JP6237334B2 - クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 - Google Patents
クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 Download PDFInfo
- Publication number
- JP6237334B2 JP6237334B2 JP2014036700A JP2014036700A JP6237334B2 JP 6237334 B2 JP6237334 B2 JP 6237334B2 JP 2014036700 A JP2014036700 A JP 2014036700A JP 2014036700 A JP2014036700 A JP 2014036700A JP 6237334 B2 JP6237334 B2 JP 6237334B2
- Authority
- JP
- Japan
- Prior art keywords
- document
- cluster
- documents
- character string
- excluded
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 59
- 230000007717 exclusion Effects 0.000 claims description 75
- 238000009826 distribution Methods 0.000 claims description 34
- 230000004044 response Effects 0.000 claims description 7
- 238000003860 storage Methods 0.000 claims description 2
- 239000000284 extract Substances 0.000 description 21
- 238000010586 diagram Methods 0.000 description 18
- 235000019504 cigarettes Nutrition 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 241000209094 Oryza Species 0.000 description 9
- 235000007164 Oryza sativa Nutrition 0.000 description 9
- 235000009566 rice Nutrition 0.000 description 9
- 102100035353 Cyclin-dependent kinase 2-associated protein 1 Human genes 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 241000208125 Nicotiana Species 0.000 description 3
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 3
- 238000000605 extraction Methods 0.000 description 2
- 241000512259 Ascophyllum nodosum Species 0.000 description 1
- 241000269851 Sarda sarda Species 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 235000019583 umami taste Nutrition 0.000 description 1
Images














Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
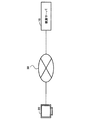
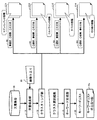
図1は、本実施形態における文書検索システムの構成を示す図である。図1に示すように、本実施形態における文書検索システムは、クライアント装置80と検索サーバ(クエリ生成装置)10とを有する。クライアント装置80は、検索サーバ10と通信ネットワーク50を介して接続する。クライアント装置80は、例えば、パーソナルコンピュータ等である。なお、図1の例では、1台のクライアント装置80を図示しているが、検索サーバ10は、複数のクライアント装置80と接続してもよい。
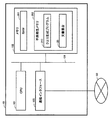
図2は、図1に示す本実施の形態例における検索サーバ10のハードウェア構成を説明する図である。図2に示す検索サーバ10は、例えば、CPU(Central Processing Unit)101、RAM(Random Access Memory)201や不揮発性メモリ202等を備えるメモリ102、通信インタフェース部103を有する。各部は、バス104を介して相互に接続する。
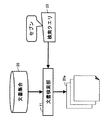
図4は、クラスタを用いるクエリ23の基本的な生成処理を説明する第1の図である。本実施の形態例では、ユーザが、コンビニエンスストアの「セブンイレブン」に関する文書を検索して抽出する場合を前提とする。「セブンイレブン」は、「セブン」と省略して用いられることが多い。したがって、ユーザは、例えば、「セブン」をクエリ23の検索語として入力する。この結果、文書検索部11は、文書内に検索語「セブン」を含む複数の文書20aを取得する。
図6は、本実施の形態例におけるクエリ生成処理を説明するフローチャート図である。初めに、検索サーバ10の文書検索部11は、クライアント装置80から文書集合20の検索を行うための検索語を受信する(S11)。なお、検索語は、複数のキーワードによる組み合わせ(キーワード集合)であってもよい。次に、文書検索部11は、検索語に基づいてクエリ23を生成し、文書集合20の検索処理を行う(S12)。文書検索部11は、検索処理の結果、クエリ23が示す条件に合致する複数の文書20aを取得する。
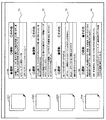
図10は、キーワードリスト22の生成処理を説明するフローチャート図である。まず、キーワードリスト生成部32は、排除クラスタ及び選択クラスタ内の文書に含まれるキーワードを複数抽出する(S31)。そして、キーワードリスト生成部32は、抽出したキーワードのスコアの値を0に初期化する(S32)。
なお、本実施の形態例における検索サーバ10は、図18、図19に示すスライドバー等のオブジェクトに加えて、ユーザのオブジェクト操作による入力に応じて選択されるキーワードを表示してもよい。例えば、検索サーバ10のキーワード選択部33は、クライアント装置80の表示ユニットに、スライドバーの値に応じて選択される排除条件のキーワードの一覧を更に表示する。
処理ユニットが、
入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示する第1の工程と、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成する第2の工程と、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する第3の工程と、
を実行することを特徴とするクエリ生成方法。
付記1において、
前記第2の工程は、前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成方法。
付記2において、
前記第2の工程は、前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成方法。
付記1乃至3のいずれかにおいて、
前記第3の工程は、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成方法。
付記4において、
前記第3の工程は、前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成方法。
付記4または5において、
前記オブジェクトは、スライドバーであるクエリ生成方法。
付記1乃至6のいずれかにおいて、
前記第2の工程は、前記文書集合の特徴を示す特徴情報を前記表示ユニットに更に表示するクエリ生成方法。
付記7において、
前記特徴情報は、前記文書集合の文書に含まれる前記検索語の使用文字列、前記文書集合の文書に含まれる頻出文字列、前記文書集合の文書に含まれる文字列であって前記検索された複数の文書における前記書集合内での出現分布率が高い文字列、のうち少なくともいずれかであるクエリ生成方法。
付記1乃至8のいずれかにおいて、
前記第2の工程は、前記排除文書集合の指定を受け付けるオブジェクトを更に前記表示ユニットに表示するクエリ生成方法。
入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する、
処理をコンピュータに実行させるクエリ生成プログラム。
付記10において、
前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成プログラム。
付記11において、
前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成プログラム。
付記10乃至12のいずれかにおいて、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成プログラム。
付記13において、
前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成プログラム。
付記13または14において、
前記オブジェクトは、スライドバーであるクエリ生成プログラム。
処理ユニットと、
複数の文書を記憶する記憶装置と、
表示装置と、を有し、
入力された検索語に基づいて前記複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示するクエリ生成装置。
付記16において、
前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成方法。
付記17において、
前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成方法。
付記16乃至18のいずれかにおいて、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成方法。
付記19において、
前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成方法。
Claims (11)
- 処理ユニットが、
入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示する第1の工程と、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成する第2の工程と、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する第3の工程と、
を実行することを特徴とするクエリ生成方法。 - 請求項1において、
前記第2の工程は、前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成方法。 - 請求項2において、
前記第2の工程は、前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成方法。 - 請求項1乃至3のいずれかにおいて、
前記第3の工程は、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成方法。 - 請求項4において、
前記第3の工程は、前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成方法。 - 請求項4または5において、
前記オブジェクトは、スライドバーであるクエリ生成方法。 - 請求項1乃至6のいずれかにおいて、
前記第2の工程は、前記文書集合の特徴を示す特徴情報を前記表示ユニットに更に表示するクエリ生成方法。 - 請求項7において、
前記特徴情報は、前記文書集合の文書に含まれる前記検索語の使用文字列、前記文書集合の文書に含まれる頻出文字列、前記文書集合の文書に含まれる文字列であって前記検索された複数の文書における前記書集合内での出現分布率が高い文字列、のうち少なくともいずれかであるクエリ生成方法。 - 請求項1乃至8のいずれかにおいて、
前記第2の工程は、前記排除文書集合の指定を受け付けるオブジェクトを更に前記表示ユニットに表示するクエリ生成方法。 - 入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する、
処理をコンピュータに実行させるクエリ生成プログラム。 - 処理ユニットと、
複数の文書を記憶する記憶装置と、
表示装置と、を有し、
入力された検索語に基づいて前記複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示するクエリ生成装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014036700A JP6237334B2 (ja) | 2014-02-27 | 2014-02-27 | クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014036700A JP6237334B2 (ja) | 2014-02-27 | 2014-02-27 | クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015162076A JP2015162076A (ja) | 2015-09-07 |
| JP6237334B2 true JP6237334B2 (ja) | 2017-11-29 |
Family
ID=54185133
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014036700A Expired - Fee Related JP6237334B2 (ja) | 2014-02-27 | 2014-02-27 | クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6237334B2 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6325502B2 (ja) * | 2015-10-08 | 2018-05-16 | Necパーソナルコンピュータ株式会社 | 情報処理装置、情報処理システムおよび情報処理方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4049317B2 (ja) * | 2003-05-14 | 2008-02-20 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 検索支援装置およびプログラム |
| CN100419753C (zh) * | 2005-12-19 | 2008-09-17 | 株式会社理光 | 数字化数据集中按照分类信息搜索目标文档的方法和装置 |
| JP2007310734A (ja) * | 2006-05-19 | 2007-11-29 | Matsushita Electric Ind Co Ltd | 検索装置 |
-
2014
- 2014-02-27 JP JP2014036700A patent/JP6237334B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015162076A (ja) | 2015-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7917489B2 (en) | Implicit name searching | |
| US7769771B2 (en) | Searching a document using relevance feedback | |
| JP5497022B2 (ja) | 入力文字列からのリソースロケータの提案 | |
| JP4437500B2 (ja) | データをタグ情報に対応付けて管理する技術 | |
| JP5661200B2 (ja) | 検索情報の提供 | |
| US9817908B2 (en) | Systems and methods for news event organization | |
| US20110167053A1 (en) | Visual and multi-dimensional search | |
| JP5786718B2 (ja) | 動向情報検索装置、動向情報検索方法およびプログラム | |
| US20090144240A1 (en) | Method and systems for using community bookmark data to supplement internet search results | |
| US20130110839A1 (en) | Constructing an analysis of a document | |
| US20110307432A1 (en) | Relevance for name segment searches | |
| US10152478B2 (en) | Apparatus, system and method for string disambiguation and entity ranking | |
| US20060179039A1 (en) | Method and system for performing secondary search actions based on primary search result attributes | |
| US20120036144A1 (en) | Information and recommendation device, method, and program | |
| CN101911042A (zh) | 用户的浏览器历史的相关性排序 | |
| JP6390139B2 (ja) | 文書検索装置、文書検索方法、プログラム、及び、文書検索システム | |
| US20140181070A1 (en) | People searches using images | |
| US8583415B2 (en) | Phonetic search using normalized string | |
| JP6533876B2 (ja) | 商品情報表示システム、商品情報表示方法、及びプログラム | |
| JP5048852B2 (ja) | 検索装置、検索方法、検索プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 | |
| JP4973503B2 (ja) | ファイル検索プログラム、方法及び装置 | |
| JP6237334B2 (ja) | クエリ生成方法、クエリ生成プログラム、及び、クエリ生成装置 | |
| JP5127553B2 (ja) | 情報処理装置、情報処理方法、プログラム及び記録媒体 | |
| US10606875B2 (en) | Search support apparatus and method | |
| JP5225331B2 (ja) | データ抽出装置及び方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20161102 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170925 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171003 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171016 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6237334 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |