JP4179660B2 - 文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 - Google Patents
文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 Download PDFInfo
- Publication number
- JP4179660B2 JP4179660B2 JP11324398A JP11324398A JP4179660B2 JP 4179660 B2 JP4179660 B2 JP 4179660B2 JP 11324398 A JP11324398 A JP 11324398A JP 11324398 A JP11324398 A JP 11324398A JP 4179660 B2 JP4179660 B2 JP 4179660B2
- Authority
- JP
- Japan
- Prior art keywords
- character string
- character
- processing target
- hash value
- string
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
【発明の属する技術分野】
この発明は、文字列に対するハッシュ値の計算方法に関し、特に、いわゆるインターネットのWWW(World Wide Web)上のホームページ等のアクセス履歴を、それらのURL(Uniform Resource Locator)から計算したハッシュ値を用いて定められる記憶領域に保存する際に、コンピュータを用いて効率的にハッシュ値を計算するための方法に関する。
【0002】
【従来の技術】
インターネットのWWW上のホームページを閲覧したりするためのプログラムとして、ブラウザと呼ばれるものが知られている。ブラウザを用いて所望のホームページを閲覧するためには、基本的にはブラウザに対してそのホームページのURLを与える。通常はブラウザは、与えられたURLにしたがってインターネット上の所定の資源にアクセスし、当該ブラウザが動作しているコンピュータのモニタ上にたとえばホームページを表示する。
【0003】
URLとは、ホームページを管理しているサーバ名と、そのサーバにおけるそのホームページのファイル名とを、アクセスに使用するプロトコル名と組み合わせたものである。たとえば「http://www.sharp.co.jp/sc/zaurus/index.html 」というURLでは、「http: 」の部分がプロトコル名(http(hypertext transfer protocol))を指定し、「//www.sharp.co.jp 」の部分がサーバ名を表し、「/sc/zaurus/index.html 」の部分が(ファイルパスを含めた)ファイル名を示している。
【0004】
サーバ名は、通常はそのサーバが提供するサービスにしたがった名前(wwwやftpなど)と、そのサーバの存在するドメイン名とからなる。ドメイン名とは、ネットワーク(この例ではインターネット)を構成する部分ネットワークに与えられた名称(インターネット上で一意)である。上の例では「www 」の部分がhttpプロトコルにしたがったwwwサービスを提供するサーバであることを示し、「sharp.co.jp 」の部分がドメイン名を表す。
【0005】
ところで、インターネットに接続されるコンピュータの数が増加してインターネット上のトラヒックが増加すると、通信速度が低下し、良好なサービスが提供されなくなるというおそれがある。また、ブラウザを使用する個々のユーザからみると、一旦アクセスして表示されたホームページに対して、それほど間隔を置かずに再度アクセスしようとする場合、一度めと同様の時間をかけて当該ホームページをアクセスしなおすのはレスポンスの点から見て問題がある。
【0006】
そこで、一般的なブラウザは、一度アクセスしたホームページについては、当該ブラウザが動作しているコンピュータの記憶装置(典型的には固定ディスク)にそのファイルをURLの履歴とともにキャッシュファイルとして保存している。そして、再度同じURLが与えられたときには、キャッシュファイルに当該URLと一致するものがないかどうか調べ、存在する場合には遠隔のサーバをアクセスすることなく、キャッシュファイル中のファイルをアクセスして表示する。キャッシュファイルに当該URLと一致するものがないときだけインターネット上の当該URLをアクセスし表示するとともにキャッシュファイルとして保存する。
【0007】
キャッシュファイルを持つことにより、インターネット上のトラヒックの増加は防止され、かつユーザは良好なレスポンスを得ることができる。キャッシュファイルの内容をどのように維持するか、については種々の方式があるが、その詳細は本願発明とは直接の関係がないのでここでは詳細には述べない。
【0008】
ファイルを固定ディスクに格納する方式としては一般的には種々考えられるが、あるURLを与えられたときに当該URLに対応するファイルがあるかどうかを高速に検索する必要があることから、キャッシュファイルの履歴を蓄積する方式は自ずと限られる。たとえば履歴として各ファイルのURLとその格納アドレスとを組にして単に履歴リスト中に順に蓄積し、URLが与えられるたびに履歴リストを先頭から調べて、一致するURLのものがあるか否かを見るという方式は、データが増大するとそのために要する平均時間が大きくなるという問題点がある。そこで、従来から一般的に、ファイルのURLから所定の計算式にしたがって算出されるハッシュ値を用いて履歴リストを二段階にする方式が採用されている。
【0009】
この方式では、与えられたURLからハッシュ値を計算する。ハッシュ値の計算には典型的にはmod演算が用いられ、URLをそのハッシュ値に基づいて複数個のグループに分類する。例えば、文字Ui(i=1…n)がURL文字列のi番目の文字を表すとして、変数SUMを次のようにして計算する。
【0010】
初期値としてSUM=0とする。以下の計算をi=1〜nに対して繰返す。
【0011】
【数1】
SUM=SUM×5+Ui
i=nまで計算が完了したら、SUMの下位32ビットをハッシュコード(ハッシュ値)とする。下位32ビットのみをハッシュコードとすることで、mod演算が行われ、ハッシュコードに基づいてURLが分類される。
【0012】
こうして計算されたハッシュコードにしたがって各URLを振り分ける。つまり、履歴リストは各ハッシュコードのリストとなり、各ハッシュコードにはそのハッシュコードをもつURLがサブリストとして連結される。各URLには、そのURLに対応したファイルの固定ディスクにおける格納アドレスが付加される。
【0013】
URLが与えられると、まずそのハッシュコードが前述の式にしたがって計算される。そして、履歴リスト内の、計算されたハッシュコードに連結されたサブリストをたどり、そのサブリスト内に目的のURLが存在するかどうかを調べる。当該URLが存在する場合にはそのURLに付されていた格納アドレスを用いて固定ディスクをアクセスし目的のファイルを取り出して表示する。なければ履歴中に存在しないものとしてインターネット上で目的URLをアクセスする。
【0014】
こうした2段階の履歴リストを用いることで、URLの検索のための文字列の比較が、最大でも、一つのハッシュコードに連結されたサブリストの要素の数となるので、履歴を順次に保存しておく場合と比較して比較の回数が大幅に減る。
【0015】
【発明が解決しようとする課題】
このようなハッシュを用いた分類を使用するときには、各ハッシュコードごとにそのハッシュコード値を持つURLの数が均等になるのが望ましい。ところが、URLについてはハッシュコードを用いても均等に分類されないという問題点があることがわかった。これは次のような要因による。
【0016】
URLは、上記したようにプロトコル名と、サーバ名と、ファイル名との組み合わせである。ところが、プロトコルの種類は限られており特にブラウザプログラムがアクセスするときにはほとんどの場合httpプロトコルが用いられるから、URL文字列のうちのプロトコルを表す部分についてはほとんどすべてが「http:// 」となる。同じ文字列がURL中の同じ部分にあると、上記した式にしたがって計算した場合にはこの部分から得られるハッシュコードは同一となる。
【0017】
またサーバ名のうち、多くの場合先頭部分も各サービスを表す文字列に固定されているのが通常である。たとえば「www 」である。すると、この部分でもハッシュコードの計算において差は生じない。
【0018】
さらに、同一のドメインに存在するデータのURLはその大部分が共通で、一部分しか相違していないことが多い。そもそも、同一のドメイン内では、URLのうちのドメイン名の部分が同一となる。この場合にもハッシュコードの計算において差が生じない。
【0019】
その結果、URLの文字列中に出現する文字の並びに偏りがあるので、ハッシュコードによるURLの分類にも偏りが生じるという問題点がある。
【0020】
このようにURLの分類に偏りが生じると、与えられたURL文字列をそのURLに対して計算されたハッシュコードと同一のハッシュコードを持つ多数のURL文字列と比較する必要が生じる。この場合には文字列をその先頭から順次比較して一致しない部分が発見されてはじめて次のURL文字列との比較が行われる。ところが、たとえば同一ドメインに属するデータのURL文字列はその先頭から大部分が等しく、異なる部分は最後の何文字かだけであるという場合が多く、その場合には先頭から多数の文字を比較して最後に近い部分になってはじめて相違が認識されるので、URL文字列ごとに各文字の比較を多数回繰返す必要が生じる。そのため、ハッシュコードによるばらつきが効率的に行われない場合には、比較対象となるURLの数自体が多くなることとあいまって、検索を非効率的にしている。
【0021】
これを避けるためには、ハッシュコードを計算するためのハッシュ関数をより複雑なものとしてハッシュコードを効率的にばらつかせる必要がある。しかしそれでも、同一のハッシュコード内で直接比較する場合に、比較の対象となる文字列が長くなるという問題を解決することはできない。また、関数が複雑であれば処理に要する時間も長くなる。
【0022】
こうした問題は、インターネットのURLをキャッシュするためのブラウザに限らず、これと同様の性質をもったデータの格納場所をハッシュにより定める場合にも遭遇する問題である。また、こうしたハッシングを行うときには、そのために必要なメモリ領域をなるべく節約し、かつハッシング計算も高速で行うことができるようにしたようが好ましい。
【0023】
それゆえにこの発明の目的は、URLのように、文字の並びの出現頻度に偏りがあるような文字列に対して効率的にハッシングが行なえる、文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置を提供することである。
【0024】
【課題を解決するための手段】
この発明のある局面に従うと、方法は、偏った頻度で文字の並びが出現する処理対象の文字列に対するハッシュ値の計算方法であって、特定の文字列を、より短い長さの変換後文字列と一意に関連付けるための機械可読なテーブルを準備するステップと、コンピュータを用いて、処理対象文字列中に出現する文字列を、テーブルを参照して対応の変換後文字列に変換するステップと、コンピュータを用いて、変換後文字列を含む処理対象文字列に基づいてハッシュ値を計算するステップとを含む。
【0025】
変換後文字列は、変換前の文字列と比較して文字列長が短くなる。そのためハッシュ値の計算が高速で行なえ、かつ文字列を記憶しておく領域の容量が少なく済む。また、ハッシュ値が同一の場合には文字列を直接比較する必要があるが、変換後の短い文字列が比較の対象となるので比較を高速に行うことができる。
【0026】
好ましくは、テーブルを準備するステップは、過去に出現した処理対象文字列をコンピュータ中に準備するステップと、過去に出現した処理対象文字列の部分文字列の各々の、出現回数と文字列長とを、コンピュータを用いて集計するステップと、集計された出現回数と文字列長とに基づき、過去に出現した処理対象文字列の部分文字列のうち、所定文字に置換したときに過去に出現した処理対象文字列を最も効率的に圧縮することが可能な部分文字列を選択しテーブルに追加するステップと、選択された部分文字列を考慮して出現回数を再計算し、さらに、追加するステップを所定の条件が成立するまで繰返すステップとを含む。
【0027】
過去に出現した処理対象文字列について、その部分文字列の出現回数と文字列長とを集計することにより、各部分文字列を所定文字列に置換したときに得られる圧縮量を計算できる。この圧縮量に基づいてテーブルにあげるべき文字列を選択することで、効果的に処理対象文字列を圧縮しハッシュの計算が行なえるようになる。
【0028】
この発明の他の局面に従うと、記録媒体は、偏った頻度で文字の並びが出現する処理対象の文字列に対するハッシュ値の計算方法を実現するプログラムを記録した機械可読な記録媒体であって、プログラムは、特定の文字列を、より短い長さの変換後文字列と一意に関連付けるための機械可読なテーブルを準備するステップと、処理対象文字列中に出現する文字列を、テーブルを参照して対応の変換後文字列に変換するステップと、変換後文字列を含む処理対象文字列に基づいてハッシュ値を計算するステップとを含む。
【0029】
変換後文字列は、変換前の文字列と比較して文字列長が短くなる。そのためハッシュ値の計算が高速で行なえ、かつ文字列を記憶しておく領域の容量が少なく済む。
【0030】
好ましくは、テーブルを準備するステップは、過去に出現した処理対象文字列を準備するステップと、過去に出現した処理対象文字列の部分文字列の各々の、出現回数と文字列長とを集計するステップと、集計された出現回数と文字列長とに基づき、過去に出現した処理対象文字列の部分文字列のうち、所定文字に置換したときに過去に出現した処理対象文字列を最も効率的に圧縮することが可能な部分文字列を選択しテーブルに追加するステップと、選択された部分文字列を考慮して出現回数を再計算し、さらに、追加するステップを所定の条件が成立するまで繰返すステップとを含む。
【0031】
過去に出現した処理対象文字列について、その部分文字列の出現回数と文字列長とを集計することにより、各部分文字列を所定文字列に置換したときに得られる圧縮量を計算できる。この圧縮量に基づいてテーブルに含ませるべき文字列を選択することで、効果的に処理対象文字列を圧縮しハッシュの計算が行なえるようになる。
【0032】
【発明の実施の形態】
[第1の実施の形態]
図1を参照して、本願発明の第1の実施の形態にかかる方法は、ブラウザ20によるキャッシュファイル領域24の管理において、ブラウザ20から与えられたURLを後述する方法にしたがって圧縮し、圧縮したURLに対してハッシュ計算を行って、圧縮後の当該URLおよびそのURLに対応するキャッシュファイルのアドレスの組からなるハッシュレコード42を、ハッシュメモリ26内の、当該URLに対して計算されたハッシュ領域40に格納する処理を行うURL圧縮装置22により実現される。なお本実施の形態はブラウザによるURLのアクセス履歴の管理について述べるが、本発明はこれに限らず、文字列をキーとしてハッシングを行い、そのハッシュ値に基づいてレコードを格納したり検索したりするシステム全般に適用することができる。
【0033】
URL圧縮装置22は、実際にはコンピュータ上で実行されるソフトウェアにより実現されるが、URLを置換する際に使用される、置換前後の文字列のテーブルである文字列リスト50と、過去のアクセス履歴ファイル46に基づいて文字列リスト50を構築するためのリスト作成処理56と、ブラウザ20から与えられたURLに含まれる部分文字列を、文字列リスト50を参照して、より短い長さの所定のコード(本実施の形態では1バイトのコード)に置換するための文字列置換処理52と、文字列置換処理52によって部分文字列をそれぞれ所定のコードに置換したURLに基づいてハッシュ計算を行って、計算により得られたハッシュ値にしたがってハッシュメモリ26を維持・管理するためのハッシュ計算処理54とを含む。
【0034】
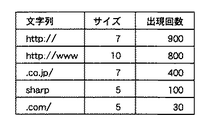
図2を参照して、文字列リスト50は、置換の対象となる文字列(左欄)と、置換後の文字列(右欄)とを組とし、この組を30個含んだものである。図2に示される例では、「http://www. 」という文字列が「1」に置換され、「http:// 」という文字列が「2」に置換され、「.co.jp./」という文字列が「3」に置換され、以下同様である。
【0035】
一般的に通常のパーソナルコンピュータではASCII(American Standard Code for Information Interchange )コードを用いている。しかし、実際に文字として使用されるのはASCIIコードで「32」以上である。そこで、圧縮後のコードとしてコード1〜31を用いれば、あるハッシュレコード42のうちのURL文字列のうちのあるバイトが、もともとのURLに含まれていた文字か、文字列置換処理52によって置換されたコードかを、そのコードの値から判別することができる。この実施の形態では置換後のコードとして1〜30を用いている。
【0036】
図3に、文字列リスト50を用いて文字列を置換する前のURL文字列(左欄)と、置換後のURL文字列との例を示す。図3において、左欄の文字列のうち「http://www. 」の部分は図2の文字列のうち1行目の左欄と一致する。図2によれば、この文字列はASCIIコードの「1」に置換される。また、図3の左欄の文字列において、最後の「.co.jp/ 」の文字列は図2の表では3行目の左欄と一致し、対応のASCIIコードは「3」である。したがって「http://www.sharp.co.jp/ 」は図3の右欄に示すとおり「[1]sharp[3] 」に変換される(コードであることを角かっこで示す)。
【0037】
このようにして部分文字列を文字列リスト50を参照しながら可能なかぎり対応のASCIIコードに変換したのち、変換後の文字列に対してハッシュ計算処理54を行う。そして、計算されたハッシュコードにしたがって当該URLを各ハッシュ領域40に振り分けて、URLの保存であれば置換後のURLと対応のキャッシュファイルのディスクアドレスとをハッシュ領域40に格納し、URLから対応のキャッシュファイルのディスク格納領域を検索する場合であれば対応のハッシュ領域40内で当該置換後のURL文字列を検索したのち、付加されているディスクアドレスをブラウザ20に返す。
【0038】
このようにすることにより次の効果が生ずる。まず、ハッシュ計算が、部分文字列を対応のより短いコードに置換した後のURLに対して行われるため、ハッシュ計算の対象となる文字列そのものが短くなりハッシュ計算の計算量が減少する。特に、ハッシュ計算のばらつきを効率的にするためにハッシュ計算式として複雑なものを選んだ場合に、計算量の増大を押さえることができる。そのためハッシュ計算をより処理を高速化できる。また、同様のばらつきを実現しようとする場合、対象となる文字列が短くなっているので、ハッシュ計算式としてそれほど複雑な式を使用しなくともよいという効果もある。
【0039】
また、ハッシュ領域40のハッシュレコード42に格納されるURLは置換後のより短い文字列となっているので、同じ容量のハッシュ領域40であればより多くの数のURLを格納することができる。または、同じ数のURLを格納するために必要なハッシュ領域40の容量が少なくて済む。すなわち、ハッシュ領域40のための記憶領域を有効に利用することができる。また、同一のハッシュ領域40内でURL文字列の比較を行わなければならない場合でも、比較の対象となる文字列の長さが短いので、比較が高速に行なえるという効果を奏する。
【0040】
前述のようにURL圧縮装置22は実際には、パーソナルコンピュータまたはワークステーションなど、コンピュータ上で実行されるソフトウェアにより実現される。図4に、文字列に対するハッシュ値の計算方法を実現するコンピュータの外観を示す。図4を参照してこのコンピュータ120は、CD−ROM(Compact Disc Read-Only Memory )駆動装置144およびFD(Flexible Disk )駆動装置142とを備えたコンピュータ本体130と、モニタ148と、プリンタ146と、キーボード136と、マウス134とを含む。
【0041】
図5に、このコンピュータ120の構成をブロック図形式で示す。図5に示されるようにコンピュータ本体130は、FD駆動装置142およびCD−ROM駆動装置144に加えて、相互にバスで接続されたCPU132(Central Processing Unit )と、メモリ138と、固定ディスク140とを含んでいる。CD−ROM駆動装置144にはCD−ROM152が装着される。FD駆動装置142にはFD150が装着される。
【0042】
既に述べたようにこの文字列に対するハッシュ値の計算方法は、コンピュータハードウェアと、CPU132により実行されるソフトウェアとにより実現される。一般的にこうしたソフトウェアは、CD−ROM152、FD150などの記憶媒体に格納されて流通し、CD−ROM駆動装置144またはFD駆動装置142などにより記憶媒体から読取られて固定ディスク140に一旦格納される。さらに固定ディスク140からメモリ138に読出されてCPU132により実行される。図4および図5に示したコンピュータのハードウェア自体は一般的なものである。したがって、本発明の最も本質的な部分はCD−ROM152、FD150、固定ディスク140などの記憶媒体に記憶されたソフトウェアである。
【0043】
なお図4および図5に示したコンピュータ自体の動作は周知であるので、ここではその詳細な説明は繰返さない。
【0044】
図6を参照して、図1に示したリスト作成処理56の詳細について説明する。なお、本実施の形態の装置では過去のアクセス履歴ファイル46から、置換前の文字列と置換後の文字列とを一意に対応つけるテーブルである文字列リスト50を作成するが、これは、過去の履歴を用いれば、最もURLの文字列の置換の効率がよくなるように文字列リスト50を作成することが可能と考えられるためである。ただし、このようにアクセス履歴ファイル46が準備できない場合には理論的に考えて文字列リスト50を手作業で作成してもよい。また、他のサイトでのアクセス履歴から作成された文字列リスト50を用いるようにしてもよい。文字列リスト50が、ブラウザ20により参照されるURLのうちに比較的高い頻度で出現するできるだけ長い文字列を短いデータに置き換えられるように文字列リスト50を用意すればよい。
【0045】
また、本実施の形態では文字列リスト50を準備するために最初の一度だけアクセス履歴ファイル46に基づいてリスト作成処理56を行うものとしているが、稼動を開始したのちその実績に基づいてリスト作成処理56を随時行い文字列リスト50を作成しなおすようにしてもよい。ただしその場合には、作りなおす前の文字列リスト50に基づいて作成されたハッシュメモリ26の内容を、作り直した後の文字列リスト50に合わせて作りなおさなければならないことは勿論である。
【0046】
図6を参照して、まずURL中の部分文字列の出現回数を各部分文字列ごとに集計する(200)。このとき、URLを単位とするだけでなく、URLに含まれる部分文字列までも含め、各文字列がアクセス履歴ファイル46中に何回出現したかを各文字列長とともに集計する。集計する部分文字列の長さは置換後のコードの長さよりも長ければよいので、この実施の形態においては3文字以上の部分文字列について全て集計することとしている。この集計の結果、3文字以上の文字列と、その文字列の文字列長と、アクセス履歴ファイル46内におけるその文字列の出現回数とが全て集計される。
【0047】
続いて変数iに0を代入する(202)。変数iは、文字列リスト50にリストされた文字列の数をカウントするための変数であり、ここでその初期値を代入している。
【0048】
次に、変数iに1を加算し(204)、変数iの値が、文字列リスト50の最大文字列数として予め定められた数(本実施の形態では30)よりも大きいか否かを判定する(206)。もしも判定結果がYESなら処理を終了する。判定結果がNOであれば制御はステップ208に進む。
【0049】
ステップ208では、ステップ200で得られた集計表のうち、最も高い圧縮効果が得られる部分文字列を選択する。圧縮効果は、たとえば以下の式にしたがって求められる。
【0050】
【数2】
総圧縮長=(文字列長−圧縮後のサイズ)×出現回数
こうして計算された総圧縮長が最も大きい部分文字列をステップ208で選択し、ステップ210で文字列リスト50に追加する。そして、この部分文字列をもとの集計表から削除する(212)。たとえば、集計表が図7に示されるようなものである場合を考える。この場合、上述の式にしたがって計算した総圧縮長が最も大きくなるのは、「http://www」である(総圧縮長=(10−1)×800=7200)。したがって、「http://www」を文字列リスト50に追加して集計表から削除する。
【0051】
このとき、この部分文字列が削除されたことにより、もとの集計表内の各文字列のうち、削除された部分文字列に含まれている文字列についてもそれぞれ当該部分文字列の出現回数分だけその出現回数を減算し集計表を再計算する(214)。図7に示される例では、「http://www」の部分文字列であって図7の表にリストされているのは「http:// 」である。「http://www」の出現回数が図7によれば800回であったから、「http:// 」の出現回数は、もとの「900」から800を減算した「100」となる(図8)。
【0052】
こうして集計表を再計算した後制御はステップ204に戻り、以下ステップ204からステップ214までを、ステップ206の判断により処理終了となるまで繰返す。もちろんこの途中で集計表に文字列が残っていない状況となったらその時点で処理を終了すればよい。
【0053】
次に図9を参照して、URLの格納をする場合の処理について説明する。まず、ブラウザ20からURLと当該URLに対応するキャッシュファイルのディスクアドレスとを受け取る(250)。次に、文字列リスト50を読込む(252)。
【0054】
以下、URLの文字列の先頭から、文字列リスト50の各行と一致する文字列があるかどうかを比較していく。まず、ステップ254で、処理対象の文字が最後の文字であるか否かを判定する。最後の文字であれば上述した比較を終了し制御はステップ260に進む。ステップ260以下については後述する。
【0055】
ステップ254で、処理対象の文字が最後の文字でないと判定されたときには、ステップ256でこの文字から始まる文字列のいずれかが文字列リスト50の文字列のいずれかと一致するか否かを判定する。一致しなければ処理対象を次の文字に進めて制御をステップ254に戻す。一致するものがあるときは、当該文字列を、文字列リスト50中でその文字列に対応するものとして示されているコードに置換する(258)。その後処理対象を次の文字に進めて制御はステップ254に戻る。このようにして、入力されたURLのうちの文字列を順次コードに置換していく。
【0056】
ステップ254の判定結果がYESとなるときには、入力されたURLのうちコードに置換されるべきものは置換されており、当初のURLの長さと比較してかなり短くなっている。この場合ステップ260で、このようにして文字列がコードに変換されたURLに基づいてハッシュが計算される。この場合のハッシュ計算式は、既に述べたようなものでもよいし、ばらつきをより均等にするためにより複雑なものであってもよい。計算の対象となるURL文字列がもとのURL文字列と比較して短くなっているのでハッシュ計算も高速に行なえる。そのためハッシュ計算を複雑にしても処理速度が不当に増大することはない。
【0057】
こうして計算されたハッシュコードに基づいて当該URLを格納すべきハッシュ領域40が選択され、当該領域内のたとえば最後のレコードとしてこの置換後のURLと、当該URLに対応のキャッシュファイルのディスクアドレスとが追加格納(または更新)される(262)。
【0058】
図10を参照して、ブラウザ20からURLの入力を受けて、ハッシュメモリ26内を検索する場合の処理について説明する。図10において、図9と同一の処理には同一のステップ番号を付してある。それら各ステップで行われる処理は互いに同じなので、ここでは説明は繰返さない。図10が図9と異なるのは、図9のステップ262に代えて、ハッシュコードにしたがって定められたハッシュ領域40をアクセスして当該URLが存在するか否かを調べるするステップ(270)と、当該URLが存在する場合に、そのURLに付加されているディスクアドレスをブラウザ20に返し、存在しない場合には存在していないことを示す情報をブラウザ20に返す処理を行うステップ272とが設けられていることである。
【0059】
図10に示される処理によって、ブラウザ20は、当該URLがキャッシュファイル領域24に存在する場合には、返されたディスクアドレスにしたがってそのキャッシュファイルにアクセスできる。当該URLがキャッシュファイル領域24に存在しない場合には、改めてインターネットを介してそのURLに対してアクセスを行う。
[第2の実施の形態]
上述の第1の実施の形態では、置換後の文字コードとして1〜30までを使用することとしていた。しかし、これよりもさらに多くの数の文字列を置換できるようにしておくとさらにハッシュ計算が効率化できると考えられる。また、この場合にもユーザごとに設定するものとは別に、全ユーザに共通の置換文字列を定めて運用できるようにすることが望ましい。そこで第2の実施の形態では、共通の置換のための文字列表と、ユーザごとの文字列表とを別個のものとすることとした。ただし、使用される文字列リストがこの二種類となることを除いて、ソフトウェアは第1の実施の形態におけるものと同様である。そこで、以下では文字列リストの詳細についてのみ述べる。
【0060】
図11に、この第2の実施の形態で使用される、複数のユーザで共通に使用される置換用文字列リストの例を示す。また図12に、ユーザごとに使用される置換用文字列リストの例を示す。
【0061】
前述のように、ASCIIコード体系を用いたシステムでは、コード0〜31は通常は用いられない。そこで、第1の実施の形態では、1〜30までのASCIIコードを置換後のコードとして用いた。しかし、この場合に置換後の文字コードとして使用可能な文字コードは最大でも0〜31までの32通りしかない。共通のものに加えて各ユーザごとに置換文字列を定義するためには、これだけでは数が不足である。
【0062】
そこでこの第2の実施の形態では、第1の実施の形態と同様に共通の置換文字列リストの置換後文字コードとして1〜30を用いる(図11参照)とともに、ユーザごとの文字列リストでは、ASCIIコード「31」をエスケープコードとし、コード「31」とその後の1バイトとによってユーザ定義の置換後文字コードを示すこととした(図12参照)。このようにエスケープコードを用いることにより、その後の文字コードの範囲には制限がなくなるから、ユーザ定義の置換後文字列にはコード「31+0」からコード「31+255」までの256種類を利用することができ、ユーザの状況に応じて効率的なURLの管理が可能となる。
【0063】
図13に、図11および図12に示される文字列リストを用いてURL文字列を置換した前後の文字列の組の例を示す。図13の左欄の1行目に示されるURLのうち、文字列「http://www.sharp.co.jp」は図12の左欄の1行目に現れている。これに対応する文字コードは「0」であり、かつその前にはエスケープコード「31」が必要とされる。また図13の残りの文字列「/index.html 」は図11の最後の行に現れており、対応の文字コードは「30」である。しかもこの場合にはエスケープコードは不要である。したがって「http://www.sharp.co.jp/index.html 」は「[31][0][30] 」に置換されることになる。その結果が図13の1行目の右欄に示されている。
【0064】
図13の2行目も同様である。ただしこの場合、文字列「slab.tnr」については置換できないので右欄にはそのまま残っている。この場合にも、置換後の文字列として通常は使用されないコード1〜31を使用しているので、置換後の文字列と置換されなかった文字列とを区別することができる。
【0065】
この第2の実施の形態によっても、第1の実施の形態と同様の効果を得ることができる上、ユーザの状況に応じてより柔軟にURLの管理を行うことが可能になり、しかも置換後の文字列として利用可能な文字コードの数が増えるので、より効率的なURLの管理を行うことができる。
[第3の実施の形態]
以上の第1の実施の形態および第2の実施の形態のいずれにおいても、使用されていないASCIIコードを置換後の文字列に割り当てていた。しかし本発明はそれには限定されない。たとえばこの第3の実施の形態におけるように、置換後の文字列として2けたの数字(「00」から「99まで」)を用いることもできる。つまり、置換後の文字列から置換前の文字列が復元でき(つまり置換文字列と置換後コードとが一意に対応付けられ)、かつ置換後には置換前よりも文字列長が確実に短くなっている限りは、置換後の文字列としてどのような文字列を用いてもよいということである。
【0066】
この第3の実施の形態では、図14に示されるように、置換後の文字列として2けたの数字を使用している。各数字自体は通常使用されているASCIIコードにおける数字と変わりはない。この場合しかし、置換後の文字列である2けたの数字と、本来の数字とを区別する必要が生じる。そこで、この第3の実施の形態では、もともとの1けたの数字を全て2けたの数字で表すこととし、かつその場合の上位1けたを「0」とすることにした(図14の右欄参照)。つまり1けたの数字を、上位1けたが「0」で下位1けたがもともとの数字と等しい2けたの数字に置換することとした。
【0067】
こうしたルールを定めることで、置換後の文字列中に数字が見い出された場合、それらを2桁ずつ取り扱って、図14の右欄から左欄を参照すれば元の文字列を復元することができる。
【0068】
図15に、図14に示される文字列リストを用いた文字列(URL)の置換例を示す。図15の1行目の左欄に示される文字列のうち、「http://www. 」は図14から「10」に置換される。「sharp 」は「50」に置換される。「.co.jp/ 」は「12」に置換される。したがって全体は「105012」となる。
【0069】
また図15の2行目の左欄に示される文字列のうち、「http://www.sharp.co.jp/ 」は前述のとおり「105012」に置換される。その後の「zaurus/ 」は置換ができないが、その後の「index 」は図14から「13」に、「0」は同じく「00」に、「.html 」は同じく「14」に、それぞれ置換される。したがって全体は「105012zaurus/130014」に変換されることになる。
【0070】
このように、置換後の文字列をどのようにするか、については様々な方式が考えられる。要は、置換によって、できるだけ多くのURLができるだけ短い文字列に置換されるように、かつそのように置換された文字列からもとのURLが間違いなく導出されるように、置換後の文字列を定めればよい。
【0071】
この第3の実施の形態では、1けたの数字が2けたの数字に置換されるので、部分的には文字列が長くなる場合がありうる。しかし、たとえばよく出現する非常に長い文字列がわずか2けたの数字に置換できるので、全体としては第1の実施の形態および第2の実施の形態と同様にURL文字列を短く圧縮することができる。そしてそのように圧縮されたURLに対してハッシュ計算を行うので、計算量が少なく、かつハッシュメモリの領域が少なくて済み、さらに同一のハッシュコード値の場合の文字列の直接比較も、比較の対象となる文字列自体が短いので高速に行なえるという効果を奏することができる。
【図面の簡単な説明】
【図1】図1は、本願発明の第1の実施の形態にかかる方法を実現するためのURL圧縮装置を、周囲の要素と共に示すブロック図である。
【図2】図2は、文字列リスト50を模式的に示す図である。
【図3】図3は、置換前後のURLを模式的に示す図である。
【図4】図4は、図5に示すコンピュータの外観図である。
【図5】図5は、本願発明の第1の実施の形態にかかる方法を実現するためのコンピュータのブロック図である。
【図6】図6は、リスト作成処理56の概略を示すフローチャートである。
【図7】図7は、再計算前の集計表の例を模式的に示す図である。
【図8】図8は、再計算後の集計表の例を模式的に示す図である。
【図9】図9は、URLの格納処理のフローチャートである。
【図10】図10は、URLの検索処理のフローチャートである。
【図11】図11は、本願発明の第2の実施の形態にかかる方法で使用される共通文字列置換表を模式的に示す図である。
【図12】図12は、本願発明の第2の実施の形態にかかる方法で使用されるユーザ定義文字列置換表を模式的に示す図である。
【図13】図13は、第2の実施の形態にかかる方法による文字列置換前後のURLを模式的に示す図である。
【図14】図14は、本願発明の第3の実施の形態にかかる方法で使用されるユーザ定義文字列置換表を模式的に示す図である。
【図15】図15は、第3の実施の形態にかかる方法による文字列置換前後のURLを模式的に示す図である。
【符号の説明】
20 ブラウザ
22 URL圧縮装置
24 キャッシュファイル領域
26 ハッシュメモリ
46 アクセス履歴
50 文字列リスト
52 文字列置換処理
54 ハッシュ計算処理
56 リスト作成処理
Claims (14)
- 文字の並びの出現頻度に偏りを有する処理対象の文字列に対するハッシュ値の計算装置であって、
前記計算装置はCPUとメモリとを含み、
1つ以上の特定の文字列それぞれを、より短い長さの変換後文字列と一意に対応付けるための機械可読なテーブルを準備する手段と、
前記CPUを用いて、処理対象文字列中に出現する文字列を、前記テーブルを参照して対応の変換後文字列に変換する手段と、
前記CPUを用いて、変換後文字列を含む前記処理対象文字列に基づいてハッシュ値を計算する手段とを含み、
前記処理対象文字列に含まれる前記変換後文字列は、前記テーブルの当該変換後文字列に対応付けられている前記特定の文字列を用いて、変換前の前記処理対象文字列中に出現する文字列に復元可能である、文字列に対するハッシュ値の計算装置。 - 前記テーブルを準備する前記手段は、
過去に出現した処理対象文字列を前記メモリに準備する手段と、
前記過去に出現した処理対象文字列の部分文字列の各々の、出現回数と文字列長とを、前記CPUを用いて集計する手段と、
前記CPUを用いて、前記集計された出現回数と文字列長とに基づき、前記過去に出現した処理対象文字列の部分文字列のうち、所定文字に置換したときに前記過去に出現した処理対象文字列を圧縮することが可能な部分文字列を選択し、選択された前記部分文字列を前記特定の文字列として前記テーブルに追加する手段とを含む、請求項1に記載の、文字列に対するハッシュ値の計算装置。 - 前記テーブルを準備する前記手段は、
前記CPUを用いて、前記選択された部分文字列の出現回数を減じることにより前記出現回数を再計算し、さらに、前記追加するステップを所定の条件が成立するまで繰返す手段を含む、請求項2に記載の、文字列に対するハッシュ値の計算装置。 - 変換前の処理対象文字列に使用される文字セットに含まれない文字を、前記変換後文字列の文字として用いることを特徴とする、請求項1から3のいずれかに記載の、文字列に対するハッシュ値の計算装置。
- 前記テーブルは、複数のユーザに共通に使用される共通テーブルと、
ユーザ毎に使用されるユーザ毎テーブルを含む、請求項1から4のいずれかに記載の、文字列に対するハッシュ値の計算装置。 - 前記ユーザ毎テーブルの前記変換後文字列には、前記共通テーブルの前記変換後文字列に用いられない文字が含まれる、請求項5に記載の、文字列に対するハッシュ値の計算装置。
- 前記共通テーブルの前記変換後文字列それぞれは1バイトの異なる文字コードを示し、かつ前記1バイトの異なる文字コードはASCIIコードの所定のコード群のうちのいずれかのコードを示し、
前記ユーザ毎テーブルの前記変換後文字列のそれぞれは複数バイトの異なる文字コードを示し、かつ前記複数バイトのうち先頭の1バイトはASCIIコード中の前記所定のコード群を除いた所定コードを示す、請求項6に記載の、文字列に対するハッシュ値の計算装置。 - 変換前の前記処理対象文字列は、URLを示す文字列である、請求項1から7のいずれかに記載の、文字列に対するハッシュ値の計算装置。
- 請求項1から8のいずれかに記載の、文字列に対するハッシュ値の計算装置により計算された前記ハッシュ値を用いて情報を管理する情報管理装置であって、
前記処理対象文字列を用いて参照されるファイルを記憶する記憶部と、
ハッシュ領域と、
計算された前記ハッシュ値が指示する前記ハッシュ領域のアドレスに、前記処理対象文字列を用いて参照される前記ファイルの前記記憶部における記憶アドレスと、変換後の前記処理対象文字列とを対応付けて格納する手段とを備える、情報管理装置。 - 請求項9に記載の、文字列に対するハッシュ値の計算装置により計算された前記ハッシュ値に従う前記ハッシュ領域のアドレスをアクセスし、当該アドレスに格納された前記変換後の処理対象文字列と対応付けて格納された前記記憶アドレスを読出す手段と、
前記読出された前記記憶アドレスに基づき前記記憶部を検索する手段とをさらに備える、請求項9に記載の情報管理装置。 - 文字の並びの出現頻度に偏りを有する処理対象の文字列に対するハッシュ値を、CPUとメモリを備えるコンピュータを用いて計算する方法を実現するプログラムを記録した機械可読な記録媒体であって、前記プログラムは、
1つ以上の特定の文字列それぞれを、より短い長さの変換後文字列と一意に対応付けるための機械可読なテーブルを準備するステップと、
前記CPUを用いて、処理対象文字列中に出現する文字列を、前記テーブルを参照して対応の変換後文字列に変換するステップと、
前記CPUを用いて、変換後文字列を含む前記処理対象文字列に基づいてハッシュ値を計算するステップとを含み、
前記処理対象文字列に含まれる前記変換後文字列は、前記テーブルの当該変換後文字列に対応付けられている前記特定の文字列を用いて、変換前の前記処理対象文字列中に出現する文字列に復元可能である、文字列に対するハッシュ値の計算方法を実現するプログラムを記録した機械可読な記録媒体。 - 前記テーブルを準備する前記ステップは、
過去に出現した処理対象文字列を前記メモリに準備するステップと、
前記過去に出現した処理対象文字列の部分文字列の各々の、出現回数と文字列長とを、前記CPUを用いて集計するステップと、
前記CPUを用いて、前記集計された出現回数と文字列長とに基づき、前記過去に出現した処理対象文字列の部分文字列のうち、所定文字に置換したときに前記過去に出現した処理対象文字列を圧縮することが可能な部分文字列を選択し、選択された前記部分文字列を前記特定の文字列として前記テーブルに追加するステップとを含む、請求項11に記載の、文字列に対するハッシュ値の計算方法を実現するプログラムを記録した機械可読な記録媒体。 - 文字の並びの出現頻度に偏りを有する処理対象の文字列に対するハッシュ値を、CPUとメモリを備えるコンピュータを用いて計算する方法であって、
1つ以上の特定の文字列それぞれを、より短い長さの変換後文字列と一意に対応付けるための機械可読なテーブルを準備するステップと、
前記CPUを用いて、処理対象文字列中に出現する文字列を、前記テーブルを参照して対応の変換後文字列に変換するステップと、
前記CPUを用いて、変換後文字列を含む前記処理対象文字列に基づいてハッシュ値を計算するステップとを含み、
前記処理対象文字列に含まれる前記変換後文字列は、前記テーブルの当該変換後文字列に対応付けられている前記特定の文字列を用いて、変換前の前記処理対象文字列中に出現する文字列に復元可能である、文字列に対するハッシュ値の計算方法。 - 前記テーブルを準備するステップは、
過去に出現した処理対象文字列を前記メモリに準備するステップと、
前記CPUを用いて、前記過去に出現した処理対象文字列の部分文字列の各々の、出現回数と文字列長とを、集計するステップと、
前記CPUを用いて、前記集計された出現回数と文字列長とに基づき、前記過去に出現した処理対象文字列の部分文字列のうち、所定文字に置換したときに前記過去に出現した処理対象文字列を圧縮することが可能な部分文字列を選択し、選択された前記部分文字列を前記特定の文字列として前記テーブルに追加するステップとを含む、請求項13に記載の、文字列に対するハッシュ値の計算方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP11324398A JP4179660B2 (ja) | 1998-04-23 | 1998-04-23 | 文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP11324398A JP4179660B2 (ja) | 1998-04-23 | 1998-04-23 | 文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH11306194A JPH11306194A (ja) | 1999-11-05 |
| JP4179660B2 true JP4179660B2 (ja) | 2008-11-12 |
Family
ID=14607205
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP11324398A Expired - Fee Related JP4179660B2 (ja) | 1998-04-23 | 1998-04-23 | 文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4179660B2 (ja) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7333801B2 (en) * | 2003-06-04 | 2008-02-19 | Qualcomm Incorporated | Method and apparatus for translating resource names in a wireless environment |
| US8301702B2 (en) * | 2004-01-20 | 2012-10-30 | Cloudmark, Inc. | Method and an apparatus to screen electronic communications |
| JP4735155B2 (ja) * | 2005-09-21 | 2011-07-27 | 富士ゼロックス株式会社 | 表示装置及び文字列データベース再定義方法 |
| JP2011008353A (ja) * | 2009-06-23 | 2011-01-13 | Nippon Telegr & Teleph Corp <Ntt> | 変換装置、変換方法および変換プログラム |
| US8601363B2 (en) * | 2009-07-20 | 2013-12-03 | Facebook, Inc. | Communicating information about a local machine to a browser application |
| JP5220141B2 (ja) * | 2011-02-08 | 2013-06-26 | ヤフー株式会社 | Url短縮装置、短縮url処理装置、方法及びプログラム |
| CN111126965B (zh) * | 2019-12-25 | 2023-08-29 | 深圳前海环融联易信息科技服务有限公司 | 审核规则优化方法、装置、计算机设备以及存储介质 |
-
1998
- 1998-04-23 JP JP11324398A patent/JP4179660B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JPH11306194A (ja) | 1999-11-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8250081B2 (en) | Resource access filtering system and database structure for use therewith | |
| JP5782214B2 (ja) | 情報検索プログラム、情報検索装置および情報検索方法 | |
| US6714926B1 (en) | Use of browser cookies to store structured data | |
| US6757675B2 (en) | Method and apparatus for indexing document content and content comparison with World Wide Web search service | |
| US20040148301A1 (en) | Compressed data structure for a database | |
| US20070106876A1 (en) | Keymap order compression | |
| US6247014B1 (en) | Method and apparatus for performing hash lookups using valid bit tables with pointers | |
| KR20090088901A (ko) | 웹 문서의 압축을 향상시키는 방법, 시스템 및 컴퓨터 판독 가능한 저장 매체 | |
| US7904432B2 (en) | Compressed data structure for extracted changes to a database and method of generating the data structure | |
| JP4179660B2 (ja) | 文字列に対するハッシュ値の計算方法およびその方法を実現するプログラムを記録した機械可読な記録媒体、文字列に対するハッシュ値の計算装置ならびに情報管理装置 | |
| US8140546B2 (en) | Computer system for performing aggregation of tree-structured data, and method and computer program product therefor | |
| JP2017513252A (ja) | 最適化されたデータ凝縮器及び方法 | |
| CN110825747B (zh) | 一种信息存取方法、装置和介质 | |
| JP5812007B2 (ja) | インデックス作成装置、データ検索装置、インデックス作成方法、データ検索方法、インデックス作成プログラムおよびデータ検索プログラム | |
| WO2011014179A1 (en) | Compression of xml data | |
| Jung et al. | A dynamic construction algorithm for the Compact Patricia trie using the hierarchical structure | |
| JP4914117B2 (ja) | データ処理システム | |
| JP2005004560A (ja) | インバーテッドファイル作成方法 | |
| JP5430128B2 (ja) | URL変換装置、URL変換方法、URL変換プログラム及びWeb情報収集システム | |
| Culpepper et al. | Revisiting bounded context block‐sorting transformations | |
| JP2003288288A (ja) | リンク先圧縮システム | |
| JP5494860B2 (ja) | 情報管理プログラム、情報管理装置および情報管理方法 | |
| JP4319827B2 (ja) | 文書検索プログラム | |
| JP2001312517A (ja) | インデクス生成装置及び文書検索装置 | |
| JP5265476B2 (ja) | ドキュメントオブジェクト・スキーマ定義間データ処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050118 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050118 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080212 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080403 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080513 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080711 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080819 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080826 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110905 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120905 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130905 Year of fee payment: 5 |
|
| LAPS | Cancellation because of no payment of annual fees |