KR20200073280A - 주변세포질 단백질 발현을 위한 박테리아 리더 서열 - Google Patents
주변세포질 단백질 발현을 위한 박테리아 리더 서열 Download PDFInfo
- Publication number
- KR20200073280A KR20200073280A KR1020207015248A KR20207015248A KR20200073280A KR 20200073280 A KR20200073280 A KR 20200073280A KR 1020207015248 A KR1020207015248 A KR 1020207015248A KR 20207015248 A KR20207015248 A KR 20207015248A KR 20200073280 A KR20200073280 A KR 20200073280A
- Authority
- KR
- South Korea
- Prior art keywords
- protein
- antibody
- polypeptide
- pseudomonas
- interest
- Prior art date
Links
- 230000014509 gene expression Effects 0.000 title claims abstract description 170
- 230000001580 bacterial effect Effects 0.000 title abstract description 20
- 108010090127 Periplasmic Proteins Proteins 0.000 title 1
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 465
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 443
- 238000000034 method Methods 0.000 claims abstract description 133
- 210000004027 cell Anatomy 0.000 claims description 237
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 223
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 188
- 229920001184 polypeptide Polymers 0.000 claims description 183
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 76
- 241000588724 Escherichia coli Species 0.000 claims description 60
- 150000007523 nucleic acids Chemical class 0.000 claims description 55
- 102000039446 nucleic acids Human genes 0.000 claims description 43
- 108020004707 nucleic acids Proteins 0.000 claims description 43
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 39
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 32
- 210000001322 periplasm Anatomy 0.000 claims description 27
- 102000004190 Enzymes Human genes 0.000 claims description 24
- 108090000790 Enzymes Proteins 0.000 claims description 24
- 238000004113 cell culture Methods 0.000 claims description 19
- 238000003776 cleavage reaction Methods 0.000 claims description 18
- 230000007017 scission Effects 0.000 claims description 18
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 14
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 14
- 239000003102 growth factor Substances 0.000 claims description 14
- 239000000427 antigen Substances 0.000 claims description 13
- 108091007433 antigens Proteins 0.000 claims description 13
- 102000036639 antigens Human genes 0.000 claims description 13
- 102000019034 Chemokines Human genes 0.000 claims description 12
- 108010012236 Chemokines Proteins 0.000 claims description 12
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 12
- 239000001963 growth medium Substances 0.000 claims description 12
- 102000004127 Cytokines Human genes 0.000 claims description 11
- 108090000695 Cytokines Proteins 0.000 claims description 11
- 229960005486 vaccine Drugs 0.000 claims description 11
- 238000012258 culturing Methods 0.000 claims description 6
- 230000001086 cytosolic effect Effects 0.000 abstract description 16
- 102000037865 fusion proteins Human genes 0.000 abstract description 3
- 108020001507 fusion proteins Proteins 0.000 abstract description 3
- 230000002093 peripheral effect Effects 0.000 abstract description 2
- 235000018102 proteins Nutrition 0.000 description 398
- 230000028327 secretion Effects 0.000 description 73
- 241000589516 Pseudomonas Species 0.000 description 61
- 230000003248 secreting effect Effects 0.000 description 48
- 125000003729 nucleotide group Chemical group 0.000 description 44
- 239000002773 nucleotide Substances 0.000 description 43
- 230000000694 effects Effects 0.000 description 39
- 108010024976 Asparaginase Proteins 0.000 description 37
- 230000014616 translation Effects 0.000 description 33
- 235000001014 amino acid Nutrition 0.000 description 32
- 239000013612 plasmid Substances 0.000 description 32
- 238000009396 hybridization Methods 0.000 description 31
- 108091028043 Nucleic acid sequence Proteins 0.000 description 28
- 108020004414 DNA Proteins 0.000 description 27
- 229940024606 amino acid Drugs 0.000 description 27
- 238000000855 fermentation Methods 0.000 description 27
- 230000004151 fermentation Effects 0.000 description 27
- 102000015790 Asparaginase Human genes 0.000 description 26
- 108091005804 Peptidases Proteins 0.000 description 26
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 26
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 26
- 150000001413 amino acids Chemical class 0.000 description 26
- 239000000523 sample Substances 0.000 description 25
- 238000013519 translation Methods 0.000 description 25
- 108020004705 Codon Proteins 0.000 description 24
- -1 regulatory proteins Chemical class 0.000 description 24
- 241000894006 Bacteria Species 0.000 description 23
- 102000035195 Peptidases Human genes 0.000 description 23
- DCXYFEDJOCDNAF-UHFFFAOYSA-M asparaginate Chemical compound [O-]C(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-M 0.000 description 23
- 229960003272 asparaginase Drugs 0.000 description 22
- 230000012010 growth Effects 0.000 description 22
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 22
- 239000002609 medium Substances 0.000 description 22
- 239000004365 Protease Substances 0.000 description 21
- 238000012217 deletion Methods 0.000 description 21
- 230000037430 deletion Effects 0.000 description 21
- 229940088598 enzyme Drugs 0.000 description 21
- 241000589540 Pseudomonas fluorescens Species 0.000 description 20
- 210000004369 blood Anatomy 0.000 description 20
- 239000012634 fragment Substances 0.000 description 20
- 230000002829 reductive effect Effects 0.000 description 20
- 239000008280 blood Substances 0.000 description 19
- 230000006698 induction Effects 0.000 description 19
- 108091033319 polynucleotide Proteins 0.000 description 18
- 102000040430 polynucleotide Human genes 0.000 description 18
- 239000002157 polynucleotide Substances 0.000 description 18
- 150000003839 salts Chemical class 0.000 description 17
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 16
- 239000013613 expression plasmid Substances 0.000 description 16
- 108091026890 Coding region Proteins 0.000 description 15
- 238000004458 analytical method Methods 0.000 description 15
- 229910052500 inorganic mineral Inorganic materials 0.000 description 14
- 235000010755 mineral Nutrition 0.000 description 14
- 239000011707 mineral Substances 0.000 description 14
- 238000012216 screening Methods 0.000 description 14
- 238000004519 manufacturing process Methods 0.000 description 13
- 238000006467 substitution reaction Methods 0.000 description 13
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 12
- 238000005457 optimization Methods 0.000 description 12
- 102100025573 1-alkyl-2-acetylglycerophosphocholine esterase Human genes 0.000 description 11
- 125000000539 amino acid group Chemical group 0.000 description 11
- 230000000875 corresponding effect Effects 0.000 description 11
- 239000000411 inducer Substances 0.000 description 11
- 230000001939 inductive effect Effects 0.000 description 11
- 239000003550 marker Substances 0.000 description 11
- 230000001105 regulatory effect Effects 0.000 description 11
- 241000192142 Proteobacteria Species 0.000 description 10
- 150000001875 compounds Chemical class 0.000 description 10
- 239000012528 membrane Substances 0.000 description 10
- 235000019419 proteases Nutrition 0.000 description 10
- 108700012359 toxins Proteins 0.000 description 10
- 102000034356 gene-regulatory proteins Human genes 0.000 description 9
- 108091006104 gene-regulatory proteins Proteins 0.000 description 9
- 230000001976 improved effect Effects 0.000 description 9
- 101150116440 pyrF gene Proteins 0.000 description 9
- 239000006228 supernatant Substances 0.000 description 9
- 230000008685 targeting Effects 0.000 description 9
- 239000003053 toxin Substances 0.000 description 9
- 231100000765 toxin Toxicity 0.000 description 9
- 102000004400 Aminopeptidases Human genes 0.000 description 8
- 108090000915 Aminopeptidases Proteins 0.000 description 8
- 108090001081 Dipeptidases Proteins 0.000 description 8
- 102000004860 Dipeptidases Human genes 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 238000005119 centrifugation Methods 0.000 description 8
- 239000002299 complementary DNA Substances 0.000 description 8
- 239000000203 mixture Substances 0.000 description 8
- 238000000527 sonication Methods 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 108010087967 type I signal peptidase Proteins 0.000 description 8
- 102000005367 Carboxypeptidases Human genes 0.000 description 7
- 108010006303 Carboxypeptidases Proteins 0.000 description 7
- 108010001496 Galectin 2 Proteins 0.000 description 7
- 102100021735 Galectin-2 Human genes 0.000 description 7
- 238000004140 cleaning Methods 0.000 description 7
- 210000000805 cytoplasm Anatomy 0.000 description 7
- 230000004927 fusion Effects 0.000 description 7
- 239000006166 lysate Substances 0.000 description 7
- 230000000813 microbial effect Effects 0.000 description 7
- 230000037361 pathway Effects 0.000 description 7
- 230000014621 translational initiation Effects 0.000 description 7
- 239000013598 vector Substances 0.000 description 7
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 6
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 6
- 108091081024 Start codon Proteins 0.000 description 6
- 238000007792 addition Methods 0.000 description 6
- 210000000170 cell membrane Anatomy 0.000 description 6
- 230000000295 complement effect Effects 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 108020004999 messenger RNA Proteins 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 101150054111 Aspg gene Proteins 0.000 description 5
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 239000003114 blood coagulation factor Substances 0.000 description 5
- 229910052799 carbon Inorganic materials 0.000 description 5
- 230000006037 cell lysis Effects 0.000 description 5
- 239000003795 chemical substances by application Substances 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 230000002209 hydrophobic effect Effects 0.000 description 5
- 210000003000 inclusion body Anatomy 0.000 description 5
- 230000000977 initiatory effect Effects 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 235000019833 protease Nutrition 0.000 description 5
- 230000005945 translocation Effects 0.000 description 5
- 238000011144 upstream manufacturing Methods 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- 241000203069 Archaea Species 0.000 description 4
- 239000002028 Biomass Substances 0.000 description 4
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 4
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 4
- 102000004506 Blood Proteins Human genes 0.000 description 4
- 108010017384 Blood Proteins Proteins 0.000 description 4
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 4
- 108700010070 Codon Usage Proteins 0.000 description 4
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 4
- 108090000194 Dipeptidyl-peptidases and tripeptidyl-peptidases Proteins 0.000 description 4
- 102000003779 Dipeptidyl-peptidases and tripeptidyl-peptidases Human genes 0.000 description 4
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 4
- 102000004877 Insulin Human genes 0.000 description 4
- 108090001061 Insulin Proteins 0.000 description 4
- 229930195725 Mannitol Natural products 0.000 description 4
- 102000005741 Metalloproteases Human genes 0.000 description 4
- 108010006035 Metalloproteases Proteins 0.000 description 4
- 108010025020 Nerve Growth Factor Proteins 0.000 description 4
- 108090000099 Neurotrophin-4 Proteins 0.000 description 4
- 102000004316 Oxidoreductases Human genes 0.000 description 4
- 108090000854 Oxidoreductases Proteins 0.000 description 4
- 108010038512 Platelet-Derived Growth Factor Proteins 0.000 description 4
- 102000010780 Platelet-Derived Growth Factor Human genes 0.000 description 4
- 241001135311 Pseudoalteromonas nigrifaciens Species 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 4
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 4
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 description 4
- QGZKDVFQNNGYKY-UHFFFAOYSA-N ammonia Natural products N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 4
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 4
- 230000004071 biological effect Effects 0.000 description 4
- 238000006664 bond formation reaction Methods 0.000 description 4
- 238000001818 capillary gel electrophoresis Methods 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 230000007812 deficiency Effects 0.000 description 4
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 4
- 239000013604 expression vector Substances 0.000 description 4
- 210000001723 extracellular space Anatomy 0.000 description 4
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 4
- 101150109249 lacI gene Proteins 0.000 description 4
- 101150066555 lacZ gene Proteins 0.000 description 4
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 4
- 239000000594 mannitol Substances 0.000 description 4
- 235000010355 mannitol Nutrition 0.000 description 4
- 238000004949 mass spectrometry Methods 0.000 description 4
- 238000005259 measurement Methods 0.000 description 4
- 238000002844 melting Methods 0.000 description 4
- 230000008018 melting Effects 0.000 description 4
- 230000002018 overexpression Effects 0.000 description 4
- 239000008188 pellet Substances 0.000 description 4
- 239000002953 phosphate buffered saline Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 210000003705 ribosome Anatomy 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 230000009897 systematic effect Effects 0.000 description 4
- 108010061238 threonyl-glycine Proteins 0.000 description 4
- RZVAJINKPMORJF-UHFFFAOYSA-N Acetaminophen Chemical compound CC(=O)NC1=CC=C(O)C=C1 RZVAJINKPMORJF-UHFFFAOYSA-N 0.000 description 3
- 102100022749 Aminopeptidase N Human genes 0.000 description 3
- 239000004475 Arginine Substances 0.000 description 3
- 102100023701 C-C motif chemokine 18 Human genes 0.000 description 3
- 102100036845 C-C motif chemokine 22 Human genes 0.000 description 3
- 102000014914 Carrier Proteins Human genes 0.000 description 3
- 108010078791 Carrier Proteins Proteins 0.000 description 3
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 3
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 3
- 102000005593 Endopeptidases Human genes 0.000 description 3
- 108010059378 Endopeptidases Proteins 0.000 description 3
- 101000703368 Escherichia coli (strain K12) L-asparaginase 2 Proteins 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 3
- 102000001398 Granzyme Human genes 0.000 description 3
- 108060005986 Granzyme Proteins 0.000 description 3
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 3
- 108090000144 Human Proteins Proteins 0.000 description 3
- 102000003839 Human Proteins Human genes 0.000 description 3
- 108091006905 Human Serum Albumin Proteins 0.000 description 3
- 102000008100 Human Serum Albumin Human genes 0.000 description 3
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 3
- 102000015696 Interleukins Human genes 0.000 description 3
- 108010063738 Interleukins Proteins 0.000 description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 3
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- 108010006519 Molecular Chaperones Proteins 0.000 description 3
- 102000005431 Molecular Chaperones Human genes 0.000 description 3
- 102000015336 Nerve Growth Factor Human genes 0.000 description 3
- 108010013381 Porins Proteins 0.000 description 3
- 102000017033 Porins Human genes 0.000 description 3
- 241000218935 Pseudomonas azotoformans Species 0.000 description 3
- 241000180027 Pseudomonas cedrina Species 0.000 description 3
- 101000703403 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) L-asparaginase 2-1 Proteins 0.000 description 3
- 101000703404 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) L-asparaginase 2-2 Proteins 0.000 description 3
- 101000901050 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) L-asparaginase 2-3 Proteins 0.000 description 3
- 101000901051 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) L-asparaginase 2-4 Proteins 0.000 description 3
- 241000607142 Salmonella Species 0.000 description 3
- 108091003202 SecA Proteins Proteins 0.000 description 3
- 241000863432 Shewanella putrefaciens Species 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- 102100040247 Tumor necrosis factor Human genes 0.000 description 3
- 108010073429 Type V Secretion Systems Proteins 0.000 description 3
- 238000002835 absorbance Methods 0.000 description 3
- 229940059720 apra Drugs 0.000 description 3
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 108010050848 glycylleucine Proteins 0.000 description 3
- 239000003112 inhibitor Substances 0.000 description 3
- 229940047122 interleukins Drugs 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 3
- 244000005700 microbiome Species 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 231100000350 mutagenesis Toxicity 0.000 description 3
- 238000002703 mutagenesis Methods 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000012846 protein folding Effects 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 239000011573 trace mineral Substances 0.000 description 3
- 235000013619 trace mineral Nutrition 0.000 description 3
- 230000032258 transport Effects 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- 108010079677 Agatoxins Proteins 0.000 description 2
- LSLIRHLIUDVNBN-CIUDSAMLSA-N Ala-Asp-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LSLIRHLIUDVNBN-CIUDSAMLSA-N 0.000 description 2
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 2
- 102000004580 Aspartic Acid Proteases Human genes 0.000 description 2
- 108010017640 Aspartic Acid Proteases Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 108010077805 Bacterial Proteins Proteins 0.000 description 2
- 102100021257 Beta-secretase 1 Human genes 0.000 description 2
- 101710150192 Beta-secretase 1 Proteins 0.000 description 2
- 102000007350 Bone Morphogenetic Proteins Human genes 0.000 description 2
- 108010007726 Bone Morphogenetic Proteins Proteins 0.000 description 2
- 102000004219 Brain-derived neurotrophic factor Human genes 0.000 description 2
- 108090000715 Brain-derived neurotrophic factor Proteins 0.000 description 2
- 241001453380 Burkholderia Species 0.000 description 2
- 102100036842 C-C motif chemokine 19 Human genes 0.000 description 2
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 2
- 102100036846 C-C motif chemokine 21 Human genes 0.000 description 2
- 102100036850 C-C motif chemokine 23 Human genes 0.000 description 2
- 102100025250 C-X-C motif chemokine 14 Human genes 0.000 description 2
- 108010049990 CD13 Antigens Proteins 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 108010080937 Carboxypeptidases A Proteins 0.000 description 2
- 102000000496 Carboxypeptidases A Human genes 0.000 description 2
- 102000005600 Cathepsins Human genes 0.000 description 2
- 108010084457 Cathepsins Proteins 0.000 description 2
- 241000863387 Cellvibrio Species 0.000 description 2
- 108091006146 Channels Proteins 0.000 description 2
- 108010078239 Chemokine CX3CL1 Proteins 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 2
- 108090000317 Chymotrypsin Proteins 0.000 description 2
- 108010005939 Ciliary Neurotrophic Factor Proteins 0.000 description 2
- 102100031614 Ciliary neurotrophic factor Human genes 0.000 description 2
- 108060005980 Collagenase Proteins 0.000 description 2
- 102000029816 Collagenase Human genes 0.000 description 2
- 108010071942 Colony-Stimulating Factors Proteins 0.000 description 2
- 206010010071 Coma Diseases 0.000 description 2
- 241000589518 Comamonas testosteroni Species 0.000 description 2
- 108010005843 Cysteine Proteases Proteins 0.000 description 2
- 102000005927 Cysteine Proteases Human genes 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 241001600125 Delftia acidovorans Species 0.000 description 2
- 102000016911 Deoxyribonucleases Human genes 0.000 description 2
- 108010053770 Deoxyribonucleases Proteins 0.000 description 2
- 101710146739 Enterotoxin Proteins 0.000 description 2
- 102000003951 Erythropoietin Human genes 0.000 description 2
- 108090000394 Erythropoietin Proteins 0.000 description 2
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 2
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 2
- 108090000386 Fibroblast Growth Factor 1 Proteins 0.000 description 2
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 2
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 102000051366 Glycosyltransferases Human genes 0.000 description 2
- 108700023372 Glycosyltransferases Proteins 0.000 description 2
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 2
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 2
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- 102100034221 Growth-regulated alpha protein Human genes 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- BDFCIKANUNMFGB-PMVVWTBXSA-N His-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CN=CN1 BDFCIKANUNMFGB-PMVVWTBXSA-N 0.000 description 2
- 101000978371 Homo sapiens C-C motif chemokine 18 Proteins 0.000 description 2
- 101000713085 Homo sapiens C-C motif chemokine 21 Proteins 0.000 description 2
- 101000713083 Homo sapiens C-C motif chemokine 22 Proteins 0.000 description 2
- 101000713081 Homo sapiens C-C motif chemokine 23 Proteins 0.000 description 2
- 101000858068 Homo sapiens C-X-C motif chemokine 14 Proteins 0.000 description 2
- AQCUAZTZSPQJFF-ZKWXMUAHSA-N Ile-Ala-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AQCUAZTZSPQJFF-ZKWXMUAHSA-N 0.000 description 2
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 description 2
- 102000006992 Interferon-alpha Human genes 0.000 description 2
- 108010047761 Interferon-alpha Proteins 0.000 description 2
- 108090000467 Interferon-beta Proteins 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000003814 Interleukin-10 Human genes 0.000 description 2
- 108090000174 Interleukin-10 Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102100039064 Interleukin-3 Human genes 0.000 description 2
- 108010002386 Interleukin-3 Proteins 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 108010054278 Lac Repressors Proteins 0.000 description 2
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 2
- RRVCZCNFXIFGRA-DCAQKATOSA-N Leu-Pro-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RRVCZCNFXIFGRA-DCAQKATOSA-N 0.000 description 2
- 102000004058 Leukemia inhibitory factor Human genes 0.000 description 2
- 108090000581 Leukemia inhibitory factor Proteins 0.000 description 2
- 241001478324 Liberibacter Species 0.000 description 2
- 102100035304 Lymphotactin Human genes 0.000 description 2
- 102000004083 Lymphotoxin-alpha Human genes 0.000 description 2
- 108090000542 Lymphotoxin-alpha Proteins 0.000 description 2
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- 102000007651 Macrophage Colony-Stimulating Factor Human genes 0.000 description 2
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical compound [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- 101710181812 Methionine aminopeptidase Proteins 0.000 description 2
- 241000589330 Methylococcaceae Species 0.000 description 2
- 108090000742 Neurotrophin 3 Proteins 0.000 description 2
- 102100029268 Neurotrophin-3 Human genes 0.000 description 2
- 102000003683 Neurotrophin-4 Human genes 0.000 description 2
- 102100033857 Neurotrophin-4 Human genes 0.000 description 2
- 108010067372 Pancreatic elastase Proteins 0.000 description 2
- 102000016387 Pancreatic elastase Human genes 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- ZRWPUFFVAOMMNM-UHFFFAOYSA-N Patulin Chemical compound OC1OCC=C2OC(=O)C=C12 ZRWPUFFVAOMMNM-UHFFFAOYSA-N 0.000 description 2
- 108090000284 Pepsin A Proteins 0.000 description 2
- 239000001888 Peptone Substances 0.000 description 2
- 108010080698 Peptones Proteins 0.000 description 2
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 2
- WOIFYRZPIORBRY-AVGNSLFASA-N Pro-Lys-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O WOIFYRZPIORBRY-AVGNSLFASA-N 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 101710194807 Protective antigen Proteins 0.000 description 2
- 101800004937 Protein C Proteins 0.000 description 2
- 241000947836 Pseudomonadaceae Species 0.000 description 2
- 241000620655 Pseudomonas brenneri Species 0.000 description 2
- 241000218936 Pseudomonas corrugata Species 0.000 description 2
- 241000429405 Pseudomonas extremorientalis Species 0.000 description 2
- 241001312498 Pseudomonas gessardii Species 0.000 description 2
- 241001277052 Pseudomonas libanensis Species 0.000 description 2
- 241001277679 Pseudomonas mandelii Species 0.000 description 2
- 241000589537 Pseudomonas marginalis Species 0.000 description 2
- 241001312486 Pseudomonas migulae Species 0.000 description 2
- 241000204709 Pseudomonas mucidolens Species 0.000 description 2
- 241000204735 Pseudomonas nitroreducens Species 0.000 description 2
- 241001291513 Pseudomonas orientalis Species 0.000 description 2
- 241001291486 Pseudomonas rhodesiae Species 0.000 description 2
- 241000218902 Pseudomonas synxantha Species 0.000 description 2
- 241001148199 Pseudomonas tolaasii Species 0.000 description 2
- 241001291485 Pseudomonas veronii Species 0.000 description 2
- 201000001718 Roberts syndrome Diseases 0.000 description 2
- 208000012474 Roberts-SC phocomelia syndrome Diseases 0.000 description 2
- 102400000827 Saposin-D Human genes 0.000 description 2
- 101800001700 Saposin-D Proteins 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 102000012479 Serine Proteases Human genes 0.000 description 2
- 108010022999 Serine Proteases Proteins 0.000 description 2
- 108030000574 Serine-type carboxypeptidases Proteins 0.000 description 2
- 102000034328 Serine-type carboxypeptidases Human genes 0.000 description 2
- JWQNAFHCXKVZKZ-UVOCVTCTSA-N Thr-Lys-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWQNAFHCXKVZKZ-UVOCVTCTSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 108090000190 Thrombin Proteins 0.000 description 2
- 102000004338 Transferrin Human genes 0.000 description 2
- 108090000901 Transferrin Proteins 0.000 description 2
- 102000046299 Transforming Growth Factor beta1 Human genes 0.000 description 2
- 102000011117 Transforming Growth Factor beta2 Human genes 0.000 description 2
- 102400001320 Transforming growth factor alpha Human genes 0.000 description 2
- 101800004564 Transforming growth factor alpha Proteins 0.000 description 2
- 101800002279 Transforming growth factor beta-1 Proteins 0.000 description 2
- 101800000304 Transforming growth factor beta-2 Proteins 0.000 description 2
- 108090000097 Transforming growth factor beta-3 Proteins 0.000 description 2
- 102000056172 Transforming growth factor beta-3 Human genes 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 102100024584 Tumor necrosis factor ligand superfamily member 12 Human genes 0.000 description 2
- 102100036922 Tumor necrosis factor ligand superfamily member 13B Human genes 0.000 description 2
- SCZJKZLFSSPJDP-ACRUOGEOSA-N Tyr-Phe-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O SCZJKZLFSSPJDP-ACRUOGEOSA-N 0.000 description 2
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 2
- APQIVBCUIUDSMB-OSUNSFLBSA-N Val-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N APQIVBCUIUDSMB-OSUNSFLBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 241000589634 Xanthomonas Species 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 239000012190 activator Substances 0.000 description 2
- 108091006088 activator proteins Proteins 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 238000003149 assay kit Methods 0.000 description 2
- 229940112869 bone morphogenetic protein Drugs 0.000 description 2
- 229940077737 brain-derived neurotrophic factor Drugs 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 229960002376 chymotrypsin Drugs 0.000 description 2
- 229960002424 collagenase Drugs 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 239000002158 endotoxin Substances 0.000 description 2
- 239000000147 enterotoxin Substances 0.000 description 2
- 231100000655 enterotoxin Toxicity 0.000 description 2
- 229940105423 erythropoietin Drugs 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 108091006086 inhibitor proteins Proteins 0.000 description 2
- 229940125396 insulin Drugs 0.000 description 2
- 230000002452 interceptive effect Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 230000033001 locomotion Effects 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 229940053128 nerve growth factor Drugs 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 235000019319 peptone Nutrition 0.000 description 2
- 150000002978 peroxides Chemical class 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 229960000856 protein c Drugs 0.000 description 2
- 238000011084 recovery Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000005001 rutherford backscattering spectroscopy Methods 0.000 description 2
- 230000009962 secretion pathway Effects 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 229910001415 sodium ion Inorganic materials 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 238000009210 therapy by ultrasound Methods 0.000 description 2
- WJCNZQLZVWNLKY-UHFFFAOYSA-N thiabendazole Chemical compound S1C=NC(C=2NC3=CC=CC=C3N=2)=C1 WJCNZQLZVWNLKY-UHFFFAOYSA-N 0.000 description 2
- 229960004072 thrombin Drugs 0.000 description 2
- 239000012581 transferrin Substances 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- LWIHDJKSTIGBAC-UHFFFAOYSA-K tripotassium phosphate Chemical compound [K+].[K+].[K+].[O-]P([O-])([O-])=O LWIHDJKSTIGBAC-UHFFFAOYSA-K 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- OVJBOPBBHWOWJI-FYNXUGHNSA-N (2S)-2-[[(2S)-1-[(2S)-2-[[(aS,1R,3aS,4S,10S,16S,19R,22S,25S,28S,34S,37S,40R,45R,48S,51S,57S,60S,63S,69S,72S,75S,78S,85R,88S,91R,94S)-40-[[(2S)-6-amino-2-[[(2S)-2-[[(2S)-4-amino-2-[[(2S,3S)-2-[[(2S,3S)-2-[[(2S,3R)-2-amino-3-hydroxybutanoyl]amino]-3-methylpentanoyl]amino]-3-methylpentanoyl]amino]-4-oxobutanoyl]amino]-3-methylbutanoyl]amino]hexanoyl]amino]-25,48,78,88,94-pentakis(4-aminobutyl)-a-(2-amino-2-oxoethyl)-22,63,72-tris(3-amino-3-oxopropyl)-69-benzyl-37-[(1R)-1-hydroxyethyl]-34,60-bis(hydroxymethyl)-51,57,75-trimethyl-16-(2-methylpropyl)-3a-(2-methylsulfanylethyl)-2a,3,5a,9,15,18,21,24,27,33,36,39,47,50,53,56,59,62,65,68,71,74,77,80,87,90,93,96,99-nonacosaoxo-7a,8a,42,43,82,83-hexathia-1a,2,4a,8,14,17,20,23,26,32,35,38,46,49,52,55,58,61,64,67,70,73,76,79,86,89,92,95,98-nonacosazahexacyclo[43.35.25.419,91.04,8.010,14.028,32]nonahectane-85-carbonyl]amino]-3-(4-hydroxyphenyl)propanoyl]pyrrolidine-2-carbonyl]amino]-3-(1H-imidazol-5-yl)propanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@H]1CSSC[C@@H]2NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](Cc3ccccc3)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]3CSSC[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@H](CSSC[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]4CCCN4C(=O)[C@H](CO)NC(=O)[C@@H](NC1=O)[C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N3)NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC2=O)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O OVJBOPBBHWOWJI-FYNXUGHNSA-N 0.000 description 1
- WNQJZQMIEZWFIN-UHFFFAOYSA-N 1-(benzenesulfonyl)-4-(2-chlorobenzoyl)piperazine Chemical compound ClC1=CC=CC=C1C(=O)N1CCN(S(=O)(=O)C=2C=CC=CC=2)CC1 WNQJZQMIEZWFIN-UHFFFAOYSA-N 0.000 description 1
- 108020004465 16S ribosomal RNA Proteins 0.000 description 1
- WVHGJJRMKGDTEC-WCIJHFMNSA-N 2-[(1R,4S,8R,10S,13S,16S,27R,34S)-34-[(2S)-butan-2-yl]-8,22-dihydroxy-13-[(2R,3S)-3-hydroxybutan-2-yl]-2,5,11,14,27,30,33,36,39-nonaoxo-27lambda4-thia-3,6,12,15,25,29,32,35,38-nonazapentacyclo[14.12.11.06,10.018,26.019,24]nonatriaconta-18(26),19(24),20,22-tetraen-4-yl]acetamide Chemical compound CC[C@H](C)[C@@H]1NC(=O)CNC(=O)[C@@H]2Cc3c([nH]c4cc(O)ccc34)[S@](=O)C[C@H](NC(=O)CNC1=O)C(=O)N[C@@H](CC(N)=O)C(=O)N1C[C@H](O)C[C@H]1C(=O)N[C@@H]([C@@H](C)[C@H](C)O)C(=O)N2 WVHGJJRMKGDTEC-WCIJHFMNSA-N 0.000 description 1
- OTLLEIBWKHEHGU-UHFFFAOYSA-N 2-[5-[[5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy]-3,4-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-4-phosphonooxyhexanedioic acid Chemical compound C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COC1C(CO)OC(OC(C(O)C(OP(O)(O)=O)C(O)C(O)=O)C(O)=O)C(O)C1O OTLLEIBWKHEHGU-UHFFFAOYSA-N 0.000 description 1
- LKDMKWNDBAVNQZ-UHFFFAOYSA-N 4-[[1-[[1-[2-[[1-(4-nitroanilino)-1-oxo-3-phenylpropan-2-yl]carbamoyl]pyrrolidin-1-yl]-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-4-oxobutanoic acid Chemical compound OC(=O)CCC(=O)NC(C)C(=O)NC(C)C(=O)N1CCCC1C(=O)NC(C(=O)NC=1C=CC(=CC=1)[N+]([O-])=O)CC1=CC=CC=C1 LKDMKWNDBAVNQZ-UHFFFAOYSA-N 0.000 description 1
- OQRXBXNATIHDQO-UHFFFAOYSA-N 6-chloropyridine-3,4-diamine Chemical compound NC1=CN=C(Cl)C=C1N OQRXBXNATIHDQO-UHFFFAOYSA-N 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 108091006112 ATPases Proteins 0.000 description 1
- 241000589220 Acetobacter Species 0.000 description 1
- 241001478307 Acidomonas Species 0.000 description 1
- 241000726119 Acidovorax Species 0.000 description 1
- 102100026041 Acrosin Human genes 0.000 description 1
- 108090000107 Acrosin Proteins 0.000 description 1
- 108010059616 Activins Proteins 0.000 description 1
- 102100032488 Acylamino-acid-releasing enzyme Human genes 0.000 description 1
- 108010061216 Acylaminoacyl-peptidase Proteins 0.000 description 1
- 102000057290 Adenosine Triphosphatases Human genes 0.000 description 1
- 229930195730 Aflatoxin Natural products 0.000 description 1
- XWIYFDMXXLINPU-UHFFFAOYSA-N Aflatoxin G Chemical compound O=C1OCCC2=C1C(=O)OC1=C2C(OC)=CC2=C1C1C=COC1O2 XWIYFDMXXLINPU-UHFFFAOYSA-N 0.000 description 1
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 1
- FJVAQLJNTSUQPY-CIUDSAMLSA-N Ala-Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN FJVAQLJNTSUQPY-CIUDSAMLSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- JDIQCVUDDFENPU-ZKWXMUAHSA-N Ala-His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CNC=N1 JDIQCVUDDFENPU-ZKWXMUAHSA-N 0.000 description 1
- GSHKMNKPMLXSQW-KBIXCLLPSA-N Ala-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C)N GSHKMNKPMLXSQW-KBIXCLLPSA-N 0.000 description 1
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 1
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 1
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- MLNSNVLOEIYJIU-ZUDIRPEPSA-N Ala-Leu-Thr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLNSNVLOEIYJIU-ZUDIRPEPSA-N 0.000 description 1
- QUIGLPSHIFPEOV-CIUDSAMLSA-N Ala-Lys-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O QUIGLPSHIFPEOV-CIUDSAMLSA-N 0.000 description 1
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 1
- NLOMBWNGESDVJU-GUBZILKMSA-N Ala-Met-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLOMBWNGESDVJU-GUBZILKMSA-N 0.000 description 1
- DWYROCSXOOMOEU-CIUDSAMLSA-N Ala-Met-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N DWYROCSXOOMOEU-CIUDSAMLSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 1
- NLYYHIKRBRMAJV-AEJSXWLSSA-N Ala-Val-Pro Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N NLYYHIKRBRMAJV-AEJSXWLSSA-N 0.000 description 1
- 108010075409 Alanine carboxypeptidase Proteins 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 108010068307 Alpha-Globulins Proteins 0.000 description 1
- 108030007066 Alternative-complement-pathway C3/C5 convertases Proteins 0.000 description 1
- 231100000729 Amatoxin Toxicity 0.000 description 1
- 102000004092 Amidohydrolases Human genes 0.000 description 1
- 108090000531 Amidohydrolases Proteins 0.000 description 1
- 241001430273 Aminobacter Species 0.000 description 1
- 102100032126 Aminopeptidase B Human genes 0.000 description 1
- 101710082401 Aminopeptidase Ey Proteins 0.000 description 1
- 108030000961 Aminopeptidase Y Proteins 0.000 description 1
- 108090000886 Ananain Proteins 0.000 description 1
- 102100035765 Angiotensin-converting enzyme 2 Human genes 0.000 description 1
- 108010064733 Angiotensins Proteins 0.000 description 1
- 102000015427 Angiotensins Human genes 0.000 description 1
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 1
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 1
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 1
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 1
- QJWLLRZTJFPCHA-STECZYCISA-N Arg-Tyr-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QJWLLRZTJFPCHA-STECZYCISA-N 0.000 description 1
- XWGJDUSDTRPQRK-ZLUOBGJFSA-N Asn-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O XWGJDUSDTRPQRK-ZLUOBGJFSA-N 0.000 description 1
- KWQPAXYXVMHJJR-AVGNSLFASA-N Asn-Gln-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KWQPAXYXVMHJJR-AVGNSLFASA-N 0.000 description 1
- BZMWJLLUAKSIMH-FXQIFTODSA-N Asn-Glu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BZMWJLLUAKSIMH-FXQIFTODSA-N 0.000 description 1
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 1
- RAQMSGVCGSJKCL-FOHZUACHSA-N Asn-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(N)=O RAQMSGVCGSJKCL-FOHZUACHSA-N 0.000 description 1
- NVWJMQNYLYWVNQ-BYULHYEWSA-N Asn-Ile-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O NVWJMQNYLYWVNQ-BYULHYEWSA-N 0.000 description 1
- XMHFCUKJRCQXGI-CIUDSAMLSA-N Asn-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O XMHFCUKJRCQXGI-CIUDSAMLSA-N 0.000 description 1
- HPASIOLTWSNMFB-OLHMAJIHSA-N Asn-Thr-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O HPASIOLTWSNMFB-OLHMAJIHSA-N 0.000 description 1
- UXHYOWXTJLBEPG-GSSVUCPTSA-N Asn-Thr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UXHYOWXTJLBEPG-GSSVUCPTSA-N 0.000 description 1
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 1
- HMQDRBKQMLRCCG-GMOBBJLQSA-N Asp-Arg-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HMQDRBKQMLRCCG-GMOBBJLQSA-N 0.000 description 1
- NAPNAGZWHQHZLG-ZLUOBGJFSA-N Asp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N NAPNAGZWHQHZLG-ZLUOBGJFSA-N 0.000 description 1
- LKIYSIYBKYLKPU-BIIVOSGPSA-N Asp-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O LKIYSIYBKYLKPU-BIIVOSGPSA-N 0.000 description 1
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 1
- PSLSTUMPZILTAH-BYULHYEWSA-N Asp-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PSLSTUMPZILTAH-BYULHYEWSA-N 0.000 description 1
- KHGPWGKPYHPOIK-QWRGUYRKSA-N Asp-Gly-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KHGPWGKPYHPOIK-QWRGUYRKSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 1
- ORRJQLIATJDMQM-HJGDQZAQSA-N Asp-Leu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O ORRJQLIATJDMQM-HJGDQZAQSA-N 0.000 description 1
- NZWDWXSWUQCNMG-GARJFASQSA-N Asp-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)C(=O)O NZWDWXSWUQCNMG-GARJFASQSA-N 0.000 description 1
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 1
- UEFODXNXUAVPTC-VEVYYDQMSA-N Asp-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O UEFODXNXUAVPTC-VEVYYDQMSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 1
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 108700016171 Aspartate ammonia-lyases Proteins 0.000 description 1
- 241000040854 Azorhizophilus Species 0.000 description 1
- 241000589154 Azotobacter group Species 0.000 description 1
- 108010028006 B-Cell Activating Factor Proteins 0.000 description 1
- PCLCDPVEEFVAAQ-UHFFFAOYSA-N BCA 1 Chemical compound CC(CO)CCCC(C)C1=CCC(C)(O)C1CC2=C(O)C(O)CCC2=O PCLCDPVEEFVAAQ-UHFFFAOYSA-N 0.000 description 1
- 241000193738 Bacillus anthracis Species 0.000 description 1
- 101710113841 Barrierpepsin Proteins 0.000 description 1
- 102100031006 Beta-Ala-His dipeptidase Human genes 0.000 description 1
- 108030004753 Beta-Ala-His dipeptidases Proteins 0.000 description 1
- 108010087504 Beta-Globulins Proteins 0.000 description 1
- 108010005785 Beta-aspartyl-peptidase Proteins 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241001626906 Blastomonas Species 0.000 description 1
- 108010051479 Bombesin Proteins 0.000 description 1
- 102000013585 Bombesin Human genes 0.000 description 1
- 108090000654 Bone morphogenetic protein 1 Proteins 0.000 description 1
- 102000004152 Bone morphogenetic protein 1 Human genes 0.000 description 1
- 108030001720 Bontoxilysin Proteins 0.000 description 1
- BTBUEUYNUDRHOZ-UHFFFAOYSA-N Borate Chemical compound [O-]B([O-])[O-] BTBUEUYNUDRHOZ-UHFFFAOYSA-N 0.000 description 1
- 241000588832 Bordetella pertussis Species 0.000 description 1
- 101000856746 Bos taurus Cytochrome c oxidase subunit 7A1, mitochondrial Proteins 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 238000009010 Bradford assay Methods 0.000 description 1
- 101800004538 Bradykinin Proteins 0.000 description 1
- 102400000967 Bradykinin Human genes 0.000 description 1
- 241000131407 Brevundimonas Species 0.000 description 1
- 108010004032 Bromelains Proteins 0.000 description 1
- 238000009631 Broth culture Methods 0.000 description 1
- 102100023702 C-C motif chemokine 13 Human genes 0.000 description 1
- 101710112613 C-C motif chemokine 13 Proteins 0.000 description 1
- 102100023705 C-C motif chemokine 14 Human genes 0.000 description 1
- 102100023698 C-C motif chemokine 17 Human genes 0.000 description 1
- 101710112622 C-C motif chemokine 19 Proteins 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 102100036848 C-C motif chemokine 20 Human genes 0.000 description 1
- 102100036849 C-C motif chemokine 24 Human genes 0.000 description 1
- 102100021933 C-C motif chemokine 25 Human genes 0.000 description 1
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 1
- 102100032366 C-C motif chemokine 7 Human genes 0.000 description 1
- 101710155834 C-C motif chemokine 7 Proteins 0.000 description 1
- 102100028990 C-X-C chemokine receptor type 3 Human genes 0.000 description 1
- 102100025279 C-X-C motif chemokine 11 Human genes 0.000 description 1
- 101710098272 C-X-C motif chemokine 11 Proteins 0.000 description 1
- 102100025277 C-X-C motif chemokine 13 Human genes 0.000 description 1
- 102100039396 C-X-C motif chemokine 16 Human genes 0.000 description 1
- 102100036150 C-X-C motif chemokine 5 Human genes 0.000 description 1
- 102400000113 Calcitonin Human genes 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 101710124576 Candidapepsin Proteins 0.000 description 1
- 102000004031 Carboxy-Lyases Human genes 0.000 description 1
- 108090000489 Carboxy-Lyases Proteins 0.000 description 1
- 102000013392 Carboxylesterase Human genes 0.000 description 1
- 108010051152 Carboxylesterase Proteins 0.000 description 1
- 108090000087 Carboxypeptidase B Proteins 0.000 description 1
- 102000003670 Carboxypeptidase B Human genes 0.000 description 1
- 102100032407 Carboxypeptidase D Human genes 0.000 description 1
- 108090000018 Carboxypeptidase D Proteins 0.000 description 1
- 102100032378 Carboxypeptidase E Human genes 0.000 description 1
- 108010058255 Carboxypeptidase H Proteins 0.000 description 1
- 108090000012 Carboxypeptidase T Proteins 0.000 description 1
- 208000006029 Cardiomegaly Diseases 0.000 description 1
- 108090000426 Caspase-1 Proteins 0.000 description 1
- 102100035882 Catalase Human genes 0.000 description 1
- 108010053835 Catalase Proteins 0.000 description 1
- 108010059081 Cathepsin A Proteins 0.000 description 1
- 102000005572 Cathepsin A Human genes 0.000 description 1
- 108090000712 Cathepsin B Proteins 0.000 description 1
- 102000004225 Cathepsin B Human genes 0.000 description 1
- 108090000267 Cathepsin C Proteins 0.000 description 1
- 102000003902 Cathepsin C Human genes 0.000 description 1
- 108090000258 Cathepsin D Proteins 0.000 description 1
- 102000003908 Cathepsin D Human genes 0.000 description 1
- 102000004173 Cathepsin G Human genes 0.000 description 1
- 108090000617 Cathepsin G Proteins 0.000 description 1
- 108090000619 Cathepsin H Proteins 0.000 description 1
- 102400001330 Cathepsin H Human genes 0.000 description 1
- 108090000613 Cathepsin S Proteins 0.000 description 1
- 102100035654 Cathepsin S Human genes 0.000 description 1
- 102100026657 Cathepsin Z Human genes 0.000 description 1
- 241000010977 Cellvibrio japonicus Species 0.000 description 1
- 101000997261 Centruroides margaritatus Potassium channel toxin alpha-KTx 2.2 Proteins 0.000 description 1
- 101000997271 Centruroides noxius Potassium channel toxin alpha-KTx 1.11 Proteins 0.000 description 1
- 108010082548 Chemokine CCL11 Proteins 0.000 description 1
- 108010082155 Chemokine CCL18 Proteins 0.000 description 1
- 108010055166 Chemokine CCL5 Proteins 0.000 description 1
- 108010014419 Chemokine CXCL1 Proteins 0.000 description 1
- 102000016950 Chemokine CXCL1 Human genes 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 229920002567 Chondroitin Polymers 0.000 description 1
- 241001670059 Chromohalobacter beijerinckii Species 0.000 description 1
- 206010061764 Chromosomal deletion Diseases 0.000 description 1
- 108090000746 Chymosin Proteins 0.000 description 1
- 108090000205 Chymotrypsin C Proteins 0.000 description 1
- 102100039511 Chymotrypsin-C Human genes 0.000 description 1
- 102100023336 Chymotrypsin-like elastase family member 3B Human genes 0.000 description 1
- 108030007055 Classical-complement-pathway C3/C5 convertases Proteins 0.000 description 1
- 241000193163 Clostridioides difficile Species 0.000 description 1
- 241000193155 Clostridium botulinum Species 0.000 description 1
- 241000193468 Clostridium perfringens Species 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108090000044 Complement Factor I Proteins 0.000 description 1
- 102000003706 Complement factor D Human genes 0.000 description 1
- 108090000059 Complement factor D Proteins 0.000 description 1
- 102100035431 Complement factor I Human genes 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 101001007355 Crotalus atrox C-type lectin Cal Proteins 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 241001670044 Curvibacter lanceolatus Species 0.000 description 1
- 101710095468 Cyclase Proteins 0.000 description 1
- 101000644356 Cyriopagopus schmidti U1-theraphotoxin-Hs1a Proteins 0.000 description 1
- 101000644364 Cyriopagopus schmidti U1-theraphotoxin-Hs1b Proteins 0.000 description 1
- YMBAVNPKBWHDAW-CIUDSAMLSA-N Cys-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N YMBAVNPKBWHDAW-CIUDSAMLSA-N 0.000 description 1
- VTBGVPWSWJBERH-DCAQKATOSA-N Cys-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CS)N VTBGVPWSWJBERH-DCAQKATOSA-N 0.000 description 1
- KZZYVYWSXMFYEC-DCAQKATOSA-N Cys-Val-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KZZYVYWSXMFYEC-DCAQKATOSA-N 0.000 description 1
- 108030001451 Cysteine-type carboxypeptidases Proteins 0.000 description 1
- 108091000069 Cystinyl Aminopeptidase Proteins 0.000 description 1
- 102000030900 Cystinyl aminopeptidase Human genes 0.000 description 1
- 102100034560 Cytosol aminopeptidase Human genes 0.000 description 1
- 108010071840 Cytosol nonspecific dipeptidase Proteins 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 108030000936 D-stereospecific aminopeptidases Proteins 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 101710121036 Delta-hemolysin Proteins 0.000 description 1
- 101000805645 Dendroaspis polylepis polylepis Kunitz-type serine protease inhibitor homolog dendrotoxin I Proteins 0.000 description 1
- 241000588700 Dickeya chrysanthemi Species 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- 102100020751 Dipeptidyl peptidase 2 Human genes 0.000 description 1
- 102100020750 Dipeptidyl peptidase 3 Human genes 0.000 description 1
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 1
- 108030006877 Dipeptidyl-dipeptidases Proteins 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- 101710121366 Disintegrin and metalloproteinase domain-containing protein 11 Proteins 0.000 description 1
- 108700036006 EC 3.4.21.67 Proteins 0.000 description 1
- 108700036055 EC 3.4.21.90 Proteins 0.000 description 1
- 108700033921 EC 3.4.23.20 Proteins 0.000 description 1
- 108700033920 EC 3.4.23.26 Proteins 0.000 description 1
- 108700033912 EC 3.4.23.28 Proteins 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 108050009340 Endothelin Proteins 0.000 description 1
- 102000002045 Endothelin Human genes 0.000 description 1
- 241001528534 Ensifer Species 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100023688 Eotaxin Human genes 0.000 description 1
- NLPRAJRHRHZCQQ-UHFFFAOYSA-N Epibatidine Natural products C1=NC(Cl)=CC=C1C1C(N2)CCC2C1 NLPRAJRHRHZCQQ-UHFFFAOYSA-N 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 102000005486 Epoxide hydrolase Human genes 0.000 description 1
- 108020002908 Epoxide hydrolase Proteins 0.000 description 1
- 244000024675 Eruca sativa Species 0.000 description 1
- 235000014755 Eruca sativa Nutrition 0.000 description 1
- 241000588698 Erwinia Species 0.000 description 1
- 241001646716 Escherichia coli K-12 Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 1
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 1
- 108010048049 Factor IXa Proteins 0.000 description 1
- 108010054265 Factor VIIa Proteins 0.000 description 1
- 108010071241 Factor XIIa Proteins 0.000 description 1
- 108010080805 Factor XIa Proteins 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 108010049003 Fibrinogen Proteins 0.000 description 1
- 102000008946 Fibrinogen Human genes 0.000 description 1
- 108010088842 Fibrinolysin Proteins 0.000 description 1
- 102000003971 Fibroblast Growth Factor 1 Human genes 0.000 description 1
- 102100031706 Fibroblast growth factor 1 Human genes 0.000 description 1
- 102100024785 Fibroblast growth factor 2 Human genes 0.000 description 1
- 102000003974 Fibroblast growth factor 2 Human genes 0.000 description 1
- 108090000378 Fibroblast growth factor 3 Proteins 0.000 description 1
- 102100028043 Fibroblast growth factor 3 Human genes 0.000 description 1
- 102100028072 Fibroblast growth factor 4 Human genes 0.000 description 1
- 108090000381 Fibroblast growth factor 4 Proteins 0.000 description 1
- 108090000380 Fibroblast growth factor 5 Proteins 0.000 description 1
- 102100028073 Fibroblast growth factor 5 Human genes 0.000 description 1
- 108090000382 Fibroblast growth factor 6 Proteins 0.000 description 1
- 102100028075 Fibroblast growth factor 6 Human genes 0.000 description 1
- 102100028071 Fibroblast growth factor 7 Human genes 0.000 description 1
- 108090000385 Fibroblast growth factor 7 Proteins 0.000 description 1
- 108010090109 Fibrolase Proteins 0.000 description 1
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 1
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 1
- 102000013818 Fractalkine Human genes 0.000 description 1
- 102100020997 Fractalkine Human genes 0.000 description 1
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 1
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 1
- 108010015133 Galactose oxidase Proteins 0.000 description 1
- 101000766307 Gallus gallus Ovotransferrin Proteins 0.000 description 1
- 102100021023 Gamma-glutamyl hydrolase Human genes 0.000 description 1
- 102000013382 Gelatinases Human genes 0.000 description 1
- 108010026132 Gelatinases Proteins 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 101000930822 Giardia intestinalis Dipeptidyl-peptidase 4 Proteins 0.000 description 1
- OETQLUYCMBARHJ-CIUDSAMLSA-N Gln-Asn-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OETQLUYCMBARHJ-CIUDSAMLSA-N 0.000 description 1
- JHPFPROFOAJRFN-IHRRRGAJSA-N Gln-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O JHPFPROFOAJRFN-IHRRRGAJSA-N 0.000 description 1
- MWERYIXRDZDXOA-QEWYBTABSA-N Gln-Ile-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MWERYIXRDZDXOA-QEWYBTABSA-N 0.000 description 1
- SOEXCCGNHQBFPV-DLOVCJGASA-N Gln-Val-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SOEXCCGNHQBFPV-DLOVCJGASA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 1
- RFDHKPSHTXZKLL-IHRRRGAJSA-N Glu-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N RFDHKPSHTXZKLL-IHRRRGAJSA-N 0.000 description 1
- 108030005223 Glu-Glu dipeptidases Proteins 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 1
- UUTGYDAKPISJAO-JYJNAYRXSA-N Glu-Tyr-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 UUTGYDAKPISJAO-JYJNAYRXSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- 102400000321 Glucagon Human genes 0.000 description 1
- 108060003199 Glucagon Proteins 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- 108010058940 Glutamyl Aminopeptidase Proteins 0.000 description 1
- 102000006485 Glutamyl Aminopeptidase Human genes 0.000 description 1
- 108010051815 Glutamyl endopeptidase Proteins 0.000 description 1
- PHONXOACARQMPM-BQBZGAKWSA-N Gly-Ala-Met Chemical compound [H]NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O PHONXOACARQMPM-BQBZGAKWSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- JVWPPCWUDRJGAE-YUMQZZPRSA-N Gly-Asn-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JVWPPCWUDRJGAE-YUMQZZPRSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 1
- IXHQLZIWBCQBLQ-STQMWFEESA-N Gly-Pro-Phe Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IXHQLZIWBCQBLQ-STQMWFEESA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- ZLCLYFGMKFCDCN-XPUUQOCRSA-N Gly-Ser-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CO)NC(=O)CN)C(O)=O ZLCLYFGMKFCDCN-XPUUQOCRSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- NWOSHVVPKDQKKT-RYUDHWBXSA-N Gly-Tyr-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O NWOSHVVPKDQKKT-RYUDHWBXSA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 1
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 1
- FNXSYBOHALPRHV-ONGXEEELSA-N Gly-Val-Lys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN FNXSYBOHALPRHV-ONGXEEELSA-N 0.000 description 1
- MUGLKCQHTUFLGF-WPRPVWTQSA-N Gly-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)CN MUGLKCQHTUFLGF-WPRPVWTQSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102000006771 Gonadotropins Human genes 0.000 description 1
- 108010086677 Gonadotropins Proteins 0.000 description 1
- 239000000095 Growth Hormone-Releasing Hormone Substances 0.000 description 1
- QXZGBUJJYSLZLT-UHFFFAOYSA-N H-Arg-Pro-Pro-Gly-Phe-Ser-Pro-Phe-Arg-OH Natural products NC(N)=NCCCC(N)C(=O)N1CCCC1C(=O)N1C(C(=O)NCC(=O)NC(CC=2C=CC=CC=2)C(=O)NC(CO)C(=O)N2C(CCC2)C(=O)NC(CC=2C=CC=CC=2)C(=O)NC(CCCN=C(N)N)C(O)=O)CCC1 QXZGBUJJYSLZLT-UHFFFAOYSA-N 0.000 description 1
- 101000856069 Hadronyche versuta Delta-hexatoxin-Hv1b Proteins 0.000 description 1
- 101000798956 Hadronyche versuta Omega-hexatoxin-Hv1a Proteins 0.000 description 1
- 241001670062 Halomonas utahensis Species 0.000 description 1
- 102000014702 Haptoglobin Human genes 0.000 description 1
- 108050005077 Haptoglobin Proteins 0.000 description 1
- 241001660422 Herbaspirillum huttiense Species 0.000 description 1
- FRJIAZKQGSCKPQ-FSPLSTOPSA-N His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CN=CN1 FRJIAZKQGSCKPQ-FSPLSTOPSA-N 0.000 description 1
- NOQPTNXSGNPJNS-YUMQZZPRSA-N His-Asn-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O NOQPTNXSGNPJNS-YUMQZZPRSA-N 0.000 description 1
- LVWIJITYHRZHBO-IXOXFDKPSA-N His-Leu-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LVWIJITYHRZHBO-IXOXFDKPSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000978381 Homo sapiens C-C motif chemokine 14 Proteins 0.000 description 1
- 101000978362 Homo sapiens C-C motif chemokine 17 Proteins 0.000 description 1
- 101000713106 Homo sapiens C-C motif chemokine 19 Proteins 0.000 description 1
- 101000897480 Homo sapiens C-C motif chemokine 2 Proteins 0.000 description 1
- 101000713099 Homo sapiens C-C motif chemokine 20 Proteins 0.000 description 1
- 101000713078 Homo sapiens C-C motif chemokine 24 Proteins 0.000 description 1
- 101000897486 Homo sapiens C-C motif chemokine 25 Proteins 0.000 description 1
- 101000916050 Homo sapiens C-X-C chemokine receptor type 3 Proteins 0.000 description 1
- 101000858064 Homo sapiens C-X-C motif chemokine 13 Proteins 0.000 description 1
- 101000889133 Homo sapiens C-X-C motif chemokine 16 Proteins 0.000 description 1
- 101000947186 Homo sapiens C-X-C motif chemokine 5 Proteins 0.000 description 1
- 101000907951 Homo sapiens Chymotrypsin-like elastase family member 3B Proteins 0.000 description 1
- 101000931862 Homo sapiens Dipeptidyl peptidase 3 Proteins 0.000 description 1
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 1
- 101000746367 Homo sapiens Granulocyte colony-stimulating factor Proteins 0.000 description 1
- 101001069921 Homo sapiens Growth-regulated alpha protein Proteins 0.000 description 1
- 101000878213 Homo sapiens Inactive peptidyl-prolyl cis-trans isomerase FKBP6 Proteins 0.000 description 1
- 101000804764 Homo sapiens Lymphotactin Proteins 0.000 description 1
- 101001095266 Homo sapiens Prolyl endopeptidase Proteins 0.000 description 1
- 101001123332 Homo sapiens Proteoglycan 4 Proteins 0.000 description 1
- 101000632056 Homo sapiens Septin-9 Proteins 0.000 description 1
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 description 1
- 101000830598 Homo sapiens Tumor necrosis factor ligand superfamily member 12 Proteins 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 102000002265 Human Growth Hormone Human genes 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- 102000004867 Hydro-Lyases Human genes 0.000 description 1
- 108090001042 Hydro-Lyases Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- 241000216643 Hydrogenophaga Species 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- 108090000571 Hypodermin C Proteins 0.000 description 1
- 101150088952 IGF1 gene Proteins 0.000 description 1
- 108700012441 IGF2 Proteins 0.000 description 1
- 108010084019 IgA-specific metalloendopeptidase Proteins 0.000 description 1
- 108010002231 IgA-specific serine endopeptidase Proteins 0.000 description 1
- LQSBBHNVAVNZSX-GHCJXIJMSA-N Ile-Ala-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N LQSBBHNVAVNZSX-GHCJXIJMSA-N 0.000 description 1
- QSPLUJGYOPZINY-ZPFDUUQYSA-N Ile-Asp-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QSPLUJGYOPZINY-ZPFDUUQYSA-N 0.000 description 1
- SLQVFYWBGNNOTK-BYULHYEWSA-N Ile-Gly-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N SLQVFYWBGNNOTK-BYULHYEWSA-N 0.000 description 1
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 1
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 1
- DLEBSGAVWRPTIX-PEDHHIEDSA-N Ile-Val-Ile Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)[C@@H](C)CC DLEBSGAVWRPTIX-PEDHHIEDSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102100036984 Inactive peptidyl-prolyl cis-trans isomerase FKBP6 Human genes 0.000 description 1
- 102100026818 Inhibin beta E chain Human genes 0.000 description 1
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 description 1
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 description 1
- 102100026720 Interferon beta Human genes 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 102000003996 Interferon-beta Human genes 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108090000177 Interleukin-11 Proteins 0.000 description 1
- 102000003815 Interleukin-11 Human genes 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 102000000588 Interleukin-2 Human genes 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 102100039897 Interleukin-5 Human genes 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 108010002586 Interleukin-7 Proteins 0.000 description 1
- 102100021592 Interleukin-7 Human genes 0.000 description 1
- 102000004890 Interleukin-8 Human genes 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- 108010002335 Interleukin-9 Proteins 0.000 description 1
- 102000000585 Interleukin-9 Human genes 0.000 description 1
- 108090000862 Ion Channels Proteins 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 102100033903 Isoaspartyl peptidase/L-asparaginase Human genes 0.000 description 1
- 241001148466 Janthinobacterium lividum Species 0.000 description 1
- 101710176219 Kallikrein-1 Proteins 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- ZUKPVRWZDMRIEO-VKHMYHEASA-N L-cysteinylglycine Chemical compound SC[C@H]([NH3+])C(=O)NCC([O-])=O ZUKPVRWZDMRIEO-VKHMYHEASA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- 108010059881 Lactase Proteins 0.000 description 1
- 241000880493 Leptailurus serval Species 0.000 description 1
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 1
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 1
- OHZIZVWQXJPBJS-IXOXFDKPSA-N Leu-His-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OHZIZVWQXJPBJS-IXOXFDKPSA-N 0.000 description 1
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 1
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- PPQRKXHCLYCBSP-IHRRRGAJSA-N Leu-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N PPQRKXHCLYCBSP-IHRRRGAJSA-N 0.000 description 1
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 1
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 1
- NJMXCOOEFLMZSR-AVGNSLFASA-N Leu-Met-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NJMXCOOEFLMZSR-AVGNSLFASA-N 0.000 description 1
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 1
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108010028275 Leukocyte Elastase Proteins 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 102000009151 Luteinizing Hormone Human genes 0.000 description 1
- 108010073521 Luteinizing Hormone Proteins 0.000 description 1
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 1
- NNCDAORZCMPZPX-GUBZILKMSA-N Lys-Gln-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N NNCDAORZCMPZPX-GUBZILKMSA-N 0.000 description 1
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 1
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 1
- HQXSFFSLXFHWOX-IXOXFDKPSA-N Lys-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCCN)N)O HQXSFFSLXFHWOX-IXOXFDKPSA-N 0.000 description 1
- IUWMQCZOTYRXPL-ZPFDUUQYSA-N Lys-Ile-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O IUWMQCZOTYRXPL-ZPFDUUQYSA-N 0.000 description 1
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 1
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 1
- VKCPHIOZDWUFSW-ONGXEEELSA-N Lys-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN VKCPHIOZDWUFSW-ONGXEEELSA-N 0.000 description 1
- 102100033320 Lysosomal Pro-X carboxypeptidase Human genes 0.000 description 1
- 108010053229 Lysyl endopeptidase Proteins 0.000 description 1
- 241001670047 Malikia spinosa Species 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 108010015302 Matrix metalloproteinase-9 Proteins 0.000 description 1
- 102000001776 Matrix metalloproteinase-9 Human genes 0.000 description 1
- 108030004769 Membrane dipeptidases Proteins 0.000 description 1
- IIPHCNKHEZYSNE-DCAQKATOSA-N Met-Arg-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O IIPHCNKHEZYSNE-DCAQKATOSA-N 0.000 description 1
- OLWAOWXIADGIJG-AVGNSLFASA-N Met-Arg-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(O)=O OLWAOWXIADGIJG-AVGNSLFASA-N 0.000 description 1
- IVCPHARVJUYDPA-FXQIFTODSA-N Met-Asn-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N IVCPHARVJUYDPA-FXQIFTODSA-N 0.000 description 1
- RZJOHSFAEZBWLK-CIUDSAMLSA-N Met-Gln-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N RZJOHSFAEZBWLK-CIUDSAMLSA-N 0.000 description 1
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 1
- CGUYGMFQZCYJSG-DCAQKATOSA-N Met-Lys-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O CGUYGMFQZCYJSG-DCAQKATOSA-N 0.000 description 1
- CIIJWIAORKTXAH-FJXKBIBVSA-N Met-Thr-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O CIIJWIAORKTXAH-FJXKBIBVSA-N 0.000 description 1
- 108030000089 Metallocarboxypeptidases Proteins 0.000 description 1
- 102000006166 Metallocarboxypeptidases Human genes 0.000 description 1
- 102000003843 Metalloendopeptidases Human genes 0.000 description 1
- 108090000131 Metalloendopeptidases Proteins 0.000 description 1
- 108090000192 Methionyl aminopeptidases Proteins 0.000 description 1
- 102000034452 Methionyl aminopeptidases Human genes 0.000 description 1
- 241000589350 Methylobacter Species 0.000 description 1
- 241001264650 Methylocaldum Species 0.000 description 1
- 241001533203 Methylomicrobium Species 0.000 description 1
- 241000321843 Methylosarcina Species 0.000 description 1
- 241000530467 Methylosphaera Species 0.000 description 1
- 108010013295 Microbial collagenase Proteins 0.000 description 1
- 241001670070 Microbulbifer elongatus Species 0.000 description 1
- 102100026632 Mimecan Human genes 0.000 description 1
- 108010047660 Mitochondrial intermediate peptidase Proteins 0.000 description 1
- 102100026934 Mitochondrial intermediate peptidase Human genes 0.000 description 1
- 101710151805 Mitochondrial intermediate peptidase 1 Proteins 0.000 description 1
- 101710151803 Mitochondrial intermediate peptidase 2 Proteins 0.000 description 1
- 108010042046 Mitochondrial processing peptidase Proteins 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 108010027383 Muramoylpentapeptide carboxypeptidase Proteins 0.000 description 1
- 101000715501 Mus musculus Cathepsin 7 Proteins 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 208000031888 Mycoses Diseases 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- 108030001194 N-formylmethionyl-peptidases Proteins 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 101000744155 Naja atra Cytotoxin 3 Proteins 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 108090000028 Neprilysin Proteins 0.000 description 1
- 102000003729 Neprilysin Human genes 0.000 description 1
- 102000007072 Nerve Growth Factors Human genes 0.000 description 1
- 102000005348 Neuraminidase Human genes 0.000 description 1
- 108010006232 Neuraminidase Proteins 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- 108090000095 Neurotrophin-6 Proteins 0.000 description 1
- 102000056189 Neutrophil collagenases Human genes 0.000 description 1
- 108030001564 Neutrophil collagenases Proteins 0.000 description 1
- 102100033174 Neutrophil elastase Human genes 0.000 description 1
- 108010066503 Non-stereospecific dipeptidase Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 108010000240 O-sialoglycoprotein endopeptidase Proteins 0.000 description 1
- 241000625726 Oceanimonas Species 0.000 description 1
- 241000293010 Oligella Species 0.000 description 1
- BEKQPDFPPJFVJP-AHSQCEKMSA-N Onchidal Chemical compound CC(=O)O\C=C\C(\C=O)=C/CC1C(=C)CCCC1(C)C BEKQPDFPPJFVJP-AHSQCEKMSA-N 0.000 description 1
- JLVLVOITZSLHPU-UHFFFAOYSA-N Onchidal Natural products CC(=O)OC(=CC(=C/CC1C(=C)CCCC1(C)C)C=O)C JLVLVOITZSLHPU-UHFFFAOYSA-N 0.000 description 1
- 102000004140 Oncostatin M Human genes 0.000 description 1
- 108090000630 Oncostatin M Proteins 0.000 description 1
- 101800002327 Osteoinductive factor Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 102000003982 Parathyroid hormone Human genes 0.000 description 1
- 108090000445 Parathyroid hormone Proteins 0.000 description 1
- 241000606860 Pasteurella Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 102100039652 Pepsin A-5 Human genes 0.000 description 1
- 108090000313 Pepsin B Proteins 0.000 description 1
- 108090000882 Peptidyl-Dipeptidase A Proteins 0.000 description 1
- 108010030544 Peptidyl-Lys metalloendopeptidase Proteins 0.000 description 1
- 102100040283 Peptidyl-prolyl cis-trans isomerase B Human genes 0.000 description 1
- 108010020062 Peptidylprolyl Isomerase Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- 241001670033 Phaseolibacter flectens Species 0.000 description 1
- FRPVPGRXUKFEQE-YDHLFZDLSA-N Phe-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FRPVPGRXUKFEQE-YDHLFZDLSA-N 0.000 description 1
- BVHFFNYBKRTSIU-MEYUZBJRSA-N Phe-His-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BVHFFNYBKRTSIU-MEYUZBJRSA-N 0.000 description 1
- DNAXXTQSTKOHFO-QEJZJMRPSA-N Phe-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 DNAXXTQSTKOHFO-QEJZJMRPSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 241000927976 Pisidae Species 0.000 description 1
- 108090000113 Plasma Kallikrein Proteins 0.000 description 1
- 102100034869 Plasma kallikrein Human genes 0.000 description 1
- 102000001938 Plasminogen Activators Human genes 0.000 description 1
- 108010001014 Plasminogen Activators Proteins 0.000 description 1
- 108090000778 Platelet factor 4 Proteins 0.000 description 1
- 102100030304 Platelet factor 4 Human genes 0.000 description 1
- 101710095622 Polyporopepsin Proteins 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 1
- FISHYTLIMUYTQY-GUBZILKMSA-N Pro-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 FISHYTLIMUYTQY-GUBZILKMSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- BLJMJZOMZRCESA-GUBZILKMSA-N Pro-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@@H]1CCCN1 BLJMJZOMZRCESA-GUBZILKMSA-N 0.000 description 1
- AWQGDZBKQTYNMN-IHRRRGAJSA-N Pro-Phe-Asp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)O)C(=O)O AWQGDZBKQTYNMN-IHRRRGAJSA-N 0.000 description 1
- FHZJRBVMLGOHBX-GUBZILKMSA-N Pro-Pro-Asp Chemical compound OC(=O)C[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H]1CCCN1)C(O)=O FHZJRBVMLGOHBX-GUBZILKMSA-N 0.000 description 1
- 101710184309 Probable sucrose-6-phosphate hydrolase Proteins 0.000 description 1
- 102100037775 Probable tRNA N6-adenosine threonylcarbamoyltransferase Human genes 0.000 description 1
- 108010064622 Procollagen N-Endopeptidase Proteins 0.000 description 1
- 102000015339 Procollagen N-endopeptidase Human genes 0.000 description 1
- 108010076181 Proinsulin Proteins 0.000 description 1
- 102000056251 Prolyl Oligopeptidases Human genes 0.000 description 1
- 108010044159 Proprotein Convertases Proteins 0.000 description 1
- 102000006437 Proprotein Convertases Human genes 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 102100038358 Prostate-specific antigen Human genes 0.000 description 1
- 101800001753 Protease Proteins 0.000 description 1
- 101710180316 Protease 2 Proteins 0.000 description 1
- 102000055027 Protein Methyltransferases Human genes 0.000 description 1
- 108700040121 Protein Methyltransferases Proteins 0.000 description 1
- 241000519590 Pseudoalteromonas Species 0.000 description 1
- 241000590028 Pseudoalteromonas haloplanktis Species 0.000 description 1
- 241000157890 Pseudoalteromonas piscicida Species 0.000 description 1
- 241001248479 Pseudomonadales Species 0.000 description 1
- 241000028636 Pseudomonas abietaniphila Species 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 241000204715 Pseudomonas agarici Species 0.000 description 1
- 241000168225 Pseudomonas alcaligenes Species 0.000 description 1
- 241001459308 Pseudomonas alcaliphila Species 0.000 description 1
- 241001522136 Pseudomonas alginovora Species 0.000 description 1
- 241000218934 Pseudomonas amygdali Species 0.000 description 1
- 241001325442 Pseudomonas andersonii Species 0.000 description 1
- 241000520869 Pseudomonas anguilliseptica Species 0.000 description 1
- 241000520871 Pseudomonas asplenii Species 0.000 description 1
- 241000202216 Pseudomonas avellanae Species 0.000 description 1
- 241001279845 Pseudomonas balearica Species 0.000 description 1
- 241001660019 Pseudomonas borealis Species 0.000 description 1
- 241000226031 Pseudomonas brassicacearum Species 0.000 description 1
- 241000204712 Pseudomonas caricapapayae Species 0.000 description 1
- 241001646398 Pseudomonas chlororaphis Species 0.000 description 1
- 241001670013 Pseudomonas chlororaphis subsp. aurantiaca Species 0.000 description 1
- 241001508466 Pseudomonas cichorii Species 0.000 description 1
- 241000520873 Pseudomonas citronellolis Species 0.000 description 1
- 241000647960 Pseudomonas coronafaciens pv. coronafaciens Species 0.000 description 1
- 241000168053 Pseudomonas denitrificans (nomen rejiciendum) Species 0.000 description 1
- 241000946440 Pseudomonas diterpeniphila Species 0.000 description 1
- 241000520898 Pseudomonas ficuserectae Species 0.000 description 1
- 241001148192 Pseudomonas flavescens Species 0.000 description 1
- 241000960597 Pseudomonas fluorescens group Species 0.000 description 1
- 241000589538 Pseudomonas fragi Species 0.000 description 1
- 241001497665 Pseudomonas frederiksbergensis Species 0.000 description 1
- 241000490004 Pseudomonas fuscovaginae Species 0.000 description 1
- 241000231049 Pseudomonas gingeri Species 0.000 description 1
- 241000042121 Pseudomonas graminis Species 0.000 description 1
- 241000620589 Pseudomonas grimontii Species 0.000 description 1
- 241000520899 Pseudomonas halodenitrificans Species 0.000 description 1
- 241001531427 Pseudomonas hydrogenovora Species 0.000 description 1
- 241001300822 Pseudomonas jessenii Species 0.000 description 1
- 241000913726 Pseudomonas kilonensis Species 0.000 description 1
- 241000357050 Pseudomonas lini Species 0.000 description 1
- 241001670039 Pseudomonas lundensis Species 0.000 description 1
- 241000218905 Pseudomonas luteola Species 0.000 description 1
- 241000145542 Pseudomonas marginata Species 0.000 description 1
- 241001670064 Pseudomonas meliae Species 0.000 description 1
- 241000589755 Pseudomonas mendocina Species 0.000 description 1
- 241001291501 Pseudomonas monteilii Species 0.000 description 1
- 241001312420 Pseudomonas mosselii Species 0.000 description 1
- 241000589781 Pseudomonas oleovorans Species 0.000 description 1
- 241000218904 Pseudomonas oryzihabitans Species 0.000 description 1
- 241001670066 Pseudomonas pertucinogena Species 0.000 description 1
- 241001223182 Pseudomonas plecoglossicida Species 0.000 description 1
- 241000589630 Pseudomonas pseudoalcaligenes Species 0.000 description 1
- 241000530526 Pseudomonas psychrophila Species 0.000 description 1
- 241000589776 Pseudomonas putida Species 0.000 description 1
- 241000231045 Pseudomonas reactans Species 0.000 description 1
- 241000520900 Pseudomonas resinovorans Species 0.000 description 1
- 101000604548 Pseudomonas sp. (strain 101) Pseudomonalisin Proteins 0.000 description 1
- 241000218901 Pseudomonas straminea Species 0.000 description 1
- 241000589614 Pseudomonas stutzeri Species 0.000 description 1
- 241000589615 Pseudomonas syringae Species 0.000 description 1
- 241000218903 Pseudomonas taetrolens Species 0.000 description 1
- 241000039935 Pseudomonas thermotolerans Species 0.000 description 1
- 241001669634 Pseudomonas thivervalensis Species 0.000 description 1
- 241000369631 Pseudomonas vancouverensis Species 0.000 description 1
- 241001464820 Pseudomonas viridiflava Species 0.000 description 1
- 241000577556 Pseudomonas wisconsinensis Species 0.000 description 1
- 241000039948 Pseudomonas xiamenensis Species 0.000 description 1
- 102100036286 Purine nucleoside phosphorylase Human genes 0.000 description 1
- 101710180958 Putative aminoacrylate hydrolase RutD Proteins 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108090000919 Pyroglutamyl-Peptidase I Proteins 0.000 description 1
- 102100031108 Pyroglutamyl-peptidase 1 Human genes 0.000 description 1
- 108090001002 Pyroglutamyl-peptidase II Proteins 0.000 description 1
- 102000004892 Pyroglutamyl-peptidase II Human genes 0.000 description 1
- 235000014443 Pyrus communis Nutrition 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 241000232299 Ralstonia Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 102400000834 Relaxin A chain Human genes 0.000 description 1
- 101800000074 Relaxin A chain Proteins 0.000 description 1
- 102400000610 Relaxin B chain Human genes 0.000 description 1
- 101710109558 Relaxin B chain Proteins 0.000 description 1
- 108090000783 Renin Proteins 0.000 description 1
- 102100028255 Renin Human genes 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 1
- 235000011449 Rosa Nutrition 0.000 description 1
- 108010091732 SEC Translocation Channels Proteins 0.000 description 1
- 102000018673 SEC Translocation Channels Human genes 0.000 description 1
- 101000715359 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Carboxypeptidase S Proteins 0.000 description 1
- 101100467813 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) RBS1 gene Proteins 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- 101001049892 Scorpio palmatus Potassium channel toxin alpha-KTx 6.2 Proteins 0.000 description 1
- 206010040070 Septic Shock Diseases 0.000 description 1
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 1
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- COAHUSQNSVFYBW-FXQIFTODSA-N Ser-Asn-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O COAHUSQNSVFYBW-FXQIFTODSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 1
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 1
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 1
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- PCMZJFMUYWIERL-ZKWXMUAHSA-N Ser-Val-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMZJFMUYWIERL-ZKWXMUAHSA-N 0.000 description 1
- 108010004832 Serine-Type D-Ala-D-Ala Carboxypeptidase Proteins 0.000 description 1
- 102000030899 Serine-Type D-Ala-D-Ala Carboxypeptidase Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108010079723 Shiga Toxin Proteins 0.000 description 1
- 108010017898 Shiga Toxins Proteins 0.000 description 1
- 101710127006 Signal peptidase I Proteins 0.000 description 1
- 101710170939 Signal peptidase I P Proteins 0.000 description 1
- 108090000233 Signal peptidase II Proteins 0.000 description 1
- 241001135312 Sinorhizobium Species 0.000 description 1
- 101710142969 Somatoliberin Proteins 0.000 description 1
- 102100022831 Somatoliberin Human genes 0.000 description 1
- 102000013275 Somatomedins Human genes 0.000 description 1
- 241000736131 Sphingomonas Species 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 108700028780 Staphylococcus aureus hlb Proteins 0.000 description 1
- 241000122971 Stenotrophomonas Species 0.000 description 1
- 241001670040 Stenotrophomonas pictorum Species 0.000 description 1
- 108010023197 Streptokinase Proteins 0.000 description 1
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 1
- 208000003028 Stuttering Diseases 0.000 description 1
- 102400000472 Sucrase Human genes 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 101710112652 Sucrose-6-phosphate hydrolase Proteins 0.000 description 1
- 108700005078 Synthetic Genes Proteins 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 108010027179 Tacrolimus Binding Proteins Proteins 0.000 description 1
- 102000018679 Tacrolimus Binding Proteins Human genes 0.000 description 1
- 241000206217 Teredinibacter Species 0.000 description 1
- 108010055044 Tetanus Toxin Proteins 0.000 description 1
- 241001670068 Thauera butanivorans Species 0.000 description 1
- 102000002933 Thioredoxin Human genes 0.000 description 1
- 101710168651 Thioredoxin 1 Proteins 0.000 description 1
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 1
- CEXFELBFVHLYDZ-XGEHTFHBSA-N Thr-Arg-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CEXFELBFVHLYDZ-XGEHTFHBSA-N 0.000 description 1
- WLDUCKSCDRIVLJ-NUMRIWBASA-N Thr-Gln-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O WLDUCKSCDRIVLJ-NUMRIWBASA-N 0.000 description 1
- XFTYVCHLARBHBQ-FOHZUACHSA-N Thr-Gly-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XFTYVCHLARBHBQ-FOHZUACHSA-N 0.000 description 1
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 1
- VGYVVSQFSSKZRJ-OEAJRASXSA-N Thr-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@H](O)C)CC1=CC=CC=C1 VGYVVSQFSSKZRJ-OEAJRASXSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- XZUBGOYOGDRYFC-XGEHTFHBSA-N Thr-Ser-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O XZUBGOYOGDRYFC-XGEHTFHBSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 102000002262 Thromboplastin Human genes 0.000 description 1
- 102000036693 Thrombopoietin Human genes 0.000 description 1
- 108010041111 Thrombopoietin Proteins 0.000 description 1
- 108010061174 Thyrotropin Proteins 0.000 description 1
- 102000011923 Thyrotropin Human genes 0.000 description 1
- 102000057032 Tissue Kallikreins Human genes 0.000 description 1
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 1
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 1
- 206010044248 Toxic shock syndrome Diseases 0.000 description 1
- 231100000650 Toxic shock syndrome Toxicity 0.000 description 1
- 101710182532 Toxin a Proteins 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 108010009583 Transforming Growth Factors Proteins 0.000 description 1
- 102000009618 Transforming Growth Factors Human genes 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 101710154918 Trigger factor Proteins 0.000 description 1
- 108010070926 Tripeptide aminopeptidase Proteins 0.000 description 1
- 108010039203 Tripeptidyl-Peptidase 1 Proteins 0.000 description 1
- 102100034197 Tripeptidyl-peptidase 1 Human genes 0.000 description 1
- 102100040411 Tripeptidyl-peptidase 2 Human genes 0.000 description 1
- 102000001400 Tryptase Human genes 0.000 description 1
- 108060005989 Tryptase Proteins 0.000 description 1
- 108030000963 Tryptophanyl aminopeptidases Proteins 0.000 description 1
- 108090000906 Tubulinyl-Tyr carboxypeptidases Proteins 0.000 description 1
- 102000004342 Tubulinyl-Tyr carboxypeptidases Human genes 0.000 description 1
- 108010065158 Tumor Necrosis Factor Ligand Superfamily Member 14 Proteins 0.000 description 1
- 101710097155 Tumor necrosis factor ligand superfamily member 12 Proteins 0.000 description 1
- 102100024586 Tumor necrosis factor ligand superfamily member 14 Human genes 0.000 description 1
- 108010084950 Tx3 neurotoxin Proteins 0.000 description 1
- 108010008681 Type II Secretion Systems Proteins 0.000 description 1
- DLZKEQQWXODGGZ-KWQFWETISA-N Tyr-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DLZKEQQWXODGGZ-KWQFWETISA-N 0.000 description 1
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- ARPONUQDNWLXOZ-KKUMJFAQSA-N Tyr-Gln-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ARPONUQDNWLXOZ-KKUMJFAQSA-N 0.000 description 1
- NOOMDULIORCDNF-IRXDYDNUSA-N Tyr-Gly-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NOOMDULIORCDNF-IRXDYDNUSA-N 0.000 description 1
- JAGGEZACYAAMIL-CQDKDKBSSA-N Tyr-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JAGGEZACYAAMIL-CQDKDKBSSA-N 0.000 description 1
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 1
- 108010009135 Uca pugilator serine collagenase 1 Proteins 0.000 description 1
- 108091023045 Untranslated Region Proteins 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 1
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 1
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 1
- COYSIHFOCOMGCF-WPRPVWTQSA-N Val-Arg-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-WPRPVWTQSA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- ZMDCGGKHRKNWKD-LAEOZQHASA-N Val-Asn-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZMDCGGKHRKNWKD-LAEOZQHASA-N 0.000 description 1
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 1
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 1
- SJLVYVZBFDTRCG-DCAQKATOSA-N Val-Lys-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N SJLVYVZBFDTRCG-DCAQKATOSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 1
- SVFRYKBZHUGKLP-QXEWZRGKSA-N Val-Met-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVFRYKBZHUGKLP-QXEWZRGKSA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- WMRWZYSRQUORHJ-YDHLFZDLSA-N Val-Phe-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WMRWZYSRQUORHJ-YDHLFZDLSA-N 0.000 description 1
- MJOUSKQHAIARKI-JYJNAYRXSA-N Val-Phe-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 MJOUSKQHAIARKI-JYJNAYRXSA-N 0.000 description 1
- GQMNEJMFMCJJTD-NHCYSSNCSA-N Val-Pro-Gln Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O GQMNEJMFMCJJTD-NHCYSSNCSA-N 0.000 description 1
- MIKHIIQMRFYVOR-RCWTZXSCSA-N Val-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C(C)C)N)O MIKHIIQMRFYVOR-RCWTZXSCSA-N 0.000 description 1
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 1
- ZLMFVXMJFIWIRE-FHWLQOOXSA-N Val-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](C(C)C)N ZLMFVXMJFIWIRE-FHWLQOOXSA-N 0.000 description 1
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 1
- ODUHAIXFXFACDY-SRVKXCTJSA-N Val-Val-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C ODUHAIXFXFACDY-SRVKXCTJSA-N 0.000 description 1
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 1
- 108010003205 Vasoactive Intestinal Peptide Proteins 0.000 description 1
- 102400000015 Vasoactive intestinal peptide Human genes 0.000 description 1
- 108090000509 Venombin A Proteins 0.000 description 1
- 108010038900 X-Pro aminopeptidase Proteins 0.000 description 1
- 102100039662 Xaa-Pro dipeptidase Human genes 0.000 description 1
- 101710171640 Xaa-Pro dipeptidase Proteins 0.000 description 1
- 108700040099 Xylose isomerases Proteins 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 241001670042 [Pseudomonas] boreopolis Species 0.000 description 1
- 241001670036 [Pseudomonas] cissicola Species 0.000 description 1
- 241001670030 [Pseudomonas] geniculata Species 0.000 description 1
- 241001670027 [Pseudomonas] hibiscicola Species 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 229910052768 actinide Inorganic materials 0.000 description 1
- 150000001255 actinides Chemical class 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000000488 activin Substances 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N adenyl group Chemical group N1=CN=C2N=CNC2=C1N GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 239000005409 aflatoxin Substances 0.000 description 1
- 238000013019 agitation Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 1
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 1
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 1
- 102000016679 alpha-Glucosidases Human genes 0.000 description 1
- 108010028144 alpha-Glucosidases Proteins 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- 108010014709 amatoxin Proteins 0.000 description 1
- 230000006229 amino acid addition Effects 0.000 description 1
- 108090000449 aminopeptidase B Proteins 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 235000019270 ammonium chloride Nutrition 0.000 description 1
- 150000003863 ammonium salts Chemical class 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 230000003698 anagen phase Effects 0.000 description 1
- 239000000538 analytical sample Substances 0.000 description 1
- 230000010100 anticoagulation Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 108010036533 arginylvaline Proteins 0.000 description 1
- 238000000149 argon plasma sintering Methods 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 235000000183 arugula Nutrition 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 108090000987 aspergillopepsin I Proteins 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 230000001746 atrial effect Effects 0.000 description 1
- 108010070189 atroxase Proteins 0.000 description 1
- 230000001651 autotrophic effect Effects 0.000 description 1
- 229940065181 bacillus anthracis Drugs 0.000 description 1
- 244000052616 bacterial pathogen Species 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 229940040591 biotech drug Drugs 0.000 description 1
- DNDCVAGJPBKION-DOPDSADYSA-N bombesin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(N)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC=1NC2=CC=CC=C2C=1)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]1NC(=O)CC1)C(C)C)C1=CN=CN1 DNDCVAGJPBKION-DOPDSADYSA-N 0.000 description 1
- 229940053031 botulinum toxin Drugs 0.000 description 1
- 108010006025 bovine growth hormone Proteins 0.000 description 1
- QXZGBUJJYSLZLT-FDISYFBBSA-N bradykinin Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(=O)NCC(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CO)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CCC1 QXZGBUJJYSLZLT-FDISYFBBSA-N 0.000 description 1
- 235000019835 bromelain Nutrition 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000008366 buffered solution Substances 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- GCDJGEWSHKXMFB-KLSUCABJSA-N cardiotoxin, cobra Chemical compound C([C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N[C@H]2CSSC[C@H](NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]3CCCN3C(=O)[C@H](C(C)C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC=3C=CC=CC=3)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=3C=CC(O)=CC=3)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H]3N(CCC3)C2=O)CSSC[C@@H](C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N2CCC[C@H]2C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N1)C(C)C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]1C(N2CCC[C@H]2C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@H](C(=O)N[C@@H](CSSC1)C(=O)N[C@@H]1C(N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CSSC1)C(=O)N[C@@H](CC(N)=O)C(O)=O)[C@@H](C)O)=O)C(C)C)C(C)C)=O)[C@@H](C)O)C1=CC=C(O)C=C1 GCDJGEWSHKXMFB-KLSUCABJSA-N 0.000 description 1
- 230000001925 catabolic effect Effects 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 230000002490 cerebral effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000001876 chaperonelike Effects 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- DLGJWSVWTWEWBJ-HGGSSLSASA-N chondroitin Chemical compound CC(O)=N[C@@H]1[C@H](O)O[C@H](CO)[C@H](O)[C@@H]1OC1[C@H](O)[C@H](O)C=C(C(O)=O)O1 DLGJWSVWTWEWBJ-HGGSSLSASA-N 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 229940080701 chymosin Drugs 0.000 description 1
- 235000019506 cigar Nutrition 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 101150093586 clpA gene Proteins 0.000 description 1
- 101150017872 clpQ gene Proteins 0.000 description 1
- 101150096566 clpX gene Proteins 0.000 description 1
- 101150054715 clpY gene Proteins 0.000 description 1
- 239000000701 coagulant Substances 0.000 description 1
- 238000005345 coagulation Methods 0.000 description 1
- 230000015271 coagulation Effects 0.000 description 1
- 229940126051 coagulation factor XIa Drugs 0.000 description 1
- 239000002642 cobra venom Substances 0.000 description 1
- 244000022782 cocaer Species 0.000 description 1
- 235000008957 cocaer Nutrition 0.000 description 1
- ZPUCINDJVBIVPJ-LJISPDSOSA-N cocaine Chemical compound O([C@H]1C[C@@H]2CC[C@@H](N2C)[C@H]1C(=O)OC)C(=O)C1=CC=CC=C1 ZPUCINDJVBIVPJ-LJISPDSOSA-N 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 230000001332 colony forming effect Effects 0.000 description 1
- 238000004737 colorimetric analysis Methods 0.000 description 1
- 108050003126 conotoxin Proteins 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 108010048032 cyclophilin B Proteins 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 108700001680 des-(1-3)- insulin-like growth factor 1 Proteins 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000012938 design process Methods 0.000 description 1
- 230000000368 destabilizing effect Effects 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- RAABOESOVLLHRU-UHFFFAOYSA-N diazene Chemical compound N=N RAABOESOVLLHRU-UHFFFAOYSA-N 0.000 description 1
- 229910000071 diazene Inorganic materials 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- AIUDWMLXCFRVDR-UHFFFAOYSA-N dimethyl 2-(3-ethyl-3-methylpentyl)propanedioate Chemical class CCC(C)(CC)CCC(C(=O)OC)C(=O)OC AIUDWMLXCFRVDR-UHFFFAOYSA-N 0.000 description 1
- 108090000212 dipeptidyl peptidase II Proteins 0.000 description 1
- MSJMDZAOKORVFC-UAIGNFCESA-L disodium maleate Chemical compound [Na+].[Na+].[O-]C(=O)\C=C/C([O-])=O MSJMDZAOKORVFC-UAIGNFCESA-L 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 239000002934 diuretic Substances 0.000 description 1
- 230000001882 diuretic effect Effects 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 108090000403 echinoidin Proteins 0.000 description 1
- 230000001516 effect on protein Effects 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000002357 endometrial effect Effects 0.000 description 1
- 108010003914 endoproteinase Asp-N Proteins 0.000 description 1
- ZUBDGKVDJUIMQQ-UBFCDGJISA-N endothelin-1 Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)NC(=O)[C@H]1NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](C(C)C)NC(=O)[C@H]2CSSC[C@@H](C(N[C@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N2)=O)NC(=O)[C@@H](CO)NC(=O)[C@H](N)CSSC1)C1=CNC=N1 ZUBDGKVDJUIMQQ-UBFCDGJISA-N 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000003912 environmental pollution Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 238000001952 enzyme assay Methods 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- NLPRAJRHRHZCQQ-IVZWLZJFSA-N epibatidine Chemical compound C1=NC(Cl)=CC=C1[C@@H]1[C@H](N2)CC[C@H]2C1 NLPRAJRHRHZCQQ-IVZWLZJFSA-N 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- OFKDAAIKGIBASY-VFGNJEKYSA-N ergotamine Chemical compound C([C@H]1C(=O)N2CCC[C@H]2[C@]2(O)O[C@@](C(N21)=O)(C)NC(=O)[C@H]1CN([C@H]2C(C3=CC=CC4=NC=C([C]34)C2)=C1)C)C1=CC=CC=C1 OFKDAAIKGIBASY-VFGNJEKYSA-N 0.000 description 1
- 229960004943 ergotamine Drugs 0.000 description 1
- XCGSFFUVFURLIX-UHFFFAOYSA-N ergotaminine Natural products C1=C(C=2C=CC=C3NC=C(C=23)C2)C2N(C)CC1C(=O)NC(C(N12)=O)(C)OC1(O)C1CCCN1C(=O)C2CC1=CC=CC=C1 XCGSFFUVFURLIX-UHFFFAOYSA-N 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- QPMJENKZJUFOON-PLNGDYQASA-N ethyl (z)-3-chloro-2-cyano-4,4,4-trifluorobut-2-enoate Chemical compound CCOC(=O)C(\C#N)=C(/Cl)C(F)(F)F QPMJENKZJUFOON-PLNGDYQASA-N 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 229940014425 exodus Drugs 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 238000013401 experimental design Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 229940012952 fibrinogen Drugs 0.000 description 1
- 229940126864 fibroblast growth factor Drugs 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- 108700014844 flt3 ligand Proteins 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 229940028334 follicle stimulating hormone Drugs 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 108090000285 fruit bromelain Proteins 0.000 description 1
- 108010074605 gamma-Globulins Proteins 0.000 description 1
- 108010062699 gamma-Glutamyl Hydrolase Proteins 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 1
- 229960004666 glucagon Drugs 0.000 description 1
- 239000006481 glucose medium Substances 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 108010013113 glutamyl carboxylase Proteins 0.000 description 1
- 108090000639 glutamyl endopeptidase II Proteins 0.000 description 1
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 108010092515 glycyl endopeptidase Proteins 0.000 description 1
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 1
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010037850 glycylvaline Proteins 0.000 description 1
- 239000002622 gonadotropin Substances 0.000 description 1
- 239000000122 growth hormone Substances 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- 108010040030 histidinoalanine Proteins 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 101150115543 hslU gene Proteins 0.000 description 1
- 101150055178 hslV gene Proteins 0.000 description 1
- 108010042252 huwentoxin I Proteins 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 125000001165 hydrophobic group Chemical class 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 231100000608 immunotoxin Toxicity 0.000 description 1
- 229940051026 immunotoxin Drugs 0.000 description 1
- 230000002637 immunotoxin Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 239000000893 inhibin Substances 0.000 description 1
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 102000028416 insulin-like growth factor binding Human genes 0.000 description 1
- 108091022911 insulin-like growth factor binding Proteins 0.000 description 1
- 230000002608 insulinlike Effects 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 229940116108 lactase Drugs 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 229940066294 lung surfactant Drugs 0.000 description 1
- 239000003580 lung surfactant Substances 0.000 description 1
- 229940040129 luteinizing hormone Drugs 0.000 description 1
- 108010019677 lymphotactin Proteins 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 108010057284 lysosomal Pro-X carboxypeptidase Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L magnesium chloride Substances [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 1
- 229910001629 magnesium chloride Inorganic materials 0.000 description 1
- 229910052943 magnesium sulfate Inorganic materials 0.000 description 1
- 235000019341 magnesium sulphate Nutrition 0.000 description 1
- WPBNNNQJVZRUHP-UHFFFAOYSA-L manganese(2+);methyl n-[[2-(methoxycarbonylcarbamothioylamino)phenyl]carbamothioyl]carbamate;n-[2-(sulfidocarbothioylamino)ethyl]carbamodithioate Chemical compound [Mn+2].[S-]C(=S)NCCNC([S-])=S.COC(=O)NC(=S)NC1=CC=CC=C1NC(=S)NC(=O)OC WPBNNNQJVZRUHP-UHFFFAOYSA-L 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 239000006151 minimal media Substances 0.000 description 1
- 108091005601 modified peptides Proteins 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- GNOLWGAJQVLBSM-UHFFFAOYSA-N n,n,5,7-tetramethyl-1,2,3,4-tetrahydronaphthalen-1-amine Chemical compound C1=C(C)C=C2C(N(C)C)CCCC2=C1C GNOLWGAJQVLBSM-UHFFFAOYSA-N 0.000 description 1
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 description 1
- 239000003900 neurotrophic factor Substances 0.000 description 1
- 229940032018 neurotrophin 3 Drugs 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- JFNLZVQOOSMTJK-KNVOCYPGSA-N norbornene Chemical compound C1[C@@H]2CC[C@H]1C=C2 JFNLZVQOOSMTJK-KNVOCYPGSA-N 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 108010009099 nucleoside phosphorylase Proteins 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 230000035764 nutrition Effects 0.000 description 1
- QYSGYZVSCZSLHT-UHFFFAOYSA-N octafluoropropane Chemical compound FC(F)(F)C(F)(F)C(F)(F)F QYSGYZVSCZSLHT-UHFFFAOYSA-N 0.000 description 1
- 108010032563 oligopeptidase Proteins 0.000 description 1
- 108090000857 oligopeptidase B Proteins 0.000 description 1
- 108010003052 omptin outer membrane protease Proteins 0.000 description 1
- 125000001477 organic nitrogen group Chemical group 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 239000006174 pH buffer Substances 0.000 description 1
- 108090000155 pancreatic elastase II Proteins 0.000 description 1
- 239000000199 parathyroid hormone Substances 0.000 description 1
- 229960001319 parathyroid hormone Drugs 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 229940066716 pepsin a Drugs 0.000 description 1
- 108090000756 peptidyl dipeptidase B Proteins 0.000 description 1
- 229940066779 peptones Drugs 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000000575 pesticide Substances 0.000 description 1
- 108010084572 phenylalanyl-valine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000027086 plasmid maintenance Effects 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229940012957 plasmin Drugs 0.000 description 1
- 229940127126 plasminogen activator Drugs 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 229910000160 potassium phosphate Inorganic materials 0.000 description 1
- 235000011009 potassium phosphates Nutrition 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 108010017378 prolyl aminopeptidase Proteins 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 230000012743 protein tagging Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000007320 rich medium Substances 0.000 description 1
- 239000012723 sample buffer Substances 0.000 description 1
- RPQXVSUAYFXFJA-HGRQIUPRSA-N saxitoxin Chemical compound NC(=O)OC[C@@H]1N=C(N)N2CCC(O)(O)[C@@]22N=C(N)N[C@@H]12 RPQXVSUAYFXFJA-HGRQIUPRSA-N 0.000 description 1
- RPQXVSUAYFXFJA-UHFFFAOYSA-N saxitoxin hydrate Natural products NC(=O)OCC1N=C(N)N2CCC(O)(O)C22NC(N)=NC12 RPQXVSUAYFXFJA-UHFFFAOYSA-N 0.000 description 1
- 238000011218 seed culture Methods 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012772 sequence design Methods 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- 238000012807 shake-flask culturing Methods 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- IYKSHBADGOZWIF-UTPLJIOFSA-N slotoxin Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C1=CC=CC=C1 IYKSHBADGOZWIF-UTPLJIOFSA-N 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 238000002798 spectrophotometry method Methods 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 108010092231 staphylococcal alpha-toxin Proteins 0.000 description 1
- 108090000346 stem bromelain Proteins 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 230000000707 stereoselective effect Effects 0.000 description 1
- 239000004575 stone Substances 0.000 description 1
- 229960005202 streptokinase Drugs 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000003467 sulfuric acid derivatives Chemical class 0.000 description 1
- 230000001502 supplementing effect Effects 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 229940118376 tetanus toxin Drugs 0.000 description 1
- CFMYXEVWODSLAX-UHFFFAOYSA-N tetrodotoxin Natural products C12C(O)NC(=N)NC2(C2O)C(O)C3C(CO)(O)C1OC2(O)O3 CFMYXEVWODSLAX-UHFFFAOYSA-N 0.000 description 1
- CFMYXEVWODSLAX-QOZOJKKESA-N tetrodotoxin Chemical compound O([C@@]([C@H]1O)(O)O[C@H]2[C@@]3(O)CO)[C@H]3[C@@H](O)[C@]11[C@H]2[C@@H](O)N=C(N)N1 CFMYXEVWODSLAX-QOZOJKKESA-N 0.000 description 1
- 229950010357 tetrodotoxin Drugs 0.000 description 1
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- 108010031354 thermitase Proteins 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 101150095421 tig gene Proteins 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 108010042974 transforming growth factor beta4 Proteins 0.000 description 1
- XETCRXVKJHBPMK-MJSODCSWSA-N trehalose 6,6'-dimycolate Chemical compound C([C@@H]1[C@H]([C@H](O)[C@@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](COC(=O)C(CCCCCCCCCCC3C(C3)CCCCCCCCCCCCCCCCCC)C(O)CCCCCCCCCCCCCCCCCCCCCCCCC)O2)O)O1)O)OC(=O)C(C(O)CCCCCCCCCCCCCCCCCCCCCCCCC)CCCCCCCCCCC1CC1CCCCCCCCCCCCCCCCCC XETCRXVKJHBPMK-MJSODCSWSA-N 0.000 description 1
- LZAJKCZTKKKZNT-PMNGPLLRSA-N trichothecene Chemical compound C12([C@@]3(CC[C@H]2OC2C=C(CCC23C)C)C)CO1 LZAJKCZTKKKZNT-PMNGPLLRSA-N 0.000 description 1
- 229930013292 trichothecene Natural products 0.000 description 1
- 108010039189 tripeptidyl-peptidase 2 Proteins 0.000 description 1
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 1
- 229940038773 trisodium citrate Drugs 0.000 description 1
- 229960001322 trypsin Drugs 0.000 description 1
- 239000012137 tryptone Substances 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 108010047303 von Willebrand Factor Proteins 0.000 description 1
- 102100036537 von Willebrand factor Human genes 0.000 description 1
- 229960001134 von willebrand factor Drugs 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 108010021321 xanthomonapepsin Proteins 0.000 description 1
- 108010078692 yeast proteinase B Proteins 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 108010064359 zinc D-Ala-D-Ala carboxypeptidase Proteins 0.000 description 1
Images








Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
- C07K14/21—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria from Pseudomonadaceae (F)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N1/00—Microorganisms, e.g. protozoa; Compositions thereof; Processes of propagating, maintaining or preserving microorganisms or compositions thereof; Processes of preparing or isolating a composition containing a microorganism; Culture media therefor
- C12N1/20—Bacteria; Culture media therefor
- C12N1/205—Bacterial isolates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
- C12N15/625—DNA sequences coding for fusion proteins containing a sequence coding for a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/78—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for Pseudomonas
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/78—Hydrolases (3) acting on carbon to nitrogen bonds other than peptide bonds (3.5)
- C12N9/80—Hydrolases (3) acting on carbon to nitrogen bonds other than peptide bonds (3.5) acting on amide bonds in linear amides (3.5.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/78—Hydrolases (3) acting on carbon to nitrogen bonds other than peptide bonds (3.5)
- C12N9/80—Hydrolases (3) acting on carbon to nitrogen bonds other than peptide bonds (3.5) acting on amide bonds in linear amides (3.5.1)
- C12N9/82—Asparaginase (3.5.1.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y305/00—Hydrolases acting on carbon-nitrogen bonds, other than peptide bonds (3.5)
- C12Y305/01—Hydrolases acting on carbon-nitrogen bonds, other than peptide bonds (3.5) in linear amides (3.5.1)
- C12Y305/01001—Asparaginase (3.5.1.1)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12R—INDEXING SCHEME ASSOCIATED WITH SUBCLASSES C12C - C12Q, RELATING TO MICROORGANISMS
- C12R2001/00—Microorganisms ; Processes using microorganisms
- C12R2001/01—Bacteria or Actinomycetales ; using bacteria or Actinomycetales
- C12R2001/38—Pseudomonas
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12R—INDEXING SCHEME ASSOCIATED WITH SUBCLASSES C12C - C12Q, RELATING TO MICROORGANISMS
- C12R2001/00—Microorganisms ; Processes using microorganisms
- C12R2001/01—Bacteria or Actinomycetales ; using bacteria or Actinomycetales
- C12R2001/38—Pseudomonas
- C12R2001/39—Pseudomonas fluorescens
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Tropical Medicine & Parasitology (AREA)
- Virology (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
Abstract
이종 단백질의 주변세포질 발현을 위한 박테리아 리더 서열, 박테리아 리더 서열을 포함하는 융합 단백질, 및 이것의 발현 방법이 본원에 제공된다.
Description
관련 출원에 대한 상호 참조
본 출원은 2017년 10월 27일에 제출된 미국 가출원 제62/578,304호를 우선권으로 주장하며, 상기 가출원은 그 전체가 본 출원에 참고로 인용된다.
서열 목록
본 출원은 ASCII 포맷으로 전자적으로 제출된 서열 목록을 포함하고, 그 전체 내용이 본 출원에 참고로 인용된다. 상기 ASCII 사본은 2018년 10월 16일에 생성되었고, 그 명칭은 38194-752_601_SL.txt이며, 크기는 13,698 바이트이다.
재조합적으로 생산된 150개를 초과하는 단백질 및 폴리펩타이드가 생명공학 약물 및 백신으로서의 사용에 대해 미국 식품의약청(FDA)에서 허가되었고, 또 다른 370개가 임상 시험 중이다. 화학적 합성을 통해 생산되는 저분자 치료제와는 달리, 단백질 및 폴리펩타이드는 살아 있는 세포에서 가장 효율적으로 생산된다. 그러나, 박테리아에서의 현재의 재조합 단백질 생산 방법으로는 부적절하게 폴딩되거나, 응집되거나 또는 불활성인 단백질이 종종 생산되고, 다수의 유형의 단백질은 공지된 방법을 사용하여 비효율적으로 달성되는 2차 변형을 필요로 한다.
공지된 방법의 한가지 중요한 문제점은 세포질 내에 응집된 단백질들로 이루어진 봉입체(inclusion body)가 형성되는 것이고, 이는 과량의 단백질이 세포 내에 축적될 때 발생한다. 재조합 단백질 생산에서의 또 다른 문제점은 발현된 단백질에 대해 적절한 2차 및 3차 형태(conformation)를 수립하는 것이다. 한가지 장벽은 종종 적절한 단백질 폴딩의 기초가 되는 다이설파이드 결합 형성을 박테리아 세포질이 활발하게 저지한다는 것이다(Derman et al., 1993, Science, 1744-7). 그 결과, 다수의 재조합 단백질, 특히 진핵생물 기원의 단백질이 박테리아에서 생산되는 경우 부적절하게 폴딩되고 불활성이다.
재조합 시스템에서 적절하게 폴딩되고, 가용성이고/이거나 활성인 단백질의 생산을 증가시키기 위해 수많은 시도들이 진행되었다. 예를 들어, 연구원들은 발효 조건을 변경시키거나, 프로모터 강도에 변화를 주거나, 봉입체의 형성을 방지하는 것을 도울 수 있는 과발현된 샤페론(chaperone) 단백질을 사용하여 왔다.
적절하게 폴딩되고, 가용성이고/이거나 활성인 단백질의 수확을 증가시키기 위한 대안적인 접근법은 단백질을 세포내 환경으로부터 분비시키는 것이다. 신호 서열이 있는 폴리펩타이드의 가장 통상적인 형태의 분비는 Sec 시스템과 관련된다. Sec 시스템은 N-말단 신호 폴리펩타이드가 있는 단백질의 세포질 막을 가로지르는 유출(export)을 담당한다.
세포로부터 상등액 내로 단백질을 배출(excretion)시키기 위한 전략들이 개발되었다. 증가된 발현을 위한 또 다른 전략은 단백질을 주변세포질로 타겟팅하는 것에 관한 것이다. 일부 연구원들은 Sec 타입이 아닌 분비(secretion)에 초점을 맞추었다. 그러나, 대다수의 연구는 Sec 타입 분비 시스템을 이용하는 외인성 단백질의 분비에 집중되어 왔다. 다수의 분비 신호는 재조합 폴리펩타이드 또는 단백질을 발현에 사용하기 위해 언급되어 왔다.
단백질을 세포질 밖으로 타겟팅하기 위해 신호 서열에 의존하는 전략들은 종종 부적절하게 프로세싱된 단백질을 생산한다. 이는 아미노-말단 분비 신호, 예를 들어 Sec 시스템을 통해 분비를 유도한 신호에 대해 특히 그러하다. 이러한 시스템을 통해 프로세싱된 단백질들은 종종 분비 신호의 일부를 유지하거나, 부적절하게 절단되는(cleaved) 연결 요소를 필요로 하거나, 또는 말단에서 절단된다(truncated).
앞에서 언급한 기술로부터 명백한 바와 같이, 단백질을 숙주 세포의 주변세포질로 타겟팅하기 위해 다수의 전략들이 개발되어 왔다. 그러나, 공지된 전략들은 종종 치료적 용도를 위해 정제되는, 지속적으로 높은 수율의 적절하게 프로세싱된 활성 재조합 단백질을 생산할 수 없었다. 기존의 전략들에서의 한가지 중요한 제한 사항은 부적절한 세포 시스템에서 불량한 분비 신호 서열을 이용하는 단백질의 발현이었다.
적절하게 프로세싱된 형태의 재조합 폴리펩타이드를 생산하기 위해 재조합 폴리펩타이드를 분비할 수 있고 적절하게 프로세싱할 수 있는 개선된 대규모 발현 시스템에 대한 요구가 존재한다.
본 출원에서 제1 부분 및 제2 부분을 보유하는 폴리펩타이드가 제공되는데, 제1 부분은 서열 번호 1-3 중 하나 이상과 상동성인 아미노산 서열을 보유하고, 제2 부분은 관심 단백질 또는 폴리펩타이드의 아미노산 서열을 보유하며, 제1 부분 및 제2 부분은 작동 가능하게 연결된다. 몇몇 실시양태에서, 폴리펩타이드의 제1 부분은 관심 단백질 또는 폴리펩타이드 태생이 아니다. 몇몇 실시양태에서, 관심 단백질은 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 폴리펩타이드는 링커를 추가로 포함한다. 몇몇 실시양태에서, 폴리펩타이드는 절단 도메인을 추가로 포함한다. 몇몇 실시양태에서, 제1 부분은 원핵 숙주 세포의 주변세포질로 관심 단백질의 발현을 유도하는 리더 펩타이드이다. 몇몇 실시양태에서, 숙주 세포는 슈도모나드(Pseudomonad) 세포 또는 이. 콜라이(E. coli) 세포로부터 선택된다.
또한, 본 출원에서 리더 펩타이드 및 관심 단백질 또는 폴리펩타이드를 포함하는 폴리펩타이드가 제공되는데, 리더 펩타이드는 서열 번호 1-3 중 하나 이상으로부터 선택된 아미노산 서열을 보유한다. 몇몇 실시양태에서, 리더 펩타이드는 관심 단백질 또는 폴리펩타이드 태생이 아니다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 폴리펩타이드는 링커를 추가로 포함한다. 몇몇 실시양태에서, 폴리펩타이드는 절단 도메인을 추가로 포함한다. 몇몇 실시양태에서, 제1 부분은 원핵 숙주 세포의 주변세포질로 관심 단백질의 발현을 유도하는 리더 펩타이드이다. 몇몇 실시양태에서, 숙주 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다.
추가로, 본 출원에서 제1 부분 및 제2 부분을 보유하는 폴리펩타이드를 코딩하는 폴리뉴클레오타이드가 제공되는데, 제1 부분은 서열 번호 4-6 중 하나 이상으로부터 선택된 핵산 서열에 의해 코딩되고, 제2 부분은 관심 단백질 또는 폴리펩타이드의 핵산 서열에 의해 코딩되며, 제1 부분 및 제2 부분은 작동 가능하게 연결된다. 몇몇 실시양태에서, 폴리펩타이드의 제1 부분은 관심 단백질 또는 폴리펩타이드 태생이 아니다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 폴리뉴클레오타이드는 링커를 코딩하는 핵산을 추가로 포함한다. 몇몇 실시양태에서, 폴리뉴클레오타이드는 절단 도메인을 코딩하는 핵산을 추가로 포함한다. 몇몇 실시양태에서, 제1 부분은 원핵 숙주 세포의 주변세포질로 관심 단백질의 발현을 유도하는 리더 펩타이드이다. 몇몇 실시양태에서, 숙주 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다.
또한, 본 출원에서 리더 펩타이드를 코딩하는 핵산을 포함하는 단백질 발현을 위한 벡터가 제공되는데, 핵산은 서열 번호 4-6 중 하나 이상으로부터 선택된 핵산 서열을 보유한다. 몇몇 실시양태에서, 벡터는 링커를 추가로 포함한다. 몇몇 실시양태에서, 벡터는 절단 도메인을 추가로 포함한다. 몇몇 실시양태에서, 리더 펩타이드는 원핵 숙주 세포의 주변세포질로 관심 단백질 또는 폴리펩타이드의 발현을 유도한다. 몇몇 실시양태에서, 숙주 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다.
또한, 본 출원에서 원핵 세포 배양으로 관심 단백질 또는 폴리펩타이드를 생산하는 방법이 제공된다. 몇몇 실시양태에서, 상기 방법은 (a) 세포 배양 성장 배지에서 관심 단백질 또는 폴리펩타이드 및 리더 펩타이드를 코딩하는 핵산을 포함하는 원핵 세포를 배양하는 단계; 및 (b) 원핵 세포의 주변세포질로부터 관심 단백질 또는 폴리펩타이드를 단리하는 단계를 포함하고, 여기서 리더 펩타이드는 서열 번호 1-3 중 하나 이상으로부터 선택된 아미노산 서열을 포함한다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 핵산은 링커를 코딩한다. 몇몇 실시양태에서, 핵산은 절단 도메인을 코딩한다. 몇몇 실시양태에서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드의 발현은 배양 배지에 IPTG를 첨가함으로써 유도된다. 몇몇 실시양태에서, 원핵 세포는 약 5.0 내지 약 8.0의 pH에서 배양된다. 몇몇 실시양태에서, 원핵 세포는 약 22℃ 내지 약 33℃의 온도에서 배양된다.
몇몇 실시양태에서, 본 출원의 방법은 원핵 세포 배양으로 관심 단백질 또는 폴리펩타이드를 생산하는 방법을 포함하는데, 상기 방법은 (a) 세포 배양 성장 배지에서 관심 단백질 또는 폴리펩타이드 및 리더 펩타이드를 코딩하는 핵산을 포함하는 원핵 세포를 배양하는 단계; 및 (b) 원핵 세포의 주변세포질로부터 관심 단백질 또는 폴리펩타이드를 단리하는 단계를 포함하고, 여기서 리더 펩타이드는 서열 번호 4-6 중 하나 이상으로부터 선택된 핵산 서열에 의해 코딩된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 핵산은 링커를 코딩한다. 몇몇 실시양태에서, 핵산은 절단 도메인을 코딩한다. 몇몇 실시양태에서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드의 발현은 배양 배지에 IPTG를 첨가함으로써 유도된다. 몇몇 실시양태에서, 원핵 세포는 약 5.0 내지 약 8.0의 pH에서 배양된다. 몇몇 실시양태에서, 원핵 세포는 약 22℃ 내지 약 33℃의 온도에서 배양된다.
몇몇 실시양태에서, 본 출원의 방법은 원핵 세포의 주변세포질에서 관심 단백질 또는 폴리펩타이드를 발현하는 방법을 포함하는데, 상기 방법은 세포 배양 성장 배지에서 관심 단백질 또는 폴리펩타이드 및 리더 펩타이드를 코딩하는 핵산을 포함하는 원핵 세포를 배양하는 단계를 포함하고, 리더 펩타이드는 서열 번호 1-3 중 하나 이상으로부터 선택된 아미노산 서열을 포함한다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 핵산은 링커를 코딩한다. 몇몇 실시양태에서, 핵산은 절단 도메인을 코딩한다. 몇몇 실시양태에서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드의 발현은 배양 배지에 IPTG를 첨가함으로써 유도된다. 몇몇 실시양태에서, 원핵 세포는 약 5.0 내지 약 8.0의 pH에서 배양된다. 몇몇 실시양태에서, 원핵 세포는 약 22℃ 내지 약 33℃의 온도에서 배양된다.
몇몇 실시양태에서, 본 출원의 방법은 원핵 세포의 주변세포질에서 관심 단백질 또는 폴리펩타이드를 발현하는 방법을 포함하는데, 상기 방법은 세포 배양 성장 배지에서 관심 단백질 또는 폴리펩타이드 및 리더 펩타이드를 코딩하는 핵산을 포함하는 원핵 세포를 배양하는 단계를 포함하고, 리더 펩타이드는 서열 번호 4-6 중 하나 이상으로부터 선택된 핵산 서열에 의해 코딩된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자 및 백신 항원으로부터 선택된다. 몇몇 실시양태에서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 전체 사슬 항체이다. 몇몇 실시양태에서, 핵산은 링커를 코딩한다. 몇몇 실시양태에서, 핵산은 절단 도메인을 코딩한다. 몇몇 실시양태에서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택된다. 몇몇 실시양태에서, 관심 단백질 또는 폴리펩타이드의 발현은 배양 배지에 IPTG의 첨가로 유도된다. 몇몇 실시양태에서, 원핵 세포는 약 5.0 내지 약 8.0의 pH에서 배양된다. 몇몇 실시양태에서, 원핵 세포는 약 22℃ 내지 약 33℃의 온도에서 배양된다.
참고 인용
본 명세서에서 언급된 모든 간행물, 특허 및 특허 출원은, 각각의 개별적인 간행물, 특허, 또는 특허 출원이 구체적이고 개별적으로 참고로 인용된 것임을 나타낸 바와 같이 동일한 정도로 본 출원에 참고로 인용된다.
본 개시내용의 신규한 특징들은 첨부한 청구범위에 특징적으로 기재된다. 본 개시내용의 특징 및 이점의 더 좋은 이해는 본 개시내용의 원칙이 이용되는 예시적인 실시양태를 기재하는 후술하는 발명의 상세한 설명 및 첨부 도면을 참고하여 획득될 것이다:
도 1은 TrxA 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 2는 Gal2 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 3은 mrPA 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 4. 크리산타스파아제 예시 서열. 크리산타스파아제를 코딩하는 예시적인 핵산 서열(서열 번호 8)은 상응하는 아미노산 서열(서열 번호 7)과 함께 나타낸다. 또한, 도 4는 서열 번호 20으로서 클로닝 부위를 포함하는 전장 뉴클레오타이드 서열를 개시한다.
도 5. SDS-CGE 겔-유사 이미지 - 크리산타스파아제 발현 플라스미드 스크린. DC454(상부 패널) 및 DC441(하부 패널) 유래의 크리산타스파아제 소규모 성장 전체 브로스 초음파 처리 가용성 샘플은 환원된 SDS-CGC에 의해 분석되었다. 가장 좌측의 레인은 분자량 마커 래더 1(상부 패널 MW 래더 48 KD, 29 KD; 하부 패널 MW 래더 48 KD, 29 KD, 21 KD)를 나타내고, 가장 우측의 레인은 동일한 래더를 나타낸다. 좌측에서 우측으로(레인 1에서 46), 래더 1의 바로 우측에서 시작하는 것은, 하기 분비 리더 펩타이드가 크리산타스파아제 단백질의 N-말단에 융합된 경우에 관찰된 발현 패턴을 나타내는 레인이다(달리 언급하는 경우를 제외하고 고 RBS): 리더 없음; DsbD; 리더 A; DsbA; DsbA-중 RBS; Azu; Azu-중 RBS; Lao; Ibp-S31A; TolB; DC432 눌(null)(단지 플라스미드 벡터만을 보유하는 야생형 호스트 균주); Tpr; Ttg2C; FlgI; CupC2; CupB2; Pbp; PbpA20V; DsbC; 리더 B; 리더 C; DC432 null; 리더 D; 리더 E; 리더 F; 리더 G; 리더 H; PorE; 리더 I; 리더 J; 리더 K; 리더 L; DC432 눌; 리더 M; 리더 N; 리더 O; 5193; 리더 P; 리더 Q; 리더 R; 8484; 리더 S; 리더 T; DC432 눌. 겔 이미지의 우측의 화살표는 크리산타스파아제 타겟 단백질(35 kDa)의 이동을 나타낸다.
도 6. SDS-CGE 겔-유사 이미지 - 이. 콜라이 아스파라기나아제 발현 플라스미드 스크린. 아스파라기나아제 소규모(0.5 ml) 성장 전체 브로스 초음파 처리 가용성(상부 패널) 및 불용성(하부 패널) 샘플은 환원된 SDS-CGE에 의해 분석되었다. 가장 좌측의 레인은 분자량 마커 래더(상부 패널 MW 래더 119 kDa, 68 KDa, 48 kDa, 29 kDa, 21 kDa, 16 kDa; 하부 패널 MW 래더 119 kDa, 68 KDa, 48 kDa, 29 kDa, 21 kDa, 16 kDa)를 나타내고, 가장 우측의 레인은 동일한 래더를 나타낸다. 좌측에서 우측으로 래더 1의 바로 우측에서 시작하는 것은 눌, STR55467, STR55689, STR55559, STR55561, STR55569, STR55575, STR55555, STR55571, STR55560, STR55570, STR55572, STR55601, STR55585, STR55592, STR55501, 및 대조군에서 관찰된 발현 패턴을 나타내는 레인이다: Sigma 이. 콜라이 L-아스파라기나아제 1000 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 500 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 250 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 125 μg/ml, 및 Sigma 이. 콜라이 L-아스파라기나아제 62.5 μg/ml. 겔 이미지의 우측의 화살표는 아스파라기나아제 타겟 단백질(35 kDa)의 이동을 나타낸다.
도 7. SDS-CGE 겔-유사 이미지 - 크리산타스파아제 진탕 플라스크 발현 분석. 가용성의 환원된 모세관 겔 전기영동(SDS-CGE)에 의해 측정된 바와 같이 상이한 성장 조건 하에서의 발현이 도시된다. 좌측에서 우측으로는 하기 샘플에서 관찰된 발현 패턴을 나타내는 레인이다: 래더 1(분자량 마커 68, 48, 29, 21, 및 16 KD); I0에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I0에서 STR55979(리더 O); I24에서 STR55979(리더 O); I24에서 STR55979(리더 O); I24에서 STR55979(리더 O); I0에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I0에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); 래더 2(래더 1에서와 동일한 마커); Sigma 이. 콜라이 AspG 1,000 ug/ml(표준 이. 콜라이 Asp2); Sigma 이. 콜라이 AspG 500 ug/ml; Sigma 이. 콜라이 AspG 250 ug/ml; Sigma 이. 콜라이 AspG 125 ug/ml; Sigma 이. 콜라이 AspG 62.5 ug/ml; 및 래더 3(래더 1에서와 동일한 마커), 이때 I0 샘플은 유도 시에 채취되고, I24 샘플은 유도 후 24 시간에 채취된다. 우측의 화살표는 이. 콜라이 L-Asp2 (35 KD)의 이동을 나타낸다.
도 8은 단백질 발현 샘플의 분석을 위한 LC-MS 출력값을 나타낸다.
도 1은 TrxA 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 2는 Gal2 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 3은 mrPA 발현에 대한 SDS-CGE 겔-유사 이미지를 나타낸다.
도 4. 크리산타스파아제 예시 서열. 크리산타스파아제를 코딩하는 예시적인 핵산 서열(서열 번호 8)은 상응하는 아미노산 서열(서열 번호 7)과 함께 나타낸다. 또한, 도 4는 서열 번호 20으로서 클로닝 부위를 포함하는 전장 뉴클레오타이드 서열를 개시한다.
도 5. SDS-CGE 겔-유사 이미지 - 크리산타스파아제 발현 플라스미드 스크린. DC454(상부 패널) 및 DC441(하부 패널) 유래의 크리산타스파아제 소규모 성장 전체 브로스 초음파 처리 가용성 샘플은 환원된 SDS-CGC에 의해 분석되었다. 가장 좌측의 레인은 분자량 마커 래더 1(상부 패널 MW 래더 48 KD, 29 KD; 하부 패널 MW 래더 48 KD, 29 KD, 21 KD)를 나타내고, 가장 우측의 레인은 동일한 래더를 나타낸다. 좌측에서 우측으로(레인 1에서 46), 래더 1의 바로 우측에서 시작하는 것은, 하기 분비 리더 펩타이드가 크리산타스파아제 단백질의 N-말단에 융합된 경우에 관찰된 발현 패턴을 나타내는 레인이다(달리 언급하는 경우를 제외하고 고 RBS): 리더 없음; DsbD; 리더 A; DsbA; DsbA-중 RBS; Azu; Azu-중 RBS; Lao; Ibp-S31A; TolB; DC432 눌(null)(단지 플라스미드 벡터만을 보유하는 야생형 호스트 균주); Tpr; Ttg2C; FlgI; CupC2; CupB2; Pbp; PbpA20V; DsbC; 리더 B; 리더 C; DC432 null; 리더 D; 리더 E; 리더 F; 리더 G; 리더 H; PorE; 리더 I; 리더 J; 리더 K; 리더 L; DC432 눌; 리더 M; 리더 N; 리더 O; 5193; 리더 P; 리더 Q; 리더 R; 8484; 리더 S; 리더 T; DC432 눌. 겔 이미지의 우측의 화살표는 크리산타스파아제 타겟 단백질(35 kDa)의 이동을 나타낸다.
도 6. SDS-CGE 겔-유사 이미지 - 이. 콜라이 아스파라기나아제 발현 플라스미드 스크린. 아스파라기나아제 소규모(0.5 ml) 성장 전체 브로스 초음파 처리 가용성(상부 패널) 및 불용성(하부 패널) 샘플은 환원된 SDS-CGE에 의해 분석되었다. 가장 좌측의 레인은 분자량 마커 래더(상부 패널 MW 래더 119 kDa, 68 KDa, 48 kDa, 29 kDa, 21 kDa, 16 kDa; 하부 패널 MW 래더 119 kDa, 68 KDa, 48 kDa, 29 kDa, 21 kDa, 16 kDa)를 나타내고, 가장 우측의 레인은 동일한 래더를 나타낸다. 좌측에서 우측으로 래더 1의 바로 우측에서 시작하는 것은 눌, STR55467, STR55689, STR55559, STR55561, STR55569, STR55575, STR55555, STR55571, STR55560, STR55570, STR55572, STR55601, STR55585, STR55592, STR55501, 및 대조군에서 관찰된 발현 패턴을 나타내는 레인이다: Sigma 이. 콜라이 L-아스파라기나아제 1000 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 500 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 250 μg/ml, Sigma 이. 콜라이 L-아스파라기나아제 125 μg/ml, 및 Sigma 이. 콜라이 L-아스파라기나아제 62.5 μg/ml. 겔 이미지의 우측의 화살표는 아스파라기나아제 타겟 단백질(35 kDa)의 이동을 나타낸다.
도 7. SDS-CGE 겔-유사 이미지 - 크리산타스파아제 진탕 플라스크 발현 분석. 가용성의 환원된 모세관 겔 전기영동(SDS-CGE)에 의해 측정된 바와 같이 상이한 성장 조건 하에서의 발현이 도시된다. 좌측에서 우측으로는 하기 샘플에서 관찰된 발현 패턴을 나타내는 레인이다: 래더 1(분자량 마커 68, 48, 29, 21, 및 16 KD); I0에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I24에서 STR55987(리더 없이 세포질 발현); I0에서 STR55979(리더 O); I24에서 STR55979(리더 O); I24에서 STR55979(리더 O); I24에서 STR55979(리더 O); I0에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I24에서 STR55980(8484 리더); I0에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); I24에서 STR55982(눌 플라스미드); 래더 2(래더 1에서와 동일한 마커); Sigma 이. 콜라이 AspG 1,000 ug/ml(표준 이. 콜라이 Asp2); Sigma 이. 콜라이 AspG 500 ug/ml; Sigma 이. 콜라이 AspG 250 ug/ml; Sigma 이. 콜라이 AspG 125 ug/ml; Sigma 이. 콜라이 AspG 62.5 ug/ml; 및 래더 3(래더 1에서와 동일한 마커), 이때 I0 샘플은 유도 시에 채취되고, I24 샘플은 유도 후 24 시간에 채취된다. 우측의 화살표는 이. 콜라이 L-Asp2 (35 KD)의 이동을 나타낸다.
도 8은 단백질 발현 샘플의 분석을 위한 LC-MS 출력값을 나타낸다.
개관
숙주 세포에서 높은 레벨의 적절하게 프로세싱된 재조합 단백질 또는 폴리펩타이드의 생산을 위한 조성물 및 방법이 제공된다. 특히, 그람 음성 박테리아의 주변세포질로 또는 세포외 환경 내로 관심 재조합 단백질 또는 폴리펩타이드의 타겟팅을 촉진하는 신규의 분비 신호가 제공된다. 본 출원에 개시된 주변세포질 분비 리더는 그람 음성 박테리아에서 내막을 가로질러 주변세포질 공간으로 단백질의 수송을 가능하게 한다. 재조합 발현의 경우, 주변세포질 발현은 주변세포질에서 다이설파이드 결합의 형성을 가능하게 하고, 몇몇 경우에, 높은 레벨의 재조합 단백질 발현을 가능하게 한다. 또한, 주변세포질 공간으로의 발현은 재조합 단백질의 더 효율적인 회수/정제를 가능하게 할 수 있다. 본 개시내용의 목적을 위해, "분비 신호", "분리 리더", "분비 신호 폴리펩타이드", "신호 펩타이드", 또는 "리더 서열"은 관심 단백질 또는 폴리펩타이드를 그람 음성 박테리아의 주변세포질로 또는 세포외 공간 내로 타겟팅하는데 유용한 펩타이드 서열(또는 펩타이드 서열을 코딩하는 폴리뉴클레오타이드)을 의미한다. 본 발명의 분비 신호 서열은 AnsB, 8484, 및 5193 분비 신호, 및 이의 단편 및 변이체로부터 선택된 분비 리더를 포함한다. 분비 신호를 위한 아미노산 서열은 서열 번호 1-3에 기재되어 있다. 서열 번호 1-3을 코딩하고 본 발명의 방법에 유용한 뉴클레오타이드의 예는 각각 서열 번호 4-6에 제공된다(표 1). 당해 기술분야의 통상의 기술자에게 공지된 바와 같이, 아미노산 서열은 유전 코드의 축퇴성으로 인해 상이한 뉴클레오타이드 서열에 의해 코딩될 수 있다. 따라서, 본 발명은 동일한 아미노산 서열을 보유하지만, 상이한 뉴클레오타이드 서열에 의해 코딩되는 펩타이드 또는 단백질의 사용을 포함한다. 또한, 본 출원에서 작동 가능하게 연결된 관심 재조합 단백질 또는 폴리펩타이드의 주변세포질 발현을 유도할 수 있는 이들 분비 신호 서열의 단편 및 변이체가 제공된다.

본 발명에 개시된 방법은 부적절하게 폴딩되거나, 응집되거나 또는 불활성인 단백질이 종종 생산되는, 현재의 박테리아에서의 재조합 단백질 생산 방법의 개선점을 제공한다. 추가적으로, 많은 타입의 단백질이 공지된 방법을 사용하여 비효율적으로 달성되는 2차 변형을 필요로 한다. 본 출원의 방법은 세포내 환경으로부터 단백질을 분비시킴으로써 적절하게 폴딩되고, 가용성이고/이거나, 활성인 단백질의 수확을 증가시킨다. 그람 음성 박테리아에서, 세포질로부터 분비된 단백질은 종종 주변세포질 공간에서, 외막에 부착되거나, 또는 세포외 브로스 내에 종착된다. 또한, 상기 방법은 응집된 단백질로 이루어진 봉입체의 형성을 방지한다. 또한, 주변세포질 공간 내로의 분비는 적합한 다이설파이드 결합 형성을 용이하게 하는 효과를 보유한다(Bardwell et al., 1994, "Pathways of Disulfide Bond Formation in Proteins In Vivo," in Phosphate in microorganisms : cellular and molecular biology, eds. Torriani-Gorini et al., pp. 270-5, 및 Manoil, 2000, Methods in Enzymol. 326:35-47, 두 문헌 모두 본 출원에 참고로 인용됨). 재조합 단백질의 분비의 이점들은 단백질의 더 효율적인 단리; 가용성 및/또는 활성 형태의 단백질의 백분율에서의 증가로 귀결되는, 트랜스제닉 단백질의 적절한 폴딩 및 다이설파이드 결합 형성; 봉입체 형성의 감소 및 숙주 세포에 대한 독성의 감소를 포함한다. 몇몇 경우에서, 배양 배지 내로의 관심 단백질의 분비에 대한 가능성은 단백질 생산을 위해 회분식 배양보다는 연속 배양을 촉진한다.
그람 음성 박테리아는 그들의 이중막을 가로지르는 단백질의 활성 유출을 위한 수많은 시스템을 진화시켜 왔다. 이들 분비 경로는, 예를 들어 원형질막과 외막 둘 다를 가로지르는 1 단계 전위를 위한, ABC(타입 I) 경로, Path/Fla(타입 III) 경로, 및 Path/Vir(타입 IV) 경로; 원형질막을 가로지르는 전위를 위한 Sec(타입 II), Tat, MscL, 및 Holins 경로; 및 원형질막과 외막을 가로지르는 2 단계 전위를 위한, Sec-플러스-핌브리알 어셔 포린(Sec-plus-fimbrial usher porin)(FUP), Sec-플러스-오토트랜스포터(autotransporter)(AT), Sec-플러스-2-파트너 분비(Sec-plus-two partner secretion)(TPS), Sec-플러스-메인 터미널 브랜치(Sec-plue-main terminal branch)(MTB), 및 Tat-플러스-MTB 경로가 포함된다. 모든 박테리아가 이러한 모든 분비 경로를 보유하고 있지는 않다.
3가지 단백질 시스템(타입 I, III 및 IV)은 단일 에너지-커플링된 단계로 양쪽 막을 가로질러 단백질을 분비한다. 4가지 시스템(Sec, Tat, MscL 및 Holins)은 내막만을 가로질러 분비하고, 또 다른 4가지 시스템(MTB, FUP, AT 및 TPS)은 외막만을 가로질러 분비한다.
몇몇 경우에서, 본 출원의 신호 서열은 Sec 분비 시스템을 이용한다. Sec 시스템은 세포질막을 가로지르는 N-말단 분비 리더를 이용하여 단백질의 유출을 담당한다(참조: Agarraberes 및 Dice, 2001, Biochim Biophys Acta 1513:1-24; Muller et al., 2001, Prog Nucleic Acid Res Mol. Biol. 66:107-157). Sec 패밀리의 단백질 복합체는 원핵생물 및 진핵생물에서 보편적으로 발견된다. 박테리아 Sec 시스템은 수송 단백질, 샤페론 단백질(SecB) 또는 신호 인식 입자(SRP) 및 신호 펩티다아제(SPase I 및 SPase II)로 구성된다. 이. 콜라이에서의 Sec 수송 복합체는 SecY, SecE 및 SecG의 3가지 내재성 내막 단백질, 및 세포질 ATPase인 SecA로 구성된다. SecA는 활성 전위 채널을 형성하도록 SecY/E/G 복합체를 동원한다. 샤페론 단백질 SecB는 신생 폴리펩타이드 사슬에 결합하여, 이의 폴딩을 방지하고, 이를 SecA에 타겟팅한다. 이어서, 선형 폴리펩타이드 사슬은 SecYEG 채널을 통해 수송되고, 신호 펩타이드의 절단 후, 단백질은 주변세포질에서 폴딩된다. 3개의 보조 단백질(SecD, SecF 및 YajC)은 분비를 필수적인 것은 아니지만, 많은 조건 하에서, 특히 저온에서 최대 10배까지 분비를 자극하는 복합체를 형성한다.
또한, 주변세포질 내로, 즉 타입 II 분비 시스템을 통해 수송되는 단백질은 추가적인 단계에서 세포외 배지 내로 유출된다. 일반적으로 상기 메커니즘은 오토트랜스포터, 2 파트너 분비 시스템, 메인 터미널 브랜치 시스템 또는 핌브리알 어셔 포린을 통한 것이다.
그람 음성 박테리아의 12개의 공지된 분비 시스템 중에서, 8개가 발현된 단백질의 일부분으로서 확인된 타겟팅 신호 펩타이드를 이용하는 것으로 공지되어 있다. 이들 신호 펩타이드는 분비 시스템의 단백질과 상호작용하여, 세포가 단백질을 그의 적합한 목적지로 유도하도록 한다. 이러한 8개의 신호 펩타이드 기반 분비 시스템 중 5개는 Sec 시스템과 관련된 것이다. 이들 5개는 Sec 의존성 세포질막 전위에 연루되는 것으로 언급되고, 몇몇 경우에 그 안에서 작동성인 그들의 신호 펩타이드는 Sec 의존성 분비 신호로 언급된다. 적합한 분비 신호의 개발에 있어서 쟁점 중 하나는 상기 신호의 적절한 발현 및 발현된 단백질로부터 절단이 담보되어야 한다는 것이다.
일반적으로, sec 경로를 위한 신호 펩타이드는 하기 3개의 도메인을 보유한다: (i) 양으로 하전된 n-영역, (ii) 소수성 영역 및 (iii) 하전되지 않았지만 극성인 c-영역. 신호 펩티다아제에 대한 절단 부위는 c-영역 내에 위치된다. 그러나, 종종 신호 서열 보존 및 길이의 정도, 뿐만 아니라 절단 부위 위치는 상이한 단백질들 사이에서 다를 수 있다.
Sec-의존성 단백질 유출에 대한 서명은 유출된 단백질 내에 짧은(아미노산 약 30개), 주로 소수성 아미노-말단 신호 서열의 존재이다. 신호 서열은 단백질 유출을 돕고, 유출된 단백질이 주변세포질에 도달하는 경우, 주변세포질 신호 펩티다아제에 의해 절단되어 제거된다. 전형적인 N-말단 Sec 신호 펩타이드는 적어도 하나의 아르기닌 또는 라이신 잔기를 보유하는 N-도메인, 이에 후속하는 일련의 소수성 잔기의 스트레치를 함유하는 도메인, 및 신호 펩티다아제에 대한 절단 부위를 함유하는 C-도메인을 함유한다.
단백질을 세포질 밖으로 타겟팅하기 위한 시도에서 관심 단백질 및 분비 신호 둘 다를 함유하는 융합 단백질로서 트랜스제닉 단백질 구축물이 조작된 박테리아 단백질 생산 시스템이 개발되어 왔다.
피. 플루오레센스는 다양한 단백질의 생산을 위한 개선된 플랫폼인 것으로 입증되었고, 몇몇 효율적인 분비 신호가 이러한 유기체로부터 확인되었다(참조: 그 전체 내용이 본 출원에 참고로 인용된, "Sec-시스템 분비를 이용하는 발현 시스템"이라는 명칭의 미국 특허 제7,985,564호). 피. 플루오레센스는 다른 박테리아 발현 시스템에서 전형적으로 확인되는 것보다 더 높은 레벨로 정확하게 프로세싱된 형태로 외인성 단백질을 생산하고, 이들 단백질을 세포의 주변세포질에 더 높은 레벨로 수송하여, 완전히 프로세싱된 재조합 단백질의 회수를 증가시킨다. 따라서, 한 실시양태에서, 본 출원에서 분비 신호에 작동 가능하게 연결된 타겟 단백질을 발현시킴으로써 피. 플루오레센스 세포에서 외인성 단백질을 생산하기 위한 방법이 제공된다.
몇몇 경우에서, 본 출원의 분비 신호 서열은 슈도모나스(Pseudomonas)에서 유용하다. 슈도모나스 시스템은 다른 박테리아 발현 시스템과 비교하여 폴리펩타이드 및 효소의 상업적인 발현을 위한 장점을 제공한다. 특히, 피. 플루오레센스는 유리한 발현 시스템으로 확인되어 왔다. 피. 플루오레센스는 토양, 물 및 식물 표면 환경에서 콜로니를 형성하는 일군의 일반적인 비-병원성 부패균(saprophyte)을 포괄한다. 피. 플루오레센스로부터 유래된 상업적인 효소들은 환경 오염을 감소시키기 위해 사용되어 왔는데, 세제 첨가물로서, 그리고 입체선택적 가수분해를 위해 사용되었다. 또한, 피. 플루오레센스는 병원체를 제어하기 위해 농업적으로 사용된다. "생물학적 살충제의 세포 캡슐화"라는 명칭의 미국 특허 제4,695,462호는 피. 플루오레센스에서의 재조합 박테리아 단백질의 발현을 기재하고 있다.
조성물
분비 리더
본 출원의 한 실시양태에서, 펩타이드가 제공되는데, 상기 펩타이드는 그람 음성 박테리아의 주변세포질로 또는 세포외 공간 내로 관심 단백질 또는 폴리펩타이드를 타겟팅하기 위해 유용한 신규 분비 리더 또는 신호이다. 한 실시양태에서, 상기 펩타이드는 AnsB, 8484, 또는 5193 분비 신호 또는 이의 단편 또는 변이체이거나, 이와 실질적으로 상동성인 아미노산 서열을 보유한다. 또한, 본 발명은 관심 타겟 단백질 또는 폴리펩타이드에 융합된 본 발명의 분비 신호 펩타이드를 포함하는 폴리펩타이드, 및 분비 신호 펩타이드 및 관심 폴리펩타이드를 포함하는 융합 단백질을 생산하는 발현 컨스트럭트를 제공한다. 실시양태에서, 분비 신호 펩타이드는 관심 폴리펩타이드에 작동 가능하게 연결된다.
실시양태에서, 분비 신호 서열은 서열 번호 1-3 중 임의의 서열 번호에 기재된 분비 신호 펩타이드와 상동성이거나, 실질적으로 상동성이거나, 또는 서열 번호 4-6 중 임의의 서열 번호에 기재된 폴리뉴클레오타이드에 의해 코딩된다. 다른 실시양태에서, 분비 신호 서열은 서열 번호 1의 적어도 아미노산 2-25, 서열 번호 2의 적어도 아미노산 2-18, 또는 서열 번호 3의 적어도 아미노산 2-29를 포함한다. 여전히 다른 실시양태에서, 분비 신호 서열은 서열 번호 1-3 중 하나의 단편을 포함하는데, 이는 아미노 말단으로부터 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 아미노산이 절단되나 생물학적 활성, 즉 분비 신호 활성은 유지된다.
한 실시양태에서, 상기 펩타이드의 아미노산 서열은 주어진 원래 펩타이드의 변이체인데, 상기 변이체의 서열은 최대 약 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, 또는 30%를 포함하는, 원래 펩타이드의 아미노산 잔기의 최대 또는 약 30%가 다른 아미노산 잔기(들)로 대체될 수 있으나, 단 변이체는 원래 펩타이드의 원하는 기능을 유지한다. 실질적인 상동성을 보유하는 변이체 아미노산은 원래 펩타이드와 적어도 약 70%, 적어도 약 75%, 적어도 약 80%, 약 85%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 또는 적어도 약 99% 상동성일 것이다. 변이체 아미노산 서열은 1 이상, 1-5, 1-10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25개, 또는 그 초과의 아미노산 치환, 결실, 삽입, 또는 이의 조합을 포함하는, 서열 번호 1-3 중 임의의 하나 이상의 아미노산의 아미노산 치환, 결실, 절단, 및 삽입을 포함하는 다양한 방식으로 얻어질 수 있다.
"실질적으로 상동성인", "실질적으로 동일한", 또는 "실질적으로 유사한"은 표준 파라미터를 이용하는 당해 기술분야에 공지되거나 본 출원에 기재된 적합한 정렬 프로그램을 이용하여 참조 서열과 비교하는 경우, 약 또는 적어도 약 60%, 약 또는 적어도 약 65%, 약 또는 적어도 약 70%, 약 또는 적어도 약 75%, 약 또는 적어도 약 80%, 약 또는 적어도 약 85%, 약 또는 적어도 약 81%, 약 또는 적어도 약 82%, 약 또는 적어도 약 83%, 약 또는 적어도 약 84%, 약 또는 적어도 약 85%, 약 또는 적어도 약 86%, 약 또는 적어도 약 87%, 약 또는 적어도 약 88%, 약 또는 적어도 약 89%, 약 또는 적어도 약 90%, 약 또는 적어도 약 91%, 약 또는 적어도 약 92%, 약 또는 적어도 약 93%, 약 또는 적어도 약 94%, 약 또는 적어도 약 95%, 약 또는 적어도 약 96%, 약 또는 적어도 약 97%, 약 또는 적어도 약 98% 또는 약 또는 적어도 약 99%, 또는 그 초과의 서열 동일성을 보유하는 아미노산 또는 뉴클레오타이드 서열을 의미한다. 당해 기술분야의 통상의 기술자는 이들 값이 코돈 축퇴성, 아미노산 유사성, 리딩 프레임 위치결정 등을 고려함으로써 2개의 뉴클레오타이드 서열에 의해 코딩되는 단백질들의 상응하는 동일성을 결정하기 위해 적절하게 조정될 수 있다는 것을 인식할 것이다.
실시양태에서, 본 발명에 사용된 펩타이드, 단백질, 또는 폴리펩타이드는 "비필수" 아미노산 잔기의 하나 이상의 변형을 포함할 수 있다. 이와 관련하여, "비필수" 아미노산 잔기는 원래 펩타이드, 단백질, 또는 폴리펩타이드(또한 "유사체" 또는 "참조" 펩타이드, 단백질, 또는 폴리펩타이드로도 언급됨)의 활성(예를 들어, 아고니스트 활성)을 없애거나 실질적으로 감소시키지 않고 신규한 아미노산 서열 내에서 변경될 수 있는, 예를 들어 결실, 치환, 또는 유도체화될 수 있는 잔기이다. 몇몇 실시양태에서, 펩타이드, 단백질, 또는 폴리펩타이드는 "필수" 아미노산 잔기의 하나 이상의 변형을 포함할 수 있다. 이와 관련하여, "필수" 아미노산 잔기는 신규한 아미노산 서열 내에서 변경되는 경우, 예를 들어 결실, 치환, 또는 유도체화되는 경우 참조 펩타이드, 단백질, 또는 폴리펩타이드의 활성이 실질적으로 감소되거나 또는 없어지는 잔기이다. 필수 아미노산 잔기가 변경되는 그러한 실시양태에서, 변형된 펩타이드, 단백질 또는 폴리펩타이드는 원래 펩타이드, 단백질, 또는 폴리펩타이드의 활성을 보유할 수 있다. 치환, 삽입 및 결실은 펩타이드, 단백질, 또는 폴리펩타이드의 N-말단 및 C-말단에 존재할 수 있거나, 또는 내부 부분에 존재할 수 있다. 예를 들어, 펩타이드, 단백질, 또는 폴리펩타이드는 펩타이드, 단백질, 또는 폴리펩타이드 분자 전체에 걸쳐 연속적인 방식 또는 이격되는 방식 둘 다로 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개, 또는 그 초과의 치환을 포함할 수 있다. 단독으로, 또는 치환과의 조합으로, 펩타이드, 단백질, 또는 폴리펩타이드는 펩타이드, 단백질, 또는 폴리펩타이드 분자 전체에 걸쳐 재차 연속적인 방식 또는 이격되는 방식으로 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개, 또는 그 초과의 삽입을 포함할 수 있다. 단독으로 또는 치환 및/또는 삽입과의 조합으로 펩타이드, 단백질, 또는 폴리펩타이드는 펩타이드, 단백질, 또는 폴리펩타이드 분자 전체에 걸쳐 재차 연속적인 방식 또는 이격되는 방식으로 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개, 또는 그 초과의 결실을 포함할 수 있다. 단독으로 또는 치환, 삽입 및/또는 결실과의 조합으로 펩타이드, 단백질, 또는 폴리펩타이드는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10개 또는 그 초과의 아미노산 부가를 포함할 수 있다.
치환은 보존적 아미노산 치환을 포함한다. "보존적 아미노산 치환"은 아미노산 잔기가 유사한 측쇄, 또는 생리화학적 특성(예를 들어, 정전, 수소 결합, 등전, 소수성 특징)을 보유하는 아미노산으로 대체되는 것이다. 아미노산은 천연 발생 또는 비천연일 수 있다. 유사한 측쇄를 보유하는 아미노산 잔기의 패밀리는 당해 기술분야에 공지되어 있다. 이들 패밀리는 염기성 측쇄를 보유하는 아미노산(예를 들어, 라이신, 아르기닌, 히스티딘), 산성 측쇄를 보유하는 아미노산(예를 들어, 아스파르트산, 글루탐산), 하전되지 않은 극성 측쇄를 보유하는 아미노산(예를 들어, 글리신, 아스파라긴, 글루타민, 세린, 트레오닌, 타이로신, 메티오닌, 시스테인), 비극성 측쇄를 보유하는 아미노산(예를 들어, 알라닌, 발린, 루신, 이소루신, 프롤린, 페닐알라닌, 트립토판), β-분지된 측쇄를 보유하는 아미노산(예를 들어, 트레오닌, 발린, 이소루신) 및 방향족 측쇄를 보유하는 아미노산(예를 들어, 타이로신, 페닐알라닌, 트립토판, 히스티딘)을 포함한다.
본 출원에 포함된 변이체 펩타이드, 단백질, 또는 폴리펩타이드는 생물학적으로 활성이다. 즉, 그들은 원래 펩타이드, 단백질, 또는 폴리펩타이드의 바람직한 생물학적 활성을 계속 보유하는데, 예를 들어 변이체 분비 리더 펩타이드는 분비 신호 활성을 유지한다. "활성을 유지한다"는 변이체가 원래 펩타이드, 단백질, 또는 폴리펩타이드의 활성, 예를 들어 분비 신호 활성의 약 또는 적어도 약 30%, 약 또는 적어도 약 35%, 약 또는 적어도 약 40%, 약 또는 적어도 약 45%, 약 또는 적어도 약 50%, 약 또는 적어도 약 55%, 약 또는 적어도 약 60%, 약 또는 적어도 약 65%, 약 또는 적어도 약 70%, 약 또는 적어도 약 75%, 약 또는 적어도 약 80%, 약 또는 적어도 약 85%, 약 또는 적어도 약 81%, 약 또는 적어도 약 82%, 약 또는 적어도 약 83%, 약 또는 적어도 약 84%, 약 또는 적어도 약 85%, 약 또는 적어도 약 86%, 약 또는 적어도 약 87%, 약 또는 적어도 약 88%, 약 또는 적어도 약 89%, 약 또는 적어도 약 90%, 약 또는 적어도 약 91%, 약 또는 적어도 약 92%, 약 또는 적어도 약 93%, 약 또는 적어도 약 94%, 약 또는 적어도 약 95%, 약 또는 적어도 약 96%, 약 또는 적어도 약 97%, 약 또는 적어도 약 98% 또는 약 또는 적어도 약 99%, 약 또는 적어도 약 100%, 약 또는 적어도 약 110%, 약 또는 적어도 약 125%, 약 또는 적어도 약 150%, 약 또는 적어도 약 200% 또는 그 초과를 보유할 것임을 의미한다.
폴리뉴클레오타이드
본 개시내용은 또한 관심 단백질 또는 폴리펩타이드를 그람 음성 박테리아의 주변세포질로 또는 세포외 공간 내로 타겟팅하는데 유용한 신규한 분비 신호를 코딩하는 서열을 보유하는 핵산을 포함한다. 한 실시양태에서, 단리된 폴리뉴클레오타이드는 AnsB, 8484, 또는 5193 분비 신호 펩타이드와 실질적으로 상동성인 펩타이드 서열을 코딩한다. 다른 실시양태에서, 본 개시내용은 서열 번호 1의 적어도 아미노산 2-25, 서열 번호 2의 적어도 아미노산 2-18, 또는 서열 번호 3의 적어도 아미노산 2-29와 실질적으로 상동성인 펩타이드 서열을 코딩하는 핵산을 제공하거나, 또는 서열 번호 4-6으로 기재된 뉴클레오타이드 서열 중 임의의 하나와 실질적으로 상동성인 핵산을 제공하는데, 이들은 이들의 생물학적으로 활성인 변이체 및 단편을 포함한다. 다른 실시양태에서, 핵산 서열은 서열 번호 4-6으로 기재된 핵산 서열 중 임의의 하나와 약 또는 적어도 약 60%, 약 또는 적어도 약 65%, 약 또는 적어도 약 70%, 약 또는 적어도 약 75%, 약 또는 적어도 약 80%, 약 또는 적어도 약 85%, 약 또는 적어도 약 81%, 약 또는 적어도 약 82%, 약 또는 적어도 약 83%, 약 또는 적어도 약 84%, 약 또는 적어도 약 85%, 약 또는 적어도 약 86%, 약 또는 적어도 약 87%, 약 또는 적어도 약 88%, 약 또는 적어도 약 89%, 약 또는 적어도 약 90%, 약 또는 적어도 약 91%, 약 또는 적어도 약 92%, 약 또는 적어도 약 93%, 약 또는 적어도 약 94%, 약 또는 적어도 약 95%, 약 또는 적어도 약 96%, 약 또는 적어도 약 97%, 약 또는 적어도 약 98% 또는 약 또는 적어도 약 99%, 또는 그 초과로 동일하다.
실시양태에서, 본 출원의 분비 신호 펩타이드는 서열 번호 4-6으로 기재된 뉴클레오타이드 서열 중 임의의 하나와 실질적으로 상동성인 뉴클레오타이드 서열에 의해 코딩된다. 본 발명의 분비 신호 서열에 대해 실질적인 동일성을 보유하는 상응하는 분비 신호 펩타이드 서열은 당해 기술분야에 공지된 임의의 적합한 방법, 예를 들어 PCR, 하이브리드화 방법, 또는 문헌에 기재된 방법을 사용하여 확인될 수 있다. 참조, 예를 들어, Sambrook J, and Russell, D. W., 2001, Molecular Cloning: A Laboratory Manual. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY; 및 Innis, et al., 1990, PCR Protocols: A Guide to Methods and Applications; Academic Press, NY. 변이체 뉴클레오타이드 서열은 예를 들어 위치 지정 돌연변이유발을 이용함으로써 생성된 합성적으로 유도된 뉴클레오타이드 서열을 포함할 수 있다. 실시양태에서, 돌연변이유발된 서열은 여전히 본 출원에 개시된 분비 신호 펩타이드를 코딩한다. 변이체 분비 신호 펩타이드는 생물학적으로 활성이다. 즉, 그들은 천연 단백질의 바람직한 생물학적 활성을 계속 보유한다. 즉, 그들은 분비 신호 활성을 유지한다. "활성을 유지한다"는 변이체가 원래 분비 신호 펩타이드의 활성의 약 30%, 약 또는 적어도 약 35%, 약 또는 적어도 약 40%, 약 또는 적어도 약 45%, 약 또는 적어도 약 50%, 약 또는 적어도 약 55%, 약 또는 적어도 약 60%, 약 또는 적어도 약 65%, 약 또는 적어도 약 70%, 약 또는 적어도 약 75%, 약 또는 적어도 약 80%, 약 또는 적어도 약 85%, 약 또는 적어도 약 81%, 약 또는 적어도 약 82%, 약 또는 적어도 약 83%, 약 또는 적어도 약 84%, 약 또는 적어도 약 85%, 약 또는 적어도 약 86%, 약 또는 적어도 약 87%, 약 또는 적어도 약 88%, 약 또는 적어도 약 89%, 약 또는 적어도 약 90%, 약 또는 적어도 약 91%, 약 또는 적어도 약 92%, 약 또는 적어도 약 93%, 약 또는 적어도 약 94%, 약 또는 적어도 약 95%, 약 또는 적어도 약 96%, 약 또는 적어도 약 97%, 약 또는 적어도 약 98% 또는 약 또는 적어도 약 99%, 약 또는 적어도 약 100%, 약 또는 적어도 약 110%, 약 또는 적어도 약 125%, 약 또는 적어도 약 150%, 약 또는 적어도 약 200%, 또는 그 초과를 보유할 것임을 의미한다. 펩타이드, 단백질, 또는 폴리펩타이드 활성, 예를 들어 분비 신호 활성을 측정하기 위한 임의의 적합한 방법은 본 출원에서 논의된 실시예와 함께 당해 기술분야에 널리 공지되어 있다.
또한, 통상의 기술자는 몇몇 경우에서, 변화는 본 출원에서 제공된 뉴클레오타이드 서열 내로 돌연변이에 의해 도입되고, 그에 따라 분비 신호 펩타이드의 생물학적 활성을 변경시키지 않으면서, 코딩된 분비 신호 펩타이드의 아미노산 서열에서의 변화를 초래할 수 있다는 것을 이해할 것이다. 따라서, 단리된 핵산 분자 변이체는 종종 코딩된 단백질 내로 하나 이상의 아미노산 치환, 부가 또는 결실이 도입되도록 하나 이상의 뉴클레오타이드 치환, 부가, 또는 결실을 본 출원에 개시된 상응하는 뉴클레오타이드 서열 내로 도입함으로써 생성될 수 있다. 돌연변이는 임의의 표준 기법, 예를 들어 위치 지정 돌연변이유발 및 PCR 매개 돌연변이유발에 의해 도입될 수 있다.
핵산 및 아미노산
상동성
핵산 및 아미노산 서열 상동성은 본 출원에 개시된 것들을 포함하나 이들로 한정되지 않는 당해 기술분야에 공지된 임의의 적합한 방법에 따라 결정된다.
예를 들어, 유사한 서열들에 대한 정렬 및 검색은 미국 NCBI(National Center for Biotechnology Information, Bethesda, MD)의 프로그램인 MegaBLAST를 사용하여 수행될 수 있다. 아미노산 서열에 대해 예를 들어 70%로 설정된, 또는 뉴클레오타이드 서열에 대해 예를 들어 90%로 설정된 동일성 백분율에 대한 옵션과 함께 이러한 프로그램을 사용하여, 질의 서열에 대한 서열 동일성이 70%, 또는 90%, 또는 그 초과인 서열들이 확인될 것이다. 또한, 당해 기술분야에 공지된 다른 소프트웨어는 유사한 서열, 예를 들어, 본 발명에 따른 분비 신호 서열을 함유하는 정보 문자열(string)에 대해 적어도 70% 또는 90% 동일한 서열을 정렬 및/또는 검색하기 위해 이용할 수 있다. 예를 들어, 종종 질의 서열에 대해 적어도 70% 또는 90% 동일한 서열을 확인하기 위한 비교용 서열 정렬은, 예를 들어 GCG 서열 분석 소프트웨어 패키지(1710 University Avenue, Madison, Wis. 53705에 소재하는 University of Wisconsin Biotechnology Center의 Genetics Computer Group으로부터 입수 가능)에서 입수 가능한 GAP, BESTFIT, BLAST, FASTA, 및 TFASTA 프로그램을 프로그램 내에 특정된 바와 같은 디폴트 파라미터 및 원하는 백분율로 설정된 서열 동일성 정도에 대한 파라미터와 함께 사용함으로써 수행될 수 있다. 또한, 예를 들어, CLUSTAL 프로그램(Mountain View, Cal.에 소재하는 Intelligenetics로부터 PC/Gene 소프트웨어 패키지로 입수 가능)이 사용될 수 있다.
이들 및 다른 서열 정렬 방법은 당해 기술 분야에 공지되어 있고, 수동 정렬에 의해, 육안 검사에 의해, 또는 서열 정렬 알고리즘, 예를 들어 상기 프로그램에 의해 구현되는 것들 중 임의의 것의 수동 또는 자동 적용에 의해 수행될 수 있다. 여러 가지 유용한 알고리즘은, 예를 들어 W. R. Pearson & D. J. Lipman, Proc. Natl. Acad. Sci. USA 85:2444-48 (April 1988)에 기재된 유사성 검색 방법; T. F. Smith & M. S. Waterman, in Adv. Appl. Math. 2:482-89 (1981) 및 J. Molec. Biol. 147:195-97 (1981)에 기재된 국소적인 상동성 방법; S. B. Needleman & C. D. Wunsch, J. Molec. Biol. 48(3):443-53 (March 1970)에 기재된 상동성 정렬 방법; 및 예를 들어, W. R. Pearson, Genomics 11(3):.635-50 (November 1991); W. R. Pearson, Methods Molec. Biol. 24:307-31 & 25:365-89 (1994); D. G. Higgins & P. M. Sharp, Comp. Appl'ns in Biosci. 5:151-53 (1989) 및 in Gene 73(1):237-44 (15 Dec. 1988)]에 의해 기재된 다양한 방법을 포함한다.
Needleman and Wunsch (1970) 상기 참조의 알고리즘을 사용하는 GAP 버전 10은 하기 파라미터를 사용하여 서열 동일성 또는 유사성을 결정하기 위해 사용될 수 있다: GAP 가중치 50 및 길이 가중치 3, 및 nwsgapdna.cmp 스코어링 매트릭스를 사용하는 뉴클레오타이드 서열에 대한 % 동일성 및 % 유사성; GAP 가중치 8 및 길이 가중치 2, 및 BLOSUM62 스코어링 프로그램을 사용하는 아미노산 서열에 대한 % 동일성 또는 % 유사성. 또한, 균등 또는 유사한 프로그램은 당해 기술분야의 통상의 기술자에 의해 이해되는 바와 같이 사용될 수 있다. 예를 들어, 질의되는 임의의 2개의 서열에 대해, GAP 버전 10에 의해 생성된 상응하는 정렬에 비교하는 경우, 동일한 뉴클레오타이드 잔기 매치 및 동일한 서열 동일성 백분율을 보유하는 정렬을 생성하는 서열 비교 프로그램이 사용될 수 있다. 실시양태에서, 서열 비교는 질의 서열 또는 대상 서열, 또는 둘 다의 전체에 걸쳐 수행된다.
하이브리드화 조건
본 출원의 다른 관점에서, AnsB, 8484, 또는 5193 분비 신호 펩타이드와 실질적으로 유사한 서열을 보유하는 펩타이드를 코딩하는 서열을 보유하는 단리된 핵산에 하이브리드화하는 핵산이 제공된다. 특정 실시양태에서, 하이브리드화 핵산은 고도의 엄격성 조건 하에서 결합할 것이다. 다양한 실시양태에서, 하이브리드화는 예를 들어 서열 번호 4-6 중 하나 이상의 실질적으로 전체적인 길이에 걸쳐 분비 신호 펩타이드를 코딩하는 뉴클레오타이드 서열의 실질적으로 전체적인 길이에 걸쳐 일어난다. 핵산 분자는, 상기 핵산 분자가 서열 번호 4-6 중 하나 이상의 전체적일 길이의 적어도 80% 이상, 상기 전체적인 길이의 적어도 85%, 적어도 90%, 또는 적어도 95%에 하이브리드화하는 경우, 본 출원에 개시된 분비 신호 코딩 뉴클레오타이드 서열의 "실질적으로 전체적인 길이"에 하이브리드화한다. 달리 언급하지 않으면, "실질적으로 전체적인 길이"는, 상기 길이가 연속하는 뉴클레오타이드에서 측정되는 경우, 분비 신호 코딩 뉴클레오타이드 서열의 전체적인 길이의 적어도 80%를 의미한다(예를 들어, 서열 번호 4의 적어도 60개의 연속하는 뉴클레오타이드, 서열 번호 5의 적어도 43개의 연속하는 뉴클레오타이드, 또는 서열 번호 6의 적어도 43개의 연속하는 뉴클레오타이드 등).
하이브리드화 방법에서, 분비 신호 펩타이드를 코딩하는 뉴클레오타이드 서열 모두 또는 이의 일부분은 cDNA 또는 게놈 라이브러리를 스크리닝하기 위해 사용된다. 그러한 cDNA 및 게놈 라이브러리의 구축 방법은 당해 기술분야에 일반적으로 공지되어 있고, Sambrook and Russell, 2001에 개시되어 있다. 소위 하이브리드화 프로브는 게놈 DNA 단편, cDNA 단편, RNA 단편, 또는 기타 올리고뉴클레오타이드일 수 있고, 검출 가능한 기 예를 들어 32P, 또는 임의의 다른 검출 가능한 마커, 예를 들어 다른 방사성 동위원소, 형광 화합물, 효소, 또는 효소 보조인자로 표지될 수 있다. 종종 하이브리드화를 위한 프로브는 본 출원에 개시된 공지된 분비 신호 펩타이드 코딩 뉴클레오타이드 서열에 기초하여 합성 올리고뉴클레오타이드를 표지함으로써 제조된다. 뉴클레오타이드 서열 또는 코딩된 아미노산 서열 내의 보존된 뉴클레오타이드 또는 아미노산 잔기를 기초로 디자인된 축퇴성 프라이머는 추가적으로 사용될 수 있다. 프로브는 본 출원의 분비 신호 펩타이드 코딩 뉴클레오타이드 서열 또는 이의 단편 또는 변이체의 적어도 약 10개, 적어도 약 11개, 적어도 약 12개, 적어도 약 13개, 적어도 약 14개, 적어도 약 15개, 적어도 약 16개, 적어도 약 17개, 적어도 약 18개, 적어도 약 19개, 적어도 약 20개, 또는 그 초과의 연속적인 뉴클레오타이드에 엄격한 조건 하에 하이브리드화하는 뉴클레오타이드 서열의 영역을 전형적으로 포함한다. 하이브리드화를 위한 프로브의 제조 방법은 당해 기술분야에 일반적으로 공지되어 있고, 본 출원에 참고로 인용된 Sambrook and Russell, 2001에 개시되어 있다.
하이브리드화 기법에서, 공지된 뉴클레오타이드 서열 모두 또는 이의 일부분은 선택된 유기체로부터의 클로닝된 DNA 단편 또는 cDNA 단편의 집단(즉, 게놈 또는 cDNA 라이브러리) 내에 존재하는 다른 상응하는 뉴클레오타이드 서열에 선택적으로 하이브리드화하는 프로브로서 사용된다. 하이브리드화 프로브는 게놈 DNA 단편, cDNA 단편, RNA 단편, 또는 다른 올리고뉴클레오타이드일 수 있고, 검출 가능한 기 예를 들어 32P, 또는 임의의 다른 검출 가능한 마커로 표지될 수 있다. 따라서, 예를 들어, 본 출원의 분비 신호 펩타이드 코딩 뉴클레오타이드 서열을 기초하여 합성 올리고뉴클레오타이드를 표지함으로써 하이브리드화를 위한 프로브가 제조된다. 하이브리드화를 위한 프로브의 제조 방법 및 cDNA 및 게놈 라이브러리의 구축 방법은 당해 기술분야에 일반적으로 공지되어 있고, Sambrook et al., 1989, Molecular Cloning: A Laboratory Manual, 2nd ed., Cold Spring Harbor Laboratory Press, Plainview, New York에 개시되어 있다.
본 출원에 개시된 전체적인 분비 신호 펩타이드 코딩 뉴클레오타이드 서열, 또는 이의 하나 이상의 일부분은 분비 신호 펩타이드를 코딩하는 상응하는 뉴클레오타이드 서열 및 전령 RNA에 특이적으로 하이브리드화할 수 있는 프로브로 사용될 수 있다. 다양한 조건 하에서의 특이적 하이브리드화를 달성하기 위해, 그러한 프로브는 독특한 서열을 포함하고, 바람직하게는 길이가 적어도 약 10개 이상의 뉴클레오타이드이거나 또는 적어도 약 15개 이상의 뉴클레오타이드이다. 그러한 프로브는 PCR에 의해 선택된 유기체로부터 상응하는 분비 신호 펩타이드 코딩 뉴클레오타이드 서열을 증폭시키기 위해 사용될 수 있다. 이러한 기법은 원하는 유기체로부터 추가적인 코딩 서열을 단리하기 위해 사용될 수 있거나, 또는 유기체 내의 코딩 서열의 존재를 결정하기 위한 진단 분석법에서 사용될 수 있다. 하이브리드화 기법은 플레이팅된 DNA 라이브러리(플라크 또는 콜로니; 예를 들어, Sambrook et al., 1989 참조)의 하이브리드화 스크리닝을 포함한다.
그러한 서열의 하이브리드화는 엄격한 조건 하에 수행될 수 있다. "엄격한 조건" 또는 "엄격한 하이브리드화 조건"은 프로브가 그의 타겟 서열에 다른 서열보다 검출 가능하게 더 큰 정도로 하이브리드화할 조건을 의미한다(예를 들어, 배경에 비해 적어도 2배). 엄격한 조건은 서열 의존적이고, 상이한 환경에서 달라질 것이다. 하이브리드화 및/또는 세정 조건의 엄격성을 제어함으로써, 프로브에 100% 상보적인 타겟 서열이 확인될 수 있다(상동성 프로빙). 대안적으로, 종종 엄격성 조건을 조정하여, 더 낮은 정도의 유사성이 검출되도록 서열 내에 약간의 미스매칭을 허용할 수 있다(이종성 프로빙). 일반적으로, 프로브는 길이가 약 1000개 미만의 뉴클레오타이드, 바람직하게는 길이가 500개 미만의 뉴클레오타이드이다.
전형적으로, 엄격한 조건은 pH 7.0 내지 8.3에서 염 농도가 Na 이온 약 1.5 M 미만, 전형적으로는 Na 이온(또는 다른 염) 농도 약 0.01 내지 1.0 M이고, 온도가 적어도 약 60℃인 조건이다. 실시양태에서, 상기 온도는 약 68℃이다. 또한, 엄격한 조건은 포름아미드와 같은 불안정화제의 첨가에 의해 달성될 수 있다. 낮은 엄격성 조건은 예를 들어 37℃에서의 30 내지 35% 포름아미드, 1 M NaCl, 1% SDS(나트륨 도데실 설페이트)의 완충용액을 이용하는 하이브리드화, 및 50 내지 55℃에서의 1X 내지 2X SSC(20X SSC = 3.0 M NaCl/0.3 M 3나트륨 시트레이트)에서의 세정을 포함한다. 예시적인 중등도의 엄격성 조건은 37℃에서의 40 내지 45% 포름아미드, 1.0 M NaCl, 1% SDS에서의 하이브리드화, 및 55 내지 60℃에서의 0.5X 내지 1X SSC에서의 세정을 포함한다. 예시적인 높은 엄격성 조건은 37℃에서의 50% 포름아미드, 1 M NaCl, 1% SDS에서의 하이브리드화, 및 60 내지 68℃에서의 0.1X SSC에서의 세정을 포함한다. 경우에 따라, 세정 완충용액은 약 0.1% 내지 약 1% SDS를 포함할 수 있다. 일반적으로, 하이브리드화의 지속 기간은 약 24 시간 미만, 전형적으로 약 4 시간 내지 약 12 시간이다.
특이성은 전형적으로 하이브리드화 후의 세정의 함수이고, 결정적인 인자는 최종 세정 용액의 이온 강도 및 온도이다. DNA-DNA 하이브리드의 경우, Meinkoth and Wahl (1984) Anal. Biochem. 138:267-284의 식으로부터 Tm의 근사값을 구할 수 있다: Tm = 81.5℃ + 16.6(log M) + 0.41(%GC) - 0.61(% form) - 500/L; 여기서, M은 1가 양이온의 몰 농도이고, %GC는 DNA 내의 구아노신 및 사이토신 뉴클레오타이드의 백분율이며, % form은 하이브리드화 용액 내의 포름아미드의 백분율이며, L은 염기 쌍 내의 하이브리드의 길이이다. Tm은 상보적인 타겟 서열의 50%가 완벽하게 매칭된 프로브에 하이브리드화하는 온도(규정된 이온 강도 및 pH 하에서의 온도)이다. Tm은 각각 1%의 미스 매칭에 대해 약 1℃만큼 감소한다; 따라서, 원하는 동일성의 서열에 하이브리드화하도록 Tm, 하이브리드화, 및/또는 세정 조건을 조정할 수 있다. 예를 들어, >90% 동일성의 서열을 찾는 경우, Tm은 종종 10℃ 감소된다. 일반적으로, 엄격한 조건은 규정된 이온 강도 및 pH에서의 특정 서열 및 이의 상보물에 대한 열 융점(Tm)보다 약 5℃ 더 낮도록 선택된다. 그러나, 과도하게 엄격한 조건은 종종 열 융점(Tm)보다 1, 2, 3, 또는 4℃ 더 낮은 온도에서의 하이브리드화 및/또는 세정을 이용하고, 중등도로 엄격한 조건은 종종 열 융점(Tm)보다 6, 7, 8, 9, 또는 10℃ 더 낮은 온도에서의 하이브리드화 및/또는 세정을 이용하며, 낮은 엄격성 조건은 종종 열 융점(Tm)보다 11, 12, 13, 14, 15, 또는 20℃ 더 낮은 온도에서의 하이브리드화 및/또는 세정을 이용한다. 관계식, 하이브리드화 및 세정 조성물, 및 원하는 Tm을 사용하여, 통상의 기술자는 하이브리드화 및/또는 세정 용액의 엄격성에서의 변동이 내재적으로 기재된다는 것을 이해할 것이다. 원하는 정도의 미스매칭이 45℃(수용액) 또는 32℃(포름아미드 용액) 미만의 Tm을 초래하는 경우, 더 높은 온도가 사용될 수 있도록 SSC 농도를 증가시키는 것이 바람직하다. 핵산의 하이브리드화에 대한 안내는 Tijssen, 1993, Laboratory Techniques in Biochemistry and Molecular Biology - Hybridization with Nucleic Acid Probes, Part I, Chapter 2(Elsevier, New York); 및 Ausubel et al., eds 1995, Current Protocols in Molecular Biology, Chapter 2(Greene Publishing and Wiley-Interscience, New York)에서 확인된다. Sambrook et al., 1989 참조.
코돈 최적화
한 실시양태에서, 본 출원의 조성물 및 방법은 관심 균주에서 코돈 용법에 대해 최적화된 컨스트럭트로부터 관심 재조합 단백질 또는 폴리펩타이드의 발현을 포함한다. 실시양태에서, 균주는 슈도모나스 숙주 세포, 예를 들어 슈도모나스 플루오레센스이다. 박테리아 호스트에서 발현을 개선하기 위해 코돈을 최적화하기 위한 방법은 당해 기술분야에 공지되어 있고, 문헌에 기재되어 있다. 예를 들어, 슈도모나스 호스트 균주에서 발현을 위한 코돈의 최적화는 예를 들어 그 전체 내용이 본 출원에 참고로 인용된 "코돈 최적화 방법"이라는 명칭의 미국 특허 출원 공보 제2007/0292918호에 기재되어 있다.
이종성 발현 시스템에서, 최적화 단계는 외래 단백질을 생산할 수 있는 호스트의 능력을 개선시킬 수 있다. 단백질 발현은 전사, mRNA 프로세싱, 및 번역의 안정성 및 개시에 영향을 미치는 것을 포함하는 다수의 요인들에 의해 통제된다. 폴리펩타이드 최적화 단계는 외래 단백질을 생산할 수 있는 호스트의 능력을 개선시키는 단계뿐만 아니라 발현 컨스트럭트를 효율적으로 디자인함에 있어서 연구자를 지원하는 단계를 포함할 수 있다. 최적화 전략은 예를 들어 번역 개시 영역의 변형, mRNA 구조 요소의 변경, 및 상이한 코돈 바이어스의 사용을 포함할 수 있다. 박테리아 호스트에서 이종성 단백질의 발현을 개선시키는 핵산 서열을 최적화하기 위한 방법은 당해 기술분야에 공지되어 있고, 문헌에 기재되어 있다. 예를 들어, 슈도모나스 호스트 균주에서 발현을 위한 코돈의 최적화는 예를 들어 그 전체 내용이 본 출원에 참고로 인용된 "코돈 최적화 방법"이라는 명칭의 미국 특허 출원 공보 제2007/0292918호에 기재되어 있다.
최적화는 이종성 유전자의 다수의 서열 특징 중 임의의 특징을 처리한다. 특정 예로서, 희귀 코돈 유도된 번역 정지는 종종 감소된 이종성 단백질 발현을 초래한다. 희귀 코돈 유도된 번역 정지는 가용한 tRNA 풀 내에서 그들의 희소성으로 인해 단백질 번역에 대해 부정적인 영향을 보유할 수 있는, 호스트 유기체 내에서 좀처럼 사용되지 않는 관심 폴리펩타이드 내의 코돈의 존재를 포함한다. 호스트 유기체 내에서 최적 번역을 개선하는 한 가지 방법은 종종 합성 폴리뉴클레오타이드 서열로부터 희귀 호스트 코돈의 제거를 초래하는 코돈 최적화를 수행하는 것을 포함한다.
또한, 교호 번역 개시는 종종 감소된 이종성 단백질 발현을 초래한다. 교호 번역 개시는 리보좀 결합 부위(RBS)로서 작용할 수 있는 모티프를 우연히 함유하는 합성 폴리뉴클레오타이드 서열을 포함한다. 몇몇 경우에서, 이들 부위는 유전자 내부 부위로부터 절단된 단백질의 번역 개시를 초래한다. 종종 정제 과정에서 제거하기 어려운 절단된 단백질의 생산 가능성을 감소시키는 한 가지 방법은 최적화된 뉴클레오타이드 서열로부터 추정적인 내부 RBS 서열을 제거하는 것을 포함한다.
종종 반복부 유도된 폴리머라아제 누출(slippage)은 감소된 이종성 단백질 발현을 초래한다. 반복부 유도된 폴리머라아제 누출은 종종 프레임쉬프트 돌연변이를 초래하는 DNA 폴리머라아제의 누출 또는 스터터링(stuttering)을 야기하는 것으로 확인되어 온 뉴클레오타이드 서열 반복부와 관련되어 있다. 또한, 이러한 반복부는 종종 RNA 폴리머라아제의 누출을 야기한다. 높은 G+C 함량 바이어스를 보유하는 유기체에서, 종종 G 또는 C 뉴클레오타이드 반복부로 구성된 더 높은 정도의 반복부가 존재한다. 따라서, RNA 폴리머라아제 누출을 유도할 확률을 감소시키는 한 가지 방법은 G 또는 C의 연장된 반복부를 변경시키는 것을 포함한다.
또한, 간섭 이차 구조는 종종 감소된 이종성 단백질 발현을 초래한다. 이차 구조는 종종 RBS 서열 또는 개시 코돈을 격리하고, 단백질 발현의 감소와 상관관계가 있어 왔다. 또한, 스템 루프 구조는 전사 정지 및 감쇠와 관련되어 있다. 최적화된 폴리뉴클레오타이드 서열은 일반적으로 개선된 전사 및 번역을 가능하도록 하기 위해 뉴클레오타이드 서열의 유전자 코딩 영역 및 RBS내 최소 이차 구조를 함유한다.
이종성 단백질 발현에 종종 영향을 미치는 다른 특징은 제한 부위의 존재이다. 호스트 발현 벡터 내로 전사 유닛의 후속적인 서브클로닝과 간섭할 수 있는 제한 부위를 제거함으로써, 폴리뉴클레오타이드 서열은 최적화된다.
예를 들어, 최적화 프로세스는 종종 호스트에 의해 이종성으로 발현되도록 원하는 아미노산 서열을 확인함으로써 개시된다. 상기 아미노산 서열로부터 후속 폴리뉴클레오타이드 또는 DNA가 디자인된다. 합성 DNA 서열의 디자인 과정 중, 코돈 용법의 빈도는 종종 호스트 발현 유기체의 코돈 용법과 비교되고, 희귀 호스트 코돈은 합성 서열로부터 제거된다. 아울러, 합성 후보 DNA 서열은 종종 바람직하지 않은 효소 제한 부위를 제거하고, 임의의 원하는 신호 서열, 링커 또는 비번역된 영역을 추가 또는 제거하기 위해 변형된다. 종종 합성 DNA 서열은 번역 프로세스와 간섭할 수 있는 이차 구조, 예를 들어 G/C 반복부 및 스템 루프 구조의 존재에 대해 분석된다. 후보 DNA 서열이 합성되기 이전에, 종종 최적화된 서열 디자인은, 상기 서열이 원하는 아미노산 서열을 올바르게 코딩하는지 검증하기 위해 검사된다. 최종적으로, 후보 DNA 서열은 당해 기술분야에 공지된 것과 같은 DNA 합성 기법을 이용하여 합성된다.
본 출원의 다른 실시양태에서, 호스트 유기체, 예를 들어 피. 플루오레센스에서의 일반적인 코돈 용법은 종종 이종성 폴리뉴클레오타이드 서열의 발현을 최적화하기 위해 사용된다. 호스트 발현 시스템 내에서 특정 아미노산에 대해 좀처럼 바람직한 것으로 고려되지 않는 코돈의 백분율 및 분포가 평가된다. 종종 5% 및 10% 용법의 값은 희귀 코돈의 결정을 위한 컷오프 값으로서 사용된다. 예를 들어, 표 2에 목록화된 코돈은 피. 플루오레센스 MB214 게놈에서 5% 미만의 계산된 출현율을 보유하고, 일반적으로 피. 플루오레센스 호스트에서 발현된 최적화된 유전자에서 회피된다.

본 개시내용은 슈도모나스 숙주 세포에서 발현을 위해 최적화된 임의의 서열을 사용하는 것을 포함하는 임의의 관심 폴리펩타이드 또는 단백질 코딩 서열의 사용을 고려한다. 사용을 위해 고려된 서열은 종종 원하는 바와 같이 임의의 정도로 최적화되는데, 이는 슈도모나스 숙주 세포에서 5% 미만으로 출현하는 코돈, 슈도모나스 숙주 세포에서 10% 미만으로 출현하는 코돈, 희귀 코돈 유도된 번역 정지, 추정적인 내부 RBS 서열, G 또는 C 뉴클레오타이드의 연장된 반복부, 간섭 2차 구조, 제한 부위, 또는 이의 조합을 제거하기 위한 최적화를 포함하나, 이들로 한정되는 것은 아니다.
또한, 본 출원에서 제공된 방법을 실시하는데 유용한 임의의 분비 리더의 아미노산 서열은 임의의 적합한 핵산 서열에 의해 코딩된다. 이. 콜라이에서의 발현을 위한 코돈 최적화는 예를 들어 Welch, et al., 2009, PLoS One, "Design Parameters to Control Synthetic Gene Expression in Escherichia coli," 4(9): e7002, Ghane, et al., 2008, Krishna R. et al., (2008) Mol Biotechnology "Optimization of the AT-content of Codons Immediately Downstream of the Initiation Codon and Evaluation of Culture Conditions for High-level Expression of Recombinant Human G-CSF in Escherichia coli," 38:221-232에 의해 기재된다.
발현 시스템
몇몇 경우에서, 본 출원의 방법은 AnsB, 8484, 또는 5193 분비 신호 서열, 또는 서열 번호 1-3으로서 본 출원에 개시된 분비 신호 펩타이드와 실질적으로 상동성인 서열로 구성되는 군으로부터 선택된 분비 신호 펩타이드에 작동 가능하게 연결된 관심 단백질 또는 폴리펩타이드를 포함하는 폴리펩타이드를 발현시키는 단계를 포함한다. 실시양태에서, 분비 신호 펩타이드 서열은 슈도모나스 숙주 세포내의 발현 컨스트럭트로부터 서열 번호 4-6으로 기재된 뉴클레오타이드 서열에 의해 코딩된다. 몇몇 경우에, 발현 컨스트럭트는 플라스미드이다. 몇몇 실시양태에서, 관심 폴리펩타이드 또는 단백질 서열을 코딩하는 플라스미드는 선택 마커를 포함하고, 플라스미드를 유지하는 숙주 세포는 선택적인 조건 하에서 성장된다. 몇몇 실시양태에서, 상기 플라스미드는 선택 마커를 포함하지 않는다. 몇몇 실시양태에서, 상기 발현 컨스트럭트는 숙주 세포 게놈 내로 통합된다.
슈도모나스 호스트 균주를 포함하는 호스트 균주에서 본 발명의 방법에서 유용한 조절 서열(예를 들어, 프로모터, 분비 리더, 및 리보좀 결합 부위)를 포함하는 이종성 단백질을 발현하기 위한 방법은 예를 들어 "증가된 발현을 위한 박테리아 리더 서열"이라는 명칭의 미국 특허 제7, 618,799호, "Sec-시스템 분비를 이용하는 발현 시스템"이라는 명칭의 미국 특허 제7,985,564호, 둘 다 "이종성 단백질의 발현에서 개선된 수율 및/또는 품질을 보유하는 특정 균주를 동정하기 위한 미생물 호스트를 신속하게 스크리닝하기 위한 방법"이라는 명칭의 미국 특허 제9,394,571호 및 제9,580,719호, "슈도모나스 플루오레센스에서 포유동물 단백질의 발현"이라는 명칭의 미국 특허 제9,453,251호, "균주 공학에 의해 개선된 단백질 발현을 위한 방법"이라는 명칭의 미국 특허 제8,603,824호, 및 "재조합 톡신 단백질의 고 레벨 발현"이라는 명칭의 미국 특허 제8,530,171호에 기재되어 있고, 이들 각각의 특허는 그 전체 내용이 본 출원에 참고로 인용된다. 실시양태에서, 본 발명의 맥락에서 사용된 분비 리더는 미국 특허 제7, 618,799호, 제7,985,564호, 제9,394,571호, 제9,580,719호, 제9,453,251호, 제8,603,824호, 및 제8,530,171호 중 임의의 특허에 개시된 바와 같은 분비 리더이다. 또한, 이들 특허는 이종성 단백질 발현을 증가시키기 위해, 폴딩 조절자를 과발현시키도록 조작되거나, 또는 프로테아제 돌연변이가 도입된 본 발명의 방법을 실시하는데 유용한 박테리아 호스트 균주를 기재하고 있다.
실시양태에서, 본 발명의 방법에 사용된 발현 균주는 표 13에 목록화된 바와 같이 실시예 4에 기재된 임의의 발현 균주이다. 실시양태에서, 본 발명의 방법에 사용된 발현 균주는 표 13에 목록화된 바와 같이 실시예 4에 기재된 발현 균주의 배경 표현형을 보유하는 미생물 발현 균주이다. 실시양태에서, 본 발명의 방법에 사용된 발현 균주는 표 13에 목록화된 바와 같이 실시예 4에 기재된 발현 균주의 배경 표현형을 보유하는 미생물 발현 균주이고, 이때 상기 균주는 표 13에 목록화된 바와 같이 각각의 분비 리더를 이용하는 융합에서 재조합 아스파라기나아제를 발현한다. 실시양태에서, 본 발명의 방법에서 사용된 발현 균주는 표 13에 목록화된 바와 같이 실시예 4에 기재된 발현 균주 STR57864, STR57865, STR57866, STR57860, STR57861, STR57862, STR57863의 배경 표현형을 보유하는 미생물 발현 균주이고, 발현 균주가 폴딩 조절자 과발현자인 것은 제외 된다. 실시양태에서, 본 발명의 방법에서 사용된 발현 균주는 만니톨 없이 배양된 표 13에 목록화된 바와 같이 실시예 4에 기재된 발현 균주 STR57864, STR57865, STR57866, STR57860, STR57861, STR57862, STR57863의 배경 표현형을 보유하는 미생물 발현 균주이다.
프로모터
본 출원의 방법에 따라 사용된 프로모터는 구성적 프로모터 또는 조절된 프로모터일 수 있다. 유용한 조절된 프로모터의 통상적인 예는 lac 프로모터(즉, lacZ 프로모터)로부터 유도된 패밀리의 프로모터, 특히 미국 특허 제4,551,433호(DeBoer)에 기재된 tac 및 trc 프로모터뿐만 아니라 Ptac16, Ptac17, PtacII, PlacUV5, 및 T7lac 프로모터를 포함한다. 한 실시양태에서, 프로모터는 숙주 세포 유기체로부터 유도되지 않는다. 특정 실시양태에서, 프로모터는 이. 콜라이 유기체로부터 유도된다.
유도성 프로모터 서열은 본 출원의 방법에 따라 관심 폴리펩타이드 또는 단백질의 발현을 조절하기 위해 사용된다. 실시양태에서, 본 출원의 방법에 유용한 유도성 프로모터는 lac 프로모터(즉, lacZ 프로모터)로부터 유도된 패밀리의 프로모터, 특히 미국 특허 제4,551,433호(DeBoer)에 기재된 tac 및 trc 프로모터뿐만 아니라 Ptac16, Ptac17, PtacII, PlacUV5, 및 T7lac 프로모터를 포함한다. 한 실시양태에서, 프로모터는 숙주 세포 유기체로부터 유도되지 않는다. 특정 실시양태에서, 프로모터는 이. 콜라이 유기체로부터 유도된다. 몇몇 실시양태에서, lac 프로모터는 플라스미드로부터 관심 폴리펩타이드 또는 단백질의 발현을 조절하기 위해 사용된다. Lac 프로모터 유도체 또는 패밀리 구성원, 예를 들어 tac 프로모터의 경우, 유도인자(inducer)는 IPTG(이소프로필-β-D-1-티오갈락토피라노사이드, "이소프로필티오갈락토사이드"로도 언급됨)이다. 특정 실시양태에서, IPTG는 슈도모나스 숙주 세포에서 lac 프로모터로부터 관심 폴리펩타이드 또는 단백질의 발현을 유도하기 위해 배양물에 첨가된다.
본 출원의 방법에 따른 발현 시스템에 유용한 비-lac 타입 프로모터의 통상적인 예는 예를 들어 표 3에 목록화된 것을 포함한다.

예를 들어 J. Sanchez-Rome & V. De Lorenz (1999) Manual of Industrial Microbiology and Biotechnology (A. Demain & J. Davies, eds.) pp. 460-74 (ASM Press, Washington, D.C.); H. Schneider (2001) Current Opinion in Biotechnology, 12:439-445; R. Slater & R. Williams (2000) Molecular Biology and Biotechnology (J. Walker & R. Replay, eds.) pp. 125-54 (The Royal Society of Chemistry, Cambridge, UK); 및 L.-M. Gunman, et al., 1995, J. Bacterial. 177(14):4121-4130을 참조할 수 있고, 이들 모두는 본 출원에 참고로 인용된다. 또한, 선택된 박테리아 숙주 세포 태생인 프로모터의 뉴클레오타이드 서열을 보유하는 프로모터, 예를 들어 슈도모나스 또는 벤조에이트 오페론 프로모터(Pant, Pben)는 관심 재조합 단백질 또는 폴리펩타이드를 코딩하는 트랜스유전자의 발현을 조절하기 위해 사용될 수 있다. 또한, 하나 이상의 프로모터가 다른 프로모터에 공유적으로 부착된 탠덤 프로모터가 사용될 수 있는데, 서열이 동일 또는 상이한 경우, 예를 들어 Pant-Pben 탠덤 프로모터(인터프로모터 하이브리드) 또는 Plac-Plac 탠덤 프로모터, 또는 동일 또는 상이한 유기체로부터 유도되는 것이 존재한다.
조절된 프로모터는 프로모터의 일부분인 유전자의 전사를 조절하기 위해 프로모터 조절 단백질을 이용한다. 본 출원에서 조절된 프로모터가 사용되는 경우, 상응하는 프로모터 조절 단백질은 또한 본 출원의 방법에 따른 발현 시스템의 일부분이 될 것이다. 프로모터 조절 단백질의 예는 활성화제 단백질, 예를 들어 이. 콜라이 이화대사산물 활성화제 단백질, MalT 단백질; AraC 패밀리 전사 활성화제; 억제인자 단백질, 예를 들어 이. 콜라이 LacI 단백질; 및 이중 기능 조절 단백질, 예를 들어 이. 콜라이 NagC 단백질을 포함한다. 많은 조절된 프로모터/프로모터 조절 단백질 쌍은 당해 기술분야에 공지되어 있다. 한 실시양태에서, 관심 타겟 단백질(들) 및 이종성 단백질을 위한 발현 컨스트럭트는 동일한 조절 요소의 조절하에 있다.
프로모터 조절 단백질은 효과 인자 화합물, 즉 조절 단백질과 가역적으로 또는 비가역적으로 연관되어 단백질이 방출되거나 또는 프로모터의 조절하에 있는 유전자의 적어도 하나의 DNA 전사 조절 영역에 결합할 수 있도록 함으로써 상기 유전자의 전사를 개시함에 있어서 효소의 작용을 허용하거나 또는 차단하는 화합물과 상호작용한다. 효과인자(effector) 화합물은 유도인자 또는 보조 억제인자로서 분류되고, 이들 화합물은 천연 효과인자 화합물 및 무상 유도인자 화합물을 포함한다. 많은 조절된 프로모터/프로모터 조절 단백질 쌍은 당해 기술분야에 공지되어 있다. 몇몇 경우에서, 효과인자 화합물은 세포 배양 또는 발효 과정 전체에 걸쳐 사용됨에도 불구하고, 조절된 프로모터가 사용되는 한 실시양태에서, 숙주 세포 바이오매스의 원하는 양 또는 밀도의 성장 후, 적합한 효과인자 화합물이 배양물에 직접적으로 또는 간접적으로 첨가되어 관심 단백질 또는 폴리펩타이드를 코딩하는 원하는 유전자(들)의 발현을 초래한다.
lac 패밀리 프로모터가 사용되는 실시양태에서, lacI 유전자는 종종 시스템 내에 존재한다. 보통 구성적으로 발현되는 유전자인 lacI 유전자는 Lac 억제인자 단백질 LacI 단백질을 코딩하는데, 이는 lac 패밀리 프로모터의 lac 오퍼레이터에 결합한다. 따라서, lac 패밀리 프로모터가 사용되는 경우, lacI 유전자는 또한 종종 발현 시스템 내에 포함되고 발현된다.
슈도모나스에 유용한 프로모터 시스템은 문헌, 예를 들어 참고적으로 상기 언급한 미국 특허 출원 공보 제2008/0269070호에 기재되어 있다.
다른 조절 요소
실시양태에서, 발현 벡터는 최적 리보좀 결합 서열을 함유한다. 관심 단백질의 번역 개시 영역을 변경시킴으로써 번역 강도를 조절하는 것은 너무 빠른 번역 속도에 기인하는 봉입체로서 주로 축적되는 이종성의 세포질 단백질의 생산을 개선시키기 위해 사용될 수 있다. 또한, 박테리아 세포의 주변세포질 공간 내로 이종성 단백질의 분비는 단백질 번역 레벨을 최대화한다기 보다는 최적화하여 번역 속도를 단백질 분비 속도와 동조되도록 함으로써 개선될 수 있다.
번역 개시 영역은 리보좀 결합 부위(RBS)의 바로 상류에서 개시 코돈의 대략 20개 뉴클레오타이드 하류에 연장되는 서열로서 규정되어 왔다(McCarthy et al. (1990) Trends in Genetics 6:78-85, 그 전체 내용이 본 출원에 참고로 인용됨). 원핵 세포에서, 대안적인 RBS 서열은 Shine 및 Dalgarno(Proc. Natl. Acad. Sci. USA 71:1342-1346, 1974)에 의해 기재된 표준 또는 컨센서스 RBS 서열(AGGAGG; 서열 번호 11)을 이용하여 번역 레벨에 대해 감소된 번역 속도를 제공함으로써 이종성 단백질의 번역 레벨을 최적화하기 위해 사용될 수 있다. "번역 속도" 또는 "번역 효율"은 세포 내에서 단백질로의 mRNA 번역의 속도를 의미한다. 대부분의 원핵 세포에서, 샤인-달가노 서열은 16S 리보좀 RNA의 피리미딘 풍부 영역과의 상호작용을 통해 mRNA 상의 개시 코돈에 대하여 30S 리보좀 성분의 결합 및 위치결정에 조력한다. RBS(본 출원에서 샤인-달가노 서열로도 언급된)는 전사 개시로부터 하류 및 번역 개시로부터 상류의 mRNA 상에 위치되는데, 전형적으로 개시 코돈의 4 내지 14개 뉴클레오타이드 상류, 더 전형적으로 개시 코돈의 8 내지 10개 뉴클레오타이드 상류에 위치된다. 번역에서 RBS 서열의 역할 때문에, 번역 효율과 RBS 서열의 효율(또는 강도) 사이에는 직접적인 관련성이 존재한다.
몇몇 실시양태에서, RBS 서열의 변형은 이종성 단백질의 번역 속도 감소를 초래한다. 이러한 번역 속도의 감소는 생산된 단백질 1 그램당 또는 호스트 단백질 1 그램 당 적절하게 프로세싱된 단백질 또는 폴리펩타이드의 레벨 증가에 대응할 수 있다. 또한, 감소된 번역 속도는 재조합 단백질 1 그램당 또는 숙주 세포 단백질 1 그램 당 생산된 횟수 가능한 단백질 또는 폴리펩타이드의 증가된 레벨과 상관관계가 있을 수 있다. 또한, 감소된 발현 속도는 증가된 발현, 증가된 활성, 증가된 용해도, 또는 증가된 전위(예를 들어, 주변세포질 구획 또는 세포외 공간으로의 분비)의 임의의 조합에 대응할 수 있다. 이러한 실시양태에서, "증가된"은 관심 단백질 또는 폴리펩타이드가 동일한 조건 하에서 발현되는 경우 생산된, 적절하게 프로세싱된, 가용성의, 및/또는 회수 가능한 단백질 또는 폴리펩타이드의 레벨에 대한 것이고, 이때 폴리펩타이드를 코딩하는 뉴클레오타이드 서열은 표준 RBS 서열을 포함한다. 유사하게, 용어 "감소된"은 관심 단백질 또는 폴리펩타이드의 번역 속도에 대한 것이고, 이때 단백질 또는 폴리펩타이드를 코딩하는 유전자는 표준 RBS 서열을 포함한다. 번역 속도는 적어도 약 5%, 적어도 약 10%, 적어도 약 15%, 적어도 약 20%, 약 25%, 약 30%, 약 35%, 약 40%, 약 45%, 약 50%, 약 55%, 약 60%, 약 65%, 약 70, 적어도 약 75% 또는 그 초과, 또는 적어도 약 2배, 약 3배, 약 4배, 약 5배, 약 6배, 약 7배, 또는 그 초과만큼 감소될 수 있다.
몇몇 실시양태에서, 본 출원에 기재된 RBS 서열 변이체는 고, 중, 또는 저의 번역 효율을 초래하는 것으로서 분류될 수 있다. 한 실시양태에서, 상기 서열은 표준 RBS 서열의 번역 활성과 비교한 번역 활성의 레벨에 따라 랭킹된다. 고 RBS 서열은 표준 서열의 활성의 약 60% 내지 약 100%를 보유한다. 중 RBS 서열은 표준 서열의 활성의 약 40% 내지 약 60%를 보유한다. 저 RBS 서열은 표준 서열의 활성의 약 40% 미만을 보유한다.
RBS 서열의 예는 표 4에 기재되어 있다. 서열들은 리포터 유전자로서 COP-GDP를 이용하여 번역 강도에 대해 스크리닝 되었고, 컨센서스 RBS 형광의 백분율에 따라 랭킹되었다. 각각의 RBS 변이체는 3개의 일반적인 형광 랭크 중 하나에 위치되었다: 고("Hi" - 100% 컨센서스 RBS 형광), 중("Med" - 46-51%의 컨센서스 RBS 형광), 및 저("Lo" - 16-29%의 컨센서스 RBS 형광).

본 발명의 방법을 실시하는데 유용한 발현 컨스트럭트는 단백질 코딩 서열 이외에 상기 서열에 작동 가능하게 연결된 후술하는 조절 요소를 포함한다: 프로모터, 리보좀 결합 부위(RBS), 전자 종결자, 및 번역 개시 및 종결 신호. 유용한 RBS는 예를 들어 미국 특허 출원 공보 제2008/0269070호 및 미국 특허 출원 제12/610,207호에 따라 발현 시스템 내에 숙주 세포로서 유용한 종 중에서 임의의 종으로부터 수득된다. 다수의 특이적인 및 다양한 컨센서스 RBS는 공지되어 있는데, 예를 들어 D. Frishman et al., Gene 234(2):257-65 (8 Jul. 1999); and B. E. Suzek et al., Bioinformatics 17(12):1123-30 (December 2001)에 기재 및 인용된 것들이다. 또한, 천연 또는 합성 RBS가 사용될 수 있는데, 예를 들어 EP 0207459(합성 RBS); O. Ikehata et al., Eur. J. Biochem. 181(3):563-70 (1989)에 기재된 것들이다. 본 출원의 방법에 유용한 방법, 벡터, 및 번역 및 전사 요소, 및 다른 요소는 예들 들어 미국 특허 제5,055,294호(Gilroy) 및 미국 특허 제5,128,130호(Gilroy et al.); 미국 특허 제5,281,532호(Rammler et al.); 미국 특허 제4,695,455호 및 제4,861,595호(Barnes et al.); 미국 특허 제4,755,465호(Gray et al.); 및 미국 특허 제5,169,760호(Wilcox)에 기재되어 있다.
호스트 균주
슈도모나드(Pseudomonads) 및 밀접하게 관련된 박테리아 유기체를 포함하는 박테리아 호스트는 본 출원의 방법을 실시하는데 사용하기 위해 고려된다. 특정 실시양태에서, 슈도모나드 숙주 세포는 슈도모나스 플루오레센스이다. 몇몇 경우에서, 숙주 세포는 이. 콜라이 세포이다.
본 출원의 방법을 실시하는데 유용한 숙주 세포 및 컨스트럭트는 문헌, 예를 들어 당해 기술분야에 공지된, 및 그 전체 내용이 본 출원에 참고로 인용된 "단백질 발현 시스템"이라는 명칭의 미국 특허 출원 공보 제2009/0325230호에 기재된 방법 및 시약을 이용하여 동정되거나, 또는 제조된다. 이러한 공보는 염색체 lacI 유전자 삽입물을 포함하는 영양요구성 슈도모나스 플루오레센스 숙주 세포 내로의 핵산 컨스트럭트의 도입에 의해 재조합 폴리펩타이드를 생산하는 것에 대해 기재되어 있다. 핵산 컨스트럭트는 숙주 세포 내에서 핵산의 발현을 유도할 수 있는 프로모터에 작동 가능하게 연결된 재조합 폴리펩타이드를 코딩하는 뉴클레오타이드 서열을 포함하고, 또한 영양요구성 선택 마커를 코딩하는 뉴클레오타이드 서열을 포함한다. 상기 영양요구성 선택 마커는 영양요구성 숙주 세포에 대해 독립영양성을 회복하는 폴리펩타이드이다. 실시양태에서, 상기 세포는 프롤린, 우라실, 또는 이의 조합에 대한 영양요구성이다. 실시양태에서, 숙주 세포는 MB101(ATCC 기탁번호 PTA-7841)로부터 유도된다. 둘 다 그 전체 내용이 본 출원에 참고로 인용된, "단백질 발현 시스템"이라는 명칭의 미국 특허 출원 공보 제2009/0325230호 및 Schneider, et al., 2005, "Auxotrophic markers pyrF and proC, in some cases, replace antibiotic markers on protein production plasmids in high-cell-density Pseudomonas fluorescens fermentation," Biotechnol. Progress 21(2): 343-8은 균주 MB101에서 pyrF 유전자를 결실시킴으로써 구축된 우라실에 대한 영양요구성인 생산 호스트 균주를 기재하고 있다. pyrF 유전자는 독립영양성을 회복하기 위해 pyrF 결실을 보충하는 플라스미드를 생성하기 위해 균주 MB214(ATCC 기탁번호 PTA-7840)로부터 클로닝되었다. 특정 실시양태에서, 피. 플루오레센스 숙주 세포 내의 이중 pyrF-proC 이중 영양요구성 선택 마커 시스템이 사용된다. 기재된 바와 같이 pyrF 결실된 생산 호스트 균주는 종종 본 출원의 방법을 실시하는데 유용한 것으로 본 출원에 기재된 것을 포함하는 다른 원하는 게놈 변화를 도입하기 위한 배경으로서 사용된다.
실시양태에서, 숙주 세포는 슈도모나달레(Pseudomonadales) 목의 것이다. 숙주 세포가 슈도모나달레 목의 것인 경우, 슈도모나스 속을 포함하는 슈도모나다세아에(Pseudomonadaceae) 과의 구성원일 수 있다. 감마 프로테오박테리아 호스트는 에스케리치아 콜라이 종의 구성원 및 슈도모나스 플루오레센스 종의 구성원을 포함한다. 슈도모나달레 목의 숙주 세포, 슈도모나다세아에 과의 숙주 세포, 또는 슈도모나스 속의 숙주 세포는 당해 기술분야의 통상의 기술자에 의해 동정될 수 있고, 문헌(예를 들어, Bergey's Manual of Systematics of Archaea and Bacteria (온라인 간행, 2015))에 기재되어 있다. 아울러, 그러한 균주에서, 당해 기술분야에 널리 알려진 방법을 이용하여, 프로테아제는 불활성화될 수 있고, 폴딩 조절자 과발현 컨스트럭트는 도입될 수 있다.
당해 기술분야의 통상의 기술자는, 본 발명의 방법에 유용한 생산 호스트 균주가 공적으로 이용 가능한 숙주 세포, 예를 들어 피. 플루오레센스를 이용하여, 예를 들어 당해 기술분야에 공지된 및 문헌에 기재된 적절한 방법을 이용하여 pyrF 유전자를 불활성화시킴으로써 생성될 수 있다는 것을 이해할 것이다. 또한, 독립영양성 회복 플라스미드는 균주 내로 형질전환될 수 있는데, 예를 들어 플라스미드는 당해 기술분야에 공지된 및 문헌에 기재된 다수의 적합한 방법 중 임의의 방법을 이용하여 균주 MB214로부터 pyrF 유전자를 운반하는 플라스미드이다. 아울러, 그러한 균주에서, 당해 기술분야에 널리 알려진 방법을 이용하여, 프로테아제는 불활성화될 수 있고, 폴딩 조절자 과발현 컨스트럭트는 도입될 수 있다.
또한, 다른 슈도모나스 유기체도 유용할 수 있다. 슈도모나드 및 밀접하게 관련된 종은 그람 음성 프로테오박테리아 서브그룹 1을 포함하는데, 이는 Bergey's Manual of Systematics of Archaea and Bacteria(온라인 간행, 2015)에 기재된 과 및/또는 속에 속하는 프로테오박테리아의 그룹을 포함한다. 표 5는 이들 유기체의 과 및 속을 나타낸다.

슈도모나스 및 밀접하게 관련된 박테리아는 일반적으로 "그람(-) 프로테오박테리아 서브그룹 1" 또는 "그람 음성 호기성 간균 및 구균"으로 정의된 그룹의 일부분이다(Bergey's Manual of Systematics of Archaea and Bacteria(온라인 간행, 2015)). 슈도모나스 호스트 균주는 문헌, 예를 들어 상기 인용된 미국 특허 출원 공보 제2006/0040352호에 기재되어 있다.
또한, "그람 음성 프로테오박테리아 서브그룹 1"은 분류에 사용된 기준에 따라 이러한 표제로 분류되는 프로테오박테리아를 포함한다. 또한, 상기 표제는 이전에는 이러한 섹션으로 분류되었지만 더 이상은 그렇지 않은 군, 예를 들어 애시도보락스(Acidovorax) 속, 브레분디모나스(Brevundimonas) 속, 부르크홀데리아(Burkholderia) 속, 히드로게노파가(Hydrogenophaga) 속, 오세아니모나스(Oceanimonas) 속, 랄스토니아(Ralstonia) 속 및 스테노트로포모나스(Stenotrophomonas) 속; 크산토모나스(Xanthomonas) 속에 속하는 (그리고 이전에는 크산토모나스 속의 종으로 칭해진) 유기체를 재분류하여 생성된 스핑고모나스(Sphingomonas) 속(및 이로부터 유래된 블라스토모나스(Blastomonas) 속); Bergey's Manual of Systematics of Archaea and Bacteria(온라인 간행, 2015)에 정의된 아세토박터(Acetobacter) 속에 속하는 유기체를 재분류하여 생성된 애시도모나스(Acidomonas) 속을 포함한다. 또한, 호스트는 슈도모나스 속, 슈도모나스 에날리아(Pseudomonas enalia)(ATCC 14393), 슈도모나스 니그리파시엔스(Pseudomonas nigrifaciens)(ATCC 19375) 및 슈도모나스 푸트레파시엔스(Pseudomonas putrefaciens)(ATCC 8071)로부터의 세포를 또한 포함할 수 있고, 이들은 각각 알테로모나스 할로플란크티스(Alteromonas haloplanktis), 알테로모나스 니그리파시엔스(Alteromonas nigrifaciens) 및 알테로모나스 푸트레파시엔스(Alteromonas putrefaciens)로 재분류되었다. 유사하게, 예를 들어, 슈도모나스 애시도보란스(Pseudomonas acidovorans)(ATCC 15668) 및 슈도모나스 테스토스테로니(Pseudomonas testosteroni)(ATCC 11996)는 각각 코마모나스 애시도보란스(Comamonas acidovorans) 및 코마모나스 테스토스테로니(Comamonas testosteroni)로 재분류되었고; 슈도모나스 니그리파시엔스(ATCC 19375) 및 슈도모나스 피스시시다(Pseudomonas piscicida)(ATCC 15057)는 각각 슈도알테로모나스 니그리파시엔스(Pseudoalteromonas nigrifaciens) 및 슈도알테로모나스 피스시다(Pseudoalteromonas piscicida)로 재분류되었다. 또한, "그람 음성 프로테오박테리아 서브그룹 1"은 임의의 하기 과에 속하는 것으로 분류된 프로토박테리아를 또한 포함한다: 슈도모나다세아에, 아조토박테라세아에(현재 슈도모나다세아에의 "아조토박터 그룹"이라는 동의어로 종종 칭해짐), 리조비아세아에, 및 메틸로모나다세아에(현재 "메틸로코카세아에(Methylococcaceae)"라는 동의어로 종종 언급됨) 따라서, 본원에 달리 기술된 속들에 더하여, "그람 음성 프로테오박테리아 서브그룹 1"에 속하는 추가적인 프로테오박테리아 속은: 1) 아조리조필루스(Azorhizophilus) 속의 아조토박터 그룹 박테리아; 2) 셀비브리오(Cellvibrio) 속, 올리겔라(Oligella) 속 및 테레디니박터(Teredinibacter) 속의 슈도모나다세아에 과 박테리아; 3) 켈라토박터(Chelatobacter) 속, 엔시페르(Ensifer) 속, 리베리박터(Liberibacter) 속("칸디다투스 리베리박터(Candidatus Liberibacter)"로 또한 칭해짐), 및 시노리조비움(Sinorhizobium) 속의 리조비아세아에 과 박테리아; 및 4) 메틸로박터(Methylobacter) 속, 메틸로칼둠(Methylocaldum) 속, 메틸로마이크로비움(Methylomicrobium) 속, 메틸로사르시나(Methylosarcina) 속 및 메틸로스파에라(Methylosphaera) 속의 메틸로코카세아에(Methylococcaceae) 과 박테리아를 포함한다.
몇몇 경우에서, 숙주 세포는 "그람 음성 프로테오박테리아 서브그룹 16"으로부터 선택될 수 있다. "그람 음성 프로테오박테리아 서브그룹 16"은 하기의 슈도모나스 종의 프로테오박테리아의 그룹으로서 정의된다(예시적인 균주(들)의 ATCC 또는 기타 기탁 번호가 괄호 안에 제시됨): 슈도모나스 아비에타니필라(Pseudomonas abietaniphila)(ATCC 700689); 슈도모나스 아에루지노사(Peudomonas aeruginosa)(ATCC 10145); 슈도모나스 알칼리게네스(Peudomonas alcaligenes)(ATCC 14909); 슈도모나스 안귈리셉티카(Pseudomonas anguilliseptica)(ATCC 33660); 슈도모나스 시트로넬로리스(Pseudomonas citronellolis)(ATCC 13674); 슈도모나스 플라베센스(Pseudomonas flavescens)(ATCC 51555); 슈도모나스 멘도시나(Pseudomonas mendocina)(ATCC 25411); 슈도모나스 니트로레두센스(Pseudomonas nitroreducens)(ATCC 33634); 슈도모나스 올레오보란스(Pseudomonas oleovorans)(ATCC 8062); 슈도모나스 슈도알칼리게네스(Pseudomonas pseudoalcaligenes)(ATCC 17440); 슈도모나스 레시노보란스(Pseudomonas resinovorans)(ATCC 14235); 슈도모나스 스트라미네아(Pseudomonas straminea)(ATCC 33636); 슈도모나스 아가리치(Pseudomonas agarici)(ATCC 25941); 슈도모나스 알칼리필라(Pseudomonas alcaliphila); 슈도모나스 알기노보라(Pseudomonas alginovora); 슈도모나스 안데르소니이(Pseudomonas andersonii); 슈도모나스 아스플레니이(Pseudomonas asplenii)(ATCC 23835); 슈도모나스 아젤라이카(Pseudomonas azelaica)(ATCC 27162); 슈도모나스 베이제린키이(Pseudomonas beijerinckii)(ATCC 19372); 슈도모나스 보레알리스(Pseudomonas borealis); 슈도모나스 보레오폴리스(Pseudomonas boreopolis)(ATCC 33662); 슈도모나스 브라시카세아룸(Pseudomonas brassicacearum); 슈도모나스 부타노보라(Pseudomonas butanovora)(ATCC 43655); 슈도모나스 셀룰로사(Pseudomonas cellulosa)(ATCC 55703); 슈도모나스 아우란티아카(Pseudomonas aurantiaca)(ATCC 33663); 슈도모나스 클로로라피스(Pseudomonas chlororaphis)(ATCC 9446, ATCC 13985, ATCC 17418, ATCC 17461); 슈도모나스 프라기(Pseudomonas fragi)(ATCC 4973); 슈도모나스 룬덴시스(Pseudomonas lundensis)(ATCC 49968); 슈도모나스 타에트롤렌스(Pseudomonas taetrolens)(ATCC 4683); 슈도모나스 시스시콜라(Pseudomonas cissicola)(ATCC 33616); 슈도모나스 코로나파시엔스(Pseudomonas coronafaciens); 슈도모나스 디테르페니필라(Pseudomonas diterpeniphila); 슈도모나스 엘롱가타(Pseudomonas elongata)(ATCC 10144); 슈도모나스 플렉텐스(Pseudomonas flectens)(ATCC 12775); 슈도모나스 아조토포르만스(Pseudomonas azotoformans); 슈도모나스 브렌네리(Pseudomonas brenneri); 슈도모나스 세드렐라(Pseudomonas cedrella); 슈도모나스 코루가타(Pseudomonas corrugata)(ATCC 29736); 슈도모나스 엑스트레모리엔탈리스(Pseudomonas extremorientalis); 슈도모나스 플루오레센스(ATCC 35858); 슈도모나스 게사르디이(Pseudomonas gessardii); 슈도모나스 리바넨시스(Pseudomonas libanensis); 슈도모나스 만델리이(Pseudomonas mandelii)(ATCC 700871); 슈도모나스 마르기날리스(Pseudomonas marginalis)(ATCC 10844); 슈도모나스 미굴라에(Pseudomonas migulae); 슈도모나스 무시돌렌스(Pseudomonas mucidolens)(ATCC 4685); 슈도모나스 오리엔탈리스(Pseudomonas orientalis); 슈도모나스 로데시아에(Pseudomonas rhodesiae); 슈도모나스 신잔타(Pseudomonas synxantha)(ATCC 9890); 슈도모나스 톨라아시이(Pseudomonas tolaasii)(ATCC 33618); 슈도모나스 베로니이(Pseudomonas veronii)(ATCC 700474); 슈도모나스 프레데릭스베르겐시스(Pseudomonas frederiksbergensis); 슈도모나스 게니쿨라타(Pseudomonas geniculata)(ATCC 19374); 슈도모나스 긴게리(Pseudomonas gingeri); 슈도모나스 그라미니스(Pseudomonas graminis); 슈도모나스 그리몬티(Pseudomonas grimontii); 슈도모나스 할로데니트리피칸스(Pseudomonas halodenitrificans); 슈도모나스 할로필라(Pseudomonas halophila); 슈도모나스 히비스시콜라(Pseudomonas hibiscicola)(ATCC 19867); 슈도모나스 후티엔시스(Pseudomonas huttiensis)(ATCC 14670); 슈도모나스 히드로게노보라(Pseudomonas hydrogenovora); 슈도모나스 제세니이(Pseudomonas jessenii)(ATCC 700870); 슈도모나스 킬로넨시스(Pseudomonas kilonensis); 슈도모나스 란세올라타(Pseudomonas lanceolata)(ATCC 14669); 슈도모나스 리니(Pseudomonas lini); 슈도모나스 마르기나타(Pseudomonas marginata)(ATCC 25417); 슈도모나스 메피티카(Pseudomonas mephitica)(ATCC 33665); 슈도모나스 데니트리피칸스(Pseudomonas denitrificans)(ATCC 19244); 슈도모나스 페르투치노게나(Pseudomonas pertucinogena)(ATCC 190); 슈도모나스 픽토룸(Pseudomonas pictorum)(ATCC 23328); 슈도모나스 사이크로필라(Pseudomonas psychrophila); 슈도모나스 필바(Pseudomonas filva)(ATCC 31418); 슈도모나스 몬테일리이(Pseudomonas monteilii)(ATCC 700476); 슈도모나스 모셀리이(Pseudomonas mosselii); 슈도모나스 오리지하비탄스(Pseudomonas oryzihabitans)(ATCC 43272); 슈도모나스 플레코글로시시다(Pseudomonas plecoglossicida)(ATCC 700383); 슈도모나스 푸티다(Pseudomonas putida)(ATCC 12633); 슈도모나스 레악탄스(Pseudomonas reactans); 슈도모나스 스피노사(Pseudomonas spinosa)(ATCC 14606); 슈도모나스 발레아리카(Pseudomonas balearica); 슈도모나스 루테올라(Pseudomonas luteola)(ATCC 43273); 슈도모나스 스투트제리(Pseudomonas stutzeri)(ATCC 17588); 슈도모나스 아미그달리(Pseudomonas amygdali)(ATCC 33614); 슈도모나스 아벨라나에(Pseudomonas avellanae)(ATCC 700331); 슈도모나스 카리카파파야에(Pseudomonas caricapapayae)(ATCC 33615); 슈도모나스 시코리이(Pseudomonas cichorii)(ATCC 10857); 슈도모나스 피쿠세렉타에(Pseudomonas ficuserectae)(ATCC 35104); 슈도모나스 푸스코바기나에(Pseudomonas fuscovaginae); 슈도모나스 멜리아에(Pseudomonas meliae)(ATCC 33050); 슈도모나스 시링가에(Pseudomonas syringae)(ATCC 19310); 슈도모나스 비리디플라바(Pseudomonas viridiflava)(ATCC 13223); 슈도모나스 테르모카록시도보란스(Pseudomonas thermocarhoxydovorans)(ATCC 35961); 슈도모나스 테르모톨레란스(Pseudomonas thermotolerans); 슈도모나스 티베르발렌시스(Pseudomonas thivervalensis); 슈도모나스 반코우베렌시스(Pseudomonas vancouverensis)(ATCC 700688); 슈도모나스 위스콘시넨시스(Pseudomonas wisconsinensis); 및 슈도모나스 시아메넨시스(Pseudomonas xiamenensis). 한 실시양태에서, 관심 폴리펩타이드 또는 단백질의 발현을 위한 숙주 세포는 슈도모나스 플루오레센스이다.
숙주 세포는 "그람 음성 프로테오박테리아 서브그룹 17"로부터 선택될 수 있다. "그람 음성 프로테오박테리아 서브그룹 17"은 예를 들어 하기의 슈도모나스 종에 속하는 것들을 포함하여 "형광성 슈도모나드"로 당해 기술분야에 공지된 프로테오박테리아의 그룹으로서 정의된다: 슈도모나스 아조토포르만스(Pseudomonas azotoformans); 슈도모나스 브렌네리(Pseudomonas brenneri); 슈도모나스 세드렐라(Pseudomonas cedrella); 슈도모나스 세드리나(Pseudomonas cedrina); 슈도모나스 코루가타(Pseudomonas corrugata); 슈도모나스 엑스트레모리엔탈리스(Pseudomonas extremorientalis); 슈도모나스 플루오레센스; 슈도모나스 게사르디이(Pseudomonas gessardii); 슈도모나스 리바넨시스(Pseudomonas libanensis); 슈도모나스 만델리이(Pseudomonas mandelii); 슈도모나스 마르기날리스(Pseudomonas marginalis); 슈도모나스 미굴라에(Pseudomonas migulae); 슈도모나스 무시돌렌스(Pseudomonas mucidolens); 슈도모나스 오리엔탈리스(Pseudomonas orientalis); 슈도모나스 로데시아에(Pseudomonas rhodesiae); 슈도모나스 신잔타(Pseudomonas synxantha); 슈도모나스 톨라아시이(Pseudomonas tolaasii); 및 슈도모나스 베로니이(Pseudomonas veronii).
프로테아제
한 실시양태에서, 본 출원에 제공된 방법은 관심 폴리펩타이드 또는 단백질을 생산하기 위해 하나 이상의 프로테아제 유전자에 하나 이상의 돌연변이(예를 들어, 부분적인 또는 완전한 결실)를 포함하는 슈도모나스 숙주 세포를 이용하는 것을 포함한다. 몇몇 실시양태에서, 프로테아제 유전자의 돌연변이는 가용성의 관심 폴리펩타이드 또는 단백질의 생성을 용이하게 한다.
예시적인 타겟 프로테아제 유전자는 아미노펩티다아제; 디펩티다아제; 디펩티딜-펩티다아제 및 트리펩티딜 펩티다아제; 펩티딜-디펩티다아제; 세린-타입 카르복시펩티다아제; 메탈로카르복시펩티다아제; 시스테인-타입 카르복시펩티다아제; 오메가펩티다아제; 세린 프로테이나아제; 시스테인 프로테이나아제; 아스파틱 프로테이나아제; 메탈로 프로테이나아제; 또는 미지 메카니즘의 프로테이나아제로서 분류된 프로테아제를 포함한다.
아미노펩티다아제는 세포질 아미노펩티다아제(루실 아미노펩티다아제), 막 알라닐 아미노펩티다아제, 시스티닐 아미노펩티다아제, 트리펩타이드 아미노펩티다아제, 프롤릴 아미노펩티다아제, 아르기닐 아미노펩티다아제, 글루타밀 아미노펩티다아제, x-pro 아미노펩티다아제, 박테리아 루실 아미노펩티다아제, 호열성 아미노펩티다아제, 클로스트리디얼 아미노펩티다아제, 세포질 알라닐 아미노펩티다아제, 라이실 아미노펩티다아제, x-trp 아미노펩티다아제, 트립토파닐 아미노펩티다아제, 메티오닐 아미노펩티다아제, d-입체특이적 아미노펩티다아제, 아미노펩티다아제 ey를 포함한다. 디펩티다아제는 x-his 디펩티다아제, x-arg 디펩티다아제, x-메틸-his 디펩티다아제, cys-gly 디펩티다아제, glu-glu 디펩티다아제, pro-x 디펩티다아제, x-pro 디펩티다아제, met-x 디펩티다아제, 비입체특이적 디펩티다아제, 세포질 비특이적 디펩티다아제, 막 디펩티다아제, 베타-ala-his 디펩티다아제를 포함한다. 디펩티딜-펩티다아제 및 트리펩티딜 펩티다아제는 디펩티딜-펩티다아제 i, 디펩티딜-펩티다아제 ii, 디펩티딜 펩티다아제 iii, 디펩티딜-펩티다아제 iv, 디펩티딜-디펩티다아제, 트리펩티딜-펩티다아제 I, 트리펩티딜-펩티다아제 II를 포함한다. 펩티딜-디펩티다아제는 펩티딜-디펩티다아제 a 및 펩티딜-디펩티다아제 b를 포함한다. 세린-타입 카르복시펩티다아제는 라이소좀 pro-x 카르복시펩티다아제, 세린-타입 D-ala-D-ala 카르복시펩티다아제, 카르복시펩티다아제 C, 카르복시펩티다아제 D를 포함한다. 메탈로르복시펩티다아제는 카르복시펩티다아제 a, 카르복시펩티다아제 B, 라이신(아르기닌) 카르복시펩티다아제, gly-X 카르복시펩티다아제, 알라닌 카르복시펩티다아제, 무라모일펜타펩타이드 카르복시펩티다아제, 카르복시펩티다아제 h, 글루타메이트 카르복시펩티다아제, 카르복시펩티다아제 M, 무라모일테트라펩타이드 카르복시펩티다아제, 아연 d-ala-d-ala 카르복시펩티다아제, 카르복시펩티다아제 A2, 막 pro-x 카르복시펩티다아제, 튜불리닐-tyr 카르복시펩티다아제, 카르복시펩티다아제 t를 포함한다. 오메가펩티다아제는 아실아미노아실-펩티다아제, 펩티딜-글라이신아미다아제, 파이로글루타밀-펩티다아제 I, beta-아스파르틸-펩티다아제, 파이로글루타밀-펩티다아제 II, n-포르밀메티오닐-펩티다아제, 프테로일폴리-[감마]-글루타메이트 카르복시펩티다아제, 감마-glu-X 카르복시펩티다아제, 아실무라모일-ala 펩티다아제를 포함한다. 세린 프로테이나아제는 키모트립신, 키모트립신 c, 메트리딘, 트립신, 트롬빈, 응고 인자 Xa, 플라스민, 엔테로펩티다아제, 아크로신, 알파-용해 프로테아제, 글루타밀 엔도펩티다아제, 카텝신 G, 응고 인자 viia, 응고 인자 ixa, 쿠쿠미시, 프롤릴 올리고펩티다아제, 응고 인자 xia, 브라키우린, 혈장 칼리크레인, 조직 칼리크레인, 췌장 엘라스타아제, 백혈구 엘라스타아제, 응고 인자 xiia, 키마아제, 보체 성분 c1r55, 보체 성분 c1s55, 고전적인 보체 경로 c3/c5 컨버타아제, 보체 인자 I, 보체 인자 D, 대안적인 보체 경로 c3/c5 컨버타아제, 세레비신, 하이포데르민 C, 라이실 엔도펩티다아제, 엔도펩티다아제 1a, 감마-레니, 베놈빈 ab, 루실 엔도펩티다아제, 트립타아제, 스쿠텔라린, 케신, 섭틸리신, 오리진, 엔도펩티다아제 k, 써모마이콜린, 써미타아제, 엔도펩티다아제 SO, T-플라스미노겐 활성제, 단백질 C, 췌장 엔도펩티다아제 E, 췌장 엘라스타아제 ii, IGA-특이적 세린 엔도펩티다아제, U-플라스미노겐 활성화제, 베놈빈 A, 푸린, 미엘로블라스틴, 세메노겔라아제, 그랜자임 A 또는 세포독성 T-림프구 프로테이나아제 1, 그랜자임 B 또는 세포독성 T-림프구 프로테아나아제 2, 스트렙토그리신 A, 트렙토그리신 B, 글루타밀 엔도펩티다아제 II, 올리고펩티다아제 B, 리물러스 응고 인자 c, 리물러스 응고 인자, 리물러스 응고 효소, 옴프틴, 억제인자 lexa, 세균 리더 펩티다아제 I, 토가비린, 플라비린을 포함한다. 시스테인 프로테이나아제는 카텝신 B, 파파인, 피신, 키모파파인, 아스클레파인, 클로스트리파인, 스트렙토파인, 액티나이드, 카텝신 1, 카텝신 H, 칼파인, 카텝신 t, 글라이실 엔도펩티다아제, 암 응고촉진제, 카텝신 S, 피코르나인 3C, 피코르나인 2A, 카리카인, 아나나인, 줄기 브로멜라인, 과일 브로멜라인, 레구마인, 히스톨리사인, 인터루킨 1-베타 전환 효소를 포함한다. 아스파르틱 프로테이나아제는 펩신 A, 펩신 B, 가스트리신, 키모신, 카텝신 D, 네오펜테신, 레닌, 레트로펩신, 프로-오피오멜라노코르틴 전환 효소, 아스퍼길로펩신 I, 아스퍼길로펩신 II, 페니실로펩신, 리조푸스펩신, 엔도티아펩신, 뮤코로펩신, 칸디다펩신, 사카로펩신, 로도토룰라펩신, 피사로펩신, 아크로실린드로펩신, 폴리포로펩신, 피크노포로펩신, 사이탈리도펩신 a, 사이탈리도펩신 b, 크산토모나펩신, 카텝신 e, 배리어펩신, 박테리아 리더 펩티다아제 I, 슈도모나펩신, 플라스멥신을 포함한다. 메탈로 프로테이나제는 아트로라이신 a, 미생물 콜라게나아제, 류코라이신, 장 콜라게나아제, 네프릴라이신, 엔벨라이신, iga-특이적 메탈로엔도펩티다아제, 프로콜라겐 N-엔도펩티다아제, 티메트 올리고펩티다아제, 뉴로라이신, 스트로메라이신 1, 메프린 A, 프로콜라겐 C-엔도펩티다아제, 펩티딜-lys 메탈로엔도펩티다아제, 아스타신, 스트로메라이신 2, 마트리라이신 겔라티나아제, 에어로모노라이신, 슈도라이신, 써모라이신, 바실로라이신, 아우레오라이신, 코코라이신, 마이코라이신, 베타-용해 메탈로엔도펩티다아제, 펩티딜-asp 메탈로엔도펩티다아제, 호중성 콜라게나아제, 겔라티나아제 B, 레쉬마노라이신, 사카로라이신, 오토라이신, 듀테로라이신, 세라라이신, 아트로라이신 B, 아트로라이신 C, 아트록사아제, 아트로라이신 E, 아트로라이신 F, 아다마라이신, 호리라이신, 루버라이신, 보트로파신, 보트로라이신, 오피오라이신, 트리메레라이신 I, 트리메레라이신 II, 뮤크로라이신, 피트리라이신, 인슐라이신, O-시알로글리코단백질 엔도펩티다아제, 러셀라이신, 미토콘드리아 중간 펩티다아제, 닥티라이신, 나르디라이신, 마그노라이신, 메프린 B, 미토콘드리아 프로세싱 펩티다아제, 마크로파지 엘라스타아제, 코리오라이신, 톡시라이신을 포함한다. 미지 메커니즘의 프로테이나아제는 써모프신 및 다중촉매성 엔도펩티다아제 복합체를 포함한다.
특정 프로테아제는 프로테아제 및 샤페론 유사 활성 둘 다를 보유한다. 이들 프로테아제가 단백질 수율 및/또는 품질에 부정적인 영향을 미치는 경우, 종종 그들의 프로테아제 활성을 특이적으로 결실시키는 것이 유용하고, 그들의 샤페론 활성이 단백질 수율 및/또는 품질에 긍정적인 영향을 미치는 경우 그들은 과발현된다. 이들 프로테아제는 Hsp100(Clp/Hsl) 패밀리 구성원 RXF04587.1(clpA), RXF08347.1, RXF04654.2(clpX), RXF04663.1, RXF01957.2(hslU), RXF01961.2(hslV); 펩티딜-프롤릴 시스-트랜스 아이소머라아제 패밀리 구성원 RXF05345.2(ppiB); 메탈로펩티다아제 M20 패밀리 구성원 RXF04892.1(아미노하이드롤라아제); 메탈로펩티다아제 M24 패밀리 구성원 RXF04693.1(메티오닌 아미노펩티다아제) 및 RXF03364.1(메티오닌 아미노펩티다아제); 및 세린 펩티다아제 S26 신호 펩티다아제 I 패밀리 구성원 RXF01181.1(신호 펩티다아제)를 포함하나, 이들로 한정되는 것은 아니다.
이들 및 다른 프로테아제 및 폴딩 조절자는 당해 기술분야에 공지되어 있고, 문헌, 예를 들어 미국 특허 제8,603,824호에 기재되어 있다. 예를 들어, 상기 특허의 표 D는 Tig(tig, 트리거 인자, FKBP 파입 PPIase(ec 5.2.1.8) RXF04655, UniProtKB - P0A850 (TIG_ECOLI))를 기재하고 있다. 본 출원에 그 전체 내용이 참고로 인용된 WO 2008/134461호 및 "이종성 단백질의 발현에서 개선된 수율 및/또는 품질을 보유하는 특정 균주를 동정하기 위해 미생물 균주를 신속하게 스크리닝하기 위한 방법"이라는 명칭의 미국 특허 제9,394,571호는 Tig(RXF04655.2, 상기 특허의 서열 번호 34), LepB(RXF01181.1, 상기 특허의 서열 번호 56), DegP1(RXF01250, 상기 특허의 서열 번호 57), AprA(RXF04304.1, 상기 특허의 서열 번호 86), Prc1(RXF06586.1, 상기 특허의 서열 번호 120), DegP2(RXF07210.1, 상기 특허의 서열 번호 124), Lon(RXF04653, 상기 특허의 서열 번호 92); DsbA(RXF01002.1, 상기 특허의 서열 번호 25), 및 DsbC(RXF03307.1, 상기 특허의 서열 번호 26)를 기재하고 있다. 또한, 이들 서열 및 다른 프로테아제에 대한 것들 및 폴딩 조절자는 미국 특허 제9,580,719호(컬럼 93-98의 서열 번호의 표)에 기재되어 있다. 예를 들어, 미국 특허 제9,580,719호는 각각 서열 번호 18 및 19로서 HslU(RXF01957.2) 및 HslV(RXF01961.2)를 코딩하는 서열을 제공한다.
고 처리량 스크린
실시양태에서, 고 처리량 스크린은 관심 재조합 단백질 또는 폴리펩타이드를 발현하기 위한 최적 조건을 결정하기 위해 수행된다. 스크린에서 변경될 수 있는 조건은 예를 들어, 숙주 세포, 숙주 세포의 유전적 배경(예를 들어, 상이한 프로테아제의 결실), 발현 컨스트럭트 내의 프로모터의 타입, 코딩된 관심 폴리펩타이드 또는 단백질에 융합된 분리 리더의 타입, 성장 온도, 유도성 프로모터가 사용되는 경우 유도의 OD, 첨가된 유도인자의 양(예를 들어, lacZ 프로모터 또는 이의 유도체가 사용되는 경우 유도를 위해 사용된 IPTG의 양), 단백질 유도의 지속기간, 배양물에 유도인자의 첨가 후 성장 온도, 배양물의 교반 속도, 플라스미드 유지를 위한 선택 방법, 용기의 배양 부피, 및 세포 용해 방법을 포함한다.
몇몇 실시양태에서, 호스트 균주의 라이브러리("어레이")가 제공되는데, 라이브러리 내의 각각의 균주(또는 "숙주 세포의 집단")는 숙주 세포 내에서 하나 이상의 타겟 유전자의 발현을 조절하기 위해 유전적으로 변경된다. "최적 호스트 균주" 또는 "최적 발현 시스템"은 종종 어레이 내에서 표현형적으로 구별되는 숙주 세포의 다른 집단과 비교하여 발현된 관심 단백질의 양, 질, 및/또는 위치에 기초하여 확인 또는 선택된다. 따라서, 최적 호스트 균주는 원하는 사양에 따라 관심 폴리펩타이드를 생산하는 균주이다. 원하는 사양은 생산하려는 폴리펩타이드에 따라 달라질 것이지만, 상기 사양은 단백질의 양 및/또는 질, 단백질이 격리 또는 분비되는지 여부, 단백질 폴딩 등을 포함한다. 예를 들어, 최적 호스트 균주 또는 최적 발현 시스템은 특정의 절대적인 레벨 또는 지표 균주, 즉 비교를 위해 사용된 균주에 의해 생산된 것에 대한 특정 레벨의 가용성의 이종성 단백질의 양, 회수 가능한 이종성 단백질의 양, 적절하게 프로세싱된 이종성 단백질의 양, 적절하게 폴딩된 이종성 단백질의 양, 활성의 이종성 단백질의 양, 및/또는 이종성 단백질의 총량을 특징으로 하는 수득량을 생산한다.
이종성 단백질의 발현에서 개선된 수율 및/또는 품질을 보유하는 균주를 확인하기 위한 미생물 호스트 스크리닝 방법은 예를 들어 미국 특허 출원 공보 제2008/0269070호에 기재되어 있다.
박테리아 성장 조건
본 출원의 방법에 유용한 성장 조건은 종종 약 4℃ 내지 약 42℃의 온도 및 약 5.7 내지 약 8.8의 pH를 포함한다. lacZ 프로모터 또는 이의 유도체를 보유하는 발현 컨스트럭트가 사용되는 경우, 발현은 종종 배양물에 약 0.01 mM 내지 약 1.0 mM의 최종 농도로 IPTG를 첨가함으로써 유도된다.
배양물의 pH는 종종 당해 기술분야의 통상의 기술자에게 공지된 방법 및 pH 완충액을 이용하여 유지된다. 또한, 배양 중 pH의 조절은 수성 암모니아를 이용하여 달성된다. 실시양태에서, 배양물의 pH는 약 5.7 내지 약 8.8이다. 특정 실시양태에서, 상기 pH는 약 5.7, 5.8, 5.9, 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9, 7.0, 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9, 8.0, 8.1, 8.2, 8.3, 8.4, 8.5, 8.6, 8.7, 또는 8.8이다. 다른 실시양태에서, 상기 pH는 약 5.7 내지 5.9, 5.8 내지 6.0, 5.9 내지 6.1, 6.0 내지 6.2, 6.1 내지 6.3, 6.2 내지 6.5, 6.4 내지 6.7, 6.5 내지 6.8, 6.6 내지 6.9, 6.7 내지 7.0, 6.8 내지 7.1, 6.9 내지 7.2, 7.0 내지 7.3, 7.1 내지 7.4, 7.2 내지 7.5, 7.3 내지 7.6, 7.4 내지 7.7, 7.5 내지 7.8, 7.6 내지 7.9, 7.7 내지 8.0, 7.8 내지 8.1, 7.9 내지 8.2, 8.0 내지 8.3, 8.1 내지 8.4, 8.2 내지 8.5, 8.3 내지 8.6, 8.4 내지 8.7, 또는 8.5 내지 8.8이다. 여전히 다른 실시양태에서, 상기 pH는 약 5.7 내지 6.0, 5.8 내지 6.1, 5.9 내지 6.2, 6.0 내지 6.3, 6.1 내지 6.4, 또는 6.2 내지 6.5이다. 특정 실시양태에서, 상기 pH는 약 5.7 내지 약 6.25이다.
실시양태에서, 성장 온도는 약 4℃ 내지 약 42℃에서 유지된다, 특정 실시양태에서, 상기 성장 온도는 약 4℃, 약 5℃, 약 6℃, 약 7℃, 약 8℃, 약 9℃, 약 10℃, 약 11℃, 약 12℃, 약 13℃, 약 14℃, 약 15℃, 약 16℃, 약 17℃, 약 18℃, 약 19℃, 약 20℃, 약 21℃, 약 22℃, 약 23℃, 약 24℃, 약 25℃, 약 26℃, 약 27℃, 약 28℃, 약 29℃, 약 30℃, 약 31℃, 약 32℃, 약 33℃, 약 34℃, 약 35℃, 약 36℃, 약 37℃, 약 38℃, 약 39℃, 약 40℃, 약 41℃, 또한 약 42℃이다. 다른 실시양태에서, 상기 성장 온도는 약 25℃ 내지 약 27℃, 약 25℃ 내지 약 28℃, 약 25℃ 내지 약 29℃, 약 25℃ 내지 약 30℃, 약 25℃ 내지 약 31℃, 약 25℃ 내지 약 32℃, 약 25℃ 내지 약 33℃, 약 26℃ 내지 약 28℃, 약 26℃ 내지 약 29℃, 약 26℃ 내지 약 30℃, 약 26℃ 내지 약 31℃, 약 26℃ 내지 약 32℃, 약 27℃ 내지 약 29℃, 약 27℃ 내지 약 30℃, 약 27℃ 내지 약 31℃, 약 27℃ 내지 약 32℃, 약 26℃ 내지 약 33℃, 약 28℃ 내지 약 30℃, 약 28℃ 내지 약 31℃, 약 28℃ 내지 약 32℃, 약 29℃ 내지 약 31℃, 약 29℃ 내지 약 32℃, 약 29℃ 내지 약 33℃, 약 30℃ 내지 약 32℃, 약 30℃ 내지 약 33℃, 약 31℃ 내지 약 33℃, 약 31℃ 내지 약 32℃, 약 30℃ 내지 약 33℃, 또는 약 32℃ 내지 약 33℃로 유지된다. 다른 실시양태에서, 상기 온도는 배양 중에 변화된다. 특정 실시양태에서, 상기 온도는 관심 폴리펩타이드 또는 단백질을 코딩하는 컨스트럭트로부터 발현을 유도하기 위한 제제를 배양물에 첨가하기 이전에 약 30℃ 내지 약 32℃로 유지되고, 상기 온도는 발현을 유도하기 위한 제제, 예를 들어 IPTG를 배양물에 첨가한 이후에 약 25℃ 내지 약 27℃로 강하된다. 한 실시양태에서, 상기 온도는 관심 폴리펩타이드 또는 단백질을 코딩하는 컨스트럭트로부터 발현을 유도하기 위한 제제를 배양물에 첨가하기 이전에 약 30℃로 유지되고, 상기 온도는 발현을 유도하는 제제를 배양물에 첨가한 이후에 약 25℃로 강하된다.
유도
본 출원의 다른 곳에 기재된 바와 같이, 유도성 프로모터, 예를 들어 lac 프로모터는 관심 폴리펩타이드 또는 단백질의 발현을 조절하기 위해 발현 컨스트럭트 내에서 종종 사용된다. lac 프로모터 유도체 또는 패밀리 구성원, 예를 들어 tac 프로모터의 경우, 효과인자 화합물은 유도인자, 예를 들어 IPTG(이소프로필-β-D-1-티오갈락토피라노사이드; "이소프로필티오갈락토사이드"로도 언급된)와 같은 무상 유도인자이다. 실시양태에서, lac 프로모터 유도체가 사용되고, 관심 폴리펩타이드 또는 단백질 발현은, 세포 밀도가 OD575에 의해 확인된 레벨로서 약 25 내지 약 160에 도달하는 경우, IPTG를 약 0.01 mM 내지 약 1.0 mM의 최종 농도로 첨가함으로써 유도된다. 실시양태에서, 관심 폴리펩타이드 또는 단백질을 위한 배양 유도 시의 OD575는 약 25, 약 50, 약 55, 약 60, 약 65, 약 70, 약 80, 약 90, 약 100, 약 110, 약 120, 약 130, 약 140, 약 150, 약 160, 약 170, 또는 약 180이다. 다른 실시양태에서, OD575는 약 80 내지 약 100, 약 100 내지 약 120, 약 120 내지 약 140, 또는 약 140 내지 약 160이다. 다른 실시양태에서, OD575는 약 80 내지 약 140, 또는 약 100 내지 160이다. 세포 밀도는 종종 다른 방법에 의해 측정되고, 다른 단위, 예를 들어 단위 부피 당 세포로 표현된다. 예를 들어, 슈도모나스 플루오레센스 배양물의 약 25 내지 약 160의 OD575는 1 mL 당 대략 4 x 1010 내지 약 1.6 x 1011 콜로니 형성 유닛 또는 11 내지 70 g/L 건조 세포 중량과 균등하다. 실시양태에서, 관심 폴리펩타이드 또는 단백질의 발현은, 세포 밀도가 약 0.05 g/g 내지 약 0.4 g/g의 습윤 중량에 도달하는 경우, 약 0.01 mM 내지 약 1.0 mM의 최종 농도로 IPTG를 첨가함으로써 유도된다. 실시양태에서, 습윤 중량은 약 0.05 g/g, 약 0.1 g/g, 약 0.15 g/g, 약 0.2 g/g, 약 0.25 g/g, 약 0.30 g/g, 약 0.35 g/g, 약 0.40 g/g, 약 0.05 g/g 내지 약 0.1 g/g, 약 0.05 g/g 내지 약 0.15 g/g, 약 0.05 g/g 내지 약 0.20 g/g, 약 0.05 g/g 내지 약 0.25 g/g, 약 0.05 g/g 내지 약 0.30 g/g, 약 0.05 g/g 내지 약 0.35 g/g, 약 0.1 g/g 내지 약 0.40 g/g, 약 0.15 g/g 내지 약 0.40 g/g, 약 0.20 g/g 내지 약 0.40 g/g, 약 0.25 g/g 내지 약 0.40 g/g, 약 0.30 g/g 내지 약 0.40 g/g, 또는 약 0.35 g/g 내지 약 0.40 g/g이다. 실시양태에서, 배양 유도 시의 세포 밀도는 세포 밀도를 결정하기 위해 사용된 방법 또는 측정값의 단위와는 무관하게 OD575에서의 흡광도에 의해 기술된 바와 같은 세포 밀도와 균등하다. 당해 기술분야의 통상의 기술자는 임의의 세포 배양을 위한 적합한 전환을 어떻게 수행하는지 알 것이다.
실시양태에서, 배양물의 최종 IPTG 농도는 약 0.01 mM, 약 0.02 mM, 약 0.03 mM, 약 0.04 mM, 약 0.05 mM, 약 0.06 mM, 약 0.07 mM, 약 0.08 mM, 약 0.09 mM, 약 0.1 mM, 약 0.2 mM, 약 0.3 mM, 약 0.4 mM, 약 0.5 mM, 약 0.6 mM, 약 0.7 mM, 약 0.8 mM, 약 0.9 mM, 또는 약 1 mM이다. 다른 실시양태에서, 배양물의 최종 IPTG 농도는 약 0.08 mM 내지 약 0.1 mM, 약 0.1 mM 내지 약 0.2 mM, 약 0.2 mM 내지 약 0.3 mM, 약 0.3 mM 내지 약 0.4 mM, 약 0.2 mM 내지 약 0.4 mM, 약 0.08 내지 약 0.2mM, 또는 약 0.1 내지 1 mM이다.
본 출원 및 문헌에 기재된 바와 같이, lac 타입이 아닌 프로모터가 사용되는 실시양태에서, 다른 유도인자 또는 효과인자가 종종 사용된다. 한 실시양태에서, 프로모터는 구성적 프로모터이다.
유도인자를 첨가한 후, 배양물은 종종 일정 시간, 예를 들어 약 24 시간 동안 성장되는데, 그동안에 관심 폴리펩타이드 또는 단백질이 발현된다. 유도인자를 첨가한 후, 배양물은 종종 약 1 hr, 약 2 hr, 약 3 hr, 약 4 hr, 약 5 hr, 약 6 hr, 약 7 hr, 약 8 hr, 약 9 hr, 약 10 hr, 약 11 hr, 약 12 hr, 약 13 hr, 약 14 hr, 약 15 hr, 약 16 hr, 약 17 hr, 약 18 hr, 약 19 hr, 약 20 hr, 약 21 hr, 약 22 hr, 약 23 hr, 약 24 hr, 약 36 hr, 또는 약 48 hr 동안 성장된다. 유도인자가 배양물에 첨가된 후, 배양물은 약 1 내지 48 hr, 약 1 내지 24 hrs, 약 10 내지 24 hrs, 약 15 내지 24 hr, 또는 약 20 내지 24 hr 동안 성장된다. 세포 배양물은 종종 원심분리에 의해 농축되고, 배양 펠렛은 후속 세포 용해 절차를 위해 적합한 용액 또는 완충액 내에 재현탁된다.
실시양태에서, 세포는 고압 기계적 세포 파쇄를 위한 장비(예를 들어, 시판되는 Microfluidics 마이크로플루이다이저, Constant 세포파쇄기, Niro-Soavi 균질환기 또는 APV-Gaulin 균질화기)를 이용하여 파쇄된다. 종종 관심 폴리펩타이드 또는 단백질을 발현하는 세포는 예를 들어 초음파 처리를 이용하여 파쇄된다. 세포를 용해하기 위해 당해 기술분야에 공지된 임의의 적합한 방법은 종종 가용성 분획을 방출하기 위해 사용된다. 예를 들어, 실시양태에서, 화학적 및/또는 효소적 세포 용해 시약, 예를 들어 세포벽 용해 효소 및 EDTA가 종종 사용된다. 또한, 동결 또는 이전에 저장된 배양물의 이용도 본 출원의 방법에서 고려된다. 배양물은 종종 OD-표준화된다. 예를 들어, 세포는 종종 약 10, 약 11, 약 12, 약 13, 약 14, 약 15, 약 16, 약 17, 약 18, 약 19, 또는 약 20의 OD600으로 표준화된다.
원심분리는 임의의 적합한 장비 및 방법을 이용하여 수행된다. 불용성 분획으로부터 가용성 분획의 분리를 목적으로 하는 세포 배양물 또는 용해물의 원심분리는 당해 기술분야에 널리 공지되어 있다. 예를 들어, 용해된 세포는 종종 20,800 x g에서 20분 동안(4℃에서) 원심분리되고, 상등액은 수동 또는 자동 액체 취급을 이용하여 제거된다. 펠렛(불용성) 분획은 완충처리된 용액, 예를 들어 인산염 완충처리된 염수(PBS), pH 7.4 내에 재현탁된다. 재현탁은 종종 예를 들어 오버헤드 혼합기에 연결된 임펠러, 마그네틱 스터-바, 로킹 쉐이커 등을 이용하여 수행된다.
배양물의 용해 및 원심분리에 의해 "가용성 분획", 즉 용해물의 원심분리 후 수득된 가용성 상등액 및 "불용성 분획", 즉 용해물의 원심분리 후 수득된 펠렛이 수득된다.
발효 포맷
한 실시양태에서, 발효는 본 출원의 관심 폴리펩타이드 및 단백질을 생산하는 방법에서 사용된다. 본 개시내용에 따른 발현 시스템은 임의의 발효 포맷으로 배양된다. 예를 들어, 회분식, 유가식, 반연속식 및 연속식 발효 모드가 본 출원에서 사용될 수 있다.
실시양태에서, 발효 배지는 리치 배지, 최소 배지, 및 미네랄 염 배지 중에서 선택될 수 있다. 다른 실시양태에서, 최소 배지 또는 미네랄 염 배지가 선택된다. 특정 실시양태에서, 미네랄 염 배지가 선택된다.
미네랄 염 배지는 미네랄 염 및 예를 들어 글루코오스, 수크로오스 또는 글리세롤과 같은 탄소원으로 구성된다. 미네랄 염 배지의 예는, 예를 들어 M9 배지, 슈도모나스 배지(ATCC 179), 및 데이비스 및 민기올리 배지를 포함한다(참조: B D Davis & E S Mingioli (1950) J. Bact. 60:17-28). 미네랄 염 배지를 제조하기 위해 사용된 미네랄 염은 예를 들어 포타슘 포스페이트, 암모늄 설페이트 또는 클로라이드, 마그네슘 설페이트 또는 클로라이드, 및 미량 미네랄, 예를 들어 칼슘 클로라이드, 보레이트, 및 철, 구리, 망간, 및 아연의 설페이트 중에서 선택된 것들을 포함한다. 전형적으로, 유기 질소원, 예를 들어 펩톤, 트립톤, 아미노산, 또는 효모 추출물은 미네랄 염 배지에는 포함되지 않는다. 대신에, 무기 질소원이 사용되고, 이는 예를 들어 암모늄 염, 수성 암모니아, 및 기체상 암모니아 중에서 선택될 수 있다. 미네랄 염 배지는 전형적으로 탄소원으로서 글루코오스 또는 글리세롤을 함유할 것이다. 미네랄 염 배지와 비교하여, 최소 배지는 종종 미네랄 염 및 탄소원을 함유하지만, 예를 들어 낮은 레벨의 아미노산, 비타민, 펩톤, 또는 다른 성분으로 보충되고, 이들은 매우 최소 레벨로 첨가된다. 배지는 종종 당해 기술분야에 기재된 방법, 예를 들어 상기 참고로 인용된 미국 특허 출원 공보 제2006/0040352호의 방법을 이용하여 제조된다. 본 출원의 방법에 유용한 미네랄 염 배지 및 배양 절차의 상세한 내용은 Riesenberg, D. et al., 1991, "High cell density cultivation of Escherichia coli at controlled specific growth rate," J. Biotechnol. 20 (1):17-27에 기재되어 있다.
발효는 임의의 규모로 수행될 수 있다. 본 개시내용에 따른 발현 시스템은 임의의 규모로 재조합 단백질 발현을 위해 유용하다. 따라서, 예를 들어 마이크로리터 규모, 밀리리터 규모, 센티리터 규모, 및 데시리터 규모 발효 부피가 사용될 수 있고, 1 리터 규모 및 더 대규모의 발효 부피도 종종 사용된다.
실시양태에서, 발효 부피는 약 1 리터 또는 그 초과이다. 실시양태에서, 발효 부피는 약 0.5 리터 내지 약 100 리터이다. 실시양태에서, 발효 부피는 약 1 리터, 약 2 리터, 약 3 리터, 약 4 리터, 약 5 리터, 약 6 리터, 약 7 리터, 약 8 리터, 약 9 리터, 또는 약 10 리터이다. 실시양태에서, 발효 부피는 약 0.5 리터 내지 약 2 리터, 약 0.5 리터 내지 약 5 리터, 약 0.5 리터 내지 약 10 리터, 약 0.5 리터 내지 약 25 리터, 약 0.5 리터 내지 약 50 리터, 약 0.5 리터 내지 약 75 리터, 약 10 리터 내지 약 25 리터, 약 25 리터 내지 약 50 리터, 또는 약 50 리터 내지 약 100 리터이다. 다른 실시양태에서, 발효 부피는 5 리터, 10 리터, 15 리터, 20 리터, 25 리터, 50 리터, 75 리터, 100 리터, 200 리터, 500 리터, 1,000 리터, 2,000 리터, 5,000 리터, 10,000 리터, 또는 50,000 리터 또는 그 초과이다.
단백질 분석
실시양태에서, 본 출원에서 제공된 방법에 의해 생산된 관심 폴리펩타이드 및 단백질이 분석된다. 관심 폴리펩타이드 및 단백질은 당해 기술분야의 통상의 기술자에게 공지된 임의의 적절한 방법, 예를 들어 생물층 간섭계, SDS-PAGE, 웨스턴 블롯, 파 웨스턴 블롯, ELISA, 흡광도, 또는 질량분석법(예를 들어, 탠덤 질량분석법)에 의해 분석될 수 있다.
몇몇 실시양태에서, 관심 폴리펩타이드 또는 단백질의 농도 및/또는 양은 예를 들어 브래드포드 어세이, 흡광도, 쿠마시 염색, 질량분석법 등에 의해 결정된다.
본 출원에 기재된 바와 같이 불용성 및 가용성 분획에서의 단백질 수율은 종종 당해 기술분야의 통상의 기술자에게 공지된 방법, 예를 들어 모세관 겔 전기영동(CGE), SDS-PAGE, 및 웨스턴 블롯 분석에 의해 결정된다. 가용성 분획은 종종 예를 들어 생물층 간섭계를 이용하여 평가된다.
단백질 수율의 유용한 측정치는 예를 들어, 배양 부피 당 재조합 단백질의 양(예를 들어, 배양물 1 리터 당 단백질 밀리그램 또는 그램), 세포 용해 후 수득된 불용성 펠렛에서 측정된 재조합 단백질의 백분율 또는 분율(예를 들어, 추출 상등액 내 재조합 단백질의 양/불용성 분획 내 단백질의 양), 활성 단백질의 백분율 또는 분율(예를 들어, 활성 단백질의 양/어세이에 사용된 단백질의 양), 전체 세포 단백질(tcp)의 백분율 또는 분율, 단백질의 양/세포, 및 건조 바이오매스 백분율을 포함한다.
실시양태에서, 본 출원의 방법은 약 20% 내지 약 90% 전체 세포 단백질의 가용성의 관심 폴리펩타이드 또는 단백질의 수율을 수득하기 위해 사용된다. 특정 실시양태에서, 가용성의 관심 폴리펩타이드 또는 단백질의 수율은 약 20% 전체 세포 단백질, 약 25% 전체 세포 단백질, 약 30% 전체 세포 단백질, 약 31% 전체 세포 단백질, 약 32% 전체 세포 단백질, 약 33% 전체 세포 단백질, 약 34% 전체 세포 단백질, 약 35% 전체 세포 단백질, 약 36% 전체 세포 단백질, 약 37% 전체 세포 단백질, 약 38% 전체 세포 단백질, 약 39% 전체 세포 단백질, 약 40% 전체 세포 단백질, 약 41% 전체 세포 단백질, 약 42% 전체 세포 단백질, 약 43% 전체 세포 단백질, 약 44% 전체 세포 단백질, 약 45% 전체 세포 단백질, 약 46% 전체 세포 단백질, 약 47% 전체 세포 단백질, 약 48% 전체 세포 단백질, 약 49% 전체 세포 단백질, 약 50% 전체 세포 단백질, 약 51% 전체 세포 단백질, 약 52% 전체 세포 단백질, 약 53% 전체 세포 단백질, 약 54% 전체 세포 단백질, 약 55% 전체 세포 단백질, 약 56% 전체 세포 단백질, 약 57% 전체 세포 단백질, 약 58% 전체 세포 단백질, 약 59% 전체 세포 단백질, 약 60% 전체 세포 단백질, 약 65% 전체 세포 단백질, 약 70% 전체 세포 단백질, 약 75% 전체 세포 단백질, 약 80% 전체 세포 단백질, 약 85% 전체 세포 단백질, 또는 약 90% 전체 세포 단백질이다. 몇몇 실시양태에서, 가용성의 관심 폴리펩타이드 또는 단백질의 수율은 약 20% 내지 약 25% 전체 세포 단백질, 약 20% 내지 약 30% 전체 세포 단백질, 약 20% 내지 약 35% 전체 세포 단백질, 약 20% 내지 약 40% 전체 세포 단백질, 약 20% 내지 약 45% 전체 세포 단백질, 약 20% 내지 약 50% 전체 세포 단백질, 약 20% 내지 약 55% 전체 세포 단백질, 약 20% 내지 약 60% 전체 세포 단백질, 약 20% 내지 약 65% 전체 세포 단백질, 약 20% 내지 약 70% 전체 세포 단백질, 약 20% 내지 약 75% 전체 세포 단백질, 약 20% 내지 약 80% 전체 세포 단백질, 약 20% 내지 약 85% 전체 세포 단백질, 약 20% 내지 약 90% 전체 세포 단백질, 약 25% 내지 약 90% 전체 세포 단백질, 약 30% 내지 약 90% 전체 세포 단백질, 약 35% 내지 약 90% 전체 세포 단백질, 약 40% 내지 약 90% 전체 세포 단백질, 약 45% 내지 약 90% 전체 세포 단백질, 약 50% 내지 약 90% 전체 세포 단백질, 약 55% 내지 약 90% 전체 세포 단백질, 약 60% 내지 약 90% 전체 세포 단백질, 약 65% 내지 약 90% 전체 세포 단백질, 약 70% 내지 약 90% 전체 세포 단백질, 약 75% 내지 약 90% 전체 세포 단백질, 약 80% 내지 약 90% 전체 세포 단백질, 약 85% 내지 약 90% 전체 세포 단백질, 약 31% 내지 약 60% 전체 세포 단백질, 약 35% 내지 약 60% 전체 세포 단백질, 약 40% 내지 약 60% 전체 세포 단백질, 약 45% 내지 약 60% 전체 세포 단백질, 약 50% 내지 약 60% 전체 세포 단백질, 약 55% 내지 약 60% 전체 세포 단백질, 약 31% 내지 약 55% 전체 세포 단백질, 약 31% 내지 약 50% 전체 세포 단백질, 약 31% 내지 약 45% 전체 세포 단백질, 약 31% 내지 약 40% 전체 세포 단백질, 약 31% 내지 약 35% 전체 세포 단백질, 약 35% 내지 약 55% 전체 세포 단백질, 또는 약 40% 내지 약 50% 전체 세포 단백질이다.
실시양태에서, 본 출원의 방법은 1 리터 당 약 1 그램 내지 1 리터 당 약 50 그램의 가용성의 관심 폴리펩타이드 또는 단백질을 수득하기 위해 사용된다. 특정 실시양태에서, 가용성의 관심 폴리펩타이드 또는 단백질의 수율은 1 리터 당 약 1 그램, 1 리터 당 약 2 그램, 1 리터 당 약 3 그램, 1 리터 당 약 4 그램, 1 리터 당 약 5 그램, 1 리터 당 약 6 그램, 1 리터 당 약 7 그램, 1 리터 당 약 8 그램, 1 리터 당 약 9 그램, 1 리터 당 약 10 그램, 1 리터 당 약 11 그램, 1 리터 당 약 12 그램, 1 리터 당 약 13 그램, 1 리터 당 약 14 그램, 1 리터 당 약 15 그램, 1 리터 당 약 16 그램, 1 리터 당 약 17 그램, 1 리터 당 약 18 그램, 1 리터 당 약 19 그램, 1 리터 당 약 20 그램, 1 리터 당 약 21 그램, 1 리터 당 약 22 그램, 1 리터 당 약 23 그램 1 리터 당 약 24 그램, 1 리터 당 약 25 그램, 1 리터 당 약 26 그램, 1 리터 당 약 27 그램, 1 리터 당 약 28 그램, 1 리터 당 약 30 그램, 1 리터 당 약 35 그램, 1 리터 당 약 40 그램, 1 리터 당 약 45 그램, 1 리터 당 약 50 그램, 1 리터 당 약 1 그램 내지 1 리터 당 약 5 그램, 1 리터 당 약 1 그램 내지 1 리터 당 약 10 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 12 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 13 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 14 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 15 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 16 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 17 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 18 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 19 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 20 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 21 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 22 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 23 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 24 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 30 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 40 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 50 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 12 그램, 1 리터 당 약 12 그램 내지 1 리터 당 약 14 그램, 1 리터 당 약 14 그램 내지 1 리터 당 약 16 그램, 1 리터 당 약 16 그램 내지 1 리터 당 약 18 그램, 1 리터 당 약 18 그램 내지 1 리터 당 약 20 그램, 1 리터 당 약 20 그램 내지 1 리터 당 약 22 그램, 1 리터 당 약 22 그램 내지 1 리터 당 약 24 그램, 1 리터 당 약 23 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 11 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 12 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 13 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 14 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 15 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 16 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 17 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 18 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 19 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 20 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 21 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 22 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 23 그램 내지 1 리터 당 약 25 그램, 또는 1 리터 당 약 24 그램 내지 1 리터 당 약 25 그램이다. 실시양태에서, 가용성 재조합 단백질 수율은 1 리터 당 약 10 그램 내지 1 리터 당 약 13 그램, 1 리터 당 약 12 그램 내지 1 리터 당 약 14 그램, 1 리터 당 약 13 그램 내지 1 리터 당 약 15 그램, 1 리터 당 약 14 그램 내지 1 리터 당 약 16 그램, 1 리터 당 약 15 그램 내지 1 리터 당 약 17 그램, 1 리터 당 약 16 그램 내지 1 리터 당 약 18 그램, 1 리터 당 약 17 그램 내지 1 리터 당 약 19 그램, 1 리터 당 약 18 그램 내지 1 리터 당 약 20 그램, 1 리터 당 약 20 그램 내지 1 리터 당 약 22 그램, 1 리터 당 약 22 그램 내지 1 리터 당 약 24 그램, 또는 1 리터 당 약 23 그램 내지 1 리터 당 약 25 그램이다. 실시양태에서, 가용성 재조합 단백질 수율은 1 리터 당 약 10 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 12 그램 내지 1 리터 당 약 24 그램, 1 리터 당 약 14 그램 내지 1 리터 당 약 22 그램, 1 리터 당 약 16 그램 내지 1 리터 당 약 20 그램, 또는 1 리터 당 약 18 그램 내지 1 리터 당 약 20 그램이다. 실시양태에서, 추출된 단백질 수율은 1 리터 당 약 5 그램 내지 1 리터 당 약 15 그램, 1 리터 당 약 5 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 15 그램, 1 리터 당 약 10 그램 내지 1 리터 당 약 25 그램, 1 리터 당 약 15 그램 내지 1 리터 당 약 20 그램, 1 리터 당 약 15 그램 내지 1 리터 당 약 25 그램, 또는 1 리터 당 약 18 그램 내지 1 리터 당 약 25 그램이다.
실시양태에서, 가용성 분획 내에서 검출된 가용성의 관심 폴리펩타이드 또는 단백질의 양은 생산된 전체 가용성의 관심 폴리펩타이드 또는 단백질의 약 10% 내지 약 100%이다. 실시양태에서, 이 양은 생산된 가용성의 관심 폴리펩타이드 또는 단백질의 양의 약 10%, 약 15%, 약 20%, 약 25%, 약 30%, 약 35%, 약 40%, 약 45%, 약 50%, 약 55%, 약 60%, 약 65%, 약 70%, 약 75%, 약 80%, 약 85%, 약 90%, 약 95% 또는 약 99%, 또는 약 100%이다. 실시양태에서, 이 양은 생산된 전체 가용성의 관심 폴리펩타이드 또는 단백질의 약 10% 내지 약 20%, 20% 내지 약 50%, 약 25% 내지 약 50%, 약 25% 내지 약 50%, 약 25% 내지 약 95%, 약 30% 내지 약 50%, 약 30% 내지 약 40%, 약 30% 내지 약 60%, 약 30% 내지 약 70%, 약 35% 내지 약 50%, 약 35% 내지 약 70%, 약 35% 내지 약 75%, 약 35% 내지 약 95%, 약 40% 내지 약 50%, 약 40% 내지 약 95%, 약 50% 내지 약 75%, 약 50% 내지 약 95%, 약 70% 내지 약 95%, 또는 약 80 내지 약 100%이다.
몇몇 실시양태에서, 가용성의 관심 폴리펩타이드 또는 단백질은 배양으로 생산된 전체 가용성 단백질의 백분율로서 표현된다. 주어진 세포 밀도에서 가용성의 관심 폴리펩타이드 또는 단백질 중량/세포 배양물의 부피로 표현된 데이터는 전체 세포 단백질 중 재조합 단백질의 백분율로서 표현된 데이터로 전환될 수 있다. 주어진 세포 밀도에서 세포 배양물의 부피 당 전체 세포 단백질의 양을 알고 있는 경우, 부피로 측정된 단백질 수율을 % 전체 세포 단백질로 전환하는 것은 통상의 기술자의 능력 범위 내에 있다. 이러한 수치는 1) 주어진 세포 밀도에서 세포 중량/배양물의 부피, 및 2) 전체 단백질에 의해 포함된 세포 중량의 백분율을 아는 경우 결정될 수 있다. 예를 들어, 1.0의 OD550에서, 이. 콜라이의 건조 세포 중량은 0.5 그램/리터로 보고되어 있다("Production of Heterologous Proteins from Recombinant DNA Escherichia coli in Bench Fermentors," Lin, N.S., and Swartz, J.R., 1992, METHODS: A Companion to Methods in Enzymology 4: 159-168). 박테리아 세포는 다당류, 지질, 및 핵산뿐만 아니라 단백질로 구성되어 있다. 이. 콜라이 세포는 이. 콜라이 세포의 52.4 중량%를 구성하는 단백질을 추산하는 Da Silva, N.A., et al., 1986, "Growth Yield Estimates for Recombinant Cells," Biotechnology and Bioengineering, Vol. XXVIII: 741-746, 및 55%의 건조 세포 중량으로서 이. 콜라이 내의 단백질 함량을 보고하는 "Escherichia coli and Salmonella typhimurium Cellular and Molecular Biology," 1987, Ed. in Chief Frederick C. Neidhardt, Vol. 1, pp. 3-6을 포함하지만, 이들로 한정되는 것은 아닌 참고 문헌에 의해 단백질이 약 52.4 내지 55%인 것으로 보고된다. 상기 측정값(즉, 0.5 그램/리터의 건조 세포 중량 및 55% 세포 중량으로서의 단백질)을 이용하면, 이. 콜라이의 경우 1.0의 A550에서 세포 배양물 부피 당 전체 세포 단백질의 양은 275 μg 전체 세포 단백질/ml/A550로 계산된다. 습윤 세포 중량에 기초한 세포 배양물의 부피 당 전체 세포 단백질의 계산은 예를 들어 이. 콜라이의 경우 1.0의 A600은 1.7 그램/리터의 습윤 세포 중량 및 0.39 그램/리터의 건조 세포 중량을 초래한다는 Glazyrina, et al. (Microbial Cell Factories 2010, 9:42, 본 출원에 참고로 인용됨)을 이용할 수 있다. 예를 들어, 이러한 습윤 세포 중량 대 건조 세포 중량 비교 및 상기한 바와 같은 55% 건조 세포 중량으로서의 단백질을 이용하면, 이. 콜라이의 경우 1.0의 A600에서 세포 배양물의 부피 당 전체 세포 단백질의 양은 215 μg 전체 세포 단백질/ml/A600로 계산될 수 있다. 슈도모나스 플루오레센스의 경우, 주어진 세포 밀도에서 세포 배양물의 부피 당 전체 세포 단백질의 양은 이. 콜라이의 경우에 확인된 것과 유사하다. 이. 콜라이와 같이 피. 플루오레센스는 그람 음성의 막대 모양의 박테리아이다. Edwards, et al., 1972, "Culture of Pseudomonas fluorescens with Sodium Maleate as a Carbon Source, "Biotechnology and Bioengineering, Vol. XIV, pages 123-147에 의해 보고된 바와 같이, 피. 플루오레센스 ATCC 11150의 건조 세포 중량은 0.5 그램/리터/A500이다. 이는 1.0의 A550에서 이. 콜라이의 경우 Lin, et al.에 의해 보고된 동일한 중량이다. 500 nm 및 550 nm에서 이루어진 빛 산란 측정값은 매우 유사한 것으로 예상된다. 피. 플루오레센스 HK44에 대해 전체 세포 단백질에 의해 포함된 세포 중량의 백분율은 예를 들어 Yarwood, et al., July 2002, "Quantitative Measurement of Bacterial Growth in Porous Media under Unsaturated-Flow Conditions, Applied and Environmental Microbiology 68(7): 3597-3605"에 의해 55%로서 기재된다. 이러한 백분율은 상기한 참고문헌에 의해 이. 콜라이의 경우에 제시된 것과 유사 또는 동일하다.
실시양태에서, 가용성의 관심 폴리펩타이드 또는 단백질의 양은 배양으로 생산된 전체 가용성 단백질의 약 0.1% 내지 약 95%이다. 실시양태에서, 이러한 양은 배양으로 생산된 전체 가용성 단백질의 약 0.1%, 0.5%, 1%, 5%, 10%, 15%, 20%, 25%, 30%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 또는 95% 초과이다. 실시양태에서, 이러한 양은 배양으로 생산된 전체 가용성 단백질의 약 0.1%, 0.5%, 1%, 5%, 10%, 15%, 20%, 25%, 30%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 또는 95%이다. 실시양태에서, 이러한 양은 배양으로 생산된 전체 가용성 단백질의 약 5% 내지 약 95%, 약 10% 내지 약 85%, 약 20% 내지 약 75%, 약 30% 내지 약 65%, 약 40% 내지 약 55%, 약 1% 내지 약 95%, 약 5% 내지 약 30%, 약 1% 내지 약 10%, 약 10% 내지 약 20%, 약 20% 내지 약 30%, 약 30% 내지 약 40%, 약 40% 내지 약 50%, 약 50 내지 약 60%, 약 60% 내지 약 70%, 또는 약 80% 내지 약 90%이다.
실시양태에서, 생산된 가용성의 관심 폴리펩타이드 또는 단백질의 양은 건조 세포 중량(DCW)의 약 0.1% 내지 약 50%이다. 실시양태에서, 이러한 양은 약 0.1%, 0.5%, 1%, 5%, 10%, 15%, 20%, 25%, 30%, 40%, 45%, 또는 50% 초과이다. 실시양태에서, 이러한 양은 DCW의 약 0.1%, 0.5%, 1%, 5%, 10%, 15%, 20%, 25%, 30%, 40%, 45%, 또는 50%이다. 실시양태에서, 이러한 양은 배양으로 생산된 전체 가용성 단백질의 약 5% 내지 약 50%, 약 10% 내지 약 40%, 약 20% 내지 약 30%, 약 1% 내지 약 20%, 약 5% 내지 약 25%, 약 1% 내지 약 10%, 약 10% 내지 약 20%, 약 20% 내지 약 30%, 약 30% 내지 약 40%, 또는 약 40% 내지 약 50%이다.
실시양태에서, 본 발명의 방법을 이용하여 생산된 분비 리더와 이종성인 가용성의 관심 폴리펩타이드 또는 단백질은, 실질적으로 유사한 조건, 예를 들어 숙주 세포를 포함하는 성장 조건 하에서 생산되는 경우, 분비 리더 태생인 단백질의 양을 초과한다. 실시양태에서, 본 발명에 따른 AnsB, 8484, 또는 5193 분비 리더에 작동 가능하게 연결된 가용성의 관심 폴리펩타이드 또는 단백질은 각각의 리더 태생인 단백질의 양을 초과하는 양으로 생산된다. 실시양태에서, AnsB, 8484, 또는 5193 분비 리더에 작동 가능하게 연결된 가용성의 이종성 관심 폴리펩타이드 또는 단백질은 실질적으로 유사한 조건 하에서 생산된 리더 태생인 단백질의 양보다 약 1.2배 내지 약 5배 초과, 약 1.2배 내지 약 2.5배, 약 1.2배 내지 약 2배, 약 1.2배 내지 약 1.5배, 약 1.4배 내지 약 3배 초과, 약 1.4배 내지 약 2.5배, 약 1.4배 내지 약 2배, 약 1.5배 내지 약 3배, 약 1.5배 내지 약 2.5배, 약 1.5배 내지 약 2배, 약 2배 내지 약 3배, 약 1.2배, 약 1.3배, 약 1.4배, 약 1.5배, 약 1.6배, 약 1.7배, 약 1.8배, 약 1.9배, 약 2배, 약 2.5배, 약 3배, 약 4배, 또는 약 5배 초과인 수율로 생산된다.
실시양태에서, 본 발명의 방법을 이용하여 생산된 분비 리더에 작동 가능하게 연결된 가용성의 관심 폴리펩타이드 또는 단백질의 양은, 실질적으로 유사한 조건, 예를 들어 성장 조건 하에서 생산되는 경우, 분비 리더 없이 또는 상이한 분비 리더를 이용하여 생산된 관심 폴리펩타이드 또는 단백질의 양을 초과한다. 성장 조건은, 예를 들어 사용된 배양 배지 및 숙주 세포를 포함할 수 있다. 실시양태에서, 본 발명에 따른 AnsB, 8484, 또는 5193 분비 리더에 작동 가능하게 연결된 가용성의 이종성 관심 폴리펩타이드 또는 단백질은 분비 리더 없이 또는 상이한 분비 리더를 이용하여 생산된 관심 폴리펩타이드 또는 단백질의 양을 초과하는 양으로 생산된다. 실시양태에서, AnsB, 8484, 또는 5193 분비 리더에 작동 가능하게 연결된 가용성의 이종성 관심 폴리펩타이드 또는 단백질은 실질적으로 유사한 조건 하에서 분비 리더 없이 또는 상이한 분비 리더를 이용하여 생산된 단백질의 양보다 약 1.2배 내지 약 20배 초과, 약 1.2배 내지 약 2.5배, 약 1.2배 내지 약 2배, 약 1.2배 내지 약 1.5배, 약 1.4배 내지 약 3배 초과, 약 1.4배 내지 약 2.5배, 약 1.4배 내지 약 2배, 약 1.5배 내지 약 3배, 약 1.5배 내지 약 2.5배, 약 1.5배 내지 약 2배, 약 2배 내지 약 5배, 약 2배 내지 약 10배, 약 5배 내지 약 15배, 약 10배 내지 약 20배, 약 1.2배, 약 1.3배, 약 1.4배, 약 1.5배, 약 1.6배, 약 1.7배, 약 1.8배, 약 1.9배, 약 2배, 약 2.5배, 약 3배, 약 4배, 약 5배 초과, 약 10배 초과, 약 15배 초과, 또는 약 20배 초과인 수율로 생산된다.
용해도 및 활성
양과 관련되어 있지만 단백질의 "용해도" 및 "활성"은 일반적으로 상이한 수단에 의해 결정된다. 단백질, 특히 소수성 단백질의 용해도는 소수성 아미노산 잔기가 폴딩된 단백질의 외부에 부적절하게 위치됨을 나타낸다. 상이한 방법, 예를 들어 후술하는 바와 같은 방법을 이용하여 종종 평가되는 단백질 활성은 적절한 단백질 형태의 다른 지표이다. 본 출원에 사용된 바와 같이 "가용성, 활성, 또는 둘 다"는 당해 기술분야의 통상의 기술자에게 공지된 방법에 의해 가용성, 활성, 또는 가용성 및 활성 둘 다로 결정된 단백질을 의미한다.
활성 어세이
관심 펩타이드, 폴리펩타이드 또는 단백질의 활성을 평가하기 위한 어세이는 당해 기술분야에 공지되어 있고, 형광측정, 비색측정, 화학발광, 분광광도측정, 및 당해 기술분야의 통상의 기술자가 이용할 수 있는 다른 효소 어세이를 포함하나, 이들로 한정되는 것은 아니다. 이들 어세이는 펩타이드, 폴리펩타이드 또는 단백질의 상업적인 또는 다른 제조물에 대해 관심 펩타이드, 폴리펩타이드 또는 단백질의 활성을 비교하기 위해 사용된다.
실시양태에서, 활성은 어세이된 총량과 비교하여 추출 상등액 중 활성 단백질의 백분율에 의해 표현된다. 이는 어세이에 사용된 단백질의 총량에 대한 어세이에 의해 활성으로 결정된 단백질의 양에 기초한다. 다른 실시양태에서, 활성은 표준, 예를 들어 천연 단백질과 비교한 단백질의 활성 레벨 %에 의해 표현된다. 이는 표준 샘플 중 활성 단백질의 양에 대한 상등액 추출 샘플 중 활성 단백질의 양에 기초한다(각각의 샘플로부터 동일한 양의 단백질이 어세이에 사용되는 경우).
실시양태에서, 관심 펩타이드, 폴리펩타이드 또는 단백질의 약 40% 내지 약 100%는 활성인 것으로 결정된다. 실시양태에서, 관심 펩타이드, 폴리펩타이드 또는 단백질의 약 40%, 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 또는 약 100%는 활성인 것으로 결정된다. 실시양태에서, 관심 펩타이드, 폴리펩타이드 또는 단백질의 약 40% 내지 약 50%, 약 50% 내지 약 60%, 약 60% 내지 약 70%, 약 70% 내지 약 80%, 약 80% 내지 약 90%, 약 90% 내지 약 100%, 약 50% 내지 약 100%, 약 60% 내지 약 100%, 약 70% 내지 약 100%, 약 80% 내지 약 100%, 약 40% 내지 약 90%, 약 40% 내지 약 95%, 약 50% 내지 약 90%, 약 50% 내지 약 95%, 약 50% 내지 약 100%, 약 60% 내지 약 90%, 약 60% 내지 약 95%, 약 60% 내지 약 100%, 약 70% 내지 약 90%, 약 70% 내지 약 95%, 약 70% 내지 약 100%, 또는 약 70% 내지 약 100%는 활성인 것으로 결정된다.
다른 실시양태에서, 관심 펩타이드, 폴리펩타이드 또는 단백질의 약 75% 내지 약 100%는 활성인 것으로 결정된다. 실시양태에서, 관심 펩타이드, 폴리펩타이드 또는 단백질의 약 75% 내지 약 80%, 약 75% 내지 약 85%, 약 75% 내지 약 90%, 약 75% 내지 약 95%, 약 80% 내지 약 85%, 약 80% 내지 약 90%, 약 80% 내지 약 95%, 약 80% 내지 약 100%, 약 85% 내지 약 90%, 약 85% 내지 약 95%, 약 85% 내지 약 100%, 약 90% 내지 약 95%, 약 90% 내지 약 100%, 또는 약 95% 내지 약 100% 는 활성인 것으로 결정된다.
관심 단백질(POI)
본 출원의 방법 및 조성물은 세포 발현 시스템에서 높은 수준의 적절하게 프로세싱된 관심 재조합 단백질 또는 폴리펩타이드를 생산하는데 유용하다. 실시양태에서, 관심 단백질 또는 폴리펩타이드(본 출원에서 "타겟 단백질" 또는 "타겟 폴리펩타이드"로도 언급됨)는 임의의 종 및 임의 크기의 것일 수 있다. 특정 실시양태에서, 관심 단백질 또는 폴리펩타이드는 치료적으로 유용한 단백질 또는 폴리펩타이드이다. 몇몇 실시양태에서, 단백질은 포유류 단백질, 예를 들어 인간 단백질, 예를 들어 성장 인자, 사이토카인, 케모카인 또는 혈액 단백질일 수 있다. 실시양태에서, 관심 단백질 또는 폴리펩타이드는 참조 단백질 또는 폴리펩타이드와 유사한 방식으로 프로세싱된다. 특정 실시양태에서, 단백질 또는 폴리펩타이드는 코딩 서열 내에 분비 신호를 포함하지 않는다. 실시양태에서, 관심 단백질 또는 폴리펩타이드는 크기가 100 kD 미만, 50 kD 미만, 또는 30 kD 미만이다. 실시양태에서, 관심 단백질 또는 폴리펩타이드는 적어도 약 5개, 10개, 15개, 20개, 30개, 40개, 50개 또는 100개의 아미노산으로 구성된다.
분자 유전학 및 유전 공학 기술에 필요한 광범위한 서열 정보는 널리 공개적으로 입수 가능하다. 포유류, 뿐만 아니라 인간의 완전한 뉴클레오타이드 서열, 유전자, cDNA 서열, 아미노산 서열 및 게놈에 대한 액세스는 GenBank로부터 웹사이트 www.ncbi.nlm.nih.gov/Entrez에서 얻을 수 있다. 또한, 추가적인 정보는 유전자 및 이의 생성물 및 생물의학 용도에 관한 정보가 통합되어 있는 전자 백과사전인 Weizmann Institute of Science Genome and Bioinformatics의 GeneCards로부터 얻을 수 있고, 또한 뉴클레오타이드 서열 정보는 EMBL Nucleotide Sequence Database 또는 DNA Databank of Japan으로부터 얻을 수 있으며; 아미노산 서열에 관한 정보에 대한 추가적인 사이트는 Georgetown의 단백질 정보 리소스 웹사이트 및 Swiss-Prot을 포함한다.
본 출원의 조성물 및 방법으로 발현될 수 있는 단백질의 예는, 예를 들어 레닌, 인간 성장 호르몬, 소 성장 호르몬을 포함하는 성장 호르몬; 성장 호르몬 방출 인자; 부갑상선 호르몬; 갑상선 자극 호르몬; 지단백질; α-1-항트립신; 인슐린 A-사슬; 인슐린 B-사슬; 프로인슐린; 트롬보포이에틴; 난포 자극 호르몬; 칼시토닌; 황체형성 호르몬; 글루카곤; 응고 인자, 예를 들어 VIIIC 인자, IX 인자, 조직 인자, 및 폰 빌레브란트 인자; 항-응고 인자, 예를 들어 단백질 C; 심방 나트륨이뇨 인자; 폐 계면활성제; 플리스미노겐 활성화제, 예를 들어 유로키나제 또는 인간 소변 또는 조직 타입 플라스미노겐 활성화제(t-PA); 봄베신; 트롬빈; 조혈 성장 인자; 종양 괴사 인자-알파 및 -베타; 엔케팔리나아제; 혈청 알부민, 예를 들어 인간 혈청 알부민; 뮬러관 억제 물질; 릴랙신 A-사슬; 릴랙신 B-사슬; 프로릴랙신; 마우스 고나도트로핀-관련 폴리펩타이드; 미생물 단백질, 예를 들어 베타-락타마아제; DNase; 인히빈; 액티빈; 혈관 내피 성장 인자(VEGF); 호르몬 또는 성장 인자에 대한 수용체; 인테그린; 단백질 A 또는 D; 류머티스 인자; 향신경 인자, 예를 들어 뇌-유래 향신경 인자(BDNF), 뉴로트로핀-3, -4, -5, 또는 -6(NT-3, NT-4, NT-5, 또는 NT-6), 또는 신경 성장 인자, 예를 들어 NGF-β; 카디오트로핀(심장 비대 인자), 예를 들어 카디오트로핀-1(CT-1); 혈소판-유래 성장 인자(PDGF); 섬유모세포 성장 인자, 예를 들어 aFGF 및 bFGF; 표피 성장 인자(EGF); 전환 성장 인자(TGF), 예를 들어 TGF-알파 및 TGF-β(TGF-β1, TGF-β2, TGF-β3, TGF-β4, 또는 TGF-β5 포함); 인슐린 유사 성장 인자-I 및 -II(IGF-I 및 IGFII); des(1-3)-IGF-I(대뇌 IGF-I), 인슐린 유사 성장인자 결합 단백질; CD 단백질, 예를 들어 CD-3, CD-4, CD-8, 및 CD-19; 에리트로포이에틴; 골유도성 인자; 면역독소; 골 형태형성 단백질(BMP); 인터페론, 예를 들어 인터페론-알파, -베타 및 -감마; 콜로니 자극 인자(CSF), 예를 들어 M-CSF, GM-CSF, 및 G-CSF; 인터루킨(IL), 예를 들어 IL-1 내지 IL-10; 항-HER-2 항체; 과산화물 디스뮤타제; T-세포 수용체; 표면 막 단백질; 붕괴(decay) 가속화 인자; 바이러스 항원, 예를 들어 AIDS 외피의 일부분; 운송 단백질; 귀소(homing) 수용체; 어드레신; 조절 단백질; 항체; 및 상기 목록화된 폴리펩타이드들 중 임의의 폴리펩타이드의 단편과 같은 분자를 포함하나, 이들로 한정되는 것은 아니다.
특정 실시양태에서, 단백질 또는 폴리펩타이드는 IL-1, IL-1a, IL-1b, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12, IL-12 엘라스티(elasti), IL-13, IL-15, EL-16, IL-18, IL-18BPa, IL-23, IL-24, VIP, 에리트로포이에틴, GM-CSF, G-CSF, M-CSF, 혈소판 유래 성장인자(PDGF), MSF, FLT-3 리간드, EGF, 섬유모세포 성장인자(FGF; 예를 들어, α-FGF(FGF-1), β-FGF(FGF-2), FGF-3, FGF-4, FGF-5, FGF-6, 또는 FGF-7), 인슐린 유사 성장인자(예를 들어, IGF-1, IGF-2); 종양 괴사 인자(예를 들어, TNF, 림프독소), 신경 성장인자(예를 들어, NGF), 혈관 내피 성장 인자(VEGF); 인터페론(예를 들어, IFN-α, IFN-β, IFN-γ); 백혈병 억제 인자(LIF); 섬모 향신경 인자(CNTF); 옹코스타틴 M; 줄기 세포 인자(SCF); 전환 성장 인자(예를 들어, TGF-α, TGF-β1, TGF-β2, TGF-β3); TNF 수퍼패밀리(예를 들어, LIGHT/TNFSF14, STALL-1/TNFSF13B(BLy5, BAFF, THANK), TNF알파/TNFSF2 및 TWEAK/TNFSF12); 또는 케모카인(BCA-1/BLC-1, BRAK/Kec, CXCL16, CXCR3, ENA-78/LIX, 이오탁신(Eotaxin)-1, 이오탁신-2/MPIF-2, 엑소더스(Exodus)-2/SLC, 프락탈킨(Fractalkine)/뉴로탁틴(Neurotactin), GRO알파/MGSA, HCC-1, I-TAC, 림포탁틴(Lymphotactin)/ATAC/SCM, MCP-1/MCAF, MCP-3, MCP-4, MDC/STCP-1/ABCD-1, MIP-1쿼드러츄어(quadrature), MIP-2쿼드러츄어./GRO쿼드러츄어., MIP-3쿼드러츄어./엑소더스/LARC, MIP-3/엑소더스-3/ELC, MIP-4/PARC/DC-CK1, PF-4, RANTES, SDF1, TARC, TECK 또는 톡신(예를 들어, ω-아가톡신, μ-아가톡신, 아이톡신, 알로푸밀로톡신 267A, ω-아트라코톡신-HV1, δ-아트라코톡신-Hv1b, 바트라코톡신, 보토세틴, 아레노부파긴, 부포탈린, 부포테닌, 시노부파긴, 마리노부파긴, 분가로톡신, 칼시루딘, 칼시스프틴, 카르디오톡신 III, 카트로콜라스타틴 C, 카리브도톡신, 코브라 베놈 사이토톡신, 코노톡신, 에치노이딘, 엘레도이신, 에피바티딘, 피브롤라아제, 헤푸톡신, 히스트리오니코톡신, 후웬톡신 I, 후웬톡신 II, J-ACTX-Hv1c 쿠니츠 타입 톡신, 덴트로톡신 K, 덴드로톡신 1, 라트로톡신, 마르가톡신, 마우로톡신, 온치달, PhTx3, 푸밀로톡신 251D, 방울뱀 렉틴, 로버스톡신, 삭시톡신, 스킬라톡신, 슬로톡신, 스트로마톡신, 타이카톡신, 타리카톡신, 테트로도톡신, 리신, 겔로닌, 아플라톡신, 아마톡신, 시트리린, 사이토칼라신, 에르고타민, 푸마길린, 푸모니신, 글리오톡신, 헬볼산, 이토텐산, 무스키몰, 오크라톡신, 파툴린, 스테리그마토시스스틴, 트리코테센, 보미톡신, 제라놀, 제아랄레논, 안트락스 톡신, 아데닐레이트 보호 항원 사이클라아제, rPA, 크라이 톡신, 보르데텔라 페르투시스(Bordetella pertussis) 톡신, 클로스트리디움 보툴리눔(Clostridium botulinum) 톡신, 클로스트리디움 디피실레(Clostridium difficile) 톡신, 클로스트리디움 페르프린겐스(Clostridium perfringens) 톡신, 파상풍 톡신, 디프테리아 톡신, 베로톡신/시가 유사 톡신, 열 안정성 엔도톡신, 열 불안정성 엔데로톡신, 엔테로톡신, 리스테리올라이신 O, 마이코박테리움 투베르쿨로시스(Mycobacterium tuberculosis) 코드 팩터, 슈도모나스 엑소톡신, 살모넬라(Salmonella) 엔도톡신, 살모넬라 엑소톡신, 시가 톡신, 스타필로콕커스 아우레우스(Staphylococcus aureus) 알파 톡신, 스타필로콕커스 아우레우스 베타 톡신, 스타필로콕커스 아우레우스 델타 톡신, 엑스폴리아틴 톡신, 독성 쇼크 증후군 톡신, 엔테로톡신, 류코시딘, 스트렙토라이신, 또는 콜레라 톡신)으로부터 선택된다.
한 실시양태에서, 관심 단백질은 멀티-서브유닛 단백질 또는 폴리펩타이드이다. 발현되는 멀티서브유닛 단백질은 호모머성(homomeric) 및 헤테로머성(heteromeric) 단백질을 포함한다. 멀티서브유닛 단백질은 동일하거나 상이할 수 있는 2개 이상의 서브유닛을 포함할 수 있다. 예를 들어, 단백질은 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개 또는 그 초과의 서브유닛을 포함하는 호모머성 단백질일 수 있다. 또한, 단백질은 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개 또는 그 초과 서브유닛을 포함하는 헤테로머성 단백질일 수 있다. 예시적인 멀티서브유닛 단백질은 수용체(이온 채널 수용체 포함); 세포외 매트릭스 단백질(콘드로이틴 포함); 콜라겐; MHC 단백질, 완전 사슬 항체, 및 항체 단편 포함을 포함하는 면역조절인자; RNA 폴리머라아제 및 DNA 폴리머라아제를 포함하는 효소; 및 막 단백질을 포함한다.
다른 실시양태에서, 관심 단백질은 종종 혈액 단백질일 수 있다. 이러한 실시양태에서 발현되는 혈액 단백질은 캐리어 단백질, 예를 들어 인간 및 소 알부민을 포함하는 알부민, 트랜스페린, 재조합 트랜스페린 반-분자, 햅토글로빈, 피브리노겐 및 다른 응고 인자, 보체 성분, 면역글로불린, 효소 억제제, 안지오텐신 및 브라디키닌과 같은 물질의 전구체, 인슐린, 엔도텔린, 및 알파, 베타 및 감마-글로불린을 포함하는 글로불린, 및 포유동물의 혈액에서 주로 발견되는 다른 타입의 단백질, 폴리펩타이드 및 이들의 단편을 포함하나, 이들로 한정되는 것을 아니다. 인간 혈청 알부민(Lawn, L. M., et al., 1981, Nucleic Acids Research, 9:6103-6114) 및 인간 혈청 트랜스페린(Yang, F, et al., 1984, Proc. Natl. Acad. Sci. USA 81:2752- 2756)에 대한 아미노산 서열을 포함하여, 수많은 혈액 단백질에 대한 아미노산 서열이 보고되어 있다(참조: S. S. Baldwin, 1993, Comp. Biochem. Physiol. 106b:203-218).
다른 실시양태에서, 관심 단백질은 종종 재조합 효소 또는 보조인자일 수 있다. 이러한 실시양태에서 발현된 효소 및 보조인자는 알돌라아제, 아민 옥시다아제, 아미노산 옥시다아제, 아스파르타아제, B12 의존성 효소, 카르복시펩티다아제, 카르복시에스테라아제, 카르복실라아제, 케모트립신, CoA 요구 효소, 시아노히드린 신테타아제, 시스타치온 신테타아제, 데카르복실라아제, 데하이드로게나아제, 알코올 데하이드로게나아제, 데히드라타아제, 디아포라아제, 디옥시게나아제, 에노에이트 리덕타아제, 에폭시드 하이드라아제, 푸머라아제, 갈락토오스 옥시다아제, 글루코오스 아이소머라아제, 글루코오스 옥시다아제, 글리코실트랜스퍼라아제, 메틸트랜스퍼라아제, 니트릴히드라아제, 뉴클레오시드 포스포릴라아제, 옥시도리덕타아제, 옥시니틸라아제, 펩티다아제, 글리코실트랜스퍼라아제, 퍼옥시다아제, 및 치료적으로 활성인 폴리펩타이드에 융합된 효소; 유로키나아제, 렙틸라아제, 스트렙토키나아제; 카탈라아제, 퍼옥사이드 디스뮤타아제; DNase, 아미노산 히드롤라아제(예를 들어, 아스파라기나아제, 아미도히드롤라아제); 카르복시펩티다아제; 프로테아제, 트립신, 펩신, 키모트립신, 파파인, 브로멜라인, 콜라게나아제; 뉴라미니다아제; 락타아제, 말타아제, 수크라아제, 및 아라비노푸라노시다아제를 포함하지만, 이들로 한정되는 것은 아니다.
다른 실시양태에서, 관심 단백질은 종종 항체 또는 항체 유도체이다. 실시양태에서, 항체 또는 항체 유도체는 인간화 항체, 변형된 항체, 단일 도메인 항체(예를 들어, 나노바디, 샤크 단일 도메인 IgNAR 또는 VNAR 항체, 카멜리드 단일 도메인 항체), 이종 특이성 항체, 3가 항체, 이중 특이성 항체(예를 들어, BiTE 분자), 단일 사슬 항체, Fab, Fab 단편, 선형 항체, 디아바디, 전체 사슬 항체 또는 이의 단편 또는 일부분이다. 단일 사슬 항체는 종종 안정적으로 폴딩된 단일 폴리펩타이드 사슬 상의 항체의 항원 결합 영역을 포함한다. Fab 단편은 종종 특정 항체의 조각이다. 통상 Fab 단편은 항원 결합 부위를 함유한다. Fab 단편은 종종 경쇄 및 중쇄 단편인 2개의 사슬을 함유한다. 이들 단편들은 링커 또는 다이설파이드 결합에 의해 연결된다. 본 발명의 방법에 유용한 항체 및 항체 유도체는 당해 기술분야에 공지되어 있고, 문헌, 예를 들어 본 출원의 다른 곳에서 참고로 인용된 미국 특허 제9,580,719호의 표 9에 기재되어 있다.
관심 단백질 또는 폴리펩타이드에 대한 코딩 서열은 입수 가능한 경우 타겟 폴리펩타이드에 대한 천연 코딩 서열일 수 있지만, 더욱 바람직하게는, 예를 들어, 슈도모나스 플루오레센스와 같은 슈도모나스 종 또는 기타 적절한 유기체의 코돈 사용 경향을 반영하도록 유전자를 합성함으로써, 선택된 숙주 세포에서 사용하기 위해 선택, 개선, 또는 최적화된 코딩 서열일 것이다. 결과적인 유전자(들)는 하나 이상의 벡터 내에 구축되거나, 또는 벡터 내로 삽입될 것이고, 그 후 벡터가 발현 숙주 세포 내로 형질전환될 것이다. "발현 가능한 형태"로 제공되는 것으로 언급되는 핵산 또는 폴리뉴클레오타이드는 선택된 발현 숙주 세포에 의해 발현될 수 있는 하나 이상의 유전자를 함유하는 핵산 또는 폴리뉴클레오타이드를 의미한다.
특정 실시양태에서, 관심 단백질은 천연 단백질, 예를 들어 천연 포유류 또는 인간 단백질이거나, 또는 이에 대해 실질적으로 상동성이다. 이들 실시양태에서, 단백질은 콘카타머(concatamer) 형태로 발견되지 않고, 분비 신호, 및 경우에 따라 정제 및/또는 인식을 위한 태그에만 연결된다.
다른 실시양태에서, 관심 단백질은 약 20℃ 내지 약 42℃의 온도에서 활성인 단백질이다. 한 실시양태에서, 단백질은 생리학적 온도에서 활성이고, 고온 또는 극한 온도, 예를 들어 65℃를 초과하는 온도로 가열되는 경우 불활성화된다.
한 실시양태에서, 관심 단백질은 약 20℃ 내지 약 42℃의 온도에서 활성이고/이거나 고온 또는 극한 온도, 예를 들어 65℃를 초과하는 온도로 가열되는 경우 불활성화되는 단백질이고; 천연 단백질, 예를 들어 천연 포유류 또는 인간 단백질이거나 이에 대해 상동성이며, 콘카타머 형태로 핵산으로부터 발현되지 않고; 프로모터는 슈도모나스 플루오레센스에서의 천연 프로모터가 아니고 다른 유기체, 예를 들어 이. 콜라이으로부터 유래된다.
다른 실시양태에서, 단백질은, 생산되는 경우, 추가적인 타겟팅 서열, 예를 들어 단백질을 세포외 배지로 타겟팅하는 서열을 또한 포함한다. 한 실시양태에서, 추가적인 타겟팅 서열은 단백질의 카르복시 말단에 작동 가능하게 연결된다. 다른 실시양태에서, 단백질은 오토트랜스포터, 2-파트너 분비 시스템, 메인 터미널 브랜치 시스템 또는 핌브리알 어셔 포린에 대한 분비 신호를 포함한다.
하기 실시예는 예시를 위해 제공되는 것이지 제한을 위해 제공되는 것은 아니다.
실시예
하기 실시예는 본 개시내용의 다양한 실시양태를 예시하기 위한 목적으로 제공되는 것이며, 어떤 형태로든 본 개시내용을 제한하려는 의도는 없다. 본 출원에 기재된 방법과 함께 본 실시예는 현재의 대표적이 실시양태이고, 예시이며, 범위에 대한 제한으로서 의도되지 않는다. 청구범위에 의해 한정되는 바와 같은 개시내용의 사상의 범위 내에 포함되는 변경 및 다른 사용은 당해 기술분야의 통상의 기술자에게 가능할 것이다.
실시예 1: 단백질 발현 분석
3개의 상이한 재조합 단백질의 가용성 발현을 유도하기 위한 3가지 피. 플루오레센스 분비 리더, AnsB, 8484, 및 5193 각각의 효율은 0.5 mL 배양 규모에서 평가되었다.
각각의 분비 리더 코딩 서열은 이. 콜라이 K-12 티오레독신 1(Trx-1 또는 TrxA, 11.9 kDa), Gal2 단일 사슬 항체(gal2 scFv, 29.6 kDa) 및 바실러스 안트라시스(Bacillus anthracis) 돌연변이체 재조합 보호성 항원(mrPA, 83.7 kDa)을 코딩하는 유전자와 함께 프레임내 융합되었다. 이들 컨스트럭트로부터의 단백질 발현은 동일한 재조합 단백질 각각에 융합된 Pbp 분비 리더 코딩 서열을 보유하는 컨스트럭트로부터의 발현뿐만 아니라 각각의 단백질의 세포질 발현을 위해 구축된 균주와 비교되었다. 세포질 발현 균주 컨스트럭트는 TrxA, Gal2 또는 mrPA 코딩 서열에 융합된, 알라닌을 수반하는 개시자 메티오닌을 코딩하였다. 플라스미드 컨스트럭트는 피. 플루오레센스 균주 DC454 내로 형질전환되었고, 포지티브 클론을 분리하기 위해 선택 배지(M9 글루코오스)에서 성장되었다. 본 테스트의 결과는 하기 표 6에 나타낸다. 예시적인 SDS-CGE 이미지는 도 1(TrxA), 도 2(Gal2 scFv), 및 도 3(mrPA)에 나타낸다.
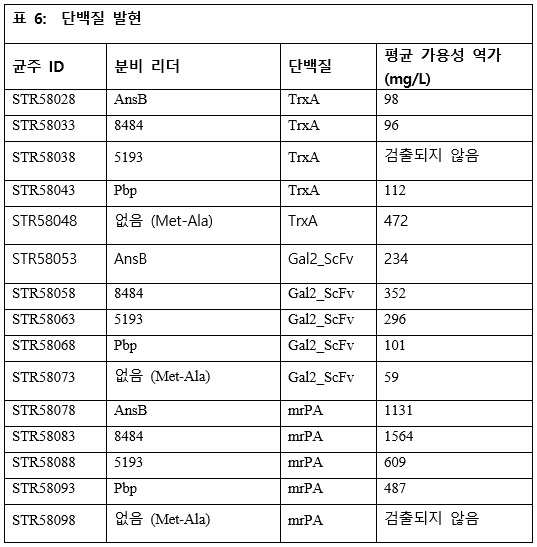
각각의 균주는 미네랄 염 배지에서 24 시간 동안 3회 성장시켰고, 이어서 IPTG를 이용하여 유도하고, 추가로 24 시간 동안 항온처리되었다. 브로스는 수집되고, PBS로 3배 희석되고, 초음파 처리되고, 원심분리되었다. 상등액은 가용성 단백질 분획으로서 수집되었고, SDS-CGE(Caliper LabChip® GXII 시스템)에 의해 분석되었다. 유도된 밴드는 시스템 내부 래더와 비교하여 정량되었다. Gal2 scFv 및 mrPA 단백질은 AnsB, 8484 및 5193 리더에 융합되는 경우 더 높은 레벨로 발현되었지만, 상기 단백질들이 세포질로 타겟팅된 경우 Gal2 또는 mrPA의 발현은 검출되지 않았다.
실시예 2: 96웰 포맷에서 크리산타스파아제 단계(Tier) 1 발현 플라스미드 스크리닝
또한, 에르위니아(Erwinia) 타입 II L-아스파라기나아제(크리산타스파아제)-리더 융합 컨스트럭트가 평가되었다.
발현 플라스미드 스크리닝을 위해, 최적화된 크리산타스파아제 단백질 코딩 서열은 피. 플루오레센스에서의 발현을 위해 디자인되고 합성되었다, 크리산타스파아제 펩타이드 서열을 코딩하는 DNA(도 4, 서열 번호 7로서 기재된 아미노산 서열 및 서열 번호 8로서 기재된 핵산 서열)는 피. 플루오레센스를 위한 적합한 코돈 용법을 반영하도록 디자인되었다. 독특한 제한 효소 부위(SapI 또는 LguI)를 함유하는 DNA 영역은 발현 벡터 내에 존재하는 분비 리더 코딩 서열과 함께 프레임 내에 직접 융합을 위해 디자인된 크리산타스파아제 코딩 서열의 상류에 첨가되었다. 3개의 종결 코돈 및 독특한 제한 효소 부위(SapI)를 함유하는 DNA 영역은 코딩 서열의 하류에 첨가되었다. 37개의 상이한 피. 플루오레센스 분비 리더에 융합된 최적화된 크리산타스파아제 유전자 및 2가지의 리보좀 결합 부위(RBS) 친화도를 보유하는 플라스미드가 구축되었다(표 7). 추가의 플라스미드는 세포의 세포질 내에 크리산타스파아제 단백질을 국부화하기 위해 주변세포질 리더 없이 크리산타스파아제 단백질을 발현하도록 구축되었다. 타겟의 발현은 Ptac 프로모터로부터 구동되었고, 번역은 고 활성 리보좀 결합 부위(RBS)로부터 개시되었다. 생성된 40개의 플라스미드는 단계(tier) 1(발현 전략) 스크리닝을 위한 80가지의 발현 균주를 생산하기 위해, 2가지의 피. 플루오레센스 호스트 균주, DC454(WT) 및 DC441(PD) 내로 형질전환었다. 발현 전략의 랭킹은 크리산타스파아제 모노머의 SDS-CGE 추정된 역가에 기초하였다. 발현 전략 스크린의 일차적인 목표는 발현 플라스미드 및 그들의 통합된 유전적 요소의 대형 서브셋을 평가하는 것, 및 낮은 또는 불량한 품질의 타겟 발현을 나타낸 발현 전략들을 제거하는 것이었다.
80개의 형질전환물(40가지의 발현 전략 x 2가지의 호스트 균주)로부터 생성된 결과적인 배양물은 실시예 2에 기재된 바와 같이 96웰 플레이트에서 성장외었다. 유도 후 24 시간에 수확된 전체 브로스 배양물 유래의 초음파 처리 샘플은 SDS-CGE에 의해 분석되었다. 크리산타스파아제 단량체에 대해 예측된 분자량(35 kDa)과 일치하고, 또한 이. 콜라이 L-Asp(Sigma 제품 #A3809)와 함께 이동된 유도된 단백질의 발현이 정량되었다. 환원된 샘플의 SDS-CGE 정량은 유도된 밴드와 이. 콜라이 L-Asp 표준 곡선을 비교함으로써 완료되었다. DC454 및 DC441 호스트 균주 둘 다로부터의 20개의 최고 성능 샘플이 추정 가용성 크리산타스파아제 모노머 역가에 기초하여 랭킹되었다(표 9). 도 5는 96웰 배양 가용성 초음파 처리 샘플의 분석으로부터 생성된 SDS-CGE 겔-유사 도면을 나타낸다. 표 9는 DC454(표의 좌측) 및 DC441(표의 우측) 호스트 균주에서 발현된 플라스미드에 대해 환원된 가용성 초음파 처리물의 SDS-CGE 분석에 의해 추정되고, LabChip® 내부 래더에 의해 정량된 바와 같은 유도 후 24 시간(I24) 역가를 나타낸다. 또한, 각각의 p743 발현 플라스미드로부터 생산된 분비 리더 융합도 나타낸다.
DC454 및 DC441 호스트 균주 둘 다로부터 유도된 상위 10개의 최고 성능 발현 균주에서 관찰된 6개의 플라스미드 및 통합된 분비 리더(p743-013(FlgI), p743-038(8484), p743-020(LolA), p743-018(DsbC), p743-009(Ibp-S31A) 및 p743-034(5193))는 표 9에 **로 표시되어 있다. 추가로, 크리산타스파아제 단백질의 세포질 발현을 위해 디자인된 p743-001 발현 플라스미드는 호스트 둘 다에서 상위 2개의 최고 가용성 성능으로 랭킹되었다. 호스트 균주 둘 다를 조합하면, 상위 10개의 최고 가용성 역가 범위는 525 내지 1,523 μg/mL였다. 불용성 성능은 p743-013 플라스미드를 이용하여 230 μg/mL를 달성하는 최고 불용성 성능으로 관찰된 모든 발현에 대해 낮았다. SDS-CGE 밴드 패턴의 관찰(도 5)은 가장 완전한 분비 리더 프로세싱(주변세포질로 유출 시 제거)이 p743-013, p743-033(리더 O), p743-038, p743-009 및 p743-018 발현 플라스미드를 이용하여 발생되었고, 반면 p743-016 및 p743-017 플라스미드는 현저한 저분자량 절단 생성물을 생산하는 것이 관찰되었음을 나타낸다. 표 8에 나타낸 10개의 발현 플라스미드는 SDS-CGE 추정 높은 가용성 역가에 기초하여 96웰 HTP 규모에서 후속 호스트 균주 스크리닝을 위해 선택되었다. 이어서, 10가지의 선택된 발현 전략은 크리산타스파아제 단백질 역가 및 품질에 추가로 영향을 미칠 수 있는 24가지의 독특한 호스트 균주와 조합되었다.
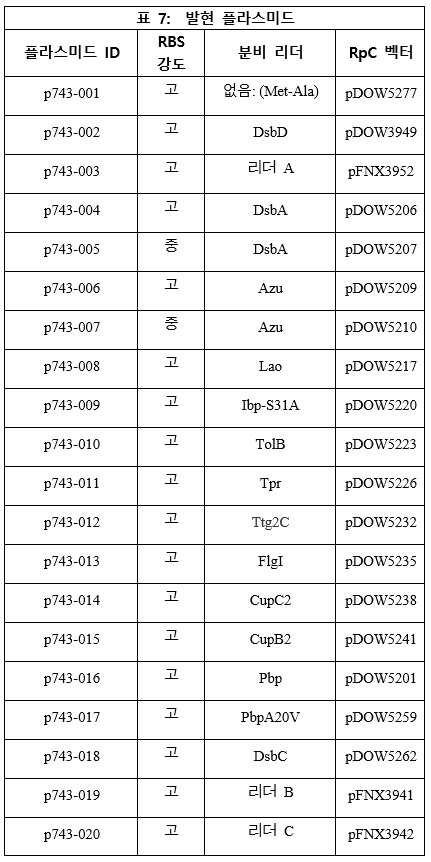


표 9는 DC454(표의 좌측) 및 DC441(표의 우측) 호스트 균주에서 발현된 플라스미드에 대해 환원된 가용성 초음파 처리물의 SDS-CGE 분석에 의해 추정되고, LabChip® 내부 래더에 의해 정량된 바와 같은 유도 후 24 시간(I24) 역가를 나타낸다. 또한, 각각의 p743 발현 플라스미드로부터 생산된 분비 리더 융합도 나타낸다.

실시예 3: 이. 콜라이 아스파라기나아제 발현 구조체의 제조
이. 콜라이 아스파라기나아제-리더 융합 컨스트럭트로부터 단백질 발현이 평가되었다.
이. 콜라이 A-1-3 L-아스파라기나아제 II 유전자는 피. 플루오레센스에서의 발현을 위해 최적화되었고, 세포질 및 주변세포질 발현을 위해 한 세트의 발현 벡터 내로 클로닝되었다. 사용된 아미노산 서열은 본 출원에 서열 번호 9로서 개시되어 있다. 사용된 핵산 서열은 본 출원에 서열 번호 10으로서 개시되어 있다.
발현은 일련의 분비 리더 서열을 이용하여 평가되었는데, 그 중 일부는 고 RBS 서열을 이용하였고, 일부는 중 RBS 서열을 이용하였다. 아울러, 리더를 이용하지 않는 세포질 발현이 평가되었다.
각각의 컨스트럭트는 피. 플루오레센스 호스트 균주 DC454(pyrF 결손, PD 또는 FMO 없음) 및 DC441(pyrF 결손 PD) 내로 형질전환되었고, 생성된 발현 균주는 0.5 mL 배양에서 이. 콜라이 A-1-3 L-아스파라기나아제 II 생산에 대해 평가되었다. 전체 브로스는 초음파 처리되었고, 원심분리되었고, 가용성 분획은 SDS-CGE에 의해 분석되었다.
96웰 포맷에서 성장 및 발현
발현 플라스미드 스크리닝을 위해, 이. 콜라이 A-1-3 L-아스파라기나아제 II 발현 플라스미드 각각에 대한 라이게이션 혼합물은 다음과 같이 피. 플루오레센스 호스트 균주 DC454 및 DC441 세포 내로 형질전환되었다. 25 마이크로리터의 컴피턴트 세포는 해동되었고, 96 멀티웰 Nucleovette®(Lonza) 내로 이전되었으며, 라이게이션 혼합물은 각각의 웰에 첨가되었다. 세포는 NicleofectorTM 96-well ShuttleTM 시스템(Lonza AG)을 이용하여 전기천공되었다. 이어서, 세포는 400 μl의 M9 염 1% 글루코오스 배지 및 미량 원소와 함께 96웰 딥 웰에 이전되었다. 96웰 플레이트(시드 플레이트)는 30℃에서 진탕하면서 48 시간 동안 항온처리되었다. 10 μl의 시드 배양물은 각각의 웰이 미량 원소 및 5% 글리세롤이 보충된 500 μl의 HTP 배지를 함유하는 96웰 딥 웰 플레이트에 2회 이전되었고, 이전과 같이 24 시간 동안 항온처리되었다. 타겟 단백질의 발현을 유도하기 위해, 이소프로필-β-D-1-티오갈락토피라노사이드(IPTG)가 24 시간 시점에서 각각의 웰에 최종 농도 0.3 mM로 첨가되었다. 폴딩 조절자 과발현 균주에서 폴딩 조절자의 발현을 유도하기 위해, 만니톨(Sigma)이 각각의 웰에 최종 농도 1%로 첨가되었다. 세포 밀도는 성장을 모니터링하기 위해 유도 후 24 시간에 600 nm(OD600)에서 광학 밀도에 의해 측정되었다. 유도 후 24시간에 세포는 수확되었고, 최종 부피 400 μl를 위해 1X PBS 내에서 1:3으로 희석되었고, 이어서 동결되었다. 샘플은 후술하는 바와 같이 제조 및 분석되었다.
발현 플라스미드 스크리닝에서 확인된 상위 샘플에 대한 발현 결과는 표 10 및 11에서 확인된다.


호스트 균주 스크리닝을 위해, 발현 플라스미드 스크리닝 결과에 기초하여 선택된 발현 플라스미드는 각각 야생형(WT) 또는 모 DC454 균주, 프로테아제 결실(PD) 균주, 폴딩 조절자 과발현(FMO) 균주 및 프로테아제 결실 + 폴딩 조절자 과발현자(PD/FMO) 균주를 포함하는 어레이 내에서 24가지의 피. 플루오레센스 호스트 균주 내로 형질전환되었다. 피. 플루오레센스 아스파라기나아제 분비 리더(AnsB)에 융합된 이. 콜라이 아스파라기나아제는 상기 어레이 내에 포함되었다(서열 번호 1에 기재된 바와 같은 아미노산 서열; 서열 번호 4에 기재된 바와 같은 코딩 서열). 폴딩 조절자가 존재하는 경우, 이는 제2 플라스미드 상에서 코딩되었고, 발현은 피. 플루오레센스 천연 만니톨 유도성 프로모터에 의해 구동되었다. 호스트 균주 스크린 형질전환은 다음과 같이 수행되었다: 25 마이크로리터의 피. 플루오레센스 호스트 균주 컴피턴트 세포는 해동되었고, 96 멀티웰 Nucleovette® 플레이트 내로 이전되었으며, 10 μl의 플라스미드 DNA(10 ng)가 각각의 웰에 첨가되었다. 세포들은 상기 플라스미드 발현 스크리닝에 대해 기재된 바와 같이 전기천공되었고, 배양되었고, HTP 포맷으로 유도되었고, 수확되었다. 샘플은 후술하는 바와 같이 제조되었고, 분석되었다.
분석을 위한 샘플의 제조
가용성 분획은 초음파 처리 후 원심분리에 의해 제조되었다. 배양 브로스 샘플(400 μL)은 24 프로브 팁 혼이 구비된 셀 라이시스 자동화 초음파 처리 시스템(CLASS, Scinomix)을 이용하여 하기 조건 하에서 초음파 처리되었다: 펄스 당 10초로 웰 당 20 펄스, 및 각각의 펄스 사이에 10초 동안 60% 파워(Sonics Ultra-Cell). 용해물은 5,500 x g에서 15분(4℃) 동안 원심분리되었고, 상등액은 수집되었다(가용성 분획).
SDS-CGE 분석
단백질 샘플은 HT 단백질 익스프레스 칩 및 상응하는 시약(PerkinElmer)과 함께 L뮤Chip GXII 장비(PerkinElmer)를 이용하여 마이크로칩 SDS 모세관 겔 전기영동에 의해 분석되었다. 샘플은 하기 제조사의 프로토콜(단백질 사용자 가이드 문서 번호 450589, Rev. 3)에 따라 제조되었다. 개략적으로, 96웰 폴리프로필렌 원추형 웰 PCR 플레이트 내에서, 4 μL의 샘플은 14 μL의 샘플 버퍼, 70 mM DTT 환원제와 함께 혼합되었고, 가열되었다.
유도 후 24 시간에 샘플링된 전체적인 브로스는 상기한 바와 같이 처리되었고, 가용성 분획은 SDS-CGE에 의해 분석되었다.
시판되는 L-아스파라기나아제 활성 어세이 키트(Sigma)는 눌 샘플과 비교하는 경우 최고 성능 균주 STR55382(Lao 리더) 유래의 HTP 배양 용해물 샘플에서 유의미한 L-아스파라기나아제 활성을 검출하였다.
발현 플라스미드 스크리닝 실험에서 스크리닝된 플라스미드 및 상응하는 분비 리더는 다음을 포함한다:
p742-006 (Azu)
p742-008 (LAO)
p742-009 (Ibp-S31A)
p742-016 (Pbp)
p742-017 (PbpA20V)
p742-021 (리더 D)
p742-037 (리더 R)
p742-038 (8484)
p742-041 (피. 플루오레센스 AnsB).
발현 균주들은 상기한 바와 같이 배양되었고, 유도되었다. 가용성 및 불용성 분획의 SDS-CGE 분석은 높은 레벨의 아스파라기나아제 발현을 나타냈다(도 6). 높은 역가는 표 12에 기재된 균주들을 포함하는 발현 균주에서 관찰되었다.

실시예 4: 균주의 구축
하기 피. 플루오레센스 아스파라기나아제 KO 호스트 균주가 생성되었다.
PF1433(PyrF, AspG1, 및 AspG2 결손)은 호스트 균주 DC454(PryF 결손)에서 aspG2 및 aspG1 유전자의 순차적인 결실에 의해 구축되었다.
PF1434(PyrF, ProC, AspG1, 및 AspG2 결손)는 호스트 균주 DC455(pyrF proC)에서 aspG1 및 aspG2 유전자의 순차적인 결실에 의해 구축되었다. 균주 DC455는 DC542 및 DC549 둘 다의 모 균주이다.
PF1442(PyrF, ProC, AspG1, AspG2, Lon, DegP1, DegP2 S219A, Prc1, 및 AprA 결손)는 호스트 균주 PF1201(PyrF, ProC, 프로테아제 Lon, DegP1, DegP2 S219A, Prc1, 및 AprA 결손)에서 aspG2 및 aspG1 유전자의 순차적인 결실에 의해 구축되었다.
PF1443(PyrF, ProC, AspG1, 및 AspG2 결손; pDOW3700로부터 발현된 FMO LepB)은 PF1434 내로 LepB-코딩 FMO 플라스미드 pDOW3700을 형질전환함으로써 구축되었다.
PF1444(PyrF, ProC, AspG1, 및 AspG2 결손; pDOW3707로부터 발현된 FMO Tig)는 PF1434 내로 Tig-코딩 FMO 플라스미드 pDOW3700을 형질전환함으로써 구축되었다.
PF1445(PyrF, ProC, AspG1, AspG2, Lon, DegP1, DegP2, S219A, Prc1, 및 AprA 결손; pFNX4142로부터 발현된 FMO DsbAC-Skp)는 DsbAC-Skp-코딩 플라스미드 pFNX4142를 이용하는 PF1442의 형질전환에 의해 구축되었다.
사용된 균주는 표 13에 기재되어 있다.

실시예 5: 선택된 발현 균주의 발효 및 가용성 %TCP의 계산
실시예 3에 기재된 균주 STR57863 및 STR57860은 2 L 발효로 스케일링되었고, 각각 최대 8가지의 상이한 발효 조건 하에서 스크리닝되었다. 2 L 규모의 발효(대략 1 L의 최종 발효 부피)는 선택된 균주의 동결 배양물 스탁을 이용하여 효모 추출물과 글리세롤로 보충된 화학적으로 한정된 배지 600 mL를 함유하는 진탕 플라스크를 접종함으로써 생성되었다. 30℃에서 진탕하면서 16 내지 24 시간 항온처리 후, 각각의 진탕 플라스크 배양물의 균일한 부분은 고 바이오매스를 지원하도록 디자인된 화학적으로 한정된 배지를 함유하는 8 유닛 멀티플렉스 발효 시스템 각각에 무균적으로 이전되었다. 2 L 발효기 내에서, 배양은 글리세롤 유가 배양 모드로 pH, 온도, 및 용존 산소에 대한 제어된 조건 하에서 수행되었다. 유가 배양 고 세포 밀도 발효 공정은 성장기, 이어서 일단 배양이 타겟 바이오매스에 도달하면(습윤 세포 중량) IPTG 및 5 g/L의 만니톨 첨가에 의해 개시된 유도기로 구성되었다. 유도기 중의 조건은 실험 디자인에 따라 변경되었다. 발효의 유도기는 대략 24 시간 동안 진행되도록 하였다. 분석 샘플은 세포 밀도(575 nm에서 광학 밀도)를 측정하기 위해 발효조로부터 채취되었고, 이어서 타겟 유전자 발현의 레벨을 평가하기 위한 후속 분석을 위해 동결되었다. 유도 후 24 시간의 최종 시점에서, 각 용기의 전체적인 발효 브로스는 15,900 x g에서 60 내지 90분 동안 원심분리에 의해 수확되었다. 세포 페이스트 및 상등액은 분리되었고, 페이스트는 -80℃에서 유지 및 동결되었다.
표 14는 몇 가지 발효 조건 하에서 균주 STR57863 및 STR57860을 이용한 발현 결과를 나타낸다. 확인할 수 있는 바와 같이, 초기 균주/발효 조건의 몇 가지 조합은 >30% TCP 아스파라기나아제 발현을 나타냈다. 총 세포 단백질은 다음과 같이 계산되었다:
0.55 DCW 총 세포 단백질 x A550에서 500 μg/mL DCW = A550=1에서 275 μg 총 세포 단백질/ml(또는 mg/L)
최종 시점(I24)에서 TCP = OD575 * 275mg/L TCP
가용성 % TCP = 100 * (가용성 역가 / TCP)

실시예 6: 아스파라기나아제 진탕 플라스크 발현
진탕 플라스크 발현(200 mL)은 크리산타스파아제, 이. 콜라이 타입 II L-아스파라기나아제, 및 피. 플루오레센스 타입 II L-아스파라기나아제 발현 균주로부터의 단백질 생산을 평가하기 위해 수행되었다. 아스파라기나아제 발현 플라스미드는, 표 15에서 확인할 수 있는 바와 같이, 발현 균주를 생성하기 위해 아스파라기나아제 결손 호스트 균주 PF1433 내로 형질전환되었다. 진탕 플라스크 샘플로부터 생성된 용해물은 LC-MS 분석에 의한 원형 질량의 확인 및 초기 활성 분석을 위해 사용되었다.

표 15는 200 mL 작용 부피 진탕 플라스크 스케일에서 분석된 PF1433 호스트 균주(천연 아스파라기나아제 결손, 야생형 균주)를 이용하여 구축된 3개의 크리산타스파아제 발현 균주의 환원된 가용성 및 불용성 초음파 처리 분획의 SDS-CGE 분석(10회의 상이한 반복)에 의해 결정된 바와 같이 평균 추정 역가를 나타낸다. SDS-CGE 역가는 이. 콜라이 L-Asp(Sigma) 표준 곡선에 대한 비교에 기초하여 추정되었다. 각각의 균주의 가용성 및 불용성 초음파 처리 분석 둘 다로부터 촬영한 SDS-CGE 겔-유사 이미지는 도 7에 나타낸다. AsnB 리더를 포함하는 컨스트럭트(STR55981, 천연 분비 리더-천연 아스파라기나아제 단백질 융합)로부터 생산된, 피. 플루오레센스 천연 L-Asp2 단백질의 역가가 AsnB 리더를 포함하는 컨스트럭트(STR55976)로부터 생산된 이. 콜라이 아스파라기나아제 단백질의 역가에 비해 실질적으로 낮았다는 점은 주목할 만한데, 즉 이때 AnsB 리더는 이종성 아스파라기나아제 단백질에 융합되었다(1011 μg/ml과 비교하여 677 μg/ml, 약 1.5배 차이).
상기 분석에는 2가지 눌 균주, 즉 STR55982 및 DC432로부터 진탕 플라스크 성장이 포함되었다. DC432 균주는 피. 플루오레센스 호스트 균주 내에 플라스미드 pDOW1169를 보유하는데, 이는 야생형 크리산타스파아제 코딩 영역을 함유하지 않는다. STR55982는 천연 아스파라기나아제 코딩 서열 둘 다의 염색체 결실을 함유하는 호스트 균주 PF1433 내에 플라스미드 pDOW1169를 보유한다. 모두 3가지의 크리산타스파아제 발현 균주는 대부분 가용성 크리산타스파아제 단백질 발현을 나타냈는데, 균주 STR55978이 최대 14 g/L의 가장 높은 가용성 역가를 나타냈다. 더구나, 유도 후 24 시간에서 각각 21.7 및 23.7의 OD600을 나타내는 STR55982 및 DC432 눌 균주와 비교하는 경우, 모두 3가지의 크리산타스파아제 발현 균주는 유도 후 24 시간에서 유사한 세포 밀도(OD600 = 23.0, 27.0 및 27.8)를 달성했기 때문에, 성장 패널티는 관찰되지 않았다.
5가지의 진탕 플라스크 발현 균주 각각으로부터 생성된 가용성 초음파 처리 샘플은 Sigma로부터 구입한 상용 키트(아스파라기나아제 활성 어세이 키트)를 이용하여 아스파라기나아제 활성에 대해 분석되었다. 이러한 키트는 생성된 아스파르테이트에 비례하는 비색 최종 생성물을 생성하는 커플링된 효소 반응을 이용하여 활성을 측정한다. Sigma의 이. 콜라이 아스파라기나아제 타입 II(A3809)는 양성 대조군으로서 STR55982 눌 용해물 내로 스파이킹되었다(최종 열).
활성 결과는 표 16에 나타낸다.

눌 샘플 둘 다는 1:25,000 희석 배수에서 측정 가능한 활성을 나타내지 않았지만, 1:25,000 희석된 균주 STR55976, STR55977, STR55978, STR55979 및 STR55980 유래의 가용성 초음파 처리 샘플은 Sigma의 이. 콜라이 L-아스파라기나아제(A3809) 250 μg/mL으로 스파이크된 유사하게 희석된 STR55982 눌 균주에 필적하는 활성을 나타냈다. 시판되는 키트를 이용하는 이들 초기 활성 결과는 피. 플루오레센스에서 발현된 크리산타스파아제 단백질 및 이. 콜라이 아스파라기나아제 단백질이 생성된 초음파 처리물 내에서 활성인 사량체 아스파라기나아제 효소를 용이하게 형성할 수 있음을 나타내는 것으로 생각된다.
표 17은 진탕 플라스크 내의 균주 STR55978, STR55979 및 STR55980에 의해 생성된 가용성 초음파 처리물 유래의 크리산타스파아제, 및 균주 STR55976 및 STR55977에 의해 생성된 가용성 초음파 처리물 유래의 이. 콜라이 아스파라기나아제의 분석으로부터의 LC-MS 원형(intact) 질량분석 결과를 나타낸다. 각각의 균주 유래의 크리산타스파아제 단백질의 관찰된 분자량(35,053 Da)은 이론적인 분자량(35054.2 Da)과 일치하는데, 이는 세 가지 균주 모두가 예측된 아미노산 서열의 생성 및 완전한 프로세싱, 또는 존재하는 경우 분비 리더의 제거를 수행하고 있음을 나타낸다. 각각의 균주 유래의 이. 콜라이 아스파라기나아제의 관찰된 분자량(34591 Da)은 이론적인 분자량(34591.96 Da)과 일치하는데, 이는 균주 둘 다 예측된 아미노산 서열의 생성 및 완전한 프로세싱, 또는 발생된 분비 리더의 제거를 수행하고 있음을 나타낸다. Sigma 이. 콜라이 L-Asp는 대조군으로서 분석되었다. 도 8은 STR55978에 대한 질량분석 판독치를 나타내는데, 이는 AnsB 리더로부터 크리산타스파아제의 적절한 절단을 나타낸다. STR55976 및 STR55977에서 발현된 이. 콜라이 Asp2는 LC-MS에 의해 각각 AnsB 및 Ibp-S31A 리더로부터 적절하게 절단되는 것으로 확인되었다.
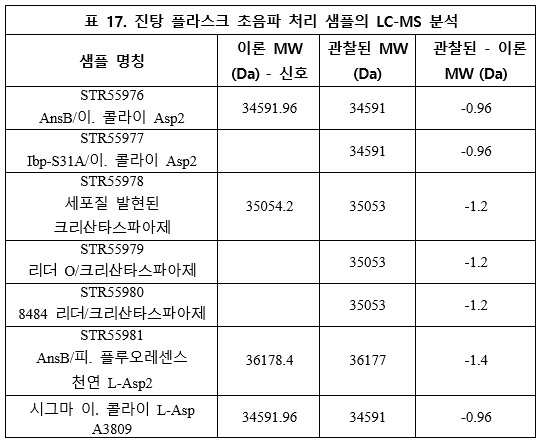



본 출원에서 본 개시내용의 바람직한 실시양태를 제시하고 기재하였지만, 그러한 실시양태는 단지 예로서 제공된다. 이제 당해 기술분야의 통상의 기술자는 본 개시내용을 벗어나지 않으면서 다수의 변이, 변화 및 치환이 가능할 것이다. 본 출원에 기재된 본 개시내용의 실시양태들에 대한 다양한 대안은 본 출원의 방법을 실시하는데 이용될 수 있음을 이해하여야 한다. 후술하는 청구범위는 본 발명의 범위를 규정하며, 이로써 이들 청구범위 및 그의 균등물의 범위 내의 방법 및 구성을 포함하는 것으로 의도된다.
SEQUENCE LISTING
<110> PFENEX INC.
<120> BACTERIAL LEADER SEQUENCES FOR PERIPLASMIC PROTEIN EXPRESSION
<130> 38194-752.601
<140>
<141>
<150> 62/578,304
<151> 2017-10-27
<160> 20
<170> PatentIn version 3.5
<210> 1
<211> 25
<212> PRT
<213> Pseudomonas fluorescens
<400> 1
Met Lys Ser Ala Leu Lys Asn Val Ile Pro Gly Ala Leu Ala Leu Leu
1 5 10 15
Leu Leu Phe Pro Val Ala Ala Gln Ala
20 25
<210> 2
<211> 18
<212> PRT
<213> Pseudomonas fluorescens
<400> 2
Met Arg Gln Leu Phe Phe Cys Leu Met Leu Met Val Ser Leu Thr Ala
1 5 10 15
His Ala
<210> 3
<211> 29
<212> PRT
<213> Pseudomonas fluorescens
<400> 3
Met Gln Ser Leu Pro Phe Ser Ala Leu Arg Leu Leu Gly Val Leu Ala
1 5 10 15
Val Met Val Cys Val Leu Leu Thr Thr Pro Ala Arg Ala
20 25
<210> 4
<211> 75
<212> DNA
<213> Pseudomonas fluorescens
<400> 4
atgaaatctg cattgaagaa cgttattccg ggcgccctgg cccttctgct gctattcccc 60
gtcgccgccc aggcc 75
<210> 5
<211> 54
<212> DNA
<213> Pseudomonas fluorescens
<400> 5
atgcgacaac tatttttctg tttgatgctg atggtgtcgc tcacggcgca cgcc 54
<210> 6
<211> 87
<212> DNA
<213> Pseudomonas fluorescens
<400> 6
atgcaaagcc tgccgttctc tgcgttacgc ctgctcggtg tgctggcagt catggtctgc 60
gtgctgttga cgacgccagc ccgtgcc 87
<210> 7
<211> 327
<212> PRT
<213> Erwinia chrysanthemi
<400> 7
Ala Asp Lys Leu Pro Asn Ile Val Ile Leu Ala Thr Gly Gly Thr Ile
1 5 10 15
Ala Gly Ser Ala Ala Thr Gly Thr Gln Thr Thr Gly Tyr Lys Ala Gly
20 25 30
Ala Leu Gly Val Asp Thr Leu Ile Asn Ala Val Pro Glu Val Lys Lys
35 40 45
Leu Ala Asn Val Lys Gly Glu Gln Phe Ser Asn Met Ala Ser Glu Asn
50 55 60
Met Thr Gly Asp Val Val Leu Lys Leu Ser Gln Arg Val Asn Glu Leu
65 70 75 80
Leu Ala Arg Asp Asp Val Asp Gly Val Val Ile Thr His Gly Thr Asp
85 90 95
Thr Val Glu Glu Ser Ala Tyr Phe Leu His Leu Thr Val Lys Ser Asp
100 105 110
Lys Pro Val Val Phe Val Ala Ala Met Arg Pro Ala Thr Ala Ile Ser
115 120 125
Ala Asp Gly Pro Met Asn Leu Leu Glu Ala Val Arg Val Ala Gly Asp
130 135 140
Lys Gln Ser Arg Gly Arg Gly Val Met Val Val Leu Asn Asp Arg Ile
145 150 155 160
Gly Ser Ala Arg Tyr Ile Thr Lys Thr Asn Ala Ser Thr Leu Asp Thr
165 170 175
Phe Lys Ala Asn Glu Glu Gly Tyr Leu Gly Val Ile Ile Gly Asn Arg
180 185 190
Ile Tyr Tyr Gln Asn Arg Ile Asp Lys Leu His Thr Thr Arg Ser Val
195 200 205
Phe Asp Val Arg Gly Leu Thr Ser Leu Pro Lys Val Asp Ile Leu Tyr
210 215 220
Gly Tyr Gln Asp Asp Pro Glu Tyr Leu Tyr Asp Ala Ala Ile Gln His
225 230 235 240
Gly Val Lys Gly Ile Val Tyr Ala Gly Met Gly Ala Gly Ser Val Ser
245 250 255
Val Arg Gly Ile Ala Gly Met Arg Lys Ala Met Glu Lys Gly Val Val
260 265 270
Val Ile Arg Ser Thr Arg Thr Gly Asn Gly Ile Val Pro Pro Asp Glu
275 280 285
Glu Leu Pro Gly Leu Val Ser Asp Ser Leu Asn Pro Ala His Ala Arg
290 295 300
Ile Leu Leu Met Leu Ala Leu Thr Arg Thr Ser Asp Pro Lys Val Ile
305 310 315 320
Gln Glu Tyr Phe His Thr Tyr
325
<210> 8
<211> 981
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 8
gcagacaaac tccctaacat cgtaatcctc gcaactggtg gtaccatcgc aggcagcgcc 60
gccaccggca cgcagaccac tggctacaag gccggcgcgc tgggcgtaga cacgctgatc 120
aacgccgtcc cggaagtgaa gaaactggcc aacgtcaagg gtgagcaatt ctccaacatg 180
gccagcgaga acatgactgg cgatgtggta ctgaagctct cgcagcgcgt gaacgaactg 240
ctcgcccgcg acgacgtgga cggcgtggtg atcacccacg gcactgatac cgtcgaagag 300
tcggcgtact ttctccacct gaccgtgaag tccgataagc ccgtggtgtt tgtcgccgcg 360
atgcgcccgg cgaccgccat cagcgccgac gggccgatga atctgttgga agccgtgcgc 420
gtggcgggtg acaagcaaag ccgcggtcgg ggcgtaatgg tcgtcctgaa cgatcggatc 480
ggtagcgcgc ggtacatcac caagacgaac gcctccacgc tggacacctt caaggcgaac 540
gaagaggggt acctgggggt gatcattggc aatcgtatct attaccagaa ccgcatcgac 600
aagctgcaca ccacccgctc ggtgttcgac gtgcgcggtc tgactagcct gcccaaggtc 660
gacatcctgt acggctacca agacgacccg gagtacctct acgacgcggc gatccagcat 720
ggcgtgaagg gcatcgtcta cgccggtatg ggtgccggct cggtgtcggt ccgcggcatc 780
gcgggtatgc gcaaggccat ggagaaaggc gtggtcgtga ttcgctcgac ccggactggc 840
aatggcatcg taccgcccga tgaagaactc ccggggctcg tgagcgatag cctcaacccc 900
gcgcacgccc ggatcctgct gatgctggcg ctcacgcgga ccagcgaccc caaggtcatt 960
caagagtact tccacaccta c 981
<210> 9
<211> 326
<212> PRT
<213> Escherichia coli
<400> 9
Leu Pro Asn Ile Thr Ile Leu Ala Thr Gly Gly Thr Ile Ala Gly Gly
1 5 10 15
Gly Asp Ser Ala Thr Lys Ser Asn Tyr Thr Ala Gly Lys Val Gly Val
20 25 30
Glu Asn Leu Val Asn Ala Val Pro Gln Leu Lys Asp Ile Ala Asn Val
35 40 45
Lys Gly Glu Gln Val Val Asn Ile Gly Ser Gln Asp Met Asn Asp Asp
50 55 60
Val Trp Leu Thr Leu Ala Lys Lys Ile Asn Thr Asp Cys Asp Lys Thr
65 70 75 80
Asp Gly Phe Val Ile Thr His Gly Thr Asp Thr Met Glu Glu Thr Ala
85 90 95
Tyr Phe Leu Asp Leu Thr Val Lys Cys Asp Lys Pro Val Val Met Val
100 105 110
Gly Ala Met Arg Pro Ser Thr Ser Met Ser Ala Asp Gly Pro Phe Asn
115 120 125
Leu Tyr Asn Ala Val Val Thr Ala Ala Asp Lys Ala Ser Ala Asn Arg
130 135 140
Gly Val Leu Val Val Met Asn Asp Thr Val Leu Asp Gly Arg Asp Val
145 150 155 160
Thr Lys Thr Asn Thr Thr Asp Val Ala Thr Phe Lys Ser Val Asn Tyr
165 170 175
Gly Pro Leu Gly Tyr Ile His Asn Gly Lys Ile Asp Tyr Gln Arg Thr
180 185 190
Pro Ala Arg Lys His Thr Ser Asp Thr Pro Phe Asp Val Ser Lys Leu
195 200 205
Asn Glu Leu Pro Lys Val Gly Ile Val Tyr Asn Tyr Ala Asn Ala Ser
210 215 220
Asp Leu Pro Ala Lys Ala Leu Val Asp Ala Gly Tyr Asp Gly Ile Val
225 230 235 240
Ser Ala Gly Val Gly Asn Gly Asn Leu Tyr Lys Thr Val Phe Asp Thr
245 250 255
Leu Ala Thr Ala Ala Lys Asn Gly Thr Ala Val Val Arg Ser Ser Arg
260 265 270
Val Pro Thr Gly Ala Thr Thr Gln Asp Ala Glu Val Asp Asp Ala Lys
275 280 285
Tyr Gly Phe Val Ala Ser Gly Thr Leu Asn Pro Gln Lys Ala Arg Val
290 295 300
Leu Leu Gln Leu Ala Leu Thr Gln Thr Lys Asp Pro Gln Gln Ile Gln
305 310 315 320
Gln Ile Phe Asn Gln Tyr
325
<210> 10
<211> 978
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 10
ctccctaaca ttactattct ggccactggc ggtacgattg caggcggcgg tgactcagcc 60
accaagtcga attacaccgc cggtaaggtc ggtgtcgaaa acctcgtcaa cgccgtgccg 120
cagctgaaag atatcgccaa cgtcaagggc gagcaagtgg tgaacatcgg ctcccaagat 180
atgaacgatg acgtgtggct gacgctggcc aagaaaatca acaccgattg cgacaagacg 240
gacgggtttg tcatcaccca cggcaccgac actatggaag agactgccta cttcctcgac 300
ctcacggtga agtgcgataa accggtagtg atggtgggcg ccatgcgccc gagcacctcg 360
atgagcgcgg acggcccgtt caatctgtac aacgccgtgg taaccgcagc ggacaaggcg 420
tccgcgaacc gcggtgtatt ggtagtgatg aacgatacgg tgctcgatgg gcgcgatgtg 480
accaagacca ataccactga tgtggccacc ttcaagagcg tgaactatgg cccgctgggc 540
tacatccata acggcaagat cgattaccag cgtactcccg cccggaagca cacctcggac 600
acccccttcg acgtgtcgaa actgaacgaa ctgcccaagg tcggcatcgt ctacaactac 660
gccaatgcga gcgatctgcc cgcgaaggcc ctggtggacg ccggctacga cgggatcgta 720
tcggcgggtg tgggcaatgg taacctgtac aagaccgtgt ttgacaccct ggcgacggcg 780
gcgaagaacg gcaccgccgt ggtccgcagc agccgcgtgc ccactggggc gaccacccaa 840
gacgccgagg tcgacgacgc gaagtacggc ttcgtagcca gcggcaccct gaacccgcaa 900
aaggcccggg tcctgctgca gctggcgctc acgcagacga aggacccgca gcaaatccaa 960
cagatcttca accagtac 978
<210> 11
<211> 6
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 11
aggagg 6
<210> 12
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS2 sequence
<400> 12
ggagcg 6
<210> 13
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS34 sequence
<400> 13
ggagcg 6
<210> 14
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS41 sequence
<400> 14
aggagt 6
<210> 15
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS43 sequence
<400> 15
ggagtg 6
<210> 16
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS48 sequence
<400> 16
gagtaa 6
<210> 17
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS1 sequence
<400> 17
agagag 6
<210> 18
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS35 sequence
<400> 18
aaggca 6
<210> 19
<211> 6
<212> DNA
<213> Unknown
<220>
<223> Description of Unknown:
RBS49 sequence
<400> 19
ccgaac 6
<210> 20
<211> 1020
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 20
atatgctctt cagccgcaga caaactccct aacatcgtaa tcctcgcaac tggtggtacc 60
atcgcaggca gcgccgccac cggcacgcag accactggct acaaggccgg cgcgctgggc 120
gtagacacgc tgatcaacgc cgtcccggaa gtgaagaaac tggccaacgt caagggtgag 180
caattctcca acatggccag cgagaacatg actggcgatg tggtactgaa gctctcgcag 240
cgcgtgaacg aactgctcgc ccgcgacgac gtggacggcg tggtgatcac ccacggcact 300
gataccgtcg aagagtcggc gtactttctc cacctgaccg tgaagtccga taagcccgtg 360
gtgtttgtcg ccgcgatgcg cccggcgacc gccatcagcg ccgacgggcc gatgaatctg 420
ttggaagccg tgcgcgtggc gggtgacaag caaagccgcg gtcggggcgt aatggtcgtc 480
ctgaacgatc ggatcggtag cgcgcggtac atcaccaaga cgaacgcctc cacgctggac 540
accttcaagg cgaacgaaga ggggtacctg ggggtgatca ttggcaatcg tatctattac 600
cagaaccgca tcgacaagct gcacaccacc cgctcggtgt tcgacgtgcg cggtctgact 660
agcctgccca aggtcgacat cctgtacggc taccaagacg acccggagta cctctacgac 720
gcggcgatcc agcatggcgt gaagggcatc gtctacgccg gtatgggtgc cggctcggtg 780
tcggtccgcg gcatcgcggg tatgcgcaag gccatggaga aaggcgtggt cgtgattcgc 840
tcgacccgga ctggcaatgg catcgtaccg cccgatgaag aactcccggg gctcgtgagc 900
gatagcctca accccgcgca cgcccggatc ctgctgatgc tggcgctcac gcggaccagc 960
gaccccaagg tcattcaaga gtacttccac acctactgat aatagttcag aagagcatat 1020
Claims (20)
- 관심 단백질 또는 폴리펩타이드에 작동 가능하게 연결된 리더 펩타이드를 포함하는 폴리펩타이드로서, 리더 펩타이드는 서열 번호 1, 2 또는 3에 기재된 아미노산 서열을 보유하는 것인 폴리펩타이드.
- 제1항에 있어서, 리더 펩타이드는 관심 단백질 또는 폴리펩타이드 태생이 아닌 것인 폴리펩타이드.
- 제1항에 있어서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자, 및 백신 항원으로부터 선택되는 것인 폴리펩타이드.
- 제2항에 있어서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 완전 사슬 항체인 폴리펩타이드.
- 제1항에 있어서 링커를 추가로 포함하는 폴리펩타이드.
- 제1항에 있어서, 절단 도메인을 추가로 포함하는 폴리펩타이드.
- 제1항에 있어서, 제1 부분이, 원핵 숙주 세포의 주변세포질로 관심 단백질 또는 폴리펩타이드의 발현을 유도하는 리더 펩타이드인 폴리펩타이드.
- 제7항에 있어서, 원핵 숙주 세포는 슈도모나드(Pseudomonad) 세포 또는 이. 콜라이(E. coli) 세포로부터 선택되는 것인 폴리펩타이드.
- 원핵 세포 배양으로 관심 단백질 또는 폴리펩타이드를 생산하는 방법으로서, 상기 방법은 (a) 세포 배양 성장 배지에서 원핵 세포를 배양하는 단계로서, 원핵 세포는 리더 펩타이드에 작동 가능하게 연결된 관심 단백질 또는 폴리펩타이드를 코딩하는 핵산을 포함하는 것인 단계; 및 (b) 원핵 세포의 주변세포질로부터 관심 단백질 또는 폴리펩타이드를 단리하는 단계를 포함하고, 여기서 리더 펩타이드는 서열 번호 1, 2 및 3으로부터 선택된 아미노산 서열을 포함하는 것인 방법.
- 제9항에 있어서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자, 및 백신 항원으로부터 선택되는 것인 방법.
- 제10항에 있어서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 완전 사슬 항체인 방법.
- 제9항에 있어서, 핵산은 링커를 코딩하는 것인 방법.
- 제9항에 있어서, 핵산은 절단 도메인을 코딩하는 것인 방법.
- 제9항에 있어서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택되는 것인 방법.
- 원핵 세포의 주변세포질에서 관심 단백질 또는 폴리펩타이드를 발현하는 방법으로서, 상기 방법은 세포 배양 성장 배지에서 리더 펩타이드에 작동 가능하게 연결된 관심 단백질 또는 폴리펩타이드를 코딩하는 핵산을 포함하는 원핵 세포를 배양하는 단계를 포함하고, 여기서 리더 펩타이드는 서열 번호 1, 2 및 3으로부터 선택된 아미노산 서열을 포함하는 것인 방법.
- 제15항에 있어서, 관심 단백질 또는 폴리펩타이드는 항체 또는 항체 유도체, 효소, 사이토카인, 케모카인, 성장 인자, 및 백신 항원으로부터 선택되는 것인 방법.
- 제16항에 있어서, 항체 또는 항체 유도체는 scFv, Fab, 인간화 항체, 변형된 항체, 단일 도메인 항체, 이종 특이성 항체, 3가 항체, 이중 특이성 항체, 단일 사슬 항체, Fab 단편, 선형 항체, 디아바디, 또는 완전 사슬 항체인 방법.
- 제15항에 있어서, 핵산은 링커를 코딩하는 것인 방법.
- 제15항에 있어서, 핵산은 절단 도메인을 코딩하는 것인 방법.
- 제15항에 있어서, 원핵 세포는 슈도모나드 세포 또는 이. 콜라이 세포로부터 선택되는 것인 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762578304P | 2017-10-27 | 2017-10-27 | |
| US62/578,304 | 2017-10-27 | ||
| PCT/US2018/056376 WO2019083795A1 (en) | 2017-10-27 | 2018-10-17 | GUIDED BACTERIAL SEQUENCES FOR EXPRESSION OF PERIPLASMIC PROTEINS |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200073280A true KR20200073280A (ko) | 2020-06-23 |
Family
ID=66242728
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207015248A KR20200073280A (ko) | 2017-10-27 | 2018-10-17 | 주변세포질 단백질 발현을 위한 박테리아 리더 서열 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US20190127744A1 (ko) |
| EP (1) | EP3700915A4 (ko) |
| JP (1) | JP2021501157A (ko) |
| KR (1) | KR20200073280A (ko) |
| CN (1) | CN111372941A (ko) |
| AU (1) | AU2018354069A1 (ko) |
| BR (1) | BR112020008369A2 (ko) |
| CA (1) | CA3077393A1 (ko) |
| SG (1) | SG11202002989SA (ko) |
| WO (1) | WO2019083795A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019083793A1 (en) | 2017-10-27 | 2019-05-02 | Pfenex Inc. | PROCESS FOR THE PRODUCTION OF RECOMBINANT ERWINIA ASPARAGINASE |
| CN116113704A (zh) * | 2020-08-24 | 2023-05-12 | 天野酶制品株式会社 | 人工改造蛋白质的制备方法 |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4551433A (en) | 1981-05-18 | 1985-11-05 | Genentech, Inc. | Microbial hybrid promoters |
| US4755465A (en) | 1983-04-25 | 1988-07-05 | Genentech, Inc. | Secretion of correctly processed human growth hormone in E. coli and Pseudomonas |
| US5281532A (en) | 1983-07-27 | 1994-01-25 | Mycogen Corporation | Pseudomas hosts transformed with bacillus endotoxin genes |
| US4695462A (en) | 1985-06-28 | 1987-09-22 | Mycogen Corporation | Cellular encapsulation of biological pesticides |
| US4695455A (en) | 1985-01-22 | 1987-09-22 | Mycogen Corporation | Cellular encapsulation of pesticides produced by expression of heterologous genes |
| GB8517071D0 (en) | 1985-07-05 | 1985-08-14 | Hoffmann La Roche | Gram-positive expression control sequence |
| US5128130A (en) | 1988-01-22 | 1992-07-07 | Mycogen Corporation | Hybrid Bacillus thuringiensis gene, plasmid and transformed Pseudomonas fluorescens |
| US5055294A (en) | 1988-03-03 | 1991-10-08 | Mycogen Corporation | Chimeric bacillus thuringiensis crystal protein gene comprising hd-73 and berliner 1715 toxin genes, transformed and expressed in pseudomonas fluorescens |
| US5169760A (en) | 1989-07-27 | 1992-12-08 | Mycogen Corporation | Method, vectors, and host cells for the control of expression of heterologous genes from lac operated promoters |
| US9453251B2 (en) | 2002-10-08 | 2016-09-27 | Pfenex Inc. | Expression of mammalian proteins in Pseudomonas fluorescens |
| CA2545610C (en) | 2003-11-19 | 2014-03-25 | Dow Global Technolgies Inc. | Auxotrophic pseudomonas fluorescens bacteria for recombinant protein expression |
| CA2546157C (en) * | 2003-11-21 | 2014-07-22 | Dow Global Technolgies Inc. | Improved expression systems with sec-system secretion |
| EP1774017B1 (en) | 2004-07-26 | 2013-05-15 | Pfenex Inc. | Process for improved protein expression by strain engineering |
| KR20090018799A (ko) | 2006-05-30 | 2009-02-23 | 다우 글로벌 테크놀로지스 인크. | 코돈 최적화 방법 |
| EP2108047B1 (en) * | 2007-01-31 | 2012-10-24 | Pfenex Inc. | Bacterial leader sequences for increased expression |
| WO2008134461A2 (en) | 2007-04-27 | 2008-11-06 | Dow Global Technologies, Inc. | Method for rapidly screening microbial hosts to identify certain strains with improved yield and/or quality in the expression of heterologous proteins |
| US9580719B2 (en) | 2007-04-27 | 2017-02-28 | Pfenex, Inc. | Method for rapidly screening microbial hosts to identify certain strains with improved yield and/or quality in the expression of heterologous proteins |
| GB0917647D0 (en) | 2009-10-08 | 2009-11-25 | Glaxosmithkline Biolog Sa | Expression system |
| AU2011238711B2 (en) | 2010-03-30 | 2015-06-18 | Pelican Technology Holdings, Inc. | High level expression of recombinant toxin proteins |
| WO2011123570A2 (en) | 2010-04-01 | 2011-10-06 | Pfenex Inc. | Methods for g-csf production in a pseudomonas host cell |
| KR102092225B1 (ko) * | 2014-04-30 | 2020-03-23 | 주식회사 엘지화학 | 고효율 분비능을 가지는 단백질 분비 인자 및 이를 포함하는 발현 벡터 |
-
2018
- 2018-10-17 WO PCT/US2018/056376 patent/WO2019083795A1/en unknown
- 2018-10-17 BR BR112020008369-0A patent/BR112020008369A2/pt not_active Application Discontinuation
- 2018-10-17 EP EP18870110.6A patent/EP3700915A4/en active Pending
- 2018-10-17 KR KR1020207015248A patent/KR20200073280A/ko not_active Application Discontinuation
- 2018-10-17 JP JP2020523446A patent/JP2021501157A/ja active Pending
- 2018-10-17 SG SG11202002989SA patent/SG11202002989SA/en unknown
- 2018-10-17 CA CA3077393A patent/CA3077393A1/en active Pending
- 2018-10-17 AU AU2018354069A patent/AU2018354069A1/en not_active Abandoned
- 2018-10-17 US US16/163,421 patent/US20190127744A1/en not_active Abandoned
- 2018-10-17 CN CN201880074902.6A patent/CN111372941A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| CA3077393A1 (en) | 2019-05-02 |
| US20190127744A1 (en) | 2019-05-02 |
| SG11202002989SA (en) | 2020-05-28 |
| JP2021501157A (ja) | 2021-01-14 |
| AU2018354069A1 (en) | 2020-06-11 |
| EP3700915A4 (en) | 2021-07-28 |
| CN111372941A (zh) | 2020-07-03 |
| WO2019083795A1 (en) | 2019-05-02 |
| BR112020008369A2 (pt) | 2020-11-03 |
| EP3700915A1 (en) | 2020-09-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6495690B2 (ja) | 発現上昇のための細菌リーダー配列 | |
| US10689640B2 (en) | Method for rapidly screening microbial hosts to identify certain strains with improved yield and/or quality in the expression of heterologous proteins | |
| US10118956B2 (en) | Fusion partners for peptide production | |
| JP5444553B2 (ja) | 微生物宿主を迅速にスクリーニングして、異種タンパク質発現の収率および/または質が改善されている特定の株を同定する方法 | |
| JP5028551B2 (ja) | Sec系分泌によって改良された発現系 | |
| US11377661B2 (en) | Method for production of recombinant Erwinia asparaginase | |
| US11046964B2 (en) | Method for production of recombinant E. coli asparaginase | |
| KR20200073280A (ko) | 주변세포질 단백질 발현을 위한 박테리아 리더 서열 | |
| CN111278979B (zh) | 重组大肠杆菌天冬酰胺酶的生产方法 | |
| US20230100757A1 (en) | Bacterial hosts for recombinant protein expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal |