JP7374615B2 - Information processing device, information processing method and program - Google Patents
Information processing device, information processing method and program Download PDFInfo
- Publication number
- JP7374615B2 JP7374615B2 JP2019097162A JP2019097162A JP7374615B2 JP 7374615 B2 JP7374615 B2 JP 7374615B2 JP 2019097162 A JP2019097162 A JP 2019097162A JP 2019097162 A JP2019097162 A JP 2019097162A JP 7374615 B2 JP7374615 B2 JP 7374615B2
- Authority
- JP
- Japan
- Prior art keywords
- blood vessel
- dimensional
- image
- motion contrast
- region
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 24
- 238000003672 processing method Methods 0.000 title claims description 8
- 210000004204 blood vessel Anatomy 0.000 claims description 361
- 238000005259 measurement Methods 0.000 claims description 227
- 238000012545 processing Methods 0.000 claims description 225
- 238000004458 analytical method Methods 0.000 claims description 130
- 238000000034 method Methods 0.000 claims description 109
- 230000008569 process Effects 0.000 claims description 48
- 230000006872 improvement Effects 0.000 claims description 36
- 238000004364 calculation method Methods 0.000 claims description 19
- 230000011218 segmentation Effects 0.000 claims description 18
- 238000012549 training Methods 0.000 claims description 18
- 239000010410 layer Substances 0.000 description 116
- 238000003384 imaging method Methods 0.000 description 98
- 230000002207 retinal effect Effects 0.000 description 64
- 230000004048 modification Effects 0.000 description 57
- 238000012986 modification Methods 0.000 description 57
- 230000003287 optical effect Effects 0.000 description 53
- 238000012014 optical coherence tomography Methods 0.000 description 50
- FCKYPQBAHLOOJQ-UHFFFAOYSA-N Cyclohexane-1,2-diaminetetraacetic acid Chemical compound OC(=O)CN(CC(O)=O)C1CCCCC1N(CC(O)=O)CC(O)=O FCKYPQBAHLOOJQ-UHFFFAOYSA-N 0.000 description 42
- 210000001525 retina Anatomy 0.000 description 30
- 230000004044 response Effects 0.000 description 28
- 239000002344 surface layer Substances 0.000 description 28
- 238000010801 machine learning Methods 0.000 description 27
- 208000005590 Choroidal Neovascularization Diseases 0.000 description 26
- 206010060823 Choroidal neovascularisation Diseases 0.000 description 26
- 230000008859 change Effects 0.000 description 22
- 239000002131 composite material Substances 0.000 description 19
- 238000012937 correction Methods 0.000 description 17
- 230000007704 transition Effects 0.000 description 17
- 238000000605 extraction Methods 0.000 description 16
- 238000003745 diagnosis Methods 0.000 description 14
- 238000010586 diagram Methods 0.000 description 14
- 238000001514 detection method Methods 0.000 description 11
- 238000013528 artificial neural network Methods 0.000 description 10
- 230000001629 suppression Effects 0.000 description 10
- 230000006870 function Effects 0.000 description 9
- 239000013307 optical fiber Substances 0.000 description 9
- 238000012360 testing method Methods 0.000 description 9
- 239000011159 matrix material Substances 0.000 description 8
- 230000002159 abnormal effect Effects 0.000 description 7
- 239000000284 extract Substances 0.000 description 7
- 230000010287 polarization Effects 0.000 description 7
- 238000007781 pre-processing Methods 0.000 description 7
- 230000002792 vascular Effects 0.000 description 7
- 210000004027 cell Anatomy 0.000 description 6
- 210000003161 choroid Anatomy 0.000 description 6
- 239000000203 mixture Substances 0.000 description 6
- 239000011165 3D composite Substances 0.000 description 5
- 238000013527 convolutional neural network Methods 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 239000000835 fiber Substances 0.000 description 5
- 210000001775 bruch membrane Anatomy 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 238000009499 grossing Methods 0.000 description 4
- 238000007689 inspection Methods 0.000 description 4
- 208000038015 macular disease Diseases 0.000 description 4
- 108091008695 photoreceptors Proteins 0.000 description 4
- 239000013598 vector Substances 0.000 description 4
- 210000004127 vitreous body Anatomy 0.000 description 4
- 238000012935 Averaging Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000017531 blood circulation Effects 0.000 description 3
- 238000012790 confirmation Methods 0.000 description 3
- 238000013135 deep learning Methods 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 3
- 230000003902 lesion Effects 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 210000001747 pupil Anatomy 0.000 description 3
- 238000007493 shaping process Methods 0.000 description 3
- 230000002194 synthesizing effect Effects 0.000 description 3
- 208000003098 Ganglion Cysts Diseases 0.000 description 2
- 208000005400 Synovial Cyst Diseases 0.000 description 2
- 206010047642 Vitiligo Diseases 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 230000004397 blinking Effects 0.000 description 2
- 210000004556 brain Anatomy 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 230000001427 coherent effect Effects 0.000 description 2
- 230000008602 contraction Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 238000005286 illumination Methods 0.000 description 2
- 238000010191 image analysis Methods 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 210000004379 membrane Anatomy 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 210000000608 photoreceptor cell Anatomy 0.000 description 2
- 238000013441 quality evaluation Methods 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 230000000306 recurrent effect Effects 0.000 description 2
- 238000011946 reduction process Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 238000002604 ultrasonography Methods 0.000 description 2
- 230000006439 vascular pathology Effects 0.000 description 2
- 206010002329 Aneurysm Diseases 0.000 description 1
- 206010011732 Cyst Diseases 0.000 description 1
- 206010012689 Diabetic retinopathy Diseases 0.000 description 1
- 208000010412 Glaucoma Diseases 0.000 description 1
- 206010025421 Macule Diseases 0.000 description 1
- 208000031481 Pathologic Constriction Diseases 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 206010064930 age-related macular degeneration Diseases 0.000 description 1
- 238000002583 angiography Methods 0.000 description 1
- 210000002565 arteriole Anatomy 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 210000000038 chest Anatomy 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 208000031513 cyst Diseases 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 230000010339 dilation Effects 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 238000002599 functional magnetic resonance imaging Methods 0.000 description 1
- 210000004220 fundus oculi Anatomy 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 230000001678 irradiating effect Effects 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 230000031700 light absorption Effects 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 208000002780 macular degeneration Diseases 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000028161 membrane depolarization Effects 0.000 description 1
- 230000015654 memory Effects 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 210000004126 nerve fiber Anatomy 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 210000003733 optic disk Anatomy 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000012958 reprocessing Methods 0.000 description 1
- 210000001210 retinal vessel Anatomy 0.000 description 1
- 210000003786 sclera Anatomy 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 238000002603 single-photon emission computed tomography Methods 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000036262 stenosis Effects 0.000 description 1
- 208000037804 stenosis Diseases 0.000 description 1
- 238000012706 support-vector machine Methods 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
Images











Landscapes
- Eye Examination Apparatus (AREA)
Description
本明細書の開示は、情報処理装置、情報処理方法及びプログラムに関する。 The disclosure of this specification relates to an information processing device, an information processing method, and a program.
光干渉断層計(OCT;Optical Coherence Tomography)を用いて非侵襲に眼底血管を描出するOCT Angiography(以下、OCTAと表記)が知られている。OCTAでは測定光で同一位置を複数回走査(クラスタ走査)し、複数のOCT断層画像を取得する。この複数のOCT断層画像(クラスタ)に基づいて赤血球の変位と測定光との相互作用により得られるモーションコントラストデータがOCTA画像として画像化される。 OCT angiography (hereinafter referred to as OCTA), which non-invasively depicts fundus blood vessels using optical coherence tomography (OCT), is known. In OCTA, the same position is scanned multiple times with measurement light (cluster scanning) to obtain multiple OCT tomographic images. Based on the plurality of OCT tomographic images (clusters), motion contrast data obtained from the interaction between the displacement of the red blood cells and the measurement light is visualized as an OCTA image.
特許文献1では3次元モーションコントラストデータを処理して3次元的に血管計測結果を得ることが開示されている。
しかしながら、例えば、モーションコントラストデータに含まれるノイズによっては3次元の血管領域を精度よく得ることが難しいために、血管計測結果の精度が低下することがあった。 However, for example, noise contained in the motion contrast data makes it difficult to obtain a three-dimensional blood vessel region with high accuracy, which may reduce the accuracy of blood vessel measurement results.
本明細書の開示の目的の一つは、3次元の血管領域等の所望の領域を精度よく得ることである。 One of the objectives of the disclosure of this specification is to accurately obtain a desired region such as a three-dimensional blood vessel region.
なお、前記目的に限らず、後述する発明を実施するための形態に示す各構成により導かれる作用効果であって、従来の技術によっては得られない作用効果を奏することも本明細書の開示の他の目的の1つとして位置付けることができる。 It should be noted that the present disclosure is not limited to the above-mentioned objects, and the disclosure of this specification also provides effects derived from each configuration shown in the detailed description of the invention described below, which cannot be obtained by conventional techniques. It can be positioned as one of the other purposes.
本明細書に開示の情報処理装置の一つは、
眼底の3次元モーションコントラストデータを高画質化する高画質化手段と、
前記高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を取得する取得手段と、
前記3次元の血管領域に関する情報を用いて3次元空間における血管計測値を算出し、前記3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータから2次元領域における血管計測値を算出する算出手段と、
前記算出された血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける手段と、を備える。
One of the information processing devices disclosed in this specification is
a high image quality means for increasing the image quality of three-dimensional motion contrast data of the fundus;
acquisition means for acquiring information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data;
A blood vessel measurement value in a three-dimensional space is calculated using the information regarding the three-dimensional blood vessel region , and a blood vessel measurement value in the two-dimensional region is calculated from two-dimensional motion contrast data obtained by projecting the three-dimensional motion contrast data in the depth direction. Calculation means for calculating blood vessel measurement values;
and means for associating the calculated blood vessel measurement value with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional area.
本明細書の開示の一つによれば、3次元の血管領域等の所望の領域を精度よく得ることができる。 According to one of the disclosures of this specification, a desired region such as a three-dimensional blood vessel region can be obtained with high accuracy.
[第1の実施形態]
本実施形態に係る画像処理装置は、網膜外層に脈絡膜新生血管(CNV)を含む被検眼から3次元の合成モーションコントラスト画像を取得し、3次元の血管強調フィルタを適用して2値化することで例えばCNVを含む血管領域を3次元で特定する。さらに特定したCNV領域の体積を算出し、正確に計測する場合について説明する。
[First embodiment]
The image processing device according to the present embodiment acquires a three-dimensional composite motion contrast image from the subject's eye including choroidal neovascularization (CNV) in the outer retinal layer, and binarizes it by applying a three-dimensional blood vessel enhancement filter. For example, a blood vessel region containing CNV is specified in three dimensions. Furthermore, a case will be described in which the volume of the specified CNV region is calculated and accurately measured.
以下、図面を参照しながら、本実施形態に係る画像処理装置を備える画像処理システムについて説明する。 An image processing system including an image processing apparatus according to this embodiment will be described below with reference to the drawings.
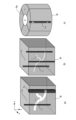
図2は、本実施形態に係る画像処理装置101を備える画像処理システム10の構成を示す図である。図2に示すように、画像処理システム10は、画像処理装置101が、インタフェースを介して断層画像撮影装置100(OCTとも言う)、外部記憶部102、入力部103、表示部104と接続されることにより構成されている。
FIG. 2 is a diagram showing the configuration of an
断層画像撮影装置100は、眼部の断層画像を撮影する装置である。本実施形態においては、断層画像撮影装置100としてSD-OCTを用いるものとする。これに限らず、例えばSS-OCTを用いて構成しても良い。
The tomographic
図2(a)において、測定光学系100-1は前眼部像、被検眼のSLO眼底像、断層画像を取得するための光学系である。ステージ部100-2は、測定光学系100-1を前後左右に移動可能にする。ベース部100-3は、後述の分光器を内蔵している。 In FIG. 2(a), a measurement optical system 100-1 is an optical system for acquiring an anterior segment image, an SLO fundus image of the eye to be examined, and a tomographic image. The stage section 100-2 allows the measurement optical system 100-1 to move back and forth and left and right. The base portion 100-3 incorporates a spectrometer to be described later.
画像処理装置101は、ステージ部100-2の制御、アラインメント動作の制御、断層画像の再構成などを実行するコンピュータである。外部記憶部102は、断層撮像用のプログラム、患者情報、撮影データ、過去検査の画像データや計測データなどを記憶する。
The
入力部103はコンピュータへの指示を行い、具体的にはキーボードとマウスから構成される。表示部104は、例えばモニタからなる。
The
(断層画像撮影装置の構成)
本実施形態の断層画像撮影装置100における測定光学系及び分光器の構成について図2(b)を用いて説明する。
(Configuration of tomographic imaging device)
The configuration of the measurement optical system and spectrometer in the
まず、測定光学系100-1の内部について説明する。被検眼200に対向して対物レンズ201が設置され、その光軸上に第1ダイクロイックミラー202及び第2ダイクロイックミラー203が配置されている。これらのダイクロイックミラーによってOCT光学系の光路250、SLO光学系と固視灯用の光路251、及び前眼観察用の光路252とに波長帯域ごとに分岐される。
First, the inside of the measurement optical system 100-1 will be explained. An
SLO光学系と固視灯用の光路251は、SLO走査手段204、レンズ205及び206、ミラー207、第3ダイクロイックミラー208、APD(Avalanche Photodiode)209、SLO光源210、固視灯211を有している。
The
ミラー207は、穴あきミラーや中空のミラーが蒸着されたプリズムであり、SLO光源210による照明光と、被検眼からの戻り光とを分離する。第3ダイクロイックミラー208はSLO光源210の光路と固視灯211の光路とに波長帯域ごとに分離する。
The
SLO走査手段204は、SLO光源210から発せられた光を被検眼200上で走査するものであり、X方向に走査するXスキャナ、Y方向に走査するYスキャナから構成されている。本実施形態では、Xスキャナは高速走査を行う必要があるためポリゴンミラーで、Yスキャナはガルバノミラーによって構成されている。
The SLO scanning means 204 scans the
レンズ205はSLO光学系及び固視灯211の焦点合わせのため、不図示のモータによって駆動される。SLO光源210は780nm付近の波長の光を発生する。APD209は、被検眼からの戻り光を検出する。固視灯211は可視光を発生して被検者の固視を促すものである。
The
SLO光源210から発せられた光は、第3ダイクロイックミラー208で反射され、ミラー207を通過し、レンズ206及び205を通ってSLO走査手段204によって被検眼200上で走査される。被検眼200からの戻り光は、照明光と同じ経路を戻った後、ミラー207によって反射され、APD209へと導かれ、SLO眼底像が得られる。
The light emitted from the
固視灯211から発せられた光は、第3ダイクロイックミラー208、ミラー207を透過し、レンズ206及び205を通り、SLO走査手段204によって被検眼200上の任意の位置に所定の形状を作り、被検者の固視を促す。
The light emitted from the
前眼観察用の光路252には、レンズ212及び213、スプリットプリズム214、赤外光を検知する前眼部観察用のCCD215が配置されている。このCCD215は、不図示の前眼部観察用照射光の波長、具体的には970nm付近に感度を持つものである。スプリットプリズム214は、被検眼200の瞳孔と共役な位置に配置されており、被検眼200に対する測定光学系100-1のZ軸方向(光軸方向)の距離を、前眼部のスプリット像として検出できる。
OCT光学系の光路250は前述の通りOCT光学系を構成しており、被検眼200の断層画像を撮影するためのものである。より具体的には、断層画像を形成するための干渉信号を得るものである。XYスキャナ216は光を被検眼200上で走査するためのものであり、図2(b)では1枚のミラーとして図示されているが、実際はXY2軸方向の走査を行うガルバノミラーである。
The
レンズ217及び218のうち、レンズ217については光カプラー219に接続されているファイバー224から出射するOCT光源220からの光を、被検眼200に焦点合わせするために不図示のモータによって駆動される。この焦点合わせによって、被検眼200からの戻り光は同時にファイバー224の先端に、スポット状に結像されて入射されることとなる。次に、OCT光源220からの光路と参照光学系、分光器の構成について説明する。220はOCT光源、221は参照ミラー、222は分散補償硝子、223はレンズ、219は光カプラー、224から227は光カプラーに接続されて一体化しているシングルモードの光ファイバー、230は分光器である。
Of the
これらの構成によってマイケルソン干渉計を構成している。OCT光源220から出射された光は、光ファイバー225を通じ、光カプラー219を介して光ファイバー224側の測定光と、光ファイバー226側の参照光とに分割される。測定光は前述のOCT光学系光路を通じ、観察対象である被検眼200に照射され、被検眼200による反射や散乱により同じ光路を通じて光カプラー219に到達する。
These configurations constitute a Michelson interferometer. The light emitted from the OCT
一方、参照光は光ファイバー226、レンズ223、測定光と参照光の波長分散を合わせるために挿入された分散補償ガラス222を介して参照ミラー221に到達し反射される。そして同じ光路を戻り、光カプラー219に到達する。
光カプラー219によって、測定光と参照光は合波され干渉光となる。
On the other hand, the reference light reaches the
The measurement light and the reference light are combined by the
ここで、測定光の光路長と参照光の光路長がほぼ同一となったときに干渉を生じる。参照ミラー221は、不図示のモータおよび駆動機構によって光軸方向に調整可能に保持され、測定光の光路長に参照光の光路長を合わせることが可能である。干渉光は光ファイバー227を介して分光器230に導かれる。
Here, interference occurs when the optical path length of the measurement light and the optical path length of the reference light become almost the same. The
また、偏光調整部228、229は、各々光ファイバー224、226中に設けられ、偏光調整を行う。これらの偏光調整部は光ファイバーをループ状に引きまわした部分を幾つか持っている。このループ状の部分をファイバーの長手方向を中心として回転させることでファイバーに捩じりを加え、測定光と参照光の偏光状態を各々調整して合わせることができる。
Further,
分光器230はレンズ232、234、回折格子233、ラインセンサ231から構成される。光ファイバー227から出射された干渉光はレンズ234を介して平行光となった後、回折格子233で分光され、レンズ232によってラインセンサ231に結像される。
The
次に、OCT光源220の周辺について説明する。OCT光源220は、代表的な低コヒーレント光源であるSLD(Super Luminescent Diode)である。中心波長は855nm、波長バンド幅は約100nmである。ここで、バンド幅は、得られる断層画像の光軸方向の分解能に影響するため、重要なパラメータである。
Next, the surroundings of the OCT
光源の種類は、ここではSLDを選択したが、低コヒーレント光が出射できればよく、ASE(Amplified Spontaneous Emission)等を用いることができる。中心波長は眼を測定することを鑑みると近赤外光が適する。また、中心波長は得られる断層画像の横方向の分解能に影響するため、なるべく短波長であることが望ましい。双方の理由から中心波長は855nmとした。 As for the type of light source, SLD is selected here, but it is sufficient that it can emit low coherent light, and ASE (Amplified Spontaneous Emission) or the like may be used. Considering that the eye is to be measured, near-infrared light is suitable as the center wavelength. Furthermore, since the center wavelength affects the lateral resolution of the obtained tomographic image, it is desirable that the center wavelength be as short as possible. For both reasons, the center wavelength was set to 855 nm.
本実施形態では干渉計としてマイケルソン干渉計を用いたが、マッハツェンダー干渉計を用いても良い。測定光と参照光との光量差に応じて、光量差が大きい場合にはマッハツェンダー干渉計を、光量差が比較的小さい場合にはマイケルソン干渉計を用いることが望ましい。 In this embodiment, a Michelson interferometer is used as the interferometer, but a Mach-Zehnder interferometer may also be used. Depending on the difference in light intensity between the measurement light and the reference light, it is desirable to use a Mach-Zehnder interferometer when the difference in light intensity is large, and to use a Michelson interferometer when the difference in light intensity is relatively small.
(画像処理装置の構成)
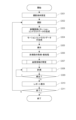
本実施形態の画像処理装置(情報処理装置)101の構成について図1を用いて説明する。
(Configuration of image processing device)
The configuration of an image processing device (information processing device) 101 of this embodiment will be explained using FIG. 1.
画像処理装置101は断層画像撮影装置100に接続されたパーソナルコンピュータ(PC)であり、画像取得部101-01、記憶部101-02、撮影制御部101-03、画像処理部101-04、表示制御部101-05を備える。また、画像処理装置101は演算処理装置CPUが画像取得部101-01、撮影制御部101-03、画像処理部101-04および表示制御部101-05を実現するソフトウェアモジュールを実行することで機能を実現する。当該ソフトウェアモジュールは例えば記憶部101-02に記憶されている。本発明はこれに限定されず、例えば画像処理部101-04をASIC等の専用のハードウェアで実現してもよいし、表示制御部101-05をCPUとは異なるGPU等の専用プロセッサを用いて実現してもよい。また断層画像撮影装置100と画像処理装置101との接続はネットワークを介した構成であってもよい。なお、CPU等のプロセッサは複数であってもよいし、プロセッサが実行するプログラムを記憶するメモリは1つであってもよいし複数であってもよい。
The
画像取得部101-01は断層画像撮影装置100により撮影されたSLO眼底像や断層画像の信号データを取得する。また画像取得部101-01は断層画像生成部101―11及びモーションコントラストデータ生成部101-12を有する。断層画像生成部101―11は断層画像撮影装置100により撮影された断層画像の信号データ(干渉信号)を取得して信号処理により断層画像を生成し、生成した断層画像を記憶部101-02に格納する。
The image acquisition unit 101-01 acquires signal data of the SLO fundus image and tomographic image photographed by the
撮影制御部101-03は、断層画像撮影装置100に対する撮影制御を行う。撮影制御には、断層画像撮影装置100に対して撮影パラメータの設定に関して指示することや、撮影の開始もしくは終了に関して指示することも含まれる。
The imaging control unit 101-03 performs imaging control for the
画像処理部101-04は、位置合わせ部101-41、合成部101-42、補正部101-43、画像特徴取得部101-44、投影部101-45、解析部101-46を有する。先に述べた画像取得部101-01は、本発明に係る取得手段の一例である。また、合成部101-42は、モーションコントラストデータ生成部101-12により生成された複数のモーションコントラストデータを位置合わせ部101-41により得られた位置合わせパラメータに基づいて合成し、合成モーションコントラスト画像を生成する。ここで、合成部101-42は、3次元モーションコントラストデータを高画質化する高画質化手段の一例である。なお、本実施形態においても、高画質化手段による処理として、合成部101-42による処理の他に、例えば、後述する第2の実施形態における機械学習による高画質化処理を適用することが可能である。また、補正部101-43はモーションコントラスト画像内に生じるプロジェクションアーチファクトを2次元もしくは3次元的に抑制する処理を行う(プロジェクションアーチファクトについてはS304で説明する)。例えば、補正部101-43は合成された3次元モーションコントラストデータにおけるプロジェクションアーチファクトを低減する処理を行う。すなわち、補正部101-43は、合成された3次元モーションコントラストデータに対してプロジェクションアーチファクトを低減する処理を行う処理手段の一例に相当する。画像特徴取得部101-44は断層画像から網膜や脈絡膜の層境界、中心窩や視神経乳頭中心の位置を取得する。投影部101-45は画像特徴取得部101-44が取得した層境界の位置に基づく深度範囲でモーションコントラスト画像を投影し、正面モーションコントラスト画像を生成する。解析部101-46は強調部101-461・抽出部101-462・計測部101-463を有し、3次元もしくは正面モーションコントラスト画像から血管領域の抽出や計測処理を行う。強調部101-461は血管強調処理を実行する。また、抽出部101-462は血管強調画像に基づいて血管領域を抽出する。さらに、計測部101-463は抽出された該血管領域や該血管領域を細線化することで取得した血管中心線データを用いて血管密度等の計測値を算出する。すなわち、本実施形態に係る画像処理装置は、高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域を抽出することができる。なお、抽出部101-462は、3次元の血管領域を抽出する抽出手段の一例である。また、本実施形態に係る画像処理装置は、高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、血管計測値を算出することができる。なお、3次元の血管領域に関する情報は、例えば、高画質化された3次元モーションコントラストデータにおける3次元の血管領域の位置情報等である。ただし、3次元の血管領域に関する情報は、高画質化された3次元モーションコントラストデータから血管計測値を算出可能な情報であれば何でもよい。 The image processing section 101-04 includes a positioning section 101-41, a composition section 101-42, a correction section 101-43, an image feature acquisition section 101-44, a projection section 101-45, and an analysis section 101-46. The image acquisition unit 101-01 described above is an example of an acquisition means according to the present invention. Furthermore, the synthesizing section 101-42 synthesizes the plurality of motion contrast data generated by the motion contrast data generating section 101-12 based on the alignment parameters obtained by the alignment section 101-41, and generates a synthesized motion contrast image. generate. Here, the synthesizing unit 101-42 is an example of an image quality improvement unit that improves the image quality of three-dimensional motion contrast data. Also in this embodiment, in addition to the processing by the compositing unit 101-42, it is possible to apply, for example, the image quality improvement processing by machine learning in the second embodiment described later as the processing by the image quality improvement means. It is. Further, the correction unit 101-43 performs processing to two-dimensionally or three-dimensionally suppress projection artifacts occurring within the motion contrast image (projection artifacts will be explained in S304). For example, the correction unit 101-43 performs processing to reduce projection artifacts in the synthesized three-dimensional motion contrast data. That is, the correction unit 101-43 corresponds to an example of a processing unit that performs processing to reduce projection artifacts on the synthesized three-dimensional motion contrast data. The image feature acquisition unit 101-44 acquires the layer boundaries of the retina and choroid, the positions of the fovea and the center of the optic disc from the tomographic image. The projection unit 101-45 projects a motion contrast image in a depth range based on the position of the layer boundary acquired by the image feature acquisition unit 101-44, and generates a front motion contrast image. The analysis unit 101-46 includes an emphasis unit 101-461, an extraction unit 101-462, and a measurement unit 101-463, and performs extraction and measurement processing of a blood vessel region from a three-dimensional or frontal motion contrast image. The emphasizing unit 101-461 executes blood vessel emphasizing processing. Further, the extraction unit 101-462 extracts a blood vessel region based on the blood vessel enhanced image. Furthermore, the measurement unit 101-463 calculates measured values such as blood vessel density using the extracted blood vessel region and blood vessel centerline data obtained by thinning the blood vessel region. That is, the image processing device according to the present embodiment can extract a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data with high image quality. Note that the extraction unit 101-462 is an example of an extraction unit that extracts a three-dimensional blood vessel region. Further, the image processing device according to the present embodiment can calculate a blood vessel measurement value using information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data. Note that the information regarding the three-dimensional blood vessel region is, for example, position information of the three-dimensional blood vessel region in high-quality three-dimensional motion contrast data. However, the information regarding the three-dimensional blood vessel region may be any information as long as it is possible to calculate blood vessel measurement values from high-quality three-dimensional motion contrast data.
外部記憶部102は、被検眼の情報(患者の氏名、年齢、性別など)と、撮影した画像(断層画像及びSLO画像・OCTA画像)や合成画像、撮影パラメータ、血管領域や血管中心線の位置データ、計測値、操作者が設定したパラメータを関連付けて保持している。入力部103は、例えば、マウス、キーボード、タッチ操作画面などであり、操作者は、入力部103を介して、画像処理装置101や断層画像撮影装置100へ指示を行う。
The
次に、図3を参照して本実施形態の画像処理装置101の処理手順を示す。図3は、本実施形態における本システム全体の動作処理の流れを示すフローチャートである。
Next, the processing procedure of the
<ステップ301>
操作者は入力部103を操作することにより、断層画像撮影装置100に対して指示するOCTA画像の撮影条件を設定する。なお、個々のOCTA撮影に関する撮影条件としては以下の3)に示すような設定項目があり、これらの設定項目を基準検査と同一の値に設定した上で、S302において基準検査と同一撮像条件のOCTA撮影を所定の回数だけ繰り返し実行する。図4は走査パターンの一例を示す図である。図4では主走査方向が水平(x軸)方向で、副走査(y軸)方向の各位置(yi;1≦i≦n)においてr回連続でBスキャンを行うOCTA撮影の例を示している。
<Step 301>
By operating the
具体的には
1)検査セットの選択もしくは登録
2)選択した検査セットにおけるスキャンモードの選択もしくは追加
3)スキャンモードに対応する撮影パラメータ設定
の手順からなり、本実施形態では以下のように設定してS302において適宜休憩を挟みながら(同一撮像条件の)OCTA撮影を所定の回数だけ繰り返し実行する。
Specifically, the procedure consists of 1) selection or registration of an examination set, 2) selection or addition of a scan mode in the selected examination set, and 3) setting of imaging parameters corresponding to the scan mode. In this embodiment, the settings are as follows. Then, in S302, OCTA imaging (under the same imaging conditions) is repeatedly performed a predetermined number of times with appropriate breaks in between.
1)Macular Disease検査セットを登録
2)OCTAスキャンモードを選択
3)以下の撮影パラメータを設定
3-1)走査パターン:Small Square
3-2)走査領域サイズ:3x3mm
3-3)主走査方向:水平方向
3-4)走査間隔:0.01mm
3-5)固視灯位置:中心窩
3-6)1クラスタあたりのBスキャン数:4
3-7)コヒーレンスゲート位置:硝子体側
3-8)既定表示レポート種別:単検査用レポート
なお、検査セットとは検査目的別に設定した(スキャンモードを含む)撮像手順や、各スキャンモードで取得したOCT画像やOCTA画像の既定の表示法を指す。また、上記の数値は例示であり他の数値であってもよい。ここで、OCTAにおいて同一位置で複数回走査することをクラスタ走査と呼ぶ。なお、異なるクラスタ間の断層画像を用いて脱相関は計算しない。また、瞬き等で再走査を行う単位はクラスタ単位である。
1) Register Macular Disease test set 2) Select OCTA scan mode 3) Set the following imaging parameters 3-1) Scanning pattern: Small Square
3-2) Scan area size: 3x3mm
3-3) Main scanning direction: horizontal direction 3-4) Scanning interval: 0.01mm
3-5) Fixation light position: fovea 3-6) Number of B scans per cluster: 4
3-7) Coherence gate position: Vitreous body side 3-8) Default display report type: Single examination report Note that an examination set refers to the imaging procedure (including scan mode) set for each examination purpose and the images acquired in each scan mode. Refers to the default display method for OCT images and OCTA images. Further, the above numerical values are just examples, and other numerical values may be used. Here, scanning the same position multiple times in OCTA is called cluster scanning. Note that decorrelation is not calculated using tomographic images between different clusters. Further, the unit in which rescanning is performed by blinking or the like is a cluster unit.
黄斑疾患眼向けの設定がなされたOCTAスキャンモードを含む検査セットが「Macular Disease」という名前で登録される。登録された検査セットは外部記憶部102に記憶される。
A test set including an OCTA scan mode configured for eyes with macular disease is registered under the name "Macular Disease." The registered test set is stored in the
本実施形態においては、図7の撮影画面710に示すように、検査セットとして「Maucular Disease」(711)、スキャンモードとして「OCTA」モード712を選択する。
In this embodiment, as shown in the photographing
<ステップ302>
操作者は入力部103を操作して図7に示す撮影画面710中の撮影開始(Capture)ボタン713を押下することにより、S301で指定した撮影条件による繰り返しOCTA撮影を開始する。
<Step 302>
The operator operates the
撮影制御部101-03は断層画像撮影装置100に対してS301で操作者が指示した設定に基づいて繰り返しOCTA撮影を実施することを指示し、断層画像撮影装置100が対応するOCT断層画像を取得する。
The imaging control unit 101-03 instructs the
なお、本実施形態では、本ステップにおける繰り返し撮像回数を3回とする。これに限らず、繰り返し撮像回数は任意の回数に設定してよい。また、本発明は繰り返し撮影間の撮影時間間隔が各繰り返し撮影内の断層像の撮影時間間隔よりも長い場合に限定されるものではなく、両者が略同一である場合も本発明に含まれる。 In addition, in this embodiment, the number of times of repeated imaging in this step is three times. The number of times of repeated imaging is not limited to this, and may be set to an arbitrary number of times. Further, the present invention is not limited to the case where the imaging time interval between repeated imaging is longer than the imaging time interval of the tomographic images in each repeated imaging, but the present invention also includes a case where both are substantially the same.
また断層画像撮影装置100はSLO画像の取得も行い、SLO動画像に基づく追尾処理を実行する。本実施形態において繰り返しOCTA撮影における追尾処理に用いる基準SLO画像は1回目の繰り返しOCTA撮影において設定した基準SLO画像とし、全ての繰り返しOCTA撮影において共通の基準SLO画像を用いる。
The
またOCTA繰り返し撮影中は、S301で設定した撮影条件に加えて
・左右眼の選択
・追尾処理の実行有無
についても同じ設定値を用いる(変更しない)ものとする。
Furthermore, during repeated OCTA imaging, in addition to the imaging conditions set in S301, the same setting values are used (not changed) for the selection of left and right eyes and whether or not to execute tracking processing.
<ステップ303>
画像取得部101-01及び画像処理部101-04は、S302で取得されたOCT断層画像に基づいてモーションコントラスト画像(モーションコントラストデータ)を生成する。具体的には、画像処理部101-04は、繰り返しOCTA撮影に基づいて、複数の3次元モーションコントラストデータを取得する。すなわち、画像処理部101-04は、眼底の3次元モーションコントラストデータを複数取得する取得手段の一例に相当する。
<Step 303>
The image acquisition unit 101-01 and the image processing unit 101-04 generate a motion contrast image (motion contrast data) based on the OCT tomographic image acquired in S302. Specifically, the image processing unit 101-04 acquires a plurality of three-dimensional motion contrast data based on repeated OCTA imaging. That is, the image processing unit 101-04 corresponds to an example of an acquisition unit that acquires a plurality of three-dimensional motion contrast data of the fundus.
まず断層画像生成部101-11は画像取得部101-01が取得した干渉信号に対して波数変換及び高速フーリエ変換(FFT)、絶対値変換(振幅の取得)を行うことで1クラスタ分の断層画像を生成する。 First, the tomographic image generation unit 101-11 performs wave number conversion, fast Fourier transform (FFT), and absolute value conversion (acquisition of amplitude) on the interference signal acquired by the image acquisition unit 101-01 to generate a tomographic image for one cluster. Generate an image.
次に位置合わせ部101-41は同一クラスタに属する断層画像同士を位置合わせし、重ねあわせ処理を行う。画像特徴取得部101-44が該重ね合わせ断層画像から層境界データを取得する。本実施形態では、層境界の取得法として可変形状モデルを用いるが、任意の公知の層境界取得手法を用いてよい。なお層境界の取得処理は必須ではなく、例えばモーションコントラスト画像の生成を3次元のみで行い、深度方向に投影した2次元のモーションコントラスト画像を生成しない場合には層境界の取得処理は省略できる。モーションコントラストデータ生成部101-12が同一クラスタ内の隣接する断層画像間でモーションコントラストを算出する。本実施形態では、モーションコントラストとして脱相関値Mxyを以下の式(1)に基づき求める。 Next, the alignment unit 101-41 aligns the tomographic images belonging to the same cluster and performs superimposition processing. An image feature acquisition unit 101-44 acquires layer boundary data from the superimposed tomographic image. In this embodiment, a variable shape model is used as a layer boundary acquisition method, but any known layer boundary acquisition method may be used. Note that the layer boundary acquisition process is not essential; for example, if a motion contrast image is generated only in three dimensions and a two-dimensional motion contrast image projected in the depth direction is not generated, the layer boundary acquisition process can be omitted. A motion contrast data generation unit 101-12 calculates motion contrast between adjacent tomographic images within the same cluster. In this embodiment, a decorrelation value Mxy is determined as the motion contrast based on the following equation (1).

ここで、Axyは断層画像データAの位置(x,y)における(FFT処理後の複素数データの)振幅、Bxyは断層データBの同一位置(x,y)における振幅を示している。0≦Mxy≦1であり、両振幅値の差異が大きいほど1に近い値をとる。式(1)のような脱相関演算処理を(同一クラスタに属する)任意の隣接する断層画像間で行い、得られた(1クラスタあたりの断層画像数-1)個のモーションコントラスト値の平均を画素値として持つ画像を最終的なモーションコントラスト画像として生成する。 Here, Axy indicates the amplitude (of complex number data after FFT processing) at the position (x, y) of the tomographic image data A, and Bxy indicates the amplitude at the same position (x, y) of the tomographic data B. 0≦Mxy≦1, and the larger the difference between both amplitude values, the closer the value is to 1. Perform the decorrelation calculation process as shown in Equation (1) between arbitrary adjacent tomographic images (belonging to the same cluster), and calculate the average of the obtained (number of tomographic images per cluster - 1) motion contrast values. An image having pixel values is generated as a final motion contrast image.
なお、ここではFFT処理後の複素数データの振幅に基づいてモーションコントラストを計算したが、モーションコントラストの計算法は上記に限定されない。例えば複素数データの位相情報に基づいてモーションコントラストを計算してもよいし、振幅と位相の両方の情報に基づいてモーションコントラストを計算してもよい。あるいは、複素数データの実部や虚部に基づいてモーションコントラストを計算してもよい。 Note that although the motion contrast is calculated here based on the amplitude of the complex number data after FFT processing, the method of calculating the motion contrast is not limited to the above. For example, motion contrast may be calculated based on phase information of complex number data, or may be calculated based on both amplitude and phase information. Alternatively, motion contrast may be calculated based on the real part or imaginary part of complex number data.
また、本実施形態では、モーションコントラストとして脱相関値を計算したが、モーションコントラストの計算法はこれに限定されない。例えば二つの値の差分に基づいてモーションコントラストを計算しても良いし、二つの値の比に基づいてモーションコントラストを計算してもよい。 Further, in this embodiment, a decorrelation value is calculated as the motion contrast, but the method of calculating the motion contrast is not limited to this. For example, the motion contrast may be calculated based on the difference between two values, or the motion contrast may be calculated based on the ratio of two values.
さらに、上記では取得された複数の脱相関値の平均値を求めることで最終的なモーションコントラスト画像を得ているが、本発明はこれに限定されない。例えば取得された複数の脱相関値の中央値、あるいは最大値を画素値として持つ画像を最終的なモーションコントラスト画像として生成しても良い。 Further, in the above, the final motion contrast image is obtained by calculating the average value of the plurality of acquired decorrelation values, but the present invention is not limited to this. For example, an image whose pixel value is the median value or maximum value of the plurality of acquired decorrelation values may be generated as the final motion contrast image.
<ステップ304>
画像処理部101-04は、繰り返しOCTA撮影を通して得られた複数の3次元モーションコントラスト画像群(図8(a))を3次元的に位置合わせし、加算平均することで図8(b)に示すように、高画質な(例えば、高コントラストな)モーションコントラスト画像の一例である合成モーションコントラスト画像を生成する。すなわち、画像処理部101-04は、複数の3次元モーションコントラストデータを合成することにより、3次元モーションコントラストを高画質化する高画質化手段の一例に相当する。ここで、本実施形態においても、高画質化手段による処理として、画像処理部101-04による処理の他に、例えば、後述する第2の実施形態における機械学習による高画質化処理を適用することが可能である。
<Step 304>
The image processing unit 101-04 three-dimensionally aligns a plurality of three-dimensional motion contrast image groups (FIG. 8(a)) obtained through repeated OCTA imaging and averages them to produce the image shown in FIG. 8(b). As shown, a composite motion contrast image, which is an example of a high-quality (for example, high contrast) motion contrast image, is generated. In other words, the image processing unit 101-04 corresponds to an example of an image quality improvement unit that improves the image quality of three-dimensional motion contrast by combining a plurality of three-dimensional motion contrast data. Here, also in this embodiment, in addition to the processing by the image processing unit 101-04, as the processing by the image quality improvement means, for example, the image quality improvement processing by machine learning in the second embodiment described later is applied. is possible.
なお、合成処理は単純加算平均に限定されない。例えば各モーションコントラスト画像の輝度値に対して任意の重みづけをした上で平均した値でもよいし、中央値をはじめとする任意の統計値を算出してもよい。また、位置合わせ処理を2次元的に行う場合も本発明に含まれる。 Note that the compositing process is not limited to simple arithmetic averaging. For example, the brightness value of each motion contrast image may be arbitrarily weighted and then averaged, or an arbitrary statistical value such as a median value may be calculated. Furthermore, the present invention also includes a case where the alignment process is performed two-dimensionally.
また、合成部101-42が合成処理に不適なモーションコントラスト画像が含まれているか否かを判定した上で、不適と判定したモーションコントラスト画像を除いて合成処理を行うよう構成してもよい。例えば、各モーションコントラスト画像に対して評価値(例えば脱相関値の平均値や、fSNR)が所定の範囲外である場合に、合成処理に不適と判定すればよい。 Furthermore, the composition unit 101-42 may be configured to determine whether or not a motion contrast image inappropriate for the composition process is included, and then perform the composition process excluding the motion contrast image determined to be inappropriate. For example, if the evaluation value (for example, the average value of decorrelation values or fSNR) for each motion contrast image is outside a predetermined range, it may be determined that the motion contrast image is unsuitable for the compositing process.
本実施形態では、合成部101-42がモーションコントラスト画像を3次元的に合成した後、補正部101-43がモーションコントラスト画像内に生じるプロジェクションアーチファクトを3次元的に抑制する処理を行う。 In this embodiment, after the synthesis unit 101-42 three-dimensionally synthesizes motion contrast images, the correction unit 101-43 performs processing to three-dimensionally suppress projection artifacts occurring in the motion contrast images.
ここで、プロジェクションアーチファクトは網膜表層血管内のモーションコントラストが深層側(網膜深層や網膜外層・脈絡膜)に映り込み、実際には血管の存在しない深層側の領域に高い脱相関値が生じる現象を指す。図8(c)に、3次元OCT断層画像上に3次元モーションコントラストデータを重畳表示した例を示す。網膜表層血管領域に対応する高い脱相関値を持つ領域801の深層側(視細胞層)に、高い脱相関値を持つ領域802が生じている。本来視細胞層に血管は存在しないにもかかわらず、網膜表層で生じている血管領域の明滅が視細胞層に血管影の明滅として映り込み、視細胞層の輝度値が変化することでアーチファクト802が生じる。 Here, projection artifact refers to a phenomenon in which motion contrast within the superficial retinal blood vessels is reflected in the deep layers (deep retina, outer retina, and choroid), resulting in high decorrelation values in deep regions where no blood vessels actually exist. . FIG. 8(c) shows an example in which three-dimensional motion contrast data is displayed superimposed on a three-dimensional OCT tomographic image. A region 802 having a high decorrelation value is generated on the deep layer side (photoreceptor cell layer) of a region 801 having a high decorrelation value corresponding to the retinal superficial blood vessel region. Even though there are no blood vessels in the photoreceptor layer, the flickering of blood vessels occurring in the surface layer of the retina is reflected in the photoreceptor layer as a flickering blood vessel shadow, and the luminance value of the photoreceptor layer changes, causing artifact 802. occurs.
補正部101-43は、3次元の合成モーションコントラスト画像上に生じたプロジェクションアーチファクト802を抑制する処理を実行する。任意の公知のプロジェクションアーチファクト抑制手法を用いてよいが、本実施形態では、Step-down Exponential Filteringを用いる。Step-down Exponential Filteringでは、3次元モーションコントラスト画像上の各Aスキャンデータに対して式(2)で表される処理を実行することにより、プロジェクションアーチファクトを抑制する。 The correction unit 101-43 executes processing to suppress the projection artifact 802 generated on the three-dimensional composite motion contrast image. Although any known projection artifact suppression technique may be used, this embodiment uses Step-down Exponential Filtering. In Step-down Exponential Filtering, projection artifacts are suppressed by executing the process expressed by equation (2) on each A-scan data on the three-dimensional motion contrast image.

ここで、γは負の値を持つ減衰係数、D(x,y,z)はプロジェクションアーチファクト抑制処理前の脱相関値、DE(x,y,z)は該抑制処理後の脱相関値を表す。 Here, γ is an attenuation coefficient with a negative value, D (x, y, z) is a decorrelation value before projection artifact suppression processing, and DE (x, y, z) is a decorrelation value after the suppression processing. represents.
図8(d)にプロジェクションアーチファクト抑制処理後の3次元合成モーションコントラストデータ(灰色)を断層画像上に重畳表示した例を示す。プロジェクションアーチファクト抑制処理前(図8(c))に視細胞層上に見られたアーチファクトが、該抑制処理によって除去されたことがわかる。 FIG. 8D shows an example in which three-dimensional composite motion contrast data (gray) after projection artifact suppression processing is displayed superimposed on a tomographic image. It can be seen that the artifacts observed on the photoreceptor layer before the projection artifact suppression process (FIG. 8(c)) were removed by the suppression process.
次に、投影部101-45はS303で画像特徴取得部101-44が取得した層境界の位置に基づく深度範囲でモーションコントラスト画像を投影し、正面モーションコントラスト画像を生成する。任意の深度範囲で投影してよいが、本実施形態においては網膜表層及び網膜外層の深度範囲で2種類の正面合成モーションコントラスト画像を生成する。また、投影法としては最大値投影(MIP;Maximum Intensity Projection)・平均値投影(AIP;Average Intensity Projection)のいずれかを選択でき、本実施形態では最大値投影で投影するものとする。 Next, the projection unit 101-45 projects a motion contrast image in a depth range based on the position of the layer boundary acquired by the image feature acquisition unit 101-44 in S303, and generates a front motion contrast image. Although projection may be performed in any depth range, in this embodiment, two types of frontal composite motion contrast images are generated in the depth range of the surface layer of the retina and the outer layer of the retina. Further, as a projection method, either maximum intensity projection (MIP) or average intensity projection (AIP) can be selected, and in this embodiment, projection is performed using maximum intensity projection.
最後に、画像処理装置101は取得した画像群(SLO画像や断層画像)と該画像群の撮影条件データや、生成した3次元及び正面モーションコントラスト画像と付随する生成条件データを検査日時、被検眼を同定する情報と関連付けて外部記憶部102へ保存する。
Finally, the
<ステップ305>
表示制御部101-05は、S303で生成した断層画像や、S304で合成した3次元及び正面モーションコントラスト画像、撮影条件や合成条件に関する情報を表示部104に表示させる。
<Step 305>
The display control unit 101-05 causes the
図8(e)にレポート画面803の例を示す。本実施形態では、SLO画像及び断層画像、S304で合成及び投影することにより生成した異なる深度範囲の正面モーションコントラスト画像、対応する正面OCT画像を表示する。図8(e)では上段に網膜表層、下段に網膜外層を各々投影深度範囲として生成した正面モーションコントラスト画像を表示しており、網膜外層の正面モーションコントラスト画像808には脈絡膜毛細血管(CNV)が描出されている。 FIG. 8(e) shows an example of the report screen 803. In this embodiment, the SLO image and the tomographic image, the frontal motion contrast images of different depth ranges generated by combining and projecting in S304, and the corresponding frontal OCT image are displayed. In FIG. 8(e), the frontal motion contrast image generated with the retinal surface layer in the upper row and the outer retinal layer in the lower row as the projection depth range is displayed, and the frontal motion contrast image 808 of the outer retinal layer shows the choriocapillaris (CNV). It is depicted.
なお、表示部104に表示するモーションコントラスト画像は正面モーションコントラスト画像に限定されるものではなく、3次元的にレンダリングした3次元モーションコントラスト画像を表示してもよい。
Note that the motion contrast image displayed on the
正面モーションコントラスト画像の投影範囲はリストボックスに表示された既定の深度範囲セット(805及び809)から操作者が選択することで変更できる。また、投影範囲の指定に用いる層境界の種類とオフセット位置を806や810のようなユーザーインターフェースから変更したり、断層像上に重畳された層境界データ(807及び811)を入力部103から操作して移動させたりすることで投影範囲を変更できる。
The projection range of the frontal motion contrast image can be changed by the operator selecting from the default depth range set (805 and 809) displayed in the list box. In addition, the type and offset position of the layer boundary used to specify the projection range can be changed from a user interface such as 806 or 810, or the layer boundary data (807 and 811) superimposed on the tomographic image can be operated from the
さらに、画像投影法やプロジェクションアーチファクト抑制処理の有無を例えばコンテキストメニューのようなユーザーインターフェースから選択することにより変更してもよい。例えば、プロジェクションアーチファクト抑制処理後のモーションコントラスト画像を3次元画像として表示部104に表示してもよい。
Furthermore, the image projection method and the presence or absence of projection artifact suppression processing may be changed by selecting from a user interface such as a context menu. For example, the motion contrast image after projection artifact suppression processing may be displayed on the
<ステップ306>
操作者が入力部103を用いてOCTA計測処理の開始を指示する。
<Step 306>
The operator uses the
本実施形態では、図8(e)のレポート画面803のモーションコントラスト画像上をダブルクリックすることで、図9(a)のようなOCTA計測画面に移行する。モーションコントラスト画像が拡大表示され、解析部101-46が計測処理を開始する。 In this embodiment, by double-clicking on the motion contrast image on the report screen 803 in FIG. 8(e), the screen shifts to an OCTA measurement screen as shown in FIG. 9(a). The motion contrast image is enlarged and displayed, and the analysis unit 101-46 starts measurement processing.
計測処理の種類として任意の計測処理を行ってよく、本実施形態では図9(a)のDensity Analysis903もしくはToolsボタン904を選択して表示される項目905に示す解析の種類と、必要に応じて解析の次元数に関する項目912を選択することにより、所望の計測の種類を指定する。 Any measurement process may be performed as the type of measurement process, and in this embodiment, the type of analysis shown in the item 905 displayed by selecting the Density Analysis 903 or Tools button 904 in FIG. By selecting the item 912 regarding the number of dimensions of analysis, the desired type of measurement is specified.
例えばToolsボタン904を選択して表示される項目905からArea/Volumeを選択した状態で血管領域もしくは無血管領域のうちの1点をユーザが入力部103を用いて選択することにより、解析の種類として血管もしくは無血管領域の面積を指定できる。ここで、3D Analysisの項目も選択している場合には、解析の種類として血管もしくは無血管領域の体積を指定できる。あるいは、Density Analysis903のArea Density(もしくはSkeleton Density)を選択することで、解析の種類として2次元のVAD(もしくはVLD)を指定できる。ここで、3D Analysisの項目も選択している場合には、解析の種類として3次元のVAD(もしくはVLD)を指定できる。なおArea Density、Skeleton Densityは後述するVAD、VLDと各々同義である。また、3次元のArea Density(VAD)はVolume Density(VVD)と言い換えてもよい。
For example, when the user selects Area/Volume from the displayed item 905 after selecting the Tools button 904 and selects one point from the vascular region or avascular region using the
ここで、3次元画像処理による計測は大きく、以下のように大別できる。
1)3次元で強調し、2次元で特定した血管領域もしくは血管中心線データに対する2次元計測(投影強調画像を2値化した画像上の2次元位置に基づく計測)
2)3次元で強調及び特定した血管領域もしくは血管中心線データに対する2次元計測(投影2値画像上の2次元位置に基づく計測、所定の条件をみたすAスキャン群に対する計測)
3)3次元で強調及び特定された血管領域もしくは血管中心線データに対する3次元計測(3次元2値画像上の3次元位置に基づく計測)
Here, measurement by three-dimensional image processing can be broadly classified as follows.
1) Two-dimensional measurement of blood vessel area or blood vessel center line data that is emphasized in three dimensions and specified in two dimensions (measurement based on the two-dimensional position on the binarized projection enhanced image)
2) Two-dimensional measurement of the vascular region or blood vessel center line data highlighted and specified in three dimensions (measurement based on the two-dimensional position on the projected binary image, measurement for A-scan groups that meet predetermined conditions)
3) 3D measurement of 3D highlighted and specified vascular region or vascular centerline data (measurement based on 3D position on 3D binary image)
1)及び2)の例として、投影画像上で上記無血管領域の面積や血管密度、血管領域の面積や径、長さ、曲率を計測したり、投影画像を生成せずに所定の条件を満たすAスキャン群の本数や水平方向の距離、水平方向の面積等を用いて2次元計測値を算出したりすることが挙げられる。計測内容は正面モーションコントラスト画像に対する計測と同様であるものの、正面モーションコントラスト画像を強調・特定して計測する場合よりも血管抽出能が向上するため計測精度が向上する。 As an example of 1) and 2), the area and blood vessel density of the above-mentioned avascular region, the area, diameter, length, and curvature of the blood vessel region may be measured on the projection image, or the predetermined conditions may be measured without generating a projection image. For example, a two-dimensional measurement value may be calculated using the number of satisfying A-scan groups, horizontal distance, horizontal area, etc. Although the measurement content is the same as the measurement for the frontal motion contrast image, the blood vessel extraction ability is improved compared to when measuring by emphasizing and specifying the frontal motion contrast image, so the measurement accuracy is improved.
また、3)の例として
3-1)血管の体積計測
3-2)任意方向の断面画像もしくは曲断面画像上の計測(血管の径もしくは断面積計測も含む)
3-3)血管の長さや曲率計測
が挙げられる。
In addition, as an example of 3), 3-1) Volume measurement of blood vessels 3-2) Measurement on cross-sectional images or curved cross-sectional images in arbitrary directions (including measurement of blood vessel diameter or cross-sectional area)
3-3) Measurement of blood vessel length and curvature.
本実施形態では、上記の3)に示した計測を行う。すなわち、本実施形態では、3次元で血管強調及び血管領域の特定処理を実行した後、3次元モーションコントラストデータから網膜表層の深度範囲で3次元の血管密度(VAD)、網膜外層の深度範囲で血管領域の体積を各々計測する。このように、深さ方向に投影した2次元モーションコントラストデータから血管密度等を算出するのではなく、3次元モーションコントラストデータから直接血管密度等を算出するため、血管が深さ方向に重なっている部分も正確に評価することが可能となる。 In this embodiment, the measurement shown in 3) above is performed. That is, in this embodiment, after performing three-dimensional blood vessel enhancement and blood vessel region identification processing, three-dimensional blood vessel density (VAD) is calculated from the three-dimensional motion contrast data in the depth range of the retinal surface layer, and three-dimensional blood vessel density (VAD) is calculated in the depth range of the outer retinal layer from the three-dimensional motion contrast data. The volume of each blood vessel region is measured. In this way, blood vessel density etc. are calculated directly from 3D motion contrast data rather than from 2D motion contrast data projected in the depth direction, so blood vessels overlap in the depth direction. It also becomes possible to accurately evaluate parts.
ここで、VADはVessel Area Densityの略であり、計測対象に含まれる血管領域の割合で定義される血管密度(単位:%)である。また、VLDはVessel Length Densityの略であり、2次元の場合は単位面積あたりに含まれる血管の長さの総和(単位:mm-1)として、また3次元の場合は単位体積あたりに含まれる血管の長さの総和(単位:mm-2)として定義される血管密度である。すなわち、血管密度にはVADとVLDとが含まれる。 Here, VAD is an abbreviation for Vessel Area Density, and is the blood vessel density (unit: %) defined by the proportion of the blood vessel area included in the measurement target. In addition, VLD is an abbreviation for Vessel Length Density, and in the case of two dimensions, it is the sum of the lengths of blood vessels included per unit area (unit: mm -1 ), and in the case of three dimensions, it is the sum of the lengths of blood vessels included per unit volume. Blood vessel density is defined as the sum of blood vessel lengths (unit: mm −2 ). That is, the blood vessel density includes VAD and VLD.
血管密度は血管の閉塞範囲や血管網の疎密の程度を定量化するための指標であり、VADが最もよく用いられている。ただし、VADでは計測値に占める大血管領域の寄与分が大きくなるため、糖尿病網膜症のように毛細血管の病態に注目して計測したい場合には(より毛細血管の閉塞に敏感な指標として)VLDが用いられる。 Blood vessel density is an index for quantifying the extent of occlusion of blood vessels and the degree of sparseness of blood vessel networks, and VAD is most commonly used. However, in VAD, the contribution of the macrovascular region to the measurement value is large, so when you want to measure by focusing on the pathology of capillaries such as diabetic retinopathy (as an indicator that is more sensitive to capillary occlusion) VLD is used.
これに限らず、例えば血管構造の複雑さを定量化するFractal Dimensionや、血管径の分布(血管の瘤や狭窄の分布)を表すVessel DiameterIndexを計測してもよい。 The measurement is not limited to this, and for example, Fractal Dimension, which quantifies the complexity of the blood vessel structure, or Vessel DiameterIndex, which represents the distribution of blood vessel diameter (distribution of blood vessel aneurysm or stenosis) may be measured.
次に、解析部101-46は計測処理の前処理を行う。任意の公知の画像処理を前処理として適用できるが、本実施形態では、前処理として画像拡大及びモルフォロジー演算(トップハットフィルタ処理)を行う。トップハットフィルタを適用することにより、背景成分の輝度ムラを軽減できる。具体的には、合成モーションコントラスト画像の画素サイズが約3μmになるように3次元Bicubic補間を用いて画像拡大し、球形の構造要素を用いてトップハットフィルタ処理を行うものとする。 Next, the analysis unit 101-46 performs preprocessing for measurement processing. Although any known image processing can be applied as preprocessing, in this embodiment, image enlargement and morphological calculation (top hat filter processing) are performed as preprocessing. By applying a top hat filter, it is possible to reduce uneven brightness of the background component. Specifically, it is assumed that the image is enlarged using three-dimensional Bicubic interpolation so that the pixel size of the composite motion contrast image becomes approximately 3 μm, and that top hat filter processing is performed using a spherical structural element.
<ステップ307>
解析部101-46が血管領域の特定処理を行う。本実施形態では、強調部101-461が3次元ヘシアンフィルタ及び3次元エッジ選択鮮鋭化に基づく血管強調処理を行う。次に抽出部101-462が2種類の血管強調画像を用いて2値化処理を行い、整形処理を行うことで血管領域を特定する。
<Step 307>
The analysis unit 101-46 performs blood vessel region identification processing. In this embodiment, the enhancement unit 101-461 performs blood vessel enhancement processing based on a three-dimensional Hessian filter and three-dimensional edge selective sharpening. Next, the extraction unit 101-462 performs binarization processing using the two types of blood vessel emphasis images, and performs shaping processing to specify the blood vessel region.
血管領域特定処理の詳細はS510~S560で説明する。 Details of the blood vessel region specifying process will be explained in S510 to S560.
<ステップ308>
計測部101-463が、操作者により指定された計測対象領域に関する情報に基づいて単検査の画像に対する血管密度の計測を行う。引き続いて表示制御部101-05が、計測結果を表示部104に表示する。より具体的には、計測部101-463は、加算平均された複数の3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、3次元空間における血管密度等を算出する。すなわち、計測部101-463は、合成された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、3次元空間における血管密度を算出する算出手段の一例に相当する。より具体的には計測部101-463はプロジェクションアーチファクトを低減する処理が実行された後に血管密度の算出を行う。すなわち、算出手段の一例である計測部101-463は、処理手段によりプロジェクションアーチファクトが低減された後の合成された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、3次元空間における血管密度を算出する。
<Step 308>
The measurement unit 101-463 measures the blood vessel density for a single examination image based on information regarding the measurement target area specified by the operator. Subsequently, the display control section 101-05 displays the measurement results on the
血管密度としてはVADとVLDの2種類の指標があり、本実施形態ではVADを計算する場合の手順を例に説明する。なお、VLDを計算する場合の手順についても後述する。 There are two types of indicators for blood vessel density: VAD and VLD, and in this embodiment, the procedure for calculating VAD will be explained as an example. Note that the procedure for calculating VLD will also be described later.
操作者が入力部103から血管領域もしくは血管中心線データを手動修正するよう指示を入力した場合には、解析部101-46が操作者から入力部103を介して指定された位置情報に基づいて血管領域もしくは血管中心線データを手動修正し、計測値を再計算する。
When the operator inputs an instruction to manually correct the blood vessel region or blood vessel center line data from the
網膜表層におけるVAD計測、網膜外層における脈絡膜新生血管の体積計測についてはS810~S820、網膜表層におけるVLD計測、網膜外層における脈絡膜新生血管の総血管長計測についてはS830~S850で各々説明する。 VAD measurement in the retinal surface layer and volume measurement of choroidal neovascularization in the outer retinal layer will be explained in S810 to S820, and VLD measurement in the retinal superficial layer and total blood vessel length measurement of choroidal neovascularization in the outer retinal layer will be explained in S830 to S850.
<ステップ309>
解析部101-46は、S307で特定した血管領域や血管中心線のデータを手動修正するか否かの指示を外部から取得する。この指示は例えば入力部103を介して操作者により入力される。手動修正処理が指示された場合はS308へ、手動修正処理が指示されなかった場合はS310へと処理を進める。
<Step 309>
The analysis unit 101-46 acquires from the outside an instruction as to whether or not to manually correct the data on the blood vessel region and blood vessel center line identified in S307. This instruction is input by the operator via the
<ステップ310>
表示制御部101-05は、S308で実施した計測結果に関するレポートを表示部104に表示する。
<Step 310>
The display control unit 101-05 displays a report regarding the measurement results performed in S308 on the
本実施形態では、単検査(Single)計測レポートの上段に網膜表層において計測したVADマップとVADセクタマップを重畳表示し、下段に網膜外層深層において特定した脈絡膜新生血管領域の2値画像や計測した体積値を表示する。これにより異なる深度位置の血管病態を一覧して把握できる。また、網膜外層におけるCNVの3次元的な位置を特定したり、存在量を正確に定量化したりできる。 In this embodiment, the VAD map and VAD sector map measured in the superficial layer of the retina are superimposed on the upper part of the single measurement report, and the lower part shows a binary image of the choroidal neovascular region identified in the deep outer retinal layer and the measured value. Display volume value. This makes it possible to view and understand the vascular pathology at different depth positions. Furthermore, it is possible to specify the three-dimensional position of CNV in the outer retinal layer and accurately quantify the amount present.
また各計測対象画像に関して、略同一位置における断層画像数やOCTA重ね合わせ処理の実施条件に関する情報、OCT断層画像もしくはモーションコントラスト画像の評価値(画質指標)に関する情報を表示部104に表示させてもよい。
Furthermore, regarding each measurement target image, the
なお、本実施形態では異なる深度範囲として網膜表層及び網膜外層の画像及び計測値を表示したが、これに限らず例えば網膜表層・網膜深層・網膜外層・脈絡膜の4種類の深度範囲の画像及び計測値を表示してもよい。 In this embodiment, images and measurement values of the retinal surface layer and the retinal outer layer are displayed as different depth ranges, but the present invention is not limited to this, and images and measurements of four types of depth ranges, for example, the retinal surface layer, the retinal deep layer, the retinal outer layer, and the choroid, may be displayed. Values may be displayed.
またモーションコントラスト画像や特定された血管領域もしくは血管中心線の2値画像は正面画像として投影表示することに限定されるものではなく、3次元的にレンダリングして3次元画像として表示してもよい。 Furthermore, the motion contrast image and the binary image of the specified blood vessel region or blood vessel center line are not limited to being projected and displayed as a frontal image, but may be rendered three-dimensionally and displayed as a three-dimensional image. .
あるいは、異なる指標の計測結果を並置して表示してもよい。例えば、上段にVADマップの時系列表示、下段にVLDマップ(もしくは無血管領域のサイズや形状値)を表示してもよい。 Alternatively, measurement results of different indicators may be displayed side by side. For example, the VAD map may be displayed in chronological order in the upper row, and the VLD map (or the size or shape value of the avascular region) may be displayed in the lower row.
また、同様に投影方法(MIP/AIP)やプロジェクションアーチファクト抑制処理についても例えばコンテキストメニューから選択するなどの方法により変更してもよい。 Similarly, the projection method (MIP/AIP) and projection artifact suppression processing may also be changed by, for example, selecting from a context menu.
<ステップ311>
画像処理装置101はS301からS311に至る一連の処理を終了するか否かの指示を外部から取得する。この指示は入力部103を介して操作者により入力される。処理終了の指示を取得した場合は処理を終了する。一方、処理継続の指示を取得した場合にはS302に処理を戻し、次の被検眼に対する処理(または同一被検眼に対する再処理)を行う。
<Step 311>
The
さらに、図5(a)に示すフローチャートを参照しながら、S307で実行される処理の詳細について説明する。 Furthermore, details of the process executed in S307 will be described with reference to the flowchart shown in FIG. 5(a).
<ステップ510>
強調部101-461は、ステップ306の前処理を実施されたモーションコントラスト画像に対してヘッセ行列の固有値に基づく血管強調フィルタ処理を行う。このような強調フィルタはヘシアンフィルタと総称され、例えばVesselness filterやMulti-scale line filterが挙げられる。本実施形態ではMulti-scale line filterを用いるが、任意の公知の血管強調フィルタを用いてよい。
<Step 510>
The enhancement unit 101-461 performs blood vessel enhancement filter processing based on the eigenvalues of the Hessian matrix on the motion contrast image that has undergone the preprocessing in step 306. Such enhancement filters are collectively referred to as Hessian filters, and include, for example, a Vesselness filter and a Multi-scale line filter. Although a multi-scale line filter is used in this embodiment, any known blood vessel enhancement filter may be used.
ヘシアンフィルタは強調したい血管の径に適したサイズで画像を平滑化した上で、該平滑化画像の各画素において輝度値の2次微分値を要素として持つヘッセ行列を算出し、該行列の固有値の大小関係に基づいて局所構造を強調する。ヘッセ行列は式(3)で与えられるような正方行列であり、該行列の各要素は例えば式(4)に示すような画像の輝度値Iを平滑化した画像の輝度値Isの2次微分値で表される。ヘシアンフィルタでは、このようなヘッセ行列の「固有値(λ1、λ2、λ3)の1つが0に近く、その他が負かつ絶対値が大きい」場合に線状構造とみなして強調する。これはモーションコントラスト画像上の血管領域が持つ特徴、すなわち「走行方向では輝度変化が小さく、走行方向に直交する方向では輝度値が大きく低下する」が成り立つ画素を線状構造とみなして強調することに相当する。 The Hessian filter smoothes an image to a size appropriate to the diameter of the blood vessel you want to emphasize, then calculates a Hessian matrix whose elements are the second-order differential values of the luminance values at each pixel of the smoothed image, and calculates the eigenvalue of the matrix. The local structure is emphasized based on the magnitude relationship of . The Hessian matrix is a square matrix as given by equation (3), and each element of the matrix is, for example, the second derivative of the brightness value Is of an image obtained by smoothing the brightness value I of the image as shown in equation (4). expressed as a value. In the Hessian filter, when "one of the eigenvalues (λ1, λ2, λ3) of the Hessian matrix is close to 0 and the others are negative and have large absolute values", it is regarded as a linear structure and emphasized. This is done by treating pixels that have the characteristics of blood vessel regions on motion contrast images, that is, ``changes in brightness are small in the direction of travel, and the brightness value decreases greatly in the direction orthogonal to the direction of travel'' as linear structures, and are emphasized. corresponds to
3次元ヘシアンフィルタを用いると、深度方向に屈曲した血管に関しても「血管走行方向の輝度変化が小さく、血管走行方向に直交する2方向の輝度が大きく低下する」という性質が成り立つため、良好に血管強調できるという利点がある。眼底血管の中には、深度方向に屈曲した血管として例えば
・脈絡膜側から網膜内に侵入する脈絡膜新生血管(CNV)
・視神経乳頭部の血管
・網膜表層毛細血管と網膜深層毛細血管との接続部
が挙げられる。
When a three-dimensional Hessian filter is used, even for blood vessels that are curved in the depth direction, the property that ``changes in brightness in the blood vessel running direction is small, and brightness in two directions orthogonal to the blood vessel running direction is greatly reduced'' holds true. It has the advantage of being able to be emphasized. Among the fundus blood vessels, there are blood vessels bent in the depth direction, such as choroidal neovascularization (CNV) that invades the retina from the choroid side.
・Vessels in the optic nerve head ・Connections between superficial retinal capillaries and deep retinal capillaries.
上記血管に対して正面モーションコントラスト画像上で2次元のヘシアンフィルタを適用すると、2次元平面内では「該平面内での血管走行方向の輝度変化が小さく、血管走行方向に直交する方向の輝度が大きく低下する」という性質が成り立たないため十分強調されず、血管領域として特定できないという課題がある。3次元ヘシアンフィルタを用いることにより、上記血管についても良好に強調でき、血管検出能が向上する。 When a two-dimensional Hessian filter is applied to the above-mentioned blood vessel on a frontal motion contrast image, it is found that within the two-dimensional plane, the brightness change in the blood vessel running direction is small, and the brightness in the direction perpendicular to the blood vessel running direction is small. There is a problem in that because the property of ``significantly decreasing'' does not hold true, it is not emphasized enough and cannot be identified as a vascular region. By using a three-dimensional Hessian filter, the blood vessels described above can be emphasized well, and the blood vessel detection ability is improved.
またモーションコントラスト画像には毛細血管から細動静脈まで様々な径の血管が含まれることから、複数のスケールでガウスフィルタにより平滑化した画像に対してヘッセ行列を用いて線強調画像を生成する。次に式(5)に示すようにガウスフィルタの平滑化パラメータσの二乗を補正係数として乗じた上で最大値演算により合成し、該合成画像Ihessianをヘシアンフィルタの出力とする。 Furthermore, since a motion contrast image includes blood vessels of various diameters from capillaries to arterioles and veins, a line-enhanced image is generated using a Hessian matrix for an image smoothed by a Gaussian filter at multiple scales. Next, as shown in equation (5), the images are multiplied by the square of the smoothing parameter σ of the Gaussian filter as a correction coefficient, and then synthesized by maximum value calculation, and the synthesized image Ihessian is used as the output of the Hessian filter.
ヘシアンフィルタはノイズに強く、血管の連続性が向上するという利点がある。一方で実際には事前に画像に含まれる血管の最大径が不明の場合が多いため、特に平滑化パラメータが画像中の血管の最大径に対して大きすぎる場合に強調された血管領域が太くなりやすいという欠点がある。 The Hessian filter has the advantage of being resistant to noise and improving the continuity of blood vessels. On the other hand, in reality, the maximum diameter of the blood vessels included in the image is often unknown in advance, so if the smoothing parameter is too large for the maximum diameter of the blood vessels in the image, the emphasized blood vessel area may become thicker. It has the disadvantage of being easy.
そこで、本実施形態ではS530で述べる別の血管強調手法で血管領域を強調した画像と演算することにより、血管領域が太くなりすぎることを防止する。 Therefore, in this embodiment, the blood vessel region is prevented from becoming too thick by performing calculations on an image in which the blood vessel region is emphasized using another blood vessel enhancement method described in S530.



<ステップ520>
抽出部101-462は、S510で生成した3次元ヘシアンフィルタによる血管強調画像(以下、3次元ヘシアン強調画像と表記)を2値化する。
<Step 520>
The extraction unit 101-462 binarizes the blood vessel enhanced image (hereinafter referred to as a three-dimensional Hessian enhanced image) generated by the three-dimensional Hessian filter in S510.
本実施形態では、3次元ヘシアン強調画像の輝度統計値(平均値や中央値等)を閾値として2値化する。大血管の高輝度領域の影響を受けて閾値が高くなって毛細血管の抽出不足が生じたり、閾値が低すぎて無血管領域を血管として誤検出したりするのを避けるために、2値化する際の閾値に上限値や下限値を設定してよい。あるいは、例えばロバスト推定法のように輝度統計値を算出する際に所定の輝度レンジ外にある輝度値の寄与が低くなるように算出した指標値に基づいて閾値を決定してもよい。また任意の公知の閾値決定法を用いてよい。 In this embodiment, the luminance statistical value (average value, median value, etc.) of a three-dimensional Hessian-enhanced image is binarized using a threshold value. In order to avoid insufficient extraction of capillaries due to a high threshold due to the influence of high-intensity regions of large blood vessels, or erroneous detection of avascular regions as blood vessels due to a threshold that is too low, binarization is performed. An upper limit value or a lower limit value may be set for the threshold value when Alternatively, the threshold value may be determined based on an index value calculated such that the contribution of brightness values outside a predetermined brightness range is reduced when calculating the brightness statistical value, as in the case of a robust estimation method, for example. Also, any known threshold determination method may be used.
あるいは、本発明は閾値処理に限定されるものではなく、任意の公知のセグメンテーション法によって2値化してよい。 Alternatively, the present invention is not limited to threshold processing, and binarization may be performed using any known segmentation method.
本実施形態では、合成モーションコントラスト画像をヘシアンフィルタで強調しているため、単独のモーションコントラスト画像をヘシアンフィルタで強調する場合に比べて2値化した血管領域の連続性がさらに向上する。 In this embodiment, since the composite motion contrast image is enhanced using a Hessian filter, the continuity of the binarized blood vessel region is further improved compared to the case where a single motion contrast image is enhanced using a Hessian filter.
さらに、本発明は3次元血管強調画像を3次元データとして2値化することに限定されるものではない。例えば、3次元血管強調画像を所定の投影深度範囲で投影した正面血管強調画像を2値化する場合も本発明に含まれる。正面血管強調画像を2値化する場合も、任意の公知の閾値決定法を用いてよい。また該正面血管強調画像を2値化する際の閾値に上限値や下限値を設定してよい。あるいは、該正面血管強調画像の2値化は閾値処理に限定されるものではなく、任意の公知のセグメンテーション法を用いて2値化してよい。 Furthermore, the present invention is not limited to binarizing a three-dimensional blood vessel enhanced image as three-dimensional data. For example, the present invention also includes the case where a frontal blood vessel emphasized image obtained by projecting a three-dimensional blood vessel emphasized image in a predetermined projection depth range is binarized. Any known threshold value determination method may be used when binarizing the front blood vessel enhanced image. Further, an upper limit value or a lower limit value may be set as a threshold value when binarizing the front blood vessel enhanced image. Alternatively, the binarization of the front blood vessel enhanced image is not limited to threshold processing, and may be binarized using any known segmentation method.
<ステップ530>
強調部101-461は、S306で生成したトップハットフィルタ適用後の合成モーションコントラスト画像に対して3次元エッジ選択鮮鋭化処理を行う。
<Step 530>
The enhancement unit 101-461 performs three-dimensional edge selection sharpening processing on the top-hat filtered synthesized motion contrast image generated in S306.
ここで、エッジ選択鮮鋭化処理とは画像のエッジ部分に重みを大きく設定した上で重みづけ鮮鋭化処理を行うことを指す。本実施形態では、前記合成モーションコントラスト画像に対して3次元のSobelフィルタを適用した画像を重みとして3次元のアンシャープマスク処理を行うことにより、エッジ選択鮮鋭化処理を実施する。 Here, the edge selective sharpening processing refers to performing weighted sharpening processing after setting a large weight to the edge portion of the image. In this embodiment, edge selective sharpening processing is performed by performing three-dimensional unsharp mask processing using an image obtained by applying a three-dimensional Sobel filter to the synthetic motion contrast image as a weight.
小さなフィルタサイズで鮮鋭化処理を実施すると、細い血管のエッジが強調され2値化した際により正確に血管領域を特定できる(血管領域が太くなる現象を防止できる)。一方で特に同一撮影位置での断層像数が少ないモーションコントラスト画像の場合にはノイズが多いため、特に血管内のノイズも一緒に強調してしまう恐れがある。そこで、エッジ選択鮮鋭化を行うことによってノイズの強調を抑制する。 When the sharpening process is performed with a small filter size, the edges of thin blood vessels are emphasized and the blood vessel region can be specified more accurately when binarized (the phenomenon of blood vessel regions becoming thicker can be prevented). On the other hand, especially in the case of a motion contrast image in which the number of tomographic images at the same imaging position is small, there is a lot of noise, so there is a risk that noise in blood vessels may also be emphasized. Therefore, noise enhancement is suppressed by performing edge selective sharpening.
<ステップ540>
抽出部101-462は、S530で生成したエッジ選択鮮鋭化処理を適用した鮮鋭化画像を2値化する。任意の公知の2値化法を用いてよいが、本実施形態では該3次元鮮鋭化画像上の各3次元局所領域内で算出した輝度統計値(平均値もしくは中央値)を閾値として2値化する。
<Step 540>
The extraction unit 101-462 binarizes the sharpened image generated in S530 to which the edge selective sharpening process has been applied. Any known binarization method may be used, but in this embodiment, the brightness statistical value (average value or median value) calculated within each three-dimensional local area on the three-dimensional sharpened image is used as a threshold, and a binary value is used. become
ただし、視神経乳頭部の大血管領域においては設定される閾値が高すぎて2値画像上の血管領域内に多数の穴が空くため、上記閾値の上限値を設定することにより特に視神経乳頭部において閾値が高くなりすぎるのを防止する。 However, in the large blood vessel region of the optic disc, the threshold value set is too high, resulting in many holes in the blood vessel region on the binary image. Prevent the threshold from becoming too high.
また、S520の場合と同様に該3次元局所領域が無血管領域中にある場合には閾値が低すぎて無血管領域の一部を血管として誤検出する場合が生じる。そこで、上記閾値の下限値を設定することにより誤検出を抑制する。 Further, as in the case of S520, if the three-dimensional local area is in an avascular area, the threshold value may be too low and a part of the avascular area may be erroneously detected as a blood vessel. Therefore, false detection is suppressed by setting the lower limit of the threshold value.
なお、S520の場合と同様に合成モーションコントラスト画像をエッジ選択鮮鋭化しているため、単独のモーションコントラスト画像をエッジ選択鮮鋭化する場合に比べて2値化した場合のノイズ状の誤検出領域をより減らすことができる。 Note that, as in the case of S520, edge-selective sharpening is performed on the composite motion contrast image, so noise-like erroneous detection areas when binarized are more reduced than when edge-selectively sharpening a single motion contrast image. can be reduced.
さらに、本発明は3次元鮮鋭化画像を3次元データとして2値化することに限定されるものではない。例えば、3次元鮮鋭化画像を所定の投影深度範囲で投影した正面鮮鋭化画像を2値化する場合も本発明に含まれる。正面鮮鋭化画像を2値化する場合も、任意の公知の閾値決定法を用いてよい。また該正面鮮鋭化画像を2値化する際の閾値に上限値や下限値を設定してよい。あるいは、該正面鮮鋭化画像の2値化は閾値処理に限定されるものではなく、任意の公知のセグメンテーション法を用いて2値化してよい。 Furthermore, the present invention is not limited to binarizing a three-dimensional sharpened image as three-dimensional data. For example, the present invention also includes the case where a front sharpened image obtained by projecting a three-dimensional sharpened image in a predetermined projection depth range is binarized. Any known threshold value determination method may be used when the front sharpened image is binarized. Further, an upper limit value or a lower limit value may be set as a threshold value when the front sharpened image is binarized. Alternatively, the binarization of the front sharpened image is not limited to threshold processing, and may be binarized using any known segmentation method.
<ステップ550>
抽出部101-462は、S520で生成した3次元ヘシアン強調画像の2値画像の輝度値と、S540で生成した3次元エッジ選択鮮鋭化画像の2値画像の輝度値の双方が0より大きい場合に血管候補領域として抽出する。当該演算処理により、ヘシアン強調画像に見られる血管径を過大評価している領域と、エッジ選択鮮鋭化画像上に見られるノイズ領域がともに抑制され、血管の境界位置が正確かつ血管の連続性が良好な2値画像を取得できる。
<Step 550>
The extraction unit 101-462 determines whether the brightness value of the binary image of the three-dimensional Hessian enhanced image generated in S520 and the brightness value of the binary image of the three-dimensional edge selective sharpening image generated in S540 are both greater than 0. The area is extracted as a blood vessel candidate area. This calculation process suppresses both the area where the vessel diameter is overestimated in the Hessian-enhanced image and the noise area seen in the edge-selective sharpened image, making it possible to accurately locate blood vessel boundaries and ensure blood vessel continuity. Good binary images can be obtained.
また双方の2値画像とも合成モーションコントラスト画像に基づく2値画像であることから、単独のモーションコントラスト画像に基づく2値画像に比べて2値化した場合のノイズ状の誤検出領域が減少するとともに、特に毛細血管領域の連続性が向上する。 In addition, since both binary images are binary images based on a composite motion contrast image, the noise-like false detection area when binarized is reduced compared to a binary image based on a single motion contrast image. , especially the continuity of the capillary region is improved.
<ステップ560>
抽出部101-462は、血管領域の整形処理として2値画像の3次元オープニング処理(収縮処理後に膨張処理を行うこと)及び3次元クロージング処理(膨張処理後に収縮処理を行うこと)を実施する。なお、整形処理はこれに限らず例えば2値画像をラベリングした場合の各ラベルの体積に基づく小領域除去を行ってもよい。
<Step 560>
The extraction unit 101-462 performs three-dimensional opening processing (performing expansion processing after contraction processing) and three-dimensional closing processing (performing contraction processing after expansion processing) of the binary image as shaping processing for the blood vessel region. Note that the shaping process is not limited to this, and for example, small area removal may be performed based on the volume of each label when a binary image is labeled.
なお、様々な径の血管が含まれるモーションコントラスト画像において血管強調する際のスケールを適応的に決定する方法はS510~S560に述べた方法に限定されない。例えば、図5(b)のS610~S650に示すように、3次元ヘシアン強調画像の輝度値と3次元エッジ選択鮮鋭化による血管強調画像の輝度値を乗じる演算を適用した画像に対する輝度統計値(例えば平均値)を閾値として2値化することによって血管領域を特定してもよい。該閾値には下限値や上限値を設定できる。 Note that the method of adaptively determining the scale for enhancing blood vessels in a motion contrast image that includes blood vessels of various diameters is not limited to the methods described in S510 to S560. For example, as shown in S610 to S650 in FIG. 5B, the brightness statistical values ( For example, the blood vessel region may be identified by binarizing using the average value) as a threshold value. A lower limit value and an upper limit value can be set for the threshold value.
あるいは、図5(c)のS710~S740に示すように、固視位置や深度範囲等に基づく各画素の3次元位置に応じてヘシアンフィルタ適用時の平滑化パラメータσの範囲を適応的に変えてヘシアンフィルタを適用し、2値化することで血管強調してもよい。例えば、乳頭部網膜表層ではσ=1~10、黄斑部網膜表層ではσ=1~8、黄斑部網膜深層ではσ=1~6のように設定できる。 Alternatively, as shown in S710 to S740 in FIG. 5(c), the range of the smoothing parameter σ when applying the Hessian filter is adaptively changed according to the three-dimensional position of each pixel based on the fixation position, depth range, etc. Blood vessels may be emphasized by applying a Hessian filter and binarizing the image. For example, it is possible to set σ=1 to 10 for the papillary retinal surface layer, σ=1 to 8 for the macular retinal surface layer, and σ=1 to 6 for the macular retinal deep layer.
また、2値化処理は閾値処理に限定されるものではなく任意の公知のセグメンテーション手法を用いてよい。 Furthermore, the binarization process is not limited to threshold processing, and any known segmentation method may be used.
さらに、図6(a)に示すフローチャートを参照しながら、S308で実行される処理の詳細について説明する。 Furthermore, details of the process executed in S308 will be described with reference to the flowchart shown in FIG. 6(a).
<ステップ810>
操作者は、入力部103を介して計測処理における関心領域を設定する。すなわち、血管密度を算出する3次元空間は、ユーザにより指定される。本実施形態では計測内容として
1)網膜表層におけるVADマップ及びVADセクタマップ
2)網膜外層における脈絡膜新生血管の体積
を算出する。
<Step 810>
The operator sets a region of interest in the measurement process via the
従って、関心領域として網膜表層においては(i)画像全体(ii)固視灯位置を中心とするセクタ領域(直径1mmの内円と直径3mmの外円で規定される環状領域内をSuperior・Inferior・Nasal・Temporalの4つの扇形に分割した領域及び該内円領域)を選択する。ただし、本実施形態でいう画像全体は深度方向に関して図9(a)の910で設定されるような層境界を用いて規定される有限の範囲に限定される。また、本実施形態でいうセクタ領域は「水平方向に関して上記のような扇形の分割領域及び内円領域、深度方向に関して図9(a)の910で設定されるような層境界で規定される3次元領域」を指す。前者は図9(a)のDensityMap/Sector902の項目の中からMap、次元数に関して3D Analysisチェックボックス912を選択することによって、また後者はDensityMap/Sector902の項目の中からSector、次元数に関して3D Analysisチェックボックスを選択することによって自動で設定される。また網膜外層においては網膜外層に相当する層境界(OPL/ONL境界と、ブルッフ膜境界を該境界深層側に20μm移動させた位置で囲まれる範囲)を指定する。関心領域の指定は眼底表面の2次元方向はセクタの移動により指定可能であり、眼底の深さ方向は表示されているEn-Face画像の深さ範囲の指定により指定することができる。なお、3次元モーションコントラストデータが表示されて状態で3次元モーションコントラストデータに対して直接関心領域を指定することとしてもよい。 Therefore, in the retinal surface layer, the areas of interest are (i) the entire image, (ii) sector areas centered on the fixation lamp position (inside the annular area defined by the inner circle with a diameter of 1 mm and the outer circle with a diameter of 3 mm), Superior and Inferior.・Select the area divided into four fan shapes (Nasal and Temporal) and the inner circle area). However, the entire image in this embodiment is limited to a finite range defined using layer boundaries such as those set at 910 in FIG. 9(a) in the depth direction. In addition, the sector area in this embodiment is defined by "a fan-shaped divided area and an inner circular area as described above in the horizontal direction, and a layer boundary as set at 910 in FIG. 9(a) in the depth direction. refers to the dimensional area. The former is done by selecting the 3D Analysis check box 912 for Map and the number of dimensions from the DensityMap/Sector 902 items in FIG. Automatically set by selecting the checkbox. Furthermore, for the outer retinal layer, a layer boundary corresponding to the outer retinal layer (an area surrounded by the OPL/ONL boundary and a position where the Bruch's membrane boundary is moved 20 μm toward the deep layer side of the boundary) is specified. The region of interest can be specified in the two-dimensional direction of the fundus surface by moving sectors, and the depth direction of the fundus can be specified by specifying the depth range of the displayed En-Face image. Note that the region of interest may be directly specified with respect to the three-dimensional motion contrast data while the three-dimensional motion contrast data is displayed.
なお、これに限らず例えば操作者が図9(a)の904に示すようなボタンを指定した上で関心領域を手動設定してもよい。該ボタン904を押した場合に表示される設定画面905から計測の種類(ここではDensity)を選択し、入力部103を介して図10(b)の灰色線部1001に示すような関心領域を設定してOKボタンを押下する。
Note that the present invention is not limited to this, and for example, the operator may manually set the region of interest by specifying a button as shown at 904 in FIG. 9(a). Select the measurement type (Density in this case) from the setting screen 905 that is displayed when the button 904 is pressed, and select the region of interest as shown in the gray line section 1001 in FIG. 10(b) via the
深度方向に関して、本実施形態では網膜表層に関しては図9(a)の910に示すような層境界を用いて規定される深度範囲とする。また網膜外層については外網状層(OPL)-外顆粒層(ONL)境界とブルッフ膜(BM)で規定される深度範囲とする。該領域内に示された数値は該領域内で計測した値(この場合は図9(a)のDensityAnalysisの項目903でArea Densityが選択されているため、VAD値)を示している。なお、関心領域は3次元領域に限られるものではなく、投影画像上で2次元領域を設定して該2次元領域内で計測値を算出してもよい。 Regarding the depth direction, in this embodiment, the depth range for the retinal surface layer is defined using layer boundaries as shown at 910 in FIG. 9(a). Regarding the outer retinal layer, the depth range is defined by the outer plexiform layer (OPL)-outer nuclear layer (ONL) boundary and Bruch's membrane (BM). The numerical value shown within the area indicates the value measured within the area (in this case, the VAD value because Area Density is selected in the Density Analysis item 903 of FIG. 9(a)). Note that the region of interest is not limited to a three-dimensional region, and a two-dimensional region may be set on the projection image and measurement values may be calculated within the two-dimensional region.
<ステップ820>
計測部101-463は、S307で得られた血管領域の2値画像に基づいて計測処理を行う。本実施形態では、S307で特定された該血管領域の2値画像を網膜表層の範囲で投影することなく、3次元のデータの各画素位置において当該画素を中心とした近傍領域内に占める非0画素(白画素)の割合を当該画素における血管密度(VAD)として算出する。さらに、各画素で算出した血管密度(VAD)の値を持つ画像(VADマップ)を生成する。
<Step 820>
The measurement unit 101-463 performs measurement processing based on the binary image of the blood vessel region obtained in S307. In this embodiment, the binary image of the blood vessel region identified in S307 is not projected within the range of the retinal surface layer, and instead of projecting the binary image of the blood vessel region specified in S307 within the range of the retinal surface layer, at each pixel position of the three-dimensional data, a non-zero The ratio of pixels (white pixels) is calculated as the blood vessel density (VAD) at the pixel. Furthermore, an image (VAD map) having a blood vessel density (VAD) value calculated for each pixel is generated.
なお、該投影2値画像上の(S810で設定した)各セクタ領域における非0画素(白画素)の割合を当該セクタにおける血管密度(VAD)として算出してもよい。さらに、各セクタ領域で算出した血管密度(VAD)の値を持つマップ(VADセクタマップ)を生成してもよい。 Note that the ratio of non-zero pixels (white pixels) in each sector area (set in S810) on the projected binary image may be calculated as the blood vessel density (VAD) in the sector. Furthermore, a map (VAD sector map) having blood vessel density (VAD) values calculated in each sector region may be generated.
また、網膜外層では、S810で設定した網膜外層に相当する関心領域内における非0画素(白画素)の体積を算出する。なお、本発明は体積の算出に限定されるものではなく、例えば網膜外層に相当する関心領域内で脈絡膜新生血管領域を強調もしくは2値化した画像を投影し、該投影強調画像を2値化した画像、もしくは投影した2値画像上で脈絡膜新生血管領域の面積を算出してもよい。 Furthermore, for the outer retinal layer, the volume of non-zero pixels (white pixels) within the region of interest corresponding to the outer retinal layer set in S810 is calculated. Note that the present invention is not limited to volume calculation; for example, an image in which the choroidal neovascular region is emphasized or binarized is projected within a region of interest corresponding to the outer layer of the retina, and the projected enhanced image is binarized. The area of the choroidal neovascular region may be calculated on the image or the projected binary image.
上記では特定された3次元血管領域に基づいて網膜表層で3次元のVADを、網膜外層で体積を計測する場合の手順を例に説明したが、3次元の血管中心線に基づいて網膜表層で3次元のVLDを、網膜外層で総血管長を計測する場合には、上記S810~820の代わりに図6(b)に示すS830~850を実行する。 Above, we explained the procedure for measuring 3D VAD in the retinal surface layer based on the identified 3D blood vessel area and volume in the outer retinal layer as an example. When measuring the total blood vessel length in the outer retinal layer using three-dimensional VLD, steps S830 to S850 shown in FIG. 6(b) are executed instead of S810 to S820.
<ステップ830>
計測部101-463は、S307で生成した血管領域の2値画像を3次元細線化処理することにより、血管の中心線に相当する線幅1画素の2値画像(以下、スケルトン画像と表記)を生成する。
<Step 830>
The measurement unit 101-463 performs three-dimensional thinning processing on the binary image of the blood vessel region generated in S307, thereby creating a binary image with a line width of 1 pixel corresponding to the center line of the blood vessel (hereinafter referred to as a skeleton image). generate.
<ステップ840>
操作者は、入力部103を介してS810と場合と同様の関心領域を設定する。本実施形態では計測内容としてVLDマップとVLDセクタマップを算出するものとする。なお、VLDもしくはVLDセクタマップをモーションコントラスト画像上に重畳表示したくない場合は、図9(a)のDensity Map/Sector902のMapもしくはSectorの項目のチェックボックスを非選択に設定すればよい。
<Step 840>
The operator sets the region of interest via the
<ステップ850>
計測部101-463はS830で得られたスケルトン画像に基づいて計測処理を行う。すなわち、網膜表層において特定された3次元スケルトンから計測する。本実施形態では、該スケルトン画像の各画素位置において当該画素を中心とした近傍領域における単位体積当たりの非0画素(白画素)の長さの総和[mm-2]を当該画素における血管密度(VLD)として算出する。さらに、各画素で算出した血管密度(VLD)の値を持つ画像(VLDマップ)を生成する。
<Step 850>
The measurement unit 101-463 performs measurement processing based on the skeleton image obtained in S830. That is, measurement is performed from the three-dimensional skeleton specified in the retinal surface layer. In the present embodiment, at each pixel position of the skeleton image, the total length [mm −2 ] of non-zero pixels (white pixels) per unit volume in a neighboring region centered on the pixel is calculated as the blood vessel density ( VLD). Furthermore, an image (VLD map) having a blood vessel density (VLD) value calculated for each pixel is generated.
また、該スケルトン画像上の(S840で設定した)各セクタ領域における単位体積当たりの非0画素(白画素)の長さの総和[mm-2]を当該セクタにおける血管密度(VLD)として算出する。さらに、各セクタ領域で算出した血管密度(VLD)の値を持つマップ(VLDセクタマップ)を生成する。 Furthermore, the sum [mm −2 ] of the lengths of non-zero pixels (white pixels) per unit volume in each sector region (set in S840) on the skeleton image is calculated as the blood vessel density (VLD) in the sector. . Furthermore, a map (VLD sector map) having blood vessel density (VLD) values calculated in each sector area is generated.
さらに、網膜外層では、S810で設定した網膜外層に相当する関心領域内における非0画素(白画素)の長さの総和を算出する。なお、本発明は3次元的な血管の長さの算出に限定されるものではなく、例えば網膜外層に相当する関心領域内でスケルトン画像を投影し、該投影2値画像上で血管の長さの総和を算出してもよい。 Furthermore, in the outer retinal layer, the total length of non-zero pixels (white pixels) within the region of interest corresponding to the outer retinal layer set in S810 is calculated. Note that the present invention is not limited to calculating the length of a three-dimensional blood vessel; for example, a skeleton image is projected within a region of interest corresponding to the outer layer of the retina, and the length of the blood vessel is calculated on the projected binary image. You may calculate the total sum.
以上述べた構成によれば、画像処理装置101は網膜外層に脈絡膜新生血管(CNV)を含む被検眼から3次元の合成モーションコントラスト画像を取得し、3次元の血管強調フィルタを適用して2値化することでCNVを含む血管領域を3次元で特定する。さらに特定したCNV領域の体積を算出し、正確に計測する。
According to the configuration described above, the
これにより、OCT断層画像の信号強度や画質の影響を抑制しながら3次元の血管領域等の所望の領域を強調もしくは特定し、正確に計測できる。 Thereby, a desired region such as a three-dimensional blood vessel region can be emphasized or specified and accurately measured while suppressing the influence of the signal intensity and image quality of the OCT tomographic image.
また、血管密度を算出する対象のデータは合成された3次元モーションコントラストデータであるため、1つの3次元モーションコントラストデータに比べてノイズが低減されている。従って、本実施形態によれば、合成された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、精度の良い血管密度等の指標を算出することが可能となる。また、上記血管密度等を算出する場合に精度を低下させる要因となるプロジェクションアーチファクトが除去された後に、血管密度等を算出するため、血管密度を精度よく算出することができる。 Furthermore, since the data for which the blood vessel density is calculated is synthesized three-dimensional motion contrast data, noise is reduced compared to one piece of three-dimensional motion contrast data. Therefore, according to the present embodiment, it is possible to calculate accurate indicators such as blood vessel density using information regarding the three-dimensional blood vessel region in at least a portion of the synthesized three-dimensional motion contrast data. In addition, since the blood vessel density and the like are calculated after projection artifacts that cause a decrease in accuracy when calculating the blood vessel density and the like are removed, the blood vessel density and the like can be calculated with high accuracy.
(変形例1)
上述した実施形態において、血管計測値の算出を、高画質化された3次元モーションコントラストデータを所定の深さ範囲で投影した2次元モーションコントラストデータから行うこととしてもよい。
(Modification 1)
In the embodiment described above, the blood vessel measurement value may be calculated from two-dimensional motion contrast data obtained by projecting high-quality three-dimensional motion contrast data in a predetermined depth range.
例えば、ユーザはユーザーインターフェースを介して、血管計測を2次元で行うか3次元で行うかを選択し、画像処理装置101(計測部101-463)はユーザによる選択を受付ける。そして、計測部101-463はユーザの選択に応じて2次元モーションコントラストデータまたは3次元モーションコントラストデータのいずれかから血管計測を行う。すなわち、計測部101-463は、高画質化された3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、2次元領域における血管計測値を算出することとしてもよい。 For example, the user selects whether to perform blood vessel measurement in two dimensions or in three dimensions via the user interface, and the image processing device 101 (measuring unit 101-463) accepts the user's selection. Then, the measurement unit 101-463 performs blood vessel measurement from either the two-dimensional motion contrast data or the three-dimensional motion contrast data according to the user's selection. That is, the measurement unit 101-463 uses information regarding the three-dimensional blood vessel region in at least a portion of the two-dimensional motion contrast data obtained by projecting the high-quality three-dimensional motion contrast data in the depth direction. It is also possible to calculate blood vessel measurement values in a two-dimensional region.
なお、計測部101-463は算出した血管計測値に対して、2次元モーションコントラストデータから算出したものか3次元モーションコントラストデータから算出したものかを識別可能な識別情報を対応付けることとしてもよい。すなわち、計測部101-463は、算出した血管計測値に対して、3次元空間上で算出した血管計測値であることを示す情報を対応付ける。具体的には、計測部101-463は、算出した血管計測値(例えば血管密度や血管領域の径、長さ、面積、体積)に対して、3次元の計測値であるか2次元の計測値であるかを識別可能な識別情報を対応付ける。 Note that the measurement unit 101-463 may associate the calculated blood vessel measurement value with identification information that can identify whether it is calculated from two-dimensional motion contrast data or three-dimensional motion contrast data. That is, the measurement unit 101-463 associates the calculated blood vessel measurement value with information indicating that the blood vessel measurement value is calculated in a three-dimensional space. Specifically, the measurement unit 101-463 determines whether the calculated blood vessel measurement values (for example, blood vessel density, diameter, length, area, and volume of the blood vessel region) are three-dimensional measurement values or two-dimensional measurement values. Associate identification information that can identify whether it is a value or not.
(変形例2)
上述した実施形態や変形例において、表示制御部101-05は、表示部104に算出された血管計測値等を時系列に沿って複数表示させることとしてもよい。このようにすれば、例えば異なる日に算出された血管密度をユーザは一覧することが可能となり被検者の状態の変化を簡単に把握することが可能となる。
(Modification 2)
In the embodiments and modifications described above, the display control unit 101-05 may display a plurality of calculated blood vessel measurement values and the like on the
時系列に沿って複数の血管計測値を表示する場合、2次元モーションコントラストデータから算出された血管計測値と3次元モーションコントラストデータから算出された血管計測値が混在してしまうと、被検者の経過を正確に把握することができなくなってしまう。そこで、表示制御部101-05は、変形例1で上述した識別情報に基づいて2次元モーションコントラストデータから算出された血管計測値と3次元モーションコントラストデータから算出された血管計測値が混在しないように時系列に沿った複数の血管計測値を表示部104に表示させる。表示制御部101-05は、2次元モーションコントラストデータから算出された血管計測値と3次元モーションコントラストデータから算出された血管計測値のうち、識別情報に基づいて例えば3次元モーションコントラストデータから算出された血管計測値のみを時系列に沿って表示部104に表示させる。すなわち、表示制御手段は、算出手段により算出された血管計測値を時系列に沿って複数表示させる場合、識別情報に基づいて、3次元空間における血管計測値と2次元領域における血管計測値とが混在しないように表示部に表示させる。
When displaying multiple blood vessel measurement values in chronological order, if blood vessel measurement values calculated from 2D motion contrast data and blood vessel measurement values calculated from 3D motion contrast data are mixed, the patient may It becomes impossible to accurately grasp the progress of the process. Therefore, the display control unit 101-05 prevents the blood vessel measurement values calculated from the two-dimensional motion contrast data and the blood vessel measurement values calculated from the three-dimensional motion contrast data based on the identification information described above in modification example 1 from being mixed. A plurality of blood vessel measurement values in time series are displayed on the
(変形例3)
上述した実施形態や各変形例においては、深度方向に屈曲した血管に対して3次元モーションコントラスト画像を用いて3次元的に血管強調もしくはセグメンテーションして計測を行う場合の対象症例として脈絡膜新生血管の場合について説明したが、本発明はこれに限られるものではない。
(Modification 3)
In the above-described embodiments and each modification example, choroidal neovascularization is a target case in which measurement is performed by three-dimensionally emphasizing or segmenting a blood vessel bent in the depth direction using a three-dimensional motion contrast image. Although the case has been described, the present invention is not limited to this.
例えば、視神経乳頭部の動静脈及び毛細血管に対してS307に示した手順で強調・セグメンテーションし、解析部101-46が特定された血管領域の径や断面積、長さ、曲率、血管密度等を計測してもよい。 For example, the arteriovenous and capillary vessels of the optic disc are highlighted and segmented by the procedure shown in S307, and the analysis unit 101-46 calculates the diameter, cross-sectional area, length, curvature, blood vessel density, etc. of the identified blood vessel region. may be measured.
あるいは網膜の表層毛細血管及び深層毛細血管をS307に示した手順で強調・セグメンテーションし、深度方向に走行する(接合部の)毛細血管領域の色を変えて表示したり、解析部101-46が該接合部の毛細血管の本数を計測したりしてもよい。 Alternatively, the superficial capillaries and deep capillaries of the retina may be highlighted and segmented using the procedure shown in S307, and the capillary regions running in the depth direction (at junctions) may be displayed with different colors, or the analysis unit 101-46 may The number of capillaries at the junction may also be measured.
(変形例4)
上述した実施形態や各変形例においては、3次元モーションコントラスト画像に対して3次元での強調処理及び特定処理を行って得られた画像に対して計測する場合について説明したが、本発明はこれに限定されない。
(Modification 4)
In the embodiment and each modification described above, the case where measurement is performed on an image obtained by performing three-dimensional enhancement processing and specific processing on a three-dimensional motion contrast image has been described, but the present invention is not limited to this. but not limited to.
例えば該3次元強調処理した画像を所定の深度範囲で投影して得られる正面強調画像に対して任意の公知のセグメンテーション法を用いて2値化処理を行い、該2次元の2値領域に関する計測(面積や円形度、血管密度等)を行う場合も本発明に含まれる。なお、S520やS540、S820で説明したように、3次元セグメンテーション処理により特定した3次元の血管領域を所定の深度範囲で投影した画像に対して計測(面積や円形度、2次元の血管密度等)を行う場合も本発明に含まれる。 For example, perform binarization processing using any known segmentation method on a front-enhanced image obtained by projecting the three-dimensional enhanced image in a predetermined depth range, and measure the two-dimensional binary area. (Area, circularity, blood vessel density, etc.) are also included in the present invention. As explained in S520, S540, and S820, measurements (area, circularity, two-dimensional blood vessel density, etc. ) is also included in the present invention.
(変形例5)
上述した実施形態や各変形例においては、3次元モーションコントラスト画像に対して3次元での強調処理及び特定処理を行って得られた画像を所定の深度範囲で投影して生成した正面画像上で計測する場合について説明したが、本発明はこれに限定されない。
(Modification 5)
In the above-described embodiments and each modification, a frontal image is generated by projecting an image obtained by performing three-dimensional enhancement processing and specific processing on a three-dimensional motion contrast image in a predetermined depth range. Although the case of measurement has been described, the present invention is not limited to this.
例えば、特定された3次元血管領域に対して任意方向の断面(MPR;Multi Planar Reconstruction)もしくは任意形状の曲断面を設定し、該断面もしくは該曲断面における血管領域の面積や直径、領域数等を計測してもよい。 For example, a cross section in an arbitrary direction (MPR; Multi Planar Reconstruction) or a curved cross section of an arbitrary shape is set for the identified three-dimensional blood vessel region, and the area, diameter, number of regions, etc. of the blood vessel region in the cross section or the curved cross section are determined. may be measured.
(変形例6)
上述した実施形態や各変形例においては、正面画像におけるセクタ単位の血管密度計測を黄斑部に対して行ったが、本発明はこれに限定されない。例えば、視神経乳頭部に対してセクタ状の関心領域を設定し、該関心領域内で計測値を算出する場合も本発明に含まれる。
(Modification 6)
In the above-described embodiments and modifications, the blood vessel density was measured in sector units in the frontal image with respect to the macular region, but the present invention is not limited thereto. For example, the present invention also includes a case where a sector-shaped region of interest is set for the optic disc and a measurement value is calculated within the region of interest.
また、本発明では3次元的な関心領域としてスラブ(slab;2つの層境界曲面間で囲まれる3次元領域)単位で血管体積計測を行う場合について説明したが、計測の際に用いる関心領域の設定法はこれに限定されない。例えば、3次元のグリッド(立方体領域もしくは四角柱領域)領域や3次元のセクタ領域(2次元のセクタ領域を深度方向に拡張して得られる領域)を3次元の関心領域として設定し、該3次元関心領域単位で計測してもよい。あるいは、該スラブ領域と該3次元グリッドもしくは3次元セクタを組み合わせて得られる3次元関心領域単位で計測する場合も本発明に含まれる。 Furthermore, in the present invention, a case has been described in which blood vessel volume is measured in units of slabs (three-dimensional regions surrounded by two layer boundary curved surfaces) as three-dimensional regions of interest. The setting method is not limited to this. For example, a three-dimensional grid (cubic area or quadrangular prism area) area or a three-dimensional sector area (an area obtained by extending a two-dimensional sector area in the depth direction) is set as a three-dimensional region of interest, and the It may be measured in units of dimensional regions of interest. Alternatively, the present invention also includes a case where measurement is performed in units of a three-dimensional region of interest obtained by combining the slab region and the three-dimensional grid or three-dimensional sector.
なお、該3次元関心領域単位で計測した計測値は所定の深度範囲ごとに(深度方向に計測値が1つの場合は計測値をそのまま、深度方向に複数ある場合は平均値投影もしくは最大値投影して)2次元マップとして表示するか、3次元マップとして表示してよい。 Note that the measured values measured in units of the three-dimensional region of interest are calculated for each predetermined depth range (if there is one measured value in the depth direction, the measured value is used as is; if there are multiple measured values in the depth direction, the measured value is projected as an average value or maximum value projected). The map may be displayed as a two-dimensional map or as a three-dimensional map.
(変形例7)
上述した実施形態や各変形例において、解析部101-46が3次元血管領域に対して算出する計測値の例は、血管体積や血管長、血管曲率、断面積や血管径に限定されない。例えば
・3次元の血管密度(3次元関心領域内に占める血管領域に属する画素の割合、または「単位体積あたりの総血管長」のセクタ内での平均)
・Vessel Cross Section Index(単位血管長あたりの血管断面積)
・3次元のFractal Dimension
を算出してもよい。
(Modification 7)
In the embodiment and each modification described above, examples of measurement values that the analysis unit 101-46 calculates for the three-dimensional blood vessel region are not limited to the blood vessel volume, blood vessel length, blood vessel curvature, cross-sectional area, and blood vessel diameter. For example: ・Three-dimensional blood vessel density (ratio of pixels belonging to the blood vessel region within the three-dimensional region of interest, or average within a sector of "total blood vessel length per unit volume")
・Vessel Cross Section Index (vascular cross-sectional area per unit vessel length)
・3D Fractal Dimension
may be calculated.
(変形例8)
上述した実施形態や各変形例においては、単検査での血管領域特定及び計測結果の表示法として正面モーションコントラスト画像上に計測マップを重畳表示する場合について説明したが、本発明はこれに限定されるものではない。例えば血管強調画像、特定された血管領域の2値画像、スケルトン画像のうちの少なくとも1つを図9(b)の906や908に表示させてもよい。あるいは、906や908にモーションコントラスト画像を表示しておき、その上に血管強調画像、特定された血管領域の2値画像、スケルトン画像の少なくとも1つを色もしくは透明度を適宜調整した上で重畳表示するよう構成する場合も本発明に含まれる。あるいは、正面断層画像もしくはBスキャン断層画像上に血管強調画像、特定された血管領域の2値画像、スケルトン画像のうちの少なくとも1つを色もしくは透明度を適宜調整した上で重畳表示してもよい。適宜906や908に断層画像の位置を示す線を表示しておき、該線を操作者が入力部103を用いて移動させることにより、対応する断層画像上の強調画像、血管領域の2値画像、スケルトンのうちの少なくとも1つを表示させるよう構成してもよい。
(Modification 8)
In the above-described embodiment and each modification example, a case has been described in which a measurement map is superimposed and displayed on a frontal motion contrast image as a method for specifying blood vessel regions and displaying measurement results in a single examination, but the present invention is not limited to this. It's not something you can do. For example, at least one of a blood vessel enhanced image, a binary image of the specified blood vessel region, and a skeleton image may be displayed in 906 or 908 in FIG. 9(b). Alternatively, a motion contrast image is displayed in 906 or 908, and at least one of a blood vessel enhancement image, a binary image of a specified blood vessel region, and a skeleton image is displayed on top of the motion contrast image after adjusting the color or transparency as appropriate. The present invention also includes a configuration in which this is the case. Alternatively, at least one of a blood vessel emphasis image, a binary image of a specified blood vessel region, and a skeleton image may be superimposed and displayed on the frontal tomographic image or the B-scan tomographic image after adjusting the color or transparency as appropriate. . A line indicating the position of the tomographic image is displayed at 906 or 908 as appropriate, and when the operator moves the line using the
(変形例9)
上述した実施形態や各変形例において、S309で操作者が入力部103から血管領域もしくは血管中心線データを手動修正するよう指示を入力した場合に、以下のような手順で手動修正してもよい。
(Modification 9)
In the embodiment and each modification described above, when the operator inputs an instruction to manually correct the blood vessel region or blood vessel center line data from the
例えば、図10(a)に示すような合成モーションコントラスト画像に対して同図(c)に示すような過抽出領域を含む2値画像が得られた場合に、操作者が入力部103を経由して指定した位置の白画素を解析部101-46が削除する。追加・移動・削除手順として、例えば「d」キーを押しながらマウスで指定した位置の白画素を削除する、「a」キーを押しながらマウスで指定した位置に白画素を追加する、「s」キーを押しながらマウスで指定した白画素をドラッグして移動させる等の方法がある。あるいは、同図(d)に示すようにモーションコントラスト画像に基づく画像上に手動修正対象である2値画像(血管領域もしくは血管中心線)の色や透明度を適宜調整して重畳表示し、過抽出もしくは抽出不足の領域が判別しやすい状態にしておく。同図(d)の矩形領域1002内を拡大した画像を同図(e)に示す。灰色が過抽出した領域で、白色が元のモーションコントラスト画像の脱相関値を示す。該過抽出(もしくは抽出不足)の領域を操作者が入力部103を用いて指定することにより、正確かつ効率的に2値画像上の血管もしく血管中心線領域を手動修正するよう構成してもよい。なお、2値画像の手動修正処理は正面画像に限定されない。例えば図9(a)の右側に示すような任意のスライス位置のBスキャン断層像上にモーションコントラストデータや血管領域の2値データもしくは血管中心線領域を色や透明度の調整後に重畳する。このように過抽出もしくは抽出不足の領域が判別しやすい状態にした上で、操作者が手動修正(追加・移動・削除)する2値データの3次元位置(x,y,z座標)を、入力部103を用いて指定して手動修正してもよい。さらに、手動修正した2次元もしくは3次元の2値データを表示部104に表示したり、外部記憶部102に保存したりしてもよい。
For example, when a binary image including an over-extracted area as shown in FIG. 10(c) is obtained from a composite motion contrast image as shown in FIG. 10(a), the operator The analysis unit 101-46 deletes the white pixel at the specified position. Addition/movement/deletion procedures include, for example, holding down the "d" key and deleting a white pixel at a position specified with the mouse, holding down the "a" key and adding a white pixel at a position specified with the mouse, or "s". There is a method of moving the specified white pixel by dragging it with the mouse while holding down the key. Alternatively, as shown in Figure (d), the color and transparency of the binary image (vascular region or blood vessel center line) to be manually corrected may be adjusted and superimposed on the image based on the motion contrast image to over-extract the image. Or, make it easy to identify areas where extraction is insufficient. An enlarged image of the inside of the rectangular area 1002 in FIG. 3(d) is shown in FIG. 2(e). Gray indicates the overextracted region, and white indicates the decorrelation value of the original motion contrast image. The system is configured such that the operator specifies the over-extracted (or under-extracted) area using the
さらに、2値画像(血管領域の2値画像もしくはスケルトン画像)が手動修正済であることを示す情報もしくは手動修正位置に関する情報を該2値画像と関連付けて外部記憶部102に保存しておき、S870で血管特定結果及び計測結果を表示部104に表示する際に該手動修正済であることを示す情報もしくは手動修正位置に関する情報を表示部104に表示してもよい。
Furthermore, information indicating that the binary image (binary image or skeleton image of the blood vessel region) has been manually corrected or information regarding the manual correction position is stored in the
(変形例10)
上述した実施形態や各変形例において、画像処理装置101が略同一走査位置で取得した断層画像の枚数が所定値未満のモーションコントラスト画像もしくは所定値未満相当の合成モーションコントラスト画像に対する血管領域の特定もしくは計測に関する指示を受け付けた場合に、表示部104に警告表示を行うよう構成してもよい。
(Modification 10)
In the embodiment and each modification described above, the
また、上述した実施形態や各変形例においては、合成部101-42が繰り返しOCTA撮影終了時に合成モーションコントラスト画像を生成する場合について説明したが、合成モーションコントラスト画像の生成手順はこれに限定されない。例えば図8(e)のレポート画面803上に合成モーションコントラスト画像生成指示ボタン812を配置しておく。OCTA撮影完了後(撮影日より後の日でもよい)に操作者が明示的に該生成指示ボタン812を押下した場合に合成部101-42が合成モーションコントラスト画像を生成するよう画像処理装置101を構成してもよい。操作者が明示的に合成画像生成指示ボタン812を押下して合成画像を生成する場合、図8(e)に示すようなレポート画面803上に合成モーションコントラスト画像804や合成条件データ、検査画像リスト上に合成画像に関する項目を表示させる。
Further, in the above-described embodiment and each modification example, a case has been described in which the synthesizing unit 101-42 generates a synthesized motion contrast image at the end of repeated OCTA imaging, but the procedure for generating a synthesized motion contrast image is not limited to this. For example, a synthetic motion contrast image generation instruction button 812 is placed on the report screen 803 in FIG. 8(e). The
また、操作者が明示的に該生成指示ボタン812を押下する場合は、表示制御部101-05が以下の処理を行う。すなわち、合成対象画像選択画面を表示させ、操作者が入力部103を操作して合成対象画像群を指定し、許容ボタンを押下した場合に合成部101-42が合成モーションコントラスト画像を生成し、表示部104に表示させる。なお、生成済の合成モーションコントラスト画像を選択して合成する場合も本発明に含まれる。
Further, when the operator explicitly presses the generation instruction button 812, the display control unit 101-05 performs the following processing. That is, when the compositing target image selection screen is displayed, the operator operates the
また操作者が合成画像生成指示ボタン812を押下した場合、3次元モーションコントラスト画像を投影した2次元画像同士を合成することにより2次元合成画像を生成してもよいし、3次元合成画像を生成後に投影することで2次元合成画像を生成してもよい。 Further, when the operator presses the composite image generation instruction button 812, a 2D composite image may be generated by combining 2D images obtained by projecting 3D motion contrast images, or a 3D composite image may be generated. A two-dimensional composite image may be generated by later projecting.
また、上述した様々な実施形態及び変形例においては、3次元モーションコントラストデータを合成することを前提としていたが、1つの3次元モーションコントラストデータに対してプロジェクションアーチファクトを低減する処理及び血管密度等の血管計測値を算出する処理(または血管領域を抽出する処理)を施してもよい。 In addition, in the various embodiments and modifications described above, it is assumed that three-dimensional motion contrast data is synthesized, but processing for reducing projection artifacts and blood vessel density etc. for one three-dimensional motion contrast data. A process of calculating a blood vessel measurement value (or a process of extracting a blood vessel region) may be performed.
また、上述した様々な実施形態及び変形例において、補正部101-43は、高画質化された3次元モーションコントラストデータに対してプロジェクションアーチファクトを低減する処理を行う処理手段の一例に相当する。ただし、処理手段による処理を実行する上で、高画質化処理は必須ではない。すなわち、処理手段は、眼底の3次元モーションコントラストデータに対してプロジェクションアーチファクトを低減する処理を行えば何でもよい。そして、抽出手段は、処理手段によりプロジェクションアーチファクトが低減された後の3次元モーションコントラストデータの少なくとも一部における3次元の血管領域を抽出してもよい。これにより、精度良く3次元の血管領域を得ることができる。また、算出手段は、処理手段によりプロジェクションアーチファクトが低減された後の3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、血管計測値を算出してもよい。 Furthermore, in the various embodiments and modifications described above, the correction unit 101-43 corresponds to an example of a processing unit that performs processing to reduce projection artifacts on high-quality three-dimensional motion contrast data. However, the image quality improvement process is not essential for executing the process by the processing means. That is, any processing means may be used as long as it performs processing to reduce projection artifacts on the three-dimensional motion contrast data of the fundus. The extraction means may extract a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data after the projection artifact has been reduced by the processing means. Thereby, a three-dimensional blood vessel region can be obtained with high accuracy. Further, the calculation means may calculate the blood vessel measurement value using information regarding a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data after projection artifacts have been reduced by the processing means.
また、上述した実施形態や各変形例においては、高画質化した3次元モーションコントラストデータから取得した3次元血管領域に基づき、網膜外層において脈絡膜新生血管の体積を計測したが、これに限らず網膜外層において3次元血管密度(VADもしくはVLD)を算出してもよい。新生血管は面内方向だけでなく深度方向にも走行しやすいため、3次元で血管密度を算出するメリットがあると考えられる。3次元VADの場合は細線化処理が不要で簡便に3次元血管密度を算出でき、3次元VLDの場合は血管のセグメンテーションの良否の影響をより受けにくくできる。 In addition, in the embodiment and each modification described above, the volume of choroidal neovascularization in the outer retinal layer was measured based on the three-dimensional blood vessel area obtained from the three-dimensional motion contrast data with high image quality. Three-dimensional blood vessel density (VAD or VLD) may be calculated in the outer layer. Since new blood vessels tend to travel not only in the in-plane direction but also in the depth direction, it is thought that there is an advantage in calculating the blood vessel density in three dimensions. In the case of three-dimensional VAD, the three-dimensional blood vessel density can be easily calculated without the need for thinning processing, and in the case of three-dimensional VLD, it can be made less susceptible to the quality of blood vessel segmentation.
[第2の実施形態]
本実施形態に係る画像処理装置は、取得した被検眼の3次元モーションコントラスト画像に対して機械学習による高画質化処理を適用し、3次元の血管領域を特定する。該3次元血管領域に基づいて、正面画像を生成することなく2次元の血管計測値として網膜の表層における2次元の血管密度、網膜外層における脈絡膜新生血管(CNV)の面積等を算出する場合について説明する。すなわち、本実施形態に係る画像処理装置は、高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域を抽出することができる。なお、抽出部101-462は、3次元の血管領域を抽出する抽出手段の一例である。また、本実施形態に係る画像処理装置は、高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、血管計測値を算出することができる。なお、3次元の血管領域に関する情報は、例えば、高画質化された3次元モーションコントラストデータにおける3次元の血管領域の位置情報等である。ただし、3次元の血管領域に関する情報は、高画質化された3次元モーションコントラストデータから血管計測値を算出可能な情報であれば何でもよい。
[Second embodiment]
The image processing device according to the present embodiment applies image quality improvement processing using machine learning to the acquired three-dimensional motion contrast image of the subject's eye, and specifies a three-dimensional blood vessel region. Regarding the case where two-dimensional blood vessel density in the surface layer of the retina, area of choroidal neovascularization (CNV) in the outer layer of the retina, etc. are calculated as two-dimensional blood vessel measurement values based on the three-dimensional blood vessel area without generating a frontal image. explain. That is, the image processing device according to the present embodiment can extract a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data with high image quality. Note that the extraction unit 101-462 is an example of an extraction unit that extracts a three-dimensional blood vessel region. Further, the image processing device according to the present embodiment can calculate a blood vessel measurement value using information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data. Note that the information regarding the three-dimensional blood vessel region is, for example, position information of the three-dimensional blood vessel region in high-quality three-dimensional motion contrast data. However, the information regarding the three-dimensional blood vessel region may be any information as long as it is possible to calculate blood vessel measurement values from high-quality three-dimensional motion contrast data.
以下、図面を参照しながら、本実施形態に係る画像処理装置を備える画像処理システムについて説明する。本実施形態に係る画像処理装置101を備える画像処理システム10の構成を図11に示す。画像処理部101-04に高画質化部101-47を備える点が第1の実施形態と異なっている。ここで、高画質化部101-47は、3次元モーションコントラストデータを高画質化する高画質化手段の一例である。なお、本実施形態においても、高画質化手段として、高画質化部101-47の他に、例えば、後述する第1の実施形態における合成部101-42を適用することが可能である。次に、本実施形態における画像処理フローを図12に示す。なお、本実施形態の画像処理フローのうちS1207、S1209、S1211については第1の実施形態の場合と同様であるので説明を省略する。
An image processing system including an image processing apparatus according to this embodiment will be described below with reference to the drawings. FIG. 11 shows the configuration of an
<ステップ1201>
操作者は入力部103を操作することにより、断層画像撮影装置100に対して指示するOCTA画像の撮影条件を設定する。
<Step 1201>
By operating the
撮影条件のうちほとんどは第1の実施形態と同様であり、繰り返しOCTA撮影を行わない、すなわち、本ステップで取得するクラスタ数が1である点が第1の実施形態と異なる。すなわち、
1)Macular Disease検査セットを登録
2)OCTAスキャンモードを選択
3)以下の撮影パラメータを設定
3-1)走査パターン:Small Square
3-2)走査領域サイズ:3x3mm
3-3)主走査方向:水平方向
3-4)走査間隔:0.01mm
3-5)固視灯位置:中心窩
3-6)1クラスタあたりのBスキャン数:4
3-7)コヒーレンスゲート位置:硝子体側
3-8)既定表示レポート種別:単検査用レポート
を撮影条件として設定する。
Most of the imaging conditions are the same as those in the first embodiment, and the second embodiment differs from the first embodiment in that repeated OCTA imaging is not performed, that is, the number of clusters acquired in this step is one. That is,
1) Register Macular Disease test set 2) Select OCTA scan mode 3) Set the following imaging parameters 3-1) Scanning pattern: Small Square
3-2) Scan area size: 3x3mm
3-3) Main scanning direction: horizontal direction 3-4) Scanning interval: 0.01mm
3-5) Fixation light position: fovea 3-6) Number of B scans per cluster: 4
3-7) Coherence gate position: Vitreous body side 3-8) Default display report type: Set a single examination report as the imaging condition.
<ステップ1202>
操作者は入力部103を操作して図7に示す撮影画面710中の撮影開始(Capture)ボタン713を押下することにより、S1201で指定した撮影条件によるOCTA撮影を開始する。撮影制御部101-03は断層画像撮影装置100に対してS1201で操作者が指示した設定に基づいてOCTA撮影を実施することを指示し、断層画像撮影装置100が対応するOCT断層画像を取得する。また、断層画像撮影装置100はSLO画像の取得も行い、SLO動画像に基づく追尾処理を実行する。
<Step 1202>
The operator operates the
<ステップ1203>
画像取得部101-01及び画像処理部101-04は、S1202で取得されたOCT断層画像に基づいてモーションコントラスト画像(モーションコントラストデータ)を生成する。第1の実施形態のS303と同様の手順でモーションコントラスト画像を生成した後、第1の実施形態のS304と同様の手順で補正部101-43が、モーションコントラスト画像上に生じたプロジェクションアーチファクト802を抑制する処理を実行する。
<Step 1203>
The image acquisition unit 101-01 and the image processing unit 101-04 generate a motion contrast image (motion contrast data) based on the OCT tomographic image acquired in S1202. After generating a motion contrast image in the same procedure as S303 of the first embodiment, the correction unit 101-43 corrects the projection artifact 802 that has occurred on the motion contrast image in the same procedure as S304 of the first embodiment. Execute the process to suppress.
<ステップ1204>
表示制御部101-05は、S1203で生成した断層画像や、3次元及び正面モーションコントラスト画像、撮影条件に関する情報を表示部104に表示させる。
<Step 1204>
The display control unit 101-05 causes the
<ステップ1205>
高画質化部101-47は、少ない枚数の断層画像から生成した低画質なモーションコントラスト画像を機械学習モデルに入力することにより、多数枚の断層画像から生成した場合と同等の高画質な(低ノイズかつ高コントラストな)モーションコントラスト画像を生成する。ここで機械学習モデルとは、処理対象として想定される所定の撮影条件で取得された低画質な画像である入力データと、入力データに対応する高画質画像である出力データのペア群で構成された教師データを用いて機械学習を行うことにより生成した関数のことを指す。
<Step 1205>
The image quality improvement unit 101-47 inputs a low-quality motion contrast image generated from a small number of tomographic images into a machine learning model, thereby producing a high-quality (low-quality) image equivalent to that generated from a large number of tomographic images. Generate motion-contrast (noisy, high-contrast) images. Here, the machine learning model is composed of a group of pairs of input data, which is a low-quality image acquired under predetermined shooting conditions assumed to be the processing target, and output data, which is a high-quality image corresponding to the input data. Refers to a function generated by performing machine learning using trained training data.
なお、所定の撮影条件には撮影部位、撮影方式、撮影画角、及び画像サイズ等が含まれる。 Note that the predetermined imaging conditions include the imaging site, imaging method, imaging angle of view, image size, and the like.
また、本実施形態では、ユーザが図9(a)のレポート画面右上に示すボタン911(Denoiseボタン)を押下することにより、高画質化部101-47がモーションコントラスト画像に対する高画質化処理を実施するものとする。 Furthermore, in this embodiment, when the user presses the button 911 (Denoise button) shown in the upper right corner of the report screen in FIG. It shall be.
本実施形態において教師データとして用いる入力データは断層画像数の少ない単一クラスタから生成された低画質モーションコントラスト画像とし、(教師データとして用いる)出力データは位置合わせ済の複数のモーションコントラストデータを加算平均して得られた高画質モーションコントラスト画像とする。なお、教師データとして用いる出力データはこれに限らず、例えば、多数枚の断層画像で構成される単一クラスタから生成された高画質なモーションコントラスト画像でもよい。また、教師データとして用いる出力データは、入力画像より高解像度な(高倍率な)モーションコントラスト画像を入力画像と同解像度(同倍率)にすることによって得られた高画質なモーションコントラスト画像でもよい。なお、機械学習モデルのトレーニングに用いる入力画像と出力画像のペアは上記に限られるものではなく、任意の公知の画像の組み合わせを用いてよい。例えば撮影装置10や他の装置で取得したモーションコントラスト画像に第一のノイズ成分を付加した画像を入力画像とし、該(撮影装置10や他の装置で取得した)モーションコントラスト画像に(第一のノイズ成分とは異なる)第二のノイズ成分を付加した画像を出力画像として機械学習モデルのトレーニングに用いてもよい。すなわち、高画質化部101-47は、眼底の3次元のモーションコントラストデータを含む学習データを学習して得た高画質化用の学習済モデルを用いて、入力画像として入力された3次元モーションコントラストデータを高画質化するものであれば何でもよい。
In this embodiment, the input data used as training data is a low-quality motion contrast image generated from a single cluster with a small number of tomographic images, and the output data (used as training data) is the sum of multiple aligned motion contrast data. A high-quality motion contrast image obtained on average is used. Note that the output data used as the teacher data is not limited to this, and may be, for example, a high-quality motion contrast image generated from a single cluster composed of a large number of tomographic images. Further, the output data used as the teacher data may be a high-quality motion contrast image obtained by making a motion contrast image having a higher resolution (higher magnification) than the input image the same resolution (same magnification) as the input image. Note that the pair of input images and output images used for training the machine learning model is not limited to the above, and any known combination of images may be used. For example, an image obtained by adding a first noise component to a motion contrast image acquired by the photographing
本実施形態に係る高画質化部101-47における機械学習モデルの構成例を図13に示す。該機械学習モデルは畳み込みニューラルネットワーク(Convolutional Newural Network;CNN)であり、入力値群を加工して出力する処理を担う複数の層群によって構成される。なお前記構成に含まれる層の種類として、畳み込み(Convolution)層、ダウンサンプリング(Downsampling)層、アップサンプリング(Upsampling)層、合成(Merger)層がある。畳み込み層は、設定されたフィルタのカーネルサイズ、フィルタの数、ストライドの値、ダイレーションの値等のパラメータに従い、入力値群に対して畳み込み処理を行う層である。なお、入力される画像の次元数に応じて、前記フィルタのカーネルサイズの次元数も変更してもよい。ダウンサンプリング層は、入力値群を間引いたり、合成したりすることによって、出力値群の数を入力値群の数よりも少なくする処理である。具体的には、例えば、Max Pooling処理がある。アップサンプリング層は、入力値群を複製したり、入力値群から補間した値を追加したりすることによって、出力値群の数を入力値群の数よりも多くする処理である。具体的には、例えば、線形補間処理がある。合成層は、ある層の出力値群や画像を構成する画素値群といった値群を、複数のソースから入力し、それらを連結したり、加算したりして合成する処理を行う層である。このような構成では、入力画像1301を構成する画素値群が畳み込み処理ブロックを経て出力された値群と、入力画像1301を構成する画素値群が、合成層で合成される。その後、合成された画素値群は最後の畳み込み層で高画質画像1302に成形される。なお、図示はしないが、CNNの構成の変更例として、例えば、畳み込み層の後にバッチ正規化(Batch Normalization)層や、正規化線形関数(Rectifier Linear Unit)を用いた活性化層を組み込む等をしても良い。
FIG. 13 shows a configuration example of a machine learning model in the image quality improvement unit 101-47 according to this embodiment. The machine learning model is a convolutional neural network (CNN), and is composed of a plurality of layers responsible for processing and outputting a group of input values. The types of layers included in the configuration include a convolution layer, a downsampling layer, an upsampling layer, and a merge layer. The convolution layer is a layer that performs convolution processing on a group of input values according to parameters such as the set filter kernel size, the number of filters, the stride value, and the dilation value. Note that the number of dimensions of the kernel size of the filter may also be changed depending on the number of dimensions of the input image. The downsampling layer is a process of thinning out or combining input value groups to make the number of output value groups smaller than the number of input value groups. Specifically, for example, there is Max Pooling processing. The upsampling layer is a process of making the number of output value groups larger than the number of input value groups by duplicating the input value group or adding a value interpolated from the input value group. Specifically, for example, there is linear interpolation processing. The compositing layer is a layer that receives a group of values, such as a group of output values of a certain layer or a group of pixel values constituting an image, from a plurality of sources, and performs a process of combining them by concatenating or adding them. In such a configuration, the group of pixel values that make up the
なお、図13では説明を簡単にするため処理対象画像を2次元画像として説明しているが、本発明はこれに限定されない。例えば、3次元の低画質モーションコントラスト画像を高画質化部101-47に入力して3次元の高画質モーションコントラスト画像を出力する場合も本発明に含まれる。 Note that although the image to be processed is described as a two-dimensional image in FIG. 13 to simplify the explanation, the present invention is not limited to this. For example, the present invention also includes a case where a three-dimensional low-quality motion contrast image is input to the high-quality image improvement unit 101-47 and a three-dimensional high-quality motion contrast image is output.
<ステップ1206>
操作者が入力部103を用いてOCTA計測処理の開始を指示する。
<Step 1206>
The operator uses the
本実施形態では、レポート画面のモーションコントラスト画像上をダブルクリックすることで、OCTA計測画面に移行する。モーションコントラスト画像が拡大表示され、解析部101-46が計測処理を開始する。 In this embodiment, double-clicking on the motion contrast image on the report screen transitions to the OCTA measurement screen. The motion contrast image is enlarged and displayed, and the analysis unit 101-46 starts measurement processing.
計測処理の種類として任意の計測処理を行ってよく、本実施形態では、図9(a)のDensity Analysis903もしくはToolsボタン904を選択して表示される項目905に示す解析の種類と、必要に応じて解析の次元数に関する項目912を選択することにより、所望の計測の種類を指定する。 Any measurement process may be performed as the type of measurement process, and in this embodiment, the type of analysis shown in the item 905 displayed by selecting Density Analysis 903 or Tools button 904 in FIG. By selecting an item 912 regarding the number of dimensions of analysis, the desired type of measurement is specified.
本実施形態では、3次元で強調及び特定した血管領域もしくは血管中心線データに対して2次元の計測値を算出する場合について説明する。具体的には、網膜の表層において2次元血管密度(VAD)、網膜外層において血管の面積を計測するものとする。 In this embodiment, a case will be described in which a two-dimensional measurement value is calculated for three-dimensionally emphasized and specified blood vessel region or blood vessel center line data. Specifically, two-dimensional blood vessel density (VAD) is measured in the surface layer of the retina, and blood vessel area is measured in the outer layer of the retina.
網膜や脈絡膜の血管は(他の器官と異なり)層構造に沿って走行するため、2次元の計測値として算出されることが多い。しかし、2次元のモーションコントラスト画像、特に正面モーションコントラスト画像を用いて血管を強調する画像処理を適用した場合には血管以外の線状構造も強調されてしまい、結果的に血管として誤検出される場合がある。例えば嚢胞領域の境界(エッジ)は2次元画像上では曲線状であるため血管領域として誤検出されやすいものの、3次元画像上では曲面状であるため誤検出されにくい。本実施形態のように、血管領域を3次元的に検出した上で2次元の計測値として算出することにより、他構造物の誤検出を減らしつつ、ユーザが理解しやすい2次元の計測値として算出できる。 Blood vessels in the retina and choroid (unlike in other organs) run along a layered structure, so they are often calculated as two-dimensional measured values. However, when image processing that emphasizes blood vessels is applied using a two-dimensional motion contrast image, especially a frontal motion contrast image, linear structures other than blood vessels are also emphasized, resulting in erroneous detection as blood vessels. There are cases. For example, the boundary (edge) of a cyst region is curved on a two-dimensional image, so it is likely to be mistakenly detected as a blood vessel region, but on a three-dimensional image, it is curved and therefore less likely to be mistakenly detected. As in this embodiment, by detecting the blood vessel region three-dimensionally and then calculating it as a two-dimensional measurement value, it is possible to reduce false detection of other structures and provide a two-dimensional measurement value that is easy for the user to understand. It can be calculated.
次に、解析部101-46は計測処理の前処理を行う。任意の公知の画像処理を前処理として適用できるが、本実施形態では、第1実施形態と同様に前処理として画像拡大及びモルフォロジー演算(トップハットフィルタ処理)を行う。 Next, the analysis unit 101-46 performs preprocessing for measurement processing. Although any known image processing can be applied as preprocessing, in this embodiment, image enlargement and morphological calculation (top hat filter processing) are performed as preprocessing, similar to the first embodiment.
<ステップ1208>
計測部101-463が、操作者により指定された計測対象領域に関する情報に基づいて単検査の画像に対する血管密度の計測を行う。引き続いて表示制御部101-05が、計測結果を表示部104に表示する。より具体的には、計測部101-463は、補正部101-43によりプロジェクションアーチファクトが低減され、高画質化部101-47により高画質化処理された後の3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、3次元的に取得された血管領域に対して2次元の血管計測値を算出する。具体的には、網膜の表層における2次元血管密度、網膜の外層における新生血管領域の面積を算出する。すなわち、計測部101-463は、高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、2次元空間における血管計測値を算出する算出手段の一例に相当する。
<Step 1208>
The measurement unit 101-463 measures the blood vessel density for a single examination image based on information regarding the measurement target area designated by the operator. Subsequently, the display control section 101-05 displays the measurement results on the
2次元の血管密度としてはVADとVLDの2種類の指標があり、本実施形態では、VADを計算する場合の手順を例に説明する。なお、VLDを計算する場合の手順についても後述する。 There are two types of indexes for two-dimensional blood vessel density: VAD and VLD, and in this embodiment, the procedure for calculating VAD will be explained as an example. Note that the procedure for calculating VLD will also be described later.
操作者が入力部103から血管領域もしくは血管中心線データを手動修正するよう指示を入力した場合には、解析部101-46が操作者から入力部103を介して指定された位置情報に基づいて血管領域もしくは血管中心線データを手動修正し、計測値を再計算する。
When the operator inputs an instruction to manually correct the blood vessel region or blood vessel center line data from the
網膜表層における2次元VAD計測、網膜外層における脈絡膜新生血管の面積計測についてはS810~S820、網膜表層における2次元VLD計測、網膜外層における脈絡膜新生血管の水平方向に関する総血管長計測についてはS830~S850で各々説明する。 S810 to S820 for two-dimensional VAD measurement in the retinal surface layer and area measurement of choroidal neovascularization in the outer retinal layer; S830 to S850 for two-dimensional VLD measurement in the retinal superficial layer and total vessel length measurement in the horizontal direction of choroidal neovascularization in the outer retinal layer. Each will be explained below.
<ステップ1210>
表示制御部101-05は、S1208で実施した計測結果に関するレポートを表示部104に表示する。
<Step 1210>
The display control unit 101-05 displays a report regarding the measurement results performed in S1208 on the
本実施形態では、図9(b)に示す単検査(Single)計測レポートの上段に網膜表層において計測したVADマップとVADセクタマップを重畳表示し、下段に網膜外層において特定した脈絡膜新生血管領域の2値画像や計測した面積値を表示する。これにより異なる深度位置の血管病態を一覧して把握できる。また、網膜外層におけるCNVの位置を特定したり、正確に定量化したりできる。 In this embodiment, the VAD map and VAD sector map measured in the retinal surface layer are superimposed on the upper row of the single measurement report shown in FIG. 9(b), and the choroidal neovascular region identified in the outer retinal layer is displayed on the lower row. Displays binary images and measured area values. This makes it possible to view and understand the vascular pathology at different depth positions. Furthermore, the position of CNV in the outer retinal layer can be identified and accurately quantified.
さらに、図6(a)に示すフローチャートを参照しながら、S1208で実行される処理の詳細について説明する。 Furthermore, details of the process executed in S1208 will be described with reference to the flowchart shown in FIG. 6(a).
<ステップ810>
操作者は、入力部103を介して計測処理における関心領域を設定する。すなわち、血管密度を算出する対象領域は、ユーザにより指定される。本実施形態では、計測内容として
1)網膜の表層における2次元VADマップ及び2次元VADセクタマップ
2)網膜外層における脈絡膜新生血管(CNV)の面積
を算出する。
<Step 810>
The operator sets a region of interest in the measurement process via the
従って、網膜表層の関心領域として面内方向に関しては(i)画像全体(ii)固視灯位置を中心とするセクタ領域(直径1mmの内円と直径3mmの外円で規定される環状領域内をSuperior・Inferior・Nasal・Temporalの4つの扇形に分割した領域及び該内円領域)とする。また、深度方向に関しては第1実施形態のS810の場合と同様の深度範囲とする。深度方向の深度範囲が図9(a)の層境界910で指定されているため、図9(a)のDensity Map/Sector902の項目の中からMap及びSector、Density Analysis903の項目の中からArea Densityを各々選択することによって自動で設定される。眼底表面の2次元方向はセクタの移動により指定可能であり、眼底の深さ方向は表示されているEn-Face画像の深さ範囲の指定により指定することができる。また網膜外層においては網膜外層に相当する層境界(OPL/ONL境界と、ブルッフ膜境界を該境界深層側に20μm移動させた位置で囲まれる範囲)を指定する。面内方向の関心領域の指定は画像全体としてもよいし、操作者が関心領域を手動設定してもよい。例えば図9(a)の904に示すようなボタン904を押した場合に表示される設定画面905から計測の種類(ここではArea/Volume)を選択した上で、入力部103を介して関心領域を設定してもよい。なお、3次元モーションコントラストデータが表示されて状態で3次元モーションコントラストデータに対して直接関心領域を指定することとしてもよい。 Therefore, in terms of the in-plane direction, the region of interest in the retinal surface layer is (i) the entire image, (ii) a sector region centered on the fixation lamp position (within an annular region defined by an inner circle with a diameter of 1 mm and an outer circle with a diameter of 3 mm). is an area divided into four fan shapes of Superior, Inferior, Nasal, and Temporal, and the inner circular area). Furthermore, in the depth direction, the depth range is the same as in S810 of the first embodiment. Since the depth range in the depth direction is specified by the layer boundary 910 in FIG. 9(a), Map and Sector are selected from the Density Map/Sector 902 items in FIG. 9(a), and Area Density is selected from the Density Analysis 903 items. Automatically set by selecting each. The two-dimensional direction of the fundus surface can be specified by moving the sector, and the depth direction of the fundus can be specified by specifying the depth range of the displayed En-Face image. Furthermore, for the outer retinal layer, a layer boundary corresponding to the outer retinal layer (an area surrounded by the OPL/ONL boundary and a position where the Bruch's membrane boundary is moved 20 μm toward the deep layer side of the boundary) is specified. The region of interest in the in-plane direction may be specified for the entire image, or the region of interest may be manually set by the operator. For example, after selecting the measurement type (Area/Volume in this case) from the setting screen 905 that is displayed when a button 904 shown in FIG. may be set. Note that the region of interest may be directly specified with respect to the three-dimensional motion contrast data while the three-dimensional motion contrast data is displayed.
<ステップ820>
計測部101-463は、S1207で得られた血管領域の2値画像に基づいて計測処理を行う。本実施形態では、S1207で特定された3次元血管領域の2値画像に対して投影画像を生成することなく所定の条件を満たすAスキャン群に関する演算処理もしくは(Aスキャン方向に)直交する方向での計測を行うことで、2次元計測値を算出する。
<Step 820>
The measurement unit 101-463 performs measurement processing based on the binary image of the blood vessel region obtained in S1207. In this embodiment, without generating a projection image for the binary image of the three-dimensional blood vessel region identified in S1207, calculation processing is performed on the A-scan group that satisfies a predetermined condition, or in a direction perpendicular to the A-scan direction. A two-dimensional measurement value is calculated by performing the measurement.
例えば2次元VADを算出する場合には計測部101-463が3次元血管領域の2値画像に対して以下のような処理を行う。すなわち、まず各Aスキャンを中心に近傍のAスキャンを含めた単位Aスキャン群Agを考える。(単位Aスキャン群Agは任意の本数のAスキャンで規定できるが、本実施形態では9本とする)単位Aスキャン群に含まれる各Aスキャンの中にS810で指定された3次元の関心領域が規定する深度範囲(図14(a)の表層側曲面Buと深層側曲面Bl)内に血管領域V1に属する画素(非0画素、すなわち図14(a)の白画素)が1画素でも含まれるようなAスキャンの本数を数える。上記のような(所定深度範囲内に非0画素を含む)Aスキャンの本数を単位Aスキャン群の本数(本実施形態では9)で除算して100を乗算することにより、当該Aスキャンが持つX-Y座標における2次元VADの値(単位:%)を算出できる。例えば単位Aスキャン群の中に上記条件を満たすAスキャンが1本だけであれば、当該Aスキャンの位置で算出される2次元VADの値は(1/9)×100%≒11.11%と算出する。本実施形態では、網膜表層で2次元VADを算出するので、網膜表層における計測では表層側曲面Buとして内境界膜境界で規定される曲面、深層側曲面Blとして神経節細胞層(GCL)-内網状層(IPL)境界で規定される曲面を指定する。なおこれに限らず、任意の深度範囲、例えば網膜深層を計測対象の深度範囲として指定してよい。さらに、各X-Y位置で算出した2次元血管密度(VAD)の値を持つ画像(2次元VADマップ)を生成する。 For example, when calculating a two-dimensional VAD, the measurement unit 101-463 performs the following processing on a binary image of a three-dimensional blood vessel region. That is, first, consider a unit A-scan group Ag that includes each A-scan at its center and neighboring A-scans. (The unit A-scan group Ag can be defined by any number of A-scans, but in this embodiment, it is nine.) The three-dimensional region of interest specified in S810 in each A-scan included in the unit A-scan group. At least one pixel (non-zero pixel, that is, a white pixel in FIG. 14(a)) belonging to the blood vessel region V1 is included in the depth range defined by (superficial curved surface Bu and deep curved surface Bl in FIG. 14(a)). Count the number of A scans that occur. By dividing the number of A scans as described above (including non-zero pixels within a predetermined depth range) by the number of unit A scan groups (9 in this embodiment) and multiplying by 100, the number of A scans that the A scan has The value (unit: %) of two-dimensional VAD in XY coordinates can be calculated. For example, if there is only one A-scan that satisfies the above conditions in a unit A-scan group, the two-dimensional VAD value calculated at the position of the A-scan is (1/9) x 100% ≒ 11.11% It is calculated as follows. In this embodiment, the two-dimensional VAD is calculated in the retinal surface layer, so in the measurement in the retinal surface layer, the superficial side curved surface Bu is a curved surface defined by the inner limiting membrane boundary, and the deep layer side curved surface Bl is the curved surface defined by the ganglion cell layer (GCL)-inner limiting membrane boundary. Specify the curved surface defined by the reticular layer (IPL) boundary. Note that the present invention is not limited to this, and any depth range, for example, the deep layer of the retina, may be designated as the depth range to be measured. Furthermore, an image (two-dimensional VAD map) having two-dimensional blood vessel density (VAD) values calculated at each XY position is generated.
また3次元血管領域の2値画像上のS810で設定した各3次元セクタ領域(図14(c)の円柱状領域Cや部分円環柱状領域(S/I/N/T))において、表層側曲面Buと深層側曲面Blの深度範囲内に血管領域に属する画素(図14(c)の白画素)が1画素でも含まれるようなAスキャンAwの本数を算出する。該算出したAwの本数を該3次元セクタ領域に属するAスキャンの本数で除算し、100を乗算した値を当該セクタにおける2次元血管密度(VAD)として算出する。さらに、各セクタ領域で算出した2次元血管密度(VAD)の値を持つマップ(2次元VADセクタマップ)を生成する。 In addition, in each three-dimensional sector region (cylindrical region C and partial circular columnar region (S/I/N/T) in FIG. 14(c)) set in S810 on the binary image of the three-dimensional blood vessel region, the surface layer The number of A-scans Aw is calculated such that at least one pixel belonging to the blood vessel region (white pixel in FIG. 14C) is included within the depth range of the side curved surface Bu and the deep side curved surface Bl. The calculated number of Aw is divided by the number of A scans belonging to the three-dimensional sector area, and the value multiplied by 100 is calculated as the two-dimensional blood vessel density (VAD) in the sector. Furthermore, a map (two-dimensional VAD sector map) having two-dimensional blood vessel density (VAD) values calculated in each sector region is generated.
また網膜外層では、S810で設定した網膜外層に相当する関心領域内におけるAスキャン群に含まれる各Aスキャンの中にS810で指定した関心領域が規定する深度範囲(図14(a)の表層側曲面Buと深層側曲面Bl)において血管領域に属する画素(図14(a)の白画素)が1画素でも含まれるようなAスキャンの本数を数える。該所定深度範囲内に非0画素を含むAスキャンの本数に対してAスキャン1本が占める面内方向の面積(単位:mm2)を乗算することで、3次元血管領域の(所定深度範囲における)面内方向に占める面積を算出できる。なお、本発明の2次元血管計測値の算出法は上記に限定されるものではない。例えば網膜外層に相当する関心領域内で脈絡膜新生血管領域を強調した画像を投影して2値化することで生成した正面2値画像、もしくは3次元で2値化した画像を投影することで生成した正面2値画像上で脈絡膜新生血管領域の面積を算出してもよい。 In addition, in the outer retinal layer, the depth range defined by the region of interest specified in S810 (on the superficial side of FIG. 14(a) The number of A scans in which at least one pixel (white pixel in FIG. 14A) belonging to the blood vessel region is included in the curved surface Bu and the deep curved surface Bl is counted. By multiplying the number of A-scans that include non-zero pixels within the predetermined depth range by the in-plane area (unit: mm 2 ) occupied by one A-scan, the (predetermined depth range) of the three-dimensional blood vessel region is calculated. The area occupied in the in-plane direction (in ) can be calculated. Note that the method for calculating two-dimensional blood vessel measurement values of the present invention is not limited to the above. For example, a frontal binary image generated by projecting and binarizing an image that emphasizes the choroidal neovascular region within a region of interest corresponding to the outer layer of the retina, or a frontal binary image generated by projecting a three-dimensional binarized image. The area of the choroidal neovascular region may be calculated on the frontal binary image.
上記では特定された3次元血管領域に基づいて網膜表層で2次元VADを、網膜外層で血管面積を計測する場合の手順を例に説明したが、3次元の血管中心線に基づいて網膜表層で2次元VLDを、網膜外層で2次元血管長を計測する場合には、上記S810~820の代わりに図6(b)に示すS830~850を実行する。 Above, we explained the procedure for measuring 2D VAD in the retinal surface layer based on the identified 3D blood vessel area and blood vessel area in the outer retinal layer as an example. When measuring the two-dimensional VLD and the two-dimensional blood vessel length in the outer retinal layer, steps S830 to S850 shown in FIG. 6(b) are executed instead of S810 to S820 described above.
<ステップ830>
計測部101-463は、S1207で生成した血管領域の2値画像を3次元細線化処理することにより、血管の中心線に相当する線幅1画素の2値画像(以下、スケルトン画像と表記)を生成する。
<Step 830>
The measurement unit 101-463 performs three-dimensional thinning processing on the binary image of the blood vessel region generated in S1207, thereby creating a binary image with a line width of 1 pixel corresponding to the center line of the blood vessel (hereinafter referred to as a skeleton image). generate.
<ステップ840>
操作者は、入力部103を介してS820と場合と同様の関心領域を設定する。本実施形態では計測内容として2次元VLDマップと2次元VLDセクタマップを算出するものとする。なお、VLDマップもしくはVLDセクタマップをモーションコントラスト画像上に重畳表示したくない場合は、図9(a)のDensity Map/Sector902のMapもしくはSectorの項目のチェックボックスを非選択に設定すればよい。
<Step 840>
The operator sets the region of interest via the
<ステップ850>
計測部101-463はS830で得られたスケルトン画像に基づいて計測処理を行う。すなわち、網膜表層において特定された3次元スケルトンから計測する。本実施形態では、該3次元スケルトン画像の各Aスキャン位置に対してS820と同様に当該Aスキャンを中心として近傍のAスキャンを含めた単位Aスキャン群Agを考える。(単位Aスキャン群Agは任意の本数のAスキャンで規定できるが、本実施形態では9本とする)単位Aスキャン群に含まれる各Aスキャンの中にS840で指定された3次元の関心領域が規定する深度範囲(図14(b)の表層側曲面Buと深層側曲面Bl)内に血管領域に属する画素(図14(b)の白画素)が1画素でも含まれるようなAスキャンの本数を算出する。算出した該Aスキャンの本数に対して、1本のAスキャンが占める(該Aスキャンに直交する方向の)サイズ(単位:mm)を乗算し、単位Aスキャン群が該Aスキャン群に直交する方向に占める面積(単位:mm2)で除算することにより2次元VLDを算出する。(単位:mm-1)さらに、各X-Y位置で算出した血管密度(2次元VLD)の値を持つ画像(2次元VLDマップ)を生成する。
<Step 850>
The measurement unit 101-463 performs measurement processing based on the skeleton image obtained in S830. That is, measurement is performed from the three-dimensional skeleton specified in the retinal surface layer. In this embodiment, for each A-scan position of the three-dimensional skeleton image, a unit A-scan group Ag including neighboring A-scans with the relevant A-scan as the center is considered, as in S820. (The unit A-scan group Ag can be defined by any number of A-scans, but in this embodiment, it is nine.) The three-dimensional region of interest specified in S840 in each A-scan included in the unit A-scan group. An A scan in which at least one pixel belonging to the blood vessel region (the white pixel in FIG. 14(b)) is included in the depth range defined by (superficial curved surface Bu and deep curved surface Bl in FIG. 14(b)) Calculate the number. The calculated number of A-scans is multiplied by the size (unit: mm) occupied by one A-scan (in the direction orthogonal to the A-scan), and the unit A-scan group is orthogonal to the A-scan group. The two-dimensional VLD is calculated by dividing by the area occupied in the direction (unit: mm 2 ). (Unit: mm −1 ) Furthermore, an image (two-dimensional VLD map) having the value of blood vessel density (two-dimensional VLD) calculated at each XY position is generated.
また3次元スケルトン画像上のS840で設定した各3次元セクタ領域(図14(c)の円柱状領域Cや部分円環柱状領域(S/I/N/T))において、表層側曲面Buと深層側曲面Blの深度範囲内に3次元スケルトン領域V2に属する画素が1画素でも含まれるようなAスキャンAwの本数を算出する。該算出したAwの本数に対して1本のAスキャンが占める(該Aスキャンに直交する方向の)サイズ(単位:mm)を乗算し、該3次元セクタ領域に属するAスキャン群が占める(該Aスキャン群に直交する方向の)面積(単位:mm2)で除算した値を当該セクタにおける2次元VLD(単位:mm-1)として算出する。さらに、各セクタ領域で算出した2次元VLDの値を持つマップ(2次元VLDセクタマップ)を生成する。 In addition, in each three-dimensional sector area set in S840 on the three-dimensional skeleton image (cylindrical area C and partial circular columnar area (S/I/N/T) in FIG. 14(c)), the surface side curved surface Bu and The number of A scans Aw is calculated so that at least one pixel belonging to the three-dimensional skeleton region V2 is included within the depth range of the deep side curved surface Bl. The calculated number of Aw is multiplied by the size (unit: mm) occupied by one A scan (in the direction orthogonal to the A scan), and the size (unit: mm) occupied by the A scan group belonging to the three-dimensional sector area is calculated. The value divided by the area (in the direction perpendicular to the A-scan group) (unit: mm 2 ) is calculated as the two-dimensional VLD (unit: mm −1 ) in the sector. Furthermore, a map (two-dimensional VLD sector map) having two-dimensional VLD values calculated in each sector area is generated.
また網膜外層では、S840で設定した網膜外層に相当する関心領域内におけるAスキャン群に含まれる各Aスキャンの中にS840で指定した関心領域が規定する深度範囲(図14(b)の表層側曲面Buと深層側曲面Bl)において3次元スケルトン領域に属する画素(図14(b)の白画素)が1画素でも含まれるようなAスキャンの本数を数える。該所定深度範囲内に非0画素を含むAスキャンの本数に対してAスキャン1本が占める面内方向の長さ(単位:mm)を乗算することで、血管領域の(所定深度範囲における)面内方向の長さの和を算出できる。なお、本発明の2次元血管計測値の算出法は上記に限定されるものではない。例えば網膜外層に相当する関心領域内で脈絡膜新生血管領域を強調した画像を投影して2値化し、細線化することで生成した正面2値画像、もしくは3次元で2値化し、細線化した画像を投影することで生成した正面2値画像上で脈絡膜新生血管領域の長さを算出してもよい。 In addition, in the outer retinal layer, the depth range defined by the region of interest specified in S840 (on the surface layer side in FIG. 14(b) The number of A scans in which at least one pixel (white pixel in FIG. 14(b)) belonging to the three-dimensional skeleton region is included in the curved surface Bu and the deep side curved surface Bl is counted. By multiplying the number of A-scans that include non-zero pixels within the predetermined depth range by the in-plane length (unit: mm) occupied by one A-scan, the blood vessel region (in the predetermined depth range) is calculated. The sum of lengths in the in-plane direction can be calculated. Note that the method for calculating two-dimensional blood vessel measurement values of the present invention is not limited to the above. For example, a frontal binary image generated by projecting an image that emphasizes the choroidal neovascular region within the region of interest corresponding to the outer layer of the retina, binarizing it, and thinning it, or an image that is binarized in three dimensions and thinning it. The length of the choroidal neovascular region may be calculated on the frontal binary image generated by projecting the choroidal neovascular region.
以上述べた構成によれば、画像処理装置101は、取得した被検眼の3次元モーションコントラスト画像に対して機械学習による高画質化処理を適用し、3次元血管領域を特定する。該3次元血管領域に基づいて、正面画像を生成することなく2次元の血管計測値として網膜の表層における2次元の血管密度、網膜外層における脈絡膜新生血管(CNV)の面積を算出する。これにより、OCT断層画像の信号強度や画質の影響を抑制しながら3次元の血管領域等の所望の領域を強調もしくは特定し、正確に計測できる。
According to the configuration described above, the
(変形例11)
上述した様々な実施形態及び変形例における画面遷移における高画質化処理の実行について、図9(a)と(b)を用いて説明を行う。図9(a)は、図9(b)におけるOCTA画像を拡大表示した画面例である。図9(a)においても、図9(b)と同様にボタン911を表示する。図9(b)から図9(a)への画面遷移は、例えば、OCTA画像をダブルクリックすることで遷移し、図9(a)から図9(b)へは閉じるボタン(不図示)で遷移する。なお、画面遷移に関しては、ここで示した方法に限らず、不図示のユーザーインターフェースを用いてもよい。
(Modification 11)
Execution of image quality enhancement processing in screen transitions in the various embodiments and modifications described above will be explained using FIGS. 9(a) and 9(b). FIG. 9(a) is an example of a screen in which the OCTA image in FIG. 9(b) is enlarged and displayed. In FIG. 9(a), a button 911 is also displayed as in FIG. 9(b). The screen transition from FIG. 9(b) to FIG. 9(a) can be made, for example, by double-clicking the OCTA image, and from FIG. 9(a) to FIG. 9(b) can be done by clicking the close button (not shown). Transition. Note that the screen transition is not limited to the method shown here, and a user interface (not shown) may be used.
画面遷移の際に高画質化処理の実行が指定されている場合(ボタン911がアクティブ)、画面遷移時においてもその状態を保つ。すなわち、図9(b)の画面で高画質画像を表示している状態で図9(a)の画面に遷移する場合、図9(a)の画面においても高画質画像を表示する。そして、ボタン911はアクティブ状態にする。図9(a)から図9(b)へ遷移する場合にも同様である。図9(a)において、ボタン911を指定して低画質画像に表示を切り替えることもできる。 If execution of image quality improvement processing is specified at the time of screen transition (button 911 is active), that state is maintained even at the time of screen transition. That is, when transitioning to the screen of FIG. 9(a) while a high-quality image is being displayed on the screen of FIG. 9(b), the high-quality image is also displayed on the screen of FIG. 9(a). Then, the button 911 is activated. The same holds true when transitioning from FIG. 9(a) to FIG. 9(b). In FIG. 9A, it is also possible to switch the display to a low-quality image by specifying a button 911.
画面遷移に関して、ここで示した画面に限らず、経過観察用の表示画面、又はパノラマ用の表示画面など同じ撮影データを表示する画面への遷移であれば、高画質画像の表示状態を保ったまま遷移を行う。すなわち、遷移後の表示画面において、遷移前の表示画面におけるボタン911の状態に対応する画像が表示される。例えば、遷移前の表示画面におけるボタン911がアクティブ状態であれば、遷移後の表示画面において高画質画像が表示される。また、例えば、遷移前の表示画面におけるボタン911のアクティブ状態が解除されていれば、遷移後の表示画面において低画質画像が表示される。なお、経過観察用の表示画面におけるボタン911がアクティブ状態になると、経過観察用の表示画面に並べて表示される異なる日時(異なる検査日)で得た複数の画像が高画質画像に切り換わるようにしてもよい。すなわち、経過観察用の表示画面におけるボタン911がアクティブ状態になると、異なる日時で得た複数の画像に対して一括で反映されるように構成してもよい。 Regarding screen transitions, it is not limited to the screens shown here, but if the transition is to a screen that displays the same imaging data, such as a follow-up display screen or a panoramic display screen, the display state of high-quality images can be maintained. Perform the transition as it is. That is, on the display screen after the transition, an image corresponding to the state of the button 911 on the display screen before the transition is displayed. For example, if the button 911 on the display screen before transition is in an active state, a high-quality image is displayed on the display screen after transition. Further, for example, if the active state of the button 911 on the display screen before the transition is released, a low-quality image is displayed on the display screen after the transition. Note that when the button 911 on the follow-up observation display screen becomes active, the multiple images obtained at different dates and times (different examination dates) displayed side by side on the follow-up observation display screen are switched to high-quality images. It's okay. That is, when the button 911 on the display screen for follow-up observation becomes active, the configuration may be such that the effect is reflected on a plurality of images obtained at different dates and times at once.
なお、経過観察用の表示画面の例を、図17に示す。検者からの指示に応じてタブ3801が選択されると、図17のように、経過観察用の表示画面が表示される。このとき、計測対象領域の深度範囲を、リストボックスに表示された既定の深度範囲セット(3802及び3803)から検者が選択することで変更できる。例えば、リストボックス3802では網膜表層が選択され、また、リストボックス3803では網膜深層が選択されている。上側の表示領域には網膜表層のモーションコントラスト画像の解析結果が表示され、また、下側の表示領域には網膜深層のモーションコントラスト画像の解析結果が表示されている。すなわち、深度範囲が選択されると、異なる日時の複数の画像について、選択された深度範囲の複数のモーションコントラスト画像の解析結果の並列表示に一括して変更される。 Note that an example of a display screen for follow-up observation is shown in FIG. When the tab 3801 is selected in response to an instruction from the examiner, a display screen for progress observation is displayed as shown in FIG. At this time, the examiner can change the depth range of the measurement target area by selecting from the default depth range set (3802 and 3803) displayed in the list box. For example, the superficial layer of the retina is selected in list box 3802, and the deep layer of the retina is selected in list box 3803. The upper display area displays the analysis result of the motion contrast image of the superficial layer of the retina, and the lower display area displays the analysis result of the motion contrast image of the deep layer of the retina. That is, when a depth range is selected, multiple images taken at different dates and times are collectively changed to parallel display of analysis results of multiple motion contrast images in the selected depth range.
このとき、解析結果の表示を非選択状態にすると、異なる日時の複数のモーションコントラスト画像の並列表示に一括して変更されてもよい。そして、検者からの指示に応じてボタン911が指定されると、複数のモーションコントラスト画像の表示が複数の高画質画像の表示に一括して変更される。 At this time, if the display of the analysis results is set to a non-selected state, the display may be changed to parallel display of a plurality of motion contrast images at different dates and times. Then, when the button 911 is designated in response to an instruction from the examiner, the display of the plurality of motion contrast images is changed to the display of the plurality of high-quality images at once.
また、解析結果の表示が選択状態である場合には、検者からの指示に応じてボタン911が指定されると、複数のモーションコントラスト画像の解析結果の表示が複数の高画質画像の解析結果の表示に一括して変更される。ここで、解析結果の表示は、解析結果を任意の透明度により画像に重畳表示させたものであってもよい。このとき、解析結果の表示への変更は、例えば、表示されている画像に対して任意の透明度により解析結果を重畳させた状態に変更したものであってもよい。また、解析結果の表示への変更は、例えば、解析結果と画像とを任意の透明度によりブレンド処理して得た画像(例えば、2次元マップ)の表示への変更であってもよい。 In addition, when the display of analysis results is in the selected state, when the button 911 is specified in response to an instruction from the examiner, the display of the analysis results of multiple motion contrast images changes to the display of the analysis results of multiple high-quality images. The display will be changed all at once. Here, the display of the analysis results may be such that the analysis results are superimposed on the image with arbitrary transparency. At this time, the display of the analysis results may be changed to, for example, a state in which the analysis results are superimposed on the displayed image with arbitrary transparency. Further, the change to the display of the analysis result may be, for example, a change to the display of an image (for example, a two-dimensional map) obtained by blending the analysis result and the image with arbitrary transparency.
また、深度範囲の指定に用いる層境界の種類とオフセット位置をそれぞれ、3805,3806のようなユーザーインターフェースから一括して変更することができる。なお、断層画像も一緒に表示させ、断層画像上に重畳された層境界データを検者からの指示に応じて移動させることにより、異なる日時の複数のモーションコントラスト画像の深度範囲を一括して変更されてもよい。このとき、異なる日時の複数の断層画像を並べて表示し、1つの断層画像上で上記移動が行われると、他の断層画像上でも同様に層境界データが移動されてもよい。 Further, the type of layer boundary and the offset position used for specifying the depth range can be changed all at once from user interfaces 3805 and 3806, respectively. By displaying the tomographic images together and moving the layer boundary data superimposed on the tomographic images according to instructions from the examiner, the depth range of multiple motion contrast images at different times can be changed at once. may be done. At this time, when a plurality of tomographic images with different dates and times are displayed side by side and the above movement is performed on one tomographic image, the layer boundary data may be similarly moved on other tomographic images.
また、画像投影法やプロジェクションアーチファクト抑制処理の有無を、例えば、コンテキストメニューのようなユーザーインターフェースから選択することにより変更してもよい。 Further, the image projection method and the presence or absence of projection artifact suppression processing may be changed by selecting from a user interface such as a context menu, for example.
また、選択ボタン3807を選択して選択画面を表示させ、該選択画面上に表示された画像リストから選択された画像が表示されてもよい。なお、図17の上部に表示されている矢印3804は現在選択されている検査であることを示す印であり、基準検査(Baseline)はFollow-up撮影の際に選択した検査(図17の一番左側の画像)である。もちろん、基準検査を示すマークを表示部に表示させてもよい。 Alternatively, a selection button 3807 may be selected to display a selection screen, and an image selected from the image list displayed on the selection screen may be displayed. Note that the arrow 3804 displayed at the top of FIG. 17 is a mark indicating the currently selected test, and the reference test (Baseline) is the test selected at the time of follow-up imaging (the one shown in FIG. 17). The leftmost image). Of course, a mark indicating the reference test may be displayed on the display section.
また、「Show Difference」チェックボックス3808が指定された場合には、基準画像上に基準画像に対する計測値分布(マップもしくはセクタマップ)を表示する。さらに、この場合には、それ以外の検査日に対応する領域に基準画像に対して算出した計測値分布と当該領域に表示される画像に対して算出した計測分布との差分計測値マップを表示する。計測結果としては、レポート画面上にトレンドグラフ(経時変化計測によって得られた各検査日の画像に対する計測値のグラフ)を表示させてもよい。すなわち、異なる日時の複数の画像に対応する複数の解析結果の時系列データ(例えば、時系列グラフ)が表示されてもよい。このとき、表示されている複数の画像に対応する複数の日時以外の日時に関する解析結果についても、表示されている複数の画像に対応する複数の解析結果と判別可能な状態で(例えば、時系列グラフ上の各点の色が画像の表示の有無で異なる)時系列データとして表示させてもよい。また、該トレンドグラフの回帰直線(曲線)や対応する数式をレポート画面に表示させてもよい。 Furthermore, when the "Show Difference" check box 3808 is designated, the measurement value distribution (map or sector map) for the reference image is displayed on the reference image. Furthermore, in this case, a difference measurement value map between the measurement value distribution calculated for the reference image and the measurement distribution calculated for the image displayed in the area is displayed in the area corresponding to the other inspection dates. do. As the measurement results, a trend graph (a graph of measurement values for images on each inspection day obtained by measuring changes over time) may be displayed on the report screen. That is, time-series data (for example, a time-series graph) of multiple analysis results corresponding to multiple images at different dates and times may be displayed. At this time, analysis results related to dates and times other than the multiple dates and times corresponding to the multiple images being displayed are also displayed in a state that allows them to be distinguished from the multiple analysis results corresponding to the multiple images being displayed (for example, in a chronological order). It may also be displayed as time series data (the color of each point on the graph differs depending on whether or not an image is displayed). Further, the regression line (curve) of the trend graph and the corresponding mathematical formula may be displayed on the report screen.
本変形例においては、モーションコントラスト画像に関して説明を行ったが、これに限らない。本変形例に係る表示、高画質化、及び画像解析等の処理に関する画像は、断層画像でもよい。さらには、断層画像だけではなく、SLO画像、眼底写真、又は蛍光眼底写真など、異なる画像であっても構わない。その場合、高画質化処理を実行するためのユーザーインターフェースは、種類の異なる複数の画像に対して高画質化処理の実行を指示するもの、種類の異なる複数の画像から任意の画像を選択して高画質化処理の実行を指示するものがあってもよい。 In this modified example, the motion contrast image has been described, but the present invention is not limited to this. Images related to processing such as display, high image quality, and image analysis according to this modification may be tomographic images. Furthermore, not only a tomographic image but also a different image such as an SLO image, a fundus photograph, or a fluorescent fundus photograph may be used. In that case, the user interface for executing image quality enhancement processing may be one that instructs execution of image quality enhancement processing on multiple images of different types, or one that instructs to execute image quality enhancement processing on multiple images of different types, or one that allows you to select any image from multiple images of different types. There may also be an instruction to execute high image quality processing.
このような構成により、本変形例に係る高画質化部101-47が処理した画像を表示制御部101-05が表示部104に表示することができる。このとき、上述したように、高画質画像の表示、解析結果の表示、表示される正面画像の深度範囲等に関する複数の条件のうち少なくとも1つが選択された状態である場合には、表示画面が遷移されても、選択された状態が維持されてもよい。
With this configuration, the display control unit 101-05 can display the image processed by the image quality improvement unit 101-47 according to this modification on the
また、上述したように、複数の条件のうち少なくとも1つが選択された状態である場合には、他の条件が選択された状態に変更されても、該少なくとも1つが選択された状態が維持されてもよい。例えば、表示制御部101-05は、解析結果の表示が選択状態である場合に、検者からの指示に応じて(例えば、ボタン911が指定されると)、低画質画像の解析結果の表示を高画質画像の解析結果の表示に変更してもよい。また、表示制御部101-05は、解析結果の表示が選択状態である場合に、検者からの指示に応じて(例えば、ボタン911の指定が解除されると)、高画質画像の解析結果の表示を低画質画像の解析結果の表示に変更してもよい。 Furthermore, as described above, when at least one of the plurality of conditions is selected, even if the other conditions are changed to the selected state, the selected state of at least one of the conditions is maintained. It's okay. For example, when the display of the analysis results is in the selected state, the display control unit 101-05 displays the analysis results of the low-quality image in response to an instruction from the examiner (for example, when the button 911 is specified). may be changed to displaying the analysis results of high-quality images. In addition, when the display of the analysis results is in the selected state, the display control unit 101-05 displays the analysis results of the high-quality image in response to an instruction from the examiner (for example, when the designation of the button 911 is canceled). The display may be changed to display the analysis results of low-quality images.
また、表示制御部101-05は、高画質画像の表示が非選択状態である場合に、検者からの指示に応じて(例えば、解析結果の表示の指定が解除されると)、低画質画像の解析結果の表示を低画質画像の表示に変更してもよい。また、表示制御部101-05は、高画質画像の表示が非選択状態である場合に、検者からの指示に応じて(例えば、解析結果の表示が指定されると)、低画質画像の表示を低画質画像の解析結果の表示に変更してもよい。また、表示制御部101-05は、高画質画像の表示が選択状態である場合に、検者からの指示に応じて(例えば、解析結果の表示の指定が解除されると)、高画質画像の解析結果の表示を高画質画像の表示に変更してもよい。また、表示制御部101-05は、高画質画像の表示が選択状態である場合に、検者からの指示に応じて(例えば、解析結果の表示が指定されると)、高画質画像の表示を高画質画像の解析結果の表示に変更してもよい。 In addition, when the display of high-quality images is not selected, the display control unit 101-05 controls the display of low-quality images in response to an instruction from the examiner (for example, when the designation of displaying analysis results is canceled). The display of the image analysis results may be changed to the display of low-quality images. In addition, when the display of high-quality images is in a non-selected state, the display control unit 101-05 controls the display of low-quality images in response to an instruction from the examiner (for example, when the display of analysis results is specified). The display may be changed to display the analysis results of low-quality images. In addition, when displaying a high-quality image is selected, the display control unit 101-05 displays a high-quality image in response to an instruction from the examiner (for example, when the designation for displaying analysis results is canceled). The display of the analysis results may be changed to the display of high-quality images. In addition, when displaying a high-quality image is selected, the display control unit 101-05 displays a high-quality image in response to an instruction from the examiner (for example, when displaying analysis results is specified). may be changed to displaying the analysis results of high-quality images.
また、高画質画像の表示が非選択状態で且つ第1の種類の解析結果の表示が選択状態である場合を考える。この場合には、表示制御部101-05は、検者からの指示に応じて(例えば、第2の種類の解析結果の表示が指定されると)、低画質画像の第1の種類の解析結果の表示を低画質画像の第2の種類の解析結果の表示に変更してもよい。また、高画質画像の表示が選択状態で且つ第1の種類の解析結果の表示が選択状態である場合を考える。この場合には、表示制御部101-05は、検者からの指示に応じて(例えば、第2の種類の解析結果の表示が指定されると)、高画質画像の第1の種類の解析結果の表示を高画質画像の第2の種類の解析結果の表示に変更してもよい。 Also, consider a case where a high-quality image is displayed in a non-selected state and a first type of analysis result is displayed in a selected state. In this case, the display control unit 101-05 performs the first type of analysis of the low-quality image in response to an instruction from the examiner (for example, when displaying the second type of analysis results is specified). The display of the results may be changed to display of the second type of analysis results of low-quality images. Also, consider a case where a high-quality image is displayed in a selected state and a first type of analysis result is displayed in a selected state. In this case, the display control unit 101-05 performs the first type of analysis of the high-quality image in response to an instruction from the examiner (for example, when displaying the second type of analysis results is specified). The display of the results may be changed to display of the second type of analysis results of high-quality images.
なお、経過観察用の表示画面においては、上述したように、これらの表示の変更が、異なる日時で得た複数の画像に対して一括で反映されるように構成してもよい。ここで、解析結果の表示は、解析結果を任意の透明度により画像に重畳表示させたものであってもよい。このとき、解析結果の表示への変更は、例えば、表示されている画像に対して任意の透明度により解析結果を重畳させた状態に変更したものであってもよい。また、解析結果の表示への変更は、例えば、解析結果と画像とを任意の透明度によりブレンド処理して得た画像(例えば、2次元マップ)の表示への変更であってもよい。 Note that, as described above, the display screen for follow-up observation may be configured so that these display changes are reflected at once on a plurality of images obtained at different dates and times. Here, the display of the analysis results may be such that the analysis results are superimposed on the image with arbitrary transparency. At this time, the display of the analysis results may be changed to, for example, a state in which the analysis results are superimposed on the displayed image with arbitrary transparency. Further, the change to the display of the analysis result may be, for example, a change to the display of an image (for example, a two-dimensional map) obtained by blending the analysis result and the image with arbitrary transparency.
(変形例12)
上述した様々な実施形態及び変形例において、表示制御部101-05は、高画質化部101-47によって生成された高画質画像と入力画像のうち、検者からの指示に応じて選択された画像を表示部104に表示させることができる。また、表示制御部101-05は、検者からの指示に応じて、表示部104上の表示を撮影画像(入力画像)から高画質画像に切り替えてもよい。すなわち、表示制御部101-05は、検者からの指示に応じて、低画質画像の表示を高画質画像の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、高画質画像の表示を低画質画像の表示に変更してもよい。
(Modification 12)
In the various embodiments and modifications described above, the display control unit 101-05 selects a high-quality image generated by the high-quality image improvement unit 101-47 and an input image according to an instruction from the examiner. The image can be displayed on the
さらに、高画質化部101-47が、高画質化エンジン(高画質化用の学習済モデル)による高画質化処理の開始(高画質化エンジンへの画像の入力)を検者からの指示に応じて実行し、表示制御部101-05が、高画質化部101-47によって生成された高画質画像を表示部104に表示させてもよい。これに対し、撮影装置(断層画像撮影装置100)によって入力画像が撮影されると、高画質化エンジンが自動的に入力画像に基づいて高画質画像を生成し、表示制御部101-05が、検者からの指示に応じて高画質画像を表示部104に表示させてもよい。ここで、高画質化エンジンとは、上述した画質向上処理(高画質化処理)を行う学習済モデルを含む。
Furthermore, the image quality improvement unit 101-47 instructs the image quality improvement engine (trained model for image quality improvement) to start image quality improvement processing (inputting images to the image quality improvement engine) in response to an instruction from the examiner. The display control unit 101-05 may cause the
なお、これらの処理は解析結果の出力についても同様に行うことができる。すなわち、表示制御部101-05は、検者からの指示に応じて、低画質画像の解析結果の表示を高画質画像の解析結果の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、高画質画像の解析結果の表示を低画質画像の解析結果の表示に変更してもよい。もちろん、表示制御部101-05は、検者からの指示に応じて、低画質画像の解析結果の表示を低画質画像の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、低画質画像の表示を低画質画像の解析結果の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、高画質画像の解析結果の表示を高画質画像の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、高画質画像の表示を高画質画像の解析結果の表示に変更してもよい。 Note that these processes can be similarly performed for outputting the analysis results. That is, the display control unit 101-05 may change the display of the analysis results of low-quality images to the display of the analysis results of high-quality images in response to instructions from the examiner. Further, the display control unit 101-05 may change the display of the analysis results of the high-quality images to the display of the analysis results of the low-quality images in response to an instruction from the examiner. Of course, the display control unit 101-05 may change the display of the analysis result of the low-quality image to the display of the low-quality image in response to an instruction from the examiner. Further, the display control unit 101-05 may change the display of the low-quality image to the display of the analysis result of the low-quality image in response to an instruction from the examiner. Further, the display control unit 101-05 may change the display of the analysis result of the high-quality image to the display of the high-quality image in response to an instruction from the examiner. Further, the display control unit 101-05 may change the display of the high-quality image to the display of the analysis result of the high-quality image in response to an instruction from the examiner.
また、表示制御部101-05は、検者からの指示に応じて、低画質画像の解析結果の表示を低画質画像の他の種類の解析結果の表示に変更してもよい。また、表示制御部101-05は、検者からの指示に応じて、高画質画像の解析結果の表示を高画質画像の他の種類の解析結果の表示に変更してもよい。 Further, the display control unit 101-05 may change the display of the analysis result of the low-quality image to the display of another type of analysis result of the low-quality image in response to an instruction from the examiner. Further, the display control unit 101-05 may change the display of the analysis result of the high-quality image to the display of another type of analysis result of the high-quality image in response to an instruction from the examiner.
ここで、高画質画像の解析結果の表示は、高画質画像の解析結果を任意の透明度により高画質画像に重畳表示させたものであってもよい。また、低画質画像の解析結果の表示は、低画質画像の解析結果を任意の透明度により低画質画像に重畳表示させたものであってもよい。このとき、解析結果の表示への変更は、例えば、表示されている画像に対して任意の透明度により解析結果を重畳させた状態に変更したものであってもよい。また、解析結果の表示への変更は、例えば、解析結果と画像とを任意の透明度によりブレンド処理して得た画像(例えば、2次元マップ)の表示への変更であってもよい。 Here, the display of the analysis result of the high-quality image may be one in which the analysis result of the high-quality image is displayed superimposed on the high-quality image with arbitrary transparency. Moreover, the display of the analysis result of the low-quality image may be one in which the analysis result of the low-quality image is displayed superimposed on the low-quality image with arbitrary transparency. At this time, the display of the analysis results may be changed to, for example, a state in which the analysis results are superimposed on the displayed image with arbitrary transparency. Further, the change to the display of the analysis result may be, for example, a change to the display of an image (for example, a two-dimensional map) obtained by blending the analysis result and the image with arbitrary transparency.
(変形例13)
上述した様々な実施形態及び変形例におけるレポート画面において、所望の層の層厚や各種の血管密度等の解析結果を表示させてもよい。また、視神経乳頭部、黄斑部、血管領域、神経線維束、硝子体領域、黄斑領域、脈絡膜領域、強膜領域、篩状板領域、網膜層境界、網膜層境界端部、視細胞、血球、血管壁、血管内壁境界、血管外側境界、神経節細胞、角膜領域、隅角領域、シュレム管等の少なくとも1つを含む注目部位に関するパラメータの値(分布)を解析結果として表示させてもよい。このとき、例えば、各種のアーチファクトの低減処理が適用された医用画像を解析することで、精度の良い解析結果を表示させることができる。なお、アーチファクトは、例えば、血管領域等による光吸収により生じる偽像領域や、プロジェクションアーチファクト、被検眼の状態(動きや瞬き等)によって測定光の主走査方向に生じる正面画像における帯状のアーチファクト等であってもよい。また、アーチファクトは、例えば、被検者の所定部位の医用画像上に撮影毎にランダムに生じるような写損領域であれば、何でもよい。また、上述したような様々なアーチファクト(写損領域)の少なくとも1つを含む領域に関するパラメータの値(分布)を解析結果として表示させてもよい。また、ドルーゼン、新生血管、白斑(硬性白斑)、シュードドルーゼン等の異常部位等の少なくとも1つを含む領域に関するパラメータの値(分布)を解析結果として表示させてもよい。
(Modification 13)
On the report screen in the various embodiments and modifications described above, analysis results such as the thickness of a desired layer and various blood vessel densities may be displayed. In addition, the optic disc, macular area, blood vessel area, nerve fiber bundle, vitreous area, macular area, choroid area, sclera area, lamina cribrosa area, retinal layer boundary, retinal layer boundary edge, photoreceptor cells, blood cells, Values (distribution) of parameters related to a region of interest including at least one of a blood vessel wall, a blood vessel inner wall boundary, a blood vessel outer wall boundary, a ganglion cell, a corneal region, an angle region, Schlemm's canal, etc. may be displayed as an analysis result. At this time, for example, by analyzing a medical image to which various artifact reduction processes have been applied, highly accurate analysis results can be displayed. Note that artifacts include, for example, false image areas caused by light absorption by blood vessel areas, projection artifacts, and band-shaped artifacts in the front image that occur in the main scanning direction of the measurement light due to the condition of the eye being examined (movement, blinking, etc.). There may be. Furthermore, the artifact may be of any type, as long as it is a defective area that randomly appears on a medical image of a predetermined region of a subject each time the image is taken. Further, the values (distribution) of parameters regarding a region including at least one of the various artifacts (impossible regions) as described above may be displayed as an analysis result. Further, the values (distribution) of parameters related to a region including at least one of an abnormal site such as drusen, new blood vessels, vitiligo (hard vitiligo), and pseudodrusen may be displayed as an analysis result.
また、解析結果は、解析マップや、各分割領域に対応する統計値を示すセクタ等で表示されてもよい。なお、解析結果は、医用画像の解析結果を学習データとして学習して得た学習済モデル(解析結果生成エンジン、解析結果生成用の学習済モデル)を用いて生成されたものであってもよい。このとき、学習済モデルは、医用画像とその医用画像の解析結果とを含む学習データや、医用画像とその医用画像とは異なる種類の医用画像の解析結果とを含む学習データ等を用いた学習により得たものであってもよい。また、学習済モデルは、正面断層画像及び正面モーションコントラスト画像のように、所定部位の異なる種類の複数の医用画像をセットとする入力データを含む学習データを用いた学習により得たものであってもよい。ここで、正面断層画像は断層画像のEn-Face画像に対応し、正面モーションコントラスト画像はOCTAのEn-Face画像に対応する。また、高画質化用の学習済モデルにより生成された高画質画像を用いて得た解析結果が表示されるように構成されてもよい。なお、高画質化用の学習済モデルは、第一の画像を入力データとし、第一の画像よりも高画質な第二の画像を正解データとする学習データを学習して得たものであってもよい。このとき、第二の画像は、例えば、複数の第一の画像の重ね合わせ処理(例えば、位置合わせして得た複数の第一の画像の平均化処理)等によって、高コントラスト化やノイズ低減等が行われたような高画質な画像であってもよい。 Further, the analysis results may be displayed as an analysis map, sectors showing statistical values corresponding to each divided area, or the like. Note that the analysis results may be generated using a trained model (analysis result generation engine, trained model for analysis result generation) obtained by learning the analysis results of medical images as learning data. . At this time, the trained model is trained using learning data that includes a medical image and an analysis result of the medical image, or learning data that includes a medical image and the analysis result of a medical image of a different type than the medical image. It may be obtained by In addition, the trained model is obtained by learning using learning data that includes input data that is a set of multiple medical images of different types of predetermined parts, such as frontal tomographic images and frontal motion contrast images. Good too. Here, the frontal tomographic image corresponds to the En-Face image of the tomographic image, and the frontal motion contrast image corresponds to the En-Face image of OCTA. Furthermore, it may be configured to display analysis results obtained using high-quality images generated by trained models for high-quality images. Note that the trained model for high image quality is obtained by learning training data in which the first image is used as input data and the second image, which has higher image quality than the first image, is used as correct data. It's okay. At this time, the second image is processed to increase contrast or reduce noise by, for example, superimposing a plurality of first images (for example, averaging processing of a plurality of first images obtained by positioning). It may be a high-quality image that has been subjected to the above process.
また、学習データに含まれる入力データとしては、高画質化用の学習済モデルにより生成された高画質画像であってもよいし、低画質画像と高画質画像とのセットであってもよい。また、学習データは、例えば、解析領域を解析して得た解析値(例えば、平均値や中央値等)、解析値を含む表、解析マップ、画像におけるセクタ等の解析領域の位置等の少なくとも1つを含む情報を(教師あり学習の)正解データとして、入力データにラベル付け(アノテーション)したデータであってもよい。なお、検者からの指示に応じて、解析結果生成用の学習済モデルにより得た解析結果が表示されるように構成されてもよい。 Further, the input data included in the learning data may be a high-quality image generated by a trained model for high-quality images, or may be a set of a low-quality image and a high-quality image. In addition, the learning data includes, for example, at least analysis values obtained by analyzing the analysis area (e.g., average value, median value, etc.), a table including the analysis values, an analysis map, the position of the analysis area such as a sector in an image, etc. The input data may be labeled (annotated) with information including one as the correct data (for supervised learning). Note that the analysis result obtained by the learned model for generating the analysis result may be displayed in response to an instruction from the examiner.
また、上述した様々な実施形態及び変形例におけるレポート画面において、緑内障や加齢黄斑変性等の種々の診断結果を表示させてもよい。このとき、例えば、上述したような各種のアーチファクトの低減処理が適用された医用画像を解析することで、精度の良い診断結果を表示させることができる。また、診断結果は、特定された異常部位等の位置を画像上に表示されてもよいし、また、異常部位の状態等を文字等によって表示されてもよい。また、異常部位等の分類結果(例えば、Curtin分類)を診断結果として表示させてもよい。また、分類結果としては、例えば、異常部位毎の確からしさを示す情報(例えば、割合を示す数値)が表示されてもよい。 Further, various diagnostic results such as glaucoma and age-related macular degeneration may be displayed on the report screen in the various embodiments and modified examples described above. At this time, for example, by analyzing a medical image to which the various artifact reduction processes described above have been applied, highly accurate diagnostic results can be displayed. Further, the diagnosis result may be displayed by displaying the position of the identified abnormal region on the image, or by displaying the state of the abnormal region by text or the like. Furthermore, the classification results (for example, Curtin classification) of abnormal regions and the like may be displayed as the diagnosis results. Further, as the classification result, for example, information indicating the probability of each abnormal site (for example, a numerical value indicating a ratio) may be displayed.
なお、診断結果は、医用画像の診断結果を学習データとして学習して得た学習済モデル(診断結果生成エンジン、診断結果生成用の学習済モデル)を用いて生成されたものであってもよい。また、学習済モデルは、医用画像とその医用画像の診断結果とを含む学習データや、医用画像とその医用画像とは異なる種類の医用画像の診断結果とを含む学習データ等を用いた学習により得たものであってもよい。また、高画質化用の学習済モデルにより生成された高画質画像を用いて得た診断結果が表示されるように構成されてもよい。 Note that the diagnostic results may be generated using a trained model (a diagnostic result generation engine, a trained model for generating diagnostic results) obtained by learning the diagnostic results of medical images as learning data. . In addition, the trained model can be trained using training data that includes a medical image and the diagnosis result of the medical image, or training data that includes the medical image and the diagnosis result of a different type of medical image than the medical image. It may be something you have obtained. Furthermore, the system may be configured to display diagnostic results obtained using high-quality images generated by trained models for high-quality images.
また、学習データに含まれる入力データとしては、高画質化用の学習済モデルにより生成された高画質画像であってもよいし、低画質画像と高画質画像とのセットであってもよい。また、学習データは、例えば、診断名、病変(異常部位)の種類や状態(程度)、画像における病変の位置、注目領域に対する病変の位置、所見(読影所見等)、診断名の根拠(肯定的な医用支援情報等)、診断名を否定する根拠(否定的な医用支援情報)等の少なくとも1つを含む情報を(教師あり学習の)正解データとして、入力データにラベル付け(アノテーション)したデータであってもよい。なお、検者からの指示に応じて、診断結果生成用の学習済モデルにより得た診断結果が表示されるように構成されてもよい。 Further, the input data included in the learning data may be a high-quality image generated by a trained model for high-quality images, or may be a set of a low-quality image and a high-quality image. In addition, the learning data includes, for example, the diagnosis name, the type and condition (degree) of the lesion (abnormal site), the position of the lesion in the image, the position of the lesion relative to the region of interest, findings (image interpretation findings, etc.), and the basis for the diagnosis name (positive The input data is labeled (annotated) as the correct data (for supervised learning), including at least one of the following: negative medical support information, etc.), grounds for denying the diagnosis (negative medical support information), etc. It may be data. Note that the configuration may be such that the diagnostic results obtained by the trained model for generating diagnostic results are displayed in response to instructions from the examiner.
また、上述した様々な実施形態及び変形例におけるレポート画面において、上述したような注目部位、アーチファクト、異常部位等の物体認識結果(物体検出結果)やセグメンテーション結果を表示させてもよい。このとき、例えば、画像上の物体の周辺に矩形の枠等を重畳して表示させてもよい。また、例えば、画像における物体上に色等を重畳して表示させてもよい。なお、物体認識結果やセグメンテーション結果は、物体認識やセグメンテーションを示す情報を正解データとして医用画像にラベル付け(アノテーション)した学習データを学習して得た学習済モデル(物体認識エンジン、物体認識用の学習済モデルセグメンテーションエンジン、セグメンテーション用の学習済モデル)を用いて生成されたものであってもよい。なお、上述した解析結果生成や診断結果生成は、上述した物体認識結果やセグメンテーション結果を利用することで得られたものであってもよい。例えば、物体認識やセグメンテーションの処理により得た注目部位に対して解析結果生成や診断結果生成の処理を行ってもよい。 Further, on the report screen in the various embodiments and modifications described above, object recognition results (object detection results) and segmentation results such as the above-mentioned regions of interest, artifacts, and abnormal regions may be displayed. At this time, for example, a rectangular frame or the like may be superimposed and displayed around the object on the image. Furthermore, for example, a color or the like may be superimposed and displayed on an object in the image. Note that object recognition results and segmentation results are generated using a trained model (object recognition engine, object recognition It may be generated using a trained model segmentation engine (a trained model for segmentation). Note that the analysis result generation and diagnosis result generation described above may be obtained by using the object recognition results and segmentation results described above. For example, analysis result generation or diagnostic result generation processing may be performed on a region of interest obtained through object recognition or segmentation processing.
また、上述した学習済モデルは、被検者の所定部位の異なる種類の複数の医用画像をセットとする入力データを含む学習データにより学習して得た学習済モデルであってもよい。このとき、学習データに含まれる入力データとして、例えば、眼底のモーションコントラスト正面画像及び輝度正面画像(あるいは輝度断層画像)をセットとする入力データが考えられる。また、学習データに含まれる入力データとして、例えば、眼底の断層画像(Bスキャン画像)及びカラー眼底画像(あるいは蛍光眼底画像)をセットとする入力データ等も考えられる。また、異なる種類の複数の医療画像は、異なるモダリティ、異なる光学系、又は異なる原理等により取得されたものであれば何でもよい。 Further, the trained model described above may be a trained model obtained by learning using learning data including input data that is a set of a plurality of different types of medical images of a predetermined region of a subject. At this time, as input data included in the learning data, for example, input data including a set of a motion contrast frontal image and a brightness frontal image (or a brightness tomographic image) of the fundus can be considered. Further, as the input data included in the learning data, for example, input data including a set of a tomographic image of the fundus (B scan image) and a color fundus image (or a fluorescent fundus image) can be considered. Further, the plurality of medical images of different types may be any image as long as they are obtained using different modalities, different optical systems, or different principles.
また、上述した学習済モデルは、被検者の異なる部位の複数の医用画像をセットとする入力データを含む学習データにより学習して得た学習済モデルであってもよい。このとき、学習データに含まれる入力データとして、例えば、眼底の断層画像(Bスキャン画像)と前眼部の断層画像(Bスキャン画像)とをセットとする入力データが考えられる。また、学習データに含まれる入力データとして、例えば、眼底の黄斑の三次元OCT画像(三次元断層画像)と眼底の視神経乳頭のサークルスキャン(又はラスタースキャン)断層画像とをセットとする入力データ等も考えられる。 Further, the trained model described above may be a trained model obtained by learning using learning data including input data that is a set of a plurality of medical images of different parts of the subject. At this time, as input data included in the learning data, for example, input data including a set of a tomographic image of the fundus (B-scan image) and a tomographic image of the anterior segment (B-scan image) can be considered. Furthermore, as input data included in the learning data, for example, input data that is a set of a three-dimensional OCT image (three-dimensional tomographic image) of the macula in the fundus and a circle scan (or raster scan) tomographic image of the optic disc in the fundus, etc. can also be considered.
なお、学習データに含まれる入力データは、被検者の異なる部位及び異なる種類の複数の医用画像であってもよい。このとき、学習データに含まれる入力データは、例えば、前眼部の断層画像とカラー眼底画像とをセットとする入力データ等が考えられる。また、上述した学習済モデルは、被検者の所定部位の異なる撮影画角の複数の医用画像をセットとする入力データを含む学習データにより学習して得た学習済モデルであってもよい。また、学習データに含まれる入力データは、パノラマ画像のように、所定部位を複数領域に時分割して得た複数の医用画像を貼り合わせたものであってもよい。このとき、パノラマ画像のような広画角画像を学習データとして用いることにより、狭画角画像よりも情報量が多い等の理由から画像の特徴量を精度良く取得できる可能性があるため、各処理の結果を向上することができる。また、学習データに含まれる入力データは、被検者の所定部位の異なる日時の複数の医用画像をセットとする入力データであってもよい。 Note that the input data included in the learning data may be a plurality of medical images of different parts and different types of the subject. At this time, the input data included in the learning data may be, for example, input data that includes a tomographic image of the anterior segment of the eye and a color fundus image. Further, the above-mentioned trained model may be a trained model obtained by learning using learning data including input data that is a set of a plurality of medical images of a predetermined region of a subject at different photographing angles of view. Further, the input data included in the learning data may be a combination of a plurality of medical images obtained by time-divisionally dividing a predetermined region into a plurality of regions, such as a panoramic image. At this time, by using wide-angle images such as panoramic images as learning data, it is possible to obtain image features with higher accuracy because they contain more information than narrow-angle images. Processing results can be improved. Furthermore, the input data included in the learning data may be input data that is a set of a plurality of medical images of a predetermined region of the subject at different times.
また、上述した解析結果と診断結果と物体認識結果とセグメンテーション結果とのうち少なくとも1つの結果が表示される表示画面は、レポート画面に限らない。このような表示画面は、例えば、撮影確認画面、経過観察用の表示画面、及び撮影前の各種調整用のプレビュー画面(各種のライブ動画像が表示される表示画面)等の少なくとも1つの表示画面に表示されてもよい。例えば、上述した学習済モデルを用いて得た上記少なくとも1つの結果を撮影確認画面に表示させることにより、検者は、撮影直後であっても精度の良い結果を確認することができる。また、上述した低画質画像と高画質画像との表示の変更は、例えば、低画質画像の解析結果と高画質画像の解析結果との表示の変更であってもよい。 Furthermore, the display screen on which at least one of the above-mentioned analysis results, diagnosis results, object recognition results, and segmentation results is displayed is not limited to the report screen. Such display screens include, for example, at least one display screen such as a shooting confirmation screen, a display screen for progress observation, and a preview screen for various adjustments before shooting (a display screen on which various live video images are displayed). may be displayed. For example, by displaying the at least one result obtained using the trained model described above on the imaging confirmation screen, the examiner can confirm highly accurate results even immediately after imaging. Further, the above-described display change between a low-quality image and a high-quality image may be, for example, a change in display between an analysis result of a low-quality image and an analysis result of a high-quality image.
ここで、上述した様々な学習済モデルは、学習データを用いた機械学習により得ることができる。機械学習には、例えば、多階層のニューラルネットワークから成る深層学習(Deep Learning)がある。また、多階層のニューラルネットワークの少なくとも一部には、例えば、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)を用いることができる。また、多階層のニューラルネットワークの少なくとも一部には、オートエンコーダ(自己符号化器)に関する技術が用いられてもよい。また、学習には、バックプロパゲーション(誤差逆伝搬法)に関する技術が用いられてもよい。ただし、機械学習としては、深層学習に限らず、画像等の学習データの特徴量を学習によって自ら抽出(表現)可能なモデルであれば何でもよい。 Here, the various learned models described above can be obtained by machine learning using learning data. Machine learning includes, for example, deep learning that consists of multilayer neural networks. Further, for example, a convolutional neural network (CNN) can be used for at least a portion of the multi-layer neural network. Further, a technique related to an autoencoder (self-encoder) may be used for at least a portion of the multi-layer neural network. Furthermore, a technique related to backpropagation (error backpropagation method) may be used for learning. However, machine learning is not limited to deep learning, and any model may be used as long as it is capable of extracting (expressing) features of learning data such as images by itself through learning.
また、高画質化エンジン(高画質化用の学習済モデル)は、高画質化エンジンにより生成された少なくとも1つの高画質画像を含む学習データを追加学習して得た学習済モデルであってもよい。このとき、高画質画像を追加学習用の学習データとして用いるか否かを、検者からの指示により選択可能に構成されてもよい。また、正解データの生成には、ラベル付け(アノテーション)等の正解データを生成するための正解データ生成用の学習済モデルが用いられてもよい。このとき、正解データ生成用の学習済モデルは、検者がラベル付け(アノテーション)して得た正解データを(順次)追加学習することにより得られたものであってもよい。 In addition, the high image quality engine (trained model for high image quality) may be a trained model obtained by additionally learning training data that includes at least one high quality image generated by the high image quality engine. good. At this time, it may be possible to select whether or not to use the high-quality image as learning data for additional learning based on an instruction from the examiner. Moreover, a learned model for generating correct data for generating correct data such as labeling (annotation) may be used to generate the correct data. At this time, the trained model for generating correct answer data may be obtained by (sequentially) additionally learning correct answer data obtained by labeling (annotation) by the examiner.
(変形例14)
上述した様々な実施形態及び変形例におけるプレビュー画面において、ライブ動画像の少なくとも1つのフレーム毎に上述した学習済モデルが用いられるように構成されてもよい。このとき、プレビュー画面において、異なる部位や異なる種類の複数のライブ動画像が表示されている場合には、各ライブ動画像に対応する学習済モデルが用いられるように構成されてもよい。これにより、例えば、ライブ動画像であっても、処理時間を短縮することができるため、検者は撮影開始前に精度の高い情報を得ることができる。このため、例えば、再撮影の失敗等を低減することができるため、診断の精度や効率を向上させることができる。なお、複数のライブ動画像は、例えば、XYZ方向のアライメントのための前眼部の動画像、及び眼底観察光学系のフォーカス調整やOCTフォーカス調整のための眼底の正面動画像であってよい。また、複数のライブ動画像は、例えば、OCTのコヒーレンスゲート調整(測定光路長と参照光路長との光路長差の調整)のための眼底の断層動画像等であってもよい。
(Modification 14)
In the preview screen in the various embodiments and modifications described above, the learned model described above may be used for each at least one frame of a live video image. At this time, if a plurality of live moving images of different parts or types are displayed on the preview screen, a learned model corresponding to each live moving image may be used. With this, for example, even for live moving images, the processing time can be shortened, so the examiner can obtain highly accurate information before starting imaging. Therefore, for example, it is possible to reduce failures in re-imaging, etc., and thus it is possible to improve the accuracy and efficiency of diagnosis. Note that the plurality of live moving images may be, for example, a moving image of the anterior segment of the eye for alignment in the XYZ directions, and a frontal moving image of the fundus for focus adjustment of the fundus observation optical system or OCT focus adjustment. Further, the plurality of live moving images may be, for example, tomographic moving images of the fundus for OCT coherence gate adjustment (adjustment of the optical path length difference between the measurement optical path length and the reference optical path length).
また、上述した学習済モデルを適用可能な動画像は、ライブ動画像に限らず、例えば、記憶部に記憶(保存)された動画像であってもよい。このとき、例えば、記憶部に記憶(保存)された眼底の断層動画像の少なくとも1つのフレーム毎に位置合わせして得た動画像が表示画面に表示されてもよい。例えば、硝子体を好適に観察したい場合には、まず、フレーム上に硝子体ができるだけ存在する等の条件を基準とする基準フレームを選択してもよい。このとき、各フレームは、XZ方向の断層画像(Bスキャン像)である。そして、選択された基準フレームに対して他のフレームがXZ方向に位置合わせされた動画像が表示画面に表示されてもよい。このとき、例えば、動画像の少なくとも1つのフレーム毎に高画質化用の学習済モデルにより順次生成された高画質画像(高画質フレーム)を連続表示させるように構成してもよい。 Further, the moving image to which the above-described learned model can be applied is not limited to a live moving image, but may be a moving image stored (saved) in a storage unit, for example. At this time, for example, a moving image obtained by aligning at least one frame of the tomographic moving image of the fundus oculi stored (saved) in the storage unit may be displayed on the display screen. For example, if you want to observe the vitreous body in a suitable manner, you may first select a reference frame based on conditions such as as much vitreous body as possible on the frame. At this time, each frame is a tomographic image (B scan image) in the XZ direction. Then, a moving image in which other frames are aligned in the XZ directions with respect to the selected reference frame may be displayed on the display screen. At this time, for example, high-quality images (high-quality frames) sequentially generated by a trained model for improving image quality may be continuously displayed for each at least one frame of the moving image.
なお、上述したフレーム間の位置合わせの手法としては、X方向の位置合わせの手法とZ方向(深度方向)の位置合わせの手法とは、同じ手法が適用されてもよいし、全て異なる手法が適用されてもよい。また、同一方向の位置合わせは、異なる手法で複数回行われてもよく、例えば、粗い位置合わせを行った後に、精密な位置合わせが行われてもよい。また、位置合わせの手法としては、例えば、断層画像(Bスキャン像)をセグメンテーション処理して得た網膜層境界を用いた(Z方向の粗い)位置合わせ、断層画像を分割して得た複数の領域と基準画像との相関情報(類似度)を用いた(X方向やZ方向の精密な)位置合わせ、断層画像(Bスキャン像)毎に生成した1次元投影像を用いた(X方向の)位置合わせ、2次元正面画像を用いた(X方向の)位置合わせ等がある。また、ピクセル単位で粗く位置合わせが行われてから、サブピクセル単位で精密な位置合わせが行われるように構成されてもよい。 Note that as the above-mentioned method for positioning between frames, the same method may be applied for the positioning method in the X direction and the method for positioning in the Z direction (depth direction), or different methods may be applied. may be applied. Furthermore, alignment in the same direction may be performed multiple times using different techniques; for example, rough alignment may be followed by precise alignment. In addition, as a method for positioning, for example, positioning using retinal layer boundaries obtained by segmenting a tomographic image (B-scan image) (coarse in the Z direction), and positioning using multiple retinal layer boundaries obtained by dividing a tomographic image Positioning (accurate in the X and Z directions) using correlation information (similarity) between the region and the reference image, and one-dimensional projection images generated for each tomographic image (B scan image) (in the X direction) ) alignment, alignment (in the X direction) using a two-dimensional front image, etc. Alternatively, the configuration may be such that rough alignment is performed pixel by pixel, and then fine alignment is performed subpixel by subpixel.
ここで、各種の調整中では、被検眼の網膜等の撮影対象がまだ上手く撮像できていない可能性がある。このため、学習済モデルに入力される医用画像と学習データとして用いられた医用画像との違いが大きいために、精度良く高画質画像が得られない可能性がある。そこで、断層画像(Bスキャン)の画質評価等の評価値が閾値を超えたら、高画質動画像の表示(高画質フレームの連続表示)を自動的に開始するように構成してもよい。また、断層画像(Bスキャン)の画質評価等の評価値が閾値を超えたら、高画質化ボタンを検者が指定可能な状態(アクティブ状態)に変更するように構成されてもよい。なお、高画質化ボタンは、高画質化処理の実行を指定するためのボタンである。もちろん、高画質化ボタンは、高画質画像の表示を指示するためのボタンであってもよい。 Here, during various adjustments, there is a possibility that the object to be photographed, such as the retina of the eye to be examined, has not yet been successfully imaged. For this reason, since there is a large difference between the medical images input to the trained model and the medical images used as learning data, there is a possibility that high-quality images cannot be obtained with high accuracy. Therefore, when an evaluation value such as image quality evaluation of a tomographic image (B scan) exceeds a threshold value, display of high-quality moving images (continuous display of high-quality frames) may be automatically started. Further, when an evaluation value such as image quality evaluation of a tomographic image (B scan) exceeds a threshold value, the image quality improvement button may be changed to a state (active state) that can be specified by the examiner. Note that the image quality improvement button is a button for specifying execution of image quality improvement processing. Of course, the high-quality image button may be a button for instructing display of a high-quality image.
また、走査パターン等が異なる撮影モード毎に異なる高画質化用の学習済モデルを用意して、選択された撮影モードに対応する高画質化用の学習済モデルが選択されるように構成されてもよい。また、異なる撮影モードで得た様々な医用画像を含む学習データを学習して得た1つの高画質化用の学習済モデルが用いられてもよい。 In addition, a different trained model for high image quality is prepared for each shooting mode with a different scanning pattern, etc., and the trained model for high image quality corresponding to the selected shooting mode is selected. Good too. Alternatively, one trained model for improving image quality obtained by learning training data including various medical images obtained in different imaging modes may be used.
(変形例15)
上述した様々な実施形態及び変形例においては、学習済モデルが追加学習中である場合、追加学習中の学習済モデル自体を用いて出力(推論・予測)することが難しい可能性がある。このため、追加学習中の学習済モデルに対する医用画像の入力を禁止することがよい。また、追加学習中の学習済モデルと同じ学習済モデルをもう一つ予備の学習済モデルとして用意してもよい。このとき、追加学習中には、予備の学習済モデルに対して医用画像の入力が実行できるようにすることがよい。そして、追加学習が完了した後に、追加学習後の学習済モデルを評価し、問題なければ、予備の学習済モデルから追加学習後の学習済モデルに置き換えればよい。また、問題があれば、予備の学習済モデルが用いられるようにしてもよい。なお、学習済モデルの評価としては、例えば、高画質化用の学習済モデルで得た高画質画像を他の種類の画像と分類するための分類用の学習済モデルが用いられてもよい。分類用の学習済モデルは、例えば、高画質化用の学習済モデルで得た高画質画像と低画質画像とを含む複数の画像を入力データとし、これらの画像の種類がラベル付け(アノテーション)されたデータを正解データとして含む学習データを学習して得た学習済モデルであってもよい。このとき、推定時(予測時)の入力データの画像の種類が、学習時の正解データに含まれる画像の種類毎の確からしさを示す情報(例えば、割合を示す数値)と合わせて表示されてもよい。なお、分類用の学習済モデルの入力データとしては、上記の画像以外にも、複数の低画質画像の重ね合わせ処理(例えば、位置合わせして得た複数の低画質画像の平均化処理)等によって、高コントラスト化やノイズ低減等が行われたような高画質な画像が含まれても良い。
(Modification 15)
In the various embodiments and modifications described above, when a trained model is undergoing additional learning, it may be difficult to output (inference/predict) using the trained model itself that is undergoing additional learning. For this reason, it is preferable to prohibit the input of medical images to a learned model that is undergoing additional learning. Further, another trained model that is the same as the trained model that is currently being additionally trained may be prepared as a preliminary trained model. At this time, during additional learning, it is preferable to allow medical images to be input to the preliminary trained model. Then, after the additional learning is completed, the trained model after the additional learning is evaluated, and if there is no problem, the preliminary trained model may be replaced with the trained model after the additional learning. Furthermore, if there is a problem, a preliminary trained model may be used. Note that for the evaluation of the trained model, for example, a trained model for classification for classifying high-quality images obtained by the trained model for high image quality from other types of images may be used. For example, a trained model for classification uses as input data multiple images including high-quality images and low-quality images obtained by a trained model for high image quality, and the types of these images are labeled (annotated). The model may be a trained model obtained by learning training data that includes the correct data as correct data. At this time, the type of image of the input data at the time of estimation (during prediction) is displayed together with information indicating the probability of each type of image included in the correct data at the time of learning (for example, a numerical value indicating a percentage). Good too. In addition to the above-mentioned images, the input data for the trained model for classification may also include superposition processing of multiple low-quality images (for example, averaging processing of multiple low-quality images obtained by positioning), etc. may include high-quality images that have undergone high contrast, noise reduction, and the like.
また、撮影部位毎に学習して得た学習済モデルを選択的に利用できるようにしてもよい。具体的には、第1の撮影部位(肺、被検眼等)を含む学習データを用いて得た第1の学習済モデルと、第1の撮影部位とは異なる第2の撮影部位を含む学習データを用いて得た第2の学習済モデルと、を含む複数の学習済モデルを用意することができる。そして、画像処理部101-04は、これら複数の学習済モデルのいずれかを選択する選択手段を有してもよい。このとき、画像処理部101-04は、選択された学習済モデルに対して追加学習として実行する制御手段を有してもよい。制御手段は、検者からの指示に応じて、選択された学習済モデルに対応する撮影部位と該撮影部位の撮影画像とがペアとなるデータを検索し、検索して得たデータを学習データとする学習を、選択された学習済モデルに対して追加学習として実行することができる。なお、選択された学習済モデルに対応する撮影部位は、データのヘッダの情報から取得したり、検者により手動入力されたりしたものであってよい。また、データの検索は、例えば、病院や研究所等の外部施設のサーバ等からネットワークを介して行われてよい。これにより、学習済モデルに対応する撮影部位の撮影画像を用いて、撮影部位毎に効率的に追加学習することができる。 Further, it may be possible to selectively use a learned model obtained by learning for each part to be imaged. Specifically, a first trained model obtained using learning data including a first imaging region (lung, eye to be examined, etc.) and a learning model including a second imaging region different from the first imaging region. A plurality of trained models including a second trained model obtained using data can be prepared. The image processing unit 101-04 may have a selection means for selecting one of the plurality of trained models. At this time, the image processing unit 101-04 may have a control unit that performs additional learning on the selected trained model. The control means searches for data in which a photographed region corresponding to the selected trained model and a photographed image of the photographed region are paired, and uses the data obtained through the search as learning data. This learning can be performed as additional learning on the selected trained model. Note that the imaged region corresponding to the selected learned model may be obtained from information in the header of the data, or may be manually input by the examiner. Further, the data search may be performed via a network, for example, from a server in an external facility such as a hospital or research institute. Thereby, additional learning can be efficiently performed for each imaged body part using the photographed images of the body part corresponding to the learned model.
なお、選択手段及び制御手段は、画像処理部101-04のCPUやMPU等のプロセッサによって実行されるソフトウェアモジュールにより構成されてよい。また、選択手段及び制御手段は、ASIC等の特定の機能を果たす回路や独立した装置等によって構成されてもよい。 Note that the selection means and the control means may be constituted by a software module executed by a processor such as a CPU or an MPU of the image processing section 101-04. Furthermore, the selection means and the control means may be constituted by a circuit that performs a specific function, such as an ASIC, or an independent device.
また、追加学習用の学習データを、病院や研究所等の外部施設のサーバ等からネットワークを介して取得する際には、改ざんや、追加学習時のシステムトラブル等による信頼性低下を低減したい。そこで、デジタル署名やハッシュ化による一致性の確認を行うことで、追加学習用の学習データの正当性を検出してもよい。これにより、追加学習用の学習データを保護することができる。このとき、デジタル署名やハッシュ化による一致性の確認した結果として、追加学習用の学習データの正当性が検出できなかった場合には、その旨の警告を行い、その学習データによる追加学習を行わない。なお、サーバは、その設置場所を問わず、例えば、クラウドサーバ、フォグサーバ、エッジサーバ等のどのような形態でもよい。 Furthermore, when acquiring learning data for additional learning via a network from a server in an external facility such as a hospital or research institute, it is desirable to reduce reliability degradation due to tampering or system trouble during additional learning. Therefore, the validity of the learning data for additional learning may be detected by checking the consistency using a digital signature or hashing. Thereby, learning data for additional learning can be protected. At this time, if the validity of the learning data for additional learning cannot be detected as a result of checking the consistency using digital signatures and hashing, a warning to that effect will be issued and additional learning will be performed using that learning data. do not have. Note that the server may take any form, such as a cloud server, fog server, or edge server, regardless of its installation location.
(変形例16)
上述した様々な実施形態及び変形例において、検者からの指示は、手動による指示(例えば、ユーザーインターフェース等を用いた指示)以外にも、音声等による指示であってもよい。このとき、例えば、機械学習により得た音声認識モデル(音声認識エンジン、音声認識用の学習済モデル)を含む機械学習モデルが用いられてもよい。また、手動による指示は、キーボードやタッチパネル等を用いた文字入力等による指示であってもよい。このとき、例えば、機械学習により得た文字認識モデル(文字認識エンジン、文字認識用の学習済モデル)を含む機械学習モデルが用いられてもよい。また、検者からの指示は、ジェスチャー等による指示であってもよい。このとき、機械学習により得たジェスチャー認識モデル(ジェスチャー認識エンジン、ジェスチャー認識用の学習済モデル)を含む機械学習モデルが用いられてもよい。
(Modification 16)
In the various embodiments and modified examples described above, the instructions from the examiner may be not only manual instructions (for example, instructions using a user interface or the like) but also instructions by voice or the like. At this time, for example, a machine learning model including a speech recognition model (speech recognition engine, trained model for speech recognition) obtained by machine learning may be used. Further, the manual instruction may be an instruction by inputting characters using a keyboard, a touch panel, or the like. At this time, for example, a machine learning model including a character recognition model (character recognition engine, trained model for character recognition) obtained by machine learning may be used. Further, the instruction from the examiner may be an instruction using a gesture or the like. At this time, a machine learning model including a gesture recognition model (gesture recognition engine, trained model for gesture recognition) obtained by machine learning may be used.
また、検者からの指示は、モニタ上の検者の視線検出結果等であってもよい。視線検出結果は、例えば、モニタ周辺から撮影して得た検者の動画像を用いた瞳孔検出結果であってもよい。このとき、動画像からの瞳孔検出は、上述したような物体認識エンジンを用いてもよい。また、検者からの指示は、脳波、体を流れる微弱な電気信号等による指示であってもよい。 Further, the instruction from the examiner may be the result of detecting the examiner's line of sight on the monitor. The line of sight detection result may be, for example, a pupil detection result using a moving image of the examiner taken from around the monitor. At this time, the pupil detection from the moving image may be performed using the object recognition engine as described above. Further, the instructions from the examiner may be instructions based on brain waves, weak electrical signals flowing through the body, or the like.
このような場合、例えば、学習データとしては、上述したような種々の学習済モデルの処理による結果の表示の指示を示す文字データ又は音声データ(波形データ)等を入力データとし、種々の学習済モデルの処理による結果等を実際に表示部に表示させるための実行命令を正解データとする学習データであってもよい。また、学習データとしては、例えば、高画質化用の学習済モデルで得た高画質画像の表示の指示を示す文字データ又は音声データ等を入力データとし、高画質画像の表示の実行命令及び高画質化ボタンをアクティブ状態に変更するための実行命令を正解データとする学習データであってもよい。もちろん、学習データとしては、例えば、文字データ又は音声データ等が示す指示内容と実行命令内容とが互いに対応するものであれば何でもよい。また、音響モデルや言語モデル等を用いて、音声データから文字データに変換してもよい。また、複数のマイクで得た波形データを用いて、音声データに重畳しているノイズデータを低減する処理を行ってもよい。また、文字又は音声等による指示と、マウス、タッチパネル等による指示とを、検者からの指示に応じて選択可能に構成されてもよい。また、文字又は音声等による指示のオン・オフを、検者からの指示に応じて選択可能に構成されてもよい。 In such a case, for example, the learning data may be text data or audio data (waveform data) indicating instructions for displaying the results of processing the various trained models as described above, and The learning data may be the correct data that is an execution command for actually displaying the results of model processing on the display unit. In addition, as input data, for example, character data or voice data indicating instructions for displaying a high-quality image obtained by a trained model for high-quality images are used as input data, and an execution command for displaying a high-quality image and a high-quality image are used as input data. The learning data may be the correct data that is an execution command for changing the image quality button to the active state. Of course, any learning data may be used as long as the instruction content and the execution command content indicated by character data or audio data correspond to each other, for example. Furthermore, audio data may be converted into character data using an acoustic model, a language model, or the like. Furthermore, processing may be performed to reduce noise data superimposed on audio data using waveform data obtained by a plurality of microphones. Further, instructions using text or voice, etc., and instructions using a mouse, touch panel, etc. may be selectable in accordance with instructions from the examiner. Further, the device may be configured to be able to select whether to turn on or off instructions using text, voice, etc. in accordance with instructions from the examiner.
ここで、機械学習には、上述したような深層学習があり、また、多階層のニューラルネットワークの少なくとも一部には、例えば、再帰型ニューラルネットワーク(RNN:Recurrernt Neural Network)を用いることができる。ここで、本変形例に係る機械学習モデルの一例として、時系列情報を扱うニューラルネットワークであるRNNに関して、図15(a)及び(b)を参照して説明する。また、RNNの一種であるLong short-term memory(以下、LSTM)に関して、図16(a)及び(b)を参照して説明する。 Here, machine learning includes deep learning as described above, and for example, a recurrent neural network (RNN) can be used for at least a part of the multilayer neural network. Here, as an example of a machine learning model according to this modification, an RNN, which is a neural network that handles time-series information, will be described with reference to FIGS. 15(a) and 15(b). Further, a long short-term memory (hereinafter referred to as LSTM), which is a type of RNN, will be explained with reference to FIGS. 16(a) and (b).
図15(a)は、機械学習モデルであるRNNの構造を示す。RNN3520は、ネットワークにループ構造を持ち、時刻tにおいてデータxt3510を入力し、データht3530を出力する。RNN3520はネットワークにループ機能を持つため、現時刻の状態を次の状態に引き継ぐことが可能であるため、時系列情報を扱うことができる。図15(b)には時刻tにおけるパラメータベクトルの入出力の一例を示す。データxt3510にはN個(Params1~ParamsN)のデータが含まれる。また、RNN3520より出力されるデータht3530には入力データに対応するN個(Params1~ParamsN)のデータが含まれる。
FIG. 15(a) shows the structure of RNN, which is a machine learning model. The
しかし、RNNでは誤差逆伝搬時に長期時間の情報を扱うことができないため、LSTMが用いられることがある。LSTMは、忘却ゲート、入力ゲート、及び出力ゲートを備えることで長期時間の情報を学習することができる。ここで、図16(a)にLSTMの構造を示す。LSTM3540において、ネットワークが次の時刻tに引き継ぐ情報は、セルと呼ばれるネットワークの内部状態ct-1と出力データht-1である。なお、図の小文字(c、h、x)はベクトルを表している。
However, since RNN cannot handle long-term information during error backpropagation, LSTM is sometimes used. LSTM can learn long-term information by providing a forgetting gate, an input gate, and an output gate. Here, the structure of LSTM is shown in FIG. 16(a). In the
次に、図16(b)にLSTM3540の詳細を示す。図16(b)において、FGは忘却ゲートネットワーク、IGは入力ゲートネットワーク、OGは出力ゲートネットワークを示し、それぞれはシグモイド層である。そのため、各要素が0から1の値となるベクトルを出力する。忘却ゲートネットワークFGは過去の情報をどれだけ保持するかを決め、入力ゲートネットワークIGはどの値を更新するかを判定するものである。CUは、セル更新候補ネットワークであり、活性化関数tanh層である。これは、セルに加えられる新たな候補値のベクトルを作成する。出力ゲートネットワークOGは、セル候補の要素を選択し次の時刻にどの程度の情報を伝えるか選択する。 Next, details of the LSTM3540 are shown in FIG. 16(b). In FIG. 16(b), FG represents a forgetting gate network, IG represents an input gate network, and OG represents an output gate network, each of which is a sigmoid layer. Therefore, a vector in which each element has a value between 0 and 1 is output. The forgetting gate network FG determines how much past information to retain, and the input gate network IG determines which value to update. CU is a cell update candidate network and an activation function tanh layer. This creates a vector of new candidate values that is added to the cell. The output gate network OG selects the elements of the cell candidates and selects how much information to convey at the next time.
なお、上述したLSTMのモデルは基本形であるため、ここで示したネットワークに限らない。ネットワーク間の結合を変更してもよい。LSTMではなく、QRNN(Quasi Recurrent Neural Network)を用いてもよい。さらに、機械学習モデルは、ニューラルネットワークに限定されるものではなく、ブースティングやサポートベクターマシン等が用いられてもよい。また、検者からの指示が文字又は音声等による入力の場合には、自然言語処理に関する技術(例えば、Sequence toSequence)が適用されてもよい。また、検者に対して文字又は音声等による出力で応答する対話エンジン(対話モデル、対話用の学習済モデル)が適用されてもよい。 Note that since the LSTM model described above is a basic form, it is not limited to the network shown here. Coupling between networks may be changed. Instead of LSTM, QRNN (Quasi Recurrent Neural Network) may be used. Furthermore, the machine learning model is not limited to neural networks, and boosting, support vector machines, etc. may also be used. Furthermore, if the examiner's instructions are input by text or voice, techniques related to natural language processing (for example, sequence to sequence) may be applied. Further, a dialogue engine (a dialogue model, a trained model for dialogue) that responds to the examiner by outputting text or voice may be applied.
(変形例17)
上述した様々な実施形態及び変形例において、高画質画像等は、検者からの指示に応じて記憶部に保存されてもよい。このとき、高画質画像等を保存するための検者からの指示の後、ファイル名の登録の際に、推奨のファイル名として、ファイル名のいずれかの箇所(例えば、最初の箇所、最後の箇所)に、高画質化用の学習済モデルを用いた処理(高画質化処理)により生成された画像であることを示す情報(例えば、文字)を含むファイル名が、検者からの指示に応じて編集可能な状態で表示されてもよい。
(Modification 17)
In the various embodiments and modifications described above, high-quality images and the like may be stored in the storage unit according to instructions from the examiner. At this time, after receiving instructions from the examiner to save high-quality images, etc., when registering the file name, select any part of the file name (for example, the first part, the last part, etc.) as the recommended file name. If the file name contains information (e.g., characters) indicating that the image was generated by processing using a trained model for high image quality (high image quality processing) in The information may be displayed in an editable state as required.
また、レポート画面等の種々の表示画面において、表示部に高画質画像を表示させる際に、表示されている画像が高画質化用の学習済モデルを用いた処理により生成された高画質画像であることを示す表示が、高画質画像とともに表示されてもよい。この場合には、検者は、当該表示によって、表示された高画質画像が撮影によって取得した画像そのものではないことが容易に識別できるため、誤診断を低減させたり、診断効率を向上させたりすることができる。なお、高画質化用の学習済モデルを用いた処理により生成された高画質画像であることを示す表示は、入力画像と当該処理により生成された高画質画像とを識別可能な表示であればどのような態様のものでもよい。また、高画質化用の学習済モデルを用いた処理だけでなく、上述したような種々の学習済モデルを用いた処理についても、その種類の学習済モデルを用いた処理により生成された結果であることを示す表示が、その結果とともに表示されてもよい。 In addition, when displaying high-quality images on the display on various display screens such as report screens, the displayed image is a high-quality image generated by processing using a trained model for high image quality. An indication that there is such a thing may be displayed together with the high-quality image. In this case, the display allows the examiner to easily identify that the displayed high-quality image is not the image obtained by photography, which reduces misdiagnosis and improves diagnostic efficiency. be able to. Note that the display indicating that the image is a high-quality image generated by processing using a trained model for high-quality image is a display that allows the input image to be distinguished from the high-quality image generated by the processing. It may take any form. Furthermore, in addition to processing using trained models for high image quality, processing using various trained models such as those described above can also be performed using the results generated by processing using that type of trained model. An indication may be displayed along with the result.
このとき、レポート画面等の表示画面は、検者からの指示に応じて記憶部に保存されてもよい。例えば、高画質化画像等と、これらの画像が高画質化用の学習済モデルを用いた処理により生成された高画質画像であることを示す表示とが並んだ1つの画像としてレポート画面が記憶部に保存されてもよい。 At this time, the display screen such as the report screen may be saved in the storage unit according to instructions from the examiner. For example, a report screen may be stored as a single image in which high-quality images are lined up with a display indicating that these images are high-quality images generated by processing using a trained model for high-quality images. It may be stored in the section.
また、高画質化用の学習済モデルを用いた処理により生成された高画質画像であることを示す表示について、高画質化用の学習済モデルがどのような学習データによって学習を行ったものであるかを示す表示が表示部に表示されてもよい。当該表示としては、学習データの入力データと正解データの種類の説明や、入力データと正解データに含まれる撮影部位等の正解データに関する任意の表示を含んでよい。なお、高画質化用の学習済モデルを用いた処理だけでなく、上述したような種々の学習済モデルを用いた処理についても、その種類の学習済モデルがどのような学習データによって学習を行ったものであるかを示す表示が表示部に表示されてもよい。 In addition, regarding the display indicating that the image is a high-quality image generated by processing using a trained model for high image quality, what kind of training data was used to train the trained model for high image quality? An indication indicating whether or not there is one may be displayed on the display unit. The display may include an explanation of the types of the input data and correct data of the learning data, and any display related to the correct data such as the imaged body part included in the input data and the correct data. Note that not only processing using a trained model for high image quality, but also processing using various trained models such as those mentioned above, depends on what kind of training data that type of trained model is used for learning. An indication may be displayed on the display unit to indicate whether the information is correct or not.
また、高画質化用の学習済モデルを用いた処理により生成された画像であることを示す情報(例えば、文字)を、高画質画像等に重畳した状態で表示又は保存されるように構成されてもよい。このとき、画像上に重畳する箇所は、撮影対象となる注目部位等が表示されている領域には重ならない領域(例えば、画像の端)であればどこでもよい。また、重ならない領域を判定し、判定された領域に重畳させてもよい。 Additionally, information indicating that the image is generated by processing using a trained model for high image quality (for example, text) is displayed or saved in a state superimposed on the high-quality image, etc. It's okay. At this time, the location to be superimposed on the image may be any region (for example, the edge of the image) that does not overlap with the region in which the region of interest to be photographed is displayed. Alternatively, a non-overlapping area may be determined and the area may be overlapped with the determined area.
また、レポート画面の初期表示画面として、高画質化ボタンがアクティブ状態(高画質化処理がオン)となるようにデフォルト設定されている場合には、検者からの指示に応じて、高画質画像等を含むレポート画面に対応するレポート画像がサーバに送信されるように構成されてもよい。また、高画質化ボタンがアクティブ状態となるようにデフォルト設定されている場合には、検査終了時(例えば、検者からの指示に応じて、撮影確認画面やプレビュー画面からレポート画面に変更された場合)に、高画質画像等を含むレポート画面に対応するレポート画像がサーバに(自動的に)送信されるように構成されてもよい。このとき、デフォルト設定における各種設定(例えば、レポート画面の初期表示画面におけるEn-Face画像の生成のための深度範囲、解析マップの重畳の有無、高画質画像か否か、経過観察用の表示画面か否か等の少なくとも1つに関する設定)に基づいて生成されたレポート画像がサーバに送信されるように構成されもよい。 In addition, if the default setting is such that the high-quality button is activated (high-quality processing is turned on) as the initial display screen of the report screen, high-quality images will be displayed in response to instructions from the examiner. The report image corresponding to the report screen including the above may be configured to be transmitted to the server. In addition, if the default setting is such that the high image quality button is activated, it will be possible to change the image quality at the end of the examination (for example, when the imaging confirmation screen or preview screen is changed to the report screen in response to instructions from the examiner). case), the report image corresponding to the report screen including a high-quality image etc. may be configured to be (automatically) transmitted to the server. At this time, various settings in the default settings (for example, the depth range for generating the En-Face image on the initial display screen of the report screen, whether or not the analysis map is superimposed, whether or not it is a high-quality image, the display screen for follow-up observation) The report image generated based on at least one setting such as whether or not the report image is sent to the server may be configured.
(変形例18)
上述した様々な実施形態及び変形例において、上述したような種々の学習済モデルのうち、第1の種類の学習済モデルで得た画像(例えば、高画質画像、解析マップ等の解析結果を示す画像、物体認識結果を示す画像、セグメンテーション結果を示す画像)を、第1の種類とは異なる第2の種類の学習済モデルに入力してもよい。このとき、第2の種類の学習済モデルの処理による結果(例えば、解析結果、診断結果、物体認識結果、セグメンテーション結果)が生成されるように構成されてもよい。
(Modification 18)
In the various embodiments and modifications described above, images obtained with the first type of trained model among the various trained models described above (e.g., high-quality images, analysis maps, etc. images, images showing object recognition results, images showing segmentation results) may be input to a second type of trained model that is different from the first type. At this time, the configuration may be such that results (for example, analysis results, diagnosis results, object recognition results, and segmentation results) are generated by processing the second type of learned model.
また、上述したような種々の学習済モデルのうち、第1の種類の学習済モデルの処理による結果(例えば、解析結果、診断結果、物体認識結果、セグメンテーション結果)を用いて、第1の種類の学習済モデルに入力した画像から、第1の種類とは異なる第2の種類の学習済モデルに入力する画像を生成してもよい。このとき、生成された画像は、第2の種類の学習済モデルにより処理する画像として適した画像である可能性が高い。このため、生成された画像を第2の種類の学習済モデルに入力して得た画像(例えば、高画質画像、解析マップ等の解析結果を示す画像、物体認識結果を示す画像、セグメンテーション結果を示す画像)の精度を向上することができる。 Furthermore, among the various trained models described above, the results of the processing of the first type of trained model (for example, analysis results, diagnosis results, object recognition results, segmentation results) are used to generate the first type of trained model. An image to be input to a second type of trained model different from the first type may be generated from an image input to the trained model. At this time, the generated image is highly likely to be an image suitable for processing by the second type of trained model. For this reason, images obtained by inputting the generated images to the second type of trained model (for example, high-quality images, images showing analysis results such as analysis maps, images showing object recognition results, and segmentation results) The accuracy of images shown) can be improved.
また、上述したような種々の学習済モデルは、被検体の2次元の医用画像を含む学習データを学習して得た学習済モデルであってもよいし、また、被検体の3次元の医用画像を含む学習データを学習して得た学習済モデルであってもよい。 Further, the various trained models described above may be trained models obtained by learning training data including two-dimensional medical images of the subject, or may be trained models obtained by learning training data including two-dimensional medical images of the subject. The model may be a trained model obtained by learning training data including images.
また、上述したような学習済モデルの処理による解析結果や診断結果等を検索キーとして、サーバ等に格納された外部のデータベースを利用した類似画像検索を行ってもよい。なお、データベースにおいて保存されている複数の画像が、既に機械学習等によって該複数の画像それぞれの特徴量を付帯情報として付帯された状態で管理されている場合等には、画像自体を検索キーとする類似画像検索エンジン(類似画像検査モデル、類似画像検索用の学習済モデル)が用いられてもよい。 Further, a similar image search may be performed using an external database stored in a server or the like using the analysis results, diagnosis results, etc. obtained by processing the learned model as described above as a search key. In addition, in cases where multiple images stored in a database have already been managed with the feature values of each of the multiple images attached as additional information through machine learning, etc., the image itself can be used as the search key. A similar image search engine (similar image inspection model, trained model for similar image search) may be used.
(変形例19)
なお、上記実施形態及び変形例におけるモーションコントラストデータの生成処理は、断層画像の輝度値に基づいて行われる構成に限られない。上記各種処理は、断層画像撮影装置100で取得された干渉信号、干渉信号にフーリエ変換を施した信号、該信号に任意の処理を施した信号、及びこれらに基づく断層画像等を含む断層データに対して適用されてよい。これらの場合も、上記構成と同様の効果を奏することができる。
(Modification 19)
Note that the motion contrast data generation process in the above embodiments and modified examples is not limited to a configuration in which it is performed based on the brightness value of a tomographic image. The various processes described above are performed on tomographic data including an interference signal acquired by the
分割手段としてカプラーを使用したファイバー光学系を用いているが、コリメータとビームスプリッタを使用した空間光学系を用いてもよい。また、断層画像撮影装置100の構成は、上記の構成に限られず、断層画像撮影装置100に含まれる構成の一部を断層画像撮影装置100と別体の構成としてもよい。
Although a fiber optical system using a coupler is used as the dividing means, a spatial optical system using a collimator and a beam splitter may also be used. Further, the configuration of the tomographic
また、上記実施形態及び変形例では、断層画像撮影装置100の干渉光学系としてマイケルソン型干渉計の構成を用いているが、干渉光学系の構成はこれに限られない。例えば、断層画像撮影装置100の干渉光学系はマッハツェンダー干渉計の構成を有していてもよい。
Furthermore, in the above embodiments and modifications, a Michelson interferometer configuration is used as the interference optical system of the
さらに、上記実施形態及び変形例では、OCT装置として、SLDを光源として用いたスペクトラルドメインOCT(SD-OCT)装置について述べたが、本発明によるOCT装置の構成はこれに限られない。例えば、出射光の波長を掃引することができる波長掃引光源を用いた波長掃引型OCT(SS-OCT)装置等の他の任意の種類のOCT装置にも本発明を適用することができる。また、ライン光を用いたLine-OCT装置に対して本発明を適用することもできる。 Further, in the above embodiments and modifications, a spectral domain OCT (SD-OCT) device using an SLD as a light source has been described as an OCT device, but the configuration of the OCT device according to the present invention is not limited to this. For example, the present invention can be applied to any other type of OCT device, such as a wavelength swept OCT (SS-OCT) device that uses a wavelength swept light source that can sweep the wavelength of emitted light. Further, the present invention can also be applied to a Line-OCT device using line light.
また、上記実施形態及び変形例では、画像処理部101-04は、断層画像撮影装置100で取得された干渉信号や画像処理部で生成された三次元断層画像等を取得した。しかしながら、画像処理部101-04がこれらの信号や画像を取得する構成はこれに限られない。例えば、画像処理部101-04は、LAN、WAN、又はインターネット等を介して接続されるサーバや撮影装置からこれらの信号を取得してもよい。
Furthermore, in the above embodiment and modification, the image processing unit 101-04 acquired the interference signal acquired by the
なお、学習済モデルは、画像処理部101-04に設けられることができる。学習済モデルは、例えば、CPU等のプロセッサによって実行されるソフトウェアモジュール等で構成されることができる。また、学習済モデルは、画像処理部101-04と接続される別のサーバ等に設けられてもよい。この場合には、画像処理部101-04は、インターネット等の任意のネットワークを介して学習済モデルを備えるサーバに接続することで、学習済モデルを用いて高画質化処理を行うことができる。 Note that the trained model can be provided in the image processing unit 101-04. The trained model can be configured of, for example, a software module executed by a processor such as a CPU. Further, the trained model may be provided in another server or the like connected to the image processing unit 101-04. In this case, the image processing unit 101-04 can perform high image quality processing using the trained model by connecting to a server provided with the trained model via any network such as the Internet.
(変形例20)
また、上述した様々な実施形態及び変形例による画像処理装置又は画像処理方法によって処理される画像は、任意のモダリティ(撮影装置、撮影方法)を用いて取得された医用画像を含む。処理される医用画像は、任意の撮影装置等で取得された医用画像や、上記実施形態及び変形例による画像処理装置又は画像処理方法によって作成された画像を含むことができる。
(Modification 20)
Furthermore, images processed by the image processing apparatus or image processing method according to the various embodiments and modifications described above include medical images acquired using any modality (imaging device, imaging method). The medical images to be processed can include medical images acquired by any imaging device or the like, and images created by the image processing apparatus or image processing method according to the embodiments and modifications described above.
さらに、処理される医用画像は、被検者(被検体)の所定部位の画像であり、所定部位の画像は被検者の所定部位の少なくとも一部を含む。また、当該医用画像は、被検者の他の部位を含んでもよい。また、医用画像は、静止画像又は動画像であってよく、白黒画像又はカラー画像であってもよい。さらに医用画像は、所定部位の構造(形態)を表す画像でもよいし、その機能を表す画像でもよい。機能を表す画像は、例えば、OCTA画像、ドップラーOCT画像、fMRI画像、及び超音波ドップラー画像等の血流動態(血流量、血流速度等)を表す画像を含む。なお、被検者の所定部位は、撮影対象に応じて決定されてよく、人眼(被検眼)、脳、肺、腸、心臓、すい臓、腎臓、及び肝臓等の臓器、頭部、胸部、脚部、並びに腕部等の任意の部位を含む。 Furthermore, the medical image to be processed is an image of a predetermined region of a subject (subject), and the image of the predetermined region includes at least a part of the predetermined region of the subject. Further, the medical image may include other parts of the subject. Further, the medical image may be a still image or a moving image, and may be a black and white image or a color image. Furthermore, the medical image may be an image representing the structure (morphology) of a predetermined region, or an image representing its function. Images representing functions include, for example, images representing blood flow dynamics (blood flow volume, blood flow velocity, etc.) such as OCTA images, Doppler OCT images, fMRI images, and ultrasound Doppler images. The predetermined parts of the subject may be determined depending on the object to be photographed, and may include human eyes (eyes to be examined), organs such as the brain, lungs, intestines, heart, pancreas, kidneys, and liver, head, chest, Includes arbitrary parts such as legs and arms.
また、医用画像は、被検者の断層画像であってもよいし、正面画像であってもよい。正面画像は、例えば、眼底正面画像や、前眼部の正面画像、蛍光撮影された眼底画像、OCTで取得したデータ(三次元のOCTデータ)について撮影対象の深さ方向における少なくとも一部の範囲のデータを用いて生成したEn-Face画像を含む。En-Face画像は、三次元のOCTAデータ(三次元のモーションコントラストデータ)について撮影対象の深さ方向における少なくとも一部の範囲のデータを用いて生成したOCTAのEn-Face画像(モーションコントラスト正面画像)でもよい。また、三次元のOCTデータや三次元のモーションコントラストデータは、三次元の医用画像データの一例である。 Furthermore, the medical image may be a tomographic image of the subject or a frontal image. The frontal image is, for example, a frontal image of the fundus, a frontal image of the anterior segment of the eye, a fluorescently photographed fundus image, or at least a partial range in the depth direction of the object to be photographed regarding data acquired by OCT (three-dimensional OCT data). Contains an En-Face image generated using the data. The En-Face image is an OCTA En-Face image (motion contrast frontal image) generated using data of at least a partial range in the depth direction of the imaging target for three-dimensional OCTA data (three-dimensional motion contrast data). ) is also fine. Furthermore, three-dimensional OCT data and three-dimensional motion contrast data are examples of three-dimensional medical image data.
また、撮影装置とは、診断に用いられる画像を撮影するための装置である。撮影装置は、例えば、被検者の所定部位に光、X線等の放射線、電磁波、又は超音波等を照射することにより所定部位の画像を得る装置や、被写体から放出される放射線を検出することにより所定部位の画像を得る装置を含む。より具体的には、上述した様々な実施形態及び変形例に係る撮影装置は、少なくとも、X線撮影装置、CT装置、MRI装置、PET装置、SPECT装置、SLO装置、OCT装置、OCTA装置、眼底カメラ、及び内視鏡等を含む。 Further, the photographing device is a device for photographing images used for diagnosis. The imaging device is, for example, a device that obtains an image of a predetermined region of a subject by irradiating the subject with radiation such as light, X-rays, electromagnetic waves, or ultrasound, or a device that detects radiation emitted from the subject. The apparatus includes a device for obtaining an image of a predetermined region. More specifically, the imaging devices according to the various embodiments and modifications described above include at least an X-ray imaging device, a CT device, an MRI device, a PET device, a SPECT device, an SLO device, an OCT device, an OCTA device, and a fundus. Includes cameras, endoscopes, etc.
なお、OCT装置としては、タイムドメインOCT(TD-OCT)装置やフーリエドメインOCT(FD-OCT)装置を含んでよい。また、フーリエドメインOCT装置はスペクトラルドメインOCT(SD-OCT)装置や波長掃引型OCT(SS-OCT)装置を含んでよい。また、SLO装置やOCT装置として、波面補償光学系を用いた波面補償SLO(AO-SLO)装置や波面補償OCT(AO-OCT)装置等を含んでよい。また、SLO装置やOCT装置として、偏光位相差や偏光解消に関する情報を可視化するための偏光SLO(PS-SLO)装置や偏光OCT(PS-OCT)装置等を含んでよい。 Note that the OCT device may include a time domain OCT (TD-OCT) device and a Fourier domain OCT (FD-OCT) device. Further, the Fourier domain OCT device may include a spectral domain OCT (SD-OCT) device or a wavelength swept OCT (SS-OCT) device. Furthermore, the SLO device and OCT device may include a wavefront compensated SLO (AO-SLO) device using a wavefront adaptive optical system, a wavefront compensated OCT (AO-OCT) device, and the like. Furthermore, the SLO device and OCT device may include a polarization SLO (PS-SLO) device, a polarization OCT (PS-OCT) device, etc. for visualizing information regarding polarization phase difference and depolarization.
[その他の実施形態]
以上、様々な実施形態及び変形例について詳述したが、開示の技術は例えば、システム、装置、方法、プログラム若しくは記録媒体(記憶媒体)等としての実施態様をとることが可能である。具体的には、複数の機器(例えば、ホストコンピュータ、インタフェース機器、撮像装置、webアプリケーション等)から構成されるシステムに適用しても良いし、また、一つの機器からなる装置に適用しても良い。
[Other embodiments]
Various embodiments and modifications have been described above in detail, but the disclosed technology can be implemented as, for example, a system, an apparatus, a method, a program, a recording medium (storage medium), or the like. Specifically, it may be applied to a system consisting of multiple devices (for example, a host computer, an interface device, an imaging device, a web application, etc.), or it may be applied to a device consisting of a single device. good.
また、本発明の目的は、以下のようにすることによって達成されることはいうまでもない。即ち、前述した様々な実施形態及び変形例の機能を実現するソフトウェアのプログラムコード(コンピュータプログラム)を記録した記録媒体(または記憶媒体)を、システムあるいは装置に供給する。係る記憶媒体は言うまでもなく、コンピュータ読み取り可能な記憶媒体である。そして、そのシステムあるいは装置のコンピュータ(またはCPUやMPU)が記録媒体に格納されたプログラムコードを読み出し実行する。この場合、記録媒体から読み出されたプログラムコード自体が前述した様々な実施形態及び変形例の機能を実現することになり、そのプログラムコードを記録した記録媒体は本発明を構成することになる。 Moreover, it goes without saying that the object of the present invention is achieved by the following steps. That is, a recording medium (or storage medium) recording software program code (computer program) that implements the functions of the various embodiments and modifications described above is supplied to the system or device. Such a storage medium is, of course, a computer-readable storage medium. Then, the computer (or CPU or MPU) of the system or device reads and executes the program code stored in the recording medium. In this case, the program code read from the recording medium itself realizes the functions of the various embodiments and modifications described above, and the recording medium on which the program code is recorded constitutes the present invention.
Claims (16)
前記高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を取得する取得手段と、
前記3次元の血管領域に関する情報を用いて3次元空間における血管計測値を算出し、前記3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータから2次元領域における血管計測値を算出する算出手段と、
前記算出された血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける手段と、
を備える、情報処理装置。 a high image quality means for increasing the image quality of three-dimensional motion contrast data of the fundus;
acquisition means for acquiring information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data;
A blood vessel measurement value in a three-dimensional space is calculated using the information regarding the three-dimensional blood vessel region , and a blood vessel measurement value in the two-dimensional region is calculated from two-dimensional motion contrast data obtained by projecting the three-dimensional motion contrast data in the depth direction. Calculation means for calculating blood vessel measurement values;
means for associating the calculated blood vessel measurement value with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional area;
An information processing device comprising:
前記算出手段は、前記処理手段によりプロジェクションアーチファクトが低減された後の前記高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を用いて、前記血管計測値を算出する、請求項1乃至3のいずれか1項に記載の情報処理装置。 Further comprising processing means for performing processing to reduce projection artifacts on the high-quality three-dimensional motion contrast data,
The calculation means calculates the blood vessel measurement value using information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data after projection artifacts have been reduced by the processing means. The information processing device according to any one of claims 1 to 3.
前記処理手段によりプロジェクションアーチファクトが低減された後の前記3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を取得する取得手段と、
前記3次元の血管領域に関する情報を用いて3次元空間における血管計測値を算出し、前記3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータから2次元領域における血管計測値を算出する算出手段と、
前記算出された血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける手段と、
を備える、情報処理装置。 processing means for performing processing to reduce projection artifacts on three-dimensional motion contrast data of the fundus;
acquisition means for acquiring information regarding a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data after projection artifacts have been reduced by the processing means;
A blood vessel measurement value in a three-dimensional space is calculated using the information regarding the three-dimensional blood vessel region , and a blood vessel measurement value in the two-dimensional region is calculated from two-dimensional motion contrast data obtained by projecting the three-dimensional motion contrast data in the depth direction. Calculation means for calculating blood vessel measurement values;
means for associating the calculated blood vessel measurement value with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional area;
An information processing device comprising:
前記2次元領域における血管計測値であり、血管領域または無血管領域の面積、2次元の血管密度、前記2次元領域において計測した血管の径と長さと曲率とのうち少なくとも1つに基づく計測値のうち少なくとも1つである、請求項1乃至5のいずれか1項に記載の情報処理装置。 The blood vessel measurement value is a blood vessel measurement value in the three -dimensional space, and includes at least one of the volume of the blood vessel, the three-dimensional blood vessel density, and the diameter, length, and curvature of the blood vessel measured in the three-dimensional space. at least one of the following:
A blood vessel measurement value in the two-dimensional region, which is a measurement value based on at least one of the area of a blood vessel region or an avascular region, the two-dimensional blood vessel density, and the diameter, length, and curvature of the blood vessel measured in the two -dimensional region. The information processing device according to any one of claims 1 to 5, which is at least one of the following.
前記表示制御手段は、前記算出された血管計測値を時系列に沿って複数表示させる場合、前記識別情報に基づいて、3次元空間における血管計測値と2次元領域における血管計測値とが混在しないように前記表示部に表示させる、請求項1乃至7のいずれか1項に記載の情報処理装置。 further comprising display control means for displaying the calculated blood vessel measurement value on a display unit,
When displaying a plurality of the calculated blood vessel measurement values in chronological order, the display control means controls, based on the identification information, blood vessel measurement values in a three-dimensional space and blood vessel measurement values in a two-dimensional area do not coexist. The information processing apparatus according to any one of claims 1 to 7 , wherein the information processing apparatus displays on the display unit.
前記取得手段により得られた血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける手段と、
を備える、情報処理装置。 A blood vessel measurement value in a three-dimensional space is obtained using information regarding a three-dimensional blood vessel region in at least a part of the three-dimensional motion contrast data of the fundus, and the three-dimensional motion contrast data is obtained by projecting the three-dimensional motion contrast data in the depth direction. acquisition means for acquiring blood vessel measurement values in a two-dimensional region using the obtained two-dimensional motion contrast data;
means for associating the blood vessel measurement value obtained by the acquisition means with identification information that can identify whether the blood vessel measurement value is in the three-dimensional space or the blood vessel measurement value in the two- dimensional area;
An information processing device comprising :
前記表示制御手段は、前記取得手段により得られた血管計測値を時系列に沿って複数表示させる場合、前記識別情報に基づいて、前記3次元空間における血管計測値と前記2次元領域における血管計測値とが混在しないように前記表示部に表示させる、請求項9に記載の情報処理装置。When displaying a plurality of blood vessel measurement values obtained by the acquisition means in chronological order, the display control means may display blood vessel measurement values in the three-dimensional space and blood vessel measurements in the two-dimensional area based on the identification information. The information processing apparatus according to claim 9, wherein the information processing apparatus is configured to display the values on the display unit so that the values are not mixed.
前記高画質化された3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を取得する取得工程と、
前記3次元の血管領域に関する情報を用いて3次元空間における血管計測値を算出し、前記3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータから2次元領域における血管計測値を算出する算出工程と、
前記算出された血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける工程と、
を含む、情報処理方法。 A high-quality image improvement process that improves the image quality of three-dimensional motion contrast data of the fundus;
an acquisition step of acquiring information regarding a three-dimensional blood vessel region in at least a portion of the high-quality three-dimensional motion contrast data;
A blood vessel measurement value in a three-dimensional space is calculated using the information regarding the three-dimensional blood vessel region , and a blood vessel measurement value in the two-dimensional region is calculated from two-dimensional motion contrast data obtained by projecting the three-dimensional motion contrast data in the depth direction. a calculation step of calculating blood vessel measurement values;
a step of associating the calculated blood vessel measurement value with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional area;
information processing methods, including
前記処理工程においてプロジェクションアーチファクトが低減された後の前記3次元モーションコントラストデータの少なくとも一部における3次元の血管領域に関する情報を取得する取得工程と、
前記3次元の血管領域に関する情報を用いて3次元空間における血管計測値を算出し、前記3次元モーションコントラストデータを深さ方向に投影することで得られた2次元モーションコントラストデータから2次元領域における血管計測値を算出する算出工程と、
前記算出された血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける工程と、
を含む、情報処理方法。 a processing step of performing processing to reduce projection artifacts on three-dimensional motion contrast data of the fundus;
an acquisition step of acquiring information regarding a three-dimensional blood vessel region in at least a portion of the three-dimensional motion contrast data after projection artifacts have been reduced in the processing step ;
A blood vessel measurement value in a three-dimensional space is calculated using the information regarding the three-dimensional blood vessel region , and a blood vessel measurement value in the two-dimensional region is calculated from two-dimensional motion contrast data obtained by projecting the three-dimensional motion contrast data in the depth direction. a calculation step of calculating blood vessel measurement values;
a step of associating the calculated blood vessel measurement value with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional area;
information processing methods, including
前記取得工程において得られた血管計測値に対して、前記3次元空間における血管計測値であるか、前記2次元領域における血管計測値であるか、を識別可能な識別情報を対応付ける工程と、a step of associating the blood vessel measurement value obtained in the acquisition step with identification information that can identify whether it is a blood vessel measurement value in the three-dimensional space or a blood vessel measurement value in the two-dimensional region;
を含む、情報処理方法。information processing methods, including
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/020876 WO2019230643A1 (en) | 2018-05-31 | 2019-05-27 | Information processing device, information processing method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018105487 | 2018-05-31 | ||
| JP2018105487 | 2018-05-31 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2019209136A JP2019209136A (en) | 2019-12-12 |
| JP2019209136A5 JP2019209136A5 (en) | 2022-03-17 |
| JP7374615B2 true JP7374615B2 (en) | 2023-11-07 |
Family
ID=68846123
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019097162A Active JP7374615B2 (en) | 2018-05-31 | 2019-05-23 | Information processing device, information processing method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7374615B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111354031B (en) * | 2020-03-16 | 2023-08-29 | 浙江一木智能科技有限公司 | 3D vision guidance system based on deep learning |
| CN111493853A (en) * | 2020-04-24 | 2020-08-07 | 天津恒宇医疗科技有限公司 | Blood vessel parameter evaluation method and system for angiodermic diseases |
| US11972544B2 (en) * | 2020-05-14 | 2024-04-30 | Topcon Corporation | Method and apparatus for optical coherence tomography angiography |
| JP2023034400A (en) * | 2021-08-31 | 2023-03-13 | DeepEyeVision株式会社 | Information processing device, information processing method and program |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013090194A (en) | 2011-10-19 | 2013-05-13 | Sony Corp | Server device, image transmission method, terminal device, image receiving method, program, and image processing system |
| JP2017042443A (en) | 2015-08-27 | 2017-03-02 | キヤノン株式会社 | Ophthalmologic apparatus, information processing method, and program |
| JP2017077414A (en) | 2015-10-21 | 2017-04-27 | 株式会社ニデック | Ophthalmic analysis apparatus and ophthalmic analysis program |
| WO2017143300A1 (en) | 2016-02-19 | 2017-08-24 | Optovue, Inc. | Methods and apparatus for reducing artifacts in oct angiography using machine learning techniques |
| JP2018038611A (en) | 2016-09-07 | 2018-03-15 | 株式会社ニデック | Ophthalmologic analyzer and ophthalmologic analysis program |
| US20180140257A1 (en) | 2016-11-21 | 2018-05-24 | International Business Machines Corporation | Retinal Scan Processing for Diagnosis of a Subject |
| JP2017221525A5 (en) | 2016-06-16 | 2019-06-13 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6703730B2 (en) * | 2016-06-16 | 2020-06-03 | 株式会社ニデック | Optical coherence tomography device and optical coherence tomography control program |
-
2019
- 2019-05-23 JP JP2019097162A patent/JP7374615B2/en active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013090194A (en) | 2011-10-19 | 2013-05-13 | Sony Corp | Server device, image transmission method, terminal device, image receiving method, program, and image processing system |
| JP2017042443A (en) | 2015-08-27 | 2017-03-02 | キヤノン株式会社 | Ophthalmologic apparatus, information processing method, and program |
| JP2017077414A (en) | 2015-10-21 | 2017-04-27 | 株式会社ニデック | Ophthalmic analysis apparatus and ophthalmic analysis program |
| WO2017143300A1 (en) | 2016-02-19 | 2017-08-24 | Optovue, Inc. | Methods and apparatus for reducing artifacts in oct angiography using machine learning techniques |
| JP2017221525A5 (en) | 2016-06-16 | 2019-06-13 | ||
| JP2018038611A (en) | 2016-09-07 | 2018-03-15 | 株式会社ニデック | Ophthalmologic analyzer and ophthalmologic analysis program |
| US20180140257A1 (en) | 2016-11-21 | 2018-05-24 | International Business Machines Corporation | Retinal Scan Processing for Diagnosis of a Subject |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2019209136A (en) | 2019-12-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7579372B2 (en) | Medical image processing device, medical image processing system, medical image processing method and program | |
| JP7250653B2 (en) | Image processing device, image processing method and program | |
| JP7341874B2 (en) | Image processing device, image processing method, and program | |
| CN112638234B (en) | Image processing device, image processing method, and computer readable medium | |
| WO2020036182A1 (en) | Medical image processing device, medical image processing method, and program | |
| WO2020183791A1 (en) | Image processing device and image processing method | |
| JP7362403B2 (en) | Image processing device and image processing method | |
| JP7374615B2 (en) | Information processing device, information processing method and program | |
| JP2021037239A (en) | Area classification method | |
| WO2020075719A1 (en) | Image processing device, image processing method, and program | |
| JP7195745B2 (en) | Image processing device, image processing method and program | |
| JP7009265B2 (en) | Image processing equipment, image processing methods and programs | |
| JP7106304B2 (en) | Image processing device, image processing method and program | |
| WO2019230643A1 (en) | Information processing device, information processing method, and program | |
| JP2021122559A (en) | Image processing device, image processing method, and program | |
| WO2020138128A1 (en) | Image processing device, image processing method, and program | |
| WO2020050308A1 (en) | Image processing device, image processing method and program | |
| JP2021164535A (en) | Image processing device, image processing method and program | |
| JP7446730B2 (en) | Image processing device, image processing method and program | |
| JP7488934B2 (en) | IMAGE PROCESSING APPARATUS, OPERATION METHOD OF IMAGE PROCESSING APPARATUS, AND PROGRAM | |
| JP7604160B2 (en) | Image processing device, image processing method, and program | |
| JP2021069667A (en) | Image processing device, image processing method and program | |
| JP2023010308A (en) | Image processing device and image processing method | |
| JP2022121202A (en) | Image processing device and image processing method | |
| JP2020174862A (en) | Ophthalmologic imaging apparatus and control method of the same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220309 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220309 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230502 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230629 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230926 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20231025 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7374615 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |