JP2022517841A - ビデオ画像の伝送方法、装置、インテリジェントインタラクティブタブレット及び記憶媒体 - Google Patents
ビデオ画像の伝送方法、装置、インテリジェントインタラクティブタブレット及び記憶媒体 Download PDFInfo
- Publication number
- JP2022517841A JP2022517841A JP2021542217A JP2021542217A JP2022517841A JP 2022517841 A JP2022517841 A JP 2022517841A JP 2021542217 A JP2021542217 A JP 2021542217A JP 2021542217 A JP2021542217 A JP 2021542217A JP 2022517841 A JP2022517841 A JP 2022517841A
- Authority
- JP
- Japan
- Prior art keywords
- image
- video
- semantic information
- communication terminal
- reconstructed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images









Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/14—Systems for two-way working
- H04N7/141—Systems for two-way working between two video terminals, e.g. videophone
- H04N7/147—Communication arrangements, e.g. identifying the communication as a video-communication, intermediate storage of the signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/14—Systems for two-way working
- H04N7/15—Conference systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/251—Fusion techniques of input or preprocessed data
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G06N3/0455—Auto-encoder networks; Encoder-decoder networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/41—Higher-level, semantic clustering, classification or understanding of video scenes, e.g. detection, labelling or Markovian modelling of sport events or news items
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/107—Static hand or arm
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/172—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a picture, frame or field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/30—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using hierarchical techniques, e.g. scalability
- H04N19/39—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using hierarchical techniques, e.g. scalability involving multiple description coding [MDC], i.e. with separate layers being structured as independently decodable descriptions of input picture data
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/44—Decoders specially adapted therefor, e.g. video decoders which are asymmetric with respect to the encoder
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/46—Embedding additional information in the video signal during the compression process
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs
- H04N21/4402—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs involving reformatting operations of video signals for household redistribution, storage or real-time display
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/478—Supplemental services, e.g. displaying phone caller identification, shopping application
- H04N21/4788—Supplemental services, e.g. displaying phone caller identification, shopping application communicating with other users, e.g. chatting
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/14—Systems for two-way working
- H04N7/141—Systems for two-way working between two video terminals, e.g. videophone
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/14—Systems for two-way working
- H04N7/15—Conference systems
- H04N7/155—Conference systems involving storage of or access to video conference sessions
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Signal Processing (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
- Television Signal Processing For Recording (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
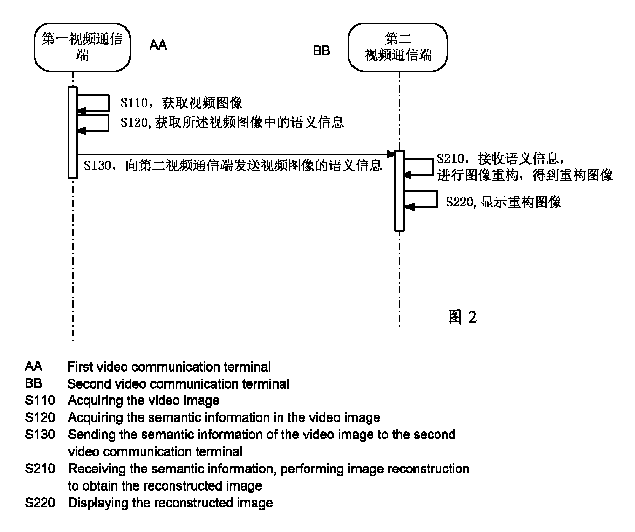
【選択図】図2
Description
ここで、g(f(I))は、ビデオ画像Iがエンコーダfにより処理されて取得された意味情報がデコーダgにより復号されて復元されて取得された再構築画像を表し、
(外1)
Claims (46)
- ビデオ画像の伝送方法であって、
第1のビデオ通信端末により撮影されたビデオ画像を取得するステップと、
前記ビデオ画像の意味情報を抽出するステップと、
第2のビデオ通信端末に前記意味情報を送信するステップと、を含み、
前記意味情報は、前記第2のビデオ通信端末で前記ビデオ画像の再構築画像を再構築するために使用される、方法。 - 前記ビデオ画像の意味情報を抽出するステップは、
訓練されたエンコーダにより前記ビデオ画像の意味情報を抽出するステップ、を含み、
前記エンコーダは、画像の意味情報を認識する、請求項1に記載の方法。 - 前記エンコーダの入力は、画像であり、
前記エンコーダの出力は、入力画像の意味情報としての入力画像に対応する低次元ベクトルである、請求項2に記載の方法。 - 前記エンコーダは、畳み込みニューラルネットワークである、請求項3に記載の方法。
- 前記ビデオ画像の意味情報は、
前記ビデオ画像における設定対象の意味情報、及び
前記ビデオ画像の大域的な意味情報のうちの何れか1つを含む、請求項2に記載の方法。 - 前記ビデオ画像における設定対象の意味情報を抽出するステップは、
前記ビデオ画像における設定対象を認識し、前記設定対象のサブ画像を取得するステップと、
訓練されたエンコーダに前記設定対象のサブ画像を入力するステップと、
前記エンコーダの出力を取得し、前記ビデオ画像における前記設定対象の意味情報を取得するステップと、を含む、請求項5に記載の方法。 - 前記設定対象は、人の顔又は人の体を含む、請求項6に記載の方法。
- 前記設定対象が人の顔である場合、前記ビデオ画像における設定対象の意味情報を抽出するステップは、
前記ビデオ画像における顔領域を認識し、顔サブ画像を取得するステップと、
訓練されたエンコーダに前記顔サブ画像を入力するステップと、
前記エンコーダの出力を取得し、前記ビデオ画像の顔意味情報を取得するステップと、を含む、請求項7に記載の方法。 - 前記設定対象が人の体である場合、前記ビデオ画像における設定対象の意味情報を抽出するステップは、
前記ビデオ画像における体領域を認識し、体サブ画像を取得するステップと、
訓練されたエンコーダに前記体サブ画像を入力するステップと、
前記エンコーダの出力を取得し、前記ビデオ画像の体意味情報を取得するステップと、を含む、請求項7に記載の方法。 - 前記ビデオ画像の大域的な意味情報を抽出するステップは、
訓練されたエンコーダに前記ビデオ画像を入力するステップと、
前記エンコーダの出力を取得し、前記ビデオ画像の大域的な意味情報を取得するステップと、を含む、請求項5に記載の方法。 - Nフレームごとに、設定された画像伝送モードを使用して、第2のビデオ通信端末に第1の参照画像を送信するステップ、をさらに含み、
設定された画像伝送モードで伝送される前記第1の参照画像のデータ量は、前記意味情報のデータ量よりも大きく、
Nは1よりも大きく、
前記第1の参照画像は、前記第1のビデオ通信端末により撮影されたビデオ画像に属し、
前記第1の参照画像は、前記第2のビデオ通信端末が前記意味情報及び前記第1の参照画像に基づいて前記ビデオ画像の再構築画像を再構築するために使用される、請求項5乃至10の何れかに記載の方法。 - 前記意味情報が設定対象の意味情報である場合、前記第1の参照画像は、前記第2のビデオ通信端末が、受信された意味情報に基づいて前記設定対象の再構築サブ画像を取得して、前記再構築サブ画像と前記第1の参照画像とを融合して、前記ビデオ画像の再構築画像を取得するために使用される、請求項11に記載の方法。
- 前記意味情報が大域的な意味情報である場合、前記第1の参照画像は、前記第2のビデオ通信端末が、受信された意味情報に基づいて初期再構築画像を取得して、前記初期再構築画像と前記第1の参照画像とを融合して、前記ビデオ画像の再構築画像を取得するために使用される、請求項11に記載の方法。
- 前記意味情報が設定対象の意味情報である場合、
前記ビデオ画像における設定対象の位置情報を取得するステップと、
前記第2のビデオ通信端末に前記位置情報を送信するステップと、をさらに含み、
前記位置情報は、前記第2のビデオ通信端末が、前記位置情報に基づいて前記設定対象の再構築サブ画像と前記第1の参照画像とを融合して、前記ビデオ画像の再構築画像を取得するために使用される、請求項12に記載の方法。 - 設定された画像伝送モードを使用して、前記第2のビデオ通信端末に第2の参照画像を送信するステップ、をさらに含み、
前記設定された画像伝送モードで伝送される前記第2の参照画像のデータ量は、前記意味情報のデータ量よりも大きく、
前記第2の参照画像は、前記設定対象の画像、及び前記第1のビデオ通信端末の環境画像のうちの少なくとも1つであり、
前記第2の参照画像は、前記第2のビデオ通信端末が前記意味情報及び前記第2の参照画像に基づいて前記ビデオ画像の再構築画像を再構築するために使用される、請求項5乃至14の何れかに記載の方法。 - ビデオ画像の伝送方法であって、
第1のビデオ通信端末により撮影されたビデオ画像の意味情報を受信するステップと、
前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップと、
第2のビデオ通信端末の表示パネルにより前記再構築画像を表示するステップと、を含む、方法。 - 前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップは、
前記意味情報及び事前に訓練されたデコーダにより画像を再構築し、前記ビデオ画像の再構築画像を取得するステップ、を含む、請求項16に記載の方法。 - 前記デコーダの入力は、画像の意味情報であり、
前記デコーダの出力は、入力された意味情報に基づいて再構築された画像である、請求項17に記載の方法。 - 前記デコーダは、畳み込みニューラルネットワークである、請求項18に記載の方法。
- 前記ビデオ画像の意味情報は、
前記ビデオ画像における設定対象の意味情報、及び
前記ビデオ画像の大域的な意味情報のうちの何れか1つを含む、請求項17に記載の方法。 - 前記設定対象は、人の顔又は人の体を含む、請求項20に記載の方法。
- 前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップは、
設定された画像伝送モードで直近に受信された第1の参照画像を取得するステップと、
前記意味情報及び前記第1の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップと、をさらに含み、
前記第1の参照画像は、前記第1のビデオ通信端末により撮影されて送信されたビデオ画像であり、
設定された画像伝送モードで受信された前記第1の参照画像のデータ量は、前記意味情報のデータ量よりも大きい、請求項21に記載の方法。 - Nフレームごとに、設定された画像伝送モードで前記第1のビデオ通信端末からの第1の参照画像を受信するステップ、をさらに含み、
Nは1よりも大きい、請求項22に記載の方法。 - 前記意味情報が設定対象の意味情報である場合、前記意味情報及び前記第1の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップは、
訓練されたデコーダに前記意味情報を入力するステップと、
前記デコーダの出力を取得し、前記設定対象の再構築サブ画像を取得するステップと、
前記設定対象の再構築サブ画像と前記第1の参照画像とを融合し、前記ビデオ画像の再構築画像を取得するステップと、を含む、請求項23に記載の方法。 - 前記意味情報が大域的な意味情報である場合、前記意味情報及び前記第1の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップは、
訓練されたデコーダに前記意味情報を入力するステップと、
前記デコーダの出力を取得し、初期再構築画像を取得するステップと、
前記初期再構築画像と前記第1の参照画像とを融合し、前記ビデオ画像の再構築画像を取得するステップと、を含む、請求項23に記載の方法。 - 前記意味情報が顔意味情報である場合、前記デコーダの出力を取得し、顔の再構築サブ画像を取得し、
前記意味情報が体意味情報である場合、前記デコーダの出力を取得し、体の再構築サブ画像を取得する、請求項24に記載の方法。 - 前記第1のビデオ通信端末により送信された、前記ビデオ画像における前記設定対象の位置情報を受信するステップ、さらに含み、
前記設定対象の再構築サブ画像と前記第1の参照画像とを融合し、前記ビデオ画像の再構築画像を取得するステップは、
前記位置情報に基づいて前記設定対象の再構築サブ画像と前記第1の参照画像とを融合し、前記ビデオ画像の再構築画像を取得するステップ、を含む、請求項24に記載の方法。 - 前記第1のビデオ通信端末により送信された位置情報を受信するステップは、
前記第1のビデオ通信端末により送信された、前記ビデオ画像における顔領域の第1の位置情報を受信するステップと、
前記第1のビデオ通信端末により送信された、前記ビデオ画像における体領域の第2の位置情報を受信するステップと、を含む、請求項27に記載の方法。 - 前記位置情報に基づいて前記設定対象の再構築サブ画像と前記第1の参照画像とを融合する前に、
前記設定対象の再構築サブ画像に対してエッジフェザリング処理を行うステップ、をさらに含む、請求項27に記載の方法。 - 前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップは、
設定された画像伝送モードで受信された第2の参照画像を取得するステップと、
前記意味情報及び前記第2の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得するステップと、を含み、
前記第2の参照画像は、設定対象の画像、及び前記第1のビデオ通信端末の環境画像のうちの少なくとも1つであり、
設定された画像伝送モードで受信された前記第2の参照画像のデータ量は、前記意味情報のデータ量よりも大きい、請求項21乃至29の何れかに記載の方法。 - ビデオ画像の伝送方法であって、
第1のビデオ通信端末が、撮影されたビデオ画像を取得し、前記ビデオ画像の意味情報を取得し、第2のビデオ通信端末に前記意味情報を送信するステップと、
前記第2のビデオ通信端末が、前記意味情報を受信し、前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得し、第2のビデオ通信端末の表示パネルにより前記再構築画像を表示するステップと、を含む、方法。 - ビデオ画像の伝送装置であって、
第1のビデオ通信端末により撮影されたビデオ画像を取得する画像取得モジュールと、
前記ビデオ画像の意味情報を抽出する情報抽出モジュールと、
第2のビデオ通信端末に前記意味情報を送信する送信モジュールと、を含み、
前記意味情報は、前記第2のビデオ通信端末で前記ビデオ画像の再構築画像を再構築するために使用される、装置。 - 前記情報抽出モジュールは、訓練されたエンコーダにより前記ビデオ画像の意味情報を抽出し、
前記エンコーダは、画像の意味情報を認識する、請求項32に記載の装置。 - 前記エンコーダの入力は、画像であり、
前記エンコーダの出力は、入力画像の意味情報としての入力画像に対応する低次元ベクトルである、請求項33に記載の装置。 - 前記ビデオ画像の意味情報は、
前記ビデオ画像における設定対象の意味情報、及び
前記ビデオ画像の大域的な意味情報のうちの何れか1つを含む、請求項33に記載の装置。 - Nフレームごとに、設定された画像伝送モードを使用して、第2のビデオ通信端末に第1の参照画像を送信する第1の参照画像送信モジュール、をさらに含み、
設定された画像伝送モードで伝送される前記第1の参照画像のデータ量は、前記意味情報のデータ量よりも大きく、
Nは1よりも大きく、
前記第1の参照画像は、前記第1のビデオ通信端末により撮影されたビデオ画像に属し、
前記第1の参照画像は、前記第2のビデオ通信端末が前記意味情報及び前記第1の参照画像に基づいて前記ビデオ画像の再構築画像を再構築するために使用される、請求項35に記載の装置。 - 設定された画像伝送モードを使用して、前記第2のビデオ通信端末に第2の参照画像を送信する第2の参照画像送信モジュール、をさらに含み、
前記設定された画像伝送モードで伝送される前記第2の参照画像のデータ量は、前記意味情報のデータ量よりも大きく、
前記第2の参照画像は、前記設定対象の画像、及び前記第1のビデオ通信端末の環境画像のうちの少なくとも1つであり、
前記第2の参照画像は、前記第2のビデオ通信端末が前記意味情報及び前記第2の参照画像に基づいて前記ビデオ画像の再構築画像を再構築するために使用される、請求項35に記載の装置。 - ビデオ画像の伝送装置であって、
第1のビデオ通信端末により撮影されたビデオ画像の意味情報を受信する情報受信モジュールと、
前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得する画像再構築モジュールと、
第2のビデオ通信端末の表示パネルにより前記再構築画像を表示する画像表示モジュールと、を含む、装置。 - 前記画像再構築モジュールは、前記意味情報及び事前に訓練されたデコーダにより画像を再構築し、前記ビデオ画像の再構築画像を取得する、請求項38に記載の装置。
- 前記ビデオ画像の意味情報は、
前記ビデオ画像における設定対象の意味情報、及び
前記ビデオ画像の大域的な意味情報のうちの何れか1つを含む、請求項39に記載の装置。 - 前記画像再構築モジュールは、
設定された画像伝送モードで直近に受信された第1の参照画像を取得する第1の参照画像取得サブモジュールと、
前記意味情報及び前記第1の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得する第1の画像再構築サブモジュールと、をさらに含み、
前記第1の参照画像は、前記第1のビデオ通信端末により撮影されて送信されたビデオ画像であり、
設定された画像伝送モードで受信された前記第1の参照画像のデータ量は、前記意味情報のデータ量よりも大きい、請求項40に記載の装置。 - Nフレームごとに、設定された画像伝送モードで前記第1のビデオ通信端末からの第1の参照画像を受信する第1の参照画像受信サブモジュール、をさらに含み、
Nは1よりも大きい、請求項41に記載の装置。 - 前記画像再構築モジュールは、
設定された画像伝送モードで受信された第2の参照画像を取得する第2の参照画像取得サブモジュールと、
前記意味情報及び前記第2の参照画像に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得する第2の画像再構築サブモジュールと、を含み、
前記第2の参照画像は、設定対象の画像、及び前記第1のビデオ通信端末の環境画像のうちの少なくとも1つであり、
設定された画像伝送モードで受信された前記第2の参照画像のデータ量は、前記意味情報のデータ量よりも大きい、請求項40に記載の装置。 - ビデオ通信を行うことが可能な第1のビデオ通信端末及び第2のビデオ通信端末を含むビデオ画像の伝送システムであって、
第1のビデオ通信端末は、撮影されたビデオ画像を取得し、前記ビデオ画像の意味情報を取得し、第2のビデオ通信端末に前記意味情報を送信し、
前記第2のビデオ通信端末は、前記意味情報を受信し、前記意味情報に基づいて画像を再構築し、前記ビデオ画像の再構築画像を取得し、第2のビデオ通信端末の表示パネルにより前記再構築画像を表示する、ビデオ画像の伝送システム。 - ビデオ画像を撮影する撮影装置と、表示パネルと、コンピュータプログラムが記憶されているメモリと、プロセッサと、を含むインテリジェントインタラクティブタブレットであって、
前記プロセッサは、前記コンピュータプログラムを実行する際に、前記撮影装置により撮影されたビデオ画像の意味情報を抽出し、他のインテリジェントインタラクティブタブレットに前記意味情報を送信するように構成され、
前記プロセッサは、前記コンピュータプログラムを実行する際に、他のインテリジェントインタラクティブタブレットにより送信されたビデオ画像の意味情報を受信し、前記意味情報に基づいて画像を再構築し、他のインテリジェントインタラクティブタブレットにより送信されたビデオ画像の再構築画像を取得し、前記表示パネルにより前記再構築画像を表示するように構成される、インテリジェントインタラクティブタブレット。 - コンピュータプログラムが記憶されているコンピュータ読み取り可能な記憶媒体であって、
プロセッサに前記コンピュータプログラムを実行させる際に、請求項1乃至30の何れかに記載の方法を実現する、記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910063004.7A CN109831638B (zh) | 2019-01-23 | 2019-01-23 | 视频图像传输方法、装置、交互智能平板和存储介质 |
| CN201910063004.7 | 2019-01-23 | ||
| PCT/CN2019/127770 WO2020151443A1 (zh) | 2019-01-23 | 2019-12-24 | 视频图像传输方法、装置、交互智能平板和存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022517841A true JP2022517841A (ja) | 2022-03-10 |
| JP7250937B2 JP7250937B2 (ja) | 2023-04-03 |
Family
ID=66861896
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021542217A Active JP7250937B2 (ja) | 2019-01-23 | 2019-12-24 | ビデオ画像の伝送方法、装置、インテリジェントインタラクティブタブレット及び記憶媒体 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US12309526B2 (ja) |
| EP (1) | EP3902247A4 (ja) |
| JP (1) | JP7250937B2 (ja) |
| KR (1) | KR102594030B1 (ja) |
| CN (1) | CN109831638B (ja) |
| AU (1) | AU2019424397B2 (ja) |
| WO (1) | WO2020151443A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023195426A1 (ja) * | 2022-04-05 | 2023-10-12 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 復号装置、符号化装置、復号方法及び符号化方法 |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109831638B (zh) | 2019-01-23 | 2021-01-08 | 广州视源电子科技股份有限公司 | 视频图像传输方法、装置、交互智能平板和存储介质 |
| CN110312139A (zh) * | 2019-06-18 | 2019-10-08 | 深圳前海达闼云端智能科技有限公司 | 图像传输的方法和装置、存储介质 |
| CN112905132B (zh) * | 2019-11-19 | 2023-07-18 | 华为技术有限公司 | 投屏方法及设备 |
| CN111246176A (zh) * | 2020-01-20 | 2020-06-05 | 北京中科晶上科技股份有限公司 | 一种节带化视频传输方法 |
| CN115699725B (zh) * | 2020-05-26 | 2025-10-10 | 华为技术有限公司 | 视频图像处理方法及装置 |
| CN114868380B (zh) | 2020-11-23 | 2025-06-10 | 京东方科技集团股份有限公司 | 一种虚拟名片的发送方法、装置、系统及可读存储介质 |
| US11659193B2 (en) * | 2021-01-06 | 2023-05-23 | Tencent America LLC | Framework for video conferencing based on face restoration |
| CN114283091B (zh) * | 2021-12-27 | 2022-08-09 | 国网黑龙江省电力有限公司伊春供电公司 | 基于视频融合的电力设备图像恢复系统 |
| CN114401406B (zh) * | 2022-01-25 | 2025-09-05 | 阿里巴巴(中国)有限公司 | 一种面部视频编码方法、解码方法及装置 |
| CN114422795B (zh) * | 2022-01-25 | 2025-09-16 | 阿里巴巴(中国)有限公司 | 一种面部视频编码方法、解码方法及装置 |
| KR102573201B1 (ko) * | 2022-08-19 | 2023-09-01 | (주)에이아이매틱스 | 이미지 재건 기술 기반 영상 통신 비용 절감 시스템 및 방법 |
| CN117692094B (zh) * | 2022-09-02 | 2026-03-20 | 北京邮电大学 | 编码方法、解码方法、编码装置、解码装置及电子设备 |
| CN115883018B (zh) * | 2022-11-03 | 2026-01-02 | 北京邮电大学 | 语义通信系统 |
| CN116132693A (zh) * | 2023-02-07 | 2023-05-16 | 深圳市网联安瑞网络科技有限公司 | 一种视频会议图像传输编码方法、系统及应用 |
| CN116847091B (zh) * | 2023-07-18 | 2024-04-26 | 华院计算技术(上海)股份有限公司 | 图像编码方法、系统、设备及介质 |
| CN116634178B (zh) * | 2023-07-26 | 2023-10-31 | 清华大学 | 一种极低码率的安防场景监控视频编解码方法及系统 |
| CN117292245B (zh) * | 2023-08-02 | 2024-11-26 | 清华大学 | 面向人脸语义编解码的人脸图像的质量评估方法和系统 |
| WO2023230638A2 (en) * | 2023-09-06 | 2023-11-30 | Futurewei Technologies, Inc. | Reduced-latency communication using behavior prediction |
| CN118368035B (zh) * | 2024-06-20 | 2024-09-27 | 鹏城实验室 | 语义通信方法、装置、设备及存储介质 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0832947A (ja) * | 1994-07-11 | 1996-02-02 | Hitachi Ltd | 画像通信装置 |
| JPH0998416A (ja) * | 1995-09-29 | 1997-04-08 | Denso Corp | 画像信号の符号化装置および画像の認識装置 |
| JP2004304794A (ja) * | 2003-03-28 | 2004-10-28 | Eastman Kodak Co | 映画を表示する方法 |
| CN102271241A (zh) * | 2011-09-02 | 2011-12-07 | 北京邮电大学 | 一种基于面部表情/动作识别的图像通信方法及系统 |
| US20130322513A1 (en) * | 2012-05-29 | 2013-12-05 | Qualcomm Incorporated | Video transmission and reconstruction |
| JP2014529233A (ja) * | 2012-03-29 | 2014-10-30 | テンセント テクノロジー (シェンツェン) カンパニー リミテッド | ビデオシミュレーション画像のための通信方法及びデバイス |
| JP2016537922A (ja) * | 2013-12-20 | 2016-12-01 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 擬似ビデオ通話方法及び端末 |
| CN106559636A (zh) * | 2015-09-25 | 2017-04-05 | 中兴通讯股份有限公司 | 一种视频通信方法、装置及系统 |
| US20180131950A1 (en) * | 2015-04-30 | 2018-05-10 | Hangzhou Hikvision Digital Technology Co., Ltd. | Video coding and decoding methods and apparatus |
| JP2018201198A (ja) * | 2017-05-26 | 2018-12-20 | Line株式会社 | 映像圧縮方法、映像復元方法及びコンピュータプログラム |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101141608B (zh) * | 2007-09-28 | 2011-05-11 | 腾讯科技(深圳)有限公司 | 一种视频即时通讯系统及方法 |
| US8686960B2 (en) | 2010-04-23 | 2014-04-01 | Lester F. Ludwig | Piecewise-linear and piecewise-affine transformations for high dimensional touchpad (HDTP) output decoupling and corrections |
| KR20120044732A (ko) * | 2010-10-28 | 2012-05-08 | 지미디어(주) | 벡터그래픽 이미지 파일의 전송 방법 및 시스템 |
| KR20130022434A (ko) * | 2011-08-22 | 2013-03-07 | (주)아이디피쉬 | 통신단말장치의 감정 컨텐츠 서비스 장치 및 방법, 이를 위한 감정 인지 장치 및 방법, 이를 이용한 감정 컨텐츠를 생성하고 정합하는 장치 및 방법 |
| KR101347840B1 (ko) | 2012-03-29 | 2014-01-09 | 한국과학기술원 | 신체 제스처 인식 방법 및 장치 |
| CN103517072B (zh) | 2012-06-18 | 2017-11-03 | 联想(北京)有限公司 | 视频通信方法和设备 |
| US9124765B2 (en) | 2012-12-27 | 2015-09-01 | Futurewei Technologies, Inc. | Method and apparatus for performing a video conference |
| US9906691B2 (en) * | 2015-03-25 | 2018-02-27 | Tripurari Singh | Methods and system for sparse blue sampling |
| CN105120195B (zh) | 2015-09-18 | 2019-04-26 | 谷鸿林 | 内容录制、再现系统和方法 |
| US10225511B1 (en) * | 2015-12-30 | 2019-03-05 | Google Llc | Low power framework for controlling image sensor mode in a mobile image capture device |
| WO2018061173A1 (ja) | 2016-09-30 | 2018-04-05 | 株式会社オプティム | Tv会議システム、tv会議方法、およびプログラム |
| US10366292B2 (en) * | 2016-11-03 | 2019-07-30 | Nec Corporation | Translating video to language using adaptive spatiotemporal convolution feature representation with dynamic abstraction |
| CN106454277B (zh) | 2016-11-30 | 2019-09-27 | 杭州联络互动信息科技股份有限公司 | 一种用于视频监控的图像分析方法以及装置 |
| CN106878268A (zh) * | 2016-12-28 | 2017-06-20 | 杰创智能科技股份有限公司 | 低带宽高质量传输监控图像的方法及系统 |
| US10986356B2 (en) * | 2017-07-06 | 2021-04-20 | Samsung Electronics Co., Ltd. | Method for encoding/decoding image and device therefor |
| CN107977634A (zh) | 2017-12-06 | 2018-05-01 | 北京飞搜科技有限公司 | 一种针对视频的表情识别方法、装置及设备 |
| CN108449569B (zh) * | 2018-03-13 | 2019-04-05 | 重庆虚拟实境科技有限公司 | 虚拟会议方法、系统、装置、计算机装置及存储介质 |
| CN109831638B (zh) * | 2019-01-23 | 2021-01-08 | 广州视源电子科技股份有限公司 | 视频图像传输方法、装置、交互智能平板和存储介质 |
-
2019
- 2019-01-23 CN CN201910063004.7A patent/CN109831638B/zh active Active
- 2019-12-24 KR KR1020217021786A patent/KR102594030B1/ko active Active
- 2019-12-24 US US17/417,550 patent/US12309526B2/en active Active
- 2019-12-24 WO PCT/CN2019/127770 patent/WO2020151443A1/zh not_active Ceased
- 2019-12-24 EP EP19911814.2A patent/EP3902247A4/en active Pending
- 2019-12-24 JP JP2021542217A patent/JP7250937B2/ja active Active
- 2019-12-24 AU AU2019424397A patent/AU2019424397B2/en active Active
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0832947A (ja) * | 1994-07-11 | 1996-02-02 | Hitachi Ltd | 画像通信装置 |
| JPH0998416A (ja) * | 1995-09-29 | 1997-04-08 | Denso Corp | 画像信号の符号化装置および画像の認識装置 |
| JP2004304794A (ja) * | 2003-03-28 | 2004-10-28 | Eastman Kodak Co | 映画を表示する方法 |
| CN102271241A (zh) * | 2011-09-02 | 2011-12-07 | 北京邮电大学 | 一种基于面部表情/动作识别的图像通信方法及系统 |
| JP2014529233A (ja) * | 2012-03-29 | 2014-10-30 | テンセント テクノロジー (シェンツェン) カンパニー リミテッド | ビデオシミュレーション画像のための通信方法及びデバイス |
| US20130322513A1 (en) * | 2012-05-29 | 2013-12-05 | Qualcomm Incorporated | Video transmission and reconstruction |
| JP2015521454A (ja) * | 2012-05-29 | 2015-07-27 | クゥアルコム・インコーポレイテッドQualcomm Incorporated | ビデオ送信および再構成 |
| JP2016537922A (ja) * | 2013-12-20 | 2016-12-01 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 擬似ビデオ通話方法及び端末 |
| US20180131950A1 (en) * | 2015-04-30 | 2018-05-10 | Hangzhou Hikvision Digital Technology Co., Ltd. | Video coding and decoding methods and apparatus |
| CN106559636A (zh) * | 2015-09-25 | 2017-04-05 | 中兴通讯股份有限公司 | 一种视频通信方法、装置及系统 |
| JP2018201198A (ja) * | 2017-05-26 | 2018-12-20 | Line株式会社 | 映像圧縮方法、映像復元方法及びコンピュータプログラム |
Non-Patent Citations (2)
| Title |
|---|
| "知的符号化、モデルベース符号化とは何か?", エレクトロニクス9月別冊 解明・情報圧縮, JPN6023005640, 1 September 1997 (1997-09-01), JP, pages 40 - 43, ISSN: 0004996343 * |
| SOO-CHANG PEI,CHING-WEN KO,MING-SHING SU: "Global motion estimation in model-based image coding by tracking three-dimensional contour feature p", IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY ( VOLUME: 8, ISSUE: 2, APR 1998), vol. 8, no. 2, JPN7023000629, 1 April 1998 (1998-04-01), US, pages 181 - 190, XP011014458, ISSN: 0004996344 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023195426A1 (ja) * | 2022-04-05 | 2023-10-12 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 復号装置、符号化装置、復号方法及び符号化方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019424397A9 (en) | 2023-04-27 |
| CN109831638B (zh) | 2021-01-08 |
| CN109831638A (zh) | 2019-05-31 |
| JP7250937B2 (ja) | 2023-04-03 |
| KR20210100707A (ko) | 2021-08-17 |
| KR102594030B1 (ko) | 2023-10-24 |
| AU2019424397B2 (en) | 2023-04-27 |
| EP3902247A1 (en) | 2021-10-27 |
| WO2020151443A1 (zh) | 2020-07-30 |
| US20220051024A1 (en) | 2022-02-17 |
| AU2019424397A1 (en) | 2021-09-09 |
| EP3902247A4 (en) | 2022-05-18 |
| US12309526B2 (en) | 2025-05-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7250937B2 (ja) | ビデオ画像の伝送方法、装置、インテリジェントインタラクティブタブレット及び記憶媒体 | |
| CN107168674B (zh) | 投屏批注方法和系统 | |
| CN103517029B (zh) | 可视通话的数据处理方法、终端和系统 | |
| CN113936119B (zh) | 一种数据渲染方法、系统及装置 | |
| CN111402399A (zh) | 人脸驱动和直播方法、装置、电子设备及存储介质 | |
| EP2775704B1 (en) | A conference call terminal and method for operating user interface thereof | |
| CN100512420C (zh) | 用于在视频通信期间构成图像的方法和设备 | |
| CN113206971A (zh) | 一种图像处理方法及显示设备 | |
| CN108900894B (zh) | 视频数据的处理方法、装置和系统 | |
| CN113822803A (zh) | 图像超分处理方法、装置、设备及计算机可读存储介质 | |
| CN106791574B (zh) | 视频标注方法、装置及视频会议系统 | |
| CN114004750A (zh) | 图像处理方法、装置和系统 | |
| CN120321436A (zh) | 视频流传输方法、设备以及存储介质 | |
| CN112558854B (zh) | 多画面分屏模式定制方法、装置和计算机设备 | |
| CN105407313A (zh) | 一种视频通话方法、设备和系统 | |
| KR102718791B1 (ko) | Ar 글래스를 활용한 실시간 수화 통역 장치 및 수화 통역 방법 | |
| CN114915852B (zh) | 视频通话交互方法、装置、计算机设备和存储介质 | |
| CN116823869A (zh) | 背景替换的方法和电子设备 | |
| US20240185384A1 (en) | Video Bandwidth Optimization | |
| CN114640882A (zh) | 视频处理方法、装置、电子设备及计算机可读存储介质 | |
| CN115695889B (zh) | 显示设备及悬浮窗显示方法 | |
| CN116977194A (zh) | 一种视频处理方法、装置及计算机设备、存储介质 | |
| KR102034277B1 (ko) | 행사 실시간 스트리밍 방송 시스템 | |
| CN118474323B (zh) | 三维图像、三维视频、单眼视图以及训练数据集生成方法、设备、存储介质及程序产品 | |
| US11368743B2 (en) | Telestration capture for a digital video production system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210720 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20210720 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220707 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220816 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221104 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230221 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230322 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7250937 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |