JP7423644B2 - 行列アクセラレータアーキテクチャのためのスパース最適化 - Google Patents
行列アクセラレータアーキテクチャのためのスパース最適化 Download PDFInfo
- Publication number
- JP7423644B2 JP7423644B2 JP2021547452A JP2021547452A JP7423644B2 JP 7423644 B2 JP7423644 B2 JP 7423644B2 JP 2021547452 A JP2021547452 A JP 2021547452A JP 2021547452 A JP2021547452 A JP 2021547452A JP 7423644 B2 JP7423644 B2 JP 7423644B2
- Authority
- JP
- Japan
- Prior art keywords
- memory
- graphics
- matrix
- processor
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000011159 matrix material Substances 0.000 title claims description 175
- 238000005457 optimization Methods 0.000 title description 5
- 230000015654 memory Effects 0.000 claims description 488
- 238000012545 processing Methods 0.000 claims description 480
- 238000000034 method Methods 0.000 claims description 163
- 238000013528 artificial neural network Methods 0.000 claims description 92
- 230000004913 activation Effects 0.000 claims description 19
- 238000003860 storage Methods 0.000 claims description 14
- 238000011068 loading method Methods 0.000 claims description 13
- 238000004590 computer program Methods 0.000 claims description 7
- 230000006870 function Effects 0.000 description 101
- 230000008569 process Effects 0.000 description 91
- 238000010801 machine learning Methods 0.000 description 74
- 238000012549 training Methods 0.000 description 70
- 239000000872 buffer Substances 0.000 description 68
- 230000001133 acceleration Effects 0.000 description 62
- 239000000047 product Substances 0.000 description 47
- 238000004891 communication Methods 0.000 description 46
- 238000010586 diagram Methods 0.000 description 41
- 239000013598 vector Substances 0.000 description 40
- 238000007667 floating Methods 0.000 description 37
- 238000005192 partition Methods 0.000 description 35
- 239000012634 fragment Substances 0.000 description 34
- 238000004422 calculation algorithm Methods 0.000 description 28
- 239000004744 fabric Substances 0.000 description 27
- 238000013527 convolutional neural network Methods 0.000 description 26
- 238000001514 detection method Methods 0.000 description 26
- 238000007906 compression Methods 0.000 description 24
- 230000006835 compression Effects 0.000 description 24
- 238000013461 design Methods 0.000 description 23
- 239000000758 substrate Substances 0.000 description 23
- 238000007726 management method Methods 0.000 description 21
- 238000004364 calculation method Methods 0.000 description 18
- 238000013519 translation Methods 0.000 description 18
- 230000014616 translation Effects 0.000 description 18
- 238000001994 activation Methods 0.000 description 17
- 238000005516 engineering process Methods 0.000 description 17
- 238000013144 data compression Methods 0.000 description 16
- 238000013135 deep learning Methods 0.000 description 15
- 230000004044 response Effects 0.000 description 14
- 238000012546 transfer Methods 0.000 description 14
- 238000012360 testing method Methods 0.000 description 13
- 230000007246 mechanism Effects 0.000 description 12
- 238000013507 mapping Methods 0.000 description 11
- 230000002093 peripheral effect Effects 0.000 description 11
- 238000011176 pooling Methods 0.000 description 11
- 238000003491 array Methods 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 9
- 210000002569 neuron Anatomy 0.000 description 8
- 238000005070 sampling Methods 0.000 description 8
- 238000013459 approach Methods 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 230000006837 decompression Effects 0.000 description 7
- 238000009826 distribution Methods 0.000 description 7
- 238000011156 evaluation Methods 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- 230000033001 locomotion Effects 0.000 description 6
- 238000002156 mixing Methods 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 239000004065 semiconductor Substances 0.000 description 6
- 208000019300 CLIPPERS Diseases 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 208000021930 chronic lymphocytic inflammation with pontine perivascular enhancement responsive to steroids Diseases 0.000 description 5
- 238000009877 rendering Methods 0.000 description 5
- 230000000007 visual effect Effects 0.000 description 5
- 238000012935 Averaging Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000013500 data storage Methods 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 238000013178 mathematical model Methods 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 230000000644 propagated effect Effects 0.000 description 4
- 230000000306 recurrent effect Effects 0.000 description 4
- 238000004088 simulation Methods 0.000 description 4
- 230000001360 synchronised effect Effects 0.000 description 4
- 230000007704 transition Effects 0.000 description 4
- 230000001960 triggered effect Effects 0.000 description 4
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 3
- 230000003190 augmentative effect Effects 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 239000011521 glass Substances 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 238000003909 pattern recognition Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000000844 transformation Methods 0.000 description 3
- 102100031051 Cysteine and glycine-rich protein 1 Human genes 0.000 description 2
- 239000004593 Epoxy Substances 0.000 description 2
- 101000922020 Homo sapiens Cysteine and glycine-rich protein 1 Proteins 0.000 description 2
- 101001019104 Homo sapiens Mediator of RNA polymerase II transcription subunit 14 Proteins 0.000 description 2
- 238000013473 artificial intelligence Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 210000004027 cell Anatomy 0.000 description 2
- 230000001427 coherent effect Effects 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 230000008713 feedback mechanism Effects 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000012805 post-processing Methods 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 239000000700 radioactive tracer Substances 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 229910052710 silicon Inorganic materials 0.000 description 2
- 239000010703 silicon Substances 0.000 description 2
- 230000007958 sleep Effects 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000003068 static effect Effects 0.000 description 2
- HPTJABJPZMULFH-UHFFFAOYSA-N 12-[(Cyclohexylcarbamoyl)amino]dodecanoic acid Chemical compound OC(=O)CCCCCCCCCCCNC(=O)NC1CCCCC1 HPTJABJPZMULFH-UHFFFAOYSA-N 0.000 description 1
- 101710092887 Integrator complex subunit 4 Proteins 0.000 description 1
- OFFWOVJBSQMVPI-RMLGOCCBSA-N Kaletra Chemical compound N1([C@@H](C(C)C)C(=O)N[C@H](C[C@H](O)[C@H](CC=2C=CC=CC=2)NC(=O)COC=2C(=CC=CC=2C)C)CC=2C=CC=CC=2)CCCNC1=O.N([C@@H](C(C)C)C(=O)N[C@H](C[C@H](O)[C@H](CC=1C=CC=CC=1)NC(=O)OCC=1SC=NC=1)CC=1C=CC=CC=1)C(=O)N(C)CC1=CSC(C(C)C)=N1 OFFWOVJBSQMVPI-RMLGOCCBSA-N 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 102100037075 Proto-oncogene Wnt-3 Human genes 0.000 description 1
- 206010038933 Retinopathy of prematurity Diseases 0.000 description 1
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 238000012884 algebraic function Methods 0.000 description 1
- 230000009118 appropriate response Effects 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000013501 data transformation Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000002059 diagnostic imaging Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000000763 evoking effect Effects 0.000 description 1
- 230000001815 facial effect Effects 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000000446 fuel Substances 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 230000008570 general process Effects 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000012886 linear function Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 238000007620 mathematical function Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000010295 mobile communication Methods 0.000 description 1
- 238000012821 model calculation Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000006855 networking Effects 0.000 description 1
- 230000009022 nonlinear effect Effects 0.000 description 1
- 239000013307 optical fiber Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 238000013139 quantization Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 210000001525 retina Anatomy 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 239000010409 thin film Substances 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
Images





























































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8046—Systolic arrays
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units
- G06F9/3887—Concurrent instruction execution, e.g. pipeline, look ahead using a plurality of independent parallel functional units controlled by a single instruction for multiple data lanes [SIMD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8007—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors single instruction multiple data [SIMD] multiprocessors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/544—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices for evaluating functions by calculation
- G06F7/5443—Sum of products
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
- G06F9/3016—Decoding the operand specifier, e.g. specifier format
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline, look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
Description
本願は、35U.S.C.119(e)の下で、2019年3月15日付けでAbhishek Appu等によって「GRAPHICS PROCESSING」と題されて出願された米国特許仮出願第62/819337号(代理人整理番号AC0271-Z)と、2019年3月15日付けでLakshminarayanan Striramassarma等によって「GRAPHICS PROCESSING」と題されて出願された米国特許仮出願第62/819435号(代理人整理番号AC0285-Z)と、2019年3月15日付けでSubramaniam Maiyuran等によって「SYSTEMS AND METHODS FOR PARTITIONING CACHE TO REDUCE CACHE ACCESS LATENCY」と題されて出願された米国特許仮出願第62/819361号(代理人整理番号AC0286-Z)と、2019年11月15日付けでAbhishek Appu等によって「SYSTOLIC ARITHMETIC ON SPARSE DATA」と題されて出願された米国特許仮出願第62/935670号(代理人整理番号AC5197-Z)とに基づく優先権の利益を主張する。これらの先の米国特許出願は、その全文を参照により本願に援用される。
本願は、概して、データ処理に関係があり、より具体的には、汎用グラフィクス処理ユニットの行列アクセラレータによるスパースデータ処理に関係がある。
図1は、本願で記載される実施形態の1つ以上の態様を実装するよう構成されたコンピューティングシステム100を表すブロック図である。コンピューティングシステム100は、インターコネクションパスを介して通信する1つ以上のプロセッサ102及びシステムメモリ104を備えている処理サブシステム101を含む。インターコネクションパスは、メモリハブ105を含んでよい。メモリハブ105は、チップセットコンポーネント内の別個のコンポーネントであってよく、あるいは、1つ以上のプロセッサ102内に組み込まれてもよい。メモリハブ105は、通信リンク106を介してI/Oサブシステム111と結合する。I/Oサブシステム111は、1つ以上の入力デバイス108から入力を受けることをコンピューティングシステム100に可能にすることができるI/Oハブ107を含む。更には、I/Oハブ107は、1つ以上のプロセッサ102に含まれ得るディスプレイコントローラが1つ以上の表示デバイス110Aへ出力を供給することを可能にすることができる。一実施形態で、I/Oハブ107と結合されている1つ以上の表示デバイス110Aは、ローカル、内蔵、又は埋め込み表示デバイスを含むことができる。
図4Aは、例えば、図2Aに示される並列プロセッサ200などの、複数のGPU410~413が、高速リンク440A~440D(例えば、バス、ポイント・ツー・ポイントインターコネクト、など)を介して複数のマルチコアプロセッサ405~406へ通信可能に結合される例示的なアーキテクチャを表す。高速リンク440A~440Dは、実施に応じて、4GB/s、30GB/s、80GB/s又はそれ以上の通信スループットをサポートする。PCIe4.0又は5.0及びNVLink2.0を含むがこれらに限られない様々なインターコネクトプロトコルが使用されてよい。しかし、本願で記載されている基礎原理は、如何なる特定の通信プロトコル又はスループットにも限定されない。


グラフィクスアクセラレーションモジュール446が複数のプロセス及びパーティションによって共有される2つのプログラミングモデル、つまり、時間スライス共有及びグラフィクス指向共有がある。


図5は、グラフィクス処理パイプライン500を表す。図2Dで見られるようなグラフィクスマルチプロセッサ234、図3Aで見られるようなグラフィクスマルチプロセッサ325、図3Bで見られるようなグラフィクスマルチプロセッサ350などのグラフィクスマルチプロセッサが、表されているグラフィクス処理パイプライン500を実装することができる。グラフィクスマルチプロセッサは、図1の並列プロセッサ112に関係があってよく、それらのうちの1つの代わりに使用されてよい図2Aの並列プロセッサ200などの、本願で記載されている並列処理サブシステム内に含まれ得る。様々な並列処理システムは、ここで記載されるような並列処理ユニット(例えば、図2Aの並列処理ユニット202)の1つ以上のインスタンスを介してグラフィクス処理パイプライン500を実装することができる。例えば、シェーダユニット(例えば、図2Cのグラフィクスマルチプロセッサ234)は、頂点処理ユニット504、テッセレーション制御処理ユニット508、テッセレーション評価処理ユニット512、ジオメトリ処理ユニット516、及びフラグメント/ピクセル処理ユニット524のうちの1つ以上の機能を実行するよう構成されてよい。データアセンブラ502、プリミティブアセンブラ506、514、518、テッセレーションユニット510、ラスタライザ522、及びラスタ動作ユニット526の機能はまた、処理クラスタ(例えば、図2Aの処理クラスタ214)及び対応するパーティションユニット(例えば、図2Aのパーティションユニット220A~220N)内の他の処理エンジンによって実行されてもよい。グラフィクス処理パイプライン500はまた、1つ以上の機能のための専用の処理ユニットを用いて実装されてもよい。グラフィクス処理パイプライン500の1つ以上の部分が、汎用プロセッサ(例えば、CPU)内の並列処理ロジックによって実行されることも可能である。任意に、グラフィクス処理パイプライン500の1つ以上の部分は、図2Aのメモリインターフェース218のインスタンスであってよいメモリインターフェース528を介してオンチップメモリ(例えば、図2Aで見られるような並列プロセッサメモリ)にアクセスすることができる。グラフィクスプロセッサパイプライン500はまた、図3Cで見られるようなマルチコアグループ365Aを介して実装されてもよい。
上記のアーキテクチャは、機械学習モデルを使用して訓練及び推論動作を実行するよう適用され得る。機械学習は、多くの種類のタスクの解決に成功している。機械学習アルゴリズム(例えば、ニューラルネットワーク)を訓練及び使用するときに生じる計算は、効率的な並列実装に必然的に役に立つ。従って、汎用グラフィック処理ユニット(GPGPU)などの並列プロセッサは、ディープニューラルネットワークの実際の実装において重要な役割を果たしている。SIMT(single instruction, multiple thread)アーキテクチャを備えた並列グラフィクスプロセッサは、グラフィクスパイプラインでの並列処理の量を最大にするよう設計される。SIMTアーキテクチャでは、並列スレッドのグループは、処理効率を高めるよう可能な限り頻繁に一緒に同期してプログラム命令を実行しようと試みる。並列な機械学習アルゴリズム実装によってもたらされる効率は、高容量ネットワークの使用を可能にし、それらのネットワークがより大きいデータセットに対して訓練されることを可能にする。
図7は、図2Aの並列プロセッサ200又は図1の並列プロセッサ112であってよい汎用グラフィクス処理ユニット700を表す。汎用処理ユニット(GPGPU)700は、ディープニューラルネットワークの訓練に関連したタイプの計算ワークロードを処理することにおいて特に効率的であるよう構成されてよい。更には、GPGPU700は、特にディープニューラルネットワークのために訓練速度を改善するためにマルチGPUクラスタを生成するようGPGPUの他のインスタンスへ直接にリンクされ得る。
本願で記載されているコンピューティングアーキテクチャは、機械学習のためにニューラルネットワークを訓練及びデプロイするのに特に適しているタイプの並列処理を実行するよう構成され得る。ニューラルネットワークは、グラフ関係を有する機能のネットワークとして一般化され得る。当該技術でよく知られているように、機械学習で使用される様々なタイプのニューラルネットワーク実装が存在する。ニューラルネットワークの1つの例示的なタイプは、上述されたように、フィードフォワードネットワークである。
機械学習は、コンピュータビジョン、自動運転及び航法、発話認識、並びに言語処理を含むがこれらに限られない様々な技術的課題を解決するために適用され得る。コンピュータビジョンは、従来から、機械学習応用の最も活発な研究分野の1つである。コンピュータビジョンの応用は、顔認識などのヒトの視覚能力を再現することから、視覚能力の新たなカテゴリを作り出すことまで多岐にわたる。例えば、コンピュータビジョンアプリケーションは、映像内で見ることができる対象に引き起こされた振動から音波を認識するよう構成され得る。並列プロセッサにより加速された機械学習は、コンピュータビジョンアプリケーションが、以前に実現可能であったよりも相当に大きい訓練データセットを用いて訓練されることを可能にし、かつ、推論システムが、より低電力の並列プロセッサを用いてデプロイされることを可能にする。
図14は、処理システム1400のブロック図である。本願のいずれかの他の図の要素と同じ又は類似した名称を有している図14の要素は、他の図で見られるのと同じ要素について記載しており、本願のどこかで記載されているものと同じように動作又は機能することができ、同じコンポーネントを有することができ、そして、他のエンティティへリンクされ得るが、そのように限定されない。システム1400は、シングルプロセッサデスクトップシステム、マルチプロセッサワークステーションシステム、又は多数のプロセッサ1402又はプロセッサコア1407を備えたサーバシステムで使用されてよい。システム1400は、ローカル又はワイドエリアネットワークへの有線又は無線接続を備えたインターネット・オブ・シングス(IoT)デバイス内など携帯型、手持ち式、埋め込み型デバイスで使用されるシステム・オン・ア・チップ(SoC)集積回路内に組み込まれた処理プラットフォームであってよい。
図17は、いくつかの実施形態に従うグラフィクスプロセッサのグラフィクス処理エンジン1710のブロック図である。グラフィクス処理エンジン(GPE)1710は、図16Aに示されたGPE1610の変形であってよく、図16Bのグラフィクスエンジンタイル1610A~1610Dを表してもよい。本願のどこかの図の要素と同じ又は類似した名称を持っている図17の要素は、他の図で見られるのと同じ要素について記載しており、本願のどこかで記載されているのと同じように動作又は機能することができ、同じコンポーネントを有することができ、他のエンティティへリンクされ得るが、そのように限定されない。例えば、図16Aの3Dパイプライン1612及びメディアパイプライン1616は、図17でも表されている。メディアパイプライン1616は、GPE1710のいくつかの実施形態では任意であり、GPE1710内に明示的に含まれてなくてもよい。例えば、少なくとも1つの実施形態では、別個のメディア及び/又は画像プロセッサがGPE1710へ結合される。
図18A~18Bは、本願で記載されている実施形態に従って、グラフィクスプロセッサコアで用いられる処理要素のアレイを含むスレッド実行ロジック1800を表す。本願のいずれかの他の図の要素と同じ又は類似した名称を有している図18A~18Bの要素は、他の図で見られるのと同じ要素について記載しており、本願のどこかで記載されているのと同じように動作又は機能することができ、同じコンポーネントを有することができ、他のエンティティへリンクされ得るが、そのように限定されない。図18A~18Bは、図15Bの各サブコア1521A~1521Fにより表されたハードウェアロジックを表し得るスレッド実行ロジック1800の概要を表す。図18Aは、汎用グラフィクスプロセッサ内の実行ユニットを表し、一方、図18Bは、計算アクセラレータ内で使用され得る実行ユニットを表す。
図21は、他の実施形態に従うグラフィクスプロセッサ2100のブロック図である。本願のいずれかの他の図の要素と同じ又は類似した名称を有する図21の要素は、他の図で見られる同じ要素について記載しており、本願のどこかで記載されているのと同じように動作又は機能することができ、同じコンポーネントを有することができ、他のエンティティへリンクされ得るが、そのように限定されない。
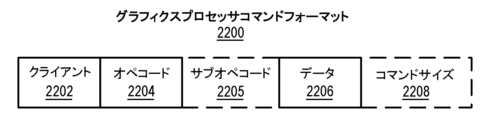
図22Aは、例えば、図16A、17、21とともに本願で記載されているパイプラインなどのグラフィクス処理パイプラインをプログラムするために使用されるグラフィクスプロセッサコマンドフォーマット2200を表すブロック図である。図22Bは、実施形態に従うグラフィクスプロセッサコマンドシーケンス2210を表すブロック図である。図22Aの実線ボックスは、一般的にグラフィクスコマンドに含まれているコンポーネントを表し、破線は、任意であるか、あるいは、グラフィクスコマンドのサブセットにしか含まれないコンポーネントを含む。図22Aの例となるグラフィクスプロセッサコマンドフォーマット2200は、クライアント2202、コマンド操作コード(オペコード)2204、及びコマンドのためのデータ2206を識別するデータフィールドを含む。サブオペコード2205及びコマンドサイズ2208も、いくつかのコマンドには含まれる。
図23は、データ処理システム2300についての例示的なグラフィクスソフトウェアアーキテクチャを表す。そのようなソフトウェアアーキテクチャは、3Dグラフィクスアプリケーション2310、オペレーティングシステム2320、及び少なくとも1つのプロセッサ2330を含んでよい。プロセッサ2330は、グラフィクスプロセッサ2332及び1つ以上の汎用プロセッサコア2334を含む。プロセッサ2330は、プロセッサ1402又は本願で記載されているプロセッサのいずれか他の変形であってよい。プロセッサ2330は、プロセッサ1402又は本願で記載されているプロセッサのいずれか他の代わりに使用されてよい。従って、プロセッサ1420又は本願で記載されているプロセッサのいずれか他と組み合わされた如何なる特徴の開示も、グラフィクスプロセッサ2330との対応する組み合わせを開示するが、そのように限定されない。更に、本願のいずれか他の図の要素と同じ又は類似した名称を有する図23の要素は、他の図で見られる同じ要素について記載しており、本願のどこかで記載されているのと同じように動作又は機能することができ、同じコンポーネントを有することができ、他のエンティティへリンクされ得るが、そのように限定されない。グラフィクスアプリケーション2310及びオペレーティングシステム2320は夫々、データ処理システムのシステムメモリ2350で実行される。
1つ以上の態様は、プロセッサなどの集積回路内のロジックを表現及び/又は定義する機械可読媒体に記憶された代表コードによって実装されてもよい。例えば、機械可読媒体は、プロセッサ内の様々なロジックを表す命令を含んでよい。機械によって読み出される場合に、命令は、機械に、本願で記載されている技術を実行するようロジックを組み立てさせ得る。「IPコア」として知られているそのような表現は、集積回路の構造を記述するハードウェアモデルとして有形な機械可読媒体に記憶され得る集積回路用ロジックの再利用可能なユニットである。ハードウェアモデルは、集積回路を製造する組立機械にハードウェアモデルをロードする様々なカスタマ又は製造設備に供給されてよい。集積回路は、回路が、本願で記載されている実施形態のいずれかと関連して記載されている動作を実行するように、組み立てられてよい。
図25~26は、1つ以上のIPコアを使用して組み立てられ得る例示的な集積回路及び関連するグラフィクスプロセッサを表す。表されているものに加えて、追加のグラフィクスプロセッサ/コア、プロセッサ/コア、ペリフェラル・インターフェース・コントローラ、又は汎用プロセッサコアを含む他のロジック及び回路が含まれてもよい。本願のいずれか他の図の要素と同じ又は類似した名称を有する図25~26の要素は、他の図で見られる同じ要素について記載しており、本願のどこかで記載されているのと同じように動作又は機能することができ、同じコンポーネントを有することができ、他のエンティティへリンクされ得るが、そのように限定されない。
図27は、実施形態に従うデータ処理システム2700のブロック図である。データ処理システム2700は、プロセッサ2702と、統合メモリ2710と、機械学習アクセラレーションロジックを含むGPGPU2720とを備える異種(heterogeneous)処理システムである。プロセッサ2702及びGPGPU2720は、本願で記載されているプロセッサ及びGPGPU/並列プロセッサのいずれかであることができる。プロセッサ2702は、システムメモリ2712に記憶されているコンパイラ2715に対する命令を実行することができる。コンパイラ2715は、ソースコード2714Aをコンパイル済みコード2714Bにコンパイルするようプロセッサ2702で実行される。コンパイル済みコード2714Bは、プロセッサ2702によって実行され得る命令及び/又はGPGPU2720によって実行され得る命令を含むことができる。コンパイル中、コンパイラ2715は、コンパイル済みコード2714Bに存在するデータ並列性(data parallelism)のレベルに関するヒント及び/又はコンパイル済みコード2714Bに基づいてディスパッチされるべきスレッドに関連したデータ局所性(data locality)に関するヒントを含むメタデータを挿入する動作を実行することができる。コンパイラ2715は、そのような動作を実行するのに必要な情報を含むことができ、あるいは、動作は、ランタイムライブラリ2716の支援を受けて実行され得る。ランタイムライブラリ2716はまた、ソースコード2714Aのコンパイルにおいてコンパイラ2715を支援することもでき、GPGPU2720でのコンパイル済みコード2714Bの実行を助けるよう、ランタイム時にコンパイル済みコード2714Bとリンクされる命令を含むこともできる。

一実施形態は、スパースデータを使用するときにシストリックアレイに対する訓練及び推論を最適化する技術を提供する。シストリックテンソルアレイ2808又はシストリックアレイ1912によって処理されるべき行列又はサブ行列が完全にゼロである場合に、行列又はサブ行列の次元値はゼロにセット可能であり、シストリックテンソルアレイ2808は、実行されるべき演算に応じて、サブ行列に関連した1つ以上の計算フェーズをバイパスしてよい。行列データの前処理中、ゼロサブ行列が識別可能であり、行列のサブ行列マップは、どのサブ行列がゼロ値しか含まないかを示すよう生成され得る。一実施形態において、少なくともいくつかの演算は、全体としてゼロ値から成る行又は列を含む行列又はサブ行列についてバイパスされてよい。一実施形態において、ただ1つの非ゼロ値も含むサブ行列も、バイパスされ得る。
GPUは、3D及びメディアアプリケーションによって使用されるピクセルデータの圧縮を可能にするデータ圧縮パイプラインを含むことができる。3D及びメディアアプリケーションによって使用されるデータは、GPUデータ圧縮の観点から、型付けされた(typed)データと見なされる。しかし、機械学習及びディープラーニング動作のためのデータなどのGPGPU計算データは、型指定されていない(untyped)データと見なされ、従来のGPGPU圧縮パイプラインは、型付けされたデータ圧縮技術を使用して、そのようなデータを圧縮することができない。例えば、型付けされたデータは、一般的に、メモリに順次に記憶されず、代わりに、圧縮されるべきデータのタイプに特有であるタイル、平面、又は他のデータフォーマットを用いて記憶されてよい。対照的に、型指定されていない計算データは、順次にメモリに記憶される。
図37は、実施形態に従うグラフィクスプロセッサ3704を含むコンピューティングデバイス3700のブロック図である。コンピューティングデバイス3700は、上述された実施形態の夫々の機能性を含むコンピューティングデバイスであることができる。コンピューティングデバイス3700は、セットトップボックス(例えば、インターネットに基づくケーブルテレビジョンセットトップボックス、など)、グローバル・ポジショニング・システム(GPS)ベースのデバイス、などのような通信デバイスであっても、あるいは、そのようなものに含まれてもよい。コンピューティングデバイス3700はまた、携帯電話機、スマートフォン、パーソナル・デジタル・アシスタント(PDA)、タブレットコンピュータ、ラップトップコンピュータ、電子リーダー、スマートテレビジョン、テレビジョンプラットフォーム、ウェアラブルデバイス(例えば、メガネ、時計、ブレスレット、スマートカード、宝石、衣服アイテム、など)、メディアプレイヤー、などのモバイルコンピューティングデバイスであっても、あるいは、そのようなものに含まれてもよい。例えば、一実施形態において、コンピューティングデバイス3700は、単一のチップ上にコンピューティングデバイス3700の様々なハードウェア及び/又はソフトウェアコンポーネントを組み込むシステム・オン・ア・チップ(「SoC」又は「SOC」)などの集積回路(「IC」)を用いるモバイルコンピューティングデバイスを含む。
Claims (20)
- キャッシュメモリと結合される複数の処理リソースを含み、少なくとも1つの処理リソースが行列アクセラレータを含み、該行列アクセラレータは、第1行列及び第2行列の複数の要素に対して行列乗算演算を実行するよう構成され、第1行列はスパース行列であり、前記第1行列は、前記スパース行列においてゼロ値要素のみを含むか又は限られた数の非ゼロ値要素しか含まない少なくとも1つのスパースサブ行列のロードがバイパスされることを可能にすることによって、スパース符号化に符号化される、計算クラスタを有し、
前記スパース符号化は、前記キャッシュメモリに格納され、
前記キャッシュメモリは、該キャッシュメモリへの書き込みに関連して前記スパース符号化を圧縮表現に圧縮する圧縮器と結合し、前記圧縮表現は、非ゼロ値要素の組と、該非ゼロ値要素の位置を特定するメタデータとを含み、
前記少なくとも1つの処理リソースは、
前記圧縮表現を前記キャッシュメモリからロードし、前記圧縮表現を前記少なくとも1つの処理リソース内のメモリに格納し、
前記第2行列の選択された要素を前記キャッシュメモリからロードし、前記選択された要素を前記少なくとも1つの処理リソース内の前記メモリに格納し、前記第2行列の前記選択された要素が、前記圧縮表現内に格納された前記第1行列の非ゼロ値と対応し、該非ゼロ値の位置を示す前記メタデータに基づき選択され、
前記圧縮表現からの要素及び前記第2行列の前記選択された要素に対して前記行列乗算演算を実行し、
前記行列乗算演算の出力を前記少なくとも1つの処理リソース内の前記メモリに書き込む
よう構成される、
汎用グラフィクスプロセッサ。 - 前記キャッシュメモリは、レベル2(L2)キャッシュメモリである、
請求項1に記載の汎用グラフィクスプロセッサ。 - 前記圧縮器は、前記L2キャッシュメモリに格納されているデータを圧縮する、
請求項2に記載の汎用グラフィクスプロセッサ。 - 前記処理リソース内の前記メモリは、レベル1(L1)キャッシュメモリを含む、
請求項1に記載の汎用グラフィクスプロセッサ。 - 前記処理リソース内の前記メモリは、レジスタファイル(RF)を含む、
請求項1に記載の汎用グラフィクスプロセッサ。 - 前記処理リソース内の前記メモリは、前記行列アクセラレータ内のメモリを含む、
請求項1に記載の汎用グラフィクスプロセッサ。 - 前記第1行列は、ニューラルネットワークに関連した重みデータを含む、
請求項1に記載の汎用グラフィクスプロセッサ。 - 前記第2行列は、前記ニューラルネットワークに関連した入力活性化データを含む、
請求項7に記載の汎用グラフィクスプロセッサ。 - 前記行列乗算演算の前記出力は、前記ニューラルネットワークに関連した出力活性化データを含む、
請求項8に記載の汎用グラフィクスプロセッサ。 - 前記行列乗算演算の前記出力は、密行列である、
請求項9に記載の汎用グラフィクスプロセッサ。 - 前記行列アクセラレータは、処理要素のシストリックアレイを含む、
請求項1に記載の汎用グラフィクスプロセッサ。 - メモリデバイスと、
請求項1乃至11のうち何れか一項に記載の汎用グラフィクスプロセッサと
を有するデータ処理システム。 - キャッシュメモリと結合される複数の処理リソースを含む計算クラスタにより、第1行列及び第2行列の複数の要素に対して行列乗算演算を実行することであり、少なくとも1つの処理リソースが行列アクセラレータを含み、第1行列はスパース行列であり、前記第1行列は、前記スパース行列においてゼロ値要素のみを含むか又は限られた数の非ゼロ値要素しか含まない少なくとも1つのスパースサブ行列のロードがバイパスされることを可能にすることによって、スパース符号化に符号化される、前記実行することと、
前記スパース符号化を前記キャッシュメモリに格納することであり、前記キャッシュメモリは、該キャッシュメモリ内の前記スパース符号化を圧縮表現に圧縮する圧縮器と結合され、前記圧縮表現は、非ゼロ値要素の組と、該非ゼロ値要素の位置を特定するメタデータとを含む、前記格納することと、
前記少なくとも1つの処理リソースにより、
前記圧縮表現を前記キャッシュメモリからロードし、
前記圧縮表現を前記少なくとも1つの処理リソース内のメモリに格納し、
前記第2行列の選択された要素を前記キャッシュメモリからロードし、
前記選択された要素を前記少なくとも1つの処理リソース内の前記メモリに格納し、前記第2行列の前記選択された要素が、前記圧縮表現内に格納された前記第1行列の非ゼロ値と対応し、該非ゼロ値の位置を示す前記メタデータに基づき選択され、
前記圧縮表現からの要素及び前記第2行列の前記選択された要素に対して前記行列乗算演算を実行し、
前記行列乗算演算の出力を前記少なくとも1つの処理リソース内の前記メモリに書き込むことと
を有する方法。 - 前記キャッシュメモリは、レベル2(L2)キャッシュメモリであり、前記圧縮器は、前記L2キャッシュメモリに格納されているデータを圧縮する、
請求項13に記載の方法。 - 前記処理リソース内の前記メモリは、レベル1(L1)キャッシュメモリを含む、
請求項13に記載の方法。 - 前記処理リソース内の前記メモリは、レジスタファイル(RF)を含む、
請求項13に記載の方法。 - 前記処理リソース内の前記メモリは、前記行列アクセラレータ内のメモリを含む、
請求項13に記載の方法。 - 実行される場合にマシンに請求項13乃至17のうち何れか一項に記載の方法を実行させるコンピュータプログラム。
- 請求項18に記載のコンピュータプログラムを記憶しているマシン可読記憶媒体。
- 請求項13乃至17のうち何れか一項に記載の方法を実行する手段を有する装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024006026A JP2024036383A (ja) | 2019-03-15 | 2024-01-18 | 行列アクセラレータアーキテクチャのためのスパース最適化 |
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962819435P | 2019-03-15 | 2019-03-15 | |
| US201962819361P | 2019-03-15 | 2019-03-15 | |
| US201962819337P | 2019-03-15 | 2019-03-15 | |
| US62/819,361 | 2019-03-15 | ||
| US62/819,435 | 2019-03-15 | ||
| US62/819,337 | 2019-03-15 | ||
| US201962935670P | 2019-11-15 | 2019-11-15 | |
| US62/935,670 | 2019-11-15 | ||
| PCT/US2020/022846 WO2020190808A1 (en) | 2019-03-15 | 2020-03-14 | Sparse optimizations for a matrix accelerator architecture |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024006026A Division JP2024036383A (ja) | 2019-03-15 | 2024-01-18 | 行列アクセラレータアーキテクチャのためのスパース最適化 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2022523762A JP2022523762A (ja) | 2022-04-26 |
| JPWO2020190808A5 JPWO2020190808A5 (ja) | 2022-07-13 |
| JP7423644B2 true JP7423644B2 (ja) | 2024-01-29 |
Family
ID=70285850
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021547450A Active JP7408671B2 (ja) | 2019-03-15 | 2020-03-14 | シストリックアレイに対するブロックスパース演算のためのアーキテクチャ |
| JP2021547288A Pending JP2022523760A (ja) | 2019-03-15 | 2020-03-14 | 行列アクセラレータアーキテクチャ内のシストリック分解 |
| JP2021547452A Active JP7423644B2 (ja) | 2019-03-15 | 2020-03-14 | 行列アクセラレータアーキテクチャのためのスパース最適化 |
| JP2024006026A Pending JP2024036383A (ja) | 2019-03-15 | 2024-01-18 | 行列アクセラレータアーキテクチャのためのスパース最適化 |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021547450A Active JP7408671B2 (ja) | 2019-03-15 | 2020-03-14 | シストリックアレイに対するブロックスパース演算のためのアーキテクチャ |
| JP2021547288A Pending JP2022523760A (ja) | 2019-03-15 | 2020-03-14 | 行列アクセラレータアーキテクチャ内のシストリック分解 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024006026A Pending JP2024036383A (ja) | 2019-03-15 | 2024-01-18 | 行列アクセラレータアーキテクチャのためのスパース最適化 |
Country Status (10)
| Country | Link |
|---|---|
| US (4) | US11113784B2 (ja) |
| EP (3) | EP3938888A1 (ja) |
| JP (4) | JP7408671B2 (ja) |
| KR (3) | KR20210135999A (ja) |
| CN (5) | CN113383310A (ja) |
| AU (1) | AU2020241262A1 (ja) |
| BR (2) | BR112021016138A2 (ja) |
| DE (2) | DE112020001249T5 (ja) |
| SG (1) | SG11202107290QA (ja) |
| WO (3) | WO2020190809A1 (ja) |
Families Citing this family (47)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10474458B2 (en) | 2017-04-28 | 2019-11-12 | Intel Corporation | Instructions and logic to perform floating-point and integer operations for machine learning |
| KR102559581B1 (ko) * | 2018-05-23 | 2023-07-25 | 삼성전자주식회사 | 재구성 가능 로직을 포함하는 스토리지 장치 및 상기 스토리지 장치의 동작 방법 |
| US20200210517A1 (en) | 2018-12-27 | 2020-07-02 | Intel Corporation | Systems and methods to accelerate multiplication of sparse matrices |
| US11934342B2 (en) | 2019-03-15 | 2024-03-19 | Intel Corporation | Assistance for hardware prefetch in cache access |
| CN113383310A (zh) | 2019-03-15 | 2021-09-10 | 英特尔公司 | 矩阵加速器架构内的脉动分解 |
| US20220180467A1 (en) | 2019-03-15 | 2022-06-09 | Intel Corporation | Systems and methods for updating memory side caches in a multi-gpu configuration |
| US11392376B2 (en) * | 2019-04-11 | 2022-07-19 | Arm Limited | Processor for sparse matrix computation |
| US11222092B2 (en) * | 2019-07-16 | 2022-01-11 | Facebook Technologies, Llc | Optimization for deconvolution |
| KR102213258B1 (ko) * | 2019-07-29 | 2021-02-08 | 한국전자기술연구원 | 효율적인 명령어 처리를 위한 프로세싱-인-메모리 제어 방법 및 이를 적용한 연산장치 |
| CN112899740B (zh) * | 2019-11-15 | 2022-04-19 | 源秩科技(上海)有限公司 | 基于电化学的加工装置和方法 |
| CN111176582A (zh) * | 2019-12-31 | 2020-05-19 | 北京百度网讯科技有限公司 | 矩阵存储方法、矩阵访问方法、装置和电子设备 |
| US11586601B2 (en) * | 2020-02-05 | 2023-02-21 | Alibaba Group Holding Limited | Apparatus and method for representation of a sparse matrix in a neural network |
| US11687831B1 (en) | 2020-06-30 | 2023-06-27 | Cadence Design Systems, Inc. | Method, product, and apparatus for a multidimensional processing array for hardware acceleration of convolutional neural network inference |
| US11823018B1 (en) | 2020-06-30 | 2023-11-21 | Cadence Design Systems, Inc. | Method, product, and apparatus for a machine learning process using weight sharing within a systolic array having reduced memory bandwidth |
| US11676068B1 (en) | 2020-06-30 | 2023-06-13 | Cadence Design Systems, Inc. | Method, product, and apparatus for a machine learning process leveraging input sparsity on a pixel by pixel basis |
| US11615320B1 (en) | 2020-06-30 | 2023-03-28 | Cadence Design Systems, Inc. | Method, product, and apparatus for variable precision weight management for neural networks |
| US11651283B1 (en) * | 2020-06-30 | 2023-05-16 | Cadence Design Systems, Inc. | Method, product, and apparatus for a machine learning process using dynamic rearrangement of sparse data and corresponding weights |
| US11848980B2 (en) * | 2020-07-09 | 2023-12-19 | Boray Data Technology Co. Ltd. | Distributed pipeline configuration in a distributed computing system |
| US20220164663A1 (en) * | 2020-11-24 | 2022-05-26 | Arm Limited | Activation Compression Method for Deep Learning Acceleration |
| US11977885B2 (en) * | 2020-11-30 | 2024-05-07 | Intel Corporation | Utilizing structured sparsity in systolic arrays |
| US20220197799A1 (en) * | 2020-12-23 | 2022-06-23 | Intel Corporation | Instruction and Micro-Architecture Support for Decompression on Core |
| US20220197642A1 (en) * | 2020-12-23 | 2022-06-23 | Intel Corporation | Processor instructions for data compression and decompression |
| US20220222319A1 (en) * | 2021-01-14 | 2022-07-14 | Microsoft Technology Licensing, Llc | Compressed matrix with sparsity metadata |
| US20230161479A1 (en) * | 2021-02-25 | 2023-05-25 | Alibab Group Holding Limited | Zero skipping techniques for reducing data movement |
| US20220293170A1 (en) * | 2021-03-10 | 2022-09-15 | Invention And Collaboration Laboratory Pte. Ltd. | Integrated scaling and stretching platform for optimizing monolithic integration and/or heterogeneous integration in a single semiconductor die |
| US20220300816A1 (en) * | 2021-03-19 | 2022-09-22 | Rebellions Inc. | Neural processing device and method for pruning thereof |
| CN113516172B (zh) * | 2021-05-19 | 2023-05-12 | 电子科技大学 | 基于随机计算贝叶斯神经网络误差注入的图像分类方法 |
| CN113076521B (zh) * | 2021-06-03 | 2021-09-21 | 沐曦集成电路(上海)有限公司 | 一种基于gpgpu可重构架构的方法及计算系统 |
| CN113268270B (zh) * | 2021-06-07 | 2022-10-21 | 中科计算技术西部研究院 | 一种针对成对隐马尔可夫模型的加速方法、系统及装置 |
| US11669331B2 (en) * | 2021-06-17 | 2023-06-06 | International Business Machines Corporation | Neural network processing assist instruction |
| US20220414053A1 (en) * | 2021-06-24 | 2022-12-29 | Intel Corporation | Systolic array of arbitrary physical and logical depth |
| US20220414054A1 (en) * | 2021-06-25 | 2022-12-29 | Intel Corporation | Dual pipeline parallel systolic array |
| US20220413851A1 (en) * | 2021-06-25 | 2022-12-29 | Intel Corporation | Register file for systolic array |
| US20220413924A1 (en) * | 2021-06-25 | 2022-12-29 | Intel Corporation | Using sparsity metadata to reduce systolic array power consumption |
| US20220413803A1 (en) * | 2021-06-25 | 2022-12-29 | Intel Corporation | Systolic array having support for output sparsity |
| US11941111B2 (en) | 2021-07-31 | 2024-03-26 | International Business Machines Corporation | Exploiting fine-grained structured weight sparsity in systolic arrays |
| US20230079975A1 (en) * | 2021-09-10 | 2023-03-16 | Arm Limited | Power management for system-on-chip |
| US20230102279A1 (en) * | 2021-09-25 | 2023-03-30 | Intel Corporation | Apparatuses, methods, and systems for instructions for structured-sparse tile matrix fma |
| US11657260B2 (en) * | 2021-10-26 | 2023-05-23 | Edgecortix Pte. Ltd. | Neural network hardware accelerator data parallelism |
| CN114218152B (zh) * | 2021-12-06 | 2023-08-15 | 海飞科(南京)信息技术有限公司 | 流处理方法、处理电路和电子设备 |
| TWI824392B (zh) * | 2022-01-21 | 2023-12-01 | 財團法人國家實驗研究院 | 適用於分散式深度學習計算的隨需即組共用資料快取方法、電腦程式、電腦可讀取媒體 |
| CN115034198B (zh) * | 2022-05-16 | 2023-05-12 | 北京百度网讯科技有限公司 | 语言模型中嵌入模块计算优化的方法 |
| KR102548582B1 (ko) * | 2022-12-26 | 2023-06-29 | 리벨리온 주식회사 | 뉴럴 프로세서 및 이의 명령어 페치 방법 |
| US11915001B1 (en) | 2022-12-26 | 2024-02-27 | Rebellions Inc. | Neural processor and method for fetching instructions thereof |
| TWI831588B (zh) * | 2023-01-30 | 2024-02-01 | 創鑫智慧股份有限公司 | 神經網路演算裝置以及在神經網路演算中的數值轉換方法 |
| TWI830669B (zh) * | 2023-02-22 | 2024-01-21 | 旺宏電子股份有限公司 | 編碼方法及編碼電路 |
| CN117093816B (zh) * | 2023-10-19 | 2024-01-19 | 上海登临科技有限公司 | 矩阵乘运算方法、装置和电子设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018125250A1 (en) | 2016-12-31 | 2018-07-05 | Intel Corporation | Systems, methods, and apparatuses for heterogeneous computing |
| WO2018213636A1 (en) | 2017-05-17 | 2018-11-22 | Google Llc | Performing matrix multiplication in hardware |
Family Cites Families (323)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2581236B2 (ja) | 1989-11-16 | 1997-02-12 | 三菱電機株式会社 | データ処理装置 |
| JP2682232B2 (ja) | 1990-11-21 | 1997-11-26 | 松下電器産業株式会社 | 浮動小数点演算処理装置 |
| US5381539A (en) | 1992-06-04 | 1995-01-10 | Emc Corporation | System and method for dynamically controlling cache management |
| GB9307359D0 (en) | 1993-04-08 | 1993-06-02 | Int Computers Ltd | Cache replacement mechanism |
| US5450607A (en) | 1993-05-17 | 1995-09-12 | Mips Technologies Inc. | Unified floating point and integer datapath for a RISC processor |
| US5574928A (en) | 1993-10-29 | 1996-11-12 | Advanced Micro Devices, Inc. | Mixed integer/floating point processor core for a superscalar microprocessor with a plurality of operand buses for transferring operand segments |
| US5623636A (en) | 1993-11-09 | 1997-04-22 | Motorola Inc. | Data processing system and method for providing memory access protection using transparent translation registers and default attribute bits |
| US5627985A (en) | 1994-01-04 | 1997-05-06 | Intel Corporation | Speculative and committed resource files in an out-of-order processor |
| GB2296155B (en) | 1994-06-22 | 1997-04-23 | Microsoft Corp | Data decompression circuit |
| US5805475A (en) | 1995-02-10 | 1998-09-08 | International Business Machines Corporation | Load-store unit and method of loading and storing single-precision floating-point registers in a double-precision architecture |
| US5651137A (en) | 1995-04-12 | 1997-07-22 | Intel Corporation | Scalable cache attributes for an input/output bus |
| US5940311A (en) | 1996-04-30 | 1999-08-17 | Texas Instruments Incorporated | Immediate floating-point operand reformatting in a microprocessor |
| US5917741A (en) | 1996-08-29 | 1999-06-29 | Intel Corporation | Method and apparatus for performing floating-point rounding operations for multiple precisions using incrementers |
| US6078940A (en) | 1997-01-24 | 2000-06-20 | Texas Instruments Incorporated | Microprocessor with an instruction for multiply and left shift with saturate |
| US5943687A (en) | 1997-03-14 | 1999-08-24 | Telefonakiebolaget Lm Ericsson | Penalty-based cache storage and replacement techniques |
| US5926406A (en) | 1997-04-30 | 1999-07-20 | Hewlett-Packard, Co. | System and method for calculating floating point exponential values in a geometry accelerator |
| SG120064A1 (en) * | 1997-07-15 | 2006-03-28 | Silverbrook Res Pty Ltd | Thermal actuator |
| AUPO793897A0 (en) * | 1997-07-15 | 1997-08-07 | Silverbrook Research Pty Ltd | Image processing method and apparatus (ART25) |
| US6856320B1 (en) | 1997-11-25 | 2005-02-15 | Nvidia U.S. Investment Company | Demand-based memory system for graphics applications |
| US7102646B1 (en) | 1997-11-25 | 2006-09-05 | Nvidia U.S. Investment Company | Demand-based memory system for graphics applications |
| US6253311B1 (en) | 1997-11-29 | 2001-06-26 | Jp First Llc | Instruction set for bi-directional conversion and transfer of integer and floating point data |
| US6049865A (en) | 1997-12-18 | 2000-04-11 | Motorola, Inc. | Method and apparatus for implementing floating point projection instructions |
| US6260008B1 (en) | 1998-01-08 | 2001-07-10 | Sharp Kabushiki Kaisha | Method of and system for disambiguating syntactic word multiples |
| US6480872B1 (en) | 1999-01-21 | 2002-11-12 | Sandcraft, Inc. | Floating-point and integer multiply-add and multiply-accumulate |
| US6529928B1 (en) | 1999-03-23 | 2003-03-04 | Silicon Graphics, Inc. | Floating-point adder performing floating-point and integer operations |
| US6788738B1 (en) | 1999-05-07 | 2004-09-07 | Xilinx, Inc. | Filter accelerator for a digital signal processor |
| US6631437B1 (en) | 2000-04-06 | 2003-10-07 | Hewlett-Packard Development Company, L.P. | Method and apparatus for promoting memory read commands |
| US6578102B1 (en) | 2000-04-18 | 2003-06-10 | International Business Machines Corporation | Tracking and control of prefetch data in a PCI bus system |
| US6412046B1 (en) | 2000-05-01 | 2002-06-25 | Hewlett Packard Company | Verification of cache prefetch mechanism |
| US8188997B2 (en) | 2000-06-19 | 2012-05-29 | Mental Images Gmbh | Accelerated ray tracing using shallow bounding volume hierarchies |
| US7499053B2 (en) | 2000-06-19 | 2009-03-03 | Mental Images Gmbh | Real-time precision ray tracing |
| US6678806B1 (en) | 2000-08-23 | 2004-01-13 | Chipwrights Design, Inc. | Apparatus and method for using tagged pointers for extract, insert and format operations |
| US6792509B2 (en) | 2001-04-19 | 2004-09-14 | International Business Machines Corporation | Partitioned cache of multiple logical levels with adaptive reconfiguration based on multiple criteria |
| US6748495B2 (en) | 2001-05-15 | 2004-06-08 | Broadcom Corporation | Random generator |
| US6947049B2 (en) | 2001-06-01 | 2005-09-20 | Nvidia Corporation | Method and system for synchronizing updates of vertex data with a graphics processor that is fetching vertex data |
| US7127482B2 (en) | 2001-11-19 | 2006-10-24 | Intel Corporation | Performance optimized approach for efficient downsampling operations |
| US7197605B2 (en) | 2002-12-30 | 2007-03-27 | Intel Corporation | Allocating cache lines |
| US7483031B2 (en) | 2003-04-17 | 2009-01-27 | Nvidia Corporation | Method for synchronizing graphics processing units |
| US7373369B2 (en) | 2003-06-05 | 2008-05-13 | International Business Machines Corporation | Advanced execution of extended floating-point add operations in a narrow dataflow |
| US7272624B2 (en) | 2003-09-30 | 2007-09-18 | International Business Machines Corporation | Fused booth encoder multiplexer |
| JP3807400B2 (ja) | 2003-10-30 | 2006-08-09 | ソニー株式会社 | 記録制御装置および記録制御方法 |
| GB2409068A (en) | 2003-12-09 | 2005-06-15 | Advanced Risc Mach Ltd | Data element size control within parallel lanes of processing |
| KR100800468B1 (ko) | 2004-01-29 | 2008-02-01 | 삼성전자주식회사 | 저전력 고속 동작을 위한 하드웨어 암호화/복호화 장치 및그 방법 |
| US8253750B1 (en) | 2004-02-14 | 2012-08-28 | Nvidia Corporation | Digital media processor |
| US7873812B1 (en) | 2004-04-05 | 2011-01-18 | Tibet MIMAR | Method and system for efficient matrix multiplication in a SIMD processor architecture |
| US7548892B2 (en) * | 2004-04-30 | 2009-06-16 | Microsoft Corporation | Processing machine learning techniques using a graphics processing unit |
| US7428566B2 (en) | 2004-11-10 | 2008-09-23 | Nvidia Corporation | Multipurpose functional unit with multiply-add and format conversion pipeline |
| US20060101244A1 (en) | 2004-11-10 | 2006-05-11 | Nvidia Corporation | Multipurpose functional unit with combined integer and floating-point multiply-add pipeline |
| US20060179092A1 (en) | 2005-02-10 | 2006-08-10 | Schmookler Martin S | System and method for executing fixed point divide operations using a floating point multiply-add pipeline |
| US20060248279A1 (en) | 2005-05-02 | 2006-11-02 | Al-Sukhni Hassan F | Prefetching across a page boundary |
| US7346741B1 (en) | 2005-05-10 | 2008-03-18 | Sun Microsystems, Inc. | Memory latency of processors with configurable stride based pre-fetching technique |
| WO2006120664A2 (en) | 2005-05-13 | 2006-11-16 | Provost Fellows And Scholars Of The College Of The Holy And Undivided Trinity Of Queen Elizabeth Near Dublin | A data processing system and method |
| US8250348B2 (en) | 2005-05-19 | 2012-08-21 | International Business Machines Corporation | Methods and apparatus for dynamically switching processor mode |
| US20070030277A1 (en) | 2005-08-08 | 2007-02-08 | Via Technologies, Inc. | Method for processing vertex, triangle, and pixel graphics data packets |
| US7659899B2 (en) | 2005-08-08 | 2010-02-09 | Via Technologies, Inc. | System and method to manage data processing stages of a logical graphics pipeline |
| US20070074008A1 (en) | 2005-09-28 | 2007-03-29 | Donofrio David D | Mixed mode floating-point pipeline with extended functions |
| US8004531B2 (en) | 2005-10-14 | 2011-08-23 | Via Technologies, Inc. | Multiple graphics processor systems and methods |
| US7616206B1 (en) | 2006-06-16 | 2009-11-10 | Nvidia Corporation | Efficient multi-chip GPU |
| US7467280B2 (en) | 2006-07-05 | 2008-12-16 | International Business Machines Corporation | Method for reconfiguring cache memory based on at least analysis of heat generated during runtime, at least by associating an access bit with a cache line and associating a granularity bit with a cache line in level-2 cache |
| US20080030510A1 (en) | 2006-08-02 | 2008-02-07 | Xgi Technology Inc. | Multi-GPU rendering system |
| US7620793B1 (en) | 2006-08-28 | 2009-11-17 | Nvidia Corporation | Mapping memory partitions to virtual memory pages |
| US7327289B1 (en) | 2006-09-20 | 2008-02-05 | Intel Corporation | Data-modifying run length encoder to avoid data expansion |
| US20080071851A1 (en) * | 2006-09-20 | 2008-03-20 | Ronen Zohar | Instruction and logic for performing a dot-product operation |
| US8122078B2 (en) | 2006-10-06 | 2012-02-21 | Calos Fund, LLC | Processor with enhanced combined-arithmetic capability |
| US20080086598A1 (en) | 2006-10-10 | 2008-04-10 | Maron William A | System and method for establishing cache priority for critical data structures of an application |
| US20080189487A1 (en) | 2007-02-06 | 2008-08-07 | Arm Limited | Control of cache transactions |
| US8781110B2 (en) | 2007-06-30 | 2014-07-15 | Intel Corporation | Unified system architecture for elliptic-curve cryptography |
| US7783859B2 (en) | 2007-07-12 | 2010-08-24 | Qnx Software Systems Gmbh & Co. Kg | Processing system implementing variable page size memory organization |
| US8990505B1 (en) | 2007-09-21 | 2015-03-24 | Marvell International Ltd. | Cache memory bank selection |
| DE112008003643A5 (de) | 2007-11-17 | 2010-10-28 | Krass, Maren | Rekonfigurierbare Fliesskomma- und Bit- ebenen Datenverarbeitungseinheit |
| US8106914B2 (en) | 2007-12-07 | 2012-01-31 | Nvidia Corporation | Fused multiply-add functional unit |
| US7941633B2 (en) | 2007-12-18 | 2011-05-10 | International Business Machines Corporation | Hash optimization system and method |
| US7870339B2 (en) | 2008-01-11 | 2011-01-11 | International Business Machines Corporation | Extract cache attribute facility and instruction therefore |
| US20090190432A1 (en) | 2008-01-28 | 2009-07-30 | Christoph Bilger | DRAM with Page Access |
| US8429351B1 (en) | 2008-03-28 | 2013-04-23 | Emc Corporation | Techniques for determining an amount of data to prefetch |
| US8146064B2 (en) | 2008-04-04 | 2012-03-27 | International Business Machines Corporation | Dynamically controlling a prefetching range of a software controlled cache |
| US8078833B2 (en) | 2008-05-29 | 2011-12-13 | Axis Semiconductor, Inc. | Microprocessor with highly configurable pipeline and executional unit internal hierarchal structures, optimizable for different types of computational functions |
| US7945768B2 (en) | 2008-06-05 | 2011-05-17 | Motorola Mobility, Inc. | Method and apparatus for nested instruction looping using implicit predicates |
| US8340280B2 (en) | 2008-06-13 | 2012-12-25 | Intel Corporation | Using a single instruction multiple data (SIMD) instruction to speed up galois counter mode (GCM) computations |
| US8041856B2 (en) * | 2008-09-30 | 2011-10-18 | Lsi Corporation | Skip based control logic for first in first out buffer |
| US8219757B2 (en) | 2008-09-30 | 2012-07-10 | Intel Corporation | Apparatus and method for low touch cache management |
| US20100162247A1 (en) | 2008-12-19 | 2010-06-24 | Adam Welc | Methods and systems for transactional nested parallelism |
| US20100185816A1 (en) | 2009-01-21 | 2010-07-22 | Sauber William F | Multiple Cache Line Size |
| US8266409B2 (en) | 2009-03-03 | 2012-09-11 | Qualcomm Incorporated | Configurable cache and method to configure same |
| US8108612B2 (en) | 2009-05-15 | 2012-01-31 | Microsoft Corporation | Location updates for a distributed data store |
| US8566801B2 (en) | 2009-05-22 | 2013-10-22 | International Business Machines Corporation | Concurrent static single assignment for general barrier synchronized parallel programs |
| US8819359B2 (en) | 2009-06-29 | 2014-08-26 | Oracle America, Inc. | Hybrid interleaving in memory modules by interleaving physical addresses for a page across ranks in a memory module |
| US8352945B2 (en) | 2009-08-11 | 2013-01-08 | International Business Machines Corporation | System, method, and apparatus for scan-sharing for business intelligence queries in an in-memory database |
| US8615637B2 (en) | 2009-09-10 | 2013-12-24 | Advanced Micro Devices, Inc. | Systems and methods for processing memory requests in a multi-processor system using a probe engine |
| US8364739B2 (en) | 2009-09-30 | 2013-01-29 | International Business Machines Corporation | Sparse matrix-vector multiplication on graphics processor units |
| US8713294B2 (en) | 2009-11-13 | 2014-04-29 | International Business Machines Corporation | Heap/stack guard pages using a wakeup unit |
| US8669990B2 (en) | 2009-12-31 | 2014-03-11 | Intel Corporation | Sharing resources between a CPU and GPU |
| US8677613B2 (en) | 2010-05-20 | 2014-03-25 | International Business Machines Corporation | Enhanced modularity in heterogeneous 3D stacks |
| US8812575B2 (en) | 2010-07-06 | 2014-08-19 | Silminds, Llc, Egypt | Decimal floating-point square-root unit using Newton-Raphson iterations |
| US8982140B2 (en) | 2010-09-24 | 2015-03-17 | Nvidia Corporation | Hierarchical memory addressing |
| US9965395B2 (en) | 2010-09-28 | 2018-05-08 | Texas Instruments Incorporated | Memory attribute sharing between differing cache levels of multilevel cache |
| US8488055B2 (en) | 2010-09-30 | 2013-07-16 | Apple Inc. | Flash synchronization using image sensor interface timing signal |
| US8745111B2 (en) | 2010-11-16 | 2014-06-03 | Apple Inc. | Methods and apparatuses for converting floating point representations |
| CN102033985A (zh) * | 2010-11-24 | 2011-04-27 | 南京理工大学 | 基于*-矩阵算法的高效时域电磁仿真方法 |
| US8847965B2 (en) | 2010-12-03 | 2014-09-30 | The University Of North Carolina At Chapel Hill | Methods, systems, and computer readable media for fast geometric sound propagation using visibility computations |
| CN102141976B (zh) * | 2011-01-10 | 2013-08-14 | 中国科学院软件研究所 | 稀疏矩阵的对角线数据存储方法及基于该方法的SpMV实现方法 |
| GB2488985A (en) | 2011-03-08 | 2012-09-19 | Advanced Risc Mach Ltd | Mixed size data processing operation with integrated operand conversion instructions |
| US8862653B2 (en) * | 2011-04-26 | 2014-10-14 | University Of South Carolina | System and method for sparse matrix vector multiplication processing |
| FR2974645A1 (fr) | 2011-04-28 | 2012-11-02 | Kalray | Operateur de multiplication et addition fusionnees a precision mixte |
| US9501392B1 (en) | 2011-05-12 | 2016-11-22 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Management of a non-volatile memory module |
| JP5813380B2 (ja) | 2011-06-03 | 2015-11-17 | 株式会社東芝 | 半導体記憶装置 |
| US9529712B2 (en) | 2011-07-26 | 2016-12-27 | Nvidia Corporation | Techniques for balancing accesses to memory having different memory types |
| US9727336B2 (en) | 2011-09-16 | 2017-08-08 | International Business Machines Corporation | Fine-grained instruction enablement at sub-function granularity based on an indicated subrange of registers |
| US20130099946A1 (en) | 2011-10-21 | 2013-04-25 | International Business Machines Corporation | Data Compression Utilizing Variable and Limited Length Codes |
| US8935478B2 (en) | 2011-11-01 | 2015-01-13 | International Business Machines Corporation | Variable cache line size management |
| US20130141442A1 (en) | 2011-12-06 | 2013-06-06 | John W. Brothers | Method and apparatus for multi-chip processing |
| US20130148947A1 (en) | 2011-12-13 | 2013-06-13 | Ati Technologies Ulc | Video player with multiple grpahics processors |
| US9960917B2 (en) | 2011-12-22 | 2018-05-01 | Intel Corporation | Matrix multiply accumulate instruction |
| US20140195783A1 (en) * | 2011-12-29 | 2014-07-10 | Krishnan Karthikeyan | Dot product processors, methods, systems, and instructions |
| US20130185515A1 (en) | 2012-01-16 | 2013-07-18 | Qualcomm Incorporated | Utilizing Negative Feedback from Unexpected Miss Addresses in a Hardware Prefetcher |
| WO2013119226A1 (en) | 2012-02-08 | 2013-08-15 | Intel Corporation | Dynamic cpu gpu load balancing using power |
| US20130218938A1 (en) | 2012-02-17 | 2013-08-22 | Qualcomm Incorporated | Floating-point adder with operand shifting based on a predicted exponent difference |
| US9036710B2 (en) * | 2012-03-08 | 2015-05-19 | Blackberry Limited | Unified transform coefficient encoding and decoding |
| US8775762B2 (en) | 2012-05-07 | 2014-07-08 | Advanced Micro Devices, Inc. | Method and apparatus for batching memory requests |
| US8892619B2 (en) | 2012-07-24 | 2014-11-18 | The Board Of Trustees Of The Leland Stanford Junior University | Floating-point multiply-add unit using cascade design |
| US9128845B2 (en) | 2012-07-30 | 2015-09-08 | Hewlett-Packard Development Company, L.P. | Dynamically partition a volatile memory for a cache and a memory partition |
| CN103581052B (zh) | 2012-08-02 | 2017-07-21 | 华为技术有限公司 | 一种数据处理方法、路由器及ndn系统 |
| US9298456B2 (en) | 2012-08-21 | 2016-03-29 | Apple Inc. | Mechanism for performing speculative predicated instructions |
| US20140075163A1 (en) | 2012-09-07 | 2014-03-13 | Paul N. Loewenstein | Load-monitor mwait |
| US9134954B2 (en) | 2012-09-10 | 2015-09-15 | Qualcomm Incorporated | GPU memory buffer pre-fetch and pre-back signaling to avoid page-fault |
| US10742475B2 (en) | 2012-12-05 | 2020-08-11 | Origin Wireless, Inc. | Method, apparatus, and system for object tracking sensing using broadcasting |
| US9317482B2 (en) * | 2012-10-14 | 2016-04-19 | Microsoft Technology Licensing, Llc | Universal FPGA/ASIC matrix-vector multiplication architecture |
| US9152382B2 (en) | 2012-10-31 | 2015-10-06 | Intel Corporation | Reducing power consumption in a fused multiply-add (FMA) unit responsive to input data values |
| US11150721B2 (en) | 2012-11-07 | 2021-10-19 | Nvidia Corporation | Providing hints to an execution unit to prepare for predicted subsequent arithmetic operations |
| US9183144B2 (en) | 2012-12-14 | 2015-11-10 | Intel Corporation | Power gating a portion of a cache memory |
| US20140173203A1 (en) | 2012-12-18 | 2014-06-19 | Andrew T. Forsyth | Block Memory Engine |
| US9317251B2 (en) | 2012-12-31 | 2016-04-19 | Nvidia Corporation | Efficient correction of normalizer shift amount errors in fused multiply add operations |
| US9971710B2 (en) | 2013-02-07 | 2018-05-15 | Microsoft Technology Licensing, Llc | Optimizing data transfers between heterogeneous memory arenas |
| US10133677B2 (en) | 2013-03-14 | 2018-11-20 | Nvidia Corporation | Opportunistic migration of memory pages in a unified virtual memory system |
| US9940286B2 (en) | 2013-03-14 | 2018-04-10 | Nvidia Corporation | PCIE traffic tracking hardware in a unified virtual memory system |
| US9478066B2 (en) | 2013-03-14 | 2016-10-25 | Nvidia Corporation | Consistent vertex snapping for variable resolution rendering |
| US9525586B2 (en) | 2013-03-15 | 2016-12-20 | Intel Corporation | QoS based binary translation and application streaming |
| GB2514397B (en) | 2013-05-23 | 2017-10-11 | Linear Algebra Tech Ltd | Corner detection |
| US9378127B2 (en) | 2013-06-21 | 2016-06-28 | Intel Corporation | Dynamic memory page policy |
| US9264066B2 (en) | 2013-07-30 | 2016-02-16 | Apple Inc. | Type conversion using floating-point unit |
| US9946666B2 (en) | 2013-08-06 | 2018-04-17 | Nvidia Corporation | Coalescing texture access and load/store operations |
| US9092345B2 (en) | 2013-08-08 | 2015-07-28 | Arm Limited | Data processing systems |
| US9710380B2 (en) | 2013-08-29 | 2017-07-18 | Intel Corporation | Managing shared cache by multi-core processor |
| TWI676898B (zh) | 2013-12-09 | 2019-11-11 | 安然國際科技有限公司 | 分散式記憶體磁碟群集儲存系統運作方法 |
| US9461667B2 (en) | 2013-12-30 | 2016-10-04 | Samsung Electronics Co., Ltd. | Rounding injection scheme for floating-point to integer conversion |
| US20150193358A1 (en) | 2014-01-06 | 2015-07-09 | Nvidia Corporation | Prioritized Memory Reads |
| US10528357B2 (en) | 2014-01-17 | 2020-01-07 | L3 Technologies, Inc. | Web-based recorder configuration utility |
| US20150205724A1 (en) | 2014-01-20 | 2015-07-23 | Honeywell International Inc. | System and method of cache partitioning for processors with limited cached memory pools |
| KR102100161B1 (ko) | 2014-02-04 | 2020-04-14 | 삼성전자주식회사 | Gpu 데이터 캐싱 방법 및 그에 따른 데이터 프로세싱 시스템 |
| US9391771B2 (en) | 2014-02-06 | 2016-07-12 | Empire Technology Development Llc | Server-client secret generation with cached data |
| US9275429B2 (en) | 2014-02-17 | 2016-03-01 | Qualcomm Incorporated | Device hang detection and recovery |
| KR20150106132A (ko) | 2014-03-11 | 2015-09-21 | 삼성전자주식회사 | 전자 장치의 캐시 메모리 제어 방법 및 장치 |
| US20150268963A1 (en) | 2014-03-23 | 2015-09-24 | Technion Research & Development Foundation Ltd. | Execution of data-parallel programs on coarse-grained reconfigurable architecture hardware |
| US9436972B2 (en) | 2014-03-27 | 2016-09-06 | Intel Corporation | System coherency in a distributed graphics processor hierarchy |
| EP2937794B1 (en) | 2014-04-22 | 2016-08-17 | DataVard GmbH | Method and system for archiving digital data |
| US9673998B2 (en) | 2014-05-15 | 2017-06-06 | Futurewei Technologies, Inc. | Differential cache for representational state transfer (REST) API |
| JP6248808B2 (ja) | 2014-05-22 | 2017-12-20 | 富士通株式会社 | 情報処理装置、情報処理システム、情報処理装置の制御方法、及び、情報処理装置の制御プログラム |
| KR102192956B1 (ko) | 2014-06-23 | 2020-12-18 | 삼성전자주식회사 | 디스플레이 장치 및 그 제어 방법 |
| US10061592B2 (en) | 2014-06-27 | 2018-08-28 | Samsung Electronics Co., Ltd. | Architecture and execution for efficient mixed precision computations in single instruction multiple data/thread (SIMD/T) devices |
| US9520192B2 (en) | 2014-06-30 | 2016-12-13 | Intel Corporation | Resistive memory write operation with merged reset |
| US20150378920A1 (en) | 2014-06-30 | 2015-12-31 | John G. Gierach | Graphics data pre-fetcher for last level caches |
| US10223333B2 (en) | 2014-08-29 | 2019-03-05 | Nvidia Corporation | Performing multi-convolution operations in a parallel processing system |
| KR102263326B1 (ko) | 2014-09-18 | 2021-06-09 | 삼성전자주식회사 | 그래픽 프로세싱 유닛 및 이를 이용한 그래픽 데이터 처리 방법 |
| US20160092118A1 (en) | 2014-09-26 | 2016-03-31 | Intel Corporation | Memory write management in a computer system |
| US9928076B2 (en) | 2014-09-26 | 2018-03-27 | Intel Corporation | Method and apparatus for unstructured control flow for SIMD execution engine |
| JP2016091242A (ja) | 2014-10-31 | 2016-05-23 | 富士通株式会社 | キャッシュメモリ、キャッシュメモリへのアクセス方法及び制御プログラム |
| US20160124709A1 (en) | 2014-11-04 | 2016-05-05 | International Business Machines Corporation | Fast, energy-efficient exponential computations in simd architectures |
| US10282227B2 (en) | 2014-11-18 | 2019-05-07 | Intel Corporation | Efficient preemption for graphics processors |
| US9898411B2 (en) | 2014-12-14 | 2018-02-20 | Via Alliance Semiconductor Co., Ltd. | Cache memory budgeted by chunks based on memory access type |
| EP3129890B1 (en) | 2014-12-14 | 2019-08-14 | VIA Alliance Semiconductor Co., Ltd. | Set associative cache memory with heterogeneous replacement policy |
| KR101817847B1 (ko) | 2014-12-14 | 2018-02-21 | 비아 얼라이언스 세미컨덕터 씨오., 엘티디. | 메모리 접근 타입에 기초한 통로에 의해 버짓화된 캐시 메모리 |
| FR3030846B1 (fr) * | 2014-12-23 | 2017-12-29 | Commissariat Energie Atomique | Representation semantique du contenu d'une image |
| US9304835B1 (en) * | 2014-12-31 | 2016-04-05 | International Business Machines Corporation | Optimized system for analytics (graphs and sparse matrices) operations |
| US20160255169A1 (en) | 2015-02-27 | 2016-09-01 | Futurewei Technologies, Inc. | Method and system for smart object eviction for proxy cache |
| US10002455B2 (en) | 2015-04-20 | 2018-06-19 | Intel Corporation | Optimized depth buffer cache apparatus and method |
| US9626299B2 (en) | 2015-05-01 | 2017-04-18 | Intel Corporation | Changing a hash function based on a conflict ratio associated with cache sets |
| US9804666B2 (en) | 2015-05-26 | 2017-10-31 | Samsung Electronics Co., Ltd. | Warp clustering |
| US20160378465A1 (en) * | 2015-06-23 | 2016-12-29 | Intel Corporation | Efficient sparse array handling in a processor |
| GB2540761B (en) | 2015-07-23 | 2017-12-06 | Advanced Risc Mach Ltd | Cache usage estimation |
| US20170039144A1 (en) | 2015-08-07 | 2017-02-09 | Intel Corporation | Loading data using sub-thread information in a processor |
| CN105068787A (zh) * | 2015-08-28 | 2015-11-18 | 华南理工大学 | 一种稀疏矩阵向量乘法的异构并行计算方法 |
| US10423354B2 (en) | 2015-09-23 | 2019-09-24 | Advanced Micro Devices, Inc. | Selective data copying between memory modules |
| US10423411B2 (en) * | 2015-09-26 | 2019-09-24 | Intel Corporation | Data element comparison processors, methods, systems, and instructions |
| US10042749B2 (en) | 2015-11-10 | 2018-08-07 | International Business Machines Corporation | Prefetch insensitive transactional memory |
| US10387309B2 (en) | 2015-10-14 | 2019-08-20 | Elastifile Ltd. | High-performance distributed caching |
| KR101843243B1 (ko) * | 2015-10-30 | 2018-03-29 | 세종대학교산학협력단 | 제로값을 피연산자로 갖는 연산자에 대한 연산을 스킵하는 연산 방법 및 연산 장치 |
| US9558156B1 (en) * | 2015-11-24 | 2017-01-31 | International Business Machines Corporation | Sparse matrix multiplication using a single field programmable gate array module |
| CN106886429B (zh) | 2015-12-16 | 2020-11-06 | 华为技术有限公司 | 一种加载驱动程序的方法和服务器 |
| US20170177336A1 (en) | 2015-12-22 | 2017-06-22 | Intel Corporation | Hardware cancellation monitor for floating point operations |
| US9996320B2 (en) | 2015-12-23 | 2018-06-12 | Intel Corporation | Fused multiply-add (FMA) low functional unit |
| KR102604737B1 (ko) | 2016-01-11 | 2023-11-22 | 삼성전자주식회사 | 가속 구조를 생성하는 방법 및 장치 |
| US10762164B2 (en) * | 2016-01-20 | 2020-09-01 | Cambricon Technologies Corporation Limited | Vector and matrix computing device |
| US20170214930A1 (en) | 2016-01-26 | 2017-07-27 | Sandia Corporation | Gpu-assisted lossless data compression |
| US9778871B1 (en) | 2016-03-27 | 2017-10-03 | Qualcomm Incorporated | Power-reducing memory subsystem having a system cache and local resource management |
| US20170308800A1 (en) | 2016-04-26 | 2017-10-26 | Smokescreen Intelligence, LLC | Interchangeable Artificial Intelligence Perception Systems and Methods |
| CN107315718B (zh) * | 2016-04-26 | 2020-08-21 | 中科寒武纪科技股份有限公司 | 一种用于执行向量内积运算的装置和方法 |
| US10509732B2 (en) | 2016-04-27 | 2019-12-17 | Advanced Micro Devices, Inc. | Selecting cache aging policy for prefetches based on cache test regions |
| CN107346148A (zh) | 2016-05-04 | 2017-11-14 | 杭州海存信息技术有限公司 | 基于背面查找表的仿真处理器 |
| US9846579B1 (en) | 2016-06-13 | 2017-12-19 | Apple Inc. | Unified integer and floating-point compare circuitry |
| US10176099B2 (en) | 2016-07-11 | 2019-01-08 | Intel Corporation | Using data pattern to mark cache lines as invalid |
| JP6665720B2 (ja) | 2016-07-14 | 2020-03-13 | 富士通株式会社 | 情報処理装置、コンパイルプログラム、コンパイル方法、およびキャッシュ制御方法 |
| US20180018266A1 (en) | 2016-07-18 | 2018-01-18 | Advanced Micro Devices, Inc. | Stride prefetcher for inconsistent strides |
| US10091904B2 (en) | 2016-07-22 | 2018-10-02 | Intel Corporation | Storage sled for data center |
| US10242311B2 (en) * | 2016-08-11 | 2019-03-26 | Vivante Corporation | Zero coefficient skipping convolution neural network engine |
| US10528864B2 (en) | 2016-08-11 | 2020-01-07 | Nvidia Corporation | Sparse convolutional neural network accelerator |
| US10891538B2 (en) * | 2016-08-11 | 2021-01-12 | Nvidia Corporation | Sparse convolutional neural network accelerator |
| US10467195B2 (en) | 2016-09-06 | 2019-11-05 | Samsung Electronics Co., Ltd. | Adaptive caching replacement manager with dynamic updating granulates and partitions for shared flash-based storage system |
| US20180107602A1 (en) | 2016-10-13 | 2018-04-19 | Intel Corporation | Latency and Bandwidth Efficiency Improvement for Read Modify Write When a Read Operation is Requested to a Partially Modified Write Only Cacheline |
| US11315018B2 (en) | 2016-10-21 | 2022-04-26 | Nvidia Corporation | Systems and methods for pruning neural networks for resource efficient inference |
| US10216479B2 (en) | 2016-12-06 | 2019-02-26 | Arm Limited | Apparatus and method for performing arithmetic operations to accumulate floating-point numbers |
| US10452551B2 (en) | 2016-12-12 | 2019-10-22 | Intel Corporation | Programmable memory prefetcher for prefetching multiple cache lines based on data in a prefetch engine control register |
| CN106683036A (zh) | 2016-12-12 | 2017-05-17 | 中国航空工业集团公司西安航空计算技术研究所 | 一种面向gpu高效绘制的帧缓冲区存储编码方法 |
| KR20180069461A (ko) | 2016-12-15 | 2018-06-25 | 삼성전자주식회사 | 가속 구조를 생성하는 방법 및 장치 |
| US20180173623A1 (en) | 2016-12-21 | 2018-06-21 | Qualcomm Incorporated | Reducing or avoiding buffering of evicted cache data from an uncompressed cache memory in a compressed memory system to avoid stalling write operations |
| US20180183577A1 (en) | 2016-12-28 | 2018-06-28 | Intel Corporation | Techniques for secure message authentication with unified hardware acceleration |
| US10558575B2 (en) | 2016-12-30 | 2020-02-11 | Intel Corporation | Processors, methods, and systems with a configurable spatial accelerator |
| US10146738B2 (en) * | 2016-12-31 | 2018-12-04 | Intel Corporation | Hardware accelerator architecture for processing very-sparse and hyper-sparse matrix data |
| US20180210836A1 (en) | 2017-01-24 | 2018-07-26 | Microsoft Technology Licensing, Llc | Thermal and reliability based cache slice migration |
| US10430912B2 (en) | 2017-02-14 | 2019-10-01 | Qualcomm Incorporated | Dynamic shader instruction nullification for graphics processing |
| GB2560159B (en) | 2017-02-23 | 2019-12-25 | Advanced Risc Mach Ltd | Widening arithmetic in a data processing apparatus |
| US10409887B1 (en) * | 2017-02-28 | 2019-09-10 | Ambarella, Inc. | Generalized dot product for computer vision applications |
| KR102499396B1 (ko) * | 2017-03-03 | 2023-02-13 | 삼성전자 주식회사 | 뉴럴 네트워크 장치 및 뉴럴 네트워크 장치의 동작 방법 |
| US10303602B2 (en) | 2017-03-31 | 2019-05-28 | Advanced Micro Devices, Inc. | Preemptive cache management policies for processing units |
| US10229059B2 (en) | 2017-03-31 | 2019-03-12 | Intel Corporation | Dynamic fill policy for a shared cache |
| US10423415B2 (en) | 2017-04-01 | 2019-09-24 | Intel Corporation | Hierarchical general register file (GRF) for execution block |
| US10503652B2 (en) | 2017-04-01 | 2019-12-10 | Intel Corporation | Sector cache for compression |
| US10861216B2 (en) | 2017-04-07 | 2020-12-08 | Intel Corporation | Ray tracing apparatus and method for memory access and register operations |
| US10304421B2 (en) | 2017-04-07 | 2019-05-28 | Intel Corporation | Apparatus and method for remote display and content protection in a virtualized graphics processing environment |
| US10346944B2 (en) * | 2017-04-09 | 2019-07-09 | Intel Corporation | Machine learning sparse computation mechanism |
| US10403003B2 (en) * | 2017-04-24 | 2019-09-03 | Intel Corporation | Compression mechanism |
| US10409614B2 (en) | 2017-04-24 | 2019-09-10 | Intel Corporation | Instructions having support for floating point and integer data types in the same register |
| US10824938B2 (en) * | 2017-04-24 | 2020-11-03 | Intel Corporation | Specialized fixed function hardware for efficient convolution |
| US10186011B2 (en) * | 2017-04-28 | 2019-01-22 | Intel Corporation | Programmable coarse grained and sparse matrix compute hardware with advanced scheduling |
| US10726514B2 (en) | 2017-04-28 | 2020-07-28 | Intel Corporation | Compute optimizations for low precision machine learning operations |
| US10474458B2 (en) | 2017-04-28 | 2019-11-12 | Intel Corporation | Instructions and logic to perform floating-point and integer operations for machine learning |
| US11488008B2 (en) | 2017-05-05 | 2022-11-01 | Intel Corporation | Hardware implemented point to point communication primitives for machine learning |
| US10776699B2 (en) * | 2017-05-05 | 2020-09-15 | Intel Corporation | Optimized compute hardware for machine learning operations |
| US10338919B2 (en) | 2017-05-08 | 2019-07-02 | Nvidia Corporation | Generalized acceleration of matrix multiply accumulate operations |
| US20180336136A1 (en) | 2017-05-17 | 2018-11-22 | Qualcomm Incorporated | Input/output-coherent Look-ahead Cache Access |
| US10102015B1 (en) | 2017-06-22 | 2018-10-16 | Microsoft Technology Licensing, Llc | Just in time GPU executed program cross compilation |
| US10282299B2 (en) | 2017-06-23 | 2019-05-07 | Cavium, Llc | Managing cache partitions based on cache usage information |
| US10969740B2 (en) | 2017-06-27 | 2021-04-06 | Nvidia Corporation | System and method for near-eye light field rendering for wide field of view interactive three-dimensional computer graphics |
| US10984049B2 (en) | 2017-06-27 | 2021-04-20 | Nvidia Corporation | Performing traversal stack compression |
| US10990648B2 (en) | 2017-08-07 | 2021-04-27 | Intel Corporation | System and method for an optimized winograd convolution accelerator |
| US10394456B2 (en) | 2017-08-23 | 2019-08-27 | Micron Technology, Inc. | On demand memory page size |
| US11232531B2 (en) | 2017-08-29 | 2022-01-25 | Intel Corporation | Method and apparatus for efficient loop processing in a graphics hardware front end |
| US10691572B2 (en) | 2017-08-30 | 2020-06-23 | Nvidia Corporation | Liveness as a factor to evaluate memory vulnerability to soft errors |
| US10725740B2 (en) * | 2017-08-31 | 2020-07-28 | Qualcomm Incorporated | Providing efficient multiplication of sparse matrices in matrix-processor-based devices |
| US10503507B2 (en) * | 2017-08-31 | 2019-12-10 | Nvidia Corporation | Inline data inspection for workload simplification |
| US10943171B2 (en) | 2017-09-01 | 2021-03-09 | Facebook, Inc. | Sparse neural network training optimization |
| US10503520B2 (en) | 2017-09-26 | 2019-12-10 | Intel Corporation | Automatic waking of power domains for graphics configuration requests |
| US10782904B2 (en) | 2017-09-28 | 2020-09-22 | Intel Corporation | Host computing arrangement, remote server arrangement, storage system and methods thereof |
| US10692244B2 (en) | 2017-10-06 | 2020-06-23 | Nvidia Corporation | Learning based camera pose estimation from images of an environment |
| US11222256B2 (en) * | 2017-10-17 | 2022-01-11 | Xilinx, Inc. | Neural network processing system having multiple processors and a neural network accelerator |
| GB2569098B (en) | 2017-10-20 | 2020-01-08 | Graphcore Ltd | Combining states of multiple threads in a multi-threaded processor |
| GB2569844B (en) | 2017-10-20 | 2021-01-06 | Graphcore Ltd | Sending data off-chip |
| GB2569271B (en) | 2017-10-20 | 2020-05-13 | Graphcore Ltd | Synchronization with a host processor |
| GB2569274B (en) | 2017-10-20 | 2020-07-15 | Graphcore Ltd | Synchronization amongst processor tiles |
| US11651223B2 (en) * | 2017-10-27 | 2023-05-16 | Baidu Usa Llc | Systems and methods for block-sparse recurrent neural networks |
| KR102414047B1 (ko) | 2017-10-30 | 2022-06-29 | 에스케이하이닉스 주식회사 | 통합 메모리 디바이스 및 그의 동작 방법 |
| US10762137B1 (en) | 2017-11-15 | 2020-09-01 | Amazon Technologies, Inc. | Page table search engine |
| US10762620B2 (en) | 2017-11-27 | 2020-09-01 | Nvidia Corporation | Deep-learning method for separating reflection and transmission images visible at a semi-reflective surface in a computer image of a real-world scene |
| US11977974B2 (en) | 2017-11-30 | 2024-05-07 | International Business Machines Corporation | Compression of fully connected / recurrent layers of deep network(s) through enforcing spatial locality to weight matrices and effecting frequency compression |
| US10579535B2 (en) | 2017-12-15 | 2020-03-03 | Intel Corporation | Defragmented and efficient micro-operation cache |
| EP3719712B1 (en) * | 2017-12-27 | 2022-09-07 | Cambricon Technologies Corporation Limited | Integrated circuit chip device |
| US10482156B2 (en) * | 2017-12-29 | 2019-11-19 | Facebook, Inc. | Sparsity-aware hardware accelerators |
| KR102533241B1 (ko) | 2018-01-25 | 2023-05-16 | 삼성전자주식회사 | 적응적으로 캐시 일관성을 제어하도록 구성된 이종 컴퓨팅 시스템 |
| US10970080B2 (en) * | 2018-02-08 | 2021-04-06 | Marvell Asia Pte, Ltd. | Systems and methods for programmable hardware architecture for machine learning |
| CN111788583A (zh) * | 2018-02-09 | 2020-10-16 | 渊慧科技有限公司 | 连续稀疏性模式神经网络 |
| US10755201B2 (en) | 2018-02-14 | 2020-08-25 | Lucid Circuit, Inc. | Systems and methods for data collection and analysis at the edge |
| JP2019148969A (ja) * | 2018-02-27 | 2019-09-05 | 富士通株式会社 | 行列演算装置、行列演算方法および行列演算プログラム |
| US20190278600A1 (en) | 2018-03-09 | 2019-09-12 | Nvidia Corporation | Tiled compressed sparse matrix format |
| US20190278593A1 (en) | 2018-03-09 | 2019-09-12 | Nvidia Corporation | Accelerating linear algebra kernels for any processor architecture |
| US10678508B2 (en) | 2018-03-23 | 2020-06-09 | Amazon Technologies, Inc. | Accelerated quantized multiply-and-add operations |
| US10572568B2 (en) | 2018-03-28 | 2020-02-25 | Intel Corporation | Accelerator for sparse-dense matrix multiplication |
| WO2019197661A1 (en) | 2018-04-13 | 2019-10-17 | Koninklijke Kpn N.V. | Frame-level super-resolution-based video coding |
| US11010092B2 (en) | 2018-05-09 | 2021-05-18 | Micron Technology, Inc. | Prefetch signaling in memory system or sub-system |
| US10572409B1 (en) * | 2018-05-10 | 2020-02-25 | Xilinx, Inc. | Sparse matrix processing circuitry |
| US11269805B2 (en) | 2018-05-15 | 2022-03-08 | Intel Corporation | Signal pathways in multi-tile processors |
| GB2574060B (en) * | 2018-05-25 | 2022-11-23 | Myrtle Software Ltd | Processing matrix vector multiplication |
| US10838864B2 (en) | 2018-05-30 | 2020-11-17 | Advanced Micro Devices, Inc. | Prioritizing local and remote memory access in a non-uniform memory access architecture |
| US10699468B2 (en) | 2018-06-09 | 2020-06-30 | Adshir Ltd. | Method for non-planar specular reflections in hybrid ray tracing |
| US20190392287A1 (en) * | 2018-06-22 | 2019-12-26 | Samsung Electronics Co., Ltd. | Neural processor |
| US10620951B2 (en) | 2018-06-22 | 2020-04-14 | Intel Corporation | Matrix multiplication acceleration of sparse matrices using column folding and squeezing |
| EP3690679A4 (en) | 2018-08-06 | 2021-02-17 | Huawei Technologies Co., Ltd. | MATRIX PROCESSING PROCESS AND APPARATUS, AND LOGIC CIRCUIT |
| EP3608828A1 (de) * | 2018-08-09 | 2020-02-12 | Olympus Soft Imaging Solutions GmbH | Verfahren zur bereitstellung eines auswertungsmittels für wenigstens ein optisches anwendungssystem einer mikroskopischen anwendungstechnologie |
| KR20200022118A (ko) | 2018-08-22 | 2020-03-03 | 에스케이하이닉스 주식회사 | 데이터 저장 장치 및 그 동작 방법 |
| US20190042457A1 (en) | 2018-08-22 | 2019-02-07 | Intel Corporation | Cache (partition) size determination method and apparatus |
| US11833681B2 (en) * | 2018-08-24 | 2023-12-05 | Nvidia Corporation | Robotic control system |
| US10846241B2 (en) | 2018-08-29 | 2020-11-24 | Vmware, Inc. | Score-based cache admission and eviction |
| US11093248B2 (en) | 2018-09-10 | 2021-08-17 | International Business Machines Corporation | Prefetch queue allocation protection bubble in a processor |
| US10817426B2 (en) | 2018-09-24 | 2020-10-27 | Arm Limited | Prefetching techniques |
| US10853067B2 (en) | 2018-09-27 | 2020-12-01 | Intel Corporation | Computer processor for higher precision computations using a mixed-precision decomposition of operations |
| US11294626B2 (en) | 2018-09-27 | 2022-04-05 | Intel Corporation | Floating-point dynamic range expansion |
| EP3857387A4 (en) | 2018-09-28 | 2022-05-18 | INTEL Corporation | ADDRESS TRANSLATION BUFFER TO IMPLEMENT AN ADAPTIVE PAGE SIZE |
| GB2578097B (en) | 2018-10-15 | 2021-02-17 | Advanced Risc Mach Ltd | Cache control circuitry and methods |
| US10768895B2 (en) * | 2018-11-08 | 2020-09-08 | Movidius Limited | Dot product calculators and methods of operating the same |
| US10963246B2 (en) | 2018-11-09 | 2021-03-30 | Intel Corporation | Systems and methods for performing 16-bit floating-point matrix dot product instructions |
| US11366663B2 (en) | 2018-11-09 | 2022-06-21 | Intel Corporation | Systems and methods for performing 16-bit floating-point vector dot product instructions |
| US20200175074A1 (en) | 2018-12-04 | 2020-06-04 | Vmware, Inc. | Tree structure aware cache eviction policy |
| US11893470B2 (en) | 2018-12-06 | 2024-02-06 | MIPS Tech, LLC | Neural network processing using specialized data representation |
| US11615307B2 (en) | 2018-12-06 | 2023-03-28 | MIPS Tech, LLC | Neural network data computation using mixed-precision |
| US20200202195A1 (en) | 2018-12-06 | 2020-06-25 | MIPS Tech, LLC | Neural network processing using mixed-precision data representation |
| GB2580151B (en) | 2018-12-21 | 2021-02-24 | Graphcore Ltd | Identifying processing units in a processor |
| US10832371B2 (en) | 2018-12-28 | 2020-11-10 | Intel Corporation | Unified architecture for BVH construction based on hardware pre-sorting and a parallel, reconfigurable clustering array |
| US10909741B2 (en) | 2018-12-28 | 2021-02-02 | Intel Corporation | Speculative execution of hit and intersection shaders on programmable ray tracing architectures |
| KR20200091623A (ko) * | 2019-01-23 | 2020-07-31 | 삼성전자주식회사 | 위노그라드 변환에 기반한 뉴럴 네트워크의 컨볼루션 연산을 수행하는 방법 및 장치 |
| US11106600B2 (en) | 2019-01-24 | 2021-08-31 | Advanced Micro Devices, Inc. | Cache replacement based on translation lookaside buffer evictions |
| US10725923B1 (en) | 2019-02-05 | 2020-07-28 | Arm Limited | Cache access detection and prediction |
| US10915461B2 (en) | 2019-03-05 | 2021-02-09 | International Business Machines Corporation | Multilevel cache eviction management |
| US11934342B2 (en) | 2019-03-15 | 2024-03-19 | Intel Corporation | Assistance for hardware prefetch in cache access |
| EP4024223A1 (en) | 2019-03-15 | 2022-07-06 | Intel Corporation | Systems and methods for cache optimization |
| CN113383310A (zh) | 2019-03-15 | 2021-09-10 | 英特尔公司 | 矩阵加速器架构内的脉动分解 |
| US20220180467A1 (en) | 2019-03-15 | 2022-06-09 | Intel Corporation | Systems and methods for updating memory side caches in a multi-gpu configuration |
| US11036642B2 (en) | 2019-04-26 | 2021-06-15 | Intel Corporation | Architectural enhancements for computing systems having artificial intelligence logic disposed locally to memory |
| US11675998B2 (en) | 2019-07-15 | 2023-06-13 | Meta Platforms Technologies, Llc | System and method for performing small channel count convolutions in energy-efficient input operand stationary accelerator |
| US11861761B2 (en) | 2019-11-15 | 2024-01-02 | Intel Corporation | Graphics processing unit processing and caching improvements |
| US11663746B2 (en) | 2019-11-15 | 2023-05-30 | Intel Corporation | Systolic arithmetic on sparse data |
| US11275561B2 (en) | 2019-12-12 | 2022-03-15 | International Business Machines Corporation | Mixed precision floating-point multiply-add operation |
| US11645145B2 (en) | 2019-12-16 | 2023-05-09 | Qualcomm Incorporated | Methods and apparatus to facilitate speculative page fault handling in a graphics processing unit |
| US20220100518A1 (en) | 2020-09-25 | 2022-03-31 | Advanced Micro Devices, Inc. | Compression metadata assisted computation |
| US20220197975A1 (en) | 2020-12-23 | 2022-06-23 | Intel Corporation | Apparatus and method for conjugate transpose and multiply |
| US20220335563A1 (en) | 2021-07-06 | 2022-10-20 | Intel Corporation | Graphics processing unit with network interfaces |
-
2020
- 2020-03-14 CN CN202080014231.1A patent/CN113383310A/zh active Pending
- 2020-03-14 JP JP2021547450A patent/JP7408671B2/ja active Active
- 2020-03-14 DE DE112020001249.2T patent/DE112020001249T5/de active Pending
- 2020-03-14 KR KR1020217025888A patent/KR20210135999A/ko unknown
- 2020-03-14 EP EP20718907.7A patent/EP3938888A1/en active Pending
- 2020-03-14 DE DE112020000846.0T patent/DE112020000846T5/de active Pending
- 2020-03-14 BR BR112021016138A patent/BR112021016138A2/pt unknown
- 2020-03-14 JP JP2021547288A patent/JP2022523760A/ja active Pending
- 2020-03-14 EP EP20718908.5A patent/EP3938889A1/en active Pending
- 2020-03-14 CN CN202110224132.2A patent/CN112905241B/zh active Active
- 2020-03-14 JP JP2021547452A patent/JP7423644B2/ja active Active
- 2020-03-14 WO PCT/US2020/022847 patent/WO2020190809A1/en active Application Filing
- 2020-03-14 BR BR112021016106A patent/BR112021016106A2/pt unknown
- 2020-03-14 KR KR1020217025943A patent/KR20210136994A/ko unknown
- 2020-03-14 CN CN202110214543.3A patent/CN112905240A/zh active Pending
- 2020-03-14 CN CN202080004209.9A patent/CN112534404A/zh active Pending
- 2020-03-14 WO PCT/US2020/022845 patent/WO2020190807A1/en active Application Filing
- 2020-03-14 CN CN202080004288.3A patent/CN112534405A/zh active Pending
- 2020-03-14 AU AU2020241262A patent/AU2020241262A1/en active Pending
- 2020-03-14 SG SG11202107290QA patent/SG11202107290QA/en unknown
- 2020-03-14 KR KR1020217025864A patent/KR20210135998A/ko unknown
- 2020-03-14 EP EP20718909.3A patent/EP3938890A1/en active Pending
- 2020-03-14 WO PCT/US2020/022846 patent/WO2020190808A1/en active Application Filing
- 2020-10-06 US US17/064,427 patent/US11113784B2/en active Active
- 2020-12-15 US US17/122,905 patent/US11842423B2/en active Active
-
2021
- 2021-06-03 US US17/303,654 patent/US11676239B2/en active Active
-
2023
- 2023-05-02 US US18/310,688 patent/US20230351543A1/en active Pending
-
2024
- 2024-01-18 JP JP2024006026A patent/JP2024036383A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018125250A1 (en) | 2016-12-31 | 2018-07-05 | Intel Corporation | Systems, methods, and apparatuses for heterogeneous computing |
| WO2018213636A1 (en) | 2017-05-17 | 2018-11-22 | Google Llc | Performing matrix multiplication in hardware |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7423644B2 (ja) | 行列アクセラレータアーキテクチャのためのスパース最適化 | |
| JP7414894B2 (ja) | ハイブリッド浮動小数点フォーマットのドット積累算命令を有するグラフィックスプロセッサ及びグラフィックス処理ユニット | |
| JP2024041918A (ja) | Socアーキテクチャの分解 | |
| EP4024223A1 (en) | Systems and methods for cache optimization | |
| US20230066626A1 (en) | Temporally amortized supersampling using a mixed precision convolutional neural network | |
| EP4109386A1 (en) | 64-bit two-dimensional block load with transpose | |
| WO2023079323A1 (en) | Temporally amortized supersampling using a kernel splatting network | |
| EP4177824A1 (en) | Motion vector refinement for temporally amortized supersampling | |
| EP4155900A1 (en) | Emulation of floating point calculation | |
| EP4109303A1 (en) | Using sparsity metadata to reduce systolic array power consumption | |
| EP4109252A1 (en) | Dynamically scalable and partitioned copy engine | |
| WO2022271230A1 (en) | Systolic array of arbitrary physical and logical depth | |
| WO2023081563A1 (en) | Combined denoising and upscaling network with importance sampling in a graphics environment | |
| WO2022271228A1 (en) | Register file for systolic array | |
| CN116091300A (zh) | 样本分布知情去噪和渲染 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220705 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220705 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230727 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230822 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231006 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20231219 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240117 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7423644 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |