JP5795592B2 - 中央制御装置により制御されるデータパケットを受信し記憶する装置および方法 - Google Patents
中央制御装置により制御されるデータパケットを受信し記憶する装置および方法 Download PDFInfo
- Publication number
- JP5795592B2 JP5795592B2 JP2012541530A JP2012541530A JP5795592B2 JP 5795592 B2 JP5795592 B2 JP 5795592B2 JP 2012541530 A JP2012541530 A JP 2012541530A JP 2012541530 A JP2012541530 A JP 2012541530A JP 5795592 B2 JP5795592 B2 JP 5795592B2
- Authority
- JP
- Japan
- Prior art keywords
- queue
- address
- data
- queues
- processor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 111
- 230000008569 process Effects 0.000 claims description 96
- 230000008859 change Effects 0.000 claims description 5
- 238000006243 chemical reaction Methods 0.000 claims description 4
- 238000012546 transfer Methods 0.000 description 13
- 230000005540 biological transmission Effects 0.000 description 9
- 238000012545 processing Methods 0.000 description 9
- 230000001360 synchronised effect Effects 0.000 description 6
- 238000004891 communication Methods 0.000 description 4
- 238000013459 approach Methods 0.000 description 3
- 241001522296 Erithacus rubecula Species 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 238000012937 correction Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000009499 grossing Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000012913 prioritisation Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
Images



Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/50—Queue scheduling
- H04L47/62—Queue scheduling characterised by scheduling criteria
- H04L47/625—Queue scheduling characterised by scheduling criteria for service slots or service orders
- H04L47/6255—Queue scheduling characterised by scheduling criteria for service slots or service orders queue load conditions, e.g. longest queue first
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/10—Flow control; Congestion control
- H04L47/12—Avoiding congestion; Recovering from congestion
- H04L47/125—Avoiding congestion; Recovering from congestion by balancing the load, e.g. traffic engineering
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/50—Queue scheduling
- H04L47/62—Queue scheduling characterised by scheduling criteria
- H04L47/622—Queue service order
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/70—Admission control; Resource allocation
- H04L47/78—Architectures of resource allocation
- H04L47/781—Centralised allocation of resources
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/70—Admission control; Resource allocation
- H04L47/82—Miscellaneous aspects
- H04L47/828—Allocation of resources per group of connections, e.g. per group of users
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/90—Buffering arrangements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/90—Buffering arrangements
- H04L49/9047—Buffering arrangements including multiple buffers, e.g. buffer pools
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L47/00—Traffic control in data switching networks
- H04L47/50—Queue scheduling
- H04L47/56—Queue scheduling implementing delay-aware scheduling
- H04L47/568—Calendar queues or timing rings
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Description
記憶部の複数のキューであって、アドレスによりそれぞれが定められる複数の記憶要素をそれぞれのキューが含む複数のキューに、記憶部が複数のデータパケットの少なくとも一部を保持するように構成され、
それぞれのプロセッサまたはプロセスが、キューの第1のグループの1つからデータをデキューイングするように構成され、個々の第1のグループのキューが重なり合わず、複数のプロセッサ/プロセスが、キューからのデータのデキューイングに関して情報を制御部に送信するように構成され、
それぞれのデータ受信・記憶部が、
・ データパケットにアクセスするかまたはデータパケットを受信するための手段と、
・ データパケットの少なくとも一部を記憶するためのアドレスを制御部から受信するための手段と、
・ 記憶部の受信されたアドレスにデータパケットの少なくとも一部が記憶されることを円滑化するための手段と
を備え、
制御部が、
・ キューの充填レベルに関する情報を決定するための手段と、
・ アドレスを、
− 受信された/アクセスされたデータパケットについて、第1のキューのグループのそれぞれからのキューをそれぞれが含む第2のキューのグループであって、第2のキューのグループ同士のキューが重なり合わない第2のキューのグループの1つを決定し、
− 決定された第2のグループの現在選択されている第1のキューの充填レベルが予め定められたレベルを超えるならば、決定された第2のグループの第2のキューを選択し、
− アドレスを、第2のグループの選択されたキューのアドレスとして選択する
ことによって選択するための手段と、
・ 受信された/アクセスされたデータパケットをもつ受信・記憶要素に、選択されたアドレスを送信するための手段と
を備え、
選択された第2のキューに関するプロセス/プロセッサが、予め定められたレベルを超過した選択された第1のキューが空になるまでこの第2のキューを処理しないように構成されているアセンブリに関する。
・ 各キューについて、データを加える次のアドレスまたはデータが加えられた最後のアドレスを識別する書出しポインタと、キューから読み取られる/デキューイングされる次のアドレスまたは読み取られた/デキューイングされた最後のアドレスを識別する読取りポインタとを保持するように構成され、
・ アドレスが選択されたときに、選択されたアドレスが関係するキューの書出しポインタを更新し、プロセッサ/プロセスから送信された情報に基づいて、データがデキューイングされたキューの読取りポインタを更新するための手段を備える。
記憶部の複数のキューであって、アドレスによりそれぞれが定められる複数の記憶要素をそれぞれのキューが含む複数のキューに、記憶部が複数のデータパケットの少なくとも一部を保持するステップと、
プロセッサまたはプロセスのそれぞれが、キューの第1のグループの1つからデータをデキューイングし、個々の第1のグループのキューが重なり合わず、プロセッサ/プロセスが、キューからのデータのデキューイングに関して情報を制御部に送信するステップと、
それぞれのデータ受信・記憶部が、
・ データパケットにアクセスするかまたはデータパケットを受信するステップと、
・ データパケットの少なくとも一部を記憶するためのアドレスを制御部から受信するステップと、
・ 記憶部の受信されたアドレスにデータパケットの少なくとも一部が記憶されることを円滑化するステップと、
制御部が、
・ キューの充填レベルに関する情報を決定するステップと、
・ アドレスを、
− 受信された/アクセスされたデータパケットについて、第1のキューのグループのそれぞれからのキューをそれぞれが含む第2のキューのグループであって、第2のグループ同士のキューが重なり合わない第2のキューのグループの1つを決定し、
− 決定された第2のグループの現在選択されている第1のキューの充填レベルが予め定められたレベルを超えるならば、決定された第2のグループの第2のキューを選択し、
− アドレスを、第2のグループの選択されたキューのアドレスとして選択する
ことによって選択するステップと、
・ 受信された/アクセスされたデータパケットをもつ受信・記憶要素に、選択されたアドレスを送信するステップと
を含み、
第2のグループの選択された第2のキューに関するプロセス/プロセッサに、予め定められたレベルを超過した第2のグループの選択された第1のキューが空になるまでこの第2のキューを処理しないように指示するステップをさらに含む方法に関する。
・ 各キューについて、データを加える次のアドレスまたはデータが加えられた最後のアドレスを識別する書出しポインタと、キューから読み取られる/デキューイングされる次のアドレスまたは読み取られた/デキューイングされた最後のアドレスを識別する読取りポインタとを保持し、
・ アドレスが選択されたときに、選択されたアドレスが関係するキューの書出しポインタを更新し、
・ プロセッサ/プロセスから送信された情報に基づいて、データがデキューイングされたキューの読取りポインタを更新する。
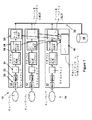
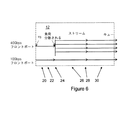
図6では、アダプタ12のPHY20や、MAC22、タイムスタンプ割当て24などの一部の要素を、解析器26や、要求元28、転送回路30などの他の要素より高速に動かしてもよいことがわかる。この状況では、要素20〜24から受信しタイムスタンプを記録したデータパケットのフローを多数のパラレルなフローに分割するために、これらのより遅い要素の様々な「具体化」を行うことができる。図6では、単一のPHY20で受信されたデータパケットが、4つのパラレルなフローに分割されている。要素20〜30は直接図示していないが、それらの位置はフロー中に示している。
記憶領域18のキューからデータを読み取るプロセッサまたはプロセス(図示せず)の負荷分散を、いくつかのやり方で行うことができる。ストリームなどでのデータパケットの順序(受信の順序か、または個々のデータパケット内のデータにより定められる順序)に関連性がないならば、プロセッサごとに単一のキューを設けてもよい。1つのプロセッサキューが一杯になった(これをどのように決定できるかは、以下でさらに記載する)場合は、アロケータ16により、単により多くのデータパケットが(1つまたは複数の)他のキューに伝送されるようにしてもよい。
そのセットアップを異なるシステムにより容易に適合させるためには、要求回路28や、転送回路30、アロケータ16だけでなく、記憶領域18内の、またはそれに接続された任意のデキューイング回路構成が仮想アドレス空間で動作することが好ましい。
受信されたフレームについてのタイムスタンプを信頼性があり比較可能なものにするためには、アダプタ12とアロケータ16でクロックを同期させることが望ましい。
記憶領域18のそれぞれのキューについて、アロケータ16は、RIFO(Random In First Out)キューと、FIRO(First In Random Out)キューの2つのキューをもつ(図4を参照)。
もちろん、記憶領域18内の1つまたは複数のキューに記憶されたデータパケットをデキューイングし、バス32を介して伝送し、アダプタ12を介して出力してもよい。記憶領域18に記憶されるデータパケットを記憶する場合と同様に、これはDMAを介して行ってもよく、それによって、例えば記憶領域18のプロセッサから介入されることなく、アダプタ12は記憶領域18内のデータパケットを直接読み取る。
Claims (12)
- データパケットを受信し記憶するための装置と、複数のプロセッサまたはプロセスとを備え、前記装置が記憶部、制御部および複数のアダプタを備えるアセンブリであって、
前記記憶部の複数のキューであって、アドレスによりそれぞれが定められる複数の記憶要素をそれぞれのキューが含む複数のキューに、前記記憶部が複数のデータパケットの少なくとも一部を保持するように構成され、
それぞれのプロセッサまたはプロセスが、前記キューの第1のグループの1つからデータをデキューイングするように構成され、個々の前記第1のグループの前記キュー同士のアドレスが重なり合わず、複数の前記プロセッサまたはプロセスが、キューからのデータのデキューイングに関して情報を前記制御部に送信するように構成され、
それぞれのアダプタが、
・ データパケットにアクセスするかまたはデータパケットを受信するための手段と、
・ 前記データパケットの少なくとも一部を記憶するためのアドレスを前記制御部から受信するための手段と、
・ 前記記憶部の受信された前記アドレスに前記データパケットの前記少なくとも一部を記憶させるための手段と
を備え、
前記制御部が、
・ 前記キューの充填レベルに関する情報を決定するための手段と、
・ アドレスを、
− 受信された/アクセスされたデータパケットについて、キューの第1のグループのそれぞれからの1つずつのキューをそれぞれが含むキューの複数の第2のグループであって、前記キュー同士のアドレスが重なり合わない複数の第2のグループの1つを決定し、
− 決定された前記第2のグループの現在選択されている第1のキューの前記充填レベルが予め定められたレベルを超えるならば、決定された前記第2のグループの第2のキューを選択し、
− 前記アドレスを、前記第2のグループの前記選択された第2のキューのアドレスとして選択する
ことによって選択するための手段と、
・ 受信された/アクセスされた前記データパケットをもつ前記アダプタに、選択された前記アドレスを送信するための手段と
を備え、
前記選択された第2のキューに関する前記プロセッサまたはプロセスが、前記予め定められたレベルを超過した前記選択された第1のキューが空になるまでこの第2のキューを処理しないように構成されているアセンブリ。 - 受信された/アクセスされた前記データパケットに関する情報を生成し、生成された前記情報を前記制御部に送信するための生成手段を、それぞれのアダプタがさらに備え、
生成された情報を受信するための手段を前記制御部がさらに備え、生成され受信された前記情報にも基づいて前記アドレスを選択するように前記選択するための手段が構成されている、請求項1に記載のアセンブリ。 - 生成された前記情報の少なくとも一部として、前記データパケットが受信された時点に関する情報を生成するように前記生成手段が構成されている、請求項2に記載のアセンブリ。
- 前記キューのそれぞれが複数の連続するアドレスとして実現されており、前記制御部が、
・ 各キューについて、データを加える次のアドレスを識別する書出しポインタと、前記キューから読み取られる/デキューイングされる次のアドレスを識別する読取りポインタとを保持するように構成され、
・ アドレスが選択されたときに、選択された前記アドレスが関係する前記キューの前記書出しポインタを更新し、前記プロセッサまたはプロセスから送信された情報に基づいて、データがデキューイングされた前記キューの前記読取りポインタを更新するための手段を備える、請求項1に記載のアセンブリ。 - 前記記憶部の前記キューの前記アドレスが、予め定められた個数の物理アドレスのグループに分けられ、前記グループが不連続に配置され、前記キューを実現する前記アドレスが、連続するアドレスとして定められた仮想アドレスであり、仮想アドレスと物理アドレスの間の変換を行うための手段を前記制御部がさらに備える、請求項4に記載のアセンブリ。
- キューをデキューイングするかどうかを前記プロセッサまたはプロセスに指示するための指示手段をさらに備え、前記記憶部に記憶されたデータを前記指示手段が含み、キューを処理するかどうかを前記データから決定するように前記プロセッサまたはプロセスが構成され、キューを空にしたときに前記データを変更するように前記プロセッサまたはプロセスが構成されている、請求項1に記載のアセンブリ。
- 複数のプロセッサまたはプロセスと、記憶部、制御部および複数のアダプタを備える装置とを備えるアセンブリを動作させる方法であって、
前記記憶部の複数のキューであって、アドレスによりそれぞれが定められる複数の記憶要素をそれぞれのキューが含む複数のキューに、前記記憶部が複数のデータパケットの少なくとも一部を保持するステップと、
前記プロセッサまたはプロセスのそれぞれが、前記キューの第1のグループの1つからデータをデキューイングし、個々の前記第1のグループの前記キュー同士のアドレスが重なり合わず、前記プロセッサまたはプロセスが、キューからのデータのデキューイングに関して情報を前記制御部に送信するステップと、
それぞれのアダプタが、
・ データパケットにアクセスするかまたはデータパケットを受信するステップと、
・ 前記データパケットの少なくとも一部を記憶するためのアドレスを前記制御部から受信するステップと、
・ 前記記憶部の受信された前記アドレスに前記データパケットの前記少なくとも一部を記憶させるステップと、
前記制御部が、
・ 前記キューの充填レベルに関する情報を決定するステップと、
・ アドレスを、
− 受信された/アクセスされたデータパケットについて、キューの第1のグループのそれぞれからの1つずつのキューをそれぞれが含むキューの複数の第2のグループであって、前記キュー同士のアドレスが重なり合わない複数の第2のグループの1つを決定し、
− 決定された前記第2のグループの現在選択されている第1のキューの前記充填レベルが予め定められたレベルを超えるならば、決定された前記第2のグループの第2のキューを選択し、
− 前記アドレスを、前記第2のグループの前記選択された第2のキューのアドレスとして選択する
ことによって選択するステップと、
・ 受信された/アクセスされた前記データパケットをもつ前記アダプタに、選択された前記アドレスを送信するステップと
を含み、
前記第2のグループの前記選択された第2のキューに関する前記プロセッサまたはプロセスに、前記予め定められたレベルを超過した前記第2のグループの前記選択された第1のキューが空になるまでこの第2のキューを処理しないように指示するステップをさらに含む方法。 - それぞれのアダプタがさらに、受信された/アクセスされた前記データパケットに関する情報を生成し、生成された前記情報を前記制御部に送信し、
生成された情報を前記制御部がさらに受信し、生成され受信された前記情報にも基づいて前記アドレスを前記選択するステップにおいて選択する、請求項7に記載の方法。 - 生成された前記情報の少なくとも一部として、前記データパケットが受信された時点に関する情報をそれぞれのアダプタが生成する、請求項8に記載の方法。
- 前記キューのそれぞれが複数の連続するアドレスとして実現されており、前記制御部が、
・ 各キューについて、データを加える次のアドレスを識別する書出しポインタと、前記キューから読み取られる/デキューイングされる次のアドレスを識別する読取りポインタとを保持し、
・ アドレスが選択されたときに、選択された前記アドレスが関係する前記キューの前記書出しポインタを更新し、
・ 前記プロセッサまたはプロセスから送信された情報に基づいて、データがデキューイングされた前記キューの前記読取りポインタを更新する、請求項9に記載の方法。 - 前記記憶部の前記キューの前記アドレスが、予め定められた個数の物理アドレスのグループに分けられ、前記グループが不連続に配置され、前記キューを実現する前記アドレスが、連続するアドレスとして定められた仮想アドレスであり、前記制御部がさらに仮想アドレスと物理アドレスの間の変換を行う、請求項10に記載の方法。
- キューを処理するかどうかを前記記憶部に記憶されたデータから前記プロセッサまたはプロセスが決定し、キューを空にしたときに前記プロセッサまたはプロセスが前記データを変更することを、前記指示するステップが含む、請求項11に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US26678809P | 2009-12-04 | 2009-12-04 | |
| US61/266,788 | 2009-12-04 | ||
| PCT/EP2010/068964 WO2011067408A1 (en) | 2009-12-04 | 2010-12-06 | An apparatus and a method of receiving and storing data packets controlled by a central controller |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013513272A JP2013513272A (ja) | 2013-04-18 |
| JP5795592B2 true JP5795592B2 (ja) | 2015-10-14 |
Family
ID=43639962
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012541530A Active JP5795592B2 (ja) | 2009-12-04 | 2010-12-06 | 中央制御装置により制御されるデータパケットを受信し記憶する装置および方法 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US8934341B2 (ja) |
| EP (1) | EP2507951B1 (ja) |
| JP (1) | JP5795592B2 (ja) |
| KR (1) | KR101720259B1 (ja) |
| CN (1) | CN102754395B (ja) |
| BR (1) | BR112012013383A2 (ja) |
| DK (1) | DK2507951T5 (ja) |
| WO (1) | WO2011067408A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20120102732A (ko) * | 2009-12-04 | 2012-09-18 | 나파테크 에이/에스 | 중앙 제어기에 의해 제어되는 데이터 패킷들을 수신 및 저장하는 장치 및 방법 |
Families Citing this family (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012100984A1 (en) * | 2011-01-28 | 2012-08-02 | Napatech A/S | An apparatus and a method for receiving and forwarding data packets |
| EP2858318B1 (en) * | 2013-09-09 | 2017-11-08 | Intercapital Services North America LLC | Method and apparatus for order entry in an electronic trading system |
| US9397946B1 (en) | 2013-11-05 | 2016-07-19 | Cisco Technology, Inc. | Forwarding to clusters of service nodes |
| US9655232B2 (en) | 2013-11-05 | 2017-05-16 | Cisco Technology, Inc. | Spanning tree protocol (STP) optimization techniques |
| US9825857B2 (en) | 2013-11-05 | 2017-11-21 | Cisco Technology, Inc. | Method for increasing Layer-3 longest prefix match scale |
| US9374294B1 (en) | 2013-11-05 | 2016-06-21 | Cisco Technology, Inc. | On-demand learning in overlay networks |
| US9769078B2 (en) | 2013-11-05 | 2017-09-19 | Cisco Technology, Inc. | Dynamic flowlet prioritization |
| US9876711B2 (en) | 2013-11-05 | 2018-01-23 | Cisco Technology, Inc. | Source address translation in overlay networks |
| US9674086B2 (en) * | 2013-11-05 | 2017-06-06 | Cisco Technology, Inc. | Work conserving schedular based on ranking |
| US10778584B2 (en) | 2013-11-05 | 2020-09-15 | Cisco Technology, Inc. | System and method for multi-path load balancing in network fabrics |
| US9502111B2 (en) | 2013-11-05 | 2016-11-22 | Cisco Technology, Inc. | Weighted equal cost multipath routing |
| US10951522B2 (en) | 2013-11-05 | 2021-03-16 | Cisco Technology, Inc. | IP-based forwarding of bridged and routed IP packets and unicast ARP |
| US9509092B2 (en) | 2013-11-06 | 2016-11-29 | Cisco Technology, Inc. | System and apparatus for network device heat management |
| US10116493B2 (en) | 2014-11-21 | 2018-10-30 | Cisco Technology, Inc. | Recovering from virtual port channel peer failure |
| US10142163B2 (en) | 2016-03-07 | 2018-11-27 | Cisco Technology, Inc | BFD over VxLAN on vPC uplinks |
| US10333828B2 (en) | 2016-05-31 | 2019-06-25 | Cisco Technology, Inc. | Bidirectional multicasting over virtual port channel |
| US11509501B2 (en) | 2016-07-20 | 2022-11-22 | Cisco Technology, Inc. | Automatic port verification and policy application for rogue devices |
| US10193750B2 (en) | 2016-09-07 | 2019-01-29 | Cisco Technology, Inc. | Managing virtual port channel switch peers from software-defined network controller |
| CN108108148B (zh) * | 2016-11-24 | 2021-11-16 | 舒尔电子(苏州)有限公司 | 一种数据处理方法和装置 |
| US10547509B2 (en) | 2017-06-19 | 2020-01-28 | Cisco Technology, Inc. | Validation of a virtual port channel (VPC) endpoint in the network fabric |
| CN108259369B (zh) * | 2018-01-26 | 2022-04-05 | 迈普通信技术股份有限公司 | 一种数据报文的转发方法及装置 |
| US20220043588A1 (en) * | 2020-08-06 | 2022-02-10 | Micron Technology, Inc. | Localized memory traffic control for high-speed memory devices |
| US11789859B1 (en) | 2021-09-30 | 2023-10-17 | Amazon Technologies, Inc. | Address generation for page collision prevention |
| US11748253B1 (en) * | 2021-09-30 | 2023-09-05 | Amazon Technologies, Inc. | Address generation for page collision prevention in memory regions |
Family Cites Families (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4025903A (en) | 1973-09-10 | 1977-05-24 | Computer Automation, Inc. | Automatic modular memory address allocation system |
| FR2443735A1 (fr) | 1978-12-06 | 1980-07-04 | Cii Honeywell Bull | Dispositif de controle automatique de la capacite memoire mise en oeuvre dans les systemes de traitements de l'information |
| US6141323A (en) | 1996-06-03 | 2000-10-31 | Whittaker Corporation | Closed loop congestion control using a queue measurement system |
| US6430191B1 (en) | 1997-06-30 | 2002-08-06 | Cisco Technology, Inc. | Multi-stage queuing discipline |
| JP3666258B2 (ja) | 1997-08-28 | 2005-06-29 | セイコーエプソン株式会社 | プリンタ |
| US6912637B1 (en) | 1998-07-08 | 2005-06-28 | Broadcom Corporation | Apparatus and method for managing memory in a network switch |
| US6671747B1 (en) | 2000-08-03 | 2003-12-30 | Apple Computer, Inc. | System, apparatus, method, and computer program for execution-order preserving uncached write combine operation |
| US6990598B2 (en) * | 2001-03-21 | 2006-01-24 | Gallitzin Allegheny Llc | Low power reconfigurable systems and methods |
| US6594234B1 (en) | 2001-05-31 | 2003-07-15 | Fujitsu Network Communications, Inc. | System and method for scheduling traffic for different classes of service |
| US7787370B1 (en) | 2001-09-06 | 2010-08-31 | Nortel Networks Limited | Technique for adaptively load balancing connections in multi-link trunks |
| US20030056073A1 (en) | 2001-09-18 | 2003-03-20 | Terachip, Inc. | Queue management method and system for a shared memory switch |
| US6967951B2 (en) * | 2002-01-11 | 2005-11-22 | Internet Machines Corp. | System for reordering sequenced based packets in a switching network |
| CN1620782A (zh) | 2002-02-22 | 2005-05-25 | 连宇通信有限公司 | 一种在无线分组数据通信中的优先级控制方法 |
| US7463585B2 (en) | 2002-05-16 | 2008-12-09 | Broadcom Corporation | System, method, and apparatus for load-balancing to a plurality of ports |
| US7289442B1 (en) | 2002-07-03 | 2007-10-30 | Netlogic Microsystems, Inc | Method and apparatus for terminating selected traffic flows |
| EP1654819B1 (en) * | 2003-08-15 | 2013-05-15 | Napatech A/S | A data merge unit, a method of producing an interleaved data stream, a network analyser and a method of analysing a network |
| US7680139B1 (en) | 2004-03-25 | 2010-03-16 | Verizon Patent And Licensing Inc. | Systems and methods for queue management in packet-switched networks |
| US7359383B2 (en) | 2004-03-29 | 2008-04-15 | Hewlett-Packard Development Company, L.P. | Load balancing with mesh tagging |
| US7941585B2 (en) * | 2004-09-10 | 2011-05-10 | Cavium Networks, Inc. | Local scratchpad and data caching system |
| US20060123423A1 (en) * | 2004-12-07 | 2006-06-08 | International Business Machines Corporation | Borrowing threads as a form of load balancing in a multiprocessor data processing system |
| JP2006189937A (ja) | 2004-12-28 | 2006-07-20 | Toshiba Corp | 受信装置、送受信装置、受信方法及び送受信方法 |
| US7623455B2 (en) | 2005-04-02 | 2009-11-24 | Cisco Technology, Inc. | Method and apparatus for dynamic load balancing over a network link bundle |
| CN100596159C (zh) * | 2005-12-01 | 2010-03-24 | 大唐软件技术有限责任公司 | 多进程消息处理方法以及多进程话单处理的方法 |
| DE602005018245D1 (de) | 2005-12-30 | 2010-01-21 | St Microelectronics Belgium Nv | Speicher mit seriellem Eingang und direktem Zugriff |
| JP4878185B2 (ja) | 2006-03-17 | 2012-02-15 | 株式会社リコー | データ通信回路および調停方法 |
| US20080120480A1 (en) | 2006-11-22 | 2008-05-22 | International Business Machines Corporation | Method and System For Preserving Critical Storage Contents Across A System Restart |
| CN100558080C (zh) * | 2006-12-12 | 2009-11-04 | 华为技术有限公司 | 集群消息传送方法及分布式集群系统 |
| KR100887417B1 (ko) | 2007-04-11 | 2009-03-06 | 삼성전자주식회사 | 멀티 프로세서 시스템에서 불휘발성 메모리의 공유적사용을 제공하기 위한 멀티패쓰 억세스블 반도체 메모리장치 |
| JP2008287600A (ja) | 2007-05-18 | 2008-11-27 | Seiko Epson Corp | ホスト装置、情報処理装置、電子機器、プログラム及びリード制御方法 |
| US8799620B2 (en) | 2007-06-01 | 2014-08-05 | Intel Corporation | Linear to physical address translation with support for page attributes |
| US8078928B2 (en) | 2007-10-12 | 2011-12-13 | Oracle America, Inc. | System and method for verifying the transmit path of an input/output component |
| WO2009093299A1 (ja) * | 2008-01-21 | 2009-07-30 | Fujitsu Limited | パケット処理装置およびパケット処理プログラム |
| JP5049834B2 (ja) * | 2008-03-26 | 2012-10-17 | 株式会社東芝 | データ受信装置、データ受信方法およびデータ処理プログラム |
| US8356125B1 (en) * | 2008-05-15 | 2013-01-15 | Xilinx, Inc. | Method and apparatus for providing a channelized buffer |
| WO2010076649A2 (en) | 2008-12-31 | 2010-07-08 | Transwitch India Pvt. Ltd. | Packet processing system on chip device |
| US8934341B2 (en) * | 2009-12-04 | 2015-01-13 | Napatech A/S | Apparatus and a method of receiving and storing data packets controlled by a central controller |
-
2010
- 2010-12-06 US US13/513,522 patent/US8934341B2/en active Active
- 2010-12-06 BR BR112012013383A patent/BR112012013383A2/pt not_active IP Right Cessation
- 2010-12-06 CN CN201080063130.XA patent/CN102754395B/zh active Active
- 2010-12-06 EP EP10795649.2A patent/EP2507951B1/en active Active
- 2010-12-06 DK DK10795649.2T patent/DK2507951T5/da active
- 2010-12-06 JP JP2012541530A patent/JP5795592B2/ja active Active
- 2010-12-06 WO PCT/EP2010/068964 patent/WO2011067408A1/en active Application Filing
- 2010-12-06 KR KR1020127016756A patent/KR101720259B1/ko active IP Right Grant
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20120102732A (ko) * | 2009-12-04 | 2012-09-18 | 나파테크 에이/에스 | 중앙 제어기에 의해 제어되는 데이터 패킷들을 수신 및 저장하는 장치 및 방법 |
| KR101720259B1 (ko) | 2009-12-04 | 2017-04-10 | 나파테크 에이/에스 | 중앙 제어기에 의해 제어되는 데이터 패킷들을 수신 및 저장하는 장치 및 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102754395A (zh) | 2012-10-24 |
| DK2507951T5 (da) | 2013-12-02 |
| US8934341B2 (en) | 2015-01-13 |
| BR112012013383A2 (pt) | 2016-03-01 |
| KR101720259B1 (ko) | 2017-04-10 |
| US20120300787A1 (en) | 2012-11-29 |
| KR20120102732A (ko) | 2012-09-18 |
| DK2507951T3 (da) | 2013-11-25 |
| CN102754395B (zh) | 2015-03-04 |
| EP2507951B1 (en) | 2013-08-14 |
| JP2013513272A (ja) | 2013-04-18 |
| WO2011067408A1 (en) | 2011-06-09 |
| EP2507951A1 (en) | 2012-10-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5795592B2 (ja) | 中央制御装置により制御されるデータパケットを受信し記憶する装置および方法 | |
| JP5749732B2 (ja) | キューの充填レベルの更新を制御することにより帯域幅を節約しながらデータを受信し記憶するアセンブリおよび方法 | |
| JP5711257B2 (ja) | タイムスタンプの記録と中央制御装置を用いた多数のアダプタによるデータフレームの分散処理 | |
| JP5640234B2 (ja) | マネージド・ネットワークでのレイヤ2のパケット集約及び断片化 | |
| EP2668753B1 (en) | An apparatus and a method for receiving and forwarding data packets | |
| US6967951B2 (en) | System for reordering sequenced based packets in a switching network | |
| US9094333B1 (en) | Systems and methods for sending and receiving information via a network device | |
| WO2012163395A1 (en) | An apparatus and a method of parallel receipt, forwarding and time stamping data packets using synchronized clocks | |
| WO2019095942A1 (zh) | 一种数据传输方法及通信设备 | |
| WO2011067404A1 (en) | An apparatus and a method of parallel receipt, forwarding and time stamping data packets using synchronized clocks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20131122 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20141125 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150107 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20150310 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20150511 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150714 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150813 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5795592 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |