[0022]たとえば3次元(3D)−HEVC(高効率ビデオコーディング)規格による3Dビデオコーディングでは、(テクスチャビューのテクスチャコンポーネントとも呼ばれる)キャプチャされたビデオデータが深度ビューの対応する深度マップに関連付けられる、マルチビュービデオ+深度フォーマットを使用して、3Dビデオデータが表される。たとえば、テクスチャビューのテクスチャコンポーネントは、実際のビデオコンテンツを表し、テクスチャコンポーネントに対応する深度コンポーネントは、テクスチャコンポーネント中のピクセルの相対深度を表す深度マップを提供する。ビデオエンコーダは、テクスチャコンポーネントと深度マップとを符号化し、テクスチャコンポーネントと深度マップとを3Dビデオビットストリーム中に多重化するように構成される。ビデオデコーダは、3Dビデオビットストリームを受信し、3Dビデオデータを再構成するためにテクスチャコンポーネントと深度マップとを復号する。
[0023]ビデオエンコーダのビデオ符号化能力とビデオデコーダの復号能力とを活用するために、ルーマサンプルが深度値を表すグレースケールビデオとして深度マップが形成される。このようにして、深度値を符号化および復号するための何らかの追加の特殊な符号化および復号の技法を利用する必要なく、ビデオエンコーダおよびビデオデコーダの既存の能力を使用して、深度値が符号化され復号され得る。
[0024]たとえば、ビデオのピクチャをコーディングするために、ビデオエンコーダは、インター予測符号化および/またはイントラ予測符号化を利用するように構成され得、ビデオデコーダは、インター予測復号および/またはイントラ予測復号を利用するように構成され得る。ビデオエンコーダおよびビデオデコーダは、同様にそれぞれ、深度マップをコーディングするためのインター予測およびイントラ予測の符号化および復号の技法を使用することができる。
[0025]場合によっては、深度マップは、シャープエッジと定数領域(constant area)とを含み、シャープエッジは、エッジの一方の側のルーマ値とエッジの他方の側のルーマ値との間に比較的大きい差があるときに発生する。深度マップサンプルのそのような異なる統計値(たとえば、ルーマ値)に起因して、2次元(2D)ビデオコーデックに基づいて深度マップのために設計された異なるコーディング方式があり得る。たとえば、2次元ビデオコーディングの場合、深度マップがないことがある。一方、深度マップを含む3Dビデオコーディングの場合、深度マップを符号化および復号するために追加のビデオコーディング技法が有用であり得る。
[0026]たとえば、3D−HEVC規格は、HEVC規格において定義されるような2Dビデオコーディングに関する概念を3Dビデオコーディングに拡張する。3D−HEVC規格は、イントラ予測符号化および復号のためにHEVC規格において定義されるイントラ予測モードを使用する。さらに、3D−HEVC規格は、深度マップのスライスのイントラ予測ユニットを符号化または復号する(すなわち、深度スライスの予測ユニット(PU)をイントラ予測する)ために、HEVCイントラ予測モードとともに深度モデリングモード(DMM)を導入した。
[0027]DMMでは、深度マップのブロックが2つの領域に区分され、各領域が定数値によって表される。ビデオエンコーダは、深度マップのブロックをイントラ予測するためにビデオエンコーダが使用する領域の各々に関する予測値を決定する。ビデオエンコーダは、領域の各々に関する予測値をビデオデコーダにシグナリングすることもでき、またはビデオデコーダは、ビデオエンコーダからの明示的なシグナリングなしで予測値を決定するように構成され得る。いずれの場合も、ビデオデコーダは、深度マップのブロックをイントラ予測するために予測値を利用することができる。
[0028](深度ブロックと呼ばれる)深度マップのブロックを区分する方法のうちの1つは、ウェッジレット区分と呼ばれる。ウェッジレット区分では、ビデオエンコーダは、深度ブロックを二等分して2つの領域を生成する線形線を決定する。このようにして、ウェッジレット区分は、線ベースの区分と考えられることがあり、いくつかの例では、非長方形パーティションを形成し得る(ただし、長方形パーティションを形成する可能性もある)。線形線は、深度ブロックの1つの側にある点から開始し、深度ブロックの反対側または直交側にある点で終了することがある。一例として、一方位では、線形線は、深度ブロックの左側にある点から開始し、深度ブロックの上側にある点で終了することがある。別の方位では、線形線は、深度ブロックの上側にある点から開始し、深度ブロックの下側にある点で終了することがある。
[0029]ウェッジレットパターンは、深度マップのブロックが二等分線形線により2つの領域に区分され得る1つの方法を指し、ブロックのために存在し得るウェッジレットパターンの数は、ブロックサイズの関数であり得る。たとえば、所与の解像度(たとえば、1ピクセル、1/2ピクセル、または1/4ピクセル)で、より小さいサイズのブロック(たとえば、4×4ブロック)の場合、より大きいサイズのブロック(たとえば、64×64)と比較して、ブロックの側に沿ってより少ない点がある。したがって、より大きいサイズのブロックと比較して、より小さいサイズのブロックの各側に沿ってより少ない開始点および終了点があり、より少ないウェッジレットパターンが生じる。
[0030]DMMモードのうちの1つが利用される例では、ビデオエンコーダは、深度ブロックに関するウェッジレットパターンを決定し、決定されたウェッジレットパターンに基づいてウェッジレットパターンをイントラ予測することができる。ビデオデコーダは、ブロックを復号するために逆のプロセスを実行するように構成され得るので、ビデオデコーダは、ビデオエンコーダが決定したウェッジレットパターンと同じウェッジレットパターンを決定することができる。たとえば、いくつかの例では、ビデオエンコーダおよびビデオデコーダはそれぞれ、ウェッジレットパターンのリストを記憶することができる。ビデオエンコーダは、ビデオビットストリームにおいて、決定されたウェッジレットパターンを識別するウェッジレットパターンのリストへのインデックスをシグナリングすることができる。次いでビデオデコーダは、ウェッジレットパターンのリストのシグナリングされたインデックスに基づいて、ビデオエンコーダと同じウェッジレットパターンを決定することができる。別の例として、ビデオエンコーダは、深度ブロックに関するウェッジレットパターンを、対応するテクスチャブロックのビデオコンテンツ特性から決定することができる。ビデオデコーダは、ビデオデコーダが決定するウェッジレットパターンおよびビデオエンコーダが決定するウェッジレットパターンが同じウェッジレットパターンになるように、ウェッジレットパターンを決定するためのビデオエンコーダと同じ技法を実施するように構成され得る。
[0031]ウェッジレットパターンを決定する上記の例では、ビデオエンコーダおよびビデオデコーダは、すべてのブロックサイズに関するすべてのウェッジレットパターンについての情報を記憶するように構成され得る。しかしながら、より大きいブロックサイズの場合、比較的多数のウェッジレットパターンを記憶するために必要なメモリの量は、望ましくないほど大きいことがある。たとえば、3D−HEVC規格のいくつかのドラフトは、64×64サイズの深度ブロックに関するウェッジレットパターンをまったく持たないことを提案した。言い換えれば、64×64サイズの深度ブロックに関するウェッジレットパターンを記憶するための大きいサイズのメモリを持つ不利益は、64×64サイズの深度ブロックをイントラ予測するためにウェッジレットパターンを使用する利益を圧倒すると考えられた。
[0032]本開示で説明する技法では、ビデオコーダ(たとえば、ビデオエンコーダまたはビデオデコーダ)は、パーティションパターン(たとえば、ウェッジレットパターン)を、第1のサイズのブロックのパーティションパターンから決定し(たとえば、第1のサイズのブロックに関連するパーティションパターンを決定し)、第1のサイズのブロックに関連する決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することができ、第1のサイズが第2のサイズよりも小さい。ビデオコーダは、決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックをイントラ予測コーディングする(たとえば、符号化または復号する)ことができる。いくつかの例では、ビデオコーダは、第2のサイズの深度ブロックサブブロック(たとえば、深度ブロック内のブロック)のパーティションパターンからのパーティションパターンを利用することができる。一例として、第2のサイズの深度ブロックはN×Nブロックであり得、サブブロックはM×Mブロックであり得、MがNよりも小さく、N×Nブロック内にある。
[0033]いくつかの例では、特定のブロックサイズに関して記憶されるためにビデオコーダが必要とするパーティションパターンの数は、特定のブロックサイズの深度ブロックに関するパーティションパターンが、より小さいサイズのブロックに関連するパーティションパターンから決定される場合には(すなわち、それに基づいて)減らされ得る。たとえば、ビデオコーダは、より小さいサイズのブロックに関連するパーティションパターンを記憶し、そして後に、より小さいサイズのブロックの記憶されたパーティションパターンから、より大きいサイズのブロックに関するパーティションパターンを決定することができる。
[0034]たとえば、以前にビデオコーダが第1のサイズの深度ブロックに関するY個のパーティションパターンと、第2のサイズの深度ブロックに関するX個のパーティションパターンとを記憶しており、第1のサイズが第2のサイズよりも小さいと仮定する。この例では、ビデオコーダは、第2のサイズのブロックに関するパーティションパターンを決定するためにY個のパーティションパターンを使用することができるので、ビデオコーダは、第2のサイズの深度ブロックに関するX個のパーティションパターンよりも少ないパーティションパターンを記憶する必要があり得る。
[0035]第1のサイズのブロックに関するパーティションパターンからは決定できない第2のサイズのブロックに関連するパーティションパターンがいくつかあることも考えられ得る。したがって、いくつかの例では、ビデオコーダは依然として、第2のサイズの深度ブロックに関するいくつかの(たとえば、少なくとも1つの)パーティションパターンを記憶し得るが、記憶される必要のあるパーティションパターンの数は、従来の技法と比較して減らされ得る。いくつかの例では、ビデオコーダは、第2の、より大きいサイズのブロックに関するパーティションパターンをまったく記憶せず、代わりに、第1の、より小さいサイズのブロックに関するパーティションパターンから、第2の、より大きいサイズのブロックに関するパーティションパターンを決定することがある。
[0036]図1は、深度コーディングのための本開示の技法を利用し得る例示的なビデオ符号化および復号システム10を示すブロック図である。図1に示すように、システム10は、宛先デバイス14によって後で復号されるべき符号化ビデオデータを提供するソースデバイス12を含む。特に、ソースデバイス12は、コンピュータ可読媒体16を介してビデオデータを宛先デバイス14に提供する。ソースデバイス12および宛先デバイス14は、デスクトップコンピュータ、ノートブック(すなわち、ラップトップ)コンピュータ、タブレットコンピュータ、セットトップボックス、いわゆる「スマート」フォンなどの電話ハンドセット、いわゆる「スマート」パッド、テレビジョン、カメラ、ディスプレイデバイス、デジタルメディアプレーヤ、ビデオゲーム機、ビデオストリーミングデバイスなどを含む、広範囲にわたるデバイスのいずれかを備え得る。場合によっては、ソースデバイス12および宛先デバイス14は、ワイヤレス通信に対する機能を備え得る。
[0037]宛先デバイス14は、コンピュータ可読媒体16を介して、復号されるべき符号化ビデオデータを受信することができる。コンピュータ可読媒体16は、ソースデバイス12から宛先デバイス14に符号化ビデオデータを移動することができる、任意のタイプの媒体またはデバイスを備え得る。一例では、コンピュータ可読媒体16は、ソースデバイス12が符号化ビデオデータを宛先デバイス14にリアルタイムで直接送信するのを可能にするための通信媒体を備え得る。
[0038]符号化ビデオデータは、ワイヤレス通信プロトコルなどの通信標準規格に従って変調され、宛先デバイス14に送信され得る。通信媒体は、無線周波(RF)スペクトルまたは1つもしくは複数の物理伝送線路など、任意のワイヤレスまたはワイヤード通信媒体を備え得る。通信媒体は、ローカルエリアネットワーク、ワイドエリアネットワーク、またはインターネットなどのグローバルネットワークなどのパケットベースのネットワークの一部を形成し得る。通信媒体は、ルータ、スイッチ、基地局、またはソースデバイス12から宛先デバイス14への通信を容易にするために有用であり得る任意の他の機器を含み得る。
[0039]いくつかの例では、符号化データは、出力インターフェース22からストレージデバイスへ出力され得る。同様に、符号化データは、ストレージデバイスから入力インターフェースによってアクセスされ得る。ストレージデバイスは、ハードドライブ、Blue−rayディスク、DVD、CD−ROM、フラッシュメモリ、揮発性もしくは不揮発性のメモリ、または符号化ビデオデータを記憶するための任意の他の適切なデジタル記憶媒体など、様々な分散されたまたはローカルにアクセスされるデータ記憶媒体のいずれかを含み得る。さらなる例では、ストレージデバイスは、ソースデバイス12によって生成された符号化ビデオを記憶することができるファイルサーバまたは別の中間ストレージデバイスに対応し得る。
[0040]宛先デバイス14は、ストリーミングまたはダウンロードを介して、ストレージデバイスから記憶されたビデオデータにアクセスすることができる。ファイルサーバは、符号化ビデオデータを記憶でき、符号化ビデオデータを宛先デバイス14に送信できる、任意のタイプのサーバとすることができる。例示的なファイルサーバは、(たとえば、ウェブサイト用の)ウェブサーバ、FTPサーバ、ネットワークアタッチドストレージ(NAS)デバイス、またはローカルディスクドライブを含む。宛先デバイス14は、インターネット接続を含む、任意の標準データ接続を介して、符号化ビデオデータにアクセスすることができる。これは、ファイルサーバ上に記憶された符号化ビデオデータにアクセスするのに適した、ワイヤレスチャネル(たとえば、Wi−Fi(登録商標)接続)、ワイヤード接続(たとえば、DSL、ケーブルモデムなど)、またはその両方の組合せを含み得る。ストレージデバイスからの符号化ビデオデータの送信は、ストリーミング送信、ダウンロード送信、またはその組合せとすることができる。
[0041]本開示の技法は、ワイヤレス応用またはワイヤレス設定に必ずしも制限されない。本技法は、無線テレビジョンブロードキャスト、ケーブルテレビジョン送信、衛星テレビジョン送信、HTTP上の動的適応ストリーミング(DASH:dynamic adaptive streaming over HTTP)などのインターネットストリーミングビデオ送信、データ記憶媒体上に符号化されたデジタルビデオ、データ記憶媒体上に記憶されたデジタルビデオの復号、または他の応用例など、様々なマルチメディア応用のいずれかをサポートするビデオコーディングに適用され得る。いくつかの例では、システム10は、ビデオストリーミング、ビデオ再生、ビデオブロードキャスト、および/またはビデオ電話などの応用をサポートするために一方向または双方向のビデオ送信をサポートするように構成され得る。
[0042]図1の例では、ソースデバイス12は、ビデオソース18と、ビデオエンコーダ20と、出力インターフェース22とを含む。宛先デバイス14は、入力インターフェース28と、ビデオデコーダ30と、ディスプレイデバイス32とを含む。本開示によれば、ソースデバイス12のビデオエンコーダ20は、マルチビューコーディングにおける動きベクトル予測のための技法を適用するように構成され得る。他の例では、ソースデバイスおよび宛先デバイスは他の構成要素または構成を含み得る。たとえば、ソースデバイス12は、外部カメラなどの外部のビデオソース18からビデオデータを受信し得る。同様に、宛先デバイス14は、集積ディスプレイデバイスを含むのではなく、外部のディスプレイデバイスとインターフェースしてもよい。
[0043]図1の図示のシステム10は一例にすぎない。本開示による技法は、任意のデジタルビデオ符号化および/または復号デバイスによって実行され得る。概して、本開示の技法はビデオ符号化デバイスおよびビデオ復号デバイスによって実行されるが、本技法は、一般に「コーデック」と呼ばれるビデオエンコーダ/デコーダによって実行されてもよい。その上、本開示の技法は、ビデオプリプロセッサによって実行されてもよい。ソースデバイス12および宛先デバイス14は、宛先デバイス14に送信するためのコーディングされたビデオデータをソースデバイス12が生成するコーディングデバイスの例にすぎない。いくつかの例では、デバイス12、14は、デバイス12、14の各々がビデオ符号化構成要素とビデオ復号構成要素とを含むように、実質的に対称の形で動作することができる。したがって、システム10は、たとえば、ビデオストリーミング、ビデオ再生、ビデオブロードキャスト、またはビデオ電話のためのビデオデバイス12、14の間の一方向または双方向のビデオ送信をサポートし得る。
[0044]ソースデバイス12のビデオソース18は、ビデオカメラなどのビデオキャプチャデバイス、前にキャプチャされたビデオを含んでいるビデオアーカイブ、および/またはビデオコンテンツプロバイダからビデオを受信するためのビデオフィードインターフェースを含み得る。さらなる代替案として、ビデオソース18は、ソースビデオとしてコンピュータグラフィックスベースのデータまたは、生ビデオと、アーカイブされたビデオと、コンピュータ生成ビデオとの組合せを生成することができる。場合によっては、ビデオソース18がビデオカメラである場合、ソースデバイス12および宛先デバイス14は、いわゆるカメラ付き電話またはビデオ付き電話を形成し得る。しかしながら、上記で述べたように、本開示で説明する技法は、一般にビデオコーディングに適用可能であり、ワイヤレスおよび/またはワイヤードの応用例に適用され得る。各場合において、キャプチャされたビデオ、前にキャプチャされたビデオ、またはコンピュータ生成ビデオは、ビデオエンコーダ20によって符号化され得る。次いで、符号化ビデオ情報は、出力インターフェース22によってコンピュータ可読媒体16に出力され得る。
[0045]コンピュータ可読媒体16は、ワイヤレスブロードキャストまたはワイヤードネットワーク送信などの一時媒体、またはハードディスク、フラッシュドライブ、コンパクトディスク、デジタルビデオディスク、Blu−ray(登録商標)ディスク、または他のコンピュータ可読媒体などの記憶媒体(すなわち、非一時的記憶媒体)を含み得る。いくつかの例では、ネットワークサーバ(図示せず)は、たとえば、ネットワーク送信を介して、ソースデバイス12から符号化ビデオデータを受信し、宛先デバイス14に符号化ビデオデータを提供することができる。同様に、ディスクスタンピング設備など、媒体製造設備のコンピューティングデバイスは、ソースデバイス12から符号化ビデオデータを受信し、その符号化ビデオデータを含んでいるディスクを生成することができる。したがって、様々な例では、コンピュータ可読媒体16は、様々な形態の1つまたは複数のコンピュータ可読媒体を含むと理解され得る。
[0046]本開示では、概して、ビデオエンコーダ20が、ある情報をビデオデコーダ30などの別のデバイスに「シグナリング」することに言及することがある。ただし、ビデオエンコーダ20は、いくつかのシンタックス要素をビデオデータの様々な符号化部分に関連付けることによって情報をシグナリングし得ることを理解されたい。すなわち、ビデオエンコーダ20は、ビデオデータの様々な符号化部分のヘッダにいくつかのシンタックス要素を格納することによって、データを「シグナリング」することができる。場合によっては、そのようなシンタックス要素は、ビデオデコーダ30によって受信され、復号されるより前に、符号化され、記憶され(たとえば、コンピュータ可読媒体16に記憶され)得る。したがって、「シグナリング」という用語は全般に、圧縮されたビデオデータを復号するためのシンタックスまたは他のデータの通信を、そのような通信がリアルタイムで発生するか、またはほぼリアルタイムで発生するか、またはある期間にわたって発生するかにかかわらず指すことがあり、ある期間にわたる通信は、シンタックス要素を符号化の時点で媒体に記憶し、次いで、シンタックス要素がこの媒体に記憶された後の任意の時点で復号デバイスによって取り出され得るときに、発生し得る。
[0047]宛先デバイス14の入力インターフェース28はコンピュータ可読媒体16から情報を受信する。コンピュータ可読媒体16の情報は、ビデオエンコーダ20によって定義され、またビデオデコーダ30によって使用される、ブロックおよび他のコーディングされたユニット、たとえば、GOPの特性および/または処理を記述するシンタックス要素を含む、シンタックス情報を含み得る。ディスプレイデバイス32は、復号されたビデオデータをユーザに表示し、陰極線管(CRT)、液晶ディスプレイ(LCD)、プラズマディスプレイ、有機発光ダイオード(OLED)ディスプレイ、または別のタイプのディスプレイデバイスなどの様々なディスプレイデバイスのうちのいずれかを備え得る。
[0048]図1には示されないが、いくつかの態様では、ビデオエンコーダ20およびビデオデコーダ30は、それぞれオーディオエンコーダおよびオーディオデコーダと統合されてよく、共通のデータストリームまたは別個のデータストリーム中のオーディオとビデオの両方の符号化を処理するための、適切なMUX−DEMUXユニット、または他のハードウェアおよびソフトウェアを含み得る。適用可能な場合、MUX−DEMUXユニットは、ITU H.223マルチプレクサプロトコル、またはユーザデータグラムプロトコル(UDP)などの他のプロトコルに準拠し得る。
[0049]ビデオエンコーダ20およびビデオデコーダ30はそれぞれ、適用可能なとき、1つまたは複数のマイクロプロセッサ、デジタル信号プロセッサ(DSP)、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、ディスクリート論理回路、ソフトウェア、ハードウェア、ファームウェア、またはそれらの任意の組合せのような、種々の好適なエンコーダまたはデコーダ回路のいずれかとして実装され得る。ビデオエンコーダ20およびビデオデコーダ30の各々は1つまたは複数のエンコーダまたはデコーダ中に含まれ得、そのいずれもが合成ビデオエンコーダ/デコーダ(コーデック)の一部として組み込まれ得る。ビデオエンコーダ20および/またはビデオデコーダ30を含むデバイスは、集積回路、マイクロプロセッサ、および/または携帯電話のようなワイヤレス通信デバイスを備え得る。
[0050]ビデオコーディング規格の一例としては、Joint Video Team(JVT)として知られる共同パートナーシップの成果として、ISO/IEC Moving Picture Experts Group(MPEG)とともにITU−T Video Coding Experts Group(VCEG)によって策定されたITU−T H.264/MPEG−4(AVC)規格がある。別のビデオコーディング規格は、それのスケーラブルビデオコーディング(SVC)およびマルチビュービデオコーディング(MVC)拡張を含む、H.264規格を含む。H.264規格は、ITU−T Study GroupによるITU−T勧告H.264、Advanced Video Coding for generic audiovisual servicesに記載されている。Joint Video Team(JVT)はH.264/MPEG−4 AVCへの拡張に取り組み続けている。MVCの最新のジョイントドラフトは、「Advanced video coding for generic audiovisual services」、ITU−T勧告H.264、2010年3月に記載されている。
[0051]いくつかの例では、ビデオエンコーダ20およびビデオデコーダ30は、高効率ビデオコーディング(HEVC)規格およびHEVC規格の拡張に従って動作し得、HEVCテストモデル(HM)に準拠し得る。HEVCが、ITU−T Video Coding Experts Group(VCEG)とISO/IEC Motion Picture Experts Group(MPEG)とのJoin Collaboration Team on Video Coding(JCT−VC)によって開発された。HEVCの最近のドラフトは、http://phenix.int−evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC−L1003−v14.zipから入手可能である。HEVC規格化の取組みは、HEVCテストモデル(HM)と呼ばれるビデオコーディングデバイスの発展的モデルに基づいていた。HMは、たとえばITU−T H.264/AVCに従う既存のデバイスに対する、ビデオコーディングデバイスの複数の追加能力を仮定する。たとえば、H.264は9個のイントラ予測符号化モードを提供するが、HMは35個ものイントラ予測符号化モードを提供し得る。
[0052]概して、HMの作業モデルは、ビデオピクチャ(または「フレーム」)が、ルーマサンプルとクロマサンプルの両方を含む一連のツリーブロックまたは最大コーディングユニット(LCU)に分割され得ることを記述する。ビットストリーム内のシンタックスデータが、ピクセルの数に関して最大のコーディングユニットであるLCUのサイズを定義し得る。スライスは、コーディング順序での、いくつかの連続するツリーブロックを含む。ピクチャは、1つまたは複数のスライスに区分され得る。各ツリーブロックは、4分木に従ってコーディングユニット(CU)に分割され得る。一般に、4分木データ構造は、1CUあたり1つのノードを含み、ルートノードがツリーブロックに対応する。CUが4つのサブCUに分割される場合には、CUに対応するノードは、4つのリーフノードを含み、リーフノードの各々がサブCUのうちの1つに対応する。
[0053]4分木データ構造の各ノードは、対応するCUのシンタックスデータを提供し得る。たとえば、4分木中のノードは、そのノードに対応するCUがサブCUに分割されるのかどうかを示す分割フラグを含むことができる。CUのシンタックス要素は、再帰的に定義され得、CUがサブCUに分割されるかどうかに依存することができる。CUがさらに分割されない場合、そのCUはリーフCUと呼ばれる。本開示では、元のリーフCUの明示的な分割が存在しない場合でも、リーフCUの4つのサブCUもリーフCUと呼ばれる。たとえば、16×16サイズのCUがさらに分割されない場合、4つの8×8サブCUも、16×16CUが分割されなくても、リーフCUと呼ばれる。
[0054]CUは、CUがサイズの特異性を有しないことを別にすれば、H.264規格のマクロブロックと同様の目的を有する。たとえば、ツリーブロックは、(サブCUとも呼ばれる)4つの子ノードに分割されてよく、各子ノードは、今度は親ノードとなり、別の4つの子ノードに分割されてよい。4分木のリーフノードと呼ばれる、最後の分割されていない子ノードは、リーフCUとも呼ばれるコーディングノードを備える。コーディングされたビットストリームに関連するシンタックスデータは、最大CU深度と呼ばれる、ツリーブロックが分割され得る最大回数を定義することができ、コーディングノードの最小サイズを定義することもできる。それに応じて、ビットストリームは最小コーディングユニット(SCU)を定義することもできる。本開示は、「ブロック」という用語を、HEVCのコンテキストにおいてCU、PU、またはTUのうちのいずれか、または他の規格のコンテキストにおいて類似のデータ構造(たとえば、H.264/AVCのマクロブロックおよびそのサブブロック)を指すために使用する。
[0055]CUは、コーディングノードと、コーディングノードに関連付けられた予測ユニット(PU)および変換ユニット(TU)とを含む。CUのサイズは、コーディングノードのサイズに対応し、形状において正方形でなければならない。CUのサイズは、8×8ピクセルから、64×64ピクセル以上の最大値を有するツリーブロックのサイズまでに及び得る。各CUは、1つまたは複数のPUと1つまたは複数のTUとを包含し得る。CUに関連付けられたシンタックスデータは、たとえば、1つまたは複数のPUへのCUの区分を記述することができる。区分モードは、CUがスキップモード符号化もしくは直接モード符号化されるのか、イントラ予測モード符号化されるのか、またはインター予測モード符号化されるのかの間で異なる可能性がある。PUは、形状において非正方形に区分され得る。CUに関連付けられたシンタックスデータは、たとえば、4分木に従う1つまたは複数のTUへのCUの区分を記述することもできる。TUは、形状において正方形または非正方形(たとえば、長方形)とすることができる。
[0056]HEVC規格は、CUごとに異なり得る、TUに従う変換を可能にする。TUは、通常、区分されたLCUについて定義される所与のCU内のPUのサイズに基づくサイズを与えられるが、必ずそうなっているとは限らない。TUは、通常、PU以下のサイズである。いくつかの例では、CUに対応する残差サンプルは、「残差4分木」(RQT)として知られている4分木構造を使用して、より小さいユニットに副分割され得る。RQTのリーフノードは、変換ユニット(TU)と呼ばれる場合がある。TUに関連付けられたピクセル差分値は、変換係数を生成するために変換され得、変換係数は量子化され得る。
[0057]リーフCUは、1つまたは複数の予測ユニット(PU)を含むことができる。一般に、PUは、対応するCUのすべてまたは一部分に対応する空間的エリアを表し、PUの参照サンプルを取り出すためのデータを含むことができる。さらに、PUは、予測に関するデータを含む。たとえば、PUがイントラモード符号化(たとえば、イントラ予測符号化)されるとき、PUのデータは、残差4分木(RQT)に含まれ得、このRQTは、PUに対応するTUのイントラ予測モードを記述するデータを含むことができる。別の例として、PUがインターモード符号化(たとえば、インター予測符号化)されるとき、PUは、PUの1つまたは複数の動きベクトルを定義するデータを含み得る。PUの動きベクトルを定義するデータは、たとえば、動きベクトルの水平成分、動きベクトルの垂直成分、動きベクトルの解像度(たとえば、1/4ピクセル精度または1/8ピクセル精度)、動きベクトルが指す参照ピクチャ、および/または動きベクトル用の参照ピクチャリスト(たとえば、RefPicList0またはRefPicList1)を記述することができる。
[0058]1つまたは複数のPUを有するリーフCUは、1つまたは複数の変換ユニット(TU)をも含むことができる。変換ユニットは、上述したように、(TU4分木構造とも呼ばれる)RQTを使用して指定され得る。たとえば、分割フラグは、リーフCUが4つの変換ユニットに分割されるのかどうかを示すことができる。その場合に、各変換ユニットは、さらなるサブTUにさらに分割され得る。TUがさらに分割されないとき、そのTUはリーフTUと呼ばれることがある。一般に、イントラコーディングの場合、リーフCUに属するすべてのリーフTUは同じイントラ予測モードを共有する。すなわち、同じイントラ予測モードが、概して、リーフCUのすべてのTUの予測値を計算するために適用される。イントラコーディングの場合、ビデオエンコーダ20は、イントラ予測モードを使用して各リーフTUの残差値を、TUに対応するCUの一部分と元のブロックとの間の差分として計算し得る。TUは、必ずしもPUのサイズに制限されるとは限らない。したがって、TUは、PUよりも大きくまたは小さくなり得る。イントラコーディング(たとえば、イントラ予測コーディング)の場合、PUは、同じCUの対応するリーフTUとコロケートされ得る。いくつかの例では、リーフTUの最大サイズは、対応するリーフCUのサイズに対応することができる。
[0059]さらに、リーフCUのTUは、残差4分木(RQT)と呼ばれるそれぞれの4分木データ構造にも関連付けられ得る。すなわち、リーフCUは、そのリーフCUがTUにどのように区分されるのかを示す4分木を含むことができる。TU4分木のルートノードは、一般に、リーフCUに対応し、CU4分木のルートノードは、一般に、ツリーブロック(またはLCU)に対応する。分割されないRQTのTUは、リーフTUと呼ばれる。一般に、本開示は、別段に記載されていない限り、CUおよびTUという用語を、それぞれ、リーフCUおよびリーフTUを指すために使用する。
[0060]ビデオシーケンスは、一般に一連のピクチャを含む。本明細書で説明する「ピクチャ」および「フレーム」という用語は互換的に使用され得る。すなわち、ビデオデータを含んでいるピクチャは、ビデオフレームまたは単に「フレーム」と呼ばれることがある。ピクチャグループ(GOP)は、概して、ビデオピクチャのうちの一連の1つまたは複数を備える。GOPは、GOP中に含まれるいくつかのピクチャを記述するシンタックスデータを、GOPのヘッダ中、ピクチャのうちの1つもしくは複数のヘッダ中、または他の場所に含み得る。ピクチャの各スライスは、それぞれのスライスのための符号化モードを記述するスライスシンタックスデータを含み得る。ビデオエンコーダ20は、一般に、ビデオデータを符号化するために、個々のビデオスライス内のビデオブロックに作用する。ビデオブロックはCU内のコーディングノードに対応する場合がある。ビデオブロックは、固定サイズまたは可変サイズを有することができ、指定されたコーディング規格に従ってサイズが異なり得る。
[0061]例として、HMは、様々なPUサイズでの予測をサポートする。特定のCUのサイズが2N×2Nであると仮定すると、HMは、2N×2NまたはN×NのPUサイズでのイントラ予測と、2N×2N、2N×N、N×2N、またはN×Nの対称PUサイズでのインター予測とをサポートする。HMは、2N×nU、2N×nD、nL×2N、およびnR×2NのPUサイズでのインター予測のための非対称区分をもサポートする。非対称区分では、CUの一方の方向は、区分されず、他方の方向は、25%と75%とに区分される。CUのうちで25%パーティションに対応する部分は、「n」とそれに続く「Up(上)」、「Down(下)」、「Left(左)」、または「Right(右)」の表示とによって示される。したがって、たとえば、「2N×nU」は、上部で2N×0.5N PU、および下部で2N×1.5N PUに水平に区分される2N×2N CUを指す。
[0062]本開示では、「N×N(NxN)」および「N×N(N by N)」は、垂直寸法および水平寸法の観点からビデオブロックのピクセル寸法、たとえば、16×16(16x16)ピクセルまたは16×16(16 by 16)ピクセルを指すために互換的に使用され得る。一般に、16×16ブロックは、垂直方向に16ピクセルを有し(y=16)、水平方向に16ピクセルを有する(x=16)。同様に、N×Nブロックは、一般に、垂直方向にNピクセル、水平方向にNピクセルを有し、Nが非負の整数値を表す。ブロック中のピクセルは、行および列に配列され得る。さらに、ブロックは、必ずしも、水平方向において垂直方向と同じ数のピクセルを有するとは限らない。たとえば、ブロックはN×Mピクセルを備え得、この場合、Mは必ずしもNに等しいとは限らない。
[0063]CUのPUを使用したイントラ予測コーディングまたはインター予測コーディングに続いて、ビデオエンコーダ20は、CUのTUに関する残差データを計算することができる。PUは、(ピクセル領域とも呼ばれる)空間領域において予測ピクセルデータを生成する方法またはモードを記述するシンタックスデータを備えることができ、TUは、残差ビデオデータに対する変換、たとえば離散コサイン変換(DCT)、整数変換、ウェーブレット変換、または概念的に同様の変換の適用に続く変換領域での係数を備えることができる。残差データは、符号化されていないピクチャのピクセルとPUに対応する予測値との間のピクセル差分に対応することができる。ビデオエンコーダ20は、CUに関する残差データを含むTUを形成し、次いで、CUに関する変換係数を生成するためにTUを変換することができる。
[0064]変換係数を生成するためのすべての変換に続いて、ビデオエンコーダ20は、変換係数の量子化を実行することができる。量子化は、一般に、係数を表すために使用されるデータの量をできるだけ低減するために、変換係数が量子化され、さらなる圧縮を実現するプロセスを指す。量子化プロセスは、係数の一部またはすべてに関連付けられたビット深度を低減し得る。たとえば、nビット値は、量子化中にmビット値に切り捨てられ得、ここで、nはmよりも大きい。
[0065]量子化の後に、ビデオエンコーダ20は、変換係数を走査して、量子化変換係数を含む2次元行列から1次元ベクトルを生成し得る。走査は、アレイの前部により高いエネルギー(したがって、より低い周波数)係数を配置し、アレイの後部により低いエネルギー(したがって、より高い周波数)係数を配置するように設計され得る。
[0066]いくつかの例では、ビデオエンコーダ20は、エントロピー符号化され得るシリアル化ベクトルを生成するために、量子化変換係数を走査するために所定の走査順序を利用し得る。他の例では、ビデオエンコーダ20は、適応走査を実行することができる。量子化変換係数を走査して1次元ベクトルを形成した後に、ビデオエンコーダ20は、たとえば、コンテキスト適応型可変長コーディング(CAVLC:context-adaptive variable length coding)、コンテキスト適応型バイナリ算術コーディング(CABAC:context-adaptive binary arithmetic coding)、シンタックスベースコンテキスト適応型バイナリ算術コーディング(SBAC:syntax-based context-adaptive binary arithmetic coding)、確率間隔区分エントロピー(PIPE:Probability Interval Partitioning Entropy)コーディング、または別のエントロピー符号化方法に従って、1次元ベクトルをエントロピー符号化し得る。ビデオエンコーダ20は、ビデオデータを復号する際のビデオデコーダ30による使用のために、符号化ビデオデータに関連付けられたシンタックス要素をエントロピー符号化することもできる。
[0067]ビデオエンコーダ20は、さらに、ブロックベースのシンタックスデータ、ピクチャベースのシンタックスデータ、およびGOPベースのシンタックスデータなどのシンタックスデータを、たとえば、ピクチャヘッダ、ブロックヘッダ、スライスヘッダ、またはGOPヘッダ中でビデオデコーダ30に送り得る。GOPシンタックスデータは、それぞれのGOP中のピクチャの数を記述し得、ピクチャシンタックスデータは、対応するピクチャを符号化するために使用される符号化/予測モードを示し得る。
[0068]ビデオデコーダ30は、ビデオデータを復号し、ピクチャを再構成するために、ビデオエンコーダ20が符号化目的で利用したのとは逆の手順を一般に実行するように構成され得る。たとえば、ビデオデコーダ30は、シグナリングされたビットストリームからシンタックス要素とビデオデータとを受信することができ、ピクチャを再構成するためにビデオデータをイントラ予測復号および/またはインター予測復号するために、逆の動作を実行することができる。
[0069]上記の説明は、ビデオエンコーダ20およびビデオデコーダ30がHEVC規格に基づいてビデオデータを符号化および復号することができる例示的な方法を提供している。本開示で説明する技法では、ビデオエンコーダ20およびビデオデコーダ30は、3次元(3D)ビデオ符号化および復号のために構成され得る。たとえば、ビデオエンコーダ20およびビデオデコーダ30は、HEVCビデオコーディング規格を活用する開発中のビデオコーディング規格を使用する3Dビデオ符号化および復号のために構成され得る。ただし、本開示で説明する技法は、そのように限定されず、他の3Dビデオ符号化および復号技法に拡張され得る。
[0070]JCT−3Vでは、マルチビュー拡張(MV−HEVC)および3Dビデオ拡張(3D−HEVC)と呼ばれる、開発中の2つのHEVC拡張がある。3D−HEVCのための最新の参照ソフトウェア3D−HTMバージョン8.0が、2014年10月13日時点では以下のリンクからダウンロードされ得る。[3D−HTMバージョン8.0]:https://hevc.hhi.fraunhofer.de/svn/svn_3DVCSoftware/tags/HTM−8.0/。最新のワーキングドラフト(文書番号:E1001(JCT3V−E1001))は、以下から入手できる。http://phenix.it−sudparis.eu/jct2/doc_end_user/documents/5_Vienna/wg11/JCT3V−E1001−v3.zip(ただし、このリンクは無効になる可能性がある)。JCT3V−E1001文書は、Sullivanらによる「3D−HEVC Draft Text 1」と題するものであり、同じく2014年10月13日時点ではhttp://phenix.it−sudparis.eu/jct2/doc_end_user/current_document.php?id=1361から入手可能である。
[0071]一般に、3Dビデオコーディング技法を使用してコーディングされたビデオデータは、3次元効果を生成するためにレンダリングされ、表示され得る。たとえば、(たとえば、わずかに異なる水平位置を有する2つのカメラパースペクティブに対応する)異なるビューの2つの画像は、一方の画像が閲覧者の左眼によって見られ、他方の画像が閲覧者の右眼によって見られるように、実質的に同時に表示され得る。
[0072]この3D効果は、たとえば、立体視(stereoscopic)ディスプレイまたは自動立体視(autostereoscopic)ディスプレイを使用して達成され得る。立体視ディスプレイは、2つの画像を相応にフィルタ処理するアイウェア(eyewear)とともに使用され得る。たとえば、パッシブ眼鏡は、正しい眼が正しい画像を閲覧することを保証するために偏光レンズまたは異なる色のレンズを使用して画像をフィルタ処理し得る。アクティブ眼鏡は、別の例として、立体視ディスプレイと協調して交互のレンズを迅速に閉じ得、それにより、左眼画像を表示することと右眼画像を表示することとを交互に行い得る。自動立体視ディスプレイは、眼鏡が必要とされないような方法で2つの画像を表示する。たとえば、自動立体視ディスプレイは、各画像が閲覧者の適切な眼に投影されるように構成されたミラーまたはプリズムを含み得る。
[0073]3Dビデオコーディングでは、複数のビューが存在し、各ビューは、テクスチャピクチャおよび深度ピクチャ、または単にテクスチャコンポーネントおよび深度マップと呼ばれる複数のピクチャを含む。各テクスチャコンポーネントは、1つの深度マップに対応し得る。テクスチャコンポーネントは、画像コンテンツを含むことができ、対応する深度マップは、テクスチャ中のピクセルの相対深度を示す。実質的に同時に表示されるべき異なるビューのテクスチャコンポーネントは、同様の画像コンテンツを含むが、異なるビューのテクスチャ中のオブジェクト間に水平視差がある。テクスチャおよび深度マップについて以下でより詳細に説明する。
[0074]3D−HEVCでは、アクセスユニットが、実質的に同時に表示されるべきテクスチャピクチャとそれらの対応する深度ピクチャとを含む。各ビュー中のテクスチャピクチャおよび深度ピクチャは、どのビューにピクチャが属するかを識別するための一意のビュー識別子(ビューid)またはビュー順序インデックスを有する。しかしながら、同じビューの深度ピクチャおよびテクスチャピクチャは、異なるレイヤ識別子(レイヤid)を有することがある。
[0075]本開示の技法は、テクスチャコンポーネントと深度マップとをコーディングすることによって3Dビデオデータをコーディングすることに関する。概して、「テクスチャ」という用語は、画像のルミナンス(輝度または「ルーマ」)値と画像のクロミナンス(色または「クロマ」)値とを表すために使用される。いくつかの例では、テクスチャ画像(すなわち、テクスチャピクチャ)は、1セットのルミナンスデータと、青色相(Cb)および赤色相(Cr)のための2セットのクロミナンスデータとを含む場合がある。4:2:2または4:2:0などの特定のクロマフォーマットでは、クロマデータは、ルーマデータに対してダウンサンプリングされる。言い換えれば、クロミナンスピクセルの空間解像度は、対応するルミナンスピクセルの空間解像度よりも低い(たとえば、ルミナンス解像度の1/2または1/4)ことがある。
[0076]深度データは、一般に、対応するテクスチャデータについての深度値を記述する。たとえば、深度画像(たとえば、深度ピクチャ)は、対応するテクスチャピクチャの対応するテクスチャデータについての深度をそれぞれ記述する深度ピクセルのセットを含む場合がある。深度データは、対応するテクスチャデータについての水平視差を決定するために使用され得る。したがって、テクスチャデータと深度データとを受信するデバイスは、一方のビュー(たとえば、左眼ビュー)のための第1のテクスチャピクチャを表示し、深度値に基づいて決定された水平視差値だけ第1のピクチャのピクセル値をオフセットすることによって、他方のビュー(たとえば、右眼ビュー)のための第2のテクスチャピクチャを生成するように第1のテクスチャピクチャを変更するために深度データを使用することができる。一般に、水平視差(または単に「視差」)は、右ビュー中の対応するピクセルに対する第1のビュー中のピクセルの水平空間オフセットを表し、2つのピクセルは、2つのビュー中で表される同じオブジェクトの同じ部分に対応する。
[0077]さらに他の例では、画像プレーンに直交するz次元におけるピクセルについて深度データが定義され得、その結果、画像について定義されたゼロ視差プレーンに対して、所与のピクセルに関連付けられた深度が定義される。そのような深度は、ピクセルを表示するための水平視差を作成するために使用され得、その結果、ピクセルは、ゼロ視差プレーンに対するピクセルのz次元深度値に応じて、左眼と右眼で異なるように表示される。ゼロ視差プレーンはビデオシーケンスの異なる部分に対して変化する場合があり、ゼロ視差プレーンに対する深度の量も変化する場合がある。ゼロ視差プレーン上に位置するピクセルは、左眼と右眼とに対して同様に定義され得る。ゼロ視差プレーンの前に位置するピクセルは、ピクセルが画像プレーンに直交するz方向の画像から出てくるように見える知覚を作成するように、(たとえば、水平視差を用いて)左眼と右眼とに対して異なるロケーションに表示され得る。ゼロ視差プレーンの後ろに位置するピクセルは、深度をわずかに知覚する程度に、わずかなぼかしとともに表示されてよく、または(たとえば、ゼロ視差プレーンの前に位置するピクセルの水平視差とは反対の水平視差を用いて)左眼と右眼とに対して異なるロケーションに表示され得る。他の多くの技法も、画像の深度データを伝達または定義するために使用され得る。
[0078]2次元ビデオデータは、概して、その各々が特定の時間インスタンスに対応する、個別ピクチャのシーケンスとしてコーディングされる。すなわち、各ピクチャは、シーケンス中の他の画像の再生時間に対する関連する再生時間を有する。これらのピクチャはテクスチャピクチャまたはテクスチャ画像と考えられ得る。深度ベースの3Dビデオコーディングでは、シーケンス中の各テクスチャピクチャは(深度マップとも呼ばれる)深度ピクチャにも対応し得る。すなわち、テクスチャピクチャに対応する深度マップは、対応するテクスチャピクチャのための深度データを表す。マルチビュービデオデータは、様々な異なるビューのためのデータを含んでよく、各ビューは、テクスチャピクチャと、対応する深度ピクチャとのそれぞれのシーケンスを含み得る。
[0079]上述したように、ピクチャは特定の時間インスタンスに対応し得る。ビデオデータは、アクセスユニットのシーケンスを使用して表され得、各アクセスユニットは、特定の時間インスタンスに対応するすべてのデータを含む。したがって、たとえば、マルチビュービデオデータ+深度の場合、共通時間インスタンスについての各ビューからのテクスチャピクチャ+テクスチャピクチャの各々についての深度マップはすべて、特定のアクセスユニット内に含まれ得る。アクセスユニットは、テクスチャピクチャに対応するテクスチャコンポーネントのためのデータと、深度マップに対応する深度コンポーネントのためのデータとを含み得る。
[0080]このようにして、3Dビデオデータは、キャプチャまたは生成されたビュー(テクスチャコンポーネント)が対応する深度マップに関連する、マルチビュービデオ+深度フォーマットを使用して表され得る。その上、3Dビデオコーディングでは、テクスチャコンポーネントおよび深度マップはコーディングされ、3Dビデオビットストリーム中に多重化され得る。深度マップはグレースケール画像としてコーディングされ得、深度マップの「ルーマ」サンプル(すなわち、ピクセル)は深度値を表す。一般に、深度データのブロック(深度マップのサンプルのブロック)は深度ブロックと呼ばれることがある。深度値は、深度サンプルに関連するルーマ値を指すことがある。
[0081]いずれの場合も、イントラコーディングおよびインターコーディング方法(たとえば、イントラ予測符号化および復号ならびにインター予測符号化および復号の技法)が深度マップコーディングに適用され得る。たとえば、上述したように、深度マップは、対応するテクスチャピクチャについての深度値を示すが、ビデオエンコーダ20およびビデオデコーダ30は、深度マップがグレースケール画像として形成されるので、ビデオコーディング技法を使用して深度マップを符号化および復号することができ、深度マップのルーマサンプルは、対応するテクスチャピクチャ中の対応するピクセルの相対深度を示す。
[0082]深度マップは、通常、シャープエッジと定数領域とを含み、深度マップ中のエッジは、一般に、対応するテクスチャピクチャの対応するテクスチャデータとの強い相関を提示する。テクスチャと対応する深度との間の異なる統計値および相関により、異なるコーディング方式が、2Dビデオコーデックに基づく深度マップのために設計されており、設計され続ける。たとえば、ベースHEVC規格において利用可能なものと比べて、深度マップをビデオコーディングするための、テクスチャと対応する深度との間の異なる統計値と相関とを活用する追加のビデオコーディング方式があり得る。
[0083]一例として、現在のHEVC規格では、各予測ユニット(PU)のルーマ成分のためのイントラ予測技法は、(2から34までインデックス付けされた)33個の角度予測モードと、(1によりインデックス付けされた)DCモードと、(0によりインデックス付けされた)平面モードとを利用することができる。図2は、方向性イントラ予測モードに関連する予測方向を概して示している。たとえば、上述のように、HEVC規格は、平面モード(モード0)と、DCモード(モード1)と、33個の方向性予測モード(モード2〜34)とを含む、35個のイントラ予測モードを含み得る。平面モードの場合、いわゆる「平面」関数を使用して予測が実行される。(たとえば、DC予測値を生成するための)DCモードの場合、ブロック内のピクセル値の平均化に基づいて予測が実行され得る。方向性予測モードの場合、(そのモードによって示される)特定の方向に沿った隣接ブロックの再構成されたピクセルに基づいて予測が実行される。概して、図2に示されている矢印の末端は、値がそこから取り出される隣接ピクセルのうちの相対的な1つを表し、矢印のヘッドは、予測ブロックを形成するために取り出された値が伝搬される方向を表す。
[0084]3D−HEVC規格は、イントラ予測モードの、HEVC規格と同じ定義を使用する。さらに、3D−HEVCは、深度マップの深度スライスの深度ブロック(たとえば、予測ユニット)をイントラ予測符号化または復号するために、HEVCイントラ予測モードとともに深度モデリングモード(DMM)を導入した。DMMは、深度マップのインター予測コーディング(符号化または復号)のための深度マップにおけるシャープエッジの表現に、より適している。
[0085]3D−HEVCワーキングドラフトのいくつかの先行バージョンは、4つのDMMモード、すなわち、モード1(明示的ウェッジレットシグナリング)と、モード2(イントラ予測ウェッジレット区分)と、モード3(コンポーネント間ウェッジレット区分)と、モード4(コンポーネント間輪郭区分)とを提供している。すべての4つのモードにおいて、ビデオエンコーダ20またはビデオデコーダ30などのビデオコーダは、DMMパターンによって指定された2つの領域に深度ブロックを区分することができ、各領域が定数値によって表される。DMMパターンは、明示的にシグナリングされる(モード1)か、空間的に隣接するブロックによって予測される(モード2)か、またはコロケートテクスチャブロックを使用して予測される(モード3およびモード4)かのいずれかであり得る。
[0086]3D−HEVCワーキングドラフトのいくつかのバージョンは、DMMモード2を除去し、DMMモード1、3および4を残した。3D−HEVCワーキングドラフトのいくつかのバージョンは、DMMモード3も除去し、DMMモード1および4を残した。
[0087]言い換えれば、DMMに新しいイントラ予測モードがある。これらのモードにおいて、ビデオエンコーダ20およびビデオデコーダ30は、(パーティションパターンと呼ばれる)DMMパターンによって指定された2つの領域に深度ブロックを区分するように構成され得、各領域が定数値によって表される。たとえば、ビデオエンコーダ20は、深度ブロックをイントラ予測符号化するために異なるパーティションパターン(パーティションパターンの例は上述している)を使用し、どのパーティションパターンが(たとえば、圧縮およびビデオ品質の点で)最適なコーディングをもたらしたかを決定するように構成され得る。その場合に、ビデオエンコーダ20は、決定されたパーティションパターンを使用して深度ブロックをイントラ予測符号化することができる。ビデオデコーダ30は、深度ブロックをイントラ予測復号するために、ビデオエンコーダ20とは逆のプロセスを実行するので、ビデオデコーダ30は、深度ブロックをイントラ予測復号するために、ビデオエンコーダ20が決定したのと同じパーティションパターンを決定するように構成され得る。
[0088]ビデオエンコーダ20は、深度モデリングモードを示す情報をビデオデコーダ30にシグナリングすることができ、ビデオデコーダ30は、深度モデリングモードを示すシグナリングされた情報から、パーティションパターンを決定することができる。たとえば、深度モデリングモードが1(DMMモード1)であることを示す情報をビデオエンコーダ20がシグナリングした場合、ビデオデコーダ30は、深度ブロックに関するパーティションパターンを識別するビデオエンコーダ20からの情報のビットストリームをパースするように構成され得る。言い換えれば、DMMモード1が使用されるべきであるとビデオエンコーダ20が決定した場合、ビデオエンコーダ20は、DMMモードが使用されることを示す情報を明示的にシグナリングし、深度ブロックに関するパーティションパターンを識別するためにビデオデコーダ30が使用する情報をシグナリングすることができる。このようにして、深度ブロックをイントラ予測コーディングするためにビデオエンコーダ20およびビデオデコーダ30が使用するパーティションパターン(たとえば、DMMパターン)は同じとなる。
[0089]DMMモード3および4の場合、ビデオエンコーダ20は、DMMモードがモード3または4であることを示す情報をシグナリングし得るが、深度ブロックに関するパーティションパターンを識別する情報をシグナリングしないことがある。むしろ、ビデオデコーダ30は、対応するテクスチャピクチャ中のコロケートテクスチャブロックから、深度ブロックに関するパーティションパターンを決定するように構成され得る。ビデオエンコーダ20およびビデオデコーダ30はそれぞれ、DMMモード3の場合に対応するテクスチャピクチャ中のコロケートテクスチャブロックからパーティションパターン(たとえば、DMMパターン)を決定するための同じプロセスを実施するように構成され、DMMモード4の場合に対応するテクスチャピクチャ中のコロケートテクスチャブロックからパーティションパターン(たとえば、DMMパターン)を決定するための同じプロセスを実施するように構成され得る。
[0090]ウェッジレット区分と輪郭区分とを含む、DMMにおいて定義されている2つのタイプの区分モードがある。図3Aおよび図3Bは、深度モデリングモード(DMM)の例を示す概念図である。図3Aは、8×8ブロックに関するウェッジレットパターンの一例を示し、図3Bは、8×8ブロックに関する輪郭パターンの例上に示す。
[0091]図3Aは、たとえば、ウェッジレット区分を使用して区分された深度ブロック110を示し、図3Bは、別の例として、輪郭区分を使用して区分された深度ブロック130を示す。3D−HEVCは、深度スライスのイントラ予測ユニットをコーディングするために、イントラ予測モードとともに、ブロックを区分するための深度モデリングモード(DMM)のための技法を含む。HTMバージョン3.1は、場合によっては深度マップ中のよりシャープなエッジをより良く表し得る、深度マップのイントラコーディングのためのDMM方法を適用する。
[0092]ウェッジレット区分と輪郭区分とを含む、DMMにおいて定義されている2つの区分モデルがある。この場合も、図3Aはウェッジレット区分の一例を示しており、図3Bは輪郭区分の一例を示している。深度ブロック110および130内の各個々の正方形は、それぞれ、深度ブロック110および130のそれぞれの個々のピクセルを表す。正方形内の数値は、対応するピクセルが領域112(図3Aの例における値「0」)に属するのか、領域114(図3Aの例における値「1」)に属するのかを表す。また、図3Aにおいて、ピクセルが領域112(白い正方形)に属するのか、領域114(灰色の影つき正方形)に属するのかを示すために陰影が使用される。
[0093]各パターン(すなわち、ウェッジレットと輪郭の両方)は、対応するサンプル(すなわち、ピクセル)が領域P1に属するのかP2に属するのか(P1は図3A中の領域112と図3B中の領域132とに対応し、P2は図3A中の領域114と図3B中の領域134A、134Bとに対応する)を標示するサイズuB×vB2進数字のアレイによって画定され得、uBおよびvBはそれぞれ、現在のPUの水平サイズおよび垂直サイズを表す。図3Aおよび図3Bの例では、PUは、それぞれブロック110および130に対応する。ビデオエンコーダ20およびビデオデコーダ30などのビデオコーダは、コーディングの開始(たとえば、符号化の開始または復号の開始)時に、ウェッジレットパターンを初期化し得る。
[0094]図3Aの例に示すように、ウェッジレット区分の場合、深度ブロック110は、(Xs,Ys)に位置する開始点118と(Xe,Ye)に位置する終了点120とをもつ直線116によって2つの領域、すなわち、領域112と領域114とに区分される。図3Aの例では、開始点118は点(8,0)として定義され得、終了点120は点(0,8)として定義され得る。
[0095]図3Bの例に示すように、輪郭区分の場合、深度ブロック130などの深度ブロックは2つの不規則形状領域に区分され得る。図3Bの例では、深度ブロック130は領域132と領域134A、134Bとに区分される。領域134A中のピクセルは領域134B中のピクセルに直接隣接しないが、領域134Aおよび134Bは、深度ブロック130のPUを予測する目的で1つの単一の領域を形成するように画定される。輪郭区分は、ウェッジレット区分よりもフレキシブルであるが、シグナリングすることが相対的により困難であり得る。DMMモード4では、3D−HEVCの場合、輪郭区分パターンは、コロケートテクスチャブロックの再構成されたルーマサンプルを使用して暗黙的に導出される。
[0096]このようにして、ビデオエンコーダ20およびビデオデコーダ30などのビデオコーダは、深度ブロック110のピクセルが(領域「P1」と呼ばれることもある)領域112に属するのか、(領域「P2」と呼ばれることもある)領域114に属するのかを決定するために、開始点118と終了点120とによって画定された線116を使用し得る。同様に、ビデオコーダは、深度ブロック130のピクセルが(領域「P1」と呼ばれることもある)領域132に属するのか、(領域「P2」と呼ばれることもある)領域134に属するのかを決定するために、図5Bの線136、138を使用し得る。領域「P1」および「P2」は、DMMに従って区分された異なる領域のためのデフォルト命名規則であり、したがって、深度ブロック110の領域P1は、深度ブロック130の領域P1と同じ領域と考えられるべきでない。
[0097]上記のように、DMMの各々は、DMMがウェッジレット区分を使用するのかまたは輪郭区分を使用するのか、およびパターンが明示的にシグナリングされるのかまたは暗黙的に決定されるのかによって定義され得る。DMMプロセスは、(図2に示す)HEVCにおいて指定されたイントラ予測モードの代替として組み込まれ得る。DMMが適用されるのかまたは従来のイントラ予測が適用されるのかを指定するために、PUごとに1ビットフラグがシグナリングされ得る。
[0098]図3Aおよび図3Bに示すように、N×Nパーティションパターンは、N×N2進ブロックを示す。本開示では、N×N2進ブロックの位置(i,j)における値は、位置(i,j)におけるパーティションパターンのパーティション値と呼ばれ、i,j=0,1,...,N−1である。N×Nパーティションパターンの位置ごとに、2進数字値は、現在の位置のパーティション(0または1)を示す。
[0099]たとえば、図3Aは、線形線(たとえば、直線116)が深度ブロック110を二等分するウェッジレットパターンの一例を示している。ただし、多くの異なるウェッジレットパターンがあり得る。たとえば、図3Aに示すような、(0,8)から開始して(8,0)において終了する線形線ではなく、別の例では、(1,8)から開始して(8,1)において終了する線形線も可能である。ウェッジレットパターンのさらに多くのそのような例があり得る。
[0100]一般に、ウェッジレットパターンの数は、ブロックサイズの関数であり得る。たとえば、より大きいサイズの深度ブロックは、より小さいサイズの深度ブロックよりも多くの開始点と終了点とを含み、これは、より大きいサイズの深度ブロックの場合にはより小さいサイズの深度ブロックの場合よりも多くの可能なウェッジレットパターンがあることを意味する。
[0101]初期化中、ビデオコーダ(たとえば、ビデオエンコーダ20およびビデオデコーダ30)は、すべての利用可能なウェッジレットパターンを生成することができ、ウェッジレットパターンリストを構成する。この目的で、開始点位置および終了点位置のすべての可能な組合せのウェッジレットパターンが生成され、ビデオコーダは、コーディングプロセスの前にブロックサイズごとに開始点位置と終了点位置とをルックアップテーブルに記憶する。深度ブロックのイントラ予測にどのウェッジレットパターンを使用すべきかをビデオエンコーダ20が識別する例では、ビデオエンコーダ20は、ウェッジレットパターンのルックアップテーブルへのインデックスをシグナリングすることができ、このインデックスは、深度ブロックをイントラ予測符号化するためにビデオエンコーダ20が使用したウェッジレットパターンを識別する。ビデオデコーダ30は、初期化中にビデオデコーダ30が構成したウェッジレットパターンのルックアップテーブルへのインデックスを受信する。次いでビデオデコーダ30は、インデックスによって識別されたウェッジレットパターンを決定し、深度ブロックのイントラ予測復号にそのウェッジレットパターンを使用することができる。このようにして、ビデオエンコーダ20およびビデオデコーダ30は、それぞれ、イントラ予測符号化およびイントラ予測復号に同じウェッジレットパターンを利用することができる。
[0102]開始点位置および終了点位置の可能な組合せは、開始点位置と終了点位置とをつなぐパーティション境界線の方位に応じて、6つのカテゴリーに分類され得る。たとえば、深度ブロックを二等分する線形線が、最上行から左列、最下行、または右列に延び得る。深度ブロックを二等分する線形線が、左列から最下行または右列に延び得る(最上行への延びは、先行事例ですでにカバーされている)。深度ブロックを二等分する線形線が、最下行から右列に延び得る(他は、先行事例ですでにカバーされている)。この方法では、深度ブロックを二等分する線形線のための6つのカテゴリーがある。これらの6つのカテゴリーを以下の表1に記載する。
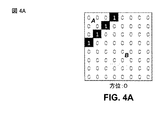
[0103]N×Nウェッジレットパーティションパターンを生成するにあたり、開始点(xS,yS)および終了点(xE,yE)位置を仮定すると、ビデオエンコーダ20およびビデオデコーダ30は最初に、すべてのサンプルが0に初期化された一時的K×Kパーティションパターンを生成し、ここで、1/2サンプル(1/2ピクセル)精度の場合にKは2Nに等しく、他の場合にKはNに等しい。ビデオエンコーダ20およびビデオデコーダ30は、(xS,yS)と(xE,yE)とをつなぐパーティション境界線を形成するサンプルを1に設定し、一時的パーティションパターンを2つの部分(たとえば、図4に示すような部分Aおよび部分B)として分割することができる。
[0104]図4A〜図4Fは、一時的パーティションパターンの例を示す概念図である。たとえば、図4A〜図4Fは、パーティション境界線(すなわち、深度ブロックを二等分する線形線)によって分割される2つの部分を示している。
[0105]ビデオエンコーダ20およびビデオデコーダ30が一時的パーティションパターンを2つの部分として分割した後、ビデオエンコーダ20およびビデオデコーダ30は、パーティション1となる2つの部分のうちの1つを選択する。ビデオエンコーダ20およびビデオデコーダ30は、ウェッジレットパターン境界線の方位に基づいて、部分のうちのどちらがパーティション1となるかを選択するように構成され得る。ビデオエンコーダ20およびビデオデコーダ30は、同じ方法で部分のうちのどちらがパーティション1となるかを選択するように構成されるので、ビデオエンコーダ20およびビデオデコーダ30は、パーティション1となる同じ部分を選択する。また、他方の部分(すなわち、パーティション1ではないパーティション)はデフォルトによってパーティション0となるので、ビデオエンコーダ20およびビデオデコーダ30は、パーティション0となる同じ部分を選択する。
[0106]上述のように、表1によって示されるように、ウェッジレットパターンの2つのパーティションに深度ブロックを二等分する線形線の6つの方位があり得る。図4A〜図4Fは、そのような方位の例を示している。図4A〜図4Fはそれぞれ、それぞれの方位の一例を示しており、他の例もあり得ることを理解されたい。たとえば、図4Bは、方位1の場合であり、上記の表1は、方位1が右列から最上行までであることを示している。図4Bでは、線形線は(8,5)から開始し、(4,0)において終了する。方位1の別の例では、線形線は(8,7)から開始し、(1,0)において終了し得る。
[0107]下記の表2は、ビデオエンコーダ20およびビデオデコーダ30がパーティション境界の方位に基づいて、どちらの部分がパーティション1となるかを選択する方法を示している。たとえば、ビデオエンコーダ20およびビデオデコーダ30は最初に、パーティション境界の方位(すなわち、深度ブロックを二等分する線形線の方位)を決定することができる。次いで、ビデオエンコーダ20およびビデオデコーダ30は、二等分線形線によって作成された2つのパーティションのうちのどちらのパーティションが1と識別されるべきか、またどちらのパーティションが0と識別されるべきかを決定することができる。
[0108]一例として、表2に示すように、方位パーティション境界が0である場合、ビデオエンコーダ20およびビデオデコーダ30は、1により識別されるパーティションとして部分Aを選択する。図4Aは、Aと標示されたパーティションが1と識別されることになり、Bと標示されたパーティションが0と識別されることになる一例を示している。ただし、図4Aは方位パーティション境界1の一例であり、方位パーティション境界1の他の例がある。ビデオエンコーダ20およびビデオデコーダ30は、表2に記載の基準に基づいて方位1〜5の場合に、どちらのパーティションが1と識別され、どちらのパーティションが0と識別されるかを決定するための同様の機能を実行することができる。
[0109]図4A〜図4Fに示す例では、線形線は深度ブロック内のピクセル(たとえば、サンプル)から開始し、深度ブロック内のピクセル(たとえば、サンプル)において終了する。そのような例では、線形線は、フルサンプル精度を有すると考えられ得る。しかしながら、本開示で説明する技法は、そのように限定されない。たとえば、技法は、1/2サンプル精度または場合によっては1/4サンプル精度に拡張され得る。
[0110]1/2サンプル精度の場合、ビデオエンコーダ20およびビデオデコーダ30は、bPatternと呼ばれるN×Nパーティションパターンを、一時的K×K(K=2N)パーティションパターンbTempPatternのダウンサンプリングされたバージョンとして生成することができる。この例では、bPattern[i][j]=bTempPattern[m][n]であり、i,j=0,1,...,N−1、そしてm,n=0,1,...,2N−1である。本開示では、一時的K×Kパーティションパターンは、開始位置(xS,yS)と終了位置(xE,yE)とを有するこのN×Nパーティションパターンの対応するウェッジレットパターンと呼ばれ、この対応するウェッジレットパターンは、開始位置(2×xS,2×yS)と終了位置(2×xE,2×yE)とを有するサイズ2N×2Nを有する。1/2サンプル精度のために、2×xS、2×yS、2×xEおよび2×yEは整数であるが、xS、yS、xE、およびyEは分数であり得る。(i,j)と(m,n)との間のマッピングは、パーティション境界線の方位に依存する。技法は、1/4サンプル精度の場合も同様に拡張され得る。
[0111]以下では、1/2サンプル精度の場合のパーティションパターンを生成する例について説明する。例示のために、例は、方位0および方位1に関して説明される。
[0112]図5Aおよび図5Bは、1/2サンプル精度のパーティションパターンサンプルのマッピングを示す概念図である。たとえば、図5Aおよび図5Bは、(たとえば、1/2サンプル精度の)2N×2NパーティションパターンサンプルからN×Nパーティションパターンサンプルへのマッピングを示している。図5Aは、開始点が最上行にあり、終了点が左列にある方位0の例を示している。図5Bは、開始点が右列にあり、終了点が最上行にある方位1の例を示している。
[0113]図5Aおよび図5Bでは、影つきブロックは、ダウンサンプリングされたN×Nパーティションパターンのサンプルを示している。たとえば、図5Aおよび図5Bにおけるブロックは、サイズが2N×2Nであり、図5Aおよび図5Bでは、影つきサンプルは、2N×2Nブロックにおいて1つおきのサンプルを示し、結果的にN×Nブロックとなる。
[0114]いくつかの例では、方位0を有するウェッジレットパターンを生成するために、ビデオエンコーダ20およびビデオデコーダ30は、方位0を有するウェッジレットパターンのすべての可能な開始点と終了点とをカバーするように、開始点((xS,yS))を(0,0)から(2N−1,0)にループし、終了点((xE,yE))を(0,0)から(0,2N−1)にループすることができる。ビデオエンコーダ20およびビデオデコーダ30はまた、方位0の場合にm=2iおよびn=2jとして、(i,j)を(m,n)にマッピングすることができる。方位1の場合、ビデオエンコーダ20およびビデオデコーダ30は、方位1を有するウェッジレットパターンのすべての可能な開始点と終了点とをカバーするように、開始点((xS,yS))を(2N−1,0)から(2N−1,2N−1)にループし、終了点((xE,yE))を(2N−1,0)から(0,0)にループすることができる。ビデオエンコーダ20およびビデオデコーダ30はまた、方位1の場合にm=2i+1およびn=2jとして、(i,j)を(m,n)にマッピングすることができる。
[0115]他の方位の場合、ビデオエンコーダ20およびビデオデコーダ30は同様に、方位に基づいて開始点と終了点とをループすることができる。すべての方位のマッピングの式は、m=2i+オフセットXおよびn=2j+オフセットYと一般化され得、オフセットX、オフセットYは、表3に指定された移動値である。ビデオエンコーダ20およびビデオデコーダ30は、方位の各々のマッピングのために、式=m=2i+オフセットXおよびn=2j+オフセットYを実施することができ、オフセットXおよびオフセットYは表3によって定義されている。
[0116]上述のように、初期化中、ビデオエンコーダ20およびビデオデコーダ30はそれぞれ、すべてのウェッジレットパターンの開始点および終了点(すなわち、方位ごとに2つのパーティションに深度ブロックを二等分する異なる可能な線形線の開始点および終了点)を含むウェッジレットパターンリストを構成することができる。場合によっては、2つのウェッジレットパターンが同じであり得る。ただし、ビデオエンコーダ20およびビデオデコーダ30は、ウェッジレットパターンリストが唯一の固有のパターンを含むように、重複するウェッジレットパターンをウェッジレットパターンリスト初期化プロセス中に除去することができる。
[0117]ウェッジレットパターンリストを生成する際、ウェッジレットパターンを生成するために使用される開始位置および終了位置の解像度は、ブロックサイズに依存する。32×32ブロックの場合、可能な開始位置および終了位置は、2サンプルの精度を有するロケーションに制限される。16×16ブロックの場合、フルサンプル精度が使用され、4×4および8×8ブロックの場合、1/2サンプル精度が使用される。したがって、異なるブロックサイズで可能なウェッジレットパターンは異なり得る。一般に、可能なウェッジレットパターンの数は、ブロックのサイズに正比例する(すなわち、ブロックサイズが大きくなるほど、ウェッジレットパターンは多くなり、ブロックサイズが小さくなるほど、ウェッジレットパターンは少なくなる)。
[0118]ウェッジレットパターンリスト初期化プロセス中に、重複するウェッジレットパターンをウェッジレットリストに追加するのを回避するために、ビデオエンコーダ20およびビデオデコーダ30はそれぞれ、新たに生成されたウェッジレットパターンがリスト中の現在のウェッジレットパターンのいずれかと同じパターンを表していないときのみ、新たに生成されたウェッジレットパターンをウェッジレットリストの終わりに追加することができる。サイズN×Nの2つのウェッジレットパターン(すなわち、パターンA[i][j]、パターンB[i][j]、i,j=0,1,...,N−1)を比較するとき、[0,N−1]の範囲におけるiおよびjのすべての可能な組合せにおいて、パターンA[i][j]が常にパターンB[i][j]に等しいか、またはパターンA[i][j]がパターンB[i][j]に等しいことが決してない場合、パターンAはパターンBと同じであると考えられる。
[0119]異なるブロックサイズと開始点位置および終了点位置の異なる精度とに起因して、以下の表4に記載のように、異なる数および異なるパターンのウェッジレットパターンが、異なるブロックサイズに利用可能である。より大きいブロックサイズの場合、ウェッジレットパターンの総数は格段に大きいことがあり、パターン生成の記憶要件および複雑性が高まり得る。
[0120]ウェッジレットリスト初期化の詳細なプロセスが、ワーキングドラフトJCT3V−E1001のH.8.4.4.2.12、H.8.4.4.2.12.1およびH.8.4.4.2.12.2に指定されている。上述のように、JCT3V−E1001文書は、Sullivanらによる「3D−HEVC Draft Text 1」と題するものであり、2014年10月13日時点ではhttp://phenix.it−sudparis.eu/jct2/doc_end_user/current_document.php?id=1361から入手可能である。
[0121]ブロックサイズ依存型ウェッジレットパターン設計に関するいくつかの問題があり得る。たとえば、大きいブロックサイズの場合、利用可能なウェッジレットパターンの総数は、非常に大きいことがある。表4に示すように、16×16のブロックサイズの場合、ウェッジレットパターンの総数は1394であり、32×32のブロックサイズの場合、ウェッジレットパターンの総数は1503である。多数のウェッジレットパターンは、大規模メモリ要件をもたらし、これは望ましくないことがある。言い換えれば、ビデオエンコーダ20およびビデオデコーダ30は、ウェッジレットパターンのすべてを記憶するために大きいサイズのメモリを必要とし得る。また、ウェッジレットパターンリストを構成するために、特により大きいブロックサイズの場合には、比較的多数のウェッジレットパターンがあるので、ビデオエンコーダ20およびビデオデコーダ30は、ウェッジレットパターンを取り出すためにメモリユニットに対する望ましくない数のメモリ呼出しを必要とし得る。
[0122]この理由(すなわち、多数のパターン)により、ウェッジレットパターンは64×64PUの場合にはサポートされない。たとえば、既存のブロックサイズ依存型ウェッジレットパターン設計では、深度ブロックのイントラ予測にウェッジレットパターンを使用することに関連する利益が、64×64サイズの深度ブロックに関するウェッジレットパターンの数の多さに圧倒され得る。したがって、64×64サイズのブロックに関するウェッジレットパターンに基づくイントラ予測に関連する利益がある場合でも、既存の技法は、64×64サイズのブロックに関するウェッジレットパターンに基づくそのようなイントラ予測をサポートしないことがある。
[0123]既存のブロックサイズ依存型ウェッジレットパターン設計に伴う問題の別の例として、3D−HEVCでは、ウェッジレットパターンを生成するプロセスが、特にブロックがより大きいサイズを有するときに複雑であり得る。さらに、3D−HEVCは、ブロックサイズごとに、1セットのウェッジレットパターンが記憶されることを必要とし得る。しかしながら、64×64サイズのブロックの場合、ウェッジレットパターンを使用するイントラ予測はサポートされないことがあるので、現在のウェッジレットパターン設計では、64×64サイズのブロックに関してウェッジレットパターンが記憶される必要はない。
[0124]既存のブロックサイズ依存型ウェッジレットパターン設計に伴う問題のまた別の例として、ウェッジレットパターンリスト初期化中に、ビデオエンコーダ20およびビデオデコーダ30は、重複するウェッジレットパターンを追加するのを回避するために、2つのウェッジレットパターン間でかなりの数の比較計算を実行することを求められ得る。そのような比較計算は、計算の複雑性を高め、ビデオエンコーダ20またはビデオデコーダ30にとって望ましくない。
[0125]本開示で説明する技法は、深度イントラコーディングのための簡略化された深度パーティションパターン生成に関する。以下の例では、深度イントラコーディングのためのそのような簡略化された深度パーティションパターン生成のための技法について説明する。以下の例示的な技法は、ビデオエンコーダ20およびビデオデコーダ30によって実行され得る。たとえば、ビデオエンコーダ20および/またはビデオデコーダ30は、深度データをイントラコーディング(たとえば、それぞれイントラ予測符号化またはイントラ予測復号)することができる。また、例示的な技法が別個に実行されることがあり、または1つもしくは複数の技法が組合せで実行されることがある。
[0126]さらに、簡潔のために、本開示で説明する技法は、ビデオコーダに関して説明され得る。ビデオコーダの例としては、ビデオデータの符号化について説明するときのビデオエンコーダ20、およびビデオデータの復号について説明するときのビデオデコーダ30がある。本開示は、「コーディングする」または「コーディング」という用語を使用することもある。この文脈では、コーディングするという用語は、符号化するまたは復号するを総称的に指し得、コーディングという用語は、符号化または復号を総称的に指し得る。たとえば、ビデオコーダはコーディングすることができ、これは、ビデオエンコーダ20が符号化することができること、またはビデオデコーダ30が復号することができることを意味する。
[0127]上述のように、既存のブロックサイズ依存型ウェッジレットパターン設計に伴う問題のうちの1つは、より大きいサイズのブロックの場合、ウェッジレットパターンの数があまりにも大きくなって、望ましくない量のメモリを必要とし、計算性の複雑性を高めることである。本開示で説明する技法では、より大きいサイズの深度ブロックに関するウェッジレットパターンに依拠するのではなく、より大きいサイズの深度ブロックに関するウェッジレットパターンが、より小さいサイズのブロックに関するウェッジレットパターンから決定され得る。このようにして、ビデオエンコーダ20およびビデオデコーダ30は、より小さいサイズのブロックに関するウェッジレットパターン(たとえば、パーティションパターン)を記憶し、より大きいサイズのブロックに関するウェッジレットパターンをより少なく記憶するか、またはまったく記憶しないことがあり、その理由は、ビデオエンコーダ20およびビデオデコーダ30が、より小さいサイズのブロックに関するウェッジレットパターンのうちのウェッジレットパターンから、より大きいサイズの深度ブロックに関するウェッジレットパターンを決定し得ることにある。
[0128]一例として、ビデオエンコーダ20およびビデオデコーダ30は、第1のブロックサイズのブロックに関するパーティションパターンリスト(たとえば、ウェッジレットパターンリスト)を構成するように構成され得る。パーティションパターンリストは、第1のブロックサイズのブロックに関連する1つまたは複数のパーティションパターンを含むことができる。第1のブロックサイズよりも大きい第2のブロックサイズの深度ブロックのイントラ予測符号化の場合、ビデオエンコーダ20は、第1のブロックサイズのブロックに関するパーティションパターンから決定されたパーティションパターン(たとえば、ウェッジレットパターン)を使用して、第2のサイズの深度ブロックをイントラ予測符号化することができる。言い換えれば、ビデオエンコーダ20は、第1のサイズのブロックに関連するパーティションパターンを使用して、第2のサイズの深度ブロックをイントラ予測符号化することができる。深度モデリングモード(DMM)1の場合、ビデオエンコーダ20は、第1のブロックサイズの1つまたは複数のパーティションパターン関連ブロックを含むパーティションパターンリストへのインデックスをシグナリングすることができる。
[0129]第2のブロックサイズの深度ブロックのイントラ予測復号の場合、ビデオデコーダ30は、第1のブロックサイズのブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストへのインデックスを受信することができ、インデックスから第1のサイズのブロックに関連するパーティションパターンを決定することができる。ここでも、パーティションパターンは、復号される深度ブロックの第2のブロックサイズよりも小さい第1のブロックサイズのブロックに関連付けられる。次いでビデオデコーダ30は、決定されたパーティションパターンから、第2のブロックサイズの深度ブロックに関するパーティションパターンを決定することができる。ビデオデコーダ30は、決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックをイントラ予測復号することができる。
[0130]上述のように、より大きいサイズのブロックに関するパーティションパターン(たとえば、ウェッジレットパターン)を記憶することは、より大きいサイズのブロックに利用可能なパーティションパターンの数が比較的大きいので、望ましくないことがある。より小さいサイズのブロックに関するパーティションパターンに基づいて、より大きいサイズのブロックに関するパーティションパターンを決定することによって、より大きいサイズのブロックに関して記憶される必要のあるパーティションパターンの数は低減され得る。たとえば、前の例では、ビデオエンコーダ20およびビデオデコーダ30は、第1のブロックサイズのブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成し、第2のより大きいサイズの深度ブロックに関するパーティションパターンを決定するために、パーティションパターンリストからパーティションパターンのうちの1つを使用することができる。したがって、ビデオエンコーダ20およびビデオデコーダ30が、第2のサイズのパーティションパターンに関するパーティションパターンリストを構成した場合、より小さいブロックサイズに関するパーティションパターンからパーティションパターンの一部が決定され得るので、パーティションパターンリスト中のパーティションパターンの数は低減されることになる。
[0131]いくつかの例では、ビデオエンコーダ20およびビデオデコーダ30は、いくつかのブロックサイズに関するパーティションリストパターンを構成しないこともある。そのような例では、ビデオエンコーダ20およびビデオデコーダ30は、ビデオエンコーダ20およびビデオデコーダ30がパーティションリストパターンを構成したブロックサイズの深度ブロックに関するパーティションパターンを決定するために、より小さいサイズのブロックに関連するパーティションパターンに依拠し得る。
[0132]また、より大きいブロックサイズの場合は、パーティションパターンリストにより少ないパーティションパターンがあること、またはパーティションパターンがまったくないことがあるので、パーティションパターンを記憶するために必要とされるメモリの量の減少があり得る。その上、より大きいブロックサイズの場合は、パーティションパターンリストにより少ないパーティションパターンがあること、またはパーティションパターンがまったくないことがあるので、パーティションパターンを生成する計算の複雑性および重複がないようにするためにパーティションパターンを比較する複雑性も低減され得る。
[0133]上述のように、より小さいサイズのブロックに関するパーティションパターンに基づいて、より大きいサイズの深度ブロックに関するパーティションパターンを決定することによって、本開示で説明する技法は、メモリ要件を低減し、複雑性を低減することができる。いくつかの例では、より小さいサイズのブロックは、より大きいサイズの深度ブロック内のブロックであり得る。しかしながら、本開示で説明する技法は、そのように限定されない。いくつかの例では、より小さいサイズのブロックは必ずしも、イントラ予測符号化または復号されている実際のブロックである必要はない。そうではなく、より小さいサイズのブロックは、より大きいサイズのブロックに関するパーティションパターンを決定するためにパーティションパターンが使用される概念的ブロックであり得る。
[0134]一例として、イントラ予測符号化または復号される深度ブロックが32×32サイズの深度ブロックであると仮定する。この例では、エンコーダ20は、サイズ16×16のブロックに関するパーティションパターンリストへのインデックスをシグナリングすることができる。ビデオデコーダ30は、サイズ16×16のブロックに関するパーティションパターンリストへのインデックスを受信し、サイズ16×16のブロックに関するパーティションパターンからパーティションパターンを決定することができる。この例では、ビデオエンコーダ20とビデオデコーダ30の両方は、サイズ16×16のブロックに関する決定されたパーティションパターンから、32×32サイズの深度ブロックに関するパーティションパターンを決定するように構成され得る。一例として、ビデオエンコーダ20およびビデオデコーダ30は、32×32サイズの深度ブロックに関するパーティションパターンを決定するために、サイズ16×16のブロックに関する決定されたパーティションパターンをアップサンプリングすることができる。
[0135]より小さいサイズのブロック(そのパーティションパターンリストを、ビデオエンコーダ20およびビデオデコーダ30がより大きいサイズのブロックに関するパーティションパターンを決定するために使用する)は、より大きいサイズのブロックの一部である必要はないが、本開示で説明する技法は、より小さいサイズのブロックがより大きいサイズのブロック内のブロックである例とともに説明される。たとえば、深度コーディング(たとえば、深度ブロックのイントラ予測コーディング)の一例では、パーティションパターンは、ブロックサイズとは無関係である。
[0136]本開示で説明する技法において、ビデオエンコーダ20およびビデオデコーダ30が、より大きいサイズのブロックに関するパーティションパターンを決定するための中間ステップとして、より小さいサイズのブロックに関するパーティションパターンを決定し得ることを理解されたい。たとえば、より小さいサイズのブロックは、より小さいサイズのブロックのパーティションパターンに基づいてイントラ予測符号化または復号されないことがある。そうではなく、より小さいサイズのブロックは、より大きいサイズのブロックのイントラ予測の一部としてイントラ予測符号化または復号され得る。
[0137]一例として、現在の深度ブロック(たとえば、現在の深度PU)はN×Nのサイズを有すると仮定する。この例では、現在の深度ブロックは、整数個のM×M(M<N)ブロックを含む。一例として、現在の深度ブロック(たとえば、イントラ予測符号化または復号されるべき深度ブロック)が32×32サイズのブロックである場合、32×32サイズのブロック内に4個の16×16サイズのブロック、または32×32サイズのブロック内に64個の4×4サイズのブロックがある。
[0138]いくつかの例では、ビデオエンコーダ20は、1つの特定のM×Mブロック(たとえば、Mは4に等しい)と、線ベースのパーティションパターン(たとえば、2つのパーティションにM×Mブロックを二等分する線形線を画定するウェッジレットパターン)とを識別する情報をシグナリングすることができる。ビデオデコーダ30は、M×Mブロックと線ベースのパーティションパターンとを識別する情報を受信することができる。特定のM×Mブロックの線ベースのパーティションパターンに基づいて、ビデオエンコーダ20およびビデオデコーダ30は、全体的N×N PUに関する線ベースのパーティションを決定する(たとえば、導出する)ことができる。言い換えれば、M×Mブロックに関するパーティションパターンに基づいて、ビデオエンコーダ20およびビデオデコーダ30は、N×N深度ブロック全体に関するパーティションパターンを決定することができ、ここで、N×N深度ブロックはM×Mブロックを含む。
[0139]一例では、線ベースのパーティションパターンは、現在の3D−HEVCの場合のように、特定のM×Mブロックに適用されるDMM1のウェッジレットパターンであり得る。たとえば、ビデオエンコーダ20は、深度モデリングモード(DMM)が1であることを示す情報をシグナリングし、N×Nブロック内のM×Mブロックを識別する情報をシグナリングし、M×Mブロックに関するパーティションパターンを識別するために使用される情報をシグナリングすることができる。(たとえば、サイズM×Mのブロックに関するパーティションパターンリストへのインデックス値)。ビデオデコーダ30は、DMMが1であることを示す情報を受信し、M×Mブロックを識別する受信された情報に基づいてN×Nブロック内のM×Mブロックを決定し、(たとえば、サイズM×Mのブロックに関するパーティションパターンリストへのインデックス値に基づいて)M×Mブロックに関するパーティションパターンを決定することができる。次いでビデオデコーダ30は、M×Mブロックに関する決定されたパーティションパターンに基づいて、全体的N×Nブロックに関するパーティションパターンを決定することができる。
[0140]本明細書で説明する「全体的」ブロックは、ブロックに含まれ得るサブブロックを含む、ブロック全体を含み得る。したがって、4個のサブブロックを有するブロックの場合、全体的ブロックは、4個のサブブロックのすべてを含むブロック全体を指し得る。
[0141]たとえば、ビデオエンコーダ20は、イントラ深度符号化(イントラ予測符号化)のためにブロック(たとえば、深度PUであるN×Nブロック)のサブブロックに関する線ベースのパーティションパターン(たとえば、2つのパーティションにM×Mブロックを二等分する線形線を画定するウェッジレットパターン)を決定することができ、ここにおいて、サブブロックがブロックよりも小さい。いくつかの例では、ビデオエンコーダ20は、ブロックのサブブロックに関する線ベースのパーティションパターンを、決定される線ベースのパーティションパターンをブロックのサイズに基づかせることなく(すなわち、ブロックサイズとは無関係に)決定することができる。ビデオエンコーダ20は、サブブロックに関する線ベースのパーティションパターンに基づいて、ブロックに関する線ベースのパーティションパターンを決定することができる。ビデオエンコーダ20は、ブロックに関する決定された線ベースのパーティションパターンに基づいて、ブロックをイントラ符号化する(イントラ予測符号化する)ことができる。ビデオエンコーダ20は、サブブロックに関する線ベースのパーティションパターンを示す情報をシグナリングする(たとえば、サブブロックに関する線ベースのパーティションパターンを示す情報を符号化する)ことができる。いくつかの例では、ビデオエンコーダ20は、ビデオエンコーダ20が線ベースのパーティションパターンを決定した、ブロック内のサブブロックを識別するために使用される情報をシグナリングすることができるが、これは、あらゆる例において必要とされるとは限らない。
[0142]ビデオエンコーダ20は、ブロックに関する線ベースのパーティションパターンを示す情報をシグナリングしないことがある。たとえば、ビデオエンコーダ20は、ブロックに関する線ベースのパーティションパターンを示す情報を符号化するのを回避すること、または符号化しないことがある。むしろ、ビデオエンコーダ20は、サブブロックに関する線ベースのパーティションパターンを示す情報をシグナリングすることがある。
[0143]ビデオデコーダ30は、イントラ深度復号のために(たとえば、イントラ予測復号のために)ブロックのサブブロックに関する線ベースのパーティションパターンを示す情報を受信する(たとえば、サブブロックに関する線ベースのパーティションパターンを示す情報を復号する)ことができる。ビデオデコーダ30は、サブブロックに関する線ベースのパーティションパターンに基づいて、ブロックに関する線ベースのパーティションパターンを決定することができる。ビデオデコーダ30は、ブロックに関する決定された線ベースのパーティションパターンに基づいて、ブロックをイントラ復号する(イントラ予測復号する)ことができる。いくつかの例では、ビデオデコーダ30は、ビデオデコーダ30によって線ベースのパーティションパターンが受信された、ブロック内のサブブロックを識別するために使用される情報を受信することができるが、これは、あらゆる例において必要とされるとは限らない。ビデオデコーダ30は、ブロックに関する線ベースのパーティションパターンを示す情報を受信することなく、ブロックに関する線ベースのパーティションパターンを決定することができる。むしろ、ビデオデコーダ30は、サブブロックから線ベースのパーティションパターンを決定することがある。また、ビデオデコーダ30は、ブロックに関する線ベースのパーティションパターンを、決定される線ベースのパーティションパターンをブロックのサイズに基づかせることなく(すなわち、ブロックサイズとは無関係に)決定することができる。
[0144]M×Mサブブロックは必ずしも、より大きいN×Nブロック内に入るブロックである必要はないことを理解されたい。そうではなく、M×Mサブブロックは、N×Nブロックに関する線ベースのパーティションパターンを決定する目的で線ベースのパーティションパターンが使用される概念的ブロックであり得る。言い換えれば、上記の例では、ビデオエンコーダ20は、第1のサイズ(たとえば、32×32)の深度ブロックに関するパーティションパターン(たとえば、ウェッジレットパターンのような線ベースのパーティションパターン)を、第2のより小さいサイズ(たとえば、16×16)のブロックに関するパーティションパターンに基づいて決定することができる。ビデオエンコーダ20は、決定されたパーティションパターンに基づいて深度ブロックをイントラ予測符号化することができる。ビデオデコーダ30は同様に、第1のサイズ(たとえば、32×32)の深度ブロックに関するパーティションパターンを、第2のより小さいサイズ(たとえば、16×16)のブロックに関するパーティションパターンに基づいて決定することができる。ここでも、このより小さいサイズのブロックは、ピクチャ中または深度ブロック内の実際のブロックである必要はなく、代わりに、より大きいブロックに関するパーティションパターンを決定するためにパーティションパターンが使用される概念的ブロックである。
[0145]いくつかの例では、ビデオエンコーダ20は、第2のサイズのブロックに関するパーティションパターンを識別する情報をシグナリングし、ビデオデコーダ30は、シグナリングされた情報に基づいて第2のサイズのブロックに関するパーティションパターンを決定する。たとえば、ビデオエンコーダ20は、第2のサイズのパーティションパターンに関するパーティションパターンリストへのインデックスをシグナリングすることができ、インデックスによって識別されるパーティションパターンは、ビデオエンコーダ20が第1のサイズの深度ブロックに関するパーティションパターンを決定するために利用したパーティションパターンである。ビデオデコーダ30は、第2のサイズのパーティションパターンに関するパーティションパターンリストへのインデックスを受信し、第2のサイズのブロックに関するパーティションパターンに基づいて、第1のサイズの深度ブロックに関するパーティションパターンを決定することができる。
[0146]上記の例では、より小さいサイズのブロックは概念的ブロックであり、必ずしも、深度ブロックを含むピクチャのブロック、または深度ブロック内のブロックであるとは限らない。ただし、いくつかの例では、より小さいブロックは、より大きいサイズのブロック内のブロックであり得る。より小さいサイズのブロックがより大きいサイズのブロック内のブロックである(たとえば、16×16ブロックが、32×32ブロック内の4個の16×16ブロックのうちの1つである)例では、ビデオエンコーダ20は、より大きいサイズのブロック中のより小さいサイズのブロックのロケーションを識別する情報をシグナリングすることができる。次いでビデオデコーダ30は、より小さいサイズのブロックに関するパーティションパターンおよびより大きいサイズのブロック内のより小さいサイズのブロックの位置に基づいて、より大きいサイズのブロックに関するパーティションパターンを決定することができる。たとえば、ビデオデコーダ30は、より小さいサイズのブロックを二等分する線形線を、より大きいサイズのブロックのエッジに線形線がぶつかるまで、外側に拡張することができる。より大きいサイズのブロックの得られる二等分は、より小さいサイズのブロックのパーティションパターンから決定された、より大きいサイズのブロックに関するパーティションパターンであり得る。
[0147]言い換えれば、ビデオデコーダ30は、サブブロックに関するパーティションパターンの線形線を深度ブロックの境界まで拡張することができる。得られる線形線は、深度ブロックをイントラ予測復号するために使用される、深度ブロックに関するパーティションパターンであり得る。ビデオエンコーダ20は同様に、サブブロックに関するパーティションパターンの線形線を深度ブロックの境界まで拡張することができ、得られる線形線は、深度ブロックをイントラ予測符号化するために使用される、深度ブロックに関するパーティションであり得る。
[0148]いくつかの例では、ビデオエンコーダ20は、より小さいサイズのブロックの位置を識別する情報をシグナリングする必要はないことがある。そのような例では、ビデオデコーダ30は、ビデオデコーダ30がより大きいサイズの深度ブロックに関するパーティションパターンを決定するためにパーティションパターンを拡張する際の起点となるブロックとして、所定のより小さいサイズのブロックを使用するように事前構成され得る。
[0149]たとえば、ビデオエンコーダ20は、iおよびjが0からN/M−1まで(両端の値を含む)の範囲内にある相対水平および垂直インデックス(i,j)とともに、ビデオデコーダ30が受信する特定のM×Mブロック(すなわち、サブブロック)のインデックスをシグナリングすることができる。この例では、M×Mブロックの左上位置は(M×i,N×j)である。このようにして、ビデオデコーダ30は、M×Mブロックの位置を決定し、さらに、以下でより詳細に説明するように、線形線を拡張することによって全体的N×Nブロックに関するパーティションパターンを決定することができる。
[0150]ビデオエンコーダ20およびビデオデコーダ30は、それぞれ、バイパスモードまたはコンテキストモデリングのいずれかにより、M×Mブロックの位置(i,j)を符号化または復号することができる。言い換えれば、ビデオエンコーダ20は、線ベースのパーティションパターンが決定されたサブブロックを識別するためにバイパスモードまたはコンテキストモデリングを使用して位置(i,j)を符号化することができ、ビデオデコーダ30は、線ベースのパーティションパターンが受信されたサブブロックを識別するためにバイパスモードまたはコンテキストモデリングを使用して位置(i,j)を復号することができる。
[0151]代替または追加として、ビデオエンコーダ20およびビデオデコーダ30は、現在のPUの左境界M×Mブロックまたは下境界M×Mブロックのいずれかにおいて常に開始するように特定のM×Mブロックを設定するように事前構成され得る。この場合、ビデオエンコーダ20は、フラグをシグナリングすることができ、たった1つのオフセットがエンコーダによってさらにシグナリングされる。たとえば、この例では、ビデオエンコーダ20は、線ベースのパーティションパターンが決定されたサブブロックを識別するためのフラグと1つのオフセットとをシグナリングすることができ、ビデオデコーダ30は、線ベースのパーティションパターンが受信されたサブブロックを識別するためのフラグと1つのオフセットとを受信することができる。
[0152]場合によっては、1つのN×Nブロック内のM×Mユニット中の水平および垂直インデックスをシグナリングする代わりに、ビデオエンコーダ20は、4分木構造によってM×Mブロックを識別することができ、各レベル表現が、ゼロまたはより多くの「0」と1つの「1」を有し、「1」に達すると終了し、より低いレベルに進む。この例では、ビデオエンコーダ20は、サブブロックを識別するための情報をシグナリングする必要がないことがあり、ビデオデコーダ30は、サブブロックを識別するための情報を受信する必要がないことがある。たとえば、ビデオデコーダ30は同様に、N×N深度ブロックに関するパーティションパターンを決定するためにビデオデコーダ30がパーティションパターンを決定したM×Mブロックを決定するために、4分木構造を使用することができる。
[0153]いくつかの例では、ビデオエンコーダ20およびビデオデコーダ30は、特定のM×Mブロックの線ベースのパーティションパターンをより大きいN×Nブロックに拡張することを、利用可能な場合にN×Nブロック内のすべてのM×Mブロックのパーティションパターンが全体的PU(すなわち、全体的深度ブロック)に関する線ベースのパーティションを一緒に形成する方法で、行うことができる。たとえば、特定のM×Mブロックの右上隅に、N×Nブロック内の別のM×Mブロックの左下隅がある。いくつかの例では、ビデオエンコーダ20およびビデオデコーダ30は、特定のM×Mブロックを二等分する線形線(たとえば、パーティション線)を、特定のM×Mブロックの右上隅に連結された他方のブロックを通って拡張することができる。同様に、特定のM×Mブロックの左下隅に、N×Nブロック内のまた別のM×Mブロックの右上隅がある。いくつかの例では、ビデオエンコーダ20およびビデオデコーダ30は、特定のM×Mブロックを二等分する線形線(たとえば、パーティション線)を、特定のM×Mブロックの左下隅に連結された他方のブロックを通って拡張することができる。このようにして、ビデオエンコーダ20およびビデオデコーダ30は、特定のM×Mブロックの線ベースのパーティションを全体的PUに拡張することができる。
[0154]上述のように、ビデオエンコーダ20およびビデオデコーダ30は、より小さいサイズのブロックを二等分する線形線を、より大きいサイズの深度ブロックに関するパーティションパターンを決定するためにより大きいサイズのブロックを線形線が二等分するように、拡張するように構成され得る。いくつかの例では、特定のM×Mの線ベースのパーティションパターンを現在のPUに(すなわち、全体的なより大きいサイズの深度ブロックに)拡張するために、ビデオエンコーダ20およびビデオデコーダ30は、最初に、パーティション境界線関数y=a×x+bを、M×Mパーティションパターンの(M×i,M×j)と開始点位置および終了点位置とによって導出することができ、aおよびbがそれぞれ、パーティション境界線の傾きおよび切片を表す。言い換えれば、ビデオエンコーダ20およびビデオデコーダ30は、傾き−線の式に基づいて線形線の線−式を決定することができる。パーティション境界線関数により、ビデオエンコーダ20およびビデオデコーダ30は、N×N2進ブロックである(bPatternと呼ばれる)N×Nパーティションパターンを、bPattern[x][y]=(y−a×x)<b?1:0として導出することができ、ここでx,y=0,1,...N−1である。一例では、さらに、aおよびbは整数に丸められる。
[0155]DMMモード3または4が可能であるとき、特定のM×Mブロックが、ビデオエンコーダ20によってシグナリングされ、ビデオデコーダ30によって受信され得る。さらに、M×Mブロック内で、ビデオエンコーダ20は線ベースのパーティションパターン(たとえば、ウェッジレットパターン)を、現在の3D−HEVCの場合のように、ビデオエンコーダ20がM×MのPU(すなわち、M×Mブロック)に関してDMMモード3でウェッジレットパターンをシグナリングする方法と同様の方法でシグナリングする。この場合、ビデオエンコーダ20は、M×MのPU(すなわち、M×Mブロック)に対するウェッジレットサブセットインデックスをシグナリングすることができる。
[0156]上述のように、本開示で説明する技法により、より大きいサイズのブロックに必要とされるパーティションパターンの数の減少があり得る。たとえば、本開示で説明する技法では、N/M(または2×N/M)個までのM×Mブロックのみがパーティションを必要とし得る(すなわち、ビデオエンコーダ20およびビデオデコーダ30は、N/M(または2×N/M)個までのM×Mブロックのみを含むパーティションリストを構成する必要があり得る)。したがって、ビデオエンコーダ20は、単に、N/M(または2×N/M)個までのM×Mブロックに関するパーティションパターンをシグナリングし、N/M(または2×N/M)個までのM×Mブロックを導出または拡張する必要があり得る。同様に、ビデオデコーダ30は、単に、N/M(または2×N/M)個までのM×Mブロックに関するパーティションパターンを受信し、N/M(または2×N/M)個までのM×Mブロックを導出または拡張する必要があり得る。
[0157]さらに、上述のように、本開示で説明する技法は、記憶される必要のあるパーティションパターンの数を減らし、パーティションパターンを使用してイントラ予測を実施する複雑性を低減することができる。したがって、技法は、64×64サイズの深度ブロックに関する線ベースの区分(たとえば、ウェッジレット区分)をサポートすることに伴う問題を克服することができる。言い換えれば、現在の3D−HEVCの場合のように、32×32までの線ベースのパーティションのみをサポートする代わりに、本開示で説明する技法を使用して、ウェッジレットパターンは、64×64であり得るN×NのPUに拡張される。
[0158]N×Nサイズの深度ブロック(すなわち、32×32以下のサイズの深度ブロックに限定されない)に関する線ベースのパーティションパターンを使用するための技法について説明することに加えて、本開示は、線ベースの区分(たとえば、ウェッジレット区分)のためにイントラ予測符号化および復号を実施する効率性を高めるための技法について説明する。たとえば、ビデオエンコーダ20において、DMM1においてN×N深度PU(すなわち、深度ブロック)のウェッジレット探索プロセスを加速させるために、元の深度ピクチャにおける現在の深度PU(すなわち、深度ブロック)の左上、右上、左下および右下のサンプルが同じ値を有するとき、ビデオエンコーダ20は、ウェッジレットパターン探索プロセスを省略することができ、ビデオエンコーダ20は、現在のPU(すなわち、現在の深度ブロック)のためにDMM1を選択することのないように構成され得る。
[0159]別の例として、代替または追加として、ビデオエンコーダ20は、複数の隣接する現在の深度PUの値をチェックすることができる。ビデオエンコーダ20は、隣接する現在の深度PUの値に基づいて、探索プロセスが省略され、DMM1であるかどうかを決定することができ、決定に基づいて現在のPUのためにDMM1を選択することができる。代替または追加として、ビデオエンコーダ20は、元の深度ピクチャにおける現在の深度PUの左上、右上、左下および右下のサンプルが同じ値を有するとき、ウェッジレットパターン探索を省略し、1サンプルパーティションパターン(たとえば、左上サンプルは、すべての他のサンプルの異なる部分に属する)を選択することができる。
[0160]いくつかの例では、DMM3モードでは、コロケートテクスチャルーマイントラモードによって指定されるN×Nウェッジレットサブセットが空である場合、ビデオエンコーダ20は、現在のPUのためにDMM3モードを省略することができる。コロケートテクスチャルーマイントラモードが空であることは、コロケートテクスチャブロックのルーマ成分がイントラ予測符号化または復号されないことを意味する。たとえば、コロケートテクスチャブロックのルーマ成分がイントラ予測コーディングされる場合、利用可能なルーマイントラモードはない。代替または追加として、ビデオデコーダ30は、コロケートテクスチャルーマイントラモードによって指定されるN×Nウェッジレットサブセットが空である場合に、ビデオデコーダ30によって復号されるDMMモードインデックスが決して現在のPUのためのDMM3モードではあり得ないように、制約され得る。
[0161]上述のように、DMM3の場合、ビデオエンコーダ20およびビデオデコーダ30は、コロケートテクスチャブロックに基づいて、深度ブロックに関するパーティションパターンを決定することができる。しかしながら、本開示で説明する技法は、そのように限定されない。いくつかの例では、DMM3モードにおいて、ビデオエンコーダ20およびビデオデコーダ30は、現在のN×NのPUとコロケートされたルーマブロックによってウェッジレットパーティションパターンを導出しないことがある。そうではなく、ビデオエンコーダ20およびビデオデコーダ30は、現在のM×Mブロックとコロケートされたルーマブロックによって線ベースのパーティションパターンを決定し得る。
[0162]N×NのPUの開始/終了点位置の1/2サンプル精度を使用するウェッジレットパターンの場合、ビデオエンコーダ20およびビデオデコーダ30は、対応するウェッジレットパターンとともに2N×2NのPUにおいて決定位置(2m,2n)が属するパーティションに基づいて、位置(m,n)がどのパーティションに属するかを決定することができる。ビデオエンコーダ20およびビデオデコーダ30は、(オフセットX,オフセットY)のオフセットベクトルにより、2N×2Nブロックにおいて決定位置(2m,2n)を移動させることなく、位置(m,n)がどのパーティションに属するかを決定することができ、ここにおいて、オフセットXまたはオフセットYが0または1に等しく、現在の3D−HEVCの場合のように様々な条件に依存する。
[0163]図6は、深度コーディングのための技法を実装し得るビデオエンコーダ20の一例を示すブロック図である。ビデオエンコーダ20は、ビデオスライス内のビデオブロックのイントラコーディングとインターコーディングとを実行し得る。イントラコーディング(すなわち、イントラ予測コーディング)は、所与のビデオフレームまたはピクチャ内のビデオの空間的冗長性を低減または除去するために空間的予測に依拠する。インターコーディング(すなわち、インター予測コーディング)は、ビデオシーケンスの隣接するフレームまたはピクチャ中のビデオの時間的冗長性を低減または除去するために時間的予測に依拠する。イントラモード(Iモード)は、いくつかの空間ベースのコーディングモードのいずれかを指し得る。単一方向予測(Pモード)または双予測(Bモード)などのインターモードは、いくつかの時間ベースのコーディングモードのいずれかを指し得る。
[0164]上述のように、ビデオエンコーダ20は、マルチビュービデオコーディングを実行するように適応され得る。いくつかの事例では、ビデオエンコーダ20は、時間インスタンス中の各ビューがビデオデコーダ30のなどのデコーダによって処理され得るように、マルチビューHEVCをコーディングするように構成され得る。HEVC−3Dの場合、各ビューに対するテクスチャマップ(すなわち、ルーマ値およびクロマ値)を符号化することに加えて、ビデオエンコーダ20はさらに、各ビューに対する深度マップを符号化し得る。
[0165]いずれの場合も、図6に示すように、ビデオエンコーダ20は、符号化されるべきビデオピクチャ内の現在のビデオブロックを受信する。図6の例では、ビデオエンコーダ20は、ビデオメモリデータ39と、モード選択ユニット40と、(復号済みピクチャバッファ(DPB)とも呼ばれる)参照ピクチャメモリ64と、加算器50と、変換処理ユニット52と、量子化ユニット54と、エントロピー符号化ユニット56とを含む。そして、モード選択ユニット40は、動き補償ユニット44と、動き推定ユニット42と、イントラ予測ユニット46と、パーティションユニット48とを含む。ビデオブロック再構成のために、ビデオエンコーダ20はまた、逆量子化ユニット58と、逆変換ユニット60と、加算器62とを含む。再構成されたビデオからブロッキネスアーティファクトを除去するためにブロック境界をフィルタ処理するためのデブロッキングフィルタ(図6には図示せず)も含まれ得る。所望される場合、デブロッキングフィルタは、通常、加算器62の出力をフィルタ処理することになる。デブロッキングフィルタに加えて、追加のフィルタ(ループ内またはループ後)も使用され得る。そのようなフィルタは簡潔のために示されていないが、所望される場合、(ループ内フィルタとして)加算器50の出力をフィルタ処理することができる。
[0166]図6に示すように、ビデオデータメモリ39は、ビデオピクチャ内の現在のビデオブロックを符号化するために使用されるビデオデータを受信する。ビデオデータメモリ39は、(たとえば、ビデオデータを記憶するように構成された)ビデオエンコーダ20の構成要素によって符号化されるべきビデオデータを記憶するか、またはビデオピクチャを符号化するために使用されるべきビデオデータを記憶することができる。たとえば、ビデオデータメモリ39は、異なるサイズのブロックに関するパーティションパターン(たとえば、ウェッジレットパーティションパターン)を記憶することができる。ビデオデータメモリ39は、ビデオエンコーダ20によって実施される初期化プロセスの一部としてパーティションパターンを記憶することができる。
[0167]いくつかの例では、ビデオデータメモリ39に記憶されるビデオデータは、たとえば、ビデオソース18から取得される場合がある。(復号ピクチャバッファ(DPB)とも呼ばれる)参照ピクチャメモリ64は、(たとえば、イントラコーディングモードまたはインターコーディングモードで)ビデオエンコーダ20によってビデオデータを符号化する際に使用するための参照ビデオデータを記憶する。ビデオデータメモリ39および参照ピクチャメモリ64は、同期DRAM(SDRAM)、磁気抵抗RAM(MRAM)、抵抗RAM(RRAM(登録商標))、または他のタイプのメモリデバイスを含む、ダイナミックランダムアクセスメモリ(DRAM)など、様々なメモリデバイスのいずれかによって形成され得る。ビデオデータメモリ39および参照ピクチャメモリ64は、同じメモリデバイスまたは別個のメモリデバイスによって設けられ得る。様々な例では、ビデオデータメモリ39は、ビデオエンコーダ20の他の構成要素とともにオンチップであってよく、またはそれらの構成要素に対してオフチップであってもよい。
[0168]符号化プロセス中に、ビデオエンコーダ20は、コーディングされるべきビデオフレームまたはスライスを受信する。フレームまたはスライスは複数のビデオブロックに分割され得る。動き推定ユニット42および動き補償ユニット44は、時間的予測を行うために、1つまたは複数の参照フレーム中の1つまたは複数のブロックに対して、受信されたビデオブロックのインター予測コーディングを実行する。イントラ予測ユニット46は代替的に、空間的予測を行うために、コーディングされるべきブロックと同じフレームまたはスライス中の1つまたは複数の隣接ブロックに対して、受信されたビデオブロックのイントラ予測コーディング(たとえば、イントラ予測符号化)を実行し得る。ビデオエンコーダ20は、たとえば、ビデオデータの各ブロックに適切なコーディングモードを選択するために、複数のコーディングパスを実行することができる。
[0169]さらに、パーティションユニット48は、以前のコーディングパスにおける以前の区分方式の評価に基づいて、ビデオデータのブロックをサブブロックに区分することができる。たとえば、パーティションユニット48は、最初に、フレームまたはスライスをLCUに区分し、レートひずみ分析(たとえば、レートひずみ最適化)に基づいて、LCUの各々をサブCUに区分することができる。モード選択ユニット40は、サブCUへのLCUの区分を示す4分木データ構造をさらに生成することができる。4分木のリーフノードCUは、1つまたは複数のPUと1つまたは複数のTUとを含み得る。
[0170]モード選択ユニット40は、たとえば、誤差結果に基づいてコーディングモードのうちの1つ、すなわち、イントラまたはインターを選択し、得られたイントラコーディングまたはインターコーディングされたブロックを、残差ブロックデータを生成するために加算器50に与え、参照フレームとして使用するための符号化されたブロックを再構成するために加算器62に与え得る。モード選択ユニット40はまた、動きベクトル、イントラモードインジケータ、パーティション情報、および他のそのようなシンタックス情報など、シンタックス要素をエントロピーコーディングユニット56に与え得る。
[0171]動き推定ユニット42および動き補償ユニット44は、高度に統合され得るが、概念的な目的のために別々に示されている。動き推定ユニット42によって実行される動き推定は、ビデオブロックの動きを推定する動きベクトルを生成するプロセスである。動きベクトルは、たとえば、現在のフレーム(または他のコーディングされたユニット)内でコーディングされている現在のブロックに対する参照フレーム(または他のコーディングされたユニット)内の予測ブロックに対する現在のビデオフレームまたはピクチャ内のビデオブロックのPUの変位を示すことができる。予測ブロックは、絶対差分和(SAD:sum of absolute difference)、2乗差分和(SSD:sum of square difference)、または他の差分メトリックによって決定され得るピクセル差分に関して、コーディングされるべきブロックにぴったり一致することがわかるブロックである。いくつかの例では、ビデオエンコーダ20は、参照ピクチャメモリ64に記憶された参照ピクチャのサブ整数ピクセル位置の値を計算し得る。たとえば、ビデオエンコーダ20は、参照ピクチャの1/4ピクセル位置、1/8ピクセル位置、または他の分数のピクセル位置の値を補間することができる。したがって、動き推定ユニット42は、フルピクセル位置および分数ピクセル位置に対する動き探索を実行し、分数ピクセル精度を有する動きベクトルを出力することができる。
[0172]動き推定ユニット42は、PUの位置を参照ピクチャの予測ブロックの位置と比較することによって、インターコーディングされたスライス中のビデオブロックのPUに関する動きベクトルを計算する。参照ピクチャは、その各々が、参照ピクチャメモリ64に記憶された1つまたは複数の参照ピクチャを識別する、第1の参照ピクチャリスト(リスト0)または第2の参照ピクチャリスト(リスト1)から選択され得る。動き推定ユニット42は、計算された動きベクトルをエントロピー符号化ユニット56と動き補償ユニット44とに送る。
[0173]動き補償ユニット44によって実行される動き補償は、動き推定ユニット42によって決定された動きベクトルに基づいて予測ブロックを取り出し、またはこれを生成することを含むことができる。やはり、動き推定ユニット42および動き補償ユニット44は、いくつかの例で、機能的に統合され得る。現在のビデオブロックのPUに関する動きベクトルを受信すると、動き補償ユニット44は、参照ピクチャリストのうちの1つにおいて動きベクトルが指す予測ブロックを位置特定することができる。加算器50は、以下で説明するように、コーディングされている現在のビデオブロックのピクセル値から予測ブロックのピクセル値を減算し、ピクセル差分値を形成することによって、残差ビデオブロックを形成する。一般に、動き推定ユニット42は、ルーマ成分に対して動き推定を実行し、動き補償ユニット44は、クロマ成分とルーマ成分の両方に関して、ルーマ成分に基づいて計算された動きベクトルを使用する。モード選択ユニット40は、ビデオスライスのビデオブロックを復号する際のビデオデコーダ30による使用のために、ビデオブロックとビデオスライスとに関連付けられたシンタックス要素を生成することもできる。
[0174]イントラ予測ユニット46は、上述のように、動き推定ユニット42と動き補償ユニット44とによって実行されるインター予測の代替として、現在のブロックをイントラ予測し得る。特に、イントラ予測ユニット46は、現在のブロックを符号化するために使用すべきイントラ予測モードを決定することができる。いくつかの例では、イントラ予測ユニット46は、たとえば別々の符号化パス中に、様々なイントラ予測モードを使用して現在のブロックを符号化することができ、イントラ予測ユニット46(または、いくつかの例ではモード選択ユニット40)は、テストされたモードから使用すべき適切なイントラ予測モードを選択することができる。
[0175]たとえば、イントラ予測ユニット46は、様々なテストされたイントラ予測モードのためのレートひずみ分析を使用してレートひずみ値を計算し、テストされたモードの間で最良のレートひずみ特性を有するイントラ予測モードを選択し得る。レートひずみ分析は、概して、符号化ブロックと、符号化ブロックを生成するために符号化された元の符号化されていないブロックとの間のひずみ(または誤差)の量、ならびに符号化ブロックを生成するために使用されるビットレート(すなわち、ビット数)を決定する。イントラ予測ユニット46は、どのイントラ予測モードがブロックについて最良のレートひずみ値を呈するかを決定するために、様々な符号化されたブロックのひずみおよびレートから比を計算することができる。
[0176]さらに、イントラ予測ユニット46は、深度マップの深度ブロックをコーディングするように構成され得る。たとえば、イントラ予測ユニット46は、深度スライスのイントラ予測されたPUをコーディングするために、(たとえば、上記で図2に関して説明したように)ベース(2D)HEVC規格からのイントラ予測モードと、(たとえば、上記で図3Aおよび図3Bに関して説明したように)深度モデリングモード(DMM)と、(たとえば、以下で図10に関して説明するように)領域境界チェーンコーディングとを使用する。
[0177]いずれの場合も、ビデオエンコーダ20は、コーディングされている元のビデオブロックから、モード選択ユニット40からの予測データを減算することによって残差ビデオブロックを形成する。加算器50は、この減算演算を実行する1つまたは複数の構成要素を表す。変換処理ユニット52は、離散コサイン変換(DCT)または概念的に同様の変換などの変換を残差ブロックに適用して、残差変換係数値を備えるビデオブロックを生成する。変換処理ユニット52は、DCTと概念的に同様である他の変換を実行することができる。ウェーブレット変換、整数変換、サブバンド変換、または他のタイプ変換も使用され得る。
[0178]いずれの場合も、変換処理ユニット52は、残差ブロックに変換を適用して、残差変換係数のブロックを生成する。変換は、ピクセル値領域からの残差情報を、周波数領域のような変換領域に変換することができる。変換処理ユニット52は、得られた変換係数を量子化ユニット54に送り得る。量子化ユニット54は、ビットレートをさらに低減するために、変換係数を量子化する。量子化プロセスは、係数の一部またはすべてに関連付けられたビット深度を低減し得る。量子化の程度は、量子化パラメータを調整することによって、変更され得る。いくつかの例では、量子化ユニット54は次いで、量子化変換係数を含む行列の走査を実行することができる。代替的に、エントロピー符号化ユニット56が走査を実行することができる。
[0179]量子化に続いて、エントロピー符号化ユニット56は、量子化変換係数をエントロピーコーディングする。たとえば、エントロピー符号化ユニット56は、コンテキスト適応型可変長コーディング(CAVLC)、コンテキスト適応型バイナリ算術コーディング(CABAC)、シンタックスベースコンテキスト適応型バイナリ算術コーディング(SBAC)、確率間隔区分エントロピー(PIPE)コーディング、または別のエントロピーコーディング技法を実行することができる。コンテキストベースのエントロピーコーディングの場合、コンテキストは、隣接ブロックに基づき得る。エントロピー符号化ユニット56によるエントロピーコーディングに続いて、符号化されたビットストリームは、別のデバイス(たとえば、ビデオデコーダ30)に送信され、または後の送信もしくは取出のためにアーカイブされ得る。
[0180]逆量子化ユニット58および逆変換ユニット60は、たとえば参照ブロックとして後で使用するために、ピクセル領域中で残差ブロックを再構成するために、それぞれ逆量子化と逆変換とを適用する。動き補償ユニット44は、参照ピクチャメモリ64のフレームのうちの1つの予測ブロックに残差ブロックを加算することによって参照ブロックを計算し得る。動き補償ユニット44はまた、動き推定において使用するためのサブ整数ピクセル値を計算するために、再構成された残差ブロックに1つまたは複数の補間フィルタを適用し得る。加算器62は、参照ピクチャメモリ64に記憶するための再構成されたビデオブロックを生成するために、動き補償ユニット44によって生成された動き補償予測ブロックに再構成された残差ブロックを加算する。再構成されたビデオブロックは、動き推定ユニット42および動き補償ユニット44によって、後続のビデオフレーム中のブロックをインターコーディングするために参照ブロックとして使用され得る。
[0181]この意味で、ビデオエンコーダ20は、本開示で説明する1つまたは複数の例示的技法を実装するように構成され得る。たとえば、イントラ予測ユニット46は、本開示で説明する深度ブロックのための例示的なイントラ予測符号化技法を実装するように構成され得る。いくつかの例では、イントラ予測ユニット46は、他のプロセッサとの組合せで、本開示で説明する技法を実装するように構成され得る。
[0182]いくつかの例では、ビデオエンコーダ20は、第1のサイズのブロックに関するパーティションパターンからパーティションパターンを決定する(たとえば、サイズ16×16のブロックに関連するパーティションパターンを決定する)ように構成され得る。ビデオエンコーダ20は、第1のサイズのブロックに関するパーティションパターンからの決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションを決定する(たとえば、サイズ16×16のブロックに関連する決定されたパーティションパターンに基づいて、サイズ32×32の深度ブロックに関するパーティションを決定する)ことができ、ここで、第2のサイズが第1のサイズよりも大きい。ビデオエンコーダ20は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ予測符号化することができる。
[0183]この例では、サイズ16×16のブロック(たとえば、第1のサイズのブロック)は、深度ブロックを含むピクチャ内の実際のブロックではないことがある。そうではなく、サイズ16×16のブロックは概念的ブロックであり、サイズ16×16のブロックに使用されるパーティションパターンが代わりにサイズ32×32のブロック(たとえば、第2のサイズの深度ブロック)に使用される。ただし、いくつかの例では、サイズ16×16のブロックは、ピクチャの実際のブロック、またはサイズ32×32のブロック内のブロックであり得る。
[0184]ビデオエンコーダ20は、イントラ深度符号化のために深度ブロック(たとえば、現在のPUであるN×Nブロック)のサブブロック(たとえば、M×Mブロック)に関するパーティションパターン(たとえば、線ベースのパーティションパターン)を決定するように構成され得る。ビデオエンコーダ20は、サブブロックに関するパーティションパターンに基づいて、全体的深度ブロックに関するパーティションパターン(たとえば、線ベースのパーティションパターン)を決定することができる。ビデオエンコーダ20は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ符号化することができる。
[0185]ビデオエンコーダ20は、サブブロックに関するパーティションパターンを示す情報を符号化することがある。ビデオエンコーダ20はまた、深度ブロックに関するパーティションパターンを示す情報の符号化を回避する(たとえば、符号化しない)ことがある。ビデオエンコーダ20はまた、深度ブロックに関するパーティションパターンを深度ブロックのサイズに基づかせることなく(たとえば、ブロックサイズとは無関係に)、深度ブロックに関するパーティションパターンを決定することができる。ビデオエンコーダ20はまた、いくつかの例では、パーティションパターンが決定されたサブブロックを識別するための情報(たとえば、インデックスまたはフラグおよび1つのオフセット)を(たとえば、バイパスモードおよび/またはコンテキストモデリングを使用して)符号化し、シグナリングすることができる。
[0186]図7は、深度コーディングのための技法を実装し得るビデオデコーダ30の一例を示すブロック図である。図7の例では、ビデオデコーダ30は、ビデオデータメモリ69と、エントロピー復号ユニット70と、動き補償ユニット72、動きベクトル予測ユニット73、およびイントラ予測ユニット74を含む予測処理ユニット71とを含む。ビデオデコーダ30はまた、逆量子化ユニット76と、逆変換処理ユニット78と、参照フレームメモリ82と、加算器80とを含む。ビデオデコーダ30は、いくつかの例では、ビデオエンコーダ20(図6)に関して説明した符号化パスとは概して逆の復号パスを実行することができる。動き補償ユニット72は、エントロピー復号ユニット70から受信された動きベクトルに基づいて予測データを生成することができ、イントラ予測ユニット74は、エントロピー復号ユニット70から受信されたイントラ予測モードインジケータに基づいて予測データを生成することができる。
[0187]図7の例では、ビデオデータメモリ69は、符号化ビデオを受信する。ビデオデータメモリ69は、ビデオデコーダ30の構成要素によって復号されるために、符号化ビデオビットストリームなど、(たとえば、ビデオデータを記憶するように構成された)ビデオデータを記憶し得る。ビデオデータメモリ68はまた、ビデオデータを復号してピクチャを再構成するためにビデオデコーダ30の構成要素によって使用されるビデオデータを記憶することができる。たとえば、ビデオデータメモリ69は、異なるサイズのブロックに関するパーティションパターン(たとえば、ウェッジレットパーティションパターン)を記憶することができる。ビデオデータメモリ69は、ビデオエンコーダ30によって実施される初期化プロセスの一部としてパーティションパターンを記憶することができる。
[0188]ビデオデータメモリ69に記憶されたビデオデータは、カメラなどのローカルビデオソースから、ビデオデータのワイヤードもしくはワイヤレスのネットワーク通信を介して、または物理データ記憶媒体にアクセスすることによって取得され得る。ビデオデータメモリ69は、符号化ビデオビットストリームからの符号化ビデオデータを記憶するコーディング済みピクチャバッファ(CPB)を形成し得る。
[0189]参照ピクチャメモリ82は、(たとえば、イントラコーディングモードまたはインターコーディングモードで)ビデオデコーダ30によってビデオデータを復号する際に使用するための参照ビデオデータを記憶する復号済みピクチャバッファ(DPB)の一例である。ビデオデータメモリ69および参照ピクチャメモリ82は、同期DRAM(SDRAM)、磁気抵抗RAM(MRAM)、抵抗RAM(RRAM)、または他のタイプのメモリデバイスを含む、ダイナミックランダムアクセスメモリ(DRAM)など、様々なメモリデバイスのいずれかによって形成され得る。ビデオデータメモリ69および参照ピクチャメモリ82は、同じメモリデバイスまたは別個のメモリデバイスによって設けられ得る。様々な例では、ビデオデータメモリ69は、ビデオデコーダ30の他の構成要素とともにオンチップであってよく、またはそれらの構成要素に対してオフチップであってもよい。
[0190]復号プロセス中に、ビデオデコーダ30はビデオエンコーダ20から、符号化ビデオスライスのビデオブロックと関連付けられるシンタックス要素とを表す符号化ビデオビットストリームを受信する。ビデオデコーダ30のエントロピー復号ユニット70は、量子化された係数と、動きベクトルまたはイントラ予測モードインジケータと、他のシンタックス要素とを生成するために、ビットストリームをエントロピー復号する。エントロピー復号ユニット70は、動きベクトルと他のシンタックス要素とを動き補償ユニット72に転送する。エントロピー復号ユニット70は、イントラ予測ユニット74にイントラ予測復号のための情報を転送する。ビデオデコーダ30は、ビデオスライスレベルおよび/またはビデオブロックレベルでシンタックス要素を受信することができる。
[0191]上述のように、ビデオデコーダ30は、マルチビュービデオコーディングを実行するように適応され得る。いくつかの例では、ビデオデコーダ30は、マルチビューHEVCを復号するように構成され得る。HEVC−3Dの場合、各ビューに対するテクスチャ値(すなわち、ルーマ値およびクロマ値)を復号することに加えて、ビデオデコーダ30はさらに、各ビューに対する深度マップを復号し得る。
[0192]いずれの場合も、ビデオスライスがイントラコーディングされた(I)スライスとしてコーディングされるとき、イントラ予測ユニット74は、シグナリングされたイントラ予測モードと、現在のフレームまたはピクチャの以前復号されたブロックからのデータとに基づいて、現在のビデオスライスのビデオブロックのための予測データを生成し得る。
[0193]イントラ予測ユニット74はまた、深度データをイントラコーディングし得る。たとえば、イントラ予測ユニット74は、深度スライスのイントラ予測されたPUをコーディングするために、(たとえば、上記で図2に関して説明したように)ベース(2D)HEVC規格からのイントラ予測モードと、(たとえば、上記で図3Aおよび図3Bに関して説明したように)深度モデリングモード(DMM)と、(たとえば、以下で図10に関して説明するように)領域境界チェーンコーディングとを使用する。
[0194]ビデオフレームがインターコーディングされた(すなわち、B(双方向予測された)、P(前のフレームから予測された)またはGPB(一般化されたPまたはBスライス))スライスとしてコーディングされるとき、動き補償ユニット72は、エントロピー復号ユニット70から受信された動きベクトルと他のシンタックス要素とに基づいて、現在のビデオスライスのビデオブロックのための予測ブロックを生成する。予測ブロックは、参照ピクチャリストのうちの1つ内の参照ピクチャのうちの1つから生成され得る。ビデオデコーダ30は、参照フレームメモリ82に記憶された参照ピクチャに基づいて、デフォルト構成技法を使用して、参照フレームリスト、すなわち、リスト0とリスト1とを構成し得る。
[0195]動き補償ユニット72は、動きベクトルと他のシンタックス要素とをパースすることによって現在のビデオスライスのビデオブロックのための予測情報を決定し、復号されている現在のビデオブロックのための予測ブロックを生成するために、その予測情報を使用する。たとえば、動き補償ユニット72は、ビデオスライスのビデオブロックをコーディングするために使用される予測モード(たとえば、イントラまたはインター予測)と、インター予測スライスタイプ(たとえば、Bスライス、Pスライス、またはGPBスライス)と、スライスに関する参照ピクチャリストのうちの1つまたは複数に関する構成情報と、スライスの各インター符号化ビデオブロックに関する動きベクトルと、スライスの各インターコーディングされたビデオブロックに関するインター予測ステータスと、現在のビデオスライス中のビデオブロックを復号するための他の情報とを決定するために、受信されたシンタックス要素のうちのいくつかを使用する。
[0196]動き補償ユニット72はまた、補間フィルタに基づいて、補間を実行することができる。動き補償ユニット72は、参照ブロックのサブ整数ピクセルのための補間値を計算するために、ビデオブロックの符号化中にビデオエンコーダ20によって使用された補間フィルタを使用し得る。この場合に、動き補償ユニット72は、受信されたシンタックス要素からビデオエンコーダ20によって使用された補間フィルタを決定し、予測ブロックを生成するために補間フィルタを使用し得る。
[0197]逆量子化ユニット76は、ビットストリーム中で提供され、エントロピー復号ユニット80によって復号された、量子化変換係数を逆量子化(inverse quantize)、すなわち、逆量子化(de-quantize)する。逆量子化プロセスは、量子化の程度を決定し、同様に、適用されるべき逆量子化の程度を決定するための、ビデオスライス中の各ビデオブロックに関してビデオデコーダ30によって計算される量子化パラメータQPYの使用を含み得る。
[0198]逆変換処理ユニット78は、ピクセル領域において残差ブロックを生成するために、逆変換、たとえば、逆DCT、逆整数変換、または概念的に同様の逆変換プロセスを変換係数に適用する。動き補償ユニット72またはイントラ予測ユニット74が、動きベクトルまたは他のシンタックス要素に基づいて現在のビデオブロック(たとえば、テクスチャブロックまたは深度ブロック)のための予測ブロックを生成した後、ビデオデコーダ30は、逆変換ユニット78からの残差ブロックを、動き補償ユニット82またはイントラ予測ユニット74によって生成された対応する予測ブロックと加算することによって、復号されたビデオブロックを形成する。加算器90は、この加算演算を実行する1つまたは複数の構成要素を表す。
[0199]所望される場合、ブロッキネスアーティファクトを除去するために復号されたブロックをフィルタ処理するためのデブロッキングフィルタも適用され得る。ピクセル推移を平滑化し、または他の形でビデオ品質を改善するために、他のループフィルタ(コーディングループ内またはコーディングループの後のいずれであれ)も使用され得る。その後、所与のフレームまたはピクチャ中の復号されたビデオブロックは、参照ピクチャメモリ82に記憶され、参照ピクチャメモリ82は、後続の動き補償に使用される参照ピクチャを記憶する。参照ピクチャメモリ82はまた、復号されたビデオを図1のディスプレイデバイス32などのディスプレイデバイス上に後で表示できるように記憶する。
[0200]この意味で、ビデオデコーダ30は、本開示で説明する1つまたは複数の例示的技法を実装するように構成され得る。たとえば、イントラ予測ユニット72は、本開示で説明する深度ブロックのための例示的なイントラ予測復号技法を実装するように構成され得る。いくつかの例では、イントラ予測ユニット72は、単独で、または他のプロセッサとの組合せで、本開示で説明する技法を実装するように構成され得る。
[0201]いくつかの例では、ビデオデコーダ30は、第1のサイズのブロックに関するパーティションパターンからパーティションパターンを決定する(たとえば、サイズ16×16のブロックに関連するパーティションパターンを決定する)ように構成され得る。ビデオデコーダ30は、第1のサイズのブロックに関するパーティションパターンからの決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションを決定する(たとえば、サイズ16×16のブロックの決定されたパーティションパターンに基づいて、サイズ32×32の深度ブロックに関するパーティションを決定する)ことができき、ここで、第2のサイズが第1のサイズよりも大きい。ビデオデコーダ30は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ予測復号することができる。
[0202]この例では、サイズ16×16のブロック(たとえば、第1のサイズのブロック)は、深度ブロックを含むピクチャ内の実際のブロックではないことがある。そうではなく、サイズ16×16のブロックは概念的ブロックであり、サイズ16×16のブロックに使用されるパーティションパターンが代わりにサイズ32×32のブロック(たとえば、第2のサイズの深度ブロック)に使用される。ただし、いくつかの例では、サイズ16×16のブロックは、ピクチャの実際のブロック、またはサイズ32×32のブロック内のブロックであり得る。
[0203]たとえば、ビデオデコーダ30は、イントラ深度復号のために深度ブロック(たとえば、現在のPUであるN×Nブロック)のサブブロック(たとえば、M×Mブロック)に関するパーティションパターンを決定する(たとえば、パーティションパターンを示す情報を受信する)ように構成され得る。パーティションパターンは、線ベースのパーティションパターンであり得る。ビデオデコーダ30は、サブブロックに関するパーティションパターンに基づいて、全体的深度ブロックに関するパーティションパターン(たとえば、線ベースのパーティションパターン)を決定することができる。ビデオデコーダ30は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ復号することができる。
[0204]ビデオデコーダ30は、サブブロックに関するパーティションパターンを示す情報を復号することがある。ビデオデコーダ30はまた、深度ブロックに関するパーティションパターンを示す情報の復号を回避する(たとえば、復号しない)ことがある。言い換えれば、ビデオデコーダ30は、深度ブロックに関するパーティションパターンを示す情報を受信することなく、深度ブロックに関するパーティションパターンを決定することができる。
[0205]ビデオデコーダ30はまた、深度ブロックに関するパーティションパターンを深度ブロックのサイズに基づかせることなく(たとえば、ブロックサイズとは無関係に)、深度ブロックに関するパーティションパターンを決定することができる。ビデオデコーダ30はまた、いくつかの例では、パーティションパターンが決定されたサブブロックを識別するための受信された情報(たとえば、インデックスまたはフラグおよび1つのオフセット)を(たとえば、バイパスモードおよび/またはコンテキストモデリングを使用して)復号することができる。
[0206]上記で説明した技法は、その両方が一般にビデオコーダと呼ばれることがある、ビデオエンコーダ20(図1および図6)および/またはビデオデコーダ30(図1および図7)によって実行され得る。さらに、ビデオコーディングは、概して、適用可能な場合、ビデオ符号化および/またはビデオ復号を指すことがある。
[0207]図8は、ビデオデータを復号する例示的な方法を示すフローチャートである。図示のように、ビデオデコーダ30は、第1のサイズのブロックに関するパーティションパターンを構成し、記憶することができる(800)。たとえば、ビデオデコーダ30は、初期化の一部として第1のサイズのブロックに関連する(たとえば、サイズ16×16のブロックに関する)1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成し、第1のサイズのブロックに関連するパーティションパターンリストをビデオメモリデータ69に記憶することができる。
[0208]ビデオデコーダ30は、第1のサイズのブロックに関連するパーティションパターンを決定することができる(802)。たとえば、ビデオデコーダ30は、第1のサイズのブロックに関連するパーティションパターンリストへのインデックスを受信することができる。ビデオデコーダ30は、パーティションパターンリストへのインデックスによって参照されるパーティションパターンを識別することができる。ビデオデコーダ30は、識別されたパーティションパターンに基づいて、第1のサイズのブロックに関連するパーティションパターンからパーティションパターンを決定することができる(すなわち、ビデオデコーダ30は、パーティションパターンリストへの受信されたインデックスに基づいて、第1のサイズのブロックに関するパーティションパターンからパーティションパターンを決定することができる)。
[0209]ビデオデコーダ30は、第1のサイズ(たとえば、16×16)のブロックに関するパーティションパターンからの決定されたパーティションパターンに基づいて、第2のサイズ(たとえば、32×32)の深度ブロックに関するパーティションパターンを決定することができる(804)。この例では、第2のサイズは、第1のサイズよりも大きい。
[0210]第1のサイズのブロックは必ずしも、ピクチャ内の実際のブロックである必要はない。むしろ、ビデオデコーダ30が第2のより大きいサイズの深度ブロックに関するパーティションパターンを決定するために使用するのは、第1のサイズのブロックのパーティションパターンである。ただし、いくつかの例では、第1のサイズのブロックは、深度ブロック内などのピクチャ内の実際のブロックであり得る。
[0211]いくつかの例では、ビデオデコーダ30は、深度ブロック内のサブブロックを識別する情報を受信することができ、サブブロックのサイズが第1のサイズである。そのような例では、ビデオデコーダ30は、サブブロックに関するパーティションパターンを決定することができる。ビデオデコーダ30はまた、サブブロックに関する決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することができる。また、これらの例示的な技法では、ビデオデコーダ30は、第2のサイズの深度ブロックに関するパーティションパターンを、サブブロックに関するパーティションパターンの線形線を深度ブロックの境界まで拡張することによって決定することができる。得られる線形線は、深度ブロックに関するパーティションパターンを備える。
[0212]ビデオデコーダ30は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ予測復号することができる(806)。たとえば、ビデオデコーダ30は、深度ブロックをイントラ予測復号するために、DMMに依拠する3D−HEVCにおいて説明されるイントラ予測復号技法を実施することができる。いくつかの例では、第1のサイズのブロックに関するパーティションパターンからのパーティションパターンは、第1のサイズのブロックに関する複数の線ベースのパーティションパターンからの線ベースのパーティションパターン(たとえば、第1のサイズのブロックに関する複数のウェッジレットパターンからのウェッジレットパターン)を備える。また、深度ブロックに関するパーティションパターンは、2つのパーティションに深度ブロックを区分する深度ブロックに関する線ベースのパーティションパターンを備える。いくつかの例では、ビデオデコーダ30は、第2のサイズの深度ブロックに関するパーティションパターンを示す情報を受信することなく、第2のサイズの深度ブロックに関するパーティションパターンを決定することができる。
[0213]図9は、ビデオデータを符号化する例示的な方法を示すフローチャートである。図示のように、ビデオエンコーダ20は、第1のサイズのブロックに関連するパーティションパターンを構成し、記憶することができる(900)。たとえば、ビデオエンコーダ20は、初期化の一部として第1のサイズのブロックに関連する(たとえば、サイズ16×16のブロックに関する)パーティションパターンリストを構成し、第1のサイズのブロックに関するパーティションパターンリストをビデオメモリデータ39に記憶することができる。
[0214]ビデオエンコーダ20は、第1のサイズのブロックに関連するパーティションパターンを決定することができる(902)。たとえば、ビデオエンコーダ20は、第2のより大きいサイズの深度ブロックに関するパーティションパターンを決定するために使用され得る適切なパーティションパターンを選択するために、複数の符号化パスを実施することができる。次いでビデオエンコーダ20は、パーティションパターンリスト中でパーティションパターンを識別することができる。たとえば、ビデオエンコーダ20は、構成されたパーティションパターンリスト中で識別されたパーティションパターンから、第1のサイズのブロックに関連するパーティションパターンからのパーティションパターンを決定することができる。ビデオエンコーダ20は、第1のサイズのブロックに関するパーティションパターンからの決定するパーティションパターンを識別する構成されたパーティションパターンリストへのインデックスをシグナリングすることができ、ビデオデコーダ30が、深度ブロックをイントラ予測復号するためにそのインデックスを使用する。
[0215]ビデオエンコーダ20は、第1のサイズのブロックに関するパーティションパターンからの決定されたパーティションパターン(たとえば、サイズ16×16のブロックに関連するパーティションパターン)に基づいて、第2のサイズ(たとえば、32×32)の深度ブロックに関するパーティションパターンを決定することができる(904)。この例では、第2のサイズは、第1のサイズよりも大きい。
[0216]第1のサイズのブロックは必ずしも、ピクチャ内の実際のブロックである必要はない。むしろ、ビデオエンコーダ20が第2のより大きいサイズの深度ブロックに関するパーティションパターンを決定するために使用するのは、第1のサイズのブロックのパーティションパターンである。ただし、いくつかの例では、第1のサイズのブロックは、深度ブロック内などのピクチャ内の実際のブロックであり得る。
[0217]いくつかの例では、ビデオエンコーダ20は、深度ブロック内のサブブロックを識別することができ、サブブロックのサイズが第1のサイズである。そのような例では、ビデオエンコーダ20は、識別されたサブブロックに関するパーティションパターンを決定することができる。ビデオエンコーダ20はまた、識別されたサブブロックに関する決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することができる。また、これらの例示的な技法では、ビデオエンコーダ20は、第2のサイズの深度ブロックに関するパーティションパターンを、サブブロックに関するパーティションパターンの線形線を深度ブロックの境界まで拡張することによって決定することができる。得られる線形線は、深度ブロックに関するパーティションパターンを画定する。
[0218]ビデオエンコーダ20は、深度ブロックに関する決定されたパーティションパターンに基づいて、深度ブロックをイントラ予測符号化することができる(906)。たとえば、ビデオエンコーダ20は、深度ブロックをイントラ予測符号化するために、DMMに依拠する3D−HEVCにおいて説明されるイントラ予測符号化技法を実施することができる。いくつかの例では、第1のサイズのブロックに関するパーティションパターンからのパーティションパターンは、第1のサイズのブロックに関する複数の線ベースのパーティションパターンからの線ベースのパーティションパターン(たとえば、第1のサイズのブロックに関する複数のウェッジレットパターンからのウェッジレットパターン)を備える。また、深度ブロックに関するパーティションパターンは、2つのパーティションに深度ブロックを区分する深度ブロックに関する線ベースのパーティションパターンを備える。いくつかの例では、ビデオエンコーダ20は、第2のサイズの深度ブロックに関するパーティションパターンを識別する情報をシグナリングしないことがある。
[0219]以下では、本開示で説明する例示的な技法を実施するいくつかの例について説明する。以下では、ボールド体およびイタリック体の文字を包含する二重角括弧([[]])は、現在の技法に対する削除を示し、下線は、現在の技法に対する追加を示す。以下の例示的な技法が、別個に、または組合せで適用され得る。
[0220]深度モードパラメータシンタックスの場合
[0221]深度モードパラメータイントラセマンティクスの場合:
...
wedge_full_tab_idx[x0][y0]は、DepthIntraMode[x0][y0]がINTRA_DEP_DMM_WFULLに等しいときの、対応する4×4パターンリストにおけるウェッジレットパターンのインデックスを指定する。
wedge_sub_col[x0][y0]およびwedge_sub_row[x0][y0]は、ウェッジレットパターンがシグナリングされる4×4ブロックの位置を指定する。
wedge_predtex_tab_idx[x0][y0]は、DepthIntraMode[x0][y0]がINTRA_DEP_DMM_WPREDTEXに等しいときの、現在の予測ユニット内の4×4ブロックのウェッジレットパターンのインデックスを指定する。
...
[0222]復号プロセスの場合
H.8.4.4.2.7 イントラ予測モードINTRA_DMM_WFULLの指定
このプロセスへの入力は以下の通りである。
− 現在のピクチャの左上サンプルに対する現在のブロックの左上サンプルを指定するサンプルロケーション(xTb,yTb)
− x=−1、y=−1..nTbS×2−1、およびx=0..nTbS×2−1、y=−1である、隣接サンプルp[x][y]
− 変換ブロックサイズを指定する変数nTbS
このプロセスの出力は以下の通りである。
− x,y=0..nTbS−1である、予測サンプルpredSamples[x][y]
x,y=0..nTbS−1である予測サンプルpredSamples[x][y]の値は、次の順序のステップによって指定されるように導出される。
1.下位条項H.8.4.4.2.12.3に指定されているウェッジレットパターン拡張プロセスは、Log2(nTbS)、wedge_full_tab_idx[xTb][yTb]、wedge_sub_col[xTb][yTb]およびwedge_sub_row[xTb][yTb]を入力として引き起こされ、出力は、wedgePatternに割り当てられる。[[2進パーティションパターンを指定する、x,y=0..nTbS−1である、変数wedgePattern[x][y]は、以下のように導出される。
2.下位条項H.8.4.4.2.11に指定されている深度パーティション値導出および割当てプロセスは、隣接サンプルp[x][y]、2進パターンwedgePattern[xTb][yTb]、変換サイズnTbS、dmm_dc_flag[xTb][yTb]に等しく設定されたdcOffsetAvailFlag、0に等しく設定されたintraChainFlag、ならびにDCオフセットのDcOffset[xTb][yTb][0]およびDcOffset[xTb][yTb][1]を入力として引き起こされ、出力は、predSamples[x][y]に割り当てられる。
3.[[x,y=0..nTbs−1(両端値を含む)として、以下が適用される。
− WedgeIdx[xTb+x][yTb+y]は、wedge_full_tab_idx[xTb][yTb]に等しく設定される。]]
H.8.4.4.2.8 イントラ予測モードINTRA_DMM_WPREDTEXの指定
このプロセスへの入力は以下の通りである。
− 現在のピクチャの左上サンプルに対する現在のブロックの左上サンプルを指定するサンプルロケーション(xTb,yTb)
− x=−1、y=−1..nTbS×2−1、およびx=0..nTbS×2−1、y=−1である、隣接サンプルp[x][y]
− 変換ブロックサイズを指定する変数nTbS
このプロセスの出力は以下の通りである。
− x,y=0..nTbS−1である、予測サンプルpredSamples[x][y]
x,y=0..nTbS−1である予測サンプルpredSamples[x][y]の値は、以下の通りである。
− textureIntraPredModeに応じて、変数wedgeIdxが、以下で指定されるように導出される。
− 下位条項H.8.4.4.2.12.3に指定されているウェッジレットパターン拡張プロセスは、Log2(nTbS)、wedgeIdx、wedge_sub_col[xTb][yTb]およびwedge_sub_row[xTb][yTb]を入力として引き起こされ、出力は、wedgePatternに割り当てられる。[[2進パーティションパターンを指定する、x,y=0..nTbS−1である、変数wedgePattern[x][y]は、以下のように導出される。
− 下位条項H.8.4.4.2.11に指定されている深度パーティション値導出および割当てプロセスは、隣接サンプルp[x][y]、2進パターンwedgePattern[x][y]、変換サイズnT、dmm_dc_flag[xTb][yTb]に等しく設定されたdcOffsetAvailFlag、0に等しく設定されたintraChainFlag、ならびにDCオフセットのDcOffset[xTb][yTb][0]およびDcOffset[xTb][yTb][1]を入力として引き起こされ、出力は、predSamples[x][y]に割り当てられる。
H.8.4.4.2.12.3 ウェッジレットパターン拡張プロセス
このプロセスへの入力は以下の通りである。
− 2進パーティションパターンサイズを指定する変数log2BlkSize
− 4×4ウェッジレットインデックスを指定する変数subIdx
− 左上4×4ブロックの水平位置を指定する変数xSub
− 左上4×4ブロックの垂直位置を指定する変数ySub
このプロセスの出力は以下の通りである。
− サイズ(1<<log2BlkSize)×(1<<log2BlkSize)の2進アレイwedgePattern[x][y]
4×4ウェッジレットパターンのパーティション線開始位置を指定する変数xSおよびySは、次のように導出される。
4×4ウェッジレットパターンのパーティション線終了位置を指定する変数xEおよびyEは、次のように導出される。
log2BlkSizeが2に等しい場合、以下が適用される。
− WedgePatternTable[2][subIdx]がwedgePatternに割り当てられる。
そうでない場合、以下が適用される。
− xS!=xEまたはyS!=yEの場合、以下が適用される。
− そうでない場合、以下が適用される。
− ySub==0の場合、以下が適用される。
− そうでない場合、以下が適用される。
H.8.4.4.3 深度値再構成プロセス
このプロセスへの入力は以下の通りである。
− 現在のピクチャの左上ルーマサンプルに対する現在のブロックの左上ルーマサンプルを指定するルーマロケーション(xTb,yTb)
− 変換ブロックサイズを指定する変数nTbS
− x,y=0..nTbS−1である、予測サンプルpredSamples[x][y]
− イントラ予測モードpredModeIntra
このプロセスの出力は以下の通りである。
− x,y=0..nTbS−1である、再構成された深度値サンプルresSamples[x][y]
predModeIntraに応じて、2進セグメント化パターンを指定する、x,y=0..nTbs−1である、アレイwedgePattern[x][y]は、次のように導出される。
− predModeIntraがINTRA_DMM_WFULLに等しい場合、下位条項H.8.4.4.2.12.3に指定されているウェッジレットパターン拡張プロセスは、Log2(nTbS)、wedge_full_tab_idx[xTb][yTb]、wedge_sub_col[xTb][yTb]およびwedge_sub_row[xTb][yTb]を入力として引き起こされ、出力は、wedgePatternに割り当てられる。[[以下が適用される。
− そうでない(predModeIntraがINTRA_DMM_WFULLに等しくない)場合、以下が適用される。
− x,y=0..nTbS−1として、wedgePattern[x][y]が0に等しく設定される。
dlt_flag[nuh_layer_id]に応じて、再構成された深度値サンプルresSamples[x][y]が、以下で指定されるように導出される。
− dlt_flag[nuh_layer_id]が0に等しい場合、以下が適用される。
− x,y=0..nTbS−1として、再構成された深度値サンプルresSamples[x][y]が、以下で指定されるように導出される。
− そうでない(dlt_flag[nuh_layer_id]が1に等しい)場合、以下が適用される。
− 変数dcPred[0]およびdcPred[1]が、以下で指定されるように導出される。
− そうでなく、predModeIntraがINTRA_PLANARに等しい場合、以下が適用される。
− そうでない(predModeIntraがINTRA_DMM_WFULLに等しい)場合、以下が適用される。
− x,y=0..nTbS−1として、再構成された深度値サンプルresSamples[x][y]が、以下で指定されるように導出される。
[0223]第2の例示的な技法では、第1の例示的な技法に類似するが、現在の3D−HEVCの復号プロセスに対する以下の変更も含まれる。この第2の例示的な技法は、N×NウェッジレットパターンによりN×NのPUにおいて位置(m,n)がどのパーティションに属するかを、対応するウェッジレットパターンにより2N×2NのPUにおいて決定位置(2m,2n)がどのパーティションに属するかと、2N×2Nのブロックにおける決定位置(2m,2n)の移動、すなわち、(2m,2n)に加えられる(オフセットX,オフセットY)のオフセットベクトルとに従って導出するために説明され、ここにおいて、オフセットXまたはオフセットYが0または1に等しく、現在の3D−HEVCの場合のような様々な条件への依存が取り除かれる。いくつかの例では、この変更は、例1に関して上記で説明した技法とともに行われ得る。他の例では、この変更は、第1の例示的な技法において説明した技法とは無関係に行われることもある。
H.8.4.4.2.12.1 ウェッジレットパターン生成プロセス
...
4.x,y=0..patternSize−1である、2進パーティションパターンwedgePattern[x][y]が、以下で指定されるように導出される。
− resShiftが1に等しい場合、以下が適用される。
− [[wedgeOriに応じて、変数xOFFおよびyOffが表H−8に指定されているように設定される。
− ]]
− x,y=0..patternSize−1として、以下が適用される。
− そうでない(resShiftが1に等しくない)場合、wedgePatternはcurPatternに等しく設定される。
[0224]第1の例示的な技法に類似するが、(第1の例示的な技法に対する、下線およびボールド体とともに示される)以下の変更はまた、N×N(N>4)ウェッジレットパターンのための提案される方法における1サンプルパーティション(パーティションパターンにおける左上サンプルは、すべての他のサンプルの異なるパーティションに属する)をカバーするようにさらに含まれ、そのような1サンプルパーティションは、第1の例示的な技法を使用して生成されることが可能ではないことがある。
H.8.4.4.2.12.3 ウェッジレットパターン拡張プロセス
このプロセスへの入力は以下の通りである。
− 2進パーティションパターンサイズを指定する変数log2BlkSize
− 4×4ウェッジレットインデックスを指定する変数subIdx
− 左上4×4ブロックの水平位置を指定する変数xSub
− 左上4×4ブロックの垂直位置を指定する変数ySub
このプロセスの出力は以下の通りである。
− サイズ(1<<log2BlkSize)×(1<<log2BlkSize)の2進アレイwedgePattern[x][y]
4×4ウェッジレットパターンのパーティション線開始位置を指定する変数xSおよびySは、次のように導出される。
4×4ウェッジレットパターンのパーティション線終了位置を指定する変数xEおよびyEは、次のように導出される。
log2BlkSizeが2に等しい場合、以下が適用される。
− WedgePatternTable[2][subIdx]がwedgePatternに割り当てられる。
そうでない場合、以下が適用される。
− xS!=xEまたはyS!=yEの場合、以下が適用される。
− そうでない場合、以下が適用される。
− xSub==0 && ySub==0の場合、以下が適用される。
− そうでなく、ySub==0の場合、以下が適用される。
− そうでない場合、以下が適用される。
[0225]本開示の技法について概して3D−HEVCに関して説明したが、本技法はこのように限定されない。上記で説明した技法はまた、他の現在の規格またはまだ開発されていない将来の規格に適用可能であり得る。たとえば、深度コーディングのための技法はまた、HEVCのマルチビュー拡張(たとえば、いわゆるMV−HEVC)、HEVCへのスケーラブル拡張、または深度コンポーネントを有する他の現在もしくは将来の規格に適用可能であり得る。
[0226]以下では、3D−HEVCにおけるイントラ予測モードに関するいくつかのさらなる技法について説明する。本開示は、本開示で説明する技法を理解するのをさらに助けるために提供される。ただし、いくつかの技法は、本開示に必要とされず、本開示で説明する技法とともに利用され得るか、または本開示で説明する技法の別の例であり得る。
[0227]領域境界チェーンコーディングモードの場合、3D−HEVCでは、領域境界チェーンコーディングモードは、深度スライスのイントラ予測ユニットをコーディングするためにHEVCイントラ予測モードおよびDMMモードとともに導入される。簡潔のために、「領域境界チェーンコーディングモード」は、本明細書で説明する本文、表および図において簡潔のために「チェーンコーディング」によって示される。
[0228]ビデオエンコーダ20は、チェーンの開始位置、チェーンコードの数、およびチェーンコードごとの、および方向インデックスにより、PUのチェーンコーディングをシグナリングし得る。チェーンは、サンプルとそれの8連結性サンプルのうちの1つとの間の連結である。図10に示すように、8つの異なるタイプのチェーンがあり、各々は、0から7にわたる方向インデックスを割り当てられる。
[0229]図10は、領域境界チェーンコーディングモードを示す概念図である。たとえば、図10の上部分は、チェーンコーディングにおいて定義される8個の可能なタイプのチェーンを示している。図10の下部分は、チェーンコーディングにおける1つの深度PUパーティションパターンとコーディングされたチェーンとを示している。
[0230]チェーンコーディングプロセスの一例が図10に示されている。図10に示す任意のパーティションパターンをシグナリングするために、ビデオエンコーダ20は、パーティションパターンを識別することができ、ビットストリームにおける以下の情報を符号化する。ビデオエンコーダ20は、チェーンが上境界から開始することをシグナリングするために、1ビット「0」を符号化し得る。ビデオエンコーダ20は、上境界における開始位置「3」をシグナリングするために、3ビット「011」を符号化し得る。ビデオエンコーダ20は、チェーンの総数が7であることをシグナリングするために、4ビット「0110」を符号化し得る。ビデオエンコーダ30は、一連の連結チェーンインデックス「3、3、3、7、1、1、1」を符号化することができ、各チェーンインデックスが、ルックアップテーブルを使用してコードワードに変換される。
[0231]3D−HEVCは、(たとえば、DMMに関して上記で説明した、コロケートテクスチャコンポーネントに基づく区分ではなく)パーティション境界の明示的シグナリングを可能にする領域境界チェーンコーディングモードを含む。上述のように、本開示では、「領域境界チェーンコーディングモード」を「チェーンコーディング」と呼ぶことがある。
[0232]概して、チェーンは、サンプルとそれの8連結性サンプルのうちの1つとの間の連結である。図10のブロック160によって示されているように、8つの異なるチェーン方向タイプがあり、各々は、0から7にわたる方向インデックスを割り当てられる。チェーン方向タイプは、ビデオコーダが深度ブロックのパーティションを決定するのを助け得る。
[0233]たとえば、図10の例は、区分構造を示すチェーン166によって分離された第1のパーティション162と第2のパーティション164とを含む。(ビデオエンコーダ20などの)ビデオエンコーダは、PUのためのチェーン166を決定し、それを符号化されたビットストリーム中でシグナリングし得、(ビデオデコーダ30などの)ビデオデコーダは、符号化ビットストリームからのチェーン166を表すデータをパースし得る。
[0234]概して、チェーン166は、開始位置と、チェーン中のリンクの数(たとえば、チェーンコードの数)の指示と、チェーンコードごとの方向インデックスとを含む。チェーン166のための他のタイプのシグナリングも使用され得る。一例では、図10の例に示された任意のパーティションパターンをシグナリングするために、ビデオエンコーダ20は、チェーン166が上境界から開始することを示すために1ビット(たとえば、0)を符号化し得る。ビデオエンコーダ20は、チェーン166が上境界の第3の深度サンプルの後に開始することを示すために3ビット(たとえば、011)を符号化し得る。ビデオエンコーダ20は、チェーン166中に合計7つのリンクがあることを示すために4ビット(たとえば、0110)を符号化し得る。ビデオエンコーダ20はまた、(たとえば、ブロック160に従って)各チェーンリンクの方向を示すために一連の連結チェーンインデックス(たとえば、3,3,3,7,1,1,1)を符号化し得る。いくつかの例では、ビデオエンコーダ20は、ルックアップテーブルを使用して各インデックスをコードワードに変換し得る。ビデオデコーダ30などのビデオデコーダは、ブロックの区分パターンを決定するために、上記で説明したシグナリングをパースし得る。ビデオデコーダ30は、次いで、各パーティションのための深度値を復号し得る。
[0235]本開示で説明する技法は、簡略深度コーディング(SDC)とともに機能することもできるが、技法はそのように限定されず、SDCが利用されない例において機能し得る。以下では、簡略深度コーディング(SDC)モードについて説明する。SDCモードは、深度スライスのイントラPUをコーディングするために、HEVCイントラ予測モード、DMMモード、およびチェーンコーディングモードとともに導入されている。現在の3D−HEVCでは、SDCは、2N×2N PUパーティションサイズのためにのみ適用される。量子化変換係数をコーディングする代わりに、SDCモードは、以下の2つのタイプの情報を用いて深度ブロックを表す。(1)DMMモード1(2つのパーティション)と平面(1つのパーティション)とを含む、現在の深度ブロックのパーティションのタイプ、および(2)パーティションごとに、(ピクセル領域における)残差値がビットストリームにおいてシグナリングされる。
[0236]それぞれ平面およびDMMモード1のパーティションタイプに対応するSDCモード1とSDCモード2とを含む2つのサブモードが、SDCにおいて定義される。簡略残差コーディングがSDCにおいて使用される。簡略残差コーディングでは、PUのパーティションごとに1つのDC残差値がシグナリングされ、変換または量子化は適用されない。
[0237]例に応じて、本明細書で説明した方法のうちのいずれかのいくつかの動作またはイベントは、異なる順序で実行されてよく、互いに追加、統合、または完全に除外され得る(たとえば、すべての説明された動作またはイベントが、本方法の実施のために必要であるとは限らない)ことを理解されたい。その上、いくつかの例では、動作またはイベントは、連続してではなく、同時に、たとえば、マルチスレッド処理、割込み処理、または複数のプロセッサを通じて実行され得る。加えて、本開示の特定の態様が、明確さの目的のため、単一のモジュールまたはユニットによって実行されるものとして説明されているが、本開示の技法は、ビデオコーダに関連付けられているユニットまたはモジュールの組合せによって実行され得ることを理解されたい。
[0238]技法の様々な態様の特定の組合せについて上記で説明したが、これらの組合せは、本開示で説明した技法の例を示すために与えられたものにすぎない。したがって、本開示の技法は、これらの例示的な組合せに限定されるべきでなく、本開示で説明した技法の様々な態様の任意の想起可能な組合せを包含し得る。
[0239]1つまたは複数の例では、説明した機能は、ハードウェア、ソフトウェア、ファームウェア、またはそれらの任意の組合せで実装され得る。ソフトウェアで実装される場合、機能は、コンピュータ可読媒体上の1つもしくは複数の命令またはコード上に記憶され、あるいはこれを介して伝送され、ハードウェアベースの処理ユニットによって実行され得る。コンピュータ可読媒体は、データ記憶媒体などの有形の媒体に対応するコンピュータ可読記憶媒体、または、たとえば、通信プロトコルに従う、ある場所から別の場所へのコンピュータプログラムの転送を容易にする任意の媒体を含む通信媒体を含み得る。
[0240]このようにして、コンピュータ可読媒体は、一般に、(1)非一時的である有形のコンピュータ可読記憶媒体、または(2)信号または搬送波のような通信媒体に対応し得る。データ記憶媒体は、本開示で説明する技法の実装のための命令、コードおよび/またはデータ構造を取り出すために、1つもしくは複数のコンピュータまたは1つもしくは複数のプロセッサによってアクセスされ得る、任意の利用可能な媒体であり得る。コンピュータプログラム製品はコンピュータ可読記憶媒体とパッケージング材料とを含み得る。
[0241]限定ではなく例として、そのようなコンピュータ可読記憶媒体は、RAM、ROM、EEPROM(登録商標)、CD−ROMもしくは他の光ディスクストレージ、磁気ディスクストレージ、もしくは他の磁気ストレージデバイス、フラッシュメモリ、または、命令またはデータ構造の形態の所望のプログラムコードを記憶するために使用され得、コンピュータによってアクセスされ得る任意の他の媒体を備え得る。また、任意の接続が、コンピュータ可読媒体と適切に呼ばれる。たとえば、命令が、ウェブサイト、サーバ、または他の遠隔ソースから、同軸ケーブル、光ファイバーケーブル、ツイストペア、デジタル加入者回線(DSL)、または赤外線、無線、およびマイクロ波などのワイヤレス技術を使用して送信される場合、同軸ケーブル、光ファイバーケーブル、ツイストペア、DSL、または赤外線、無線、マイクロ波などのワイヤレス技術は、媒体の定義に含まれる。
[0242]ただし、コンピュータ可読記憶媒体およびデータ記憶媒体は、接続、搬送波、信号、または他の一時的媒体を含まないが、代わりに、非一時的な有形記憶媒体を対象とすることを理解されたい。本明細書で使用するディスク(disk)およびディスク(disc)は、コンパクトディスク(disc)(CD)、レーザーディスク(登録商標)(disc)、光ディスク(disc)、デジタル多用途ディスク(disc)(DVD)、フロッピー(登録商標)ディスク(disk)、およびblu−rayディスク(disc)を含み、ディスク(disk)は、通常、データを磁気的に再生し、ディスク(disc)は、データをレーザーで光学的に再生する。上記の組合せも、コンピュータ可読媒体の範囲の中に含まれるべきである。
[0243]命令は、1つもしくは複数のデジタル信号プロセッサ(DSP)、汎用マイクロプロセッサ、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、または他の同等の集積回路もしくはディスクリート論理回路などの1つまたは複数のプロセッサによって実行され得る。したがって、「プロセッサ」という用語は、本明細書で使用されるときに、前述の構造のいずれかまたは本明細書で説明した技法の実装に適切な任意の他の構造を指すことができる。加えて、いくつかの態様では、本明細書で説明した機能は、符号化および復号のために構成されるか、または複合コーデックに組み込まれる、専用のハードウェアモジュールおよび/またはソフトウェアモジュール内で提供され得る。また、本技法は、1つまたは複数の回路または論理素子において完全に実装され得る。
[0244]本開示の技法は、ワイヤレスハンドセット、集積回路(IC)またはICのセット(たとえば、チップセット)を含む、多種多様なデバイスまたは装置で実装され得る。様々な構成要素、モジュール、またはユニットは、開示されている技術を実行するように構成されたデバイスの機能的態様を強調するように本開示において説明されているが、異なるハードウェアユニットによる実現を必ずしも必要としない。そうではなく、上記で説明したように、様々なユニットは、コーデックハードウェアユニット中で組み合わせられるか、または上記で説明した1つまたは複数のプロセッサを含む、適切なソフトウェアおよび/またはファームウェアとともに相互動作可能なハードウェアユニットの集合によって提供され得る。
[0245]本開示の様々な態様が説明されてきた。これらおよび他の態様は以下の特許請求の範囲内に入る。
以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。
[C1]
ビデオデータを復号する方法であって、
第1のサイズのブロックに関連するパーティションパターンを決定することと、
前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することと、ここにおいて、前記第2のサイズが前記第1のサイズよりも大きい、
前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測復号することと
を備える方法。
[C2]
前記第1のサイズのブロックに関連する前記パーティションパターンは、サイズ16×16のブロックに関連するパーティションパターンを備え、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、サイズ16×16の前記ブロックに関連する前記決定されたパーティションパターンに基づいて、サイズ32×32の前記深度ブロックに関する前記パーティションパターンを決定することを備える、C1に記載の方法。
[C3]
前記第1のサイズの前記ブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成することと、
前記パーティションパターンリストへのインデックスを受信することと
をさらに備え、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定することは、前記パーティションパターンリストへの前記受信されたインデックスに基づいて、前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定することを備える、C1に記載の方法。
[C4]
前記深度ブロック内のサブブロックを識別する情報を受信することをさらに備え、前記サブブロックのサイズが前記第1のサイズであり、
前記第1のサイズのブロックに関連する前記パーティションパターンを決定することは、前記サブブロックに関する前記パーティションパターンを決定することを備え、
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、前記サブブロックに関する前記決定されたパーティションパターンに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することを備える、C1に記載の方法。
[C5]
前記サブブロックに関する前記決定されたパーティションパターンに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、前記サブブロックに関する前記パーティションパターンの線形線を前記深度ブロックの境界まで拡張することを備え、得られる線形線が、前記深度ブロックに関する前記パーティションパターンを画定する、C4に記載の方法。
[C6]
前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンは、前記第1のサイズの前記ブロックに関連する複数の線ベースのパーティションパターンからの線ベースのパーティションパターンを備え、前記深度ブロックに関する前記パーティションパターンは、2つのパーティションに前記深度ブロックを区分する前記深度ブロックに関する線ベースのパーティションパターンを備える、C1に記載の方法。
[C7]
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを示す情報を受信することなく、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することを備える、C1に記載の方法。
[C8]
ビデオデータを符号化する方法であって、
第1のサイズのブロックに関連するパーティションパターンを決定することと、
前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することと、ここにおいて、前記第2のサイズが前記第1のサイズよりも大きい、
前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測符号化することと
を備える方法。
[C9]
前記第1のサイズのブロックに関連する前記パーティションパターンは、サイズ16×16のブロックに関連するパーティションパターンを備え、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、サイズ16×16の前記ブロックに関連する前記決定されたパーティションパターンに基づいて、サイズ32×32の前記深度ブロックに関する前記パーティションパターンを決定することを備える、C8に記載の方法。
[C10]
前記第1のサイズの前記ブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成すること
をさらに備え、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定することは、前記構成されたパーティションパターンリストにおいて識別されたパーティションパターンから、前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定することを備える、C8に記載の方法。
[C11]
前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンを識別する前記構成されたパーティションパターンリストへのインデックスをシグナリングすることをさらに備え、ビデオデコーダが、前記深度ブロックをイントラ予測復号するために前記インデックスを使用する、C10に記載の方法。
[C12]
前記深度ブロック内のサブブロックを識別することをさらに備え、前記サブブロックのサイズが前記第1のサイズであり、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定することは、前記識別されたサブブロックに関する前記パーティションパターンを決定することを備え、
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、前記識別されたサブブロックに関する前記決定されたパーティションに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することを備える、C8に記載の方法。
[C13]
前記識別されたサブブロックに関する前記決定されたパーティションパターンに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することは、前記識別されたサブブロックに関する前記パーティションパターンの線形線を前記深度ブロックの境界まで拡張することを備え、得られる線形線が、前記深度ブロックに関する前記パーティションパターンを画定する、C12に記載の方法。
[C14]
前記第1のサイズの前記ブロックに関連する前記パーティションパターンは、前記第1のサイズの前記ブロックに関連する複数の線ベースのパーティションパターンからの線ベースのパーティションパターンを備え、前記深度ブロックに関する前記パーティションパターンは、2つのパーティションに前記深度ブロックを区分する前記深度ブロックに関する線ベースのパーティションパターンを備える、C8に記載の方法。
[C15]
ビデオコーディングのためのデバイスであって、
第1のサイズのブロックに関連する1つまたは複数のパーティションパターンを記憶するビデオデータメモリと、
1つまたは複数のプロセッサを備えるビデオコーダとを備え、前記ビデオコーダは、
前記記憶された1つまたは複数のパーティションパターンから、前記第1のサイズの前記ブロックに関連するパーティションパターンを決定することと、
前記第1のサイズの前記ブロック関連する前記決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することと、ここにおいて、前記第2のサイズが前記第1のサイズよりも大きい、
前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測コーディングすることと
を行うように構成される、デバイス。
[C16]
前記第1のサイズのブロックに関連する前記パーティションパターンは、サイズ16×16のブロック関連するパーティションパターンを備え、前記第2のサイズの前記深度ブロックは、サイズ32×32の深度ブロックを備え、前記ビデオコーダは、サイズ16×16の前記ブロックに関連する前記決定されたパーティションパターンに基づいて、サイズ32×32の前記深度ブロックに関する前記パーティションパターンを決定するように構成される、C15に記載のデバイス。
[C17]
前記ビデオコーダはビデオデコーダを備え、
前記ビデオデコーダは、
前記第1のサイズの前記ブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成することと、
前記パーティションパターンリストへのインデックスを受信することと
を行うように構成され、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するために、前記ビデオデコーダは、前記パーティションパターンリストへの前記受信されたインデックスに基づいて、前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するように構成され、
前記深度ブロックをイントラ予測コーディングするために、前記ビデオデコーダは、前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測復号するように構成される、C15に記載のデバイス。
[C18]
前記ビデオコーダはビデオデコーダを備え、
前記ビデオデコーダは、前記深度ブロック内のサブブロックを識別する情報を受信するように構成され、前記サブブロックのサイズが前記第1のサイズであり、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するために、前記ビデオデコーダは、前記サブブロックに関する前記パーティションパターンを決定するように構成され、
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するために、前記ビデオデコーダは、前記サブブロックに関する前記決定されたパーティションパターンに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するように構成される、C15に記載のデバイス。
[C19]
前記ビデオコーダはビデオデコーダを備え、
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するために、前記ビデオデコーダは、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを示す情報を受信することなく、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するように構成される、C15に記載のデバイス。
[C20]
前記ビデオコーダはビデオエンコーダを備え、
前記ビデオエンコーダは、前記第1のサイズの前記ブロックに関連する1つまたは複数のパーティションパターンを含むパーティションパターンリストを構成するように構成され、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するために、前記ビデオエンコーダは、前記構成されたパーティションパターンリストにおいて識別されたパーティションパターンから、前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するように構成され、
前記深度ブロックをイントラ予測コーディングするために、前記ビデオエンコーダは、前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測符号化するように構成される、C15に記載のデバイス。
[C21]
前記ビデオエンコーダは、前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンを識別する前記構成されたパーティションパターンリストへのインデックスをシグナリングするように構成され、ビデオデコーダが、前記深度ブロックをイントラ予測復号するために前記インデックスを使用する、C20に記載のデバイス。
[C22]
前記ビデオコーダはビデオエンコーダを備え、
前記ビデオエンコーダは、前記深度ブロック内のサブブロックを識別するように構成され、前記サブブロックのサイズが前記第1のサイズであり、
前記第1のサイズの前記ブロックに関連する前記パーティションパターンを決定するために、前記ビデオエンコーダは、前記識別されたサブブロックに関する前記パーティションパターンを決定するように構成され、
前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するために、前記ビデオエンコーダは、前記識別されたサブブロックに関する前記決定されたパーティションに基づいて、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定するように構成される、C15に記載のデバイス。
[C23]
前記第1のサイズの前記ブロックに関連する前記パーティションパターンは、前記第1のサイズの前記ブロックに関連する複数の線ベースのパーティションパターンからの線ベースのパーティションパターンを備え、前記深度ブロックに関する前記パーティションパターンは、2つのパーティションに前記深度ブロックを区分する前記深度ブロックに関する線ベースのパーティションパターンを備える、C15に記載のデバイス。
[C24]
集積回路(IC)、
マイクロコントローラ、および
前記ビデオコーダを備えるワイヤレスデバイス
のうちの1つを備える、C15に記載のデバイス。
[C25]
ビデオコーディングのためのデバイスの1つまたは複数のプロセッサによって実行されたときに、前記1つまたは複数のプロセッサに、
第1のサイズのブロックに関連するパーティションパターンを決定することと、
前記第1のサイズの前記ブロックに関連する前記決定されたパーティションパターンに基づいて、第2のサイズの深度ブロックに関するパーティションパターンを決定することと、ここにおいて、前記第2のサイズが前記第1のサイズよりも大きい、
前記深度ブロックに関する前記決定されたパーティションパターンに基づいて、前記深度ブロックをイントラ予測コーディングすることと
を行わせる命令を記憶したコンピュータ可読記憶媒体。
[C26]
前記第1のサイズの前記ブロックに関連する前記パーティションパターンは、サイズ16×16のブロックに関するパーティションパターンを備え、前記1つまたは複数のプロセッサに、前記第2のサイズの前記深度ブロックに関する前記パーティションパターンを決定することを行わせる前記命令は、前記1つまたは複数のプロセッサに、サイズ16×16の前記ブロックに関する前記決定されたパーティションパターンに基づいて、サイズ32×32の前記深度ブロックに関する前記パーティションパターンを決定することを行わせる命令を備える、C25に記載のコンピュータ可読記憶媒体。
[C27]
前記第1のサイズのブロックに前記関連する前記パーティションパターンは、前記第1のサイズの前記ブロックに関連する複数の線ベースのパーティションパターンからの線ベースのパーティションパターンを備え、前記深度ブロックに関する前記パーティションパターンは、2つのパーティションに前記深度ブロックを区分する前記深度ブロックに関する線ベースのパーティションパターンを備える、C25に記載のコンピュータ可読記憶媒体。