[0022]本開示では、合成画像とシーン構造マップとに基づいて現在画像をビデオコード化(例えば、符号化又は復号)するための様々な技法について説明する。このようにして、従来の動き補償は、少なくとも現在画像の一部分について、ビデオコード化のために必要でないことがある。本開示の他の場所でより詳細に説明するように、シーン構造マップを構築するために必要とされる情報の量は比較的少ないことがあり、合成画像は、標準ハードウェアを使用してシーン構造マップと(1つ又は複数の)前の画像とで構築され得る。従って、本開示で説明する技法は、従来の動き補償技法に対して、ビデオコード化のために必要とされる帯域幅を低減し得る。更に、本技法は標準ハードウェア上で実装され得るので、本開示で説明する技法を実装するために追加の構成要素は必要とされないことがある。
[0023]シーン構造マップは、画像内の数個のポイント(例えば、キーポイント)のための座標値を含み得る。例えば、画像は3次元(3D)画像であり得る。この場合、3D画像は、立体視画像ではなく、むしろ、オブジェクトの相対深度がその内にある画像である(例えば、画像は2D空間を包含しているにもかかわらず、あるオブジェクトが別のオブジェクトに対してより後方にあるように見える)。
[0024]シーン構造マップは、各ポイントのためのx、y及びz座標を含み得る。シーン構造マップのポイントは、互いに接続されたとき、画像の構造を定義するメッシュを形成する、多角形(例えば、三角形)の頂点を定義し得る。この意味で、シーン構造マップの相互接続は画像のプロキシジオメトリと考えられ得る。本開示では、プロキシジオメトリを作成するために使用されるシーン構造マップは、以下でより詳細に説明するように、現在画像のシーン構造マップあるいは前に符号化又は復号された画像のシーン構造マップであり得る。
[0025]シーン構造マップを生成するための様々な方法があり得る。シーン構造マップを生成するための1つの例示的な方法は、同時ローカライゼーション及びマッピング(SLAM:simultaneous localization and mapping)技法を使用することである。しかしながら、本開示で説明する技法は、シーン構造マップを生成するための他の方法に拡張可能であり得る。説明の目的で、シーン構造マップを生成するための技法についてSLAM技法に関して説明する。例えば、本開示で説明する技法について、シーン構造マップを生成するSLAMプロセッサ(例えば、SLAM技法を実装するように構成されたプロセッサ)の観点から説明する。
[0026]幾つかの例では、SLAMプロセッサは、現在画像に基づいて、又は前に符号化又は復号された画像に基づいて、現在画像を符号化又は復号するために使用されるシーン構造マップを生成し得る。例えば、ビデオ符号化を実施する機器はSLAMプロセッサを含み得る。この例では、SLAMプロセッサは、現在画像に基づいて現在画像のためのシーン構造マップを生成し得る。エンコーダプロセッサが、本開示の他の場所でより詳細に説明するように、生成されたシーン構造マップに基づいて現在画像を符号化し、生成されたシーン構造マップを出力し得る。ビデオ復号を実施する機器が、同じく本開示の他の場所でより詳細に説明するように、シーン構造マップを受信し、シーン構造マップに基づいて現在画像を復号し得る。
[0027]ある例では、SLAMプロセッサは、現在画像に基づいてシーン構造マップを生成する必要がないことがある。これらの例では、エンコーダプロセッサは、前に生成されたシーン構造マップ(例えば、エンコーダプロセッサが前に生成したシーン構造マップ)に基づいて現在画像を符号化し得る。同様に、デコーダプロセッサは、前に受信されたシーン構造マップ(例えば、デコーダプロセッサが前に受信したシーン構造マップ)に基づいて現在画像を復号し得る。
[0028]シーン構造マップに加えて、エンコーダプロセッサ及びデコーダプロセッサは、現在画像をそれぞれ符号化及び復号するために合成画像を利用する。合成画像を生成するように構成された、ビデオ符号化を実施する機器又はビデオ復号を実施する機器内の様々な構成要素があり得る。説明の目的で、以下では、合成画像を生成するグラフィックス処理ユニット(GPU)に関して説明する。
[0029]ビデオ符号化のための機器とビデオ復号のための機器の両方はそれぞれのGPUを含む。GPUの各々は、合成画像を生成するために実質的に同じ機能を実施する。従って、GPUが合成画像を生成する様式の以下の説明は、ビデオ符号化のための機器とビデオ復号のための機器の両方に適用可能である。
[0030]GPUは、1つ又は複数の画像(例えば、前に復号された画像)とシーン構造マップとに基づいて合成画像を生成し得る。この場合も、シーン構造マップは、現在画像から生成されたシーン構造マップ又は前に符号化若しくは復号された画像から生成されたシーン構造マップであり得る。GPUが合成画像を生成するために2つ以上の画像を使用する例では、GPU又は何らかの他の構成要素は、複合画像を生成するために、画像(例えば、前に復号又は符号化されたピクチャ)のうちの2つ又はそれ以上をブレンドするためのブレンディング演算を実施し得る。GPUが1つの画像のみを使用する例では、その画像は複合画像と考えられ得る。
[0031]GPUはテクスチャエンジンを含み、テクスチャエンジンの機能は、テクスチャマップを多角形の相互接続上にオーバーレイすることである。本開示で説明する技法によれば、GPUは、例えば頂点シェーダ又は入力アセンブラを使用して、シーン構造マップのまばらに分布されたポイントを相互接続する。まばらに分布されたポイントの例は以下で与えられる。例えば、シーン構造マップのポイントは、GPUがメッシュを形成するために相互接続する三角形の頂点と考えられ得る。GPUは、プロキシジオメトリを形成するためにシーン構造マップのポイントを相互接続し得る。上記で説明したように、シーン構造マップのポイントはx、y及びz座標によって定義され、従って、シーン構造マップは3D空間において定義される。
[0032]複合画像(例えば、1つの画像又は2つ以上の画像のブレンド)はテクスチャマップと考えられ得る。この例では、複合画像のコンテンツは3Dであり得るが、各画素はx及びy座標によって識別される。シーン構造マップのx、y及びz座標との混同を回避するために、複合画像(例えば、テクスチャマップ)の画素のx座標及びy座標は、それぞれu座標及びv座標と呼ばれる。
[0033]GPUのテクスチャエンジンは、複合画像をシーン構造マップ上にオーバーレイするために、複合画像の各画素を3Dシーン構造マップ上にマッピングし得る。言い換えれば、テクスチャエンジンは、(u,v)座標によって定義される画素の各々をシーン構造マップの(x,y,z)座標上にマッピングする。テクスチャエンジンの結果は画像ベースモデル(IBM)と考えられ得る。このIBMモデルは、それの画素が(x,y,z)座標によって定義されるグラフィカル構築体であり得る。
[0034]GPUは、合成画像を生成するためにIBMをレンダリングし得る。例えば、GPUは、合成画像をレンダリングするために、IBMを処理するために標準グラフィックス処理タスクを実施する。合成画像は、(例えば、表示器上で(x,y)画素座標によって定義される画素をもつ)最終表示可能画像(final viewable image)と考えられ得る。しかしながら、表示のために合成画像を出力するのではなく、エンコーダプロセッサ及びデコーダプロセッサは合成画像を予測画像として利用し得る。
[0035]エンコーダプロセッサは、現在画像と合成画像との間の、残差画像と呼ばれる差分を決定し得、残差画像を示す情報を出力する。デコーダプロセッサは、(例えば、残差画像を示す受信された情報に基づいて)残差画像を決定し、現在画像を再構築するために、残差画像を、ローカルで生成された合成画像と加算する。
[0036]SLAMプロセッサが現在画像に基づいてシーン構造マップを生成した例では、エンコーダプロセッサは、更に、シーン構造マップの情報(例えば、シーン構造マップのポイントの座標)を出力し得る。これらの例では、デコーダプロセッサはシーン構造マップの情報を受信し、デコーダプロセッサ側のGPUは、受信されたシーン構造マップに基づいて合成画像を生成する。SLAMプロセッサが現在画像に基づいてシーン構造マップを生成せず、GPUが合成画像を生成するために前のシーン構造マップを代わりに再利用した例では、エンコーダプロセッサはシーン構造マップの情報を出力しないことがある。デコーダプロセッサ側のGPUは、合成画像を生成するために同じ前のシーン構造マップを再利用し得る。
[0037]SLAMプロセッサが、エンコーダプロセッサ側のGPUが合成画像を生成するために使用した現在画像に基づいてシーン構造マップを生成した幾つかの例では、エンコーダプロセッサは、必ずしもシーン構造マップのポイントの座標を出力する必要があるとは限らない。そうではなく、エンコーダプロセッサは、前のシーン構造マップに対するシーン構造マップのポイントへの増分更新を出力し得る。デコーダプロセッサはシーン構造マップのこれらの更新値を受信し、GPUは、現在画像を復号するための合成画像を生成するためにGPUが使用するシーン構造マップを生成するために、前のシーン構造マップを更新する。本開示では、シーン構造マップの情報は、シーン構造マップのポイントの座標又は前のシーン構造マップに対するポイントの座標のための更新値を含む)。
[0038]本開示で説明する技法は、概して、ビデオ符号化及び復号に適用可能であり得る。一例として、本技法は、移動しているカメラによってシーンが観測される例及びリアルタイムビデオ符号化及び復号が必要とされる例において使用され得る。例えば、ビデオテレフォニー又はビデオ会議では、ビデオ符号化及び復号はリアルタイムで必要とされ得、本開示で説明する技法は、そのようなリアルタイムビデオ符号化及び復号を可能にする。例えば、GPUは、合成画像を比較的迅速に生成して、リアルタイムビデオ符号化及び復号を可能にすることができ、シーン構造マップを出力及び受信するために必要とされる帯域幅の量は比較的少ないことがある。
[0039]上記では、リアルタイムビデオ符号化及び復号に関して、及び移動しているカメラを用いる例に関して説明したが、本技法はそのように限定されないことを理解されたい。幾つかの例では、ビデオ符号化及びビデオ復号技法は、オフラインビデオ符号化及び復号技法(例えば、非リアルタイム)に適用可能であり、カメラが静止している場合のビデオ符号化及び復号技法に適用可能である。
[0040]また、カメラが移動している幾つかの例では、エンコーダプロセッサは、カメラ姿勢と呼ばれるカメラの方向及び位置をデコーダプロセッサに示す情報を出力し得る。デコーダプロセッサは、現在画像を復号(例えば、再構築)する目的でカメラ姿勢を利用する。例えば、カメラ姿勢情報は画像が「どこから」撮られたかを示す。カメラが移動している例では、現在画像についてのカメラ姿勢は、前にコード化された画像についてのカメラ姿勢とは異なり得る。従って、合成画像をレンダリングするために、それぞれのGPUは、合成画像と現在画像とについてのカメラ姿勢が同じになるように、現在画像のカメラ姿勢情報を利用し得る。また、それぞれのGPUは、複合画像をシーン構造マップにマッピングするとき、複合画像を構築するために使用された1つ又は複数の前にコード化された画像についてのカメラ姿勢情報を利用し得る。
[0041]上記の例では、それぞれのGPUは、合成画像をレンダリングするために現在画像についてのカメラ姿勢情報を使用し、複合画像をシーン構造マップにマッピングするために(例えば、GPUがエンコーダ側にあるのかデコーダ側にあるのかに基づいて)前に符号化又は復号された画像のうちの1つ又は複数のカメラ姿勢情報を使用する。従って、幾つかの例では、エンコーダプロセッサは、現在画像を符号化するためにカメラ姿勢情報を使用し得、各画像についてのカメラ姿勢情報を信号伝達し得る。デコーダプロセッサは、各画像についてのカメラ姿勢情報を受信し得、現在画像を復号するためにカメラ姿勢情報を使用し得る。カメラが移動していない例では、カメラ姿勢情報は、暗黙的に導出され得るか、又は一定値に設定され得る。そのような例では、エンコーダプロセッサは、必ずしも各画像についてのカメラ姿勢情報を信号伝達する必要があるとは限らず、デコーダプロセッサは、必ずしも各画像についてのカメラ姿勢情報を受信する必要があるとは限らない。
[0042]上記の例では、デコーダプロセッサは、エンコーダプロセッサのプロセスとは逆のプロセスを実装するように構成され得る。本開示では、「コーダプロセッサ」という用語は、一般的にデコーダプロセッサ又はエンコーダプロセッサを指すために使用されることがある。例えば、コーダプロセッサは、複合画像とシーン構造マップとに基づいて合成画像を生成し得る。シーン構造マップは、現在画像のシーン構造マップ又は前にコード化された(例えば、適用可能なとき、符号化又は復号された)画像のシーン構造マップを備え、シーン構造マップは、現在画像又は前にコード化された画像内の3次元ポイントのための座標値を含む。この場合、デコーダプロセッサとエンコーダプロセッサの両方は、実質的に同様の様式で合成画像を生成するように構成され得、従って、この例について、コーダプロセッサによって実施されるものとして説明する。
[0043]コーダプロセッサは、現在画像の残差画像に基づいて現在画像をコード化(例えば、適用可能なとき、符号化又は復号)し得る。残差画像は、現在画像と合成画像との間の差分を示す。
[0044]例えば、コーダプロセッサがデコーダプロセッサを指す場合、デコーダプロセッサは残差画像を受信したことに基づいて残差画像を決定し得、現在画像を復号するために、ビデオデコーダは、合成画像と残差画像とに基づいて現在画像を再構築し得る。コーダプロセッサがエンコーダプロセッサを指す場合、エンコーダプロセッサは、合成画像と現在画像とに基づいて残差画像を決定し、現在画像を符号化するために、(現在画像を復号するためにデコーダプロセッサによって使用される)残差画像を示す情報を出力し得る。
[0045]本開示では、前にコード化された(例えば、符号化又は復号された)画像は、前に表示された画像を指すことがあるが、本技法はそのように限定されない。例えば、前にコード化された画像は、表示順序において時間的により早いピクチャであり得る。しかしながら、幾つかの例では、前にコード化された画像は、現在画像と同時に又は時間的に極めてすぐに表示される画像であり得る(例えば、立体視ビュー)。
[0046]一例として、立体視ビューでは、2つ又はそれ以上の画像が同時に又は交互に極めてすぐに表示される。立体視ビューでは、画像のうちの1つが、立体視ビューの別の画像をコード化(例えば、符号化又は復号)するために使用され得る。そのような例では、コード化するために使用される画像は、これらの画像が、残差を決定するためにこれらのコード化画像を使用する現在画像の前に符号化又は復号されるので、前にコード化された画像の例である。
[0047]本開示では、時々、前の画像という用語が使用される。前の画像は、そこでは、前の画像が現在画像よりも早く表示される場合(これは1つの可能性であるが)に限定されないことを理解されたい。そうではなく、前の画像は、現在画像に対して前に符号化又は復号された画像を指す。前に符号化又は復号された画像は、現在画像の前に表示され得るか、(例えば、立体視又は3Dビューのために)現在画像とほぼ同時に表示され得るか、又は場合によっては現在画像の後に表示され得る。また、本開示では、「画像」及び「ピクチャ」という用語は互換的に使用され得る。
[0048]図1は、本開示で説明する1つ又は複数の例示的なビデオコード化技法を実装又はさもなければ利用するように構成され得る例示的なビデオ符号化及び復号システム10を示すブロック図である。図1の例では、発信源機器12は、ビデオ発信源18と、エンコーダプロセッサ20と、出力インターフェース22とを含む。宛先機器14は、入力インターフェース28と、デコーダプロセッサ30と、表示装置32とを含む。本開示によれば、発信源機器12のエンコーダプロセッサ20及び宛先機器14のデコーダプロセッサ30は、本開示で説明する例示的な技法を実装するように構成され得る。幾つかの例では、発信源機器及び宛先機器は他の構成要素又は構成を含み得る。例えば、発信源機器12は、外部カメラなど、外部ビデオ発信源18からビデオデータを受信し得る。同様に、宛先機器14は、内蔵表示装置を含むのではなく、外部表示装置とインターフェースし得る。
[0049]図1に示されているように、システム10は、宛先機器14によって復号されるべき符号化ビデオデータを与える発信源機器12を含む。特に、発信源機器12は、リンク16を介してビデオデータを宛先機器14に与える。発信源機器12及び宛先機器14は、デスクトップコンピュータ、ノートブック(即ち、ラップトップ)コンピュータ、タブレットコンピュータ、セットトップボックス、所謂「スマート」フォンなどの電話ハンドセット、所謂「スマート」パッド、テレビジョン、カメラ、表示装置、デジタルメディアプレーヤ、ビデオゲームコンソール、ビデオストリーミング機器などを含む、広範囲にわたる機器のいずれかを備え得る。場合によっては、発信源機器12及び宛先機器14はワイヤレス通信のために装備され得る。
[0050]宛先機器14は、リンク16を介して復号されるべき符号化ビデオデータを受信し得る。リンク16は、発信源機器12から宛先機器14に符号化ビデオデータを移動することが可能な任意のタイプの媒体又は機器を備え得る。一例では、リンク16は、発信源機器12が符号化ビデオデータをリアルタイムで宛先機器14に直接送信することを可能にするための通信媒体(ワイヤード又はワイヤレス媒体)を備え得る。符号化ビデオデータは、ワイヤレス通信プロトコルなどの通信規格に従って変調され、宛先機器14に送信され得る。通信媒体は、無線周波数(RF)スペクトル又は1つ以上の物理伝送線路など、任意のワイヤレス又はワイヤード通信媒体を備え得る。通信媒体は、ローカルエリアネットワーク、ワイドエリアネットワーク又はインターネットなどのグローバルネットワークなど、パケットベースネットワークの一部を形成し得る。通信媒体は、ルータ、スイッチ、基地局又は発信源機器12から宛先機器14への通信を可能にするために有用であり得る任意の他の機器を含み得る。
[0051]幾つかの例では、符号化データは、出力インターフェース22から、記憶装置31など、記憶装置に出力され得る。同様に、符号化データは入力インターフェース28によって記憶装置31からアクセスされ得る。記憶装置31は、ハードドライブ、Blu−ray(登録商標)ディスク、DVD、CD−ROM、フラッシュメモリ、揮発性又は不揮発性メモリ若しくは符号化ビデオデータを記憶するための任意の他の好適なデジタル記憶媒体など、様々な分散された、又はローカルにアクセスされるデータ記憶媒体のいずれかを含み得る。更なる一例では、記憶装置31は、発信源機器12によって生成された符号化ビデオを記憶し得るファイルサーバ又は別の中間記憶装置に対応し得る。宛先機器14は、ストリーミング又はダウンロードを介して記憶装置から記憶されたビデオデータにアクセスし得る。ファイルサーバは、符号化ビデオデータを記憶し、その符号化ビデオデータを宛先機器14に送信することが可能な任意のタイプのサーバであり得る。例示的なファイルサーバとしては、(例えば、ウェブサイトのための)ウェブサーバ、FTPサーバ、ネットワーク接続記憶(NAS)装置又はローカルディスクドライブがある。宛先機器14は、インターネット接続を含む、任意の標準のデータ接続を通して符号化ビデオデータにアクセスし得る。これは、ファイルサーバに記憶された符号化ビデオデータにアクセスするのに好適であるワイヤレスチャネル(例えば、Wi−Fi(登録商標)接続)、ワイヤード接続(例えば、DSL、ケーブルモデムなど)又はその両方の組合せを含み得る。記憶装置からの符号化ビデオデータの送信は、ストリーミング送信、ダウンロード送信又はそれらの組合せであり得る。
[0052]本開示の技法は、必ずしもワイヤレス適用例又は設定に限定されるとは限らない。本技法は、無線テレビジョン放送、ケーブルテレビジョン送信、衛星テレビジョン送信、動的適応ストリーミングオーバーHTTP(DASH)などのインターネットストリーミングビデオ送信、データ記憶媒体上に符号化されたデジタルビデオ、データ記憶媒体に記憶されたデジタルビデオの復号又は他の適用例など、様々なマルチメディア適用例のいずれかをサポートするビデオコード化に適用され得る。幾つかの例では、システム10は、ビデオストリーミング、ビデオ再生、ビデオブロードキャスティング及び/又はビデオテレフォニーなどの適用例をサポートするために一方向又は双方向のビデオ送信をサポートするように構成され得る。
[0053]図1の図示されたシステム10は一例にすぎず、本開示で説明する技法は、任意のデジタルビデオ符号化及び/又は復号機器によって実施され得る。概して、本開示の技法はビデオ符号化/復号機器によって実施されるが、本技法は、一般に「コーデック」と呼ばれるエンコーダプロセッサ/デコーダプロセッサによっても実施され得る。その上、本開示の技法はビデオプリプロセッサによっても実施され得る。発信源機器12及び宛先機器14は、発信源機器12が宛先機器14に送信するためのコード化ビデオデータを生成するような、コード化機器の例にすぎない。幾つかの例では、機器12、14は、機器12、14の各々がビデオ符号化構成要素とビデオ復号構成要素とを含むように、実質的に対称的に動作し得る。従って、システム10は、例えば、ビデオストリーミング、ビデオ再生、ビデオブロードキャスティング又はビデオテレフォニーのための機器12と機器14との間の一方向又は双方向のビデオ送信をサポートし得る。
[0054]発信源機器12のビデオ発信源18は、ビデオカメラなどの撮像装置、前に撮られたビデオを含んでいるビデオアーカイブ及び/又はビデオコンテンツプロバイダからビデオを受信するためのビデオフィードインターフェースを含み得る。更なる代替として、ビデオ発信源18は、発信源ビデオとしてのコンピュータグラフィックスベースのデータ又はライブビデオとアーカイブビデオとコンピュータ生成ビデオとの組合せを生成し得る。但し、上述のように、本開示で説明する技法は、概してビデオコード化に適用可能であり得、ワイヤレス及び/又はワイヤード適用例に適用され得る。各場合において、撮られたビデオ、前に撮られたビデオ又はコンピュータ生成ビデオは、エンコーダプロセッサ20によって符号化され得る。出力インターフェース22は、次いで、リンク16上に又は記憶装置31に符号化ビデオ情報を出力し得る。
[0055]宛先機器14の入力インターフェース28は、リンク16及び/又は記憶装置31から情報を受信する。受信された情報は、エンコーダプロセッサ20によって生成され、またデコーダプロセッサ30によって使用される、画像の特性及び/又は処理を記述するシンタックス要素を含む、シンタックス情報を含み得る。表示装置32は、ユーザに復号ビデオデータを表示し、陰極線管(CRT)、液晶表示器(LCD)、プラズマ表示器、有機発光ダイオード(OLED)表示器又は別のタイプの表示装置など、様々な表示装置のいずれかを備え得る。
[0056]図1には示されていないが、幾つかの態様では、エンコーダプロセッサ20及びデコーダプロセッサ30は、それぞれオーディオエンコーダ及びデコーダと統合され得、共通のデータストリーム又は別個のデータストリーム中のオーディオとビデオの両方の符号化を処理するための、適切なMUX−DEMUXユニット又は他のハードウェア及びソフトウェアを含み得る。適用可能な場合、MUX−DEMUXユニットは、ITU H.223マルチプレクサプロトコル又はユーザデータグラムプロトコル(UDP)などの他のプロトコルに準拠し得る。
[0057]エンコーダプロセッサ20及びデコーダプロセッサ30はそれぞれ、1つ又は複数のマイクロプロセッサ、デジタル信号プロセッサ(DSP)、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、ディスクリート論理回路、集積回路(IC)、ソフトウェア、ハードウェア、ファームウェアなど、様々な好適な回路のいずれか、又はそれらの任意の組合せとして実装され得る。エンコーダプロセッサ20及び/又はデコーダプロセッサ30を含む機器は、集積回路、マイクロプロセッサ及び/又はセルラー電話などのワイヤレス通信機器を備え得る。本技法が部分的にソフトウェアで実装されるとき、機器は、ソフトウェアのための命令を好適なコンピュータ可読記憶媒体に記憶し得、本開示の技法を実施するために1つ又は複数のプロセッサを使用してハードウェアでその命令を実行し得る。
[0058]本開示で説明する技法によれば、エンコーダプロセッサ20はビデオ発信源18からビデオデータを受信する。ビデオデータは、現在画像のためのビデオデータを含む、ビデオを一緒に形成する複数の画像のためのビデオデータを含む。現在画像のためのビデオデータは、現在画像の画素のための画素値(例えば、色値)と座標とを含む。現在画像を符号化するために、エンコーダプロセッサ20はシーン構造マップを利用する。幾つかの例では、エンコーダプロセッサ20は、現在画像のビデオデータに基づいてシーン構造マップを生成する。幾つかの例では、エンコーダプロセッサ20は、前に生成されたシーン構造マップ(例えば、前に符号化された画像のために生成されたシーン構造マップ)を再利用する。
[0059]シーン構造マップは、現在画像又は前の画像(例えば、前に符号化された画像)のまばらな数のポイントための3次元(3D)座標を含む。例えば、シーン構造マップ中で定義されているポイントの数は、現在画像中の画素の総数よりも少ない。本開示で説明する技法では、シーン構造マップ中のポイントの3D座標を送信するために必要とされるバイトの量は、現在画像を送信するために必要とされるバイトの量よりもかなり少ないことがある。場合によっては、現在画像と比較して、1%未満(例えば、0.26%)のバイトが、シーン構造マップを送信するために必要とされる。その上、幾つかの例では、シーン構造マップの全てのポイントが出力されるとは限らず、シーン構造マップへの更新のみが出力され、その結果、画像と比較してシーン構造マップについての情報を送信するために必要とされるバイトは更に少なくなる。
[0060]本開示で説明する技法では、現在画像は2D空間を包含することを理解されたい。しかしながら、現在画像内のオブジェクトは、前景、背景又はその中間のどこかにあるように見える。言い換えれば、現在画像中の画素は2D座標によって定義されているが、現在画像中のオブジェクトの相対深度があるように見える。エンコーダプロセッサ20は、シーン構造マップの3D座標を形成するために、現在画像中のオブジェクトのこの相対深度を利用する。例えば、エンコーダプロセッサ20は、シーン構造マップを形成するために、現在画像のまばらなポイントの3D座標を形成するために同時ローカライゼーション及びマッピング(SLAM)技法を使用し得る。幾つかの例では、エンコーダプロセッサ20は、必ずしも現在画像のためのシーン構造マップを形成する必要があるとは限らず、現在画像を符号化するために前に構築されたシーン構造マップを再利用し得る。これらの例では、エンコーダプロセッサ20は、同様の技法(例えば、SLAM技法)を使用して、前に符号化された画像からシーン構造マップを構築していることがある。
[0061]SLAM技法について以下でより詳細に説明する。しかしながら、SLAM技法について、シーン構造マップを構築するための単なる1つの方法として説明する。シーン構造マップを構築する他の方法が可能であり得、本技法は、シーン構造マップを構築するためにSLAM技法を使用することに限定されない。
[0062]シーン構造マップは、画像(例えば、現在画像又は前に符号化された画像)のプロキシジオメトリと考えられ得る。例えば、シーン構造マップによって定義されるポイントは多角形(例えば、三角形)の頂点と考えられ得る。ポイントが相互接続された場合(例えば、エンコーダプロセッサ20又はデコーダプロセッサ30がポイントを相互接続した場合)、結果は、画像の3次元構造であり、従って「シーン構造マップ」と呼ばれる。
[0063]シーン構造マップは、マルチビュービデオコード化において使用される深度マップと混同されるべきではない。マルチビュービデオコード化では、複数の画像が実質的に同様の時間に提示され、視聴者の右眼は画像のうちの1つを見、視聴者の左眼は画像のうちの別の1つを見る。各眼が異なる画像を見ることの結果は、視聴者が、3次元視聴ボリュームを包含する画像を経験することを生じる。
[0064]マルチビュービデオコード化では、現在画像の深度マップが様々なビデオコード化技法のために利用される。深度マップはそれ自体が、深度マップ中の画素の画素値テクスチャマップ中の対応する画素の相対深度示す画像(即ち、実際のコンテンツを含む画像)のように扱われる。
[0065]シーン構造マップは、本開示で説明するように、深度マップとは異なり画像ではない。シーン構造マップは、画像中のまばらな数のポイントのための座標を含む。一方、深度マップは、画像中のまばらな数のポイントよりもはるかに多くのポイントのための相対深度値を与える。場合によっては、画像中のポイントの数は、従来のビデオコード化技法を使用して圧縮される深度マップとは異なり、シーン構造マップを出力するときに圧縮が必要とされないほど小さいことがある。その上、より詳細に説明するように、エンコーダプロセッサ20は、現在画像を符号化するための予測画像として使用される合成画像を形成するためにシーン構造マップを利用する。マルチビュービデオコード化における深度マップは、そのような目的のために使用されない。言い換えれば、深度マップの形態が、深度マップを、シーン構造マップとは異なり、本開示で説明する技法のために使用不可能にし得、深度マップのデータの量は、シーン構造マップと比較して追加の帯域幅を必要とし得る。
[0066]エンコーダプロセッサ20は、合成画像を形成するためにシーン構造マップを利用する。例えば、エンコーダプロセッサ20は、1つの前の画像又は複数の前の画像(例えば、前に符号化されたピクチャ)を取り出し、複合画像を形成する(例えば、前に符号化された画像をブレンドすることによって、又は複数の画像が使用されない場合、複合画像は単一の画像であり得る)。エンコーダプロセッサ20は、次いで、メッシュを形成するためにシーン構造マップのポイントを相互接続し得、複合画像をメッシュ上にオーバーレイする。例えば、複合画像はテクスチャマップと考えられ得、エンコーダプロセッサ20は、グラフィックス処理技法を使用して、テクスチャマップをシーン構造マップのメッシュ上にオーバーレイする。結果は、シーン構造マップのメッシュ上の複合画像の3次元グラフィカル構築である画像ベースモデル(IBM)である。エンコーダプロセッサ20は、2次元画像を形成するために3次元グラフィカル構築をレンダリングする。この2次元画像が合成画像である。
[0067]エンコーダプロセッサ20は、合成画像を予測画像として利用し、残差画像と呼ばれる、現在画像と合成画像との間の差分を決定する。エンコーダプロセッサ20は、残差画像に対して追加の(随意の)符号化を実施し、残差画像を示す情報(例えば、残差画像がそれから決定され得る情報)を出力し得る。幾つかの例では、エンコーダプロセッサ20はまた、シーン構造マップを出力するか、又は前のシーン構造マップに対するシーン構造マップの増分変化を出力し得る。シーン構造マップ又は増分変化中の情報の量は比較的小さいことがあり、そのような情報を更に圧縮することは可能であるが、そのような情報の更なる圧縮は必要とされないことがある。シーン構造マップ又は増分変化を出力することは、あらゆる例のために必要であるとは限らない。例えば、エンコーダプロセッサ20は、合成画像を構築するために前のシーン構造マップを再利用し得、その場合、エンコーダプロセッサ20は、シーン構造マップ又はシーン構造マップの増分変化を出力しないことがある。
[0068]幾つかの例では、エンコーダプロセッサ20は、カメラ姿勢情報と呼ばれる、ビデオ発信源18からのカメラ位置及び/又はカメラ方向情報を受信し得る。幾つかの例では、エンコーダプロセッサ20は、カメラ位置を決定するためにSLAM技法を利用し得る。しかしながら、外部追跡システムなど、カメラ位置及び/又はカメラ姿勢を決定するための他の技法が利用され得る。エンコーダプロセッサ20は、現在画像を符号化するためにカメラ姿勢情報を利用し得る。例えば、画像についてのカメラ姿勢情報は、画像がそこから撮られた方向及び位置と考えられ得る。
[0069]エンコーダプロセッサ20は、複合画像をシーン構造マップ上にどのようにオーバーレイするかを決定するために、複合画像を構築するために使用された1つ又は複数の前に符号化された画像についてのカメラ姿勢情報を利用し得る。例えば、1つ又は複数の前に符号化された画像のカメラ姿勢情報によって示された視点に基づいて、エンコーダプロセッサ20は、画像ベースモデル(IBM)を形成するためにシーン構造マップ上で特定の画素がどこに配置されるべきかを決定し得る。例えば、カメラ姿勢情報が、1つ又は複数の前に符号化された画像についてのカメラの位置及び方向がまっすぐであることを示す場合、エンコーダプロセッサ20が画素をシーン構造マップにマッピングするであろう場所(location)は、カメラ姿勢情報が、カメラの位置及び方向がある角度にあることを示す場合とは異なるであろう。これは、その画素を含むオブジェクトが、視野角に基づいて異なる相対場所にあるように見えるであろうからである。
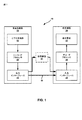
[0070]エンコーダプロセッサ20はまた、現在画像についてのカメラ姿勢情報を利用し得る。例えば、上記で説明したように、合成画像は予測画像を形成する。残差データを低減するために(即ち、合成画像と現在画像との間の差分を最小限に抑えるために)、エンコーダプロセッサ20は、合成画像のカメラ姿勢と現在画像のカメラ姿勢とが同じになるように、現在画像のカメラ姿勢情報に基づいて画像ベースモデル(IBM)をレンダリングし得る。
[0071]幾つかの例では、エンコーダプロセッサ20は、デコーダプロセッサ30が、エンコーダプロセッサ20と同様にして、但し現在画像を復号するために、カメラ姿勢情報を利用し得るように、各画像についてのカメラ姿勢情報を出力し得る。幾つかの例では、エンコーダプロセッサ20は、場合によっては、出力される必要がある情報の量を低減するために、出力するより前にカメラ姿勢情報を圧縮する。
[0072]カメラ姿勢情報は、ビデオテレフォニー又はビデオ会議においてなど、カメラが移動している(即ち、ビデオシーケンス中の1つ又は複数の画像についてのカメラ姿勢情報が異なる)例において有用であり得る。しかしながら、場合によっては、カメラ姿勢は一定であり得る。そのような例では、エンコーダプロセッサ20は、必ずしも各画像についてのカメラ姿勢情報を出力する必要があるとは限らず、カメラ姿勢情報を1回出力し得る。幾つかの例では、エンコーダプロセッサ20及びデコーダプロセッサ30は、それぞれ特定のカメラ姿勢情報を用いて事前構成され得、その場合、エンコーダプロセッサ20はカメラ姿勢情報を出力しないことがある。カメラ姿勢情報が変化しない例においても、エンコーダプロセッサ20は、依然として画像のうちの1つ又は複数についてのカメラ姿勢情報を送信し得ることを理解されたい。
[0073]残差データ、シーン構造マップ情報及び/又はカメラ姿勢情報などのビデオデータを更に圧縮するために、エンコーダプロセッサ20は、1つ又は複数の例示的な技法を利用し得る。一例として、残差データは画像と考えられ得る。エンコーダプロセッサ20は、ブロックベース符号化など、ビデオ圧縮技法を使用して残差データを圧縮し得る。別の例として、エンコーダプロセッサ20は、ブロックベース符号化の一部として、シーン構造マップ情報及び/又はカメラ姿勢情報のために、コンテキスト適応型可変長コード化(CAVLC:context-adaptive variable length coding)、コンテキスト適応型バイナリ算術コード化(CABAC:context-adaptive binary arithmetic coding)、シンタックスベースコンテキスト適応型バイナリ算術コード化(SBAC:syntax-based context-adaptive binary arithmetic coding)、確率間隔区分エントロピー(PIPE:Probability Interval Partitioning Entropy)コード化又は別のエントロピー符号化方法などのエントロピー符号化技法を利用し得る。エントロピー符号化技法は一例として記載されているにすぎない。他の符号化技法が可能である。
[0074]幾つかの例では、エンコーダプロセッサ20は現在画像のビデオデータをセグメント化し得る。例えば、エンコーダプロセッサ20は、現在画像のどの部分が前の画像(例えば、前に符号化された画像)に対して静的であるかを決定し得、現在画像のどの部分が変化しているか(例えば、非静的であるか)を決定し得る。エンコーダプロセッサ20は、静的部分から現在画像の非静的部分を分離し得る(例えば、非静的部分は、静的部分を含むレイヤとは異なるレイヤである)。エンコーダプロセッサ20は、非静的部分に対して従来のビデオコード化技法を適用しながら、静的部分に対して本開示で説明する技法を利用し得る。しかしながら、エンコーダプロセッサ20は、静的部分と非静的部分の両方に対して本開示で説明する技法を使用することが可能であり得る。
[0075]現在画像のどの部分が静的であり、どの部分が非静的であるかを決定するための様々な方法があり得る。一例として、ビデオ発信源18が最初にシーンを撮り得て、エンコーダプロセッサ20が背景の画像ベースモデル(IBM)を作成し得る。ビデオ発信源18は、次いで、前に記録された空間を通って移動している人など、実際のシーンを撮り得る。エンコーダプロセッサ20は、2つのビデオシーケンス間(例えば、背景ビデオシーケンスと、移動しているオブジェクト(この例では人)をもつシーケンスとの間)の差分を決定し得る。エンコーダプロセッサ20は、次いで、非静的部分と静的部分とを決定し得る。この例では、上記と同様に、エンコーダプロセッサ20は、それぞれのIBMから合成画像をレンダリングするために、非静的画像と静止画像との記録プロセス(ビデオキャプチャプロセス)においてビデオ発信源18からカメラ姿勢情報を受信し得る。
[0076]デコーダプロセッサ30は、エンコーダプロセッサ20の逆プロセスを実施する。しかしながら、デコーダプロセッサ30はシーン構造マップを構築する必要がない。そうではなく、デコーダプロセッサ30は、現在画像のためのシーン構造マップを受信するか、又は前のシーン構造マップに対する現在画像のためのシーン構造マップについての増分変化を受信する。幾つかの例では、デコーダプロセッサ30は、シーン構造マップの情報を受信せず、前のシーン構造マップ(例えば、前に復号された画像のために生成されたシーン構造マップ)を再利用する。
[0077]一例として、デコーダプロセッサ30は残差データを復号し得る。例えば、残差データがブロックベース符号化される場合、デコーダプロセッサ30は残差データをブロックベース復号し得る。残差データは他の方法でも符号化され得る。幾つかの例では、残差データは符号化されないことがあり、その場合、デコーダプロセッサ30は残差データを復号しない。いずれの場合も、デコーダプロセッサ30は残差データ(例えば、符号化された残差データ又は符号化されていない残差データのいずれか)を受信する。
[0078]更に、デコーダプロセッサ30は、現在画像についてのカメラ姿勢情報を受信し、カメラ姿勢情報が符号化される場合、そのような情報を復号し得る。上記で説明したように、デコーダプロセッサ30はまた、シーン構造マップ又は前のシーン構造マップに対する現在画像のためのシーン構造マップについての増分変化を受信し得る。幾つかの例では、シーン構造マップ又は増分変化の情報は、符号化又はさもなければ圧縮されないことがあり、デコーダプロセッサ30は、シーン構造マップ又は増分変化についての情報を復号する必要がないことがある。
[0079]エンコーダプロセッサ20と同様に、デコーダプロセッサ30は、シーン構造マップと複合画像とを利用して合成画像を生成し、ここで、合成画像は予測画像である。デコーダプロセッサ30がカメラ姿勢情報を受信する例では、デコーダプロセッサ30は、合成画像を生成するためにカメラ姿勢情報を使用し得る。例えば、エンコーダプロセッサ20のように、デコーダプロセッサ30は、複合画像を形成するために1つ又は複数の前の画像(例えば、前に復号された画像)をブレンドし得るか、又は単一の前に復号された画像が複合画像であり得る。デコーダプロセッサ30は、IBMを形成するために、複合画像をシーン構造マップにマッピングし得(及び場合によってはカメラ姿勢情報を使用し)、合成画像を生成するためにIBMをレンダリングし得る。デコーダプロセッサ30は、現在画像を再構築するために合成画像に残差データを加算し得る。
[0080]エンコーダプロセッサ20及びデコーダプロセッサ30は一般的にコーダプロセッサと呼ばれることがある。例えば、エンコーダプロセッサ20とデコーダプロセッサ30の両方は、現在画像のための予測画像を形成する合成画像を生成するように構成され得る。合成画像を生成するために、エンコーダプロセッサ20及びデコーダプロセッサ30は、同様の機能を実施するように構成され得、簡単のために、これらの機能について、(その例がエンコーダプロセッサ20とデコーダプロセッサ30とを含む)コーダプロセッサによって実施されるものとして説明する。
[0081]例えば、コーダプロセッサは、ビデオメモリに記憶された通す複合画像と、シーン構造マップとに基づいて、合成画像を生成するように構成され得る。シーン構造マップは、現在画像のシーン構造マップ又は前にコード化された画像のシーン構造マップを含み、シーン構造マップは、現在画像又は前にコード化された画像内の3次元ポイントのための座標値を含む。
[0082]コーダプロセッサは、現在画像の残差画像に基づいて現在画像をコード化するように構成され得、ここで、残差画像は、現在画像と合成画像との間の差分を示す。例えば、コーダプロセッサがデコーダプロセッサ30である場合、デコーダプロセッサ30は、受信された残差画像と合成画像とに基づいて現在画像を再構築することによって現在画像を復号し得る。コーダプロセッサがエンコーダプロセッサ20である場合、エンコーダプロセッサ20は、残差画像を決定し、残差画像の情報を出力することによって、現在画像を符号化し得る。
[0083]幾つかの他の技法は、ビデオコード化目的のためにSLAM技法を使用することを提案している。例えば、これらの他の技法では、(エンコーダプロセッサ20及びデコーダプロセッサ30とは異なり)コーダプロセッサは、まばらに分布されたポイントに基づくのではなく、極めて詳細なシーン構造マップを決定する。これらの他の技法の詳細なシーン構造マップは、前の画像を詳細な構造マップ上にオーバーレイすることが現在画像と同じ画像を生じるほど詳細であり得る。
[0084]これらの他の技法では、詳細なシーン構造マップのためのポイント座標は出力及び受信されるが、残差データは送られないか、又は受信されない。これは、前の画像を詳細なシーン構造マップ上にオーバーレイすることが、現在画像と基本的に同じである画像を生じるからである。従って、これらの他の技法は残差データに依拠しない。これらの他の技法では、合成画像は予測画像でないが、代わりに、現在画像のコピーと考えられる。
[0085]これらの他の技法には幾つかの欠点があり得る。例えば、詳細なシーン構造マップのための座標を出力及び受信することは、帯域幅が広大となり得る。また、(例えば、前の画像が詳細なシーン構造マップ上にオーバーレイされた)得られた画像は、現在画像にあまりよく一致しないことがある。従って、画像品質は他のビデオコード化技法よりも悪いことがある。
[0086]本開示で説明する技法では、コーダプロセッサは、現在画像又は前にコード化された画像中のより少数のポイントに基づいて合成画像を生成し、この合成画像は予測画像として形成する。従って、より少数のポイントが出力及び受信される必要があり得、合成画像と現在画像との間の差分は、限られたデータが出力及び受信される必要があるほど十分小さいことがある(例えば、残差画像は比較的小量のデータを有する)。このようにして、送信及び受信される必要があるデータの量の低減があり得、帯域幅効率を促進する。また、合成画像が予測画像であり、残差画像が送信及び受信されるので、再構築された現在画像は、残差画像が送られない例よりも品質が良好であり得る。
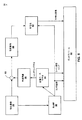
[0087]図2は、本開示で説明する1つ又は複数の例示的なビデオ符号化技法を実装又はさもなければ利用するように構成されたエンコーダプロセッサ20の一例を示すブロック図である。図示のように、エンコーダプロセッサ20は、同時ローカライゼーション及びマッピング(SLAM)プロセッサ34と、グラフィックス処理ユニット(GPU)36と、ビデオメモリ38と、エンコーダ48とを含む。幾つかの例では、SLAMプロセッサ34、GPU36及びエンコーダ48は、システムオンチップ(SoC)を形成するために単一のチップ上に一緒に形成され得る。幾つかの例では、SLAMプロセッサ34、GPU36及びエンコーダ48は個別のチップ上に形成され得る。
[0088]エンコーダプロセッサ20は、1つ又は複数のマイクロプロセッサ、デジタル信号プロセッサ(DSP)、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、ディスクリート論理、ソフトウェア、ハードウェア、ファームウェアなど、様々な好適なエンコーダ回路のいずれか、又はそれらの任意の組合せとして実装され得る。例えば、本開示で説明する技法について、装置又は機器の観点から説明することがある。一例として、装置又は機器は、エンコーダプロセッサ20(例えば、ワイヤレス通信機器の一部としての発信源機器12)を含み得、エンコーダプロセッサ20は、本開示で説明する技法を実装するように構成された1つ又は複数のプロセッサを含み得る。別の例として、装置又は機器は、エンコーダプロセッサ20を含むマイクロプロセッサ又は集積回路(IC)を含み得、マイクロプロセッサ又はICは、発信源機器12又は別のタイプの機器の一部であり得る。
[0089]エンコーダプロセッサ20の構成要素は発信源機器12の既存の例の一部であり得る。例えば、標準ハードウェアの一部として、発信源機器(例えば、発信源機器12)のほとんどの例は、GPU36などのGPUと、エンコーダ48などのエンコーダと、ビデオメモリ38などのビデオメモリとを含む。機器がSLAMプロセッサ34を含まない場合でも、機器の中央処理ユニット(CPU)がSLAMプロセッサ34として機能するように構成され得る。例えば、機器のCPU又はホストプロセッサ上でソフトウェア又はファームウェアを実行することによって、CPU又はホストプロセッサは、SLAMプロセッサ34の機能を満たすように構成され得る。
[0090]更に、GPU36は、本開示で説明する例示的な技法を実装するように構成された1つの例示的な構成要素として示されている。GPU36の高速並列処理能力は、GPU36を、本開示で説明する技法を実装するための好適なオプションにする。しかしながら、本技法はそのように限定されない。例示的な技法を実装するために、CPUを含む、GPU36以外の構成要素を利用することが可能であり得る。更に、幾つかのGPUは、汎用GPU(GPGPU)として機能するための処理能力を含む。幾つかの例では、GPU36は、GPGPUであり得、SLAMプロセッサ34の機能を実施するように構成され得る(即ち、SLAMプロセッサ34及びGPU36は同じGPGPUの一部であり得る)。
[0091]ビデオメモリ38は、エンコーダプロセッサ20を形成するチップの一部であり得る。幾つかの例では、ビデオメモリ38は、エンコーダプロセッサ20の外部にあり得、発信源機器12のシステムメモリの一部であり得る。幾つかの例では、ビデオメモリ38は、エンコーダプロセッサ20の内部のメモリとシステムメモリとの組合せであり得る。
[0092]ビデオメモリ38は、現在画像を符号化するために使用されるデータを記憶し得る。例えば、図示のように、ビデオメモリは、現在画像のためにSLAMプロセッサ34によって生成された場合にシーン構造マップ40を記憶し、前のシーン構造マップ42(例えば、SLAMプロセッサ34が前に符号化された画像のために生成したシーン構造マップ)と、1つ又は複数の画像44(例えば、前に符号化された画像)と、GPU36が生成する合成画像46とを記憶する。ビデオメモリ38は、シンクロナスDRAM(SDRAM)を含むダイナミックランダムアクセスメモリ(DRAM)、磁気抵抗RAM(MRAM)、抵抗性RAM(RRAM(登録商標))又は他のタイプのメモリ機器など、様々なメモリ機器のいずれかによって形成され得る。
[0093]図2に示されているように、SLAMプロセッサ34は、現在画像を受信し、シーン構造マップ40を生成する。SLAMプロセッサ34は、現在画像からまばらな3Dポイントクラウド再構築を抽出するように構成され、場合によっては、スクリーン空間における再構築されたポイントの平衡分散を保証し得る。
[0094]幾何学的周辺マップを作成するためのSLAM技法は、旧来、幾何学的周辺マップを作成するためにセンサーのフィードバックに依拠するロボット及び自律走行車両において利用されている。SLAMプロセッサ34は、幾何学的周辺マップを生成するために視覚的SLAM(VSLAM)検知技法を利用するように構成され得る。例えば、SLAMプロセッサ34は、ビデオ発信源18から撮られた画像を受信し、幾何学的周辺マップを生成するためにSLAM技法を実施し得る。
[0095]幾何学的マップを生成する際に、SLAMプロセッサ34は、ビデオ発信源18の3Dカメラ姿勢を追跡し得る。例えば、ユーザがモバイル機器をもって歩いているビデオテレフォニー又はカメラ位置及び方向が制御されているビデオ会議などの例では、カメラは移動する傾向があるが、シーンは大部分が静的である。カメラの場所が変化するので、画像がそこから撮られる視点も変化する。カメラの3D位置及び方向(姿勢)を追跡することによって、SLAMプロセッサ34は幾何学的周辺マップをより良く構築することが可能であり得る。幾つかの例では、SLAMプロセッサ34は、カメラ位置を決定するためにSLAM技法を利用し得る。
[0096]場合によっては、SLAM技法は拡張現実(AR)のために使用される。例えば、グラフィカルビデオ又は画像が背景エリア上にオーバーレイされる。SLAMプロセッサ34は、SLAM技法を使用してシーン構造をマッピングし、ARビデオは、(例えば、オーバーレイされたARビデオをもつ)変更ビデオストリームを見せる。SLAMがARのために使用された古典的な例は、ロボットR2D2がレイア姫の動画記録を投影する、映画「スターウォーズ:エピソードIV−新たなる希望」からのシーンである。
[0097]幾何学的周辺マップを生成するために、SLAMプロセッサ34はシーン構造マップを構築する。上記で説明したように、シーン構造マップは、現在画像中のまばらな数のポイントための(x,y,z)座標を含む。現在画像中のポイントのためのx,y,z座標は、カメラ姿勢に基づき、所与のカメラ姿勢のためのポイントの各々の相対場所を示し得る。例えば、z座標の値は、視聴者がそのポイントをどのくらい遠くに知覚するであろうかを示す、特定のポイントの相対深度を示し得る。この場合も、現在画像は2Dエリアを包含するが、画像のコンテンツは、z座標によって示されるポイントの相対深度を含む。
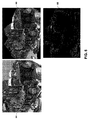
[0098]図3A及び図3Bは、シーン構造マップの例を示すグラフ図である。例えば、図3A及び図3Bは異なる画像を示す。図3A及び図3Bに示されたポイントは、これらの画像のシーン構造マップを形成する。例えば、図3A及び図3Bは、y座標の特定の値についてのx方向とz方向とに延びるグリッドを示す。このグリッド上に存在するポイントは、それらのx、y及びz座標によって定義される。
[0099]SLAMプロセッサ34は、生成されたシーン構造マップをビデオメモリ38に記憶する(例えば、シーン構造マップ40をビデオメモリ38に記憶する)。しかしながら、SLAMプロセッサ34は、必ずしも各画像のためのシーン構造マップを生成する必要があるとは限らない。図示のように、ビデオメモリ38は前のシーン構造マップ42をも記憶し得る。SLAMプロセッサ34は、前の画像(例えば、現在画像の前に符号化された画像)のためのシーン構造マップを生成していることがある。前の画像が生成されたときに、SLAMプロセッサ34は、得られたシーン構造マップをビデオメモリ38に記憶していることがある。その場合、現在画像にとって、前に生成されたシーン構造マップは前のシーン構造マップ42になる。
[0100]本開示で説明する技法によれば、GPU36は、(利用可能な場合)シーン構造マップ40又は(シーン構造マップ40が利用可能でない場合)前のシーン構造マップ42のうちの1つを取り出し得る。GPU36は、プロキシジオメトリを形成するためにシーン構造マップのポイントを相互接続し得る。例えば、シーン構造マップのポイントは多角形(例えば、三角形)の頂点と考えられ得る。GPU36は、シーン構造マップのポイントを相互接続するために、頂点シェーダを実行し得るか、又はハードワイヤード入力アセンブラを利用し得る。一例として、GPU36は、ポイントを相互接続するために増分ドロネー三角形分割技法を利用し得る。
[0101]ポイントの相互接続の結果は、シーン構造マップを生成するために使用される画像の構造を表すプロキシジオメトリである。概念的に、プロキシジオメトリ中のポイントの相互接続は、シーン構造マップを生成するために使用される画像の相対3次元構造の概算推定を形成する三角メッシュを形成する。例えば、ポイントの相互接続は、深度の近似を与え、実際の深度マップよりもはるかにまばらである。しかしながら、三角メッシュを形成するためのポイントの相互接続は、以下でより詳細に説明するように、予測画像を生成するために複合画像をオーバーレイするのに十分な詳細を与え得る。
[0102]図4は、シーン構造マップのポイントの相互接続の一例を示す概念図である。例えば、図示のように、図4は、プロキシジオメトリを形成する複数の三角形を含み、三角形の頂点はシーン構造マップによって定義される。頂点の各々は、x、y及びz座標によって定義され得る。例えば、図示されたプロキシジオメトリは数個の3Dポイントと3D三角形とを含む。幾つかの例では、GPU36は、(例えば、イン入力アセンブラ又は頂点シェーダを介して)プロキシジオメトリを生成するように構成され得る。GPU36は、プロキシジオメトリを増分的に構築し得、プロキシジオメトリを一時的に(例えば、以下で説明するように、合成画像を生成するためにのみ)記憶し得る。
[0103]前のシーン構造マップ42及び/又はシーン構造マップ40を記憶することに加えて、ビデオメモリ38はまた、カメラが移動している例においてなど、1つ又は複数の画像44(例えば、前に符号化された画像)とそれらの対応するカメラ姿勢情報とを記憶し得る。1つ又は複数の画像44は、エンコーダプロセッサ20が前に符号化した画像である。ビデオメモリ38は、エンコーダプロセッサ20が前に符号化した元の画像を記憶するか、又は、エンコーダ48が、符号化画像を再構築するためのフィードバック経路を含み、ビデオメモリ38は、これらの再構築画像を1つ又は複数の画像44として記憶する。幾つかの例では、1つ又は複数の画像44は現在画像よりも早く表示され得るが、1つ又は複数の画像44が現在画像よりも早く表示されることは要件ではなく、1つ又は複数の画像44は、幾つかの例では(例えば、立体視ビューのために)現在画像とほぼ同時に、又は現在画像の後に表示され得る。
[0104]幾つかの例では、1つ又は複数の画像44(例えば、前に符号化された画像)は、Iフレームとも呼ばれるキーフレームであり得る。例えば、幾つかの例では、符号化エラーを伝搬することを回避するために、エンコーダプロセッサ20は、時々、別の予測画像の参照なしに画像を符号化し得る。例えば、エンコーダ48は、他の画像からの値からではなく、画像内の画素のサンプル値を使用して画像を符号化し得る。画像内のサンプルのみを参照して符号化された画像はIフレーム又はキーフレームと呼ばれる。他の画像から予測された画像はPフレームと呼ばれる。
[0105]1つ又は複数の画像44は、必ずしもあらゆる例においてキーフレームである必要があるとは限らない。しかしながら、例及び例示のために、本技法は、キーフレームである1つ又は複数の画像44に関して説明した。
[0106]更に、本開示で説明する技法は、複数のキーフレーム(例えば、複数の画像44)を利用する必要がなく、単一のキーフレーム(例えば、単一の画像44)を利用し得る。複数の画像44が利用される例では、GPU36は、複合画像を形成するために、2つ又はそれ以上の画像44に対してブレンディング演算を実施し得る。例えば、GPU36は、それのグラフィックスパイプライン中に、画素値をブレンドするように特に構成されたブレンディングユニットを含む。複数の画像44はブレンディングユニットへの入力であり得、ブレンディングユニットの出力はブレンドされた画像であり得る。必要な場合、追加のグラフィックス処理の後に、GPU36の出力は複合画像である。図示されていないが、GPU36は複合画像をビデオメモリ38に記憶する。1つの画像44のみが利用される例では、GPU36はブレンドしないことがあり、単一の画像44が複合画像である。
[0107]本開示で説明する技法によれば、複合画像はテクスチャマップであり、プロキシジオメトリ(例えば、シーン構造マップのポイントを相互接続することによって形成されるメッシュ)は、テクスチャマップがそれにマッピングされるオブジェクトである。例えば、テクスチャマッピングでは、テクスチャマップは2次元座標(u,v)で定義され、テクスチャマップがそれにマッピングされるオブジェクトは3次元で定義される。GPU36の機能のうちの1つは、グラフィカルレンダリングのためにテクスチャマッピングを実施することであり得、本技法は、ビデオ符号化及び復号のための予測画像として使用される合成画像を生成するために、高速で効率的な方法でテクスチャマッピングを実施するGPU36の能力を活用する。
[0108]例えば、GPU36は、テクスチャエンジンを実行し得るか、又はテクスチャ関数を実施するようにハードウェアで事前構成され得る。いずれの例でも、GPU36は、テクスチャマップからの2次元ポイントをグラフィカルオブジェクト上にマッピングし、本質的には、テクスチャマップをオブジェクト上にオーバーレイする。テクスチャリングの結果は、純粋なグラフィカル構築よりも現実のように見える高度に詳細なグラフィカルオブジェクトである。一例として、オブジェクトは球体であり、テクスチャマップは世界の2D画像である。テクスチャマッピングの一部として世界の2D画像を3次元球体上にラッピングすることによって、GPU36は、地球をグラフィカルに構築することと比較して、はるかに詳細で視覚的に喜びを与える地球をレンダリングし得る。
[0109]図2に示された例では、GPU36は、複合画像からの画素をプロキシジオメトリ上の3次元場所にマッピングする。上記で説明したように、幾つかの例では、GPU36は、複合画像からの画素をプロキシジオメトリ上の3次元場所にマッピングするために、複合画像を構築するために使用された1つ又は複数の画像44のカメラ姿勢情報を利用し得る(例えば、カメラ姿勢情報は、画素がそれにマッピングすることになる3次元場所に影響を及ぼす)。複合画像のコンテンツは相対深度を示すが、複合画像の画素の全ては2次元(u,v)座標によって定義される。プロキシジオメトリは3次元であるので、テクスチャマッピングの結果は、画像ベースモデル(IBM)と呼ばれる3次元オブジェクトである。
[0110]GPU36は、IBMに対して更なるグラフィックス行列を実施する。例えば、GPU36はIBMをレンダリングし得る。レンダリングプロセスの一部として、GPU36は、IBMの3次元座標を、合成画像46を形成する2次元スクリーン座標に変換する。幾つかの例では、GPU36は、現在のカメラ位置に基づいてIBMをレンダリングし得る。例えば、合成画像46が予測画像を形成するので、GPU36は、合成画像46と現在画像との間の比較が有効であり、残差データが最小限に抑えられるように、現在のカメラ姿勢情報に基づいてIBMをレンダリングし得る。
[0111]GPU36は、レンダリングの結果を合成画像46としてビデオメモリ38に記憶する。合成画像46は、各座標のための画素値をもつ2次元画像であり得る。本開示で説明する技法では、合成画像46は予測画像を形成する。
[0112]例えば、エンコーダ48は、合成画像46と現在画像とを受信し、現在画像と合成画像との間の残差画像(例えば、残差データ)を決定する。エンコーダ48は、得られた残差画像を符号化ビデオデータとしてビットストリーム中に出力し得る。幾つかの例では、残差画像を出力するより前に、エンコーダ48は、残差画像のエントロピー符号化又はブロックベース符号化などの幾つかの追加の符号化を実施し得る。このようにして、エンコーダ48が残差画像の追加の符号化を実施するか否かにかかわらず、エンコーダ48は、残差画像を示す情報(例えば、残差画像がそれから決定され得る情報)を出力し得る。
[0113]幾つかの例では、エンコーダ48は、本開示で説明する技法を実装するように構成され得、従来のビデオ符号化プロセスをも実装するように構成され得る。例えば、エンコーダ48は、画像内のサンプルのみに基づいて画像を符号化する(例えば、Iフレームであるように画像を符号化する)ように構成され得る。エンコーダ48は、従来のビデオ符号化を利用してそのようなビデオ符号化技法を実施し得る。
[0114]別の例として、幾つかの例では、現在画像中の非静的前景オブジェクトが他のビデオ符号化技法を使用して符号化され、静的背景オブジェクトが本開示で説明する技法を使用して符号化される場合、符号化利得が実現され得る。例えば、エンコーダ48は、本開示で説明する技法を使用して画像の部分を符号化することと、他の技法を使用して画像の他の部分を符号化することとの間で選択するモード選択ユニットを含み得る。本開示で説明する技法を使用して符号化される部分が1つのレイヤを形成し得、他の技法を使用して符号化される部分が別のレイヤを形成し得る。本開示で説明する技法を使用して現在画像全体を符号化することが可能であることを理解されたい。
[0115]前景非静的部分が1つのレイヤを形成し、背景静的部分が別のレイヤを形成する例では、SLAMプロセッサ34が前景に対してSLAM技法を実施する。そのような例では、エンコーダ48は、前景レイヤと背景レイヤとを別々に符号化し得る。
[0116](図2に破線で示された)幾つかの例では、SLAMプロセッサ34はエンコーダ48にカメラ姿勢情報を出力する。エンコーダ48は、(例えば、符号化ビデオデータの一部として)ビットストリーム中に出力するためにカメラ姿勢情報を符号化する。更に、幾つかの例では、SLAMプロセッサ34はエンコーダ48にシーン構造マップ40の情報を出力し得、エンコーダ48はシーン構造マップ40の情報を符号化する。幾つかの例では、エンコーダプロセッサ20がシーン構造マップ40を利用するとき、エンコーダ48は、シーン構造マップ40と前のシーン構造マップ42との間の差分を決定し得、シーン構造マップ40の実効値ではなく、(例えば、シーン構造マップ中の増分変化を表す)差分を出力し得る。上記で説明したように、エンコーダプロセッサ20は、あらゆる例においてシーン構造マップ40を利用するとは限らない。これらの例では、エンコーダ48は、シーン構造マップ40の情報又はシーン構造マップ40と前のシーン構造マップ42との間の差分を出力しないことがある。これらの例の幾つかでは、エンコーダ48は、デコーダプロセッサ30がローカルに記憶された前のシーン構造マップを利用すべきであることを示すシンタックス要素を出力し得る。
[0117]図5は、本開示による1つ又は複数の例示的なビデオ符号化技法を示すデータフロー図である。図5の例に示されているように、エンコーダプロセッサ20は現在画像50を受信する。SLAMプロセッサ34は、SLAM52と呼ばれる、シーン構造マップを生成するためのSLAM技法を実装する。GPU36は、画像ベースモデル54を形成するために複合画像とシーン構造マップとを利用する。GPU36は、予測画像56である合成画像46を生成するために画像ベースモデル54をレンダリングする。
[0118]減算ユニット53は現在画像50から予測画像56を減算する。減算の結果は残差画像58である。上記で説明したように、エンコーダ48は、図5では符号化60として示されている追加の符号化を実施し得る。幾つかの例では、現在画像50から予測画像56を減算するために、減算ユニット53は、予測画像56の値に−1を乗算し、結果に現在画像50を加算する。簡単のために、本開示は、現在画像50から予測画像56を減算するものとして減算ユニット53を説明し、直線的減算によって、一方の画像の負数を決定し(例えば、値に−1を乗算し)、それを他方の画像に加算することによって、又は何らかの他の技法によってそのような演算を実施し得る。
[0119]エンコーダ48は、得られた符号化画像を符号化ビデオデータビットストリーム62の一部として出力する。更に、ビットストリーム62は、現在画像50についてのカメラ姿勢情報を含み得る。ビットストリーム62はまた、シーン構造マップの情報又はシーン構造マップと前のシーン構造マップとの間の相違を示す(例えば、前のシーン構造マップに対するシーン構造マップの増分変化を示す)情報を含み得る。しかしながら、ビットストリーム62は、必ずしも、あらゆる例において、シーン構造マップ又はシーン構造マップと前のシーン構造マップとの間の差分を含む必要があるとは限らない。
[0120]図6は、本開示で説明する技法によるビデオ符号化の一例を示す概念図である。図6において、画像64は現在画像であり、画像66は合成画像である。画像68は残差画像(例えば、画像64−画像66)を示す。
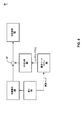
[0121]図7は、本開示で説明する1つ又は複数の例示的なビデオ復号技法を実装又はさもなければ利用するように構成されたデコーダプロセッサ30の一例を示すブロック図である。図示のように、デコーダプロセッサ30は、GPU70と、デコーダ80と、ビデオメモリ82とを含む。幾つかの例では、GPU70及びデコーダ80は、システムオンチップ(SoC)を形成するために単一のチップ上に一緒に形成され得る。幾つかの例では、GPU70及びデコーダ80は個別のチップ上に形成され得る。
[0122]デコーダプロセッサ30は、1つ又は複数のマイクロプロセッサ、デジタル信号プロセッサ(DSP)、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、ディスクリート論理、ソフトウェア、ハードウェア、ファームウェアなど、様々な好適なエンコーダ回路のいずれか、又はそれらの任意の組合せとして実装され得る。例えば、本開示で説明する技法について、装置又は機器の観点から説明することがある。一例として、装置又は機器は、デコーダプロセッサ30(例えば、ワイヤレス通信機器の一部としての宛先機器14)を含み得、デコーダプロセッサ30は、本開示で説明する技法を実装するように構成された1つ又は複数のプロセッサを含み得る。別の例として、装置又は機器は、デコーダプロセッサ30を含むマイクロプロセッサ又は集積回路(IC)を含み得、マイクロプロセッサ又はICは、宛先機器14又は別のタイプの機器の一部であり得る。
[0123]デコーダプロセッサ30の構成要素は宛先機器14の既存の例の一部であり得る。例えば、標準ハードウェアの一部として、宛先機器14のほとんどの例は、GPU70などのGPUと、デコーダ80などのデコーダと、ビデオメモリ82などのビデオメモリとを含む。GPU70は、本開示で説明する例示的な技法を実装するように構成された1つの例示的な構成要素として示されている。GPU70の高速並列処理能力は、GPU70を、本開示で説明する技法を実装するための好適なオプションにし得る。しかしながら、本技法はそのように限定されない。例示的な技法を実装するために、宛先機器14のCPUを含む、GPU70以外の構成要素を利用することが可能であり得る。更に、幾つかのGPUは、汎用GPU(GPGPU)として機能するための処理能力を含む。幾つかの例では、GPU70は、GPGPUであり得、デコーダ80の機能を実施するように構成され得る(即ち、デコーダ80及びGPU70は同じGPGPUの一部であり得る)。
[0124]ビデオメモリ82は、デコーダプロセッサ30を形成するチップの一部であり得る。幾つかの例では、ビデオメモリ82は、デコーダプロセッサ30の外部にあり得、宛先機器14のシステムメモリの一部であり得る。幾つかの例では、ビデオメモリ82は、デコーダプロセッサ30の内部のメモリとシステムメモリとの組合せであり得る。
[0125]ビデオメモリ82は、現在画像を復号するために使用されるデータを記憶し得る。例えば、図示のように、ビデオメモリ82は、符号化ビデオデータビットストリームの一部として受信された場合にシーン構造マップ72を記憶し、前のシーン構造マップ74と、1つ又は複数の画像76と、GPU70が生成する合成画像78とを記憶する。ビデオメモリ82は、シンクロナスDRAM(SDRAM)を含むダイナミックランダムアクセスメモリ(DRAM)、磁気抵抗RAM(MRAM)、抵抗性RAM(RRAM)又は他のタイプのメモリ装置など、様々なメモリ機器のいずれかによって形成され得る。
[0126]デコーダ80は、現在画像のための残差画像の情報を含むビデオデータのビットストリームを受信する(例えば、残差画像は、現在画像からの合成画像の減算から生成される)。デコーダ80はカメラ姿勢情報をも受信する。幾つかの例では、デコーダ80は、現在画像のシーン構造マップの情報を受信し、デコーダ80は、その情報をシーン構造マップ72としてビデオメモリ82に記憶する。幾つかの例では、デコーダ80は、現在画像のためのシーン構造マップと前のシーン構造マップ(例えば、前のシーン構造マップ74)との間の差分を示す情報を受信する。デコーダ80は、差分値を前のシーン構造マップ74の値と加算し、得られた値をシーン構造マップ72として記憶する。
[0127]GPU70は、シーン構造マップ72又は前のシーン構造マップ74のうちの1つを受信し、例えば、頂点シェーダ又は入力アセンブラを使用して、プロキシジオメトリの形成するためにポイントを相互接続する。更に、GPU70は、複合画像を形成するために画像76のうちの2つ又はそれ以上をブレンドするか、又は画像76のうちの単一の画像を複合画像として使用する。
[0128]デコーダプロセッサ30のGPU70及びエンコーダプロセッサ20のGPU36は、画像(例えば、前に復号されたピクチャ)のまったく同じセットを利用するように構成され得る。例えば、GPU36のように、GPU70は1つ又は複数のキーフレーム(例えば、Iフレーム)を利用し得、1つ又は複数の画像76は全てキーフレームであり得る。このようにして、GPU70が形成する複合画像は、GPU36が形成する複合画像と実質的に同じである。
[0129]GPU70は、複合画像をテクスチャマップとして使用し、プロキシジオメトリを、テクスチャマップがそれにマッピングされるオブジェクトとして使用して、テクスチャマッピングを実施し得る。GPU70は、次いで、合成画像78を作成するために結果をレンダリングし得る。GPU70は、合成画像78を生成するために、GPU36が合成画像46を生成するために実装した実質的に同じプロセスを実装し得る。例えば、GPU70は、プロキシジオメトリを形成するためにGPU36と同じシーン構造マップを利用し、複合画像を形成するためにGPU36と同じ画像を利用するので、合成画像78と合成画像46とは実質的に同様であり得る。更に、GPU70は、同様に、IBMを生成するためのテクスチャマッピングのために、複合画像を構築するために使用された1つ又は複数の画像76のカメラ姿勢情報を利用し、合成画像をレンダリングするために現在画像のカメラ姿勢情報を利用し得る。
[0130]デコーダ80は合成画像78に残差画像を加算し得る。加算の結果は再構築された現在画像である。
[0131]更に、エンコーダ48と同様に、デコーダ80は、本開示で説明する技法を実装するように構成され得、従来のビデオ復号プロセスをも実装するように構成され得る。例えば、デコーダ80は、画像内のサンプルのみに基づいて画像を復号する(例えば、Iフレームであるように画像を復号する)ように構成され得る。デコーダ80は、従来のビデオ復号を利用してそのようなビデオ復号技法を実施し得る。
[0132]別の例として、幾つかの例では、現在画像中の非静的前景オブジェクトが他のビデオ復号技法を使用して復号され、静的背景オブジェクトが本開示で説明する技法を使用して復号される場合、復号利得が実現され得る。例えば、デコーダ80は、本開示で説明する技法を使用して画像の部分を復号することと、従来の技法を使用して画像の他の部分を復号することとの間で選択するモード選択ユニットを含み得る。例えば、デコーダ80は、本開示で説明する技法を使用して符号化された現在画像の部分をもつ1つのレイヤと、他の技法を使用して符号化された現在画像の部分をもつ別のレイヤとを受信し得る。
[0133]前景非静的部分が1つのレイヤを形成し、背景静的部分が別のレイヤを形成する例では、デコーダ80は、前景レイヤと背景レイヤとを別々に復号し得る。デコーダプロセッサ30は、前景非静的レイヤと背景静的レイヤとを別々に再生し得る。
[0134]デコーダ80はまた、復号情報を与えるシンタックス要素を復号するように構成され得る。例えば、GPU70が、プロキシジオメトリを生成するために前のシーン構造マップ74を使用すべきである例では、デコーダ80は、GPU70が前のシーン構造マップ74を使用すべきであることを示すシンタックス要素を復号し得る。
[0135]図8は、本開示による1つ又は複数の例示的なビデオ復号技法を示すデータフロー図である。例えば、デコーダ80は、復号84として示された、ビットストリーム(例えば、ビットストリーム62)の復号を実施する。デコーダ80は、エンコーダプロセッサ20が出力した残差画像を示す情報に基づいて残差画像86を決定する。幾つかの例では、デコーダ80は、(例えば、直接又はシーン構造マップと前のシーン構造マップとの間の差分を示す情報を前のシーン構造マップの値に加算することによって)シーン構造マップを出力する。
[0136]GPU70は、受信されたシーン構造マップからプロキシジオメトリを形成する。幾つかの例では、GPU70は前のシーン構造マップを利用し得る。例えば、復号84は、シーン構造マップ又はシーン構造マップと前のシーン構造マップとの間の差分を復号することを伴わないことがある。そのような例では、GPU70は前のシーン構造マップを再利用する。
[0137]本開示で説明する技法では、GPU70は、シーン構造マップと複合画像とに基づいてプロキシジオメトリを生成し、テクスチャマップである複合画像と、テクスチャマップがそれにマッピングされるオブジェクトであるプロキシジオメトリとを用いてテクスチャマッピングを実施する。テクスチャマッピングの結果は画像ベースモデル88である。GPU70は、予測画像90によって表される合成画像を生成するために画像ベースモデル88をレンダリングする。
[0138]加算ユニット87は予測画像90に残差画像86を加算する。加算の結果は現在画像92である。
[0139]このようにして、本開示で説明する例示的な技法は、ビデオ符号化及び復号のための例示的な技法を提供する。幾つかの例では、従来の動き補償は必要とされないことがある。例えば、動きベクトル、参照ピクチャリストについての情報及び従来の動き補償において使用される他のそのような情報は必要とされないことがあり、必要とされる帯域幅の量の低減を可能にする。動き補償情報は必要とされないが、カメラ姿勢及びシーン構造マップ(又はシーン構造マップの変化)情報は出力される必要があり得る。しかしながら、カメラ行列とシーン構造マップの3Dポイントとのために画像ごとにほんの数バイトが必要とされ、無視できる帯域幅要件を生じる。
[0140]更に、本開示で説明する技法は、オンザフライビデオ符号化及び復号に好適であり得る。例えば、エンコーダプロセッサ20及びデコーダプロセッサ30は、それぞれのGPUを用いてそれぞれの予測画像(例えば、合成画像)をオンザフライで生成することが可能である。これは、復号中にGPU上でテクスチャマッピング及び深度バッファハードウェアによって行われる動き補償と同様と考えられ得る。
[0141]その上、本技法は、立体視表示器のためにも利用され得る。例えば、合成画像は、理論的には、現在画像のカメラ姿勢の代わりに、立体視ビューのための画像を生成するために使用され得る視点など、任意の視点からレンダリングされ得る。この場合、得られた合成画像は、非立体視ビューにおける予測目的には理想的でないことがあるが、小さい変化については合成画像は十分であり得る。そのような技法は、制限付き自由視点と呼ばれることがある。
[0142]図9は、ビデオデータを符号化する例示的な方法を示すフローチャートである。図9の例に示されているように、エンコーダプロセッサ20のGPU36は、複合画像と、現在画像のシーン構造マップ又は前に符号化された画像のシーン構造マップとに基づいて合成画像を生成する(100)。複合画像は、前に符号化された1つ又は複数の画像から構築される。例えば、複合画像は、2つ又はそれ以上の前に符号化されたキーフレームのブレンド又は単一の前に符号化されたキーフレームであり得る。シーン構造マップは、ビデオデータの現在画像又は前に符号化されたビデオデータの画像内の3次元ポイントのための座標値を含む。例えば、エンコーダプロセッサ20のSLAMプロセッサ34は、同時ローカライゼーション及びマッピング(SLAM)技法を利用してシーン構造マップを生成し得る。
[0143]幾つかの例では、合成画像を生成するために、GPU36は、プロキシジオメトリを形成するためにシーン構造マップのポイントを相互接続し得る。GPU36は、画像ベースモデルを形成するために複合画像をプロキシジオメトリにテクスチャマッピングし得る。幾つかの例では、GPU36は、画像ベースモデルを形成するために、複合画像を構築するために使用された1つ又は複数の画像のカメラ姿勢情報に基づいて、複合画像をプロキシジオメトリにテクスチャマッピングし得る。GPU36は、合成画像を生成するために画像ベースモデルをレンダリングし得る。幾つかの例では、GPU36は、合成画像を生成するために、現在画像のカメラ姿勢情報に基づいて画像ベースモデルをレンダリングし得る。
[0144]エンコーダプロセッサ20のエンコーダ48は、合成画像と現在画像とに基づいて残差画像を決定する(102)。残差画像は、現在画像と合成画像との間の差分を示す。エンコーダ48は、ビデオデータの現在画像を符号化するために残差画像を出力する(例えば、残差画像を示す情報を出力する)(104)。幾つかの例では、エンコーダ48はまた、現在画像のシーン構造マップの情報又は現在画像のシーン構造マップと前に符号化された画像のシーン構造マップとの間の差分を示す情報のうちの1つを出力し得、カメラ位置とカメラ方向の一方又は両方を出力し得る。
[0145]幾つかの例では、エンコーダプロセッサ20又は発信源機器12の幾つかの他のユニットは、現在画像の前景非静的部分と現在画像の背景静的部分とを決定し得る。これらの例では、残差画像を決定するために、エンコーダ48は、合成画像と現在画像の背景静的部分とに基づいて残差画像を決定するように構成され得る。また、これらの例では、残差データを出力するために、エンコーダ48は、現在画像の前景非静的部分のための残差データを含む第2のレイヤとは異なる第1のレイヤ中の残差データを出力するように構成され得る。
[0146]図10は、ビデオデータを復号する例示的な方法を示すフローチャートである。デコーダプロセッサ30のデコーダ80は、ビデオデータの現在画像の残差画像を決定する(200)。残差画像は、現在画像と合成画像との間の差分を示す。例えば、デコーダ80は、エンコーダプロセッサ20が出力した残差画像を示す情報を受信し得る。残差画像を示すこの情報は、符号化された情報又は符号化されていない情報であり得る。いずれの例でも、デコーダ80は、エンコーダプロセッサ20が出力した残差画像を示す情報に基づいて残差画像を決定(例えば、残差画像を再構築)し得る。
[0147]デコーダプロセッサ30のGPU70は、複合画像と、現在画像のシーン構造マップ又は前に復号された画像のシーン構造マップとに基づいて合成画像を生成する(202)。複合画像は、前に復号された1つ又は複数の画像から構築される。シーン構造マップは、ビデオデータの現在画像のシーン構造マップ又は前に復号されたビデオデータの画像のシーン構造マップを備え、シーン構造マップは、現在画像又は前に復号された画像内の3次元ポイントのための座標値を含む。デコーダ80は、合成画像と残差画像とに基づいて現在画像を再構築する(204)。
[0148]例えば、GPU36のように、GPU70は、プロキシジオメトリを形成するためにシーン構造マップのポイントを相互接続し得る。GPU70は、画像ベースモデルを形成するために、及び前に復号された1つ又は複数の画像のカメラ姿勢情報に潜在的に基づいて、複合画像をプロキシジオメトリにテクスチャマッピングし得る。GPU70は、合成画像を生成するために、及び現在画像のカメラ姿勢情報に潜在的に基づいて、画像ベースモデルをレンダリングし得る。
[0149]幾つかの例では、複合画像は、2つ又はそれ以上の前に復号されたキーフレームのブレンド又は単一の前に復号されたキーフレームであり得る。シーン構造マップは、現在画像又は前に復号された画像内の3次元ポイントのための座標値を含む。
[0150]デコーダ80は、現在画像のシーン構造マップの情報又は現在画像のシーン構造マップと前に復号された画像のシーン構造マップとの間の差分を示す情報のうちの1つを受信し得る。幾つかの例では、デコーダ80は、カメラ位置とカメラ方向の一方又は両方をも受信し得る。
[0151]幾つかの例では、デコーダ80は、現在画像の背景静的部分のための残差画像を受信し得る。これらの例では、デコーダ80は、合成画像と現在画像の背景静的部分のための残差データとに基づいて現在画像を再構築し得る。
[0152]上記例に応じて、本明細書で説明した技法のうちのいずれかの幾つかの行為又はイベントは、異なるシーケンスで実施され得、追加、マージ又は完全に除外され得る(例えば、全ての説明した行為又はイベントが本技法の実施のために必要であるとは限らない)ことを認識されたい。その上、幾つかの例では、行為又はイベントは、連続的にではなく、例えば、マルチスレッド処理、割込み処理又は複数のプロセッサを通して同時に実施され得る。
[0153]1つ又は複数の例では、説明した機能は、ハードウェア、ソフトウェア、ファームウェア又はそれらの任意の組合せで実装され得る。ソフトウェアで実装される場合、機能は、1つ又は複数の命令又はコードとして、コンピュータ可読媒体上に記憶されるか、あるいはコンピュータ可読媒体を介して送信され、ハードウェアベースの処理ユニットによって実行され得る。コンピュータ可読媒体は、データ記憶媒体などの有形媒体に対応する、コンピュータ可読記憶媒体を含み得るか、又は、例えば、通信プロトコルに従って、ある場所から別の場所へのコンピュータプログラムの転送を可能にする任意の媒体を含む通信媒体を含み得る。このようにして、コンピュータ可読媒体は、概して、(1)非一時的である有形コンピュータ可読記憶媒体、あるいは(2)信号又は搬送波などの通信媒体に対応し得る。データ記憶媒体は、本開示で説明した技法の実装のための命令、コード及び/又はデータ構造を取り出すために、1つ又は複数のコンピュータあるいは1つ又は複数のプロセッサによってアクセスされ得る任意の利用可能な媒体であり得る。コンピュータプログラム製品はコンピュータ可読媒体を含み得る。
[0154]限定ではなく例として、そのようなコンピュータ可読記憶媒体は、RAM、ROM、EEPROM(登録商標)、CD−ROM又は他の光ディスクストレージ、磁気ディスクストレージ又は他の磁気記憶装置、フラッシュメモリ、あるいは命令又はデータ構造の形態の所望のプログラムコードを記憶するために使用され得、コンピュータによってアクセスされ得る、任意の他の媒体を備えることができる。また、いかなる接続もコンピュータ可読媒体と適切に呼ばれる。例えば、命令が、同軸ケーブル、光ファイバーケーブル、ツイストペア、デジタル加入者線(DSL)又は赤外線、無線及びマイクロ波などのワイヤレス技術を使用してウェブサイト、サーバ又は他のリモート発信源から送信される場合、同軸ケーブル、光ファイバーケーブル、ツイストペア、DSL又は赤外線、無線及びマイクロ波などのワイヤレス技術は媒体の定義に含まれる。但し、コンピュータ可読記憶媒体及びデータ記憶媒体は、接続、搬送波、信号又は他の一時的媒体を含まないが、代わりに非一時的有形記憶媒体を対象とすることを理解されたい。本明細書で使用するディスク(disk)及びディスク(disc)は、コンパクトディスク(disc)(CD)、レーザーディスク(登録商標)(disc)、光ディスク(disc)、デジタル多用途ディスク(disc)(DVD)、フロッピー(登録商標)ディスク(disk)及びBlu−rayディスク(disc)を含み、ここで、ディスク(disk)は、通常、データを磁気的に再生し、ディスク(disc)は、データをレーザーで光学的に再生する。上記の組合せもコンピュータ可読媒体の範囲内に含まれるべきである。
[0155]命令は、1つ又は複数のデジタル信号プロセッサ(DSP)、汎用マイクロプロセッサ、特定用途向け集積回路(ASIC)、フィールドプログラマブル論理アレイ(FPGA)、あるいは他の等価な集積回路又はディスクリート論理回路など、1つ又は複数のプロセッサによって実行され得る。従って、本明細書で使用する「プロセッサ」という用語は、前述の構造又は本明細書で説明した技法の実装に好適な他の構造のいずれかを指すことがある。更に、幾つかの態様では、本明細書で説明した機能は、符号化及び復号のために構成された専用ハードウェア及び/又はソフトウェアモジュール内に与えられるか、あるいは複合コーデックに組み込まれ得る。また、本技法は、1つ又は複数の回路又は論理要素で十分に実装され得る。
[0156]本開示の技法は、ワイヤレスハンドセット、集積回路(IC)又はICのセット(例えば、チップセット)を含む、多種多様な機器又は装置で実装され得る。本開示では、開示した技法を実施するように構成された機器の機能的態様を強調するために様々な構成要素、モジュール又はユニットについて説明したが、それらの構成要素、モジュール又はユニットは、必ずしも異なるハードウェアユニットによる実現を必要とするとは限らない。むしろ、上記で説明したように、様々なユニットが、好適なソフトウェア及び/又はファームウェアとともに、上記で説明した1つ又は複数のプロセッサを含めて、コーデックハードウェアユニットにおいて組み合わせられるか、又は相互動作可能なハードウェアユニットの集合によって与えられ得る。
[0157]様々な例について説明した。これら及び他の例は以下の特許請求の範囲内に入る。