JP6165657B2 - 情報処理装置、情報処理方法およびプログラム - Google Patents
情報処理装置、情報処理方法およびプログラム Download PDFInfo
- Publication number
- JP6165657B2 JP6165657B2 JP2014058246A JP2014058246A JP6165657B2 JP 6165657 B2 JP6165657 B2 JP 6165657B2 JP 2014058246 A JP2014058246 A JP 2014058246A JP 2014058246 A JP2014058246 A JP 2014058246A JP 6165657 B2 JP6165657 B2 JP 6165657B2
- Authority
- JP
- Japan
- Prior art keywords
- topic
- document
- feature amount
- candidate
- calculation unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/93—Document management systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Business, Economics & Management (AREA)
- Computational Linguistics (AREA)
- General Business, Economics & Management (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
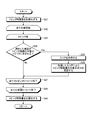
図1は、第1実施形態に係る情報処理装置10の構成を示す図である。図2は、トピック数が50個のトピック情報の一例を示す図である。
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation." the Journal of machine Learning research 3 (2003): P.993-1022.

つぎに、第1実施形態の第1変形例に係る情報処理装置10について説明する。
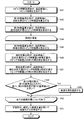
つぎに、第1実施形態の第2変形例に係る情報処理装置10について説明する。図13は、第2変形例に係るトピック情報の一例を示す図である。
つぎに、第2実施形態に係る情報処理装置10について説明する。なお、第2実施形態に係る情報処理装置10は、第1実施形態に係る情報処理装置10と略同一の機能および構成を有する。従って、略同一の機能および構成を有する要素には同一の符号を付けて、相違点を除き詳細な説明を省略する。
sim_A(t,C_{n1})=0.74*0.79+0.11*0.03=0.59、かつ、sim_B(t´,C_{n1})=0.10*0.10+0.8*0.8=0.65
図20は、実施形態に係る情報処理装置10のハードウェア構成の一例を示す図である。実施形態に係る情報処理装置10は、CPU101(Central Processing Unit)等の制御装置と、ROM102(Read Only Memory)およびRAM103(Random Access Memory)等の記憶装置と、ネットワークに接続して通信を行う通信I/F104と、各部を接続するバスとを備えている。
21 目的文書格納部
22 候補コーパス格納部
23 トピック情報取得部
24 第1特徴量算出部
25 第2特徴量算出部
26 類似度算出部
27 選択部
28 学習部
61 類似目的文書格納部
62 第3特徴量算出部
71 第1算出部
72 第2算出部
101 CPU
102 ROM
103 RAM
104 通信I/F
Claims (10)
- 複数の候補文書から言語モデルの学習に用いる文書を選択する情報処理装置であって、
前記言語モデルが利用される目的に合致した目的文書について、それぞれのトピックに対する文書の関連の強さを表すトピック特徴量を算出する第1特徴量算出部と、
前記複数の候補文書のそれぞれについて、前記トピック特徴量を算出する第2特徴量算出部と、
前記複数の候補文書のそれぞれの前記トピック特徴量について、前記目的文書の前記トピック特徴量との類似度を算出する類似度算出部と、
前記類似度が基準値より大きい候補文書を、前記言語モデルの学習に用いる文書として選択する選択部と、
を備える情報処理装置。 - トピック毎に、単語と、前記単語のトピックとの関連の強さを表すスコアとのペアの集合を含むトピック情報を取得するトピック情報取得部をさらに備え、
前記第1特徴量算出部および前記第2特徴量算出部は、前記トピック情報に基づき、前記トピック特徴量を算出する
請求項1に記載の情報処理装置。 - 前記第1特徴量算出部および前記第2特徴量算出部は、トピック毎に、対象の文書に含まれる単語のスコアを累積して、前記トピック特徴量を算出する
請求項2に記載の情報処理装置。 - 選択された前記候補文書に基づき、前記言語モデルを学習する学習部
をさらに備える請求項1に記載の情報処理装置。 - 前記トピック情報取得部は、前記複数の候補文書を用いて前記トピック情報を生成する
請求項2に記載の情報処理装置。 - 前記トピック情報取得部は、異なるトピック数の複数の前記トピック情報を生成し、生成した複数の前記トピック情報に基づき、前記目的文書の複数の前記トピック特徴量を算出し、算出した複数の前記トピック特徴量に基づき、生成した複数の前記トピック情報のうちの1つの前記トピック情報を選択する
請求項5に記載の情報処理装置。 - 前記トピック情報取得部は、品詞群毎に前記トピック情報を生成し、
前記第1特徴量算出部および前記第2特徴量算出部は、前記品詞群毎の前記トピック情報に基づき、前記品詞群毎の前記トピック特徴量を算出する
請求項5に記載の情報処理装置。 - 前記目的文書と内容が異なり前記言語モデルの学習の基準となる
学習対象の言語モデルと類似した用途で用いられる言語モデルを学習するための類似目的文書に対する、品詞群毎の前記トピック特徴量を算出する第3特徴量算出部をさらに備え、
前記類似度算出部は、
前記複数の候補文書のそれぞれの第1の品詞群に関する前記トピック特徴量に対して、前記目的文書の前記第1の品詞群に関する前記トピック特徴量との第1の類似度を算出し、
前記複数の候補文書のそれぞれの第2の品詞群に関する前記トピック特徴量に対して、前記類似目的文書の前記第2の品詞群に関する前記トピック特徴量との第2の類似度を算出し、
前記選択部は、前記第1の類似度が第1の基準値より大きく、且つ、前記第2の類似度が第2の基準値より大きい候補文書を、前記言語モデルの学習に用いる文書として選択する
請求項7に記載の情報処理装置。 - 複数の候補文書から言語モデルの学習に用いる文書を選択する情報処理方法であって、
前記言語モデルが利用される目的に合致した目的文書について、それぞれのトピックに対する文書の関連の強さを表すトピック特徴量を算出する第1特徴量算出ステップと、
前記複数の候補文書のそれぞれについて、前記トピック特徴量を算出する第2特徴量算出ステップと、
前記複数の候補文書のそれぞれの前記トピック特徴量について、前記目的文書の前記トピック特徴量との類似度を算出する類似度算出ステップと、
前記類似度が基準値より大きい候補文書を、前記言語モデルの学習に用いる文書として選択する選択ステップと、
を実行する情報処理方法。 - コンピュータを、複数の候補文書から言語モデルの学習に用いる文書を選択する情報処理装置として機能させるためのプログラムであって、
前記情報処理装置は、
前記言語モデルが利用される目的に合致した目的文書について、それぞれのトピックに対する文書の関連の強さを表すトピック特徴量を算出する第1特徴量算出部と、
前記複数の候補文書のそれぞれについて、前記トピック特徴量を算出する第2特徴量算出部と、
前記複数の候補文書のそれぞれの前記トピック特徴量について、前記目的文書の前記トピック特徴量との類似度を算出する類似度算出部と、
前記類似度が基準値より大きい候補文書を、前記言語モデルの学習に用いる文書として選択する選択部と、
を備えるプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014058246A JP6165657B2 (ja) | 2014-03-20 | 2014-03-20 | 情報処理装置、情報処理方法およびプログラム |
| US14/644,395 US20150269162A1 (en) | 2014-03-20 | 2015-03-11 | Information processing device, information processing method, and computer program product |
| CN201510109856.7A CN104933022B (zh) | 2014-03-20 | 2015-03-13 | 信息处理装置和信息处理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014058246A JP6165657B2 (ja) | 2014-03-20 | 2014-03-20 | 情報処理装置、情報処理方法およびプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2015184749A JP2015184749A (ja) | 2015-10-22 |
| JP6165657B2 true JP6165657B2 (ja) | 2017-07-19 |
Family
ID=54120191
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014058246A Active JP6165657B2 (ja) | 2014-03-20 | 2014-03-20 | 情報処理装置、情報処理方法およびプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20150269162A1 (ja) |
| JP (1) | JP6165657B2 (ja) |
| CN (1) | CN104933022B (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105302797B (zh) * | 2015-11-20 | 2019-02-01 | 百度在线网络技术(北京)有限公司 | 识别文本题材的方法和装置 |
| US11288590B2 (en) * | 2016-05-24 | 2022-03-29 | International Business Machines Corporation | Automatic generation of training sets using subject matter experts on social media |
| CN107798113B (zh) * | 2017-11-02 | 2021-11-12 | 东南大学 | 一种基于聚类分析的文档数据分类方法 |
| CN109635290B (zh) * | 2018-11-30 | 2022-07-22 | 北京百度网讯科技有限公司 | 用于处理信息的方法、装置、设备和介质 |
| JP7456137B2 (ja) * | 2019-12-05 | 2024-03-27 | 富士フイルムビジネスイノベーション株式会社 | 情報処理装置及びプログラム |
| JP7497997B2 (ja) | 2020-02-26 | 2024-06-11 | 本田技研工業株式会社 | 文書分析装置 |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04314171A (ja) * | 1991-04-12 | 1992-11-05 | Nippon Telegr & Teleph Corp <Ntt> | メニュー学習型テキストベース検索装置 |
| WO2001011559A1 (en) * | 1999-08-06 | 2001-02-15 | Lexis-Nexis | System and method for classifying legal concepts using legal topic scheme |
| JP2003242176A (ja) * | 2001-12-13 | 2003-08-29 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
| US7610313B2 (en) * | 2003-07-25 | 2009-10-27 | Attenex Corporation | System and method for performing efficient document scoring and clustering |
| CN100543735C (zh) * | 2005-10-31 | 2009-09-23 | 北大方正集团有限公司 | 基于文档结构的文档相似性度量方法 |
| JP4853915B2 (ja) * | 2006-10-19 | 2012-01-11 | Kddi株式会社 | 検索システム |
| CN100570611C (zh) * | 2008-08-22 | 2009-12-16 | 清华大学 | 一种基于观点检索的信息检索文档的评分方法 |
| JP2010097318A (ja) * | 2008-10-15 | 2010-04-30 | National Institute Of Information & Communication Technology | 情報処理装置、情報処理方法、及びプログラム |
| JP5475795B2 (ja) * | 2008-11-05 | 2014-04-16 | グーグル・インコーポレーテッド | カスタム言語モデル |
| US8352386B2 (en) * | 2009-07-02 | 2013-01-08 | International Business Machines Corporation | Identifying training documents for a content classifier |
| US8315849B1 (en) * | 2010-04-09 | 2012-11-20 | Wal-Mart Stores, Inc. | Selecting terms in a document |
| JP5403696B2 (ja) * | 2010-10-12 | 2014-01-29 | 株式会社Nec情報システムズ | 言語モデル生成装置、その方法及びそのプログラム |
| EP2546760A1 (en) * | 2011-07-11 | 2013-01-16 | Accenture Global Services Limited | Provision of user input in systems for jointly discovering topics and sentiment |
| JP5723711B2 (ja) * | 2011-07-28 | 2015-05-27 | 日本放送協会 | 音声認識装置および音声認識プログラム |
| CN103425710A (zh) * | 2012-05-25 | 2013-12-04 | 北京百度网讯科技有限公司 | 一种基于主题的搜索方法和装置 |
| US9275135B2 (en) * | 2012-05-29 | 2016-03-01 | International Business Machines Corporation | Annotating entities using cross-document signals |
| CN103473280B (zh) * | 2013-08-28 | 2017-02-08 | 中国科学院合肥物质科学研究院 | 一种网络可比语料的挖掘方法 |
| US20150120379A1 (en) * | 2013-10-30 | 2015-04-30 | Educational Testing Service | Systems and Methods for Passage Selection for Language Proficiency Testing Using Automated Authentic Listening |
-
2014
- 2014-03-20 JP JP2014058246A patent/JP6165657B2/ja active Active
-
2015
- 2015-03-11 US US14/644,395 patent/US20150269162A1/en not_active Abandoned
- 2015-03-13 CN CN201510109856.7A patent/CN104933022B/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20150269162A1 (en) | 2015-09-24 |
| JP2015184749A (ja) | 2015-10-22 |
| CN104933022A (zh) | 2015-09-23 |
| CN104933022B (zh) | 2018-11-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6165657B2 (ja) | 情報処理装置、情報処理方法およびプログラム | |
| Huang et al. | Multi-accent deep neural network acoustic model with accent-specific top layer using the KLD-regularized model adaptation. | |
| CN110990685B (zh) | 基于声纹的语音搜索方法、设备、存储介质及装置 | |
| JP5932869B2 (ja) | N−gram言語モデルの教師無し学習方法、学習装置、および学習プログラム | |
| US12001465B2 (en) | Response selecting apparatus, response selecting method, and response selecting program | |
| JP5496863B2 (ja) | 感情推定装置、その方法、プログラム及びその記録媒体 | |
| US9142211B2 (en) | Speech recognition apparatus, speech recognition method, and computer-readable recording medium | |
| JP2015219583A (ja) | 話題決定装置、発話装置、方法、及びプログラム | |
| CN110738061B (zh) | 古诗词生成方法、装置、设备及存储介质 | |
| JP2020077159A (ja) | 対話システム、対話装置、対話方法、及びプログラム | |
| CN104750677A (zh) | 语音传译装置、语音传译方法及语音传译程序 | |
| JP2016001242A (ja) | 質問文生成方法、装置、及びプログラム | |
| KR20190024148A (ko) | 음성 인식 장치 및 음성 인식 방법 | |
| US20150371627A1 (en) | Voice dialog system using humorous speech and method thereof | |
| JP2017045054A (ja) | 言語モデル改良装置及び方法、音声認識装置及び方法 | |
| JP6556381B2 (ja) | モデル学習装置及びモデル学習方法 | |
| JPWO2011071174A1 (ja) | テキストマイニング方法、テキストマイニング装置及びテキストマイニングプログラム | |
| US20110224985A1 (en) | Model adaptation device, method thereof, and program thereof | |
| US20210312333A1 (en) | Semantic relationship learning device, semantic relationship learning method, and storage medium storing semantic relationship learning program | |
| JP6775465B2 (ja) | 対話ルール照合装置、対話装置、対話ルール照合方法、対話方法、対話ルール照合プログラム、及び対話プログラム | |
| US20180082681A1 (en) | Bilingual corpus update method, bilingual corpus update apparatus, and recording medium storing bilingual corpus update program | |
| JP2018180459A (ja) | 音声合成システム、音声合成方法、及び音声合成プログラム | |
| JP6821542B2 (ja) | 複数種の対話を続けて実施可能な対話制御装置、プログラム及び方法 | |
| JP6723188B2 (ja) | 対話ルール選択装置、対話装置、対話ルール選択方法、対話方法、及び対話ルール選択プログラム | |
| JP4735958B2 (ja) | テキストマイニング装置、テキストマイニング方法およびテキストマイニングプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7421 Effective date: 20151102 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160830 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170523 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170519 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170621 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 6165657 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 Free format text: JAPANESE INTERMEDIATE CODE: R313114 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |