JP2012256197A - 表記ゆれ検出装置及び表記ゆれ検出プログラム - Google Patents
表記ゆれ検出装置及び表記ゆれ検出プログラム Download PDFInfo
- Publication number
- JP2012256197A JP2012256197A JP2011128731A JP2011128731A JP2012256197A JP 2012256197 A JP2012256197 A JP 2012256197A JP 2011128731 A JP2011128731 A JP 2011128731A JP 2011128731 A JP2011128731 A JP 2011128731A JP 2012256197 A JP2012256197 A JP 2012256197A
- Authority
- JP
- Japan
- Prior art keywords
- notation fluctuation
- similarity
- term
- terms
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/247—Thesauruses; Synonyms
Abstract
【課題】
精度よく表記ゆれ候補を検出する表記ゆれ検出装置を提供することである。
【解決手段】
実施形態の表記ゆれ検出装置は、文書データから用語を抽出する用語抽出部と、抽出された用語の任意のペアの類似度を算出する類似度算出部と、類似度に基づいて、用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、表記ゆれ候補である用語のペアに共通に含まれる文字列に基づいて表記ゆれ候補をグループ分けするグループ分類部と、を備える。
【選択図】図2
精度よく表記ゆれ候補を検出する表記ゆれ検出装置を提供することである。
【解決手段】
実施形態の表記ゆれ検出装置は、文書データから用語を抽出する用語抽出部と、抽出された用語の任意のペアの類似度を算出する類似度算出部と、類似度に基づいて、用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、表記ゆれ候補である用語のペアに共通に含まれる文字列に基づいて表記ゆれ候補をグループ分けするグループ分類部と、を備える。
【選択図】図2
Description
本発明の実施形態は、表記ゆれ検出装置及び表記ゆれ検出プログラムに関する。
一般に、同じ概念に対して複数の表記(単語)が存在していることを表記ゆれという。この表記ゆれが文書中に存在すると、ユーザが文書を検索する際や、文書から特定の用語を抽出する際などに、同じ概念の用語であるにも関わらず、適切に抽出されない場合がある。
ここで、表記ゆれに関し、これまでに種々の技術がある。 例えば、対象となる文書から表記ゆれ候補と考えられる文字列を予め選別して辞書を作成し、この辞書に基づいて表記ゆれの候補の文字列を検出する方法もある。
しかしながら、この方法では予め表記ゆれの候補を人手で選別するなどして辞書を作成する必要があるため、効率が悪いという欠点があった。
本発明が解決しようとする課題は、精度よく表記ゆれ候補を検出する表記ゆれ検出装置を提供することである。
実施形態の表記ゆれ検出装置は、文書データから用語を抽出する用語抽出部と、抽出された用語の任意のペアの類似度を算出する類似度算出部と、類似度に基づいて、用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、表記ゆれ候補である用語のペアに共通に含まれる文字列に基づいて表記ゆれ候補をグループ分けするグループ分類部と、を備える。
以下、本発明の実施形態について図面を参照して説明する。
図1は本実施形態の表記ゆれ検出装置100の全体構成を示すブロック図である。図1に示すように、表記ゆれ検出装置100は、文書入力部1、用語抽出部2、類似度算出部3、重み付け部4、表記ゆれ候補判定部5、グループ解析部6、表記ゆれ種類判定部7、出力データ生成部8、文書データ記憶部10、および重み付け情報記憶部11を備える。
表記ゆれを検出する対象の文書データは、文書入力部1によって入力される。文書入力部1は例えばキーボードやマウスであり、文書データ記憶部10に格納された文書データから検出対象の文書データを選択する。文書データ記憶部10に記憶されている文書データは、当該文書データの種類と対応付けて記憶されている。文書データの種類とは、例えば、「契約書」、「規程」、「法令文書」、「ニュース記事」などがある。
すなわち、文書入力部1から、表記ゆれ検出対象の文書データと当該文書データの種類とが入力される。なお、文書入力部1から直接に文書データと当該文書データの種類とが入力されてもよい。
用語抽出部2は、入力された文書データから用語(ここでは単語や複合語を意味する)の抽出を行う。本実施形態の用語抽出部2は、複数の抽出方法で用語を抽出する。
類似度算出部3は、抽出された用語群の中の2つの用語の類似度を算出する。なお、類似度の算出は、編集距離に基づいて行う。編集距離とは、2つの文字列がどの程度異なっているかを示す数値である。また、編集距離及び類似度の算出については後述する。
重み付け部4は、重み付け情報記憶部11に格納された重み付け情報に基づいて、類似度算出部3で算出された類似度に文書データの種類ごとの重み付けをする重み付け処理を行う。なお、重み付け処理の詳細については後述する。
表記ゆれ候補判定部5は、重み付け後の類似度に基づいて、抽出された用語群の中の2つの用語が表記ゆれ候補であるかを判定する。グループ解析部6は、判定された表記ゆれ候補群の共通の文字列と類似度とに基づき、表記ゆれ候補のグループを解析して分類する。
表記ゆれ種類判定部7は、各表記ゆれの候補の表記ゆれの種類を判定し、表記ゆれ判定処理を行う。表記ゆれ検出部が検出した表記ゆれ候補は、出力部8から出力される。この出力部8は、例えば液晶ディスプレイなどの表示装置である。
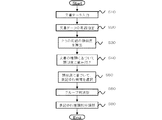
ここで、図2乃至図12を参照して表記ゆれ検出装置100における表記ゆれ検出処理について説明する。図2は表記ゆれ検出装置100の表記ゆれ検出処理の一例を示すフローチャートである。
まず、ユーザが、表記ゆれ検出装置100の文書データ入力部1を用いて、文書データ記憶部10から表記ゆれ検出対象の文書データを入力する(ステップS10)。図3に、入力される文書データの一例である文書データ101を示す。図3に示すように文書データ101は文書種類102と文書データ本体103とを含む。文書データ101の文書種類102は、ここでの説明で一例として「規程」を挙げる。文書データ101が入力されると、用語抽出部2は、文書データ101から用語の抽出を行う(ステップS20)。用語抽出部2の用語抽出は、例えば形態素解析や字面解析などの方法で行う。ここでは、用語抽出部2は、2種類の抽出方法「抽出方法A」および「抽出方法B」によって、それぞれ用語抽出を行ったとする。
図4に、用語抽出部2による用語抽出結果を示すように、用語抽出部2は、所定の抽出法で用語とその用語の抽出箇所を示す文書データの行番号とを対応付けて抽出する。
図4の(a)は、抽出手法Aで抽出された用語を示す抽出用語テーブル201であり、図4の(b)は抽出手法Bで抽出された用語を示す抽出用語テーブル202である。抽出用語テーブルは201および202は、用語IDカラム203、用語カラム204、行番号カラム205、抽出手法カラム206を含む。用語ID203には、抽出用語の識別子が格納される。用語カラム204には、用語抽出部2によって抽出された用語が格納される。行番号205には用語カラム204が抽出された行番号が格納される。抽出手法カラム206には、用語抽出部2によって用語を抽出した際に抽出書法が格納される。なお、用語抽出の際に、抽出する用語毎に抽出元の文書名や品詞の情報などが付与されてもよい。
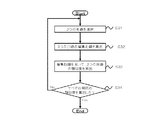
続いて、類似度算出部3は、抽出された用語から任意の2つの用語を選択し、選択した2つの用語の類似度を算出する(ステップS30)。ここで、図5を参照して類似度算出部3の類似度算出処理の一例について説明する。
まず、類似度算出部3では用語抽出部2の抽出結果から2つの用語が選択される(ステップS31)。なお、用語抽出部2が複数の抽出方法で用語を抽出した場合は、同じ用語抽出方法で抽出された用語の中から2つを選択する。
類似度算出部3は、選択した2つの用語の編集距離を算出する(ステップS32)。編集距離は2つの文字列がどの程度異なるかを示す数値であり、例えば2つ用語の一方を編集して他方の用語と一致させるためにかかる操作の回数に基づいて算出される。
操作とは、例えば、削除・置換・挿入などが挙げられる。これらの操作1回あたりのコストをあらかじめ「1」として設定しておき、一方の用語に操作を行い、他方の用語と同一の用語になるまでのコストを合計したものを編集距離とする。
なお、本実施形態では、操作の種類ごとのコストを設定して編集距離を算出する。例えば、置換の操作のうち、表記ゆれの可能性が高い、「全角/半角」、「平仮名/片仮名」、「大文字/小文字」などの文字種置換のコストを「0.1」とする。このように、操作ごとのコストをあらかじめ設定することにより、表記ゆれ検出の精度を向上することが可能である。
類似度算出部3は、算出した編集距離を用いて2つの用語の類似度を算出する(ステップS33)。類似度は、例えば2つの用語の文字列の長さの和に対する編集距離の割合を算出し、算出した割合を1から引くことで算出される。
例えば図4の(a)に示すテーブルの用語IDカラム203が3の用語(以下、用語3という)と用語IDカラム203が5の用語(以下、用語5という)の類似度を算出する。用語3と用語5を同一の用語にするために用語3を編集する場合、用語3の「PL」の「P(全角)」を「P(半角)」に置換し、「L(全角)」を「L(半角)」に置換する。すなわち操作回数は「全角/半角」置換が2回であり、置換のコストを「0.1」とすると、編集距離は「0.2」である。
用語3と用5の文字列の長さの合計は「4」であるため、用語3と用語5の類似度は、「0.95」となる。
類似度を算出していない用語が、用語抽出部2に抽出された用語の中にある場合(ステップS34がNo)、ステップS31に戻り、類似度算出処理を繰り返す。すべての用語の類似度を算出した場合(ステップS34がYes)、類似度算出処理を終了する。
図6及び図7に、類似度算出部3が算出した類似度の一例を示す。ここでは、図4に示した抽出用語テーブル201と抽出用語テーブル202のテーブルに基づいて類似度を算出したとする。
図6及び図7は、類似度を算出した用語ペアごとの類似度を示す類似度テーブルを示す図である。図6は図4の(a)に示した抽出用語テーブル201に基づいて類似度を算出した類似度テーブル301である。図7は、図4の(b)に示した抽出用語テーブル202に基づいて類似度を算出した類似度テーブル302である。類似度テーブル301および302には、用語ペアIDカラム303、抽出手法カラム304、用語Aカラム305、用語Bカラム306、用語A行番号カラム307、用語B行番号カラム308、類似度カラム309が含まれる。用語ペアIDカラム303は、類似度算出対象の用語ペアの識別子が格納される。抽出手法カラム304は抽出手法カラム206の内容が格納される。用語Aカラム305には、類似度算出対象の用語ペアの片方の用語が格納される。用語Bカラム306には、類似度算出対象の用語ペアの他方の用語が格納される。用語A行番号カラム307には、用語Aカラム305に格納された用語の抽出元の行番号カラム205の内容が格納される。用語B行番号カラム308には、用語Bカラム306に格納された用語の抽出元の行番号カラム205の内容が格納される。類似度カラム309には、類似度算出部3が算出した類似度が格納される。
ここで、図2の説明に戻る。類似度が算出されると、類似度重み付け部4は、表記ゆれ検出対象の文書の種類と、類似度を算出した用語の抽出方法とに基づいて、類似度に重み付けを行う(ステップS40)。
図8を参照して、類似度重み付け部4による類似度重み付け処理について説明する。
図8は類似度重み付け情報テーブル111である。類似度重み付け情報テーブル111は、文書の種類112および類似度を算出した用語の抽出方法113ごとの重み付け情報が格納されている。この重み付け情報はあらかじめシステム設計者やユーザによって設定されている。本実施例では、文書の種類112として「法令文書」、「ニュース記事」、「新聞」、「規程」、及び「学術文書」が挙げられている。また、用語抽出の手法113として、「抽出手法A」、及び「抽出手法B」が挙げられている。
すなわち、図2のステップS40で、類似度重み付け部4は、表記ゆれ検出対象の文書データの文書種類102と、類似度を算出した用語の抽出方法とに基づいて、類似度重み付け情報テーブル111を参照し、類似度に重み付けを行う。
続いて、表記ゆれ候補判定部5は、重み付けされた用語ペアごとの類似度に基づいて、表記ゆれ候補を判定する(ステップS50)。表記ゆれ候補の判定は、例えば類似度があらかじめ設定された閾値以上の用語ペアを抽出するなどの方法で行う。本実施形態は、類似度の閾値を0.6とする。
ここで、図9の表記ゆれ候補テーブル401に、表記ゆれ候補を示す。図9の表記ゆれ候補テーブル401は、類似度テーブル301および302から表記ゆれ候補判定部7によって判定された表記ゆれ候補を示すものであり、類似度テーブル301および302に含まれる項目に表記ゆれ候補の識別子である表記ゆれ候補IDカラム402を追加したテーブルである。重み付け部4によって類似度に重み付けが行われたため、図6及び図7に示した類似度テーブルに含まれる用語ペアのうち、類似度が0.6を超える用語ペアは「抽出手法A」の「用語ペアID11」の用語ペアと、「抽出手法B」の「用語ペアID2,4,6,9」の用語ペアの5つである。
表記ゆれ候補が判定されると、グループ解析部6は、表記ゆれ候補の共通文字列や類似度を参照して、表記ゆれ候補のグループ分けを行う(ステップS60)。
グループ解析部6における表記ゆれ候補のグループ分け処理は、選択した任意の2つの表記ゆれ候補XとYに含まれる用語をそれぞれ比較することによって行われる。グループ解析部6は、表記ゆれ候補Xに含まれる用語のうち少なくとも一方の用語の文字列が、表記ゆれ候補Yに含まれる用語の文字列に含まれる場合、表記ゆれ候補XおよびYを同一のグループと判別し、同一のグループIDを付与する。
図10は、グループ解析部6によるグループ解析処理の一例を示すフローチャートである。なお、表記ゆれ候補に付与するグループIDを1以上の整数であるnとし、グループ解析処理開始時はn=1であるとする。
図10に示すように、グループ解析部6は、まず、表記ゆれ候補判定部5によって判定された表記ゆれ候補の中から任意の表記ゆれ候補を選択する(ステップS61)。ここで選択した表記ゆれ候補を基準候補Xとする。また、基準候補X以外の表記ゆれ候補を、被解析候補という。
選択した表記ゆれ候補XにグループIDが付与されている場合(ステップS62がNo)、グループ解析部6は、ステップS61に戻り、再び表記ゆれ候補を選択する。
選択した表記ゆれ候補XにグループIDが付与されていない場合(ステップS62がYes)、グループ解析部6は、被解析候補の中から表記ゆれ候補を選択する(ステップS63)。ここで選択された表記ゆれ候補を被解析候補Yとする。
基準候補Xに含まれる用語Aと用語Bのどちらか一方が、表記ゆれ候補Yに含まれる場合(ステップS64がYes)、グループ解析部6は、非判別候補YにグループIDが付与されているかどうかを判定する(ステップS65)。なお、基準候補Xに含まれる用語Aと用語Bのどちらも、判別候補Yに含まれない場合(ステップS64がNo)、グループ解析部6はステップS63に戻り、判別候補から候補を再度選択する。
非判別候補YにグループIDが付与されていない場合(ステップS65がYes)、基準候補Xと被解析候補Yとは同一のグループであると判定し、候補Xと候補YのグループIDを「n」とする(ステップS66)。
グループIDを付与すると、グループ解析部6はn=n+1とし(ステップS67)、ステップS68に進む。
非判別候補YにグループIDが付与されている場合(ステップS65がNo)、基準候補Xに被解析候補Yとは同一のグループIDを付与する(ステップS70)。その後、ステップS68に進む。
グループ解析処理を行われていない被解析候補が存在する場合(ステップS68がNo)、ステップS63に戻り、再び被解析候補を選択する。なお、グループ解析処理を行われていない被解析候補が存在するかどうかの判定は、例えば「候補総数−1」とグループID付与済みの候補総数を比較することにより行う。具体的には、「候補総数−1」がグループID付与済みの候補総数未満である場合、グループ解析部6は、すべての被解析候補にグループ解析処理を行っていると判定する。逆に、「候補総数−1」がグループID付与済みの候補総数以上である場合、グループ解析部6は、グループ解析処理を行われていない被解析候補が存在すると判定する。
グループ解析処理を行われていない被解析候補が存在しない場合(ステップS68がYes)、グループ解析部6は、すべての表記ゆれ候補にグループ判定処理を行ったか否かを判定する(ステップS69)。グループ解析処理を行われていない被解析候補が存在しない場合(ステップS69がNo)、ステップS61にもどり、表記ゆれ候補から基準候補Xを選択し処理を繰り返す。すべての表記ゆれ候補にグループ判定処理を行った場合(ステップS69がYes)、すなわち、すべての表記ゆれ候補にグループIDが付与された場合グループ解析処理を終了する。
上述のように、本実施形態のグループ解析部6は、表記ゆれ候補をグループ分けする。また、グループ解析部6は、すでにグループIDが付与された表記ゆれ候補に基づいてグループ関係を抽出するため、関連する表記ゆれ候補を効率よく抽出することが可能である。
続いて、図2の説明に戻る。表記ゆれ種類判定部7は、表記ゆれ候補の種類を判定する(ステップS80)。表記ゆれ種類判定部7によって判定される表記ゆれ種類は、例えば、「スペース違い」、「半角全角違い」、「後方一致」、「前方一致」、「片仮名平仮名違い」、「一文字違い」、「複数字違い」である。
「スペース違い」は、表記ゆれ候補に含まれる用語それぞれのスペースを削除した場合に同一の用語になる。「半角全角違い」は、表記ゆれ候補に含まれる用語それぞれを全角もしくは半角に統一した場合に同一の用語になる。「後方一致」は、表記ゆれ候補に含まれる用語のそれぞれの後方の文字が一致する状態をいう。「前方一致」は、表記ゆれ候補に含まれる用語のそれぞれの前方の文字が一致する状態をいう。「片仮名平仮名違い」は、表記ゆれ候補に含まれる用語それぞれを平仮名もしくは片仮名に統一した場合に同一の用語になる。「一文字違い」は、表記ゆれ候補に含まれる用語が一文字違いである。「複数字違い」は、表記ゆれ候補に含まれる用語が複数文字違いである。
図11に、グループ解析部6によるグループ解析処理の結果、および表記ゆれ種類分類部7による表記ゆれ種類分類処理の結果の一例を示す。図11は、表記ゆれ候補テーブル401に、グループカラム502、表記ゆれ種類カラム503が追加された表記ゆれ候補テーブル501である。
グループカラム502には、グループ解析部6によるグループ解析処理の結果が格納される。表記ゆれ種類カラム503は、表記ゆれ種類分類部7による表記ゆれ種類分類処理の結果が格納される。
図12は、本実施形態の表記ゆれ検出処理後の、出力部8の一例を示す図である。図12に示すように、出色部8には表記ゆれ検出画面601が表示される。表記ゆれ検出画面601には、ソートボタン602と、ソート設定ボタン603と、表記ゆれ検出結果表示領域604を有する。表記ゆれ検出結果表示領域604には、検出結果として、用語Aカラム305、用語Bカラム306、用語A行番号カラム307、用語B行番号カラム308、類似度カラム309、グループカラム502、表記ゆれ種類カラム503が表示される。ソートボタン602は、ソート設定ボタン603の設定に基づいて表記ゆれ検出結果表示領域604に表示された表記ゆれ検出結果の表示順序の並べ替えを行う。ここでは、ソート設定ボタン603が「グループ順」と設定されているため、グループカラム502に格納されたグループIDが小さい順に表示されている。
上述のように、本実施形態の表記ゆれ検出装置は、あらかじめ辞書を作成することなく、表記ゆれ候補を検出することが可能である。また、編集距離の算出の際に文字種置換操作を加え、文字種置換操作をその他の操作による編集距離よりも短くすることにより、精度の高い表記ゆれ候補検出を可能とする。また、文書データの種類毎に重み付けを行うことにより、表記ゆれ候補検出の精度を向上する。
また、本実施形態の表記ゆれ検出装置は、検出した表記ゆれ候補のグループ関係を解析し、グループID毎に出力部8から出力することによって、表記ゆれの候補をユーザが効率的に確認することを可能にする。同様に、表記ゆれ候補の種類の分類毎に表示部に表示することも可能である。
なお、本実施形態の表記ゆれ検出装置100は、用語を登録する辞書記憶部を備えてもよい。この場合、辞書記憶部には所定の文書データから抽出された表記ゆれ候補を登録する。類似度算出部5は、用語抽出部2が抽出した用語と、辞書記憶部に登録された用語との類似度を算出する。これにより、社内規程など、同じ語句が使用されると思われる文書データから効率よく表記ゆれを検出することが可能となる。
また、辞書記憶部に除外条件を登録し、除外条件を満たす表記ゆれ候補を表記ゆれ候補から削除するようにしてもよい。上記の除外条件とは、例えば、「先頭に『各』という文字があり、『各』に続く文字列が一致する用語ペア」、「末尾に『等』という文字があり『等』の前の文字列が一致する用語ペア」、「末尾に『書』という文字があり、『書』の前の文字列が一致する用語ペア」などの条件である。
また、用語抽出部2が文書データから用語抽出を行う際に、用語を抽出した行番号と用語が何文字目の文字かを示す位置情報を抽出した用語に付与しても良い。これにより、同一の位置から抽出された用語が表記ゆれ候補にならないため、表記ゆれ候補の検出精度を向上することが可能である。
以上、本発明の実施形態を説明したが、この実施形態はあくまでも例として提示したものであり、発明の範囲を限定することは意図していない。この新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。この実施形態やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
1…文書データ入力部、2…用語抽出部、3…類似度算出部、4…類似度重み付け部、5…表記ゆれ候補判定部、6…グループ関係抽出部、7…表記ゆれ種類判定部、10…文書データ記憶部、11…重み付け情報記憶部
Claims (6)
- 文書データから用語を抽出する用語抽出部と、
前記抽出された用語の任意のペアの類似度を算出する類似度算出部と、
前記類似度に基づいて、前記用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、
前記表記ゆれ候補である前記用語のペアに共通に含まれる文字列に基づいて前記表記ゆれ候補をグループ分けするグループ分類部と、
を備える表記ゆれ検出装置。 - 文書データから用語を抽出する用語抽出部と、
前記抽出された用語の任意のペアに対して文字種置換を含む操作を行い、前記操作の回数に基づいて編集距離を算出し、前記編集距離に基づいて類似度を算出する類似度算出部と、
前記類似度に基づき、前記用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、
を備える表記ゆれ検出装置。 - 前記類似度算出部は、前記抽出された用語のペアの一方の用語に置換、削除、挿入もしくは文字種置換の操作を繰り返し適用することで編集距離を求め、類似度を算出する請求項1に記載の表記ゆれ検出装置
- 前記表記ゆれ候補である前記用語のペアに共通に含まれる文字列に基づいて前記表記ゆれ候補をグループ分けするグループ分類部をさらに備える請求項2に記載の表記ゆれ検出装置。
- 文書データから用語を抽出する用語抽出部と、前記抽出された用語の任意のペアを用いて類似度を算出する類似度算出部と、前記類似度に基づいて、前記用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、前記表記ゆれ候補である前記用語のペアに共通に含まれる文字列に基づいて前記表記ゆれ候補をグループ分けするグループ分類部と、を備える表記ゆれ検出装置に用いられる表記ゆれ検出プログラムであって、
前記表記ゆれ検出装置に対して、
前記用語抽出部が文書データから用語を抽出する機能と、
前記類似度算出部が前記抽出された用語の任意のペアを用いて類似度を算出する機能と、
前記表記ゆれ候補判定部が前記類似度に基づいて、前記用語のペアが表記ゆれ候補であるかを判定する機能と、
前記グループ分類部が前記表記ゆれ候補である用語のペアに含まれる共通文字列に基づいて前記表記ゆれ候補をグループ分けする機能と、
を実現させる表記ゆれ検出プログラム。 - 文書データから用語を抽出する用語抽出部と、前記抽出された用語の任意のペアに対して文字種置換を含む操作を行い、前記操作の回数に基づいて編集距離を算出し、前記編集距離に基づいて類似度を算出する類似度算出部と、前記類似度に基づき、前記用語のペアが表記ゆれ候補であるかを判定する表記ゆれ候補判定部と、を備える表記ゆれ検出装置に用いられる表記ゆれ検出プログラムであって、
前記表記ゆれ検出装置に対して
前記用語抽出部が文書データから用語を抽出する機能と、
前記類似度算出部が前記抽出された用語の任意のペアに対して文字種置換を含む操作を行い、前記操作の回数に基づいて編集距離を算出し、前記編集距離に基づいて類似度を算出する機能と、
前記表記ゆれ候補判定部が前記の類似度に基づき、前記用語の任ペアが表記ゆれ候補であるかを判定する機能と、
を実現させる表記ゆれ検出プログラム。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011128731A JP2012256197A (ja) | 2011-06-08 | 2011-06-08 | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
| SG2013016753A SG188435A1 (en) | 2011-06-08 | 2012-05-23 | Orthographical variant detection apparatus and orthographical variant detection program |
| CN2012800025648A CN103080937A (zh) | 2011-06-08 | 2012-05-23 | 表述不一致检测装置及表述不一致检测程序 |
| PCT/JP2012/003357 WO2012169128A1 (ja) | 2011-06-08 | 2012-05-23 | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
| US13/759,528 US9128923B2 (en) | 2011-06-08 | 2013-02-05 | Orthographical variant detection apparatus and orthographical variant detection method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011128731A JP2012256197A (ja) | 2011-06-08 | 2011-06-08 | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2012256197A true JP2012256197A (ja) | 2012-12-27 |
Family
ID=47295721
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011128731A Pending JP2012256197A (ja) | 2011-06-08 | 2011-06-08 | 表記ゆれ検出装置及び表記ゆれ検出プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9128923B2 (ja) |
| JP (1) | JP2012256197A (ja) |
| CN (1) | CN103080937A (ja) |
| SG (1) | SG188435A1 (ja) |
| WO (1) | WO2012169128A1 (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5696280B1 (ja) * | 2014-04-08 | 2015-04-08 | 幸治 松村 | 用語統一システム及び用語統一プログラム、並びに用語統一方法 |
| JP2017156890A (ja) * | 2016-02-29 | 2017-09-07 | 富士通株式会社 | 同義語検出装置、同義語検出方法及び同義語検出用コンピュータプログラム |
| JP2020173675A (ja) * | 2019-04-11 | 2020-10-22 | 富士通株式会社 | 同一事象判定プログラム、同一事象判定方法および同一事象判定システム |
| WO2023286340A1 (ja) * | 2021-07-14 | 2023-01-19 | ソニーグループ株式会社 | 情報処理装置および情報処理方法 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016058138A1 (en) * | 2014-10-15 | 2016-04-21 | Microsoft Technology Licensing, Llc | Construction of lexicon for selected context |
| JP5963328B2 (ja) * | 2014-10-30 | 2016-08-03 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 生成装置、生成方法、およびプログラム |
| CN106610965A (zh) * | 2015-10-21 | 2017-05-03 | 北京瀚思安信科技有限公司 | 确定文本串公共子序列的方法和设备 |
| CN107657471B (zh) * | 2016-09-22 | 2021-04-30 | 腾讯科技(北京)有限公司 | 一种虚拟资源的展示方法、客户端及插件 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07225763A (ja) * | 1994-02-10 | 1995-08-22 | Fujitsu Ltd | 文書処理装置 |
| JP2005352888A (ja) * | 2004-06-11 | 2005-12-22 | Hitachi Ltd | 表記揺れ対応辞書作成システム |
| JP2007179505A (ja) * | 2005-12-28 | 2007-07-12 | Ricoh Co Ltd | 検索装置、検索システム、検索方法、検索プログラムおよび記録媒体 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6098034A (en) * | 1996-03-18 | 2000-08-01 | Expert Ease Development, Ltd. | Method for standardizing phrasing in a document |
| US6963871B1 (en) * | 1998-03-25 | 2005-11-08 | Language Analysis Systems, Inc. | System and method for adaptive multi-cultural searching and matching of personal names |
| JP2006053866A (ja) | 2004-08-16 | 2006-02-23 | Advanced Telecommunication Research Institute International | カタカナ文字列の表記ゆれの検出方法 |
| US7716229B1 (en) * | 2006-03-31 | 2010-05-11 | Microsoft Corporation | Generating misspells from query log context usage |
| JP2008033887A (ja) | 2006-06-30 | 2008-02-14 | Toshiba Corp | 文書データ処理装置 |
| WO2008043582A1 (en) * | 2006-10-13 | 2008-04-17 | International Business Machines Corporation | Systems and methods for building an electronic dictionary of multi-word names and for performing fuzzy searches in said dictionary |
| US8457959B2 (en) * | 2007-03-01 | 2013-06-04 | Edward C. Kaiser | Systems and methods for implicitly interpreting semantically redundant communication modes |
| JP2011221662A (ja) | 2010-04-06 | 2011-11-04 | Toshiba Corp | 辞書編集装置およびプログラム |
| JP5542744B2 (ja) | 2011-06-07 | 2014-07-09 | 株式会社東芝 | 文章抽出装置およびプログラム |
-
2011
- 2011-06-08 JP JP2011128731A patent/JP2012256197A/ja active Pending
-
2012
- 2012-05-23 WO PCT/JP2012/003357 patent/WO2012169128A1/ja active Application Filing
- 2012-05-23 CN CN2012800025648A patent/CN103080937A/zh active Pending
- 2012-05-23 SG SG2013016753A patent/SG188435A1/en unknown
-
2013
- 2013-02-05 US US13/759,528 patent/US9128923B2/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07225763A (ja) * | 1994-02-10 | 1995-08-22 | Fujitsu Ltd | 文書処理装置 |
| JP2005352888A (ja) * | 2004-06-11 | 2005-12-22 | Hitachi Ltd | 表記揺れ対応辞書作成システム |
| JP2007179505A (ja) * | 2005-12-28 | 2007-07-12 | Ricoh Co Ltd | 検索装置、検索システム、検索方法、検索プログラムおよび記録媒体 |
Non-Patent Citations (2)
| Title |
|---|
| CSNJ200910115164; 久保村 千明: '送りがな異表記と混ぜ書き異表記の処理の統合' 電子情報通信学会2009年基礎・境界ソサイエティ大会講演論文集 , 20090901, p.164, 社団法人電子情報通信学会 * |
| JPN6013047004; 久保村 千明: '送りがな異表記と混ぜ書き異表記の処理の統合' 電子情報通信学会2009年基礎・境界ソサイエティ大会講演論文集 , 20090901, p.164, 社団法人電子情報通信学会 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5696280B1 (ja) * | 2014-04-08 | 2015-04-08 | 幸治 松村 | 用語統一システム及び用語統一プログラム、並びに用語統一方法 |
| JP2017156890A (ja) * | 2016-02-29 | 2017-09-07 | 富士通株式会社 | 同義語検出装置、同義語検出方法及び同義語検出用コンピュータプログラム |
| JP2020173675A (ja) * | 2019-04-11 | 2020-10-22 | 富士通株式会社 | 同一事象判定プログラム、同一事象判定方法および同一事象判定システム |
| JP7234763B2 (ja) | 2019-04-11 | 2023-03-08 | 富士通株式会社 | 同一事象判定プログラム、同一事象判定方法および同一事象判定システム |
| WO2023286340A1 (ja) * | 2021-07-14 | 2023-01-19 | ソニーグループ株式会社 | 情報処理装置および情報処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2012169128A1 (ja) | 2012-12-13 |
| US20130151239A1 (en) | 2013-06-13 |
| US9128923B2 (en) | 2015-09-08 |
| SG188435A1 (en) | 2013-04-30 |
| CN103080937A (zh) | 2013-05-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2012169128A1 (ja) | 表記ゆれ検出装置及び表記ゆれ検出プログラム | |
| KR101412763B1 (ko) | 문맥적 입력 방법 | |
| JP2018524725A (ja) | 口語語義解析システム及び方法 | |
| CN108776709B (zh) | 计算机可读存储介质及词典更新方法 | |
| Riedl et al. | How text segmentation algorithms gain from topic models | |
| CN108304377A (zh) | 一种长尾词的提取方法及相关装置 | |
| KR101379128B1 (ko) | 사전 생성 장치, 사전 생성 방법 및 사전 생성 프로그램을 기억하는 컴퓨터 판독 가능 기록 매체 | |
| CN111753534B (zh) | 标识文档中的序列标题 | |
| US10387543B2 (en) | Phoneme-to-grapheme mapping systems and methods | |
| CN105528404A (zh) | 种子关键字字典建立方法和装置及关键词提取方法和装置 | |
| JP2009277099A (ja) | 類似文書検索装置及び方法及びプログラム及びコンピュータ読取可能な記録媒体 | |
| CN103049434A (zh) | 一种变形词证认系统及证认方法 | |
| JP2010026996A (ja) | タグ付け支援方法とその装置、プログラム及び記録媒体 | |
| CN107609006B (zh) | 一种基于地方志研究的搜索优化方法 | |
| WO2015075920A1 (ja) | 入力支援装置、入力支援方法及び記録媒体 | |
| KR101351555B1 (ko) | 대용량 데이터의 텍스트마이닝을 위한 의미기반 분류 추출시스템 | |
| KR20160086255A (ko) | 개체의 표면형 문자열 용례학습기반에 의한 텍스트에서의 개체 범위 인식 장치 및 그 방법 | |
| CN107491424B (zh) | 一种基于多权重体系的中文文档基因匹配方法 | |
| KR101113787B1 (ko) | 텍스트 색인 장치 및 방법 | |
| US10606875B2 (en) | Search support apparatus and method | |
| JP2009176148A (ja) | 未知語判定システム、方法及びプログラム | |
| Mande et al. | Regular Expression Rule-Based Algorithm for Multiple Documents Key Information Extraction | |
| Kocher et al. | Author clustering using spatium | |
| JP2005301855A (ja) | 文書検索方法、文書検索プログラムおよびこれを実行する文書検索装置 | |
| Nawab et al. | External plagiarism detection using information retrieval and sequence alignment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130705 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130830 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130920 |