JP5520779B2 - 分岐誤予測バッファを用いるためのシステム及び方法 - Google Patents
分岐誤予測バッファを用いるためのシステム及び方法 Download PDFInfo
- Publication number
- JP5520779B2 JP5520779B2 JP2010246340A JP2010246340A JP5520779B2 JP 5520779 B2 JP5520779 B2 JP 5520779B2 JP 2010246340 A JP2010246340 A JP 2010246340A JP 2010246340 A JP2010246340 A JP 2010246340A JP 5520779 B2 JP5520779 B2 JP 5520779B2
- Authority
- JP
- Japan
- Prior art keywords
- branch
- instruction
- instructions
- prediction
- bmb
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 47
- 230000015654 memory Effects 0.000 claims description 110
- 238000004422 calculation algorithm Methods 0.000 claims description 6
- 230000008569 process Effects 0.000 description 24
- 230000007246 mechanism Effects 0.000 description 12
- 230000003068 static effect Effects 0.000 description 5
- 230000009471 action Effects 0.000 description 3
- 238000004590 computer program Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000002730 additional effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000007787 long-term memory Effects 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 230000036316 preload Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3802—Instruction prefetching
- G06F9/3804—Instruction prefetching for branches, e.g. hedging, branch folding
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3802—Instruction prefetching
- G06F9/3804—Instruction prefetching for branches, e.g. hedging, branch folding
- G06F9/3806—Instruction prefetching for branches, e.g. hedging, branch folding using address prediction, e.g. return stack, branch history buffer
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3802—Instruction prefetching
- G06F9/3808—Instruction prefetching for instruction reuse, e.g. trace cache, branch target cache
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3802—Instruction prefetching
- G06F9/3808—Instruction prefetching for instruction reuse, e.g. trace cache, branch target cache
- G06F9/381—Loop buffering
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3861—Recovery, e.g. branch miss-prediction, exception handling
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Advance Control (AREA)
- Executing Machine-Instructions (AREA)
Description
プログラムメモリユニット3は、通常、コンピュータプログラムを動作させるための命令及び規則一式を記憶し、一方、データメモリユニット2は、通常、予め生成された(即ち、静的な)データやスクラッチパッド(即ち、動的な)データ等の、プログラム命令を動作させつつ生成されたデータを記憶する。しかしながら、メモリ又は複数のメモリに命令やデータを記憶するための他の構成を用いてもよい。
・IF1−プログラムメモリアドレス(プログラム制御ユニット8によって動作)
・IF2−プログラムメモリをフェッチ(フェッチユニット12によって動作)
・D1−命令ディスパッチ(プログラム制御ユニット8によって動作)
・D2−命令復号(復号ユニット6によって動作)
・D3乃至D4−レジスタファイル読み出し(レジスタファイル9を用いる)
・E1乃至E4−実行、データメモリアクセス、及びレジスタファイル書き戻し(実行ユニット11、ロード/ストアユニット7、及びレジスタファイル9によって動作)
他の又は追加のパイプラインステージ及び動作装置構成要素を用いてもよい。
しかしながら、予測された分岐命令が実際の分岐命令と合致しない場合、実際の分岐命令は、プログラムメモリ3からフェッチする。従って、分岐メカニズム14が分岐結果を誤予測する度に、プロセスは、プログラムメモリ3から正しい命令をフェッチするという、例えば、3サイクル(IF1乃至D1)の時間遅延及び演算ペナルティを被る。この時間遅延又はサイクル数は、異なるプロセッサ1のパイプラインに対して変わる。
図2−4において、表中の各行は、単一の命令のプロセッサパイプラインステージを示す。(列1に列挙された)命令は、処理する順番に、即ち、命令が最初にプロセッサパイプラインに(動作IF1において)投入する順番に、一連の行に順序よく並べられる。一連の各列は、一連の各演算サイクルにおいて生じる命令で実行される動作を示す。即ち、一旦、各行の命令が最初にプロセッサパイプラインに入ると、一連の各列において、プロセッサは、命令により一連の動作、例えば、プログラムメモリアドレス指定(IF1)、フェッチ処理(IF2)、ディスパッチ処理(D1)、復号処理(D2)、レジスタファイル読み出し(D3乃至D4)、実行、データメモリアクセス、及びレジスタファイル書き戻し(E1乃至E4)を実行する。他の又は追加の動作を用いてもよい。
・buf_validがクリアされ、buf_activeがクリアされる場合、プログラムカウンタは、BMB17の範囲外にある命令にアクセスする。この状況では、命令は、プログラムメモリ3からフェッチする。
・buf_validがクリアされ、buf_activeが設定される場合、命令は、プログラムメモリ3からフェッチして、BMB17に書き込む。
・buf_validが設定され、buf_activeが設定される場合、命令は、BMB17から直接フェッチする。
・割込み又は選択された分岐により、BMB17の範囲外にあるプログラムアドレスにプログラムカウンタがジャンプした場合、buf_validが設定され、buf_activeがクリアされる。この状況では、命令は、プログラムメモリ3からフェッチされる。サブルーチン又は割込みから戻る際、buf_activeを設定する(又は他の選択肢として、一旦、brloop_write命令に遭遇した時のみ、buf_activeを設定する)。
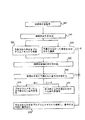
動作500時、プロセッサは、条件分岐命令を復号する。
動作510時、分岐予測ユニットは、分岐に続く後続の命令を予測する。
動作525時、プロセッサは、予測されなかった命令を分岐誤予測バッファ(BMB)から、例えば、命令キャッシュタグと合致するBMBキャッシュタグの有無をチェックすることによって、検索する。動作520及び525は、実質的に同時に、例えば、同じクロックサイクルにおいて動作させる。
動作540時、プロセッサは、分岐に続く実際の後続の命令と、プログラムメモリから検索された予測された命令とを比較する。実際の命令が予測された命令と合致する場合、プロセスは、動作550に進む。実際の命令が予測された命令と合致しない場合、プロセスは、動作560に進む。
動作560時、プロセッサは、BMBから検索された予測されなかった命令を復号する。
他の動作又は一連の動作を用いてもよい。
Claims (11)
- 分岐予測器と、プログラムメモリと、分岐誤予測バッファとを備え、
分岐予測器は、条件分岐命令についての分岐予測を行うものであり、
プログラムメモリは、分岐予測器による分岐予測により予測された分岐方向にある命令が検索されるものであり、
分岐予測器により予測された分岐方向にある命令がプログラムメモリにおいて検索されるのと同時に、分岐誤予測バッファは、分岐予測器による分岐予測により予測されなかった分岐方向にある命令を得ることが試みられるものであり、
プログラムメモリは、分岐予測器による分岐予測が正しくなかったことが判明し、かつ、分岐誤予測バッファに、分岐予測器による分岐予測により予測されなかった分岐方向にある命令が存在しなかったことが判明したときに、分岐予測器による分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令が検索されるものであり、
分岐誤予測バッファは、分岐予測器による分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令が、プログラムメモリから検索されたときに、その検索された命令を記憶するものである、システム。 - 請求項1に記載のシステムにおいて、プロセッサをさらに備え、
プロセッサは、プロセッサパイプラインにおいて、条件分岐命令を復号した後に、条件分岐命令による実際の分岐方向にある命令を復号するものである、システム。 - 請求項1に記載のシステムにおいて、プロセッサをさらに備え、
プロセッサは、条件分岐命令による実際の分岐方向が判明した後に、分岐予測器による分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令を復号するものである、システム。 - 請求項1に記載のシステムにおいて、分岐誤予測バッファは、ディスパッチされる命令を記憶するものである、システム。
- 請求項1に記載のシステムにおいて、分岐誤予測バッファは、最長時間未使用法(LRU)アルゴリズムを用いて命令を記憶するものである、システム。
- 請求項1に記載のシステムにおいて、分岐誤予測バッファは、ループを形成する命令も記憶するものである、システム。
- 条件分岐命令についての分岐予測により予測された分岐方向にある命令をプログラムメモリから検索する段階と、
条件分岐命令についての分岐予測により予測された分岐方向にある命令をプログラムメモリから検索する段階と同時に、条件分岐命令についての分岐予測により予測されなかった分岐方向にある命令を分岐誤予測バッファから得ることを試みる段階と、
条件分岐命令についての分岐予測が正しくなかったことが判明し、かつ、分岐誤予測バッファに、条件分岐命令についての分岐予測により予測されなかった分岐方向にある命令が存在しなかったことが判明したときに、条件分岐命令についての分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令を、プログラムメモリから検索する段階と、
条件分岐命令についての分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令が、プログラムメモリから検索されたときに、その検索された命令を分岐誤予測バッファに記憶する段階と、を備える方法。 - 請求項7に記載の方法において、条件分岐命令による実際の分岐方向が判明した後に、条件分岐命令についての分岐予測により予測されなかった分岐方向にある命令であって、条件分岐命令による実際の分岐方向にある命令を復号する段階を更に備えた方法。
- 請求項7に記載の方法において、分岐誤予測バッファは、ディスパッチされた命令を記憶するものである、方法。
- 請求項7に記載の方法において、
分岐誤予測バッファに、ループを形成する命令も記憶する段階と、
ループを形成する命令のうちの分岐命令において分岐が成立する間は、分岐誤予測バッファからループを形成する命令を得る段階と、を更に備えた方法。 - 請求項7に記載の方法において、分岐誤予測バッファは、最長時間未使用法(LRU)アルゴリズムを用いて命令を記憶するものである、方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/611,937 | 2009-11-04 | ||
| US12/611,937 US9952869B2 (en) | 2009-11-04 | 2009-11-04 | System and method for using a branch mis-prediction buffer |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2011100454A JP2011100454A (ja) | 2011-05-19 |
| JP2011100454A5 JP2011100454A5 (ja) | 2013-12-19 |
| JP5520779B2 true JP5520779B2 (ja) | 2014-06-11 |
Family
ID=43413571
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010246340A Active JP5520779B2 (ja) | 2009-11-04 | 2010-11-02 | 分岐誤予測バッファを用いるためのシステム及び方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US9952869B2 (ja) |
| EP (1) | EP2330500B1 (ja) |
| JP (1) | JP5520779B2 (ja) |
| CA (1) | CA2719615C (ja) |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120005462A1 (en) * | 2010-07-01 | 2012-01-05 | International Business Machines Corporation | Hardware Assist for Optimizing Code During Processing |
| US9342432B2 (en) | 2011-04-04 | 2016-05-17 | International Business Machines Corporation | Hardware performance-monitoring facility usage after context swaps |
| US8868886B2 (en) | 2011-04-04 | 2014-10-21 | International Business Machines Corporation | Task switch immunized performance monitoring |
| US20130055033A1 (en) | 2011-08-22 | 2013-02-28 | International Business Machines Corporation | Hardware-assisted program trace collection with selectable call-signature capture |
| US8874884B2 (en) | 2011-11-04 | 2014-10-28 | Qualcomm Incorporated | Selective writing of branch target buffer when number of instructions in cache line containing branch instruction is less than threshold |
| US9235419B2 (en) | 2012-06-11 | 2016-01-12 | International Business Machines Corporation | Branch target buffer preload table |
| US9557999B2 (en) * | 2012-06-15 | 2017-01-31 | Apple Inc. | Loop buffer learning |
| US9753733B2 (en) * | 2012-06-15 | 2017-09-05 | Apple Inc. | Methods, apparatus, and processors for packing multiple iterations of loop in a loop buffer |
| US9471322B2 (en) | 2014-02-12 | 2016-10-18 | Apple Inc. | Early loop buffer mode entry upon number of mispredictions of exit condition exceeding threshold |
| US9135015B1 (en) * | 2014-12-25 | 2015-09-15 | Centipede Semi Ltd. | Run-time code parallelization with monitoring of repetitive instruction sequences during branch mis-prediction |
| US10296346B2 (en) | 2015-03-31 | 2019-05-21 | Centipede Semi Ltd. | Parallelized execution of instruction sequences based on pre-monitoring |
| US10296350B2 (en) | 2015-03-31 | 2019-05-21 | Centipede Semi Ltd. | Parallelized execution of instruction sequences |
| US9916164B2 (en) * | 2015-06-11 | 2018-03-13 | Intel Corporation | Methods and apparatus to optimize instructions for execution by a processor |
| US10908902B2 (en) * | 2016-05-26 | 2021-02-02 | International Business Machines Corporation | Distance based branch prediction and detection of potential call and potential return instructions |
| JP2019101543A (ja) | 2017-11-29 | 2019-06-24 | サンケン電気株式会社 | プロセッサ及びパイプライン処理方法 |
| US10901743B2 (en) * | 2018-07-19 | 2021-01-26 | International Business Machines Corporation | Speculative execution of both paths of a weakly predicted branch instruction |
| US10915322B2 (en) * | 2018-09-18 | 2021-02-09 | Advanced Micro Devices, Inc. | Using loop exit prediction to accelerate or suppress loop mode of a processor |
| JP7100258B2 (ja) * | 2018-10-10 | 2022-07-13 | 富士通株式会社 | 演算処理装置及び演算処理装置の制御方法 |
| US11182166B2 (en) * | 2019-05-23 | 2021-11-23 | Samsung Electronics Co., Ltd. | Branch prediction throughput by skipping over cachelines without branches |
| CN110688160B (zh) * | 2019-09-04 | 2021-11-19 | 苏州浪潮智能科技有限公司 | 一种指令流水线处理方法、系统、设备及计算机存储介质 |
| JP7417159B2 (ja) * | 2020-04-07 | 2024-01-18 | 日本電信電話株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| WO2022212220A1 (en) * | 2021-03-27 | 2022-10-06 | Ceremorphic, Inc. | Mitigation of branch misprediction penalty in a hardware multi-thread microprocessor |
| US20220308887A1 (en) * | 2021-03-27 | 2022-09-29 | Redpine Signals, Inc. | Mitigation of branch misprediction penalty in a hardware multi-thread microprocessor |
| US20220308888A1 (en) * | 2021-03-27 | 2022-09-29 | Redpine Signals, Inc. | Method for reducing lost cycles after branch misprediction in a multi-thread microprocessor |
| JP7319439B1 (ja) | 2022-08-30 | 2023-08-01 | 株式会社スギノマシン | バリ取り工具 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS549456B2 (ja) | 1972-07-05 | 1979-04-24 | ||
| JPS6051948A (ja) | 1983-08-31 | 1985-03-23 | Hitachi Ltd | 情報処理装置 |
| JPH01106141A (ja) | 1987-10-19 | 1989-04-24 | Mitsubishi Electric Corp | データ処理装置 |
| GB9412487D0 (en) * | 1994-06-22 | 1994-08-10 | Inmos Ltd | A computer system for executing branch instructions |
| US5850542A (en) * | 1995-09-15 | 1998-12-15 | International Business Machines Corporation | Microprocessor instruction hedge-fetching in a multiprediction branch environment |
| US5734881A (en) * | 1995-12-15 | 1998-03-31 | Cyrix Corporation | Detecting short branches in a prefetch buffer using target location information in a branch target cache |
| SE510295C2 (sv) | 1997-07-21 | 1999-05-10 | Ericsson Telefon Ab L M | Metod vid processor för att hantera villkorade hoppinstruktioner samt processor anpassad att verka enligt den angivna metoden |
| US8285976B2 (en) * | 2000-12-28 | 2012-10-09 | Micron Technology, Inc. | Method and apparatus for predicting branches using a meta predictor |
| US7010675B2 (en) * | 2001-07-27 | 2006-03-07 | Stmicroelectronics, Inc. | Fetch branch architecture for reducing branch penalty without branch prediction |
| US6918030B2 (en) * | 2002-01-10 | 2005-07-12 | International Business Machines Corporation | Microprocessor for executing speculative load instructions with retry of speculative load instruction without calling any recovery procedures |
| US7197630B1 (en) * | 2004-04-12 | 2007-03-27 | Advanced Micro Devices, Inc. | Method and system for changing the executable status of an operation following a branch misprediction without refetching the operation |
| WO2006057084A1 (ja) * | 2004-11-25 | 2006-06-01 | Matsushita Electric Industrial Co., Ltd. | 命令供給装置 |
| US7437543B2 (en) * | 2005-04-19 | 2008-10-14 | International Business Machines Corporation | Reducing the fetch time of target instructions of a predicted taken branch instruction |
| TWI328771B (en) * | 2005-07-15 | 2010-08-11 | Nvidia Corp | Pipelined central processing unit structure and method of processing a sequence of instructions |
-
2009
- 2009-11-04 US US12/611,937 patent/US9952869B2/en active Active
-
2010
- 2010-10-27 EP EP10189135.6A patent/EP2330500B1/en active Active
- 2010-11-02 JP JP2010246340A patent/JP5520779B2/ja active Active
- 2010-11-02 CA CA2719615A patent/CA2719615C/en active Active
-
2018
- 2018-01-23 US US15/877,408 patent/US10409605B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011100454A (ja) | 2011-05-19 |
| US20110107071A1 (en) | 2011-05-05 |
| US20180210735A1 (en) | 2018-07-26 |
| EP2330500A1 (en) | 2011-06-08 |
| US10409605B2 (en) | 2019-09-10 |
| CA2719615A1 (en) | 2011-05-04 |
| US9952869B2 (en) | 2018-04-24 |
| EP2330500B1 (en) | 2013-08-28 |
| CA2719615C (en) | 2019-04-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5520779B2 (ja) | 分岐誤予測バッファを用いるためのシステム及び方法 | |
| US7917731B2 (en) | Method and apparatus for prefetching non-sequential instruction addresses | |
| US9378020B2 (en) | Asynchronous lookahead hierarchical branch prediction | |
| EP3850480B1 (en) | Controlling accesses to a branch prediction unit for sequences of fetch groups | |
| US8578141B2 (en) | Loop predictor and method for instruction fetching using a loop predictor | |
| TW200813822A (en) | D-cache miss prediction and scheduling | |
| US20070186049A1 (en) | Self prefetching L2 cache mechanism for instruction lines | |
| US11099850B2 (en) | Branch prediction circuitry comprising a return address prediction structure and a branch target buffer structure | |
| US20120311308A1 (en) | Branch Predictor with Jump Ahead Logic to Jump Over Portions of Program Code Lacking Branches | |
| US8028180B2 (en) | Method and system for power conservation in a hierarchical branch predictor | |
| US10853075B2 (en) | Controlling accesses to a branch prediction unit for sequences of fetch groups | |
| US20080040576A1 (en) | Associate Cached Branch Information with the Last Granularity of Branch instruction in Variable Length instruction Set | |
| EP4020167A1 (en) | Accessing a branch target buffer based on branch instruction information | |
| US10922082B2 (en) | Branch predictor | |
| US10740102B2 (en) | Hardware mechanism to mitigate stalling of a processor core | |
| EP2348399B1 (en) | System and method for processing interrupts in a computing system | |
| EP4081899A1 (en) | Controlling accesses to a branch prediction unit for sequences of fetch groups |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20120112 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131101 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20131101 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20131101 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20131125 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20131203 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140228 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140311 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140407 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5520779 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |