JP4869281B2 - 機械翻訳装置、プログラム及び方法 - Google Patents
機械翻訳装置、プログラム及び方法 Download PDFInfo
- Publication number
- JP4869281B2 JP4869281B2 JP2008102395A JP2008102395A JP4869281B2 JP 4869281 B2 JP4869281 B2 JP 4869281B2 JP 2008102395 A JP2008102395 A JP 2008102395A JP 2008102395 A JP2008102395 A JP 2008102395A JP 4869281 B2 JP4869281 B2 JP 4869281B2
- Authority
- JP
- Japan
- Prior art keywords
- translation
- language
- sentence
- original
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






Landscapes
- Machine Translation (AREA)
Description
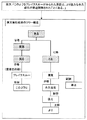
(a)語彙部
少なくとも第1言語の語彙の各々についての活用情報、意味情報、分野情報、訳語情報、訳語毎の分野情報。
(b)形態素解析規則
第1言語の入力文を形態素解析するための知識。
(c) 構文・意味解析規則
第1言語の入力文を形態素解析した後、構文的・意味的な解析を行うための知識。
(d)変換規則
構文・意味解析された結果の第1言語の意味構造を第2言語の意味構造へ変換するための知識。
(e)構文生成規則
第2言語の意味構造から第2言語の単語列を生成するための知識。
(f)形態素生成規則
第2言語の語の活用を反映し、最終的な訳文を出力するための知識。
S1:磁気ベアリングは航空宇宙産業向けの用途に開発されてきたが、ごく最近、エネルギー貯蔵システムの心臓部としての実現性が実証された。
S2:このようなブレイクスルーが見られた原因は、より強力な永久磁石が最近開発されたことにある。
S3:そのような磁石が10ポンドあれば、2トンのローターを支持できる。
T1-a. Although the magnetic bearing had been developed for aerospace and aircraft works, the implementability as a core of an energy storage system was proved very much recently.
T2-a. There is a cause by which such a breakthrough was seen in the more powerful permanent magnet having been developed recently.
T3-a. If there are 10 pounds of such magnets, a 2t rotor can be supported.
原文中の下線を引いた語は、論理展開上重要な語であり、かつ文頭に位置する語である。これらの語を辿ってみると、原文の論理展開を辿ることができる。一方、原文にて下線を引いた語の翻訳結果における文中の位置を見てみると、原文では各文の文頭にあった語が、訳文T2、T3では文中に埋もれてしまっている。その結果、訳文の英文は、1文単位で意味は通じるが、全体の論理の流れが英文として不明確になってしまっている。
S1:「磁気ベアリング」は「航空宇宙産業」向けの用途に「開発」されてきたが、ごく最近、「エネルギー貯蔵システム」の「心臓部」としての「実現性」が実証された。
S2:このような「ブレイクスルー」が見られた原因は、より強力な「永久磁石」が最近「開発」されたことにある。
S3:そのような「磁石」が10ポンドあれば、2トンの「ローター」を「支持」できる。
S2:このような[ブレイクスルー]が見られた原因は、より強力な永久磁石が最近開発されたことにある。
S3:そのような[磁石]が10ポンドあれば、2トンのローターを支持できる。
T2-b. [The breakthrough] is due to the recent development of stronger permanent magnets.
T3-b. Only ten pounds of [such magnets] could support two tons of rotor.
以上まとめると、本発明による機械翻訳装置においては、ユーザが原文において指定した語またはその語を含むフレーズ(ここでは「ブレイクスルー」)ができるだけ文頭に近い位置に存在するような訳文の生成方法を選択する。例えば、以下の表1に挙げたような翻訳結果候補1〜4があった場合、本発明による機械翻訳装置では、ユーザが原文において指定した語(ブレイクスルー)が最も文頭に近い位置に存在する訳文(翻訳結果候補2)が翻訳結果となるように訳文の生成方法を選択する。

[*1.prop=keisiki_v]
上記の*1と*2は単語を示す。”syusyoku_”は、”syusyoku_”の右側の文字列が「原因」を修飾していることを示し、”jyoshi”は、*1の単語と*2の単語が助詞(この例では「が」)でつながっていることを示している。[*1.prop=keisiki_v]の部分は、この規則が適用されるための条件で、:1の単語の属性が形式名詞(keisiki_V)であることを示している。形式動詞とは、「が見られる」「〜と聞く」「〜という」などのように、具体的な動作としての意味を失っている動詞のことである。例えば、keisiki_v:形式動詞(見る、聞く、言う・・・)である。
Claims (7)
- 翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置を備えた機械翻訳装置において、前記機械翻訳装置は、入力装置から入力された第1言語の原文に対してユーザから指定された第1言語の語句を受け付ける主要キーワード指定部と、入力された原文全体に対して、前記主要キーワード指定部で指定された第1言語の語句またはその語句を含むフレーズの訳語が、翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行う翻訳部と、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を出力装置に出力処理する出力処理部とを備える機械翻訳装置。
- 前記入力装置からの指令に基づき入力された前記原文からキーワードを推定するキーワード推定部を設け、前記出力処理部は前記原文とともに前記キーワード推定部で推定されたキーワードを前記出力装置に出力する請求項1記載の機械翻訳装置。
- 翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置を備えた機械翻訳装置において、前記機械翻訳装置は、入力装置から入力された第1言語の原文からキーワードを推定するキーワード推定部と、入力された原文全体に対して、前記キーワード推定部で推定されたキーワードのうち原文において最も文頭に近い位置に存在する第1言語の語が翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行う翻訳部と、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を前記出力装置に出力処理する出力処理部とを備える機械翻訳装置。
- 機械翻訳プログラム、翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータに用いられる機械翻訳プログラムにおいて、前記コンピュータに、入力装置から入力された第1言語の原文に対してユーザから指定された第1言語の語句を受け付ける手順と、入力された原文全体に対して、指定された第1言語の語句またはその語句を含むフレーズの訳語が翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行う手順と、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を出力装置に出力処理する手順とを実行させるための機械翻訳プログラム。
- 機械翻訳プログラム、翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータに用いられる機械翻訳プログラムにおいて、前記コンピュータに、入力装置から入力された第1言語の原文からキーワードを推定する手順と、入力された原文全体に対して、推定されたキーワードのうち原文において最も文頭に近い位置に存在する第1言語の語が翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行う手順と、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を前記出力装置に出力処理する手順とを実行させるための機械翻訳プログラム。
- 機械翻訳プログラム、翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備え、機械翻訳を行う機械翻訳方法において、入力装置から入力された第1言語の原文に対してユーザから指定された第1言語の語句を受け付けるステップと、入力された原文全体に対して、指定された第1言語の語句またはその語句を含むフレーズの訳語が、翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行うステップと、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を出力装置に出力処理するステップとを備える機械翻訳方法。
- 機械翻訳プログラム、翻訳に必要な知識情報・規則を蓄積した翻訳辞書部を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備え、機械翻訳を行う機械翻訳方法において、入力装置から入力された第1言語の原文からキーワードを推定するステップと、入力された原文全体に対して、キーワードのうち原文において最も文頭に近い位置に存在する第1言語の語が翻訳後の第2言語の訳文の文頭に最も近い位置に存在する訳文を生成する規則を選択して翻訳を行うステップと、翻訳対象の原文や前記翻訳部による翻訳後の第2言語の訳文を前記出力装置に出力処理するステップとを備える機械翻訳方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008102395A JP4869281B2 (ja) | 2008-04-10 | 2008-04-10 | 機械翻訳装置、プログラム及び方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008102395A JP4869281B2 (ja) | 2008-04-10 | 2008-04-10 | 機械翻訳装置、プログラム及び方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009252143A JP2009252143A (ja) | 2009-10-29 |
| JP4869281B2 true JP4869281B2 (ja) | 2012-02-08 |
Family
ID=41312752
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008102395A Expired - Fee Related JP4869281B2 (ja) | 2008-04-10 | 2008-04-10 | 機械翻訳装置、プログラム及び方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4869281B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7322428B2 (ja) * | 2019-02-28 | 2023-08-08 | 富士フイルムビジネスイノベーション株式会社 | 学習装置及び学習プログラム並びに文生成装置及び文生成プログラム |
| CN112487831B (zh) * | 2020-11-27 | 2024-10-15 | 江苏省舜禹信息技术有限公司 | 一种拆分式人工智能翻译方法 |
| CN114091483B (zh) * | 2021-10-27 | 2023-02-28 | 北京百度网讯科技有限公司 | 翻译处理方法、装置、电子设备及存储介质 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4870878B2 (ja) * | 2001-05-02 | 2012-02-08 | 株式会社リコー | コンテンツ内容の説明文生成方法およびコンテンツ内容の説明文生成装置 |
-
2008
- 2008-04-10 JP JP2008102395A patent/JP4869281B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009252143A (ja) | 2009-10-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20050171757A1 (en) | Machine translation | |
| JP2005507525A (ja) | 機械翻訳 | |
| WO2010046782A2 (en) | Hybrid machine translation | |
| Wong | Example-based machine translation | |
| JP4869281B2 (ja) | 機械翻訳装置、プログラム及び方法 | |
| JP2015060458A (ja) | 機械翻訳装置、方法、及びプログラム | |
| JP2017151553A (ja) | 機械翻訳装置、機械翻訳方法、及びプログラム | |
| JP2008077512A (ja) | 文書解析装置、および文書解析方法、並びにコンピュータ・プログラム | |
| JP4007413B2 (ja) | 自然言語処理システム及び自然言語処理方法、並びにコンピュータ・プログラム | |
| JP2005284723A (ja) | 自然言語処理システム及び自然言語処理方法、並びにコンピュータ・プログラム | |
| Rajendran | Parsing in tamil: Present state of art | |
| JP4033093B2 (ja) | 自然言語処理システム及び自然言語処理方法、並びにコンピュータ・プログラム | |
| WO2009144890A1 (ja) | 翻訳前換言規則生成システム | |
| JP5245291B2 (ja) | 文書解析装置、および文書解析方法、並びにコンピュータ・プログラム | |
| JP4812811B2 (ja) | 機械翻訳装置及び機械翻訳プログラム | |
| Rikters | K-Translate-Interactive Multi-system Machine Translation | |
| KR100413966B1 (ko) | 한국어 표준 문형 규칙에 의한 표준 문형 유도 장치 및 그방법 | |
| JP2006011842A (ja) | 翻訳装置および翻訳プログラム | |
| JP3389313B2 (ja) | 機械翻訳装置 | |
| JP2007317140A (ja) | 文一致度分析装置および方法、ならびに言語変換装置および方法 | |
| JP4092861B2 (ja) | 自然言語パターン作成装置及び方法 | |
| JP3233800B2 (ja) | 機械翻訳装置 | |
| JP4023384B2 (ja) | 自然言語翻訳方法及び装置及び自然言語翻訳プログラム | |
| JP3313810B2 (ja) | アスペクト処理装置 | |
| JP3353873B2 (ja) | 機械翻訳装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110201 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110317 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110412 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110519 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110906 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20111005 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20111025 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20111115 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4869281 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141125 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |