JP7444248B2 - 分析装置、分析方法および分析プログラム - Google Patents
分析装置、分析方法および分析プログラム Download PDFInfo
- Publication number
- JP7444248B2 JP7444248B2 JP2022524810A JP2022524810A JP7444248B2 JP 7444248 B2 JP7444248 B2 JP 7444248B2 JP 2022524810 A JP2022524810 A JP 2022524810A JP 2022524810 A JP2022524810 A JP 2022524810A JP 7444248 B2 JP7444248 B2 JP 7444248B2
- Authority
- JP
- Japan
- Prior art keywords
- meaning
- data
- conversion rule
- conversion
- analysis
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000004458 analytical method Methods 0.000 title claims description 182
- 238000006243 chemical reaction Methods 0.000 claims description 314
- 238000000034 method Methods 0.000 claims description 37
- 230000008569 process Effects 0.000 claims description 31
- 238000004364 calculation method Methods 0.000 description 35
- 238000010586 diagram Methods 0.000 description 22
- 206010028980 Neoplasm Diseases 0.000 description 20
- 201000011510 cancer Diseases 0.000 description 20
- 239000000284 extract Substances 0.000 description 9
- 238000004891 communication Methods 0.000 description 4
- 230000010365 information processing Effects 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
- G06F16/258—Data format conversion from or to a database
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
また、本発明による分析装置は、1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段と、与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析手段とを備え、個々の変換ルールにそれぞれコストが予め定められていて、各変換ルールに基づいて、データの意味を表すノードの集合と、変換ルールIDを表すノードの集合とを含む有向2部グラフを生成するグラフ生成手段と、前記有向2部グラフにおける個々のデータの意味に対して、コストの初期値を設定するコスト初期値設定手段とを備え、前記分析手段が、前記与えられた1つ以上のデータの意味に対応する各ノードを探索開始点と定めた後に、前記有向2部グラフにおいて、前記探索開始点から1つのエッジが向かっている変換ルールIDに対応するノードのうち、前記探索開始点に対応するデータの意味のコストと、前記変換ルールIDが表す変換ルールのコストとの和が、所定のコスト上限値以下であるという条件を満たすノードのみを、前記探索開始点から1つのエッジを介して到達されるノードとして特定し、特定された前記ノードに対応する変換ルールIDが表す変換ルールにおける変換前のデータの意味に対応する各ノードが全て探索開始点であり、特定された前記ノードが当該探索開始点の全てから到達されている場合に、前記変換ルールにおける変換後のデータの意味を表すノードまでの探索ルートを導出し、前記変換後のデータの意味を表すノードを探索開始点として定めるとともに、所定の条件を満たす場合に、当該ノードに対応するデータの意味のコストを更新することを繰り返し、新たな探索ルートが導出できなくなった時点までに導出された探索ルートを、前記情報として定めることを特徴とする。
また、本発明による分析装置は、1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段と、与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析手段とを備え、前記分析手段が、変換前のデータの意味が、前記与えられた1つ以上のデータの意味に包含されているという条件を満たす変換ルールを抽出し、抽出した各変換ルールにおける変換後のデータの意味と、前記与えられた1つ以上のデータの意味との和集合を求め、当該和集合を前記与えられた1つ以上のデータの意味とみなすことを繰り返し、抽出した変換ルールと、前回抽出した変換ルールとが同一になったならば、前記抽出した変換ルールの集合を、前記情報として定めることを特徴とする。
図4は、本発明の第2の実施形態の分析装置の例を示すブロック図である。本実施形態の分析装置1は、取得部2と、意味推定部3と、意味記憶部4と、変換ルール記憶部5と、グラフ生成部7と、グラフ記憶部8と、分析部26とを備える。
図12は、本発明の第3の実施形態の分析装置の例を示すブロック図である。本実施形態の分析装置1は、取得部2と、意味推定部3と、意味記憶部4と、変換ルール記憶部5と、グラフ生成部7と、グラフ記憶部8と、コスト初期値設定部31と、コスト記憶部32と、分析部36とを備える。
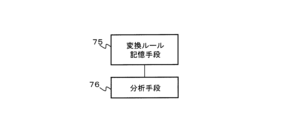
分析手段76(例えば、分析部26)が、
与えられた1つ以上のデータの意味に対応する各ノードを探索開始点と定めた後に、
有向2部グラフにおいて、探索開始点から1つのエッジを介して到達する変換ルールIDに対応するノードを特定し、
特定されたノードに対応する変換ルールIDが表す変換ルールにおける変換前のデータの意味に対応する各ノードが全て探索開始点であり、特定されたノードが当該探索開始点の全てから到達されている場合に、その変換ルールにおける変換後のデータの意味を表すノードまでの探索ルートを導出し、
その変換後のデータの意味を表すノードを探索開始点として定めること
を繰り返し、
新たな探索ルートが導出できなくなった時点までに導出された探索ルートを、上記の情報として定める
構成であってもよい。
各変換ルールに基づいて、データの意味を表すノードの集合と、変換ルールIDを表すノードの集合とを含む有向2部グラフを生成するグラフ生成手段(例えば、グラフ生成部7)と、
有向2部グラフにおける個々のデータの意味に対して、コストの初期値を設定するコスト初期値設定手段(例えば、コスト初期値設定部31)とを備え、
分析手段76(例えば、分析部36)が、
与えられた1つ以上のデータの意味に対応する各ノードを探索開始点と定めた後に、
有向2部グラフにおいて、探索開始点から1つのエッジが向かっている変換ルールIDに対応するノードのうち、その探索開始点に対応するデータの意味のコストと、変換ルールIDが表す変換ルールのコストとの和が、所定のコスト上限値以下であるという条件を満たすノードのみを、その探索開始点から1つのエッジを介して到達されるノードとして特定し、
特定されたノードに対応する変換ルールIDが表す変換ルールにおける変換前のデータの意味に対応する各ノードが全て探索開始点であり、特定されたノードが当該探索開始点の全てから到達されている場合に、その変換ルールにおける変換後のデータの意味を表すノードまでの探索ルートを導出し、
その変換後のデータの意味を表すノードを探索開始点として定めるとともに、所定の条件を満たす場合に、当該ノードに対応するデータの意味のコストを更新すること
を繰り返し、
新たな探索ルートが導出できなくなった時点までに導出された探索ルートを、上記の情報として定める
構成であってもよい。
与えられた1つ以上のデータの意味のコストをそれぞれ0に設定し、残りのデータの意味のコストを無限大に設定し、
分析手段76(例えば、分析部36)が、
導出された探索ルート上の最後の変換ルールIDが表す変換ルールのコストと、その変換ルールIDに対応するノードに到達する全ての探索開始点に対応する各データの意味のコストの総和との和が、その変換ルールにおける変換後のデータの意味のコスト以下である場合に、当該データの意味のコストを、上記の和で更新する
構成であってもよい。
変換前のデータの意味が、与えられた1つ以上のデータの意味に包含されているという条件を満たす変換ルールを抽出し、
抽出した各変換ルールにおける変換後のデータの意味と、与えられた1つ以上のデータの意味との和集合を求め、当該和集合を与えられた1つ以上のデータの意味とみなすことを繰り返し、
抽出した変換ルールと、前回抽出した変換ルールとが同一になったならば、その抽出した変換ルールの集合を、上記の情報として定める
構成であってもよい。
2 取得部
3 意味推定部
4 意味記憶部
5 変換ルール記憶部
6,26,36 分析部
7 グラフ生成部
8 グラフ記憶部
31 コスト初期値設定部
32 コスト記憶部
Claims (7)
- 1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段と、
与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析手段と、
各変換ルールに基づいて、データの意味を表すノードの集合と、変換ルールIDを表すノードの集合とを含む有向2部グラフを生成するグラフ生成手段とを備え、
前記分析手段は、
前記与えられた1つ以上のデータの意味に対応する各ノードを探索開始点と定めた後に、
前記有向2部グラフにおいて、前記探索開始点から1つのエッジを介して到達する変換ルールIDに対応するノードを特定し、
特定された前記ノードに対応する変換ルールIDが表す変換ルールにおける変換前のデータの意味に対応する各ノードが全て探索開始点であり、特定された前記ノードが当該探索開始点の全てから到達されている場合に、前記変換ルールにおける変換後のデータの意味を表すノードまでの探索ルートを導出し、
前記変換後のデータの意味を表すノードを探索開始点として定めること
を繰り返し、
新たな探索ルートが導出できなくなった時点までに導出された探索ルートを、前記情報として定める
ことを特徴とする分析装置。 - 1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段と、
与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析手段とを備え、
個々の変換ルールにそれぞれコストが予め定められていて、
各変換ルールに基づいて、データの意味を表すノードの集合と、変換ルールIDを表すノードの集合とを含む有向2部グラフを生成するグラフ生成手段と、
前記有向2部グラフにおける個々のデータの意味に対して、コストの初期値を設定するコスト初期値設定手段とを備え、
前記分析手段は、
前記与えられた1つ以上のデータの意味に対応する各ノードを探索開始点と定めた後に、
前記有向2部グラフにおいて、前記探索開始点から1つのエッジが向かっている変換ルールIDに対応するノードのうち、前記探索開始点に対応するデータの意味のコストと、前記変換ルールIDが表す変換ルールのコストとの和が、所定のコスト上限値以下であるという条件を満たすノードのみを、前記探索開始点から1つのエッジを介して到達されるノードとして特定し、
特定された前記ノードに対応する変換ルールIDが表す変換ルールにおける変換前のデータの意味に対応する各ノードが全て探索開始点であり、特定された前記ノードが当該探索開始点の全てから到達されている場合に、前記変換ルールにおける変換後のデータの意味を表すノードまでの探索ルートを導出し、
前記変換後のデータの意味を表すノードを探索開始点として定めるとともに、所定の条件を満たす場合に、当該ノードに対応するデータの意味のコストを更新すること
を繰り返し、
新たな探索ルートが導出できなくなった時点までに導出された探索ルートを、前記情報として定める
ことを特徴とする分析装置。 - 前記コスト初期値設定手段は、
前記与えられた1つ以上のデータの意味のコストをそれぞれ0に設定し、残りのデータの意味のコストを無限大に設定し、
前記分析手段は、
導出された探索ルート上の最後の変換ルールIDが表す変換ルールのコストと、前記変換ルールIDに対応するノードに到達する全ての探索開始点に対応する各データの意味のコストの総和との和が、前記変換ルールにおける変換後のデータの意味のコスト以下である場合に、当該データの意味のコストを、前記和で更新する
請求項2に記載の分析装置。 - 1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段と、
与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析手段とを備え、
前記分析手段は、
変換前のデータの意味が、前記与えられた1つ以上のデータの意味に包含されているという条件を満たす変換ルールを抽出し、
抽出した各変換ルールにおける変換後のデータの意味と、前記与えられた1つ以上のデータの意味との和集合を求め、当該和集合を前記与えられた1つ以上のデータの意味とみなすことを繰り返し、
抽出した変換ルールと、前回抽出した変換ルールとが同一になったならば、前記抽出した変換ルールの集合を、前記情報として定める
ことを特徴とする分析装置。 - データが与えられた場合に、当該データの意味を推定する意味推定手段を備える
請求項1から請求項4のうちのいずれか1項に記載の分析装置。 - 1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段を備えるコンピュータが、
与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出し、
前記情報を導出するときに、
変換前のデータの意味が、前記与えられた1つ以上のデータの意味に包含されているという条件を満たす変換ルールを抽出し、
抽出した各変換ルールにおける変換後のデータの意味と、前記与えられた1つ以上のデータの意味との和集合を求め、当該和集合を前記与えられた1つ以上のデータの意味とみなすことを繰り返し、
抽出した変換ルールと、前回抽出した変換ルールとが同一になったならば、前記抽出した変換ルールの集合を、前記情報として定める
ことを特徴とする分析方法。 - 1つ以上のデータの意味を、1つ以上の別のデータの意味に変換する変換ルールを複数個記憶する変換ルール記憶手段を備えるコンピュータに、
与えられた1つ以上のデータの意味と、前記変換ルールとに基づいて、前記意味を持つデータを用いてどのような分析を行えるかを示す情報を導出する分析処理を実行させ、
前記分析処理で、
変換前のデータの意味が、前記与えられた1つ以上のデータの意味に包含されているという条件を満たす変換ルールを抽出させ、
抽出した各変換ルールにおける変換後のデータの意味と、前記与えられた1つ以上のデータの意味との和集合を求め、当該和集合を前記与えられた1つ以上のデータの意味とみなすことを繰り返させ、
抽出した変換ルールと、前回抽出した変換ルールとが同一になったならば、前記抽出した変換ルールの集合を、前記情報として定めさせる
ための分析プログラム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/020144 WO2021234916A1 (ja) | 2020-05-21 | 2020-05-21 | 分析装置、分析方法および分析プログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JPWO2021234916A1 JPWO2021234916A1 (ja) | 2021-11-25 |
| JPWO2021234916A5 JPWO2021234916A5 (ja) | 2022-10-19 |
| JP7444248B2 true JP7444248B2 (ja) | 2024-03-06 |
Family
ID=78707831
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022524810A Active JP7444248B2 (ja) | 2020-05-21 | 2020-05-21 | 分析装置、分析方法および分析プログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20230195746A1 (ja) |
| JP (1) | JP7444248B2 (ja) |
| WO (1) | WO2021234916A1 (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007241901A (ja) | 2006-03-10 | 2007-09-20 | Univ Of Tsukuba | 意思決定支援システム及び意思決定支援方法 |
| JP2008310650A (ja) | 2007-06-15 | 2008-12-25 | Nec Corp | コミュニケーション弊害原因推定システム、方法及びプログラム |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4010516B2 (ja) * | 2000-01-27 | 2007-11-21 | 株式会社日立製作所 | 変換規則導出システム |
| JP4100156B2 (ja) * | 2002-12-06 | 2008-06-11 | 株式会社日立製作所 | データ変換システム |
| US20200409951A1 (en) * | 2019-06-26 | 2020-12-31 | Michael Kowolenko | Intelligence Augmentation System for Data Analysis and Decision Making |
-
2020
- 2020-05-21 JP JP2022524810A patent/JP7444248B2/ja active Active
- 2020-05-21 WO PCT/JP2020/020144 patent/WO2021234916A1/ja active Application Filing
- 2020-05-21 US US17/925,516 patent/US20230195746A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007241901A (ja) | 2006-03-10 | 2007-09-20 | Univ Of Tsukuba | 意思決定支援システム及び意思決定支援方法 |
| JP2008310650A (ja) | 2007-06-15 | 2008-12-25 | Nec Corp | コミュニケーション弊害原因推定システム、方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021234916A1 (ja) | 2021-11-25 |
| WO2021234916A1 (ja) | 2021-11-25 |
| US20230195746A1 (en) | 2023-06-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7375861B2 (ja) | 関連スコア算出システム、方法およびプログラム | |
| KR20170133692A (ko) | 의료 기록 문서에서의 의료 단어의 연관 규칙 생성 방법 및 그 장치 | |
| CN111754278A (zh) | 物品推荐方法、装置、计算机存储介质和电子设备 | |
| JP6079270B2 (ja) | 情報提供装置 | |
| US20140236869A1 (en) | Interactive variable selection device, interactive variable selection method, and interactive variable selection program | |
| JP7444248B2 (ja) | 分析装置、分析方法および分析プログラム | |
| KR20190101718A (ko) | 사용자 리뷰 기반 평점 재산정 장치 및 방법, 이를 기록한 기록매체 | |
| JPWO2013157603A1 (ja) | 検索クエリ分析装置、検索クエリ分析方法、及びプログラム | |
| JP6059598B2 (ja) | 情報抽出方法、情報抽出装置及び情報抽出プログラム | |
| KR101958555B1 (ko) | 검색 결과 제공 장치 및 방법 | |
| JP6984729B2 (ja) | 意味推定システム、方法およびプログラム | |
| JP6988991B2 (ja) | 意味推定システム、方法およびプログラム | |
| CN116415063A (zh) | 云服务推荐方法及装置 | |
| JP2005010848A (ja) | 情報検索装置、情報検索方法、情報検索プログラム、及び記録媒体 | |
| JP6001173B2 (ja) | データ分析装置、rdfデータの拡張方法、およびデータ分析プログラム | |
| JP2022045416A (ja) | データ処理プログラム、データ処理装置、及びデータ処理方法 | |
| JP6563549B1 (ja) | データ傾向分析方法、データ傾向分析システム及び絞り込み及び復元装置 | |
| WO2022049681A1 (ja) | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム | |
| JP7333891B2 (ja) | 情報処理装置、情報処理方法、及び情報処理プログラム | |
| WO2024069941A1 (ja) | 情報処理装置、検索方法、及び検索プログラム | |
| US20230306037A1 (en) | Non-transitory computer-readable recording medium storing information processing program, information processing method, and information processing apparatus | |
| JP7424501B2 (ja) | 結合テーブル特定システム、結合テーブル探索装置、方法およびプログラム | |
| Liu et al. | Mixed-frequency models | |
| JP6622856B2 (ja) | データ構造、雑音抑圧装置、雑音抑圧方法、プログラム | |
| WO2022049682A1 (ja) | テーブル統合システム、方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220809 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220809 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20231003 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231122 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240123 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240205 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7444248 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |