JP2009520306A - 並列マルチレート回路シミュレーション - Google Patents
並列マルチレート回路シミュレーション Download PDFInfo
- Publication number
- JP2009520306A JP2009520306A JP2008547473A JP2008547473A JP2009520306A JP 2009520306 A JP2009520306 A JP 2009520306A JP 2008547473 A JP2008547473 A JP 2008547473A JP 2008547473 A JP2008547473 A JP 2008547473A JP 2009520306 A JP2009520306 A JP 2009520306A
- Authority
- JP
- Japan
- Prior art keywords
- matrix
- circuit
- preconditioned
- instructions
- splitting
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/36—Circuit design at the analogue level
- G06F30/367—Design verification, e.g. using simulation, simulation program with integrated circuit emphasis [SPICE], direct methods or relaxation methods
Landscapes
- Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Microelectronics & Electronic Packaging (AREA)
- Evolutionary Computation (AREA)
- Geometry (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Complex Calculations (AREA)
Abstract
【選択図】図4
Description

Claims (47)
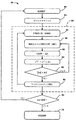
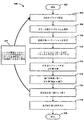
- 集積回路のシミュレーションオペレーションのためのコンピュータ実装された方法であって、
集積回路のオペレーションをモデル化する微分代数方程式(DAE)の系を生成するステップと、
前記DAEの系を離散化するステップと、
前記DAEが非線形である場合、離散化されたDAEを線形化して回路ヤコビ行列をもつ線形系を形成するステップと、
線形化された回路ヤコビ行列ソルバーを用いて前記線形系を解くステップとを含み、
前記線形系を解くステップは、
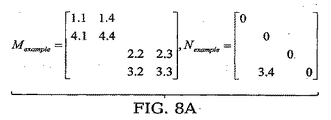
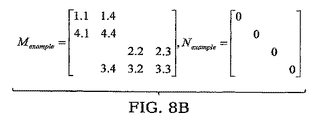
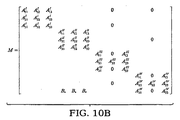
前記回路ヤコビ行列を二つの行列MとNにスプリットするステップと、
対角成分が1で非対角成分がゼロの恒等行列をIとして、前記二つの行列をプレコンディションしてI+M−1Nの形の行列をもつプレコンディションされた方程式を形成するステップと、
直接・反復組み合わせ解法を用いて前記プレコンディションされた方程式におけるI+M−1Nに対する解を求めるステップとを含むことを特徴とする方法。 - 前記DAEの系を生成するステップは、集積回路に対する設計をDAEの系にマッピングするステップを含み、DAEの系は集積回路の複数のノードのそれぞれにおける電圧の変化を定義し、前記電圧の変化は定義可能な期間にわたって発生するものであることを特徴とする請求項1の方法。
- 前記DAEの系を解くステップはさらに、
前記解を前記離散化された方程式に代入して複数のノードのそれぞれに対して電圧の変化を求めるステップと、
前記DAEの有限差分離散化と非線形反復法を用いて電圧の変化を解くための前記線形系を求めるステップと、
複数のノードのそれぞれに対して電圧の変化を現在の電圧ベクトルに足すことにより、各ノードの新しい電圧値を与える新しい電圧ベクトルを求めるステップと、
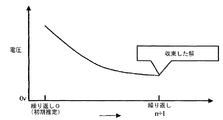
次のタイムステップでDAEの新しい系を解くために1タイムステップ進め、続くタイムステップに対して当該解くステップを繰り返すことにより、集積回路の過渡的な振る舞いをモデル化するステップとを含むことを特徴とする請求項2の方法。 - Mは並列処理に適した行列であり、Nは結合行列であることを特徴とする請求項1の方法。
- 行列I+M−1Nを解くステップは、
Uを上三角行列、Lを下三角行列として、M−1をU−1L−1に置き換えることにより項U−1L−1Nを形成するステップと、
U−1L−1Nを第1、第2、第3の三つの部分にスプリットするステップとを含み、
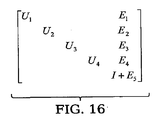
前記第1の部分は行列の相対的に大きい値であるエントリを含み、前記第2の部分と前記第3の部分は、計算過程で相対的に小さな値であるエントリを含むことを特徴とする請求項1の方法。 - 前記第1の部分は行列Eであり、前記第2の部分は行列(LU)−1F1であり、前記第3の部分は行列F2であり、U−1L−1N=E+(LU)−1F1+F2を満たすことを特徴とする請求項5の方法。
- F1はL−1N=E0+L−1F1の計算過程で形成され、
F2は、U−1L−1N=U−1(E0+L−1F1)=E+U−1F2+U−1L−1F1の計算過程で形成されることを特徴とする請求項6の方法。 - M−1が部分系(I+E+U−1F2+U−1L−1F1)x=U−1L−1rにより与えられ、xは、回路ノードにおける以前の近似からの電圧の変化を含むベクトルを表すΔvとして定義され、
であり、vはノードの電圧ベクトルであり、Q(v)はノードの電荷であり、i(v)はノードの電流であり、u0は回路の電源を表すことを特徴とする請求項5の方法。 - 部分系行列(I+E)|Sを形成するために、前記部分系はプレコンディショナー行列I+Eを射影することによってプレコンディションされ、このプレコンディションは、((I+E)|S)−1(I+E+U−1F2+U−1L−1F1)|Sx|S=((I+E)|S)−1(U−1L−1r)|Sを与えることを特徴とする請求項8の方法。
- 回路ヤコビ行列をM+Nにスプリットするステップ、M−1をU−1L−1に置き換えるステップ、およびU−1L−1Nを三つの部分にスプリットするステップは、再帰的に部分系行列(I+E)|Sに対して実行されることを特徴とする請求項8の方法。
- 最終的な部分系のサイズが所定の閾値より小さくなるか、前記部分系が行列特性解析を通じて直接解法にとって効率的であると判定されたとき、プレコンディションおよび再帰は停止し、最終的な部分系を解くために直接法が利用されることを特徴とする請求項10の方法。
- 回路ヤコビ行列は頂点セパレータの集合にしたがってリオーダーされることを特徴とする請求項1の方法。
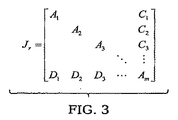
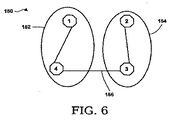
- 回路ヤコビ行列は、頂点セパレータに対応する列をスプリットアウトすることにより、行列MとNにスプリットされることを特徴とする請求項12の方法。
- 行列Mは上行列Uと下行列Lに分解され、プレコンディションするステップは、前記下行列Lを用いて行列MとNをプレコンディションし、プレコンディションされた回路方程式を形成することを特徴とする請求項13の方法。
- プレコンディションされた回路方程式は、L−1JΔv=L−1(M+N)Δv=(U+L−1N)Δv=L−1rにより定義され、Δvは回路ノードにおける以前の近似からの電圧の変化を含むベクトルを表し、
であり、vはノードの電圧ベクトルであり、Q(v)はノードの電荷であり、i(v)はノードの電流であり、u0は回路の電源を表すことを特徴とする請求項14の方法。 - プレコンディションされた回路方程式(U+L−1N)Δv=L−1rは、L−1NをL−1N=E+L−1Fを満たすような第1の部分Eと第2の部分L−1Fにスプリットすることにより解かれ、第1の部分EはL−1Nの計算の後、相対的に大きいエントリを含み、第2の部分L−1Fは相対的に小さいエントリを含むことを特徴とする請求項15の方法。
- L−1Nのスプリッティングは、エントリの値を比較することによりL−1Nの計算をする過程でなされることを特徴とする請求項16の方法。
- 前記第1の部分と前記第2の部分を最初の方程式に代入した結果、(U+E+L−1F)Δv=L−1rによって定義される解くべき線形系が得られることを特徴とする請求項15の方法。
- 前記解くべき線形系はプレコンディショナー(U+E)を用いてプレコンディションされ、(U+E)−1(U+E+L−1F)Δv=(I+(U+E)−1L−1F)Δv=(U+E)−1L−1rで定義されるプレコンディションされた線形系が形成されることを特徴とする請求項18の方法。
- 回路ヤコビ行列をリオーダーするステップ、回路ヤコビ行列を行列MとNにスプリットしてプレコンディションされた回路方程式を形成するステップ、プレコンディションされた回路方程式を形成するために下行列Lを利用するステップ、および、L−1Nを二つの部分にスプリットしプレコンディショナー(U+E)で系をプレコンディションすることにより、プレコンディションされた回路方程式を解くステップを含む一連のオペレーションを再帰的に実行するステップと、
縮小された部分系のサイズが所定の閾値より小さくなるか、縮小された部分系が行列特性解析を通じて直接解法にとって効率的であると判定されたとき、再帰を停止するステップとをさらに含むことを特徴とする請求項19の方法。 - Krylov部分空間反復法はプレコンディションされた線形系の部分系に適用され、この部分系は頂点セパレータに対応することを特徴とする請求項19の方法。
- 前記直接・反復組み合わせ解法はKrylov部分空間反復法を含むことを特徴とする請求項1の方法。
- 集積回路のすべてのアクティブなパーティションのグループは一緒に解かれ、すべてのアクティブなパーティションのグループは、各タイムステップで各非線形の反復過程で動的に成長しうることを特徴とする請求項1の方法。
- DAEの系は集積回路の静的な回路オペレーションをモデル化することを特徴とする請求項1の方法。
- DAEの系は集積回路の周期的または準周期的な安定状態のオペレーションをモデル化することを特徴とする請求項1の方法。
- 疎結合のパーティションに分割された回路ヤコビ行列を用いて、集積回路のオペレーションをモデル化する微分代数方程式(DAE)の系を解くことをコンピュータシステムに実行させるプログラムインストラクションが記録されたマシーン読み取り可能な媒体であって、当該マシーン読み取り可能な媒体は、
複数のノードのそれぞれにおける電圧の値を含む電圧ベクトルと前記回路ヤコビ行列を前記パーティションにしたがってリオーダーするためのインストラクションと、
前記回路ヤコビ行列を二つの行列MとNにスプリットするためのインストラクションと、
対角成分が1で非対角成分がゼロの恒等行列をIとして、前記二つの行列をプレコンディションしてI+M−1Nの形の行列をもつプレコンディションされた方程式を形成するためのインストラクションと、
直接・反復組み合わせ解法を用いて前記プレコンディションされた方程式におけるI+M−1Nに対する解を求めるためのインストラクションとを含むことを特徴とするマシーン読み取り可能媒体。 - Mは並列処理に適した行列であり、Nは結合行列であることを特徴とする請求項26のマシーン読み取り可能媒体。
- 行列I+M−1Nを解くためのインストラクションは、
Uを上三角行列、Lを下三角行列として、M−1をU−1L−1に置き換えることにより項U−1L−1Nを形成するためのインストラクションと、
U−1L−1Nを第1、第2、第3の三つの部分にスプリットするためのインストラクションとを含み、
前記第1の部分は行列の相対的に大きい値であるエントリを含み、前記第2の部分と前記第3の部分は、計算過程で相対的に小さな値であるエントリを含むことを特徴とする請求項26のマシーン読み取り可能媒体。 - 前記第1の部分は行列Eであり、前記第2の部分は行列(LU)−1F1であり、前記第3の部分は行列F2であり、U−1L−1N=E+(LU)−1F1+F2を満たすことを特徴とする請求項28のマシーン読み取り可能媒体。
- F1はL−1N=E0+L−1F1の計算過程で形成され、
F2は、U−1L−1N=U−1(E0+L−1F1)=E+U−1F2+U−1L−1F1の計算過程で形成されることを特徴とする請求項29のマシーン読み取り可能媒体。 - M−1が部分系(I+E+U−1F2+U−1L−1F1)x=U−1L−1rにより与えられ、xは、回路ノードにおける以前の近似からの電圧の変化を含むベクトルを表すΔvとして定義され、
であり、vはノードの電圧ベクトルであり、Q(v)はノードの電荷であり、i(v)はノードの電流であり、u0は回路の電源を表すことを特徴とする請求項29のマシーン読み取り可能媒体。 - 部分系行列(I+E)|Sを形成するために、前記部分系はプレコンディショナー行列I+Eを射影することによってプレコンディションされ、このプレコンディションは、((I+E)|S)−1(I+E+U−1F2+U−1L−1F1)|Sx|S=((I+E)|S)−1(U−1L−1r)|Sを与えることを特徴とする請求項31のマシーン読み取り可能媒体。
- 回路ヤコビ行列をM+Nにスプリットするためのインストラクション、M−1をU−1L−1に置き換えるためのインストラクション、およびU−1L−1Nを三つの部分にスプリットするためのインストラクションを、再帰的に部分系行列(I+E)|Sに対して実行するためのインストラクションをさらに含むことを特徴とする請求項31のマシーン読み取り可能媒体。
- 縮小された部分系のサイズ、あるいはその縮小された部分系が行列特性解析を通じて直接解法にとって効率的であるかどうかの判定にもとづいて、再帰を停止するかどうかを決定するためのインストラクションと、
再帰の停止の後、直接法によって前記縮小された部分系を解くためのインストラクションとをさらに含むことを特徴とする請求項33のマシーン読み取り可能媒体。 - 回路ヤコビ行列は頂点セパレータの集合にしたがってリオーダーされることを特徴とする請求項26のマシーン読み取り可能媒体。
- 回路ヤコビ行列は、頂点セパレータに対応する列をスプリットアウトすることにより、行列MとNにスプリットされることを特徴とする請求項35のマシーン読み取り可能媒体。
- 行列Mは上行列Uと下行列Lに分解するためのインストラクションをさらに含み、プレコンディションするためのインストラクションは、前記下行列Lを用いて行列MとNをプレコンディションし、L−1JΔv=L−1(M+N)Δv=(U+L−1N)Δv=L−1rにより定義されるプレコンディションされた回路方程式を形成するためのインストラクションを含み、
Δvは回路ノードにおける以前の近似からの電圧の変化を含むベクトルを表し、
であり、vはノードの電圧ベクトルであり、Q(v)はノードの電荷であり、i(v)はノードの電流であり、u0は回路の電源を表すことを特徴とする請求項36のマシーン読み取り可能媒体。 - プレコンディションされた回路方程式(U+L−1N)Δv=L−1rは、L−1NをL−1N=E+L−1Fを満たすような第1の部分Eと第2の部分L−1Fにスプリットすることにより解くためのインストラクションをさらに含み、第1の部分EはL−1Nの計算の後、相対的に大きいエントリを含み、第2の部分L−1Fは相対的に小さいエントリを含むことを特徴とする請求項37のマシーン読み取り可能媒体。
- L−1Nのスプリッティングは、エントリの値を比較することによりL−1Nの計算をする過程でなされることを特徴とする請求項38のマシーン読み取り可能媒体。
- 前記第1の部分と前記第2の部分を最初の方程式に代入した結果、(U+E+L−1F)Δv=L−1rによって定義される解くべき線形系が得られることを特徴とする請求項38のマシーン読み取り可能媒体。
- 前記解くべき線形系を(U+E)を用いてプレコンディションし、(U+E)−1(U+E+L−1F)Δv=(I+(U+E)−1L−1F)Δv=(U+E)−1L−1rで定義されるプレコンディションされた線形系を形成するためのインストラクションをさらに含むことを特徴とする請求項40のマシーン読み取り可能媒体。
- 回路ヤコビ行列をリオーダーするためのインストラクション、回路ヤコビ行列を行列MとNにスプリットしてプレコンディションされた回路方程式を形成するためのインストラクション、プレコンディションされた回路方程式を形成するために下行列Lを利用するためのインストラクション、および、L−1Nを二つの部分にスプリットしプレコンディショナー(U+E)で系をプレコンディションすることにより、プレコンディションされた回路方程式を解くためのインストラクションを再帰的に実行するためのインストラクションステップと、
縮小された部分系のサイズ、あるいはその縮小された部分系が行列特性解析を通じて直接解法にとって効率的であるかどうかの判定にもとづいて、再帰を停止するかどうかを決定するためのインストラクションと、
再帰の停止の後、直接法によって前記縮小された部分系を解くためのインストラクションとをさらに含むことを特徴とする請求項41のマシーン読み取り可能媒体。 - Krylov部分空間反復法はプレコンディションされた線形系の部分系に適用され、この部分系は頂点セパレータに対応することを特徴とする請求項41のマシーン読み取り可能媒体。
- 前記直接・反復組み合わせ解法はKrylov部分空間反復法を含むことを特徴とする請求項26のマシーン読み取り可能媒体。
- 集積回路のすべてのアクティブなパーティションのグループは一緒に解かれ、すべてのアクティブなパーティションのグループは、各タイムステップで各非線形の反復過程で動的に成長しうることを特徴とする請求項26のマシーン読み取り可能媒体。
- DAEの系は集積回路の静的な回路オペレーションをモデル化することを特徴とする請求項26のマシーン読み取り可能媒体。
- DAEの系は集積回路の周期的または準周期的な安定状態のオペレーションをモデル化することを特徴とする請求項26のマシーン読み取り可能媒体。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US75221705P | 2005-12-19 | 2005-12-19 | |
| US60/752,217 | 2005-12-19 | ||
| US78937606P | 2006-04-04 | 2006-04-04 | |
| US60/789,376 | 2006-04-04 | ||
| PCT/US2006/048551 WO2007075757A2 (en) | 2005-12-19 | 2006-12-18 | Parallel multi-rate circuit simulation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009520306A true JP2009520306A (ja) | 2009-05-21 |
| JP4790816B2 JP4790816B2 (ja) | 2011-10-12 |
Family
ID=38218555
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008547473A Active JP4790816B2 (ja) | 2005-12-19 | 2006-12-18 | 並列マルチレート回路シミュレーション |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US7783465B2 (ja) |
| EP (1) | EP1964010B1 (ja) |
| JP (1) | JP4790816B2 (ja) |
| TW (1) | TWI340906B (ja) |
| WO (1) | WO2007075757A2 (ja) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8711146B1 (en) * | 2006-11-29 | 2014-04-29 | Carnegie Mellon University | Method and apparatuses for solving weighted planar graphs |
| US20080208553A1 (en) * | 2007-02-27 | 2008-08-28 | Fastrack Design, Inc. | Parallel circuit simulation techniques |
| US8091052B2 (en) * | 2007-10-31 | 2012-01-03 | Synopsys, Inc. | Optimization of post-layout arrays of cells for accelerated transistor level simulation |
| US8543360B2 (en) | 2009-06-30 | 2013-09-24 | Omniz Design Automation Corporation | Parallel simulation of general electrical and mixed-domain circuits |
| TWI476616B (zh) * | 2010-02-12 | 2015-03-11 | Synopsys Shanghai Co Ltd | Estimation Method and Device of Initial Value for Simulation of DC Working Point |
| CN101937481B (zh) * | 2010-08-27 | 2012-02-01 | 天津大学 | 基于自动微分技术的分布式发电系统暂态仿真方法 |
| US8555229B2 (en) | 2011-06-02 | 2013-10-08 | International Business Machines Corporation | Parallel solving of layout optimization |
| US20130226535A1 (en) * | 2012-02-24 | 2013-08-29 | Jeh-Fu Tuan | Concurrent simulation system using graphic processing units (gpu) and method thereof |
| US9117043B1 (en) * | 2012-06-14 | 2015-08-25 | Xilinx, Inc. | Net sensitivity ranges for detection of simulation events |
| US9135383B2 (en) * | 2012-11-16 | 2015-09-15 | Freescale Semiconductor, Inc. | Table model circuit simulation acceleration using model caching |
| US9170836B2 (en) * | 2013-01-09 | 2015-10-27 | Nvidia Corporation | System and method for re-factorizing a square matrix into lower and upper triangular matrices on a parallel processor |
| US20150178438A1 (en) * | 2013-12-20 | 2015-06-25 | Ertugrul Demircan | Semiconductor manufacturing using design verification with markers |
| CN105205191B (zh) * | 2014-06-12 | 2018-10-12 | 济南概伦电子科技有限公司 | 多速率并行电路仿真 |
| JP6384331B2 (ja) * | 2015-01-08 | 2018-09-05 | 富士通株式会社 | 情報処理装置、情報処理方法、および情報処理プログラム |
| JP6803173B2 (ja) * | 2015-08-24 | 2020-12-23 | エスエーエス アイピー,インコーポレーテッドSAS IP, Inc. | 時間ドメイン分解過渡シミュレーションのためのプロセッサ実行システム及び方法 |
| US10867008B2 (en) * | 2017-09-08 | 2020-12-15 | Nvidia Corporation | Hierarchical Jacobi methods and systems implementing a dense symmetric eigenvalue solver |
| US11663383B2 (en) * | 2018-06-01 | 2023-05-30 | Icee Solutions Llc. | Method and system for hierarchical circuit simulation using parallel processing |
| EP3803644A4 (en) | 2018-06-01 | 2022-03-16 | ICEE Solutions LLC | METHOD AND SYSTEM FOR HIERARCHICAL CIRCUIT SIMULATION USING PARALLEL PROCESSING |
| CN112949232A (zh) * | 2021-03-17 | 2021-06-11 | 梁文毅 | 一种基于分布式建模的电气仿真方法 |
| CN117077607A (zh) * | 2023-07-26 | 2023-11-17 | 南方科技大学 | 大规模线性电路仿真方法、系统、电路仿真器及存储介质 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050076318A1 (en) * | 2003-09-26 | 2005-04-07 | Croix John F. | Apparatus and methods for simulation of electronic circuitry |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AUPO904597A0 (en) * | 1997-09-08 | 1997-10-02 | Canon Information Systems Research Australia Pty Ltd | Method for non-linear document conversion and printing |
| US6154716A (en) * | 1998-07-29 | 2000-11-28 | Lucent Technologies - Inc. | System and method for simulating electronic circuits |
| US6530065B1 (en) * | 2000-03-14 | 2003-03-04 | Transim Technology Corporation | Client-server simulator, such as an electrical circuit simulator provided by a web server over the internet |
| US6792475B1 (en) * | 2000-06-23 | 2004-09-14 | Microsoft Corporation | System and method for facilitating the design of a website |
| US20030097246A1 (en) * | 2001-11-16 | 2003-05-22 | Tsutomu Hara | Circuit simulation method |
| US7328195B2 (en) * | 2001-11-21 | 2008-02-05 | Ftl Systems, Inc. | Semi-automatic generation of behavior models continuous value using iterative probing of a device or existing component model |
| US8069075B2 (en) * | 2003-03-05 | 2011-11-29 | Hewlett-Packard Development Company, L.P. | Method and system for evaluating performance of a website using a customer segment agent to interact with the website according to a behavior model |
| US20050273298A1 (en) * | 2003-05-22 | 2005-12-08 | Xoomsys, Inc. | Simulation of systems |
| US7441219B2 (en) * | 2003-06-24 | 2008-10-21 | National Semiconductor Corporation | Method for creating, modifying, and simulating electrical circuits over the internet |
| US7401304B2 (en) * | 2004-01-28 | 2008-07-15 | Gradient Design Automation Inc. | Method and apparatus for thermal modeling and analysis of semiconductor chip designs |
| US20060074843A1 (en) * | 2004-09-30 | 2006-04-06 | Pereira Luis C | World wide web directory for providing live links |
| CN101432696A (zh) * | 2004-10-20 | 2009-05-13 | 卡登斯设计系统公司 | 模型编译方法 |
| JP4233513B2 (ja) * | 2004-11-04 | 2009-03-04 | シャープ株式会社 | 解析装置、解析プログラム、および解析プログラムを記録したコンピュータ読取可能な記録媒体 |
| US8020122B2 (en) * | 2005-06-07 | 2011-09-13 | The Regents Of The University Of California | Circuit splitting in analysis of circuits at transistor level |
| US7606693B2 (en) * | 2005-09-12 | 2009-10-20 | Cadence Design Systems, Inc. | Circuit simulation with decoupled self-heating analysis |
| US7587691B2 (en) * | 2005-11-29 | 2009-09-08 | Synopsys, Inc. | Method and apparatus for facilitating variation-aware parasitic extraction |
-
2006
- 2006-12-18 WO PCT/US2006/048551 patent/WO2007075757A2/en active Search and Examination
- 2006-12-18 US US11/612,335 patent/US7783465B2/en active Active
- 2006-12-18 EP EP06847808.0A patent/EP1964010B1/en active Active
- 2006-12-18 JP JP2008547473A patent/JP4790816B2/ja active Active
- 2006-12-19 TW TW095147717A patent/TWI340906B/zh active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050076318A1 (en) * | 2003-09-26 | 2005-04-07 | Croix John F. | Apparatus and methods for simulation of electronic circuitry |
Non-Patent Citations (2)
| Title |
|---|
| JPN7010003961, Jack Sifri, 大規模RFICのシミュレーション技術, 20021015, アジレント・テクノロジー株式会社 * |
| JPN7010003962, Jun Zhang, "On Preconditioning Schur Complement And Schur Complement Preconditioning", Electronic Transactions on Numerical Analysis, 2000, Vol. 10, pp. 115−130 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US7783465B2 (en) | 2010-08-24 |
| TWI340906B (en) | 2011-04-21 |
| EP1964010A2 (en) | 2008-09-03 |
| EP1964010B1 (en) | 2017-07-19 |
| WO2007075757A3 (en) | 2008-08-14 |
| US20070157135A1 (en) | 2007-07-05 |
| TW200736942A (en) | 2007-10-01 |
| WO2007075757A2 (en) | 2007-07-05 |
| EP1964010A4 (en) | 2010-03-31 |
| JP4790816B2 (ja) | 2011-10-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4790816B2 (ja) | 並列マルチレート回路シミュレーション | |
| US8515724B2 (en) | Technology computer-aided design (TCAD)-based virtual fabrication | |
| Huang et al. | Arbitrary order Krylov deferred correction methods for differential algebraic equations | |
| US7421671B2 (en) | Graph pruning scheme for sensitivity analysis with partitions | |
| WO2010039325A1 (en) | Method for solving reservoir simulation matrix equation using parallel multi-level incomplete factorizations | |
| Zhao et al. | Power grid analysis with hierarchical support graphs | |
| Gao et al. | An implementation and evaluation of the AMLS method for sparse eigenvalue problems | |
| US20080208553A1 (en) | Parallel circuit simulation techniques | |
| Carr et al. | Preconditioning parametrized linear systems | |
| CN115167813A (zh) | 一种大型稀疏矩阵加速求解方法、系统及存储介质 | |
| US8832635B2 (en) | Simulation of circuits with repetitive elements | |
| Kwiatkowska et al. | Dual-processor parallelisation of symbolic probabilistic model checking | |
| Zecevic et al. | A partitioning algorithm for the parallel solution of differential-algebraic equations by waveform relaxation | |
| US8483999B2 (en) | Method and system for simplifying models | |
| Liu et al. | pGRASS-Solver: A Graph Spectral Sparsification Based Parallel Iterative Solver for Large-Scale Power Grid Analysis | |
| CN115587560A (zh) | 用于分布式引擎的运行时和存储器高效的属性查询处理 | |
| Xia et al. | Effective matrix-free preconditioning for the augmented immersed interface method | |
| JP7466665B2 (ja) | リーク電流に統計的ばらつきをもつダイナミックランダムアクセスメモリパストランジスタの設計 | |
| US20110257943A1 (en) | Node-based transient acceleration method for simulating circuits with latency | |
| Han et al. | TinySPICE Plus: Scaling up statistical SPICE simulations on GPU leveraging shared-memory based sparse matrix solution techniques | |
| Qin et al. | RCLK-VJ network reduction with Hurwitz polynomial approximation | |
| Radi et al. | Amigos: Analytical model interface & general object-oriented solver | |
| Wang et al. | Convergence-boosted graph partitioning using maximum spanning trees for iterative solution of large linear circuits | |
| US8819086B2 (en) | Naming methodologies for a hierarchical system | |
| Diosady | A linear multigrid preconditioner for the solution of the Navier-Stokes equations using a discontinuous Galerkin discretization |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101207 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110302 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20110408 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20110408 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110705 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110720 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140729 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4790816 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |