JP6271812B2 - 透過的画素フォーマット変換器 - Google Patents
透過的画素フォーマット変換器 Download PDFInfo
- Publication number
- JP6271812B2 JP6271812B2 JP2017517240A JP2017517240A JP6271812B2 JP 6271812 B2 JP6271812 B2 JP 6271812B2 JP 2017517240 A JP2017517240 A JP 2017517240A JP 2017517240 A JP2017517240 A JP 2017517240A JP 6271812 B2 JP6271812 B2 JP 6271812B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- format
- address
- processor
- data format
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/60—Memory management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/1027—Address translation using associative or pseudo-associative address translation means, e.g. translation look-aside buffer [TLB]
- G06F12/1036—Address translation using associative or pseudo-associative address translation means, e.g. translation look-aside buffer [TLB] for multiple virtual address spaces, e.g. segmentation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/10—Address translation
- G06F12/109—Address translation for multiple virtual address spaces, e.g. segmentation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/65—Details of virtual memory and virtual address translation
- G06F2212/657—Virtual address space management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2200/00—Indexing scheme for image data processing or generation, in general
- G06T2200/28—Indexing scheme for image data processing or generation, in general involving image processing hardware
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Image Generation (AREA)
- Image Processing (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Description
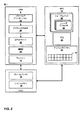
[0039] グラフィックスメモリ40は、GPU12の集積回路に物理的に統合されたオンチップ記憶装置、またはメモリを含み得る。グラフィックスメモリ40がオンチップである場合、GPU12は、システムバスを介してシステムメモリ10から値を読み取ること、またはシステムメモリ10に値を書き込むことより速くグラフィックスメモリ40から値を読み取り、またはグラフィックスメモリ40に値を書き込むことが可能であり得る。
言替えると、CPU6は、TFC24を通じて、グラフィックスメモリ40に保存された画素データを、それがサポートする画素フォーマットで読み書き可能である。例えば、画素データがグラフィックスメモリ40にタイル画素フォーマットで保存される場合であって、CPU6がNV12のような線形画素フォーマットをサポートする場合に、TFC24は、画素データ41がCPU6によってサポートされるNV12のような線形フォーマットで整列されてCPU6に現れるようにして、画素データ41の線形ベースビューをCPU6に提供し得る。TFC24は、CPU6によってサポートされる画素フォーマットに従う画素データ41に対するCPU6によるどの書き込みもそれがグラフィックメモリ40に保存されるフォーマットに戻すように翻訳し得る。このため、TFC24は、画素データ41がCPU6によってサポートされる画素フォーマットにあったかのように画素データ41を扱うことをCPU6にイネーブルして、画素データ41がCPU6によってサポートされない画素フォーマットでグラフィックスメモリ40に保存される一方でCPU6が画素データ41をCPU6によってサポートされる画素フォーマットに従って読み書きできるようにする。
[0069] 本開示の技法は、ワイヤレスハンドセット、集積回路(IC)またはICsのセット(例えば、チップセット)を含む、幅広い様々なデバイスまたは装置で実施され得る。様々なコンポーネント、モジュール、またはユニットは、開示された技法を行うように構成されるデバイスの機能的な態様を強調するように本開示において説明されるが、必ずしも異なるハードウェアユニットによる実現を必要としない。むしろ、上に説明されたように、様々なユニットは、コーデックハードウェアユニットに組み合わされ得るか、または適切なソフトウェアおよび/またはファームウェアと併せて、上に説明されたような1つまたは複数のプロセッサを含む、相互運用のハードウェアユニット(interoperative hardware units)の集合によって提供され得る。
以下に本願の出願当初の特許請求の範囲に記載された発明を付記する。
[C1] 画素処理のための方法であって、
第1のデータバッファに保存されたデータに関する、少なくとも1つのプロセッサによる要求が第1のデータフォーマットにある前記データに関する要求を示すものであると、透過的フォーマット変換器(TFC)によって、決定することと、
前記第1のデータバッファに保存されたデータに関する前記要求に少なくとも一部基づいて、第2のデータフォーマットにある前記データを前記第1のデータバッファから、前記TFCによって、取得することと、
前記取得されたデータを前記第2のデータフォーマットから前記第1のデータフォーマットへ、前記TFCによって、変換することと、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに、前記TFCによって、保存することと
を備える、方法。
[C2] 前記第1のデータバッファに保存されたデータに関する、前記少なくとも1つのプロセッサによる前記要求は、仮想アドレスに保存されたデータに関する要求を備え、
前記第2のデータフォーマットにある前記データを前記第1のデータバッファから、前記TFCによって、取得することは、前記第2のデータフォーマットにある前記データを、前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから、前記TFCによって、取得することをさらに備える、C1に記載の方法。
[C3] 前記仮想アドレスに少なくとも一部基づいて翻訳されたアドレスを、メモリ管理ユニット(MMU)によって、決定することと、
前記翻訳されたアドレスに少なくとも一部基づいて前記物理アドレスを、前記TFCによって、決定することと
をさらに備える、C2に記載の方法。
[C4] 前記翻訳されたアドレスの1つまたは複数の最上位ビットは1つまたは複数のカラービットを備え、前記1つまたは複数のカラービットは前記1つまたは複数のプロセッサによってサポートされた少なくとも画素フォーマットをインジケートする、C3に記載の方法。
[C5] 前記翻訳されたアドレスを決定することは、前記仮想アドレスに少なくとも一部基づいて前記1つまたは複数のカラービットを、MMUによって、決定することをさらに備える、C3に記載の方法。
[C6] 前記仮想アドレスに少なくとも一部基づいて中間物理アドレスを、第1のレベルページテーブルを使用するMMUによって、決定することと、
前記中間物理アドレスに少なくとも一部基づいて前記翻訳されたアドレスを、第2のレベルページテーブルを使用するMMUによって、決定することとをさらに備える、C3に記載の方法。
[C7] 前記翻訳されたアドレスに少なくとも一部基づいて前記物理アドレスを、前記TFCによって、決定することは、1つまたは複数のページテーブルのカーネルアドレス空間部分に少なくとも一部基づいて前記物理アドレスを、前記TFCによって、決定することをさらに備える、C3に記載の方法。
[C8] 前記第2のデータバッファは前記少なくとも1つのプロセッサのためのキャッシュを備える、C1に記載の方法。
[C9] 前記データは画素データを備え、
前記第1のデータフォーマットは第1の画素フォーマットを備え、
前記第2のデータフォーマットは第2の画素フォーマットを備える、C1に記載の方法。
[C10] 前記第1のデータフォーマットにある第2のデータを、前記少なくとも1つのプロセッサから前記TFCによって、受け取ることと、
前記第2のデータを前記第1のデータフォーマットから前記第2のデータフォーマットへ、前記TFCによって、変換することと、
前記第2のデータフォーマットにある前記変換されたデータを前記第1のデータバッファに、前記TFCによって、保存することと
をさらに備える、C1に記載の方法。
[C11] 第1のデータバッファと、
第2のデータバッファと、
少なくとも1つのプロセッサと、
前記第1のデータバッファに保存されたデータに関する、少なくとも1つのプロセッサによる要求が第1のデータフォーマットにある前記データに関する要求を示すものであると決定し、
前記第1のデータバッファに保存されたデータに関する前記要求に少なくとも一部基づいて、第2のデータフォーマットにある前記データを前記第1のデータバッファから取得し、
前記取得されたデータを前記第2のデータフォーマットから前記第1のデータフォーマットへ変換し、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である前記第2のデータバッファに保存するように構成される透過的フォーマット変換器と
を備える、計算デバイス。
[C12] 前記第1のデータバッファに保存されたデータに関する、前記少なくとも1つのプロセッサによる前記要求は、仮想アドレスに保存されたデータに関する要求を備え、
前記TFCは、前記第2のデータフォーマットにある前記データを、前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから取得するようにさらに構成される、C11に記載の計算デバイス。
[C13] 前記仮想アドレスに少なくとも一部基づいて翻訳されたアドレスを決定するように構成されるメモリ管理ユニット(MMU)をさらに備え、
前記TFCは、前記翻訳されたアドレスに少なくとも一部基づいて前記物理アドレスを決定するようにさらに構成される、C12に記載の計算デバイス。
[C14] 前記翻訳されたアドレスの1つまたは複数の最上位ビットは1つまたは複数のカラービットを備え、前記1つまたは複数のカラービットは前記1つまたは複数のプロセッサによってサポートされた少なくとも画素フォーマットをインジケートする、C13に記載の計算デバイス。
[C15] 前記MMUは、前記仮想アドレスに少なくとも一部基づいて前記1つまたは複数のカラービットを決定するようにさらに構成される、C13に記載の計算デバイス。
[C16] 前記MMUは、
第1のレベルページテーブルを使用し、前記仮想アドレスに少なくとも一部基づいて中間物理アドレスを決定し、
第2のレベルページテーブルを使用し、前記中間物理アドレスに少なくとも一部基づいて前記翻訳されたアドレスを決定する
ようにさらに構成される、C13に記載の計算デバイス。
[C17] 前記TFCは、1つまたは複数のページテーブルのカーネルアドレス空間部分に少なくとも一部基づいて前記物理アドレスを決定するようにさらに構成される、C13に記載の計算デバイス。
[C18] 前記第2のデータバッファは前記少なくとも1つのプロセッサのためのキャッシュを備える、C11に記載の計算デバイス。
[C19] 前記データは画素データを備え、
前記第1のデータフォーマットは第1の画素フォーマットを備え、
前記第2のデータフォーマットは第2の画素フォーマットを備える、C11に記載の計算デバイス。
[C20] 前記TFCは、
前記第1のデータフォーマットにある第2のデータを前記少なくとも1つのプロセッサから受け取り、
前記第2のデータを前記第1のデータフォーマットから前記第2のデータフォーマットへ変換し、
前記第2のデータフォーマットにある前記変換されたデータを前記第1のデータバッファに保存する
ようにさらに構成される、C11に記載の計算デバイス。
[C21] 第1のデータバッファに保存されたデータに関する、少なくとも1つのプロセッサによる要求が第1のデータフォーマットにある前記データに関する要求を示すものであると決定するための手段と、
前記第1のデータバッファに保存されたデータに関する前記要求に少なくとも一部基づいて、第2のデータフォーマットにある前記データを前記第1のデータバッファから取得するための手段と、
前記取得されたデータを前記第2のデータフォーマットから前記第1のデータフォーマットへ変換するための手段と、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに保存するための手段と
を備える、装置。
[C22] 前記第1のデータバッファに保存されたデータに関する、前記少なくとも1つのプロセッサによる前記要求は、仮想アドレスに保存されたデータに関する要求を備え、
前記第2のデータフォーマットにある前記データを前記第1のデータバッファから取得するための前記手段は、前記第2のデータフォーマットにある前記データを、前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから取得するための手段をさらに備える、C21に記載の装置。
[C23] 前記仮想アドレスに少なくとも一部基づいて翻訳されたアドレスを決定するための手段と、
前記翻訳されたアドレスに少なくとも一部基づいて前記物理アドレスを決定するための手段と
をさらに備える、C22に記載の装置。
[C24] 前記翻訳されたアドレスの1つまたは複数の最上位ビットは1つまたは複数のカラービットを備え、前記1つまたは複数のカラービットは前記1つまたは複数のプロセッサによってサポートされた少なくとも画素フォーマットをインジケートする、C23に記載の装置。
[C25] 前記翻訳されたアドレスを決定するための前記手段は、前記仮想アドレスに少なくとも一部基づいて前記1つまたは複数のカラービットを決定するための手段をさらに備える、C23に記載の装置。
[C26] 第1のデータバッファに保存されたデータに関する、少なくとも1つのプロセッサによる要求が第1のデータフォーマットにある前記データに関する要求を示すものであると、透過的フォーマット変換器(TFC)によって、決定することと、
前記第1のデータバッファに保存されたデータに関する前記要求に少なくとも一部基づいて、第2のデータフォーマットにある前記データを前記第1のデータバッファから、前記TFCによって、取得することと、
前記取得されたデータを前記第2のデータフォーマットから前記第1のデータフォーマットへ、前記TFCによって、変換することと、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに、前記TFCによって、保存することと
をプログラマブルプロセッサにさせるための命令を備える、コンピュータ可読媒体。
[C27] 前記第1のデータバッファに保存されたデータに関する、前記少なくとも1つのプロセッサによる前記要求は、仮想アドレスに保存されたデータに関する要求を備え、
前記第2のデータフォーマットにある前記データを前記第1のデータバッファから、前記TFCによって、取得することは、前記第2のデータフォーマットにある前記データを、前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから、前記TFCによって、取得することをさらに備える、C26に記載のコンピュータ可読媒体。
[C28] 前記仮想アドレスに少なくとも一部基づいて翻訳されたアドレスを、メモリ管理ユニット(MMU)によって、決定することと、
前記翻訳されたアドレスに少なくとも一部基づいて前記物理アドレスを、前記TFCによって、決定することと
をさらに備える、C27に記載のコンピュータ可読媒体。
[C29] 前記翻訳されたアドレスの1つまたは複数の最上位ビットは1つまたは複数のカラービットを備え、前記1つまたは複数のカラービットは前記1つまたは複数のプロセッサによってサポートされた少なくとも画素フォーマットをインジケートする、C28に記載のコンピュータ可読媒体。
[C30] 前記翻訳されたアドレスを決定することは、前記仮想アドレスに少なくとも一部基づいて前記1つまたは複数のカラービットを、MMUによって、決定することをさらに備える、C28に記載のコンピュータ可読媒体。
Claims (14)
- 画素処理のための方法であって、
第1のデータフォーマットをサポートする少なくとも1つのプロセッサから、第1のデータバッファに保存されたデータに関する要求を、グラフィックス処理ユニット(GPU)によって受信することと、ここにおいて、前記要求は、前記データの仮想アドレスを備える、
前記第1のデータフォーマットと関連する仮想アドレス範囲内にある、前記データの前記仮想アドレスに少なくとも一部基づいて、前記少なくとも1つのプロセッサによってサポートされる前記第1のデータフォーマットをインジケートする1つまたは複数のカラービットを、前記GPUのメモリ管理ユニット(MMU)によって、決定することと、
前記1つまたは複数のカラービットに連結される前記データの前記仮想アドレスで構成される、翻訳されたアドレスを、前記MMUによって、決定することと、
第2のデータフォーマットにある前記データを、前記翻訳されたアドレスにおける前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから、透過的フォーマット変換器(TFC)によって、取得することと、
前記取得されたデータを前記第2のデータフォーマットから、前記翻訳されたアドレスにおける前記1つまたは複数のカラービットによってインジケートされる前記第1のデータフォーマットへ、前記TFCによって、変換することと、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに、前記TFCによって、保存することと
を備える、方法。 - 前記第1のデータフォーマットと関連する前記仮想アドレス範囲内にある、前記データの前記仮想アドレスに少なくとも一部基づいて、前記少なくとも1つのプロセッサによってサポートされる前記第1のデータフォーマットをインジケートする前記1つまたは複数のカラービットを決定することは、
前記仮想アドレスに少なくとも一部基づいて中間物理アドレスを、第1のレベルページテーブルを使用する前記MMUによって、決定することと、
前記中間物理アドレスに少なくとも一部基づいて前記翻訳されたアドレスを、第2のレベルページテーブルを使用する前記MMUによって、決定することと
をさらに備える、請求項1に記載の方法。 - 1つまたは複数のページテーブルのカーネルアドレス空間部分に少なくとも一部基づいて前記物理アドレスを、前記TFCによって、決定することをさらに備える、請求項1に記載の方法。
- 前記第2のデータバッファは前記少なくとも1つのプロセッサのためのキャッシュを備える、請求項1に記載の方法。
- 前記データは画素データを備え、
前記第1のデータフォーマットは第1の画素フォーマットを備え、
前記第2のデータフォーマットは第2の画素フォーマットを備える、請求項1に記載の方法。 - 前記第1のデータフォーマットにある第2のデータを、前記少なくとも1つのプロセッサから前記TFCによって、受け取ることと、
前記第2のデータを前記第1のデータフォーマットから前記第2のデータフォーマットへ、前記TFCによって、変換することと、
前記第2のデータフォーマットにある前記変換されたデータを前記第1のデータバッファに、前記TFCによって、保存することと
をさらに備える、請求項1に記載の方法。 - 第1のデータバッファと、
第2のデータバッファと、
第1のデータフォーマットをサポートする少なくとも1つのプロセッサと、
前記第1のデータバッファに保存されたデータに関する、前記少なくとも1つのプロセッサによる要求を受信すること、ここにおいて、前記要求は、前記データの仮想アドレスを備える、
を行うように構成されるグラフィックス処理ユニット(GPU)と、
前記第1のデータフォーマットと関連する仮想アドレス範囲内にある、前記データの前記仮想アドレスに少なくとも一部基づいて、前記少なくとも1つのプロセッサによってサポートされる前記第1のデータフォーマットをインジケートする1つまたは複数のカラービットを決定することと、
前記1つまたは複数のカラービットに連結される前記データの前記仮想アドレスで構成される、翻訳されたアドレスを決定することと、
前記翻訳されたアドレスに少なくとも一部基づいて前記仮想アドレスに対応する物理アドレスを決定することと
を行うように構成される前記GPUのメモリ管理ユニット(MMU)と、
第2のデータフォーマットにある前記データを、前記翻訳されたアドレスにおける前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから取得することと、
前記取得されたデータを前記第2のデータフォーマットから、前記翻訳されたアドレスにおける前記1つまたは複数のカラービットによってインジケートされる前記第1のデータフォーマットへ変換することと、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である前記第2のデータバッファに保存することと
を行うように構成される、前記GPUの透過的フォーマット変換器(TFC)と
を備える、計算デバイス。 - 前記MMUは、
第1のレベルページテーブルを使用し、前記仮想アドレスに少なくとも一部基づいて中間物理アドレスを決定し、
第2のレベルページテーブルを使用し、前記中間物理アドレスに少なくとも一部基づいて前記翻訳されたアドレスを決定する
ようにさらに構成される、請求項7に記載の計算デバイス。 - 前記TFCは、1つまたは複数のページテーブルのカーネルアドレス空間部分に少なくとも一部基づいて前記物理アドレスを決定するようにさらに構成される、請求項7に記載の計算デバイス。
- 前記第2のデータバッファは前記少なくとも1つのプロセッサのためのキャッシュを備える、請求項7に記載の計算デバイス。
- 前記データは画素データを備え、
前記第1のデータフォーマットは第1の画素フォーマットを備え、
前記第2のデータフォーマットは第2の画素フォーマットを備える、請求項7に記載の計算デバイス。 - 前記TFCは、
前記第1のデータフォーマットにある第2のデータを前記少なくとも1つのプロセッサから受け取り、
前記第2のデータを前記第1のデータフォーマットから前記第2のデータフォーマットへ変換し、
前記第2のデータフォーマットにある前記変換されたデータを前記第1のデータバッファに保存する
ようにさらに構成される、請求項7に記載の計算デバイス。 - 第1のデータバッファに保存されたデータに関する第1のデータフォーマットをサポートする少なくとも1つのプロセッサによる要求を受信するための手段と、ここにおいて、前記要求は、前記データの仮想アドレスを備える、
前記第1のデータフォーマットと関連する仮想アドレス範囲内にある、前記データの前記仮想アドレスに少なくとも一部基づいて、前記少なくとも1つのプロセッサによってサポートされる前記第1のデータフォーマットをインジケートする1つまたは複数のカラービットを決定するための手段と、
前記1つまたは複数のカラービットに連結される前記データの前記仮想アドレスで構成される、翻訳されたアドレスを決定するための手段と、
第2のデータフォーマットにある前記データを、前記翻訳されたアドレスにおける前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから取得するための手段と、
前記取得されたデータを前記第2のデータフォーマットから、前記翻訳されたアドレスにおける前記1つまたは複数のカラービットによってインジケートされる前記第1のデータフォーマットへ変換するための手段と、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに保存するための手段と
を備える、装置。 - 第1のデータバッファに保存されたデータに関する要求を受信することと、ここにおいて、前記要求は、前記データの仮想アドレスを備える、
前記第1のデータフォーマットと関連する仮想アドレス範囲内にある、前記データの前記仮想アドレスに少なくとも一部基づいて、前記少なくとも1つのプロセッサによってサポートされる前記第1のデータフォーマットをインジケートする1つまたは複数のカラービットを決定することと、
前記1つまたは複数のカラービットに連結される前記データの前記仮想アドレスで構成される、翻訳されたアドレスを決定することと、
第2のデータフォーマットにある前記データを、前記翻訳されたアドレスにおける前記仮想アドレスに対応する物理アドレスで前記第1のデータバッファから取得することと、
前記取得されたデータを前記第2のデータフォーマットから、前記翻訳されたアドレスにおける前記1つまたは複数のカラービットによってインジケートされる前記第1のデータフォーマットへ変換することと、
前記第1のデータフォーマットにある前記変換されたデータを、前記少なくとも1つのプロセッサによってアクセス可能である第2のデータバッファに保存することと
を、プログラマブルプロセッサにさせるための命令を備える、非一時的なコンピュータ可読媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/504,047 US9779471B2 (en) | 2014-10-01 | 2014-10-01 | Transparent pixel format converter |
| US14/504,047 | 2014-10-01 | ||
| PCT/US2015/050465 WO2016053628A1 (en) | 2014-10-01 | 2015-09-16 | Transparent pixel format converter |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2017535848A JP2017535848A (ja) | 2017-11-30 |
| JP2017535848A5 JP2017535848A5 (ja) | 2018-01-18 |
| JP6271812B2 true JP6271812B2 (ja) | 2018-01-31 |
Family
ID=54200119
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017517240A Expired - Fee Related JP6271812B2 (ja) | 2014-10-01 | 2015-09-16 | 透過的画素フォーマット変換器 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9779471B2 (ja) |
| EP (1) | EP3201872A1 (ja) |
| JP (1) | JP6271812B2 (ja) |
| CN (1) | CN106796712A (ja) |
| WO (1) | WO2016053628A1 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10127627B2 (en) * | 2015-09-23 | 2018-11-13 | Intel Corporation | Mapping graphics resources to linear arrays using a paging system |
| CN110377534B (zh) * | 2018-04-13 | 2023-11-17 | 华为技术有限公司 | 数据处理方法及装置 |
| US10872458B1 (en) * | 2019-09-06 | 2020-12-22 | Apple Inc. | Graphics surface addressing |
| CN111343404B (zh) * | 2020-02-19 | 2022-05-24 | 精微视达医疗科技(三亚)有限公司 | 成像数据处理方法及装置 |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6336180B1 (en) * | 1997-04-30 | 2002-01-01 | Canon Kabushiki Kaisha | Method, apparatus and system for managing virtual memory with virtual-physical mapping |
| US5469190A (en) * | 1991-12-23 | 1995-11-21 | Apple Computer, Inc. | Apparatus for converting twenty-four bit color to fifteen bit color in a computer output display system |
| US5469228A (en) * | 1992-12-31 | 1995-11-21 | Hyundai Electronics Industries Co., Ltd. | Memory address and display control apparatus for high definition television |
| US5734874A (en) | 1994-04-29 | 1998-03-31 | Sun Microsystems, Inc. | Central processing unit with integrated graphics functions |
| US5867178A (en) * | 1995-05-08 | 1999-02-02 | Apple Computer, Inc. | Computer system for displaying video and graphic data with reduced memory bandwidth |
| JP4298006B2 (ja) * | 1997-04-30 | 2009-07-15 | キヤノン株式会社 | 画像プロセッサ及びその画像処理方法 |
| AU739533B2 (en) * | 1997-04-30 | 2001-10-18 | Canon Kabushiki Kaisha | Graphics processor architecture |
| US7010177B1 (en) * | 1998-08-27 | 2006-03-07 | Intel Corporation | Portability of digital images |
| JP2003084751A (ja) * | 2001-07-02 | 2003-03-19 | Hitachi Ltd | 表示制御装置およびマイクロコンピュータならびにグラフィックシステム |
| US7155236B2 (en) * | 2003-02-18 | 2006-12-26 | Qualcomm Incorporated | Scheduled and autonomous transmission and acknowledgement |
| WO2004084535A2 (en) | 2003-03-14 | 2004-09-30 | Starz Encore Group Llc | Video aspect ratio manipulation |
| US20040257434A1 (en) | 2003-06-23 | 2004-12-23 | Robert Davis | Personal multimedia device video format conversion across multiple video formats |
| GB0323284D0 (en) * | 2003-10-04 | 2003-11-05 | Koninkl Philips Electronics Nv | Method and apparatus for processing image data |
| US8086575B2 (en) | 2004-09-23 | 2011-12-27 | Rovi Solutions Corporation | Methods and apparatus for integrating disparate media formats in a networked media system |
| US7346762B2 (en) * | 2006-01-06 | 2008-03-18 | Apple Inc. | Replacing instruction and corresponding instructions in a queue according to rules when shared data buffer is accessed |
| US7545382B1 (en) * | 2006-03-29 | 2009-06-09 | Nvidia Corporation | Apparatus, system, and method for using page table entries in a graphics system to provide storage format information for address translation |
| GB2469526B (en) | 2009-04-17 | 2015-06-24 | Advanced Risc Mach Ltd | Generating and resolving pixel values within a graphics processing pipeline |
| CN101996609B (zh) * | 2009-08-13 | 2013-01-23 | 上海奇码数字信息有限公司 | 图形处理中的像素格式转换方法和装置 |
| US20110126104A1 (en) | 2009-11-20 | 2011-05-26 | Rovi Technologies Corporation | User interface for managing different formats for media files and media playback devices |
| US8786625B2 (en) * | 2010-09-30 | 2014-07-22 | Apple Inc. | System and method for processing image data using an image signal processor having back-end processing logic |
| US8732496B2 (en) * | 2011-03-24 | 2014-05-20 | Nvidia Corporation | Method and apparatus to support a self-refreshing display device coupled to a graphics controller |
| US8966171B2 (en) * | 2012-04-16 | 2015-02-24 | Renmin University Of China | Access optimization method for main memory database based on page-coloring |
| US9373182B2 (en) * | 2012-08-17 | 2016-06-21 | Intel Corporation | Memory sharing via a unified memory architecture |
| US9378572B2 (en) * | 2012-08-17 | 2016-06-28 | Intel Corporation | Shared virtual memory |
| US9595075B2 (en) | 2013-09-26 | 2017-03-14 | Nvidia Corporation | Load/store operations in texture hardware |
| US9606769B2 (en) | 2014-04-05 | 2017-03-28 | Qualcomm Incorporated | System and method for adaptive compression mode selection for buffers in a portable computing device |
-
2014
- 2014-10-01 US US14/504,047 patent/US9779471B2/en active Active
-
2015
- 2015-09-16 JP JP2017517240A patent/JP6271812B2/ja not_active Expired - Fee Related
- 2015-09-16 WO PCT/US2015/050465 patent/WO2016053628A1/en active Application Filing
- 2015-09-16 EP EP15771408.0A patent/EP3201872A1/en not_active Withdrawn
- 2015-09-16 CN CN201580052355.8A patent/CN106796712A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| EP3201872A1 (en) | 2017-08-09 |
| US20160098813A1 (en) | 2016-04-07 |
| WO2016053628A1 (en) | 2016-04-07 |
| US9779471B2 (en) | 2017-10-03 |
| JP2017535848A (ja) | 2017-11-30 |
| CN106796712A (zh) | 2017-05-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9134954B2 (en) | GPU memory buffer pre-fetch and pre-back signaling to avoid page-fault | |
| JP6385614B1 (ja) | グラフィックス処理ユニットのためのハードウェア強制コンテンツ保護 | |
| CN108701366B (zh) | 用于图形处理中的阴影光线的树遍历的开始节点确定的方法、设备及可读存储媒体 | |
| JP5917784B1 (ja) | グラフィックス処理ユニットのためのハードウェアによるコンテンツ保護 | |
| KR101820621B1 (ko) | 광선 추적 어플리케이션들에서 트리 순회를 위한 시작 노드 결정 | |
| JP6271768B2 (ja) | 共有されるデータチャネルを用いるシェーダパイプライン | |
| JP6110044B2 (ja) | ページ常駐に関する条件付きページフォールト制御 | |
| KR102006584B1 (ko) | 레이트 심도 테스팅과 컨서버티브 심도 테스팅 간의 동적 스위칭 | |
| JP2018514855A (ja) | ハイブリッド2d/3dグラフィックスレンダリング | |
| KR102554419B1 (ko) | 프리페칭된 그래픽스 데이터를 이용하여 타일 기반 렌더링을 수행하는 방법 및 장치 | |
| JP6271812B2 (ja) | 透過的画素フォーマット変換器 | |
| JP2018529168A (ja) | 帯域幅圧縮グラフィックスデータの記憶 | |
| JP2018523876A (ja) | グラフィックス処理ユニットのためのハードウェア強制コンテンツ保護 | |
| JP2018510416A (ja) | 単一パスの表面スプラッティング | |
| WO2017052873A1 (en) | Mapping graphics resources to linear arrays using a paging system | |
| CN107209926B (zh) | 具有拜耳映射的图形处理单元 | |
| JP6542352B2 (ja) | 算術論理ユニットにおいて使用するためのベクトルスケーリング命令 | |
| US10157443B1 (en) | Deferred batching of incremental constant loads |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20171116 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20171116 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20171116 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20171127 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171205 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171227 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6271812 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |