KR100445542B1 - 프로세서의커스텀오퍼레이션들을위한방법및장치 - Google Patents
프로세서의커스텀오퍼레이션들을위한방법및장치 Download PDFInfo
- Publication number
- KR100445542B1 KR100445542B1 KR1019970703017A KR19970703017A KR100445542B1 KR 100445542 B1 KR100445542 B1 KR 100445542B1 KR 1019970703017 A KR1019970703017 A KR 1019970703017A KR 19970703017 A KR19970703017 A KR 19970703017A KR 100445542 B1 KR100445542 B1 KR 100445542B1
- Authority
- KR
- South Korea
- Prior art keywords
- bits
- significant bits
- processor
- operand data
- instruction
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 29
- 238000012545 processing Methods 0.000 claims abstract description 21
- 238000004364 calculation method Methods 0.000 claims description 14
- 239000004065 semiconductor Substances 0.000 claims 1
- 239000000758 substrate Substances 0.000 claims 1
- 230000006870 function Effects 0.000 abstract description 38
- 230000008901 benefit Effects 0.000 abstract description 11
- 101150099915 Rsrc2 gene Proteins 0.000 description 39
- 239000011159 matrix material Substances 0.000 description 15
- 238000007792 addition Methods 0.000 description 9
- 238000010586 diagram Methods 0.000 description 7
- 238000007667 floating Methods 0.000 description 5
- 230000006835 compression Effects 0.000 description 3
- 238000007906 compression Methods 0.000 description 3
- 230000006837 decompression Effects 0.000 description 3
- 230000001343 mnemonic effect Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 241000613118 Gryllus integer Species 0.000 description 1
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000003416 augmentation Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
Images


































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7828—Architectures of general purpose stored program computers comprising a single central processing unit without memory
- G06F15/7832—Architectures of general purpose stored program computers comprising a single central processing unit without memory on one IC chip (single chip microprocessors)
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30025—Format conversion instructions, e.g. Floating-Point to Integer, decimal conversion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30072—Arrangements for executing specific machine instructions to perform conditional operations, e.g. using predicates or guards
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
Abstract
커스텀 오퍼레이션은 멀티미디어 기능을 포함하는 기능을 수행하는 프로세서 시스템에 사용한다. 이런 커스텀 오퍼레이션은 특수 목적과 부가된 솔루션 즉, 저비용과 칩 수의 이점과, 일반 목적의 프로세서의 프로그램 재작성 능력을 유지하는 반면에 실시간 멀티미디어 능력을 제공하기 위해 PC 시스템과 같은 시스템의 질을 향상시킨다. 이러한 커스텀 오퍼레이션은 오퍼랜드 데이터를 갖는 입력 데이터를 공급하고, 오퍼랜드 데이터에 대해 오퍼레이션을 실행하고, 결과 데이터를 목적지 레지스터에 공급하는 컴퓨터 시스템에서 동작한다. 실행된 오퍼레이션은 클립핑 또는 포화 오퍼레이션을 포함하는 오디오와 비디오 처리를 포함할 수 있다. 본 발명은 또한 입력 레지스터에서의 선택 오퍼랜드 데이터에 대해 병렬 오퍼레이션을 실행하고 목적지 레지스터에 그 결과를 저장시킨다.
Description
1. 발명의 분야
본 발명은 멀티미디어 기능을 포함하는 기능들을 실행하는 프로세서 시스템, 예를 들어 고품질의 비디오 및 오디오를 처리하여 특정화된 고기능의 오퍼레이션을 실행하는 능력을 갖춘 시스템에서 사용하기 위한 커스텀 오퍼레이션에 관한 것이다.
2. 관련 기술의 설명
시스템은 다기능 PC 증강 수단으로서 기능하는 일반 목적 CPU와 추가 유니트를 포함하고 있다. 커스텀, PC는 다표준 비디오 및 오디오 스트림을 처리하여야 하며, 유저는 가능하다면 압축 해제 및 압축을 원한다. PC에서 사용되는 CPU칩들은 저해상도의 실시간 비디오 압축을 하면서, 고품질의 비디오 압축 해제 및 압축은 가능하지가 않다. 또한 유저는 시스템의 반응능력을 회생하지 않고 시스템이 라이브 비디오 및 오디오를 제공할 것을 요구한다.
일반 목적 및 내장된 마이크로프로세서를 근간으로한 응용에 있어서, 하이레벨의 언어로 프로그램밍하는 것이 바람직하다. 최적 컴파일러와 단순 프로그래밍 모델을 효과적으로 지원하기 위해서는 선형 어드레스 포인터의 조종을 직접적으로 지원하는 대형의 선형 어드레스 공간, 일반 목적 레지스터, 레지스터와 레지스터간 오퍼레이션과 같은 어떤 마이크로프로세서 아키텍쳐 특징들을 필요로 한다. 최근에 일반적으로 선택하는 마이크로프로세서 아키텍쳐는 현재 64 비트들과 128비트들 시스템이 개발중 이지만 32비트들 선형 어드레스, 32 비트들 레지스터, 32 비트들 정수 오퍼레이션이다.
그러나, 많은 알고리즘으로 데이터 조정을 하기 위해서는 전체 비트들 수(즉, 32 비트들 시스템의 32 비트들)를 이용한 데이터 오퍼레이션은 고가의 실리콘 자원을 낭비하는 것이다. MPEG 비디오 시스템의 압축 해제와 같은 중요한 멀티미디어 응용이 8비트들 데이터 항목을 다루는 대부분의 실행 시간을 소비하는 것이다. 작은 데이터 항목을 조정하기 위해 32, 64, 128 비트들 오퍼레이션을 이용하면 구현 시 32, 64, 128 비트들 실행 하드웨어를 비효율적으로 이용하는 것이다. 그러므로, 커스텀 오퍼레이션은 데이터 항목들을 동시에 오퍼레이션하여 적은 구현 비용으로 중요 요소에 의해 성능을 향상한다.
비록, 다른 수단을 통한 유사한 성능 증대가 달성될 수 있을 지라도, 예를 들어 주기당 커스텀의 마이크로프로세서 명령의 상위 넘버를 실행마면, 다른 수단은 저렴한 목표 응용을 위해 다른 수단은 일반적으로 고가인 것을 피한다. 부가적으로, n 비트들의 작은 데이터 항목을 조정하기 위해서 m 비트들 오퍼레이션, 예를 들어 32 비트를 오퍼레이션을 이용하는 것은(여기서, n<m이다), 구현시 m 비트들 오퍼레이션 하드웨어의 비효율적인 사용이다.
종래의 DSP(디지털 신호 처리) 오퍼레이션은 모듈로값(modulo value)을 계산하고 있다. 본 발명의 클립핑 또는 포화 오퍼레이션(saturation operation)은 레지스터의 물리적 한계를 초과하여 실행하는 데이터를 프로세싱이 발생하는 신호 처리 응용에서 특히 값어치가 있다. 종래에는 이러한 상황이 일어나면 데이터는 물리적으로 이용 가능한 범위의 다른 끝에서 맵된다. 신호 처리에 있어서, 이러한 주기적인 매핑은 위험할 수 있다. 예를 들면, 매우 작은 오디오 볼륨은 종래의 방법을 이용하여 최상위 끝에서 맵되어야 한다. 제어 응용 및 비디오/오디오 응용에 있어서 모듈로 값은 제어 범위나 세기 범위가 포화할 때 바람직하지 않다.
미국 특허 5,239,654로부터 단일 32 비트 명령 또는 다중 16 또는 18비트 명령들과 같은 어떤 명령들을 프로세서가 수행하는지를 제어하는 옵션들 레지스터를 갖는 프로세서가 공지된다. 이 프로세서가 가산과 같은 그러한 명령을 실행할 때, 명령은 프로세서가 32비트 가산과 같은 입력 레지스터의 컨텐츠상에 단일 32비트 오퍼레이션을 수행하거나, 동일 입력 레지스터의 컨텐츠상에 두 개의 16비트 오퍼레이션 또는 4개의 8비트 오퍼레이션들을 수행(두개의 16비트 가산, 또는 4개의 8비트 가산과 같음)하도록 제어한다.
본 출원은 1995년 9월 1일자로 출원된 미국 가출원 제 60/003,140호와 1995년 9월 25일자로 출원된 미국 가출원 제 60/004,642호의 이익을 청구한다.
다음의 출원들이 VLIW 프로세싱 시스템을 설명하기 위해 여기서 참조 문헌으로 결합되어 있다.
발명의 명칭이 "Data Processing Module And Video Processing System Incorporating Same(데이터 처리 모듈과 이를 내장한 비디오 프로세싱 시스템)"인 미국 특허 제 5,103,311호,
발명의 명칭이 "VLIW Processor Which Uses Path Information Generated By A Branch Control Unit To Inhibit Operations Which Are Not On A Correct Path(올바른 경로에 있지 않은 오퍼레이션을 금지하기 위해 브랜치 제어에 의해 발생된 경로 정보를 이용하는 VLIW 프로세서)"인 미국 특허 제 5,450, 556호,
발명의 명칭이 "Mutiport Memory Bypass Under Software Control(소프트웨어의 제어하의 멀티포트 메모리 바이패스)"인 미국 특허 5,313,551호,
발명의 명칭이 "VLIW Processor With Less Instruction Issue Slots Than Functional Units(기능 단위 보다 적은 명령 이슈 슬롯을 가진 VLIW 프로세서)"인 미국 특허 출원 제 07/998,080호",
발명의 명칭이 "Processing Device Including A Memory Circuit And A Group of Functional Unit(기능 단위의 그룹과 메모리 회로를 포함하는 처리 장치)"인 미국 특허 출원 제 07/594,534호,
발명의 명칭이 "Exception Recovery In A Data Processing System(데이터 프로세싱 시스템의 예외 리커버리)"인 미국 특허 출원 제 08/358,127호,
발명의 명칭이 클립핑 기능을 이용한 멀티미디어 어플리케이션의 커스텀 오퍼레이션 방법 및 장치와, 싱글 명령의 제어하에서 병렬 프로세싱하는 다중 오퍼랜드를 이용한 커스텀 오퍼레이션 방법 및 장치인 동시에 제출된 출원.
도 1은 본 발명으로 사용하기 위한 예증 시스템의 블록도.
도 2는 CPU 레지스터 아키텍쳐의 일례를 도시하는 도면.
도 3(a)은 메모리 매트릭스의 구성의 일례를 도시하는 도면.
도 3(b)은 일례로서 실행될 태스크를 도시하는 도면.
도 4는 커스텀 오퍼레이션을 이용하는 바이트 전치 행렬(byte-matrix transposition)의 응용예를 도시하는 도면.
도 5(a), 5(b)는 도 4에서 도시한 바이트 전치 행렬을 실행하기 위한 오퍼레이션 리스트를 도시하는 도면.
도 6은 dspiadd 오퍼레이션을 도시하는 도면.
도 7은 dspuadd 오퍼레이션을 도시하는 도면.
도 8은 dspidualadd 오퍼레이션을 도시하는 도면.
도 9는 dspuguadaddui 오퍼레이션을 도시하는 도면.
도 10은 dspimul 오퍼레이션을 도시하는 도면.
도 11은 dspuml 오퍼레이션을 도시하는 도면.
도 12는 dspidualmul 오퍼레이션을 도시하는 도면.
도 13은 dspisub 오퍼레이션을 도시하는 도면.
도 14는 dspusub 오퍼레이션을 도시하는 도면.
도 15는 dspidualsub 오퍼레이션을 도시하는 도면.
도 16은 ifir16 오퍼레이션을 도시하는 도면.
도 17은 ifir8ii 오퍼레이션을 도시하는 도면.
도 18은 ifir8ui 오퍼레이션을 도시하는 도면.
도 19는 ufir16 오퍼레이션을 도시하는 도면.
도 20은 mergelsb 오퍼레이션을 도시하는 도면.
도 21은 mergelsb 오퍼레이션을 도시하는 도면.
도 22는 mergemsb 오퍼레이션을 도시하는 도면.
도 23은 pack161sb 오퍼레이션을 도시하는 도면.
도 24는 pack16msb 오퍼레이션을 도시하는 도면.
도 25는 packbytes 오퍼레이션을 도시하는 도면.
도 26은 guadavg 오퍼레이션을 도시하는 도면.
도 27은 guadumulmsb 오퍼레이션을 도시하는 도면.
도 28은 ume8ii 오퍼레이션을 도시하는 도면.
도 29는 ume8uu 오퍼레이션을 도시하는 도면.
도 30은 iclipi 오퍼레이션을 도시하는 도면.
도 31은 uclipi 오퍼레이션을 도시하는 도면.
도 32는 uclipi 오퍼레이션을 도시하는 도면.
발명의 요약
본 발명은 특수 목적의 내장된 솔루션의 장점, 즉 저렴한 비용 및 칩 수의 장점과, 일반 목적 프로세서 재프로그램 능력의 장점들을 유지하면서 실시간 멀티미디어 능력을 제공하는 PC 시스템과 같은 시스템을 향상시키는 것입니다. PC 응용에 있어서, 본 발명은 고정 기능의 멀티미디어 칩의 능력을 능가하는 것이다.
따라서, 본 발명의 목적은 저가로 고성능의 멀티미디어를 달성하는 것이다.
본 발명의 다른 목적은 응용들의 작은 커널(kernel)들에서 처리 속도를 증가시키는 것이다.
본 발명의 또 다른 목적은 과도한 바이트 조정 명령 수를 필요로 하지 않으면서 캐시/메모리 대역폭의 완전한 이점을 달성하는 것이다.
본 발명의 또 다른 목적은 멀티미디어 응용의 성능을 향상하는 고기능 오퍼레이션을 제공하는 것이다.
본 발명의 또 다른 목적은 오퍼레이션 실행시 특정화된 비트들 실행 하드웨어를 효율적으로 이용하는 커스텀 오퍼레이션을 제공하는 것이다.
본 발명의 또 다른 목적은 멀티미디어 응용과 같은 특수 응용에 맞추어진 커스텀 오퍼레이션을 제공하는 것이다.
본 발명의 또 다른 목적은 단일 명령의 제어하에서 병렬 처리를 위한 복수 오퍼랜드를 저장하는 복수 오퍼랜드 레지스터를 이용하는 것이다. 이는 특히, 샘플들이 8비트들이거나 16비트들인 오디오 및/또는 비디오 응용에서 바람직하다.
본 발명의 목적은 트렁크드 범위(truncated range)의 정확한 측면에서 오디오나 비디오 신호와 같은 수신 신호를 유지하기 위한 클립핑 오퍼레이션을 이용하는 것이다.
본 발명은 커스텀의 PC를 위한 재프로그램 가능한 다목적 플러그인 카드에서 비디오폰과 같은 단일 목적의 저렴한 시스템에서 사용 가능하다. 또한, 본 발명은 MPEG-1, MPEG-2와 같은 대중적인 멀티미디어 표준을 손쉽게 구현하는 시스템에서 사용 가능하다. 그러나, 강력한 일반 목적 CPU에 입각한 본 발명의 방향은 개방형이거나 독점이든지 각종 멀티미디어 알고리즘을 구현할 수 있다.
소스 코드 레벨에서 소프트웨어 호환성을 정의하면 비용과 성능간의 최적 균형을 맞추기 위한 이점을 가진다. 강력한 컴파일러는 비휴대용 어셈블러 프로그래밍에 의존할 필요가 없게 한다. 본 발명에 의하면 친숙한 기능 호출 신택스(a familiar function call syntax)로 개선된 DSP형 오퍼레이션으로 소스 코드로부터의 강력한 로우 레벨의 오퍼레이션이 이용 가능하다.
본 발명에 따른 컴퓨터 시스템은 청구항 1의 특징부에 의해 특징된다. 본 발명에 따른 컴퓨터 시스템은 제 1 및 제 2 명령을 둘 다 포함하는 명령 세트를 가지는 프로세서를 갖는 컴퓨터 시스템을 제공한다. 재 1 명령은 프로세서가 전체적으로 입력 레지스터로부터 M비트 입력 데이터에 대한 오퍼레이션하도록 제어한다. 제 2 명령은 프로세서가 병렬적으로 각각 M비트 입력 데이터의 N비트들 상에(여기서 N<M) Q 오퍼레이션들을 수행하도록 제어한다. 제 1 및 제 2 명령은 프로세서가 이 방식으로 오퍼레이션하도록 항상 제어한다. 그 결과 M비트 입력 데이터로부터 Q N 비트 수(bit number)들 상에 또는 전체적으로 M비트 입력 데이터에 대한 오퍼레이션하도록 프로세서를 각각의 명령이 제어하는 지를 선택하기 위한 명령들을 실행하는 어떤 제어 비트들을 미리 설정할 필요가 없다. 제 1 및 제 2 명령은 가산과 같은 산술적으로 동일 타입의 오퍼레이션에 대한 것일 수 있다. 명령들의 실행은 클립핑(clipping) 또는 포화(saturation) 오퍼레이션을 포함할 수 있다. 또한, 명령들은 병렬적으로 수행될 수 있다.
본 발명의 또 다른 목적과 이점은 당업자라면 이후의 상세한 설명으로부터 용이하게 이해할 수 있을 것이다. 본 발명을 실행하기 위한 최상의 모드가 단지 일실시예로서 도시되고 기술되었다. 본 발명의 다른 상이한 실시예들이 가능하며 본 발명의 범위를 일탈하지 않는 각종 변형이 가능하고 도면 및 설명은 본 발명의 일례이며 이에 한정되는 것은 아니다.
이후, 본 발명의 보다 상세한 설명을 위해 첨부된 도면을 참조하여 설명하기로 한다.
도 1은 본 발명과 함께 사용되는 시스템의 블록도이다. 상기 시스템은 마이크로프로세서, 동기적 동적(synchronous dynamic) RAM (SDRAM)과 입력되거나/및 출력되는 멀티미디어 데이터 스트림들에 대한 인터페이스하는 외부회로로 구성되어 있다.
이 보기에서는, 32 비트들 CPU가 VLIW 프로세서 코어(processor core)를 형성한다. CPU는 32비트들 선형 어드레스 공간(linear address space)과 128개의 일반용으로 사용되는 32비트들 레지스터들로 구성되어 있다. 본 시스템에서는, 레지스터들이 뱅크들로(bank)분리되지 않는다. 대신에, 오퍼레이션은 어떠한 오퍼랜드 (operand)에 대해서 어떠한 레지스터를 사용할 수 있다.
이 시스템에서는, CPU가 VLIW 명령-세트 구조를 사용하므로, 최대 5개의 오퍼레이션지시가 나오게된다. 이러한 오퍼레이션들은, 이 보기에서는, 정수 및 부동점 수학단위(floating-point arithmetic units)와 데이터-패러렐(data-parallel)dsp와 같은 단위들과 CPU내에 있는 27개의 기능단위들 중 5개를 가리키게 된다.
본 발명을 사용하는 CPU의 작업세트(operation set)는 표준 비디오 압축과 비압축(decompression) 알고리즘의 수행을 빨리 수행시키는 멀티미디어 작업 뿐만 아니라 마이크로프로세서 오퍼레이션들을 포함하고 있다. 한 개의 특별한 또는"일반적인" 오퍼레이션은 단일한 명령으로 지시된 몇몇 오퍼레이션들 중 한 개인 오퍼레이션이다. 이 보기에서는 5개의 오퍼레이션들이 최대 11개의 마이크로프로세서 오퍼레이션들을 수행할 수 있다. VLIW, RISC 또는 다른 구조에서 수행되는 멀티미디어 오퍼레이션들은 멀티미디어 응용을 위해 엄청난 처리량(throughput)을 가져오게 된다. 본 발명은 이러한 멀티미디어 작업들을 수행하기 위하여, 32, 63,128,... 비트들로 된 한 개의 레지스터를 사용하고 있다.
도 2는 CPU 레지스터 구조의 한 보기를 도시하고 있다. 본 실시예의 CPU는 r0...r127로 표시된 128개의 일반목적용 32비트들 레지스터를 가지고 있다. 이 실시예에서는, 레지스터(r0,r1)들은 특수 목적을 위해 사용되며, r2에서 r127까지는 일반목적으로 사용되는 레지스터들이다.
본 시스템에서는, 프로세서가 한 클락주기 마다 항 개의 기다란 명령어를 출력한다. 각각의 이러한 명령어는 몇 개의 오퍼레이션 내용들을 포함하고 있다.( 본 실시예에서는 5개의 작업들) 각각의 오퍼레이션은 RISC 기계 명령어와 대응한다. 그 차이점은 오퍼레이션의 수행이 일반목적지 레지스터의 내용에 따라 수행된다는 점이다.
레지스터에 있는 데이터는, 예를 들면, 정수표현 또는 부동점 표현형태로 되어 있다.
정수들은, 본 실시예에서, 2진수와 정수들의 보수(complement) 비트들 패턴들로 표현된 '부호없는 정수(또는 부호없는)' 또는 '부호 있는 정수(또는 부호)'로 가정된다. 정수들에 대한 계산은 문제점을 발생시킨다. 만약에 결과가 충분히 내용을 표현하고 있지 않다면, 돌아온 비트들 패턴은 작업 설명부분에 정의된 것과 같이, 오퍼레이션을 지시하고 있다. 대표적인 경우들은 다음과 같다. 일반적인 가감(add and subtract) 형태의 오퍼레이션들을 위해 랩 어라운드하는 것(wrap around), dsp 형태의 작업들을 위해 최소 또는 최대 값에 대해 클램핑하는 것 (clamping) 또는 64 비트들의 결과값 중 가장 중요하지 않은 (least significant) 32 비트들을 돌려보내는 것(returning)이 있다. (보기: 정수/부호가 없는 곱셈(multifly))
본 실시예는 32 비트들 구조이므로, 멀티미디어 오퍼레이션에서 사용되는 데이터 값들에 대해서는 부동점 표현을 사용하지 않는다. 그러나 64비트들,128비트들,...구조에 대해서는 부동점표현은 멀티미디어 오퍼레이션에서 사용되는 데이터 값들에 대해서 사용되어질 수 있다. 예를 들면, 단일 정확도를 표현하는 (32 비트들)IEEE-754 부동점 표현과/또는 2배 정확도를 표현하는(64비트들)IEEE-754 부동점 표현은 데이터 값들을 나타내는데 사용되어진다.
본 발명의 구조에 있어서, 모든 오퍼레이션들은 선택적으로 "가드(guard)"되어진다. 가드된 오퍼레이션은 "가드" 레지스터(rguard)에 있는 값에 따라, 조건적으로 실행한다. 예를 들면, 가드된 정수 합산(iadd)은 다음과 같이 쓸 수 있다.
이 보기에서는, "if r23 then r14 := r14 + r10" 이다.'if r23'은 r23내에 있는 LSB(Least Significant Bit)에 따라 TRUE 또는 FALSE를 판별한다. r23의 LSB에 따라서, r23은 변하지 않거나, 또는 r14와 r10의 정수 합을 포함하도록 설정되어진다. 예를 들면, 본 발명의 실시예에서는, 만약 LSB가 1로 평가가 되면, 목적지 레지스터(destination register: rdest), 이 예에서는 r13, 이 기록된다. 가드(guarding)는 프로그래머가 볼 수 있는 시스템의 상태들, 즉 레지스터의 값들, 메모리 내용 그리고 장치 상태들에 관한 영향을 제어한다.
본 발명에 있는 메모리는 바이트 어드레스가 가능하다(byte addressable). 부하들(loads)과 저장장치(stores)들은 자연적으로 정렬된다. 즉 16비트들의 부하 또는 저장장치는 2의 배수인 어드레스를 처리하고 있다. 32 비트들의 부하 또는 저장장치는 4의 배수인 어드레스를 처리하고 있다. 기술자들은 이러한 이론을 쉽게 수정할 수 있다.
계산작업은 레지스터를 프로세싱하는 작업들(register-to-register operations)이다. 특정 오퍼레이션은 한 개 도는 두 개의 소스(source) 레지스터에 대해 행해진다. 그리고 결과가 목적지 레지스터(rdest)에 입력된다.
커스텀(custom) 작업들은 특별한 계산 작업들이며, 정상적인 계산작업들과 비슷하다. 그러나 이러한 커스텀 오퍼레이션들은 멀티미디어 응용분야에 대해서 수행된다. 본 발명의 커스텀 작업들은 특수하며, 다른 응용 분야 뿐만 아니라 중요한멀티미디어 분야에서 성능을 대폭 개선시키기 위해 설계된 고기능의 오퍼레이션들이다. 커스텀 오퍼레이션들이 응용 소스 코드(application source code)에 적절하게 포함되었을 때에, 본 발명은 필립스 전자회사에서 만든 Trimedia TM-1 칩과 같은 병렬 마이크로프로세서 이용할 수 있다.
일반 목적과 내장된 마이크로프로세서 응용을 위해, 고수준의 언어로 된 프로그래밍이 바람직하다. 최적의 컴파일러(optimizing compilers)와 단일한 프로그래밍 모델을 효과적으로 지원하기 위해, 크고 선형인 어드레스 공간, 일반 목적용 레지스터들과, 선형 어드레스 포인터(pointers)들의 제어를 직접 지원하는 레지스터 방식의 작업들과 같은 어떤 마이크로 프로세서 구조의 특징들이 필요하다.
본 발명은 2개의 16 비트들 데이터 아이템(item)들 또는 4개의 8비트들 데이터 아이템들을 동시에 처리하기 위해서, 예를 들면, 32비트들 자원들(resources)과 같은 시스템 전체 자원들을 사용할 수 있다. 이러한 자원들을 사용하게 되면, 단지 구현 비용을 약간만 증가시킴으로써, 주요 인자에 의한 성능(performance by significant factor)을 개선시킬 수 있다. 게다가, 상기 과정은 표준 마이크로 프로세서 자원들을 근거로 하여 높은 실행속도를 얻게된다.
몇몇 고기능의 커스텀 오퍼레이션들은 조건 브랜치(branches)들을 생략시킬 수 있다. 상기 이론은 스케줄러(scheduler)가 TM-1 명령어를 갖고 있는 필립스 TM-1 칩과 같은 본 발명의 시스템의 각 명령어내에 있는 5개의 오퍼레이션 슬롯(slot)들을 효과적으로 사용할 수 있도록 도와준다. 5개의 슬롯들을 모두 채우는 과정은 계산과정이 중요한 멀티미디어 응용분야의 내부 루프(inner loop)에서 중요하다.커스텀 오퍼레이션들은 본 발명이 가능한 가장 낮은 비용으로 매우 높은 멀티미디어 성능을 얻을 수 있도록 도와주고 있다.
표 1은 본 발명의 커스텀 오퍼레이션들의 목록이다. 몇 가지 커스텀 오퍼레이션들은 각각의 오퍼랜드(operand)와 결과들이 서로 다른 몇몇 형태에서 존재한다. 서로 다른 므니모닉이나 또는 이름들이 할당될 수 있지만, 서로 다른 형태에 대한 므니모닉(mnemonics)은 적절한 오퍼레이션의 선택을 돕기 위해서, 각각의 처리과정을 명확히 해주고 있다.
-이하 여백-
표 1. 함수형에 의해 리스트되는 커스텀 연산

본 발명의 커스텀 오퍼레이션을 설명하기 위해서 한 가지 보기가 제시되어 있다. 이 보기는 바이트-매트릭스(byte-matrix) 치환(transposition)이며, 커스텀 오퍼레이션들이 작은 커늘(kernel)내에서 처리속도를 크게 증가시키는 방법을 설명해주고 있다. 커스텀 오퍼레이션들이 사용되는 대부분의 곳에서와 같이, 이 경우에서는 커스텀 오퍼레이션들의 성능은 병렬상태에 있는 많은 데이터 아이템들을 처리할 수 있는 능력으로 평가된다.
예를 들면, 메모리 내에 있는 모두 차 있고, 바이트로 된 4*4 매트릭스를 치환시키는 작업을 보기로 하자. 매트릭스는 8비트들의 픽셀(pixel) 값들을 포함할 수 있다. 도(3a)는 메모리 내에 있는 매트릭스의 구조를 도시하고 있으며, 도(3b)는 표준 수학적 표시로 수행될 작업을 도시하고 있다.
전통적인 마이크로프로세서 명령어로 이 오퍼레이션을 수행시키는 과정은 다른 과정을 거치지 않고 바로 수행되는 직접적인 방법이나 시간이 소요된다. 상기 오퍼레이션을 수행하는 방법은 바이트를 적재(load) 시키기 위해 12 개의 부하-바이트(load-byte) 명령어를 수행시킨다. (왜냐하면, 16 바이트들 중 단지 12개만이 재배열될 필요가 있기 때문이다.) 그리고 그들의 새로운 위치들에 있는 메모리내에 바이트를 다시 저장시키기 위해서, 12 개의 저장-바이트 명령어들을 수행시킨다. 다른 방법은 4 개의 부하-단어 명령어들을 수행시키고, 적재된(loaded) 단어들의 바이트들을 레지스터 내에 재배열시키며, 4 개의 저장-단어 명령어들을 수행시킨다. 불행하게도, 레지스터 내에 바이트들을 재배치시키는 일은 바이트들을 적절하게 이동시키고 마스크하기 위해서(shift and mask), 많은 명령어들을 요구하고 있다. 24 개의 적재와 저장과정을 수행하는 과정은 적재/저장 장치내에 있는 이동과 마스킹 하드웨어를 사용하여, 더 짧은 명령 시퀀스(sequence)를 만들어낸다.
24 개의 적재/저장과정을 수행할 때의 문제점은 적재와 저장 과정들이 늦게 처리된다는 것이다. 상기 과정들은 최소한 캐시(cache)와 메모리 서열( hierarchy)내에 있는 속도가 늦은 층(layers) 들을 엑세스해야 한다. 게다가 32 비트 워드 방식의 억세스가 빨리 진행이 될 때에, 바이트 적재와 저장과정을 수행하는 단계는 캐시/메모리 인터페이스(interface)의 기능을 사용하게 된다. 지나치게 많은 바이트 처리 명령어를 요구하지 않으면서, 캐시/메모리 밴드폭을 최대한 활용하는 빠른 알고리즘(fast algorithm)이 바람직스럽다.
본 발명은 바이트들을 직접적으로 그리고 병렬형태로 합치며 (merge)(mergemsb, mergelsb), 16 비트들의 반어들(half-words)과 바이트들을 채우는(pack)(pack16msb, pack16lsb)명령어들을 가지고 있다. 이러한 명령어들 중 4개는 본 발명에 적용될 수 있으며, 바이트들을 단어들 내에 채우는 처리속도를 증가시킬 수 있게 된다.
도 4는 바이트 행렬 전위의 예에 대한 이 구조들의 응용을 예시한다. 도 5(a)는 행렬 전위를 구현하기 위해 필요한 오퍼레이션 리스트를 도시한다. 실제 명령으로 어셈블될 때, 이 커스텀의 오퍼레이션들은 예를 들어 한 명령에 다섯가지 오퍼레이션이 가능하도록 하는 종속관계만큼 단단히 패킷될 것이다. 도 5(a)에서 로우 레벨 코드는 단지 예시 목적상 도시되었다.
도 5(a)에서 4개의 로드 워드 오퍼레이션이 연속하는 제 1 순열은 입력 행렬의 패킷 워드를 레지스터(r10,r1,r12, 및 r13)에 전달한다. 4개의 합병 오퍼레이션 (mergemsb와 mergelsb)의 제 2 순열은 레지스터(r14,r15,r16 및 r17)에 중간결과를 생성한다. 이때, 다음 4개 팩 오퍼레이션(pack16msb 와 pack16lsb)의 순열은 원래 오퍼랜드를 대처할 수 있거나 또는 또 다른 계산에 원래 행렬의 오퍼랜드를 필요로한다면 각 레지스터에 전위 행렬을 저장할 것이다(TM-1 최적 C 컴파일러는 이러한 분석을 자동적으로 실행할 수 있다). 본 예에서, 전위행렬은 각 레지스터(st32d), 레지스터(r18,r19,r20 및 r21)에 저장된다. 마지막 4개의 스토어 워드 오퍼레이션은 메모리내 마지막 위치에 전위 행렬을 저장시킨다.
그러므로, 본 발명의 커스텀 오퍼레이션을 이용한다면 바이트 행렬 전위는 4가지 워드 오퍼레이션과 4가지 스토어 워드 오퍼레이션(가능한 최소) 및 레지스터-레지스터 8가지 데이터 처리 오퍼레이션을 필요로 한다. 도 5(b)는 동등한 C 언어 프래그먼트를 예시한다.
24 로드와 스토어 바이트 명령을 이용하는 브루트 포스 코드에 관한 알고리즘을 근거로한 커스텀 오퍼레이션이 단지 본 예에서의 8가지 오퍼레이션에 대해서만 이점을 보이는 것 같지만, 실제로 그 이점은 보다 크다. 먼저, 커스텀 오퍼레이션을 이용한다면, 메모리 검색 횟수는 24번에서 8번으로 감소된다. 즉, 인수 3에 의해 감소된다. 메모리 검색이 레지스터-레지스터 오퍼레이션보다 느리므로 메모리 검색의 감소는 중요한 사항이다.
더욱이, TM-1마이크로 프로세서 하드웨어가 가지고 있는 기본 성능을 개발하기 위한 본 시스템(TM-1 시스템)의 컴파일 시스템 기능은 코드를 근거로 한 커스텀의 오퍼레이션에 의해 향상된다. 구체적으로, 컴파일 시스템은 메모리 검색 횟수와 레지스터-레지스터 오퍼레이션 횟수와 균형을 맞출 때 코드의 최적 스케줄(배열)을 보다 쉽게 생성한다. 일반적으로, 고성능 마이크로프로세서에서는 단일 주기에서 처리될 수 있는 메모리 검색의 횟수가 제한되어 있다. 그 결과, 단지 메모리 검색만을 포함하는 코드의 긴 순열은 긴 TM-1명령에서 빈 오퍼레이션 슬롯을 초래하므로 하드웨어의 최대 성능이 낭비된다.
도시된 바와 같이, 이 예를 통해서 본 발명의 커스텀 오퍼레이션의 이용이 계산을 실행하는데 필요되는 절대적인 오퍼레이션 횟수를 감소시킬 수 있다는 것과 또한 각 CPU의 최대 성능을 충분히 활용하고자 하는 컴파일 시스템 제품 코드에 도움이 되다는 것을 알 수 있다. 예를 들어 완전 MPEG 비디오 디코딩 알고리즘을 위한 이러한 MPEG 영상 재생등과 같은 다른 응용과 작동 판단 커널은 비록 충분하지는 않더라도 본 발명의 커스텀 오퍼레이션을 이용함으로써 이로울 수 있다.
본 발명은 표 1에 열거된 커스텀 오퍼레이션을 포함한다. 이들 커스텀 오퍼레이션의 각 오퍼레이션이 이하에서 구체적으로 나타난다. 아래에 주어진 기능 코드에서, 표준 심볼, 문장(syntax)등이 이용된다. 예를 들어, temp1과 temp2는 임시 레지스터를 나타낸다. 또한, 예에서 처럼, 기능 temp1← sign_ext16to32(rsrc1<15:0>)에서 temp1은 16내지 32비트들(부호 비트들 확장)로 확장되는 부호비트들(이 예에서, 15번째 비트들이다)에 의해 rsrc1레지스터의 15:0 비트들(비트들 0내지 15)과 함께 로드된다. 유사하게, temp2← sign_ext16to32(rsrc1<16:31>)은 rsrc1의 16번째부터 31번째 비트들이 추출되고(그리고 계산을 위하여 0내지 15번째 비트들에 배치된다), 그리고 이 예에서는 31번째 비트들인 부호비트들이 16번째 내지 32 번째 비트들로 부호 확장된다. 이 부호 확장은 이 예에서는 정수인 부호화된 값에 대해 이용된다. 부호화되지 않은 값에 대해, 0이 채워진다. 예를 들어, zero_ext8to32(rsrc1<15:0>)는 15내지 0비트들의 값이 이용되고 있고, 8내지 32번째 비트들은 0으로 채워졌다는 것을 의미한다. rsrc1,rsrc2와 rdest는 앞에서 기술된 바와 같이 이용 가능한 레지스터중 임의의 레지스터이다.
아래 열거된 각 오퍼레이션에 대해, 이 오퍼레이션은 rguard에 특정 guard를 선택적으로 취한다. guard가 존재한다면, 이 예에서, LSB는 목적지 레지스터의 수정을 제어한다. 이 예에서, rguard의 LSB가 1이라면, 이 예에서, rdest가 기록되고, 그렇지 않으면, rdest는 변경되지 않는다.
dspiabs : dspiabs는 클립핑된 부호 절대 값 오퍼레이션, 즉 h_dspiabs에 대한 수우도-오피(pseudo-op)이다. 이 오퍼레이션은 다음 기능을 갖는다.

dspiabs 오퍼레이션은 스케줄러에 의해 일정한 제 1 배열의 0을 갖는 h_dspiabs로 변형된 수우도 오퍼레이션이며, 제 2 배열은 dspiabs배열과 같다. 일반적으로 수우도 오퍼레이션은 어셈블리 소스 파일에 이용되지 않는다. h_dspiabs는 동일 기능을 실행한다.:그러나, 이 오퍼레이션은 제 1 배열에서 처럼 0을 필요로 한다.
dapiabs오퍼레이션은 rsrc1의 절대값을 계산하고, [231-1...0]범위 또는 [0x7fffffff...O]로 상기 결과를 간략하게 하고, 그리고 rdest(목적지 레지스터)로이 축소된 값을 저장한다. 모든 값들은 부호화된 정수이다.
dspidualabs : dspidualabs는 부호화된 16비트들 하드웨어 오퍼레이션 (h_dspidualabs에 대한 수우도-오피:하드웨어 dspidualabs)의 이중 클립핑 절대 값이다. 이 오퍼레이션은 다음 기능을 갖는다.

dspidualabs 오퍼레이션은 이 예에서, 제 1 변수로서 상수 0과 제 2 변수로서 dspidualabs 변수와 같이 스케쥴러에 의해 h_dspidualabs 로 변형되는 수도우 (pseudo) 오퍼레이션이다.
dspidualabs 오퍼레이션은 2개의 16비트들 클립핑된 부호 절대 값 계산을 rsrc1의 하이 및 로우 16비트들 하프워드에 관하여 각각 실행된다. 2개의 절대값은 범위 [0x0..0x7fff]로 간략되고, 그리고 rdes의 대응 하프워드로 기록된다. 모든 값들은 부호화된 16비트들 정수이다. h_dspidualabs는 동일 기능을 실행한다.: 그러나, 이 오퍼레이션은 제 1 배열에서 처럼 0을 필요로 한다.
dspiadd : dspiadd는 클립핑된 부호 가산 오퍼레이션이다. 이 오퍼레이션은다음과 같은 기능을 갖는다.

도 6에 도시된 바와 같이, dspiadd오퍼레이션은 부호화된 rsrc1+rsrc2의 합을 계산하여 32비트들 부호 범위[231-1...-231] 또는 [0x7fffffff...0x8OOOOOOO]로 상기 결과를 간략하고 그리고 이 클립핑된 값을 rdest 에 저장한다. 모든 값은 부호화된 정수이다.
dspuadd : dspuaddd는 클립핑된 부호 가산 오퍼레이션이다. 이 오퍼레이션은 다음과 같은 기능을 갖는다.

도 7에 도시된 바와 같이, dspuadd오퍼레이션은 부호화된 rsrc1+rsrc2의 합을 계산하여 32비트들 부호 범위[232-1...0] 또는 [0xffffffff...O]로 상기 결과를 간략하고 그리고 이 클립핑된 값을 rdest 에 저장한다.
dspidualadd : dspidualadd는 부호화된 16비트들 하드웨어 오퍼레이션의 이중클립핑 가산이다. 이 오퍼레이션은 다음 기능을 갖는다.

도 8에 도시된 바와 같이, dspidualadd 오퍼레이션은 2개의 16비트들 클립핑된 부호 합계산을 rsrc1과 rsrc2의 하이 및 로우 16비트들 하프워드의 각 쌍에 관하여 각각 실행된다. 2가지 합은 범위 [215-1...215] [0x7fff...0x8OOO]로 간략되고, 그리고 rdest의 대응 하프워드로 기록된다. 모든 값들은 부호화된 16비트들 정수이다.
dspuguadaddui : dspuguadadui는 부호화되지 않은 바이트, 그리고 부호화된 바이트 오퍼레이션의 이중 클립핑 가산이다. 이 오퍼레이션은 다음 기능을 갖는다.

도 9에 도시된 바와 같이, dspuguadadui 오퍼레이션은 rsrc1과 rsrc2의 대응 8비트들 바이트의 4개의 각 쌍의 각 합을 4번 실행한다. rsrc1에서 바이트는 부호화되지 않은 값으로 간주된다.: rsrc2에서 바이트는 부호화된 값으로 간주된다. 4번의 합은 부호화되지 않은 범위 [255...0] 또는 [0xff...O]로 간략된다.: 그러므로, 바이트 합의 결과는 부호화되지 않는다. 모든 계산은 정확하게 계산된다.
dspimul : dspimul은 클립핑된 부호 곱셈오퍼레이션이다. 이 오퍼레이션은 다음과 같은 기능을 갖는다.

도 10에 도시된 바와 같이, dspimul 오퍼레이션은 곱 rsrc1x rsrc2를 계산하고, 그 결과를 범위[231-1...-231] 또는 [0×7fffffff...0×8OOOOOOO]으로 제한하며, 상기 제한된 값을 rdest에 저장시킨다. 모든 값은 부호 정수이다.
dspumu1 : dspumu1은 제한된 부호없는 곱셈 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 11에 도시된 바와 같이, dspumu1 오퍼레이션은 부호없는 곱 rsrc1×rsrc2을 계산하고, 그 결과를 부호없는 범위 [231-1...0] 또는 [0×ffffffff]로 제한하며, 제한된 값을 rdest에 저장시키다.
dspidualmul : dspidualmul은 부호 16비트들 하프워드 오퍼레이션의 이중 제한된 곱셈이다.

도 12에 도시된 바와 같이, dspidualmul 오퍼레이션은 rsrc1과 rsrc2의 2개의 하이 및 로우 16비트들 하프워드쌍상에 독립적으로 부호 곱으로 제한된 2개의 16비트들을 계산한다. 2개의 곱은 범위 [215-1...-215] 또는 범위[0×7fff...0×8OOO]으로 제한되며, rdest의 대응하는 하프워드에 기입된다. 모든 값은 부호 16비트들 정수이다.
dspisub : dspisub는 제한된 부호 감산 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다.

도 13에 도시된 바와 같이, dspisub 오퍼레이션은 차분 rsrc1-rsrc2를 계산하고, 그 결과를 범위 [0×8OOOOOOO...0×7fffffff]로 제한하며, 제한된 값을 rdest에 저장시킨다. 모든 값은 부호 정수이다.
dspusub : dspusub는 제한된 부호없는 감산 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 14에 도시된 바와 같이, dspusub 오퍼레이션은 부호없는 차분 rsrc1-rsrc2를 계산하고, 그 결과를 부호화되지 않은 범위[0.0×ffffffff]로 제한하며, 상기 제한된 값을 rdest에 저장시킨다.
dspidualsub : dspidualsub은 부호 16비트들 하프워드 오퍼레이션의 이중 제한된 감산이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 15에 도시된 바와 같이, dspidualsub 오퍼레이션은 rsrc1과 rsrc2의 2개의 하이 및 로우 16비트들 하프워드 쌍상에 독립적으로 부호 차분으로 제한된 2개의 16비트들을 계산한다. 2개의 차분은 범위 [215-1...-215] 또는 범위[0×7fff...0×8OOO]으로 제한되며, rdest의 대응하는 하프워드에 기입된다. 모든 값은 부호 16비트들 정수이다.
ifir16 : ifir16은 부호 16비트들 하프워드의 곱의 합이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 16에 도시된 바와 같이, ifir16 오퍼레이션은 rsrc1과 rsrc2의 대응하는 2개의 16비트들 하프워드쌍 각각의 2개의 독립된 곱을 계산하고, 상기 2개의 곱은 합해지며, 그 결과는 rdest에 기입된다. 따라서, 곱 및 곱의 최종 합계는 부호가 달린다. 모든 계산은 오차없이 수행된다.
ifir8ii : ifir8ii는 부호 바이트 오퍼레이션의 곱의 부호 합이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 17에 도시된 바와 같이, ifir8ii는 rsrc1과 rsrc2의 4개의 대응하는 8비트들 바이트쌍 각각의 4개의 독립된 곱을 계산한다. 4개의 곱은 합산되며, 그 결과는 rdset에 기입된다. 모든 값이 부호있다고 가정하면, 이에 따라 곱 및 곱의 최종 합은 부호가 달린다. 모든 계산은 오차없이 수행된다.
ifir8ui : ifir8ui은 부호없는/부호 바이트 오퍼레이션의 곱의 부호 합이다.상기 오퍼레이션은 다음의 함수를 갖는다:

도 18에 도시된 바와 같이, ifir8ui 오퍼레이션은 rsrc1과 rsrc2의 4개의 대응하는 8비트들 바이트쌍 각각의 4개의 독립된 곱을 계산한다. 4개의 곱은 합산되며, 그 결과는 rdset에 기입된다. rsrc2에서의 바이트가 부호없는 것이라고 가정하고, rsrc2에서의 바이트가 부호달린다고 가정하면, 이에 따라 곱 및 곱의 최종 합은 부호가 달린다. 모든 계산은 오차없이 수행된다.
ufir16 : ufir16은 부호없는 16비트들 하프워드 오퍼레이션의 곱의 합이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 19에 도시된 바와 같이, ufir16 오퍼레이션은 rsrc1과 rsrc2의 2개의 대응하는 16비트들 하프워드쌍 각각의 2개의 독립된 곱을 계산하고, 2개의 곱은 합산되며, 그 결과는 rdest에 기입된다. 모든 하프워드가 부호없다고 가정하면, 이에 따라 곱 및 곱의 최종 합은 부호가 없다. 모든 계산은 오차없이 수행된다. 곱의 최종 합은 rdest에 기입되기 전에 범위 [0×ffffffff...O]으로 제한된다.
ufir8uu : ufir8uu는 부호없는 바이트 오퍼레이션의 곱의 부호없는 합이다.상기 오퍼레이션은 다음의 함수를 갖는다:

도 20에 도시된 바와 같이, ufir8uu 오퍼레이션은 rsrc1과 rsrc2의 4개의 대응하는 8비트들 바이트쌍 각각의 2개의 독립된 곱을 계산하고, 4개의 곱은 합산되며, 그 결과는 rdest에 기입된다. 모든 바이트는 부호가 없다고 가정하면, 모든 계산은 오차없이 수행된다.
mergelsb : mergelsb는 최하위 바이트(least-significant bytes) 머지 (merge) 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 21에 도시된 바와 같이, mergelsb 오퍼레이션은 인수 rsrc1과 rsrc2로부터 rdest에 2개의 최하위 바이트쌍 각각을 인터리브한다. rsrc2로부터의 최하위 바이트는 rdest의 최하위 바이트에 팩되고, rsrc1으로부터의 최하위 바이트는 제 2 최하위 바이트 또는 rdest에 팩되고, rsrc2로부터의 제 2 최하위 바이트는 rdest의 제 2 최상위 바이트에 팩되고, rsrc1으로부터의 제 2 최하위 바이트는 rdest의 최상위 바이트에 팩된다.
mergemsb : mergemsb는 최상위 바이트 머지 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 22에 도시된 바와 같이, mergemsb 오퍼레이션은 인수 rsrc1과 rsrc2로부터의 2개의 최상위 바이트쌍 각각을 rdest에 인터리브한다. rsrc2로부터의 제 2 최상위 바이트는 rdest의 최하위 바이트에 팩되고, rsrc1으로부터의 제 2 최상위 바이트는 제 2 최하위 바이트 또는 rdest에 팩되고, rsrc2로부터의 최상위 바이트는 rdest의 제 2 최상위 바이트에 팩되고, rsrc1으로부터의 최상위 바이트는 rdest의 최상위 바이트에 팩된다.
pack16lsb : pack16lsb는 팩 최하위 16비트들 하프워드들 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:

도 23에 도시된 바와 같이, pack16lsb 오퍼레이션은 인자 rsrc1과 rsrc2에서 rdest로의 2개의 최하위 하프워드를 저장한다. rsrc1으로부터의 하프워드는 rdest의 최상위 하프워드에 저장되고, rsrc2로부터의 하프워드는 최하위 하프워드 또는 rdest에 저장된다.
pack16msb : pack16msb는 팩 최상위 16 비트들 오퍼레이션이다. 상기 오퍼레이션은 다음의 함수를 갖는다:
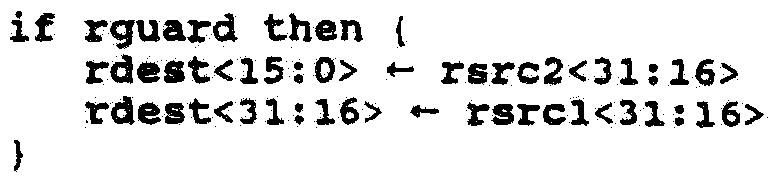
도 13에 도시된 바와 같이, pack16msb 오퍼레이션은 두 각각의 최상위 하프워드를 독립변수 rsrc1과 rsrc2에서 rdest로 저장한다. rsrc1에서의 하프워드는 rdest의 최상위 하프워드로 저장되고 rsrc2에서의 하프워드는 rdest의 최하위 하프워드로 저장된다.
packbytes : packbytes는 팩 최하위 바이트 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다:

도 25에 도시한 바와 같이 packbytes 오퍼레이션은 두 각각의 최하위 바이트를 독립변수 rsrc1과 rsrc2에서 rdest로 저장한다. rsrc1에서의 바이트는 rsrc1의 제2-하위 바이트로 팩되고 rsrc2에서의 바이트는 rdest의 최하위 바이트로 저장된다. rdest의 두 최상위 바이트는 zero로 채워진다.
quadavg : quadavg는 부호없는 바이트-방식 쿼드 평균 오퍼레이션(unsignedbyte-wise quad average operation)이다. 이 오퍼레이션은 다음의 기능을 갖는다:

도 26에 도시한 바와 같이, quadavg 오퍼레이션은 rsrc1과 rsrc2의 8-비트들 바이트에 대응하는 네개의 각각의 쌍의 네개의 분리 평균을 계산한다. 전체 바이트는 부호없는된 것으로 간주한다. 각 평균의 최하위 8비트들은 rdest의 해당 바이트에 기록된다.
quadumulmsb : quadumulmsb는 부호없는 쿼드 8-비트들 곱셈 최상위 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다.

도 27에 도시한 바와 같이, quadumulmsb 오퍼레이션은 rsrc1과 rsrc2의 8-비트들 바이트에 대응하는 네개의 각 쌍의 네 분리 곱을 계산한다. 전체 바이트는 부호없는된 것으로 간주된다. 각 16-비트들 곱의 최하위 8 비트들은 rdest의 해당 바이트에 기록된다.
ume8ii : ume8ii는 부호 8-비트들 차의 절대 값의 부호없는 합 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다.

도 28에 도시한 바와 같이, ume8ii 오퍼레이션은 rsrc1과 rsrc2의 부호 8-비트들 바이트에 대응하는 네개의 각 쌍의 네 분리 차분을 계산하고, 네 차의 절대값을 합하고, 그 합을 rdest에 기록한다. 전 계산은 정확도의 손실 없이 실행된다.
ume8uu : ume8uu는 부호없는 8-비트들 차분의 절대값의 합이다. 이 오퍼레이션은 다음의 기능을 갖는다.

도 29에 도시한 바와 같이, ume8uu 오퍼레이션은 rsrc1과 rsrc2의 부호없는 8-비트들 바이트에 대응하는 네개의 각 쌍의 네 분리 차분를 계산한다. 네 차분의 절대값들이 합해지고 그 합은 rdest에 기록된다. 전체 계산은 정확도의 손실 없이 실행된다.
iclipi : iclipi는 클립 부호-대-부호 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다.
iclipi 오퍼레이션은 부호없는 정수 범위 (-rsrc2-1)로 클리프된 rsrc1의 값을 rsrc2로 복귀한다. 독립변수 rsrc1은 부호 정수로 간주되고; rsrc2는 부호없는 된 정수로 간주되고 0과 0x7fffffff사이의 값을 가져야 한다.
uclipi : uclipi는 클립 부호 대 부호없는 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다.
uclipi 오퍼레이션은 부호없는 정수 범위 0으로 클리프된 rsrc1의 값을 rsrc2로 복귀한다. 독립변수 rsrc1은 부호없는 정수로 간주되고; rsrc2는 부호없는 정수로 간주된다.
uclipu : uclipu는 클립 부호없는 대 부호없는 오퍼레이션이다. 이 오퍼레이션은 다음의 기능을 갖는다.

uclipu 오퍼레이션은 미표신 정수 범위 0으로 클리프된 rsrc1의 값을 rsrc2로 복귀한다. 독립변수 rsrc1과 rsrc2는 부호없는 정수로 간주된다.
상기 커스텀 멀티미디어 오퍼레이션을 사용함으로써, 상기 응용은 낮은 비용으로 멀티미디어 기능을 갖는 고 병렬식 마이크로프로세서를 구현하는 이점을 갖는다.
상기 명세에서, 본 발명이 VLIW와 RISC와 슈퍼 스칼라 등의 명령 서식을 사용하는 많은 고 병렬식 마이크로프로세서 구현에 사용될 수 있다는 것을 확실히 이해할 것이다. 부가적으로, 기술에 있어 숙련된 사람은 상기 개념에 기초한 부가적 오퍼레이션을 쉽게 추가할 수 있다. 예를 들어, 바이트의 쿼드 클리프된 감산은 특별히 설명하지 않는다. 하지만, 확실히 기술에 있어 숙련된 사람은 상기 명세에 기초한 이 오퍼레이션을 쉽게 발전시킬 수 있다.
멀티미디어 기능을 실행하는데 사용하기 위해 커스텀 오퍼레이션의 시스템과 방법을 적절히 설명하였다.
본 명세에서, 본 발명의 우선의 실시예만을 도시하고 설명한다. 하지만 전술한 바와 같이, 본 발명은 다양한 또 다른 조합과 환경에 사용할 수 있고 여기에 표현된 바의 발명 개념의 의도 내에서 바꾸고 변경하는 것이 가능하다.
Claims (13)
- 컴퓨터 시스템에 있어서,입력 데이터를 수신하는 입력 레지스터들로서, 각각의 상기 입력 데이터는 M 비트들을 포함하며, 각각의 입력 데이터는 단일(single number)의 M 비트 제 1 오퍼랜드 데이터로서 및 복수(plurality of numbers)의 N 비트 제 2 오퍼랜드 데이터로서 선택하여 사용가능하며, 상기 N은 M 비트들보다 작은, 상기 입력 레지스터들과,명령 세트를 갖도록 배열되는 프로세서로서, 상기 명령 세트는 실행될 때 상기 프로세서가 상기 입력 데이터의 상기 제 1 오퍼랜드 데이터에 대해 오퍼레이션을 수행하여 M비트들을 포함하는 제 1 결과 데이터를 생성하도록 제어하는 제 1 명령을 포함하고, 상기 명령 세트는 상기 제 1 명령 대신에 실행될 때 상기 프로세서가 병렬적으로 상기 입력 데이터의 상기 제 2 오퍼랜드 데이터에 대해 복수의 Q 오퍼레이션들을 수행하여 상기 Q 오퍼레이션들의 각각이 N비트들을 포함하는 제 2 결과 데이터를 생성하도록 제어하는 제 2 명령을 포함하는, 상기 프로세서와,각각 상기 제 1 또는 제 2 명령의 실행 결과로서, 상기 제 1 결과 데이터 및 Q 그룹들의 상기 제 2 결과 데이터를 M비트들의 하나의 출력으로서 선택하여 저장하기 위한 M비트들의 목적지 레지스터를 포함하며,상기 제 1 명령은 실행될 때 상기 프로세서가 상기 입력 데이터의 상기 제 1 오퍼랜드 데이터에 대해 상기 오퍼레이션을 수행하여 M비트들을 포함하는 제 1 결과 데이터를 생성하도록 제어하고, 상기 제 2 명령은 실행될 때 상기 프로세서가 병렬적으로 상기 입력 데이터의 상기 제 2 오퍼랜드 데이터에 대해 Q 오퍼레이션들을 수행하도록 항상 제어하는 것을 특징으로 하는 컴퓨터 시스템.
- 제 1 항에 있어서,상기 제 1 및 제 2 명령들의 제어하에 수행되는 오퍼레이션들은 다른 수의 비트들을 포함하는 오퍼랜드들에 대해 실행되는 것을 제외하고 산술적으로 동일한 오퍼레이션들인, 컴퓨터 시스템.
- 제 1 항 또는 제 2 항에 있어서,상기 Q 오퍼레이션들은 클립핑(clipping)을 포함하는, 컴퓨터 시스템.
- 제 1 항에 있어서,상기 프로세서는 서로에 대해 두 개의 M 비트 수들(bit numbers)을 가산하기 위한 제 1 수단과 병렬적으로 N비트 수들의 Q쌍들을 가산하는 제 2 수단을 포함하고, 상기 제 1 명령은 상기 프로세서가 상기 제 1 오퍼랜드 데이터를 M 비트 수에 가산하도록 제어하고, 상기 제 2 명령은 상기 프로세서가 각각의 또다른 오퍼랜드 데이터에 상기 복수의 N비트 제 2 오퍼랜드 데이터의 각각을 가산하도록 제어하여, N비트 수들 중 개개의 하나와 상기 또다른 오퍼랜드 데이터 중 개개의 하나의 개개의 합들을 각각 생성하고, 상기 프로세서는 개개의 클립핑된 결과들을 생성하기 위해 각각의 합을 특정 범위 내로 클립핑하는 수단을 포함하고, 각각의 클립핑된 결과는 N비트들이 되며;상기 목적지 레지스터는 상기 개개의 클립핑된 결과들을 함께 저장하는, 컴퓨터 시스템.
- 제 1 항 또는 제 2 항에 있어서,상기 프로세서는,각각의 계산이 N비트들의 개개의 절대값을 생성하는, 각각의 오퍼랜드 데이터의 절대값을 계산하는 수단과;개개의 클립핑된 결과들을 생성하기 위해 각각의 개개의 절대값을 특정 범위내로 클립핑하는 수단으로서, 각각의 클립핑된 결과는 N비트들이되는, 상기 클립핑하는 수단을 포함하며,상기 목적지 레지스터는 상기 개개의 클립핑된 결과들을 함께 저장하는, 컴퓨터 시스템.
- 제 1 항 또는 제 2 항에 있어서,상기 프로세서는 병렬적으로 N비트 수들의 Q쌍들을 곱하는 제 1 수단을 포함하며, 상기 제 2 명령은 개개의 또다른 오퍼랜드 데이터와 상기 복수의 N비트 제 2 오퍼랜드 데이터의 각각을 곱하여, N비트 수들 중 개개의 하나와 상기 또다른 오퍼랜드 데이터 중 개개의 하나의 개개의 곱들을 각각 생성하도록 상기 프로세서를 제어하고, 상기 프로세서는 개개의 클립핑된 결과들을 생성하기 위해 각각의 곱을 특정 범위 내로 클립핑하는 수단을 포함하며, 각각의 클립핑된 결과는 N비트들이 되며;상기 목적지 레지스터는 상기 개개의 클립핑된 결과들을 함께 저장하는, 컴퓨터 시스템.
- 제 1 항 또는 제 2 항에 있어서,상기 프로세서는 병렬적으로 N비트 수들의 Q쌍들을 감산하는 제 1 수단을 포함하며, 상기 제 2 명령은 개개의 또다른 오퍼랜드 데이터로부터 상기 복수의 N비트 제 2 오퍼랜드 데이터의 각각을 감산하여, 상기 N비트 수들 중 개개의 하나와 상기 또다른 오퍼랜드 데이터 중 개개의 하나의 개개의 차를 각각 생성하도록 상기 프로세서를 제어하고, 상기 프로세서는 개개의 클립핑된 결과들을 생성하기 위해 각각의 차를 특정 범위 내로 클립핑하는 수단을 포함하며, 각각의 클립핑된 결과는 N비트들이 되며;상기 목적지 레지스터는 상기 개개의 클립핑된 결과들을 함께 저장하는, 컴퓨터 시스템.
- 제 1 항에 있어서,상기 명령 세트는 제 3 명령을 포함하고, 이는 실행될 때 상기 프로세서가 상기 제 2 오퍼랜드 데이터의 복수의 N비트 수들 각각의 최상위 비트들(msb)의 세트를 검색하도록 항상 제어하며, 최상위 비트들(msb)의 각각의 세트는 상기 최상위 비트들의 최상위 비트들(mmsb)과 상기 최상위 비트들의 최하위 비트들(lmsb)로서 공급되고,상기 프로세서는 상기 최상위 비트들의 최상위 비트들(mmsb)을 상기 목적지 레지스터의 최상위 비트들로서 저장하는 저장수단을 포함하고, 상기 저장 수단은 또다른 오퍼랜드 데이터의 최상위 비트들의 최상위 비트들을 상기 목적지 레지스터의 다음 최상위 비트들로서 저장하고, 상기 저장 수단은 또다른 오퍼랜드 데이터의 최상위 비트들의 최하위 비트들(lmsb)을 상기 목적지 레지스터의 최하위 비트들로서 저장하고, 상기 저장 수단은 상기 제 2 오퍼랜드 데이터의 최상위 비트들의 최하위 비트들(lmsb)을 상기 목적지 레지스터의 다음 최하위 비트들로서 저장하는, 컴퓨터 시스템.
- 제 1 항에 있어서,상기 명령 세트는 제 3 명령을 포함하고, 이는 실행될 때 상기 프로세서가 상기 제 2 오퍼랜드 데이터의 복수의 N비트 수들 각각의 최하위 비트들(lsb)의 세트를 검색하도록 항상 제어하며, 최하위 비트들(lsb)의 각각의 세트는 상기 최하위 비트들의 최상위 비트들(mlsb)과 상기 최하위 비트들의 최하위 비트들(llsb)로서 공급되고,상기 프로세서는 상기 최하위 비트들의 최상위 비트들(mlsb)을 상기 목적지 레지스터의 최상위 비트들로서 저장하는 저장수단을 포함하고, 상기 저장 수단은또다른 오퍼랜드 데이터의 최하위 비트들의 최상위 비트들을 상기 목적지 레지스터의 다음 최상위 비트들로서 저장하고, 상기 저장 수단은 상기 또다른 오퍼랜드 데이터의 최하위 비트들의 최하위 비트들(llsb)을 상기 목적지 레지스터의 최하위 비트들로서 저장하고, 상기 저장 수단은 상기 제 2 오퍼랜드 데이터의 최하위 비트들의 최하위 비트들(llsb)을 상기 목적지 레지스터의 다음 최하위 비트들로서 저장하는, 컴퓨터 시스템.
- 제 1 항에 있어서,상기 명령 세트는 제 3 명령을 포함하고, 이는 실행될 때 상기 프로세서가 각각의 제 1 오퍼랜드 데이터의 최하위 비트들(lsb)의 세트를 검색하도록 항상 제어하며,상기 프로세서는 상기 최하위 비트들을 상기 목적지 레지스터의 최하위 비트들로서 저장하는 저장수단을 포함하고, 상기 저장 수단은 또다른 오퍼랜드 데이터의 최하위 비트들을 상기 목적지 레지스터의 다음 최하위 비트들로서 저장하고, 상기 저장 수단은 상기 목적지 레지스터의 최상위 비트들을 미리 특정 비트 값들로 저장하는, 컴퓨터 시스템.
- 제 1, 2, 4, 8 내지 10 항 중 어느 한 항에 있어서,상기 제 2 오퍼랜드 데이터는 오디오 처리 및 비디오 처리 중 적어도 하나에 사용하기 위한 복수의 신호 값들을 포함하는, 컴퓨터 시스템.
- 제 1, 2, 4, 8 내지 10 항 중 어느 한 항에 있어서,상기 컴퓨터 시스템은 반도체 기판 상에 집적되는, 컴퓨터 시스템.
- 제 1, 2, 4, 8 내지 10 항 중 어느 한 항에 있어서,상기 프로세서가 상기 제 1 및 제 2 명령을 실행하도록 배열되어서 상기 제 1 및 제 2 명령에 특정 조건이 각각 달성되었는지에 의존하여 상기 컴퓨터 시스템의 프로그래머 가시 상태에 대한 상기 제 1 및 제 2 명령의 실행이 실행되거나 또는 실행되지 않는, 컴퓨터 시스템.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US314095P | 1995-09-01 | 1995-09-01 | |
| US003,140 | 1995-09-01 | ||
| US464295P | 1995-09-25 | 1995-09-25 | |
| US004,642 | 1995-09-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR100445542B1 true KR100445542B1 (ko) | 2004-11-20 |
Family
ID=26671377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1019970703017A KR100445542B1 (ko) | 1995-09-01 | 1996-08-30 | 프로세서의커스텀오퍼레이션들을위한방법및장치 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US5963744A (ko) |
| EP (1) | EP0789870B1 (ko) |
| JP (1) | JP3739403B2 (ko) |
| KR (1) | KR100445542B1 (ko) |
| CN (1) | CN1153129C (ko) |
| AU (2) | AU6905496A (ko) |
| DE (1) | DE69625790T2 (ko) |
| WO (2) | WO1997009671A1 (ko) |
Families Citing this family (71)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7301541B2 (en) | 1995-08-16 | 2007-11-27 | Microunity Systems Engineering, Inc. | Programmable processor and method with wide operations |
| EP0918280B1 (en) * | 1997-11-19 | 2004-03-24 | IMEC vzw | System and method for context switching on predetermined interruption points |
| US6041404A (en) | 1998-03-31 | 2000-03-21 | Intel Corporation | Dual function system and method for shuffling packed data elements |
| ATE467171T1 (de) * | 1998-08-24 | 2010-05-15 | Microunity Systems Eng | System mit breiter operandenarchitektur und verfahren |
| US7932911B2 (en) * | 1998-08-24 | 2011-04-26 | Microunity Systems Engineering, Inc. | Processor for executing switch and translate instructions requiring wide operands |
| GB2343319B (en) * | 1998-10-27 | 2003-02-26 | Nokia Mobile Phones Ltd | Video coding |
| US6247112B1 (en) * | 1998-12-30 | 2001-06-12 | Sony Corporation | Bit manipulation instructions |
| US20020135611A1 (en) * | 1999-03-04 | 2002-09-26 | Trevor Deosaran | Remote performance management to accelerate distributed processes |
| EP1059781B1 (de) * | 1999-05-06 | 2007-09-05 | Siemens Aktiengesellschaft | Kommunikationseinrichtung mit Mitteln zur Echtzeitverarbeitung von zu übertragenden Nutzdaten |
| WO2000068783A2 (en) * | 1999-05-12 | 2000-11-16 | Analog Devices, Inc. | Digital signal processor computation core |
| US6542989B2 (en) * | 1999-06-15 | 2003-04-01 | Koninklijke Philips Electronics N.V. | Single instruction having op code and stack control field |
| US6757023B2 (en) * | 1999-10-14 | 2004-06-29 | Mustek Systems Inc. | Method and apparatus for displaying and adjusting subtitles of multiple languages between human-machine interfaces |
| US7890566B1 (en) * | 2000-02-18 | 2011-02-15 | Texas Instruments Incorporated | Microprocessor with rounding dot product instruction |
| US7124160B2 (en) * | 2000-03-08 | 2006-10-17 | Sun Microsystems, Inc. | Processing architecture having parallel arithmetic capability |
| TW525091B (en) * | 2000-10-05 | 2003-03-21 | Koninkl Philips Electronics Nv | Retargetable compiling system and method |
| US7681013B1 (en) | 2001-12-31 | 2010-03-16 | Apple Inc. | Method for variable length decoding using multiple configurable look-up tables |
| US7114058B1 (en) | 2001-12-31 | 2006-09-26 | Apple Computer, Inc. | Method and apparatus for forming and dispatching instruction groups based on priority comparisons |
| US7558947B1 (en) | 2001-12-31 | 2009-07-07 | Apple Inc. | Method and apparatus for computing vector absolute differences |
| US6877020B1 (en) | 2001-12-31 | 2005-04-05 | Apple Computer, Inc. | Method and apparatus for matrix transposition |
| US6693643B1 (en) | 2001-12-31 | 2004-02-17 | Apple Computer, Inc. | Method and apparatus for color space conversion |
| US7467287B1 (en) | 2001-12-31 | 2008-12-16 | Apple Inc. | Method and apparatus for vector table look-up |
| US6573846B1 (en) | 2001-12-31 | 2003-06-03 | Apple Computer, Inc. | Method and apparatus for variable length decoding and encoding of video streams |
| US7055018B1 (en) | 2001-12-31 | 2006-05-30 | Apple Computer, Inc. | Apparatus for parallel vector table look-up |
| US6822654B1 (en) | 2001-12-31 | 2004-11-23 | Apple Computer, Inc. | Memory controller chipset |
| US7034849B1 (en) | 2001-12-31 | 2006-04-25 | Apple Computer, Inc. | Method and apparatus for image blending |
| US7305540B1 (en) | 2001-12-31 | 2007-12-04 | Apple Inc. | Method and apparatus for data processing |
| US7015921B1 (en) | 2001-12-31 | 2006-03-21 | Apple Computer, Inc. | Method and apparatus for memory access |
| US6931511B1 (en) | 2001-12-31 | 2005-08-16 | Apple Computer, Inc. | Parallel vector table look-up with replicated index element vector |
| US6697076B1 (en) | 2001-12-31 | 2004-02-24 | Apple Computer, Inc. | Method and apparatus for address re-mapping |
| JP3857614B2 (ja) * | 2002-06-03 | 2006-12-13 | 松下電器産業株式会社 | プロセッサ |
| US7047383B2 (en) | 2002-07-11 | 2006-05-16 | Intel Corporation | Byte swap operation for a 64 bit operand |
| JP3958662B2 (ja) | 2002-09-25 | 2007-08-15 | 松下電器産業株式会社 | プロセッサ |
| US20040062308A1 (en) * | 2002-09-27 | 2004-04-01 | Kamosa Gregg Mark | System and method for accelerating video data processing |
| US6707397B1 (en) | 2002-10-24 | 2004-03-16 | Apple Computer, Inc. | Methods and apparatus for variable length codeword concatenation |
| US6707398B1 (en) | 2002-10-24 | 2004-03-16 | Apple Computer, Inc. | Methods and apparatuses for packing bitstreams |
| US6781528B1 (en) | 2002-10-24 | 2004-08-24 | Apple Computer, Inc. | Vector handling capable processor and run length encoding |
| US6781529B1 (en) * | 2002-10-24 | 2004-08-24 | Apple Computer, Inc. | Methods and apparatuses for variable length encoding |
| US20040098568A1 (en) * | 2002-11-18 | 2004-05-20 | Nguyen Hung T. | Processor having a unified register file with multipurpose registers for storing address and data register values, and associated register mapping method |
| US7925891B2 (en) * | 2003-04-18 | 2011-04-12 | Via Technologies, Inc. | Apparatus and method for employing cryptographic functions to generate a message digest |
| GB2409068A (en) * | 2003-12-09 | 2005-06-15 | Advanced Risc Mach Ltd | Data element size control within parallel lanes of processing |
| GB2411973B (en) * | 2003-12-09 | 2006-09-27 | Advanced Risc Mach Ltd | Constant generation in SMD processing |
| GB2411974C (en) * | 2003-12-09 | 2009-09-23 | Advanced Risc Mach Ltd | Data shift operations |
| GB2409061B (en) * | 2003-12-09 | 2006-09-13 | Advanced Risc Mach Ltd | Table lookup operation within a data processing system |
| GB2409064B (en) * | 2003-12-09 | 2006-09-13 | Advanced Risc Mach Ltd | A data processing apparatus and method for performing in parallel a data processing operation on data elements |
| GB2409059B (en) * | 2003-12-09 | 2006-09-27 | Advanced Risc Mach Ltd | A data processing apparatus and method for moving data between registers and memory |
| GB2409066B (en) * | 2003-12-09 | 2006-09-27 | Advanced Risc Mach Ltd | A data processing apparatus and method for moving data between registers and memory |
| GB2409065B (en) * | 2003-12-09 | 2006-10-25 | Advanced Risc Mach Ltd | Multiplexing operations in SIMD processing |
| GB2409063B (en) * | 2003-12-09 | 2006-07-12 | Advanced Risc Mach Ltd | Vector by scalar operations |
| GB2409062C (en) * | 2003-12-09 | 2007-12-11 | Advanced Risc Mach Ltd | Aliasing data processing registers |
| GB2411976B (en) * | 2003-12-09 | 2006-07-19 | Advanced Risc Mach Ltd | A data processing apparatus and method for moving data between registers and memory |
| GB2411975B (en) * | 2003-12-09 | 2006-10-04 | Advanced Risc Mach Ltd | Data processing apparatus and method for performing arithmetic operations in SIMD data processing |
| GB2409067B (en) * | 2003-12-09 | 2006-12-13 | Advanced Risc Mach Ltd | Endianess compensation within a SIMD data processing system |
| GB2409060B (en) * | 2003-12-09 | 2006-08-09 | Advanced Risc Mach Ltd | Moving data between registers of different register data stores |
| US9081681B1 (en) | 2003-12-19 | 2015-07-14 | Nvidia Corporation | Method and system for implementing compressed normal maps |
| GB2410097B (en) * | 2004-01-13 | 2006-11-01 | Advanced Risc Mach Ltd | A data processing apparatus and method for performing data processing operations on floating point data elements |
| GB2411978B (en) * | 2004-03-10 | 2007-04-04 | Advanced Risc Mach Ltd | Inserting bits within a data word |
| US9557994B2 (en) | 2004-07-13 | 2017-01-31 | Arm Limited | Data processing apparatus and method for performing N-way interleaving and de-interleaving operations where N is an odd plural number |
| US7961195B1 (en) | 2004-11-16 | 2011-06-14 | Nvidia Corporation | Two component texture map compression |
| US8078656B1 (en) | 2004-11-16 | 2011-12-13 | Nvidia Corporation | Data decompression with extra precision |
| US7928988B1 (en) | 2004-11-19 | 2011-04-19 | Nvidia Corporation | Method and system for texture block swapping memory management |
| US7916149B1 (en) | 2005-01-04 | 2011-03-29 | Nvidia Corporation | Block linear memory ordering of texture data |
| US8127117B2 (en) * | 2006-05-10 | 2012-02-28 | Qualcomm Incorporated | Method and system to combine corresponding half word units from multiple register units within a microprocessor |
| US8417922B2 (en) * | 2006-08-02 | 2013-04-09 | Qualcomm Incorporated | Method and system to combine multiple register units within a microprocessor |
| US20080170611A1 (en) * | 2007-01-17 | 2008-07-17 | Srikrishna Ramaswamy | Configurable functional multi-processing architecture for video processing |
| US8078836B2 (en) | 2007-12-30 | 2011-12-13 | Intel Corporation | Vector shuffle instructions operating on multiple lanes each having a plurality of data elements using a common set of per-lane control bits |
| US8610732B2 (en) * | 2008-12-11 | 2013-12-17 | Nvidia Corporation | System and method for video memory usage for general system application |
| JP6273010B2 (ja) * | 2013-12-23 | 2018-01-31 | インテル コーポレイション | 入出力データアライメント |
| US9785565B2 (en) | 2014-06-30 | 2017-10-10 | Microunity Systems Engineering, Inc. | System and methods for expandably wide processor instructions |
| US11074305B1 (en) * | 2016-03-10 | 2021-07-27 | Amazon Technologies, Inc. | Extending data store operations using function objects |
| CN110704368B (zh) * | 2019-09-25 | 2020-11-06 | 支付宝(杭州)信息技术有限公司 | 基于fpga的安全智能合约处理器的高效运算方法及装置 |
| CN112199118A (zh) * | 2020-10-13 | 2021-01-08 | Oppo广东移动通信有限公司 | 指令合并方法、乱序执行设备、芯片及存储介质 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5239654A (en) * | 1989-11-17 | 1993-08-24 | Texas Instruments Incorporated | Dual mode SIMD/MIMD processor providing reuse of MIMD instruction memories as data memories when operating in SIMD mode |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4209852A (en) * | 1974-11-11 | 1980-06-24 | Hyatt Gilbert P | Signal processing and memory arrangement |
| JPS6057090B2 (ja) * | 1980-09-19 | 1985-12-13 | 株式会社日立製作所 | データ記憶装置およびそれを用いた処理装置 |
| US5189636A (en) * | 1987-11-16 | 1993-02-23 | Intel Corporation | Dual mode combining circuitry |
| US5047975A (en) * | 1987-11-16 | 1991-09-10 | Intel Corporation | Dual mode adder circuitry with overflow detection and substitution enabled for a particular mode |
| US5692139A (en) * | 1988-01-11 | 1997-11-25 | North American Philips Corporation, Signetics Div. | VLIW processing device including improved memory for avoiding collisions without an excessive number of ports |
| NL8800053A (nl) * | 1988-01-11 | 1989-08-01 | Philips Nv | Videoprocessorsysteem, alsmede afbeeldingssysteem en beeldopslagsysteem, voorzien van een dergelijk videoprocessorsysteem. |
| US4931950A (en) * | 1988-07-25 | 1990-06-05 | Electric Power Research Institute | Multimedia interface and method for computer system |
| US5313551A (en) * | 1988-12-28 | 1994-05-17 | North American Philips Corporation | Multiport memory bypass under software control |
| DE69129569T2 (de) * | 1990-09-05 | 1999-02-04 | Philips Electronics Nv | Maschine mit sehr langem Befehlswort für leistungsfähige Durchführung von Programmen mit bedingten Verzweigungen |
| FR2693287B1 (fr) * | 1992-07-03 | 1994-09-09 | Sgs Thomson Microelectronics Sa | Procédé pour effectuer des calculs numériques, et unité arithmétique pour la mise en Óoeuvre de ce procédé. |
| JPH0792654B2 (ja) * | 1992-10-23 | 1995-10-09 | インターナショナル・ビジネス・マシーンズ・コーポレイション | ビデオ・データ・フレーム伝送方法および装置 |
| JP3206619B2 (ja) * | 1993-04-23 | 2001-09-10 | ヤマハ株式会社 | カラオケ装置 |
| US5598514A (en) * | 1993-08-09 | 1997-01-28 | C-Cube Microsystems | Structure and method for a multistandard video encoder/decoder |
| US5883824A (en) * | 1993-11-29 | 1999-03-16 | Hewlett-Packard Company | Parallel adding and averaging circuit and method |
| US5390135A (en) * | 1993-11-29 | 1995-02-14 | Hewlett-Packard | Parallel shift and add circuit and method |
| US5509129A (en) * | 1993-11-30 | 1996-04-16 | Guttag; Karl M. | Long instruction word controlling plural independent processor operations |
| US5497373A (en) * | 1994-03-22 | 1996-03-05 | Ericsson Messaging Systems Inc. | Multi-media interface |
| US5579253A (en) * | 1994-09-02 | 1996-11-26 | Lee; Ruby B. | Computer multiply instruction with a subresult selection option |
| US5798753A (en) * | 1995-03-03 | 1998-08-25 | Sun Microsystems, Inc. | Color format conversion in a parallel processor |
| US5774600A (en) * | 1995-04-18 | 1998-06-30 | Advanced Micro Devices, Inc. | Method of pixel averaging in a video processing apparatus |
| US5835782A (en) * | 1996-03-04 | 1998-11-10 | Intel Corporation | Packed/add and packed subtract operations |
-
1996
- 1996-08-30 US US08/836,852 patent/US5963744A/en not_active Expired - Lifetime
- 1996-08-30 DE DE69625790T patent/DE69625790T2/de not_active Expired - Lifetime
- 1996-08-30 WO PCT/US1996/013900 patent/WO1997009671A1/en active IP Right Grant
- 1996-08-30 AU AU69054/96A patent/AU6905496A/en not_active Abandoned
- 1996-08-30 WO PCT/US1996/014155 patent/WO1997009679A1/en active Application Filing
- 1996-08-30 EP EP96929788A patent/EP0789870B1/en not_active Expired - Lifetime
- 1996-08-30 AU AU69134/96A patent/AU6913496A/en not_active Abandoned
- 1996-08-30 KR KR1019970703017A patent/KR100445542B1/ko not_active IP Right Cessation
- 1996-08-30 JP JP51128197A patent/JP3739403B2/ja not_active Expired - Lifetime
- 1996-08-30 US US08/706,059 patent/US6141675A/en not_active Expired - Lifetime
- 1996-08-30 CN CNB961912456A patent/CN1153129C/zh not_active Expired - Lifetime
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5239654A (en) * | 1989-11-17 | 1993-08-24 | Texas Instruments Incorporated | Dual mode SIMD/MIMD processor providing reuse of MIMD instruction memories as data memories when operating in SIMD mode |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0789870B1 (en) | 2003-01-15 |
| US6141675A (en) | 2000-10-31 |
| EP0789870A1 (en) | 1997-08-20 |
| AU6913496A (en) | 1997-03-27 |
| AU6905496A (en) | 1997-03-27 |
| US5963744A (en) | 1999-10-05 |
| JPH10512988A (ja) | 1998-12-08 |
| WO1997009671A1 (en) | 1997-03-13 |
| DE69625790T2 (de) | 2003-11-20 |
| DE69625790D1 (de) | 2003-02-20 |
| EP0789870A4 (en) | 1999-06-09 |
| CN1173931A (zh) | 1998-02-18 |
| CN1153129C (zh) | 2004-06-09 |
| JP3739403B2 (ja) | 2006-01-25 |
| WO1997009679A1 (en) | 1997-03-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100445542B1 (ko) | 프로세서의커스텀오퍼레이션들을위한방법및장치 | |
| WO1997009671A9 (en) | Method and apparatus for custom operations of a processor | |
| WO1997009679A9 (en) | Method and apparatus for custom processor operations | |
| JP3958662B2 (ja) | プロセッサ | |
| US5680339A (en) | Method for rounding using redundant coded multiply result | |
| US5640578A (en) | Arithmetic logic unit having plural independent sections and register storing resultant indicator bit from every section | |
| US6116768A (en) | Three input arithmetic logic unit with barrel rotator | |
| US6098163A (en) | Three input arithmetic logic unit with shifter | |
| US5805913A (en) | Arithmetic logic unit with conditional register source selection | |
| US5634065A (en) | Three input arithmetic logic unit with controllable shifter and mask generator | |
| US5960193A (en) | Apparatus and system for sum of plural absolute differences | |
| US5600847A (en) | Three input arithmetic logic unit with mask generator | |
| US6032170A (en) | Long instruction word controlling plural independent processor operations | |
| US6058473A (en) | Memory store from a register pair conditional upon a selected status bit | |
| US5465224A (en) | Three input arithmetic logic unit forming the sum of a first Boolean combination of first, second and third inputs plus a second Boolean combination of first, second and third inputs | |
| US5485411A (en) | Three input arithmetic logic unit forming the sum of a first input anded with a first boolean combination of a second input and a third input plus a second boolean combination of the second and third inputs | |
| US6016538A (en) | Method, apparatus and system forming the sum of data in plural equal sections of a single data word | |
| US6067613A (en) | Rotation register for orthogonal data transformation | |
| US6026484A (en) | Data processing apparatus, system and method for if, then, else operation using write priority | |
| US5512896A (en) | Huffman encoding method, circuit and system employing most significant bit change for size detection | |
| Gwennap | Altivec vectorizes powerPC | |
| US5974539A (en) | Three input arithmetic logic unit with shifter and mask generator | |
| US20020065860A1 (en) | Data processing apparatus and method for saturating data values | |
| EP1131699B1 (en) | A data processing system and method for performing an arithmetic operation on a plurality of signed data values | |
| US5689695A (en) | Conditional processor operation based upon result of two consecutive prior processor operations |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20110802 Year of fee payment: 8 |
|
| FPAY | Annual fee payment |
Payment date: 20120802 Year of fee payment: 9 |
|
| LAPS | Lapse due to unpaid annual fee |