JP6171658B2 - 並列処理最適化プログラム、並列処理最適化方法および情報処理装置 - Google Patents
並列処理最適化プログラム、並列処理最適化方法および情報処理装置 Download PDFInfo
- Publication number
- JP6171658B2 JP6171658B2 JP2013150945A JP2013150945A JP6171658B2 JP 6171658 B2 JP6171658 B2 JP 6171658B2 JP 2013150945 A JP2013150945 A JP 2013150945A JP 2013150945 A JP2013150945 A JP 2013150945A JP 6171658 B2 JP6171658 B2 JP 6171658B2
- Authority
- JP
- Japan
- Prior art keywords
- cores
- parallel processing
- threads
- performance
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/501—Performance criteria
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Devices For Executing Special Programs (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Quality & Reliability (AREA)
Description
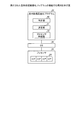
実施例1に係る情報処理装置10の構成について説明する。図1は、情報処理装置の概略的な構成の一例を示した図である。
次に、本実施例に係る情報処理装置10が並列処理最適化プログラム32を実行した際に並列処理に適したコア数を決定する並列処理最適化処理の流れについて説明する。図9は、実施例1に係る並列処理最適化処理の手順の一例を示すフローチャートである。この並列処理最適化処理は、例えば、並列処理プログラム31が並列処理を実行するタイミングで実行される。
上述してきたように、本実施例に係る情報処理装置10は、並列処理を実行可能なコア24の数の範囲内で、並列して実行する所定数の処理を、割り振る処理数を変えて同程度ずつコアに割り振る場合に、処理が実行されるコア数を特定する。そして、情報処理装置10は、特定したコア数のなかから、処理性能の最も高いコア数を並列処理を実行するコア数と決定する。これにより、情報処理装置10は、高効率で並列処理を実行可能なコア数を速やかに求めることができる。
スレッド数b=2:X=43、32、26、22、19、・・・1
スレッド数b=3:X=43、29、22、18、15、・・・1
スレッド数b=4:X=32、22、16、13、11、・・・1
次に、実施例2に係る情報処理装置10が並列処理最適化プログラム32を実行した際に並列処理に適したコア数を決定する並列処理最適化処理の流れについて説明する。図15は、実施例2に係る並列処理最適化処理の手順の一例を示すフローチャートである。実施例2に係る並列処理最適化処理の一部は、図9に示した実施例1に係る並列処理最適化処理と同一であるため、同一部分については同一の符号を付し、主に異なる処理について説明する。
上述してきたように、本実施例に係る情報処理装置10は、コア24の並列処理を実行可能なスレッド数および並列処理を実行可能なコア数の範囲内で、処理が実行されるスレッド数およびコア数を特定する。そして、情報処理装置10は、特定したスレッド数およびコア数のなかから、処理性能の最も高いスレッド数およびコア数を並列処理を実行するスレッド数およびコア数と決定する。これにより、情報処理装置10は、高効率で並列処理を実行可能なスレッド数およびコア数を速やかに求めることができる。
次に、実施例3に係る情報処理装置10が並列処理最適化プログラム32を実行した際に並列処理に適したコア数を決定する並列処理最適化処理の流れについて説明する。図17は、実施例3に係る並列処理最適化処理の手順の一例を示すフローチャートである。実施例3に係る並列処理最適化処理の一部は、図15に示した実施例2に係る並列処理最適化処理と同一であるため、同一部分については同一の符号を付し、主に異なる処理について説明する。
上述してきたように、本実施例に係る情報処理装置10は、特定したスレッド数およびコア数のなかから、所定の予測モデルを用いて、並列処理を実行するスレッド数およびコア数を決定する。これにより、情報処理装置10は、並列処理を実行するスレッド数およびコア数をより速やかに求めることができる。
20 プロセッサ
24 コア
25 スレッド
31 並列処理プログラム
32 並列処理最適化プログラム
50 特定部
51 決定部
52 プロセッサ制御部
Claims (7)
- コンピュータに、
並列処理を実行可能なコア数の範囲内で、並列して実行する所定数の処理を、割り振る最大処理数を変えて、それぞれ当該最大処理数以下の範囲で、かつ、処理が割り振られるコアの数が最も少なくなるようにコアに割り振る場合に、前記最大処理数数毎に、処理が割り振られるコア数を特定し、
特定したコア数のなかから、処理性能の最も高いコア数を並列処理を実行するコア数と決定する
処理を実行させることを特徴とする並列処理最適化プログラム。 - 前記コアは、並列処理を実行可能な複数のスレッドを有し、
前記特定する処理は、コアの並列処理を実行可能なスレッド数および並列処理を実行可能なコア数の範囲内で、各コアで動作させるスレッド数および前記最大処理数を変えて、それぞれ当該最大処理数以下の範囲で、かつ、処理が割り振られるコアの数が最も少なくなるようにスレッドに前記所定数の処理を割り振る場合に、処理が割り振られるスレッド数およびコア数を特定し、
前記決定する処理は、特定したスレッド数およびコア数のなかから、処理性能の最も高いスレッド数およびコア数を並列処理を実行するスレッド数およびコア数と決定する
ことを特徴とする請求項1に記載の並列処理最適化プログラム。 - 前記特定する処理は、特定したコア数のなかから、コア数の多い順に性能の評価を行って性能を順次比較し、少ないコア数の性能が多いコア数の性能を最初に下回った際の多い側のコア数を並列処理を実行するコア数と決定する
ことを特徴とする請求項1に記載の並列処理最適化プログラム。 - 前記特定する処理は、特定したスレッド数およびコア数をスレッド数が多いものから、スレッド数毎に、コア数の多い順に性能の評価を行って性能を順次比較し、少ないコア数の性能が多いコア数の性能を最初に下回った際の多い側のコア数を当該スレッド数の最も良い性能のコア数と特定し、少ないスレッド数の最も良い性能が多いスレッド数の最も良い性能を最初に下回った際の多い側のスレッド数およびコア数を並列処理を実行するスレッド数およびコア数と決定する
ことを特徴とする請求項2に記載の並列処理最適化プログラム。 - 前記決定する処理は、特定したスレッド数およびコア数のなかから、所定の予測モデルを用いて、並列処理を実行するスレッド数およびコア数を決定する
ことを特徴とする請求項2に記載の並列処理最適化プログラム。 - コンピュータが、
並列処理を実行可能なコア数の範囲内で、並列して実行する所定数の処理を、割り振る最大処理数を変えて、それぞれ当該最大処理数以下の範囲で、かつ、処理が割り振られるコアの数が最も少なくなるようにコアに割り振る場合に、前記最大処理数数毎に、処理が割り振られるコア数を特定し、
特定したコア数のなかから、処理性能の最も高いコア数を並列処理を実行するコア数と決定する
処理を実行することを特徴とする並列処理最適化方法。 - 並列処理を実行可能な複数のコアと、
並列処理を実行可能なコア数の範囲内で、並列して実行する所定数の処理を、割り振る最大処理数を変えて、それぞれ当該最大処理数以下の範囲で、かつ、処理が割り振られるコアの数が最も少なくなるようにコアに割り振る場合に、前記最大処理数数毎に、処理が割り振られるコア数を特定する特定部と、
前記特定部により特定されたコア数のなかから、処理性能の最も高いコア数を並列処理を実行するコア数と決定する決定部と、
を有することを特徴とする情報処理装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013150945A JP6171658B2 (ja) | 2013-07-19 | 2013-07-19 | 並列処理最適化プログラム、並列処理最適化方法および情報処理装置 |
| US14/310,679 US10223168B2 (en) | 2013-07-19 | 2014-06-20 | Parallel processing optimization method, and information processing device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013150945A JP6171658B2 (ja) | 2013-07-19 | 2013-07-19 | 並列処理最適化プログラム、並列処理最適化方法および情報処理装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015022574A JP2015022574A (ja) | 2015-02-02 |
| JP6171658B2 true JP6171658B2 (ja) | 2017-08-02 |
Family
ID=52344249
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013150945A Expired - Fee Related JP6171658B2 (ja) | 2013-07-19 | 2013-07-19 | 並列処理最適化プログラム、並列処理最適化方法および情報処理装置 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10223168B2 (ja) |
| JP (1) | JP6171658B2 (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101770234B1 (ko) * | 2013-10-03 | 2017-09-05 | 후아웨이 테크놀러지 컴퍼니 리미티드 | 소프트웨어 프로그램의 연산 블록을 멀티-프로세서 시스템의 코어에 할당하는 방법 및 시스템 |
| GB201319591D0 (en) * | 2013-11-06 | 2013-12-18 | Microsoft Corp | Network Access |
| US9696787B2 (en) * | 2014-12-10 | 2017-07-04 | Qualcomm Innovation Center, Inc. | Dynamic control of processors to reduce thermal and power costs |
| JP6528531B2 (ja) * | 2015-05-12 | 2019-06-12 | 富士通株式会社 | コンパイラプログラム、コンパイル方法、及び情報処理装置 |
| CN106919452B (zh) * | 2015-12-28 | 2020-11-27 | 中兴通讯股份有限公司 | 多核异构系统及其硬件资源的管理方法 |
| US11204805B2 (en) | 2017-04-27 | 2021-12-21 | Nec Corporation | Computational resource management apparatus which optimizes computational resources to be allocated to tasks having a dependency relationship, computational resource management method and computer readable recording medium |
| US11112514B2 (en) | 2019-02-27 | 2021-09-07 | Saudi Arabian Oil Company | Systems and methods for computed resource hydrocarbon reservoir simulation and development |
| US11886960B2 (en) * | 2019-05-07 | 2024-01-30 | International Business Machines Corporation | Elastic training of machine learning models via re-partitioning based on feedback from the training algorithm |
| US11573803B2 (en) | 2019-05-07 | 2023-02-07 | International Business Machines Corporation | Parallel training of machine learning models |
| DE102020132291A1 (de) | 2020-12-04 | 2022-06-09 | Dinnovative Gmbh | Antimikrobielles Filtermaterial |
| US11934291B2 (en) * | 2021-02-23 | 2024-03-19 | Kyocera Document Solutions Inc. | Measurement of parallelism in multicore processors |
| US12013743B2 (en) * | 2021-10-29 | 2024-06-18 | Verizon Patent And Licensing Inc. | Software-based power management for virtualization platforms |
| KR20230070741A (ko) * | 2021-11-15 | 2023-05-23 | 삼성전자주식회사 | 하드웨어 가속을 위한 하이브리드 압축 기법을 이용하는 전자 장치 및 그 동작 방법 |
| JPWO2024209580A1 (ja) * | 2023-04-05 | 2024-10-10 | ||
| US12411671B1 (en) * | 2025-04-04 | 2025-09-09 | Kevin D. Howard | Software systems and methods for advanced output-affecting linear pathways |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3839259B2 (ja) | 2000-01-25 | 2006-11-01 | 富士通株式会社 | マルチスレッド制御方法、マルチスレッド制御装置、記録媒体、及びプログラム |
| JP4086846B2 (ja) | 2002-11-13 | 2008-05-14 | 富士通株式会社 | マルチスレッディングプロセッサにおけるスケジューリング方法およびマルチスレッディングプロセッサ |
| US7249268B2 (en) * | 2004-06-29 | 2007-07-24 | Intel Corporation | Method for performing performance optimization operations for a processor having a plurality of processor cores in response to a stall condition |
| JP4740561B2 (ja) | 2004-07-09 | 2011-08-03 | 富士通株式会社 | トランスレータプログラム、プログラム変換方法およびトランスレータ装置 |
| US7437581B2 (en) * | 2004-09-28 | 2008-10-14 | Intel Corporation | Method and apparatus for varying energy per instruction according to the amount of available parallelism |
| US20070300239A1 (en) * | 2006-06-23 | 2007-12-27 | International Business Machines Corporation | Dynamic application instance placement in data center environments |
| JP5067425B2 (ja) * | 2007-09-21 | 2012-11-07 | 富士通株式会社 | 翻訳装置と翻訳方法および翻訳プログラムとプロセッサコアの制御方法およびプロセッサ |
| US20110213950A1 (en) * | 2008-06-11 | 2011-09-01 | John George Mathieson | System and Method for Power Optimization |
| US8571924B2 (en) * | 2011-07-05 | 2013-10-29 | Yahoo! Inc. | High performance personalized advertisement serving by exploiting thread assignments in a multiple core computing environment |
-
2013
- 2013-07-19 JP JP2013150945A patent/JP6171658B2/ja not_active Expired - Fee Related
-
2014
- 2014-06-20 US US14/310,679 patent/US10223168B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015022574A (ja) | 2015-02-02 |
| US20150025848A1 (en) | 2015-01-22 |
| US10223168B2 (en) | 2019-03-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6171658B2 (ja) | 並列処理最適化プログラム、並列処理最適化方法および情報処理装置 | |
| US8707314B2 (en) | Scheduling compute kernel workgroups to heterogeneous processors based on historical processor execution times and utilizations | |
| US8635606B2 (en) | Dynamic optimization using a resource cost registry | |
| EP2472398B1 (en) | Memory-aware scheduling for NUMA architectures | |
| EP2466460A1 (en) | Compiling apparatus and method for a multicore device | |
| US9442696B1 (en) | Interactive partitioning and mapping of an application across multiple heterogeneous computational devices from a co-simulation design environment | |
| KR102402584B1 (ko) | 사용자 어플리케이션의 특성에 따른 연산 디바이스 동적 제어 기법 | |
| JP2015146154A (ja) | ジョブスケジューリング装置、ジョブスケジューリング方法、およびジョブスケジューリングプログラム | |
| US20190065271A1 (en) | Optimized allocation of tasks in heterogeneous computing systems | |
| US9733982B2 (en) | Information processing device and method for assigning task | |
| KR20120066189A (ko) | 매니코어 시스템에서 응용 프로그램의 상태를 동적으로 재구성하는 장치 및 방법 | |
| Shen et al. | Improving performance by matching imbalanced workloads with heterogeneous platforms | |
| KR101177059B1 (ko) | 병렬 제어 모듈을 동적으로 할당하는 방법 | |
| WO2017020941A1 (en) | Category based execution scheduling | |
| CN108885546B (zh) | 一种基于异构系统的程序处理方法和装置 | |
| JP2018139064A (ja) | 仮想計算機システムおよびそのリソース割当て方法 | |
| US12056475B2 (en) | Offload server, offload control method, and offload program | |
| CN108139929B (zh) | 用于调度多个任务的任务调度装置和方法 | |
| CN105988855B (zh) | 即时编译参数优化方法及装置 | |
| JP6435980B2 (ja) | 並列計算機、スレッド再割当判定方法及びスレッド再割当判定プログラム | |
| KR102022972B1 (ko) | 이종 멀티 프로세싱 시스템 환경 기반 런타임 관리장치 및 방법 | |
| CN110969565A (zh) | 图像处理的方法和装置 | |
| Singh et al. | Snowpack: Efficient parameter choice for GPU kernels via static analysis and statistical prediction | |
| KR102376155B1 (ko) | 병렬계산 가속기 할당률 결정 장치 및 방법 | |
| US12033235B2 (en) | Offload server, offload control method, and offload program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160405 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170131 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170421 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170606 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170619 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6171658 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |