JP6981753B2 - 複数のグラフィックカードの管理 - Google Patents
複数のグラフィックカードの管理 Download PDFInfo
- Publication number
- JP6981753B2 JP6981753B2 JP2017000116A JP2017000116A JP6981753B2 JP 6981753 B2 JP6981753 B2 JP 6981753B2 JP 2017000116 A JP2017000116 A JP 2017000116A JP 2017000116 A JP2017000116 A JP 2017000116A JP 6981753 B2 JP6981753 B2 JP 6981753B2
- Authority
- JP
- Japan
- Prior art keywords
- graphic
- resource
- abstract
- graphic resource
- render engine
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/14—Digital output to display device ; Cooperation and interconnection of the display device with other functional units
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5011—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T15/00—3D [Three Dimensional] image rendering
- G06T15/005—General purpose rendering architectures
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09G—ARRANGEMENTS OR CIRCUITS FOR CONTROL OF INDICATING DEVICES USING STATIC MEANS TO PRESENT VARIABLE INFORMATION
- G09G5/00—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators
- G09G5/36—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators characterised by the display of a graphic pattern, e.g. using an all-points-addressable [APA] memory
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09G—ARRANGEMENTS OR CIRCUITS FOR CONTROL OF INDICATING DEVICES USING STATIC MEANS TO PRESENT VARIABLE INFORMATION
- G09G5/00—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators
- G09G5/36—Control arrangements or circuits for visual indicators common to cathode-ray tube indicators and other visual indicators characterised by the display of a graphic pattern, e.g. using an all-points-addressable [APA] memory
- G09G5/363—Graphics controllers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2210/00—Indexing scheme for image generation or computer graphics
- G06T2210/52—Parallel processing
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09G—ARRANGEMENTS OR CIRCUITS FOR CONTROL OF INDICATING DEVICES USING STATIC MEANS TO PRESENT VARIABLE INFORMATION
- G09G2360/00—Aspects of the architecture of display systems
- G09G2360/06—Use of more than one graphics processor to process data before displaying to one or more screens
-
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09G—ARRANGEMENTS OR CIRCUITS FOR CONTROL OF INDICATING DEVICES USING STATIC MEANS TO PRESENT VARIABLE INFORMATION
- G09G2360/00—Aspects of the architecture of display systems
- G09G2360/08—Power processing, i.e. workload management for processors involved in display operations, such as CPUs or GPUs
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Graphics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Human Computer Interaction (AREA)
- Processing Or Creating Images (AREA)
- Advance Control (AREA)
- Image Generation (AREA)
- Stored Programmes (AREA)
- Geometry (AREA)
Description
− レンダエンジンが、少なくとも2つの論理層、レンダエンジンに対するアクセスをアプリケーションに提供する上位層、およびグラフィックライブラリに対するアクセスをレンダエンジンに提供する下位層を備え、抽象グラフィックリソースを作成することは、上位層と下位層の間に備えられた抽象層によって実行される、
− 抽象グラフィックリソースを作成するステップの前に、下位層による、グラフィックライブラリ上で、グラフィックカードのうちの少なくとも1つに関するグラフィックリソースの識別子にアクセスするステップ、およびアクセスされた識別子を抽象層に提供するステップを備える、
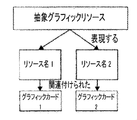
− 作成された抽象グラフィックリソースが、グラフィックリソースの識別子、およびグラフィックカードのうちの少なくとも1つの識別子を記憶する、
− 抽象グラフィックリソースを作成するステップは、抽象グラフィックリソースをテーブルに記憶することをさらに備え、アクセスをレンダエンジンに提供するステップは、前記グラフィックリソースを扱うための抽象グラフィックリソースを記憶するテーブルに対するアクセスをレンダエンジンに提供することを備える、
− 前記グラフィックリソース上で実行されるべきグラフィックライブラリアクションを受け取るステップであって、アクションは、レンダエンジンに対するアクセスを有するアプリケーションによって要求される、ステップ、前記グラフィックリソースに関して作成された抽象グラフィックリソースを識別するステップ、グラフィックカードのうちの少なくとも1つに関するグラフィックリソースの識別子を取り出すステップ、および、グラフィックリソースにアクセスし、かつグラフィックリソース上でグラフィックライブラリアクションを実行するステップを備える、
− 前記グラフィックリソースを削除する命令を受け取るステップであって、アクションは、レンダエンジンに対するアクセスを有するアプリケーションによって要求される、ステップ、前記グラフィックリソースに関して作成された抽象グラフィックリソースを識別するステップ、グラフィックカードのうちの少なくとも1つに関するグラフィックリソースの識別子を取り出すステップ、およびグラフィックリソースにアクセスし、かつグラフィックカードのうちの少なくとも1つのグラフィックリソースを削除するステップを備える、
− 抽象グラフィックリソースを上位層に提供するステップを備える、
− 抽象リソースを作成することの前に、使用されるべき少なくとも1つのグラフィックリソースを扱うための少なくとも1つのグラフィックカードを選択するステップを備える、
− 抽象グラフィックリソースが、複数のグラフィックカードのうちの各グラフィックカードに関してグラフィックリソースの識別子を記憶し、グラフィックリソースは、複数のグラフィックカードのうちの各グラフィックカード上にコピーされる。
Claims (13)
- 複数のグラフィックカードを管理するためのコンピュータ実施方法であって、グラフィックカードは、1または複数のグラフィックプロセッシングユニットを備え、方法は、
レンダエンジンにシーンをロードするステップであって、前記シーンは、前記シーンのビューをレンダリングするために使用されるべき少なくとも1つのグラフィックデータを備える、ステップと、
前記少なくとも1つのグラフィックデータのグラフィックリソースに関して抽象グラフィックリソースを作成するステップであって、前記抽象グラフィックリソースは、グラフィックカードのうちの少なくとも1つに関する前記グラフィックリソースの識別子を記憶する、ステップと、
前記少なくとも1つのグラフィックカード上で、前記少なくとも1つのグラフィックデータの前記グラフィックリソースをコピーするステップと、
前記グラフィックリソースを扱うための前記抽象グラフィックリソースに対するアクセスを前記レンダエンジンに提供するステップと
を備えることを特徴とするコンピュータ実施方法。 - 前記レンダエンジンは、少なくとも2つの論理層、前記レンダエンジンに対するアクセスをアプリケーションに提供する上位層、およびグラフィックライブラリに対するアクセスを前記レンダエンジンに提供する下位層を備え、前記抽象グラフィックリソースを作成する前記ステップは、前記上位層と前記下位層の間に備えられた抽象層によって実行されることを特徴とする請求項1に記載のコンピュータ実施方法。
- 前記抽象グラフィックリソースを作成する前記ステップの前に、
前記下位層による、グラフィックライブラリ上で、グラフィックカードのうちの前記少なくとも1つに関する前記グラフィックリソースの前記識別子にアクセスするステップと、
前記アクセスされた識別子を前記抽象層に提供するステップと
をさらに備えることを特徴とする請求項2に記載のコンピュータ実施方法。 - 前記作成された抽象グラフィックリソースは、グラフィックリソースの前記識別子、およびグラフィックカードのうちの前記少なくとも1つの識別子を記憶することを特徴とする請求項1乃至3のいずれか1つに記載のコンピュータ実施方法。
- 前記抽象グラフィックリソースを作成する前記ステップは、前記抽象グラフィックリソースをテーブルに記憶することをさらに備え、アクセスを前記レンダエンジンに提供する前記ステップは、前記グラフィックリソースを扱うための前記抽象グラフィックリソースを記憶する前記テーブルに対するアクセスを前記レンダエンジンに提供するステップを備えることを特徴とする請求項1乃至4のいずれか1つに記載のコンピュータ実施方法。
- 前記グラフィックリソース上で実行されるべきグラフィックライブラリアクションを受け取るステップであって、前記アクションは、前記レンダエンジンに対するアクセスを有するアプリケーションによって要求される、該ステップと、
前記グラフィックリソースに関して作成された前記抽象グラフィックリソースを識別するステップと、
グラフィックカードのうちの少なくとも1つに関する前記グラフィックリソースの前記識別子を取り出すステップと、
前記グラフィックリソースにアクセスし、かつ前記グラフィックリソース上で前記グラフィックライブラリアクションを実行するステップと
をさらに備えることを特徴とする請求項1乃至5のいずれか1つに記載のコンピュータ実施方法。 - 前記グラフィックリソースを削除する命令を受け取るステップであって、前記アクションは、前記レンダエンジンに対するアクセスを有するアプリケーションによって要求される、ステップと、
前記グラフィックリソースに関して作成された前記抽象グラフィックリソースを識別するステップと、
グラフィックカードのうちの前記少なくとも1つに関する前記グラフィックリソースの前記識別子を取り出すステップと、
前記グラフィックリソースにアクセスし、かつグラフィックカードのうちの前記少なくとも1つの前記グラフィックリソースを削除するステップと
をさらに備えることを特徴とする請求項6に記載のコンピュータ実施方法。 - 前記抽象グラフィックリソースを前記上位層に提供するステップをさらに備えることを特徴とする請求項2又は3に記載のコンピュータ実施方法。
- 抽象リソースを作成するステップの前に、使用されるべき前記グラフィックリソースを扱うための前記少なくとも1つのグラフィックカードを選択するステップをさらに備えることを特徴とする請求項1乃至8のいずれか1つに記載のコンピュータ実施方法。
- 前記抽象グラフィックリソースは、前記複数のグラフィックカードのうちの各グラフィックカードに関してグラフィックリソースの識別子を記憶し、前記グラフィックリソースは、前記複数のグラフィックカードのうちの各グラフィックカード上にコピーされることを特徴とする請求項1乃至9のいずれか1つに記載のコンピュータ実施方法。
- 請求項1乃至10のいずれか1つに記載の方法を実行するための指示を備えることを特徴とするレンダエンジンコンピュータプログラム。
- 請求項11に記載のレンダエンジンコンピュータプログラムが記録されていることを特徴とするコンピュータ可読ストレージメディア。
- メモリおよびグラフィカルユーザインターフェースに結合された処理回路を備えるシステムであって、
前記メモリは請求項11に記載のレンダエンジンコンピュータプログラムが記録されていることを特徴とするシステム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15307166.7A EP3188014B1 (en) | 2015-12-29 | 2015-12-29 | Management of a plurality of graphic cards |
| EP15307166.7 | 2015-12-29 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017123171A JP2017123171A (ja) | 2017-07-13 |
| JP2017123171A5 JP2017123171A5 (ja) | 2020-02-06 |
| JP6981753B2 true JP6981753B2 (ja) | 2021-12-17 |
Family
ID=55129483
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017000116A Active JP6981753B2 (ja) | 2015-12-29 | 2017-01-04 | 複数のグラフィックカードの管理 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10127708B2 (ja) |
| EP (1) | EP3188014B1 (ja) |
| JP (1) | JP6981753B2 (ja) |
| CN (1) | CN107067364B (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3188013B1 (en) * | 2015-12-29 | 2022-07-13 | Dassault Systèmes | Management of a plurality of graphic cards |
| CN108434742B (zh) * | 2018-02-02 | 2019-04-30 | 网易(杭州)网络有限公司 | 游戏场景中虚拟资源的处理方法和装置 |
| US11620795B2 (en) * | 2020-03-27 | 2023-04-04 | Snap Inc. | Displaying augmented reality content in messaging application |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080211816A1 (en) * | 2003-07-15 | 2008-09-04 | Alienware Labs. Corp. | Multiple parallel processor computer graphics system |
| US8028292B2 (en) * | 2004-02-20 | 2011-09-27 | Sony Computer Entertainment Inc. | Processor task migration over a network in a multi-processor system |
| US9058292B2 (en) * | 2004-12-29 | 2015-06-16 | Intel Corporation | System and method for one step address translation of graphics addresses in virtualization |
| US20070052715A1 (en) * | 2005-09-07 | 2007-03-08 | Konstantin Levit-Gurevich | Device, system and method of graphics processing |
| US8307360B2 (en) * | 2008-01-22 | 2012-11-06 | Advanced Micro Devices, Inc. | Caching binary translations for virtual machine guest |
| US8612633B2 (en) * | 2010-03-31 | 2013-12-17 | Microsoft Corporation | Virtual machine fast emulation assist |
| US20120001925A1 (en) * | 2010-06-30 | 2012-01-05 | Ati Technologies, Ulc | Dynamic Feedback Load Balancing |
| US9814977B2 (en) * | 2010-07-13 | 2017-11-14 | Sony Interactive Entertainment Inc. | Supplemental video content on a mobile device |
| US9606936B2 (en) * | 2010-12-16 | 2017-03-28 | Advanced Micro Devices, Inc. | Generalized control registers |
| WO2013091185A1 (en) * | 2011-12-21 | 2013-06-27 | Intel Corporation | Gpu accelerated address translation for graphics virtualization |
| US8941670B2 (en) * | 2012-01-17 | 2015-01-27 | Microsoft Corporation | Para-virtualized high-performance computing and GDI acceleration |
| US9697579B2 (en) * | 2013-06-07 | 2017-07-04 | Apple Inc. | Multi-processor graphics rendering |
| US9900378B2 (en) * | 2016-02-01 | 2018-02-20 | Sas Institute Inc. | Node device function and cache aware task assignment |
-
2015
- 2015-12-29 EP EP15307166.7A patent/EP3188014B1/en active Active
-
2016
- 2016-12-28 CN CN201611273156.2A patent/CN107067364B/zh active Active
- 2016-12-29 US US15/393,675 patent/US10127708B2/en active Active
-
2017
- 2017-01-04 JP JP2017000116A patent/JP6981753B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP3188014A1 (en) | 2017-07-05 |
| EP3188014B1 (en) | 2022-07-13 |
| CN107067364B (zh) | 2022-03-22 |
| CN107067364A (zh) | 2017-08-18 |
| US10127708B2 (en) | 2018-11-13 |
| US20170186214A1 (en) | 2017-06-29 |
| JP2017123171A (ja) | 2017-07-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6721332B2 (ja) | 3dモデル化されたアセンブリ上で境界ボックスを生成すること | |
| US11256832B2 (en) | Replica selection | |
| US11087052B2 (en) | Automatic partitioning of a 3D scene into a plurality of zones processed by a computing resource | |
| US8812272B2 (en) | Designing a modeled object within a session of a computer-aided design system interacting with a database | |
| JP6585423B2 (ja) | 順次更新の実行 | |
| JP6721333B2 (ja) | オブジェクトのセットの視点の選択 | |
| KR20060070462A (ko) | 제품 수명주기 관리 데이터베이스를 이용하여 뷰의오브젝트를 렌더링하는 프로세스 및 시스템 | |
| US20180137118A1 (en) | Querying A Database Based On A Parametric View Function | |
| JP6981753B2 (ja) | 複数のグラフィックカードの管理 | |
| JP6981754B2 (ja) | 複数のグラフィックカードの管理 | |
| JP2020115340A (ja) | 弱型定義を用いるモデリング | |
| JP2016045967A (ja) | 順次更新の実行 | |
| JP2016119103A (ja) | マルチフィジックスシステムの設計 | |
| JP7017852B2 (ja) | 記述子を用いた3dオブジェクトの位置特定 | |
| JP6947503B2 (ja) | 量子化を用いた3dオブジェクトの位置特定 | |
| US12073526B2 (en) | Flexible modeling using a weak type definition | |
| KR20140063475A (ko) | 오브젝트들의 원형 스태거드 패턴의 설계 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191217 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191217 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20210129 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210209 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20210510 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210806 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20211019 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20211118 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6981753 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |