JP5384483B2 - マルチプレクサを設計する方法及び装置 - Google Patents
マルチプレクサを設計する方法及び装置 Download PDFInfo
- Publication number
- JP5384483B2 JP5384483B2 JP2010510350A JP2010510350A JP5384483B2 JP 5384483 B2 JP5384483 B2 JP 5384483B2 JP 2010510350 A JP2010510350 A JP 2010510350A JP 2010510350 A JP2010510350 A JP 2010510350A JP 5384483 B2 JP5384483 B2 JP 5384483B2
- Authority
- JP
- Japan
- Prior art keywords
- multiplexer
- multiplexers
- representation
- integrated circuit
- partition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/32—Circuit design at the digital level
- G06F30/327—Logic synthesis; Behaviour synthesis, e.g. mapping logic, HDL to netlist, high-level language to RTL or netlist
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/34—Circuit design for reconfigurable circuits, e.g. field programmable gate arrays [FPGA] or programmable logic devices [PLD]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/34—Circuit design for reconfigurable circuits, e.g. field programmable gate arrays [FPGA] or programmable logic devices [PLD]
- G06F30/343—Logical level
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/39—Circuit design at the physical level
- G06F30/392—Floor-planning or layout, e.g. partitioning or placement
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03K—PULSE TECHNIQUE
- H03K19/00—Logic circuits, i.e. having at least two inputs acting on one output; Inverting circuits
- H03K19/02—Logic circuits, i.e. having at least two inputs acting on one output; Inverting circuits using specified components
- H03K19/173—Logic circuits, i.e. having at least two inputs acting on one output; Inverting circuits using specified components using elementary logic circuits as components
- H03K19/1733—Controllable logic circuits
- H03K19/1737—Controllable logic circuits using multiplexers
Landscapes
- Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Geometry (AREA)
- Evolutionary Computation (AREA)
- Architecture (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Design And Manufacture Of Integrated Circuits (AREA)
- Logic Circuits (AREA)
- Electronic Switches (AREA)
Description
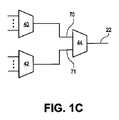
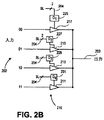
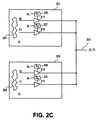
202:入力
203:出力
204:選択ライン
211、213、215、217:3状態ドライバ
225、227、229:デコードロジック
251、253:集積回路
261、263:ロジック
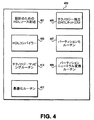
401:設計のためのHDLソース記述
403:HDLコンパイラー
405:テクノロジー独立のRTLネットリスト
407:パーティション化ルーチン
409:パーティションニュートラル変換ルーチン
411:最適化ルーチン
413:テクノロジーマッピングルーチン
501:プロセッサ
503:メモリ
505:大量記憶装置
507:バス
509:ディスプレイ装置
511:I/O装置
Claims (16)
- 実行時に、データ処理システムが、
第1マルチプレクサの表現を受け取るステップと、
前記第1マルチプレクサの表現を前記第1マルチプレクサのパーティションニュートラル表現へと分解するステップであって、前記パーティションニュートラル表現は、(a)複数の3状態ドライバ、(b)ワイヤードORアレイ、又は(c)ワイヤードANDアレイの1つを含む、前記分解するステップと、
少なくとも1つの集積回路の部分の間で前記第1マルチプレクサのパーティションニュートラル表現をパーティション化して、前記パーティションニュートラル表現から複数の第2マルチプレクサを生成し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置するステップと、
を備えた方法を遂行するようにさせる実行可能なプログラムインストラクションを含むマシン読み取り可能な記憶媒体。 - 前記複数の第2マルチプレクサは、第1サブセットのマルチプレクサ及び第2サブセットのマルチプレクサを含み、第1サブセットのマルチプレクサは、集積回路(IC)の第1部分に配置されるように設計されると共に、第2サブセットのマルチプレクサは、ICの第2部分に配置されるように設計され、第1サブセットは、1つ以上のマルチプレクサを含み、そして第2サブセットは、1つ以上のマルチプレクサを含む、請求項1に記載の記憶媒体。
- 前記第1マルチプレクサの表現は、RTLネットリスト内のレジスタ転送レベル(RTL)形態にあり、そして前記変換は、自動的に遂行される、請求項1に記載の記憶媒体。
- 前記方法は、前記第1マルチプレクサのデコードロジックを複製するステップを更に備えた、請求項1に記載の記憶媒体。
- 第1マルチプレクサの表現を受け取るステップと、
前記第1マルチプレクサの表現を前記第1マルチプレクサのパーティションニュートラル表現へと分解するステップであって、前記パーティションニュートラル表現は、(a)複数の3状態ドライバ、(b)ワイヤードORアレイ、又は(c)ワイヤードANDアレイの1つを含む、前記分解するステップと、
少なくとも1つの集積回路の部分の間で前記第1マルチプレクサのパーティションニュートラル表現をパーティション化して、前記パーティションニュートラル表現から複数の第2マルチプレクサを生成し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置するステップと、
を備えたマシン具現化方法。 - 第1マルチプレクサの表現を受け取る手段と、
前記第1マルチプレクサの表現を前記第1マルチプレクサのパーティションニュートラル表現へと分解する手段であって、前記パーティションニュートラル表現は、(a)複数の3状態ドライバ、(b)ワイヤードORアレイ、又は(c)ワイヤードANDアレイの1つを含む、前記分解する手段と、
少なくとも1つの集積回路の部分の間で前記第1マルチプレクサのパーティションニュートラル表現をパーティション化して、前記パーティションニュートラル表現から複数の第2マルチプレクサを生成し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置する手段と、
を備えたマシン。 - 実行時に、データ処理システムが、
出力を有する第1マルチプレクサの表現を受け取るステップと、
前記第1マルチプレクサの表現を第2マルチプレクサの複数の表現へと分解するステップであって、第2マルチプレクサは、前記第1マルチプレクサの出力に一致する共通出力において、第2マルチプレクサとその共通の出力との間にマルチプレクサを介在せずに、一緒に結合されるようなステップと、
前記第2マルチプレクサを少なくとも1つの集積回路の部分と部分との間でパーティション化し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置するステップと、
を備えた方法を遂行するようにさせる実行可能なプログラムインストラクションを含むマシン読み取り可能な記憶媒体。 - 前記第2マルチプレクサの複数の表現は、前記第1マルチプレクサのパーティションニュートラル形態である、請求項7に記載の記憶媒体。
- 出力を有する第1マルチプレクサの表現を受け取るステップと、
前記第1マルチプレクサの表現を第2マルチプレクサの複数の表現へと分解するステップであって、第2マルチプレクサは、前記第1マルチプレクサの出力に一致する共通出力において、第2マルチプレクサとその共通の出力との間にマルチプレクサを介在せずに、一緒に結合されるようなステップと、
前記第2マルチプレクサを少なくとも1つの集積回路の部分と部分との間でパーティション化し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置するステップと、
を備えたマシン具現化方法。 - 出力を有する第1マルチプレクサの表現を受け取る手段と、
前記第1マルチプレクサの表現を第2マルチプレクサの複数の表現へと分解する手段であって、第2マルチプレクサは、前記第1マルチプレクサの出力に一致する共通出力において、第2マルチプレクサとその共通の出力との間にマルチプレクサを介在せずに、一緒に結合されるような手段と、
前記第2マルチプレクサを少なくとも1つの集積回路の部分と部分との間でパーティション化し、集積回路の第1の部分に前記複数の第2マルチプレクサの1つを配置し、集積回路の第2の部分に前記複数の第2マルチプレクサの他の1つを配置する手段と、
を備えたマシン。 - 実行時に、データ処理システムが、
N入力加算器であるパーティションニュートラル分解を行うことのできる第1ロジックコンポーネントの表現を受け取るステップと、
前記第1ロジックコンポーネントの表現を、前記N入力加算器をワイヤーのバスとして表現するパーティションニュートラル表現へと分解するステップと、
少なくとも1つの集積回路の部分の間で前記パーティションニュートラル表現をパーティション化して前記パーティションニュートラル表現から複数のロジックコンポーネントを生成し、集積回路の第1の部分に前記複数のロジックコンポーネントの1つを配置し、集積回路の第2の部分に前記複数のロジックコンポーネントの他の1つを配置し、前記複数のロジックコンポーネントが共に結合されて前記第1ロジックコンポーネントの結果を与えるステップと、
を備えた方法を遂行するようにさせる実行可能なプログラムインストラクションを含むマシン読み取り可能な記憶媒体。 - 前記方法は、前記第1マルチプレクサの選択ラインを駆動するロジックを含むように前記第1マルチプレクサのデコードロジックを拡張することを更に含む、請求項1に記載の記憶媒体。
- 前記拡張は、前記変換の前に行われ、更に、前記拡張は、複製されるべき制御ロジックを定義するようにカットされた信号を含む、請求項12に記載の記憶媒体。
- 前記第1マルチプレクサの選択ラインを駆動するロジックを含むように前記第1マルチプレクサのデコードロジックを拡張することを更に含む、請求項5に記載の方法。
- 前記拡張は、前記変換の前に行われ、更に、前記拡張は、複製されるべき制御ロジックを定義するようにカットされた信号を含む、請求項14に記載の方法。
- 前記方法は、各パーティション内のパーティションニュートラル表現をRTL(レジスタ転送レベル)コンポーネントへと変換することを更に含む、請求項1に記載の記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/809,613 | 2007-05-31 | ||
| US11/809,613 US7730438B2 (en) | 2007-05-31 | 2007-05-31 | Methods and apparatuses for designing multiplexers |
| PCT/US2008/006831 WO2008150435A1 (en) | 2007-05-31 | 2008-05-30 | Methods and apparatuses for designing multiplexers |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2010530660A JP2010530660A (ja) | 2010-09-09 |
| JP2010530660A5 JP2010530660A5 (ja) | 2011-07-21 |
| JP5384483B2 true JP5384483B2 (ja) | 2014-01-08 |
Family
ID=39748526
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010510350A Active JP5384483B2 (ja) | 2007-05-31 | 2008-05-30 | マルチプレクサを設計する方法及び装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US7730438B2 (ja) |
| EP (1) | EP2153360A1 (ja) |
| JP (1) | JP5384483B2 (ja) |
| CN (1) | CN101790730B (ja) |
| WO (1) | WO2008150435A1 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8751986B2 (en) * | 2010-08-06 | 2014-06-10 | Synopsys, Inc. | Method and apparatus for automatic relative placement rule generation |
| JP6127807B2 (ja) * | 2013-07-26 | 2017-05-17 | 富士通株式会社 | 送信回路、通信システム及び通信方法 |
| US9361417B2 (en) | 2014-02-07 | 2016-06-07 | Synopsys, Inc. | Placement of single-bit and multi-bit flip-flops |
| JP6735095B2 (ja) * | 2015-12-25 | 2020-08-05 | ザインエレクトロニクス株式会社 | 信号多重化装置 |
| US10528692B1 (en) | 2017-11-07 | 2020-01-07 | Synopsis, Inc. | Cell-aware defect characterization for multibit cells |
| US12387022B2 (en) * | 2022-03-02 | 2025-08-12 | Taiwan Semiconductor Manufacturing Company, Ltd. | Apparatus and method of optimizing an integrated circuit design |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0651343B1 (en) * | 1988-10-05 | 2004-04-28 | Quickturn Design Systems, Inc. | Method of using electronically reconfigurable gate array logic and apparatus formed thereby |
| US6505337B1 (en) * | 1998-11-24 | 2003-01-07 | Xilinx, Inc. | Method for implementing large multiplexers with FPGA lookup tables |
| US6438735B1 (en) | 1999-05-17 | 2002-08-20 | Synplicity, Inc. | Methods and apparatuses for designing integrated circuits |
| US6449762B1 (en) | 1999-10-07 | 2002-09-10 | Synplicity, Inc. | Maintaining correspondence between text and schematic representations of circuit elements in circuit synthesis |
| US6711729B1 (en) * | 2000-12-05 | 2004-03-23 | Synplicity, Inc. | Methods and apparatuses for designing integrated circuits using automatic reallocation techniques |
| US6973632B1 (en) | 2002-06-11 | 2005-12-06 | Synplicity, Inc. | Method and apparatus to estimate delay for logic circuit optimization |
| US7506278B1 (en) * | 2005-03-08 | 2009-03-17 | Xilinx, Inc. | Method and apparatus for improving multiplexer implementation on integrated circuits |
-
2007
- 2007-05-31 US US11/809,613 patent/US7730438B2/en active Active
-
2008
- 2008-05-30 WO PCT/US2008/006831 patent/WO2008150435A1/en not_active Ceased
- 2008-05-30 EP EP08767951A patent/EP2153360A1/en not_active Ceased
- 2008-05-30 CN CN2008800181264A patent/CN101790730B/zh active Active
- 2008-05-30 JP JP2010510350A patent/JP5384483B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN101790730A (zh) | 2010-07-28 |
| EP2153360A1 (en) | 2010-02-17 |
| US7730438B2 (en) | 2010-06-01 |
| WO2008150435A1 (en) | 2008-12-11 |
| CN101790730B (zh) | 2013-10-23 |
| JP2010530660A (ja) | 2010-09-09 |
| US20080301608A1 (en) | 2008-12-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8640061B2 (en) | Automated circuit design | |
| Dally et al. | The role of custom design in ASIC chips | |
| US8095899B1 (en) | Verifiable multimode multipliers | |
| US20080005716A1 (en) | Method for programming a mask-programmable logic device and device so programmed | |
| CN103870390B (zh) | 用于支持统一的调试环境的方法和装置 | |
| US9026967B1 (en) | Method and apparatus for designing a system on multiple field programmable gate array device types | |
| JP5384483B2 (ja) | マルチプレクサを設計する方法及び装置 | |
| US10790829B2 (en) | Logic circuits with simultaneous dual function capability | |
| US8402400B1 (en) | Method and apparatus for implementing a processor interface block with an electronic design automation tool | |
| US8793629B1 (en) | Method and apparatus for implementing carry chains on FPGA devices | |
| US7171633B1 (en) | Estimating quality during early synthesis | |
| EP3722985A1 (en) | Method and apparatus for implementing an application aware system on a programmable logic device | |
| US8578306B2 (en) | Method and apparatus for performing asynchronous and synchronous reset removal during synthesis | |
| US8443334B1 (en) | Method and apparatus for generating graphical representations of slack potential for slack paths | |
| US11216249B2 (en) | Method and apparatus for performing field programmable gate array packing with continuous carry chains | |
| Raaijmakers | Run-Time Partial Reconfiguration on the Virtex-II Pro | |
| CN107632816B (zh) | 通过在设计编制期间替换用于执行除法的部件来改进系统操作的方法和设备 | |
| US9891904B1 (en) | Method and apparatus for optimizing implementation of a soft processor executing a fixed program on a target device | |
| US9355198B1 (en) | Method and apparatus for performing late binding of control status registers in a design compilation flow | |
| US8281271B1 (en) | Method and apparatus for performing lutmask based delay modeling | |
| Palma et al. | Core Communication Interface for FPGAs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110530 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110530 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120726 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130213 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130228 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20130531 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20130607 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20130701 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20130708 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130731 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130902 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20131002 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5384483 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |