JP4679438B2 - 品質スペクトルの自動検出 - Google Patents
品質スペクトルの自動検出 Download PDFInfo
- Publication number
- JP4679438B2 JP4679438B2 JP2006153999A JP2006153999A JP4679438B2 JP 4679438 B2 JP4679438 B2 JP 4679438B2 JP 2006153999 A JP2006153999 A JP 2006153999A JP 2006153999 A JP2006153999 A JP 2006153999A JP 4679438 B2 JP4679438 B2 JP 4679438B2
- Authority
- JP
- Japan
- Prior art keywords
- spectrum
- intensity
- vector
- peak
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000001228 spectrum Methods 0.000 title claims description 118
- 238000001514 detection method Methods 0.000 title 1
- 239000013598 vector Substances 0.000 claims description 48
- 238000000034 method Methods 0.000 claims description 44
- 238000012549 training Methods 0.000 claims description 30
- 239000012634 fragment Substances 0.000 claims description 24
- 238000010606 normalization Methods 0.000 claims description 9
- 238000012545 processing Methods 0.000 claims description 8
- 230000004044 response Effects 0.000 claims description 2
- 230000003595 spectral effect Effects 0.000 description 40
- 150000002500 ions Chemical class 0.000 description 27
- 108090000765 processed proteins & peptides Proteins 0.000 description 21
- 238000012706 support-vector machine Methods 0.000 description 19
- 230000006870 function Effects 0.000 description 18
- 235000018102 proteins Nutrition 0.000 description 16
- 102000004169 proteins and genes Human genes 0.000 description 16
- 108090000623 proteins and genes Proteins 0.000 description 16
- 238000010586 diagram Methods 0.000 description 12
- 238000001914 filtration Methods 0.000 description 11
- 230000008569 process Effects 0.000 description 11
- 238000004458 analytical method Methods 0.000 description 10
- 102000004196 processed proteins & peptides Human genes 0.000 description 9
- 238000010847 SEQUEST Methods 0.000 description 7
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 229940098773 bovine serum albumin Drugs 0.000 description 5
- 150000001413 amino acids Chemical class 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 238000005192 partition Methods 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000007704 transition Effects 0.000 description 4
- 238000013528 artificial neural network Methods 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- 241000606161 Chlamydia Species 0.000 description 2
- 241000283073 Equus caballus Species 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 238000001360 collision-induced dissociation Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 238000000132 electrospray ionisation Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000005040 ion trap Methods 0.000 description 2
- 238000012417 linear regression Methods 0.000 description 2
- 238000001819 mass spectrum Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000001303 quality assessment method Methods 0.000 description 2
- 238000013442 quality metrics Methods 0.000 description 2
- 101000741065 Bos taurus Beta-casein Proteins 0.000 description 1
- 102000018832 Cytochromes Human genes 0.000 description 1
- 108010052832 Cytochromes Proteins 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 108010067372 Pancreatic elastase Proteins 0.000 description 1
- 102000016387 Pancreatic elastase Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108010065084 Phosphorylase a Proteins 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 108010026552 Proteome Proteins 0.000 description 1
- 108090000787 Subtilisin Proteins 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 108010062636 apomyoglobin Proteins 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000007635 classification algorithm Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000003795 desorption Methods 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 238000001211 electron capture detection Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000001641 gel filtration chromatography Methods 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 238000000752 ionisation method Methods 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 108091005601 modified peptides Proteins 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
Images











Classifications
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J49/00—Particle spectrometers or separator tubes
- H01J49/004—Combinations of spectrometers, tandem spectrometers, e.g. MS/MS, MSn
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/10—Pre-processing; Data cleansing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/10—Machine learning using kernel methods, e.g. support vector machines [SVM]
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10T—TECHNICAL SUBJECTS COVERED BY FORMER US CLASSIFICATION
- Y10T436/00—Chemistry: analytical and immunological testing
- Y10T436/24—Nuclear magnetic resonance, electron spin resonance or other spin effects or mass spectrometry
Description
以下に説明される種々のフィルタは、不良なスペクトルのおよそ75%又はそれ以上を除去し、高品質(識別可能な)スペクトルはおよそ10%だけ損失することを示す。
例示的な本実施形態の一態様においては、マスフラグメントスペクトル又はこうしたスペクトルの一部にアクセスするステップを与えるコンピュータにより制御されるフィルタ処理方法が記載される。この場合、スペクトルのピーク差異に応じたデータ構造(アレイ等)が構築され、この構築されたデータ構造に応じたスペクトルが選択される。
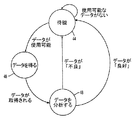
図1は、タンデムマス分光計のデータをタンパク質配列ライブラリからの配列と相関させるプロセスのブロック図である。図1は、フィルタをどこに使用することができるかについての一例を示す。フィルタは、さらに、品質スペクトルを使用する必要がある統計分析、並びに、本発明によりここで可能になる将来の用途等の他の用途に使用することもできる。このプロセスでは、スペクトルと配列ライブラリとの間の比較の前に、フィルタ処理作用を行うようにフィルタを組み込む。分析のための材料の入力は、未知のペプチド試料10であり、これらに限定されるものではないが、多糖類、脂質、又はポリヌクレオチドを含む他の試料とすることができる。典型的には、ペプチドは、一部が断片化したタンパク質を分離するのに使用されたクロマトグラフィの列から出力される。タンパク質は、例えば、ゲル濾過クロマトグラフィ及び/又は高性能液体クロマトグラフィ(HPLC)により断片化することができる。試料10は、電気噴霧イオン化(ES)等のイオン化法によって、タンデムマス分光計12に導入される。第1のマス分光計14において、ペプチド・イオンが選択されて、特定のマスの目標とされる成分が、試料10の残りから分離される。目標とされる成分は、活性化させられるか又は分解される。ペプチドの場合は、結果として、イオン化された親ペプチド(「先駆体イオン」)と種々の状態にイオン化されるより低いマスの成分ペプチドとの混合物がもたらされる。衝突誘起解離(CID)、電子捕獲解離、マトリックス支援レーザ脱離/イオン化解離等を含む多数の活性化法を使用することができる。
追って説明するフィルタを生成する際に、68,978のタンデムマススペクトルは、4つの異なるプロテアーゼ(トリプシン、エラスターゼ、スブチリシン、及びプロテイナーゼK)で消化された5つのタンパク質(ウサギ・ホスホリラーゼa、ウマ・シトクロムc、ウマ・アポミオグロビン、ウシ血清アルブミン、及びウシβ−カゼイン)の公知の混合物から取得された。68,978のスペクトルのうち、5,678が「良好」と表示が付され、これは、907,654の入力項目をもつ全米バイオテクノロジ情報センター(NCBI)の非冗長的なタンパク質データベースに対するSEQUEST検索により、混合物中の5つのタンパク質の1つ、又はケラチン若しくは消化に用いられる酵素の1つのような汚染物質と思われるものと整合することを意味する。他の63,300のスペクトルは「不良」と表示が付されたが、これらのうちの幾つかは、変異又は改質ペプチドの高品質スペクトルであった。「不良な」スペクトルのこうした大きな割合は、HPLCに典型的なものであり、そこで、溶出されたペプチドは、マス分光計の中に連続して電気噴霧される。スペクトル検査に使用することができる1つのMS装置は、m/z(電荷上マス)がカット・オフから200ないし300デカまでであり、1000までのm/zにおいて解像度が0.3デカまでであるイオン・トラップ装置である。他のMS装置もまた用いることもできる。デカは、単位電荷当たりのダルトンの代わりに略式で書かれるものである。
I.強度の正規化
図2は、順位を用いるための特に単純な方法を正当化するものである。上述のように、順位対確率のグラフは、負の指数関数に極めて良好に適合する。このように、この文献において支持されている、確率的な採点関数に対するピークxの寄与は、ピークがbイオン及びyイオンである寄与の合計が、定数にログ尤度を加えたものに等しくなるように、定数に1/Rank(x)を加えたもに比例すると考えられる。従って、最大の堅牢性については、相対強度ではなく、順位に基づく強度の正規化が、フィルタの生成に用いるのに選択され、そこでは、最も強いピークが順位=1、2番目に強いものが順位=2等を有する。
ステップ36において、入力スペクトルデータを取得する。或る場合においては、入力スペクトルデータは、種々の長さのペプチド等の、より小さい断片に消化されたタンパク質を含む。より小さい断片は、それぞれの断片についてスペクトルを生成するタンデムマス分光計(MS/MS)に与えることができる。他の態様においては、入力スペクトルデータは、スペクトルによって表すことができる他のエンティティと関連付けることができる。さらに、入力スペクトルデータは、ステップ36において、個別の試料の状態で及び/又はストリームとして与えることができる。ステップ38において、入力スペクトルデータを、n次元空間内に位置決めする。ここで説明されるように、様々に成形された決定表面は、訓練によって、例えば公知の「良好な」及び「不良な」データをもつ1つ又はそれ以上の訓練の組によって、n次元空間について生成することができる。こうした訓練は、ステップ38において、入力スペクトルデータを受信する前に実行することができる。別の態様においては、こうした表面を生成し、(例えば、ファイルとして)保存し、必要なときに検索することができる。ステップ40において、入力スペクトルデータが上述の表面に関して、n次元空間内のその位置の関数として「良好な」データであるか又は「不良な」データであるかについて判断がなされる。例えば、入力スペクトルデータは、n次元空間の「良好な」(又は「OK」)領域内にあるときに「良好な」データと表示を付すことができ、入力スペクトルデータが、n次元空間の「良好な」領域内にないときには「不良な」データと表示を付すことができる。ステップ42において、「良好」と判断された入力スペクトルデータは、(例えば、SEQUESTにより)図1と関連させて説明された配列データベースについてのスペクトルの比較/識別のように、さらに処理することができる。「不良」と判断された入力スペクトルデータは、無視、破棄、削除する等してよい。図3においては、入力スペクトルデータの後に続く試料及び/又はストリームについて、これらのステップを繰り返すことができる。
以下は、図3ないし図5の1つ又はそれ以上と関連させて説明されたステップの1つ又はそれ以上を実施するのに使用することができる例示的な擬似コードを与える。
Main{
global multidimensional_space surface[];
spectrum_buffer[];
surface=train(training_samples);
while true{
spectrum_buffer=read(input_spectrum);
if(spectrum_OK(spectrum_buffer,surface))write(spectrum_buffer);
}
}
擬似コード・リスト1
擬似コード・リスト1に注意して、任意の関数「訓練」は、入力を受け取り、n次元空間内に表面を生成することができる。この関数は、ここで生成されるものではなく、以前に生成された表面を記憶装置(例えば、メモリ、ディスク、CD等)から読み取ることができるという点で任意的である。例えば、フィルタを最初に訓練して、表面を記憶装置(例えば、ファイル)に保存して、後に続くフィルタの呼び出しにおいて、以前に保存されたファイルから、フィルタにより、この表面を入力することができる。擬似コードは、好適な表面が既に存在するかどうかをチェックして判断する付加的な記述(図示せず)を含むことができる。既存の表面又は新たに生成された表面のいずれかを使用することができる。別の例では、訓練関数を呼び出すべきかどうかを示すフラッグを、引数として又は(例えば、オブジェクト指向プログラミング法の)コンストラクタによって送ることができる。表面が取得されるか又は定められる(すなわち、フィルタが訓練される)と、フィルタは、入力スペクトルデータを読み取り、(スペクトル・バッファ内の)この入力スペクトルデータが表面の関数としてn次元空間の「良好な」領域内にあるかどうか判断する。次いで、試験されるスペクトルが「良好」(すなわち、「OK」)であると判断された場合には、さらに別の識別動作に使用されるべきスペクトルデータが書き込まれる(又は送られる)。訓練データは、良好又は不良の分類を与えられた、以前に分析されたスペクトルである。訓練データは、スペクトル分析プログラムにより生成される「良好」又は「不良」の値を含むことができる。
回帰法を使用する場合には、訓練データは、各々の訓練データのスペクトル上に連続する品質採点を有する。この方法は、この訓練データから回帰関数を生成し、新規なスペクトルが与えられると、訓練データと一致する品質採点を割り当てる。
フィルタがバイナリ又は連続する品質メトリック型のものであるかどうかにかかわらず、概して、これらのフィルタを生成するのに2つの手法が存在する。第1の手法が、専門知識を組み込む多数の特化された特徴を考案するものであるのに対して、代替的手法は、これらに限定されるものではないが、訓練データから学習することができる、Support Vector Machines(SVM)、Support Vector Regression(SVR)及びNeural Networks(NN)等の学習モデル又は分類アルゴリズムに、あまり処理されていない高次元データを供給するものである。
II.特化された特徴を用いた分類
Norm/(x)=max{0,C1−(C2/MaxmZ)・Rank(x)}
を用いることに注目し、ここで、MaxmZは、スペクトル内の最大有効m/z値であり、C1及びC2は定数である。MaxmZは、一般に、より多いピークが、より長いペプチドに考慮されることを意味する。
特徴ごとのC1及びC2の値は、訓練の組において「良好」と「不良」との間の最良の区別を与えたC1及びC2の値を選出することによって別々に学習された。例えば、Good−Diff Fraction特徴については、C1=28及びC2=400であり、典型的な値であるMaxmZ=2000のときに、Rank(x)が#140である場合には、Norm/(x)がゼロより大きいことを意味する。一般に、フィルタを作る際には、C1及びC2は、はるかに低い順位のピークを使用する、追って説明する同位体特徴を除いては、異なる特徴についてほぼ同じであった。或るピークが別のピークに対して適切なm/z及び強度を有し、ピークの尤度を増加させるという事実は、有意義であるように見える。これは、どのように順位を品質フィルタに組み込むかについての一例に過ぎない。
以下は、7次元データ構造(f1,f2,...,f7)、7次元空間(R7)内の点について述べ、ここで、fiは、下記のi番目の特徴値である。以下は、7次元空間より小さい又はこれより大きい次元空間において実施することができるものであり、しかも、7つの特徴により表される7次元空間より大きい又は小さい次元空間において用いるために、本出願の概念により他の特徴を生成することができ、Npeaksの特徴1(f1)、Total Intensityの特徴2(f2)、Good−Diff Fractionの特徴3(f3)、Isotopesの特徴4(f4)、Complementsの特徴5(f5)、Watrer Lossesの特徴6(f6)、及びIntensity Balanceの特徴7(f7)を含む、以下に説明される7つの特徴により表され、この7つの特徴は、次のように定義される。
(1)Npeaks。スペクトル内のピーク数。この特徴は、多くの場合、スペクトル品質のヒューマン・アセスメントに使用される。
(2)Total Intensity。スペクトル内のピークの未処理の強度の総計。
(3)Good−Diff Fraction。この特徴は、2つのピークがアミノ酸のマスにおいて、どれだけ異なる可能性があるかを判断する。或るi=1,2,...,20について、
(4)Isotopes。関連付けられた同位体ピークとの正規化されたピーク強度の合計。すなわち、次式となる。
spectra_OK(spectra_buffer){
peak_array[] //array of peaks where each peak has a mass and intensity spectrum_buffer[];
difference_array[masses]; //array of mass differences
peak_array=convert_mass_intensity(spectrum_buffer);//determine peaks and
//peak intensities
for every relevant pair of peaks(p1,p2)in peak_array{
n=get_mass_difference(p1.p2);
n=round(n)//round n to an appropriate resolution difference_array(n)+=intensity(p1,p2);
}
spectra_OK=analyze(peak_array,difference_array);//analyze spectrum
}
擬似コード・リスト2
analyze(peak_array,difference_array){
double vector[];
vector[1]=feature1(peak_array,difference_array);
vector[2]=feature2(peak_array,difference_array);
...
analyze=compare_v_s(vector,surface);//determine where vector
//falls in the n−dimensional space
}
擬似コード・リスト3
以下の擬似コード・リスト及び図8は、「特徴4」(Isotope)の生成を記述するものである。
feature4(peak_array,difference_array){
feature4=0
For all k near 1{//the spectra peaks that differ by one Dalton,
//up to an appropriate resolution
feature4=feature4+difference_array[k];
}
}
擬似コード・リスト4
擬似コード・リスト及び図9のブロック図により示される、差異の対に依存しない「特徴7」(例えば、特徴7(Intesity Balance))の記述を以下に示す。
feature7(peak_vector,difference_vector){
partitions[] //stores limits of each band
intensity[] //stores intensity of each band
partitions=partitionvector(peak_vector); //divide peak_vector into bands by
//m/z(the mass coord)
for each band
intesity[band]=determine_intensity(peak_vector,partions[band]);
sort(intesity);
feature7=sum(intensity of most intense bands)−sum(intensity of least intense bands);
}
擬似コード・リスト5
フィルタによる分類については、「良好」と「不良」との間の二次的な決定境界を定める二次判別分析(QDA)を使用した。この単純な方法は、特に、中心極限定理による近似ガウス分布を有する、ここで使用されるもののような加算特徴と良好に作用する。
表1

compare_v_s関数が、n次元空間内にベクトル又は点を位置決めし、ベクトルが表面のどちら側に入るかに応じて、真/偽の値を戻し、このようにしてバイナリ分類法に対応する。回帰法を用いる場合には、当業者であれば、回帰(IV)のセクションに関して後で説明されるように、回帰関数をベクトルに適用した後で品質採点を戻す異なる関数が呼び出されることになることを理解するであろう。
III.SVM等の学習モデルによる分類
図10及び以下の擬似コード・リストは、異なるベクトルの分類を可能にするSVMフィルタ(分類器)についての手順を示す。
analyze(difference_vector){
analyze=svm_classify(difference_vector,surface);
}
擬似コード・リスト6
表IIは、異なるダルトン範囲での動作について、SVMフィルタの動作により取得された結果を与える。具体的には、1から187までの1デカのビンをもつ差異ヒストグラムに加えて、1から384までの1デカのビン及び1から187までの0.5デカのビンをもつ、より大きい差異ヒストグラムもまたSVMへの入力として考慮された。
表II
SVM手法は、特化された特徴の手法より明らかに良好な結果を与えることが判明し、性能は、入力ベクトルの増大するサイズと共に僅かに改善した。稼動時間は、サイズが増加するに伴い遅くなる。一般に、SVMフィルタ(分類器)は、QDAフィルタ(分類器)より低速であるが、SEQUEST自体を稼動させるほど低速ではない。最速のSVMフィルタ(1から187までの1デカのビン)は、20,000スペクトルを処理するのに362秒をかかるのに対して、QDAフィルタは、同じスペクトルを処理するのに114秒かかる。SEQUESTは、小規模(1MB)データベースを用いると、1スペクトル当たり1秒までかかり、大規模(100MB)データベースについては、1スペクトル当たり15秒までかかる。
IV.回帰
品質の連続的な値は、高強度のピーク間で観測されたbイオン及びyイオンの断片であると定義された。より具体的には、Lengthがペプチド中のアミノ酸の数を示すとすると、Qualityは、次式のように定義される。
Quality=1/2(#b+#y)/(Length−1)
ここで、#bは、順位<6・Lengthである場合のbイオンのピーク数であり、#yは、順位<6・Lengthである場合のyイオンのピーク数である。この値は、「良好な」スペクトルの帰納的解析を用いて算出することができる。例えば、ピークの単純な存在/不在ではなく正規化された強度を用いた類似定義のような他のQualityの定義、及び、識別されていないピークについてペナルティを科された別の定義が考慮された。種々のQuality定義が、同様な結果を与えた。引用された定義は、人間により最も解釈可能であるため選択され、この特徴は、いずれのbイオン及びyイオンも観測されない0から、すべての可能性のあるbイオン及びyイオンが観測された1.0まで及ぶ。さらに、データベース検索及びde novoの両方の多くのペプチド識別プログラムは、或る種の正規化された強度ではなく、bイオン及びyイオンの存在/不在に依存する。
回帰は、予測されたQualityが「良好な」スペクトルの平均Qualityより良好な採点である、0.28までであった数千もの不良なスペクトルを識別し、これは、すべての可能性のあるbイオン及びyイオンの28%のみがスペクトル内の最良順位のピークにおいて出現したことを意味する。6つの最良の「不良な」スペクトル(すべてが、0.44を上回る予測Qualityをもつ)を、Lutefisk、すなわち、de novoペプチド・シーケンサにサブミットした。6つのスペクトルのうちの2つについて、Lutefiskは、BLAST整合アルゴリズムにより、ウシ血清アルブミンと独特に整合することができる部分配列を与えた。表IIIは、これらの成功の1つを示し、括弧付きの数値は、そのマスを合計する、場合によっては改質された識別されていない残留物を意味する「マスの相違」を示す。
表III
最良の不良なスペクトルについての上位5つのLutefisk識別
このようなフィルタ処理装置は、タンデムマス分光計と共に含んでもよいし、又はこれに取り付けてもよい。さらに、既存のde novo又はデータベース検索識別プログラムは、ここで開示されたフィルタを含むことができる。
18:フラグメントスペクトル
20:フィルタ
21:シーケンサ
Claims (5)
- マスフラグメントスペクトルの一部にアクセスするステップと、
前記マスフラグメントスペクトルの一部の強度バランスに応じて、前記マスフラグメントスペクトルの一部を評価するステップと、
前記評価ステップに応じて前記マスフラグメントスペクトルを処理するステップと、
を含み、
前記評価するステップが、
前記マスフラグメントスペクトルの前記強度バランスに応じてベクトルを構築するステップと、
少なくとも1つの表面により分離された複数の領域を含む多次元空間を生成するステップであって、前記少なくとも1つの表面が任意の関数によって決定されるものであるステップと、
前記ベクトルを前記多次元空間内に配置するステップと、
をさらに含み、
前記表面が、前記任意の関数に「良好な」及び「不良な」データ訓練の組を適用することにより決定される、
ことを特徴とするコンピュータにより制御される方法。 - 前記ベクトルを前記多次元空間内に配置し、該ベクトルが前記表面のいずれの側に入るかに応じて真/偽の値を戻し、バイナリ分類法に対応する、という比較関数を用いるステップをさらに含む、請求項1に記載の方法。
- 生成された前記表面を再利用のために電子ファイルに格納するステップをさらに含む、請求項1に記載の方法。
- 前記マスフラグメントスペクトルの前記強度バランスに応じてベクトルを構築するステップをさらに含み、
前記ベクトル及び/又は前記ピーク対の差異が、およそ18デカ(Da)だけ異なるm/z値を有するピーク対の正規化された強度に応じたものである、請求項1に記載の方法。 - 前記正規化が、順位に基づいた強度正規化方式を用いたものである、請求項4に記載の方法。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/122,364 US7230235B2 (en) | 2005-05-05 | 2005-05-05 | Automatic detection of quality spectra |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2006317457A JP2006317457A (ja) | 2006-11-24 |
| JP2006317457A5 JP2006317457A5 (ja) | 2009-06-18 |
| JP4679438B2 true JP4679438B2 (ja) | 2011-04-27 |
Family
ID=36803445
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006153999A Expired - Fee Related JP4679438B2 (ja) | 2005-05-05 | 2006-05-02 | 品質スペクトルの自動検出 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7230235B2 (ja) |
| EP (1) | EP1720114A1 (ja) |
| JP (1) | JP4679438B2 (ja) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020115056A1 (en) | 2000-12-26 | 2002-08-22 | Goodlett David R. | Rapid and quantitative proteome analysis and related methods |
| GB0305796D0 (en) * | 2002-07-24 | 2003-04-16 | Micromass Ltd | Method of mass spectrometry and a mass spectrometer |
| EP2458619B1 (en) * | 2004-05-24 | 2017-08-02 | Ibis Biosciences, Inc. | Mass spectrometry with selective ion filtration by digital thresholding |
| US20070166033A1 (en) * | 2006-01-10 | 2007-07-19 | Fujitsu Limited | Analyzing the quality of an optical waveform |
| EP2208990B1 (en) * | 2007-10-22 | 2015-02-25 | Shimadzu Corporation | Mass analysis data processing method |
| US8344315B2 (en) * | 2010-05-27 | 2013-01-01 | Math Spec, Inc. | Process for rapidly finding the accurate masses of subfragments comprising an unknown compound from the accurate-mass mass spectral data of the unknown compound obtained on a mass spectrometer |
| US11798656B2 (en) * | 2019-02-22 | 2023-10-24 | Nevada Research & Innovation Corporation | Computer-implemented methods and systems for identifying a species from mass spectra |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09510780A (ja) * | 1994-03-14 | 1997-10-28 | ユニバーシティ オブ ワシントン | 質量分析法によるヌクレオチド、アミノ酸又は炭水化物の同定 |
| JP2004503792A (ja) * | 2000-06-12 | 2004-02-05 | ジ アリゾナ ボード オブ リージェンツ オン ビハーフ オブ ザ ユニバーシティー オブ アリゾナ | マススペクトルデータをマイニングする方法とシステム |
| JP2005510732A (ja) * | 2001-11-30 | 2005-04-21 | ヨーロピアン モレキュラー バイオロジー ラボラトリー | 質量分析法によって自動的にタンパク質の配列決定を行うシステムおよび方法 |
| JP2007093582A (ja) * | 2005-05-05 | 2007-04-12 | Palo Alto Research Center Inc | 品質スペクトルの自動検出 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9821393D0 (en) | 1998-10-01 | 1998-11-25 | Brax Genomics Ltd | Protein profiling 2 |
| US6489121B1 (en) | 1999-04-06 | 2002-12-03 | Micromass Limited | Methods of identifying peptides and proteins by mass spectrometry |
| US6799121B2 (en) | 2000-03-30 | 2004-09-28 | York University | Sequencing of peptides by mass spectrometry |
| GB0212470D0 (en) * | 2002-05-30 | 2002-07-10 | Shimadzu Res Lab Europe Ltd | Mass spectrometry |
| US6770871B1 (en) | 2002-05-31 | 2004-08-03 | Michrom Bioresources, Inc. | Two-dimensional tandem mass spectrometry |
-
2005
- 2005-05-05 US US11/122,364 patent/US7230235B2/en not_active Expired - Fee Related
-
2006
- 2006-05-02 JP JP2006153999A patent/JP4679438B2/ja not_active Expired - Fee Related
- 2006-05-05 EP EP06009373A patent/EP1720114A1/en not_active Ceased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09510780A (ja) * | 1994-03-14 | 1997-10-28 | ユニバーシティ オブ ワシントン | 質量分析法によるヌクレオチド、アミノ酸又は炭水化物の同定 |
| JP2004503792A (ja) * | 2000-06-12 | 2004-02-05 | ジ アリゾナ ボード オブ リージェンツ オン ビハーフ オブ ザ ユニバーシティー オブ アリゾナ | マススペクトルデータをマイニングする方法とシステム |
| JP2005510732A (ja) * | 2001-11-30 | 2005-04-21 | ヨーロピアン モレキュラー バイオロジー ラボラトリー | 質量分析法によって自動的にタンパク質の配列決定を行うシステムおよび方法 |
| JP2007093582A (ja) * | 2005-05-05 | 2007-04-12 | Palo Alto Research Center Inc | 品質スペクトルの自動検出 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006317457A (ja) | 2006-11-24 |
| US7230235B2 (en) | 2007-06-12 |
| EP1720114A1 (en) | 2006-11-08 |
| US20060249667A1 (en) | 2006-11-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2007093582A (ja) | 品質スペクトルの自動検出 | |
| Bern et al. | Automatic quality assessment of peptide tandem mass spectra | |
| JP4679438B2 (ja) | 品質スペクトルの自動検出 | |
| Listgarten et al. | Statistical and computational methods for comparative proteomic profiling using liquid chromatography-tandem mass spectrometry | |
| US7899625B2 (en) | Method and system for robust classification strategy for cancer detection from mass spectrometry data | |
| US8987662B2 (en) | System and method for performing tandem mass spectrometry analysis | |
| JP4549314B2 (ja) | イオン化分子フラグメントを分類するための方法、装置、及びプログラム製品 | |
| Liu et al. | Methods for peptide identification by spectral comparison | |
| Flikka et al. | Improving the reliability and throughput of mass spectrometry‐based proteomics by spectrum quality filtering | |
| CN113362899B (zh) | 一种基于深度学习的蛋白质质谱数据的分析方法及系统 | |
| Bhanot et al. | A robust meta‐classification strategy for cancer detection from MS data | |
| Chouaib et al. | Feature selection combining genetic algorithm and adaboost classifiers | |
| US20020046002A1 (en) | Method to evaluate the quality of database search results and the performance of database search algorithms | |
| CN107563148B (zh) | 一种基于离子索引的整体蛋白质鉴定方法与系统 | |
| Salmi et al. | Filtering strategies for improving protein identification in high‐throughput MS/MS studies | |
| Wolski et al. | Transformation and other factors of the peptide mass spectrometry pairwise peak-list comparison process | |
| Marchiori et al. | Robust SVM-based biomarker selection with noisy mass spectrometric proteomic data | |
| US20180137236A1 (en) | System, method and device for identifying discriminant biological factors and for classifying proteomic profiles | |
| Fang et al. | Feature selection in validating mass spectrometry database search results | |
| Loo et al. | Classification of SELDI-ToF mass spectra of ovarian cancer serum samples using a proteomic pattern recognizer | |
| Altartouri et al. | A versatile combination of classifiers for protein function prediction | |
| Timm et al. | Peak intensity prediction for pmf mass spectra using support vector regression | |
| Spivak | Analysis of mass spectrometry data for protein identification in complex biological mixtures | |
| Yang et al. | A clustering based hybrid system for mass spectrometry data analysis | |
| Settelmeier | Theoretical Fundamentals of Computational Proteomics and Deep Learning-Based Identification of Chimeric Mass Spectrometry Data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070517 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090501 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090501 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20091228 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100301 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100526 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100921 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101215 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110117 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110201 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140210 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |