KR20180013909A - 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 - Google Patents
개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 Download PDFInfo
- Publication number
- KR20180013909A KR20180013909A KR1020177034002A KR20177034002A KR20180013909A KR 20180013909 A KR20180013909 A KR 20180013909A KR 1020177034002 A KR1020177034002 A KR 1020177034002A KR 20177034002 A KR20177034002 A KR 20177034002A KR 20180013909 A KR20180013909 A KR 20180013909A
- Authority
- KR
- South Korea
- Prior art keywords
- context
- value
- syntax element
- current
- previously
- Prior art date
Links
Images













Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/12—Selection from among a plurality of transforms or standards, e.g. selection between discrete cosine transform [DCT] and sub-band transform or selection between H.263 and H.264
- H04N19/122—Selection of transform size, e.g. 8x8 or 2x4x8 DCT; Selection of sub-band transforms of varying structure or type
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/124—Quantisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/124—Quantisation
- H04N19/126—Details of normalisation or weighting functions, e.g. normalisation matrices or variable uniform quantisers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/13—Adaptive entropy coding, e.g. adaptive variable length coding [AVLC] or context adaptive binary arithmetic coding [CABAC]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
- H04N19/159—Prediction type, e.g. intra-frame, inter-frame or bidirectional frame prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/174—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a slice, e.g. a line of blocks or a group of blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H04N19/436—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation using parallelised computational arrangements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/577—Motion compensation with bidirectional frame interpolation, i.e. using B-pictures
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/60—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding
- H04N19/625—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding using discrete cosine transform [DCT]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/91—Entropy coding, e.g. variable length coding [VLC] or arithmetic coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/172—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a picture, frame or field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/184—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being bits, e.g. of the compressed video stream
Abstract
비디오 코딩 디바이스는 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하도록 구성된 프로세서 (들) 를 포함한다. 프로세서 (들) 는 이전에 코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성된다. 이전에 코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 프로세서 (들) 는 이전에 코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니라, i 번째 빈을 오직 이용하도록 구성된다. 'i' 는 비-음의 정수를 표현한다.
Description
이 출원은 2015 년 5 월 29 일자로 출원된 미국 가출원 제 62/168,571 호의 이익을 주장하고, 그 전체 내용들은 참조에 의해 본원에 편입된다.
이 개시물은 비디오 코딩에 관한 것이다.
디지털 비디오 기능들은, 디지털 텔레비전들, 디지털 다이렉트 브로드캐스트 시스템 (digital direct broadcast system) 들, 무선 브로드캐스트 시스템들, 개인 정보 단말 (personal digital assistant; PDA) 들, 랩톱 또는 데스크톱 컴퓨터들, 태블릿 컴퓨터들, 전자책 (e-book) 리더들, 디지털 카메라들, 디지털 레코딩 디바이스들, 디지털 미디어 플레이어들, 비디오 게임용 디바이스들, 비디오 게임 콘솔들, 셀룰러 또는 위성 라디오 전화들, 소위 "스마트폰들", 화상 원격회의 디바이스들, 비디오 스트리밍 디바이스들 등을 포함하는 광범위한 디바이스들 내로 편입될 수 있다. 디지털 비디오 디바이스들은 MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, Part 10, 진보된 비디오 코딩 (Advanced Video Coding; AVC) 에 의해 정의된 표준들, 현재 개발 중에 있는 고효율 비디오 코딩 (High Efficiency Video Coding; HEVC) 표준, 및 이러한 표준들의 확장들에서 설명된 것들과 같은 비디오 코딩 기법들을 구현한다. 비디오 디바이스들은 이러한 비디오 코딩 기법들을 구현함으로써 디지털 비디오 정보를 더 효율적으로 송신하고, 수신하고, 인코딩하고, 디코딩하고, 및/또는 저장할 수도 있다.
비디오 코딩 기법들은 비디오 시퀀스들에 내재된 중복성을 감소시키거나 제거하기 위한 공간적 (인트라-픽처 (intra-picture)) 예측 및/또는 시간적 (인터-픽처 (inter-picture)) 예측을 포함한다. 블록-기반 비디오 코딩을 위하여, 비디오 슬라이스 (예컨대, 비디오 프레임 또는 비디오 프레임의 부분) 는 비디오 블록들로 파티셔닝 (partitioning) 될 수도 있으며, 이 비디오 블록들은 또한, 트리블록 (treeblock) 들, 코딩 유닛 (coding unit; CU) 들 및/또는 코딩 노드들로서 지칭될 수도 있다. 픽처의 인트라-코딩된 (intra-coded) (I) 슬라이스 내의 비디오 블록들은 동일한 픽처에서의 이웃하는 블록들 내의 참조 샘플들에 대한 공간적 예측을 이용하여 인코딩된다. 픽처의 인터-코딩된 (inter-coded) (P 또는 B) 슬라이스 내의 비디오 블록들은 동일한 픽처에서의 이웃하는 블록들 내의 참조 샘플들에 대한 공간적 예측, 또는 다른 참조 픽처들에서의 참조 샘플들에 대한 시간적 예측을 이용할 수도 있다. 픽처들은 프레임들로서 지칭될 수도 있고, 참조 픽처들은 참조 프레임들로서 지칭될 수도 있다.
공간적 또는 시간적 예측은 코딩될 블록에 대한 예측 블록으로 귀착된다. 잔차 데이터 (residual data) 는 코딩될 원래의 블록과 예측 블록 사이의 픽셀 차이들을 나타낸다. 인터-코딩된 블록은 예측 블록을 형성하는 참조 샘플들의 블록을 지시하는 모션 벡터와, 코딩된 블록과 예측 블록과의 사이의 차이를 표시하는 잔차 데이터에 따라 인코딩된다. 인트라-코딩된 블록은 인트라-코딩 모드 및 잔차 데이터에 따라 인코딩된다. 추가의 압축을 위하여, 잔차 데이터는 픽셀 도메인으로부터 변환 도메인으로 변환되어 잔차 변환 계수들로 귀착될 수도 있고, 다음으로, 이들은 양자화될 수도 있다. 초기에 2 차원 어레이로 배치된 양자화된 변환 계수들은 변환 계수들의 1 차원 벡터를 생성하기 위하여 스캔될 수도 있고, 엔트로피 코딩은 훨씬 더 많은 압축을 달성하기 위하여 적용될 수도 있다.
이 개시물은 블록-기반 하이브리드 비디오 코딩에서의 엔트로피 코딩 모듈에 관련된 일 예의 기법들을 설명한다. 이 기법들은 HEVC (고효율 비디오 코딩) 와 같은 임의의 현존하는 비디오 코덱들에 적용될 수도 있거나, 또는 이 기법들은 임의의 미래의 비디오 코딩 표준들 또는 다른 독점적 또는 비-독점적 코딩 기법들에서 효율적인 코딩 툴일 수도 있다. 다양한 양태들은 2 진 산술 코딩 (binary arithmetic coding; BAC) 기반 코딩 디바이스들을 위한 컨텍스트 모델링 (context modeling) 및 컨텍스트 초기화 (context initialization) 개량들에 관한 것이다. 몇몇 기법들이 본원에서 설명되고, 이 개시물에 따르면, 비디오 코딩 디바이스들은 별도로 또는 다양한 조합들로 기법들을 구현할 수도 있다.
하나의 예에서, 이 개시물은 비디오 데이터를 디코딩하기 위한 방법에 관한 것으로, 방법은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈 (bin) 들의 각각에 대하여, 하나 이상의 이전에-디코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하는 단계를 포함하고, 여기서, 컨텍스트들을 결정하는 단계는 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계를 포함하고, 여기서, i 는 비-음의 (non-negative) 정수를 포함하고, 여기서, 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하는 것은 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하는 것을 포함한다. 방법은 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 컨텍스트 적응 2 진 산술 코딩 (context adaptive binary arithmetic coding; CABAC) 디코딩하는 단계를 더 포함할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 디코딩하기 위한 방법에 관한 것으로, 방법은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈 (bin) 들의 각각에 대하여, 하나 이상의 이전에-인코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하는 단계를 포함하고, 여기서, 컨텍스트들을 결정하는 단계는 이전에-인코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계를 포함하고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-인코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하는 것은 이전에-인코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-인코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하는 것을 포함한다. 방법은 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 인코딩하는 단계를 더 포함할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 코딩하기 위한 디바이스에 관한 것으로, 디바이스는 비디오 데이터를 저장하도록 구성된 메모리, 및 하나 이상의 프로세서들을 포함한다. 하나 이상의 프로세서들은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하도록 구성될 수도 있고, 여기서, 컨텍스트들을 결정하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하도록 구성된다. 프로세서 (들) 는 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩하도록 추가로 구성될 수도 있다.
또 다른 예에서, 이 개시물은 비디오 코딩 장치에 관한 것이다. 비디오 코딩 장치는 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하기 위한 수단을 포함할 수도 있고, 여기서, 컨텍스트들을 결정하기 위한 수단은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위한 수단을 포함하고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위한 수단은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하기 위한 수단을 포함한다. 비디오 코딩 장치는 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩하기 위한 수단을 더 포함할 수도 있다.
또 다른 예에서, 이 개시물은 명령들로 인코딩된 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 명령들은, 실행될 경우, 비디오 코딩 디바이스의 하나 이상의 프로세서들로 하여금, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하게 할 수도 있고, 여기서, 컨텍스트들을 결정하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하도록 구성된다. 명령들은, 실행될 경우, 추가로, 비디오 코딩 디바이스의 하나 이상의 프로세서들로 하여금, 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩하게 할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 디코딩하는 방법에 관한 것이다. 방법은 이전에-디코딩된 슬라이스의 이전에-디코딩된 블록의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계 (inherit) 함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하는 단계, 및 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 디코딩하는 단계를 포함할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 인코딩하는 방법에 관한 것이다. 방법은 이전에-인코딩된 슬라이스의 이전에-인코딩된 블록의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하는 단계, 및 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 인코딩하는 단계를 포함할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 코딩하기 위한 디바이스에 관한 것으로, 디바이스는 비디오 데이터를 저장하도록 구성된 메모리, 및 하나 이상의 프로세서들을 포함한다. 하나 이상의 프로세서들은 저장된 비디오 데이터의 이전에-코딩된 슬라이스의 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하고, 그리고 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 코딩하도록 구성될 수도 있다.
또 다른 예에서, 이 개시물은 비디오 코딩 장치에 관한 것이다. 비디오 코딩 장치는 이전에-코딩된 슬라이스의 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하기 위한 수단, 및 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 코딩하기 위한 수단을 포함할 수도 있다.
또 다른 예에서, 이 개시물은 명령들로 인코딩된 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 명령들은, 실행될 경우, 비디오 코딩 디바이스의 하나 이상의 프로세서들로 하여금, 이전에-코딩된 슬라이스의 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하게 하고, 그리고 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 코딩하게 할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 프로세싱하는 방법에 관한 것이다. 방법은 현재의 변환 계수를 포함하는 계수 그룹 (coefficient group; CG) 을 식별하는 단계를 포함할 수도 있고, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현한다. 방법은 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하는 단계를 더 포함할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 코딩하기 위한 디바이스에 관한 것으로, 디바이스는 비디오 데이터를 저장하도록 구성된 메모리, 및 하나 이상의 프로세서들을 포함한다. 하나 이상의 프로세서들은 비디오 데이터의 현재의 변환 계수를 포함하는 계수 그룹 (CG) 을 식별하도록 구성될 수도 있고, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현한다. 하나 이상의 프로세서들은 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하도록 추가로 구성될 수도 있다.
또 다른 예에서, 이 개시물은 명령들로 인코딩된 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 명령들은, 실행될 경우, 비디오 코딩 디바이스의 하나 이상의 프로세서들로 하여금, 비디오 데이터의 현재의 변환 계수를 포함하는 계수 그룹 (CG) 을 식별하게 하는 것으로서, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현하는, 상기 계수 그룹 (CG) 을 식별하게 하고, 그리고 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하게 할 수도 있다.
또 다른 예에서, 이 개시물은 비디오 데이터를 코딩하기 위한 장치에 관한 것이다. 장치는 현재의 변환 계수를 포함하는 계수 그룹 (CG) 을 식별하기 위한 수단을 포함할 수도 있고, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현한다. 장치는 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하기 위한 수단을 더 포함할 수도 있다.
또 다른 예에서, 이 개시물은 인코딩된 비디오 비트스트림을 저장하는 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 비트스트림은, 비디오 디코딩 디바이스에 의해 프로세싱될 경우, 비디오 디코딩 디바이스의 하나 이상의 프로세서들로 하여금, 비디오 데이터의 현재의 변환 계수를 포함하는 계수 그룹 (CG) 을 식별하게 하는 것으로서, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현하는, 상기 계수 그룹 (CG) 을 식별하게 하고, 그리고 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하게 할 수도 있다.
또 다른 예에서, 이 개시물은 인코딩된 비디오 비트스트림을 저장하는 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 비트스트림은, 비디오 디코딩 디바이스에 의해 프로세싱될 경우, 비디오 디코딩 디바이스의 하나 이상의 프로세서들로 하여금, 이전에-코딩된 슬라이스의 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하게 하고, 그리고 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 코딩하게 할 수도 있다.
또 다른 예에서, 이 개시물은 인코딩된 비디오 비트스트림을 저장하는 비일시적 컴퓨터 판독가능 저장 매체에 관한 것이다. 비트스트림은, 비디오 디코딩 디바이스에 의해 프로세싱될 경우, 비디오 디코딩 디바이스의 하나 이상의 프로세서들로 하여금, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하게 할 수도 있고, 여기서, 컨텍스트들을 결정하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하도록 구성된다. 비트스트림은, 비디오 디코딩 디바이스에 의해 프로세싱될 경우, 비디오 디코딩 디바이스의 하나 이상의 프로세서들로 하여금, 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩하게 할 수도 있다.
개시물의 하나 이상의 양태들의 세부 사항들은 동반된 도면들 및 이하의 설명에서 기재된다. 이 개시물에서 설명된 기법들의 다른 특징들, 목적들, 및 이점들은 설명 및 도면들로부터, 그리고 청구범위로부터 명백히 알 수 있을 것이다.
도 1 은 개량된 컨텍스트-적응 2 진 산술 코딩 (CABAC) 설계에 따라 데이터를 코딩하기 위한 기법들을 사용할 수도 있는 일 예의 비디오 인코딩 및 디코딩 시스템을 예시하는 블록도이다.
도 2a 및 도 2b 는 2 진 산술 코딩 (BAC) 에 따른 범위 업데이팅 기법들을 예시하는 개념도들이다.
도 3 은 범위에 따라 BAC 출력의 예들을 도시하는 개념도이다.
도 4 는 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 인코더의 예를 예시하는 블록도이다.
도 5 는 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 인코딩 유닛의 블록도이다.
도 6 은 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 디코더의 예를 예시하는 블록도이다.
도 7 은 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 인코딩 유닛의 블록도이다.
도 8 은 표-기반 2 진 산술 코딩을 위한 일 예의 프로세스를 예시하는 플로우차트이다.
도 9 는 잔차 쿼드트리 구조에 기초한 변환 방식을 예시하는 개념도이다.
도 10 은 엔트로피 디코딩 유닛 및/또는 엔트로피 인코딩 유닛이 본원에서 설명된 컨텍스트 모델링 기법들에 대하여 이용할 수도 있는 템플릿의 하나의 예를 도시한다.
도 11 은 계수 그룹들에 기초한 일 예의 계수 스캔을 예시하는 개념도이다.
도 12 는 빈 유도의 예를 예시하는 개념도이다.
도 13 은 상이한 루마 빈들에 대하여, TU 내에서의 상이한 위치들에 대한 컨텍스트 인덱스들의 범위를 예시하는 개념도이다.
도 14 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 컨텍스트 모델링 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 15 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 승계-기반 (inheritance-based) 컨텍스트 초기화 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 16 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 기법들 중의 하나 이상을 비디오 디코딩 프로세스의 일부로서 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 17 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 하나 이상의 계수 그룹 (CG) 크기-결정 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
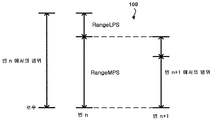
도 2a 및 도 2b 는 2 진 산술 코딩 (BAC) 에 따른 범위 업데이팅 기법들을 예시하는 개념도들이다.
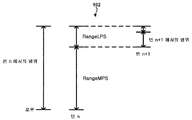
도 3 은 범위에 따라 BAC 출력의 예들을 도시하는 개념도이다.
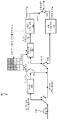
도 4 는 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 인코더의 예를 예시하는 블록도이다.
도 5 는 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 인코딩 유닛의 블록도이다.
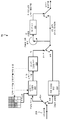
도 6 은 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 디코더의 예를 예시하는 블록도이다.
도 7 은 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 인코딩 유닛의 블록도이다.
도 8 은 표-기반 2 진 산술 코딩을 위한 일 예의 프로세스를 예시하는 플로우차트이다.
도 9 는 잔차 쿼드트리 구조에 기초한 변환 방식을 예시하는 개념도이다.
도 10 은 엔트로피 디코딩 유닛 및/또는 엔트로피 인코딩 유닛이 본원에서 설명된 컨텍스트 모델링 기법들에 대하여 이용할 수도 있는 템플릿의 하나의 예를 도시한다.
도 11 은 계수 그룹들에 기초한 일 예의 계수 스캔을 예시하는 개념도이다.
도 12 는 빈 유도의 예를 예시하는 개념도이다.
도 13 은 상이한 루마 빈들에 대하여, TU 내에서의 상이한 위치들에 대한 컨텍스트 인덱스들의 범위를 예시하는 개념도이다.
도 14 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 컨텍스트 모델링 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 15 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 승계-기반 (inheritance-based) 컨텍스트 초기화 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 16 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 기법들 중의 하나 이상을 비디오 디코딩 프로세스의 일부로서 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
도 17 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 하나 이상의 계수 그룹 (CG) 크기-결정 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스를 예시하는 플로우차트이다.
이 개시물의 기법들은 블록-기반 하이브리드 비디오 코딩에서의 엔트로피 코딩에 일반적으로 관련된다. 이 기법들은 HEVC (고효율 비디오 코딩) 와 같은 임의의 현존하는 비디오 코덱들에 적용될 수도 있거나, 또는 이 기법들은 임의의 미래의 비디오 코딩 표준들 또는 다른 독점적 또는 비-독점적 코딩 기법들에서 효율적인 코딩 툴일 수도 있다. 예 및 설명의 목적들을 위하여, 이 개시물의 기법들은 HEVC (또는 ITU-T H.265) 및/또는 ITU-T H.264 에 대하여 일반적으로 설명된다.
비디오 코딩 표준들은 그 스케일러블 비디오 코딩 (SVC) 및 멀티-뷰 비디오 코딩 (MVC) 확장들을 포함하는, ITU-T H.261, ISO/IEC MPEG-1 비주얼 (Visual), ITU-T H.262 또는 ISO/IEC MPEG-2 비주얼, ITU-T H.263, ISO/IEC MPEG-4 비주얼, 및 ITU-T H.264 (또한, ISO/IEC MPEG-4 AVC 로서 알려짐) 를 포함한다.
게다가, 그 범위 확장, 멀티뷰 확장 (MV-HEVC), 및 스케일러블 확장 (SHVC) 를 포함하는 새로운 비디오 코딩 표준, 즉, 고효율 비디오 코딩 (HEVC) 또는 ITU-T H.265 는 비디오 코딩에 관한 공동 협력 팀 (Joint Collaboration Team on Video Coding; JCT-VC) 뿐만 아니라, ITU-T 비디오 코딩 전문가들 그룹 (Video Coding Experts Group; VCEG) 및 ISO/IEC 모션 픽처 전문가들 그룹 (Motion Picture Experts Group; MPEG) 의 3D 비디오 코딩 확장 개발에 관한 공동 협력 팀 (Joint Collaboration Team on 3D Video Coding Extension Development; JCT-3V) 에 의해 최근에 개발되었다. 이하에서 HEVC WD 로서 지칭된 HEVC 초안 사양은 phenix.int-evry.fr/jct/doc_end_user/documents/14_Vienna/wg11/JCTVC-N1003-v1.zip 로부터 입수가능하다.
이 개시물의 기법들은 CABAC 코딩과 연관된 다양한 문제들을 극복할 수도 있다. 특히, 이 기법들은 단독으로 또는 함께 이용될 수도 있는 개량된 CABAC 설계 및 더 효율적인 변환 계수 컨텍스트 모델링 기법을 포함한다. 엔트로피 코딩에서, 신택스 엘리먼트들에 대한 값들은 2 진 형식으로 표현되고, 각각의 비트 (또는 "빈 (bin)") 는 특정한 컨텍스트를 이용하여 코딩된다. 이 개시물의 다양한 양태들에 따르면, 신택스 엘리먼트에 대한 값의 빈들의 세트에 대한 컨텍스트 정보는 이전의 변환 계수들의 신택스 엘리먼트에 대한 이전에-코딩된 값들의 개개의 빈들을 이용하여 결정될 수도 있다. 추가적인 세부사항들은 이하에서 논의된다.
도 1 은 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 사용할 수도 있는 일 예의 비디오 인코딩 및 디코딩 시스템 (10) 을 예시하는 블록도이다. 도 1 에서 도시된 바와 같이, 시스템 (10) 은 목적지 디바이스 (14) 에 의해 더 이후의 시간에 디코딩될 인코딩된 비디오 데이터를 제공하는 소스 디바이스 (12) 를 포함한다. 특히, 소스 디바이스 (12) 는 컴퓨터 판독가능 매체 (16) 를 통해 비디오 데이터를 목적지 디바이스 (14) 에 제공한다. 소스 디바이스 (12) 및 목적지 디바이스 (14) 는, 데스크톱 컴퓨터들, 노트북 (즉, 랩톱) 컴퓨터들, 태블릿 컴퓨터들, 셋톱 (set-top) 박스들, 소위 "스마트" 폰들과 같은 전화 핸드셋들, 소위 "스마트" 패드들, 텔레비전들, 카메라들, 디스플레이 디바이스들, 디지털 미디어 플레이어들, 비디오 게임용 콘솔들, 비디오 스트리밍 디바이스들 등을 포함하는 광범위한 디바이스들 중의 임의의 것을 포함할 수도 있다. 일부 경우들에는, 소스 디바이스 (12) 및 목적지 디바이스 (14) 가 무선 통신을 위하여 구비될 수도 있다.
목적지 디바이스 (14) 는 컴퓨터 판독가능 매체 (16) 를 통해, 디코딩될 인코딩된 비디오 데이터를 수신할 수도 있다. 컴퓨터 판독가능 매체 (16) 는 인코딩된 비디오 데이터를 소스 디바이스 (12) 로부터 목적지 디바이스 (14) 로 이동시킬 수 있는 임의의 타입의 매체 또는 디바이스를 포함할 수도 있다. 하나의 예에서, 컴퓨터 판독가능 매체 (16) 는 소스 디바이스 (12) 가 인코딩된 비디오 데이터를 실시간으로 목적지 디바이스 (14) 로 직접 송신하는 것을 가능하게 하기 위한 통신 매체를 포함할 수도 있다. 인코딩된 비디오 데이터는 무선 통신 프로토콜과 같은 통신 표준에 따라 변조될 수도 있고, 목적지 디바이스 (14) 로 송신될 수도 있다. 통신 매체는 라디오 주파수 (radio frequency; RF) 스펙트럼 또는 하나 이상의 물리적 송신 라인들과 같은 임의의 무선 또는 유선 통신 매체를 포함할 수도 있다. 통신 매체는 로컬 영역 네트워크, 광역 네트워크, 또는 인터넷과 같은 글로벌 네트워크와 같은 패킷-기반 네트워크의 일부를 형성할 수도 있다. 통신 매체는 라우터들, 스위치들, 기지국들, 또는 소스 디바이스 (12) 로부터 목적지 디바이스 (14) 로의 통신을 가능하게 하기 위해 유용할 수도 있는 임의의 다른 장비를 포함할 수도 있다.
일부 예들에서, 인코딩된 데이터는 출력 인터페이스 (22) 로부터 저장 디바이스로 출력될 수도 있다. 유사하게, 인코딩된 데이터는 입력 인터페이스에 의해 저장 디바이스로부터 액세스될 수도 있다. 저장 디바이스는 하드 드라이브, 블루-레이 (Blu-ray) 디스크들, DVD 들, CD-ROM 들, 플래시 메모리, 휘발성 또는 비-휘발성 메모리, 또는 인코딩된 비디오 데이터를 저장하기 위한 임의의 다른 적당한 디지털 저장 매체들과 같은, 다양한 분산되거나 로컬로 액세스된 데이터 저장 매체들 중의 임의의 것을 포함할 수도 있다. 추가의 예에서, 저장 디바이스는 소스 디바이스 (12) 에 의해 생성된 인코딩된 비디오를 저장할 수도 있는 파일 서버 또는 또 다른 중간 저장 디바이스에 대응할 수도 있다. 목적지 디바이스 (14) 는 스트리밍 또는 다운로드를 통해 저장 디바이스로부터 저장된 비디오 데이터에 액세스할 수도 있다. 파일 서버는 인코딩된 비디오 데이터를 저장할 수 있으며 그 인코딩된 비디오 데이터를 목적지 디바이스 (14) 로 송신할 수 있는 임의의 타입의 서버일 수도 있다. 일 예의 파일 서버들은 (예컨대, 웹사이트를 위한) 웹 서버, FTP 서버, 네트워크 연결 저장 (network attached storage; NAS) 디바이스들, 또는 로컬 디스크 드라이브를 포함한다. 목적지 디바이스 (14) 는 인터넷 접속을 포함하는 임의의 표준 데이터 접속을 통해 인코딩된 비디오 데이터에 액세스할 수도 있다. 이것은, 파일 서버 상에 저장된 인코딩된 비디오 데이터에 액세스하기에 적당한 무선 채널 (예컨대, Wi-Fi 접속), 유선 접속 (예컨대, DSL, 케이블 모뎀 등), 또는 양자의 조합을 포함할 수도 있다. 저장 디바이스로부터의 인코딩된 비디오 데이터의 송신은 스트리밍 송신, 다운로드 송신, 또는 그 조합일 수도 있다.
이 개시물의 기법들은 무선 애플리케이션들 또는 세팅들로 반드시 제한되는 것은 아니다. 기법들은 오버-디-에어 (over-the-air) 텔레비전 브로드캐스트들, 케이블 텔레비전 송신들, 위성 텔레비전 송신들, HTTP 를 통한 동적 적응 스트리밍 (DASH) 과 같은 인터넷 스트리밍 비디오 송신들, 데이터 저장 매체 상으로 인코딩되는 디지털 비디오, 데이터 저장 매체 상에 저장된 디지털 비디오의 디코딩, 또는 다른 애플리케이션들과 같은, 다양한 멀티미디어 애플리케이션들 중의 임의의 것의 지원 하에서 비디오 코딩에 적용될 수도 있다. 일부 예들에서, 시스템 (10) 은 비디오 스트리밍, 비디오 재생, 비디오 브로드캐스팅, 및/또는 화상 통화 (video telephony) 와 같은 애플리케이션들을 지원하기 위하여 일방향 (one-way) 또는 양방향 (two-way) 비디오 송신을 지원하도록 구성될 수도 있다.
도 1 의 예에서, 소스 디바이스 (12) 는 비디오 소스 (18), 비디오 인코더 (20), 및 출력 인터페이스 (22) 를 포함한다. 목적지 디바이스 (14) 는 입력 인터페이스 (28), 비디오 디코더 (30), 및 디스플레이 디바이스 (32) 를 포함한다. 이 개시물에 따르면, 소스 디바이스 (12) 의 비디오 인코더 (20) 는 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 적용하도록 구성될 수도 있다. 다른 예들에서, 소스 디바이스 및 목적지 디바이스는 다른 컴포넌트들 또는 배열들을 포함할 수도 있다. 예를 들어, 소스 디바이스 (12) 는 외부 카메라와 같은 외부 비디오 소스 (18) 로부터 비디오 데이터를 수신할 수도 있다. 마찬가지로, 목적지 디바이스 (14) 는 통합된 디스플레이 디바이스를 포함하는 것이 아니라, 외부 디스플레이 디바이스와 인터페이스할 수도 있다.
도 1 의 예시된 시스템 (10) 은 단지 하나의 예이다. 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들은 임의의 디지털 비디오 인코딩 및/또는 디코딩 디바이스에 의해 수행될 수도 있다. 일반적으로, 이 개시의 기법들은 비디오 인코딩 디바이스에 의해 수행되지만, 기법들은 또한, "CODEC" 으로서 전형적으로 지칭된 비디오 인코더/디코더에 의해 수행될 수도 있다. 또한, 이 개시물의 기법들은 또한, 비디오 프리프로세서 (video preprocessor) 에 의해 수행될 수도 있다. 소스 디바이스 (12) 및 목적지 디바이스 (14) 는, 소스 디바이스 (12) 가 목적지 디바이스 (14) 로의 송신을 위한 코딩된 비디오 데이터를 생성하는 이러한 코딩 디바이스들의 단지 예들이다. 일부 예들에서, 디바이스들 (12, 14) 은, 디바이스들 (12, 14) 의 각각이 비디오 인코딩 및 디코딩 컴포넌트들을 포함하도록 실질적으로 대칭적인 방식으로 동작할 수도 있다. 이 때문에, 시스템 (10) 은 예컨대, 비디오 스트리밍, 비디오 재생, 비디오 브로드캐스팅, 또는 화상 통화를 위하여, 비디오 디바이스들 (12, 14) 사이의 일방향 또는 양방향 비디오 송신을 지원할 수도 있다.
소스 디바이스 (12) 의 비디오 소스 (18) 는 비디오 카메라와 같은 비디오 캡처 디바이스, 이전에 캡처된 비디오를 포함하는 비디오 아카이브 (video archive), 및/또는 비디오 컨텐츠 제공자로부터 비디오를 수신하기 위한 비디오 공급 인터페이스를 포함할 수도 있다. 추가의 대안으로서, 비디오 소스 (18) 는 소스 비디오로서, 또는 라이브 비디오 (live video), 아카이빙된 비디오 (archived video), 및 컴퓨터 생성된 비디오의 조합으로서, 컴퓨터 그래픽-기반 (computer graphics-based) 데이터를 생성할 수도 있다. 일부 경우들에는, 비디오 소스 (18) 가 비디오 카메라일 경우, 소스 디바이스 (12) 및 목적지 디바이스 (14) 는 소위 카메라 폰들 또는 비디오 폰들을 형성할 수도 있다. 그러나, 위에서 언급된 바와 같이, 이 개시물에서 설명된 기법들은 일반적으로 비디오 코딩에 적용가능할 수도 있고, 무선 및/또는 유선 애플리케이션들에 적용될 수도 있다. 각각의 경우에 있어서, 캡처된, 프리-캡처된 (pre-captured), 또는 컴퓨터-생성된 비디오는 비디오 인코더 (20) 에 의해 인코딩될 수도 있다. 다음으로, 인코딩된 비디오 정보는 출력 인터페이스 (22) 에 의해 컴퓨터 판독가능 매체 (16) 상으로 출력될 수도 있다.
컴퓨터 판독가능 매체 (16) 는 무선 브로드캐스트 또는 유선 네트워크 송신과 같은 순시적 매체 (transient medium) 들, 또는 하드 디스크, 플래시 드라이브, 컴팩트 디스크, 디지털 비디오 디스크, 블루-레이 디스크, 또는 다른 컴퓨터 판독가능 매체들과 같은 저장 매체들 (즉, 비일시적 저장 매체들) 을 포함할 수도 있다. 일부 예들에서, 네트워크 서버 (도시되지 않음) 는 예컨대, 네트워크 송신을 통해, 소스 디바이스 (12) 로부터 인코딩된 비디오 데이터를 수신할 수도 있으며 인코딩된 비디오 데이터를 목적지 디바이스 (14) 에 제공할 수도 있다. 유사하게, 디스크 스탬핑 (disc stamping) 설비와 같은 매체 생산 설비의 컴퓨팅 디바이스는 소스 디바이스 (12) 로부터 인코딩된 비디오 데이터를 수신할 수도 있고, 인코딩된 비디오 데이터를 포함하는 디스크를 생산할 수도 있다. 그러므로, 컴퓨터 판독가능 매체 (16) 는 다양한 예들에서, 다양한 형태들의 하나 이상의 컴퓨터 판독가능 매체들을 포함하는 것으로 이해될 수도 있다.
목적지 디바이스 (14) 의 입력 인터페이스 (28) 는 컴퓨터 판독가능 매체 (16) 로부터 정보를 수신한다. 컴퓨터 판독가능 매체 (16) 의 정보는, 블록들 및 다른 코딩된 유닛들, 예컨대, GOP 들의 특성들 및/또는 프로세싱을 설명하는 신택스 엘리먼트들을 포함하는 신택스 정보로서, 비디오 인코더 (20) 에 의해 정의되며 또한, 비디오 디코더 (30) 에 의해 이용되는 상기 신택스 정보를 포함할 수도 있다. 디스플레이 디바이스 (32) 는 디코딩된 비디오 데이터를 사용자에게 디스플레이하고, 음극선관 (cathode ray tube; CRT), 액정 디스플레이 (liquid crystal display; LCD), 플라즈마 디스플레이, 유기 발광 다이오드 (organic light emitting diode; OLED) 디스플레이, 또는 또 다른 타입의 디스플레이 디바이스와 같은 다양한 디스플레이 디바이스들 중의 임의의 것을 포함할 수도 있다.
비디오 인코더 (20) 및 비디오 디코더 (30) 는 ITU-T H.265 로서 또한 지칭된 고효율 비디오 코딩 (HEVC) 표준과 같은 비디오 코딩 표준에 따라 동작할 수도 있다. 대안적으로, 비디오 인코더 (20) 및 비디오 디코더 (30) 는 다른 독점적 또는 산업 표준들, 이를 테면 MPEG-4, Part 10, 진보된 비디오 코딩 (AVC) 로서 대안적으로 지칭된 ITU-T H.264 표준, 또는 이러한 표준들의 확장들에 따라 동작할 수도 있다. 그러나, 이 개시물의 기법들은 임의의 특정한 코딩 표준으로 제한되지는 않는다. 비디오 코딩 표준들의 다른 예들은 MPEG-2 및 ITU-T H.263 을 포함한다. 도 1 에서 도시되지 않았지만, 일부 양태들에서, 비디오 인코더 (20) 및 비디오 디코더 (30) 는 각각 오디오 인코더 및 디코더와 통합될 수도 있고, 공통의 데이터 스트림 또는 별도의 데이터 스트림들에서 오디오 및 비디오 양자의 인코딩을 처리하기 위한 적절한 MUX-DEMUX 유닛들, 또는 다른 하드웨어 및 소프트웨어를 포함할 수도 있다. 적용가능한 경우, MUX-DEMUX 유닛들은 ITU H.223 멀티플렉서 프로토콜, 또는 사용자 데이터그램 프로토콜 (user datagram protocol; UDP) 과 같은 다른 프로토콜들을 준수할 수도 있다.
비디오 인코더 (20) 및 비디오 디코더 (30) 는 각각, 하나 이상의 마이크로프로세서들, 디지털 신호 프로세서 (digital signal processor; DSP) 들, 주문형 집적 회로 (application specific integrated circuit; ASIC) 들, 필드 프로그래밍가능한 게이트 어레이 (field programmable gate array; FPGA) 들, 개별 로직, 소프트웨어, 하드웨어, 펌웨어 또는 그 임의의 조합들과 같은 다양한 적당한 인코더 회로부 중의 임의의 것으로서 구현될 수도 있다. 기법들이 소프트웨어로 부분적으로 구현될 때, 디바이스는 소프트웨어를 위한 명령들을 적당한 비일시적 컴퓨터 판독가능한 매체에 저장할 수도 있고, 이 개시물의 기법들을 수행하기 위하여 하나 이상의 프로세서들을 이용하여 명령들을 하드웨어로 실행할 수도 있다. 비디오 인코더 (20) 및 비디오 디코더 (30) 의 각각은 하나 이상의 인코더들 또는 디코더들 내에 포함될 수도 있고, 인코더들 또는 디코더들 중의 어느 하나는 조합된 인코더/디코더 (combined encoder/decoder; CODEC) 의 일부로서 각각의 디바이스 내에 통합될 수도 있다.
일반적으로, ITU-T H.265 에 따르면, 비디오 프레임 또는 픽처는 루마 및 크로마 샘플들의 양자를 포함하는 최대 코딩 유닛 (LCU) 들 또는 트리블록들의 시퀀스 (sequence) 로 분할될 수도 있다. 비트스트림 내에서의 신택스 데이터는 픽셀들의 수의 측면에서 최대 코딩 유닛인 LCU 에 대한 크기를 정의할 수도 있다. 슬라이스는 코딩 순서에서 다수의 연속적인 트리블록들을 포함한다. 비디오 프레임 또는 픽처는 하나 이상의 슬라이스들로 파티셔닝될 수도 있다. 각각의 트리블록은 쿼드트리에 따라 코딩 유닛 (CU) 들로 분할될 수도 있다. 일반적으로, 쿼드트리 데이터 구조는 CU 당 하나의 노드를 포함하고, 루트 노드 (root node) 는 트리블록에 대응한다. CU 가 4 개의 서브-CU 들로 분할될 경우, CU 에 대응하는 노드는 4 개의 리프 노드 (leaf node) 들을 포함하고, 이들의 각각은 서브-CU 들 중의 하나에 대응한다.
쿼드트리 데이터 구조의 각각의 노드는 대응하는 CU 에 대한 신택스 데이터를 제공할 수도 있다. 예를 들어, 쿼드트리에서의 노드는, 노드에 대응하는 CU 가 서브-CU 들로 분할되는지 여부를 표시하는 분할 플래그 (split flag) 를 포함할 수도 있다. CU 에 대한 신택스 엘리먼트들은 재귀적으로 정의될 수도 있고, CU 가 서브-CU 들로 분할되는지 여부에 종속될 수도 있다. CU 가 추가로 분할되지 않을 경우, 그것은 리프-CU 로서 지칭된다. 이 개시물에서는, 원래의 리프-CU 의 명시적 분할이 없더라도, 리프-CU 의 4 개의 서브-CU 들은 또한 리프-CU 들로서 지칭될 것이다. 예를 들어, 16x16 크기에서의 CU 가 추가로 분할되지 않을 경우, 16x16 CU 가 결코 분할되지 않았지만, 4 개의 8x8 서브-CU 들이 또한 리프-CU 들로서 지칭될 것이다.
CU 가 크기 구분 (size distinction) 을 가지지 않는다는 것을 제외하고는, CU 는 H.264 표준의 매크로블록 (macroblock) 과 유사한 목적을 가진다. 예를 들어, 트리블록은 4 개의 자식 노드 (child node) 들 (또한 서브-CU 들로서 지칭됨) 로 분할될 수도 있고, 각각의 자식 노드는 궁극적으로 부모 노드 (parent node) 일 수도 있고, 또 다른 4 개의 자식 노드들로 분할될 수도 있다. 쿼드트리의 리프 노드로서 지칭된, 최종적인 분할되지 않은 자식 노드는 리프-CU 로서 또한 지칭된 코딩 노드를 포함한다. 코딩된 비트스트림과 연관된 신택스 데이터는 최대 CU 심도로서 지칭된, 트리블록이 분할될 수도 있는 최대 횟수를 정의할 수도 있고, 또한, 코딩 노드들의 최소 크기를 정의할 수도 있다. 따라서, 비트스트림은 또한, 최소 코딩 유닛 (smallest coding unit; SCU) 을 정의할 수도 있다. 이 개시물은 HEVC 의 문맥에서의 CU, 예측 유닛 (prediction unit; PU), 또는 변환 유닛 (transform unit; TU) 중의 임의의 것, 또는 다른 표준들의 문맥에서의 유사한 데이터 구조들 (예컨대, H.264/AVC 에서의 매크로블록들 및 그 서브-블록들) 을 지칭하기 위하여 용어 "블록" 을 이용한다.
CU 는 코딩 노드와, 코딩 노드와 연관된 예측 유닛 (PU) 들 및 변환 유닛 (TU) 들을 포함한다. CU 의 크기는 코딩 노드의 크기에 대응하고, 형상에 있어서 일반적으로 정사각형이다. CU 의 크기는 8x8 픽셀들로부터, 최대 크기, 예컨대, 64x64 픽셀들 이상을 갖는 트리블록의 크기까지의 범위일 수도 있다. 각각의 CU 는 하나 이상의 PU 들 및 하나 이상의 TU 들을 포함할 수도 있다. CU 와 연관된 신택스 데이터는 예를 들어, 하나 이상의 PU 들로의 CU 의 파티셔닝을 설명할 수도 있다. 파티셔닝 모드들은 CU 가 스킵 (skip) 또는 직접 모드 인코딩되는지, 인트라-예측 모드 인코딩되는지, 또는 인터-예측 모드 인코딩되는지 여부의 사이에서 상이할 수도 있다. PU 들은 형상에 있어서 비-정사각형 (non-square) 이 되도록 파티셔닝될 수도 있다. CU 와 연관된 신택스 데이터는 또한, 예를 들어, 쿼드트리에 따른 하나 이상의 TU 들로의 CU 의 파티셔닝을 설명할 수도 있다. TU 는 형상에 있어서 정사각형 또는 비-정사각형 (예컨대, 직사각형) 일 수 있다.
HEVC 표준은 상이한 CU 들에 대해 상이할 수도 있는, TU 들에 따른 변환들을 허용한다. TU 들은 전형적으로, 파티셔닝된 LCU 에 대해 정의된 소정의 CU 내에서의 PU 들의 크기에 기초하여 크기가 정해지지만, 이것은 항상 그러하지는 않을 수도 있다. TU 들은 전형적으로 동일한 크기이거나 PU 들보다 더 작다. 일부 예들에서, CU 에 대응하는 잔차 샘플들은 "잔차 쿼드 트리" (residual quad tree; RQT) 로서 알려진 쿼드트리 구조를 이용하여 더 작은 유닛들로 재분할될 수도 있다. RQT 의 리프 노드들은 변환 유닛 (TU) 들로서 지칭될 수도 있다. TU 들과 연관된 픽셀 차이 값들은 양자화될 수도 있는 변환 계수들을 생성하기 위하여 변환될 수도 있다.
리프-CU 는 하나 이상의 예측 유닛 (PU) 들을 포함할 수도 있다. 일반적으로, PU 는 대응하는 CU 의 전부 또는 부분에 대응하는 공간적인 영역을 표현하고, PU 에 대한 참조 샘플을 취출하고 및/또는 생성하기 위한 데이터를 포함할 수도 있다. 또한, PU 는 예측에 관련된 데이터를 포함한다. 예를 들어, PU 가 인트라-모드 인코딩될 때, PU 에 대한 데이터는 PU 에 대응하는 TU 에 대한 인트라-예측 모드를 설명하는 데이터를 포함할 수도 있는 잔차 쿼드트리 (residual quadtree; RQT) 내에 포함될 수도 있다. RQT 는 또한, 변환 트리 (transform tree) 로서 지칭될 수도 있다. 일부 예들에서, 인트라-예측 모드는 RQT 대신에, 리프-CU 신택스에서 시그널링될 수도 있다. 또 다른 예로서, PU 가 인터-모드 인코딩될 때, PU 는 PU 에 대한 하나 이상의 모션 벡터들과 같은 모션 정보를 정의하는 데이터를 포함할 수도 있다. PU 에 대한 모션 벡터를 정의하는 데이터는 예를 들어, 모션 벡터의 수평 컴포넌트, 모션 벡터의 수직 컴포넌트, 모션 벡터에 대한 해상도 (예컨대, 1/4 픽셀 정밀도 또는 1/8 픽셀 정밀도), 모션 벡터가 지시하는 참조 픽처, 및/또는 모션 벡터에 대한 참조 픽처 리스트 (예컨대, List 0, List 1, 또는 List C) 를 설명할 수도 있다.
하나 이상의 PU 들을 가지는 리프-CU 는 또한, 하나 이상의 변환 유닛 (TU) 들을 포함할 수도 있다. 위에서 논의된 바와 같이, 변환 유닛들은 RQT (또한, TU 쿼드트리 구조로서 지칭됨) 를 이용하여 특정될 수도 있다. 예를 들어, 분할 플래그는 리프-CU 가 4 개의 변환 유닛들로 분할되는지 여부를 표시할 수도 있다. 다음으로, 각각의 변환 유닛은 추가의 서브-TU 들로 추가로 분할될 수도 있다. TU 가 추가로 분할되지 않을 때, 그것은 리프-TU 로서 지칭될 수도 있다. 일반적으로, 인트라 코딩을 위하여, 리프-CU 에 속하는 모든 리프-TU 들은 동일한 인트라 예측 모드를 공유한다. 즉, 동일한 인트라-예측 모드는 리프-CU 의 모든 TU 들에 대한 예측된 값들을 계산하기 위하여 일반적으로 적용된다. 인트라 코딩을 위하여, 비디오 인코더는 TU 에 대응하는 CU 의 부분과 원래의 블록과의 사이의 차이로서, 인트라 예측 모드를 이용하여 각각의 리프-TU 에 대한 잔차 값을 계산할 수도 있다. TU 는 반드시 PU 의 크기로 제한되는 것은 아니다. 이에 따라, TU 들은 PU 보다 더 크거나 더 작을 수도 있다. 인트라 코딩을 위하여, PU 는 동일한 CU 에 대한 대응하는 리프-TU 와 공동위치 (collocate) 될 수도 있다. 일부 예들에서, 리프-TU 의 최대 크기는 대응하는 리프-CU 의 크기에 대응할 수도 있다.
또한, 리프-CU 들의 TU 들은 또한, 잔차 쿼드트리 (RQT) 들로서 지칭된 개개의 쿼드트리 데이터 구조들과 연관될 수도 있다. 즉, 리프-CU 는 리프-CU 가 어떻게 TU 들로 파티셔닝되는지를 표시하는 쿼드트리를 포함할 수도 있다. TU 쿼드트리의 루트 노드는 일반적으로 리프-CU 에 대응하는 반면, CU 쿼드트리의 루트 노드는 일반적으로 트리블록 (또는 LCU) 에 대응한다. 분할되지 않은 RQT 의 TU 들은 리프-TU 들로서 지칭된다. 일반적으로, 이와 다르게 언급되지 않으면, 이 개시물은 리프-CU 및 리프-TU 를 각각 지칭하기 위하여 용어들 CU 및 TU 를 이용한다.
비디오 시퀀스는 전형적으로 일련의 비디오 프레임들 또는 픽처들을 포함한다. 픽처들의 그룹 (group of pictures; GOP) 은 일반적으로 비디오 픽처들 중의 일련의 하나 이상을 포함한다. GOP 는, GOP 내에 포함된 다수의 픽처들을 설명하는, GOP 의 헤더, 픽처들 중의 하나 이상의 픽처의 헤더, 또는 다른 곳에서의 신택스 데이터를 포함할 수도 있다. 픽처의 각각의 슬라이스는 개개의 슬라이스에 대한 인코딩 모드를 설명하는 슬라이스 신택스 데이터를 포함할 수도 있다. 비디오 인코더 (20) 는 전형적으로 비디오 데이터를 인코딩하기 위하여 개별적인 비디오 슬라이스들 내에서의 비디오 블록들에 대해 동작한다. 비디오 블록은 CU 내에서의 코딩 노드에 대응할 수도 있다. 비디오 블록들은 고정된 또는 변동되는 크기들을 가질 수도 있고, 특정된 코딩 표준에 따라 크기에 있어서 상이할 수도 있다.
예로서, 예측은 다양한 크기들의 PU 들에 대하여 수행될 수도 있다. 특정한 CU 의 크기가 2Nx2N 인 것으로 가정하면, 인트라-예측은 2Nx2N 또는 NxN 의 PU 크기들에 대해 수행될 수도 있고, 인터-예측은 2Nx2N, 2NxN, Nx2N, 또는 NxN 의 대칭적인 PU 크기들에 대해 수행될 수도 있다. 인터-예측을 위한 비대칭적인 파티셔닝은 또한, 2NxnU, 2NxnD, nLx2N, 및 nRx2N 의 PU 크기들에 대하여 수행될 수도 있다. 비대칭적인 파티셔닝에서는, CU 의 하나의 방향이 파티셔닝되지 않는 반면, 다른 방향은 25 % 및 75 % 로 파티셔닝된다. 25 % 파티션에 대응하는 CU 의 부분은 "n" 과, 그 다음으로, "상부 (Up)", "하부 (Down)", "좌측 (Left)", 또는 "우측 (Right)" 의 표시에 의해 표시된다. 이에 따라, 예를 들어, "2N x nU" 는 상부의 2Nx0.5N PU 및 하부의 2Nx1.5N PU 로 수평으로 파티셔닝되는 2Nx2N CU 를 지칭한다.
이 개시물에서, "NxN" 및 "N 대 (by) N" 은 수직 및 수평 차원들의 측면에서의 비디오 블록의 픽셀 차원들, 예를 들어, 16x16 픽셀들 또는 16 대 16 픽셀들을 지칭하기 위하여 상호 교환가능하게 이용될 수도 있다. 일반적으로, 16x16 블록은 수직 방향에서의 16 개의 픽셀들 (y = 16) 및 수평 방향에서의 16 개의 픽셀들 (x = 16) 을 가질 것이다. 마찬가지로, NxN 블록은 일반적으로, 수직 방향에서의 N 개의 픽셀들 및 수평 방향에서의 N 개의 픽셀들을 가지며, 여기서, N 은 비음의 정수 (nonnegative integer) 값을 나타낸다. 블록 내의 픽셀들은 행 (row) 들 및 열 (column) 들로 배열될 수도 있다. 또한, 블록들은 수직 방향에서와 동일한 수의 픽셀들을 수평 방향에서 반드시 가질 필요는 없다. 예를 들어, 블록들은 NxM 픽셀들을 포함할 수도 있으며, 여기서, M 은 반드시 N 과 동일하지는 않다.
CU 의 PU 들을 이용한 인트라-예측 또는 인터-예측 코딩에 후속하여, 비디오 인코더 (20) 는 CU 의 TU 들에 대한 잔차 데이터를 계산할 수도 있다. PU 들은 공간 도메인 (픽셀 도메인으로서 또한 지칭됨) 에서 예측 픽셀 데이터를 생성하는 방법 또는 모드를 설명하는 신택스 데이터를 포함할 수도 있고, TU 들은 변환, 예컨대, 이산 코사인 변환 (DCT), 정수 변환, 웨이블렛 변환, 또는 개념적으로 유사한 변환의 잔차 비디오 데이터로의 적용에 후속하는 변환 도메인에서의 계수들을 포함할 수도 있다. 잔차 데이터는 인코딩되지 않은 픽처의 픽셀들과 PU 들에 대응하는 예측 값들과의 사이의 픽셀 차이들에 대응할 수도 있다. 비디오 인코더 (20) 는 CU 에 대한 잔차 데이터를 표현하는 양자화된 변환 계수들을 포함하기 위하여 TU 들을 형성할 수도 있다. 즉, 비디오 인코더 (20) 는 (잔차 블록의 형태로) 잔차 데이터를 계산할 수도 있고, 변환 계수들의 블록을 생성하기 위하여 잔차 블록을 변환할 수도 있고, 그 다음으로, 양자화된 변환 계수들을 형성하기 위하여 변환 계수들을 양자화할 수도 있다. 비디오 인코더 (20) 는 양자화된 변환 계수들 뿐만 아니라, 다른 신택스 정보 (예컨대, TU 에 대한 분할 정보) 를 포함하는 TU 를 형성할 수도 있다.
위에서 언급된 바와 같이, 변환 계수들을 생성하기 위한 임의의 변환들에 후속하여, 비디오 인코더 (20) 는 변환 계수들의 양자화를 수행할 수도 있다. 양자화는 일반적으로, 계수들을 표현하기 위하여 이용된 데이터의 양을 아마도 감소시키기 위하여 변환 계수들이 양자화되어 추가의 압축을 제공하는 프로세스를 지칭한다. 양자화 프로세스는 계수들의 일부 또는 전부와 연관된 비트 심도 (bit depth) 를 감소시킬 수도 있다. 예를 들어, n-비트 값은 양자화 동안에 m-비트 값으로 버림 (round down) 될 수도 있으며, 여기서, n 은 m 보다 더 크다.
양자화에 후속하여, 비디오 인코더는 변환 계수들을 스캔 (scan) 하여, 양자화된 변환 계수들을 포함하는 2 차원 행렬로부터 1 차원 벡터를 생성할 수도 있다. 스캔은 더 높은 에너지 (그리고 이에 따라, 더 낮은 주파수) 계수들을 어레이의 전방에 배치하고 더 낮은 에너지 (그리고 이에 따라, 더 높은 주파수) 계수들을 어레이의 후방에 배치하도록 설계될 수도 있다. 일부 예들에서, 비디오 인코더 (20) 는 양자화된 변환 계수들을 스캔하여, 엔트로피 인코딩될 수 있는 직렬화된 벡터 (serialized vector) 를 생성하기 위하여 미리 정의된 스캔 순서를 사용할 수도 있다. 다른 예들에서, 비디오 인코더 (20) 는 적응적 스캔 (adaptive scan) 을 수행할 수도 있다. 1 차원 벡터를 형성하기 위하여 양자화된 변환 계수들을 스캔한 후에, 비디오 인코더 (20) 는 예컨대, 이 개시물에서 설명된 개량된 컨텍스트-적응 2 진 산술 코딩 (CABAC) 설계에 따라, 1 차원 벡터를 엔트로피 인코딩할 수도 있다. 비디오 인코더 (20) 는 또한, 비디오 데이터를 디코딩함에 있어서 비디오 디코더 (30) 에 의한 이용을 위한 인코딩된 비디오 데이터와 연관된 신택스 엘리먼트들을 엔트로피 인코딩할 수도 있다.
일반적으로, 비디오 디코더 (30) 는 인코딩된 데이터를 디코딩하기 위하여 비디오 인코더 (20) 에 의해 수행된 것과 실질적으로 유사하지만, 상반적인 프로세스를 수행한다. 예를 들어, 비디오 디코더 (30) 는 잔차 블록을 재현하기 위하여, 수신된 TU 의 계수들을 역양자화하고 역변환한다. 비디오 디코더 (30) 는 예측된 블록을 형성하기 위하여 시그널링된 예측 모드 (인트라-예측 또는 인터-예측) 를 이용한다. 그 다음으로, 비디오 디코더 (30) 는 원래의 블록을 재현하기 위하여 예측된 블록 및 잔차 블록을 (픽셀-대-픽셀 (pixel-by-pixel) 에 기초하여) 조합한다. 블록 경계들을 따라 시각적 아티팩트들을 감소시키기 위하여 디블록킹 프로세스를 수행하는 것과 같은 추가적인 프로세싱이 수행될 수도 있다. 또한, 비디오 디코더 (30) 는 비디오 인코더 (20) 의 CABAC 인코딩 프로세스와 실질적으로 유사하지만, 상반적인 방식으로 CABAC 를 이용하여 신택스 엘리먼트들을 디코딩할 수도 있다.
이 개시물의 기법들에 따르면, 비디오 인코더 (20) 및 비디오 디코더 (30) 는 개량된 CABAC 설계에 따라 데이터를 코딩하도록 구성될 수도 있다. 개별적으로 또는 임의의 조합으로 적용될 수도 있는 어떤 기법들이 이하에서 논의된다. 이 개시물은 일반적으로, 비디오 인코더 (20) 가 어떤 정보를 비디오 디코더 (30) 와 같은 또 다른 디바이스로 "시그널링하는 것" 을 지칭할 수도 있다. 그러나, 어떤 신택스 엘리먼트들을 비디오 데이터의 다양한 인코딩된 부분들과 연관시킴으로써 비디오 인코더 (20) 가 정보를 시그널링할 수도 있다는 것을 이해해야 한다. 즉, 비디오 인코더 (20) 는 어떤 신택스 엘리먼트들을 비디오 데이터의 다양한 인코딩된 부분들의 헤더들에 저장함으로써 데이터를 "시그널링" 할 수도 있다. 일부 경우들에는, 이러한 신택스 엘리먼트들이 비디오 디코더 (30) 에 의해 수신되고 디코딩되기 이전에, 인코딩되고 저장될 수도 있다. 이에 따라, 용어 "시그널링" 은 일반적으로, 이러한 통신이 매체에 저장된 후의 임의의 시간에 디코딩 디바이스에 의해 후에 취출 (retrieve) 될 수도 있는 신택스 엘리먼트들을 인코딩 시에 매체에 저장할 때에 발생할 수도 있는 것과 같이, 시간의 기간 동안에 또는 실시간으로 또는 근-실시간으로 발생하든지 간에, 압축된 비디오 데이터를 디코딩하기 위한 신택스 또는 다른 데이터의 통신을 지칭할 수도 있다.
다음의 단락들은 BAC 및 CABAC 기법들을 더 상세하게 설명한다. BAC 는 일반적으로, 재귀적 간격-재분할 절차이다. BAC 는 H.264/AVC 및 H.265/HEVC 비디오 코딩 표준들에서의 CABAC 프로세스에서 빈들을 인코딩하기 위하여 이용된다. BAC 코더의 출력은 최종적인 코딩된 확률 간격 내에서의 확률에 대한 값 또는 포인터를 표현하는 2 진 스트림이다. 확률 간격은 범위 및 하부 종료 값에 의해 특정된다. 범위는 확률 간격의 확장이다. "로우 (Low)" 는 코딩 간격의 하한 (lower bound) 이다.
비디오 코딩으로의 산술 코딩의 적용은 D. Marpe, H. Schwarz, 및 T. Wiegand "Context-Based Adaptive Binary Arithmetic Coding in the H.264/AVC Video Compression Standard (H.264/AVC 비디오 압축 표준에서의 컨텍스트-기반 적응적 2 진 산술 코딩)" IEEE Trans. Circuits and Systems for Video Technology, vol. 13, no. 7, July 2003 에서 설명되어 있다. CABAC 는 3 개의 주요 기능들, 즉, 2 진화 (binarization), 컨텍스트 모델링, 및 산술 코딩을 수반한다. 2 진화는 신택스 엘리먼트들을 2 진 심볼들 (또는 "빈들") 에 맵핑하는 기능을 지칭한다. 2 진 심볼들은 또한, "빈 스트링 (bin string) 들" 로서 지칭될 수도 있다. 컨텍스트 모델링은 다양한 빈들의 확률을 추정하는 기능을 지칭한다. 산술 코딩은 추정된 확률에 기초하여, 빈들을 비트들로 압축하는 추후의 기능을 지칭한다. 2 진 산술 코더와 같은 다양한 디바이스들 및/또는 그 모듈들은 산술 코딩의 기능을 수행할 수도 있다.
1 진수 (unary; U), 절단된 1 진수 (truncated unary; TU), k 번째-차수 지수-골롬 (kth-order Exp-Golomb; EGk), 및 고정된 길이 (fixed length; FL) 를 포함하는 몇몇 상이한 2 진화 프로세스들이 HEVC 에서 이용된다. 다양한 2 진화 프로세스들의 세부사항들은 V. Sze 및 M. Budagavi, "High throughput CABAC entropy coding in HEVC (HEVC 에서의 높은 스루풋의 CABAC 엔트로피 코딩)" IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), vol. 22, no. 12, pp. 1778-1791, December 2012 에서 설명된다.
CABAC 에서의 각각의 컨텍스트 (즉, 확률 모델) 는 상태 및 가장 높은 확률 심볼 (most probable symbol; MPS) 값에 의해 표현된다. 각각의 상태 (σ) 는 가장 낮은 확률 심볼 (Least Probable Symbol; LPS) 인 특정한 심볼 (예컨대, 빈) 의 확률 (pσ) 을 묵시적으로 표현한다. 심볼은 LPS 또는 가장 높은 확률 심볼 (MPS) 일 수 있다. 심볼들은 2 진수이고, 이와 같이, MPS 및 LPS 는 0 또는 1 일 수 있다. 확률은 대응하는 컨텍스트에 대하여 추정되고, 산술 코더를 이용하여 심볼을 엔트로피 코딩하기 위하여 (묵시적으로) 이용된다.
BAC 의 프로세스는 코딩하기 위한 컨텍스트 및 코딩되고 있는 빈의 값에 따라 그 내부 값들 '범위' 및 '로우' 를 변경하는 상태 머신에 의해 처리된다. 컨텍스트의 상태 (즉, 그 확률) 에 따라, 범위는 rangeMPSσ (stateσ 에서의 가장 높은 확률 심볼의 범위) 및 rangeLPSσ (stateσ 에서의 가장 낮은 확률 심볼의 범위) 로 분할된다. 이론에 있어서, 확률 stateσ 의 rangeLPSσ 값은 승산에 의해 유도된다:
rangeLPSσ= range × pσ,
여기서, pσ 는 LPS 를 선택하기 위한 확률이다. 물론, MPS 의 확률은 1-pσ 이다. 동등하게, rangeMPSσ 는 범위 마이너스 (minus) rangeLPSσ 와 동일하다. BAC 는 현재의 범위, 및 코딩되고 있는 빈 (즉, LPS 또는 MPS 와 동일한 빈임) 의 값을 코딩하기 위하여 컨텍스트 빈의 상태에 따라 범위를 반복적으로 업데이트한다.
비디오 인코더 (20) 는 예컨대, 프레임 헤더, 블록 헤더, 슬라이스 헤더, 또는 GOP 헤더에서, 블록-기반 신택스 데이터, 프레임-기반 신택스 데이터, 및 GOP-기반 신택스 데이터와 같은 신택스 데이터를 비디오 디코더 (30) 로 추가로 전송할 수도 있다. GOP 신택스 데이터는 개개의 GOP 에서의 다수의 프레임들을 설명할 수도 있고, 프레임 신택스 데이터는 대응하는 프레임을 인코딩하기 위하여 이용된 인코딩/예측 모드를 표시할 수도 있다.
비디오 인코더 (20) 및 비디오 디코더 (30) 는 각각, 적용가능한 바와 같이, 하나 이상의 마이크로프로세서들, 디지털 신호 프로세서 (DSP) 들, 주문형 집적 회로 (ASIC) 들, 필드 프로그래밍가능한 게이트 어레이 (FPGA) 들, 개별 로직 회로부, 소프트웨어, 하드웨어, 펌웨어 또는 그 임의의 조합들과 같은 다양한 적당한 인코더 또는 디코더 회로부 중의 임의의 것으로서 구현될 수도 있다. 비디오 인코더 (20) 및 비디오 디코더 (30) 의 각각은 하나 이상의 인코더들 또는 디코더들 내에 포함될 수도 있고, 인코더들 또는 디코더들 중의 어느 하나는 조합된 비디오 인코더/디코더 (CODEC) 의 일부로서 통합될 수도 있다. 비디오 인코더 (20) 및/또는 비디오 디코더 (30) 를 포함하는 디바이스는 집적 회로, 마이크로프로세서, 및/또는 셀룰러 전화와 같은 무선 통신 디바이스를 포함할 수도 있다.
도 2a 및 도 2b 는 BAC 에 따른 범위 업데이팅 기법들을 예시하는 개념도들이다. 도 2a 및 도 2b 는 빈 n 에서의 이 프로세스의 예들을 도시한다. 도 2a 의 예 (100) 에서, 빈 n 에서, 빈 2 에서의 범위는 어떤 컨텍스트 상태 (σ) 에 의해 주어진 LPS (pσ) 의 확률에 의해 주어진 RangeMPS 및 RangeLPS 를 포함한다. 예 (100) 는 빈 n 의 값이 MPS 와 동일할 때에 빈 n+1 에서의 범위의 업데이트를 도시한다. 이 예에서, 로우는 동일하게 머무르지만, 빈 n+1 에서의 범위의 값은 빈 n 에서의 RangeMPS 의 값으로 감소된다. 도 2b 의 예 (102) 는 빈 n 의 값이 MPS 와 동일하지 않을 (즉, LPS 와 동일함) 때에 빈 n+1 에서의 범위의 업데이트를 도시한다. 이 예에서, 로우는 빈 n 에서의 RangeLPS 의 더 낮은 범위 값으로 이동된다. 게다가, 빈 n+1 에서의 범위의 값은 빈 n 에서의 RangeLPS 의 값으로 감소된다.
HEVC 에서, 범위는 9 비트들로, 그리고 로우는 10 비트들로 표현된다. 범위 및 로우 값들을 충분한 정밀도로 유지하기 위한 재정규화 (renormalization) 프로세스가 있다. 재정규화는 범위가 256 보다 더 작을 때마다 발생한다. 그러므로, 범위는 재정규화 후에 항상 256 이상이다. 범위 및 로우의 값들에 따라, BAC 는 '0' 또는 '1' 을 비트스트림으로 출력하거나, 미래의 출력들에 대하여 유지하기 위한 내부 변수 (BO: 비트들-현저함(bits-outstanding) 로 칭해짐) 를 업데이트한다.
도 3 은 범위에 따라 BAC 출력의 예들을 도시하는 개념도이다. 예를 들어, '1' 은 범위 및 로우가 어떤 임계치 (예컨대, 512) 를 초과할 때에 비트스트림으로 출력된다. '0' 은 범위 및 로우가 어떤 임계치 (예컨대, 512) 미만일 때에 비트스트림으로 출력된다. 범위 및 로우가 어떤 임계치들 사이에 있을 때에는, 어떤 것도 비트스트림으로 출력되지 않는다. 그 대신에, BO 값이 증분 (increment) 되고 다음 빈이 인코딩된다.
HEVC 의 CABAC 컨텍스트 모델에서는, 128 개의 상태들이 있다. 0 부터 63 까지일 수 있는 (상태 σ 에 의해 나타내어진) 64 개의 가능한 LPS 확률들이 있다. 각각의 MPS 는 제로 (zero) 또는 1 일 수 있다. 이와 같이, 128 개의 상태들은 64 개의 상태 확률들과 MPS 에 대한 2 개의 가능한 값들 (0 또는 1) 의 곱이다. 그러므로, 확률 모델들은 7-비트 엔트리들로서 저장될 수도 있다. 각각의 7-비트 엔트리에서, 6 비트들은 확률 상태를 표현하기 위하여 할당될 수도 있고, 1 비트는 적용가능한 컨텍스트 메모리에서의 가장 높은 확률 심볼 (MPS) 을 위하여 할당될 수도 있다.
LPS 범위들 (rangeLPSσ) 을 유도하는 연산을 감소시키기 위하여, 모든 경우들에 대한 결과들은 사전-계산되고, HEVC 에서의 룩업 테이블에서 근사치들로서 저장된다. 그러므로, LPS 범위는 간단한 표 룩업을 이용함으로써 임의의 승산 없이 획득될 수 있다. 승산을 회피하는 것은, 이 동작이 많은 하드웨어 아키텍처들에서 상당한 레이턴시 (latency) 를 야기시킬 수도 있으므로, 일부 디바이스들 또는 애플리케이션들을 위하여 중요할 수 있다.
4-열 사전-계산된 LPS 범위 표는 승산 대신에 이용될 수도 있다. 범위는 4 개의 세그먼트들로 분할된다. 세그먼트 인덱스는 질문 (범위>>6)&3 에 의해 유도될 수 있다. 사실상, 세그먼트 인덱스는 실제적인 범위로부터 비트들을 시프트하고 누락시킴으로써 유도된다. 다음의 표 1 은 가능한 범위들 및 그 대응하는 인덱스들을 도시한다.

그 다음으로, LPS 범위 표는 64 엔트리들 (각각의 확률 상태에 대하여 하나) 과 4 (각각의 범위 인덱스에 대하여 하나) 의 곱을 가진다. 각각의 엔트리는 범위 LPS, 즉, 범위와 LPS 확률을 승산하는 값이다. 이 표의 일부의 예는 다음의 표 2 에서 도시되어 있다. 표 2 는 확률 상태들 9 내지 12 를 도시한다. HEVC 에 대한 하나의 제안에서, 확률 상태들은 0 내지 63 의 범위일 수도 있다.

각각의 세그먼트 (즉, 범위 값) 에서, 각각의 확률 상태 σ 의 LPS 범위는 미리 정의된다. 다시 말해서, 확률 stateσ 의 LPS 범위는 4 개의 값들 (즉, 각각의 범위 인덱스에 대한 하나의 값) 로 양자화된다. 소정의 포인트에서 이용된 특정 LPS 범위는 범위가 어느 세그먼트에 속하는지에 종속된다. 표에서 이용된 가능한 LPS 범위들의 수는 표 열들의 수 (즉, 가능한 LPS 범위 값들의 수) 와 LPS 범위 정밀도 사이의 절충이다. 일반적으로 말하면, 더 많은 열들은 LPS 범위 값들의 더 작은 양자화 에러들로 귀착되지만, 또한, 표를 저장하기 위한 더 많은 메모리에 대한 필요성을 증가시킨다. 더 적은 열들은 양자화 에러들을 증가시키지만, 표를 저장하기 위하여 필요한 메모리를 감소시킨다.
위에서 설명된 바와 같이, 각각의 LPS 확률 상태는 대응하는 확률을 가진다. HEVC 에서, 64 개의 대표적인 확률 값들  은 재귀적 수학식인 이하의 수학식 (1) 에 따라 LPS (가장 낮은 확률 심볼) 에 대하여 유도된다.
은 재귀적 수학식인 이하의 수학식 (1) 에 따라 LPS (가장 낮은 확률 심볼) 에 대하여 유도된다.

상기 예에서, 양자의 선택된 스케일링 인자  및 확률들의 세트의 기수 N = 64 는 확률 표현의 정확도와 고속 적응에 대한 희망 사이의 양호한 타협을 표현한다. 일부 예들에서, 1 에 더 근접한
및 확률들의 세트의 기수 N = 64 는 확률 표현의 정확도와 고속 적응에 대한 희망 사이의 양호한 타협을 표현한다. 일부 예들에서, 1 에 더 근접한  의 값은 더 높은 정확도를 갖는 느린 적응 ("정상-상태 거동") 으로 귀착될 수도 있는 반면, 더 빠른 적응은 감소된 정확도를 희생시키면서
의 값은 더 높은 정확도를 갖는 느린 적응 ("정상-상태 거동") 으로 귀착될 수도 있는 반면, 더 빠른 적응은 감소된 정확도를 희생시키면서  의 감소하는 값들을 갖는 비-정지의 경우 (non-stationary case) 에 대하여 달성될 수 있다. 스케일링 인자
의 감소하는 값들을 갖는 비-정지의 경우 (non-stationary case) 에 대하여 달성될 수 있다. 스케일링 인자  는 현재의 업데이트에 대해 상당한 영향을 가지는 이전에 인코딩된 빈들의 수를 표시하는 윈도우 크기에 대응할 수도 있다. MPS (가장 높은 확률 심볼) 의 확률은 1 마이너스 (minus) LPS (가장 낮은 확률 심볼) 의 확률과 동일하다. 다시 말해서, MPS 의 확률은 공식 (1 - LPS) 에 의해 표현될 수 있고, 여기서, 'LPS' 는 LPS 의 확률을 표현한다. 그러므로, HEVC 에서 CABAC 에 의해 표현될 수 있는 확률 범위는 [0.01875, 0.98125 (=1-0.01875)] 이다.
는 현재의 업데이트에 대해 상당한 영향을 가지는 이전에 인코딩된 빈들의 수를 표시하는 윈도우 크기에 대응할 수도 있다. MPS (가장 높은 확률 심볼) 의 확률은 1 마이너스 (minus) LPS (가장 낮은 확률 심볼) 의 확률과 동일하다. 다시 말해서, MPS 의 확률은 공식 (1 - LPS) 에 의해 표현될 수 있고, 여기서, 'LPS' 는 LPS 의 확률을 표현한다. 그러므로, HEVC 에서 CABAC 에 의해 표현될 수 있는 확률 범위는 [0.01875, 0.98125 (=1-0.01875)] 이다.
CABAC 는 신택스 엘리먼트에 값의 비트들 (또는 "빈들") 을 코딩하기 위하여 이용된 컨텍스트 모델의 확률 상태들이 신호 통계들 (즉, 예컨대, 신택스 엘리먼트에 대한 이전에 코딩된 빈들의 값들) 을 따르기 위하여 업데이트되기 때문에 적응적이다. 업데이트 프로세스는 다음과 같다. 소정의 확률 상태에 대하여, 업데이트는 상태 인덱스와, LPS 또는 MPS 의 어느 하나로서 식별된 인코딩된 심볼의 값에 종속된다. 업데이팅 프로세스의 결과로서, 잠재적으로 수정된 LPS 확률 추정치 및 필요할 경우, 수정된 MPS 값을 포함하는 새로운 확률 상태가 유도된다.
컨텍스트 스위칭은 각각의 빈의 코딩 후에 발생할 수도 있다. 빈 값이 MPS 와 동일할 경우에는, 소정의 상태 인덱스가 간단하게 1 만큼 증분된다. 이것은 MPS 가 상태 인덱스 62 에서 발생할 때를 제외한 모든 상태들에 대한 것이고, 여기서, LPS 확률은 이미 그 최소치이다 (또는 동등하게, 최대 MPS 확률에 도달됨). 이 경우, 상태 인덱스는 LPS 가 보여질 때까지 고정된 상태로 남아 있거나, 최후의 빈 값은 인코딩된다 (특수한 종료 상태는 최후 빈 값의 특수한 경우에 대하여 이용됨). LPS 가 발생할 때, 상태 인덱스는 이하의 수학식에서 도시된 바와 같이, 상태 인덱스를 어떤 양만큼 감분 (decrement) 시킴으로써 변경된다. 이 규칙은 다음의 예외를 갖는 LPS 의 각각의 발생에 대해 일반적으로 적용한다. LPS 가 동등-확률의 경우 (equi-probable case) 에 대응하는 인덱스 σ=0 인 상태에서 인코딩된 것으로 가정하면, 상태 인덱스는 고정된 상태로 남아 있지만, MPS 값은 LPS 및 MPS 의 값이 상호 교환되도록 토글 (toggle) 될 것이다. 모든 다른 경우들에는, 어느 심볼이 인코딩되었더라도, MPS 값은 변경되지 않을 것이다. 일반적으로, 비디오 코더는 소정의 LPS 확률  과 그 업데이트된 대응부
과 그 업데이트된 대응부  사이의 관계를 도시하는 수학식 (2) 에 따라 새로운 확률 상태를 유도할 수도 있다.
사이의 관계를 도시하는 수학식 (2) 에 따라 새로운 확률 상태를 유도할 수도 있다.

복잡도를 감소시키기 위하여, 비디오 코더는 모든 천이 규칙 (transition rule) 들이 각각이 다수의 엔트리들을 가지는 기껏해야 2 개의 표들에 의해 실현될 수 있도록 CABAC 를 구현할 수도 있다. 하나의 예로서, 모든 천이 규칙들은 각각이 7-비트 무부호 정수 값들의 128 개의 엔트리들을 가지는 기껏해야 2 개의 표들 (예컨대, 이하의 표들 3 및 4) 에 의해 실현될 수도 있다. 또 다른 예로서, 모든 천이 규칙들은 각각이 6-비트 무부호 정수 값들의 63 개의 엔트리들을 가지는 기껏해야 2 개의 표들 (예컨대, HEVC 의 표 9-41) 에 의해 실현될 수도 있다. 상태 인덱스 i 가 주어질 경우, 업데이트한 후에, 비디오 코더는 새로운 상태 인덱스로서, MPS 값이 코딩될 때에는 TransIdxMPS[ i ], 또는 LPS 값이 코딩될 때에는 TransIdxLPS[ i ] 를 정의할 수도 있다.


일부 예들에서, 비디오 코더는, LPS 가 관측되었을 경우에, 소정의 상태 인덱스 σ 에 대하여 새로운 업데이트된 상태 인덱스 TransIdxLPS [σ] 를 결정하는 단일 표 TransIdxLPS 로 상태 천이들을 결정할 수도 있다. MPS-구동된 천이들은 1 의 고정된 값에 의한 상태 인덱스의 간단한 (포화된) 증분에 의해 획득될 수 있어서, 업데이트된 상태 인덱스 min( σ+1, 62) 로 귀착될 수 있다.
위에서 논의된 바와 같이, 컨텍스트 모델링은 더 높은 코딩 효율을 달성하기 위한 기여 인자인 정확한 확률 추정을 제공한다. 따라서, 컨텍스트 모델링은 적응적 프로세스이다. 상이한 컨텍스트 모델들은 상이한 빈들에 대하여 이용될 수 있고, 컨텍스트 모델들의 확률은 이전에-코딩된 빈들의 값들에 기초하여 업데이트될 수도 있다. 유사한 분포들을 갖는 빈들은 동일한 컨텍스트 모델을 종종 공유한다. 각각의 빈에 대한 컨텍스트 모델은 신택스 엘리먼트의 타입, 신택스 엘리먼트에서의 빈 위치 (binIdx), 루마/크로마 정보, 이웃하는 정보 등에 기초하여 선택될 수 있다.
소정의 슬라이스를 코딩하기 전에, 확률 모델들은 하나 이상의 미리 정의된 값들에 기초하여 초기화된다. 예를 들어, qp 에 의해 나타내어진 입력 양자화 파라미터와, initVal 에 의해 나타내어진 미리 정의된 값이 주어질 경우, (상태 및 MPS 에 의해 나타내어진) 확률 모델의 7-비트 엔트리는 이하의 수학식 (3) 에 따라 유도될 수 있다.

유도된 상태 인덱스는 MPS 정보를 묵시적으로 포함한다. 더 구체적으로, 상태 인덱스가 짝수 값일 때, MPS 값은 0 과 동일하다. 반대로, 상태 인덱스가 홀수 값일 때, MPS 값은 1 과 동일하다. "initVal" 의 값은 8-비트 정밀도를 갖는 [0, 255] 의 범위에 있다. 미리 정의된 값 "initVal" 은 슬라이스-종속적이다. 다시 말해서, 각각 I, P, 및 B 슬라이스들에서 각각 하나인, 확률 모델들에 대한 컨텍스트 초기화 파라미터들의 3 개의 세트들이 이용된다. 이러한 방법으로, CABAC 를 수행하도록 구성된 비디오 인코딩 디바이스는, 상이한 코딩 시나리오들 및/또는 상이한 타입들의 비디오 컨텐츠에 대한 더 양호한 맞춤이 달성될 수 있도록, 3 개의 초기화 표들 사이의 이 슬라이스 타입들에 대하여 선택하는 것이 가능하게 된다.
HEVC 에 따르면, 또 다른 툴이 하나의 P (또는 B) 슬라이스가 B (또는 P) 슬라이스들로 초기화되는 것을 허용하기 위하여 적용될 수 있다. 예를 들어, 툴은 하나의 P 슬라이스가 B 슬라이스들에 대하여 저장된 컨텍스트 초기화 파라미터들의 세트로 초기화되는 것을 허용하기 위하여 적용될 수 있다. 반대로, 툴은 하나의 B 슬라이스가 P 슬라이스들에 대하여 저장된 컨텍스트 초기화 파라미터들의 세트로 초기화되는 것을 허용하기 위하여 적용될 수 있다. 관련된 신택스 엘리먼트들은 (HEVC 의 섹션 7.3.6.1 에 대응하는) 이하의 표 5 에서 설명되고, 관련된 시맨틱들 및 디코딩 프로세스는 표 5 후에 이하에서 설명된다.


표 5 의 신택스 엘리먼트들에 대한 시맨틱들은 다음과 같이 정의될 수도 있다:
1 과 동일한 cabac_init_present_flag 는 cabac_init_flag 가 PPS 를 참조하는 슬라이스 헤더들에서 존재한다는 것을 특정한다. 0 과 동일한 cabac_init_present_flag 는 cabac_init_flag 가 PPS 를 참조하는 슬라이스 헤더들에서 존재하지 않는다는 것을 특정한다.
cabac_init_flag 는 이하에서 설명된 디코딩 프로세스에서 정의된 바와 같이, 컨텍스트 변수들에 대한 초기화 프로세스에서 이용된 초기화 표를 결정하기 위한 방법을 특정한다. cabac_init_flag 가 존재하지 않을 때, 그것은 0 과 동일한 것으로 추론된다.
디스크립터들:
ae(v): 컨텍스트-적응 산술 엔트로피-코딩된 신택스 엘리먼트.
b(8): 비트 스트링의 임의의 패턴을 가지는 바이트 (8 비트들).
f(n): 좌측 비트 우선으로 (좌측으로부터 우측으로) 기입된 n 비트들을 이용한 고정된-패턴 비트 스트링.
se(v): 좌측 비트 우선을 갖는 부호 정수 0 번째 차수 지수-골롬-코딩된 (Exp-Golomb-coded) 신택스 엘리먼트.
u(n): n 비트들을 이용한 무부호 정수. n 이 신택스 표에서 "v" 일 때, 비트들의 수는 다른 신택스 엘리먼트들의 값에 대해 종속적인 방식으로 변동된다.
ue(v): 좌측 비트 우선을 갖는 무부호 정수 0 번째 차수 지수-골롬-코딩된 신택스 엘리먼트.
HEVC 의 표 9-4 는 3 개의 초기화 타입들의 각각에 대하여 초기화가 필요한 컨텍스트 인덱스 (ctxIdx) 를 열거한다. 각각의 ctxIdx 는 initType 변수에 대응하는 변수에 의해 HEVC 표 9-4 에서 특정된다. HEVC 표 9-4 는 또한, 초기화를 위하여 필요한 initValue 의 값들의 각각을 포함하는 표 번호를 열거한다. P 및 B 슬라이스 타입들에 대하여, initType 의 유도는 cabac_init_flag 신택스 엘리먼트의 값에 종속된다. 비디오 코더는 다음의 의사코드에 의해 설명된 동작들을 이용하여 변수 initType 를 유도할 수도 있다:

HEVC-호환 비디오 디코더와 같은 비디오 코딩 디바이스는 다양한 스테이지들에서 컨텍스트 모델에 대한 확률 상태를 업데이트할 수도 있다. 소정의 확률 상태에 대하여, 업데이트는 상태 인덱스와, LPS 또는 MPS 의 어느 하나로서 식별된 인코딩된 심볼의 값에 종속된다. 업데이팅 프로세스를 구현함으로써, 비디오 코딩 디바이스는 대응하는 컨텍스트 모델에 대한 새로운 확률 상태를 유도한다. 새로운 확률 상태는 확률적으로-수정된 LPS 확률 추정치, 및 적용가능할 경우, 수정된 MPS 값으로 구성될 수도 있다. LPS 확률에 대한 천이 규칙들의 유도는 소정의 LPS 확률  과 LPS 확률의 업데이트된 대응부
과 LPS 확률의 업데이트된 대응부  사이의 다음의 관계에 기초한다:
사이의 다음의 관계에 기초한다:
복잡도를 감소시키기 위하여, 비디오 코딩 디바이스는 모든 천이 규칙들이 각각의 표가 7-비트 무부호 정수 값들의 128 개의 엔트리들을 가지는 기껏해야 2 개의 표들을 이용하여 실현될 수 있는 그러한 방법으로 CABAC 를 구현할 수도 있다. 상태 인덱스 "i" 가 주어질 경우, 비디오 코딩 디바이스는 업데이트한 후의 새로운 상태 인덱스를, MPS 값이 코딩될 때에 TransIdxMPS[ i ], 또는 LPS 값이 코딩될 때에 TransIdxLPS[ i ] 로서 정의할 수도 있다. TransIdxMPS 표 및 TransIdxLPS 표는 이하에서 예시된다.


산술 코딩은 재귀적 간격 분할에 기초한다. 기존의 산술 코딩에서는, 0 내지 1 의 초기 값을 갖는 범위가 빈의 확률에 기초하여 2 개의 하위간격 (subinterval) 들로 분할된다. 인코딩된 비트들은, 2 진 분수로 변환될 때, 2 개의 하위간격들 중의 하나의 선택을 제공하는 오프셋을 제공한다. 선택된 하위간격은 디코딩된 빈의 값을 표시한다. 매 디코딩된 빈 후에, 비디오 디코더는 범위를 선택된 하위간격과 동일하게 업데이트할 수도 있다. 결국, 비디오 디코더는 간격 분할을 재귀적 절차로서 구현하기 위하여, 간격 분할 프로세스를 반복할 수도 있다. 범위 및 오프셋은 비트 정밀도를 제한하였고, 이에 따라, 비디오 디코더는 언더플로우 (underflow) 를 방지하기 위하여, 범위가 어떤 (예컨대, 미리 결정된) 값 미만으로 떨어지는 사례들에서 재정규화를 구현할 수도 있다. 비디오 디코더는 각각의 빈이 디코딩된 후에 재정규화를 수행할 수도 있다.
비디오 코딩 디바이스는 다양한 방법들로 획득되는 확률 정보에 기초하여 산술 코딩을 수행할 수도 있다. 산술 코딩의 "규칙적인 코딩 모드 (regular coding mode)" 에 따르면, 비디오 코딩 디바이스는 추정된 확률을 이용할 수도 있다. 규칙적인 코딩 모드에 따른 산술 코딩의 경우들에는, 빈 스트링이 컨텍스트 코딩된다고 말해진다. 산술 코딩의 "우회 모드 (bypass mode)" 에 따르면, 비디오 코딩 디바이스는 0.5 의 가정된 동일한 확률을 이용할 수도 있다. 우회 모드에 따른 산술 코딩의 경우들에는, 빈 스트링이 우회 코딩된다고 말해진다. 우회-코딩된 빈들에 대하여, 비디오 코딩 디바이스는 시프트 (shift) 를 이용하여 범위를 하위간격들로 분할할 수도 있다. 대조적으로, 비디오 코딩 디바이스는 컨텍스트-코딩된 빈들의 경우에는 범위를 분할하기 위하여 룩업 테이블을 이용할 수도 있다. HEVC 에 따른 산술 코딩은 H.264/AVC 에 따른 산술 코딩과 동일하다. HEVC 및 H.264/AVC 에 따르면, 비디오 코딩 디바이스는 표-기반 2 진 산술 코딩을 채용할 수도 있고, 산술 코딩을 위한 규칙적인 코딩 모드의 흐름은 동반되는 도면들에 대하여 다음의 단락들에서 더욱 상세하게 설명된다.
비디오 인코더 (20) 및 비디오 디코더 (30) (어느 하나 또는 양자는 이 개시물의 다양한 부분들에서 "비디오 코더" 로서 일반적으로 지칭됨) 는 변환 계수 데이터의 컨텍스트 모델링을 위한 이 개시물의 기법들로 구성될 수도 있다. 하나의 변환 계수가 그 크기 및 부호 플래그에 의해 표현된다는 것을 가정하면, 크기는 2 진화 후에, 0 부터 M (M 은 양의 정수임) 까지의 빈 인덱스를 갖는 빈 스트링에 의해 나타내어진다. 이 개시물의 다양한 CABAC 개량들은 비디오 인코더 (20), 비디오 디코더 (30), 및/또는 그 하나 이상의 컴포넌트들에 대하여 이하에서 설명된다. 이 개시물의 다양한 기법들은 개별적으로, 또는 서로 및/또는 본원에서 설명된 임의의 다른 기법들과의 그 임의의 조합으로 구현될 수도 있다는 것이 인식될 것이다.
이 개시물은 위에서 논의된 바와 같은 다양한 현존하는 CABAC 기법들이 어떤 문제들을 조우할 수도 있다는 것을 인식한다. 예를 들어, HEVC 에서의 컨텍스트 모델링 방법들은 64x64 보다 더 크지 않은 CTU 들에 대하여 구체적으로 설계된다. 더 큰 CTU 들 (예컨대, 128x128, 256x256, 또는 심지어 더 큰 것) 이 이용될 때, 현재의 컨텍스트 모델링 방법들을 직접적으로 재이용하는 것은 덜 효율적일 수도 있고 및/또는 파싱 쟁점 (parsing issue) 들로 귀착될 수도 있다. 또 다른 예로서, (도 12 에 대하여 이하에서 더욱 상세하게 논의되는) 변경들 제안된 JCTVC-H0228 은 더 양호한 코딩 성능을 잠재적으로 제공할 수도 있지만, 단일-패스 코딩에 의한 다수-패스 코딩의 대체는 병렬화를 위하여 해롭고, 상이한 컨텍스트 모델 세트들의 스위칭은 스루풋을 감소시킨다. 또 다른 예로서, 미리 정의된 초기화 값들로부터 유도된 초기화된 확률들은 슬라이스-타입 종속적이다. 그러나, 하나의 슬라이스 타입에 대한 고정된 초기화된 확률들은 CABAC 의 코딩 성능을 한정하는 코딩된 정보의 통계들에 기초하여 적응적이지 않을 수도 있다.
도 4 는 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 인코더 (20) 의 예를 예시하는 블록도이다. 비디오 인코더 (20) 는 비디오 슬라이스들 내에서의 비디오 블록들의 인트라-코딩 및 인터-코딩을 수행할 수도 있다. 인트라 코딩은 소정의 비디오 프레임 또는 픽처 내에서의 비디오에 있어서의 공간적 중복성을 감소시키거나 제거하기 위하여 공간적 예측에 의존한다. 인터-코딩은 비디오 시퀀스의 인접한 프레임들 또는 픽처들 내에서의 비디오에 있어서의 시간적 중복성을 감소시키거나 제거하기 위하여 시간적 예측에 의존한다. 인트라-모드 (I 모드) 는 몇몇 공간 기반 코딩 모드들 중의 임의의 것을 지칭할 수도 있다. 단방향 예측 (P 모드) 또는 양방향-예측 (B 모드) 과 같은 인터-모드들은 몇몇 시간-기반 코딩 모드들 중의 임의의 것을 지칭할 수도 있다.
도 4 에서 도시된 바와 같이, 비디오 인코더 (20) 는 인코딩될 비디오 프레임 내에서의 현재의 비디오 블록을 수신한다. 도 4 의 예에서, 비디오 인코더 (20) 는 모드 선택 유닛 (40), 참조 픽처 메모리 (64) (디코딩된 픽처 버퍼 (decoded picture buffer; DPB) 로서 또한 지칭될 수도 있음), 합산기 (50), 변환 프로세싱 유닛 (52), 양자화 유닛 (54), 및 엔트로피 인코딩 유닛 (56) 을 포함한다. 모드 선택 유닛 (40) 은 궁극적으로, 모션 보상 유닛 (44), 모션 추정 유닛 (42), 인트라 예측 유닛 (46), 및 파티션 유닛 (48) 을 포함한다. 비디오 블록 복원을 위하여, 비디오 인코더 (20) 는 또한, 역양자화 유닛 (58), 역변환 유닛 (60), 및 합산기 (62) 를 포함한다. 디블록킹 필터 (deblocking filter; 도 4 에서 도시되지 않음) 는 또한, 블록 경계들을 필터링하여 복원된 비디오로부터 블록화 아티팩트 (blockiness artifact) 들을 제거하기 위하여 포함될 수도 있다. 희망하는 경우, 디블록킹 필터는 전형적으로 합산기 (62) 의 출력을 필터링할 것이다. (루프 내의 또는 루프 이후의) 추가적인 필터들은 또한, 디블록킹 필터에 추가하여 이용될 수도 있다. 이러한 필터들은 간결함을 위하여 도시되어 있지 않지만, 희망하는 경우, (인-루프 (in-loop) 필터로서) 합산기 (50) 의 출력을 필터링할 수도 있다.
인코딩 프로세스 동안, 비디오 인코더 (20) 는 코딩될 비디오 프레임 또는 슬라이스를 수신한다. 프레임 또는 슬라이스는 다수의 비디오 블록들로 분할될 수도 있다. 모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 은 시간적 예측을 제공하기 위하여, 하나 이상의 참조 프레임들 내의 하나 이상의 블록들에 관하여 수신된 비디오 블록의 인터-예측 인코딩을 수행한다. 인트라 예측 유닛 (46) 은 대안적으로, 공간적 예측을 제공하기 위하여, 코딩될 블록과 동일한 프레임 또는 슬라이스에서의 하나 이상의 이웃하는 블록들에 관하여 수신된 비디오 블록의 인트라-예측 인코딩을 수행할 수도 있다. 비디오 인코더 (20) 는 예컨대, 비디오 데이터의 각각의 블록에 대한 적절한 코딩 모드를 선택하기 위하여, 다수의 코딩 패스 (coding pass) 들을 수행할 수도 있다.
또한, 파티션 유닛 (48) 은 이전의 코딩 패스들에서의 이전의 파티셔닝 방식들의 평가에 기초하여, 비디오 데이터의 블록들을 서브-블록들로 파티셔닝할 수도 있다. 예를 들어, 파티션 유닛 (48) 은 초기에, 프레임 또는 슬라이스를 LCU 들로 파티셔닝할 수도 있고, 레이트-왜곡 (rate-distortion) 분석 (예컨대, 레이트-왜곡 최적화) 에 기초하여 LCU 들의 각각을 서브-CU 들로 파티셔닝할 수도 있다. 모드 선택 유닛 (40) 은 서브-CU 들로의 LCU 의 파티셔닝을 표시하는 쿼드트리 데이터 구조를 추가로 생성할 수도 있다. 쿼드트리의 리프-노드 CU 들은 하나 이상의 PU 들 및 하나 이상의 TU 들을 포함할 수도 있다.
모드 선택 유닛 (40) 은 예컨대, 에러 결과들에 기초하여 예측 모드들 중의 하나, 인트라 또는 인터를 선택할 수도 있고, 결과적인 예측된 블록을, 잔차 데이터를 생성하기 위하여 합산기 (50) 에, 그리고 참조 프레임으로서의 이용을 위한 인코딩된 블록을 복원하기 위하여 합산기 (62) 에 제공한다. 모드 선택 유닛 (40) 은 또한, 모션 벡터들, 인트라-모드 표시자들, 파티션 정보, 및 다른 이러한 신택스 정보와 같은 신택스 엘리먼트들을 엔트로피 인코딩 유닛 (56) 에 제공한다.
모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 은 고도로 통합될 수도 있지만, 개념적인 목적들을 위하여 별도로 예시되어 있다. 모션 추정 유닛 (42) 에 의해 수행된 모션 추정은 비디오 블록들에 대한 모션을 추정하는 모션 벡터들을 생성하는 프로세스이다. 예를 들어, 모션 벡터는 현재의 프레임 (또는 다른 코딩된 유닛) 내에서 코딩되고 있는 현재의 블록에 관한 참조 프레임 (또는 다른 코딩된 유닛) 내에서의 예측 블록에 관하여 현재의 비디오 프레임 또는 픽처 내에서의 비디오 블록의 PU 의 변위를 표시할 수도 있다. 예측 블록은, 절대차의 합 (sum of absolute difference; SAD), 제곱차의 합 (sum of square difference; SSD), 또는 다른 차이 메트릭들에 의해 결정될 수도 있는 픽셀 차이의 측면에서, 코딩될 블록과 근접하게 정합하는 것으로 구해지는 블록이다. 일부 예들에서, 비디오 인코더 (20) 는 참조 픽처 메모리 (64) 내에 저장된 참조 픽처들의 정수-미만 (sub-integer) 픽셀 위치들에 대한 값들을 계산할 수도 있다. 예를 들어, 비디오 인코더 (20) 는 참조 픽처의 1/4 픽셀 위치들, 1/8 픽셀 위치들, 또는 다른 분수 픽셀 위치들의 값들을 보간할 수도 있다. 그러므로, 모션 추정 유닛 (42) 은 전체 픽셀 위치들 및 분수 픽셀 위치들에 관하여 모션 검색을 수행할 수도 있고, 분수 픽셀 정밀도를 갖는 모션 벡터를 출력할 수도 있다.
모션 추정 유닛 (42) 은 PU 의 위치를 참조 픽처의 예측 블록의 위치와 비교함으로써, 인터-코딩된 슬라이스에서의 비디오 블록의 PU 에 대한 모션 벡터를 계산한다. 참조 픽처는 제 1 참조 픽처 리스트 (List 0) 또는 제 2 참조 픽처 리스트 (List 1) 로부터 선택될 수도 있고, 이들의 각각은 참조 픽처 메모리 (64) 내에 저장된 하나 이상의 참조 픽처들을 식별한다. 모션 추정 유닛 (42) 은 계산된 모션 벡터를 엔트로피 인코딩 유닛 (56) 및 모션 보상 유닛 (44) 으로 전송한다.
모션 보상 유닛 (44) 에 의해 수행된 모션 보상은 모션 추정 유닛 (42) 에 의해 결정된 모션 벡터에 기초하여 예측 블록을 페치 (fetch) 하거나 생성하는 것을 수반할 수도 있다. 또한, 모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 은 일부 예들에서, 기능적으로 통합될 수도 있다. 현재의 비디오 블록의 PU 에 대한 모션 벡터를 수신할 시에, 모션 보상 유닛 (44) 은 모션 벡터가 참조 픽처 리스트들 중의 하나에서 지시하는 예측 블록을 위치시킬 수도 있다. 합산기 (50) 는 이하에서 논의된 바와 같이, 코딩되고 있는 현재의 비디오 블록의 픽셀 값들로부터 예측 블록의 픽셀 값들을 감산하여 픽셀 차이 값들을 형성함으로써 잔차 비디오 블록을 형성한다. 일반적으로, 모션 추정 유닛 (42) 은 루마 컴포넌트들에 관하여 모션 추정을 수행하고, 모션 보상 유닛 (44) 은 크로마 컴포넌트들 및 루마 컴포넌트들의 양자에 대한 루마 컴포넌트들에 기초하여 계산된 모션 벡터들을 이용한다. 모드 선택 유닛 (40) 은 또한, 비디오 슬라이스의 비디오 블록들을 디코딩함에 있어서 비디오 디코더 (30) 에 의한 이용을 위한 비디오 블록들 및 비디오 슬라이스와 연관된 신택스 엘리먼트들을 생성할 수도 있다.
인트라 예측 유닛 (46) 은 위에서 설명된 바와 같이, 모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 에 의해 수행된 인터-예측에 대한 대안으로서, 현재의 블록을 인트라-예측할 수도 있다. 특히, 인트라 예측 유닛 (46) 은 현재의 블록을 인코딩하기 위하여 이용하기 위한 인트라-예측 모드를 결정할 수도 있다. 일부 예들에서, 인트라 예측 유닛 (46) 은 예컨대, 별도의 인코딩 패스들 동안에 다양한 인트라-예측 모드들을 이용하여 현재의 블록을 인코딩할 수도 있고, 인트라 예측 유닛 (46) (또는 일부 예들에서, 모드 선택 유닛 (40)) 은 테스팅된 모드들로부터 이용하기 위한 적절한 인트라-예측 모드를 선택할 수도 있다.
예를 들어, 인트라 예측 유닛 (46) 은 다양한 테스팅된 인트라-예측 모드들에 대한 레이트-왜곡 분석을 이용하여 레이트-왜곡 값들을 계산할 수도 있고, 테스팅된 모드들 중에서 최상의 레이트-왜곡 특성들을 가지는 인트라-예측 모드를 선택할 수도 있다. 레이트-왜곡 분석은 일반적으로, 인코딩된 블록과, 인코딩된 블록을 생성하기 위하여 인코딩되었던 원래의 인코딩되지 않은 블록과의 사이의 왜곡 (또는 에러) 의 양뿐만 아니라, 인코딩된 블록을 생성하기 위하여 이용된 비트레이트 (즉, 비트들의 수) 를 결정한다. 인트라 예측 유닛 (46) 은 어느 인트라-예측 모드가 블록에 대한 최상의 레이트-왜곡 값을 나타내는지를 결정하기 위하여 다양한 인코딩된 블록들에 대한 왜곡들 및 레이트들로부터 비율 (ratio) 들을 계산할 수도 있다.
블록에 대한 인트라-예측 모드를 선택한 후, 인트라 예측 유닛 (46) 은 블록에 대한 선택된 인트라-예측 모드를 표시하는 정보를 엔트로피 인코딩 유닛 (56) 에 제공할 수도 있다. 엔트로피 인코딩 유닛 (56) 은 선택된 인트라-예측 모드를 표시하는 정보를 인코딩할 수도 있다. 비디오 인코더 (20) 는 복수의 인트라-예측 모드 인덱스 표들 및 복수의 수정된 인트라-예측 모드 인덱스 표들 (또한 코드워드 맵핑 표 (codeword mapping table) 들로서 지칭됨) 을 포함할 수도 있는 송신된 비트스트림 구성 데이터에서, 다양한 블록들에 대한 인코딩 컨텍스트들의 정의들과, 컨텍스트들의 각각에 대해 이용하기 위한 가장 가능성 있는 인트라-예측 모드, 인트라-예측 모드 인덱스 표, 및 수정된 인트라-예측 모드 인덱스 표의 표시들을 포함할 수도 있다.
비디오 인코더 (20) 는 코딩되고 있는 원래의 비디오 블록으로부터 모드 선택 유닛 (40) 으로부터의 예측 데이터를 감산함으로써 잔차 비디오 블록을 형성한다. 합산기 (50) 는 이 감산 연산을 수행하는 컴포넌트 또는 컴포넌트들을 표현한다. 변환 프로세싱 유닛 (52) 은 이산 코사인 변환 (DCT) 또는 개념적으로 유사한 변환과 같은 변환을 잔차 블록에 적용하여, 변환 계수 값들을 포함하는 비디오 블록을 생성한다. 웨이블렛 변환들, 정수 변환들, 서브-대역 변환들, 개별 사인 변환 (discrete sine transform; DST), 또는 다른 타입들의 변환들이 DCT 대신에 이용될 수 있다. 어떤 경우에도, 변환 프로세싱 유닛 (52) 은 변환을 잔차 블록에 적용하여, 변환 계수들의 블록을 생성한다. 변환은 잔차 정보를 픽셀 도메인으로부터, 주파수 도메인과 같은 변환 도메인으로 변환할 수도 있다. 변환 프로세싱 유닛 (52) 은 결과적인 변환 계수들을 양자화 유닛 (54) 으로 전송할 수도 있다. 양자화 유닛 (54) 은 비트 레이트를 추가로 감소시키기 위하여 변환 계수들을 양자화한다. 양자화 프로세스는 계수들의 일부 또는 전부와 연관된 비트 심도를 감소시킬 수도 있다. 양자화도는 양자화 파라미터를 조절함으로써 수정될 수도 있다.
양자화에 후속하여, 엔트로피 인코딩 유닛 (56) 은 양자화된 변환 계수들을 엔트로피 코딩한다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 기법들에 따라 CABAC 및/또는 개량된 CABAC 를 수행할 수도 있다. 컨텍스트-기반 엔트로피 코딩의 경우, 컨텍스트는 이웃하는 블록들에 기초할 수도 있다. 엔트로피 인코딩 유닛 (56) 에 의한 엔트로피 코딩에 후속하여, 인코딩된 비트스트림은 또 다른 디바이스 (예컨대, 비디오 디코더 (30)) 에 송신될 수도 있거나, 더 이후의 송신 또는 취출을 위해 아카이빙될 수도 있다.
역양자화 유닛 (58) 및 역변환 유닛 (60) 은 픽셀 도메인에서의 잔차 블록을 복원하기 위하여 역양자화 및 역변환을 각각 적용한다. 특히, 합산기 (62) 는 참조 픽처 메모리 (64) 에서의 저장을 위한 복원된 비디오 블록을 생성하기 위하여, 복원된 잔차 블록을, 모션 보상 유닛 (44) 또는 인트라 예측 유닛 (46) 에 의해 더 이전에 생성된 모션 보상된 예측 블록에 가산한다. 복원된 비디오 블록은 추후의 비디오 프레임에서의 블록을 인터-코딩하기 위하여, 모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 에 의해 참조 블록으로서 이용될 수도 있다.
엔트로피 인코딩 유닛 (56) 과 같은 비디오 인코더 (20) 의 다양한 컴포넌트들은 컨텍스트 모델링을 수행하기 위하여 이 개시물의 개량된 CABAC 기법들을 구현할 수도 있다. 이 개시물의 다양한 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 하나 이상의 이전에-인코딩된 변환 계수들의 i 번째 빈들의 값들을 이용하여 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링을 수행할 수도 있다. 바꾸어 말하면, 현재의 변환 계수에 대한 i 번째 빈의 컨텍스트 모델링은 엔트로피 인코딩 유닛 (56) 이 이미 인코딩한 하나 이상의 변환 계수들의 대응하는 i 번째 빈들의 값들에 종속적이다. i 번째 빈의 컨텍스트 모델링은 변환 계수들에 대한 값들의 복수의 빈들에 대한 컨텍스트 모델링이 병렬로 수행되는 것을 허용하기 위하여, 이전에-인코딩된 변환 계수들에 대한 값들의 다른 빈들의 이용을 배제할 수도 있다.
이전에-인코딩된 변환의 i 번째 빈들의 값들을 이용하여 현재의 변환 계수의 빈에 대한 컨텍스트 모델링을 수행함으로써, 엔트로피 인코딩 유닛 (56) 은 현존하는 CABAC 코더들에 비해 하나 이상의 잠재적인 개선들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이러한 장점의 예로서, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 기법들을 구현함으로써 컨텍스트 모델링 동작의 병렬화를 개선시킬 수도 있다. 더 구체적으로, 엔트로피 인코딩 유닛 (56) 은 현재 인코딩되고 있는 변환 계수의 다수의 빈들에 대하여, 컨텍스트 모델링을 병렬로 수행할 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 이 다수의 빈들에 대응하는 빈 값들이 이전에-인코딩된 변환 계수 (들) 로부터 이용가능한 것으로 결정할 경우, 엔트로피 인코딩 유닛 (56) 은 현재 인코딩되고 있는 변환 계수의 빈들에 대한 컨텍스트 모델링 동작들을 적어도 부분적으로 병렬화할 수도 있다.
엔트로피 인코딩 유닛 (56) 은 멀티-패스 코딩 방식에 따라 이 개시물의 병렬화된 컨텍스트 모델링을 수행할 수도 있다. 더 구체적으로, 멀티-패스 코딩 방식은 엔트로피 인코딩 유닛 (56) 이 별도의 스레드 (thread) 들을 각각의 특정한 빈에 배정하게 하는 코딩 기법 (예컨대, 제 1 빈에 대한 스레드 1, 제 2 빈에 대한 스레드 2 등) 을 지칭한다. 이에 따라, 멀티-패스 코딩에 따르면, 모든 bin0 인스턴스들은 시퀀스로 코딩되는 bin1 인스턴스들에 독립적으로 시퀀스로 인코딩될 수 있고, 양자는 시퀀스로 인코딩되는 bin2 인스턴스들에 독립적으로 코딩되는 등과 같다. 일부 예들에서, 엔트로피 인코딩 유닛 (56) 은 단일 블록의 변환 유닛들에 대하여 멀티-패스 코딩을 수행할 수도 있다. 또한, 규칙적인 모드에 따라 인코딩되는 빈들에 대하여, 엔트로피 인코딩 유닛 (56) 은 몇몇 인코딩 패스들을 수행할 수도 있다. 각각의 패스는 모든 변환 계수들의 단일의 대응하는 빈에 속할 수도 있다. 다시 말해서, 각각의 패스 동안에, 엔트로피 인코딩 유닛 (56) 은 다른 패스들에 관련되는 정보를 사용하지 않는다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 제 1 패스에서 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 (필요할 경우) 제 1 빈을 인코딩할 수도 있다. 이 예에서, 제 2 패스에서, 엔트로피 인코딩 유닛 (56) 은 필요할 경우, 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 2 빈을 인코딩할 수도 있는 등과 같다.
하나의 예의 이용 경우에 있어서, 엔트로피 인코딩 유닛 (56) 은 이전에-코딩된 이웃하는 변환 계수의 bin0 의 값을 이용하여 현재-코딩된 변환 계수의 bin0 에 대한 컨텍스트 모델링을 수행할 수도 있고, 이전에-코딩된 이웃하는 변환 계수의 bin1 의 값을 이용하여 현재-코딩된 변환 계수의 bin1 에 대한 컨텍스트 모델링을 수행할 수도 있는 등과 같다. 위에서 논의된 바와 같이 병렬화를 허용하기 위하여, 엔트로피 인코딩 유닛 (56) 은 특정한 빈의 컨텍스트 모델링을 수행할 때에 상이한 빈들을 이용하는 것을 회피하도록 구성될 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 이전에-코딩된 변환 계수들의 임의의 bin0 값들을 이용하지 않으면서, 현재의 변환 계수의 bin1 을 엔트로피 인코딩하기 위한 컨텍스트를 결정할 수도 있다. 빈들의 세트가 병렬로 엔트로피 인코딩되는 경우들에는, 빈 컨텍스트들을 결정하기 위하여 필요한 개개의 빈들이 이용가능할 때, 엔트로피 인코딩 유닛 (56) 은 이전에-코딩된 변환 계수에 대한 개개의 이용가능한 빈 값들을 이용할 수도 있고, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 변환 계수의 다수의 빈들에 대한 컨텍스트 모델링을 병렬로 수행할 수도 있다. 위에서 설명된 이용 경우의 시나리오에서, bin0 및 bin1 이 양자 모두 이전에-코딩된 이웃 변환 계수로부터 이용가능할 경우, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 변환 계수에 대한 bin0 및 bin1 의 컨텍스트 모델링을 병렬화할 수도 있다. 이러한 방식으로, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 모델링 동작들의 병렬화를 가능하게 하고 잠재적으로 활용함으로써 현재의 변환 계수의 빈들에 대한 컨텍스트 선택을 개선시키면서, HEVC 에서 설명된 바와 같이 멀티-패스 코딩의 원리들 내에서 CABAC 를 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다.
엔트로피 인코딩 유닛 (56) 은 모든 이러한 빈들의 전체 컨텍스트 모델링을 병렬로 수행할 수 있지만, 반드시 그러한 것은 아닐 수도 있다는 것이 인식될 것이다. 더 구체적으로, 엔트로피 인코딩 유닛 (56) 은 다수의 빈들의 컨텍스트 모델링의 일부 부분들을 동시에 수행할 수도 있다. 이러한 방법으로, 엔트로피 인코딩 유닛 (56) 은 멀티코어 프로세싱 기술 및/또는 다수의 프로세서들을 이용하여 현재-코딩된 변환 계수에 대한 컨텍스트 모델링 동작들을 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
가능하게 된 병렬화로 상이한 변환 계수들의 대응하는 빈들을 인코딩함으로써, 엔트로피 인코딩 유닛 (56) 은 현존하는 멀티-패스 CABAC 기법들에 비해 하나 이상의 장점들을 제공할 수도 있다. 예를 들어, 단일 패스에서 다수의 변환 계수들의 대응하는 빈들 (예컨대, 개개의 bin0) 을 코딩함으로써, 엔트로피 인코딩 유닛 (56) 은 빈 천이들에서 빈번하게 새로운 컨텍스트 모델을 저장하고 취출하기 위한 필요성을 회피할 수도 있다. 그 대신에, 패스는 다수의 변환 계수들에 걸쳐 대응하는 빈들 (예컨대, 개개의 bin0) 을 타겟으로 하므로, 엔트로피 인코딩 유닛 (56) 은 소정의 패스에 걸쳐 단일 컨텍스트 모델을 이용할 수도 있다. 이러한 방법으로, 엔트로피 인코딩 유닛 (56) 은 빈번한 컨텍스트-스위칭으로부터 발생하는 시간 지연들 및 자원 회전을 완화시키거나 또는 잠재적으로 제거하기 위하여 이 개시물의 병렬화된 컨텍스트 선택 기법들을 구현할 수도 있다. 대조적으로, 현존하는 멀티-패스 코딩은 제 1 변환 계수에 대하여, bin0, bin1, bin2 등을 인코딩하고, 그 다음으로, 제 2 변환 계수에 대하여 bin0, bin1, bin2 등을 인코딩하는 등으로 인해, 빈번한 컨텍스트 모델 저장 및 취출 동작들을 요구할 것이다.
예를 들어, 엔트로피 인코딩 유닛 (56) 은 본원에서 설명된 i 번째 빈 컨텍스트 모델링 기능성들을 위하여 이용하기 위한 하나 이상의 미리 정의된 템플릿들을 생성할 수도 있거나, 또는 그렇지 않을 경우에 이에 액세스할 수도 있다. 엔트로피 인코딩 유닛 (56) 이 현재-코딩된 변환 계수의 i 번째 빈의 컨텍스트 모델링을 위하여 이용할 수도 있는 미리 정의된 템플릿의 하나의 비-제한적인 예는 도 10 에서 예시되어 있다. 도 10 의 템플릿 (140) 과 같은 미리 정의된 템플릿은 8x8 변환 블록에 대하여 대각선 스캔 순서를 정의하고, 여기서, 'L' 은 최후의 중요한 스캔 위치를 나타내고, 'x' 는 현재의 스캔 위치를 나타내고, "xi" 는 로컬 템플릿 (local template) (140) 에 의해 커버된 이웃들을 나타낸다. xi 에 대하여, "i" 의 값은 제로 내지 4 의 범위에 있고, 범위 제약은 i ∈ [0,4] 로서 표현된다. 이 개시물의 하나 이상의 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 현재 인코딩되고 있는 변환 계수의 대응하는 i 번째 빈의 컨텍스트 모델링을 위하여 로컬 템플릿 (140) 에서 위치된 변환 계수들의 i 번째 빈들을 이용할 수도 있다. 일부 구현예들에 따르면, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 병렬화된 빈 컨텍스트 모델링을 수행하기 위하여 다수의 템플릿들을 이용할 수도 있다. 하나의 예에서, 템플릿 크기 및/또는 형상은 다음의 기준들 중의 하나 이상에 종속적이다: (i) 변환 유닛들의 크기; 또는 (ii) 모드들; 또는 (iii) 현재의 변환 유닛 또는 계수 그룹 (CG) 내에서의 현재의 변환 계수들의 위치; 또는 (iv) 루마 및/또는 크로마 컴포넌트 정보와 같은 컬러 컴포넌트 정보.
빈 값들에 대하여 이전에-코딩된 TU 를 횡단하기 위하여 하나 이상의 미리 정의된 템플릿들을 이용함으로써, 엔트로피 인코딩 유닛 (56) 은 현존하는 CABAC 기술에 비해 하나 이상의 개량들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 도 10 의 로컬 템플릿 (140) 과 같은 TU 횡단 템플릿을 이용함으로써, 엔트로피 인코딩 유닛 (56) 은 상이한 코딩 패스들에 대하여 횡단 방식을 별도로 결정하기 위한 필요성을 회피할 수도 있다. 이에 따라, 이 개시물의 템플릿-기반 병렬화된 컨텍스트 선택 기법들을 구현함으로써, 엔트로피 인코딩 유닛 (56) 은 코딩 정밀도를 유지하면서, 빈 코딩에 대한 스루풋을 증가시킬 수도 있다.
또 다른 예의 구현예에 따르면, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 병렬화된 컨텍스트 모델링 기법들을 현재-코딩된 변환 계수의 처음 'K' 빈들에 오직 적용할 수도 있고, 여기서, 'K' 는 M 보다 더 작고, 여기서, 'M' 은 이용가능한 빈 인덱스들의 상한을 나타내고, 여기서, M 은 0 으로부터 시작한다. 엔트로피 인코딩 유닛 (56) 은 또 다른 컨텍스트 모델링 기법을 이용하여, 또는 우회 모드에 따라 코딩되고 있는 나머지 (M+1-K) 빈들을 인코딩할 수도 있다.
또 다른 예의 구현예에 따르면, 엔트로피 인코딩 유닛 (56) 은 이전에-코딩된 변환 계수들의 모집단 (universe) 을, 현재 인코딩되고 있는 변환 계수 전의 현재의 변환 유닛 또는 CG 내에서의 인코딩 순서에서의 'N' 연속 변환 계수들로서 정의할 수도 있다. 대안적으로, 엔트로피 인코딩 유닛 (56) 은 N 을 변수인 것으로 결정할 수도 있다. 하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 현재의 변환 유닛에서의 현재-인코딩된 변환 계수의 상대적인 위치에 종속적인 N 의 값을 결정할 수도 있다. 또 다른 예에서, 엔트로피 인코딩 유닛 (56) 은 변환 유닛 크기에 종속적인 N 의 값을 결정할 수도 있다.
또 다른 구현예에서, 엔트로피 인코딩 유닛 (56) 은 이전에-인코딩된 변환 계수들의 모집단을, 현재의 변환 유닛 또는 CG 내에서의 현재의 위치의 이웃에 위치된 그 변환 계수들로서 정의할 수도 있다. 하나의 예에서, 현재의 위치의 이웃은 현재의 위치에 직접적으로 인접한 그 위치들, 또는 현재의 위치에 직접적으로 인접하거나 현재의 위치로부터 분리된 것 중의 하나인 위치들로 제약된다. 또 다른 예에서, 이웃은 또한, 이 위치들을 포함할 수도 있지만, 하나 이상의 공간적 이웃하는 변환 유닛들에서의 위치들을 포함하도록 확대할 수도 있다.
이 개시물의 다양한 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 빈의 컨텍스트 인덱스를, 하나 이상의 이전에-코딩된 변환 계수들과 연관된 값들의 함수로서 정의할 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 이전에-코딩된 변환 계수들의 모든 i 번째 빈 값들의 합을 산출하는 함수를 이용할 수도 있다. 더 구체적으로, 이 예에서, 엔트로피 인코딩 유닛 (56) 은 TU/CG 의 모든 이전에-인코딩된 변환 계수들의 이용가능한 i 번째 빈 값들의 값들의 합산을 수행할 수도 있다. 결국, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링 동안에 결과적인 합을 컨텍스트 인덱스 (CtIdx) 로서 이용할 수도 있다. 또 다른 예에서, 엔트로피 인코딩 유닛 (56) 은 차단 값 (cut-off value) 을 정의할 수도 있다. 이 예에서, 함수의 출력이 미리 정의된 차단 값을 초과할 때, 엔트로피 인코딩 유닛 (56) 은 현재 코딩되고 있는 빈에 대하여 동일한 컨텍스트를 이용할 수도 있다. 일부 예들에서, 엔트로피 인코딩 유닛 (56) 은 차단 값이 빈 인덱스/변환 유닛 크기/코딩 모드/하나의 변환 유닛 내에서의 변환 계수 위치에 기초하는 것 (또는 종속적임) 으로 결정할 수도 있다.
일부 예들에서, 엔트로피 인코딩 유닛 (56) 은 이 빈들이 동일한 컨텍스트 모델들을 공유하도록, 상이한 패스들에서 코딩된 대응하는 빈들을 인코딩할 수도 있다. 하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 인덱스 유도 방법, 예컨대, 상이한 패스들에서의 빈들에 대하여 컨텍스트 인덱스를 계산하기 위한 함수가 상이한 것으로 결정할 수도 있다. 하나의 예에 따르면, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 인덱스 유도 방법, 예컨대, 상이한 패스들에서의 빈들에 대하여 컨텍스트 인덱스를 계산하기 위한 함수가 동일할 수도 있는 것으로 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 인덱스 유도 규칙을, 변환 유닛들의 상이한 크기들에서의 동일한 패스에 대하여 미변경된 것으로 유지할 수도 있다. 그러나, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 빈에 대한 컨텍스트 모델링을 수행하기 위하여 오프셋을 컨텍스트 인덱스에 적용할 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 2 개의 상이한 변환 크기들이 컨텍스트 모델들의 2 개의 세트들을 가지는 것으로 결정할 수도 있다. 결국, 엔트로피 인코딩 유닛 (56) 은 오프셋을, 하나의 이러한 세트에서의 컨텍스트 모델들의 수로서 정의할 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 이 TU 크기가 미리 정의된 차원들 MxM 의 정사각형보다 더 작은 것으로 결정할 경우, 엔트로피 인코딩 유닛 (56) 은 각각의 이러한 TU (MxM 보다 더 작음) TU 크기가 컨텍스트 모델들의 그 자신의 개개의 세트를 가지는 것으로 결정할 수도 있다. 반대로, 엔트로피 인코딩 유닛 (56) 은 MxM 과 동일하거나 그보다 더 큰 크기들을 갖는 모든 TU 들이 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다.
다양한 이용 경우의 시나리오들에서, 엔트로피 인코딩 유닛 (56) 은 M 의 값을 16 으로 설정할 수도 있다. 더 구체적으로, 이 예들에서, 엔트로피 인코딩 유닛 (56) 이 현재-코딩된 TU 의 크기가 16x16 정사각형보다 더 작은 것으로 결정할 경우, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 TU 가 TU 의 특정한 크기에 대응하는 컨텍스트 모델들의 세트와 연관되는 것으로 결정할 수도 있다. 반대로, 엔트로피 인코딩 유닛이 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 것으로 결정할 경우, 엔트로피 인코딩 유닛 (56) 은 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 모든 다른 TU 들과 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다. 일부 예들에서, 엔트로피 인코딩 유닛 (56) 은 TU 크기-기반 컨텍스트 선택을 오직 루마 블록들에 적용할 수도 있다.
일부 예들에 따르면, 나머지 빈들을 코딩하기 위하여 이용된 라이스 파라미터 (Rice parameter) 는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 라이스 파라미터는 코딩 모드에 종속적일 수도 있다. 하나의 예에서, coeff_abs_level_remaining 에 대하여 골롬-라이스 (Golomb-Rice) 코드를 이용하는 대신에, 엔트로피 인코딩 유닛 (56) 은 다른 2 진화 기법들을 이용할 수도 있다. 대안적으로 또는 추가적으로, 하나를 초과하는 2 진화 방법은 coeff_abs_level_remaining 신택스 엘리먼트를 코딩하기 위하여 적용될 수도 있다. 하나의 예에서, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 코딩 모드들에 종속적이다. 대안적으로, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 하나의 TU 내에서의 상대적인 위치에 종속적일 수도 있다. 대안적으로, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 스캔 순서에서의 제 1 코딩된/디코딩된 변환 계수로부터의 거리에 종속적일 수도 있다. 일부 사례들에서, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 변환 유닛에 관한 코딩 그룹 위치에 종속적이다.
이 개시물의 일부 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 변환 크기에 기초하여 계수 그룹 (CG) 크기를 결정할 수도 있다. 다시 말해서, 이 양태들에 따르면, CG 크기는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 엔트로피 인코딩 유닛 (56) 은 코딩 모드에 기초하여 CG 크기를 결정할 수도 있다. 이 예들에서, 엔트로피 인코딩 유닛 (56) 은 CG 크기를 변환 크기 및/또는 코딩 모드 중의 하나 또는 양자에 종속적인 것으로서 결정할 수도 있다. 대안적으로 또는 추가적으로, 엔트로피 인코딩 유닛 (56) 은 변환 행렬 (transform matrix) 에 기초하여 CG 크기를 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 또한, 병렬화된 컨텍스트 모델링 기법들을, 변환 우회 모드 (또한, "변환 스킵 모드" 로서 지칭됨) 를 이용하여 인코딩되는 블록들에 적용할 수 있다. 변환 우회 모드는, 비디오 인코더 (20) 가 무손실 코딩 출력을 제공하기 위하여, 코딩 모드에 따라, 인코딩의 변환 및 양자화 동작들을 스킵할 수도 있는 코딩 모드를 지칭한다. 이에 따라, 이 개시물의 어떤 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 무손실 코딩의 사례들에서 잠재적으로 결과적인 장점들을 제공하기 위하여 병렬화된 컨텍스트 선택 기법들을 확대할 수도 있다.
이 개시물의 다양한 변환 계수 컨텍스트 모델링 기법들의 일 예의 세부사항들은 이하에서 더욱 상세하게 논의된다. 멀티-패스 코딩에 따른 컨텍스트 모델링의 하나의 예가 이하에서 설명된다. 이 예에 따르면, 엔트로피 인코딩 유닛 (56) 은 HEVC 에서 제시된 바와 같은 코딩 엘리먼트들 및 코딩 순서 (다중 패스 코딩, 및 CG-기반) 를 적용할 수도 있다. 게다가, 엔트로피 인코딩 유닛 (56) 은 변환 계수들의 크기들을 미변경된 상태로 유지하면서, 2 진화 기법들을 적용할 수도 있다. 그러나, 엔트로피 인코딩 유닛 (56) 은 변환 계수들의 크기들을 코딩하기 위한 컨텍스트 인덱스 및 라이스 파라미터 계산 방법을 수정할 수도 있다.
bin0 (중요한 플래그) 에 대한 컨텍스트 인덱스 계산은 다음의 정보에 종속적일 수도 있다: 템플릿에서의 비-제로 계수들의 수 (즉, 계수들의 크기들이 0 보다 더 큼); 현재의 TU 내에서의 현재의 계수의 위치; 루마 컴포넌트에 대한 TU 크기; 및 컬러 컴포넌트들. 컬러 컴포넌트 종속성에 대하여, 루마 및 크로마는 별도로 고려된다. 추가적으로, 루마 컴포넌트에 대한 TU 크기를 고려할 시에, 컨텍스트 인덱스 계산은 루마에 대한 TU 크기와 독립적이다. 루마 컴포넌트의 TU 크기는 3 개의 세트들, 즉, 4x4 TU, 8x8 TU, 16x16 이상의 TU 들을 포함할 수도 있다.
bin1 및 bin2 (1 보다 더 크고, 2 보다 더 큼) 에 대하여, 컨텍스트 인덱스 계산은 다음의 정보에 종속적이다: (bin1 에 대하여) 1 보다 더 크고 (bin2 에 대하여) 2 보다 더 큰 템플릿에서의 absLevels 의 수; 현재의 TU 내에서의 현재의 계수의 위치; 및 컬러 컴포넌트들. 라이스 파라미터 유도 프로세스는 우회 코딩 정보 및 sum_absolute_levelMinus1 신택스 엘리먼트의 값에 종속적이다.
하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 템플릿에서의 계수들의 수를 반환하기 위하여 함수 sum_template(k) 를 정의할 수도 있어서, 계수들의 크기들은 k 보다 더 크다. sum_template(k) 함수의 예는 다음과 같다:

추가적으로, 이 예에서, 엔트로피 인코딩 유닛 (56) 은 위치 정보를 처리하기 위한 함수  , 및 컴포넌트 정보를 처리하기 위한 함수 또 다른 함수
, 및 컴포넌트 정보를 처리하기 위한 함수 또 다른 함수  를 다음과 같이 정의할 수도 있다:
를 다음과 같이 정의할 수도 있다:

도 10 은 엔트로피 디코딩 유닛 (70) 및/또는 엔트로피 인코딩 유닛 (56) 이 본원에서 설명된 컨텍스트 모델링 기법들에 대하여 이용할 수도 있는 템플릿 (로컬 템플릿 (140)) 의 하나의 예를 도시한다. 현재의 변환 계수는 'X' 로서 표기되고, 5 개의 공간적 이웃들은 'Xi' ('i' 는 0 내지 4 로부터의 정수를 표현함) 로서 표기된다. 다음의 조건들 중의 임의의 하나가 충족될 경우, 엔트로피 인코딩 유닛 (56) 은 Xi 를 이용불가능하고 컨텍스트 인덱스 유도 프로세스에서 이용되지 않는 것으로서 표기할 수도 있다:
● Xi 의 위치 및 현재의 변환 계수 X 는 동일한 변환 유닛에서 위치되지 않거나; 또는
● Xi 의 위치는 픽처의 수평 또는 수직 경계들의 외부에 위치되거나; 또는
● 변환 계수 Xi 가 아직 코딩되지 않았다. 멀티-패스 코딩의 경우, 동일한 코딩 패스에서의 빈들이 코딩될 때마다, 빈들은 컨텍스트 인덱스 유도 프로세스에서 이용될 수 있다. 그러므로, 디코딩의 관점으로부터, 하나의 변환 계수를 완전히 디코딩하는 것은 필요하지 않다.
대안적으로, 엔트로피 인코딩 유닛 (56) 은 이웃하는 변환 유닛으로부터의 정보를 포함할 수 있는 하나 이상의 다른 템플릿들을 적용할 수도 있다. 다양한 예들에서, 이웃하는 TU 는 공간적 이웃 또는 시간적 이웃일 수도 있다. 본원에서 설명된 컨텍스트 모델링 기법들 중의 하나 이상에 따르면, 컨텍스트 인덱스 계산들은 다음의 단락들에서 설명된 바와 같이 정의될 수도 있다.
bin0 에 대하여, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

여기서,

하나의 예에서, c0 의 범위에 기초하여, 루마 컨텍스트들의 하나의 세트는 NumberLumaCtxOneset 의 값과 동일한 수의 컨텍스트 모델들을 포함할 수도 있다. 예를 들어, 루마 컨텍스트들의 세트는 18 개의 컨텍스트 모델들을 포함할 수도 있다. 루마 bin0 들을 코딩하기 위한 ('w' 에 의해 나타내어진 변환 폭을 갖는) 상이한 변환 크기들에 대하여, 엔트로피 인코딩 유닛 (56) 은 각각의 변환 크기에 대하여 상이한 세트를 선택할 수도 있다. 게다가, 크로마 및 루마 컨텍스트들은 코딩 성능을 추가로 개선시키기 위하여 분리된다. YCbCr 입력들에 대하여, 3 개의 컬러 컴포넌트들, 즉, Y, Cb, 및 Cr 은 각각 0, 1, 및 2 와 동일한 컴포넌트 인덱스 v 로 표현된다.
이 예들에서, 엔트로피 인코딩 유닛 (56) 은 bin1 에 대한 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

추가적으로, 이 예들에서, 엔트로피 인코딩 유닛 (56) 은 bin2 에 대한 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

하나의 예에서, N 은 0 과 동일하다. 또 다른 예에서, N 은 1 과 동일하다. 대안적으로 또는 추가적으로, N 이 1 과 동일할 때, 엔트로피 인코딩 유닛 (56) 은 0 과 동일한 컨텍스트 인덱스 c1 또는 c2 로 제 1 bin1 또는 bin2 를 코딩할 수도 있다. 이 예에서, 엔트로피 인코딩 유닛 (56) 은 상기 수학식들에 따라 bin1 들 및 bin2 들의 다른 인스턴스들을 코딩할 수도 있다.
하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 모델들의 동일한 세트이지만, 상이한 인덱스들로 bin1 및 bin2 를 인코딩할 수도 있다. 대안적으로, bin1 및 bin2 는 컨텍스트 모델들의 2 개의 세트들로 코딩되고, 그것들 사이의 종속성은 존재하지 않는다. 나머지 빈들에 대하여, 엔트로피 인코딩 유닛 (56) 은 HEVC 에서 제시된 설계, 또는 JCTVC-H0228 에서의 설계를 적용할 수도 있다. 다양한 예들에서, 엔트로피 인코딩 유닛 (56) 은 위에서 설명된 다양한 함수들을 구축함에 있어서 상이한 상수 값들을 이용할 수도 있다.
이 개시물의 추가적인 양태들은 컨텍스트 초기화 개량들에 관한 것이다. 이 개시물의 컨텍스트 초기화 개량들은 위에서 설명된 병렬화된 컨텍스트 선택 기법들에 관계 없이 구현될 수도 있거나, 위에서 설명된 병렬화된 컨텍스트 선택 기법들 중의 임의의 하나 이상과 조합하여 구현될 수도 있다. 이 개시물의 컨텍스트 초기화 기법들 중의 하나 이상은 이전에-인코딩된 정보로부터의 컨텍스트 정보를 재이용하는 것에 관한 것이다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 현재의 픽처 또는 이전에-인코딩된 픽처에 속할 수도 있는 이전에-인코딩된 슬라이스로부터 스테이터스 (status) 를 복사함으로써, 슬라이스에 대한 컨텍스트 정보를 승계할 수도 있거나, 또는 그렇지 않을 경우에 유도할 수도 있다. 이 개시물의 승계-기반 컨텍스트 초기화 기법들에 따른 다양한 예들에서, 용어 '스테이터스' 는 상태 정보 및 가장 높은 확률 심볼 (MPS) 값의 조합을 지칭한다. 다음의 설명에서, 용어 '슬라이스' 는 용어 '타일 (tile)' 과 상호 교환가능하게 이용될 수도 있다.
이전에-인코딩된 슬라이스로부터 컨텍스트 초기화 정보를 승계함으로써, 엔트로피 인코딩 유닛 (56) 은 현존하는 CABAC 컨텍스트 초기화 기법들에 비해 개량된 정확도를 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 현존하는 CABAC 컨텍스트 초기화 기법들은 표로부터 컨텍스트 스테이터스 정보를 획득하는 것에 의존한다. 그러나, 표는 정적 정보를 이용하여 형성된다. 그러나, 이 개시물의 승계-기반 컨텍스트 초기화 기법들에 따르면, 엔트로피 인코딩 유닛은, 동일한 슬라이스 타입이고 및/또는 현재 인코딩되고 있는 슬라이스와 동일한 양자화 파라미터 (quantization parameter; QP) 들을 가지는 이전에-인코딩된 슬라이스로부터 컨텍스트 초기화 정보를 인출할 수도 있다. 이러한 방법으로, 엔트로피 인코딩 유닛 (56) 은 현재의 슬라이스에 대하여 이용된 컨텍스트 초기화 정보의 정확도를 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
일부 구현예들에 따르면, 엔트로피 인코딩 유닛 (56) 은 이전에-인코딩된 슬라이스의 중심 LCU 를, 컨텍스트 초기화 정보를 그로부터 승계하기 위한 슬라이스로서 식별할 수도 있다. 다양한 예들에서, 엔트로피 인코딩 유닛 (56) 은 다수의 대응하는 이전에-인코딩된 슬라이스들로부터 현재의 픽처의 다수의 슬라이스들에 대한 컨텍스트 초기화를 승계할 수도 있다. 하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 컨텍스트 초기화 기법들에 따라 인코딩된 다수의 슬라이스들의 전부에 대한 컨텍스트 초기화 정보를 그로부터 승계하기 위한 이전에-인코딩된 픽처의 동일한 블록 (즉, 중심 LCU) 을 이용할 수도 있다. 또 다른 예에서, 엔트로피 인코딩 유닛 (56) 은 이전에-인코딩된 픽처의 대응하는 슬라이스들의 각각으로부터의 개개의 중심 LCU 로부터 다수의 슬라이스들의 각각에 대한 컨텍스트 초기화 정보를 승계할 수도 있다.
예를 들어, 이전에-인코딩된 픽처의 중심 LCU 를 인코딩한 후에, 엔트로피 인코딩 유닛 (56) 은 슬라이스 컨텍스트 초기화에 대한 스테이터스 정보의 전부를 저장할 수도 있다. 결국, 엔트로피 인코딩 유닛 (56) 은 복사된 스테이터스 정보를 액세스할 수도 있거나 판독할 수도 있고, 현재 인코딩되고 있는 픽처의 하나 이상의 슬라이스들에 대한 컨텍스트를 초기화하기 위한 스테이터스 정보를 이용할 수도 있다. 현재의 픽처의 슬라이스들에 대한 컨텍스트 초기화를 수행하기 위하여 이전에-인코딩된 픽처로부터의 스테이터스 정보를 이용함으로써, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 초기화의 목적을 위하여 정적 정보의 고정된 표에 대한 의존성을 감소시킬 수도 있다. 예를 들어, 제 1 픽처의 슬라이스들에 대한 것뿐만 아니라, 임의의 인트라-코딩된 픽처들에 대한 컨텍스트를 초기화하기 위하여 고정된 표를 이용한 후에, 엔트로피 인코딩 유닛 (56) 은 추후에 인코딩되는 인터-코딩된 픽처들에 대한 컨텍스트 초기화를 수행할 수도 있다. 엔트로피 인코딩 유닛 (56) 은 P 슬라이스들 및/또는 B 슬라이스들에 대하여 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 구현할 수도 있다.
이 개시물의 컨텍스트 초기화 기법들에 대한 추가적인 예의 세부사항들이 이하에서 설명된다. 엔트로피 인코딩 유닛 (56) 은 추가적으로 또는 대안적으로, 이하에서 논의된 바와 같이, 컨텍스트 초기화에 대한 이 개시물에 따른 기법들을 수행하도록 구성될 수도 있다. 엔트로피 인코딩 유닛 (56) 은 현재의 슬라이스를 코딩하기 위한 초기화된 컨텍스트 정보로서 이전에 인코딩된 픽처에서 위치된 하나의 블록을 인코딩한 후의 컨텍스트 정보를 승계하기 위하여 이 개시물의 컨텍스트 초기화 기법들을 구현할 수도 있다. 엔트로피 인코딩 유닛 (56) 은 승계-기반 컨텍스트 초기화 기법들을 P 및/또는 B 슬라이스들에 적용할 수도 있다. 추가적으로, 위에서 지칭된 '하나의 블록' 의 위치는 미리 정의되고, 하나의 전체 시퀀스에 대하여 고정된다. 예를 들어, 최대 코딩 유닛 크기 (LCU) 는 "NxN" 에 의해 나타내어지고, 픽처 폭은 "W" 에 의해 나타내어지고, 픽처 높이는 "H" 에 의해 나타내어진다. 이 예에서, "PicWidthInCtbsY" 에 의해 나타내어진, 하나의 LCU 행 내에서의 LCU 들의 수는 천장 함수 (ceiling function), 즉, Ceil( W ÷ N ) 의 출력과 동일하다. 추가적으로, 이 예에서, "PicHeightInCtbsY" 에 의해 나타내어진 LCU 행들의 수는 Ceil( H ÷ N ) 과 동일하고, 여기서, 천장 함수 Ceil (x) 는 x 이상인 가장 작은 정수를 표현한다.
일부 예들에 따르면, 위치는 이전에 코딩된 픽처에서의 최초 슬라이스의 중심 LCU 로서 정의된다. numLCUinSlice 가 최초 슬라이스에서의 LCU 수를 표현하는 것으로 추정하면, 위치는 다음으로서 정의된다: TargetCUAddr = numLCUinSlice/2. 하나의 예에서, 위치는 다음으로서 정의된다: TargetCUAddr = (PicWidthInCtbsY* PicHeightInCtbsY)/2 + PicWidthInCtbsY /2. 또한, TargetCUAddr 이 (PicWidthInCtbsY* PicHeightInCtbsY) 이상일 때 (예컨대, PicHeightInCtbsY 는 1 과 동일함), TargetCUAddr 은 최후 LCU 에 대응하고 있는 (PicWidthInCtbsY* PicHeightInCtbsY - 1) 로 재설정된다. 하나의 예에서, 위치는 이전에 코딩된 픽처의 최후 LCU, 또는 하나의 프레임 내에서의 중심 LCU (즉, PicWidthInCtbsY* PicHeightInCtbsY/2), 또는 중심 LCU 행의 최후 LCU (즉, PicWidthInCtbsY* (PicHeightInCtbsY/2) - 1), 또는 k 번째 LCU 행의 최후 LCU (예컨대, k 는 1 과 동일함) 로서 정의된다. 하나의 예에 따르면, 위치는 이전에-인코딩된 픽처에서의 최초 슬라이스의 최후 LCU 로서 정의된다. 이 개시물의 컨텍스트 초기화 기법들의 일부 구현예들에 따르면, 상이한 해상도들은 코딩 블록의 위치의 상이한 정의들을 가질 수도 있다.
일부 예들에서, '하나의 블록' 의 위치는 시퀀스 파라미터 세트 (sequence parameter set; SPS) 또는 픽처 파라미터 세트 (picture parameter set; PPS) 와 같은 파라미터 세트에서 시그널링된다. SPS 들 및/또는 PPS 들과 같은 파라미터 세트들은 현재의 픽처의 슬라이스들에 대하여 대역외 (out-of-band) 로 시그널링될 수 있다. 일부 예들에서, '하나의 블록' 의 위치는 슬라이스 헤더에서 시그널링될 수 있다. 슬라이스 헤더는 대응하는 슬라이스에 대하여 대역내 (in-band) 로 시그널링될 수도 있다. 이러한 그리고 다른 예들에서, 참조 픽처 인덱스, 대응하는 픽처 순서 카운트 차이 (또는 델타 POC) 와 같은 이전에-인코딩된 픽처의 표시는 파라미터 세트 또는 슬라이스 헤더에서 시그널링될 수도 있다.
일부 예들에서, '이전에-코딩된 픽처' 는 현재의 픽처 바로 전에 (직전에) 인코딩/디코딩되는 픽처로서 정의된다. 일부 예들에서, '이전에-코딩된 픽처' 는 현재의 픽처 전에 인코딩되거나 디코딩된 최후 픽처인 픽처로서 정의되어, 이전의 픽처에서의 최초 슬라이스는 현재의 슬라이스에 대한 동일한 슬라이스 타입을 가진다. 일부 예들에 따르면, '이전에-코딩된 픽처' 는 현재의 픽처 전의 인코딩된/디코딩된 픽처인 픽처로서 정의되고, 이전의 픽처에서의 최초 슬라이스는 현재의 슬라이스에 대한 동일한 초기화된 양자화 파라미터들을 가진다. 일부 예들에 따르면, '이전에-코딩된 픽처' 는, 현재의 슬라이스 및/또는 동일한 초기화된 양자화 파라미터들로서, 동일한 슬라이스 타입, 또는 양자의 동일한 슬라이스 타입 및 양자화 파라미터 (들), 또는 양자의 동일한 슬라이스 타입 및 시간적 계층을 가지는 이전에 코딩된 슬라이스를 포함하는 픽처로서 정의된다. 일부 예들에서, '이전에-코딩된 픽처' 는 (코딩된 픽처 버퍼 또는 디코딩된 픽처 버퍼와 같은) 픽처 버퍼에서 존재하는 픽처로서 정의되고, 참조 픽처로서 현재의 픽처에 대하여 이용될 수도 있다. 이 예들에 따르면, HEVC 기반 플랫폼에서와 같이, 이전의 슬라이스는 참조 픽처 세트 (RPS) 에서의 픽처, 또는 RPS 의 다음의 서브세트들 중의 하나에서의 픽처에 속해야 한다: RefPicSetStCurrBefore, RefPicSetStCurrAfter, 및 RefPicSetLtCurr.
이 개시물의 컨텍스트 초기화 기법들의 일부 구현예들에 따르면, 디스플레이 순서에서의 하나의 인트라-코딩된 픽처 후에 코딩된 픽처들의 전부가 동일한 슬라이스 타입들 및 동일한 초기화된 양자화 파라미터들을 가지지 않을 경우, 컨텍스트 정보의 승계는 디스에이블될 수도 있다. 이 경우, 기존의 초기화 방법이 적용되고, 예컨대, 엔트로피 인코딩 유닛 (56) 은 초기화 스테이터스 정보를 그로부터 인출하기 위한 고정된 표를 이용할 수도 있다. 일부 구현예들에 따르면, 엔트로피 인코딩 유닛 (56) 은 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 다른 컨텍스트 모델들이 아니라, 특정 컨텍스트 모델들에 적용할 수도 있다. 추가적으로 또는 대안적으로, '하나의 블록' 의 위치는 상이한 컨텍스트 모델들에 대하여 상이할 수도 있다. 위에서 열거된 다양한 구현 옵션들은 이 개시물의 컨텍스트 초기화 기법들에 따라, 개별적으로 또는 다양한 조합들로 구현될 수도 있다는 것이 인식될 것이다.
이 개시물의 컨텍스트 초기화 기법들의 일부 예들에서, 엔트로피 인코딩 유닛 (56) 이 cabac_init_present_flag 가 인에이블되는 것으로 결정할 경우, 엔트로피 인코딩 유닛 (56) 은 '이전에-인코딩된 픽처' 내에 포함된 슬라이스가 현재-인코딩된 슬라이스와 동일한 타입을 가져야 하는 것으로 결정할 수도 있다. 바꾸어 말하면, 이 예에서, cabac_init_present_flag 가 인에이블될 경우, 이전에-인코딩된 픽처의 정의는 정합하는 슬라이스 타입들에 종속적이다. 추가적으로, 디코딩의 관점으로부터, 시그널링된 cabac_init_flag 는 이 구현예 따라 고려되지 않는다. 일부 사례들에서, 대안적으로, 엔트로피 인코딩 유닛 (56) 은 cabac_init_flag 및 '이전에-인코딩된 픽처' 의 선택에 기초하여 현재의 슬라이스의 슬라이스 타입을 먼저 수정할 수도 있다.
이 개시물의 컨텍스트 초기화 기법들에 대한 추가적인 예의 세부사항들이 이하에서 설명된다. 일부 구현예들에 따르면, 엔트로피 인코딩 유닛 (56) 은 인트라 랜덤 액세스 픽처들 (Intra Random Access Picture; IRAP) 들에 대하여 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 적용하지 않을 수도 있다. 예를 들어, 엔트로피 인코딩 (56) 은 IRAP 들의 3 개의 타입들, 즉, 순간적 디코딩 리프레시 (instantaneous decoding refresh; IDR) 픽처들, 클린 랜덤 액세스 (clean random access; CRA) 픽처들, 및 파손 링크 액세스 (broken link access; BLA) 픽처들 중의 임의의 것에 대하여 승계-기반 컨텍스트 초기화 기법들을 구현하지 않을 수도 있다.
이전에 코딩된 정보에 기초한 승계-기반 컨텍스트 초기화의 하나의 예에서, 엔트로피 인코딩 유닛 (56) 은 하나의 슬라이스로 하나의 픽처를 인코딩할 수도 있다. 이 예에서, 엔트로피 인코딩 유닛 (56) 은 컨텍스트 모델들의 초기화된 상태들을 유도하기 위하여 다음의 규칙들 중의 하나 이상을 적용할 수도 있다. 제 1 규칙은 이전에-인코딩된 픽처의 슬라이스가 현재-인코딩된 슬라이스에 대한 슬라이스 타입과 동일한 슬라이스 타입을 가진다는 것이다. 대안적으로 또는 추가적으로, 초기화된 슬라이스 양자화 파라미터 (QP) 는 현재-인코딩된 슬라이스를 코딩하기 위하여 이용된 슬라이스 QP 와 동일하다.
이 개시물의 일부 양태들에 따르면, 엔트로피 인코딩 유닛 (56) 은 상이한 QP 들이 현재의 슬라이스 및 예측자 슬라이스에 대하여 이용될 때, 이전에-인코딩된 슬라이스로부터 컨텍스트 초기화 정보를 승계할 수도 있다. 이 예들에서, 엔트로피 인코딩 유닛 (56) 은 현재의 슬라이스를 인코딩하기 위한 컨텍스트 초기화 정보를 이용하기 전에, 컨텍스트 상태들에 대하여 맵핑 프로세스를 적용할 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 하나의 상태를 또 다른 상태로 변환하기 위하여, 하나 이상의 초기화 함수들 (예컨대, HEVC 에서 특정된 초기화 함수) 뿐만 아니라, 2 개의 QP 들 및 컨텍스트를 사용할 수도 있다. 일부 사례들에서, 엔트로피 인코딩 유닛 (56) 은 이전에 코딩된 픽처에서의 미리 정의된 어드레스로 하나의 블록을 인코딩한 후에 상태 정보 (예컨대, 상태들) 를 레코딩할 수도 있고, 레코딩된 상태 정보를, 현재-인코딩된 슬라이스에 대한 초기화된 상태 정보로서 이용할 수도 있다.
하나의 예에서, '하나의 블록' 은 최대 코딩 유닛 (LCU) 을 표현한다. 예를 들어, LCU 크기 (차원성) 은 'NxN' 에 의해 나타내어질 수도 있고, 픽처 폭은 'W' 에 의해 나타내어질 수도 있고, 픽처 높이는 'H' 에 의해 나타내어질 수도 있다. 하나의 LCU 행 내에서의 LCU 들의 수는 PicWInCtbsY 에 의해 나타내어질 수도 있고, 천장 함수 Ceil( W ÷ N ) 의 출력과 동일하다. PicHInCtbsY 에 의해 나타내어진, 픽처에서의 LCU 행들의 수는 천장 함수 Ceil( H ÷ N ) 의 출력과 동일하다. 포괄적으로 설명하면, 함수 Ceil (x) 는 x 이상인 가장 작은 정수를 반환한다. 추가적으로, LCU 들의 단위들로 측정된 픽처의 폭과, LCU 들로 측정된 픽처의 높이는 위에서 설명된 천장 함수들을 이용하여 획득된 PicWInCtbsY 및 PicHInCtbsY 값들에 의해 각각 표현된다. 하나의 예에서, LCU 의 어드레스는 다음의 수학식에 따라 정의된다:
또한, TargetCUAddr 가 (PicWInCtbsY* PicHInCtbsY) 의 값 이상일 때, 엔트로피 인코딩 유닛 (56) 은 TargetCUAddr 을 (PicWInCtbsY* PicHInCtbsY - 1) 의 값으로 재설정할 수도 있다. 예를 들어, TargetCUAddr 은 PicHInCtbsY 가 1 과 동일한 경우들에는 상기 값과 동일할 수도 있거나 이를 초과할 수도 있다. 추가적으로, (PicWInCtbsY* PicHInCtbsY - 1) 의 값은 하나의 픽처에서의 최후 LCU 에 대응한다.
일부 사례들에서, 또한, 엔트로피 인코딩 유닛 (56) 은 디스플레이 순서에서의 새로운 인트라-코딩된 픽처 후의 최초의 하나 이상의 픽처들에 대하여 위에서 설명된 규칙들-기반 컨텍스트 초기화 기법들을 적용하지 않을 수도 있다. 엔트로피 인코딩 유닛 (56) 이 규칙들-기반 컨텍스트 초기화를 적용하지 않을 수도 있는 예는, 엔트로피 인코딩 유닛 (56) 이 처음으로 새로운 슬라이스 타입 또는 새로운 QP 를 조우한 경우 (예컨대, 새로운 슬라이스 타입 또는 새로운 QP 가 나타남) 이다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 랜덤 액세스에 관련된 쟁점들을 완화시킬 수도 있거나 잠재적으로 회피할 수도 있다. 이 기법의 예는 도 9 에서 도시되어 있고, 28 로부터 35 까지의 픽처 순서 카운트 (POC) 값들을 갖는 픽처들에 대한 코딩 (그리고 이것에 의해, 디코딩) 순서는 다음과 같다: 32, 28, ... 30, 29, 31, 40, 36, 34, 33, 35.
디스플레이 순서의 측면에서, 40 과 동일한 POC 값을 갖는 픽처는 32 와 동일한 POC 값을 갖는 I-픽처 후에 디코딩되는 제 1 픽처이다. 24 의 POC 값을 갖는 픽처는 40 과 동일한 POC 를 갖는 픽처와 동일한 QP 를 가지고, 양자는 동일한 슬라이스 타입들을 공유하지만, 엔트로피 인코딩 유닛 (56) 은 24 와 동일한 POC 를 갖는 픽처의 코딩된 정보를 이용하여 40 과 동일한 POC 값을 갖는 픽처를 예측하지 않을 수도 있다. 유사하게, 엔트로피 인코딩 유닛 (56) 은 31 과 동일한 POC 를 갖는 픽처의 코딩된 정보를 이용하여 33 과 동일한 POC 갖는 픽처를 예측하지 않을 수도 있다. 그러나, 양자의 픽처들은 (디스플레이 순서에서) I-픽처에 후속하므로, 엔트로피 인코딩 유닛 (56) 은 33 과 동일한 POC 를 갖는 픽처의 코딩된 정보를 이용하여 35 와 동일한 POC 를 갖는 픽처를 예측할 수도 있다.
이전에 코딩된 픽처로부터의 예측이 허용되지 않거나, 디스에이블되거나, 또는 그렇지 않을 경우에 엔트로피 인코딩 유닛 (56) 에 의해 이용가능하지 않는 사례들에서, 엔트로피 인코딩 유닛 (56) 은 HEVC 에서 정의된 바와 같이 컨텍스트 초기화 기법들을 적용할 수도 있다. 위에서 설명된 바와 같이, 도 4 의 비디오 인코더 (20) 는 단독으로 또는 임의의 조합으로, 개량된 CABAC 를 위하여 이 개시물의 다양한 기법들 중의 임의의 것을 수행하도록 구성될 수도 있는 비디오 인코더의 예를 표현한다. 일부 예들에서, 비디오 인코더 (20) 는 변환 유닛을 인코딩하기 위한 코딩 모드를 선택하도록 구성된다. 일부 예들에서, 비디오 인코더 (20) 는 비디오 데이터의 적어도 부분을 캡처하도록 구성된 카메라를 포함하는 디바이스를 포함할 수도 있거나, 이 디바이스일 수도 있거나, 이 디바이스의 일부일 수도 있다. 일부 예들에서, 비디오 인코더 (20) 는 카메라로부터 캡처된 비디오 데이터를 수신하도록 구성되는 메모리 디바이스를 포함할 수도 있다.
도 5 는 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 인코딩 유닛 (56) 의 블록도이다. 신택스 엘리먼트 (118) 는 엔트로피 인코딩 유닛 (56) 으로 입력된다. 신택스 엘리먼트가 이미 2진-값 신택스 엘리먼트 (예컨대, 0 및 1 의 값을 오직 가지는 플래그 또는 다른 신택스 엘리먼트) 일 경우, 2 진화의 단계가 스킵될 수도 있다. 신택스 엘리먼트가 비-2진 값의 신택스 엘리먼트 (예컨대, 1 또는 0 이외의 값들 가질 수도 있는 신택스 엘리먼트) 일 경우, 비-2진 값의 신택스 엘리먼트는 2진화기 (120) 에 의해 2 진화된다. 2진화기 (120) 는 2 진 판정들의 시퀀스로의 비-2진 값의 신택스 엘리먼트의 맵핑을 수행한다. 이 2 진 판정들은 종종 "빈들" 로 칭해진다. 예를 들어, 변환 계수 레벨들에 대하여, 레벨의 값은 연속적인 빈들로 분해될 수도 있고, 각각의 빈은 계수 레벨의 절대 값이 일부 값보다 더 큰지 아닌지 여부를 표시할 수도 있다. 예를 들어, 빈 0 (때때로 중요도 플래그로 칭해짐) 은 변환 계수 레벨의 절대 값이 0 보다 더 큰지 아닌지를 표시한다. 빈 1 은 변환 계수 레벨의 절대 값이 1 보다 더 큰지 아닌지 등을 표시한다. 고유한 맵핑은 각각의 비-2진 값의 신택스 엘리먼트에 대하여 전개될 수도 있다.
2진화기 (120) 에 의해 생성된 각각의 빈은 엔트로피 인코딩 유닛 (56) 의 2 진 산술 코딩 측으로 공급된다. 즉, 비-2진 값의 신택스 엘리먼트들의 미리 결정된 세트에 대하여, 각각의 빈 타입 (예컨대, 빈 0) 은 다음 빈 타입 (예컨대, 빈 1) 전에 코딩된다. 코딩은 규칙적 모드 또는 우회 모드의 어느 하나에서 수행될 수도 있다. 우회 모드에서, 우회 코딩 엔진 (126) 은 고정된 확률 모델을 이용하여, 예를 들어, 골롬-라이스 또는 지수 골롬 코딩을 이용하여 산술 코딩을 수행한다. 우회 모드는 더 예측가능한 신택스 엘리먼트들에 대하여 일반적으로 이용된다.
규칙적 모드에서의 코딩은 CABAC 를 수행하는 것을 수반한다. 규칙적 모드 CABAC 는 빈 값들을 코딩하기 위한 것이고, 여기서, 빈의 값의 확률은 이전에-인코딩된 빈들의 값들이 주어질 경우에 예측가능하다. LPS 인 빈의 확률은 컨텍스트 모델러 (122) 에 의해 결정된다. 컨텍스트 모델러 (122) 는 컨텍스트 모델에 대한 빈 값 및 확률 상태 (예컨대, LPS 의 값 및 LPS 가 발생하는 확률을 포함하는 확률 상태 σ) 를 출력한다. 컨텍스트 모델은 일련의 빈들에 대한 초기 컨텍스트 모델일 수도 있거나, 이전에 코딩된 빈들의 코딩된 값들에 기초하여 결정될 수도 있다. 위에서 설명된 바와 같이, 컨텍스트 모델러 (122) 는 수신된 빈이 MPS 또는 LPS 이었는지 아닌지의 여부에 기초하여 상태를 업데이트할 수도 있다. 컨텍스트 모델 및 확률 상태 σ 가 컨텍스트 모델러 (122) 에 의해 결정된 후에, 규칙적 코딩 엔진 (124) 은 빈 값에 대해 BAC 를 수행한다.
컨텍스트 모델러 (122) 는 병렬화된 방식으로 컨텍스트 모델링을 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이 개시물의 다양한 양태들에 따르면, 컨텍스트 모델러 (122) 는 하나 이상의 이전에-인코딩된 변환 계수들의 i 번째 빈들의 값들을 이용하여 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링을 수행할 수도 있다. 이러한 방법으로, 현재의 변환 계수에 대한 i 번째 빈의 컨텍스트 모델링은 컨텍스트 모델러 (122) 가 이미 컨텍스트를 선택한 하나 이상의 변환 계수들의 대응하는 i 번째 빈들의 값들에 종속적이다.
이전에-인코딩된 변환의 i 번째 빈들의 값들을 이용하여 현재의 변환 계수의 빈에 대한 컨텍스트 모델링을 수행함으로써, 컨텍스트 모델러 (122) 는 현존하는 CABAC 코딩 디바이스들에 비해 하나 이상의 잠재적인 개선들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이러한 장점의 예로서, 컨텍스트 모델러 (122) 는 이 개시물의 기법들을 구현함으로써 컨텍스트 모델링 동작의 병렬화를 개선시킬 수도 있다. 예를 들어, 컨텍스트 모델러 (122) 는 현재 인코딩되고 있는 변환 계수의 다수의 빈들에 대하여, 컨텍스트 모델링을 병렬로 수행할 수도 있다. 하나의 예로서, 컨텍스트 모델러 (122) 가 다수의 빈들에 대응하는 빈 값들이 이전에-인코딩된 변환 계수 (들) 로부터 이용가능한 것으로 결정할 경우, 컨텍스트 모델러 (122) 는 현재 인코딩되고 있는 변환 계수의 빈들에 대한 컨텍스트 모델링 동작들을 적어도 부분적으로 병렬화할 수도 있다.
컨텍스트 모델러 (122) 는 멀티-패스 코딩 방식에 따라 이 개시물의 병렬화된 컨텍스트 모델링을 수행할 수도 있다. 더 구체적으로, 멀티-패스 코딩 방식은 엔트로피 인코딩 유닛 (56) 이 별도의 스레드들을 각각의 특정한 빈에 배정하게 하는 코딩 기법 (예컨대, 제 1 빈에 대한 스레드 1, 제 2 빈에 대한 스레드 2 등) 을 지칭한다. 이에 따라, 멀티-패스 코딩에 따르면, 모든 bin0 인스턴스들은 시퀀스로 코딩되는 bin1 인스턴스들에 독립적으로 시퀀스로 인코딩될 수 있고, 양자는 시퀀스로 인코딩되는 bin2 인스턴스들에 독립적으로 코딩되는 등과 같다. 일부 예들에서, 컨텍스트 모델러 (122) 는 단일 블록의 변환 유닛들에 대하여 멀티-패스 코딩을 수행할 수도 있다. 또한, 규칙적 모드에 따라 인코딩되는 빈들에 대하여, 컨텍스트 모델러 (122) 는 다수의 패스들에서 컨텍스트 선택을 수행할 수도 있다. 각각의 패스는 모든 변환 계수들의 단일의 대응하는 빈에 속할 수도 있다. 다시 말해서, 각각의 패스 동안에, 컨텍스트 모델러 (122) 는 다른 패스들에 관련되는 정보를 사용하지 않는다. 예를 들어, 컨텍스트 모델러 (122) 는 제 1 패스에서 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 1 빈에 대한 컨텍스트를 선택할 수도 있다. 이 예에서, 제 2 패스에서, 컨텍스트 모델러 (122) 는 필요할 경우, 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 2 빈에 대한 컨텍스트를 선택할 수도 있는 등과 같다.
하나의 예의 이용 경우에 있어서, 컨텍스트 모델러 (122) 는 이전에-코딩된 이웃하는 변환 계수의 bin0 의 값을 이용하여 현재-코딩된 변환 계수의 bin0 에 대한 컨텍스트 모델링을 수행할 수도 있고, 이전에-코딩된 이웃하는 변환 계수의 bin1 의 값을 이용하여 현재-코딩된 변환 계수의 bin1 에 대한 컨텍스트 모델링을 수행할 수도 있는 등과 같다. 이전에-코딩된 변환 계수에 대하여 이용가능한 임의의 빈 값들을 이용하면, 컨텍스트 모델러 (122) 는 현재-코딩된 변환 계수의 다수의 빈들에 대한 컨텍스트 모델링을 병렬로 수행할 수도 있다. 위에서 설명된 이용 경우의 시나리오에서, bin0 및 bin1 이 양자 모두 이전에-코딩된 이웃 변환 계수로부터 이용가능할 경우, 컨텍스트 모델러 (122) 는 현재-코딩된 변환 계수에 대한 bin0 및 bin1 의 컨텍스트 모델링을 병렬화할 수도 있다. 이러한 방식으로, 컨텍스트 모델러 (122) 는 컨텍스트 모델링 동작들의 병렬화를 가능하게 하고 잠재적으로 활용함으로써 현재의 변환 계수의 빈들에 대한 컨텍스트 선택을 개선시키면서, HEVC 에서 설명된 바와 같이 멀티-패스 코딩의 원리들 내에서 CABAC 를 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다.
컨텍스트 모델러 (122) 는 모든 이러한 빈들의 전체 컨텍스트 모델링을 병렬로 수행할 수 있지만, 반드시 그러한 것은 아닐 수도 있다는 것이 인식될 것이다. 더 구체적으로, 컨텍스트 모델러 (122) 는 다수의 빈들의 컨텍스트 모델링의 일부 부분들을 동시에 수행할 수도 있다. 이러한 방법으로, 컨텍스트 모델러 (122) 는 멀티코어 프로세싱 기술 및/또는 다수의 프로세서들을 이용하여 현재-코딩된 변환 계수에 대한 컨텍스트 모델링 동작들을 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
단일 패스에서 상이한 변환 계수들의 대응하는 빈들을 인코딩함으로써, 컨텍스트 모델러 (122) 는 현존하는 멀티-패스 CABAC 기법들에 비해 하나 이상의 장점들을 제공할 수도 있다. 예를 들어, 단일 패스에서 다수의 변환 계수들의 대응하는 빈들 (예컨대, 개개의 bin0) 을 코딩함으로써, 컨텍스트 모델러 (122) 는 빈 천이들에서 빈번하게 새로운 컨텍스트 모델을 저장하고 취출하기 위한 필요성을 회피할 수도 있다. 그 대신에, 패스는 다수의 변환 계수들에 걸쳐 대응하는 빈들 (예컨대, 개개의 bin0) 을 타겟으로 하므로, 컨텍스트 모델러 (122) 는 소정의 패스에 걸쳐 단일 컨텍스트 모델을 이용할 수도 있다. 이러한 방법으로, 컨텍스트 모델러 (122) 는 빈번한 컨텍스트-스위칭으로부터 발생하는 시간 지연들 및 자원 회전을 완화시키거나 또는 잠재적으로 제거하기 위하여 이 개시물의 병렬화된 컨텍스트 선택 기법들을 구현할 수도 있다. 대조적으로, 현존하는 멀티-패스 코딩은 제 1 변환 계수에 대하여, bin0, bin1, bin2 등을 인코딩하고, 그 다음으로, 제 2 변환 계수에 대하여 bin0, bin1, bin2 등을 인코딩하는 등으로 인해, 빈번한 컨텍스트 모델 저장 및 취출 동작들을 요구할 것이다.
예를 들어, 컨텍스트 모델러 (122) 는 본원에서 설명된 i 번째 빈 컨텍스트 모델링 기능성들을 위하여 이용하기 위한 하나 이상의 미리 정의된 템플릿들을 생성할 수도 있거나, 또는 그렇지 않을 경우에 이에 액세스할 수도 있다. 컨텍스트 모델러 (122) 가 현재-코딩된 변환 계수의 i 번째 빈의 컨텍스트 모델링을 위하여 이용할 수도 있는 미리 정의된 템플릿의 하나의 비-제한적인 예는 도 10 에서 예시되어 있다. 도 10 의 템플릿 (140) 과 같은 미리 정의된 템플릿은 8x8 변환 블록에 대하여 대각선 스캔 순서를 정의하고, 여기서, 'L' 은 최후의 중요한 스캔 위치를 나타내고, 'x' 는 현재의 스캔 위치를 나타내고, "xi" 는 로컬 템플릿 (140) 에 의해 커버된 이웃들을 나타낸다. xi 에 대하여, "i" 의 값은 제로 내지 4 의 범위에 있고, 범위 제약은 i ∈ [0,4] 로서 표현된다. 이 개시물의 하나 이상의 양태들에 따르면, 컨텍스트 모델러 (122) 는 현재 인코딩되고 있는 변환 계수의 대응하는 i 번째 빈의 컨텍스트 모델링을 위하여 로컬 템플릿 (140) 에서 위치된 변환 계수들의 i 번째 빈들을 이용할 수도 있다. 일부 구현예들에 따르면, 컨텍스트 모델러 (122) 는 이 개시물의 병렬화된 빈 컨텍스트 모델링을 수행하기 위하여 다수의 템플릿들을 이용할 수도 있다. 하나의 예에서, 템플릿 크기 및/또는 형상은 다음의 기준들 중의 하나 이상에 종속적이다: (i) 변환 유닛들의 크기; (ii) 모드들; 또는 (iii) 현재의 변환 유닛 또는 계수 그룹 (CG) 내에서의 현재의 변환 계수들의 위치.
빈 값들에 대하여 이전에-코딩된 TU 를 횡단하기 위하여 하나 이상의 미리 정의된 템플릿들을 이용함으로써, 컨텍스트 모델러 (122) 는 현존하는 CABAC 기술에 비해 하나 이상의 개량들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 도 10 의 로컬 템플릿 (140) 과 같은 TU 횡단 템플릿을 이용함으로써, 컨텍스트 모델러 (122) 는 상이한 코딩 패스들에 대하여 횡단 방식을 별도로 결정하기 위한 필요성을 회피할 수도 있다. 이에 따라, 이 개시물의 템플릿-기반 병렬화된 컨텍스트 선택 기법들을 구현함으로써, 컨텍스트 모델러 (122) 는 코딩 정밀도를 유지하면서, 빈 코딩에 대한 스루풋을 증가시킬 수도 있다.
또 다른 예의 구현예에 따르면, 컨텍스트 모델러 (122) 는 이 개시물의 병렬화된 컨텍스트 모델링 기법들을 현재-코딩된 변환 계수의 처음 'K' 빈들에 오직 적용할 수도 있고, 여기서, 'K' 는 M 보다 더 작고, 여기서, 'M' 은 이용가능한 빈 인덱스들의 상한을 나타낸다. 컨텍스트 모델러 (122) 는 또 다른 컨텍스트 모델링 기법을 이용하여, 또는 우회 모드에 따라 코딩되고 있는 나머지 (M+1-K) 빈들을 인코딩할 수도 있다.
또 다른 예의 구현예에 따르면, 컨텍스트 모델러 (122) 는 이전에-코딩된 변환 계수들의 모집단을, 현재 인코딩되고 있는 변환 계수 전의 현재의 변환 유닛 또는 CG 내에서의 인코딩 순서에서의 'N' 연속 변환 계수들로서 정의할 수도 있다. 대안적으로, 컨텍스트 모델러 (122) 는 N 을 변수인 것으로 결정할 수도 있다. 하나의 예에서, 컨텍스트 모델러 (122) 는 현재의 변환 유닛에서의 현재-인코딩된 변환 계수의 상대적인 위치에 종속적인 N 의 값을 결정할 수도 있다. 또 다른 예에서, 컨텍스트 모델러 (122) 는 변환 유닛 크기에 종속적인 N 의 값을 결정할 수도 있다.
또 다른 구현예에서, 컨텍스트 모델러 (122) 는 이전에-인코딩된 변환 계수들의 모집단을, 현재의 변환 유닛 또는 CG 내에서의 현재의 위치의 이웃에 위치된 그 변환 계수들로서 정의할 수도 있다. 하나의 예에서, 현재의 위치의 이웃은 현재의 위치에 직접적으로 인접한 그 위치들, 또는 현재의 위치에 직접적으로 인접하거나 현재의 위치로부터 분리된 것 중의 하나인 위치들로 제약된다. 또 다른 예에서, 이웃은 또한, 이 위치들을 포함할 수도 있지만, 하나 이상의 공간적 이웃하는 변환 유닛들에서의 위치들을 포함하도록 확대할 수도 있다.
이 개시물의 다양한 양태들에 따르면, 컨텍스트 모델러 (122) 는 빈의 컨텍스트 인덱스를, 하나 이상의 이전에-코딩된 변환 계수들과 연관된 값들의 함수로서 정의할 수도 있다. 예를 들어, 컨텍스트 모델러 (122) 는 이전에-코딩된 변환 계수들의 모든 i 번째 빈 값들의 합을 산출하는 함수를 이용할 수도 있다. 더 구체적으로, 이 예에서, 컨텍스트 모델러 (122) 는 TU/CG 의 모든 이전에-인코딩된 변환 계수들의 이용가능한 i 번째 빈 값들의 값들의 합산을 수행할 수도 있다. 결국, 컨텍스트 모델러 (122) 는 현재-코딩된 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링 동안에 결과적인 합을 컨텍스트 인덱스 (CtIdx) 로서 이용할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (122) 는 컨텍스트 인덱스 유도 규칙을, 변환 유닛들의 상이한 크기들에서의 동일한 패스에 대하여 미변경된 것으로 유지할 수도 있다. 그러나, 컨텍스트 모델러 (122) 는 현재-코딩된 빈에 대한 컨텍스트 모델링을 수행하기 위하여 오프셋을 컨텍스트 인덱스에 적용할 수도 있다. 예를 들어, 컨텍스트 모델러 (122) 는 2 개의 상이한 변환 크기들이 컨텍스트 모델들의 2 개의 세트들을 가지는 것으로 결정할 수도 있다. 결국, 컨텍스트 모델러 (122) 는 오프셋을, 하나의 이러한 세트에서의 컨텍스트 모델들의 수로서 정의할 수도 있다. 예를 들어, 컨텍스트 모델러 (122) 가 TU 크기가 미리 정의된 차원들 MxM 의 정사각형보다 더 작은 것으로 결정할 경우, 컨텍스트 모델러 (122) 는 각각의 이러한 TU (MxM 보다 더 작음) TU 크기가 컨텍스트 모델들의 그 자신의 개개의 세트를 가지는 것으로 결정할 수도 있다. 반대로, 엔트로피 인코딩 유닛 (56) 은 MxM 과 동일하거나 그보다 더 큰 크기들을 갖는 모든 TU 들이 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다.
다양한 이용 경우의 시나리오들에서, 컨텍스트 모델러 (122) 는 M 의 값을 16 으로 설정할 수도 있다. 더 구체적으로, 이 예들에서, 컨텍스트 모델러 (122) 가 현재-코딩된 TU 의 크기가 16x16 정사각형보다 더 작은 것으로 결정할 경우, 컨텍스트 모델러 (122) 는 현재-코딩된 TU 가 TU 의 특정한 크기에 대응하는 컨텍스트 모델들의 세트와 연관되는 것으로 결정할 수도 있다. 반대로, 엔트로피 인코딩 유닛이 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 것으로 결정할 경우, 컨텍스트 모델러 (122) 는 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 모든 다른 TU 들과 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다. 일부 예들에서, 컨텍스트 모델러 (122) 는 TU 크기-기반 컨텍스트 선택을 오직 루마 블록들에 적용할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (122) 는 변환 크기에 기초하여 계수 그룹 (CG) 크기를 결정할 수도 있다. 다시 말해서, 이 양태들에 따르면, CG 크기는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 컨텍스트 모델러 (122) 는 코딩 모드에 기초하여 CG 크기를 결정할 수도 있다. 이 예들에서, 컨텍스트 모델러 (122) 는 CG 크기를 변환 크기 및/또는 코딩 모드 중의 하나 또는 양자에 종속적인 것으로서 결정할 수도 있다. 대안적으로 또는 추가적으로, 컨텍스트 모델러 (122) 는 변환 행렬에 기초하여 CG 크기를 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (122) 는 또한, 병렬화된 컨텍스트 모델링 기법들을, 변환 우회 모드 (또한, "변환 스킵 모드" 로서 지칭됨) 를 이용하여 인코딩되는 블록들에 적용할 수 있다. 변환 우회 모드는, 비디오 인코더 (20) 가 무손실 코딩 출력을 제공하기 위하여, 코딩 모드에 따라, 인코딩의 변환 및 양자화 동작들을 스킵할 수도 있는 코딩 모드를 지칭한다. 이에 따라, 이 개시물의 어떤 양태들에 따르면, 컨텍스트 모델러 (122) 는 무손실 코딩의 사례들에서 잠재적으로 결과적인 장점들을 제공하기 위하여 병렬화된 컨텍스트 선택 기법들을 확대할 수도 있다.
도 4 로 돌아가면, 일부 경우들에 있어서, 엔트로피 인코딩 유닛 (56) 또는 비디오 인코더 (20) 의 또 다른 유닛은 엔트로피 코딩에 추가하여, 다른 코딩 기능들을 수행하도록 구성될 수도 있다. 예를 들어, 엔트로피 인코딩 유닛 (56) 은 CU 들 및 PU 들에 대한 코딩된 블록 패턴 (coded block pattern; CBP) 값들을 결정하도록 구성될 수도 있다. 또한, 일부 경우들에는, 엔트로피 인코딩 유닛 (56) 이 계수들의 실행 길이 코딩 (run length coding) 을 수행할 수도 있다. 게다가, 엔트로피 인코딩 유닛 (56) 또는 다른 프로세싱 유닛들은 또한, 양자화 행렬의 값들과 같은 다른 데이터를 코딩할 수도 있다.
위에서 논의된 바와 같이, 역양자화 유닛 (58) 및 역변환 프로세싱 유닛 (60) 은 예컨대, 참조 블록으로서의 더 이후의 이용을 위하여, 픽셀 도메인에서 잔차 블록을 복원하기 위하여 역양자화 및 역변환을 각각 적용한다. 모션 보상 유닛 (44) 은 잔차 블록을 참조 픽처 메모리 (64) 의 프레임들 중의 하나의 프레임의 예측 블록에 가산함으로써 참조 블록을 계산할 수도 있다. 모션 보상 유닛 (44) 은 또한, 모션 추정에서의 이용을 위한 정수-미만 픽셀 값들을 계산하기 위하여 하나 이상의 보간 필터들을 복원된 잔차 블록에 적용할 수도 있다. 합산기 (62) 는 참조 픽처 메모리 (64) 에서의 저장을 위한 복원된 비디오 블록을 생성하기 위하여, 복원된 잔차 블록을 모션 보상 유닛 (44) 에 의해 생성된 모션 보상된 예측 블록에 가산한다. 복원된 비디오 블록은 추후의 비디오 프레임에서의 블록을 인터-코딩하기 위하여, 모션 추정 유닛 (42) 및 모션 보상 유닛 (44) 에 의해 참조 블록으로서 이용될 수도 있다.
도 6 은 개량된 CABAC 설계에 따라 데이터를 코딩하기 위한 기법들을 구현할 수도 있는 비디오 디코더 (30) 의 예를 예시하는 블록도이다. 도 3 의 예에서, 비디오 디코더 (30) 는 엔트로피 디코딩 유닛 (70), 모션 보상 유닛 (72), 인트라 예측 유닛 (74), 역양자화 유닛 (76), 역변환 유닛 (78), 참조 픽처 메모리 (82), 및 합산기 (80) 를 포함한다. 일부 예들에서, 비디오 디코더 (30) 는 비디오 인코더 (20) (도 4) 에 대하여 설명된 인코딩 패스와 일반적으로 상반되는 디코딩 패스를 수행할 수도 있다. 모션 보상 유닛 (72) 은 엔트로피 디코딩 유닛 (70) 으로부터 수신된 모션 벡터들에 기초하여 예측 데이터를 생성할 수도 있는 반면, 인트라 예측 유닛 (74) 은 엔트로피 디코딩 유닛 (70) 으로부터 수신된 인트라-예측 모드 표시자들에 기초하여 예측 데이터를 생성할 수도 있다.
디코딩 프로세스 동안, 비디오 디코더 (30) 는 인코딩된 비디오 슬라이스의 비디오 블록들 및 연관된 신택스 엘리먼트들을 표현하는 인코딩된 비디오 비트스트림을 비디오 인코더 (20) 로부터 수신한다. 비디오 디코더 (30) 의 엔트로피 디코딩 유닛 (70) 은 양자화된 계수들, 모션 벡터들 또는 인트라-예측 모드 표시자들, 및 다른 신택스 엘리먼트들을 생성하기 위하여 비트스트림을 엔트로피 디코딩한다. 일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 기법들에 따라 CABAC 및/또는 개량된 CABAC 를 수행할 수도 있다. 엔트로피 디코딩 유닛 (70) 은 모션 벡터들 및 다른 신택스 엘리먼트들을 모션 보상 유닛 (72) 으로 포워딩한다. 비디오 디코더 (30) 는 비디오 슬라이스 레벨 및/또는 비디오 블록 레벨에서 신택스 엘리먼트들을 수신할 수도 있다.
비디오 슬라이스가 인트라-코딩된 (I) 슬라이스로서 코딩될 때, 인트라 예측 유닛 (74) 은 시그널링된 인트라 예측 모드와, 현재의 프레임 또는 픽처의 이전에 디코딩된 블록들로부터의 데이터에 기초하여, 현재의 비디오 슬라이스의 비디오 블록에 대한 예측 데이터를 생성할 수도 있다. 비디오 프레임이 인터-코딩된 (즉, B, P, 또는 GPB) 슬라이스로서 코딩될 때, 모션 보상 유닛 (72) 은 모션 벡터들과, 엔트로피 디코딩 유닛 (70) 으로부터 수신된 다른 신택스 엘리먼트들에 기초하여, 현재의 비디오 슬라이스의 비디오 블록에 대한 예측 블록들을 생성한다. 예측 블록들은 참조 픽처 리스트들 중의 하나 내의 참조 픽처들 중의 하나로부터 생성될 수도 있다. 비디오 디코더 (30) 는 참조 픽처 메모리 (82) 내에 저장된 참조 픽처들에 기초하여, 디폴트 구성 (default construction) 기법들을 이용하여 참조 프레임 리스트들, List 0 및 List 1 을 구성할 수도 있다. 모션 보상 유닛 (72) 은 모션 벡터들 및 다른 신택스 엘리먼트들을 파싱 (parsing) 함으로써 현재의 비디오 슬라이스의 비디오 블록에 대한 예측 정보를 결정하고, 디코딩되고 있는 현재의 비디오 블록에 대한 예측 블록들을 생성하기 위하여 예측 정보를 이용한다. 예를 들어, 모션 보상 유닛 (72) 은 비디오 슬라이스의 비디오 블록들을 코딩하기 위해 이용된 예측 모드 (예컨대, 인트라-예측 또는 인터-예측), 인터-예측 슬라이스 타입 (예컨대, B 슬라이스, P 슬라이스, 또는 GPB 슬라이스), 슬라이스에 대한 참조 픽처 리스트들 중의 하나 이상에 대한 구성 정보, 슬라이스의 각각의 인터-인코딩된 비디오 블록에 대한 모션 벡터들, 슬라이스의 각각의 인터-코딩된 비디오 블록에 대한 인터-예측 스테이터스, 및 현재의 비디오 슬라이스에서의 비디오 블록들을 디코딩하기 위한 다른 정보를 결정하기 위하여, 수신된 신택스 엘리먼트들의 일부를 이용한다.
모션 보상 유닛 (72) 은 또한, 보간 필터들에 기초하여 보간을 수행할 수도 있다. 모션 보상 유닛 (72) 은 참조 블록들의 정수-미만 픽셀들에 대한 보간된 값들을 계산하기 위하여, 비디오 블록들의 인코딩 동안에 비디오 인코더 (20) 에 의해 이용된 바와 같은 보간 필터들을 이용할 수도 있다. 이 경우, 모션 보상 유닛 (72) 은 수신된 신택스 엘리먼트들로부터 비디오 인코더 (20) 에 의해 이용된 보간 필터들을 결정할 수도 있고, 예측 블록들을 생성하기 위하여 보간 필터들을 이용할 수도 있다.
역양자화 유닛 (76) 은, 비트스트림에서 제공되며 엔트로피 디코딩 유닛 (70) 에 의해 디코딩된 양자화된 변환 계수들을 역양자화, 즉, 탈양자화(de-quantize) 한다. 역양자화 프로세스는 적용될 양자화도 및 마찬가지로 역양자화도를 결정하기 위하여, 비디오 슬라이스에서의 각각의 비디오 블록에 대해 비디오 디코더 (30) 에 의해 계산된 양자화 파라미터 QPY 의 이용을 포함할 수도 있다.
역변환 유닛 (78) 은 픽셀 도메인에서 잔차 블록들을 생성하기 위하여, 역변환, 예컨대, 역 DCT, 역정수 변환, 또는 개념적으로 유사한 역변환 프로세스를 변환 계수들에 적용한다.
모션 보상 유닛 (72) 이 모션 벡터들 및 다른 신택스 엘리먼트들에 기초하여 현재의 비디오 블록에 대한 예측 블록을 생성한 후, 비디오 디코더 (30) 는 역변환 유닛 (78) 으로부터의 잔차 블록들을 모션 보상 유닛 (72) 에 의해 생성된 대응하는 예측 블록들과 합산함으로써 디코딩된 비디오 블록을 형성한다. 합산기 (80) 는 이 합산 연산을 수행하는 컴포넌트 또는 컴포넌트들을 표현한다. 희망하는 경우, 디블록킹 필터는 또한, 블록화 아티팩트들을 제거하기 위하여 디코딩된 블록들을 필터링하도록 적용될 수도 있다. (코딩 루프 내 또는 코딩 루프 이후 중의 어느 하나에서의) 다른 루프 필터들은 또한, 픽셀 천이 (pixel transition) 들을 평탄화하거나, 또는 이와 다르게 비디오 품질을 개선시키기 위하여 이용될 수도 있다. 다음으로, 소정의 프레임 또는 픽처에서의 디코딩된 비디오 블록들은, 추후의 모션 보상을 위하여 이용된 참조 픽처들을 저장하는 참조 픽처 메모리 (82) 내에 저장된다. 참조 픽처 메모리 (82) 는 또한, 도 1 의 디스플레이 디바이스 (32) 와 같은 디스플레이 디바이스 상에서의 더 이후의 제시를 위한 디코딩된 비디오를 저장한다.
도 6 의 비디오 디코더 (30) 는 단독으로 또는 임의의 조합으로, 개량된 CABAC 를 위하여 이 개시물의 다양한 기법들 중의 임의의 것을 수행하도록 구성될 수도 있는 비디오 디코더의 예를 표현한다. 이 때문에, 위에서 설명된 기법들은 비디오 인코더 (20) (도 1 및 도 4) 및/또는 비디오 디코더 (30) (도 1 및 도 5) 에 의해 수행될 수도 있고, 이들 양자는 일반적으로 비디오 코더로서 지칭될 수도 있다. 유사하게, 비디오 코딩은 적용가능한 경우, 비디오 인코딩 또는 비디오 디코딩을 지칭할 수도 있다. 엔트로피 디코딩 유닛 (70) 과 같은 비디오 디코더 (30) 의 다양한 컴포넌트들은 컨텍스트 모델링을 수행하기 위하여 이 개시물의 개량된 CABAC 기법들을 구현할 수도 있다. 이 개시물의 다양한 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 하나 이상의 이전에-디코딩된 변환 계수들의 i 번째 빈들의 값들을 이용하여 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링을 수행할 수도 있다. 바꾸어 말하면, 현재의 변환 계수에 대한 i 번째 빈의 컨텍스트 모델링은 엔트로피 디코딩 유닛 (70) 이 이미 디코딩한 하나 이상의 변환 계수들의 대응하는 i 번째 빈들의 값들에 종속적이다.
이전에-디코딩된 변환의 i 번째 빈들의 값들을 이용하여 현재의 변환 계수의 빈에 대한 컨텍스트 모델링을 수행함으로써, 엔트로피 디코딩 유닛 (70) 은 현존하는 CABAC 코더들에 비해 하나 이상의 잠재적인 개선들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이러한 장점의 예로서, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 기법들을 구현함으로써 컨텍스트 모델링 동작의 병렬화를 개선시킬 수도 있다. 더 구체적으로, 엔트로피 디코딩 유닛 (70) 은 현재 디코딩되고 있는 변환 계수의 다수의 빈들에 대하여, 컨텍스트 모델링을 병렬로 수행할 수도 있다. 예를 들어, 엔트로피 디코딩 유닛 (70) 이 다수의 빈들에 대응하는 빈 값들이 이전에-디코딩된 변환 계수 (들) 로부터 이용가능한 것으로 결정할 경우, 엔트로피 디코딩 유닛 (70) 은 현재 디코딩되고 있는 변환 계수의 빈들에 대한 컨텍스트 모델링 동작들을 적어도 부분적으로 병렬화할 수도 있다.
엔트로피 디코딩 유닛 (70) 은 멀티-패스 코딩 방식에 따라 이 개시물의 병렬화된 컨텍스트 모델링을 수행할 수도 있다. 더 구체적으로, 멀티-패스 코딩 방식은 엔트로피 디코딩 유닛 (70) 이 별도의 스레드들을 각각의 특정한 빈에 배정하게 하는 코딩 기법 (예컨대, 제 1 빈에 대한 스레드 1, 제 2 빈에 대한 스레드 2 등) 을 지칭한다. 이에 따라, 멀티-패스 코딩에 따르면, 모든 bin0 인스턴스들은 시퀀스로 디코딩되는 bin1 인스턴스들에 독립적으로 시퀀스로 디코딩될 수 있고, 양자는 시퀀스로 디코딩되는 bin2 인스턴스들에 독립적으로 디코딩되는 등과 같다. 일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 단일 블록의 변환 유닛들에 대하여 멀티-패스 코딩을 수행할 수도 있다. 또한, 규칙적인 모드에 따라 디코딩되는 빈들에 대하여, 엔트로피 디코딩 유닛 (70) 은 몇몇 디코딩 패스들을 수행할 수도 있다. 각각의 패스는 모든 변환 계수들의 단일의 대응하는 빈에 속할 수도 있다. 다시 말해서, 각각의 패스 동안에, 엔트로피 디코딩 유닛 (70) 은 다른 패스들에 관련되는 정보를 사용하지 않는다. 예를 들어, 엔트로피 디코딩 유닛 (70) 은 제 1 패스에서 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 (필요할 경우) 제 1 빈을 디코딩할 수도 있다. 이 예에서, 제 2 패스에서, 엔트로피 디코딩 유닛 (70) 은 필요할 경우, 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 2 빈을 디코딩할 수도 있는 등과 같다.
하나의 예의 이용 경우에 있어서, 엔트로피 디코딩 유닛 (70) 은 이전에-코딩된 이웃하는 변환 계수의 bin0 의 값을 이용하여 현재-코딩된 변환 계수의 bin0 에 대한 컨텍스트 모델링을 수행할 수도 있고, 이전에-코딩된 이웃하는 변환 계수의 bin1 의 값을 이용하여 현재-코딩된 변환 계수의 bin1 에 대한 컨텍스트 모델링을 수행할 수도 있는 등과 같다. 이전에-코딩된 변환 계수에 대하여 이용가능한 임의의 빈 값들을 이용하면, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 변환 계수의 다수의 빈들에 대한 컨텍스트 모델링을 병렬로 수행할 수도 있다. 위에서 설명된 이용 경우의 시나리오에서, bin0 및 bin1 이 양자 모두 이전에-코딩된 이웃 변환 계수로부터 이용가능할 경우, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 변환 계수에 대한 bin0 및 bin1 의 컨텍스트 모델링을 병렬화할 수도 있다. 이러한 방식으로, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 모델링 동작들의 병렬화를 가능하게 하고 잠재적으로 활용함으로써 현재의 변환 계수의 빈들에 대한 컨텍스트 선택을 개선시키면서, HEVC 에서 설명된 바와 같이 멀티-패스 코딩의 원리들 내에서 CABAC 를 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다.
엔트로피 디코딩 유닛 (70) 은 모든 이러한 빈들의 전체 컨텍스트 모델링을 병렬로 수행할 수 있지만, 반드시 그러한 것은 아닐 수도 있다는 것이 인식될 것이다. 더 구체적으로, 엔트로피 디코딩 유닛 (70) 은 다수의 빈들의 컨텍스트 모델링의 일부 부분들을 동시에 수행할 수도 있다. 이러한 방법으로, 엔트로피 디코딩 유닛 (70) 은 멀티코어 프로세싱 기술 및/또는 다수의 프로세서들을 이용하여 현재-코딩된 변환 계수에 대한 컨텍스트 모델링 동작들을 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
단일 패스에서 상이한 변환 계수들의 대응하는 빈들을 디코딩함으로써, 엔트로피 디코딩 유닛 (70) 은 현존하는 멀티-패스 CABAC 기법들에 비해 하나 이상의 장점들을 제공할 수도 있다. 예를 들어, 단일 패스에서 다수의 변환 계수들의 대응하는 빈들 (예컨대, 개개의 bin0) 을 디코딩함으로써, 엔트로피 디코딩 유닛 (70) 은 빈 천이들에서 빈번하게 새로운 컨텍스트 모델을 저장하고 취출하기 위한 필요성을 회피할 수도 있다. 그 대신에, 패스는 다수의 변환 계수들에 걸쳐 대응하는 빈들 (예컨대, 개개의 bin0) 을 타겟으로 하므로, 엔트로피 디코딩 유닛 (70) 은 소정의 패스에 걸쳐 단일 컨텍스트 모델을 이용할 수도 있다. 이러한 방법으로, 엔트로피 디코딩 유닛 (70) 은 빈번한 컨텍스트-스위칭으로부터 발생하는 시간 지연들 및 자원 회전을 완화시키거나 또는 잠재적으로 제거하기 위하여 이 개시물의 병렬화된 컨텍스트 선택 기법들을 구현할 수도 있다. 대조적으로, 현존하는 멀티-패스 코딩은 제 1 변환 계수에 대하여, bin0, bin1, bin2 등을 디코딩하고, 그 다음으로, 제 2 변환 계수에 대하여 bin0, bin1, bin2 등을 디코딩하는 등으로 인해, 빈번한 컨텍스트 모델 저장 및 취출 동작들을 요구할 것이다.
예를 들어, 엔트로피 디코딩 유닛 (70) 은 본원에서 설명된 i 번째 빈 컨텍스트 모델링 기능성들을 위하여 이용하기 위한 하나 이상의 미리 정의된 템플릿들을 생성할 수도 있거나, 또는 그렇지 않을 경우에 이에 액세스할 수도 있다. 엔트로피 디코딩 유닛 (70) 이 현재-코딩된 변환 계수의 i 번째 빈의 컨텍스트 모델링을 위하여 이용할 수도 있는 미리 정의된 템플릿의 하나의 비-제한적인 예는 도 10 에서 예시되어 있다. 도 10 의 템플릿 (140) 과 같은 미리 정의된 템플릿은 8x8 변환 블록에 대하여 대각선 스캔 순서를 정의하고, 여기서, 'L' 은 최후의 중요한 스캔 위치를 나타내고, 'x' 는 현재의 스캔 위치를 나타내고, "xi" 는 로컬 템플릿 (140) 에 의해 커버된 이웃들을 나타낸다. xi 에 대하여, "i" 의 값은 제로 내지 4 의 범위에 있고, 범위 제약은 i ∈ [0,4] 로서 표현된다. 이 개시물의 하나 이상의 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 현재 디코딩되고 있는 변환 계수의 대응하는 i 번째 빈의 컨텍스트 모델링을 위하여 로컬 템플릿 (140) 에서 위치된 변환 계수들의 i 번째 빈들을 이용할 수도 있다. 일부 구현예들에 따르면, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 병렬화된 빈 컨텍스트 모델링을 수행하기 위하여 다수의 템플릿들을 이용할 수도 있다. 하나의 예에서, 템플릿 크기 및/또는 형상은 다음의 기준들 중의 하나 이상에 종속적이다: (i) 변환 유닛들의 크기; (ii) 모드들; 또는 (iii) 현재의 변환 유닛 또는 계수 그룹 (CG) 내에서의 현재의 변환 계수들의 위치.
빈 값들에 대하여 이전에-코딩된 TU 를 횡단하기 위하여 하나 이상의 미리 정의된 템플릿들을 이용함으로써, 엔트로피 디코딩 유닛 (70) 은 현존하는 CABAC 기술에 비해 하나 이상의 개량들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 도 10 의 로컬 템플릿 (140) 과 같은 TU 횡단 템플릿을 이용함으로써, 엔트로피 디코딩 유닛 (70) 은 상이한 코딩 패스들에 대하여 횡단 방식을 별도로 결정하기 위한 필요성을 회피할 수도 있다. 이에 따라, 이 개시물의 템플릿-기반 병렬화된 컨텍스트 선택 기법들을 구현함으로써, 엔트로피 디코딩 유닛 (70) 은 코딩 정밀도를 유지하면서, 빈 코딩에 대한 스루풋을 증가시킬 수도 있다.
또 다른 예의 구현예에 따르면, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 병렬화된 컨텍스트 모델링 기법들을 현재-코딩된 변환 계수의 처음 'K' 빈들에 오직 적용할 수도 있고, 여기서, 'K' 는 M 보다 더 작고, 여기서, 'M' 은 이용가능한 빈 인덱스들의 상한을 나타낸다. 엔트로피 디코딩 유닛 (70) 은 또 다른 컨텍스트 모델링 기법을 이용하여, 또는 우회 모드에 따라 코딩되고 있는 나머지 (M+1-K) 빈들을 디코딩할 수도 있다.
또 다른 예의 구현예에 따르면, 엔트로피 디코딩 유닛 (70) 은 이전에-코딩된 변환 계수들의 모집단 (universe) 을, 현재 디코딩되고 있는 변환 계수 전의 현재의 변환 유닛 또는 CG 내에서의 디코딩 순서에서의 'N' 연속 변환 계수들로서 정의할 수도 있다. 대안적으로, 엔트로피 디코딩 유닛 (70) 은 N 을 변수인 것으로 결정할 수도 있다. 하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 현재의 변환 유닛에서의 현재-디코딩된 변환 계수의 상대적인 위치에 종속적인 N 의 값을 결정할 수도 있다. 또 다른 예에서, 엔트로피 디코딩 유닛 (70) 은 N 이 변환 유닛 크기에 종속적이도록, N 의 값을 결정할 수도 있다.
또 다른 구현예에서, 엔트로피 디코딩 유닛 (70) 은 이전에-디코딩된 변환 계수들의 모집단을, 현재의 변환 유닛 또는 CG 내에서의 현재의 위치의 이웃에 위치된 그 변환 계수들로서 정의할 수도 있다. 하나의 예에서, 현재의 위치의 이웃은 현재의 위치에 직접적으로 인접한 그 위치들, 또는 현재의 위치에 직접적으로 인접하거나 현재의 위치로부터 분리된 것 중의 하나인 위치들로 제약된다. 또 다른 예에서, 이웃은 또한, 이 위치들을 포함할 수도 있지만, 하나 이상의 공간적 이웃하는 변환 유닛들에서의 위치들을 포함하도록 확대할 수도 있다.
이 개시물의 다양한 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 빈의 컨텍스트 인덱스를, 하나 이상의 이전에-코딩된 변환 계수들과 연관된 값들의 함수로서 정의할 수도 있다. 예를 들어, 엔트로피 디코딩 유닛 (70) 은 이전에-코딩된 변환 계수들의 모든 i 번째 빈 값들의 합을 산출하는 함수를 이용할 수도 있다. 더 구체적으로, 이 예에서, 엔트로피 디코딩 유닛 (70) 은 TU/CG 의 모든 이전에-디코딩된 변환 계수들의 이용가능한 i 번째 빈 값들의 값들의 합산을 수행할 수도 있다. 결국, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링 동안에 결과적인 합을 컨텍스트 인덱스 (CtIdx) 로서 이용할 수도 있다. 또 다른 예에서, 엔트로피 디코딩 유닛 (70) 은 차단 값을 정의할 수도 있다. 이 예에서, 함수의 출력이 미리 정의된 차단 값을 초과할 때, 엔트로피 디코딩 유닛 (70) 은 현재 코딩되고 있는 빈에 대하여 동일한 컨텍스트를 이용할 수도 있다. 일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 차단 값이 빈 인덱스/변환 유닛 크기/코딩 모드/하나의 변환 유닛 내에서의 변환 계수 위치에 기초하는 것 (또는 종속적임) 으로 결정할 수도 있다.
일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 이 빈들이 동일한 컨텍스트 모델들을 공유하도록, 상이한 패스들에서 코딩된 대응하는 빈들을 디코딩할 수도 있다. 하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 인덱스 유도 방법, 예컨대, 상이한 패스들에서의 빈들에 대하여 컨텍스트 인덱스를 계산하기 위한 함수가 상이한 것으로 결정할 수도 있다. 하나의 예에 따르면, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 인덱스 유도 방법, 예컨대, 상이한 패스들에서의 빈들에 대하여 컨텍스트 인덱스를 계산하기 위한 함수가 동일할 수도 있는 것으로 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 인덱스 유도 규칙을, 변환 유닛들의 상이한 크기들에서의 동일한 패스에 대하여 미변경된 것으로 유지할 수도 있다. 그러나, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 빈에 대한 컨텍스트 모델링을 수행하기 위하여 오프셋을 컨텍스트 인덱스에 적용할 수도 있다. 예를 들어, 엔트로피 디코딩 유닛 (70) 은 2 개의 상이한 변환 크기들이 컨텍스트 모델들의 2 개의 세트들을 가지는 것으로 결정할 수도 있다. 결국, 엔트로피 디코딩 유닛 (70) 은 오프셋을, 하나의 이러한 세트에서의 컨텍스트 모델들의 수로서 정의할 수도 있다. 예를 들어, 엔트로피 디코딩 유닛 (70) 이 TU 크기가 미리 정의된 차원들 MxM 의 정사각형보다 더 작은 것으로 결정할 경우, 엔트로피 디코딩 유닛 (70) 은 각각의 이러한 TU (MxM 보다 더 작음) TU 크기가 컨텍스트 모델들의 그 자신의 개개의 세트를 가지는 것으로 결정할 수도 있다. 반대로, 엔트로피 디코딩 유닛 (70) 은 MxM 과 동일하거나 그보다 더 큰 크기들을 갖는 모든 TU 들이 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다.
다양한 이용 경우의 시나리오들에서, 엔트로피 디코딩 유닛 (70) 은 M 의 값을 16 으로 설정할 수도 있다. 더 구체적으로, 이 예들에서, 엔트로피 디코딩 유닛 (70) 이 현재-코딩된 TU 의 크기가 16x16 정사각형보다 더 작은 것으로 결정할 경우, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 TU 가 TU 의 특정한 크기에 대응하는 컨텍스트 모델들의 세트와 연관되는 것으로 결정할 수도 있다. 반대로, 엔트로피 디코딩 유닛 (70) 이 현재-디코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 것으로 결정할 경우, 엔트로피 디코딩 유닛 (70) 은 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 모든 다른 TU 들과 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다. 일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 TU 크기-기반 컨텍스트 선택을 오직 루마 블록들에 적용할 수도 있다.
일부 예들에 따르면, 나머지 빈들을 코딩하기 위하여 이용된 라이스 파라미터는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 라이스 파라미터는 코딩 모드에 종속적일 수도 있다. 하나의 예에서, coeff_abs_level_remaining 에 대하여 골롬-라이스 코드를 이용하는 대신에, 엔트로피 디코딩 유닛 (70) 은 다른 2 진화 기법들을 이용할 수도 있다. 대안적으로 또는 추가적으로, 하나를 초과하는 2 진화 방법은 coeff_abs_level_remaining 신택스 엘리먼트를 코딩하기 위하여 적용될 수도 있다. 하나의 예에서, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 코딩 모드들에 종속적이다. 대안적으로, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 하나의 TU 내에서의 상대적인 위치에 종속적일 수도 있다. 대안적으로, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 스캔 순서에서의 제 1 코딩된/디코딩된 변환 계수로부터의 거리에 종속적일 수도 있다. 일부 사례들에서, coeff_abs_level_remaining 를 코딩하기 위하여 이용된 2 진화 방법 (예컨대, 라이스 파라미터) 은 변환 유닛에 관한 코딩 그룹 위치에 종속적이다.
이 개시물의 일부 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 변환 크기에 기초하여 계수 그룹 (CG) 크기를 결정할 수도 있다. 다시 말해서, 이 양태들에 따르면, CG 크기는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 엔트로피 디코딩 유닛 (70) 은 코딩 모드에 기초하여 CG 크기를 결정할 수도 있다. 이 예들에서, 엔트로피 디코딩 유닛 (70) 은 CG 크기를 변환 크기 및/또는 코딩 모드 중의 하나 또는 양자에 종속적인 것으로서 결정할 수도 있다. 대안적으로 또는 추가적으로, 엔트로피 디코딩 유닛 (70) 은 변환 행렬에 기초하여 CG 크기를 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 또한, 병렬화된 컨텍스트 모델링 기법들을, 변환 우회 모드 (또한, "변환 스킵 모드" 로서 지칭됨) 를 이용하여 인코딩되는 블록들에 적용할 수 있다. 변환 우회 모드는, 비디오 디코더 (30) 가 비디오 비트스트림의 무손실-인코딩된 부분을 프로세싱하기 위하여, 코딩 모드에 따라, 디코딩의 역변환 및 역양자화 동작들을 스킵할 수도 있는 코딩 모드를 지칭한다. 이에 따라, 이 개시물의 어떤 양태들에 따르면, 엔트로피 디코딩 유닛 (70) 은 수신된 인코딩된 비디오 스트림이 무손실로 인코딩되는 사례들에서 잠재적으로 결과적인 장점들을 제공하기 위하여 병렬화된 컨텍스트 선택 기법들을 확대할 수도 있다.
이 개시물의 다양한 변환 계수 컨텍스트 모델링 기법들의 일 예의 세부사항들은 이하에서 더욱 상세하게 논의된다. 멀티-패스 코딩에 따른 컨텍스트 모델링의 하나의 예가 이하에서 설명된다. 이 예에 따르면, 엔트로피 디코딩 유닛 (70) 은 HEVC 에서 제시된 바와 같은 코딩 엘리먼트들 및 코딩 순서 (다중 패스 코딩, 및 CG-기반) 를 적용할 수도 있다. 게다가, 엔트로피 디코딩 유닛 (70) 은 변환 계수들의 크기들을 미변경된 상태로 유지하면서, 2 진화 기법들을 적용할 수도 있다. 그러나, 엔트로피 디코딩 유닛 (70) 은 변환 계수들의 크기들을 코딩하기 위한 컨텍스트 인덱스 및 라이스 파라미터 계산 방법을 수정할 수도 있다.
bin0 (중요한 플래그) 에 대한 컨텍스트 인덱스 계산은 다음의 정보에 종속적이다: 템플릿에서의 비-제로 계수들의 수 (즉, 계수들의 크기들이 0 보다 더 큼); 현재의 TU 내에서의 현재의 계수의 위치; 루마 컴포넌트에 대한 TU 크기; 및 컬러 컴포넌트들. 컬러 컴포넌트 종속성에 대하여, 루마 및 크로마는 별도로 고려된다. 추가적으로, 루마 컴포넌트에 대한 TU 크기를 고려할 시에, 컨텍스트 인덱스 계산은 루마에 대한 TU 크기와 독립적이다. 루마 컴포넌트의 TU 크기는 3 개의 세트들, 즉, 4x4 TU, 8x8 TU, 16x16 이상의 TU 들을 포함할 수도 있다.
in1 및 bin2 (1 보다 더 크고, 2 보다 더 큼) 에 대하여, 컨텍스트 인덱스 계산은 다음의 정보에 종속적이다: (bin1 에 대하여) 1 보다 더 크고 (bin2 에 대하여) 2 보다 더 큰 템플릿에서의 absLevels 의 수; 현재의 TU 내에서의 현재의 계수의 위치; 및 컬러 컴포넌트들. 라이스 파라미터 유도 프로세스는 우회 코딩 정보 및 sum_absolute_levelMinus1 신택스 엘리먼트의 값에 종속적이다.
하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 템플릿에서의 계수들의 수를 반환하기 위하여 함수 sum_template(k) 를 정의할 수도 있어서, 계수들의 크기들은 k 보다 더 크다. sum_template(k) 함수의 예는 다음과 같다:

추가적으로, 이 예에서, 엔트로피 디코딩 유닛 (70) 은 위치 정보를 처리하기 위한 함수  , 및 컴포넌트 정보를 처리하기 위한 또 다른 함수
, 및 컴포넌트 정보를 처리하기 위한 또 다른 함수  를 다음과 같이 정의할 수도 있다:
를 다음과 같이 정의할 수도 있다:

도 10 은 엔트로피 디코딩 유닛 (70) 이 본원에서 설명된 컨텍스트 모델링 기법들에 대하여 이용할 수도 있는 템플릿 (로컬 템플릿 (140)) 의 하나의 예를 도시한다. 현재의 변환 계수는 'X' 로서 표기되고, 5 개의 공간적 이웃들은 'Xi' ('i' 는 0 내지 4 로부터의 정수를 표현함) 로서 표기된다. 다음의 조건들 중의 임의의 하나가 충족될 경우, 엔트로피 디코딩 유닛 (70) 은 Xi 를 이용불가능하고 컨텍스트 인덱스 유도 프로세스에서 이용되지 않는 것으로서 표기할 수도 있다:
● Xi 의 위치 및 현재의 변환 계수 X 는 동일한 변환 유닛에서 위치되지 않거나; 또는
● Xi 의 위치는 픽처의 수평 또는 수직 경계들의 외부에 위치되거나; 또는
● 변환 계수 Xi 가 아직 코딩되지 않았다. 멀티-패스 코딩의 경우, 동일한 코딩 패스에서의 빈들이 코딩될 때마다, 빈들은 컨텍스트 인덱스 유도 프로세스에서 이용될 수 있다. 그러므로, 디코딩의 관점으로부터, 하나의 변환 계수를 완전히 디코딩하는 것은 필요하지 않다.
대안적으로, 엔트로피 디코딩 유닛 (70) 은 이웃하는 변환 유닛으로부터의 정보를 포함할 수 있는 하나 이상의 다른 템플릿들을 적용할 수도 있다. 다양한 예들에서, 이웃하는 TU 는 공간적 이웃 또는 시간적 이웃일 수도 있다. 본원에서 설명된 컨텍스트 모델링 기법들 중의 하나 이상에 따르면, 컨텍스트 인덱스 계산들은 다음의 단락들에서 설명된 바와 같이 정의될 수도 있다.
bin0 에 대하여, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

여기서,

하나의 예에서, c0 의 범위에 기초하여, 루마 컨텍스트들의 하나의 세트는 NumberLumaCtxOneset 의 값과 동일한 수의 컨텍스트 모델들을 포함할 수도 있다. 예를 들어, 루마 컨텍스트들의 세트는 18 개의 컨텍스트 모델들을 포함할 수도 있다. 루마 bin0 들을 코딩하기 위한 ('w' 에 의해 나타내어진 변환 폭을 갖는) 상이한 변환 크기들에 대하여, 엔트로피 디코딩 유닛 (70) 은 각각의 변환 크기에 대하여 상이한 세트를 선택할 수도 있다. 게다가, 크로마 및 루마 컨텍스트들은 코딩 성능을 추가로 개선시키기 위하여 분리된다. YCbCr 입력들에 대하여, 3 개의 컬러 컴포넌트들, 즉, Y, Cb, 및 Cr 은 각각 0, 1, 및 2 와 동일한 컴포넌트 인덱스 v 로 표현된다.
이 예들에서, 엔트로피 디코딩 유닛 (70) 은 bin1 에 대한 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

추가적으로, 이 예들에서, 엔트로피 디코딩 유닛 (70) 은 bin2 에 대한 컨텍스트 인덱스를 다음과 같이 유도할 수도 있다:

하나의 예에서, N 은 0 과 동일하다. 또 다른 예에서, N 은 1 과 동일하다. 대안적으로 또는 추가적으로, N 이 1 과 동일할 때, 엔트로피 디코딩 유닛 (70) 은 0 과 동일한 컨텍스트 인덱스 c1 또는 c2 로 제 1 bin1 또는 bin2 를 코딩할 수도 있다. 이 예에서, 엔트로피 디코딩 유닛 (70) 은 상기 수학식들에 따라 bin1 들 및 bin2 들의 다른 인스턴스들을 코딩할 수도 있다.
하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 모델들의 동일한 세트이지만, 상이한 인덱스들로 bin1 및 bin2 를 디코딩할 수도 있다. 대안적으로, bin1 및 bin2 는 컨텍스트 모델들의 2 개의 세트들로 코딩되고, 그것들 사이의 종속성은 존재하지 않는다. 나머지 빈들에 대하여, 엔트로피 디코딩 유닛 (70) 은 HEVC 에서 제시된 설계, 또는 JCTVC-H0228 에서의 설계를 적용할 수도 있다. 다양한 예들에서, 엔트로피 디코딩 유닛 (70) 은 위에서 설명된 다양한 함수들을 구축함에 있어서 상이한 상수 값들을 이용할 수도 있다.
이 개시물의 추가적인 양태들은 컨텍스트 초기화 개량들에 관한 것이다. 이 개시물의 컨텍스트 초기화 개량들은 위에서 설명된 병렬화된 컨텍스트 선택 기법들에 관계 없이 구현될 수도 있거나, 위에서 설명된 병렬화된 컨텍스트 선택 기법들 중의 임의의 하나 이상과 조합하여 구현될 수도 있다. 이 개시물의 컨텍스트 초기화 기법들 중의 하나 이상은 이전에-디코딩된 정보로부터의 컨텍스트 정보를 재이용하는 것에 관한 것이다. 예를 들어, 엔트로피 디코딩 유닛 (70) 은 현재의 픽처 또는 이전에-디코딩된 픽처에 속할 수도 있는 이전에-디코딩된 슬라이스로부터 스테이터스를 복사함으로써, 슬라이스에 대한 컨텍스트 정보를 승계할 수도 있거나, 또는 그렇지 않을 경우에 유도할 수도 있다.
이전에-디코딩된 슬라이스로부터 컨텍스트 초기화 정보를 승계함으로써, 엔트로피 디코딩 유닛 (70) 은 현존하는 CABAC 컨텍스트 초기화 기법들에 비해 개량된 정확도를 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 현존하는 CABAC 컨텍스트 초기화 기법들은 표로부터 컨텍스트 스테이터스 정보를 획득하는 것에 의존한다. 그러나, 표는 정적 정보를 이용하여 형성된다. 그러나, 이 개시물의 승계-기반 컨텍스트 초기화 기법들에 따르면, 엔트로피 디코딩 유닛 (70) 은, 동일한 슬라이스 타입이고 및/또는 현재 디코딩되고 있는 슬라이스와 동일한 양자화 파라미터 (QP) 들을 가지는 이전에-디코딩된 슬라이스로부터 컨텍스트 초기화 정보를 인출할 수도 있다. 이러한 방법으로, 엔트로피 디코딩 유닛 (70) 은 현재의 슬라이스에 대하여 이용된 컨텍스트 초기화 정보의 정확도를 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
일부 구현예들에 따르면, 엔트로피 디코딩 유닛 (70) 은 이전에-디코딩된 슬라이스의 중심 LCU 를, 컨텍스트 초기화 정보를 그로부터 승계하기 위한 슬라이스로서 식별할 수도 있다. 다양한 예들에서, 엔트로피 디코딩 유닛 (70) 은 다수의 대응하는 이전에-디코딩된 슬라이스들로부터 현재의 픽처의 다수의 슬라이스들에 대한 컨텍스트 초기화를 승계할 수도 있다. 하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 컨텍스트 초기화 기법들에 따라 디코딩된 다수의 슬라이스들의 전부에 대한 컨텍스트 초기화 정보를 그로부터 승계하기 위한 이전에-디코딩된 픽처의 동일한 블록 (즉, 중심 LCU) 을 이용할 수도 있다. 또 다른 예에서, 엔트로피 디코딩 유닛 (70) 은 이전에-디코딩된 픽처의 대응하는 슬라이스들의 각각으로부터의 개개의 중심 LCU 로부터 다수의 슬라이스들의 각각에 대한 컨텍스트 초기화 정보를 승계할 수도 있다.
예를 들어, 이전에-디코딩된 픽처의 중심 LCU 를 디코딩한 후에, 엔트로피 디코딩 유닛 (70) 은 슬라이스 컨텍스트 초기화에 대한 스테이터스 정보의 전부를 저장할 수도 있다. 결국, 엔트로피 디코딩 유닛 (70) 은 복사된 스테이터스 정보를 액세스할 수도 있거나 판독할 수도 있고, 현재 디코딩되고 있는 픽처의 하나 이상의 슬라이스들에 대한 컨텍스트를 초기화하기 위한 스테이터스 정보를 이용할 수도 있다. 현재의 픽처의 슬라이스들에 대한 컨텍스트 초기화를 수행하기 위하여 이전에-디코딩된 픽처로부터의 스테이터스 정보를 이용함으로써, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 초기화의 목적을 위하여 정적 정보의 고정된 표에 대한 의존성을 감소시킬 수도 있다. 예를 들어, 제 1 픽처의 슬라이스들에 대한 것뿐만 아니라, 임의의 인트라-코딩된 픽처들에 대한 컨텍스트를 초기화하기 위하여 고정된 표를 이용한 후에, 엔트로피 디코딩 유닛 (70) 은 추후에 디코딩되는 인터-코딩된 픽처들에 대한 컨텍스트 초기화를 수행할 수도 있다. 엔트로피 디코딩 유닛 (70) 은 P 슬라이스들 및/또는 B 슬라이스들에 대하여 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 구현할 수도 있다.
이 개시물의 컨텍스트 초기화 기법들에 대한 추가적인 예의 세부사항들이 이하에서 설명된다. 엔트로피 디코딩 유닛 (70) 은 추가적으로 또는 대안적으로, 이하에서 논의된 바와 같이, 컨텍스트 초기화에 대한 이 개시물에 따른 기법들을 수행하도록 구성될 수도 있다. 엔트로피 디코딩 유닛 (70) 은 현재의 슬라이스를 코딩하기 위한 초기화된 컨텍스트 정보로서 이전에 디코딩된 픽처에서 위치된 하나의 블록을 인코딩한 후의 컨텍스트 정보를 승계하기 위하여 이 개시물의 컨텍스트 초기화 기법들을 구현할 수도 있다. 엔트로피 디코딩 유닛 (70) 은 승계-기반 컨텍스트 초기화 기법들을 P 및/또는 B 슬라이스들에 적용할 수도 있다. 추가적으로, 위에서 지칭된 '하나의 블록' 의 위치는 미리 정의되고, 하나의 전체 시퀀스에 대하여 고정된다. 예를 들어, 최대 코딩 유닛 크기 (LCU) 는 "NxN" 에 의해 나타내어지고, 픽처 폭은 "W" 에 의해 나타내어지고, 픽처 높이는 "H" 에 의해 나타내어진다. 이 예에서, "PicWidthInCtbsY" 에 의해 나타내어진, 하나의 LCU 행 내에서의 LCU 들의 수는 천장 함수, 즉, Ceil( W ÷ N ) 의 출력과 동일하다. 추가적으로, 이 예에서, "PicHeightInCtbsY" 에 의해 나타내어진 LCU 행들의 수는 Ceil( H ÷ N ) 과 동일하고, 여기서, 천장 함수 Ceil (x) 는 x 이상인 가장 작은 정수를 표현한다.
일부 예들에 따르면, 위치는 이전에-디코딩된 픽처에서의 최초 슬라이스의 중심 LCU 로서 정의된다. numLCUinSlice 가 최초 슬라이스에서의 LCU 수를 표현하는 것으로 추정하면, 위치는 다음으로서 정의된다: TargetCUAddr = numLCUinSlice/2. 하나의 예에서, 위치는 다음으로서 정의된다: TargetCUAddr = (PicWidthInCtbsY* PicHeightInCtbsY)/2 + PicWidthInCtbsY /2. 또한, TargetCUAddr 이 (PicWidthInCtbsY* PicHeightInCtbsY) 이상일 때 (예컨대, PicHeightInCtbsY 는 1 과 동일함), TargetCUAddr 은 최후 LCU 에 대응하고 있는 (PicWidthInCtbsY* PicHeightInCtbsY - 1) 로 재설정된다. 하나의 예에서, 위치는 이전에 코딩된 픽처의 최후 LCU, 또는 하나의 프레임 내에서의 중심 LCU (즉, PicWidthInCtbsY* PicHeightInCtbsY/2), 또는 중심 LCU 행의 최후 LCU (즉, PicWidthInCtbsY* (PicHeightInCtbsY/2) - 1), 또는 k 번째 LCU 행의 최후 LCU (예컨대, k 는 1 과 동일함) 로서 정의된다. 하나의 예에 따르면, 위치는 이전에-디코딩된 픽처에서의 최초 슬라이스의 최후 LCU 로서 정의된다. 이 개시물의 컨텍스트 초기화 기법들의 일부 구현예들에 따르면, 상이한 해상도들은 코딩 블록의 위치의 상이한 정의들을 가질 수도 있다.
일부 예들에서, 엔트로피 디코딩 유닛 (70) 은 인코딩된 비디오 비트스트림에서 시그널링되는 시퀀스 파라미터 세트 (SPS) 또는 픽처 파라미터 세트 (PPS) 와 같은 파라미터 세트로부터 '하나의 블록' 의 위치를 획득할 수도 있다. SPS 들 및/또는 PPS 들과 같은 파라미터 세트들은 현재의 픽처의 슬라이스들에 대하여 대역외로 시그널링될 수 있다. 일부 예들에서, '하나의 블록' 의 위치는 슬라이스 헤더에서 시그널링될 수 있다. 슬라이스 헤더는 대응하는 슬라이스에 대하여 대역내로 시그널링될 수도 있다. 이러한 그리고 다른 예들에서, 참조 픽처 인덱스, 대응하는 픽처 순서 카운트 차이 (또는 델타 POC) 와 같은 이전에-디코딩된 픽처의 표시는 파라미터 세트 또는 슬라이스 헤더에서 시그널링될 수도 있다.
일부 예들에서, '이전에-코딩된 픽처' 는 현재의 픽처 바로 전에 (직전에) 디코딩되는 픽처로서 정의된다. 일부 예들에서, '이전에-코딩된 픽처' 는 현재의 픽처 전에 디코딩된 최후 픽처인 픽처로서 정의되어, 이전의 픽처에서의 최초 슬라이스는 현재의 슬라이스에 대한 동일한 슬라이스 타입을 가진다. 일부 예들에 따르면, '이전에-코딩된 픽처' 는 현재의 픽처 전의 디코딩된 픽처인 픽처로서 정의되고, 이전의 픽처에서의 최초 슬라이스는 현재의 슬라이스에 대한 동일한 초기화된 양자화 파라미터들을 가진다. 일부 예들에 따르면, '이전에-코딩된 픽처' 는, 현재의 슬라이스 및/또는 동일한 초기화된 양자화 파라미터들로서, 동일한 슬라이스 타입, 또는 양자의 동일한 슬라이스 타입 및 양자화 파라미터 (들), 또는 양자의 동일한 슬라이스 타입 및 시간적 계층을 가지는 이전에 코딩된 슬라이스를 포함하는 픽처로서 정의된다. 일부 예들에서, '이전에-코딩된 픽처' 는 (디코딩된 픽처 버퍼와 같은) 픽처 버퍼에서 존재하는 픽처로서 정의되고, 참조 픽처로서 현재의 픽처에 대하여 이용될 수도 있다. 이 예들에 따르면, HEVC 기반 플랫폼에서와 같이, 이전의 슬라이스는 참조 픽처 세트 (RPS) 에서의 픽처, 또는 RPS 의 다음의 서브세트들 중의 하나에서의 픽처에 속해야 한다: RefPicSetStCurrBefore, RefPicSetStCurrAfter, 및 RefPicSetLtCurr.
이 개시물의 컨텍스트 초기화 기법들의 일부 구현예들에 따르면, 디스플레이 순서에서의 하나의 인트라-코딩된 픽처 후에 코딩된 픽처들의 전부가 동일한 슬라이스 타입들 및 동일한 초기화된 양자화 파라미터들을 가지지 않을 경우, 컨텍스트 정보의 승계는 디스에이블될 수도 있다. 이 경우, 기존의 초기화 방법이 적용되고, 예컨대, 엔트로피 디코딩 유닛 (70) 은 초기화 스테이터스 정보를 그로부터 인출하기 위한 고정된 표를 이용할 수도 있다. 일부 구현예들에 따르면, 엔트로피 디코딩 유닛 (70) 은 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 다른 컨텍스트 모델들이 아니라, 특정 컨텍스트 모델들에 적용할 수도 있다. 추가적으로 또는 대안적으로, '하나의 블록' 의 위치는 상이한 컨텍스트 모델들에 대하여 상이할 수도 있다. 위에서 열거된 다양한 구현 옵션들은 이 개시물의 컨텍스트 초기화 기법들에 따라, 개별적으로 또는 다양한 조합들로 구현될 수도 있다는 것이 인식될 것이다.
이 개시물의 컨텍스트 초기화 기법들의 일부 예들에서, 엔트로피 디코딩 유닛 (70) 이 cabac_init_present_flag 가 인에이블되는 것으로 결정할 경우, 엔트로피 디코딩 유닛 (70) 은 '이전에-디코딩된 픽처' 내에 포함된 슬라이스가 현재-인코딩된 슬라이스와 동일한 타입을 가져야 하는 것으로 결정할 수도 있다. 바꾸어 말하면, 이 예에서, cabac_init_present_flag 가 인에이블될 경우, 이전에-디코딩된 픽처의 정의는 정합하는 슬라이스 타입들에 종속적이다. 추가적으로, 디코딩의 관점으로부터, 시그널링된 cabac_init_flag 는 이 구현예 따라 고려되지 않는다. 일부 사례들에서, 대안적으로, 엔트로피 디코딩 유닛 (70) 은 cabac_init_flag 및 '이전에-디코딩된 픽처' 의 선택에 기초하여 현재의 슬라이스의 슬라이스 타입을 먼저 수정할 수도 있다.
이 개시물의 컨텍스트 초기화 기법들에 대한 추가적인 예의 세부사항들이 이하에서 설명된다. 일부 구현예들에 따르면, 엔트로피 디코딩 유닛 (70) 은 인트라 랜덤 액세스 픽처들 (IRAP) 들에 대하여 이 개시물의 승계-기반 컨텍스트 초기화 기법들을 적용하지 않을 수도 있다. 예를 들어, 엔트로피 디코딩 (70) 은 IRAP 들의 3 개의 타입들, 즉, 순간적 디코딩 리프레시 (IDR) 픽처들, 클린 랜덤 액세스 (CRA) 픽처들, 및 파손 링크 액세스 (BLA) 픽처들 중의 임의의 것에 대하여 승계-기반 컨텍스트 초기화 기법들을 구현하지 않을 수도 있다.
이전에 코딩된 정보에 기초한 승계-기반 컨텍스트 초기화의 하나의 예에서, 엔트로피 디코딩 유닛 (70) 은 하나의 슬라이스로 하나의 픽처를 디코딩할 수도 있다. 이 예에서, 엔트로피 디코딩 유닛 (70) 은 컨텍스트 모델들의 초기화된 상태들을 유도하기 위하여 다음의 규칙들 중의 하나 이상을 적용할 수도 있다. 제 1 규칙은 이전에-디코딩된 픽처의 슬라이스가 현재-디코딩된 슬라이스에 대한 슬라이스 타입과 동일한 슬라이스 타입을 가진다는 것이다. 대안적으로 또는 추가적으로, 초기화된 슬라이스 양자화 파라미터 (QP) 는 현재-디코딩된 슬라이스를 코딩하기 위하여 이용된 슬라이스 QP 와 동일하다. 일부 사례들에서, 엔트로피 디코딩 유닛 (70) 은 이전에-디코딩된 픽처에서의 미리 정의된 어드레스로 하나의 블록을 디코딩한 후에 상태 정보 (예컨대, 상태들) 를 레코딩할 수도 있고, 레코딩된 상태 정보를, 현재-디코딩된 슬라이스에 대한 초기화된 상태 정보로서 이용할 수도 있다.
하나의 예에서, '하나의 블록' 은 최대 코딩 유닛 (LCU) 을 표현한다. 예를 들어, LCU 크기 (차원성) 은 'NxN' 에 의해 나타내어질 수도 있고, 픽처 폭은 'W' 에 의해 나타내어질 수도 있고, 픽처 높이는 'H' 에 의해 나타내어질 수도 있다. 하나의 LCU 행 내에서의 LCU 들의 수는 PicWInCtbsY 에 의해 나타내어질 수도 있고, 천장 함수 Ceil( W ÷ N ) 의 출력과 동일하다. PicHInCtbsY 에 의해 나타내어진, 픽처에서의 LCU 행들의 수는 천장 함수 Ceil( H ÷ N ) 의 출력과 동일하다. 포괄적으로 설명하면, 함수 Ceil (x) 는 x 이상인 가장 작은 정수를 반환한다. 추가적으로, LCU 들의 단위들로 측정된 픽처의 폭과, LCU 들로 측정된 픽처의 높이는 위에서 설명된 천장 함수들을 이용하여 획득된 PicWInCtbsY 및 PicHInCtbsY 값들에 의해 각각 표현된다. 하나의 예에서, LCU 의 어드레스는 다음의 수학식에 따라 정의된다:
또한, TargetCUAddr 가 (PicWInCtbsY* PicHInCtbsY) 의 값 이상일 때, 엔트로피 디코딩 유닛 (70) 은 TargetCUAddr 을 (PicWInCtbsY* PicHInCtbsY - 1) 의 값으로 재설정할 수도 있다. 예를 들어, TargetCUAddr 은 PicHInCtbsY 가 1 과 동일한 경우들에는 상기 값과 동일할 수도 있거나 이를 초과할 수도 있다. 추가적으로, (PicWInCtbsY* PicHInCtbsY - 1) 의 값은 하나의 픽처에서의 최후 LCU 에 대응한다.
일부 사례들에서, 또한, 엔트로피 디코딩 유닛 (70) 은 디스플레이 순서에서의 새로운 인트라-코딩된 픽처 후의 최초의 하나 이상의 픽처들에 대하여 위에서 설명된 규칙들-기반 컨텍스트 초기화 기법들을 적용하지 않을 수도 있다. 엔트로피 디코딩 유닛 (70) 이 규칙들-기반 컨텍스트 초기화를 적용하지 않을 수도 있는 예는, 엔트로피 디코딩 유닛 (70) 이 처음으로 새로운 슬라이스 타입 또는 새로운 QP 를 조우한 경우 (예컨대, 새로운 슬라이스 타입 또는 새로운 QP 가 나타남) 이다. 예를 들어, 엔트로피 디코딩 유닛 (70) 은 랜덤 액세스에 관련된 쟁점들을 완화시킬 수도 있거나 잠재적으로 회피할 수도 있다. 이 기법의 예는 도 9 에서 도시되어 있고, 28 로부터 35 까지의 픽처 순서 카운트 (POC) 값을 갖는 픽처들에 대한 디코딩 순서는 다음과 같다: 32, 28, ... 30, 29, 31, 40, 36, 34, 33, 35.
디스플레이 순서의 측면에서, 40 과 동일한 POC 값을 갖는 픽처는 32 와 동일한 POC 값을 갖는 I-픽처 후에 디코딩되는 제 1 픽처이다. 24 의 POC 값을 갖는 픽처는 40 과 동일한 POC 를 갖는 픽처와 동일한 QP 를 가지고, 양자는 동일한 슬라이스 타입들을 공유하지만, 엔트로피 디코딩 유닛 (70) 은 24 와 동일한 POC 를 갖는 픽처의 코딩된 정보를 이용하여 40 과 동일한 POC 값을 갖는 픽처를 예측하지 않을 수도 있다. 유사하게, 엔트로피 디코딩 유닛 (70) 은 31 과 동일한 POC 를 갖는 픽처에 대하여 디코딩된 정보를 이용하여 33 과 동일한 POC 갖는 픽처를 복원하지 않을 수도 있다. 그러나, 양자의 픽처들은 (디스플레이 순서에서) I-픽처에 후속하므로, 엔트로피 디코딩 유닛 (70) 은 33 과 동일한 POC 를 갖는 픽처의 코딩된 정보를 이용하여 35 와 동일한 POC 를 갖는 픽처를 복원할 수도 있다.
이전에-디코딩된 픽처들을 이용한 복원이 허용되지 않거나, 디스에이블되거나, 또는 그렇지 않을 경우에 엔트로피 디코딩 유닛 (70) 에 의해 이용가능하지 않는 사례들에서, 엔트로피 디코딩 유닛 (70) 은 HEVC 에서 정의된 바와 같이 컨텍스트 초기화 기법들을 적용할 수도 있다. 위에서 설명된 바와 같이, 도 6 의 비디오 디코더 (30) 는 단독으로 또는 임의의 조합으로, 개량된 CABAC 를 위하여 이 개시물의 다양한 기법들 중의 임의의 것을 수행하도록 구성되는 비디오 디코딩 디바이스의 예를 표현한다.
도 7 은 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 디코딩 유닛 (70) 의 블록도이다. 도 7 의 엔트로피 디코딩 유닛 (70) 은 도 6 의 엔트로피 디코딩 유닛 (70) 의 일 예의 구현예이다. 다양한 예들에서, 엔트로피 디코딩 유닛 (70) 은 도 5 에서 설명된 엔트로피 디코딩 유닛 (70) 의 그것과 반대의 방식으로 CABAC 를 수행한다. 비트스트림 (218) 으로부터의 코딩된 비트들은 엔트로피 디코딩 유닛 (70) 으로 입력된다. 코딩된 비트들은 그것들이 우회 모드 또는 규칙적 모드를 이용하여 엔트로피 코딩되었는지 아닌지 여부에 기초하여 컨텍스트 모델러 (220) 또는 우회 코딩 엔진 (222) 의 어느 하나로 공급된다. 코딩된 비트들이 우회 모드에서 코딩되었을 경우, 우회 디코딩 엔진은 비-2진 신택스 엘리먼트들의 2진-값의 신택스 엘리먼트들 또는 빈들을 취출하기 위하여, 예를 들어, 골롬-라이스 또는 지수 골롬 디코딩을 이용할 것이다.
코딩된 비트들이 규칙적 모드에서 코딩되었을 경우, 컨텍스트 모델러 (220) 는 코딩된 비트들에 대한 확률 모델을 결정할 수도 있고, 규칙적 디코딩 엔진 (224) 은 비-2진 값의 신택스 엘리먼트들의 빈들 (또는 2진-값일 경우에 신택스 엘리먼트들 자체) 을 생성하기 위하여 코딩된 비트들을 디코딩할 수도 있다. 컨텍스트 모델 및 확률 상태 σ 가 컨텍스트 모델러 (220) 에 의해 결정된 후에, 규칙적 디코딩 엔진 (224) 은 빈 값에 대해 BAC 를 수행한다.
도 5 는 이 개시물의 기법들에 따라 CABAC 를 수행하도록 구성될 수도 있는 일 예의 엔트로피 디코딩 유닛 (70) 의 블록도이다. 신택스 엘리먼트 (118) 는 엔트로피 디코딩 유닛 (70) 으로 입력된다. 신택스 엘리먼트가 이미 2진-값 신택스 엘리먼트 (예컨대, 0 및 1 의 값을 오직 가지는 플래그 또는 다른 신택스 엘리먼트) 일 경우, 2 진화의 단계가 스킵될 수도 있다. 신택스 엘리먼트가 비-2진 값의 신택스 엘리먼트 (예컨대, 1 또는 0 이외의 값들 가질 수도 있는 신택스 엘리먼트) 일 경우, 비-2진 값의 신택스 엘리먼트는 2진화기 (120) 에 의해 2 진화된다. 2진화기 (120) 는 2 진 판정들의 시퀀스로의 비-2진 값의 신택스 엘리먼트의 맵핑을 수행한다. 이 2 진 판정들은 종종 "빈들" 로 칭해진다. 예를 들어, 변환 계수 레벨들에 대하여, 레벨의 값은 연속적인 빈들로 분해될 수도 있고, 각각의 빈은 계수 레벨의 절대 값이 일부 값보다 더 큰지 아닌지 여부를 표시할 수도 있다. 예를 들어, 빈 0 (때때로 중요도 플래그로 칭해짐) 은 변환 계수 레벨의 절대 값이 0 보다 더 큰지 아닌지를 표시한다. 빈 1 은 변환 계수 레벨이 1 보다 더 큰지 아닌지 등을 표시한다. 고유한 맵핑은 각각의 비-2진 값의 신택스 엘리먼트에 대하여 개발될 수도 있다.
2진화기 (120) 에 의해 생성된 각각의 빈은 엔트로피 인코딩 유닛 (56) 의 2 진 산술 코딩 측으로 공급된다. 즉, 비-2진 값의 신택스 엘리먼트들의 미리 결정된 세트에 대하여, 각각의 빈 타입 (예컨대, 빈 0) 은 다음 빈 타입 (예컨대, 빈 1) 전에 코딩된다. 코딩은 규칙적 모드 또는 우회 모드의 어느 하나에서 수행될 수도 있다. 우회 모드에서, 우회 코딩 엔진 (126) 은 고정된 확률 모델을 이용하여, 예를 들어, 골롬-라이스 또는 지수 골롬 코딩을 이용하여 산술 코딩을 수행한다. 우회 모드는 더 예측가능한 신택스 엘리먼트들에 대하여 일반적으로 이용된다.
규칙적 모드에서의 코딩은 CABAC 를 수행하는 것을 수반한다. 규칙적 모드 CABAC 는 빈 값들을 코딩하기 위한 것이고, 여기서, 빈의 값의 확률은 이전에-디코딩된 빈들의 값들이 주어질 경우에 복원될 수 있다. LPS 인 빈의 확률은 컨텍스트 모델러 (220) 에 의해 결정된다. 컨텍스트 모델러 (220) 는 컨텍스트 모델에 대한 빈 값 및 확률 상태 (예컨대, LPS 의 값 및 LPS 가 발생하는 확률을 포함하는 확률 상태 σ) 를 출력한다. 컨텍스트 모델은 일련의 빈들에 대한 초기 컨텍스트 모델일 수도 있거나, 이전에 복원된 빈들의 값들에 기초하여 결정될 수도 있다. 위에서 설명된 바와 같이, 컨텍스트 모델러 (220) 는 수신된 빈이 MPS 또는 LPS 이었는지 아닌지의 여부에 기초하여 상태를 업데이트할 수도 있다. 컨텍스트 모델 및 확률 상태 σ 가 컨텍스트 모델러 (220) 에 의해 결정된 후에, 규칙적 디코딩 엔진 (224) 은 빈 값에 대해 BAC 를 수행한다.
컨텍스트 모델러 (220) 는 병렬화된 방식으로 컨텍스트 모델링을 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이 개시물의 다양한 양태들에 따르면, 컨텍스트 모델러 (220) 는 하나 이상의 이전에-디코딩된 변환 계수들의 i 번째 빈들의 값들을 이용하여 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링을 수행할 수도 있다. 이러한 방법으로, 현재의 변환 계수에 대한 i 번째 빈의 컨텍스트 모델링은 컨텍스트 모델러 (220) 가 이미 컨텍스트를 선택한 하나 이상의 변환 계수들의 대응하는 i 번째 빈들의 값들에 종속적이다.
이전에-디코딩된 변환의 i 번째 빈들의 값들을 이용하여 현재의 변환 계수의 빈에 대한 컨텍스트 모델링을 수행함으로써, 컨텍스트 모델러 (220) 는 현존하는 CABAC 코딩 디바이스들에 비해 하나 이상의 잠재적인 개선들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 이러한 장점의 예로서, 컨텍스트 모델러 (220) 는 이 개시물의 기법들을 구현함으로써 컨텍스트 모델링 동작의 병렬화를 개선시킬 수도 있다. 예를 들어, 컨텍스트 모델러 (220) 는 현재 디코딩되고 있는 변환 계수의 다수의 빈들에 대하여, 컨텍스트 모델링을 병렬로 수행할 수도 있다. 하나의 예로서, 컨텍스트 모델러 (220) 가 다수의 빈들에 대응하는 빈 값들이 이전에-디코딩된 변환 계수 (들) 로부터 이용가능한 것으로 결정할 경우, 컨텍스트 모델러 (220) 는 현재 디코딩되고 있는 변환 계수의 빈들에 대한 컨텍스트 모델링 동작들을 적어도 부분적으로 병렬화할 수도 있다.
컨텍스트 모델러 (220) 는 멀티-패스 디코딩 방식에 따라 이 개시물의 병렬화된 컨텍스트 모델링을 수행할 수도 있다. 더 구체적으로, 멀티-패스 디코딩 방식은 엔트로피 디코딩 유닛 (70) 이 별도의 스레드들을 각각의 특정한 빈에 배정하게 하는 디코딩 기법 (예컨대, 제 1 빈에 대한 스레드 1, 제 2 빈에 대한 스레드 2 등) 을 지칭한다. 이에 따라, 멀티-패스 코딩에 따르면, 모든 bin0 인스턴스들은 시퀀스로 디코딩되는 bin1 인스턴스들에 독립적으로 시퀀스로 디코딩될 수 있고, 양자는 시퀀스로 디코딩되는 bin2 인스턴스들에 독립적으로 디코딩되는 등과 같다. 일부 예들에서, 컨텍스트 모델러 (220) 는 단일 블록의 변환 유닛들에 대하여 멀티-패스 디코딩을 수행할 수도 있다. 또한, 규칙적 모드에 따라 디코딩되는 빈들에 대하여, 컨텍스트 모델러 (220) 는 다수의 패스들에서 컨텍스트 선택을 수행할 수도 있다. 각각의 패스는 모든 변환 계수들의 단일의 대응하는 빈에 속할 수도 있다. 다시 말해서, 각각의 패스 동안에, 컨텍스트 모델러 (220) 는 다른 패스들에 관련되는 정보를 사용하지 않는다. 예를 들어, 컨텍스트 모델러 (220) 는 제 1 패스에서 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 1 빈에 대한 컨텍스트를 선택할 수도 있다. 이 예에서, 제 2 패스에서, 컨텍스트 모델러 (220) 는 필요할 경우, 하나의 변환 유닛/CG 내에서의 모든 변환 계수들의 제 2 빈에 대한 컨텍스트를 선택할 수도 있는 등과 같다.
하나의 예의 이용 경우에 있어서, 컨텍스트 모델러 (220) 는 이전에-코딩된 이웃하는 변환 계수의 bin0 의 값을 이용하여 현재-코딩된 변환 계수의 bin0 에 대한 컨텍스트 모델링을 수행할 수도 있고, 이전에-코딩된 이웃하는 변환 계수의 bin1 의 값을 이용하여 현재-코딩된 변환 계수의 bin1 에 대한 컨텍스트 모델링을 수행할 수도 있는 등과 같다. 이전에-코딩된 변환 계수에 대하여 이용가능한 임의의 빈 값들을 이용하면, 컨텍스트 모델러 (220) 는 현재-코딩된 변환 계수의 다수의 빈들에 대한 컨텍스트 모델링을 병렬로 수행할 수도 있다. 위에서 설명된 이용 경우의 시나리오에서, bin0 및 bin1 이 양자 모두 이전에-코딩된 이웃 변환 계수로부터 이용가능할 경우, 컨텍스트 모델러 (220) 는 현재-코딩된 변환 계수에 대한 bin0 및 bin1 의 컨텍스트 모델링을 병렬화할 수도 있다. 이러한 방식으로, 컨텍스트 모델러 (220) 는 컨텍스트 모델링 동작들의 병렬화를 가능하게 하고 잠재적으로 활용함으로써 현재의 변환 계수의 빈들에 대한 컨텍스트 선택을 개선시키면서, HEVC 에서 설명된 바와 같이 멀티-패스 디코딩의 원리들 내에서 CABAC 를 수행하기 위하여 이 개시물의 기법들을 구현할 수도 있다.
컨텍스트 모델러 (220) 는 모든 이러한 빈들의 전체 컨텍스트 모델링을 병렬로 수행할 수 있지만, 반드시 그러한 것은 아닐 수도 있다는 것이 인식될 것이다. 더 구체적으로, 컨텍스트 모델러 (220) 는 다수의 빈들의 컨텍스트 모델링의 일부 부분들을 동시에 수행할 수도 있다. 이러한 방법으로, 컨텍스트 모델러 (220) 는 멀티코어 프로세싱 기술 및/또는 다수의 프로세서들을 이용하여 현재-코딩된 변환 계수에 대한 컨텍스트 모델링 동작들을 개선시키기 위하여 이 개시물의 기법들을 구현할 수도 있다.
단일 패스에서 상이한 변환 계수들의 대응하는 빈들을 디코딩함으로써, 컨텍스트 모델러 (220) 는 현존하는 멀티-패스 CABAC 기법들에 비해 하나 이상의 장점들을 제공할 수도 있다. 예를 들어, 단일 패스에서 다수의 변환 계수들의 대응하는 빈들 (예컨대, 개개의 bin0) 을 디코딩함으로써, 컨텍스트 모델러 (220) 는 빈 천이들에서 빈번하게 새로운 컨텍스트 모델을 저장하고 취출하기 위한 필요성을 회피할 수도 있다. 그 대신에, 패스는 다수의 변환 계수들에 걸쳐 대응하는 빈들 (예컨대, 개개의 bin0) 을 타겟으로 하므로, 컨텍스트 모델러 (220) 는 소정의 패스에 걸쳐 단일 컨텍스트 모델을 이용할 수도 있다. 이러한 방법으로, 컨텍스트 모델러 (220) 는 빈번한 컨텍스트-스위칭으로부터 발생하는 시간 지연들 및 자원 회전을 완화시키거나 또는 잠재적으로 제거하기 위하여 이 개시물의 병렬화된 컨텍스트 선택 기법들을 구현할 수도 있다. 대조적으로, 현존하는 멀티-패스 코딩은 제 1 변환 계수에 대하여, bin0, bin1, bin2 등을 디코딩하고, 그 다음으로, 제 2 변환 계수에 대하여 bin0, bin1, bin2 등을 디코딩하는 등으로 인해, 빈번한 컨텍스트 모델 저장 및 취출 동작들을 요구할 것이다.
예를 들어, 컨텍스트 모델러 (220) 는 본원에서 설명된 i 번째 빈 컨텍스트 모델링 기능성들을 위하여 이용하기 위한 하나 이상의 미리 정의된 템플릿들을 생성할 수도 있거나, 또는 그렇지 않을 경우에 이에 액세스할 수도 있다. 컨텍스트 모델러 (220) 가 현재-코딩된 변환 계수의 i 번째 빈의 컨텍스트 모델링을 위하여 이용할 수도 있는 미리 정의된 템플릿의 하나의 비-제한적인 예는 도 10 에서 예시되어 있다. 도 10 의 템플릿 (140) 과 같은 미리 정의된 템플릿은 8x8 변환 블록에 대하여 대각선 스캔 순서를 정의하고, 여기서, 'L' 은 최후의 중요한 스캔 위치를 나타내고, 'x' 는 현재의 스캔 위치를 나타내고, "xi" 는 로컬 템플릿 (140) 에 의해 커버된 이웃들을 나타낸다. xi 에 대하여, "i" 의 값은 제로 내지 4 의 범위에 있고, 범위 제약은 i ∈ [0,4] 로서 표현된다. 이 개시물의 하나 이상의 양태들에 따르면, 컨텍스트 모델러 (220) 는 현재 디코딩되고 있는 변환 계수의 대응하는 i 번째 빈의 컨텍스트 모델링을 위하여 로컬 템플릿 (140) 에서 위치된 변환 계수들의 i 번째 빈들을 이용할 수도 있다. 일부 구현예들에 따르면, 컨텍스트 모델러 (220) 는 이 개시물의 병렬화된 빈 컨텍스트 모델링을 수행하기 위하여 다수의 템플릿들을 이용할 수도 있다. 하나의 예에서, 템플릿 크기 및/또는 형상은 다음의 기준들 중의 하나 이상에 종속적이다: (i) 변환 유닛들의 크기; (ii) 모드들; 또는 (iii) 현재의 변환 유닛 또는 계수 그룹 (CG) 내에서의 현재의 변환 계수들의 위치.
빈 값들에 대하여 이전에-코딩된 TU 를 횡단하기 위하여 하나 이상의 미리 정의된 템플릿들을 이용함으로써, 컨텍스트 모델러 (220) 는 현존하는 CABAC 기술에 비해 하나 이상의 개량들을 제공하기 위하여 이 개시물의 기법들을 구현할 수도 있다. 예를 들어, 도 10 의 로컬 템플릿 (140) 과 같은 TU 횡단 템플릿을 이용함으로써, 컨텍스트 모델러 (220) 는 상이한 디코딩 패스들에 대하여 횡단 방식을 별도로 결정하기 위한 필요성을 회피할 수도 있다. 이에 따라, 이 개시물의 템플릿-기반 병렬화된 컨텍스트 선택 기법들을 구현함으로써, 컨텍스트 모델러 (220) 는 픽처 정확도를 유지하면서, 빈 디코딩에 대한 스루풋을 증가시킬 수도 있다.
또 다른 예의 구현예에 따르면, 컨텍스트 모델러 (220) 는 이 개시물의 병렬화된 컨텍스트 모델링 기법들을 현재-코딩된 변환 계수의 처음 'K' 빈들에 오직 적용할 수도 있고, 여기서, 'K' 는 M 보다 더 작고, 여기서, 'M' 은 이용가능한 빈 인덱스들의 상한을 나타낸다. 컨텍스트 모델러 (220) 는 또 다른 컨텍스트 모델링 기법을 이용하여, 또는 우회 모드에 따라 코딩되고 있는 나머지 (M+1-K) 빈들을 디코딩할 수도 있다.
또 다른 예의 구현예에 따르면, 컨텍스트 모델러 (220) 는 이전에-코딩된 변환 계수들의 모집단을, 현재 디코딩되고 있는 변환 계수 전의 현재의 변환 유닛 또는 CG 내에서의 디코딩 순서에서의 'N' 연속 변환 계수들로서 정의할 수도 있다. 대안적으로, 컨텍스트 모델러 (220) 는 N 을 변수인 것으로 결정할 수도 있다. 하나의 예에서, 컨텍스트 모델러 (220) 는 현재의 변환 유닛에서의 현재-디코딩된 변환 계수의 상대적인 위치에 종속적인 N 의 값을 결정할 수도 있다. 또 다른 예에서, 컨텍스트 모델러 (220) 는 변환 유닛 크기에 종속적인 N 의 값을 결정할 수도 있다.
또 다른 구현예에서, 컨텍스트 모델러 (220) 는 이전에-디코딩된 변환 계수들의 모집단을, 현재의 변환 유닛 또는 CG 내에서의 현재의 위치의 이웃에 위치된 그 변환 계수들로서 정의할 수도 있다. 하나의 예에서, 현재의 위치의 이웃은 현재의 위치에 직접적으로 인접한 그 위치들, 또는 현재의 위치에 직접적으로 인접하거나 현재의 위치로부터 분리된 것 중의 하나인 위치들로 제약된다. 또 다른 예에서, 이웃은 또한, 이 위치들을 포함할 수도 있지만, 하나 이상의 공간적 이웃하는 변환 유닛들에서의 위치들을 포함하도록 확대할 수도 있다.
이 개시물의 다양한 양태들에 따르면, 컨텍스트 모델러 (220) 는 빈의 컨텍스트 인덱스를, 하나 이상의 이전에-코딩된 변환 계수들과 연관된 값들의 함수로서 정의할 수도 있다. 예를 들어, 컨텍스트 모델러 (220) 는 이전에-코딩된 변환 계수들의 모든 i 번째 빈 값들의 합을 산출하는 함수를 이용할 수도 있다. 더 구체적으로, 이 예에서, 컨텍스트 모델러 (220) 는 TU/CG 의 모든 이전에-디코딩된 변환 계수들의 이용가능한 i 번째 빈 값들의 값들의 합산을 수행할 수도 있다. 결국, 컨텍스트 모델러 (220) 는 현재-코딩된 변환 계수의 i 번째 빈에 대한 컨텍스트 모델링 동안에 결과적인 합을 컨텍스트 인덱스 (CtIdx) 로서 이용할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (220) 는 컨텍스트 인덱스 유도 규칙을, 변환 유닛들의 상이한 크기들에서의 동일한 패스에 대하여 미변경된 것으로 유지할 수도 있다. 그러나, 컨텍스트 모델러 (220) 는 현재-코딩된 빈에 대한 컨텍스트 모델링을 수행하기 위하여 오프셋을 컨텍스트 인덱스에 적용할 수도 있다. 예를 들어, 컨텍스트 모델러 (220) 는 2 개의 상이한 변환 크기들이 컨텍스트 모델들의 2 개의 세트들을 가지는 것으로 결정할 수도 있다. 결국, 컨텍스트 모델러 (220) 는 오프셋을, 하나의 이러한 세트에서의 컨텍스트 모델들의 수로서 정의할 수도 있다. 예를 들어, 컨텍스트 모델러 (220) 가 TU 크기가 미리 정의된 차원들 MxM 의 정사각형보다 더 작은 것으로 결정할 경우, 컨텍스트 모델러 (220) 는 각각의 이러한 TU (MxM 보다 더 작음) TU 크기가 컨텍스트 모델들의 그 자신의 개개의 세트를 가지는 것으로 결정할 수도 있다. 반대로, 엔트로피 디코딩 유닛 (70) 은 MxM 과 동일하거나 그보다 더 큰 크기들을 갖는 모든 TU 들이 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다.
다양한 이용 경우의 시나리오들에서, 컨텍스트 모델러 (220) 는 M 의 값을 16 으로 설정할 수도 있다. 더 구체적으로, 이 예들에서, 컨텍스트 모델러 (220) 가 현재-코딩된 TU 의 크기가 16x16 정사각형보다 더 작은 것으로 결정할 경우, 컨텍스트 모델러 (220) 는 현재-코딩된 TU 가 TU 의 특정한 크기에 대응하는 컨텍스트 모델들의 세트와 연관되는 것으로 결정할 수도 있다. 반대로, 엔트로피 디코딩 유닛 (70) 이 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 것으로 결정할 경우, 컨텍스트 모델러 (220) 는 현재-코딩된 TU 가 16x16 과 동일하거나 그보다 더 큰 크기를 가지는 모든 다른 TU 들과 컨텍스트 모델들의 동일한 세트를 공유하는 것으로 결정할 수도 있다. 일부 예들에서, 컨텍스트 모델러 (220) 는 TU 크기-기반 컨텍스트 선택을 오직 루마 블록들에 적용할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (220) 는 변환 크기에 기초하여 계수 그룹 (CG) 크기를 결정할 수도 있다. 다시 말해서, 이 양태들에 따르면, CG 크기는 변환 크기에 종속적이다. 대안적으로 또는 추가적으로, 컨텍스트 모델러 (220) 는 코딩 모드에 기초하여 CG 크기를 결정할 수도 있다. 이 예들에서, 컨텍스트 모델러 (220) 는 CG 크기를 변환 크기 및/또는 코딩 모드 중의 하나 또는 양자에 종속적인 것으로서 결정할 수도 있다. 대안적으로 또는 추가적으로, 컨텍스트 모델러 (220) 는 변환 행렬에 기초하여 CG 크기를 결정할 수도 있다.
이 개시물의 일부 양태들에 따르면, 컨텍스트 모델러 (220) 는 또한, 병렬화된 컨텍스트 모델링 기법들을, 변환 우회 모드 (또한, "변환 스킵 모드" 로서 지칭됨) 를 이용하여 디코딩되는 블록들에 적용할 수 있다. 변환 우회 모드는, 비디오 디코더 (30) 가 비트스트림 (218) 이 무손실로 인코딩되는 경우들에서와 같이, 코딩 모드에 따라, 디코딩의 역변환 및 역양자화 동작들을 스킵할 수도 있는 코딩 모드를 지칭한다. 이에 따라, 이 개시물의 어떤 양태들에 따르면, 컨텍스트 모델러 (220) 는 비트스트림 (218) 이 무손실로 인코딩되는 사례들에서 잠재적으로 결과적인 장점들을 제공하기 위하여 병렬화된 컨텍스트 선택 기법들을 확대할 수도 있다.
도 8 은 표-기반 2 진 산술 코딩을 위한 일 예의 프로세스 (150) 를 예시하는 플로우차트이다. 즉, 도 8 은 규칙적 코딩 모드를 이용하여 단일 빈 값 (binVal) 에 대한 (단계들 (158 및 160) 에 대한 회색 음영처리된 박스들에서의) 확률 추정의 업데이팅 프로세스를 포함하는 2 진 산술 인코딩 프로세스를 예시한다. 특히, 도 8 의 프로세스 (150) 는 규칙적 코딩 모드를 이용하여 소정의 빈 값 binVal 에 대한 2 진 산술 인코딩 프로세스를 예시한다. 산술 인코딩 엔진의 내부 상태는 2 개의 양들에 의해 특징지어진다: 현재의 간격 범위 R 및 현재의 코드 간격의 기저부 (하부 종점) L. 그러나, (규칙적 및 우회 모드의 양자에서) CABAC 엔진 내에 이 레지스터들을 저장하기 위하여 필요한 정밀도는 각각 9 및 10 비트들에 이르기까지 감소될 수 있다. 확률 상태 인덱스  및 MPS 의 값
및 MPS 의 값  을 갖는 컨텍스트에서 관측된 소정의 2 진 값 binVal 의 인코딩은 다음과 같이 4 개의 기초적인 단계들의 시퀀스에서 수행된다.
을 갖는 컨텍스트에서 관측된 소정의 2 진 값 binVal 의 인코딩은 다음과 같이 4 개의 기초적인 단계들의 시퀀스에서 수행된다.
프로세스 (150) 는, 비디오 코딩 디바이스가 소정의 확률 추정치들에 따라 현재의 간격을 재분할하는 단계 (152) 에서 시작할 수도 있다. 이 간격 재분할 프로세스는 프로세스 (150) 의 단계 (152) 에서 도시된 바와 같이 3 개의 기초적인 동작들을 수반한다. 첫째, 현재의 간격 범위 R 은 4 개의 셀들로의 전체 범위  의 동등-파티션 (equi-partition) 을 이용하여 양자화된 값 Q(R) 에 의해 근사화된다. 그러나, CABAC 엔진에서 대응하는 대표적인 양자화된 범위 값들, Q0, Q1, Q2, 및 Q3 을 명시적으로 이용하는 대신에, 시프트 및 비트-마스팅 동작의 조합에 의해 효율적으로 컴퓨팅될 수 있는 그 양자화기 인덱스
의 동등-파티션 (equi-partition) 을 이용하여 양자화된 값 Q(R) 에 의해 근사화된다. 그러나, CABAC 엔진에서 대응하는 대표적인 양자화된 범위 값들, Q0, Q1, Q2, 및 Q3 을 명시적으로 이용하는 대신에, 시프트 및 비트-마스팅 동작의 조합에 의해 효율적으로 컴퓨팅될 수 있는 그 양자화기 인덱스  , 즉, 이하에 의해 오직 해결된다:
, 즉, 이하에 의해 오직 해결된다:
그 다음으로, 이 인덱스  및 확률 상태 인덱스
및 확률 상태 인덱스  는 도 8 에서 도시된 바와 같이, (근사적인) LPS 관련된 하위간격 범위 RLPS 를 결정하기 위하여 2-D 표 TabRangeLPS 에서의 엔트리들로서 이용된다. 여기서, 표 TabRangeLPS 는 8-비트 정밀도에서의
는 도 8 에서 도시된 바와 같이, (근사적인) LPS 관련된 하위간격 범위 RLPS 를 결정하기 위하여 2-D 표 TabRangeLPS 에서의 엔트리들로서 이용된다. 여기서, 표 TabRangeLPS 는 8-비트 정밀도에서의  및
및  에 대하여
에 대하여  에 대한 모든 64x4 사전-컴퓨팅된 곱셈 값들을 포함한다. MPS 에 대한 이중 하위간격 범위가 주어질 경우, 소정의 빈 값 binVal 에 대응하는 하위간격은 프로세스 (150) 의 판정 블록 (94) 에서 선택된다. binVal 이 MPS 값과 동일할 경우 (판정 블록 (150) 의 아니오 가지), 비디오 코딩 디바이스는 하부 하위간격을 선택할 수도 있어서, L 은 미변경된다. 그렇지 않을 경우 (판정 블록 (154) 의 예 가지), 비디오 코딩 디바이스는 RLPS 와 동일한 범위를 갖는 상부 하위간격을 선택할 수도 있다 (156).
에 대한 모든 64x4 사전-컴퓨팅된 곱셈 값들을 포함한다. MPS 에 대한 이중 하위간격 범위가 주어질 경우, 소정의 빈 값 binVal 에 대응하는 하위간격은 프로세스 (150) 의 판정 블록 (94) 에서 선택된다. binVal 이 MPS 값과 동일할 경우 (판정 블록 (150) 의 아니오 가지), 비디오 코딩 디바이스는 하부 하위간격을 선택할 수도 있어서, L 은 미변경된다. 그렇지 않을 경우 (판정 블록 (154) 의 예 가지), 비디오 코딩 디바이스는 RLPS 와 동일한 범위를 갖는 상부 하위간격을 선택할 수도 있다 (156).
프로세스 (90) 단계들 (158 및 160) 에서, 확률 상태들의 업데이트는 (회색 음영처리된 박스들을 이용하여 예시된) ITU-T H.264, § 1.2.2.2 에서 설명된 바와 같이 수행된다. 단계 (162) 는 레지스터들 L 및 R 의 재정규화 (도 1 에서의 "RenormE" 박스) 로 구성된다. 단계 (164) 는 프로세스 (150) 의 종료를 표현한다.
2-D 표 TabRangeLPS 는 다음과 같이 정의된다:



디코딩 프로세스는 HEVC 사양의 섹션 9.3.4.3.2.2 에서 설명된다.
도 9 는 잔차 쿼드트리 구조에 기초한 변환 방식을 예시하는 개념도이다. 잔차 블록들의 다양한 특성들을 적응시키기 위하여, 잔차 쿼드트리 (RQT) 를 이용한 변환 코딩 구조가 HEVC 에서 적용된다. 잔차 쿼드트리 구조가 이하에서 설명된다. 추가적인 세부사항들은 www.hhi.fraunhofer.de/fields-of-competence/image-processing/researchgroups/image-video-coding/hevc-high-efficiency-video-coding/transform-coding-using-the-residual-quadtree-rqt.html 에서 설명되고 입수가능하다.
도 9 에서 예시된 잔차 쿼드트리 구조에 따르면, 각각의 픽처는 코딩 트리 유닛 (coding tree unit; CTU) 들로 분할된다. 픽처의 CTU 들은 특정 타일 또는 슬라이스에 대한 래스터 스캔 순서 (raster scan order) 로 코딩 (예컨대, 인코딩 및/또는 디코딩) 된다. CTU 는 정사각형 블록이고, 쿼드트리 또는 코딩 트리의 루트를 표현한다. CTU 크기는 8×8 로부터 64×64 까지의 범위일 수도 있고, 폭 및 길이는 루마 샘플들의 단위들로 표현될 수도 있다. 64×64 차원성은 HEVC-호환 코딩 디바이스들에 의해 통상적으로 이용된다. 각각의 CTU 는 코딩 유닛 (CU) 들로 칭해진 더 작은 정사각형 블록들로 추가로 분할될 수 있다. CTU 가 CU 들로 (때때로 재귀적으로) 분할된 후, 각각의 CU 는 예측 유닛 (PU) 들 및 변환 유닛 (TU) 들로 추가로 분할된다. PU 들 및 CU 들은 정사각형 폼 팩터 (form factor) 를 또한 가진다. TU 들로의 CU 의 파티셔닝은 쿼드트리 접근법에 기초하여 재귀적으로 수행된다. 그러므로, 각각의 CU 의 잔차 신호는 트리 구조, 즉, 잔차 쿼드트리 (RQT) 를 이용하여 코딩된다. RQT 는 4x4 로부터 32x32 까지의 (루마 샘플들의 단위들로 정사각형 차원성들로서 표현된) TU 크기들을 허용한다.
도 9 는 CU 가 10 개의 TU 들을 포함하는 예를 도시한다. TU 들은 글자들 a 내지 j 로 표기되고, 각각의 TU 라벨은 대응하는 블록 파티셔닝 내부에서 예시된다. RQT 의 각각의 노드는 변환 유닛 (TU) 이다. 개별적인 TU 들은 심도-우선 트리 횡단 순서 (depth-first tree traversal order) 로 프로세싱된다. 도 9 에 대한 심도-우선 트리 횡단의 결과는 알파벳 순서에 따라 도 9 에서 예시되어 있다. 더 구체적으로, 도 9 는 심도-우선 횡단을 갖는 재귀적 Z-스캔의 예를 예시한다. 도 9 에서 예시된 쿼드트리 접근법은 잔차 신호의 변동되는 공간-주파수 특성들로의 변환의 적응을 가능하게 한다.
많은 예들에서, 더 큰 공간적 지원을 가지는 더 큰 변환 블록 크기는 더 양호한 주파수 분해능을 제공한다. 그러나, 더 작은 공간적 지원을 가지는 더 작은 변환 블록 크기는 더 양호한 공간적 분해능을 제공한다. 둘 (공간적 및 주파수 분해능들) 사이의 절충은 인코더 모드 판정을 통해 선택된다. 예를 들어, 인코더 모드 판정은 레이트-왜곡 (rate-distortion; RD) 최적화 기법에 기초할 수도 있다. 레이트-왜곡 최적화 기법은 코딩 비트들 및 복원 왜곡의 가중화된 합을 계산한다. 예를 들어, 모드 선택 유닛 (40) 은 모드 선택 판정을 각각의 코딩 모드에 대한 레이트-왜곡 코스트 (rate-distortion cost) 에 기초할 수도 있다. 일부 예들에서, 각각의 이용가능한 모드에 대한 레이트-왜곡 코스트는 각각의 코딩 모드와 연관된 특정 RQT 분할 구조에 상관될 수도 있다. RD 코스트-기반 판정 방식에서, 모드 선택 유닛은 가장 낮은 (또는 가장 작은) 레이트-왜곡 코스트를 갖는 코딩 모드를 최상의 이용가능한 모드로서 선택할 수도 있다.
3 개의 파라미터들은 RQT 파티셔닝 방식에서 정의된다. 파라미터들은 트리의 최대 심도, 최소 허용된 변환 크기, 및 최대 허용된 변환 크기이다. HEVC 의 일부 양태들에 따르면, 최소 및 최대 변환 크기들은 4x4 로부터 32 x 32 까지의 샘플들의 범위 내에서 변동될 수 있다. 4x4 로부터 32 x 32 까지의 샘플들의 범위는 위에서 논의된 지원된 블록 변환들에 대응한다. RQT 의 최대 허용된 심도는 RQT 파티셔닝 방식이 산출할 수 있는 TU 들의 수를 한정하거나 제약한다. 제로와 동일한 최대 심도는, 각각의 포함된 TU 가 최대 허용된 변환 크기, 예컨대, 32x32 에 도달할 경우에, CTU 가 더 이상 분할될 수 없다는 것을 의미한다.
위에서 논의된 파라미터들의 전부는 상호작용하고 (예컨대, 상승 작용에 의해 이용됨), RQT 구조에 영향을 준다. 루트 CTU 크기가 64x64 이고, 최대 심도가 제로와 동일하고, 최대 변환 크기가 32x32 와 동일한 이용-경우의 시나리오가 이하에서 설명된다. 이 경우, 비디오 코딩 디바이스는 CTU 를 적어도 한 번 파티셔닝할 필요가 있을 것이다. CTU 가 파티셔닝되지 않을 경우, RQT 는 제 3 파라미터마다 허용되지 않는 64x64 TU 를 산출할 것이다. 비디오 인코더 (20) 는 시퀀스 파라미터 세트 (SPS) 레벨에서, 비트스트림에서의 (최대 RQT 심도 및 최소 및 최대 변환 크기를 포함하지만, 이것으로 제한되지는 않는) RQT 파라미터들을 포함할 수도 있다. 비디오 인코더 (20) 는 인트라-코딩된 및 인터-코딩된 CU 들에 대하여 RQT 심도에 대한 상이한 값들을 특정할 수도 있고 시그널링할 수도 있다. 결국, 비디오 디코더 (30) 는 수신된 비트스트림으로부터 RQT 파라미터들을 복구할 수도 있고, 시그널링된 파라미터들에서 특정된 제약들을 이용하여 RQT 파티셔닝을 수행할 수도 있다.
비디오 인코더 (20) 및/또는 비디오 디코더 (30) 는 양자의 인트라 및 인터 잔차 블록들에 대한 쿼드트리 변환을 적용할 수도 있다. 많은 예들에서, 비디오 인코더 (20) 및/또는 비디오 디코더 (30) 는 잔차 블록에 대하여 적용되는 현재의 잔차 쿼드트리 파티션의 동일한 크기의 DCT-II 변환을 적용할 수도 있다. 그러나, 현재의 잔차 쿼드트리 블록이 4x4 이고 인트라 예측에 의해 생성될 경우, 비디오 인코더 (20) 및/또는 비디오 디코더 (30) 는 위에서 설명된 4x4 DST-VII 변환을 적용할 수도 있다. HEVC 에서, 더 큰 크기의 변환들, 예컨대, 64x64 변환들은 주로 그 제한된 장점들, 및 상대적으로 더 작은 해상도 비디오들에 대한 상대적으로 높은 복잡도로 인해 채택되지 않는다.
도 10 은 비디오 코딩 디바이스가 본원에서 설명된 컨텍스트 모델링 기법들에 대하여 이용할 수도 있는 일 예의 템플릿 (로컬 템플릿 (140)) 을 도시하는 개념도이다. 현재의 변환 계수는 'X' 로서 표기되고, 5 개의 공간적 이웃들은 'Xi' ('i' 는 0 내지 4 로부터의 정수를 표현함) 로서 표기된다. 조건들의 세트 중의 임의의 하나가 충족될 경우, 비디오 코딩 디바이스들은 Xi 를 이용불가능하고 컨텍스트 인덱스 유도 프로세스에서 이용되지 않는 것으로서 표기할 수도 있다. 조건들의 세트에서의 제 1 조건은 Xi 의 위치 및 현재의 변환 계수 X 가 동일한 변환 유닛에서 위치되지 않는다는 것이다. 조건들의 세트에서의 제 2 조건은 Xi 의 위치가 픽처들의 수평 또는 수직 경계들의 외부에 위치된다는 것이다. 조건들의 세트에서의 제 3 조건은 변환 계수 Xi 가 아직 코딩되지 않았다는 것이다. 멀티-패스 코딩의 경우, 동일한 코딩 패스에서의 빈들이 코딩될 때마다, 빈들은 컨텍스트 인덱스 유도 프로세스에서 이용될 수 있다. 그러므로, 디코딩의 관점으로부터, 하나의 변환 계수를 완전히 디코딩하는 것은 필요하지 않다.
도 11 은 계수 그룹들에 기초한 일 예의 계수 스캔을 예시하는 개념도이다. TU 크기에 관계 없이, 변환 유닛의 잔차는 비-중첩된 계수 그룹 (CG) 들로 코딩되고, 각각은 TU 의 4x4 블록의 계수들을 포함한다. 예를 들어, 32x32 TU 는 총 64 개의 CG 들을 가지고, 16x16 TU 는 총 16 개의 CG 들을 가진다. TU 내부의 CG 들은 어떤 미리 정의된 스캔 순서에 따라 코딩될 수도 있다. 각각의 CG 를 코딩할 때, 현재의 CG 내부의 계수들은 4x4 블록에 대한 어떤 미리 정의된 스캔 순서에 따라 스캔되고 코딩된다. 도 11 은 4 개의 CG 들을 포함하는 8x8 TU 에 대한 계수 스캔을 예시한다.
신택스 엘리먼트 표는 다음과 같이 정의된다:



각각의 컬러 컴포넌트에 대하여, 비디오 인코더 (20) 는 현재의 TU 가 적어도 하나의 비-제로 계수를 가지는지 여부를 표시하기 위하여 하나의 플래그를 먼저 시그널링할 수도 있다. 현재의 TU 에서 적어도 하나의 비-제로 계수가 있을 경우, 비디오 인코더 (20) 는 변환 유닛의 상부-좌측 코너에 관한 좌표를 갖는 TU 에서 계수 스캔 순서에서의 최후의 중요한 계수의 위치를 명시적으로 인코딩할 수도 있다. 좌표의 수직 또는 수평 컴포넌트는 그 프리픽스 (prefix) 및 서픽스 (suffix) 에 의해 표현되고, 여기서, 프리픽스는 절단된 라이스 (truncated rice; TR) 로 2 진화되고, 서픽스는 고정된 길이로 2 진화된다.
시맨틱들:
last_ sig _ coeff _x_prefix 는 변환 블록 내에서 스캔 순서에서의 최후의 중요한 계수의 열 위치의 프리픽스를 특정한다. last_sig_coeff_x_prefix 의 값들은 0 내지 ( log2TrafoSize << 1 ) - 1 까지의 범위에 있을 것이다.
last_ sig _ coeff _y_prefix 는 변환 블록 내에서 스캔 순서에서의 최후의 중요한 계수의 행 위치의 프리픽스를 특정한다. last_sig_coeff_y_prefix 의 값들은 0 내지 ( log2TrafoSize << 1 ) - 1 까지의 범위에 있을 것이다.
last_ sig _ coeff _x_suffix 는 변환 블록 내에서 스캔 순서에서의 최후의 중요한 계수의 열 위치의 서픽스를 특정한다. last_sig_coeff_x_suffix 의 값들은 0 내지 ( 1 << ( ( last_sig_coeff_x_prefix >> 1 ) - 1 ) ) - 1 까지의 범위에 있을 것이다.
변환 블록 내에서의 스캔 순서에서의 최후의 중요한 계수 LastSignificantCoeffX 의 열 위치는 다음과 같이 유도된다:
- last_sig_coeff_x_suffix 가 존재하지 않을 경우, 다음이 적용된다:
LastSignificantCoeffX = last_sig_coeff_x_prefix
- 그렇지 않을 경우 (last_sig_coeff_x_suffix 가 존재함), 다음이 적용된다:
LastSignificantCoeffX = ( 1 << ( (last_sig_coeff_x_prefix >> 1 ) - 1 ) ) * ( 2 + (last_sig_coeff_x_prefix & 1 ) ) + last_sig_coeff_x_suffix
last_ sig _ coeff _y_suffix 는 변환 블록 내에서 스캔 순서에서의 최후의 중요한 계수의 행 위치의 서픽스를 특정한다. last_sig_coeff_y_suffix 의 값들은 0 내지 ( 1 << ( ( last_sig_coeff_y_prefix >> 1 ) - 1 ) ) - 1 까지의 범위에 있을 것이다.
변환 블록 내에서의 스캔 위치에서의 최후의 중요한 계수 LastSignificantCoeffY 의 행 위치는 다음과 같이 유도된다:
- last_sig_coeff_y_suffix 가 존재하지 않을 경우, 다음이 적용된다:
LastSignificantCoeffY = last_sig_coeff_y_prefix
- 그렇지 않을 경우 (last_sig_coeff_y_suffix 가 존재함), 다음이 적용된다:
LastSignificantCoeffY = ( 1 << ( ( last_sig_coeff_y_prefix >> 1 ) - 1 ) ) * ( 2 + ( last_sig_coeff_y_prefix & 1 ) ) + last_sig_coeff_y_suffix
scanIdx 가 2 와 동일할 때, 좌표들은 다음과 같이 교환된다:
(LastSignificantCoeffX, LastSignificantCoeffY)=Swap( LastSignificantCoeffX, LastSignificantCoeffY )
코딩된 이러한 위치와 또한, CG 들의 계수 스캔 순서로, 하나의 플래그는 그것이 비-제로 계수들을 포함하는지 여부를 표시하는 (스캔 순서에서의) 최후 CG 를 제외한 CG 들에 대하여 추가로 시그널링된다.
CG 플래그의 컨텍스트 모델링. 하나의 CG 가 비-제로 계수들을 가지는지 여부, 즉, CG 플래그 (HEVC 사양에서의 coded_sub_block_flag) 를 코딩할 때, 이웃하는 CG 들의 정보는 컨텍스트를 구축하기 위하여 사용된다. 더 구체적으로 하자면, CG 플래그를 코딩하기 위한 컨텍스트 선택은 다음과 같이 정의된다:
(이용가능한 우측 CG && 우측 CG 의 플래그는 1 과 동일함) || (이용가능한 하부 CG && 하부 CG 의 플래그는 1 과 동일함)
여기서, 우측 및 하부 CG 는 현재의 CG 에 근접한 2 개의 이웃하는 CG 들이다. 예를 들어, 도 11 에서, 상부-좌측 4x4 블록을 인코딩할 때, 비디오 인코더 (20) 는 우측 CG 를 상부-우측 4x4 블록으로서 정의할 수도 있고, 하부 CG 는 좌측-하부 4x4 블록으로서 정의된다. 크로마 및 루마는 컨텍스트 모델들의 상이한 세트들을 이용하지만, 그것들 중의 하나를 선택하기 위한 동일한 규칙과 함께 이용한다. 컨텍스트 인덱스 증분의 유도의 세부사항들은 HEVC 의 9.3.4.2.4 에서 발견될 수 있다.
하나의 CG 내에서의 변환 계수 코딩: 비-제로 계수들을 포함할 수도 있는 그 CG 들에 대하여, 비디오 인코더 (20) 는 미리 정의된 4x4 계수 스캔 순서에 따라 중요한 플래그들 (significant_flag), (coeff_abs_level_greater1_flag, coeff_abs_level_greater2_flag, 및 coeff_abs_level_remaining 를 포함하는) 계수들의 절대 값들, 및 각각의 계수에 대한 부호 정보 (coeff_sign_flag) 를 추가로 인코딩할 수도 있다 (그리고 비디오 디코더 (30) 는 추가로 디코딩할 수도 있음). 변환 계수 레벨들의 코딩 (예컨대, 인코딩 및/또는 디코딩) 은 다수의 스캔 패스들로 분리된다.
제 1 빈 코딩의 제 1 패스: 이 패스에서는, 특정 변환 계수가 0 과 동일하다는 것이 유도될 수 있는 것을 제외하고는, 하나의 CG 내에서의 각각의 위치에서의 변환 계수들의 모든 제 1 빈들 (또는 빈 인덱스 0, bin0) 이 코딩된다. 변수 sigCtx 는 현재의 TU 의 상부-좌측 위치에 관한 현재의 로케이션, 컬러 컴포넌트 인덱스 cIdx, 변환 블록 크기, 및 신택스 엘리먼트 coded_sub_block_flag 의 이전에 디코딩된 빈들에 종속된다. 상이한 규칙들은 TU 크기에 따라 적용된다. 컨텍스트 인덱스 증분의 선택의 일 예의 세부사항들은 HEVC 의 9.3.4.2.5 에서 정의된다.
제 2 빈 코딩의 제 2 패스: coeff_abs_level_greater1_flags 의 코딩은 이 패스에서 적용된다. 컨텍스트 모델링은 컬러 컴포넌트 인덱스, 현재의 서브-블록 스캔 인덱스, 및 현재의 서브-블록 내에서의 현재의 계수 스캔 인덱스에 종속적이다. 컨텍스트 인덱스 증분의 선택의 일 예의 세부사항들은 HEVC 의 9.3.4.2.6 에서 정의된다.
제 3 빈 코딩의 제 3 패스: coeff_abs_level_greater2_flags 의 코딩은 이 패스에서 적용된다. 컨텍스트 모델링은 coeff_abs_level_greater1_flags 에 의해 이용된 것과 유사하다. 컨텍스트 인덱스 증분의 선택의 일 예의 세부사항들은 HEVC 의 9.3.4.2.7 에서 정의된다. 스루풋을 개선시키기 위하여, 제 2 및 제 3 패스들은 CG 에서의 모든 계수들을 프로세싱하지 않을 수도 있다. CG 에서의 최초의 8 개의 coeff_abs_level_greater1_flags 는 규칙적 모드에서 코딩된다. 그 후에, 값들은 신택스 coeff_abs_level_remaining 에 의해 제 5 패스에서 우회 모드에서 코딩되도록 남겨진다. 유사하게, 1 보다 더 큰 크기를 갖는 CG 에서의 최초 계수에 대한 오직 coeff_abs_level_greater2_flags 가 코딩된다. CG 의 1 보다 더 큰 크기를 갖는 계수들의 나머지는 값을 코딩하기 위하여 coeff_abs_level_remaining 을 이용한다. 이 방법은 계수 레벨들에 대한 규칙적 빈들의 수를 CG 당 9 의 최대치로 제한한다: coeff_abs_level_greater1_flags 에 대한 8 및 coeff_abs_level_greater2_flags 에 대한 1.
부호 정보의 제 4 패스: HEVC 의 일부 예들에서, 각각의 비제로 계수의 부호는 우회 모드에서 제 4 스캔 패스에서 코딩된다. 각각의 CG 에 대하여, 그리고 기준에 따라, (역방향 스캔 순서에서의) 최후의 비제로 계수의 부호를 인코딩하는 것은 부호 데이터 은닉 (sign data hidding; SDH) 을 이용할 때에 간단하게 생략된다. 그 대신에, 부호 값은 미리 정의된 관례를 이용하여 CG 의 레벨들의 합의 패리티에서 내장되고: 짝수는 "+" 대응하고 홀수는 "-" 에 대응한다. SDH 를 이용하기 위한 기준은 CG 의 최초 및 최후 비제로 계수들 사이의 스캔 순서에서의 거리이다. 이 거리가 사(4) 이상일 경우, SDH 가 이용된다. 사 (4) 의 값은 그것이 HEVC 테스트 시퀀스들에 대한 최대 이득을 제공하므로 선택되었다.
나머지 빈들의 최후 패스: 나머지 빈들은 추가의 스캔 패스에서 코딩된다. 계수의 baseLeve 을 이하와 같이 정의되도록 한다:
baseLevel = significant_flag + coeff_abs_level_greater1_flag+ coeff_abs_level_greater2_flag
여기서, 플래그는 0 또는 1 의 값을 가지고, 존재하지 않을 경우에 0 인 것으로 추론된다. 그 다음으로, 계수의 절대 값은 다음과 같이 정의된다:
absCoeffLevel = baseLevel + coeff_abs_level_remaining.
라이스 파라미터는 각각의 CG 의 시작부에서 0 으로 설정되고, 그것은 파라미터의 이전의 값 및 현재의 절대 레벨에 따라 조건적으로 다음과 같이 업데이트된다:
absCoeffLevel > 3 × 2m 일 경우, m= min(4,m + 1) 이다.
신택스 엘리먼트 coeff_abs_level_remaining 는 우회 모드에서 코딩될 수도 있다. 게다가, HEVC 의 일부 예들은 작은 값들에 대하여 골롬-라이스 코드들을 채용하고, 더 큰 값들에 대하여 지수-골롬 코드로 스위칭한다. 코드들 사이의 천이 포인트는 전형적으로 1 진 코드 길이가 4 와 동일할 때이다. 파라미터 업데이트 프로세스는 큰 값들이 분포에서 관측될 때, 2 진화가 계수 통계들에 적응하는 것을 허용한다.
inter_pred_idc 의 컨텍스트 모델링. inter_pred_idc 는 list0, list1, 또는 양방향-예측이 현재의 예측 유닛에 대하여 이용되는지 여부를 특정한다. 신택스 엘리먼트는 2 개에 이르는 빈들을 가지고, 그 양자는 CABAC 컨텍스트 코딩된다. 2 진화된 빈 스트링은 다음과 같이 정의된다:

여기서, nPbW 및 nPbH 는 각각 현재의 루마 예측 블록 폭 및 높이를 표현한다.
각각의 인터-코딩된 슬라이스, 예컨대, P 슬라이스 또는 B 슬라이스에 대하여, 컨텍스트 선택은 다음의 규칙에 기초한다:
합 ( nPbW + nPbH ) 이 12 와 동일하지 않을 경우, 제 1 빈은 4 개의 컨텍스트들을 이용하여 코딩되고, 제 2 빈은 하나의 컨텍스트로 코딩된다. 제 1 빈에 대한 컨텍스트 선택은 현재의 CU 심도에 따른다. HEVC 에서, CU 심도는 0 내지 3 까지의 범위에 있다. 0 내지 3 의 포괄적 범위는 [0,3] 으로서 표현될 수 있다.
JCTVC-H0228 (T. Nguyen, D. Marpe, T. Wiegand, "Non-CE11: Proposed Cleanup for Transform Coefficient Coding (변환 계수 코딩을 위한 제안된 클린업)", JCTVC-H0228, 8 차 회의: San  CA, USA, 1-10 February, 2012) 에서는, 1-스캔 패스 코딩이 제안되었다. 제안되었던 1-스캔 패스에 따르면, 변환 계수 레벨에 대한 모든 정보는 HEVC 에서와 같은 다수의 패스 코딩 대신에, 단일 단계에서 코딩된다. 각각의 스캔 위치에 대하여, 로컬 템플릿에 의해 커버된 이웃들은 HEVC 의 현재의 설계에서 bin0 (significant_coeff_flag 또는 coeff_abs_greater0_flag 로서 또한 지칭된, 빈 스트링의 제 1 빈) 에 대하여 행해진 것으로서 평가된다. 이 평가로부터, 컨텍스트 모델들과, 나머지 절대 값의 적응적 2 진화를 제어하는 라이스 파라미터가 유도된다. 더 구체적으로 말하면, bin0 , bin1 , bin2 에 대한 컨텍스트 모델들 및 라이스 파라미터들은 로컬 템플릿에서 위치된 변환 계수 크기들에 기초하여 모두 선택된다(bin1 및 bin2 는 coeff_abs_greater1_flag 및 coeff_abs_greater2_flag 로서 또한 지칭됨).
CA, USA, 1-10 February, 2012) 에서는, 1-스캔 패스 코딩이 제안되었다. 제안되었던 1-스캔 패스에 따르면, 변환 계수 레벨에 대한 모든 정보는 HEVC 에서와 같은 다수의 패스 코딩 대신에, 단일 단계에서 코딩된다. 각각의 스캔 위치에 대하여, 로컬 템플릿에 의해 커버된 이웃들은 HEVC 의 현재의 설계에서 bin0 (significant_coeff_flag 또는 coeff_abs_greater0_flag 로서 또한 지칭된, 빈 스트링의 제 1 빈) 에 대하여 행해진 것으로서 평가된다. 이 평가로부터, 컨텍스트 모델들과, 나머지 절대 값의 적응적 2 진화를 제어하는 라이스 파라미터가 유도된다. 더 구체적으로 말하면, bin0 , bin1 , bin2 에 대한 컨텍스트 모델들 및 라이스 파라미터들은 로컬 템플릿에서 위치된 변환 계수 크기들에 기초하여 모두 선택된다(bin1 및 bin2 는 coeff_abs_greater1_flag 및 coeff_abs_greater2_flag 로서 또한 지칭됨).
로컬 템플릿 (140) 에 대한 예는 대각선 스캔을 갖는 8x8 변환 블록에 대하여 도 10 에서 주어지고, 여기서, L 은 최후의 중요한 스캔 위치를 나타내고, x 는 현재의 스캔 위치를 나타내고, i ∈ [0,4] 인 xi 는 로컬 템플릿에 의해 커버된 이웃들을 나타낸다.
이웃들의 절대 합을 표시하는 sum_absolute_level 과, 각각의 레벨 마이너스 1 의 절대 합을 표시하는 sum_absolute_levelMinus1 은 bin0, bin1, bin2 에 대한 컨텍스트 인덱스들을 유도하기 위하여, 그리고 라이스 파라미터 r 을 결정하기 위하여 이용된다.


bin0 에 대하여, 로컬 템플릿 평가로부터의 결과적인 sum_absolute_level 은 5 의 차단 값을 갖는 컨텍스트 모델 인덱스에 직접적으로 맵핑된다. 동일한 규칙은 sum_absolute_levelMinus1 및 4 의 차단 값을 이용함으로써, bin1 및 bin2 의 컨텍스트 모델 인덱스의 계산을 위하여 적용된다. 이 유도 규칙은 다음에서 요약되고, c0 은 bin0 에 대한 컨텍스트 모델 인덱스를 표현하고, c1 은 bin1 에 대한 컨텍스트 모델 인덱스를 표현하고, c2 는 bin2 에 대한 컨텍스트 모델 인덱스를 표현한다.

도 12 는 빈 유도의 예를 예시하는 개념도이다. bin1 및 bin2 에 대한 유도 규칙은 동일하다. 다음으로, 루마 컴포넌트에 대하여, 추가적인 오프셋은 루마 변환 레벨들의 bin0, bin1, 및 bin2 에 대하여 계산된다. 추가적인 컨텍스트 인덱스 (즉, 오프셋) 는 현재의 스캔 위치의 로케이션에 종속된다. 도 12 는 이 프로세스의 예를 예시한다. 특히, 도 12 는 (a) 루마 bin0 에 대하여, (b) 루마 bin1 및 bin2 (순방향 스캔 순서에서의 최후 계수가 아님) 에 대하여, 하나의 TU 내에서의 상이한 영역들에 대한 컨텍스트 인덱스 범위들을 도시한다.
요약하면, 전체 개념은 다음의 공식들에서 요약되고, 여기서, x 는 현재의 스캔 위치의 변환 블록 내부의 수평 공간적 로케이션을 나타내고, y 는 수직 공간적 로케이션을 나타내고, cIdx 는 루마에 대하여 0 스탠드 (stand) 들을 갖는 현재의 평면 타입을 나타낸다. 추가적으로, 상이한 위치들에 대한 컨텍스트 인덱스의 범위는 도 13 에서 표기된다.

위에서 도시된 바와 같이, c1 에 대한 he 공식은 c2 에 대하여 동일하다. bin1 및 bin2 에 대한 동일한 컨텍스트 모델 인덱스에 추가하여, 동일한 컨텍스트 모델이 bin1 및 bin2 의 코딩을 위하여 이용된다. 또한, 코딩 순서에서의 제 1 스캔 위치 (즉, 최후의 중요 스캔 위치) 에 대하여, 별도의 컨텍스트 모델 인덱스가 bin1 및 bin2 에 대하여 이용된다. 제 1 빈 인덱스 (bin0) 는 최후의 중요 스캔 위치에 대하여 추론된다. 이 별도의 컨텍스트 모델은 결코 컨텍스트 모델 선택 방식에 의해 다시 선택되지 않고, c1=0 으로서 배정된다. 컨텍스트 모델들의 총 수는 다음의 표로 도표화된다:

라이스 파라미터 r 은 다음과 같이 유도된다. 각각의 스캔 위치에 대하여, 파라미터는 0 으로 설정된다. 그 다음으로, sum_absolute_levelMinus1 은 임계치 세트 tR = {3, 9, 21} 에 대하여 비교된다. 다시 말해서, 라이스 파라미터는 sum_absolute_levelMinus1 이 제 1 간격으로 떨어질 경우에 0 이고, sum_absolute_levelMinus1 이 제 2 간격으로 떨어질 경우에 1 등이다. 라이스 파라미터 r 의 유도는 다음으로 요약된다:

도 13 은 상이한 루마 빈들에 대하여, TU 내에서의 상이한 위치들에 대한 컨텍스트 인덱스들의 범위를 예시하는 개념도이다. 도 13 의 예에서, 좌측의 블록은 루마 bin0 에 대한 TU 내에서의 상이한 영역들에 대한 컨텍스트 인덱스 범위를 예시한다. 우측의 블록은 루마 bin1 및 bin2 에 대한 TU 내에서의 상이한 영역들에 대한 컨텍스트 인덱스 범위를 예시한다. 특정한 위치들은 도 13 의 루마 빈들 내에서의 숫자들을 이용하여 호출되고, 상이한 영역들은 음영처리를 이용하여 구별된다.
하나 이상의 예들에서, 설명된 기능들은 하드웨어, 소프트웨어, 펌웨어, 또는 그 임의의 조합으로 구현될 수도 있다. 소프트웨어로 구현될 경우, 기능들은 하나 이상의 명령들 또는 코드로서, 컴퓨터 판독가능 매체 상에 저장되거나 컴퓨터 판독가능 매체를 통해 송신될 수도 있고, 하드웨어-기반 프로세싱 유닛에 의해 실행될 수도 있다. 컴퓨터 판독가능 매체들은 데이터 저장 매체들과 같은 유형의 매체에 대응하는 컴퓨터 판독가능 저장 매체들, 또는 예컨대, 통신 프로토콜에 따라 하나의 장소로부터 또 다른 장소로 컴퓨터 프로그램의 전송을 용이하게 하는 임의의 매체를 포함하는 통신 매체들을 포함할 수도 있다. 이러한 방식으로, 컴퓨터 판독가능 매체들은 일반적으로 (1) 비일시적인 유형의 컴퓨터 판독가능 저장 매체들, 또는 (2) 신호 또는 반송파와 같은 통신 매체에 대응할 수도 있다. 데이터 저장 매체들은 이 개시물에서 설명된 기법들의 구현을 위한 명령들, 코드 및/또는 데이터 구조들을 취출하기 위해 하나 이상의 컴퓨터들 또는 하나 이상의 프로세서들에 의해 액세스될 수 있는 임의의 이용가능한 매체들일 수도 있다. 컴퓨터 프로그램 제품은 컴퓨터 판독가능 매체를 포함할 수도 있다.
도 14 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 컨텍스트 모델링 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스 (300) 를 예시한다. 프로세스 (300) 는 다양한 디바이스들에 의해 수행될 수도 있지만, 프로세스 (300) 는 비디오 디코더 (30) 에 대하여 본원에서 설명된다. 프로세스 (300) 는 비디오 디코더 (30) 가 제 1 TU 를 코딩 (예컨대, 디코딩) 할 때에 시작할 수도 있다 (302). 결국, 비디오 디코더 (30) 는 제 2 TU 를 코딩하는 제 1 패스를 시작할 수도 있다 (304). 이와 같이, 제 1 TU 는 제 2 TU 에 대한 이전에-코딩된 블록을 표현한다.
비디오 디코더 (30) 는 코딩의 제 1 패스 내에서 제 2 TU 의 모든 i 번째 빈들을 코딩하기 위하여 제 1 TU 의 i 번째 빈을 이용할 수도 있다 (306). 예를 들어, 비디오 디코더 (30) 는 제 2 TU 에 대한 멀티-패스 디코딩 프로세스의 제 1 패스 동안에, 제 2 TU 의 변환 계수들의 개개의 i 번째 빈에 대한 컨텍스트 인덱스를 선택하기 위하여 제 1 TU 의 bin0 을 이용할 수도 있다. 이러한 방법으로, 비디오 디코더 (30) 는 현재 코딩되고 있는 TU 의 모든 변환 계수들의 모든 i 번째 빈에 대한 컨텍스트 선택을 완료하기 위하여 이전에-코딩된 블록의 빈들을 이용함으로써, 병렬화를 개선시키기 위하여 이 개시물의 컨텍스트 모델링 기법들을 구현할 수도 있다.
이러한 방법으로, 비디오 디코더 (30) 는 비디오 데이터를 저장하도록 구성된 메모리, 및 하나 이상의 프로세서들을 포함하는 비디오 코딩 디바이스의 예를 표현한다. 프로세서 (들) 는 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하도록 구성될 수도 있다. 컨텍스트들을 결정하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, 여기서, i 는 비-음의 정수를 포함하고, 여기서, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용하도록 구성된다. 프로세서 (들) 는 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩 (예컨대, CABAC 디코딩) 하도록 추가로 구성될 수도 있다.
일부 예들에서, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 하나 이상의 프로세서들은 현재의 변환 계수를 CABAC 디코딩하기 위하여 이용될 하나 이상의 이웃하는 변환 계수들을 식별하는 템플릿을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성된다. 일부 예들에서, 하나 이상의 프로세서들은 현재의 변환 계수를 포함하는 변환 유닛의 크기, 변환 유닛을 포함하는 코딩 유닛과 연관된 코딩 모드, 현재의 변환 계수를 포함하는 변환 유닛에서의 현재의 변환 계수의 위치, 또는 현재의 변환 계수를 포함하는 계수 그룹에서의 현재의 변환 계수의 위치 중의 적어도 하나에 기초하여, 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하도록 추가로 구성된다. 일부 예들에서, 하나 이상의 프로세서들은 컬러 컴포넌트 정보에 기초하여 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하도록 추가로 구성되고, 컬러 컴포넌트 정보는 루마 컴포넌트 정보 또는 크로마 컴포넌트 정보 중의 하나 또는 양자를 포함한다.
일부 예들에서, 현재의 변환 계수는 변환 유닛 내에 포함되고, 여기서, 변환 유닛의 일부 또는 모든 빈들은 규칙적 모드에 따라 CABAC 인코딩되고, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 CABAC 코딩하기 위하여, 하나 이상의 프로세서들은 변환 유닛의 모든 변환 계수들의 모든 대응하는 i 번째 빈들이 그 동안에 CABAC 코딩되는 i 번째 코딩 패스 동안에 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 코딩하도록 구성된다. 일부 예들에서, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 하나 이상의 프로세서들은 이전에-코딩된 변환 계수들의 함수를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트 인덱스를 결정하도록 구성된다. 일부 예들에서, 이전에-코딩된 변환 계수들은 템플릿에서 위치된다. 일부 예들에서, 이전에-코딩된 변환 계수들의 함수를 이용하기 위하여, 하나 이상의 프로세서들은 처음 'M' 이전에-코딩된 변환 계수들의 함수를 이용하도록 구성되고, 여기서, 'M' 은 비-음의 값을 표현한다. 일부 예들에서, 함수는 합산 함수를 포함하고, 이전에-코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈은 복수의 이전에-코딩된 변환 계수들의 신택스 엘리먼트들에 대한 값들의 복수의 대응하는 i 번째 빈들 내에 포함된다.
일부 예들에서, 합산 함수를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트 인덱스를 결정하기 위하여, 하나 이상의 프로세서들은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트 인덱스를, 복수의 이전에-코딩된 변환 계수들의 신택스 엘리먼트들에 대한 값들의 복수의 대응하는 i 번째 빈들의 전부의 합으로서 정의하도록 구성된다. 일부 예들에서, 하나 이상의 프로세서들은 미리 정의된 범위 내에 있는 클립된 합 (clipped sum) 을 형성하기 위하여 합산 함수의 결과를 클립 (clip) 하도록 추가로 구성된다. 바꾸어 말하면, 하나 이상의 프로세서들은 미리 정의된 범위 내에 있는 클립된 합을 형성하기 위하여 합산 함수의 결과를 클립하는 것을 포함하는 방법을 수행할 수도 있다. 일부 예들에서, 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 하나 이상의 프로세서들은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트 인덱스를 결정하고 오프셋을 결정된 컨텍스트 인덱스에 가산하도록 구성된다. 일부 예들에서, 하나 이상의 프로세서들은 현재의 변환 계수를 포함하는 변환 유닛의 크기에 기초하여 오프셋을 결정하도록 추가로 구성된다.
일부 예들에서, 하나 이상의 프로세서들은 변환 유닛이 임계치 크기 내에 있는지 여부를 결정하고, 변환 유닛이 임계치 크기 내에 있을 경우, 변환 유닛이 임계치 크기 내에 있는 모든 변환 유닛들에 공통적인 컨텍스트 모델들의 세트와 연관되는 것으로 결정하도록 추가로 구성된다. 일부 예들에서, 임계치 크기는 16x16 차원성과 연관된다. 일부 예들에서, 저장된 비디오 데이터는 인코딩된 비디오 데이터를 포함하고, 하나 이상의 프로세서들은 복원된 비디오 데이터를 형성하기 위하여 인코딩된 비디오 데이터의 적어도 부분을 디코딩하도록 추가로 구성되고, 비디오 디코더 (30) 는 복원된 비디오 데이터의 적어도 부분을 디스플레이하도록 구성된 디스플레이 디바이스를 포함하는 디바이스를 포함할 수도 있거나, 디바이스일 수도 있거나, 디바이스의 일부일 수도 있다. 일부 예들에서, 하나 이상의 프로세서들은 저장된 비디오 데이터의 적어도 부분을 인코딩하도록 추가로 구성되고, 이전에-코딩된 변환 계수는 이전에-인코딩된 변환 계수를 포함한다.
도 15 는 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 승계-기반 컨텍스트 초기화 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스 (320) 를 예시하는 플로우차트이다. 프로세스 (320) 는 다양한 디바이스들에 의해 수행될 수도 있지만, 프로세스 (320) 는 비디오 디코더 (30) 에 대하여 본원에서 설명된다. 프로세스 (320) 는 비디오 디코더 (30) 가 제 1 픽처를 코딩 (예컨대, 디코딩) 할 때에 시작할 수도 있다 (322). 이에 따라, 제 1 픽처는 비디오 디코더 (30) 가 추후에 복원할 수도 있는 픽처들에 대한 이전에-코딩된 (예컨대, 이전에-디코딩된) 픽처를 표현한다. 결국, 비디오 디코더 (30) 는 제 2 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 그로부터 승계하기 위한 제 1 의 블록을 식별할 수도 있다 (324). 이와 같이, 제 2 픽처는 비디오 디코더 (30) 가 제 2 픽처를 현재 디코딩하고 있다는 점에서 "현재의 픽처" 를 표현할 수도 있고, 현재의 슬라이스는 비디오 디코더 (30) 가 디코딩하고 있는 제 2 픽처의 특정한 슬라이스를 표현할 수도 있다.
비디오 디코더 (30) 는 제 1 픽처로부터 승계된 컨텍스트 정보를 이용하여 현재의 슬라이스에 대한 컨텍스트 정보를 초기화할 수도 있다 (326). 예를 들어, 비디오 디코더 (30) 는 승계된 컨텍스트 정보의 하나 이상의 스테이터스들을 저장할 수도 있고, 현재의 슬라이스에 대한 컨텍스트를 초기화하기 위하여 저장된 스테이터스 (들) 를 취출할 수도 있다. 결국, 비디오 디코더 (30) 는 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스를 코딩할 수도 있다 (328).
이러한 방법으로, 비디오 디코더 (30) 는 비디오 데이터를 저장하도록 구성된 메모리, 및 하나 이상의 프로세서들을 포함하는 비디오 코딩 디바이스의 예를 표현한다. 프로세서 (들) 는 저장된 비디오 데이터의 이전에-코딩된 슬라이스의 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계함으로써 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하고, 그리고 초기화된 컨텍스트 정보를 이용하여 현재의 슬라이스의 데이터를 코딩하도록 구성된다. 일부 예들에서, 이전에-코딩된 블록은 이전에-코딩된 슬라이스 내의 중심 위치, 또는 이전에-코딩된 슬라이스와 연관된 이전에-코딩된 픽처 내의 중심 위치에 있는 최대 코딩 유닛 (LCU) 을 포함한다. 일부 예들에서, 현재의 슬라이스는 단방향 예측된 슬라이스 (P-슬라이스) 를 포함하고, 이전에-코딩된 슬라이스는 양방향 예측된 슬라이스 (B-슬라이스) 를 포함한다. 일부 예들에서, 현재의 슬라이스는 양방향 예측된 슬라이스 (B-슬라이스) 를 포함하고, 이전에-코딩된 슬라이스는 단방향 예측된 슬라이스 (P-슬라이스) 를 포함한다.
일부 예들에서, 현재의 슬라이스는 컨텍스트 정보가 이전에-코딩된 픽처로부터 승계되는 현재의 픽처에서의 복수의 슬라이스들 내에 포함되고, 프로세서 (들) 는 이전에-코딩된 슬라이스 내의 중심 위치에 있는 LCU 를 코딩한 후의 컨텍스트 정보를 승계함으로써 복수의 슬라이스들의 전부에 대한 개개의 컨텍스트 정보를 초기화하도록 추가로 구성된다. 일부 예들에서, 프로세서 (들) 는 현재의 슬라이스가 인터-코딩되는지 여부를 결정하고 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하도록 추가로 구성되고, 프로세서 (들) 는 현재의 슬라이스가 인터-코딩된다는 결정에 기초하여 이전에-코딩된 블록을 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 코딩한 후의 컨텍스트 정보를 승계하도록 구성된다.
일부 예들에서, 프로세서 (들) 는 이전에-코딩된 슬라이스가 인터-코딩되는지 여부를 결정하도록 구성된다. 일부 예들에서, 프로세서 (들) 는 현재의 슬라이스 및 이전에-코딩된 블록이 동일한 양자화 파라미터 (QP) 들을 공유하는지 여부를 결정하고, 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하도록 추가로 구성되고, 프로세서 (들) 는 현재의 슬라이스 및 이전에-코딩된 슬라이스가 동일한 QP 들을 공유한다는 결정에 기초하여 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 승계하도록 구성된다. 일부 예들에서, 프로세서 (들) 는 인트라 랜덤 액세스 픽처 (IRAP) 가 출력 순서에서, 현재의 픽처와 이전에-코딩된 슬라이스와 연관된 이전에-코딩된 픽처 사이에 위치되는지 여부를 결정하도록 추가로 구성된다.
일부 예들에서, 현재의 픽처의 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하기 위하여, 프로세서 (들) 는 IRAP 가 출력 순서에서 현재의 픽처와 이전에-코딩된 픽처 사이에 위치되지 않는다는 결정에 기초하여 이전에-코딩된 픽처의 이전에-코딩된 블록의 컨텍스트 정보를 현재의 픽처의 현재의 슬라이스에 대한 초기화된 컨텍스트 정보로서 승계하도록 구성된다. 일부 예들에서, 프로세서 (들) 는 다음의 수학식에 따라 이전에-코딩된 블록의 위치를 정의하도록 추가로 구성된다: TargetCUAddr = (PicWidthInCtbsY* PicHeightInCtbsY)/2 + PicWidthInCtbsY /2, 여기서, "PicWidthInCtbsY" 는 이전에-코딩된 블록의 단일 행 내에 포함된 최대 코딩 유닛 (LCU) 들의 수를 나타내고, 여기서, "PicHeightInCtbsY" 는 이전에-코딩된 블록 내에 포함된 LCU 행들의 총 수를 나타낸다. 일부 예들에서, 컨텍스트 정보는 현재의 슬라이스와 연관된 하나 이상의 컨텍스트 상태들을 포함한다.
일부 예들에서, 컨텍스트 정보는 가장 높은 확률 상태 (MPS) 정보와 연관된 값들을 더 포함한다. 일부 예들에서, 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 승계함으로써 현재의 슬라이스에 대한 컨텍스트 정보를 초기화하기 위하여, 프로세서 (들) 는 이전에-코딩된 블록을 코딩한 후의 컨텍스트 정보를 승계함으로써 현재의 슬라이스에 대한 컨텍스트 정보의 전부가 아닌 일부의 컨텍스트들을 초기화하도록 구성된다. 일부 예들에서, 이전에-코딩된 슬라이스는 (i) 현재의 픽처에서의 슬라이스, 여기서, 이전에-코딩된 슬라이스는 현재의 슬라이스와는 상이하고, 또는 (ii) 이전에-코딩된 픽처에서의 슬라이스 중의 하나를 포함한다. 일부 예들에서, 프로세서 (들) 는 이전에-코딩된 픽처를, 현재의 픽처와 동일한 양자화 파라미터 (QP) 들 및 슬라이스 타입들을 공유하는, 출력 순서에서 현재의 픽처 전의 최후의 픽처로서 식별함으로써 이전에-코딩된 픽처를 선택하도록 추가로 구성된다. 일부 예들에서, 저장된 비디오 데이터는 인코딩된 비디오 데이터를 포함하고, 프로세서 (들) 는 복원된 비디오 데이터를 형성하기 위하여 인코딩된 비디오 데이터의 적어도 부분을 디코딩하도록 추가로 구성되고, 비디오 코딩 디바이스는 복원된 비디오 데이터의 적어도 부분을 디스플레이하도록 구성된 디스플레이 디바이스를 더 포함한다.
도 16 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 기법들 중의 하나 이상을 비디오 디코딩 프로세스의 일부로서 구현하기 위하여 수행할 수도 있는 일 예의 프로세스 (330) 를 예시하는 플로우차트이다. 프로세스 (330) 는 다양한 디바이스들에 의해 수행될 수도 있지만, 프로세스 (330) 는 비디오 디코더 (30) 에 대하여 본원에서 설명된다. 프로세스 (330) 는 비디오 디코더 (30) 가 현재의 블록에 대한 엔트로피 인코딩된 데이터를 수신할 때에 시작할 수도 있다 (332). 추가적으로, 비디오 디코더 (30) 는 현재의 블록의 변환 계수들에 대한 엔트로피 인코딩된 데이터를 취출할 수도 있다 (334).
결국, 비디오 디코더 (30) 는 현재의 블록의 변환 계수들에 대한 인코딩된 데이터를 엔트로피 디코딩할 수도 있다 (336). 예를 들어, 변환 계수들을 엔트로피 디코딩하기 위하여, 비디오 디코더 (30) 는 현재의 변환 계수의 대응하는 현재의 빈들에 대한 컨텍스트 정보를 결정하기 위하여 이전에-디코딩된 변환 계수들의 빈들을 이용할 수도 있다 (336). 비디오 디코더 (30) 는 (예컨대, 역변환 유닛 (78) 을 호출함으로써) 잔차 블록을 형성하기 위하여 역변환을 변환 계수들에 적용할 수도 있다 (338). 결국, 비디오 디코더 (30) 는 예측된 블록을 형성하기 위하여 현재의 블록을 예측할 수도 있다 (340). 비디오 디코더 (30) 는 현재의 블록을 디코딩하기 위하여 예측된 블록을 잔차 블록과 조합할 수도 있다 (342).
도 17 은 비디오 코딩 디바이스 또는 그 다양한 컴포넌트들이 이 개시물의 하나 이상의 계수 그룹 (CG) 크기-결정 기법들 중의 하나 이상을 구현하기 위하여 수행할 수도 있는 일 예의 프로세스 (350) 를 예시하는 플로우차트이다. 프로세스 (320) 는 다양한 디바이스들에 의해 수행될 수도 있지만, 프로세스 (350) 는 비디오 디코더 (30) 에 대하여 본원에서 설명된다. 프로세스 (350) 는 비디오 디코더 (30) 가 변환 유닛 (TU) 을 식별할 때에 시작할 수도 있다 (352). 예를 들어, 비디오 디코더 (30) 는 현재 디코딩되고 있는 TU 와 같은 현재의 TU 를 식별할 수도 있다. 추가적으로, 비디오 디코더 (30) 는 현재의 TU 를 포함하는 계수 그룹을 식별할 수도 있고, 여기서, 계수 그룹은 현재의 TU 의 변환 계수들의 서브세트를 표현한다 (354). 비디오 디코더 (30) 는 변환 유닛과 연관된 변환 크기, 및 (i) 변환 유닛과 연관된 코딩 모드, 또는 (ii) 변환 유닛과 연관된 변환 행렬 중의 하나 또는 양자의 조합에 기초하여 CG 의 크기를 결정할 수도 있다 (356).
이러한 방법으로, 비디오 디코더 (30) 는 비디오 데이터를 저장하도록 구성된 메모리 디바이스, 및 하나 이상의 프로세서들을 포함하는 비디오 코딩 디바이스의 예를 표현한다. 프로세스 (들) 는 비디오 데이터의 현재의 변환 계수를 포함하는 계수 그룹 (CG) 을 식별하는 것으로서, CG 는 변환 유닛 내에서의 변환 계수들의 서브세트를 표현하는, 상기 계수 그룹 (CG) 을 식별하고, 그리고 변환 유닛과 연관된 변환 크기에 기초하여 CG 의 크기를 결정하도록 구성된다. 일부 예들에서, 프로세스 (들) 는 변환 유닛과 연관된 변환 크기, 및 (i) 변환 유닛과 연관된 코딩 모드, 또는 (ii) 변환 유닛과 연관된 변환 행렬 중의 하나 또는 양자의 조합에 기초하여 CG 의 크기를 결정할 수도 있다. 일부 예들에서, 저장된 비디오 데이터는 인코딩된 비디오 데이터를 포함하고, 하나 이상의 프로세서들은 디코딩된 비디오 데이터를 형성하기 위하여 인코딩된 비디오 데이터의 적어도 부분을 디코딩하도록 구성된다. 일부 예들에서, 저장된 비디오 데이터는 인코딩된 비디오 데이터를 포함하고, 하나 이상의 프로세서들은 디코딩된 비디오 데이터를 형성하기 위하여 인코딩된 비디오 데이터의 적어도 부분을 디코딩하도록 구성된다.
일부 예들에서, 변환 유닛은 인코딩된 변환 유닛을 포함하고, 여기서, 변환 유닛과 연관된 코딩 모드는 인코딩된 변환 유닛을 형성하기 위하여 이용된 코딩 모드를 포함한다. 일부 예들에서, 비디오 디코더 (30) 는 디코딩된 비디오 데이터의 적어도 부분을 디스플레이하도록 구성된 디스플레이를 포함하는 디바이스를 포함하거나, 디바이스이거나, 디바이스의 일부이다. 일부 예들에서, 하나 이상의 프로세서들은 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-디코딩된 변환 계수들의 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하도록 추가로 구성된다. 일부 예들에서, 컨텍스트들을 결정하기 위하여, 하나 이상의 프로세서들은 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, 여기서, i 는 비-음의 정수를 포함한다. 일부 예들에서, 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 프로세서 (들) 는 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 다른 빈들이 아니라, 이전에-디코딩된 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 오직 이용한다. 일부 이러한 예들에서, 프로세서 (들) 는 결정된 컨텍스트를 이용하여 현재의 변환 계수의 신택스 엘리먼트에 대한 값의 i 번째 빈을 컨텍스트 적응 2 진 산술 코딩 (context adaptive binary arithmetic coding; CABAC) 디코딩할 수도 있다. 일부 예들에서, CG 는 블록들의 정사각형 영역을 포함하고, CG 의 크기는 블록들의 단위들로 표현된 4x4 이다.
일부 예들에서, 코딩 모드는 CG-기반 코딩 모드를 포함한다. 일부 예들에서, 비디오 디코더 (30) 는 하나 이상의 집적 회로들; 하나 이상의 디지털 신호 프로세서 (DPS) 들; 하나 이상의 필드 프로그래밍가능 게이트 어레이 (FPGA) 들; 데스크톱 컴퓨터; 랩톱 컴퓨터; 태블릿 컴퓨터; 전화; 텔레비전; 카메라; 디스플레이 디바이스; 디지털 미디어 플레이어; 비디오 게임 콘솔; 비디오 게임 디바이스; 비디오 스트리밍 디바이스; 또는 무선 통신 디바이스 중의 하나 이상을 포함하는 디바이스를 포함하거나, 디바이스이거나, 또는 디바이스의 일부이다.
제한이 아닌 예로서, 이러한 컴퓨터 판독가능 저장 매체들은 RAM, ROM, EEPROM, CD-ROM 또는 다른 광학 디스크 저장, 자기 디스크 저장, 또는 다른 자기 저장 디바이스들, 플래시 메모리, 또는 명령들 또는 데이터 구조들의 형태로 희망하는 프로그램 코드를 저장하기 위하여 이용될 수 있으며 컴퓨터에 의해 액세스될 수 있는 임의의 다른 매체를 포함할 수 있다. 또한, 임의의 접속은 컴퓨터 판독가능 매체로 적절하게 칭해진다. 예를 들어, 동축 케이블, 광섬유 케이블, 트위스트 페어 (twisted pair), 디지털 가입자 회선 (digital subscriber line; DSL), 또는 적외선, 라디오 (radio), 및 마이크로파 (microwave) 와 같은 무선 기술들을 이용하여 웹사이트, 서버, 또는 다른 원격 소스로부터 명령들이 송신될 경우, 동축 케이블, 광섬유 케이블, 트위스트 페어, DSL, 또는 적외선, 라디오, 및 마이크로파와 같은 무선 기술들은 매체의 정의 내에 포함된다. 그러나, 컴퓨터 판독가능 저장 매체들 및 데이터 저장 매체들은 접속들, 반송파들, 신호들, 또는 다른 일시적 매체들을 포함하는 것이 아니라, 그 대신에, 비일시적, 유형의 저장 매체들에 관한 것이라는 것을 이해해야 한다. 본원에서 이용된 바와 같은 디스크 (disk) 및 디스크 (disc) 는 컴팩트 디스크 (compact disc; CD), 레이저 디스크 (laser disc), 광학 디스크 (optical disc), 디지털 다기능 디스크 (digital versatile disc; DVD), 플로피 디스크 (floppy disk) 및 블루레이 디스크 (Blu-ray disc) 를 포함하고, 여기서 디스크 (disk) 들은 통상 데이터를 자기적으로 재생하는 반면, 디스크 (disc) 들은 데이터를 레이저들로 광학적으로 재생한다. 상기의 조합들은 컴퓨터 판독가능 매체들의 범위 내에 또한 포함되어야 한다.
명령들은 하나 이상의 디지털 신호 프로세서 (digital signal processor; DSP) 들, 범용 마이크로프로세서들, 주문형 집적 회로 (application specific integrated circuit; ASIC) 들, 필드 프로그래밍가능한 게이트 어레이 (field programmable gatec array; FPGA) 들, 또는 다른 등가의 통합된 또는 개별 로직 회로부와 같은 하나 이상의 프로세서들에 의해 실행될 수도 있다. 따라서, 본원에서 이용된 바와 같은 용어 "프로세서" 는 상기한 구조, 또는 본원에서 설명된 기법들의 구현을 위해 적당한 임의의 다른 구조 중의 임의의 것을 지칭할 수도 있다. 게다가, 일부 양태들에서는, 본원에서 설명된 기능성이 인코딩 및 디코딩을 위해 구성되거나 조합된 코덱 내에 통합된 전용 하드웨어 및/또는 소프트웨어 모듈들 내에서 제공될 수도 있다. 또한, 기법들은 하나 이상의 회로들 또는 로직 엘리먼트들에서 완전히 구현될 수 있다.
이 개시물의 기법들은 무선 핸드셋, 집적 회로 (IC) 또는 IC 들의 세트 (예를 들어, 칩셋) 를 포함하는 광범위한 디바이스들 또는 장치들에서 구현될 수도 있다. 다양한 컴포넌트들, 모듈들, 또는 유닛들은 개시된 기법들을 수행하도록 구성된 디바이스들의 기능적 양태들을 강조하기 위하여 이 개시물에서 설명되어 있지만, 상이한 하드웨어 유닛들에 의한 실현을 반드시 요구하지는 않는다. 오히려, 위에서 설명된 바와 같이, 다양한 유닛들은 코덱 하드웨어 유닛 내에 조합될 수도 있거나, 적당한 소프트웨어 및/또는 펌웨어와 함께, 위에서 설명된 바와 같은 하나 이상의 프로세서들을 포함하는 상호동작하는 하드웨어 유닛들의 집합에 의해 제공될 수도 있다.
다양한 예들이 설명되었다. 이러한 그리고 다른 예들은 다음의 청구항들의 범위 내에 있다.
Claims (49)
- 비디오 데이터를 디코딩하는 방법으로서,
현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈 (bin) 들의 각각에 대하여, 하나 이상의 이전에-디코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하는 단계로서,
상기 컨텍스트들을 결정하는 단계는 이전에-디코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계를 포함하고, i 는 비-음의 (non-negative) 정수를 포함하고, 상기 이전에-디코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하는 것은 상기 이전에-디코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 다른 빈들이 아니고, 상기 이전에-디코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 오직 이용하는 것을 포함하는, 상기 컨텍스트들을 결정하는 단계; 및
결정된 상기 컨텍스트를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 컨텍스트 적응 2 진 산술 코딩 (context adaptive binary arithmetic coding; CABAC) 디코딩하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 1 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는, 상기 현재의 변환 계수를 CABAC 디코딩하기 위하여 이용될 하나 이상의 이웃하는 변환 계수들을 식별하는 템플릿을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트를 결정하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 2 항에 있어서,
상기 현재의 변환 계수를 포함하는 변환 유닛의 크기, 상기 변환 유닛을 포함하는 코딩 유닛과 연관된 코딩 모드, 상기 현재의 변환 계수를 포함하는 상기 변환 유닛에서의 상기 현재의 변환 계수의 위치, 또는 상기 현재의 변환 계수를 포함하는 계수 그룹에서의 상기 현재의 변환 계수의 위치 중의 적어도 하나에 기초하여, 상기 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하는 단계를 더 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 1 항에 있어서,
상기 현재의 변환 계수는 변환 유닛 내에 포함되고,
상기 변환 유닛의 일부 또는 모든 빈들은 규칙적 모드에 따라 CABAC 인코딩되고, 그리고
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 디코딩하는 단계는, 상기 변환 유닛의 모든 변환 계수들의 모든 대응하는 i 번째 빈들이 CABAC 디코딩되는 i 번째 코딩 패스 동안에 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 디코딩하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 1 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는, 상기 이전에-디코딩된 변환 계수들의 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 5 항에 있어서,
상기 이전에-디코딩된 변환 계수들은 템플릿에서 위치되는, 비디오 데이터를 디코딩하는 방법. - 제 5 항에 있어서,
상기 이전에-디코딩된 변환 계수들의 함수를 이용하는 것은 처음 'M' 이전에-디코딩된 변환 계수들의 함수를 이용하는 것을 포함하고, 'M' 은 비-음의 값을 표현하는, 비디오 데이터를 디코딩하는 방법. - 제 5 항에 있어서,
상기 함수는 합산 함수를 포함하고, 그리고
이전에-디코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 대응하는 i 번째 빈은 복수의 이전에-디코딩된 변환 계수들의 신택스 엘리먼트들에 대한 값들의 복수의 대응하는 i 번째 빈들 내에 포함되는, 비디오 데이터를 디코딩하는 방법. - 제 8 항에 있어서,
상기 합산 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를 결정하는 단계는, 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를, 상기 복수의 이전에-디코딩된 변환 계수들의 상기 신택스 엘리먼트들에 대한 값들의 상기 복수의 대응하는 i 번째 빈들의 전부의 합으로서 정의하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 8 항에 있어서,
미리 정의된 범위 내에 있는 클립된 합을 형성하기 위하여 상기 합산 함수의 결과를 클립하는 단계를 더 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 1 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하는 단계; 및
오프셋을 결정된 상기 컨텍스트 인덱스에 가산하는 단계를 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 11 항에 있어서,
상기 현재의 변환 계수를 포함하는 변환 유닛의 크기에 기초하여 상기 오프셋을 결정하는 단계를 더 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 12 항에 있어서,
상기 변환 유닛이 임계치 크기 내에 있는지 여부를 결정하는 단계; 및
상기 변환 유닛이 상기 임계치 크기 내에 있을 경우, 상기 변환 유닛이 상기 임계치 크기 내에 있는 모든 변환 유닛들에 공통적인 컨텍스트 모델들의 세트와 연관되는 것으로 결정하는 단계를 더 포함하는, 비디오 데이터를 디코딩하는 방법. - 제 13 항에 있어서,
상기 임계치 크기는 16x16 차원성과 연관되는, 비디오 데이터를 디코딩하는 방법. - 제 1 항에 있어서,
상기 현재의 변환 계수는 우회 모드에 따라 인코딩되는 변환 유닛 내에 포함되는, 비디오 데이터를 디코딩하는 방법. - 비디오 데이터를 인코딩하는 방법으로서,
현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-인코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하는 단계로서,
상기 컨텍스트들을 결정하는 단계는 이전에-인코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계를 포함하고, i 는 비-음의 정수를 포함하고, 상기 이전에-인코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하는 것은 상기 이전에-인코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 다른 빈들이 아니고, 상기 이전에-인코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 오직 이용하는 것을 포함하는, 상기 컨텍스트들을 결정하는 단계; 및
결정된 상기 컨텍스트를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 인코딩하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 16 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는, 상기 현재의 변환 계수를 CABAC 디코딩하기 위하여 이용될 하나 이상의 이웃하는 변환 계수들을 식별하는 템플릿을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트를 결정하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 17 항에 있어서,
상기 현재의 변환 계수를 포함하는 변환 유닛의 크기, 상기 변환 유닛을 포함하는 코딩 유닛과 연관된 코딩 모드, 상기 현재의 변환 계수를 포함하는 상기 변환 유닛에서의 상기 현재의 변환 계수의 위치, 또는 상기 현재의 변환 계수를 포함하는 계수 그룹에서의 상기 현재의 변환 계수의 위치 중의 적어도 하나에 기초하여, 상기 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하는 단계를 더 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 16 항에 있어서,
상기 현재의 변환 계수는 변환 유닛 내에 포함되고,
상기 변환 유닛의 모든 빈들은 규칙적 모드에 따라 CABAC 인코딩되고, 그리고
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 인코딩하는 단계는, 상기 변환 유닛의 모든 변환 계수들의 모든 대응하는 i 번째 빈들이 CABAC 인코딩되는 i 번째 코딩 패스 동안에 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 인코딩하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 16 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는, 상기 이전에-인코딩된 변환 계수들의 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 20 항에 있어서,
상기 이전에-인코딩된 변환 계수들은 템플릿에서 위치되는, 비디오 데이터를 인코딩하는 방법. - 제 20 항에 있어서,
상기 이전에-인코딩된 변환 계수들의 함수를 이용하는 것은 처음 'M' 이전에-인코딩된 변환 계수들의 함수를 이용하는 것을 포함하고, 'M' 은 비-음의 값을 표현하는, 비디오 데이터를 인코딩하는 방법. - 제 20 항에 있어서,
상기 함수는 합산 함수를 포함하고, 그리고
이전에-인코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 대응하는 i 번째 빈은 복수의 이전에-인코딩된 변환 계수들의 신택스 엘리먼트들에 대한 값들의 복수의 대응하는 i 번째 빈들 내에 포함되는, 비디오 데이터를 인코딩하는 방법. - 제 23 항에 있어서,
상기 합산 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를 결정하는 단계는, 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를, 상기 복수의 이전에-인코딩된 변환 계수들의 상기 신택스 엘리먼트들에 대한 값들의 상기 복수의 대응하는 i 번째 빈들의 전부의 합으로서 정의하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 16 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하는 단계는,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하는 단계; 및
오프셋을 결정된 상기 컨텍스트 인덱스에 가산하는 단계를 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 25 항에 있어서,
상기 현재의 변환 계수를 포함하는 변환 유닛의 크기에 기초하여 상기 오프셋을 결정하는 단계를 더 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 26 항에 있어서,
상기 변환 유닛이 임계치 크기 내에 있는지 여부를 결정하는 단계; 및
상기 변환 유닛이 상기 임계치 크기 내에 있을 경우, 상기 변환 유닛이 상기 임계치 크기 내에 있는 모든 변환 유닛들에 공통적인 컨텍스트 모델들의 세트와 연관되는 것으로 결정하는 단계를 더 포함하는, 비디오 데이터를 인코딩하는 방법. - 제 27 항에 있어서,
상기 임계치 크기는 16x16 차원성과 연관되는, 비디오 데이터를 인코딩하는 방법. - 비디오 코딩 디바이스로서,
비디오 데이터를 저장하도록 구성된 메모리; 및
하나 이상의 프로세서들을 포함하고,
상기 하나 이상의 프로세서들은,
현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하는 것으로서,
상기 컨텍스트들을 결정하기 위하여, 상기 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, i 는 비-음의 정수를 포함하고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 상기 하나 이상의 프로세서들은 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 다른 빈들이 아니고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 오직 이용하도록 구성되는, 상기 컨텍스트들을 결정하고; 그리고
결정된 상기 컨텍스트를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 코딩하도록 구성되는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 상기 하나 이상의 프로세서들은 상기 현재의 변환 계수를 CABAC 디코딩하기 위하여 이용될 하나 이상의 이웃하는 변환 계수들을 식별하는 템플릿을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트를 결정하도록 구성되는, 비디오 코딩 디바이스. - 제 30 항에 있어서,
상기 하나 이상의 프로세서들은 상기 현재의 변환 계수를 포함하는 변환 유닛의 크기, 상기 변환 유닛을 포함하는 코딩 유닛과 연관된 코딩 모드, 상기 현재의 변환 계수를 포함하는 상기 변환 유닛에서의 상기 현재의 변환 계수의 위치, 또는 상기 현재의 변환 계수를 포함하는 계수 그룹에서의 상기 현재의 변환 계수의 위치 중의 적어도 하나에 기초하여, 상기 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하도록 추가로 구성되는, 비디오 코딩 디바이스. - 제 30 항에 있어서,
상기 하나 이상의 프로세서들은 컬러 컴포넌트 정보에 기초하여 상기 템플릿의 크기 또는 형상 중의 적어도 하나를 결정하도록 추가로 구성되고, 상기 컬러 컴포넌트 정보는 루마 컴포넌트 정보 또는 크로마 컴포넌트 정보 중의 하나 또는 양자를 포함하는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 현재의 변환 계수는 변환 유닛 내에 포함되고,
상기 변환 유닛의 일부 또는 모든 빈들은 규칙적 모드에 따라 CABAC 인코딩되고, 그리고
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 코딩하기 위하여, 상기 하나 이상의 프로세서들은 상기 변환 유닛의 모든 변환 계수들의 모든 대응하는 i 번째 빈들이 CABAC 코딩되는 i 번째 코딩 패스 동안에 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 코딩하도록 구성되는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 상기 하나 이상의 프로세서들은 상기 이전에-코딩된 변환 계수들의 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하도록 구성되는, 비디오 코딩 디바이스. - 제 34 항에 있어서,
상기 이전에-코딩된 변환 계수들은 템플릿에서 위치되는, 비디오 코딩 디바이스. - 제 34 항에 있어서,
상기 이전에-코딩된 변환 계수들의 함수를 이용하기 위하여, 상기 하나 이상의 프로세서들은 처음 'M' 이전에-코딩된 변환 계수들의 함수를 이용하도록 구성되고, 'M' 은 비-음의 값을 표현하는, 비디오 코딩 디바이스. - 제 34 항에 있어서,
상기 함수는 합산 함수를 포함하고, 그리고
이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 대응하는 i 번째 빈은 복수의 이전에-코딩된 변환 계수들의 신택스 엘리먼트들에 대한 값들의 복수의 대응하는 i 번째 빈들 내에 포함되는, 비디오 코딩 디바이스. - 제 37 항에 있어서,
상기 합산 함수를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를 결정하기 위하여, 상기 하나 이상의 프로세서들은 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 상기 컨텍스트 인덱스를, 상기 복수의 이전에-코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 상기 복수의 대응하는 i 번째 빈들의 전부의 합으로서 정의하도록 구성되는, 비디오 코딩 디바이스. - 제 38 항에 있어서,
상기 하나 이상의 프로세서들은 미리 정의된 범위 내에 있는 클립된 합을 형성하기 위하여 상기 합산 함수의 결과를 클립하도록 추가로 구성되는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위하여, 상기 하나 이상의 프로세서들은,
상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈에 대한 컨텍스트 인덱스를 결정하고; 그리고
오프셋을 결정된 상기 컨텍스트 인덱스에 가산하도록 구성되는, 비디오 코딩 디바이스. - 제 40 항에 있어서,
상기 하나 이상의 프로세서들은 상기 현재의 변환 계수를 포함하는 변환 유닛의 크기에 기초하여 상기 오프셋을 결정하도록 추가로 구성되는, 비디오 코딩 디바이스. - 제 40 항에 있어서,
상기 하나 이상의 프로세서들은,
상기 변환 유닛이 임계치 크기 내에 있는지 여부를 결정하고; 그리고
상기 변환 유닛이 상기 임계치 크기 내에 있을 경우, 상기 변환 유닛이 상기 임계치 크기 내에 있는 모든 변환 유닛들에 공통적인 컨텍스트 모델들의 세트와 연관되는 것으로 결정하도록 추가로 구성되는, 비디오 코딩 디바이스. - 제 42 항에 있어서,
상기 임계치 크기는 16x16 차원성과 연관되는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
저장된 상기 비디오 데이터는 인코딩된 비디오 데이터를 포함하고,
상기 하나 이상의 프로세서들은 복원된 비디오 데이터를 형성하기 위하여 상기 인코딩된 비디오 데이터의 적어도 부분을 디코딩하도록 추가로 구성되고, 그리고
상기 비디오 코딩 디바이스는 상기 복원된 비디오 데이터의 적어도 부분을 디스플레이하도록 구성된 디스플레이 디바이스를 더 포함하는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 하나 이상의 프로세서들은 상기 저장된 것의 적어도 부분을 인코딩하도록 추가로 구성되고, 그리고
상기 이전에-코딩된 변환 계수는 이전에-인코딩된 변환 계수를 포함하는, 비디오 코딩 디바이스. - 제 45 항에 있어서,
상기 비디오 데이터의 적어도 부분을 캡처하도록 구성된 카메라를 더 포함하는, 비디오 코딩 디바이스. - 제 29 항에 있어서,
상기 현재의 변환 계수는 우회 모드에 따라 코딩되는 변환 유닛 내에 포함되는, 비디오 코딩 디바이스. - 비디오 코딩 장치로서,
현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하기 위한 수단으로서,
상기 컨텍스트들을 결정하기 위한 수단은 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하기 위한 수단을 포함하고, i 는 비-음의 정수를 포함하고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위한 수단은 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 다른 빈들이 아니고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 오직 이용하기 위한 수단을 포함하는, 상기 컨텍스트들을 결정하기 위한 수단; 및
결정된 상기 컨텍스트를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 코딩하기 위한 수단을 포함하는, 비디오 코딩 장치. - 명령들로 인코딩된 비일시적 컴퓨터 판독가능 저장 매체로서,
상기 명령들은, 실행될 경우, 비디오 코딩 디바이스의 하나 이상의 프로세서들로 하여금,
현재의 변환 계수의 신택스 엘리먼트에 대한 값의 복수의 빈들의 각각에 대하여, 하나 이상의 이전에-코딩된 변환 계수들의 상기 신택스 엘리먼트에 대한 값들의 개개의 대응하는 빈들을 이용하여 컨텍스트들을 결정하게 하는 것으로서,
상기 컨텍스트들을 결정하기 위하여, 상기 하나 이상의 프로세서들은 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 i 번째 빈에 대한 컨텍스트를 결정하도록 구성되고, i 는 비-음의 정수를 포함하고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 값의 대응하는 i 번째 빈을 이용하기 위하여, 하나 이상의 프로세서들은 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 다른 빈들이 아니고, 상기 이전에-코딩된 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 오직 이용하도록 구성되는, 상기 컨텍스트들을 결정하게 하고; 그리고
결정된 상기 컨텍스트를 이용하여 상기 현재의 변환 계수의 상기 신택스 엘리먼트에 대한 상기 값의 상기 i 번째 빈을 CABAC 코딩하게 하는, 비일시적 컴퓨터 판독가능 저장 매체.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562168571P | 2015-05-29 | 2015-05-29 | |
| US62/168,571 | 2015-05-29 | ||
| US15/166,153 | 2016-05-26 | ||
| US15/166,153 US10574993B2 (en) | 2015-05-29 | 2016-05-26 | Coding data using an enhanced context-adaptive binary arithmetic coding (CABAC) design |
| PCT/US2016/034828 WO2016196369A1 (en) | 2015-05-29 | 2016-05-27 | Coding data using an enhanced context-adaptive binary arithmetic coding (cabac) design |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20180013909A true KR20180013909A (ko) | 2018-02-07 |
Family
ID=57397705
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177034002A KR20180013909A (ko) | 2015-05-29 | 2016-05-27 | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 |
| KR1020177034003A KR20180013910A (ko) | 2015-05-29 | 2016-05-27 | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 |
| KR1020177034005A KR102600724B1 (ko) | 2015-05-29 | 2016-05-27 | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177034003A KR20180013910A (ko) | 2015-05-29 | 2016-05-27 | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 |
| KR1020177034005A KR102600724B1 (ko) | 2015-05-29 | 2016-05-27 | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 |
Country Status (10)
| Country | Link |
|---|---|
| US (3) | US11233998B2 (ko) |
| EP (3) | EP3304915A1 (ko) |
| JP (3) | JP6619028B2 (ko) |
| KR (3) | KR20180013909A (ko) |
| CN (3) | CN107690807B (ko) |
| AU (3) | AU2016271137B2 (ko) |
| BR (3) | BR112017025484B1 (ko) |
| ES (1) | ES2905415T3 (ko) |
| TW (3) | TWI699110B (ko) |
| WO (3) | WO2016196379A1 (ko) |
Families Citing this family (69)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9369723B2 (en) * | 2011-07-14 | 2016-06-14 | Comcast Cable Communications, Llc | Preserving image quality in temporally compressed video streams |
| US11233998B2 (en) | 2015-05-29 | 2022-01-25 | Qualcomm Incorporated | Coding data using an enhanced context-adaptive binary arithmetic coding (CABAC) design |
| CN107710759B (zh) * | 2015-06-23 | 2020-11-03 | 联发科技(新加坡)私人有限公司 | 转换系数编解码的方法及装置 |
| CN113411579B (zh) * | 2016-05-13 | 2024-01-23 | 夏普株式会社 | 图像解码装置及其方法、图像编码装置及其方法 |
| US10616582B2 (en) | 2016-09-30 | 2020-04-07 | Qualcomm Incorporated | Memory and bandwidth reduction of stored data in image/video coding |
| EP3544300B1 (en) | 2016-11-21 | 2021-10-13 | Panasonic Intellectual Property Corporation of America | Devices and methods for image coding and decoding using a block size dependent split ratio |
| EP3528498A1 (en) * | 2016-11-21 | 2019-08-21 | Panasonic Intellectual Property Corporation of America | Coding device, decoding device, coding method, and decoding method |
| US10757412B2 (en) | 2017-01-03 | 2020-08-25 | Avago Technologies International Sales Pte. Limited | Architecture flexible binary arithmetic coding system |
| US11265561B2 (en) * | 2017-01-06 | 2022-03-01 | Mediatek Inc. | Method and apparatus for range derivation in context adaptive binary arithmetic coding |
| CN114449270B (zh) * | 2017-07-04 | 2023-09-26 | 三星电子株式会社 | 使用多核变换的视频解码/编码方法和设备 |
| US10127913B1 (en) * | 2017-07-07 | 2018-11-13 | Sif Codec Llc | Method of encoding of data stream, method of decoding of data stream, and devices for implementation of said methods |
| US10506258B2 (en) * | 2017-07-13 | 2019-12-10 | Google Llc | Coding video syntax elements using a context tree |
| CA3069635C (en) | 2017-07-14 | 2022-06-14 | Mediatek, Inc. | Method and apparatus for range derivation in context adaptive binary arithmetic coding |
| US11039143B2 (en) | 2017-11-20 | 2021-06-15 | Qualcomm Incorporated | Memory reduction for context initialization with temporal prediction |
| EP3490253A1 (en) * | 2017-11-23 | 2019-05-29 | Thomson Licensing | Encoding and decoding methods and corresponding devices |
| CN116132673A (zh) * | 2017-12-13 | 2023-05-16 | 三星电子株式会社 | 视频解码方法及其装置以及视频编码方法及其装置 |
| US10869062B2 (en) | 2017-12-21 | 2020-12-15 | Qualcomm Incorporated | Probability initialization and signaling for adaptive arithmetic coding in video coding |
| EP3503557A1 (en) * | 2017-12-22 | 2019-06-26 | Thomson Licensing | Method and apparatus for video encoding and decoding based on context switching |
| US10863199B2 (en) * | 2018-03-26 | 2020-12-08 | Qualcomm Incorporated | Minimization of transform memory and latency via parallel factorizations |
| CN117119195A (zh) | 2018-03-29 | 2023-11-24 | 弗劳恩霍夫应用研究促进协会 | 变换系数块编码 |
| CN117294838A (zh) * | 2018-03-29 | 2023-12-26 | 弗劳恩霍夫应用研究促进协会 | 用于增强并行编码能力的构思 |
| TWI813126B (zh) | 2018-03-29 | 2023-08-21 | 弗勞恩霍夫爾協會 | 相依量化技術 |
| US20190313108A1 (en) | 2018-04-05 | 2019-10-10 | Qualcomm Incorporated | Non-square blocks in video coding |
| EP3562156A1 (en) * | 2018-04-27 | 2019-10-30 | InterDigital VC Holdings, Inc. | Method and apparatus for adaptive context modeling in video encoding and decoding |
| US10992937B2 (en) * | 2018-06-18 | 2021-04-27 | Qualcomm Incorporated | Coefficient coding with grouped bypass bins |
| CN110650343A (zh) * | 2018-06-27 | 2020-01-03 | 中兴通讯股份有限公司 | 图像的编码、解码方法及装置、电子设备及系统 |
| WO2020004277A1 (ja) * | 2018-06-28 | 2020-01-02 | シャープ株式会社 | 画像復号装置、および画像符号化装置 |
| US10687081B2 (en) * | 2018-06-29 | 2020-06-16 | Tencent America LLC | Method, apparatus and medium for decoding or encoding |
| US10666981B2 (en) | 2018-06-29 | 2020-05-26 | Tencent America LLC | Method, apparatus and medium for decoding or encoding |
| EP3818705A1 (en) * | 2018-07-02 | 2021-05-12 | InterDigital VC Holdings, Inc. | Context-based binary arithmetic encoding and decoding |
| TWI816858B (zh) * | 2018-08-16 | 2023-10-01 | 大陸商北京字節跳動網絡技術有限公司 | 用於變換矩陣選擇的隱式編碼 |
| US11483575B2 (en) * | 2018-08-24 | 2022-10-25 | Hfi Innovation Inc. | Coding transform coefficients with throughput constraints |
| TWI734178B (zh) * | 2018-08-24 | 2021-07-21 | 聯發科技股份有限公司 | 具有產出限制的編碼轉換係數 |
| US11336918B2 (en) * | 2018-09-05 | 2022-05-17 | Qualcomm Incorporated | Regular coded bin reduction for coefficient coding |
| CN117201785A (zh) * | 2018-09-11 | 2023-12-08 | Lg电子株式会社 | 图像解码设备、图像编码设备和比特流发送设备 |
| WO2020064745A1 (en) * | 2018-09-24 | 2020-04-02 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Efficient coding of transform coefficients using or suitable for a combination with dependent scalar quantization |
| WO2020067440A1 (ja) * | 2018-09-27 | 2020-04-02 | シャープ株式会社 | 動画像符号化装置および動画像復号装置 |
| KR20230125331A (ko) | 2018-09-28 | 2023-08-29 | 파나소닉 인텔렉츄얼 프로퍼티 코포레이션 오브 아메리카 | 부호화 장치, 복호 장치, 부호화 방법, 및 복호 방법 |
| US20220014787A1 (en) * | 2018-10-11 | 2022-01-13 | Lg Electronics Inc. | Transform coefficient coding method and device |
| CN112970264A (zh) * | 2018-11-05 | 2021-06-15 | 交互数字Vc控股公司 | 基于相邻样本相关参数模型的译码模式的简化 |
| CN112997505B (zh) * | 2018-11-12 | 2023-03-24 | 三星电子株式会社 | 用于对系数等级进行熵编码的方法和装置以及用于对系数等级进行熵解码的方法和装置 |
| WO2020135371A1 (zh) * | 2018-12-24 | 2020-07-02 | 华为技术有限公司 | 一种标志位的上下文建模方法及装置 |
| US11671598B2 (en) * | 2019-01-02 | 2023-06-06 | Lg Electronics Inc. | Image decoding method and device using residual information in image coding system |
| US11523136B2 (en) * | 2019-01-28 | 2022-12-06 | Hfi Innovation Inc. | Methods and apparatuses for coding transform blocks |
| US11134273B2 (en) * | 2019-02-14 | 2021-09-28 | Qualcomm Incorporated | Regular coded bin reduction for coefficient coding |
| AU2019201653A1 (en) * | 2019-03-11 | 2020-10-01 | Canon Kabushiki Kaisha | Method, apparatus and system for encoding and decoding a tree of blocks of video samples |
| US11202100B2 (en) * | 2019-03-11 | 2021-12-14 | Qualcomm Incorporated | Coefficient coding for transform skip mode |
| US11178399B2 (en) | 2019-03-12 | 2021-11-16 | Qualcomm Incorporated | Probability initialization for video coding |
| TW202046730A (zh) * | 2019-04-24 | 2020-12-16 | 美商松下電器(美國)知識產權公司 | 編碼裝置、解碼裝置、編碼方法、及解碼方法 |
| US10818083B1 (en) * | 2019-04-30 | 2020-10-27 | International Business Machines Corporation | Pyramid generation via depth-first walk |
| WO2020228762A1 (en) | 2019-05-14 | 2020-11-19 | Beijing Bytedance Network Technology Co., Ltd. | Context modeling for residual coding |
| JP7436519B2 (ja) | 2019-05-31 | 2024-02-21 | バイトダンス インコーポレイテッド | イントラブロックコピー予測を備えたパレットモード |
| US11368511B2 (en) * | 2019-06-20 | 2022-06-21 | Tencent America LLC | Unification of rice parameter lookup table |
| CN112118456B (zh) | 2019-06-20 | 2022-03-25 | 腾讯美国有限责任公司 | 莱斯参数选择方法、装置、计算机设备及存储介质 |
| CN113994679A (zh) * | 2019-06-21 | 2022-01-28 | 北京字节跳动网络技术有限公司 | 关于上下文编解码二进制位的数量的限制 |
| WO2020264456A1 (en) | 2019-06-28 | 2020-12-30 | Bytedance Inc. | Chroma intra mode derivation in screen content coding |
| WO2020264457A1 (en) * | 2019-06-28 | 2020-12-30 | Bytedance Inc. | Techniques for modifying quantization parameter in transform skip mode |
| CN114402605A (zh) * | 2019-07-10 | 2022-04-26 | Lg电子株式会社 | 图像编码系统中使用残差编码方法的标志的图像解码方法以及用于其的装置 |
| EP4024861A4 (en) * | 2019-08-31 | 2023-06-28 | LG Electronics Inc. | Method for decoding video for residual coding and device therefor |
| EP4032259A4 (en) * | 2019-09-20 | 2022-11-23 | Alibaba Group Holding Limited | QUANTIFICATION PARAMETER SIGNALING IN VIDEO PROCESSING |
| CN114391257A (zh) * | 2019-09-25 | 2022-04-22 | 松下电器(美国)知识产权公司 | 编码装置、解码装置、编码方法和解码方法 |
| AU2019284053A1 (en) * | 2019-12-23 | 2021-07-08 | Canon Kabushiki Kaisha | Method, apparatus and system for encoding and decoding a block of video samples |
| US11863789B2 (en) * | 2020-03-31 | 2024-01-02 | Tencent America LLC | Method for signaling rectangular slice partitioning in coded video stream |
| US11785219B2 (en) * | 2020-04-13 | 2023-10-10 | Qualcomm Incorporated | Coefficient coding for support of different color formats in video coding |
| US11765370B2 (en) * | 2021-07-27 | 2023-09-19 | Mediatek Inc. | Video residual decoding apparatus using neighbor storage device with smaller storage size to store neighbor data for context selection and associated method |
| WO2023172706A1 (en) * | 2022-03-09 | 2023-09-14 | Innopeak Technology, Inc. | Attribute level coding for geometry point cloud coding |
| WO2023182673A1 (ko) * | 2022-03-21 | 2023-09-28 | 현대자동차주식회사 | 컨텍스트 모델 초기화를 사용하는 비디오 코딩을 위한 방법 및 장치 |
| WO2023193724A1 (en) * | 2022-04-05 | 2023-10-12 | Beijing Bytedance Network Technology Co., Ltd. | Method, apparatus, and medium for video processing |
| CN114928747B (zh) * | 2022-07-20 | 2022-12-16 | 阿里巴巴(中国)有限公司 | 基于av1熵编码的上下文概率处理电路、方法及相关装置 |
Family Cites Families (55)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040122693A1 (en) * | 2002-12-23 | 2004-06-24 | Michael Hatscher | Community builder |
| KR100703773B1 (ko) | 2005-04-13 | 2007-04-06 | 삼성전자주식회사 | 향상된 코딩 효율을 갖는 엔트로피 코딩 및 디코딩 방법과이를 위한 장치, 이를 포함하는 비디오 코딩 및 디코딩방법과 이를 위한 장치 |
| KR100703776B1 (ko) | 2005-04-19 | 2007-04-06 | 삼성전자주식회사 | 향상된 코딩 효율을 갖는 컨텍스트 기반 적응적 산술 코딩및 디코딩 방법과 이를 위한 장치, 이를 포함하는 비디오코딩 및 디코딩 방법과 이를 위한 장치 |
| US7983343B2 (en) * | 2006-01-12 | 2011-07-19 | Lsi Corporation | Context adaptive binary arithmetic decoding for high definition video |
| JP4660433B2 (ja) | 2006-06-29 | 2011-03-30 | 株式会社東芝 | 符号化回路、復号回路、エンコーダ回路、デコーダ回路、cabac処理方法 |
| CA2629482A1 (en) * | 2007-04-21 | 2008-10-21 | Avid Technology, Inc. | Using user context information to select media files for a user in a distributed multi-user digital media system |
| US8516505B2 (en) | 2008-03-14 | 2013-08-20 | Microsoft Corporation | Cross-platform compatibility framework for computer applications |
| PL2346030T3 (pl) * | 2008-07-11 | 2015-03-31 | Fraunhofer Ges Forschung | Koder audio, sposób kodowania sygnału audio oraz program komputerowy |
| BR122019001455B1 (pt) * | 2008-10-24 | 2021-01-19 | Merial, Inc. | vacina contra o vírus da doença equina africana |
| US8873626B2 (en) * | 2009-07-02 | 2014-10-28 | Qualcomm Incorporated | Template matching for video coding |
| TWI403170B (zh) | 2010-05-21 | 2013-07-21 | Univ Nat Chiao Tung | 背景調適性二進制算術解碼裝置及其解碼方法 |
| US8344917B2 (en) | 2010-09-30 | 2013-01-01 | Sharp Laboratories Of America, Inc. | Methods and systems for context initialization in video coding and decoding |
| US9497472B2 (en) * | 2010-11-16 | 2016-11-15 | Qualcomm Incorporated | Parallel context calculation in video coding |
| CN102231830B (zh) | 2010-11-23 | 2013-04-17 | 浙江大学 | 用于上下文算术编解码的运算单元 |
| US9215473B2 (en) | 2011-01-26 | 2015-12-15 | Qualcomm Incorporated | Sub-slices in video coding |
| US9338449B2 (en) | 2011-03-08 | 2016-05-10 | Qualcomm Incorporated | Harmonized scan order for coding transform coefficients in video coding |
| WO2012134246A2 (ko) | 2011-04-01 | 2012-10-04 | 엘지전자 주식회사 | 엔트로피 디코딩 방법 및 이를 이용하는 디코딩 장치 |
| FR2977111A1 (fr) | 2011-06-24 | 2012-12-28 | France Telecom | Procede de codage et decodage d'images, dispositif de codage et decodage et programmes d'ordinateur correspondants |
| WO2013003777A1 (en) | 2011-06-29 | 2013-01-03 | General Instrument Corporation | Methods and system for using a scan coding pattern during intra coding |
| US20130083856A1 (en) | 2011-06-29 | 2013-04-04 | Qualcomm Incorporated | Contexts for coefficient level coding in video compression |
| US9060173B2 (en) | 2011-06-30 | 2015-06-16 | Sharp Kabushiki Kaisha | Context initialization based on decoder picture buffer |
| US8693401B2 (en) | 2011-07-20 | 2014-04-08 | Connectem Inc. | Method and system for optimized handling of context using hierarchical grouping (for machine type communications) |
| SI3145197T1 (sl) | 2011-10-31 | 2018-09-28 | Samsung Electronics Co., Ltd, | Postopek določanja kontekstnega modela za entropijsko dekodiranje na stopnji transformnega koeficienta |
| US20130114691A1 (en) | 2011-11-03 | 2013-05-09 | Qualcomm Incorporated | Adaptive initialization for context adaptive entropy coding |
| CN103918260A (zh) | 2011-11-15 | 2014-07-09 | 英特尔公司 | 每时钟cabac编码采用2个bin的视频编码器 |
| US9743098B2 (en) | 2011-11-19 | 2017-08-22 | Blackberry Limited | Multi-level significance map scanning |
| KR101802334B1 (ko) | 2011-12-02 | 2017-12-29 | 삼성전자주식회사 | 적응적 탬플릿을 이용한 이진 영상의 부호화 방법 및 장치, 그 복호화 방법 및 장치 |
| WO2013106987A1 (en) | 2012-01-16 | 2013-07-25 | Mediatek Singapore Pte. Ltd. | Methods and apparatuses of bypass coding and reducing contexts for some syntax elements |
| CN103931188B (zh) | 2012-01-16 | 2017-05-10 | 寰发股份有限公司 | 语法元素的基于上下文的自适应二进制算术编码装置及方法 |
| US9191670B2 (en) | 2012-01-17 | 2015-11-17 | Qualcomm Incorporated | Throughput improvement for CABAC coefficient level coding |
| US9749661B2 (en) | 2012-01-18 | 2017-08-29 | Qualcomm Incorporated | Sub-streams for wavefront parallel processing in video coding |
| US9654772B2 (en) * | 2012-01-19 | 2017-05-16 | Qualcomm Incorporated | Context adaptive entropy coding with a reduced initialization value set |
| AU2012200319B2 (en) * | 2012-01-19 | 2015-11-26 | Canon Kabushiki Kaisha | Method, apparatus and system for encoding and decoding the significance map for residual coefficients of a transform unit |
| US9106918B2 (en) | 2012-01-20 | 2015-08-11 | Sony Corporation | Coefficient coding harmonization in HEVC |
| AU2012200345B2 (en) * | 2012-01-20 | 2014-05-01 | Canon Kabushiki Kaisha | Method, apparatus and system for encoding and decoding the significance map residual coefficients of a transform unit |
| US9866829B2 (en) | 2012-01-22 | 2018-01-09 | Qualcomm Incorporated | Coding of syntax elements that correspond to coefficients of a coefficient block in video coding |
| US9363510B2 (en) | 2012-03-02 | 2016-06-07 | Qualcomm Incorporated | Scan-based sliding window in context derivation for transform coefficient coding |
| US9036710B2 (en) * | 2012-03-08 | 2015-05-19 | Blackberry Limited | Unified transform coefficient encoding and decoding |
| CN103327316B (zh) | 2012-03-22 | 2016-08-10 | 上海算芯微电子有限公司 | 视频宏块的上下文信息存取方法和系统 |
| US9237344B2 (en) | 2012-03-22 | 2016-01-12 | Qualcomm Incorporated | Deriving context for last position coding for video coding |
| US9264706B2 (en) | 2012-04-11 | 2016-02-16 | Qualcomm Incorporated | Bypass bins for reference index coding in video coding |
| KR102096566B1 (ko) | 2012-04-13 | 2020-04-02 | 지이 비디오 컴프레션, 엘엘씨 | 저지연 화상 코딩 |
| US9491463B2 (en) | 2012-04-14 | 2016-11-08 | Qualcomm Incorporated | Group flag in transform coefficient coding for video coding |
| US9124872B2 (en) * | 2012-04-16 | 2015-09-01 | Qualcomm Incorporated | Coefficient groups and coefficient coding for coefficient scans |
| EP2654296A1 (en) * | 2012-04-16 | 2013-10-23 | BlackBerry Limited | Modified HEVC level coding of video data |
| US9294779B2 (en) * | 2012-06-15 | 2016-03-22 | Blackberry Limited | Multi-bit information hiding using overlapping subsets |
| US9088769B2 (en) | 2012-06-28 | 2015-07-21 | Blackberry Limited | Reduced worst-case context-coded bins in video compression with parity hiding |
| PH12017501838A1 (en) | 2012-09-26 | 2018-07-02 | Velos Media Int Ltd | Image coding method, image decoding method, image coding apparatus, image decoding apparatus, and image coding and decoding apparatus |
| JP2014090326A (ja) | 2012-10-30 | 2014-05-15 | Mitsubishi Electric Corp | 動画像符号化装置、動画像復号装置、動画像符号化方法及び動画像復号方法 |
| MY170156A (en) | 2013-01-04 | 2019-07-09 | Samsung Electronics Co Ltd | Method for entropy-encoding slice segment and apparatus therefor, and method for entropy-decoding slice segment and apparatus therefor |
| KR102218196B1 (ko) * | 2013-10-28 | 2021-02-23 | 삼성전자주식회사 | 인코더, 이의 동작 방법과, 상기 인코더를 포함하는 장치들 |
| US20150334425A1 (en) | 2014-05-14 | 2015-11-19 | Blackberry Limited | Adaptive context initialization |
| US9425822B2 (en) | 2014-08-05 | 2016-08-23 | Broadcom Corporation | Simplified range and context update for multimedia context-adaptive binary arithmetic coding design |
| CN107077383B (zh) | 2014-09-25 | 2021-05-11 | 甲骨文国际公司 | 用于在多租户应用服务器环境中确定分区标识符的系统和方法 |
| US11233998B2 (en) | 2015-05-29 | 2022-01-25 | Qualcomm Incorporated | Coding data using an enhanced context-adaptive binary arithmetic coding (CABAC) design |
-
2016
- 2016-05-26 US US15/166,144 patent/US11233998B2/en active Active
- 2016-05-26 US US15/166,132 patent/US10334248B2/en active Active
- 2016-05-26 US US15/166,153 patent/US10574993B2/en active Active
- 2016-05-27 KR KR1020177034002A patent/KR20180013909A/ko unknown
- 2016-05-27 EP EP16729147.5A patent/EP3304915A1/en not_active Withdrawn
- 2016-05-27 BR BR112017025484-0A patent/BR112017025484B1/pt active IP Right Grant
- 2016-05-27 EP EP16729148.3A patent/EP3304901A1/en not_active Withdrawn
- 2016-05-27 TW TW105116832A patent/TWI699110B/zh active
- 2016-05-27 KR KR1020177034003A patent/KR20180013910A/ko not_active Application Discontinuation
- 2016-05-27 EP EP16730580.4A patent/EP3304916B1/en active Active
- 2016-05-27 WO PCT/US2016/034850 patent/WO2016196379A1/en active Application Filing
- 2016-05-27 JP JP2017561300A patent/JP6619028B2/ja active Active
- 2016-05-27 AU AU2016271137A patent/AU2016271137B2/en active Active
- 2016-05-27 CN CN201680030293.5A patent/CN107690807B/zh active Active
- 2016-05-27 TW TW105116830A patent/TW201711467A/zh unknown
- 2016-05-27 WO PCT/US2016/034839 patent/WO2016196376A1/en active Application Filing
- 2016-05-27 ES ES16730580T patent/ES2905415T3/es active Active
- 2016-05-27 CN CN201680030423.5A patent/CN107660339B/zh active Active
- 2016-05-27 JP JP2017561310A patent/JP2018521553A/ja not_active Ceased
- 2016-05-27 WO PCT/US2016/034828 patent/WO2016196369A1/en active Application Filing
- 2016-05-27 BR BR112017025521A patent/BR112017025521A2/pt not_active Application Discontinuation
- 2016-05-27 BR BR112017025556A patent/BR112017025556A2/pt not_active Application Discontinuation
- 2016-05-27 JP JP2017561313A patent/JP6873051B2/ja active Active
- 2016-05-27 AU AU2016271130A patent/AU2016271130B2/en active Active
- 2016-05-27 CN CN201680030204.7A patent/CN107667531B/zh not_active Expired - Fee Related
- 2016-05-27 TW TW105116831A patent/TW201711464A/zh unknown
- 2016-05-27 AU AU2016271140A patent/AU2016271140B2/en active Active
- 2016-05-27 KR KR1020177034005A patent/KR102600724B1/ko active IP Right Grant
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102600724B1 (ko) | 개량된 컨텍스트-적응 2 진 산술 코딩 (cabac) 설계를 이용한 데이터의 코딩 | |
| AU2016270634B2 (en) | Advanced arithmetic coder | |
| IL269614A (en) | Context Reduction for Binary Mathematics Coding Adaptive | |
| EP2834977B1 (en) | Weighted prediction parameter coding | |
| KR101676938B1 (ko) | 비디오 코딩을 위한 장기 참조 화상들에 대한 데이터 시그널링 | |
| KR101699600B1 (ko) | 비디오 코딩을 위해 최종 포지션 코딩을 위한 콘텍스트의 도출 | |
| KR20140120337A (ko) | 감소된 초기화 값 세트를 갖는 콘텍스트 적응 엔트로피 코딩 | |
| WO2013067156A1 (en) | Adaptive initialization for context adaptive entropy coding |