KR101479040B1 - 태그들을 문서에 자동으로 추가하는 방법, 장치 및 컴퓨터 저장 매체 - Google Patents
태그들을 문서에 자동으로 추가하는 방법, 장치 및 컴퓨터 저장 매체 Download PDFInfo
- Publication number
- KR101479040B1 KR101479040B1 KR1020147019605A KR20147019605A KR101479040B1 KR 101479040 B1 KR101479040 B1 KR 101479040B1 KR 1020147019605 A KR1020147019605 A KR 1020147019605A KR 20147019605 A KR20147019605 A KR 20147019605A KR 101479040 B1 KR101479040 B1 KR 101479040B1
- Authority
- KR
- South Korea
- Prior art keywords
- document
- words
- corpus
- characteristic
- tag
- Prior art date
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
- G06F40/169—Annotation, e.g. comment data or footnotes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/117—Tagging; Marking up; Designating a block; Setting of attributes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
본 발명의 실시예들은 태그를 문서에 자동으로 추가하는 방법 및 장치를 제공하고, 상기 방법은: 복수의 후보 태그 단어들을 결정하고; 다수의 텍스트들을 포함하는 말뭉치를 결정하고; 말뭉치로부터 흔한 단어들을 특성 단어들로서 선택하고; 각각의 특성 단어 및 후보 태그 단어에 대해, 특성 단어가 발생하는 경우에, 후보 태그 단어가 동시에 발생하는 동시 발생 확률을 결정하고; 문서로부터 특성 단어들을 추출하고, 각 추출된 특성 단어에 대해, 이 특성 단서의 가중치를 계산하고; 말뭉치 내에서, 후보 태그 단어들에 대해, 후보 태그 단어들 및 문서에서 발생하는 특성 단어들 모두의 가중 동시 발생 확률을 계수하고; 가장 높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하는 것을 포함한다. 본 발명의 실시예들은 태그를 문서에 추가하기 위한 지능화를 실현할 수 있고, 태그들은 문서에서 발생되는 키워드들로 제한되지 않는다.
Description
본 출원은 "METHOD AND APPARATUS FOR AUTOMATICALLY ADDING TAG TO DOCUMENT"라는 명칭으로 2012년 1월 5일에 국가지식산권국(State Intellectual Property Office)에 제출된 중국 특허 출원번호 201210001611.9의 우선권을 주장하고, 이 출원은 전체가 본원에 참조로서 통합되어 있다.
본 발명은 인터넷 문서의 기술에 관한 것으로, 특히 태그(tag)를 문서에 자동으로 추가하는 방법 및 장치에 관한 것이다.
인터넷 상의 컨텐츠를 조직화하는 데 사용되는 태그들은 문서에 고도로 관련되는 핵심 단어들이다. 문서의 컨텐츠들은 검색 및 공유를 용이하게 하기 위해 태그들에 의해 간략하게 기술되고 분류된다.
현재, 태그를 문서에 추가하기 위하여 주로 세 가지 방식들이 존재한다: 1) 특정한 태그가 문서에 수동으로 지정되는, 수동 태그의 방식; 2) 문서의 컨텐츠들을 분석함으로써 문서로부터 자동으로 추출되는 중요한 키워드(keyword)가 태그로서 취해지는 키워드 태그 방식; 및 3) 태그가 사용자 자신에 의해 사용자의 문서에 추가되는 사회화 태그(socialized tag) 방식. 이 세 방식들 모두에서는 문제들이 있는데, 예를 들어, 1) 수동 태그 방식에 관하여, 태그들은 대량의 문서들에 자동으로 추가될 수 없고; 2) 키워드 태그 방식에 관하여, 단지 문서에서 발생하는 키워드만이 태그로서 선택될 수 있는 반면에, 키워드들 모두가 태그에 적합한 것은 아니고; 그리고 3) 사회화 태그의 방식들에 관하여, 이는 사용자가 태그들을 홀로 문서에 추가할 것을 요구하므로, 결과적으로 상이한 사용자들의 일치하지 않는 표준들로 인해 태그들이 정렬되지 않는다.
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 방법 및 장치가 제공되고, 이로 인해 문서 내의 키워드들로 제한되지 않은 태그가 문서에 지능적으로 추가될 수 있다.
본 발명의 하나의 실시예에 대한 해법은 다음과 같이 구현된다.
태그를 문서에 자동으로 추가하는 방법은:
문서에 대응하는 다수의 후보 태그 단어들을 결정하는 단계;
다수의 텍스트들을 포함하는 말뭉치(corpus)를 결정하고; 말뭉치로부터 흔히 사용되는 단어들을 특성 단어(characteristic word)들로서 선택하고; 특성 단어들 각각 및 후보 태그 단어들 각각에 대해, 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하는 단계;
문서로부터 특성 단어들을 추출하고, 추출된 특성 단어들의 각각에 대한 가중치를 계산하는 단계; 및
말뭉치에서, 후보 태그 단어들의 각각이 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하고; 높은 가중 동시 발생 확률을 가진 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하는 단계를 포함한다.
태그를 문서에 자동으로 추가하는 장치는:
문서에 대응하는 복수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈;
복수의 텍스트들을 포함하는 말뭉치를 결정하고, 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로서 선택하고, 특성 단어들 각각 및 후보 태그 단어들 각각에 대해, 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈;
문서로부터 특성 단어들을 추출하고, 추출된 특성 단어들의 각각에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈;
말뭉치에서, 후보 태그 단어들의 각각이 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈; 및
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈을 포함한다.
본 발명의 실시예에 따라 태그를 문서에 자동으로 추가하는 방법 및 장치에서, 문서 내의 키워드로 제한되지 않는 태그는 특성 단어가 말뭉치 내의 후보 태그 단어와 동시 발생할 확률을 계산하고, 동시 발생 확률을 특성 단어로부터 후보 태그 단어로의 표(vote)로 전환하고, 가장 많은 표들을 획득한 후보 태그 단어를 문서에 추가될 태그 단어로서 취함으로써 문서에 지능적으로 추가될 수 있다.
도 1은 본 발명의 하나의 실시예에 따라 태그를 문서에 자동으로 추가하기 위한 방법의 흐름도이다.
도 2는 본 발명의 하나의 실시예에 따라 태그를 문서에 자동으로 추가하기 위한 장치의 구조에 대한 개략도이다.
도 2는 본 발명의 하나의 실시예에 따라 태그를 문서에 자동으로 추가하기 위한 장치의 구조에 대한 개략도이다.
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 방법이 제공된다. 도 1은 다음과 같은 단계들을 포함하는 방법의 흐름도이다.
단계 101에서, 문서에 대응하는 다수의 후보 태그 단어들이 결정된다.
이 단계에서, 문서에 대응하는 다수의 후보 태그 단어들은 다음과 같은 세 방식들에 의해 결정될 수 있으나, 이로 제한되지 않는다:
1) 특정한 태그가 문서에 수동으로 명시되는, 수동 태그의 방식;
2) 문서의 컨텐츠들을 분석함으로써 문서로부터 자동으로 추출되는 중요한 키워드가 태그로서 취해지는 키워드 태그 방식; 및
3) 태그가 사용자 자신에 의해 사용자의 문서에 추가되는 사회화 태그 방식.
후보 태그 단어들이 수동 태그 방식 또는 사회화 태그 방식에 의해 결정되는 경우에 후보 태그 단어들은 문서에서 발생하는 단어들로 제한되지 않는다.
단계 102에서, 다수의 텍스트들을 포함하는 말뭉치(corpus)가 결정된다.
예를 들어, 인터넷으로부터 일백만 개의 텍스트들이 획득되면, 일백만 개의 획득된 텍스트들이 일괄적으로 말뭉치로 칭해진다.
단계 103에서, 흔히 사용되는 단어들이 말뭉치로부터 특성 단어들로서 선택되고, 특성 단어들의 각 단어별로 그리고 후보 태그 단어들의 각 단어별로, 후보 태그 단어와 특성 단어가 동시 발생할 확률이 말뭉치에서 결정된다.
단계 104에서, 특성 단어들이 문서로부터 추출되고, 특성 단어들의 각 단어에 대한 가중치가 계산된다.
단계 105에서, 후보 태그 단어들의 각 단어 별로, 후보 태그 단어가 문서에서 발생하는 특성 단어들 모두와 동시 발생할 가중 확률이 말뭉치에서 계산되고; 높은 가중 동시 발생 확률을 가지는 후보 태그 단어가 문서에 추가될 태그 단어로서 선택된다.
단계 103에서, 동시 발생 확률은 P(X|Y)로서 표시되고, 여기서 X는 후보 태그 단어들 중 하나를 표시하고 Y는 말뭉치에서 발생하는 특성 단어들 중 하나를 표시한다. P(X|Y)는 다음과 같은 다양한 방식들에 의해 결정될 수 있다.
제 1 방식에서, P(X|Y)는 말뭉치에 포함되는 동일한 텍스트 내에서의 X가 Y와 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생하는 횟수로 나눈 결과와 동일하다.
제 2 방식에서,  이고, 여기서 H(X, Y)는 X 및 Y의 결합 엔트로피(combination entropy)를 표시하고, I(X,Y)는 X 및 Y의 상호 정보를 표시하고, H(X)는 X의 정보 엔트로피(information entropy)를 표시하고, H(Y)는 Y의 정보 엔트로피를 표시한다.
이고, 여기서 H(X, Y)는 X 및 Y의 결합 엔트로피(combination entropy)를 표시하고, I(X,Y)는 X 및 Y의 상호 정보를 표시하고, H(X)는 X의 정보 엔트로피(information entropy)를 표시하고, H(Y)는 Y의 정보 엔트로피를 표시한다.
제 3 방식에서, P(X|Y)는 wordnet과 같은 어휘 데이터베이스를 사용함으로써 결정된다.
단계 104에서, 추출된 특성 단어들의 각 단어 별로, 문서 내에서 특성 단어가 발생한 횟수 및 특성 단어가 발생한 말뭉치 내의 텍스트의 수에 기초하여 특성 단어에 대한 가중치가 계산될 수 있다.
문서에서 추출되는 특성 단어(Y)에 대한 가중치는 WY로 표시되고, WY는: WY가 Y가 문서에서 발생한 횟수 및 Y가 발생한 말뭉치 내의 텍스트들의 수의 곱(product)과 동일하다는 것에 의해 계산될 수 있다.
단계 105에서, 가중 동시 발생 확률은  로 표시되고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,
로 표시되고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,  는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시한다.
는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시한다.
단계 105에서, 가중 동시 발생 확률 PX는 모든 후보 태그 단어들에 대해서보다는 오히려, 단지 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 후보 태그 단어에 대해서 계산될 수 있다.
특정한 실시예들이 아래에서 더 상세하게 도입될 것이다.
제 1 실시예
단계 1에서, 태그 단어 세트가 준비된다.
원하는 바에 따라 태그 단어 세트를 구성하기 위하여 문서에 대응하는 다수의 후보 태그 단어들이 획득된다. 예를 들어, 태그를 영화와 관련되는 문서들에 추가할 필요가 있는 경우, 태그 단어 세트는 영화의 종류 및 유명인과 같은 태그 단어들을 포함할 수 있다.
단계 2에서, 말뭉치가 준비된다.
다수의 관련 텍스트들은 인터넷으로부터 단어들 사이의 동시 발생 관계들의 통계에 사용될 말뭉치로서 수집될 수 있다.
단계 3에서, 말뭉치로부터 특성 단어들이 추출된다.
말뭉치 내의 텍스트들에 대해 단어 구분(word segmentation)이 수행된다. 그리고 나서 각 단어의 어구 빈도수(term frequency; TF)가 계수된다. 고 빈도수 단어들, 사용되지 않은 단어들 및 저 빈도수 단어들은 제거되고, 나머지 흔히 사용되는 단어들이 특성 단어들로서 선택된다.
단계 4에서, 특성 단어의 각각이 후보 태그 단어의 각각과 동시 발생할 확률 P(X|Y)이 계산된다.
P(X|Y)는 말뭉치에 포함되는 동일한 텍스트에서 X 및 Y가 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생한 횟수로 나눈 결과와 동일하다.
여기서, X는 후보 태그 단어들 중 하나를 표시하고, Y는 특성 단어들 중 하나를 표시한다.
단계 5에서, 태그 단어들은 문서에 자동으로 추가되고, 이의 특정한 단계들은 다음과 같다:
단계 Ⅰ에서, 문서에 대한 단어 구분을 수행하고;
단계 Ⅱ에서, 단어 구분 결과에 따라 문서 내에서 발생하는 특성 단어들 모두를 추출하고, 각각의 추출된 특성 단어 Y에 대한 가중치(WY)를 WY=TF×IDF로서 계산하고, 여기서 TF는 Y가 문서 내에서 발생하는 횟수를 표시하고 IDF는 Y가 발생하는 말뭉치 내의 텍스트의 수를 표시한다;
단계 Ⅲ에서, 단계 4에서 계산된 동시 발생 확률에 기초하여 적어도 하나의 특성 단어와 동시 발생하는(즉, 동시 발생 확률은 0이 아니다) 후보 태그 단어들을 추출하고;
단계 Ⅳ에서, 추출되는 후보 태그 단어들의 각각에 대해, 문서로부터 추출되는 특성 단어들 모두와의 추출되는 후보 태그 단어의 가중 동시 발생 확률  을 계산하고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,
을 계산하고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,  는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시하고; 그리고
는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시하고; 그리고
단계 Ⅴ에서, Px 값들의 내림 차순으로 추출되는 후보 태그 단어들 모두를 순위화하고, 가장 높은 PX를 가지는 하나 이상의 후보 태그 단어들을 문서에 추가될 태그 단어들로서 선택한다.
이 단계에서, 후보 태그 단어들 중 서너 단어는 우선 단계 Ⅲ에서 추출되고, 그 후에 가중 동시 발생 확률은 이 추출된 후보 태그 단어들 각각에 대해 계산된다. 이것은 계산 속도를 증가시키고 시스템 자원을 절약할 수 있다. 본 발명의 다른 실시예들에 따르면, 가중 동시 발생 확률은 후보 태그 단어들 모두에 대해 계산될 수 있다. 특성 단어들 어느 것과도 동시 발생 관계를 가지지 않는 후보 태그 단어의 경우, 계산되는 가중 동시 발생 확률 PX = 0이고 후보 태그 단어는 단계 Ⅴ에서 후보 태그 단어들의 줄(queue)의 말미에 순위가 정해질 것이다.
본 발명의 다른 실시예에서, 특성 단어 및 후보 태그 단어의 동시 발생 확률 P(X|Y)는 다른 방식들로 계산될 수 있다. 예를 들어, P(X|Y)는 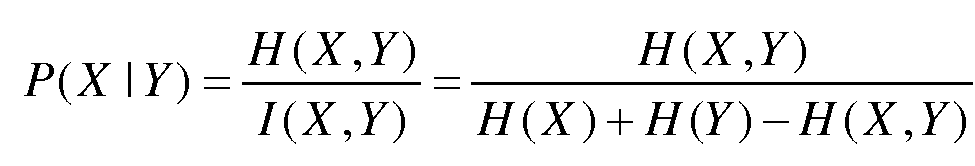 로 계산될 수 있고, 여기서 H(X,Y)는 X 및 Y의 결합 엔트로피를 표시하고, I(X,Y)는 X 및 Y의 상호 정보를 표시하고, H(X)는 X의 정보 엔트로피를 표시하고, H(Y)는 Y의 정보 엔트로피를 표시한다. 대안으로, 특성 단어 및 후보 태그 단어 사이의 관계는 wordnet과 같은 어휘 데이터베이스를 사용함으로써 결정된다.
로 계산될 수 있고, 여기서 H(X,Y)는 X 및 Y의 결합 엔트로피를 표시하고, I(X,Y)는 X 및 Y의 상호 정보를 표시하고, H(X)는 X의 정보 엔트로피를 표시하고, H(Y)는 Y의 정보 엔트로피를 표시한다. 대안으로, 특성 단어 및 후보 태그 단어 사이의 관계는 wordnet과 같은 어휘 데이터베이스를 사용함으로써 결정된다.
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 장치가 더 제공된다. 도 2는 상기 장치의 구조에 대한 개략도이고, 이는:
문서에 대응하는 다수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈(201);
다수의 텍스트들을 포함하는 말뭉치를 결정하고, 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로 선택하고, 특성 단어들의 각 단어 및 후보 태그 단어들의 각 단어에 대해, 말뭉치 내에서 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈(202);
문서로부터 특성 단어들을 추출하고 특성 단어들의 각 단어에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈(203);
말뭉치 내에서, 후보 태그 단어들의 각 단어가 문서에서 발생하는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈(204); 및
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈(205)을 포함한다.
상술한 장치에서, 동시 발생 확률은 P(X|Y)로 표시될 수 있고, 여기서 X는 후보 태그 단어들 중 하나를 표시하고 Y는 말뭉치 내에서 발생하는 특성 단어들 중 하나를 표시한다. 동시 발생 확률 결정 모듈(202)은 P(X|Y)를 다음과 같이 계산할 수 있다.
P(X|Y)는 말뭉치에 포함되는 동일한 텍스트에서가 X 및 Y가 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생하는 횟수로 나눈 결과와 동일하다.
대안으로,  이고, 여기서 H(X,Y)는 X 및 Y의 결합 엔트로피를 표시하고, I(X,Y)는 X 및 Y의 상호 정보(mutual information)를 표시한다.
이고, 여기서 H(X,Y)는 X 및 Y의 결합 엔트로피를 표시하고, I(X,Y)는 X 및 Y의 상호 정보(mutual information)를 표시한다.
대안으로, P(X|Y)는 어휘 데이터베이스를 사용함으로써 결정된다.
상술한 장치에서, 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, 이는 가중치 계산 모듈(203)에 의해: WY는 문서에서 Y가 발생하는 횟수 및 Y가 발생하는 말뭉치에서의 텍스트들의 수의 곱과 동일하다는 것에 의해 계산될 수 있다.
상술한 장치에서, 가중 동시 발생 확률은  로서 표시될 수 있고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,
로서 표시될 수 있고, 여기서 Yi는 문서로부터 추출되는 특성 단어들 중 하나를 표시하고,  는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시한다.
는 Yi에 대한 가중치를 표시하고, n은 문서로부터 추출되는 특성 단어들의 수를 표시한다.
상술한 장치에서, 가중 동시 발생 확률 계산 모듈(204)은 단지 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 후보 태그 단어에 대한 가중 동시 발생 확률을 계산할 수 있다.
결론적으로, 본 발명의 실시예들에 따라 태그를 문서에 자동으로 추가하는 방법 및 장치에서, 문서에서 발생하는 키워드로 제한되지 않는 태그는 특성 단어가 말뭉치 내의 후보 태그 단어와 동시 발생할 확률을 계산하고, 동시 발생 확률을 특성 단어로부터 후보 태그 단어로의 표(vote)로 전환하고, 최대 표들을 획득한 후보 태그 단어를 문서에 추가될 태그 단어로 취함으로써 지능적으로 문서에 추가될 수 있다. 태그 단어 및 문서 사이의 관련성은 본 발명의 실시예들에 따른 동시 발생 확률에 대한 통계에 기초하여 향상된다.
본 발명의 하나의 실시예에 따르면, 기계가 본원에서 기술되는 바와 같이 태그를 문서에 자동으로 추가하는 방법을 실행할 수 있도록 하는 명령들을 저장하는 기계 판독가능 저장 매체가 더 제공된다. 상술한 실시예들 중 임의의 실시예의 기능을 구현하는 소프트웨어 프로그램 코드들이 저장되어 있는 저장 매체를 포함하는 시스템 또는 장치가 제공될 수 있고, 이 시스템 또는 장치 내의 컴퓨터(또는 CPU 또는 MPU)는 저장 매체 내에 저장된 프로그램 코드들을 판독 및 실행할 수 있다.
이 경우에, 저장 매체로부터 판독되는 프로그램 코드들은 상술한 실시예들 중 임의의 하나의 기능을 구현할 수 있다. 그러므로, 프로그램 코드들 및 프로그램 코드들을 저장하는 저장 매체는 본 발명의 일부를 구성한다.
프로그램 코드들을 제공하는 저장 매체의 예들은 소프트 디스크, 하드 디스크, 자기 광 디스크, 광 디스크(CD-ROM, CD-R, CD-RW, DVD-ROM, DVD-RAM, DVD-RW 및 DVD+RW와 같은), 자기 테이프, 비휘발성 메모리 및 ROM을 포함한다. 선택적으로, 프로그램 코드들은 통신 네트워크를 통해 서버 컴퓨터로부터 다운로드될 수 있다.
더욱이, 상술한 실시예들 중 임의의 하나의 기능은 컴퓨터에 의해 판독되는 프로그램 코드들을 실행할 뿐만 아니라 컴퓨터 상에서 동작하는 운영 시스템에 프로그램 코드들에 기초하여 지시함으로써 수행되는 실제 동작들 중 서너 개 또는 모두를 통해 구현될 수 있음이 인정될 것이다.
더욱이, 상술한 실시예들 중 임의의 하나의 기능은 저장 매체로부터 판독되는 프로그램 코드들을 컴퓨터 내에 삽입되는 확장 보드에서 제공되는 메모리에 기록하거나 프로그램 코드들을 컴퓨터에 접속되는 확장 유닛에서 제공되는 메모리에 기록하고 나서 실제 동작들 중 서너 개 또는 모두를 수행하는 프로그램 코드들에 기초하여 확장 보드 또는 확장 유닛에 장착되는 CPU 등에게 지시함으로써 구현될 수 있음이 이해되어야 한다.
상기 진술된 본 발명의 바람직한 실시예들은 본 발명의 범위를 제한하도록 의도되지 않는다. 본 발명의 사상 및 원리들 내에서 행해지는 임의의 변형들, 등가들, 개선들은 본 발명의 범위에 해당한다.
Claims (15)
- 태그(tag)를 문서에 자동으로 추가하는 방법으로서:
상기 문서에 대응하는 복수의 후보 태그 단어들을 결정하는 단계;
복수의 텍스트들을 포함하는 말뭉치(corpus)를 결정하고; 상기 말뭉치로부터 흔히 사용되는 단어들을 특성 단어(characteristic word)들로서 선택하고; 상기 특성 단어들 각각 및 상기 후보 태그 단어들 각각에 대해, 상기 후보 태그 단어가 상기 특성 단어와 동시 발생할 확률을 결정하는 단계;
상기 문서로부터 특성 단어들을 추출하고, 상기 추출된 특성 단어들의 각각에 대한 가중치를 계산하는 단계; 및
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 상기 특성 단어들 모두와 동시 발생할 가중 확률을 계산하고; 높은 가중 동시 발생 확률을 가진 후보 태그 단어를 상기 문서에 추가될 태그 단어로서 선택하는 단계를 포함하며,
상기 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, WY는 Y가 상기 문서에서 발생하는 횟수와 Y가 발생하는 상기 말뭉치 내의 텍스트들의 수의 곱(product)과 동일한 것인 태그를 문서에 자동으로 추가하는 방법.
- 제 1 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는 상기 말뭉치에 포함되는 동일한 텍스트 내에서 X 및 Y가 동시 발생하는 횟수를 상기 말뭉치에서 Y가 발생하는 횟수로 나눈 결과로서 결정되는 태그를 문서에 자동으로 추가하는 방법.
- 제 1 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는로서 결정되고, H(X,Y)는 X 및 Y의 결합 엔트로피(combination entropy)를 표시하고, I(X,Y)는 X 및 Y의 상호 정보(mutual information)를 표시하는 태그를 문서에 자동으로 추가하는 방법.
- 제 1 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는 어휘 데이터베이스를 사용함으로써 결정되는 태그를 문서에 자동으로 추가하는 방법.
- 삭제
- 제 1 항에 있어서,
상기 가중 동시 발생 확률은로서 표시되고, Yi는 상기 문서로부터 추출되는 특성 단어들 중 하나를 표시하고, 는 Yi에 대한 가중치를 표시하고, n은 상기 문서로부터 추출되는 특성 단어들의 수를 표시하는 태그를 문서에 자동으로 추가하는 방법.
는 Yi에 대한 가중치를 표시하고, n은 상기 문서로부터 추출되는 특성 단어들의 수를 표시하는 태그를 문서에 자동으로 추가하는 방법.
- 제 1 항에 있어서,
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하는 것은:
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 가중 확률을 계산하는 것을 포함하는 태그를 문서에 자동으로 추가하는 방법.
- 태그를 문서에 자동으로 추가하는 장치로서:
상기 문서에 대응하는 복수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈;
복수의 텍스트들을 포함하는 말뭉치를 결정하고, 상기 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로서 선택하고, 상기 특성 단어들 각각 및 상기 후보 태그 단어들 각각에 대해, 상기 후보 태그 단어가 상기 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈;
상기 문서로부터 특성 단어들을 추출하고, 상기 추출된 특성 단어들의 각각에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈;
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈; 및
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈을 포함하고,
상기 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, 상기 가중치 계산 모듈은 WY를 Y가 상기 문서에서 발생하는 횟수 및 Y가 발생하는 상기 말뭉치 내의 텍스트들의 수의 곱과 동일한 것으로 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
- 제 8 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 P(X|Y)를 상기 말뭉치에 포함되는 동일한 텍스트 내에서 X 및 Y가 동시 발생하는 횟수를 상기 말뭉치에서 Y가 발생하는 횟수로 나눈 결과로서 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
- 제 8 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 P(X|Y)를로서 계산하도록 구성되고, H(X,Y)는 X 및 Y의 결합 엔트로피를 표시하고, I(X,Y)는 X 및 Y의 상호 정보를 표시하는 태그를 문서에 자동으로 추가하는 장치.
- 제 8 항에 있어서,
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 어휘 데이터베이스를 사용함으로써 P(X|Y)를 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
- 삭제
- 제 8 항 내지 제 11 항 중 어느 한 항에 있어서,
상기 가중 동시 발생 확률은로서 표시되고, Yi는 상기 문서로부터 추출되는 특성 단어들 중 하나를 표시하고, 는 Yi에 대한 가중치를 표시하고, n은 상기 문서로부터 추출되는 특성 단어들의 수를 표시하는 태그를 문서에 자동으로 추가하는 장치.
는 Yi에 대한 가중치를 표시하고, n은 상기 문서로부터 추출되는 특성 단어들의 수를 표시하는 태그를 문서에 자동으로 추가하는 장치.
- 제 8 항 내지 제 11 항 중 어느 한 항에 있어서,
상기 가중 동시 발생 확률 계산 모듈은 상기 말뭉치 내에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 가중 확률을 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
- 제 1 항 내지 제 4 항, 제 6 항, 및 제 7 항 중 어느 한 항에 따른 방법을 구현하는 컴퓨터 프로그램을 저장하는 컴퓨터 저장 매체.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210001611.9 | 2012-01-05 | ||
| CN201210001611.9A CN103198057B (zh) | 2012-01-05 | 2012-01-05 | 一种自动给文档添加标签的方法和装置 |
| PCT/CN2012/086733 WO2013102396A1 (zh) | 2012-01-05 | 2012-12-17 | 一种自动给文档添加标签的方法、装置以及计算机存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140093762A KR20140093762A (ko) | 2014-07-28 |
| KR101479040B1 true KR101479040B1 (ko) | 2015-01-05 |
Family
ID=48720627
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020147019605A KR101479040B1 (ko) | 2012-01-05 | 2012-12-17 | 태그들을 문서에 자동으로 추가하는 방법, 장치 및 컴퓨터 저장 매체 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9146915B2 (ko) |
| EP (1) | EP2801917A4 (ko) |
| JP (1) | JP2015506515A (ko) |
| KR (1) | KR101479040B1 (ko) |
| CN (1) | CN103198057B (ko) |
| WO (1) | WO2013102396A1 (ko) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104199898B (zh) * | 2014-08-26 | 2018-05-15 | 北京小度互娱科技有限公司 | 一种属性信息的获取方法及装置、推送方法及装置 |
| JP6208105B2 (ja) * | 2014-09-18 | 2017-10-04 | 株式会社東芝 | タグ付与装置、方法、及びプログラム |
| CN105488077B (zh) * | 2014-10-10 | 2020-04-28 | 腾讯科技(深圳)有限公司 | 生成内容标签的方法和装置 |
| CN104361033B (zh) * | 2014-10-27 | 2017-06-09 | 深圳职业技术学院 | 一种癌症相关信息自动收集方法及系统 |
| CN104462360B (zh) * | 2014-12-05 | 2020-02-18 | 北京奇虎科技有限公司 | 一种为文本集合生成语义标识的方法和装置 |
| CN105989018B (zh) * | 2015-01-29 | 2020-04-21 | 深圳市腾讯计算机系统有限公司 | 标签生成方法及标签生成装置 |
| US20180075361A1 (en) * | 2015-04-10 | 2018-03-15 | Hewlett-Packard Enterprise Development LP | Hidden dynamic systems |
| JP6535858B2 (ja) * | 2015-04-30 | 2019-07-03 | 国立大学法人鳥取大学 | 文書解析装置、プログラム |
| WO2017011483A1 (en) * | 2015-07-12 | 2017-01-19 | Aravind Musuluri | System and method for ranking documents |
| CN105573968A (zh) * | 2015-12-10 | 2016-05-11 | 天津海量信息技术有限公司 | 基于规则的文本标引方法 |
| CN105740404A (zh) * | 2016-01-28 | 2016-07-06 | 上海晶赞科技发展有限公司 | 标签关联方法及装置 |
| CN106066870B (zh) * | 2016-05-27 | 2019-03-15 | 南京信息工程大学 | 一种语境标注的双语平行语料库构建系统 |
| CN107818092B (zh) * | 2016-09-12 | 2023-05-26 | 百度在线网络技术(北京)有限公司 | 文档处理方法及装置 |
| CN106682149A (zh) * | 2016-12-22 | 2017-05-17 | 湖南科技学院 | 一种基于元搜索引擎的标签自动生成方法 |
| CN107436922B (zh) * | 2017-07-05 | 2021-06-08 | 北京百度网讯科技有限公司 | 文本标签生成方法和装置 |
| CN108536800B (zh) * | 2018-04-03 | 2022-04-19 | 有米科技股份有限公司 | 文本分类方法、系统、计算机设备和存储介质 |
| CN109857957B (zh) * | 2019-01-29 | 2021-06-15 | 掌阅科技股份有限公司 | 建立标签库的方法、电子设备及计算机存储介质 |
| CN109992774A (zh) * | 2019-03-25 | 2019-07-09 | 北京理工大学 | 基于词属性注意力机制的关键短语识别方法 |
| US20220277138A1 (en) * | 2019-07-17 | 2022-09-01 | Nippon Telegraph And Telephone Corporation | Training data generation device, training data generation method and training data generation program |
| CN110399491A (zh) * | 2019-07-19 | 2019-11-01 | 电子科技大学 | 一种基于特征词共现图的微博事件演化分析方法 |
| CN113343684B (zh) * | 2021-06-22 | 2023-05-26 | 广州华多网络科技有限公司 | 核心产品词识别方法、装置、计算机设备及存储介质 |
| CN113486266B (zh) * | 2021-06-29 | 2024-05-21 | 平安银行股份有限公司 | 页面标签添加方法、装置、设备及存储介质 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090045520A (ko) * | 2007-11-02 | 2009-05-08 | 조광현 | 시맨틱 기술을 이용한 태그어 자동 생성 방법 |
| KR101011726B1 (ko) | 2009-06-09 | 2011-01-28 | 성균관대학교산학협력단 | 스니펫 제공 장치 및 방법 |
Family Cites Families (47)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3266246B2 (ja) * | 1990-06-15 | 2002-03-18 | インターナシヨナル・ビジネス・マシーンズ・コーポレーシヨン | 自然言語解析装置及び方法並びに自然言語解析用知識ベース構築方法 |
| JP3220885B2 (ja) * | 1993-06-18 | 2001-10-22 | 株式会社日立製作所 | キーワード付与システム |
| US5675819A (en) * | 1994-06-16 | 1997-10-07 | Xerox Corporation | Document information retrieval using global word co-occurrence patterns |
| JP2809341B2 (ja) * | 1994-11-18 | 1998-10-08 | 松下電器産業株式会社 | 情報要約方法、情報要約装置、重み付け方法、および文字放送受信装置。 |
| US6480841B1 (en) * | 1997-09-22 | 2002-11-12 | Minolta Co., Ltd. | Information processing apparatus capable of automatically setting degree of relevance between keywords, keyword attaching method and keyword auto-attaching apparatus |
| US6317740B1 (en) * | 1998-10-19 | 2001-11-13 | Nec Usa, Inc. | Method and apparatus for assigning keywords to media objects |
| US7130848B2 (en) * | 2000-08-09 | 2006-10-31 | Gary Martin Oosta | Methods for document indexing and analysis |
| EP1346559A4 (en) * | 2000-11-16 | 2006-02-01 | Mydtv Inc | SYSTEM AND METHOD FOR DETERMINING THE POPULARITY OF VIDEO PROGRAM EVENTS |
| JP4679003B2 (ja) * | 2001-08-24 | 2011-04-27 | ヤフー株式会社 | データからの特徴アイテム抽出方法 |
| ATE466345T1 (de) * | 2002-01-16 | 2010-05-15 | Elucidon Group Ltd | Abruf von informationsdaten, wobei daten in bedingungen, dokumenten und dokument-corpora organisiert sind |
| US7395256B2 (en) * | 2003-06-20 | 2008-07-01 | Agency For Science, Technology And Research | Method and platform for term extraction from large collection of documents |
| US20060074900A1 (en) * | 2004-09-30 | 2006-04-06 | Nanavati Amit A | Selecting keywords representative of a document |
| TWI254880B (en) * | 2004-10-18 | 2006-05-11 | Avectec Com Inc | Method for classifying electronic document analysis |
| CN101069177A (zh) * | 2004-11-05 | 2007-11-07 | 株式会社Ipb | 关键字抽取装置 |
| JP2006323517A (ja) * | 2005-05-17 | 2006-11-30 | Mitsubishi Electric Corp | テキスト分類装置およびプログラム |
| US7711737B2 (en) * | 2005-09-12 | 2010-05-04 | Microsoft Corporation | Multi-document keyphrase extraction using partial mutual information |
| US7627559B2 (en) * | 2005-12-15 | 2009-12-01 | Microsoft Corporation | Context-based key phrase discovery and similarity measurement utilizing search engine query logs |
| US8856145B2 (en) * | 2006-08-04 | 2014-10-07 | Yahoo! Inc. | System and method for determining concepts in a content item using context |
| US7996393B1 (en) * | 2006-09-29 | 2011-08-09 | Google Inc. | Keywords associated with document categories |
| US8073850B1 (en) * | 2007-01-19 | 2011-12-06 | Wordnetworks, Inc. | Selecting key phrases for serving contextually relevant content |
| JP2009015743A (ja) * | 2007-07-09 | 2009-01-22 | Fujifilm Corp | 文書作成支援システム、文書作成支援方法、並びに文書作成支援プログラム |
| US7917355B2 (en) * | 2007-08-23 | 2011-03-29 | Google Inc. | Word detection |
| US9317593B2 (en) | 2007-10-05 | 2016-04-19 | Fujitsu Limited | Modeling topics using statistical distributions |
| US8280892B2 (en) * | 2007-10-05 | 2012-10-02 | Fujitsu Limited | Selecting tags for a document by analyzing paragraphs of the document |
| WO2009059297A1 (en) * | 2007-11-01 | 2009-05-07 | Textdigger, Inc. | Method and apparatus for automated tag generation for digital content |
| US8090724B1 (en) * | 2007-11-28 | 2012-01-03 | Adobe Systems Incorporated | Document analysis and multi-word term detector |
| US8055688B2 (en) * | 2007-12-07 | 2011-11-08 | Patrick Giblin | Method and system for meta-tagging media content and distribution |
| US8280886B2 (en) * | 2008-02-13 | 2012-10-02 | Fujitsu Limited | Determining candidate terms related to terms of a query |
| US20090299998A1 (en) * | 2008-02-15 | 2009-12-03 | Wordstream, Inc. | Keyword discovery tools for populating a private keyword database |
| US8606795B2 (en) * | 2008-07-01 | 2013-12-10 | Xerox Corporation | Frequency based keyword extraction method and system using a statistical measure |
| CA2638558C (en) * | 2008-08-08 | 2013-03-05 | Bloorview Kids Rehab | Topic word generation method and system |
| US20100076976A1 (en) * | 2008-09-06 | 2010-03-25 | Zlatko Manolov Sotirov | Method of Automatically Tagging Image Data |
| US8166051B1 (en) * | 2009-02-03 | 2012-04-24 | Sandia Corporation | Computation of term dominance in text documents |
| JP2010224622A (ja) | 2009-03-19 | 2010-10-07 | Nomura Research Institute Ltd | タグ付与方法およびタグ付与プログラム |
| US20110004465A1 (en) * | 2009-07-02 | 2011-01-06 | Battelle Memorial Institute | Computation and Analysis of Significant Themes |
| US8370286B2 (en) * | 2009-08-06 | 2013-02-05 | Yahoo! Inc. | System for personalized term expansion and recommendation |
| CN101650731A (zh) * | 2009-08-31 | 2010-02-17 | 浙江大学 | 基于用户反馈的赞助搜索广告的建议关键词生成方法 |
| US8245135B2 (en) * | 2009-09-08 | 2012-08-14 | International Business Machines Corporation | Producing a visual summarization of text documents |
| CN102043791B (zh) * | 2009-10-10 | 2014-04-30 | 深圳市世纪光速信息技术有限公司 | 分词评价方法及装置 |
| US8266228B2 (en) * | 2009-12-08 | 2012-09-11 | International Business Machines Corporation | Tagging communication files based on historical association of tags |
| CN103038764A (zh) * | 2010-04-14 | 2013-04-10 | 惠普发展公司,有限责任合伙企业 | 用于关键字提取的方法 |
| US8463786B2 (en) * | 2010-06-10 | 2013-06-11 | Microsoft Corporation | Extracting topically related keywords from related documents |
| CN102081642A (zh) * | 2010-10-28 | 2011-06-01 | 华南理工大学 | 搜索引擎检索结果聚类的中文标签提取方法 |
| US8375022B2 (en) * | 2010-11-02 | 2013-02-12 | Hewlett-Packard Development Company, L.P. | Keyword determination based on a weight of meaningfulness |
| EP2635965A4 (en) * | 2010-11-05 | 2016-08-10 | Rakuten Inc | SYSTEMS AND METHODS RELATING TO KEYWORD EXTRACTION |
| US9483557B2 (en) * | 2011-03-04 | 2016-11-01 | Microsoft Technology Licensing Llc | Keyword generation for media content |
| US8700599B2 (en) * | 2011-11-21 | 2014-04-15 | Microsoft Corporation | Context dependent keyword suggestion for advertising |
-
2012
- 2012-01-05 CN CN201210001611.9A patent/CN103198057B/zh active Active
- 2012-12-17 US US14/370,418 patent/US9146915B2/en active Active
- 2012-12-17 KR KR1020147019605A patent/KR101479040B1/ko active IP Right Grant
- 2012-12-17 EP EP12864434.1A patent/EP2801917A4/en not_active Ceased
- 2012-12-17 WO PCT/CN2012/086733 patent/WO2013102396A1/zh active Application Filing
- 2012-12-17 JP JP2014550620A patent/JP2015506515A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090045520A (ko) * | 2007-11-02 | 2009-05-08 | 조광현 | 시맨틱 기술을 이용한 태그어 자동 생성 방법 |
| KR101011726B1 (ko) | 2009-06-09 | 2011-01-28 | 성균관대학교산학협력단 | 스니펫 제공 장치 및 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| US9146915B2 (en) | 2015-09-29 |
| EP2801917A4 (en) | 2015-08-26 |
| CN103198057A (zh) | 2013-07-10 |
| CN103198057B (zh) | 2017-11-07 |
| EP2801917A1 (en) | 2014-11-12 |
| WO2013102396A1 (zh) | 2013-07-11 |
| JP2015506515A (ja) | 2015-03-02 |
| KR20140093762A (ko) | 2014-07-28 |
| US20150019951A1 (en) | 2015-01-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101479040B1 (ko) | 태그들을 문서에 자동으로 추가하는 방법, 장치 및 컴퓨터 저장 매체 | |
| CA2832909C (en) | System and method for matching comment data to text data | |
| US8781817B2 (en) | Phrase based document clustering with automatic phrase extraction | |
| TWI506460B (zh) | 內容推薦系統及方法 | |
| US8171029B2 (en) | Automatic generation of ontologies using word affinities | |
| US8010539B2 (en) | Phrase based snippet generation | |
| CN1728142B (zh) | 信息检索系统中的短语识别方法和设备 | |
| US20130110839A1 (en) | Constructing an analysis of a document | |
| JP5010885B2 (ja) | 文書検索装置、文書検索方法および文書検索プログラム | |
| CN112395395B (zh) | 文本关键词提取方法、装置、设备及存储介质 | |
| CN103186556B (zh) | 得到和搜索结构化语义知识的方法及对应装置 | |
| CN111090731A (zh) | 基于主题聚类的电力舆情摘要提取优化方法及系统 | |
| JP5273735B2 (ja) | テキスト要約方法、その装置およびプログラム | |
| CN107844493B (zh) | 一种文件关联方法及系统 | |
| CN103430172A (zh) | 检索装置、检索方法及程序 | |
| WO2008144457A2 (en) | Efficient retrieval algorithm by query term discrimination | |
| US20150120708A1 (en) | Information aggregation, classification and display method and system | |
| CN103064880A (zh) | 一种基于搜索信息向用户提供网站选择的方法、装置和系统 | |
| JP5952711B2 (ja) | 予測対象コンテンツにおける将来的なコメント数を予測する予測サーバ、プログラム及び方法 | |
| JP2010055164A (ja) | 文章検索装置、文章検索方法、文章検索プログラムおよびその記録媒体 | |
| JP2004054882A (ja) | 類義語検索装置、方法、プログラム及び記憶媒体 | |
| Doan et al. | Improving key concept extraction using word association measurement | |
| KR101108600B1 (ko) | 온톨로지를 이용한 문서간 유사도 측정 방법 및 장치 | |
| CN115221264A (zh) | 一种文本处理方法、装置及可读存储介质 | |
| JP2012226470A (ja) | シリーズアイテム群抽出システム、シリーズアイテム群抽出方法、およびシリーズアイテム群抽出プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| A302 | Request for accelerated examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20171219 Year of fee payment: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20181219 Year of fee payment: 5 |