JP7425685B2 - 電子制御装置 - Google Patents
電子制御装置 Download PDFInfo
- Publication number
- JP7425685B2 JP7425685B2 JP2020117161A JP2020117161A JP7425685B2 JP 7425685 B2 JP7425685 B2 JP 7425685B2 JP 2020117161 A JP2020117161 A JP 2020117161A JP 2020117161 A JP2020117161 A JP 2020117161A JP 7425685 B2 JP7425685 B2 JP 7425685B2
- Authority
- JP
- Japan
- Prior art keywords
- memory area
- processing
- electronic control
- control device
- memory
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 claims description 330
- 230000008569 process Effects 0.000 claims description 277
- 238000012545 processing Methods 0.000 claims description 133
- 238000004364 calculation method Methods 0.000 claims description 57
- 238000013461 design Methods 0.000 claims description 40
- 230000003111 delayed effect Effects 0.000 claims 1
- 238000007726 management method Methods 0.000 description 31
- 238000010586 diagram Methods 0.000 description 23
- 230000006399 behavior Effects 0.000 description 12
- 238000011161 development Methods 0.000 description 10
- 238000012546 transfer Methods 0.000 description 8
- 239000000872 buffer Substances 0.000 description 6
- 238000012795 verification Methods 0.000 description 6
- 230000008859 change Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 238000004891 communication Methods 0.000 description 4
- 238000013523 data management Methods 0.000 description 3
- 238000010521 absorption reaction Methods 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 230000009471 action Effects 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000007850 degeneration Effects 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
Images




















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
- G06F15/163—Interprocessor communication
- G06F15/167—Interprocessor communication using a common memory, e.g. mailbox
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/52—Program synchronisation; Mutual exclusion, e.g. by means of semaphores
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/54—Interprogram communication
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Multi Processors (AREA)
- Memory System (AREA)
Description
以下、本発明に係る第1の実施例について図面を用いて説明する。
(処理Aの周期)/(処理Bの周期)
の小数点以下を切り上げた数を最小値とする値が取られることとなる。
以下、本発明に係る第2の実施例について図面を用いて説明する。想定するCPU構成(図1)や適用する時刻同期型タイミング設計方式(図2)は実施例1に準拠するが、本実施例では複数の処理Aおよび処理Bの間に一方向のデータ依存関係があるケース、すなわち処理Aの実行結果を利用して処理Bが実行されるが、逆は存在しないケースにおける本発明の適用事例を、主に実施例1との差分に着目して説明する。
以下、本発明に係る第3の実施例について図面を用いて説明する。
以下、本発明に係る第4の実施例について図面を用いて説明する。
2:CPUコア
21:L1キャッシュ
22:L2キャッシュ
3:内部バス
4:外部メモリ
5:センサ
Claims (9)
- 異なる周期で動作する複数の処理を実行する複数のコアを含むプロセッサと、
前記複数の処理を実行する前記複数のコアごとにそれぞれアクセス可能な複数のメモリ領域を含むメモリと、を備え、
データ書込みを行う先行処理とデータ読出しを行う後続処理とがそれぞれアクセス可能な前記メモリ領域を前記処理の進捗に応じて変更する電子制御装置であって、
前記プロセッサは、
最新の前記処理の結果が書き込まれておらず、かつ読出し中でない書込み可能な前記メモリ領域を探索し、書込み可能な前記メモリ領域が存在しない場合、新たな前記メモリ領域を確保し、新たな前記メモリ領域を前記処理の結果の書き込み先とすることで、前記先行処理から前記後続処理へ前記処理の結果を受け渡すこと、を特徴とする電子制御装置。 - 請求項1に記載の電子制御装置であって、
前記複数の処理のそれぞれの開始時刻および終了時刻においてタイマ割込みが入ること、を特徴とする電子制御装置。 - 請求項2に記載の電子制御装置であって、
前記メモリ領域は3つの異なるメモリ領域から構成されること、を特徴とする電子制御装置。 - 請求項2に記載の電子制御装置であって、
前記メモリ領域は2つの異なるメモリ領域から構成され、
前記プロセッサは、
書込み可能な前記メモリ領域が存在しない場合、新たな前記メモリ領域を確保すること、を特徴とする電子制御装置。 - 請求項4に記載の電子制御装置であって、
前記メモリ領域として3つ以上のメモリアドレスを有している条件において、
前記プロセッサは、
1つのメモリアドレスが最新の前記処理の結果の書込み先ではなく、かつ読出し中でもない場合において、前記1つのメモリアドレスを解放すること、を特徴とする電子制御装置。 - 請求項1に記載の電子制御装置であって、
前記メモリ領域の管理処理は、
前記プロセッサが専用のミドルウェアを実行することにより実現されること、を特徴とする電子制御装置。 - 請求項6に記載の電子制御装置であって、
前記ミドルウェアを実行する前記プロセッサは、
前記複数の処理のそれぞれの終了時刻において、処理未完了を検出した場合に強制的に当該処理を停止させる未完了処理を行うこと、を特徴とする電子制御装置。 - 請求項6に記載の電子制御装置であって、
前記ミドルウェアを実行する前記プロセッサは、
前記複数の処理のそれぞれの終了時刻において、処理未完了を検出した場合において、当該処理の演算結果を用いて演算を行う後続処理の開始時刻を、設計時に規定される猶予時間分だけ遅らせることにより、後続処理において最新の演算処理結果を用いて演算を継続すること、を特徴とする電子制御装置。 - 請求項1に記載の電子制御装置であって、
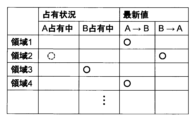
前記メモリ領域ごとの占有状況と前記処理の結果の最新値の有無を格納するテーブルを備え、
前記プロセッサは、
前記テーブルのすべての前記メモリ領域について、前記占有状況が専有を示し、または前記最新値の有無が最新値を格納していることを示す場合、書込み可能な前記メモリ領域が存在しないと判定すること、を特徴とする電子制御装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020117161A JP7425685B2 (ja) | 2020-07-07 | 2020-07-07 | 電子制御装置 |
| PCT/JP2021/024626 WO2022009741A1 (ja) | 2020-07-07 | 2021-06-29 | 電子制御装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020117161A JP7425685B2 (ja) | 2020-07-07 | 2020-07-07 | 電子制御装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2022014679A JP2022014679A (ja) | 2022-01-20 |
| JP2022014679A5 JP2022014679A5 (ja) | 2023-02-06 |
| JP7425685B2 true JP7425685B2 (ja) | 2024-01-31 |
Family
ID=79553102
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020117161A Active JP7425685B2 (ja) | 2020-07-07 | 2020-07-07 | 電子制御装置 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7425685B2 (ja) |
| WO (1) | WO2022009741A1 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023161698A (ja) * | 2022-04-26 | 2023-11-08 | 日立Astemo株式会社 | 電子制御装置 |
| CN115878549A (zh) * | 2023-03-03 | 2023-03-31 | 上海聪链信息科技有限公司 | 核间通信系统 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010119932A1 (ja) | 2009-04-17 | 2010-10-21 | 日本電気株式会社 | マルチプロセッサシステム、マルチプロセッサシステムにおけるメモリ管理方法及び通信プログラム |
| JP2010244096A (ja) | 2009-04-01 | 2010-10-28 | Seiko Epson Corp | データ処理装置、印刷システムおよびプログラム |
-
2020
- 2020-07-07 JP JP2020117161A patent/JP7425685B2/ja active Active
-
2021
- 2021-06-29 WO PCT/JP2021/024626 patent/WO2022009741A1/ja active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010244096A (ja) | 2009-04-01 | 2010-10-28 | Seiko Epson Corp | データ処理装置、印刷システムおよびプログラム |
| WO2010119932A1 (ja) | 2009-04-17 | 2010-10-21 | 日本電気株式会社 | マルチプロセッサシステム、マルチプロセッサシステムにおけるメモリ管理方法及び通信プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022009741A1 (ja) | 2022-01-13 |
| JP2022014679A (ja) | 2022-01-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109997112B (zh) | 数据处理 | |
| EP3531292B1 (en) | Methods and apparatus for supporting persistent memory | |
| US8473950B2 (en) | Parallel nested transactions | |
| US7805582B2 (en) | Method of managing memory in multiprocessor system on chip | |
| US11132294B2 (en) | Real-time replicating garbage collection | |
| JP4963018B2 (ja) | スケジューリング方法およびスケジューリング装置 | |
| US20240264940A1 (en) | Write data cache method and system, device, and storage medium | |
| US5825649A (en) | Kernel substitution method in multi-processor system and multi-processor system having kernel substitution function | |
| JP7425685B2 (ja) | 電子制御装置 | |
| CN111857993B (zh) | 一种内核态调用用户态函数的方法 | |
| WO2005048010A2 (en) | Method and system for minimizing thread switching overheads and memory usage in multithreaded processing using floating threads | |
| CN111666210A (zh) | 一种芯片验证方法及装置 | |
| US8954969B2 (en) | File system object node management | |
| CN103329102A (zh) | 多处理器系统 | |
| US20200272512A1 (en) | Hardware for supporting os driven observation and anticipation based on more granular, variable sized observation units | |
| CN118377637B (zh) | 减少冗余缓存一致性操作的方法、装置、设备和存储介质 | |
| CN114780248A (zh) | 资源访问方法、装置、计算机设备及存储介质 | |
| JP5999216B2 (ja) | データ処理装置 | |
| JP2000029691A (ja) | デ―タ処理装置 | |
| US10719357B1 (en) | Hardware for supporting OS driven load anticipation based on variable sized load units | |
| JP2005521937A (ja) | コンピュータオペレーティングシステムにおけるコンテキスト切り替え方法及び装置 | |
| JP7204443B2 (ja) | 車両制御装置およびプログラム実行方法 | |
| CN111831327A (zh) | 可执行指令的电子装置以及指令执行方法 | |
| JP7078380B2 (ja) | 命令制御装置、命令制御方法およびプログラム | |
| JP4755232B2 (ja) | コンパイラ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230127 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230127 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240116 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240119 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7425685 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |