JP4920395B2 - 動画要約自動作成装置、方法、及びコンピュータ・プログラム - Google Patents
動画要約自動作成装置、方法、及びコンピュータ・プログラム Download PDFInfo
- Publication number
- JP4920395B2 JP4920395B2 JP2006334555A JP2006334555A JP4920395B2 JP 4920395 B2 JP4920395 B2 JP 4920395B2 JP 2006334555 A JP2006334555 A JP 2006334555A JP 2006334555 A JP2006334555 A JP 2006334555A JP 4920395 B2 JP4920395 B2 JP 4920395B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- image data
- scene
- video
- moving image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Description
前記動画データを前記シーンに分割し、分割した前記シーンごとにシーン動画データを抽出するシーン抽出部と、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成する音声認識部と、
前記テキストデータからキーワードとなる重要語を抽出する重要語抽出部と、
前記シーン動画データから前記シーンを代表する画像となる代表画像データを抽出する代表画像抽出部と、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して動画要約データを作成するシーン統合部と、を備える動画要約自動作成装置。
前記重要語抽出部は、前記文字データと、前記音声認識部により生成された前記テキストデータと、から重要語を抽出する、(1)記載の動画要約自動作成装置。
前記動画データを前記シーンに分割し、分割した前記シーンごとにシーン動画データを抽出するステップと、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成するステップと、
前記テキストデータからキーワードとなる重要語を抽出するステップと、
前記シーン動画データから前記シーンを代表する画像となる代表画像データを抽出するステップと、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して動画要約データを作成するステップと、を含む動画要約自動作成方法。
前記重要語を抽出するステップは、前記文字データと、前記テキストデータを生成するステップにより生成された前記テキストデータと、から重要語を抽出する、(6)記載の動画要約自動作成方法。
前記動画データを前記シーンに分割し、分割した前記シーンごとにシーン動画データを抽出するステップと、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成するステップと、
前記テキストデータからキーワードとなる重要語を抽出するステップと、
前記シーン動画データから前記シーンを代表する画像となる代表画像データを抽出するステップと、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して動画要約データを作成するステップと、をコンピュータに実行させるコンピュータ・プログラム。
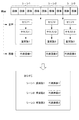
図1は、本発明の好適な実施形態の一例に係るコンピュータ・システム1の全体構成、及びあらすじ作成装置10の機能構成を示すブロック図である。
図2は、本発明の好適な実施形態の一例に係るあらすじ作成装置10によりあらすじが作成されるまでの概念図を示したものである。
図3は、本発明の好適な実施形態の一例に係るあらすじ作成装置10によりシーンを切り分ける例を示したものである。
図4は、本発明の好適な実施形態の一例に係るメイン処理であるあらすじ作成処理についてのメインフローを示したものである。

図9は、本発明の好適な実施形態の一例に係るあらすじ作成装置10のハードウェア構成を示す図である。あらすじ作成装置10は、シーン抽出部51、音声認識部52、重要語抽出部53、代表画像抽出部54、及びシーン統合部55を含む、制御部50を構成するCPU(Central Processing Unit)110(マルチプロセッサ構成ではCPU120等複数のCPUが追加されてもよい)、バスライン105、通信I/F140、メインメモリ150、BIOS(Basic Input Output System)160、USBポート190、I/Oコントローラ170、並びにキーボード及びマウス180等の入力手段や表示装置122を備える。
10 あらすじ作成装置
20 ユーザ端末
30 通信回線
50 制御部
51 シーン抽出部
52 音声認識部
53 重要語抽出部
54 代表画像抽出部
55 シーン統合部
60 記憶部
62 動画DB
64 代表画像抽出DB
66 あらすじDB
Claims (6)
- 複数の画像データと音声データとにより構成された動画データを、ひとかたまりの前記画像データにより構成されるシーン毎に分割し、分割した前記シーンごとの動画データをシーン動画データとして抽出するシーン抽出部と、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成する音声認識部と、
前記シーンごとに、前記生成されたテキストデータから前記シーンの重要語をそれぞれ抽出する重要語抽出部と、
前記シーン動画データに含まれる画像データから前記シーンを代表する画像となる代表画像データを選択し抽出する代表画像抽出部と、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して統合データを作成し、この作成した各シーンの前記統合データを順番につなぎ合わせて動画要約データを作成するシーン統合部と、
を備え、
前記代表画像抽出部は、前記シーン動画データを構成する画像データからオブジェクトを抽出し、前記画像データの全体の表示面積、前記オブジェクトの表示面積、前記オブジェクトを含む画像データ数、及び前記シーン動画データを構成する画像データ数から、所定の計算式で算出した結果を用いて前記代表画像データを導き出す、動画要約自動作成装置。 - 前記動画データは、前記画像データと共に文字データをさらに有し、
前記重要語抽出部は、前記文字データと、前記音声認識部により生成された前記テキストデータと、から重要語を抽出する、請求項1記載の動画要約自動作成装置。 - 前記重要語抽出部は、前記テキストデータに対してTF*IDF法を用いて前記重要語を抽出する、請求項1又は2記載の動画要約自動作成装置。
- 前記シーン統合部は、前記シーン動画データごとに作成された前記動画要約データを、さらに前記動画データの最初に表示されるように統合する、請求項1乃至3のいずれか1項に記載の動画要約自動作成装置。
- 複数の画像データと音声データとにより構成された動画データを、ひとかたまりの前記画像データにより構成されるシーン毎に分割し、分割した前記シーンごとの動画データをシーン動画データとして抽出するステップと、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成するステップと、
前記シーンごとに、前記生成されたテキストデータから前記シーンの重要語をそれぞれ抽出するステップと、
前記シーン動画データを構成する画像データからオブジェクトを抽出し、前記画像データの全体の表示面積、前記オブジェクトの表示面積、前記オブジェクトを含む画像データ数、及び前記シーン動画データを構成する画像データ数から、所定の計算式で算出した結果を用いて、前記シーンを代表する画像となる代表画像データを導き出すステップと、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して統合データを作成し、この作成した各シーンの前記統合データを順番につなぎ合わせて動画要約データを作成するステップと、の全ステップを動画要約自動作成装置が実行する動画要約自動作成方法。 - 複数の画像データと音声データとにより構成された動画データを、ひとかたまりの前記画像データにより構成されるシーン毎に分割し、分割した前記シーンごとの動画データをシーン動画データとして抽出するステップと、
前記シーン動画データに含まれる音声データを認識し、前記音声データからテキストデータを生成するステップと、
前記シーンごとに、前記生成されたテキストデータから前記シーンの重要語をそれぞれ抽出するステップと、
前記シーン動画データを構成する画像データからオブジェクトを抽出し、前記画像データの全体の表示面積、前記オブジェクトの表示面積、前記オブジェクトを含む画像データ数、及び前記シーン動画データを構成する画像データ数から、所定の計算式で算出した結果を用いて、前記シーンを代表する画像となる代表画像データを導き出すステップと、
前記重要語と、前記代表画像データと、を前記シーンごとに統合して統合データを作成し、この作成した各シーンの前記統合データを順番につなぎ合わせて動画要約データを作成するステップと、
をコンピュータに実行させるためのコンピュータ・プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006334555A JP4920395B2 (ja) | 2006-12-12 | 2006-12-12 | 動画要約自動作成装置、方法、及びコンピュータ・プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006334555A JP4920395B2 (ja) | 2006-12-12 | 2006-12-12 | 動画要約自動作成装置、方法、及びコンピュータ・プログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2008148121A JP2008148121A (ja) | 2008-06-26 |
| JP2008148121A5 JP2008148121A5 (ja) | 2009-05-07 |
| JP4920395B2 true JP4920395B2 (ja) | 2012-04-18 |
Family
ID=39607780
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006334555A Expired - Fee Related JP4920395B2 (ja) | 2006-12-12 | 2006-12-12 | 動画要約自動作成装置、方法、及びコンピュータ・プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4920395B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015108236A1 (ko) * | 2014-01-14 | 2015-07-23 | 삼성테크윈 주식회사 | 요약 영상 브라우징 시스템 및 방법 |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011049919A (ja) | 2009-08-28 | 2011-03-10 | Sanyo Electric Co Ltd | 画像処理装置 |
| JP5537285B2 (ja) * | 2010-06-28 | 2014-07-02 | 日本放送協会 | 要約映像生成装置及び要約映像生成プログラム |
| KR101883178B1 (ko) * | 2011-10-12 | 2018-07-30 | 엘지전자 주식회사 | 영상표시장치 및 그 동작방법 |
| KR101956373B1 (ko) * | 2012-11-12 | 2019-03-08 | 한국전자통신연구원 | 요약 정보 생성 방법, 장치 및 서버 |
| JP6095381B2 (ja) * | 2013-01-25 | 2017-03-15 | キヤノン株式会社 | データ処理装置、データ処理方法及びプログラム |
| KR20160057864A (ko) | 2014-11-14 | 2016-05-24 | 삼성전자주식회사 | 요약 컨텐츠를 생성하는 전자 장치 및 그 방법 |
| JP6410329B2 (ja) * | 2014-12-26 | 2018-10-24 | Necディスプレイソリューションズ株式会社 | 映像記録作成装置、映像記録作成方法およびプログラム |
| KR101700040B1 (ko) * | 2015-07-06 | 2017-01-25 | 한국과학기술원 | 이미지 기반 동영상 콘텐츠 제공 방법 및 그 시스템 |
| US9906820B2 (en) | 2015-07-06 | 2018-02-27 | Korea Advanced Institute Of Science And Technology | Method and system for providing video content based on image |
| JP6973567B2 (ja) * | 2015-09-16 | 2021-12-01 | 富士フイルムビジネスイノベーション株式会社 | 情報処理装置及びプログラム |
| JP2017058978A (ja) * | 2015-09-16 | 2017-03-23 | 富士ゼロックス株式会社 | 情報処理装置及びプログラム |
| KR102085908B1 (ko) | 2018-05-10 | 2020-03-09 | 네이버 주식회사 | 컨텐츠 제공 서버, 컨텐츠 제공 단말 및 컨텐츠 제공 방법 |
| KR20210132855A (ko) | 2020-04-28 | 2021-11-05 | 삼성전자주식회사 | 음성 처리 방법 및 장치 |
| JP2023043782A (ja) * | 2021-09-16 | 2023-03-29 | ヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
| JP7225460B1 (ja) | 2021-12-27 | 2023-02-20 | 株式会社博報堂Dyホールディングス | 情報処理システム、データ加工方法、及びコンピュータプログラム |
| JP7164698B1 (ja) | 2021-12-27 | 2022-11-01 | 株式会社博報堂Dyホールディングス | 情報処理システム、データ加工方法、及びコンピュータプログラム |
| KR102652009B1 (ko) * | 2023-09-07 | 2024-03-27 | 아이보람 주식회사 | 모국어 습득 원리를 적용한 영어 교육을 수행함에 있어, 뉴럴 네트워크를 이용하여 사용자 단말에게 동영상을 기반으로 하는 이북을 제공하는 방법 및 장치 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3432348B2 (ja) * | 1996-01-30 | 2003-08-04 | 三菱電機株式会社 | 代表画像表示方法、代表画像表示装置およびこの装置を用いた動画検索装置 |
| JPH09247597A (ja) * | 1996-03-11 | 1997-09-19 | Mitsubishi Electric Corp | 磁気記録方法及び磁気記録再生装置 |
| JPH1139343A (ja) * | 1997-07-17 | 1999-02-12 | Media Rinku Syst:Kk | 映像検索装置 |
| JP3555418B2 (ja) * | 1997-12-11 | 2004-08-18 | 株式会社日立製作所 | 撮影装置及び撮影方法 |
| JP4253139B2 (ja) * | 2000-06-30 | 2009-04-08 | 株式会社東芝 | フレーム情報記述方法、フレーム情報生成装置及び方法、映像再生装置及び方法並びに記録媒体 |
| JP2002150751A (ja) * | 2000-11-07 | 2002-05-24 | Sony Corp | 記録再生装置及び記録方法 |
| JP4536940B2 (ja) * | 2001-01-26 | 2010-09-01 | キヤノン株式会社 | 画像処理装置、画像処理方法、記憶媒体、及びコンピュータプログラム |
| JP2004023661A (ja) * | 2002-06-19 | 2004-01-22 | Ricoh Co Ltd | 記録情報処理方法、記録媒体及び記録情報処理装置 |
| JP4127668B2 (ja) * | 2003-08-15 | 2008-07-30 | 株式会社東芝 | 情報処理装置、情報処理方法、およびプログラム |
| JP2005173731A (ja) * | 2003-12-08 | 2005-06-30 | Ricoh Co Ltd | コンテンツ縮約装置、コンテンツ縮約方法およびコンテンツ縮約プログラム |
| JP4168940B2 (ja) * | 2004-01-26 | 2008-10-22 | 三菱電機株式会社 | 映像表示システム |
| JP2006166407A (ja) * | 2004-11-09 | 2006-06-22 | Canon Inc | 撮像装置及びその制御方法 |
-
2006
- 2006-12-12 JP JP2006334555A patent/JP4920395B2/ja not_active Expired - Fee Related
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015108236A1 (ko) * | 2014-01-14 | 2015-07-23 | 삼성테크윈 주식회사 | 요약 영상 브라우징 시스템 및 방법 |
| US10032483B2 (en) | 2014-01-14 | 2018-07-24 | Hanwha Techwin Co., Ltd. | Summary image browsing system and method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2008148121A (ja) | 2008-06-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4920395B2 (ja) | 動画要約自動作成装置、方法、及びコンピュータ・プログラム | |
| KR102080315B1 (ko) | 동영상 서비스 제공 방법 및 이를 이용하는 서비스 서버 | |
| KR100684484B1 (ko) | 비디오 세그먼트를 다른 비디오 세그먼트 또는 정보원에링크시키는 방법 및 장치 | |
| US7181757B1 (en) | Video summary description scheme and method and system of video summary description data generation for efficient overview and browsing | |
| US8204317B2 (en) | Method and device for automatic generation of summary of a plurality of images | |
| KR100922390B1 (ko) | 멀티미디어 프리젠테이션들의 자동 콘텐트 분석 및 표현 | |
| JP4635891B2 (ja) | 情報処理装置および方法、並びにプログラム | |
| US20110243529A1 (en) | Electronic apparatus, content recommendation method, and program therefor | |
| TW202002611A (zh) | 視頻字幕顯示方法及裝置 | |
| JP2009181216A (ja) | 電子機器および画像処理方法 | |
| KR20160057864A (ko) | 요약 컨텐츠를 생성하는 전자 장치 및 그 방법 | |
| JP2006319980A (ja) | イベントを利用した動画像要約装置、方法及びプログラム | |
| JP2006163877A (ja) | メタデータ生成装置 | |
| CN110781328A (zh) | 基于语音识别的视频生成方法、系统、装置和存储介质 | |
| CN113626641B (zh) | 一种基于多模态数据和美学原理的神经网络生成视频摘要的方法 | |
| KR100374040B1 (ko) | 비디오 텍스트 합성 키 프레임 추출방법 | |
| CN103984772A (zh) | 文本检索字幕库生成方法和装置、视频检索方法和装置 | |
| US8406606B2 (en) | Playback apparatus and playback method | |
| Bost | A storytelling machine?: automatic video summarization: the case of TV series | |
| JP2005167456A (ja) | Avコンテンツ興趣特徴抽出方法及びavコンテンツ興趣特徴抽出装置 | |
| JP2021012466A (ja) | メタデータ生成システム、映像コンテンツ管理システム及びプログラム | |
| US20100204980A1 (en) | Real-time translation system with multimedia display function and method thereof | |
| CN113709561B (zh) | 视频剪辑方法、装置、设备及存储介质 | |
| WO2018115878A1 (en) | A method and system for digital linear media retrieval | |
| KR102523817B1 (ko) | 영상에서 등장하는 전문 용어에 대한 뜻풀이를 제공하는 전자 장치 및 그 동작 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090318 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090318 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110203 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110208 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110411 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110621 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110822 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120124 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120201 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4920395 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150210 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees | ||
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |