JP2010020764A - ハイブリッドマルチサンプル/スーパーサンプルアンチエイリアシング - Google Patents
ハイブリッドマルチサンプル/スーパーサンプルアンチエイリアシング Download PDFInfo
- Publication number
- JP2010020764A JP2010020764A JP2009158615A JP2009158615A JP2010020764A JP 2010020764 A JP2010020764 A JP 2010020764A JP 2009158615 A JP2009158615 A JP 2009158615A JP 2009158615 A JP2009158615 A JP 2009158615A JP 2010020764 A JP2010020764 A JP 2010020764A
- Authority
- JP
- Japan
- Prior art keywords
- supersample
- computing device
- pixel
- cluster
- primitive
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/70—Denoising; Smoothing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2200/00—Indexing scheme for image data processing or generation, in general
- G06T2200/12—Indexing scheme for image data processing or generation, in general involving antialiasing
Landscapes
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Image Generation (AREA)
Abstract
【解決手段】 プリミティブのシェーディング中にピクセルサンプリングレートをダイナミックに調整するためのシステム及び方法は、映像クオリティを改善するか又はシェーディング性能を高めることができる。ハイブリッドアンチエイリアシングは、ピクセル断片当たりにシェーディングされるサンプルの数を選択することにより遂行される。スーパーサンプル及びマルチサンプルアンチエイリアシングの組み合わせが使用され、断片シェーダーパイプラインを通る各パスに対してサブピクセルサンプル(マルチサンプル)のクラスターが処理される。各クラスターにおけるマルチサンプル及びシェーダーパスの数は、レンダリング状態に基づきプリミティブごとにダイナミックに決定することができる。
【選択図】図5C
Description
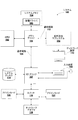
[0018]図1は、本発明の1つ以上の態様を実施するように構成されたコンピュータシステム100を示すブロック図である。このコンピュータシステム100は、メモリブリッジ105を含むバス経路を経て通信する中央処理ユニット(CPU)102及びシステムメモリ104を備えている。例えば、ノースブリッジ(Northbridge)チップでよいメモリブリッジ105は、バス又は他の通信経路106(例えば、ハイパートランスポートリンク)を経てI/O(入力/出力)ブリッジ107に接続される。例えば、サウスブリッジ(Southbridge)チップでよいI/Oブリッジ107は、1つ以上のユーザ入力装置108(例えば、キーボード、マウス)からユーザ入力を受け取り、そしてその入力を、経路106及びメモリブリッジ105を経てCPU102へ転送する。メモリブリッジ105には、バス又は他の通信経路113(例えば、PCIエクスプレス、アクセラレーテッドグラフィックポート又はハイパートランスポートリンク)を経て並列処理サブシステム112が結合され、一実施形態では、この並列処理サブシステム112は、ディスプレイ装置110(例えば、従来のCRT又はLCDベースのモニタ)へピクセルを配送するグラフィックサブシステムである。システムメモリ104に記憶される装置ドライバ103は、CPU102により実行されるプロセス、例えば、アプリケーションプログラムと、並列処理サブシステム112との間をインターフェイスし、並列処理サブシステム112により実行するために必要に応じてプログラム命令を変換する。
[0031]図3は、本発明の1つ以上の態様に基づく図2の並列処理サブシステム112のコア208のブロック図である。PPU202は、非常に多数のスレッドを並列に実行するように構成されたコア208(又は複数コア208)を備え、ここで、「スレッド(thread)」という語は、コンテクストのインスタンス、即ち入力データの特定セットに対して実行される特定プログラムを指す。ある実施形態では、単一インストラクション複数データ(SIMD)のインストラクション発行技術を使用して、複数の独立したインストラクションユニットを設けずに、非常に多数のスレッドの並列実行がサポートされる。
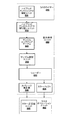
[0040]図4は、本発明の1つ以上の態様に基づくグラフィック処理パイプライン400の概念図である。PPU202は、グラフィック処理パイプライン400を形成するように構成できる。例えば、コア208は、頂点処理ユニット444、幾何学的処理ユニット448、及び断片処理ユニット460のうちの1つ以上の機能を遂行するように構成できる。データアッセンブラー442、プリミティブアッセンブラー446、ラスタライザー455及びラスタオペレーションユニット465の機能も、コア208により遂行することができる。或いは又、グラフィック処理パイプライン40は、頂点処理ユニット444、幾何学的処理ユニット448、断片処理ユニット460、データアッセンブラー442、プリミティブアッセンブラー446、ラスタライザー455、及びラスタオペレーションユニット465のうちの1つ以上に対して専用の処理ユニットを使用して実施することができる。
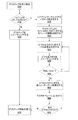
[0046]上述したように、PPU202は、種々のサンプリングレートでシェーディングを遂行して、映像クオリティを改善するか又はシェーディング性能を改善するように構成することができる。ハイブリッドアンチエイリアス制御ユニットは、プリミティブ内の各ピクセルをシェーディングするのに使用されるシェーダーパスの数を決定する。ピクセル当たり1つ以上のマルチサンプル(サブピクセルサンプル)のスーパーサンプルクラスターが、各パスに対して断片処理ユニット460として構成されたコア208により処理されて、シェーディングされた単一のカラー値を発生し、これが、スーパーサンプルクラスターにおける全てのマルチサンプルに対して複写される。シーンがレンダリングされた後に、スーパーサンプルクラスターのサンプルが、アンチエイリアスされた映像を発生するように合成される。
Claims (10)
- ハイブリッドアンチエイリアシングを使用してグラフィックプリミティブをシェーディングするように構成されたコンピューティング装置において、
ラスタライザーと、断片シェーディングユニットとを備え、
前記ラスタライザーが、ハイブリッドアンチエイリアス制御ユニットを含み、
このハイブリッドアンチエイリアス制御ユニットが、
前記グラフィックプリミティブを受け取り、
前記グラフィックプリミティブに交差する各ピクセルをアンチエイリアスするように使用されるスーパーサンプルクラスターの数を決定し、
前記スーパーサンプルクラスターの各1つに対して前記グラフィックプリミティブを処理するように使用されるマルチサンプルの数を決定する、
ように構成されており、
前記断片シェーディングユニットが、前記ラスタライザーに結合されており、この断片シェーディングユニットを通る複数のパスを使用して前記グラフィックプリミティブをシェーディングするように構成されており、
グラフィックプリミティブに交差する各ハイブリッドアンチエイリアス処理ピクセルを発生するのに使用される複数のパスの数が、スーパーサンプルクラスターの数以下である、コンピューティング装置。 - 前記スーパーサンプルクラスターの数が、前記コンピューティング装置のレンダリング状態に基づいて決定される、請求項1に記載のコンピューティング装置。
- 前記レンダリング状態が、高クオリティモード設定、高性能設定、アルファテスト設定、及び高周波数コンテンツを伴うテクスチャマップの使用の1つ以上を含む、請求項2に記載のコンピューティング装置。
- 前記断片シェーディングユニットが、更に、前記スーパーサンプルクラスターの各1つに対してグラフィックプリミティブによりどのマルチサンプルがカバーされるか指示する後シェーダーカバレージを発生するように構成されている、請求項1に記載のコンピューティング装置。
- ラスタオペレーションユニットを更に備え、
前記ラスタオペレーションユニットが、前記断片シェーディングユニットに結合されており、前記後シェーダーカバレージに基づき、グラフィックプリミティブによりカバーされるマルチサンプルの各1つに対してグラフィックプリミティブをzテストして、zテスト値を発生するように構成されている、請求項4に記載のコンピューティング装置。 - 前記ラスタオペレーションユニットが、更に、前記グラフィックプリミティブの各1つに交差するzバッファの一部分に対して前記zテスト値を圧縮するように構成されている、請求項5に記載のコンピューティング装置。
- 前記グラフィックプリミティブの第1のプリミティブに交差する各ピクセルをアンチエイリアシングするのに使用されるスーパーサンプルクラスターの数が、前記グラフィックプリミティブの第2のプリミティブに交差する各ピクセルをアンチエイリアシングするのに使用されるスーパーサンプルクラスターの数とは異なる、請求項1に記載のコンピューティング装置。
- グラフィックプリミティブに交差する各ハイブリッドアンチエイリアス処理ピクセルを発生するのに使用される複数パスの数が、前記グラフィックプリミティブによりカバーされる少なくとも1つのマルチサンプルを伴わないスーパーサンプルクラスターに対するパスを含まない、請求項1に記載のコンピューティング装置。
- 前記断片シェーディングユニットが、更に、前記スーパーサンプルクラスターの各1つにおけるマルチサンプルの1つのみに対してシェード値を計算し、そして同じスーパーサンプルクラスター内の他のマルチサンプルに対してシェード値を複写することにより、前記グラフィックプリミティブをシェーディングするように構成されている、請求項1に記載のコンピューティング装置。
- 前記断片シェーディングユニットは、更に、前記スーパーサンプルクラスターのうちの第1スーパーサンプルクラスターに対するシェード値を、
前記第1スーパーサンプルクラスター内の第1マルチサンプルの位置を使用し、
グラフィックプリミティブによりカバーされる前記第1スーパーサンプルクラスター内のマルチサンプルの幾何学的セントロイドであるセントロイドを使用し、又は
グラフィックプリミティブによりカバーされ且つ前記第1スーパーサンプルクラスターの幾何学的セントロイドに最も近い前記第1スーパーサンプルクラスター内のマルチサンプルである近似セントロイドを使用する、
ことにより、計算するように構成されている、請求項1に記載のコンピューティング装置。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/167,997 | 2008-07-03 | ||
| US12/167,998 | 2008-07-03 | ||
| US12/167,997 US8605086B2 (en) | 2008-07-03 | 2008-07-03 | Hybrid multisample/supersample antialiasing |
| US12/167,998 US8605087B2 (en) | 2008-07-03 | 2008-07-03 | Hybrid multisample/supersample antialiasing |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010020764A true JP2010020764A (ja) | 2010-01-28 |
| JP4744624B2 JP4744624B2 (ja) | 2011-08-10 |
Family
ID=41705532
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009158615A Active JP4744624B2 (ja) | 2008-07-03 | 2009-07-03 | ハイブリッドマルチサンプル/スーパーサンプルアンチエイリアシング |
Country Status (3)
| Country | Link |
|---|---|
| JP (1) | JP4744624B2 (ja) |
| KR (1) | KR101009557B1 (ja) |
| TW (1) | TWI425440B (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013137756A (ja) * | 2011-12-05 | 2013-07-11 | Arm Ltd | コンピュータグラフィックスを処理する方法およびコンピュータグラフィックスを処理するための装置 |
| JP2013536490A (ja) * | 2010-06-21 | 2013-09-19 | マイクロソフト コーポレーション | テキストレンダリングのためのルックアップテーブル |
| JP2013539095A (ja) * | 2010-07-19 | 2013-10-17 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | アンチエイリアシングされたサンプルの分割ストレージ |
| JP2017516200A (ja) * | 2014-04-05 | 2017-06-15 | ソニー インタラクティブ エンタテインメント アメリカ リミテッド ライアビリテイ カンパニー | オブジェクト及び/またはプリミティブ識別子を追跡することによるグラフィック処理の向上 |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101926570B1 (ko) | 2011-09-14 | 2018-12-10 | 삼성전자주식회사 | 포스트 프레그먼트 쉐이더를 사용하는 그래픽 처리 방법 및 장치 |
| US9569883B2 (en) * | 2013-12-12 | 2017-02-14 | Intel Corporation | Decoupled shading pipeline |
| WO2015108218A1 (ko) * | 2014-01-20 | 2015-07-23 | (주)넥셀 | 그래픽 처리 장치 및 방법 |
| US9934606B2 (en) * | 2014-09-16 | 2018-04-03 | Intel Corporation | Deferred coarse pixel shading |
| US9466124B2 (en) | 2014-11-10 | 2016-10-11 | Intel Corporation | Compression using index bits in MSAA |
| KR102680270B1 (ko) | 2016-12-16 | 2024-07-01 | 삼성전자주식회사 | 그래픽스 처리 장치 및 그래픽스 처리 장치에서 그래픽스 파이프라인을 처리하는 방법 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06243247A (ja) * | 1993-02-18 | 1994-09-02 | Matsushita Electric Ind Co Ltd | 形状記述装置 |
| JPH07134776A (ja) * | 1993-05-28 | 1995-05-23 | Nippon Yunishisu Kk | 画像レンダリング方法とその装置 |
| JPH0877385A (ja) * | 1994-08-29 | 1996-03-22 | Internatl Business Mach Corp <Ibm> | コンピュータ・グラフィクス装置 |
| JP2003058905A (ja) * | 2001-08-21 | 2003-02-28 | Nintendo Co Ltd | グラフィックスレンダリングシステムにおいて視覚的に重要なz成分の精度を最大化しz近傍クリッピングを回避するためのz近傍範囲におけるz値のクランピング |
| WO2006056806A1 (en) * | 2004-11-29 | 2006-06-01 | Arm Norway As | Processing of computer graphics |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6768491B2 (en) * | 2001-12-21 | 2004-07-27 | Ati Technologies Inc. | Barycentric centroid sampling method and apparatus |
| US7495672B2 (en) * | 2002-12-20 | 2009-02-24 | Telefonaktiebolaget Lm Ericsson (Publ) | Low-cost supersampling rasterization |
| EP1480171B1 (en) * | 2003-05-22 | 2016-11-02 | Telefonaktiebolaget LM Ericsson (publ) | Method and system for supersampling rasterization of image data |
| US6967663B1 (en) * | 2003-09-08 | 2005-11-22 | Nvidia Corporation | Antialiasing using hybrid supersampling-multisampling |
| US7173631B2 (en) * | 2004-09-23 | 2007-02-06 | Qualcomm Incorporated | Flexible antialiasing in embedded devices |
| US8879635B2 (en) * | 2005-09-27 | 2014-11-04 | Qualcomm Incorporated | Methods and device for data alignment with time domain boundary |
| US20080143720A1 (en) * | 2006-12-13 | 2008-06-19 | Autodesk, Inc. | Method for rendering global illumination on a graphics processing unit |
-
2009
- 2009-07-02 TW TW098122471A patent/TWI425440B/zh not_active IP Right Cessation
- 2009-07-03 JP JP2009158615A patent/JP4744624B2/ja active Active
- 2009-07-03 KR KR1020090060607A patent/KR101009557B1/ko active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06243247A (ja) * | 1993-02-18 | 1994-09-02 | Matsushita Electric Ind Co Ltd | 形状記述装置 |
| JPH07134776A (ja) * | 1993-05-28 | 1995-05-23 | Nippon Yunishisu Kk | 画像レンダリング方法とその装置 |
| JPH0877385A (ja) * | 1994-08-29 | 1996-03-22 | Internatl Business Mach Corp <Ibm> | コンピュータ・グラフィクス装置 |
| JP2003058905A (ja) * | 2001-08-21 | 2003-02-28 | Nintendo Co Ltd | グラフィックスレンダリングシステムにおいて視覚的に重要なz成分の精度を最大化しz近傍クリッピングを回避するためのz近傍範囲におけるz値のクランピング |
| WO2006056806A1 (en) * | 2004-11-29 | 2006-06-01 | Arm Norway As | Processing of computer graphics |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013536490A (ja) * | 2010-06-21 | 2013-09-19 | マイクロソフト コーポレーション | テキストレンダリングのためのルックアップテーブル |
| US9129441B2 (en) | 2010-06-21 | 2015-09-08 | Microsoft Technology Licensing, Llc | Lookup tables for text rendering |
| JP2013539095A (ja) * | 2010-07-19 | 2013-10-17 | アドバンスト・マイクロ・ディバイシズ・インコーポレイテッド | アンチエイリアシングされたサンプルの分割ストレージ |
| JP2013137756A (ja) * | 2011-12-05 | 2013-07-11 | Arm Ltd | コンピュータグラフィックスを処理する方法およびコンピュータグラフィックスを処理するための装置 |
| US9805447B2 (en) | 2011-12-05 | 2017-10-31 | Arm Limited | Methods of and apparatus for processing computer graphics |
| JP2017516200A (ja) * | 2014-04-05 | 2017-06-15 | ソニー インタラクティブ エンタテインメント アメリカ リミテッド ライアビリテイ カンパニー | オブジェクト及び/またはプリミティブ識別子を追跡することによるグラフィック処理の向上 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101009557B1 (ko) | 2011-01-18 |
| KR20100004890A (ko) | 2010-01-13 |
| TW201007610A (en) | 2010-02-16 |
| TWI425440B (zh) | 2014-02-01 |
| JP4744624B2 (ja) | 2011-08-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8605087B2 (en) | Hybrid multisample/supersample antialiasing | |
| US8605086B2 (en) | Hybrid multisample/supersample antialiasing | |
| JP4744624B2 (ja) | ハイブリッドマルチサンプル/スーパーサンプルアンチエイリアシング | |
| US9947084B2 (en) | Multiresolution consistent rasterization | |
| JP5303787B2 (ja) | 単一パステセレーション | |
| US9734548B2 (en) | Caching of adaptively sized cache tiles in a unified L2 cache with surface compression | |
| US9542189B2 (en) | Heuristics for improving performance in a tile-based architecture | |
| CN105321199B (zh) | 图形处理流水线及其操作方法与介质 | |
| US9153209B2 (en) | Method and system for generating a displacement map from a normal map | |
| US9953455B2 (en) | Handling post-Z coverage data in raster operations | |
| CN104050706B (zh) | 用于低功率图形渲染的像素着色器旁路 | |
| CN103871019B (zh) | 用于处理路径图像以促进光栅化的方法和设备 | |
| TWI645371B (zh) | 在上游著色器內設定下游著色狀態 | |
| CN105321143A (zh) | 来自片段着色程序的采样掩膜的控制 | |
| US9396515B2 (en) | Rendering using multiple render target sample masks | |
| US9721381B2 (en) | System, method, and computer program product for discarding pixel samples | |
| US9342891B2 (en) | Stencil then cover path rendering with shared edges | |
| EP3926577B1 (en) | Input/output filter unit for graphics processing unit | |
| CN104050619B (zh) | 具有共享边缘的模板然后覆盖路径渲染 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110404 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110412 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110510 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140520 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4744624 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |