KR20200085362A - 항원-특이적 tcr의 신규 생성 - Google Patents
항원-특이적 tcr의 신규 생성 Download PDFInfo
- Publication number
- KR20200085362A KR20200085362A KR1020207019363A KR20207019363A KR20200085362A KR 20200085362 A KR20200085362 A KR 20200085362A KR 1020207019363 A KR1020207019363 A KR 1020207019363A KR 20207019363 A KR20207019363 A KR 20207019363A KR 20200085362 A KR20200085362 A KR 20200085362A
- Authority
- KR
- South Korea
- Prior art keywords
- antigen
- specific
- tcr
- leu
- ser
- Prior art date
Links
- 239000000427 antigen Substances 0.000 title claims abstract description 290
- 108091007433 antigens Proteins 0.000 title claims abstract description 281
- 102000036639 antigens Human genes 0.000 title claims abstract description 281
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 273
- 238000000034 method Methods 0.000 claims abstract description 117
- 241000282414 Homo sapiens Species 0.000 claims abstract description 93
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 68
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 66
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 59
- 239000012634 fragment Substances 0.000 claims abstract description 55
- 238000000338 in vitro Methods 0.000 claims abstract description 21
- 238000004519 manufacturing process Methods 0.000 claims abstract description 20
- 230000003612 virological effect Effects 0.000 claims abstract description 14
- 210000004027 cell Anatomy 0.000 claims description 137
- 210000000612 antigen-presenting cell Anatomy 0.000 claims description 78
- 239000002773 nucleotide Substances 0.000 claims description 74
- 125000003729 nucleotide group Chemical group 0.000 claims description 74
- 230000002132 lysosomal effect Effects 0.000 claims description 61
- 210000002472 endoplasmic reticulum Anatomy 0.000 claims description 45
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 44
- 230000001086 cytosolic effect Effects 0.000 claims description 42
- 108010009489 Lysosomal-Associated Membrane Protein 3 Proteins 0.000 claims description 37
- 102100038213 Lysosome-associated membrane glycoprotein 3 Human genes 0.000 claims description 37
- 102100032937 CD40 ligand Human genes 0.000 claims description 35
- 108010029697 CD40 Ligand Proteins 0.000 claims description 33
- 230000004913 activation Effects 0.000 claims description 31
- 108010074328 Interferon-gamma Proteins 0.000 claims description 30
- 102100039717 G antigen 1 Human genes 0.000 claims description 29
- 101000886137 Homo sapiens G antigen 1 Proteins 0.000 claims description 29
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 claims description 29
- 108010009254 Lysosomal-Associated Membrane Protein 1 Proteins 0.000 claims description 28
- 108020001507 fusion proteins Proteins 0.000 claims description 28
- 102000037865 fusion proteins Human genes 0.000 claims description 28
- 239000003550 marker Substances 0.000 claims description 19
- 210000004443 dendritic cell Anatomy 0.000 claims description 18
- 210000001616 monocyte Anatomy 0.000 claims description 18
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 claims description 18
- 230000033001 locomotion Effects 0.000 claims description 17
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 claims description 16
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 15
- 238000012546 transfer Methods 0.000 claims description 11
- 102100038225 Lysosome-associated membrane glycoprotein 2 Human genes 0.000 claims description 10
- 210000004698 lymphocyte Anatomy 0.000 claims description 10
- 101000934372 Homo sapiens Macrosialin Proteins 0.000 claims description 9
- 108010009491 Lysosomal-Associated Membrane Protein 2 Proteins 0.000 claims description 9
- 102100025136 Macrosialin Human genes 0.000 claims description 9
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 8
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 8
- 230000000694 effects Effects 0.000 claims description 8
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 claims description 7
- 108010038453 Interleukin-2 Receptors Proteins 0.000 claims description 7
- 108090000978 Interleukin-4 Proteins 0.000 claims description 7
- 108060008682 Tumor Necrosis Factor Proteins 0.000 claims description 7
- 238000012258 culturing Methods 0.000 claims description 7
- 102000008070 Interferon-gamma Human genes 0.000 claims description 6
- 229960003130 interferon gamma Drugs 0.000 claims description 6
- 101000831496 Homo sapiens Toll-like receptor 3 Proteins 0.000 claims description 5
- 229940124613 TLR 7/8 agonist Drugs 0.000 claims description 5
- 102100024324 Toll-like receptor 3 Human genes 0.000 claims description 5
- 239000000556 agonist Substances 0.000 claims description 5
- 102000010789 Interleukin-2 Receptors Human genes 0.000 claims description 4
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 4
- 101150056647 TNFRSF4 gene Proteins 0.000 claims description 4
- 229960002986 dinoprostone Drugs 0.000 claims description 3
- XEYBRNLFEZDVAW-ARSRFYASSA-N dinoprostone Chemical compound CCCCC[C@H](O)\C=C\[C@H]1[C@H](O)CC(=O)[C@@H]1C\C=C/CCCC(O)=O XEYBRNLFEZDVAW-ARSRFYASSA-N 0.000 claims description 3
- XEYBRNLFEZDVAW-UHFFFAOYSA-N prostaglandin E2 Natural products CCCCCC(O)C=CC1C(O)CC(=O)C1CC=CCCCC(O)=O XEYBRNLFEZDVAW-UHFFFAOYSA-N 0.000 claims description 3
- 230000035800 maturation Effects 0.000 claims description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 claims 2
- 108010092372 Granulocyte-Macrophage Colony-Stimulating Factor Receptors Proteins 0.000 claims 1
- 102100020873 Interleukin-2 Human genes 0.000 claims 1
- 102100040678 Programmed cell death protein 1 Human genes 0.000 claims 1
- 108091008874 T cell receptors Proteins 0.000 abstract description 226
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 abstract description 196
- 239000013604 expression vector Substances 0.000 abstract description 38
- 150000001413 amino acids Chemical class 0.000 description 65
- 239000013598 vector Substances 0.000 description 47
- 101000814512 Homo sapiens X antigen family member 1 Proteins 0.000 description 36
- 102100039490 X antigen family member 1 Human genes 0.000 description 36
- 230000014509 gene expression Effects 0.000 description 32
- 238000003501 co-culture Methods 0.000 description 25
- 230000028327 secretion Effects 0.000 description 25
- 102100037850 Interferon gamma Human genes 0.000 description 24
- 150000007523 nucleic acids Chemical group 0.000 description 22
- 108020004414 DNA Proteins 0.000 description 19
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 17
- 108090000765 processed proteins & peptides Proteins 0.000 description 17
- 102100040485 HLA class II histocompatibility antigen, DRB1 beta chain Human genes 0.000 description 16
- 108010039343 HLA-DRB1 Chains Proteins 0.000 description 16
- 210000000265 leukocyte Anatomy 0.000 description 16
- 101710122229 Epstein-Barr nuclear antigen 6 Proteins 0.000 description 15
- 230000021194 SRP-dependent cotranslational protein targeting to membrane Effects 0.000 description 15
- 201000011510 cancer Diseases 0.000 description 14
- 210000001163 endosome Anatomy 0.000 description 14
- 238000011534 incubation Methods 0.000 description 14
- 238000002955 isolation Methods 0.000 description 14
- 239000000203 mixture Substances 0.000 description 14
- 102000004127 Cytokines Human genes 0.000 description 13
- 108090000695 Cytokines Proteins 0.000 description 13
- 108091028043 Nucleic acid sequence Proteins 0.000 description 13
- 210000003712 lysosome Anatomy 0.000 description 13
- 230000001868 lysosomic effect Effects 0.000 description 13
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 12
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 11
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 11
- 102000004196 processed proteins & peptides Human genes 0.000 description 11
- 238000011068 loading method Methods 0.000 description 10
- 230000035772 mutation Effects 0.000 description 10
- 239000013612 plasmid Substances 0.000 description 10
- 241000880493 Leptailurus serval Species 0.000 description 9
- XDMCWZFLLGVIID-SXPRBRBTSA-N O-(3-O-D-galactosyl-N-acetyl-beta-D-galactosaminyl)-L-serine Chemical compound CC(=O)N[C@H]1[C@H](OC[C@H]([NH3+])C([O-])=O)O[C@H](CO)[C@H](O)[C@@H]1OC1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 XDMCWZFLLGVIID-SXPRBRBTSA-N 0.000 description 9
- 108010093581 aspartyl-proline Proteins 0.000 description 9
- 108010078144 glutaminyl-glycine Proteins 0.000 description 9
- 108020004705 Codon Proteins 0.000 description 8
- 238000002965 ELISA Methods 0.000 description 8
- 102000000588 Interleukin-2 Human genes 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 210000003719 b-lymphocyte Anatomy 0.000 description 8
- 108020004999 messenger RNA Proteins 0.000 description 8
- 108020004707 nucleic acids Proteins 0.000 description 8
- 102000039446 nucleic acids Human genes 0.000 description 8
- 238000001890 transfection Methods 0.000 description 8
- 102100028496 Galactocerebrosidase Human genes 0.000 description 7
- 102000043131 MHC class II family Human genes 0.000 description 7
- 108091054438 MHC class II family Proteins 0.000 description 7
- 239000004480 active ingredient Substances 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 230000014102 antigen processing and presentation of exogenous peptide antigen via MHC class I Effects 0.000 description 7
- 230000002209 hydrophobic effect Effects 0.000 description 7
- 238000002826 magnetic-activated cell sorting Methods 0.000 description 7
- 230000037452 priming Effects 0.000 description 7
- 108010061238 threonyl-glycine Proteins 0.000 description 7
- 230000010474 transient expression Effects 0.000 description 7
- 210000004881 tumor cell Anatomy 0.000 description 7
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 6
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 6
- 102100039283 Hyaluronidase-1 Human genes 0.000 description 6
- 108010002350 Interleukin-2 Proteins 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 6
- 108700026244 Open Reading Frames Proteins 0.000 description 6
- 102100040247 Tumor necrosis factor Human genes 0.000 description 6
- 108010092854 aspartyllysine Proteins 0.000 description 6
- 229910052804 chromium Inorganic materials 0.000 description 6
- 239000011651 chromium Substances 0.000 description 6
- 239000002299 complementary DNA Substances 0.000 description 6
- 239000003814 drug Substances 0.000 description 6
- 230000003993 interaction Effects 0.000 description 6
- 239000008194 pharmaceutical composition Substances 0.000 description 6
- 238000003757 reverse transcription PCR Methods 0.000 description 6
- 238000011282 treatment Methods 0.000 description 6
- PRXCTTWKGJAPMT-ZLUOBGJFSA-N Cys-Ala-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O PRXCTTWKGJAPMT-ZLUOBGJFSA-N 0.000 description 5
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 5
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 5
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 5
- -1 SSX-4 Proteins 0.000 description 5
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 5
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 5
- 108010077245 asparaginyl-proline Proteins 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 210000000182 cd11c+cd123- dc Anatomy 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 201000010099 disease Diseases 0.000 description 5
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 238000000684 flow cytometry Methods 0.000 description 5
- 108010050848 glycylleucine Proteins 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 238000012216 screening Methods 0.000 description 5
- 230000008685 targeting Effects 0.000 description 5
- WQVYAWIMAWTGMW-ZLUOBGJFSA-N Ala-Asp-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N WQVYAWIMAWTGMW-ZLUOBGJFSA-N 0.000 description 4
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 4
- 102100031317 Alpha-N-acetylgalactosaminidase Human genes 0.000 description 4
- OGSQONVYSTZIJB-WDSOQIARSA-N Arg-Leu-Trp Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCN=C(N)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OGSQONVYSTZIJB-WDSOQIARSA-N 0.000 description 4
- 102100022146 Arylsulfatase A Human genes 0.000 description 4
- 102100031491 Arylsulfatase B Human genes 0.000 description 4
- 102100033890 Arylsulfatase G Human genes 0.000 description 4
- 101150013553 CD40 gene Proteins 0.000 description 4
- 102100036495 Di-N-acetylchitobiase Human genes 0.000 description 4
- 108010042681 Galactosylceramidase Proteins 0.000 description 4
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 4
- 102100024025 Heparanase Human genes 0.000 description 4
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 4
- 102100021081 Hyaluronidase-4 Human genes 0.000 description 4
- 108010065920 Insulin Lispro Proteins 0.000 description 4
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 4
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 4
- JVTYXRRFZCEPPK-RHYQMDGZSA-N Leu-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC(C)C)N)O JVTYXRRFZCEPPK-RHYQMDGZSA-N 0.000 description 4
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 4
- 102100033342 Lysosomal acid glucosylceramidase Human genes 0.000 description 4
- 206010027476 Metastases Diseases 0.000 description 4
- 102100027661 N-sulphoglucosamine sulphohydrolase Human genes 0.000 description 4
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 4
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 4
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 4
- JEHPKECJCALLRW-CUJWVEQBSA-N Ser-His-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEHPKECJCALLRW-CUJWVEQBSA-N 0.000 description 4
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 4
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 4
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 4
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 4
- 102000003425 Tyrosinase Human genes 0.000 description 4
- 108060008724 Tyrosinase Proteins 0.000 description 4
- BZOSBRIDWSSTFN-AVGNSLFASA-N Val-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N BZOSBRIDWSSTFN-AVGNSLFASA-N 0.000 description 4
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 108010016616 cysteinylglycine Proteins 0.000 description 4
- 238000004520 electroporation Methods 0.000 description 4
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010089804 glycyl-threonine Proteins 0.000 description 4
- 238000002347 injection Methods 0.000 description 4
- 239000007924 injection Substances 0.000 description 4
- 108010000761 leucylarginine Proteins 0.000 description 4
- 230000009401 metastasis Effects 0.000 description 4
- 230000007935 neutral effect Effects 0.000 description 4
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 4
- 230000004936 stimulating effect Effects 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 210000001550 testis Anatomy 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- 238000013518 transcription Methods 0.000 description 4
- 230000035897 transcription Effects 0.000 description 4
- 108010073969 valyllysine Proteins 0.000 description 4
- SSOORFWOBGFTHL-OTEJMHTDSA-N (4S)-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-5-carbamimidamido-1-[[(2S)-5-carbamimidamido-1-[[(1S)-4-carbamimidamido-1-carboxybutyl]amino]-1-oxopentan-2-yl]amino]-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-1-oxohexan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-[[(2S)-2-[[(2S)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SSOORFWOBGFTHL-OTEJMHTDSA-N 0.000 description 3
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 3
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 3
- DRARURMRLANNLS-GUBZILKMSA-N Ala-Met-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O DRARURMRLANNLS-GUBZILKMSA-N 0.000 description 3
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 3
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 3
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 3
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 3
- BFDDUDQCPJWQRQ-IHRRRGAJSA-N Arg-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O BFDDUDQCPJWQRQ-IHRRRGAJSA-N 0.000 description 3
- VYLVOMUVLMGCRF-ZLUOBGJFSA-N Asn-Asp-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VYLVOMUVLMGCRF-ZLUOBGJFSA-N 0.000 description 3
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 3
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 3
- 102100035526 B melanoma antigen 1 Human genes 0.000 description 3
- 101710089436 Cathepsin 7 Proteins 0.000 description 3
- 102100037328 Chitotriosidase-1 Human genes 0.000 description 3
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 3
- 102100021654 Extracellular sulfatase Sulf-2 Human genes 0.000 description 3
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 3
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 3
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 3
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 3
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 3
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 3
- MTBIKIMYHUWBRX-QWRGUYRKSA-N Gly-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN MTBIKIMYHUWBRX-QWRGUYRKSA-N 0.000 description 3
- GAAHQHNCMIAYEX-UWVGGRQHSA-N Gly-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GAAHQHNCMIAYEX-UWVGGRQHSA-N 0.000 description 3
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 3
- AYUOWUNWZGTNKB-ULQDDVLXSA-N His-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AYUOWUNWZGTNKB-ULQDDVLXSA-N 0.000 description 3
- 101000874316 Homo sapiens B melanoma antigen 1 Proteins 0.000 description 3
- 101000820626 Homo sapiens Extracellular sulfatase Sulf-2 Proteins 0.000 description 3
- 101000860395 Homo sapiens Galactocerebrosidase Proteins 0.000 description 3
- 101000962530 Homo sapiens Hyaluronidase-1 Proteins 0.000 description 3
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 3
- 101001057156 Homo sapiens Melanoma-associated antigen C2 Proteins 0.000 description 3
- 101000829992 Homo sapiens N-acetylglucosamine-6-sulfatase Proteins 0.000 description 3
- 101710199679 Hyaluronidase-1 Proteins 0.000 description 3
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 3
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 3
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 3
- IIKJNQWOQIWWMR-CIUDSAMLSA-N Leu-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N IIKJNQWOQIWWMR-CIUDSAMLSA-N 0.000 description 3
- PPBKJAQJAUHZKX-SRVKXCTJSA-N Leu-Cys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC(C)C PPBKJAQJAUHZKX-SRVKXCTJSA-N 0.000 description 3
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 3
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 3
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 3
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 3
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 3
- CANPXOLVTMKURR-WEDXCCLWSA-N Lys-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN CANPXOLVTMKURR-WEDXCCLWSA-N 0.000 description 3
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 3
- 102100027252 Melanoma-associated antigen C2 Human genes 0.000 description 3
- SODXFJOPSCXOHE-IHRRRGAJSA-N Met-Leu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O SODXFJOPSCXOHE-IHRRRGAJSA-N 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 3
- 102100023282 N-acetylglucosamine-6-sulfatase Human genes 0.000 description 3
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 3
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 3
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 3
- KIGGUSRFHJCIEJ-DCAQKATOSA-N Pro-Asp-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O KIGGUSRFHJCIEJ-DCAQKATOSA-N 0.000 description 3
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 3
- 108010003201 RGH 0205 Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 3
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 3
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 3
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 3
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 3
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 3
- 101710143177 Synaptonemal complex protein 1 Proteins 0.000 description 3
- 102100036234 Synaptonemal complex protein 1 Human genes 0.000 description 3
- RZAGEHHVNYESNR-RNXOBYDBSA-N Tyr-Trp-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RZAGEHHVNYESNR-RNXOBYDBSA-N 0.000 description 3
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 3
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 3
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 3
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 3
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 3
- 108010030291 alpha-Galactosidase Proteins 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 238000013459 approach Methods 0.000 description 3
- 108010038633 aspartylglutamate Proteins 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 210000004748 cultured cell Anatomy 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 238000001415 gene therapy Methods 0.000 description 3
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 3
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 3
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 3
- 108010015792 glycyllysine Proteins 0.000 description 3
- 108010081551 glycylphenylalanine Proteins 0.000 description 3
- 108010077515 glycylproline Proteins 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 108010018006 histidylserine Proteins 0.000 description 3
- 230000002163 immunogen Effects 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 210000002540 macrophage Anatomy 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- PUPNJSIFIXXJCH-UHFFFAOYSA-N n-(4-hydroxyphenyl)-2-(1,1,3-trioxo-1,2-benzothiazol-2-yl)acetamide Chemical compound C1=CC(O)=CC=C1NC(=O)CN1S(=O)(=O)C2=CC=CC=C2C1=O PUPNJSIFIXXJCH-UHFFFAOYSA-N 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 210000003289 regulatory T cell Anatomy 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 235000002020 sage Nutrition 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 230000011664 signaling Effects 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 230000010473 stable expression Effects 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 3
- 108010020532 tyrosyl-proline Proteins 0.000 description 3
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 2
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 2
- FBFJOZZTIXSPPR-UHFFFAOYSA-N 1-(4-aminobutyl)-2-(ethoxymethyl)imidazo[4,5-c]quinolin-4-amine Chemical compound C1=CC=CC2=C(N(C(COCC)=N3)CCCCN)C3=C(N)N=C21 FBFJOZZTIXSPPR-UHFFFAOYSA-N 0.000 description 2
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 2
- 108010055851 Acetylglucosaminidase Proteins 0.000 description 2
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 2
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 2
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 2
- LNNSWWRRYJLGNI-NAKRPEOUSA-N Ala-Ile-Val Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O LNNSWWRRYJLGNI-NAKRPEOUSA-N 0.000 description 2
- VHVVPYOJIIQCKS-QEJZJMRPSA-N Ala-Leu-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHVVPYOJIIQCKS-QEJZJMRPSA-N 0.000 description 2
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 2
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 2
- JJHBEVZAZXZREW-LFSVMHDDSA-N Ala-Thr-Phe Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O JJHBEVZAZXZREW-LFSVMHDDSA-N 0.000 description 2
- LFFOJBOTZUWINF-ZANVPECISA-N Ala-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O)=CNC2=C1 LFFOJBOTZUWINF-ZANVPECISA-N 0.000 description 2
- 102100035028 Alpha-L-iduronidase Human genes 0.000 description 2
- 102100034561 Alpha-N-acetylglucosaminidase Human genes 0.000 description 2
- 102100038910 Alpha-enolase Human genes 0.000 description 2
- 102100026277 Alpha-galactosidase A Human genes 0.000 description 2
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 2
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 2
- NKNILFJYKKHBKE-WPRPVWTQSA-N Arg-Gly-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NKNILFJYKKHBKE-WPRPVWTQSA-N 0.000 description 2
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 2
- JQHASVQBAKRJKD-GUBZILKMSA-N Arg-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JQHASVQBAKRJKD-GUBZILKMSA-N 0.000 description 2
- LYJXHXGPWDTLKW-HJGDQZAQSA-N Arg-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O LYJXHXGPWDTLKW-HJGDQZAQSA-N 0.000 description 2
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 2
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 2
- 101710115232 Arylsulfatase G Proteins 0.000 description 2
- QYXNFROWLZPWPC-FXQIFTODSA-N Asn-Glu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QYXNFROWLZPWPC-FXQIFTODSA-N 0.000 description 2
- SUEIIIFUBHDCCS-PBCZWWQYSA-N Asn-His-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SUEIIIFUBHDCCS-PBCZWWQYSA-N 0.000 description 2
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 2
- ZMUQQMGITUJQTI-CIUDSAMLSA-N Asn-Leu-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZMUQQMGITUJQTI-CIUDSAMLSA-N 0.000 description 2
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 2
- ZVUMKOMKQCANOM-AVGNSLFASA-N Asn-Phe-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVUMKOMKQCANOM-AVGNSLFASA-N 0.000 description 2
- QXOPPIDJKPEKCW-GUBZILKMSA-N Asn-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O QXOPPIDJKPEKCW-GUBZILKMSA-N 0.000 description 2
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 2
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 2
- NPZJLGMWMDNQDD-GHCJXIJMSA-N Asn-Ser-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NPZJLGMWMDNQDD-GHCJXIJMSA-N 0.000 description 2
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 2
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 2
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 2
- JUWISGAGWSDGDH-KKUMJFAQSA-N Asp-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=CC=C1 JUWISGAGWSDGDH-KKUMJFAQSA-N 0.000 description 2
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 2
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 102100026189 Beta-galactosidase Human genes 0.000 description 2
- 101710195294 Beta-galactosidase 1 Proteins 0.000 description 2
- 102100026031 Beta-glucuronidase Human genes 0.000 description 2
- 102100035793 CD83 antigen Human genes 0.000 description 2
- 102100024940 Cathepsin K Human genes 0.000 description 2
- 108090000624 Cathepsin L Proteins 0.000 description 2
- 102000004172 Cathepsin L Human genes 0.000 description 2
- 108090000613 Cathepsin S Proteins 0.000 description 2
- 102100035654 Cathepsin S Human genes 0.000 description 2
- 102000005600 Cathepsins Human genes 0.000 description 2
- 108010084457 Cathepsins Proteins 0.000 description 2
- 108010036867 Cerebroside-Sulfatase Proteins 0.000 description 2
- 102100038731 Chitinase-3-like protein 2 Human genes 0.000 description 2
- 108010022172 Chitinases Proteins 0.000 description 2
- 102000012286 Chitinases Human genes 0.000 description 2
- 108010026719 Chondroitin Lyases Proteins 0.000 description 2
- 102000018963 Chondroitin Lyases Human genes 0.000 description 2
- 108090000819 Chondroitin-sulfate-ABC endolyases Proteins 0.000 description 2
- 102000037716 Chondroitin-sulfate-ABC endolyases Human genes 0.000 description 2
- 101710106625 Chondroitinase-AC Proteins 0.000 description 2
- 102100034665 Clathrin heavy chain 2 Human genes 0.000 description 2
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 2
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 2
- WXKWQSDHEXKKNC-ZKWXMUAHSA-N Cys-Asp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N WXKWQSDHEXKKNC-ZKWXMUAHSA-N 0.000 description 2
- KCPOQGRVVXYLAC-KKUMJFAQSA-N Cys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CS)N KCPOQGRVVXYLAC-KKUMJFAQSA-N 0.000 description 2
- DRXOWZZHCSBUOI-YJRXYDGGSA-N Cys-Thr-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CS)N)O DRXOWZZHCSBUOI-YJRXYDGGSA-N 0.000 description 2
- 102100027819 Cytosolic beta-glucosidase Human genes 0.000 description 2
- 102100022166 E3 ubiquitin-protein ligase NEURL1 Human genes 0.000 description 2
- 101710179962 Endo-beta-N-acetylglucosaminidase F1 Proteins 0.000 description 2
- 101710179963 Endo-beta-N-acetylglucosaminidase F3 Proteins 0.000 description 2
- 108010008655 Epstein-Barr Virus Nuclear Antigens Proteins 0.000 description 2
- DLOHWQXXGMEZDW-CIUDSAMLSA-N Gln-Arg-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DLOHWQXXGMEZDW-CIUDSAMLSA-N 0.000 description 2
- AAOBFSKXAVIORT-GUBZILKMSA-N Gln-Asn-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O AAOBFSKXAVIORT-GUBZILKMSA-N 0.000 description 2
- PXAFHUATEHLECW-GUBZILKMSA-N Gln-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N PXAFHUATEHLECW-GUBZILKMSA-N 0.000 description 2
- LVSYIKGMLRHKME-IUCAKERBSA-N Gln-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N LVSYIKGMLRHKME-IUCAKERBSA-N 0.000 description 2
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 2
- FFVXLVGUJBCKRX-UKJIMTQDSA-N Gln-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCC(=O)N)N FFVXLVGUJBCKRX-UKJIMTQDSA-N 0.000 description 2
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 2
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 2
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 2
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 2
- UXXIVIQGOODKQC-NUMRIWBASA-N Gln-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UXXIVIQGOODKQC-NUMRIWBASA-N 0.000 description 2
- YRHZWVKUFWCEPW-GLLZPBPUSA-N Gln-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YRHZWVKUFWCEPW-GLLZPBPUSA-N 0.000 description 2
- ARYKRXHBIPLULY-XKBZYTNZSA-N Gln-Thr-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ARYKRXHBIPLULY-XKBZYTNZSA-N 0.000 description 2
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 2
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 2
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 2
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 2
- RBXSZQRSEGYDFG-GUBZILKMSA-N Glu-Lys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O RBXSZQRSEGYDFG-GUBZILKMSA-N 0.000 description 2
- VNCNWQPIQYAMAK-ACZMJKKPSA-N Glu-Ser-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O VNCNWQPIQYAMAK-ACZMJKKPSA-N 0.000 description 2
- XIJOPMSILDNVNJ-ZVZYQTTQSA-N Glu-Val-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XIJOPMSILDNVNJ-ZVZYQTTQSA-N 0.000 description 2
- 108010017544 Glucosylceramidase Proteins 0.000 description 2
- 108010060309 Glucuronidase Proteins 0.000 description 2
- 102000053187 Glucuronidase Human genes 0.000 description 2
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 2
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 2
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 2
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 2
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 2
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 2
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 2
- 102100028640 HLA class II histocompatibility antigen, DR beta 5 chain Human genes 0.000 description 2
- 102000025850 HLA-A2 Antigen Human genes 0.000 description 2
- 108010074032 HLA-A2 Antigen Proteins 0.000 description 2
- 108010004141 HLA-B35 Antigen Proteins 0.000 description 2
- 108010016996 HLA-DRB5 Chains Proteins 0.000 description 2
- 102100026973 Heat shock protein 75 kDa, mitochondrial Human genes 0.000 description 2
- 108010053317 Hexosaminidase A Proteins 0.000 description 2
- 102000016871 Hexosaminidase A Human genes 0.000 description 2
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 2
- FDQYIRHBVVUTJF-ZETCQYMHSA-N His-Gly-Gly Chemical compound [O-]C(=O)CNC(=O)CNC(=O)[C@@H]([NH3+])CC1=CN=CN1 FDQYIRHBVVUTJF-ZETCQYMHSA-N 0.000 description 2
- 101001019502 Homo sapiens Alpha-L-iduronidase Proteins 0.000 description 2
- 101000923070 Homo sapiens Arylsulfatase B Proteins 0.000 description 2
- 101000925538 Homo sapiens Arylsulfatase G Proteins 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000765010 Homo sapiens Beta-galactosidase Proteins 0.000 description 2
- 101000933465 Homo sapiens Beta-glucuronidase Proteins 0.000 description 2
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 2
- 101000883325 Homo sapiens Chitinase-3-like protein 2 Proteins 0.000 description 2
- 101000879661 Homo sapiens Chitotriosidase-1 Proteins 0.000 description 2
- 101000928786 Homo sapiens Di-N-acetylchitobiase Proteins 0.000 description 2
- 101000973232 Homo sapiens E3 ubiquitin-protein ligase NEURL1 Proteins 0.000 description 2
- 101001047819 Homo sapiens Heparanase Proteins 0.000 description 2
- 101001041120 Homo sapiens Hyaluronidase-4 Proteins 0.000 description 2
- 101000604998 Homo sapiens Lysosome-associated membrane glycoprotein 3 Proteins 0.000 description 2
- 101000651201 Homo sapiens N-sulphoglucosamine sulphohydrolase Proteins 0.000 description 2
- 101000832248 Homo sapiens STAM-binding protein Proteins 0.000 description 2
- 101710199677 Hyaluronidase-4 Proteins 0.000 description 2
- 102100029199 Iduronate 2-sulfatase Human genes 0.000 description 2
- KMBPQYKVZBMRMH-PEFMBERDSA-N Ile-Gln-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O KMBPQYKVZBMRMH-PEFMBERDSA-N 0.000 description 2
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 2
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 2
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 2
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 2
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 108010002586 Interleukin-7 Proteins 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 2
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 2
- 102100025640 Lactase-like protein Human genes 0.000 description 2
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 2
- DUBAVOVZNZKEQQ-AVGNSLFASA-N Leu-Arg-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CCCN=C(N)N DUBAVOVZNZKEQQ-AVGNSLFASA-N 0.000 description 2
- XVSJMWYYLHPDKY-DCAQKATOSA-N Leu-Asp-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O XVSJMWYYLHPDKY-DCAQKATOSA-N 0.000 description 2
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 2
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 2
- IFMPDNRWZZEZSL-SRVKXCTJSA-N Leu-Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O IFMPDNRWZZEZSL-SRVKXCTJSA-N 0.000 description 2
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 2
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 2
- POMXSEDNUXYPGK-IHRRRGAJSA-N Leu-Met-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N POMXSEDNUXYPGK-IHRRRGAJSA-N 0.000 description 2
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 2
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 2
- MAXILRZVORNXBE-PMVMPFDFSA-N Leu-Phe-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 MAXILRZVORNXBE-PMVMPFDFSA-N 0.000 description 2
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 2
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- LJADEBULDNKJNK-IHRRRGAJSA-N Lys-Leu-Val Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LJADEBULDNKJNK-IHRRRGAJSA-N 0.000 description 2
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 2
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 2
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 2
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 2
- VHTOGMKQXXJOHG-RHYQMDGZSA-N Lys-Thr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VHTOGMKQXXJOHG-RHYQMDGZSA-N 0.000 description 2
- 102100033448 Lysosomal alpha-glucosidase Human genes 0.000 description 2
- 102100038212 Lysosome-associated membrane glycoprotein 5 Human genes 0.000 description 2
- 102000043129 MHC class I family Human genes 0.000 description 2
- 108091054437 MHC class I family Proteins 0.000 description 2
- 102000000440 Melanoma-associated antigen Human genes 0.000 description 2
- 108050008953 Melanoma-associated antigen Proteins 0.000 description 2
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 2
- WDTLNWHPIPCMMP-AVGNSLFASA-N Met-Arg-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O WDTLNWHPIPCMMP-AVGNSLFASA-N 0.000 description 2
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 2
- XOMXAVJBLRROMC-IHRRRGAJSA-N Met-Asp-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOMXAVJBLRROMC-IHRRRGAJSA-N 0.000 description 2
- SXWQMBGNFXAGAT-FJXKBIBVSA-N Met-Gly-Thr Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SXWQMBGNFXAGAT-FJXKBIBVSA-N 0.000 description 2
- PHKBGZKVOJCIMZ-SRVKXCTJSA-N Met-Pro-Arg Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PHKBGZKVOJCIMZ-SRVKXCTJSA-N 0.000 description 2
- MFDDVIJCQYOOES-GUBZILKMSA-N Met-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N MFDDVIJCQYOOES-GUBZILKMSA-N 0.000 description 2
- 101000906941 Mus musculus Chitinase-like protein 3 Proteins 0.000 description 2
- 108010027520 N-Acetylgalactosamine-4-Sulfatase Proteins 0.000 description 2
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 2
- 108010006140 N-sulfoglucosamine sulfohydrolase Proteins 0.000 description 2
- 241001631646 Papillomaviridae Species 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- LGBVMDMZZFYSFW-HJWJTTGWSA-N Phe-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CC=CC=C1)N LGBVMDMZZFYSFW-HJWJTTGWSA-N 0.000 description 2
- AGYXCMYVTBYGCT-ULQDDVLXSA-N Phe-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O AGYXCMYVTBYGCT-ULQDDVLXSA-N 0.000 description 2
- MECSIDWUTYRHRJ-KKUMJFAQSA-N Phe-Asn-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O MECSIDWUTYRHRJ-KKUMJFAQSA-N 0.000 description 2
- OJUMUUXGSXUZJZ-SRVKXCTJSA-N Phe-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OJUMUUXGSXUZJZ-SRVKXCTJSA-N 0.000 description 2
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 2
- BFYHIHGIHGROAT-HTUGSXCWSA-N Phe-Glu-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFYHIHGIHGROAT-HTUGSXCWSA-N 0.000 description 2
- IWZRODDWOSIXPZ-IRXDYDNUSA-N Phe-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 IWZRODDWOSIXPZ-IRXDYDNUSA-N 0.000 description 2
- NJJBATPLUQHRBM-IHRRRGAJSA-N Phe-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CO)C(=O)O NJJBATPLUQHRBM-IHRRRGAJSA-N 0.000 description 2
- ZLAKUZDMKVKFAI-JYJNAYRXSA-N Phe-Pro-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O ZLAKUZDMKVKFAI-JYJNAYRXSA-N 0.000 description 2
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 2
- UMIHVJQSXFWWMW-JBACZVJFSA-N Phe-Trp-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UMIHVJQSXFWWMW-JBACZVJFSA-N 0.000 description 2
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 2
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 2
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 2
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 2
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 2
- XZONQWUEBAFQPO-HJGDQZAQSA-N Pro-Gln-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZONQWUEBAFQPO-HJGDQZAQSA-N 0.000 description 2
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 2
- BODDREDDDRZUCF-QTKMDUPCSA-N Pro-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@@H]2CCCN2)O BODDREDDDRZUCF-QTKMDUPCSA-N 0.000 description 2
- 102100030122 Protein O-GlcNAcase Human genes 0.000 description 2
- 102100024472 STAM-binding protein Human genes 0.000 description 2
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 2
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 2
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 2
- YMAWDPHQVABADW-CIUDSAMLSA-N Ser-Gln-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O YMAWDPHQVABADW-CIUDSAMLSA-N 0.000 description 2
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 2
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 2
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 2
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 2
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 2
- BUYHXYIUQUBEQP-AVGNSLFASA-N Ser-Phe-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CO)N BUYHXYIUQUBEQP-AVGNSLFASA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 2
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 2
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 2
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 2
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 2
- 102100028760 Sialidase-1 Human genes 0.000 description 2
- 101710128612 Sialidase-1 Proteins 0.000 description 2
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 2
- GNHRVXYZKWSJTF-HJGDQZAQSA-N Thr-Asp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GNHRVXYZKWSJTF-HJGDQZAQSA-N 0.000 description 2
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 2
- XDARBNMYXKUFOJ-GSSVUCPTSA-N Thr-Asp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDARBNMYXKUFOJ-GSSVUCPTSA-N 0.000 description 2
- GARULAKWZGFIKC-RWRJDSDZSA-N Thr-Gln-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GARULAKWZGFIKC-RWRJDSDZSA-N 0.000 description 2
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 2
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 2
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 2
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 2
- WNQJTLATMXYSEL-OEAJRASXSA-N Thr-Phe-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WNQJTLATMXYSEL-OEAJRASXSA-N 0.000 description 2
- 102000017340 Tissue alpha-L-fucosidases Human genes 0.000 description 2
- 108050005351 Tissue alpha-L-fucosidases Proteins 0.000 description 2
- 101710204707 Transforming growth factor-beta receptor-associated protein 1 Proteins 0.000 description 2
- SSNGFWKILJLTQM-QEJZJMRPSA-N Trp-Gln-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SSNGFWKILJLTQM-QEJZJMRPSA-N 0.000 description 2
- JTMZSIRTZKLBOA-NWLDYVSISA-N Trp-Thr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O JTMZSIRTZKLBOA-NWLDYVSISA-N 0.000 description 2
- RPTAWXPQXXCUGL-OYDLWJJNSA-N Trp-Trp-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O RPTAWXPQXXCUGL-OYDLWJJNSA-N 0.000 description 2
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 2
- ARPONUQDNWLXOZ-KKUMJFAQSA-N Tyr-Gln-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ARPONUQDNWLXOZ-KKUMJFAQSA-N 0.000 description 2
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 2
- AVIQBBOOTZENLH-KKUMJFAQSA-N Tyr-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AVIQBBOOTZENLH-KKUMJFAQSA-N 0.000 description 2
- GYKDRHDMGQUZPU-MGHWNKPDSA-N Tyr-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GYKDRHDMGQUZPU-MGHWNKPDSA-N 0.000 description 2
- FMXFHNSFABRVFZ-BZSNNMDCSA-N Tyr-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FMXFHNSFABRVFZ-BZSNNMDCSA-N 0.000 description 2
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 2
- GBESYURLQOYWLU-LAEOZQHASA-N Val-Glu-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GBESYURLQOYWLU-LAEOZQHASA-N 0.000 description 2
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 2
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 2
- APEBUJBRGCMMHP-HJWJTTGWSA-N Val-Ile-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 APEBUJBRGCMMHP-HJWJTTGWSA-N 0.000 description 2
- AGXGCFSECFQMKB-NHCYSSNCSA-N Val-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N AGXGCFSECFQMKB-NHCYSSNCSA-N 0.000 description 2
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 2
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 2
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 2
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 2
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 2
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 2
- GTACFKZDQFTVAI-STECZYCISA-N Val-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 GTACFKZDQFTVAI-STECZYCISA-N 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 2
- 230000000735 allogeneic effect Effects 0.000 description 2
- 102000005840 alpha-Galactosidase Human genes 0.000 description 2
- 108010028144 alpha-Glucosidases Proteins 0.000 description 2
- 108010015684 alpha-N-Acetylgalactosaminidase Proteins 0.000 description 2
- 108010009380 alpha-N-acetyl-D-glucosaminidase Proteins 0.000 description 2
- 230000000259 anti-tumor effect Effects 0.000 description 2
- 108010008355 arginyl-glutamine Proteins 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 230000000711 cancerogenic effect Effects 0.000 description 2
- 231100000315 carcinogenic Toxicity 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 108010033380 cathepsin-6 Proteins 0.000 description 2
- 238000002659 cell therapy Methods 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 108010048429 chondroitinase B Proteins 0.000 description 2
- 230000001684 chronic effect Effects 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 2
- 108010010147 glycylglutamine Proteins 0.000 description 2
- 108010020688 glycylhistidine Proteins 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 210000002443 helper t lymphocyte Anatomy 0.000 description 2
- 108010037536 heparanase Proteins 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 108010085325 histidylproline Proteins 0.000 description 2
- 102000053262 human LAMP1 Human genes 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 239000007972 injectable composition Substances 0.000 description 2
- 230000002452 interceptive effect Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 230000002147 killing effect Effects 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 108010009298 lysylglutamic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 210000003071 memory t lymphocyte Anatomy 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 230000002085 persistent effect Effects 0.000 description 2
- 108010084525 phenylalanyl-phenylalanyl-glycine Proteins 0.000 description 2
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 2
- 229940115272 polyinosinic:polycytidylic acid Drugs 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 108010090894 prolylleucine Proteins 0.000 description 2
- 230000002285 radioactive effect Effects 0.000 description 2
- 230000007420 reactivation Effects 0.000 description 2
- 230000009257 reactivity Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 108010026333 seryl-proline Proteins 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 239000013605 shuttle vector Substances 0.000 description 2
- 238000010186 staining Methods 0.000 description 2
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 238000012250 transgenic expression Methods 0.000 description 2
- 230000005945 translocation Effects 0.000 description 2
- 238000012795 verification Methods 0.000 description 2
- ISJKIHHTPAQLLW-TUFLPTIASA-N (2S)-2-[[(2S)-3-(4-hydroxyphenyl)-2-[[(2S)-1-[(2S)-pyrrolidine-2-carbonyl]pyrrolidine-2-carbonyl]amino]propanoyl]amino]-4-methylpentanoic acid Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ISJKIHHTPAQLLW-TUFLPTIASA-N 0.000 description 1
- MSWZFWKMSRAUBD-IVMDWMLBSA-N 2-amino-2-deoxy-D-glucopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O MSWZFWKMSRAUBD-IVMDWMLBSA-N 0.000 description 1
- 102000002627 4-1BB Ligand Human genes 0.000 description 1
- 108010082808 4-1BB Ligand Proteins 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- GOZMBJCYMQQACI-UHFFFAOYSA-N 6,7-dimethyl-3-[[methyl-[2-[methyl-[[1-[3-(trifluoromethyl)phenyl]indol-3-yl]methyl]amino]ethyl]amino]methyl]chromen-4-one;dihydrochloride Chemical compound Cl.Cl.C=1OC2=CC(C)=C(C)C=C2C(=O)C=1CN(C)CCN(C)CC(C1=CC=CC=C11)=CN1C1=CC=CC(C(F)(F)F)=C1 GOZMBJCYMQQACI-UHFFFAOYSA-N 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- PBAMJJXWDQXOJA-FXQIFTODSA-N Ala-Asp-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PBAMJJXWDQXOJA-FXQIFTODSA-N 0.000 description 1
- WXERCAHAIKMTKX-ZLUOBGJFSA-N Ala-Asp-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O WXERCAHAIKMTKX-ZLUOBGJFSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 1
- ROLXPVQSRCPVGK-XDTLVQLUSA-N Ala-Glu-Tyr Chemical compound N[C@@H](C)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O ROLXPVQSRCPVGK-XDTLVQLUSA-N 0.000 description 1
- AAXVGJXZKHQQHD-LSJOCFKGSA-N Ala-His-Met Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N AAXVGJXZKHQQHD-LSJOCFKGSA-N 0.000 description 1
- QQACQIHVWCVBBR-GVARAGBVSA-N Ala-Ile-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QQACQIHVWCVBBR-GVARAGBVSA-N 0.000 description 1
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 1
- NOGFDULFCFXBHB-CIUDSAMLSA-N Ala-Leu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N NOGFDULFCFXBHB-CIUDSAMLSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- ZBLQIYPCUWZSRZ-QEJZJMRPSA-N Ala-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 ZBLQIYPCUWZSRZ-QEJZJMRPSA-N 0.000 description 1
- SGFBVLBKDSXGAP-GKCIPKSASA-N Ala-Phe-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N SGFBVLBKDSXGAP-GKCIPKSASA-N 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- NUBPTCMEOCKWDO-DCAQKATOSA-N Arg-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N NUBPTCMEOCKWDO-DCAQKATOSA-N 0.000 description 1
- MAISCYVJLBBRNU-DCAQKATOSA-N Arg-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N MAISCYVJLBBRNU-DCAQKATOSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 1
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 1
- OGUPCHKBOKJFMA-SRVKXCTJSA-N Arg-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N OGUPCHKBOKJFMA-SRVKXCTJSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- IIAXFBUTKIDDIP-ULQDDVLXSA-N Arg-Leu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IIAXFBUTKIDDIP-ULQDDVLXSA-N 0.000 description 1
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 1
- MJINRRBEMOLJAK-DCAQKATOSA-N Arg-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N MJINRRBEMOLJAK-DCAQKATOSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- OQPAZKMGCWPERI-GUBZILKMSA-N Arg-Ser-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OQPAZKMGCWPERI-GUBZILKMSA-N 0.000 description 1
- AIFHRTPABBBHKU-RCWTZXSCSA-N Arg-Thr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AIFHRTPABBBHKU-RCWTZXSCSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- FOWOZYAWODIRFZ-JYJNAYRXSA-N Arg-Tyr-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCN=C(N)N)N FOWOZYAWODIRFZ-JYJNAYRXSA-N 0.000 description 1
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- ANPFQTJEPONRPL-UGYAYLCHSA-N Asn-Ile-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O ANPFQTJEPONRPL-UGYAYLCHSA-N 0.000 description 1
- NYGILGUOUOXGMJ-YUMQZZPRSA-N Asn-Lys-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O NYGILGUOUOXGMJ-YUMQZZPRSA-N 0.000 description 1
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 1
- JTXVXGXTRXMOFJ-FXQIFTODSA-N Asn-Pro-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O JTXVXGXTRXMOFJ-FXQIFTODSA-N 0.000 description 1
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 1
- SUIJFTJDTJKSRK-IHRRRGAJSA-N Asn-Pro-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUIJFTJDTJKSRK-IHRRRGAJSA-N 0.000 description 1
- SONUFGRSSMFHFN-IMJSIDKUSA-N Asn-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(O)=O SONUFGRSSMFHFN-IMJSIDKUSA-N 0.000 description 1
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 1
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 1
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- CXBOKJPLEYUPGB-FXQIFTODSA-N Asp-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N CXBOKJPLEYUPGB-FXQIFTODSA-N 0.000 description 1
- AXXCUABIFZPKPM-BQBZGAKWSA-N Asp-Arg-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O AXXCUABIFZPKPM-BQBZGAKWSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- GISFCCXBVJKGEO-QEJZJMRPSA-N Asp-Glu-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GISFCCXBVJKGEO-QEJZJMRPSA-N 0.000 description 1
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 1
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- YRBGRUOSJROZEI-NHCYSSNCSA-N Asp-His-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O YRBGRUOSJROZEI-NHCYSSNCSA-N 0.000 description 1
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- MYLZFUMPZCPJCJ-NHCYSSNCSA-N Asp-Lys-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MYLZFUMPZCPJCJ-NHCYSSNCSA-N 0.000 description 1
- HJZLUGQGJWXJCJ-CIUDSAMLSA-N Asp-Pro-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJZLUGQGJWXJCJ-CIUDSAMLSA-N 0.000 description 1
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 1
- FOXXZZGDIAQPQI-XKNYDFJKSA-N Asp-Pro-Ser-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FOXXZZGDIAQPQI-XKNYDFJKSA-N 0.000 description 1
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- BPAUXFVCSYQDQX-JRQIVUDYSA-N Asp-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)O)N)O BPAUXFVCSYQDQX-JRQIVUDYSA-N 0.000 description 1
- 102000030431 Asparaginyl endopeptidase Human genes 0.000 description 1
- 101150118014 BNRF1 gene Proteins 0.000 description 1
- 101000588395 Bacillus subtilis (strain 168) Beta-hexosaminidase Proteins 0.000 description 1
- 102100021277 Beta-secretase 2 Human genes 0.000 description 1
- 101710150190 Beta-secretase 2 Proteins 0.000 description 1
- 102100036301 C-C chemokine receptor type 7 Human genes 0.000 description 1
- 102100025222 CD63 antigen Human genes 0.000 description 1
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010059081 Cathepsin A Proteins 0.000 description 1
- 102000005572 Cathepsin A Human genes 0.000 description 1
- 108090000712 Cathepsin B Proteins 0.000 description 1
- 102000004225 Cathepsin B Human genes 0.000 description 1
- 108090000267 Cathepsin C Proteins 0.000 description 1
- 102000003902 Cathepsin C Human genes 0.000 description 1
- 102000003908 Cathepsin D Human genes 0.000 description 1
- 108090000258 Cathepsin D Proteins 0.000 description 1
- 108090000610 Cathepsin F Proteins 0.000 description 1
- 102000004176 Cathepsin F Human genes 0.000 description 1
- 108090000619 Cathepsin H Proteins 0.000 description 1
- 102000004175 Cathepsin H Human genes 0.000 description 1
- 108090000625 Cathepsin K Proteins 0.000 description 1
- 102100026540 Cathepsin L2 Human genes 0.000 description 1
- 102100026657 Cathepsin Z Human genes 0.000 description 1
- 108010061117 Cathepsin Z Proteins 0.000 description 1
- 102100025024 Cation-dependent mannose-6-phosphate receptor Human genes 0.000 description 1
- 102100038196 Chitinase-3-like protein 1 Human genes 0.000 description 1
- 102100026127 Clathrin heavy chain 1 Human genes 0.000 description 1
- 101710123900 Clathrin heavy chain 1 Proteins 0.000 description 1
- 101710123899 Clathrin heavy chain 2 Proteins 0.000 description 1
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 1
- GRNOCLDFUNCIDW-ACZMJKKPSA-N Cys-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N GRNOCLDFUNCIDW-ACZMJKKPSA-N 0.000 description 1
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 1
- RRIJEABIXPKSGP-FXQIFTODSA-N Cys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CS RRIJEABIXPKSGP-FXQIFTODSA-N 0.000 description 1
- SBMGKDLRJLYZCU-BIIVOSGPSA-N Cys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N)C(=O)O SBMGKDLRJLYZCU-BIIVOSGPSA-N 0.000 description 1
- UUERSUCTHOZPMG-SRVKXCTJSA-N Cys-Asn-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UUERSUCTHOZPMG-SRVKXCTJSA-N 0.000 description 1
- HNNGTYHNYDOSKV-FXQIFTODSA-N Cys-Cys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CS)N HNNGTYHNYDOSKV-FXQIFTODSA-N 0.000 description 1
- VBPGTULCFGKGTF-ACZMJKKPSA-N Cys-Glu-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VBPGTULCFGKGTF-ACZMJKKPSA-N 0.000 description 1
- BCSYBBMFGLHCOA-ACZMJKKPSA-N Cys-Glu-Cys Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BCSYBBMFGLHCOA-ACZMJKKPSA-N 0.000 description 1
- DZIGZIIJIGGANI-FXQIFTODSA-N Cys-Glu-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O DZIGZIIJIGGANI-FXQIFTODSA-N 0.000 description 1
- VTJLJQGUMBWHBP-GUBZILKMSA-N Cys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N VTJLJQGUMBWHBP-GUBZILKMSA-N 0.000 description 1
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 1
- TXCCRYAZQBUCOV-CIUDSAMLSA-N Cys-Pro-Gln Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O TXCCRYAZQBUCOV-CIUDSAMLSA-N 0.000 description 1
- ABLQPNMKLMFDQU-BIIVOSGPSA-N Cys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CS)N)C(=O)O ABLQPNMKLMFDQU-BIIVOSGPSA-N 0.000 description 1
- 101710104596 Cytosolic beta-glucosidase Proteins 0.000 description 1
- 102100035149 Cytosolic endo-beta-N-acetylglucosaminidase Human genes 0.000 description 1
- 108010037897 DC-specific ICAM-3 grabbing nonintegrin Proteins 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- 102100029921 Dipeptidyl peptidase 1 Human genes 0.000 description 1
- 101710087078 Dipeptidyl peptidase 1 Proteins 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 101710144190 Endo-beta-N-acetylglucosaminidase Proteins 0.000 description 1
- 108700039887 Essential Genes Proteins 0.000 description 1
- LMPBBFWHCRURJD-LAEOZQHASA-N Gln-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LMPBBFWHCRURJD-LAEOZQHASA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- AJDMYLOISOCHHC-YVNDNENWSA-N Gln-Gln-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AJDMYLOISOCHHC-YVNDNENWSA-N 0.000 description 1
- NPTGGVQJYRSMCM-GLLZPBPUSA-N Gln-Gln-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPTGGVQJYRSMCM-GLLZPBPUSA-N 0.000 description 1
- UFNSPPFJOHNXRE-AUTRQRHGSA-N Gln-Gln-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UFNSPPFJOHNXRE-AUTRQRHGSA-N 0.000 description 1
- ZQPOVSJFBBETHQ-CIUDSAMLSA-N Gln-Glu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZQPOVSJFBBETHQ-CIUDSAMLSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 1
- KHGGWBRVRPHFMH-PEFMBERDSA-N Gln-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N KHGGWBRVRPHFMH-PEFMBERDSA-N 0.000 description 1
- UESYBOXFJWJVSB-AVGNSLFASA-N Gln-Phe-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O UESYBOXFJWJVSB-AVGNSLFASA-N 0.000 description 1
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 description 1
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 1
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 1
- ININBLZFFVOQIO-JHEQGTHGSA-N Gln-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O ININBLZFFVOQIO-JHEQGTHGSA-N 0.000 description 1
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 1
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 1
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 1
- IRDASPPCLZIERZ-XHNCKOQMSA-N Glu-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N IRDASPPCLZIERZ-XHNCKOQMSA-N 0.000 description 1
- RSUVOPBMWMTVDI-XEGUGMAKSA-N Glu-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCC(O)=O)C)C(O)=O)=CNC2=C1 RSUVOPBMWMTVDI-XEGUGMAKSA-N 0.000 description 1
- RCCDHXSRMWCOOY-GUBZILKMSA-N Glu-Arg-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCCDHXSRMWCOOY-GUBZILKMSA-N 0.000 description 1
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- WLIPTFCZLHCNFD-LPEHRKFASA-N Glu-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O WLIPTFCZLHCNFD-LPEHRKFASA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- XMPAXPSENRSOSV-RYUDHWBXSA-N Glu-Gly-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XMPAXPSENRSOSV-RYUDHWBXSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 1
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 1
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 1
- ZWMYUDZLXAQHCK-CIUDSAMLSA-N Glu-Met-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O ZWMYUDZLXAQHCK-CIUDSAMLSA-N 0.000 description 1
- YHOJJFFTSMWVGR-HJGDQZAQSA-N Glu-Met-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YHOJJFFTSMWVGR-HJGDQZAQSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- SFKMXFWWDUGXRT-NWLDYVSISA-N Glu-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N)O SFKMXFWWDUGXRT-NWLDYVSISA-N 0.000 description 1
- YMUFWNJHVPQNQD-ZKWXMUAHSA-N Gly-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN YMUFWNJHVPQNQD-ZKWXMUAHSA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- JVACNFOPSUPDTK-QWRGUYRKSA-N Gly-Asn-Phe Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JVACNFOPSUPDTK-QWRGUYRKSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 1
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 1
- UUWOBINZFGTFMS-UWVGGRQHSA-N Gly-His-Met Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(O)=O UUWOBINZFGTFMS-UWVGGRQHSA-N 0.000 description 1
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 1
- DGKBSGNCMCLDSL-BYULHYEWSA-N Gly-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN DGKBSGNCMCLDSL-BYULHYEWSA-N 0.000 description 1
- HKSNHPVETYYJBK-LAEOZQHASA-N Gly-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)CN HKSNHPVETYYJBK-LAEOZQHASA-N 0.000 description 1
- YIFUFYZELCMPJP-YUMQZZPRSA-N Gly-Leu-Cys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O YIFUFYZELCMPJP-YUMQZZPRSA-N 0.000 description 1
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 1
- JBCLFWXMTIKCCB-VIFPVBQESA-N Gly-Phe Chemical compound NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-VIFPVBQESA-N 0.000 description 1
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- BXDLTKLPPKBVEL-FJXKBIBVSA-N Gly-Thr-Met Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O BXDLTKLPPKBVEL-FJXKBIBVSA-N 0.000 description 1
- NWOSHVVPKDQKKT-RYUDHWBXSA-N Gly-Tyr-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O NWOSHVVPKDQKKT-RYUDHWBXSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 1
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 1
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 102210042925 HLA-A*02:01 Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 102210026621 HLA-DRB1*13 Human genes 0.000 description 1
- 108010022901 Heparin Lyase Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 1
- OQDLKDUVMTUPPG-AVGNSLFASA-N His-Leu-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OQDLKDUVMTUPPG-AVGNSLFASA-N 0.000 description 1
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 1
- XGBVLRJLHUVCNK-DCAQKATOSA-N His-Val-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O XGBVLRJLHUVCNK-DCAQKATOSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000716065 Homo sapiens C-C chemokine receptor type 7 Proteins 0.000 description 1
- 101000934368 Homo sapiens CD63 antigen Proteins 0.000 description 1
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 1
- 101000761509 Homo sapiens Cathepsin K Proteins 0.000 description 1
- 101000983577 Homo sapiens Cathepsin L2 Proteins 0.000 description 1
- 101000910979 Homo sapiens Cathepsin Z Proteins 0.000 description 1
- 101001050955 Homo sapiens Cation-dependent mannose-6-phosphate receptor Proteins 0.000 description 1
- 101000883515 Homo sapiens Chitinase-3-like protein 1 Proteins 0.000 description 1
- 101000946482 Homo sapiens Clathrin heavy chain 2 Proteins 0.000 description 1
- 101000859692 Homo sapiens Cytosolic beta-glucosidase Proteins 0.000 description 1
- 101000599940 Homo sapiens Interferon gamma Proteins 0.000 description 1
- 101001004623 Homo sapiens Lactase-like protein Proteins 0.000 description 1
- 101001122938 Homo sapiens Lysosomal protective protein Proteins 0.000 description 1
- 101000604993 Homo sapiens Lysosome-associated membrane glycoprotein 2 Proteins 0.000 description 1
- 101000605006 Homo sapiens Lysosome-associated membrane glycoprotein 5 Proteins 0.000 description 1
- 101000578784 Homo sapiens Melanoma antigen recognized by T-cells 1 Proteins 0.000 description 1
- 101000615492 Homo sapiens Methyl-CpG-binding domain protein 4 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101000938702 Homo sapiens N-acetyltransferase ESCO1 Proteins 0.000 description 1
- 101000644045 Homo sapiens Protein unc-13 homolog D Proteins 0.000 description 1
- 101000893741 Homo sapiens Tissue alpha-L-fucosidase Proteins 0.000 description 1
- 108010003272 Hyaluronate lyase Proteins 0.000 description 1
- 102100021102 Hyaluronidase PH-20 Human genes 0.000 description 1
- 101710096421 Iduronate 2-sulfatase Proteins 0.000 description 1
- 108010003381 Iduronidase Proteins 0.000 description 1
- 102000004627 Iduronidase Human genes 0.000 description 1
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 1
- VNDQNDYEPSXHLU-JUKXBJQTSA-N Ile-His-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N VNDQNDYEPSXHLU-JUKXBJQTSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 1
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 1
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 1
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 1
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 1
- 101710188170 Lactase-like protein Proteins 0.000 description 1
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 1
- FJUKMPUELVROGK-IHRRRGAJSA-N Leu-Arg-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N FJUKMPUELVROGK-IHRRRGAJSA-N 0.000 description 1
- BAJIJEGGUYXZGC-CIUDSAMLSA-N Leu-Asn-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N BAJIJEGGUYXZGC-CIUDSAMLSA-N 0.000 description 1
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 1
- MDVZJYGNAGLPGJ-KKUMJFAQSA-N Leu-Asn-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MDVZJYGNAGLPGJ-KKUMJFAQSA-N 0.000 description 1
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 1
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 1
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 1
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 1
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 1
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 1
- LZHJZLHSRGWBBE-IHRRRGAJSA-N Leu-Lys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LZHJZLHSRGWBBE-IHRRRGAJSA-N 0.000 description 1
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 1
- AIRUUHAOKGVJAD-JYJNAYRXSA-N Leu-Phe-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIRUUHAOKGVJAD-JYJNAYRXSA-N 0.000 description 1
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 1
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 1
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 1
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 1
- LXGSOEPHQJONMG-PMVMPFDFSA-N Leu-Trp-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N LXGSOEPHQJONMG-PMVMPFDFSA-N 0.000 description 1
- RIHIGSWBLHSGLV-CQDKDKBSSA-N Leu-Tyr-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O RIHIGSWBLHSGLV-CQDKDKBSSA-N 0.000 description 1
- VJGQRELPQWNURN-JYJNAYRXSA-N Leu-Tyr-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJGQRELPQWNURN-JYJNAYRXSA-N 0.000 description 1
- VQHUBNVKFFLWRP-ULQDDVLXSA-N Leu-Tyr-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 VQHUBNVKFFLWRP-ULQDDVLXSA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 1
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 1
- FLCMXEFCTLXBTL-DCAQKATOSA-N Lys-Asp-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N FLCMXEFCTLXBTL-DCAQKATOSA-N 0.000 description 1
- HWMZUBUEOYAQSC-DCAQKATOSA-N Lys-Gln-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O HWMZUBUEOYAQSC-DCAQKATOSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 1
- WGLAORUKDGRINI-WDCWCFNPSA-N Lys-Glu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGLAORUKDGRINI-WDCWCFNPSA-N 0.000 description 1
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 1
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 1
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 1
- MXMDJEJWERYPMO-XUXIUFHCSA-N Lys-Ile-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MXMDJEJWERYPMO-XUXIUFHCSA-N 0.000 description 1
- OJDFAABAHBPVTH-MNXVOIDGSA-N Lys-Ile-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O OJDFAABAHBPVTH-MNXVOIDGSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- MGKFCQFVPKOWOL-CIUDSAMLSA-N Lys-Ser-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N MGKFCQFVPKOWOL-CIUDSAMLSA-N 0.000 description 1
- VWPJQIHBBOJWDN-DCAQKATOSA-N Lys-Val-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O VWPJQIHBBOJWDN-DCAQKATOSA-N 0.000 description 1
- RPWQJSBMXJSCPD-XUXIUFHCSA-N Lys-Val-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(O)=O RPWQJSBMXJSCPD-XUXIUFHCSA-N 0.000 description 1
- 102100028524 Lysosomal protective protein Human genes 0.000 description 1
- 101710116774 Lysosome-associated membrane glycoprotein 5 Proteins 0.000 description 1
- 108010090665 Mannosyl-Glycoprotein Endo-beta-N-Acetylglucosaminidase Proteins 0.000 description 1
- 102100028389 Melanoma antigen recognized by T-cells 1 Human genes 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- HKRYNJSKVLZIFP-IHRRRGAJSA-N Met-Asn-Tyr Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HKRYNJSKVLZIFP-IHRRRGAJSA-N 0.000 description 1
- YORIKIDJCPKBON-YUMQZZPRSA-N Met-Glu-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YORIKIDJCPKBON-YUMQZZPRSA-N 0.000 description 1
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 1
- UZVKFARGHHMQGX-IUCAKERBSA-N Met-Gly-Met Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCSC UZVKFARGHHMQGX-IUCAKERBSA-N 0.000 description 1
- LRALLISKBZNSKN-BQBZGAKWSA-N Met-Gly-Ser Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LRALLISKBZNSKN-BQBZGAKWSA-N 0.000 description 1
- BMHIFARYXOJDLD-WPRPVWTQSA-N Met-Gly-Val Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O BMHIFARYXOJDLD-WPRPVWTQSA-N 0.000 description 1
- YYEIFXZOBZVDPH-DCAQKATOSA-N Met-Lys-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O YYEIFXZOBZVDPH-DCAQKATOSA-N 0.000 description 1
- CRVSHEPROQHVQT-AVGNSLFASA-N Met-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N CRVSHEPROQHVQT-AVGNSLFASA-N 0.000 description 1
- PCTFVQATEGYHJU-FXQIFTODSA-N Met-Ser-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O PCTFVQATEGYHJU-FXQIFTODSA-N 0.000 description 1
- KLGIQJRMFHIGCQ-ZFWWWQNUSA-N Met-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CCSC)C(=O)NCC(O)=O)=CNC2=C1 KLGIQJRMFHIGCQ-ZFWWWQNUSA-N 0.000 description 1
- LPNWWHBFXPNHJG-AVGNSLFASA-N Met-Val-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN LPNWWHBFXPNHJG-AVGNSLFASA-N 0.000 description 1
- 102100021290 Methyl-CpG-binding domain protein 4 Human genes 0.000 description 1
- 101150076359 Mhc gene Proteins 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101000715501 Mus musculus Cathepsin 7 Proteins 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- 125000003047 N-acetyl group Chemical group 0.000 description 1
- 102100031688 N-acetylgalactosamine-6-sulfatase Human genes 0.000 description 1
- 101710099863 N-acetylgalactosamine-6-sulfatase Proteins 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 108010055817 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Proteins 0.000 description 1
- 102000000447 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Human genes 0.000 description 1
- 208000037581 Persistent Infection Diseases 0.000 description 1
- MDHZEOMXGNBSIL-DLOVCJGASA-N Phe-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N MDHZEOMXGNBSIL-DLOVCJGASA-N 0.000 description 1
- YMORXCKTSSGYIG-IHRRRGAJSA-N Phe-Arg-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N YMORXCKTSSGYIG-IHRRRGAJSA-N 0.000 description 1
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 1
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 1
- WYPVCIACUMJRIB-JYJNAYRXSA-N Phe-Gln-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N WYPVCIACUMJRIB-JYJNAYRXSA-N 0.000 description 1
- MGBRZXXGQBAULP-DRZSPHRISA-N Phe-Glu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MGBRZXXGQBAULP-DRZSPHRISA-N 0.000 description 1
- BIYWZVCPZIFGPY-QWRGUYRKSA-N Phe-Gly-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O BIYWZVCPZIFGPY-QWRGUYRKSA-N 0.000 description 1
- SMFGCTXUBWEPKM-KBPBESRZSA-N Phe-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 SMFGCTXUBWEPKM-KBPBESRZSA-N 0.000 description 1
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 1
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 1
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 1
- ACJULKNZOCRWEI-ULQDDVLXSA-N Phe-Met-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O ACJULKNZOCRWEI-ULQDDVLXSA-N 0.000 description 1
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- AOKZOUGUMLBPSS-PMVMPFDFSA-N Phe-Trp-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O AOKZOUGUMLBPSS-PMVMPFDFSA-N 0.000 description 1
- APECKGGXAXNFLL-RNXOBYDBSA-N Phe-Trp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 APECKGGXAXNFLL-RNXOBYDBSA-N 0.000 description 1
- GCFNFKNPCMBHNT-IRXDYDNUSA-N Phe-Tyr-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)NCC(=O)O)N GCFNFKNPCMBHNT-IRXDYDNUSA-N 0.000 description 1
- ZOGICTVLQDWPER-UFYCRDLUSA-N Phe-Tyr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O ZOGICTVLQDWPER-UFYCRDLUSA-N 0.000 description 1
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 1
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 1
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 1
- WSRWHZRUOCACLJ-UWVGGRQHSA-N Pro-Gly-His Chemical compound C([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H]1NCCC1)C1=CN=CN1 WSRWHZRUOCACLJ-UWVGGRQHSA-N 0.000 description 1
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 1
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 1
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 1
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 1
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102100020988 Protein unc-13 homolog D Human genes 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- CGNLCCVKSWNSDG-UHFFFAOYSA-N SYBR Green I Chemical compound CN(C)CCCN(CCC)C1=CC(C=C2N(C3=CC=CC=C3S2)C)=C2C=CC=CC2=[N+]1C1=CC=CC=C1 CGNLCCVKSWNSDG-UHFFFAOYSA-N 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 1
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 1
- WTPKKLMBNBCCNL-ACZMJKKPSA-N Ser-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N WTPKKLMBNBCCNL-ACZMJKKPSA-N 0.000 description 1
- YPUSXTWURJANKF-KBIXCLLPSA-N Ser-Gln-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YPUSXTWURJANKF-KBIXCLLPSA-N 0.000 description 1
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 1
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- QKQDTEYDEIJPNK-GUBZILKMSA-N Ser-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO QKQDTEYDEIJPNK-GUBZILKMSA-N 0.000 description 1
- GRSLLFZTTLBOQX-CIUDSAMLSA-N Ser-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N GRSLLFZTTLBOQX-CIUDSAMLSA-N 0.000 description 1
- GZBKRJVCRMZAST-XKBZYTNZSA-N Ser-Glu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZBKRJVCRMZAST-XKBZYTNZSA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- OWCVUSJMEBGMOK-YUMQZZPRSA-N Ser-Lys-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O OWCVUSJMEBGMOK-YUMQZZPRSA-N 0.000 description 1
- IFLVBVIYADZIQO-DCAQKATOSA-N Ser-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N IFLVBVIYADZIQO-DCAQKATOSA-N 0.000 description 1
- WOJYIMBIKTWKJO-KKUMJFAQSA-N Ser-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CO)N WOJYIMBIKTWKJO-KKUMJFAQSA-N 0.000 description 1
- WBAXJMCUFIXCNI-WDSKDSINSA-N Ser-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O WBAXJMCUFIXCNI-WDSKDSINSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- NMZXJDSKEGFDLJ-DCAQKATOSA-N Ser-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CCCCN)C(=O)O NMZXJDSKEGFDLJ-DCAQKATOSA-N 0.000 description 1
- VFWQQZMRKFOGLE-ZLUOBGJFSA-N Ser-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O VFWQQZMRKFOGLE-ZLUOBGJFSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- TYIHBQYLIPJSIV-NYVOZVTQSA-N Ser-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CO)N TYIHBQYLIPJSIV-NYVOZVTQSA-N 0.000 description 1
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 1
- HAUVENOGHPECML-BPUTZDHNSA-N Ser-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 HAUVENOGHPECML-BPUTZDHNSA-N 0.000 description 1
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 1
- QYBRQMLZDDJBSW-AVGNSLFASA-N Ser-Tyr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYBRQMLZDDJBSW-AVGNSLFASA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- ODRUTDLAONAVDV-IHRRRGAJSA-N Ser-Val-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ODRUTDLAONAVDV-IHRRRGAJSA-N 0.000 description 1
- 102000005262 Sulfatase Human genes 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 230000037453 T cell priming Effects 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- JBHMLZSKIXMVFS-XVSYOHENSA-N Thr-Asn-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JBHMLZSKIXMVFS-XVSYOHENSA-N 0.000 description 1
- WLDUCKSCDRIVLJ-NUMRIWBASA-N Thr-Gln-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O WLDUCKSCDRIVLJ-NUMRIWBASA-N 0.000 description 1
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- XFTYVCHLARBHBQ-FOHZUACHSA-N Thr-Gly-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XFTYVCHLARBHBQ-FOHZUACHSA-N 0.000 description 1
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 1
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- MUAFDCVOHYAFNG-RCWTZXSCSA-N Thr-Pro-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MUAFDCVOHYAFNG-RCWTZXSCSA-N 0.000 description 1
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- 102100040526 Tissue alpha-L-fucosidase Human genes 0.000 description 1
- BRBCKMMXKONBAA-KWBADKCTSA-N Trp-Ala-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 BRBCKMMXKONBAA-KWBADKCTSA-N 0.000 description 1
- HQJOVVWAPQPYDS-ZFWWWQNUSA-N Trp-Gly-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQJOVVWAPQPYDS-ZFWWWQNUSA-N 0.000 description 1
- KULBQAVOXHQLIY-HSCHXYMDSA-N Trp-Ile-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 KULBQAVOXHQLIY-HSCHXYMDSA-N 0.000 description 1
- KBKTUNYBNJWFRL-UBHSHLNASA-N Trp-Ser-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 KBKTUNYBNJWFRL-UBHSHLNASA-N 0.000 description 1
- XKTWZYNTLXITCY-QRTARXTBSA-N Trp-Val-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 XKTWZYNTLXITCY-QRTARXTBSA-N 0.000 description 1
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 1
- JRXKIVGWMMIIOF-YDHLFZDLSA-N Tyr-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JRXKIVGWMMIIOF-YDHLFZDLSA-N 0.000 description 1
- JFDGVHXRCKEBAU-KKUMJFAQSA-N Tyr-Asp-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O JFDGVHXRCKEBAU-KKUMJFAQSA-N 0.000 description 1
- QHLIUFUEUDFAOT-MGHWNKPDSA-N Tyr-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QHLIUFUEUDFAOT-MGHWNKPDSA-N 0.000 description 1
- WDGDKHLSDIOXQC-ACRUOGEOSA-N Tyr-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 WDGDKHLSDIOXQC-ACRUOGEOSA-N 0.000 description 1
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 1
- NVZVJIUDICCMHZ-BZSNNMDCSA-N Tyr-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O NVZVJIUDICCMHZ-BZSNNMDCSA-N 0.000 description 1
- SZEIFUXUTBBQFQ-STQMWFEESA-N Tyr-Pro-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SZEIFUXUTBBQFQ-STQMWFEESA-N 0.000 description 1
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- NZBSVMQZQMEUHI-WZLNRYEVSA-N Tyr-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NZBSVMQZQMEUHI-WZLNRYEVSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- KLOZTPOXVVRVAQ-DZKIICNBSA-N Tyr-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 KLOZTPOXVVRVAQ-DZKIICNBSA-N 0.000 description 1
- IZFVRRYRMQFVGX-NRPADANISA-N Val-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N IZFVRRYRMQFVGX-NRPADANISA-N 0.000 description 1
- XPYNXORPPVTVQK-SRVKXCTJSA-N Val-Arg-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCSC)C(=O)O)N XPYNXORPPVTVQK-SRVKXCTJSA-N 0.000 description 1
- AUMNPAUHKUNHHN-BYULHYEWSA-N Val-Asn-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N AUMNPAUHKUNHHN-BYULHYEWSA-N 0.000 description 1
- HZYOWMGWKKRMBZ-BYULHYEWSA-N Val-Asp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HZYOWMGWKKRMBZ-BYULHYEWSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 1
- HQYVQDRYODWONX-DCAQKATOSA-N Val-His-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N HQYVQDRYODWONX-DCAQKATOSA-N 0.000 description 1
- CPGJELLYDQEDRK-NAKRPEOUSA-N Val-Ile-Ala Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O CPGJELLYDQEDRK-NAKRPEOUSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- BMOFUVHDBROBSE-DCAQKATOSA-N Val-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N BMOFUVHDBROBSE-DCAQKATOSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 1
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 230000006786 activation induced cell death Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 239000000853 adhesive Substances 0.000 description 1
- 230000001070 adhesive effect Effects 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010087924 alanylproline Proteins 0.000 description 1
- 108010061314 alpha-L-Fucosidase Proteins 0.000 description 1
- 102000012086 alpha-L-Fucosidase Human genes 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 108010001271 arginyl-glutamyl-arginine Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 108010055066 asparaginylendopeptidase Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 238000010805 cDNA synthesis kit Methods 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 108010057052 chitotriosidase Proteins 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 230000001447 compensatory effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 238000003568 cytokine secretion assay Methods 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000007402 cytotoxic response Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 210000003162 effector t lymphocyte Anatomy 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 230000008029 eradication Effects 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 229960002442 glucosamine Drugs 0.000 description 1
- 108010033719 glycyl-histidyl-glycine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 108010006406 heparinase II Proteins 0.000 description 1
- 108010083213 heparitinsulfate lyase Proteins 0.000 description 1
- 108010045982 hexosaminidase C Proteins 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010048296 hyaluronidase PH-20 Proteins 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 238000010820 immunofluorescence microscopy Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000007914 intraventricular administration Methods 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 230000005923 long-lasting effect Effects 0.000 description 1
- 108010045758 lysosomal proteins Proteins 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000001394 metastastic effect Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 108010068488 methionylphenylalanine Proteins 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- 238000007481 next generation sequencing Methods 0.000 description 1
- 231100000590 oncogenic Toxicity 0.000 description 1
- 230000002246 oncogenic effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- XJMOSONTPMZWPB-UHFFFAOYSA-M propidium iodide Chemical compound [I-].[I-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CCC[N+](C)(CC)CC)=C1C1=CC=CC=C1 XJMOSONTPMZWPB-UHFFFAOYSA-M 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 102000006581 rab27 GTP-Binding Proteins Human genes 0.000 description 1
- 108010033990 rab27 GTP-Binding Proteins Proteins 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 238000002271 resection Methods 0.000 description 1
- 210000003660 reticulum Anatomy 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 108010005652 splenotritin Proteins 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 108060007951 sulfatase Proteins 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000004114 suspension culture Methods 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010045269 tryptophyltryptophan Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 1
- 108010009962 valyltyrosine Proteins 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Images









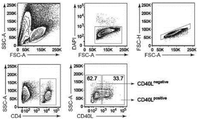
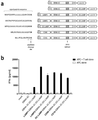
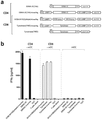
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/00119—Melanoma antigens
- A61K39/001191—Melan-A/MART
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4615—Dendritic cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/462—Cellular immunotherapy characterized by the effect or the function of the cells
- A61K39/4622—Antigen presenting cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464484—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464484—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/464486—MAGE
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464484—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
- A61K39/464488—NY-ESO
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/46449—Melanoma antigens
- A61K39/464491—Melan-A/MART
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
- C12N5/0638—Cytotoxic T lymphocytes [CTL] or lymphokine activated killer cells [LAK]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0639—Dendritic cells, e.g. Langherhans cells in the epidermis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/515—Animal cells
- A61K2039/5154—Antigen presenting cells [APCs], e.g. dendritic cells or macrophages
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001184—Cancer testis antigens, e.g. SSX, BAGE, GAGE or SAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/06—Fusion polypeptide containing a localisation/targetting motif containing a lysosomal/endosomal localisation signal
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/22—Colony stimulating factors (G-CSF, GM-CSF)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/23—Interleukins [IL]
- C12N2501/2304—Interleukin-4 (IL-4)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/20—Cytokines; Chemokines
- C12N2501/24—Interferons [IFN]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2502/00—Coculture with; Conditioned medium produced by
- C12N2502/11—Coculture with; Conditioned medium produced by blood or immune system cells
- C12N2502/1114—T cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2506/00—Differentiation of animal cells from one lineage to another; Differentiation of pluripotent cells
- C12N2506/11—Differentiation of animal cells from one lineage to another; Differentiation of pluripotent cells from blood or immune system cells
- C12N2506/115—Differentiation of animal cells from one lineage to another; Differentiation of pluripotent cells from blood or immune system cells from monocytes, from macrophages
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Cell Biology (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Biomedical Technology (AREA)
- Microbiology (AREA)
- Epidemiology (AREA)
- Zoology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Mycology (AREA)
- Wood Science & Technology (AREA)
- Biochemistry (AREA)
- Oncology (AREA)
- Hematology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Developmental Biology & Embryology (AREA)
- Virology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
Abstract
본 발명은 인간 항원-특이적 T 림프구를 생성하기 위한 방법을 고찰한다. 상기 방법은 RNA-코딩 단백질의 MHC 클래스 제시를 수득하기 위해 항원 또는 이의 단편에 융합된 MHC 클래스-II 표적 신호를 사용한다. 따라서, 본 발명은 MHC 클래스-II 표적 신호 및 적어도 하나의 항원 또는 이의 단편을 포함하는 발현 벡터, 및 항원-특이적 T 림프구의 생체 외(in vitro) 생성을 위한 이의 용도에 관한 것이다. T 세포 클론 및 종양 항원 또는 바이러스 항원에 특이적인 T 세포 수용체 (TCRs) 또한 기술된다.
Description
본 발명은 인간 항원-특이적 T 림프구의 생성을 위한 방법을 고찰한다. 상기 방법은 RNA-코딩 단백질의 MHC 클래스 I 및 II 제시를 수득하기 위해 항원 또는 이의 단편에 융합된 MHC 클래스-II 표적 신호를 사용한다. 따라서, 본 발명은 MHC 클래스-II 표적 신호 및 적어도 하나의 항원 또는 이의 단편을 포함하는 발현 벡터, 및 항원-특이적 T 림프구의 생체 외(in vitro) 생성을 위한 이의 용도에 관한 것이다. T 세포 클론 및 종양 항원 또는 바이러스 항원에 특이적인 T 세포 수용체 (TCRs) 또한 기술된다.
양자 T 세포 전이는 만성 바이러스 감염 및 종양을 제어하기 위해 T 세포-기반 세포독성 반응을 이용한다. 환자의 암에 대해 자연적 또는 유전자 조작 반응성을 갖는 T 세포는 생체 외(in vitro)에서 생성된 다음 환자에게 다시 전달된다. 자가 종양-침윤 림프구 (TIL)의 양자 전이는 진행성 종양(advanced tumor)을 갖는 환자를 성공적으로 치료하기 위해 사용되어 왔다. 임상에서의 폭넓은 적용에 대한 TIL 치료법의 주요 한계점은 종종 자가-항원-특이성을 갖는 T 세포를 효율적으로 제거하는 흉선에서의 음성 T 세포 선택의 메커니즘과 종양의 불충분한 면역원성이다. 따라서, 다수의 경우, 종양-특이적 항원에 대한 높은 친화성을 갖는 T 세포도 바람직한 특이성을 갖는 T 세포도 환자 혈액 또는 종양 절제물로부터 분리할 수 없다. 이를 위해, 유전적으로 재조합된(redirected) 말초 혈액 림프구(PBL)의 전이는 이러한 한계를 극복할 수 있는 가능성을 제공한다.
또한, 암성 및 만성 감염에서 T 리프구는 기능을 상실하여 고갈된다.
T 세포 수용체(TCR) 유전자 치료법의 도움으로, 백만의 종양-반응성 T 세포가 환자의 혈액으로부터 빠르게 생성될 수 있다. TCR 유전자 치료법은 종양 특이성을 확장가능하고 기능적으로 유망한 T 세포 아집단으로 전이시키는 유연한 방법으로 나아가고 있다. 이는 소정의 항원-특이적 T 세포 클론의 분리된 TCR 유전자를 인간 백혈구 항원 (HLA)-매칭 공여자의 수용 T 림프구로 전이시켜 그들이 요구되는 항원 특이성을 갖도록 한다.
CD8+ 세포독성 T 림프구 (CTL)을 이용한 양자 T 세포 치료법은 암 또는 바이러스 질환에 유망한 면역요법이다. 임상적 반응을 높이기 위해, CD4+ 헬퍼 T 세포의 보상 전이는 CD8+ CTL 반응을 강화하는 기회를 제공한다. CD4+ T 림프구는 장기간 지속되는 CD8+ 메모리 T 세포의 생성에 중요한 영향을 미칠 뿐만 아니라 CD8+ CTL에 대해 중추적인 도움을 제공하는 것으로 알려져 있다. 따라서, 종양 항원-특이적 CD4+ 및 CD8+ T 림프구의 신속하고 효과적인 분리와 특성화가 중요하다.
수많은 종양은 MHC 클래스 II 분자를 발현하므로 CD4+ T 세포로부터의 TCR은 특히 이들 종양을 직접적으로 공격하는데 유용하다.
더 빠르게 성장하는 종양 또는 만성 바이러스 질환을 갖는 환자를 치료하기 위한 양자 세포 치료법 (ACT)을 사용할 수 있는 능력을 확장시키기 위해, 바이러스 또는 종양 세포를 효과적으로 공격하는 이의 리간드 특이성에 대해 선택되지만, 정상 조직의 심각한 공격을 피할 수 있는 풍부한 펩티드-특이적 효과기 T 세포 (CD4 T 헬퍼 세포 및 세포독성 T 림프구)를 전달하는 것이 목적이다. 이들 세포는 탈체(ex vivo)에서 많은 수로 급속히 확장되어 ACT에 사용된다. 다르게는, 수용자 말초 혈액 림프구 또는 잘 성장하고 정상 숙주 조직을 공격하는 능력이 없는 소정의 특이성을 갖는 활성 T 세포 클론을 사용하여, 이러한 리간드-특이적 T 세포의 T 세포 수용체 (TCR)가 복제되고 활성 림프구에서 TCR 전이 유전자로 발현될 수 있다.
결과적으로, 항원-특이적 TCR 및 이러한 TCR의 분리를 위한 효율적인 방법이 요구된다.
따라서, 본 발명의 목적은 항원-특이적 TCR을 갖는 T 세포의 분리를 위한 효율적인 방법을 제공하는 것이다. CD4 TCR 및/또는 CD8 TCR의 생성을 위한 방법을 제공하는 것이 바람직하다. 또한, 본 발명의 목적은 TCR 또는 CDR3 영역과 같은 이의 기능적인 부분을 제공하는 것이다. 종양 항원에 대한 높은 및/또는 최적의 친화성을 나타내는 TCR을 획득하는 것이 유리할 것이다.
따라서, 본 발명의 제1 측면은 다음의 단계를 포함하는 인간 항원-특이적 T 림프구의 생성 방법을 고찰한다:
A) 항원 제시 세포에서 다음을 포함하는 적어도 하나의 융합 단백질을 발현하는 단계; 및
- 적어도 하나의 항원 또는 이의 단편,
- 항원의 N-말단 앞의 소포체 (ER)- 이동 (translocation) 신호 서열, 및
- 항원의 C-말단 다음의 엔도솜/리소좀 표적 서열을 포함하는 막관통
및 세포질 도메인,
B) 항원 제시 세포에 의해 발현되는 항원에 대해 특이적인 항원-특이적 T 림프구를 활성화 시키기 위해 생체 외(in vitro)에서 단계 A)의 항원 제시 세포에 T 림프구를 포함하는 세포 집단을 노출시키는 단계.
특히, ER-이동 신호 서열과 조합된 표적 서열과 바람직한 항원 또는 이의 단편의 융합은 MHC 클래스 II 복합체 및 통상적으로 MHC 클래스-I 복합체를 통해 제시되는 세포 단백질에 대한 효율적인 로딩을 가능하게 한다. 또한 MHC 클래스-I 복합체의 로딩은 전술한 방법으로 이루어진다. 따라서, 상기 방법은 CD8+ TCR 뿐만 아니라 CD4+ TCR의 생성을 가능하게 한다.
단계 A)에서 적어도 하나의 융합 단백질의 발현은 일시적인 발현 또는 안정한 발현, 바람직하게는, 예를 들어 적어도 하나의 융합 단백질을 코딩하는 ivt-RNA를 도입하는 일시적인 발현일 수 있다. ivt-RNA의 발현은 품질-제어 ivt-RNA가 빠르게 생성될 수 있고 어떠한 면역원성 단백질 오염물도 운반하지 않는 장점을 갖는다.
구체적인 실시예에서, 상기 융합 단백질은 적어도 2 종의 항원 또는 이의 단편을 포함할 수 있다.
일부 실시예에서, 상기 방법은 활성화된 T 림프구를 농축시키는 단계를 추가로 포함할 수 있다. 이러한 농축 단계는 전형적으로 다음의 단계를 포함한다:
(a) 상기 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 활성화된 T 림프구에 의해 특이적으로 발현되는 적어도 하나의 마커 단백질에 특이적으로 결합하는 적어도 하나의 결합 분자와 접촉시키는 단계;
(b) 상기 적어도 하나의 결합 분자가 결합된 T 림프구를 분리하는 단계.
바람직한 실시예에서, 상기 활성화된 T 림프구에 의해 특이적으로 발현되는 적어도 하나의 마커 단백질은 Ox40, CD137, CD40L, PD-1, IL-2 수용체, 인터페론 γ, IL-2, GM-CSF 및 TNF-α를 포함하는 군으로부터 선택된다. 또한, 단계 (a)에서, 상기 세포는 CD4에 특이적으로 결합하는 결합 분자 및/또는 CD8에 특이적으로 결합하는 결합 분자와 추가로 접촉될 수 있다.
구체적인 실시예에서, CD4 T 세포를 선별하는 것은 다음의 단계를 포함한다:
(a1) 항원 제시 세포의 CD40-CD40L과 항원 특이적 T 림프구 사이의 상호작용을 차단하고 CD40L을 T 림프구 표면에 축적시키기 위해, 단계 B)의 세포 집단과 CD40에 대한 항체를 접촉시키는 단계;
(a2) 상기 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 항-CD40L 항체와 접촉시키는 단계;
(b) 항-CD40L 항체 및 항-CD4 항체로 표지된 T 림프구를 분리하는 단계.
다른 일실시예는 전술한 청구항 중 어느 한 항에 따른 방법에 관한 것으로, 상기 방법은 C2) 다음의 단계를 포함하는 항원-특이적 T 림프구를 확인하는 단계를 추가로 포함한다:
a) 상기 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단의 확장된 세포 클론을,
(i) 단계 A)에 정의된 항원 제시 세포, 및
(ii) 대조구 (control) 항원 제시 세포와 배양하는 단계;
b) 상기 배양의 활성 프로파일을 각 세포 클론에 대한 (i) 및 (ii)와 비교하는 단계;
c) 상기 b)의 비교를 바탕으로 항원-특이적 세포 클론을 확인하는 단계;
여기에서, (ii)가 아닌 (i)에 의한 활성화는 상기 세포 클론이 항원-특이적임을 나타내고; (i) 및 (ii) 둘 다에 의한 활성화는 상기 세포 클론이 항원 비특이적임을 나타내며; (i)에 의해서도 (ii)에 의해서도 활성화되지 않은 것은 상기 세포 클론이 활성화지 않음을 나타낸다.
단계 B)에서, 상기 항원 제시 세포는 T 림프구를 포함하는 세포 집단에 적어도 1회, 또는 적어도 2회, 또는 적어도 3회, 또는 3회 첨가된다. 항원 제시 세포의 반복된 첨가 사이의 시간 간격은 7 내지 21일, 12 내지 16일, 또는 13 내지 15일, 또는 14일일 수 있다.
ER 이동 신호 서열은 엔도솜/리소좀 관련 단백질로부터 유래된다. 상기 엔도좀/리소좀 관련 단백질은 LAMP1, LAMP2, DC-LAMP, CD68 또는 CD1b로 이루어진 군으로부터 선택될 수 있고, 바람직하게 상기 엔도솜/리소좀 관련 단백질은 LAMP1이다. 바람직하게, 상기 ER 이동 신호 서열은 인간이다. 구체적인 실시예에서, 상기 ER 이동 신호 서열은 서열번호 33의 서열 또는 이의 단편을 포함한다. 보다 구체적인 실시예에서, 상기 ER 이동 신호 서열은 다음의 서열번호 33의 서열로 이루어진다.
엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 바람직하게는 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 인간이다.
전형적으로, 상기 항원 제시 세포는 수지상 세포, 활성화된 B 세포, 단핵구, 대식세포, EBV-형질전환 림프아구 세포주(EBV-transformed lymphoblastoid cell line)로부터 선택되고, 바람직하게는 수지상 세포, 더욱 바람직하게는 단핵구 유래 수지상 세포이다.
통상적으로, 상기 T 림프구를 포함하는 세포 집단은 말초 혈액 림프구의 집단이다. 상기 T 림프구를 포함하는 세포 집단은 분리되지 않은 말초 혈액 림프구의 집단일 수 있다. 상기 세포 집단은 당해 기술분야의 통상의 기술자에게 공지된 방법으로 T 림프구, 바람직하게는 CD8+ 및/또는 CD4+ T 림프구에 대해 농축될 수 있다.
본 출원의 또 다른 하나의 측면은 본원에 기재된 상기 방법으로 수득 가능한 T 림프구이다.
본 발명의 추가의 측면은 다음을 포함하는 발현 벡터와 관련된다:
- 인간 소포체 (ER)- 이동 신호, 및
- 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인.
상기 벡터는 생체 외(in vitro) mRNA 전사를 위한 프로모터를 포함할 수 있다. 상기 ER 이동 신호 서열은 엔도솜/리소좀 관련 단백질, 예를 들어 LAMP1, LAMP2, DC-LAMP, CD68, CD1b, 가장 바람직하게는 LAMP1로부터 유래된다. 바람직하게, 상기 ER 이동 신호 서열은 인간이다. 구체적인 실시예에서, 상기 ER 이동 신호 서열은 서열번호 33의 서열 또는 이의 단편을 포함한다. 보다 구체적인 실시예에서, 상기 ER 이동 신호 서열은 다음의 서열번호 34의 서열로 이루어진다.
상기 엔도솜/리소좀 표적 서열은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 상기 엔도솜/리소좀 표적 서열은 전형적으로 막통과 및 세포질 도메인의 일부이다. 따라서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 엔도솜 및/또는 리소좀 표적 서열을 포함하는 바람직하게는 상기 막통과 및 세포질 도메인은 인간이다. 전형적으로, 상기 엔도솜/리소좀 표적 서열은 소수성 아미노산이 뒤따르는 Y-XX 모티프 (X는 모든 자연발생 아미노산을 나타냄)(서열번호 38)를 포함한다. 바람직하게, 상기 엔도솜/리소좀 표적 서열은 YQRI(서열번호 39)이다. 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 서열번호 54의 서열 또는 이의 단편을 포함할 수 있다. 예를 들어, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 서열번호 35의 서열 또는 이의 단편을 포함할 수 있다.
일부 실시예에서, 상기 발현 벡터는 상기 ER 이동 신호 서열 및 엔도솜/리소좀 표적 서열을 포함하는 상기 인간 막통과 및 세포질 도메인 사이에 제한 부위를 추가로 포함한다. 다른 실시예에서, 상기 벡터는 인간 소포체 (ER)- 이동 신호 서열, 및 상기 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인 사이에 삽입되는 적어도 하나의 항원, 또는 이의 단편을 추가로 포함한다.
구체적인 실시예에서, 상기 벡터는 적어도 2종의 항원 또는 이의 단편을 코딩하는 서열을 포함한다. 일부 실시예에서, 상기 벡터는 항원의 전장 아미노산 서열을 코딩하는 핵산 서열을 포함한다. 다르게는, 상기 벡터는 항원의 아미노산 서열을 코딩하는 핵산 서열의 단편을 포함한다.
전형적으로, 상기 항원은 종양 항원 또는 바이러스 항원이다. 상기 종양 항원은 바이러스 종양 항원, 종양-특이적 항원, 종양 관련 항원 및 환자 특이적 돌연변이를 운반하고 상기 환자의 종양 세포에 발현되는 항원으로 이루어진 군으로부터 선택될 수 있다. 상기 종양 항원은 종양 관련 항원이고, 바람직하게 상기 종양 관련 항원은 암/고환 항원 (C/T 항원)이다. 상기 C/T 항원은 MAGE 패밀리 멤버, 예를 들어 MAGE-A1, MAGE-A3, MAGE-A4를 포함하는 군으로부터 선택될 수 있으나, 이로 제한되지 않으며, 단일 점 돌연변이를 포함하는 종양 항원, NY-ESO1, 종양/고환-항원 1B, GAGE-1, SSX-4, XAGE-1, BAGE, GAGE, SCP-1, SSX-2, SSX-4, CTZ9, CT10, SAGE 및 CAGE를 포함한다. 바람직하게 상기 C/T 항원은 GAGE-1, SSX-4 및 XAGE-1로 이루어진 군으로부터 선택될 수 있다.
본 발명의 또 다른 일 측면은 생체 외(in vitro)에서 항원-특이적 T 림프구의 생성을 위한 본원에 기재된 바와 같은 발현 벡터의 사용과 관련된다.
본 발명의 추가의 측면은 본원에 기재된 방법으로 생성된 T-림프구를 포유동물에게 투여하는 것을 포함하는, 암 예방 또는 치료 방법에 사용하기 위한 T-림프구와 관련된다.
다른 측면은 전술한 방법의 단계를 포함하고, 추가로 본원에 기재된 방법으로 생성된 활성화된 항원-특이적 림프구로부터 TCR을 분리하는 단계를 포함하는 항원-특이적 TCR을 생성하기 위한 방법과 관련된다.
또 다른 측면은 각각 GAGE-1, SSX-4 및 XAGE-1에 특이적인 TCR과 관련된다.
본 발명은 인간 항원-특이적 T 림프구의 생성을 위한 방법을 고찰한다. 상기 방법은 RNA-코딩 단백질의 MHC 클래스 I 및 II 제시를 수득하기 위해 항원 또는 이의 단편에 융합된 MHC 클래스-II 표적 신호를 사용한다. 따라서, 본 발명은 MHC 클래스-II 표적 신호 및 적어도 하나의 항원 또는 이의 단편을 포함하는 발현 벡터, 및 항원-특이적 T 림프구의 생체 외(in vitro) 생성을 위한 이의 용도에 관한 것이다. T 세포 클론 및 종양 항원 또는 바이러스 항원에 특이적인 T 세포 수용체 (TCRs) 또한 기술된다.
본 발명은 인간 항원-특이적 T 림프구를 생성하기 위한 방법을 고찰한다.
도 1: 항원-특이적 CD4+ T 세포의 활성화 및 단리를 위한 표적화된 MHC 클래스s-II 제시(presentation). (a) CrossTAg-신호(LAMP1 및 DC-LAMP)의 기능성과 필요성을 검증하기 위해 사용된 다양한 EBNA-3C 컨스트럭의 도식적 표현. ORF (ATG to STOP), CrossTAg-신호(LAMP1 및 DC-LAMP)의 다양한 구성요소, HLA-DR11-제한된 EBNA-3C 에피토프 (3H10) 및 폴리A120 스트레치(stretch)를 나타낸다. (b) CrossTAg 신호는 효율적인 MHC class-II 교차-제시(cross-presentation)를 용이하게 한다. ivt-RNA-형질감염된 APC(단핵구-유래 DC 3일간 준비(3d-mDC) 또는 미니-엡스타인-바(mini-Epstein-Barr) 바이러스-(EBV)-형질전환된 림포아구 세포주((mLCL))와의 16시간 동안 배양에서의 EBNA-3C- 특이적 CD4+ T 세포 클론 3H10의 IFN-γ 분비. 값은 3회 평균 + SD로 표시된다. (c) 활성화 마커 CD40L의 발현은 항원- 특이적 CD4+ T 세포의 단리에 적합하다. CellTraceTM 바이올렛 3H10 세포를 감소된 농도(decreasing concentrations)의 자가(autologous) PBL과 혼합하고 자가 공여자(autologous donor)의 EBNA-3C-CrossTAg ivt-RNA-형질감염된 mDC (APC)와 공동배양하였다. CD4+ T 세포에서 활성화에 의해 유도된 CD40L 발현을 6 시간의 공동배양(co-culture)에서 평가하였다.
도 2: 분리되지 않은 PBL에서 C/T-항원-특이적 CD4+ T 세포의 유도 및 농축. (a) C/T-항원-감작된 PBL(C/T-antigen-primed PBL)로부터의 CD4+ T 세포에서 활성화-유도된 CD40L 및 CD137 표면 발현. 활성화 마커 발현은 시험관 내에서 각각 배양13 일 및 27일째에 PBL의 특이적 재자극(specific re-stimulation) 6 시간 후에 측정되었다. (b) 대량(bulk) CD40Lpositive 및 CD40Lnegative CD4+ T 세포주의 증식 능력 직접 비교. 28일째에, CD4+ T 세포는 그들의 CD40L 발현에 따라 감작된 PBL 배양물로부터 단리되었다. 총 세포 수는 FACS 분리 (0 일) 후 특이적 재자극 (14 일) 후 14 일 간격의 끝(end)에서 평가되었다. 그 결과는 0 일에 비해 x-배의 증식을 나타낸다. (c) 항원 특이적 재자극 후 유도된 사이토카인 분비의 비교. 대량의 CD40Lpositive 및 CD40Lnegative CD4+ T 세포주의 IFN-γ분비는 CrossTAg 항원 ivt-RNA-형질감염된 mDC와 함께 16 시간 공동배양하여 측정하였다. 값은 3 회의 평균 + SD로 표시된다.
도 3: C/T-항원-특이적 CD4+ T 세포 클론에 대한 스크리닝. (a) C/T-항원- 감작된 PBL 배양물로부터 유래된 클론의 예시적인(exemplary) 스크리닝 데이터. IFN-γ 분비는 CrossTAg-항원 ivt-RNA-형질감염된mDC (4 가지 항원의 혼합물)와의 16 시간 배양에서 평가하였다. 막대는 단일 값을 나타낸다. (b) 선택된 T 세포 클론의 C/T-항원 반응성의 평가. 사이토카인 분비 (IFN-γ 및 GM-CSF)는 ivt-RNA- 형질감염된 mLCL (4 가지 항원의 혼합물)과 함께 배양한 후에 평가 하였다. 데이터는 단일 값(single values)으로 표시된다 (c) CD4 보조 수용체(co-receptor) 발현의 확인. 예시적인 클론이 도시되어 있다.
도 4: 항원 특이성의 평가. 단일 C/T-항원-특이성을 나타내는 것으로 밝혀진 CD4+ T 세포 클론에 대한 예시적인 데이터. IFN-γ 분비는 ivt-RNA-형질감염된 mLCL과 함께 공동배양한 후에 측정하였다. 값은 2회의 평균 + SD 또는 (*)표시된 경우 단일 데이터 포인트로 나타낸다.
도 5: CrossTAg-신호와 단백질 인식의 필요성. (a) ivt-RNA 기반 CD4+ T 세포 클론 활성화를 위한 CrossTAg-신호의 필요성. (b) 생리학적으로 처리된 외인성 재조합 단백질의 인식. CrossTAg-신호가 없는 항원-IVIT-RNA (a)로 형질감염된 mLCL 또는 특이적 TCR을 갖는 분리된 CD4+ T 세포 클론의 IFN-γ 분비에 의해 측정된 재조합 단백질로 로딩된 mLCL과 직접 비교한 항원-CrossTAg ivt-RNA-형질감염된 APC (mLCL)의 자극 능력. 모의 APC 및 T 세포가 대조군으로 사용되었다. 값은회 3 회의 평균 + SD로 표시된다.
도 6: MHC 클래스-II 에피토프 코어 서열의 정의. 직접 MHC 클래스 II 에피토프 식별(direct MHC class-II epitope identification)(DEPI)(점선으로 된 박스)에 의해 발견된 펩타이드 조각은 짧은 CrossTAg-ivt-RNA 컨스트럭을 사용하여 확인되었다. GAGE-1-TCR-2 형질 전환 3H10 T 세포 (a) 또는 XAGE-1-TCR-1 및 -TCR-2 T 세포 (b)를 중첩된 짧은 CrossTAg-ivt-RNA 컨스트럭- (검은 막대로 표시) 또는 전장 항원-CrossTAg ivt-RNA-형질감염된 APC (mLCL)과 공동 배양하였다. IFN-γ분비는 16 시간의 공동 배양에서 평가하였고, 인식된 에피토프 코어 서열을 나타내었다(실선으로 된 상자). 모의 형질감염된 APC와의 공동 배양물 또는 T 세포 단독(alone)이 대조군으로 사용되었다. 값은 3 회의 평균 + SD로 표시된다.
도 7: C/T-항원-특이적 CD4+ T 세포 수용체의 트랜스제닉(transgenic) 발현. 3H10 T 세포를 CD4+ T 세포 클론 GAGE-1-TCR-1, XAGE-1-TCR-1 또는 -TCR-2의 상응하는 TCR-α 및 -β 사슬을 코딩하는 ivt-RNA로 형질 감염시켰다. TCR- 트랜스제닉 3H10 세포를 항원-로딩된 APC (mLCL)와 함께 배양하고, IFN-γ 분비를 16 시간의 공동배양에서 검출하였다. 모의 형질감염된 APC와의 공동 배양물 또는 T 세포 단독(alone)이 대조군으로 사용되었다. 값은 3 회의 평균 + SD로 표시된다.
도 8: CrossTAg 신호는 세포 내 [내인성] 제시 경로를 통해 MHC 클래스 II 로딩을 촉진한다. HLA-DRB1 * 11:01-양성 및 HLA-DRB1*11:01-음성 DC는 EBNA-3C-CrossTAg ivt-RNA로 형질감염시켰다. 형질감염된(Transfected) 및 형질감염되지않은(un-transfected) DCs는 가능한 모든 조합으로 공동 배양하고 12 시간 후 EBNA-3C 특이적 CD4+ T 세포 클론 3H10과 함께 공동배양 하였다. 3H10 세포의 IFN-γ 분비는 DC와의 16 시간의 공동 배양에서 측정되었다. 값은 3회의 평균 + SD로 표시된다.
도 9: PBL 감작(priming)을 위한 3d mDC의 특성. (a) 단일클론 항체(열린 곡선) 및 매칭되는 아이소타입(isotype) 대조군(채워진 회색 곡선)으로 염색하여 검출된 표면 마커. (b) ivt-RNA-형질감염된 mDC의 항원 mRNA 수준. 비-형질감염된(non-transfected) mDC와 관련하여 항원 mRNA 카피 수의 x-배 증가로 나타낸다. 항원-특이적인 프라이머를 사용하여 qRT-PCR에 의해 항원 mRNA 카피 수를 평가하였다.
도10: C/T-항원-특이적 CD4+ T 세포의 CD40L 기반 분류를 위한 게이팅 전략. 림프구는 순방향 (FSC; FSC-A:전방 산란 영역; FSC-H: 전방 산란 높이)과 측방 산란(SSC-A)에 따라 선택되었다. DAPI는 죽은 세포를 배제하기 위해 사용되었다. 단일 세포 분획 (FSC-A / FSC-H)의 CD4-양성 세포를 CD40L 발현에 따라 분류하고 대량의 CD40Lpositive 및 CD40Lnegative CD4+ T 세포주로 확립하였다. 또한 CD40 positive CD4+ T 세포를 단일 세포 기준으로 96-웰 플레이트로 분류하였다.
도 11: 대체(alternative) ER 전좌 신호 서열
(a) ivt-RNA 생산에 사용되는 벡터 구조의 개략도. 특성화된 CD4+ T 세포 클론 3H10 (EBNA-3C-특이적, HLA-DRB1*11:01-제한)의 표적 항원을 인간 LAMP1, LAMP2, DC-LAMP, CD68 또는 CD1b (항원 서열에 대한 5 ') 의 ER 전좌 신호의 조합 및 인간 DC-LAMP (항원 서열에 대한 3 ')의 엔도좀/리소좀 표적 서열, DC-LAMP의 엔도좀/ 리소좀 표적 서열 단독 또는 전좌 및 표적 서열 없음(no translocation and targeting sequence)을 포함하는 pGEM 벡터 시스템으로 클로닝하였다. 또한, 사용된 신호 펩타이드 서열(ER 전좌 신호)의 아미노산 서열이 예측된 펩티다아제 절단 부위를 나타내었다. (b) CD4+ T 세포 클론 3H10 세포를 단일 ivt-RNA 종(species)-형질감염된 APC(mLCL)와 함께 배양하였다. 모의 형질감염된 APC와의 공동배양물을 대조군으로 사용하였다. IFN-γ분비는 공동배양 시작 후 16 시간 째 표준 IFN-γ ELISA에 의해 검출되었다. 값은 3 회의 평균 + SD로 표시된다.
도 12: CrossTAg 타겟팅 신호를 사용하는, 동시(Simultaneous) MHC 클래스-II 및 MHC 클래스-I 표시(presentation). (a) ivt-RNA 생산에 사용된 벡터 구조의 개략도. 특성화된 CD4+ T 세포 클론 3H10 (EBNA-3C 특이적, HLA-DRB1*11:01- 제한적) 및 특성화된 CD8+ T 세포 클론 IVSB (티로시나제 특이 적, HLA-A2*01:01- 제한적)의 표적 항원을 CrossTAg 표적화 서열을 갖거나 갖지 않는 pGEM 벡터 시스템으로 클로닝시켰다. EBNA-3C는 전체 유전자 서열의 1kb 단편 (aa 421-780)으로 클로닝되고 클론 3H10에 대한 에피토프를 포함한다. IVSB-3H10(Epitope)-CrossTAg 컨스트럭을 생성하기 위하여, 완전한 항원 서열 대신에, 클론 3H10 (EBNA-3C, aa 628-641, VVRMFMRERQLPQS; SEQ ID NO: 36)의 에피토프를 포함하는 미니-유전자 및 IVSB-3H10 (Epitope) 클론 IVSB (티로시나제, aa 369-377, YMDGTMSQV; SEQ ID NO: 37)를 순차적으로 pGEM-CrossTAg 벡터 백본으로 클로닝하였다. 세포질에서 전사된 ivt-RNA 종의 안정화를 촉진하기 위해, 모든 pGEM 벡터 컨스트럭은 오픈 리딩 프레임 (ORF)의 120 아데닌 염기쌍 (폴리-A120)3'을 포함하는 폴리-A 테일을 갖는다. (b) HLA-A2*01:01-, HLA-DRB1*11:01- 이중 양성 공여자의 성숙한 DC (mDC)의 분리 분획을 (a)에 열거된 단일 ivt-RNA 종으로 형질감염시켰다. 형질감염 후 7 시간 째에, 뚜렷한 mDC 집단의 1*105 세포를 CD4+ T 세포 클론 3H10 또는 CD8+ T 세포 클론 IVSB의 1*105 세포와 공동배양하였다(1:1 비율). 모의 형질감염된 mDC (H2O)와의 공동배양물 또는 T 세포 단독을 대조군으로 사용하였다. IFN-γ 분비는 공동배양 시작 후 16 시간 째 표준 IFN-γ ELISA에 의해 검출되었다. 값은 3 회의 평균 + SD로 표시된다.
도 2: 분리되지 않은 PBL에서 C/T-항원-특이적 CD4+ T 세포의 유도 및 농축. (a) C/T-항원-감작된 PBL(C/T-antigen-primed PBL)로부터의 CD4+ T 세포에서 활성화-유도된 CD40L 및 CD137 표면 발현. 활성화 마커 발현은 시험관 내에서 각각 배양13 일 및 27일째에 PBL의 특이적 재자극(specific re-stimulation) 6 시간 후에 측정되었다. (b) 대량(bulk) CD40Lpositive 및 CD40Lnegative CD4+ T 세포주의 증식 능력 직접 비교. 28일째에, CD4+ T 세포는 그들의 CD40L 발현에 따라 감작된 PBL 배양물로부터 단리되었다. 총 세포 수는 FACS 분리 (0 일) 후 특이적 재자극 (14 일) 후 14 일 간격의 끝(end)에서 평가되었다. 그 결과는 0 일에 비해 x-배의 증식을 나타낸다. (c) 항원 특이적 재자극 후 유도된 사이토카인 분비의 비교. 대량의 CD40Lpositive 및 CD40Lnegative CD4+ T 세포주의 IFN-γ분비는 CrossTAg 항원 ivt-RNA-형질감염된 mDC와 함께 16 시간 공동배양하여 측정하였다. 값은 3 회의 평균 + SD로 표시된다.
도 3: C/T-항원-특이적 CD4+ T 세포 클론에 대한 스크리닝. (a) C/T-항원- 감작된 PBL 배양물로부터 유래된 클론의 예시적인(exemplary) 스크리닝 데이터. IFN-γ 분비는 CrossTAg-항원 ivt-RNA-형질감염된mDC (4 가지 항원의 혼합물)와의 16 시간 배양에서 평가하였다. 막대는 단일 값을 나타낸다. (b) 선택된 T 세포 클론의 C/T-항원 반응성의 평가. 사이토카인 분비 (IFN-γ 및 GM-CSF)는 ivt-RNA- 형질감염된 mLCL (4 가지 항원의 혼합물)과 함께 배양한 후에 평가 하였다. 데이터는 단일 값(single values)으로 표시된다 (c) CD4 보조 수용체(co-receptor) 발현의 확인. 예시적인 클론이 도시되어 있다.
도 4: 항원 특이성의 평가. 단일 C/T-항원-특이성을 나타내는 것으로 밝혀진 CD4+ T 세포 클론에 대한 예시적인 데이터. IFN-γ 분비는 ivt-RNA-형질감염된 mLCL과 함께 공동배양한 후에 측정하였다. 값은 2회의 평균 + SD 또는 (*)표시된 경우 단일 데이터 포인트로 나타낸다.
도 5: CrossTAg-신호와 단백질 인식의 필요성. (a) ivt-RNA 기반 CD4+ T 세포 클론 활성화를 위한 CrossTAg-신호의 필요성. (b) 생리학적으로 처리된 외인성 재조합 단백질의 인식. CrossTAg-신호가 없는 항원-IVIT-RNA (a)로 형질감염된 mLCL 또는 특이적 TCR을 갖는 분리된 CD4+ T 세포 클론의 IFN-γ 분비에 의해 측정된 재조합 단백질로 로딩된 mLCL과 직접 비교한 항원-CrossTAg ivt-RNA-형질감염된 APC (mLCL)의 자극 능력. 모의 APC 및 T 세포가 대조군으로 사용되었다. 값은회 3 회의 평균 + SD로 표시된다.
도 6: MHC 클래스-II 에피토프 코어 서열의 정의. 직접 MHC 클래스 II 에피토프 식별(direct MHC class-II epitope identification)(DEPI)(점선으로 된 박스)에 의해 발견된 펩타이드 조각은 짧은 CrossTAg-ivt-RNA 컨스트럭을 사용하여 확인되었다. GAGE-1-TCR-2 형질 전환 3H10 T 세포 (a) 또는 XAGE-1-TCR-1 및 -TCR-2 T 세포 (b)를 중첩된 짧은 CrossTAg-ivt-RNA 컨스트럭- (검은 막대로 표시) 또는 전장 항원-CrossTAg ivt-RNA-형질감염된 APC (mLCL)과 공동 배양하였다. IFN-γ분비는 16 시간의 공동 배양에서 평가하였고, 인식된 에피토프 코어 서열을 나타내었다(실선으로 된 상자). 모의 형질감염된 APC와의 공동 배양물 또는 T 세포 단독(alone)이 대조군으로 사용되었다. 값은 3 회의 평균 + SD로 표시된다.
도 7: C/T-항원-특이적 CD4+ T 세포 수용체의 트랜스제닉(transgenic) 발현. 3H10 T 세포를 CD4+ T 세포 클론 GAGE-1-TCR-1, XAGE-1-TCR-1 또는 -TCR-2의 상응하는 TCR-α 및 -β 사슬을 코딩하는 ivt-RNA로 형질 감염시켰다. TCR- 트랜스제닉 3H10 세포를 항원-로딩된 APC (mLCL)와 함께 배양하고, IFN-γ 분비를 16 시간의 공동배양에서 검출하였다. 모의 형질감염된 APC와의 공동 배양물 또는 T 세포 단독(alone)이 대조군으로 사용되었다. 값은 3 회의 평균 + SD로 표시된다.
도 8: CrossTAg 신호는 세포 내 [내인성] 제시 경로를 통해 MHC 클래스 II 로딩을 촉진한다. HLA-DRB1 * 11:01-양성 및 HLA-DRB1*11:01-음성 DC는 EBNA-3C-CrossTAg ivt-RNA로 형질감염시켰다. 형질감염된(Transfected) 및 형질감염되지않은(un-transfected) DCs는 가능한 모든 조합으로 공동 배양하고 12 시간 후 EBNA-3C 특이적 CD4+ T 세포 클론 3H10과 함께 공동배양 하였다. 3H10 세포의 IFN-γ 분비는 DC와의 16 시간의 공동 배양에서 측정되었다. 값은 3회의 평균 + SD로 표시된다.
도 9: PBL 감작(priming)을 위한 3d mDC의 특성. (a) 단일클론 항체(열린 곡선) 및 매칭되는 아이소타입(isotype) 대조군(채워진 회색 곡선)으로 염색하여 검출된 표면 마커. (b) ivt-RNA-형질감염된 mDC의 항원 mRNA 수준. 비-형질감염된(non-transfected) mDC와 관련하여 항원 mRNA 카피 수의 x-배 증가로 나타낸다. 항원-특이적인 프라이머를 사용하여 qRT-PCR에 의해 항원 mRNA 카피 수를 평가하였다.
도10: C/T-항원-특이적 CD4+ T 세포의 CD40L 기반 분류를 위한 게이팅 전략. 림프구는 순방향 (FSC; FSC-A:전방 산란 영역; FSC-H: 전방 산란 높이)과 측방 산란(SSC-A)에 따라 선택되었다. DAPI는 죽은 세포를 배제하기 위해 사용되었다. 단일 세포 분획 (FSC-A / FSC-H)의 CD4-양성 세포를 CD40L 발현에 따라 분류하고 대량의 CD40Lpositive 및 CD40Lnegative CD4+ T 세포주로 확립하였다. 또한 CD40 positive CD4+ T 세포를 단일 세포 기준으로 96-웰 플레이트로 분류하였다.
도 11: 대체(alternative) ER 전좌 신호 서열
(a) ivt-RNA 생산에 사용되는 벡터 구조의 개략도. 특성화된 CD4+ T 세포 클론 3H10 (EBNA-3C-특이적, HLA-DRB1*11:01-제한)의 표적 항원을 인간 LAMP1, LAMP2, DC-LAMP, CD68 또는 CD1b (항원 서열에 대한 5 ') 의 ER 전좌 신호의 조합 및 인간 DC-LAMP (항원 서열에 대한 3 ')의 엔도좀/리소좀 표적 서열, DC-LAMP의 엔도좀/ 리소좀 표적 서열 단독 또는 전좌 및 표적 서열 없음(no translocation and targeting sequence)을 포함하는 pGEM 벡터 시스템으로 클로닝하였다. 또한, 사용된 신호 펩타이드 서열(ER 전좌 신호)의 아미노산 서열이 예측된 펩티다아제 절단 부위를 나타내었다. (b) CD4+ T 세포 클론 3H10 세포를 단일 ivt-RNA 종(species)-형질감염된 APC(mLCL)와 함께 배양하였다. 모의 형질감염된 APC와의 공동배양물을 대조군으로 사용하였다. IFN-γ분비는 공동배양 시작 후 16 시간 째 표준 IFN-γ ELISA에 의해 검출되었다. 값은 3 회의 평균 + SD로 표시된다.
도 12: CrossTAg 타겟팅 신호를 사용하는, 동시(Simultaneous) MHC 클래스-II 및 MHC 클래스-I 표시(presentation). (a) ivt-RNA 생산에 사용된 벡터 구조의 개략도. 특성화된 CD4+ T 세포 클론 3H10 (EBNA-3C 특이적, HLA-DRB1*11:01- 제한적) 및 특성화된 CD8+ T 세포 클론 IVSB (티로시나제 특이 적, HLA-A2*01:01- 제한적)의 표적 항원을 CrossTAg 표적화 서열을 갖거나 갖지 않는 pGEM 벡터 시스템으로 클로닝시켰다. EBNA-3C는 전체 유전자 서열의 1kb 단편 (aa 421-780)으로 클로닝되고 클론 3H10에 대한 에피토프를 포함한다. IVSB-3H10(Epitope)-CrossTAg 컨스트럭을 생성하기 위하여, 완전한 항원 서열 대신에, 클론 3H10 (EBNA-3C, aa 628-641, VVRMFMRERQLPQS; SEQ ID NO: 36)의 에피토프를 포함하는 미니-유전자 및 IVSB-3H10 (Epitope) 클론 IVSB (티로시나제, aa 369-377, YMDGTMSQV; SEQ ID NO: 37)를 순차적으로 pGEM-CrossTAg 벡터 백본으로 클로닝하였다. 세포질에서 전사된 ivt-RNA 종의 안정화를 촉진하기 위해, 모든 pGEM 벡터 컨스트럭은 오픈 리딩 프레임 (ORF)의 120 아데닌 염기쌍 (폴리-A120)3'을 포함하는 폴리-A 테일을 갖는다. (b) HLA-A2*01:01-, HLA-DRB1*11:01- 이중 양성 공여자의 성숙한 DC (mDC)의 분리 분획을 (a)에 열거된 단일 ivt-RNA 종으로 형질감염시켰다. 형질감염 후 7 시간 째에, 뚜렷한 mDC 집단의 1*105 세포를 CD4+ T 세포 클론 3H10 또는 CD8+ T 세포 클론 IVSB의 1*105 세포와 공동배양하였다(1:1 비율). 모의 형질감염된 mDC (H2O)와의 공동배양물 또는 T 세포 단독을 대조군으로 사용하였다. IFN-γ 분비는 공동배양 시작 후 16 시간 째 표준 IFN-γ ELISA에 의해 검출되었다. 값은 3 회의 평균 + SD로 표시된다.
일부 바람직한 실시예와 관련하여 본 발명이 상세하게 설명되기 전에, 다음과 같은 일반적인 정의가 제공된다.
다음에 예시적으로 기술된 본 발명은 명세서에 구체적으로 개시되지 않은 임의의 요소 또는 요소들, 제한 또는 제한들이 없는 경우에 적합하게 실시될 수 있다.
본 발명은 특정 실시예 및 특정 도면을 참조하여 설명될 것이나, 본 발명은 이에 한정되지 않고 청구 범위에 의해서만 제한된다.
용어 "포함하는 (comprising)"이 본 명세서 및 청구 범위에서 사용되는 경우, 다른 요소를 배제하지 않는다. 본 발명의 목적을 위해, "이루어지는 (consisting of)"이라는 용어는 "포함하는(comprising of)"이라는 용어의 바람직한 구현 예로 간주된다. 이하 그룹이 적어도 특정 숫자의 실시 양태를 포함하도록 정의되는 경우, 이는 또한 바람직하게는 단지 이들 실시 양태로만 이루어진 그룹을 개시하는 것으로 이해되어야 한다.
단수 명사를 언급할 때 부정관사 또는 정관사(indefinite or definite article), 예를 들어 "a", "an" 또는 "the"가 사용되는 경우, 이는 특별히 명기된 것이 없는 한 해당 명사의 복수형을 포함한다.
본원에 사용된 용어 "발현(expression)"은 유전자의 핵산 서열에 기초하여 폴리 펩타이드가 생산되는 과정을 의미한다. 따라서, 용어 "발현된" 단백질 또는 폴리 펩타이드는, 제한없이, 세포 내(intracellula), 트랜스멤브레인(transmembrane) 및 분비 단백질들(secreted proteins) 또는 폴리 펩타이드들(polypeptides)을 포함한다.
기술 용어는 상식 (common sense)으로 사용된다. 만일 특정 의미가 특정 용어로 전달되는 경우 용어가 사용되는 문맥의 다음에 용어의 정의가 제공될 것이다.
본 발명의 일 측면은 하기 단계를 포함하는 인간 항원-특이적 T 림프구(antigen-specific T lymphocyte)를 생성시키는 방법에 관한 것이다:
A) 항원 제시 세포에서(in antigen presenting cells), 다음을 포함하는 적어도 하나의 융합 단백질의 발현
- 적어도 하나의 항원 또는 그의 단편(fragment),
- 항원의 N-말단에 선행하는 소포체(ER)- 전좌 신호 서열((translocation signal sequence), 및
- 항원의 C-말단 다음의 엔도좀/리소좀 표적 서열 (endosomal/lysosomal targeting sequence)을 포함하는 트랜스멤브레인(transmembrane) 및 세포질 도메인(cytoplasmic domain),
; 및
B) 항원 제시 세포에 의해 발현된 항원에 특이적인 항원-특이적 T 림프구를 활성화시키기 위하여 시험관 내(in vitro)에서 T 림프구를 포함하는 세포 집단을 단계 A)의 항원 제시 세포에 노출
상기 단편(fragment)은 이 항원에 특이적인, 즉 포유류, 특히 인간의 다른 단백질 또는 펩타이드에서 발생하지 않는 항원 서열일 수 있다. 단편은 항원 서열보다 적어도 5 %, 적어도 10 %, 적어도 30 %, 적어도 50 %, 적어도 70 %, 적어도 90 % 더 짧을 수있다. 상기 단편은 적어도 9, 적어도 10, 적어도 11, 적어도 12, 적어도 13, 적어도 14, 적어도 15 또는 그 이상의 아미노산 길이를 가질 수 있다.
일 구체예에서, 상기 융합 단백질은 2 개 이상의 항원 또는 이의 단편을 포함한다. 융합 단백질은 적어도3, 적어도4, 적어도 5, 적어도 6, 적어도 7, 적어도 8, 적어도 9 , 적어도 10 개의 항원 또는 이의 단편을 포함할 수 있다. 융합 단백질은 100 개 미만, 50 개 미만, 40 개 미만, 30 개 미만, 20 개 미만, 10 개 미만의 항원 또는 그의 단편을 포함할 수 있다.
용어 "항원-특이적 T 림프구 활성화 (activate antigen-specific T lymphocytes) "는 나이브(naive) T 세포 (de novo induction)의 활성화와 기억 T 림프구(memory T lymphocytes)의 활성화(재활성화, reactivation)를 나타낸다.
일반적으로 항원 제시 세포 및 T 림프구(T lymphocytes)를 포함하는 세포 집단은 동일한 공여자(donor)로부터 유래한다. 유럽 특허 제1910521호에 기술된 바와 같은 알로레스트릭된 셋-업 (allorestricted set-ups)이 또한 고려되는데, 여기에서 MHC 분자를 코딩하는 핵산은, 전달되는 상기 MHC 분자에 상응하는 MHC 유전자를 갖지 않는 공여자의 항원 제시 세포에서 발현된다.
단계 A)에서 적어도 하나의 융합 단백질의 발현은 일과성 발현 (transient expression) 또는 안정발현(stable expression)일 수있다. 바람직한 실시 양태에서, 발현은 예를 들어 적어도 하나의 융합 단백질을 코딩하는 ivt-RNA의 도입에 의한 일과성 발현이다. ivt-RNA의 발현은 품질관리된(quality-controlled) ivt-RNA가 신속하게 생산될 수 있고 면역원성 단백질 오염물 (immunogenic protein contaminants)을 갖지 않는다는 이점을 갖는다.
프라이밍(priming)이라고도 지칭되는, T 림프구의 노출에 의해, 여러 가지 다른 활성화된 림프구 집단이 시험관 내(in vitro)에서 나타난다(출현한다). 일반적으로, 단계 B)에서의 노출은 T 림프구를 포함하는 세포 집단과 항원 제시 세포를 공동 배양하는 것이다. 항원 제시 세포의 MHC:에피토프 복합체 (MHC:epitope complexes)를 인식하는 T 세포가 활성화되며, 이의 일부는 단계 A)에서 발현된 항원의 에피토프를 나타내는 MHC 분자의 복합체에 특이적이다. 이러한 탐색된 T 세포(sought-after T cells)는 단계 A)에서 발현된 항원으로부터 유래되지 않은 에피토프를 나타내는 펩타이드 또는 MHC 분자와 무관하게 MHC 분자를 인식하는 T 세포로부터 분리되어야 한다.
단계 B)에서 항원 제시 세포의 노출을 위해, 항원 제시 세포는 T 림프구를 포함하는 집단에 적어도 한번 첨가된다. 항원 제시 세포의 첫 번째 첨가 (the first addition) 는 또한 프라이밍(priming)으로 지칭된다. 항원 제시 세포는 수회, 예를 들어, 적어도 2 회 또는 3 회 첨가될 수 있다. 이 단계에서 이미 활성화된 T 림프구가 추가 증식을 위한 추가적인 자극을 받기 때문에 항원 제시 세포의 두 번째(the second) 및 이후의 모든 첨가는 재자극(restimulation)으로 지칭된다. 특정 실시 양태에서, 항원 제시 세포는 한번 첨가된다. 다른 구체예에서, 항원 제시 세포는 2 회 첨가된다. 또 다른 실시 양태에서, 항원 제시 세포는 3 회 첨가된다. 추가의 실시 양태는 항원 제시 세포가 3 회 이상 첨가되는 방법에 관한 것이다. 새로운 APC는 T 세포 배양에 7 ~ 21 일마다, 또는 12 ~ 16 일마다, 또는 13 ~ 15 일마다, 또는 14 일마다 첨가될 수 있다. 당업자는 세포가 보충 사이토카인(supplementary cytokines)을 함유하는 새로운 배양 배지(culture medium)를 정기적으로 제공받는다는 것을 이해한다.
시험관 내에서 T 림프구를 포함하는 세포 집단을 항원 제시 세포에 노출시키는 것은, 포유 동물과 같은 유기체에서 노출이 일어나지 않지만, 노출은 시험관 내 세포 배양에서 일어난다는 것을 의미한다. 세포 배양 조건은 당업자에게 공지되어 있으며, 생성되는 T 세포의 유형에 따라, IL-2, IL-4, IL-7 및/또는 IL-15와 같은 사이토카인의 첨가를 포함한다 (Schendel, DJ 등, Human CD8 + T lymphocytes 1997. In: The Immunology Methods Manual (I. Lefkovits, Ed.) 670-690 페이지, Regn, S., et al. 2001. The generation of monospecific and bispecific anti-viral cytotoxic T lymphocytes (CTL) for the prophylaxis of patients receiving an allogeneic bone marrow transplant. Bone Marrow Transplant. 27: 53-64; Su, Z. et al. Antigen presenting cells transfected with LMP2a RNA induce CD4+ LMP2a-specific cytotoxic T lymphocytes which kill via a Fas-independent mechanism. Leuk. Lymphoma 43(8): 1651-62.).
일부 실시 양태에서, 상기 방법은 활성화 및/또는 항원 특이적 T 림프구의 농축 (enrichment) 단계를 더 포함할 수 있다. 이 농축 단계는 일반적으로 다음 단계를 포함한다:
(a) 활성화된 항원-특이적 T 림프구(activated antigen-specific T lymphocytes)를 포함하는 세포 집단을, 활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질과 특이적으로 결합하는 적어도 하나의 결합 분자(binding molecule) 또는 원하는 항원의 에피토프를 나타내는 적어도 하나의 MHC 분자와 접촉시키는 단계;
(b) 적어도 하나의 결합 분자 또는 원하는 항원의 에피토프를 나타내는 적어도 하나의 MHC 분자가 결합된 T 림프구를 단리하는(isolating) 단계.
특정 실시 양태에서, 상기 방법은 활성화된 T 림프구의 농축 단계를 포함할 수 있다. 이 농축 단계는 일반적으로 다음 단계를 포함한다:
(a) 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을, 활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질에 특이적으로 결합하는 적어도 하나의 결합 분자와 접촉시키는 단계;
(b) 적어도 하나의 결합 분자가 결합된 T 림프구를 단리하는 단계.
다른 특정 실시 양태에서, 상기 방법은 원하는 항원에 특이적인 T 림프구의 농축 단계를 포함할 수 있다. 이 농축 단계는 일반적으로 다음 단계를 포함한다:
(a) 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 원하는 항원의 에피토프를 나타내는 MHC 분자와 접촉시키는 단계;
(b) 원하는 항원의 에피토프를 나타내는 적어도 하나의 MHC 분자가 결합된 T 림프구를 단리하는 단계.
활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질에 기초한 활성화 된 T 림프구의 농축은, 제한 (restriction) 및 특정 에피토프(specific epitope)와 독립적으로 활성화된 T 세포의 광범위한 스펙트럼을 풍부하게 한다. 마커 단백질에 특이적으로 결합하는 결합 분자는 항체, 항체 유도체, 항체 단편, 또는 상기 분자와 추가 분자(further molecule)의 접합체일 수 있으나, 이에 한정되는 것은 아니다. 결합 단백질은 예를 들어 FACS 또는 MACS와 같은 분류 절차를 용이하게 하기 위해 표지될 수 있다.
활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질은 활성화된 T 림프구에 의해 발현되고 비활성화된 T 림프구에 의해 실질적으로 발현되지 않는 임의의 표면 단백질(surface protein) 또는 분비 단백질(secreted protein)일 수 있다. 바람직한 실시 양태에서, 활성화된 T 림프구에 의해 특이적으로 발현되는 하나 이상의 마커 단백질은 Ox40, CD137, CD40L, PD-1, IL-2 수용체, 인터페론-γ, IL-2, GM-CSF 및 TNF-α를 포함하는 그룹에서 선택된다.
이러한 마커를 사용하면 TCR에 의해 제시된 특정 에피토프로부터 독립적으로 활성화된 T 림프구가 농축(enrichment)될 수 있다. 이 방법은 선택된 항원의 모든 잠재적인 면역원성 에피토프를 인식하는 T 세포의 분리를 용이하게 하며, 예를 들어 불완전하게 정의된 항원(poorly defined antigens)에 대해 특히 유용하다.
농축 단계(enrichment step)에서 선택된 세포를 하위 집단(subpopulations) 으로 모으거나 단일 세포 클론(single cell clones)으로 직접 분리할 수 있다. 특정 실시 양태에서, 세포는 제1 농축 단계(first enrichment step)에서 모으고, 추가 농축 단계에서는 단일 클론으로 분리한다. 단일 클론 분리는 제한 희석(limited dilution) 또는, FACS 또는 MACS를 이용한 자동 단일 세포 분류(automated single cell sorting)를 통해 제한없이 발생할 수 있다. 단일 세포 분류는 FACS에 의해 수행하는 것이 바람직하다.
특정 실시 양태에서, 활성화된 CD4 T 세포를 선택하는 것은 하기 단계를 포함한다:
(a1) 항원 제시 세포의 CD40-CD40L과 항원-특이적 T 림프구 사이의 상호 작용을 차단하고 T 림프구의 표면에 CD40L을 축적시키기 위해, 단계 A)의 하나 이상의 융합 단백질을 발현하는 항원 제시 세포를 CD4에 대한 항체와 접촉시키는 단계;
(b) 항-CD40L 항체 및 항-CD4 항체로 표지된(marked) T 림프구를 단리하는 단계.
분비 단백질에 의해 활성화된 T 세포의 선택을 사용(employ the selection)하기 위하여, 예를 들어 인터페론-γ와 같은 사이토카인, T 세포 표면 마커 및 표적화된 사이토카인을 인식하는 이중-특이적 분자(bi-specific molecules)는 세포 표면에서 분비된 사이토카인을 포획하고, 이는 Becker et al에 기재된 바와 같이 표지된 검출 항체에 의해 검출될 수 있다(Becker, C et al. 2001. Adoptive tumor therapy with T lymphocytes enriched through an IFN capture assay. Nature Med. 7(10): 1159-1162.).
또한, 단계 (a)에서, 세포는 CD4에 특이적으로 결합하는 결합 분자 및/또는 CD8에 특이적으로 결합하는 결합 분자와 추가적으로 접촉될 수있다.
대안적으로, 농축은 원하는 항원 (즉, 단계 A의 항원 제시 세포에 의해 외인성으로 발현되는 항원)의 에피토프를 나타내는 MHC 분자를 사용함으로써 수행될 수있다. MHC 분자는 예를 들어 분류 절차를 용이하게 하기 위해 FACS 또는 MACS와 같이 표지될 수있다. TCR과 상응하는 펩타이드(corresponding peptide):MHC 복합체 사이의 낮은 친화도 상호 작용(low affinity interaction)은 Wilde et al의 문헌((Dendritic cells pulsed with RNA encoding allogeneic MHC and antigen induce T cells with superior antitumor activity and higher TCR functional avidity. Blood 114(10): 2131-2139; 2009)에 기재된 바와 같은 펩타이드:MHC 분자의 가용성 다량체(soluble multimers)의 조합에 의해 극복 될 수있다. 상기 다량체는 예를 들어 다이머, 트라이머, 테트라머, 펜타머, 헥사머, 헵타머 또는 옥타머 등이 있으나 이에 제한되는 것은 아니다. 또한, TCR에 가역적으로 결합하여 기능적 변화 또는 활성화 유도된 세포 사멸(activation induced cell death)의 위험 없이 고친화성 TCR의 단리를 허용하는, 소위 펩타이드:MHC 스트렙타머(streptamers)를 사용할 수 있다(Knabel et al. (2002) Reversible MHC multimer staining for functional isolation of T-cell populations and effective adoptive transfer. Nature Medicine, 8(6), 631-7.). T 세포의 가역적 성질:스트렙타머 상호 작용은 스트렙타머(streptamer)의 백본(backbone)으로 작용하는 스트렙트아비딘(strep-tactin)의 변형된 형태(modified form)을 기반으로 한다.
이러한 접근법은 특이적 제한(specific restriction)을 갖는 에피토프 특이적 TCR (epitope specific TCR)의 표적화된 농축(targeted enrichment)을 허용한다.
활성화된 및/또는 항원-특이적 T 림프구의 단리(isolation)는 FACS (fluorescence-activated cell sorting) 및 MACS (magnetic-activated cell sorting)에 의해 수행될 수있다. FACS의 경우, 마커 단백질에 특이적으로 결합하는 결합 분자 또는 원하는 항원의 에피토프를 나타내는 MHC 분자를 형광 염료로 표지한다. FACS는 고순도 (high purity)의 작은 수 (small numbers)의 단리에 특히 유용하다. MACS의 경우, 마커 단백질에 특이적으로 결합하는 결합 분자 또는 원하는 항원의 에피토프를 나타내는 MHC 분자는 자성 비드와 같은 자성 입자로 표지된다. MACS는 대량 배양물(bulk cultures)의 신속한 분류에 특히 적합하다.
또한, 단계 (a)에서, 세포는 CD4에 특이적으로 결합하여 CD4를 더욱 풍부하게 하는 결합분자 및/또는 CD8에 특이적으로 결합하는 결합분자와 추가로 접촉될 수있다.
또 다른 실시 양태는 상기 클레임들 중 어느 하나에 따른 방법과 관련되며, 여기서 상기 방법은 단계를 더 포함한다:
C2) 다음의 단계를 포함하는, 항원-특이적 T 림프구의 동정(identification):
a) 다음을 갖는 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단의 증식된 세포 클론 (expanded cell clones)의 항온 배양(incubation)
(i) 단계 A)에서 정의된 항원 제시 세포, 및
(ii) 대조 항원 제시 세포;
b) 각각의 세포 클론에 대한 (i) 및 (ii)와의 항온 배양의 활성화 프로파일의 비교;
c) b)의 비교에 기초한 항원-특이적 세포 클론의 동정;
여기서 (ii)에 의한 것이 아닌, (i)에 의한 활성화는 세포 클론이 항원 특이적임을 나타낸다.
항원-특이적 T 림프구의 단계 C2) 동정은 단계 C1) 활성화된 T 림프구의 농축 이후에 수행되거나, 또는 농축 단계 C1) 없이 단계 B) T 림프구를 포함하는 세포 집단을 항원 제시 세포에 노출시킨 후에 수행될 수 있다.
또 다른 실시 양태는 상기 클레임 중 어느 하나에 따른 방법과 관련되며, 상기 방법은 단계를 더 포함한다:
C2)다음의 단계를 포함하는, 항원-특이적 T 림프구의 동정:
a) 다음을 갖는 활성화된 항원 특이적 T 림프구를 포함하는 세포 집단의 세포의 적어도 하나의 분획의 항온 배양
(i) 단계 A)에서 정의 된 항원 제시 세포, 및
(ii) 대조 항원 제시 세포 또는 항원 제시 세포의 부재 하;
b) 세포의 적어도 하나의 분획에 대한 (i) 및 (ii)와의 항온 배양의 활성화 프로파일의 비교;
c) b)의 비교에 기초하여 항원 특이 적 세포 분획의 동정;
c) b)의 비교에 기초하여 항원 특이 적 세포 분획의 동정;
여기서 (ⅱ)에 의한 것이 아닌, (ⅰ)에 의한 활성화 세포의 분획이 항원-특이적임을 나타낸다.
또 다른 실시 양태는 상기 클레임 중 어느 하나에 따른 방법과 관련되며, 상기 방법은 단계를 더 포함한다.
C2) 다음의 단계를 포함하는, 항원- 특이적 T 림프구의 동정:
a) 다음을 갖는 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단의 증식된 T 세포 클론의 항온 배양
(i) 단계 A)에서 정의된 항원 제시 세포, 및
(ii) 항원 제시 세포 또는 항원 제시 세포의 부재 하;
b) 각각의 세포 클론에 대한 (i) 및 (ii) 와의 항온 배양의 활성화 프로파일의 비교;
c) b)의 비교에 기초한 항원-특이적인 세포 클론의 동정;
여기서, (ii)에 의한 것이 아닌, (i)에 의한 활성화는 세포 클론이 항원- 특이적임을 나타낸다.
T 림프구의 활성화 프로파일은 예를 들어 활성화-유도된 사이토카인 방출 또는 항원-유도된 살생 용량 (killing capacity)을 측정함으로써 결정될 수있다.
활성화-유발성(activation-induced) 사이토카인 분비를 측정하기 위해, T 세포는 항원-로딩된(antigen-loaded)APC와 함께 공동배양될 수 있다. 다양한 이펙터 세포(effector cell) 대 표적 세포 (E:T) 비율이 적용될 수 있다.
대조 항원 제시(control antigen presenting), 즉 모의-트랜스펙션된(mock-transfected) APC와 함께 배양되거나 T 세포 또는 자극 세포의 부재 하에서 배양된 T 세포는 음성 대조군으로서 사용될 수 있다.
배양 상등액(culture supernatants)은 표준 ELISA (enzyme-linked immunosorbent assay)에 의해 평가된다.
마커의 예로는 과립구-대식세포 콜로니-자극 인자(granulocyte-macrophage colony-stimulating factor, GM-CSF), 인터페론- γ(interferon-γ, IFN-γ), IL-2 및 TNF-α 분비 (TNF-α secretion)가 있으나 이에 제한되는 것은 아니다. 항원 접촉(antigen encounter) 시 IFN-g, IL-2 및 TNF-α 분비는 향상된 항-종양 기능(anti-tumor function)과 관련이 있으므로, D8+ 세포 독성 T 세포의 항원-유도된(antigen-induced) 사이토카인 분비를 측정 할 때 특히 유용하다.
또한 IFN--γ 및 GM-CSF (granulocyte-macrophage colony-stimulating factor F)는 항원-특이적 CD4+ T 헬퍼(helper)-1(Th1)-분극(polarized) T 세포 클론의 평가용으로 잘 정의된(well-defined) 사이토카인이다.
1 차 T 세포(primary T cell) 유도를 위해 여러 항원이 동시에 사용되는 경우, 각 프라이밍 항원을 발현하는 개별 APC 집단은 동일한 비율로 혼합되어 T 세포 공동배양(co-culture)에 사용될 수 있다. 따라서, 특이성을 평가하기 위해 수행 된 초기 스크리닝 어세이는 전체 전개된 표적 항원(total deployed target antigens)에 대한 전체 항원-반응성(antigen-reactivity)의 예측만을 허용한다. 단일-항원 특이성(single-antigen specificities)의 평가는 항원 반응성 T 세포와 단일-종(single-species) ivtRNA-형질감염된(transfected) APC의 후속 공동배양을 필요로 한다.
또한, 개별 T 세포(individual T cell) 클론의 세포 독성 활성은 예를 들어 크롬 방출 분석(chromium release assays)에 의해 측정될 수있다. 그러한 분석에서, 표적 세포는 방사성 크롬으로 표지되고 T 세포에 노출된다. 살생(killing) 시, 방사성 크롬은 상등액으로 방출되고 공동배양 시작 후 4 시간 이내에 검출 가능하다. 특정 크롬 방출(Specific chromium release)은 이펙터(effector) 세포의 부재에서 표적 세포를 배양하는 것에 의해 평가되는 자발 방출에 대해 노멀라이즈(normalize)된다. 따라서, 상층액 중의 다량의 크롬은 탁월한 세포 용해성(cytolytic) T 세포 활성과 상관 관계가 있다. 크롬 방출 분석은 바람직하게는 종양 항원-특이적 CD8+ T 세포를 스크리닝하기 위해 수행된다.
항원-특이적 T 림프구의 동정에 사용하기에 적합한 항원 제시 세포는 예를 들어 원하는 항원 및 필요한 MHC 분자를 발현하는 종양 세포주, 통상적인 MHC 분자를 발현하는 확립된(established) 항원 제시 세포주 또는 T 림프구를 포함하는 집단과 동일한 공여자로부터 유래된 항원 제시 세포일 수 있다.
확립된 항원 제시 세포주의 한 예는, 결함있는 고유의 에피토프 제시 (defective intrinsic epitope presentation)를 나타내고 예를 들어 합성 펩타이드와 같은 짧은 펩티드로 외부적으로 로딩될 수 있는 빈번한 HLA-A*02:01 대립 유전자(allele)를 발현하는 인간 림프구(human lymphoid) T2 세포주이다: 이 세포주는 HLA-A*02:01-제한된(restricted) CD8+ T 림프구의 스크리닝에 사용될 수 있다. 다른 예는 관심있는 HLA 분자(any HLA molecule of interest)가 안정적으로 또는 일시적으로 도입되어 CD8+ T 림프구 및 CD4+ T 림프구 스크리닝 모두에 사용될 수 있는 HLA 클래스 I 및 II 발현이 결여된 인간 K562 세포주이다.
공여자 유래의 항원 제시 세포는 예를 들어 수지상세포(dendritic cells)로 성숙된 단리 단핵구 (isolated monocytes) 일 수있다. 성숙된 수지상세포는 최적 활성 용량을 나타낸다.
유용한 공여자-유래 APC에 대한 또 다른 예는 소위 림프아구 세포주 (lymphoblastoid cell line, LCL)라고 불리는 엡스타인- 바(Epstein-Barr) 바이러스(EBV)-면역화된 B 림프구이다. LCL은 자연적으로 B 세포에서 유래되기 때문에, 이러한 APC는 항원 처리(antigen processing) 및 제시 (presentation) 에 능숙한 기능을 제공한다. 또한 LCL은 B7.1 (CD80) 및 B7.2 (CD86)와 같은 동시 자극 분자(co-stimulatory molecules) 뿐만 아니라 자극 수용력(stimulatory capacity)을 향상시키는 데 도움이 되는 적절한 접착 분자 (adhesion molecules)를 발현한다. 게놈-감소된(Genome-reduced) 돌연변이 EBV(mini-EBV) 균주는 대부분의 용균 주기 유전자(lytic cycle genes)가 결여된 미니 EBV-형질 전환된 B 세포(mini-EBV-transformed B cells)(mLCL)를 생성하는데 사용되며, 결과적으로 T 림프구의 EBV- 의존성 활성화를 감소시킨다(Kempkes, B.et al. (1995) Immortalization of human B lymphocytes by a plasmid containing 71 kilobase pairs of EpsteinBarr virus DNA. J Virol 69(1): 231-238., 1995; Moosmann, et al. (2002) B cells immortalized by a mini-Epstein-Barr virus encoding a foreign antigen efficiently reactivate specific cytotoxicT cells. Blood 100(5): 1755-1764).
공여자-유래 LCL/mLCL은, 특히 다수의 분리된 T 세포 클론을 평가할 필요가 있을 때, T 세포 특이성을 평가하는 데 사용될 수 있다. LCL/mLCL의 항원 로딩은 예를 들어 레트로 바이러스 (retroviral) 형질 도입 (transduction) ivtRNA 형질감염(transfection) 및 외부 펩타이드 또는 단백질 공급에 의해 달성될 수있다.
항원-특이적 T 림프구의 단리는 (i) 원하는 항원을 발현하는 항원 제시 세포 에서, 및 (ii) 대조 항원 제시 세포 또는 항원 제시 세포의 부재 하에서 배양된 T 림프구의 활성화 프로파일의 비교에 기초한다.
(i) 원하는 항원을 발현하는 항원 제시 세포에 의한 활성화는, (ii) 항원 제시 세포에 의한 또는 항원 제시 세포의 부재하에 의한 것이 아닌, T 세포 클론이 항원-특이적임을 나타낸다. 활성화되지 않은 경우와 비교하여 활성화된 것은 원하는 항원을 발현하는 항원 제시 세포와 함께 항온 배양(incubation)된 T 림프구의 밸류(value)(즉, IFN-g 분비)의 적어도30 %, 적어도 40 %, 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %의 감소를 의미한다.
ER 전좌 신호 서열은 엔도좀/리소좀(endosomal/ lysosomal) 관련 단백질로부터 유래될 수있다.
개시된 방법에서 사용된 ER-전좌 신호 서열은 엔도좀/리소좀성 편재 단백질(endosomal/lysosomal localized protein)의 선별 서열(sorting sequence)일 수 있다. 본원에서 사용 된 엔도좀/리소좀성 편재 단백질은 세포의 엔도좀 및/또는 리소좀의 막(membrane) 또는 루멘(lumen)에 편재된 단백질을 지칭한다.
엔도좀 또는 리소좀성 편재 단백질의 예는 알파-갈락토시다아제 A/GLA (alpha-galactosidase A/GLA), 엔도-베타-N 아세틸글루코사미니다아제 H/Endo H(endo-beta-N-acetylglucosaminidase H/Endo H), 알파-N-아세틸갈락토사미니다아제/NAGA(alpha-N-acetylgalactosaminidase/NAGA), 갈락토실세라미다아제/GALC(galactosylceramidase/GALC), 알파-N-아세틸글루코사미니다아제//NAGLU(alpha-N-acetylglucosaminidase/NAGLU), 글루코실세라미다아제/GBA(glucosylceramidase/GBA), 알파-갈락토시다아제/a-Gal(alpha-galactosidase/a-Gal), 헤파라나아제/HPSE(heparanase/HPSE), 알파-L-푸코시다아제(alpha-L-fucosidase), 헤파라나아제 I(heparinase I), 티슈 알파-L-푸코시다아제/FUCA1(tissue alpha-L-fucosidase/FUCA1), 헤파리나아제 II (heparinase II), 베타-갈락토시다아제-1/GLB1(beta-galactosidase-1/GLB1), 헤파리나아제 III(heparinase III), 베타-글루쿠로니다아제/GUSB(beta-glucuronidase/GUSB), 헥소사미니다아제 A/HEXA(hexosaminidase A/HEXA), 베타 (1-3)-갈락토시다아제(beta (1-3)-galactosidase), 히알루론산 리아제 (hyaluronan Lyase), 베타(1-4)-갈락토시다아제(beta (1-4)-galactosidase), 히알루로니다아제 1/HYAL1(hyaluronidase 1/HYAL1), 키티나아제 3-형 1(chitinase 3-like 1), 히알루로니다아제 4/HYAL4(hyaluronidase 4/HYAL4), 키티나아제 3-형 2(chitinase 3-like 2), 알파-L-이두로니다아제/IDUA(alpha-L-iduronidase/IDUA), 키티나아제 3-형 2/ECF-L(chitinase 3-like 3/ECF-L), 키토비아제//CTBS(chitobiase/CTBS), 키토트리오시다아제/CHIT1 (chitotriosidase/CHIT1), 락타아제-형 단백질/LCTL(lactase-like protein/LCTL), 콘드로이틴 B 리아제/콘드로이티나아제 B (chondroitin B Lyase/chondroitinase B), 리소좀 알파-글루코시다아제(lysosomal alpha-glucosidase), 콘드로이티나아제 ABC(chondroitinase ABC), MBD4, 콘드로이티나아제 AC(chondroitinase AC), NEU-1/시알리다아제-1(NEU-1/Sialidase-1), 사이토솔릭 베타-글루코시다아제//GBA3(cytosolic beta-glucosidase/GBA3), O-GlcNAcase/OGA, 엔도-베타-N-아세틸글루코사미니다아제 F1/Endo F1(endo-beta-N-acetylglucosaminidase F1/Endo F1), PNGase F, 엔도-베타-N-아세틸글루코사미니다아제 F3/Endo F3(endo-beta-N-acetylglucosaminidase F3/Endo F3), SPAM1와 같은 글리코시다아제(glycosidases); AMSH/STAMBP, 카텝신 H(cathepsin H), 카텝신 3(cathepsin 3), 카텝신 K(cathepsin K), 카텝신 6(cathepsin 6), 카텝신 L(cathepsin L), 카텝신 7/카텝신 1(cathepsin 7/cathepsin 1), 카텝신 0 (cathepsin O), 카텝신 A/리소좀 카르복시펩티다아제 A(cathepsin A/lysosomal carboxypeptidase A), 카텝신 S(cathepsin S), 카텝신 B(cathepsin B), 카텝신 V(cathepsin V), 카텝신 C/DPPI(cathepsin C/DPPI), 카텝신 X/Z/P(cathepsin X/Z/P), 카텝신 D(cathepsin D), 갈락토실세라미다아제/ GALC (galactosylceramidase/GALC), 카텝신(cathepsin F), 어구메인/아스파라기닐 엔도펩티다제(oegumain/asparaginyl endopeptidase)와 같은 리소좀 프로테아제(lysosomal proteases); 아릴설퍼타아제 A/ARSA(arylsulfatase A/ARSA), 이두로네이트 2-설퍼타아제/IDS(iduronate 2-sulfatase/IDS), 아릴설퍼타아제 B/ARSB(arylsulfatase B/ARSB), N-아세틸갈락토사민-6-설퍼타아제/GALNSv(N-acetylgalactosamine-6-sulfatase/GALNSv), 아릴설퍼타아제 G/ARSG(arylsulfatase G/ARSG), 설퍼미다아제/SGSH (sulfamidase/SGSH), 글루코사민 (N-아세틸)-6-설퍼타아제/GNS (glucosamine (N-acetyl)-6-sulfatase/GNS), 설퍼타아제-2/SULF2(sulfatase-2/SULF2)와 같은 설퍼타아제(sulfatases); 또는 BAD-LAMP/LAMP5와 같은 다른 리소좀 단백질(lysosomal proteins); 히알루로니다아제1/HYAL1(hyaluronidase 1/HYAL1); CD63; LAMP1/CD107a; CD-M6PR; LAMP2/CD107b; 클라트린 H사슬 1/CHC17(clathrin Heavy Chain 1/CHC17); Rab27a; 클라트린 H사슬 2/CHC22(clathrin Heavy Chain 2/CHC22); UNC13D, CD68, CD1b 또는 DC-LAMP가 있다.
ER 전좌 신호 서열은 엔도좀/리소좀 관련 단백질로부터 유래된다.
엔도좀/리소좀 관련 단백질은 LAMP1, LAMP2, DC-LAMP, CD68 또는 CD1b, 바람직하게는 LAMP1일 수있다. 바람직하게는, ER 전좌 신호는 인간이다. ER 전좌 신호 서열은 SEQ ID NO: 33, SEQ ID NO: 40, SEQ ID NO: 42, SEQ ID NO: 44 및 SEQ ID NO: 46 중 적어도 하나의 서열을 포함할 수있다. 일부 실시 양태에서, ER 전좌 신호 서열은 SEQ ID NO: 34, SEQ ID NO: 41, SEQ ID NO: 43, SEQ ID NO: 45, SEQ ID NO: 47로 이루어진 군으로부터 선택된 서열 중 하나로 이루어질 수있다. 특정 실시 양태에서, ER 전달 신호 서열은 SEQ ID NO: 33의 서열 또는 그의 단편을 포함한다. 보다 특정한 실시 양태에서, ER 전좌 신호 서열은 하기 서열의 SEQ ID NO: 34로 이루어진다.
엔도좀/리소좀 표적 서열은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 엔도좀/리소좀 표적 서열은 일반적으로 트랜스멤브레인(transmembrane) 및 세포질 도메인(cytoplasmic domain)의 일부이다. 따라서, 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수있다. 바람직하게는 엔도좀/리소좀성 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 인간이다. 일반적으로 엔도좀/리소좀 표적 서열은 Y-XX 모티프 다음에 소수성 아미노산을 포함한다. 바람직하게는, 엔도좀/리소좀 표적 신호 서열은 YQRI이다. 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 SEQ ID NO: 54의 서열 또는 이의 단편을 포함할 수있다. 예를 들어, 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 SEQ ID NO: 35 또는 그의 단편 서열을 포함할 수 있다.
소수성 아미노산(hydrophobic amino acid)이라는 용어는 당업자에게 잘 알려져있다. 소수성 아미노산의 예는 Ala, Ile, Leu, Phe, Val, Pro, Gly, Met, Trp, Tyr, Pro, Cys이다.
일반적으로, 항원 제시 세포는 수지상 세포(dendritic cells), 활성화된 B 세포 (activated B cells), 단핵구(monocytes), 대식 세포(macrophages), EBV-형질 전환된 림프아구 세포주(EBV-transformed lymphoblastoid cell lines), 바람직하게는 수지상 세포, 보다 바람직하게는 수지상 세포로부터 유래된 단핵구 세포로부터 선택된다.
항원 제시 세포는 항원 제시 세포의 다양한 모집단(different populations)을 포함할 수 있으며, 각각의 모집단은 다양한 항원 융합 단백질을 발현한다.
일부 실시 양태에서 항원 제시 세포는, 하기 단계를 포함하는 방법에 의해 생성된 성숙한 수지상 세포이다:
i) 단핵구(monocytes)의 제공;
ii) 단계 i)의 단핵구를 IL-4 및 GM-CSF와 함께 항온 배양(incubation); iii) 성숙 칵테일(maturation cocktail)과 조합하여 IL-4 및 GM-CSF와 함께 단계 ii)의 단핵구를 항온 배양.
성숙 칵테일은 IL-β, TNF-α, INF-γ, TLR7/8 아고니스트(agonist), PGE2 및 TLR3 아고니스트 또는 이들의 조합으로 이루어진 군으로부터 선택된 성분 중 하나 이상을 포함할 수있다. 예를 들어, TLR7/8 아고니스트는 R848일 수 있고/있거나 TLR3 아고니스트는 폴리(I:C)일 수 있다. 단계 ii)의 항온 배양은 적어도 2 일 동안 지속될 수 있다. 단계 iii)의 항온 배양은 적어도 12 시간, 바람직하게는 24 시간 동안 지속될 수 있다.
일반적으로, T 림프구를 포함하는 세포 집단은 말초 혈액 림프구의 집단(population)이다. T 림프구를 포함하는 세포 집단은 분리되지 않은 말초 혈액 림프구의 집단일 수 있다. 세포 집단은 T 림프구, 바람직하게는 CD8+ 및 /또는 CD4+ T 림프구를 위해 농축될 수 있다
본 발명의 추가의 양태는 다음을 포함하는 발현 벡터(expression vector)와 관련된다:
- 인간의 소포체(endoplasmatic reticulum, ER) - 전좌 신호 서열, 및
- 엔도좀/리소좀 표적 서열을 포함하는 인간 트랜스멤브레인 및 및 세포질 도메인.
벡터는 시험관 내 mRNA 전사를 위한 프로모터를 포함할 수 있다. ER 전좌 신호 서열은 엔도좀/리소좀 관련 단백질, 예를 들어 LAMP1, LAMP2, DC-LAMP, CD68, CD1b, 바람직하게는 LAMP1로부터 유래된다. 바람직하게는, ER 전좌 신호는 인간이다. 특정 실시 양태에서, ER 전좌 신호는 서열 SEQ ID NO: 33 또는 그의 단편을 포함한다. 보다 구체적인 실시 양태에서, ER 전좌 신호는 하기 서열 SEQ ID NO: 34로 이루어진다.
엔도좀/리소좀 표적 서열은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 엔도좀/리소좀 표적 서열은 일반적으로 트랜스멤브레인 및 세포질 도메인의 일부이다. 따라서, 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래될 수 있다. 바람직하게는 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 인간이다.
전형적으로 엔도좀/리소좀 표적 서열은 Y-XX 모티프 다음에 소수성 아미노산 (X는 임의의 자연 발생 아미노산을 나타낸다)을 포함한다. 바람직하게는, 엔도좀/리소좀 표적 신호는 YQRI이다. 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 서열 SEQ ID NO: 54 또는 이의 단편을 포함할 수 있다. 예를 들어, 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인은 서열 SEQ ID NO: 35 또는 그의 단편 서열을 포함할 수 있다.
일부 실시 양태에서, 발현 벡터는 엔도좀/리소좀 표적 서열을 포함하는 ER 전좌 신호와 인간 트랜스멤브레인 및 세포질 도메인 사이의 제한 부위(restriction sites)를 추가로 포함한다. 다른 구체예에서, 벡터는 인간 소포체(ER)- 전좌 신호와, 엔도좀/리소좀 표적 서열을 포함하는 인간 트랜스멤브레인 및 세포질 도메인 사이에 삽입된 적어도 하나의 항원 또는 이의 단편을 추가로 포함한다.
특정 실시 양태에서, 벡터는 적어도 2 개의 항원 또는 그의 단편을 코딩하는 서열을 포함한다. 벡터는 적어도 3, 적어도 4, 적어도 5, 적어도 6, 적어도 7 , 적어도 8, 적어도 9, 적어도 10 개의 항원 또는 그 단편을 코딩하는 서열을 포함할 수 있다. 벡터는 100 미만, 50 미만, 40 미만, 30 미만, 20 미만, 10 미만의 항원 또는 그의 단편을 코딩하는 서열을 포함 할 수 있다.
일부 실시 양태에서, 벡터는 항원의 전장(full length) 아미노산 서열을 코딩하는 핵산 서열을 포함한다. 대안적으로, 벡터는 항원의 아미노산 서열을 코딩하는 핵산 서열의 단편을 포함한다. 도 12에 도시된 바와 같이, 2 개의 상이한 항원의 단편을 포함하는 벡터가 도입된 항원 제시 세포는 2 개의 항원에 대해 특이적인 상이한 TCR의 활성화를 유도할 수 있다.
일반적으로, 항원은 종양 항원(tumor antigen) 또는 바이러스 항원(viral antigen) 이다. 종양 항원은 바이러스 성 종양 항원, 종양-특이적 항원, 종양 관련 항원 및 환자 특이적 돌연변이를 수반하고(carrying) 환자의 종양 세포에서 발현되는 항원으로 이루어진 군에서 선택될 수 있다.
발암성 바이러스성 항원(oncogenic viral antigens)으로도 불리는 바이러스성 종양 항원(Viral tumor antigens)은 발암성 DNA 바이러스, 예를 들어 B 형 간염 바이러스(hepatitis B viruses), 헤르페스 바이러스 (herpesviruses) 및 유두종 바이러스 (papillomaviruses) 및 발암성 RNA 바이러스와 같은 종양 바이러스의 항원이다. 종양 특이적 항원은 종양 세포에서만 독점적으로 발현되는 종양 관련 돌연변이를 의미한다. 종양 관련 항원군은 예를 들어 조직 특이적 암/고환 항원(cancer/testis antigens) 또는 조직 분화 항원, 예컨대 MART-1, 티로시나제 또는 CD20을 포함한다. 바람직하게는 종양 항원은 종양 관련 항원이며,보다 바람직하게 종양 관련 항원은 암/고환 항원 (C/T 항원)이다. C/T 항원은 MAGE 계열 멤버들(family members), 예를 들어 MAGE-A1, MAGE-A3, MAGE-A4를 포함하는 군에서 선택될 수 있지만, 이들로 한정되지는 않으며, 단일 점 돌연변이(single point mutations)를 포함하는 종양 항원, NY-ESO1, 종양/고환-항원1B(tumor/testis-antigen 1B), 종양/GAGE-1, GAGE-1, SSX-4, XAGE-1, BAGE, GAGE, SCP-1, SSX-2, SSX-4, CTZ9, CT10, SAGE alc CAGE를 포함한다.
바람직하게는 C/T 항원은 GAGE-1, SSX-4 및 XAGE-1로 이루어진 군으로부터 선택될 수있다. 바람직하게는 환자 특이적 변이(patient specific mutations) 를 수반하고(carrying) 환자의 종양 세포에서 발현되는 항원은 환자의 비-암성 세포에서 발현되지 않는다.
본 발명의 다른 측면은 다음을 포함하는 적어도 하나의 융합 단백질을 발현하는 항원 제시 세포, 특히 수지상 세포에 관한 것이다.
- 적어도 하나의 항원 또는 그의 단편,
- 소포체 (endoplasmatic reticulum, ER)- 항원의 N- 말단에 선행하는 전좌 신호 서열 및
- 항원의 C- 말단 다음의 엔도좀/리소좀 표적 서열을 포함하는 트랜스멤브레인 및 세포질 도메인.
본 발명의 다른 양태는, 본원에 기재된 바와 같이, 항원 특이적인 T 림프구의 시험관 내 생성을 위한 발현 벡터의 용도에 관한 것이다.
본 발명의 또 다른 양태는 본원에 기재된 방법에 의해 생성된 T- 림프구를 포유 동물에게 투여하는 것을 포함하는, 암을 예방 또는 치료하는 방법에 사용하기 위한 T- 림프구에 관한 것이다.
또 다른 양태는 전술한 방법의 단계를 포함하고, 본원에 기재된 방법에 의해 생성된 활성화된 항원-특이적 림프구로부터 TCR을 단리하는 단계를 추가로 포함하는, 항원 특이적인 TCR을 생성시키는 방법에 관한 것이다.
TCR의 단리 및 후속 서열 분석은 예를 들어 Steinle et al. (In vivo expansion of HLA-B35 alloreactive T cells sharing homologous T cell receptors: evidence for maintenance of an oligoclonally dominated allospecificity by persistent stimulation with an autologous MHC/peptide complex. The Journal of Experimental Medicine, 181(2), 503-13; 1995)에 개시되어 있다. 서열 분석은 예를 들어 PCR 또는 차세대 시퀀싱 방법에 의해 수행 될 수있다. 핵산의 서열을 확인하는 방법은 당업자에게 공지되어 있다.
TCR은 두 개의 서로 다른 단백질 사슬인 a와 b로 구성된다. TCR α 사슬은 가변 (variable, V), 결합 (joining, J) 및 불변 (constant , C) 영역을 포함한다. TCR α 사슬은 가변 (V), 다양성 (diversity, D), 결합 (J) 및 불변 (C) 영역을 포함한다. TCR α 및 TCR β 사슬 모두의 재 배열 된 V (D) J 영역은 초 가변 영역(hypervariable regions) (CDR, 상보성 결정 영역)을 포함하며, 그 중 CDR3 영역은 특이적인 에피토프 인식을 결정한다.
본 발명의 한 측면은 GAGE-1에 특이적인 TCR에 관한 것이다. 일 구체예에서, GAGE-1에 특이적인 TCR은 SEQ ID NO: 48 및 SEQ ID NO: 49로 이루어진 군으로부터 선택된 아미노산 서열 중 적어도 하나 또는 이의 단편을 특이적으로 인식한다. 상기 단편은 적어도 9, 적어도 10, 적어도 11, 적어도 12, 적어도 13, 적어도 14 , 적어도 15 또는 그 이상의 아미노산 길이를 가질 수 있다. TCR은 SEQ ID NO : 48 및 SEQ ID NO : 49로 이루어진 군으로부터 선택된 아미노산 서열 중 적어도 하나 또는 이의 단편에 특이적으로 결합할 수 있다.
GAGE-1에 특이적인 TCR은 SEQ ID No: 7과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95%, 적어도 96%, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는 TCR α 사슬을 포함할 수 있고, SEQ ID No: 8와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는 TCR β사슬을 포함할 수 있다.
특정 실시 양태는 SEQ ID No : 7의 아미노산 서열을 갖는 TCR α 사슬 및 SEQ ID No : 8의 아미노산 서열을 포함하는 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체와 관련되며, 여기에서
- TCR α 사슬은 SEQ ID No: 7과 적어도 80 % (80 % 이상) 동일한 아미노산 서열을 포함하고, SEQ ID No: 3의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 8과 적어도 80 % (80 % 이상) 동일한 아미노산 서열을 포함하고, SEQ ID No: 4의 서열을 갖는 CDR3을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서
- TCR α 사슬은 SEQ ID No: 7 과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 3의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 8 과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 4의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 SEQ ID No: 5 와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열(nucleotide sequence)에 의해 코딩되는 TCRα 사슬 및 SEQ ID No: 6과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되는 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다.
특정 실시 양태는 뉴클레오타이드 서열SEQ ID No: 5에 의해 코딩되는 TCR α 사슬 및 뉴클레오타이드 서열SEQ ID No: 6에 의해 코딩되는 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 5 와 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고 SEQ ID No: 1에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함하고;
- TCR β 사슬은 SEQ ID No: 6과 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 2로 기재되는 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 GAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 5 와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 1에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 6과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 2에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
본 출원의 또 다른 양태는 SEQ ID No: 15 와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는 TCRα 사슬 및 SEQ ID No: 16과 적어도 50%, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR에 관한 것이다.
특정 실시 양태는 SEQ ID NO: 15의 아미노산 서열을 갖는 TCR α 사슬 및 SEQ ID NO: 16의 아미노산 서열을 포함하는 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 15 와 적어도 80 % 동일한 아미노산 서열을 포함하고 SEQ ID No: 11의 서열을 갖는 CDR3를 포함하고;
- TCR β 사슬은 SEQ ID No: 16과 적어도 80 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 12의 서열을 CDR3 영역을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다. 여기에서
- TCR α 사슬은 SEQ ID No: 15와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 11의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 16 과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 12의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 SEQ ID No: 13 과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열(nucleotide sequence)에 의해 코딩되는 TCRα 사슬 및 SEQ ID No: 14와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되는 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다.
특정 실시 양태는 뉴클레오타이드 서열 SEQ ID No: 13에 의해 코딩되는 TCRα 사슬 및 뉴클레오타이드 서열 SEQ ID No: 14에 의해 코딩되는 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 SSX-4 에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 13과 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고 SEQ ID No: 9에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 14와 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 10으로 기재되는 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 SSX-4에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 13과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 9에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 14와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 10에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
본 발명의 하나의 양태는 XAGE-1에 특이적인 TCR에 관한 것이다. 일 실시예에서, XAGE-1에 특이적인 TCR은 SEQ ID NO: 50 및 SEQ ID NO: 51로 이루어진 군으로부터 선택된 아미노산 서열 중 적어도 하나 또는 이의 단편을 특이적으로 인식한다. 상기 단편은 적어도 9, 적어도 10, 적어도 11, 적어도 12, 적어도 13, 적어도14, 적어도 15 또는 그 이상의 아미노산 길이를 가질 수 있다. TCR은 SEQ ID NO : 50 및 SEQ ID NO : 51로 이루어진 군으로부터 선택된 아미노산 서열 중 적어도 하나 또는 이의 단편에 특이적으로 결합할 수 있다.
XAGE-1 에 특이적인 TCR은SEQ ID No: 23과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는 TCRα 사슬 및 SEQ ID No: 24와 적어도 50%, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는TCR β 사슬을 포함할 수 있다.
특정 실시 양태는 SEQ ID No: 23의 아미노산 서열을 갖는 TCR α 사슬 및 SEQ ID No: 24 의 아미노산 서열을 포함하는 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 23과 적어도 80 % 동일한 아미노산 서열을 포함하고 SEQ ID No: 19의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 24와 적어도 80 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 20의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다. 여기에서
- TCR α 사슬은 SEQ ID No: 23과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 19의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 24와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 20의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 SEQ ID No: 21과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열(nucleotide sequence)에 의해 코딩되는 TCRα 사슬 및 SEQ ID No: 22와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되는 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다.
특정 실시 양태는 뉴클레오타이드 서열 SEQ ID No: 21에 의해 코딩되는 TCRα 사슬 및 뉴클레오타이드 서열 SEQ ID No: 22에 의해 코딩되는 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 21과 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고 SEQ ID No: 17에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 22와 적어도 80 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 18로 기재되는 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 21과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 17에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 22와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 18에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
본 출원의 또 다른 양태는 SEQ ID No: 31과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는 TCRα 사슬 및 SEQ ID No: 32와 적어도 50%, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 갖는TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR에 관한 것이다.
특정 실시 양태는 SEQ ID No: 31의 아미노산 서열을 갖는 TCR α 사슬 및 SEQ ID No: 32 의 아미노산 서열을 포함하는 TCR β 사슬을 포함하는XAGE-1에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 31과 적어도 80 % 동일한 아미노산 서열을 포함하고 SEQ ID No: 27의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 32와 적어도 80 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 28의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 31과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 27의 서열을 갖는 CDR3를 포함한다;
- TCR β 사슬은 SEQ ID No: 32와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 아미노산 서열을 포함하고, SEQ ID No: 28의 서열을 갖는 CDR3를 포함한다.
특정 실시 양태는 SEQ ID No: 29과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열(nucleotide sequence)에 의해 코딩되는 TCRα 사슬 및 SEQ ID No: 30과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되는 TCR β 사슬을 포함하는 XAGE-1에 특이적인 TCR 수용체에 관한 것이다.
특정 실시 양태는 뉴클레오타이드 서열 SEQ ID No: 29에 의해 코딩되는 TCRα 사슬 및 뉴클레오타이드 서열 SEQ ID No:3에 의해 코딩되는 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다.
또한, 본 출원은 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 29와 적어도 80 %(80 % 이상) 동일한 뉴클레오타이드 서열에 의해 코딩되고 SEQ ID No: 25에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 30과 적어도 80 %(80 % 이상) 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 26으로 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
특정 실시 양태는 TCR α 사슬 및 TCR β 사슬을 포함하는 XAGE-1 에 특이적인 TCR 수용체에 관한 것이다. 여기에서,
- TCR α 사슬은 SEQ ID No: 29와 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 25에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다;
- TCR β 사슬은 SEQ ID No: 30과 적어도 50 %, 적어도 60 %, 적어도 70 %, 적어도 80 %, 적어도 85 %, 적어도 90 %, 적어도 95 %, 적어도 96 %, 적어도 97 %, 적어도 98 %, 적어도 99 % 동일한 뉴클레오타이드 서열에 의해 코딩되고, SEQ ID No: 26에 기재된 뉴클레오타이드 서열에 의해 코딩되는 CDR3 영역을 포함한다.
본 출원은 또한 상기 정의된 TCR을 코딩하는 핵산 분자에 관한 것이다.
전체 핵산 서열의 유용한 변화(useful changes)는 코돈 최적화(codon optimization)에 있을 수 있다.
발현된 아미노산 서열 내에서 보존적 치환(conservative substitutions)을 유도하는 변형이 이루어질 수 있다. 이러한 변형은 기능에 영향을 미치지 않는 TCR 사슬의 아미노산 서열의 상보성 결정(complementarity determining) 및 비-상보성 결정 영역 (non-complementarity determining regions)에서 이루어질 수 있다. 일반적으로 첨가(additions) 및 결실(deletions)은 CDR3 영역에서 수행해서는 안 된다.
"보존적 아미노산 치환(conservative amino acid substitutions)"의 개념은 당업자에 의해 이해되며, 바람직하게는 양으로 하전된(positively-charged) 잔기(H, K 및 R)를 코딩하는 코돈이 양으로 하전된 잔기를 코딩하는 코돈으로, 음으로 하전된(negatively-charged) 잔기(D 및 E)를 코딩하는 코돈은 음으로 하전된 잔기를 코딩하는 코돈으로 치환되고, 중성 극성 잔기 (C, G, N, Q, S, T 및 Y)를 코딩하는 코돈은 중성 극성 잔기를 코딩하는 코돈으로 치환되고, 중성 비-극성 잔기(A, F, I, L, M, P, V 및 W)는 중성의 비극성 잔기를 코딩하는 코돈으로 치환된다. 이러한 변이는 자연 발생적으로 발생하거나, 무작위 돌연변이유발 (mutagenesis)에 의해 도입되거나, 지시된 돌연변이유발 (directed mutagenesis)에 의해 도입될 수있다. 그러한 변화는 이러한 폴리 펩타이드의 본질적인 특성(essential characteristics)의 손상없이 이루어질 수 있다. 당업자는 당해 기술 분야에 공지된 방법에 의해 이러한 변이가 실질적으로 리간드 결합 능력을 감소시키거나 파괴하는지를 결정하기 위해 변형 아미노산 및/또는이를 코딩하는 핵산을 쉽게 그리고 통상적으로 스크리닝할 수 있다.
에피토프 태그 (epitope tags)는 특정한 항체를 올릴 수있는 짧은 길이의 아미노산이며, 일부 실시예에서는 살아있는 유기체 또는 배양 된 세포에 첨가된 태그화된 단백질(tagged protein) 을 특이적으로 확인하고 추적 할 수있다. 태그화된 분자(tagged molecule)의 검출은 다수의 상이한 기술을 사용하여 달성될 수 있다. 그러한 기술의 예로는 면역조직화학법(immunohistochemistry), 면역침전법 (immunoprecipitation), 유동세포계측법(flow cytometry), 면역형광현미경법 (immunofluorescence microscopy), ELISA, 면역블로팅("Western") 및 친화성 크로마토 그래피(affinity chromatography)가 있다.
에피토프 태그는 대상 단백질에 알려진 에피토프(항체 결합 부위)를 첨가하여, 공지된 고친화성(high-affinity) 항체의 결합을 제공함으로써, 살아있는 유기체 또는 배양된 세포에 첨가된 태그 단백질을 특이적으로 식별하고 추적할 수 있게 한다.
본 발명과 관련하여, "기능적(functional)" TCR α- 및/또는 β- 사슬 융합 단백질은 TCR 또는 TCR 변이체, 예를 들어 아미노산의 첨가, 결실 또는 치환에 의해 변형된 것을 의미하고, 이는 적어도 실질적인 생물학적 활동을 유지하는 것을 의미한다. TCR의 α- 및/또는 β- 사슬의 경우, 이는 양 사슬이 생물학적 기능을 발휘하는, 특히 상기 TCR의 특이적 펩타이드-MHC 복합체에 대한 결합 및/또는 특이적 펩타이드:MHC 상호 작용시 기능적 신호 전달(transduction)에 있어서, T-세포 수용체 (변형되지 않은 α- 및/또는 β- 사슬 또는 다른 인벤티브한(inventive) 융합 단백질 α- 및/또는 β- 사슬과 함께)을 형성할 수 있음을 의미한다.
특정 실시 양태에서, TCR은 기능적 T 세포 수용체 (TCR) α- 및/또는 β- 사슬 융합 단백질로 변형될 수 있으며, 여기에서 상기 에피토프-태그는 6 내지 15 의 아미노산, 바람직하게는 9 내지 11의 아미노산 길이를 가진다. 또 다른 실시 양태에서, TCR은 기능적 T 세포 수용체 (TCR) α- 및/또는 β- 사슬 융합 단백질로 변형될 수 있으며, 여기에서 상기 T- 세포 수용체 (TCR) α- 및/ 또는 β- 사슬 융합 단백질은 이격되거나 직접 탠덤방식으로(directly in tandem) 존재하는 2 또는 그 이상의 에피토프-태그를 포함할 수 있다. 융합 단백질의 실시 양태는 융합 단백질이 그의 생물학적 활성/활성들("기능성(functional) ")을 유지하는 한, 2, 3, 4, 5 또는 그 이상의 에피토프-태그를 함유할 수 있다.
본 발명에 따른 기능성 T 세포 수용체(TCR) α- 및/또는 β- 사슬 융합 단백질이 바람직하며, 상기 에피토프-태그는 CD20 또는 Her2/neu 태그, 또는 myc-태그, FLAG-태그, T7-태그, HA(hemagglutinin)-태그, His-태그, S-태그, GST-태그, 또는 GFP-태그와 같은 기타 기존 태그(other conventional tags) 로부터 선택될 수 있으나, 이에 제한되는 것은 아니다. myc, T7, GST, GFP 태그는 기존 분자에서 유래된 에피토프이다.
대조적으로, FLAG는 높은 항원성을 위해 고안된 합성 에피토프 태그이다 (예를 들어, 미국 특허 제 4,703,004 호 및 제 4,851,341 호 참조). myc 태그는, 고품질 시약이 그것의 감지를 위해 이용 가능하기 때문에, 바람직하게 사용될 수 있다. 에피토프 태그는 당연히 항체에 의한 인식을 넘어, 하나 이상의 추가 기능을 가질 수 있다. 이들 태그의 서열은 문헌에 기재되어 있고 당업자에게 공지되어 있다.
본 발명의 다른 측면은 상기 정의 된 TCR을 발현하는 T 세포에 관한 것이다.
또한, 본 발명은 상기 정의된 TCR을 코딩하는 하나 이상의 핵산 서열을 포함하는 벡터에 관한 것이다. 상기 벡터는 바람직하게는 플라스미드, 셔틀 벡터, 파지미드(phagemide), 코스미드(cosmid), 발현 벡터, 레트로 바이러스 벡터(retroviral vector), 아데노 바이러스 벡터 (adenoviral vector) 또는 입자 (particle) 및/또는 유전자 치료에 사용되는 벡터이다.
"벡터"는 코딩된 폴리펩티드의 합성이 일어날 수 있는 적합한 숙주 세포 내로 핵산 서열을 운반할 수있는 임의의 분자 또는 조성물이다. 전형적으로 및 바람직하게는, 벡터는 당해 분야에 공지된 재조합 DNA 기술을 사용하여 원하는 핵산 서열 (예를 들어, 본 발명의 핵산)을 도입하도록 조작된 핵산이다. 벡터는 DNA 또는 RNA를 포함할 수 있고/포함할 수 있거나 리포좀을 포함할 수 있다. 벡터는 유전자 치료에 사용되는 플라스미드, 셔틀 벡터, 파지미드, 코스미드, 발현 벡터, 레트로 바이러스 벡터, 아데노 바이러스 벡터 또는 입자 및 /또는 벡터일 수 있다. 벡터는 복제 원점(origin of replication)과 같이 숙주 세포에서 복제를 허용하는 핵산 서열을 포함할 수 있다. 벡터는 또한 하나 이상의 선택 가능한 마커 유전자 및 당업자에게 공지된 다른 유전 요소를 포함 할 수 있다. 벡터는 바람직하게는 상기 핵산의 발현을 허용하는 서열에 작동 가능하게 연결된 본 발명에 따른 핵산을 포함하는 발현 벡터이다.
본 발명의 또 다른 양태에서, 전술한 바와 같은 TCR을 암호화하는 핵산 서열이 도입된 세포가 제공된다. T 세포에서, 상기 기술된 TCR을 암호화하는 핵산 서열을 포함하는 상기 기술된 벡터가 도입되거나 또는 시험관 내(in vitro)에서 상기 TCR을 암호화하는 전사된(transcribed) RNA가 도입될 수 있다. 상기 세포는 T 세포와 같은 말초 혈액 림프구(peripheral blood lymphocyte)일 수 있다. TCR의 클로닝 및 외인성 발현 방법은 예를 들어 Engels et al(Relapse or eradication of cancer is predicted by peptide-major histocompatibility complex affinity. Cancer Cell, 23(4), 516-26. 2013)에 개시된다.
본원의 또 다른 양태는 약물(medicament)로서 사용하기 위한 상기 정의된 TCR 또는 TCR을 발현하는 세포에 관한 것이다. 따라서, 본 출원은 또한 전술한 바와 같은 TCR 또는 TCR을 발현하는 세포 및 약학적으로 허용 가능한 담체를 포함하는 약제학적 조성물을 고려한다. 특정 실시 양태는 GAGE-1, SSX-4, XAGE-1 또는 이들의 혼합물을 발현하는 악성 세포(malignant cells)와 관련된 질환의 치료에 사용하기 위한 상기 정의된 TCR 또는 TCR을 발현하는 세포에 관한 것이다. 따라서, 본 출원은 또한 암 치료에 사용하기 위한 상기 정의된 TCR과 관련된다. 따라서, 본 출원은 입양 세포 치료(adoptive cell therapy)를 필요로 하는 환자를 치료하는 방법에 관련되며, 상기 방법은 본원에서 정의된 바와 같이 제약 조성물을 상기 환자에게 투여하는 것을 포함한다. 상기 환자는 GAGE-1, SSX-4, XAGE-1 또는 이들의 혼합물을 발현하는 악성 세포와 관련된 질환을 겪을 수 있다.
본 발명의 활성 성분은 바람직하게는 허용 가능한 담체 또는 담체 물질과 혼합 된 투여량으로 이러한 약학적 조성물에 사용되어, 질병을 치료하거나 적어도 완화시킬 수 있다. 그러한 조성물은 (활성 성분 및 담체 이외에) 공지된 최신 물질인 충전재(filling material), 염, 완충액, 안정화제, 가용화제 및 기타 물질을 포함할 수 있다.
용어 "약학적으로 허용되는(pharmaceutically acceptable)"은 활성 성분의 생물학적 활성의 효과를 방해하지 않는 무독성 물질을 정의한다. 캐리어의 선택은 어플리케이션에 따라 다르다.
약학 조성물은 활성 성분의 활성을 강화시키거나 또는 처리를 보충하는 추가의 성분을 함유할 수있다. 이러한 부가적인 성분 및/또는 인자는 상승 작용 효과를 달성하거나 불리한 또는 바람직하지 않은 영향을 최소화하기 위한 약학 조성물의 일부일 수 있다.
본 발명의 활성 성분의 제형 또는 제제 및 적용/약물 치료에 대한 기술은 "Remington 's Pharmaceutical Sciences", Mack Publishing Co., Easton, PA, 최신판에 발표되어 있다. 적절한 적용은 근육 내(intramuscular), 피하 (subcutaneous), 골수 내(intramedular) 주사뿐만 아니라 척수강 내 (intrathecal), 직접 심실 내(direct intraventricular), 정맥 내(intravenous), 결절 내(intranodal), 복강 내(intraperitoneal) 또는 종양 내 주사(intratumoral injections)와 같은 비경구 투여이다. 정맥 주사는 환자에게 선호되는 치료법이다
바람직한 실시 양태에 따르면, 약제학적 조성물은 주입( infusion) 또는 주사 (injection)이다.
주사 가능한 조성물(injectable compositions)은 TCR을 발현하는 증식된 T 세포 집단 (예를 들어, 치료 될 환자에게 자가(autologous) 또는 동종 (allogenic))과 같은 적어도 하나의 활성 성분을 포함하는 약학적으로 허용 가능한 유체 조성물이다. 활성 성분은 일반적으로 생리학적으로 허용되는 담체에 용해되거나 현탁되고, 조성물은 소량의 하나 이상의 비-독성 보조 물질, 예컨대 유화제, 방부제 및 pH 완충제 등을 추가로 포함할 수있다. 본원의 융합 단백질과 함께 사용하기에 유용한 그러한 주사 가능한 조성물은 통상적인 것이며; 적절한 제제는 당업자에게 잘 알려져 있다.
실시예
CrossTAg 벡터에 의한 효율적인 MHC 클래스-II 교차 제시의 검증
RNA-코딩 단백질의 MHC 클래스-II 교차-제시를 수득하기 위해, 선택된 항원 DNA 서열을 MHC 클래스-II 표적 신호(CrossTAg)와 결합시켰다. 이를 위해, 인간 리소좀-관련 멤버 단백질 1 (LAMP-1) 5'의 ER-이동 신호를 인간 DC-LAMP의 막통과 및 세포질 도메인에 융합시켰다. 이들 2종의 신호 부분은 CrossTAg와 함께 프레임에서 선택된 항원 서열의 통합을 가능하게 하는 고유의 제한 부위에 의해 분리되었다. 상기 LAMP-1 신호 펩타이드는 새롭게 합성된 단백질을 ER로 공동-번역 이동을 촉진하는데 사용되었다. 이동 후, 세포질 DC-LAMP 표적 신호 (YXXΦ 모티프; X는 모든 자연발생 아미노산을 나타내고; Φ는 모든 소수성 아미노산을 나타냄; 서열번호 38)는 엔도솜/리소좀 구획으로 효율적인 단백질 셔틀을 보장해야 한다.
본 발명자들은 HLA-DRB1*11:01 제한인 EBNA-3C-특이적 CD4+ T 세포 클론 3H10에 대해 공지된 에피토프를 함유하는 1kb 단편을 코딩하는, 엡스타인-바 바이러스 핵 항원 (EBNA)-3C의 일부 코딩 서열을 통합시켰다 (Xiaojun Yu 등의 Antigen-armed antibodies targeting B lymphoma cells effectively activate antigen-specific CD4+ T cells. Blood 2015 Mar 5;125(10):1601-10.; http://www.iedb.org/assayId/2445148에 기재됨). 2 종의 신호 중 하나만 포함하거나 둘 다 포함하지 않는 추가의 컨스트럭트를 사용하여 바람직한 MHC 클래스-II 교차 제시를 위한 각 서열의 필요성을 평가하였다 (도 1a). 그 다음 RNA를 상기 선형화된 플라스미드로부터 생체 외(in vitro)에서 전사시켰고, 필요한 제한 요소인 HLA-DRB1*11:01을 발현하는 상이한 APC에 트랜스펙션시켰다. 클론 3H10에 의한 특이적 항원 인식 시 IFN-γ 생성의 측정은 DC와의 공동-배양 실험에서 내인성으로 번역되고 처리된 단백질의 효율적인 MHC 클래스-II 교차-제시의 검출뿐만 아니라, EBNA-3C CrossTAg-RNA로 트랜스펙션된, 미니-EBV-형질전환된 림프아구 세포주 (mLCL)의 검출을 가능하게 한다 (도 1b). LAMP-1 ER-이동 신호를 함유하는 ivt-RNA만이 검출가능한 T 세포 활성화를 유도하였다. EBNA-3C-CrossTAg-RNA로 달성되는 뚜렷한 MHC 클래스-II 제시와 비교하여, 상기 LAMP-1 신호 펩타이드 단독으로도 작은 교차-제시 능력을 부여하였다. 본 발명자들은 EBV-항원 BNRF1의 HLA-DRB1*15:01-제한 에피토프에 특이적인 하나의 추가 CD4+ T 세포 클론을 사용하여 이 데이터를 확인하였다 (데이터 미도시).
다음으로, 본 발명자들은 CrossTAg 신호가 1) 단백질 분비 및 재흡수 또는 2) 세포 내부 제시 경로를 통해 MHC 클래스-II 제시를 유도하였는지 여부를 밝히기 위해 3H10 T 세포를 사용하였다. 이를 위해, 본 발명자들은 HLA-DRB1*11:01-양성 또는 HLA-DRB1*11:01-음성 DC를 EBNA-3C-CrossTAg-RNA로 트랜스펙션시켰다. 트랜스펙션된 DC와 트랜스펙션되지 않은 DC를 모든 가능한 조합(HLA-DRB1*11:01-양성/-음성)으로 공동-배양하고 이후 3H10 세포와 함께 공동-배양하였다. APC의 인식은 HLA-DRB1*11:01-양성 DC가 항원-CrossTAg-RNA로 트랜스펙션된 경우에만 검출된다. HLA-DRB1*11:01-음성 DC에 의해 분비되는 흡수(taken-up) 및 처리된 항원을 잠재적으로 갖는 트랜스펙션되지 않은 HLA-DRB1*11:01-양성 DC의 인식은 검출되지 않았다 (도 8).
항원-CrossTAg-유도 CD40L 발현
항원-특이적 CD4+ T 세포의 선택적인 농축을 위한 신속한 방법을 개발하기 위해, 본 발명자들은 반응 CD4+ T 세포에서 CD40L 발현을 유도하는 항원-CrossTAg-RNA-트랜스펙션된 DC의 능력을 평가하였다. 이를 위해, 본 발명자들은 3H10 T 세포를 형광 추적 염료로 염색하고 이들을 자가 PBL과 혼합하여 최종 농도가 총 세포의 10%, 5%, 1% 또는 0.1%가 되도록 하였다 (도 1c). 이러한 상이한 분획을 EBNA-3C-CrossTAg ivt-RNA-트랜스펙션된 자가 DC와 공동 배양하고, CD40L 발현에 대해 염색하였다. 공동-배양 6시간에, EBNA-3C-특이적 3H10 세포 상에서 상당한 CD40L 발현이 검출되었으나, 자가 PBL 상에서는 미미한 CD40L 발현만이 관찰되었다. 3H10 세포 (0.1%)의 가장 낮은 농도에서도, CD40L-양성 CD4+ T 세포의 차후 분류 (sorting)는 66% 3H10 세포의 집단을 초래하였다.
대체 ER 이동 신호 서열
클론 3H10에 의한 특이적 항원 인식 시 IFN-γ의 생성을 측정하여, CrossTAg-RNA로 표지된 상이한 EBNA-3C와 CrossTAg-RNA에 대한 다른 대안으로 트랜스펙션된 APC를 이용한 공-배양 실험에서 내인성으로 번역 및 처리되는 단백질의 효율적인 MHC 클래스-II 교차-제시를 검출하는데 사용할 수 있었다 (도 11).
효율적인 MHC 클래스-II 및 MHC 클래스-I 제시
본 발명자들은 CrossTAg 신호의 사용이 MHC 클래스-II 제시뿐만 아니라 MHC 클래스-I 제시를 용이하게 한다는 것을 보여줄 수 있었다 (도 12).
동일한 ivt-mRNA 분자에 의해 코딩되는 여러 가지 항원의 효율적인 제시
더 나아가, 본 발명자들은 동일한 ivt-RNA에 의해 상이한 항원으로부터 유래한 여러 가지 에피토프를 제시하는 효율적인 접근법을 확립할 수 있었다. 도 12에 나타난 바와 같이, 상이한 항원으로부터 유래한 2종의 에피토프를 포함하는 상기 컨스트럭트를 발현하는 항원 제시 세포는 EBNA-3C 특이적 클론 3H10뿐만 아니라 티로시나아제 특이적 클론 IVSB를 활성화시킨다. 따라서, 2종의 상이한 에피토프를 갖는 상기 ivt 컨스트럭트는 2종의 에피토프를 모두 제시할 수 있다.
RNA-진동 DC를 이용한 PBL의 활성화
고속-대량 접근법으로 진행하여, 본 발명자들은 CD4+ T 세포 프라이밍(priming)을 위한 다수의 후보 항원을 동시에 이용할 수 있는 가능성을 모색하였다. 따라서, 분리되지 않은 PBL에 존재하는 CD4+ T 세포는 CrossTAg 신호에 융합된 4종의 상이한 C/T 항원 (GAGE-1, MAGE-A4, SSX-4 및 XAGE-1)을 코딩하는 ivt-RNA로 트랜스펙션된 DC를 이용하여 활성화 시켰다. DC는 다음의 문헌에 기재된 바와 같이, 전기천공을 통해 각각의 ivt-RNA로 개별적으로 트랜스펙션되었다 (Javorovic, M. 등의 (2008) Inhibitory effect of RNA pool complexity on stimulatory capacity of RNA-pulsed dendritic cells. J Immunother 31(1): 52-62.). 본 발명자들은 유세포 분석으로 공동-자극 분자 발현의 수준에 의해 트랜스펙션된 DC의 성숙한 상태를 측정하였다. 우리의 DC는 공동-자극 분자 (CD80, CD83, CD86)와 HLA 클래스 II의 고발현을 갖는 성숙한 표현형을 나타내었다 (도 9a).
트랜스펙션의 효율을 평가하기 위해, 트랜스펙션된 DC로부터 추출된 mRNA로부터 유래된 항원 cDNA를 정량적 RT-PCR로 분석하였다. 수득된 데이터는 전기천공후, C/T-항원 mRNA 카피 수가 1.5*105 내지 2*107 배의 범위로 증가함을 나타내었다 (도 9b). 추가로, 약 68%의 DC는 대조군 eGFP ivt-RNA로 트랜스펙션된지 12시간 후에 유세포 분석으로 검출된 바와 같이 증가된 녹색 형광 단백질 (eGFP)을 발현하였다 (데이터 미도시).
항원-CrossTAg RNA로 트랜스펙션시킨 후, 4종의 분리된 DC 집단을 모으고, 건강한 공여자의 비-분리된 자가 PBL을 대비시키기 위해 동시에 사용하였다. 후속 확장 과정은 2회의 APC 자극을 포함하였다. 초기 DC 표본의 동결된 부분표본을 해동하고 재자극 배양을 위해 사용하였다.
활성화된 CD4
+
T 세포의 분리
DC 공동-배양의 각 14일 간격 후, 대비된 자가 PBL은 전체적으로 3-4배 증가된 세포 수를 나타내었다. CD4:CD8 비율의 변화는 활성화된 CD4+ T 세포의 팽창을 추적하기 위해 여러 시점에서 측정되었다. 추가적으로, PBL 샘플을 CD40-차단 항체의 존재하에 항원-로딩 DC와 함께 공동-배양하였고 이후에 CD4, CD137 및 CD40L에 대한 특이적 mAb를 사용하여 유세포 분석으로 분석하였다 (도 2a). 모니터링 기간 동안, 상기 CD4:CD8 비율은 0 일째에 1.7에서 27일째에 0.7로 역전되었고, 이는 CD8+ T 세포의 개선된 증식을 반영한다 (데이터 미도시). 그러나, CD4+ T 세포 집단 내에서, CD40L-양성 T 세포의 비율은 13일째에 4.6%에서 27일째에 30% 이상으로 상승하였다. 대조적으로, CD137 단일-양성 CD4+ T 세포 (Schoenbrunn 등의 A converse 4-1BB and CD40 ligand expression pattern delineates activated regulatory T cells (Treg) and conventional T cells enabling direct isolation of alloantigen-reactive natural Foxp3+ Treg.J Immunol. 2012;189(12):5985-94.)로 기재되는 추정 조절 T 세포 (Tregs)의 수는 약 36% 감소하였다.
세 번째 자극 사이클 후, CD40L-양성 CD4+ T 세포는 PBL 배양물로부터 농축되었고 FACS에 의해 96웰 플레이트로 직접 클로닝되었다 (도 10). 클로닝된 CD4+ T 세포를 확장시켰다. 클로닝 과정으로부터의 과량의 세포를 대량의 CD40L-양성 (CD40Lpos) 및 CD40L-음성 (CD40Lneg) CD4+ T 세포주로 확립시켰다. CD40Lpos-분류된 CD4+ T 세포는 C/T-항원-특이적 재자극 후 14일 동안 거의 4배 증식하였고 CD40Lneg T 세포에 비교하여 RNA-트랜스펙션된 APC와 공동-배양한 후 현저하게 많은 양의 IFN-γ를 방출하였 때문에, 이들의 분석은 C/T-항원-특이적인 CD4+ T 림프구의 성공적인 농축을 나타내었다 (도 2b 및 2c).
C/T-항원-반응성 CD4
+
T 세포 클론에 대한 스크리닝
본 발명자들은 FACS 클로닝 후 12일째부터 시작되는 IFN-γ 방출 어세이의 항원 반응성에 대해 96웰 플레이트에서 확장된 T 세포 클론을 테스트하였다 (도 3a). 4종의 모든 항원-CrossTAg RNA-로딩 DC의 혼합물을 사용한 공동-배양은, 비-반응성 및 비특이적인 T 세포 클론 옆에 다중 항원-반응성 T 세포 클론이 존재하였음을 나타내었다. 몇몇의 경우를 제외하고, 항원-반응성 T 세포 클론은 모의-트랜스펙션된(mock-transfected) DC와의 공동-배양에서 백그라운드 활성화를 나타내지 않았다.
이러한 관찰을 검증하기 위해, APC의 대체원으로 ivt-RNA-트랜스펙션된 mLCL를 이용하여 하루 후에 선택된 클론을 다시 테스트하였다. IFN-γ 및 GM-CSF 방출 어세이는 DC를 이용한 이전의 결과를 확인하였다 (도 3b). 추가로, 선택된 T 세포 클론은 CD4 및 CD8 표면 발현을 위해 염색하였고 모두 CD4 공동-수용체를 발현하는 것으로 확인되었다 (도 3c).
항원-특이적 CD4
+
T 세포 클론의 분자적 및 기능적 특성화
항원-반응성 CD4+ T 세포 클론의 개별 항원 특이성을 분석하기 위해, 이어서 항원-CrossTAg RNA의 단일 종으로 트랜스펙션된 APC의 별개의 집단과 함께 개별 클론을 공동-배양하였다. 반응은 표준 ELISA를 이용하여 IFN-γ 분비를 통해 측정하였다 (도 4). 본 발명자들은 프라이밍을 위해 사용한 4종의 C/T-항원 각각을 인식하는 항원-특이적 CD4+ T 세포 클론을 검출하였다. T 세포 클론은 모의-트랜스펙션된 APC에 의한 백그라운드 활성화를 나타내지 않았고, 프라이밍 동안 이들이 노출된 다른 항원에 대한 어떠한 검출가능한 교차 반응성도 나타내지 않았다.
TCR 레퍼토리 분석을 이용하여, 다수의 분리된 클론으로부터 4종의 고유한 T 세포 수용체 서열을 확인하였다. MHC 제한 어세이는 상이한 T 세포가 상이한 MHC 클래스 II 알로타입(allotype)에 의해 제시되는 에피토프를 인식한다는 것을 보여주었다 (데이터 미도시).
본 발명자들은 이러한 신호 없이 ivt-RNA로 제공되는 DC가 분리된 CD4+ T 세포 클론에 의해 IFN-γ 분비를 유도할 수 없다는 사실로 CrossTAg 신호에 융합된 항원을 갖는 것이 중요하다는 것을 입증하였다 (도 5a). CD4+ T 세포 클론이 항원-CrossTAg RNA로 트랜스펙션된 APC와 공동-배양되는 경우에만, 활성화-유도된 IFN-γ 분비가 유도되었다. 한 가지 예외는 GAGE-1-TCR-2를 발현하는 T 세포 클론이었고, 실질적으로 낮은 수준임에도 불구하고, 이는 또한 각 분류 신호가 결여된 RNA로 트랜스펙션된 APC를 인식하였다.
우리의 분리된 CD4+ T 세포 클론의 항원 특이성을 확인하기 위해, 본 발명자들은 재조합 단백질을 갖는 APC를 로딩하였다. CD4+ T 세포 클론은 항원-CrossTAg RNA-트랜스펙션된 APC와의 공동-배양에서 보여지는 활성화에 필적하는 단백질-로딩 APC에 대한 양성 IFN-γ 분비를 나타내었다 (도 5b).
직접적인 MHC 클래스-II 에피토프 확인
이들 4종의 클론에 대해, MHC 클래스-II 에피토프 (DEPI)의 직접적인 맵핑을 위한 방법 (Milosevic, S. 등의 (2006) Identification of major histocompatibility complex class II-restricted antigens and epitopes of the Epstein-Barr virus)은 MHC 클래스-II 분자와 공동으로 그들이 인식하는 에피토프를 정의하기 위해 사용하였다. 본 발명자들은 짧은 중복 CrossTAg-RNA 컨스트럭트를 갖는 분리된 항원 단편의 인식을 검증하고, 이들을 이용하여 최소 에피토프 서열을 추가로 수탁하였다 (도 6a 및 6b). 이로써, GAGE-1-TCR-1은 HLA-DRB5*01:01에 의해 제시된 GAGE-176-98 에피토프를 인식하는 것으로 확인되었다. 흥미롭게도, 2종의 XAGE-1-특이적 CD4+ T 세포 클론은 2종의 상이한 MHC-II 알로타입 (HLA-DRB1*13:02 및 HLA-DRB5*01:01)에 의해 제시되는 동일한 XAGE-137-49 에피토프를 인식하였다.
C/T-항원-특이적 TCR의 유전자이식 발현
TCR 레퍼토리 분석 후, 본 발명자들은 TCR 발현 벡터를 사용하여 분리된 TCR 서열을 재구성하였다. 3H10 클론 (EBNA-3C-특이적 및 HLA-DRB1*11:01 제한)의 CD4+ T 세포를 CD4+ T 세포 클론 GAGE-1-TCR-2, XAGE-1-TCR-1 또는 TCR-2의 상응하는 TCR-α- 및 β-사슬로 트랜스펙션시켰다. TCR-조작 3H10 세포를 C/T-항원-로딩 APC와 함께 공동-배양하였다 (도 7). IFN-γ 분비를 측정함으로써, 이들의 내인성 EBV-특이적 TCR을 손상시키지 않으면서, 모든 CD4+ T 세포 클론의 특이성이 성공적으로 3H10 세포에 전달되었음을 입증하였다. 따라서, TCR 트랜스펙션 후, 상기 3H10 세포는 상응하는 C/T-항원-CrossTAg ivt-RNA로 트랜스펙션된 APC 뿐만 아니라 EBNA-3C-CrossTAg ivt-RNA-트랜스펙션된 APC를 인식하였다.
방법
유전적 컨스트럭트
pGEM-eGFP-A120 벡터는 CrossTAg-벡터 (S. Milosevic)에 대한 개시 컨스트럭트로 사용하였다. 본래의 pGEM 벡터의 이러한 polyA120 변이체는 더 높은 안정성을 갖는 전사된 RNA를 제공하고 단백질 발현을 개선시켰다. 플라스미드는 추가로 eGFP cDNA의 5' 말단에 고유한 AgeI 부위를 함유하고 3' 말단에 고유한 EcoRI 부위를 함유하고 있다. 폴리-A 꼬리 다음에는 ivt-RNA 생산을 위한 플라스미드의 선형화를 허용하는 SpeI 부위가 뒤따른다.
pGEM-CrossTAg-A120 플라스미드는 CrossTAg 표적 신호를 코딩하는 cDNA로 eGFP를 대체하여 클로닝하였다. CrossTAg 서열은 DC-LAMP (접근번호: NP_055213, aa 376-416)의 막통과 및 세포질 도메인 5'에 융합된 인간 리소좀-관련 막 단백질-1(LAMP-1, 접근번호: NP_005552, aa 1-28)의 ER-이동 신호로 이루어진다. 항원-코딩 cDNA의 삽입을 위해, LAMP1 오픈 리딩 프레임 (ORF)을 방해하지 않으면서 NheI, KpnI 및 PstI 제한 부위를 함유하는 18-bp 스페이서에 의해 별개의 CrossTAg 서열을 분리하였다. 코돈 최적화된 Cross-Tag 서열이 컴퓨터 클로닝 소프트웨어를 이용하여 가상으로 고안되었고 GeneArt에 의해 합성되었다 (레겐스부르크). 다음으로, 완전한 CrossTAg 서열은 AgeI (5' 말단) 및 EcoRI (3' 말단) 제한 부위를 사용하여 플라스미드 DNA로부터 절단되었고 동일하게 분해된 pGEM-A120 벡터의 MCS에 연결시켰다.
다양한 C/T 항원-CrossTAg 컨스트럭트 (pGEM-GAGE-1-CrossTAg-A120, pGEM-MAGE-A4-CrossTAg-A120, pGEM-NY-ESO-1-CrossTAg-A120, pGEM-SSX-4-CrossTAg-A120, pGEM-XAGE-1-CrossTAg-A120)의 클로닝을 위해, 항원 cDNA를 정방향 및 역방향 유전자-특이적 프라이머를 이용하여 PCR로 플라스미드로부터 증폭하였고 (접근번호: GAGE-1, U19142; MAGE-A4, NM_001011550; NY-ESO1, AJ003149; SSX-4, U90841; XAGE-1, AF251237) NheI 및 PstI/NotI 제한 부위를 통해 연결시켰다. PCR 반응에 사용된 프라이머는 요청 시 모두 이용가능하다. 모든 항원 서열은 초기 ORF를 방해하지 않고 pGEM-CrossTAg-A120의 분리된 CrossTAg 신호에 삽입되었다. CD4+ T 세포 에피토프의 검증을 위해, 상보적인 올리고뉴클레오타이드가 합성되고 (Metabion) 어닐링되었다. 어닐링시 생성된, 부착 말단은 이들 짧은 항원 서열을 CrossTAg 벡터로 직접 연결하기 위해 사용되었다.
ivt-RNA의 생산
SpeI 선형화 후, pGEM-플라스미드를 제조업자의 지시에 따라 mMESSAGE mMACHINE T7 키트 (Ambion)를 이용하여 단일 종 생체 외(in vitro) 전사 (ivt)-RNA 생산을 위한 주형으로 사용하였다. 품질 제어를 위해, ivt-RNA 생산물의 길이는 아가로스 겔 전기영동으로 분석하였다. 농도 및 순도는 Nanodrop ND-1000 분광 광도계 (Thermo Scientific)를 이용하여 측정하였다.
세포 배양
단핵구-유래 3d mDC를 Burdek 등의 문헌 [Journal of Translational Medicine 2010, 8:90]에 기재된 바와 같이 생성하고 트랜스펙션시켰다. mDC의 RNA 트랜스펙션 및 미니-엡스타인-바 바이러스-(EBV)-형질전환된 림프아구 세포주 (mLCL)는 Burdek 등의 문헌 [Three-day dendritic cells for vaccine development: Antigen uptake, processing and presentation. Journal of Translational Medicine 2010, 8:90]에 기재된 바와 같이 전기천공으로 이루어졌다.
mLCL은 종래에 기술된 바와 같이 LCL 배지에서 현택배양으로 성장시켰다 (Milosevic, S. 등의 (2006) Identification of major histocompatibility complex class II-restricted antigens and epitopes of the Epstein-Barr virus). mLCL의 단백질 로딩은 25 μg 재조합 인간 GAGE-1, MAGE-A4, SSX-4 또는 XAGE-1 단백질 (HEK-293T 세포에서 발현 후 6x-cHis 태그를 통해 농축됨)의 존재 하에 2 ml LCL 배지의 24 웰 플레이트에서 16시간 동안 2*106 세포를 배양함으로써 이루어졌다. 배양 기간의 종료 시, 상기 세포를 RPMI 1640을 사용하여 2회 세척하였고 특이적 CD4+ T 세포 클론과 공동-배양하였다.
정량적 RT-PCR
트랜스펙션된 DC와 트랜스펙션되지 않은 DC의 세포 RNA를 분리하였고 상응하는 cDNA는 RT-PCR을 위한 First Strand cDNA Synthesis Kit for RT-PCR (AMV) (Roche)를 사용하여 올리고-dT 프라이머로 합성하였다. 항원 주형 수의 차이는 제조업자의 지시에 따라, LightCycler® 480 SYBR Green I Master 키트 (Roche)를 사용하여 정량적 RT-PCR (qRT-PCR)로 측정하였다. RT-PCR 반응에 사용된 유전자-특이적 프라이머 (αEnolase, GAGE-1, MAGE-A4, SSX-4 및 XAGE-1)는 모두 요청 시 이용가능하다. 측정은 하우스키핑 유전자 αEnolase로 정규화시켰고 ΔΔCP-방법에 따라 분석하였다.
T 세포 및 DC의 표면 표현형
T 세포 및 DC에 의해 발현된 표면 마커를 다음의 항체로 검출하였다: PE-결합 CCR7-특이적 항체 (3D12) (eBioscience), Hz450-결합 CD4-특이적 항체 (RPA-T4), Hz500-결합 CD8-특이적 항체 (RPA-T8), FITC-결합 CD14-특이적 항체 (M5E2), PE-결합 CD40-특이적 항체 (5C3), PE-결합 CD40L-특이적 항체 (TRAP1), PE-결합 CD80-특이적 항체 (L307.4), FITC-결합 CD83-특이적 항체 (HB15e), FITC-결합 CD86-특이적 항체 (2331), APC-결합 CD137-특이적 항체 (4B4-1), FITC-결합 DC-SIGN-특이적 항체 (DCN46), PE-결합 HLA-DR-특이적 항체 (G46-6) (모두 BD Biosciences로부터 입수). 세척 후, 세포를 4 °C 에서 30분 동안 염색하였고, 죽은 세포를 배제하기 위해 프로피디움 요오드화물(2 μg/ml)을 첨가하였다. 유세포 분석으로 모든 표면 마커의 발현을 분석하였다 (LSRII, BD). 수집 후 데이터 분석은 FlowJo 8 소프트웨어 (TreeStar)를 사용하여 수행하였다. T 세포 상의 CD40L 표면 발현의 분석은 문헌 [Frentsch, M. 등의 (2005) Direct access to CD4+ T cells specific for defined antigens according to CD154 expression. Nat Med 11(10): 1118-1124]에 기재된 바와 같이 2 μg/ml αCD40 항체 (M. Frentsch로부터 제공받은 클론 G28.5, 베를린-브란덴부르크 재생 치료 센터)를 사용하여 수행하였고 T 세포:APC 공동-배양의 개시 후 6 시간 째에 평가하였다.
RNA-트랜스펙션된 DC를 이용한 PBL의 드 노보 (De novo) 프라이밍
건겅한 공여자의 3d mDC를 C/T-항원 GAGE-1, MAGE-A4, SSX-4 및 XAGE-1을 코딩하는 2종의 단일-종 CrossTAg-RNA를 갖는 개별 집단에 트랜스펙션시켰다. 전기천공 이후, 상기 트랜스펙션된 mDC를 수확하였고 이러한 혼합물의 혼합 mDC를 1:2 비율의 말초 혈액 림프구 (PBL) 내에 공동-배양하였으며, 이는 mDC 생성 과정에서 PBMC의 인공 부착 (plastic adherence) 동안 비-부착성이었다. 상기 세포를 습한 대기 조건의 37°C에서 배양하였다. 인터류킨-2 (IL-2, 20 U/ml; Chiron Behring)와 5 ng IL-7/ml (Promokine)을 하루 후에 첨가한 다음 격일로 첨가하였다. PBL 공동-배양에 사용되지 않았던 혼합된 mDC는 냉동보관하였고 드 노보 (De novo) 유도 PBL 배양의 재자극을 위해 해동되었다.
항원-특이적 CD4+ T 세포의 분리 및 확장
프라이밍된 PBL을 문헌 [Frentsch, M.의 (2005) Direct access to CD4+ T cells specific for defined antigens according to CD154 expression. Nat Med 11(10): 1118--1124.)에 기재된 바와 같이 αCD40 항체의 존재 하에 6 시간 동안 CrossTAg-RNA-트랜스펙션된 mDC (4-항원 믹스)와 2:1의 비율로 공동-배양하였다. 자극 기간 이후, 세포를 αCD4- 및 αCD40L-특이적 항체 (SK3 및 TRAP1; BD Biosciences)로 염색하였다. 죽은 세포를 배제하기 위해 DAPI를 첨가하였다. FACSAria III (BD Biosciences)를 사용하여, 살아있는 CD40L-양성 CD4+ T 세포를 둥근 바닥 96 웰 플레이트의 웰에 단일 세포로 분류하였다. 96 웰 플레이트의 CD4+ T 세포 클론을 항원-CrossTAg ivt-RNA-트랜스펙션된 mLCL, 배양보조세포 및 IL-2를 사용하여 확장시켰다.
사이토카인 방출 어세이
활성화 유도된 사이토카인 분비를 측정하기 위해, 37°C의 습한 대기 조건에서 둥근 바닥 96웰 플레이트의 200 μl T 세포 배지에 1*105 ivt-RNA-로딩 APCs (DC/mLCL) APC와 함께 5*104 T 세포를 공동-배양하였다. 모의-트랜스펙션된 APC를 갖는 T 세포 또는 자극 세포가 없는 T 세포를 음성 대조군으로 사용하였다. 공동-배양 16 시간 후, 상등액을 수확하고, OptEIA 인간 IFN-γ 또는 GM-CSF 세트 (모두 BD Biosciences로부터 입수)를 사용하여 ELISA (enzyme-linked immunosorbent assay)로 평가하였다.
Ivt-RNA-기반 TCR 유전자 이동
TCR-α- 및 TCR-β-쇄 재배열 및 서열은 문헌 [Steinle, A., et al. (1995) In vivo expansion of HLA-B35 alloreactive T cells sharing homologous T cell receptors: evidence formaintenance of an oligoclonally dominated allospecificity by persistent stimulationwith an autologous MHC/peptide complex. J Exp Med 181(2): 503-513.]에 기재된 바와 같이 TCR-Vα- 및 TCR-Vβ-특이적 프라이머의 패널을 사용하여 PCR로 측정하였다. 뮤린 대응부로 TCR 쇄 둘 다의 불변 영역을 치환한 후, 코돈-최적화된 TCR-α- 및 TCR-β-쇄 서열을 합성하였고 RNA 생산을 위한 발현 벡터에 클로닝하였다. 이러한 TCR 서열의 특이성을 검증하기 위해, T 세포 클론 3H10 (HLA-DRB1*11:01 제한, EBV EBNA-3C-특이적)의 세포를 TCR-α- 및 TCR-β-ivt-RNA와 함께 공동-배양하였고 사이토카인 분비 어세이에 사용하였다.
본 출원은 다음의 실시예를 추가로 포함한다:
실시예 1: 다음의 단계를 포함하는 인간 항원-특이적 T 림프구를 생성하는 방법:
A) 다음을 포함하는 적어도 하나의 융합 단백질을 항원 제시 세포에서 발현하는 단계; 및
- 적어도 하나의 항원 또는 이의 단편,
- 상기 항원의 N-말단 앞의 소포체 (ER)-이동 신호 서열, 및
- 상기 항원의 C-말단 다음의 엔도솜/리소좀 표적 서열을 포함하는
막통과 및 세포질 도메인,
B) 항원 제시 세포에 의해 발현되는 항원에 대해 특이적인 항원-특이적 T 림프구를 활성화 시키기 위해 생체 외(in vitro)에서 단계 A)의 항원 제시 세포에 T 림프구를 포함하는 세포 집단을 노출시키는 단계.
실시예 2: 실시예 1에 있어서, 단계 B)의 노출은 상기 항원 제시 세포를 T 림프구를 포함하는 세포 집단과 공동-배양하는 것인 방법.
실시예 3: 실시예 1 또는 2에 있어서, 단계 A)의 상기 발현은 일시적인 발현 또는 안정한 발현, 바람직하게는 일시적인 발현인 것인 방법.
실시예 4: 실시예 3에 있어서, 상기 일시적인 발현은 상기 적어도 하나의 융합 단백질을 코딩하는 ivt-RNA를 도입함으로써 이루어지는 것인 방법.
실시예 5: 전술한 실시예 중 어느 하나에 있어서, 상기 방법은 C1) 활성화된 및/또는 항원 특이적 T 림프구를 농축하는 단계를 추가로 포함하는 것인 방법.
실시예 6: 실시예 5에 있어서, 상기 활성화된 T 림프구의 농축은 다음의 단계를 포함하는 것인 방법:
(a) 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질에 특이적으로 결합하는 결합 분자 또는 상기 바람직한 항원의 에피토프를 제시하는 MHC 분자와 접촉시키는 단계;
(b) 상기 결합 분자 또는 상기 바람직한 항원의 에피토프를 제시하는 MHC 분자가 결합된 T 림프구를 분리하는 단계.
실시예 7: 실시예 6에 있어서, 상기 마커 단백질에 특이적으로 결합하는 결합 분자는 항체, 항체 유도체, 항체 단편, 또는 전술된 것과 추가 분자의 접합체인 것인 방법.
실시예 8: 실시예 6 또는 7에 있어서, 활성화된 T 림프구에 의해 특이적으로 발현되는 상기 적어도 하나의 마커 단백질은 Ox40, CD137, CD40L, PD-1, IL-2 수용체, 인터페론-γ, IL-2, GM-CSF 및 TNF-α를 포함하는 군으로부터 선택되는 것인 방법.
실시예 9: 실시예 8에 있어서, 단계 (a)에서 상기 세포는 CD4에 특이적으로 결합하는 결합 분자와 추가로 접촉시키는 것인 방법.
실시예 10: 실시예 8 또는 9에 있어서, 단계 (a)에서 상기 세포는 CD8에 특이적으로 결합하는 결합 분자와 추가로 접촉시키는 것인 방법.
실시예 11: 실시예 6에 있어서, 활성화된 CD4 T 세포를 선택하는 것은 다음의 단계를 포함하는 것인 방법:
(a1) 항원 제시 세포의 CD40-CD40L과 항원 특이적 T 림프구 사이의 상호작용을 차단하고 CD40L을 T 림프구 표면에 축적시키기 위해, 단계 B)의 세포 집단과 CD40에 대한 항체를 접촉시키는 단계;
(a2) 상기 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 항-CD40L 항체와 접촉시키는 단계;
(b) 항-CD40L 항체 및 항-CD4 항체로 표지된 T 림프구를 분리하는 단계.
실시예 12:
전술한 실시예 중 어느 하나에 있어서, 상기 방법은 C2) 다음의 단계를 포함하는, 항원-특이적 T 림프구를 확인하는 단계를 추가로 포함하는 것인 방법:
a) 상기 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단의 확장된 세포 클론을,
(i) 단계 A)에 정의된 항원 제시 세포, 및
(ii) 대조구 (control) 항원 제시 세포와 배양하는 단계;
b) 상기 배양의 활성 프로파일을 각 세포 클론에 대한 (i) 및 (ii)와 비교하는 단계;
c) 상기 b)의 비교를 바탕으로 항원-특이적 세포 클론을 확인하는 단계;
여기에서, (ii)가 아닌 (i)에 의한 활성화는 상기 세포 클론이 항원-특이적인 것인 방법.
실시예 13:
전술한 실시예 중 어느 하나에 있어서, 단계 B)에서 상기 항원 제시 세포는 T 림프구를 포함하는 세포 집단에 적어도 1회, 선택적으로 적어도 2회, 선택적으로 적어도 3회, 선택적으로 3회 첨가되는 것인 방법.
실시예 14: 실시예 12에 있어서, 항원 제시 세포의 반복된 추가 사이의 시간 간격은 7 내지 21일이고, 바람직하게는 12일 내지 16일, 보다 바람직하게는 13 내지 15일, 보다 더 바람직하게는 14일인 것인 방법.
실시예 15: 전술한 실시예 중 어느 하나에 있어서, 상기 ER 이동 신호 서열은 엔도솜/리소좀 관련 단백질로부터 유래된 것인 방법.
실시예 16: 실시예 15에 있어서, 상기 엔도솜/리소좀 관련 단백질은 LAMP1, LAMP2, DC-LAMP, CD68 및 CD1b를 포함하는 군으로부터 선택되고, 바람직하게는 LAMP1인 것인 방법.
실시예 17: 전술한 실시예 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래된 것인 방법.
실시예 18: 전술한 실시예 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래된 것인 방법.
실시예 19: 전술한 실시예 중 어느 하나에 있어서, 상기 ER 이동 신호 서열은 인간인 것인 방법.
실시예 20: 전술한 실시예 중 어느 하나에 있어서, 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 인간인 것인 방법.
실시예 21: 전술한 실시예 중 어느 하나에 있어서, 상기 ER 이동 신호는 서열번호 33의 서열 또는 이의 단편을 포함하는 것인 방법.
실시예 22: 실시예 20에 있어서, 상기 ER 이동 신호 서열은 서열번호 34의 서열로 이루어지는 것인 방법.
실시예 23: 전술한 실시예 중 어느 하나에 있어서, 상기 항원 제시 세포는 수지상 세포, 활성화된 B 세포, 단핵구, 대식세포, EBV-형질전환 림프아구 세포주(EBV-transformed lymphoblastoid cell line)로부터 선택되고, 바람직하게는 수지상 세포, 보다 바람직하게는 단핵구 유래 수지상 세포인 것인 방법.
실시예 24: 전술한 실시예 중 어느 하나에 있어서, 상기 항원 제시 세포는 항원 제시 세포의 상이한 집단, 상이한 항원 융합 단백질을 발현하는 각각의 집단을 포함하는 것인 방법.
실시예 25: 전술한 실시예 중 어느 하나에 있어서, 상기 항원 제시 세포는 다음의 단계를 포함하는 방법으로 생성된 성숙한 수지상 세포인 것인 방법:
i) 단핵구를 제공하는 단계;
ii) 단계 i)의 단핵구를 IL-4 및 GM-CSF와 배양하는 단계;
iii) 단계 ii)의 단핵구를 성숙한 칵테일과 조합한 IL-4 및 GM-CSF와 배양하는 단계.
실시예 26: 실시예 25에 있어서, 상기 성숙한 칵테일은 IL-ß, TNF-α, INF-γ, TLR7/8 작용제, PGE2 및TLR3 작용제의 조합을 포함하는 것인 방법.
실시예 27: 실시예 25 또는 26에 있어서, 단계 ii)의 배양은 적어도 2일 지속되는 것인 방법.
실시예 28: 실시예 25 내지 27에 있어서, 단계 iii)의 배양은 적어도 12시간, 바람직하게는 24시간 지속되는 것인 방법.
실시예 29: 실시예 28에 있어서, 상기 TLR7/8 작용제는 R848이고 상기 TLR3 작용제는 poly(I:C)인 것인 방법.
실시예 30: 전술한 실시예 중 어느 하나에 있어서, 상기 T 림프구를 포함하는 세포 집단은 말초 혈액 림프구의 집단인 것인 방법.
실시예 31: 전술한 실시예 중 어느 하나에 있어서, T 림프구를 포함하는 세포 집단은 분리되지 않은 말초 혈액 림프구의 집단인 것인 방법.
실시예 32: 전술한 실시예 중 어느 하나에 있어서, 상기 세포 집단은 T 림프구, 바람직하게는 CD8+ 및/또는 CD4+ T 림프구에 대해 농축된 것인 방법.
실시예 33: 전술한 실시예 중 어느 하나에 있어서, 상기 융합 단백질은 적어도 2종의 항원 또는 이의 단편을 포함하는 것인 방법.
실시예 34: 실시예 1 내지 33에 따른 방법에 의해 수득가능한 T 림프구.
실시예 35:
다음을 포함하는 발편 벡터:
- 인간 소포체 (ER)- 이동 신호 서열, 및
- 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인.
실시예 36: 실시예 1에 있어서, 상기 벡터는 생체 외(in vitro)에서 mRNA 전사를 위한 프로모터를 포함하는 것인 발현 벡터.
실시예 37:
실시예 35 또는 36에 있어서, 상기 ER 이동 신호 서열은 엔도솜/리소좀 관련 단백질로부터 유래된 것인 발현 벡터.
실시예 38: 실시예 35 내지 37 중 어느 하나에 있어서, 상기 엔도솜/리소좀 관련 단백질은 LAMP1, LAMP2, DC-LAMP, CD68, CD1b를 포함하는 군으로부터 선택된 것인 발현 벡터.
실시예 39: 실시예 35 내지 38 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래된 것인 발현 벡터.
실시예 40: 실시예 35 내지 39 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 LAMP1 또는 DC-LAMP, 바람직하게는 DC-LAMP로부터 유래된 것인 발현 벡터.
실시예 41: 실시예 35 내지 40 중 어느 하나에 있어서, 상기 ER 이동 신호 서열은 인간인 것인 발현 벡터.
실시예 42: 실시예 35 내지 41 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 인간인 것인 발현 벡터.
실시예 43: 실시예 35 내지 42 중 어느 하나에 있어서, ER 이동 신호 서열은 SEQ ID NO: 33의 서열 또는 이의 단편을 포함하는 것인 발현 벡터.
실시예 44: 실시예 35 내지 43 중 어느 하나에 있어서, ER 이동 신호는 서열번호 34의 서열로 구성되는 것인 발현 벡터.
실시예 45: 실시예 35 내지 44 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열은 서열번호 38의 모티프를 포함하는 것인 발현 벡터.
실시예 46: 실시예 35 내지 45 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 신호 서열은 서열번호 39의 서열인 것인 발현 벡터.
실시예 47: 실시예 35내지 46 중 어느 하나에 있어서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인은 서열번호 54의 서열 또는 이의 단편, 예를 들어 서열번호 35 또는 이의 단편을 포함하는 것인 발현 벡터.
실시예 48: 실시예 35 내지 47 중 어느 하나에 있어서, 상기 ER 이동 신호 서열과 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인 사이에 제한 부위를 추가로 포함하는 것인 발현 벡터.
실시예 49: 실시예 35 내지 48 중 어느 하나에 있어서, 상기 벡터는 상기 인간 소포체(ER)-이동 신호 서열과 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인 사이에 삽입되는 적어도 하나의 항원, 또는 이의 단편을 추가로 포함하는 것인 발현 벡터.
실시예 50: 실시예 49 중 어느 하나에 있어서, 상기 벡터는 상기 인간 소포체(ER)-이동 신호 서열과 엔도솜/리소좀 표적 서열을 포함하는 인간 막통과 및 세포질 도메인 사이에 삽입되는 적어도 2 종의 항원, 또는 이의 항원을 포함하는 것인 발현 벡터.
실시예 51:
실시예 35 내지 50 중 어느 하나에 있어서, 상기 벡터는 항원의 전장 아미노산 서열을 코딩하는 핵산 서열을 포함하는 것인 발현 벡터.
실시예 52: 실시예 35 내지 51 중 어느 하나에 있어서, 상기 벡터는 항원의 아미노산 서열을 코딩하는 핵산 서열의 단편을 포함하는 것인 발현 벡터.
실시예 53: 실시예 52에 있어서, 상기 항원은 종양 항원 또는 바이러스 항원인 것인 발현 벡터.
실시예 54: 실시예 53에 있어서, 상기 종양 항원은 바이러스 종양 항원, 종양-특이적 항원, 종양 관련 항원 및 환자 특이적 돌연변이를 운반하고 상기 환자의 종양 세포에서 발현되는 항원인 것인 발현 벡터.
실시예 55: 실시예 35 내지 54 중 어느 하나에 있어서, 상기 종양 항원은 종양 관련 항원인 것인 발현 벡터.
실시예 56: 실시예 35 내지 55 중 어느 하나에 있어서, 종양 관련 항원은 암/고환 항원 (C/T 항원)인 것인 발현 벡터.
실시예 57: 실시예 35 내지 56 중 어느 하나에 있어서, 상기 C/T 항원은 MAGE-A1, MAGE-A3, MAGE-A4, NY-ESO1, 종양/고환-항원 1B, GAGE-1, SSX-4, XAGE-1, BAGE, GAGE, SCP-1, SSX-2, SSX-4, CTZ9, CT10, SAGE 및 CAGE를 포함하는 군으로부터 선택되는 것인 발현 벡터.
실시예 58: 실시예 35 내지 57 중 어느 하나에 있어서, 상기 C/T 항원은 GAGE-1, SSX-4 및 XAGE-1로 이루어진 군으로부터 선택되는 것인 발현 벡터..
실시예 59: 실시예 35 내지 58 중 어느 하나에 따른 발현 벡터의 항원-특이적 T 림프구의 생체 외(in vitro) 생성을 위한 용도.
실시예 60: 실시예 34에 따른 상기 T-림프구를 포유동물에 투여하는 것을 포함하는 암의 예방 또는 치료 방법에 사용하기 위한 T-림프구.
실시예 61: 실시예 1 내지 33 중 어느 하나에 따른 방법의 단계를 포함하고, 상기 활성화된 항원-특이적 림프구로부터 TCR을 분리하는 단계를 추가로 포함하는 항원-특이적 TCR을 생성하기 위한 방법.
실시예 62: 실시예 34에 따른 림프구로부터 분리된 TCR.
실시예 63: 다음을 포함하는, GAGE-1에 특이적인 TCR
- 서열번호 5에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 6에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR β 쇄.
실시예 64: 실시예 63에 있어서, 다음을 포함하는 GAGE-1에 특이적인 TCR:
- 서열번호 5와 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 1에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 6과 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 2에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR β 쇄.
실시예 65: 다음을 포함하는 SSX-4에 특이적인 TCR
- 서열번호 13에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 14에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR β 쇄.
실시예 66: 실시예 65에 있어서, 다음을 포함하는 SSX-4에 특이적인 TCR:
- 서열번호 13과 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 9에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 14와 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 10에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR β 쇄.
실시예 67: 다음을 포함하는 XAGE-1에 특이적인 TCR
- 서열번호 21에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 22에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR  쇄.
쇄.
실시예 68: 실시예 66에 있어서, 다음을 포함하는 XAGE-1에 특이적인 TCR:
- 서열번호 21과 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 17에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 22와 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 18에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR β 쇄.
실시예 69: 다음을 포함하는 XAGE-1에 특이적인 TCR
- 서열번호 29에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 30에 기재된 염기서열에 의해 코딩되는 CDR 영역을 포함하는 TCR β 쇄.
실시예 70: 실시예 68에 있어서, 다음을 포함하는 XAGE-1에 특이적인 TCR
- 서열번호 29와 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 25에 기재된 염기서열에 의해 코딩되는 CDR3 영역을 포함하는 TCR α 쇄,
- 서열번호 30과 적어도 80% 동일한 염기서열에 의해 코딩되고, 서열번호 26에 기재된 염기서열에 의해 코딩되는 CDR 영역을 포함하는 TCR β 쇄.
실시예 71:
실시예 62 내지 70 중 어느 하나에 있어서, 암의 예방 또는 치료 방법에 사용하기 위한 것인 TCR.
실시예 72:
실시예 62 내지 70 중 어느 하나에 따른 TCR을 포유동물에 투여하는 단계를 포함하는 암을 예방 또는 치료하기 위한 방법.
<110> Medigene Immunotherapies GmbH
Helmholtz Zentrum Muchen Deutsches Forschungszentrum fuR Gesundheit und Umwelt (GmbH)
<120> Novel generation of antigen-specific TCRs
<130> M10977
<150> EP15202329
<151> 2015-12-23
<150> EP16190399
<151> 2016-09-23
<160> 54
<170> PatentIn version 3.5
<210> 1
<211> 42
<212> DNA
<213> Homo sapiens
<400> 1
tgtgctgagc ggactcaggg cggatctgaa aagctggtct tt 42
<210> 2
<211> 33
<212> DNA
<213> Homo sapiens
<400> 2
tgtgccaccc agagaaacac tgaagctttc ttt 33
<210> 3
<211> 14
<212> PRT
<213> Homo sapiens
<400> 3
Cys Ala Glu Arg Thr Gln Gly Gly Ser Glu Lys Leu Val Phe
1 5 10
<210> 4
<211> 11
<212> PRT
<213> Homo sapiens
<400> 4
Cys Ala Thr Gln Arg Asn Thr Glu Ala Phe Phe
1 5 10
<210> 5
<211> 825
<212> DNA
<213> Homo sapiens
<400> 5
atgatgaagt gtccacaggc tttactagct atcttttggc ttctactgag ctgggtgagc 60
agtgaagaca aggtggtaca aagccctcta tctctggttg tccacgaggg agacaccgta 120
actctcaatt gcagttatga agtgactaac tttcgaagcc tactatggta caagcaggaa 180
aagaaagctc ccacatttct atttatgcta acttcaagtg gaattgaaaa gaagtcagga 240
agactaagta gcatattaga taagaaagaa ctttccagca tcctgaacat cacagccacc 300
cagaccggag actcggccat ctacctctgt gctgagcgga ctcagggcgg atctgaaaag 360
ctggtctttg gaaagggaac gaaactgaca gtaaacccat atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gctga 825
<210> 6
<211> 927
<212> DNA
<213> Homo sapiens
<400> 6
atgggcacaa ggttgttctt ctatgtggcc ctttgtctcc tgtggacagg acacatggat 60
gctggaatca cccagagccc aagacacaag gtcacagaga caggaacacc agtgactctg 120
agatgtcacc agactgagaa ccaccgctat atgtactggt atcgacaaga cccggggcat 180
gggctgaggc tgatccatta ctcatatggt gttaaagata ctgacaaagg agaagtctca 240
gatggctata gtgtctctag atcaaagaca gaggatttcc tcctcactct ggagtccgct 300
accagctccc agacatctgt gtacttctgt gccacccaga gaaacactga agctttcttt 360
ggacaaggca ccagactcac agttgtagag gacctgaaaa acgtgttccc acccgaggtc 420
gctgtgtttg agccatcaga agcagagatc tcccacaccc aaaaggccac actggtgtgc 480
ctggccacag gcttctaccc cgaccacgtg gagctgagct ggtgggtgaa tgggaaggag 540
gtgcacagtg gggtcagcac agacccgcag cccctcaagg agcagcccgc cctcaatgac 600
tccagatact gcctgagcag ccgcctgagg gtctcggcca ccttctggca gaacccccgc 660
aaccacttcc gctgtcaagt ccagttctac gggctctcgg agaatgacga gtggacccag 720
gatagggcca aacctgtcac ccagatcgtc agcgccgagg cctggggtag agcagactgt 780
ggcttcacct ccgagtctta ccagcaaggg gtcctgtctg ccaccatcct ctatgagatc 840
ttgctaggga aggccacctt gtatgccgtg ctggtcagtg ccctcgtgct gatggccatg 900
gtcaagagaa aggattccag aggctga 927
<210> 7
<211> 274
<212> PRT
<213> Homo sapiens
<400> 7
Met Met Lys Cys Pro Gln Ala Leu Leu Ala Ile Phe Trp Leu Leu Leu
1 5 10 15
Ser Trp Val Ser Ser Glu Asp Lys Val Val Gln Ser Pro Leu Ser Leu
20 25 30
Val Val His Glu Gly Asp Thr Val Thr Leu Asn Cys Ser Tyr Glu Val
35 40 45
Thr Asn Phe Arg Ser Leu Leu Trp Tyr Lys Gln Glu Lys Lys Ala Pro
50 55 60
Thr Phe Leu Phe Met Leu Thr Ser Ser Gly Ile Glu Lys Lys Ser Gly
65 70 75 80
Arg Leu Ser Ser Ile Leu Asp Lys Lys Glu Leu Ser Ser Ile Leu Asn
85 90 95
Ile Thr Ala Thr Gln Thr Gly Asp Ser Ala Ile Tyr Leu Cys Ala Glu
100 105 110
Arg Thr Gln Gly Gly Ser Glu Lys Leu Val Phe Gly Lys Gly Thr Lys
115 120 125
Leu Thr Val Asn Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 8
<211> 308
<212> PRT
<213> Homo sapiens
<400> 8
Met Gly Thr Arg Leu Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Thr
1 5 10 15
Gly His Met Asp Ala Gly Ile Thr Gln Ser Pro Arg His Lys Val Thr
20 25 30
Glu Thr Gly Thr Pro Val Thr Leu Arg Cys His Gln Thr Glu Asn His
35 40 45
Arg Tyr Met Tyr Trp Tyr Arg Gln Asp Pro Gly His Gly Leu Arg Leu
50 55 60
Ile His Tyr Ser Tyr Gly Val Lys Asp Thr Asp Lys Gly Glu Val Ser
65 70 75 80
Asp Gly Tyr Ser Val Ser Arg Ser Lys Thr Glu Asp Phe Leu Leu Thr
85 90 95
Leu Glu Ser Ala Thr Ser Ser Gln Thr Ser Val Tyr Phe Cys Ala Thr
100 105 110
Gln Arg Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu Thr Val
115 120 125
Val Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu
130 135 140
Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys
145 150 155 160
Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val
165 170 175
Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu
180 185 190
Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg
195 200 205
Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg
210 215 220
Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln
225 230 235 240
Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly
245 250 255
Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu
260 265 270
Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr
275 280 285
Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys
290 295 300
Asp Ser Arg Gly
305
<210> 9
<211> 39
<212> DNA
<213> Homo sapiens
<400> 9
tgtgctctgc gtcaaacctc ctacgacaag gtgatattt 39
<210> 10
<211> 45
<212> DNA
<213> Homo sapiens
<400> 10
tgtgccagca gcttagcgga cagggggagt gaaaaactgt ttttt 45
<210> 11
<211> 13
<212> PRT
<213> Homo sapiens
<400> 11
Cys Ala Leu Arg Gln Thr Ser Tyr Asp Lys Val Ile Phe
1 5 10
<210> 12
<211> 15
<212> PRT
<213> Homo sapiens
<400> 12
Cys Ala Ser Ser Leu Ala Asp Arg Gly Ser Glu Lys Leu Phe Phe
1 5 10 15
<210> 13
<211> 819
<212> DNA
<213> Homo sapiens
<400> 13
atgaactatt ctccaggctt agtatctctg atactcttac tgcttggaag aacccgtgga 60
aattcagtga cccagatgga agggccagtg actctctcag aagaggcctt cctgactata 120
aactgcacgt acacagccac aggataccct tcccttttct ggtatgtcca atatcctgga 180
gaaggtctac agctcctcct gaaagccacg aaggctgatg acaagggaag caacaaaggt 240
tttgaagcca cataccgtaa agaaaccact tctttccact tggagaaagg ctcagttcaa 300
gtgtcagact cagcggtgta cttctgtgct ctgcgtcaaa cctcctacga caaggtgata 360
tttgggccag ggacaagctt atcagtcatt ccaaatatcc agaaccctga ccctgccgtg 420
taccagctga gagactctaa atccagtgac aagtctgtct gcctattcac cgattttgat 480
tctcaaacaa atgtgtcaca aagtaaggat tctgatgtgt atatcacaga caaaactgtg 540
ctagacatga ggtctatgga cttcaagagc aacagtgctg tggcctggag caacaaatct 600
gactttgcat gtgcaaacgc cttcaacaac agcattattc cagaagacac cttcttcccc 660
agcccagaaa gttcctgtga tgtcaagctg gtcgagaaaa gctttgaaac agatacgaac 720
ctaaactttc aaaacctgtc agtgattggg ttccgaatcc tcctcctgaa agtggccggg 780
tttaatctgc tcatgacgct gcggctgtgg tccagctga 819
<210> 14
<211> 936
<212> DNA
<213> Homo sapiens
<400> 14
atgggcacca ggctcctctg ctgggcggcc ctctgtctcc tgggagcaga actcacagaa 60
gctggagttg cccagtctcc cagatataag attatagaga aaaggcagag tgtggctttt 120
tggtgcaatc ctatatctgg ccatgctacc ctttactggt accagcagat cctgggacag 180
ggcccaaagc ttctgattca gtttcagaat aacggtgtag tggatgattc acagttgcct 240
aaggatcgat tttctgcaga gaggctcaaa ggagtagact ccactctcaa gatccagcct 300
gcaaagcttg aggactcggc cgtgtatctc tgtgccagca gcttagcgga cagggggagt 360
gaaaaactgt tttttggcag tggaacccag ctctctgtct tggaggacct gaacaaggtg 420
ttcccacccg aggtcgctgt gtttgagcca tcagaagcag agatctccca cacccaaaag 480
gccacactgg tgtgcctggc cacaggcttc ttccccgacc acgtggagct gagctggtgg 540
gtgaatggga aggaggtgca cagtggggtc agcacggacc cgcagcccct caaggagcag 600
cccgccctca atgactccag atactgcctg agcagccgcc tgagggtctc ggccaccttc 660
tggcagaacc cccgcaacca cttccgctgt caagtccagt tctacgggct ctcggagaat 720
gacgagtgga cccaggatag ggccaaaccc gtcacccaga tcgtcagcgc cgaggcctgg 780
ggtagagcag actgtggctt tacctcggtg tcctaccagc aaggggtcct gtctgccacc 840
atcctctatg agatcctgct agggaaggcc accctgtatg ctgtgctggt cagcgccctt 900
gtgttgatgg ccatggtcaa gagaaaggat ttctga 936
<210> 15
<211> 272
<212> PRT
<213> Homo sapiens
<400> 15
Met Asn Tyr Ser Pro Gly Leu Val Ser Leu Ile Leu Leu Leu Leu Gly
1 5 10 15
Arg Thr Arg Gly Asn Ser Val Thr Gln Met Glu Gly Pro Val Thr Leu
20 25 30
Ser Glu Glu Ala Phe Leu Thr Ile Asn Cys Thr Tyr Thr Ala Thr Gly
35 40 45
Tyr Pro Ser Leu Phe Trp Tyr Val Gln Tyr Pro Gly Glu Gly Leu Gln
50 55 60
Leu Leu Leu Lys Ala Thr Lys Ala Asp Asp Lys Gly Ser Asn Lys Gly
65 70 75 80
Phe Glu Ala Thr Tyr Arg Lys Glu Thr Thr Ser Phe His Leu Glu Lys
85 90 95
Gly Ser Val Gln Val Ser Asp Ser Ala Val Tyr Phe Cys Ala Leu Arg
100 105 110
Gln Thr Ser Tyr Asp Lys Val Ile Phe Gly Pro Gly Thr Ser Leu Ser
115 120 125
Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
130 135 140
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
145 150 155 160
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
165 170 175
Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
180 185 190
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
195 200 205
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
210 215 220
Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn
225 230 235 240
Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu
245 250 255
Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
260 265 270
<210> 16
<211> 311
<212> PRT
<213> Homo sapiens
<400> 16
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Glu Leu Thr Glu Ala Gly Val Ala Gln Ser Pro Arg Tyr Lys Ile Ile
20 25 30
Glu Lys Arg Gln Ser Val Ala Phe Trp Cys Asn Pro Ile Ser Gly His
35 40 45
Ala Thr Leu Tyr Trp Tyr Gln Gln Ile Leu Gly Gln Gly Pro Lys Leu
50 55 60
Leu Ile Gln Phe Gln Asn Asn Gly Val Val Asp Asp Ser Gln Leu Pro
65 70 75 80
Lys Asp Arg Phe Ser Ala Glu Arg Leu Lys Gly Val Asp Ser Thr Leu
85 90 95
Lys Ile Gln Pro Ala Lys Leu Glu Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Ala Asp Arg Gly Ser Glu Lys Leu Phe Phe Gly Ser Gly
115 120 125
Thr Gln Leu Ser Val Leu Glu Asp Leu Asn Lys Val Phe Pro Pro Glu
130 135 140
Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys
145 150 155 160
Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu
165 170 175
Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr
180 185 190
Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr
195 200 205
Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro
210 215 220
Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
225 230 235 240
Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser
245 250 255
Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr
260 265 270
Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly
275 280 285
Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala
290 295 300
Met Val Lys Arg Lys Asp Phe
305 310
<210> 17
<211> 42
<212> DNA
<213> Homo sapiens
<400> 17
tgtgctgtga gagataattc aggaaacaca cctcttgtct tt 42
<210> 18
<211> 42
<212> DNA
<213> Homo sapiens
<400> 18
tgtgccagta gtataatcca gggcagtgct ggctacacct tc 42
<210> 19
<211> 14
<212> PRT
<213> Homo sapiens
<400> 19
Cys Ala Val Arg Asp Asn Ser Gly Asn Thr Pro Leu Val Phe
1 5 10
<210> 20
<211> 14
<212> PRT
<213> Homo sapiens
<400> 20
Cys Ala Ser Ser Ile Ile Gln Gly Ser Ala Gly Tyr Thr Phe
1 5 10
<210> 21
<211> 810
<212> DNA
<213> Homo sapiens
<400> 21
atgtggggag ttttccttct ttatgtttcc atgaagatgg gaggcactac aggacaaaac 60
attgaccagc ccactgagat gacagctacg gaaggtgcca ttgtccagat caactgcacg 120
taccagacat ctgggttcaa cgggctgttc tggtaccagc aacatgctgg cgaagcaccc 180
acatttctgt cttacaatgt tctggatggt ttggaggaga aaggtcgttt ttcttcattc 240
cttagtcggt ctaaagggta cagttacctc cttttgaagg agctccagat gaaagactct 300
gcctcttacc tctgtgctgt gagagataat tcaggaaaca cacctcttgt ctttggaaag 360
ggcacaagac tttctgtgat tgcaaatatc cagaaccctg accctgccgt gtaccagctg 420
agagactcta aatccagtga caagtctgtc tgcctattca ccgattttga ttctcaaaca 480
aatgtgtcac aaagtaagga ttctgatgtg tatatcacag acaaaactgt gctagacatg 540
aggtctatgg acttcaagag caacagtgct gtggcctgga gcaacaaatc tgactttgca 600
tgtgcaaacg ccttcaacaa cagcattatt ccagaagaca ccttcttccc cagcccagaa 660
agttcctgtg atgtcaagct ggtcgagaaa agctttgaaa cagatacgaa cctaaacttt 720
caaaacctgt cagtgattgg gttccgaatc ctcctcctga aagtggccgg gtttaatctg 780
ctcatgacgc tgcggctgtg gtccagctga 810
<210> 22
<211> 930
<212> DNA
<213> Homo sapiens
<400> 22
atgagcaacc aggtgctctg ctgtgtggtc ctttgtttcc tgggagcaaa caccgtggat 60
ggtggaatca ctcagtcccc aaagtacctg ttcagaaagg aaggacagaa tgtgaccctg 120
agttgtgaac agaatttgaa ccacgatgcc atgtactggt accgacagga cccagggcaa 180
gggctgagat tgatctacta ctcacagata gtaaatgact ttcagaaagg agatatagct 240
gaagggtaca gcgtctctcg ggagaagaag gaatcctttc ctctcactgt gacatcggcc 300
caaaagaacc cgacagcttt ctatctctgt gccagtagta taatccaggg cagtgctggc 360
tacaccttcg gttcggggac caggttaacc gttgtagagg acctgaacaa ggtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttcttcccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcacg gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acccgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gctttacctc ggtgtcctac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatcc tgctagggaa ggccaccctg tatgctgtgc tggtcagcgc ccttgtgttg 900
atggccatgg tcaagagaaa ggatttctga 930
<210> 23
<211> 269
<212> PRT
<213> Homo sapiens
<400> 23
Met Trp Gly Val Phe Leu Leu Tyr Val Ser Met Lys Met Gly Gly Thr
1 5 10 15
Thr Gly Gln Asn Ile Asp Gln Pro Thr Glu Met Thr Ala Thr Glu Gly
20 25 30
Ala Ile Val Gln Ile Asn Cys Thr Tyr Gln Thr Ser Gly Phe Asn Gly
35 40 45
Leu Phe Trp Tyr Gln Gln His Ala Gly Glu Ala Pro Thr Phe Leu Ser
50 55 60
Tyr Asn Val Leu Asp Gly Leu Glu Glu Lys Gly Arg Phe Ser Ser Phe
65 70 75 80
Leu Ser Arg Ser Lys Gly Tyr Ser Tyr Leu Leu Leu Lys Glu Leu Gln
85 90 95
Met Lys Asp Ser Ala Ser Tyr Leu Cys Ala Val Arg Asp Asn Ser Gly
100 105 110
Asn Thr Pro Leu Val Phe Gly Lys Gly Thr Arg Leu Ser Val Ile Ala
115 120 125
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
130 135 140
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
145 150 155 160
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr
165 170 175
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
180 185 190
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
195 200 205
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
210 215 220
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
225 230 235 240
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
245 250 255
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
260 265
<210> 24
<211> 309
<212> PRT
<213> Homo sapiens
<400> 24
Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala
1 5 10 15
Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg
20 25 30
Lys Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His
35 40 45
Asp Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala
65 70 75 80
Glu Gly Tyr Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr
85 90 95
Val Thr Ser Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser
100 105 110
Ser Ile Ile Gln Gly Ser Ala Gly Tyr Thr Phe Gly Ser Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe
305
<210> 25
<211> 42
<212> DNA
<213> Homo sapiens
<400> 25
tgtgctgccc tccgtggagg tagcaactat aaactgacat tt 42
<210> 26
<211> 42
<212> DNA
<213> Homo sapiens
<400> 26
tgcgccagca gcttggccag gggagtcaat gagcagttct tc 42
<210> 27
<211> 14
<212> PRT
<213> Homo sapiens
<400> 27
Cys Ala Ala Leu Arg Gly Gly Ser Asn Tyr Lys Leu Thr Phe
1 5 10
<210> 28
<211> 14
<212> PRT
<213> Homo sapiens
<400> 28
Cys Ala Ser Ser Leu Ala Arg Gly Val Asn Glu Gln Phe Phe
1 5 10
<210> 29
<211> 825
<212> DNA
<213> Homo sapiens
<400> 29
atgctcctgc tgctcgtccc agtgctcgag gtgattttta ccctgggagg aaccagagcc 60
cagtcggtga cccagcttgg cagccacgtc tctgtctctg aaggagccct ggttctgctg 120
aggtgcaact actcatcgtc tgttccacca tatctcttct ggtatgtgca ataccccaac 180
caaggactcc agcttctcct gaagtacaca tcagcggcca ccctggttaa aggcatcaac 240
ggttttgagg ctgaatttaa gaagagtgaa acctccttcc acctgacgaa accctcagcc 300
catatgagcg acgcggctga gtacttctgt gctgccctcc gtggaggtag caactataaa 360
ctgacatttg gaaaaggaac tctcttaacc gtgaatccaa atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gctga 825
<210> 30
<211> 936
<212> DNA
<213> Homo sapiens
<400> 30
atgggctcca ggctgctctg ttgggtgctg ctttgtctcc tgggagcagg cccagtaaag 60
gctggagtca ctcaaactcc aagatatctg atcaaaacga gaggacagca agtgacactg 120
agctgctccc ctatctctgg gcataggagt gtatcctggt accaacagac cccaggacag 180
ggccttcagt tcctctttga atacttcagt gagacacaga gaaacaaagg aaacttccct 240
ggtcgattct cagggcgcca gttctctaac tctcgctctg agatgaatgt gagcaccttg 300
gagctggggg actcggccct ttatctttgc gccagcagct tggccagggg agtcaatgag 360
cagttcttcg ggccagggac acggctcacc gtgctagagg acctgaaaaa cgtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttctacccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcaca gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acctgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gcttcacctc cgagtcttac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatct tgctagggaa ggccaccttg tatgccgtgc tggtcagtgc cctcgtgctg 900
atggccatgg tcaagagaaa ggattccaga ggctga 936
<210> 31
<211> 274
<212> PRT
<213> Homo sapiens
<400> 31
Met Leu Leu Leu Leu Val Pro Val Leu Glu Val Ile Phe Thr Leu Gly
1 5 10 15
Gly Thr Arg Ala Gln Ser Val Thr Gln Leu Gly Ser His Val Ser Val
20 25 30
Ser Glu Gly Ala Leu Val Leu Leu Arg Cys Asn Tyr Ser Ser Ser Val
35 40 45
Pro Pro Tyr Leu Phe Trp Tyr Val Gln Tyr Pro Asn Gln Gly Leu Gln
50 55 60
Leu Leu Leu Lys Tyr Thr Ser Ala Ala Thr Leu Val Lys Gly Ile Asn
65 70 75 80
Gly Phe Glu Ala Glu Phe Lys Lys Ser Glu Thr Ser Phe His Leu Thr
85 90 95
Lys Pro Ser Ala His Met Ser Asp Ala Ala Glu Tyr Phe Cys Ala Ala
100 105 110
Leu Arg Gly Gly Ser Asn Tyr Lys Leu Thr Phe Gly Lys Gly Thr Leu
115 120 125
Leu Thr Val Asn Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 32
<211> 311
<212> PRT
<213> Homo sapiens
<400> 32
Met Gly Ser Arg Leu Leu Cys Trp Val Leu Leu Cys Leu Leu Gly Ala
1 5 10 15
Gly Pro Val Lys Ala Gly Val Thr Gln Thr Pro Arg Tyr Leu Ile Lys
20 25 30
Thr Arg Gly Gln Gln Val Thr Leu Ser Cys Ser Pro Ile Ser Gly His
35 40 45
Arg Ser Val Ser Trp Tyr Gln Gln Thr Pro Gly Gln Gly Leu Gln Phe
50 55 60
Leu Phe Glu Tyr Phe Ser Glu Thr Gln Arg Asn Lys Gly Asn Phe Pro
65 70 75 80
Gly Arg Phe Ser Gly Arg Gln Phe Ser Asn Ser Arg Ser Glu Met Asn
85 90 95
Val Ser Thr Leu Glu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser
100 105 110
Ser Leu Ala Arg Gly Val Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Ser Arg Gly
305 310
<210> 33
<211> 28
<212> PRT
<213> Homo sapiens
<400> 33
Met Ala Ala Pro Gly Ser Ala Arg Arg Pro Leu Leu Leu Leu Leu Leu
1 5 10 15
Leu Leu Leu Leu Gly Leu Met His Cys Ala Ser Ala
20 25
<210> 34
<211> 29
<212> PRT
<213> Homo sapiens
<400> 34
Met Ala Ala Pro Gly Ser Ala Arg Arg Pro Leu Leu Leu Leu Leu Leu
1 5 10 15
Leu Leu Leu Leu Gly Leu Met His Cys Ala Ser Ala Ala
20 25
<210> 35
<211> 40
<212> PRT
<213> Homo sapiens
<400> 35
Ser Ser Asp Tyr Thr Ile Val Leu Pro Val Ile Gly Ala Ile Val Val
1 5 10 15
Gly Leu Cys Leu Met Gly Met Gly Val Tyr Lys Ile Arg Leu Arg Cys
20 25 30
Gln Ser Ser Gly Tyr Gln Arg Ile
35 40
<210> 36
<211> 14
<212> PRT
<213> Epstein-Barr virus
<400> 36
Val Val Arg Met Phe Met Arg Glu Arg Gln Leu Pro Gln Ser
1 5 10
<210> 37
<211> 9
<212> PRT
<213> Homo sapiens
<400> 37
Tyr Met Asp Gly Thr Met Ser Gln Val
1 5
<210> 38
<211> 4
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<222> (2)..(3)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> MISC_FEATURE
<222> (4)
<223> Xaa can be any hydrophobic amino acid
<400> 38
Tyr Xaa Xaa Xaa
1
<210> 39
<211> 4
<212> PRT
<213> Homo sapiens
<400> 39
Tyr Gln Arg Ile
1
<210> 40
<211> 28
<212> PRT
<213> Homo sapiens
<400> 40
Met Val Cys Phe Arg Leu Phe Pro Val Pro Gly Ser Gly Leu Val Leu
1 5 10 15
Val Cys Leu Val Leu Gly Ala Val Arg Ser Tyr Ala
20 25
<210> 41
<211> 29
<212> PRT
<213> Homo sapiens
<400> 41
Met Val Cys Phe Arg Leu Phe Pro Val Pro Gly Ser Gly Leu Val Leu
1 5 10 15
Val Cys Leu Val Leu Gly Ala Val Arg Ser Tyr Ala Leu
20 25
<210> 42
<211> 27
<212> PRT
<213> Homo sapiens
<400> 42
Met Pro Arg Gln Leu Ser Ala Ala Ala Ala Leu Phe Ala Ser Leu Ala
1 5 10 15
Val Ile Leu His Asp Gly Ser Gln Met Arg Ala
20 25
<210> 43
<211> 28
<212> PRT
<213> Homo sapiens
<400> 43
Met Pro Arg Gln Leu Ser Ala Ala Ala Ala Leu Phe Ala Ser Leu Ala
1 5 10 15
Val Ile Leu His Asp Gly Ser Gln Met Arg Ala Lys
20 25
<210> 44
<211> 21
<212> PRT
<213> Homo sapiens
<400> 44
Met Arg Leu Ala Val Leu Phe Ser Gly Ala Leu Leu Gly Leu Leu Ala
1 5 10 15
Ala Gln Gly Thr Gly
20
<210> 45
<211> 22
<212> PRT
<213> Homo sapiens
<400> 45
Met Arg Leu Ala Val Leu Phe Ser Gly Ala Leu Leu Gly Leu Leu Ala
1 5 10 15
Ala Gln Gly Thr Gly Asn
20
<210> 46
<211> 17
<212> PRT
<213> Homo sapiens
<400> 46
Met Leu Leu Leu Pro Phe Gln Leu Leu Ala Val Leu Phe Pro Gly Gly
1 5 10 15
Asn
<210> 47
<211> 18
<212> PRT
<213> Homo sapiens
<400> 47
Met Leu Leu Leu Pro Phe Gln Leu Leu Ala Val Leu Phe Pro Gly Gly
1 5 10 15
Asn Ser
<210> 48
<211> 23
<212> PRT
<213> Homo sapiens
<400> 48
Gln Glu Gln Gly His Pro Gln Thr Gly Cys Glu Cys Glu Asp Gly Pro
1 5 10 15
Asp Gly Gln Glu Met Asp Pro
20
<210> 49
<211> 40
<212> PRT
<213> Homo sapiens
<400> 49
Glu Asp Glu Gly Ala Ser Ala Gly Gln Gly Pro Lys Pro Glu Ala Asp
1 5 10 15
Ser Gln Glu Gln Gly His Pro Gln Thr Gly Cys Glu Cys Glu Asp Gly
20 25 30
Pro Asp Gly Gln Glu Met Asp Pro
35 40
<210> 50
<211> 13
<212> PRT
<213> Homo sapiens
<400> 50
Pro Glu Val Trp Ile Leu Ser Pro Leu Leu Arg His Gly
1 5 10
<210> 51
<211> 28
<212> PRT
<213> Homo sapiens
<400> 51
Pro Ala Thr Arg Val Pro Glu Val Trp Ile Leu Ser Pro Leu Leu Arg
1 5 10 15
His Gly Gly Pro His Thr Gln Thr Gln Asn His Thr
20 25
<210> 52
<211> 46
<212> PRT
<213> Homo sapiens
<400> 52
Gln Glu Gly Glu Asp Glu Gly Ala Ser Ala Gly Gln Gly Pro Lys Pro
1 5 10 15
Glu Ala Asp Ser Gln Glu Gln Gly His Pro Gln Thr Gly Cys Glu Cys
20 25 30
Glu Asp Gly Pro Asp Gly Gln Glu Met Asp Pro Pro Asn Pro
35 40 45
<210> 53
<211> 34
<212> PRT
<213> Homo sapiens
<400> 53
Ser Cys Glu Pro Ala Thr Arg Val Pro Glu Val Trp Ile Leu Ser Pro
1 5 10 15
Leu Leu Arg His Gly Gly Pro His Thr Gln Thr Gln Asn His Thr Ala
20 25 30
Ser Pro
<210> 54
<211> 42
<212> PRT
<213> Homo sapiens
<400> 54
Asp Pro Ser Ser Asp Tyr Thr Ile Val Leu Pro Val Ile Gly Ala Ile
1 5 10 15
Val Val Gly Leu Cys Leu Met Gly Met Gly Val Tyr Lys Ile Arg Leu
20 25 30
Arg Cys Gln Ser Ser Gly Tyr Gln Arg Ile
35 40
Claims (12)
- 인간 항원-특이적 CD4+ 및 CD8+ T 림프구를 생성하는 방법으로서,
A) 항원 제시 세포에서
- 적어도 하나의 항원 또는 이의 단편,
- 상기 항원의 N-말단 앞의 소포체 (ER)-이동 신호 서열, 및
- 상기 항원의 C-말단 다음의 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인
을 포함하는 적어도 하나의 융합 단백질을 발현시키는 단계;
B) 상기 항원 제시 세포에 의해 발현되는 항원에 특이적인 항원-특이적 T 림프구를 활성화시키기 위해 시험관 내(in vitro)에서 단계 A)의 항원 제시 세포에 T 림프구를 포함하는 세포 집단을 노출시키는 단계; 및
C1) 다음의 단계를 포함하는, 활성화된 항원 특이적 T 림프구를 농축하는 단계:
(a) 활성화된 항원-특이적 T 림프구를 포함하는 세포 집단을 활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질에 특이적으로 결합하는 결합 분자와 또는 상기 적어도 하나의 항원의 에피토프를 제시하는 MHC 분자와 접촉시키는 단계;
(b) 상기 결합 분자 또는 상기 적어도 하나의 항원의 에피토프를 제시하는 MHC 분자가 결합된 T 림프구를 분리하는 단계,
를 포함하고,
여기서 상기 융합 단백질은 적어도 2종의 항원 또는 이의 단편을 포함하며,
상기 항원은 종양 항원 또는 바이러스 항원인 방법. - 제1항에 있어서, 활성화된 T 림프구에 의해 특이적으로 발현되는 마커 단백질이 Ox40, CD137, CD40L, PD-1, IL-2 수용체, 인터페론γ, IL-2, GM-CSF 및 TNF-α로 이루어진 군으로부터 선택되는 것인 방법.
- 제1항에 있어서,
C2) 다음의 단계를 포함하는, 항원-특이적 T 림프구를 확인하는 단계를 추가로 포함하고:
a) 활성화된 항원-특이적 T 림프구를 포함하는 상기 세포 집단의 확장된 세포 클론을,
(i) 단계 A)에 정의된 항원 제시 세포, 및
(ii) 대조구 (control) 항원 제시 세포와 배양하거나 항원 제시 세포의 부재 하에 배양하는 단계;
b) 상기 배양의 활성 프로파일을 각 세포 클론에 대한 (i) 및 (ii)와 비교하는 단계; 및
c) b)의 비교를 바탕으로 항원-특이적 세포 클론을 확인하는 단계;
여기서 (ii)가 아닌 (i)에 의한 활성화는 상기 세포 클론이 항원-특이적임을 나타내는 것인 방법. - 제1항에 있어서, 상기 ER 이동 신호 서열이 LAMP1, LAMP2, DC-LAMP, CD68 및 CD1b를 포함하는 군으로부터 선택된 엔도솜/리소좀 관련 단백질로부터 유래된 것인 방법.
- 제1항에 있어서, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인이 LAMP1 또는 DC-LAMP로부터 유래된 것인 방법.
- 제1항에 있어서, 상기 ER 이동 신호 서열이 인간의 것이고, 상기 엔도솜/리소좀 표적 서열을 포함하는 막통과 및 세포질 도메인이 인간의 것인 방법.
- 제1항에 있어서, 상기 항원 제시 세포가 항원 제시 세포의 상이한 집단을 포함하고, 각각의 집단은 상이한 항원 융합 단백질을 발현하는 것인 방법.
- 제1항에 있어서, 상기 항원 제시 세포가 다음의 단계를 포함하는 방법으로 생성된 성숙한 수지상 세포인 방법:
i) 단핵구를 제공하는 단계;
ii) 단계 i)의 단핵구를 IL-4 및 GM-CSF와 배양하는 단계;
iii) 단계 ii)의 단핵구를 IL-ß, TNF-α, INF-γ, TLR7/8 작용제, PGE2 및 TLR3 작용제의 조합을 선택적으로 포함하는 성숙 칵테일과 조합한 IL-4 및 GM-CSF와 배양하는 단계. - 제1항에 있어서, T 림프구를 포함하는 세포 집단이 분리되지 않은 말초 혈액 림프구의 집단인 방법.
- 제1항에 있어서, T 림프구를 포함하는 세포 집단이 T 림프구에 대해 농축되는 것인 방법.
- 제1항 내지 제10항 중 어느 한 항에 따른 방법의 단계를 포함하고 상기 활성화된 항원-특이적 림프구로부터 TCR을 분리하는 단계를 추가로 포함하는 항원-특이적 TCR을 제조하기 위한 방법.
- 제11항에 있어서, TCR이 GAGE-1에 특이적이고
- 서열번호 5의 뉴클레오타이드 서열에 의해 코딩되는 TCR α 쇄; 및
- 서열번호 6의 뉴클레오타이드 서열에 의해 코딩되는 TCR β 쇄
를 포함하는 것인 항원-특이적 TCR을 제조하기 위한 방법.
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15202329.7 | 2015-12-23 | ||
| EP15202329 | 2015-12-23 | ||
| EP16190399.2 | 2016-09-23 | ||
| EP16190399 | 2016-09-23 | ||
| PCT/EP2016/082443 WO2017109109A1 (en) | 2015-12-23 | 2016-12-22 | Novel generation of antigen-specific tcrs |
| KR1020187017846A KR20180093954A (ko) | 2015-12-23 | 2016-12-22 | 항원-특이적 tcr의 신규 생성 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187017846A Division KR20180093954A (ko) | 2015-12-23 | 2016-12-22 | 항원-특이적 tcr의 신규 생성 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200085362A true KR20200085362A (ko) | 2020-07-14 |
| KR102319839B1 KR102319839B1 (ko) | 2021-11-01 |
Family
ID=57794260
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207019363A KR102319839B1 (ko) | 2015-12-23 | 2016-12-22 | 항원-특이적 tcr의 신규 생성 |
| KR1020187017846A KR20180093954A (ko) | 2015-12-23 | 2016-12-22 | 항원-특이적 tcr의 신규 생성 |
| KR1020187017847A KR20180089446A (ko) | 2015-12-23 | 2016-12-22 | 수지상 세포 조성물 |
| KR1020207023474A KR20200100858A (ko) | 2015-12-23 | 2016-12-22 | 수지상 세포 조성물 |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187017846A KR20180093954A (ko) | 2015-12-23 | 2016-12-22 | 항원-특이적 tcr의 신규 생성 |
| KR1020187017847A KR20180089446A (ko) | 2015-12-23 | 2016-12-22 | 수지상 세포 조성물 |
| KR1020207023474A KR20200100858A (ko) | 2015-12-23 | 2016-12-22 | 수지상 세포 조성물 |
Country Status (17)
| Country | Link |
|---|---|
| US (2) | US11155589B2 (ko) |
| EP (4) | EP3394247B1 (ko) |
| JP (3) | JP6697562B2 (ko) |
| KR (4) | KR102319839B1 (ko) |
| CN (2) | CN108473960A (ko) |
| AU (2) | AU2016374873B2 (ko) |
| BR (2) | BR112018012694A2 (ko) |
| CA (2) | CA3009564C (ko) |
| DK (2) | DK3394247T3 (ko) |
| EA (2) | EA201891460A1 (ko) |
| ES (2) | ES2865484T3 (ko) |
| HU (1) | HUE053674T2 (ko) |
| MX (2) | MX2018007842A (ko) |
| PH (2) | PH12018501336A1 (ko) |
| PL (2) | PL3394248T3 (ko) |
| TW (2) | TWI772282B (ko) |
| WO (2) | WO2017109110A1 (ko) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11292838B2 (en) | 2015-06-01 | 2022-04-05 | Medigene Immunotherapies Gmbh | Method for generating antibodies against T cell receptor |
| WO2016193299A1 (en) | 2015-06-01 | 2016-12-08 | Medigene Immunotherapies Gmbh | T cell receptor library |
| KR102319839B1 (ko) | 2015-12-23 | 2021-11-01 | 메디진 이뮤노테라피스 게엠바하 | 항원-특이적 tcr의 신규 생성 |
| KR20200115484A (ko) | 2017-12-04 | 2020-10-07 | 더 유나이티드 스테이츠 오브 어메리카, 애즈 리프리젠티드 바이 더 세크러테리, 디파트먼트 오브 헬쓰 앤드 휴먼 서비씨즈 | 돌연변이 ras에 대한 hla 클래스 i-제한 t 세포 수용체 |
| US10808465B2 (en) * | 2018-04-27 | 2020-10-20 | Canrig Robotic Technologies As | System and method for conducting subterranean operations |
| US11015402B2 (en) | 2018-04-27 | 2021-05-25 | Canrig Robotic Technologies As | System and method for conducting subterranean operations |
| WO2019243537A1 (en) | 2018-06-21 | 2019-12-26 | Universiteit Gent | Method for the in vitro differentiation and maturation of dendritic cells for therapeutic use |
| CN110172091B (zh) * | 2019-04-28 | 2020-04-03 | 天津亨佳生物科技发展有限公司 | 一种针对egfr l858r基因突变的特异性t细胞受体及其应用 |
| JP2022535045A (ja) * | 2019-06-03 | 2022-08-04 | ザ スクリプス リサーチ インスティテュート | 細胞間近接相互作用の検出および免疫療法用の腫瘍特異的抗原反応性t細胞の単離のための化学酵素的方法 |
| JP2023509527A (ja) * | 2020-01-10 | 2023-03-08 | エルジー・ケム・リミテッド | Mhcおよび腫瘍抗原を同時発現する抗原提示細胞を含む組成物およびこれを用いた癌治療 |
| CN112133372B (zh) * | 2020-08-18 | 2022-06-03 | 北京臻知医学科技有限责任公司 | 抗原特异性tcr数据库的建立方法及抗原特异性tcr的评估方法 |
| WO2022086185A1 (ko) * | 2020-10-20 | 2022-04-28 | 연세대학교 산학협력단 | 단일 세포 분석법을 이용한 tcr-항원의 특이성을 확인하는 방법 |
| WO2022115415A1 (en) * | 2020-11-24 | 2022-06-02 | Providence Health & Services - Oregon | T cell receptors specific for a mutant form of the ret oncogene and uses thereof |
| WO2023060163A2 (en) * | 2021-10-06 | 2023-04-13 | Board Of Regents, The University Of Texas System | Shp1 modified dendritic cells and extracellular vesicles derived therefrom and associated methods |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2700708A2 (en) * | 2012-08-23 | 2014-02-26 | Vrije Universiteit Brussel | Enhancing the T-cell stimulatory capacity of human antigen presenting cells in vitro and in vivo and its use in vaccination |
Family Cites Families (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4703004A (en) | 1984-01-24 | 1987-10-27 | Immunex Corporation | Synthesis of protein with an identification peptide |
| US4851341A (en) | 1986-12-19 | 1989-07-25 | Immunex Corporation | Immunoaffinity purification system |
| US5766947A (en) | 1988-12-14 | 1998-06-16 | Astra Ab | Monoclonal antibodies reactive with an epitope of a Vβ3.1 variable region of a T cell receptor |
| IL162181A (en) | 1988-12-28 | 2006-04-10 | Pdl Biopharma Inc | A method of producing humanized immunoglubulin, and polynucleotides encoding the same |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| WO1991007508A1 (en) | 1989-11-15 | 1991-05-30 | National Jewish Center For Immunology And Respiratory Medicine | Method for measuring t-cell surface antigens in humans |
| EP0542897B1 (en) | 1990-08-09 | 1997-01-29 | National Jewish Center For Immunology And Respiratory Medicine | Producing monoclonal antibodies against human Vbeta T-cell receptor element using recombinant DNA vectors |
| US5871732A (en) | 1990-11-27 | 1999-02-16 | Biogen, Inc. | Anti-CD4 antibody homologs useful in prophylaxis and treatment of AIDS, ARC and HIV infection |
| US5480895A (en) | 1991-09-27 | 1996-01-02 | New York Society For The Relief Of The Ruptured And Crippled, Maintaining The Hospital For Special Surgery | Method of producing antibodies to a restricted population of T lymphocytes, antibodies produced therefrom and methods of use thereof |
| JPH07501451A (ja) | 1991-11-25 | 1995-02-16 | エンゾン・インコーポレイテッド | 多価抗原結合タンパク質 |
| ATE249840T1 (de) | 1991-12-13 | 2003-10-15 | Xoma Corp | Verfahren und materialien zur herstellung von modifizierten variablen antikörperdomänen und ihre therapeutische verwendung |
| CA2135642C (en) | 1992-08-21 | 1999-12-14 | James G. Barsoum | Tat-derived transport polypeptides |
| US6372716B1 (en) | 1994-04-26 | 2002-04-16 | Genetics Institute, Inc. | Formulations for factor IX |
| US6685940B2 (en) | 1995-07-27 | 2004-02-03 | Genentech, Inc. | Protein formulation |
| DE19625191A1 (de) | 1996-06-24 | 1998-01-02 | Boehringer Mannheim Gmbh | Nierenkarzinom-spezifische T-Zellen |
| US6284879B1 (en) * | 1998-04-16 | 2001-09-04 | The General Hospital Corporation | Transport associated protein splice variants |
| US6566329B1 (en) | 1999-06-28 | 2003-05-20 | Novo Nordisk A/S | Freeze-dried preparation of human growth hormone |
| US20050112141A1 (en) * | 2000-08-30 | 2005-05-26 | Terman David S. | Compositions and methods for treatment of neoplastic disease |
| EP1118661A1 (en) | 2000-01-13 | 2001-07-25 | Het Nederlands Kanker Instituut | T cell receptor libraries |
| EP1259601A2 (en) | 2000-02-22 | 2002-11-27 | Ahuva Nissim | Chimeric and tcr phage display libraries, chimeric and tcr reagents and methods of use thereof |
| EP2248910A1 (en) * | 2000-04-28 | 2010-11-10 | Mannkind Corporation | Epitope synchronization in antigen presenting cells |
| IL136459A0 (en) | 2000-05-30 | 2001-06-14 | Galim Galil Immunology Ltd | Antibody library |
| US7829084B2 (en) | 2001-01-17 | 2010-11-09 | Trubion Pharmaceuticals, Inc. | Binding constructs and methods for use thereof |
| FR2822846B1 (fr) | 2001-04-03 | 2004-01-23 | Technopharm | Procede de preparation et de selection d'anticorps |
| EP1433793A4 (en) | 2001-09-13 | 2006-01-25 | Inst Antibodies Co Ltd | METHOD FOR CREATING A CAMEL ANTIBODY LIBRARY |
| NZ570811A (en) | 2002-11-09 | 2009-11-27 | Immunocore Ltd | T cell receptor display |
| GB0411773D0 (en) | 2004-05-26 | 2004-06-30 | Avidex Ltd | Method for the identification of polypeptides which bind to a given peptide mhc complex or cd 1-antigen complex |
| GB0411771D0 (en) | 2004-05-26 | 2004-06-30 | Avidex Ltd | Nucleoproteins displaying native T cell receptor libraries |
| WO2007017201A1 (en) | 2005-08-05 | 2007-02-15 | Helmholtz Zentrum München Deutsches Forschungszentrum Für Gesundheit Und Umwelt Gmbh | Generation of antigen specific t cells |
| JP2007097580A (ja) | 2005-09-06 | 2007-04-19 | Shizuoka Prefecture | T細胞レセプターβ鎖遺伝子 |
| EP1840206A1 (en) * | 2006-03-28 | 2007-10-03 | Gsf-Forschungszentrum Für Umwelt Und Gesundheit, Gmbh | Compositions for the preparation of mature dendritic cells |
| AU2007248019B2 (en) | 2006-05-03 | 2012-10-11 | Government Of The United States Of America, Represented By The Secretary, Department Of Health And Human Services | Chimeric T cell receptors and related materials and methods of use |
| BRPI0817052A2 (pt) * | 2007-08-30 | 2015-03-24 | Genentech Inc | Métodos para o tratamento de uma doença auto-imune e distúrbio, método de inibição de atividade biológica, método para aumentar uma atividade biológica, método para a detecção de uma doença auto-imune, população de células t cd4+, método para isolar uma população de células t cd4+, kit, uso de um modulador crtam, modulador crtam e anticorpo. |
| US8394778B1 (en) * | 2009-10-08 | 2013-03-12 | Immune Disease Institute, Inc. | Regulators of NFAT and/or store-operated calcium entry |
| WO2011053789A2 (en) * | 2009-10-30 | 2011-05-05 | James Cameron Oliver | Pharmaceutical composition and methods to enhance cytotoxic t-cell recognition and maintain t-cell memory against a pathogenic disease |
| WO2011107409A1 (en) | 2010-03-02 | 2011-09-09 | F. Hoffmann-La Roche Ag | Expression vector |
| CN102719399A (zh) * | 2012-04-28 | 2012-10-10 | 北京爱根生物科技有限公司 | 自体特异性t细胞的体外扩增方法及所制备的t细胞体系、体系的药物应用和组分监测方法 |
| PT2861240T (pt) | 2012-06-15 | 2020-11-09 | Immunomic Therapeutics Inc | Ácidos nucleicos para tratamento de alergias |
| TW201425336A (zh) | 2012-12-07 | 2014-07-01 | Amgen Inc | Bcma抗原結合蛋白質 |
| AU2015228751B2 (en) | 2014-03-14 | 2019-06-20 | Adaptimmune Limited | TCR libraries |
| WO2016057986A1 (en) | 2014-10-10 | 2016-04-14 | The Trustees Of Columbia University In The City Of New York | Tandem epitope constructs for presentation of cd4 and cd8 epitopes and uses thereof |
| US11292838B2 (en) | 2015-06-01 | 2022-04-05 | Medigene Immunotherapies Gmbh | Method for generating antibodies against T cell receptor |
| BR112017025332A2 (pt) | 2015-06-01 | 2018-07-31 | Medigene Immunotherapies Gmbh | anticorpos específicos de receptor de célula t |
| WO2016193299A1 (en) | 2015-06-01 | 2016-12-08 | Medigene Immunotherapies Gmbh | T cell receptor library |
| KR102319839B1 (ko) | 2015-12-23 | 2021-11-01 | 메디진 이뮤노테라피스 게엠바하 | 항원-특이적 tcr의 신규 생성 |
-
2016
- 2016-12-22 KR KR1020207019363A patent/KR102319839B1/ko active IP Right Grant
- 2016-12-22 PL PL16825765T patent/PL3394248T3/pl unknown
- 2016-12-22 ES ES16825765T patent/ES2865484T3/es active Active
- 2016-12-22 AU AU2016374873A patent/AU2016374873B2/en active Active
- 2016-12-22 CN CN201680075578.0A patent/CN108473960A/zh active Pending
- 2016-12-22 CN CN201680075559.8A patent/CN108603171A/zh active Pending
- 2016-12-22 JP JP2018533086A patent/JP6697562B2/ja active Active
- 2016-12-22 MX MX2018007842A patent/MX2018007842A/es unknown
- 2016-12-22 WO PCT/EP2016/082445 patent/WO2017109110A1/en active Application Filing
- 2016-12-22 CA CA3009564A patent/CA3009564C/en active Active
- 2016-12-22 DK DK16825764.0T patent/DK3394247T3/da active
- 2016-12-22 KR KR1020187017846A patent/KR20180093954A/ko not_active IP Right Cessation
- 2016-12-22 TW TW105142799A patent/TWI772282B/zh active
- 2016-12-22 PL PL16825764T patent/PL3394247T3/pl unknown
- 2016-12-22 ES ES16825764T patent/ES2863733T3/es active Active
- 2016-12-22 AU AU2016374874A patent/AU2016374874B2/en active Active
- 2016-12-22 EA EA201891460A patent/EA201891460A1/ru unknown
- 2016-12-22 CA CA3009542A patent/CA3009542C/en active Active
- 2016-12-22 BR BR112018012694A patent/BR112018012694A2/pt not_active Application Discontinuation
- 2016-12-22 EP EP16825764.0A patent/EP3394247B1/en active Active
- 2016-12-22 HU HUE16825764A patent/HUE053674T2/hu unknown
- 2016-12-22 DK DK16825765.7T patent/DK3394248T3/da active
- 2016-12-22 KR KR1020187017847A patent/KR20180089446A/ko not_active Application Discontinuation
- 2016-12-22 US US16/065,024 patent/US11155589B2/en active Active
- 2016-12-22 WO PCT/EP2016/082443 patent/WO2017109109A1/en active Application Filing
- 2016-12-22 US US16/065,037 patent/US10882891B2/en active Active
- 2016-12-22 MX MX2018007841A patent/MX2018007841A/es unknown
- 2016-12-22 EA EA201891459A patent/EA201891459A1/ru unknown
- 2016-12-22 EP EP21155881.2A patent/EP3889253A1/en not_active Withdrawn
- 2016-12-22 EP EP21155874.7A patent/EP3901254A1/en active Pending
- 2016-12-22 BR BR112018012826A patent/BR112018012826A2/pt not_active Application Discontinuation
- 2016-12-22 TW TW105142798A patent/TWI752930B/zh active
- 2016-12-22 KR KR1020207023474A patent/KR20200100858A/ko active Application Filing
- 2016-12-22 JP JP2018533099A patent/JP6676759B2/ja active Active
- 2016-12-22 EP EP16825765.7A patent/EP3394248B1/en active Active
-
2018
- 2018-06-21 PH PH12018501336A patent/PH12018501336A1/en unknown
- 2018-06-21 PH PH12018501335A patent/PH12018501335A1/en unknown
-
2020
- 2020-03-12 JP JP2020042812A patent/JP2020114222A/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2700708A2 (en) * | 2012-08-23 | 2014-02-26 | Vrije Universiteit Brussel | Enhancing the T-cell stimulatory capacity of human antigen presenting cells in vitro and in vivo and its use in vaccination |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102319839B1 (ko) | 항원-특이적 tcr의 신규 생성 | |
| US20220169699A1 (en) | Pd-1-cd28 fusion proteins and their use in medicine | |
| JP2023145687A (ja) | Tcr及びペプチド | |
| JP2024009805A (ja) | 初代細胞の遺伝子編集 | |
| AU2017205637A1 (en) | Compositions and libraries comprising recombinant T-cell receptors and methods of using recombinant T-cell receptors | |
| KR20210057750A (ko) | 암 면역치료요법을 위한 mr1 제한된 t 세포 수용체 | |
| WO2023133540A1 (en) | Il-12 affinity variants | |
| US20230399402A1 (en) | Hla class ii-restricted tcrs against the kras g12>v activating mutation | |
| EA041619B1 (ru) | Способ продуцирования человеческих антигенспецифических т-лимфоцитов | |
| US20230057987A1 (en) | Antigen binding proteins specifically binding ct45 | |
| US20220096615A1 (en) | Compositions and methods for treating immunological dysfunction | |
| WO2023175069A1 (en) | Tcr constant region pairing library for pramevld tcrs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X701 | Decision to grant (after re-examination) | ||
| GRNT | Written decision to grant |