JP6175900B2 - 翻訳装置、方法、及びプログラム - Google Patents
翻訳装置、方法、及びプログラム Download PDFInfo
- Publication number
- JP6175900B2 JP6175900B2 JP2013109037A JP2013109037A JP6175900B2 JP 6175900 B2 JP6175900 B2 JP 6175900B2 JP 2013109037 A JP2013109037 A JP 2013109037A JP 2013109037 A JP2013109037 A JP 2013109037A JP 6175900 B2 JP6175900 B2 JP 6175900B2
- Authority
- JP
- Japan
- Prior art keywords
- translation
- candidate
- sentence
- original sentence
- translated
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/51—Translation evaluation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/58—Use of machine translation, e.g. for multi-lingual retrieval, for server-side translation for client devices or for real-time translation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Description
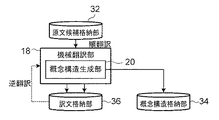
図1に、第1実施形態に係る翻訳装置10を示す。翻訳装置10は、図1に示すように、原文入力部12、言語解析部14、原文候補生成部16、機械翻訳部18、概念構造生成部20、選択部22、及び翻訳結果出力部24を備えている。
原文候補1:機械翻訳により翻訳作業を効率化
訳文候補1:It is efficiency improvement according to the machine translation as for the translation work.
逆翻訳文1:翻訳業務のような機械翻訳によると、それは効率化です。
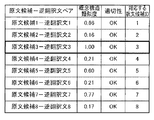
上記の例では、原文候補1(原文のまま)の文法には不適切な部分があるため、順翻訳時に正確な日本語の言語解析が行えない。このような不十分な日本語の言語解析結果に基づく順翻訳の翻訳結果である訳文候補1は、翻訳品質が良いとは言えない。訳文候補1を逆翻訳した逆翻訳文1と原文候補1との意味がかけ離れていることからも、訳文候補1の品質が低いことが分かる。
原文候補7:機械翻訳により翻訳作業[の]効率化
訳文候補7:The efficiency improvement of the translation work according to the machine translation.
逆翻訳文7:機械翻訳に従った翻訳業務の効率化。
上記の例の場合、訳文候補7を逆翻訳した逆翻訳文7と原文候補7との意味が近いことから、訳文候補7の翻訳品質が良いことが分かる。すなわち、原文候補7は原文に対して適切な前編集規則が適用されて生成された原文候補であると言える。
原文候補2:機械翻訳により翻訳作業を効率化[する]
訳文候補2:The translation work is made efficiency by the machine translation.
逆翻訳文2:機械翻訳によって翻訳業務は人工の効率です。
上記の例の場合、訳文候補2を逆翻訳した逆翻訳文2と原文候補2との意味がかけ離れていることから、訳文候補2の翻訳品質が悪いことが分かる。すなわち、原文候補2は原文に対して不適切な前編集が適用されて生成された原文候補であると言える。
原文候補:これは昨日私が作った計算機だ。
訳文候補:This is a computer that I made yesterday.
逆翻訳文:これは、私が昨日作ったコンピュータです。
・中心概念に対する点数:α
・中心概念以外の概念ノードに対する点数:β
・ノード関係に対する点数:γ
・ノード属性に対する点数:δ
・両概念構造に含まれる中心概念以外の概念ノードの数:X
・両概念構造に含まれるノード関係の数:Y
・両概念構造に含まれるノード属性の数:Z
・概念構造間の中心概念の相違:R
※例えば、中心概念が一致する場合はR=0、相違する場合はR=1
・概念構造間で相違する概念ノード数:X’
※相違する概念ノード:一方の概念構造にしか存在しない概念ノード。概念ノードの位置及び概念ノード間の関係を考慮しない。
・概念構造間で相違するノード関係の数:Y’
※相違するノード関係:ノード関係の種類またはノード関係が連結する概念ノードが異なるノード関係
・概念構造間で相違するノード属性の数:Z’
※相違するノード属性:ノード属性の種類またはノード属性が付属する概念ノードが異なるノード属性
概念構造の構造点数=α*2+β*X+γ*Y+δ*Z
概念構造間の相違点数=α*R+β*X’+γ*Y’+δ*Z’
概念構造類似度
=(概念構造の構造点数−概念構造間の相違点数)/(概念構造の構造点数)
・原文候補と逆翻訳文との形態素単位編集距離:D2
・原文候補の表記長さ:L1
・逆翻訳結果の表記長さ:L2
・原文候補の形態素列長さ:M1
・逆翻訳結果の形態素列長さ:M2
表記類似度=(D1/(L1+L2))+(D2/(M1+M2))
(「機械翻訳」、「翻訳」、及び「作業」)
・逆翻訳文1の構造概念に含まれる中心概念以外の概念ノードの数:3
(「機械翻訳」、「翻訳業務」、及び「それ」)
・両構造概念に含まれる中心概念以外の概念ノードの数:X=6
(「機械翻訳」と「効率化」間の[影響対象]、「効率化」と「作業」間の[主題]、及び「翻訳」と「作業」間の[修飾])
・逆翻訳文1の概念構造に含まれるノード関係の数:3
(「機械翻訳」と「効率化」間の[影響対象]、「効率化」と「それ」間の[述語対象]、及び「機械翻訳」と「翻訳業務」間の[類似])
・両概念構造に含まれるノード関係の数:Y=6
(「効率化」に付属する<属性:述語>、「作業」に付属する<助詞:を>、及び「翻訳」に付属する<連語>)
・逆翻訳文1の概念構造に含まれるノード属性の数:4
(「効率化」に付属する<属性:述語>、「効率化」に付属する<語尾:です>、「機械翻訳」に付属する<語尾:読点>、及び「それ」に付属する<助詞:は>)
・両概念構造に含まれるノード属性の数:Z=7
=50*2+10*6+5*6+2*7=204
・概念構造間で相違する概念ノード数:X’=4
(原文候補1の概念構造内の「翻訳」及び「作業」、並びに逆翻訳文1の概念構造内の「翻訳業務」及び「それ」)
・概念構造間で相違するノード関係の数:Y’=4
(原文候補1の概念構造内の「効率化」と「作業」間の[主題]及び「翻訳」と「作業」間の[修飾]、並びに逆翻訳文1の概念構造内の「効率化」と「それ」間の[述語対象]及び「機械翻訳」と「翻訳業務」間の[類似])
・概念構造間で相違するノード属性の数:Z’=5
(原文候補1の概念構造内の「作業」に付属する<助詞:を>及び「翻訳」に付属する<連語>、並びに逆翻訳文1の概念構造内の「効率化」に付属する<語尾:です>、「機械翻訳」に付属する<語尾:読点>、及び「それ」に接続する<助詞:は>)
=50*0+10*4+5*4+2*5=70
概念構造類似度
=(概念構造の構造点数−概念構造間の相違点数)/(概念構造の構造点数)
=(204−70)/204=0.66
・逆翻訳文3の構造概念に含まれる中心概念以外の概念ノードの数:3
・両構造概念に含まれる中心概念以外の概念ノードの数:X=6
・原文候補3の概念構造に含まれるノード関係の数:3
・逆翻訳文3の概念構造に含まれるノード関係の数:3
・両概念構造に含まれるノード関係の数:Y=6
・原文候補3の概念構造に含まれるノード属性の数:2
・逆翻訳文3の概念構造に含まれるノード属性の数:2
・両概念構造に含まれるノード属性の数:Z=4
・概念構造の構造点数=α*2+β*X+γ*Y+δ*Z
=50*2+10*6+5*6+2*4=198
・概念構造間で相違する概念ノード数:X’=0
・概念構造間で相違するノード関係の数:Y’=0
・概念構造間で相違するノード属性の数:Z’=0
・概念構造間の相違点数=α*R+β*X’+γ*Y’+δ*Z’
=50*0+10*0+5*0+2*0=0
=(概念構造の構造点数−概念構造間の相違点数)/(概念構造の構造点数)
=(198−0)/198=1.00
・逆翻訳文5の構造概念に含まれる中心概念以外の概念ノードの数:3
・両構造概念に含まれる中心概念以外の概念ノードの数:X=6
・原文候補5の概念構造に含まれるノード関係の数:3
・逆翻訳文5の概念構造に含まれるノード関係の数:3
・両概念構造に含まれるノード関係の数:Y=6
・原文候補5の概念構造に含まれるノード属性の数:3
・逆翻訳文5の概念構造に含まれるノード属性の数:5
・両概念構造に含まれるノード属性の数:Z=8
・概念構造の構造点数=α*2+β*X+γ*Y+δ*Z
=50*2+10*6+5*6+2*8=206
・概念構造間で相違する概念ノード数:X’=4
・概念構造間で相違するノード関係の数:Y’=6
・概念構造間で相違するノード属性の数:Z’=6
・概念構造間の相違点数=α*R+β*X’+γ*Y’+δ*Z’
=50*0+10*4+5*6+2*6=82
=(概念構造の構造点数−概念構造間の相違点数)/(概念構造の構造点数)
=(206−82)/206=0.60
次に、第2実施形態について説明する。図17に示すように、第2実施形態に係る翻訳装置210は、第1実施形態に係る翻訳装置10に前編集規則判定部26を加えた構成であるため、以下、前編集規則判定部26について説明する。
第1言語により表現された原文に、予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成する原文候補生成部と、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳する翻訳部と、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成する概念構造生成部と、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が所定値以上の原文候補に対応する訳文候補を選択する選択部と、
を含む翻訳装置。
前記翻訳部は、前記概念構造生成部により生成された前記原文候補の概念構造を用いて、前記複数の原文候補の各々を前記訳文候補の各々に翻訳し、前記概念構造生成部により生成された前記逆翻訳文の概念構造を用いて、前記訳文候補の各々を前記逆翻訳文の各々に翻訳する付記1記載の翻訳装置。
前記概念構造は、複数の異なる種類の要素を含み、
前記選択部は、前記原文候補の概念構造及び前記逆翻訳文の概念構造の各々に含まれる種類毎の要素数、及び概念構造間で相違する種類毎の要素数を用いた概念構造の類似度を計算する付記1または付記2記載の翻訳装置。
前記選択部は、前記要素の種類に応じて重み付けした概念構造の類似度を計算する付記3記載の翻訳装置。
前記概念構造の類似度に基づいて、前記原文候補を生成する際に前記原文に適用された前記前編集規則または前記組み合わせ規則の適切性を判定する判定部を含む付記1〜付記4のいずれかに記載の翻訳装置。
前記選択部は、前記原文候補の表記と前記原文候補に対応する前記逆翻訳文の表記との類似度に基づいて、訳文候補の翻訳結果としての適切性を判定する付記1〜付記5のいずれかに記載の翻訳装置。
コンピュータに、
第1言語により表現された原文に、予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成し、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳し、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成し、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が最大の訳文候補をデフォルトの訳語として選択する
ことを含む処理を実行させる翻訳方法。
コンピュータに、
前記原文候補の概念構造を用いて、前記複数の原文候補の各々を前記訳文候補の各々に翻訳し、前記逆翻訳文の概念構造を用いて、前記訳文候補の各々を前記逆翻訳文の各々に翻訳することを含む処理を実行させる付記7記載の翻訳方法。
前記概念構造は、複数の異なる種類の要素を含み、コンピュータに、前記原文候補の概念構造及び前記逆翻訳文の概念構造の各々に含まれる種類毎の要素数、及び概念構造間で相違する種類毎の要素数を用いた概念構造の類似度を計算することを含む処理を実行させる付記7または付記8記載の翻訳方法。
コンピュータに、前記要素の種類に応じて重み付けした概念構造の類似度を計算することを含む処理を実行させる付記9記載の翻訳方法。
コンピュータに、
前記概念構造の類似度に基づいて、前記原文候補を生成する際に前記原文に適用された前記前編集規則または前記組み合わせ規則の適切性を判定することを含む処理を実行させる付記7〜付記10のいずれかに記載の翻訳方法。
コンピュータに、前記原文候補の表記と前記原文候補に対応する前記逆翻訳文の表記との類似度に基づいて、訳文候補の翻訳結果としての適切性を判定することを含む処理を実行させる付記7〜付記11のいずれかに記載の翻訳方法。
コンピュータに、
第1言語により表現された原文に、予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成し、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳し、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成し、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が最大の訳文候補をデフォルトの訳語として選択する
ことを含む処理を実行させるための翻訳プログラム。
前記原文候補の概念構造を用いて、前記複数の原文候補の各々を前記訳文候補の各々に翻訳し、前記逆翻訳文の概念構造を用いて、前記訳文候補の各々を前記逆翻訳文の各々に翻訳する付記13記載の翻訳プログラム。
前記概念構造は、複数の異なる種類の要素を含み、
前記原文候補の概念構造及び前記逆翻訳文の概念構造の各々に含まれる種類毎の要素数、及び概念構造間で相違する種類毎の要素数を用いた概念構造の類似度を計算する付記13または付記14記載の翻訳プログラム。
前記要素の種類に応じて重み付けした概念構造の類似度を計算する付記15記載の翻訳プログラム。
コンピュータに、前記概念構造の類似度に基づいて、前記原文候補を生成する際に前記原文に適用された前記前編集規則または前記組み合わせ規則の適切性を判定することを含む処理を実行させるための付記13〜付記16のいずれかに記載の翻訳プログラム。
前記原文候補の表記と前記原文候補に対応する前記逆翻訳文の表記との類似度に基づいて、訳文候補の翻訳結果としての適切性を判定する付記13〜付記17のいずれかに記載の翻訳プログラム。
12 原文入力部
14 言語解析部
16 原文候補生成部
18 機械翻訳部
20 概念構造生成部
22 選択部
24 翻訳結果出力部
26 前編集規則判定部
30 前編集規則DB
32 原文候補格納部
34 概念構造格納部
36 訳文格納部
40 コンピュータ
222 類似度計算部
224 適切性判定部
226 訳文候補選択部
Claims (8)
- 第1言語により表現された原文に、言語解析結果の特徴を用いて表された表現パターンに相当する箇所を他の表現パターンに変化するための予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成する原文候補生成部と、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳する翻訳部と、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成する概念構造生成部と、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が所定値以上の原文候補に対応する訳文候補を選択する選択部と、
を含む翻訳装置。 - 前記翻訳部は、前記概念構造生成部により生成された前記原文候補の概念構造を用いて、前記複数の原文候補の各々を前記訳文候補の各々に翻訳し、前記概念構造生成部により生成された前記逆翻訳文の概念構造を用いて、前記訳文候補の各々を前記逆翻訳文の各々に翻訳する請求項1記載の翻訳装置。
- 前記概念構造は、複数の異なる種類の要素を含み、
前記選択部は、前記原文候補の概念構造及び前記逆翻訳文の概念構造の各々に含まれる種類毎の要素数、及び概念構造間で相違する種類毎の要素数を用いた概念構造の類似度を計算する請求項1または請求項2記載の翻訳装置。 - 前記選択部は、前記要素の種類に応じて重み付けした概念構造の類似度を計算する請求項3記載の翻訳装置。
- 前記前編集規則及び前記組み合わせ規則は記憶部に記憶されており、
前記概念構造の類似度に基づいて、前記原文候補を生成する際に前記原文に適用された前記前編集規則または前記組み合わせ規則の適切性を判定し、判定結果に基づいて前記記憶部に記憶された前記前編集規則または前記組み合わせ規則を更新する判定部を含む請求項1〜請求項4のいずれか1項記載の翻訳装置。 - 前記選択部は、前記原文候補の表記と前記原文候補に対応する前記逆翻訳文の表記との類似度に基づいて、訳文候補の翻訳結果としての適切性を判定する請求項1〜請求項5のいずれか1項記載の翻訳装置。
- コンピュータに、
第1言語により表現された原文に、言語解析結果の特徴を用いて表された表現パターンに相当する箇所を他の表現パターンに変化するための予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成し、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳し、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成し、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が最大の訳文候補をデフォルトの訳語として選択する
ことを含む処理を実行させる翻訳方法。 - コンピュータに、
第1言語により表現された原文に、言語解析結果の特徴を用いて表された表現パターンに相当する箇所を他の表現パターンに変化するための予め定めた複数の異なる前編集規則の各々または前記前編集規則を組み合わせた組み合わせ規則を適用して、複数の原文候補を生成し、
前記複数の原文候補の各々を前記第1言語とは異なる第2言語により表現された訳文候補の各々に翻訳すると共に、前記訳文候補の各々を前記第1言語により表現された逆翻訳文の各々に翻訳し、
前記原文候補の各々及び前記逆翻訳文の各々の意味的構造を表す概念構造を生成し、
前記原文候補の概念構造と前記原文候補に対応する前記逆翻訳文の概念構造との類似度が最大の訳文候補をデフォルトの訳語として選択する
ことを含む処理を実行させるための翻訳プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013109037A JP6175900B2 (ja) | 2013-05-23 | 2013-05-23 | 翻訳装置、方法、及びプログラム |
| US14/254,226 US20140350913A1 (en) | 2013-05-23 | 2014-04-16 | Translation device and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013109037A JP6175900B2 (ja) | 2013-05-23 | 2013-05-23 | 翻訳装置、方法、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014229122A JP2014229122A (ja) | 2014-12-08 |
| JP6175900B2 true JP6175900B2 (ja) | 2017-08-09 |
Family
ID=51935939
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013109037A Expired - Fee Related JP6175900B2 (ja) | 2013-05-23 | 2013-05-23 | 翻訳装置、方法、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20140350913A1 (ja) |
| JP (1) | JP6175900B2 (ja) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9424597B2 (en) * | 2013-11-13 | 2016-08-23 | Ebay Inc. | Text translation using contextual information related to text objects in translated language |
| CN105335343A (zh) * | 2014-07-25 | 2016-02-17 | 北京三星通信技术研究有限公司 | 文本编辑方法和装置 |
| JP2016071439A (ja) * | 2014-09-26 | 2016-05-09 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 翻訳方法及び翻訳システム |
| US10409919B2 (en) * | 2015-09-28 | 2019-09-10 | Konica Minolta Laboratory U.S.A., Inc. | Language translation for display device |
| CN107870900B (zh) * | 2016-09-27 | 2023-04-18 | 松下知识产权经营株式会社 | 提供翻译文的方法、装置以及记录介质 |
| JP6870421B2 (ja) * | 2017-03-28 | 2021-05-12 | 富士通株式会社 | 判定プログラム、判定装置および判定方法 |
| US10679014B2 (en) * | 2017-06-08 | 2020-06-09 | Panasonic Intellectual Property Management Co., Ltd. | Method for providing translation information, non-transitory computer-readable recording medium, and translation information providing apparatus |
| JP7030434B2 (ja) * | 2017-07-14 | 2022-03-07 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 翻訳方法、翻訳装置及び翻訳プログラム |
| CN107632982B (zh) * | 2017-09-12 | 2021-11-16 | 郑州科技学院 | 语音控制外语翻译设备用的方法和装置 |
| CN107783968B (zh) * | 2017-11-23 | 2021-04-02 | 浪潮金融信息技术有限公司 | 一种语言转换方法、装置、可读介质及存储控制器 |
| WO2019107625A1 (ko) * | 2017-11-30 | 2019-06-06 | 주식회사 시스트란인터내셔널 | 기계 번역 방법 및 이를 위한 장치 |
| CN108009152A (zh) * | 2017-12-04 | 2018-05-08 | 陕西识代运筹信息科技股份有限公司 | 一种基于Spark-Streaming的文本相似性分析的数据处理方法和装置 |
| JP2019121241A (ja) * | 2018-01-09 | 2019-07-22 | パナソニックIpマネジメント株式会社 | 翻訳装置、翻訳方法、及びプログラム |
| JP7170984B2 (ja) * | 2018-03-02 | 2022-11-15 | 国立研究開発法人情報通信研究機構 | 疑似対訳データ生成装置、機械翻訳処理装置、および疑似対訳データ生成方法 |
| US10929617B2 (en) * | 2018-07-20 | 2021-02-23 | International Business Machines Corporation | Text analysis in unsupported languages using backtranslation |
| JP7322428B2 (ja) * | 2019-02-28 | 2023-08-08 | 富士フイルムビジネスイノベーション株式会社 | 学習装置及び学習プログラム並びに文生成装置及び文生成プログラム |
| EP3995975A1 (en) * | 2020-11-06 | 2022-05-11 | Tata Consultancy Services Limited | Method and system for identifying semantic similarity |
| CN112818712B (zh) * | 2021-02-23 | 2024-06-11 | 语联网(武汉)信息技术有限公司 | 基于翻译记忆库的机器翻译方法及装置 |
| CN114757214B (zh) * | 2022-05-12 | 2023-01-31 | 北京百度网讯科技有限公司 | 用于优化翻译模型的样本语料的选取方法、相关装置 |
| US20230385561A1 (en) * | 2022-05-26 | 2023-11-30 | Jitterbit, Inc. | Data driven translation and translation validation of digital content |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008511883A (ja) * | 2004-08-31 | 2008-04-17 | テックマインド ソシエタ ア レスポンサビリタ リミタータ | 第1言語から第2言語への自動翻訳のための方法および/またはそのための集積回路処理装置における処理機能およびその方法を実行するための装置 |
| JP4886244B2 (ja) * | 2005-08-19 | 2012-02-29 | 株式会社東芝 | 機械翻訳装置および機械翻訳プログラム |
-
2013
- 2013-05-23 JP JP2013109037A patent/JP6175900B2/ja not_active Expired - Fee Related
-
2014
- 2014-04-16 US US14/254,226 patent/US20140350913A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| US20140350913A1 (en) | 2014-11-27 |
| JP2014229122A (ja) | 2014-12-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6175900B2 (ja) | 翻訳装置、方法、及びプログラム | |
| JP4532863B2 (ja) | 2言語コーパスを整列させるための方法および装置 | |
| JP6955963B2 (ja) | 検索装置、類似度算出方法、およびプログラム | |
| RU2610241C2 (ru) | Способ и система синтеза текста на основе извлеченной информации в виде rdf-графа с использованием шаблонов | |
| JP5071373B2 (ja) | 言語処理装置、言語処理方法および言語処理用プログラム | |
| JP6471074B2 (ja) | 機械翻訳装置、方法及びプログラム | |
| JP2004199427A (ja) | 対訳依存構造対応付け装置、方法及びプログラム、並びに、対訳依存構造対応付けプログラムを記録した記録媒体 | |
| JP2005507525A (ja) | 機械翻訳 | |
| JP2005507524A (ja) | 機械翻訳 | |
| JP2017208097A (ja) | エンティティの多音字の曖昧さ回避方法及びエンティティの多音字の曖昧さ回避装置 | |
| CN108804526A (zh) | 兴趣确定系统、兴趣确定方法及存储介质 | |
| JP2006268375A (ja) | 翻訳メモリシステム | |
| JP2017058804A (ja) | 検出装置、方法およびプログラム | |
| JP2018206262A (ja) | 単語連接識別モデル学習装置、単語連接検出装置、方法、及びプログラム | |
| JP5441760B2 (ja) | 文書間距離算出器および文章検索器 | |
| JP5623380B2 (ja) | 誤り文修正装置、誤り文修正方法およびプログラム | |
| JP7511381B2 (ja) | 文生成装置、文生成方法および文生成プログラム | |
| JP2013054607A (ja) | 並べ替え規則学習装置、方法、及びプログラム、並びに翻訳装置、方法、及びプログラム | |
| JP6558856B2 (ja) | 形態素解析装置、モデル学習装置、及びプログラム | |
| JP4476609B2 (ja) | 中国語解析装置、中国語解析方法および中国語解析プログラム | |
| CN108694163B (zh) | 计算句子中的词的概率的方法、装置和神经网络 | |
| JPWO2009113289A1 (ja) | 新規事例生成装置、新規事例生成方法及び新規事例生成用プログラム | |
| JP4869281B2 (ja) | 機械翻訳装置、プログラム及び方法 | |
| JP2005092682A (ja) | 翻字装置、及び翻字プログラム | |
| JP2014164575A (ja) | 文書処理装置およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160226 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161108 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161111 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170110 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170613 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170626 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6175900 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |