KR20110043645A - 기계 번역을 위한 파라미터들의 최적화 - Google Patents
기계 번역을 위한 파라미터들의 최적화 Download PDFInfo
- Publication number
- KR20110043645A KR20110043645A KR1020117002721A KR20117002721A KR20110043645A KR 20110043645 A KR20110043645 A KR 20110043645A KR 1020117002721 A KR1020117002721 A KR 1020117002721A KR 20117002721 A KR20117002721 A KR 20117002721A KR 20110043645 A KR20110043645 A KR 20110043645A
- Authority
- KR
- South Korea
- Prior art keywords
- translation
- grid
- program product
- weights
- hypothesis
- Prior art date
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/44—Statistical methods, e.g. probability models
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Algebra (AREA)
- Pure & Applied Mathematics (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- Machine Translation (AREA)
Abstract
언어 번역을 위한 방법들, 시스템들, 및 컴퓨터 프로그램 제품들을 포함하는 장치들이 개시된다. 일 구현에서, 한 방법이 제공된다. 이 방법은 가설 공간에 접근하는 단계; 증거 공간에 관하여 계산된 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 가설 공간에 대하여 디코딩을 수행하는 단계; 상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함한다.
Description
본 명세서는 통계적 기계 번역에 관한 것이다.
인간 조작자가 텍스트를 수동 번역하는 것은 시간이 소비되고 비용이 많이 들 수 있다. 기계 번역의 한 목적은 소스 언어의 텍스트를 목적 언어의 상응하는 텍스트로 자동 번역하는 것이다. 예문-기반(example-based) 기계 번역 및 통계적 기계 번역을 포함하는 기계 번역에는 여러 가지 다른 접근법이 있다. 통계적 기계 번역은 소스 언어로 특정 입력이 주어지면 목적 언어에서 가장 가능성이 높은 번역을 식별하기 위하여 시도한다. 예를 들어, 프랑스에서 영어로 문장을 번역할 때, 통계적 기계 번역은 주어진 프랑스어 문장에 대하 가장 가능성 높은 영어 문장을 식별한다. 이 최우도 번역(maximum likelihood translation)은 다음과 같이 표현될 수 있다.

이것은모든 가능한 문장들 중에서 영어 문장(e)이 P(e|f)에 대하여 가장 높은 값을 제공함을 나타낸다. 또한, 베이즈의 규칙(Bayes Rule)은 다음을 규정하고 있다.

베이즈의 규칙을 사용하면, 이 최우도 문장은 다음과 같이 쓰일 수 있다.

결과적으로, 최우도 e(즉, 최우도 영어 번역)는 e가 발생할 확률과 e가 f로 번역될 확률(즉, 주어진 영어 문장이 프랑스어 문장으로 번역될 확률)의 곱을 최대화하는 것이다.
언어 번역 작업의 번역 부분을 수행하는 구성요소들은 대개 디코더들(decoders)로 지칭된다. 소정 실시예에서, 제1 디코더(제1 패스(pass) 디코더)는 가능한 번역들의 리스트(예컨대, N-최적 리스트)를 생성할 수 있다. 예컨대, 최소 베이즈-리스크(MBR; Minimum Bayes-Risk) 디코더인 제2 디코더(제2 패스 디코더)가 이 리스트에 적용되어, 식별의 일부인 손실 함수(loss function)를 최소함으로써 측정되는, 가능한 번역들 중 가장 정확한 번역을 이상적으로 식별할 수 있다. 통상, N-최적 리스트는 100 내지 10,000개의 후보 번역들 또는 가설들(hypotheses)을 포함한다. 후보 번역들의 개수를 증가시키면 MBR 디코더의 번역 성능이 개선된다.
본 발명은 기계 번역을 위하여 파라미터들을 더욱 최적화하는 시스템, 방법 및 장치를 제공하는 것을 해결 과제로 한다.
본 명세서는 언어 번역에 관한 기술들을 설명한다.
일반적으로, 본 명세서에 설명된 주제의 일 양태는 복수의 후보 번역들을 나타내는 번역 격자에 접근하는 단계; 상기 번역 격자 내의 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 번역 격자에 대하여 디코딩을 수행하는 단계; 상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 방법으로 구체화될 수 있다.
이들 및 다른 실시예들은 하나 이상의 후술하는 특징을 선택적으로 포함할 수 있다. 이 방법은 소스 언어로 된 소스 샘플을 디코더에 제공하는 것을 포함하는 상기 번역 격자를 생성하는 단계를 더 포함한다. MBR 디코딩을 수행하는 단계는 코퍼스 BLEU 이득의 근사화를 계산하는 단계를 포함한다. 상기 코퍼스 BLEU 이득의 근사화는  로 표현될 수 있고, 여기서, w는 단어,
로 표현될 수 있고, 여기서, w는 단어,  는 상수, E는 후보 번역, E'는 자동 번역,
는 상수, E는 후보 번역, E'는 자동 번역,  는 E'에 w가 출현하는 회수, 및
는 E'에 w가 출현하는 회수, 및  는
는 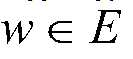 이면 1, 그 외는 0이다.
이면 1, 그 외는 0이다.
상기 격자에 대하여 디코딩을 수행하는 단계는 MBR(Minimum Bayes-Risk) 디코딩을 수행하는 단계를 포함한다. MBR 디코딩을 수행하는 단계는 다음 식을 계산하는 것을 포함하고,

여기서, w는 단어,  는 상수, E'는 자동 번역,
는 상수, E'는 자동 번역,  는 E'에 w가 출현하는 회수,
는 E'에 w가 출현하는 회수,  는 번역 격자를 나타내고,
는 번역 격자를 나타내고,  는 상기 번역 격자 내 w의 사후 확률이다.
는 상기 번역 격자 내 w의 사후 확률이다.  이고, 여기서,
이고, 여기서,  는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고,
는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고,  는
는  내 경로들의 가중치 합을 나타내고,
내 경로들의 가중치 합을 나타내고,  는
는  내 경로들의 가중치 합을 나타낸다.
내 경로들의 가중치 합을 나타낸다.
일반적으로, 본 명세서에 설명된 주제의 다른 양태는 복수의 후보 번역들을 나타내는 가설 공간(hypothesis space)에 접근하는 단계; 증거 공간(evidence space)에 관하여 계산된 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 가설 공간에 대하여 디코딩을 수행하는 단계; 상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 방법으로 구체화될 수 있다. 이 양태의 다른 실시예들은 상응하는 시스템들, 장치들 및 컴퓨터 프로그램 제품들을 포함한다.
이들 및 다른 실시예들은 후술하는 특징들을 하나 이상 선택적으로 포함할 수 있다. 상기 가설 공간은 격자로서 나타내진다. 상기 증거 공간은 N-최적(best) 리스트로서 나타내진다.
본 명세서에 설명된 주제의 특정 실시예들은 후술하는 장점들을 하나 이상 실현하도록 구현될 수 있다. 격자의 MBR 디코딩은 가설 및 증거 공간들의 크기를 증가시켜서, 가용한 후보 번역들의 개수 및 정확한 번역을 획득할 가능성을 증가시킨다. 또한, MBR 디코딩은 코퍼스 BLEU 점수(아래에서 더욱 상세히 설명됨)의 더욱 우수한 근사화를 제공하여, 번역 성능을 더욱 개선한다. 더욱이, 격자의 MBR 디코딩은 런타임 효율적(runtime efficient)이며, 디코딩이 런타임에서 수행될 수 있으므로 통계적 기계 번역의 유연성을 증가시킨다.
일반적으로, 본 명세서에 설명된 주제의 다른 양태는 번역 격자 내 복수의 특징 함수들에 대하여, 상기 번역 격자에 나타낸 하나 이상의 후보 번역들 각각에 대한 상응하는 복수의 에러 표면들을 결정하는 단계; 훈련 세트(training set) 내 구절들(phrases)에 대한 복수의 에러 표면들의 조합을 횡단함으로써, 상기 특징 함수들에 대한 가중치들을 조정하는 단계; 상기 횡단된 조합에 대한 에러 카운트들을 최소화하는 가중치들을 선택하는 단계; 및 샘플 텍스트를 제1 언어에서 제2 언어로 변환하기 위하여, 상기 선택된 가중치들을 적용하는 단계를 포함하는 방법으로 구체화될 수 있다. 이 양태의 다른 실시예들은 상응하는 시스템들, 장치들 및 컴퓨터 프로그램 제품들을 포함한다.
이들 및 다른 실시예들은 후술하는 특징들을 하나 이상 선택적으로 포함할 수 있다. 상기 번역 격자는 구절 격자를 포함한다. 상기 구절 격자 내의 아크들(arcs)은 구절 가설들을 나타내고, 상기 구절 격자내의 노드들은 부분 번역 가설들이 재조합된 상태들(states)을 나타낸다. 상기 에러 표면들은 라인 최적화 기술(line optimization technique)을 사용하여 결정되고 횡단된다. 상기 라인 최적화 기술은, 그룹 내의 특징 함수 각각과 문장(sentence)에 대하여, 후보 번역들의 집합 상의 에러 표면을 결정 및 횡단한다. 상기 라인 최적화 기술은 파라미터 공간 내의 랜덤한 지점(random point)에서부터 시작하여 상기 에러 표면을 결정 및 횡단한다. 상기 라인 최적화 기술은 상기 가중치들을 조정하기 위하여, 랜덤한 방향들(random directions)을 사용하여 상기 에러 표면을 결정 및 횡단한다.
상기 가중치들은 한정들(restrictions)에 의해 제한된다. 상기 가중치들은 가중치 프라이어들(priors)을 사용하여 조정된다. 상기 가중치들은 문장들의 한 그룹 내 모든 문장들에 걸쳐 조정된다. 본 방법은 복수의 후보 번역들로부터, 상기 번역 격자에 대한 사후 확률(posteriori probability)을 최대화하는 대상 번역을 선택하는 단계를 더 포함한다. 상기 번역 격자는 십억개 이상의 후보 번역들을 나타낸다. 상기 구절들은 문장들을 포함한다. 상기 구절들 모두는 문장들을 포함한다.
일반적으로, 본 명세서에 설명된 주제의 다른 양태는 언어 모델을 포함하는 시스템들로 구현될 수 있다. 상기 언어 모델은 번역 격자 내 특징 함수들의 수집(collection); 후보 언어 번역들의 집합에 대하여, 상기 특징 함수들에 걸친 복수의 에러 표면들; 및 상기 에러 표면들의 횡단에 대한 에러를 최소화하도록 선택된 특징 함수들에 대한 가중치들을 포함한다. 이 양태의 다른 실시예들은 상응하는 방법들, 장치들 및 컴퓨터 프로그램 제품들을 포함한다.
본 명세서에 설명된 주제의 특정 실시예들은 후술하는 장점들을 하나 이상 실현하도록 구현될 수 있다. 격자의 MBR 디코딩은 가설 및 증거 공간들의 크기를 증가시켜서, 가용한 후보 번역들의 개수 및 정확한 번역을 획득할 가능성을 증가시킨다. 또한, MBR 디코딩은 코퍼스 BLEU 점수(아래에서 더욱 상세히 설명됨)의 더욱 우수한 근사화를 제공하여, 번역 성능을 더욱 개선한다. 더욱이, 격자의 MBR 디코딩은 런타임 효율적이며, 디코딩이 런타임에서 수행될 수 있으므로 통계적 기계 번역의 유연성을 증가시킨다.
격자 기반 최소 에러율 훈련(MERT)은 번역 격자 내 모든 번역들에 대하여 정확한 에러 표면들을 제공하여, 통계적 기계 번역 시스템의 번역 성능을 더욱 개선한다. 격자-기반 MERT를 위한 시스템들과 방법들은 또한 공간 및 런타임 효율적이며, 사용된 메모리의 양을 감소(예컨대, 격자의 크기와 선형적으로 연관(최대한도)되도록 메모리 요구사항을 제한함)시키고 번역 속도 성능을 증가시킨다.
본 명세서에 설명된 주제에 관한 하나 이상의 실시예들의 상세한 내용은 첨부 도면 및 이하의 상세한 설명에 개시된다. 본 주제의 다른 특징들, 양태들, 장점들은 상세한 설명, 도면들 및 청구항들로부터 명확하게 된다.
도1은 입력 텍스트를 소스 언어에서 목적 언어로 번역하는 예시적 프로세스를 나타내는 개념도이다.
도2a는 예시적 번역 격자를 도시한다.
도2b는 도2a의 번역 격자에 대한 예시적 MBR 오토메이션을 도시한다.
도3은 예시적 번역 격자의 일부를 도시한다.
도4는 MBR 디코딩을 위한 예시적 프로세스를 나타낸다.
도5a는 격자에서 최소 에러율 훈련(MERT; Minimum Error Rate Training)에 대한 예시적 프로세스를 나타낸다.
도5b는 예시적 최소 에러율 훈련기를 도시한다.
도6은 범용 컴퓨터 디바이스와 범용 모바일 컴퓨터 디바이스의 예를 나타낸다.
여러 도면에서 유사한 참조 번호 및 표기는 유사한 요소를 가리킨다.
도2a는 예시적 번역 격자를 도시한다.
도2b는 도2a의 번역 격자에 대한 예시적 MBR 오토메이션을 도시한다.
도3은 예시적 번역 격자의 일부를 도시한다.
도4는 MBR 디코딩을 위한 예시적 프로세스를 나타낸다.
도5a는 격자에서 최소 에러율 훈련(MERT; Minimum Error Rate Training)에 대한 예시적 프로세스를 나타낸다.
도5b는 예시적 최소 에러율 훈련기를 도시한다.
도6은 범용 컴퓨터 디바이스와 범용 모바일 컴퓨터 디바이스의 예를 나타낸다.
여러 도면에서 유사한 참조 번호 및 표기는 유사한 요소를 가리킨다.
통계적 번역 개관(Statistical Translation Overview)
기계 번역은 한 언어로 된 입력 텍스트를 취하고 그 입력을 다른 언어의 텍스트로 정확하게 변환하는 것을 추구한다. 일반적으로, 번역의 정확도는 인간 전문가가 그 입력을 번역하는 방식들(ways)에 대하여 측정된다. 자동 번역 시스템은 한 언어에서 다른 언어로 통계적 번역 모델을 형성하기 위하여, 인간 전문가가 수행한 이전의 번역들을 분석할 수 있다. 하지만 이러한 모델은 완성될 수 없는데, 단어들의 의미는 문맥에 대개 의존하기 때문이다. 따라서 한 언어에서 다른 언어로 단어들을 단어 대 단어로 단계적으로 변환하는 것은 수용할 만한 결과들을 제공하지 못할 수 있다. 예를 들어, "babe in the wood"와 같은 관용구들이나 속어 문구들(slang phrases)은 문자 상의 단어 대 단어 변환으로는 잘 번역되지 않는다.
적절한 언어 모델들이 그러한 문맥을 자동화 번역 프로세스에 제공하는 것에 도움을 줄 수 있다. 예를 들어, 이 모델들은 2개의 단어들이 정상적 용법(예컨대 훈련 데이터)에서 서로 나란히 나타나는 빈도 또는 다수의 단어들 또는 요소들(n-그램들(grams))의 다른 그룹들이 한 언어에서 나타내는 빈도에 관한 표시를 제공할 수 있다. n-그램은 n개의 연속한 토큰들(예컨대, 단어들 또는 글자들)의 시퀀스이다. n-그램은 n-그램 내 토큰들의 수인 차수(order) 또는 크기를 갖는다. 예를 들어, 1-그램(또는 유니그램)은 하나의 토큰을 구비하고, 2-그램(또는 바이-그램)은 2개의 토큰을 구비한다.
주어진 n-그램은 그 n-그램의 여러 부분들에 따라서 기술될 수 있다. n-그램은 컨텍스트와 추가 토큰, (context, w)으로 기술될 수 있으며, 여기서, 컨텍스트는 n-1의 길이를 갖고, w는 추가 토큰을 나타낸다. 예를 들어, 3-그램 "c1c2c3" 는 n-그램 컨텍스트와 추가 토큰의 표현으로 기술될 수 있고, 여기서, c1, c2 및 c3 각각은 문자를 나타낸다. n-그램 좌측 컨텍스트는 그 n-그램의 마지막 토큰에 선행하는 n-그램의 모든 토큰을 포함한다. 위의 예에서, "c1c2"가 컨텍스트이다. 컨텍스트의 최좌측 토큰은 좌측 토큰으로 지칭된다. 추가 토큰은 그 n-그램의 마지막 토큰이고, 상기 예에서 "c3"이다. n-그램은 우측 컨텍스트에 관하여 기술될 수 있다. 우측 컨텍스트는 n-그램의 첫 번째 토큰에 후속하는 그 n-그램의 모든 토큰을 포함하며, (n-1)-그램으로 표현된다. 상기한 예에서, "c2c3"이 우측 컨텍스트이다.
n-그램 각각은 연관된 확률 추정(예컨대, 훈련 데이터에서 총 출현 회수에 대한 그 훈련 데이터에서 출현 회수의 함수로서 계산되는 로그-확률)을 가질 수 있다. 일부 구현예에서, n-그램들이 입력 텍스트의 번역일 확률들이, 그 n-그램들이 훈련 데이터 내의 소스 언어로 된 상응하는 텍스트의 기준 번역(reference translation)으로서 대상 언어에서 제시되는 상대 빈도를 사용하여 훈련되며, 상기 훈련 데이터는 예를 들어, 소스 언어로 된 텍스트와 대상 언어로 된 상응하는 텍스트의 집합을 포함한다.
부가적으로, 일부 구현예에서, 대규모 훈련 데이터(예컨대, 테라바이트의 데이터)에 대하여 분산 훈련 환경이 사용된다. 분산 훈련에 대한 하나의 예시적 기술은 MapReduce이다. MapReduce에 대한 상세 사항은 J. Dean 및 S. Ghemawat가 저술한 "MapReduce : Simplified Data Processing on Large Clusters"(Proceedings of the 6th Symposium on Operating Systems Design and Implementation, pp. 137-150, 2004년 12월 6일)에 설명되어 있다.
훈련 집합이 제시한 과거 용법(past usage)은 한 언어로 된 샘플들이 대상 언어로 어떻게 번역되어야 하는지 예측하는데 사용될 수 있다. 특히, 확률 추정들과 연관된 n-그램들 및 각각의 회수는 디코더(예컨대, 베이시안 디코더)가 입력 텍스트에 대한 번역을 식별하는데 사용할 수 있도록, 언어 모델에 저장될 수 있다. 입력 텍스트가 대상 언어의 상응하는 텍스트로 번역될 가능성을 나타내는 점수(score)는 입력 텍스트에 포함된 n-그램들을 특정 번역을 위한 연관된 확률 추정들에 맵핑(mapping)함으로써 계산될 수 있다.
예시적 번역 프로세스(Example Translation Process)
도1은 입력 텍스트를 소스 언어에서 대상 언어로 번역하는 예시적 프로세스(100)의 개념도이다. 중국어 텍스트의 단락으로서 도시된 소스 샘플(102)이 제1 디코더(104)에 제공된다. 디코더(104)는 다양한 형태를 취할 수 있으며, 디코더(104)에 대한 훈련 시기 동안 디코더(104)에 제공된 문서들의 훈련 집합(106)이 주어지면, 그 문단에 대하여 사후 확률(posterior probability)의 최대화를 시도하는데 사용될 수 있다. 샘플(102)을 번역하는데 있어서, 디코더(104)는 그 문서 내로부터 n-그램들을 선택하고, 그 n-그램들의 번역을 시도할 수 있다. 디코더(104)에는 여러 가능한 모델들 중에서 재정리(re-ordering) 모델, 정렬(alignment) 모델 및 언어 모델이 제공될 수 있다. 모델들은 디코더(104)에 지시하여, 번역을 위하여 샘플(102) 내로부터 n-그램들을 선택하도록 한다. 하나의 예로서, 모델은 경계기호(예컨대 콤마나 마침표와 같은 구두점)를 사용하여, 한 단어를 나타낼 수 있는 n-그램의 끝(End)을 식별할 수 있다.
디코더(104)는 다양한 출력(예컨대, 가능한 번역들을 구비한 데이터 구조들)을 만들 수 있다. 예를 들어, 디코더(104)는 번역들의 N-최적 리스트를 만들 수 있다. 일부 구현예에서, 디코더(104)는 아래에서 자세히 설명되는 번역 격자(108)를 생성할 수 있다.
다음 제2 디코더(110)는 번역 격자(108)를 처리한다. 일반적으로 제1 디코더(104)는 번역의 사후 확률을 최대화하는 것(즉, 입력을, 다른 문단들의 과거 전문가 수동 번역들에 가장 잘 매칭한다고 문서들의 역사적 수집(historical collection; 106)이 가리키는 것에 매칭시킴)을 목적으로 하는 반면, 제2 디코더(110)는 번역에 대한 품질 척도를 최대화하는 것을 목적으로 한다. 이와 같이 하여, 제2 디코더(110)는, 시스템(100)의 사용자에게 디스플레이될 수 있는 "최선"의 번역을 만들기 위하여, 번역 격자 내에 존재하는 후보 번역들을 재정렬(re-rank)할 수 있다. 이 번역은 중국어 샘플(102)의 번역에 상응하는 영어 샘플(112)에 의해 나타내진다.
제2 디코더(110)는 분류에 있어서 예상 에러를 최소화하는 가설(hypothesis)(또는 후부 번역)을 탐색하는 MBR 디코딩으로 알려진 프로세스를 사용할 수 있다. 따라서 이 프로세스는 번역을 선택하는 결정 기준에 손실 함수를 직접 삽입한다.
최소 베이즈 위험 디코딩(Minimum Bayes Risk Decoding)
최소 베이즈 위험(MBR) 디코딩은 확률 모델 하에서 최소 예상 에러를 갖는 가설(예컨대, 후보 번역)을 찾는 것을 목적으로 한다. 통계적 기계 번역은 소스 언어로 된 텍스트 F를 대상 언어로 번역된 텍스트 E로 맵핑하는 것으로 설명될 수 있다. 디코더 δ(F)(예컨대, 디코더(104))는 이 맵핑을 수행할 수 있다. 참조 번역 E가 알려져 있으면, 디코더 성능은 손실 함수 L(E,δ(F))에 의해 측정될 수 있다. 자동 번역(E')와 참조 번역(E) 사이의 손실 함수 L(E,E') 및 기저(underlying) 확률 모델 P(E,F')를 가정하면, MBR 디코더(예컨대, 제2 디코더(110))는 다음과 같이 표시될 수 있다.

여기서, R(E)는 손실 함수 L하에서 후보 번역 E'의 베이즈 위험을 나타내고, Ψ는 번역들의 공간(space of translations)을 나타낸다. N-최적 MBR에 대하여, 공간 Ψ는 예컨대 제1 디코더(104)가 생성한 N-최적 리스트이다. 번역 격자가 사용되면, Ψ는 번역 격자 내로 인코딩된 후보 번역들을 나타낸다.
임의의 2개 가설들 사이의 손실 함수가 구속될 수 있으면(즉, L(E,E') ≤ Lmax), MBR 디코더는 이득 함수(G(E,E') = Lmax - L(E,E'))의 항으로 다음과 같이 쓰일 수 있다.

일부 구현예에서, MBR 디코딩은 가설 선택과 위험 계산에 다른 공간들을 사용한다. 예를 들어, N-최적 리스트로부터 선택될 수 있고, 위험은 번역 격자에 기초하여 계산될 수 있다. 이 예에서, MBR 디코더는 다음과 같이 쓰일 수 있다.

여기서,  는 가설 공간을 나타내고,
는 가설 공간을 나타내고,  는 베이즈 위험을 계산하는데 사용되는 증거 공간을 나타낸다.
는 베이즈 위험을 계산하는데 사용되는 증거 공간을 나타낸다.
더 큰 공간(즉, 가설 및 위험 계산 공간들)을 사용하여 MBR 디코딩을 개선할 수 있다. 격자들은 N-최적 리스트보다 많은 후보 번역들을 포함할 수 있다. 예를 들어, 격자들은 10억개 이상의 후보 번역들을 포함할 수 있다. 이와 같이 하여, 격자들을 사용하여 가설 및 위험 계산 공간들을 나타내는 것은 MBR 디코딩의 정확도를 증가시키고, 따라서 정확한 번역이 제공될 가능성을 증가시킨다.
예시적 번역 격자 및 MBR 디코딩
도2a는 예시적 번역 격자(200)를 도시한다. 특히, 번역 격자(200)는 번역 n-그램 격자이며, n-그램 격자는 번역 가설들 및 그들의 가능성으로 된 매우 큰 N-최적 리스트들에 대한 축약(compact) 표현으로 간주될 수 있다. 특히, 격자는 상태들(예컨대, 상태0 내지 상태6) 및 이 상태들 사이의 천이들을 나타내는 아크(arc)들을 포함하는 비주기 가중 유한 상태 수용체(acyclic weighted finite state acceptor)이다. 아크 각각은 n-그램(예컨대, 단어 또는 구절) 및 가중치와 연관된다. 예를 들어, 번역 격자(200)에서, n-그램들은 라벨들 "a", "b", "c", "d" 및 "e"에 의하여 표현된다. 상태0은 상태1로의 경로를 제공하는 제1 아크, 상태1로부터 상태4로의 경로를 제공하는 제2 아크, 상태4로부터 상태5로의 경로를 제공하는 제3 아크에 연결된다. 제1 아크는 "a" 및 가중치 "0.5"와 연관되고, 제2 아크는 "b" 및 가중치 "0.6"과 연관되고, 제3 아크는 "d" 및 가중치 "0.3"과 또한 연관된다.
초기 상태(예컨대, 상태0)에서 시작하여 최종 상태(예컨대, 상태6)에서 종료하는 연속된 천이들을 포함하는 번역 격자(200) 내의 각 경로는 후보 번역을 표현한다. 한 경로를 따른 가중치들의 합은 모델에 따라서 그 경로의 후보 번역 H(E,F)의 가중치를 만든다. 경로의 후보 번역의 가중치는 소스 문장 F가 주어진 경우 번역 E의 사후 확률을 다음과 같이 나타낸다.

여기서 α ∈(0, ∞)는 스케일링 인자이고, α<1일 때 분포를 평탄화하고, α>1일 때, 분포를 뾰족하게 한다.
일부 구현예에서, 이득 함수G는 국소 이득 함수  의 항으로서 표현된다. 이득 함수가 가중 유한 상태 변환기들(WFSTs; Weighted Finite State Transducers) 성분을 사용하는 격자 내의 모든 경로들에 적용될 수 있어서, 결과적으로 o(N)이 격자 내 상태들의 수(N)를 증가시키면, 이득 함수는 국소 이득 함수로 간주될 수 있다. 국소 이득 함수들은 n-그램들을 가중할 수 있다. 예를 들어, n-그램의 세트
의 항으로서 표현된다. 이득 함수가 가중 유한 상태 변환기들(WFSTs; Weighted Finite State Transducers) 성분을 사용하는 격자 내의 모든 경로들에 적용될 수 있어서, 결과적으로 o(N)이 격자 내 상태들의 수(N)를 증가시키면, 이득 함수는 국소 이득 함수로 간주될 수 있다. 국소 이득 함수들은 n-그램들을 가중할 수 있다. 예를 들어, n-그램의 세트  이 주어지면, 국소 이득 함수
이 주어지면, 국소 이득 함수  , 여기서 w∈N, 는 다음과 같이 표현될 수 있다.
, 여기서 w∈N, 는 다음과 같이 표현될 수 있다.
이 전체 이득 함수를 사용하면, 위험(즉, 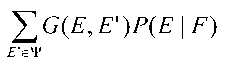 )은 격자(식 1에 있음)에 대한 MBR 디코더가 다음과 같이 표현되도록 바꿔 쓰일 수 있다.
)은 격자(식 1에 있음)에 대한 MBR 디코더가 다음과 같이 표현되도록 바꿔 쓰일 수 있다.

여기서,  는 격자 내 n-그램 w의 사후 확률, 즉
는 격자 내 n-그램 w의 사후 확률, 즉  이고, 다음과 같이 표현될 수 있다.
이고, 다음과 같이 표현될 수 있다.

여기서,  는 n-그램 w를 적어도 한번 포함하는 격자의 경로들을 나타내고,
는 n-그램 w를 적어도 한번 포함하는 격자의 경로들을 나타내고,  와
와  는 각각 격자(
는 각각 격자( 및
및 ) 내 모든 경로들의 가중치 합을 나타낸다.
) 내 모든 경로들의 가중치 합을 나타낸다.
일부 구현예에서, MBR 디코더(식 2)는 WFSTs를 사용하여 구현한다. 격자 내에 포함된 n-그램들의 세트를, 그 격자 내 아크들을 위상 순으로(topological order) 횡단(traverse)하여 추출할 수 있다. 격자 내 각 상태는 n-그램 프리픽스들(prefixes)의 상응하는 세트를 갖는다. 하나의 상태를 떠나는 아크 각각은 그 상태의 프리픽스들 각각을 단일 단어에 의해 확장한다. 그 격자 내에서 아크가 뒤따르는 상태에 출현하는 n-그램들은 이 세트에 포함된다. 초기화 단계로서, 각 상태의 세트에 빈 프리픽스가 초기에 부가될 수 있다.
n-그램 w 각각에 대하여, 그 n-그램을 포함하는 오토메이션(예컨대, 다른 격자) 매칭 경로들이 생성되고, 이 오토메이션은 n-그램(즉,  )을 포함하는 경로들의 세트를 찾기 위하여 그 격자와 교차된다. 예를 들어,
)을 포함하는 경로들의 세트를 찾기 위하여 그 격자와 교차된다. 예를 들어,  가 가중된 격자를 나타내면,
가 가중된 격자를 나타내면,  는 다음과 같이 표현될 수 있다.
는 다음과 같이 표현될 수 있다.
n-그램 w의 사후 확률  는 상기 식3에서 주어진 바와 같이,
는 상기 식3에서 주어진 바와 같이,  내 경로들의 총 가중치들 대 원 격자
내 경로들의 총 가중치들 대 원 격자  내 모든 경로들의 총 가중치들의 비로서 계산될 수 있다.
내 모든 경로들의 총 가중치들의 비로서 계산될 수 있다.
각 n-그램 w에 대한 사후 확률은 상기한 바와 같이 계산되고, 그 후에 식2와 관련하여 설명한 바와 같이,  (n-그램 인자)로 곱해질 수 있다. 입력에 n-그램이 발생한 회수와
(n-그램 인자)로 곱해질 수 있다. 입력에 n-그램이 발생한 회수와  의 곱과 동일한 가중치를 갖는 상기 입력 받아들이는 오토메이션이 생성된다. 이 오토메이션은 가중된 정규 식을 사용하여 표현될 수 있다.
의 곱과 동일한 가중치를 갖는 상기 입력 받아들이는 오토메이션이 생성된다. 이 오토메이션은 가중된 정규 식을 사용하여 표현될 수 있다.
여기서,  는 n-그램 w를 포함하지 않는 모든 문자열들(strings)을 포함하는 언어이다.
는 n-그램 w를 포함하지 않는 모든 문자열들(strings)을 포함하는 언어이다.
생성된 오토메이션 각각은 격자의 비 가중된 사본(copy)으로서 발생하는 제2 오토메이션들과 연속적으로 교차한다. 이들 2차 오토메이션 각각은  를 받아들이는 오토메이션과 비가중된 격자를 교차시킴으로써 생성된다. 결과로 얻어지는 오토메이션은 각 경로의 총 예상 이득을 나타낸다.
를 받아들이는 오토메이션과 비가중된 격자를 교차시킴으로써 생성된다. 결과로 얻어지는 오토메이션은 각 경로의 총 예상 이득을 나타낸다.
워드 시퀀스 E'를 나타내는 결과로 얻어진 오토메이션에 있는 경로는 비용을 갖는다:
예컨대 식2에 따른 최소 비용과 연관된 경로는 상기 결과로 얻어진 오토메이션에서 추출되어, 격자 MBR 후보 번역을 생성한다.
가설 및 증거 공간 격자들이 서로 다른 구현예에 있어서, 증거 공간 격자는 n-그램들을 추출하고 연관된 사후 확률들을 계산하는데 사용된다. MBR 오토메이션은 가설 공간 격자의 비가중된 사본으로 시작하여 구축된다. n-그램 오토마타(automata) 각각은 가설 공간 격자의 비가중된 사본과 연속적으로 교차된다.
BLEU 점수에 대한 근사화는 국소 이득 함수들의 합인 전체 이득 함수 G(E,E')의 분해를 계산하는데 이용될 수 있다. BLEU 점수는 기계 번역된 텍스트의 번역 품질을 나타내는 지시자이다. Bleu에 대한 추가적인 상세 사항은 K. Papinene, S. Roukes, T. Ward, 및 W. Zhu가 저술하고, 2001 공개되며, IBM 연구소, 기술 보고서 RC22176(W0109-022)인 Bleu: a Method for Automatic Evaluation of Machine Translation에 설명되어 있다. 특히, 이 시스템은 코퍼스(corpus)에 문장을 포함하는 것으로부터 그 문장을 포함하지 않는 것까지, 코퍼스 BLEU 점수의 변화에 대한 1차 테일러 급수 근사를 계산한다.
코퍼스의 참조 길이 r(예컨대, 참조 문장의 길이 또는 다수 참조 문장들의 길이 합), 후보 길이 및 n-그램 매칭 회수
및 n-그램 매칭 회수  를 가정하면, 코퍼스 BLEU 점수
를 가정하면, 코퍼스 BLEU 점수  는 다음과 같이 근사될 수 있다.
는 다음과 같이 근사될 수 있다.

여기서,  은 후보에 있는 단어들의 수와 n-그램들의 수 사이의 차이이고,
은 후보에 있는 단어들의 수와 n-그램들의 수 사이의 차이이고,  은 무시할 수 있다고 가정한다.
은 무시할 수 있다고 가정한다.
코퍼스 log(BLEU) 이득은 새로운 문장의 (E') 통계가 코퍼스 통계에 포함될 때 log(BLEU)의 변화로서 정의되고, 다음과 같이 표현된다.
여기서 B'의 카운트들(counts)은 현재 문장에 대한 카운트들에 가산된 B의 카운트들이다. 일부 구현예에서,  이라는 가정이 사용되고,
이라는 가정이 사용되고,  만이 변수로서 취급된다. 따라서 코퍼스 log(BLEU) 이득은
만이 변수로서 취급된다. 따라서 코퍼스 log(BLEU) 이득은 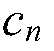 의 초기 값들에 관한 1차 벡터 테일러 급수 확장에 의해 다음과 같이 근사화될 수 있다.
의 초기 값들에 관한 1차 벡터 테일러 급수 확장에 의해 다음과 같이 근사화될 수 있다.

여기서, 편미분들은 다음과 같이 표현된다.


따라서 코퍼스 log(BLEU) 이득은 다음과 같이 고쳐 쓸 수 있다.

여기서 △항들은 코퍼스 전체로서가 아니라 관심 문장 내의 여러 통계들을 반영한다. 이들 근사는 예컨대, 식2의  및
및  의 값들이 다음과 같이 표현될 수 있음을 제안한다.
의 값들이 다음과 같이 표현될 수 있음을 제안한다.


n-그램 각각의 정확성은 상수 비(constant ratio) r 및 상응하는 (n-1)-그램 정확성의 곱이라고 가정하면, BLEU 점수는 문장 레벨에서 누적될 수 있다. 예를 들어, 코퍼스의 평균 문장 길이가 25 단어들이라고 가정하면,

유니그램 정확성이 p이면,
n-그램 인자들( )은 파라미터들 p와 r, 및 유니그램 토큰들의 개수 T의 함수로서, 다음과 같이 표현될 수 있다.
)은 파라미터들 p와 r, 및 유니그램 토큰들의 개수 T의 함수로서, 다음과 같이 표현될 수 있다.


일부 구현예에서, p는 유니그램 정확성의 평균값으로 설정되고, r은 다수의 훈련 세트들에 걸친 정확성 비의 평균값으로 설정된다. n-그램 인자들을 식2에서 대체하면, MBR 디코더(예컨대, MBR 결정 규칙)는 T에 의존하지 않으며, 다수의 T 값들이 사용될 수 있다.
도2b는 도2a의 번역 격자에 대한 예시적 MBR 오토메이션을 예시한다. 도2a의 번역 격자(200) 내에 있는 굵은 경로는 최대 사후(Maximum A Posteriori; MAP) 가설이고, 도2b의 MBR 오토메이션 내에 있는 굵은 경로는 MBR 가설이다. 도2a와 2b에 의해 예시된 예에서, T =10, p=0,85, 및 r=0.75이다. MBR 가설(bcde)의 디코더 비용은 MAP 가설(abde)의 디코더 비용에 비하여 높다. 하지만 bcde는 abde 보다 높은 예상 이득을 받는데, 이것은 bcde가 제3 랭크된 가설(bcda)과 더 많은 n-그램들을 공유하기 때문이며, 격자가 MAP 번역과 다른 MBR 번역들을 선택하는 것을 어떻게 돕는지 예시한다.
최소 에러 레이트 훈련(Minimum Error Rate Training; MERT) 개관
최소 에러 레이트 훈련(MERT)은 분류를 위한 판정 규칙(decision rule)의 에러 계량(error metric)을 측정한다. 예컨대, 판정 규칙은 0-1 손실 함수를 사용하는 MBR 판정 규칙이다. 특히, MERT는 0-1 손실 함수 하의 판정이 훈련 코퍼스에 대한 엔드-엔드 성능(end-to-end performance) 측정을 최대화시키도록 모델 파라미터들을 추정한다. 로그-선현(log-linear) 모델들과 조합하여, 훈련 절차는 비평탄화된 에러 카운트를 최적화한다. 앞서 기술한 바와 같이, 사후 확률을 최대화하는 번역은  에 기초하여 선택될 수 있다.
에 기초하여 선택될 수 있다.
진정한 사후 분포는 알려져 있지 않으므로,  는 예컨대, 하나 이상의 특징 함수들
는 예컨대, 하나 이상의 특징 함수들 을 특징 함수 가중치들
을 특징 함수 가중치들 (여기서, m은 1,..., M)과 조합하는 로그-선형 번역 모델로 근사화된다. 로그-선형 번역 모델은 다음과 같이 표현될 수 있다.
(여기서, m은 1,..., M)과 조합하는 로그-선형 번역 모델로 근사화된다. 로그-선형 번역 모델은 다음과 같이 표현될 수 있다.

특징 함수 가중치들은 이 모델의 파라미터들이고, MERT 판단기준은 훈련 문장들의 대표적인 세트에 대한 에러 카운트를 최소화하는 파라미터 세트  를 예컨대,
를 예컨대,  인 판정 규칙을 사용하여 발견한다. 훈련 코퍼스의 소스 문장들
인 판정 규칙을 사용하여 발견한다. 훈련 코퍼스의 소스 문장들  , 참조 번역들
, 참조 번역들  및 K 후보 번역들의 세트
및 K 후보 번역들의 세트  를 가정하면, 번역들
를 가정하면, 번역들  에 대한 코퍼스-기반 에러 카운트는 개별 문장들의 에러 카운트들로 가산적으로 분해가능하다(additively decomposable). 즉,
에 대한 코퍼스-기반 에러 카운트는 개별 문장들의 에러 카운트들로 가산적으로 분해가능하다(additively decomposable). 즉, 이다. MERT 판단기준은 다음과 같이 표현될 수 있다.
이다. MERT 판단기준은 다음과 같이 표현될 수 있다.
여기서,  이다.
이다.
선형 최적화 기술이 사용되어 MERT 판별 기준 하의 선형 모델을 훈련시킬 수 있다. 선형 최적화는 각 특징 함수  와 문장
와 문장  에 대하여, 후보 번역들의 집합
에 대하여, 후보 번역들의 집합 상에서 정확한 에러 표면(error surface)을 결정한다. 다음에, 특징 함수 가중치들은, 상기 훈련 코퍼스에서 문장들의 조합된 에러 표면들을 횡단(traversing)하고 또한 결과 에러가 최소인 지점에 가중치들을 설정함으로써 조정된다.
상에서 정확한 에러 표면(error surface)을 결정한다. 다음에, 특징 함수 가중치들은, 상기 훈련 코퍼스에서 문장들의 조합된 에러 표면들을 횡단(traversing)하고 또한 결과 에러가 최소인 지점에 가중치들을 설정함으로써 조정된다.
라인  를 따른
를 따른  에서 가장 가능성 높은 문장 가설은 다음과 같이 정의될 수 있다.
에서 가장 가능성 높은 문장 가설은 다음과 같이 정의될 수 있다.

임의의 후보 번역에 대한 총 점수는 독립 변수로서 와 동일 평면에 있는 라인에 상응한다. 종합적으로,
와 동일 평면에 있는 라인에 상응한다. 종합적으로,  는 K 라인들을 정의하고, K 라인 각각은 다른 K-1 라인들과의 교차 가능성에 의해 최대 K 라인 세그먼트들로 분할될 수 있다.
는 K 라인들을 정의하고, K 라인 각각은 다른 K-1 라인들과의 교차 가능성에 의해 최대 K 라인 세그먼트들로 분할될 수 있다.
격자 상의 MERT
소스 문자 f에 대한 격자(예컨대, 구절 격자)는 정점들(vertices)의 집합 , 고유 소스 및 싱크 노드들(unique source and sink nodes)
, 고유 소스 및 싱크 노드들(unique source and sink nodes)  , 아크들의 집합
, 아크들의 집합 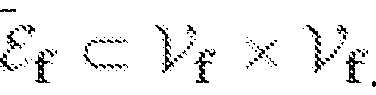 에 의해, 연결되고 지향된 비주기 그래프
에 의해, 연결되고 지향된 비주기 그래프  로서 정의될 수 있다. 아크 각각은 구절
로서 정의될 수 있다. 아크 각각은 구절  및 이 구절의 (국소) 특징 함수 값들
및 이 구절의 (국소) 특징 함수 값들  로 라벨링된다. Gf 내의 경로
로 라벨링된다. Gf 내의 경로  (여기서,
(여기서,  이고,
이고,  의 꼬리(tail)와 머리(head)로서
의 꼬리(tail)와 머리(head)로서  ) 는 (f의) 부분 번역 e를 정의하며, 이 부분 번역은 이 경로를 따른 모든 구절들의 연결이다. 관련된 특징 함수 값들은 아크-특정(arc-specific) 특징 함수 값들을 합산하여 얻어진다.
) 는 (f의) 부분 번역 e를 정의하며, 이 부분 번역은 이 경로를 따른 모든 구절들의 연결이다. 관련된 특징 함수 값들은 아크-특정(arc-specific) 특징 함수 값들을 합산하여 얻어진다.

후속하는 설명에서, 입장(v)과 퇴장(v)의 표기는 각각 노드  에 대하여, 인입(incoming)하는 아크들의 집합 및 인출(outgoing)하는 아크들의 집합을 가리킨다. 유사하게, head(ε)와 tail(ε)는 아크 ε의 머리와 꼬리를 각각 나타낸다.
에 대하여, 인입(incoming)하는 아크들의 집합 및 인출(outgoing)하는 아크들의 집합을 가리킨다. 유사하게, head(ε)와 tail(ε)는 아크 ε의 머리와 꼬리를 각각 나타낸다.
도3은 예시적 번역 격자(300)의 일부를 나타낸다. 도3에서, 인입 아크들(302, 304, 및 306)은 노드 v(310)에 입장한다. 또한, 인출 아크들(312 및 314)은 노드 v(310)를 떠난다.
소스 노드 s에서 시작하고 v에서 끝나는 각 경로는 라인으로 표현될 수 있는 부분 번역 가설을 정의한다(식 4 참조). 이들 부분 번역 가설들에 대한 상위 엔벨로프가 알려져 있고, 이 엔벨로프를 정의하는 라인들이  으로 표기된다고 가정한다. 집합 퇴장(v)의 요소들인 인출 아크들 ε(예컨대, 아크(312))은 이들 부분 후보 번역들의 계속(continuations)을 나타낸다. 인출 아크 각각은 g(ε)로 표기된 다른 라인을 정의한다. g(ε)의 파라미터들을
으로 표기된다고 가정한다. 집합 퇴장(v)의 요소들인 인출 아크들 ε(예컨대, 아크(312))은 이들 부분 후보 번역들의 계속(continuations)을 나타낸다. 인출 아크 각각은 g(ε)로 표기된 다른 라인을 정의한다. g(ε)의 파라미터들을  집합 내의 모든 라인들에 부가하면,
집합 내의 모든 라인들에 부가하면,  로 정의되는 상위 엔벨로프가 만들어진다.
로 정의되는 상위 엔벨로프가 만들어진다.
g(ε)의 부가는 라인 세그먼트들의 개수나 엔벨로프에서 그들의 상대적 순위를 변화시키지 않으므로, 볼록한 꼭지의 구조는 보존된다. 따라서 결과적으로 얻은 상위 엔벨로프는 인출 아크 ε를 통해 후계 노드 에 전파될 수 있다.
에 전파될 수 있다.  에 대한 그 밖의 인입 아크들은 다른 상위 엔벨로프들과 연관될 수 있다. 상위 엔벨로프들은 단일의 조합된 엔벨로프로 병합되고, 이 단일의 조합된 엔벨로프는 개별 엔벨로프들을 구성하는 라인 집합들 상 유니온(union)의 볼록한 꼭지이다. 인입 아크
에 대한 그 밖의 인입 아크들은 다른 상위 엔벨로프들과 연관될 수 있다. 상위 엔벨로프들은 단일의 조합된 엔벨로프로 병합되고, 이 단일의 조합된 엔벨로프는 개별 엔벨로프들을 구성하는 라인 집합들 상 유니온(union)의 볼록한 꼭지이다. 인입 아크  각각에 대한 상위 엔벨로프들을 조합함으로써, 소스 노드 s에서 시작하고
각각에 대한 상위 엔벨로프들을 조합함으로써, 소스 노드 s에서 시작하고  에서 끝나는 경로들과 연관된 모든 부분 후보 번역들에 대한 상위 엔벨로프가 생성된다.
에서 끝나는 경로들과 연관된 모든 부분 후보 번역들에 대한 상위 엔벨로프가 생성된다.
다른 구현들도 가능하다. 특히, (격자에 대한) MERT의 성능을 개선하기 위하여 추가적 한정이 수행될 수 있다. 예를 들어, 선형 최적화 기술이 양호하지 않은 국소 최적에서 멈추는 것을 방지하기 위하여, MERT는 파라미터 공간을 샘플링하여 랜덤하게 선택된 추가적 시작점들을 개척할 수 있다. 또 다른 예로서, 일부 또는 모든 특징 함수 가중치들의 범위가 가중치 한정(restriction)을 정의함으로써 제한될 수 있다. 특히, 특징 함수 에 대한 가중치 한정은
에 대한 가중치 한정은  구간(interval)으로서 특정될 수 있고, 이 구간은 특징 함수 가중치
구간(interval)으로서 특정될 수 있고, 이 구간은 특징 함수 가중치  이 선택될 수 있는 허용 가능한 영역을 정의한다. 라인 최적화가 가중치 한정하에서 수행되면,
이 선택될 수 있는 허용 가능한 영역을 정의한다. 라인 최적화가 가중치 한정하에서 수행되면,  는 다음과 같이 선택된다.
는 다음과 같이 선택된다.
일부 구현에서, 가중치 프라이어들(priors)이 사용될 수 있다. 가중치 프라이어들은 새로운 가중치가 소정의 대상값 와 매칭하도록 선택되면, 목적 함수에 작은(양 또는 음) 상승 w를 제공한다.
와 매칭하도록 선택되면, 목적 함수에 작은(양 또는 음) 상승 w를 제공한다.

0 가중치 프라이어  은 특징 선택을 허용하는데, 구별이 되지 않는, 특징 함수들의 가중치들이 0으로 설정되기 때문이다. 예를 들어, 초기 가중치 프라이어
은 특징 선택을 허용하는데, 구별이 되지 않는, 특징 함수들의 가중치들이 0으로 설정되기 때문이다. 예를 들어, 초기 가중치 프라이어  는 갱신된 파라미터들의 세트가 초기 가중치 세트에 비하여 작은 차이들을 갖도록, 파라미터들의 변화를 제한하는데 사용될 수 있다.
는 갱신된 파라미터들의 세트가 초기 가중치 세트에 비하여 작은 차이들을 갖도록, 파라미터들의 변화를 제한하는데 사용될 수 있다.
일부 구현예에서, 에러 카운트의 변화  가 0과 동일한 번역 가설의 구간
가 0과 동일한 번역 가설의 구간  은 좌측-인접 번역 가설의 구간
은 좌측-인접 번역 가설의 구간  과 병합된다. 결과적인 구간
과 병합된다. 결과적인 구간 은 보다 큰 영역을 갖고,
은 보다 큰 영역을 갖고,  의 최적값 선택의 신뢰성은 향상될 수 있다.
의 최적값 선택의 신뢰성은 향상될 수 있다.
일부 구현예에서, 시스템은 다수의 특징 함수들을 동시에 갱신하기 위하여 랜덤한 방향을 사용한다. 라인 최적화에 사용되는 방향들이 M 차원 파라미터 공간의 좌표축들이면, 각 반복에 의해 단일 특징 함수의 갱신이 달성된다. 이 갱신 기술이 특징 함수들의 랭킹(ranking)을 그들의 분별력(discriminative power)에 따라서 제공하지만(예컨대, 각 반복은 상응하는 가중치의 변경이 최고 이득을 산출하는 특징 함수를 선택함), 이 갱신 기술은 특징 함수들 사이의 가능한 상관을 설명하지 않는다. 결과적으로, 최적화는 양호하지 않은 국소 최적에서 멈출 수 있다. 랜덤한 방향의 사용에 의하여 다수의 특징 함수들이 동시에 최적화될 수 있다. 랜덤한 방향들의 사용은, M차원 초구체(hyper sphere) 표면 상에 있는 하나 이상의 랜덤한 점들을 그 초구체의 중심(초기 파라미터 세트에 의해 정의됨)과 연결하는 라인들을 선택함으로써 구현될 수 있다.
도4는 MBR 디코딩을 위한 예시적 프로세스(400)를 나타낸다. 편의를 위하여, MBR 디코딩은 그 디코딩을 수행하는 시스템과 관련하여 설명된다. 시스템은 가설 공간에 접근한다(410). 가설 공간은 예컨대, 소스 언어로 된 상응하는 입력 텍스트의 대상 언어로 된 복수의 후보 번역들을 나타낸다. 예를 들어, 디코더(예컨대, 도1의 제2 디코더(110))는 번역 격자(예컨대, 번역 격자(108))를 액세스할 수 있다. 시스템은 증거 공간과 관련하여 계산된 분류에서의 예상 에러를 최소화하는 번역 가설을 얻기 위하여, 가설 공간에 대하여 디코딩을 수행한다(420). 예를 들어, 디코더가 디코딩을 수행한다. 시스템은 획득된 번역 가설을 제공하고, 사용자는 이 가설을 제안된 번역으로서 대상 번역 내에서 사용한다. 예를 들어, 디코더는 사용자가 사용하도록 번역 텍스트(예컨대, 영어 샘플(112))를 제공할 수 있다.
도5a는 격자 상의 MERT에 대한 예시적 프로세스(500)를 나타낸다. 편의를 위하여, MERT의 수행은 훈련을 수행하는 시스템과 관련하여 설명된다. 시스템은, 번역 격자 내 복수의 특징 함수들에 대하여, 그 번역 격자에 나타낸 하나 이상의 후보 번역들 각각에 대한 상응하는 복수의 에러 표면들을 결정한다(510). 도5b의 최소 에러 레이트 훈련기(550) 내에 있는 예컨대 에러 표면 생성 모듈(560)은 상응하는 복수의 에러 표면들을 결정할 수 있다. 시스템은 훈련 세트 내 구절들에 대한 복수의 에러 표면들의 조합을 횡단함으로써, 특징 함수들에 대한 가중치를 조정한다(520). 예를 들어, 최소 에러 레이트 훈련기(550)의 갱신 모듈(570)은 가중치들을 조정할 수 있다. 시스템은 횡단된 조합에 대한 에러 카운트들을 최소화하는 가중치들을 선택한다(530). 예를 들어, 최소 에러 레이트 훈련기(550)의 에러 최소화 모듈(580)은 가중치들을 선택할 수 있다. 시스템은 선택된 가중치를 적용하여 샘플 텍스트를 제1 언어에서 제2 언어로 변환한다(540). 예를 들어, 최소 에러 레이트 훈련기(550)는 이 선택된 가중치들을 디코더에 적용할 수 있다.
도 6은 상기한 기술들(예컨대, 프로세스들(400 및 500))과 함께 사용될 수 있는 일반적인 컴퓨터 디바이스(600)와 일반적인 휴대 컴퓨터 디바이스(650)의 예를 도시한다. 컴퓨터 디바이스(600)는 랩탑, 데스크탑, 워크스테이션, 개인용 휴대 단말기(PDA), 서버, 블레이드 서버(blade servers), 메인프레임(mainframe) 또는 그 밖의 적절한 컴퓨터들과 같이 다양한 형태의 디지털 컴퓨터들을 대표한다. 컴퓨터 디바이스(650)는 개인용 휴대 단말기(PDA), 셀룰러 전화, 스마트폰, 및 그 밖의 유사한 컴퓨팅 디바이스들과 같은 다양한 형태의 모바일 디바이스를 대표한다. 여기에 도시된 구성요소들, 구성요소들의 연결과 관계, 및 구성요소들의 기능들은 단지 예시적인 것이고, 본 명세서에서 설명 및/또는 청구된 시스템들과 기술들의 구현을 제한하는 것은 아니다.
컴퓨팅 디바이스(600)는 프로세서(602), 메모리(604), 저장 디바이스(606), 메모리(604)와 고속 확장 포트(610)들에 연결된 고속 인터페이스(608), 및 저속 버스(614)와 저장 디바이스(606)에 연결된 저속 인터페이스(612)를 포함한다. 구성요소들(602, 604, 606, 608, 610 및 612) 각각은 다양한 버스들을 이용하여 서로 연결되어 있고, 공통 마더보드(motherboard)에 탑재되거나 그 밖의 적절한 방식으로 탑재될 수 있다. 프로세서(602)는 메모리(604)나 저장 디바이스(606)에 저장된 명령들을 포함하는 명령들을 컴퓨터 디바이스(606) 내에서 실행하기 위하여 처리하여, 고속 인터페이스(608)와 결합한 디스플레이(616)와 같은 외부 입/출력 디바이스에서 GUI용 그래픽 정보를 표시할 수 있다. 다른 구현에 있어서, 다중 프로세서 및/또는 다중 버스들은 적절하게, 다중 메모리 및 메모리 유형들과 함께 사용될 수 있다. 또한, 다중 컴퓨터 디바이스(600)가 예컨대, 서버 뱅크, 블레이드 서버들의 그룹, 또는 멀티프로세서 시스템으로서 서로 접속되고, 각 컴퓨터 디바이스가 필요한 동작들의 일부를 제공한다.
메모리(604)는 컴퓨팅 디바이스(600) 내에 정보를 저장한다. 일 구현에 있어, 메모리(604)는 휘발성 메모리 유닛 또는 유닛들이다. 다른 구현에 있어, 메모리(604)는 비휘발성 메모리 유닛 또는 유닛들이다. 또한 메모리 유닛(604)은 자기 또는 광디스크와 같은 다른 형태의 컴퓨터-판독가능 매체일 수 있다.
저장 디바이스(606)는 컴퓨터 디바이스(600)에 대량 저장소를 제공할 수 있다. 일 구현에 있어, 저장 디바이스(606)는 플로피 디스크 디바이스, 하드 디스크 디바이스, 광학 디스크 디바이스 또는 테이프 디바이스, 플래시 메모리 또는 유사한 고체 상태 메모리 디바이스, 또는 저장 영역 네트워크 또는 그 밖의 구성에 있는 디바이스들을 포함하는 디바이스들의 배열과 같은 컴퓨터판독 가능한 매체이거나 이러한 매체를 포함할 수 있다. 컴퓨터 프로그램 제품은 정보 운반체(carrier)에 유형적으로 구현될 수 있다. 컴퓨터 프로그램 제품은 명령들을 포함하고, 명령들은 실행되면 상술한 하나 이상의 방법들을 실행한다. 정보 운반체는 메모리(604), 저장 디바이스(606), 프로세서(602)에 있는 메모리와 같은 컴퓨터 또는 기계판독가능한 매체이다.
저속 컨트롤러(612)가 낮은 대역폭 집중 동작들을 관리하는 반면, 고속 컨트롤러(608)는 컴퓨터 디바이스(600)를 위한 대역폭 집중 동작들을 관리한다. 그러한 기능의 할당은 단지 예시적인 것이다. 일 구현에 있어, 고속 컨트롤러(608)는 메모리(604), (예를 들어 그래픽 프로세서 또는 가속기를 통한) 디스플레이(616), 및 다양한 확장 카드들(도시하지 않음)을 수납할 수 있는 고속 확장 포트(610)들에 연결되어 있다. 이 구현에 있어, 저속 컨트롤러(612)는 저장 디바이스(606)와 저속 확장 포트(614)에 결합되어 있다. 다양한 통신 포트들(예컨대, USB, 블루투스, 이더넷, 무선 이더넷)을 포함하는 저속 확장 포트는 키보드, 포인팅 디바이스, 스캐너와 같은 하나 이상의 입/출력 디바이스 또는 스위치나 라우터와 같은 네트워킹 디바이스에 예를 들어 네트워크 어댑터를 통해 결합되어 있다.
컴퓨터 디바이스(600)는 도면에 도시한 바와 같이 여러 다른 형태로 구현된다. 예를 들어, 컴퓨터 디바이스(600)는 표준 서버(620)로서 또는 그러한 서버들의 그룹으로서 구현될 수 있다. 컴퓨터 디바이스(600)는 또한 랙 서버 시스템(rack server system)(624)의 일부로서 구현될 수 있다. 게다가, 랩탑 컴퓨터(622)와 같은 개인용 컴퓨터에서 구현될 수도 있다. 대안적으로 컴퓨터 디바이스(600)에 있는 구성요소들은 디바이스(650)와 같은 모바일 디바이스(도시하지 않음)에 있는 다른 구성요소들과 결합될 수 있다. 그러한 디바이스들 각각은 하나 이상의 컴퓨터 디바이스(600, 650)를 포함하고, 전체 시스템은 서로 통신하는 다중 컴퓨터 디바이스(600, 650)로 구성될 수 있다.
컴퓨터 디바이스(650)는 다른 구성요소들 중에서도 프로세서(652), 메모리(664), 디스플레이(654)와 같은 입/출력 디바이스, 통신 인터페이스(666) 및 송수신기(668)를 포함한다. 또한 디바이스(650)에는 추가적인 저장 공간을 제공하기 위하여, 마이크로 드라이브나 다른 디바이스와 같이 저장 디바이스가 제공될 수 있다. 구성요소들(650, 652, 654, 666 및 668) 각각은 다양한 버스들을 이용하여 서로 연결되고, 여러 구성요소들은 공통 마더보드 상에 탑재되거나 적절히 다른 방식으로 탑재될 수 있다.
프로세서(652)는 메모리(664) 안에 저장된 명령들을 포함하는 명령들을 컴퓨터 디바이스(650) 내에서 실행할 수 있다. 프로세서는 개별적이고 다수인 아날로그 및 디지털 프로세서들을 포함하는 칩들의 칩셋으로서 구현될 수 있다. 예를 들어, 프로세서는 사용자 인터페이스의 컨트롤, 디바이스(650)에 의해 구동되는 애플리케이션, 및 디바이스(650)에 의한 무선 통신과 같은, 디바이스(650)의 다른 구성요소들의 조정을 제공할 수 있다.
프로세서(652)는 디스플레이(654)에 결합된 컨트롤 인터페이스(658)와 디스플레이 인터페이스(656)를 통해 사용자와 통신한다. 디스플레이(654)는 예를 들어 TFT LCD 디스플레이, OLED(Organic Light Emitting Diode) 디스플레이 또는 다른 적절한 기술의 디스플레이이다. 디스플레이 인터페이스(656)는 사용자에게 그래픽 및 다른 정보를 제시하기 위하여 디스플레이(654)를 구동하는 적절한 회로를 포함할 수 있다. 컨트롤 인터페이스(658)는 사용자로부터 지령을 받고, 프로세서(652)로 제출하기 위해 그것들을 변환한다. 또한 외부 인터페이스(662)는 디바이스(650)가 다른 디바이스들과 근거리 통신할 수 있도록, 프로세서(652)와 통신 가능하게 제공될 수 있다. 외부 인터페이스(662)는, 예를 들어, 일부 구현에서 유선 통신을 제공하고, 다른 구현에서는 무선 통신을 위해 제공하며, 다수의 인터페이스들이 또한 사용될 수 있다.
메모리(664)는 컴퓨터 디바이스(650) 내에 정보를 저장한다. 메모리(664)는 하나 이상의 컴퓨터 판독 가능 매체 또는 미디어, 휘발성 메모리 유닛 또는 유닛들, 또는 비휘발성 메모리 유닛 또는 유닛들로서 구현될 수 있다. 또한 확장 메모리(674)는 예를 들어 SIMM(Single In Line Memory Module) 카드 인터페이스를 포함하는 확장 인터페이스(672)를 통해 디바이스(650)에 제공되고 연결될 수 있다. 그러한 확장 메모리(674)는 디바이스(650)에 추가적인 저장 공간을 제공하거나 디바이스(650)용 애플리케이션이나 다른 정보를 저장한다. 구체적으로, 확장 메모리(674)는 상술한 프로세스들을 수행하거나 보완하기 위한 명령들을 포함하고, 또한 보안 정보를 포함할 수 있다. 그러므로 예를 들어, 확장 메모리(674)는 디바이스(650)를 위한 보안 모듈로서 제공되고, 또한 디바이스(650)의 보안된 사용을 허용하는 명령들로 프로그램될 수 있다. 또한 보안 애플리케이션들은 SIMM 카드를 통해 제공될 수 있는데, 해킹 방지 방식으로 SIMM 카드 상에 식별 정보를 배치하는 것과 같은 추가 정보와 함께 제공될 수 있다.
메모리는 예를 들어 아래에 설명되는 플래시 메모리 및/또는 MRAM 메모리를 포함할 수 있다. 일 구현에 있어, 컴퓨터 프로그램 제품은 정보 운반체(carrier) 에 유형적으로 구현된다. 컴퓨터 프로그램 제품은 실행되면, 상술한 바와 같은 하나 이상의 방법들을 수행하는 명령들을 포함한다. 정보 운반체는 메모리(664), 확장 메모리(674), 프로세서(652) 상의 메모리, 또는 송수신기(668) 또는 외부 인터페이스(662)를 통해 수신될 수 있는 전파 신호와 같은, 컴퓨터-판독가능 매체 또는 기계-판독가능 매체이다.
디바이스(650)는 필요한 디지털 신호처리 회로를 포함하는 통신 인터페이스(666)를 통해 무선으로 통신한다. 통신 인터페이스(666)는 여러 모드나 프로토콜 중에서도 GSM 음성 통화, SMS, EMS, 또는 MMS메시지, CDMA, TDMA, PDC, WCDMA, CDMA2000 또는 GPRS와 같은 다양한 모드나 프로토콜 하에서 통신을 제공한다. 이러한 통신은 예컨대 라디오주파수 송수신기(668)를 통해 일어날 수 있다. 또한, 단거리 통신은 블루투스, 와이파이(WiFi) 또는 그 밖의 송수신기(도시하지 않음)를 이용하여 일어날 수 있다. 더욱이, GPS 수신기 모듈(670)은 디바이스(650)에 추가적인 내비게이션- 및 위치-관련 무선 데이터를 제공할 수 있고, 디바이스(650)상에서 실행되고 있는 애플리케이션은 이 무선 데이터를 적절히 사용할 수 있다. 디바이스(650)는 또한 사용자로부터 발화(spoken) 정보를 받고 그것을 사용가능한 디지털 정보로 변환하는 오디오 코덱(660)을 이용하여 청취 가능하게 통신할 수 있다. 오디오 코덱(660)은 예를 들어 디바이스(650)의 수화기에 있는 스피커를 통하여 사용자를 위한 가청음을 생성할 수 있다. 그러한 가청음은 음성 전화 통화로부터의 소리를 포함할 수 있고, 녹음된 소리(예컨대 음성 메시지, 음악 파일 등)를 포함할 수 있으며, 또한 디바이스(650)에서 작동하는 애플리케이션이 생성한 소리를 포함할 수 있다.
컴퓨터 디바이스(650)는 도면에 도시된 바와 같이 다수의 다른 형태로 구현될 수 있다. 예를 들어, 컴퓨터 디바이스(650)는 셀룰러 전화기(680)로서 구현될 수 있다. 또한, 스마트폰(682), 개인용 휴대용 단말기(PDA) 또는 그 밖의 유사한 모바일 디바이스의 일부로서 구현될 수 있다.
본 명세서에 설명된 시스템과 기술들의 다양한 구현들은 디지털 전자 회로, 집적 회로, 특별히 설계된 ASICs(application specific integrated circuits), 컴퓨터 하드웨어, 펌웨어, 소프트웨어 및/또는 이들의 조합으로 실현될 수 있다. 이러한 다양한 구현들은 적어도 하나의 프로그래머블 프로세서를 포함하는 프로그래머블 시스템 상에서 실행되고 및/또는 번역될 수 있는 하나 이상의 컴퓨터 프로그램들에서의 구현을 포함할 수 있고, 상기 시스템의 프로세서는 전용 또는 범용의 프로세서이고, 저장 시스템, 적어도 하나의 입력 디바이스, 및 적어도 하나의 출력 디바이스에 결합되어 이들과 데이터 및 명령들을 송수신한다.
이러한 컴퓨터 프로그램들(또한, 프로그램, 소프트웨어, 소프트웨어 애플리케이션들 또는 코드로 알려짐)은 프로그래머블 프로세서를 위한 기계 명령들을 포함하고, 상위-레벨 절차적 및/또는 객체지향 프로그래밍 언어 및/또는 어셈블리/기계 언어로 구현될 수 있다. 본 명세서에 사용되는 바와 같이, "기계판독 가능한 매체", "컴퓨터판독 가능한 매체"라는 용어들은, 프로그래머블 프로세서에 기계 명령들 및/또는 데이터를 제공하는데 사용되는 임의의 컴퓨터 프로그램 제품, 장치 및/또는 디바이스(예컨대, 자기디스크, 광학디스크, 메모리, PLDs(Programmable Logic Devices)를 가리키며, 기계판독가능한 신호로서의 기계 명령들을 수신하는 기계판독 가능한 매체도 포함한다. "기계판독 가능한 신호"라는 용어는 프로그래머블 프로세서에 기계 명령들 및/또는 데이터를 제공하는데 사용되는 임의의 신호를 가리킨다.
사용자와의 상호작용을 제공하기 위해, 본 명세서에 설명된 시스템과 기술들은 사용자에게 정보를 디스플레이하기 위한 디스플레이 디바이스(예컨대, CRT(cathode ray tube) 또는 LCD(liquid crystal display) 모니터) 및 사용자가 컴퓨터에 입력을 제공하는데 사용하는 키보드와 포인팅 디바이스(예컨대, 마우스 또는 트랙볼(trackball))를 구비한 컴퓨터에서 구현될 수 있다. 다른 종류의 디바이스들도 사용자와의 상호작용을 제공하는데 사용될 수 있다. 예를 들어, 사용자에게 제공된 피드백은 임의 형태의 감각 피드백(예컨대, 시각 피드백, 청각 피드백, 또는 촉각 피드백)일 수 있다. 그리고 사용자로부터의 입력은 음향, 구어 또는 촉각 입력을 포함하는 임의 형태로 수신될 수 있다.
본 명세서에 설명된 시스템과 기술은 백엔드(back-end) 구성요소(예컨대, 데이터 서버), 또는 미들웨어(middleware) 구성요소(예컨대, 애플리케이션 서버), 또는 프론트엔드(front-end) 구성요소(예컨대, 사용자가 본 명세서에 설명된 시스템과 기술들의 구현과 상호작용할 수 있는 그래픽 사용자 인터페이스 또는 웹브라우저를 갖는 클라이언트 컴퓨터), 또는 그러한 백엔드, 미들웨어 또는 프론트엔드 구성요소들의 임의 조합을 포함하는 컴퓨터 시스템에서 구현될 수 있다. 이 시스템의 구성요소들은 임의 형태나 매체의 디지털 데이터 통신(예, 통신 네트워크)에 의해 서로 연결될 수 있다. 통신 네트워크의 예에는 근거리통신망("LAN"), 광역 통신망("WAN")및 인터넷이 있다.
컴퓨터 시스템은 클라이언트들과 서버들을 포함할 수 있다. 클라이언트와 서버는 일반적으로 서로 떨어져 있고, 통상은 통신 네트워크를 통해 상호작용한다. 클라이언트와 서버의 관계는 각 컴퓨터에서 실행되고 서로 클라이언트-서버 관계를 갖는 컴퓨터 프로그램들에 의해 비롯된다.
본 명세서가 다수의 특정한 구현의 상세 사항을 포함하고 있지만, 이는 임의 구현의 범위나 청구 범위에 대한 제한으로서 이해되어서는 안 되며, 특정 구현의 실시 형태에 고유할 수 있는 특징들의 설명으로서 이해되어야 한다. 별개의 실시형태와 관련하여 본 명세서에서 설명된 소정 특징들은 조합되어 단일 실시형태로 구현될 수 있다. 반대로, 단일 실시형태와 관련하여 설명한 다양한 특징들은 복수의 실시형태에서 별개로 구현되거나 임의의 적당한 서브조합(subcombination)으로서도 구현 가능하다. 또한, 앞에서 특징들이 소정 조합으로 동작하는 것으로서 설명되고 그와 같이 청구되었지만, 청구된 조합으로부터의 하나 이상의 특징은 일부 경우에 당해 조합으로부터 삭제될 수 있으며, 청구된 조합은 서브조합이나 서브조합의 변형에 관한 것일 수 있다.
마찬가지로, 도면에서 특정한 순서로 동작을 묘사하고 있지만, 그러한 동작들이 바람직한 결과를 얻기 위해, 도시한 특정 순서나 순차적인 순서로 수행되어야 한다거나, 설명한 모든 동작들이 수행되어야 한다는 것을 요구하는 것으로 이해되어서는 안 된다. 소정 환경에서, 멀티태스킹 및 병렬 프로세싱이 바람직할 수 있다. 또한, 상술한 실시형태에 있어서 다양한 시스템 구성요소들의 분리는 모든 실시형태에서 그러한 분리를 요구하는 것으로 이해해서는 안 되며, 설명한 프로그램 구성요소들과 시스템들은 단일 소프트웨어 제품으로 통합되거나 또는 복수의 소프트웨어 제품으로 패키지될 수 있다는 점을 이해해야 한다.
본 명세서에 기술된 주제의 특정 실시예들이 설명되었다. 그 밖의 실시예들도 후술하는 청구항의 범위 내에 있다. 예를 들어, 청구항에 언급된 동작들은 다른 순서로 수행되어도 여전히 바람직한 결과들을 달성할 수 있다. 하나의 예로서, 첨부 도면에 도시된 프로세스들은 바람직한 결과들을 달성하기 위하여, 도시된 특정 순서나 순차적 순서를 반드시 요구하는 것은 아니다. 소정 구현에서, 멀티태스킹 및 병렬 프로세싱이 바람직할 수 있다.
102 ... 중국어 텍스트
104 ... 제1 디코더
106 ... 훈련 데이터
108 ... 번역 격자
110 ... 제2 디코더
112 ... 영어 텍스트
104 ... 제1 디코더
106 ... 훈련 데이터
108 ... 번역 격자
110 ... 제2 디코더
112 ... 영어 텍스트
Claims (54)
- 컴퓨터 구현 방법으로서,
복수의 후보 번역들을 나타내는 번역 격자에 접근하는 단계;
상기 번역 격자 내의 분류(classification)에서 예상 에러(expected error)를 최소화하는 번역 가설을 획득하기 위하여 상기 번역 격자에 대하여 디코딩을 수행하는 단계;
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 방법. - 청구항1에 있어서, 소스 언어로 된 소스 샘플을 디코더에 제공하는 것을 포함하는 상기 번역 격자를 생성하는 단계를 더 포함하는 방법.
- 청구항1에 있어서, 상기 격자에 대하여 디코딩을 수행하는 단계는 MBR(minimum Bayes-Risk) 디코딩을 수행하는 단계를 포함하는 방법.
- 청구항3에 있어서, MBR 디코딩을 수행하는 단계는 코퍼스(corpus) BLEU 이득의 근사화(approximation)를 계산하는 단계를 포함하는 방법.
- 청구항4에 있어서, 상기 코퍼스 BLEU 이득의 근사화는,
로 표현되고,
여기서, w는 단어,는 상수, E는 후보 번역, E'는 자동 번역, 는 E'에 w가 출현하는 회수, 및
는 E'에 w가 출현하는 회수, 및 는
는 이면 1, 그 외는 0인 방법.
이면 1, 그 외는 0인 방법.
- 청구항3에 있어서, MBR 디코딩을 수행하는 단계는 다음 식을 계산하는 단계를 포함하고,

여기서, w는 단어,는 상수, E'는 자동 번역, 는 E'에 w가 출현하는 회수,
는 E'에 w가 출현하는 회수, 는 번역 격자를 나타내고,
는 번역 격자를 나타내고, 는 상기 번역 격자 내 w의 사후 확률인 방법.
는 상기 번역 격자 내 w의 사후 확률인 방법.
- 청구항6에 있어서,이고, 여기서,
 는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고,
는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고, 는
는 내 경로들의 가중치 합을 나타내고,
내 경로들의 가중치 합을 나타내고, 는
는 내 경로들의 가중치 합을 나타내는 방법.
내 경로들의 가중치 합을 나타내는 방법.
- 컴퓨터 구현 방법으로서,
복수의 후보 번역들을 나타내는 가설 공간(hypothesis space)에 접근하는 단계;
증거 공간(evidence space)에 관하여 계산된 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 가설 공간에 대하여 디코딩을 수행하는 단계;
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 방법. - 청구항8에 있어서, 상기 가설 공간은 격자로서 나타내지는 방법.
- 청구항9에 있어서, 상기 증거 공간은 N-최적(best) 리스트로서 나타내지는 방법.
- 유형의 프로그램 운반체(carrier)에 부호화된 컴퓨터 프로그램 제품으로서, 데이터 처리 장치로 하여금,
복수의 후보 번역들을 나타내는 번역 격자에 접근하는 단계;
상기 번역 격자 내의 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 번역 격자에 대하여 디코딩을 수행하는 단계;
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 동작을 수행하도록 작동할 수 있는 컴퓨터 프로그램 제품. - 청구항11에 있어서, 상기 동작은 소스 언어로 된 소스 샘플을 디코더에 제공하는 것을 포함하는 상기 번역 격자를 생성하는 단계를 더 포함하는 컴퓨터 프로그램 제품.
- 청구항11에 있어서, 상기 격자에 대하여 디코딩을 수행하는 단계는 MBR 디코딩을 수행하는 단계를 포함하는 컴퓨터 프로그램 제품.
- 청구항13에 있어서, MBR 디코딩을 수행하는 단계는 코퍼스 BLEU 이득의 근사화를 계산하는 단계를 포함하는 컴퓨터 프로그램 제품.
- 청구항14에 있어서, 상기 코퍼스 BLEU 이득의 근사화는,
로 표현되고,
여기서, w는 단어,는 상수, E는 후보 번역, E'는 자동 번역, 는 E'에 w가 출현하는 회수, 및
는 E'에 w가 출현하는 회수, 및 는
는 이면 1, 그 외는 0인 컴퓨터 프로그램 제품.
이면 1, 그 외는 0인 컴퓨터 프로그램 제품.
- 청구항13에 있어서, MBR 디코딩을 수행하는 단계는 다음 식을 계산하는 단계를 포함하고,

여기서, w는 단어,는 상수, E'는 자동 번역, 는 E'에 w가 출현하는 회수,
는 E'에 w가 출현하는 회수, 는 번역 격자를 나타내고,
는 번역 격자를 나타내고, 는 상기 번역 격자 내 w의 사후 확률인 컴퓨터 프로그램 제품.
는 상기 번역 격자 내 w의 사후 확률인 컴퓨터 프로그램 제품.
- 청구항16에 있어서,이고, 여기서,
 는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고,
는 적어도 한번 w를 포함하는 번역 격자의 경로들을 나타내고, 는
는 내 경로들의 가중치 합을 나타내고,
내 경로들의 가중치 합을 나타내고, 는
는 내 경로들의 가중치 합을 나타내는 컴퓨터 프로그램 제품.
내 경로들의 가중치 합을 나타내는 컴퓨터 프로그램 제품.
- 유형의 프로그램 운반체에 부호화된 컴퓨터 프로그램 제품으로서, 데이터 처리 장치로 하여금,
복수의 후보 번역들을 나타내는 가설 공간에 접근하는 단계;
증거 공간에 관하여 계산된 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 가설 공간에 대하여 디코딩을 수행하는 단계;
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 동작을 수행하도록 작동할 수 있는 컴퓨터 프로그램 제품. - 청구항18에 있어서, 상기 가설 공간은 격자로서 나타내지는 컴퓨터 프로그램 제품.
- 청구항19에 있어서, 상기 증거 공간은 N-최적 리스트로서 나타내지는 컴퓨터 프로그램 제품.
- 시스템으로서,
프로그램 제품을 구비하는 기계-판독가능 저장 디바이스;
상기 프로그램 제품을 실행할 수 있는 하나 이상의 프로세서로서,
복수의 후보 번역들을 나타내는 번역 격자에 접근하는 단계;
상기 번역 격자 내의 분류(classification)에서 예상 에러(expected error)를 최소화하는 번역 가설을 획득하기 위하여 상기 번역 격자에 대하여 디코딩을 수행하는 단계; 및
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 동작을 수행하는 상기 하나 이상의 프로세서를 포함하는 시스템. - 청구항21에 있어서, 상기 격자에 대하여 디코딩을 수행하는 단계는 MBR 디코딩을 수행하는 단계를 포함하는 시스템.
- 시스템으로서,
프로그램 제품을 구비하는 기계-판독가능 저장 디바이스;
상기 프로그램 제품을 실행할 수 있는 하나 이상의 프로세서로서,
복수의 후보 번역들을 나타내는 가설 공간에 접근하는 단계;
증거 공간에 관하여 계산된 분류에서 예상 에러를 최소화하는 번역 가설을 획득하기 위하여 상기 가설 공간에 대하여 디코딩을 수행하는 단계;
상기 획득된 번역 가설을, 사용자가 제안된 번역으로서 대상 번역 내에서 사용하도록 제공하는 단계를 포함하는 동작을 수행하는 상기 하나 이상의 프로세서를 포함하는 시스템. - 청구항23에 있어서, 상기 가설 공간은 격자로서 나타내지는 시스템.
- 컴퓨터 구현 방법으로서,
번역 격자 내 복수의 특징 함수들에 대하여, 상기 번역 격자에 나타낸 하나 이상의 후보 번역들 각각에 대한 상응하는 복수의 에러 표면들을 결정하는 단계;
훈련 세트(training set) 내 구절들(phrases)에 대한 복수의 에러 표면들의 조합을 횡단함으로써, 상기 특징 함수들에 대한 가중치들을 조정하는 단계;
상기 횡단된 조합에 대한 에러 카운트들을 최소화하는 가중치들을 선택하는 단계; 및
샘플 텍스트를 제1 언어에서 제2 언어로 변환하기 위하여, 상기 선택된 가중치들을 적용하는 단계를 포함하는 방법. - 청구항25에 있어서, 상기 번역 격자는 구절 격자를 포함하는 방법.
- 청구항26에 있어서, 상기 구절 격자 내의 아크들(arcs)은 구절 가설들을 나타내고, 상기 구절 격자내의 노드들은 부분 번역 가설들이 조합된 상태들(states)을 나타내는 방법.
- 청구항25에 있어서, 상기 에러 표면들은 라인 최적화 기술(line optimization technique)을 사용하여 결정되고 횡단되는(determined and traversed) 방법.
- 청구항28에 있어서, 상기 라인 최적화 기술은, 그룹 내의 특징 함수 각각과 문장(sentence)에 대하여, 후보 번역들의 집합 상의 에러 표면을 결정 및 횡단하는 방법.
- 청구항29에 있어서, 상기 라인 최적화 기술은 파라미터 공간 내의 랜덤한 지점(random point)에서부터 시작하여 상기 에러 표면을 결정 및 횡단하는 방법.
- 청구항29에 있어서, 상기 라인 최적화 기술은 상기 가중치들을 조정하기 위하여, 랜덤한 방향들(random directions)을 사용하여 상기 에러 표면을 결정 및 횡단하는 방법.
- 청구항25에 있어서, 상기 가중치들은 한정들(restrictions)에 의해 제한되는 방법.
- 청구항25에 있어서, 상기 가중치들은 가중치 프라이어들(priors)을 사용하여 조정되는 방법.
- 청구항25에 있어서, 상기 가중치들은 문장들의 한 그룹 내 모든 문장들에 걸쳐 조정되는 방법.
- 청구항25에 있어서, 복수의 후보 번역들로부터, 상기 번역 격자에 대한 사후 확률(posteriori probability)을 최대화하는 대상 번역을 선택하는 단계를 더 포함하는 방법.
- 청구항25에 있어서, 상기 번역 격자는 십억개 이상의 후보 번역들을 나타내는 방법.
- 청구항25에 있어서, 상기 구절들은 문장들을 포함하는 방법.
- 청구항25에 있어서, 상기 구절들 모두는 문장들을 포함하는 방법.
- 유형의 프로그램 운반체에 부호화된 컴퓨터 프로그램 제품으로서, 데이터 처리 장치로 하여금,
번역 격자 내 복수의 특징 함수들에 대하여, 상기 번역 격자에 나타낸 하나 이상의 후보 번역들 각각에 대한 상응하는 복수의 에러 표면들을 결정하는 단계;
훈련 세트 내 구절들에 대한 복수의 에러 표면들의 조합을 횡단함으로써, 상기 특징 함수들에 대한 가중치들을 조정하는 단계;
상기 횡단된 조합에 대한 에러 카운트들을 최소화하는 가중치들을 선택하는 단계; 및
샘플 텍스트를 제1 언어에서 제2 언어로 변환하기 위하여, 상기 선택된 가중치들을 적용하는 단계를 포함하는 동작을 수행하도록 작동할 수 있는 컴퓨터 프로그램 제품. - 청구항39에 있어서, 상기 번역 격자는 구절 격자를 포함하는 컴퓨터 프로그램 제품.
- 청구항40에 있어서, 상기 구절 격자 내의 아크들은 구절 가설들을 나타내고, 상기 구절 격자내의 노드들은 부분 번역 가설들이 조합된 상태들을 나타내는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 에러 표면들은 라인 최적화 기술을 사용하여 결정되고 횡단되는 컴퓨터 프로그램 제품.
- 청구항42에 있어서, 상기 라인 최적화 기술은, 그룹 내의 특징 함수 각각과 문장에 대하여, 후보 번역들의 집합 상의 에러 표면을 결정 및 횡단하는 컴퓨터 프로그램 제품.
- 청구항43에 있어서, 상기 라인 최적화 기술은 파라미터 공간 내의 랜덤한 지점에서부터 시작하여 상기 에러 표면을 결정 및 횡단하는 컴퓨터 프로그램 제품.
- 청구항43에 있어서, 상기 라인 최적화 기술은 상기 가중치들을 조정하기 위하여, 랜덤한 방향들을 사용하여 상기 에러 표면을 결정 및 횡단하는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 가중치들은 한정들에 의해 제한되는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 가중치들은 가중치 프라이어들을 사용하여 조정되는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 가중치들은 문장들의 한 그룹 내 모든 문장들에 걸쳐 조정되는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 복수의 후보 번역들로부터, 상기 번역 격자에 대한 사후 확률을 최대화하는 대상 번역을 선택하는 단계를 더 포함하는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 번역 격자는 십억개 이상의 후보 번역들을 나타내는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 구절들은 문장들을 포함하는 컴퓨터 프로그램 제품.
- 청구항39에 있어서, 상기 구절들 모두는 문장들을 포함하는 컴퓨터 프로그램 제품.
- 시스템으로서,
프로그램 제품을 포함하는 기계-판독가능한 저장 디바이스; 및
상기 프로그램 제품을 실행하도록 작동가능한 하나 이상의 컴퓨터로서,
번역 격자 내 복수의 특징 함수들에 대하여, 상기 번역 격자에 나타낸 하나 이상의 후보 번역들 각각에 대한 상응하는 복수의 에러 표면들을 결정하는 단계;
훈련 세트 내 구절들에 대한 복수의 에러 표면들의 조합을 횡단함으로써, 상기 특징 함수들에 대한 가중치들을 조정하는 단계;
상기 횡단된 조합에 대한 에러 카운트들을 최소화하는 가중치들을 선택하는 단계; 및
샘플 텍스트를 제1 언어에서 제2 언어로 변환하기 위하여, 상기 선택된 가중치들을 적용하는 단계를 포함하는 동작을 수행하는 상기 하나 이상의 컴퓨터를 포함하는 시스템. - 컴퓨터-구현 시스템으로서,
언어 모델을 포함하고, 상기 언어 모델은
번역 격자 내 특징 함수들의 수집(collection);
후보 언어 번역들의 집합에 대하여, 상기 특징 함수들에 걸친 복수의 에러 표면들; 및
상기 에러 표면들의 횡단에 대한 에러를 최소화하도록 선택된 특징 함수들에 대한 가중치들을 포함하는 컴퓨터-구현 시스템.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US7826208P | 2008-07-03 | 2008-07-03 | |
| US61/078,262 | 2008-07-03 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20110043645A true KR20110043645A (ko) | 2011-04-27 |
| KR101623891B1 KR101623891B1 (ko) | 2016-05-24 |
Family
ID=41465058
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020117002721A KR101623891B1 (ko) | 2008-07-03 | 2009-07-02 | 기계 번역을 위한 파라미터들의 최적화 |
Country Status (6)
| Country | Link |
|---|---|
| US (2) | US8744834B2 (ko) |
| EP (1) | EP2318953A4 (ko) |
| JP (1) | JP5572624B2 (ko) |
| KR (1) | KR101623891B1 (ko) |
| CN (1) | CN102150156B (ko) |
| WO (1) | WO2010003117A2 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101719107B1 (ko) * | 2016-10-27 | 2017-04-06 | 박성국 | 번역을 위한 서버 및 번역 방법 |
Families Citing this family (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8097081B2 (en) * | 2008-06-05 | 2012-01-17 | Soraa, Inc. | High pressure apparatus and method for nitride crystal growth |
| US8744834B2 (en) * | 2008-07-03 | 2014-06-03 | Google Inc. | Optimizing parameters for machine translation |
| US9176952B2 (en) * | 2008-09-25 | 2015-11-03 | Microsoft Technology Licensing, Llc | Computerized statistical machine translation with phrasal decoder |
| WO2010046782A2 (en) | 2008-10-24 | 2010-04-29 | App Tek | Hybrid machine translation |
| US8843359B2 (en) * | 2009-02-27 | 2014-09-23 | Andrew Nelthropp Lauder | Language translation employing a combination of machine and human translations |
| US8285536B1 (en) | 2009-07-31 | 2012-10-09 | Google Inc. | Optimizing parameters for machine translation |
| US8265923B2 (en) * | 2010-05-11 | 2012-09-11 | Xerox Corporation | Statistical machine translation employing efficient parameter training |
| JP5650440B2 (ja) * | 2010-05-21 | 2015-01-07 | 日本電信電話株式会社 | 素性重み学習装置、N−bestスコアリング装置、N−bestリランキング装置、それらの方法およびプログラム |
| US9201871B2 (en) | 2010-06-11 | 2015-12-01 | Microsoft Technology Licensing, Llc | Joint optimization for machine translation system combination |
| US8326600B2 (en) * | 2010-08-11 | 2012-12-04 | Google Inc. | Evaluating and modifying transliteration rules |
| KR101735438B1 (ko) * | 2010-10-18 | 2017-05-15 | 한국전자통신연구원 | 실시간 번역 지식 자동 추출/검증 방법 및 그 장치 |
| US8660836B2 (en) | 2011-03-28 | 2014-02-25 | International Business Machines Corporation | Optimization of natural language processing system based on conditional output quality at risk |
| US8798984B2 (en) * | 2011-04-27 | 2014-08-05 | Xerox Corporation | Method and system for confidence-weighted learning of factored discriminative language models |
| JP5548176B2 (ja) * | 2011-09-16 | 2014-07-16 | 日本電信電話株式会社 | 翻訳最適化装置、方法、及びプログラム |
| JP5694893B2 (ja) * | 2011-10-20 | 2015-04-01 | 日本電信電話株式会社 | 最適翻訳文選択装置、翻訳文選択モデル学習装置、方法、及びプログラム |
| US9323746B2 (en) * | 2011-12-06 | 2016-04-26 | At&T Intellectual Property I, L.P. | System and method for collaborative language translation |
| US8874428B2 (en) * | 2012-03-05 | 2014-10-28 | International Business Machines Corporation | Method and apparatus for fast translation memory search |
| US20140046651A1 (en) * | 2012-08-13 | 2014-02-13 | Xerox Corporation | Solution for max-string problem and translation and transcription systems using same |
| JP5985344B2 (ja) * | 2012-10-10 | 2016-09-06 | 日本電信電話株式会社 | システムパラメータ最適化装置、方法、及びプログラム |
| CN103020002B (zh) * | 2012-11-27 | 2015-11-18 | 中国人民解放军信息工程大学 | 可重构多处理器系统 |
| US9195644B2 (en) | 2012-12-18 | 2015-11-24 | Lenovo Enterprise Solutions (Singapore) Pte. Ltd. | Short phrase language identification |
| JP5889225B2 (ja) * | 2013-01-31 | 2016-03-22 | 日本電信電話株式会社 | 近似オラクル文選択装置、方法、及びプログラム |
| JP6315980B2 (ja) * | 2013-12-24 | 2018-04-25 | 株式会社東芝 | デコーダ、デコード方法およびプログラム |
| US9653071B2 (en) * | 2014-02-08 | 2017-05-16 | Honda Motor Co., Ltd. | Method and system for the correction-centric detection of critical speech recognition errors in spoken short messages |
| US9940658B2 (en) | 2014-02-28 | 2018-04-10 | Paypal, Inc. | Cross border transaction machine translation |
| US9881006B2 (en) | 2014-02-28 | 2018-01-30 | Paypal, Inc. | Methods for automatic generation of parallel corpora |
| US9530161B2 (en) | 2014-02-28 | 2016-12-27 | Ebay Inc. | Automatic extraction of multilingual dictionary items from non-parallel, multilingual, semi-structured data |
| US9569526B2 (en) | 2014-02-28 | 2017-02-14 | Ebay Inc. | Automatic machine translation using user feedback |
| US20170024659A1 (en) * | 2014-03-26 | 2017-01-26 | Bae Systems Information And Electronic Systems Integration Inc. | Method for data searching by learning and generalizing relational concepts from a few positive examples |
| US9530404B2 (en) * | 2014-10-06 | 2016-12-27 | Intel Corporation | System and method of automatic speech recognition using on-the-fly word lattice generation with word histories |
| JP6620934B2 (ja) * | 2016-01-29 | 2019-12-18 | パナソニックIpマネジメント株式会社 | 翻訳支援方法、翻訳支援装置、翻訳装置及び翻訳支援プログラム |
| KR102565275B1 (ko) | 2016-08-10 | 2023-08-09 | 삼성전자주식회사 | 병렬 처리에 기초한 번역 방법 및 장치 |
| CN107798386B (zh) * | 2016-09-01 | 2022-02-15 | 微软技术许可有限责任公司 | 基于未标注数据的多过程协同训练 |
| US10055400B2 (en) | 2016-11-11 | 2018-08-21 | International Business Machines Corporation | Multilingual analogy detection and resolution |
| US10061770B2 (en) | 2016-11-11 | 2018-08-28 | International Business Machines Corporation | Multilingual idiomatic phrase translation |
| KR102458244B1 (ko) | 2017-11-23 | 2022-10-24 | 삼성전자주식회사 | 기계 번역 방법 및 장치 |
| CN109118113B (zh) * | 2018-08-31 | 2021-08-10 | 传神语联网网络科技股份有限公司 | Etm架构及词移距离 |
| US11341340B2 (en) * | 2019-10-01 | 2022-05-24 | Google Llc | Neural machine translation adaptation |
| CN114881008A (zh) * | 2022-04-24 | 2022-08-09 | 北京有竹居网络技术有限公司 | 一种文本生成方法、装置、电子设备及介质 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2126380C (en) * | 1993-07-22 | 1998-07-07 | Wu Chou | Minimum error rate training of combined string models |
| JPH07334368A (ja) * | 1994-06-08 | 1995-12-22 | Hitachi Ltd | 知識ベースシステムおよび認識システム |
| US8874431B2 (en) * | 2001-03-16 | 2014-10-28 | Meaningful Machines Llc | Knowledge system method and apparatus |
| US20030110023A1 (en) * | 2001-12-07 | 2003-06-12 | Srinivas Bangalore | Systems and methods for translating languages |
| US7571098B1 (en) | 2003-05-29 | 2009-08-04 | At&T Intellectual Property Ii, L.P. | System and method of spoken language understanding using word confusion networks |
| JP2004362249A (ja) * | 2003-06-04 | 2004-12-24 | Advanced Telecommunication Research Institute International | 翻訳知識最適化装置、翻訳知識最適化のためのコンピュータプログラム、コンピュータ及び記憶媒体 |
| JP2006053683A (ja) * | 2004-08-10 | 2006-02-23 | Advanced Telecommunication Research Institute International | 音声認識および機械翻訳装置 |
| JP4084789B2 (ja) * | 2004-09-28 | 2008-04-30 | 株式会社国際電気通信基礎技術研究所 | 統計機械翻訳装置および統計機械翻訳プログラム |
| JP4058057B2 (ja) * | 2005-04-26 | 2008-03-05 | 株式会社東芝 | 日中機械翻訳装置、日中機械翻訳方法および日中機械翻訳プログラム |
| US7536295B2 (en) * | 2005-12-22 | 2009-05-19 | Xerox Corporation | Machine translation using non-contiguous fragments of text |
| US7848917B2 (en) | 2006-03-30 | 2010-12-07 | Microsoft Corporation | Common word graph based multimodal input |
| US8209163B2 (en) | 2006-06-02 | 2012-06-26 | Microsoft Corporation | Grammatical element generation in machine translation |
| JP4393494B2 (ja) * | 2006-09-22 | 2010-01-06 | 株式会社東芝 | 機械翻訳装置、機械翻訳方法および機械翻訳プログラム |
| US7856351B2 (en) | 2007-01-19 | 2010-12-21 | Microsoft Corporation | Integrated speech recognition and semantic classification |
| US8744834B2 (en) | 2008-07-03 | 2014-06-03 | Google Inc. | Optimizing parameters for machine translation |
-
2009
- 2009-07-02 US US12/497,184 patent/US8744834B2/en active Active
- 2009-07-02 EP EP09774566.5A patent/EP2318953A4/en not_active Withdrawn
- 2009-07-02 WO PCT/US2009/049613 patent/WO2010003117A2/en active Application Filing
- 2009-07-02 KR KR1020117002721A patent/KR101623891B1/ko active IP Right Grant
- 2009-07-02 JP JP2011516890A patent/JP5572624B2/ja not_active Expired - Fee Related
- 2009-07-02 CN CN200980133134.8A patent/CN102150156B/zh not_active Expired - Fee Related
- 2009-07-02 US US12/497,169 patent/US20100004919A1/en not_active Abandoned
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101719107B1 (ko) * | 2016-10-27 | 2017-04-06 | 박성국 | 번역을 위한 서버 및 번역 방법 |
| WO2018080228A1 (ko) * | 2016-10-27 | 2018-05-03 | 주식회사 네오픽시스 | 번역을 위한 서버 및 번역 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102150156B (zh) | 2015-06-10 |
| EP2318953A4 (en) | 2013-10-30 |
| US20100004920A1 (en) | 2010-01-07 |
| JP2011527471A (ja) | 2011-10-27 |
| WO2010003117A2 (en) | 2010-01-07 |
| CN102150156A (zh) | 2011-08-10 |
| KR101623891B1 (ko) | 2016-05-24 |
| US8744834B2 (en) | 2014-06-03 |
| JP5572624B2 (ja) | 2014-08-13 |
| WO2010003117A3 (en) | 2010-11-18 |
| US20100004919A1 (en) | 2010-01-07 |
| WO2010003117A8 (en) | 2010-03-11 |
| EP2318953A2 (en) | 2011-05-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20110043645A (ko) | 기계 번역을 위한 파라미터들의 최적화 | |
| US8285536B1 (en) | Optimizing parameters for machine translation | |
| US8849665B2 (en) | System and method of providing machine translation from a source language to a target language | |
| US9123333B2 (en) | Minimum bayesian risk methods for automatic speech recognition | |
| US10832658B2 (en) | Quantized dialog language model for dialog systems | |
| US9176936B2 (en) | Transliteration pair matching | |
| KR102375115B1 (ko) | 엔드-투-엔드 모델들에서 교차-언어 음성 인식을 위한 음소-기반 컨텍스트화 | |
| JP5705472B2 (ja) | 一般化された巡回セールスマン問題としてのフレーズ−ベースの統計的機械翻訳 | |
| US20200168213A1 (en) | Method for re-aligning corpus and improving the consistency | |
| JP2016513269A (ja) | 音響言語モデルトレーニングのための方法およびデバイス | |
| US11423237B2 (en) | Sequence transduction neural networks | |
| US11328712B2 (en) | Domain specific correction of output from automatic speech recognition | |
| US10394960B2 (en) | Transliteration decoding using a tree structure | |
| WO2017210095A2 (en) | No loss-optimization for weighted transducer | |
| JP2022151649A (ja) | 音声認識モデルのトレーニング方法、装置、機器、および記憶媒体 | |
| KR20220125327A (ko) | 종단간 음성 인식에서 고유 명사 인식 | |
| Li et al. | Variational decoding for statistical machine translation | |
| JP7096199B2 (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| CN114722796A (zh) | 用于中文文本错误识别与校正的架构 | |
| Riyadh et al. | Joint approach to deromanization of code-mixed texts | |
| KR20230156425A (ko) | 자체 정렬을 통한 스트리밍 asr 모델 지연 감소 | |
| JP2005092682A (ja) | 翻字装置、及び翻字プログラム | |
| Riyadh | Deromanization of Code-mixed Texts | |
| Nugues | Part-of-Speech Tagging Using Statistical Techniques | |
| Jiang et al. | An Automated Evaluation Metric for Chinese Text Entry |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20190515 Year of fee payment: 4 |