JP2022017561A - 情報処理装置、歌唱音声の出力方法、及びプログラム - Google Patents
情報処理装置、歌唱音声の出力方法、及びプログラム Download PDFInfo
- Publication number
- JP2022017561A JP2022017561A JP2021183657A JP2021183657A JP2022017561A JP 2022017561 A JP2022017561 A JP 2022017561A JP 2021183657 A JP2021183657 A JP 2021183657A JP 2021183657 A JP2021183657 A JP 2021183657A JP 2022017561 A JP2022017561 A JP 2022017561A
- Authority
- JP
- Japan
- Prior art keywords
- voice
- user
- singing
- response system
- content
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 53
- 230000010365 information processing Effects 0.000 title description 2
- 230000004044 response Effects 0.000 claims abstract description 232
- 238000006243 chemical reaction Methods 0.000 claims abstract description 24
- 230000003993 interaction Effects 0.000 abstract description 4
- 230000015572 biosynthetic process Effects 0.000 description 79
- 238000003786 synthesis reaction Methods 0.000 description 77
- 230000008451 emotion Effects 0.000 description 63
- 230000006870 function Effects 0.000 description 58
- 238000012545 processing Methods 0.000 description 57
- 238000004458 analytical method Methods 0.000 description 50
- 230000008569 process Effects 0.000 description 23
- 238000003860 storage Methods 0.000 description 22
- 239000000203 mixture Substances 0.000 description 21
- 239000000463 material Substances 0.000 description 20
- 238000010586 diagram Methods 0.000 description 19
- 238000005316 response function Methods 0.000 description 16
- 238000000354 decomposition reaction Methods 0.000 description 11
- 238000004891 communication Methods 0.000 description 10
- 238000000605 extraction Methods 0.000 description 10
- 239000012634 fragment Substances 0.000 description 10
- 235000015220 hamburgers Nutrition 0.000 description 10
- 238000012937 correction Methods 0.000 description 8
- 239000004615 ingredient Substances 0.000 description 7
- 238000013473 artificial intelligence Methods 0.000 description 6
- 239000000284 extract Substances 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 230000033764 rhythmic process Effects 0.000 description 5
- 230000005236 sound signal Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 4
- 238000005520 cutting process Methods 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 241000234282 Allium Species 0.000 description 3
- 235000002732 Allium cepa var. cepa Nutrition 0.000 description 3
- 235000009508 confectionery Nutrition 0.000 description 3
- 230000001186 cumulative effect Effects 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 230000036760 body temperature Effects 0.000 description 2
- 230000002996 emotional effect Effects 0.000 description 2
- 230000008921 facial expression Effects 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 238000000465 moulding Methods 0.000 description 2
- 238000003825 pressing Methods 0.000 description 2
- 235000013547 stew Nutrition 0.000 description 2
- 230000002194 synthesizing effect Effects 0.000 description 2
- 238000012549 training Methods 0.000 description 2
- 230000001960 triggered effect Effects 0.000 description 2
- 241001342895 Chorus Species 0.000 description 1
- 206010012289 Dementia Diseases 0.000 description 1
- 241001417093 Moridae Species 0.000 description 1
- 229910017435 S2 In Inorganic materials 0.000 description 1
- 206010039740 Screaming Diseases 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- HAORKNGNJCEJBX-UHFFFAOYSA-N cyprodinil Chemical compound N=1C(C)=CC(C2CC2)=NC=1NC1=CC=CC=C1 HAORKNGNJCEJBX-UHFFFAOYSA-N 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000002715 modification method Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000001308 synthesis method Methods 0.000 description 1
Images














Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/63—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for estimating an emotional state
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Hospice & Palliative Care (AREA)
- Psychiatry (AREA)
- Child & Adolescent Psychology (AREA)
- General Health & Medical Sciences (AREA)
- Heart & Thoracic Surgery (AREA)
- Biophysics (AREA)
- Medical Informatics (AREA)
- Molecular Biology (AREA)
- Surgery (AREA)
- Animal Behavior & Ethology (AREA)
- Pathology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Biomedical Technology (AREA)
- Social Psychology (AREA)
- Psychology (AREA)
- Educational Technology (AREA)
- Developmental Disabilities (AREA)
- Signal Processing (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Measurement Of The Respiration, Hearing Ability, Form, And Blood Characteristics Of Living Organisms (AREA)
Abstract
Description
これに対し本発明は、ユーザとのインタラクションに応じて歌唱音声を出力する技術を提供する。
声における伴奏のアレンジを含んでもよい。
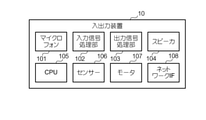
図1は、一実施形態に係る音声応答システム1の概要を示す図である。音声応答システム1は、ユーザが声によって入力(又は指示)を行うと、それに対し自動的に音声による応答を出力するシステムであり、いわゆるAI(Artificial Intelligence)音声アシスタントである。以下、ユーザから音声応答システム1に入力される音声を「入力音声」といい、入力音声に対し音声応答システム1から出力される音声を「応答音声」という。特にこの例において、音声応答は歌唱を含む。すなわち、音声応答システム1は、歌唱合成システムの一例である。例えば、音声応答システム1に対しユーザが「何か歌って」と話しかけると、音声応答システム1は自動的に歌唱を合成し、合成された歌唱を出力する。
2-1.構成
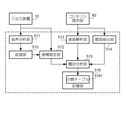
図5は、学習機能51に係る機能構成を例示する図である。学習機能51に係る機能要素として、音声応答システム1は、音声分析部511、感情推定部512、楽曲解析部513、歌詞抽出部514、嗜好分析部515、記憶部516、及び処理部510を有する。また、入出力装置10は、ユーザの入力音声を受け付ける受け付け部、及び応答音声を出力する出力部として機能する。
図6は、学習機能51に係る音声応答システム1の動作の概要を示すフローチャートである。ステップS11において、音声応答システム1は、入力音声を分析する。ステップS12において、音声応答システム1は、入力音声により指示された処理を行う。ステップS13において、音声応答システム1は、入力音声が学習の対象となる事項を含むか判断する。入力音声が学習の対象となる事項を含むと判断された場合(S13:YES)、音声応答システム1は、処理をステップS14に移行する。入力音声が学習の対象となる事項を含まないと判断された場合(S13:NO)、音声応答システム1は、処理をステップS18に移行する。ステップS14において、音声応答システム1は、ユーザの感情を推定する。ステップS15において、音声応答システム1は、再生が指示された楽曲を解析する。ステップS16において、音声応答システム1は、再生が指示された楽曲の歌詞を取得する。ステップS17において、音声応答システム1は、ステップS14~S16において得られた情報を用いて、分類テーブルを更新する。
3-1.構成
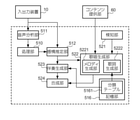
図9は、歌唱合成機能52に係る機能構成を例示する図である。歌唱合成機能52に係
る機能要素として、音声応答システム1は、音声分析部511、感情推定部512、記憶部516、検知部521、歌唱生成部522、伴奏生成部523、及び合成部524を有する。歌唱生成部522は、メロディ生成部5221及び歌詞生成部5222を有する。以下において、学習機能51と共通する要素については説明を省略する。
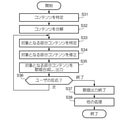
図10は、歌唱合成機能52に係る音声応答システム1の動作(歌唱合成方法)の概要を示すフローチャートである。ステップS21において、音声応答システム1は、歌唱合成をトリガするイベントが発生したか判断する。すなわち、音声応答システム1は、歌唱合成をトリガするイベントを検知する。歌唱合成をトリガするイベントは、例えば、ユーザから音声入力が行われたというイベント、カレンダーに登録されたイベント(例えば、アラーム又はユーザの誕生日)、ユーザから音声以外の手法(例えば入出力装置10に無線接続されたスマートフォン(図示略)への操作)により歌唱合成の指示が入力されたというイベント、及びランダムに発生するイベントのうち少なくとも1つを含む。歌唱合成をトリガするイベントが発生したと判断された場合(S21:YES)、音声応答システム1は、処理をステップS22に移行する。歌唱合成をトリガするイベントが発生していないと判断された場合(S21:NO)、音声応答システム1は、歌唱合成をトリガするイベントが発生するまで待機する。
6において、音声応答システム1は、使用する素片データベースを選択する。ステップS27において、音声応答システム1は、ステップS23、S26、及びS27において得られた、メロディ、歌詞、及び素片データベースを用いて歌唱合成を行う。ステップS28において、音声応答システム1は、伴奏を生成する。ステップS29において、音声応答システム1は、歌唱音声と伴奏とを合成する。ステップS23~S29の処理は、図6のフローにおけるステップS18の処理の一部である。以下、歌唱合成機能52に係る音声応答システム1の動作をより詳細に説明する。
ップS211)。歌詞生成部5222は、例えば、歌詞素材を複数、組み合わせることにより歌詞を生成する。あるいは、各ソースは1曲全体分の歌詞を記憶していてもよく、この場合、歌詞生成部5222は、ソースが記憶している歌詞の中から、歌唱合成に用いる1曲分の歌詞を選択してもよい。歌詞生成部5222は、生成した歌詞を歌唱生成部522に出力する(ステップS212)。
2)。この要求は、歌唱合成におけるメロディを示す情報を含む。伴奏生成部523は、要求に含まれるメロディに応じて伴奏を生成する(ステップS223)。メロディに対し自動的に伴奏を付ける技術としては、周知の技術が用いられる。メロディデータベースにおいてメロディのコード進行を示すデータ(以下「コード進行データ」)が記録されている場合、伴奏生成部523は、このコード進行データを用いて伴奏を生成してもよい。あるいは、メロディデータベースにおいてメロディに対する伴奏用のコード進行データが記録されている場合、伴奏生成部523は、このコード進行データを用いて伴奏を生成してもよい。さらにあるいは、伴奏生成部523は、伴奏のオーディオデータをあらかじめ複数、記憶しておき、その中からメロディのコード進行に合ったものを読み出してもよい。また、伴奏生成部523は、例えば伴奏の曲調を決定するために分類テーブル5161を参照し、ユーザの嗜好に応じた伴奏を生成してもよい。伴奏生成部523は、生成された伴奏のデータを合成部524に出力する(ステップS224)。
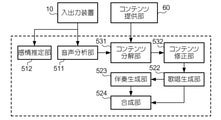
図12は、応答機能53に係る音声応答システム1の機能構成を例示する図である。応答機能53に係る機能要素として、音声応答システム1は、音声分析部511、感情推定部512、及びコンテンツ分解部531を有する。以下において、学習機能51及び歌唱合成機能52と共通する要素については説明を省略する。コンテンツ分解部531は、一のコンテンツを複数の部分コンテンツに分解する。この例においてコンテンツとは、応答音声として出力される情報の内容をいい、具体的には、例えば、楽曲、ニュース、レシピ、又は教材(スポーツ教習、楽器教習、学習ドリル、クイズ)をいう。
そのまま話声として、又はそのコンテンツを歌詞として用いた歌唱音声として出力されてもよい。音声応答システム1は、ユーザの入力音声に応じて、又は出力されるコンテンツに応じて、部分コンテンツに分解するか、分解せずそのまま出力するか判断してもよい。
以下、具体的な動作例をいくつか説明する。各動作例において特に明示はしないが、各動作例は、それぞれ、上記の学習機能、歌唱合成機能、及び応答機能の少なくとも1つ以上に基づくものである。なお以下の動作例はすべて日本語が使用される例を説明するが、使用される言語は日本語に限定されず、どのような言語でもよい。
図14は、音声応答システム1の動作例1を示す図である。この例において、ユーザは「佐藤一太郎(実演者名)の『さくらさくら』(楽曲名)をかけて」という入力音声により、楽曲の再生を要求する。音声応答システム1は、この入力音声に従って楽曲データベースを検索し、要求された楽曲を再生する。このとき、音声応答システム1は、この入力音声を入力したときのユーザの感情及びこの楽曲の解析結果を用いて、分類テーブルを更新する。分類テーブルは、楽曲の再生が要求される度に分類テーブルを更新する。分類テーブルは、ユーザが音声応答システム1に対し楽曲の再生を要求する回数が増えるにつれ(すなわち、音声応答システム1の累積使用時間が増えるにつれ)、よりそのユーザの嗜好を反映したものになっていく。
図15は、音声応答システム1の動作例2を示す図である。この例において、ユーザは「何か楽しい曲歌って」という入力音声により、歌唱合成を要求する。音声応答システム1は、この入力音声に従って歌唱合成を行う。歌唱合成に際し、音声応答システム1は、分類テーブルを参照する。分類テーブルに記録されている情報を用いて、歌詞及びメロディを生成する。したがって、ユーザの嗜好を反映した楽曲を自動的に作成することができる。
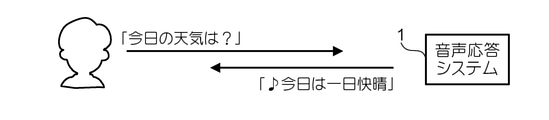
図16は、音声応答システム1の動作例3を示す図である。この例において、ユーザは「今日の天気は?」という入力音声により、気象情報の提供を要求する。この場合、処理部510はこの要求に対する回答として、コンテンツ提供部60のうち気象情報を提供するサーバにアクセスし、今日の天気を示すテキスト(例えば「今日は一日快晴」)を取得する。処理部510は、取得したテキストを含む、歌唱合成の要求を歌唱生成部522に出力する。歌唱生成部522は、この要求に含まれるテキストを歌詞として用いて、歌唱合成を行う。音声応答システム1は、入力音声に対する回答として「今日は一日快晴」にメロディ及び伴奏を付けた歌唱音声を出力する。
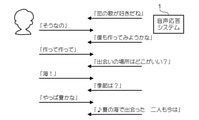
図17は、音声応答システム1の動作例4を示す図である。この例において、図示された応答が開始される前に、ユーザは音声応答システム1を2週間、使用し、恋愛の歌をよく再生していた。そのため、分類テーブルには、そのユーザが恋愛の歌が好きであることを示す情報が記録される。音声応答システム1は、「出会いの場所はどこがいい?」や、「季節はいつがいいかな?」など、歌詞生成のヒントとなる情報を得るためにユーザに質問をする。音声応答システム1は、これらの質問に対するユーザの回答を用いて歌詞を生成する。なおこの例において、使用期間がまだ2週間と短いため、音声応答システム1の分類テーブルは、まだユーザの嗜好を十分に反映できておらず、感情との対応付けも十分ではない。そのため、本当はユーザはバラード調の曲が好みであるにも関わらず、それとは異なるロック調の曲を生成したりする。
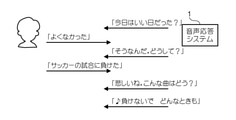
図18は、音声応答システム1の動作例5を示す図である。この例は、動作例3からさらに音声応答システム1の使用を続け、累積使用期間が1月半となった例を示している。動作例3と比較すると分類テーブルはユーザの嗜好をより反映したものとなっており、合成される歌唱はユーザの嗜好に沿ったものになっている。ユーザは、最初は不完全だった音声応答システム1の反応が徐々に自分の嗜好に合うように変化していく体験をすることができる。
図19は、音声応答システム1の動作例6を示す図である。この例において、ユーザは、「ハンバーグのレシピを教えてくれる?」という入力音声により、「ハンバーグ」の「レシピ」のコンテンツの提供を要求する。音声応答システム1は、「レシピ」というコンテンツが、あるステップが終了してから次のステップに進むべきものである点を踏まえ、コンテンツを部分コンテンツに分解し、ユーザの反応に応じて次の処理を決定する態様で再生することを決定する。
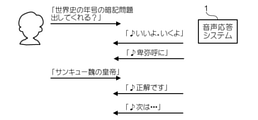
図20は、音声応答システム1の動作例7を示す図である。この例において、ユーザは、「世界史の年号の暗記問題出してくれる?」という入力音声により、「世界史」の「暗記問題」のコンテンツの提供を要求する。音声応答システム1は、「暗記問題」というコンテンツが、ユーザの記憶を確認するためのものである点を踏まえ、コンテンツを部分コンテンツに分解し、ユーザの反応に応じて次の処理を決定する態様で再生することを決定する。
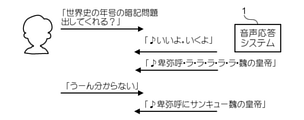
図21は、音声応答システム1の動作例8を示す図である。動作例7と同様、ユーザは、「世界史」の「暗記問題」のコンテンツの提供を要求する。音声応答システム1は、「暗記問題」というコンテンツが、ユーザの記憶を確認するためのものである点を踏まえ、このコンテンツの一部を隠して出力する。隠すべき部分は、例えばコンテンツにおいて定義されていてもよいし、処理部510すなわちAIが形態素解析等の結果に基づいて判断してもよい。
図22は、音声応答システム1の動作例9を示す図である。この例において、ユーザは、「工場における工程の手順書を読み上げてくれる?」という入力音声により、「手順書」のコンテンツの提供を要求する。音声応答システム1は、「手順書」というコンテンツが、ユーザの記憶を確認するためのものである点を踏まえ、コンテンツを部分コンテンツに分解し、ユーザの反応に応じて次の処理を決定する態様で再生することを決定する。
ンツに分解する。音声応答システム1は、一の部分コンテンツの歌唱を出力すると、ユーザの反応を待つ。例えば「スイッチAを押した後、メータBの値が10以下となったところでスイッチBを押す」という手順のコンテンツにつき、音声応答システム1が「スイッチAを押した後」という部分を歌唱し、ユーザの反応を待つ。ユーザが何か音声を発すると、音声応答システム1は、次の部分コンテンツの歌唱を出力する。あるいはこのとき、ユーザが次の部分コンテンツを正しく言えたか否かに応じて、次の部分コンテンツの歌唱のスピードを変更してもよい。具体的には、ユーザが次の部分コンテンツを正しく言えた場合、音声応答システム1は、次の部分コンテンツの歌唱のスピードを上げる。あるいは、ユーザが次の部分コンテンツを正しく言えなかった場合、音声応答システム1は、次の部分コンテンツの歌唱のスピードを下げる。
図23は、音声応答システム1の動作例10を示す図である。動作例10は、高齢者の認知症対策の動作例である。この例において、ユーザが高齢者であることはあらかじめユーザ登録等により設定されている。音声応答システム1は、例えばユーザの指示に応じて既存の歌を歌い始める。音声応答システム1は、ランダムな位置、又は所定の位置(例えばサビの手前)において歌唱を一時停止する。その際、「うーん分からない」、「忘れちゃった」等のメッセージを発し、あたかも歌詞を忘れたかのように振る舞う。音声応答システム1は、この状態でユーザの応答を待つ。ユーザが何か音声を発すると、音声応答システム1は、ユーザが発した言葉(の一部)を正解の歌詞として、その言葉の続きから歌唱を出力する。なお、ユーザが何か言葉を発した場合、音声応答システム1は「ありがとう」等の応答を出力してもよい。ユーザの応答待ちの状態で所定時間が経過したときは、音声応答システム1は、「思い出した」等の話声を出力し、一時停止した部分の続きから歌唱を再開してもよい。
図24は、音声応答システム1の動作例11を示す図である。この例において、ユーザは「何か楽しい曲歌って」という入力音声により、歌唱合成を要求する。音声応答システム1は、この入力音声に従って歌唱合成を行う。歌唱合成の際に用いる素片データベースは、例えばユーザ登録時に選択されたキャラクタに応じて選択される(例えば、男性キャラクタが選択された場合、男性歌手による素片データベースが用いられる)。ユーザは、歌の途中で「女性の声に変えて」等、素片データベースの変更を指示する入力音声を発する。音声応答システム1は、ユーザの入力音声に応じて、歌唱合成に用いる素片データベースを切り替える。素片データベースの切り替えは、音声応答システム1が歌唱音声を出力しているときに行われてもよいし、動作例7~10のように音声応答システム1がユーザの応答待ちの状態のときに行われてもよい。
本発明は上述の実施形態に限定されるものではなく、種々の変形実施が可能である。以下、変形例をいくつか説明する。以下の変形例のうち2つ以上のものが組み合わせて用い
られてもよい。
Claims (1)
- コンテンツに含まれる文字列を分解して得られた複数の部分コンテンツの中から第1の部分コンテンツを特定するステップと、
前記第1の部分コンテンツに含まれる文字列を用いて合成された歌唱音声を出力するステップと、
前記歌唱音声に対するユーザの反応を受け付けるステップと、
前記反応に応じて、前記第1の部分コンテンツに続く第2の部分コンテンツに含まれる文字列を用いて合成された歌唱音声を出力するステップと
を有する歌唱音声の出力方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021183657A JP7424359B2 (ja) | 2017-06-14 | 2021-11-10 | 情報処理装置、歌唱音声の出力方法、及びプログラム |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017116831A JP6977323B2 (ja) | 2017-06-14 | 2017-06-14 | 歌唱音声の出力方法、音声応答システム、及びプログラム |
| JP2021183657A JP7424359B2 (ja) | 2017-06-14 | 2021-11-10 | 情報処理装置、歌唱音声の出力方法、及びプログラム |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017116831A Division JP6977323B2 (ja) | 2017-06-14 | 2017-06-14 | 歌唱音声の出力方法、音声応答システム、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022017561A true JP2022017561A (ja) | 2022-01-25 |
| JP7424359B2 JP7424359B2 (ja) | 2024-01-30 |
Family
ID=64660282
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017116831A Active JP6977323B2 (ja) | 2017-06-14 | 2017-06-14 | 歌唱音声の出力方法、音声応答システム、及びプログラム |
| JP2021183657A Active JP7424359B2 (ja) | 2017-06-14 | 2021-11-10 | 情報処理装置、歌唱音声の出力方法、及びプログラム |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017116831A Active JP6977323B2 (ja) | 2017-06-14 | 2017-06-14 | 歌唱音声の出力方法、音声応答システム、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (2) | JP6977323B2 (ja) |
| WO (1) | WO2018230670A1 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6594577B1 (ja) * | 2019-03-27 | 2019-10-23 | 株式会社博報堂Dyホールディングス | 評価システム、評価方法、及びコンピュータプログラム。 |
| JP2020177534A (ja) * | 2019-04-19 | 2020-10-29 | 京セラドキュメントソリューションズ株式会社 | 透過型ウェアラブル端末 |
| TWI749447B (zh) * | 2020-01-16 | 2021-12-11 | 國立中正大學 | 同步語音產生裝置及其產生方法 |
| WO2022113914A1 (ja) * | 2020-11-25 | 2022-06-02 | ヤマハ株式会社 | 音響処理方法、音響処理システム、電子楽器およびプログラム |
| CN113488007B (zh) * | 2021-07-07 | 2024-06-11 | 北京灵动音科技有限公司 | 信息处理方法、装置、电子设备及存储介质 |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1115489A (ja) * | 1997-06-24 | 1999-01-22 | Yamaha Corp | 歌唱音合成装置 |
| JPH11175082A (ja) * | 1997-12-10 | 1999-07-02 | Toshiba Corp | 音声対話装置及び音声対話用音声合成方法 |
| JP2001043126A (ja) * | 1999-07-27 | 2001-02-16 | Tadamitsu Ryu | ロボットシステム |
| JP2002221978A (ja) * | 2001-01-26 | 2002-08-09 | Yamaha Corp | ボーカルデータ生成装置、ボーカルデータ生成方法および歌唱音合成装置 |
| JP2002258872A (ja) * | 2001-02-27 | 2002-09-11 | Casio Comput Co Ltd | 音声情報サービスシステム及び音声情報サービス方法 |
| KR20090046003A (ko) * | 2007-11-05 | 2009-05-11 | 주식회사 마이크로로봇 | 로봇 완구 장치 |
| WO2013190963A1 (ja) * | 2012-06-18 | 2013-12-27 | エイディシーテクノロジー株式会社 | 音声応答装置 |
| JP2014098844A (ja) * | 2012-11-15 | 2014-05-29 | Ntt Docomo Inc | 対話支援装置、対話システム、対話支援方法及びプログラム |
| JP2016161774A (ja) * | 2015-03-02 | 2016-09-05 | ヤマハ株式会社 | 楽曲生成装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3508470B2 (ja) * | 1996-05-29 | 2004-03-22 | ヤマハ株式会社 | 作詞支援装置、作詞支援方法および記憶媒体 |
| JPH11219195A (ja) * | 1998-02-04 | 1999-08-10 | Atr Chino Eizo Tsushin Kenkyusho:Kk | 対話型詩朗読システム |
| JP2003131548A (ja) * | 2001-10-29 | 2003-05-09 | Mk Denshi Kk | 言語学習装置 |
| JP2006227589A (ja) * | 2005-01-20 | 2006-08-31 | Matsushita Electric Ind Co Ltd | 音声合成装置および音声合成方法 |
| JP6295531B2 (ja) * | 2013-07-24 | 2018-03-20 | カシオ計算機株式会社 | 音声出力制御装置、電子機器及び音声出力制御プログラム |
-
2017
- 2017-06-14 JP JP2017116831A patent/JP6977323B2/ja active Active
-
2018
- 2018-06-14 WO PCT/JP2018/022816 patent/WO2018230670A1/ja active Application Filing
-
2021
- 2021-11-10 JP JP2021183657A patent/JP7424359B2/ja active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1115489A (ja) * | 1997-06-24 | 1999-01-22 | Yamaha Corp | 歌唱音合成装置 |
| JPH11175082A (ja) * | 1997-12-10 | 1999-07-02 | Toshiba Corp | 音声対話装置及び音声対話用音声合成方法 |
| JP2001043126A (ja) * | 1999-07-27 | 2001-02-16 | Tadamitsu Ryu | ロボットシステム |
| JP2002221978A (ja) * | 2001-01-26 | 2002-08-09 | Yamaha Corp | ボーカルデータ生成装置、ボーカルデータ生成方法および歌唱音合成装置 |
| JP2002258872A (ja) * | 2001-02-27 | 2002-09-11 | Casio Comput Co Ltd | 音声情報サービスシステム及び音声情報サービス方法 |
| KR20090046003A (ko) * | 2007-11-05 | 2009-05-11 | 주식회사 마이크로로봇 | 로봇 완구 장치 |
| WO2013190963A1 (ja) * | 2012-06-18 | 2013-12-27 | エイディシーテクノロジー株式会社 | 音声応答装置 |
| JP2014098844A (ja) * | 2012-11-15 | 2014-05-29 | Ntt Docomo Inc | 対話支援装置、対話システム、対話支援方法及びプログラム |
| JP2016161774A (ja) * | 2015-03-02 | 2016-09-05 | ヤマハ株式会社 | 楽曲生成装置 |
Non-Patent Citations (2)
| Title |
|---|
| 中津良平: ""人間の感性とロボット、エージェント"", 日本ロボット学会誌, vol. 17, no. 7, JPN6022042225, 15 October 1999 (1999-10-15), pages 6 - 13, ISSN: 0004893685 * |
| 西村綾乃 他: ""conteXinger:日常のコンテクストを取り込み歌うVOCALOID"", 情報処理学会研究報告, vol. 113, no. 38, JPN6022042224, 9 May 2013 (2013-05-09), pages 193 - 198, ISSN: 0005158606 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6977323B2 (ja) | 2021-12-08 |
| JP7424359B2 (ja) | 2024-01-30 |
| WO2018230670A1 (ja) | 2018-12-20 |
| JP2019003000A (ja) | 2019-01-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7424359B2 (ja) | 情報処理装置、歌唱音声の出力方法、及びプログラム | |
| JP7363954B2 (ja) | 歌唱合成システム及び歌唱合成方法 | |
| AU2012213646B2 (en) | Semantic audio track mixer | |
| EP3675122B1 (en) | Text-to-speech from media content item snippets | |
| JP2021516787A (ja) | オーディオ合成方法、並びにそのコンピュータプログラム、コンピュータ装置及びコンピュータ装置により構成されるコンピュータシステム | |
| EP3759706B1 (en) | Method, computer program and system for combining audio signals | |
| US20140046667A1 (en) | System for creating musical content using a client terminal | |
| JP5598516B2 (ja) | カラオケ用音声合成システム,及びパラメータ抽出装置 | |
| Lesaffre et al. | The MAMI Query-By-Voice Experiment: Collecting and annotating vocal queries for music information retrieval | |
| JP4808641B2 (ja) | 似顔絵出力装置およびカラオケ装置 | |
| JP3931442B2 (ja) | カラオケ装置 | |
| CN110782866A (zh) | 一种演唱声音转换器 | |
| Bresin et al. | Rule-based emotional coloring of music performance | |
| Dai et al. | An Efficient AI Music Generation mobile platform Based on Machine Learning and ANN Network | |
| JP6611633B2 (ja) | カラオケシステム用サーバ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211111 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20211111 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220929 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20221011 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221209 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230411 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230612 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230926 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231003 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20231219 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240101 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7424359 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |