JP6896552B2 - Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program - Google Patents
Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program Download PDFInfo
- Publication number
- JP6896552B2 JP6896552B2 JP2017150873A JP2017150873A JP6896552B2 JP 6896552 B2 JP6896552 B2 JP 6896552B2 JP 2017150873 A JP2017150873 A JP 2017150873A JP 2017150873 A JP2017150873 A JP 2017150873A JP 6896552 B2 JP6896552 B2 JP 6896552B2
- Authority
- JP
- Japan
- Prior art keywords
- evaluation
- sentence
- unit
- explanatory text
- product
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images














Landscapes
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
本願は、説明文評価方法、説明文評価装置及び説明文評価プログラムに関する。 The present application relates to an explanatory text evaluation method, an explanatory text evaluation device, and an explanatory text evaluation program.
商品のパッケージやTV、新聞、雑誌等における宣伝広告には、通常、使用方法、使用効果等を示した説明文が記載されている。消費者が品質、有効性、安全性等を適切に把握し商品を購入し及び使用できるように、医薬品医療機器法(薬機法)や景品表示法等の様々な法令によって、説明文に対して様々な規制やガイドラインの策定がなされている。 Advertisements on product packages, TVs, newspapers, magazines, etc. usually contain explanatory texts indicating how to use them, their effects, and the like. In order for consumers to properly understand quality, effectiveness, safety, etc., and to purchase and use products, various laws and regulations such as the Pharmaceutical and Medical Device Law (Pharmaceutical Machinery Law) and the Freebie Labeling Law are required for explanations. Various regulations and guidelines have been formulated.
商品の特長を表わす表現は、様々な法令等の規制のもとで、消費者が通常理解するであろう効能及び効果の範囲を超えた内容を含んではならない。このようなことから、商品の説明文は、通常、熟練者等によってチェックされている。 Expressions that describe the features of a product must not include content that goes beyond the indications and effects that consumers would normally understand under the regulations of various laws and regulations. For this reason, the description of the product is usually checked by an expert or the like.
説明文として適切な語を選択するために、文書内の未知の語の前後の語から未知の語となり得る語を予測する技術等(例えば、特許文献1参照)を用いることが考えられる。 In order to select an appropriate word as an explanatory sentence, it is conceivable to use a technique or the like (see, for example, Patent Document 1) for predicting a word that can be an unknown word from the words before and after the unknown word in the document.
しかしながら、説明文は、商品を計画及び開発する担当者が、様々な法令等の規制に従い適切な表現であるか否かを評価することは難しく、不明な場合は、熟練者に問合せて確認することが行われている。 However, it is difficult for the person in charge of planning and developing the product to evaluate whether or not the description is appropriate in accordance with regulations such as various laws and regulations. Is being done.
一方、熟練者の教育には時間を要し、また、今日では各部門の担当者からの問合せも増加傾向にあり、対応に追われる状況にある。また、説明文は熟練者の経験に基づき評価された場合、熟練者により異なる判断となる場合があり、一定の評価を得ることが難しいといった問題がある。 On the other hand, it takes time to educate skilled workers, and today, the number of inquiries from the persons in charge of each department is increasing, and the situation is that they are busy responding. Further, when the explanation is evaluated based on the experience of the expert, the judgment may be different depending on the expert, and there is a problem that it is difficult to obtain a certain evaluation.
したがって、一つの側面では、本発明は、商品の説明文に対し安定した評価を迅速に得ることを目的とする。 Therefore, in one aspect, the present invention aims to quickly obtain a stable evaluation of the description of a product.
一つの形態によれば、商品に添付される説明文の評価要求の受信に応じて、該説明文を単文化する単文化処理ステップと、単文ごとに該単文の内容が少なくとも前記商品の説明表現に係る法令に従った内容であるか否かを、予め機械学習により得られたモデルを用いて評価する単文単位評価ステップと、評価結果ごとに商品の説明としての相応しさに関する文章を対応付けた定義テーブルを参照することで、前記単文単位評価ステップによる評価結果に対応する該文章を取得し、前記説明文を表示する画面上で前記単文の選択に応じて該文章を表示可能とする結果表示データを作成する結果表示データ作成ステップと、をコンピュータが行う説明文評価方法が提供される。 According to one form, in response to the reception of the evaluation request of the explanatory text attached to the product, the monocultural processing step of monoculturing the explanatory text and the content of the simple text for each simple sentence are at least the explanatory representation of the product. A simple sentence unit evaluation step that evaluates whether or not the content complies with the laws and regulations related to the above using a model obtained by machine learning in advance, and a sentence about the suitability as a description of the product are associated with each evaluation result. By referring to the definition table, the sentence corresponding to the evaluation result by the simple sentence unit evaluation step is acquired, and the result display that enables the sentence to be displayed according to the selection of the simple sentence on the screen for displaying the explanation. Result display of data creation A data creation step and a description evaluation method performed by a computer are provided.
また、上記課題を解決するための手段として、説明文評価装置及び説明文評価プログラムとすることもできる。 Further, as a means for solving the above-mentioned problems, an explanatory text evaluation device and an explanatory text evaluation program can be used.
説明文に対し安定した評価を迅速に得ることができる。 A stable evaluation can be quickly obtained for the explanation.
以下、本発明を実施するための形態について図面を参照して説明するが、本発明は、下記の実施形態に制限されることはなく、本発明の範囲を逸脱することなく、下記の実施形態に種々の変形および置換を加えることができる。 Hereinafter, embodiments for carrying out the present invention will be described with reference to the drawings, but the present invention is not limited to the following embodiments and does not deviate from the scope of the present invention. Can be modified and substituted in various ways.
[第1実施例]
先ず、販売される商品、サービス(役務)等に関する説明文を、商品分野、それぞれの国又は地域(以下、国という。)の法令等に従った内容であるかを評価する説明文評価システム1000の概要を説明する。
[First Example]
First, the explanation evaluation system 1000 that evaluates whether the explanation about the products, services (services), etc. to be sold complies with the laws and regulations of the product field and each country or region (hereinafter referred to as the country). The outline of is explained.
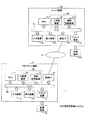
図1は、第1実施例における説明文評価システムのネットワーク構成例を示す図である。図1において、説明文評価システム1000は、サーバ装置100と、複数のクライアント端末3とを有し、それぞれは、ネットワーク2を介して接続可能である。
FIG. 1 is a diagram showing a network configuration example of the explanatory text evaluation system in the first embodiment. In FIG. 1, the explanatory text evaluation system 1000 has a
サーバ装置100は、クライアント端末3から説明文の評価要求4rを受信すると、評価要求4rの選択情報4sで指定される商品分野、国、及び評価観点に基づいて、評価要求4rに含まれる説明文4qの評価を行う。その評価結果に基づいて、評価説明情報5pが付加された結果表示データ5rをクライアント端末3に提供する。説明文4qは、テキストデータ、音声データ等である。
When the
サーバ装置100は、評価要求4rを受信すると、評価要求4rの選択情報4sで指定される評価観点に基づき予め作成したモデルを用いて説明文4qを評価し、その評価結果に基づいて、評価説明情報5pが付加された結果表示データ5rを出力する。
When the
評価説明情報5pは、リスクのある文章及び単語を識別可能に表示させるコード、リスクのある文章及び単語が選択された場合に説明文が表示されるように文章及び単語にそれぞれの説明文をリンクさせるコード、説明文等のデータを含む。説明文に加え、代替案を含んでもよい。
The
クライアント端末3は、ユーザの操作に応じて、ユーザによって指定された評価する説明文4qを含む評価要求4rをサーバ装置100へ送信し、サーバ装置100から結果表示データ5rを受信して表示する。
The
このような、評価説明情報5pを提供するサーバ装置100は、商品、サービス(役務)等の説明文4qを対象としてもよい。一例として、化粧品、食品、不動産・金融等である。さまざまな商品の説明文4qに対応するために、図1に例示されるように、サーバ装置100は、化粧品の商品分野SB1と、食品の商品分野SB2と、不動産・金融の商品分野SB3等のそれぞれにおいて、判別モデル群を備えるようにする。判別モデル群は、国ごとに備えられてもよい。ここでは、各商品分野で国ごとに判別モデル群を備えた場合の機能構成の概要を示す。
The
例えば、サーバ装置100は、モデル作成検証部1150と、説明文評価部1180と、説明文DB1137と、化粧品の商品分野SB1に対して、国ごとの判別モデル群HMG1、HMG2、HMG3、HMG4、HMG5等(総称して、複数の判別モデル群HMGという場合がある。)を有する。
For example, the
判別モデル群HMG1は、日本の法令等に対応した、評価観点a1に基づく判別モデルSB1a、評価観点b1に基づく判別モデルSB1b等を有する。判別モデル群HMG2は、韓国の法令等に対応した、評価観点a2に基づく判別モデルSB2a、評価観点b2に基づく判別モデルSB2b等である。 Discrimination model group HMG1 corresponded to Japanese laws and regulations, with the discriminant model SB1a based on the evaluation aspect a 1, a discrimination model SB1b like based on the evaluation aspect b 1. Discrimination model group HMG2 corresponded to Korean laws and regulations, discriminant model SB2a based on the evaluation aspect a 2, a discrimination model SB2b like based on the evaluation aspect b 2.
判別モデル群HMG3は、中国の法令等に対応した、評価観点a3に基づく判別モデルSB3a、評価観点b3に基づく判別モデルSB3b等である。判別モデル群HMG4は、米国の法令等に対応した、評価観点a4に基づく判別モデルSB4a、評価観点b4に基づく判別モデルSB4b等である。 Discrimination model group HMG3 corresponded to Chinese laws and regulations, discriminant model SB3a based on the evaluation aspect a 3, a discrimination model SB3b like based on the evaluation aspect b 3. Discrimination model group HMG4 corresponded to US laws and regulations, discriminant model SB4a based on the evaluation aspect a 4, a discriminant model SB4b like based on the evaluation aspect b 4.
判別モデル群HMG5は、欧州の法令等に対応した、評価観点a5に基づく判別モデルSB5a、評価観点b5に基づく判別モデルSB5b等を有する。判別モデルSB1a、・・・、SB5b等は、いずれかを特定しない限り、単に、判別モデルSBという。 Discrimination model group HMG5 corresponded to European law, discriminant model SB5a based on the evaluation aspect a 5, has a discriminant model SB5b like based on the evaluation aspect b 5. The discrimination models SB1a, ..., SB5b and the like are simply referred to as discrimination models SB unless any of them is specified.
これらの判別モデルSBの各々は、モデル作成検証部1150によって、判別モデル作成用に収集した多くの説明文を蓄積した説明文DB1137を用いて、同様の処理により作成され適正性が検証されたモデルである。
Each of these discriminant model SBs is a model created by the model
説明文DB1137は、各商品分野において国毎に収集し蓄積した説明文を管理するデータベースである。収集し蓄積した説明文はコーパスデータに相当し、説明文DB1137は、商品分野及び国毎のコーパスデータを含んでいる。 The explanatory text DB1137 is a database that manages the explanatory texts collected and accumulated for each country in each product field. The collected and accumulated explanatory text corresponds to corpus data, and the explanatory text DB1137 includes corpus data for each product field and country.
モデル作成検証部1150及び説明文評価部1180は、後述されるCPU111(図2)が対応するプログラムを実行することによる処理によって実現され、それらの処理については後述される。
The model
図1では、クライアント端末3とサーバ装置100とがネットワーク2を介して接続されるネットワーク構成で説明したが、サーバ装置100の機能を有するスタンドアロン装置でユーザが説明文4qの評価を行う形態でもよい。また、商品分野ごとに個別のサーバ装置に同様の機能構成を持たせるようにしてもよい。或いは、国ごとに個別のサーバ装置としてもよい。
In FIG. 1, the network configuration in which the
ここで、商品分野ごとに関連する法令には、次の様なものがある。
・化粧品
薬機法等
・食品(一般食品、特定保健用食品、栄養機能食品、機能性表示食品、健康食品)
景品表示法、特定商取引法、JAS法等
・不動産・金融
景品表示法等
である。
Here, the laws and regulations related to each product field are as follows.
・ Cosmetics, Pharmaceutical Machinery Law, etc. ・ Foods (general foods, foods for specified health use, nutritionally functional foods, foods with functional claims, health foods)
The prize labeling law, the Specified Commercial Transactions Law, the JAS law, etc., the real estate / financial prize labeling law, etc.
更に、化粧品に関して、主な国ごとの法令を示す。
・韓国
化粧品法、広告ガイドライン等
・中国
化粧品衛星監督条例、中華人民共和国消費者権益保護法等
・米国
Federal Food, Drug, and Cosmetic Act、 Federal Trade Commission Act、Fair Packaging and Labeling Act等
・欧州
Cosmetic Regulation, Unfair commercial practices directive等
である。
In addition, regarding cosmetics, the laws and regulations of each major country are shown.
・ Korea Cosmetics Law, Advertising Guidelines, etc. ・ China Cosmetics Satellite Supervision Ordinance, People's Republic of China Consumer Rights Protection Law, etc. ・ United States
Federal Food, Drug, and Cosmetic Act, Federal Trade Commission Act, Fair Packaging and Labeling Act, etc.-Europe
Cosmetic Regulation, Unfair commercial practices directive, etc.
以下の説明では、1つのサーバ装置100において、少なくとも1つの商品分野に対して、複数の国のそれぞれの法令に基づいて判別モデルを作成する場合で説明する。
In the following description, a case where a discrimination model is created for at least one product field in one
第1実施例では、国内及び諸外国の様々な法令に十分に精通していないユーザであっても、作成した説明文4qの評価を行うことができる。 In the first embodiment, even a user who is not sufficiently familiar with various domestic and foreign laws and regulations can evaluate the created explanatory text 4q.
図2は、第1実施例における説明文評価システムにおけるハードウェア構成を示す図である。図2において、サーバ装置100は、コンピュータによって制御される情報処理装置であって、CPU(Central Processing Unit)111と、主記憶装置112と、補助記憶装置113と、入力装置114と、表示装置115と、通信I/F(インターフェース)117と、ドライブ装置118とを有し、バスB1に接続される。
FIG. 2 is a diagram showing a hardware configuration in the explanatory text evaluation system according to the first embodiment. In FIG. 2, the
CPU111は、主記憶装置112に格納されたプログラムに従ってサーバ装置100を制御するプロセッサに相当する。主記憶装置112には、RAM(Random Access Memory)、ROM(Read Only Memory)等が用いられ、CPU111にて実行されるプログラム、CPU111での処理に必要なデータ、CPU111での処理にて得られたデータ等を記憶又は一時保存する。
The CPU 111 corresponds to a processor that controls the
補助記憶装置113には、HDD(Hard Disk Drive)等が用いられ、各種処理を実行するためのプログラム等のデータを格納する。補助記憶装置113に格納されているプログラムの一部が主記憶装置112にロードされ、CPU111に実行されることによって、各種処理が実現される。記憶部130は、主記憶装置112及び/又は補助記憶装置113に相当する。
An HDD (Hard Disk Drive) or the like is used in the
入力装置114は、マウス、キーボード等を有し、ユーザがサーバ装置100による処理に必要な各種情報を入力するために用いられる。表示装置115は、CPU111の制御のもとに必要な各種情報を表示する。入力装置114と表示装置115とは、一体化したタッチパネル等によるユーザインタフェースであってもよい。通信I/F117は、有線又は無線などのネットワークを通じて通信を行う。通信I/F117による通信は無線又は有線に限定されるものではない。
The
サーバ装置100によって行われる処理を実現するプログラムは、例えば、プログラムを提供する外部サーバ装置からネットワーク2を介してダウンロードすることで取得する。
The program that realizes the processing performed by the
ドライブ装置118は、ドライブ装置118にセットされた記憶媒体119(例えば、CD−ROM等)とサーバ装置100とのインターフェースを行う。本実施例に係る処理を実現するプログラムは、CD−ROM(Compact Disc Read-Only Memory)等の記憶媒体119によってサーバ装置100に提供してもよい。
The
この場合、後述される本実施の形態に係る種々の処理を実現するプログラムを格納した記憶媒体119をドライブ装置118に設定することにより、この記憶媒体119に格納されたプログラムをサーバ装置100にインストールしてもよい。インストールされたプログラムは、サーバ装置100により実行可能となる。
In this case, the program stored in the
尚、プログラムを格納する記憶媒体119はCD−ROMに限定されず、コンピュータが読み取り可能な、データとしての構造(structure)を有する1つ以上の非一時的(non-transitory)な、有形(tangible)な媒体であればよい。コンピュータ読取可能な記憶媒体として、CD−ROMの他に、DVD(Digital Versatile Disk)ディスク、USBメモリ等の可搬型記録媒体、フラッシュメモリ等の半導体メモリであっても良い。
The
クライアント端末3は、コンピュータによって制御される情報処理装置であって、CPU(Central Processing Unit)11と、主記憶装置12と、補助記憶装置13と、入力装置14と、表示装置15と、通信I/F(インターフェース)17と、ドライブ装置18とを有し、バスB2に接続される。
The
CPU11は、主記憶装置12に格納されたプログラムに従ってクライアント端末3を制御するプロセッサに相当する。主記憶装置12には、RAM(Random Access Memory)、ROM(Read Only Memory)等が用いられ、CPU11にて実行されるプログラム、CPU11での処理に必要なデータ、CPU11での処理にて得られたデータ等を記憶又は一時保存する。
The CPU 11 corresponds to a processor that controls the
補助記憶装置13には、HDD(Hard Disk Drive)等が用いられ、各種処理を実行するためのプログラム等のデータを格納する。補助記憶装置13に格納されているプログラムの一部が主記憶装置12にロードされ、CPU11に実行されることによって、各種処理が実現される。記憶部30は、主記憶装置12及び/又は補助記憶装置13に相当する。
An HDD (Hard Disk Drive) or the like is used in the
入力装置14は、マウス、キーボード等を有し、ユーザがクライアント端末3による処理に必要な各種情報を入力するために用いられる。表示装置15は、CPU11の制御のもとに必要な各種情報を表示する。入力装置14と表示装置15とは、一体化したタッチパネル等によるユーザインタフェースであってもよい。通信I/F17は、有線又は無線などのネットワークを通じて通信を行う。通信I/F17による通信は無線又は有線に限定されるものではない。
The
クライアント端末3によって行われる処理は、Webブラウザを介してサーバ装置100と接続することにより実現されればよい。
The processing performed by the
ドライブ装置18は、ドライブ装置18にセットされた記憶媒体19(例えば、CD−ROM等)とクライアント端末3とのインターフェースを行う。
The
クライアント端末3によって行われる処理を実現する他の方法として、記憶媒体19に、後述される本実施の形態に係る種々の処理を実現するプログラムを格納し、この記憶媒体19に格納されたプログラムは、ドライブ装置18を介してクライアント端末3にインストールしてもよい。インストールされたプログラムは、クライアント端末3により実行可能となる。
As another method for realizing the processing performed by the
尚、この場合、プログラムを格納する記憶媒体19はCD−ROMに限定されず、コンピュータが読み取り可能な、データとしての構造(structure)を有する1つ以上の非一時的(non-transitory)な、有形(tangible)な媒体であればよい。コンピュータ読取可能な記憶媒体として、CD−ROMの他に、DVD(Digital Versatile Disk)ディスク、USBメモリ等の可搬型記録媒体、フラッシュメモリ等の半導体メモリであっても良い。
In this case, the
クライアント端末3は、ラップトップ、タブレット端末等であってもよい。その場合、記憶媒体19は、SD(Secure Digital)メモリカード等であり、ドライブ装置18は、ドライブ装置18にセットされた記憶媒体19と端末3とのインターフェースを行う。
The
モデル作成検証部1150によるモデル作成検証処理について説明する。図3は、第1実施例におけるモデル作成検証処理を説明するためのフローチャート図である。図3において、説明文DB1137から商品分野、国、及び評価観点の組み合せ毎に複数の説明文(コーパスデータ)を選択し、各組み合せに対して、以下の処理を行う。説明文DB1137からのコーパスデータの選択は、商品分野及び国を選択する画面を、表示装置115に表示させ、ユーザの指定に基づき、一致または関連する種類のコーパスデータを抽出すればよい。
The model creation verification process by the model
先ず、モデル作成検証部1150は、収集・構造化処理を行う(ステップS110)。収集・構造化処理では、モデル作成検証部1150は、判別モデル作成用の説明文を収集し、収集した説明文からサンプリングして、適正性ラベルを関連付けて構造化する。説明文DB1137から抽出したコーパスデータにおいて、サンプリングされた説明文に対して適正性が判断され、その判断結果が適正性ラベルに相当する。適正性ラベルは、不適切、要注意、又は適正のいずれかを示す。適正性ラベルが関連付けられた説明文が教師データ138となる。
First, the model creation /
適正性の判断は、商品分野に関する種々の法令とその運用方針、質疑応答集に基づき、専門性を有する熟練者の判断により行われる。 Judgment of appropriateness is made by the judgment of a skilled person with expertise based on various laws and regulations related to the product field, its operation policy, and a collection of questions and answers.
次に、モデル作成検証部1150は、特徴抽出処理を行う(ステップS120)。特徴抽出処理では、モデル作成検証部1150は、形態素分解を行ったうえで、自然言語処理を行い、文章特徴を抽出するアルゴリズムを作成する。そして、モデル作成検証部1150は、作成したアルゴリズムにより文章ベクター空間を生成する。
Next, the model creation /
そして、モデル作成検証部1150は、機械学習による判別モデル作成処理を行う(ステップS130)。判別モデル作成処理では、モデル作成検証部1150は、文章特徴に対し、説明文DB1137に蓄積した説明文のうち、教師データ138に基づいて判別モデルSBiを作成する。
Then, the model creation /
機械学習では、一例として、マルチサポートベクターマシン(マルチSVM)等を用いて、文章ベクター空間における、適正性ラベルの分類を示す境界面3fを学習する。境界面3fの学習の過程で、モデル作成検証部1150は、精度検証処理を行う(ステップS140)。精度検証処理では、モデル作成検証部1150は、適正性ラベルのない説明文を用いて、モデルに含まれる種々の係数を変化させながらモデルの精度を算出する処理を繰り返し、最も高い精度で分類できるモデルを生成する。
In machine learning, as an example, a multi-support vector machine (multi-SVM) or the like is used to learn the boundary surface 3f indicating the classification of aptitude labels in the sentence vector space. In the process of learning the boundary surface 3f, the model
また、教師データ138に加えて、適宜、オーバサンプリングを行う。オーバサンプリングでは、文章ベクター空間において、適正性ラベルと紐付いた文章特徴を示す点と点の間に、所定の距離で定められる近傍に文書特徴点が存在するように仮想的に点(以下、仮想点3vという)を追加することである。このような仮想点3vを追加することで、収集した教師データ138に適正性ラベルの偏りがある場合であってもモデルの精度を維持することができる。このような処理の一例として、SMOTE(Synthetic Minority Over-sampling Technique)等を用いればよい。
In addition to the
このモデル作成検証処理全体を繰り返すことで、商品分野、国、及び評価観点の組み合せ毎の判別モデルが作成される。即ち、1又は複数の判別モデルSBiが作成される。 By repeating this model creation verification process as a whole, a discrimination model for each combination of product fields, countries, and evaluation viewpoints is created. That is, one or a plurality of discrimination models SBi are created.
図4は、第1実施例における説明文評価システムにおける説明文の評価処理を説明するためのフローチャート図である。図4において、クライアント端末3は、表示装置15に表示されたサーバ装置100に説明文4qを評価させるための画面から、商品分野、国、及び評価観点の選択を受け付け(ステップS211)、更に、ユーザによって指定された評価する説明文を読み込む(ステップS212)。
FIG. 4 is a flowchart for explaining the evaluation process of the explanatory text in the explanatory text evaluation system in the first embodiment. In FIG. 4, the
クライアント端末3は、ステップS211で受け付けた、商品分野、国、及び評価観点を指定した選択情報4sと、ステップS212で読み込んだ説明文とを含む評価要求4rを作成し、サーバ装置100へ送信する(ステップS213)。評価要求4rがサーバ装置100へと送信される。
The
サーバ装置100では、クライアント端末3から評価要求4rを受信すると、説明文評価部1180は、受信した評価要求4rの選択情報4sから商品分野、及び1以上の評価観点を特定する(ステップS321)。
When the
そして、説明文評価部1180は、選択情報4sで指定される商品分野及び国に基づいて、判別モデル群HMGを選択する(ステップS322)。また、説明文評価部1180は、選択情報4sで指定される1以上の評価観点に基づいて、評価観点ごとの判別モデルSBを選択する(ステップS323)。
Then, the explanatory
次に、説明文評価部1180は、評価要求4rに含まれる説明文4qを解析して、ステップS323で選択した判別モデルSBごとに、リスクの有無を判定し(ステップS234)、評価説明情報5pを含む結果表示データ5rを作成し、クライアント端末3へ送信する(ステップS235)。サーバ装置100における説明文評価部1180による説明文評価処理は終了する。
Next, the explanatory
端末3では、結果表示データ5rを受信すると、結果表示データ5rから評価説明情報5pを取得して、表示装置15に表示して(ステップS214)、端末3での処理を終了する。
When the
以下に、上述した第1実施例における、米国の法令に基づいて化粧品を説明した訴求文を評価する判別モデルを作成し、作成した判別モデルを用いて評価対象の訴求文を評価する場合を第2実施例とし、その具体的な処理内容を説明する。第2実施例において、訴求文4p(図5)は、第1実施例の説明文4qの一例である。
The following is a case where a discrimination model for evaluating an appeal sentence explaining cosmetics is created based on the US law in the first embodiment described above, and the appeal sentence to be evaluated is evaluated using the created discrimination model. 2 Examples will be used, and the specific processing contents will be described. In the second embodiment, the
[第2実施例]
図5は、第2実施例における訴求文評価システムにおける機能構成例を示す図である。図5に示す訴求文評価システム1002では、サーバ装置100は、主に、知識ベース作成部60と、判別モデル作成部70と、訴求文評価部80とを有する。知識ベース作成部60と、判別モデル作成部70と、訴求文評価部80とは、CPU111が対応するプログラムを実行することで行われる処理により実現される。
[Second Example]
FIG. 5 is a diagram showing a functional configuration example in the appeal sentence evaluation system in the second embodiment. In the appeal sentence evaluation system 1002 shown in FIG. 5, the
ここで、知識ベース作成部60と、判別モデル作成部70とは、事前処理を行い、第1実施例のモデル作成検証部1150に相当する。また、訴求文評価部80は、第1実施例の説明文評価部1180に相当する。
Here, the knowledge
また、記憶部130は、説明文DB1137、知識ベース137、教師データ138、判別モデル139、定義テーブル140、評価要求4r、結果表示データ5r等を記憶する。第2実施例における知識ベース137及び教師データ138は、第1実施例の説明文DB1137内の商品分野「化粧品」及び国「米国」に分類されるコーパスデータに相当する。
Further, the
知識ベース作成部60は、評価要求4rの選択情報4sで指定された商品分野「化粧品」及び国「米国」に基づいて、説明文DB1137から対応する化粧品の訴求文を抽出し、抽出した化粧品の訴求文に対して、単文単位に区切り、区切り毎の単語(又は文)の分散表現(ベクトル表現)を解析する。抽出した化粧品の訴求文は、コーパスデータに相当する。その解析結果を知識ベース137として記憶部130に記憶する。知識ベース作成部60は、訴求文収集部62と、単文化処理部64と、分散表現解析部66とを有する。
The knowledge
訴求文収集部62は、訴求文を収集し、訴求文について専門知識を有する熟練者の操作に応じて、対象としたい領域(美類)の文章を選別させる。美類の文章の選別は、収集の段階で十分であれば省略可能である。 The appeal sentence collection unit 62 collects the appeal sentences and causes the sentences of the area (beauty) to be targeted to be selected according to the operation of a skilled person who has specialized knowledge about the appeal sentences. The selection of beauty texts can be omitted if sufficient at the collection stage.
単文化処理部64は、収集された訴求文において予め選別された対象となる領域の文章、即ち、美類の文章に対して、単文単位に区切る。単文化処理部64は、日本語の場合には、文書に対しては単語の区切り認識も行う。
The
分散表現解析部66は、単文化処理部64によって区切られた単語の分散表現を解析する。分散表現解析部66の一例として、Google(登録商標)のオープンソースコードであるDoc2Vec(登録商標)又はWord2Vec(登録商標)等を利用すればよい。ここでは、教師データのない機械学習が行われ、分散表現の解析結果が知識ベース137として記憶部130に出力される。
The distributed
判別モデル作成部70は、訴求文が法律やガイドラインに沿っており、評価観点において化粧品として適切な内容となっているかを判別する判別モデル139を作成する。
The discrimination
評価観点は、一つに限定されるものではない。評価観点は複数あってもよいし、各評価観点において更に詳細にレベル分けされてもよい。 The evaluation viewpoint is not limited to one. There may be a plurality of evaluation viewpoints, and each evaluation viewpoint may be divided into more detailed levels.
本実施例では、化粧品の訴求としての相応しさ(ふさわしさ)をリスク値として示す。 In this embodiment, the suitability (suitability) of cosmetics as an appeal is shown as a risk value.
判別モデル作成部70は、更に、単文化処理部72と、リスク値取得部74と、機械学習部76とを有する。単文化処理部72は、収集した訴求文から学習用にサンプリングした訴求文(以下、学習用訴求文)を単文化する。
The discrimination
リスク値取得部74は、単文化処理部72から単文を受信すると、評価画面等を熟練者のクライアント端末3に表示するなどして、熟練者からリスク値を取得する。熟練者は、化粧品の訴求としての相応しさをリスク値として設定する。リスク値は、予め設定された定義テーブル140に順ずる。単文がリスク値と関連付けられ、教師データ138として記憶部130に格納される。
When the risk
機械学習部76は、知識ベース作成部60で得た知識ベース137上で、リスク値取得部74によって得られた教師データ138をより精度良く分類できるような判別モデル139を作成する。機械学習部76は、マルチSVM等を用いる。教師データに偏りがある場合には、機械学習部76は、SMOTE等を用いて、仮想点3vを追加するオーバサンプリングを行うようにする。
The
判別モデル139は、訴求文内の単語又は文章が化粧品の訴求として相応しいか否かを判別するモデルである。判別モデル139は、第1実施例の米国用の判別モデル群HMG4の1つに相当する。説明の便宜のため、一つの判別モデル139で説明するが、複数の判別モデルを備えてもよい。
The
訴求文評価部80は、ネットワーク2を介してクライアント端末3から送信され、通信I/F117で受信した評価要求4rに応じて、評価要求4rに含まれる訴求文4pを評価する。評価要求4rは、記憶部130に記憶される。訴求文評価部80は、単文化処理部82と、単文単位評価部84と、結果表示データ作成部86とを有する。
The appeal
単文化処理部82は、評価要求4rに含まれる訴求文4pの入力に応じて、訴求文4pを単文化し、単文単位評価部84に入力される。
The
単文単位評価部84は、判別モデル139を用いて、訴求文4pを単文単位で評価し、単文が化粧品の訴求として相応しいか否かを判定する。評価結果が評価結果送信部85に通知される。評価結果には、評価した単文と、定義テーブル140で定義されたリスク値とが示される。
The simple sentence
結果表示データ作成部86は、単文単位評価部84による評価結果に基づいて、評価説明情報5pを付加した結果表示データ5rを評価要求4rの要求元のクライアント端末3へネットワーク2を介して送信する。
The result display
クライアント端末3は、ユーザの操作に応じて、Webブラウザ(またはアプリケーション)によりサーバ装置100へアクセスすることにより、訴求文4pをサーバ装置100に評価させ、サーバ装置100から結果表示データ5rを受信する。結果表示データ5rに基づいて、訴求文4p内の問題となる箇所を特定して、リスクの程度を示した評価説明が表示装置15に表示する。
The
クライアント端末3に、評価するための画面G90が表示装置15に表示されると、ユーザは、所望の訴求文4pを設定し、サーバ装置100に評価させる操作を行う。
When the screen G90 for evaluation is displayed on the
サーバ装置100からの結果表示データ5rの受信に応じて、画面G90には、評価説明情報5pに基づいて、訴求文4p内における見直しの箇所が特定され、見直しの理由が文章で説明されることにより、ユーザは、見直し対象となった単語(又は文章)をどの程度改訂すればよいかを容易に判断できる。
In response to the reception of the result display data 5r from the
図6は、第2実施例における定義テーブルのデータ構成例を示す図である。図6において、定義テーブル140は、評価観点毎に、リスク値と説明とを対応付けたテーブルであり、評価観点、リスク値、説明等の項目を有する。 FIG. 6 is a diagram showing a data configuration example of the definition table in the second embodiment. In FIG. 6, the definition table 140 is a table in which a risk value and an explanation are associated with each evaluation viewpoint, and has items such as an evaluation viewpoint, a risk value, and an explanation.
評価観点は、例えば化粧品の訴求としての相応しさを示す。熟練者にあらかじめ特定された評価観点に該当する単語は、その評価観点内におけるリスクの高さが指定される。リスク値はリスクの高さを示す。評価観点は複数あってもよい。 The evaluation viewpoint shows, for example, the suitability of cosmetics as an appeal. Words corresponding to the evaluation viewpoint specified in advance by the expert are specified to have a high risk within the evaluation viewpoint. The risk value indicates the high risk. There may be multiple evaluation viewpoints.
説明には、リスク値のそれぞれに対する説明文が設定されている。クライアント端末3に送信される結果表示データ5rにおいて、単文単位評価部84によって判定されたリスク値に対応する説明文が評価説明情報5pに含まれる。
In the explanation, explanations for each of the risk values are set. In the result display data 5r transmitted to the
このデータ構成例では、リスク値が「1」から「3」まで定義されている。リスク値「3」の場合、「化粧品の範疇を逸脱しており、NG」であることを示す。リスク値「2」の場合、「化粧品の範疇を逸脱していると取られるリスクがある」ことを示す。リスク値「1」の場合、「化粧品の範疇の表現であり、問題なし」であることを示す。 In this data structure example, the risk value is defined from "1" to "3". If the risk value is "3", it means that the risk value is "NG because it is out of the category of cosmetics". If the risk value is "2", it means that "there is a risk of being taken if it is out of the category of cosmetics". When the risk value is "1", it indicates that "it is an expression in the category of cosmetics and there is no problem".
このような評価観点のリスク値に基づく説明が画面G90にてなされることで、訴求文に専門知識が十分にない部門のユーザに対しても安定した評価を提供することができる。 By giving an explanation based on the risk value from such an evaluation viewpoint on the screen G90, it is possible to provide a stable evaluation even to a user in a department who does not have sufficient expertise in the appeal statement.
図7は、第2実施例における教師データのデータ構成例を示す図である。図7において、教師データ138は、リスク値取得部74によって得られた訴求文ごとに評価結果を示したテーブルであり、商品名、評価結果、訴求文等の項目を有する。
FIG. 7 is a diagram showing a data structure example of the teacher data in the second embodiment. In FIG. 7, the
商品名は、訴求文を記載する対象商品の名称を示す。商品名は省略してもよい。評価結果の値は、図6に例示したような定義テーブル140のリスク値である。訴求文は、評価済みの文章を示す。 The product name indicates the name of the target product in which the appeal statement is described. The product name may be omitted. The value of the evaluation result is the risk value of the definition table 140 as illustrated in FIG. The appeal sentence indicates the evaluated sentence.
図7のデータ構成例では、主に、英文の訴求文を示しているが、日本語、他の言語であってもよい。一例として、商品名「AAA」の化粧品に対して、評価された訴求文は、「AAA completely erases acne scars rejuvenating dermal collagen.」であり、その評価結果は、リスク値「3」が示され、つまり、明らかに化粧品の範疇を逸脱しており、NGである、ことが示されている。 In the data structure example of FIG. 7, an appeal sentence in English is mainly shown, but Japanese or another language may be used. As an example, the appeal statement evaluated for cosmetics with the product name "AAA" is "AAA completely erases acne scars rejuvenating dermal collagen.", And the evaluation result shows a risk value of "3", that is, , Clearly out of the category of cosmetics, and has been shown to be NG.
図7では、評価観点が1つの場合の例を示しているが、2以上の評価観点が選択された場合には、評価観点毎のリスク値が示される。また、理解を容易とするため、訴求文を文章で示したが、文章ベクター空間における座標を示してもよい。 FIG. 7 shows an example when there is one evaluation viewpoint, but when two or more evaluation viewpoints are selected, the risk value for each evaluation viewpoint is shown. Moreover, although the appeal sentence is shown in a sentence for easy understanding, the coordinates in the sentence vector space may be shown.
教師データ138をより多く蓄積することで、訴求文評価部80による評価結果の精度を改善することができる。教師データ138は、訴求文の収集時に専門的な知識を有する熟練者により評価された訴求文のみに限定されない。
By accumulating
クライアント端末3に提供済みの評価結果をログとして記憶部130に記憶し、専門的な知識を有する熟練者により、再度評価された場合には、教師データ138に追加するようにしてもよい。
The evaluation result provided to the
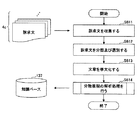
次に、各処理部60、70及び80による処理についてフローチャートで説明する。先ず、知識ベース作成部60による知識ベース作成処理について説明する。図8は、第2実施例における知識ベース作成処理を説明するためのフローチャート図である。
Next, the processing by each processing
図8において、知識ベース作成部60では、訴求文収集部62が複数の訴求文4cを収集する(ステップS611)。訴求文4cの収集では、一例として、英文の場合、約90、000件程度収集される。訴求文4cごとに商品名を取得してもよい。
In FIG. 8, in the knowledge
また、訴求文収集部62は、訴求文4cを分類して選別する(ステップS612)。訴求文4cの分類及び選別は、既に、十分になされていれば省略してもよい。
In addition, the appeal sentence collection unit 62 classifies and selects the
次に、単文化処理部64は、訴求文4cの文章を単文化する(ステップS613)。製品単位で訴求文を単文単位に切り分ける。訴求文4cが日本語の場合、単語の区切り認識も行う。
Next, the
そして、分散表現解析部66は、単文ごとに、分散表現の解析処理を行う(ステップS614)。分散表現の解析処理では、教師データ無しの機械学習により、単語(又は文)の分散表現(ベクトル表現)が解析され、解析結果が知識ベース137に蓄積される。
Then, the distributed
次に、判別モデル作成部70による判別モデル作成処理について説明する。図9は、第2実施例における判別モデル作成処理を説明するためのフローチャート図である。
Next, the discriminant model creation process by the discriminant
図9において、判別モデル作成部70では、学習用に訴求文(以下、学習用訴求文4t)を選定する(ステップS631)。熟練者により、収集した訴求文4cから学習用訴求文4tを選定してもよいし、ランダムに抽出してもよい。選定された学習用訴求文4tは、記憶部130に記憶される。
In FIG. 9, the discrimination
単文化処理部72は、学習用訴求文4tの文章を単文化し(ステップS632)、リスク値取得部74は、熟練者から単文ごとのリスク値を取得する(ステップS633)。リスク値取得部74は、熟練者のクライアント端末3にリスク値の設定画面を表示して熟練者から単文ごとのリスク値を取得してもよい。リスク値の設定画面は、単文に対してリスク値が設定可能な画面であればよい。設定されたリスク値は、単文ごとに対応付けて教師データ138に蓄積される。
The monoculture processing unit 72 monocultures the sentence of the
機械学習部76は、教師データ138を用いて、リスク値毎に単文の数をカウントし(ステップS634)、教師データ138に含まれる単文の総数に対するリスク値毎の単文の割合を算出する(ステップS635)。
The
機械学習部76は、リスク値ごとの文章サンプル数の偏りの度合いについて評価する(ステップS636)。リスク値ごとの文章数の割合が所定の閾値を超えている場合(ステップS636のYES)、機械学習部76は、該当リスク値の教師データ138に偏りがあると判断し、オーバーサンプリングを行い(ステップS637)、ステップS637へと進む。一方、リスク値ごとの文章数の割合が所定の閾値を超えていない場合(ステップS636のNO)、機械学習部76は、ステップS637へと進む。
The
ステップS637のオーバーサンプリングを行う代わりに、教師データ138に対して統計的な有意性を担保できる前提であれば、教師データ138において、割合が高いリスク値を持つ単文を一部用いないようにしてもよい(ダウンサンプリング)。
Instead of oversampling in step S637, if it is a premise that statistical significance can be guaranteed for
学習用訴求文4tのすべてに対して単文ごとにリスク値が設定され、バラツキの少ない教師データ138が準備できると、機械学習部76は、教師データ138を用いた知識ベース137の機械学習を行う(ステップS638)。
When the risk value is set for each simple sentence for all of the
よって、化粧品の訴求として相応しいか否かを判別する判別モデル139が記憶部130に出力される(ステップS639)。
Therefore, the
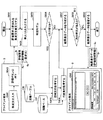
次に、訴求文評価部80による訴求文評価処理について説明する。図10は、第2実施例における訴求文評価処理を説明するためのフローチャート図である。図10において、先ず、クライアント端末3にて、ユーザが評価したい訴求文4pを画面G90で入力し(ステップS641)、評価ボタン91a(図11)が押下されることにより(ステップS643)、ユーザが入力した訴求文4pを含む評価要求4rがサーバ装置100へ送信される。
Next, the appeal sentence evaluation process by the appeal
サーバ装置100では、評価要求4rを受信すると、訴求文評価部80に通知され、訴求文評価部80において、単文化処理部82は、選択情報4sで指定される国から言語を特定し、評価要求4rに含まれる訴求文4pを単文化し(ステップS651)、単文1文を単文単位評価部84に入力する(ステップS652)。
When the
単文単位評価部84は、選択情報4sで指定される商品分野から判別モデル139を選択し、化粧品の訴求としての相応しさの判別用の判別モデル139を用いて、入力された単文1文が化粧品の訴求としての相応しさに該当するリスク値を判別し(ステップS653)、リスク有りか否かを判断する(ステップS654)。即ち、図6の定義テーブル140より、リスク値が「2」以上であるか否かを判断すればよい。
The simple sentence
評価結果のリスク値が「2」以上である場合、結果表示データ作成部86は、定義テーブル140を用いて、リスク値に対応付けられた説明文を取得する(ステップS655)。
When the risk value of the evaluation result is "2" or more, the result display
また、リスク値が「2」以上である場合、結果表示データ作成部86は、知識ベース137を用いて、入力された単文に類似する単文を探索して代替案として取得する(ステップS656)。
When the risk value is "2" or more, the result display
その後、結果表示データ作成部86は、評価結果に基づいて、リスク値「2」以上の単文に対して得た説明文、代替案等を用いて結果表示データ5rを作成する(ステップS657)。訴求文4p内のリスク値「2」以上の単文に対して、文字色を変える、ハイライトする、下線を付加する等により区別可能な表示とし、単文の指定に応じて代替案を表示可能とするデータが結果表示データ5rに追加される。
After that, the result display
結果表示データ作成部86の処理の終了に応じて、単文化処理部82は、未処理の次の単文があるか否かを判断する(ステップS658)。未処理の次の単文が存在する場合(ステップS658のYES)、単文化処理部82は、ステップS652へと戻り、未処理の次の単文を単文単位評価部84に入力し、上述した同様の処理が繰り返される。
Upon completion of the processing of the result display
一方、未処理の次の単文が存在しない場合(ステップS658のNO)、訴求文4pに対する評価を終了したと判断され、訴求文評価部80は、記憶部130に記憶されている結果表示データ5rを評価要求4rの送信元のクライアント端末3に送信する(ステップS659)。
On the other hand, when the next unprocessed simple sentence does not exist (NO in step S658), it is determined that the evaluation of the
クライアント端末3では、画面G90に、ステップS641で入力した訴求文4pに対して、リスクのある文章及び単語が識別可能に表示され、それら文章又は単語が選択された場合には、リスクの説明文が表示される。説明文には、代替案が含まれていてもよい。
On the
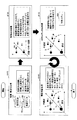
図11は、第2実施例におけるクライアント端末に表示される初期の画面例を示す図である。クライアント端末3の表示装置15には、図11に示すような、画面G90が表示される。図11において、初期に表示される画面G90は、リスクチェック領域9aのみを有する。リスクチェック領域9aは、訴求文入力域7a、評価ボタン7b、リセットボタン7c等を有する。
FIG. 11 is a diagram showing an example of an initial screen displayed on the client terminal in the second embodiment. The screen G90 as shown in FIG. 11 is displayed on the
訴求文入力域7aは、ユーザが訴求文4pを入力する領域であり、初期状態では、ユーザに訴求文4pの入力を促すメッセージ等を表示するようにしてもよい。評価ボタン7bは、訴求文入力域7aに入力された訴求文4pが化粧品の訴求として適正であるかを評価するためのボタンである。評価ボタン7bの押下に応じて、評価要求4rがサーバ装置100へ送信される。リセットボタン7cは、訴求文入力域7aを初期状態に戻すためのボタンである。
The appeal
ユーザが、画面G90の訴求文入力域7aに訴求文4pを入力し、評価ボタン7bを押下すると、クライアント端末3からサーバ装置100へと評価要求4rが送信される。サーバ装置100から結果表示データ5rを受信すると、例えば、画面G90は、図12に示すように画面遷移する。
When the user inputs the
図12は、第2実施例における結果表示データの受信時の画面例を示す図である。図12に示す画面G90では、リスクチェック領域9aに加えて、評価結果領域9bを有する。リスクチェック領域9aの構成は、図11で説明した通りであるためその説明を省略する。
FIG. 12 is a diagram showing a screen example at the time of receiving the result display data in the second embodiment. The screen G90 shown in FIG. 12 has an
評価結果領域9bは、保存形式選択領域9cと、評価結果表示域8aとを有する。保存形式選択領域9cは、クライアント端末3でデータ形式を選択して、評価結果を保存するための領域である。評価結果表示域8aは、サーバ装置100から受信した結果表示データ5rに基づいて、リスクチェック領域9aの訴求文入力域7aに入力された訴求文4pに対する評価結果を変更可能な表示域8mを有する。
The
表示域8mは、リスク値等を表示すると共に、ユーザによる見直しによって評価結果を変更可能に表示する領域であって、ID、判定文、リスク値、リスクワード数、類似文、不明ワード数等の項目を有する。
The
IDは、リスクチェック領域9aの訴求文入力域7aに入力された訴求文4pを文単位に区切り、一文ごとに付与した識別番号である。判定文は、区切られた一文を示す。リスク値は、文章に対する化粧品の初級としての相応しさの程度を示す。評価結果は、3レベルのリスク値うちのどのレベルであるかを示し、熟練者等のユーザにより修正可能なように表示される。
The ID is an identification number assigned to each sentence by dividing the
リスクワード数は、該当文内に存在するリスクがあると判断された単語数を示す。類似文は、知識ベース137に訴求文4pと類似する文章が存在するか否かを示す。不明ワード数は、化粧品の訴求として適正であるか否かを判別できない単語数を示す。
The number of risk words indicates the number of words that are judged to be at risk in the sentence. The similar sentence indicates whether or not there is a sentence similar to the
この例では、ユーザが入力した訴求文4pは、一つの文章7d「AAA completely erases acne scars rejuvenating dermal collagen.」のみであるため、評価結果表示域8aでは、ID「1」、判定文「AAA completely erases acne scars rejuvenating ...」、リスク値「3」、リスクワード数「2」、類似文「あり」、および不明ワード数「0」であったことが示されている。ユーザがID「1」の横の選択ボタン8pを押下すると、例えば、図13のように、評価結果の詳細が表示される。
In this example, the
図13は、第2実施例における評価結果の詳細の表示例を示す図である。図13において、画面G90の評価結果領域9bには、図12に示す保存形式選択領域9cと、評価結果表示域8aとに加えて、判定文表示域8b、リスクワード表示域8c、不明ワード表示域8d、類似文表示域8e、備考表示域8f等の詳細情報が表示される。
FIG. 13 is a diagram showing a display example of details of the evaluation result in the second embodiment. In FIG. 13, in the
判定文表示域8bは、ID「1」の文章7dの全体を表示する領域である。リスクワード表示域8cは、文章7d内で検出されたリスクワードと、そのリスク値とが示される。不明ワード表示域8dは、文章7d内で判定できなかった単語が示される。類似文表示域8eは、知識ベース137から検索された文章7dに類似する文章と、そのリスク値および類似度(%)を示す。備考表示域8fは、文章7dに対するリスク値の根拠、対策等の説明文を表示する。
The determination
この例において、判定文表示域8bには、文章7d「AAA completely erases acne scars rejuvenating dermal collagen.」が表示されると共に、リスク有りと判定された「acne」および「dermal」の部分9rが、容易に判別可能に表示される。部分9rは、他の単語の色とは異なる色、またはハイライトされて示されれば良い。
In this example, the
リスクワード表示域8cには、判定文表示域8bで判別可能に表示された部分9rの「acne」および「dermal」ごとにリスク値「2」と判定されたことが示されている。不明ワード表示域8dは、空白または「−」等により、この文章7dでは検出されたなかったことを示している。
In the risk
類似文表示域8eは、3つの類似文が示され、それぞれのリスク値と類似度とが示されている。類似文「AAA erases △△△ … .」は、リスク値「1」および類似度「77%」であったことが示されている。また、類似文「○○○○ moderately ○○○○ … .」は、リスク値「1」および類似度「75%」であったことが示されている。更に、類似文「AAA reduces □□□□ … .」は、リスク値「1」および類似度「75%」であったことが示されている。
In the similar
備考表示域8fには、「化粧品の範囲を逸脱しています。」等の説明文が表示されている。この説明文は、経験を有する熟練者等のユーザにより変更されてもよい。
Remarks In the
図12及び図13では、1つの文章7dのみを有する訴求文4pの例を説明したが、訴求文4pは、複数の文章から構成されていてもよい。訴求文4pが複数の文章を含む場合、文章ごとに評価結果が示される。
In FIGS. 12 and 13, an example of the
図14は、第2実施例における結果表示データの受信時の他の画面例を示す図である。図14において、画面G90の構成は、図12と同様であるため、その説明を省略する。図14では、画面G90のリスクチェック領域9aに、ユーザが、文章7e、7f、7g、7h、および7iの複数の文章からなる訴求文4pを入力した場合を示している。
FIG. 14 is a diagram showing another screen example when the result display data in the second embodiment is received. In FIG. 14, the configuration of the screen G90 is the same as that in FIG. 12, so the description thereof will be omitted. FIG. 14 shows a case where the user inputs an
具体的には、訴求文4pは、文章7eの「BBB cream has been repackaged and is now available in a newly designed pack.」と、文章7fの「○○○○ ○○○ ○○○○.」と、文章7gの「This product is 100% protection against uv.」と、文章7hの「△△△△ … .」と、文章7iの「□□□□□□□ … .」とを有するものとする。
Specifically, the
サーバ装置100は、訴求文4pを文章ごとに分割する。例えば、この訴求文4pは、5文章に分割される。サーバ装置100は、分割した5文章のそれぞれにIDを付与し、単文単位評価部84により評価結果を得る。
The
評価結果領域9bでは、訴求文4pを分割した5文章それぞれを、ID「1」、ID「2」、ID「3」、ID「4」、およびID「5」で識別し、各文章の評価結果が示される。この例では、ID「1」の文章7eの評価結果は、リスク値「1」、リスクワード数「0」、類似文「なし」、不明ワード数「0」等を示す。ID「2」の文章7fの評価結果は、リスク値「2」、リスクワード数「1」、類似文「なし」、不明ワード数「0」等を示す。
In the
また、ID「3」の文章7gの評価結果は、リスク値「3」、リスクワード数「1」、類似文「あり」、不明ワード数「0」等を示す。ID「4」の文章7hの評価結果は、リスク値「3」、リスクワード数「1」、類似文「あり」、不明ワード数「0」等を示す。ID「5」の文章7iの評価結果は、リスク値「1」、リスクワード数「0」、類似文「なし」、不明ワード数「0」等を示す。
Further, the evaluation result of the
ここで、リスクのレベルを識別可能に表示することが望ましい。一例として、リスク値が最も高い値「3」を示すID「3」およびID「4」の文章7gおよび7hは赤色系の色で示し、リスク値が次に高い「2」を示すID「2」の文章7fは黄色系の色で示し、リスク値が最も小さい(リスク無しと判断された)ID「1」およびID「5」の文章7eおよび7iは青色系の色で示せばよい。
Here, it is desirable to display the level of risk in an identifiable manner. As an example, the
図14の画面G90の評価結果領域9bにおいて、評価結果表示域8aの「リスク値」にカーソルを近付けることで、リスク値の凡例9dを表示させることができる。凡例9dには、リスクのレベルを示すリスク値の値ごとに説明が示される。例えば、値「1」は「化粧品の範疇の表現であり、問題なし」、値「2」は「化粧品の範疇を逸脱していると取られるリスクがある」、また、値「3」は「明らかに化粧品の範疇を逸脱しており、NG」等の説明が表示される。
By moving the cursor closer to the "risk value" in the evaluation result display area 8a in the
この画面G90において、ユーザがID「3」の選択ボタン8pを押下すると、図15に示すような評価結果の詳細が表示される。
When the user presses the
図15は、第2実施例における評価結果の詳細の他の表示例を示す図である。図15において、画面G90の評価結果領域9bには、ユーザが選択したID「3」の文章7gの評価結果の詳細が示される。
FIG. 15 is a diagram showing another display example of the details of the evaluation result in the second embodiment. In FIG. 15, the
この場合、判定文表示域8bには、文章7g「This product is 100% protection against uv.」が表示されると共に、リスク有りと判定された「100% protection against uv」の部分9tが、容易に判別可能に表示される。部分9tは、他の単語の色とは異なる色、またはハイライトされて示されれば良い。
In this case, the
リスクワード表示域8cには、判定文表示域8bで判別可能に表示された部分9rの「100% protection against uv」がリスク値「3」と判定されたことが示されている。不明ワード表示域8dは、空白または「−」等により、この文章7dでは検出されたなかったことを示している。
In the risk
類似文表示域8eは、3つの類似文が示され、それぞれのリスク値と類似度とが示されている。類似文「The product is environmentally-friendly and cruelty-free.」は、リスク値「1」および類似度「36%」であったことが示されている。また、類似文「The product is said to help *** **.」は、リスク値「1」および類似度「34%」であったことが示されている。更に、類似文「This product retails in 100g pack.」は、リスク値「1」および類似度「30%」であったことが示されている。
In the similar
備考表示域8fには、「化粧品の範疇を逸脱しています。」等の説明文が表示されている。この説明文は、経験を有する熟練者等のユーザにより変更されてもよい。
Remarks In the
このように、第2実施例では、訴求文4p内のリスクのある表現を自動判別し、判別理由、代替案等を表示させることにより、いずれのユーザに対しても安定した評価を提供することができる。また、リスクの高い単語及び文章に対して、好ましい表現への変更を容易に行なうことができる。更に、熟練者にとって、種々の部門からの訴求文に関する問い合わせに掛る時間を削減でき、負担を軽減することができる。
In this way, in the second embodiment, the risky expression in the
[第3実施例]
次に、上述した第1実施例における、日本の法令に基づいて食品の説明文を評価する場合を第3実施例として、定義テーブル、教師データ、及び評価結果の例で説明する。第3実施例では、その機能構成の詳細は第2実施例と同様であるため省略される。
[Third Example]
Next, the case of evaluating the description of food based on Japanese laws and regulations in the above-mentioned first embodiment will be described as a third embodiment with a definition table, teacher data, and an example of evaluation results. In the third embodiment, the details of the functional configuration are the same as those in the second embodiment, and thus are omitted.
図16は、第3実施例における定義テーブルのデータ構成例を示す図である。図16において、定義テーブル240は、第2実施例と同様に、評価観点毎に、リスク値と説明とを対応付けたテーブルであり、評価観点、リスク値、説明等の項目を有する。 FIG. 16 is a diagram showing a data configuration example of the definition table in the third embodiment. In FIG. 16, the definition table 240 is a table in which a risk value and an explanation are associated with each evaluation viewpoint, as in the second embodiment, and has items such as an evaluation viewpoint, a risk value, and an explanation.
評価観点は、第1実施例同様に、例えば食品の説明としての相応しさを示す。熟練者にあらかじめ特定された評価項目に該当する単語は、その評価項目内におけるリスクの高さが指定される。リスク値はリスクの高さを示す。評価観点は複数あってもよい。 The evaluation viewpoint shows, for example, the suitability as an explanation of food, as in the first embodiment. For words that correspond to the evaluation items specified in advance by the expert, the high risk within the evaluation items is specified. The risk value indicates the high risk. There may be multiple evaluation viewpoints.
説明には、リスク値のそれぞれに対する説明文が設定されている。クライアント端末3に送信される結果表示データ5rにおいて、単文単位評価部84によって判定されたリスク値に対応する説明文が評価説明情報5pに含まれる。
In the explanation, explanations for each of the risk values are set. In the result display data 5r transmitted to the
このデータ構成例では、リスク値が「1」から「3」まで定義されている。リスク値「3」の場合、「食品の説明は誤認表示に該当しており、NG」であることを示す。リスク値「2」の場合、「食品の説明は誤認表示に該当すると取られるリスクがある」ことを示す。リスク値「1」の場合、「食品の説明は適正な表現であり、問題なし」であることを示す。 In this data structure example, the risk value is defined from "1" to "3". When the risk value is "3", it indicates that "the description of the food corresponds to a misidentification label and is NG". When the risk value is "2", it indicates that "the description of the food has a risk of being taken if it corresponds to a misidentification label". When the risk value is "1", it indicates that "the description of the food is an appropriate expression and there is no problem".
このような評価観点のリスク値に基づく説明が、第2実施例と同様に、画面G90にてなされることで、食品の説明文に専門知識が十分にない部門のユーザに対しても安定した評価を提供することができる。 As in the second embodiment, the explanation based on the risk value from the evaluation viewpoint is given on the screen G90, so that it is stable even for users in the department who do not have sufficient expertise in the explanation of food. An evaluation can be provided.
図17は、第3実施例における教師データのデータ構成例を示す図である。図17において、教師データ238は、第2実施例のリスク値取得部74と同様の処理部によって得られた説明文ごとに評価結果を示したテーブルであり、商品名、評価結果、説明文等の項目を有する。
FIG. 17 is a diagram showing a data structure example of teacher data in the third embodiment. In FIG. 17, the teacher data 238 is a table showing the evaluation results for each explanatory text obtained by the same processing unit as the risk
商品名は、説明文を記載する対象商品の名称を示す。商品名は省略してもよい。評価結果の値は、図17に例示したような定義テーブル240のリスク値である。説明文は、評価済みの文章を示す。 The product name indicates the name of the target product in which the description is described. The product name may be omitted. The value of the evaluation result is the risk value of the definition table 240 as illustrated in FIG. The descriptive text indicates the evaluated text.
図17のデータ構成例では、主に、日本語の説明文を示しているが、他の言語であってもよい。一例として、商品名「あいうえお」の商品に対して、評価された説明文は、「一日一回の飲料で、運動や食事制限なく、体脂肪が劇的に減少!!」であり、その評価結果は、リスク値「3」が示され、つまり、明らかに食品の説明は誤認表示に該当しており、NGである、ことが示されている。 In the data structure example of FIG. 17, Japanese explanations are mainly shown, but other languages may be used. As an example, the description evaluated for the product with the product name "Aiueo" is "Dramatically reduce body fat with a drink once a day without exercise or dietary restrictions !!" The evaluation result shows a risk value of "3", that is, it is clearly shown that the description of the food corresponds to the misidentification label and is NG.
図17では、評価観点が1つの場合の例を示しているが、2以上の評価観点が選択された場合には、評価観点毎のリスク値が示される。また、理解を容易とするため、説明文を文章で示したが、文章ベクター空間における座標が示されてもよい。 FIG. 17 shows an example when there is one evaluation viewpoint, but when two or more evaluation viewpoints are selected, the risk value for each evaluation viewpoint is shown. In addition, although the explanatory text is shown in sentences for ease of understanding, the coordinates in the text vector space may be shown.
図18は、第3実施例における評価結果の詳細の表示例を示す図である。図18において、第2実施例と同様に、画面G90の評価結果領域9bには、説明文4qに含まれていた文章7kの評価結果の詳細が示される。
FIG. 18 is a diagram showing a display example of details of the evaluation result in the third embodiment. In FIG. 18, as in the second embodiment, the
この場合、判定文表示域8bには、文章7k「1日3錠で、免疫力アップ!生活習慣病、ガン予防に抜群の効果!!」が表示されると共に、リスク有りと判定された「ガン予防に抜群の効果」の部分9wが、容易に判別可能に表示される。部分9wは、他の単語の色とは異なる色、またはハイライトされて示されれば良い。
In this case, in the judgment
リスクワード表示域8cには、判定文表示域8bで判別可能に表示された部分9wの「ガン予防に抜群の効果」がリスク値「3」と判定されたことが示されている。不明ワード表示域8dは、空白または「−」等により、この文章7kでは検出されたなかったことを示している。
In the risk
類似文表示域8eは、1つの類似文が示され、そのリスク値と類似度とが示されている。類似文「日常の食事に不足しがちな栄養成分を補充できます。」は、リスク値「1」および類似度「29%」であったことが示されている。
In the similar
備考表示域8fには、「食品の誤認表示に該当しています。」等の説明文が表示されている。この説明文は、経験を有する熟練者等のユーザにより変更されてもよい。
Remarks In the
このように、第3実施例では、説明文4q内のリスクのある表現を自動判別し、判別理由、代替案等を表示させることにより、いずれのユーザに対しても安定した評価を提供することができる。また、リスクの高い単語及び文章に対して、好ましい表現への変更を容易に行なうことができる。更に、熟練者にとって、種々の部門からの説明文に関する問い合わせに掛る時間を削減でき、負担を軽減することができる。 In this way, in the third embodiment, the risky expression in the explanatory text 4q is automatically discriminated, and the reason for the discriminant, the alternative plan, etc. are displayed to provide a stable evaluation to any user. Can be done. In addition, high-risk words and sentences can be easily changed to preferable expressions. Further, for a skilled person, the time required for inquiries about explanatory texts from various departments can be reduced, and the burden can be reduced.
2 ネットワーク
3 クライアント端末
4r 評価要求
4p 訴求文
4q 説明文
4s 選択情報
5r 結果表示データ
5p 評価説明情報
60 知識ベース作成部
62 訴求文収集部
64 単文化処理部
66 分散表現解析部
70 判別モデル作成部
72 単文化処理部
74 リスク値取得部
76 機械学習部
80 訴求文評価部
82 単文化処理部
84 単文単位評価部
86 結果表示データ作成部
100 サーバ装置
11、111 CPU
12、112 主記憶装置
13、113 補助記憶装置
14、114 入力装置
15、115 表示装置
17、117 通信I/F
18、118 ドライブ装置
19、119 記憶媒体
30、130 記憶部
137 知識ベース
138 教師データ
139 判別モデル
G90 画面
1137 説明文DB
1150 モデル作成検証部
1180 説明文評価部
2
12, 112
18, 118
1150 Model
Claims (10)
単文ごとに該単文の内容が少なくとも前記商品の説明表現に係る法令に従った内容であるか否かを、予め機械学習により得られたモデルを用いて評価する単文単位評価ステップと、
評価結果ごとに商品の説明としての相応しさに関する文章を対応付けた定義テーブルを参照することで、前記単文単位評価ステップによる評価結果に対応する該文章を取得し、前記説明文を表示する画面上で前記単文の選択に応じて該文章を表示可能とする結果表示データを作成する結果表示データ作成ステップと、
をコンピュータが行う説明文評価方法。 In response to the reception of the evaluation request of the description attached to the product, the monoculture processing step to monoculture the description and
A simple sentence unit evaluation step for evaluating whether or not the content of the simple sentence is at least in accordance with the laws and regulations related to the explanatory expression of the product for each simple sentence using a model obtained by machine learning in advance.
By referring to the definition table in which sentences related to the suitability as a description of the product are associated with each evaluation result, the sentence corresponding to the evaluation result by the single sentence unit evaluation step is acquired, and the description is displayed on the screen. In the result display data creation step of creating the result display data that makes it possible to display the sentence according to the selection of the simple sentence,
A description evaluation method performed by a computer.
予め収集した説明文に対して分散表現の解析結果を蓄積した知識ベースを参照して、前記評価要求の説明文の単文に類似する文を代替案として取得し、前記説明文を表示する画面上で前記単文の選択に応じて該文章に加え、代替案を表示可能とする結果表示データを作成する
ことを特徴とする請求項1記載の説明文評価方法。 The result display data creation step further
With reference to the knowledge base that accumulates the analysis results of distributed expressions for the explanations collected in advance, a sentence similar to the simple sentence of the explanation of the evaluation request is acquired as an alternative, and the explanation is displayed on the screen. The explanatory text evaluation method according to claim 1, wherein, in addition to the text, result display data that enables display of alternatives is created according to the selection of the simple text.
前記評価要求の訴求文を単文単位で評価する
ことを特徴とする請求項1又は2記載の説明文評価方法。 The simple sentence unit evaluation step is
The explanatory text evaluation method according to claim 1 or 2, wherein the appeal text of the evaluation request is evaluated in units of simple sentences.
前記評価要求の指定に対応する前記モデルを選択するモデル選択ステップ
を更に有することを特徴とする請求項1乃至3のいずれか一項記載の説明文評価方法。 The evaluation request specifies at least one of the product fields, countries, and evaluation viewpoints to which the product belongs.
The explanatory text evaluation method according to any one of claims 1 to 3, further comprising a model selection step for selecting the model corresponding to the designation of the evaluation request.
前記単文単位評価ステップは、選択した前記モデル毎に、前記単文の内容を前記法令に従って評価する
ことを特徴とする請求項4記載の説明文評価方法。 In the model selection step, when two or more evaluation viewpoints are specified, the model is selected for each evaluation viewpoint.
The explanatory text evaluation method according to claim 4, wherein the simple sentence unit evaluation step evaluates the content of the simple sentence for each selected model in accordance with the above-mentioned laws and regulations.
前記サンプリングした前記説明文を解析して文章特徴を抽出して文章ベクター空間を生成する特徴抽出ステップと、
前記適正性が判定された説明文を教師データとして用いた機械学習により前記文章特徴を分類することで、前記モデルを作成するモデル作成ステップと、
を更に有する請求項1乃至5のいずれか一項記載の説明文評価方法。 A plurality of explanations related to the plurality of products collected for creating the model are collected, sampled from the collected explanations, the appropriateness of the sampled explanations is judged in accordance with the above-mentioned laws and regulations, and the result of the judgment is obtained. Collection and structuring steps to associate and structure,
A feature extraction step of analyzing the sampled explanatory text to extract sentence features to generate a sentence vector space, and
A model creation step for creating the model by classifying the sentence features by machine learning using the explanatory text for which the appropriateness has been determined as teacher data.
The explanatory text evaluation method according to any one of claims 1 to 5, further comprising.
ことを特徴とする請求項6記載の説明文評価方法。 In the model creation step, the teacher data is classified using a multi-support vector machine, and if the number of teacher data for each classification is biased, the text vector space is located near a predetermined distance. The explanatory text evaluation method according to claim 6, wherein oversampling is performed by adding points so that document feature points exist.
ことを特徴とする請求項6乃至7のいずれか一項記載の説明文評価方法。 Any of claims 6 to 7, wherein the collection / structuring step, the feature extraction step, and the model creation step are repeated for each combination of the product field, country, and evaluation viewpoint to which the product belongs. The explanation evaluation method described in one item.
単文ごとに該単文の内容が少なくとも前記商品の説明表現に係る法令に従った内容であるか否かを、予め機械学習により得られたモデルを用いて評価する単文単位評価部と、
評価結果ごとに商品の説明としての相応しさに関する文章を対応付けた定義テーブルを参照することで、前記単文単位評価部による評価結果に対応する該文章を取得し、前記説明文を表示する画面上で前記単文の選択に応じて該文章を表示可能とする結果表示データを作成する結果表示データ作成部と、
を有する説明文評価装置。 In response to the reception of the evaluation request of the explanation attached to the product, the monoculture processing department that monocultures the explanation, and
A simple sentence unit evaluation unit that evaluates whether or not the content of the simple sentence is at least in accordance with the laws and regulations related to the explanatory expression of the product for each simple sentence using a model obtained by machine learning in advance.
By referring to the definition table in which sentences related to the suitability as a description of the product are associated with each evaluation result, the sentence corresponding to the evaluation result by the single sentence unit evaluation unit is acquired, and the description is displayed on the screen. In the result display data creation unit that creates the result display data that makes it possible to display the sentence according to the selection of the simple sentence,
Explanatory text evaluation device with.
商品に添付される説明文の評価要求の受信に応じて、該説明文を単文化する単文化処理手段、
単文ごとに該単文の内容が少なくとも前記商品の説明表現に係る法令に従った内容であるか否かを、予め機械学習により得られたモデルを用いて評価する単文単位評価手段、
評価結果ごとに商品の説明としての相応しさに関する文章を対応付けた定義テーブルを参照することで、前記単文単位評価手段による評価結果に対応する該文章を取得し、前記説明文を表示する画面上で前記単文の選択に応じて該文章を表示可能とする結果表示データを作成する結果表示データ作成手段、
として機能させる説明文評価プログラム。 Computer,
A monoculture processing means that monocultures the description in response to the reception of the evaluation request of the description attached to the product.
A simple sentence unit evaluation means for evaluating whether or not the content of the simple sentence is at least in accordance with the laws and regulations related to the explanatory expression of the product for each simple sentence using a model obtained by machine learning in advance.
By referring to the definition table in which sentences related to the suitability as a description of the product are associated with each evaluation result, the sentence corresponding to the evaluation result by the simple sentence unit evaluation means is acquired, and the description is displayed on the screen. Result display data creation means for creating result display data that enables the sentence to be displayed according to the selection of the simple sentence.
An explanatory text evaluation program that functions as.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017150873A JP6896552B2 (en) | 2017-08-03 | 2017-08-03 | Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017150873A JP6896552B2 (en) | 2017-08-03 | 2017-08-03 | Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2019028937A JP2019028937A (en) | 2019-02-21 |
| JP6896552B2 true JP6896552B2 (en) | 2021-06-30 |
Family
ID=65478545
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017150873A Active JP6896552B2 (en) | 2017-08-03 | 2017-08-03 | Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6896552B2 (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6623316B1 (en) * | 2019-03-28 | 2019-12-18 | クレコン・リサーチアンドコンサルティング株式会社 | Information processing system, information processing apparatus, information processing method, and program |
| KR102419648B1 (en) * | 2019-11-15 | 2022-07-12 | 한국과학기술원 | Method and system for predicting and improving persuasiveness of document based on concreteness and the order of persuasion strategy |
| KR102591138B1 (en) * | 2021-02-08 | 2023-10-19 | 인제대학교 산학협력단 | Methods and systems for verification of plant procedures' compliance to writing manuals |
| WO2022071637A1 (en) * | 2020-09-29 | 2022-04-07 | 인제대학교 산학협력단 | Method for verifying whether or not guidelines for preparation of plant procedures have been complied with, and system therefor |
| JP7453116B2 (en) * | 2020-09-30 | 2024-03-19 | 日鉄ソリューションズ株式会社 | Information processing device, information processing method, and program |
| JP7273439B1 (en) | 2022-09-09 | 2023-05-15 | Dcアーキテクト株式会社 | Information processing system, information processing method and program |
| JP7273442B1 (en) | 2022-10-07 | 2023-05-15 | Dcアーキテクト株式会社 | Information processing system, information processing method and program |
| CN119963236B (en) * | 2025-04-10 | 2025-11-25 | 珠海澳新数字科技有限公司 | Merchant early warning monitoring methods, systems, and terminal devices based on multi-dimensional data fusion |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5930217B2 (en) * | 2013-10-03 | 2016-06-08 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | Method for detecting expressions that can be dangerous expressions depending on a specific theme, electronic device for detecting the expressions, and program for the electronic device |
| JP2016143099A (en) * | 2015-01-30 | 2016-08-08 | カシオ計算機株式会社 | Output data creation device and program |
-
2017
- 2017-08-03 JP JP2017150873A patent/JP6896552B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2019028937A (en) | 2019-02-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6896552B2 (en) | Explanatory text evaluation method, explanatory text evaluation device and explanatory text evaluation program | |
| US10671619B2 (en) | Information processing system and information processing method | |
| US20150149372A1 (en) | Document classification system, document classification method, and document classification program | |
| Kanal | Interactive pattern analysis and classification systems: A survey and commentary | |
| JP6301966B2 (en) | DATA ANALYSIS SYSTEM, DATA ANALYSIS METHOD, DATA ANALYSIS PROGRAM, AND RECORDING MEDIUM OF THE PROGRAM | |
| US10417338B2 (en) | External resource identification | |
| CN110287341B (en) | Data processing method, device and readable storage medium | |
| KR102576231B1 (en) | Natural language processing method for identification of counterfeit products and counterfeit product detection system | |
| CN111475731B (en) | Data processing method, device, storage medium and equipment | |
| Bajić et al. | Data visualization classification using simple convolutional neural network model | |
| US20160239559A1 (en) | Document classification system, document classification method, and document classification program | |
| US20180129738A1 (en) | Data analysis system, data analysis method, and data analysis program | |
| Khumtaveeporn et al. | AI sentiment analysis for destination branding: A case study of Buriram, Thailand | |
| US11900060B2 (en) | Information processing device, information processing method, and computer program product | |
| Maruf et al. | Covid-19 vaccine sentiment detection and analysis using machine learning technique and NLP | |
| KR20240076913A (en) | System for providing cosmetics matching service and method the same | |
| CN117112907A (en) | Intelligent interactive medicine information searching method | |
| CN111475652B (en) | Data mining methods and systems | |
| KR101781597B1 (en) | Apparatus and method for creating information on electronic publication | |
| CN115393865A (en) | Text retrieval method, device, and computer-readable storage medium | |
| CN116739710A (en) | Food recommendation method, device, computer equipment and storage medium | |
| CN113836305A (en) | Industry category identification method and device based on text | |
| CN116701960B (en) | Feature importance assessment methods and apparatus, electronic devices, storage media | |
| JP7599671B1 (en) | Information processing device and program | |
| CN118505285B (en) | A method for analyzing skin care product market trends based on big data social media |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200722 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20210430 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210518 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210609 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6896552 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313115 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |