KR20200045439A - Recombinant Pseudomonas putida strains and method for producing mevalonate using the same - Google Patents
Recombinant Pseudomonas putida strains and method for producing mevalonate using the same Download PDFInfo
- Publication number
- KR20200045439A KR20200045439A KR1020190131749A KR20190131749A KR20200045439A KR 20200045439 A KR20200045439 A KR 20200045439A KR 1020190131749 A KR1020190131749 A KR 1020190131749A KR 20190131749 A KR20190131749 A KR 20190131749A KR 20200045439 A KR20200045439 A KR 20200045439A
- Authority
- KR
- South Korea
- Prior art keywords
- strain
- gene
- dna
- recombinant
- pseudomonas putida
- Prior art date
Links
Images



















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/40—Preparation of oxygen-containing organic compounds containing a carboxyl group including Peroxycarboxylic acids
- C12P7/42—Hydroxy-carboxylic acids
Landscapes
- Organic Chemistry (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Wood Science & Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Microbiology (AREA)
- General Chemical & Material Sciences (AREA)
- Biotechnology (AREA)
- Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
Description
본 발명은 재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법에 관한 것으로서, 더욱 상세하게는 유기용매 독성 저항력이 강한 슈도모나스 푸티다 균주 내에 메발론산 생합성 경로를 구축하여 탄소원인 에탄올로부터 메발론산을 생산하는 방법에 관한 것이다.The present invention relates to a recombinant Pseudomonas putida strain and a method for producing mevalonic acid using the same, and more specifically, to construct mevalonic acid biosynthetic pathway in a Pseudomonas putida strain having strong organic solvent resistance to produce mevalonic acid from carbon source ethanol. It's about how.
메발론산은 화장품, 바이오 플라스틱의 원료이자 매우 다양한 생화학 물질 군인 테르페노이드의 주요 전구체인 물질로써 미생물 전환 공정으로 생산할 경우 안정적으로 대량 생산이 가능하다는 이점이 있는 가치가 높은 물질이다. 메발론산은 생합성 전구체로 Acetyl-CoA를 사용하는데, 기존의 당을 탄소원으로 사용할 경우 해당과정 중간의 물질로부터 생산되는 부산물로 인해 고농도 생산이 힘든 상황이다. 또한 메발론산으로부터 생산되는 테르페노이드는 탄화수소로써 비극성을 띄므로 미생물에 대한 독성이 매우 강하여 미생물 공정 개발의 어려움을 겪고 있다. Mevalonic acid is a raw material for cosmetics and bioplastics, and is a material that is a major precursor to terpenoids, which are a wide variety of biochemical substances. Mevalonic acid uses Acetyl-CoA as a biosynthetic precursor. However, when existing sugars are used as carbon sources, high concentration production is difficult due to by-products produced from substances in the process. In addition, terpenoids produced from mevalonic acid are non-polar as hydrocarbons, so they are very toxic to microorganisms and have difficulty in developing microbial processes.
본 발명자들은 고농도 생산이 어려운 메발론산를 고농도로 생산할 수 있는 생물공정을 개발하고자 노력하였다. 그 결과, 유기용매 독성 저항력이 강한 슈도모나스 푸티다 균주에 외래 유전자를 도입하여 메발론산 생합성 경로를 구축함으로써 탄소원인 에탄올로부터 메발론산을 높은 수율로 생산할 수 있음을 규명함으로써 본 발명을 완성하였다. The present inventors tried to develop a bioprocess capable of producing mevalonic acid, which is difficult to produce at high concentration, at a high concentration. As a result, the present invention was completed by examining the high yield of mevalonic acid from ethanol, a carbon source, by introducing a foreign gene into the Pseudomonas putida strain, which has strong resistance to toxicity of organic solvents, to build a biosynthetic pathway for mevalonic acid.
본 발명의 목적은 재조합 슈도모나스 푸티다 균주를 제공하는 것이다.It is an object of the present invention to provide a recombinant Pseudomonas putida strain.
본 발명의 다른 목적은 메발론산 생산용 조성물을 제공하는 것이다.Another object of the present invention is to provide a composition for producing mevalonic acid.
본 발명의 또 다른 목적은 메발론산의 생산 방법을 제공하는 것이다.Another object of the present invention is to provide a method for producing mevalonic acid.
본 발명의 일 양태에 따르면, 본 발명은 서열번호 1로 표시되는 아세틸 조효소 아세틸전달효소(Acetyl coenzyme A Acetyltransferase)의 핵산서열, 서열번호 2로 표시되는 HMG CoA 합성효소(3-hydroxy-3-methylglutaryl coenzyme A synthetase)의 핵산서열 및 서열번호 3으로 표시되는 HMG CoA 환원효소(3-hydroxy-3-methylglutaryl coenzyme A reductase)의 핵산서열을 포함하는 재조합 벡터로 형질전환되고, 엔도뉴클레아제 A(endonuclease A, endA) 유전자 및 엔도뉴클레아제 X(endonuclease A, endX) 유전자가 결손된 재조합 슈도모나스 푸티다(Pseudomonas putida) 균주에 관한 것이다. According to an aspect of the present invention, the present invention is a nucleic acid sequence of acetyl coenzyme A Acetyltransferase represented by SEQ ID NO: 1, HMG CoA synthetase represented by SEQ ID NO: 2 (3-hydroxy-3-methylglutaryl A nucleic acid sequence of coenzyme A synthetase and a recombinant vector comprising the nucleic acid sequence of HMG CoA reductase (3-hydroxy-3-methylglutaryl coenzyme A reductase) represented by SEQ ID NO: 3, is transformed into endonuclease A (endonuclease A) A, endA) and the endonuclease X (endonuclease A, endX) gene is related to a recombinant Pseudomonas putida ( Pseudomonas putida ) strain.
본 발명자들은 고농도 생산이 어려운 메발론산을 고농도로 생산할 수 있는 생물공정을 개발하고자 노력하였고 그 결과, 유기용매 독성 저항력이 강한 슈도모나스 푸티다 균주에 외래 유전자를 도입하여 메발론산 생합성 경로를 구축함으로써 탄소원인 에탄올로부터 메발론산을 높은 수율로 생산할 수 있음을 규명하였다. The present inventors tried to develop a bioprocess capable of producing mebalonic acid at a high concentration, which is difficult to produce at high concentrations. As a result, the carbon cause was obtained by introducing a foreign gene into the Pseudomonas putida strain, which has strong resistance to toxic organic solvents, and constructing a biosynthetic pathway for mevalonic acid It has been found that mevalonic acid can be produced from ethanol in high yield.
본 발명에 따르면, 본 발명의 재조합 슈도모나스 푸티다 균주는 서열번호 1로 표시되는 아세틸 조효소 아세틸전달효소의 핵산서열, 서열번호 2로 표시되는 HMG CoA 합성효소의 핵산서열 및 서열번호 3으로 표시되는 HMG CoA 환원효소의 핵산서열을 포함하는 재조합 벡터로 형질전환된 균주로서 상기 아세틸 조효소 아세틸전달효소, HMG CoA 합성효소 및 HMG CoA 환원효소 유전자의 도입에 의해 상부 메발론산 경로(Upper Mevalonate Pathway)를 구축할 수 있다. According to the present invention, the recombinant Pseudomonas putida strain of the present invention is a nucleic acid sequence of acetyl coenzyme acetyl transferase represented by SEQ ID NO: 1, a nucleic acid sequence of HMG CoA synthetase represented by SEQ ID NO: 2 and HMG represented by SEQ ID NO: 3 As a strain transformed with a recombinant vector containing a nucleic acid sequence of CoA reductase, an upper mevalonate pathway is constructed by introducing the acetyl coenzyme acetyl transferase, HMG CoA synthetase and HMG CoA reductase genes. You can.
본 발명의 일 구현예에 따르면, 본 발명의 재조합 슈도모나스 푸티다 균주는 추가적으로 서열번호 4로 표시되는 아세틸 조효소 합성효소(Acetyl coenzyme A synthetase)의 핵산서열을 포함하는 재조합 벡터로 형질전환될 수 있다. 본 발명의 재조합 슈도모나스 푸티다 균주는 상기 아세틸 조효소 합성효소 유전자 도입에 의해 1차적으로 아세트산을 Acetyl-CoA로 전환함으로써 균주 내 아세트산의 축적을 막을 수 있다. According to one embodiment of the present invention, the recombinant Pseudomonas putida strain of the present invention may be additionally transformed into a recombinant vector comprising a nucleic acid sequence of acetyl coenzyme A synthetase represented by SEQ ID NO: 4. The recombinant Pseudomonas putida strain of the present invention can prevent the accumulation of acetic acid in the strain by primarily converting acetic acid to Acetyl-CoA by introducing the acetyl coenzyme synthase gene.
본 발명의 다른 구현예에 따르면, 본 발명의 재조합 슈도모나스 푸티다 균주는 엔도뉴클레아제 A(endonuclease A, endA) 유전자 및 엔도뉴클레아제 X(endonuclease A, endX) 유전자가 결손된 균주일 수 있다. 상기 유전자의 결손에 의해 재조합 벡터를 통해 도입된 외부 유전자의 안정성을 향상시킬 수 있다. 상기 엔도뉴클레아제 A 유전자는 서열번호 5의 핵산 서열로 표시될 수 있고, 엔도뉴클레아제 X 유전자는 서열번호 6의 핵산 서열로 표시될 수 있다. According to another embodiment of the present invention, the recombinant Pseudomonas putida strain of the present invention may be a strain in which the endonuclease A (endonuclease A, endA) gene and the endonuclease X (endonuclease A, endX) gene are deleted. . The stability of the foreign gene introduced through the recombinant vector can be improved by the deletion of the gene. The endonuclease A gene may be represented by the nucleic acid sequence of SEQ ID NO: 5, and the endonuclease X gene may be represented by the nucleic acid sequence of SEQ ID NO: 6.
본 발명의 또 다른 구현예에 따르면, 본 발명의 재조합 슈도모나스 푸티다 균주는 퀴노단백질 에탄올 탈수소효소 I(Quinoprotein Ethanol Dehydrogenase I) 유전자 및 퀴노단백질 에탄올 탈수소효소 II(Quinoprotein Ethanol Dehydrogenase II) 유전자가 추가로 결손된 균주일 수 있다. 상기 유전자의 결손에 의해 에탄올의 세포질(periplasmic) 산화를 방지할 수 있다. 상기 퀴노단백질 에탄올 탈수소효소 I 유전자는 서열번호 7의 핵산 서열로 표시될 수 있고, 퀴노단백질 에탄올 탈수소효소 II 유전자는 서열번호 8의 핵산 서열로 표시될 수 있다.According to another embodiment of the present invention, the recombinant Pseudomonas putida strain of the present invention is quinoprotein Ethanol Dehydrogenase I (Quinoprotein Ethanol Dehydrogenase I) gene and quinoprotein Ethanol Dehydrogenase II (Quinoprotein Ethanol Dehydrogenase II) gene is additionally defective It may be a strain. The deficiency of the gene can prevent periplasmic oxidation of ethanol. The quinoprotein ethanol dehydrogenase I gene may be represented by the nucleic acid sequence of SEQ ID NO: 7, and the quinoprotein ethanol dehydrogenase II gene may be represented by the nucleic acid sequence of SEQ ID NO: 8.
상기 용어 "벡터(vector)"는 숙주세포에서 목적 유전자를 발현시키기 위한 수단을 의미한다. 예를 들어, 플라스미드 벡터, 코즈미드 벡터 및 박테리오파아지 벡터, 아데노바이러스 벡터, 레트로바이러스 벡터 및 아데노연관 바이러스 벡터와 같은 바이러스 벡터를 포함한다. 상기 재조합 벡터로 사용될 수 있는 벡터는 당업계에서 사용되는 플라스미드(예를 들면, pSC101, pGV1106, pACYC177, ColE1, pKT230, pME290, pBR322, pUC8/9, pUC6, pUC19, pUCP19, pTrc99A, pCM184, pAWP89, pBD9, pHC79, pIJ61, pLAFR1, pHV14, pGEX 시리즈, pET 시리즈 및 pUC19 등), 파지 (예를 들면, λgt4λB, λ-Charon, λΔz1 및 M13 등) 또는 바이러스(예를 들면, SV40 등)를 조작하여 제작될 수 있으나 이에 제한되지 않는다.The term "vector" means a means for expressing a target gene in a host cell. For example, viral vectors such as plasmid vectors, cosmid vectors and bacteriophage vectors, adenovirus vectors, retroviral vectors and adenoassociated virus vectors. Vectors that can be used as the recombinant vector include plasmids used in the art (e.g., pSC101, pGV1106, pACYC177, ColE1, pKT230, pME290, pBR322, pUC8 / 9, pUC6, pUC19, pUCP19, pTrc99A, pCM184, pAWP89, pBD9, pHC79, pIJ61, pLAFR1, pHV14, pGEX series, pET series and pUC19, etc.), phages (e.g., λgt4λB, λ-Charon, λΔz1 and M13, etc.) or viruses (e.g., SV40, etc.) It can be produced, but is not limited thereto.
상기 재조합 벡터는, 전형적으로 클로닝을 위한 벡터 또는 발현을 위한 벡터로서 구축될 수 있다. 상기 발현용 벡터는 당업계에서 식물, 동물 또는 미생물에서 외래의 단백질을 발현하는 데 사용되는 통상의 것을 사용할 수 있다. 상기 재조합 벡터는 당업계에 공지된 다양한 방법을 통해 구축될 수 있다.The recombinant vector can typically be constructed as a vector for cloning or for expression. The expression vector can be used in the art, conventional ones used to express foreign proteins in plants, animals or microorganisms. The recombinant vector can be constructed through various methods known in the art.
상기 재조합 벡터는 원핵세포 또는 진핵세포를 숙주로 하여 구축될 수 있다. 예를 들어, 사용되는 벡터가 발현 벡터이고, 원핵세포를 숙주로 하는 경우에는, 전사를 진행시킬 수 있는 강력한 프로모터(예를 들어, pLλ 프로모터, CMV 프로모터, trp 프로모터, lac 프로모터, tac 프로모터, T7 프로모터 등), 해독의 개시를 위한 라이보좀 결합 자리 및 전사/해독 종결 서열을 포함하는 것이 일반적이다. 진핵세포를 숙주로 하는 경우에는, 벡터에 포함되는 진핵세포에서 작동하는 복제원점은 f1 복제원점, SV40 복제원점, pMB1 복제원점, 아데노 복제원점, AAV 복제원점 및 BBV 복제원점 등을 포함하나, 이에 한정되는 것은 아니다. 또한, 포유동물 세포의 게놈으로부터 유래된 프로모터(예를 들어, 메탈로티오닌 프로모터) 또는 포유동물 바이러스로부터 유래된 프로모터(예를 들어, 아데노바이러스 후기 프로모터, 백시니아 바이러스 7.5K 프로모터, SV40 프로모터, 사이토메갈로바이러스 프로모터 및 HSV의 tk 프로모터)가 이용될 수 있으며, 전사 종결 서열로서 폴리아데닐화 서열을 일반적으로 갖는다.The recombinant vector can be constructed using prokaryotic or eukaryotic cells as hosts. For example, when the vector used is an expression vector, and a prokaryotic cell is a host, a strong promoter capable of progressing transcription (eg, pLλ promoter, CMV promoter, trp promoter, lac promoter, tac promoter, T7) Promoter, etc.), a ribosome binding site for initiation of translation and a transcription / detox termination sequence. When eukaryotic cells are used as hosts, the origin of replication operating in eukaryotic cells included in the vector includes f1 origin of replication, SV40 origin of replication, pMB1 origin of replication, adeno origin of replication, AAV origin of replication, and BBV origin of replication. It is not limited. In addition, a promoter derived from the genome of a mammalian cell (eg, a metallothionine promoter) or a promoter derived from a mammalian virus (eg, adenovirus late promoter, vaccinia virus 7.5K promoter, SV40 promoter, Cytomegalovirus promoter and HSV's tk promoter) can be used and generally have a polyadenylation sequence as the transcription termination sequence.
본 발명의 일 예에서, 재조합 벡터를 숙주세포에 삽입함으로써 형질전환체를 만들 수 있으며, 상기 형질전환체는 상기 재조합 벡터를 적절한 숙주세포에 도입시킴으로써 얻어진 것일 수 있다. In one example of the present invention, a transformant can be made by inserting a recombinant vector into a host cell, and the transformant may be obtained by introducing the recombinant vector into an appropriate host cell.
상기 숙주세포는 상기 발현벡터를 안정되면서 연속적으로 클로닝 또는 발현시킬 수 있는 세포로서 당업계에 공지된 어떠한 숙주세포도 이용할 수 있다.The host cell is a cell capable of continuously cloning or expressing the expression vector while being stable, and any host cell known in the art can be used.
본 발명에서 사용된 숙주세포로는 대장균, 효모, 동물세포, 식물세포, 또는 곤충세포 등을 포함할 수 있으며, 원핵세포로는, 예를 들어, E. coli DH10B, E. coli JM109, E. coli BL21, E. coli RR1, E. coli LE392, E. coli B, E. coli X 1776, E. coli W3110, 바실러스 서브틸리스, 바실러스 츄린겐시스와 같은 바실러스 속 균주, 그리고 살모넬라 티피무리움, 세라티아 마르세슨스 및 다양한 슈도모나스 종과 같은 장내균과 균주 등이 있으며, 진핵세포에 형질 전환시키는 경우에는 숙주세포로서, 효모(Saccharomyce cerevisiae), 곤충세포, 식물세포 및 동물세포, 예를 들어, Sp2/0, CHO(Chinese hamster ovary) K1, CHO DG44, PER.C6, W138, BHK, COS7, 293, HepG2, Huh7, 3T3, RIN, MDCK 세포주 등이 이용될 수 있으나, 이에 제한되는 것은 아니다. The host cells used in the present invention may include E. coli, yeast, animal cells, plant cells, or insect cells. Prokaryotic cells include, for example, E. coli DH10B, E. coli JM109, E. coli BL21, E. coli RR1, E. coli LE392, E. coli B, E. coli X 1776, E. coli W3110, Bacillus subtilis, Bacillus thuringiensis and Bacillus strains, and Salmonella typhimurium, Enteric bacteria and strains such as Ceratia Marcesons and various Pseudomonas species, etc. When transformed into eukaryotic cells, as host cells, yeast (Saccharomyce cerevisiae), insect cells, plant cells and animal cells, for example, Sp2 / 0, CHO (Chinese hamster ovary) K1, CHO DG44, PER.C6, W138, BHK, COS7, 293, HepG2, Huh7, 3T3, RIN, MDCK cell line, etc. may be used, but is not limited thereto.
상기 폴리뉴클레오타이드 또는 이를 포함하는 재조합 벡터의 숙주세포 내로의 운반(도입)은, 당업계에 널리 알려진 운반 방법을 사용할 수 있다. 상기 운반 방법은 예를 들어, 숙주세포가 원핵세포인 경우, CaCl2 방법 또는 전기 천공 방법 등을 사용할 수 있고, 숙주세포가 진핵세포인 경우에는, 미세 주입법, 칼슘 포스페이트 침전법, 전기 천공법, 리포좀매개 형질감염법 및 유전자 밤바드먼트 등을 사용할 수 있으나, 이에 한정하지는 않는다.The transport (introduction) of the polynucleotide or a recombinant vector containing the same into a host cell can be carried out using a transport method well known in the art. For the transport method, for example, when the host cell is a prokaryotic cell, a CaCl 2 method or an electroporation method can be used. When the host cell is a eukaryotic cell, a micro-injection method, a calcium phosphate precipitation method, an electroporation method, Liposomal mediated transfection and gene bombardment may be used, but are not limited thereto.
상기 형질 전환된 숙주세포를 선별하는 방법은 선택 표지에 의해 발현되는 표현형을 이용하여, 당업계에 널리 알려진 방법에 따라 용이하게 실시할 수 있다. 예를 들어, 상기 선택 표지가 특정 항생제 내성 유전자인 경우에는, 상기 항생제가 함유된 배지에서 형질전환체를 배양함으로써 형질전환체를 용이하게 선별할 수 있다.The method for selecting the transformed host cell can be easily carried out according to a method well known in the art using a phenotype expressed by a selection label. For example, when the selection marker is a specific antibiotic resistance gene, the transformant can be easily selected by culturing the transformant in a medium containing the antibiotic.
본 발명의 다른 양태에 따르면, 본 발명은 서열번호 1로 표시되는 아세틸 조효소 아세틸전달효소의 핵산서열, 서열번호 2로 표시되는 HMG CoA 합성효소의 핵산서열 및 서열번호 3으로 표시되는 HMG CoA 환원효소의 핵산서열을 포함하는 재조합 벡터로 형질전환되고, 엔도뉴클레아제 A 유전자 및 엔도뉴클레아제 X 유전자가 결손된 재조합 슈도모나스 푸티다 균주를 포함하는 메발론산 생산용 조성물에 관한 것이다. According to another aspect of the present invention, the present invention is a nucleic acid sequence of acetyl coenzyme acetyl transferase represented by SEQ ID NO: 1, a nucleic acid sequence of HMG CoA synthetase represented by SEQ ID NO: 2 and HMG CoA reductase represented by SEQ ID NO: 3 It is transformed with a recombinant vector containing a nucleic acid sequence of, and relates to a composition for producing mevalonic acid comprising a recombinant Pseudomonas putida strain, wherein the endonuclease A gene and the endonuclease X gene are deleted.
본 발명의 메발론산 생산용 조성물은 상기 재조합 슈도모나스 푸티다 균주를 포함하는 것으로서 이들 간에 중복되는 내용은 본 명세서의 복잡성을 고려하여 생략한다.The composition for producing mevalonic acid of the present invention includes the recombinant Pseudomonas putida strain, and overlapping information between them is omitted in consideration of the complexity of the present specification.
상기 재조합 슈도모나스 푸티다 균주는 메발론산 생산능을 갖는 균주이므로 상기 균주는 메발론산을 생산하기 위한 조성물로 이용될 수 있다.Since the recombinant Pseudomonas putida strain is a strain having mevalonic acid production capacity, the strain can be used as a composition for producing mevalonic acid.
상기 메발론산 생산용 조성물은 상기 재조합 슈도모나스 푸티다 균주의 배양에 필요한 물질, 예를 들어, 배양 배지를 포함할 수 있다. 상기 배양 배지는 특별히 한정되지 않으며 적당한 탄소원, 질소원, 아미노산 또는 비타민 등이 함유된 통상의 미생물 배양용 배지를 포함할 수 있다. The composition for producing mevalonic acid may include a substance necessary for culturing the recombinant Pseudomonas putida strain, for example, a culture medium. The culture medium is not particularly limited and may include a medium for culturing a normal microorganism containing a suitable carbon source, nitrogen source, amino acid or vitamin.
본 발명의 다른 일 양태에 따르면, 본 발명은 다음 단계를 포함하는 메발론산의 생산 방법에 관한 것이다:According to another aspect of the invention, the invention relates to a method of producing mevalonic acid comprising the following steps:
상기 재조합 슈도모나스 푸티다 균주를 배양하는 단계; 및Culturing the recombinant Pseudomonas putida strain; And
상기 배양 결과물로부터 메발론산을 수득하는 단계. Obtaining mevalonic acid from the culture result.
상기 재조합 슈도모나스 푸티다 균주는 적당한 탄소원, 질소원, 아미노산 또는 비타민 등이 함유된 통상의 미생물 배양용 배지에서 배양할 수 있다. The recombinant Pseudomonas putida strain can be cultured in a medium for culturing microorganisms containing a suitable carbon source, nitrogen source, amino acid or vitamin.
본 발명의 일 구현예에 따르면, 아래 표 3에 기재된 조성의 배양 배지에서 상기 재조합 슈도모나스 푸티다 균주를 배양할 수 있다. According to one embodiment of the present invention, the recombinant Pseudomonas putida strain can be cultured in a culture medium having the composition shown in Table 3 below.
상기 재조합 슈도모나스 푸티다 균주의 배양은 통상의 미생물 배양 조건에서 실시할 수 있고, 예를 들어, 아래 표 4에 기재된 배양 조건 하에서 배양할 수 있다. The recombinant Pseudomonas putida strain can be cultured under normal microbial culture conditions, for example, can be cultured under the culture conditions shown in Table 4 below.
본 발명의 일 구현예에 따르면, 상기 재조합 슈도모나스 푸티다 균주는 pH 6.5 내지 pH 7.0 범위에서 배양할 수 있고, 예를 들어, pH 6.75에서 배양할 수 있다.According to one embodiment of the present invention, the recombinant Pseudomonas putida strain can be cultured in a pH range of 6.5 to pH 7.0, for example, at pH 6.75.
본 발명은 재조합 슈도모나스 푸티다 균주 및 이를 이용한 메발론산 생산 방법에 관한 것으로 슈도모나스 푸티다 균주에 메발론산 생합성 회로를 구축하고, 외부 유전자 안정성 향상, 에탄올 이화작용 회로 조절, 지방산 생합성 회로 조절 등의 연구를 통해 메발론산 생산 수율이 현저히 향상된 재조합 슈도모나스 균주를 제조하였고, 상기 재조합 슈도모나스 균주를 이용하여 고농도로 메발론산을 생산할 수 있다. 본 발명의 재조합 슈도모나스 푸티다 균주는 유기용매 독성 저항력이 강하기 때문에 메발론산을 전구체로 하여 생산되는 테르페노이드에 대해 독성 저항력을 가지며 그에 따라 고농도 테르페노이드 생산을 위한 생촉매로도 이용될 수 있다. The present invention relates to a recombinant Pseudomonas putida strain and a method for producing mevalonic acid using the same, to construct a mevalonic acid biosynthesis circuit in the Pseudomonas putida strain, to improve external gene stability, control ethanol catabolism, and control fatty acid biosynthesis circuits. A recombinant Pseudomonas strain having a significantly improved production yield of mevalonic acid was prepared, and mevalonic acid can be produced at a high concentration using the recombinant Pseudomonas strain. The recombinant Pseudomonas putidae strain of the present invention has strong toxicity resistance to organic solvents, and thus has toxicity resistance to terpenoids produced using mevalonic acid as a precursor, and thus can also be used as a biocatalyst for producing high concentration terpenoids. .
도 1은 P. putida 균주 내 에탄올 대사경로를 보여주는 모식도이다.
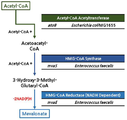
도 2a는 상부 메발론산 경로에 대한 모식도이다.
도 2b는 pSGP10 벡터 맵이다.
도 3은 pK19mobsacB 매개 Markerless 결손 방법에 대한 모식도이다.
도 4a 및 4b는 P. putida 내 에탄올 이화작용 경로 및 조절에 대한 모식도이다.
도 5는 에탄올 이화작용 조절 유전자 재조합에 대한 모식도이다.
도 6은 지방산 생합성 조절 경로 및 유전자 재조합에 대한 모식도이다.
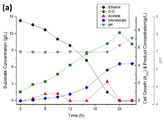
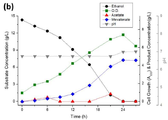
도 7a는 재조합 균주 ELPP000의 대사 프로파일에 대한 그래프이다.
도 7b는 재조합 균주 ELPP010의 대사 프로파일에 대한 그래프이다.
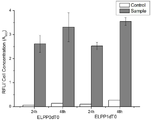
도 8은 엔도뉴클레아제(endA, endX) 결손 여부에 따른 외부 유전자 삽입 벡터의 안정성 증대 효과를 dTomato 형광 분석을 통해 확인한 결과이다.
도 9는 재조합 균주 ELPP110의 대사 프로파일에 대한 그래프이다.
도 10a는 재조합 균주 ELPP111의 대사 프로파일에 대한 그래프이다.
도 10b는 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 10c는 재조합 균주 ELPP212의 대사 프로파일에 대한 그래프이다.
도 10d는 재조합 균주 ELPP213의 대사 프로파일에 대한 그래프이다.
도 11a는 재조합 균주 ELPP221의 대사 프로파일에 대한 그래프이다.
도 11b는 재조합 균주 ELPP311의 대사 프로파일에 대한 그래프이다.
도 12는 Nile-red 염색을 통해 재조합 균주 내 지방산을 분석한 그래프이다.
도 13a는 pH 7.0 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 13b는 pH 6.75 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.
도 13c는 pH 6.5 조건에서 배양한 재조합 균주 ELPP211의 대사 프로파일에 대한 그래프이다.1 is a schematic diagram showing the ethanol metabolic pathway in the P. putida strain.
2A is a schematic diagram of the upper mevalonic acid pathway.
2B is a pSGP10 vector map.
3 is a schematic diagram of a pK19 mobsacB- mediated Markerless deletion method.
4A and 4B are schematic diagrams for the ethanol catabolism pathway and regulation in P. putida .
5 is a schematic diagram for ethanol catabolism regulatory gene recombination.
6 is a schematic diagram of fatty acid biosynthesis control pathway and gene recombination.
7A is a graph for the metabolic profile of the recombinant strain ELPP000.
7B is a graph for the metabolic profile of the recombinant strain ELPP010.
8 is a result of confirming the effect of increasing the stability of an external gene insertion vector according to whether an endonuclease ( endA, endX ) is deleted through dTomato fluorescence analysis.
9 is a graph for the metabolic profile of the recombinant strain ELPP110.
10A is a graph for the metabolic profile of the recombinant strain ELPP111.
10B is a graph for the metabolic profile of the recombinant strain ELPP211.
10C is a graph for the metabolic profile of the recombinant strain ELPP212.
10D is a graph for the metabolic profile of the recombinant strain ELPP213.
11A is a graph for the metabolic profile of the recombinant strain ELPP221.
11B is a graph for the metabolic profile of the recombinant strain ELPP311.
12 is a graph analyzing fatty acids in a recombinant strain through Nile-red staining.
13A is a graph of the metabolic profile of recombinant strain ELPP211 cultured at pH 7.0.
13B is a graph for the metabolic profile of recombinant strain ELPP211 cultured at pH 6.75.
13C is a graph of metabolic profile of recombinant strain ELPP211 cultured at pH 6.5.
이하, 본 발명을 하기의 실시예에 의하여 더욱 상세히 설명한다. 그러나 이들 실시예는 본 발명을 예시하기 위한 것일 뿐이며, 본 발명의 범위가 이들 실시예에 의하여 한정되는 것은 아니다.Hereinafter, the present invention will be described in more detail by the following examples. However, these examples are only for illustrating the present invention, and the scope of the present invention is not limited by these examples.
실시예 1: 메발론산 생산 회로를 갖는 균주의 제조Example 1: Preparation of strains with mevalonic acid production circuit
미생물 내에서 에탄올은 아세트알데히드-아세트산을 거치는 산화반응을 통해 Acetyl-CoA로 전환되고 세포 내 주요 중간물질인 Acetyl-CoA는 TCA Cycle 및 지방산 생합성 회로로 유입되어 에너지-세포구성물질 합성 등 다양한 생합성 경로로 유입된다. 따라서, 고효율의 메발론산 생산 촉매 개발을 위해, 미생물 내 Acetyl-CoA를 메발론산 경로로 유입시키는 것이 중요하다.In the microorganism, ethanol is converted to Acetyl-CoA through an oxidation reaction through acetaldehyde-acetic acid, and Acetyl-CoA, the main intermediate in the cell, enters the TCA cycle and fatty acid biosynthesis circuit, and various biosynthetic pathways such as energy-cell composition synthesis Flows into Therefore, in order to develop a high-efficiency mevalonic acid production catalyst, it is important to introduce Acetyl-CoA in the microorganism into the mevalonic acid pathway.
P. putida 균주 내 메발론산 경로의 중간체인 메발론산까지의 상부 메발론산 경로를 구현함으로써, 미생물 내 Acetyl-CoA 중간체를 얼마나 메발론산 경로로 유입시킬 수 있는지 확인하는 연구를 진행하였다.By implementing the upper mevalonic acid pathway to mevalonic acid, which is an intermediate of the mevalonic acid pathway in the P. putida strain, a study was conducted to confirm how much the microbial Acetyl-CoA intermediate can be introduced into the mevalonic acid pathway.
상부 메발론산 경로를 구축하고 에탄올로부터 메발론산의 생산 여부를 확인하기 위해 3가지 단계의 유전자 발현을 진행하였다. Acetyl-CoA 두 분자를 Acetoacetyl-CoA로 전환하는 Acetyl-CoA Acetyltransferase 유전자(atoB from Escherichia coli MG1655), Acetoacetyl-CoA 와 Acetyl-CoA를 중합하여 3-Hydroxy-3-Methyl-Glutaryl-CoA(HMG-CoA)를 합성하는 HMG-CoA Synthase 유전자(mvaS from Enterococcus faecalis), HMG-CoA를 환원시켜 메발론산을 합성하는 HMG-CoA Reductase 유전자(mvaE from Enterococcus faecalis)를 Pseudomonas putida의 Codon usage에 따라 코돈 최적화하여 본 발명에서 개발한 pSGP10 E. coli-Pseudomonas Shuttle Expression Vector(Tetracycline Selection Marker, trc Promoter)에 Gibson Assembly를 이용하여 삽입한 후 P. putida에 형질전환하여 재조합 균주를 제작하였다.In order to construct the upper mevalonic acid pathway and to confirm the production of mevalonic acid from ethanol, three steps of gene expression were performed. Acetyl-CoA Acetyl-CoA Acetyltransferase gene ( atoB from Escherichia coli MG1655), which converts two molecules to Acetoacetyl-CoA, polymerizes Acetoacetyl-CoA and Acetyl-CoA to 3-Hydroxy-3-Methyl-Glutaryl-CoA (HMG-CoA ) To synthesize HMG-CoA Synthase gene ( mvaS from Enterococcus faecalis ), and HMG-CoA to reduce HMG-CoA Reductase gene ( mvaE from Enterococcus faecalis ) to optimize codon according to Codon usage of Pseudomonas putida After inserting the pSGP10 E. coli - Pseudomonas Shuttle Expression Vector (Tetracycline Selection Marker, trc Promoter) developed in the invention using a Gibson Assembly, it was transformed into P. putida to produce a recombinant strain.
Negative Control인 ELPP000의 경우 에탄올을 활용하여 성장 가능하지만 세포 성장이 일어나며 아세트산이 축적이 되어 결국 모든 탄소원을 소모하지 못하고 세포가 사멸하는 결과를 보이는 반면, 메발론산 생산 회로를 구축한 ELPP010 균주의 경우 아세트산이 축적되지 않고 모든 에탄올을 소모하여 약 1.7 g/L의 메발론산을 생산하였다. 하지만 수율이 매우 낮다는 문제가 있으며 이를 극복하기 위해 외부 도입 유전자 안정성 향상 실험을 진행하였다.In the case of ELPP000, which is a negative control, it is possible to grow using ethanol, but cell growth occurs and acetic acid accumulates, eventually consuming all the carbon sources and killing cells, whereas in the case of the ELPP010 strain that built the mevalonic acid production circuit, acetic acid Without accumulation, all ethanol was consumed to produce about 1.7 g / L mevalonic acid. However, there is a problem that the yield is very low, and in order to overcome this, an experiment was conducted to improve the stability of the gene introduced outside.
실시예 2. 외부 도입 유전자 안정성이 향상된 균주의 제조Example 2. Preparation of strains with improved transgene stability
P. putida 균주를 이용한 대사공학 연구의 문제점 중 하나는 외부 도입 유전자(플라스미드 벡터)의 안정성이 낮아 오랜 배양시간 동안의 유전자 발현의 유지력이 좋지 않다는 것이다. 이러한 플라스미드 벡터의 낮은 안정성은 P. putida 균주 자체가 외부 유전자를 분해 및 재조합 하는 방어 기작에 기인한다고 알려져 있으며, 본 연구에서는 P. putida의 외부 도입 유전자 안정성을 향상시킨 선행 연구 사례를 참조하여, 외부 유전자를 분해하는 역할을 하는 Endonuclease를 Coding하는 endA 및 endX 를 pK19mobsacB mediated Markerless Deletion 방법을 통해 결손 시켰다.One of the problems of metabolic engineering studies using P. putida strain is that the stability of the gene expression during long incubation time is poor due to the low stability of the introduced gene (plasmid vector). Low stability of such plasmid vectors are known to the P. putida strains themselves due to the defense mechanism of decomposition and recombination of foreign genes, this study, with reference to the prior research studies that improve the stability of transgene external P. putida, outside EndA and endX, which encode Endonuclease, which serves to degrade genes, were deleted through the pK19 mobsacB mediated Markerless Deletion method.
Endonuclease 유전자를 결손 시킴으로써, 실제로 외부 유전자가 삽입된 벡터의 안정성이 증대되었는지 확인하기 위해 Fluorescence Protein인 dTomato 유전자를 pSGP10 Vector에 삽입하여 Wild-Type과 Endonuclease 결손 균주에 형질전환 하였다.By deleting the Endonuclease gene, in order to confirm that the stability of the vector into which the external gene was inserted was increased, the dTomato gene, a fluorescence protein, was inserted into the pSGP10 Vector and transformed into Wild-Type and Endonuclease-deficient strains.
Endonuclease(endA, endX) 결손으로 인한 외부 유전자 삽입 벡터의 안정성 증대 효과를 알아보기 위해, dTomato Protein을 발현시킨 후 발현 시간에 따른 Fluorescence Intensity의 증가 경향을 확인하였다. Fluorescence Intensity는 Fluorescence Microplate Leader로 측정하였으며 Excitation 파장 544 nm, Emission 파장 590 nm의 조건에서 분석하였다. endA, endX 결손 균주인 ELPP1dT0의 경우 24시간에서 48시간까지의 Fluorescence Intensity의 증가량이 더 컸으며 같은 실험 간의 표준편차의 감소도 확인되어 외부 유전자 삽입 벡터의 안정성 증대 효과를 확인하였다.In order to investigate the effect of increasing the stability of the external gene insertion vector due to the endonuclease ( endA, endX ) deficiency, the tendency of the increase in fluorescence intensity according to the expression time after the expression of dTomato Protein was confirmed. Fluorescence Intensity was measured with a Fluorescence Microplate Leader and analyzed under conditions of excitation wavelength 544 nm and emission wavelength 590 nm. In the case of the endA and endX- deficient strains ELPP1dT0, the increase in Fluorescence Intensity from 24 to 48 hours was greater, and the decrease in the standard deviation between the same experiments was also confirmed, confirming the effect of increasing the stability of the external gene insertion vector.
Endonuclease(endA, endX) 결손 균주에 메발론산 회로를 구축한 ELPP110을 배양한 결과, 메발론산 생산은 약 2.43 g/L로 증가하였지만 일부 플라스크에서 아세트산이 빠르게 축적되어 세포 대사능력을 잃어버리는 현상이 발생하였다. 이는 Endonuclease의 결손으로 인한 돌연변이 대처 능력 저하로 인한 세포의 생장 능력이 떨어진 상황에서 Ethanol의 Periplasmic Oxidation의 속도가 너무 빠른 것에 기인하는 것으로 생각되어 에탄올 이화작용 회로를 조절하였다.As a result of incubation of ELPP110 with a mevalonic acid circuit in an endonuclease ( endA, endX ) -deficient strain, mevalonic acid production increased to about 2.43 g / L, but acetic acid rapidly accumulated in some flasks, resulting in loss of cell metabolism. Did. This was thought to be due to the speed of Ethanol's Periplasmic Oxidation being too fast in a situation where the cell's growth capacity was reduced due to a decrease in the ability to cope with mutations due to the deletion of the endonuclease, thereby regulating the ethanol catabolism circuit.
실시예 3. 에탄올 이화작용 회로를 조절한 균주 제조Example 3. Preparation of strains with controlled ethanol catabolism circuit
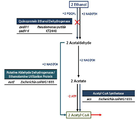
에탄올을 메발론산으로 전환하는 배양 중 특정 실험 세트에서 아세트산의 과도한 축적으로 인한 세포활성 저하 및 메발론산 생산 재현성이 감소되는 문제가 발생하였다. 이를 극복하기 위하여 우선적으로 P. putida의 이화작용 경로를 파악한 후 아세트산이 축적되지 않도록 이화작용 경로를 전반적으로 재설계 하였다.During a culture in which ethanol was converted to mevalonic acid, there was a problem in that a specific experimental set reduced cell activity due to excessive accumulation of acetic acid and reduced reproducibility of mevalonic acid production. To overcome this, the catabolism pathway of P. putida was first identified, and the catabolic pathway was generally redesigned so that acetic acid did not accumulate.
아세트산의 축적을 막기 위해 1차적으로 아세트산을 Acetyl-CoA로 전환하는 Acetyl-CoA Synthetase(acs from Escherichia coli MG1655) 유전자를 Broad-Host Range Vector pAWP89-0에 삽입하여 형질전환 하였다.To prevent the accumulation of acetic acid, the Acetyl-CoA Synthetase ( acs from Escherichia coli MG1655) gene, which primarily converts acetic acid to Acetyl-CoA, was inserted into the Broad-Host Range Vector pAWP89-0 and transformed.
또한, P. putida는 E. coli와 다르게 에탄올과 같은 알코올류를 Periplasm에서 빠르게 산화시키는 PQQ(Pyrroloquinoline quinone) Dependent Periplasmic Ethanol Dehydrogenase를 가지고 있어, 에탄올의 산화속도가 매우 빠른데 반해 아세트산을 Acetyl-CoA로 전화하는 속도는 그 속도에 미치지 못해 아세트산이 축적될 것이라 생각하였으며, 에탄올의 Periplasmic 산화를 방지하기 위해 Quinoprotein Ethanol Dehydrogenase(qedH-I, qedH-II) 유전자를 pK19mobsacB를 이용한 Markerless Deletion을 통해 결손 하였다.In addition, P. putida , unlike E. coli , has PQQ (Pyrroloquinoline quinone) Dependent Periplasmic Ethanol Dehydrogenase, which rapidly oxidizes alcohols such as ethanol in Periplasm, whereas acetic acid is converted to Acetyl-CoA while ethanol oxidation is very fast. It was thought that acetic acid would accumulate at a rate less than that, and the Quinoprotein Ethanol Dehydrogenase ( qedH-I , qedH-II ) gene was deleted through Markerless Deletion using pK19 mobsacB to prevent periplasmic oxidation of ethanol.
또한, 아세트산을 거치지 않고 Acetaldehyde를 Acetyl-CoA로 바로 전환할 수 있는 Putative Aldehyde Dehydrogenase(eutE from Escherichia coli MG1655)를 추가로 발현시킴으로써, Acetate의 축적을 추가로 방지하고 Acetate를 Acetyl-CoA로 전환하는데 필요한 ATP 소모를 줄이고자 하였다.In addition, by additionally expressing Putative Aldehyde Dehydrogenase ( eutE from Escherichia coli MG1655) that can directly convert Acetaldehyde to Acetyl-CoA without going through acetic acid, it is necessary to further prevent Acetate accumulation and convert Acetate to Acetyl-CoA. To reduce ATP consumption.
아세트산의 축적을 막기 위해 아세트산을 Acetyl-CoA로 전환할 수 있는 acs 유전자를 발현시킨 ELPP111 균주의 경우 메발론산 생산능력이 ELPP110 균주에 비해 소폭 증가하였지만 근본적인 아세트산의 축적 문제를 해결하지 못하였다.In order to prevent the accumulation of acetic acid, in the case of the ELPP111 strain expressing the acs gene capable of converting acetic acid to Acetyl-CoA, the mevalonic acid production capacity increased slightly compared to the ELPP110 strain, but it did not solve the fundamental acetic acid accumulation problem.
에탄올의 Periplasmic Oxidation을 막기 위한 qedH 유전자 결손 균주에 메발론산 회로와 acs 유전자를 발현시킨 ELPP211 균주의 경우 안정적으로 높은 농도의 메발론산을 생산 할 수 있음을 확인하였고, 약 4.07 g/L의 메발론산을 생산하였다.In the case of the ELPP211 strain expressing the mevalonic acid circuit and the acs gene in the qedH gene-deficient strain to prevent ethanol periplasmic oxidation, it was confirmed that it can stably produce high concentrations of mevalonic acid, and a mevalonic acid of about 4.07 g / L. Produced.
아세트산을 거치지 않고 아세트알데히드를 Acetyl-CoA로 직접 전환 가능한 eutE 유전자를 acs 없이 발현시킨 균주(ELPP212)의 경우 오히려 아세트산의 축적을 야기시키는 결과를 보였으며, 이는 세포 내 아세트알데히드 농도가 매우 낮기 때문에 Reversible Enzyme인 eutE 가 오히려 Acetyl-CoA를 아세트알데히드로 전환시킨 후 다시 아세트산으로 산화되는 과정을 유도했을 것으로 예상 할 수 있다. acs와 eutE를 같이 발현시킨 균주(ELPP213)의 경우 eutE 가 없는 ELPP211 균주와 크게 다르지 않은 결과를 보였고, 이를 통해 acs 유전자의 발현이 에탄올 대사에 중요한 요소임을 확일 할 수 있었다.The eutE gene that can convert acetaldehyde to acetyl-CoA without going through acetic acid without acs In the case of the expressed strain (ELPP212), rather, it showed a result that causes the accumulation of acetic acid, and since the concentration of acetaldehyde in the cell is very low, eutE , a Reversible Enzyme, rather converts Acetyl-CoA to acetaldehyde and then oxidizes to acetic acid again. It can be expected to have led to the process. In the case of the strain expressing acs and eutE together (ELPP213), the results showed that the ELPP211 strain without eutE was not significantly different. Through this, it was confirmed that the expression of the acs gene is an important factor for ethanol metabolism.
실시예 4. 지방산 생합성 경로를 조절한 균주 제조Example 4. Preparation of a strain that modulates the fatty acid biosynthetic pathway
메발론산의 생산 수율을 높이기 위해 Acetyl-CoA를 전구체로 사용하는 경쟁 회로 중 하나인 지방산 생합성 경로를 조절하여, Acetyl-CoA를 메발론산 생합성으로 더 많이 유입되도록 하였다. 지방산 생합성 경로 조절의 모식도는 다음 그림과 같다.In order to increase the production yield of mevalonic acid, the fatty acid biosynthesis pathway, which is one of the competitive circuits using acetyl-CoA as a precursor, was controlled to allow more acetyl-CoA to be introduced into mevalonic acid biosynthesis. The schematic diagram of fatty acid biosynthesis pathway regulation is as follows.
첫번째로, 지방산 생합성으로 유입되는 Malonyl-CoA를 Acetoacetyl-CoA로 전환하여 메발론산 회로로 유입시키는 역할을 할 수 있는 Acetoacetyl-CoA Synthase(nphT7 from Streptomyces sp. CL190)를 pSGP11 벡터(atoB, mvaS, mvaE 삽입 벡터)에 추가 삽입하여 발현시켰다.First, the pSGP11 vector ( atoB, mvaS, mvaE ) of Acetoacetyl-CoA Synthase ( nphT7 from Streptomyces sp.CL190), which can serve to convert Malonyl-CoA introduced into fatty acid biosynthesis into Acetoacetyl-CoA into the mevalonic acid cycle, Insertion vector).
또한, Pseudomonas putida는 자체적으로 탄소원을 지방산으로 합성한 후 중합하여 저장한다고 알려져 있다. 이러한 Polyhydroxyalkanoate(PHA) 생합성을 막고 탄소원의 불필요한 소모를 막기 위해 PHA 생합성의 주요 단계인 (R)-3-hydroxydecanoyl-ACP : CoA transacylase(phaG) 유전자를 결손시켰다.In addition, Pseudomonas putida is known to synthesize and store carbon sources as fatty acids by itself. In order to prevent such polyhydroxyalkanoate (PHA) biosynthesis and to prevent unnecessary consumption of carbon sources, the (R) -3-hydroxydecanoyl-ACP: CoA transacylase ( phaG ) gene, a major step in PHA biosynthesis, was deleted.
지방산 생합성 경로로 유입되는 Malonyl-CoA와 Acetyl-CoA를 중합하여 Acetoacetyl-CoA를 합성하는 nphT7 유전자를 발현시킨 ELPP212 균주의 경우 매우 큰 생장 저해가 발생하였으며 이를 통해 Malonyl-CoA의 지방산 생합성으로의 흐름을 너무 과도하게 메발론산 합성으로 가져오는 역효과가 일어났음을 알 수 있으며, nphT7 유전자의 발현을 조금 더 세밀하게 조절할 수 있는 메커니즘이 필요함을 확인할 수 있었다.Of Malonyl-CoA, and by polymerizing the Acetyl-CoA For ELPP212 strains which express the nphT7 gene synthesized Acetoacetyl-CoA were a very large growth inhibition occurs Malonyl-CoA through which flowing in the fatty acid biosynthesis pathway, the flow of the fatty acid biosynthesis It can be seen that the adverse effects of excessively high synthesis of mevalonic acid occurred, and it was confirmed that a mechanism for controlling the expression of the nphT7 gene in more detail is needed.
PHA 생합성 회로의 주요 단계인 phaG 유전자를 결손시킨 ELPP311 균주의 경우 기존의 ELPP211 균주에 비해 메발론산 생산량이 증가하지 않았다. phaG 유전자를 결손시킴으로써 PHA 축적이 정말 저해됐는지, 그렇다면 왜 메발론산 생산량이 증가하지 않았는지 확인하기 위해 기존 논문에 알려진 방법을 참고하여 Nile-red 염색 후 세포 파괴 없이 Fluorescence Analysis를 통해 세포 내 지방산 성분의 정량적 차이를 확인하였다. Fluorescence Intensity는 Fluorescence Microplate Leader로 측정하였으며 Excitation 파장 530 nm, Emission 파장 590 nm의 조건에서 분석하였다.In the case of the ELPP311 strain in which the phaG gene, which is the main step of the PHA biosynthetic circuit, was deleted, the mevalonic acid production did not increase compared to the conventional ELPP211 strain. Deletion of the phaG gene was used to determine if PHA accumulation was really inhibited, and if so, why the mevalonic acid production did not increase. Quantitative differences were confirmed. Fluorescence Intensity was measured with a Fluorescence Microplate Leader and analyzed under conditions of excitation wavelength 530 nm and emission wavelength 590 nm.
Nile-red 염색을 통한 세포 내 지방산 성분 분석 결과 메발론산 회로가 없는 ELPP000 균주의 경우 배양시간이 지남에 따라 지방산 함량이 증가함을 확인할 수 있으나, 메발론산 회로가 도입된 ELPP211과 ELPP311 균주는 phaG 결손과 상관없이 세포 내 지방산 함량이 일정하게 유지되거나 감소하는 경향을 보였다. 따라서 메발론산 회로를 구축함으로써 자연스럽게 세포 내 지방산(PHA) 축적을 저해시킬 수 있고 이러한 이유로 ELPP311 균주의 메발론산 생산량이 증가하지 않은 이유를 확인할 수 있었다.As a result of analyzing the fatty acid component in cells through Nile-red staining, it can be seen that the fatty acid content increases with the incubation time for the ELPP000 strain without the mevalonic acid cycle, but the ELPP211 and ELPP311 strains incorporating the mevalonic acid cycle are defective in phaG. Regardless of this, the fatty acid content in the cells tended to remain constant or decrease. Therefore, by constructing the mevalonic acid circuit, it was possible to naturally inhibit the accumulation of fatty acids (PHA) in the cell, and for this reason, it was confirmed that the mevalonic acid production of the ELPP311 strain did not increase.
상기 실시예 1 내지 4에서 제조한 재조합 균주에 대한 정보는 표 1과 같다. Information on the recombinant strains prepared in Examples 1 to 4 is shown in Table 1.
상기 표 1의 재조합 균주 제조에 이용된 플라스미드에 관한 정보는 표 2와 같다.Information on the plasmid used in the production of the recombinant strain of Table 1 is shown in Table 2.
상기 표 2의 플라스미드 제조에 이용된 프라이머에 관한 정보는 표 3과 같다.Information on the primers used in the preparation of the plasmid of Table 2 is shown in Table 3.
실시예 5: 재조합 균주를 이용한 메발론산 생산Example 5: Production of mevalonic acid using recombinant strain
실시예 1 내지 4에서 제조한 균주들은 -80℃에서 글리세롤 25%의 냉동 Stock 형태로 보관하였으며, LB(kanamycin 75 mg/L, tetracyclin 30 mg/L)에서 약 14시간정도 Seed Culture 후 M9D(Dextrose 12 g/L)에 2% 접종하여 24시간 배양한 후 M9E(Ethanol 200 mM)에 O.D.=1 이 되도록 수확하여 접종하였다. 배양에 사용된 M9 Media의 조성은 표 4, 세부 배양조건은 표 5와 같다.The strains prepared in Examples 1 to 4 were stored in a frozen stock form of 25% glycerol at -80 ° C, and after about 14 hours of seed culture in LB (kanamycin 75 mg / L, tetracyclin 30 mg / L), M9D (Dextrose 12 g / L), inoculated with 2%, incubated for 24 hours, and then harvested and inoculated to M9E (Ethanol 200 mM) so that OD = 1. The composition of M9 Media used for culture is shown in Table 4, and detailed culture conditions are shown in Table 5.
KH2PO4 8.0 g/L K 2 HPO 4 16.0 g / L
KH 2 PO 4 8.0 g / L
(11.7 mL/L)
Dextrose 1 g/LEthanol 200mM
(11.7 mL / L)
Dextrose 1 g / L
Ethanol 200 mM (9.2 g/L)
O.D. = 1.0 Inoculation
from M9D (Dextrose 12 g/L)
CultureM9E Media
Ethanol 200 mM (9.2 g / L)
OD = 1.0 Inoculation
from M9D (Dextrose 12 g / L)
Culture
Working Volume : 50 mL
Agitation : 230rpm
Temperature : 30℃
IPTG Induction : 0.1 mMBaffled Flask
Working Volume: 50 mL
Agitation: 230rpm
Temperature: 30 ℃
IPTG Induction: 0.1 mM
기질인 에탄올과 부산물인 아세트산, 생산물인 메발론산 모두 HPLC 분석을 통해 정량화하였고, 그 조건은 표 6과 같다.Both ethanol as a substrate, acetic acid as a by-product, and mevalonic acid as a product were quantified through HPLC analysis, and the conditions are shown in Table 6.
Scale-Up 가능성과 pH에 따른 메발론산 생산 경향 분석을 위해 P. putida 생장 최적 pH로 알려진 pH 7.0에서 pH 6.5까지(pH 7.0, pH 6.75, pH 6.5) 3가지 조건에서 1L 회분배양을 진행하였다. pH 7.0 조건은 생장 속도가 가장 빠르고 에탄올 소모속도도 빨랐으나 세포 생장이 많아 메발론산 생산량은 pH 6.75조건보다 낮았으며, pH 6.5 조건은 발효 중간부터 아세트산이 급격히 축적되어 세포 활성을 잃게 됨을 확인하였고, 따라서 pH 6.75의 조건이 메발론산 생산에 최적화된 pH임을 확인하였다. 하지만 플라스크 발효(4.07 g/L from 200 mM of Ethanol - Yp/x = 0.41 g/g)에 비해 회분배양의 메발론산의 수율이 낮았는데(4.60 g/L from 300 mM of Ethanol - Yp/x = 0.32 g/g) 이는 휘발성 탄소원인 에탄올이 직접적인 공기 분사로 인해 증발되어 누출되었음을 확인하였으며 이는 추후 배출가스 처리 등의 공정의 보완을 통해 극복될 수 있을 것으로 판단된다.In order to analyze the scale-up possibility and the tendency of mevalonic acid production according to pH, 1 L batch culture was performed under three conditions from pH 7.0 to pH 6.5 (pH 7.0, pH 6.75, pH 6.5), known as the optimum pH for P. putida growth. The pH 7.0 condition showed the fastest growth rate and the fastest ethanol consumption rate, but the cell growth was high, so the production of mevalonic acid was lower than the pH 6.75 condition. Therefore, it was confirmed that the condition of pH 6.75 is a pH optimized for mevalonic acid production. However, the yield of mevalonic acid in batch culture was lower compared to flask fermentation (4.07 g / L from 200 mM of Ethanol-Yp / x = 0.41 g / g) (4.60 g / L from 300 mM of Ethanol-Yp / x = 0.32 g / g) This confirmed that the volatile carbon source, ethanol, evaporated and leaked due to direct air injection, and this can be overcome by supplementing processes such as exhaust gas treatment.
<110> SOGANG UNIVERSITY RESEARCH FOUNDATION <120> Recombinant Pseudomonas putida strains and method for producing mevalonate using the same <130> PN180366P <150> KR 18/0125997 <151> 2018-10-22 <160> 75 <170> KoPatentIn 3.0 <210> 1 <211> 1216 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA acetyltransferase <400> 1 agtccgctgg gtagactaag gaggttatag tatgaagaac tgcgtgatcg tgagcgccgt 60 gcgcaccgcc atcggcagct tcaacggcag cctggccagc accagcgcca tcgatctggg 120 tgccaccgtg atcaaagccg ccatcgagcg tgccaagatc gacagccagc acgtggacga 180 ggtgatcatg ggcaacgtgc tgcaagccgg tctgggtcag aacccagcgc gtcaggccct 240 gctgaaaagc ggtctggccg aaaccgtgtg cggcttcacc gtgaacaagg tgtgcggcag 300 cggtctgaag tcggtggccc tggccgcgca agccatccaa gcgggtcaag cccagagcat 360 cgtggccggt ggcatggaaa acatgtcgct ggccccatac ctgctggacg ccaaagcgcg 420 tagcggctac cgcctgggtg acggccaggt gtacgacgtg atcctgcgcg acggcctgat 480 gtgcgcgacc cacggctacc acatgggcat caccgccgag aacgtggcca aagagtacgg 540 catcacccgc gagatgcagg acgagctggc cctgcacagc cagcgtaaag ccgccgccgc 600 gatcgagagc ggtgccttca ccgcggaaat cgtgccggtg aacgtggtga cccgcaagaa 660 aaccttcgtg ttcagccagg acgagttccc gaaggccaac agcaccgcgg aggccctggg 720 tgccctgcgt ccagccttcg ataaagccgg caccgtgacc gccggtaacg ccagcggcat 780 caacgacggt gccgccgcgc tggtcatcat ggaagaaagc gcggccctgg cggccggtct 840 gaccccactg gcgcgtatca agagctacgc gagcggtggt gtcccgccag cgctgatggg 900 tatgggtcca gtgccagcca cccagaaggc cctgcaactg gcgggtctgc agctggccga 960 catcgacctg atcgaggcca acgaggcctt cgccgcgcag ttcctggccg tgggcaagaa 1020 cctgggcttc gacagcgaga aggtgaacgt caacggtggt gcgatcgccc tgggccatcc 1080 gatcggtgcc agcggtgccc gtatcctggt gaccctgctg catgccatgc aagcccgtga 1140 caagaccctg ggcctggcga ccctgtgcat cggtggcggt cagggtatcg ccatggtgat 1200 cgagcgcctg aactga 1216 <210> 2 <211> 1185 <212> DNA <213> Artificial Sequence <220> <223> Hydroxymethylglutaryl-CoA synthase <400> 2 tcctagacac tttcaccata aggaaatatt ttaatgacca tcggcatcga taaaatcagc 60 ttcttcgtgc ccccgtatta catcgacatg actgctttgg ccgaagcacg caacgtcgat 120 ccagggaaat ttcacatcgg catcggccag gaccagatgg cggtaaaccc gatcagccaa 180 gacatcgtca ccttcgccgc caacgccgcc gaggcgatcc tcaccaagga agataaggag 240 gctattgaca tggtgatcgt ggggaccgag agcagcatcg acgagtccaa ggccgccgcc 300 gtggtgctgc accgcctgat gggcattcag ccgttcgcgc gctcgttcga gatcaaggaa 360 gcctgctacg gcgcaacggc aggcctgcag ctggccaaga accacgttgc gctgcatccg 420 gacaaaaagg tgctggtcgt ggcggctgat atcgcgaagt acggtctgaa cagcggcggc 480 gaacccaccc agggcgcggg cgccgtggcc atgctcgtgg cctcggagcc gcggattctg 540 gccctgaagg aagacaatgt catgttgacc caggacatct acgacttctg gcgtcctacc 600 ggccacccgt accccatggt cgacggcccg ctgagcaacg agacctacat ccagtccttc 660 gcacaggtgt gggacgagca caagaagcgc accggcctcg atttcgccga ctatgatgcg 720 ctggcctttc acatcccgta caccaagatg ggcaaaaagg cgctgctggc gaagatcagc 780 gatcagacgg aggccgagca agagcggatc ctggcccgtt acgaggagtc gatcatctac 840 agccgccgcg tcggcaatct gtacaccggc agcctgtacc tgggtctgat ttcgctgctg 900 gagaacgcta ccaccctgac cgcggggaac cagatcggcc tgttcagcta cggtagtggc 960 gccgtggccg agttcttcac cggcgagctg gtggccggct accagaacca tctgcagaag 1020 gagacgcacc tcgccctgct ggacaatcgc accgagctgt cgatcgccga gtacgaggcc 1080 atgttcgcgg agaccctgga cacggacatc gaccagaccc tggaggacga gctgaaatac 1140 agcatctccg ccatcaacaa caccgtgcgc agctatcgca actaa 1185 <210> 3 <211> 2430 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA acetyltransferase / Hydroxymethylglutaryl-CoA reductase <400> 3 atttaaggag aactttatat gaagaccgtg gtcatcatcg atgccctgcg caccccgatc 60 ggcaaataca aaggctcgct cagccaggtc tcggccgtgg acctgggcac ccacgtgacc 120 acccagttgc tgaagcgcca cagcacgatc agcgaagaga tcgaccaggt tatctttggg 180 aacgtgctgc aggcgggtaa cggccagaac cccgcgcgtc agatcgccat caactcgggg 240 ctgtcgcatg aaatcccggc catgaccgtg aatgaggtct gcggctccgg catgaaggcg 300 gtcatcctgg ctaagcagct gatccagctg ggcgaagccg aggtgctcat cgccggcggc 360 atcgaaaaca tgagccaggc cccgaagctg cagcggttca actatgaaac tgagagttac 420 gacgccccgt tcagcagcat gatgtacgac ggcctgacgg atgcgttcag cggccaggca 480 atgggcctga ccgccgagaa cgtggccgag aagtaccacg tgacccgcga ggaacaggac 540 cagttcagcg tgcactccca gctgaaggcc gcacaggccc aagccgaagg catcttcgcc 600 gacgagattg cgcccctgga agttagcggc acgctcgtgg agaaggatga gggcatccgt 660 ccaaactcga gcgtggagaa actgggcacc ctgaagaccg tgttcaagga ggacggcacc 720 gtcactgccg ggaacgcgtc caccatcaac gacggggcct cggccctgat tatcgctagt 780 caggaatatg ccgaggccca tggcctgccg tacttggcga tcatccgcga ctcggtggag 840 gtcggcatcg acccggcgta catgggcatc agcccgatca aagccatcca gaagctcttg 900 gcccgcaacc aactgacgac cgaagagatc gatctgtacg aaatcaatga ggccttcgct 960 gccaccagca tcgtcgtaca gcgcgaactg gcgctgccgg aggaaaaggt gaacatctac 1020 ggtggtggca tcagcctggg tcacgcgatc ggcgcaaccg gcgcccgcct gctgaccagc 1080 ctttcctacc agctgaacca aaaggagaaa aagtatggtg tcgccagcct ctgcattggg 1140 ggcggcctgg gccttgccat gctgttggag cgtccgcagc agaaaaagaa ttcgcgcttt 1200 taccagatgt ccccggagga gcgcctggcc tccctgctga acgaaggcca gatctcggcg 1260 gataccaaga aggagttcga gaacacggct ctgagctcgc agatcgccaa ccacatgatt 1320 gagaaccaga tcagcgagac cgaggttccc atgggcgtcg gcctgcacct gaccgtggat 1380 gagaccgact acctggtgcc gatggccacc gaggagccga gtgtcatcgc cgcactgagc 1440 aacggcgcca agatcgcgca gggcttcaaa accgtgaacc agcagcgcct gatgcggggc 1500 cagatcgtgt tctacgacgt ggcggacgcc gaaagcctga tcgacgagct gcaggtgcgc 1560 gagaccgaga tcttccaaca ggccgagctc agctacccga gcatcgtaaa gcgcggcggg 1620 ggcctgcgcg acctgcaata ccgggcgttc gacgagtctt tcgttagtgt ggatttcctg 1680 gtcgacgtca aggacgcgat gggtgccaac atcgtgaatg caatgttgga aggtgtcgcc 1740 gagctgttcc gcgaatggtt cgccgaacaa aaaatcctgt tcagcatcct gtccaactac 1800 gccaccgagt cggtcgtgac gatgaagacg gcgatcccgg taagccgcct cagcaaaggt 1860 agcaacggcc gcgagatcgc agaaaagatc gtgctggcct cacgctatgc cagcctggac 1920 ccctaccgcg ccgtgaccca taacaagggc atcatgaacg gtattgaggc ggtagtgctg 1980 gcgaccggca atgacacccg tgccgtgagc gcatcgtgcc acgcatttgc cgtcaaggaa 2040 ggccggtacc agggcttgac ctcctggacc ctggacggcg aacagctgat tggcgaaatc 2100 agcgtgccgc tcgcgcttgc caccgtgggc ggggccacta aggtgctgcc gaaaagccag 2160 gccgccgctg acctgctggc ggttaccgat gcaaaagagc tgtcgcgcgt cgtcgccgct 2220 gtggggctgg cccaaaactt ggccgccctg cgcgcgctcg tgtcggaggg catccagaag 2280 ggccacatgg ctctgcaggc ccgtagcctg gccatgacag tgggggccac cggcaaggag 2340 gtcgaagcgg tagcgcagca gctgaagcgc cagaaaacca tgaaccagga ccgcgccctg 2400 gctatcctga acgatttgcg taagcaataa 2430 <210> 4 <211> 1994 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA synthetase <400> 4 ctgagaatag ccctcaacta cgtaaggagg tatttatgag ccagatccac aagcacacca 60 tcccagccaa catcgccgac cgctgcctga tcaacccgca gcagtacgag gccatgtacc 120 agcagagcat caacgtgccg gacaccttct ggggtgagca gggcaagatc ctggactgga 180 tcaagccgta ccagaaggtc aagaacacca gcttcgcccc aggcaacgtg agcatcaagt 240 ggtacgagga cggcaccctg aacctggccg ccaactgcct ggaccgccat ctgcaagaga 300 acggcgaccg caccgccatc atctgggaag gcgacgacgc cagccagagc aagcacatca 360 gctacaaaga actgcaccgc gacgtgtgcc gcttcgcgaa caccctgctg gaactgggca 420 tcaagaaagg cgacgtggtg gccatctaca tgccgatggt gccggaagcc gccgtggcca 480 tgctggcctg cgcgcgtatc ggtgccgtgc acagcgtgat cttcggtggc ttcagcccag 540 aggccgtggc cggtcgcatc atcgacagca acagccgtct ggtcatcacc agcgacgagg 600 gcgtgcgtgc cggtcgtagc atcccgctga agaagaacgt cgacgacgcg ctgaaaaacc 660 cgaacgtgac cagcgtggaa cacgtggtgg tgctgaaacg caccggtggc aagatcgact 720 ggcaagaggg tcgcgatctg tggtggcacg acctggtgga acaggccagc gaccagcacc 780 aggccgagga aatgaacgcg gaggacccgc tgttcatcct gtacaccagc ggcagcaccg 840 gcaagccgaa gggcgtgctg cataccaccg gtggttacct ggtgtatgcc gcgctgacct 900 tcaagtacgt gttcgactac catccgggtg acatctactg gtgcaccgcc gatgtcggtt 960 gggtcaccgg tcacagctac ctgctgtacg gtccgctggc gtgcggtgcg accaccctga 1020 tgttcgaagg cgtgccgaac tggccgaccc cagcgcgtat ggcccaggtg gtggacaagc 1080 accaggtgaa catcctgtat accgcgccaa ccgccatccg tgcgctgatg gccgaaggcg 1140 acaaggccat cgaaggcacc gaccgcagca gcctgcgtat cctgggcagc gtgggcgagc 1200 cgatcaaccc cgaagcctgg gagtggtact ggaagaagat cggcaacgag aagtgcccag 1260 tggtcgacac ctggtggcag accgaaaccg gtggcttcat gatcacccca ctgccaggtg 1320 ccaccgagct gaaagccggt agcgcgaccc gtccgttctt cggcgtgcag ccagcgctgg 1380 tcgacaacga gggcaacccg ctggaaggtg cgaccgaggg cagcctggtg atcaccgaca 1440 gctggccagg ccaagcgcgt accctgttcg gcgaccacga gcgcttcgag cagacctact 1500 tcagcacctt caagaacatg tacttcagcg gtgacggtgc ccgtcgtgac gaggatggct 1560 actactggat caccggtcgc gtggacgacg tcctgaacgt gagcggtcac cgtctgggca 1620 ccgcggagat cgaaagcgcc ctggtggccc atccgaagat cgccgaagcc gcggtggtgg 1680 gcatcccgca caacatcaag ggccaagcca tctacgccta cgtgaccctg aaccacggcg 1740 aggaaccgtc gccagagctg tacgccgagg tgcgcaactg ggtgcgcaaa gagatcggtc 1800 ccctggcgac cccagacgtg ctgcactgga ccgacagcct gccaaagacc cgcagcggca 1860 aaatcatgcg tcgcatcctg cgcaagatcg cggccggtga caccagcaac ctgggcgaca 1920 cctcgaccct ggccgatcca ggcgtggtgg aaaagctgct ggaagagaag caagcgatcg 1980 ccatgccgag ctga 1994 <210> 5 <211> 966 <212> DNA <213> Artificial Sequence <220> <223> endA <400> 5 atgaaatcac tgctttacgc cgtaacctta ttattttcct ttaccctccc cgctctggcc 60 aacccgccgg ccaccttcac cgaagccaag gtggtggcca agcagaaggt ctacctggac 120 caggccagca gtgccatggg cgacctgtac tgcggttgca aatggacctg ggtgggcaag 180 tctggcgggc gcatcgacgc tgcctcgtgt ggttaccaga cacgcaagca gcagaaccgt 240 gccgaacgca ccgagtggga acacatcgtg cccgcccaca ccttcggcaa ccagcgccag 300 tgctggaaga acggcggccg tgagcactgc gtggacaacg acccggtgtt ccgcgccatg 360 gaggccgacc tgttcaacct ttacccggcc gtgggtgagg tcaacggtga ccgcagcaac 420 ttcaactacg gcatggtcac tggcaatgcc ggcgaatacg gccaatgcac caccaaggtc 480 gatttcgtcc agcgcaccgc cgaaccgcgt gacgaagtca aaggcctggt ggcccgcacc 540 acgttctaca tgttcgaccg ctacaagctg aacatgtcgc gccaacagca acagctgctg 600 atggcctggg acaagcaaca ccccgtgtcg gcctgggaga aagaacgcga ccggcgcatt 660 gccgcgatca tgggccatgc caacccgttc gtaagcggcg aacgcaagtg gactgccggc 720 tacaagccgg ttggcagcgg cgtggtagag gcggtgccgg taaacgcagc caagccagag 780 gccaaaccaa gcctggccag cgccggttcg gtcggcgccg tgcttggcaa ccgcaacagc 840 cacgtctatc acctgtcagt cggctgcccg ggctacaacc aggttacagc gaagaaccag 900 gttaccttcg caaacgaagg tgaagcgcag gcagcggggt atcgcaaggc aggcaactgc 960 cgctga 966 <210> 6 <211> 693 <212> DNA <213> Artificial Sequence <220> <223> endX <400> 6 atgagagttt cgcttttcgc agcagcctgc ctgttactga ccactccgct tgctcaagcc 60 gacgccccgc gcaccttcca ggaggccaag aaggtcgcct ggaagctcta tgcaccacaa 120 tcgaccgagt tttattgcgg ctgtaaatac aagggcaaca aggtcaacct ggcctcctgc 180 ggctatgccc cacgcaagaa tgcccagcgc gcgtcacgca tcgagtggga gcacatcgta 240 cccgcctggc agatcggcca tcagcgccag tgctggcaga gtggcggacg caagcagtgc 300 tcgcagcatg acgaagtgta ccaacgcgcc gaagccgacc tgcacaacct ggtgcccagc 360 atcggtgagg tcaacggcga ccgcagcaac ttcagtttcg gctggctacc agaacaacgc 420 ggccagtatg gccgctgcct gacccaggtc gacttcaagg cgaggaaggt gatgccgcgc 480 ccgtcgatcc gcggcatgat cgcccgcacc tacttctaca tgagcaagca gtacaacctg 540 cgcctgtcca aacaggatcg ccagttgttc gaggcctgga acaagaccta cccgccgcaa 600 gcctgggagc ggcaacgcaa ccaacaggtc gcctgcgtga tggggcgggg aaacgcgttc 660 gtggggccgg tcaacctcaa ggcgtgcggt tga 693 <210> 7 <211> 1896 <212> DNA <213> Artificial Sequence <220> <223> qedH-I <400> 7 atgacaataa gatcgctacc cgccctttcc ccgctggccc tgagcgtgcg cgtcctgctg 60 atggccggta gcctggccct gggcaatgtg gcaacagcgg ccagcacacc cgctgcacct 120 gccggcaaga acgtcacctg ggaagacatc gccaatgacc acctgaccac ccaggacgtg 180 ctgcagtacg gcatgggcac caatgcccag cgctggagcc cgctggccca ggtcaatgac 240 aagaacgtgt tcaagctgac cccggcctgg tcctactcct tcggcgacga gaagcagcgc 300 ggccaggaat cccaggccat cgtcagcgat ggcgtggtct acgtcaccgg ttcgtactca 360 cgggtattcg ccctcgatgc caagaccggc aaacgcctgt ggacctacaa ccaccgcctg 420 cccgacaaca ttcgtccctg ctgcgacgtg gtcaaccgcg gggcggcgat ctacggcgac 480 aagatctact ttggcaccct cgatgcgcgt gtcatcgccc tcgacaagcg caccggcaaa 540 gtggtgtgga acaagaagtt cggcgaccac agcgccggct acaccatgac cggtgcgcca 600 gtgctgatca aggacaagac cagcggcaag gtgctgctga tccacggcag ctccggcgat 660 gaattcggcg tggtcggcca gctgttcgcg cgcgacccgg acaccggtga agaagtgtgg 720 atgcggccct tcgtggaggg ccacatgggc cgcctgaacg gcaaggacag caccccgacc 780 ggtgacgtca aggcgccgtc ctggccagac gaccctacca ccgaaaccgg caaggtcgaa 840 gcctggagcc acggcggcgg tgccccttgg caaagcgcga gcttcgaccc cgaaaccaac 900 accatcattg tcggcgctgg caaccccggc ccttggaata cctgggcgcg cacgtcgaag 960 gacggcaacc cgcatgactt cgacagcctg tacacctccg gccaggtcgg cgtcgacccg 1020 agcaccggcg aggtcaagtg gttctaccag cacaccccca acgatgcctg ggacttctcc 1080 ggcaacaacg agctggtgct gttcgactac aaggacaaga acggcaacgt ggtcaaggcc 1140 accgcccacg ccgaccgcaa cggtttcttc tatgtggttg accgcaacaa cggcaagctg 1200 caaaacgctt tccccttcgt cgacaacatc acctgggcca gccatatcga cctgaagacc 1260 gggcgcccgg tggaaaaccc cggccaacgc ccggccaagc cgctgccggg tgaaaccaag 1320 ggcaagccgg tggaagtctc gccaccgttc ctgggcggca agaactggaa ccccatggcc 1380 tacagccagg acaccgggct gttctacatc cccggcaacc agtggaaaga ggaatactgg 1440 accgaggaag tgaactacaa gaagggctcg gcttatctgg gcatgggctt ccgtatcaag 1500 cgcatgtacg acgaccacgt cggcacgttg cgcgccatgg acccgaccac cggcaagctg 1560 gtgtgggaac acaaggaaca cctgccgtta tgggccggtg tgttggcgac caagggcaac 1620 ctggtgttca ccggcacggg cgacggcttc ttcaaggcct tcgacgccaa gacgggcaaa 1680 gagctgtgga agttccagac cggcagcggc atcgtctcgc cgcccatcac ctgggagcag 1740 gacggcgagc agtacatcgg cgtgaccgtg ggctacggcg gtgcagtacc gctgtggggc 1800 ggcgacatgg ccgagctgac caaaccggtg gctcagggtg gttcgttctg ggtgttcaag 1860 atcccgagct gggacaacaa gactgcacaa cgttga 1896 <210> 8 <211> 1788 <212> DNA <213> Artificial Sequence <220> <223> qedH-II <400> 8 atgacccgat ccccacgtcg ccccttgttc gccgtgagcc tggtgctcag cgccatgctg 60 cttgccggcg cggctcacgc cgctgtcagc aatgaagaaa tcctccagga cccgaagaac 120 ccgcagcaga tcgtgaccaa tggcctgggc gtgcagggcc agcgctacag cccgctggac 180 ctgctcaatg tcaataacgt caaggagctg cgcccggtct gggcgttctc cttcggcggg 240 gagaagcagc gcggccagca ggcccagccg ctgatcaagg acggggtgat gtacctgacc 300 ggctcctact cgcgggtgtt cgccgtggat gcccgcaccg gcaagaaact gtggcaatac 360 gatgcacgtc tgccggatga catccgcccc tgctgcgacg taatcaaccg cggcgtcgcg 420 ctgtacggca acctggtgtt cttcggcacg ctggacgcca agctggtggc cctgaacaag 480 gacaccggca aggtggtctg gagcaagaag gtcgccgacc acaaagaagg ctactccatc 540 agcgccgcgc cgatgatcgt caatggcaag ctgatcacag gcgttgccgg cggcgagttc 600 ggcgtggtgg gcaagatcca ggcgtacaac ccggagaacg gcgaactgct gtggatgcgc 660 cccaccgtgg aagggcacat gggctatgtg tacaaggatg gcaaggcgat cgagaacggt 720 atttccggcg gtgaggcggg caagacctgg cctggcgacc tgtggaagac cggcggcgcc 780 gcgccgtggc tggggggtta ctacgaccct gaaaccaacc tgatcctgtt tggtaccggt 840 aacccggcgc cgtggaactc gcacctgcgc cccggtgaca acctgtactc ctcctcacgc 900 ctggcactga acccggacga cggcaccatc aagtggcact tccagagcac gccgcatgac 960 ggctgggact tcgacggcgt caacgagctg atctcgttca actacaagga cggcggcaag 1020 gaggtcaagg ctgccgccac ggcagaccgc aacggtttct tctacgtgct cgaccgcacc 1080 aacggcaagt tcatccgcgg cttccccttc gtggacaaga tcacctgggc cactggcctg 1140 gacaaggacg gccggccgat ctacaacgac gccagccgcc cgggcgcacc cggcagcgag 1200 gccaagggca gctcggtgtt cgtcgcgccg gccttcctcg gcgccaagaa ctggatgccg 1260 atggcctaca acaaggacac agggctgttc tacgtgccgt ccaacgagtg gggcatggac 1320 atctggaacg aaggcatcgc ctataagaaa ggtgcggcgt tcctcggtgc cggcttcacc 1380 atcaagccgc tcaatgaaga ctacatcggc gtgctgcgcg ccatcgaccc ggtcagcggc 1440 aaggaagtgt ggcgccacaa gaactatgcg ccgctgtggg gcggtgtgct gaccaccaag 1500 ggcaacctgg tgttcacggg cacgccagag ggcttcctgc aggcattcaa cgccaagacc 1560 ggcgacaagg tctgggaatt ccagaccggc tcgggcgtgc tcggctcgcc cgtcacctgg 1620 gaaatggacg gcgagcaata cgtttcggta gtctccggct ggggcggcgc ggtgccgctg 1680 tggggcggcg aagtggccaa acgggtcaag gacttcaacc agggcggcat gctctggacc 1740 ttcaagttgc ccaagcagtt gcagcaaacg gcaagcgtca agccataa 1788 <210> 9 <211> 1432 <212> DNA <213> Artificial Sequence <220> <223> Putative aldehyde dehydrogenase / ethanolamine utilization protein <400> 9 agaaagacaa gagataagga ggtattttat gaaccagcag gacatcgaac aggtggtgaa 60 ggccgtgctg ctgaagatgc agagcagcga caccccgagc gccgccgtgc atgagatggg 120 tgtgttcgcc agcctggacg acgccgtggc cgccgccaag gtggcccagc aaggtctgaa 180 gtcggtggcc atgcgtcagc tggcgatcgc ggccatccgc gaagccggtg agaagcatgc 240 ccgtgacctg gccgaactgg ccgtgagcga aaccggcatg ggtcgcgtcg aggacaagtt 300 cgccaagaac gtggcccaag cgcgtggcac cccaggcgtg gaatgcctgt cgccacaggt 360 gctgaccggt gacaacggtc tgaccctgat cgagaacgcg ccatggggtg tcgtggccag 420 cgtgacccca agcaccaacc cagccgccac cgtgatcaac aacgccatca gcctgatcgc 480 cgccggtaac agcgtgatct tcgccccaca tccagccgcg aagaaagtga gccagcgtgc 540 gatcaccctg ctgaaccagg ccatcgtggc ggccggtggt ccggaaaacc tgctggtgac 600 cgtggcgaac cccgacatcg aaaccgcgca gcgcctgttc aagttcccag gcatcggcct 660 gctggtcgtc accggtggcg aagccgtggt ggaagccgcg cgtaagcaca ccaacaagcg 720 cctgatcgcg gccggtgcgg gtaacccacc agtggtggtg gacgaaaccg ccgacctggc 780 gcgtgccgcg cagagcatcg tgaagggtgc cagcttcgac aacaacatca tctgcgccga 840 cgagaaggtg ctgatcgtgg tggacagcgt ggccgacgag ctgatgcgcc tgatggaagg 900 ccagcacgcc gtgaagctga ccgccgaaca ggcccagcag ctgcagccgg tcctgctgaa 960 aaacatcgac gagcgtggca agggcaccgt gagccgtgat tgggtgggtc gtgatgccgg 1020 taagatcgcc gcggccatcg gcctgaaggt gccgcaagaa acccgtctgc tgttcgtgga 1080 aaccaccgcc gagcatccgt tcgccgtgac cgaactgatg atgcccgtgc tgccggtggt 1140 gcgcgtggcc aacgtggccg atgcgatcgc cctggccgtc aagctggaag gcggttgcca 1200 tcacaccgcc gccatgcaca gccgcaacat cgagaacatg aaccagatgg ccaacgcgat 1260 cgacaccagc atcttcgtga agaacggtcc gtgcatcgcc ggtctgggcc tgggtggcga 1320 aggctggacc accatgacca tcaccacccc gaccggtgag ggcgtgacca gcgcgcgtac 1380 cttcgtgcgt ctgcgtcgct gcgtgctggt cgacgccttc cgcatcgtgt ga 1432 <210> 10 <211> 1026 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA:malonyl-CoA acyltransferase <400> 10 ttaagttctg tagggccgag actaaggagg ttttttatga ccgacgtgcg cttccgcatc 60 atcggcaccg gtgcgtacgt gccggaacgc atcgtgagca acgacgaggt gggtgcccca 120 gccggtgtgg acgacgattg gatcacccgc aagaccggca tccgccagcg tcgttgggcc 180 gccgatgatc aggccacctc ggacctggcc accgccgccg gtcgtgccgc gctgaaagcc 240 gccggtatca ccccagagca gctgaccgtg atcgccgtgg cgaccagcac cccagatcgt 300 ccgcagccac caaccgccgc ctacgtgcag catcacctgg gtgccaccgg caccgcggcc 360 ttcgacgtga acgccgtgtg cagcggcacc gtgttcgccc tgagcagcgt ggcgggcacc 420 ctggtgtatc gcggtggcta cgccctggtg atcggtgccg acctgtacag ccgcatcctg 480 aacccagccg accgcaaaac cgtggtgctg ttcggcgacg gtgcgggtgc catggtgctg 540 ggtccgacct cgaccggcac cggtccaatc gtgcgtcgcg tggccctgca caccttcggt 600 ggtctgaccg acctgatccg cgtgccagcc ggtggtagcc gtcagccgct ggataccgat 660 ggcctggatg cgggtctgca gtacttcgcc atggacggtc gcgaggtgcg tcgcttcgtg 720 accgagcatc tgccgcagct gatcaagggc ttcctgcacg aagcgggtgt cgatgccgcc 780 gacatcagcc acttcgtgcc gcaccaagcc aacggcgtga tgctggacga ggtgttcggt 840 gagctgcatc tgccacgtgc caccatgcac cgtaccgtgg aaacctacgg caacaccggt 900 gcggcgagca tccccatcac catggatgcg gccgtgcgtg ccggtagctt ccgtccgggt 960 gaactggtgc tgctggccgg tttcggtggc ggtatggccg ccagcttcgc gctgatcgag 1020 tggtga 1026 <210> 11 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> F-lacI <400> 11 tgcatgcctg caggtcgact ctagagacac catcgaatgg tgc 43 <210> 12 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> R-lacI <400> 12 aaaacgacgg ccagtgaatt ctcactgccc gctttcc 37 <210> 13 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> F-endA-upstream <400> 13 ctatgaccat gattacgcca agctttgctg ctcttgaaat gaacc 45 <210> 14 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-endA-upstream <400> 14 tttgaaacgg ggggaaaaca tatttcaggt tg 32 <210> 15 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> F-endA-downstream <400> 15 tgttttcccc ccgtttcaaa ggctgcg 27 <210> 16 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-endA-downstream <400> 16 tgcaccattc gatggtgtct ctagaatgaa gaagcgaatc gtcct 45 <210> 17 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-endX-upstream <400> 17 ctatgaccat gattacgcca agcttgtgct tccccctcag gg 42 <210> 18 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> R-endX-upstream <400> 18 ggcctgagga gcgcagtcaa tcttccttcg 30 <210> 19 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> F-endX-downstream <400> 19 ttgactgcgc tcctcaggcc agcgtttg 28 <210> 20 <211> 44 <212> DNA <213> Artificial Sequence <220> <223> R-endX-downstream <400> 20 tgcaccattc gatggtgtct ctagaaccag taaaagtggc gccg 44 <210> 21 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-I-upstream <400> 21 ctatgaccat gattacgcca agcttgtggc catgaactgg cg 42 <210> 22 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-I-upstream <400> 22 ccgctgcagg ggttgcagtt cccagtgga 29 <210> 23 <211> 25 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-I-downstream <400> 23 aactgcaacc cctgcagcgg ggagc 25 <210> 24 <211> 49 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-I-downstream <400> 24 tgcaccattc gatggtgtct ctagaatgaa tatcgtgttg gtcgatgac 49 <210> 25 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-II-upstream <400> 25 ctatgaccat gattacgcca agcttgtggc catgaactgg cg 42 <210> 26 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-II-upstream <400> 26 taggcaggcg gacggctacc tttggttttt ttg 33 <210> 27 <211> 26 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-II-downstream <400> 27 ggtagccgtc cgcctgccta ctgccg 26 <210> 28 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-II-downstream <400> 28 tgcaccattc gatggtgtct ctagattaga agaagcccag cggat 45 <210> 29 <211> 44 <212> DNA <213> Artificial Sequence <220> <223> F-phaG-upstream <400> 29 ctatgaccat gattacgcca agcttgtgtc tgcagtgaaa cccg 44 <210> 30 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-phaG-upstream <400> 30 gccgagccgc gtcatcgact cctggcgc 28 <210> 31 <211> 23 <212> DNA <213> Artificial Sequence <220> <223> F-phaG-downstream <400> 31 agtcgatgac gcggctcggc gcc 23 <210> 32 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> R-phaG-downstream <400> 32 tgcaccattc gatggtgtct ctagactaac cctgttcggt cacttg 46 <210> 33 <211> 21 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-upstream <400> 33 cgattcatta atgcagctgg c 21 <210> 34 <211> 21 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 34 tccacttttt cccgcgtttt c 21 <210> 35 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 35 ggcacgatgt gttcccac 18 <210> 36 <211> 19 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 36 aagccagagg ccaaaccaa 19 <210> 37 <211> 23 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 37 tttacagccg caataaaact cgg 23 <210> 38 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 38 aagcctggga gcggcaa 17 <210> 39 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 39 tggccgctgt tgcca 15 <210> 40 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 40 cgtgggctac ggcgg 15 <210> 41 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 41 gcatcgagca tgcgcaag 18 <210> 42 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 42 atctccaggt ccgccgc 17 <210> 43 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 43 gccgtggtgg ccagc 15 <210> 44 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 44 cccgcaatgt catgctgg 18 <210> 45 <211> 20 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-endA <400> 45 tgctgctctt gaaatgaacc 20 <210> 46 <211> 20 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-endA <400> 46 atgaagaagc gaatcgtcct 20 <210> 47 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-endX <400> 47 gcaacgtcac cgacacc 17 <210> 48 <211> 16 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-endX-R <400> 48 agctctgcgg tggagc 16 <210> 49 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-qedH-I <400> 49 gcatcgagca tgcgcaag 18 <210> 50 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-qedH-I <400> 50 atctccaggt ccgccgc 17 <210> 51 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-qedH-II <400> 51 caccgcctga ggttgct 17 <210> 52 <211> 16 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-qedH-II <400> 52 agccacggtg ccttcg 16 <210> 53 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-phaG <400> 53 tccgcaacac cgtaccg 17 <210> 54 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-phaG <400> 54 gccgatcagg atcggcc 17 <210> 55 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> F-lacI+Ptrc (pSGP10) <400> 55 gtgcggtatt tcacaccgca tatgggcttc accttcaacc caacac 46 <210> 56 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-lacI+Ptrc (pSGP10) <400> 56 cgatggtgtc gagcgtcaga ccccgtag 28 <210> 57 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> F-ori+TetR (pSGP10) <400> 57 tctgacgctc gacaccatcg aatggtgca 29 <210> 58 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> R-ori+TetR (pSGP10) <400> 58 gacctgcagg catgcaagct tcatggtctg tttcctgtgt gaa 43 <210> 59 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> F-dTomato <400> 59 tgcatgcctg caggtcgact ctagaatggt gagcaagggc gag 43 <210> 60 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-dTomato <400> 60 tgaattcgag ctcggtaccc gggctacttg tacagctcgt ccatg 45 <210> 61 <211> 59 <212> DNA <213> Artificial Sequence <220> <223> F-mvaE_opti <400> 61 aagcttgcat gcctgcaggt cgactctaga atttaaggag aactttatat gaagaccgt 59 <210> 62 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> R-mvaE_opti <400> 62 aaagtgtcta ggattattgc ttacgcaaat cgttca 36 <210> 63 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> F-mvaS_opti <400> 63 gcgtaagcaa taatcctaga cactttcacc ataagga 37 <210> 64 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-mvaS_opti <400> 64 tacccagcgg actttagttg cgatagctgc gc 32 <210> 65 <211> 34 <212> DNA <213> Artificial Sequence <220> <223> F-atoB_opti <400> 65 ctatcgcaac taaagtccgc tgggtagact aagg 34 <210> 66 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> R-atoB_opti <400> 66 gccagtgaat tcgagctcgg tacccgggtc agttcaggcg ctcgatc 47 <210> 67 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-atoB_opti (pSGP12) <400> 67 ctacagaact taatcagttc aggcgctcga tc 32 <210> 68 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> F-nphT7_opti <400> 68 gcgcctgaac tgattaagtt ctgtagggcc gagac 35 <210> 69 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> R-nphT7_opti <400> 69 gccagtgaat tcgagctcgg tacccgggtc accactcgat cagcgc 46 <210> 70 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> F-acs_opti <400> 70 tttcacacag gaaacagcgg gcccctgaga atagccctca actacgt 47 <210> 71 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> F-acs_opti (pAWP89-3) <400> 71 catcgtgtga ctgagaatag ccctcaacta cgt 33 <210> 72 <211> 41 <212> DNA <213> Artificial Sequence <220> <223> R-acs_opti <400> 72 gatagtctag aaggtaccag aattctcagc tcggcatggc g 41 <210> 73 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> F-eutE_opti <400> 73 tttcacacag gaaacagcgg gcccagaaag acaagagata aggaggt 47 <210> 74 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> R-eutE_opti <400> 74 gatagtctag aaggtaccag aattctcaca cgatgcggaa ggc 43 <210> 75 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-eutE_opti (pAWP89-3) <400> 75 ctattctcag tcacacgatg cggaaggc 28 <110> SOGANG UNIVERSITY RESEARCH FOUNDATION <120> Recombinant Pseudomonas putida strains and method for producing mevalonate using the same <130> PN180366P <150> KR 18/0125997 <151> 2018-10-22 <160> 75 <170> KoPatentIn 3.0 <210> 1 <211> 1216 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA acetyltransferase <400> 1 agtccgctgg gtagactaag gaggttatag tatgaagaac tgcgtgatcg tgagcgccgt 60 gcgcaccgcc atcggcagct tcaacggcag cctggccagc accagcgcca tcgatctggg 120 tgccaccgtg atcaaagccg ccatcgagcg tgccaagatc gacagccagc acgtggacga 180 ggtgatcatg ggcaacgtgc tgcaagccgg tctgggtcag aacccagcgc gtcaggccct 240 gctgaaaagc ggtctggccg aaaccgtgtg cggcttcacc gtgaacaagg tgtgcggcag 300 cggtctgaag tcggtggccc tggccgcgca agccatccaa gcgggtcaag cccagagcat 360 cgtggccggt ggcatggaaa acatgtcgct ggccccatac ctgctggacg ccaaagcgcg 420 tagcggctac cgcctgggtg acggccaggt gtacgacgtg atcctgcgcg acggcctgat 480 gtgcgcgacc cacggctacc acatgggcat caccgccgag aacgtggcca aagagtacgg 540 catcacccgc gagatgcagg acgagctggc cctgcacagc cagcgtaaag ccgccgccgc 600 gatcgagagc ggtgccttca ccgcggaaat cgtgccggtg aacgtggtga cccgcaagaa 660 aaccttcgtg ttcagccagg acgagttccc gaaggccaac agcaccgcgg aggccctggg 720 tgccctgcgt ccagccttcg ataaagccgg caccgtgacc gccggtaacg ccagcggcat 780 caacgacggt gccgccgcgc tggtcatcat ggaagaaagc gcggccctgg cggccggtct 840 gaccccactg gcgcgtatca agagctacgc gagcggtggt gtcccgccag cgctgatggg 900 tatgggtcca gtgccagcca cccagaaggc cctgcaactg gcgggtctgc agctggccga 960 catcgacctg atcgaggcca acgaggcctt cgccgcgcag ttcctggccg tgggcaagaa 1020 cctgggcttc gacagcgaga aggtgaacgt caacggtggt gcgatcgccc tgggccatcc 1080 gatcggtgcc agcggtgccc gtatcctggt gaccctgctg catgccatgc aagcccgtga 1140 caagaccctg ggcctggcga ccctgtgcat cggtggcggt cagggtatcg ccatggtgat 1200 cgagcgcctg aactga 1216 <210> 2 <211> 1185 <212> DNA <213> Artificial Sequence <220> <223> Hydroxymethylglutaryl-CoA synthase <400> 2 tcctagacac tttcaccata aggaaatatt ttaatgacca tcggcatcga taaaatcagc 60 ttcttcgtgc ccccgtatta catcgacatg actgctttgg ccgaagcacg caacgtcgat 120 ccagggaaat ttcacatcgg catcggccag gaccagatgg cggtaaaccc gatcagccaa 180 gacatcgtca ccttcgccgc caacgccgcc gaggcgatcc tcaccaagga agataaggag 240 gctattgaca tggtgatcgt ggggaccgag agcagcatcg acgagtccaa ggccgccgcc 300 gtggtgctgc accgcctgat gggcattcag ccgttcgcgc gctcgttcga gatcaaggaa 360 gcctgctacg gcgcaacggc aggcctgcag ctggccaaga accacgttgc gctgcatccg 420 gacaaaaagg tgctggtcgt ggcggctgat atcgcgaagt acggtctgaa cagcggcggc 480 gaacccaccc agggcgcggg cgccgtggcc atgctcgtgg cctcggagcc gcggattctg 540 gccctgaagg aagacaatgt catgttgacc caggacatct acgacttctg gcgtcctacc 600 ggccacccgt accccatggt cgacggcccg ctgagcaacg agacctacat ccagtccttc 660 gcacaggtgt gggacgagca caagaagcgc accggcctcg atttcgccga ctatgatgcg 720 ctggcctttc acatcccgta caccaagatg ggcaaaaagg cgctgctggc gaagatcagc 780 gatcagacgg aggccgagca agagcggatc ctggcccgtt acgaggagtc gatcatctac 840 agccgccgcg tcggcaatct gtacaccggc agcctgtacc tgggtctgat ttcgctgctg 900 gagaacgcta ccaccctgac cgcggggaac cagatcggcc tgttcagcta cggtagtggc 960 gccgtggccg agttcttcac cggcgagctg gtggccggct accagaacca tctgcagaag 1020 gagacgcacc tcgccctgct ggacaatcgc accgagctgt cgatcgccga gtacgaggcc 1080 atgttcgcgg agaccctgga cacggacatc gaccagaccc tggaggacga gctgaaatac 1140 agcatctccg ccatcaacaa caccgtgcgc agctatcgca actaa 1185 <210> 3 <211> 2430 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA acetyltransferase / Hydroxymethylglutaryl-CoA reductase <400> 3 atttaaggag aactttatat gaagaccgtg gtcatcatcg atgccctgcg caccccgatc 60 ggcaaataca aaggctcgct cagccaggtc tcggccgtgg acctgggcac ccacgtgacc 120 acccagttgc tgaagcgcca cagcacgatc agcgaagaga tcgaccaggt tatctttggg 180 aacgtgctgc aggcgggtaa cggccagaac cccgcgcgtc agatcgccat caactcgggg 240 ctgtcgcatg aaatcccggc catgaccgtg aatgaggtct gcggctccgg catgaaggcg 300 gtcatcctgg ctaagcagct gatccagctg ggcgaagccg aggtgctcat cgccggcggc 360 atcgaaaaca tgagccaggc cccgaagctg cagcggttca actatgaaac tgagagttac 420 gacgccccgt tcagcagcat gatgtacgac ggcctgacgg atgcgttcag cggccaggca 480 atgggcctga ccgccgagaa cgtggccgag aagtaccacg tgacccgcga ggaacaggac 540 cagttcagcg tgcactccca gctgaaggcc gcacaggccc aagccgaagg catcttcgcc 600 gacgagattg cgcccctgga agttagcggc acgctcgtgg agaaggatga gggcatccgt 660 ccaaactcga gcgtggagaa actgggcacc ctgaagaccg tgttcaagga ggacggcacc 720 gtcactgccg ggaacgcgtc caccatcaac gacggggcct cggccctgat tatcgctagt 780 caggaatatg ccgaggccca tggcctgccg tacttggcga tcatccgcga ctcggtggag 840 gtcggcatcg acccggcgta catgggcatc agcccgatca aagccatcca gaagctcttg 900 gcccgcaacc aactgacgac cgaagagatc gatctgtacg aaatcaatga ggccttcgct 960 gccaccagca tcgtcgtaca gcgcgaactg gcgctgccgg aggaaaaggt gaacatctac 1020 ggtggtggca tcagcctggg tcacgcgatc ggcgcaaccg gcgcccgcct gctgaccagc 1080 ctttcctacc agctgaacca aaaggagaaa aagtatggtg tcgccagcct ctgcattggg 1140 ggcggcctgg gccttgccat gctgttggag cgtccgcagc agaaaaagaa ttcgcgcttt 1200 taccagatgt ccccggagga gcgcctggcc tccctgctga acgaaggcca gatctcggcg 1260 gataccaaga aggagttcga gaacacggct ctgagctcgc agatcgccaa ccacatgatt 1320 gagaaccaga tcagcgagac cgaggttccc atgggcgtcg gcctgcacct gaccgtggat 1380 gagaccgact acctggtgcc gatggccacc gaggagccga gtgtcatcgc cgcactgagc 1440 aacggcgcca agatcgcgca gggcttcaaa accgtgaacc agcagcgcct gatgcggggc 1500 cagatcgtgt tctacgacgt ggcggacgcc gaaagcctga tcgacgagct gcaggtgcgc 1560 gagaccgaga tcttccaaca ggccgagctc agctacccga gcatcgtaaa gcgcggcggg 1620 ggcctgcgcg acctgcaata ccgggcgttc gacgagtctt tcgttagtgt ggatttcctg 1680 gtcgacgtca aggacgcgat gggtgccaac atcgtgaatg caatgttgga aggtgtcgcc 1740 gagctgttcc gcgaatggtt cgccgaacaa aaaatcctgt tcagcatcct gtccaactac 1800 gccaccgagt cggtcgtgac gatgaagacg gcgatcccgg taagccgcct cagcaaaggt 1860 agcaacggcc gcgagatcgc agaaaagatc gtgctggcct cacgctatgc cagcctggac 1920 ccctaccgcg ccgtgaccca taacaagggc atcatgaacg gtattgaggc ggtagtgctg 1980 gcgaccggca atgacacccg tgccgtgagc gcatcgtgcc acgcatttgc cgtcaaggaa 2040 ggccggtacc agggcttgac ctcctggacc ctggacggcg aacagctgat tggcgaaatc 2100 agcgtgccgc tcgcgcttgc caccgtgggc ggggccacta aggtgctgcc gaaaagccag 2160 gccgccgctg acctgctggc ggttaccgat gcaaaagagc tgtcgcgcgt cgtcgccgct 2220 gtggggctgg cccaaaactt ggccgccctg cgcgcgctcg tgtcggaggg catccagaag 2280 ggccacatgg ctctgcaggc ccgtagcctg gccatgacag tgggggccac cggcaaggag 2340 gtcgaagcgg tagcgcagca gctgaagcgc cagaaaacca tgaaccagga ccgcgccctg 2400 gctatcctga acgatttgcg taagcaataa 2430 <210> 4 <211> 1994 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA synthetase <400> 4 ctgagaatag ccctcaacta cgtaaggagg tatttatgag ccagatccac aagcacacca 60 tcccagccaa catcgccgac cgctgcctga tcaacccgca gcagtacgag gccatgtacc 120 agcagagcat caacgtgccg gacaccttct ggggtgagca gggcaagatc ctggactgga 180 tcaagccgta ccagaaggtc aagaacacca gcttcgcccc aggcaacgtg agcatcaagt 240 ggtacgagga cggcaccctg aacctggccg ccaactgcct ggaccgccat ctgcaagaga 300 acggcgaccg caccgccatc atctgggaag gcgacgacgc cagccagagc aagcacatca 360 gctacaaaga actgcaccgc gacgtgtgcc gcttcgcgaa caccctgctg gaactgggca 420 tcaagaaagg cgacgtggtg gccatctaca tgccgatggt gccggaagcc gccgtggcca 480 tgctggcctg cgcgcgtatc ggtgccgtgc acagcgtgat cttcggtggc ttcagcccag 540 aggccgtggc cggtcgcatc atcgacagca acagccgtct ggtcatcacc agcgacgagg 600 gcgtgcgtgc cggtcgtagc atcccgctga agaagaacgt cgacgacgcg ctgaaaaacc 660 cgaacgtgac cagcgtggaa cacgtggtgg tgctgaaacg caccggtggc aagatcgact 720 ggcaagaggg tcgcgatctg tggtggcacg acctggtgga acaggccagc gaccagcacc 780 aggccgagga aatgaacgcg gaggacccgc tgttcatcct gtacaccagc ggcagcaccg 840 gcaagccgaa gggcgtgctg cataccaccg gtggttacct ggtgtatgcc gcgctgacct 900 tcaagtacgt gttcgactac catccgggtg acatctactg gtgcaccgcc gatgtcggtt 960 gggtcaccgg tcacagctac ctgctgtacg gtccgctggc gtgcggtgcg accaccctga 1020 tgttcgaagg cgtgccgaac tggccgaccc cagcgcgtat ggcccaggtg gtggacaagc 1080 accaggtgaa catcctgtat accgcgccaa ccgccatccg tgcgctgatg gccgaaggcg 1140 acaaggccat cgaaggcacc gaccgcagca gcctgcgtat cctgggcagc gtgggcgagc 1200 cgatcaaccc cgaagcctgg gagtggtact ggaagaagat cggcaacgag aagtgcccag 1260 tggtcgacac ctggtggcag accgaaaccg gtggcttcat gatcacccca ctgccaggtg 1320 ccaccgagct gaaagccggt agcgcgaccc gtccgttctt cggcgtgcag ccagcgctgg 1380 tcgacaacga gggcaacccg ctggaaggtg cgaccgaggg cagcctggtg atcaccgaca 1440 gctggccagg ccaagcgcgt accctgttcg gcgaccacga gcgcttcgag cagacctact 1500 tcagcacctt caagaacatg tacttcagcg gtgacggtgc ccgtcgtgac gaggatggct 1560 actactggat caccggtcgc gtggacgacg tcctgaacgt gagcggtcac cgtctgggca 1620 ccgcggagat cgaaagcgcc ctggtggccc atccgaagat cgccgaagcc gcggtggtgg 1680 gcatcccgca caacatcaag ggccaagcca tctacgccta cgtgaccctg aaccacggcg 1740 aggaaccgtc gccagagctg tacgccgagg tgcgcaactg ggtgcgcaaa gagatcggtc 1800 ccctggcgac cccagacgtg ctgcactgga ccgacagcct gccaaagacc cgcagcggca 1860 aaatcatgcg tcgcatcctg cgcaagatcg cggccggtga caccagcaac ctgggcgaca 1920 cctcgaccct ggccgatcca ggcgtggtgg aaaagctgct ggaagagaag caagcgatcg 1980 ccatgccgag ctga 1994 <210> 5 <211> 966 <212> DNA <213> Artificial Sequence <220> <223> endA <400> 5 atgaaatcac tgctttacgc cgtaacctta ttattttcct ttaccctccc cgctctggcc 60 aacccgccgg ccaccttcac cgaagccaag gtggtggcca agcagaaggt ctacctggac 120 caggccagca gtgccatggg cgacctgtac tgcggttgca aatggacctg ggtgggcaag 180 tctggcgggc gcatcgacgc tgcctcgtgt ggttaccaga cacgcaagca gcagaaccgt 240 gccgaacgca ccgagtggga acacatcgtg cccgcccaca ccttcggcaa ccagcgccag 300 tgctggaaga acggcggccg tgagcactgc gtggacaacg acccggtgtt ccgcgccatg 360 gaggccgacc tgttcaacct ttacccggcc gtgggtgagg tcaacggtga ccgcagcaac 420 ttcaactacg gcatggtcac tggcaatgcc ggcgaatacg gccaatgcac caccaaggtc 480 gatttcgtcc agcgcaccgc cgaaccgcgt gacgaagtca aaggcctggt ggcccgcacc 540 acgttctaca tgttcgaccg ctacaagctg aacatgtcgc gccaacagca acagctgctg 600 atggcctggg acaagcaaca ccccgtgtcg gcctgggaga aagaacgcga ccggcgcatt 660 gccgcgatca tgggccatgc caacccgttc gtaagcggcg aacgcaagtg gactgccggc 720 tacaagccgg ttggcagcgg cgtggtagag gcggtgccgg taaacgcagc caagccagag 780 gccaaaccaa gcctggccag cgccggttcg gtcggcgccg tgcttggcaa ccgcaacagc 840 cacgtctatc acctgtcagt cggctgcccg ggctacaacc aggttacagc gaagaaccag 900 gttaccttcg caaacgaagg tgaagcgcag gcagcggggt atcgcaaggc aggcaactgc 960 cgctga 966 <210> 6 <211> 693 <212> DNA <213> Artificial Sequence <220> <223> endX <400> 6 atgagagttt cgcttttcgc agcagcctgc ctgttactga ccactccgct tgctcaagcc 60 gacgccccgc gcaccttcca ggaggccaag aaggtcgcct ggaagctcta tgcaccacaa 120 tcgaccgagt tttattgcgg ctgtaaatac aagggcaaca aggtcaacct ggcctcctgc 180 ggctatgccc cacgcaagaa tgcccagcgc gcgtcacgca tcgagtggga gcacatcgta 240 cccgcctggc agatcggcca tcagcgccag tgctggcaga gtggcggacg caagcagtgc 300 tcgcagcatg acgaagtgta ccaacgcgcc gaagccgacc tgcacaacct ggtgcccagc 360 atcggtgagg tcaacggcga ccgcagcaac ttcagtttcg gctggctacc agaacaacgc 420 ggccagtatg gccgctgcct gacccaggtc gacttcaagg cgaggaaggt gatgccgcgc 480 ccgtcgatcc gcggcatgat cgcccgcacc tacttctaca tgagcaagca gtacaacctg 540 cgcctgtcca aacaggatcg ccagttgttc gaggcctgga acaagaccta cccgccgcaa 600 gcctgggagc ggcaacgcaa ccaacaggtc gcctgcgtga tggggcgggg aaacgcgttc 660 gtggggccgg tcaacctcaa ggcgtgcggt tga 693 <210> 7 <211> 1896 <212> DNA <213> Artificial Sequence <220> <223> qedH-I <400> 7 atgacaataa gatcgctacc cgccctttcc ccgctggccc tgagcgtgcg cgtcctgctg 60 atggccggta gcctggccct gggcaatgtg gcaacagcgg ccagcacacc cgctgcacct 120 gccggcaaga acgtcacctg ggaagacatc gccaatgacc acctgaccac ccaggacgtg 180 ctgcagtacg gcatgggcac caatgcccag cgctggagcc cgctggccca ggtcaatgac 240 aagaacgtgt tcaagctgac cccggcctgg tcctactcct tcggcgacga gaagcagcgc 300 ggccaggaat cccaggccat cgtcagcgat ggcgtggtct acgtcaccgg ttcgtactca 360 cgggtattcg ccctcgatgc caagaccggc aaacgcctgt ggacctacaa ccaccgcctg 420 cccgacaaca ttcgtccctg ctgcgacgtg gtcaaccgcg gggcggcgat ctacggcgac 480 aagatctact ttggcaccct cgatgcgcgt gtcatcgccc tcgacaagcg caccggcaaa 540 gtggtgtgga acaagaagtt cggcgaccac agcgccggct acaccatgac cggtgcgcca 600 gtgctgatca aggacaagac cagcggcaag gtgctgctga tccacggcag ctccggcgat 660 gaattcggcg tggtcggcca gctgttcgcg cgcgacccgg acaccggtga agaagtgtgg 720 atgcggccct tcgtggaggg ccacatgggc cgcctgaacg gcaaggacag caccccgacc 780 ggtgacgtca aggcgccgtc ctggccagac gaccctacca ccgaaaccgg caaggtcgaa 840 gcctggagcc acggcggcgg tgccccttgg caaagcgcga gcttcgaccc cgaaaccaac 900 accatcattg tcggcgctgg caaccccggc ccttggaata cctgggcgcg cacgtcgaag 960 gacggcaacc cgcatgactt cgacagcctg tacacctccg gccaggtcgg cgtcgacccg 1020 agcaccggcg aggtcaagtg gttctaccag cacaccccca acgatgcctg ggacttctcc 1080 ggcaacaacg agctggtgct gttcgactac aaggacaaga acggcaacgt ggtcaaggcc 1140 accgcccacg ccgaccgcaa cggtttcttc tatgtggttg accgcaacaa cggcaagctg 1200 caaaacgctt tccccttcgt cgacaacatc acctgggcca gccatatcga cctgaagacc 1260 gggcgcccgg tggaaaaccc cggccaacgc ccggccaagc cgctgccggg tgaaaccaag 1320 ggcaagccgg tggaagtctc gccaccgttc ctgggcggca agaactggaa ccccatggcc 1380 tacagccagg acaccgggct gttctacatc cccggcaacc agtggaaaga ggaatactgg 1440 accgaggaag tgaactacaa gaagggctcg gcttatctgg gcatgggctt ccgtatcaag 1500 cgcatgtacg acgaccacgt cggcacgttg cgcgccatgg acccgaccac cggcaagctg 1560 gtgtgggaac acaaggaaca cctgccgtta tgggccggtg tgttggcgac caagggcaac 1620 ctggtgttca ccggcacggg cgacggcttc ttcaaggcct tcgacgccaa gacgggcaaa 1680 gagctgtgga agttccagac cggcagcggc atcgtctcgc cgcccatcac ctgggagcag 1740 gacggcgagc agtacatcgg cgtgaccgtg ggctacggcg gtgcagtacc gctgtggggc 1800 ggcgacatgg ccgagctgac caaaccggtg gctcagggtg gttcgttctg ggtgttcaag 1860 atcccgagct gggacaacaa gactgcacaa cgttga 1896 <210> 8 <211> 1788 <212> DNA <213> Artificial Sequence <220> <223> qedH-II <400> 8 atgacccgat ccccacgtcg ccccttgttc gccgtgagcc tggtgctcag cgccatgctg 60 cttgccggcg cggctcacgc cgctgtcagc aatgaagaaa tcctccagga cccgaagaac 120 ccgcagcaga tcgtgaccaa tggcctgggc gtgcagggcc agcgctacag cccgctggac 180 ctgctcaatg tcaataacgt caaggagctg cgcccggtct gggcgttctc cttcggcggg 240 gagaagcagc gcggccagca ggcccagccg ctgatcaagg acggggtgat gtacctgacc 300 ggctcctact cgcgggtgtt cgccgtggat gcccgcaccg gcaagaaact gtggcaatac 360 gatgcacgtc tgccggatga catccgcccc tgctgcgacg taatcaaccg cggcgtcgcg 420 ctgtacggca acctggtgtt cttcggcacg ctggacgcca agctggtggc cctgaacaag 480 gacaccggca aggtggtctg gagcaagaag gtcgccgacc acaaagaagg ctactccatc 540 agcgccgcgc cgatgatcgt caatggcaag ctgatcacag gcgttgccgg cggcgagttc 600 ggcgtggtgg gcaagatcca ggcgtacaac ccggagaacg gcgaactgct gtggatgcgc 660 cccaccgtgg aagggcacat gggctatgtg tacaaggatg gcaaggcgat cgagaacggt 720 atttccggcg gtgaggcggg caagacctgg cctggcgacc tgtggaagac cggcggcgcc 780 gcgccgtggc tggggggtta ctacgaccct gaaaccaacc tgatcctgtt tggtaccggt 840 aacccggcgc cgtggaactc gcacctgcgc cccggtgaca acctgtactc ctcctcacgc 900 ctggcactga acccggacga cggcaccatc aagtggcact tccagagcac gccgcatgac 960 ggctgggact tcgacggcgt caacgagctg atctcgttca actacaagga cggcggcaag 1020 gaggtcaagg ctgccgccac ggcagaccgc aacggtttct tctacgtgct cgaccgcacc 1080 aacggcaagt tcatccgcgg cttccccttc gtggacaaga tcacctgggc cactggcctg 1140 gacaaggacg gccggccgat ctacaacgac gccagccgcc cgggcgcacc cggcagcgag 1200 gccaagggca gctcggtgtt cgtcgcgccg gccttcctcg gcgccaagaa ctggatgccg 1260 atggcctaca acaaggacac agggctgttc tacgtgccgt ccaacgagtg gggcatggac 1320 atctggaacg aaggcatcgc ctataagaaa ggtgcggcgt tcctcggtgc cggcttcacc 1380 atcaagccgc tcaatgaaga ctacatcggc gtgctgcgcg ccatcgaccc ggtcagcggc 1440 aaggaagtgt ggcgccacaa gaactatgcg ccgctgtggg gcggtgtgct gaccaccaag 1500 ggcaacctgg tgttcacggg cacgccagag ggcttcctgc aggcattcaa cgccaagacc 1560 ggcgacaagg tctgggaatt ccagaccggc tcgggcgtgc tcggctcgcc cgtcacctgg 1620 gaaatggacg gcgagcaata cgtttcggta gtctccggct ggggcggcgc ggtgccgctg 1680 tggggcggcg aagtggccaa acgggtcaag gacttcaacc agggcggcat gctctggacc 1740 ttcaagttgc ccaagcagtt gcagcaaacg gcaagcgtca agccataa 1788 <210> 9 <211> 1432 <212> DNA <213> Artificial Sequence <220> <223> Putative aldehyde dehydrogenase / ethanolamine utilization protein <400> 9 agaaagacaa gagataagga ggtattttat gaaccagcag gacatcgaac aggtggtgaa 60 ggccgtgctg ctgaagatgc agagcagcga caccccgagc gccgccgtgc atgagatggg 120 tgtgttcgcc agcctggacg acgccgtggc cgccgccaag gtggcccagc aaggtctgaa 180 gtcggtggcc atgcgtcagc tggcgatcgc ggccatccgc gaagccggtg agaagcatgc 240 ccgtgacctg gccgaactgg ccgtgagcga aaccggcatg ggtcgcgtcg aggacaagtt 300 cgccaagaac gtggcccaag cgcgtggcac cccaggcgtg gaatgcctgt cgccacaggt 360 gctgaccggt gacaacggtc tgaccctgat cgagaacgcg ccatggggtg tcgtggccag 420 cgtgacccca agcaccaacc cagccgccac cgtgatcaac aacgccatca gcctgatcgc 480 cgccggtaac agcgtgatct tcgccccaca tccagccgcg aagaaagtga gccagcgtgc 540 gatcaccctg ctgaaccagg ccatcgtggc ggccggtggt ccggaaaacc tgctggtgac 600 cgtggcgaac cccgacatcg aaaccgcgca gcgcctgttc aagttcccag gcatcggcct 660 gctggtcgtc accggtggcg aagccgtggt ggaagccgcg cgtaagcaca ccaacaagcg 720 cctgatcgcg gccggtgcgg gtaacccacc agtggtggtg gacgaaaccg ccgacctggc 780 gcgtgccgcg cagagcatcg tgaagggtgc cagcttcgac aacaacatca tctgcgccga 840 cgagaaggtg ctgatcgtgg tggacagcgt ggccgacgag ctgatgcgcc tgatggaagg 900 ccagcacgcc gtgaagctga ccgccgaaca ggcccagcag ctgcagccgg tcctgctgaa 960 aaacatcgac gagcgtggca agggcaccgt gagccgtgat tgggtgggtc gtgatgccgg 1020 taagatcgcc gcggccatcg gcctgaaggt gccgcaagaa acccgtctgc tgttcgtgga 1080 aaccaccgcc gagcatccgt tcgccgtgac cgaactgatg atgcccgtgc tgccggtggt 1140 gcgcgtggcc aacgtggccg atgcgatcgc cctggccgtc aagctggaag gcggttgcca 1200 tcacaccgcc gccatgcaca gccgcaacat cgagaacatg aaccagatgg ccaacgcgat 1260 cgacaccagc atcttcgtga agaacggtcc gtgcatcgcc ggtctgggcc tgggtggcga 1320 aggctggacc accatgacca tcaccacccc gaccggtgag ggcgtgacca gcgcgcgtac 1380 cttcgtgcgt ctgcgtcgct gcgtgctggt cgacgccttc cgcatcgtgt ga 1432 <210> 10 <211> 1026 <212> DNA <213> Artificial Sequence <220> <223> Acetyl-CoA: malonyl-CoA acyltransferase <400> 10 ttaagttctg tagggccgag actaaggagg ttttttatga ccgacgtgcg cttccgcatc 60 atcggcaccg gtgcgtacgt gccggaacgc atcgtgagca acgacgaggt gggtgcccca 120 gccggtgtgg acgacgattg gatcacccgc aagaccggca tccgccagcg tcgttgggcc 180 gccgatgatc aggccacctc ggacctggcc accgccgccg gtcgtgccgc gctgaaagcc 240 gccggtatca ccccagagca gctgaccgtg atcgccgtgg cgaccagcac cccagatcgt 300 ccgcagccac caaccgccgc ctacgtgcag catcacctgg gtgccaccgg caccgcggcc 360 ttcgacgtga acgccgtgtg cagcggcacc gtgttcgccc tgagcagcgt ggcgggcacc 420 ctggtgtatc gcggtggcta cgccctggtg atcggtgccg acctgtacag ccgcatcctg 480 aacccagccg accgcaaaac cgtggtgctg ttcggcgacg gtgcgggtgc catggtgctg 540 ggtccgacct cgaccggcac cggtccaatc gtgcgtcgcg tggccctgca caccttcggt 600 ggtctgaccg acctgatccg cgtgccagcc ggtggtagcc gtcagccgct ggataccgat 660 ggcctggatg cgggtctgca gtacttcgcc atggacggtc gcgaggtgcg tcgcttcgtg 720 accgagcatc tgccgcagct gatcaagggc ttcctgcacg aagcgggtgt cgatgccgcc 780 gacatcagcc acttcgtgcc gcaccaagcc aacggcgtga tgctggacga ggtgttcggt 840 gagctgcatc tgccacgtgc caccatgcac cgtaccgtgg aaacctacgg caacaccggt 900 gcggcgagca tccccatcac catggatgcg gccgtgcgtg ccggtagctt ccgtccgggt 960 gaactggtgc tgctggccgg tttcggtggc ggtatggccg ccagcttcgc gctgatcgag 1020 tggtga 1026 <210> 11 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> F-lacI <400> 11 tgcatgcctg caggtcgact ctagagacac catcgaatgg tgc 43 <210> 12 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> R-lacI <400> 12 aaaacgacgg ccagtgaatt ctcactgccc gctttcc 37 <210> 13 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> F-endA-upstream <400> 13 ctatgaccat gattacgcca agctttgctg ctcttgaaat gaacc 45 <210> 14 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-endA-upstream <400> 14 tttgaaacgg ggggaaaaca tatttcaggt tg 32 <210> 15 <211> 27 <212> DNA <213> Artificial Sequence <220> <223> F-endA-downstream <400> 15 tgttttcccc ccgtttcaaa ggctgcg 27 <210> 16 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-endA-downstream <400> 16 tgcaccattc gatggtgtct ctagaatgaa gaagcgaatc gtcct 45 <210> 17 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-endX-upstream <400> 17 ctatgaccat gattacgcca agcttgtgct tccccctcag gg 42 <210> 18 <211> 30 <212> DNA <213> Artificial Sequence <220> <223> R-endX-upstream <400> 18 ggcctgagga gcgcagtcaa tcttccttcg 30 <210> 19 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> F-endX-downstream <400> 19 ttgactgcgc tcctcaggcc agcgtttg 28 <210> 20 <211> 44 <212> DNA <213> Artificial Sequence <220> <223> R-endX-downstream <400> 20 tgcaccattc gatggtgtct ctagaaccag taaaagtggc gccg 44 <210> 21 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-I-upstream <400> 21 ctatgaccat gattacgcca agcttgtggc catgaactgg cg 42 <210> 22 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-I-upstream <400> 22 ccgctgcagg ggttgcagtt cccagtgga 29 <210> 23 <211> 25 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-I-downstream <400> 23 aactgcaacc cctgcagcgg ggagc 25 <210> 24 <211> 49 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-I-downstream <400> 24 tgcaccattc gatggtgtct ctagaatgaa tatcgtgttg gtcgatgac 49 <210> 25 <211> 42 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-II-upstream <400> 25 ctatgaccat gattacgcca agcttgtggc catgaactgg cg 42 <210> 26 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-II-upstream <400> 26 taggcaggcg gacggctacc tttggttttt ttg 33 <210> 27 <211> 26 <212> DNA <213> Artificial Sequence <220> <223> F-qedH-II-downstream <400> 27 ggtagccgtc cgcctgccta ctgccg 26 <210> 28 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-qedH-II-downstream <400> 28 tgcaccattc gatggtgtct ctagattaga agaagcccag cggat 45 <210> 29 <211> 44 <212> DNA <213> Artificial Sequence <220> <223> F-phaG-upstream <400> 29 ctatgaccat gattacgcca agcttgtgtc tgcagtgaaa cccg 44 <210> 30 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-phaG-upstream <400> 30 gccgagccgc gtcatcgact cctggcgc 28 <210> 31 <211> 23 <212> DNA <213> Artificial Sequence <220> <223> F-phaG-downstream <400> 31 agtcgatgac gcggctcggc gcc 23 <210> 32 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> R-phaG-downstream <400> 32 tgcaccattc gatggtgtct ctagactaac cctgttcggt cacttg 46 <210> 33 <211> 21 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-upstream <400> 33 cgattcatta atgcagctgg c 21 <210> 34 <211> 21 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 34 tccacttttt cccgcgtttt c 21 <210> 35 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 35 ggcacgatgt gttcccac 18 <210> 36 <211> 19 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 36 aagccagagg ccaaaccaa 19 <210> 37 <211> 23 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 37 tttacagccg caataaaact cgg 23 <210> 38 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 38 aagcctggga gcggcaa 17 <210> 39 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 39 tggccgctgt tgcca 15 <210> 40 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 40 cgtgggctac ggcgg 15 <210> 41 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 41 gcatcgagca tgcgcaag 18 <210> 42 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 42 atctccaggt ccgccgc 17 <210> 43 <211> 15 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm1-upstream <400> 43 gccgtggtgg ccagc 15 <210> 44 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm1-downstream <400> 44 cccgcaatgt catgctgg 18 <210> 45 <211> 20 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-endA <400> 45 tgctgctctt gaaatgaacc 20 <210> 46 <211> 20 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-endA <400> 46 atgaagaagc gaatcgtcct 20 <210> 47 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-endX <400> 47 gcaacgtcac cgacacc 17 <210> 48 <211> 16 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-endX-R <400> 48 agctctgcgg tggagc 16 <210> 49 <211> 18 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-qedH-I <400> 49 gcatcgagca tgcgcaag 18 <210> 50 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-qedH-I <400> 50 atctccaggt ccgccgc 17 <210> 51 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-qedH-II <400> 51 caccgcctga ggttgct 17 <210> 52 <211> 16 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-qedH-II <400> 52 agccacggtg ccttcg 16 <210> 53 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> F-Confirm2-phaG <400> 53 tccgcaacac cgtaccg 17 <210> 54 <211> 17 <212> DNA <213> Artificial Sequence <220> <223> R-Confirm2-phaG <400> 54 gccgatcagg atcggcc 17 <210> 55 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> F-lacI + Ptrc (pSGP10) <400> 55 gtgcggtatt tcacaccgca tatgggcttc accttcaacc caacac 46 <210> 56 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-lacI + Ptrc (pSGP10) <400> 56 cgatggtgtc gagcgtcaga ccccgtag 28 <210> 57 <211> 29 <212> DNA <213> Artificial Sequence <220> <223> F-ori + TetR (pSGP10) <400> 57 tctgacgctc gacaccatcg aatggtgca 29 <210> 58 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> R-ori + TetR (pSGP10) <400> 58 gacctgcagg catgcaagct tcatggtctg tttcctgtgt gaa 43 <210> 59 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> F-dTomato <400> 59 tgcatgcctg caggtcgact ctagaatggt gagcaagggc gag 43 <210> 60 <211> 45 <212> DNA <213> Artificial Sequence <220> <223> R-dTomato <400> 60 tgaattcgag ctcggtaccc gggctacttg tacagctcgt ccatg 45 <210> 61 <211> 59 <212> DNA <213> Artificial Sequence <220> <223> F-mvaE_opti <400> 61 aagcttgcat gcctgcaggt cgactctaga atttaaggag aactttatat gaagaccgt 59 <210> 62 <211> 36 <212> DNA <213> Artificial Sequence <220> <223> R-mvaE_opti <400> 62 aaagtgtcta ggattattgc ttacgcaaat cgttca 36 <210> 63 <211> 37 <212> DNA <213> Artificial Sequence <220> <223> F-mvaS_opti <400> 63 gcgtaagcaa taatcctaga cactttcacc ataagga 37 <210> 64 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-mvaS_opti <400> 64 tacccagcgg actttagttg cgatagctgc gc 32 <210> 65 <211> 34 <212> DNA <213> Artificial Sequence <220> <223> F-atoB_opti <400> 65 ctatcgcaac taaagtccgc tgggtagact aagg 34 <210> 66 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> R-atoB_opti <400> 66 gccagtgaat tcgagctcgg tacccgggtc agttcaggcg ctcgatc 47 <210> 67 <211> 32 <212> DNA <213> Artificial Sequence <220> <223> R-atoB_opti (pSGP12) <400> 67 ctacagaact taatcagttc aggcgctcga tc 32 <210> 68 <211> 35 <212> DNA <213> Artificial Sequence <220> <223> F-nphT7_opti <400> 68 gcgcctgaac tgattaagtt ctgtagggcc gagac 35 <210> 69 <211> 46 <212> DNA <213> Artificial Sequence <220> <223> R-nphT7_opti <400> 69 gccagtgaat tcgagctcgg tacccgggtc accactcgat cagcgc 46 <210> 70 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> F-acs_opti <400> 70 tttcacacag gaaacagcgg gcccctgaga atagccctca actacgt 47 <210> 71 <211> 33 <212> DNA <213> Artificial Sequence <220> <223> F-acs_opti (pAWP89-3) <400> 71 catcgtgtga ctgagaatag ccctcaacta cgt 33 <210> 72 <211> 41 <212> DNA <213> Artificial Sequence <220> <223> R-acs_opti <400> 72 gatagtctag aaggtaccag aattctcagc tcggcatggc g 41 <210> 73 <211> 47 <212> DNA <213> Artificial Sequence <220> <223> F-eutE_opti <400> 73 tttcacacag gaaacagcgg gcccagaaag acaagagata aggaggt 47 <210> 74 <211> 43 <212> DNA <213> Artificial Sequence <220> <223> R-eutE_opti <400> 74 gatagtctag aaggtaccag aattctcaca cgatgcggaa ggc 43 <210> 75 <211> 28 <212> DNA <213> Artificial Sequence <220> <223> R-eutE_opti (pAWP89-3) <400> 75 ctattctcag tcacacgatg cggaaggc 28
Claims (7)
Nucleic acid sequence of acetyl coenzyme A Acetyltransferase represented by SEQ ID NO: 1, nucleic acid sequence of HMG CoA synthetase (3-hydroxy-3-methylglutaryl coenzyme A synthetase) represented by SEQ ID NO: 2 and SEQ ID NO: 3 It is transformed into a recombinant vector containing a nucleic acid sequence of HMG CoA reductase (3-hydroxy-3-methylglutaryl coenzyme A reductase), endonuclease A (endonuclease A, endA) gene and endonuclease X (endonuclease A, endX) Recombinant Pseudomonas putida strain with a missing gene.
The recombinant Pseudomonas putida strain of claim 1, wherein the recombinant vector further comprises a nucleic acid sequence of Acetyl coenzyme A synthetase represented by SEQ ID NO: 4.
The method of claim 1, wherein the strain is a quinoprotein ethanol dehydrogenase I (Quinoprotein Ethanol Dehydrogenase I) gene and quinoprotein ethanol dehydrogenase II (Quinoprotein Ethanol Dehydrogenase II) gene is further deleted, recombinant Pseudomonas putida ( Pseudomonas). putida ) strain.
Nucleic acid sequence of acetyl coenzyme A Acetyltransferase represented by SEQ ID NO: 1, nucleic acid sequence of HMG CoA synthetase (3-hydroxy-3-methylglutaryl coenzyme A synthetase) represented by SEQ ID NO: 2 and SEQ ID NO: 3 It is transformed with a recombinant vector containing a nucleic acid sequence of HMG CoA reductase (3-hydroxy-3-methylglutaryl coenzyme A reductase), endonuclease A (endonuclease A, endA) gene and endonuclease X (endonuclease A, endX) A composition for producing mevalonate comprising a recombinant Pseudomonas putida strain having a missing gene.
The composition for producing mevalonic acid according to claim 4, wherein the recombinant vector further comprises a nucleic acid sequence of acetyl coenzyme A synthetase represented by SEQ ID NO: 4.
According to claim 4, The strain is a quinoprotein ethanol dehydrogenase I (Quinoprotein Ethanol Dehydrogenase I) gene and a quinoprotein ethanol dehydrogenase II (Quinoprotein Ethanol Dehydrogenase II) gene is further deleted, the composition for producing mevalonic acid.
상기 제 1 항 내지 제 3 항 중 어느 한 항의 재조합 슈도모나스 푸티다 균주를 배양하는 단계; 및
상기 배양 결과물로부터 메발론산을 수득하는 단계. Method for producing mevalonic acid comprising the following steps:
Culturing the recombinant Pseudomonas putida strain of any one of claims 1 to 3; And
Obtaining mevalonic acid from the culture result.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20180125997 | 2018-10-22 | ||
| KR1020180125997 | 2018-10-22 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200045439A true KR20200045439A (en) | 2020-05-04 |
Family
ID=70732690
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190131749A KR20200045439A (en) | 2018-10-22 | 2019-10-22 | Recombinant Pseudomonas putida strains and method for producing mevalonate using the same |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20200045439A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023027335A1 (en) * | 2021-08-26 | 2023-03-02 | 한국생명공학연구원 | Recombinant microorganism for producing mevalonic acid and method for producing mevalonic acid using same |
| WO2023186037A1 (en) * | 2022-04-02 | 2023-10-05 | 元素驱动(杭州)生物科技有限公司 | Method for preparing glycine, acetyl coenzyme a, and acetyl coenzyme a derivative by using threonine |
-
2019
- 2019-10-22 KR KR1020190131749A patent/KR20200045439A/en unknown
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023027335A1 (en) * | 2021-08-26 | 2023-03-02 | 한국생명공학연구원 | Recombinant microorganism for producing mevalonic acid and method for producing mevalonic acid using same |
| WO2023186037A1 (en) * | 2022-04-02 | 2023-10-05 | 元素驱动(杭州)生物科技有限公司 | Method for preparing glycine, acetyl coenzyme a, and acetyl coenzyme a derivative by using threonine |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11905539B2 (en) | Isopropylmalate synthase variant and a method of producing L-leucine using the same | |
| AU760575C (en) | Pyruvate carboxylase overexpression for enhanced production of oxaloacetate-derived biochemicals in microbial cells | |
| CA3158505A1 (en) | Methods for the production of psilocybin and intermediates or side products | |
| CN110546255B (en) | Modification of lysine decarboxylase enzymes | |
| CN110904018B (en) | 5-aminolevulinic acid production strain and construction method and application thereof | |
| CN115803442A (en) | Method for preparing guanidinoacetic acid by fermentation | |
| KR20200045439A (en) | Recombinant Pseudomonas putida strains and method for producing mevalonate using the same | |
| BR112021009177A2 (en) | IMPROVED RIBOFLAVIN PRODUCTION | |
| CN116096908A (en) | Method for preparing guanidinoacetic acid by fermentation | |
| RU2678139C2 (en) | Escherichia species microorganism having l-tryptophan production capacity and method for producing l-tryptophan using same | |
| EP1235903A2 (en) | Metabollically engineered cells overexpressing pyruvate carboxylase or pyruvate phosphoenolpyruvate carbokylase, and methods to produce and use such cells | |
| ES2619176T3 (en) | Biocatalyst to produce D-lactic acid | |
| CN110713962B (en) | Genetic engineering bacterium for high-yield production of malonyl coenzyme A and construction method and application thereof | |
| US20190338293A1 (en) | High growth capacity auxotrophic escherichia coli and methods of use | |
| US20130045515A1 (en) | Heterogeneous e. coli for improving fatty acid content using fatty acid biosynthesis and preparation method thereof | |
| CN111406104B (en) | Reduction of accumulation of imine/enamine for production of amino acid or amino acid derivative products | |
| KR20140044469A (en) | Corynebacterium sp. microorganism having enhanced l-threonine productivity by regulation of dapa activity and a method of producing l-threonine using the same | |
| RU2694041C1 (en) | Embodiment of o-acetyl-homoserine-sulfhydrylase and method of producing l-methionine using this embodiment | |
| KR102110156B1 (en) | Microorganisms for lactic acid production, method for producing the same and method for producing lactic acid | |
| KR102572849B1 (en) | Mutant microorganism of Corynebacterium genus producing L-glutamic acid and method for producing L-glutamic acid using the same | |
| KR102636674B1 (en) | Mutant microorganism of Corynebacterium genus producing L-glutamic acid and method for producing L-glutamic acid using the same | |
| KR102226445B1 (en) | Escherichia coli with improved GABA productivity, method for preparing thereof and method for producing GABA using the same | |
| KR20230113696A (en) | 1,4-Butanediol producing microorganism and method for producing 1,4-butanediol using the same | |
| KR20180113441A (en) | Recombinant microorganism producing 5-Aminolevulinic acid and method of producing 5-Aminolevulinic acid using the same | |
| KR102614733B1 (en) | Novel variant of phosphoenolpyruvate caboxylase and method for producing 5'-inosinic acid using the same |