KR20110003549A - 깊이 신호의 코딩 - Google Patents
깊이 신호의 코딩 Download PDFInfo
- Publication number
- KR20110003549A KR20110003549A KR1020107026463A KR20107026463A KR20110003549A KR 20110003549 A KR20110003549 A KR 20110003549A KR 1020107026463 A KR1020107026463 A KR 1020107026463A KR 20107026463 A KR20107026463 A KR 20107026463A KR 20110003549 A KR20110003549 A KR 20110003549A
- Authority
- KR
- South Korea
- Prior art keywords
- partial
- depth
- image
- motion vector
- depth value
- Prior art date
Links
Images








Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T9/00—Image coding
- G06T9/001—Model-based coding, e.g. wire frame
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/20—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using video object coding
- H04N19/23—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using video object coding with coding of regions that are present throughout a whole video segment, e.g. sprites, background or mosaic
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/537—Motion estimation other than block-based
- H04N19/543—Motion estimation other than block-based using regions
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
Abstract
다양한 구현예가 기술된다. 몇몇 구현예는 전체 코딩 구획을 표현하는 깊이값의 결정, 제공, 또는 사용과 관련된다. 일반적인 태양에 따르면, 이미지의 제1 부분은 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩된다. 상기 제1 부분은 제1 크기를 갖는다. 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값이 결정된다. 이미지의 제2 부분은 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩된다. 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 갖는다. 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값이 결정된다.
Description
본 출원은 모든 목적을 위해 본 명세서에 그 전체가 참고로서 포함되는, 2008년 4월 25일에 출원된 "Coding of Depth Signal"이라는 명칭의 미국 임시 특허 출원 제61/125,674호의 이익을 청구한다.
코팅 시스템들과 관련된 구현예들이 기술된다. 다양한 특정한 구현예들이 깊이 신호의 코딩과 관련된다.
다시점 비디오 코딩(Multi-view Video Coding; MVC)(예컨대 H.264/MPEG-4 AVC 또는 다른 표준들뿐만 아니라 비표준 접근법들에 대한 MVC 확장)은 자유 시점 및 3D 비디오 응용예들, 홈 엔터테인먼트 및 감시를 포함하는 다양한 응용예에 이바지하는 주요 기술이다. 깊이 데이터는 각 시점과 관련될 수 있고, 예컨대 시점 합성에 사용될 수 있다. 이러한 다시점 응용예들에서, 수반되는 비디오 및 깊이 데이터의 양은 일반적으로 막대하다. 따라서, 현재의 비디오 코딩 솔루션들의 코딩 효율 개선을 돕는 프레임워크(framework)에 대한 요구가 존재한다.
일반적인 태양에 따르면, 이미지의 인코딩된 제1 부분은 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩된다. 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 갖는다. 제1 부분 깊이값이 처리된다. 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는다. 상기 이미지의 인코딩된 제2 부분은 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩된다. 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리킨다. 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 갖는다. 제2 부분 깊이값이 처리된다. 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는다.
다른 일반적인 태양에 따르면, 비디오 신호 또는 비디오 신호 구조는 다음의 섹션들을 포함한다. 이미지의 인코딩된 제1 부분에 대한 제1 이미지 섹션이 포함된다. 상기 제1 부분은 제1 크기를 갖는다. 제1 부분 깊이값에 대한 제1 깊이 섹션이 포함된다. 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는다. 상기 이미지의 제1 부분을 인코딩하는 데 사용되는 제1 부분 움직임 벡터에 대한 제1 움직임 벡터 섹션이 포함된다. 상기 제1 부분 움직임 벡터는 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않는다. 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킨다. 이미지의 인코딩된 제2 부분에 대한 제2 이미지 섹션이 포함된다. 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 갖는다. 제2 부분 깊이값에 대한 제2 깊이 섹션이 포함된다. 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는다. 상기 이미지의 제2 부분을 인코딩하는 데 사용되는 제2 부분 움직임 벡터에 대한 제2 움직임 벡터 섹션이 포함된다. 상기 제2 부분 움직임 벡터는 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않는다. 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킨다.
다른 일반적인 태양에 따르면, 이미지의 제1 부분은 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩된다. 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킨다. 상기 제1 부분은 제1 크기를 갖는다. 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값이 결정된다. 이미지의 제2 부분은 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩된다. 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 갖는다. 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값이 결정된다. 상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값은 구조화된 형식으로 조립된다.
하나 이상의 구현예의 세부 사항들은 첨부된 도면들과 아래의 설명에서 제시된다. 하나의 특정한 방식으로 도시되더라도, 구현예들이 다양한 방식으로 구성 또는 구현될 수 있음이 명백하다. 예컨대, 구현예는 방법으로서 수행되거나, 또는 장치로서, 예컨대 동작들의 집합을 수행하도록 구성되는 장치나 동작들의 집합을 수행하기 위한 명령들을 저장하는 장치로서 구현되거나, 또는 신호로 구현될 수 있다. 다른 태양들 및 특징들이 첨부된 도면들 및 청구항들과 함께 고찰되는 아래의 상세한 설명으로부터 자명해질 것이다.
도 1은 인코더의 구현예의 도면.
도 2는 디코더의 구현예의 도면.
도 3은 비디오 송신 시스템의 구현예의 도면.
도 4는 비디오 수신 시스템의 구현예의 도면.
도 5는 비디오 처리 장치의 구현예의 도면.
도 6은 시간적(temporal) 및 시점간(inter-view) 예측 모두를 위한 계층적 B 화상들을 갖는 다시점 코딩 구조의 구현예의 도면.
도 7은 깊이 정보를 갖는 다시점 비디오를 송신 및 수신하기 위한 시스템의 구현예의 도면.
도 8은 깊이를 갖는 3개의 입력 시점(K=3)으로부터 9개의 출력 시점(N=9)을 생성하기 위한 프레임워크의 구현예의 도면.
도 9는 깊이 맵의 예를 도시하는 도면.
도 10은 1/4 해상도에 상당하는 깊이 신호의 예의 도면.
도 11은 1/8 해상도에 상당하는 깊이 신호의 예의 도면.
도 12는 1/16 해상도에 상당하는 깊이 신호의 예의 도면.
도 13은 제1 인코딩 프로세스의 구현예의 도면.
도 14는 제1 디코딩 프로세스의 구현예의 도면.
도 15는 제2 인코딩 프로세스의 구현예의 도면.
도 16은 제2 디코딩 프로세스의 구현예의 도면.
도 17은 제3 인코딩 프로세스의 구현예의 도면.
도 18은 제3 디코딩 프로세스의 구현예의 도면.
도 2는 디코더의 구현예의 도면.
도 3은 비디오 송신 시스템의 구현예의 도면.
도 4는 비디오 수신 시스템의 구현예의 도면.
도 5는 비디오 처리 장치의 구현예의 도면.
도 6은 시간적(temporal) 및 시점간(inter-view) 예측 모두를 위한 계층적 B 화상들을 갖는 다시점 코딩 구조의 구현예의 도면.
도 7은 깊이 정보를 갖는 다시점 비디오를 송신 및 수신하기 위한 시스템의 구현예의 도면.
도 8은 깊이를 갖는 3개의 입력 시점(K=3)으로부터 9개의 출력 시점(N=9)을 생성하기 위한 프레임워크의 구현예의 도면.
도 9는 깊이 맵의 예를 도시하는 도면.
도 10은 1/4 해상도에 상당하는 깊이 신호의 예의 도면.
도 11은 1/8 해상도에 상당하는 깊이 신호의 예의 도면.
도 12는 1/16 해상도에 상당하는 깊이 신호의 예의 도면.
도 13은 제1 인코딩 프로세스의 구현예의 도면.
도 14는 제1 디코딩 프로세스의 구현예의 도면.
도 15는 제2 인코딩 프로세스의 구현예의 도면.
도 16은 제2 디코딩 프로세스의 구현예의 도면.
도 17은 제3 인코딩 프로세스의 구현예의 도면.
도 18은 제3 디코딩 프로세스의 구현예의 도면.
적어도 하나의 구현예에서, 깊이 신호를 코딩하기 위한 프레임워크를 제안한다. 적어도 하나의 구현예에서, 장면의 깊이값을 비디오 신호의 일부로서 코딩하는 것을 제안한다. 본 명세서에 기술된 적어도 하나의 구현예에서, 깊이 신호를 상호 예측된 매크로블록들(inter-predicted macroblocks)에 대한 움직임 벡터의 추가적인 성분으로서 취급한다. 적어도 하나의 구현예에서, 내부 예측된(intra-predicted) 매크로블록들의 경우, 내부 모드(intra-mode)에 따라 깊이값을 단일 값으로서 발송한다.
따라서, 적어도 하나의 구현예가 대처하는 적어도 하나의 문제는 다시점 비디오 시퀀스들(또는 단시점 비디오 시퀀스들)에 대한 깊이 신호의 효율적인 코딩이다. 다시점 비디오 시퀀스는 상이한 시점들로부터 동일한 장면을 포착하는 둘 이상의 비디오 시퀀스의 집합이다. 장면에 추가하여, 시점 합성을 사용하여 중간 시점들을 생성할 수 있도록 깊이 신호가 각 시점에 대해 존재할 수 있다.
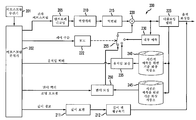
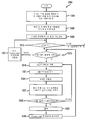
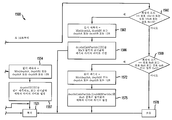
도 1은 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는 인코더(100)를 도시한다. 인코더(100)는 변환기(110)의 입력과 신호 통신하도록 접속되는 출력을 갖는 결합기(105)를 포함한다. 변환기(110)의 출력은 양자화기(115)의 입력과 신호 통신하도록 접속된다. 양자화기(115)의 출력은 엔트로피 코더(entropy coder)(120)의 입력 및 역양자화기(inverse quantizer)(125)의 입력과 신호 통신하도록 접속된다. 역양자화기(125)의 출력은 역변환기(130)의 입력과 신호 통신하도록 접속된다. 역변환기(130)의 출력은 결합기(135)의 제1 비반전 입력과 신호 통신하도록 접속된다. 결합기(135)의 출력은 내부 예측기(intra predictor)(145)의 입력 및 디블로킹 필터(deblocking filter)(150)의 입력과 신호 통신하도록 접속된다. 디블로킹 필터(150)는 예컨대 매크로블록 경계들을 따라 존재하는 허상(artifact)들을 제거한다. 디블로킹 필터(150)의 제1 출력은 기준 화상 저장소(155)(시간적 예측을 위한 것임)의 입력 및 기준 화상 저장소(160)(시점간 예측을 위한 것임)의 제1 입력과 신호 통신하도록 접속된다. 기준 화상 저장소(155)의 출력은 움직임 보상기(175)의 제1 입력 및 움직임 추정기(180)의 제1 입력과 신호 통신하도록 접속된다. 움직임 추정기(180)의 출력은 움직임 보상기(175)의 제2 입력과 신호 통신하도록 접속된다. 기준 화상 저장소(160)의 제1 출력은 변이 추정기(disparity estimator)(170)의 제1 입력과 신호 통신하도록 접속된다. 기준 화상 저장소(160)의 제2 출력은 변이 보상기(165)의 제1 입력과 신호 통신하도록 접속된다. 변이 추정기(170)의 출력은 변이 보상기(165)의 제2 입력과 신호 통신하도록 접속된다.
엔트로피 디코더(120)의 출력, 모드 결정 모듈(122)의 제1 출력 및 깊이 예측기 및 코더(163)의 출력은 각각 비트스트림을 출력하기 위한 인코더(100)의 각 출력들로서 이용 가능하다. 화상/깊이 구획기(picture/depth partitioner)는 시점 i에 대한 화상 및 깊이 데이터를 수신하기 위한 인코더에 대한 입력으로서 이용 가능하다.
움직임 보상기(175)의 출력은 스위치(185)의 제1 입력과 신호 통신하도록 접속된다. 변이 보상기(165)의 출력은 스위치(185)의 제2 입력과 신호 통신하도록 접속된다. 내부 예측기(145)의 출력은 스위치(185)의 제3 입력과 신호 통신하도록 접속된다. 스위치(185)의 출력은 결합기(105)의 반전 입력 및 결합기(135)의 제2 비반전 입력과 신호 통신하도록 접속된다. 모드 결정 모듈(122)의 제1 출력은 어느 입력이 스위치(185)에 제공될지를 결정한다. 모드 결정 모듈(122)의 제2 출력은 깊이 예측기 및 코더(163)의 제2 출력과 신호 통신하도록 접속된다.
화상/깊이 구획기(161)의 제1 출력은 깊이 표현 계산기(162)의 입력과 신호 통신하도록 접속된다. 깊이 표현 계산기(162)의 출력은 깊이 예측기 및 코더(163)의 제1 입력과 신호 통신하도록 접속된다. 화상/깊이 구획기(161)의 제2 출력은 결합기(105)의 비반전 입력, 움직임 보상기(175)의 제3 입력, 움직임 추정기(180)의 제2 입력 및 변이 추정기(170)의 제2 입력과 신호 통신하도록 접속된다.
도 1의 부분들은 또한 개별적으로 또는 집합적으로 예컨대 블록들(110, 115 및 120)과 같은 인코더, 인코딩 유닛, 또는 액세싱 유닛으로 일컬어질 수 있다. 유사하게, 블록들(125, 130, 135 및 150)은 또한 개별적으로 또는 집합적으로 디코더 또는 디코딩 유닛으로 일컬어질 수 있다.
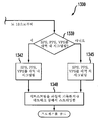
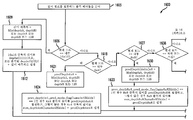
도 2는 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는 디코더(200)를 도시한다. 디코더(200)는 역양자화기(210)의 입력과 신호 통신하도록 접속되는 출력을 갖는 엔트로피 디코더(205)를 포함한다. 역양자화기의 출력은 역변환기(215)의 입력과 신호 통신하도록 접속된다. 역변환기(215)의 출력은 결합기(220)의 제1 비반전 입력과 신호 통신하도록 접속된다. 결합기(220)의 출력은 디블로킹 필터(225)의 입력 및 내부 예측기(230)의 입력과 신호 통신하도록 접속된다. 디블로킹 필터(225)의 제1 출력은 기준 화상 저장소(240)(시간적 예측을 위한 것임)의 입력 및 기준 화상 저장소(245)(시점간 예측을 위한 것임)의 제1 입력과 신호 통신하도록 접속된다. 기준 화상 저장소(240)의 출력은 움직임 보상기(235)의 제1 입력과 신호 통신하도록 접속된다. 기준 화상 저장소(245)의 출력은 변이 보상기(250)의 제1 입력과 신호 통신하도록 접속된다.
비트스트림 수신기(201)의 출력은 비트스트림 분석기(202)의 입력과 신호 통신하도록 접속된다. 비트스트림 분석기(202)의 제1 출력{잔차 비트스트림(residue bitstream)을 제공하기 위한 것임}은 엔트로피 디코더(205)의 입력과 신호 통신하도록 접속된다. 비트스트림 분석기(202)의 제2 출력{어느 입력이 스위치(255)에 의해 선택될지를 제어하기 위한 제어 구문(control syntax)을 제공하기 위한 것임}은 모드 선택기(222)의 입력과 신호 통신하도록 접속된다. 비트스트림 분석기(202)의 제3 출력(움직임 벡터를 제공하기 위한 것임)은 움직임 보상기(235)의 제2 입력과 신호 통신하도록 접속된다. 비트스트림 분석기(202)의 제4 출력(변이 벡터 및/또는 조명 오프셋을 제공하기 위한 것임)은 변이 보상기(250)의 제2 입력과 신호 통신하도록 접속된다. 비트스트림 분석기(202)의 제5 출력(깊이 정보를 제공하기 위한 것임)은 깊이 표현 계산기(211)의 입력과 신호 통신하도록 접속된다. 조명 오프셋은 선택적인 입력이며, 구현예에 따라 사용되거나 사용되지 않을 수 있음을 이해해야 한다.
스위치(255)의 출력은 결합기(220)의 제2 비반전 입력과 신호 통신하도록 접속된다. 스위치(255)의 제1 입력은 변이 보상기(250)의 출력과 신호 통신하도록 접속된다. 스위치(255)의 제2 입력은 움직임 보상기(235)의 출력과 신호 통신하도록 접속된다. 스위치(255)의 제3 입력은 내부 예측기(230)의 출력과 신호 통신하도록 접속된다. 모드 모듈(222)의 출력은 어느 입력이 스위치(255)에 의해 선택될지를 제어하기 위해 스위치(255)와 신호 통신하도록 접속된다. 디블로킹 필터(225)의 제2 출력은 디코더(200)의 출력으로서 이용 가능하다.
깊이 표현 계산기(211)의 출력은 깊이 맵 재구축기(212)의 입력과 신호 통신하도록 접속된다. 깊이 맵 재구축기(212)의 출력은 디코더(200)의 출력으로서 이용 가능하다.
도 2의 부분들은 또한 개별적으로 또는 집합적으로 예컨대 비트스트림 분석기(202) 및 특정한 데이터 또는 정보에 대한 액세스를 제공하는 임의의 다른 블록과 같은 액세싱 유닛으로 일컬어질 수 있다. 유사하게, 블록들(205, 210, 215, 220 및 225)은 또한 개별적으로 또는 집합적으로 디코더 또는 디코딩 유닛으로 일컬어질 수 있다.
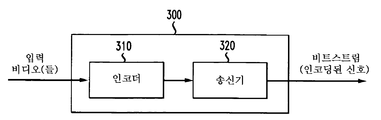
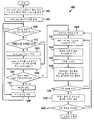
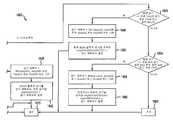
도 3은 본 발명의 원리들의 구현예에 따라 본 발명의 원리들이 적용될 수 있는 비디오 송신 시스템(300)을 도시한다. 비디오 송신 시스템(300)은 예컨대 위성, 케이블, 전화선, 또는 지상파 방송과 같은 다양한 매체 중 임의의 것을 사용하여 신호를 송신하기 위한 헤드엔드(head-end) 또는 송신 시스템일 수 있다. 송신은 인터넷 또는 소정의 다른 네트워크 상에서 제공될 수 있다.
비디오 송신 시스템(300)은 다양한 모드 중 임의의 것을 사용하여 인코딩된 비디오 컨텐트를 생성 및 전달할 수 있다. 예컨대, 이는 깊이 정보, 또는 예컨대 디코더를 가질 수 있는 수신기 말단에서 깊이 정보를 합성하는 데 사용될 수 있는 정보를 포함하는 인코딩된 신호(들)을 생성함으로써 달성될 수 있다.
비디오 송신 시스템(300)은 인코더(310) 및 인코딩된 신호를 송신할 수 있는 송신기(320)를 포함한다. 인코더(310)는 비디오 정보를 수신하고, 그로부터 인코딩된 신호(들)을 생성한다. 인코더(310)는 예컨대 위에서 상세히 기술된 인코더(300)일 수 있다. 인코더(310)는 예컨대 다양한 정보를 수신하고 이를 저장 또는 송신을 위한 구조화된 형식으로 조립하기 위한 조립 유닛을 포함하는 서브모듈(sub-module)들을 포함할 수 있다. 다양한 정보는 예컨대 코딩되거나 코딩되지 않은 비디오, 코딩되거나 코딩되지 않은 깊이 정보 및 예컨대 움직임 벡터들, 코딩 모드 지시자들 및 구문 요소들과 같은 코딩되거나 코딩되지 않은 요소들을 포함할 수 있다.
송신기(320)는 예컨대 인코딩된 화상들 및/또는 그와 관련된 정보를 나타내는 하나 이상의 비트스트림을 갖는 프로그램 신호를 송신하도록 적응될 수 있다. 전형적인 송신기들은 예컨대 오류 정정 코딩의 제공, 신호 내 데이터의 인터리빙(interleaving), 신호 내 에너지의 무작위화(randomizing) 및 하나 이상의 반송파에 대한 신호의 변조 중 하나 이상과 같은 기능들을 수행한다. 송신기는 안테나(도시되지 않음)를 포함하거나 안테나에 연결될 수 있다. 따라서, 송신기(320)의 구현예들은 변조기를 포함하거나 변조기로 한정될 수 있다.
도 4는 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는 비디오 수신 시스템(400)을 도시한다. 비디오 수신 시스템(400)은 예컨대 위성, 케이블, 전화선, 또는 지상파 방송과 같은 다양한 매체 상에서 신호들을 수신하도록 구성될 수 있다. 신호들은 인터넷 또는 소정의 다른 네트워크 상에서 수신될 수 있다.
비디오 수신 시스템(400)은 예컨대 휴대 전화, 컴퓨터, 셋톱박스(set-top box), 텔레비전, 또는 인코딩된 비디오를 수신하고 예컨대 디코딩된 비디오를 사용자에 대한 디스플레이 또는 저장을 위해 제공하는 다른 장치일 수 있다. 따라서, 비디오 수신 시스템(400)은 자신의 출력을 예컨대 텔레비전의 화면, 컴퓨터 모니터, 컴퓨터(저장, 처리, 또는 디스플레이를 위해), 또는 소정의 다른 저장, 처리, 또는 디스플레이 장치에 제공할 수 있다.
비디오 수신 시스템(400)은 비디오 정보를 포함하는 비디오 컨텐트를 수신 및 처리할 수 있다. 비디오 수신 시스템(600)은 예컨대 본 출원의 구현예들에서 기술된 신호들과 같은 인코딩된 신호를 수신할 수 있는 수신기(410) 및 수신된 신호를 디코딩할 수 있는 디코더(420)를 포함한다.
수신기(410)는 예컨대 인코딩된 화상들을 나타내는 복수의 비트스트림을 갖는 프로그램 신호를 수신하도록 적응될 수 있다. 전형적인 수신기들은 예컨대 변조 및 인코딩된 데이터 신호의 수신, 하나 이상의 반송파로부터의 데이터 신호의 복조, 신호 내 에너지의 역무작위화, 신호 내 데이터의 역인터리빙 및 신호의 오류 정정 디코딩 중 하나 이상과 같은 기능들을 수행한다. 수신기(410)는 안테나(도시되지 않음)를 포함하거나 안테나에 연결될 수 있다. 따라서, 수신기(410)의 구현예들은 복조기를 포함하거나 변조기로 한정될 수 있다.
디코더(420)는 비디오 정보 및 깊이 정보를 포함하는 비디오 신호들을 출력한다. 디코더(420)는 예컨대 위에서 상세히 기술된 디코더(400)일 수 있다.
도 5는 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는 비디오 처리 장치(500)를 도시한다. 비디오 처리 장치(500)는 예컨대 셋톱박스 또는 인코딩된 비디오를 수신하고 예컨대 디코딩된 비디오를 사용자에 대한 디스플레이 또는 저장을 위해 제공하는 다른 장치일 수 있다. 따라서, 비디오 처리 장치(500)는 자신의 출력을 텔레비전, 컴퓨터 모니터, 또는 컴퓨터나 다른 처리 장치에 제공할 수 있다.
비디오 처리 장치(500)는 프론트엔드(Front End; FE) 장치(505) 및 디코더(510)를 포함한다. 프론트엔드 장치(505)는 예컨대 인코딩된 화상들을 나타내는 복수의 비트스트림을 갖는 프로그램 신호를 수신하고 상기 복수의 비트스트림으로부터 디코딩을 위한 하나 이상의 비트스트림을 선택하도록 적응되는 수신기일 수 있다. 전형적인 수신기는 변조 및 인코딩된 데이터 신호의 수신, 데이터 신호의 복조, 하나 이상의 인코딩(예컨대 채널 코딩 및/또는 소스 코딩)으로 된 데이터 신호의 디코딩 및/또는 데이터 신호의 오류 정정 중 하나 이상과 같은 기능들을 수행한다. 프론트엔드 장치(505)는 예컨대 안테나(도시되지 않음)로부터 프로그램 신호를 수신할 수 있다. 프론트엔드 장치(505)는 수신된 데이터 신호를 디코더(510)에 제공한다.
디코더(510)는 데이터 신호(520)를 수신한다. 데이터 신호(520)는 예컨대 하나 이상의 AVC(Advanced Video Coding), SVC(Scalable Video Coding) 또는 MVC(Multi-view Video Coding) 호환 스트림을 포함할 수 있다. 디코더(510)는 수신된 신호(520)의 전부 또는 일부를 디코딩하고, 디코딩된 비디오 신호(530)를 출력으로서 제공한다. 디코딩된 비디오(530)는 선택기(550)에 제공된다. 장치(500)는 또한 사용자 입력(570)을 수신하는 사용자 인터페이스(560)를 포함한다. 사용자 인터페이스(560)는 사용자 입력(570)에 기초하여 화상 선택 신호(580)를 선택기(550)에 제공한다. 화상 선택 신호(580) 및 사용자 입력(570)은 사용자가 복수의 화상, 시퀀스, 가변 버전(scalable version), 시점, 또는 이용 가능한 디코딩된 데이터의 다른 선택 사항들 중 어느 것이 디스플레이되기를 원하는지를 나타낸다. 선택기(550)는 선택된 화상(들)을 출력(590)으로서 제공한다. 선택기(550)는 화상 선택 정보(580)를 사용하여, 디코딩된 비디오(530) 내의 화상들 중 어느 것을 출력(590)으로서 제공할지를 선택한다.
다양한 구현예에 있어서 선택기(550)는 사용자 인터페이스(560)를 포함하고, 다른 구현예들에서는 별개의 인터페이스 기능이 수행되지 않고 선택기(550)가 직접 사용자 입력(570)을 수신하기 때문에 사용자 인터페이스(560)가 필요하지 않다. 선택기(550)는 예컨대 소프트웨어로 구현되거나 또는 집적 회로로서 구현될 수 있다. 일 구현예에서 선택기(550)는 디코더(510)와 합쳐지고, 다른 구현예에서 디코더(510), 선택기(550) 및 사용자 인터페이스(560)는 모두 통합된다.
일 응용예에서, 프론트엔드(505)는 다양한 텔레비전 쇼의 방송을 수신하고, 그 중 하나를 처리를 위해 선택한다. 하나의 쇼를 선택하는 것은 시청하기를 원하는 채널에 관한 사용자 입력에 기초한다. 프론트엔드 장치(505)에 대한 사용자 입력이 도 5에 도시되지 않았으나, 프론트엔드 장치(505)는 사용자 입력(570)을 수신한다. 프론트엔드(505)는 방송을 수신하고, 방송 스펙트럼의 관련 부분을 복조하고 복조된 쇼의 임의의 외부 인코딩을 디코딩함으로써 원하는 쇼를 처리한다. 프론트엔드(505)는 디코딩된 쇼를 디코더(510)에 제공한다. 디코더(510)는 장치들(560 및 550)을 포함하는 통합된 유닛이다. 따라서, 디코더(510)는 쇼에서 시청하기를 원하는 시점에 관한 사용자 공급 표시인 사용자 입력을 수신한다. 디코더(510)는 선택된 시점뿐만 아니라 다른 시점들로부터의 임의의 필요한 기준 화상들을 디코딩하고, 디코딩된 시점(590)을 텔레비전(도시되지 않음) 상에서의 디스플레이를 위해 제공한다.
위의 응용예를 계속 살펴보면, 사용자는 디스플레이되는 시점을 전환하기를 원할 수 있고, 이후 디코더(510)에 새로운 입력을 제공할 수 있다. 사용자로부터 "시점 변경"을 수신한 후, 디코더(510)는 이전의 시점과 새로운 시점뿐만 아니라 이전의 시점과 새로운 시점 사이에 있는 임의의 시점들을 디코딩한다. 즉, 디코더(510)는 이전의 시점을 취하는 카메라와 새로운 시점을 취하는 카메라 사이에 물리적으로 위치한 카메라들로부터 취해지는 임의의 시점들을 디코딩한다. 프론트엔드 장치(505)는 또한 이전의 시점, 새로운 시점 및 그 사이의 시점들을 식별하는 정보를 수신한다. 이러한 정보는 예컨대 시점들의 위치들에 관한 정보를 갖는 제어기(도 5에 도시되지 않음) 또는 디코더(510)에 의해 제공될 수 있다. 다른 구현예들은 프론트엔드 장치와 통합된 제어기를 갖는 프론트엔드 장치를 사용할 수 있다.
디코더(510)는 이러한 디코딩된 시점들 전부를 출력(590)으로서 제공한다. 후처리기(도 5에 도시되지 않음)는 시점들 사이를 내삽(interpolate)하여 이전의 시점과 새로운 시점 사이의 부드러운 전환을 제공하고, 이러한 전환을 사용자에게 디스플레이한다. 새로운 시점으로 전환한 후에, 후처리기는 (도시되지 않은 하나 이상의 통신 링크를 통해) 디코더(510) 및 프론트엔드 장치(505)에게 새로운 시점만이 필요함을 알린다. 이후, 디코더(510)는 출력(590)으로서 새로운 시점만을 제공한다.
시스템(500)은 이미지들의 시퀀스의 복수의 시점을 수신하고, 디스플레이를 위해 단일 시점을 제시하며, 부드러운 방식으로 다양한 시점 사이를 전환하는 데 사용될 수 있다. 부드러운 방식은 다른 시점으로 이동하기 위해 시점들 사이를 내삽하는 것을 수반할 수 있다. 또한, 시스템(500)은 사용자가 객체 또는 장면을 회전하거나 또는 그렇지 않으면 객체 또는 장면의 3차원 표현을 보도록 할 수 있다. 객체의 회전은 예컨대 시점들 간의 부드러운 전환을 얻기 위해, 또는 단순히 3차원 표현을 얻기 위해 시점에서 시점으로 이동하거나 시점들 사이를 내삽하는 것에 대응할 수 있다. 즉, 사용자는 내삽된 시점을 디스플레이될 "시점"으로서 "선택"할 수 있다.
다시점 비디오 코딩(예컨대 H.264/MPEG-4 AVC 또는 다른 표준들뿐만 아니라 비표준 접근법들에 대한 MVC 확장)은 자유 시점 및 3D 비디오 응용예들, 홈 엔터테인먼트 및 감시를 포함하는 다양한 응용예에 이바지하는 주요 기술이다. 또한, 깊이 데이터는 전형적으로 각 시점과 연관된다. 깊이 데이터는 예컨대 시점 합성에 사용된다. 이러한 다시점 응용예들에서, 수반되는 비디오 및 깊이 데이터의 양은 일반적으로 막대하다. 따라서, 예컨대 독립적인 시점들의 동시 방송(simulcast)을 수행하는 현재의 비디오 코딩 솔루션들의 코딩 효율 개선을 돕는 프레임워크에 대한 요구가 존재한다.
다시점 비디오 소스는 동일한 장면의 복수의 시점을 포함하기 때문에, 복수의 시점 이미지들 사이에 고도의 상관 관계가 존재한다. 따라서, 시간적 중복 외에 시점 중복이 활용될 수 있고, 이는 상이한 시점들에 걸쳐 시점 예측을 수행함으로써 달성된다.
현실적인 시나리오에서, 다시점 비디오 시스템들은 성기게 배치된 카메라들을 사용하여 장면을 포착할 것이고, 이후 이러한 카메라들 사이의 시점들은 가용 깊이 데이터 및 포착된 시점들을 사용하여 시점 합성/내삽에 의해 생성될 수 있다.
또한, 일부 시점들은 깊이 정보만을 지닐 수 있고, 이에 후속하여 이러한 시점들에 대한 화소값들은 연관된 깊이 데이터를 사용하여 디코더에서 합성된다. 깊이 데이터는 또한 중간 가상 시점들을 생성하는 데 사용될 수 있다. 깊이 데이터는 비디오 신호와 함께 송신되므로, 데이터의 양이 증가한다. 따라서, 깊이 데이터를 효율적으로 압축하기 위한 요구가 생겨난다.
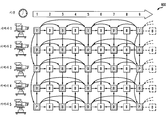
다양한 방법이 깊이 압축에 사용될 수 있다. 예컨대, 하나의 기법은 상이한 깊이들의 상이한 중요성을 반영하기 위해 ROI(Region of Interest) 기반 코딩 및 깊이의 동적 범위의 재정형(reshaping)을 사용한다. 다른 기법은 깊이 신호에 대한 삼각망(triangular mesh) 표현을 사용한다. 다른 기법은 층을 이룬 깊이 이미지들을 압축하기 위한 방법을 사용한다. 다른 기법은 웨이블릿(wavelet) 영역에서 깊이 맵들을 코딩하기 위한 방법을 사용한다. 계층적 예측 구조 및 시점간 예측은 컬러 비디오에 유용한 것으로 잘 알려져 있다. 계층적 예측 구조를 사용하는 시점간 예측은 도 6에 도시된 바와 같은 깊이 맵 시퀀스들을 코딩하는 데 추가적으로 적용될 수 있다. 특히, 도 6은 시간적 및 시점간 예측 모두를 위한 계층적 B 화상들을 갖는 다시점 코딩 구조를 도시하는 도면이다. 도 6에서, 왼쪽으로부터 오른쪽으로 또는 오른쪽으로부터 왼쪽으로 향하는 화살표들은 시간적 예측을 가리키며, 위로부터 아래로 또는 아래로부터 위로 향하는 화살표들은 시점 예측을 가리킨다.
컬러 비디오와 독립하여 깊이 시퀀스를 인코딩하는 대신, 구현예들은 대응하는 컬러 비디오로부터의 움직임 정보를 재사용할 수 있는데, 이는 깊이 시퀀스가 종종 동일한 시간적인 움직임을 공유할 가능성이 많기 때문에 유용할 수 있다.
FTV(Free-viewpoint TV)는 다시점 비디오에 대한 코딩된 표현 및 깊이 정보를 포함하고 수신기에서의 고품질 중간 시점들의 생성을 목표로 하는 프레임워크이다. 이는 자유 시점 기능 및 자동 다중 시야(auto-multiscopic) 디스플레이들에 대한 시점 생성을 가능하게 한다.
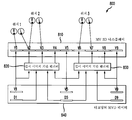
도 7은 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는, 깊이 정보를 갖는 다시점 비디오를 송신 및 수신하기 위한 시스템(700)을 도시한다. 도 7에서, 비디오 데이터는 실선으로 표시되고, 깊이 데이터는 파선으로 표시되며, 메타 데이터는 점선으로 표시된다. 시스템(700)은 예컨대 자유 시점 텔레비전 시스템일 수 있지만, 이에 한정되지 않는다. 송신기 측(710)에서, 시스템(700)은 복수의 소스 각각으로부터 비디오, 깊이 및 메타 데이터 중 하나 이상을 수신하기 위한 복수의 입력을 갖는 3차원(3D) 컨텐트 생성기(720)를 포함한다. 이러한 소스들은 스테레오 카메라(711), 깊이 카메라(712), 다중 카메라 설정(713) 및 2차원/3차원(2D/3D) 변환 프로세스들(714)을 포함할 수 있지만, 이에 한정되지 않는다. 하나 이상의 네트워크(730)가 다시점 비디오 코딩(MVC) 및 디지털 비디오 방송(Digital Video Broadcasting; DVB)과 관련된 비디오, 깊이 및 메타 데이터 중 하나 이상을 송신하는 데 사용될 수 있다.
수신기 측(740)에서, 깊이 이미지 기반 렌더러(renderer)(750)는 깊이 이미지 기반 렌더링을 수행하여 신호를 다양한 유형의 디스플레이들에 투영한다. 이러한 응용 시나리오는 좁은 각도 획득(20도 미만)과 같은 특정한 제약들을 부과할 수 있다. 깊이 이미지 기반 렌더러(750)는 구성 정보 및 사용자 기호를 수신할 수 있다. 깊이 이미지 기반 렌더러(750)의 출력은 2D 디스플레이(761), M 시점 3D 디스플레이(762) 및/또는 머리 추적(head-tracked) 스테레오 디스플레이(763) 중 하나 이상에 제공될 수 있다.
송신될 데이터의 양을 감소시키기 위해, 조밀한 배열의 카메라들(V1, V2,...,V9)이 서브샘플링(sub-sample)될 수 있고, 성긴 집합의 카메라들만이 실제로 장면을 포착한다. 도 8은 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는, 깊이를 갖는 3개의 입력 시점(K=3)으로부터 9개의 출력 시점(N=9)을 생성하기 위한 프레임워크(800)를 도시한다. 프레임워크(800)는 복수의 시점의 출력을 지원하는 자동 스테레오 시야 3D 디스플레이(810), 제1 깊이 이미지 기반 렌더러(820), 제2 깊이 이미지 기반 렌더러(830) 및 디코딩된 데이터를 위한 버퍼(840)를 수반한다. 디코딩된 데이터는 MVD(Multiple View plus Depth) 데이터로 알려진 표현이다. 9개의 카메라는 V1 내지 V9로 표기된다. 3개의 입력 시점에 대한 대응하는 깊이 맵들은 D1, D5 및 D9로 표기된다. 포착되는 카메라 위치들(예컨대 위치 1, 위치 2, 위치 3) 사이의 실질적으로 어떠한 카메라 위치도 도 8에 도시된 바와 같은 가용 깊이 맵들(D1, D5, D9)을 사용하여 생성될 수 있다.
본 명세서에 기술된 적어도 하나의 구현예에서, 깊이 신호의 코딩 효율 개선 문제에 대처하는 것을 제안한다.
도 9는 본 발명의 원리들의 실시예에 따라 본 발명의 원리들이 적용될 수 있는 깊이 맵(900)을 도시한다. 특히, 깊이 맵(900)은 시점 0에 대한 것이다. 도 9로부터 볼 수 있는 바처럼, 깊이 신호는 많은 영역에서 상대적으로 평탄한데(음영은 깊이를 나타내고, 일정한 음영은 일정한 깊이를 나타냄), 이는 많은 영역이 현저히 변하지 않는 깊이값을 가짐을 의미한다. 이미지 내에는 많은 부드러운 영역들이 존재한다. 그 결과, 깊이 신호는 상이한 영역들에서 상이한 해상도들로 코딩될 수 있다.
깊이 이미지를 생성하기 위해, 하나의 방법은 먼저 변이 이미지를 계산하고 이를 투영 행렬에 기초하여 깊이 이미지로 변환하는 단계를 수반한다. 일 구현예에서, 변이 이미지에 대한 변이의 단순한 선형 매핑은 다음과 같이 표현된다.

여기서 d는 변이이고, dmin 및 dmax는 변이 범위이며, Y는 변이 이미지의 화소값이다. 이러한 구현예에서, 변이 이미지의 화소값은 0 내지 255의 범위에 속한다.
(1) 카메라가 1차원 병렬식으로 배열되어 있고, (2) 다시점 시퀀스들이 잘 조정(rectify)되어 있으며(즉, 회전 행렬이 모든 시점에 대해 동일하고, 초점 거리가 모든 시점에 대해 동일하며, 모든 시점의 주점들이 기준선에 평행한 선을 따라 존재함), (3) 모든 카메라 좌표들의 x 축이 모두 기준선을 따라 존재한다고 가정하면, 깊이와 변이의 관계는 아래의 식으로 단순화될 수 있다. 아래는 3D 지점과 카메라 좌표 사이의 깊이값을 계산하도록 수행된다.

여기서 f는 초점 거리이고, l은 기준선에 따른 평행 이동의 양이며, du는 기준선에 따른 주점 사이의 차이이다.
수학식 2로부터, 변이 이미지가 이것의 깊이 이미지와 동일하다는 점이 도출될 수 있으며, 진정한 깊이값이 아래와 같이 복구될 수 있다.

여기서, Y는 변이/깊이 이미지의 화소값이고, Znear 및 Zfar는 아래와 같이 계산되는 깊이 범위이다.

수학식(1)에 기초하는 깊이 이미지는 각 화소에 대한 깊이 레벨을 제공하고, 진정한 깊이값은 수학식 3을 사용하여 도출될 수 있다. 진정한 깊이값을 재구축하기 위해, 디코더는 깊이 이미지 자체 외에도 Znear 및 Zfar를 사용한다. 이러한 깊이값은 3D 재구축에 사용될 수 있다.
종래의 비디오 코딩에서는, 화상이 몇몇 매크로블록(MB)들로 이루어진다. 이후 각 MB는 특정한 코딩 모드로 코딩된다. 모드는 상호(inter) 또는 내부(intra) 모드일 수 있다. 또한, 매크로블록들은 서브매크로블록 모드들로 분할될 수 있다. AVC 표준을 살펴보면, 예컨대 내부 16x16, 내부 4x4, 내부 8x8, 상호 16x16에서 상호 4x4에 이르는 몇몇 매크로블록 모드가 존재한다. 일반적으로, 큰 구획들이 부드러운 영역들 또는 더 큰 객체들에 사용된다. 더 작은 구획들이 객체 경계들 및 미세한 텍스처(texture)를 따라 더 사용될 수 있다. 각 내부 매크로블록은 연관된 내부 예측 모드를 갖고, 상호 매크로블록은 움직임 벡터들을 갖는다. 각 움직임 벡터는 2개의 성분 x 및 y를 갖는데, 이는 기준 이미지에서의 현재의 매크로블록의 변위(displacement)를 나타낸다. 이러한 움직임 벡터들은 현재의 매크로블록의 하나의 화상으로부터 다른 화상으로의 움직임을 나타낸다. 기준 화상이 시점간 화상인 경우, 움직임 벡터는 변이를 나타낸다.
적어도 하나의 구현예에서, (상호 매크로블록들의 경우에) 움직임 벡터의 2개의 성분(mvx, mvy) 외에도, 현재의 매크로블록 또는 서브매크로블록에 대한 깊이를 나타내는 추가적인 성분(깊이)이 송신된다. 내부 매크로블록들에 대해, 내부 예측 모드 외에도 추가적인 깊이 신호가 송신된다. 송신되는 깊이 신호의 양은 매크로블록 유형(16x16, 16x8, 8x16, ... , 4x4)에 의존한다. 이것의 배후에 있는 근거는 이것이 일반적으로 부드러운 영역들에 대해 매우 낮은 해상도의 깊이를 코딩하고 객체 경계들에 대해 더 높은 해상도의 깊이를 코딩하기에 충분하다는 점이다. 이는 움직임 구획들의 속성들에 대응한다. 깊이 신호 내의 객체 경계들(특히 더 낮은 깊이 범위들에 있음)은 비디오 신호 내의 객체 경계들과 상관 관계를 갖는다. 따라서, 비디오 신호에 대한 이러한 객체 경계들을 코딩하기 위해 선택되는 매크로블록 모드들은 대응하는 깊이 신호에도 적합할 것임이 예상될 수 있다. 본 명세서에 기술되는 적어도 하나의 구현예는, 본 명세서에 기술된 바처럼 특히 객체 경계들에 있는 비디오 신호의 특성들과 밀접한 관련이 있는 깊이 신호의 특성에 기초하여 깊이의 해상도를 적응적으로 코딩하는 것을 가능하게 한다. 깊이 신호를 디코딩한 후에, 깊이 신호를 다시 이것의 전체 해상도로 내삽한다.
깊이 신호들이 더 낮은 해상도들로 서브샘플링된 후 0차 홀드(zero-order hold)에 의해 업샘플링(up-sample)되는 경우 어떻게 보일지에 관한 예가 도 10, 11 및 12에 도시된다. 특히, 도 10은 1/4 해상도에 상당하는 깊이 신호(1000)를 도시하는 도면이다. 도 11은 1/8 해상도에 상당하는 깊이 신호(1100)를 도시하는 도면이다. 도 12는 1/16 해상도에 상당하는 깊이 신호(1200)를 도시하는 도면이다.
도 13 및 14는 깊이 신호를 포함하는 비디오 데이터를 각각 인코딩 및 디코딩하기 위한 방법들의 예들을 도시한다.
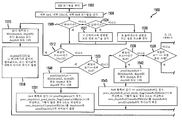
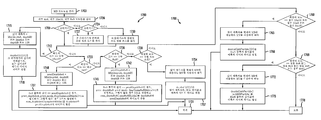
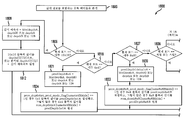
특히, 도 13은 본 발명의 원리들의 실시예에 따라, 깊이 신호를 포함하는 비디오 데이터를 인코딩하기 위한 방법(1300)을 도시하는 흐름도이다. 단계(1303)에서, 인코더 구성 파일이 판독되고, 각 시점에 대한 깊이 데이터가 이용 가능하게 된다. 단계(1306)에서, 앵커(anchor) 및 비 앵커 화상 기준들이 SPS 확장 내에 설정된다. 단계(1309)에서, N은 시점의 개수로 설정되고, 변수 i 및 j가 0으로 초기화된다. 단계(1312)에서, i<N인지 여부가 결정된다. 그러한 경우, 제어가 단계(1315)로 전달된다. 그렇지 않은 경우, 제어가 단계(1339)로 전달된다.
단계(1315)에서, j가 시점 i 내의 화상의 개수(num)보다 작은지 여부가 결정된다. 그러한 경우, 제어가 단계(1318)로 전달된다. 그렇지 않은 경우, 제어가 단계(1351)로 전달된다.
단계(1318)에서, 현재의 매크로블록의 인코딩이 개시된다. 단계(1321)에서, 매크로블록 모드들이 검사된다. 단계(1324)에서, 현재의 매크로블록이 인코딩된다. 단계(1327)에서, 깊이 신호가 화소 복제(pixel replication) 또는 복소 필터링(complex filtering)을 사용하여 재구축된다. 단계(1330)에서, 모든 매크로블록이 인코딩되었는지 여부가 결정된다. 그러한 경우, 제어가 단계(1333)로 전달된다. 그렇지 않은 경우, 제어가 단계(1315)로 복귀된다.
단계(1333)에서, 변수 j가 증가된다. 단계(1336)에서, frame_num 및 POC가 증가된다.
단계(1339)에서, SPS, PPS 및/또는 VPS를 대역 내 시그널링(in-band signal)할지 여부가 결정된다. 그러한 경우, 제어가 단계(1342)로 전달된다. 그렇지 않은 경우, 제어가 단계(1345)로 전달된다.
단계(1342)에서, SPS, PPS 및/또는 VPS가 대역 내 시그널링된다.
단계(1345)에서, SPS, PPS 및/또는 VPS가 대역 외(out-of-band) 시그널링된다.
단계(1348)에서, 비트스트림이 파일에 기록되거나 네트워크 상에서 스트리밍된다. 인코더(310)에 관한 논의에서 기술된 것과 같은 조립 유닛이 비트스트림을 조립하고 기록하는 데 사용될 수 있다.
단계(1351)에서, 변수 i가 증가되고, frame_num 및 POC가 재설정된다.
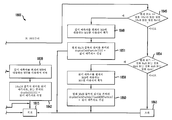
도 14는 본 발명의 원리들의 실시예에 따라, 깊이 신호를 포함하는 비디오 데이터를 디코딩하기 위한 방법(1400)을 도시하는 흐름도이다. 단계(1403)에서, view_id가 SPS, PPS, VPS, 슬라이스 헤더(slice header) 및/또는 NAL(Network Abstraction Layer) 유닛 헤더로부터 분석된다. 단계(1406)에서, 다른 SPS 파라미터들이 분석된다. 단계(1409)에서, 현재의 화상이 디코딩을 필요로 하는지 여부가 결정된다. 그러한 경우, 제어가 단계(1412)로 전달된다. 그렇지 않은 경우, 제어가 단계(1448)로 전달된다.
단계(1412)에서, POC(현재)가 POC(이전)과 같지 않은지 여부가 결정된다. 그러한 경우, 제어가 단계(1415)로 전달된다. 그렇지 않은 경우, 제어가 단계(1418)로 전달된다.
단계(1415)에서, view_num이 0으로 설정된다.
단계(1418)에서, view_id 정보는 시점 코딩 순서를 결정하도록 고레벨에서 색인되고, view_num이 증가된다.
단계(1421)에서, 현재의 화상(pic)이 예상 코딩 순서에 있는지 여부가 결정된다. 그러한 경우, 제어가 단계(1424)로 전달된다. 그렇지 않은 경우, 제어가 단계(1451)로 전달된다.
단계(1424)에서, 슬라이스 헤더가 분석된다. 단계(1427)에서, 매크로블록(MB) 모드, 움직임 벡터(mv), ref_idx 및 depthd가 분석된다. 단계(1430)에서, 현재의 블록에 대한 깊이값이 depthd에 기초하여 재구축된다. 단계(1433)에서, 현재의 매크로블록이 디코딩된다. 단계(1436)에서, 재구축된 깊이가 가능하게는 화소 복제 또는 복소 필터링에 의해 필터링된다. 단계(1436)는 재구축된 깊이값을 사용하여 화소당 깊이 맵(per-pixel depth map)을 선택적으로 획득한다. 단계(1436)는 예컨대 깊이값과 연관된 모든 화소에 대한 깊이값을 반복하거나, 또는 외삽(extrapolation) 및 내삽을 포함하는 알려진 방식들로 깊이값을 필터링하는 것과 같은 동작들을 사용할 수 있다.
단계(1439)에서, 모든 매크로블록들이 처리되었는지(디코딩되었는지)가 결정된다. 그러한 경우, 제어가 단계(1442)로 전달된다. 그렇지 않은 경우, 제어가 단계(1427)로 복귀된다.
단계(1442)에서, 현재의 화상 및 재구성된 깊이가 디코딩된 화상 버퍼(Decoded Picture Buffer; DPB) 내로 삽입된다. 단계(1445)에서, 모든 화상이 디코딩되었는지 여부가 결정된다. 그러한 경우, 디코딩이 종결된다. 그렇지 않은 경우, 제어가 단계(1424)로 복귀된다.
단계(1448)에서, 다음 화상이 획득된다.
단계(1451)에서, 현재의 화상이 숨겨진다.
실시예1
제1 실시예의 경우, AVC 디코더에 대한 슬라이스 계층, 매크로블록 계층 및 서브매크로블록 구문에 대한 수정치들이 표 1, 표 2 및 표 3에 각각 도시된다. 표들로부터 볼 수 있는 바처럼, 각 매크로블록 유형은 연관된 깊이값을 갖는다. 표 1 내지 3의 다양한 부분이 이탤릭체로 강조되어 있다. 따라서, 여기에서는 각 매크로블록 유형에 대해 깊이가 어떻게 발송되는지를 상술한다.



넓게 말해, AVC에는 2개의 매크로블록 유형이 존재한다. 하나의 매크로블록 유형은 내부 매크로블록이고, 다른 매크로블록 유형은 상호 매크로블록이다. 이들 둘 각각은 몇몇 상이한 서브매크로블록 모드로 더 하위 분할된다.
내부 매크로블록들
내부 매크로블록의 코딩을 살펴보자. 내부 매크로블록은 내부 4x4, 내부 8x8, 또는 내부 16x16 유형일 수 있다.
내부 4x4
매크로블록 유형이 내부 4x4인 경우, 내부 4x4 예측 모드를 코딩하는 데 사용된 것과 유사한 방법을 따른다. 표 2로부터 볼 수 있는 바처럼, 2개의 값을 송신하여 각각의 4x4 블록에 대한 깊이를 시그널링한다. 2개의 구문에 관한 의미는 아래와 같이 지정된다.
prev_depth4x4_pred_mode_flag[luma4x4Blkldx] 및 rem_depth4x4[luma4x4Blkldx]는 색인 luma4x4Blkldx=0..15를 갖는 4x4 블록의 깊이 예측을 지정한다.
Depth4x4[luma4x4Blkldx]는 아래의 절차를 적용함으로써 도출된다.
predDepth4x4 = Min( depthA, depthB )
mbA가 존재하지 않는 경우, predDepth4x4 = depthB
mbB가 존재하지 않는 경우, predDepth4x4 = depthA
mbA 및 mbB가 존재하지 않는 경우, predDepth4x4 = 128
prev_depth4x4_pred_mode_flag[luma4x4Blkldx]인 경우,
Depth4x4[luma4x4Blkldx] = predDepth4x4
그렇지 않은 경우,
Depth4x4[luma4x4Blkldx]=predDepth4x4+rem_depth4x4[luma4x4Blkldx]
여기서 depthA는 왼쪽에 이웃하는 MB의 재구축된 깊이 신호이고, depthB는 위쪽에 이웃하는 MB의 재구축된 깊이 신호이다.
내부 8x8
유사한 프로세스가 내부 8x8 예측 모드를 갖는 매크로블록들에 적용되고, 4x4가 8x8에 의해 대체된다.
내부 16x16
내부 16x16 내부 예측 모드에 대해, 하나의 옵션은 현재의 매크로블록의 깊이 신호를 명시적으로 송신하는 것이다. 이는 표 2에 도시되어 있다.
이러한 경우, 표 2의 구문은 아래의 의미를 가질 것이다.
depthd[0][0]는 현재의 매크로블록에 대해 사용될 깊이값을 지정한다.
다른 옵션은 내부 4x4 예측 모드와 유사한 인접 깊이값들과 대비되는 차이값을 송신하는 것이다.
내부 16x16 예측 모드를 갖는 매크로블록에 대한 깊이값을 획득하기 위한 프로세스는 아래와 같이 지정될 수 있다.
predDepth16x16 = Min( depthA, depthB )
mbA가 존재하지 않는 경우, predDepth16x16 = depthB
mbB가 존재하지 않는 경우, predDepth16x16 = depthA
mbA 및 mbB가 존재하지 않는 경우, predDepth16x16 = 128
depth 16x16 = predDepth16x16 + depthd[0][0]
이러한 경우, 표 2의 구문에 대한 의미는 아래와 같이 지정될 것이다.
depth[0][0]은 현재의 매크로블록에 대해 사용될 깊이값과 이것의 예측값 사이의 차이를 지정한다.
상호 매크로블록들
AVC 사양에 지정된 몇몇 유형의 상호 매크로블록과 서브매크로블록 모드들이 존재한다. 따라서, 각각의 경우에 대해 깊이가 어떻게 송신되는지를 지정한다.
직접 MB 또는 스킵(skip) MB
스킵 매크로블록의 경우 단일 플래그(flag) 만이 발송되는데, 그 까닭은 매크로블록과 연관된 다른 데이터가 존재하지 않기 때문이다. 모든 정보가 공간적인 이웃으로부터 도출된다(사용되지 않는 잔차 정보는 제외). 직접 매크로블록의 경우, 잔차 정보만이 발송되고, 다른 데이터는 공간적 또는 시간적 이웃으로부터 도출된다.
이러한 두 모드에 대해, 깊이 신호를 복구하는 두 가지 옵션이 존재한다.
옵션 1
깊이 차이를 명시적으로 송신할 수 있다. 이는 표 1에 도시된다. 이후 깊이는 내부 16x16 모드와 유사한 자신의 이웃으로부터의 예측값을 사용함으로써 복구된다.
깊이값의 예측값(predDepthSkip)은 아래와 같이 AVC 사양에서 움직임 벡터 예측에 대해 지정된 프로세스와 유사한 프로세스를 따른다.
DepthSkip=predDepthSkip+depthd[0][0]
이러한 경우, 표 2의 구분에 대한 의미는 아래와 같이 지정될 것이다.
depthd[0][0]는 현재의 매크로블록에 대해 사용될 깊이값과 이것의 예측값 사이의 차이를 지정한다.
옵션 2
그 대신, 매크로블록에 대한 예측값으로서 예측 신호를 직접 사용할 수 있다. 따라서, 깊이 차이를 송신하는 것을 피할 수 있다. 예컨대, 표 1의 depthd[0][0]의 명시적인 구문 요소들이 회피될 수 있다.
따라서, 아래와 같이 될 것이다.
DepthSkip=predDepthSkip
상호 16x16, 16x8, 8x16 MB
상호 예측 모드들의 경우, 각 구획에 대한 깊이값을 송신한다. 이는 표 2에 도시된다. 구문 depthd[mbPartldx][0]을 시그널링한다.
구획에 대한 최종 깊이는 아래와 같이 도출된다.
DepthSkip = predDepthSkip + depthd[mbPartldx][O]
여기서 깊이값의 예측값(predDepthSkip)은 AVC 사양에서 움직임 벡터 예측에 대해 지정된 프로세스와 유사한 프로세스를 따른다.
depthd[mbPartldx][0]에 대한 의미는 아래와 같이 지정된다.
depthd[mbPartldx][0]는 사용될 깊이값과 이것의 예측값 사이의 차이를 지정한다. 색인 mbPartldx는 어느 매크로블록 구획에 depthd가 할당되는지를 지정한다. 매크로블록의 구획은 mb_type에 의해 지정된다.
서브매크로블록 모드들(8x8, 8x4, 4x8, 4x4)
이러한 상호 예측 모드들의 경우, 각 구획에 대한 깊이값을 송신한다. 이는 표 3에 도시된다. 구문 depthd[mbPartldx][subMbPartldx]을 시그널링한다.
구획에 대한 최종 깊이는 아래와 같이 도출된다.
DepthSkip = predDepthSkip + depthd[mbPartldx][subMbPartldx]
여기서 깊이값의 예측값(predDepthSkip)은 AVC 사양에서 움직임 벡터 예측에 대해 지정된 프로세스와 유사한 프로세스를 따른다.
depthd[mbPartldx][subMbPartldx]에 대한 의미는 아래와 같이 지정된다.
depthd[mbPartldx][subMbPartldx]는 사용될 깊이값과 이것의 예측값 사이의 차이를 지정한다. 이는 subMbPartldx를 갖는 서브매크로블록 구획 색인에 적용된다. 색인 mbPartldx 및 subMbPartldx는 어느 매크로블록 구획 및 서브매크로블록 구획에 depthd가 할당되는지를 지정한다.
도 15 및 16은 실시예 1에 따른 깊이 신호를 포함하는 비디오 데이터를 각각 인코딩 및 디코딩하기 위한 방법들의 예들을 도시한다.
특히, 도 15는 제1 실시예(실시예 1)에 따라 깊이 신호를 포함하는 비디오 데이터를 인코딩하기 위한 방법(1500)을 도시하는 흐름도이다. 단계(1503)에서, 매크로블록 모드들이 검사된다. 단계(1506)에서, 내부 4x4, 내부 16x16 및 내부 8x8 모드들이 검사된다. 단계(1509)에서, 현재의 슬라이스가 I 슬라이스인지 여부가 결정된다. 그러한 경우, 제어가 단계(1512)로 전달된다. 그렇지 않은 경우, 제어가 단계(1524)로 전달된다.
단계(1512)에서, 최상의 모드가 내부 16x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1515)로 전달된다. 그렇지 않은 경우, 제어가 단계(1533)로 전달된다.
단계(1515)에서, 깊이 예측자(depth predictor)는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1518)에서, depthd[0][0]은 그 위치에서의 깊이의 절대값으로, 또는 깊이값과 예측자 사이의 차이로 설정된다. 단계(1521)에서, 복귀가 이루어진다.
단계(1524)에서, 현재의 슬라이스가 P 슬라이스인지 여부가 결정된다. 그러한 경우, 제어가 단계(1527)로 전달된다. 그렇지 않은 경우, 제어가 단계(1530)로 전달된다.
단계(1527)에서, P 슬라이스와 관련된 모든 상호 모드가 검사된다.
단계(1530)에서, B 슬라이스와 관련된 모든 상호 모드가 검사된다.
단계(1533)에서, 최상의 모드가 내부 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1548)로 전달된다. 그렇지 않은 경우, 제어가 단계(1536)로 전달된다.
단계(1548)에서, predDepth4x4는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1551)에서, 4x4 블록의 깊이가 predDepth4x4와 같은 경우, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]=1로 설정한다. 그렇지 않은 경우, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]=0으로 설정하고, rem_depth4x4[luma4x4Blkldx]를 depth4x4와 predDepth4x4의 차이로서 발송한다.
단계(1536)에서, 최상의 모드가 내부 8x8인지 여부가 결정된다. 그러한 경우, 제어가 단계(1542)로 전달된다. 그렇지 않은 경우, 제어가 단계(1539)로 전달된다.
단계(1542)에서, predDepth8x8=Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1545)에서, 8x8 블록의 깊이가 predDepth8x8과 같은 경우, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]=1로 설정한다. 그렇지 않은 경우, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]=0으로 설정하고, rem_depth8x8[luma8x8Blkldx]를 depth8x8과 predDepth8x8의 차이로서 발송한다.
단계(1539)에서, 최상의 모드가 직접 또는 스킵인지 여부가 결정된다. 그러한 경우, 제어가 단계(1554)로 전달된다. 그렇지 않은 경우, 제어가 단계(1560)로 전달된다.
단계(1554)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1557)에서, depthd[0][0]은 깊이 예측자로, 또는 깊이값과 예측자 사이의 차이로 설정된다.
단계(1560)에서, 최상의 모드가 상호 16x16 또는 상호 16x8 또는 상호 8x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1563)로 전달된다. 그렇지 않은 경우, 제어가 단계(1569)로 전달된다.
단계(1563)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1566)에서, depthd[mbPartldc][0]은 MxN 블록의 깊이값과 예측자 사이의 차이로 설정된다.
단계(1569)에서, 최상의 모드가 상호 8x8 또는 상호 8x4 또는 상호 4x8 또는 상호 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1572)로 전달된다. 그렇지 않은 경우, 제어가 단계(1578)로 전달된다.
단계(1572)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1575)에서, depthd[mbPartldx][subMBPartldx]은 MxN 블록의 깊이값과 예측자 사이의 차이로 설정된다.
단계(1578)에서 오류가 표시된다.
도 16은 제1 실시예(실시예 1)에 따라 깊이 신호를 포함하는 비디오 데이터를 디코딩하기 위한 방법(1600)을 도시하는 흐름도이다. 단계(1603)에서, 깊이 정보를 포함하는 블록 헤더들이 분석된다. 단계(1606)에서, 현재(curr) 모드가 내부 16x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1609)로 전달된다. 그렇지 않은 경우, 제어가 단계(1618)로 전달된다.
단계(1609)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1612)에서, 16x16 블록의 깊이는 depthd[0][0]으로, 또는 분석된 depthd[0][0] + 깊이 예측자로 설정된다. 단계(1615)에서, 복귀가 이루어진다.
단계(1618)에서, 현재 모드가 내부 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1621)로 전달된다. 그렇지 않은 경우, 제어가 단계(1627)로 전달된다.
단계(1621)에서, predDepth4x4는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1624)에서, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]가 1인 경우, 4x4 블록의 깊이는 predDepth4x4로 설정된다. 그렇지 않은 경우, 4x4 블록의 깊이는 rem_depth4x4[luma4x4Blkldx] + predDepth4x4로 설정된다.
단계(1627)에서, 현재 모드가 내부 8x8인지 여부가 결정된다. 그러한 경우, 제어가 단계(1630)로 전달된다. 그렇지 않은 경우, 제어가 단계(1636)로 전달된다.
단계(1630)에서, predDepth[delta]x8는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1633)에서, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]가 1인 경우, 8x8 블록의 깊이는 predDepth8x8로 설정된다. 그렇지 않은 경우, 8x8 블록의 깊이는 rem_depth8x8[luma8x8Blkldx] + predDepth8x8로 설정된다.
단계(1636)에서, 현재 모드가 직접 또는 스킵인지 여부가 결정된다. 그러한 경우, 제어가 단계(1639)로 전달된다. 그렇지 않은 경우, 제어가 단계(1645)로 전달된다.
단계(1639)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1642)에서, 16x16 블록의 깊이는 깊이 예측자로, 또는 분석된 depthd[0][0] + 깊이 예측자로 설정된다.
단계(1645)에서, 현재 모드가 상호 16x16 또는 상호 16x8 또는 상호 8x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1648)로 전달된다. 그렇지 않은 경우, 제어가 단계(1654)로 전달된다.
단계(1648)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1651)에서, 현재 MxN 블록의 깊이는 분석된 depthd[mbPartldx][0] + 깊이 예측자로 설정된다.
단계(1654)에서, 현재 모드가 상호 8x8 또는 상호 8x4 또는 상호 4x8 또는 상호 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1659)로 전달된다. 그렇지 않은 경우, 제어가 단계(1663)로 전달된다.
단계(1659)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1660)에서, 현재 MxN 블록의 깊이는 분석된 depthd[mbPartldc][subMBPartldx] + 깊이 예측자로 설정된다.
단계(1663)에서 오류가 표시된다.
실시예 2
이 실시예에서, 상호 블록들에 대한 움직임 정보에 의해 깊이 신호를 예측하는 것을 제안한다. 움직임 정보는 비디오 신호와 연관된 것과 동일하다. 내부 블록들에 대한 깊이는 실시예 1과 동일하다. 움직임 벡터 정보를 사용하여 predDepthSkip를 도출하는 것을 제안한다. 따라서, 전체 해상도 깊이 신호를 저장하기 위한 추가적인 기준 버퍼가 추가된다. 상호 블록들에 대한 구문 및 도출은 실시예 1과 동일하다.
일 실시예에서, predDepthSkip=DepthRef(x+mvx, y+mvy)로 설정되는데, x, y는 목표 블록의 좌측 상단의 좌표들이고, mvx 및 mvy는 비디오 신호로부터의 현재 매크로블록과 연관된 움직임 벡터의 x 및 y 성분이며, DepthRef는 디코딩된 화상 버퍼(DPB)에 저장되는 재구축된 기준 깊이 신호이다.
다른 일 실시예에서, predDepthSkip은 목표 블록에 대한 움직임 벡터에 의해 지시되는 모든 기준 깊이 화소의 평균으로 설정된다.
다른 일 실시예에서, mvx=mvy=0으로 가정할 수 있고, 따라서 함께 배치된 블록 깊이값을 예측에 사용한다. 즉, predDepthSkip = DepthRef(x, y)이다.
도 17 및 18은 실시예 2에 따라 깊이 신호를 포함하는 비디오 데이터를 각각 인코딩 및 디코딩하기 위한 방법들의 예들을 도시한다.
도 17은 제2 실시예(실시예 2)에 따라 깊이 신호를 포함하는 비디오 데이터를 인코딩하기 위한 방법(1700)을 도시하는 흐름도이다. 단계(1703)에서, 매크로블록 모드들이 검사된다. 단계(1706)에서, 내부 4x4, 내부 16x16 및 내부 8x8 모드들이 검사된다. 단계(1709)에서, 현재의 슬라이스가 I 슬라이스인지 여부가 결정된다. 그러한 경우, 제어가 단계(1712)로 전달된다. 그렇지 않은 경우, 제어가 단계(1724)로 전달된다.
단계(1712)에서, 최상의 모드가 내부 16x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1715)로 전달된다. 그렇지 않은 경우, 제어가 단계(1733)로 전달된다.
단계(1715)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1718)에서, depthd[0][0]은 그 위치에서의 깊이의 절대값으로, 또는 깊이값과 예측자 사이의 차이로 설정된다. 단계(1721)에서, 복귀가 이루어진다.
단계(1724)에서, 현재의 슬라이스가 P 슬라이스인지 여부가 결정된다. 그러한 경우, 제어가 단계(1727)로 전달된다. 그렇지 않은 경우, 제어가 단계(1730)로 전달된다.
단계(1727)에서, P 슬라이스와 관련된 모든 상호 모드가 검사된다.
단계(1730)에서, B 슬라이스와 관련된 모든 상호 모드가 검사된다.
단계(1733)에서, 최상의 모드가 내부 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1748)로 전달된다. 그렇지 않은 경우, 제어가 단계(1736)로 전달된다.
단계(1748)에서, predDepth4x4는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1751)에서, 4x4 블록의 깊이가 predDepth4x4와 같은 경우, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]=1로 설정한다. 그렇지 않은 경우, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]=0으로 설정하고, rem_depth4x4[luma4x4Blkldx]를 depth4x4와 predDepth4x4의 차이로서 발송한다.
단계(1736)에서, 최상의 모드가 내부 8x8인지 여부가 결정된다. 그러한 경우, 제어가 단계(1742)로 전달된다. 그렇지 않은 경우, 제어가 단계(1739)로 전달된다.
단계(1742)에서, predDepth8x8=Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1745)에서, 8x8 블록의 깊이가 predDepth8x8과 같은 경우, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]=1로 설정한다. 그렇지 않은 경우, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]=0으로 설정하고, rem_depth8x8[luma8x8Blkldx]를 depth8x8과 predDepth8x8의 차이로서 발송한다.
단계(1739)에서, 최상의 모드가 직접 또는 스킵인지 여부가 결정된다. 그러한 경우, 제어가 단계(1754)로 전달된다. 그렇지 않은 경우, 제어가 단계(1760)로 전달된다.
단계(1754)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1757)에서, depthd[0][0]은 깊이 예측자로, 또는 깊이값과 예측자 사이의 차이로 설정된다.
단계(1760)에서, 최상의 모드가 상호 16x16 또는 상호 16x8 또는 상호 8x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1763)로 전달된다. 그렇지 않은 경우, 제어가 단계(1769)로 전달된다.
단계(1763)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1766)에서, depthd[mbPartldc][0]은 MxN 블록의 깊이값과 예측자 사이의 차이로 설정된다.
단계(1769)에서, 최상의 모드가 상호 8x8 또는 상호 8x4 또는 상호 4x8 또는 상호 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1772)로 전달된다. 그렇지 않은 경우, 제어가 단계(1778)로 전달된다.
단계(1772)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1775)에서, depthd[mbPartldx][subMBPartldx]은 MxN 블록의 깊이값과 예측자 사이의 차이로 설정된다.
단계(1778)에서 오류가 표시된다.
도 18은 제2 실시예(실시예 12에 따라 깊이 신호를 포함하는 비디오 데이터를 디코딩하기 위한 방법(1800)을 도시하는 흐름도이다. 단계(1803)에서, 깊이 정보를 포함하는 블록 헤더들이 분석된다. 단계(1806)에서, 현재(curr) 모드가 내부 16x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1809)로 전달된다. 그렇지 않은 경우, 제어가 단계(1818)로 전달된다.
단계(1809)에서, 깊이 예측자는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1812)에서, 16x16 블록의 깊이는 depthd[0][0]으로, 또는 분석된 depthd[0][0] + 깊이 예측자로 설정된다. 단계(1815)에서, 복귀가 이루어진다.
단계(1818)에서, 현재 모드가 내부 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1821)로 전달된다. 그렇지 않은 경우, 제어가 단계(1827)로 전달된다.
단계(1821)에서, predDepth4x4는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1824)에서, prev_depth4x4_pred_mode_flag[luma4x4Blkldx]가 1인 경우, 4x4 블록의 깊이는 predDepth4x4로 설정된다. 그렇지 않은 경우, 4x4 블록의 깊이는 rem_depth4x4[luma4x4Blkldx] + predDepth4x4로 설정된다.
단계(1827)에서, 현재 모드가 내부 8x8인지 여부가 결정된다. 그러한 경우, 제어가 단계(1830)로 전달된다. 그렇지 않은 경우, 제어가 단계(1836)로 전달된다.
단계(1830)에서, predDepth[delta]x8는 Min(depthA, depthB) 또는 depthA 또는 depthB 또는 128로 설정된다. 단계(1833)에서, prev_depth8x8_pred_mode_flag[luma8x8Blkldx]가 1인 경우, 8x8 블록의 깊이는 predDepth8x8로 설정된다. 그렇지 않은 경우, 8x8 블록의 깊이는 rem_depth8x8[luma8x8Blkldx] + predDepth8x8로 설정된다.
단계(1836)에서, 현재 모드가 직접 또는 스킵인지 여부가 결정된다. 그러한 경우, 제어가 단계(1839)로 전달된다. 그렇지 않은 경우, 제어가 단계(1845)로 전달된다.
단계(1839)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1842)에서, 16x16 블록의 깊이는 깊이 예측자로, 또는 분석된 depthd[0][0] + 깊이 예측자로 설정된다.
단계(1845)에서, 현재 모드가 상호 16x16 또는 상호 16x8 또는 상호 8x16인지 여부가 결정된다. 그러한 경우, 제어가 단계(1848)로 전달된다. 그렇지 않은 경우, 제어가 단계(1854)로 전달된다.
단계(1848)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1851)에서, 현재 MxN 블록의 깊이는 분석된 depthd[mbPartldx][0] + 깊이 예측자로 설정된다.
단계(1854)에서, 현재 모드가 상호 8x8 또는 상호 8x4 또는 상호 4x8 또는 상호 4x4인지 여부가 결정된다. 그러한 경우, 제어가 단계(1859)로 전달된다. 그렇지 않은 경우, 제어가 단계(1863)로 전달된다.
단계(1859)에서, 깊이 예측자는 현재의 매크로블록(MB)에 대응하는 움직임 벡터(MV)를 사용하여 획득된다. 단계(1860)에서, 현재 MxN 블록의 깊이는 분석된 depthd[mbPartldc][subMBPartldx] + 깊이 예측자로 설정된다.
단계(1863)에서 오류가 표시된다.
도 13, 15 및 17의 실시예들은 깊이 신호를 포함하는 비디오 데이터를 인코딩할 수 있다. 깊이 신호는 인코딩될 필요가 없지만, 예컨대 차등 인코딩 및/또는 엔트로피 인코딩을 사용하여 인코딩될 수 있다. 유사하게, 도 14, 16 및 18의 실시예들은 깊이 신호를 포함하는 비디오 데이터를 디코딩할 수 있다. 도 14, 16 및 18에 의해 수신 및 디코딩되는 데이터는 예컨대 도 13, 15 또는 17의 실시예들 중 하나에 의해 제공되는 데이터일 수 있다. 도 14, 16 및 18의 실시예들은 다양한 방식으로 깊이값들을 처리할 수 있다. 이러한 처리는 구현예에 따라 예컨대 수신된 깊이값들의 분석, 깊이값들의 디코딩(깊이값들이 인코딩된 것으로 가정함) 및 깊이값들에 기초한 깊이 맵의 전부 또는 일부의 생성을 포함할 수 있다. 깊이값들을 처리하기 위한 처리 유닛은 예컨대 (1) 비트스트림 분석기(202), (2) 깊이값이 예측값으로부터의 차이인 구현예들에 대해 예측자 값을 추가시키는 것과 같은 다양한 동작을 수행할 수 있는 깊이 표현 계산기(211), (3) 깊이 맵 재구축기(212) 및 (4) 엔트로피 코딩된 깊이값들을 디코딩하기 위한 소정의 구현예들에서 사용될 수 있는 엔트로피 디코더(205)를 포함할 수 있음에 주목한다.
깊이 데이터 내삽
다양한 구현예에서, 깊이 데이터는 이것의 전체 해상도로 내삽된다. 즉, 디코더는 깊이 데이터(예컨대 단일 깊이값을 생성하도록 디코딩되는 단일 depthd 코딩된 값)를 수신하고 연관된 영역(예컨대 매크로블록 또는 서브매크로블록)에 대한 전체 화소당 깊이 맵을 생성한다. 단순한 복사(0차 내삽), 즉 동일한 값의 depthMxN(M, N=16, 8, 4)으로 블록을 채울 수 있다. 또한, 이중 선형(bilinear) 및 이중 3차(bicubic) 내삽 등과 같은 다른 더 복잡한 내삽 방법들을 적용할 수 있다. 즉, 본 발명의 원리들은 임의의 특정한 내삽 방법으로 한정되지 않고, 따라서 본 발명의 원리들의 취지를 유지하면서 임의의 내삽 방법이 본 발명의 원리들에 따라 사용될 수 있다. 필터가 내삽 전 또는 후에 적용될 수 있다.
아래의 논점들은 적어도 부분적으로 이전에 논의된 개념들을 상술할 수 있고, 다양한 구현예의 세부 사항들을 제공할 수 있다. 아래의 이러한 구현예들은 위의 구현예들에 대응할 수 있거나, 변형예들 및/또는 새로운 구현예들을 제시할 수 있다.
다른 구현예들은 3D 움직임 벡터(MV)를 제공하는 것으로 일컬어질 수 있다. 움직임 벡터는 대개 (x,y)를 갖는 2D이고, 다양한 구현예들에서 깊이("D")에 대한 단일 값이 추가되며, 깊이값은 움직임 벡터에 대한 제3 차원으로 간주될 수 있다. 그 대신 깊이는 별개의 화상으로서 코딩될 수 있는데, 이는 이후 AVC 코딩 기법들을 사용하여 인코딩될 수 있다.
위에서 지적한 바처럼, 매크로블록의 구획들은 종종 또한 깊이에 대한 만족스러운 크기를 가질 것이다. 예컨대, 평탄한 영역들은 일반적으로 큰 구획들을 잘 수용할 것인데, 그 까닭은 단일 움직임 벡터로 충분할 것이기 때문이고, 이러한 평탄한 영역들은 또한 깊이 코딩을 위한 큰 구획들도 잘 수용하는데, 그 까닭은 이들이 평탄하므로 평탄한 구획값에 대해 단일 깊이값을 사용하는 것이 일반적으로 양호한 인코딩을 제공할 것이기 때문이다. 또한, 움직임 벡터는 깊이(D) 값을 결정 또는 예측하는 데 사용하기에 좋을 수 있는 구획들을 가리킨다. 따라서, 깊이는 예측 가능하게 인코딩될 수 있다.
구현예들은 전체 구획(서브매크로블록)에 대해 깊이에 대한 단일 값을 사용할 수 있다. 다른 구현예들은 복수의 값, 또는 심지어 각 화소에 대한 별개의 값을 사용할 수 있다. 깊이에 사용되는 값(들)은 예컨대 중간값, 평균값, 또는 서브매크로블록의 깊이값들에 대한 다른 필터링 동작의 결과와 같은 다양한 방식으로 몇몇 예들에 대해 위에서 보인 바처럼 결정될 수 있다. 깊이값(들)은 또한 다른 구획들/블록들 내의 깊이의 값들에 기초할 수 있다. 이러한 다른 구획들/블록들은 동일한 화상(공간적으로 인접하거나 그렇지 않음) 내에 있거나, 다른 시점으로부터의 화상 내에 있거나, 또는 다른 시간적인 인스턴스(instance)의 동일한 시점으로부터의 화상 내에 있을 수 있다. 깊이값(들)을 다른 구획/블록으로부터의 깊이에 기초하도록 하는 것은 예컨대 외삽의 형태를 사용할 수 있고, 이러한 구획(들)/블록(들)로부터의 재구축된 깊이값들, 인코딩된 깊이값들, 또는 인코딩 전의 실제의 깊이값들에 기초할 수 있다.
깊이값 예측자들은 다양한 정보에 기초할 수 있다. 이러한 정보는 예컨대 가까운(인접하거나 그렇지 않을 수 있음) 매크로블록 또는 서브매크로블록에 대해 결정된 깊이값 및/또는 움직임 벡터에 의해 지시되는 대응하는 매크로블록 또는 서브매크로블록에 대해 결정된 깊이값을 포함한다. 소정의 실시예들의 일부 모드들에서는 단일 깊이값이 전체 매크로블록에 대해 생성되는 반면, 다른 모드들에서는 단일 깊이값이 매크로블록 내의 각 구획에 대해 생성됨에 주목한다.
본 발명의 개념은 원하는 경우 단일 매크로블록에만, 또는 화상의 임의의 부분 집합 또는 부분들에 적용될 수 있음을 이해해야 한다. 또한, 본 명세서에서 사용되는 바처럼, "화상"이라는 용어는 예컨대 프레임(frame) 또는 필드(field)일 수 있다.
AVC는 보다 구체적으로 기존의 ISO/IEC(International Organization for Standardization/International Electrotechnical Commission) MPEG-4(Moving Picture Experts Group-4) 10부 AVC(Advanced Video Coding) 표준/ITU-T(International Telecommunication Union, Telecommunication Sector) H.264 권고안(이하, "H.264/MPEG-4 AVC 표준", 또는 이것의 변형으로서 "AVC 표준" 또는 간단히 "AVC"라고 지칭됨)을 지칭한다. MVC는 전형적으로 보다 구체적으로 AVC 표준의 MVC(Multi-view Video Coding) 확장(부록 H)을 지칭하며, H.264/MPEG-4 AVC, MVC 확장("MVC 확장" 또는 간단히 "MVC")으로 일컬어진다. SVC는 전형적으로 보다 구체적으로 AVC 표준의 가변 비디오 코딩(Scalable Video Coding; SVC) 확장(부록 G)을 지칭하며, H.264/MPEG-4 AVC, SVC 확장("SVC 확장" 또는 간단히 "SVC")으로 일컬어진다.
본 출원에 기술된 구현예들 및 특징들 중 몇몇은 H.264/MPEG-4 AVC(AVC) 표준, 또는 MVC 확장을 갖는 AVC 표준, 또는 SVC 확장을 갖는 AVC 표준의 맥락에서 사용될 수 있다. 그러나, 이러한 구현예들 및 특징들은 다른 표준(기존의 또는 장래의 표준)의 맥락에서, 또는 표준을 수반하지 않는 맥락에서 사용될 수 있다.
또한, 구현예들은 SEI 메시지들, 슬라이스 헤더들, 다른 고레벨 구문, 비 고레벨 구문, 대역외 정보, 데이터스트림 데이터 및 암시적 시그널링을 포함하지만 이에 한정되지 않는 다양한 기법을 사용하여 정보를 시그널링할 수 있다. 시그널링 기법들은 표준이 사용되는지 여부에 따라, 그리고 표준이 사용되는 경우 어느 표준이 사용되는지에 따라 달라질 수 있다.
본 명세서에서 본 발명의 원리들의 "일 실시예" 또는 "하나의 실시예" 또는 "일 구현예" 또는 "하나의 구현예"뿐만 아니라 이들의 다른 변형을 참조하는 것은, 실시예와 관련하여 기술된 특정한 특징, 구조 및 특성 등이 본 발명의 원리들의 적어도 하나의 실시예에 포함됨을 의미한다. 따라서, 본 명세서 전반에 걸쳐 다양한 장소에 나타나는 "일 실시예" 또는 "하나의 실시예" 또는 "일 구현예" 또는 "하나의 구현예"와 같은 구문과 임의의 다른 변형들의 출현은 반드시 모두 동일한 실시예를 지칭하는 것이 아니다.
예컨대 "A/B", "A 및/또는 B"와 "A 및 B 중 적어도 하나"와 같은 경우에 "/", "및/또는"과 "... 중 적어도 하나" 중 임의의 것을 사용하는 것은 처음 열거된 옵션(A)만의 선택, 또는 두 번째 열거된 옵션(B)만의 선택, 또는 두 옵션들 모두(A 및 B)의 선택을 포괄하고자 하는 것임을 이해해야 한다. 추가적인 예로서, "A, B 및/또는 C"와 "A, B 및 C 중 적어도 하나"와 같은 경우에, 이러한 문구들은 처음 열거된 옵션(A)만의 선택, 또는 두 번째 열거된 옵션(B)만의 선택, 또는 세 번째 열거된 옵션(C)만의 선택, 또는 처음과 두 번째 열거된 옵션들(A 및 B)만의 선택, 또는 처음과 세 번째 열거된 옵션들(A 및 C)만의 선택, 또는 두 번째와 세 번째 열거된 옵션들(B 및 C)만의 선택, 또는 세 옵션들 모두(A 및 B 및 C)의 선택을 포괄하고자 하는 것이다. 본 기술 분야 및 관련 기술 분야의 당업자가 쉽게 알 수 있는 바처럼, 이는 많은 항목이 열거되는 경우에 대해서 확장될 수 있다.
본 명세서에 기술된 구현예들은 예컨대 방법 또는 프로세스, 장치, 소프트웨어 프로그램, 데이터 스트림, 또는 신호로 구현될 수 있다. 단일 형태의 구현예의 맥락에서만 논의되었다 하더라도(예컨대 방법으로서만 논의됨), 논의된 특징들의 구현예는 또한 다른 형태들(예컨대 장치 또는 프로그램)로 구현될 수 있다. 장치는 예컨대 적합한 하드웨어, 소프트웨어 및 펌웨어로 구현될 수 있다. 예컨대, 방법들은 일반적으로 예컨대 컴퓨터, 마이크로프로세서, 집적 회로, 또는 프로그램 가능한 로직 장치를 포함하는 처리 장치들을 지칭하는 예컨대 프로세서와 같은 장치로 구현될 수 있다. 프로세서들은 또한 예컨대 컴퓨터, 휴대 전화, PDA(Portable/Personal Digital Assistant) 및 최종 사용자들 사이의 정보 통신을 촉진시키는 다른 장치들과 같은 통신 장치들을 포함한다.
본 명세서에 기술된 다양한 프로세스 및 특징의 구현예들은 다양한 상이한 장비 또는 애플리케이션들, 특히 예컨대 데이터 인코딩 및 디코딩과 연관된 장비 또는 애플리케이션들로 구현될 수 있다. 이러한 장비의 예들은 인코더, 디코더, 디코더로부터의 출력을 처리하는 후처리기, 인코더에 입력을 제공하는 전처리기, 비디오 코더, 비디오 디코더, 비디오 코덱(codec), 비디오 서버, 셋톱박스, 랩톱, 개인용 컴퓨터, 휴대 전화, PDA 및 다른 통신 장치들을 포함한다. 명백히, 상기 장비는 이동형일 수 있고, 이동 차량에 설치될 수도 있다.
또한, 상기 방법들은 프로세서에 의해 수행되는 명령들에 의해 구현될 수 있고, 이러한 명령들(및/또는 구현예에 의해 생성되는 데이터 값들)은 예컨대 집적 회로, 소프트웨어 운반자 또는 예컨대 하드 디스크, 컴팩트 디스켓, RAM(Random Access Memory), 또는 ROM(Read-Only Memory)과 같은 다른 저장 장치와 같은 프로세서 판독 가능 매체 상에 저장될 수 있다. 상기 명령들은 프로세서 판독 가능 매체 상에 유형적으로 구현되는 애플리케이션 프로그램을 형성할 수 있다. 명령들은 예컨대 하드웨어, 펌웨어, 소프트웨어, 또는 그 결합일 수 있다. 명령들은 예컨대 운영 체제, 별개의 애플리케이션, 또는 그 둘의 결합에서 찾아볼 수 있다. 따라서, 프로세서는 예컨대 프로세스를 수행하도록 구성된 장치와 프로세스를 수행하기 위한 명령들을 갖는 프로세서 판독 가능 매체를 포함하는 장치(예컨대 저장 장치) 둘 다로서 특징지어질 수 있다. 또한, 프로세서 판독 가능 매체는 명령들에 추가하여 또는 그 대신에 구현예에 의해 생성된 데이터 값들을 저장할 수 있다.
본 기술 분야의 당업자에게 자명한 바처럼, 구현예들은 예컨대 저장 또는 송신될 수 있는 정보를 운반하기 위한 형식을 갖는 다양한 신호를 생성할 수 있다. 상기 정보는 예컨대 방법을 수행하기 위한 명령들, 또는 기술된 구현예들 중 하나에 의해 생성되는 데이터를 포함할 수 있다. 예컨대, 신호는 기술된 실시예의 구문을 기록 또는 판독하기 위한 규칙들을 데이터로서 운반하거나, 또는 기술된 실시예에 의해 기록된 실제의 구문값들을 데이터로서 운반하기 위한 형식을 가질 수 있다. 이러한 신호는 예컨대 전자기파(예컨대 스펙트럼의 무선 주파수 부분을 사용함) 또는 기저 대역 신호로서의 형식을 가질 수 있다. 형식화는 예컨대 데이터 스트림을 인코딩하고 인코딩된 데이터 스트림으로 반송파를 변조하는 것을 포함할 수 있다. 신호가 운반하는 정보는 예컨대 아날로그 또는 디지털 정보일 수 있다. 공지된 바처럼, 신호는 다양한 상이한 유선 또는 무선 링크들 상에서 송신될 수 있다. 신호는 프로세서 판독 가능 매체 상에 저장될 수 있다.
따라서, 특정한 특징들 및 태양들을 갖는 하나 이상의 실시예가 제공된다. 그러나, 기술된 구현예들의 특징들 및 태양들은 또한 다른 구현예들을 위해 적응될 수 있다. 따라서, 본 명세서에 기술된 구현예들이 특정한 맥락에서 기술될 수 있지만, 이러한 설명들은 상기 특징들 및 개념들을 이러한 구현예들 또는 맥락들로 한정하는 것으로 받아들여지지 않아야 한다.
또한, 다양한 수정이 이루어질 수 있음을 이해할 것이다. 예컨대, 상이한 구현예들의 요소들은 다른 구현예들을 생성하도록 결합, 보충, 수정, 또는 제거될 수 있다. 또한, 본 기술 분야의 당업자는 다른 구조들 및 프로세스들이 개시된 것들을 대체할 수 있고, 결과적인 구현예들은 개시된 구현예들과 적어도 실질적으로 동일한 방식(들)로 적어도 실질적으로 동일한 기능(들)을 수행하여 적어도 실질적으로 동일한 결과(들)을 달성할 것이다. 따라서, 이러한 그리고 다른 구현예들이 본 출원에 의해 고려되며, 아래의 청구항들의 범위 내에 있다.
Claims (38)
- 이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값을 처리하는 단계 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ; 및
제2 부분 깊이값을 처리하는 단계 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
를 포함하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값은 인코딩되어 있고,
상기 제1 부분 깊이값을 처리하는 단계는 상기 제1 부분 깊이값을 디코딩하는 단계를 포함하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값을 처리하는 단계는, 상기 제1 부분 깊이값을 분석(parse)하는 단계, 상기 제1 부분 깊이값을 디코딩하는 단계, 또는 상기 제1 부분 깊이값에 기초하여 깊이 맵의 적어도 일부를 생성하는 단계 중 하나 이상을 포함하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값을 처리하는 단계는 상기 제1 부분 깊이값에 기초하여 깊이 맵의 제1 부분을 생성하는 단계를 포함하고,
상기 깊이 맵의 제1 부분은 상기 이미지의 제1 부분 내의 각 화소에 대한 별개의 깊이값을 갖는 방법. - 제4항에 있어서,
상기 제1 부분 깊이값은 인코더에서 깊이 예측자(depth predictor)로부터 결정된 잔차(residue)이고,
상기 깊이 맵의 제1 부분을 생성하는 단계는,
상기 제1 부분 전체에 대한 실제 깊이를 표현하는 표현 깊이값(representative depth value)에 대한 예측값을 생성하는 단계;
상기 예측값을 상기 제1 부분 깊이값과 조합하여 상기 이미지의 제1 부분에 대한 재구축된 표현 깊이값을 결정하는 단계; 및
상기 재구축된 표현 깊이값에 기초하여 상기 깊이 맵의 제1 부분을 채우는(populating) 단계
를 포함하는 방법. - 제5항에 있어서,
상기 채우는 단계는 상기 재구축된 표현 깊이값을 상기 깊이 맵의 제1 부분 전체에 복사하는 단계를 포함하는 방법. - 제1항에 있어서,
상기 제1 부분은 매크로블록 또는 서브매크로블록이고, 상기 제2 부분은 매크로블록 또는 서브매크로블록인 방법. - 제1항에 있어서,
디코딩된 상기 제1 부분과 디코딩된 상기 제2 부분을 디스플레이를 위해 제공하는 단계를 더 포함하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값과 상기 제1 부분 움직임 벡터를 포함하는 구조를 액세스하는 단계를 더 포함하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값은 상기 제1 부분에 대한 깊이의 평균, 상기 제1 부분에 대한 깊이의 중간값, 상기 이미지 내의 인접 부분에 대한 깊이 정보, 또는 대응하는 시간적 또는 시점간 부분(inter-view portion) 내의 부분에 대한 깊이 정보 중 하나 이상에 기초하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값은 인코더에서 깊이 예측자로부터 결정된 잔차이고,
상기 방법은 상기 제1 부분 전체에 대한 실제 깊이를 표현하는 표현 깊이값에 대한 예측값을 생성하는 단계를 더 포함하며,
상기 예측값은 상기 제1 부분에 대한 깊이의 평균, 상기 제1 부분에 대한 깊이의 중간값, 상기 이미지 내의 인접 부분에 대한 깊이 정보, 또는 대응하는 시간적 또는 시점간 부분 내의 부분에 대한 깊이 정보 중 하나 이상에 기초하는 방법. - 제1항에 있어서,
상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 실제 깊이를 표현하는 표현 깊이값인 방법. - 제1항에 있어서,
상기 방법은 디코더에서 수행되는 방법. - 제1항에 있어서,
상기 방법은 인코더에서 수행되는 방법. - 이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하기 위한 수단 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값을 처리하기 위한 수단 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하기 위한 수단 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ; 및
제2 부분 깊이값을 처리하기 위한 수단 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
을 포함하는 장치. - 프로세서 판독 가능 매체로서,
프로세서로 하여금,
이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값을 처리하는 단계 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ; 및
제2 부분 깊이값을 처리하는 단계 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
를 적어도 수행하도록 야기하기 위한 명령어들을 저장하는 프로세서 판독 가능 매체. - 장치로서,
이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값을 처리하는 단계 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ; 및
제2 부분 깊이값을 처리하는 단계 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
를 적어도 수행하도록 구성되는 프로세서를 포함하는 장치. - 장치로서,
이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하는 동작 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값을 처리하는 동작 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하는 동작 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ; 및
제2 부분 깊이값을 처리하는 동작 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
을 수행하기 위한 디코딩 유닛을 포함하는 장치. - 제18항에 있어서,
상기 장치는 인코더를 포함하는 장치. - 디코더로서,
신호를 수신 및 복조하기 위한 복조기 - 상기 신호는 이미지의 인코딩된 제1 부분 및 깊이 정보의 제1 부분의 깊이값 표현을 포함하고, 상기 깊이 정보의 제1 부분은 상기 이미지의 제1 부분에 대응함 - 와,
이미지의 인코딩된 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 디코딩하는 동작 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ; 및
상기 이미지의 인코딩된 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 디코딩하는 동작 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 상기 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 -
을 수행하기 위한 디코딩 유닛과,
제1 부분 깊이값을 처리하는 동작 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ; 및
제2 부분 깊이값을 처리하는 동작 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 -
을 수행하기 위한 처리 유닛
을 포함하는 디코더. - 비디오 신호 구조로서,
이미지의 인코딩된 제1 부분에 대한 제1 이미지 섹션 - 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값에 대한 제1 깊이 섹션 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제1 부분을 인코딩하는 데 사용되는 제1 부분 움직임 벡터에 대한 제1 움직임 벡터 섹션 - 상기 제1 부분 움직임 벡터는 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 - ;
이미지의 인코딩된 제2 부분에 대한 제2 이미지 섹션 - 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
제2 부분 깊이값에 대한 제2 깊이 섹션 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제2 부분을 인코딩하는 데 사용되는 제2 부분 움직임 벡터에 대한 제2 움직임 벡터 섹션 - 상기 제2 부분 움직임 벡터는 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 -
을 포함하는 비디오 신호 구조. - 정보를 포함하도록 포맷팅된 비디오 신호로서,
이미지의 인코딩된 제1 부분에 대한 제1 이미지 섹션 - 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값에 대한 제1 깊이 섹션 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제1 부분을 인코딩하는 데 사용되는 제1 부분 움직임 벡터에 대한 제1 움직임 벡터 섹션 - 상기 제1 부분 움직임 벡터는 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 - ;
이미지의 인코딩된 제2 부분에 대한 제2 이미지 섹션 - 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
제2 부분 깊이값에 대한 제2 깊이 섹션 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제2 부분을 인코딩하는 데 사용되는 제2 부분 움직임 벡터에 대한 제2 움직임 벡터 섹션 - 상기 제2 부분 움직임 벡터는 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 -
을 포함하는 비디오 신호. - 프로세서 판독 가능 매체로서,
이미지의 인코딩된 제1 부분에 대한 제1 이미지 섹션 - 상기 제1 부분은 제1 크기를 가짐 - ;
제1 부분 깊이값에 대한 제1 깊이 섹션 - 상기 제1 부분 깊이값은 상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제1 부분을 인코딩하는 데 사용되는 제1 부분 움직임 벡터에 대한 제1 움직임 벡터 섹션 - 상기 제1 부분 움직임 벡터는 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제1 부분 움직임 벡터는 상기 제1 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 - ;
이미지의 인코딩된 제2 부분에 대한 제2 이미지 섹션 - 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
제2 부분 깊이값에 대한 제2 깊이 섹션 - 상기 제2 부분 깊이값은 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않음 - ;
상기 이미지의 제2 부분을 인코딩하는 데 사용되는 제2 부분 움직임 벡터에 대한 제2 움직임 벡터 섹션 - 상기 제2 부분 움직임 벡터는 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않으며, 상기 제2 부분 움직임 벡터는 상기 제2 부분을 디코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리킴 -
을 포함하는 비디오 신호 구조를 저장하는 프로세스 판독 가능 매체. - 이미지의 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하는 단계;
이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하는 단계;
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립(assemble)하는 단계
를 포함하는 방법. - 제24항에 있어서,
상기 구조화된 포맷을 송신 또는 저장을 위해 제공하는 단계를 더 포함하는 방법. - 제24항에 있어서,
상기 제1 부분 깊이값을 결정하는 단계는 깊이 맵의 제1 부분에 기초하고,
상기 깊이 맵의 제1 부분은 상기 이미지의 제1 부분 내의 각 화소에 대한 별개의 깊이값을 갖는 방법. - 제24항에 있어서,
상기 조립 단계 전에 상기 제1 부분 깊이값 및 상기 제2 부분 깊이값을 인코딩하는 단계를 더 포함하고,
상기 제1 부분 깊이값 및 상기 제2 부분 깊이값을 상기 구조화된 포맷이 되도록 조립하는 단계는 상기 제1 부분 깊이값 및 제2 부분 깊이값의 인코딩된 버전들을 조립하는 단계를 포함하는 방법. - 제24항에 있어서,
상기 제1 부분 전체에 대한 실제 깊이를 표현하는 표현 깊이값을 결정하는 단계;
상기 표현 깊이값에 대한 예측값을 생성하는 단계; 및
상기 예측값을 상기 표현 깊이값과 결합하여 상기 제1 부분 깊이값을 결정하는 단계
를 더 포함하는 방법. - 제28항에 있어서,
상기 예측값을 생성하는 단계는, 상기 제1 부분에 대한 깊이의 평균, 상기 제1 부분에 대한 깊이의 중간값, 상기 이미지 내의 인접 부분에 대한 깊이 정보, 또는 대응하는 시간적 또는 시점간 부분 내의 부분에 대한 깊이 정보 중 하나 이상에 기초하는 예측값을 생성하는 단계를 포함하는 방법. - 제24항에 있어서,
상기 제1 부분 깊이값은 상기 제1 부분에 대한 깊이의 평균, 상기 제1 부분에 대한 깊이의 중간값, 상기 이미지 내의 인접 부분에 대한 깊이 정보, 또는 대응하는 시간적 또는 시점간 부분 내의 부분에 대한 깊이 정보 중 하나 이상에 기초하는 방법. - 제24항에 있어서,
상기 제1 부분은 매크로블록 또는 서브매크로블록이고, 상기 제2 부분은 매크로블록 또는 서브매크로블록인 방법. - 제24항에 있어서,
상기 조립 단계는 상기 제1 부분 움직임 벡터를 상기 구조화된 포맷이 되도록 조립하는 단계를 더 포함하는 방법. - 제24항에 있어서,
상기 방법은 인코더에서 수행되는 방법. - 이미지의 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩하기 위한 수단 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하기 위한 수단;
이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩하기 위한 수단 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하기 위한 수단;
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립하기 위한 수단
을 포함하는 장치. - 프로세서 판독 가능 매체로서,
프로세서로 하여금,
이미지의 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하는 단계;
이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하는 단계;
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립하는 단계
를 적어도 수행하도록 야기하기 위한 명령어들을 저장하는 프로세서 판독 가능 매체. - 장치로서,
이미지의 제1 부분을 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - ;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하는 단계;
이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩하는 단계 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - ;
상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하는 단계;
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립하는 단계
를 적어도 수행하도록 구성되는 프로세서를 포함하는 장치. - 장치로서,
이미지의 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - 하고, 이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - 하기 위한 인코딩 유닛;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하고, 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하기 위한 깊이 표현 계산기; 및
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립하기 위한 조립 유닛
을 포함하는 장치. - 인코더로서,
이미지의 제1 부분을, 상기 제1 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제1 부분 움직임 벡터를 사용하여 인코딩 - 상기 제1 부분 움직임 벡터는 상기 제1 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제1 부분은 제1 크기를 가짐 - 하고, 이미지의 제2 부분을, 상기 제2 부분과 연관되고 상기 이미지의 다른 부분들과 연관되지 않은 제2 부분 움직임 벡터를 사용하여 인코딩 - 상기 제2 부분 움직임 벡터는 상기 제2 부분을 인코딩하는 데 사용될 기준 이미지 내의 대응하는 부분을 가리키고, 상기 제2 부분은 상기 제1 크기와 상이한 제2 크기를 가짐 - 하기 위한 인코딩 유닛;
상기 제1 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제1 부분 깊이값을 결정하고, 상기 제2 부분 전체에 대한 깊이 정보를 제공하고 다른 부분들에 대한 깊이 정보는 제공하지 않는 제2 부분 깊이값을 결정하기 위한 깊이 표현 계산기;
상기 인코딩된 제1 부분, 상기 제1 부분 깊이값, 상기 인코딩된 제2 부분 및 상기 제2 부분 깊이값을 구조화된 포맷이 되도록 조립하기 위한 조립 유닛; 및
상기 구조화된 포맷을 변조하기 위한 변조기
를 포함하는 인코더.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12567408P | 2008-04-25 | 2008-04-25 | |
| US61/125,674 | 2008-04-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20110003549A true KR20110003549A (ko) | 2011-01-12 |
Family
ID=41217338
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020107026463A KR20110003549A (ko) | 2008-04-25 | 2009-04-24 | 깊이 신호의 코딩 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20110038418A1 (ko) |
| EP (1) | EP2266322A2 (ko) |
| JP (2) | JP2011519227A (ko) |
| KR (1) | KR20110003549A (ko) |
| CN (1) | CN102017628B (ko) |
| BR (1) | BRPI0911447A2 (ko) |
| WO (1) | WO2009131703A2 (ko) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013022297A3 (ko) * | 2011-08-09 | 2013-04-04 | 삼성전자 주식회사 | 다시점 비디오 데이터의 깊이맵 부호화 방법 및 장치, 복호화 방법 및 장치 |
| WO2013022296A3 (ko) * | 2011-08-09 | 2013-04-11 | 삼성전자 주식회사 | 다시점 비디오 데이터의 부호화 방법 및 장치, 복호화 방법 및 장치 |
| WO2014051320A1 (ko) * | 2012-09-28 | 2014-04-03 | 삼성전자주식회사 | 움직임 벡터와 변이 벡터를 예측하는 영상 처리 방법 및 장치 |
| KR20140046385A (ko) * | 2012-10-09 | 2014-04-18 | 한국전자통신연구원 | 비디오 데이터 디코딩 방법 및 비디오 데이터 디코딩 장치 |
| KR20210158088A (ko) * | 2020-06-23 | 2021-12-30 | 주식회사 에스원 | 동영상 부호화 방법, 복호화 방법 및 그 장치 |
Families Citing this family (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4901772B2 (ja) * | 2007-02-09 | 2012-03-21 | パナソニック株式会社 | 動画像符号化方法及び動画像符号化装置 |
| JP5566385B2 (ja) | 2008-08-20 | 2014-08-06 | トムソン ライセンシング | 洗練された奥行きマップ |
| US8913105B2 (en) | 2009-01-07 | 2014-12-16 | Thomson Licensing | Joint depth estimation |
| WO2010093351A1 (en) * | 2009-02-13 | 2010-08-19 | Thomson Licensing | Depth map coding to reduce rendered distortion |
| KR101624649B1 (ko) * | 2009-08-14 | 2016-05-26 | 삼성전자주식회사 | 계층적인 부호화 블록 패턴 정보를 이용한 비디오 부호화 방법 및 장치, 비디오 복호화 방법 및 장치 |
| US8774267B2 (en) * | 2010-07-07 | 2014-07-08 | Spinella Ip Holdings, Inc. | System and method for transmission, processing, and rendering of stereoscopic and multi-view images |
| KR101640404B1 (ko) * | 2010-09-20 | 2016-07-18 | 엘지전자 주식회사 | 휴대 단말기 및 그 동작 제어방법 |
| JP5478740B2 (ja) * | 2011-01-12 | 2014-04-23 | 三菱電機株式会社 | 動画像符号化装置、動画像復号装置、動画像符号化方法及び動画像復号方法 |
| US8902982B2 (en) * | 2011-01-17 | 2014-12-02 | Samsung Electronics Co., Ltd. | Depth map coding and decoding apparatus and method |
| JP2014112748A (ja) * | 2011-03-18 | 2014-06-19 | Sharp Corp | 画像符号化装置および画像復号装置 |
| US20140044347A1 (en) * | 2011-04-25 | 2014-02-13 | Sharp Kabushiki Kaisha | Mage coding apparatus, image coding method, image coding program, image decoding apparatus, image decoding method, and image decoding program |
| US20140085418A1 (en) * | 2011-05-16 | 2014-03-27 | Sony Corporation | Image processing device and image processing method |
| US9363535B2 (en) | 2011-07-22 | 2016-06-07 | Qualcomm Incorporated | Coding motion depth maps with depth range variation |
| JP5749595B2 (ja) * | 2011-07-27 | 2015-07-15 | 日本電信電話株式会社 | 画像伝送方法、画像伝送装置、画像受信装置及び画像受信プログラム |
| WO2013032512A1 (en) * | 2011-08-30 | 2013-03-07 | Intel Corporation | Multiview video coding schemes |
| WO2013035452A1 (ja) * | 2011-09-05 | 2013-03-14 | シャープ株式会社 | 画像符号化方法、画像復号方法、並びにそれらの装置及びプログラム |
| EP2777266B1 (en) | 2011-11-11 | 2018-07-25 | GE Video Compression, LLC | Multi-view coding with exploitation of renderable portions |
| WO2013068493A1 (en) * | 2011-11-11 | 2013-05-16 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Multi-view coding with effective handling of renderable portions |
| KR20240027889A (ko) | 2011-11-11 | 2024-03-04 | 지이 비디오 컴프레션, 엘엘씨 | 깊이-맵 추정 및 업데이트를 사용한 효율적인 멀티-뷰 코딩 |
| WO2013068548A2 (en) | 2011-11-11 | 2013-05-16 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Efficient multi-view coding using depth-map estimate for a dependent view |
| EP2781091B1 (en) | 2011-11-18 | 2020-04-08 | GE Video Compression, LLC | Multi-view coding with efficient residual handling |
| US20130287093A1 (en) * | 2012-04-25 | 2013-10-31 | Nokia Corporation | Method and apparatus for video coding |
| US9307252B2 (en) * | 2012-06-04 | 2016-04-05 | City University Of Hong Kong | View synthesis distortion model for multiview depth video coding |
| JP5876933B2 (ja) * | 2012-07-09 | 2016-03-02 | 日本電信電話株式会社 | 動画像符号化方法、動画像復号方法、動画像符号化装置、動画像復号装置、動画像符号化プログラム、動画像復号プログラム及び記録媒体 |
| RU2012138174A (ru) * | 2012-09-06 | 2014-03-27 | Сисвел Текнолоджи С.Р.Л. | Способ компоновки формата цифрового стереоскопического видеопотока 3dz tile format |
| KR102186605B1 (ko) * | 2012-09-28 | 2020-12-03 | 삼성전자주식회사 | 다시점 영상 부호화/복호화 장치 및 방법 |
| CN110996100B (zh) | 2012-10-01 | 2022-11-25 | Ge视频压缩有限责任公司 | 解码器、解码方法、编码器和编码方法 |
| KR101737595B1 (ko) * | 2012-12-27 | 2017-05-18 | 니폰 덴신 덴와 가부시끼가이샤 | 화상 부호화 방법, 화상 복호 방법, 화상 부호화 장치, 화상 복호 장치, 화상 부호화 프로그램 및 화상 복호 프로그램 |
| US9369708B2 (en) * | 2013-03-27 | 2016-06-14 | Qualcomm Incorporated | Depth coding modes signaling of depth data for 3D-HEVC |
| US9516306B2 (en) | 2013-03-27 | 2016-12-06 | Qualcomm Incorporated | Depth coding modes signaling of depth data for 3D-HEVC |
| WO2014163465A1 (ko) * | 2013-04-05 | 2014-10-09 | 삼성전자 주식회사 | 깊이맵 부호화 방법 및 그 장치, 복호화 방법 및 그 장치 |
| GB2513111A (en) * | 2013-04-08 | 2014-10-22 | Sony Corp | Data encoding and decoding |
| EP2932720A4 (en) * | 2013-04-10 | 2016-07-27 | Mediatek Inc | METHOD AND APPARATUS FOR DIVIDING VECTOR DIVIDER FOR THREE-DIMENSIONAL AND MULTI-VIEW VIDEO CODING |
| CN105103555A (zh) * | 2013-04-11 | 2015-11-25 | Lg电子株式会社 | 处理视频信号的方法及装置 |
| WO2014166116A1 (en) * | 2013-04-12 | 2014-10-16 | Mediatek Inc. | Direct simplified depth coding |
| US10080036B2 (en) | 2013-05-16 | 2018-09-18 | City University Of Hong Kong | Method and apparatus for depth video coding using endurable view synthesis distortion |
| US20160050440A1 (en) * | 2014-08-15 | 2016-02-18 | Ying Liu | Low-complexity depth map encoder with quad-tree partitioned compressed sensing |
| JP2017532871A (ja) * | 2014-09-30 | 2017-11-02 | 寰發股▲ふん▼有限公司HFI Innovation Inc. | 深さコーディングにおける深さモデリングモードのルックアップテーブルサイズ減少方法 |
| CN104333760B (zh) | 2014-10-10 | 2018-11-06 | 华为技术有限公司 | 三维图像编码方法和三维图像解码方法及相关装置 |
| US10368104B1 (en) * | 2015-04-01 | 2019-07-30 | Rockwell Collins, Inc. | Systems and methods for transmission of synchronized physical and visible images for three dimensional display |
| CN108353157B (zh) * | 2015-11-11 | 2021-06-08 | 索尼公司 | 编码设备和编码方法以及解码设备和解码方法 |
| JP6911765B2 (ja) * | 2015-11-11 | 2021-07-28 | ソニーグループ株式会社 | 画像処理装置および画像処理方法 |
| JP7009996B2 (ja) * | 2015-11-11 | 2022-01-26 | ソニーグループ株式会社 | 画像処理装置および画像処理方法 |
| US11949889B2 (en) | 2018-01-19 | 2024-04-02 | Interdigital Vc Holdings, Inc. | Processing a point cloud |
| JP2022502892A (ja) * | 2018-10-05 | 2022-01-11 | インターデジタル ヴイシー ホールディングス, インコーポレイテッド | 3d点を符号化/再構築するための方法およびデバイス |
Family Cites Families (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| ATE159396T1 (de) * | 1991-06-04 | 1997-11-15 | Qualcomm Inc | System zur adaptiven kompression der blockgrössen eines bildes |
| JP3104439B2 (ja) * | 1992-11-13 | 2000-10-30 | ソニー株式会社 | 高能率符号化及び/又は復号化装置 |
| US5614952A (en) * | 1994-10-11 | 1997-03-25 | Hitachi America, Ltd. | Digital video decoder for decoding digital high definition and/or digital standard definition television signals |
| JP3679426B2 (ja) * | 1993-03-15 | 2005-08-03 | マサチューセッツ・インスティチュート・オブ・テクノロジー | 画像データを符号化して夫々がコヒーレントな動きの領域を表わす複数の層とそれら層に付随する動きパラメータとにするシステム |
| JP3778960B2 (ja) * | 1994-06-29 | 2006-05-24 | 株式会社東芝 | 動画像符号化方法及び装置 |
| US6064393A (en) * | 1995-08-04 | 2000-05-16 | Microsoft Corporation | Method for measuring the fidelity of warped image layer approximations in a real-time graphics rendering pipeline |
| US5864342A (en) * | 1995-08-04 | 1999-01-26 | Microsoft Corporation | Method and system for rendering graphical objects to image chunks |
| JP3231618B2 (ja) * | 1996-04-23 | 2001-11-26 | 日本電気株式会社 | 3次元画像符号化復号方式 |
| JPH10178639A (ja) * | 1996-12-19 | 1998-06-30 | Matsushita Electric Ind Co Ltd | 画像コーデック部および画像データ符号化方法 |
| JP2001501348A (ja) * | 1997-07-29 | 2001-01-30 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 3次元シーンの再構成方法と、対応する再構成装置および復号化システム |
| US6320978B1 (en) * | 1998-03-20 | 2001-11-20 | Microsoft Corporation | Stereo reconstruction employing a layered approach and layer refinement techniques |
| US6348918B1 (en) * | 1998-03-20 | 2002-02-19 | Microsoft Corporation | Stereo reconstruction employing a layered approach |
| US6188730B1 (en) * | 1998-03-23 | 2001-02-13 | Internatonal Business Machines Corporation | Highly programmable chrominance filter for 4:2:2 to 4:2:0 conversion during MPEG2 video encoding |
| JP2000078611A (ja) * | 1998-08-31 | 2000-03-14 | Toshiba Corp | 立体映像受信装置及び立体映像システム |
| US6504872B1 (en) * | 2000-07-28 | 2003-01-07 | Zenith Electronics Corporation | Down-conversion decoder for interlaced video |
| JP2002058031A (ja) * | 2000-08-08 | 2002-02-22 | Nippon Telegr & Teleph Corp <Ntt> | 画像符号化方法及び装置、並びに、画像復号化方法及び装置 |
| FI109633B (fi) * | 2001-01-24 | 2002-09-13 | Gamecluster Ltd Oy | Menetelmä videokuvan pakkauksen nopeuttamiseksi ja/tai sen laadun parantamiseksi |
| US6940538B2 (en) * | 2001-08-29 | 2005-09-06 | Sony Corporation | Extracting a depth map from known camera and model tracking data |
| US7003136B1 (en) * | 2002-04-26 | 2006-02-21 | Hewlett-Packard Development Company, L.P. | Plan-view projections of depth image data for object tracking |
| US7289674B2 (en) * | 2002-06-11 | 2007-10-30 | Nokia Corporation | Spatial prediction based intra coding |
| US7006709B2 (en) * | 2002-06-15 | 2006-02-28 | Microsoft Corporation | System and method deghosting mosaics using multiperspective plane sweep |
| US20030235338A1 (en) * | 2002-06-19 | 2003-12-25 | Meetrix Corporation | Transmission of independently compressed video objects over internet protocol |
| KR20060105409A (ko) * | 2005-04-01 | 2006-10-11 | 엘지전자 주식회사 | 영상 신호의 스케일러블 인코딩 및 디코딩 방법 |
| DE602004008794T2 (de) * | 2003-09-30 | 2008-06-12 | Koninklijke Philips Electronics N.V. | Bildwiedergabe mit interaktiver bewegungsparallaxe |
| EP1542167A1 (en) * | 2003-12-09 | 2005-06-15 | Koninklijke Philips Electronics N.V. | Computer graphics processor and method for rendering 3D scenes on a 3D image display screen |
| US7292257B2 (en) * | 2004-06-28 | 2007-11-06 | Microsoft Corporation | Interactive viewpoint video system and process |
| US7561620B2 (en) * | 2004-08-03 | 2009-07-14 | Microsoft Corporation | System and process for compressing and decompressing multiple, layered, video streams employing spatial and temporal encoding |
| US7671894B2 (en) * | 2004-12-17 | 2010-03-02 | Mitsubishi Electric Research Laboratories, Inc. | Method and system for processing multiview videos for view synthesis using skip and direct modes |
| KR100667830B1 (ko) * | 2005-11-05 | 2007-01-11 | 삼성전자주식회사 | 다시점 동영상을 부호화하는 방법 및 장치 |
| KR100747598B1 (ko) * | 2005-12-09 | 2007-08-08 | 한국전자통신연구원 | 디지털방송 기반의 3차원 입체영상 송수신 시스템 및 그방법 |
| US20070171987A1 (en) * | 2006-01-20 | 2007-07-26 | Nokia Corporation | Method for optical flow field estimation using adaptive Filting |
| JP4605715B2 (ja) * | 2006-06-14 | 2011-01-05 | Kddi株式会社 | 多視点画像圧縮符号化方法、装置及びプログラム |
| CN100415002C (zh) * | 2006-08-11 | 2008-08-27 | 宁波大学 | 多模式多视点视频信号编码压缩方法 |
| CN101166271B (zh) * | 2006-10-16 | 2010-12-08 | 华为技术有限公司 | 一种多视点视频编码中的视点差补偿方法 |
| US8593506B2 (en) * | 2007-03-15 | 2013-11-26 | Yissum Research Development Company Of The Hebrew University Of Jerusalem | Method and system for forming a panoramic image of a scene having minimal aspect distortion |
| GB0708676D0 (en) * | 2007-05-04 | 2007-06-13 | Imec Inter Uni Micro Electr | A Method for real-time/on-line performing of multi view multimedia applications |
| KR101450670B1 (ko) * | 2007-06-11 | 2014-10-15 | 삼성전자 주식회사 | 블록 기반의 양안식 영상 포맷 생성 방법과 장치 및 양안식영상 복원 방법과 장치 |
| JP5566385B2 (ja) * | 2008-08-20 | 2014-08-06 | トムソン ライセンシング | 洗練された奥行きマップ |
| US8913105B2 (en) * | 2009-01-07 | 2014-12-16 | Thomson Licensing | Joint depth estimation |
| US20100188476A1 (en) * | 2009-01-29 | 2010-07-29 | Optical Fusion Inc. | Image Quality of Video Conferences |
-
2009
- 2009-04-24 BR BRPI0911447A patent/BRPI0911447A2/pt not_active IP Right Cessation
- 2009-04-24 EP EP09735918A patent/EP2266322A2/en not_active Withdrawn
- 2009-04-24 JP JP2011506303A patent/JP2011519227A/ja active Pending
- 2009-04-24 CN CN2009801145664A patent/CN102017628B/zh not_active Expired - Fee Related
- 2009-04-24 KR KR1020107026463A patent/KR20110003549A/ko not_active Application Discontinuation
- 2009-04-24 US US12/736,591 patent/US20110038418A1/en not_active Abandoned
- 2009-04-24 WO PCT/US2009/002539 patent/WO2009131703A2/en active Application Filing
-
2014
- 2014-05-14 JP JP2014100744A patent/JP2014147129A/ja not_active Ceased
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013022297A3 (ko) * | 2011-08-09 | 2013-04-04 | 삼성전자 주식회사 | 다시점 비디오 데이터의 깊이맵 부호화 방법 및 장치, 복호화 방법 및 장치 |
| WO2013022296A3 (ko) * | 2011-08-09 | 2013-04-11 | 삼성전자 주식회사 | 다시점 비디오 데이터의 부호화 방법 및 장치, 복호화 방법 및 장치 |
| AU2012295044B2 (en) * | 2011-08-09 | 2016-06-16 | Samsung Electronics Co., Ltd. | Method and device for encoding a depth map of multi viewpoint video data, and method and device for decoding the encoded depth map |
| US9402066B2 (en) | 2011-08-09 | 2016-07-26 | Samsung Electronics Co., Ltd. | Method and device for encoding a depth map of multi viewpoint video data, and method and device for decoding the encoded depth map |
| WO2014051320A1 (ko) * | 2012-09-28 | 2014-04-03 | 삼성전자주식회사 | 움직임 벡터와 변이 벡터를 예측하는 영상 처리 방법 및 장치 |
| KR20140046385A (ko) * | 2012-10-09 | 2014-04-18 | 한국전자통신연구원 | 비디오 데이터 디코딩 방법 및 비디오 데이터 디코딩 장치 |
| KR20210158088A (ko) * | 2020-06-23 | 2021-12-30 | 주식회사 에스원 | 동영상 부호화 방법, 복호화 방법 및 그 장치 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20110038418A1 (en) | 2011-02-17 |
| EP2266322A2 (en) | 2010-12-29 |
| WO2009131703A3 (en) | 2010-08-12 |
| WO2009131703A2 (en) | 2009-10-29 |
| CN102017628A (zh) | 2011-04-13 |
| JP2014147129A (ja) | 2014-08-14 |
| JP2011519227A (ja) | 2011-06-30 |
| BRPI0911447A2 (pt) | 2018-03-20 |
| CN102017628B (zh) | 2013-10-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20110003549A (ko) | 깊이 신호의 코딩 | |
| JP5346076B2 (ja) | 奥行きを用いた視点間スキップモード | |
| KR101663819B1 (ko) | 정제된 깊이 맵 | |
| US9420310B2 (en) | Frame packing for video coding | |
| KR101653724B1 (ko) | 가상 레퍼런스 뷰 | |
| KR102273025B1 (ko) | 선택적인 노이즈제거 필터링을 이용한 스케일러블 비디오 부호화 방법 및 그 장치, 선택적인 노이즈제거 필터링을 이용한 스케일러블 비디오 복호화 방법 및 그 장치 | |
| KR102233965B1 (ko) | 필터링을 수반한 비디오 부호화 및 복호화 방법 및 그 장치 | |
| WO2017158236A2 (en) | A method, an apparatus and a computer program product for coding a 360-degree panoramic images and video | |
| KR20130116832A (ko) | 트리 구조의 부호화 단위에 기초한 다시점 비디오 부호화 방법 및 그 장치, 트리 구조의 부호화 단위에 기초한 다시점 비디오 복호화 방법 및 그 장치 | |
| KR20160132857A (ko) | 스케일러블 비디오 부호화/복호화 방법 및 장치 | |
| EP3094093A1 (en) | Scalable video encoding/decoding method and apparatus | |
| JP2013518515A (ja) | ブロックに基づくインターリーブ | |
| WO2010021664A1 (en) | Depth coding | |
| CN115668935A (zh) | 基于卷绕运动补偿的图像编码/解码方法和设备及存储比特流的记录介质 | |
| WO2019158812A1 (en) | A method and an apparatus for motion compensation | |
| CN115699755A (zh) | 基于卷绕运动补偿的图像编码/解码方法和装置及存储比特流的记录介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |