JP6662847B2 - 分散コンピューティング用のプロアクティブ障害回復モデル - Google Patents
分散コンピューティング用のプロアクティブ障害回復モデル Download PDFInfo
- Publication number
- JP6662847B2 JP6662847B2 JP2017505069A JP2017505069A JP6662847B2 JP 6662847 B2 JP6662847 B2 JP 6662847B2 JP 2017505069 A JP2017505069 A JP 2017505069A JP 2017505069 A JP2017505069 A JP 2017505069A JP 6662847 B2 JP6662847 B2 JP 6662847B2
- Authority
- JP
- Japan
- Prior art keywords
- node
- computing
- nodes
- computing node
- mtbf
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000011084 recovery Methods 0.000 title claims description 71
- 238000000034 method Methods 0.000 claims description 199
- 230000008569 process Effects 0.000 claims description 125
- 238000013500 data storage Methods 0.000 claims description 20
- 230000009471 action Effects 0.000 claims description 11
- 230000005055 memory storage Effects 0.000 claims description 3
- 238000012545 processing Methods 0.000 description 32
- 238000004891 communication Methods 0.000 description 21
- 230000001419 dependent effect Effects 0.000 description 19
- 238000003860 storage Methods 0.000 description 18
- 238000004590 computer program Methods 0.000 description 13
- 230000006870 function Effects 0.000 description 11
- 238000013461 design Methods 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 230000008901 benefit Effects 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 230000005012 migration Effects 0.000 description 3
- 238000013508 migration Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 238000012958 reprocessing Methods 0.000 description 3
- 238000004088 simulation Methods 0.000 description 3
- 230000000007 visual effect Effects 0.000 description 3
- 239000008186 active pharmaceutical agent Substances 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000013515 script Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 208000017387 Ectodermal dysplasia-cutaneous syndactyly syndrome Diseases 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000002149 energy-dispersive X-ray emission spectroscopy Methods 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000013404 process transfer Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/203—Failover techniques using migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0706—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment
- G06F11/0721—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment within a central processing unit [CPU]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0751—Error or fault detection not based on redundancy
- G06F11/0754—Error or fault detection not based on redundancy by exceeding limits
- G06F11/0757—Error or fault detection not based on redundancy by exceeding limits by exceeding a time limit, i.e. time-out, e.g. watchdogs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1405—Saving, restoring, recovering or retrying at machine instruction level
- G06F11/1407—Checkpointing the instruction stream
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/1438—Restarting or rejuvenating
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1446—Point-in-time backing up or restoration of persistent data
- G06F11/1458—Management of the backup or restore process
- G06F11/1461—Backup scheduling policy
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1471—Saving, restoring, recovering or retrying involving logging of persistent data for recovery
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
Description
優先権の主張
本願は、2014年7月29日に出願された米国特許出願第14/445,369号に基づく優先権を主張し、当該米国特許出願のすべての記載内容を援用する。
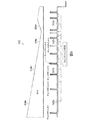
112において、ノードのチェックポイントは全く取得されず、MaxLimitはMTBFと等しくなるよう更新される。いくつかの実装において、特定の閾値より上のMaxLimitは、MaxLimitが高すぎる旨の警告の生成を開始できる。112から、方法100bは110に進む。
[第1の局面]
複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築するステップと;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ハードウェアプロセッサによって、ノード障害予測モデルを実行するステップと;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、コンピューティングノードのチェックポイントを実行するかどうかを決定するステップと;
前記コンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行するステップと;
前記異なるコンピューティングノード上で前記プロセスの実行を再開するステップと;を備える、
コンピュータに実装される方法。
[第2の局面]
前記各コンピューティングノードに対し、少なくともコンピューティング能力パラメータ値及びノード位置パラメータ値を収集するステップと;
前記ノード位置パラメータに基づいて、コンピューティングノードをコレクションに分割するステップと;
前記コンピューティング能力パラメータに基づいて、前記各コレクション内のノードをソートするステップと;をさらに備える、
第1の局面の方法。
[第3の局面]
ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定するステップと;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内のコンピューティングノードを水平レベルにソートするステップと;
前記水平レベル配置及び垂直配置を、各コンピューティングノードに関連したノード記録情報テーブルに記録するステップと;
指定された回復ノードを前記各ノード記録情報テーブルに登録するステップと;をさらに備える、
第2の局面の方法。
[第4の局面]
前記上限及び前記下限が、前記各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直配置が、前記各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
第3の局面の方法。
[第5の局面]
前記MTBFが、ネットワーク又はデータストレージ障害に少なくとも基づいて計算される、
第1の局面の方法。
[第6の局面]
前記コンピューティングノードのMTBFが前記下限未満である場合にチェックポイントを作成するステップと;
前記MTBFに等しくなるように、前記コンピューティングノードに関連する下限を更新するステップと;をさらに備える、
第1の局面の方法。
[第7の局面]
前記コンピューティングノードの障害が発生したことを判断するステップと;
前記コンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いるステップとをさらに備える;
第6の局面の方法。
[第8の局面]
コンピュータ読取可能命令を格納している非一時的なコンピュータストレージ媒体であって、
コンピュータにより実行可能な前記命令が、
複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築する;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行する;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、コンピューティングノードのチェックポイントを実行するかどうかを決定する;
前記コンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行する;および、
前記異なるコンピューティングノード上で前記プロセスの実行を再開する;ように構成されている、
非一時的なコンピュータストレージ媒体。
[第9の局面]
前記各コンピューティングノードに対し、少なくともコンピューティング能力パラメータ値及びノード位置パラメータ値を収集する;
前記ノード位置パラメータに基づいて、コンピューティングノードをコレクションに分割する;および、
前記コンピューティング能力パラメータに基づいて、前記各コレクション内のノードをソートする;命令をさらに含む、
第8の局面の媒体。
[第10の局面]
ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定する;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内のコンピューティングノードを水平レベルにソートする;
前記水平レベル配置及び垂直配置を、各コンピューティングノードに関連したノード記録情報テーブルに記録する;および、
指定された回復ノードを前記各ノード記録情報テーブルに登録する;命令をさらに含む、
第9の局面の媒体。
[第11の局面]
前記上限及び前記下限が、前記各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直配置が、前記各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
第10の局面の媒体。
[第12の局面]
前記MTBFが、ネットワーク又はデータストレージ障害に少なくとも基づいて計算される、
第8の局面の媒体。
[第13の局面]
前記コンピューティングノードのMTBFが前記下限未満である場合にチェックポイントを作成する;および、
前記MTBFに等しくなるように、前記コンピューティングノードに関連する下限を更新する;命令をさらに含む、
第8の局面の媒体。
[第14の局面]
前記コンピューティングノードの障害が発生したことを判断する;および、
前記コンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いる;命令をさらに含む、
第13の局面の媒体。
[第15の局面]
メモリストレージと相互運用可能な少なくとも1つのハードウェアプロセッサを備え:
複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築する;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行する;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、コンピューティングノードのチェックポイントを実行するかどうかを決定する;
前記コンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行する;および、
前記異なるコンピューティングノード上で前記プロセスの実行を再開する;ように構成された、
コンピュータシステム。
[第16の局面]
前記各コンピューティングノードに対し、少なくともコンピューティング能力パラメータ値及びノード位置パラメータ値を収集する;
前記ノード位置パラメータに基づいて、コンピューティングノードをコレクションに分割する;および、
前記コンピューティング能力パラメータに基づいて、前記各コレクション内のノードをソートする;ようにさらに構成された、
第15の局面のシステム。
[第17の局面]
ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定する;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内のコンピューティングノードを水平レベルにソートする;
前記水平レベル配置及び垂直配置を、各コンピューティングノードに関連したノード記録情報テーブルに記録する;および、
指定された回復ノードを前記各ノード記録情報テーブルに登録する;ようにさらに構成された、
第16の局面のシステム。
[第18の局面]
前記上限及び前記下限が、前記各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直配置が、各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
第17の局面のシステム。
[第19の局面]
前記MTBFが、ネットワーク又はデータストレージ障害に少なくとも基づいて計算される、
第15の局面のシステム。
[第20の局面]
前記コンピューティングノードのMTBFが前記下限未満である場合にチェックポイントを作成する;
前記MTBFに等しくなるように、前記コンピューティングノードに関連する下限を更新する;
前記コンピューティングノードの障害が発生したことを判断する;および、
前記コンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いる;ようにさらに構成された、
第15の局面のシステム。
Claims (23)
- 親/子型の関係で通信するようにマッピングされた、複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築するステップであって、前記コンピューティングノードのそれぞれに対して、1つ又は複数の直接の子供が初期設定の回復ノードとして指定され、別のノードがチェックポイントノードとして指定される、前記構築するステップと;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ハードウェアプロセッサによって、ノード障害予測モデルを実行するステップと;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行することを決定するステップと;
前記第1のコンピューティングノードから、前記第1のコンピューティングノードのために指定された初期設定の回復ノードへ、プロセスを移行するステップと;
前記第1のコンピューティングノードのために指定された初期設定の回復ノード上で前記プロセスの実行を再開するステップと;を備える、
コンピュータに実装される方法。 - 各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集するステップと;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクション(集合体)に分割するステップと;
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートするステップと;をさらに備える、
請求項1に記載のコンピュータに実装される方法。 - 複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築するステップと;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ハードウェアプロセッサによって、ノード障害予測モデルを実行するステップと;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行するかどうかを決定するステップと;
前記第1のコンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行するステップと;
前記異なるコンピューティングノード上で前記プロセスの実行を再開するステップと;
各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集するステップと;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクションに分割するステップと;
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートするステップと;を備える、
コンピュータに実装される方法。 - ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定するステップと;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内の前記コンピューティングノードを水平レベルにソートするステップと;
前記水平レベルの配置及び垂直の配置を、各コンピューティングノードに関連したそれぞれのノード記録情報テーブルに記録するステップと;
指定された初期設定の回復ノードを前記ノード記録情報テーブルに登録するステップと;をさらに備える、
請求項2または請求項3に記載のコンピュータに実装される方法。 - 前記上限及び前記下限が、各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直の配置が、各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
請求項4に記載のコンピュータに実装される方法。 - 前記MTBFが、ネットワーク又はデータストレージの障害に少なくとも基づいて計算される、
請求項1または請求項3に記載のコンピュータに実装される方法。 - 前記コンピューティングノードのMTBFが前記最小閾値未満である場合にチェックポイントを作成するステップと;
前記MTBFに等しくなるように、前記コンピューティングノードに関連する前記最小閾値を更新するステップと;をさらに備える、
請求項1または請求項3に記載のコンピュータに実装される方法。 - 前記第1のコンピューティングノードの障害が発生したことを判断するステップと;
前記第1のコンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いるステップと;をさらに備える、
請求項7に記載のコンピュータに実装される方法。 - コンピュータ読取可能命令を格納している非一時的なコンピュータ読取可能媒体であって、
コンピュータにより実行可能な前記命令は:
親/子型の関係で通信するようにマッピングされた、複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築することであって、前記コンピューティングノードのそれぞれに対して、1つ又は複数の直接の子供が初期設定の回復ノードとして指定され、別のノードがチェックポイントノードとして指定される、前記構築することと;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行することと;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行することを決定することと;
前記第1のコンピューティングノードから、前記第1のコンピューティングノードのために指定された初期設定の回復ノードへ、プロセスを移行することと;
前記第1のコンピューティングノードのために指定された初期設定の回復ノード上で前記プロセスの実行を再開することと;を含む動作をコンピュータに実行させるためのものである、
非一時的なコンピュータ読取可能媒体。 - 前記動作は:
各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集することと;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクション(集合体)に分割することと;
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートすることと;をさらに含む、
請求項9に記載のコンピュータ読取可能媒体。 - コンピュータ読取可能命令を格納している非一時的なコンピュータ読取可能媒体であって、
コンピュータにより実行可能な前記命令は:
複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築することと;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行することと;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行するかどうかを決定することと;
前記第1のコンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行することと;
前記異なるコンピューティングノード上で前記プロセスの実行を再開することと;
各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集することと;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクションに分割することと;
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートすることと;を含む動作をコンピュータに実行させるためのものである、
非一時的なコンピュータ読取可能媒体。 - 前記動作は:
ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定することと;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内の前記コンピューティングノードを水平レベルにソートすることと;
前記水平レベルの配置及び垂直の配置を、各コンピューティングノードに関連したそれぞれのノード記録情報テーブルに記録することと;
指定された初期設定の回復ノードを前記ノード記録情報テーブルに登録することと;をさらに含む、
請求項10または請求項11に記載のコンピュータ読取可能媒体。 - 前記上限及び前記下限が、各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直の配置が、各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
請求項12に記載のコンピュータ読取可能媒体。 - 前記MTBFが、ネットワーク又はデータストレージの障害に少なくとも基づいて計算される、
請求項9または請求項11に記載のコンピュータ読取可能媒体。 - 前記動作は:
前記コンピューティングノードのMTBFが前記最小閾値未満である場合にチェックポイントを作成することと;
前記MTBFに等しくなるように、前記コンピューティングノードに関連する前記最小閾値を更新することと;をさらに含む、
請求項9または請求項11に記載のコンピュータ読取可能媒体。 - 前記動作は:
前記第1のコンピューティングノードの障害が発生したことを判断することと;
前記第1のコンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いることと;をさらに含む、
請求項15に記載のコンピュータ読取可能媒体。 - メモリストレージと相互運用可能な少なくとも1つのハードウェアプロセッサを備え:
親/子型の関係で通信するようにマッピングされた、複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築する、なお、前記コンピューティングノードのそれぞれに対して、1つ又は複数の直接の子供が初期設定の回復ノードとして指定され、別のノードがチェックポイントノードとして指定される;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行する;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行することを決定する;
前記第1のコンピューティングノードから、前記第1のコンピューティングノードのために指定された前記初期設定の回復ノードへ、プロセスを移行する;および、
前記第1のコンピューティングノードのために指定された初期設定の回復ノード上で前記プロセスの実行を再開する;ように構成された、
コンピュータシステム。 - 各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集する;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクション(集合体)に分割する;および、
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートする;ようにさらに構成された、
請求項17に記載のコンピュータシステム。 - メモリストレージと相互運用可能な少なくとも1つのハードウェアプロセッサを備え:
複数のコンピューティングノードの仮想ツリー状コンピューティング構造を構築する;
前記仮想ツリー状コンピューティング構造の各コンピューティングノードに対して、コンピューティングノードに関連する平均故障間隔(MTBF)を計算するために、ノード障害予測モデルを実行する;
計算された前記MTBFと、最大閾値及び最小閾値との比較に基づいて、第1のコンピューティングノードのチェックポイントを実行するかどうかを決定する;
前記第1のコンピューティングノードから、回復ノードとして機能する異なるコンピューティングノードへ、プロセスを移行する;
前記異なるコンピューティングノード上で前記プロセスの実行を再開する;
各コンピューティングノードに対し、少なくともコンピューティング能力パラメータの値及びノード位置パラメータの値を収集する;
前記ノード位置パラメータに基づいて、前記コンピューティングノードをコレクションに分割する;および、
前記コンピューティング能力パラメータに基づいて、各コレクション内の前記コンピューティングノードをソートする;ように構成された、
コンピュータシステム。 - ソートした前記コンピューティングノードのレベルを決定するために、上限及び下限を特定する;
前記コンピューティング能力パラメータ並びに前記上限及び前記下限に基づいて、各コレクション内の前記コンピューティングノードを水平レベルにソートする;
前記水平レベルの配置及び垂直の配置を、各コンピューティングノードに関連したそれぞれのノード記録情報テーブルに記録する;および、
指定された初期設定の回復ノードを前記ノード記録情報テーブルに登録する;ようにさらに構成された、
請求項18または請求項19に記載のコンピュータシステム。 - 前記上限及び前記下限が、各コンピューティングノードに対して収集されたコンピューティング能力及びノード位置パラメータのクロスプロットから決定され、
前記垂直の配置が、各コンピューティングノードに対するノード位置パラメータに少なくとも基づいて決定される、
請求項20に記載のコンピュータシステム。 - 前記MTBFが、ネットワーク又はデータストレージの障害に少なくとも基づいて計算される、
請求項17または請求項19に記載のコンピュータシステム。 - 前記コンピューティングノードのMTBFが前記最小閾値未満である場合にチェックポイントを作成する;
前記MTBFに等しくなるように、前記コンピューティングノードに関連する前記最小閾値を更新する;
前記第1のコンピューティングノードの障害が発生したことを判断する;および、
前記第1のコンピューティングノードに対して取得された最新のチェックポイントをプロセス状態として用いる;ようにさらに構成された、
請求項17または請求項19に記載のコンピュータシステム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/445,369 | 2014-07-29 | ||
| US14/445,369 US9348710B2 (en) | 2014-07-29 | 2014-07-29 | Proactive failure recovery model for distributed computing using a checkpoint frequency determined by a MTBF threshold |
| PCT/US2015/041121 WO2016018663A1 (en) | 2014-07-29 | 2015-07-20 | Proactive failure recovery model for distributed computing |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017527893A JP2017527893A (ja) | 2017-09-21 |
| JP2017527893A5 JP2017527893A5 (ja) | 2018-08-30 |
| JP6662847B2 true JP6662847B2 (ja) | 2020-03-11 |
Family
ID=53801170
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017505069A Active JP6662847B2 (ja) | 2014-07-29 | 2015-07-20 | 分散コンピューティング用のプロアクティブ障害回復モデル |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9348710B2 (ja) |
| EP (1) | EP3175361B1 (ja) |
| JP (1) | JP6662847B2 (ja) |
| CN (1) | CN106796540B (ja) |
| CA (1) | CA2956567A1 (ja) |
| WO (1) | WO2016018663A1 (ja) |
Families Citing this family (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160155098A1 (en) * | 2014-12-01 | 2016-06-02 | Uptake, LLC | Historical Health Metrics |
| CN105988918B (zh) | 2015-02-26 | 2019-03-08 | 阿里巴巴集团控股有限公司 | 预测gpu故障的方法和装置 |
| JP6259414B2 (ja) * | 2015-03-24 | 2018-01-10 | ファナック株式会社 | 不揮発性メモリに格納されたデータ等のメインテナンス機能を備えた数値制御装置 |
| US9727366B2 (en) * | 2015-04-23 | 2017-08-08 | International Business Machines Corporation | Machine learning for virtual machine migration plan generation |
| US10496421B1 (en) * | 2015-09-29 | 2019-12-03 | EMC IP Holding Company LLC | Simulation of asynchronous modifications of shared data objects by a distributed application |
| US10437880B2 (en) | 2016-02-08 | 2019-10-08 | Bank Of America Corporation | Archive validation system with data purge triggering |
| US10437778B2 (en) | 2016-02-08 | 2019-10-08 | Bank Of America Corporation | Archive validation system with data purge triggering |
| US9823958B2 (en) | 2016-02-08 | 2017-11-21 | Bank Of America Corporation | System for processing data using different processing channels based on source error probability |
| US10460296B2 (en) | 2016-02-08 | 2019-10-29 | Bank Of America Corporation | System for processing data using parameters associated with the data for auto-processing |
| US10067869B2 (en) | 2016-02-12 | 2018-09-04 | Bank Of America Corporation | System for distributed data processing with automatic caching at various system levels |
| US9952942B2 (en) * | 2016-02-12 | 2018-04-24 | Bank Of America Corporation | System for distributed data processing with auto-recovery |
| CN105868398B (zh) * | 2016-04-20 | 2019-04-26 | 国网福建省电力有限公司 | 一种基于Fat-B树的分布式文件系统低开销数据传输方法 |
| US9985823B1 (en) * | 2016-06-17 | 2018-05-29 | Gravic, Inc. | Method and system for mitigating correlated failure modes |
| US10261874B2 (en) * | 2016-12-01 | 2019-04-16 | International Business Machines Corporation | Enabling a cloud controller to communicate with power systems |
| CN106685710B (zh) * | 2016-12-21 | 2019-11-05 | 海南大学 | 一种基于中间件的服务失败迁移方法 |
| US10747606B1 (en) * | 2016-12-21 | 2020-08-18 | EMC IP Holding Company LLC | Risk based analysis of adverse event impact on system availability |
| WO2018236350A1 (en) * | 2017-06-20 | 2018-12-27 | Hewlett-Packard Development Company, L.P. | MANAGING RETAIL POSITION DEVICES |
| CN107391301A (zh) * | 2017-08-16 | 2017-11-24 | 北京奇虎科技有限公司 | 存储系统的数据管理方法、装置、计算设备及存储介质 |
| KR20200088803A (ko) | 2017-11-16 | 2020-07-23 | 인텔 코포레이션 | 분산형 소프트웨어 정의식 산업 시스템 |
| KR102468737B1 (ko) * | 2017-12-19 | 2022-11-21 | 에스케이하이닉스 주식회사 | 메모리 시스템 및 메모리 시스템의 동작방법 |
| US10938696B2 (en) | 2017-12-21 | 2021-03-02 | Apple Inc. | Health status monitoring for services provided by computing devices |
| US10884843B2 (en) | 2018-01-12 | 2021-01-05 | International Business Machines Corporation | Traffic and geography based cognitive disaster recovery |
| US20190324832A1 (en) * | 2018-04-18 | 2019-10-24 | Alberto Avritzer | Metric for the assessment of distributed high-availability architectures using survivability modeling |
| US10776225B2 (en) | 2018-06-29 | 2020-09-15 | Hewlett Packard Enterprise Development Lp | Proactive cluster compute node migration at next checkpoint of cluster cluster upon predicted node failure |
| EP3799653B1 (en) * | 2018-06-29 | 2023-04-12 | Microsoft Technology Licensing, LLC | Multi-phase cloud service node error prediction |
| CN108921229A (zh) * | 2018-07-17 | 2018-11-30 | 成都西加云杉科技有限公司 | 数据恢复方法及装置 |
| TWI686696B (zh) * | 2018-08-14 | 2020-03-01 | 財團法人工業技術研究院 | 計算節點及其失效偵測方法與雲端資料處理系統 |
| US11474915B2 (en) * | 2018-08-28 | 2022-10-18 | Hewlett Packard Enterprise Development Lp | Cluster recovery manager to remediate failovers |
| US11586510B2 (en) * | 2018-10-19 | 2023-02-21 | International Business Machines Corporation | Dynamic checkpointing in a data processing system |
| US10997204B2 (en) * | 2018-12-21 | 2021-05-04 | Elasticsearch B.V. | Cross cluster replication |
| US11209808B2 (en) | 2019-05-21 | 2021-12-28 | At&T Intellectual Property I, L.P. | Systems and method for management and allocation of network assets |
| US11641395B2 (en) * | 2019-07-31 | 2023-05-02 | Stratus Technologies Ireland Ltd. | Fault tolerant systems and methods incorporating a minimum checkpoint interval |
| CN112632005B (zh) * | 2019-10-08 | 2024-01-23 | 中国石油化工股份有限公司 | 基于mpi的地震数据计算方法及系统 |
| US11093358B2 (en) | 2019-10-14 | 2021-08-17 | International Business Machines Corporation | Methods and systems for proactive management of node failure in distributed computing systems |
| US11593221B2 (en) * | 2020-02-28 | 2023-02-28 | EMC IP Holding Company LLC | Methods and systems for determining backup schedules |
| US11554783B2 (en) * | 2020-04-15 | 2023-01-17 | Baidu Usa Llc | Systems and methods to enhance early detection of performance induced risks for an autonomous driving vehicle |
| US20220258334A1 (en) * | 2021-02-17 | 2022-08-18 | Bank Of America Corporation | System for decentralized edge computing enablement in robotic process automation |
| JP7355778B2 (ja) * | 2021-04-27 | 2023-10-03 | 株式会社日立製作所 | ストレージシステム、ストレージノード仮想計算機復旧方法、及び復旧プログラム |
| US20230342258A1 (en) * | 2022-04-22 | 2023-10-26 | Dell Products L.P. | Method and apparatus for detecting pre-arrival of device or component failure |
| CN116755941B (zh) * | 2023-08-21 | 2024-01-09 | 之江实验室 | 一种节点故障感知的分布式模型训练的方法及装置 |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL99923A0 (en) * | 1991-10-31 | 1992-08-18 | Ibm Israel | Method of operating a computer in a network |
| US6161219A (en) * | 1997-07-03 | 2000-12-12 | The University Of Iowa Research Foundation | System and method for providing checkpointing with precompile directives and supporting software to produce checkpoints, independent of environment constraints |
| US6032194A (en) | 1997-12-24 | 2000-02-29 | Cisco Technology, Inc. | Method and apparatus for rapidly reconfiguring computer networks |
| US6353902B1 (en) | 1999-06-08 | 2002-03-05 | Nortel Networks Limited | Network fault prediction and proactive maintenance system |
| US6609212B1 (en) | 2000-03-09 | 2003-08-19 | International Business Machines Corporation | Apparatus and method for sharing predictive failure information on a computer network |
| US6820215B2 (en) | 2000-12-28 | 2004-11-16 | International Business Machines Corporation | System and method for performing automatic rejuvenation at the optimal time based on work load history in a distributed data processing environment |
| US7028228B1 (en) | 2001-03-28 | 2006-04-11 | The Shoregroup, Inc. | Method and apparatus for identifying problems in computer networks |
| US6978398B2 (en) | 2001-08-15 | 2005-12-20 | International Business Machines Corporation | Method and system for proactively reducing the outage time of a computer system |
| US7007084B1 (en) | 2001-11-07 | 2006-02-28 | At&T Corp. | Proactive predictive preventative network management technique |
| US7269706B2 (en) * | 2004-12-09 | 2007-09-11 | International Business Machines Corporation | Adaptive incremental checkpointing |
| JP2006172065A (ja) * | 2004-12-15 | 2006-06-29 | Hitachi Ltd | チェックポイント採取方法、システム及びプログラム |
| US7392433B2 (en) * | 2005-01-25 | 2008-06-24 | International Business Machines Corporation | Method and system for deciding when to checkpoint an application based on risk analysis |
| JP2006251999A (ja) * | 2005-03-09 | 2006-09-21 | Mitsubishi Electric Corp | 計算機クラスタシステム |
| JP2007213670A (ja) * | 2006-02-08 | 2007-08-23 | Funai Electric Co Ltd | ハードディスク装置 |
| US7721157B2 (en) | 2006-03-08 | 2010-05-18 | Omneon Video Networks | Multi-node computer system component proactive monitoring and proactive repair |
| US7571347B2 (en) * | 2006-03-20 | 2009-08-04 | Sun Microsystems, Inc. | Method and apparatus for providing fault-tolerance in parallel-processing systems |
| DE102006019896A1 (de) | 2006-04-28 | 2007-10-31 | Siemens Ag | Verfahren zur Fehlerbaumanalyse |
| US7730364B2 (en) * | 2007-04-05 | 2010-06-01 | International Business Machines Corporation | Systems and methods for predictive failure management |
| US7975175B2 (en) * | 2008-07-09 | 2011-07-05 | Oracle America, Inc. | Risk indices for enhanced throughput in computing systems |
| US8127154B2 (en) * | 2008-10-02 | 2012-02-28 | International Business Machines Corporation | Total cost based checkpoint selection |
| US8103916B2 (en) * | 2008-12-01 | 2012-01-24 | Sap Ag | Scheduling of checks in computing systems |
| US8140914B2 (en) | 2009-06-15 | 2012-03-20 | Microsoft Corporation | Failure-model-driven repair and backup |
| US8880931B2 (en) | 2010-01-04 | 2014-11-04 | Nec Corporation | Method, distributed system and computer program for failure recovery |
| US8250405B2 (en) | 2010-05-27 | 2012-08-21 | International Business Machines Corporation | Accelerating recovery in MPI environments |
| WO2012013509A1 (en) | 2010-07-28 | 2012-02-02 | Ecole Polytechnique Federale De Lausanne (Epfl) | A method and device for predicting faults in an it system |
| US9495477B1 (en) * | 2011-04-20 | 2016-11-15 | Google Inc. | Data storage in a graph processing system |
| WO2013101142A1 (en) * | 2011-12-30 | 2013-07-04 | Intel Corporation | Low latency cluster computing |
| US10467116B2 (en) * | 2012-06-08 | 2019-11-05 | Hewlett Packard Enterprise Development Lp | Checkpointing using FPGA |
| CN103197982B (zh) * | 2013-03-28 | 2016-03-09 | 哈尔滨工程大学 | 一种任务局部最优检查点间隔搜索方法 |
| US9436552B2 (en) * | 2014-06-12 | 2016-09-06 | International Business Machines Corporation | Checkpoint triggering in a computer system |
-
2014
- 2014-07-29 US US14/445,369 patent/US9348710B2/en active Active
-
2015
- 2015-07-20 JP JP2017505069A patent/JP6662847B2/ja active Active
- 2015-07-20 CA CA2956567A patent/CA2956567A1/en not_active Abandoned
- 2015-07-20 EP EP15748354.6A patent/EP3175361B1/en active Active
- 2015-07-20 WO PCT/US2015/041121 patent/WO2016018663A1/en active Application Filing
- 2015-07-20 CN CN201580052408.6A patent/CN106796540B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2017527893A (ja) | 2017-09-21 |
| US9348710B2 (en) | 2016-05-24 |
| US20160034362A1 (en) | 2016-02-04 |
| CA2956567A1 (en) | 2016-02-04 |
| EP3175361B1 (en) | 2022-07-20 |
| CN106796540A (zh) | 2017-05-31 |
| CN106796540B (zh) | 2021-01-05 |
| WO2016018663A1 (en) | 2016-02-04 |
| EP3175361A1 (en) | 2017-06-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6662847B2 (ja) | 分散コンピューティング用のプロアクティブ障害回復モデル | |
| US9729401B2 (en) | Automatic remediation of poor-performing virtual machines for scalable applications | |
| US10817501B1 (en) | Systems and methods for using a reaction-based approach to managing shared state storage associated with a distributed database | |
| US11321197B2 (en) | File service auto-remediation in storage systems | |
| US9690829B2 (en) | Dynamic load balancing during distributed query processing using query operator motion | |
| US9659057B2 (en) | Fault tolerant distributed query processing using query operator motion | |
| US20170017537A1 (en) | Apparatus and method of leveraging semi-supervised machine learning principals to perform root cause analysis and derivation for remediation of issues in a computer environment | |
| US10073739B2 (en) | Methods, apparatus and system for selective duplication of subtasks | |
| US9229839B2 (en) | Implementing rate controls to limit timeout-based faults | |
| Yang et al. | Computing at massive scale: Scalability and dependability challenges | |
| Pourmajidi et al. | On challenges of cloud monitoring | |
| Mahallat | Fault-tolerance techniques in cloud storage: a survey | |
| US20230222002A1 (en) | Techniques for modifying cluster computing environments | |
| KR20170041715A (ko) | 시스템 장애로부터 클라우드 기반 서비스의 사용성 복구 기법 | |
| US9529656B2 (en) | Computer recovery method, computer system, and storage medium | |
| US9678838B2 (en) | Protecting virtual machines from network failures | |
| CN105308553A (zh) | 动态提供存储 | |
| Rehman et al. | Fault-tolerance in the scope of cloud computing | |
| Yang et al. | Automatic and Scalable Data Replication Manager in Distributed Computation and Storage Infrastructure of Cyber-Physical Systems. | |
| US10516756B1 (en) | Selection of a distributed network service | |
| US20230342174A1 (en) | Intelligent capacity planning for storage in a hyperconverged infrastructure | |
| Rahman et al. | Aggressive fault tolerance in cloud computing using smart decision agent | |
| US20220189615A1 (en) | Decentralized health monitoring related task generation and management in a hyperconverged infrastructure (hci) environment | |
| WO2018099301A1 (zh) | 一种数据分析方法及装置 | |
| Bóhorquez et al. | Running mpi applications over an opportunistic infrastructure |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180720 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180720 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20181228 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190205 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20190507 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20190705 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190805 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200213 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6662847 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |