いくつかの実施形態および例示的な図面によって本開示がここに記載されるが、当業者は、本開示が記載の実施形態または図面に限定されないことを認識するであろう。なお、図面および詳細な記載は、開示される特定の形態に本開示を限定する意図はなく、逆に、本開示は、添付の請求項によって定義される精神および範囲内のすべての変更、均等物、および代替物を包含するものである。ここで使用される標題は、編成のみを目的としており、明細書または請求項の範囲を限定する意図はない。ここで使用される、「し得る(may)」の単語は、強制的な意味(すなわち、不可欠であるという意味)ではなく、許容的な意味(すなわち、可能性があるという意味)で使用されている。同様に、「含む(include)」、「含んでいる(including)」、および「含む(includes)」の単語は含むことを意味しており、限定を意味するものではない。
実施形態の詳細な説明
上記のように、統計カウンタの使用は、多くの大きなソフトウェアシステムにおいて非常に一般的である。共用統計カウンタへのアクセスは、ハードウェアおよび/またはソフトウェアのトランザクションメモリを支持するシステムにおいて実行されるものを含む、マルチスレッドアプリケーションの同時スレッド間の競合の原因となり得る。マルチコアマシンは、サイズが大きくなっており、シンプルなバスベースの設計からNUMAおよびCC−NUMAスタイルのメモリアーキテクチャへ移行されている。この移行に伴い、スケーラブル統計カウンタの必要性が増している。ここに記載のシステムおよび方法は、一部の実施形態において、スケーラブル統計カウンタを実施するために使用され得る。異なる実施形態において、ここに記載されるスケーラブル統計カウンタは、カウンタを複数のコンポーネントに分割して各コンポーネントにおける競合を減少させることにより、またはより低い頻度でカウンタを更新する技術を採用することにより、このスケーラビリティを実現する。両方のクラスの技術は、それらを使用する同時に実行されるアトミックトランザクション間のコンフリクトを大きく減少させ、成功の機会を向上させるとともに、スケーラブル性能の実現を助ける。
異なる実施形態において、ここに記載される技術は、ノンブロッキング(non-blocking)であるとともに、一般的に使用されるナイーブカウンタと比較して劇的に良好なスケーラビリティおよび正確性特性を提供する、正確カウンタおよび/または確率的(統計的)カウンタを実施するために使用され得る。確率的カウンタは、完全に一致したカウントを提供し得ないが、たとえば構成可能な正確性パラメータにより、高い確率で正確なカウントから逸脱「しすぎない」ような統計的性質を有し得る。一部の実施形態において、ここに記載されるカウンタは、競合が低い場合であってもナイーブカウンタと競合し得る。概して、ここに記載される統計カウンタは、高頻度で起こる可能性の高い事象をカウントするためにこれらが使用されるアプリケーションに適し得る一方、性能監視および診断に共通するように、カウンタの値が読み取られる頻度は低くなり得る。ここに記載されるカウンタの多くは、1だけインクリメントされ、または全くデクリメントされないと仮定される一方で、他の実施形態において、ここに記載される技術は、これらの仮定を弱める、および/または回避するように一般化され得る。
一部の実施形態において、ここに記載される技術は、競合する統計カウンタの複数の連続的なインクリメントを、NUMAシステムの1つのノードにおいて、他のノードでカウンタ更新が発生する前に促し得る。これらの連続的な更新間のノード間通信を回避することにより、一部の実施形態において、NUMAノード間の高コストな通信トラフィックが劇的に減少し、処理能力およびスケーラビリティが向上する。一部の実施形態において、これらの技術は、スペースオーバーヘッドの追加をほぼ伴わず、一般に使用されるナイーブ手法よりも良好にスケールを変更する正確な統計カウンタを提供し得る。
概して、同期することなく共用カウンタをシンプルにインクリメントすることは、マルチスレッドアプリケーションにおいては功を奏さない。なぜなら、1つのスレッドによる更新は、他のスレッドによる更新によって上書きされ得て、これによってカウンタ上の1つ以上のインクリメントの効果が失われる。一部の場合において、このようなカウンタは、ロックを用いてそれらを保護することによってスレッドセーフとなり得る。しかしながら、最新の共用メモリマルチプロセッサにおいては、コンペア・アンド・スワップ(CAS)型命令などのアトミック命令を使用してカウンタをインクリメントするほうが良い。カウンタをインクリメントするためにCAS型命令が使用される場合、インクリメントするスレッドがインクリメントの前にみることが見込まれる値をカウンタが保持し、演算がカウンタ値の更新に成功した時のみに成功が示される。それ以外に、場合によっては一部のバックオフ期間(back-off period)の後にインクリメント演算がリトライされ得る。この解決法は、シンプル、正確、およびノンブロッキングであるが、より大きく増大するNUMAシステムにスケールを変更するものではない。シングルスレッドのインクリメント演算を使用して(たとえば、カウンタを更新するために別個のロードおよび格納命令を使用して)CAS型命令のオーバーヘッドをなくしてレイテンシを減少させること(たとえば、カウンタの正確な値を知ることが必要でない場合)は、NUMAシステムにおいて多くのスレッドによって変数が変更された場合に起こる可能性が高いリモートキャッシュミスを解決する主要なコストを回避することにはならない。加えて、この手法は、単に競合時に更新の時々の損失につながるのではなく、多数のスレッド(たとえば、32以上)によって共用された場合に更新の大部分の損失につながることが示されてきた。皮肉にも、この問題は競合がインクリメントするにつれて悪化し、これはカウンタが検知することが意図されるシナリオである場合が多い。
カウンタをスケーラブルにする1つの手法は、カウンタをスレッドごとのコンポーネントに分割することであり、各スレッドは同期することなく各自のコンポーネントをインクリメントする。しかしながら、この手法にはいくつかの欠点があり得る。たとえば、カウンタがスレッドの動的セットによって使用される場合、スレッドは登録および登録取消される必要があり得て、カウンタを読み取るためにスレッドのコンポーネントを繰り返す方法が必要となり得る。加えて、この手法は、カウンタを使用するスレッドの数の要因によってスペース要件を増加させ得る。様々な実施形態において、ここに記載される技術は、異なる程度にこれらの欠点を軽減し得る。
追加のスペースオーバーヘッドが望ましくない、または許容できないとともに、カウンタが正確でなければならない状況において、ランダムバックオフ(RBO)技術が使用され、重度の競合における完全な崩壊が少なくとも回避され得る。一部の実施形態において、NUMAロックアルゴリズムまたはコホートロック(これは、所与のNUMAノード内においてロックが他のノード上で取得される前にロックを複数回にわたって渡すことによって競合下で性能およびスケーラビリティを大きく向上させる)は、RBOを採用するカウンタの競合管理を向上させ得る。たとえば、CAS型命令を使用してカウンタをインクリメントする試みにスレッドが失敗した時(たとえば、競合が生じた時)、スレッドは、コホートロックが取得された後のみにカウンタをインクリメントする試みをリトライし得て、他のノードにおける更新の前に1つのNUMAノード上における複数の更新を促し得る。この技術は、RBOの性能を向上させるのに効果的であることが示されてきた。しかしながら、コホートロックのスペースオーバーヘッドにより、この技術はここで記載する他の手法に対する利点をほとんどもたらし得ない。
一部の実施形態において、上記のNUMAロックに類似するが大きなスペースオーバーヘッドを加えない手法は、カウンタ値の数ビットを使用して、NUMAスタイルメモリアーキテクチャにおけるノードのうちいずれのノードが現在プライオリティを有しているのかを識別する。このような実施形態において、カウンタがインクリメントされると、これらのビットの値は、(通常の演算の一部として)時間の経過とともに変化し、カウンタを更新するプライオリティを他のノードに与え得る。言い換えると、いくつかのインクリメント演算の後(優先ノードを示すビットの位置に応じて)、これらのインクリメント演算の結果としてのこれらのビットの値の変化により、他のノードが優先ノードとなり得る。このような実施形態において、他のノード上のスレッドは、それらの更新を遅らせ、優先ノード上のスレッドが連続的な更新を行なう可能性を高め得る。なお、概して、優先ノードを識別するために使用されるビットは、最低位ビット(すなわち、最も頻繁に変化するもの)を含み得ないが、不合理な遅れを回避するのに十分な頻度で優先度が変化するように選択され得る。この手法は、シンプルであり、スペースオーバーヘッドを加えず、すべてのノードにわたって比較的均等にインクリメント演算が広がる時に良好に行なわれることが示された。しかしながら、均一性の低い作業負荷には良好に適さないものとなり得る。
NUMAアウェア共用カウンタ(たとえば、NUMAアウェアRBO型カウンタまたは他のタイプのNUMAアウェアカウンタ)を実施する方法の一実施形態は、図1のフロー図によって示される。110に示されるように、この例において、方法は、NUMAメモリアーキテクチャを実施するシステムの所与のノード上で実行されるスレッドが共用カウンタのインクリメントを開始することを含み得る。また、方法は、システムにおける他のノード上で実行されるスレッドがカウンタを更新するプライオリティを現在有しているか、またはカウンタを更新するプライオリティを要求したか否かをスレッドが判定することを含む(120のように)。たとえば、一部の実施形態において、カウンタの数ビットは、最も新しくカウンタを更新したスレッドが実行されたノードを識別するために使用され得る(したがって、ノードを優先ノードとして指定する)、または、カウンタの数ビットは、他の基準に基づいて優先ノードとして現在指定されているノードを識別し得る。一部の実施形態において、スレッドがカウンタを更新するプライオリティを有しているか(またはこのようなプライオリティを要求したか)を指定するために他の方法が使用され得て、この方法は、アンチスタベーション変数(ここでより詳細に記載される)の使用を含み得る。
この例において示されるように、方法は、130のように、少なくとも部分的に判定(システムにおける他のノード上で実行されるスレッドが、カウンタを更新するプライオリティを現在有しているか、またはカウンタを更新するプライオリティを要求したか)に依存し、スレッドが共用カウンタをインクリメントするように試みる、またはカウンタをインクリメントする試みを遅らせることを含み得る。たとえば、一部の実施形態において、(たとえば、カウンタにおける指定された数ビットの値に基づいて、または他の優先ノード指標に基づいて)他のノード上で実行されるスレッドがカウンタを更新するプライオリティを有している(または要求した)とスレッドが判定した場合、スレッドは、たとえば試みが成功するまで、または所定のリトライ限界に達するまで(様々な競合管理ポリシーに応じて)、カウンタをインクリメントする試みを遅らせ得る、および続いてカウンタをインクリメントする試みを1回以上リトライし得る。(たとえば、カウンタにおける指定された数ビットの値に基づいて、または他の優先ノード指標に基づいて)プライオリティが設定(または要求)されていない、またはスレッドが実行されるノードがカウンタを更新するプライオリティを現在有している(または要求している)とスレッドが判定した場合、スレッドは、カウンタをインクリメントする1つ以上の試みを進め得る(たとえば、試みのうちの1つが成功するまで、または所定のリトライ限界に達するまで)。なお、一部の実施形態において、優先ノードを識別するものとして指定されるカウンタビットの(または専用の優先ノード指標の)所定のデフォルトもしくは初期値は、プライオリティがまだ要求もしくは設定されていないことを示し得る。
ここに記載される例の多くにおいて、コンピュータシステムはプロセッサコアのクラスタに構成されるものと仮定され得て、その各々は、クラスタのローカルコア間で共用される1つ以上のキャッシュを有する。このような実施形態において、クラスタ間の通信は、クラスタ内通信よりもかなり高コストとなり得る。ここに記載の例の少なくとも一部において、「クラスタ」および「ノード」の用語は、プロセッサコアの集合を言うために使用され得て、このコアの集合は、システムにおいて実施されるNUMAマシンのサイズに応じて、単一のマルチコアチップ上のコア、または同じメモリもしくはキャッシング構造に近接するマルチコアチップの集合上のコアを含み得る。また、これらの例においては、クラスタ上のすべてのスレッドに知られる固有クラスタIDを各クラスタが有すると仮定され得る。
図2は、NUMAスタイルメモリアーキテクチャを実施するコンピュータシステムの部分を示す。この例において、コンピュータシステムは、インターコネクト250を介して互いに通信する複数のCPUボード200(200a〜200nとして示される)を含む。これらのCPUボードのうちの1つ(200a)は、他よりも詳細に示される。一部の実施形態において、CPUボード200の各々は、CPUボード200aについて示されたものと同じもしくは同様のアーキテクチャを含み得る。他の実施形態において、CPUボードの各々は、異なる数および/または配置のプロセッサチップ、プロセッサコア、キャッシュなどを含み得る。たとえば、一部の実施形態において、各プロセッサチップに密接に結合される1つ以上のメモリチップが設けられ得て、そのプロセッサコアのための「ローカルメモリ」として機能する(図示せず)。図2に示されるように、コンピュータシステムは、1つ以上のシステムメモリ260および/または他のコンポーネント270も含み得る。この例において、CPUボード200aは、インターコネクト240を介して互いに通信する4つのプロセッサチップ(プロセッサチップ210a〜210dとして示される)を含み、それらの内の1つはより詳細に示される。この例においては、プロセッサチップ210b〜210dが、プロセッサチップ210aと同様のメモリアーキテクチャを含むものとして仮定される。
図2に示される例において、プロセッサチップ210aは、8つのプロセッサコア(220a〜220hとして示される)を含み、各プロセッサコアは、それぞれ(専用の)レベル1(L1)キャッシュ(230a〜230hとして示される)を有する。各プロセッサコアは、一部の実施形態において、マルチスレッドコアであり得る。たとえば、一実施形態において、各プロセッサコアは、8つのハードウェアスレッドを同時に実行することが可能であり得る。所与のプロセッサコア220上で実行されるスレッドは、そのプロセッサコア220のためのレベル1キャッシュ230を共用し得て、プロセッサコア220およびそのハードウェアスレッドのローカルであると考えられるこのレベル1キャッシュへのアクセスは、非常に速くなり得る。加えて、8つのプロセッサコア220は、プロセッサチップ210aのためのレベル2(L2)キャッシュ240を共用し得て、各プロセッサコアのレベル1キャッシュへのアクセスほど速くはないが、このレベル2キャッシュへのアクセスも速くなり得る。この例において、同じCPUボード220上の異なるプロセッサチップ210のキャッシュへのアクセス、異なるCPUボード200上のプロセッサチップ210のキャッシュへのアクセス、および様々なシステムメモリ260へのアクセス(これらすべては、プロセッサチップ210aの特定のプロセッサコア220を実行するハードウェアスレッドに対するリモートアクセスであると考えられ得る)は、レベル1およびレベル2キャッシュならびに/またはハードウェアスレッドのローカルの他のメモリへのアクセスと比較すると、漸増的に高いレイテンシを示し得る。
上述のように、一部の実施形態において、カウンタを連続的にインクリメントするよう高い相互メモリ局所性を有するスレッド(たとえば、同じプロセッサチップ上のプロセッサコア上、または互いに近いプロセッサコア上で実行されるスレッド)を促す共用カウンタを採用することにより、NUMAアーキテクチャにおいて性能の向上が得られ、複数のスレッドがこれらのカウンタをインクリメントする試みを開始した時に全体的なキャッシュミスのレベルが減少する。NUMAアウェア共用カウンタ(たとえば、1つ以上のシステムメモリ260に常駐するカウンタデータ構造であって、その一部は、システムにおける対応のプロセッサコア上で実行されるスレッドによって更新および/または読み取られると様々なキャッシュに持ち込まれ得る)を実施するためのここに記載されるシステムおよび方法により、このような高いメモリ局所性がもたらされ得る。なぜなら、これらの技術は、単一のクラスタにおけるスレッド(たとえば、レベル1もしくはレベル2キャッシュを共用するスレッド)からのこのようなカウンタをインクリメントするよう要求のバッチを促すためである。
上記のようなNUMAアウェアRBOカウンタの一実施形態は、以下の例示的な疑似コードによってさらに示され得る。
上記の例示的な疑似コードに示されるように、一部の実施形態において、カウンタは、カウンタを更新するプライオリティを現在有するスレッドのノードの表示を格納するために使用される数ビット分が増大され得る(または、代替的にカウンタから数ビットを抜き取り、その範囲を制限する)。この手法では、NUMAノードの識別子(たとえば、ノードID)に1ビット加えたものを格納するのに十分な追加のビットのみを必要とする。
示される例において、技術は、Nビットを使用して0から
の範囲内の値を保持するカウンタを収容し得る。
たとえば、一実施形態において、カウンタは32ビットを含み得て、そのうちの3つがNUMAノードIDを格納するために抜き取られ得て、カウンタの範囲が229−1に制限される。この例において、これらの3つのビットは、カウンタが最後にインクリメントされたノードのIDをカウンタと合わせて格納するために使用され得て、識別されたノード上での連続的なインクリメントを促すために他のノード上のスレッドがカウンタをインクリメントする試みを控えることが許容および/または要求される。他の実施形態において、カウンタデータ構造の異なるビット数が使用され得て、カウンタを更新するプライオリティを現在有するスレッドのノードの識別子が格納される。
図3A〜図3Fは、ここに記載される異なるカウンタデータ構造の一部の様々な実施形態を示すブロック図である。たとえば、図3Aは、ノードIDを格納する追加のビット310の分だけカウンタ305が増大されたカウンタ構造300を示す。図3Bは、格納されたカウント値320のビットの最高位部分集合(325として示される)がカウント値フィールドから「抜き取られ」、ノードIDを示すために使用された、カウンタ構造315を示す。一部の実施形態において、このビットの部分集合は、ノードIDを格納するために確保され得て、様々なノードID値がカウンタ構造315のこの部分に明示的に書き込まれ得る(たとえば、カウント値320が更新された場合)。他の実施形態において、これらのビットの値は、カウンタ構造315に格納されるカウント値320の対応するビット値をシンプルに反映し得る。図3Cは、カウント値335の最高位ビットを含まないビットの部分集合(340として示される)がノードIDを表わすカウンタ構造330を示す。この例において、これらのビットの値は、カウンタ構造330に格納されるカウント値335の対応するビット値をシンプルに反映し得る。概して、格納されたカウント値のビットの任意の部分集合は、異なる実施形態において、ノードIDを示すものとして指定され得て、ビットの部分集合の選択は、単一ノード上で実行されるスレッドによる連続的なインクリメント演算の数に影響を与え得る。
以下により詳細に記載されるように、図3D〜図3Eは、一部の実施形態において特定の条件に応答して拡張され得るカウンタ構造を示す。たとえば、図3Dは、カウンタ部分350がカウント値または他の構造に対するポインタを格納するかを確保されたビット355が示すカウンタ構造345を示す。この例において、確保されたビット355の値がゼロであることから、カウンタ部分350はカウント値を格納する。同様に、図3Eは、カウンタ部分365がカウント値または他の構造へのポインタを格納するかをカウンタ値350の確保されたビット370が示すカウンタ構造360を示す。この例において、確保されたビット370の値が1であることから、カウンタ部分365はポインタ値を格納しており、このポインタ値が追加のカウンタ構造375へポイントする。この例において、カウンタ構造375は、380a〜380nとして示される複数のカウント値を格納する。図3Fは、一部の実施形態において、確率的カウンタを実施するために使用され得るデータ構造を示す。この例において、図3Fは、仮数部分390と指数部分396とを含むカウンタ構造385を示す。
なお、上記の例示的な疑似コードによって表されるカウンタを含む上記のNUMAアウェアカウンタの一部の実施形態において、カウンタを更新する試みを長く待ち過ぎているスレッドは性急となり得て、この点において、そのノードIDをアンチスタベーション変数へ格納し得る。このような実施形態において、各共用カウンタはこのようなアンチスタベーション変数に関連付けられ得るが、カウンタごとに別個のアンチスタベーション変数を有する必要はない。たとえば、一部の実施形態において、単一のアンチスタベーション変数が採用され得て、アンチスタベーション変数に関連付けられた1つ以上の共用カウンタを更新する試みを待つように他のノード上のスレッドに対して要求し、これによって、性急なスレッドを有するノード上のスレッドが、カウンタを含むキャッシュラインをそのノードへ持ち込み、カウンタをインクリメントすることが可能となる。しかしながら、この手法は、他のスレッド(たとえば、同じノード上の他のスレッド)が性急なスレッドの前にカウンタをインクリメントすることを防止し得るものではない(したがって、カウンタのノンブロッキング特性を確保する)。上記の発見的方法(heuristic approach)は、重度の競合下であっても実際上は飢餓を防止するものとして示された。なお、上記の疑似コードに示される例を含む一部の実施形態において、単一のグローバルアンチスタベーション変数が採用され得て、マルチスレッドアプリケーションへアクセス可能な共用カウンタの一部またはすべてを更新する試みを待つように他のノード上のスレッドに要求する。
共用カウンタをインクリメントするこのNUMAアウェア手法を採用する一部の実施形態において、性急となったスレッドと同じノード上のスレッドは、性急なスレッドがアンチスタベーション変数を設定することに応答して遅れ(たとえば、遅いバックオフ)を中止し得るとともに、直ちにカウンタのインクリメントを試み得る。このような実施形態においては、ノード上のいずれのスレッドがカウンタをインクリメントするかに関わらず、適切なキャッシュラインをノードに持ち込むという結果を有し得て、これによってそのノード上のすべてのスレッドにカウンタをインクリメントする良好な機会が与えられ得る。このような実施形態においては、性急となるスレッドが確実に次にカウンタをインクリメントするように試みるのではなく、性急なスレッドを補助するであろうインクリメントを行なう近くのスレッドが性急なスレッドの前にカウンタをインクリメントすることが許容され得る。この手法は、他のより制限的な手法よりも良好な性能を得られることが分かった。
NUMAアウェア共用カウンタをインクリメントする方法の一実施形態が、図4のフロー図によって示される。410に示されるように、この例において、方法は、NUMAスタイルメモリアーキテクチャを実施するシステムの所与のノード上で実行されるスレッドが共用カウンタのインクリメントを開始することを含み得る。方法は、415のように、他のノード上で実行されるスレッドの代わりにカウンタを更新するプライオリティを他のノード上のスレッドが要求したことをグローバル変数が示したかを判定すること(たとえば、カウンタをインクリメントする試みの一部として)を含み得る。たとえば、様々な実施形態において、アンチスタベーション変数が設定される、特定の所定値を保持する、または他のノードの識別子を保持する場合、アンチスタベーション変数は、カウンタを更新するプライオリティを他のノード上のスレッドが要求したことを示し得る。他のノード上のスレッドが他のノード上のスレッドのためのプライオリティを要求したことをグローバル変数が示す場合(415からの肯定の出口として示される)、方法は、420のように、スレッドがカウンタをインクリメントする試みを遅らせることを含み得る。たとえば、異なる実施形態において、スレッドは、所定量またはランダムな量だけ試みを遅らせ得て、その後にスレッドは共用カウンタをインクリメントするとともに(たとえば、カウンタ構造に格納されるカウント値をインクリメントすることにともなってアトミックに)、スレッドが実行されるノードを反映するようにカウンタ構造のノードID部分を更新するよう試み得る(425のように)。なお、一部の実施形態において、試みを遅らせる時間を制御する1つ以上のパラメータは、異なるノード上のスレッドによって最後の更新が行なわれたことをノードIDフィールドが示す時とは異なる値を、同じノード上のスレッドによって最後の更新が行なわれたことをノードIDフィールドが示す時に有し得る。
この例において、他のノード上のスレッドがカウンタを更新するプライオリティを要求しなかったことをグローバル変数が示す場合(415からの否定の出口として示される)、方法は、共用カウンタをインクリメントするとともに(たとえば、カウンタ構造に格納されるカウンタ値をインクリメントすることにともなってアトミックに)スレッドが実行されるノードを反映するようにカウンタ構造のノードID部分を更新するようスレッドが試みることを含み得る(425のように)。一部の実施形態において、カウント値をインクリメントするとともにカウンタ構造のノードID部分を更新する試みは、単一のCAS型演算または同様の同期演算を使用して行なわれ得る。この例に示されるように、カウンタおよびノードIDをインクリメントする試みが成功した場合(430からの肯定の出口として示される)、435のように、インクリメント演算が完了し得る。他方、カウンタおよびノードIDをインクリメントする試みが成功しなかった場合(430からの否定の出口として示される)、および他のノード上のスレッドがカウンタを更新した最も新しいスレッドであることをカウンタ構造のノードID部分が示さない場合(440からの否定の出口として示される)、方法は、460のように、カウンタをインクリメントする試みをスレッドが遅らせることを含み得る。たとえば、異なる実施形態において、スレッドは、所定量またはランダムな量だけ試みを遅らせ得て、その後にスレッドは、共用カウンタをインクリメントするとともにカウンタ構造のノードID部分を更新する試みをリトライし、スレッドが実行されるノードを反映する(460から425へのフィードバックとして示される)。
この例に示されるように、カウンタおよびノードIDをインクリメントする試みが成功しなかった場合(430からの否定の出口として示される)、および他のノード上のスレッドがカウンタを更新した最も新しいスレッドであることをカウンタ構造のノードID部分が示す場合(440からの肯定の出口として示される)、方法は、他のノード上のスレッドがノードプライオリティを要求したことをグローバル変数が示すかを判定することを含む(445のように)。そうであれば(445からの肯定の出口として示される)、方法は、460のように、カウンタをインクリメントする試みをスレッドが遅れさせることを含み得る。たとえば、異なる実施形態において、スレッドは、試みを所定量またはランダムな量だけ遅らせ得て、その後に共用のカウンタをインクリメントするとともにカウンタ構造のノードID部分を更新する試みをリトライし得て、スレッドが実行されるノードを反映する(460から425へのフィードバックとして示される)。他のノード上のスレッドがノード優先を要求したことをグローバル変数が示さなかったが(445からの否定の出口として示される)、スレッドの忍耐が尽きた場合(450からの否定の出口として示される)、方法は、460のように、カウンタをインクリメントする試みをスレッドが遅らせることを含み得る。たとえば、異なる実施形態において、スレッドは試みを所定量またはランダムな量だけ遅らせ得て、その後にスレッドは共用カウンタをインクリメントするとともにカウンタ構造のノードID部分を更新する試みをリトライし得て、スレッドが実行されるノードを反映する(460から425へのフィードバックとして示される)。それ以外に、(445からの否定の出口および450からの否定の出口として示される)方法は、スレッドが、グローバル変数を更新してノードのための優先を要求して(455のように)、460のようにカウンタをインクリメントする試みを遅らせることを含み得る。
上記の共用カウンタをインクリメントするNUMAアウェア手法は、一部の実施形態において、重度の競合下において標準的なRBO手法よりも良好な処理能力をもたらし得るが、低競合シナリオにおいて大きなオーバーヘッドが課され得る。たとえば、これまで記載した手法は、カウンタをインクリメントする各試みの前にアンチスタベーションフラグをテストすることを含む。他の実施形態において、カウンタが経験した現在、最近、または過去の競合量にインクリメント演算が依存する適応NUMAアウェア手法が採用され得る。たとえば、一部の実施形態において、適応NUMAアウェア手法は、カウンタを最も新しくインクリメントしたスレッドのノードIDを記録しない標準カウンタをインクリメントすることによって、カウンタをインクリメントする要求に最初に応答する。たとえば、カウンタデータ構造は、カウンタのノードID部分への書き込みをすることなくカウンタをインクリメントするようスレッドが試み得ることを示す初期もしくはデフォルト値に初期化され得る(たとえば、マルチスレッドアプリケーションの初期化段階において)。このような実施形態において、ノードIDが記録されていないことから、アンチスタベーション変数をチェックする必要がなくなり得る。
この適応NUMAアウェア手法において、カウンタのインクリメントに成功する前に所定回数より多く(たとえば、迅速かつ連続的に3回よりも多い回数のあと、ランダム化されたバックオフ期間を伴って16回)カウンタをインクリメントする試みをリトライするスレッドは、(ひとたび最終的に成功すると)そのノードIDをカウンタに記録する。その後、カウンタをインクリメントする後続の要求に応答して、上記の遅いながらもよりスケーラブルなNUMAアウェア技術が適用され得る。一部の実施形態において、カウンタはたまに(たとえば、周期的または様々なポリシーに従い、共用カウンタの競合の減少を含む)通常のカウンタにリセットされ得る(または戻され得る)ことから、たまに起こる競合の効果は永久には続かない。たとえば、カウンタのノードID部分は、カウンタをインクリメントするプライオリティをいずれのノード上のスレッドも有していない(または要求しなかった)ことを示す初期もしくはデフォルト値にたまにリセットされ得て、カウンタのノードID部分にこの初期もしくはデフォルト値が格納された時にカウンタをインクリメントしようと試みるスレッドは、カウンタのノードID部分へ値を書き込むことなくカウンタをインクリメントしようと試み得る。この適応NUMAアウェア手法は、すべての競合レベルにおいて、既存のRBO手法のうちの最高のものおよび上記の非適応NUMA手法と競合することが示されてきた。
共用カウンタの競合に依存するNUMAアウェア共用カウンタをインクリメントする方法の一実施形態は、図5のフロー図によって示される。510に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが共用カウンタのインクリメントを開始することを含み得る。共用カウンタのノードID部分がプライオリティを有する(または要求した)ノードを識別した場合(515からの肯定の出口として示される)、方法は、要素415で始まる、図4に示される方法のように共用カウンタをインクリメントする試みを継続することを含み得る。共用カウンタのノードID部分がプライオリティを有する(または要求した)ノードを識別しなかった場合(515からの否定の出口として示される)、方法は、520のように、スレッドが共用のカウンタをインクリメントするよう試みることを含み得る。一部の実施形態において、共用カウンタをインクリメントする試みは、CAS型演算または同様の同期演算を使用して行なわれ得る。
この例に示されるように、共用カウンタをインクリメントする試みが成功した場合(530からの肯定の出口として示される)、インクリメント演算は完了し得る(535のように)。他方、共用カウンタをインクリメントする試みが成功しなかった(530からの否定の出口として示される)がリトライ限界にまだ達していない場合(540からの否定の出口として示される)、方法は、545のように、遅れの有無に関わらず、スレッドが共用カウンタをインクリメントする試みを1回以上リトライすることを含み得る。たとえば、スレッドは、介在するバックオフ期間の有無に関わらず単一のCAS型演算または同様の同期演算を使用して共用カウンタをインクリメントする試みを繰り返し得る。これは、545から530へのフィードバックによって図5に示される。共用カウンタをインクリメントする試みが成功せず(530からの否定の出口として示される)、リトライ限界に達した場合(540からの肯定の出口として示される)、方法は、550のように、遅れの有無に関わらず、スレッドが共用カウンタをインクリメントするとともにカウンタ構造のノードID部分を更新するよう試みることを含み得て、スレッドが実行されるノードを反映する。この例に示されるように、この試みが成功しなかった場合(555からの肯定の出口として示される)、方法は、共用カウンタをインクリメントするとともにカウンタ構造のノードID部分を更新する試みを、成功するまで(または様々な適用可能なリトライもしくは競合管理ポリシーによって中止されるまで)1回以上繰り返すことを含み得る。これは、555から550へのフィードバックによって図5に示される。共用カウンタをインクリメントするとともにカウンタ構造のノードID部分を更新する試みがひとたび成功すると(555からの肯定の出口として示される)、560のように、インクリメント演算が完了し得る。
様々な実施形態において、これまで記載したカウンタは、重度の競合下において良好な単一スレッド性能およびスケーラビリティを実現し得る。しかしながら、シンプルなRBO型カウンタに対するこれらの利点は、適度な負荷がかかった状態において減少し得る。なぜなら、同一のノードに対して連続的なインクリメントを行なう機会がより少なくなり得るためである。加えて、これらのカウンタは、システム専用の調整に対して感度が高く、一部の他の手法よりも安定性が低くなり得る。他の実施形態において、一部が以下に記載される、少し大きなスペースを使用するカウンタは、これらの効果を減少または消滅させ得る。
一部の実施形態において、「マルチライン」手法と言われる手法が使用され、上記のスレッドごとのカウンタコンポーネントの欠点を招くことなく高コストなノード間通信が回避され得る。たとえば、一部の実施形態において、マルチライン手法は、NUMAノードごとに別個のカウンタコンポーネントを採用し得る。このような実施形態において、カウンタをインクリメントする試み間のランダム化されたバックオフ期間の有無に関わらず、カウンタコンポーネントの各々をインクリメントするためにCAS型命令を使用してノードごとのコンポーネントの同期が実施され得る。なお、この場合において同期のためにCAS型命令を使用する場合、ノード間競合の心配はない。マルチライン手法を採用する場合、カウンタの読み取りには、同期することなく各コンポーネントを読み取ること、および読み取られた値の合計を返すことが含まれ得る。なお、この手法の正確さは、インクリメント演算によって1のみがカウントに加えられるという仮定に依存し得る。しかしながら、この仮定が適用されない実施形態において、同じ効果に対して他の技術が採用され得る。
マルチライン手法を採用した場合のスペースの増加はノードの数によって限定されるが、まれにのみインクリメントされるカウンタについては全体的にスペースの増加を回避することが好ましいものとなり得る。一部の実施形態において、ここでは「マルチライン適応」手法と言われる適応手法が採用され得る。この手法においては、インクリメント演算は、現在、最近、または過去のカウンタの競合量に依存する。たとえば、一部の実施形態において、マルチライン適応手法は、最初は標準的カウンタを採用およびインクリメントし得て、標準的カウンタをインクリメントする所定数の試み(たとえば、一実施形態においては4回)よりも多くの回数にわたって失敗した場合にのみ上記のマルチライン技術を使用するように「拡張」され得る。たとえば、リモートキャッシュミスが頻繁に起こる場合にカウンタを拡張するなど、他のポリシーが他の実施形態において適用され得る。一部の実施形態において、カウンタを拡張することは、ノードごとに1つのカウンタを含む追加の構造を割り当てること、および標準的カウンタをその構造へのポインタと置き換えることを含み得る。一部のこのような実施形態において、初期(標準)カウンタ構造の1つのビットが確保され、追加の構造もしくはカウンタ値へのポインタを初期構造が格納するかが区別され得る。このようなカウンタの一例は、図3D〜図3Eに示されるとともに上に記載されている。
一部の実施形態において、マルチライン適応手法を採用する低競合カウンタのためのスペースオーバーヘッドが単に確保されたビットであり得て(これは、実際上はカウンタの範囲を半減させる)、高いスペースオーバーヘッドは、高い競合を経験するカウンタのみに適用され得る(様々な所定の競合管理ポリシーによる)。一部の実施形態において、マルチライン適応手法は、競合したカウンタのために追加レベルの間接指定を導入し得て、これによってカウンタのためのインクリメント演算が遅くなり得る。しかしながら、実際上、これはカウンタが競合した場合に大きな性能上の問題とはなり得ない。なぜなら、初期カウンタ構造上のCAS型インクリメント試みが減少し得るためである(これ故に、マルチスレッドアプリケーションによって経験する全体的な競合が減少する)。
競合に応答して共用カウンタを拡張する方法の一実施形態が図6のフロー図によって示される。610に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが共用カウンタのインクリメントを開始することを含み得る。一部の実施形態において、スレッドは、たとえば、介在するバックオフ期間の有無に関わらずCAS型演算を使用して、共用カウンタをインクリメントするよう試み得る(620のように)。共用カウンタをインクリメントする試みが成功した場合(630からの肯定の出口として示される)、インクリメント演算は完了し得る(635のように)。共用カウンタをインクリメントする試みが成功しなかったが(630からの否定の出口として示される)、適用可能なリトライ限界条件が満たされなかった場合(640からの否定の出口として示される)、方法は、成功するまで、またはリトライ限界条件が満たされるまで、スレッドがカウンタをインクリメントする試みを1回以上繰り返すことを含み得る。これは、640から620へのフィードバックによって図6に示される。様々な実施形態において、リトライ限界条件は、成功しなかった試みの数、キャッシュミスの数、または他の適用可能なリトライもしくは競合管理ポリシーに基づき得る。
この例において示されるように、共用カウンタをインクリメントする試みが成功せず(630からの否定の出口として示される)、適用可能なリトライ限界条件が満たされなかった場合(640からの肯定の出口として示される)、方法は、650のように、共用カウンタ(またはそのカウント部分)を、ノードごとに1つのカウンタ(すなわち、1つ以上のノードローカルカウンタ)を含む構造へのポインタと置き換えることを含み得る。たとえば、一部の実施形態において、カウンタの1ビットは、カウンタ部分の値が現在カウント値を表わす、または複数カウンタ構造へのポインタを表わすかを示すために使用され得る。方法は、660のように、成功するまでスレッドがノードローカルカウンタをインクリメントすることを1回以上試みることを含み得る。たとえば、スレッドは、介在するバックオフ期間の有無に関わらず、CAS型演算または同様の同期演算を使用して、ノードローカルカウンタをインクリメントすることを試み得る。この例に示されるように、一部の実施形態において、ノードの1つにおけるスレッドが共用カウンタの値を読み取る後続の演算は、ノードローカルカウンタのすべてを読み取ってそのカウンタ値の合計を返すことによって行なわれ得る。
一部の実施形態において、ここに記載されるマルチライン適応手法は、低レベルの競合において、スペースオーバーヘッドおよび処理能力の両方が競合し得るカウンタに対し、上記の基本的なRBOカウンタを提供し得て、これにより、増加する競合に対してスケールが良好に変更され、高い競合において基本的なRBOカウンタよりもかなり高い処理能力がもたらされる(たとえば、一部の実験においては、700倍よりも高い処理能力)。なお、一部の実施形態において、マルチラインおよびマルチライン適応手法を採用するカウンタは、単一のコンポーネントを使用する同じノード上のスレッド間での競合により、高い競合レベルとなり得る。一部のこのような実施形態において、このタイプの競合は、ノードごとのコンポーネントをより多く使用することによって緩和され得る。たとえば、ノード間のフォールスシェアリングを回避するためにノードごとのコンポーネントを別個のキャッシュラインに置かなければならないところ、1つより多いコンポーネントがノードごとに採用される場合、同じキャッシュラインにおいて単一のノードに対して複数のコンポーネントを置くことは不合理とはなり得ない。この場合においてフォールスシェアリングが幾分のオーバーヘッドを負わせ得るものであることから、1つのNUMAノード内のみとなり得る。加えて、この場合においてはCAS障害が少なくなることから、複数のコンポーネントを使用することの利益があり得る。したがって、一部の実施形態においては、この手法を使用することにより、スペース使用を増加させることなく性能を向上させることが可能となり得る。
なお、一部の実施形態において、マルチライン手法によって引き起こされる追加のスペースオーバーヘッドは、大部分が重度に競合していない多数の統計カウンタを有するシステムにおいては受け入れられ得ない。上記のマルチライン適応手法は競合するカウンタのみについてこのスペースオーバーヘッドを引き起こし得るところ、異なるカウンタが異なる回数にわたって競合した場合、これによって時間とともに過剰なオーバーヘッドが起こり得る。さらに、一部の実施形態において、これらの手法は、一部の状況において、カウンタを読み取る演算のレイテンシを増加させ得る、および/または動的に割り当てられたメモリの使用によって受け入れ不可能となり得る。以下により詳細に記載するように、一部の実施形態において、これらの問題の一部またはすべては、カウンタが正確である必要がない場合には回避され得る。
前述のように、シンプルな非同期カウンタは、通常、競合が適度なレベルにあったとしても、カウンタ更新の大部分を失う。カウンタは様々なシステム事象の過剰な割合を検知するために使用される場合が多いことから、これらのナイーブ実施は、(皮肉にも)提供すべきデータが最も重要である場合に有効性が最小となる。それにもかかわらず、一部の状況において、および一部の適用のために、正確なカウントは必要となり得ない。以下により詳細に記載するように、一部の実施形態において、カウンタは、この柔軟性を利用する一方、ナイーブカウンタ実施によって実現されない所定レベルの正確さを維持することを目的としている。
1つの既存の確率的カウンタ(「モーリス(Morris)カウンタ」と言われる場合もある)は、通常含まれるビット数(たとえば、8ビット)よりも大きな値の範囲を表わし得る。モーリスカウンタは、以下に基づいて、ここでv(n)と言われるカウント値の確率的近似を格納することによってこれを行なう。nは正確なカウントである(すなわち、対応するインクリメント演算が何度呼び出されたか)。
v(n)=log(1+n/a)/log(1+1/a)
この例において、aは、以下で説明するように、カウンタの正確性を制御する値のパラメータである。この例において、(分母にみられるように)n/aに1を加えることにより、関数が良好に定義され、n=0の時にゼロに等しくなることが保証される。加えて、log(1+1/a)で割ることにより、n=1の時に関数が1となることが保証される。言い換えると、この近似により、少なくとも0および1の値について正確な値をカウンタが含むことが保証される。この定義に続いて、カウンタに格納される値がvである時、表わされる正確なカウントは以下のとおりとなる。
n(v)=a((1+1/a)v-1)
ここでの様々な記載において、確率的カウンタに物理的に格納される値vは「格納値」と言われ得て、それが表わす値n(v)は、確率的カウンタによって「カウントされる」タイプの発生事象の数の「予測値」または「推測値」と言われ得る。言い換えると、モーリスカウンタは、確率的近似v(n)を格納し、nは正確なカウントである。この例において、この例が8ビットのみを使用するものと仮定されることから、格納値は整数でなければならない。結果として、格納値から正確なカウントを判定することはできない。このため、カウンタの値が高い格納値によって表されるように十分なインクリメントが発生したことを反映するためにカウンタに格納される値をいつインクリメントするかを知る確定的な方法はない。これらの問題に対処するために、モーリスカウンタアルゴリズムは、以下のように、カウンタが値vを含む時に、確率p(v)を用いて格納値をインクリメントする。
p(v)=1/(n(v+1)-n(v))
直観的に、これは、平均的に、モーリスカウンタに格納された値が、任意の値vが格納された後にn(v+1)−n(v)インクリメント演算からひとたび外れるとインクリメントされることを意味する。これにより、格納値によって予測される値が、正確なカウントに等しい期待値を有するランダム変数であることが保証される。各インクリメントに対する確率の演算を回避するために、この確率的カウンタを実施する既存のアルゴリズムは、所与の値aについてのすべての256通りの確率を事前に演算し、それらをルックアップテーブルに格納する。この例において、ルックアップテーブルは、各カウンタについて複製される必要はなく、各正確性クラスのみについて複製される(すなわち、aの各選択)。
この例において、パラメータaは、モーリスカウンタが表わすことのできる範囲、および予測値と実際のカウントとの間の期待誤差の両方を判定し得る。期待誤差は、予測値と実際のカウントとの間の標準偏差(STDV)間の比率として測定される(相対STDVまたはRSTDVという場合もある)。
正確なカウントがnである時の予測値の変動は、σ
2=n(n-1)/2aによって与えられ、これに続き、RSTDVは、nが大きくなるにつれおおよそ
となる。
1つの例において、a=30の正確性パラメータを選択することにより、約1/8のRSTDVがもたらされる。この例において、このaの選択により、カウンタはn(255)を表わし、これは約130,000である。8ビットのみを使用するカウンタ構造においてこれは強い効果を生むものとなり得るところ、これは近代のコンピュータシステムにおいて使用される統計カウンタの多くのタイプに対して(範囲および/または正確性の点において)満足なものとはなり得ない。以下により詳細に記載されるように、この手法は、一部の実施形態において、より大きな範囲および高い正確性を伴うスケーラブルカウンタを実施するために変更され得る。
なお、n(v)はvにおける指数であることから、モーリスカウンタに対する更新は、正確なカウントが増えるにつれて頻度が下がる。一部の実施形態において、確率的カウンタは、期待誤差を制限しながら、頻繁に更新された共用カウンタの競合を減少させるために、この特性を活用し得る。一部の実施形態において、確率的カウンタが実施され得て、上記のモーリスカウンタ手法の使用によって可能な範囲および正確性よりも大きな範囲および高い正確性を提供する。なお、より多くのカウンタビットが使用されるにつれてすべての可能な格納値について更新確率値を事前に計算することは望ましくないものとなり得ることから、より多くのビットを使用するモーリスカウンタへ上記の手法をシンプルに拡張することは、一部の状況においては受け入れ可能となり得ない。一部の実施形態において、確率的カウンタおよび以下に記載の対応するインクリメント演算は、この要件を回避するように上記の技術を拡張し得る。たとえば、以下に示すように、格納カウントをvからv+1へインクリメントする可能性は、a/(a+1)の関数を用いたvにおける等比級数であることが認められている。
このため、一部の実施形態において、所与の値p(y)について、p(v+1)の値は、シンプルに値p(v)をa/(a+1)だけインクリメントすることによって計算され得る。一部の実施形態において、この定数は、この浮動小数点割り算演算を繰り返し行なうことを回避するために事前に計算され得る。また、(たとえば、上記の)n(v)=a(1/p(v)−1)であることも認められた。このため、一部の実施形態において、確率的カウンタの格納カウンタ値vの予測値n(v)は、vを知ることなくp(y)から直接的に計算され得る。実際には、これを行なう一部の実施形態は、n(v)をvから直接的に計算するよりも約5倍の速さとなり得る。このため、一部の実施形態において、確率的カウンタにvを格納するのではなく、上記のモーリスカウンタの例のように、確率的カウンタのためのカウンタ構造が浮動小数点値p(v)を代わりに格納し得る。1つの例において、このようなカウンタ構造は、p(v)の32ビット浮動小数点表現を格納し得るが、他の実施形態においては、64ビットの倍長語を使用してp(v)の値を格納することによってさらに範囲および/または正確性が拡張され得る。一部の実施形態において、この手法を使用して、カウンタをターゲットとする各呼び出されたインクリメント演算については、カウンタに格納された値pが読み出され得て、確率pを用いてp*a/(a+1)に等しい値と置き換えられ得る。この手法は、上記のモーリスカウンタ手法と比較した場合、予測値のより速い評価を提供し得るとともに、カウンタを表わすためにbビットが使用される場合にすべての2bビットについて事前に計算および格納する必要を回避し得る。代わりに、所望のRSTDVをもたらすaの値および対応するa(a+1)の値のみを事前に計算する必要があり得る。
このような確率的カウンタの様々な実施形態において、カウンタをターゲットとする各インクリメント演算時において、格納値は、確率pを用いて更新され得て、これは格納された確率値(すなわち、最も新しく格納された値)に等しくなり得る(またはこれに依存して判定され得る)。たとえば、一実施形態において、インクリメント演算は、パラメータ(6、21、7)を伴うスレッド−ローカルXORシフト擬似乱数生成部を採用し得て、1と最大正数値MaxInt(これは、たとえば、223−1に等しい)との間の値を有する整数iを返し得る。この例において、格納値は、i/MaxInt≦pの場合に更新され得る。一部の実施形態において、確率的カウンタ構造は、(MaxInt*p)(たとえば、浮動小数点数として)を格納し得て、インクリメント演算は、格納値を更新するかを判定するためにiを格納値と比較することのみを必要とする。この格納値は、ここでは「閾値」と言われ得る。この例において、初期閾値T0=MaxIntであって、格納値が更新される時、現在値Tiは、疑似乱数生成部によって返される数が最大でTiである場合のみに値Ti+1=Ti*a/(a+1))と置き換えられ得る。一実施形態に従う、この技術を実施するために使用され得る例示的な疑似コードは、以下に示される。
浮動小数点値を格納する確率的カウンタをインクリメントする方法の一実施形態は、図7のフロー図によって示される。710に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが、浮動小数点更新確率値(ここに記載されるようなもの)を格納する共用確率的カウンタのインクリメントを開始することを含み得る。また、方法は、720のように、格納された確率値および整数乱数の値に応じて、共用カウンタがインクリメントされるべきかをスレッドが判定することを含み得る。たとえば、一部の実施形態において、判定は、値が0と所定の最大値(たとえば、maxint)との間である整数乱数変数の値に依存し得る。なお、一部の実施形態において、判定には、更新確率値の浮動小数点表示をこの整数乱数と比較する浮動小数点演算の使用が含まれ得る。共用カウンタをインクリメントすべきでないとスレッドが判定した場合(730からの否定の出口として示される)、755のようにインクリメント演算は完了し得る(すなわち、共用カウンタをインクリメントすることなく)。
この例に示されるように、共用カウンタをインクリメントすべきとスレッドが判定した場合(730からの肯定の出口として示される)、方法は、740のように、所望の正確性パーセンテージに依存する確率要因と掛け合わされた格納された更新確率値に等しい共用カウンタにおける新しい値を格納する試みによってスレッドがカウンタをインクリメントするよう試みることを含む。たとえば、一部の実施形態において、スレッドは、介在するバックオフ期間の有無に関わらず、単一のCAS型演算(または同様の同期演算)を使用して共用カウンタに新しい値を格納しようと試み得る。共用カウンタをインクリメントする試みが成功しなかった場合(750からの否定の出口として示される)、方法は、試みが成功するまで(または、図示されていないが、様々な適用可能なリトライもしくは競合管理ポリシーによって試みが中止されるまで)共用カウンタをインクリメントする試みを1回以上繰り返すことを含み得る。これは、図7の750から720へのフィードバックによって示される。なお、この場合において、方法は、(更新確率値に基づいて)格納値を更新するか(否か)の判定を繰り返すことを含み得る。なぜなら、共用カウンタをインクリメントする試みがコンフリクトによって失敗した場合、これは、以前の判定が行なわれてから他の演算(たとえば、他のスレッドのインクリメント演算)によって更新確率値が変更されたことを示し得るためである。ひとたび共用カウンタをインクリメントする試みが成功すると(750からの肯定の出口として示される)、755のように、インクリメント演算が完了し得る。この例に示されるように、一部の実施形態において、760のように、共用カウンタを読み取るスレッドの後続の演算は、格納された更新確率値を読み取り、格納された更新確率値および所望の正確性パーセンテージに応じて共用カウンタの予測値を計算することによって行なわれ得る。
上記の確率的カウンタの一部の実施形態において、Tiが小さくなり過ぎた場合には更新を回避するよう注意する必要があり得る。これによってカウンタの特性が失われ得るためである。特に、この手法は整数乱数生成部を使用することから、格納された閾値の整数部が更新によって減少しない場合、これは実際には更新の確率に影響を与え得ない。
一部の実施形態において、少なくともTi≧a+1である間はTi−Ti+1以上であることが観察された。このため、一部の実施形態において、確率的カウンタは、もはや真でない場合にはリセットされ得る。他の実施形態において、所与の状況において、および/または所与のマルチスレッドアプリケーションについてこれが好ましい場合は、この場合においてエラーが生じ得る。a=5000が選択され(たとえば、1%のRSTDVを実現するために)、32ビットカウンタが使用される例において、この閾値は、予測値がMaxInt値よりも約0.02%下回る場合には取り消され得る。したがって、ナイーブ32ビットカウンタと比較した場合、確率的カウンタは、実施されたカウンタの範囲を大きく減少させることなく、低い相対誤差および良好なスケーラビリティを実現し得る。
一部の実施形態において、ここまで記載された確率的カウンタ手法は、カウンタが競合するとともに高い値に達した時に非常に良好に仕事を実行し得るが、競合が低く予測値が低い時は標準的なCASベースのカウンタよりもかなり遅くなり得る。一部の実施形態において、この確率的カウンタのハイブリッド版(ここでは「確率適応」カウンタと言われる)が採用され得て、インクリメント演算はカウンタの現在、最近、または過去の競合量に依存する。たとえば、一部の実施形態において、この適応確率的カウンタは、標準的な同時カウンタをインクリメントすることによって(たとえば、CAS型命令を使用して)カウンタをインクリメントする要求に最初に応答し得るが、CAS演算が複数回にわたって失敗した場合(たとえば、所定のリトライ限界または他の競合管理ポリシーに基づいて)、上記の確率的カウントスキームに切り換えられ得る。たとえば、一実施形態において、確率的カウンタ構造は、64ビット語の半分を標準的カウンタに格納し、他の半分を確率的カウンタに格納する。競合に遭遇すると、インクリメント演算は、構造の標準的カウンタ部分の更新から、確率的カウンタ部分の更新へ切り換えられ得る。この例において、カウンタを読み取ることは、カウンタ構造の確率的カウンタ部分によって予測された値を構造の標準的カウンタ部分によって格納された値に加えることを含み得る。この適応手法は、特に、ごく少数のみが競合する場合が多い(または常に競合する)数千のカウンタにアクセスするマルチスレッドアプリケーションにおける使用に良好に適し得る。
カウンタの競合に応じてハイブリッドカウンタをインクリメントする方法の一実施形態は、図8のフロー図によって示される。810に示されるように、この例において、方法は、マルチスレッドアプリケーションのスレッドが、ハイブリッド共用カウンタ(たとえば、標準的カウンタ部分と確率的カウンタ部分とを含むもの)のインクリメントを開始することを含む。なお、この例および他の例において、共用カウンタのインクリメントを開始するスレッドは、複数の同時に実行されるアトミックトランザクションを集合的に表わす複数のスレッドのうちの1つであり得て、共用カウンタはこれらのトランザクションのうちの1つ以上からアクセスされ得る。また、方法は、820のように、共用カウンタの標準的カウンタ部分をインクリメントするようスレッドが試みることを含み得る(たとえば、CAS型演算または同様の同期演算を使用する)。試みが成功した場合(830からの肯定の出口として示される)、870のように、インクリメント演算が完了し得る。ハイブリッド共用カウンタの標準的カウンタ部分をインクリメントする試みが成功しなかった(830からの否定の出口として示される)が、リトライ限界条件に到達しなかった場合(840からの否定の出口として示される)、方法は、845のように、スレッドが、遅れの有無に関わらず共用カウンタの標準的カウンタ部分をインクリメントする試みを1回以上リトライすること、およびこれらの試みが成功したかどうかを判定すること(845から830へのフィードバックとして示される)を含み得る。なお、様々な実施形態において、リトライ限界条件は、1つ以上の以前のCAS型演算がカウンタの標準的部分のインクリメントに失敗したこと、および/または共用カウンタ上の競合を示す1つ以上の他の要因であり得る。
ハイブリッド共用カウンタの標準的カウンタ部分をインクリメントする試みが成功せず(830からの否定の出口として示される)、リトライ限界条件に到達した場合(840からの肯定の出口として示される)、方法は、スレットが、共用カウンタの確率的カウンタ部分をインクリメントするよう試みることによってハイブリッド共用カウンタをインクリメントするよう試みることを含み得る(850のように)。この試みが成功しなかった場合(860からの否定の出口として示される)、方法は、試みが成功するまで(または、図示されないが、様々な適用可能なリトライもしくは競合管理ポリシーによって試みが中止されるまで)、ハイブリッド共用カウンタの確率的カウンタ部分をインクリメントする試みをスレッドが繰り返すことを含み得る。これは、860から850へのフィードバックによって図8に示される。ハイブリッド共用カウンタの確率的カウンタ部分をインクリメントする試みが成功した場合(860からの肯定の出口として示される)、870のように、インクリメント演算が完了し得る。この例に示されるように、一部の実施形態において、880のように、ハイブリッド共用カウンタを読み取るスレッドの後続の演算は、標準的カウンタ部分の値および確率的カウンタ部分の値を読み取り、合計を返すことによって行なわれ得る。
上記の確率的カウンタは、それらの正確性、低競合下における性能、高競合下におけるスケーラビリティ、およびスペース使用の点から、多くの状況における使用、および多くのタイプのマルチスレッドアプリケーションに適したものとなり得る。しかしながら、他の状況において、浮動小数点演算を使用することなく同様の特性を提供する確率的カウンタがより適したものとなり得る。このため、一部の実施形態において、更新確率値は、常に2の負数乗(non-positive powers of two)となるように制限され得る。これにより、カウンタを更新するかどうかについての判断(適切な確率を伴う)することが比較的容易となり、更新する場合、浮動小数点演算を使用することなく次の更新確率値を計算することが比較的容易となり得る。2つのこのようなカウンタは、以下に記載される(対応するインクリメントおよび読み取り演算とともに)。
更新確率値について2の負数乗のみが使用される実施形態において、カウンタをインクリメントする要求に応答して、インクリメント演算は、確率整数乱数の低位kビットがすべてゼロであるかどうかを判定することにより(浮動小数点計算を行なう必要なく)、1/2kを用いてカウンタを更新するかを判断し得る。なお、この手法は、上記の手法よりもきめが粗い更新確率値を採用する。これは、a/(a+1)の要因によって減少させることとは対照的に、各更新は更新確率値を半分にするのみであるためである。更新確率値を減少させることは、性能およびスケーラビリティのためには重要である(少なくともある程度までは)。しかしながら、更新ごとに更新確率値が半減する場合、小さくなるのが速すぎることから、カウンタの正確性を減少させ得る。このため、一部の実施形態において、ここに例が記載されるこのトレードオフを管理する様々なポリシーにより、実際に減少させる前に同じ更新確率値が繰り返し使用され得る。
以下に記載される例において、カウンタ値は、2進浮動小数点(BFP)を使用して表わされ得る。たとえば、カウンタは、ペア(m,e)を格納し得て、これは予測値m*2eを表わす(すなわち、mは仮数であり、eは指数である)。mおよびeを格納するために、カウンタ変数における異なるビットフィールドが使用される。たとえば、eの値を格納するために4ビットが使用され、mの値を格納するために28ビットが使用され、カウンタ構造は、(228−1)*215までのカウンタ値、またはMaxIntの約2000倍のカウンタ値を表わすことができる。
以下に記載される例において、指数がeである場合、カウンタは確率2−eを用いて更新され得る。以前の例のように、カウンタの期待される予測値を現在までに行なわれたインクリメントの合計数と等しく維持するために、確率2−eを用いてカウンタをインクリメントする時に2eが予測値に加えられ得る。なお、様々な実施形態において、2eは、(m,e)で表わされるカウンタの予測値に対し、少なくとも2つの異なる方法によって加えられる。たとえば、1つの方法は、格納値を(m+1,e)に更新することである。mが奇数であって指数フィールドが満たされていない時のみに適用される他の方法は、カウンタを((m+1)/2,e+1)に更新することである。両方の場合において、予測値に加えられる量は、2eとして容易にみられる。この一般的な手法に基づいた以下に記載される実施形態は、カウンタを更新する時にどの方法を使用するかについて制御する1つ以上のポリシーにおいて異なり得る。
2進浮動小数点値を格納する確率的カウンタをインクリメントする方法の一実施形態は、図9のフロー図によって示される。910に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが、確率的カウンタ値を2進浮動小数点数として格納する共用確率的カウンタのインクリメントを開始することを含み得て、更新確率値は、確率的カウンタ値の指数部分から計算可能であり、2の負数乗に制限される。たとえば、一部の実施形態において、カウンタ構造は、仮数部分と指数部分とを含み得て、これらは合わせてm*2eの予測(または期待)値を表わすために使用される。また、方法は、共用確率的カウンタをインクリメントするべきかをスレッドが判定することを含み得る(920のように)。たとえば、共用確率的カウンタは、一部の実施形態において、1/2eを用いて更新され得る。
この例において、共用確率的カウンタをインクリメントすべきでないとスレッドが判定した場合(930からの否定の出口として示される)、955のようにインクリメント演算は完了し得る(すなわち、共用確率的カウンタをインクリメントすることなく)。他方、共用確率的カウンタをインクリメントすべきとスレッドが判定した場合(930からの肯定の出口として示される)、方法は、940のように、新しい予測値が以前の予測値と2eとの合計に等しくなるように、共用確率的カウンタに新しい値を格納するよう試みることにより、カウンタをインクリメントするようスレッドが試みることを含み得る。たとえば、カウンタをインクリメントする試みは、バックオフの有無に関わらずCAS型演算を使用して行なわれ得る。なお、この方法でカウンタをインクリメントすることにより(たとえば、(m,e)を((m+1)/2,e+1)に置き換えることにより)、カウンタを更新する確率が半減する。共用確率的カウンタをインクリメントする試みが成功した場合(950からの肯定の出口として示される)、インクリメント演算は完了し得る(955のように)。共用確率的カウンタをインクリメントする試みが成功しなかった場合(950からの否定の出口として示される)、方法は、試みが成功するまで(または、図示されないが、様々な適用可能なリトライまたは競合管理ポリシーによって試みが中止されるまで)共用確率的カウンタをインクリメントする試みを1回以上繰り返すことを含み得る。なお、この例において、確率的カウンタをインクリメントする試みを繰り返すことは、インクリメントを行なうか(否か)についての決定を繰り返すことを含み得る。これは、950から920へのフィードバックによって図9に示される。この例に示されるように、一部の実施形態において、960のように、共用確率的カウンタを読み取るスレッドの後続の演算は、格納された確率的カウンタ値を読み取って予測値を計算する(すなわち、この例においては、指数値によってシフトされたままの仮数値を返す)ことによって行なわれ得る。なお、この例において、これはm*2eを演算することに等しい。
一部の実施形態において、確率的カウンタ値を2進浮動小数点数として格納する確率的カウンタは、決定的更新ポリシーを採用し得て、更新確率値は、確率的カウンタ値の指数部分から計算可能である。このようなカウンタ(ここではBFP−DUPカウンタと言われる)の一例は、上記の確率的カウンタの特性と同様の特性を示し得て、たとえば、RSTDVの所望の境界が指定され得て、所望のRSTDV境界を保証しながらスケーラビリティを向上させるために、対応する更新処理は、可能な限り速く更新確率値を減少させ得る。一部の実施形態において、指定された境界を保証することは、更新確率値の減少が速くなり過ぎないよう保証することを含み得る。一部の実施形態において、更新ポリシーにより、カウンタに対する更新は、デフォルトで仮数をインクリメントさせ得る。しかしながら、仮数をインクリメントすることによって、偶数となることが必要とされ得る所定の限界(ここでは「仮数閾値」という)に到達し得る場合、インクリメント演算は、代わりに仮数を半減させ(インクリメント後)、指数をインクリメントする。この手法を使用することにより、インクリメントの第1の仮数閾値数は、確率20=1を用いてカウンタを更新し得て、誤差をもたらすことなくカウンタが仮数閾値に到達することを保証する。その後、カウンタが更新される仮数閾値/2回ごとに指数がインクリメントされ得る(および仮数が半分となり得る)。一部の実施形態において、仮数閾値の選択により、どのくらい速く指数が増加するか(およびどのくらい速く更新確率値が減少するか)が決定され得る。仮数閾値を選択する様々な方法がここに記載される。
上記のようなBFP−DUPカウンタの一実施形態は、以下に示される例示的な疑似コードによって示され得る。
複数の更新オプションを含む確率的カウンタをインクリメントする方法の一実施形態は、図10のフロー図に示される。1010に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが、確率的カウンタ値を2進浮動小数点数として格納する共用確率カウンタのインクリメントを開始することを含み得て、確率的カウンタ値の指数部分から計算可能な更新確率値は、2の負数乗に制限される。たとえば、一部の実施形態において、カウンタ構造は、仮数部分および指数部分が合わせてm*2eの予測(期待)値を表わすことを含み得る。また、方法は、格納された確率的カウンタ値および整数乱数の値に応じて、共用確率的カウンタをインクリメントすべきかをスレッドが判定することを含み得る(1020のように)。たとえば、一実施形態において、確率1/2eを用いてカウンタを更新するために、方法は、整数乱数の低位eビットがすべてゼロであるかを判定することを含み得る(浮動小数点数値演算は不要)。そうである場合、ここに記載する方法でカウンタを更新することにより、カウンタを更新する確率が半分に減少し得る。一部の実施形態において、カウンタの更新を行なうために使用される方法は、カウンタの仮数部分がインクリメントされた場合にオーバーフローし得るか、および/またはカウンタの指数部分が満たされているかに依存し得る。
この例に示されるように、共用カウンタをインクリメントすべきでない(1030からの否定の出口として示される)とスレッドが判定した場合、1080のように、インクリメント演算は完了し得る(すなわち、共用確率的カウンタをインクリメントすることなく)。他方、共用確率的カウンタをインクリメントすべきとスレッドが判定した場合(1030からの肯定の出口として示される)、および仮数をインクリメントしても正確性依存閾値に等しくならない場合(1040からの否定の出口として示される)、方法は、共用カウンタの仮数部分をインクリメントするよう試みることによってカウンタをインクリメントするようスレッドが試み得て(1070のように)、この点においてインクリメント演算が完了し得る(1080のように)。一部の実施形態において、共用カウンタの仮数部分をインクリメントする試みは、介在するバックオフ期間(図示せず)の有無に関わらず、試みが成功するまで(または様々な適用可能なリトライまたは競合管理ポリシーによって中止されるまで)CAS型演算(または同様の同期演算)を使用して1回以上行なうことであり得る。他の例のように、共用カウンタの仮数部分をインクリメントする試みが失敗すると、方法は、要素1020から始まる図10に示される演算の少なくとも一部を繰り返すことを含み得る(図示せず)。
この例に示されるように、共用確率的カウンタをインクリメントすべきであるとスレッドが判定したが(1030からの肯定の出口として示される)、仮数をインクリメントすることによって正確性依存閾値に等しくなり(1040からの肯定の出口として示される)、共用確率的カウンタの指数部分が既に最大値にある場合(1050からの肯定の出口として示される)、方法は、スレッドがカウンタをゼロにリセットすることを含み得て(1055のように)、この点においてインクリメント演算が完了し得る(1080のように)。言い換えると、方法は、(仮数,指数)ペアを(0,0)の値にリセットすることを含み得る。仮数をインクリメントすることによって正確性依存閾値に等しくなるが(1040からの肯定の出口として示される)、共用確率的カウンタの指数部分が最大値でない場合(1050からの否定の出口として示される)、方法は、仮数をインクリメントし、インクリメントされた仮数を半減させ、指数をインクリメントするよう試みることによってスレッドがカウンタをインクリメントするよう試みることを含み得て(1060のように)、その後にインクリメント演算が完了し得る(1080のように)。一部の実施形態において、共用カウンタを更新する試みは、単一のCAS型演算または同様の同期演算を使用して行なわれ得て、これは、(必要であれば)成功するまで(または、図示されないが、様々な適用可能なリトライまたは競合管理ポリシーによって試みが中止されるまで)繰り返され得る。他の例のように、共用カウンタを更新する試みが失敗した場合、方法は、要素1020から始まる図10に示される演算の少なくとも一部を繰り返すことを含み得る(図示せず)。
上記の例示的な疑似コードに示されるように、BFPカウンタクラスは、一部の実施形態において、(テンプレート引数として)RSTVD上の所望の境界をパーセンテージとして受け入れ得る(たとえば、1の正確性パラメータ値は、1%のRSTDV上の所望の境界に対応し得る)。一部の実施形態において、以下で説明するように、仮数閾値パラメータの値が所望の正確性に基づいて判定され得る。この例において、インクリメント演算(Incとして示される)は、確率1−1/2eを用いて、カウンタを更新しないように決定し得て、ここでeはカウンタ内に現在格納されている指数値である(上記の疑似コードの36〜46行目のように)。この例において、カウンタを更新する決定がなされた場合、インクリメント演算は、まず、カウンタが既に最大値に達したかをみるためにチェックを行い(52行目のように)、この場合においては、カウンタをゼロに更新するように試み得る。なお、他の実施形態において、インクリメント演算は、たとえば所与の状況において、または所与のアプリケーションのために好ましい場合は、この場合においてエラーを代わりに発信する。その他に、現在のペアに基づいて新しいペアが判定され得る(上記の56〜61行目に示されるように)。最後に、インクリメント演算は、たとえばCAS型命令を使用して新しいペアをカウンタに格納するよう試み得て、カウンタが既に変更されていないことを確認する(63行目のように)。この例において、CAS演算が失敗した場合、演算は、カウンタを更新するか(否か)についての判定から始まり、リトライされ得る。他の実施形態において、他の競合管理ポリシーが適用され得る。
一部の実施形態において、ここに記載されるインクリメント演算の様々な最適化により、全体的な性能が向上し得る。たとえば、一部の実施形態において、インクリメント演算を実施するコードは、共通の更新の場合(すなわち、カウンタを更新するCAS型演算が成功した場合)を「インライン化」し得るとともに、失敗したCAS型演算の戻値を使用し、インクリメント演算をリトライする前のカウンタデータ(たとえば、上記の例示的なコードにおけるbfpData)を再び読み取る必要を回避し得る。一部の実施形態において、同時更新(たとえば、マルチスレッドアプリケーションの他のスレッドによって更新が試みられる)に伴うコンフリクトによってCAS型演算が失敗した場合、新しい値に基づいて更新を適用すべきかを判定するテストがバックオフ前に行なわれ得るが、常にそうではない。一部の実施形態において、カウンタについての上記のすべての計算は、ビットのシフトおよびマスク演算を使用して(すなわち、浮動小数点演算なしに)行なわれ得る。
なお、上記のものと類似の既存の連続的な近似カウントアルゴリズムは、同時更新を支持せず、上記の手法よりも柔軟性が小さい。この既存のアルゴリズムにおいては、カウンタが更新された時に仮数および指数を明示的に更新するのではなく、格納値を単にインクリメントすることによって更新が行なわれる。この既存のアルゴリズムにおいては、カウンタの仮数部分がその最大値を超えてインクリメントされる場合、オーバーフローによって自然に指数フィールドがインクリメントされ得る(これを保証するために適切に配置され得る)。この選択の結果として、既存のアルゴリズムにおいて使用される更新関数は、上記のものよりも幾分シンプルとなり得る。しかしながら、時間の経過とともにカウンタの更新頻度が下がることから、性能に対する影響は小さくなり得る。既存のアルゴリズムの他の暗示としては、更新が指数をインクリメントする(および後続の演算について更新確率値を減少させる)頻度は、2の乗数とする必要がある。さらに、既存のアルゴリズムは、カウンタに格納されるデータから予測値を計算する異なる方法を実施しなければならない。なぜなら、指数がインクリメントされると格納データの仮数部分がゼロになるためである。
一部の実施形態において、ここに記載されるBFP−DUPカウンタは、指数をインクリメントする前の仮数のインクリメントを後続の指数のインクリメント間に行なわれるインクリメントの2倍行ない得て、既存のアルゴリズムは、指数の各インクリメント前に同じ数の仮数に対するインクリメントを行なう。結果として、BFP−DUPカウンタをモデル化するために使用されるマルコフ連鎖は、既存のアルゴリズムによって使用される連鎖と同様の連鎖の前に仮数閾値/2の長さの決定的連鎖を含む。しかしながら、これは限界における結果を変更し得るものではない。なぜなら、これらの仮数の決定的インクリメントは確率1で発生し、このため、カウンタの不正確性を増加させない。
上記の確率適応カウンタに関連する演算とは対照的に、このBFP−DUPカウンタにおいて、RSTDVの境界は、行なわれるインクリメント演算の数から独立し得ない。むしろ、これらの技術は、インクリメントの数nが無限大に近づくにつれて、限界における期待RSTDVの境界を提供し得る。より正確には、これは以下のとおり記載され得る。
この例において、Anは、インクリメント演算後の期待RSTDVを表わし、Mは、指数のインクリメント間の仮数(この例においては、仮数閾値/2に等しい)のインクリメントの数を表わす。一部の実施形態において、この式は、所望の境界を実現するためにMの選択を判定するために使用され得る。たとえば、上記の疑似コードにおけるBFPカウンタクラスはその正確性引数をパーセンテージとして受け入れることから(上記のとおり)、上記の式は以下を意味し得る。
M≦((30,000/正確性2)+3)/8
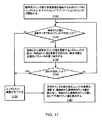
この例において、仮数閾値について対応する式は、上記の疑似コード(および仮数閾値=2M)の18行目に見つけられる。なお、一部の実施形態において、BFP−DUPカウンタは、指数のインクリメント間の仮数に対するインクリメントの数を2の乗数に制限しないことから、この手法を使用することにより、この計算に基づいて仮数閾値を選択する柔軟性が提供され得て、正確性と性能のトレードオフに対するよりきめ細かい制御が得られる。一部の実施形態において(ここに記載される様々な実験においてモデル化されたものを含む)、RSTDVに対する1%の制限を反映するように正確性パラメータ値が設定され、結果として仮数閾値が7500に設定される。
構成可能な正確性パラメータに応じて確率的カウンタをインクリメントする方法の一実施形態は、図11のフロー図によって示される。1110に示され得るように、この例において、方法は、確率的カウンタの多値表現を格納する共用カウンタのインクリメントをマルチスレッドアプリケーションのスレッドが開始することを含み得て、予測値は、格納された確率的カウンタ値から計算され得る。格納された確率的カウンタ値を更新すべきであるとスレッドが判定した場合(1120からの肯定の出口として示される)、方法は、格納された確率的カウンタ値を更新するようスレッドが試みることを含み、格納された確率的カウンタ値を更新する試みは、構成可能な正確性パラメータの値に依存する(1130のように)。なお、一部の実施形態において、格納された確率的カウンタ値を更新する試み(および/またはそれを行なう判定)は、格納された確率的カウンタ値自体(すなわち、現在格納されている値)に基づき得る。
この例に示されるように、格納された確率的カウンタ値を更新する試みが成功した場合(1140からの肯定の出口として示される)、インクリメント演算が完了し得る(1150のように)。他方、格納された確率的カウンタ値を更新する試みが成功しなかった場合(1140からの否定の出口として示される)、方法は、試みが成功するまで、または様々な適用可能なリトライもしくは競合管理ポリシーによって試みが中止されるまで、格納された確率的カウンタ値を更新する試みを繰り返すことを含み得る。なお、この例において、格納された確率的カウンタを更新する試みを繰り返すことは、更新を行なうか(否か)の判定を繰り返すことを含み得る。これは、1140から1120へのフィードバックとして図11に示される。この例に示されるように、一部の実施形態において、1160のように、共用カウンタを読み取るスレッドの後続の演算は、格納された確率的カウンタ値を読み取り、格納された確率的カウンタ値に応じて予測値を計算することによって行なわれ得る。
様々な実施形態において、BFP−DUPカウンタによって使用される決定的更新ポリシーは、様々な状況において、および様々なマルチスレッドアプリケーションにおいて使用するのが好ましい。しかしながら、スケーラビリティおよび性能のために、カウンタが増加するにつれて更新確率値を減少させることが重要である一方、所与のシステムおよび作業負荷のための一部の点において、カウンタ変数の競合は実質的にゼロに減少され得て、カウンタの更新についてのオーバーヘッドは、重要でなくなる場合がある。この点を超えて、更新確率値をさらに減少させることは、カウンタの正確性を増加させるよう作用するのみとなり得る。このため、一部の実施形態は、競合感知更新ポリシーなど、適応性および/または競合感知更新ポリシーを採用する。たとえば、一部の実施形態において、インクリメント演算は、カウンタの競合がある(またはあった)場合にのみ指数を更新する(これにより、更新確率値を減少させる)ことを選択し得る。言い換えると、適応BFPカウンタは、カウンタについての現在、最近、または過去の競合量に応じたインクリメント演算を採用し得る。たとえば、一部の実施形態において、インクリメント演算は、CAS型命令を使用して1回(または所定回数にわたって)仮数をインクリメントする(たとえば、無条件に、またはオーバーフローするまで)よう試み得て、それが失敗した場合にのみ、上記のBFP−DUPカウンタにおいて使用されるものと同様のポリシーを使用し、指数を更新して仮数を半減させるかを決定し得る。このような競合感知更新ポリシーを採用するBFPカウンタは、ここではBFP−CSUPカウンタと言われ得る。様々な実験において、BFP−CSUPカウンタは、実際に高い正確性を実現しながら、上記のBFP−DUPカウンタの性能と同様の性能をもたらし得ることが示された。
共用カウンタの競合に応じてカウンタ値を表わす2進浮動小数点値を格納する確率的カウンタをインクリメントする方法の一実施形態は、図12のフロー図によって示される。1210に示されるように、この例において、方法は、所与のノード上で実行されるスレッドが確率的カウンタ値を2進浮動小数点数として格納する共用確率的カウンタのインクリメントを開始することを含み得て、確率的カウンタ値の指数部分から計算可能な更新確率値は、2の負数乗となるように制限される。たとえば、一部の実施形態において、カウンタ構造は仮数部分と指数部分とを含み得て、これらは合わせてm*2eの予測(期待)値を表わす。カウンタの仮数部分をインクリメントすることによって値が正確性依存閾値に等しくなる場合(1220からの肯定の出口として示される)、方法は、要素1040から始まる図10に示される方法のように共用確率的カウンタをインクリメントする試みを継続することを含み得る。
この例に示されるように、カウンタの仮数部分をインクリメントしてもその値が正確性依存閾値に等しくならない場合(1220からの否定の出口として示される)、方法は、仮数をインクリメントする試みを1回以上行なうことによってスレッドが共用確率的カウンタをインクリメントするよう試みることが含まれ得る(1230のように)。様々な実施形態において、スレッドが試みをリトライし得る回数は、1つ以上の適用可能なリトライもしくは競合管理ポリシーに依存し得て、介在するバックオフ期間の有無に関わらず複数のリトライの試みが行なわれ得る。スレッドが共用確率的カウンタのインクリメントに成功した場合(1240からの肯定の出口として示される)、インクリメント演算は完了し得る(1250のように)。スレッドが共用確率的カウンタのインクリメントに成功しなかった場合(1240からの否定の出口として示される)、方法は、要素1040から始まる図10に示される方法のように共用確率的カウンタをインクリメントする試みを継続することを含み得る。
異なる実施形態において、現在、最近、または過去の競合に基づき、統計カウンタを更新するか、いつ更新するか、および/またはどのように更新するかを判定するために、様々な競合感知法が適用され得る。共用カウンタの競合に応じて共用カウンタをインクリメントするか(および/またはいつインクリメントするか)を判定するとともに共用カウンタをインクリメントする方法の一実施形態は、図13のフロー図によって示される。1310に示されるように、この例において、方法は、マルチスレッドアプリケーションの複数の同時に実行されるスレッドのうちの1つが共用カウンタのインクリメントを開始することを含み得る。一部の実施形態において、スレッドは、複数の同時に実行されるアトミックトランザクションを集合的に実施する複数のスレッドのうちの1つであり得る。方法は、スレッドが共用カウンタを更新するか、またはいつ更新するかを判定することを含み得て、共用カウンタを更新するか、またはいつ更新するかを判定する方法は、同時に実行されるスレッド間の共用カウンタの競合の量に依存する(1320のように)。たとえば、方法は、現在、最近、または過去の共用カウンタの競合に少なくとも部分的に依存し得る。
共用カウンタを更新すべきでないとスレッドが判定した場合(1330からの否定の出口として示される)、1360のように、インクリメント演算は完了し得る(すなわち、共用カウンタを更新することなく)。他方、共用カウンタを更新すべきとスレッドが判定した場合(1330からの肯定の出口として示される)、方法は、スレッドが共用カウンタを更新するよう試みることを含み得て、共用カウンタを更新するよう試みる方法は、同時に実行されるスレッド間における共用カウンタの競合の量に依存する(1340のように)。再び、方法は、現在、最近、または過去の共用カウンタの競合に少なくとも部分的に依存し得る。この例に示されるように、共用カウンタを更新する試みが成功した場合(1350からの肯定の出口として示される)、インクリメント演算は完了し得る(1360のように)。他方、共用カウンタを更新する試みが成功しなかった場合(1350からの否定の出口として示される)、方法は、試みが成功するまで(または、図示されないが、様々な適用可能なリトライまたは競合管理ポリシーによって試みが中止されるまで)共用カウンタを更新する試みをスレッドが1回以上リトライすることを含み得る。なお、この例において、共用カウンタを更新する試みを繰り返すことは、カウンタを更新するか(否か)、またはカウンタをいつ更新するかについての判定を繰り返すことを含み得る。これは、1350から1320へのフィードバックによって図13に示される。なお、一部の実施形態において、試みのリトライの性能(および/または試みがリトライされ得る回数)は、カウンタの競合の量(この最も新しい失敗を引き起こした競合を含む)に依存し得る。なお、図13に示される例においては、1320に示される演算および1340に示される演算は、カウンタの競合の量に依存するものとして記載されるが、他の実施形態において、これらの演算のうちの1つのみが、現在、最近、または過去のカウンタの競合の量に依存し得る。
ここに記載される例の大部分は、多くのカウンタがあって、そのうちの一部が頻繁にインクリメントされる状況における使用に統計カウンタを実施する技術に焦点を当ててきた。このため、例は、低いスペースオーバーヘッド、競合がない場合における低いオーバーヘッド、および重度の競合下における良好なスケーラビリティを示す技術を含む。これらの技術は必ずしも読み取り性能(たとえば、カウンタをターゲットとした読み取り動作)のために最適化されなかったが、一部の実施形態において、これらの読み取り動作に関連付けられたコストは、ここに記載される技術の多くにおいて合理的に低いものとなり得る。
なお、概して、カウンタの値を引き出すコストについては、2つの主な構成部分があり得る。1つの構成部分は、必要なデータを読み取るコストに関連付けられたコストであり、他の構成部分は、読み取られたデータから戻値を計算することに関連付けられたコストである。ここに記載されるシナリオの多くにおいて、まずこれらのコストが所与のカウンタに関連付けられたカウント値を引き出すコストを左右する可能性が高い。なぜなら、カウンタ下にあるデータは、読み取り演算を実行するスレッドのキャッシュにない可能性が高いためである。このため、データは、メモリから、または他のキャッシュから取ってくる必要があり得て、システムにおいて異なるNUMAノードにあり得る。
なお、既存のナイーブカウンタの値を読み取ることは、カウンタ自体に格納されたデータを読み取り、読み取られた値を返すことを単に含み得る。これ故に、読み取りコストは(最大でも)単一のキャッシュミスのコストである。一部の実施形態において、ここに記載されるNUMAアウェアRBO型カウンタもしくは適応NUMAアウェアRBO型カウンタ、またはここでBFP−DUPおよびBFP−CSUPと言われる手法を採用するカウンタは単一のキャッシュミスのコストも引き起こし得るが、これらのカウンタはカウンタ予測値を判定するための様々なマスクおよび/またはシフト動作のコストも引き起こし得る。ここに記載されるマルチラインカウンタを読み取ることは、カウンタ下のキャッシュラインの各々を読み取ることを必要とし得る。しかしながら、これらは独立した読み取りであり、ほとんどの最新のアーキテクチャにおいては並行して大きく解消され得る。ここに記載するマルチライン適応手法を採用するカウンタ上のリード演算は、拡張される更新の競合を十分にカウンタが経験しない限り既存のシンプルなカウンタのものと同様であり、この場合、リード演算は、カウンタに割り当てられた複数のキャッシュラインだけでなく、どこにあるかを判定するポインタも読み取らなければならない。割り当てられたキャッシュラインのリード演算は、ポインタの値に依存し、このため、リード演算のレイテンシは、すべての割り当てられたラインが平行に読み取りを行なう場合であっても、連続的に少なくとも2つのキャッシュミスのコストを含む可能性が高くなり得る。モーリスおよび「確率適応」カウンタをターゲットとしたリード演算は、両方とも、頻繁に実行された場合に顕著なオーバーヘッドを加える可能性の高い複数の浮動小数点演算を含み得る。このため、BFPベースのカウンタは、このようなシナリオにおいて好ましいものとなり得る。代替的に、(実質的に)カウンタの格納値が稀にのみ変更され得る(たとえば、更新確率値が十分に減少した後)と仮定すると、格納値から計算された予測値を記録する最適化は有益となり得る。
一部の実施形態において、ここに記載されるスケーラブル統計カウンタは、トランザクションメモリ支持がハードウェア、ソフトウェア、またはハードウェアおよびソフトウェアの両方の組み合わせのいずれを用いて実施されても、トランザクションメモリ支持を含むシステムにおいて使用された場合に特に価値あるものとなり得る。たとえば、統計カウンタは、ハッシュ表におけるエントリの数の記録、または特定のコードがどのくらい頻繁に実行されるかについての統計を維持するなど、このようなシステムにおける様々な目的に使用され得る。アトミックトランザクション内のカウンタの使用がすべてのトランザクションのペアがカウンタを更新することからコンフリクトさせるという共通の経験がある。ここに記述されるように、カウンタは、複数の更新が並行して発生し得るように分割する(上記のマルチライン手法のように)、または更新の頻度を減少させることで(ここに記載の確率的カウンタのように)競合を減少させることにより、よりスケーラブルものとなり得る。一部の実施形態において、これらの技術は、ナイーブ非スケーラブルカウンタを採用するトランザクションと比較し、これらのカウンタを使用したアトミックトランザクションが互いにコンフリクトする頻度を大きく減少させるという副作用を有し得て、これによって通常はスケールがとぼしくなる、および/または高度に不正確なカウントがもたらされる。
様々な実施形態において、様々なカウンタ技術(そのうちの一部は正確なカウントを提供し、そのうちの他の部分は合理的な相対誤差に向けられ、多数回にわたってインクリメントされるカウント値を検知する目的において有用である)は、ナイーブ同時カウンタよりもスケーラビリティおよび/または正確性の点において良好な結果をもたらし得る。ここに記載のカウンタのうちのいくつかは、特にNUMAシステムにおいて、スペースオーバーヘッドを低く保ちながら、処理能力および正確性の点において、一般に使用される統計カウンタよりも劇的に優れたものとなり得る。
ここに記載のカウンタ技術の多くは、ロックフリーであることが容易に分かる。さらに、ここに記載の確率的カウンタ技術を採用した場合、カウンタをインクリメントする試みをリトライする必要が時間の経過とともに下がり、これはカウンタの更新確率値が時間の経過とともに下がるためである(特に、上記のBFP−CSUP技術を採用するカウンタに競合がある場合)。一部の実施形態において、ここに記載されるカウンタは、待機フリーとなるように変更され得て、これは一部の場合においてオーバーヘッドおよび/または複雑性を加え得る。カウンタを待機フリーとなるように変更することにより、付加的な制約がもたらされ得る(事前にスレッドの最大値を知る必要があるなど)、またはこのような制約を回避するためにさらなるオーバーヘッドおよび複雑性が必要となり得る。しかしながら、実際上、ロックフリーとすることは、一部の実施形態において、マルチスレッドアプリケーションの同時スレッドの進行を保証するのに十分に強い特性となり得る。ただし、カウンタに競合がある場合には、一部のタイプのバックオフスキームが適用され得る。
図14は、様々な実施形態による、ここに記載される方法を実施するように構成されたコンピューティングシステムを示す。コンピュータシステム1400は、パーソナルコンピュータシステム、デスクトップコンピュータ、ラップトップもしくはノート型コンピュータ、メインフレームコンピュータシステム、ハンドヘルドコンピュータ、ワークステーション、ネットワークコンピュータ、消費者機器、アプリケーションサーバ、記憶装置、スイッチ、モデム、ルータなどの周辺機器、または一般の任意のタイプの計算装置を含む様々なタイプの装置であり得るが、これらに限定されない。一部の実施形態において、コンピュータシステム1400は、NUMAスタイルメモリアーキテクチャおよび/またはNUCA特性を採用するシステムにおける複数のノードのうちの1つ、または概して一部のタイプのメモリ(たとえば、キャッシュ、ローカルメモリ、リモートメモリなど)に結合された少なくとも1つのプロセッサコアを含む任意のタイプの計算ノードであり得る。
ここに記載のスケーラブル統計カウンタのいずれかまたはすべてを実施する機構は、様々な実施形態に係る処理を行なうコンピュータシステム(または他の電子機器)をプログラミングするために使用され得る命令を格納する、非一時的コンピュータ読み取り可能記憶媒体を含み得る、コンピュータプログラム製品またはソフトウェアとして提供され得る。コンピュータ読み取り可能記憶媒体は、マシン(たとえば、コンピュータ)によって読み取り可能な形式の情報(たとえば、ソフトウェア、処理アプリケーション)を格納する任意の機構を含み得る。マシン読み取り可能記憶媒体は、磁気記憶媒体(たとえば、フロッピー(登録商標)ディスケット)、光記憶媒体(たとえば、CD−ROM)、光磁気記憶媒体、読み取り専用メモリ(ROM)、ランダムアクセスメモリ(RAM)、消去およびプログラム可能メモリ(たとえば、EPROMおよびEEPROM)、フラッシュメモリ、プログラム命令を格納するのに適した電気的もしくは他のタイプの媒体を含み得るが、これらに限定されない。加えて、プログラム命令は、光、音、または他の形式の伝播信号(たとえば、搬送波、赤外線信号、デジタル信号など)を使用して伝達され得る。
様々な実施形態において、コンピュータシステム1400は、1つ以上のプロセッサ1470を含み得て、各々はマルチコアを含み得て、そのうちのいずれかはシングルもしくはマルチスレッドであり得る。たとえば、図2に示されるように、複数のプロセッサコアは、単一のプロセッサチップ(たとえば、単一のプロセッサ1470)に含まれ得て、複数のプロセッサチップはCPUボード上に含まれ得て、そのうちの2つ以上はコンピュータシステム1400に含まれ得る。プロセッサ1470の各々は、様々な実施形態において、キャッシュの階層を含み得る。たとえば、図2に示されるように、各プロセッサチップ1470は、複数のL1キャッシュ(たとえば、プロセッサコアごとに1つ)と、単一のL2キャッシュ(プロセッサチップ上でプロセッサコアによって共有され得る)とを含み得る。コンピュータシステム1400は、1つ以上の持続的記憶装置1450(たとえば、光学記憶装置、磁気記憶装置、ハードドライブ、テープドライブ、ソリッドステートメモリなど)と、1つ以上のシステムメモリ1410(たとえば、キャッシュ、SRAM、DRAM、RDRAM、EDORAM、DDR10RAM、SDRAM、ラムバスRAM、EEPROMなどのうちの1つ以上)とを含み得る。様々な実施形態は、より少ないコンポーネント、または図14に示されない付加的なコンポーネントを含み得る(たとえば、ビデオカード、音声カード、付加的なネットワークインターフェイス、周辺機器、ATMインターフェイス、イーサネット(登録商標)インターフェイス、フレームリレーインターフェイスなどのネットワークインターフェイス)。
1つ以上のプロセッサ1470、記憶装置1450、およびシステムメモリ1410は、システムインターコネクト1440に結合され得る。システムメモリ1410のうちの1つ以上は、プログラム命令1420を含み得る。プログラム命令1420は、1つ以上のアプリケーション1422(ここに記載されるように、共用統計カウンタへの1つ以上のアクセスを含み得る)、共有ライブラリ1424、またはオペレーティングシステム1426を実施するよう実行可能であり得る。一部の実施形態において、プログラム命令1420は、競合マネージャ(図示せず)を実施するよう実行可能であり得る。プログラム命令1420は、プラットフォームネイティブバイナリ、Java(登録商標)バイトコードなどの任意のインタープリタ型言語、またはC/C++やJava(登録商標)などの他の言語、またはこれらの任意の組み合わせにコード化され得る。プログラム命令1420は、ここに記載されるように、スケーラブル統計カウンタおよび関連付けられた関数を実施する関数、演算、および/または他の処理(たとえば、スケーラブル統計カウンタをターゲットとしたインクリメント演算および/またはリード演算)を含み得る。このような支持および関数は、様々な実施形態において、共有ライブラリ1424、オペレーティングシステム1426、またはアプリケーション1422のうちの1つ以上に存在し得る。システムメモリ1410は、データが格納され得るプライベートメモリロケーション1430および/または共有メモリロケーション1435をさらに含み得る。たとえば、様々な実施形態において、共有メモリロケーション1435は、同時に実行されるスレッド、処理、またはアトミックトランザクションにアクセス可能なデータを格納し得て、共用統計カウンタ(たとえば、ここに記載される正確カウンタまたは確率的カウンタのうちの1つ)を実施する1つ以上の構造に格納されるデータを含み得る。
上記の実施形態は、かなり詳細に記載されたが、当業者が上記の開示をひとたび完全に理解すると、多くの変形および変更が明白となる。すべてのこのような変形および変更を含むように以下の請求項が解釈されることが意図される。