JP4741363B2 - Image processing apparatus, image processing method, and image processing program - Google Patents
Image processing apparatus, image processing method, and image processing program Download PDFInfo
- Publication number
- JP4741363B2 JP4741363B2 JP2005364920A JP2005364920A JP4741363B2 JP 4741363 B2 JP4741363 B2 JP 4741363B2 JP 2005364920 A JP2005364920 A JP 2005364920A JP 2005364920 A JP2005364920 A JP 2005364920A JP 4741363 B2 JP4741363 B2 JP 4741363B2
- Authority
- JP
- Japan
- Prior art keywords
- paper
- symbol
- processing
- content
- image processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



















Landscapes
- Facsimiles In General (AREA)
- Editing Of Facsimile Originals (AREA)
Description
本発明は、画像処理装置、画像処理方法、及び、画像処理プログラムに関する。 The present invention relates to an image processing apparatus, an image processing method, and an image processing program.
従来から、電子文書のコンテンツが印刷された紙に加筆した内容を読み取り、所定の処理を行う装置等がある。このような装置では、前記コンテンツが印刷された紙にユーザがシンボル等を手書きし、その紙をスキャナ等で読み取ることにより、処理内容や処理を行う対象を定めることができる。例えば、次の文献があげられる。 2. Description of the Related Art Conventionally, there are apparatuses that read a content that has been added to paper on which content of an electronic document is printed, and perform a predetermined process. In such an apparatus, the user can hand-write a symbol or the like on the paper on which the content is printed, and read the paper with a scanner or the like, thereby determining the processing content and the target to be processed. For example, the following documents can be cited.
特開2002−252732号公報(特許文献1)には、複数の処理内容及びチェック欄を有するメニュー用紙を印刷し、該メニュー用紙のチェック欄に加筆し、前記メニュー用紙及び処理を行う対象となるコンテンツが印刷された紙をスキャナで読み取らせることにより、ユーザが所望する処理内容及び処理を行う対象となるコンテンツを入力するシステムが開示されている。 Japanese Patent Laid-Open No. 2002-252732 (Patent Document 1) prints a menu sheet having a plurality of processing contents and a check column, adds the menu sheet to the check column of the menu sheet, and performs the menu sheet and processing. There is disclosed a system for inputting processing content desired by a user and content to be processed by causing the scanner to read the paper on which the content is printed.
また、特開2004−78973号公報(特許文献2)には、文書内の文字と該文字に対応するリンク先を管理するデータベースとを有する装置の例が開示されている。この例では、まず、文書と該文書を特定するバーコードが印刷された紙に、ユーザが所定のマークを記入して前記リンクを有する文字を選択する。次に、前記紙をスキャナ等で読み込ませることにより、前記所定のマークが記された位置及び該位置に印刷されている文字を検出する。そして、該文字にリンクされている文書をデータベースを参照して取得し、印刷出力を行う。
しかしながら、特許文献1に記載されたシステムでは、処理内容が記されたメニュー用紙、及び、処理の対象となるコンテンツを、それぞれスキャナ等で読み込ませることによって入力するため、文書の校正等、コンテンツ内の各部分で異なる処理や、対象となる範囲を指定する処理ができない他、コンテンツを読み込んでテキストデータにする場合に、文字イメージを正しく取得できないなどの不具合があった。
However, in the system described in
また、特許文献2に記載された装置では、予め文字とリンク先が対応したハイパーテキストが必要であり、リンクされていない情報は取得できないという不具合があった。
Further, the apparatus described in
本発明は、上記の点に鑑みて、これらの問題を解消するために発明されたものであり、コンテンツを紙等に印刷し、該紙に手書きすることにより前記コンテンツを処理する場合に、処理内容、処理範囲等をユーザが定める任意のシンボルによって指定することができる画像処理装置を提供することを目的としている。 The present invention has been invented in order to solve these problems in view of the above points, and in the case of processing the content by printing the content on paper or the like and handwriting on the paper, An object of the present invention is to provide an image processing apparatus capable of designating contents, a processing range, and the like by an arbitrary symbol defined by a user.
上記目的を達成するために、本発明の画像処理装置、画像処理方法、及び、画像処理プログラムは次のような構成を採用した。 In order to achieve the above object, the image processing apparatus, the image processing method, and the image processing program of the present invention employ the following configurations.
上記目的を達成するために、本発明の画像処理装置は、第一の紙に印刷されたコンテンツと、前記第一の紙に印刷された該第一の紙を識別する紙識別情報、及び、前記第一の紙に手書きされた第一のシンボルに基づき、前記コンテンツの処理を行う画像処理装置において、前記紙識別情報と前記コンテンツとを対応させて管理する紙識別情報管理手段と、第二の紙に印刷された複数の処理内容と該処理内容毎に手書きされた第二のシンボルとを読み込んだ結果に基づき、前記第一の紙に手書きされた前記第一のシンボルと前記第二のシンボルとが一致性を有する場合に、前記第一の紙に印刷されたコンテンツに対して前記第二のシンボルに対応する処理内容を出力する、処理シンボル管理手段と、前記処理シンボル管理手段が出力する処理内容に基づき、前記紙識別情報に対応する前記コンテンツを処理する処理実行手段とを有し、前記処理実行手段は、前記第二のシンボルとの一致性を有するか否かの判断に応じて、前記第一のシンボルを、前記コンテンツに上書きするように構成することができる。 In order to achieve the above object, an image processing apparatus of the present invention includes a content printed on a first paper, paper identification information for identifying the first paper printed on the first paper, and A paper identification information managing means for managing the paper identification information and the content in association with each other in the image processing apparatus for processing the content based on the first symbol handwritten on the first paper; Based on the result of reading a plurality of processing contents printed on the paper and a second symbol handwritten for each processing content, the first symbol handwritten on the first paper and the second symbol A processing symbol management unit that outputs a processing content corresponding to the second symbol for the content printed on the first paper when the symbol has a match, and the processing symbol management unit outputs In the process Based on, possess a process executing means for processing the content corresponding to the paper identification information, the processing execution unit, in response to the second determination of whether a match with the symbols, the a first symbol can Rukoto forming structure to overwrite the contents.
これにより、コンテンツを紙に印刷し、該紙に手書きすることにより前記コンテンツを処理する場合に、処理内容、処理範囲等をユーザが定める任意のシンボルによって指定し、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認可能な画像処理装置を提供することができる。 Thus, when processing the content by printing the content on paper and handwriting on the paper, the processing content, processing range, etc. are designated by an arbitrary symbol defined by the user, and the processed content portion and processing It is possible to provide an image processing apparatus that allows the user to easily confirm the contents .
なお、本特許請求の範囲、及び、本明細書における画像処理装置が行う処理とは、「コンテンツの編集」、「コンテンツを印刷により出力する」、又は、「コンテンツの再生」等の所定の処理を言う。 Note that the processing performed by the image processing apparatus in the claims and in the present specification refers to predetermined processing such as “content editing”, “content output by printing”, or “content playback”. Say.
上記目的を達成するために、本発明の画像処理装置が有する前記処理実行手段は、前記第二のシンボルとの一致性を有すると判断された前記第一のシンボルを前記コンテンツに上書きするように構成することができる。 In order to achieve the above object, the processing execution means included in the image processing apparatus of the present invention overwrites the content with the first symbol determined to be consistent with the second symbol. Can be configured.
これにより、第二のシンボルとの一致性を有すると判断され、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認することができる。 As a result, it is determined that there is a match with the second symbol, and the user can easily confirm the processed content portion and the processing content .
上記目的を達成するために、本発明の画像処理装置が有する前記処理実行手段は、前記第二のシンボルとの一致性を有すると判断されなかった前記第一のシンボルを前記コンテンツに上書きするように構成することができる。 In order to achieve the above object, the processing execution means included in the image processing apparatus of the present invention overwrites the content with the first symbol that has not been determined to be consistent with the second symbol. Can be configured.
これにより、第二のシンボルとの一致性を有すると判断されず、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認することができる。 Accordingly, it is not determined that the second symbol is consistent, and the user can easily confirm the processed content portion and the processing content .
上記目的を達成するために、本発明の画像処理装置は、前記コンテンツを前記第一の紙に印刷する場合に、該第一の紙を識別する紙識別情報を、前記紙識別情報管理手段が管理する対応づけに従い前期第一の紙に印刷する印刷手段を有するように構成することができる。 In order to achieve the above object, in the image processing apparatus of the present invention , when the content is printed on the first paper, the paper identification information managing means identifies the paper identification information for identifying the first paper. It can comprise so that it may have a printing means which prints on the 1st paper of the previous period according to the matching to manage .
これにより、処理の対象である、紙に印刷されたコンテンツの電子データを特定することができる。 Thereby, the electronic data of the content printed on the paper, which is the object of processing, can be specified .
上記目的を達成するために、本発明の画像処理装置が読み込む前記第二の紙は、印刷された前記第二の紙の識別情報を有する構成とすることができる。 In order to achieve the above object, the second paper read by the image processing apparatus of the present invention can be configured to have identification information of the printed second paper .
これにより、複数枚の紙を用いて処理内容を入力する場合に、該複数枚の紙を区別することができる。 Thereby, when the processing content is input using a plurality of sheets of paper , the plurality of sheets of paper can be distinguished .
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、前記一致性を有するか否かを判断する場合に、前記第一のシンボルと前記第二のシンボルとの類似度が所定の範囲内にあることを判断するように構成することができる。 In order to achieve the above object, the processing symbol management means included in the image processing apparatus of the present invention determines whether the first symbol and the second symbol are the same when determining whether or not they have the coincidence. It can be configured to determine that the similarity is within a predetermined range .
これにより、処理内容等を指定するシンボルをユーザが任意に定めることができ、さらに、前記第一のシンボル及び前記第二のシンボルを一のユーザが記すことにより、類似度が高くなり、判断の精度を高くすることができる。 As a result, the user can arbitrarily determine a symbol for designating the processing content and the like. Further, when one user writes the first symbol and the second symbol, the degree of similarity is increased, and the determination is made. The accuracy can be increased .
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、処理を行う範囲、処理を行う対象となるコンテンツ、及び、処理内容を前記第二のシンボルと対応させて保持するように構成することができる。 In order to achieve the above object, the processing symbol management means included in the image processing apparatus of the present invention associates the range to be processed, the content to be processed, and the processing content with the second symbol. It can be configured to hold .
これにより、処理を行う範囲、処理を行う対象となるコンテンツ、及び、処理内容をユーザが任意に指定することができる。 Accordingly, the user can arbitrarily specify the range to be processed, the content to be processed, and the processing details .
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、前記処理を行う範囲、前記処理を行う対象となるコンテンツ、及び、前記処理内容について、選択欄を有する第二の紙にユーザが手書きにより選択した内容に基づいて、前記第二のシンボルと前記処理内容とを対応させる構成とすることができる。 In order to achieve the above object, the processing symbol management means included in the image processing apparatus of the present invention includes a selection column for the range to be processed, the content to be processed, and the processing details. Based on the content selected by handwriting on the second paper, the second symbol and the processing content can be made to correspond to each other .
これにより、シンボルに対応する処理内容を、ユーザが指定することができる。 Thereby , the user can specify the processing content corresponding to the symbol.
上記目的を達成するために、前記第一の紙に手書きされた前記第一のシンボルに代えて前記第一の紙に手書きする場合の第一のストロークデータ、及び、前記第二の紙に手書きされた前記第二のシンボルに代えて前記第二の紙に手書きする場合の第二のストロークデータを用いるように構成することができる。 To achieve the above object, first stroke data when handwritten on the first paper instead of the first symbol handwritten on the first paper, and handwritten on the second paper Instead of the second symbol, the second stroke data when handwritten on the second paper can be used.
これにより、シンボルよりも情報量の多いストロークデータを用いることにより、第一のストロークデータと第二のストロークデータとの類似性を判断する場合の精度を高めることができる。 Thereby, the accuracy in determining the similarity between the first stroke data and the second stroke data can be increased by using the stroke data having a larger amount of information than the symbol.
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、前記第一のストロークデータと前記第二のストロークデータとの類似性を、ストロークの座標の値、ストロークの筆記速度の値、及び、ストロークの色の値の内、一以上のストロークを表す値を用いて判断するように構成することができる。 In order to achieve the above object, the processing symbol management means of the image processing apparatus of the present invention uses the similarity between the first stroke data and the second stroke data, the coordinate value of the stroke, The writing speed value and the stroke color value can be determined using a value representing one or more strokes.
これにより、第一のストロークデータと第二のストロークデータとの類似性の判断の精度を高めることができる。 Thereby, the precision of the judgment of the similarity between the first stroke data and the second stroke data can be improved.
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、複数の前記第二のストロークデータの内容である、ストロークの色の値、ストロークの位置を表す値、ストロークの大きさの値、及び、ストロークの筆記速度の値の内、一以上のストロークを表す値により、前記第二のストロークデータに対応する処理を行う優先の度合いを保持している構成とすることができる。 In order to achieve the above object, the processing symbol management means included in the image processing apparatus of the present invention includes a stroke color value, a stroke position value, and a stroke, which are the contents of the plurality of second stroke data. The degree of priority for performing the processing corresponding to the second stroke data is held by a value representing one or more strokes among the value of the stroke size and the value of the stroke writing speed. Can do.
これにより、複数の処理を一の第一の紙を用いて行う場合に、全ての処理が行われた結果を単一にすることができる。 As a result, when a plurality of processes are performed using one first paper, a result obtained by performing all the processes can be unified.
上記目的を達成するために、本発明の画像処理装置が有する前記処理シンボル管理手段は、複数の前記第二のストロークデータに対応する処理毎に、該処理を行う優先順を決める構成とすることができる。 In order to achieve the above object, the processing symbol management means included in the image processing apparatus of the present invention is configured to determine a priority order for performing the processing for each processing corresponding to the plurality of second stroke data. Can do.
上記目的を達成するために、本発明の画像処理方法は、第一の紙に印刷されたコンテンツ、前記第一の紙に印刷された該第一の紙を識別する紙識別情報、及び、前記第一の紙に手書きされた第一のシンボルに基づき、前記コンテンツの処理を行う、前記紙識別情報と前記コンテンツとを対応させて管理する紙識別情報管理手段を有する画像処理装置における画像処理方法において、第二の紙に印刷された複数の処理内容と該処理内容毎に手書きされた第二のシンボルとを読み込む第一の読み込みステップと、前記第一の紙に印刷されたコンテンツ、前記第一の紙を識別する紙識別情報、及び、前記第一の紙に手書きされた前記第一のシンボルを読み込む第二の読み込みステップと、前記第一及び第二の読み込みステップで読み込まれた、前記第二のシンボル及び前記第一のシンボルとが一致性を有する場合に、前記第二のシンボルに対応する処理内容を出力する、処理シンボル管理ステップと、前記処理シンボル管理ステップにより出力された処理内容に基づき、前記紙識別情報に対応する前記コンテンツを処理する処理実行ステップとを有し、前記処理実行ステップは、前記第二のシンボルとの一致性を有するか否かの判断に応じて、前記第一のシンボルを、前記コンテンツに上書きするように構成することができる。 In order to achieve the above object, an image processing method of the present invention includes a content printed on a first paper, paper identification information for identifying the first paper printed on the first paper, and the An image processing method in an image processing apparatus having paper identification information management means for managing the content in association with each other based on the first symbol handwritten on the first paper A first reading step of reading a plurality of processing contents printed on the second paper and a second symbol handwritten for each processing content; a content printed on the first paper; The paper reading information for identifying one paper, the second reading step for reading the first symbol handwritten on the first paper, and the first and second reading steps, When a second symbol and the first symbol are coincident, the processing content corresponding to the second symbol is output, and the processing content is output by the processing symbol management step. based, possess a processing execution step of processing the content corresponding to the paper identification information, said processing execution step, in response to the second determination of whether a match with the symbols, the first One symbol can be configured to overwrite the content .
これにより、コンテンツを紙に印刷し、該紙に手書きすることにより前記コンテンツを処理する場合に、処理内容、処理範囲等をユーザが定める任意のシンボルによって指定し、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認可能な画像処理方法を提供することができる。 Thus, when processing the content by printing the content on paper and handwriting on the paper, the processing content, processing range, etc. are designated by an arbitrary symbol defined by the user, and the processed content portion and processing It is possible to provide an image processing method that allows the user to easily confirm the contents .
上記目的を達成するために、本発明の画像処理方法における前記処理実行ステップは、前記第二のシンボルとの一致性を有すると判断された前記第一のシンボルを前記コンテンツに上書きする構成とすることができる。 To achieve the above object, the processing execution step in the image processing method of the present invention is configured to overwrite the content with the first symbol determined to be consistent with the second symbol. be able to.
これにより、第二のシンボルとの一致性を有すると判断され、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認することができる。 As a result, it is determined that there is a match with the second symbol, and the user can easily confirm the processed content portion and the processing content .
上記目的を達成するために、本発明の画像処理方法における前記処理実行ステップは、前記第二のシンボルとの一致性を有すると判断されなかった前記第一のシンボルを前記コンテンツに上書きする構成とすることができる。 In order to achieve the above object, in the image processing method of the present invention, the processing execution step overwrites the content with the first symbol that has not been determined to be consistent with the second symbol. can do.
これにより、第二のシンボルとの一致性を有すると判断されず、処理されたコンテンツの部分及び処理内容を、ユーザが容易に確認することができる。 Accordingly, it is not determined that the second symbol is consistent, and the user can easily confirm the processed content portion and the processing content .
上記目的を達成するために、本発明の画像処理方法は、前記コンテンツを前記第一の紙に印刷する場合に、該第一の紙を識別する紙識別情報を、前記紙識別情報管理手段が管理する対応づけに従い前記第一の紙に印刷する印刷ステップを有する構成とすることができる。 In order to achieve the above object, according to the image processing method of the present invention , when the content is printed on the first paper, the paper identification information managing means identifies the paper identification information for identifying the first paper. It can be configured to have a printing step for printing on the first paper in accordance with the managed association .
これにより、処理の対象である、紙に印刷されたコンテンツの電子データを特定することができる。 Thereby, the electronic data of the content printed on the paper, which is the object of processing, can be specified .
上記目的を達成するために、本発明の画像処理方法において読み込まれる、前記第二の紙は、印刷された前記第二の紙の識別情報を有する構成とすることができる。 To achieve the above object, is read Oite the image processing method of the present invention, the second sheet can be configured to have identification information printed the second sheet.
これにより、複数枚の紙を用いて処理内容を入力する場合に、該複数枚の紙を区別することができる。 Thereby, when the processing content is input using a plurality of sheets of paper , the plurality of sheets of paper can be distinguished .
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、前記一致性を有するか否かを判断する場合に、前記第一のシンボルと前記第二のシンボルとの類似度が所定の範囲内にあることを判断するように構成することができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention is similar to the first symbol and the second symbol when determining whether or not they have the coincidence. It can be configured to determine that the degree is within a predetermined range .
これにより、処理内容等を指定するシンボルをユーザが任意に定めることができ、さらに、前記第一のシンボル及び前記第二のシンボルを一のユーザが記すことにより、類似度が高くなり、判断の精度を高くすることができる。 As a result, the user can arbitrarily determine a symbol for designating the processing content and the like. Further, when one user writes the first symbol and the second symbol, the degree of similarity is increased, and the determination is made. The accuracy can be increased .
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、処理を行う範囲、処理を行う対象となるコンテンツ、及び、処理内容を前記第二のシンボルと対応させて保持する構成とすることができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention holds the range to be processed, the content to be processed, and the processing content in association with the second symbol. It can be set as the structure to do.
これにより、処理を行う範囲、処理を行う対象となるコンテンツ、及び、処理内容をユーザが任意に指定することができる。 Accordingly, the user can arbitrarily specify the range to be processed, the content to be processed, and the processing details .
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、前記処理を行う範囲、前記処理を行う対象となるコンテンツ、及び、前記処理内容について、選択欄を有する第二の紙にユーザが手書きにより選択した内容に基づいて、前記第二のシンボルと前記処理内容とを対応させる構成とすることができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention includes a selection column for the range to be processed, the content to be processed, and the processing details. The second symbol and the processing content can be made to correspond to each other based on the content selected by handwriting on the paper .
これにより、シンボルに対応する処理内容を、ユーザが指定することができる。 Thereby , the user can specify the processing content corresponding to the symbol .
上記目的を達成するために、前記第一の紙に手書きされた前記第一のシンボルに代えて前記第一の紙に手書きする場合の第一のストロークデータ、及び、前記第二の紙に手書きされた前記第二のシンボルに代えて前記第二の紙に手書きする場合の第二のストロークデータを用いるように構成することができる。 To achieve the above object, first stroke data when handwritten on the first paper instead of the first symbol handwritten on the first paper, and handwritten on the second paper Instead of the second symbol, the second stroke data when handwritten on the second paper can be used.
これにより、シンボルよりも情報量の多いストロークデータを用いることにより、第一のストロークデータと第二のストロークデータとの類似性を判断する場合の精度を高めることができる。 Thereby, the accuracy in determining the similarity between the first stroke data and the second stroke data can be increased by using the stroke data having a larger amount of information than the symbol.
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、前記第一のストロークデータと前記第二のストロークデータとの類似性を、ストロークの座標の値、ストロークの筆記速度の値、及び、ストロークの色の値の内、一以上のストロークを表す値を用いて判断するように構成することができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention includes the similarity between the first stroke data and the second stroke data, the value of the coordinate of the stroke, and the writing of the stroke. The determination can be made using a value representing one or more strokes among the velocity value and the stroke color value.
これにより、第一のストロークデータと第二のストロークデータとの類似性の判断の精度を高めることができる。 Thereby, the precision of the judgment of the similarity between the first stroke data and the second stroke data can be improved.
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、複数の前記第二のストロークデータの内容である、ストロークの色の値、ストロークの位置を表す値、ストロークの大きさの値、及び、ストロークの筆記速度の値の内、一以上のストロークを表す値により、前記第二のストロークデータに対応する処理を行う優先の度合いを保持している構成とすることができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention includes a stroke color value, a stroke position value, a stroke position, which are the contents of the plurality of second stroke data. Among the size value and the stroke writing speed value, a value representing one or more strokes may be used to hold a priority level for performing processing corresponding to the second stroke data. it can.
これにより、複数の処理の指定を一の第一の紙を用いて行う場合に、全ての処理が行われた結果を一意に定めることができる。 As a result, when a plurality of processes are specified using one first sheet, the result of all the processes can be uniquely determined.
上記目的を達成するために、本発明の画像処理方法における前記処理シンボル管理ステップは、複数の前記第二のストロークデータに対応する処理毎に、該処理を行う優先順を決める構成とすることができる。 In order to achieve the above object, the processing symbol management step in the image processing method of the present invention is configured to determine a priority order for performing the processing for each processing corresponding to the plurality of second stroke data. it can.
上記目的を達成するために、本発明の画像処理プログラムは、請求項17ないし32のいずれか一項に記載の画像処理方法を実行させる画像処理プログラムとすることができる。 In order to achieve the above object, the image processing program of the present invention can be an image processing program for executing the image processing method according to any one of claims 17 to 32.
これにより、コンテンツを紙に印刷し、該紙に手書きすることにより前記コンテンツを処理する場合に、処理内容、処理範囲等をユーザが定める任意のシンボルによって指定する画像処理プログラムを提供することができる。 Thereby, when processing the content by printing the content on paper and handwriting on the paper, it is possible to provide an image processing program that specifies the processing content, processing range, and the like by an arbitrary symbol defined by the user. .
本発明によれば、コンテンツを紙等に印刷し、該紙に手書きすることにより前記コンテンツを処理する場合に、処理内容、処理範囲等をユーザが定める任意のシンボルによって指定することができる画像処理装置を提供することができる。 According to the present invention, when processing the content by printing the content on paper or the like and handwriting on the paper, the image processing that can specify the processing content, processing range, etc. by any symbol determined by the user An apparatus can be provided.
以下、本発明の実施例を図面に基づき説明する。 Embodiments of the present invention will be described below with reference to the drawings.
図19は、本発明の構成原理図である。 FIG. 19 is a structural principle diagram of the present invention.
図19では、コンテンツ等が印刷された第一の紙1910に、ユーザがシンボルを記入し、該第一の紙を読み取ることにより、画像処理装置1940が前記コンテンツに対して処理を行い、処理されたコンテンツ1960を出力する。
In FIG. 19, when a user fills in a symbol on a
画像処理装置1940は、第一の紙1910及び第二の紙1920を読み取った結果から、第一の紙に印刷されたコンテンツの処理を行う装置であり、紙識別情報管理手段1941、処理シンボル管理手段1942、及び、処理実行手段1943から構成されている。
The
紙識別情報管理手段1941は、第一の紙1910を読み取った結果から、印刷されている紙識別情報1911に対応するコンテンツのデータを記憶装置1950より取得し、処理実行手段に出力する。紙識別情報管理手段1941は、また、第一の紙を読み取った結果と、記憶装置1950より取得したコンテンツのデータとを比較することにより、ユーザが第一の紙1910に記入した第一のシンボル1913を抽出し、処理シンボル管理手段1942へ出力する。
The paper identification information management means 1941 acquires content data corresponding to the printed
処理シンボル管理手段1942は、第二の紙1920を読み取った結果に基づき、処理内容1921と、該処理内容1921に対応してユーザが記入した第二のシンボル1922とを管理する。そして、紙識別情報管理手段1941より第一のシンボル1913が入力された場合に、該第一のシンボル1913と第二のシンボル1922とを比較し、類似度が所定の範囲内の場合に、前記第二のシンボル1922に対応する処理内容1921を、処理実行手段1943に出力する。
The processing
処理実行手段1943は、紙識別情報管理手段1941から入力されたコンテンツ1912のデータに対して、処理シンボル管理手段1942から入力された処理内容1921の処理を行い、処理されたコンテンツ1960を出力する。
The
第一の紙1910は、該紙を識別する紙識別情報1911及びコンテンツ1912が印刷された紙であって、ユーザが手書きによって第一のシンボル1913を記入した紙である。
The
第二の紙1920は、処理内容1921が印刷された紙であって、ユーザが手書きによって前記処理内容に対応する第二のシンボル1922を記入した紙である。ここで、第二の紙には、該第二の紙を識別する紙識別情報が印刷されていても良い。
The
読み取り手段1930は、第一の紙1910及び第二の紙1920に印刷されている内容、並びに、ユーザが手書きによって記入した前記第一のシンボル及び前記第二のシンボルを読み取ってイメージデータとして取得する。また、記憶装置1950は、コンテンツのデータを格納する装置である。
(図1の説明)
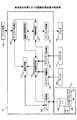
図1は、本発明の画像処理装置101の機能ブロック、及び、その周辺の装置を示したものである。画像処理装置101は、紙に手書きによって記入されたシンボル等に基づき、前記紙に印刷されたコンテンツの処理を行う画像処理装置であって、ユーザI/Fデバイス119、紙入力装置であるスキャナ116及びデジタイザ117、プリンタ等の紙出力装置118、並びに、ディスク装置107と接続されている。
The
(Description of FIG. 1)
FIG. 1 shows functional blocks of an
画像処理装置101は、ユーザI/F制御部102、スキャナI/F制御部108、デジタイザI/F制御部109、紙情報取得部110、筆記処理部111、プリンタI/F制御部112、印刷処理部113、紙識別情報管理部114、及び、ディスクI/F制御部115から構成されている。
The
ユーザI/F制御部102は、外部入力デバイスから紙情報取得命令または文書印刷命令を受け取り、紙情報取得部110及び印刷処理部113へ出力する。また、筆記処理部111から入力された外部への出力を要求する信号をディスプレイ103及びスピーカ104等の外部出力デバイスへ送信する。また、ディスクI/F制御部115は、ディスク装置107を制御し、コンテンツである文書データの取得や格納を行う。
The user I /
スキャナI/F制御部108は、スキャナ116を制御することにより、紙識別情報(ID)、及び、手書きにより加筆されたシンボル等を含む文書のイメージを取得し、紙情報取得部110へ送信する。デジタイザI/F制御部109は、デジタイザ117を制御し、ユーザが紙に手書きする際の動作の情報であるストロークデータ、及び、イメージで表される紙識別情報を取得し、紙情報取得部110へ送信する。
The scanner I /
なお、本明細書においては、紙識別情報を「ID」と表記する。IDは、紙に印刷された文書を特定するための情報を示す符号であり、例えば、前記文書を紙に印刷する場合に、全ての紙に対して一意に付与される番号等である。IDと文書の情報とを後述する紙識別情報管理部114が対応づけて管理する。文書の情報とは、例えば、記憶装置に格納されているコンテンツの「ファイル名」「ページ番号」「コンテンツの種類」及び「ファイルのディスク上の位置を表すパス名又はアドレス」等であり、これらがIDと関連づけて管理されることにより、紙に印刷された文書のIDを取得した場合に、前記文書のデータを記憶装置等から読み出すことができる。 In this specification, the paper identification information is expressed as “ID”. The ID is a code indicating information for specifying a document printed on paper, and is, for example, a number uniquely assigned to all paper when the document is printed on paper. A paper identification information management unit 114 (to be described later) manages IDs and document information in association with each other. Document information includes, for example, “file name”, “page number”, “content type”, and “path name or address representing the location of the file on the disk” of the content stored in the storage device. Is managed in association with the ID, the data of the document can be read from a storage device or the like when the ID of the document printed on paper is acquired.
印刷処理部113、紙識別情報管理部114、紙情報取得部110、及び、筆記処理部111の詳細な動作は後述するが、ここでは各部の動作の概略について説明する。
Although detailed operations of the
印刷処理部113は、ディスク装置107等に格納されていた文書データに、IDを付加し、紙出力装置であるプリンタ118で出力するためのイメージを生成する。プリンタI/F制御部112は、プリンタ118を制御することにより、紙に文書等のイメージを印刷する処理を行う。
The
紙識別情報管理部114は、文書の各ページとIDの関係が一対一になるように紙識別情報管理テーブルによって管理し、IDの登録、削除、参照等を行う。
The paper identification
紙情報取得部110は、スキャナ116及びデジタイザ117等で読み取ったイメージに基づいてIDを取得し、紙情報である、前記IDに対応する文書の情報、及び、前記読み取ったイメージを筆記処理部111に出力する。
The paper
なお、本明細書においては、文書等のコンテンツを読み取ったイメージ、及び、IDに対応する文書の情報を「紙情報」とする。文書の情報とは、例えば、記憶装置に格納されているコンテンツの「ファイル名」「ページ番号」「コンテンツの種類」及び「ファイルのディスク上の位置を表すパス名又はアドレス」等である。 Note that in this specification, the image of content such as a document and the document information corresponding to the ID are referred to as “paper information”. The document information includes, for example, “file name”, “page number”, “content type”, “path name or address indicating the position of the file on the disk”, and the like of the content stored in the storage device.
筆記処理部111は、紙情報取得部110より入力されたIDに対応する文書の情報から、前記IDに対応する文書をディスクI/F制御部115を介してディスク装置107より取得し、紙情報取得部110より入力されたイメージと比較して処理することにより、ユーザが手書きしたシンボル等を取得し、該シンボルに対応する処理を前記IDに対応する文書に実行する。
The
ユーザI/Fデバイス119は、画像処理装置110に対してユーザが入力を行い、又は、画像処理装置110が表示を行うI/Fであり、ディスプレイ103、スピーカ104、キーボード105、及び、マウス106とから構成されている。キーボード105及びマウス106は、ユーザが各種の命令を入力するデバイスであり、紙情報の取得の命令や、文書を印刷して出力する命令を入力する。ディスプレイ103及びスピーカ104は、ユーザが命令を入力等する操作の際に、画像処理装置110が必要な情報を出力する。
The user I /
ディスク装置107は、コンテンツである文書のデータを格納し、プリンタ118は、イメージを紙面に形成して出力する。
The
スキャナ116は、紙面を走査して2次元画像データであるイメージを取得する装置である。また、本実施例のデジタイザ117は、IDを読み取ることができるように構成されており、さらに、ユーザの筆致動作であるストロークを検出し、2次元データであるストロークデータに変換する装置である。図示しない紙識別情報読み取り装置とは、例えば、CCDカメラ、2次元コードリーダ、又は、1次元バーコードリーダ等がある。
(ストロークデータの説明)
図3は、ストロークデータの一例である。表301の各項目は、手書きの文字またはシンボルを構成する複数の座標の取得順であるシーケンス302、使用したペンの種類を示すペンの識別情報303、前記複数の座標の取得時刻であるタイムスタンプ304、前記複数の座標のX成分305、前記複数の座標のY成分306、前記複数の座標のそれぞれを取得した時に、ペンと紙面が接していたか否かを表すペンダウン/ペンアップ307、及び、前記複数の座標が属するストロークを区別するストロークのラベル308である。一のストロークとは、シーケンス302の項目表される数字の順に、ペンダウン/ペンアップ307が、ペンダウンとなる座標点を記す動作から、ペンアップとなる座標点を記す動作までの複数の座標点を記す筆致動作のことである。また、シンボルを表す情報の一つである色に代えて、ストロークではペンの識別情報303が用いられる。
The
(Explanation of stroke data)
FIG. 3 is an example of stroke data. Each item in the table 301 includes a
次に、本発明の特徴である紙情報の取得及び該紙情報による処理を行う、印刷処理部113、紙情報取得部110、紙識別情報管理部114、及び、筆記処理部111の動作について、以下説明する。
(印刷処理部113の動作)
図4は、ユーザI/F制御部102から文書の印刷を要求する信号を受けたときの印刷処理部113の動作を説明する流れ図である。
Next, regarding the operations of the
(Operation of the print processing unit 113)
FIG. 4 is a flowchart for explaining the operation of the
ステップ401では、印刷処理部113が、ユーザI/F制御部より、印刷する文書の情報を取得する。文書の情報とは、例えば、ディスク装置107に格納されている文書の「ファイル名」「ページ番号」「文書の種類」及び「ファイルのディスク上の位置を表すパス名又はアドレス」等である。
In
ステップ402では、紙識別情報管理部114が、印刷処理部113より文書の情報を受信し、該文書の情報に基づき、IDを発行、登録するとともに、該IDを印刷処理部113へ送信する。
In
ステップ403では、印刷処理部113が、文書の情報に基づき、ディスクI/F制御部115を介してディスク装置107に記録されている文書を取得する。ステップ404では、印刷処理部113が、IDを符号に変換する。
In
ステップ405では、印刷処理部113が、取得した文書のイメージを生成し、該イメージにID、及び、印刷した紙面を読み取ってスキュー補正を行う場合に必要となるタイミングマークを重畳した印刷イメージを生成する。
In
ステップ406では、印刷処理部113が、印刷を要求する命令とともに、印刷イメージをプリンタ118に送信する。
(紙識別情報管理部114の管理データの例)
図5は、紙識別情報管理部114が管理するIDテーブルの一例である。
In
(Example of management data of the paper identification information management unit 114)
FIG. 5 is an example of an ID table managed by the paper identification
IDテーブル501は、コンテンツである文書を一意に識別する番号と該文書のファイル名及び/又はパス名等を管理するIDテーブルであり、各列の項目は、文書を一意に識別する番号であるID502、該文書をディスク装置から読み出す場合のアドレス等を表すパス名及びファイル名503、該文書内の頁番号504、該文書の種類505から構成されている。IDテーブル501の各行が、一の文書の情報となり、行506は、IDが0001の文書の情報である。複数頁の文書を処理する場合には、行506の構成を有する情報が頁数だけ必要となる。
The ID table 501 is an ID table that manages a number that uniquely identifies a document as a content and a file name and / or path name of the document, and each column item is a number that uniquely identifies the document. The
文書の種類505は、数値によって文書の種類を分類する項目であり、例えば、後述する処理シンボル入力シートを「0」、その他の文書を「1」とする他、更に詳細に分類してもよい。また、数値による分類の他、文字その他の任意のデータ形式で分類してもよい。
(印刷イメージの説明)
図6は、文書のイメージの一例であり、図7は、印刷処理部113が図6のイメージである文書から生成した印刷イメージの例である。
The
(Description of print image)
FIG. 6 is an example of a document image, and FIG. 7 is an example of a print image generated by the
図6のイメージ601には、文字及び画像が含まれている。印刷処理部113が、紙識別情報管理部114より受信したIDを符号化し、イメージ601に重畳することにより、図7におけるイメージ701が生成される。イメージ701において、マーク702から705は、イメージ701が印刷された紙を読み込み、スキュー補正を行う場合に用いるタイミングマークである。マーク702から705は、イメージ内の所定の4箇所に形成されており、読み込みの際に歪み等が生じた場合に、画像処理装置101が有する規定の値と比較することにより、読み込んだイメージに対する補正を行う。符号706は、イメージ601の文書に対応するIDである。また、イメージ707は、イメージ601のコンテンツに相当する部分である。
(紙情報取得部110の動作)
図8は、紙情報取得部110の動作を説明する流れ図であり、図9は、イメージ701が印刷された紙に対して、ユーザがシンボル等を加筆したイメージを説明する図である。
The
(Operation of the paper information acquisition unit 110)
FIG. 8 is a flowchart for explaining the operation of the paper
ステップ801では、紙情報取得部110が、ユーザI/F制御部より、使用する紙入力機器を指定する信号を取得する。本実施例においては、紙入力機器は、スキャナ116及びデジタイザ117であり、ユーザは、ユーザI/Fデバイス119から、これら紙入力機器のいずれかを指定して入力する。
In
ステップ802では、紙情報取得部110が受信した、紙入力機器を指定する信号の内容が、スキャナ116か、デジタイザ117かを判断する。前記信号の内容がスキャナ116である場合には、ステップ803から807の処理が行われる。
In step 802, it is determined whether the content of the signal specifying the paper input device received by the paper
ステップ803では、スキャナ116が指定された場合に、紙情報取得部110が、スキャナI/F制御部108に対して紙面の読み取りを指示し、イメージのデータを受信する。ステップ804では、紙情報取得部110が、受信したイメージからスキュー補正のマーク702から705を検出し、規定の値と比較することにより、前記イメージに対してスキュー補正を行う。ステップ805では、紙情報取得部116が、スキュー補正を行った前記イメージから、符号化されたID706を検出し、これを復号することにより文書のIDを得る。
In step 803, when the
ステップ806では、紙情報取得部110が、取得した文書のIDに基づく文書の情報を、紙識別情報管理部114より受信する。文書の情報とは、例えば、記憶装置に格納されているコンテンツの「ファイル名」「ページ番号」「コンテンツの種類」及び「ファイルのディスク上の位置を表すパス名又はアドレス」等である。
In step 806, the paper
ステップ807では、紙情報取得部110が、取得したイメージのデータ及び文書の情報からなる紙情報を筆記処理部111に送信し、本流れ図の処理である、紙情報取得部110の動作が終了する。
In step 807, the paper
ステップ802において、紙情報取得部110が受信した、紙入力機器を指定する信号の内容がデジタイザ117である場合には、ステップ808から810の処理が行われる。
In step 802, if the content of the signal specifying the paper input device received by the paper
ステップ808では、紙情報取得部110が、デジタイザI/F制御部109に対して、印刷された紙面にユーザがストロークする際のストロークデータ、及び、前記印刷された紙面上に形成されている符号化されたIDのイメージの取得を指示する。符号化されたIDのイメージとは、例えば、バーコード等で表されるIDのことである。紙情報取得部110が、前記ストロークデータ及び前記符号化されたIDのイメージを取得し、該IDのイメージを処理することにより、文書のIDを得る。ステップ809では、紙情報取得部110が、文書のIDに基づく文書の情報を、紙識別情報管理部114より受信する。ステップ810では、紙情報取得部110が、取得したストロークデータ及び文書の情報からなる紙情報を筆記処理部111に送信し、本流れ図の処理である、紙情報取得部110の動作が終了する。
In
読み取りを行う紙が複数枚ある場合には、ステップ803からステップ807の処理、又は、ステップ808からステップ810の処理を、紙の枚数と同数だけ行う。
(処理シンボル入力シートの場合の処理)
処理シンボル入力シートの構成についは後述するが、ここでは、処理シンボル入力シートが読み込まれた場合の、紙情報取得部110の動作について説明する。
When there are a plurality of sheets to be read, the processes from step 803 to step 807 or the processes from
(Processing for processing symbol input sheet)
The configuration of the processing symbol input sheet will be described later. Here, the operation of the paper
処理シンボル入力シートのうち、マーク702から705及び符号706を有していない処理シンボル入力シートが、スキャナ116によって読み込まれた場合は、ステップ804からステップ806の処理は行われない。また、符号706を有していない処理シンボル入力シートが、デジタイザ117によって読み込まれた場合は、ステップ808において、紙情報取得部110は、デジタイザ制御手段117よりストロークデータのみを受信し、ステップ809の処理は行われない。また、ステップ810において、紙情報取得部110は、ストロークデータのみを筆記処理部111に送信する。
(ユーザがシンボルを手書きした紙面の説明)
図9において、紙面901は、イメージ701が印刷された紙であって、ユーザがシンボル等を上書きしたものである。紙面901は、イメージ701を構成する要素である、スキュー補正のためのタイミングマーク702から705、文書の符号化されたID706、並びに、文書の内容である、タイトル文字902、文字領域903、及び、イラスト904を有する。紙面901は、さらに、イメージ701が印刷された紙面にユーザが上書きしたシンボル等905から908を有する。
(筆記処理部111の動作)
図10、図11、及び、図15は、筆記処理部111の動作を説明する流れ図である。
When the processing symbol input sheet that does not have the
(Description of the page on which the user has handwritten the symbol)
In FIG. 9, a
(Operation of the writing processing unit 111)
10, 11, and 15 are flowcharts for explaining the operation of the
図10は、紙情報取得部110から紙情報を受信した場合の筆記処理部111の動作を説明する図である。ステップ1001からステップ1005は、受信した紙情報の数だけ処理を繰り返し、処理されていない紙情報が無くなった場合に、処理を終了する。
FIG. 10 is a diagram for explaining the operation of the
ステップ1001では、筆記処理部111が、処理されていない紙情報の有無を判断し、処理されていない紙情報が一つ以上存在する場合には、ステップ1002へ進む。
In
ステップ1002では、筆記処理部111が、処理する紙情報に対応する文書が、処理シンボル対応シートか否かを判断し、処理シンボル対応シートである場合には、ステップ1003へ進み、処理シンボル対応シートではない場合には、ステップ1004へ進む。
In
ステップ1002では、筆記処理部111が、処理シンボル対応シートの紙情報に基づき、処理内容に対応したシンボル等を取得する。ステップ1004では、筆記処理部111が、処理内容に対応したシンボル等の取得が終了しているか否かを判断し、処理内容に対応したシンボル等の取得が終了している場合には、ステップ1005に進む。処理内容に対応したシンボル等の取得が終了していない場合には、ステップ1001に戻る。ステップ1005では、筆記処理部111が、ステップ1003で取得した、処理内容に対応したシンボル等と、ステップ1005に入力された紙情報から得られるシンボル等とを比較して一致性を判断することにより、対応する処理を行う。
(処理シンボル対応シートを処理する流れの説明)
図11は、ステップ1003の処理の詳細であり、筆記処理部111が、読み込んだ処理シンボル対応シートのイメージから、処理内容に対応するシンボル等のデータを取得する動作を説明する流れ図である。 筆記処理部111は、読み込んだ処理シンボル対応シートのイメージ又はストロークデータを含む紙情報を、既に有している。
In
(Explanation of the flow to process the processing symbol correspondence sheet)
FIG. 11 shows details of the processing in
ステップ1101では、筆記処理部111が、ディスクI/F制御部115を介してディスク装置107より、筆記処理部111が有する紙情報に含まれている文書の情報に対応する処理シンボル対応シートのデータを取得する。前記紙情報に文書の情報が含まれていない場合、即ち、読み取った紙に符号化されたIDが印刷されていない場合には、筆記処理部111が取得する処理シンボル対応シートのデータは、予め情報処理装置101が有しているデータ、又は、予めディスク装置107等に記憶されている所定のデータとなる。
In
ステップ1102では、筆記処理部111が、該筆記処理部111が有する紙情報が、イメージを含んでいるか、ストロークデータを含んでいるかを判断し、イメージの場合には、ステップ1103へ、ストロークデータの場合には、ステップ1107へ進む。
In
ステップ1103では、筆記処理部111が、紙情報に含まれている読み込んだイメージと、文書の情報に対応する処理シンボル対応シートのデータから生成されたイメージとの画素毎の差分を計算することにより、ユーザが手書きによって記入したシンボルのみが描かれたイメージを生成する。
In
ステップ1104では、筆記処理部111が、ステップ1103で生成されたシンボルのみが描かれたイメージについて、処理シンボル対応シートのデータから、紙面上でユーザが記入する欄の位置情報を取得してそれぞれの欄を記入部分とし、該記入部分毎に、差分画像をシンボルとして抽出する。
In
ステップ1105では、筆記処理部111が、ステップ1104で抽出した部分画像と、
該部分画像が描かれた紙面上の位置に対応する処理内容とを関連づけたデータ対としてディスク装置107等に記憶させる。
In
The data is stored in the
ステップ1106では、筆記処理部111が、全ての記入部分について、ステップ1104とステップ1105の処理が行われているか否かを判断し、未処理の記入部分を有する場合には、ステップ1104へ進み、全ての記入部分の処理が終了した場合には、ステップ1001へ進む。
In
一方、筆記処理部111が有する紙情報が、ストロークデータを含む場合には、ステップ1107からステップ1109の処理を行う。
On the other hand, when the paper information included in the
ステップ1107では、筆記処理部111が、処理シンボル対応シートのデータから、紙面上でユーザが記入する欄の位置情報を取得してそれぞれの欄を部分領域とし、該部分領域毎に、含まれるストロークデータを生成する。
In step 1107, the
ステップ1108では、筆記処理部111が、ステップ1107で生成したストロークデータと、該ストロークデータを有する部分領域に対応する処理内容とを関連づけたデータ対として、ディスク装置107等に記憶させる。
In
ステップ1109では、筆記処理部111が、処理シンボル対応シートに含まれている全てのユーザが記入する欄について、処理が終了しているか否かを判断し、未処理の欄がある場合にはステップ1107へ進み、全ての欄が終了している場合には、ステップ1001へ進む。
(処理シンボル対応シートの説明)
図12は、処理シンボル対応シートのイメージの一例である。
In
(Explanation of processing symbol sheet)
FIG. 12 is an example of an image of a processing symbol corresponding sheet.
処理シンボル対応シートのイメージ1201は、表1210、タイトルの文字列1211、ユーザがシンボルを記入する欄1202から1205、及び、該記入欄にそれぞれ対応する処理内容を表す文字列1206から1209を有する。表1210は、処理内容とユーザがシンボルを記入する欄を対応させて表示する表であり、タイトル1211は、処理シンボル対応シートの表題を表す文字列である。
The processing symbol
記入欄1202から1205は、それぞれ記入されたシンボル等に対する処理が定められている。記入欄1202及び記入欄1203は、ユーザが記入したチェック記号の有無により、対応する処理の実行の有無を定める。例えば、記入欄1202にチェック記号が手書きされた場合には、対応する処理である「シンボルを重畳表示」について、前記処理を実行することを示す値を前記処理内容と対応させる。前記対応する処理の実行の有無を示す値は、ブーリアン型の変数としてもよい。また、例えば、記入欄1204に記入されたシンボルは、イメージ又はストロークデータとして、処理内容1208に対応させて記録され、記入欄1205に記入されたシンボルに基づくイメージ又はストロークデータは、処理内容1209に対応させて記録される。
In the entry fields 1202 to 1205, processing for each entered symbol or the like is defined. The
図13は、処理シンボル対応シートにユーザがシンボルを記入したイメージの一例である。 FIG. 13 is an example of an image in which a user enters a symbol on the processing symbol correspondence sheet.
処理シンボル対応シートのイメージ1301は、処理シンボル対応シートのイメージ1201が有する要素に加えて、ユーザが手書きしたシンボル1302から1304を有する。記入欄1203に記入されたシンボル1302が、処理内容を表す文字列1207に対応し、記入欄1204に記入されたシンボル1303が、処理内容を表す文字列1208に対応し、記入欄1205に記入されたシンボル1304が、処理内容を表す文字列1209に対応するデータとして記録される。
The processing symbol corresponding
ここで、処理シンボル対応シートのイメージ1301は、スキュー補正のためのタイミングマーク702から705、及び、前記処理シンボル対応シートの符号化されたID706を有している。このような場合は、処理シンボル対応シート1301は、複数枚を区別して使用することができる。
Here, the processing symbol corresponding
図14は、処理シンボル対応シートのイメージ1301に基づく、シンボルと処理内容とを対応させて管理する、処理シンボル管理テーブルの例である。
FIG. 14 is an example of a processing symbol management table that manages symbols and processing contents in association with each other based on the processing symbol corresponding
記入欄1202及び1203にそれぞれ対応する処理内容である「シンボルを重畳表示」及び「シンボル以外の筆記を重畳表示」は、ブーリアン型の変数に対応される。記入欄1204及び1205にそれぞれ対応する処理内容は、「コンテンツの抽出範囲」「処理を行うコンテンツの種類」及び「処理内容」のそれぞれについて定められており、前記処理内容に、ユーザが記入したシンボル1303及び1304がそれぞれ対応される。
(一致性の判断の処理の説明)
図15は、筆記処理部111が行う、ステップ1005におけるシンボル等の一致性を判断する処理を説明する流れ図である。
The processing contents corresponding to the entry fields 1202 and 1203, “superimpose symbol display” and “superimpose writing other than symbols”, correspond to Boolean variables. The processing contents respectively corresponding to the entry fields 1204 and 1205 are defined for each of “content extraction range”, “type of content to be processed”, and “processing content”. Symbols entered by the user in the
(Explanation of consistency judgment process)
FIG. 15 is a flowchart for explaining the process performed by the
ステップ1501では、筆記処理部111が、ディスクI/F制御部115を介してディスク装置107より紙情報に対応する文書のデータを取得する。ステップ1502では、紙情報に含まれているデータが、イメージかストロークデータであるかを判断し、イメージの場合には、ステップ1503へ進み、ストロークデータの場合には、ステップ1511へ進む。
In step 1501, the
イメージの場合には、筆記処理部111が、ステップ1503において、ステップ1501で取得した文書のデータからイメージを生成し、該イメージと、紙情報に含まれている読み込んだイメージとの画素毎の差分を計算して差分画像を得ることにより、ユーザが手書きしたシンボルから構成される画像を得る。
In the case of an image, the
ステップ1504では、筆記処理部111が、ステップ1503で生成した差分画像について、画素毎の近接と領域からクラスタリングを行い、複数の筆記クラスタを得、該筆記クラスタ毎に、外接する矩形の領域の頂点座標を取得する。
In
一方、ストロークデータの場合には、筆記処理部111が、ステップ1511において、紙情報に含まれているストロークデータを、筆記領域と座標点を描画した時刻とを用いてクラスタリングを行い、複数の筆記クラスタを得、該筆記クラスタ毎に、外接する矩形の頂点座標を取得する。
On the other hand, in the case of stroke data, the
図16は、イメージ901上から抽出した筆記クラスタを説明する図である。
FIG. 16 is a diagram for explaining a writing cluster extracted from the
ユーザが筆記したシンボルは、イメージの差分画像、又は、ストロークデータとしてイメージ901上から抽出され、クラスタリングによって、クラスタ905から908として取得され、それぞれのクラスタについて、外接する矩形1601から1604が得られる。矩形1601から1604は、それぞれ4点の頂点座標によって識別される。
The symbol written by the user is extracted from the
ステップ1505では、筆記処理部111が、紙情報に含まれているIDに対応する文書のデータをPDF(Portable Document Format)に変換する。なお、イメージを構成する要素である、文字の領域、及び、画像の領域のイメージ上の位置を保持し、かつ、個々の要素を別個に扱って処理を行うことが可能なフォーマットであれば、PDFに限らない。
In
ステップ1506では、筆記処理部111が、未処理の筆記クラスタの有無を判断し、未処理の筆記クラスタが存在する場合には、ステップ1507へ進み、全ての筆記クラスタの処理が終了している場合には、ステップ1510へ進む。
In step 1506, the
ステップ1507では、筆記処理部111が、処理シンボル対応シートに基づいて処理内容とシンボルとを対応させて管理する、処理シンボル管理テーブルが有するシンボルと、一の筆記クラスタとを比較し、一致性を判断する。一致性を有すると判断された場合には、ステップ1508へ進み、一致性を有すると判断されない場合には、ステップ1506へ進む。
In step 1507, the
一致性の判断は、パターンマッチング等の公知の手法を用いる。シンボルがイメージの場合には、例えば、シンボルを構成する点の座標と、筆記クラスタの座標とを比較し、一致する点の割合によって類似度を判断し、類似度が所定の値を超える場合に、処理シンボル管理テーブルが有するシンボルと、筆記クラスタとが一致性を有すると判断する。 The determination of coincidence uses a known method such as pattern matching. When the symbol is an image, for example, the coordinates of the points constituting the symbol are compared with the coordinates of the writing cluster, the similarity is judged by the ratio of the matching points, and the similarity exceeds a predetermined value. Then, it is determined that the symbols included in the processing symbol management table and the writing cluster have a match.
さらに、シンボルのイメージが、座標点の他に色の値を有する場合には、前記処理シンボル管理テーブルが有するシンボルの色の値と、筆記クラスタの色の値とを比較し、これらの値の差が所定の値以下の場合に、一致性を有するとし、座標及び色の値の双方が一致性を有する場合に、前記処理シンボル管理テーブルが有するシンボルと筆記クラスタとが一致性を有すると判断する。 Further, when the symbol image has color values in addition to the coordinate points, the symbol color values of the processing symbol management table are compared with the color values of the writing cluster, and the values of these values are compared. When the difference is equal to or smaller than a predetermined value, it is assumed that there is a match, and when both the coordinate and color values have a match, the symbol included in the processing symbol management table and the writing cluster have a match. to decide.
シンボルがストロークデータの場合には、ストロークを表す値として例えば、座標及び色の値に加えて筆記速度によっても一致性の判断を行う。筆記速度は、ストロークデータを構成する点のうち、任意の一点のタイムスタンプと、該任意の一点と筆記順が直前の点のタイムスタンプとから、それらの点の間の平均的な筆記速度を算出し、これを用いる。 In the case where the symbol is stroke data, the consistency is determined based on , for example, the writing speed in addition to the coordinate and color values as values representing the stroke . The writing speed is calculated by calculating the average writing speed between these points from the time stamp of any one of the points constituting the stroke data and the time stamp of the point immediately before the writing order. Calculate and use this.
ステップ1508では、筆記処理部111が、一致性を有すると判断した筆記クラスタについて、該筆記クラスタのイメージ901上の位置の所定の範囲内に、該筆記クラスタと一致性を有すると判断された処理シンボル管理テーブルが有するシンボルと対応する処理内容を満たすコンテンツの有無を判断する。当該コンテンツが存在する場合には、ステップ1509へ進み、存在しない場合には、ステップ1506へ進む。
例えば、シンボル1304と筆記クラスタ905とが一致性を有すると判断された場合には、図14に示す、シンボル1304に対応する処理内容である、「シンボル領域内」に「画像」のコンテンツが存在するか否かを判断する。筆記処理部111は、イメージ901のPDFデータが有する各要素の座標から、筆記クラスタ905の領域内には、画像領域904が存在すると判断し、ステップ1509へ進む。
In step 1508, for the writing cluster that the
For example, if it is determined that the
ステップ1509では、ステップ1508において筆記クラスタの位置の所定の範囲内に存在するコンテンツについて、前記筆記クラスタと一致性を有するシンボルに対応する処理内容を実行する。例えば、筆記クラスタ905内に存在する画像コンテンツ904について、シンボル1304に対応する処理内容である「取得」の処理を行う。取得した画像データは、例えば、ユーザI/Fデバイス119からの入力に従って保存される。
In
ステップ1510は、全ての筆記クラスタについて、ステップ1507からステップ1509の処理が終了した場合に、ステップ1507で処理シンボル管理テーブルが有するシンボルとの一致性を有すると判断されなかった筆記クラスタ、及び、前記一致性を有すると判断された筆記クラスタのそれぞれについて、予め処理シンボル管理シート等で定められている処理を行う。例えば、筆記クラスタ907及び908が、前記一致性を有すると判断されなかった場合に、図14の処理シンボル管理テーブルに基づき、筆記クラスタ907及び908を、イメージ601に上書きする。
(構成の変形例)
図2は、本発明の画像処理装置201について、入出力デバイスをネットワークを介して接続したものである。画像処理装置201は、ユーザI/Fデバイス119と接続され、ネットワーク203を介してネットワークスキャナ204、ネットワークデジタイザ205、ネットワークプリンタ206、ネットワークサーバ207、及び、クライアントPC208と接続されている。
Step 1510 includes, for all the writing clusters, when the processing from Step 1507 to Step 1509 is completed, the writing cluster that is not determined to be consistent with the symbols included in the processing symbol management table in Step 1507, and For each writing cluster that is determined to have a match, a process defined in advance in the process symbol management sheet or the like is performed. For example, when the writing
(Configuration variation)
FIG. 2 shows an
画像処理装置201は、画像処理装置101が有する、スキャナI/F制御部108、デジタイザ制御部109、プリンタI/F制御部112、及び、ディスクI/F制御部115に代えて、ネットワークI/F制御部202を有し、該ネットワークI/F制御部202が、前記ネットワーク203に接続された各種デバイスの制御及びデータの入出力等を行う。
The
ネットワークサーバ207は、ディスク装置119を有し、該ディスク装置119からのデータ出力、及び、データを記憶させる処理を行う。クライアントPC208は、FTP(File Transfer Protocol)によるデータの転送や、データの格納等の処理を行う。
The
また、図2では、紙入力装置、紙出力装置等をネットワークを介して画像処理装置201に接続しているが、これらの一部をネットワークを介して接続し、他の装置は画像処理装置101が有する各種I/F制御部によって直接接続されて制御する構成でもよい。
(処理シンボル管理シートの変形例)
図17に、処理シンボル管理シートの図12とは異なる例を示す。
In FIG. 2, a paper input device, a paper output device, and the like are connected to the
(Modification of processing symbol management sheet)
FIG. 17 shows an example different from FIG. 12 of the processing symbol management sheet.
イメージ1701は、処理シンボル管理シートのイメージであり、処理内容を表す文字列1204に代えて、選択欄1702から1704、及び、処理内容を表す文字列1205に代えて、選択欄1705から1707を有している。
An
選択欄1702から1707は、それぞれ、図14における処理内容を表す各項目である「コンテンツ抽出範囲」「処理を行うコンテンツの種類」及び「処理内容」に対応している。選択欄1702から1707が有する各選択肢に、ユーザがチェック記号を記入することにより、処理内容を表す各項目について、その内容が定められる。
(筆記クラスタの形状の変形例)
図18は、筆記クラスタの筆記領域の形状を表す説明図である。本発明の実施例では、筆記クラスタ906の筆記領域を、外接する矩形1601を用いて表したが、必ずしも矩形に限定されるものではなく、例えば、領域1801のように、筆記クラスタ906を囲む形状であれば良い。
(コンピュータプログラムの実施例)
図20は、本発明をコンピュータのプログラムによって構成する説明図である。
The
(Modification of the shape of the writing cluster)
FIG. 18 is an explanatory diagram showing the shape of the writing area of the writing cluster. In the embodiment of the present invention, the writing area of the writing
(Example of computer program)
FIG. 20 is an explanatory diagram for constructing the present invention by a computer program.
コンピュータ2001は、紙に手書きによって記入されたシンボル等に基づき、前記紙に印刷されたコンテンツの処理を行う画像処理プログラムを有するコンピュータであって、ユーザI/Fデバイス119、紙入力装置2005、プリンタ等の紙出力装置118、及び、ディスク装置108と接続されている。
A
コンピュータ2001は、CPU2002、ROM2003、及び、RAM2004から構成されており、CPU2002が、ROM2003に記録されているプログラムを実行することにより、コンピュータを構成する部分の各種制御、及び、コンピュータに接続されたデバイスである116から119及びディスク装置107等の制御を行う。
A
ROM2003は、本発明の実施の形態である画像処理プログラムを保持している。RAM2004は、CPU2002が処理を行う場合に、一時データ等を格納するメモリである。
(その他の処理の実施例)
なお、上記の例では、コンテンツから画像データを取得する場合、及び、コンテンツの内容を変更する場合の処理について説明したが、上記の例に限定されることなく、例えば、コンテンツを印刷により出力する場合、コンテンツを再生する場合等の所定の処理について、実施することが可能である。
以上、発明を実施するための最良の形態について説明を行ったが、本発明は、この最良の形態で述べた実施の形態に限定されるものではない。本発明の主旨をそこなわない範囲で変更することが可能である。
The
(Example of other processing)
In the above example, the processing for acquiring image data from content and changing the content is described. However, the present invention is not limited to the above example, and for example, the content is output by printing. In this case, it is possible to carry out predetermined processing such as when content is reproduced.
Although the best mode for carrying out the invention has been described above, the present invention is not limited to the embodiment described in the best mode. Modifications can be made without departing from the spirit of the present invention.
111 筆記処理部
110 紙情報取得部
114 紙識別情報管理部
113 印刷処理部
1941 紙識別情報管理手段
1942 処理シンボル管理手段
1943 処理実行手段
111
Claims (25)
前記紙識別情報と前記コンテンツとを対応させて管理する紙識別情報管理手段と、
第二の紙に印刷された複数の処理内容と該処理内容毎に手書きされた第二のシンボルとを読み込んだ結果に基づき、前記第一の紙に手書きされた前記第一のシンボルと前記第二のシンボルとが一致性を有する場合に、前記第一の紙に印刷されたコンテンツに対して前記第二のシンボルに対応する処理内容を出力する、処理シンボル管理手段と、
前記処理シンボル管理手段が出力する処理内容に基づき、前記紙識別情報に対応する前記コンテンツを処理する処理実行手段とを有し、
前記処理実行手段は、前記第二のシンボルとの一致性を有するか否かの判断に応じて、前記第一のシンボルを、前記コンテンツに上書き
することを特徴とする画像処理装置。 Based on the content printed on the first paper, the paper identification information for identifying the first paper printed on the first paper, and the first symbol handwritten on the first paper, In an image processing apparatus for processing the content,
Paper identification information management means for managing the paper identification information and the content in association with each other;
Based on the result of reading a plurality of processing contents printed on the second paper and a second symbol handwritten for each processing content, the first symbol handwritten on the first paper and the first symbol Processing symbol management means for outputting processing contents corresponding to the second symbol for the content printed on the first paper when the two symbols have a match;
Based on the processing contents to be outputted by the processing symbol managing unit, it possesses a process executing means for processing the content corresponding to the paper identification information,
The image processing apparatus , wherein the processing execution means overwrites the content with the first symbol in accordance with a determination as to whether or not the second symbol has consistency. .
第二の紙に印刷された複数の処理内容と該処理内容毎に手書きされた第二のシンボルとを読み込む第一の読み込みステップと、
前記第一の紙に印刷されたコンテンツ、前記第一の紙を識別する紙識別情報、及び、前記第一の紙に手書きされた前記第一のシンボルを読み込む第二の読み込みステップと、
前記第一及び第二の読み込みステップで読み込まれた、前記第二のシンボル及び前記第一のシンボルとが一致性を有する場合に、前記第二のシンボルに対応する処理内容を出力する、処理シンボル管理ステップと、
前記処理シンボル管理ステップにより出力された処理内容に基づき、前記紙識別情報に対応する前記コンテンツを処理する処理実行ステップとを有し、
前記処理実行ステップは、前記第二のシンボルとの一致性を有するか否かの判断に応じて、前記第一のシンボルを、前記コンテンツに上書き
することを特徴とする画像処理方法。 Based on the content printed on the first paper, the paper identification information for identifying the first paper printed on the first paper, and the first symbol handwritten on the first paper, In an image processing method in an image processing apparatus having a paper identification information management unit that performs processing of content and manages the paper identification information and the content in association with each other,
A first reading step of reading a plurality of processing contents printed on the second paper and a second symbol handwritten for each processing content;
A second reading step of reading the content printed on the first paper, the paper identification information for identifying the first paper, and the first symbol handwritten on the first paper;
A processing symbol that outputs the processing content corresponding to the second symbol when the second symbol and the first symbol read in the first and second reading steps have a match. Administrative steps;
Based on the processing content that is output by the process symbol management step, it possesses a processing execution step of processing the content corresponding to the paper identification information,
The image processing method characterized in that, in the processing execution step, the first symbol is overwritten on the content in accordance with a determination as to whether or not the second symbol is consistent. .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005364920A JP4741363B2 (en) | 2005-12-19 | 2005-12-19 | Image processing apparatus, image processing method, and image processing program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005364920A JP4741363B2 (en) | 2005-12-19 | 2005-12-19 | Image processing apparatus, image processing method, and image processing program |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2007173938A JP2007173938A (en) | 2007-07-05 |
| JP2007173938A5 JP2007173938A5 (en) | 2009-02-05 |
| JP4741363B2 true JP4741363B2 (en) | 2011-08-03 |
Family
ID=38299969
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005364920A Expired - Fee Related JP4741363B2 (en) | 2005-12-19 | 2005-12-19 | Image processing apparatus, image processing method, and image processing program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4741363B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5214277B2 (en) * | 2008-02-29 | 2013-06-19 | 卓雄 田中 | Medical diagnosis support system |
| JP5089524B2 (en) * | 2008-08-05 | 2012-12-05 | 株式会社リコー | Document processing apparatus, document processing system, document processing method, and document processing program |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001147751A (en) * | 1999-11-24 | 2001-05-29 | Sharp Corp | Information terminal and control method therefor |
| JP2003271651A (en) * | 2002-03-13 | 2003-09-26 | Oki Electric Ind Co Ltd | Symbol mark search system, client terminal, symbol mark search server, and program used for client terminal |
| JP2004080601A (en) * | 2002-08-21 | 2004-03-11 | Canon Inc | Device, system, and method for processing image and control program |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0357066A (en) * | 1989-07-26 | 1991-03-12 | Canon Inc | Document proofreading device |
| JPH08202796A (en) * | 1995-01-23 | 1996-08-09 | Canon Inc | Image processor |
-
2005
- 2005-12-19 JP JP2005364920A patent/JP4741363B2/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001147751A (en) * | 1999-11-24 | 2001-05-29 | Sharp Corp | Information terminal and control method therefor |
| JP2003271651A (en) * | 2002-03-13 | 2003-09-26 | Oki Electric Ind Co Ltd | Symbol mark search system, client terminal, symbol mark search server, and program used for client terminal |
| JP2004080601A (en) * | 2002-08-21 | 2004-03-11 | Canon Inc | Device, system, and method for processing image and control program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007173938A (en) | 2007-07-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4557765B2 (en) | Image processing apparatus and method | |
| JP4533273B2 (en) | Image processing apparatus, image processing method, and program | |
| US7926732B2 (en) | OCR sheet-inputting device, OCR sheet, program for inputting an OCR sheet and program for drawing an OCR sheet form | |
| US8675260B2 (en) | Image processing method and apparatus, and document management server, performing character recognition on a difference image | |
| JP5154292B2 (en) | Information management system, form definition management server, and information management method | |
| JP2008146605A (en) | Image processor and its control method | |
| JP7337612B2 (en) | Image processing device, image processing system, image processing method, and program | |
| JP2008145611A (en) | Information processor and program | |
| EP1594044A2 (en) | Digital pen and paper | |
| JP2006025129A (en) | System and method for image processing | |
| JP5979918B2 (en) | Information processing system, information processing system control method, information processing apparatus, and computer program | |
| US7983485B2 (en) | System and method for identifying symbols for processing images | |
| JP4542050B2 (en) | Digital pen input system | |
| JP4741363B2 (en) | Image processing apparatus, image processing method, and image processing program | |
| JP5089524B2 (en) | Document processing apparatus, document processing system, document processing method, and document processing program | |
| JP2008257530A (en) | Electronic pen input data processing system | |
| US20080049258A1 (en) | Printing Digital Documents | |
| JP2006119712A (en) | Information management terminal device and program, and document for electronic pen | |
| JP2005234790A (en) | Handwritten slip processing system and method | |
| JP4788780B2 (en) | Information processing system, program and electronic pen form | |
| JP2005196536A (en) | Entry information processing system, program, book for electronic pen | |
| JP2006119713A (en) | Editing terminal device, program, and document for electronic pen | |
| JP4984590B2 (en) | Electronic pen form manufacturing system and program | |
| JP5906608B2 (en) | Information processing apparatus and program | |
| JP5935376B2 (en) | Copy machine |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081212 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20081212 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20101209 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110118 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110316 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110412 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110506 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140513 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |