JP6430970B2 - 異なる命令セットアーキテクチャを有するプロセッサ上におけるオペレーティングシステムの実行 - Google Patents
異なる命令セットアーキテクチャを有するプロセッサ上におけるオペレーティングシステムの実行 Download PDFInfo
- Publication number
- JP6430970B2 JP6430970B2 JP2015558884A JP2015558884A JP6430970B2 JP 6430970 B2 JP6430970 B2 JP 6430970B2 JP 2015558884 A JP2015558884 A JP 2015558884A JP 2015558884 A JP2015558884 A JP 2015558884A JP 6430970 B2 JP6430970 B2 JP 6430970B2
- Authority
- JP
- Japan
- Prior art keywords
- processor
- operating system
- execution
- code
- instruction set
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000006870 function Effects 0.000 claims description 93
- 238000000034 method Methods 0.000 claims description 66
- 238000012545 processing Methods 0.000 claims description 32
- 238000013507 mapping Methods 0.000 claims description 14
- 230000001427 coherent effect Effects 0.000 claims description 6
- 230000000977 initiatory effect Effects 0.000 claims description 3
- 230000004044 response Effects 0.000 claims description 3
- 230000007704 transition Effects 0.000 claims description 2
- 238000010586 diagram Methods 0.000 description 10
- 230000008569 process Effects 0.000 description 6
- 230000008901 benefit Effects 0.000 description 5
- 235000019800 disodium phosphate Nutrition 0.000 description 4
- 238000013508 migration Methods 0.000 description 3
- 230000005012 migration Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000009249 intrinsic sympathomimetic activity Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 125000002066 L-histidyl group Chemical group [H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H] 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3005—Arrangements for executing specific machine instructions to perform operations for flow control
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/32—Address formation of the next instruction, e.g. by incrementing the instruction counter
- G06F9/322—Address formation of the next instruction, e.g. by incrementing the instruction counter for non-sequential address
- G06F9/323—Address formation of the next instruction, e.g. by incrementing the instruction counter for non-sequential address for indirect branch instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45504—Abstract machines for programme code execution, e.g. Java virtual machine [JVM], interpreters, emulators
- G06F9/45516—Runtime code conversion or optimisation
- G06F9/4552—Involving translation to a different instruction set architecture, e.g. just-in-time translation in a JVM
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/505—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering the load
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
- G06F9/5088—Techniques for rebalancing the load in a distributed system involving task migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/509—Offload
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
- Stored Programmes (AREA)
Description
本出願は、2013年2月26日に出願された参照によりその内容の全体を本明細書に明示的に組み込むものとする本願の所有者が所有する米国非仮特許出願第13/777,314号からの優先権を主張するものである。
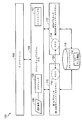
102 アプリケーション
104 オペレーティングシステム(O/S)
106 スケジューラ
107 イベントハンドラ
108 選択基準
110 第1のプロセッサ
112 第2のプロセッサ
114 タスク
116 コヒーレントメモリ
118 オペレーティングシステムデータ構造
202 メモリ
210 第1のテーブル
212 第2のテーブル
220 テーブル
222 テーブル
230 テーブル
500 電子デバイス
510 CPU
522 システムオンチップデバイス
526 ディスプレイコントローラ
528 ディスプレイ
530 入力デバイス
532 メモリ
534 CODEC
536 スピーカ
538 マイクロフォン
540 ワイヤレスコントローラ
542 アンテナ
544 電源
556 実行可能命令
558 オペレーティングシステムデータ構造
570 第1のコア
572 第2のコア
574 DSP
576 第1のハードウェアスレッド
578 第2のハードウェアスレッド
Claims (14)
- 複数のプロセッサを備えるシステムにおいて、複数のプロセッサ上でオペレーティングシステムの単一のインスタンスを実行する方法であって、各プロセッサは関連付けられた異なる命令セットアーキテクチャを有し、前記方法は、
第1の命令セットアーキテクチャと関連付けられ、かつ仮想アドレスに基づいて共有データ構造内の第1のテーブルエントリにアクセスするように構成される第1のプロセッサ上で第1のコードを実行するステップであって、前記第1のテーブルエントリは前記仮想アドレスにマッピングされる、ステップと、
前記オペレーティングシステムによって、前記第1のコードを実行する間に、オペレーティングシステムイベントを実行するステップであって、前記オペレーティングシステムは、前記第1のプロセッサおよび第2のプロセッサの上で同時に実行可能であり、前記第2のプロセッサは、第2の異なる命令セットアーキテクチャと関連付けられ、かつ前記仮想アドレスに基づいて前記共有データ構造内の第2のテーブルエントリにアクセスするように構成される、ステップと、
前記オペレーティングシステムによって、前記オペレーティングシステムイベントを実行するときに、前記第1のコードの実行を停止するとともに、前記第2のプロセッサ上で前記オペレーティングシステムイベントを取り扱うための第2のコードの実行を始動するステップであって、前記第2のテーブルエントリは前記仮想アドレスにマッピングされる、ステップと、
前記オペレーティングシステムによって、前記オペレーティングシステムイベントを取り扱う前記第2のコードの実行が完了するときに、前記第2のコードを停止するとともに前記第1のプロセッサ上で前記第1のコードの実行を再開するステップであって、前記第1のテーブルエントリと前記第2のテーブルエントリは前記共有データ構造内の第1の位置特定識別子と第2の位置特定識別子のそれぞれに対応する、ステップと
を含み、
前記第1の位置特定識別子と前記第2の位置特定識別子とは異なる、方法。 - 前記第1のプロセッサと前記第2のプロセッサの各々は、前記共有データ構造を備える同じコヒーレントメモリにアクセスするように構成され、前記第1のプロセッサおよび前記第2のプロセッサはモバイルコンピューティングデバイスに一体化される、請求項1に記載の方法。
- 前記共有データ構造の共通の仮想アドレス空間は、
前記第1のプロセッサ上で実行するようにコンパイルされた機能の第1のバージョンに対応する第1の機能テーブルであって、前記機能の前記第1のバージョンは前記第1のコードを用いて表される、第1の機能テーブルと、
前記第2のプロセッサ上で実行するようにコンパイルされた前記機能の第2のバージョンに対応する第2の機能テーブルであって、前記機能の前記第2のバージョンは前記第2のコードを用いて表される、第2の機能テーブルと
を備える、請求項1または2に記載の方法。 - 前記第1のプロセッサおよび前記第2のプロセッサは、プロセッサ間メッセージ伝達、共有メモリ、アプリケーションプログラミングインターフェース(API)、またはこれらの任意の組合せを介して互いに通信するように構成される、請求項1〜3のいずれか一項に記載の方法。
- 前記第1のプロセッサは複数のハードウェアスレッドを有するデジタル信号プロセッサ(DSP)を備え、前記第2のプロセッサはマルチコア中央処理ユニット(CPU)を備える、請求項1〜4のいずれか一項に記載の方法。
- 前記オペレーティングシステムイベントは、ページフォールト、トラップ、システムフォールト、システムリクエスト、ハードウェアエラー、アドレスエラー、許可違反、またはこれらの任意の組合せを備える、請求項1〜5のいずれか一項に記載の方法。
- 前記オペレーティングシステムイベントは、実行の流れをオペレーティングシステムのユーザモードから前記オペレーティングシステムのカーネルモードに遷移させる、請求項1〜6のいずれか一項に記載の方法。
- 複数のプロセッサを備えるシステムにおいて、複数のプロセッサ上でオペレーティングシステムの単一のインスタンスを実行する方法であって、各プロセッサは関連付けられた異なる命令セットアーキテクチャを有し、前記方法は、
第1の命令セットアーキテクチャを有する第1のプロセッサおよび第2の異なる命令セットアーキテクチャを有する第2のプロセッサ上で同時に実行可能なオペレーティングシステムのスケジューラによって、前記第1のプロセッサまたは前記第2のプロセッサ上での実行のためにタスクをスケジュール設定させる要求を受け取るステップであって、前記第1のプロセッサは仮想アドレスに基づいて共有データ構造内の第1のテーブルエントリにアクセスするように構成され、前記第1のテーブルエントリは前記仮想アドレスにマッピングされ、前記第2のプロセッサは前記仮想アドレスに基づいて前記共有データ構造内の第2のテーブルエントリにアクセスするように構成され、前記第2のテーブルエントリは前記仮想アドレスにマッピングされる、受け取るステップと、
前記要求および、前記タスクが前記第1のプロセッサ上の前記第1の命令セットアーキテクチャを用いた実行のために利用可能でありかつ前記第2のプロセッサ上の前記第2の命令セットアーキテクチャを用いた実行のために利用可能であると前記スケジューラが判定したことに応答して、前記スケジューラによって、少なくとも1つの選択基準に基づいて前記第1のプロセッサを選択して前記第1のプロセッサ上で前記タスクをスケジュール設定するステップと、
前記スケジューラによって、前記タスクの実行の間に、前記第1のプロセッサを使用する他のタスクのために、前記タスクの実行を前記第1のプロセッサから前記第2のプロセッサに切り替えるステップと
を含む、方法。 - 前記少なくとも1つの選択基準は、前記タスクと関連付けられた最低パワー使用を備える、請求項8に記載の方法。
- 前記少なくとも1つの選択基準は、最小負荷のプロセッサ、前記タスクのタイプ、前記タスクと関連付けられた最低パワー使用、またはこれらの任意の組合せを備え、前記タスクの実行を切り替えるステップは、
前記第1のプロセッサからのシステムコールを始動するステップと、
前記タスクを前記第1のプロセッサのスケジュールから除去するステップと、
前記タスクを前記第2のプロセッサのスケジュールに追加するステップと、
前記第2のプロセッサ上の前記システムコールから復帰するステップと
を含む、請求項8または9に記載の方法。 - 複数のプロセッサを備えるシステムにおいて、複数のプロセッサ上でオペレーティングシステムの単一のインスタンスを実行するための装置であって、各プロセッサは関連付けられた異なる命令セットアーキテクチャを有し、前記装置は、
第1の命令セットアーキテクチャと関連付けられ、かつ仮想アドレスに基づいて共有データ構造内の第1のテーブルエントリにアクセスするように構成される第1のプロセッサと、
第2の異なる命令セットアーキテクチャと関連付けられ、かつ前記仮想アドレスに基づいて前記共有データ構造内の第2のテーブルエントリにアクセスするように構成される第2のプロセッサと、
前記第1のプロセッサおよび前記第2のプロセッサの上で同時に実行可能な前記オペレーティングシステムの少なくとも一部分を記憶するメモリであって、前記オペレーティングシステムは、
前記第1のプロセッサ上で第1のコードを実行することであって、前記第1のテーブルエントリは前記仮想アドレスにマッピングされる、実行することと、
前記第1のコードを実行する間に、オペレーティングシステムイベントを実行することと、
前記オペレーティングシステムイベントを実行するときに、前記第1のコードの実行を停止するとともに、前記第2のプロセッサ上で前記オペレーティングシステムイベントを取り扱うための第2のコードの実行を始動することであって、前記第2のテーブルエントリは前記仮想アドレスにマッピングされる、始動することと、
前記オペレーティングシステムイベントを取り扱う前記第2のコードの実行が完了するときに、前記第2のコードを停止するとともに前記第1のプロセッサ上で前記第1のコードの実行を再開することであって、前記第1のテーブルエントリと前記第2のテーブルエントリは前記共有データ構造内の第1の位置特定識別子と第2の位置特定識別子のそれぞれに対応する、停止かつ再開することと
を行う、メモリと
を備え、
前記第1の位置特定識別子と前記第2の位置特定識別子とは異なる、装置。 - 前記第1のテーブルエントリと前記第2のテーブルエントリは異なり、
前記第1のプロセッサおよび前記第2のプロセッサはモバイルコンピューティングデバイスに一体化される、請求項11に記載の装置。 - 複数のプロセッサを備えるシステムにおいて、複数のプロセッサ上でオペレーティングシステムの単一のインスタンスを実行するための装置であって、各プロセッサは関連付けられた異なる命令セットアーキテクチャを有し、前記装置は、
第1の命令セットアーキテクチャと関連付けられ、かつ仮想アドレスに基づいて共有データ構造内の第1のテーブルエントリにアクセスするように構成される第1のプロセッサと、
第2の異なる命令セットアーキテクチャと関連付けられ、かつ前記仮想アドレスに基づいて前記共有データ構造内の第2のテーブルエントリにアクセスするように構成される第2のプロセッサと、
前記第1のプロセッサおよび前記第2のプロセッサの上で同時に実行可能なオペレーティングシステムの少なくとも一部分を記憶するメモリであって、前記オペレーティングシステムは、
前記オペレーティングシステムのスケジューラにおいて、前記第1のプロセッサまたは前記第2のプロセッサ上での実行のためにタスクをスケジュール設定させる要求を受け取ることであって、前記第1のテーブルエントリは前記仮想アドレスにマッピングされ、前記第2のテーブルエントリは前記仮想アドレスにマッピングされる、受け取ることと、
前記要求および、前記タスクが前記第1のプロセッサ上の前記第1の命令セットアーキテクチャを用いた実行のために利用可能でありかつ前記第2のプロセッサ上の前記第2の命令セットアーキテクチャを用いた実行のために利用可能であると前記スケジューラが判定したことに応答して、少なくとも1つの選択基準に基づいて前記第1のプロセッサを選択して前記第1のプロセッサ上で前記タスクをスケジュール設定することと、
前記タスクの実行の間に、前記第1のプロセッサを使用する他のタスクのために、前記タスクの実行を前記第1のプロセッサから前記第2のプロセッサに切り替えることと
を備える、メモリと
を備える、装置。 - オペレーティングシステムの単一のインスタンスを備える非一時的コンピュータ可読記録媒体であって、
前記オペレーティングシステムの前記単一のインスタンスは、第1のプロセッサおよび第2のプロセッサを備える電子デバイスで実行されるときに、前記プロセッサに請求項1〜10のいずれか一項に記載の方法を実施させる、非一時的コンピュータ可読記録媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/777,314 | 2013-02-26 | ||
| US13/777,314 US10437591B2 (en) | 2013-02-26 | 2013-02-26 | Executing an operating system on processors having different instruction set architectures |
| PCT/US2014/016391 WO2014133784A2 (en) | 2013-02-26 | 2014-02-14 | Executing an operating system on processors having different instruction set architectures |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2016507849A JP2016507849A (ja) | 2016-03-10 |
| JP2016507849A5 JP2016507849A5 (ja) | 2017-03-02 |
| JP6430970B2 true JP6430970B2 (ja) | 2018-11-28 |
Family
ID=50272697
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015558884A Active JP6430970B2 (ja) | 2013-02-26 | 2014-02-14 | 異なる命令セットアーキテクチャを有するプロセッサ上におけるオペレーティングシステムの実行 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US10437591B2 (ja) |
| EP (2) | EP2962198B1 (ja) |
| JP (1) | JP6430970B2 (ja) |
| KR (1) | KR102140061B1 (ja) |
| CN (1) | CN105074666B (ja) |
| WO (1) | WO2014133784A2 (ja) |
Families Citing this family (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9606818B2 (en) | 2013-03-14 | 2017-03-28 | Qualcomm Incorporated | Systems and methods of executing multiple hypervisors using multiple sets of processors |
| US9396012B2 (en) | 2013-03-14 | 2016-07-19 | Qualcomm Incorporated | Systems and methods of using a hypervisor with guest operating systems and virtual processors |
| US10114756B2 (en) * | 2013-03-14 | 2018-10-30 | Qualcomm Incorporated | Externally programmable memory management unit |
| WO2016003646A1 (en) * | 2014-06-30 | 2016-01-07 | Unisys Corporation | Enterprise management for secure network communications over ipsec |
| US9910721B2 (en) * | 2014-12-09 | 2018-03-06 | Intel Corporation | System and method for execution of application code compiled according to two instruction set architectures |
| CN107273101A (zh) * | 2016-04-06 | 2017-10-20 | 晨星半导体股份有限公司 | 嵌入式系统的操作方法与控制芯片 |
| US10216599B2 (en) | 2016-05-26 | 2019-02-26 | International Business Machines Corporation | Comprehensive testing of computer hardware configurations |
| US10223235B2 (en) | 2016-05-26 | 2019-03-05 | International Business Machines Corporation | Comprehensive testing of computer hardware configurations |
| US10157164B2 (en) * | 2016-09-20 | 2018-12-18 | Qualcomm Incorporated | Hierarchical synthesis of computer machine instructions |
| JP6859642B2 (ja) * | 2016-09-23 | 2021-04-14 | カシオ計算機株式会社 | 制御装置、電子時計、処理制御方法、及びプログラム |
| US10684984B2 (en) * | 2016-12-21 | 2020-06-16 | Intel Corporation | Computing devices and server systems with processing cores having different instruction set architectures |
| US10552207B2 (en) | 2016-12-21 | 2020-02-04 | Intel Corporation | Systems and methods for multi-architecture computing including program stack translation |
| US10713213B2 (en) | 2016-12-21 | 2020-07-14 | Intel Corporation | Systems and methods for multi-architecture computing |
| EP3343267B1 (en) | 2016-12-30 | 2024-01-24 | Magic Leap, Inc. | Polychromatic light out-coupling apparatus, near-eye displays comprising the same, and method of out-coupling polychromatic light |
| CN106791152B (zh) * | 2016-12-30 | 2019-08-27 | Oppo广东移动通信有限公司 | 一种通信方法及移动终端 |
| US11275709B2 (en) | 2017-05-02 | 2022-03-15 | Intel Corporation | Systems and methods for multi-architecture computing |
| US10578870B2 (en) | 2017-07-26 | 2020-03-03 | Magic Leap, Inc. | Exit pupil expander |
| CN111448497B (zh) | 2017-12-10 | 2023-08-04 | 奇跃公司 | 光波导上的抗反射涂层 |
| KR102491606B1 (ko) * | 2018-01-09 | 2023-01-26 | 삼성전자주식회사 | 커맨드 세트 기반 리플레이를 통해 수행 정보를 수집하는 프로세서 장치 |
| CN112136152A (zh) | 2018-03-15 | 2020-12-25 | 奇跃公司 | 由观看设备的部件变形导致的图像校正 |
| US11579441B2 (en) | 2018-07-02 | 2023-02-14 | Magic Leap, Inc. | Pixel intensity modulation using modifying gain values |
| WO2020014324A1 (en) * | 2018-07-10 | 2020-01-16 | Magic Leap, Inc. | Thread weave for cross-instruction set architecture procedure calls |
| US10795458B2 (en) | 2018-08-03 | 2020-10-06 | Magic Leap, Inc. | Unfused pose-based drift correction of a fused pose of a totem in a user interaction system |
| US12016719B2 (en) | 2018-08-22 | 2024-06-25 | Magic Leap, Inc. | Patient viewing system |
| US10831698B2 (en) | 2018-09-25 | 2020-11-10 | International Business Machines Corporation | Maximizing high link bandwidth utilization through efficient component communication in disaggregated datacenters |
| US11650849B2 (en) | 2018-09-25 | 2023-05-16 | International Business Machines Corporation | Efficient component communication through accelerator switching in disaggregated datacenters |
| US11163713B2 (en) | 2018-09-25 | 2021-11-02 | International Business Machines Corporation | Efficient component communication through protocol switching in disaggregated datacenters |
| US11182322B2 (en) * | 2018-09-25 | 2021-11-23 | International Business Machines Corporation | Efficient component communication through resource rewiring in disaggregated datacenters |
| US11012423B2 (en) | 2018-09-25 | 2021-05-18 | International Business Machines Corporation | Maximizing resource utilization through efficient component communication in disaggregated datacenters |
| US10802988B2 (en) | 2018-09-25 | 2020-10-13 | International Business Machines Corporation | Dynamic memory-based communication in disaggregated datacenters |
| US10915493B2 (en) | 2018-09-25 | 2021-02-09 | International Business Machines Corporation | Component building blocks and optimized compositions thereof in disaggregated datacenters |
| WO2020132484A1 (en) | 2018-12-21 | 2020-06-25 | Magic Leap, Inc. | Air pocket structures for promoting total internal reflection in a waveguide |
| WO2021025284A1 (en) * | 2019-08-07 | 2021-02-11 | Samsung Electronics Co., Ltd. | Electronic device for executing instructions using processor cores and various versions of instruction set architectures |
| US11080400B2 (en) * | 2019-08-28 | 2021-08-03 | Palo Alto Networks, Inc. | Analyzing multiple CPU architecture malware samples |
| US10840961B1 (en) * | 2019-10-23 | 2020-11-17 | Motorola Solutions, Inc. | Method and apparatus for managing feature based user input routing in a multi-processor architecture using single user interface control |
| US11334324B2 (en) * | 2019-11-08 | 2022-05-17 | Software Ag | Systems and/or methods for error-free implementation of non-java program code on special purpose processors |
| EP4058936A4 (en) | 2019-11-14 | 2023-05-03 | Magic Leap, Inc. | SYSTEMS AND METHODS FOR VIRTUAL AND AUGMENTED REALITY |
| US11256522B2 (en) * | 2019-11-22 | 2022-02-22 | Advanced Micro Devices, Inc. | Loader and runtime operations for heterogeneous code objects |
| CN115004158A (zh) * | 2020-01-30 | 2022-09-02 | 华为技术有限公司 | 在多核处理器上执行扩展集中的处理器指令的设备、方法和计算机程序 |
| US11962518B2 (en) | 2020-06-02 | 2024-04-16 | VMware LLC | Hardware acceleration techniques using flow selection |
| US11824931B2 (en) | 2020-09-28 | 2023-11-21 | Vmware, Inc. | Using physical and virtual functions associated with a NIC to access an external storage through network fabric driver |
| US11606310B2 (en) | 2020-09-28 | 2023-03-14 | Vmware, Inc. | Flow processing offload using virtual port identifiers |
| US11636053B2 (en) | 2020-09-28 | 2023-04-25 | Vmware, Inc. | Emulating a local storage by accessing an external storage through a shared port of a NIC |
| US12021759B2 (en) * | 2020-09-28 | 2024-06-25 | VMware LLC | Packet processing with hardware offload units |
| US11829793B2 (en) | 2020-09-28 | 2023-11-28 | Vmware, Inc. | Unified management of virtual machines and bare metal computers |
| CN113176928B (zh) * | 2021-04-27 | 2022-08-30 | 深圳市研唐科技有限公司 | 一种异构虚拟机的运行方法和装置 |
| US11748074B2 (en) | 2021-05-28 | 2023-09-05 | Software Ag | User exit daemon for use with special-purpose processor, mainframe including user exit daemon, and associated methods |
| US11995024B2 (en) | 2021-12-22 | 2024-05-28 | VMware LLC | State sharing between smart NICs |
| US11863376B2 (en) | 2021-12-22 | 2024-01-02 | Vmware, Inc. | Smart NIC leader election |
| US11928062B2 (en) | 2022-06-21 | 2024-03-12 | VMware LLC | Accelerating data message classification with smart NICs |
| US11899594B2 (en) | 2022-06-21 | 2024-02-13 | VMware LLC | Maintenance of data message classification cache on smart NIC |
| US11928367B2 (en) | 2022-06-21 | 2024-03-12 | VMware LLC | Logical memory addressing for network devices |
Family Cites Families (57)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62286155A (ja) | 1986-06-05 | 1987-12-12 | Sharp Corp | マルチcpu制御方式 |
| US5369767A (en) * | 1989-05-17 | 1994-11-29 | International Business Machines Corp. | Servicing interrupt requests in a data processing system without using the services of an operating system |
| US6286092B1 (en) | 1999-05-12 | 2001-09-04 | Ati International Srl | Paged based memory address translation table update method and apparatus |
| US6526462B1 (en) | 1999-11-19 | 2003-02-25 | Hammam Elabd | Programmable multi-tasking memory management system |
| US6904483B2 (en) | 2001-03-20 | 2005-06-07 | Wind River Systems, Inc. | System and method for priority inheritance |
| GB2378277B (en) | 2001-07-31 | 2003-06-25 | Sun Microsystems Inc | Multiple address translations |
| JP2003099272A (ja) | 2001-09-20 | 2003-04-04 | Ricoh Co Ltd | タスク切替システムと方法およびdspとモデム |
| US6981072B2 (en) | 2003-06-05 | 2005-12-27 | International Business Machines Corporation | Memory management in multiprocessor system |
| US7424709B2 (en) | 2003-09-15 | 2008-09-09 | Intel Corporation | Use of multiple virtual machine monitors to handle privileged events |
| US20050251806A1 (en) | 2004-05-10 | 2005-11-10 | Auslander Marc A | Enhancement of real-time operating system functionality using a hypervisor |
| US7707341B1 (en) | 2004-05-11 | 2010-04-27 | Advanced Micro Devices, Inc. | Virtualizing an interrupt controller |
| US8271976B2 (en) | 2004-06-30 | 2012-09-18 | Microsoft Corporation | Systems and methods for initializing multiple virtual processors within a single virtual machine |
| US7299337B2 (en) | 2005-05-12 | 2007-11-20 | Traut Eric P | Enhanced shadow page table algorithms |
| US20070006178A1 (en) | 2005-05-12 | 2007-01-04 | Microsoft Corporation | Function-level just-in-time translation engine with multiple pass optimization |
| JP4457047B2 (ja) * | 2005-06-22 | 2010-04-28 | 株式会社ルネサステクノロジ | マルチプロセッサシステム |
| US7739476B2 (en) | 2005-11-04 | 2010-06-15 | Apple Inc. | R and C bit update handling |
| US7945913B2 (en) | 2006-01-19 | 2011-05-17 | International Business Machines Corporation | Method, system and computer program product for optimizing allocation of resources on partitions of a data processing system |
| JP4936517B2 (ja) | 2006-06-06 | 2012-05-23 | 学校法人早稲田大学 | ヘテロジニアス・マルチプロセッサシステムの制御方法及びマルチグレイン並列化コンパイラ |
| US8468532B2 (en) * | 2006-06-21 | 2013-06-18 | International Business Machines Corporation | Adjusting CPU time allocated to next thread based on gathered data in heterogeneous processor system having plurality of different instruction set architectures |
| US8082551B2 (en) | 2006-10-30 | 2011-12-20 | Hewlett-Packard Development Company, L.P. | System and method for sharing a trusted platform module |
| US7685409B2 (en) | 2007-02-21 | 2010-03-23 | Qualcomm Incorporated | On-demand multi-thread multimedia processor |
| US8789063B2 (en) | 2007-03-30 | 2014-07-22 | Microsoft Corporation | Master and subordinate operating system kernels for heterogeneous multiprocessor systems |
| US8250254B2 (en) | 2007-07-31 | 2012-08-21 | Intel Corporation | Offloading input/output (I/O) virtualization operations to a processor |
| US8284205B2 (en) | 2007-10-24 | 2012-10-09 | Apple Inc. | Methods and apparatuses for load balancing between multiple processing units |
| US8296743B2 (en) | 2007-12-17 | 2012-10-23 | Intel Corporation | Compiler and runtime for heterogeneous multiprocessor systems |
| US8245236B2 (en) | 2008-02-27 | 2012-08-14 | International Business Machines Corporation | Lock based moving of threads in a shared processor partitioning environment |
| US20090282198A1 (en) | 2008-05-08 | 2009-11-12 | Texas Instruments Incorporated | Systems and methods for optimizing buffer sharing between cache-incoherent cores |
| US8166254B2 (en) | 2008-06-06 | 2012-04-24 | International Business Machines Corporation | Hypervisor page fault processing in a shared memory partition data processing system |
| US8464011B2 (en) | 2008-10-27 | 2013-06-11 | Advanced Micro Devices, Inc. | Method and apparatus for providing secure register access |
| US8301863B2 (en) | 2008-11-17 | 2012-10-30 | International Business Machines Corporation | Recursive logical partition real memory map |
| CN101739235A (zh) | 2008-11-26 | 2010-06-16 | 中国科学院微电子研究所 | 将32位dsp与通用risc cpu无缝混链的处理器装置 |
| US8291414B2 (en) | 2008-12-11 | 2012-10-16 | International Business Machines Corporation | Shared resource service provisioning using a virtual machine manager |
| US20100242014A1 (en) | 2009-03-17 | 2010-09-23 | Xiaohan Zhu | Symmetric multi-processor operating system for asymmetric multi-processor architecture |
| US20110010716A1 (en) * | 2009-06-12 | 2011-01-13 | Arvind Raghuraman | Domain Bounding for Symmetric Multiprocessing Systems |
| US9152200B2 (en) | 2009-06-23 | 2015-10-06 | Hewlett-Packard Development Company, L.P. | Resource and power management using nested heterogeneous hypervisors |
| US8479196B2 (en) | 2009-09-22 | 2013-07-02 | International Business Machines Corporation | Nested virtualization performance in a computer system |
| US8719839B2 (en) | 2009-10-30 | 2014-05-06 | Intel Corporation | Two way communication support for heterogenous processors of a computer platform |
| US8868848B2 (en) | 2009-12-21 | 2014-10-21 | Intel Corporation | Sharing virtual memory-based multi-version data between the heterogenous processors of a computer platform |
| US8443376B2 (en) | 2010-06-01 | 2013-05-14 | Microsoft Corporation | Hypervisor scheduler |
| US20110320766A1 (en) | 2010-06-29 | 2011-12-29 | Youfeng Wu | Apparatus, method, and system for improving power, performance efficiency by coupling a first core type with a second core type |
| WO2012023150A2 (en) | 2010-08-19 | 2012-02-23 | Ineda Systems Pvt. Ltd | Handheld electronic devices |
| US8739171B2 (en) | 2010-08-31 | 2014-05-27 | International Business Machines Corporation | High-throughput-computing in a hybrid computing environment |
| US20120072638A1 (en) | 2010-09-16 | 2012-03-22 | Unisys Corp. | Single step processing of memory mapped accesses in a hypervisor |
| CN103339604B (zh) | 2011-01-31 | 2016-10-26 | 株式会社索思未来 | 程序生成装置、程序生成方法、处理器装置以及多处理器系统 |
| US8307169B2 (en) | 2011-03-10 | 2012-11-06 | Safenet, Inc. | Protecting guest virtual machine memory |
| JP5648544B2 (ja) | 2011-03-15 | 2015-01-07 | 富士通株式会社 | スケジューリングプログラム、および情報処理装置 |
| US8984330B2 (en) | 2011-03-28 | 2015-03-17 | Siemens Corporation | Fault-tolerant replication architecture |
| WO2012141677A1 (en) | 2011-04-11 | 2012-10-18 | Hewlett-Packard Development Company, L.P. | Performing a task in a system having different types of hardware resources |
| US9043562B2 (en) | 2011-04-20 | 2015-05-26 | Microsoft Technology Licensing, Llc | Virtual machine trigger |
| US8677360B2 (en) | 2011-05-12 | 2014-03-18 | Microsoft Corporation | Thread-related actions based on historical thread behaviors |
| US20130013889A1 (en) | 2011-07-06 | 2013-01-10 | Jaikumar Devaraj | Memory management unit using stream identifiers |
| US9250969B2 (en) | 2011-08-30 | 2016-02-02 | At&T Intellectual Property I, L.P. | Tagging a copy of memory of a virtual machine with information for fetching of relevant portions of the memory |
| US20140053272A1 (en) | 2012-08-20 | 2014-02-20 | Sandor Lukacs | Multilevel Introspection of Nested Virtual Machines |
| US20140101405A1 (en) * | 2012-10-05 | 2014-04-10 | Advanced Micro Devices, Inc. | Reducing cold tlb misses in a heterogeneous computing system |
| US10114756B2 (en) | 2013-03-14 | 2018-10-30 | Qualcomm Incorporated | Externally programmable memory management unit |
| US9606818B2 (en) | 2013-03-14 | 2017-03-28 | Qualcomm Incorporated | Systems and methods of executing multiple hypervisors using multiple sets of processors |
| US9396012B2 (en) | 2013-03-14 | 2016-07-19 | Qualcomm Incorporated | Systems and methods of using a hypervisor with guest operating systems and virtual processors |
-
2013
- 2013-02-26 US US13/777,314 patent/US10437591B2/en active Active
-
2014
- 2014-02-14 WO PCT/US2014/016391 patent/WO2014133784A2/en active Application Filing
- 2014-02-14 JP JP2015558884A patent/JP6430970B2/ja active Active
- 2014-02-14 KR KR1020157025501A patent/KR102140061B1/ko active IP Right Grant
- 2014-02-14 CN CN201480009390.7A patent/CN105074666B/zh not_active Expired - Fee Related
- 2014-02-14 EP EP14709781.0A patent/EP2962198B1/en active Active
- 2014-02-14 EP EP19156727.0A patent/EP3525099A1/en not_active Ceased
Also Published As
| Publication number | Publication date |
|---|---|
| KR102140061B1 (ko) | 2020-07-31 |
| WO2014133784A2 (en) | 2014-09-04 |
| JP2016507849A (ja) | 2016-03-10 |
| CN105074666A (zh) | 2015-11-18 |
| KR20150122178A (ko) | 2015-10-30 |
| CN105074666B (zh) | 2020-04-21 |
| US20140244983A1 (en) | 2014-08-28 |
| EP2962198B1 (en) | 2019-04-24 |
| WO2014133784A3 (en) | 2014-10-23 |
| EP2962198A2 (en) | 2016-01-06 |
| US10437591B2 (en) | 2019-10-08 |
| EP3525099A1 (en) | 2019-08-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6430970B2 (ja) | 異なる命令セットアーキテクチャを有するプロセッサ上におけるオペレーティングシステムの実行 | |
| JP7087029B2 (ja) | 中央処理装置(cpu)と補助プロセッサとの間の改善した関数コールバック機構 | |
| US9529643B2 (en) | Method and system for accelerating task control flow | |
| JP4690988B2 (ja) | 持続的なユーザレベルスレッド用の装置、システムおよび方法 | |
| US10114756B2 (en) | Externally programmable memory management unit | |
| US9606818B2 (en) | Systems and methods of executing multiple hypervisors using multiple sets of processors | |
| US9619298B2 (en) | Scheduling computing tasks for multi-processor systems based on resource requirements | |
| US20140282507A1 (en) | Systems and methods of using a hypervisor with guest operating systems and virtual processors | |
| JP5710434B2 (ja) | アシスト・ハードウエア・スレッドの拡張可能な状態追跡のための方法、情報処理システム、およびプロセッサ | |
| JP2016149164A (ja) | トランザクションメモリ動作を実行するように構成されたプロセッサ | |
| WO2016193774A1 (en) | Multi-core processor for execution of strands of instructions grouped according to criticality | |
| US11526358B2 (en) | Deterministic execution replay for multicore systems | |
| TWI760756B (zh) | 共用代碼之系統與代碼共用方法 | |
| US20150363227A1 (en) | Data processing unit and method for operating a data processing unit | |
| US20160078246A1 (en) | Notification of Blocking Tasks | |
| US20140019990A1 (en) | Integrated circuit device and method for enabling cross-context access |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A529 | Written submission of copy of amendment under article 34 pct |
Free format text: JAPANESE INTERMEDIATE CODE: A529 Effective date: 20150820 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170125 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20170125 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20180124 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20180205 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180406 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20181005 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20181101 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6430970 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |