JP4233541B2 - 目標変数の自動データパースペクティブ生成 - Google Patents
目標変数の自動データパースペクティブ生成 Download PDFInfo
- Publication number
- JP4233541B2 JP4233541B2 JP2005117562A JP2005117562A JP4233541B2 JP 4233541 B2 JP4233541 B2 JP 4233541B2 JP 2005117562 A JP2005117562 A JP 2005117562A JP 2005117562 A JP2005117562 A JP 2005117562A JP 4233541 B2 JP4233541 B2 JP 4233541B2
- Authority
- JP
- Japan
- Prior art keywords
- subtree
- data
- alternative
- score
- decision tree
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000003066 decision tree Methods 0.000 claims description 86
- 230000003750 conditioning effect Effects 0.000 claims description 82
- 238000000034 method Methods 0.000 claims description 78
- 238000010801 machine learning Methods 0.000 claims description 26
- 238000012545 processing Methods 0.000 claims description 15
- 238000005192 partition Methods 0.000 claims description 12
- 238000004458 analytical method Methods 0.000 claims description 5
- 238000000638 solvent extraction Methods 0.000 claims 2
- 230000006870 function Effects 0.000 description 27
- 230000008569 process Effects 0.000 description 21
- 238000010586 diagram Methods 0.000 description 15
- 238000004891 communication Methods 0.000 description 7
- 238000007418 data mining Methods 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 6
- 230000003287 optical effect Effects 0.000 description 6
- 238000010276 construction Methods 0.000 description 5
- 238000003860 storage Methods 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 4
- 230000005055 memory storage Effects 0.000 description 4
- 238000011045 prefiltration Methods 0.000 description 4
- 238000010845 search algorithm Methods 0.000 description 4
- 238000013459 approach Methods 0.000 description 3
- 230000001143 conditioned effect Effects 0.000 description 3
- 238000013500 data storage Methods 0.000 description 3
- 230000006855 networking Effects 0.000 description 3
- 239000004187 Spiramycin Substances 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000002452 interceptive effect Effects 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000000802 evaporation-induced self-assembly Methods 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/283—Multi-dimensional databases or data warehouses, e.g. MOLAP or ROLAP
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2216/00—Indexing scheme relating to additional aspects of information retrieval not explicitly covered by G06F16/00 and subgroups
- G06F2216/03—Data mining
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
- Y10S707/99936—Pattern matching access
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99943—Generating database or data structure, e.g. via user interface
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Air Conditioning Control Device (AREA)
- Feedback Control In General (AREA)
Description
ここで、cは、ユーザによって選択される「複雑さ」要因である。ユーザは、さらに、変数の数の閾値および/または結果のピボットテーブル内のセルの個数の閾値を指定することができる。
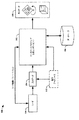
104 入力データ
106 データベース
108 出力データ
110 ユーザ
112 他のデータソース
202 データパースペクティブ生成コンポーネント
204 変数決定コンポーネント
206 データパースペクティブビルダコンポーネント
208 ユーザ
210 関心を持ったデータ
212 目標変数
214 複雑さパラメータ
216 ユーティリティパラメータ
218 集約関数
220 他の入力データ
222 データベース
224 出力データ
302 データパースペクティブ生成コンポーネント
304 入力データ
306 出力データ
308 データ前置フィルタコンポーネント
310 変数決定コンポーネント
312 データパースペクティブビルダコンポーネント
314 変数オプティマイザコンポーネント
316 決定木ジェネレータコンポーネント
318 決定木エバリュエータコンポーネント
320 ユーザコンテキストデータ
322 集約関数
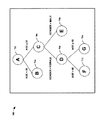
402 地域
404 販売販売代理人
406 月
408 売上
1204 処理ユニット
1206 システムメモリ
1208 バス
1226 ハードディスクドライブインターフェース
1228 磁気ディスクドライブインターフェース
1230 光ドライブインターフェース
1232 オペレーティングシステム
1234 アプリケーションプログラム
1236 他のプログラムモジュール
1238 プログラムデータ
1244 シリアルポートインターフェース
1246 モニタ
1248 ビデオアダプタ
1260 リモートコンピュータ
1264 ローカルエリアネットワーク
1266 広域ネットワーク
1268 ネットワークインターフェース
1270 モデム
1302 クライアント
1304 サーバ
1306 サーバデータストア
1308 通信フレームワーク
1310 クライアントデータストア
Claims (22)
- データパースペクティブ生成を容易にする、コンピュータにより実行される、1又はそれ以上のコンピュータ読取可能媒体にストアされたプログラムであって、コンピュータに、
データベースからの目標変数およびパースペクティブを生成すべきデータを含む、ユーザ指定の入力データを受け取るステップと、
少なくとも部分的に前記ユーザ指定の入力データおよび前記データベースから導出される、前記目標変数のデータパースペクティブの少なくとも1つの条件付け変数の自動生成を行うステップであって、
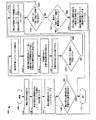
目標変数の標準決定木を学習するステップ(1104)、
現在の最良の標準部分木をルートノードとして初期化し、スコア付けするステップ(1106)、
得られたスコアを現在の最良の標準部分木のスコアとしてセットするステップ(1107)、
前記現在の最良の標準部分木が前記学習された標準決定木と等しいかどうかを判定するステップ(1108)、
等しい場合に、前記現在の最良の標準部分木を単一の決定木として設定するステップ(1110)、
等しくない場合に、最良の代替の完全な部分木のスコアをマイナス無限大にセットするステップ(1112)、
前記現在の最良の標準部分木より1つ多い分割を有する代替部分木を作成し、前記学習された標準決定木に適合させるステップ(1114)、
前記代替部分木から代替の完全な部分木を作成してスコア付けするステップ(1118、1120)、
前記作成された代替の完全な部分木のスコアが前記最良の代替の完全な部分木のスコアより大きいかどうかを判定するステップ(1122)、
大きい場合に、前記代替部分木を最良の代替部分木としてセットし、最良の代替の完全な部分木のスコアを前記作成された代替の完全な部分木のスコアと等しくなるようにセットするステップ(1124)、
さらなる分割を有する代替案がまだあるかどうかを判定するステップ(1126)、
代替案がある場合には、代替部分木を作成し学習された標準決定木に適合させる前記ステップ(1114)に戻るステップ、
代替案がない場合には、前記最良の代替の完全な部分木のスコアが前記現在の最良の標準部分木のスコアを超えるかどうかを判定するステップ(1128)、
超えない場合に、前記現在の最良の標準部分木を単一の決定木として設定するステップ(1110)、
超える場合に、前記最良の代替の完全な部分木を現在の最良の標準部分木としてセットするステップ(1130)、及び、
現在の最良の標準部分木が学習された標準決定木と等しいかどうかを判定する前記ステップ(1108)に戻るステップ
により、条件付け変数のセットおよび前記条件付け変数の対応する値に変換される完全な単一の決定木を構成するステップと、
条件付け変数およびその細かさの少なくとも1つの最良のセットを見つけるために前記単一の決定木の少なくとも1つの部分木を検索するステップと
からなる、少なくとも1つの条件付け変数の自動生成を行うステップと
を実行させることを特徴とする、コンピュータにより実行されるプログラム。 - 前記データパースペクティブは、ピボットテーブルおよび多次元分析(OLAP)キューブを有する群から選択される少なくともその1つを含むことを特徴とする請求項1に記載のプログラム。
- 少なくとも1つの自動的に生成された条件付け変数を使用して、前記データパースペクティブを自動的に生成するステップ
をコンピュータにさらに実行させることを特徴とする請求項1に記載のプログラム。 - 前記データパースペクティブを自動的に生成するステップは、機械学習手法に基づいて、ユーザへの提示の質を高めるために前記データパースペクティブのユーザビューをさらに自動的に調整するステップを含むことを特徴とする請求項3に記載のプログラム。
- 前記プログラムは、少なくとも1つのユーザ制御入力をコンピュータに使用させることを特徴とする請求項4に記載のプログラム。
- 前記少なくとも1つの条件付け変数の自動生成を行うステップは、前記条件付け変数の前記自動生成を容易にする少なくとも1つの機械学習手法を使用するステップを含むことを特徴とする請求項1に記載のプログラム。
- 前記機械学習手法は、前記目標変数の前記データパースペクティブのトップセットおよび左セットからなる群から選択される少なくとも1つについて少なくとも1つの条件付け変数を特定することを特徴とする請求項6に記載のプログラム。
- 前記条件付け変数は、ユーザ制御入力を介して制御可能であることを特徴とする請求項7に記載のプログラム。
- 前記条件付け変数は、離散条件付け変数および連続条件付け変数からなる群から選択される少なくとも1つを含むことを特徴とする請求項7に記載のプログラム。
- 前記機械学習手法は、さらに、離散化を介して前記条件付け変数の細かさを自動的に決定することを特徴とする請求項9に記載のプログラム。
- 前記細かさは、ユーザ制御入力を介して調整可能であることを特徴とする請求項10に記載のプログラム。
- 前記機械学習手法は、前記連続条件付け変数の少なくとも1つの範囲を自動的に決定し、前記範囲を新しい条件付け変数として表すことを特徴とする請求項9に記載のプログラム。
- 前記範囲は、ユーザ制御入力を介して調整可能であることを特徴とする請求項12に記載のプログラム。
- 前記機械学習手法は、前記条件付け変数の前記範囲の決定を容易にする少なくとも1つの完全な決定木を使用することを特徴とする請求項12に記載のプログラム。
- コンピュータによって少なくとも一部が実行されるデータパースペクティブ生成を容易にする方法であって、
ユーザ入力デバイスを介して指定された、データベースからの目標変数およびパースペクティブを生成すべきデータを含むユーザ指定の入力データを受け取るステップと、
コンピュータの処理ユニットにおいて、少なくとも部分的に前記ユーザ指定の入力データおよび前記データベースから導出される、前記目標変数のデータパースペクティブの少なくとも1つの条件付け変数を自動的に生成するステップであって、
目標変数の標準決定木を学習するステップ(1104)、
現在の最良の標準部分木をルートノードとして初期化し、スコア付けするステップ(1106)、
得られたスコアを現在の最良の標準部分木のスコアとしてセットするステップ(1107)、
前記現在の最良の標準部分木が前記学習された標準決定木と等しいかどうかを判定するステップ(1108)、
等しい場合に、前記現在の最良の標準部分木を単一の決定木として設定するステップ(1110)、
等しくない場合に、最良の代替の完全な部分木のスコアをマイナス無限大にセットするステップ(1112)、
前記現在の最良の標準部分木より1つ多い分割を有する代替部分木を作成し、前記学習された標準決定木に適合させるステップ(1114)、
前記代替部分木から代替の完全な部分木を作成してスコア付けするステップ(1118、1120)、
前記作成された代替の完全な部分木のスコアが前記最良の代替の完全な部分木のスコアより大きいかどうかを判定するステップ(1122)、
大きい場合に、前記代替部分木を最良の代替部分木としてセットし、最良の代替の完全な部分木のスコアを前記作成された代替の完全な部分木のスコアと等しくなるようにセットするステップ(1124)、
さらなる分割を有する代替案がまだあるかどうかを判定するステップ(1126)、
代替案がある場合には、代替部分木を作成し学習された標準決定木に適合させる前記ステップ(1114)に戻るステップ、
代替案がない場合には、前記最良の代替の完全な部分木のスコアが前記現在の最良の標準部分木のスコアを超えるかどうかを判定するステップ(1128)、
超えない場合に、前記現在の最良の標準部分木を単一の決定木として設定するステップ(1110)、
超える場合に、前記最良の代替の完全な部分木を現在の最良の標準部分木としてセットするステップ(1130)、及び、
現在の最良の標準部分木が学習された標準決定木と等しいかどうかを判定する前記ステップ(1108)に戻るステップ
により、条件付け変数のセットおよび前記条件付け変数の対応する値に変換される完全な単一の決定木を構成するステップと、
条件付け変数およびその細かさの少なくとも1つの最良のセットを見つけるために前記単一の決定木の少なくとも1つの部分木を検索するステップと
からなる、少なくとも1つの条件付け変数の自動生成を行うステップと
を含むことを特徴とする方法。 - 前記データパースペクティブを自動的に生成するステップは、
前記条件付け変数の自動的生成を容易にする少なくとも1つの機械学習手法を使用するステップ
をさらに含むことを特徴とする請求項15に記載の方法。 - 少なくとも1つのユーザ制御入力に基づいて、条件付け変数、条件付け変数の細かさ、および連続条件付け変数の範囲からなる群から選択される少なくとも1つを調整するステップ
をさらに含むことを特徴とする請求項16に記載の方法。 - 少なくとも1つの自動的に生成された条件付け変数を使用して前記データパースペクティブを自動的に生成するステップ
をさらに含むことを特徴とする請求項15に記載の方法。 - 機械学習手法に基づいて、ユーザへの提示の質を高めるために前記データパースペクティブのビューを自動的に調整するステップ
をさらに含むことを特徴とする請求項18に記載の方法。 - 前記方法は、少なくとも1つのユーザ制御入力を使用することを特徴とする請求項19に記載の方法。
- 前記データパースペクティブは、ピボットテーブルおよび多次元分析(OLAP)キューブからなる群から選択される少なくとも1つを含むことを特徴とする請求項15に記載の方法。
- データパースペクティブ生成を容易にするシステムであって、
データベースからの目標変数およびパースペクティブを生成すべきデータを含むユーザ指定の入力データを受け取る手段と、
少なくとも部分的に前記ユーザ指定の入力データおよび前記データベースから導出される、前記目標変数のデータパースペクティブの少なくとも1つの条件付け変数を自動的に生成する手段であって、
目標変数の標準決定木を学習し(1104)、
現在の最良の標準部分木をルートノードとして初期化し、スコア付けし(1106)、
得られたスコアを現在の最良の標準部分木のスコアとしてセットし(1107)、
前記現在の最良の標準部分木が前記学習された標準決定木と等しいかどうかを判定し(1108)、
等しい場合に、前記現在の最良の標準部分木を単一の決定木として設定し(1110)、
等しくない場合に、最良の代替の完全な部分木のスコアをマイナス無限大にセットし(1112)、
前記現在の最良の標準部分木より1つ多い分割を有する代替部分木を作成し、前記学習された標準決定木に適合し(1114)、
前記代替部分木から代替の完全な部分木を作成してスコア付けし(1118、1120)、
前記作成された代替の完全な部分木のスコアが前記最良の代替の完全な部分木のスコアより大きいかどうかを判定し(1122)、
大きい場合に、前記代替部分木を最良の代替部分木としてセットし、最良の代替の完全な部分木のスコアを前記作成された代替の完全な部分木のスコアと等しくなるようにセットし(1124)、
さらなる分割を有する代替案がまだあるかどうかを判定し(1126)、
代替案がある場合には、代替部分木を作成し学習された標準決定木に適合させる動作(1114)に戻り、
代替案がない場合には、前記最良の代替の完全な部分木のスコアが前記現在の最良の標準部分木のスコアを超えるかどうかを判定し(1128)、
超えない場合に、前記現在の最良の標準部分木を単一の決定木として設定し(1110)、
超える場合に、前記最良の代替の完全な部分木を現在の最良の標準部分木としてセットし(1130)、そして
現在の最良の標準部分木が学習された標準決定木と等しいかどうかを判定する動作(1108)に戻る
ことにより、条件付け変数のセットおよび前記条件付け変数の対応する値に変換される完全な単一の決定木を構成し、且つ、
条件付け変数およびその細かさの少なくとも1つの最良のセットを見つけるために前記単一の決定木の少なくとも1つの部分木を検索する
ように構成された、少なくとも1つの条件付け変数を自動的に生成する手段と
を含むことを特徴とするシステム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/824,108 US7225200B2 (en) | 2004-04-14 | 2004-04-14 | Automatic data perspective generation for a target variable |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005302040A JP2005302040A (ja) | 2005-10-27 |
| JP2005302040A5 JP2005302040A5 (ja) | 2008-02-21 |
| JP4233541B2 true JP4233541B2 (ja) | 2009-03-04 |
Family
ID=34939156
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005117562A Expired - Fee Related JP4233541B2 (ja) | 2004-04-14 | 2005-04-14 | 目標変数の自動データパースペクティブ生成 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US7225200B2 (ja) |
| EP (1) | EP1587008A3 (ja) |
| JP (1) | JP4233541B2 (ja) |
| KR (1) | KR101130524B1 (ja) |
| CN (1) | CN100426289C (ja) |
Families Citing this family (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10233609A1 (de) * | 2002-07-24 | 2004-02-19 | Siemens Ag | Verfahren zur Ermittlung einer in vorgegebenen Daten vorhandenen Wahrscheinlichkeitsverteilung |
| EP1577792B1 (en) * | 2004-03-16 | 2010-10-13 | Sap Ag | A method, computer program product and data processing system for displaying a plurality of data objects |
| US20050234761A1 (en) * | 2004-04-16 | 2005-10-20 | Pinto Stephen K | Predictive model development |
| EP1643364A1 (en) * | 2004-09-30 | 2006-04-05 | Sap Ag | Systems and methods for general aggregation of characteristics and key figures |
| WO2006066556A2 (de) * | 2004-12-24 | 2006-06-29 | Panoratio Database Images Gmbh | Relationale komprimierte datenbank-abbilder (zur beschleunigten abfrage von datenbanken) |
| US7587410B2 (en) * | 2005-03-22 | 2009-09-08 | Microsoft Corporation | Dynamic cube services |
| US8457997B2 (en) * | 2005-04-29 | 2013-06-04 | Landmark Graphics Corporation | Optimization of decisions regarding multiple assets in the presence of various underlying uncertainties |
| EP1941432A4 (en) | 2005-10-25 | 2011-04-20 | Angoss Software Corp | STRATEGY TREES FOR DATA MINING |
| US20080172671A1 (en) * | 2007-01-11 | 2008-07-17 | International Business Machines Corporation | Method and system for efficient management of resource utilization data in on-demand computing |
| US8645390B1 (en) * | 2007-08-31 | 2014-02-04 | Google Inc. | Reordering search query results in accordance with search context specific predicted performance functions |
| US8001158B2 (en) * | 2007-12-13 | 2011-08-16 | Hewlett-Packard Development Company, L.P. | Systems and processes for evaluating database complexities |
| US8015129B2 (en) * | 2008-04-14 | 2011-09-06 | Microsoft Corporation | Parsimonious multi-resolution value-item lists |
| CA2708911C (en) | 2009-07-09 | 2016-06-28 | Accenture Global Services Gmbh | Marketing model determination system |
| JP5175903B2 (ja) | 2009-08-31 | 2013-04-03 | アクセンチュア グローバル サービスィズ ゲーエムベーハー | 適応分析多次元処理システム |
| US20120005151A1 (en) * | 2010-07-01 | 2012-01-05 | Vineetha Vasudevan | Methods and systems of content development for a data warehouse |
| US8712989B2 (en) | 2010-12-03 | 2014-04-29 | Microsoft Corporation | Wild card auto completion |
| US8774515B2 (en) * | 2011-04-20 | 2014-07-08 | Xerox Corporation | Learning structured prediction models for interactive image labeling |
| US9135233B2 (en) | 2011-10-13 | 2015-09-15 | Microsoft Technology Licensing, Llc | Suggesting alternate data mappings for charts |
| US10061473B2 (en) | 2011-11-10 | 2018-08-28 | Microsoft Technology Licensing, Llc | Providing contextual on-object control launchers and controls |
| US8793567B2 (en) * | 2011-11-16 | 2014-07-29 | Microsoft Corporation | Automated suggested summarizations of data |
| US9275334B2 (en) | 2012-04-06 | 2016-03-01 | Applied Materials, Inc. | Increasing signal to noise ratio for creation of generalized and robust prediction models |
| US9304746B2 (en) * | 2012-06-07 | 2016-04-05 | Carmel-Haifa University Economic Corporation Ltd. | Creating a user model using component based approach |
| EP2864856A4 (en) | 2012-06-25 | 2015-10-14 | Microsoft Technology Licensing Llc | SEIZURE METHOD EDITOR APPLICATION PLATFORM |
| US9563674B2 (en) * | 2012-08-20 | 2017-02-07 | Microsoft Technology Licensing, Llc | Data exploration user interface |
| US10001897B2 (en) | 2012-08-20 | 2018-06-19 | Microsoft Technology Licensing, Llc | User interface tools for exploring data visualizations |
| EP2989568A4 (en) | 2013-05-31 | 2016-12-07 | Landmark Graphics Corp | DETERMINING THE IMPORTANCE OF ATTRIBUTES |
| US10416871B2 (en) | 2014-03-07 | 2019-09-17 | Microsoft Technology Licensing, Llc | Direct manipulation interface for data analysis |
| US10824799B2 (en) | 2014-06-30 | 2020-11-03 | Microsoft Technology Licensing, Llc | Summary data autofill |
| US20160364772A1 (en) | 2015-05-29 | 2016-12-15 | Nanigans, Inc. | Graphical user interface for high volume data analytics |
| US20170011418A1 (en) | 2015-05-29 | 2017-01-12 | Claude Denton | System and method for account ingestion |
| CN108369584B (zh) | 2015-11-25 | 2022-07-08 | 圆点数据公司 | 信息处理系统、描述符创建方法和描述符创建程序 |
| US10140344B2 (en) | 2016-01-13 | 2018-11-27 | Microsoft Technology Licensing, Llc | Extract metadata from datasets to mine data for insights |
| WO2018079225A1 (ja) * | 2016-10-31 | 2018-05-03 | 日本電気株式会社 | 自動予測システム、自動予測方法および自動予測プログラム |
| JP7199345B2 (ja) | 2017-03-30 | 2023-01-05 | ドットデータ インコーポレイテッド | 情報処理システム、特徴量説明方法および特徴量説明プログラム |
| US10581953B1 (en) * | 2017-05-31 | 2020-03-03 | Snap Inc. | Real-time content integration based on machine learned selections |
| CN107562821A (zh) * | 2017-08-17 | 2018-01-09 | 平安科技(深圳)有限公司 | 基于数据库的数据透视方法、装置和计算机存储介质 |
| JPWO2019069507A1 (ja) | 2017-10-05 | 2020-11-05 | ドットデータ インコーポレイテッド | 特徴量生成装置、特徴量生成方法および特徴量生成プログラム |
| KR20200068043A (ko) * | 2018-11-26 | 2020-06-15 | 전자부품연구원 | 영상 기계학습을 위한 객체 gt 정보 생성 방법 및 시스템 |
| CN112783890B (zh) * | 2019-11-08 | 2024-05-07 | 珠海金山办公软件有限公司 | 一种生成数据透视表行的方法及装置 |
| CN112883023A (zh) * | 2019-11-29 | 2021-06-01 | 北京沃东天骏信息技术有限公司 | 数据透视的方法和装置 |
| CN115618193A (zh) * | 2022-12-01 | 2023-01-17 | 北京维恩咨询有限公司 | 基于数据透视表的超级时间维度分析方法、装置和设备 |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5537589A (en) | 1994-06-30 | 1996-07-16 | Microsoft Corporation | Method and system for efficiently performing database table aggregation using an aggregation index |
| JPH1010995A (ja) | 1996-06-20 | 1998-01-16 | Fujitsu General Ltd | 液晶プロジェクタ照明装置 |
| EP0863469A3 (en) | 1997-02-10 | 2002-01-09 | Nippon Telegraph And Telephone Corporation | Scheme for automatic data conversion definition generation according to data feature in visual multidimensional data analysis tool |
| JP3431482B2 (ja) * | 1998-01-23 | 2003-07-28 | 株式会社日立情報システムズ | 分類項目解析方法及びこのプログラムを記録した記録媒体 |
| US6430545B1 (en) * | 1998-03-05 | 2002-08-06 | American Management Systems, Inc. | Use of online analytical processing (OLAP) in a rules based decision management system |
| US6044366A (en) | 1998-03-16 | 2000-03-28 | Microsoft Corporation | Use of the UNPIVOT relational operator in the efficient gathering of sufficient statistics for data mining |
| US6298342B1 (en) | 1998-03-16 | 2001-10-02 | Microsoft Corporation | Electronic database operations for perspective transformations on relational tables using pivot and unpivot columns |
| US6374251B1 (en) | 1998-03-17 | 2002-04-16 | Microsoft Corporation | Scalable system for clustering of large databases |
| US6216134B1 (en) | 1998-06-25 | 2001-04-10 | Microsoft Corporation | Method and system for visualization of clusters and classifications |
| US6360224B1 (en) | 1999-04-23 | 2002-03-19 | Microsoft Corporation | Fast extraction of one-way and two-way counts from sparse data |
| US6411313B1 (en) | 1999-06-14 | 2002-06-25 | Microsoft Corporation | User interface for creating a spreadsheet pivottable |
| US6626959B1 (en) | 1999-06-14 | 2003-09-30 | Microsoft Corporation | Automatic formatting of pivot table reports within a spreadsheet |
| US6405207B1 (en) | 1999-10-15 | 2002-06-11 | Microsoft Corporation | Reporting aggregate results from database queries |
| US6484163B1 (en) | 2000-03-01 | 2002-11-19 | International Business Machines Corporation | Technique for data mining of large scale relational databases using SQL |
| US6519599B1 (en) | 2000-03-02 | 2003-02-11 | Microsoft Corporation | Visualization of high-dimensional data |
| US6505185B1 (en) | 2000-03-30 | 2003-01-07 | Microsoft Corporation | Dynamic determination of continuous split intervals for decision-tree learning without sorting |
| EP1195694A3 (en) | 2000-10-06 | 2006-01-11 | International Business Machines Corporation | Automatic determination of OLAP Cube dimensions |
| US7818286B2 (en) * | 2001-01-22 | 2010-10-19 | Sas Institute Inc. | Computer-implemented dimension engine |
| US20040193633A1 (en) | 2003-03-28 | 2004-09-30 | Cristian Petculescu | Systems, methods, and apparatus for automated dimensional model definitions and builds utilizing simplified analysis heuristics |
| US7089266B2 (en) * | 2003-06-02 | 2006-08-08 | The Board Of Trustees Of The Leland Stanford Jr. University | Computer systems and methods for the query and visualization of multidimensional databases |
| US20050021489A1 (en) * | 2003-07-22 | 2005-01-27 | Microsoft Corporation | Data mining structure |
-
2004
- 2004-04-14 US US10/824,108 patent/US7225200B2/en not_active Expired - Fee Related
-
2005
- 2005-04-06 EP EP05102695A patent/EP1587008A3/en not_active Ceased
- 2005-04-13 KR KR1020050030779A patent/KR101130524B1/ko not_active IP Right Cessation
- 2005-04-14 JP JP2005117562A patent/JP4233541B2/ja not_active Expired - Fee Related
- 2005-04-14 CN CNB2005100673750A patent/CN100426289C/zh not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005302040A (ja) | 2005-10-27 |
| CN1684068A (zh) | 2005-10-19 |
| EP1587008A2 (en) | 2005-10-19 |
| KR20060045677A (ko) | 2006-05-17 |
| CN100426289C (zh) | 2008-10-15 |
| KR101130524B1 (ko) | 2012-03-28 |
| EP1587008A3 (en) | 2006-07-05 |
| US7225200B2 (en) | 2007-05-29 |
| US20050234960A1 (en) | 2005-10-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4233541B2 (ja) | 目標変数の自動データパースペクティブ生成 | |
| Zappia et al. | Clustering trees: a visualization for evaluating clusterings at multiple resolutions | |
| Yu et al. | Using Bayesian network inference algorithms to recover molecular genetic regulatory networks | |
| US10713572B2 (en) | Data discovery nodes | |
| JP5025891B2 (ja) | 単純化された発見型分析(analysisheuristics)を利用する自動化されたディメンション・モデルの定義および構築のためのシステム、方法および装置 | |
| JP2006012140A (ja) | データパースペクティブ中の異常検出 | |
| Pisharath et al. | NU-MineBench 2.0 | |
| Arredondo et al. | Inferring number of populations and changes in connectivity under the n-island model | |
| US9305076B1 (en) | Flattening a cluster hierarchy tree to filter documents | |
| KR20060044772A (ko) | 트리를 학습하기 위한 테이블 사용 방법 | |
| Ioannakis et al. | RETRIEVAL—an online performance evaluation tool for information retrieval methods | |
| Tornede et al. | Run2Survive: A decision-theoretic approach to algorithm selection based on survival analysis | |
| CN108038238B (zh) | 一种支持个性化教学过程自动生成的教学资源建模方法及系统 | |
| Darkins et al. | Accelerating Bayesian hierarchical clustering of time series data with a randomised algorithm | |
| US10509800B2 (en) | Visually interactive identification of a cohort of data objects similar to a query based on domain knowledge | |
| Zhou et al. | Structural factor equation models for causal network construction via directed acyclic mixed graphs | |
| Hatwágner et al. | Behavioral analysis of fuzzy cognitive map models by simulation | |
| Fang | A study on the application of data mining techniques in the management of sustainable education for employment | |
| JP2000040079A (ja) | 並列データ分析装置 | |
| Richter | Spectral analysis of transient amplifiers for death–birth updating constructed from regular graphs | |
| Olsson et al. | Hard cases in source code to architecture mapping using Naive Bayes | |
| Betke et al. | Classifying temporal characteristics of job i/o using machine learning techniques | |
| Al-Najdi et al. | Multiple consensuses clustering by iterative merging/splitting of clustering patterns | |
| Sekanina et al. | Visualisation and analysis of genetic records produced by Cartesian genetic programming | |
| Munoz‐Erazo et al. | Creation of High‐Dimensional Reduction Analysis‐Compatible Histocytometry Files from Images of Densely‐Packed Cells and/or Variable Stain Intensity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20071122 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20071226 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071228 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071228 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20071228 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20080212 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080219 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080515 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081022 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081028 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20081126 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20081209 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20111219 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4233541 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20111219 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20121219 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131219 Year of fee payment: 5 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |