JP2011123771A - 文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 - Google Patents
文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 Download PDFInfo
- Publication number
- JP2011123771A JP2011123771A JP2009282215A JP2009282215A JP2011123771A JP 2011123771 A JP2011123771 A JP 2011123771A JP 2009282215 A JP2009282215 A JP 2009282215A JP 2009282215 A JP2009282215 A JP 2009282215A JP 2011123771 A JP2011123771 A JP 2011123771A
- Authority
- JP
- Japan
- Prior art keywords
- document
- modifiers
- word
- threshold
- modifier
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
【課題】 仕様書などの文書に記述されている内容を評価することのできる文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体を提供する。
【解決手段】 複数の文が含まれる文書の内容を評価するための文書評価装置は、評価対象の文書を取得する文書取得手段と、文書取得手段によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手段と、主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手段と、主要な語ごとに、集計手段によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手段とを備える。
【選択図】 図1
【解決手段】 複数の文が含まれる文書の内容を評価するための文書評価装置は、評価対象の文書を取得する文書取得手段と、文書取得手段によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手段と、主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手段と、主要な語ごとに、集計手段によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手段とを備える。
【選択図】 図1
Description
本発明は、仕様書などの文書に記述された内容を評価するための文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体に関する。
ソフトウェア開発においては、まず要求仕様を決めて仕様書に文書化し、その仕様書の内容に基づいて、プログラム作成作業(以下、「コーディング」と記す)が行われている。したがって、仕様書に記載漏れなどの不備があることに気付かずにコーディングが行われてしまうと、少なくともコーディングの一部が無駄となってしまい、開発期間も延長してしまうことになる。
また、仕様書は通常、概略仕様書から詳細仕様書へと徐々に詳細化して仕様を定めることによって階層的な構造になっているため、上位の仕様書に不備があることに気付かずに下位の仕様書が作成されてしまうと、仕様書作成作業の一部が無駄となってしまい、開発期間も延長してしまうことになる。
それ故、上位の仕様書ほど不備の有無について、より慎重にレビューする必要がある。従来から、レビューは、複数のチェック項目が定められたチェックリストなどを使用して人間によって行われているため、レビューを行う人の経験に左右されてしまい、レビューを通過した仕様書の品質にばらつきが発生してしまっている。このような問題を解決するために、仕様書の品質を客観的に評価する手法が、たとえば特許文献1において提案されている。
特許文献1に記載の手法では、開発者によって作成された仕様書について、「ページ数」、「項目数」、「ページ当たりの図/表の数」、「ページまたがりの項目数」および「各記述項目の記述量(バイト数)」を計測し、これら各計測項目についての計測結果と、管理者によって設定された各計測項目に対する品質評価値と比較することによって、仕様書の品質を客観的に評価している。
しかしながら、このような手法による仕様書の品質の評価では、仕様書の体裁について客観的に評価されているだけであり、仕様書の内容として、本当に必要なことが記述されているかどうかについては評価されておらず、記述内容の評価としては不十分であるという問題がある。
本発明の目的は、仕様書などの文書に記述されている内容を評価することのできる文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体を提供することである。
本発明は、複数の文が含まれる文書の内容を評価するための文書評価装置であって、
評価対象の文書を取得する文書取得手段と、
文書取得手段によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手段と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手段と、
主要な語ごとに、集計手段によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手段とを備えることを特徴とする文書評価装置である。
評価対象の文書を取得する文書取得手段と、
文書取得手段によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手段と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手段と、
主要な語ごとに、集計手段によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手段とを備えることを特徴とする文書評価装置である。
また本発明は、表記は異なるが意味が同じである2以上の語に対して1つの代表語を定めた同義語テーブルに基づき、特定手段によって特定された各主要な語および各修飾語句を対応する代表語に置換する同義語置換手段をさらに備えることを特徴とする。
また本発明は、主要な語に対して記述されている複数の修飾語句から余分な修飾語句を削除する修飾語句縮退手段をさらに備えることを特徴とする。
また本発明は、前記判定手段は、修飾語句の数が閾値よりも大きいとき、閾値を該修飾語句の数を用いて更新することを特徴とする。
また本発明は、複数の文が含まれる文書の内容を評価するための文書評価方法であって、
評価対象の文書を取得する文書取得工程と、
文書取得工程によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定工程と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計工程と、
主要な語ごとに、集計工程によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定工程とを有することを特徴とする文書評価方法である。
評価対象の文書を取得する文書取得工程と、
文書取得工程によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定工程と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計工程と、
主要な語ごとに、集計工程によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定工程とを有することを特徴とする文書評価方法である。
また本発明は、コンピュータに、
複数の文が含まれる、評価対象の文書を取得する文書取得手順と、
文書取得手順によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手順と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手順と、
主要な語ごとに、集計手順によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手順とを実行させることを特徴とする文書評価プログラムである。
複数の文が含まれる、評価対象の文書を取得する文書取得手順と、
文書取得手順によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手順と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手順と、
主要な語ごとに、集計手順によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手順とを実行させることを特徴とする文書評価プログラムである。
また本発明は、前記文書評価プログラムを記録したコンピュータ読取り可能な記録媒体である。
本発明によれば、仕様書などの文書に記述されている内容が十分であるか否かを客観的に評価することが可能となる。
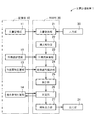
図1は、本発明の一実施形態に係る文書評価装置1の構成を示すブロック図である。文書評価装置1は、複数の文が含まれる文書の内容を評価するための処理(以下、「文書評価処理」と記す)を実行するように構成され、具体的には、評価対象の文書および文書評価処理実行時に用いられる各種のデータなどが格納される記憶部10と、所定のプログラムに従って文書評価処理を実行する制御部20と、指示および情報を入力するための入力部30と、演算結果などを出力するための出力部31とを含んで構成される。
文書評価装置1は、詳細には、記憶部10は、評価対象の文書が格納される文書記憶部11と、文書評価処理実行時に用いられる各種のデータが格納される同義語記憶部12、包含関係記憶部13および過去事例記憶部14とを含んで構成される。また、制御部20は、文書取得部21と、構文解析部22と、同義語置換部23と、修飾語句縮退部24と、集計部25と、判定部26と、結果出力部27とを含んで構成される。各部の詳細については後述する。
本実施形態では、制御部20の各機能部21〜27は、CPU(Central Processing
Unit)を用いてソフトウェアによって実現される。すなわち、文書評価装置1は、前記の各機能部21〜27を実現する制御プログラム(以下、「文書評価プログラム」と記す)の命令を実行するCPU(Central Processing Unit)と、文書評価プログラムを格納したROM(Read Only Memory)と、文書評価プログラムを展開するRAM(Random
Access Memory)と、各種データを格納するメモリおよびハードディスクなどの記憶装置と、キーボードおよびポインティングデバイスなどの入力装置と、LCD(Liquid
Crystal Display)およびPDP(Plasma Display Panel)などによって実現される表示装置ならびにプリンタなどの出力装置とを備えている汎用のパーソナルコンピュータによって実現される。なお、入力装置として、後述するように、文書読取装置やメモリカードリーダをさらに備えていてもよい。また、制御部20の各機能部21〜27は、他の実施形態では、ハードウェアロジックによって構成されてもよい。
Unit)を用いてソフトウェアによって実現される。すなわち、文書評価装置1は、前記の各機能部21〜27を実現する制御プログラム(以下、「文書評価プログラム」と記す)の命令を実行するCPU(Central Processing Unit)と、文書評価プログラムを格納したROM(Read Only Memory)と、文書評価プログラムを展開するRAM(Random
Access Memory)と、各種データを格納するメモリおよびハードディスクなどの記憶装置と、キーボードおよびポインティングデバイスなどの入力装置と、LCD(Liquid
Crystal Display)およびPDP(Plasma Display Panel)などによって実現される表示装置ならびにプリンタなどの出力装置とを備えている汎用のパーソナルコンピュータによって実現される。なお、入力装置として、後述するように、文書読取装置やメモリカードリーダをさらに備えていてもよい。また、制御部20の各機能部21〜27は、他の実施形態では、ハードウェアロジックによって構成されてもよい。
以下、本実施形態に係る文書評価装置1の構成について詳細に説明する。
文書記憶部11には、複数の文が含まれる評価対象の文書が格納され、詳細には、文書評価処理を実行する際に制御部20が処理可能なデータ形式で格納される。本実施形態では、評価対象の文書として、ソフトウェア開発のために作成される各種の仕様書が格納される。
文書記憶部11には、複数の文が含まれる評価対象の文書が格納され、詳細には、文書評価処理を実行する際に制御部20が処理可能なデータ形式で格納される。本実施形態では、評価対象の文書として、ソフトウェア開発のために作成される各種の仕様書が格納される。
文書記憶部11に格納される仕様書は、制御部20が処理可能なデータ形式で作成されたものであればよく、たとえば、文書評価装置1に備えられるキーボードを利用して作成されてもよく、また、スキャナとOCR(Optical Character Reader)とによって構成される文書読取装置を利用して、記録用紙に印字されている内容を読取ることによって作成されてもよい。さらに、メモリカードなどの記憶装置に格納されている場合には、メモリカードリーダなどを利用して入力されて、文書記憶部11に格納される。
文書取得手段である文書取得部21は、入力部30から与えられる指令に基づいて、評価対象の仕様書を文書記憶部11から取得する。
特定手段である構文解析部22は、文書取得部21によって取得された仕様書に含まれる各文について、構文解析を行い、主要な語である主語、およびその主語についての説明を与える、すなわち主語を修飾する修飾語句を特定する。
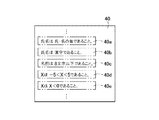
図2は、仕様書40の一部を示す図である。たとえば図2に示すように、仕様書40の一部に、『氏名は氏・名の順であること。』という文40aと、『氏名は漢字であること。』という文40bと、『名前は8文字以下であること。』という文40cと、『Xは−5<X<5であること。』という文40dと、『XはX<0であること。』という文40eという5つの文が含まれている場合、構文解析部22は、文40aについて、主語を『氏名』、修飾語句を『氏・名の順』であると特定し、文40bについて、主語を『氏名』、修飾語句を『漢字』であると特定し、文40cについて、主語を『名前』、修飾語句を『8文字以下』であると特定し、文40dについて、主語を『X』、修飾語句を『−5<X』および『X<5』であると特定し、文40eについて、主語を『X』、修飾語句を『X<0』であると特定する。このようにして、構文解析部22は、取得された仕様書40に含まれる全ての文について、主語および修飾語句を特定する。
なお、文40dのような場合、すなわち、1つの文において、1つの式に1つしか含み得ない不等号および等号などの記号が複数含まれている場合、これらの記号を予め登録しておくことにより、1つの主語に対して、複数の修飾語句を特定することができる。文40dの場合には、『−5<X<5』という修飾語句が、『−5<XかつX<5』と解釈されることにより、上記のように2つの修飾語句として特定される。
また、図示しないが、仕様書40において、『それ』および『これ』といった指示代名詞を用いて記述されている文については、その文よりも前に記述されている文から、指示代名詞が指し示す言葉を特定する。
なお、主語および修飾語句を特定する技術については、たとえば仮名漢字変換処理や翻訳処理において利用されているような、従来から周知の技術を適宜用いることができる。また、指示代名詞が指し示す言葉を特定する技術についても、従来から周知の技術を適宜用いることができる。
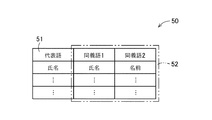
同義語置換手段である同義語置換部23は、構文解析部22によって特定された各主語および各修飾語句を、同義語記憶部12に格納されている同義語テーブル50を参照することによって、必要に応じて別の言葉に置換する。図3は、同義語記憶部12に格納される同義語テーブル50の一例を示す図である。同義語テーブル50は、表記に揺らぎのある、すなわち表記は異なるが意味が同じである2以上の言葉が同義語としてそれぞれ登録される同義語フィールド52と、同義語フィールド52に登録されている複数の言葉を代表する言葉が登録される代表語フィールド51とを含む。このような同義語テーブル50は、予め作成されて同義語記憶部12に格納される。
たとえば図3に示すように、1つのデータセットには、同義語として『氏名』および『名前』という2つの言葉が登録され、代表する言葉として『氏名』が登録されている。同義語置換部23は、構文解析部22によって特定された各主語および各修飾語について、同義語テーブル50の同義語フィールド52に登録されている言葉であるか否かを判定し、同義語フィールド52に登録されている言葉であった場合には、そのデータセットに基づいて、判定対象の言葉を代表語フィールド51の言葉に置換する。図2に示す仕様書40の一部に対し、図3に示す同義語テーブル50を適用すると、文40cにおける主語『名前』が、『氏名』という言葉に置換される。
修飾語句縮退手段である修飾語句縮退部24は、同義語置換部23による同義語の置換後の仕様書40に対し、同じ主語を有する複数の文において修飾語句を縮退することができる場合、包含関係記憶部13に格納されている条件に基づいて、修飾語句を縮退する処理を行う。換言すれば、同じ主語を有する複数の文について、その主語を修飾している修飾語句に余分なものがなくなるように、複数の修飾語句から不要な修飾語句を取り除いて、有効な修飾語句を残存させる処理を行う。
たとえば、図2の仕様書40に示される場合、『X』という主語が特定されている文40dおよび文40eという2つの文に対し、前述するように、『−5<X』、『X<5』および『X<0』という3つの数値範囲に関する修飾語句が特定される。この場合、実際に必要な数値範囲は−5<X<0であるので、修飾語句縮退部24は、3つの修飾語句のうち、『X<5』という修飾語句を削除し、『−5<X』および『X<0』という2つの修飾語句を残存させる。このとき、修飾語句縮退部24は、包含関係記憶部13に格納されている「X<a(条件1)とX<b(条件2)という2つの数値範囲について、a<bであるとき、条件1が成立すれば必ず条件2が成立する」という条件に基づいて、条件2に相当する『X<5』は余分な修飾語句であると判断し、『X<5』という修飾語句を削除する。
上記では修飾語句が数値範囲である場合を例に挙げているが、これに限られることなく、たとえば、『Zは白い』という文と、『Zは赤くない』という文が仕様書に含まれている場合には、『白い』という修飾語句による条件が成立すれば、『赤くない』という修飾語句による条件は必ず成立するので、修飾語句縮退部24は、『赤くない』は余分な修飾語句であると判断し、『赤くない』という修飾語句を削除する。このように、修飾語句縮退部24は、同じ主語を有する複数の文において、修飾語句として、同列で比較可能な言葉が特定された場合に、包含関係記憶部13に格納されている条件に基づいて、修飾語句を縮退する処理を行う。
集計手段である集計部25は、修飾語句縮退部24による修飾語句の縮退処理が行われた後の仕様書40に対し、主語ごとに修飾語句の数を集計する。そして、集計された数に基づいて、各主語に対する修飾語句の数を分かり易く表現した特徴ベクトルを生成する。
たとえば、仕様書40において、『X』という主語に対し、『−5<X』および『X<0』という2つの修飾語句が特定され、『Y』という主語に対し、『0≦Y』、『Y≦10』および『Y≠5』という3つの修飾語句が特定されている場合、集計部25は、仕様書40の特徴ベクトルvを、v=(X,Y)=(2,3)として生成する。実際には、仕様書中に含まれる文は膨大であるので、集計部25によって生成される特徴ベクトルvは、次元の大きなベクトルになる。
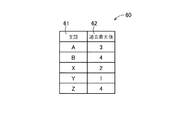
判定手段である判定部26は、集計部25によって生成された特徴ベクトルvと、過去事例記憶部14に格納されている過去事例テーブル60とを比較し、特徴ベクトルvの各要素が過去事例テーブル60に登録されている条件を満足しているか否かを判定する。図4は、過去事例記憶部14に格納される過去事例テーブル60の一例を示す図である。過去事例テーブル60は、評価対象の仕様書における記述が、過去に評価された仕様書における記述に対して、十分であるか否かを評価するために用いられるテーブルである。過去事例テーブル60は、図4に示すように、過去に評価された仕様書において使用されていた主語が登録される主語フィールド61と、主語フィールド61に登録されている各主語に関して、過去に評価された複数の仕様書のうち、最も多くの修飾語句が用いられたときの修飾語句の数が登録される過去最大値フィールド62とを含む。
判定部26は、集計部25によって生成される特徴ベクトルvの各要素を順に取り出し、取り出した要素に係る主語を、過去事例テーブル60の主語フィールド61に登録されている主語の中から検索する。そして、取り出した要素に係る主語が発見された場合には、その主語に対応する過去最大値フィールド62の数値を抽出し、特徴ベクトルvの取り出した要素の数値と比較する。取り出した要素の数値が過去最大値フィールド62の数値よりも小さい場合には、仕様書において、その要素に係る主語の記述が不十分であると判定し、取り出した要素の数値が過去最大値フィールド62の数値に等しい場合には、仕様書において、その要素に係る主語の記述が十分であると判定する。また、取り出した要素の数値が過去最大値フィールド62の数値以上である場合には、仕様書において、その要素に係る主語の記述が十分であると判定するとともに、取り出した要素の数値を用いて、過去最大値フィールド62の数値を更新する。
また、取り出した要素に係る主語を、過去事例テーブル60の主語フィールド61に登録されている主語の中から検索する際に、取り出した要素に係る主語が発見されなかった場合には、仕様書において、その要素に係る主語の記述が十分であると判定するとともに、取り出した要素に係る主語およびその数値を、過去事例テーブル60に新たに登録する。
たとえば、集計部25において、特徴ベクトルv=(X,Y)=(2,3)が生成された場合、判定部26は、図4に示す過去事例テーブル60を用いることによって、仕様書40において、『X』という主語に関する記述は十分であると判定するとともに、過去事例テーブル60における主語『X』に係るデータセットにおいて、過去最大値を『1』から『2』に更新する。また、『Y』という主語に関する記述については不十分であると判定する。
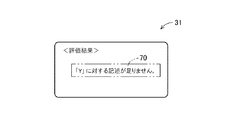
結果出力部27は、判定部26における判定結果に基づいて、仕様書において記述が不十分な主語が存在していることをユーザに報知するための警告メッセージを出力部31に出力させる。図5は、出力部31である表示装置の画面に表示された警告メッセージ70の一例を示す図である。ユーザは、結果出力部27によって出力された判定結果に基づき、警告メッセージ70が出力された場合には、仕様書を修正する作業を実行する。
以上のように、本実施形態に係る文書評価装置1を用いれば、仕様書に記述されている内容が十分であるか否かを客観的に評価することができる。
なお本実施形態では、主語が主要な語であるとして説明しているが、受動形の文を考慮した場合には、主語以外の語が主要な語となり得る。たとえば、『Aボタンが押されたら』と『ユーザがAボタンを押したら』とは同じ内容を表しているが、構文解析を行うことにより主語を特定すると、前者は『Aボタン』であり、後者は『ユーザ』である。このような場合、前者は英文法における「V(動詞)+O(目的語)」(受動形であることからS(主語)が省略されていると判断する)に相当し、後者は「S+V+O」に相当することから、SとOとに相当する語を主要な語として登録しておけばよい。
前述するように、文書評価装置1は、各機能部21〜27を実現する文書評価プログラムの命令を実行するCPU、文書評価プログラムを格納したROM、文書評価プログラムを展開するRAM、各種データを格納するメモリ等の記憶装置(記録媒体)などを備えている。そして、本発明の目的は、各機能部21〜27を実現するソフトウェアである文書評価プログラムのプログラムコード(実行形式プログラム、中間コードプログラム、ソースプログラム)をコンピュータで読み取り可能に記録した記録媒体を、文書評価装置1に供給し、そのコンピュータ(またはCPUやMPU(Micro Processi ng Unit))が記録媒体に記録されているプログラムコードを読み出し実行することによっても、達成可能である。
このような記録媒体としては、たとえば、磁気テープやカセットテープ等のテープ系、フロッピー(登録商標)ディスク/ハードディスク等の磁気ディスクやCD−ROM(
Compact Disc Read-Only Memory)/MO(Magneto-Optical)/MD(Mini Disc)/DVD(digital video disk)/CD−R(CD Recordable)等の光ディスクを含むディスク系、ICカード(メモリカードを含む)/光カード等のカード系、あるいはマスクROM/EPROM(Erasable Programmable Read-Only Memory)/EEPROM(
Electrically Erasable and Programmable Read-Only Memory)/フラッシュROM等の半導体メモリ系などを用いることができる。
Compact Disc Read-Only Memory)/MO(Magneto-Optical)/MD(Mini Disc)/DVD(digital video disk)/CD−R(CD Recordable)等の光ディスクを含むディスク系、ICカード(メモリカードを含む)/光カード等のカード系、あるいはマスクROM/EPROM(Erasable Programmable Read-Only Memory)/EEPROM(
Electrically Erasable and Programmable Read-Only Memory)/フラッシュROM等の半導体メモリ系などを用いることができる。
また、文書評価装置1を通信ネットワークと接続可能に構成し、上記プログラムコードを通信ネットワークを介して供給してもよい。この通信ネットワークとしては、特に限定されず、たとえば、インターネット、イントラネット、エキストラネット、LAN(
Local Area Network)、ISDN(Integrated Services Digital Network)、VAN(
Value-Added Network)、CATV(Community Antenna Television)通信網、仮想専用網(Virtual Private Network)、電話回線網、移動体通信網、衛星通信網等が利用可能である。また、通信ネットワークを構成する伝送媒体としては、特に限定されず、たとえば、IEEE(Institute of Electrical and Electronic Engineers)1394、USB
(Universal Serial Bus)、電力線搬送、ケーブルTV回線、電話線、ADSL(
Asymmetric Digital Subscriber Line)回線等の有線でも、IrDA(Infrared Data
Association)やリモコンのような赤外線、Bluetooth(登録商標)、802.11無線、HDR(High Data Rate)、携帯電話網、衛星回線、地上波デジタル網等の無線でも利用可能である。なお、本発明は、上記プログラムコードが電子的な伝送で具現化された、搬送波に埋め込まれたコンピュータデータ信号の形態でも実現され得る。
Local Area Network)、ISDN(Integrated Services Digital Network)、VAN(
Value-Added Network)、CATV(Community Antenna Television)通信網、仮想専用網(Virtual Private Network)、電話回線網、移動体通信網、衛星通信網等が利用可能である。また、通信ネットワークを構成する伝送媒体としては、特に限定されず、たとえば、IEEE(Institute of Electrical and Electronic Engineers)1394、USB
(Universal Serial Bus)、電力線搬送、ケーブルTV回線、電話線、ADSL(
Asymmetric Digital Subscriber Line)回線等の有線でも、IrDA(Infrared Data
Association)やリモコンのような赤外線、Bluetooth(登録商標)、802.11無線、HDR(High Data Rate)、携帯電話網、衛星回線、地上波デジタル網等の無線でも利用可能である。なお、本発明は、上記プログラムコードが電子的な伝送で具現化された、搬送波に埋め込まれたコンピュータデータ信号の形態でも実現され得る。
1 文書評価装置
10 記憶部
11 文書記憶部
12 同義語記憶部
13 包含関係記憶部
14 過去事例記憶部
20 制御部
21 文書取得部
22 構文解析部
23 同義語置換部
24 修飾語句縮退部
25 集計部
26 判定部
27 結果出力部
30 入力部
31 出力部
10 記憶部
11 文書記憶部
12 同義語記憶部
13 包含関係記憶部
14 過去事例記憶部
20 制御部
21 文書取得部
22 構文解析部
23 同義語置換部
24 修飾語句縮退部
25 集計部
26 判定部
27 結果出力部
30 入力部
31 出力部
Claims (7)
- 複数の文が含まれる文書の内容を評価するための文書評価装置であって、
評価対象の文書を取得する文書取得手段と、
文書取得手段によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手段と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手段と、
主要な語ごとに、集計手段によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手段とを備えることを特徴とする文書評価装置。 - 表記は異なるが意味が同じである2以上の語に対して1つの代表語を定めた同義語テーブルに基づき、特定手段によって特定された各主要な語および各修飾語句を対応する代表語に置換する同義語置換手段をさらに備えることを特徴とする請求項1に記載の文書評価装置。
- 主要な語に対して記述されている複数の修飾語句から余分な修飾語句を削除する修飾語句縮退手段をさらに備えることを特徴とする請求項1または2に記載の文書評価装置。
- 前記判定手段は、修飾語句の数が閾値よりも大きいとき、閾値を該修飾語句の数を用いて更新することを特徴とする請求項1〜3のいずれか1つに記載の文書評価装置。
- 複数の文が含まれる文書の内容を評価するための文書評価方法であって、
評価対象の文書を取得する文書取得工程と、
文書取得工程によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定工程と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計工程と、
主要な語ごとに、集計工程によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定工程とを有することを特徴とする文書評価方法。 - コンピュータに、
複数の文が含まれる、評価対象の文書を取得する文書取得手順と、
文書取得手順によって取得された文書に含まれる各文について、主要な語および該主要な語を修飾する修飾語句を特定する特定手順と、
主要な語ごとに、主要な語に対して記述されている修飾語句の数を集計する集計手順と、
主要な語ごとに、集計手順によって集計された修飾語句の数と所定の閾値とを比較し、修飾語句の数が閾値よりも小さいときに記述が不十分であると判定し、修飾語句の数が閾値以上のときに記述が十分であると判定する判定手順とを実行させることを特徴とする文書評価プログラム。 - 請求項6に記載の文書評価プログラムを記録したコンピュータ読取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009282215A JP2011123771A (ja) | 2009-12-11 | 2009-12-11 | 文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009282215A JP2011123771A (ja) | 2009-12-11 | 2009-12-11 | 文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2011123771A true JP2011123771A (ja) | 2011-06-23 |
Family
ID=44287583
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009282215A Pending JP2011123771A (ja) | 2009-12-11 | 2009-12-11 | 文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2011123771A (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018128978A (ja) * | 2017-02-10 | 2018-08-16 | 株式会社日立システムズ | 設計書評価装置、設計書評価方法、及びプログラム |
-
2009
- 2009-12-11 JP JP2009282215A patent/JP2011123771A/ja active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018128978A (ja) * | 2017-02-10 | 2018-08-16 | 株式会社日立システムズ | 設計書評価装置、設計書評価方法、及びプログラム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Wang et al. | Improving the accessibility of scientific documents: Current state, user needs, and a system solution to enhance scientific PDF accessibility for blind and low vision users | |
| US20140212040A1 (en) | Document Alteration Based on Native Text Analysis and OCR | |
| CN107644011A (zh) | 用于细粒度医疗实体提取的系统和方法 | |
| CN106294107A (zh) | 生成网页页面的测试用例的方法和装置 | |
| JP6237168B2 (ja) | 情報処理装置及び情報処理プログラム | |
| CN110032734B (zh) | 近义词扩展及生成对抗网络模型训练方法和装置 | |
| CN109284372A (zh) | 用户操作行为分析方法、电子装置及计算机可读存储介质 | |
| Abubakar et al. | Using Principal Component Analysis and Logistics Regression to Model Major Types of Cancer among Youth: A Review | |
| JP7053219B2 (ja) | 文書検索装置および方法 | |
| JP6592574B1 (ja) | 記事解析装置、および、記事解析方法 | |
| Kikuchi et al. | Generative colorization of structured mobile web pages | |
| CN102402684B (zh) | 确定证书类型的方法和装置以及翻译证书的方法和装置 | |
| KR102166102B1 (ko) | 개인 정보 보호를 위한 장치 및 기록 매체 | |
| CN110852131A (zh) | 一种考试卡的信息采集方法、系统及终端 | |
| US12093653B2 (en) | Analyzer, moral analysis method, and recording medium | |
| JP2011123771A (ja) | 文書評価装置、文書評価方法、文書評価プログラムおよび該プログラムを記録したコンピュータ読取り可能な記録媒体 | |
| Liu et al. | Measuring linguistic complexity in Chinese: An information-theoretic approach | |
| US20240184985A1 (en) | Information representation structure analysis device, and information representation structure analysis method | |
| CN118378638A (zh) | 基于大语言模型的文本翻译方法、装置、设备 | |
| Choi et al. | Typeface network and the principle of font pairing | |
| CN110163975B (zh) | 空间直线的绘制方法、装置、设备及存储介质 | |
| JP2017228014A (ja) | 評価装置、評価方法および評価プログラム | |
| Yıldız et al. | Using Qualitative Data Analysis Software (QDAS) in Communication Studies: A Systematic Review | |
| CN112199683B (zh) | 一种数据检测方法、装置、终端及存储介质 | |
| JP6167591B2 (ja) | 単語表示制御装置、単語表示制御方法及び単語表示制御プログラム |