KR101479040B1 - Method, apparatus, and computer storage medium for automatically adding tags to document - Google Patents
Method, apparatus, and computer storage medium for automatically adding tags to document Download PDFInfo
- Publication number
- KR101479040B1 KR101479040B1 KR1020147019605A KR20147019605A KR101479040B1 KR 101479040 B1 KR101479040 B1 KR 101479040B1 KR 1020147019605 A KR1020147019605 A KR 1020147019605A KR 20147019605 A KR20147019605 A KR 20147019605A KR 101479040 B1 KR101479040 B1 KR 101479040B1
- Authority
- KR
- South Korea
- Prior art keywords
- document
- words
- corpus
- characteristic
- tag
- Prior art date
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
- G06F40/169—Annotation, e.g. comment data or footnotes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/117—Tagging; Marking up; Designating a block; Setting of attributes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Abstract
본 발명의 실시예들은 태그를 문서에 자동으로 추가하는 방법 및 장치를 제공하고, 상기 방법은: 복수의 후보 태그 단어들을 결정하고; 다수의 텍스트들을 포함하는 말뭉치를 결정하고; 말뭉치로부터 흔한 단어들을 특성 단어들로서 선택하고; 각각의 특성 단어 및 후보 태그 단어에 대해, 특성 단어가 발생하는 경우에, 후보 태그 단어가 동시에 발생하는 동시 발생 확률을 결정하고; 문서로부터 특성 단어들을 추출하고, 각 추출된 특성 단어에 대해, 이 특성 단서의 가중치를 계산하고; 말뭉치 내에서, 후보 태그 단어들에 대해, 후보 태그 단어들 및 문서에서 발생하는 특성 단어들 모두의 가중 동시 발생 확률을 계수하고; 가장 높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하는 것을 포함한다. 본 발명의 실시예들은 태그를 문서에 추가하기 위한 지능화를 실현할 수 있고, 태그들은 문서에서 발생되는 키워드들로 제한되지 않는다.Embodiments of the present invention provide a method and apparatus for automatically adding a tag to a document, the method comprising: determining a plurality of candidate tag words; Determining a corpus containing a plurality of texts; Selecting common words from the corpus as characteristic words; For each characteristic word and candidate tag word, if a characteristic word occurs, determine the coincidence probability of the candidate tag word occurring at the same time; Extracting characteristic words from the document, calculating weight of the characteristic cues for each extracted characteristic word; Within the corpus, for candidate tag words, count the weighted coincidence probabilities of both candidate tag words and characteristic words occurring in the document; And selecting the candidate tag word having the highest probability of weighted coincidence as the tag word to be added to the document. Embodiments of the present invention can realize intelligence for adding tags to a document, and tags are not limited to keywords generated in a document.
Description
본 출원은 "METHOD AND APPARATUS FOR AUTOMATICALLY ADDING TAG TO DOCUMENT"라는 명칭으로 2012년 1월 5일에 국가지식산권국(State Intellectual Property Office)에 제출된 중국 특허 출원번호 201210001611.9의 우선권을 주장하고, 이 출원은 전체가 본원에 참조로서 통합되어 있다.This application claims the priority of Chinese Patent Application No. 201210001611.9, filed on January 5, 2012 with the title "METHOD AND APPARATUS FOR AUTOMATICALLY ADDED TAG TO DOCUMENT", filed with the State Intellectual Property Office, Are incorporated herein by reference in their entirety.
본 발명은 인터넷 문서의 기술에 관한 것으로, 특히 태그(tag)를 문서에 자동으로 추가하는 방법 및 장치에 관한 것이다.
The present invention relates to the art of Internet documents, and more particularly to a method and apparatus for automatically adding tags to a document.
인터넷 상의 컨텐츠를 조직화하는 데 사용되는 태그들은 문서에 고도로 관련되는 핵심 단어들이다. 문서의 컨텐츠들은 검색 및 공유를 용이하게 하기 위해 태그들에 의해 간략하게 기술되고 분류된다.The tags used to organize content on the Internet are key words that are highly related to the document. The contents of the document are briefly described and classified by the tags to facilitate searching and sharing.
현재, 태그를 문서에 추가하기 위하여 주로 세 가지 방식들이 존재한다: 1) 특정한 태그가 문서에 수동으로 지정되는, 수동 태그의 방식; 2) 문서의 컨텐츠들을 분석함으로써 문서로부터 자동으로 추출되는 중요한 키워드(keyword)가 태그로서 취해지는 키워드 태그 방식; 및 3) 태그가 사용자 자신에 의해 사용자의 문서에 추가되는 사회화 태그(socialized tag) 방식. 이 세 방식들 모두에서는 문제들이 있는데, 예를 들어, 1) 수동 태그 방식에 관하여, 태그들은 대량의 문서들에 자동으로 추가될 수 없고; 2) 키워드 태그 방식에 관하여, 단지 문서에서 발생하는 키워드만이 태그로서 선택될 수 있는 반면에, 키워드들 모두가 태그에 적합한 것은 아니고; 그리고 3) 사회화 태그의 방식들에 관하여, 이는 사용자가 태그들을 홀로 문서에 추가할 것을 요구하므로, 결과적으로 상이한 사용자들의 일치하지 않는 표준들로 인해 태그들이 정렬되지 않는다.
Currently, there are mainly three ways to add tags to a document: 1) the manner of a passive tag, where a particular tag is manually assigned to the document; 2) a keyword tag method in which an important keyword, which is extracted automatically from a document by analyzing contents of the document, is taken as a tag; And 3) a socialized tag method in which the tag is added to the user's document by the user himself. There are problems with all three approaches, for example: 1) With regard to the passive tag approach, tags can not be automatically added to a large amount of documents; 2) With respect to the keyword tag method, only keywords occurring in the document can be selected as tags, while not all of the keywords are suitable for the tag; And 3) With respect to the methods of socialization tags, this requires the user to add tags to the document alone, resulting in tags not being aligned due to inconsistent standards of different users.
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 방법 및 장치가 제공되고, 이로 인해 문서 내의 키워드들로 제한되지 않은 태그가 문서에 지능적으로 추가될 수 있다.According to one embodiment of the present invention, a method and apparatus are provided for automatically adding tags to a document, whereby tags that are not limited to keywords in the document can be intelligently added to the document.
본 발명의 하나의 실시예에 대한 해법은 다음과 같이 구현된다.The solution to one embodiment of the present invention is implemented as follows.
태그를 문서에 자동으로 추가하는 방법은:To automatically add tags to your document:
문서에 대응하는 다수의 후보 태그 단어들을 결정하는 단계;Determining a plurality of candidate tag words corresponding to the document;
다수의 텍스트들을 포함하는 말뭉치(corpus)를 결정하고; 말뭉치로부터 흔히 사용되는 단어들을 특성 단어(characteristic word)들로서 선택하고; 특성 단어들 각각 및 후보 태그 단어들 각각에 대해, 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하는 단계;Determining a corpus comprising a plurality of texts; Selecting words that are commonly used from corpus as characteristic words; Determining, for each of the characteristic words and the candidate tag words, a probability that the candidate tag word coincides with the characteristic word;
문서로부터 특성 단어들을 추출하고, 추출된 특성 단어들의 각각에 대한 가중치를 계산하는 단계; 및Extracting characteristic words from a document, and calculating a weight for each of the extracted characteristic words; And
말뭉치에서, 후보 태그 단어들의 각각이 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하고; 높은 가중 동시 발생 확률을 가진 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하는 단계를 포함한다.Calculating, in the corpus, a weighted probability that each of the candidate tag words will occur simultaneously with all of the characteristic words extracted from the document; Selecting a candidate tag word having a high probability of occurrence of weighted weighting as a tag word to be added to the document.
태그를 문서에 자동으로 추가하는 장치는:Devices that automatically add tags to a document are:
문서에 대응하는 복수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈;A candidate tag word determination module configured to determine a plurality of candidate tag words corresponding to a document;
복수의 텍스트들을 포함하는 말뭉치를 결정하고, 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로서 선택하고, 특성 단어들 각각 및 후보 태그 단어들 각각에 대해, 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈;To select a corpus containing a plurality of texts, to select commonly used words from the corpus as characteristic words, and for each of the characteristic words and each of the candidate tag words to determine the probability that the candidate tag word coincides with the characteristic word A concurrent occurrence probability determination module configured;
문서로부터 특성 단어들을 추출하고, 추출된 특성 단어들의 각각에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈;A weight calculation module configured to extract characteristic words from a document and calculate a weight for each of the extracted characteristic words;
말뭉치에서, 후보 태그 단어들의 각각이 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈; 및A weighted coincidence probability calculation module configured to calculate, in a corpus, a weighted probability that each of the candidate tag words will occur simultaneously with all of the characteristic words extracted from the document; And
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈을 포함한다.And a tag word addition module configured to select a candidate tag word having a high weighted coincidence probability as a tag word to be added to the document.
본 발명의 실시예에 따라 태그를 문서에 자동으로 추가하는 방법 및 장치에서, 문서 내의 키워드로 제한되지 않는 태그는 특성 단어가 말뭉치 내의 후보 태그 단어와 동시 발생할 확률을 계산하고, 동시 발생 확률을 특성 단어로부터 후보 태그 단어로의 표(vote)로 전환하고, 가장 많은 표들을 획득한 후보 태그 단어를 문서에 추가될 태그 단어로서 취함으로써 문서에 지능적으로 추가될 수 있다.
In a method and apparatus for automatically adding a tag to a document in accordance with an embodiment of the present invention, a tag that is not limited to a keyword in the document calculates the probability that the feature word coincides with the candidate tag word in the corpus, Can be intelligently added to a document by switching to a vote from a word to a candidate tag word and taking the candidate tag word that has acquired the most votes as the tag word to be added to the document.
도 1은 본 발명의 하나의 실시예에 따라 태그를 문서에 자동으로 추가하기 위한 방법의 흐름도이다.
도 2는 본 발명의 하나의 실시예에 따라 태그를 문서에 자동으로 추가하기 위한 장치의 구조에 대한 개략도이다.1 is a flow diagram of a method for automatically adding a tag to a document in accordance with one embodiment of the present invention.
Figure 2 is a schematic diagram of the structure of an apparatus for automatically adding tags to a document in accordance with one embodiment of the present invention.
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 방법이 제공된다. 도 1은 다음과 같은 단계들을 포함하는 방법의 흐름도이다.According to one embodiment of the present invention, a method of automatically adding a tag to a document is provided. 1 is a flow chart of a method including the following steps.
단계 101에서, 문서에 대응하는 다수의 후보 태그 단어들이 결정된다.In
이 단계에서, 문서에 대응하는 다수의 후보 태그 단어들은 다음과 같은 세 방식들에 의해 결정될 수 있으나, 이로 제한되지 않는다:At this stage, a plurality of candidate tag words corresponding to a document may be determined by, but not limited to, the following three methods:
1) 특정한 태그가 문서에 수동으로 명시되는, 수동 태그의 방식;1) the manner of a passive tag, where a particular tag is manually specified in the document;
2) 문서의 컨텐츠들을 분석함으로써 문서로부터 자동으로 추출되는 중요한 키워드가 태그로서 취해지는 키워드 태그 방식; 및2) a keyword tag method in which an important keyword automatically extracted from a document is extracted as a tag by analyzing contents of the document; And
3) 태그가 사용자 자신에 의해 사용자의 문서에 추가되는 사회화 태그 방식.3) The social tag method in which the tag is added to the user's document by the user himself.
후보 태그 단어들이 수동 태그 방식 또는 사회화 태그 방식에 의해 결정되는 경우에 후보 태그 단어들은 문서에서 발생하는 단어들로 제한되지 않는다.In the case where the candidate tag words are determined by the manual tag method or the social tag method, the candidate tag words are not limited to words occurring in the document.
단계 102에서, 다수의 텍스트들을 포함하는 말뭉치(corpus)가 결정된다.In
예를 들어, 인터넷으로부터 일백만 개의 텍스트들이 획득되면, 일백만 개의 획득된 텍스트들이 일괄적으로 말뭉치로 칭해진다.For example, if one million texts are obtained from the Internet, one million acquired texts are collectively referred to as corpus.
단계 103에서, 흔히 사용되는 단어들이 말뭉치로부터 특성 단어들로서 선택되고, 특성 단어들의 각 단어별로 그리고 후보 태그 단어들의 각 단어별로, 후보 태그 단어와 특성 단어가 동시 발생할 확률이 말뭉치에서 결정된다.In
단계 104에서, 특성 단어들이 문서로부터 추출되고, 특성 단어들의 각 단어에 대한 가중치가 계산된다.In
단계 105에서, 후보 태그 단어들의 각 단어 별로, 후보 태그 단어가 문서에서 발생하는 특성 단어들 모두와 동시 발생할 가중 확률이 말뭉치에서 계산되고; 높은 가중 동시 발생 확률을 가지는 후보 태그 단어가 문서에 추가될 태그 단어로서 선택된다.In
단계 103에서, 동시 발생 확률은 P(X|Y)로서 표시되고, 여기서 X는 후보 태그 단어들 중 하나를 표시하고 Y는 말뭉치에서 발생하는 특성 단어들 중 하나를 표시한다. P(X|Y)는 다음과 같은 다양한 방식들에 의해 결정될 수 있다.At
제 1 방식에서, P(X|Y)는 말뭉치에 포함되는 동일한 텍스트 내에서의 X가 Y와 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생하는 횟수로 나눈 결과와 동일하다.In the first scheme, P (X | Y) is equal to the result of dividing the number of times X coincides with Y in the same text included in the corpus by the number of times Y occurs in the corpus.
제 2 방식에서, 
제 3 방식에서, P(X|Y)는 wordnet과 같은 어휘 데이터베이스를 사용함으로써 결정된다.In the third scheme, P (X | Y) is determined by using a vocabulary database such as wordnet.
단계 104에서, 추출된 특성 단어들의 각 단어 별로, 문서 내에서 특성 단어가 발생한 횟수 및 특성 단어가 발생한 말뭉치 내의 텍스트의 수에 기초하여 특성 단어에 대한 가중치가 계산될 수 있다.At
문서에서 추출되는 특성 단어(Y)에 대한 가중치는 WY로 표시되고, WY는: WY가 Y가 문서에서 발생한 횟수 및 Y가 발생한 말뭉치 내의 텍스트들의 수의 곱(product)과 동일하다는 것에 의해 계산될 수 있다.Weight for the characteristic word (Y) to be extracted from a document is represented by W Y, W Y is: W and Y is as Y are same as the product of the number of the text in the generated number of times, and Y generated in the document corpus (product) Lt; / RTI >
단계 105에서, 가중 동시 발생 확률은 
![]()
![]()
단계 105에서, 가중 동시 발생 확률 PX는 모든 후보 태그 단어들에 대해서보다는 오히려, 단지 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 후보 태그 단어에 대해서 계산될 수 있다.In
특정한 실시예들이 아래에서 더 상세하게 도입될 것이다.Certain embodiments will be introduced in more detail below.
제 1 실시예First Embodiment
단계 1에서, 태그 단어 세트가 준비된다.In step 1, a tag word set is prepared.
원하는 바에 따라 태그 단어 세트를 구성하기 위하여 문서에 대응하는 다수의 후보 태그 단어들이 획득된다. 예를 들어, 태그를 영화와 관련되는 문서들에 추가할 필요가 있는 경우, 태그 단어 세트는 영화의 종류 및 유명인과 같은 태그 단어들을 포함할 수 있다.A number of candidate tag words corresponding to the document are obtained to construct a tag word set as desired. For example, if a tag needs to be added to documents associated with a movie, the tag word set may include tag types such as movie types and celebrities.
단계 2에서, 말뭉치가 준비된다.In step 2, a corpus is prepared.
다수의 관련 텍스트들은 인터넷으로부터 단어들 사이의 동시 발생 관계들의 통계에 사용될 말뭉치로서 수집될 수 있다.A number of related texts may be collected as a corpus to be used for statistics of concurrent relationships between words from the Internet.
단계 3에서, 말뭉치로부터 특성 단어들이 추출된다.In step 3, characteristic words are extracted from the corpus.
말뭉치 내의 텍스트들에 대해 단어 구분(word segmentation)이 수행된다. 그리고 나서 각 단어의 어구 빈도수(term frequency; TF)가 계수된다. 고 빈도수 단어들, 사용되지 않은 단어들 및 저 빈도수 단어들은 제거되고, 나머지 흔히 사용되는 단어들이 특성 단어들로서 선택된다.Word segmentation is performed on the texts in the corpus. Then the term frequency (TF) of each word is counted. High frequency words, unused words and low frequency words are removed and the remaining commonly used words are selected as characteristic words.
단계 4에서, 특성 단어의 각각이 후보 태그 단어의 각각과 동시 발생할 확률 P(X|Y)이 계산된다.In step 4, the probability P (X | Y) that each of the characteristic words occurs simultaneously with each of the candidate tag words is calculated.
P(X|Y)는 말뭉치에 포함되는 동일한 텍스트에서 X 및 Y가 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생한 횟수로 나눈 결과와 동일하다.P (X | Y) is equivalent to the number of simultaneous X and Y occurrences in the same text included in the corpus divided by the number of occurrences of Y in the corpus.
여기서, X는 후보 태그 단어들 중 하나를 표시하고, Y는 특성 단어들 중 하나를 표시한다.Where X denotes one of the candidate tag words, and Y denotes one of the characteristic words.
단계 5에서, 태그 단어들은 문서에 자동으로 추가되고, 이의 특정한 단계들은 다음과 같다:In step 5, the tag words are automatically added to the document, the specific steps of which are:
단계 Ⅰ에서, 문서에 대한 단어 구분을 수행하고;In step I, word breaking is performed on the document;
단계 Ⅱ에서, 단어 구분 결과에 따라 문서 내에서 발생하는 특성 단어들 모두를 추출하고, 각각의 추출된 특성 단어 Y에 대한 가중치(WY)를 WY=TF×IDF로서 계산하고, 여기서 TF는 Y가 문서 내에서 발생하는 횟수를 표시하고 IDF는 Y가 발생하는 말뭉치 내의 텍스트의 수를 표시한다;In step II, all of the characteristic words occurring in the document are extracted according to the word classification result, and the weight (W Y ) for each extracted characteristic word Y is calculated as W Y = TF × IDF, Y indicates the number of occurrences in the document and IDF indicates the number of texts in the corpus in which Y occurs;
단계 Ⅲ에서, 단계 4에서 계산된 동시 발생 확률에 기초하여 적어도 하나의 특성 단어와 동시 발생하는(즉, 동시 발생 확률은 0이 아니다) 후보 태그 단어들을 추출하고; Extracting candidate tag words coincident with at least one characteristic word (i. E., The coincidence probability is not zero) based on the coincidence probabilities calculated in step 4;
단계 Ⅳ에서, 추출되는 후보 태그 단어들의 각각에 대해, 문서로부터 추출되는 특성 단어들 모두와의 추출되는 후보 태그 단어의 가중 동시 발생 확률 
![]()
![]()
단계 Ⅴ에서, Px 값들의 내림 차순으로 추출되는 후보 태그 단어들 모두를 순위화하고, 가장 높은 PX를 가지는 하나 이상의 후보 태그 단어들을 문서에 추가될 태그 단어들로서 선택한다.In step V, all of the candidate tag words extracted in descending order of P x values are ranked, and one or more candidate tag words having the highest P X are selected as tag words to be added to the document.
이 단계에서, 후보 태그 단어들 중 서너 단어는 우선 단계 Ⅲ에서 추출되고, 그 후에 가중 동시 발생 확률은 이 추출된 후보 태그 단어들 각각에 대해 계산된다. 이것은 계산 속도를 증가시키고 시스템 자원을 절약할 수 있다. 본 발명의 다른 실시예들에 따르면, 가중 동시 발생 확률은 후보 태그 단어들 모두에 대해 계산될 수 있다. 특성 단어들 어느 것과도 동시 발생 관계를 가지지 않는 후보 태그 단어의 경우, 계산되는 가중 동시 발생 확률 PX = 0이고 후보 태그 단어는 단계 Ⅴ에서 후보 태그 단어들의 줄(queue)의 말미에 순위가 정해질 것이다.At this stage, a few of the candidate tag words are first extracted in step III, and then a weighted coincidence probability is calculated for each of the extracted candidate tag words. This can speed computation and save system resources. According to other embodiments of the invention, the weighted coincidence probability can be calculated for all of the candidate tag words. For a candidate tag word that does not have a coincidence relationship with any of the characteristic words, the calculated weighted coincidence probability P X = 0 and the candidate tag word is ranked at the end of the queue of candidate tag words in step V Will be.
본 발명의 다른 실시예에서, 특성 단어 및 후보 태그 단어의 동시 발생 확률 P(X|Y)는 다른 방식들로 계산될 수 있다. 예를 들어, P(X|Y)는 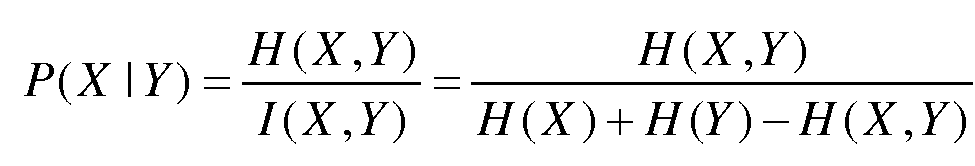
본 발명의 하나의 실시예에 따르면, 태그를 문서에 자동으로 추가하는 장치가 더 제공된다. 도 2는 상기 장치의 구조에 대한 개략도이고, 이는:According to one embodiment of the present invention, there is further provided an apparatus for automatically adding a tag to a document. Figure 2 is a schematic view of the structure of the device,
문서에 대응하는 다수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈(201);A candidate tag word determination module (201) configured to determine a plurality of candidate tag words corresponding to a document;
다수의 텍스트들을 포함하는 말뭉치를 결정하고, 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로 선택하고, 특성 단어들의 각 단어 및 후보 태그 단어들의 각 단어에 대해, 말뭉치 내에서 후보 태그 단어가 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈(202);Determining a corpus containing a plurality of texts, selecting commonly used words from the corpus as characteristic words, and for each word of the characteristic words and each word of the candidate tag words, A coincidence probability determination module (202) configured to determine a coincidence probability;
문서로부터 특성 단어들을 추출하고 특성 단어들의 각 단어에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈(203);A weight calculation module (203) configured to extract characteristic words from a document and calculate a weight for each word of characteristic words;
말뭉치 내에서, 후보 태그 단어들의 각 단어가 문서에서 발생하는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈(204); 및Within a corpus, a weighted coincidence probability calculation module (204) configured to calculate a weighted probability that each word of candidate tag words will occur simultaneously with all of the characteristic words occurring in the document; And
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈(205)을 포함한다.And a tag word addition module (205) configured to select a candidate tag word having a high weighted coincidence probability as a tag word to be added to the document.
상술한 장치에서, 동시 발생 확률은 P(X|Y)로 표시될 수 있고, 여기서 X는 후보 태그 단어들 중 하나를 표시하고 Y는 말뭉치 내에서 발생하는 특성 단어들 중 하나를 표시한다. 동시 발생 확률 결정 모듈(202)은 P(X|Y)를 다음과 같이 계산할 수 있다.In the above-described apparatus, the coincidence probability can be expressed as P (X | Y), where X denotes one of the candidate tag words and Y denotes one of the characteristic words occurring in the corpus. The coincidence
P(X|Y)는 말뭉치에 포함되는 동일한 텍스트에서가 X 및 Y가 동시 발생하는 횟수를 말뭉치 내에서 Y가 발생하는 횟수로 나눈 결과와 동일하다.P (X | Y) is the same as the result of dividing the number of simultaneous X and Y occurrences in the corpus by the number of occurrences of Y in the corpus.
대안으로, 
대안으로, P(X|Y)는 어휘 데이터베이스를 사용함으로써 결정된다.Alternatively, P (X | Y) is determined by using a lexical database.
상술한 장치에서, 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, 이는 가중치 계산 모듈(203)에 의해: WY는 문서에서 Y가 발생하는 횟수 및 Y가 발생하는 말뭉치에서의 텍스트들의 수의 곱과 동일하다는 것에 의해 계산될 수 있다.In the above-described apparatus, the weight for the characteristic word Y extracted from the document is represented by W Y , which is calculated by the weight calculation module 203: W Y is the number of times Y occurs in the document, Is equal to the product of the number of texts.
상술한 장치에서, 가중 동시 발생 확률은 ![]()
![]()
![]()
![]()
상술한 장치에서, 가중 동시 발생 확률 계산 모듈(204)은 단지 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 후보 태그 단어에 대한 가중 동시 발생 확률을 계산할 수 있다.In the apparatus described above, the weighted coincidence
결론적으로, 본 발명의 실시예들에 따라 태그를 문서에 자동으로 추가하는 방법 및 장치에서, 문서에서 발생하는 키워드로 제한되지 않는 태그는 특성 단어가 말뭉치 내의 후보 태그 단어와 동시 발생할 확률을 계산하고, 동시 발생 확률을 특성 단어로부터 후보 태그 단어로의 표(vote)로 전환하고, 최대 표들을 획득한 후보 태그 단어를 문서에 추가될 태그 단어로 취함으로써 지능적으로 문서에 추가될 수 있다. 태그 단어 및 문서 사이의 관련성은 본 발명의 실시예들에 따른 동시 발생 확률에 대한 통계에 기초하여 향상된다.In conclusion, in a method and apparatus for automatically adding a tag to a document according to embodiments of the present invention, a tag that is not limited to a keyword occurring in a document calculates a probability that a characteristic word coincides with a candidate tag word in a corpus , The simultaneous occurrence probability can be added to the document intelligently by converting the candidate word tag from the characteristic word into a vote vote and taking the candidate tag word obtained from the maximum tags as a tag word to be added to the document. The relevance between the tag word and the document is improved based on statistics on the coincidence probability according to embodiments of the present invention.
본 발명의 하나의 실시예에 따르면, 기계가 본원에서 기술되는 바와 같이 태그를 문서에 자동으로 추가하는 방법을 실행할 수 있도록 하는 명령들을 저장하는 기계 판독가능 저장 매체가 더 제공된다. 상술한 실시예들 중 임의의 실시예의 기능을 구현하는 소프트웨어 프로그램 코드들이 저장되어 있는 저장 매체를 포함하는 시스템 또는 장치가 제공될 수 있고, 이 시스템 또는 장치 내의 컴퓨터(또는 CPU 또는 MPU)는 저장 매체 내에 저장된 프로그램 코드들을 판독 및 실행할 수 있다.According to one embodiment of the present invention, there is further provided a machine-readable storage medium storing instructions that enable a machine to perform a method of automatically adding a tag to a document, as described herein. A system or apparatus may be provided that includes a storage medium on which software program codes embodying the functions of any of the above embodiments are stored, and a computer (or CPU or MPU) Lt; RTI ID = 0.0 > and / or < / RTI >
이 경우에, 저장 매체로부터 판독되는 프로그램 코드들은 상술한 실시예들 중 임의의 하나의 기능을 구현할 수 있다. 그러므로, 프로그램 코드들 및 프로그램 코드들을 저장하는 저장 매체는 본 발명의 일부를 구성한다.In this case, the program codes read from the storage medium may implement any one of the above-described embodiments. Therefore, the storage medium storing the program codes and program codes constitutes a part of the present invention.
프로그램 코드들을 제공하는 저장 매체의 예들은 소프트 디스크, 하드 디스크, 자기 광 디스크, 광 디스크(CD-ROM, CD-R, CD-RW, DVD-ROM, DVD-RAM, DVD-RW 및 DVD+RW와 같은), 자기 테이프, 비휘발성 메모리 및 ROM을 포함한다. 선택적으로, 프로그램 코드들은 통신 네트워크를 통해 서버 컴퓨터로부터 다운로드될 수 있다.Examples of storage media that provide the program codes are a hard disk, a hard disk, a magnetic optical disk, an optical disk (CD-ROM, CD-R, CD-RW, DVD-ROM, DVD-RAM, DVD- , Magnetic tape, non-volatile memory, and ROM. Optionally, the program codes may be downloaded from the server computer via the communications network.
더욱이, 상술한 실시예들 중 임의의 하나의 기능은 컴퓨터에 의해 판독되는 프로그램 코드들을 실행할 뿐만 아니라 컴퓨터 상에서 동작하는 운영 시스템에 프로그램 코드들에 기초하여 지시함으로써 수행되는 실제 동작들 중 서너 개 또는 모두를 통해 구현될 수 있음이 인정될 것이다.Furthermore, any one of the above-described embodiments may be implemented in a computer-readable medium, such as a computer-readable medium or a computer-readable recording medium, As will be appreciated by those skilled in the art.
더욱이, 상술한 실시예들 중 임의의 하나의 기능은 저장 매체로부터 판독되는 프로그램 코드들을 컴퓨터 내에 삽입되는 확장 보드에서 제공되는 메모리에 기록하거나 프로그램 코드들을 컴퓨터에 접속되는 확장 유닛에서 제공되는 메모리에 기록하고 나서 실제 동작들 중 서너 개 또는 모두를 수행하는 프로그램 코드들에 기초하여 확장 보드 또는 확장 유닛에 장착되는 CPU 등에게 지시함으로써 구현될 수 있음이 이해되어야 한다.Furthermore, any one of the above-described embodiments may be implemented by writing program codes read from a storage medium to a memory provided in an expansion board inserted in the computer, or writing the program codes into a memory provided in an expansion unit connected to the computer And then instructing the CPU or the like mounted on the expansion board or expansion unit based on the program codes that perform some or all of the actual operations.
상기 진술된 본 발명의 바람직한 실시예들은 본 발명의 범위를 제한하도록 의도되지 않는다. 본 발명의 사상 및 원리들 내에서 행해지는 임의의 변형들, 등가들, 개선들은 본 발명의 범위에 해당한다.The above-described preferred embodiments of the present invention are not intended to limit the scope of the invention. Any modifications, equivalents, and improvements that fall within the spirit and principles of the present invention are within the scope of the present invention.
Claims (15)
상기 문서에 대응하는 복수의 후보 태그 단어들을 결정하는 단계;
복수의 텍스트들을 포함하는 말뭉치(corpus)를 결정하고; 상기 말뭉치로부터 흔히 사용되는 단어들을 특성 단어(characteristic word)들로서 선택하고; 상기 특성 단어들 각각 및 상기 후보 태그 단어들 각각에 대해, 상기 후보 태그 단어가 상기 특성 단어와 동시 발생할 확률을 결정하는 단계;
상기 문서로부터 특성 단어들을 추출하고, 상기 추출된 특성 단어들의 각각에 대한 가중치를 계산하는 단계; 및
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 상기 특성 단어들 모두와 동시 발생할 가중 확률을 계산하고; 높은 가중 동시 발생 확률을 가진 후보 태그 단어를 상기 문서에 추가될 태그 단어로서 선택하는 단계를 포함하며,
상기 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, WY는 Y가 상기 문서에서 발생하는 횟수와 Y가 발생하는 상기 말뭉치 내의 텍스트들의 수의 곱(product)과 동일한 것인 태그를 문서에 자동으로 추가하는 방법.
A method to automatically add a tag to a document:
Determining a plurality of candidate tag words corresponding to the document;
Determining a corpus comprising a plurality of texts; Selecting words commonly used from the corpus as characteristic words; Determining, for each of the characteristic words and the candidate tag words, a probability that the candidate tag word coincides with the characteristic word;
Extracting characteristic words from the document and calculating a weight for each of the extracted characteristic words; And
Calculating, in the corpus, a weighted probability that each of the candidate tag words will occur simultaneously with all of the characteristic words extracted from the document; Selecting a candidate tag word having a high probability of weighted occurrence as a tag word to be added to the document,
Weight for the characteristic word Y to be extracted from said document that is represented by W Y, W Y is Y is identical to the product of the text, the number of (product) in the corpus that the number and Y generated by the document generation tags To the document automatically.
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는 상기 말뭉치에 포함되는 동일한 텍스트 내에서 X 및 Y가 동시 발생하는 횟수를 상기 말뭉치에서 Y가 발생하는 횟수로 나눈 결과로서 결정되는 태그를 문서에 자동으로 추가하는 방법.
The method according to claim 1,
Wherein the coincidence probability is represented as P (X | Y), where X represents one of the candidate tag words and Y represents one of the characteristic words occurring in the corpus;
A method of automatically adding a tag to a document determined as a result of dividing the number of simultaneous occurrences of X and Y in the same text included in the corpus by the number of occurrences of Y in the corpus.
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는

The method according to claim 1,
Wherein the coincidence probability is denoted as P (X | Y), X denotes one of the candidate tag words and Y denotes one of the characteristic words occurring in the corpus;
P (X | Y)
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
P(X|Y)는 어휘 데이터베이스를 사용함으로써 결정되는 태그를 문서에 자동으로 추가하는 방법.
The method according to claim 1,
Wherein the coincidence probability is denoted as P (X | Y), X denotes one of the candidate tag words and Y denotes one of the characteristic words occurring in the corpus;
P (X | Y) is a method of automatically adding tags to a document determined by using a vocabulary database.
상기 가중 동시 발생 확률은
The method according to claim 1,
The weighted probability of simultaneous occurrence is
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하는 것은:
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 가중 확률을 계산하는 것을 포함하는 태그를 문서에 자동으로 추가하는 방법.
The method according to claim 1,
In the corpus, calculating the weighted probability that each of the candidate tag words will occur simultaneously with all of the characteristic words extracted from the document:
Wherein in the corpus, calculating a weighted probability that each of the candidate tag words coincides with at least one characteristic word extracted from the document.
상기 문서에 대응하는 복수의 후보 태그 단어들을 결정하도록 구성되는 후보 태그 단어 결정 모듈;
복수의 텍스트들을 포함하는 말뭉치를 결정하고, 상기 말뭉치로부터 흔히 사용되는 단어들을 특성 단어들로서 선택하고, 상기 특성 단어들 각각 및 상기 후보 태그 단어들 각각에 대해, 상기 후보 태그 단어가 상기 특성 단어와 동시 발생할 확률을 결정하도록 구성되는 동시 발생 확률 결정 모듈;
상기 문서로부터 특성 단어들을 추출하고, 상기 추출된 특성 단어들의 각각에 대한 가중치를 계산하도록 구성되는 가중치 계산 모듈;
상기 말뭉치에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 특성 단어들 모두와 동시 발생할 가중 확률을 계산하도록 구성되는 가중 동시 발생 확률 계산 모듈; 및
높은 가중 동시 발생 확률을 가지는 후보 태그 단어를 문서에 추가될 태그 단어로서 선택하도록 구성되는 태그 단어 추가 모듈을 포함하고,
상기 문서로부터 추출되는 특성 단어 Y에 대한 가중치는 WY로 표시되고, 상기 가중치 계산 모듈은 WY를 Y가 상기 문서에서 발생하는 횟수 및 Y가 발생하는 상기 말뭉치 내의 텍스트들의 수의 곱과 동일한 것으로 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
A device that automatically adds tags to a document:
A candidate tag word determination module configured to determine a plurality of candidate tag words corresponding to the document;
Determining a corpus containing a plurality of texts, selecting words commonly used from the corpus as characteristic words, and for each of the characteristic words and the candidate tag words, determining whether the candidate tag word is concurrent with the characteristic word A coincidence probability determination module configured to determine a probability of occurrence;
A weight calculation module configured to extract characteristic words from the document and to calculate a weight for each of the extracted characteristic words;
A weighted coincidence probability calculation module configured to calculate, in the corpus, a weighted probability that each of the candidate tag words will occur simultaneously with all of the characteristic words extracted from the document; And
And a tag word addition module configured to select a candidate tag word having a high weighted coincidence probability as a tag word to be added to the document,
The weight for the characteristic word Y extracted from the document is represented by W Y and the weight calculation module is equal to the product of W Y by the number of times Y occurs in the document and the number of texts in the corpus where Y occurs A device that automatically adds tags to a document that are configured to calculate.
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 P(X|Y)를 상기 말뭉치에 포함되는 동일한 텍스트 내에서 X 및 Y가 동시 발생하는 횟수를 상기 말뭉치에서 Y가 발생하는 횟수로 나눈 결과로서 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
9. The method of claim 8,
Wherein the coincidence probability is represented as P (X | Y), where X represents one of the candidate tag words and Y represents one of the characteristic words occurring in the corpus;
Wherein the simultaneous occurrence probability determination module calculates a tag configured to calculate P (X | Y) as a result of dividing the number of simultaneous occurrence of X and Y in the same text included in the corpus by the number of times Y occurs in the corpus A device that automatically adds to a document.
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 P(X|Y)를

9. The method of claim 8,
Wherein the coincidence probability is denoted as P (X | Y), X denotes one of the candidate tag words and Y denotes one of the characteristic words occurring in the corpus;
The coincidence probability determination module determines P (X | Y) as
상기 동시 발생 확률은 P(X|Y)로서 표시되고, X는 상기 후보 태그 단어들 중 하나를 표시하고 Y는 상기 말뭉치 내에서 발생하는 상기 특성 단어들 중 하나를 표시하고;
상기 동시 발생 확률 결정 모듈은 어휘 데이터베이스를 사용함으로써 P(X|Y)를 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
9. The method of claim 8,
Wherein the coincidence probability is denoted as P (X | Y), X denotes one of the candidate tag words and Y denotes one of the characteristic words occurring in the corpus;
Wherein the coincidence probability determination module automatically adds a tag to a document that is configured to calculate P (X | Y) by using a lexical database.
상기 가중 동시 발생 확률은
The method according to any one of claims 8 to 11,
The weighted probability of simultaneous occurrence is
상기 가중 동시 발생 확률 계산 모듈은 상기 말뭉치 내에서, 상기 후보 태그 단어들의 각각이 상기 문서로부터 추출되는 하나 이상의 특성 단어와 동시 발생하는 가중 확률을 계산하도록 구성되는 태그를 문서에 자동으로 추가하는 장치.
The method according to any one of claims 8 to 11,
Wherein the weighted coincidence probability calculation module automatically adds within the corpus a tag that is configured to calculate a weighted probability that each of the candidate tag words coincides with one or more characteristic words extracted from the document.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210001611.9 | 2012-01-05 | ||
| CN201210001611.9A CN103198057B (en) | 2012-01-05 | 2012-01-05 | One kind adds tagged method and apparatus to document automatically |
| PCT/CN2012/086733 WO2013102396A1 (en) | 2012-01-05 | 2012-12-17 | Method, apparatus, and computer storage medium for automatically adding tags to document |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140093762A KR20140093762A (en) | 2014-07-28 |
| KR101479040B1 true KR101479040B1 (en) | 2015-01-05 |
Family
ID=48720627
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020147019605A KR101479040B1 (en) | 2012-01-05 | 2012-12-17 | Method, apparatus, and computer storage medium for automatically adding tags to document |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9146915B2 (en) |
| EP (1) | EP2801917A4 (en) |
| JP (1) | JP2015506515A (en) |
| KR (1) | KR101479040B1 (en) |
| CN (1) | CN103198057B (en) |
| WO (1) | WO2013102396A1 (en) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104199898B (en) * | 2014-08-26 | 2018-05-15 | 北京小度互娱科技有限公司 | Acquisition methods and device, the method for pushing and device of a kind of attribute information |
| JP6208105B2 (en) * | 2014-09-18 | 2017-10-04 | 株式会社東芝 | Tag assigning apparatus, method, and program |
| CN105488077B (en) * | 2014-10-10 | 2020-04-28 | 腾讯科技(深圳)有限公司 | Method and device for generating content label |
| CN104361033B (en) * | 2014-10-27 | 2017-06-09 | 深圳职业技术学院 | A kind of automatic collection method of cancer relevant information and system |
| CN104462360B (en) * | 2014-12-05 | 2020-02-18 | 北京奇虎科技有限公司 | Method and device for generating semantic identification for text set |
| CN105989018B (en) * | 2015-01-29 | 2020-04-21 | 深圳市腾讯计算机系统有限公司 | Label generation method and label generation device |
| US20180075361A1 (en) * | 2015-04-10 | 2018-03-15 | Hewlett-Packard Enterprise Development LP | Hidden dynamic systems |
| JP6535858B2 (en) * | 2015-04-30 | 2019-07-03 | 国立大学法人鳥取大学 | Document analyzer, program |
| WO2017011483A1 (en) * | 2015-07-12 | 2017-01-19 | Aravind Musuluri | System and method for ranking documents |
| CN105573968A (en) * | 2015-12-10 | 2016-05-11 | 天津海量信息技术有限公司 | Text indexing method based on rules |
| CN105740404A (en) * | 2016-01-28 | 2016-07-06 | 上海晶赞科技发展有限公司 | Label association method and device |
| CN106066870B (en) * | 2016-05-27 | 2019-03-15 | 南京信息工程大学 | A kind of bilingual teaching mode building system of context mark |
| CN107818092B (en) * | 2016-09-12 | 2023-05-26 | 百度在线网络技术(北京)有限公司 | Document processing method and device |
| CN106682149A (en) * | 2016-12-22 | 2017-05-17 | 湖南科技学院 | Label automatic generation method based on meta-search engine |
| CN107436922B (en) | 2017-07-05 | 2021-06-08 | 北京百度网讯科技有限公司 | Text label generation method and device |
| CN108536800B (en) * | 2018-04-03 | 2022-04-19 | 有米科技股份有限公司 | Text classification method, system, computer device and storage medium |
| CN109857957B (en) * | 2019-01-29 | 2021-06-15 | 掌阅科技股份有限公司 | Method for establishing label library, electronic equipment and computer storage medium |
| CN109992774A (en) * | 2019-03-25 | 2019-07-09 | 北京理工大学 | The key phrase recognition methods of word-based attribute attention mechanism |
| WO2021009885A1 (en) * | 2019-07-17 | 2021-01-21 | 日本電信電話株式会社 | Teacher data generation device, teacher data generation method, and teacher data generation program |
| CN110399491A (en) * | 2019-07-19 | 2019-11-01 | 电子科技大学 | A kind of microblogging event evolution analysis method based on feature word co-occurrence graph |
| CN113343684B (en) * | 2021-06-22 | 2023-05-26 | 广州华多网络科技有限公司 | Core product word recognition method, device, computer equipment and storage medium |
| CN113486266A (en) * | 2021-06-29 | 2021-10-08 | 平安银行股份有限公司 | Page label adding method, device, equipment and storage medium |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090045520A (en) * | 2007-11-02 | 2009-05-08 | 조광현 | Method of generating tag word automatically by semantics |
| KR101011726B1 (en) | 2009-06-09 | 2011-01-28 | 성균관대학교산학협력단 | Apparatus and method for providing snippet |
Family Cites Families (47)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3266246B2 (en) * | 1990-06-15 | 2002-03-18 | インターナシヨナル・ビジネス・マシーンズ・コーポレーシヨン | Natural language analysis apparatus and method, and knowledge base construction method for natural language analysis |
| JP3220885B2 (en) * | 1993-06-18 | 2001-10-22 | 株式会社日立製作所 | Keyword assignment system |
| US5675819A (en) * | 1994-06-16 | 1997-10-07 | Xerox Corporation | Document information retrieval using global word co-occurrence patterns |
| JP2809341B2 (en) * | 1994-11-18 | 1998-10-08 | 松下電器産業株式会社 | Information summarizing method, information summarizing device, weighting method, and teletext receiving device. |
| US6480841B1 (en) * | 1997-09-22 | 2002-11-12 | Minolta Co., Ltd. | Information processing apparatus capable of automatically setting degree of relevance between keywords, keyword attaching method and keyword auto-attaching apparatus |
| US6317740B1 (en) * | 1998-10-19 | 2001-11-13 | Nec Usa, Inc. | Method and apparatus for assigning keywords to media objects |
| US7130848B2 (en) * | 2000-08-09 | 2006-10-31 | Gary Martin Oosta | Methods for document indexing and analysis |
| EP1346559A4 (en) * | 2000-11-16 | 2006-02-01 | Mydtv Inc | System and methods for determining the desirability of video programming events |
| JP4679003B2 (en) | 2001-08-24 | 2011-04-27 | ヤフー株式会社 | Feature item extraction method from data |
| WO2003060766A1 (en) * | 2002-01-16 | 2003-07-24 | Elucidon Ab | Information data retrieval, where the data is organized in terms, documents and document corpora |
| US7395256B2 (en) * | 2003-06-20 | 2008-07-01 | Agency For Science, Technology And Research | Method and platform for term extraction from large collection of documents |
| US20060074900A1 (en) * | 2004-09-30 | 2006-04-06 | Nanavati Amit A | Selecting keywords representative of a document |
| TWI254880B (en) * | 2004-10-18 | 2006-05-11 | Avectec Com Inc | Method for classifying electronic document analysis |
| KR20070084004A (en) * | 2004-11-05 | 2007-08-24 | 가부시키가이샤 아이.피.비. | Keyword extracting device |
| JP2006323517A (en) | 2005-05-17 | 2006-11-30 | Mitsubishi Electric Corp | Text classification device and program |
| US7711737B2 (en) * | 2005-09-12 | 2010-05-04 | Microsoft Corporation | Multi-document keyphrase extraction using partial mutual information |
| US7627559B2 (en) * | 2005-12-15 | 2009-12-01 | Microsoft Corporation | Context-based key phrase discovery and similarity measurement utilizing search engine query logs |
| US8856145B2 (en) * | 2006-08-04 | 2014-10-07 | Yahoo! Inc. | System and method for determining concepts in a content item using context |
| US7996393B1 (en) * | 2006-09-29 | 2011-08-09 | Google Inc. | Keywords associated with document categories |
| US8073850B1 (en) * | 2007-01-19 | 2011-12-06 | Wordnetworks, Inc. | Selecting key phrases for serving contextually relevant content |
| JP2009015743A (en) * | 2007-07-09 | 2009-01-22 | Fujifilm Corp | Document creation support system, document creation support method, and document creation support program |
| US7917355B2 (en) * | 2007-08-23 | 2011-03-29 | Google Inc. | Word detection |
| US8280892B2 (en) * | 2007-10-05 | 2012-10-02 | Fujitsu Limited | Selecting tags for a document by analyzing paragraphs of the document |
| US9317593B2 (en) * | 2007-10-05 | 2016-04-19 | Fujitsu Limited | Modeling topics using statistical distributions |
| WO2009059297A1 (en) * | 2007-11-01 | 2009-05-07 | Textdigger, Inc. | Method and apparatus for automated tag generation for digital content |
| US8090724B1 (en) * | 2007-11-28 | 2012-01-03 | Adobe Systems Incorporated | Document analysis and multi-word term detector |
| US8055688B2 (en) * | 2007-12-07 | 2011-11-08 | Patrick Giblin | Method and system for meta-tagging media content and distribution |
| US8280886B2 (en) * | 2008-02-13 | 2012-10-02 | Fujitsu Limited | Determining candidate terms related to terms of a query |
| US20090299998A1 (en) * | 2008-02-15 | 2009-12-03 | Wordstream, Inc. | Keyword discovery tools for populating a private keyword database |
| US8606795B2 (en) * | 2008-07-01 | 2013-12-10 | Xerox Corporation | Frequency based keyword extraction method and system using a statistical measure |
| CA2638558C (en) * | 2008-08-08 | 2013-03-05 | Bloorview Kids Rehab | Topic word generation method and system |
| US20100076976A1 (en) * | 2008-09-06 | 2010-03-25 | Zlatko Manolov Sotirov | Method of Automatically Tagging Image Data |
| US8166051B1 (en) * | 2009-02-03 | 2012-04-24 | Sandia Corporation | Computation of term dominance in text documents |
| JP2010224622A (en) * | 2009-03-19 | 2010-10-07 | Nomura Research Institute Ltd | Method and program for applying tag |
| US20110004465A1 (en) * | 2009-07-02 | 2011-01-06 | Battelle Memorial Institute | Computation and Analysis of Significant Themes |
| US8370286B2 (en) | 2009-08-06 | 2013-02-05 | Yahoo! Inc. | System for personalized term expansion and recommendation |
| CN101650731A (en) * | 2009-08-31 | 2010-02-17 | 浙江大学 | Method for generating suggested keywords of sponsored search advertisement based on user feedback |
| US8245135B2 (en) * | 2009-09-08 | 2012-08-14 | International Business Machines Corporation | Producing a visual summarization of text documents |
| CN102043791B (en) * | 2009-10-10 | 2014-04-30 | 深圳市世纪光速信息技术有限公司 | Method and device for evaluating word classification |
| US8266228B2 (en) * | 2009-12-08 | 2012-09-11 | International Business Machines Corporation | Tagging communication files based on historical association of tags |
| CN103038764A (en) * | 2010-04-14 | 2013-04-10 | 惠普发展公司,有限责任合伙企业 | Method for keyword extraction |
| US8463786B2 (en) * | 2010-06-10 | 2013-06-11 | Microsoft Corporation | Extracting topically related keywords from related documents |
| CN102081642A (en) | 2010-10-28 | 2011-06-01 | 华南理工大学 | Chinese label extraction method for clustering search results of search engine |
| US8375022B2 (en) * | 2010-11-02 | 2013-02-12 | Hewlett-Packard Development Company, L.P. | Keyword determination based on a weight of meaningfulness |
| EP2635965A4 (en) * | 2010-11-05 | 2016-08-10 | Rakuten Inc | Systems and methods regarding keyword extraction |
| US9483557B2 (en) * | 2011-03-04 | 2016-11-01 | Microsoft Technology Licensing Llc | Keyword generation for media content |
| US8700599B2 (en) * | 2011-11-21 | 2014-04-15 | Microsoft Corporation | Context dependent keyword suggestion for advertising |
-
2012
- 2012-01-05 CN CN201210001611.9A patent/CN103198057B/en active Active
- 2012-12-17 EP EP12864434.1A patent/EP2801917A4/en not_active Ceased
- 2012-12-17 JP JP2014550620A patent/JP2015506515A/en active Pending
- 2012-12-17 WO PCT/CN2012/086733 patent/WO2013102396A1/en active Application Filing
- 2012-12-17 KR KR1020147019605A patent/KR101479040B1/en active IP Right Grant
- 2012-12-17 US US14/370,418 patent/US9146915B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20090045520A (en) * | 2007-11-02 | 2009-05-08 | 조광현 | Method of generating tag word automatically by semantics |
| KR101011726B1 (en) | 2009-06-09 | 2011-01-28 | 성균관대학교산학협력단 | Apparatus and method for providing snippet |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2801917A4 (en) | 2015-08-26 |
| CN103198057B (en) | 2017-11-07 |
| CN103198057A (en) | 2013-07-10 |
| JP2015506515A (en) | 2015-03-02 |
| US20150019951A1 (en) | 2015-01-15 |
| WO2013102396A1 (en) | 2013-07-11 |
| EP2801917A1 (en) | 2014-11-12 |
| KR20140093762A (en) | 2014-07-28 |
| US9146915B2 (en) | 2015-09-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101479040B1 (en) | Method, apparatus, and computer storage medium for automatically adding tags to document | |
| CA2832909C (en) | System and method for matching comment data to text data | |
| US8781817B2 (en) | Phrase based document clustering with automatic phrase extraction | |
| US8402036B2 (en) | Phrase based snippet generation | |
| TWI506460B (en) | System and method for recommending files | |
| US8171029B2 (en) | Automatic generation of ontologies using word affinities | |
| JP5010885B2 (en) | Document search apparatus, document search method, and document search program | |
| CN112395395B (en) | Text keyword extraction method, device, equipment and storage medium | |
| JP5273735B2 (en) | Text summarization method, apparatus and program | |
| CN103430172A (en) | Search apparatus, search method, and program | |
| CN107844493B (en) | File association method and system | |
| CN111090731A (en) | Electric power public opinion abstract extraction optimization method and system based on topic clustering | |
| WO2008144457A2 (en) | Efficient retrieval algorithm by query term discrimination | |
| US20150120708A1 (en) | Information aggregation, classification and display method and system | |
| CN103064880A (en) | Method, device and system based on searching information for providing users with website choice | |
| JP2005250980A (en) | Document retrieval system, retrieval condition input device, retrieval execution device, document retrieval method and document retrieval program | |
| JP5952711B2 (en) | Prediction server, program and method for predicting future number of comments in prediction target content | |
| Xu et al. | Mining Web search engines for query suggestion | |
| JP2004054882A (en) | Synonym retrieval device, method, program and storage medium | |
| JP2010055164A (en) | Sentence retrieval device, sentence retrieval method, sentence retrieval program and its storage medium | |
| KR101108600B1 (en) | Method and apparatus for measuring similarity of documents | |
| KR100525617B1 (en) | Method and system for identifying related search terms in the internet search system | |
| CN115221264A (en) | Text processing method and device and readable storage medium | |
| JP2012226470A (en) | Series item group extraction system, series item group extraction method and series item group extraction program | |
| WO2015117771A1 (en) | Robust stream filtering based on reference documents |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| A302 | Request for accelerated examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20171219 Year of fee payment: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20181219 Year of fee payment: 5 |