JP4804829B2 - 回路 - Google Patents
回路 Download PDFInfo
- Publication number
- JP4804829B2 JP4804829B2 JP2005243111A JP2005243111A JP4804829B2 JP 4804829 B2 JP4804829 B2 JP 4804829B2 JP 2005243111 A JP2005243111 A JP 2005243111A JP 2005243111 A JP2005243111 A JP 2005243111A JP 4804829 B2 JP4804829 B2 JP 4804829B2
- Authority
- JP
- Japan
- Prior art keywords
- network
- group
- arithmetic elements
- terminals
- arithmetic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/15—Interconnection of switching modules
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/10—Packet switching elements characterised by the switching fabric construction
- H04L49/101—Packet switching elements characterised by the switching fabric construction using crossbar or matrix
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/15—Interconnection of switching modules
- H04L49/1515—Non-blocking multistage, e.g. Clos
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L49/00—Packet switching elements
- H04L49/55—Prevention, detection or correction of errors
- H04L49/557—Error correction, e.g. fault recovery or fault tolerance
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Multi Processors (AREA)
Description
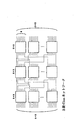
ロスバースイッチブロックのスイッチ数は、8×8=n0.5×n0.5 であり、このよう
なクロスバースイッチブロックが3段×8個=3×n0.5個設けられている。したがって
、図1を一般化すれば、スイッチの数は、3n1.5となる。
ットワーク入力端子を第1のネットワーク出力端子に接続したときに、第2のネットワーク入力端子をいずれかの第2のネットワーク出力端子にさらに接続することができない、そのようなネットワーク入力端子とネットワーク出力端子との組合せに対する制約が存在する閉塞ネットワーク網を構成し、前記ネットワーク出力端子のうちの2つのネットワーク出力端子が同時に接続することができないネットワーク入力端子の組に含まれるネットワーク入力端子数として定義される制約強度について、同一の演算素子に入力される複数の出力端子間の制約強度が最小となるように、前記演算素子とネットワーク出力端子とを接続した回路である。
本リコンフィギュラブル回路は、プロセッシングエレメント(本発明の演算素子に相当)として互換性のない複数種類のプロセッシングエレメントを接続したネットワークを想定する。そこで、本実施形態では、プロセッシングエレメントの入力の論理的互換性、およびプロセッシングエレメント間の論理的互換性を考慮して、基本閉塞ネットワーク網で接続することにより、一度に搭載できるアプリケーションの対象を拡大する回路構造を提案する。ここで、基本閉塞ネットワーク網は、ベースライン網や3キューブネットワーク
網といった3段のn×mのクロスバースイッチングブロック(以下、単にスイッチブロッ
クともいう)で構成したネットワークを想定する。
(評価基準1)各プロセッシングエレメントの入力端子間における距離が最小になるように接続する。なお、本実施形態では、各プロセッシングエレメントの入力端子間の代わりにその入力端子が接続されるネットワーク側の出力端子を用いて計算する場合がある。その場合に、上記評価基準1は、「各プロセッシングエレメントの入力端子に接続されるネットワーク側出力端子間における距離が最小になるように接続する。」と言い換えることができる。すなわち、本実施形態では、各プロセッシングエレメントの入力端子とその入力端子に接続されるネットワーク側の出力端子とは、等価なものとして取り扱う。
(評価基準2)互換性のあるプロセッシングエレメントの入力端子間の距離が最小になるように接続する。この評価基準2は、「互換性のあるプロセッシングエレメントの入力端子に接続されるネットワーク側出力端子間の距離が最小になるように接続する」と言い換えることができる。
子数;
またプロセッシングエレメントPkおよびPlの間の距離LP(k,l)を以下のように定義する。
Tiの接続先∈Pk,Tjの接続先∈Pl
これらの定義により、先ほどの評価基準1、2を表すと、以下の2つの関数がそれぞれ最小となるように接続することになる。優先度は、上から順に高いとする。
kはすべての演算素子 Ti,Tjの接続先∈Pk
F2()=Σ( ΣLP(k, l) );
すべての演算素子の種類 Pk,Plは同一種類の演算素子
《第1実施例》
実施例として、図2の8入力8出力の間接バイナリ3キューブネットワークを例にとる。このネットワークでは、端子間の距離は以下のようになる。
クの出力端子である場合)
LT(i,j)=2;(TiおよびTjが図2の第1段目のいずれかの1つのクロスバース
イッチブロックの1つの出力端子から到達可能な第3段目のクロスバースイッチブロックの出力端子である場合);
LT(i,j)=0;(上記以外の場合)
このような基本閉塞ネットワークを使用して、加算器2個(2入力1出力)、乗算器2個(2入力1出力)、外部入力2つ、レジスタ2つを接続する場合を考える。
Ak(k=0〜7):3ビットで表現される入力端子の番号であり、図9の000〜111である。
Bk(k=0〜7):3ビットで表現される出力端子の番号であり、図9の000〜111である。
Pk(k=0〜7):24ビットで表されるネットワークパターンの数値表現である。Pkの3kビット目から3k+2ビット目までの3ビットp3k+2p3k+1p3kはBkの出力端子に接続す
る入力端子の番号を示す。ここで、kは3ビットごとのビット位置を示す番号である。
図11に計算プログラムのフローチャートを示す。
を選んで(S2)、実装の可能性を検証する(S3)。まず、P0=00000000(8)(添え字の(8)は8進数であることを示す)を選択したとする。これは、すべての出力端子に0(8)=000(2)の番号の入力端子を接続するパターンである。実装性の検証は以下の2つの閉塞規則
にしたがってチェックする。
チブロックの2つの出力端子(図2におけるZ1とZ2、Z3とZ4、Z5とZ6、およびZ7とZ8のそれぞれの組)は、そのスイッチブロックの入力端子の1つにつながっているネットワーク入力端子の組(図2におけるX1〜X4の組またはX5〜X7の組)の中の異なる2つのネットワーク入力端子に同時に接続することはできない」を出力端子Bkに接続されるビットパターンで表現したものである。
同じで、かつ下位1ビット異なるものが存在する場合には実装できない。
されるビットパターンで表現したものである。
00(2)と5=101(2)であり、閉塞規則1に該当するため実装できない。しかしながら、図9
では、B0とB4は乗算器1の入力端子であるため、交換可能である。そこで、フローチャートの「同一プロセッシングエレメントの互換性のある入力端子への接続の入れ替え」を実施し、再度実装性について検証すると、実装可能であることが判明する。なぜなら、B0へ接続される入力端子は1=001(2)であり、B5への接続入力端子5=101(2)とは、閉塞規則1に該当しないからである。これによりP4196672=10004500(8)と互換性のある回路の実装が可能であることがわかる。
《第2実施例》
他の例として4入力4出力のクロスバースイッチを基本ブロックとし、それらを3段接続して構成した64入力64出力の間接3キューブネットワークを例に本発明を適用した例を説明する。図13は、4入力4出力のクロスバースイッチによる64入力64出力の間接3キューブネットワークの例である。
16のネットワーク出力端子(例えば、Ma20〜Ma23の16個の出力端子)につながっているため、これらの16のネットワーク出力端子は、1段目の各基本ブロックの4つの入力端子から1つしか選択することはできない。
2つの出力端子である場合)
LT(i,j)=4;(TiおよびTjが図13の第1段目のいずれかの基本ブロックの1
つの出力端子から到達可能な第3段目の基本ブロックの出力端子である場合);
LT(i,j)=0;(上記以外の場合)
今、このネットワークに対してALU(2入力1出力)14個、乗算器(2入力1出力)4個、内部メモリ(2入力1出力)4個、レジスタファイル4個(4入力8出力)、外部出力4、外部入力4をつなげる場合を考える。
子数が1ないし2となるように割り当てればよい。
このようにして、各プロセッシングエレメントの入力端子を図13のネットワークの出力端子にアサインした例を図15に示す。
上記第1実施形態および第2実施形態では、いずれも基本ブロックの行を3段組み合わせて構成されるネットワークの3段目の出力端子に異なる種類のプロセッシングエレメントを接続する場合において、アプリケーションの実装率を改善できる構成を説明した。しかし、本発明の実施は、そのような構成には、限定されない。
Claims (6)
- 入力されるデジタルデータに対して数値演算または論理演算を実行し、数値演算または論理演算の出力信号を出力する、複数の演算素子と、
前記演算素子の入力側に接続されるネットワーク出力端子と、
前記演算素子の出力信号または前記演算素子の出力信号以外の外部信号が入力されるネットワーク入力端子と、
前記ネットワーク入力端子をネットワーク出力端子に接続するネットワーク部と備え、
前記ネットワーク部は、
第1のネットワーク入力端子を第1のネットワーク出力端子に接続したときに、第2のネットワーク入力端子をいずれかの第2のネットワーク出力端子にさらに接続することができない、そのようなネットワーク入力端子とネットワーク出力端子との組合せに対する制約が存在する閉塞ネットワーク網を構成し、
前記ネットワーク出力端子間の距離LT(i,j)を以下の式により定義したときに、
ネットワーク出力端子の2つの組み(Ti、Tj)を前記距離LT(i,j)にしたがって分類したネットワーク出力端子TiのグループGiと、ネットワーク出力端子TjのグループGjとの間で、互いに距離LT(i,j)が最も小さくなるように前記ネットワーク出力端子が分類されており、
前記演算素子の2つの入力端子をそれぞれ異なるグループGi,Gjに含まれるネットワーク出力端子Ti,Tjに接続し、
前記グループGiにおいては、ネットワーク出力端子の2つの組み(Ti、Tj)を前記距離LT(i,j)にしたがって分類したネットワーク出力端子Tiのサブグループgiiと、ネットワーク出力端子Tjのサブグループgijとの間で、互いに距離LT(i,j)が最も小さくなるように前記ネットワーク出力端子が分類されており、同一種類の複数の演算素子の入力端子をそれぞれ異なるサブグループgii,gijに含まれるネットワーク出力端子Ti,Tjに接続し、
前記グループGjにおいては、ネットワーク出力端子の2つの組み(Ti、Tj)を前記距離LT(i,j)にしたがって分類したネットワーク出力端子Tiのサブグループgjiと、ネットワーク出力端子Tjのサブグループgjjとの間で、互いに距離LT(i,j)が最も小さくなるように分類されており、同一種類の複数の演算素子の入力端子をそれぞれ異なるグループgji,gjjに含まれるネットワーク出力端子Ti,Tjに接
続した回路。
(式1)
LT(i,j) = ネットワーク出力端子TiおよびTjが同時に接続することができないネットワーク入力端子数; - さらに、前記演算素子のうち、同一種類の演算を実行する複数の演算素子に接続される出力端子間の制約強度のすべての演算素子の種類についての合計が最小となるように、前記演算素子とネットワーク出力端子とを接続した請求項1に記載の回路。
- 前記ネットワーク出力端子が接続される演算素子PkおよびPlの間の制約強度LP(k,l)を以下の(式2)により定義したときに、2つの関数F1()およびF2()がそれぞれ最小となるように前記演算素子とネットワーク出力端子とを接続する請求項2に記載の回路。
(式2)
LP(k, l) = ΣLT(i, j);
Tiの接続先∈Pk,Tjの接続先∈Pl
F1()=Σ( ΣLT(i, j) );
kはすべての演算素子 Ti,Tjの接続先∈Pk
F2()=Σ( ΣLP(k,l) );
すべての演算素子の種類 Pk、Plは同一種類の演算素子 - 前記演算素子は、複数のグループに分離され、異なるグループに属する演算素子間で信号が授受されており、
前記ネットワーク部は、第1のネットワーク部と第2のネットワーク部とを有し、
前記第1のネットワーク部は、第1のグループの演算素子ないし第2のグループの演算素子の一部の出力信号を入力し、第1のグループの演算素子に出力信号を出力し、
前記第2のネットワーク部は、第1のグループの演算素子ないし第2のグループの演算素子の一部の出力信号を入力し、第2のグループの演算素子に出力信号を出力する請求項1から3のいずれかに記載の回路。 - 前記第1のネットワーク部は、前記第1のグループの演算素子と第2のグループの演算素子の出力端子と、前記第1のグループの演算素子の入力端子との間を接続し、
第2のネットワーク部は、前記第1のグループの演算素子と第2のグループの演算素子の出力端子と、前記第2のグループの演算素子の入力端子との間を接続する請求項4に記載の回路。 - 前記第1のネットワーク部と第2のネットワーク部とは、互いに直列に前記第1のグループの演算素子の出力端子と第2のグループの演算素子の入力端子との間、および前記第2のグループの演算素子の出力端子と第1のグループの演算素子の入力端子との間を接続する請求項4に記載の回路。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005243111A JP4804829B2 (ja) | 2005-08-24 | 2005-08-24 | 回路 |
| EP20060251789 EP1758322B1 (en) | 2005-08-24 | 2006-03-30 | Reconfigurable network of blocking type |
| US11/395,125 US7391234B2 (en) | 2005-08-24 | 2006-04-03 | Circuit and circuit connecting method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005243111A JP4804829B2 (ja) | 2005-08-24 | 2005-08-24 | 回路 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007058571A JP2007058571A (ja) | 2007-03-08 |
| JP4804829B2 true JP4804829B2 (ja) | 2011-11-02 |
Family
ID=36593627
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005243111A Expired - Fee Related JP4804829B2 (ja) | 2005-08-24 | 2005-08-24 | 回路 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7391234B2 (ja) |
| EP (1) | EP1758322B1 (ja) |
| JP (1) | JP4804829B2 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7768301B2 (en) * | 2006-01-17 | 2010-08-03 | Abound Logic, S.A.S. | Reconfigurable integrated circuits with scalable architecture including a plurality of special function elements |
| US7274215B2 (en) * | 2006-01-17 | 2007-09-25 | M2000 Sa. | Reconfigurable integrated circuits with scalable architecture including one or more adders |
| JP5907607B2 (ja) * | 2011-02-16 | 2016-04-26 | キヤノン株式会社 | 処理配置方法及びプログラム |
| CN111602126B (zh) * | 2017-10-31 | 2024-10-22 | 美光科技公司 | 具有混合线程处理器的系统、具有可配置计算元件的混合线程组构以及混合互连网络 |
| US11093251B2 (en) * | 2017-10-31 | 2021-08-17 | Micron Technology, Inc. | System having a hybrid threading processor, a hybrid threading fabric having configurable computing elements, and a hybrid interconnection network |
| EP3776243B1 (en) * | 2018-03-31 | 2025-01-01 | Micron Technology, Inc. | Backpressure control using a stop signal for a multi-threaded, self-scheduling reconfigurable computing fabric |
| US10831507B2 (en) | 2018-11-21 | 2020-11-10 | SambaNova Systems, Inc. | Configuration load of a reconfigurable data processor |
| US11188497B2 (en) | 2018-11-21 | 2021-11-30 | SambaNova Systems, Inc. | Configuration unload of a reconfigurable data processor |
| US10698853B1 (en) | 2019-01-03 | 2020-06-30 | SambaNova Systems, Inc. | Virtualization of a reconfigurable data processor |
| US11050680B2 (en) * | 2019-05-03 | 2021-06-29 | Raytheon Company | Non-blocking switch matrix for multi-beam antenna |
| US11386038B2 (en) | 2019-05-09 | 2022-07-12 | SambaNova Systems, Inc. | Control flow barrier and reconfigurable data processor |
| US11055141B2 (en) | 2019-07-08 | 2021-07-06 | SambaNova Systems, Inc. | Quiesce reconfigurable data processor |
| US11487694B1 (en) | 2021-12-17 | 2022-11-01 | SambaNova Systems, Inc. | Hot-plug events in a pool of reconfigurable data flow resources |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS5883943A (ja) * | 1981-11-12 | 1983-05-19 | オリンパス光学工業株式会社 | 超音波送受信装置 |
| JPS5894035A (ja) * | 1981-11-30 | 1983-06-04 | Nippon Telegr & Teleph Corp <Ntt> | デ−タ処理システム |
| JPS6024634A (ja) * | 1983-07-21 | 1985-02-07 | Matsushita Electric Ind Co Ltd | デイジタル信号処理装置 |
| JPH0771353B2 (ja) * | 1986-11-25 | 1995-07-31 | 日本電信電話株式会社 | スイツチング回路網の制御方法 |
| JP2786246B2 (ja) | 1989-05-09 | 1998-08-13 | 日本電信電話株式会社 | 自己ルーチング通話路 |
| JPH05189200A (ja) * | 1992-07-23 | 1993-07-30 | Matsushita Electric Ind Co Ltd | ディジタル信号処理装置 |
| US6745317B1 (en) * | 1999-07-30 | 2004-06-01 | Broadcom Corporation | Three level direct communication connections between neighboring multiple context processing elements |
| JP2001184335A (ja) * | 1999-12-24 | 2001-07-06 | Kanazawa Inst Of Technology | プログラマブル・ディジタル演算icとそのプログラマブル・ディジタル演算icを用いた装置ならびにそのプログラマブル・ディジタル演算icの製造方法 |
| US6754208B2 (en) * | 2001-03-19 | 2004-06-22 | Sycamore Networks, Inc. | Traffic spreading to reduce blocking in a groomed CLOS communication switch |
| US20040136717A1 (en) * | 2002-09-03 | 2004-07-15 | Xinxiong Zhang | Non-blocking tunable filter with flexible bandwidth for reconfigurable optical networks |
| EP1690354A2 (en) * | 2003-10-30 | 2006-08-16 | Teak Technologies, Inc. | Nonblocking and deterministic multicast packet scheduling |
-
2005
- 2005-08-24 JP JP2005243111A patent/JP4804829B2/ja not_active Expired - Fee Related
-
2006
- 2006-03-30 EP EP20060251789 patent/EP1758322B1/en not_active Not-in-force
- 2006-04-03 US US11/395,125 patent/US7391234B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007058571A (ja) | 2007-03-08 |
| US20070046326A1 (en) | 2007-03-01 |
| EP1758322B1 (en) | 2013-04-24 |
| US7391234B2 (en) | 2008-06-24 |
| EP1758322A1 (en) | 2007-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1758322B1 (en) | Reconfigurable network of blocking type | |
| JP3202074B2 (ja) | 並列ソート方式 | |
| JPH0766718A (ja) | プログラム可能論理用ウェファ・スケール構造 | |
| US10412025B2 (en) | Fast scheduling and optmization of multi-stage hierarchical networks | |
| Masson | Binomial switching networks for concentration and distribution | |
| US5299317A (en) | Method and apparatus for simulating an interconnection network | |
| Jahanshahi et al. | A new approach to improve reliability of the multistage interconnection networks | |
| CN113114220B (zh) | 一种具有重映射功能的芯片系统及芯片重映射配置系统 | |
| Chen et al. | Fault-tolerant gamma interconnection networks by chaining | |
| Fu | Hamiltonicity of the WK-recursive network with and without faulty nodes | |
| CN101141374A (zh) | 自路由集线器以分治网络构成交换结构的方法 | |
| Anderson et al. | Performance-based constraints for multidimensional networks | |
| Zegura | Evaluating blocking probability in generalized connectors | |
| Bruneel et al. | TROUTE: A reconfigurability-aware FPGA router | |
| US12015566B1 (en) | Fast scheduling and optimization of multi-stage hierarchical networks | |
| Sengupta | Interconnection networks for parallel processing | |
| JP3532102B2 (ja) | 間接ローテータグラフネットワーク及び間接ローテータグラフネットワークにおける伝送経路の設定方法 | |
| CN1984011B (zh) | 数据传输网络和数据传输网络的运用方法 | |
| Aulakh | Reliability analysis of MUX-DEMUX replicated multistage interconnection networks | |
| Rau et al. | Destination tag routing techniques based on a state model for the LADM network | |
| Nitin et al. | A New Fault-Tolerant Routing Algorithm for MALN-2 | |
| Giglmayr | Spatial extension of multistage interconnection networks | |
| Chen et al. | Rearrangeable nonblocking optical interconnection network fabrics with crosstalk constraints | |
| Zhou et al. | Adaptive message routing in a class of fault-tolerant multistage interconnection networks | |
| Biswas et al. | A centrally controlled shuffle network for reconfigurable and fault-tolerant architecture |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080321 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100202 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100223 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100426 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110221 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110802 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110810 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4804829 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140819 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |