR
- South Korea
- Prior art keywords
- cancer
- tcr
- cell
- clone
- cells
- Prior art date
Links
- 239000003446 ligand Substances 0.000 title abstract description 16
- 102000011778 gamma-delta T-Cell Antigen Receptors Human genes 0.000 title description 2
- 108010062214 gamma-delta T-Cell Antigen Receptors Proteins 0.000 title description 2
- 108091008874 T cell receptors Proteins 0.000 claims abstract description 134
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims abstract description 130
- 210000004027 cell Anatomy 0.000 claims abstract description 123
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 65
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 59
- 201000011510 cancer Diseases 0.000 claims abstract description 53
- 239000013598 vector Substances 0.000 claims abstract description 31
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims abstract description 29
- 229960005486 vaccine Drugs 0.000 claims abstract description 16
- 238000000034 method Methods 0.000 claims abstract description 15
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 14
- 238000011282 treatment Methods 0.000 claims abstract description 14
- 239000000677 immunologic agent Substances 0.000 claims abstract description 12
- 229940124541 immunological agent Drugs 0.000 claims abstract description 11
- 108090000623 proteins and genes Proteins 0.000 claims description 39
- 108010029485 Protein Isoforms Proteins 0.000 claims description 11
- 102000001708 Protein Isoforms Human genes 0.000 claims description 11
- 239000012634 fragment Substances 0.000 claims description 10
- 201000001441 melanoma Diseases 0.000 claims description 10
- 206010005003 Bladder cancer Diseases 0.000 claims description 8
- 206010006187 Breast cancer Diseases 0.000 claims description 8
- 208000026310 Breast neoplasm Diseases 0.000 claims description 8
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 8
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 8
- 201000005202 lung cancer Diseases 0.000 claims description 8
- 208000020816 lung neoplasm Diseases 0.000 claims description 8
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 8
- 206010005949 Bone cancer Diseases 0.000 claims description 6
- 208000018084 Bone neoplasm Diseases 0.000 claims description 6
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 6
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 6
- 206010038389 Renal cancer Diseases 0.000 claims description 6
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 6
- 201000010881 cervical cancer Diseases 0.000 claims description 6
- 201000010982 kidney cancer Diseases 0.000 claims description 6
- 229920001184 polypeptide Polymers 0.000 claims description 6
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 6
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 6
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 5
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 5
- 206010060862 Prostate cancer Diseases 0.000 claims description 5
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 5
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 5
- 239000003795 chemical substances by application Substances 0.000 claims description 5
- 201000005787 hematologic cancer Diseases 0.000 claims description 5
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 claims description 5
- 206010046766 uterine cancer Diseases 0.000 claims description 5
- 206010033128 Ovarian cancer Diseases 0.000 claims description 4
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 4
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 4
- 208000015634 Rectal Neoplasms Diseases 0.000 claims description 4
- 208000024313 Testicular Neoplasms Diseases 0.000 claims description 4
- 206010057644 Testis cancer Diseases 0.000 claims description 4
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 4
- 210000001728 clone cell Anatomy 0.000 claims description 4
- 201000010536 head and neck cancer Diseases 0.000 claims description 4
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 4
- 201000007270 liver cancer Diseases 0.000 claims description 4
- 208000014018 liver neoplasm Diseases 0.000 claims description 4
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 4
- 201000002528 pancreatic cancer Diseases 0.000 claims description 4
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 4
- 206010038038 rectal cancer Diseases 0.000 claims description 4
- 201000001275 rectum cancer Diseases 0.000 claims description 4
- 201000003120 testicular cancer Diseases 0.000 claims description 4
- 201000002510 thyroid cancer Diseases 0.000 claims description 4
- 230000009258 tissue cross reactivity Effects 0.000 claims description 4
- 239000003814 drug Substances 0.000 claims description 3
- 239000002246 antineoplastic agent Substances 0.000 claims description 2
- 238000004519 manufacturing process Methods 0.000 claims description 2
- 230000002163 immunogen Effects 0.000 claims 3
- 239000000203 mixture Substances 0.000 claims 2
- 238000011284 combination treatment Methods 0.000 claims 1
- 238000009472 formulation Methods 0.000 claims 1
- 230000036039 immunity Effects 0.000 claims 1
- 102100037242 Amiloride-sensitive sodium channel subunit alpha Human genes 0.000 description 31
- 101000740448 Homo sapiens Amiloride-sensitive sodium channel subunit alpha Proteins 0.000 description 31
- 241000282414 Homo sapiens Species 0.000 description 19
- 238000011156 evaluation Methods 0.000 description 18
- 230000004913 activation Effects 0.000 description 16
- 101150082646 scnn1a gene Proteins 0.000 description 16
- 108020005004 Guide RNA Proteins 0.000 description 15
- 108091033409 CRISPR Proteins 0.000 description 13
- 102000004169 proteins and genes Human genes 0.000 description 13
- 239000000427 antigen Substances 0.000 description 12
- 108091007433 antigens Proteins 0.000 description 12
- 102000036639 antigens Human genes 0.000 description 12
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 12
- 230000014509 gene expression Effects 0.000 description 10
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 9
- 230000009257 reactivity Effects 0.000 description 8
- 210000001519 tissue Anatomy 0.000 description 8
- 238000010354 CRISPR gene editing Methods 0.000 description 7
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 7
- 210000003719 b-lymphocyte Anatomy 0.000 description 7
- 239000011324 bead Substances 0.000 description 7
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 7
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 6
- 230000005859 cell recognition Effects 0.000 description 6
- 239000013612 plasmid Substances 0.000 description 6
- 229950010131 puromycin Drugs 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- CRCPLBFLOSEABN-BEVDRBHNSA-N (2r)-n-[(2s)-1-[[(2s)-1-amino-1-oxopropan-2-yl]amino]-3-naphthalen-2-yl-1-oxopropan-2-yl]-n'-hydroxy-2-(2-methylpropyl)butanediamide Chemical compound C1=CC=CC2=CC(C[C@H](NC(=O)[C@@H](CC(=O)NO)CC(C)C)C(=O)N[C@@H](C)C(N)=O)=CC=C21 CRCPLBFLOSEABN-BEVDRBHNSA-N 0.000 description 5
- 102000009839 Endothelial Protein C Receptor Human genes 0.000 description 5
- 108010009900 Endothelial Protein C Receptor Proteins 0.000 description 5
- 238000009169 immunotherapy Methods 0.000 description 5
- 230000007774 longterm Effects 0.000 description 5
- 238000007481 next generation sequencing Methods 0.000 description 5
- 238000012163 sequencing technique Methods 0.000 description 5
- 210000004881 tumor cell Anatomy 0.000 description 5
- 206010009944 Colon cancer Diseases 0.000 description 4
- 150000001413 amino acids Chemical class 0.000 description 4
- 208000029742 colonic neoplasm Diseases 0.000 description 4
- 230000009089 cytolysis Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 210000003494 hepatocyte Anatomy 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- 238000010361 transduction Methods 0.000 description 4
- 230000026683 transduction Effects 0.000 description 4
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 3
- 101100125371 Caenorhabditis elegans cil-1 gene Proteins 0.000 description 3
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 3
- 108020004414 DNA Proteins 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 3
- 102000043129 MHC class I family Human genes 0.000 description 3
- 108091054437 MHC class I family Proteins 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 229910052804 chromium Inorganic materials 0.000 description 3
- 239000011651 chromium Substances 0.000 description 3
- 230000001886 ciliary effect Effects 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 3
- 238000003209 gene knockout Methods 0.000 description 3
- 108010050848 glycylleucine Proteins 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 229910052618 mica group Inorganic materials 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 210000004882 non-tumor cell Anatomy 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 230000004043 responsiveness Effects 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- NINQYGGNRIBFSC-CIUDSAMLSA-N Ala-Lys-Ser Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CO)C(O)=O NINQYGGNRIBFSC-CIUDSAMLSA-N 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 2
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 2
- 101000991061 Homo sapiens MHC class I polypeptide-related sequence B Proteins 0.000 description 2
- 101000649128 Homo sapiens T cell receptor delta variable 1 Proteins 0.000 description 2
- 101000679305 Homo sapiens T cell receptor gamma variable 3 Proteins 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 241000880493 Leptailurus serval Species 0.000 description 2
- 102100030300 MHC class I polypeptide-related sequence B Human genes 0.000 description 2
- CXGLFEOYCJFKPR-RCWTZXSCSA-N Pro-Thr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O CXGLFEOYCJFKPR-RCWTZXSCSA-N 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 102100022591 T cell receptor gamma variable 3 Human genes 0.000 description 2
- XPNSAQMEAVSQRD-FBCQKBJTSA-N Thr-Gly-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)NCC(O)=O XPNSAQMEAVSQRD-FBCQKBJTSA-N 0.000 description 2
- 108700019146 Transgenes Proteins 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- 101150063416 add gene Proteins 0.000 description 2
- 125000000539 amino acid group Chemical group 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- 229910001628 calcium chloride Inorganic materials 0.000 description 2
- 239000001110 calcium chloride Substances 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 231100000135 cytotoxicity Toxicity 0.000 description 2
- 230000003013 cytotoxicity Effects 0.000 description 2
- 231100000263 cytotoxicity test Toxicity 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 231100000517 death Toxicity 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 210000002919 epithelial cell Anatomy 0.000 description 2
- 210000000981 epithelium Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 2
- 210000002865 immune cell Anatomy 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000010445 mica Substances 0.000 description 2
- 239000011325 microbead Substances 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 238000004806 packaging method and process Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 230000009145 protein modification Effects 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 238000005199 ultracentrifugation Methods 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- MDSIZRKJVDMQOQ-GORDUTHDSA-N (2E)-4-hydroxy-3-methylbut-2-en-1-yl diphosphate Chemical compound OCC(/C)=C/COP(O)(=O)OP(O)(O)=O MDSIZRKJVDMQOQ-GORDUTHDSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- KQESEZXHYOUIIM-CQDKDKBSSA-N Ala-Lys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KQESEZXHYOUIIM-CQDKDKBSSA-N 0.000 description 1
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 1
- BIOCIVSVEDFKDJ-GUBZILKMSA-N Arg-Arg-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O BIOCIVSVEDFKDJ-GUBZILKMSA-N 0.000 description 1
- JTKLCCFLSLCCST-SZMVWBNQSA-N Arg-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JTKLCCFLSLCCST-SZMVWBNQSA-N 0.000 description 1
- FBLMOFHNVQBKRR-IHRRRGAJSA-N Arg-Asp-Tyr Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FBLMOFHNVQBKRR-IHRRRGAJSA-N 0.000 description 1
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 1
- FRMQITGHXMUNDF-GMOBBJLQSA-N Arg-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N FRMQITGHXMUNDF-GMOBBJLQSA-N 0.000 description 1
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 1
- DDBMKOCQWNFDBH-RHYQMDGZSA-N Arg-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O DDBMKOCQWNFDBH-RHYQMDGZSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- BZWRLDPIWKOVKB-ZPFDUUQYSA-N Asn-Leu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BZWRLDPIWKOVKB-ZPFDUUQYSA-N 0.000 description 1
- XIDSGDJNUJRUHE-VEVYYDQMSA-N Asn-Thr-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O XIDSGDJNUJRUHE-VEVYYDQMSA-N 0.000 description 1
- PIABYSIYPGLLDQ-XVSYOHENSA-N Asn-Thr-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PIABYSIYPGLLDQ-XVSYOHENSA-N 0.000 description 1
- JDHOJQJMWBKHDB-CIUDSAMLSA-N Asp-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N JDHOJQJMWBKHDB-CIUDSAMLSA-N 0.000 description 1
- UJGRZQYSNYTCAX-SRVKXCTJSA-N Asp-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UJGRZQYSNYTCAX-SRVKXCTJSA-N 0.000 description 1
- QNIACYURSSCLRP-GUBZILKMSA-N Asp-Lys-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O QNIACYURSSCLRP-GUBZILKMSA-N 0.000 description 1
- VSMYBNPOHYAXSD-GUBZILKMSA-N Asp-Lys-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O VSMYBNPOHYAXSD-GUBZILKMSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 1
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 1
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100021277 Beta-secretase 2 Human genes 0.000 description 1
- 101710150190 Beta-secretase 2 Proteins 0.000 description 1
- 210000001239 CD8-positive, alpha-beta cytotoxic T lymphocyte Anatomy 0.000 description 1
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 1
- VYZAMTAEIAYCRO-BJUDXGSMSA-N Chromium-51 Chemical compound [51Cr] VYZAMTAEIAYCRO-BJUDXGSMSA-N 0.000 description 1
- CVOZXIPULQQFNY-ZLUOBGJFSA-N Cys-Ala-Cys Chemical compound C[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CS)C(O)=O CVOZXIPULQQFNY-ZLUOBGJFSA-N 0.000 description 1
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 1
- XABFFGOGKOORCG-CIUDSAMLSA-N Cys-Asp-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XABFFGOGKOORCG-CIUDSAMLSA-N 0.000 description 1
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 1
- JXVFJOMFOLFPMP-KKUMJFAQSA-N Cys-Leu-Tyr Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JXVFJOMFOLFPMP-KKUMJFAQSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 206010015108 Epstein-Barr virus infection Diseases 0.000 description 1
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 1
- NPMFDZGLKBNFOO-SRVKXCTJSA-N Gln-Pro-His Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NPMFDZGLKBNFOO-SRVKXCTJSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 1
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 1
- ALCAUWPAMLVUDB-FXQIFTODSA-N Glu-Gln-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ALCAUWPAMLVUDB-FXQIFTODSA-N 0.000 description 1
- ZCOJVESMNGBGLF-GRLWGSQLSA-N Glu-Ile-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZCOJVESMNGBGLF-GRLWGSQLSA-N 0.000 description 1
- ZSWGJYOZWBHROQ-RWRJDSDZSA-N Glu-Ile-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSWGJYOZWBHROQ-RWRJDSDZSA-N 0.000 description 1
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 1
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 1
- MIIGESVJEBDJMP-FHWLQOOXSA-N Glu-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 MIIGESVJEBDJMP-FHWLQOOXSA-N 0.000 description 1
- MXJYXYDREQWUMS-XKBZYTNZSA-N Glu-Thr-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O MXJYXYDREQWUMS-XKBZYTNZSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 1
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 1
- CVFOYJJOZYYEPE-KBPBESRZSA-N Gly-Lys-Tyr Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CVFOYJJOZYYEPE-KBPBESRZSA-N 0.000 description 1
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 1
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- JHVCZQFWRLHUQR-DCAQKATOSA-N His-Arg-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N JHVCZQFWRLHUQR-DCAQKATOSA-N 0.000 description 1
- UPJODPVSKKWGDQ-KLHWPWHYSA-N His-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)O UPJODPVSKKWGDQ-KLHWPWHYSA-N 0.000 description 1
- UXZMINKIEWBEQU-SZMVWBNQSA-N His-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N UXZMINKIEWBEQU-SZMVWBNQSA-N 0.000 description 1
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 1
- 101000619708 Homo sapiens Peroxiredoxin-6 Proteins 0.000 description 1
- 101000649129 Homo sapiens T cell receptor delta variable 2 Proteins 0.000 description 1
- 101000680681 Homo sapiens T cell receptor gamma variable 9 Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 1
- GTSAALPQZASLPW-KJYZGMDISA-N Ile-His-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N GTSAALPQZASLPW-KJYZGMDISA-N 0.000 description 1
- FZWVCYCYWCLQDH-NHCYSSNCSA-N Ile-Leu-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N FZWVCYCYWCLQDH-NHCYSSNCSA-N 0.000 description 1
- XLXPYSDGMXTTNQ-UHFFFAOYSA-N Ile-Phe-Leu Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 XLXPYSDGMXTTNQ-UHFFFAOYSA-N 0.000 description 1
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 1
- COWHUQXTSYTKQC-RWRJDSDZSA-N Ile-Thr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N COWHUQXTSYTKQC-RWRJDSDZSA-N 0.000 description 1
- DLEBSGAVWRPTIX-PEDHHIEDSA-N Ile-Val-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)[C@@H](C)CC DLEBSGAVWRPTIX-PEDHHIEDSA-N 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 1
- WGCKDDHUFPQSMZ-ZPFDUUQYSA-N Lys-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCCN WGCKDDHUFPQSMZ-ZPFDUUQYSA-N 0.000 description 1
- WVJNGSFKBKOKRV-AJNGGQMLSA-N Lys-Leu-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVJNGSFKBKOKRV-AJNGGQMLSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- ZOKVLMBYDSIDKG-CSMHCCOUSA-N Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCCN ZOKVLMBYDSIDKG-CSMHCCOUSA-N 0.000 description 1
- CUHGAUZONORRIC-HJGDQZAQSA-N Lys-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O CUHGAUZONORRIC-HJGDQZAQSA-N 0.000 description 1
- GIKFNMZSGYAPEJ-HJGDQZAQSA-N Lys-Thr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O GIKFNMZSGYAPEJ-HJGDQZAQSA-N 0.000 description 1
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 1
- 108700005092 MHC Class II Genes Proteins 0.000 description 1
- 108010031034 MHC class I-related chain A Proteins 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 108010072489 Met-Ile-Phe-Leu Proteins 0.000 description 1
- JCMMNFZUKMMECJ-DCAQKATOSA-N Met-Lys-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O JCMMNFZUKMMECJ-DCAQKATOSA-N 0.000 description 1
- ZRACLHJYVRBJFC-ULQDDVLXSA-N Met-Lys-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZRACLHJYVRBJFC-ULQDDVLXSA-N 0.000 description 1
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 102100022239 Peroxiredoxin-6 Human genes 0.000 description 1
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 1
- LWPMGKSZPKFKJD-DZKIICNBSA-N Phe-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O LWPMGKSZPKFKJD-DZKIICNBSA-N 0.000 description 1
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 1
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 1
- FUVBEZJCRMHWEM-FXQIFTODSA-N Pro-Asn-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FUVBEZJCRMHWEM-FXQIFTODSA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 1
- DWPXHLIBFQLKLK-CYDGBPFRSA-N Pro-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 DWPXHLIBFQLKLK-CYDGBPFRSA-N 0.000 description 1
- 101800004937 Protein C Proteins 0.000 description 1
- 102000017975 Protein C Human genes 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 101800001700 Saposin-D Proteins 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 1
- GVMUJUPXFQFBBZ-GUBZILKMSA-N Ser-Lys-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GVMUJUPXFQFBBZ-GUBZILKMSA-N 0.000 description 1
- CRJZZXMAADSBBQ-SRVKXCTJSA-N Ser-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO CRJZZXMAADSBBQ-SRVKXCTJSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 1
- ATEQEHCGZKBEMU-GQGQLFGLSA-N Ser-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N ATEQEHCGZKBEMU-GQGQLFGLSA-N 0.000 description 1
- FVFUOQIYDPAIJR-XIRDDKMYSA-N Ser-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FVFUOQIYDPAIJR-XIRDDKMYSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 101000910035 Streptococcus pyogenes serotype M1 CRISPR-associated endonuclease Cas9/Csn1 Proteins 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 229940126530 T cell activator Drugs 0.000 description 1
- 102100027949 T cell receptor delta variable 1 Human genes 0.000 description 1
- 102100027948 T cell receptor delta variable 2 Human genes 0.000 description 1
- 102100022393 T cell receptor gamma variable 9 Human genes 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 210000000662 T-lymphocyte subset Anatomy 0.000 description 1
- UYTYTDMCDBPDSC-URLPEUOOSA-N Thr-Ile-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N UYTYTDMCDBPDSC-URLPEUOOSA-N 0.000 description 1
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- WFAUDCSNCWJJAA-KXNHARMFSA-N Thr-Lys-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(O)=O WFAUDCSNCWJJAA-KXNHARMFSA-N 0.000 description 1
- MEBDIIKMUUNBSB-RPTUDFQQSA-N Thr-Phe-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MEBDIIKMUUNBSB-RPTUDFQQSA-N 0.000 description 1
- GQPQJNMVELPZNQ-GBALPHGKSA-N Thr-Ser-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N)O GQPQJNMVELPZNQ-GBALPHGKSA-N 0.000 description 1
- KHTIUAKJRUIEMA-HOUAVDHOSA-N Thr-Trp-Asp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 KHTIUAKJRUIEMA-HOUAVDHOSA-N 0.000 description 1
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 1
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 1
- CURFABYITJVKEW-QTKMDUPCSA-N Thr-Val-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O CURFABYITJVKEW-QTKMDUPCSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- GKUROEIXVURAAO-BPUTZDHNSA-N Trp-Asp-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GKUROEIXVURAAO-BPUTZDHNSA-N 0.000 description 1
- DVWAIHZOPSYMSJ-ZVZYQTTQSA-N Trp-Glu-Val Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O)=CNC2=C1 DVWAIHZOPSYMSJ-ZVZYQTTQSA-N 0.000 description 1
- ABRICLFKFRFDKS-IHPCNDPISA-N Trp-Ser-Tyr Chemical compound C([C@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 ABRICLFKFRFDKS-IHPCNDPISA-N 0.000 description 1
- YCEHCFIOIYNQTR-NYVOZVTQSA-N Trp-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)N[C@@H](CO)C(=O)O)N YCEHCFIOIYNQTR-NYVOZVTQSA-N 0.000 description 1
- YCQKQFKXBPJXRY-PMVMPFDFSA-N Trp-Tyr-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)N[C@@H](CCCCN)C(=O)O)N YCQKQFKXBPJXRY-PMVMPFDFSA-N 0.000 description 1
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 1
- HKYTWJOWZTWBQB-AVGNSLFASA-N Tyr-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HKYTWJOWZTWBQB-AVGNSLFASA-N 0.000 description 1
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 1
- YKCXQOBTISTQJD-BZSNNMDCSA-N Tyr-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N YKCXQOBTISTQJD-BZSNNMDCSA-N 0.000 description 1
- ZOBLBMGJKVJVEV-BZSNNMDCSA-N Tyr-Lys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O ZOBLBMGJKVJVEV-BZSNNMDCSA-N 0.000 description 1
- UUBKSZNKJUJQEJ-JRQIVUDYSA-N Tyr-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O UUBKSZNKJUJQEJ-JRQIVUDYSA-N 0.000 description 1
- OJCISMMNNUNNJA-BZSNNMDCSA-N Tyr-Tyr-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 OJCISMMNNUNNJA-BZSNNMDCSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- KSGKJSFPWSMJHK-JNPHEJMOSA-N Tyr-Tyr-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KSGKJSFPWSMJHK-JNPHEJMOSA-N 0.000 description 1
- WOCYUGQDXPTQPY-FXQIFTODSA-N Val-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N WOCYUGQDXPTQPY-FXQIFTODSA-N 0.000 description 1
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 1
- HNWQUBBOBKSFQV-AVGNSLFASA-N Val-Arg-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N HNWQUBBOBKSFQV-AVGNSLFASA-N 0.000 description 1
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 1
- VUTHNLMCXKLLFI-LAEOZQHASA-N Val-Asp-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VUTHNLMCXKLLFI-LAEOZQHASA-N 0.000 description 1
- SDUBQHUJJWQTEU-XUXIUFHCSA-N Val-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C(C)C)N SDUBQHUJJWQTEU-XUXIUFHCSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- ZZGPVSZDZQRJQY-ULQDDVLXSA-N Val-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(O)=O ZZGPVSZDZQRJQY-ULQDDVLXSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- PQSNETRGCRUOGP-KKHAAJSZSA-N Val-Thr-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O PQSNETRGCRUOGP-KKHAAJSZSA-N 0.000 description 1
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 1
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000001464 adherent effect Effects 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 230000000735 allogeneic effect Effects 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 238000010370 cell cloning Methods 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 108700010039 chimeric receptor Proteins 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 150000001875 compounds Chemical group 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000011181 container closure integrity test Methods 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000004720 fertilization Effects 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 238000012224 gene deletion Methods 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010037850 glycylvaline Proteins 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 210000003917 human chromosome Anatomy 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 208000025113 myeloid leukemia Diseases 0.000 description 1
- 230000037125 natural defense Effects 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000003672 processing method Methods 0.000 description 1
- 108010020432 prolyl-prolylisoleucine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 229960000856 protein c Drugs 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 108010045647 puromycin N-acetyltransferase Proteins 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 108010045269 tryptophyltryptophan Proteins 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Images










Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4632—T-cell receptors [TCR]; antibody T-cell receptor constructs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1037—Screening libraries presented on the surface of microorganisms, e.g. phage display, E. coli display
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/15011—Lentivirus, not HIV, e.g. FIV, SIV
- C12N2740/15041—Use of virus, viral particle or viral elements as a vector
- C12N2740/15043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Zoology (AREA)
- Cell Biology (AREA)
- Microbiology (AREA)
- Epidemiology (AREA)
- Engineering & Computer Science (AREA)
- Mycology (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Virology (AREA)
- Oncology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Crystallography & Structural Chemistry (AREA)
- Hematology (AREA)
- Developmental Biology & Embryology (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
본 발명은 신규한 T-세포 수용체(TCR), 상세하게는 이의 적어도 하나의 상보성 결정 영역(CDR); 상기 TCR을 발현하는 T-세포; 상기 TCR을 발현하는 클론; 상기 TCR을 암호화하는 벡터; 상기 TCR의 가용성 버전; 상기 TCR, 상기 세포, 상기 클론 또는 상기 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신; 암 치료를 위한 상기 TCR 또는 상기 세포 또는 상기 클론 또는 상기 벡터 또는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신의 용도; 상기 TCR, 상기 세포, 상기 클론 또는 상기 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신을 이용하는 암 치료 방법; 및 상기 TCR과 결합하는 리간드에 관한 것이다.
Description
본 발명은 신규한 T-세포 수용체(TCR), 상세하게는 이의 적어도 하나의 상보성 결정 영역(CDR); 상기 TCR을 발현하는 T-세포; 상기 TCR을 발현하는 클론; 상기 TCR을 암호화하는 벡터; 상기 TCR의 가용성 버전; 상기 TCR, 상기 세포, 상기 클론 또는 상기 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신; 암 치료를 위한 상기 TCR 또는 상기 세포 또는 상기 클론 또는 상기 벡터 또는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신의 용도; 상기 TCR, 상기 세포, 상기 클론 또는 상기 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신을 이용하는 암 치료 방법; 및 상기 TCR과 결합하는 리간드에 관한 것이다.
본 발명자들은 인식을 위해 온전한 SCNN1A 유전자를 발현하는 타겟 세포를 필요로 하는, 암 치료에 효과적인 새로운 종류의 γδ T-세포를 발견하였다. 상기 T-세포는 타겟 인식을 위하여 특정 인간 백혈구 항원(HLA; Human Leukocyte Antigen)을 요구하는 관례를 따르지 않으므로, 비통상적인 것으로 불린다. HLA 유전자좌(locus)는 17,000가지가 넘는 대립유전자를 가지고 있어 높은 다양성이 있는 것으로 오늘날 알려져 있다. 따라서, HLA를 통한 치료학적 접근은 일부 소수의 환자들에게만 효과적이다. 대조적으로, 전체 인간 집단은 SCNN1A를 발현하고, 상기 유전자는 ?? TCR 및 이와 상응하는 신규한 T-세포 클론(이하, SW.3G1)을 통한 암 세포 인식을 위해 필요하다. 상기 클론은 건강한 B세포를 인간 헤르페스 바이러스(HHV-4; Human herpesvirus 4)로도 불리는 Epstein-Barr virus (EBV)에 감염시켜 제작한 림프아구성 세포주(LCL; Lymphoblastoid Cell Line)를 인식할 수 있는 γδ T-세포 스크리닝을 하는 동안 발견되었다. 이롭게도, SW.3G1 γδ T-세포 클론은 건강한 B-세포 또는 다른 건강한 세포주에는 반응하지 않는다.
추가 연구에서 볼 수 있듯이, SW.3G1 γδ T-세포 클론이, 전부는 아닐지라도, 대부분의 암 세포를 인식할 수 있음을 확인하였다. 상기 SCNN1A 유전자는 이러한 인식에 필요하며, SW.3G1 TCR에 결합하는 바인딩 리간드이다.
알려진 바와 같이, 도 2에서 볼 수 있듯이, TCR은 일반적으로 불변의 CD3 결합 분자와 결합하여 완전한 기능의 TCR 형태를 이루는 매우 가변적인 감마 및 델타 사슬로 이루어지는 이황화-결합 막-고정 이종이량체 단백질이다. 이 수용체를 발현하는 T-세포는 γ:δ (또는 γδ) T-세포라 불린다.
상기 g 및 d 사슬은 불변 (c) 영역 및 가변 (v) 영역을 포함하는 세포외 도메인으로 구성된다. 불변의 영역은 세포막에 근접하고, 막 관통 영역 및 짧은 세포질 꼬리가 뒤이어 따라오며, 가변 영역은 리간드에 결합한다. 대부분의 γδ T-세포에 대한 상기 리간드는 알려져 있지 않다.
상기 TCR γ-사슬 및 δ 사슬의 가변 도메인 모두 각각 상보적 결정 영역 (CDR)이라 불리는 3개의 가변 영역을 갖는다. 일반적으로, 항원-결합 부위는 TCR γ-사슬 및 δ-사슬의 CDR 루프에 의해 형성된다. CDR1γ 및 CDR2γ는 개별 Vγ 유전자에 의해 암호화 되는 반면, CDR1δ 및 CDR2δ는 개별 Vδ 유전자에 의해 암호화된다. 상기 TCR γ-사슬의 CDR3은 V영역의 결합 및 결합 영역 주위의 뉴클레오티드 삽입 또는 제거의 가능성으로 인해 초가변적이다. 상기 TCR δ-사슬 CDR3은 VDJ 재조합이 발생한 후 다양성 (D) 유전자를 포함할 수 있으므로 더 많은 변이 능력을 갖는다.
2015년에는 약 9천5십만명이 암에 걸렸다. 한 해에 약 1천4백십만건의 새로운 사례가 발생한다(흑색종 이외의 피부암은 포함되지 않음). 이는 8백8십만명의 인류의 사망(15.7%)을 일으킨다. 남성에서 가장 흔한 유형의 암은 폐암, 전립선암, 결장암, 및 위암이다. 여성에게서 가장 흔한 암의 유형은 유방암, 결장암, 폐암, 및 자궁 경부암이다. 흑색종을 제외한 피부암을 매년 새로운 암 발생 사례에 포함할 경우, 이는 약 40%의 사례를 차지할 것이다. 어린아이의 경우, 비호즈킨성림프종(non-Hodgkin lymphoma)이 더 많이 일어나는 아프리카를 제외하고 급성 림프구성 백혈병(acute lymphoblastic leukaemia) 및 뇌종양이 가장 흔하다. 2012년에는 15세 미만의 어린이 약 165,000명이 암 진단을 받았다. 암의 위험은 나이가 들어감에 따라 크게 증가하며 많은 암이 선진국에서 더 흔하게 일어난다. 많은 사람들이 더 오래 살수록 또한 개발도상국에서 라이프스타일(lifestyle)의 변화가 일어날수록 비율이 증가한다. 암의 재정 비용은 2010년 기준으로 연간 1.16조 달러로 추산되었다. 이 질병을 치료하고 근절하는 더 낫고 더 안전한 방법을 제공할 필요성이 있다. 신체의 자연 방어 시스템을 사용하여 비정상적 조직을 죽이는 면역 요법은 화학적 개입보다 안전하지만, 효과적이기 위해서는, 반드시 암 특이적이어야 한다. 게다가, 모든 유형의 암에 대하여 효과적인 면역 요법을 발견하는 것은 많은 유형의 암으로부터 고통받는 개체에게 이로울 뿐만 아니라(즉, 범-인구적 적용을 할 수 있음), 하나 이상의 암 유형으로부터 고통받는 개체에게도 이로울 것이다. 또한, 주요조직 적합유전자 복합체(Major Histocompatibility Complex; MHC)를 제한하지 않는 면역 요법의 발견은 MHC 조직 유형과 관계 없이 어느 개체에나 투여할 수 있음을 의미하기에 매우 이로울 것이다.
본 발명에서 확인한 T-세포는 어느 유형의 암이든 효과적이고, MHC 제한적이 아니며, 인식에 필요한 SCNN1A 유전자 산물의 흔한 발현으로 인해 범-인구적 적용이 가능하기에, 상기의 이로운 특징을 갖는다.
본 발명의 하나의 양태에 따르면, 적어도 하나의 CATWDRRDYKKLF (서열번호 1) 및/또는 CALGVLPTVTGGGLIF (서열번호 2) 를 포함하거나 이로 이루어진 상보성 결정 영역(complementarity-determining region; CDR)을 특징으로 하는, 종양 특이적 T-세포 수용체(TCR), 또는 이의 단편을 제공한다.
본 발명의 바람직한 실시양태에서, 상기 CDR은 CATWDRRDYKKLF (서열번호 1) 및/또는 CALGVLPTVTGGGLIF (서열번호 2) 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 88%의 동일성을 공유하는 CDR을 포함하거나 이로 이루어진 것이다.
본 발명에 기재된 CDR은 상기 TCR의 CDR3을 나타내며, 처리된 항원 또는 리간드를 인식하는 역할을 하는 주요 CDR이다. 다른 CDR(CDR1감마, CDR2감마, CDR1델타 및 CDR2델타)은 생식세포계열(germline)에 의해 암호화 된다. 따라서, 본 발명은 또한 하나 또는 그 이상의 이러한 다른 CDR 즉 CDR1감마, CDR2감마, CDR1델타 및/또는 CDR2델타와 하나 또는 그 이상의 CDR3 서열의 조합을 또한 포함하는 TCR에 관한 것이다.
따라서, 바람직한 실시양태에서, 상기 TCR은 하기 상보적 결정 영역의 임의의 조합을 포함하는 하나 또는 그 이상을 포함하거나 이로 이루어지는 것이다:
VTNTFY (CDR1 γ) (서열번호 3)
YDVSTARD (CDR2 γ) (서열번호 4)
TSWWSYY (CDR1 δ) (서열번호 5)
QGS (CDR2 δ) (서열번호 6)
본 발명에서 참조되는 종양특이적 TCR은 SCNN1A 유전자 발현에 있어서, 종양 세포 또는 종양 세포 리간드를 특이적으로 인식하고, 이에 의해 활성화되지만 비-종양 세포 또는 비-종양 세포 리간드에는 활성화되지 않는 TCR인 것이다.
본 발명의 바람직한 실시양태에서, 상기 TCR은 γ 사슬 및 δ 사슬을 갖는 γδ TCR이고, 상기 γ 사슬의 상기 CDR은 CDR: CATWDRRDYKKLF (서열번호 1) 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 이와 88%의 동일성을 공유하는 CDR을 포함하거나 이로 이루어진 것이며, 상기 δ 사슬의 상기 CDR은 CDR: CALGVLPTVTGGGLIF (서열번호 2) 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 이와 88%의 동일성을 공유하는 CDR을 포함하거나 이로 이루어진 것이다. 그에 따라, 상기 TCR은 상기 CDR을 하나 또는 둘 모두를 포함할 수 있으며, 바람직한 실시양태에서 상기 CDR을 둘 모두를 포함할 수 있다.
본 발명의 다른 바람직한 실시양태에서, 상기 TCR의 CDR은 CALWEVDYKKLF (서열번호 9)인 감마 사슬 서열; 및/또는 CALGEPVLFAVRGLIF (서열번호 10) 및/또는 CACDLLGDRYTDKLIF (서열번호 11)인 델타 사슬 서열 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 이와 88%의 동일성을 공유하는 CDR을 추가적으로 또는 대안적으로 포함하거나 이로 이루어진 것이다.
본 발명의 또 다른 바람직한 실시양태에서, 상기 TCR은 MHC-제한적이지 않고, 오히려 SCNN1A 유전자 발현 상황에서 종양 특이적 리간드와 결합하는 비통상적인 것이다. 상기 T-세포 및 이들의 TCR이 MHC-제한적이지 않다는 것은, 이들이 범-인구적(pan-population) 치료의 가능성 및 매우 중요한 새로운 암 치료법을 제시했다는 것을 의미한다.
본 발명의 다른 바람직한 실시양태에서, 상기 TCR γ 사슬은SSNLEGRTKSVTRQTGSSAEITCDLT VTNTFY IHWYLHQEGKAPQRLLY YDVSTARD VLESGLSPGKYYTHTPRRWSWILRLQNLIENDSGVYY CATWDRRDYKKLF GSGTTLVVTDKQLDADVSPKPTIFLPSIAETKLQKAGTYLCLLEKFFPDVIKIHWQEKKSNTILGSQEGNTMKTNDTYMKFSWLTVPEKSLDKEHRCIVRHENNKNGVDQEIIFPPIKT (서열번호 7) 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 이와 88%의 동일성을 갖는 염기서열을 포함하거나 이로 이루어진 것이다.
본 발명의 다른 바람직한 실시양태에서, 상기 TCR δ 사슬은AQKVTQAQSSVSMPVRKAVTLNCLYE TSWWSYY IFWYKQLPSKEMIFLIR QGS DEQNAKSGRYSVNFKKAAKSVALTISALQLEDSAKYF CALGVLPTVTGGGLIF GKGTRVTVEPNSQPHTKPSVFVMKNGTNVACLVKEFYPKDIRINLVSSKKITEFDPAIVISPSGKYNAVKLGKYEDSNSVTCSVQHDNKTVHSTDFEVKTDST (서열번호 8) 또는 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%와 같이, 적어도 88%의 동일성을 갖는 염기서열을 포함하거나 이로 이루어진 것이다.
(상기 문단에서, 볼드 및 밑줄 표시된 부분은 순서대로 CDR들 즉 1, 2, 및 3을 나타낸다.)
본 발명의 또 다른 바람직한 실시양태에서, 상기 TCR은, 상기 TCR γ 사슬 및 상기 TCR δ 사슬을 포함하는 것이다.
본 발명의 또 다른 바람직한 실시양태에서, 상기 TCR은 가용성 TCR, 또는 sTCR이며, 막 통과(transmembrane)가 없는 것이고, 또한, 이상적으로는 세포 내 도메인인 것이다.
본 발명의 다른 바람직한 실시양태에서, 상기 TCR은 본원에 기재된 기능을 가지는 키메릭(chimeric) 수용체의 일부인 것이다. 이상적으로는, 상기 TCR은 αβ TCR 불변의 도메인과 융합된 것이다.
대안적으로, 이의 단량체 부분과 같은 상기 TCR의 단편을 제공하며, 이상적으로 TCR의 단일 사슬 형태이다.
본 발명의 다른 하나의 양태에 따르면, 본 발명의 상기 TCR을 발현하는 T-세포를 제공하며, 이상적으로, 가용성이거나 또는 막 통과 영역(transmembrane region) 및 세포 내 영역을 갖는 형태의 세포막 호환성 형태인 것이다.
본 발명의 또 다른 하나의 양태에 따르면, 본 발명의 상기 TCR을 발현하는 T-세포 클론을 제공하며, 이상적으로, 가용성이거나 또는 막 통과 영역(transmembrane region) 및 세포 내 영역을 갖는 형태의 세포막 호환성 형태인 것이다. 바람직하게, 상기 클론은 본원에 기재된 SW.3G1 클론인 것이다.
본 발명의 또 다른 하나의 양태에 따르면, 본 발명의 상기 TCR을 암호화 하는 벡터를 제공한다.
본 발명의 또 다른 하나의 양태에 따르면, 본 발명의 상기 TCR 또는 세포 또는 클론 또는 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신을 제공한다.
본 발명의 바람직한 실시양태에서, 상기 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신은 직장암, 폐암, 신장암, 전립선암, 방광암, 자궁 경부암, 흑색종 (피부), 뼈암, 유방암, 혈액암, 뇌암, 췌장암, 고환암, 난소암, 두경부암, 간암, 방광암, 갑상선암, 및 자궁암 중 임의의 암을 치료하는데 사용된다.
본 발명의 또 다른 하나의 양태는, 암 치료에 사용하기 위한, 본원에 기재된 상기 TCR 또는 세포 또는 클론 또는 벡터를 제공한다.
본 발명의 또 다른 하나의 실시 양태는, 상기 TCR 또는 세포 또는 클론 또는 벡터를, 개체를 치료하기 위하여 투여하는 단계를 포함하는, 암 치료 방법을 제공한다.
이상적으로, 상기 암은 모든 암일 수 있으나 특히 직장암, 폐암, 신장암, 전립선암, 방광암, 자궁 경부암, 흑색종 (피부), 뼈암, 유방암, 혈액암, 뇌암, 췌장암, 고환암, 난소암, 두경부암, 간암, 방광암, 갑상선암, 및 자궁암 중 임의의 암인 것이다.
본 발명의 바람직한 방법으로서, 상기 TCR, 세포, 클론 또는 벡터는 이제 제한되는 것은 아니나, 이중특이성(bispecific)과 같은 항암제와 조합하여 투여되는 것일 수 있다.
본원에서 참조되는 이중특이성(bispecific)은, 동시에 두 종류의 다른 항원과 결합할 수 있는 인공 단백질인 이중특이적 단일클론 항체(BsMAb, BsAb)에 대해 참조된다.
또한 대안적으로, 상기 TCR은 이중특이성의 일부를 형성할 수 있고, 여기에서 이중특이성은, 암세포의 리간드 및 면역 세포 활성 요소 또는 살해 T-세포(Killer T-cell)와 같은 면역 세포와 결합하거나 활성화하는 리간드와 결합하기 위한 목적으로, 상기 TCR을 포함한다.
본 발명의 또 다른 하나의 양태에 따르면, 상기 TCR 또는 세포 또는 클론 또는 벡터의 암 치료를 위한 의약의 제조를 위한 용도를 제공한다.
본 발명의 또 다른 하나의 실시 양태에 따르면,
a) 상기 TCR, 또는 세포 또는 클론 또는 벡터 또는 면역학 제제 또는 이중특이성(bispecific) 또는 백신
b) 추가의 암 치료용 제제; 의 조합을 포함하는 암 치료를 위한 조합 치료제를 제공한다.
본 발명의 또 다른 하나의 양태에 따르면, 도 9에 표시된 적어도 하나의 SCNNA1 유전자 산물 동형체(isoform) 및 이의 특정한 세포외 도메인과 결합하는 TCR 또는 폴리펩타이드 또는 이중특이성(bispecific) 또는 항체, 또는 상기 항체의 단편을 제공한다.
본 발명의 바람직한 실시양태에서, 상기 폴리펩타이드, 항체 또는 단편은 상기SCNNA1 유전자 산물의 활성을 억제하는 것이며, 이상적으로, 상기 항체의 경우, 대부분 단일클론인 것이다.
본 발명의 하기 청구항 및 상기의 설명에서, 표현 언어 또는 필요한 함축 때문에 달리 요구되는 상황을 제외하고, 단어 “포함하는(comprises)”, 또는 “포함하는(comprises)” 또는 “포함하여(comprising)”와 같은 변형은 포괄적 의미로, 즉, 서술된 특징의 명시를 명확히 하기 위하여, 하지만 본 발명의 다양한 실시양태에서의 추가적 특징의 명시 또는 추가를 배제하지 않기 위하여 사용된다.
본 명세서에서 인용된 각각의 모든 특허 또는 특허 출원을 포함하는 모든 참조는 본 명세서에 참조로 포함한다. 임의의 참조가 종래의 기술로 여겨지는 것은 용인되지 않는다. 또한, 당 업계에서 흔히 알려진 일반 상식의 일부가 종래기술로 여겨지는 것도 용인되지 않는다.
본 발명의 각 양태의 바람직한 특징은 임의의 다른 실시 양태와 관련하여 설명될 수 있다.
본 발명의 다른 특징은 하기 실시 예로부터 분명해질 것이다. 일반적으로, 상기 발명은 본 명세서에서 밝힌 특징들(첨부된 청구항 및 도면을 포함)의 임의의 신규한 것, 또는 임의의 신규한 조합으로 확장된다. 따라서, 특정 실시 양태, 구체적인 예 또는 발명의 예와 설명한 특징, 정수(integer), 특성, 화합물 또는 화학적 모이어티(moietie)의 결합은, 양립할 수 없는 것이 아닌 한, 상기에 서술된 또 다른 실시 양태, 구체적인 예 또는 실시 예에 적용할 수 있는 것으로 이해되어야 한다.
또한, 달리 언급되지 않는 한, 본 명세서에 개시된 임의의 특징은 동일하거나 유사한 목적을 제공하는 대안적 특징으로 대체될 수 있다.
본 명세서의 상세한 설명 및 청구항에 있어서, 단수의 표현은 문맥상 달리 요구되지 않는 한 복수를 포함한다. 특히, 부정 관사가 사용되는 경우, 본 명세서는 문맥상 달리 요구되지 않는 한, 복수 뿐만 아니라 단수로 고려하는 것도 이해되어야 한다.
본 발명의 실시양태는 실시 예 및 하기 참조에 의해 설명될 것이다.
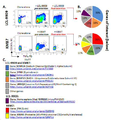
도 1은 자가 및 비-자가 림프아구성 세포주(lymphoblastoid cell lines; LCL)에 반응하는 γδ T-세포주(T-cell line)가 어떻게 클로노타입(clonotyped)되고, 각각 CDR3 CATWDRRDYKKLF (서열번호 1) 및 CALGVLPTVTGGGLIF (서열번호 2)을 갖는 TRGV3 및 TRDV1 유전자를 포함하는 TCR을 어떻게 발현하는지 나타낸다. 상기 TCR을 발현하는 클론은 제한된 희석을 통해 성장시켰으며, SW.3G1이라고 명명하였다. (A) 건강한 공여자 9909로부터 얻은 정제된 γδ T-세포에 세 명의 공여자(0439, pt146, 및 Hom-2)로부터 얻은 LCL의 풀(pool)로 초회항원자극)(0일차) 및 재자극 하였다(14일차). 28일 째, T-세포주는 초회항원자극을 위해 사용한 LCL 및 자가 LCL-9909와 함께 4시간 배양하였으며, TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 활성화 평가를 하였다. 활성화된 세포는 유세포분석기를 통해 분류하였고 T-세포 수용체(TCR)는 차세대 염기서열 분석에 의해 분석하였다. 원형 도표는 분류된 세포에서 보여지는 TCR 사슬 및 CDR3s의 비율을 나타낸다. 유세포 분석 플롯(plot)에 대한 활성화 세포의 백분율은 각 분포도 위에 표시된다. T-세포 클론 SW.3G1은 도 2에 표시된 전체 TCR 서열과 하이라이트 된 TCR 사슬을 발현하는 세포주로부터 얻었다. (B) 클론 SW.3G1은 항체와 함께 표현형분석하였고(phenotyped) TCRδ1사슬을 발현하는 것으로 확인되었다. SW.3G1은 통상적인 펩타이드-HLA 항원의 인식과 관련된 αβTCR 또는 CD8 또는 CD4 당단백질을 발현하지 않았다.
도 2는 클론 SW.3G1의 γ 및 δ TCR 사슬의 T-세포 수용체 서열을 나타낸다. 상기 mRNA 구조 (위)는 각 CDR1 및 CDR2 사슬이 생식세포계열(germline) 내에 암호화되어 있음을 보여준다. CDR3은 T-세포 수용체(TCR)-γ 사슬의 V-J 결합(join) 및 TCR-δ 사슬 내 V-D-J 결합에서의 접합 다양성의 산물이다. CDR3는 따라서 초가변적이다. CDR 루프를 위해 채택한 색상 코드(colour code)는 도면 전체에 걸쳐 유지된다. 회색으로 칠해진 영역은 TCR의 불변 및 가변 도메인을 나타낸다(초가변적 CDR 루프는 포함되지 않았다). 오른쪽 패널은 예상되는 단백질 접힘을 나타낸다. TCR은 분자의 막 말단(distal end)에 CDR 루프를 위치시키는 유사한 3차 구조를 채택한다. 6개의 CDR 루프는 함께 항원 결합 부위를 형성한다.
도 3은 SW.3G1이 다양한 조직 기원의 건강한 세포가 아닌, 자가 또는 비-자가 LCL을 인식하고 사멸할 수 있음을 나타낸다. (A) SW.3G1과 LCL을 4시간 동안 공동배양하고, TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 활성화 평가를 하였다. (B) 상기 (A)와 동일한 LCL을 사용하여 크로뮴(chromium) 방출 세포독성 검사를 6.5시간 수행하고, (C) 공여자 9909로부터 직접 ex-vivo를 통해 자성으로 정제한 건강한 자가 B-세포는 상기 A와 같이 활성화 평가에 사용되었으며, 활성화를 위한 양성대조군으로 LCL-9909를 함께 사용하였다. (D) 활성화 측정은 A와 같이 LCL-9909를 사용하였으며, 건강한 세포주, CIL-1(non-pigmented ciliary epithelium; 염색되지 않은 섬모 상피세포) 및 Hep2(hepatocyte; 간세포)를 사용하여 수행하였다. 게이팅(gated) 된 세포의 백분율은 표기되어 있다.
도 4는 SW.3G1이 공통 HLA를 공유하지 않는 다수의 공여자로부터 얻은 LCL 및 서로 다른 조직으로부터 얻은 암세포주의 어레이(array)들의 용해로 매개되었음을 나타낸다. SW.3G1은 6.5시간 동안 크로뮴 방출 세포독성 검사에 사용되었다. (A) 24명의 공여자(x축에 이름 표기)로부터 얻은 LCL 패널(panel). 붉은 바는 SW.3G1이 클로닝 된, 공여자 9909로부터 얻은 T-세포주를 생성하는데 사용한 LCL이다. T-세포 대 LCL 비율은 1:1. (B) T-세포 대 암세포 비율이 10:1일 때, 서로 다른 조직 기원의(key) 암세포주의 패널의 SW.3G1-매개 사멸.
도 5는 SW.3G1이 알려진 메커니즘에 의해 타겟 세포를 인식하지 않는 것을 나타낸다. (A) γδ SW.3G1 클론은 HMB-PP, LCL-9909 및 식물성혈구응집소(phytohaemaglutinin; PHA)와 함께 4시간 동안 배양하였다. 또한, T-세포는 홀로 배양하였다. T-세포 활성화는 TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 수행하였으며, 활성화된 세포의 백분율은 게이팅된 세포 위에 표시하였다. (B) (A)와 동일한 활성화 평가를 사용하여, SW.3G1은 x-축에 표기된 단백질들과 결합하는 항체(Ab)로 사전-라벨링된 LCL과 함께 배양하였다. 또한, SW.3G1은 Ab가 없는 LCL과 함께 배양하기도 하였다(no Ab 대조군). 반응성의 백분율은 그래픽으로 표시된다(y축). MICA/B (MHC class-I 관련 사슬 A/B) 및 EPCR(Endothelial protein C receptor; 내피 단백질 C 수용체). 항-MHC class-I 및 II 항체도 포함되어 있다.
도 6은 SW.3G1에 의한 타겟 세포의 인식에 관여하는 후보 유전자/단백질을 확인하는데 사용하는 전체 게놈 CRISPR/Cas9 접근법을 나타낸다.
도 7은 SW.3G1에 의한 타겟 세포 인식을 위한 다수의 후보 유전자를 확인하는 전체 게놈 CRISPR/Cas9 접근법의 결과를 나타낸다. (A) 자가 LCL-9909 및 암 세포주 KBM7에 전체 게놈 CRISPR/Cas9 라이브러리를 형질도입 하였다. 상기 라이브러리는 용해에 저항성을 갖는 타겟 세포주를 생성하기 위하여 SW.3G1 T-세포 클론을 사용하는 몇몇 선별을 통해 삽입되었다. 살아남은 타겟 세포(선별-후)는 선별-전 세포주와 함께 SW.3G1을 첨가하여 활성화 평가를 실시하였다. 활성화 평가는 TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 수행되었다. (B) 선별-후 라이브러리 서열분석은 (C)에 표시된 유전자에 반응하는 농축된 가이드 RNA를 밝혀냈다. (C) LCL-9909 및 KBM7 라이브러리 모두에서 나타나거나, 또는 오직 LCL-9909 또는 KBM7에서만 나타나는 후보 유전자. 유전자 및 (단백질)의 명칭은 추가 정보를 위한 웹사이트 링크와 함께 표기하였다.
도 8은 전체 게놈 CRISPR/Cas9 라이브러리 접근법에 의해 밝혀진 후보 유전자/단백질 SCNN1A에 대한 정보를 나타낸다.
도 9는 5개의 발현된 스플라이스 변형과 함께 얼라인(aligned)된 SCNN1A의 표준 단백질(canonical protein) 서열을 나타낸다. 동형체 1은 표준 서열(동형체 1 UniProt P37088-1)이다. 검은색으로 하이라이트 된 아미노산: 본 발명에서 다클론 Ab를 생성하기 위해 사용한 영역. 붉은색으로 하이라이트 된 아미노산: 표시된 다른 아미노산 잔기로 인한 단백질 변형 영역. 상기 단백질 변형 및 표시되지 않은 아미노산 잔기는 http://www.uniprot.org/uniprot/P37088 에서 볼 수 있다. 파란색으로 하이라이트 된 아미노산: 스플라이스 동형체 사이의 달라지는 아미노산 차이.
도 10은 SW.3G1에 의한 타겟 세포의 인식에 있어서 SCNN1A의 역할을 입증하기 위한 실험의 결과를 나타낸다. (A) 전체 게놈 GeCKO 라이브러리(number 1)의 가이드 RNA(gRNA) 영역 및 본 발명에서 디자인한 다른 검증 gRNA SCNN1A 염기서열(number 2)이 포함된 SCNN1A 유전자 및 단백질의 모식도이다. 그림은 Chen 2014에서 인용하였다. (B) LCL.174 야생형, GeCKO gRNA-1 및 gRNA-2 녹아웃 LCL.174 세포와 함께 SW.3G1을 사용한 장기간 사멸 평가. (C) SCNN1A를 위해 gRNA-2를 받은 유방암 세포주 MDA-MB-231의 웨스턴블롯 평가. 76 kDa SCNN1A 단백질을 가리키는 빨간 화살표와 함께, 비교를 위해 사용한 야생형 세포. (D) (C)의 MDA-MB-231 세포 및 흑색종 MM909.24, 야생형 및 SCNN1A 녹아웃 (KO) 세포주를 SW.3G1과 함께 장기간 사멸 평가에 사용하였다. 암 세포는 세포주로 사용하였으며, gRNA를 발현하며, 차후의 세포 클로닝이 없게 하기 위한 퓨로마이신 처리에 의해 선별하였다.
도 11은 3명의 건강한 공여자로의 αβ T-세포에 타겟 세포 반응성을 부여하는 SW.3G1의 TCR의 전달을 나타낸다. (A) 3명의 공여자로부터 얻어 정제된 CD8+ T-세포는 수여자 T-세포 TCRβ 사슬 음성 (퓨로마이신에 의해 선별) (Legut et al 2017)을 만들기 위하여 SW.3G1 T-세포 수용체 사슬 (마커 및 rat(r)CD2를 통한 정제) 및 gRNA가 함께 형질도입 되었다. 세포의 순도는 rCD2 항체 (Ab) 및 항-γδ TCR Ab를 사용하여 확인하였다. (B) 한 명의 공여자로부터 얻은 세포는 장기간 사멸 평가를 통해 평가하였다(아래 그래프). LCL.174 세포주는 야생형, SCNN1A 녹아웃(gRNA-1 및 -2를 사용) 및 SCNN1A 녹-인(knock-in)(코돈 최적화된 SCNN1A 이식 유전자를 받은 KO 세포) 세포를 사용하였다.
도 2는 클론 SW.3G1의 γ 및 δ TCR 사슬의 T-세포 수용체 서열을 나타낸다. 상기 mRNA 구조 (위)는 각 CDR1 및 CDR2 사슬이 생식세포계열(germline) 내에 암호화되어 있음을 보여준다. CDR3은 T-세포 수용체(TCR)-γ 사슬의 V-J 결합(join) 및 TCR-δ 사슬 내 V-D-J 결합에서의 접합 다양성의 산물이다. CDR3는 따라서 초가변적이다. CDR 루프를 위해 채택한 색상 코드(colour code)는 도면 전체에 걸쳐 유지된다. 회색으로 칠해진 영역은 TCR의 불변 및 가변 도메인을 나타낸다(초가변적 CDR 루프는 포함되지 않았다). 오른쪽 패널은 예상되는 단백질 접힘을 나타낸다. TCR은 분자의 막 말단(distal end)에 CDR 루프를 위치시키는 유사한 3차 구조를 채택한다. 6개의 CDR 루프는 함께 항원 결합 부위를 형성한다.
도 3은 SW.3G1이 다양한 조직 기원의 건강한 세포가 아닌, 자가 또는 비-자가 LCL을 인식하고 사멸할 수 있음을 나타낸다. (A) SW.3G1과 LCL을 4시간 동안 공동배양하고, TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 활성화 평가를 하였다. (B) 상기 (A)와 동일한 LCL을 사용하여 크로뮴(chromium) 방출 세포독성 검사를 6.5시간 수행하고, (C) 공여자 9909로부터 직접 ex-vivo를 통해 자성으로 정제한 건강한 자가 B-세포는 상기 A와 같이 활성화 평가에 사용되었으며, 활성화를 위한 양성대조군으로 LCL-9909를 함께 사용하였다. (D) 활성화 측정은 A와 같이 LCL-9909를 사용하였으며, 건강한 세포주, CIL-1(non-pigmented ciliary epithelium; 염색되지 않은 섬모 상피세포) 및 Hep2(hepatocyte; 간세포)를 사용하여 수행하였다. 게이팅(gated) 된 세포의 백분율은 표기되어 있다.
도 4는 SW.3G1이 공통 HLA를 공유하지 않는 다수의 공여자로부터 얻은 LCL 및 서로 다른 조직으로부터 얻은 암세포주의 어레이(array)들의 용해로 매개되었음을 나타낸다. SW.3G1은 6.5시간 동안 크로뮴 방출 세포독성 검사에 사용되었다. (A) 24명의 공여자(x축에 이름 표기)로부터 얻은 LCL 패널(panel). 붉은 바는 SW.3G1이 클로닝 된, 공여자 9909로부터 얻은 T-세포주를 생성하는데 사용한 LCL이다. T-세포 대 LCL 비율은 1:1. (B) T-세포 대 암세포 비율이 10:1일 때, 서로 다른 조직 기원의(key) 암세포주의 패널의 SW.3G1-매개 사멸.
도 5는 SW.3G1이 알려진 메커니즘에 의해 타겟 세포를 인식하지 않는 것을 나타낸다. (A) γδ SW.3G1 클론은 HMB-PP, LCL-9909 및 식물성혈구응집소(phytohaemaglutinin; PHA)와 함께 4시간 동안 배양하였다. 또한, T-세포는 홀로 배양하였다. T-세포 활성화는 TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 수행하였으며, 활성화된 세포의 백분율은 게이팅된 세포 위에 표시하였다. (B) (A)와 동일한 활성화 평가를 사용하여, SW.3G1은 x-축에 표기된 단백질들과 결합하는 항체(Ab)로 사전-라벨링된 LCL과 함께 배양하였다. 또한, SW.3G1은 Ab가 없는 LCL과 함께 배양하기도 하였다(no Ab 대조군). 반응성의 백분율은 그래픽으로 표시된다(y축). MICA/B (MHC class-I 관련 사슬 A/B) 및 EPCR(Endothelial protein C receptor; 내피 단백질 C 수용체). 항-MHC class-I 및 II 항체도 포함되어 있다.
도 6은 SW.3G1에 의한 타겟 세포의 인식에 관여하는 후보 유전자/단백질을 확인하는데 사용하는 전체 게놈 CRISPR/Cas9 접근법을 나타낸다.
도 7은 SW.3G1에 의한 타겟 세포 인식을 위한 다수의 후보 유전자를 확인하는 전체 게놈 CRISPR/Cas9 접근법의 결과를 나타낸다. (A) 자가 LCL-9909 및 암 세포주 KBM7에 전체 게놈 CRISPR/Cas9 라이브러리를 형질도입 하였다. 상기 라이브러리는 용해에 저항성을 갖는 타겟 세포주를 생성하기 위하여 SW.3G1 T-세포 클론을 사용하는 몇몇 선별을 통해 삽입되었다. 살아남은 타겟 세포(선별-후)는 선별-전 세포주와 함께 SW.3G1을 첨가하여 활성화 평가를 실시하였다. 활성화 평가는 TAPI-0, 항-CD107a 및 항-TNFα 항체를 첨가하여 수행되었다. (B) 선별-후 라이브러리 서열분석은 (C)에 표시된 유전자에 반응하는 농축된 가이드 RNA를 밝혀냈다. (C) LCL-9909 및 KBM7 라이브러리 모두에서 나타나거나, 또는 오직 LCL-9909 또는 KBM7에서만 나타나는 후보 유전자. 유전자 및 (단백질)의 명칭은 추가 정보를 위한 웹사이트 링크와 함께 표기하였다.
도 8은 전체 게놈 CRISPR/Cas9 라이브러리 접근법에 의해 밝혀진 후보 유전자/단백질 SCNN1A에 대한 정보를 나타낸다.
도 9는 5개의 발현된 스플라이스 변형과 함께 얼라인(aligned)된 SCNN1A의 표준 단백질(canonical protein) 서열을 나타낸다. 동형체 1은 표준 서열(동형체 1 UniProt P37088-1)이다. 검은색으로 하이라이트 된 아미노산: 본 발명에서 다클론 Ab를 생성하기 위해 사용한 영역. 붉은색으로 하이라이트 된 아미노산: 표시된 다른 아미노산 잔기로 인한 단백질 변형 영역. 상기 단백질 변형 및 표시되지 않은 아미노산 잔기는 http://www.uniprot.org/uniprot/P37088 에서 볼 수 있다. 파란색으로 하이라이트 된 아미노산: 스플라이스 동형체 사이의 달라지는 아미노산 차이.
도 10은 SW.3G1에 의한 타겟 세포의 인식에 있어서 SCNN1A의 역할을 입증하기 위한 실험의 결과를 나타낸다. (A) 전체 게놈 GeCKO 라이브러리(number 1)의 가이드 RNA(gRNA) 영역 및 본 발명에서 디자인한 다른 검증 gRNA SCNN1A 염기서열(number 2)이 포함된 SCNN1A 유전자 및 단백질의 모식도이다. 그림은 Chen 2014에서 인용하였다. (B) LCL.174 야생형, GeCKO gRNA-1 및 gRNA-2 녹아웃 LCL.174 세포와 함께 SW.3G1을 사용한 장기간 사멸 평가. (C) SCNN1A를 위해 gRNA-2를 받은 유방암 세포주 MDA-MB-231의 웨스턴블롯 평가. 76 kDa SCNN1A 단백질을 가리키는 빨간 화살표와 함께, 비교를 위해 사용한 야생형 세포. (D) (C)의 MDA-MB-231 세포 및 흑색종 MM909.24, 야생형 및 SCNN1A 녹아웃 (KO) 세포주를 SW.3G1과 함께 장기간 사멸 평가에 사용하였다. 암 세포는 세포주로 사용하였으며, gRNA를 발현하며, 차후의 세포 클로닝이 없게 하기 위한 퓨로마이신 처리에 의해 선별하였다.
도 11은 3명의 건강한 공여자로의 αβ T-세포에 타겟 세포 반응성을 부여하는 SW.3G1의 TCR의 전달을 나타낸다. (A) 3명의 공여자로부터 얻어 정제된 CD8+ T-세포는 수여자 T-세포 TCRβ 사슬 음성 (퓨로마이신에 의해 선별) (Legut et al 2017)을 만들기 위하여 SW.3G1 T-세포 수용체 사슬 (마커 및 rat(r)CD2를 통한 정제) 및 gRNA가 함께 형질도입 되었다. 세포의 순도는 rCD2 항체 (Ab) 및 항-γδ TCR Ab를 사용하여 확인하였다. (B) 한 명의 공여자로부터 얻은 세포는 장기간 사멸 평가를 통해 평가하였다(아래 그래프). LCL.174 세포주는 야생형, SCNN1A 녹아웃(gRNA-1 및 -2를 사용) 및 SCNN1A 녹-인(knock-in)(코돈 최적화된 SCNN1A 이식 유전자를 받은 KO 세포) 세포를 사용하였다.
방법 및 재료
T-세포주 생성 및 클론 준비(clonotyping)
말초 혈액 단핵세포(Peripheral blood mononuclear cells; PBMC)는 표준 밀도 구배 분리(standard density gradient separation)를 통해 건강한 공여자(코드 9909)의 혈액으로부터 얻어 정제되었다. 말초혈액에 많이 분포되어있는 γδ T-세포는 Vγ9Vδ2 TCR을 발현하며, 전형적으로 박테리아로부터 유래되는 항원에 반응한다. γδTCR+/Vδ2- T-세포를 농축하여 암 반응성 T-세포의 발견 가능성을 높이기 위하여, 자성 기반 정화 프로토콜을 수정하였다. 첫 수정은 PBMC를 항-Vδ2 항체(clone B6, BioLegend, San Diego, CA)와 결합된 PE로 염색하였다. 다음으로, γδTCR+ T-세포는 제조사의 지시를 따라 γδTCR-세포를 양성적으로 제거하여 음성적으로(negatively) 농축하였다(Miltheyi Biotec, Bergish Gladbach, Germany). 두 번째 수정은 γδTCR 정제 키트의 비드에 항-PE 마이크로비드(Miltneyi Biotec)를 더하여, δ2+ 세포와 γδTCR- 세포를 동시에 제거하는 것을 포함한다. 정제된 세포는, EBV(Epstein-Barr Virus)로 불멸화된(immortalizing) B-세포에 의한 PBMC로부터 생성된, 세 명의 공여자로부터 얻어 방사선이 조사된(3000-3100 rad) LCL과 함께 배양하였다. 모든 LCL은 R10 배지(RPMI-1640, 열-불활성화된 10% 송아지 태아 혈청, 2mM L-글루타민, 100U/mL 페니실린 및 100μg/mL 스트렙토마이신, all Life Technologies, Carlsbad, CA)에서 부유 세포 상태로 배양하였다. 14일 후, T-세포를 동일한 공여자로부터 얻은 방사선이 조사된 LCL로 재자극하였다. 28일 째, T-세포를 채취하여 LCL에 대한 반응성 평가를 수행하기 위한 활성 평가에 사용하였다. T-세포 (30,000)는 4시간동안 96 U 웰 플레이트에서 동일한 개수의 LCL과 함께 배양하였다. 평가 시작 시, 30 mM의 TNFα 처리 억제제-0(TAPI-0, Sigma Aldrich) ((Haney et al., 2011), 항-CD107a Ab (H4A2, Becton Dickinson (BD), Franklin Lakes, NJ), 및 항-TNFα Ab (cA2, Miltenyi Biotec)을 세포 생존 염색약, Vivid (Life Technologies, PBS에 1:40으로 희석한 뒤, 50μL 염색약 당 2μL) 및 항-CD3 항체 (Ab) (BW264/56, Miltenyi Biotec)로 염색한 세포와 함께 평가 배양액에 첨가하였다. 활성화 된 세포는 TCR 사슬의 서열분석(sequencing)을 위하여 BD FACS Aria를 통해 RLT Plus 버퍼 (40mM의 DTT가 보충된) (Qiagen) 내로 분리하였다. RNA는 RNEasy Micro 키트 (Qiagen, Hilden, Germany)를 이용하여 추출하였다. cDNA는 제조사의 지시를 따라 5’/3’ SMARTer 키트 (Clontech, Paris, France)를 사용하여 합성하였다. 상기 SMARTer 처리 방법은 보편적으로 고정 서열(anchor sequence)이라고 알려진 서열 옆에 배치되는 cDNA 주형을 만들기 위하여, Murine Moloney Leukaemia Virus (MMLV) 역전사효소인, 3’ 올리고-dT 프라이머 및 5’올리고뉴클레오티드(oligonucleotide)를 사용하였다. PCR은 γ 또는 δ TCR 서열의 불변 영역의 고정-특이적 정방향 프라이머 및 역방향 프라이머를 사용하였다. 최종 PCR 산물은 차세대 염기서열 분석을 위하여 겔 정제를 통해 준비하였다 (Donia et al., 2017).
클론 SW.3G1 획득 및 표현형(phenotyping) 측정
T-세포는 제한희석을 통해 T-세포주로부터 직접 클로닝 하였다(Theaker et al., 2016). 배양 4주 후, 배양 용량 50%의 각 클론을 추출하여 상기와 같이 LCL과 함께 활성화 평가를 위해 사용하였다. 활성화 평가 수행 전, T-세포 클론을 세척하고 혈청을 감소시킨 배양액에서 24시간 배양하였다. LCL에 대하여 반응성을 보인 클론은 TCR 염기서열 분석 (아래)을 위하여 충분한 숫자가 되도록 성장시켰다. 클론 SW.3G1은 표면에 발현하는 CD3(Miltenyi Biotec), CD8(BW135/80, Miltenyi Biotec), CD4(M-T466, Miltenyi Biotec), αβ TCR(BW242/412, Miltenyi Biotec) 및 TCR Vδ1 사슬(REA173, Miltenyi Biotec)에 대한 항체로 염색하였다.
SW.3G1 TCR 염기서열 분석
상기와 같이, 스탠다드 염기서열 분석을 위하여, 최종 PCR 후 정제된 PCR 산물과 T-세포주를 Zero-Blunt TOPO 내로 클로닝 한 후 반응력이 있는 E.coli (One Shot Chemically Competent E.coli) 세포에 형질전환 하였다(Life Technologies).
LCL은 인식하고 건강한 세포는 인식하지 않는 SW.3G1
LCL에 대한 SW.3G1의 반응성을 확인하기 위하여, 상기의 활성화 평가, 및 크로뮴 방출 세포독성 평가를 수행하였다. 건강한 B-세포는 공여자 9909로부터 PE 결합된 항-CD19 Ab (HIB19, Miltenyi Biotec)를 사용하고, 항-PE 마이크로비드 (Miltenyi Biotec)와의 양성적 캡쳐(positive capture)를 통해 정제하고, 즉시 평가에 사용하였다. 다른 건강한 세포주 및 이의 전매 배지인: CIL-1 (human non-pigmented ciliary epithelium) 및 Hep2 (human hepatocyte)는 ScienceII (Carlsbad, CA)로부터 얻었으며, 상기 활성화에 사용하였다.
SW.3G1의 모든 불멸화 된 암 세포주 사멸 평가
LCL 및 종양 세포는 세포독성 평가를 위해 크로뮴 51로 라벨링 하였으며(Ekeruche-Makinde et al., 2012), T-세포와 타겟 세포의 비율은 1:1(LCL) 또는 10:1(암 세포)이다. LCL은 상기와 같이 유지하였다. 암 세포주(ATCC® reference for background and culture information)/ 조직 기원: SiHa (HTB-35) 및 MS751 (HTB-34) / 자궁암; MCF7 (HTB-22), MDA-MB-231 (CRM-HTB-26) 및 SKBR3 (HTB-30) / 유방암; TK143 (CRL-8303) 및 U20S (HTB-96) / 뼈암; HCT-116 (CCL-247) 및 Colo205 (CCL-222) / 결장암; Jurkat (TIB-152), K562 (CCL-243), THP-1 (TIB-202), U266 (TIB-196) 및 Molt-3 (CRL-1552) / 혈액암; Caki-1 (HTB-46) / 신장암; A549 (CCL-185) 및 H69 (HTB-119) / 폐암. MM909.11, MM909.12, MM909.15, MM909.46 및 MM909.24 / 흑색종 (피부)은 암 면역 치료 센터(CCIT; Center for Cancer Immune Therapy, Herlev Hospital, Copenhagen, Denmark)에서 치료 받은 암 환자로부터 수득하였다. ‘MM’세포주 및 흑색종 Mel 526 및 Mel 624는 부착세포로서 R10 유지하였으며, 일주일에 한 번 또는 세포 포화정도(confluence)가 20 ~ 80%이 되도록 필요할 시에 계대배양 하였다. 세포는 D-PBS로 헹군 후 37℃에서 2mM EDTA와 D-PBS와 함께 분리될 때까지 배양하여 조직 배양 플라스크로부터 분리하였다.
알려진 메커니즘으로 타겟 세포를 인식하지 않는 SW.3G1
Vγ9Vδ2 T-세포 활성제 (E)-4-Hydroxy-3-methyl-but-2-enyl pyrophosphate (HMB-PP) (Sigma Aldrich)는 DMSO에 녹이고 평가 웰에 직접 추가하였다. 블락킹 어세이(blocking assay)를 위해서는 하기의 단클론 Ab를 이용하였으며, 최종 농도 10μg/mL에서 사용하였다: 항-HLA, -B, -C (클론 W6/32, Biolegend), 항-HLA-DR, -DP, -DQ (클론 Tu39, Bioloegend), 항-EPCR (다클론, R&D systems), 항-MICA/MICB (클론 6D4, BioLegend) 및 항-CD1d (클론 51.1, Miltenyi Biotech).
전체 게놈 CRISPR에 의한 유전자 트래핑(Gene trapping)
전체 게놈 CRISPR/Cas9 라이브러리 처리방법을 실시하였다 (도 5). Dr. Feng Zhang (Patel et al., 2017)으로부터 제공받은 GeCKO v2 하위-라이브러리(sub-libraries) A 및 B (Adgene plasmid, #1000000048)를 사용하여 LCL-9909 및 KBM7을 타겟으로 하는 전체 게놈을 SW.3G1을 선별하기 위하여 사용하였다. 간략히는, 퓨로마이신(puromycin)으로 선별된 성공적으로 형질도입된 타겟 세포는 사전에 정해진 비율로 2 - 3주, 96 U 웰 플레이트에서 SW.3G1과 함께 배양하였다. 활성화 평가(상기)는 선별된 세포에 대한 SW.3G1 활성의 손실을 확인하기 위하여 사전 및 사후로 선별된 타겟 세포와 함께 수행하였다. 두 차례의 SW.3G1 선별로부터 살아남은 타겟 세포로부터 얻은 유전체 DNA를 가이드 RNA 및 후보 유전자를 밝히기 위한 차세대 염기서열 분석을 위해 사용하였다.
타겟 세포의 인식에 있어서 SCNN1A의 역할 확인
렌티바이러스 입자는 타겟 세포로의 형질도입에 앞서 8 μg/mL의 폴리브렌(polybrene) 및 스핀감염(spinfection)를 사용하여, HEK293T 세포에 염화칼슘(calcium chloride) 형질주입을 하고, 초원심분리기(ultracentrifugation)를 통해 농축하여 생상하였다. gRNA는 SpCas9 단백질 및 퓨로마이신(puromycin) 저항성 마커 유전자(pac, puromycin N-acetyltransferase)를 암호화 하는 pLentiCRISPR v2 플라스미드(Dr. Feng Zhang로부터 제공받은 Addgene plasmid 52961) 내로 클로닝 하고, 패키징 플라스미드 pMD2.G 및 엔벨롭 플라스미드인 psPAX2 (Addgene)와 함께 감염시켰다. 전체-길이(Full-length) 코돈 최적화된 SCNN1A 전이유전자(transgene) (Isoform 1, UniProt P37088-1)는 3세대 렌티바이러스 전이 벡터(transfer vector) pELNS (Dr. James Riley, University of Pennsylvania, PA로부터 제공)로 클로닝 되었다. pELNS 벡터는 항-rCD2 PE Ab(OX-34, BioLegend) 사용하는 세포 선별을 위한 랫트 CD2 (rCD2) 유전자를 포함한다. 타겟 세포 내 SCNN1A 발현은 유세포 분석기 (데이터는 도시하지 않음) 및 제조사의 지시를 따른 웨스턴블롯 실험을 위한 토끼 항-SCNN1A 다클론 항체 (PA1-902A, ThermoFisher Scientific)를 이용하여 평가하였다.
SW.3G1을 형질도입한 다클론 T-세포의 타겟 세포 인식 수여
셀프-클리빙 2A 서열(self-cleaving 2A sequence)에의해 분리되어 코돈 최적화 된전장 길이 TCR 사슬은 합성되어(Genewiz), 3세대 렌티바이러스 전이 벡터 pENLS(Dr. James Riley, University of Pennsylvania, PA로부터 제공) 내로 클로닝 되었다. 상기 pELNS 벡터는 또 다른 셀프-클리빙 2A 서열에 의해 TCR로부터 분리된 랫트 CD2(rCD2) 마커 유전자를 포함한다. 또한, 세포는 두 TCR-β 불변 도메인 타겟팅에 의해 수여 세포 내 TCRβ 사슬 발현을 막기 위하여 gRNA와 함께 형질도입 되었다(현재 Blood지 출판을 위한 원고). 렌티바이러스 입자는 HEK293T 세포의 염화칼슘 형질주입에 의해 생성되었다. TCR 전이 벡터는 패키징 및 엔벨롭 플라스미드인 pMD2.G, pRSV-Rev 및 pMDLg/pRRE와 함께 형질주입되었다. 렌티 바이러스 입자는 5 μg/ml의 폴리브렌을 이용한 CD8+ T-세포의 형질도입에 앞서 초원심분리에 의해 농축되었으며, 상기 CD8+T-세포는 건강한 세명의 공여자로부터 24시간 전에 자성 분리(Miltenyi Biotec)를 통해 정제되었으며, 비드와 T-세포의 비율을 3:1로 하여 CD3/CD28 비드와 함께 밤새 활성화되었다. 바이러스를 흡수한 T-세포는 2μg/ml의 퓨로마이신(TCRβ 사슬이 녹아웃)과 함께 배양하고, 항-rCD2 PE Ab(OX-34, Biolegend)를 처리한 뒤, 항-PE 자성 비드를 통해 선별하였다. 형질도입 14일 후, T-세포는 동종 이계 피더(feeder) 및 PHA와 함께 키웠다. TCR 형질도입 세포는 LCL.174 타겟은 클로닝하여 50,000 세포/웰 농도로 96 U 웰 플레이트에 접종하여 장기간 사멸 평가에 사용되었다. SW.3G1을 타겟에 더하여 7일간 배양하였다. 타겟 세포는 또한 100% 생존하는 대조군을 위하여 T-세포 없이 접종하였다. 세포를 수확하여, PBS로 세척하고, Vivid 및 항-CD3 항체(T-세포를 제거를 위한)로 염색하였다. 추출/세척에 앞서, 내부통제로서 CountBright™ Absolute Counting Beads (Life Technologies)를 각 웰에 더하였다(대략 10,000 비드/웰). 샘플은 FACS Canto II를 통해, 샘플당 적어도 1,000개의 비드 이벤트(event)를 수득하였다. 타겟 세포의 생존율은 하기의 공식에 의해 계산되었다.

결과
클론 특성분석
1. 건강한 공여자 (9909)로부터 얻은 정제된 γδ T-세포 세 개의 비-자가 림푸아구성(lymphoblastoid) 세포주(-0439, -pt146 및 -HOM-2)을 통해 초회항원자극 및 재자극하였다. 각 세포주에 대한 반응성은 28일째 평가하였다(도 1). 상기 T-세포주는 또한 자가 LCL-9909을 인식하였다(도 1).
2. 상기 세포주로부터 얻은 T-세포는 차세대 염기서열 분석을 통해 분석한 각 LCL 및 이들의 TCR에 대한 반응성을 기반으로하는 유세포분석기를 통해 분류하였다(도 1). γ-사슬 서열분석에서, 2개의 특이적인 CDR3이 가변사슬 TRGV9 및 TRGV3과 함께 존재하였다. δ-사슬에서는, 3개의 CDR3이 가변영역 TRDV1 및 TRDV2 함께 존재하였다.
3. 공여자 9909 T-세포주로부터 입수된 T-세포 클론은 반응 사슬에 대한 γ3δ1 TCR 및 CDR3 CATWDRRDYKKL 및 CALGVLPTVTGGGLIF을 발현하였다(도 1 및 도 2). 배양한 모든 클론은 같은 TCR을 발현하였고, 이 클론을 SW.3G1이라 명명하였다.
SW.3G1의 Ab 염색은 Vδ1 사슬, 및 αβ TCR-/CD8 low/CD4- 발현을 확인하였다(도 1B).
4. 판독을 위하여 TNFα 및 CD107a를 사용한 활성화 평가는 자가 LCL-9909 및 비-자가 LCL-0439에 대한 SW.3G1 반응성을 확인하였다(도 3A). 공여자 9909 및 0439는 두 MHC 클래스 I 및 II 대립형질에 대해 완전히 HLA 불일치하였기에, SW.3G1은 HLA-독립적 방법으로 타겟 세포를 인식하였다. SW.3G1은 또한 LCL-9909 및 -0439를 용해하였으며, 따라서 세포독성이 있었다 (도 3B). LCL의 인식은 B-세포의 EBV 감염을 통한 불멸화 과정에 의존하는 것이므로, 9909로부터 직접 ex-vivo 정제한 건강한 자가 B-세포는 SW.3G1의 타겟이 되지 않았다(도 3C). 유사하게, 건강한 CIL-1(상피 세포) 및 Hep2(간세포)는 SW.3G1 활성화를 일으키지 않았다(도 3D).
5. SW.3G1은 테스트를 거친 모든 24명 공여자의 LCL을 용해할 수 있어(자가 LCL을 나타내는 도 3B 및 23개의 비-자가 LCL을 나타내는 도 4) SW.3G1은 HLA 독립적 방법으로 작용하는 것을 추가로 확인할 수 있었다. 게다가, LCL.174(도 4A, 왼쪽에서부터 4번째 바)는 MHC 유전자좌를 지니는 인간 염색체6의 하나의 카피만을 발현한다. 상기 LCL.174 세포 내 염색체6은 다수의 결실을 포함하며 MHC 클래스 II의 유전자 및 MHC 클래스 I 항원 프로세싱에 관여하는 다수의 구성 요소들을 포함하지 않는다.
6. SW.3G1은 8개의 다른 조직(피부/흑색종, 신장암, 결장암, 유방암, 혈액암/백혈병, 폐암, 자궁경부암 및 뼈암)에서부터 유래한 23개의 암 세포주를 사멸시켰다(도 4B).
7. SW.3G1은 자가 피로인산(pyrophosphate)의 인식과 유사한 방법으로 Vγ9Vδ2 TCR T-세포 서브셋(subset)에 의한 병원균에 감염된 세포의 인식을 유도하는, 알려진 γδ T-세포 항원(HMB-PP)과 반응하지 않았다(도 5A). 이 경로는 Butyrophillin 3A1을 발현하는 타겟 세포를 필요로 한다. LCL-9909 (자가) -0439 및 -pt146에 대한 SW.3G1의 반응성은 알려진 γδ T-세포 리간드인 MHC(Major Histocompatibility Complex) 클래스-I 관련 사슬 A 및 B(MICA/MICB), EPCR 상피 단백질 C 수용체(EPCR; Endothelial Protein C Receptor) 및 CD1d에 결합하는 블락킹 항체의 봉입에 의하여 방해받지 않았다(도 5B). 또한 MHC 클래스 I 및 클래스 II 역시 SW.3G1 활성화를 차단하지 못하였다. 비록 광범위한 배제 과정은 아니지만, 상기 데이터는 SW.3G1이 암 세포 표면의 알려지지 않은 γδ TCR 리간드를 인식 할 수 있음을 시사하였다. 따라서, 타겟 세포의 SW.3G1 인식에 관여하는 후보 유전자/단백질을 찾기 위하여 전체 게놈(genome) CRISPR/Cas9 라이브러리 접근법을 채택하였다(도 6).
8. 전체 게놈 CRISPR/Cas9 라이브러리는 자가 LCL-9909 및 반수체 골수성 백혈병 (haploid myeloid leukaemia) 세포주 KBM7 내 유전자 녹아웃을 만들기 위하여 사용하였다. 두 라이브러리는 gRNA를 포함하는 타겟 세포를 농축하여 성공적인 선별과정을 위해 SW.3G1과 함께 배양하였고, SW.3G1-매개 용해를 피할 수 있었다(도 7A). SW.3G1 반응성은 LCL-9909 선별-전 59%에서 선별-후 12%로 떨어졌다. KMB7 반응성은 12%에서 4.2%로 바뀌었다. 상기 선별-후 LCL-9909 및 KBM7은 농축된 gRNA를 확인하기 위한 차세대 염기서열 분석을 위하여 사용하였다. 중요 유전자는 LCL-9909와 KBM7 라이브러리 사이에 공유되는 전체 7개의 유전자 중 4개로 확인되었다(도 7B 및 7C). 나트륨 채널 상피 1 알파 서브유닛(protein Sodium Channel Epithelial 1 Alpha Subunit) 단백질을 암호화 하는 SCNN1A 유전자 (암호화된 단백질에 또한 사용됨) 특이적인 가이드는 두 라이브러리 내에서 월등히 농축되어 전재하였다(도 7B 및 C). SCNN1A 유전자 및 단백질은 도 8에 알려진 바와 같다. 상기 단백질은 세포 표면에서 발현된 것이며 따라서 추가 연구를 위한 좋은 후보 물질이다. SCNN1A는 6개의 스플라이스 변형 동형체(splice variant isoform)을 지니며, 다양한 자연 발생 돌연변이를 지닌다(도 8 및 도 9).
9. 전체 게놈 라이브러리에서 얻은 SCNN1A gRNA이 형질 도입된 LCL.174 또는 자체 제작한 다른 가이드 (gRNA-2) (도 10A)는 SW.3G1을 더 이상 타겟으로 하지 않기에, 타겟 세포 인식 내 SCNN1A의 역할을, 야생형 세포 100% 사멸과 비교하여 녹아웃 세포주의 용해가 5% 미만으로 떨어지는지를 확인하였다(도 10B). SCNN1A 유전자 녹아웃 세포주는 부분적 또는 전체적으로 SW.3G1에 의해 용해되지 않는 두 암세포에서 만들어졌다(도 10C). 본 발명을 통해 제작한 SCNN1A 녹아웃 세포를 세포주로 사용하고, 실행 평가(performing assay) 전에 클로닝하지 않은 것은 주목할만하다. 이는 퓨로마이신 선별로부터 회피되고/되었거나, SCNN1A 유전자가 성공적으로 제거되지 않았기에, SCNN1A를 여전히 발현하는 녹아웃 세포주 내의 세포의 소수 부분으로서, '녹아웃' 세포주의 일부로 보여지는 잔여의 반응을 계산할 수 있다. SW.3G1 활성 평가를 위한 SCNN1A 녹아웃 MDA-MB-231 세포의 웨스턴블롯 조사 결과 유전자 녹아웃을 확인을 위한 야생형 세포(도 10C)와 비교하여 녹아웃 세포주 내 SCNN1A 단백질의 상당한 감소가 있는 것이 확인되었다. 상기 사용된 항체는 모든 SCNN1A 동형체를 인식할 수 있다(도 9). 본 발명에서는 또한 광범위한 배양 (3주 이상)을 통해 생존 가능성이 적어진 SCNN1A 녹아웃 세포 및 세포 분열이 완전히 중단된 일부 케이스에 주목하였다. gRNA가 형질도입된 동일한 세포주 중 세포 성장 및 생존에 있어서 많은 다른 유전자에서는 동일한 변화가 나타나지 않았으나, SCNN1A gRNA에서만 상기 결과를 확인할 수 있었다. 이를 통해, SCNN1A 유전자는 세포 배양의 장기간 성장에 있어서 필수적인 것을 확인하였다.
10. 3명의 건강한 공여자로부터 얻은 다클론 CD8+ T-세포로의 SW.3G1 TCR 전달은 타겟 세포 LCL-pt146에 대한 반응성을 부여하였다(도 11A). TCR이 형질도입된 세포는 상기의 SW.3G1 클론에 대한 SCNN1A 녹아웃 세포와 동일한 기능적 프로파일을 나타냈다(도 11B). SCNN1A 녹아웃 데이터를 보완하고, 타겟 세포 인식에서의 SCNN1A의 역할을 추가 확인하기 위하여, SCNN1A 유전자를 녹아웃 세포에 형질도입 하였다. SCNN1A gRNA를 발현하는 녹아웃 세포로의 천연(native) SCNN1A 유전자 형질도입은 전이유전자(transgene)의 유전자 삭제를 유도할 수 있다. 따라서, 천연 유전자(native gene)(동형체 1 UniProt P37088-1, 도 9)의 DNA 서열이 다르지만, 동일한 단백질을 발현하는 코돈-최적화된 유전자를 도입하였다. gRNA-1 또는 gRNA-2이 형질도입된 세포의 사멸은 제거되었지만 녹아웃 세포 내 SCNN1A 유전자의 발현은 회복되었다(도 11B).
결론
SW.3G1 TCR은 T-세포가 광범위한 암을 인식하게 하였다. 상기 인식은 SCNN1A 유전자 산물에 의해 일어난다. SW.3G1 T-세포 클론은 MHC 제한의 부재로 인해 암-세포 특이적 SCNN1A 리간드를 인식한다.
본 발명은 T-세포 클론 SW.3G1 내에서 확인된 TCR에 대한 것이다. 상기 TCR은 SCNN1A의 발현을 통해 광범위한 암 세포를 인식할 수 있다. 상기 TCR은 비-종양 세포는 인식하지 않는다. 종양 세포주로부터 SCNN1A를 녹아웃한 CRISPR/Cas9 또는 항체 블락킹은 종양 세포의 인식을 위하여 TCR이 SCNN1A 유전자 산물을 필요로 하는 것을 입증한다. 상기 SW.3G1 TCR은 다양한 암 면역치료 전략에 사용할 수 있다. 상기 TCR을 이용한 넓은 범위의 종양 인식 및 인간 백혈구 항원(HLA)-비의존적 인식은 범(pan)-암, 범-인구 면역치료의 흥미로운 가능성을 열었다.
인용문헌(REFERENCES)
Chen, J., TR Kleyman and S. Sheng. 2014 Deletion of α-subunit exon 11 of the epithelial Na+ channel reveals a regulatory module. Am J Physiol. Renal Physiol 306, F561-7.
Donia, M., Kjeldsen, J.W., Andersen, R., Westergaard, M.C.W., Bianchi, V., Legut, M., Attaf, M., Szomolay, B., Ott, S., Dolton, G., Lyngaa, R., Hadrup, S.R., Sewell, A.K., Svane, I.M., 2017. PD-1 + polyfunctional T cells dominate the periphery after tumor-infiltrating lymphocyte therapy for cancer. Clin. Cancer Res. clincanres.1692.2016.
Ekeruche-Makinde, J., Clement, M., Cole, D.K., Edwards, E.S.J., Ladell, K., Miles, J.J., Matthews, K.K., Fuller, A., Lloyd, K.A., Madura, F., Dolton, G.M., Pentier, J., Lissina, A., Gostick, E., Baxter, T.K., Baker, B.M., Rizkallah, P.J., Price, D.A., Wooldridge, L., Sewell, A.K., 2012. T-cell receptor-optimized peptide skewing of the T-cell repertoire can enhance antigen targeting. J. Biol. Chem. 287, 37269-81.
Haney, D., Quigley, M.F., Asher, T.E., Ambrozak, D.R., Gostick, E., Price, D.A., Douek, D.C., Betts, M.R., 2011. Isolation of viable antigen-specific CD8+ T cells based on membrane-bound tumor necrosis factor (TNF)-alpha expression. J. Immunol. Methods 369, 33-41.
Legut, M., G Dolton, A.A. Mian, O. Ottmann and A.K. Sewell. 2017 CRISPR-mediated TCR replacement generates superior anticancer transgenic T-cells. Blood [Epub ahead of print] doi: https://doi.org/10.1182/blood-2017-05-787598
Patel, S.J., Sanjana, N.E., Kishton, R.J., Eidizadeh, A., Vodnala, S.K., Cam, M., Gartner, J.J., Jia, L., Steinberg, S.M., Yamamoto, T.N., Merchant, A.S., Mehta, G.U., Chichura, A., Shalem, O., Tran, E., Eil, R., Sukumar, M., Guijarro, E.P., Day, C.-P., Robbins, P., Feldman, S., Merlino, G., Zhang, F., Restifo, N.P., 2017. Identification of essential genes for cancer immunotherapy. Nature 548, 537-542.
Theaker, S.M., Rius, C., Greenshields-Watson, A., Lloyd, A., Trimby, A., Fuller, A., Miles, J.J., Cole, D.K., Peakman, M., Sewell, A.K., Dolton, G., 2016. T-cell libraries allow simple parallel generation of multiple peptide-specific human T-cell clones. J. Immunol. Methods 430, 43-50.
<110> University College Cardiff Consultants Limited
<120> NOVEL GAMMA DELTA T-CELL RECEPTOR AND ITS LIGAND
<130> IPA200376-GB
<150> GB1719169.3
<151> 2017-11-20
<160> 13
<170> PatentIn version 3.5
<210> 1
<211> 13
<212> PRT
<213> Homo sapiens
<400> 1
Cys Ala Thr Trp Asp Arg Arg Asp Tyr Lys Lys Leu Phe
1 5 10
<210> 2
<211> 16
<212> PRT
<213> Homo sapiens
<400> 2
Cys Ala Leu Gly Val Leu Pro Thr Val Thr Gly Gly Gly Leu Ile Phe
1 5 10 15
<210> 3
<211> 6
<212> PRT
<213> Homo sapiens
<400> 3
Val Thr Asn Thr Phe Tyr
1 5
<210> 4
<211> 8
<212> PRT
<213> Homo sapiens
<400> 4
Tyr Asp Val Ser Thr Ala Arg Asp
1 5
<210> 5
<211> 7
<212> PRT
<213> Homo sapiens
<400> 5
Thr Ser Trp Trp Ser Tyr Tyr
1 5
<210> 6
<211> 3
<212> PRT
<213> Homo sapiens
<400> 6
Gln Gly Ser
1
<210> 7
<211> 226
<212> PRT
<213> Homo sapiens
<400> 7
Ser Ser Asn Leu Glu Gly Arg Thr Lys Ser Val Thr Arg Gln Thr Gly
1 5 10 15
Ser Ser Ala Glu Ile Thr Cys Asp Leu Thr Val Thr Asn Thr Phe Tyr
20 25 30
Ile His Trp Tyr Leu His Gln Glu Gly Lys Ala Pro Gln Arg Leu Leu
35 40 45
Tyr Tyr Asp Val Ser Thr Ala Arg Asp Val Leu Glu Ser Gly Leu Ser
50 55 60
Pro Gly Lys Tyr Tyr Thr His Thr Pro Arg Arg Trp Ser Trp Ile Leu
65 70 75 80
Arg Leu Gln Asn Leu Ile Glu Asn Asp Ser Gly Val Tyr Tyr Cys Ala
85 90 95
Thr Trp Asp Arg Arg Asp Tyr Lys Lys Leu Phe Gly Ser Gly Thr Thr
100 105 110
Leu Val Val Thr Asp Lys Gln Leu Asp Ala Asp Val Ser Pro Lys Pro
115 120 125
Thr Ile Phe Leu Pro Ser Ile Ala Glu Thr Lys Leu Gln Lys Ala Gly
130 135 140
Thr Tyr Leu Cys Leu Leu Glu Lys Phe Phe Pro Asp Val Ile Lys Ile
145 150 155 160
His Trp Gln Glu Lys Lys Ser Asn Thr Ile Leu Gly Ser Gln Glu Gly
165 170 175
Asn Thr Met Lys Thr Asn Asp Thr Tyr Met Lys Phe Ser Trp Leu Thr
180 185 190
Val Pro Glu Lys Ser Leu Asp Lys Glu His Arg Cys Ile Val Arg His
195 200 205
Glu Asn Asn Lys Asn Gly Val Asp Gln Glu Ile Ile Phe Pro Pro Ile
210 215 220
Lys Thr
225
<210> 8
<211> 209
<212> PRT
<213> Homo sapiens
<400> 8
Ala Gln Lys Val Thr Gln Ala Gln Ser Ser Val Ser Met Pro Val Arg
1 5 10 15
Lys Ala Val Thr Leu Asn Cys Leu Tyr Glu Thr Ser Trp Trp Ser Tyr
20 25 30
Tyr Ile Phe Trp Tyr Lys Gln Leu Pro Ser Lys Glu Met Ile Phe Leu
35 40 45
Ile Arg Gln Gly Ser Asp Glu Gln Asn Ala Lys Ser Gly Arg Tyr Ser
50 55 60
Val Asn Phe Lys Lys Ala Ala Lys Ser Val Ala Leu Thr Ile Ser Ala
65 70 75 80
Leu Gln Leu Glu Asp Ser Ala Lys Tyr Phe Cys Ala Leu Gly Val Leu
85 90 95
Pro Thr Val Thr Gly Gly Gly Leu Ile Phe Gly Lys Gly Thr Arg Val
100 105 110
Thr Val Glu Pro Asn Ser Gln Pro His Thr Lys Pro Ser Val Phe Val
115 120 125
Met Lys Asn Gly Thr Asn Val Ala Cys Leu Val Lys Glu Phe Tyr Pro
130 135 140
Lys Asp Ile Arg Ile Asn Leu Val Ser Ser Lys Lys Ile Thr Glu Phe
145 150 155 160
Asp Pro Ala Ile Val Ile Ser Pro Ser Gly Lys Tyr Asn Ala Val Lys
165 170 175
Leu Gly Lys Tyr Glu Asp Ser Asn Ser Val Thr Cys Ser Val Gln His
180 185 190
Asp Asn Lys Thr Val His Ser Thr Asp Phe Glu Val Lys Thr Asp Ser
195 200 205
Thr
<210> 9
<211> 12
<212> PRT
<213> Homo sapiens
<400> 9
Cys Ala Leu Trp Glu Val Asp Tyr Lys Lys Leu Phe
1 5 10
<210> 10
<211> 16
<212> PRT
<213> Homo sapiens
<400> 10
Cys Ala Leu Gly Glu Pro Val Leu Phe Ala Val Arg Gly Leu Ile Phe
1 5 10 15
<210> 11
<211> 16
<212> PRT
<213> Homo sapiens
<400> 11
Cys Ala Cys Asp Leu Leu Gly Asp Arg Tyr Thr Asp Lys Leu Ile Phe
1 5 10 15
<210> 12
<211> 104
<212> DNA
<213> Homo sapiens
<400> 12
gaattactct cacttccacc acccgatgta tggaaactgc tatactttca atgacaagaa 60
caactccaac ctctggatgt cttccatgcc tggaatcaac aacg 104
<210> 13
<211> 104
<212> DNA
<213> Homo sapiens
<400> 13
gaattactct cacttccacc acccgatgta tggaaactgc tatactttca atgacaagaa 60
caactccaac ctctggatgt cttccatgcc tggaatcaac aacg 104
Claims (24)
- 적어도 하나의, CATWDRRDYKKLF (서열번호 1) 및/또는 CALGVLPTVTGGGLIF (서열번호 2)를 포함하거나 이로 이루어진 상보성 결정 영역(complementarity-determining region; CDR) 또는 상기 CDR(서열번호 1 또는 2)과 적어도 88%의 동일성을 공유하는 CDR을 특징으로 하는, 종양 특이적 T-세포 수용체(TCR), 또는 이의 단편.
- 제1항에 있어서, 상기 TCR은 상기 CDR 둘 모두를 포함하는 것인, 종양 특이적 T-세포 수용체.
- 제1항 또는 제2항에 있어서, 상기 TCR은 하기 상보성 결정 영역의 임의의 조합을 포함하는 하나 또는 그 이상을 포함하거나 이로 이루어지는 것인, 종양 특이적 T-세포 수용체:
VTNTFY (CDR1γ) (서열번호 3)
YDVSTARD (CDR2γ) (서열번호 4)
TSWWSYY (CDR1δ) (서열번호 5) 또는
QGS (CDR2δ) (서열번호 6).
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 TCR은 SSNLEGRTKSVTRQTGSSAEITCDLTVTNTFYIHWYLHQEGKAPQRLLYYDVSTARDVLESGLSPGKYYTHTPRRWSWILRLQNLIENDSGVYYCATWDRRDYKKLFGSGTTLVVTDKQLDADVSPKPTIFLPSIAETKLQKAGTYLCLLEKFFPDVIKIHWQEKKSNTILGSQEGNTMKTNDTYMKFSWLTVPEKSLDKEHRCIVRHENNKNGVDQEIIFPPIKT (서열번호 7)을 포함하거나 이로 이루어진 감마 사슬, 또는 이와 적어도 88%의 동일성을 공유하는 감마 사슬인 것인, 종양 특이적 T-세포 수용체.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 TCR은 AQKVTQAQSSVSMPVRKAVTLNCLYETSWWSYYIFWYKQLPSKEMIFLIRQGSDEQNAKSGRYSVNFKKAAKSVALTISALQLEDSAKYFCALGVLPTVTGGGLIFGKGTRVTVEPNSQPHTKPSVFVMKNGTNVACLVKEFYPKDIRINLVSSKKITEFDPAIVISPSGKYNAVKLGKYEDSNSVTCSVQHDNKTVHSTDFEVKTDST (서열번호 8)을 포함하거나 이로 이루어진 델타 사슬, 또는 이와 적어도 88%의 동일성을 공유하는 델타 사슬인 것인, 종양 특이적 T-세포 수용체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 TCR의 CDR은 CALWEVDYKKLF (서열번호 9)인 감마 사슬 서열; 및/또는 CALGEPVLFAVRGLIF (서열번호 10) 및/또는 CACDLLGDRYTDKLIF (서열번호 11)인 델타 사슬 서열; 또는 상기 감마 사슬 서열 또는 델타 사슬 서열과 적어도 88%의 동일성을 공유하는 CDR을 추가적으로 또는 대안적으로 포함하거나 이로 이루어진 것인, 종양 특이적 T-세포 수용체.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 TCR은 가용성인 것인, 종양 특이적 T-세포 수용체.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR을 발현하는, T-세포.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR을 발현하는, T-세포 클론.
- 제9항에 있어서, 상기 클론은 SW.3G1 클론인 것인, T-세포 클론.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR을 암호화하는, 벡터.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR, 또는 제8항에 따른 세포, 또는 제9항 또는 제10항에 따른 클론, 또는 제11항에 따른 벡터를 포함하는 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신.
- 암 치료에의 사용을 위한, 제1항 내지 제7항 중 어느 한 항에 따른 TCR, 또는 제8항에 따른 세포, 또는 제9항 또는 제10항에 따른 클론, 또는 제11항에 따른 벡터, 또는 제12항에 따른 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신.
- 제13항에 있어서, 상기 암은 직장암, 폐암, 신장암, 전립선암, 방광암, 자궁 경부암, 흑색종 (피부), 뼈암, 유방암, 혈액암, 뇌암, 췌장암, 고환암, 난소암, 두경부암, 간암, 방광암, 갑상선암, 및 자궁암을 포함하거나 이로 이루어진 군으로부터 선택되는 것인, TCR, 세포, 클론, 벡터, 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR, 또는 제8항에 따른 세포, 또는 제9항 또는 제10항에 따른 클론 또는 제11항에 따른 벡터, 또는 제12항에 따른 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신을, 개체를 치료하기 위하여 투여하는 단계를 포함하는, 암 치료 방법.
- 제15항에 있어서, 상기 암은 직장암, 폐암, 신장암, 전립선암, 방광암, 자궁 경부암, 흑색종 (피부), 뼈암, 유방암, 혈액암, 뇌암, 췌장암, 고환암, 난소암, 두경부암, 간암, 방광암, 갑상선암, 및 자궁암을 포함하거나 이로 이루어진 군으로부터 선택되는 것인, 방법.
- 제15항 또는 제16항에 있어서, 상기 TCR, 세포, 클론, 벡터, 약학적 조성물, 또는 면역성 제제, 또는 이중특이성(bispecific) 또는 백신은 항암제와 조합하여 투여되는 것인, 방법.
- 제1항 내지 제7항에 따른 TCR, 또는 제8항에 따른 세포, 또는 제9항 또는 제10항에 따른 클론, 또는 제11항에 따른 벡터의, 암 치료를 위한 의약의 제조를 위한 용도.
- a) 제1항 내지 제7항에 따른 TCR, 또는 제8항에 따른 세포, 또는 제9항 또는 제10항에 따른 클론, 또는 제11항에 따른 벡터, 또는 제12항에 따른 약학적 조성물 또는 면역성 제제 또는 이중특이성(bispecific) 또는 백신;
b) 추가의 암 치료용 제제; 의 조합을 포함하는, 암 치료를 위한 조합 치료제.
- 도 9에 표시된 적어도 하나의 SCNNA1 유전자 산물 동형체(isoform)와 결합하는, TCR 또는 폴리펩타이드 또는 이중특이성(bispecific) 또는 항체, 또는 상기 항체의 단편.
- 제20항에 있어서, 상기 동형체의 세포외 도메인과 결합하는 것인, TCR 또는 폴리펩타이드 또는 이중특이성(bispecific) 또는 항체, 또는 상기 항체의 단편.
- 제20항 또는 제21항에 있어서, 상기 항체는 모노클로날(monoclonal)인 것인, TCR 또는 폴리펩타이드 또는 이중특이성(bispecific) 또는 항체, 또는 상기 항체의 단편.
- 제1항 내지 제7항 중 어느 한 항에 따른 TCR과 결합하는, 도 9에 표시된 적어도 하나의 SCNNA1 유전자 산물 동형체, 또는 이의 단편.
- 본 발명에 실질적으로 기재된 TCR, 세포, 클론, 벡터, 약학적 조성물, 면역성 제제, 이중특이성, 또는 백신, 또는 폴리펩타이드, 또는 항체, 또는 상기 항체의 단편.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB1719169.3A GB201719169D0 (en) | 2017-11-20 | 2017-11-20 | Novel T-cell receptor and ligand |
| GB1719169.3 | 2017-11-20 | ||
| PCT/GB2018/053321 WO2019097244A1 (en) | 2017-11-20 | 2018-11-16 | Novel gamma delta t-cell receptor and its ligand |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200085776A true KR20200085776A (ko) | 2020-07-15 |
Family
ID=60805814
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207014073A KR20200085776A (ko) | 2017-11-20 | 2018-11-16 | 신규한 감마 델타 t-세포 수용체 및 이의 리간드 |
Country Status (15)
| Country | Link |
|---|---|
| US (1) | US11850264B2 (ko) |
| EP (1) | EP3713954A1 (ko) |
| JP (1) | JP2021505190A (ko) |
| KR (1) | KR20200085776A (ko) |
| CN (1) | CN111372944A (ko) |
| AU (1) | AU2018369698A1 (ko) |
| BR (1) | BR112020007469A2 (ko) |
| CA (1) | CA3079156A1 (ko) |
| EA (1) | EA202091276A1 (ko) |
| GB (1) | GB201719169D0 (ko) |
| IL (1) | IL274482A (ko) |
| MX (1) | MX2020005200A (ko) |
| SG (1) | SG11202002993UA (ko) |
| WO (1) | WO2019097244A1 (ko) |
| ZA (1) | ZA202002417B (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4059955A1 (en) | 2021-03-19 | 2022-09-21 | Medizinische Hochschule Hannover | Hla-dr-specific gamma delta tcr constructs and use thereof |
| WO2023148494A1 (en) | 2022-02-03 | 2023-08-10 | University College Cardiff Consultants Limited | Novel t-cell receptor |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5260223A (en) * | 1986-07-03 | 1993-11-09 | President & Fellows Of Harvard College | Methods for detection of human gamma, γ T cell receptor |
| WO1996013593A2 (en) * | 1994-10-26 | 1996-05-09 | Procept, Inc. | Soluble single chain t cell receptors |
| CA2328144A1 (en) | 1998-05-19 | 1999-11-25 | Avidex Limited | Multivalent t cell receptor complexes |
| WO2002087306A2 (en) * | 2001-05-01 | 2002-11-07 | Senomyx, Inc. | High throughput cell-based assay for monitoring sodium channel activity and discovery of salty taste modulating compounds |
| US20030152559A1 (en) * | 2001-12-10 | 2003-08-14 | Lili Yang | Method for the generation of antigen-specific lymphocytes |
| AU2004263845A1 (en) | 2003-07-10 | 2005-02-17 | Senomyx, Inc. | Improved electrophysiological assays using oocytes that express human ENaC and the use of phenamil to improve the effect of ENaC enhancers in assays using membrane potential reporting dyes |
| WO2013155406A1 (en) * | 2012-04-12 | 2013-10-17 | The Chinese University Of Hong Kong | Contragestion and treating inflammation by modulating sodium channel activity in the epithelium |
| JP6673838B2 (ja) * | 2014-02-14 | 2020-04-01 | セレクティスCellectis | 免疫細胞と病的細胞の両方に存在する抗原を標的とするように操作された、免疫療法のための細胞 |
| CN106103490B (zh) | 2014-03-19 | 2020-03-03 | 塞勒克提斯公司 | 用于癌症免疫疗法的cd123特异性嵌合抗原受体 |
| SG11201609370QA (en) | 2014-05-13 | 2016-12-29 | Chugai Pharmaceutical Co Ltd | T cell-redirected antigen-binding molecule for cells having immunosuppression function |
| ES2876925T3 (es) | 2014-07-29 | 2021-11-15 | Cellectis | Receptores de antígeno quiméricos específicos para ROR1 (NTRKR1) para inmunoterapia contra el cáncer |
| SG11201707540QA (en) * | 2015-03-16 | 2017-10-30 | Max-Delbrück-Centrum Für Molekulare Medizin In Der Helmholtz-Gemeinschaft | Method of detecting new immunogenic t cell epitopes and isolating new antigen-specific t cell receptors by means of an mhc cell library |
-
2017
- 2017-11-20 GB GBGB1719169.3A patent/GB201719169D0/en not_active Ceased
-
2018
- 2018-11-16 AU AU2018369698A patent/AU2018369698A1/en not_active Abandoned
- 2018-11-16 KR KR1020207014073A patent/KR20200085776A/ko not_active Application Discontinuation
- 2018-11-16 CA CA3079156A patent/CA3079156A1/en active Pending
- 2018-11-16 SG SG11202002993UA patent/SG11202002993UA/en unknown
- 2018-11-16 MX MX2020005200A patent/MX2020005200A/es unknown
- 2018-11-16 WO PCT/GB2018/053321 patent/WO2019097244A1/en unknown
- 2018-11-16 EA EA202091276A patent/EA202091276A1/ru unknown
- 2018-11-16 EP EP18808079.0A patent/EP3713954A1/en active Pending
- 2018-11-16 BR BR112020007469-1A patent/BR112020007469A2/pt unknown
- 2018-11-16 CN CN201880074771.1A patent/CN111372944A/zh active Pending
- 2018-11-16 JP JP2020544990A patent/JP2021505190A/ja active Pending
-
2020
- 2020-05-04 ZA ZA2020/02417A patent/ZA202002417B/en unknown
- 2020-05-06 IL IL274482A patent/IL274482A/en unknown
- 2020-05-19 US US16/877,928 patent/US11850264B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021505190A (ja) | 2021-02-18 |
| IL274482A (en) | 2020-06-30 |
| SG11202002993UA (en) | 2020-06-29 |
| US11850264B2 (en) | 2023-12-26 |
| EP3713954A1 (en) | 2020-09-30 |
| ZA202002417B (en) | 2021-07-28 |
| GB201719169D0 (en) | 2018-01-03 |
| CA3079156A1 (en) | 2019-05-23 |
| AU2018369698A1 (en) | 2020-04-30 |
| US20200316124A1 (en) | 2020-10-08 |
| CN111372944A (zh) | 2020-07-03 |
| MX2020005200A (es) | 2020-08-20 |
| EA202091276A1 (ru) | 2020-09-04 |
| BR112020007469A2 (pt) | 2020-11-03 |
| WO2019097244A1 (en) | 2019-05-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102609624B1 (ko) | 방법 | |
| KR102483822B1 (ko) | 태그된 키메라 이펙터 분자 및 그의 리셉터 | |
| WO2017044661A1 (en) | Ny-eso-1 specific tcrs and methods of use thereof | |
| KR20200108278A (ko) | 조작된 t 세포의 조성물을 제조하는 방법 | |
| KR20170101206A (ko) | 조작된 감마 델타 t 세포 | |
| KR20150128997A (ko) | 면역치료용 조성물 및 방법 | |
| US20170267737A1 (en) | Glypican-3-specific T-cell receptors and their uses for immunotherapy of hepatocellular carcinoma | |
| EP3664820B1 (en) | Methods for producing genetically engineered cell compositions and related compositions | |
| AU2017232431A1 (en) | Chimeric antigen receptor | |
| KR20200108277A (ko) | 세포를 배양하기 위한 무혈청 배지 제형 및 이의 사용 방법 | |
| US20220064256A1 (en) | Cd22-specific t cell receptors and adoptive t cell therapy for treatment of b cell malignancies | |
| JP2021512637A (ja) | サイクリンa1特異的t細胞受容体およびその使用 | |
| US11850264B2 (en) | Gamma delta T-cell receptor and its ligand | |
| JP2022527813A (ja) | Magea1特異的t細胞受容体およびその使用 | |
| CA3174779A1 (en) | Cd28h domain-containing chimeric antigen receptors and methods of use | |
| WO2019140278A1 (en) | Immunotherapy targeting core binding factor antigens | |
| US20210403528A1 (en) | Novel T-Cell Receptor and Ligand | |
| US20240189351A1 (en) | Il-13ra2 chimeric antigen receptors and methods of use |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |