以下、図面にしたがって本発明の実施の形態について説明する。ただし、本発明の技術的範囲はこれらの実施の形態に限定されず、特許請求の範囲に記載された事項とその均等物まで及ぶものである。
[文書検索システム]
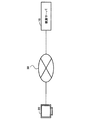
図1は、本実施形態における文書検索システムの構成を示す図である。図1に示すように、本実施形態における文書検索システムは、クライアント装置80と検索サーバ(クエリ生成装置)10とを有する。クライアント装置80は、検索サーバ10と通信ネットワーク50を介して接続する。クライアント装置80は、例えば、パーソナルコンピュータ等である。なお、図1の例では、1台のクライアント装置80を図示しているが、検索サーバ10は、複数のクライアント装置80と接続してもよい。
クライアント装置80は、Webページを閲覧するブラウザを介して、検索サーバ10に、検索語等の検索条件を入力する。検索サーバ10は、クライアント装置80から入力された検索条件に基づいてクエリを生成し、文書集合からクエリに対応する文書を抽出する。そして、検索サーバ10は、抽出した文書をクライアント装置80に送信する。本実施の形態例における検索サーバ10は、クライアント装置80からの検索条件や入力情報に基づいて、適切なクエリを生成する。クライアント装置80は、例えば、CPU(Central Processing Unit)、メモリ、表示ユニット、入力ユニット等を有する(不図示)。
[検索サーバの構成]
図2は、図1に示す本実施の形態例における検索サーバ10のハードウェア構成を説明する図である。図2に示す検索サーバ10は、例えば、CPU(Central Processing Unit)101、RAM(Random Access Memory)201や不揮発性メモリ202等を備えるメモリ102、通信インタフェース部103を有する。各部は、バス104を介して相互に接続する。
CPU101は、バス104を介してメモリ102等と接続すると共に、検索サーバ10全体の制御を行う。メモリ102のRAM201は、CPU101が処理を行うデータ等を記憶する。メモリ102の不揮発性メモリ202は、CPU101が実行するOS(Operating System)のプログラムを格納する領域(図示せず)や、本実施の形態例におけるクエリ生成プログラムを格納する領域210を備える。また、不揮発性メモリ202は、文書集合を格納する領域20を有する。文書集合を格納する領域(以下、文書集合と称する)20は、例えば、ソーシャルネットワークの記事の集合である。記事は、例えば、ブログの記事やコメント等である。不揮発性メモリ202は、HDD(Hard disk drive)、不揮発性半導体メモリ等によって構成される。
クエリ生成プログラム領域210のクエリ生成プログラム(以下、クエリ生成プログラム210と称する)は、CPU101の実行によって、本実施の形態例におけるクエリ生成処理を実現する。また、通信インタフェース部103は、ネットワーク50を介して、クライアント装置80等の通信機器との間でデータの送受信を制御する。
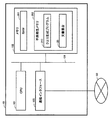
図3は、図1、図2に示す検索サーバ10のソフトウェアブロック図である。検索サーバ10のクエリ生成プログラム210(図2)は、例えば、文書検索モジュール(以下、文書検索部と称する)11、クラスタリングモジュール(以下、クラスタリング部と称する)12、キーワード生成モジュール(以下、キーワード生成部と称する)13を有する。
文書検索部11は、ユーザが入力した検索語をクライアント装置80から受信し(a1)、検索語に基づいて検索サーバ10が格納する文書集合20を検索して、複数の文書を抽出する。なお、図2、図3の例では、検索対象となる文書集合20は、検索サーバ10に格納される。しかしながら、この例に限定されるものではない。文書集合20は、ネットワーク50を介して接続する1つまたは複数の他のサーバに格納されていてもよい。クラスタリング部12は、文書検索部11が検索して抽出した複数の文書を、文書の類似度に基づいて複数の文書集合(以下、クラスタと称する)に分類する。
キーワード生成部13は、クラスタ指定受付モジュール(以下、クラスタ指定受付部と称する)31と、キーワードリスト生成モジュール(以下、キーワードリスト生成部と称する)32と、キーワード選択モジュール(以下、キーワード選択部と称する)33を有する。
クラスタ指定受付部31は、複数のクラスタを識別する情報をクライアント装置80の表示ユニットに表示させるとともに、複数のクラスタのうち、検索結果から排除すべき排除対象のクラスタ(以下、排除クラスタと称する)、及び、検索結果として選択すべき選択対象のクラスタ(以下、選択クラスタと称する)の指定をユーザから受け付ける(a2)。キーワードリスト生成部32は、排除クラスタ、選択クラスタに基づいて、クエリ23における検索語の排除条件となるキーワードのリスト22を作成する。
キーワード選択部33は、キーワードリスト22内のキーワード数に比例する値を示すスライドバーをクライアント装置80の表示ユニットに表示する。また、キーワード選択部33は、ユーザによるスライドバーの操作を受け付けるとともに(a3)、スライドバーの値に対応するキーワードを含む文書の割合をクラスタ毎に表示する。スライドバーの値に対応するキーワードがクエリ23の排除条件となる。
次に、本実施の形態例におけるクエリ生成処理を説明する前に、クラスタを用いたクエリ23の基本的な生成処理を図に基づいて説明する。
[クラスタを用いたクエリの生成]
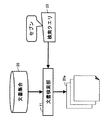
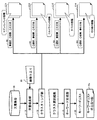
図4は、クラスタを用いるクエリ23の基本的な生成処理を説明する第1の図である。本実施の形態例では、ユーザが、コンビニエンスストアの「セブンイレブン」に関する文書を検索して抽出する場合を前提とする。「セブンイレブン」は、「セブン」と省略して用いられることが多い。したがって、ユーザは、例えば、「セブン」をクエリ23の検索語として入力する。この結果、文書検索部11は、文書内に検索語「セブン」を含む複数の文書20aを取得する。
ただし、検索語「セブン」にしたがって検索された複数の文書20aは、「セブンイレブン」に関する記事に加えて、「ウルトラセブン」や「セブンスター」、映画の「セブン」に関する記事も含む。検索された複数の文書20aを対象として、マーケティング等の分析処理を行う場合、「セブンイレブン」に関する記事以外の記事が含まることにより、分析の精度が下がる。したがって、検索結果から、「セブンイレブン」に関する記事以外の記事が排除されることが望ましい。そこで、クラスタリング部12は、検索語「セブン」にしたがって検索された複数の文書20aを、複数のクラスタに分類する。
図5は、クラスタを用いたクエリ23の基本的な生成処理を説明する第2の図である。クラスタリング部12は、検索語「セブン」に基づいて抽出された複数の文書20aを、類似性のある文書同士をまとめて、複数のクラスタを生成する。図5の例では、クラスタリング部12は、例えば、複数の文書20a内の各文書を、いずれかのクラスタに分類する。
図5の例において、クラスタリング部12は、複数の文書20aを、複数のクラスタC11〜C14に分類する。クラスタC11は、例えば、セブンイレブンの話題に関する文書を多く含む。また、クラスタC12は、ウルトラマンのセブンの話題に関する文書を、クラスタC13は煙草のマイルドセブンの話題に関する文書を多く含む。クラスタC14は、セブンイレブン、ウルトラマン、煙草以外の話題に関する文書を含む。
次に、クラスタリング部12は、例えば、クラスタC11〜C14に基づいて、各クラスタを代表する語句(以下、代表語と称する)Ckを抽出する。代表語Ckとは、例えば、対象のクラスタにより多く頻出し、対象のクラスタ以外のクラスタにはほとんど含まれない単語である。例えば、クラスタリング部12は、対象のクラスタへの出現頻度が高く、かつ、対象外のクラスタへの出現頻度が少ない単語を代表語として抽出する。図5の例において、クラスタC11の代表語は、「コンビニ」「アイス」等である。また、クラスタC12の代表語は、「ウルトラマン」「フィギュア」等であって、クラスタC13の代表語は、「マイルドセブン」煙草」等である。ユーザは、代表語を、検索語と組み合わせる排除条件(NOT)の候補として使用する。
例えば、ユーザは、代表語「フィギュア」を用いて、クエリ23「セブン and NOTフィギュア」を生成する。これにより、ユーザは、検索語「セブン」を含み、かつ、代表語「フィギュア」を含まない文書の集合を抽出できる。つまり、ユーザは、ウルトラマンの話題を示すクラスタC12が含む文書の多くを検索結果から排除することができる。しかしながら、クエリ23「セブン and NOTフィギュア」に基づいて文書集合を検索すると、例えば、「セブンイレブンでフィギュアを買った」等の文章を含む文書が検索結果から排除されてしまう。つまり、検索によって抽出したい文書についても、検索結果から排除されてしまう。
このように、クラスタの代表語を用いることによって、検索語による検索結果から不要な文書を排除するキーワード候補が取得可能になるものの、検索によって抽出したいユーザ所望の文書についても検索結果から排除されてしまうことがある。したがって、代表語を用いてクエリ23を生成する場合であっても、所望の文書を抽出できるとは限らない。また、検索結果を分類した複数のクラスタから所望のクラスタを選択して文書を抽出する場合であっても、クラスタリングの精度が完全ではないことから、不要な文書が抽出されてしまう場合がある。
また、クエリ23による文書検索では、根本的には、ユーザが所望する完全な文書集合を取得することは困難である。つまり、クエリ23による文書検索によると、不要な文書を完全に排除することや、抽出したい文書を完全に選択することは困難である。したがって、ユーザは、所望の文書集合とできるだけ近い文書集合を抽出可能にするクエリ23を生成する。ただし、ユーザは、所望する完全な文書の集合の内容を、予め検知していない場合がある。したがって、ユーザは、クラスタの代表語を用いて試行錯誤を重ねながら、所望の文書集合と近いと思われる文書集合を抽出可能なクエリ23を生成する。
しかしながら、各クラスタの代表語を組み合わせたとしても、所望の文書集合と近い文書集合を抽出するクエリ23を生成することは容易ではない。また、ユーザは所望の文書集合の内容を予め検知しているわけではないため、試行錯誤を重ねたとしても最適な文書集合が抽出されるとは限らない。
本実施の形態例における検索サーバ10は、複数のクラスタを識別する情報を表示して、ユーザに、検索結果から排除すべき文書を多く有する排除クラスタを指定させる。そして、検索サーバ10は、排除クラスタ内のキーワードを抽出し、抽出したキーワード毎の、検索された複数の文書における排除クラスタ内での出現分布率を示すスコアを計算し、スコアの降順にソートされたキーワードのキーワードリスト22を生成する。そして、検索サーバ10は、キーワードリスト22内のキーワード数に比例する値を示すスライドバー等の操作オブジェクトを表示して、ユーザのスライドバー等の入力に応じて、キーワードリスト22の上位数分のキーワードを排除条件のクエリ23の候補として選択し、選択したキーワードを含む文書の割合をクラスタ毎に計算して表示する。
即ち、本実施の形態例における検索サーバ10は、検索語による検索結果を分類した複数のクラスタから、排除すべき文書を多く有する排除クラスタをユーザに指定させる。検索サーバ10は、排除クラスタの指定に基づいて、排除クラスタ内の文書をより多く排除可能であって、排除クラスタ以外のクラスタから排除される文書量を抑えるキーワードをその有効性の順に有するリストを生成する。したがって、ユーザは、排除クラスタを指定するだけで、検索サーバ10に、クエリ23の排除条件のキーワード候補(キーワードリスト22)を生成させることができる。
そして、検索サーバ10は、キーワードのリスト内のキーワード数に比例する値を示すスライドバーとともに、スライドバーの値に対応する上位数分のキーワードを含む文書の割合をクラスタ毎に表示する。これにより、ユーザは、スライドバーの値に応じて、排除クラスタ内で排除される文書の割合と、排除クラスタ以外のクラスタ内で排除される文書の割合とのバランスを確認しながら、スライドバーの値を指定することができる。つまり、ユーザは、排除すべきクラスタから排除される文書の割合と、選択したいクラスタから排除される文書の割合とのバランスを確認できることにより、最適なバランスを選択することができる。
検索サーバ10は、スライドバーの値が示す上位数分のキーワードを、クエリ23の排除条件として選択しクエリ23を生成する。したがって、ユーザは、キーワード自体を意識することなく、最適なクエリ23を取得することができる。
このように、ユーザは、所望する完全な文書の集合の内容を予め検知していなくても、排除クラスタの指定とスライドバーによる指定とを行うだけで、ユーザが所望する文書集合を抽出可能にするクエリ23を生成させることが可能になる。つまり、本実施の形態例における検索サーバ10は、試行錯誤を重ねることなく、簡易な操作にしたがって、ユーザの意図を反映させた排除条件のキーワードの絞込みを可能にする。また、ユーザは、所望の文書集合に近い文書集合を確実に抽出可能になる。
次に、本実施の形態例におけるクエリ生成処理をフローチャート図に基づいて説明する。
[フローチャート]
図6は、本実施の形態例におけるクエリ生成処理を説明するフローチャート図である。初めに、検索サーバ10の文書検索部11は、クライアント装置80から文書集合20の検索を行うための検索語を受信する(S11)。なお、検索語は、複数のキーワードによる組み合わせ(キーワード集合)であってもよい。次に、文書検索部11は、検索語に基づいてクエリ23を生成し、文書集合20の検索処理を行う(S12)。文書検索部11は、検索処理の結果、クエリ23が示す条件に合致する複数の文書20aを取得する。
次に、検索サーバ10のクラスタリング部12は、検索によって取得した複数の文書20aを、文書の類似性に基づいて複数のクラスタに分類する(S12)。クラスタリング部12は、例えば、k−means、ワン・パスクラスタリング等の公知の技術を用いて、クラスタを生成する。例えば、本実施の形態例におけるクラスタリング部12は、論文「Criterion Functions for Document Clustering Experiments and Analysis (文献名:Technical Report CS Dept. 01-40, Univ. Minnesota, Ying Zhao and George Karypis 2001年)」に記述されるクラスタリングの技術に基づいて、クラスタを生成する。
次に、キーワード生成部13のクラスタ指定受付部31は、クライアント装置80の表示ユニットに、生成した複数のクラスタを識別する情報を表示させる(S14)。複数のクラスタを識別する情報は、例えば、クラスタIDやアイコン等である。クラスタ指定受付部31は、例えば、複数のクラスタを識別する情報をクライアント装置80にダウンロードさせ、クライアント装置80で動作するウェブブラウザを介して表示させる。また、クラスタ指定受付部31は、さらに、複数のクラスタのうち、排除クラスタ、選択クラスタに対する指定を受け付けるオブジェクトを表示する(S15)。オブジェクトは、例えば、ラジオボタンである。
また、クラスタ指定受付部31は、選択クラスタ及び排除クラスタのユーザによる指定を可能にするために、各クラスタの特徴を表す特徴情報を表示する(S16)。ユーザは、特徴情報を参照することによって、クラスタが有する話題を識別することができる。ユーザは、クラスタが有する話題に基づいて、クラスタが有する文書が検索結果から排除されることが望ましいか否か、クラスタが有する文書が検索結果として選択されることが望ましいか否かを判断可能になる。
特徴情報とは、例えば、クラスタの文書に含まれる検索語を使用する文字列の一部、クラスタの文書に含まれる頻出語、クラスタの文書に含まれる単語であって検索された複数の文書に対する文書集合への出現比率が高い単語(代表語)等である。ただし、特徴情報は、この例に限定されるものではなく、クラスタが有する文書の主題が識別可能になる情報であればいずれの情報であってもよい。
次に、クラスタ指定受付部31は、ユーザによる選択クラスタ、排除クラスタの指定を受け付ける(S17)。ユーザは、少なくとも、排除クラスタを1つ指定する。また、選択クラスタは、必ずしも指定されなくてもよい。ユーザは、排除すべき文書を多く有するクラスタを排除クラスタに指定する。また、ユーザは、検索結果として選択されることが望ましい文書を多く有するクラスタを選択クラスタに指定する。
ユーザによるクラスタの指定を受け付けると(S18のYES)、キーワード生成部13のキーワードリスト生成部32は、キーワードリスト22を生成する(S19)。キーワードリスト22は、クエリ23の排除条件の候補となる複数のキーワードを有する。また、キーワードリスト22は、検索された文書に対する排除クラスタへの出現分布率が高いときにより大きい値を有するスコアの降順に、キーワードを有する。キーワードリスト22の詳細については、別の図にしたがって後述する。
このように、ユーザは、複数のクラスタから排除クラスタを指定するだけで、クラスタに対する指定項目(排除、選択)を反映させた、クエリ23の排除条件のキーワード候補を検索サーバ10に生成させることができる。したがって、ユーザは、クエリ23の排除条件のキーワードの候補を考える必要がない。
次に、キーワード生成部13のキーワード選択部33は、クライアント装置80にスライドバーを表示させ(S20)、ユーザによるスライドバーに対する操作を受け付ける(S21)。スライドバーの値は、キーワードリスト22内のキーワード数に比例する。つまり、ユーザは、スライドバーの値を変更させることによって、クエリ23の排除条件となるキーワードの数を変動させることができる。
そして、キーワード選択部33は、スライドバーの値に応じた、キーワードリスト22の上位数分のキーワードをクエリ23の排除条件の候補として選択し、選択したキーワードを含む文書の割合をクラスタ毎に計算する(S22)。選択したキーワードを含む文書の割合とは、選択したキーワードが排除条件として適用されることによって、排除される文書の割合を表す。そして、キーワード選択部33は、クラスタ毎に、選択したキーワードを含む文書の割合を表示する(S23)。
キーワード選択部33は、スライドバーが示す値が更新される度に、クラスタ毎の排除される文書の割合を計算し直して、表示する(S22、S23)。スライドバーの値が確定すると(S24のYES)、キーワード選択部33は、検索語と、排除条件とする上位数分のキーワードとの組み合わせによって、クエリ23を生成する(S25)。そして、例えば、キーワード選択部33は、検索語と排除条件である上位数分のキーワードとに基づいたクエリ23をクライアント装置80の表示ユニットや、検索サーバ10のメモリ102に出力する。または、キーワード選択部33は、検索語と排除条件である上位数分のキーワードとに基づいたクエリ23にしたがって文書集合20を検索し直し、文書集合を抽出する。
クエリ23の排除条件の候補として選択するキーワードの数が変動することによって、各クラスタから排除される文書量も変動する。このとき、排除クラスタから排除される文書の量と、選択クラスタから抽出される文書の量とは、トレードオフの関係にある。具体的に、キーワードの数を増加させて排除クラスタから排除される文書量を増加させるようとする、選択クラスタから抽出される文書量も低減する傾向にある。一方、キーワードの数を低減させて選択クラスタから抽出される文書量を増加させようとすると、排除クラスタから排除される文書量も低減してしまう傾向にある。
排除クラスタから排除される文書量と、選択クラスタから抽出される文書量との望ましいバランスは、検索ケースによって異なる。例えば、排除クラスタの文書を可能な限り検索結果から排除したい場合、選択クラスタから抽出される文書量が低下したとても、排除クラスタから排除される文書量が多い方が望ましい。したがって、排除クラスタの文書を可能な限り検索結果から排除したい場合、キーワードの数が多い方が、ユーザが所望する文書集合に近い文書集合を抽出可能になり易い。
一方、選択クラスタの文書を可能な限り検索結果として抽出したい場合、排除クラスタから排除される文書量が少なかったとしても、選択クラスタから抽出される文書量が多い方が望ましい。したがって、選択クラスタの文書を可能な限り検索結果として抽出したい場合、キーワードの数が少ない方が、ユーザが所望する文書集合に近い文書集合を抽出可能になり易い。
このように、排除クラスタから排除される文書量と選択クラスタから抽出される文書量との望ましいバランス数が検索ケースによって異なるところ、ユーザは、排除クラスタから排除される文書量と選択クラスタから抽出される文書量とのバランスを確認しながら、スライドバーの値を選択することができる。これにより、ユーザは、意図に沿った文書集合を抽出可能にするクエリ23の排除条件のキーワード数を選択可能になる。また、ユーザは、スライドバー等のオブジェクトを操作するだけで、キーワード自体を意識することなくクエリ23を生成させることが可能になる。
次に、図6で説明したフローチャート図の処理を具体例に対応させて説明する。
図7は、本実施の形態例におけるクラスタの生成処理を説明する図である。本実施の形態例における検索サーバ10の文書検索部11は、図4で説明した処理と同様にして、受け付けた検索語「セブン」に基づいて、文書集合20を検索する(図6のS11、S12)。この結果、文書検索部11は、文書内に検索語「セブン」を含む複数の文書20aを取得する。次に、クラスタリング部12は、検索語「セブン」にしたがって検索された複数の文書20aを、複数のクラスタC11〜C14に分類する(S13)。クラスタC11〜C14は、図4で説明したとおりである。
次に、クラスタ指定受付部31は、クライアント装置80の表示ユニットに、複数のクラスタを識別する情報を表示させるとともに(図6のS14)、ラジオボタン等のオブジェクトを表示して、排除クラスタ及び選択クラスタへの指定を受け付ける(S15)。このとき、クラスタ指定受付部31は、選択クラスタ及び排除クラスタのユーザによる指定を可能にするために、各クラスタの特徴を表す特徴情報を表示する(S16)。
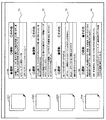
図8は、クラスタの指定を受け付けるクライアント装置80の表示ユニットが表示する画面の一例を示す図である。図8は、クラスタ毎に、クラスタを識別する文書マークで示されるアイコンに加えて、クラスタの指定を受け付けるボタンメニューR1〜R4と、クラスタの特徴情報であるクラスタ内の検索語の使用例T1〜T4とを有する。図8の例において、各クラスタC11〜C14を識別する情報は、文書マークで示されるアイコンである。
また、ボタンメニューR1〜R4は、「選択」「排除」「その他」のいずれかを指定させるラジオボタンである。例えば、初め、全てのクラスタは、「その他」に指定される。「その他」に指定されるクラスタの文書は、キーワードリスト22の生成処理に使用されない。処理の詳細については後述するが、キーワード生成部13は、排除クラスタ、選択クラスタに基づいて、キーワードリスト22を生成する。クラスタの話題が識別できない場合、ユーザは、例えば、クラスタを「その他」のクラスタとする。
図8の例において、クラスタ内の検索語「セブン」の使用例T1〜T4は、クラスタ内の文書のうち、一部の文書における検索語の使用部分の文字列である。例えば、クラスタC11の検索語の使用部分の文字列T1は、「この夏6、7、8、9月、私がよく購入した商品を発表したと思います。第1位 昆布とかつおのうま味・おでん[セブンイレブン]」である。また、図8に示すように、検索語の使用部分の文字列のうち検索語「セブン」は、例えば、太字等によって強調され表示される。なお、検索語は、例えば、斜体、下線等によって強調されて表示されてもよい。ユーザは、クラスタ内の検索語の使用例を参照することによって、クラスタ内の文書で検索語「セブン」がどのように参照されているかを確認可能になり、クラスタが有する話題を識別することができる。
なお、クラスタ内の検索語の使用例T1〜T4は、ユーザがクラスタC11〜C14それぞれからランダムに選択した文書内での検索語の使用例であってもよい。また、図6のフローチャート図で前述したとおり、特徴情報は、検索語の使用例T1〜T4の他に、例えば、クラスタ内の頻出語や代表語等であってもよい。
図8の例において、クラスタC12の検索語の使用例T2によるとクラスタC12が「ウルトラマン」に関する話題を有することが識別可能になる。本実施の形態例では、「セブンイレブン」に関する文書を抽出することを目的とする。したがって、「ウルトラマン」の話題を有する文書は、検索結果として抽出したい文書に当たらない可能性があることから、ユーザは、例えば、クラスタC12を排除クラスタとしてボタンメニューR2に指定する。また、クラスタC13の検索語の使用例T3によると、クラスタC13が「タバコ」に関する話題を有することが識別可能になる。同様にして、「タバコ」の話題を有する文書は、検索結果として抽出したい文書に当たらない可能性があることから、ユーザは、例えば、クラスタC13を排除クラスタとしてボタンメニューR3に指定する。
図8の例では、排除クラスタに加えて、選択クラスタが指定される。クラスタC11の検索語の使用例T1によると、クラスタC11が「セブンイレブン」に関する話題を有することが識別可能になる。したがって、ユーザは、例えば、クラスタC11を選択クラスタとしてボタンメニューR1に指定する。また、クラスタC14は、特定の話題を有していない。したがって、ユーザは、例えば、クラスタC14を、その他のクラスタとする(R4)。
図9は、キーワードリスト22の生成処理を説明する図である。キーワードリスト生成部32は、図8の画面において指定された排除クラスタC12、C13、及び、選択クラスタC11が有する文書を入力として、クエリ23の排除条件の候補となるスコア付きのキーワードのリストを生成する(図6のS18、S19)。排除クラスタのみが指定される場合、キーワードリスト生成部32は、排除クラスタ内の文書に含まれるキーワードを抽出し、キーワードの複数のクラスタにおける排除クラスタ内での出現分布率に基づいてスコアを算出する。この場合、スコアは、複数のクラスタにおける排除クラスタ内での出現分布率が高いときにより大きい値となる。
また、排除クラスタに加えて選択クラスタが指定される場合、キーワードリスト生成部32は、排除クラスタ及び選択クラスタ内の文書に含まれるキーワードを抽出し、キーワードの複数のクラスタにおける排除クラスタ内での出現分布率に基づいてスコアを算出する。この場合、スコアは、複数のクラスタにおける排除クラスタ内での出現分布率が高く、かつ、選択クラスタ内での出現分布率が低いときにより大きい値となる。
ここで、キーワードリスト22の生成処理をより具体的に説明する。
[キーワードリストの生成]
図10は、キーワードリスト22の生成処理を説明するフローチャート図である。まず、キーワードリスト生成部32は、排除クラスタ及び選択クラスタ内の文書に含まれるキーワードを複数抽出する(S31)。そして、キーワードリスト生成部32は、抽出したキーワードのスコアの値を0に初期化する(S32)。
なお、各クラスタは、クラスタ内に含まれる単語毎にtfidf(term frequency inverse document frequency)値を有する。tfidf値は、例えば、単語が、クラスタ内で特徴的である度合いを識別するための指標である。この例では、tfidf値は、対象のクラスタにより偏って出現する度合いを表す。tfidf値は、単語がクラスタ内に出現する回数「tf」と、全文書において当該単語が出現する文書数「df」とに基づいて、計算式「tfidf=tf/log(df/N)」にしたがって算出される。計算式内の値「N」は全文書数を表す。
tfidf値は、例えば、対象のクラスタへの出現頻度が高く、かつ、全クラスタ内への出現率が少ない場合により大きい値を有する。言い換えると、対象のクラスタへの出現頻度が高くても全クラスタ内での出現率が高い場合は、いずれのクラスタにも出現することを示すため、tfidf値は大きな値にはならない。単語毎のtfidf値の例については、図11で例示する。
そして、キーワードリスト生成部32は、選択クラスタとして指定されたクラスタがあるか否かを判定する(S33)。選択クラスタがある場合(S33のYES)、キーワードリスト生成部32は、抽出したキーワードにしたがって、選択クラスタ内の各文書を検索する(S34)。文書にキーワードが含まれる場合(S35のYES)、キーワードリスト生成部32は、キーワードのtfidf値をスコアから減算する(S36)。つまり、キーワードが選択クラスタ内に出現する場合、排除条件のキーワードとして不適切である可能性が高いため、スコアの値は減算される。一方、キーワードが含まれない場合(S35のNO)、キーワードリスト生成部32は、tfidf値をスコアから減算しない。キーワードリスト生成部32は、選択クラスタ内の全ての文書について(S37のYES)、工程S34〜S36の処理を行う。
次に、キーワードリスト生成部32は、抽出したキーワードにしたがって、排除クラスタ内の各文書を検索する(S38)。文書にキーワードが含まれる場合(S39のYES)、キーワードリスト生成部32は、キーワードのtfidf値をスコアに加算する(S40)。つまり、キーワードが排除クラスタ内に出現する場合、排除条件のキーワードとして適切である可能性が高いため、スコアの値は加算される。一方、キーワードが含まれない場合(S39のNO)、キーワードリスト生成部32は、tfidf値をスコアに加算しない。
キーワードリスト生成部32は、排除クラスタ内の全ての文書について(S41のYES)、工程S38〜S40の処理を行う。そして、キーワードリスト生成部32は、スコアの降順にキーワードをソートする(S42)。これにより、キーワードリスト生成部32は、スコアの降順にキーワードを有するキーワードのリスト22を生成する。なお、前述したように、キーワード生成部32は、「その他」に指定されるクラスタ内の文書を加味することなく、キーワードリスト22を生成する。
次に、キーワードリスト22の生成処理を具体例に対応させて説明する。
図11は、キーワード毎のtfidf値を例示する図である。図11の表H1は、クラスタID、文書ID、単語、tfidf値を有する。クラスタIDは、クラスタを識別する情報であって、文書IDは、文書を識別する情報である。単語は、クラスタ内の文書に含まれる単語である。図11の表H1において、例えば、ID「1」のクラスタC1は、文書doc1、doc2等を有する。また、例えば、ID「2」のクラスタC2は、文書doc303等を有する。なお、この例では、文書の一部の情報を表しているが、実際には、各クラスタは多数の文書を有する。
図11の例において、文書doc1は、例えば、単語「コンビニ」「おにぎり」等を含む。この例では、一部の単語を表しているが、実際には、各文書は多数の単語を有する。単語「コンビニ」のtfidf値は「42.7」であって、単語「おにぎり」のtfidf値は「40.3」である。また、文書doc2は、例えば、単語「四国」「コンビニ」等を含み、単語「四国」のtfidf値は「58.7」であって、単語「コンビニ」のtfidf値は「42.7」である。つまり、単語「四国」は、単語「おにぎり」「コンビニ」よりも、ID「1」のクラスタC1により偏って出現することを意味する。
また、表H1において、文書doc303は、例えば、単語「コンビニ」「マイルドセブン」「煙草」等を含む。この例では、一部の単語を表しているが、実際には、各文書は多数の単語を有する。単語「コンビニ」のtfidf値は「38.1」、単語「マイルドセブン」のtfidf値は「37.8」、単語「煙草」のtfidf値は「33.6」である。ID「1」のクラスタC1内の文書doc1、doc2、ID「2」のクラスタC2内の文書doc303はいずれも、単語「コンビニ」のtfidf値を有する。これは、単語「コンビニ」が、文書doc1、doc2、doc303のいずれにも含まれることを示す。また、ID「2」のクラスタの単語「コンビニ」のtfidf値は、ID「1」のクラスタC1の単語「コンビニ」のtfidf値より小さい。これは、単語「コンビニ」が、ID「2」のクラスタC2内の文書doc303よりも、ID「1」のクラスタC1内の文書doc1、doc2に、より偏って出現することを示す。
図12は、キーワード生成処理の具体例を説明する第1の図である。図12の表H1は、図11の表H1と同一である。また、この例において、ID「1」のクラスタC1は選択クラスタ、ID「2」のクラスタC2は排除クラスタに該当する。
キーワードリスト生成部32は、ID「1」の選択クラスタC1、及び、ID「2」の排除クラスタC2内の文書から、例えば、キーワード「コンビニ」「おにぎり」「四国」「マイルドセブン」「煙草」等を抽出する(図9のS31)。そして、キーワードリスト生成部32は、抽出した各キーワードのスコアを0に初期化したキーワードリスト22を生成する(S32)。具体例において、選択クラスタ(ID「1」)が存在することから(S33のYES)、キーワードリスト生成部32は、キーワード「コンビニ」「おにぎり」「四国」「マイルドセブン」「煙草」にしたがって、ID「1」の選択クラスタC1内の文書を検索する(S34)。
具体例において、ID「1」の選択クラスタC1内の文書doc1は、キーワード「コンビニ」「おにぎり」を含む(S35のYES)。したがって、キーワードリスト生成部32は、キーワード「コンビニ」のtfidf値「42.7」(Y11)、キーワード「おにぎり」のtfidf値「40.3」(Y12)をそれぞれスコアから減算する(S36)。したがって、図12のキーワードリスト22−1におけるキーワード「コンビニ」のスコアは値「−42.7」(Y13)、キーワード「おにぎり」のスコアは値「−40.3」(Y14)となる。
図13は、キーワード生成処理の具体例を説明する第2の図である。図13の表H1は、図11の表H1と同一である。具体例において、ID「1」の選択クラスタC1内の文書doc2は、キーワード「四国」「コンビニ」を含む(S35のYES)。したがって、キーワードリスト生成部32は、キーワード「四国」のtfidf値「58.4」(Y21)、キーワード「コンビニ」のtfidf値「42.7」(Y22)をそれぞれスコアから減算する(S36)。したがって、図13のキーワードリスト22−2におけるキーワード「コンビニ」のスコアは値「−85.4(=−42.7−42.7)」(Y23)、キーワード「四国」のスコアは値「−58.4」(Y24)となる。
図14は、キーワード生成処理の具体例を説明する第3の図である。図14の表H1は、図11の表H1と同一である。次に、キーワードリスト生成部32は、抽出したキーワード「コンビニ」「おにぎり」「四国」「マイルドセブン」「煙草」にしたがって、ID「2」の排除クラスタC2内の各文書を検索する(S38)。具体例において、ID「2」の排除クラスタC2内の文書doc303は、キーワード「コンビニ」「マイルドセブン」「煙草」を含む(S35のYES)。したがって、キーワードリスト生成部32は、キーワード「コンビニ」のtfidf値「38.1」(Y31)をスコアに加算する(S36)。したがって、図14のキーワードリスト22−3におけるキーワード「コンビニ」のスコアは値「(−47.3=−85.4+38.1)」(Y32)となる。
図15は、キーワード生成処理の具体例を説明する第4の図である。図15の表H1は、図11の表H1と同一である。次に、キーワードリスト生成部32は、キーワード「マイルドセブン」のtfidf値「37.8」(Y41)をスコアに加算するとともに、キーワード「煙草」のtfidf値「33.6」(Y42)をスコアに加算する(S36)。したがって、図13のキーワードリスト22−4におけるキーワード「マイルドセブン」のスコアは値「37.8」(Y43)、キーワード「煙草」のスコアは値「33.6」(Y44)となる。
図16は、具体例において生成されるキーワードリスト22−5を示す図である。図16のキーワードリスト22−5は、スコアの降順にキーワードを有する。図16のキーワードリスト22−5において、最もスコアの高いキーワードは「マイルドセブン」である。これは、キーワード「マイルドセブン」が、クエリ23の排除条件として有効性が高いことを示す。次に、排除条件として有効性が高いキーワードは、「煙草」である。
このように、キーワードリスト生成部32は、ユーザから指定された排除クラスタ、選択クラスタに基づいて、排除クラスタ内への出現分布率が高く、かつ、選択クラスタ内での出現分布率が低いときにより大きい値を有するスコアの降順にキーワードを有するキーワードリスト22を生成することができる。なお、図11〜図16の具体例では、排除クラスタに加えて選択クラスタが指定される場合を例示しているが、排除クラスタのみが指定される場合、キーワードリスト生成部32は、排除クラスタへの出現分布率が高いときにより大きい値を有するスコアの降順にキーワードを有するキーワードリスト22を生成する。
図17は、本実施の形態例におけるキーワードの選択処理を説明する図である。図16のようなキーワードリスト22を生成すると、キーワード選択部33は、キーワードリスト22内のキーワード数の比例した値を示すスライドバー等のオブジェクトを、クライアント装置80に表示させる(図6のS20)。そして、キーワード選択部33は、ユーザのスライドバーに対する操作にしたがって、キーワードリスト22の上位数分のキーワード22aを排除条件のクエリ23候補として選択する(S22)。キーワードリスト22は、スコアの降順にキーワードを有する。したがって、キーワードリスト22の上位から順に排除条件とするキーワードが選択されることによって、排除条件とするキーワードを効率的に選択することが可能になる。
図18は、スライドバーSBを表示するクライアント装置80の表示ユニットが表示する画面の一例を示す図である。図18は、クラスタを識別する情報とクラスタの指定を示すボタンメニューR1〜R4とに加えて、スライドバーSBを有する。なお、キーワード選択部33は、例えば、スライドバーSBの代わりに、キーワードリスト22内のキーワード数に比例する複数の項目(例えば、高、中、低等)を表示するドロップダウンリストや、ボタン等を表示して、ユーザに選択させてもよい。
また、図18の例において、例えば、スライドバーSBの左端の値に対応するキーワードの数は0個である。一方、スライドバーSBの右端の値に対応するキーワードの数は、例えば、排除クラスタ内の文書がすべて検索結果から排除される上位数分のキーワード数に対応する。この場合、スライドバーSBの値が右端に設定される場合のキーワードの数は、検索ケースによって異なる。ただし、スライドバーSBの右端の値に対応するキーワードの数は、所定の値に予め設定されていてもよいし、スコアが所定値以上のキーワードの数であってもよい。
ユーザは、例えば、図18に示すスライドバーSBのノブ(つまみ)ppの位置を変化させることによって、スライドバーSBの示す値を変更させる。図18の例において、スライドバーSBのノブppを右方向に変更させた場合、スライドバーSBの値に応じて選択されるキーワード数が増加する。
図19は、排除される文書の割合を表示するクライアント装置80の表示ユニットが表示する画面の一例を示す図である。図19は、スライドバーSBに加えて、クラスタ毎に、スライドバーSBによって示される排除条件のキーワードが適用された場合に排除される文書の割合を示す棒グラフEB1〜EB4を表示する。図19の例において、棒グラフEB1〜EB4に加えて、クラスタが排除クラスタであるか、選択クラスタであるかが識別可能に表示されることにより、ユーザは、排除クラスタの文書がどの程度排除され、選択クラスタの文書がどの程度、排除されずに残るかを確認することができる。
したがって、ユーザは、スライドバーの値に応じて、排除すべきクラスタから排除される文書の割合と、選択したいクラスタから排除される文書の割合とのバランスを確認できる。ユーザは、排除クラスタ内で排除される文書の割合と、排除クラスタ以外のクラスタ内で排除される文書の割合とのバランスを確認しながら、最適なバランスを実現するスライドバーの値を指定することができる。したがって、ユーザは、スライドバーの値に対応する、所望の文書に近い文書集合を抽出可能な排除条件のキーワードを取得することができる。
なお、ユーザは、その他に指定されるクラスタの文書がどの程度、排除されるかを検知することによって、その他に指定されるクラスタとして指定されるクラスタが有する特徴を識別することが可能になる。クラスタの文書が有する特徴を識別することが可能になることによって、ユーザは、その他に指定されるクラスタを、例えば、排除クラスタや選択クラスタに指定し直すことが可能になる。これにより、ユーザは、クラスタの指定と、スライドバー等のオブジェクト操作によるキーワード数の調整とを繰り返すことによって、所望の文書により近い文書の集合を抽出することができる。
以上のように、本実施の形態例におけるクエリ生成方法は、処理ユニットが、入力された検索語に基づいて複数の文書を検索し、検索された複数の文書を類似度にしたがって複数の文書集合に分類し、複数の文書集合を識別する情報を表示ユニットに表示する第1の工程を有する。また、本実施の形態例におけるクエリ生成方法は、表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、抽出した文字列毎の、検索された複数の文書における排除文書集合内での出現分布率を示すスコアを計算し、スコアの降順にソートされた文字列の文字列リストを生成する第2の工程を有する。また、本実施の形態例におけるクエリ生成方法は、文字列リスト内の文字列数に比例する入力に応じて、文字列リストの上位数分の文字列を排除条件のクエリ23の候補として選択し、選択した文字列を含む文書の割合を文書集合毎に計算し表示ユニットに表示する第3の工程を有する。
したがって、ユーザは、排除クラスタを指定するだけで、検索サーバ10に、クエリ23の排除条件のキーワード候補(キーワードリスト22)を生成させることができる。また、ユーザは、スライドバーの値に応じて、排除クラスタ内で排除される文書の割合と、排除クラスタ以外のクラスタ内で排除される文書の割合とのバランスを確認しながら、スライドバーの値を指定することができる。つまり、ユーザは、排除すべきクラスタから排除される文書の割合と、選択したいクラスタから排除される文書の割合とのバランスを確認できることにより、最適なバランスを選択することができる。また、ユーザは、キーワード自体を意識することなく、最適なクエリ23を取得することができる。
したがって、ユーザは、所望する完全な文書の集合の内容を予め検知していなくても、排除クラスタの指定とスライドバーによる指定とを行うだけで、ユーザが所望する文書集合を抽出可能にするクエリ23を生成させることが可能になる。つまり、本実施の形態例における検索サーバ10は、試行錯誤を重ねることなく、簡易な操作にしたがって、ユーザの意図を反映させた排除条件のキーワードの絞込みを可能にする。また、ユーザは、所望の文書集合に近い文書集合を確実に抽出可能になる。
また、本実施の形態例におけるクエリ生成方法によると、第2の工程は、抽出した文字列毎に、排除文書集合内の当該文字列の頻度に応じて、検索された複数の文書における排除文書集合内での出現分布値を加算してスコアを算出する。これにより、全てのクラスタにおける排除クラスタ内での出現分布率が高いときにより大きい値を有するスコアを算出可能になる。
また、本実施の形態例におけるクエリ生成方法によると、第2の工程は、抽出した文字列毎に、さらに、検索された複数の文書における排除文書集合以外の文書集合内での出現分布値をスコアから減算して、スコアを算出する。これにより、全てのクラスタにおける排除クラスタ内での出現分布率が高く、かつ、選択クラスタ内での出現分布率が低いときにより大きい値を有するスコアを算出可能になる。
また、本実施の形態例におけるクエリ生成方法によると、第3の工程は、文字列リスト内の文字列数に比例する値を示すオブジェクトを表示ユニットに表示し、オブジェクトに対するユーザの入力に比例する、文字列リストの上位数分の文字列を選択する。これにより、ユーザは、オブジェクトを操作することによって、クエリの排除条件として選択するキーワード自体を意識することなく、キーワードの数を指定することができる。
また、本実施の形態例におけるクエリ生成方法によると、第2の工程は、文書集合の特徴を示す特徴情報を表示ユニットに更に表示する。また、特徴情報は、文書集合の文書に含まれる検索語の使用文字列、文書集合の文書に含まれる頻出文字列、文書集合の文書に含まれる文字列であって検索された複数の文書における書集合内での出現分布率が高い文字列、のうち少なくともいずれかである。ユーザは、クラスタの特徴情報を参照することにより、クラスタが有する話題を識別可能になり、複数のクラスタから検索結果から排除すべきクラスタ、及び、検索結果に残したいクラスタを指定することができる。
また、本実施の形態例におけるクエリ生成方法によると、第2の工程は、排除文書集合の指定を受け付けるオブジェクトを更に表示ユニットに表示する。これにより、ユーザは、オブジェクトを操作することによって、複数のクラスタのうち、検索結果から排除すべきクラスタを簡易に指定することができる。
[他の実施の形態例]
なお、本実施の形態例における検索サーバ10は、図18、図19に示すスライドバー等のオブジェクトに加えて、ユーザのオブジェクト操作による入力に応じて選択されるキーワードを表示してもよい。例えば、検索サーバ10のキーワード選択部33は、クライアント装置80の表示ユニットに、スライドバーの値に応じて選択される排除条件のキーワードの一覧を更に表示する。
これにより、ユーザは、スライドバー等のオブジェクトの値の変化に応じて選択されるキーワードと、当該キーワードを含むクラスタ毎の文書量とを同時に把握しながら、オブジェクトの値を調整することができる。したがって、クエリの排除条件となるキーワード自体を把握しながらオブジェクトを操作して、キーワード数を選択したいユーザにとって利便性が高い。
なお、上記の例では、検索サーバ10が、複数のクラスタを生成し、排除クラスタ、選択クラスタのユーザによる指定に基づいて、キーワードリスト22を生成し、ユーザのスライドバー等のオブジェクトの操作に応じて選択されるキーワードを含む文書の量をクラスタ毎に表示する。ただし、例えば、検索サーバ10が検索対象となる文書集合20を格納し、クライアント装置80が、文書集合20の検索結果に基づいて、クラスタの生成、キーワードリスト22の生成、及び、ユーザのオブジェクトの操作に応じて選択されるキーワードを含む文書の量の表示を行ってもよい。
以上の実施の形態をまとめると、次の付記のとおりである。
(付記1)
処理ユニットが、
入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示する第1の工程と、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成する第2の工程と、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する第3の工程と、
を実行することを特徴とするクエリ生成方法。
(付記2)
付記1において、
前記第2の工程は、前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成方法。
(付記3)
付記2において、
前記第2の工程は、前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成方法。
(付記4)
付記1乃至3のいずれかにおいて、
前記第3の工程は、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成方法。
(付記5)
付記4において、
前記第3の工程は、前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成方法。
(付記6)
付記4または5において、
前記オブジェクトは、スライドバーであるクエリ生成方法。
(付記7)
付記1乃至6のいずれかにおいて、
前記第2の工程は、前記文書集合の特徴を示す特徴情報を前記表示ユニットに更に表示するクエリ生成方法。
(付記8)
付記7において、
前記特徴情報は、前記文書集合の文書に含まれる前記検索語の使用文字列、前記文書集合の文書に含まれる頻出文字列、前記文書集合の文書に含まれる文字列であって前記検索された複数の文書における前記書集合内での出現分布率が高い文字列、のうち少なくともいずれかであるクエリ生成方法。
(付記9)
付記1乃至8のいずれかにおいて、
前記第2の工程は、前記排除文書集合の指定を受け付けるオブジェクトを更に前記表示ユニットに表示するクエリ生成方法。
(付記10)
入力された検索語に基づいて複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、
前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示する、
処理をコンピュータに実行させるクエリ生成プログラム。
(付記11)
付記10において、
前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成プログラム。
(付記12)
付記11において、
前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成プログラム。
(付記13)
付記10乃至12のいずれかにおいて、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成プログラム。
(付記14)
付記13において、
前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成プログラム。
(付記15)
付記13または14において、
前記オブジェクトは、スライドバーであるクエリ生成プログラム。
(付記16)
処理ユニットと、
複数の文書を記憶する記憶装置と、
表示装置と、を有し、
入力された検索語に基づいて前記複数の文書を検索し、前記検索された複数の文書を類似度にしたがって複数の文書集合に分類し、前記複数の文書集合を識別する情報を表示ユニットに表示し、前記表示された複数の文書集合のうち排除すべき文書集合として指定された、排除文書集合内の文字列を抽出し、前記抽出した文字列毎の、前記検索された複数の文書における前記排除文書集合内での出現分布率を示すスコアを計算し、前記スコアの降順にソートされた前記文字列の文字列リストを生成し、前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リストの上位数分の前記文字列を排除条件のクエリの候補として選択し、前記選択した文字列を含む文書の割合を文書集合毎に計算し前記表示ユニットに表示するクエリ生成装置。
(付記17)
付記16において、
前記抽出した文字列毎に、前記排除文書集合内の当該文字列の頻度に応じて、前記検索された複数の文書における前記排除文書集合内での前記出現分布値を加算して前記スコアを算出するクエリ生成方法。
(付記18)
付記17において、
前記抽出した文字列毎に、さらに、前記検索された複数の文書における前記排除文書集合以外の文書集合内での前記出現分布値を前記スコアから減算して、前記スコアを算出するクエリ生成方法。
(付記19)
付記16乃至18のいずれかにおいて、
前記文字列リスト内の文字列数に比例する入力に応じて、前記文字列リスト内の文字列数に比例する値を示すオブジェクトを前記表示ユニットに表示し、前記オブジェクトに対する前記ユーザの入力に比例する、前記文字列リストの上位数分の前記文字列を選択するクエリ生成方法。
(付記20)
付記19において、
前記オブジェクトに対する入力に応じて選択される前記文字列を前記表示ユニットに更に表示するクエリ生成方法。