JP7317850B2 - オーディオ合成方法、並びにそのコンピュータプログラム、コンピュータ装置及びコンピュータ装置により構成されるコンピュータシステム - Google Patents
オーディオ合成方法、並びにそのコンピュータプログラム、コンピュータ装置及びコンピュータ装置により構成されるコンピュータシステム Download PDFInfo
- Publication number
- JP7317850B2 JP7317850B2 JP2020549777A JP2020549777A JP7317850B2 JP 7317850 B2 JP7317850 B2 JP 7317850B2 JP 2020549777 A JP2020549777 A JP 2020549777A JP 2020549777 A JP2020549777 A JP 2020549777A JP 7317850 B2 JP7317850 B2 JP 7317850B2
- Authority
- JP
- Japan
- Prior art keywords
- song
- target
- melody
- control model
- self
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/0008—Associated control or indicating means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/63—Querying
- G06F16/638—Presentation of query results
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/68—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/686—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using information manually generated, e.g. tags, keywords, comments, title or artist information, time, location or usage information, user ratings
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H7/00—Instruments in which the tones are synthesised from a data store, e.g. computer organs
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
- G10L13/0335—Pitch control
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/04—Details of speech synthesis systems, e.g. synthesiser structure or memory management
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11B—INFORMATION STORAGE BASED ON RELATIVE MOVEMENT BETWEEN RECORD CARRIER AND TRANSDUCER
- G11B20/00—Signal processing not specific to the method of recording or reproducing; Circuits therefor
- G11B20/10—Digital recording or reproducing
- G11B20/10527—Audio or video recording; Data buffering arrangements
-
- G—PHYSICS
- G11—INFORMATION STORAGE
- G11B—INFORMATION STORAGE BASED ON RELATIVE MOVEMENT BETWEEN RECORD CARRIER AND TRANSDUCER
- G11B27/00—Editing; Indexing; Addressing; Timing or synchronising; Monitoring; Measuring tape travel
- G11B27/02—Editing, e.g. varying the order of information signals recorded on, or reproduced from, record carriers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/021—Background music, e.g. for video sequences, elevator music
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/101—Music Composition or musical creation; Tools or processes therefor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/325—Musical pitch modification
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/005—Non-interactive screen display of musical or status data
- G10H2220/011—Lyrics displays, e.g. for karaoke applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2220/00—Input/output interfacing specifically adapted for electrophonic musical tools or instruments
- G10H2220/091—Graphical user interface [GUI] specifically adapted for electrophonic musical instruments, e.g. interactive musical displays, musical instrument icons or menus; Details of user interactions therewith
- G10H2220/101—Graphical user interface [GUI] specifically adapted for electrophonic musical instruments, e.g. interactive musical displays, musical instrument icons or menus; Details of user interactions therewith for graphical creation, edition or control of musical data or parameters
- G10H2220/106—Graphical user interface [GUI] specifically adapted for electrophonic musical instruments, e.g. interactive musical displays, musical instrument icons or menus; Details of user interactions therewith for graphical creation, edition or control of musical data or parameters using icons, e.g. selecting, moving or linking icons, on-screen symbols, screen regions or segments representing musical elements or parameters
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2240/00—Data organisation or data communication aspects, specifically adapted for electrophonic musical tools or instruments
- G10H2240/121—Musical libraries, i.e. musical databases indexed by musical parameters, wavetables, indexing schemes using musical parameters, musical rule bases or knowledge bases, e.g. for automatic composing methods
- G10H2240/131—Library retrieval, i.e. searching a database or selecting a specific musical piece, segment, pattern, rule or parameter set
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2240/00—Data organisation or data communication aspects, specifically adapted for electrophonic musical tools or instruments
- G10H2240/121—Musical libraries, i.e. musical databases indexed by musical parameters, wavetables, indexing schemes using musical parameters, musical rule bases or knowledge bases, e.g. for automatic composing methods
- G10H2240/131—Library retrieval, i.e. searching a database or selecting a specific musical piece, segment, pattern, rule or parameter set
- G10H2240/141—Library retrieval matching, i.e. any of the steps of matching an inputted segment or phrase with musical database contents, e.g. query by humming, singing or playing; the steps may include, e.g. musical analysis of the input, musical feature extraction, query formulation, or details of the retrieval process
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/311—Neural networks for electrophonic musical instruments or musical processing, e.g. for musical recognition or control, automatic composition or improvisation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/315—Sound category-dependent sound synthesis processes [Gensound] for musical use; Sound category-specific synthesis-controlling parameters or control means therefor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/315—Sound category-dependent sound synthesis processes [Gensound] for musical use; Sound category-specific synthesis-controlling parameters or control means therefor
- G10H2250/455—Gensound singing voices, i.e. generation of human voices for musical applications, vocal singing sounds or intelligible words at a desired pitch or with desired vocal effects, e.g. by phoneme synthesis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2250/00—Aspects of algorithms or signal processing methods without intrinsic musical character, yet specifically adapted for or used in electrophonic musical processing
- G10H2250/471—General musical sound synthesis principles, i.e. sound category-independent synthesis methods
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Description
ターゲットテキストを取得するステップと、
選択指令に応じて選択されたターゲット歌曲を確定するステップと、
前記ターゲットテキストを歌詞とする、曲調整制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得するステップと、
前記自製歌曲を再生するステップとを含むオーディオ合成方法を提供する。
ターゲットテキストを取得するための取得モジュールと、
選択指令に応じて選択されたターゲット歌曲を確定するための確定モジュールと、
自製歌曲を再生するための再生モジュールとを備え、
前記取得モジュールは、さらに、前記ターゲットテキストを歌詞とする、曲調整制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得するオーディオ合成装置を提供する。
前記コンピュータプログラムは、プロセッサによって実行されるときに、
ターゲットテキストを取得するステップと、
選択指令に応じて選択されたターゲット歌曲を確定するステップと、
曲調整制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成され、前記ターゲットテキストを歌詞とする自製歌曲を取得するステップと、
前記自製歌曲を再生するステップとをプロセッサに実行させるコンピュータ読取可能な記憶媒体を提供する。
前記コンピュータプログラムは、前記プロセッサによって実行されるときに、
ターゲットテキストを取得するステップと、
選択指令に応じて選択されたターゲット歌曲を確定するステップと、
曲調整制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成され、前記ターゲットテキストを歌詞とする自製歌曲を取得するステップと、
前記自製歌曲を再生するステップとをプロセッサに実行させるコンピュータ読取可能な記憶媒体を提供する。



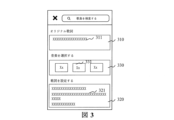
120 サーバ
310 テキスト入力ボックス
311 テキスト
320 テキストテンプレートリスト
321 テキスト
330 候補歌曲リスト
331 歌曲
610 動画フレーム
620 対話エントリ
631 テキスト入力ボックス
632 アナログビデオ通話エントリ
711 ピクチャ
721 ピクチャ
722 画像
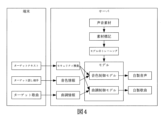
800 オーディオ合成装置
801 取得モジュール
802 確定モジュール
803 再生モジュール
804 トレーニングモジュール
805 録画モジュール
Claims (6)
- コンピュータ装置システムが実行するオーディオ合成方法であって、
ターゲットテキストを取得するステップと、
選択指令に応じて選択されたターゲット歌曲を確定するステップと、
曲調制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得するステップであって、前記自製歌曲は前記ターゲットテキストを歌詞とする、ステップであって、前記曲調制御モデルは、テキストサンプルおよび候補歌曲曲調に基づいてトレーニングされて得られた、ステップと、を含み、
前記曲調制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得する前記ステップは、
前記ターゲット歌曲とマッチングする曲調情報を検索するステップと、
前記ターゲットテキストと前記曲調情報とを曲調制御モデルに入力し、前記曲調制御モデルの隠れ層によって、前記曲調情報に基づいて前記ターゲットテキストにおける各文字のそれぞれに対応する曲調特徴を決定するステップと、
前記曲調制御モデルの出力層によって、前記ターゲットテキストにおける各文字に対応する曲調特徴に基づいて音声合成された自製歌曲を出力するステップと、を含む、オーディオ合成方法。 - 曲調制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得する前記ステップは、
端末が前記ターゲットテキストおよび前記ターゲット歌曲の歌曲識別子をサーバに送信するステップと、
端末が前記サーバからフィードバックされた自製歌曲を受信するステップと、を含み、
前記ターゲットテキストおよび前記歌曲識別子とは、前記歌曲識別子に対応する曲調情報を検索した後、曲調制御モデル、前記ターゲットテキストおよび前記曲調情報に基づいて自製歌曲を合成するようにサーバに指示するためのものである、
ことを特徴とする請求項1に記載の方法。 - 曲調制御モデルをトレーニングするステップをさらに含み、
前記ターゲット歌曲は、候補歌曲から選択されるものであり、
前記曲調制御モデルをトレーニングするステップは、
候補歌曲に対応する候補歌曲オーディオを収集するステップと、
収集した候補歌曲オーディオに基づいて、各候補歌曲に対応する候補歌曲曲調を決定するステップと、
テキストサンプルを取得するステップと、
前記テキストサンプルおよび前記候補歌曲曲調に基づいてトレーニングすることによって前記曲調制御モデルを得るステップと、を含む、
ことを特徴とする請求項1に記載の方法。 - ターゲット話し相手を決定するステップをさらに含み、
曲調制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得する前記ステップは、
前記ターゲット話し相手に対応する曲調制御モデルを検索するステップと、
検索した前記曲調制御モデル、前記ターゲットテキストおよび前記ターゲット歌曲の曲調情報に基づいて合成された自製歌曲を取得するステップとを含み、
前記自製歌曲の音色は、前記ターゲット話し相手に適合する、
ことを特徴とする請求項1に記載の方法。 - 請求項1から4のいずれか一項に記載の方法を実行させるコンピュータプログラム。
- コンピュータプログラムが記憶されるメモリと、プロセッサとを備えるコンピュータ装置により構成されるコンピュータ装置システムであって、
請求項1、2、および4のいずれか一項に記載の方法を実行させる
ことを特徴とするコンピュータ装置システム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810730283.3A CN110189741A (zh) | 2018-07-05 | 2018-07-05 | 音频合成方法、装置、存储介质和计算机设备 |
| CN201810730283.3 | 2018-07-05 | ||
| PCT/CN2019/089678 WO2020007148A1 (zh) | 2018-07-05 | 2019-05-31 | 音频合成方法、存储介质和计算机设备 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2021516787A JP2021516787A (ja) | 2021-07-08 |
| JP7317850B2 true JP7317850B2 (ja) | 2023-07-31 |
Family
ID=67713854
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020549777A Active JP7317850B2 (ja) | 2018-07-05 | 2019-05-31 | オーディオ合成方法、並びにそのコンピュータプログラム、コンピュータ装置及びコンピュータ装置により構成されるコンピュータシステム |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20200372896A1 (ja) |
| EP (1) | EP3736806A4 (ja) |
| JP (1) | JP7317850B2 (ja) |
| KR (1) | KR102500087B1 (ja) |
| CN (1) | CN110189741A (ja) |
| TW (1) | TWI774967B (ja) |
| WO (1) | WO2020007148A1 (ja) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110910917B (zh) * | 2019-11-07 | 2021-08-31 | 腾讯音乐娱乐科技(深圳)有限公司 | 音频片段的拼接方法及装置 |
| CN111161695B (zh) * | 2019-12-26 | 2022-11-04 | 北京百度网讯科技有限公司 | 歌曲生成方法和装置 |
| CN111429881B (zh) * | 2020-03-19 | 2023-08-18 | 北京字节跳动网络技术有限公司 | 语音合成方法、装置、可读介质及电子设备 |
| CN111415399B (zh) * | 2020-03-19 | 2023-12-22 | 北京奇艺世纪科技有限公司 | 图像处理方法、装置、电子设备及计算机可读存储介质 |
| CN111445892B (zh) * | 2020-03-23 | 2023-04-14 | 北京字节跳动网络技术有限公司 | 歌曲生成方法、装置、可读介质及电子设备 |
| CN111477199B (zh) * | 2020-04-02 | 2021-11-30 | 北京瑞迪欧文化传播有限责任公司 | 一种嵌入式音乐控制系统 |
| CN111653265B (zh) * | 2020-04-26 | 2023-08-18 | 北京大米科技有限公司 | 语音合成方法、装置、存储介质和电子设备 |
| CN111583972B (zh) * | 2020-05-28 | 2022-03-25 | 北京达佳互联信息技术有限公司 | 歌唱作品生成方法、装置及电子设备 |
| CN111757163B (zh) * | 2020-06-30 | 2022-07-01 | 北京字节跳动网络技术有限公司 | 视频播放的控制方法、装置、电子设备和存储介质 |
| CN111899706A (zh) * | 2020-07-30 | 2020-11-06 | 广州酷狗计算机科技有限公司 | 音频制作方法、装置、设备及存储介质 |
| CN112331222A (zh) * | 2020-09-23 | 2021-02-05 | 北京捷通华声科技股份有限公司 | 一种转换歌曲音色的方法、系统、设备及存储介质 |
| CN112509538A (zh) * | 2020-12-18 | 2021-03-16 | 咪咕文化科技有限公司 | 音频处理方法、装置、终端及存储介质 |
| CN113223486B (zh) * | 2021-04-29 | 2023-10-17 | 北京灵动音科技有限公司 | 信息处理方法、装置、电子设备及存储介质 |
| CN113436601A (zh) * | 2021-05-27 | 2021-09-24 | 北京达佳互联信息技术有限公司 | 音频合成方法、装置、电子设备及存储介质 |
| CN113591489B (zh) * | 2021-07-30 | 2023-07-18 | 中国平安人寿保险股份有限公司 | 语音交互方法、装置及相关设备 |
| CN113946254B (zh) * | 2021-11-01 | 2023-10-20 | 北京字跳网络技术有限公司 | 内容显示方法、装置、设备及介质 |
| CN113763924B (zh) * | 2021-11-08 | 2022-02-15 | 北京优幕科技有限责任公司 | 声学深度学习模型训练方法、语音生成方法及设备 |
| CN113920979B (zh) * | 2021-11-11 | 2023-06-02 | 腾讯科技(深圳)有限公司 | 语音数据的获取方法、装置、设备及计算机可读存储介质 |
| CN117012169A (zh) * | 2022-04-29 | 2023-11-07 | 脸萌有限公司 | 一种音乐生成方法、装置、系统以及存储介质 |
| CN117012170A (zh) * | 2022-04-29 | 2023-11-07 | 脸萌有限公司 | 一种音乐生成方法、装置、系统及存储介质 |
| CN117059052A (zh) * | 2022-05-07 | 2023-11-14 | 脸萌有限公司 | 歌曲生成方法、装置、系统及存储介质 |
| CN116153338B (zh) * | 2023-04-23 | 2023-06-20 | 深圳市声菲特科技技术有限公司 | 一种调音参数的加载方法、装置、设备及存储介质 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002132281A (ja) | 2000-10-26 | 2002-05-09 | Nippon Telegr & Teleph Corp <Ntt> | 歌声メッセージ生成・配信方法及びその装置 |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9711339D0 (en) * | 1997-06-02 | 1997-07-30 | Isis Innovation | Method and apparatus for reproducing a recorded voice with alternative performance attributes and temporal properties |
| JP2003195876A (ja) * | 2001-12-26 | 2003-07-09 | Funai Electric Co Ltd | カラオケシステム |
| TW200515186A (en) * | 2003-10-24 | 2005-05-01 | Inventec Multimedia & Telecom | System and method for integrating multimedia data for editing and playing |
| JP2005321706A (ja) * | 2004-05-11 | 2005-11-17 | Nippon Telegr & Teleph Corp <Ntt> | 電子書籍の再生方法及びその装置 |
| KR100731761B1 (ko) * | 2005-05-02 | 2007-06-22 | 주식회사 싸일런트뮤직밴드 | 인터넷을 통한 음악제작 시스템 및 방법 |
| TWI394142B (zh) * | 2009-08-25 | 2013-04-21 | Inst Information Industry | 歌聲合成系統、方法、以及裝置 |
| CN101789255A (zh) * | 2009-12-04 | 2010-07-28 | 康佳集团股份有限公司 | 一种基于手机原有歌曲更改歌词的处理方法及手机 |
| US20110219940A1 (en) * | 2010-03-11 | 2011-09-15 | Hubin Jiang | System and method for generating custom songs |
| JP5598056B2 (ja) * | 2010-03-30 | 2014-10-01 | ヤマハ株式会社 | カラオケ装置およびカラオケ曲紹介プログラム |
| JP5974436B2 (ja) * | 2011-08-26 | 2016-08-23 | ヤマハ株式会社 | 楽曲生成装置 |
| JP6083764B2 (ja) * | 2012-12-04 | 2017-02-22 | 国立研究開発法人産業技術総合研究所 | 歌声合成システム及び歌声合成方法 |
| CN103117057B (zh) * | 2012-12-27 | 2015-10-21 | 安徽科大讯飞信息科技股份有限公司 | 一种特定人语音合成技术在手机漫画配音中的应用方法 |
| WO2016029217A1 (en) * | 2014-08-22 | 2016-02-25 | Zya, Inc. | System and method for automatically converting textual messages to musical compositions |
| US9305530B1 (en) * | 2014-09-30 | 2016-04-05 | Amazon Technologies, Inc. | Text synchronization with audio |
| JP6728754B2 (ja) * | 2015-03-20 | 2020-07-22 | ヤマハ株式会社 | 発音装置、発音方法および発音プログラム |
| JP6622505B2 (ja) * | 2015-08-04 | 2019-12-18 | 日本電信電話株式会社 | 音響モデル学習装置、音声合成装置、音響モデル学習方法、音声合成方法、プログラム |
| CN105068748A (zh) * | 2015-08-12 | 2015-11-18 | 上海影随网络科技有限公司 | 触屏智能设备的摄像头实时画面中用户界面交互方法 |
| CN106131475A (zh) * | 2016-07-28 | 2016-11-16 | 努比亚技术有限公司 | 一种视频处理方法、装置及终端 |
| CN107799119A (zh) * | 2016-09-07 | 2018-03-13 | 中兴通讯股份有限公司 | 音频制作方法、装置及系统 |
| CN106652984B (zh) * | 2016-10-11 | 2020-06-02 | 张文铂 | 一种使用计算机自动创作歌曲的方法 |
| CN106971703A (zh) * | 2017-03-17 | 2017-07-21 | 西北师范大学 | 一种基于hmm的歌曲合成方法及装置 |
| US10818308B1 (en) * | 2017-04-28 | 2020-10-27 | Snap Inc. | Speech characteristic recognition and conversion |
| CN109716326A (zh) * | 2017-06-21 | 2019-05-03 | 微软技术许可有限责任公司 | 在自动聊天中提供个性化歌曲 |
| US11475867B2 (en) * | 2019-12-27 | 2022-10-18 | Spotify Ab | Method, system, and computer-readable medium for creating song mashups |
| WO2023058173A1 (ja) * | 2021-10-06 | 2023-04-13 | ヤマハ株式会社 | 音制御装置およびその制御方法、電子楽器、プログラム |
| CN115346503A (zh) * | 2022-08-11 | 2022-11-15 | 杭州网易云音乐科技有限公司 | 歌曲创作方法、歌曲创作装置、存储介质及电子设备 |
-
2018
- 2018-07-05 CN CN201810730283.3A patent/CN110189741A/zh active Pending
-
2019
- 2019-05-31 JP JP2020549777A patent/JP7317850B2/ja active Active
- 2019-05-31 KR KR1020207024631A patent/KR102500087B1/ko active IP Right Grant
- 2019-05-31 WO PCT/CN2019/089678 patent/WO2020007148A1/zh unknown
- 2019-05-31 EP EP19830395.0A patent/EP3736806A4/en active Pending
- 2019-07-04 TW TW108123649A patent/TWI774967B/zh active
-
2020
- 2020-08-11 US US16/990,869 patent/US20200372896A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002132281A (ja) | 2000-10-26 | 2002-05-09 | Nippon Telegr & Teleph Corp <Ntt> | 歌声メッセージ生成・配信方法及びその装置 |
Non-Patent Citations (2)
| Title |
|---|
| Masanari Nishimura et al.,"Singing voice synthesis based on deep neural networks",Proceedings of the INTERSPEECH 2016,2016年9月8日,pp.2478-2482 |
| 徳田、南角、大浦、「歌い手の声質・歌い方を自動で学習・再現できる統計モデルに基づく歌声合成システム」、公益財団法人電気通信普及財団 調査研究助成報告書、2017年、第32号 |
Also Published As
| Publication number | Publication date |
|---|---|
| TWI774967B (zh) | 2022-08-21 |
| WO2020007148A1 (zh) | 2020-01-09 |
| KR102500087B1 (ko) | 2023-02-16 |
| CN110189741A (zh) | 2019-08-30 |
| TW202006534A (zh) | 2020-02-01 |
| EP3736806A1 (en) | 2020-11-11 |
| EP3736806A4 (en) | 2021-10-06 |
| JP2021516787A (ja) | 2021-07-08 |
| US20200372896A1 (en) | 2020-11-26 |
| KR20200115588A (ko) | 2020-10-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7317850B2 (ja) | オーディオ合成方法、並びにそのコンピュータプログラム、コンピュータ装置及びコンピュータ装置により構成されるコンピュータシステム | |
| US10964298B2 (en) | Network musical instrument | |
| CN108806656B (zh) | 歌曲的自动生成 | |
| JP2021507309A (ja) | モジュラー自動音楽制作サーバー | |
| US20140006031A1 (en) | Sound synthesis method and sound synthesis apparatus | |
| JP6665446B2 (ja) | 情報処理装置、プログラム及び音声合成方法 | |
| JP2010518459A (ja) | 配布オーディオファイル編集用ウェブポータル | |
| US11120782B1 (en) | System, method, and non-transitory computer-readable storage medium for collaborating on a musical composition over a communication network | |
| CN110675886A (zh) | 音频信号处理方法、装置、电子设备及存储介质 | |
| JP6977323B2 (ja) | 歌唱音声の出力方法、音声応答システム、及びプログラム | |
| WO2019000054A1 (en) | SYSTEMS, METHODS, AND APPLICATIONS FOR MODULATING AUDIBLE PERFORMANCE | |
| JP2022092032A (ja) | 歌唱合成システム及び歌唱合成方法 | |
| CN114125543B (zh) | 弹幕处理方法、计算设备及弹幕处理系统 | |
| CN113407275A (zh) | 音频编辑方法、装置、设备及可读存储介质 | |
| Bacot et al. | The creative process of sculpting the air by Jesper Nordin: conceiving and performing a concerto for conductor with live electronics | |
| Furduj | Virtual orchestration: a film composer's creative practice | |
| Furduj | Acoustic instrument simulation in film music contexts | |
| Kokoras | AUDIOVISUAL CONCATENATIVE SYNTHESIS AND REPLICA | |
| CN113703882A (zh) | 歌曲处理方法、装置、设备及计算机可读存储介质 | |
| JP2009244607A (ja) | デュエットパート歌唱生成システム | |
| Gullö et al. | Innovation in Music: Technology and Creativity | |
| Puckette et al. | Between the Tracks: Musicians on Selected Electronic Music | |
| Bakke | Nye lyder, nye kreative muligheter. Akustisk trommesett utvidet med live elektronikk | |
| Cleland | Sound and Vision: Developing a Method of Audiovisual Composition and Improvisation for Drum Set | |
| from Hell | Sounds from The Garden |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200916 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200916 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20211029 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20211108 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220201 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20220704 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221028 |
|
| C60 | Trial request (containing other claim documents, opposition documents) |
Free format text: JAPANESE INTERMEDIATE CODE: C60 Effective date: 20221028 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20221115 |
|
| C21 | Notice of transfer of a case for reconsideration by examiners before appeal proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C21 Effective date: 20221121 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20230113 |
|
| C211 | Notice of termination of reconsideration by examiners before appeal proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C211 Effective date: 20230123 |
|
| C22 | Notice of designation (change) of administrative judge |
Free format text: JAPANESE INTERMEDIATE CODE: C22 Effective date: 20230130 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230719 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7317850 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |