以下に、本発明の実施の形態について図面を参照して説明する。図1は、本発明を適用した情報処理システムの一実施の形態の構成を示す図である。図1に示したシステムは、デジタルデータにされた書籍を扱うシステムである。デジタルデータにされた書籍とは、ここでは、デジタルデータを取り扱うユーザ側の所定の端末で閲覧できるテキスト、画像、若しくは、これらの組み合わせにより構成されるものである。
現在一般的には、紙媒体の書籍(紙書籍)が流通している。そのような紙書籍は、出版社1−1乃至1−Nにより作成され、出版される。そのような紙書籍を出版している出版社1−1乃至1−Nが、デジタルデータ化された書籍(以下、適宜、電子書籍と記述する)も出版するとして説明する。
なお、以下の説明において、出版社1−1乃至1−Nを個々に区別する必要がない場合、単に、出版社1と記述する。また、他の部分も同様に記述する。
各出版社1からのデータは、データ作成装置2に供給される。出版社1は、電子書籍用のデータを、自社で取り扱っているデータ形式で作成し、そのデータをデータ作成装置2に供給する。そのため、各出版社1から供給されるデータは、必ずしも同一の形式のデータであるとは限らないため、データ作成装置2では、主に、異なるデータ形式を同一のデータ形式に変換する(コンバートする)処理を実行する。
例えば、各出版社1から供給されるデータ形式には、HTML(Hyper Text Markup Language)、PDF(Portable Document Format:Adobe Systems社のソフトウェアAcrobatで扱うファイル形式)、Open eBook仕様の形式などがある。よって、各出版社1から供給される電子書籍のデータは、同一の形式のデータではない可能性があるため、データ作成装置2により、データのコンバートが行われる。
データ作成装置2により作成されたデータは、市場3またはネットワーク4を介してユーザ側に提供(配信)される。ここでは、市場3を介してユーザ側に提供されるのは、パッケージメディア5であるとする。パッケージメディア5とは、例えば、メモリースティック(商標)などの記録媒体のことであり、ユーザ側の端末で扱うことができる媒体である。
ネットワーク4は、インターネットなどである。その構成は、有線でも無線でも良く、WAN(World Area Network)やLAN(Local Area Network)などで構成される。なお、図1には記載していないが、出版社1とデータ作成装置2は、ネットワーク4を介してデータの授受を行うようにしても良い。さらに説明を加えるならば、出版社1とデータ作成装置2の間でのデータの授受は、ネットワークなどを介したものであっても良いし、所定の記録媒体にデータを記録し、郵便などで授受されるようにしても良く、そのデータの授受の形態はどのようなものでも良い。
ネットワーク4には、PC(Personal Computer)6−1,6−2が接続されている。PC6―1,6−2には、電子書籍を閲覧するためのユーザ端末7−1,7−2が接続されるように構成されている。また、ユーザ端末7−3,7−4は、ネットワーク4と直接接続されるように構成されている。
PC6は、ネットワーク4を介して他の装置(ここでは、データ作成装置2)とデータの授受を行う機能を通常有している。PC6が用いられる場合、データ作成装置2からのデータは、PC6により受信され、PC6を介してユーザ端末7に供給され、記憶される。
また、PC6が用いられない場合、データ作成装置2から直接的にユーザ端末7にデータが供給され、記憶される。
ユーザ端末7は、データ作成装置2とPC6を介する経路のみで、データの授受を行えるように構成されていても良いし、PC6を介さない経路のみで、データに授受が行えるように構成されていても良い。もちろん、PC6を介する経路と、PC6を介さない経路の、両方の経路をユーザが選択できるような構成とされていても良い。
さらに、ユーザ端末7は、データ作成装置2からのデータをパッケージメディア5に記録されている状態で供給を受けるような構成にされている。ユーザ端末7の構成などについての詳細は後述する。
図2は、データ作成装置2の機能を示す機能ブロック図である。データ作成装置2は、XML(eXtensible Markup Language)コンバータ部21、データコンバータ部22、著作権保護処理部23、配信部24、および、パッケージメディア作成部25から構成されている。
XMLコンバータ部21は、出版社1から供給されるさまざまな形式のデータを、XML形式のデータにコンバート(変換)する。XMLコンバータ部21によりコンバートされたデータは、データコンバータ部22に供給される。データコンバータ部22は、供給されたXML形式のデータを、電子書籍として配信する形式のデータ(バイナリーデータ)に変換する。またその変換を行う際、データコンバータ部22は、オブジェクトで構成されるコンテンツデータに変換する。
データコンバータ部22には、出版社1から、XML形式のデータも、直接的に供給される。すなわち、XML形式のデータであれば、XMLコンバータ部21による処理を必要としないため、XMLコンバータ部21を介さずに、直接的に、データコンバータ部22に出版社1からデータが供給されるようにしても良い。
データコンバータ部22によりコンバートされたデータは、著作権保護処理部23に供給される。著作権保護処理部23は、電子書籍に係わる著作権を保護するための処理を行う部分であり、具体的には、供給されたデータに暗号化などの処理を施したり、著作権データを埋め込んだりする。この著作権保護処理部23による処理は、必要に応じて行われれば良く、例えば、無料で配布される場合で、著作権の保護が必要ないようなデータに対しては行われないようにしても良い。
なお、本情報処理システムには、例えば、本出願人が先に出願した特願2003−163968号に開示されたコンテンツ配信技術を適用することができる。この技術を適用した場合、著作権保護処理部23は、データコンバータ部22によりコンバートされたデータを暗号化して被暗号化コンテンツを作成し、この被暗号化コンテンツに、コンテンツ識別情報、デジタル権利管理情報、ライセンス識別情報、有効化キーブロックEKB、および、暗号化されたコンテンツキーからなるヘッダー部分を付加して、コンテンツファイルを作成する。
著作権保護処理部23から出力されたデータは、配信部24により配信される。配信部24は、内部または外部に記憶部(不図示)を有し、その記憶部に、供給されたデータを記憶し、必要に応じ(PC6やユーザ端末7からの要求に応じ)、その記憶しているデータを読み出し、ネットワーク4を介して配信する。
パッケージメディア作成部25は、パッケージメディア5に、電子書籍のデータを記録させることにより、市場4で売買されるパッケージメディア5を作成する。このパッケージメディア5に記録されるデータは、データコンバータ部22から供給されるデータ、著作権保護処理部23から供給されデータの、どちらか一方、または、両方から構成されるデータである。
例えば、宣伝などの目的で、無料で配布されるようなパッケージメディア5に対しては、データコンバータ部22から供給されるデータのみが記録される。また、販売目的で、特定のユーザ(購入したユーザ)のみに配布されるようなパッケージメディア5に対しては、著作権保護処理部23からのデータのみが記録される。または、販売目的であっても、例えば、最初の100頁は、データコンバータ部22からのデータが記録され、残りの頁は、著作権保護処理部23からのデータが記録されるようにしても良い。
ここでは、図2に示したように、データ作成装置2として1つの装置のように図示し、説明するが、図2に示したデータ作成装置2内の各部は、それぞれ異なる装置として構成し、データ作成装置2は、複数の装置から構成されるシステムとしても良い。
例えば、各部を、1つのサーバとして構成した場合、各サーバは、所定のネットワークで接続され、互いにデータの授受が行えるように構成される。このように、各部を1つのサーバとして構成するようにした場合、出版社1は、XML形式のデータ以外のデータを供給するときには、XMLコンバータ部21を構成するサーバと接続し、XML形式のデータを供給するときには、データコンバータ部22と接続するようにする。
このように接続する先を異ならせるようにした場合(必ずしも、各部が1つのサーバとして構成されている必要性はなく、図2に示したように構成されていても良いが)、課金額を接続先により変更するようにしても良い。
データ作成装置2は、この場合、出版社1とは別に設けられているわけだが、そのデータ作成装置2を管理する管理者としては、このようなサービスを提供する場合、何らかのかたちで、料金を徴収する。その料金の徴収先としては、まず、出版社1が考えられる。出版社1から料金を徴収(課金)する場合、XMLコンバータ部21によるコンバートを必要とした場合と、必要としなかった場合とで課金額を変更するようにしても良い。
このようにすれば、課金額が低い額として設定されるであろう、XMLコンバータ部21を介さない、すなわち、データコンバータ部22を接続先とし、XMLデータを供給する接続が増加すると考えられる。そのような接続の増加に伴い、XMLコンバータ部21が必要ないと判断されるようになった場合、XMLコンバータ部21を削除する構成とすることも可能となる。そのことにより、データ作成装置2のメンテナンスなどに係る費用を軽減させることができる。
また、そのことにより、換言すれば、出版社1側が、XML形式でデータを作成するようになることにより、電子書籍用のデータは、XML形式にすることが主流となり、その結果、電子書籍用のデータをXML形式以外のデータで扱う出版社や、その出版社からデータの供給を受ける側の会社などと差別化を図ることが可能となると考えられる。
データ作成装置2を1または複数の装置で構成するようにした場合、データ作成装置2を構成する装置は、パーソナルコンピュータなどで構成することが可能である。データ作成装置2をパーソナルコンピュータなどで構成した場合の内部構成を、図3に示す。
図3に示したデータ作成装置2のCPU(Central Processing Unit)41は、ROM(Read Only Memory)42に記憶されているプログラムに従って各種の処理を実行する。RAM(Random Access Memory)43には、CPU41が各種の処理を実行する上において必要なデータやプログラムなどが適宜記憶される。入出力インタフェース45は、キーボードやマウスから構成される入力部46が接続され、入力部46に入力された信号をCPU41に出力する。また、入出力インタフェース45には、ディスプレイやスピーカなどから構成される出力部47も接続されている。
さらに、入出力インタフェース45には、ハードディスクなどから構成される記憶部48、および、インターネットなどのネットワークを介して他の装置(例えば、ユーザ端末7)とデータの授受を行う通信部49も接続されている。ドライブ50は、磁気ディスク61、光ディスク62、光磁気ディスク63、半導体メモリ64などの記録媒体からデータを読み出したり、データを書き込んだりするときに用いられる。
図2に示したデータ作成装置2の機能ブロック図と、図3に示したデータ作成装置2の内部構成例との対応関係を示す。XMLコンバータ部21は、例えば、CPU41が、RAM43(またはROM42)に展開されるプログラムに基づく処理を実行することにより実現される。データコンバータ部21や、著作権保護処理部23も、同様に、CPU41がRAM43に展開されるプログラムに基づく処理を実行することにより実現される。
なお、著作権保護処理部23が必要とする著作権の情報などは、記憶部48に記憶される。
出版社1からのデータは、通信部49を介して提供される。または、磁気ディスク61、光ディスク62、光磁気ディスク63、半導体メモリ64などの記録媒体に記録され、ドライブ50から読み込まれることにより供給される。
配信部24は、記憶部48と通信部49により構成される。記憶部48には、ユーザ側に配信する電子書籍のデータが記憶され、その電子書籍のデータが必要に応じ読み出され、通信部49により配信される。もちろん、このような処理の制御を行うのは、CPU41である。
パッケージメディア作成部25は、ドライブ50により構成される。ドライブ50には、上述したように磁気ディスク61などの記録媒体(パッケージメディア5)が挿入され、その記録媒体に、記憶部48に記憶されているデータが記録されることにより、電子書籍のデータが記録されたパッケージメディア5が作成される。もちろん、大量生産するためには、複数のドライブ50が必要であり、また、同時に書き込みが行えるように構成されていることが好ましい。
上述したように、データ作成装置2は、1台の装置で構成される必要はないため、図3に示した構成の装置が、例えば、XMLコンバータ部21としての機能のみを有するサーバとして構成されるようにしても良い。
なお、パッケージメディア5として配布(販売)する場合、電子書籍は紙書籍と異なり、その作成には時間を要しない。換言すれば、パッケージメディア5に、電子書籍のデータを記録させるのに必要な時間は、同じ書籍を紙書籍とする時間に比べれば短い時間である。そのことを利用し、パッケージメディア作成部25は、書店などの店頭に、専用の端末として設置されるようにしても良い。
書店などの店頭に設置された場合、ユーザが、その端末を操作し、所望の電子書籍を選択すると、例えば、ネットワーク4を介して接続されている配信部24と接続され、そのユーザが所望とした電子書籍の情報が送信される。そして、その情報に基づき、対応する電子書籍のデータが端末に送信される。端末は、その送信されてきたデータを記録媒体に記録する。
もちろん、書店などに設置される端末自体に、電子書籍のデータを記憶させておき、そのデータが、記録媒体に記録されるようにして良い。しかしながら、データ作成装置2に接続され、その配信部24からデータが配信されるようにした場合、電子書籍のデータを一元的に、データ作成装置2側で管理することができるため、新たなデータの追加、古くなったデータの削除など、データの更新などに係わる処理を行いやすくなる。
また、データ作成装置2側のみでデータを管理するようにすれば、例えば、よく売れる書籍や、逆に売れない書籍などに関する統計を取りやすくなる。
書店などに端末などが設置される場合、ユーザが端末の前で、操作を開始してから、所望の電子書籍のデータが記録された記録媒体を取得するまでに係る時間は、ユーザが許容できる範囲内であると考えられるため、そのような端末やシステムは、普及すると考えられる。そのため、端末を製造する製造会社も、利益を得ることができる。
また、このようにすれば、出版社1側は、在庫を抱えるというリスクをなくすことができるという利点がある。また、紙媒体の場合、売れなければ、その書籍は処分されるため、紙の無駄な消費につながり、出版社1側にとっても、無駄な出費となるが、上述したような処理が行われることにより、パッケージメディア5が販売されるようになれば、記録媒体自体が無駄になるということを防ぐことが可能となる。
さらに、パッケージメディア5として、揮発性の記録媒体を用いれば、紙書籍の場合と同様に、パッケージメディア5に予めデータを記録させた状態で、書店に並べて販売するとしても、仮に売れなく、回収することになっても、記録媒体自体は、再利用することができ、リスクの軽減、コストの軽減を図ることが可能となる。
なお、ここでは、出版社1から電子書籍のデータが供給されるとしたが、必ずしも、出版社1からのみ電子書籍のデータが供給される必要はない。例えば、作者が、データ作成装置2にデータを直接的に送信するような仕組みを設けても良い。このようにすれば、例えば、自主出版などと称され、作者が自己の資金で出版物を出版するような場合においても、電子書籍であれば、紙媒体にする必要がなく、紙代、印刷代などを削減することができ、さらに、上述したような形態を取ることにより、在庫を抱えることがなくなるので、売れるたぶんの経費だけですむことになる。
すなわち、作者側としては、出版にかかるコストの削減を図ることができ、データ作成装置2を管理する側としては、出版社1以外の顧客からも収益を得ることができる。また、ユーザ側も、今まで、発売されなかったような有名ではない作者の作品を、または、有名名作者であっても商業ベースにのせることができないなどの判断のために、一般的に販売されなかったような作品を、より簡便に購入することができるようになり、さまざまな作者の作品を購入することができる(選択の幅が広がる)。
次に、このようなデータ作成装置2により作成される電子書籍のデータを処理し、ユーザにテキストや画像などで構成される書籍を提供するユーザ端末7について説明を加える。図4は、ユーザ端末7の外観の構成を示す図である。ユーザ端末7は、電子書籍としてのテキストや画像(以下、適宜、コンテンツと記述する)を表示するための表示部71を備える。その表示部71を有する面に対して、側面に位置する部分には、まず、USB(Universal Serial Bus)インタフェース72が設けられている。
このUSBインタフェース72は、PC6(図1)と接続し、データの授受を行うために設けられている。ユーザ端末7は、USBインタフェース72の他に、イーサネット(登録商標)に接続するためのイーサネットインタフェース73も備えている。イーサネットインタフェース73は、ネットワーク4(図1)を介してデータ作成装置2とデータの授受を行うために設けられている。
イーサネットインタフェース73は、無線、有線を問わず、ネットワーク4に接続できる機能を有し、データ作成装置2とデータの授受を行える機能を有していればよい。
ユーザ端末7は、その側面にドライブ74を有する。このドライブ74には、パッケージメディア5が挿入される。ドライブ74は、挿入されたパッケージメディア5から電子書籍のデータを読み出せるように構成されている。
さらに、ユーザ端末7は、その側面に、送りボタン75と戻りボタン76の2つのボタンを有する。この送りボタン75と戻りボタン76は、表示部72に表示されているコンテンツをスクロールする際に操作される。この送りボタン75と同様の役割を有するボタンとして、送りボタン77が、表示部71の下側に設けられている。また、戻りボタン76と同様の役割を有するボタンとして、戻りボタン78も、表示部71の下側に設けられている。
このように、同様の役割を有するボタンを異なる部分に配置するのは、ユーザの使い勝手を考慮してのことである。USBインタフェース72、イーサネットインタフェース73、および、ドライブ74は、それぞれ、図4に示したように、ユーザ端末7の側面に、必ずしも設けられなくてはならないわけではなく、どのような位置に設けられても良い。しかしながら、送りボタン75と戻りボタン76は、ユーザがユーザ端末7を手で保持したときに、操作しやすい位置に設けられる方が好ましい。
ユーザ端末7の表示部71の下側には、送りボタン77と戻りボタン78との間に、ジョグダイヤル(商標)が設けられており、送りボタン77や戻りボタン78と同様に、表示部71に表示されているコンテンツをスクロールさせる際などに操作される。なお、ジョグダイヤル79は、表示部71に対して水平の方向(図中上下方向)に操作されるように構成されていると共に、垂直方向に押下されるようにも構成されているようにしても良く、その押下という処理により、決定などが指示されるように構成されていても良い。
ユーザ端末7は、さらに、拡大ボタン80と決定ボタン81を表示部71の下側に備える。拡大ボタン80は、表示部71に表示されているコンテンツの文字の大きさなどを拡大したいときに操作される。決定ボタン81は、何らかの選択、例えば、後述するスクラップする領域の選択などのときに、その選択で決定する際に操作される。
なお、図4に示したユーザ端末7の構成では、拡大ボタン80のみが備えられているとして説明するが、縮小ボタンも備えられるようにしても良い。図4に示したように、拡大ボタン80のみが備えられるような構成とされる場合には、例えば、所定の回数だけ、その拡大ボタン80が操作されると、拡大処理ではなく、100パーセントの表示戻るように設定される。
ユーザ端末7は、このような複数のボタンなどを備える構成とされているが、図4に示した構成は、一例であり、限定を示すものではない。すなわち、図4に示したボタン以外のボタンが設けられるようにしても良いし、逆に、必要がなければ(他のボタンと共用するなどして必要がなくなれば)削除された構成としても良い。また、そのボタンなどの配置も、図4に示した配置に限定されるものではなく、適宜変更可能である。
図5は、ユーザ端末7の内部構成例を示す図である。図5に示したユーザ端末7のCPU101は、ROM102に記憶されているプログラムに従って各種の処理を実行する。RAM103には、CPU101が各種の処理を実行する上において必要なデータやプログラムなどが適宜記憶される。入出力インタフェース105は、入力部106が接続され、入力部106に入力された信号をCPU101に出力する。
入力部106は、送りボタン75、戻りボタン76、送りボタン77、戻りボタン78、ジョグダイヤル79、拡大ボタン80、および、決定ボタン81から構成される。
入出力インタフェース105には、表示部71も接続されている。さらに、入出力インタフェース105には、ハードディスクなどから構成される記憶部107、および、他の装置(例えば、データ作成装置2)とデータの授受を行う通信部108も接続されている。通信部108は、この場合、USBインタフェース72とイーサネットインタフェース73から構成されている。
ドライブ74は、パッケージメディア5としての記録媒体からデータを読み出したり、必要に応じデータを書き込んだりするときに用いられる。
データ作成装置2から提供され、通信部108により受信されたデータは、記憶部107に記憶され、その記憶されたデータに基づくテキストや画像が、表示部71に表示される。または、ドライブ74にセットされたパッケージメディア5に記録されているデータが読み出され、その読み出されたデータに基づくテキストや画像が、表示部71に表示される。以下の説明においては、表示部71に表示されるテキストや画像を、適宜、コンテンツと記述すると共に、そのコンテンツに係わるデータをコンテンツデータと記述する。
図6は、表示部71に表示されるコンテンツの一例を示す図である。図6に示した例では、表示部71内の上側の位置に、コンテンツのタイトルが表示されるタイトル表示ブロック111が表示されている。そのタイトル表示ブロック111の下側の、左側の位置には、画像が表示される画像表示ブロック112が表示されており、その右側の位置には、テキストが表示されるテキスト表示ブロック113−1が表示されている。
さらに表示部71の下側の位置には、テキストを表示するテキスト表示ブロック113−2が表示されている。以下の説明においてはタイトル表示ブロック111、画像表示ブロック112、テキスト表示ブロック113−1,43−2を、適宜、ブロックと総称する。
図6に示した表示部71に表示されるコンテンツは、一例であり、限定を示すものではない。すなわち、レイアウトなどは、コンテンツにより変更されるし、説明の都合上、例えば、タイトルが表示されるタイトル表示ブロック111が表示されるとして示したが、タイトルがないコンテンツにおいては、タイトル表示ブロック111は表示されないし、タイトルが表示されるときであっても、その位置は、表示部71の上側に限定されなくても良い。
さらに付言するに、これらの表示ブロック111乃至113は、予め表示部71に設定されている領域ではなく、換言すれば、例えば、タイトル表示ブロック111というブロックが予め設定されているのではなく、説明のために付したものであり、上述したように、これらのブロックの表示される位置や内容は、記憶部107に記憶されているデータや、パッケージメディア5に記録されているデータなどに基づき決定されるものである。
従って、例えば、小説のようなコンテンツが表示される場合、表示部71には、テキストしか表示されない。このような場合、テキスト表示ブロック113が表示部71上に設けられ、その設けられた(領域として確保された)テキスト表示ブロック113内に、テキストが表示される。
ここで、コンテンツ(書籍)の種類について説明を加える。まず、漫画のような絵とテキストから構成され、かつ、その1コマ毎の配置(レイアウト)が作者の意図通りでなければならない(レイアウトを変更してしまうと、内容が変化してしまう)ような書籍がある。このような書籍は、拡大などがされたとしても、そのレイアウトが変更されることがないように設定されていなければならない。
本実施の形態においては、このような特徴を有する書籍(例えば、漫画のような書籍)は、画像(イメージ:IMAGE)として扱うとする。よって、漫画のような書籍は、画像表示ブロック112として取り扱われて表示部71上に表示される。
小説のようなテキストのみから構成される書籍がある。テキストのみから構成されるため、そのテキスト(文字)の拡大や縮小が行われたとしても、その文字列の並びが変更されなければ(例えば、“あいう”という文字列が、“あいう”のままであれば、拡大や縮小が行われとしても)良い。
小説のようなテキストのみから構成される書籍は、本実施の形態においては、テキストデータとして扱うとする。よって、小説のような書籍は、テキスト表示ブロック113として取り扱われ、表示部71上に表示される。
雑誌などのように、テキストと画像から構成される書籍もある。テキストは、小説のような場合と同様に、拡大や縮小が行われたとしても、その文字列の並びが変更されなければ良い。画像も同様に拡大や縮小が行われたとしても、その比率などが変化しなければ良い。
また、テキストと画像は、レイアウトが変更されないことが好ましいが、拡大や縮小などの処理が行われることにより、そのレイアウトが変更されたとしても、漫画のように、内容が変わってしまう可能性は低いため、そのレイアウトは変更することも可能である。しかしながら、例えば、所定のテキストの次に、そのテキストが示す内容に関連した画像が表示されるようにすることが好ましく、このような観点からは、レイアウトが変更されても、実質的にユーザが閲覧する順番としてのレイアウトは、変更されない方が好ましい。
このような異なる特徴を有するさまざまな書籍を取り扱うわけだが、本発明においては、コンテンツに対して拡大などの処理が行われたとしても、その拡大などの処理により、コンテンツの作成者が意図したレイアウトを崩されるようなことがないように処理されることが1つの特徴である。そのような特徴を有するコンテンツのコンテンツデータについて説明する。そのコンテンツデータは、データ作成装置2により作成される。
まず、出版社1から供給されたデータが、XMLコンバータ部21によりコンバートされた後のデータ構造、換言すれば、データコンバータ部22に供給されるXML形式のデータのデータ構造について説明する。
最終的にユーザ側のユーザ端末6に配信されるコンテンツデータが作成されるには、XMLフォーマットによるソースデータがまず作成される。このソースデータは、図7に示すように、書誌情報部131、ストリームデータ部132、および、オブジェクトデータ部133から構成される。書誌情報部131には、コンテンツについての情報が記述される。
ストリームデータ部132には、コンテンツの主文の内容と流れを示すデータが記述される。コンテンツの主文の内容とは、例えば、小説の場合における本文であり、その本文のテキストデータと、その本文の流れ、すなわち、順序に関する情報が、ストリームデータ部132には記述される。
オブジェクトデータ部133には、画像や音声、その他の情報などが記述される。その他の情報とは、例えば、レイアウトに関する情報である。オブジェクトデータ部133には、ストリームデータ部132に記述されているデータに対して、付加価値的な情報が記述される。
このように、ストリームデータ部132とオブジェクトエータ部133を分離することにより、文字情報を主な情報源とする電子書籍用のコンテンツデータのコンバートが容易となり、また、表示する装置(ここでは、ユーザ端末7にコンテンツは表示されるとして説明しているが、PC6の表示装置としてのディスプレイ上や、PDA(Personal Digital Assistant)などの装置)毎に変化するレイアウト情報などを、文字情報と独立して(別々に)編集できるため、編集がしやすくなる。このような場合、文字情報の方は共用できる。
なお、表示装置毎に変化するレイアウト情報とは、例えば、PC6のディスプレイ(不図示)と、ユーザ端末7の表示部71の大きさは異なるため、1度に表示できるデータ量(結果として、文字数や画像のサイズなどに係わる)が異なるため、同一のデータにより表示が行われると、レイアウトが崩れてしまう可能性があり、適宜、コンテンツを表示させる装置により、レイアウト情報を変える必要がある。
本実施の形態においては、上述したように、ストリームデータ部132とオブジェクトデータ部133を分離しているため、また、以下に説明を加えるようなデータを有することにより、レイアウト情報の編集などの処理も簡便に行える。
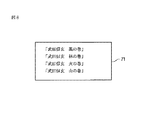
書誌情報部131に記述されるデータについて説明を加える。図8は、書誌情報部131に記述されているデータが再生されることにより、ユーザ端末7の表示部71に表示されるタイトル一覧の表示例を示す図である。図8に示した表示例では、「武田信玄 風の巻」、「武田信玄 林の巻」、「武田信玄 火の巻」、「武田信玄 山の巻」の順で表示されている。
この場合、“武田信玄”というシリーズの書籍で、1巻目が「風の巻」、2巻目が「林の巻」、3巻目が「火の巻」、4巻目が「山の巻」とされているタイトルが表示されている状態である。このような並びは、例えば、日本人であるならば、「風林火山」という言葉を思い出し、“風の巻”の次には、“林の巻”がくるのだなと理解できため、“1巻”、“2巻”などという表記でなくても、その前後関係を理解することができる。
しかしながら、ユーザ端末7でタイトルを、このような概念的な情報により並び替えて正確に表示させるには、そのような概念的な情報を予めユーザ端末7側に入力しておくなどの処理が必要であるが、全ての情報を予め用意し、入力しておくことは不可能である。
一般的には、このようなタイトルなどの並び替えは、例えば、50音順に従って行われる。そのような50音順に従った並び替えであれば、例えば、文字コードなどを利用することができるため、予め情報を用意し、入力するという処理を特に必要とはせず、ユーザ端末7が有する機能のみで、並び替えの機能を実現することが可能である。
しかしながら、図8に示したような“武田信玄”というシリーズの書籍のタイトルを並び変えるような場合、まず、“武田信玄”という部分は同一であるので、この部分だけでは、並び替えを行うことができない。そこで、次に、“風”、“林”、“火”、“山”の部分で並び替えが行われるわけだが、文字コードなどで並び替えが行われた場合、必ずしも、“風林火山”の順番になるとは限らない。
並び替えが正常に行われなければ、ユーザにとって、見づらいタイトルの並びとなってしまい、そのようなことが起こることは防がなければならない。そこで、本実施の形態においては、「reading」という属性を設け、常に、ユーザに対しては、正しい並び替えによる結果のみが提供されるようにする。この「reading」という属性は、ソートの対象となるものに付けられる。図8に示したような表示になるように、「reading」という属性が付けられたデータの一例を以下に示す。
<Title reading=“タケダシンゲン 1”> 武田信玄 風の巻 </Title>
<Title reading=“タケダシンゲン 2”> 武田信玄 林の巻 </Title>
<Title reading=“タケダシンゲン 3”> 武田信玄 火の巻 </Title>
<Title reading=“タケダシンゲン 4”> 武田信玄 山の巻 </Title>
例えば、<Title reading=“タケダシンゲン 1”>という属性が付けられたタイトルは、「武田信玄 風の巻」であることを示している。また、“タケダシンゲン”という読みが与えられている書籍の中では、並び替えが行われときに、“1”番目に表記されるタイトルであることが示されている。<Title reading=“タケダシンゲン 1”>の中で、“タケダシンゲン”という読みの情報が含まれるのは、他の書籍(他のタイトル)との並び替えが行われるときの情報として用いられるからである。
<Title reading=“タケダシンゲン 1”>は、ユーザ端末7側でコンテンツデータを識別するための、また、コンテンツデータの、所定の規則に従った並び替えを行うときの情報として用いられる。その後に続く“武田信玄 風の巻”という情報は、ユーザ側が、コンテンツデータを識別するために用いられる(提供される)情報である。このように、「reading」という属性のデータは、ユーザ端末7側で用いられる情報と、ユーザ側に実施に提供される情報から構成される。
また、この「reading」という属性に関するデータは、出版社1側から提供されるデータに含まれていても良いし(出版社1またはコンテンツを作成した作成者などが付加するようにしても良いし)、データ作成装置2側で、付加するようにしても良い。
このような「reading」という属性が付けられたデータを含む、書誌情報部131に記述されるデータの一例を、図9に示す。なお、図9には、データを線で囲み、その線の外側に、数字を付したが、その線と数字は、説明のために付したものであり、データ自体に付されているものではない。以下の説明においても、同様の記述(図示)は、同様の意味を有するとする。
1行目の<?xml version>や2行目の<Info version>には、該当するフォーマットのバージョンが記述される。3行目の<BookInfo>は、以下の部分に書誌情報が記述されていることを示す。4行目の<Title reading>には、コンテンツのタイトルが記述される。5行目の<Author reading>には、コンテンツの著者名が記述される。
6行目の<BookID>には、該当するコンテンツを唯一識別できる情報が記述され、その情報により、コンテンツが特定されるようにする。7行目の<Publisher reading >には、コンテンツを出版する出版社名(出版社1の社名)が記述される。8行目の<Label reading >には、コンテンツを出版する出版社が設けた発行商標が記述される。
この1乃至8行目に記載されるデータのうち、4行目の<Title reading>に記述されるタイトル、5行目の<Author reading>に記述される著者名、7行目の<Publisher reading >に記述される出版社名、および、8行目の<Label reading >に記述されるレーベル名の、これら4つの要素は、文字の表現が重視されるため、意味をもたせるためのreading属性を記述できるようにされている。
これら4つの要素にreading属性を持たせることにより、ユーザは、タイトル、著者名、出版社名、および、レーベル名のいずれか(または、複数)により並び替えを行うことができる。このように、複数の情報により並び替えが行えるように設定しておくことにより、ユーザが、所望の書籍を検索する際など、容易にその所望の書籍を検索することができるようになる。
また、「reading」という概念を用いることにより、並び替えの段階であっても、その「reading」の部分に記述される表示順序を示す数字を、コンテンツの作成者の意図により割り当てることが可能となるため、その作成者の意図を、並び替えという段階においても反映させることができるようになる。
9行目の<Category>には、該当するコンテンツが、どういったジャンルのものかが記述され、ユーザが、電子書籍を整理しやすいようにするための情報として用いられる。10行目の<Classification>には、どのようなデータが、コンテンツに含まれているのかが記述される。
例えば、紙書籍の場合、雑誌などに付録などが添付されているときがある。そのようなとき、紙書籍であれば、その雑誌の形(膨らみなど)から、付録が添付されていることをユーザが推測することができる。しかしながら、電子書籍のような電子情報の場合、そのような雑誌などの外観から推測できることと同様な推測を行わすための表現ができない。そこで、この<Classification>において、ユーザに、付録が付いていることを明示するための情報を記述することにより、その電子書籍にはどのようなデータが含まれているのかを認識させるための情報が設定されるようにする。
11行目の<FreeText>には、コンテンツのあらすじなどが記述される。その記述された情報は、そのコンテンツが、どのような内容なのかを、ユーザに認識(理解)させるような情報として用いられる。16行目の<DocInfo>は、ドキュメントの情報が以下に記述されていることを示す。17行目の<Language>には、コンテンツの主言語が、例えば、ISO639で規定された言語コードで記述される。
18行目の<Creator>には、コンテンツの作成者名、作成スタジオ名などが記述される。19行目の<CreationDate>には、コンテンツが作成された日時が記述される。20行目の<Producer>には、制作者、生産者などが記述される。21行目の<Page>には、コンテンツを表示するのに必要な見かけ上のページ数が記述される。
ページについての概念は、通常の紙書籍とは異なり電子書籍の場合、明確に規定することができない。例えば、本実施の形態においては、上述したように、表示部71に表示される文字などは、ユーザの所望の大きさに拡大できるように構成されている。
仮に所定の倍率で、ユーザ端末7の表示部71に1度に表示されるコンテンツを1ページであると設定した場合、そのページに対して拡大の指示が出され、その指示が出された結果、拡大されると、1ページでは表示されきれずに、例えば、2ページにわたって表示されることになるときもある。従って、拡大率などに依存し、表示される状況により、同一のコンテンツであっても、ページ数は変化するし、ページという概念の規定の仕方により、ページ数も変化するために、21行目の<Page>には、見かけ上のページ数が記述されるようにしている。
23行目の<Keyword>には、コンテンツをユーザが検索する際に用いられる言葉が記述される。
書誌情報部131には、このようなデータがコンテンツ毎に書き込まれている。なお、図9に示したデータは、一例であり、必要に応じ、他のデータが(他のデータも)記述されるようにすることも可能である。また、逆に、必要がなければ、削除する(省略する)ことも可能である。このことは、以下の説明(他のデータ構造)においても、同様である。
次に、ストリームデータ部132に記述されるデータについて説明する。ストリームデータ部132には、電子書籍としてのコンテンツの主となる内容が、データの表示順に記述される。通常、ページ送り機能によって表示される内容は、このストリームデータ部132に記述される。
上述したように、紙書籍では、大きく分けて3種類のページの表現方法がある。漫画のようにページをイメージデータとして取得し、それを貼り付けるもの、雑誌のように、文字のかたまりを適当な位置に配置することによって、ページを表現するもの、小説のように、文字の流れを中心にレイアウトが組まれるものの3種類である。
これらの異なる表現であっても、同じフォーマットを利用するため(同じフォーマットを利用できるようにするため)、本実施の形態においては、仮想ページ(仮想描画領域)という概念を導入する。仮想ページとは、その仮想ページ内の領域に記述された内容を1ページとして扱うが、実際に表示部71に表示させる際には、そのページ内で、表示可能な領域だけを表示するというものである。図10を参照して、仮想ページについて説明を加える。
表示部71に一度に表示できる領域を表示可能領域151としたとき、必ずしも、1ページとして扱うべき領域(仮想ページ)が、表示可能領域上に1ページとして表示される(すなわち、一度に表示される)わけではない。図10中の上側の図は、表示可能領域151と、仮想描画領域152−1が、同一の領域である状態を示している。なお、図10中の上側の図においては、説明のため、仮想描画領域152―1よりも小さい枠として表示可能領域151を示しているが、同一の大きさに規定されている。
図10中の下側の図に示した仮想描画領域152−1は、図10中の上側の図に示した仮想描画領域152−1の2倍の大きさとされている。本実施の形態におけるユーザ端末7においては、表示部71に表示されている文字などが小さい場合、ユーザにより所望の大きさに拡大できるように構成されている。そのため、ユーザの指示により、表示部71に表示さている文字の拡大が2倍と指示される場合があり、そのようなときには、図10中の上側の図に示した状況から図10中の下側の図に示した状況に変化する。
すなわち、図10中の上側の図に示した状態では、“ABCDE”というアルファベットが、仮想描画領域152−1に描画されている状態(1ページ分の文字として“ABCDE”というアルファベットが描画される状態)と、実際に表示部71に表示される表示可能領域151が一致しているため、表示部71には、“ABCDE”という文字列が表示される。
この状態から、2倍の表示が指示されると、仮想描画領域152−2は、この場合、横方向が2倍の大きさに拡大される。“ABCDE”という文字列も、仮想描画領域152−2内で、2倍の大きさに拡大される。しかしながら、表示可能領域151は、表示部71の大きさと等しいという制限があるため、変化することなく、固定的な大きさである。従って、図10中の上側の図の状態では、“ABCDE”という文字列全てが表示部71に表示される状態であっても、図10中の下側の図の状態では、“AB”と“C”の半分程度しか、表示部71には表示されない状態となる。
図10中の上側の図から図10中の下側の図の状態に変化したことにより、1ページで表示されているものが、2ページにわたって表示されることになる。このように、本実施の形態における電子書籍のデータ、および、そのデータを扱うユーザ端末7は、拡大という処理が行えるように構成されているために、普遍的なページという概念を用いることができない。換言すれば、紙書籍で100ページの書籍が、電子書籍でも100ページと設定されていても、拡大の処理が指示されれば、そのページ数は増加することになり、必ずしも100ページとして処理することはできない。
よって、本実施の形態においては、仮想ページという概念を導入する。この仮想ページは、拡大などの処理が指示されたとして場合であっても、1ページと設定されているページは1ページとして扱うためのものである。そして、そのページが仮想的に展開される領域が仮想描画領域152である。仮想描画領域152に描画されている仮想ページのうち、実際に表示部71に表示される領域が、表示可能領域151である。
なお、表示可能領域151、仮想描画領域152などについて、また、拡大が指示されたときの拡大方法(後述するBlockstyleまたはブロックルール)については、本出願人が、先に出願した特願2002−280257号に開示している方法を適用することが可能である。
このような仮想ページ(仮想描画領域)などの概念を用いて、以下に説明を加える。
ストリームデータ部132に記述されるデータについての説明に戻り、漫画のように、画像やテキストを表示する位置が厳密に定められているものは、イメージデータとして、ストリームデータ部132に記述される。上述したように、漫画のような書籍は、レイアウトが変更されると、その内容まで変更されてしまう可能性があり、たとえ、拡大などが指示されたとしても、そのレイアウトが変更されてしまうような拡大などは行われるようなことがないように設定されていなければならない。
そこで、ここでは、漫画など、レイアウトの変更が許可されないような書籍は、イメージデータとして扱うようにする。図11に示したように、紙書籍で1ページにあたる部分は、電子書籍でも1ページとして扱われるように設定される。すなわち、1ページの仮想描画領域152は、表示可能領域151と、実質的に同じ大きさとされる。
図11に示すように、漫画などでは、複数のコマ(枠)から1ページが構成される。その複数のコマから構成される1ページが1ページとして表示されるように制御がされる。このようなページに対して拡大が指示された場合、拡大の指示があっても、拡大処理が行われないか、または、縦と横が同じ比率で拡大されるかのいずれかである。どちらにしても、レイアウトの変更などはされないため書籍の作成者の意図が、崩れてしまうようなことはない。
図11に示したような場合、画面サイズ(表示可能領域151)とイメージサイズ(仮想描画領域152)を同じ大きさであると設定し、ページ記述部(図12に示すデータ)に、それ以外の記述をしなければ、実際に表示される「ページ」と仮想ページの大きさが等しくなる。
図11に示したようなページのデータ(イメージデータ)は、図12に示したような構成とされる。図12に示したデータ構成例は、<Page>タグが利用された、1仮想ページの記述内容を示している。1行目の<Page>タグに続く“objid”は、そのページ(イメージデータ)を識別するための情報で、そのページを特定したい場合に用いられる情報である。
また、“pagestyle”は、ページのレイアウト情報を記述するオブジェクトを呼び出す部分(オブジェクトデータ部133(図7)に記述されているデータを読み出すための情報が記述される部分)で、このコマンドによってページのマージンなどに関するデータが読み出され、決定される。
2行目の<ImageBlock>タグには、描画するイメージ(画像)についての設定を行うための情報が記述される。<ImageBlock>タグ内の“objid”は、そのImageBlockを識別するための情報が記述される。なお、このタグにより、イメージブロックとして扱うことが宣言されている。
その後に続く“x0,y0,x1,y1”の情報で、描画される画像が、元画像のどの位置に存在するものなのかを示し、切り取った画像をxsize, ysizeで指定した大きさで表示する。
図12に示したデータ例では、横600ドット、縦800ドットのサイズで画像を表示することが示されている。その画像が表示される画面サイズが横600ドット、縦800ドットの場合、画面全体に画像が表示されることになる。他の例を挙げれば、画像サイズが、横1000ドット、縦1200ドットであり、画面サイズが横600ドット、縦800ドットの場合、画像全体のうちの一部分である、600×800ドットの部分の画像が、実際に表示され、ユーザに提供されることになる。
“refobj”では、実際に描画される画像の元データ(画像が表示部71に表示される際に処理される画像データ)の情報が、記述された部分を参照しており、図12に示した例では、“objid”が“201”のもの(データ)を描画することを意味する。この参照先のデータは、オブジェクトデータ部133に記述されている。
また、“blockstyle”では、描画される画像が格納されるブロックの情報を参照している。この“blockstyle”の実データは、オブジェクトデータ部133に記述されている。図6を参照して説明したように、イメージ(画像)やテキストなどは、全てこのブロックの中に描画され、ページレイアウトは、ブロックの中に表示される内容に依存せず、このブロックに対して行われることになる。
ブロック情報には、ブロックの大きさや枠を付ける、または付けないなどの情報が記述される。画像を表示する際は、ブロックの大きさと画像の表示サイズが同じになるように記述される。
次に、主にテキストから構成されるテキストデータについて説明する。図13に、ストリームデータ部132に記述されるテキストに関するデータの構成例を示す。小説のように、文字の流れから(内容から)ページの順番が決められるようなコンテンツは、図13に示すように、<Page>タグで区切られる領域に、章のような大きな単位の文章の集まりが記述される。
図13に示した例では、<Page>タグで区切られる領域に<TextBlock>タグで示されるテキスト情報が記述されている。1行目に記述されている“Page objid”や、“Pagestyle”については、上述したイメージブロックの場合と同様である。<TextBlock>タグ内の“textstyle”で、描画するテキストについての情報を記述しているオブジェクトが呼び出される。このオブジェクトでは、縦書きや横書きの設定、文字の大きさなどが指定される。
テキストブロックのデータは、図13に示したように、テキストデータが、実データとして直接記述されている。換言すれば、図12を参照して説明したイメージブロックのデータでは、実データは、オブジェクトデータ部133に記述されており、その参照先の情報が、ストリームデータ部132に記述されているが、テキストブロックのデータの場合は、参照先の情報ではなく、実データそのものがストリームデータ部132に記述される。
ここで、このように設定する利点について説明する。ここでは、電子書籍として、特許明細書の場合を例に挙げて説明する。特許明細書には、必要に応じ図面が添付される。明細書は、テキストデータとして扱われるようにし、図面はイメージデータとして扱われるようにする。明細書中において、図面によっては、何度も参照される図面がある。それに対して、明細書の文章(テキスト)中の同じ文章が何度も参照されることはなく、たとえ、同じ文章が存在しているとしても、それは、内容的な流れに沿っているものであり、前の文章を参照しているわけではない。
このようなことを換言すれば、図などのイメージデータは、何度も利用されることがあるが、文章のテキストデータは、1度だけ利用される。よって、テキストデータの実データは、ストリームデータ部132のデータとして記述される。そして、イメージデータの実データは、オブジェクトデータ部133に記述されることにより、異なる場面で、何度、参照されても良いように設定される。
図14は、図13に示したデータが処理されることにより表示部71に表示されるテキストについて説明するための図である。図14に示したように、図13に示したデータに基づくテキストを、仮想描画領域152に展開した場合、その仮想描画領域152は、表示可能領域151の4倍の大きさに相当する。すなわち、ユーザ側には、所定の倍率のときに4ページと見なされるページ数として提供される。もちろん、拡大などの処理が指示された場合、その指示に基づいて、ページ数は変化する。
次に、雑誌のような画像やテキストが混じった書籍のデータについて説明する。図15は、ストリームデータ部132に記述されるデータの一例を示す図である。雑誌のように、文のかたまりや、画像を意図した位置に配置することによってページが作り上げられるコンテンツは、<Page>タグで区切られた領域に、複数のブロックオブジェクトが描画され、それらの距離が<BlockSpace>タグ(例えば、図15において2行目に記載されている情報)で指定されることによって実現される。
図15に示したデータのうち、1行目に記述されている情報については、上述した場合と同様である。2行目や8行目の<BlockSpace>の情報は、前のBlock(ブロック)と後のBlockとの相対距離を指定するための情報である。
このように、ブロック間で、相対的に位置が決定されるようにすることにより、所定のブロックに対して拡大などの処理が指示され、そのブロックを含むページ全体のレイアウトが崩れてしまうようなことが発生しても、ブロックの前後関係は、必ず保つことができる。ブロックの前後関係を保つことができることにより、コンテンツを作成した作成者が意図した順番で、ユーザに閲覧させることは、常に可能となる。よって、再レイアウトして綺麗な表示をすることができる。
図16は、図15に示したデータが処理されることにより表示部71に表示される画像やテキストについて説明するための図である。図16においては、図中左右方向をX軸、図中上下方向をY軸としたが、この軸の設定自体も、後述するオブジェクトデータ部133のデータの一部として記述されており、その記述に従って、設定されるため、必ずしも、図16に図示したように設定されるものではない。
テキスト表示ブロック113は、図15に示した3乃至7行目のデータにより作成される。その位置は、2行目の<BlockSpace>の情報により決定される。その決定された位置に、テキストデータとしての“今日の天気”という文字列が表示される。
そのテキスト表示ブロック113の下側に、画像表示ブロック112が表示されるが、その表示位置は、テキスト表示ブロック113からの相対位置であり、8行目の<BlockSpace>の情報に基づいた位置である。すなわち、8行目には、<BlockSpace x=”20”>との記述があるが、テキスト表示ブロック113からX方向に20だけ(20ドット、20ミリなど予め規定されている単位分)移動した位置に、画像表示ブロック112が表示される。
その画像表示ブロック112に表示される画像の実データは、9行目の<ImageBlock objid=”122”>という情報に基づいて取得されるわけだが、この場合、objidとして122が与えられ、オブジェクトデータ部133に記述されているデータである。
また、その画像の大きさ(画像表示ブロック112のサイズ)は、9,10行目の< x0=”0” y0=”0” x1=”300” y1=”100” xsize=”300” ysize=”100>により規定される。このうち、前半部分の<x0=”0” y0=”0” x1=”300” y1=”100”>の情報は、画像のうちのどの部分を取得するかを指示する情報であり、後半部分の<xsize=”300” ysize=”100>の情報は、倍率を示す。この場合、座標で示すと、(0、0)から(300、100)の領域を表示することが示され、その領域を300×100で表示する、すなわち、1倍で表示することが示されている。
図15に示したデータ構造では、2つのブロックが、図16に示したように1ページに表示される例を示しているが、複数のブロックで1ページが構成されることもあり(例えば、図6に示したような場合)、そのような場合には複数のブロックの情報が、図15に示したような形式で、ブロック毎に記述される。
このように、本実施の形態においては、ブロック単位で処理が行われ、各ブロックの表示位置は、前のブロックからの相対位置で規定されている。このように、前のブロックからの相対位置で表示位置が決定されるということは、各ブロック間で、その表示順序が決定されるということである。すなわち、前のブロックが表示された後でないと、そのブロックの表示位置から相対的に表示位置が求められる後のブロックが表示されないため、結果として表示の順序を規定していることにもなる。
表示の順序が規定されるということは、ユーザにコンテンツが提供される際、ユーザがコンテンツを読む順序も規定される(通常、上から下、左から右に読むということを前提としている)ことになる。これにより、拡大などの処理が行われることにより、レイアウトが変更されてしまったような場合においても、表示される順序には変化がないため、結果として、ユーザがコンテンツを読む順序には変更がないということになる。
このようなデータがストリームデータ部132には記述される。さらに電子書籍では、紙媒体とは異なるため、以下のようなことが可能であり、そのようなことを実現するためのデータもストリームデータ部132には記述される。まず、紙媒体とは異なるために可能となることについて、図17を参照して説明する。
紙書籍では、全てのページが連続して存在する。換言すれば、紙書籍では、ページ毎に順次、連続的な数が割り振られている。ここで、紙書籍における雑誌とその雑誌に添付されている付録のような関係について考える。まず、雑誌の方に注目すると、その雑誌自体には、その雑誌のページ毎に順次、連続的な数が割り振られている。また、付録の方に注目すると、その付録自体にも、その付録のページ毎に順次、連続的な数が割り振られている。
すなわち、雑誌の方も、付録の方も、それぞれ独自に連続的なページ番号が割り振られている。図17においては、雑誌にたとえたページ群を連続ページ群171とし、付録にたとえたページ群を独立ページ群172−1,172−2としている。紙書籍の場合、雑誌から付録へとページを変えるとき、雑誌をわきに置いて付録を持ち、その付録の所望のページを、ページをめくりつつ探すといった処理を行わなくてはならないが、電子書籍では、ページジャンプという機能によって、連続ページ群171から独立ページ群172内の所望のページに移動するといったことを、ユーザは、容易に行える。
ここでは、独立ページ群172は、連続ページ群171からジャンプ機能により閲覧可能なページ群であるとする。また、独立ページ群172にページがジャンプした後、元の連続ページ群171の所定のページに戻ることは可能であるように構成されている。また、独立ページ群172―1から独立ページ群172−2(その逆も可)にジャンプすることも可能であるように構成されている。
しかしながら、独立ページ群172の所定のページのみを、連続ページ群171からジャンプすることなしに閲覧することは不可能とされている。すなわち、独立ページ群172のみを始めから再生させるコンテンツとして指定することはできないように構成されている。これは、連続ページ群171と独立ページ群172との間には、主従関係が設定されているからである。
独立ページ群172は、独立ページ群172だけで識別されるものではなく、連続ページ群171と共に識別されるものとされている。独立ページ群172は、連続ページ群171の付加的な情報を提供するものとされている。そのために、連続ページ群171と切り離して独立ページ群172を存在させても、その独立ページ群172は、意味のないページの集まりと解される可能性がある。
独立ページ群172の各ページ(各ブロック)に記載されていることは、内容的には関連性がなく、各ページが独立的に存在していても良い。換言すれば、ページ(内容)が入れ替えられても全体としての内容的な入れ替えはなく、問題はない。すなわち、独立ページ群172に記載されている記事は、それぞれ独立した記事であり、それぞれの記事に、必ずしも関連性や順番付けがあるものではない。
他の具体例を挙げるなら、連続ページ群171は、例えば小説そのものを内容とし、独立ページ群172は、その小説に登場する登場人物の説明や、背景などの説明などを内容とする。よって、独立ページ群172に記載されている、登場人物の説明は、それぞれの登場人物毎に異なるものであり、それぞれの登場人物毎に独立して存在していても(特定の登場人物の説明だけをユーザに提供しても)、内容的には問題がない。
連続ページ群171内に、所定の登場人物が登場すると、例えば、その登場人物の名前がクリックできるように構成されており、その名前がクリックされると、独立ページ群172の、その登場人物の説明が記述されている部分に表示が切り換えられる。
ユーザは、その独立ページ群172に記載されている内容を閲覧し続けることができる。その登場人物以外の説明なども続けて閲覧できるようにされている。またユーザは、そのような独立ページ群172の所定の内容から、元の連続ページ群171の所定のページに戻ることができる。
また、例えば、登場人物の説明だけをまとめた独立ページ群172−1と、背景の説明だけをまとめた独立ページ群172−2といった、2つの独立ページ群172が、1つの連続ページ群171に対して存在していても良い。そのような場合、独立ページ群172−1から独立ページ群172−2に移動することは可能とされている。また、その逆の独立ページ群172−2から独立ページ群172−1に移動することも可能とされている。
しかしながら、ユーザは、直接、独立ページ群172だけを閲覧することはできないように構成されている。ユーザは、連続ページ群171を閲覧している状態からでないと、独立ページ群172の内容を閲覧できないようにされている。さらに換言するならば、連続ページ群171のコンテンツデータからのみ独立ページ群172のコンテンツデータは、閲覧可能であるというように設定されている。
このような関係を有している場合、独立ページ群172のコンテンツデータのコンテンツは、連続ページ群171のコンテンツデータのコンテンツに対して、付加的な情報を提供する内容であると言える。
このような連続ページ群171のコンテンツデータと独立ページ群172のコンテンツデータは、主従関係が存在しているため、共に配信されるようにした方が良く、独立ページ群172のコンテンツデータのみが配信されるということはないようにされている方が好ましい。また、このような連続ページ群171のコンテンツデータと独立ページ群172のコンテンツデータは、出版社1側で作成し、データ作成装置2に提供するようにしても良いし、データ作成装置2側で、出版社1側から供給されたデータを基に作成するようにしても良い。
このような独立ページ群172は、主たる内容を表示する連続ページ群171と分けて記述することにより、ページ内部の記述を特殊にすることなく実現することができる。そのデータ構造例を図18に示す。
1乃至8行目が連続ページ群171のデータであり、9乃至26行目が、独立ページ群172のデータである。1乃至8行目には連続ページ群171のデータが記述されているわけだが、そのデータは、連続ページ群171を構成するページを識別する識別子<Page objid>が列記されている。<Page objid>がわかれば、ページを決定することができるため、連続ページ群171のデータとしては、この識別子だけが列記されていればよい。
10乃至26行目には、独立ページ群172のデータが記述されているわけだが、そのデータは、まず、<Pages objid>という情報が記述されるが、その<Pages objid>は、独立ページ群172を識別する識別子である。図17と対応付けると、独立ページ群172−1が、10行目の<Pages objid=”1001”>であり、独立ページ群172−2が、18行目の<Pages objid=”1002”>である。
11乃至17行目で、独立ページ群172−1を構成する各ページの識別子の情報が記述されている。図18を参照するに、独立ページ群172−1(識別子としてのPages objidが”1001”であるページ群)は、<Page objid>が、”201”、”202”、および、”203”から構成されていることが示されている。このように、連続ページ群171と独立ページ群172を、それぞれ構成するページの情報が、ストリームデータ部132に記述される。
例えば、ユーザが、ユーザ端末7で、連続ページ群171の所定のページを閲覧しているときに、独立ページ群172の所定のページを閲覧したくなった場合、所定のボタンを操作するだけで、その所望のページを閲覧することができる。そして、その後、ユーザは、その独立ページ群172のページの閲覧を継続することも可能であるし、所定の操作を行うことで、ジャンプする前の元の連続ページ群171のページに戻ることも可能とされている。
このようなデータも、ストリームデータ部132には記述される。
次に、オブジェクトデータ部133(図7)に記述されるデータについて説明する。オブジェクトデータ部133には、ストリームデータ部132に記述されているデータが参照するデータが記述される。そのデータとしては、電子書籍としてのコンテンツを装飾するためのスタイル情報がまずある。そして、イメージデータや音声データなどの実データがあり、それらのデータは、ストリームデータ部132には、直接的に記述されない内容のものである。
また、オブジェクトデータ部133には、ウィンドウ情報や、ボタン情報など、電子書籍ならではの表現についてのデータも記述される。ウィンドウ情報は、例えば、表示部71に表示されている文章中の難しい単語などの意味を、ウィンドウ(窓)として、その文章上に表示する際などに用いられる情報である。ボタン情報は、例えば、表示部71上にボタンを表示させ、そのボタンに対してクリックなどの所定の操作が行われたときに、所定の情報を表示する際などに用いられる情報である。
表示部71に表示されるボタンの例としては、後述するスクラップブック内で、スクラップされた記事が、画像として設定され、保存されたときに、その画像を表示させるためのボタンがある。
オブジェクトデータ部133に記述されるデータは、電子書籍としてのコンテンツを装飾するための情報が記述されるわけだが、そのデータの種類としては、例えば、PageStyle, BlockStyle, TextStyleなどの情報がある。これらの情報(データ)は、それぞれが識別子として持つ“stylelabel”によって呼び出されるため、同じ“stylelabel”を呼び出されているオブジェクトは、スタイル情報が変わることによって一括して変更される。
図12に示したイメージブロックのデータの1行目や、図13に示したテキストブロックのデータの1行目などには、そのブロックの識別子である“Page objid”とともに、そのブロックをどのように表示部71に表示させるかを規定するための“Pagestyle”が記述されている。この“Pagestyle”の部分で記述される情報で参照されるデータが、オブジェクトデータ部133に記述されている。
その“Pagestyle”で参照される情報(スタイル情報)について、まず説明する。図19は、オブジェクトデータ部133に記述されるスタイル情報のデータ構造例を示す図である。PageStyleは、PageStyleタグによって記述される。
1行目の“objid”属性で、“PageStyle”を識別するための情報が記述され、同じく“stylelabel”にユーザが自由に名前を変えられるラベルが記述できるようにされている。このようなユーザ、この場合、主に編集者になるが、その編集者が、オブジェクトに名前を任意に付けられるようにしておくことで、例えば、編集中の電子書籍に、このスタイルのオブジェクトを用いることはもちろんだが、後の時点で、他の電子書籍に、このスタイルのオブジェクトを適用する際、このスタイルのオブジェクトを自分が付けた名前(ラベル)で識別できるので、容易に、所望のオブジェクトを探し出すことが可能となる。
図19に示した“stylelabel”は、“Honbun”となっているが、図12または図13を参照するに、図12や図13に示したデータの1行目の“Pagestyle”には、“Honbun”と記述されている。
よって、この場合、例えば、図12に示したイメージブロックが描画される際、“Pagestyle”として、図19のデータが、オブジェクトデータ部133から読み出される(参照される)ことになる。また、図13に示したテキストブロックが描画される際も、図19のデータが参照される。このように、1つの“Pagestyle”のデータは、複数のデータから参照されることがある。
このように、複数のデータから参照されるデータが共用されるようにすることで、電子書籍の全体のコンテンツデータ自体の容量を小さくすることができる。また、このようにすることで、図19に示したような“Pagestyle”の情報を書き換えるだけで、複数のブロックに係わる表示を、一括して書き換えることができることになる。このことは、編集などの処理が容易に行えることを意味している。
図19に示した“Pagestyle”のデータ構造について説明を続けるに、2乃至5行目の“evenfooterid”、“evenheaderid”、“oddfooterid”、“oddheaderid”では、見開き表示を考慮し、偶数ページ、奇数ページで利用されるヘッダーおよびフッターのオブジェクトのobjidが記述される。なお、図19の説明におけるページとは、表示可能領域151(図10)のことであり、表示部71のサイズを1ページとした場合のことである。
ここで、見開き表示とは、図4に示したようなユーザ端末7のように1面だけの表示部71を有するのではなく、2面の表示部71を有するような装置における表示や、擬似的に2面構成で表示されるときの表示である。
6行目の“pageposition”では、見開き表示時に、そのページがどちら側に表示されるか(どの位置に表示されるのか)を指示するための情報が記述される。この指示によって、文字の拡大が指示され、結果として、拡大されていない状態でのレイアウトが崩れたときでも、意図したページデザインを保つことが可能となる。
7行目の“setemptyview”では、文字の拡大などの処理により所定のページの後に表示すべきページとの間に、空白のページの描画が必要となったとき、その空白のページにヘッダーやフッターを描画するかしないかを指示するための情報が記述される。例えば、showを指定された場合、ヘッダーやフッターが描画され、emptyが指定された場合、ヘッダーやフッターがない完全に空白なページが表示される。
8乃至16行目の各行における、“topmargin”、“headheight”、“headsep”、“oddsidemargin”、“evensidemargin”、“textheight”、“textwidth”、“footspace”、“footheight”の各情報に従って、ページ内のレイアウト(マージンなどの余白など)が決定される。また、17行目の“layout”の指定によって、ページ内の座標系を縦書き用の座標系にするか、横書き用の座標系にするかが指定される。
次に、図20を参照して、オブジェクトデータ部133に記述されるデータのうち、Textstyleに関するデータについて説明する。図20に示したTextstyleのデータは、例えば、図13に示したデータ内の2行目の記述に基づいて読み出される(参照される)データである。図13に示したデータ内の2行目には、<Textstyle=”tategaki”>との記述があるが、この”tategaki”というラベルにより識別されるデータが、オブジェクトデータ部133から読み出され、この場合、その読み出されるデータが、図20に示したようなデータである。
“TextStyle”は、TextStyleタグによって記述される。1行目の“objid”属性に“TextStyle”を識別するための情報が記述され、同じく“stylelabel”にユーザが自由に名前を変えられるラベルが記述できるようにされている。2行目の“fontsize”で、描画される文字の大きさを指定するための情報が記述される。
3行目と4行目の“fontescapement”と“fontorientation”には、描画される文字を、どのように回転させ、どの向きに進ませるかを指定するための情報が記述される。これらの情報は、テキストにおいて、そのテキストが、縦書きであるか横書きであるかに依存する情報である。5行目の“fontfacename”には、描画される文字のフォントフェイス名の情報が記述される。例えば、図20に示した例では、フォントフェイス名として“明朝”が指示されている。
6行目の“textcolor”には、描画される文字の色を指定するための情報が記述される。この情報により、ユーザは、好みの色で文字を描画させるようにすることができる。7乃至9行目の“wordspace”、“letterspace”、“charspace”には、それぞれ英単語間の空間距離、英字(アルファベット)間の空間距離、和文字間の空間距離を指定するための情報が記述される。
10行目の“baselineskip”には、行間隔を指定するための情報が記述され、11行目の“linespace”には、最低限保証すべき行と行の空間を指定するための情報が記述される。この“linespace”の情報により、レイアウトが崩れても最低限保証される隙間が明示されているため、綺麗に再描画することが可能となる。
次に、図21を参照して、オブジェクトデータ部133に記述されるデータのうち、BlockStyleに関するデータについて説明する。図21に示したBlockStyleのデータは、例えば、図13に示したデータの内の2行目に記述に基づいて読み出される(参照される)データである。図13に示したデータの内の2行目には、<Blockstyle=”textblock”>との記述があるが、この”textblock”というラベルにより識別されるデータが、オブジェクトデータ部133から読み出され、この場合、その読み出されるデータが、図21に示したようなデータである。
“BlockStyle”は、“BlockStyle”タグによって記述される。1行目の“objid”属性で、“BlockStyle”を識別するための情報が記述され、同じく“stylelabel”にユーザが自由に名前を変えられるラベルが記述できるようにされている。2行目の“blockheight”には、描画用に確保するブロックの高さを指定するための情報が記述される。
ここで、図21に示したデータ内には、“blockheight”によりブロックの高さは指定されているが、ブロックの横幅は、指定されていない。描画されるブロックの横幅は、“blockwidth”により指定される。図21に示したデータは、ブロック内部に縦書きのテキストが記述される場合(図13に示したテキストブロックにより読み出されるデータである場合)であり、そのようなときには、その文字数やその文字の大きさによって横幅が変化するため、ブロックの横幅を“blockwidth”で指定する意味がなく、また、指定することができないため、図21に示したデータ内には、ブロックの横幅を指定する情報は、記述されていない。
3行目の“blockrule”には、そのブロックをどのように描画するかを指定するための情報が記述される。この“blockrule”は、主に、拡大が指示されたときの拡大方法に関する情報であり、図21に示した例では、”vert-fixed”が指定されている。この”vert-fixed”は、拡大が指示されたときに、ブロックの縦方向のサイズは固定し、横方向のサイズのみを拡大することを意味する。他のルールとしては、縦方向と横方向を同じ比率で拡大するなどのルールが設定されており、ブロック内に表示される内容(画像、テキスト)に合わせたルールが設定される。
4行目の“layout”には、ブロック内部の座標系および組方向を指定するための情報が記述される。図21に示した例では、“TbRl”が指定されている。この“TbRl”は、テキストブロックの右上を原点とし、テキストを縦書きで描画することを指示する際に用いられる。“LrTb”は、テキストブロックの左上を原点とし、テキストを横書きで描画することを指示する際に用いられる。
5乃至7行目の“topskip”、“sidemargin”、“footskip”には、ブロック内でのレイアウトを設定するための情報が記述される。
このようなデータが、オブジェクトデータ部133には記述される。なお、図を参照して説明したデータは、一例であり、限定を示すものではない。すなわち、上述したデータ以外のデータが、データとして記述されることもある(例えば、図示はしていないが、画像の実データなど)し、上述したデータであっても、そのデータ内に、適用されるコンテンツには必要がないデータであれば、削除(省略)することもこともある。
このようなデータの変更が容易であるのは、すなわち、データの編集、変更が容易であるのは、ストリームデータ部132とオブジェクトデータ部133を分離したことにある。ストリームデータ部132とオブジェクトデータ部133を分離することにより、以下のような利点がある。
通常、書籍の原稿は、ページレイアウトに依存することなく作成される。この著作者(作成者)が作成する原稿を有効利用するには、ページレイアウトに依存する部分と文章の部分をきちんと分離する必要がある。本実施の形態において利用されるフォーマット(すなわち、上述したデータ)は、文章の部分(ストリームデータ部132)とレイアウトの部分(オブジェクトデータ部133)を分離している。
また、ストリームデータ部132には、文章の流れを分断することなく記述することが可能であるため、デジタル入稿形式としても利用できるようになっている。そのため、本発明におけるフォーマットで原稿を作成すれば、電子書籍のコンテンツを作成する際に行われる、データのコンバートをする必要がなく、かつ、通常の原稿データとしても利用することができる。
XMLコンバータ部21(図2)は、出版社1から供給されたデータを、図7に示したようなデータ構造で、図8乃至図21を参照して説明したデータを含むデータにコンバートする。このように変換されたデータは、この場合、XML形式のデータである。さらに、ユーザ端末7に提供するためのバイナリデータ(バイナリファイル)にするための処理が、データコンバータ部22(図2)において行われる。
次に、データコンバータ部22において行われる処理について説明する。図22は、データコンバータ部22によりコンバートされた結果、生成されるファイル(すなわち、ユーザ端末7に対して配布されるデータ)の構成を示す図である。図22に示しように、データコンバータ部22によりコンバートされたデータは、バイナリファイルとされ、全てのコンテンツ情報がオブジェクトとして管理されるような構成に変換される。オブジェクトとして管理されるようにすることにより、データへのアクセスが高速に行えるようになり、また、圧縮や暗号をオブジェクト毎にかけることができるようになることから、データの利用を効率的に行えるようになる。
データへのアクセスが高速に行えるようになることにより、ユーザが、データの処理にかかる時間を待ち時間として認識することもなく、ストレスを感じさせるようなことを防ぐことができる。
また、オブジェクト毎に圧縮や暗号をかけることができるようにすることで、例えば、コンテンツデータ全体に暗号をかけなくても、一部のオブジェクトだけに暗号をかけておけば、結果的にコンテンツデータ全体に暗号をかけたときと同様の効果を得ることができる。詳細は以下に説明するが、オブジェクト同士は、参照するような関係がある。その参照する一方のオブジェクトに暗号をかけておけば、他方は、暗号がかけられていなくても、結果として、暗号をかけられているオブジェクトを利用することができないため、結果として再生することができない。
このように、暗号は、コンテンツデータ全体にかける必要がなく、最小限かけておけば良く、もって、暗号化や復号にかかる時間を少なくすることができ、そのためにかかる能力なども低くてすむため、他の処理に、残った能力を割り当てることができる。
配布されるデータは、図22に示すように、配布されるデータそのものについての情報が記述されるヘッダー情報部181、コンテンツの内容を示すオブジェクト情報部182、および、オブジェクトの位置を示すオブジェクトテーブル情報部183の3つに部分から構成される。
ヘッダー情報部181には、ファイルのフォーマットの情報、暗号化されているか否かを示すフラグ、コンテンツが表示されると想定されるスクリーン(例えば、ユーザ端末7の表示部71(図4))のサイズなどの情報が記述される。スクリーンのサイズの情報は、ユーザ端末7以外の端末などでも、適切にコンテンツが表示されるようにするために記述される情報である。
ヘッダー情報部181に含まれる、または、異なる部分として構成されるようにしても良いが、適宜、文献情報なども記述される。文献情報とは、図7に示した書誌情報部131に記述されている情報を含む情報であり、コンテンツのタイトルなどの情報や、サムネイル画像のデータなどから構成される情報である。
オブジェクト情報部182には、コンテンツの内容を表示するのに必要な情報をオブジェクトという単位で扱い、それらのオブジェクトの情報が記述される。そして、オブジェクトテーブル情報部183には、各オブジェクトにアクセスするのに必要な情報が記述される。
なお、オブジェクト情報部182の直前や、オブジェクトテーブル情報部183の直前には、文書を成形するためなどの理由で、なんらかのデータが挿入される構成とされていても良い。また、成形のためのデータが挿入されることも、必要に応じ許可される。
オブジェクトテーブル情報部183には、オブジェクト番号、オブジェクトデータの開始アドレス、オブジェクトデータのサイズがセットになって記述されている。そして、オブジェクトが取得される場合、このオブジェクトテーブル情報部183に記述された番号が検索され、その開始アドレスが取得され、オブジェクトの読み込みに必要なメモリ領域(例えば、ユーザ端末7のRAM103(図5)の領域)が確保される。
各オブジェクトは、それぞれのオブジェクトのタイプによって、オブジェクト内部の記述方法が異なる。オブジェクトのタイプとして、図23に示すようなものが挙げられる。
“PageTree”は、ページ順序をツリー構造(木構造)で表現(管理)するためのオブジェクトである。“Page”は、ページ内容が記述されるオブジェクトである。“Header”は、ページのヘッダー部の内容が記述されるオブジェクトである。“Footer”は、ページのフッター部の内容が記述されるオブジェクトである。“PageAtr”(Page属性)は、Pageオブジェクトの属性が記述されるオブジェクトである。
“Block”は、ページ内に配置されるブロック(テキストや画像など)の内容が記述されるオブジェクトである。“BlockAtr”(Block属性)は、Blockオブジェクトの属性が記述されるオブジェクトである。“MiniPage”は、ページ内によりレイアウト情報の強い領域を指定するとともに、その領域内の内容が記述されるオブジェクトである。
“BlockList”は、ブロックをリスト化するときに記述されるオブジェクトである。“Text”は、ブロック内にテキストを表示するときに、その内容が記述されるオブジェクトである。“TextAtr”(Text属性)は、“Text”のオブジェクトの属性が記述されるオブジェクトである。“Image”は、ブロック内に画像を表示すためのオブジェクトである。“Canvas”は、ページ内にレイアウトを保持するような領域を指定するとともに、その領域内の内容が記述されるオブジェクトである。
“ParagraphAtr”(段落属性)は、段落内容の属性が記述されるオブジェクトである。“ImageStream”(Imageデータ)は、画像データが記述されるオブジェクトである。“Button”は、ボタンの情報が記述されるオブジェクトである。“Window”は、Window(ウィンドウ)として表示させる内容が記述されるオブジェクトである。“PopUpWin”は、ポップアップウィンドウで表示する内容が記述されるオブジェクトである。
“Sound”は、音声ファイルを鳴らすときの情報が記述されるオブジェクトである。“SoundStream”(Soundデータ)は、音声ファイル情報が記述されるオブジェクトである。“Font”は、フォント情報が記述されるオブジェクトである。“ObjectInfo”(Object情報)は、呼び出し元のオブジェクトの附属情報が記述されるオブジェクトである。“BookAtr”(書籍情報)は、書籍の初期設定を行うオブジェクトである。“TOC”(目次情報)は、Table Of Contents が記述されるオブジェクトである。
これらのタイプの異なるオブジェクトが参照しあうことにより、電子書籍のコンテンツが表現される。データコンバータ部22(図2)は、供給されたXML形式のデータを、このような内容が記述されたオブジェクトに変換するわけだが、図25を参照し、具体例を挙げて、XML形式のデータ(以下、適宜、そのXML形式のデータを構成する要素を、XML要素と記述する)と、オブジェクトの関係について説明する。
図24中の左側を参照するに、データコンバータ部22に供給されるXML形式のデータは、書誌情報部131、ストリームデータ部132、および、オブジェクトデータ部133から構成されるデータである。この構成および各部に記述される内容については、図7を参照して説明した通りである。図24に示した例において、書誌情報部131には、“題名”XML要素191と“著者名”XML要素192が記述されている。これらのデータは、データコンバータ部22により、ヘッダー情報部181に記述される。ヘッダー情報部181には、データコンバータ部22により作成された設定情報も、必要に応じて書き込まれる。
図24に示した例では、ストリームデータ部132には、“第1章本文”XML要素193と“あとがき”XML要素194が記述されている。まず“第1章本文”XML要素193は、データコンバート部22において、Pageオブジェクト201−1、Textオブジェクト202−1、および、Blockオブジェクト203−1に変換される。同様に、“あとがき”XML要素194は、データコンバート部22において、Pageオブジェクト201−2、Textオブジェクト202−2、および、Blockオブジェクト203−2に変換される。
“第1章本文”XML要素193と“あとがき”XML要素194は、共に、内容がテキストで表されるものであるため、Textオブジェクト202−1,202−2に変換される。また、このTextオブジェクト202−1,202−2は、ブロック内にテキストを表示するときに記述されるオブジェクトであるが、そのテキストが表示されるブロックに関する情報は、それぞれ、Blockオブジェクト203−1,203−2に記述されている。さらに、このBlockオブジェクト203−1,203−2に基づくブロックが設けられる所定のページ内における位置などに関する情報が、Pageオブジェクト201−1,201−2に記述される。
このように、1つのXML要素は、複数のオブジェクトに変換される。
さらに説明を続けるに、データコンバータ部22に供給されるデータのうち、オブジェクトデータ部133に記述されている“挿絵画像データ”XML要素195は、Blockオブジェクト203−3とImageオブジェクト204に変換される。この場合、“挿絵画像データ”XML要素195は、画像データを参照するためのデータであるため、Imageオブジェクト204に変換される。
“挿入画像データ”XML要素195は、画像データそのものではなく、対応する画像データを参照するためのデータであり、その画像データそのものは、“画像データ”XML要素196として、オブジェクトデータ部133に記述されている。この“画像データ”XML要素196は、データコンバータ部22により、Imageデータオブジェクト205に変換される。この場合、Imageデータオブジェクト205に基づく画像は、Imageオブジェクト204に記述されている内容に従って、ブロック内に表示されるとともに、Blockオブジェクト203−3に記述されている内容に従って、所定のページ内に表示される。
データコンバータ部22に供給されるXML形式のデータのオブジェクトデータ部133には、図24に示した例では、“PageStyle”XML要素197、“TextStyle”XML要素198、および、“BlockStyle”XML要素199が含まれる。これらのXML要素は、データコンバータ部22により、それぞれ、Page属性オブジェクト206、Text属性オブジェクト207、および、Block属性オブジェクト208に変換される。これらのオブジェクトは、それぞれ、Pageオブジェクト201、Textオブジェクト202、および、Blockオブジェクト203から参照されるオブジェクトであり、それぞれの属性が記述されている。
このように、データコンバータ部22は、入力されるXML形式のデータを解析し、所定の変換ルールに基づいて複数のオブジェクトに変換する。所定のルールとは、例えば、“第1章本文”XML要素193というテキストに関わるXML要素の場合、Pageオブジェクト、Textオブジェクト、および、Blockオブジェクトといった3つのオブジェクトに変換するといったルールである。
データコンバータ部22は、XML形式のデータをオブジェクトに変換する際、そのオブジェクト(バイナリデータ)をどの領域に格納するのかも判断する。また、この変換時に、データコンバータ部22は、各オブジェクトを、オブジェクト番号(オブジェクトID)(例えば、図24において、Pageオブジェクト201―1のオブジェクトIDは“100”である)と称される識別用の番号で管理し、そのオブジェクトID、そのオブジェクトIDで管理されるオブジェクトが格納されている領域のアドレス、および、そのオブジェクトIDで管理されるオブジェクトのサイズを、それぞれ関連付けたオブジェクト配置順序情報212を作成する。
そして、データコンバータ部22は、作成したオブジェクト配置順序情報212を、オブジェクテーブル情報部183に記述する。
オブジェクト情報部182にオブジェクトが格納される際、その格納される領域は、近接した領域に同一の種類のオブジェクトが格納されるようにデータコンバート部22により制御される(このように制御される方が好ましい)。図24を参照し、一例を挙げて説明すると、Pageオブジェクト201―1とPageオブジェクト201―2は、Pageオブジェクトという同一の種類のオブジェクトであるため、オブジェクト情報部182の図中上側の近接した領域に格納されるように制御されている。
データコンバータ部22において、このような変換および制御が行われることにより、図23に示したような構成を有するバイナリ形式のデータが作成される。その作成されたバイナリ形式のデータが、ユーザ側に配布されるデータとされる。
オブジェクトについてさらに他の例を挙げて、説明を加える。図25に、これらのオブジェクトが利用されてページ(電子書籍)を構成する場合の模式図を示す。図25において、1つの四角形は、1つのオブジェクトを示す。
PageTreeオブジェクト221は、電子書籍としての本のページ構造が記述されているオブジェクトである。そのPageTreeオブジェクト221により示されるページ構成は、図25に示した例では、Pageオブジェクト222乃至225から本が構成されていることを示している。Pageオブジェクト222乃至225は、実際に表示部71に表示されるコンテンツの紙面(レイアウト)が、どのように構成されるかなどの情報が記述されている。
Pageオブジェクト222は、Page属性オブジェクト226を参照し、Pageオブジェクト223乃至225は、Page属性オブジェクト227を参照する。Page属性オブジェクト226,227には、それぞれ、ページのマージン、ヘッダー、フッターなどの情報が記述されている。上述した説明においては、図19を参照して説明したPageStyleの情報が、このPage属性オブジェクトには記述されている。
図25に示したように、Page属性オブジェクトは、複数のPageオブジェクトから参照されるように設定されている場合もある。共通に参照できる情報は、共用できるようにすることで、データ構成を簡略化することができ、コンテンツデータ全体のデータ量を小さくすることができる。また、編集なども容易に行えるようになる。
Pageオブジェクト225は、Blockオブジェクト228およびBlockオブジェクト229を参照する。Blockオブジェクト228,229には、ページの本文領域などに配置され、内部に描画するテキストやイメージなどの領域を確保するとともに、文字の拡大をしたときの動作を規定するための情報が記述されている。
このBlockオブジェクト228,229は、共に、Block属性オブジェクト230を参照する。Block属性オブジェクト230は、ブロックのサイズや、拡大が指示されたときの成型方法などが記述されている。上述した説明においては、図21を参照して説明したBlockStyleの情報が、このBlock属性オブジェクトには記述されている。
Blockオブジェクトには、ページ内に配置されるテキストやイメージなどに関する情報が記述されているが、図25に示したBlockオブジェクト228は、ページ内にテキストを表示させるための情報であるため、Textオブジェクト231を参照している。Textオブジェクト231には、ブロック内にテキストを記述するための情報が記述されている。
Textオブジェクト231は、Text属性オブジェクト232を参照している。Text属性オブジェクト232には、この場合、Textオブジェクト231の属性が記述されており、フォント情報や行間などの初期値の情報などが記述されている。上述した説明においては、図20を参照して説明したTextStyleの情報が、このText属性オブジェクトには記述されている。
一方、図25に示したBlockオブジェクト229は、ページに内に画像(イメージ)を表示させるための情報であるため、Imageオブジェクト233を参照している。Imageオブジェクト233には、ブロック内に画像を記述するための情報(位置やサイズなどの情報)が記述されている。
図25に示した例では、ページ上に画像が描画される場合、Blockオブジェクト229が作成され、そのBlockオブジェクト229が、Imageオブジェクト233を呼び出すような構成とされている。また、実際の画像データは、Imageデータ234が参照されることによって取得されるように構成されている。
このように、データをオブジェクト化することによって、各オブジェクトの参照関係が明確になるとともに、フォーマットの拡張も行いやすくなる。フォーマットの拡張を行いやすいということに関し具体例を挙げて説明すると、図25に示した例において、Imageオブジェクト233をMovieオブジェクト(動画像を表示させるためのオブジェクト)に変更し、動画を扱えるようにしても、ページレイアウトを記述するPageオブジェクト225を変更する必要はない。
すなわち、簡単に、静止画像(Image)を動画像(Movie)に変更することができる。もちろん、他の静止画像に置き換えることも可能である。
さらに、所定のコンテンツを表現する要素が、全てオブジェクトとして管理されているため、他のコンテンツのオブジェクトを使って本を表現したりすることも可能となる。例えば、所定のコンテンツ(本)を表現するために作成されたデータを、他のコンテンツ(本)を同じように表現させるためのデータとして流用することも可能となる。
このことを利用し、必要なオブジェクトだけを取り出といったようなことも容易に行うことができる。そのようなことに対して、具体的な例を挙げて説明を加える。ここまでの説明は、データ作成装置2における処理であったが、ここで、データ作成装置2により作成されたデータを扱うユーザ端末7側の処理について説明する。その処理の1つとして、スクラップブックの作成という処理がある。
このスクラップブックの作成処理について説明することにより、上述したように、データをオブジェクトとして扱うことによる利点についてさらに説明を加える。
ここで、スクラップブックとは、ユーザが、所定の書籍内の気に入ったセンテンスや画像などを残しておくための本のことである。例えば、紙媒体の新聞の場合、ユーザがその新聞から、気に入った記事を切り取り、ノートなどに貼り付けて管理するときの、そのノートのことを、ここではスクラップブックと称し、そのスクラップブックを電子書籍の1つとして作成することができる機能をスクラップブック機能と称する。
作成されたスクラップブックは、他の電子書籍と同様に扱うことができる。そのスクラップブックの作成に係わるユーザ側の基本的な操作としては、保存しておきたい部分(スクラップにしたい部分)を選択し、選択完了後にその部分をスクラップブックに追加(保存)させる。
図26と図27を参照し、スクラップブックについてさらに説明を加える。図25に示したような構成を有する電子書籍を、ユーザがユーザ端末7で閲覧しているとき、その電子書籍内の、Imageデータオブジェクト234を処理することにより表示されている画像をスクラップにしたいと所望し、スクラップにするための所定の処理(後述)を行ったとする。
所定の処理が行われることにより、図26に示したデータがコピーされる(図25に示したツリー構造のデータの内の、一部分である枝が切り取られる)。そして、その切り取られた枝の部分が追加されたスクラップブックの一例を、図27に示す。図27に示したスクラップブック250は、PageTreeオブジェクト251で記述される電子書籍である。
スクラップブック250は、Pageオブジェクト252乃至254から構成される。スクラップされる記事(スクラップされた枝)が増加すると、スクラップブック自体のページ数も増加するため、Pageオブジェクトも、そのページの増加に対応して作成される。図27に示した例では、Pageオブジェクト252乃至254は、全て、Page属性オブジェクト255を参照する構成とされている。
このようにすることで、スクラップブック250としてユーザに提供される本は、各ページが統一されたスタイルとなり、見やすいものとなる。スクラップブック250は、さまざまな本から切り抜かれたテキストや画像などから構成されるため、切り抜かれたままの状態が維持されて貼り付けられると、例えば、縦書きのテキストの次に、横書きのテキストがレイアウトされるなどする可能性がある。
そのようなページは、統一性がないページとなり、ユーザにとって見づらいものとなってしまう可能性がある。そこで、ページ毎のスタイルに統一性を持たせるようにする。すなわち、本実施の形態においては、全てのPageオブジェクトが、同じPage属性オブジェクトを参照させるように構成することにより、そのようなことを実現する。
図27に示した例では、Pageオブジェクト254が、スクラップブック250内での最後のページであると設定されている。その為、その最後のページであるPageオブジェクト254に対して、図26に示した切り取られた枝(データ)が貼り付けられる。このことにより、貼り付けられた枝は、Pageオブジェクト255で参照されるデータとなる。
本発明を適用していない電子書籍における、スクラップブックのような、必要な部分を取り出すような手法は、取り出したテキストデータをスクラップブック用の形式で取り出すことになる。しかしながら、本フォーマットは、上述したように、全てのデータがオブジェクト化されているため、フォーマット形式を変えることなく、スクラップした部分を追加することができる。すなわち、本発明によれば、データの切り張りが容易に行うことができる。
スクラップブックの作成について、さらに説明を加える。まず、図28のフローチャートを参照し、ユーザが行うスクラップにする部分の選択に関する処理について説明する。ステップS11において、ユーザは、ユーザ端末7の表示部71に、所望のコンテンツ(本文)を表示させる。そして、その表示されている本文中に、スクラップしたい部分が存在している場合、所定の操作を行い、メニュー画面を表示部71に表示させる(ステップS12)。
所定の操作は、例えば、入力部106(図5)を構成するジョグダイヤル79(図4)などが操作されることにより行われる。ユーザは、表示されたメニュー内から、スクラップの処理を実行させるための「文字クリップ」という項目を選択する。なお、表示されるメニューについての図示および説明は省略するが、そのメニュー内の項目には、どのような項目が設けられていても良い。
ステップS13において、スクラップの処理を実行するための「文字クリップ」という項目が選択されると、ステップS14において、先頭枠が指定される。図29は、表示部71に表示されている本文上に、先頭枠270が表示された状態を示している。先頭枠270とは、スクラップにする部分の先頭の文字(位置)を指定できる範囲を示す枠である。
この先頭枠270は、Pageオブジェクトで規定されるページ内(仮想ページ内)のみを移動できるように設定されている。ここで、再度ページについて説明を加えるに、ページとは、Pageオブジェクトで規定されており、そのPageオブジェクトで規定されるページは、例えば、1ページであっても、実際のページ(仮に紙書籍としたときのページ、または、表示部71に所定の倍率のときに一度に表示される範囲を1ページとしたときのページ)数では、100ページに相当させることもできるように設定されている。
また、Pageオブジェクトで規定されているページは、仮想描画領域152(図10)内に描画されるものが1ページと設定される。従って、表示部71に一度に表示されるもの(表示可能領域151に描画されるもの)を1ページと把握した場合、数ページにわたって表示されるものであっても、1つのPageオブジェクトで規定されているページ内であれば、1ページとして扱われる。
よって、先頭枠270は、表示可能領域151と仮想描画領域152が一致している場合(図10中の上側の図に示したような場合)は、表示部71内に表示されている本文以外の部分に移動することはないが、表示可能領域151と仮想描画領域152が一致していない場合(図10中の下側の図に示したような場合)は、ユーザ側から見れば、複数ページにわたって先頭枠270が移動可能にされていると把握されるような移動がされるときもある。
いずれにせよ、先頭枠270は、Pageオブジェクトで規定されるページ外に移動されることはないように設定されている。これは、上述したように、本実施の形態においては、データをオブジェクト化して扱うようにしているためである。この場合、1つのPageオブジェクトに対して処理がされるのであって、複数のPageオブジェクトに対して行われるのではない。
このようにすることで、すなわち、複数のPageオブジェクトに対して処理(スクラップに係わる処理)が行われることがないため、例えば、複数のPageオブジェクトを含む1冊分のデータ全てが、1回のスクラップの処理により実行されてしまうようなことを防ぐことができる。さらに換言するならば、このようにすることで、違法なコピーを防ぐことができる。
後述するように、スクラップが指示された部分は、著作権などの関係で、コピーが許可されない場合もある。例えば、1冊の本を複数のPageオブジェクトで構成し、さらに、それらのPageオブジェクト内の少なくとも1つを、コピー不可に設定されている場合を考える。1冊の本を全てコピーしようとした場合、ユーザ側は、複数のPageオブジェクト毎にスクラップの処理を繰り返し行わなくてはならず面倒である。よって、この時点で、まずユーザは、コピーを断念すると考えられる。
さらに、ユーザがスクラップ処理を繰り返すことを断念しなくても、そのコピーしようとしている本の中の、少なくとも1つのPageオブジェクトはコピーが不可なので、結果として、1冊分をコピーすることは不可能である。このように、コピーに対して、実質、少なくとも2段階のプロテクトがかかっていることになるため、不正なコピーを防ぐことが可能となる。
図28のフローチャートの説明に戻り、ステップS14において、先頭枠270が、ユーザが所望する部分に移動されると、ステップS15において、先頭文字が指定される。なお、この先頭枠270の移動は、入力部106(図5)としての例えば、ジョグダイヤル79(図4)が操作されることにより行われ、位置の決定は、決定ボタン81が操作されることにより行われる。以下に説明する先頭文字や末尾文字の選択に係わる操作も、基本的に同様に、ジョグダイヤル79などにより移動が指示され、決定ボタン81により決定が指示される。
図30を参照するに、先頭文字が指定されるときには、表示部71上に、かつ、先頭枠270内に、文字指定枠271が表示される。この文字指定枠271は、スクラップする文章(画像)の最初の文字(位置)を指定する際に表示され、ユーザの操作により、先頭枠270内で上下左右に移動可能にされている。
先頭文字が選択(指定)されると、ステップS16において、末尾枠(基本的に、先頭枠270と同一の枠)が指定され、ステップS17において、末尾文字が指定される(基本的に、文字指定枠271と同一の枠が用いられて指定される)。このステップS16とステップS17の処理は、基本的に、ステップS14とステップS15の処理と同様であるので、その詳細な説明は省略する。
なお、ここでは、選択する文字の範囲を指定するための枠が指定され、その後、その枠内から文字が選択されるとして説明したが、直接的に文字が選択されるようにしても良い。しかしながら、選択できる範囲を指定する枠を用いることにより、例えば、画像とテキストが入り交じっているようなページから、スクラップにする部分が選択される場合、その枠があることにより、画像が選択範囲内にあるのか、テキストが選択範囲内にあるのかをユーザにはっきりと明示することができると考えられる。
このようにして、スクラップする部分が選択される。ユーザは、その選択した部分で良ければ、ステップS18によって、スクラップブックへの登録を決定する。なお、各ステップにおいて、ユーザは、元の処理に戻すことが可能とされており、随時、所望のステップの処理を行えるようになっている。
このようなスクラップブックへの登録に係わる処理は、ユーザ側は、入力部106(図5)を操作することにより指示し、ユーザ端末7側は、CPU101が、入力部106からの信号が示す内容を判断し、その判断に基づき、また、RAM103などに展開されているプログラムやデータに基づき、先頭枠270の移動などの処理を実行することにより行われる。
スクラップブックへの登録の処理が行われる際の、ユーザ端末7側で行われる処理について図31乃至図33のフローチャートを参照して説明する。ステップS31において、スクラップブックへの新たな記事(テキスト、画像などであり、コンテンツの一部分を示すもの)の登録が指示された場合、既に、作成されているスクラップブックがあるか否かが判断される。例えば、図27に示したような構造を有するスクラップブック250が、記憶部107(図5)に記憶されているか否かが、CPU101により判断される。
なお、ユーザ端末7に対して、着脱自在の記録媒体に、スクラップブック250が、記録されるように設定されている、または、記録媒体にも記録できるように設定されている場合、その記録媒体は、ドライブ74にセットされるため、CPU101は、ドライブ74にセットされている記録媒体(パッケージメディア5でも良い)に記録されているデータも参照し、ステップS31における処理を実行する。
いずれにせよ、ステップS31において、作成されているスクラップブックが存在していないと判断された場合、ステップS32に処理が進められ、存在していると判断された場合、ステップS33に処理が進められる。ステップS32に処理が進められた場合、すなわち、スクラップブックは存在しないと判断された場合、新たにスクラップブックが作成され、そのスクラップブックの1ページ目に、新たに登録が指示された記事が追加できるような状態に設定される。
一方、ステップS33に処理が進められた場合、すなわち、スクラップブックは存在すると判断された場合、その存在すると判断されたスクラップブックの最終ページ(例えば、図27においては、Pageオブジェクト254で規定されるページ)に、新たに登録が指示された記事が追加できるような状態に設定される。
ステップS32またはステップS33の処理において、スクラップブックへ新たに記事を追加できる状態に設定されると、ステップS34に処理が進められる。ステップS34において、スクラップブックへの登録が指示された記事は、登録(保存)が許可されている記事であるか否かが判断される。保存が指示された記事に対して制限無くコピーされる事を許可すると、著作権などの関係から好ましくない状況が発生する可能性がある。
例えば、購入者に対しては1回のみコピーを許可する、制限無くコピーを許可する、ページ内の一部分ならコピーを許可するなどのコピーに対するライセンス条件が、コンテンツデータには記載されており(例えば、図22のヘッダー情報部181に含まる。また、データ作成装置2の著作権保護処理部23(図2)により付加される情報)、そのライセンス条件が参照されることにより、ステップS34の処理が実行される。
ステップS34において、ライセンス情報を参照した結果、保存が許可されていないと判断された場合、ステップS35に処理が進められ、保存が許可されていると判断された場合、ステップS36に処理が進められる。
ステップS35において、スクラップブックに登録するとして指示された記事は、コピーが許可されていないため、保存はできないということをユーザに認識させるようなメッセージが表示部71に表示される。そして、図31に示したフローチャートの処理、すなわち、スクラップブックに係わる処理は終了される。
このように、コピーは許可されていない記事は、保存できないため、その後の処理が行われることはない。よって、ステップS34における処理をステップS31の前に行うようにし、結果として、無駄な処理となってしまうような処理がされないようにしても良い。
また、同様の理由から、例えば、図28のフローチャートのステップS13において、スクラップブックへの登録処理を実行するための「文字クリップ」という項目が選択された場合、かつ、その選択されたときに表示されている記事(本文)が、コピー禁止のものであると判断される場合(この時点で、ステップS34における処理を実行する)、その時点で、表示されている記事はコピーできない記事であることをユーザに知らせるためのメッセージが表示される(ステップS35における処理を実行する)ようにしても良い。
換言すれば、スクラップにできない記事が選択されていると判断された時点で、ユーザ側に、そのようなことを認識させるような処理が実行されるようにしても良い。なお、ステップS34の処理に限らず、各ステップの処理は、必要に応じ、その処理の順番を入れ替えることは可能である。
図31に示したフローチャートの処理の説明に戻り、ステップS34において、ライセンス条件を参照した結果、選択された記事は、コピー(保存)が許可されている記事であると判断された場合、ステップS36に処理が進められる。ステップS36において、スクラップブックへの登録は、クリップ(Clip)保存であるか引用(Quotation)保存であるかが判断される。クリップ保存とは、見た目をそのまま保存し、引用保存は、文書内のデータをそのままコピーする保存である。
また、クリップ保存が選択された結果保存されたデータは、表示部71に表示されたボタンが操作されたときに表示されるように設定される。引用保存が選択された結果保存されたデータは、標準の書式で描画(スクラップブックにおいて設定されている書式での描画)がされるように設定される。クリップ保存は、主に、画像をスクラップする際に用いられ、引用保存は、主に、テキストをスクラップする際に用いられる。
このように、2つの保存方式を用いるのは、まず、テキストの場合、その表示にかかる処理は比較的軽く、また、複数のテキストを、スクラップブックの1ページとして、表示部71に1回の表示で表示させる事も可能であり、そのようにしても、見づらくはならないと考えられる。
テキストに対し画像の場合、その表示かかる処理は比較的重いため、複数の画像を、同一ページ内に表示する場合、そのページを表示させるまでに時間がかかってしまう可能性がある。また、画像の場合、複数の画像を、表示部71に1回の表示で表示させると、1枚の画像は小さいものとなってしまい、見づららいものになってしまうと考えられる。また、画像は、必ずしも常に表示させておく必要性はなく、必要に応じて(ユーザが所望したとき)表示されればよいと考えられる。
そこで、本実施の形態においては、2つの保存方式を用い、ユーザによりその選択が行えるようにしている。なお、ここでは、ユーザが選択できるとして説明するが、ユーザが選択するのではなく、単に、画像が選択されたと判断されるときには、クリップ保存し、テキストが選択されたと判断されるときには引用保存するといったように、ユーザ端末7側で判断するように設定されていても良い。
ステップS36において、新たに登録が指示された記事の保存方法は、クリップ保存であると判断された場合、ステップS37に処理が進められる。クリップ保存が指示された場合、その指示された(スクラップにされた)記事は、画像オブジェクト(Imageオブジェクト)とされて保存(記録)される。
一方、ステップS36において、新たに登録が指示された記事の保存方法は、引用保存であると判断された場合、ステップS38に処理が進められる。引用保存が指示された場合、その指示された記事の文字列が取得される。この取得される文字列とは、図28乃至図30を参照して説明したような処理が行われることによりユーザにより選択された先頭文字から末尾文字までの文字列である。
文字列が取得されると、ステップS39において、その追加された文字列を指定するための指定オブジェクトの取得処理が実行される。このステップS39における指定オブジェクト取得処理に関しては、図32を参照して後述する。
ステップS37までの処理、または、ステップS39までの処理が実行されることにより、ユーザが指定した記事が、スクラップブックに新たに追加するためのオブジェクトとして作成されたので、そのオブジェクトの追加の処理が、ステップS40において実行される。このステップS40におけるオブジェクト追加処理については、図33を参照して後述する。
ステップS41において、新たにオブジェクトが追加されたスクラップブックが、記憶部107(図5)またはドライブ74(図5)にセットされている記録媒体(不図示)に記録(保存)される。このようにして、スクラップブックの更新が行われる。
図32のフローチャートを参照して、ステップS39における指定オブジェクト取得処理について説明する。ステップS61において、3つのIDが取得される。第1のIDは、スクラップブックに追加保存するとして指定された記事に係わるPageオブジェクトのIDである。例えば、図25を再度参照するに、Textオブジェクト231で規定されるテキスト内の部分が、スクラップ用の記事として指定された場合、Pageオブジェクト225のIDが取得される。
第2のIDは、保存する記事の先頭となるBlockオブジェクトのIDである。このIDをここでは、start_idとする。第3のIDは、保存する記事の末尾となるBlockオブジェクトのIDである。このIDをここでは、end_idとする。図34を参照して、start_idとend_idについて説明する。図34には、所定のページとそのページ内に含まれるブロックを図示している。
Page281は、3つのBlock282乃至284から構成されている。ユーザが、Block283内の所定の文字を先頭文字として選択し(ステップS14,15(図28)の処理として選択し)、Block284内の所定の文字を末尾文字として選択した(ステップS16,S17の処理として選択した)場合、その間に存在する文字列が、記事として選択された範囲となる。
図28乃至図30を参照して説明したように、ユーザは、1ページ内であれば、枠270を移動させることが可能であるし、その枠270内であれば、先頭文字や末尾文字を選択することが可能であるので、スクラップにするとして指定される記事が、複数のブロックにまたがることも起こりえることである。
図34に示したような場合、先頭文字が存在するBlock283のBlockオブジェクトのIDが、start_idとされ、末尾文字が存在するBlock284のBlockオブジェクトのIDが、end_idとされる。図34には図示していないが、先頭文字と末尾文字の両方が、例えば、Block283内に存在するような場合、そのBlock283のBlockオブジェクトのIDが、start_idとend_idの両方に設定される。
また、Page281が、1つのBlock(例えば、Block282)のみで構成されているような場合、先頭文字と末尾文字の両方が、そのブロックに必然的に含まれることになるため、start_idとend_idは、結果として同一のものとなる。
このような3つのIDが、ステップS61において取得される。IDが取得されると、ステップS62に処理が進めらる。ステップS62において、その時点で、スクラップブック内で使われているオブジェクトIDの最大値が取得される。その取得されるオブジェクトIDの最大値を、ここでは、Old_IDと設定する。
図25を再度参照するに、図25に示した各オブジェクトに付された符号(221乃至234)を、そのオブジェクトのIDであるとし、図25に示した構成の本がスクラップブックであるとすると、そのスクラップブック内のオブジェクトの内、最大の値が付されているのは、Imageオブジェクト234である。よって、この場合、Old_IDは、“234”と設定される。
なお、このように、その時点でのスクラップブックの最大値を有するIDを検出するのは、新たにオブジェクトを追加(保存)するわけだが、その追加されるオブジェクトに付されるIDと同じにならないようにするためである。よって、ステップS63において、新たなオブジェクトに付されるIDが設定される。その設定は、Old_IDに1だけ加算された値とされる。このIDをNew_IDと設定する。
なお、1つの記事が選択されると、複数のオブジェクトが追加されることになる。例えば、図26を参照して説明したように、Imageデータ234’による画像がスクラップされる記事として選択されたときには、4つのオブジェクトがスクラップブックに追加されることになる。よって、新たに追加されるオブジェクトが幾つになるかは、ステップS63の時点では不明なため、New_IDは、新たに追加されるオブジェクトの1つに対して付されるIDであり、追加される他のオブジェクトに対しては、New_IDと連続する番号が、順次付されていくことになる。
ステップS63において、New_idが設定されると、ステップS64に処理が進められる。ステップS64において、指定されたPageオブジェクト(ステップS61により取得された第1のIDに対応するPageオブジェクト)の解析が開始される。そのPageオブジェクトに記述されているデータが1行毎(処理単位毎)に解析される。
ステップS65において、解析対象とされている行に記載されているデータは、コマンドであるか否かが判断される。なお、このステップS65においては、Pageオブジェクト内には、解析していないコマンドが存在しているか否か(Pageオブジェクト内に記載されているデータの最後の行であるか否か)もあわせて判断されている。
ステップS65において、解析対象とされているデータは、コマンドであると判断された場合、ステップS66に処理が進められ、そのコマンドは、Blockオブジェクトを参照する指示を出すためのコマンドであるか否かが判断される。
ステップS66において、Blockオブジェクトを参照する指示を出すコマンドではないと判断された場合、ステップS64に戻り、それ以降の処理が繰り返される。一方、ステップS66において、Blockオブジェクトを参照する指示を出すコマンドであると判断された場合、ステップS65に処理が進められる。ステップS65において、解析対象とされているコマンドが参照するBlockオブジェクトのIDは、start_idとend_idとに挟まれる番号のIDであるか否かが判断される。
図34を再度参照して説明する。図34において、Block282乃至284に付されている符号を、Block282乃至284に対応するBlockオブジェクトのIDであるとする。図34に示したような場合、Page281に対応するPageオブジェクトに記述されているコマンドには、Block282乃至284に対応するBlockオブジェクトを、それぞれ参照するためのコマンドが含まれている。
解析対象とされているコマンドが、Block282に対応するBlockオブジェクトを参照する指示を出すものであった場合、そのBlockオブジェクトのIDは、“282”である。この場合、start_id=283であるため、start_idより前の番号であるので、ステップS67においては、NOと判断される。すなわち、この場合、スクラップにする記事に関係のないBlockオブジェクトであるので、ステップS67以降の処理を行う必要がないため、ステップS64に処理が戻される。
これに対し、解析対象とされているコマンドが、Block283に対応するBlockオブジェクトを参照する指示を出すものであった場合、そのBlockオブジェクトのIDは、“283”である。また、解析対象とされているコマンドが、Block284に対応するBlockオブジェクトを参照する指示を出すものであった場合、そのBlockオブジェクトのIDは、“284”である。
このような場合、start_id=283であり、end_id=284であるため、IDが“283”と“284”は、start_idとend_idに挟まれる(この場合、イコール関係が成り立つ)ので、ステップS67においては、YESと判断される。すなわち、この場合、スクラップにする記事に関係のあるBlockオブジェクトであるので、ステップS67以降の処理が行われることになる。
ステップS67において、解析対象とされているコマンドが参照するBlockオブジェクトのIDは、start_idとend_idとに挟まれる番号のIDではないと判断された場合、ステップS64に処理が戻されるが、そのとき解析対象とされるのは、次の行に記述されているデータ(次の処理単位にあたるデータ)である。
一方、ステップS67において、解析対象とされているコマンドが参照するBlockオブジェクトのIDは、start_idとend_idとに挟まれる番号のIDであると判断された場合、換言すれば、スクラップの対象とさている記事を含むブロックのBlockオブジェクトのIDであると判断された場合、ステップS68に処理が進められ、そのBlockオブジェクトが参照しているのは、Textオブジェクトであるか否かが判断される。
例えば、図34において、Block283内に表示されているのはテキストであるが、Block284内に表示されているのは画像である場合も考えられる。そこで、ステップS68において、処理対象とされているBlockオブジェクトが参照しているのは、Textオブジェクトであるか否かが判断される。ステップS68において、処理対象とされているBlockオブジェクトが参照しているのは、Textオブジェクトではないと判断された場合、ステップS69に処理が進められる。
ステップS69において、処理対象とされているBlockオブジェクト、そのBlockオブジェクトが参照しているオブジェクト、そのオブジェクトを描画(処理)するのに必要な全てのオブジェクトの情報が取得される。このステップS69における処理について、図25を再度参照して説明する。例えば、図25に示したような構造を有する本から、Pageオブジェクト225内のBlockオブジェクト229が処理対象とされている場合を考える。
処理対象とされているBlockオブジェクト229が参照しているオブジェクトは、Imageオブジェクト233と、Block属性オブジェクト230である。そして、そのオブジェクトを描画するのに必要な全てのオブジェクトとしては、Imageオブジェクト233のImageを描画するための必要なImageデータオブジェクト234である。
よって、このような場合、ステップS69において取得される情報は、Blockオブジェクト229、Block属性オブジェクト230、Imageオブジェクト233、および、Imageデータオブジェクト234の情報である。このようにして、順次、必要なオブジェクトの情報が取得される。
図32のフローチャートの説明に戻り、ステップS68において、処理対象とされているBlockオブジェクトが参照しているのは、Textオブジェクトであると判断された場合、ステップS70に処理が進められる。ステップS70において、参照されている(処理対象とされる)BlockオブジェクトとTextオブジェクトの描画属性が、スクラップブック専用のものに変更される。
上述したように、スクラップブックには、さまざまな記事がスクラップにされる可能性がある。その記事はテキストだけであると想定した場合であっても、縦書きのテキスト、横書きのテキストなどがあり、さらに、文字のフォント、文字色など、さまざまな形態が考えられる。そのような様々な形態の記事が、そのままの形式で、1冊のスクラップブックに貼り付けられるとすると、そのスクラップブックは見づらいものとなってしまう。
そこで、スクラップブックに貼り付けられる記事は、統一性のある描画属性にすることにより、見やすいものとする。具体的には、全て横書き(または、縦書き)に統一し、フォントや色なども同一のものにする。そのような変更が終了されると、ステップS71に処理が進められる。ステップS71において、Textオブジェクトから参照されている全てのオブジェクトの情報が取得される。
このようにして、スクラップブックに登録が指示されたオブジェクトに関する情報が取得される。このようなステップS64乃至71までの処理が、繰り返されることにより、Pageオブジェクトの内容が、順次解析され、スクラップされた記事に係わるBlockオブジェクトなどの情報が取得される。そして、Pageオブジェクト内の全ての行に対して解析が終了されると、ステップS65において、Pageオブジェクト内に解析されていないコマンドはないと判断されるため、ステップS72に処理が進められる。
ステップS72において、引用した文献(その文献を識別する(示す)情報)と日付を表示するためのオブジェクトが作成される。このステップS72において、引用した文献と日付を表示するためのオブジェクトが作成されるのは、違法なコピーが行われないようにするためであり、さらに、違法なコピーがインターネットなどで流通しないように(流通したとしても、その著作権者などが明記されている状態に常にしておくように)するためである。
このようにして作成されたオブジェクトは、ステップS40(図31)においてスクラップブックに追加される。なお、このようにして作成されたオブジェクトには、順次、ステップS63において設定されたNew_IDから始まる番号が、IDとして割り振られる。
図33は、ステップS40(図31)におけるオブジェクト追加処理について説明するフローチャートである。ステップS91において、その時点でのスクラップブックの最終ページに対応するPageオブジェクトのIDが取得される。例えば、その時点で図27に示したような構造のスクラップブック250が存在していたような場合、最終ページに対応するPageオブジェクトは、Pageオブジェクト254であり、そのPageオブジェクト254のIDが、ステップS91の処理として取得される。
ステップS91において、PageオブジェクトのIDが取得されると、ステップS92に処理が進められ、取得されたIDに対応するPageオブジェクトにより描画されるページ(最終ページ)に、新たなブロックを追加することができるか否かが判断される。この判断は、1ページには3つのブロックしか存在させることができないなどの条件を設定し、その条件を満たすか否かを判断することにより行われるようにしても良いし、1ページの描画領域の大きさを設定し、その領域内に新たなブロックの領域を確保できるか否かを判断することにより行われるようにしても良い。
または、他の方法により判断が行われるようにしても良い。いずれの方法によっても良いが、上述したようにPageオブジェクトには、複数のブロックを無制限に追加することが可能とされているため、何らかの設定を設け、所定のブロック数のみが、1つのPageオブジェクトに登録されるように制御される必要がある。ステップS92において、最終ページに新たなブロックを追加することができないと判断された場合、ステップS93に処理が進められ、新たなブロックを追加するためのページが作成される。
すなわち、ステップS93に処理が進められた場合、新規に、Pageオブジェクトが作成される。そして、その新規に作成されるPageオブジェクトに対して、そのオブジェクトを識別するためのIDが割り振られる。その割り振られるIDは、スクラップブックを構成するオブジェクト内のIDで、最も大きい値を有するIDに1だけ加算した値の番号である。そのような番号をIDとして付加されたPageオブジェクトが、ステップS94以降の処理において、そのスクラップブック内の最終ページとして取り扱われる。
一方、ステップS92において、最終ページに新たなブロックを追加できると判断された場合、新たなページを作成する必要がないため、ステップS93の処理は省略され、ステップS94に処理が進められる。ステップS94において、最終ページに対応するPageオブジェクトの最後のコマンドの後に、取得されたBlockオブジェクト、および、引用された文献と日付を表示するために、ステップS72(図32)の処理として作成されたオブジェクトが、それぞれ参照されるようなコマンドが付加される。
そして、ステップS95において、取得されたオブジェクト、および、引用された文献と日付を表示するためのオブジェクトのデータが、スクラップブックのデータに追記される。このように、オブジェクトが追記されたので、その追記されたオブジェクトに関するデータ(オブジェクトテーブル)が、ステップS96において更新される。
このようにして、オブジェクトの追加が行われる。このような処理がユーザ端末7で行われることにより、ユーザは、所望の記事から構成されるスクラップブックを作成することができる。
このように、電子書籍においては、紙書籍では手間のかかる処理であっても、同様の処理を簡便に行うことができる。しかしながら、例えば、紙書籍の場合、ユーザは、その紙書籍の厚さを見るだけで、読み終わるのにかかる日数などを概算することができるが、電子書籍の場合は、目に見える厚さというものがないので、そのようなことはしづらいといったことが考えられる。
そのようなことを換言すれば、ユーザは、紙書籍の場合、パラパラとページをめくることにより、文字の大きさなどを把握し、ページ数を把握することにより、読み終わるための日数などを概算することもある。また、例えば、辞書などの場合、調べたい文字が、どの辺に記載されているかを、ページ数の感覚で把握することができる。
しかしながら、電子書籍の場合、紙書籍では不可能である文字を拡大して表示するということができる。そのために、拡大率により、同じ書籍であっても、ページ数が変化してしまう。よって、電子書籍で、パラパラとページをめくり(ボタンを操作し続け)、文字の大きさやページ数を把握し、読み終わる日数を概算するといったことは難しく、また、電子書籍が辞書などの場合、紙書籍の辞書ではできた、ページ数を感覚で把握するといったことが難しいと考えられる。
具体的に表現すれば、例えば、紙媒体の辞書において、10ページ目に表示されている単語は、いつでも10ページ目に表示(印刷)されているため、ユーザは、その単語を調べたければ、10ページ当たりに存在しているという感覚を把握し、次回、同じ単語を調べたければ、10ページ当たりであるという感覚をいかして調べることができる。
しかしながら、電子書籍の場合、拡大率が異なれば、前回調べた単語が、10ページ目に存在していても、次回調べるときには、10ページ目に存在するとは限らず、また、10ページ目という紙の厚さや、ページのめくる速度による得られる感覚を把握することもできないために、単語を調べづらいといったことが考えられる。
このような、長い間ユーザに親しまれてきた紙書籍の場合に得られる感覚というものを、電子書籍でも、同様の感覚を得られるようにすることは、電子書籍の普及(その電子書籍のデータの販売による普及という意味はもちろん含むが、ユーザ端末7の普及も含む)につながると考えられる。
そこで、本実施の形態においては、アンカーという概念を導入し、電子書籍でも紙書籍のような、ページをパラパラとめくるということにより、ユーザが得られる感覚というものを実現できるようにする。そのような感覚というものを実現できるようにすることにより、上述したように、電子書籍の普及につながることはもちろんであるが、電子書籍におけるページの概念を、明確にできるという利点もある。
すなわち、上述したように、電子書籍では、ページは、文字の拡大などにより可変的に変化してしまう。さらに、本実施の形態においては、Pageオブジェクトで記述されるものを1ページとしているため、その1ページの長さが固定的なものでなく可変的なものである。さらに、ユーザ端末7の表示部71に一度に表示されるものが、1ページであるとは言えない。
例えば、表示部71に表示されているものが小説であるような場合、1行毎にスクロールされる(例えば、2行目に表示されていた文章が、1行目にスクロールされ、そのスクロールに対応して、他の行も1行ずつスクロールされる)こともあり、そのようなときには、ページという感覚は得られず、1ページの区切りは、どの部分に存在するかが把握しづらくなると考えられる。
このようにとらえると、電子書籍においては、ページという概念は曖昧であるといえる。そのことによる利点もあるが、問題点もある。しかしながら、以下に説明するようなアンカーという概念を導入することにより、ページに対する概念を明確にすることができ、ページという概念が曖昧であることに起因する問題点も解決されると考えられる。
そのような利点を有するアンカーについて説明する。図35は、アンカーとページの関係について説明するための図である。図35においては、ページ302−1乃至302−4は、100パーセントの表示が指示されているときに、表示部71に一度に表示される量であるとする。換言すれば、ページ302−1乃至302−4は、それぞれが、仮想描画領域152−1(図10)に描画される1ページであり、表示可能領域151と大きさが一致している場合であるとする。すなわち、図10中の上側に示した図の状態であるとする。
そのようなページ302−1乃至302−4(4ページ)に対して、文字の拡大の指示が出された場合、また、ここでは、その拡大率が、2倍(200パーセント)である場合、図35中の下側に示したように、ページ303−1乃至303−8の8ページの構成に変更される。すなわち、文字が2倍に拡大されることにより、ページ数も2倍になる。
ページ303−1乃至303−8の状態は、図10中の下側に示した図の状態である。ページ303−1乃至303−8の各ページは、それぞれが、表示可能領域151と同じサイズとされているが、仮想描画領域152−2には、例えば、ページ303−1とページ303−2の2ページが描画されている状態である。
例えば、ユーザが、100パーセントの表示で閲覧しているときに、ページ送りを実行すると、ページ301−1の次にページ303−2が表示され、ページ301−2の次にページ303−3が表示されるといったように、順次、ページを閲覧することになる。ユーザは、ページ302−1から303−4に移動するときには、3ページ先のページに移動させればよいという感覚を得る。
換言すれば、ページ302−1に表示されている“A”という文字(ここでは、文字はもちろん、記事、単語など含む意味とする)から、ページ302−4に表示されている“H”という文字(記事)に移動する際、ユーザは、ページ302−1から3ページ分(ページ302−2,302−3,303−4)先のページに、目的とする“H”という文字が存在していることを感覚的に把握する。感覚的に把握するとは、例えば、ページ送りのためのボタン(例えば、図4の送りボタン57)を操作している時間などである。
または、表示部71上に、表示されているページが全体のページのうちのどの辺のページであるかを示す、例えばバーみたいなものが表示されている場合、ユーザは、そのバーの位置を参照することによりだいたいの位置を把握することができる。そのようなバーの位置などを認識することで、ページの位置を把握するようなことも、感覚的に把握しているという表現に該当する。
同じことが、200パーセントの表示で閲覧されているときに行われたとする。すなわち、ページ303−1に表示されている“A”という文字から、ページ303−8に表示されている“H”の文字まで移動させるとき、ユーザが、100パーセントの表示時と同じ感覚で、3ページ先に移動させると、ページ303−4に移動してしまい、所望のページであるページ303−8に移動されないことになる。
これは、各倍率のときに、その倍率におけるページ数で移動の処理が行われるからである。具体的には、100パーセントの表示において、ページ送りが実行されると、ページ302−1→ページ302−2→ページ302−3→ページ302−4の順でページ送りされ、200パーセントの表示において、ページ送りが実行されると、ページ303−1→ページ303−2→ページ303−3→ページ303−4→ページ303−5→ページ303−6→ページ303−7→ページ303−8の順でページ送りされる。
図35に示したように、アンカー301−1乃至301−5が、100パーセントの表示が行われる際の各ページの先頭に打たれている。具体的には、ページ302−1の先頭にアンカー301―1が、ページ302−2の先頭にアンカー301―2が、ページ302−3の先頭にアンカー301―3が、ページ302−4の先頭にアンカー301―4が、それぞれ打たれている。
このようなアンカーという、各ページの先頭を示す情報が用いられてページ送りの処理が実行される。100パーセントの表示時で、ページ303−1が表示されている状態のときに、ページ送りの処理が指示された場合、アンカーの情報が用いられて、そのページ送りの処理が実行される。すなわち、ページ303−1が表示されている状態であるので、まず、アンカー301−2が読み出され、そのアンカー301−2が指し示すページ302−2がページ送り先として表示される。
さらに、ボタンが操作され続けてページ送りの指示が継続されている状態であれば、アンカー301−3の情報が読み出され、そのアンカー301−3が指し示すページ302−3が、次のページ送り先として表示される。このようなアンカー情報が用いられたページ送りの処理が、ページ送りが指示されている間、繰り返し行われる。
200パーセントの表示がされているときについて説明する。ページ303−1が表示部71上に表示されているときに、ページ送りが指示されると、アンカー301−2の情報が読み出される。アンカー301−2は、ページ303−3の先頭を示す情報である。このように、アンカーの情報は、表示倍率に依存しない情報(100パーセント表示を基準とし、その100パーセントの表示時のみに依存する情報であり、他の拡大率のときには依存していない情報)とされている。
さらに、ボタンが操作され続けてページ送りの指示が継続されている状態であれば、アンカー301−3の情報が読み出され、そのアンカー301−3が指し示すページ303−5が、次のページ送り先として表示される。すなわち、この場合、2ページづつページが送られることになる。このようなアンカー情報が用いられたページ送りの処理が、ページ送りが指示されている間、繰り返し行われる。
このようなアンカーという情報が用いられたページ送りの処理が実行されれば、例えば、ページ303−1に表示されている“A”という文字から、ページ303−8に表示されている“H”という文字に移動させるときに、ユーザは、3ページ分の移動を指示すればよいことになる。すなわち、ユーザは、100パーセントのときと同じ感覚で、ページ送りをすれば、同じページ先に移動させることができる。よって、拡大率によらず、同じ感覚で処理を実行させることが可能となる。
このアンカーの情報は、存在しなくても電子書籍を読むこと(書籍を扱うこと)は可能であるが、存在することによって、該当する電子書籍のコンテンツが何ページで表現されているのかがわかり、また、Pageオブジェクトの大小にかかわらず、リニアに見た目のページを移動することができる。よって、紙書籍のような感覚的な扱いを、電子書籍でも提供することができる。
ところで、図35を参照して説明したような100パーセントの表示がされているときに、表示部71に一度に表示されるのが、1ページであり、その1ページが、Pageオブジェクトにより規定される1ページである場合、換言すれば、図10中の上側に示したように、表示可能領域151と仮想描画領域152−1が同一の大きさとされている場合、上述したようなページ送りの処理がされれば有効であると考えられる。
しかしながら、1つのPageオブジェクトにより規定されるページが、表示部71に一度に表示されるのを1ページと表現したとき、100ページ分に相当する場合もある。そのように設定することは可能である。よって、1つのPageオブジェクトにより規定されるページ内に、複数のアンカー情報を持たせ、できる限り、100ページ分に相当するならば、100ページとしてページ送りがされるように設定される方が好ましい。
図36と図37を参照し、アンカーについてさらに説明を加える。図36,36においては、仮想描画領域152は、2つ分の表示可能領域151から構成されている。図36と図37では、説明の都合上、2つの表示可能領域151を縦に並べて、また、一辺が接触した状態で図示している。図36に示した例では、仮想描画領域152には、Block311乃至314の4つのブロックが存在している。換言すれば、Pageオブジェクトにより規定されるページには、4つのBlockオブジェクトにより規定される領域が確保されている。
図36に示した状況は、Block311乃至313は、上段に示した描画可能領域151に含まれた状態であり、Block314は、下段に示した描画可能領域151に含まれた状態である。ブロック内に表示されるコンテンツが画像の場合、その画像が途中で分断されるのは好ましい表示ではないので、図36に示したように、ブロックの全ての領域が、表示可能領域151内に含まれるように制御される。
図36に示した状態は、仮想描画領域152(仮想ページ)が、Pageオブジェクトから参照される、Block313に対応するBlockオブジェクトと、Block314に対応するBlockオブジェクトの間で分断されている例を示している。
図37に示した状況は、Block321とBlock322が上段に示した描画可能領域151に含まれているが、Block323は、上段と下段に示した描画可能領域152に含まれる。すなわち、Block323は分断されている。このようなことは、Block323内に表示されるコンテンツが、テキストである場合などに、起こりうることである。図37に示した状態は、仮想描画領域152が、Textオブジェクトを参照するBlockオブジェクトの途中で分断される場合を示している。
このように、異なるBlockの間で分断される場合と、同一Block内で分断される場合とが存在する。図36に示したようなときには、Block311にところに、アンカー315が打たれ、Block314のところにアンカー316が打たれる。同様に、図37に示したようなときには、Block321のところに、アンカー324が打たれ、Block323のと途中に、アンカー325が打たれる。
このようにアンカーが打たれれば、異なるBlockの間で分断される場合と、同一Block内で分断される場合とで、状況が異なっても、アンカーの数は同じになる。よって、見た目上のページ数(この場合、2ページ)を同じにすることが可能となる。
図36または図37に示したような状況では、1つのPageオブジェクトは、2つのアンカー情報を有することになる。このように、1つのPageオブジェクトは、複数のアンカー情報を有することができる。また、図37に示したように、アンカーの情報は、必ずしも所定のBlockの先頭位置を示すのではなく、Block内の所定の位置を示すようにしても良い。
図38は、このようなことを考慮したときのPageTreeオブジェクトに記述されている情報と、アンカー情報との関係を説明するための図である。PageTreeオブジェクトには、図38に示すように、参照するPageオブジェクトの情報が記述されている。図38に示した例では、PageTreeオブジェクトは、Pageオブジェクト1乃至6(Page1乃至6)を参照している。このようなときのアンカー打ち情報としては、図38に示した例ではPage1が1、Page2が5、Page3が3、Page4が3、Page5が2、Page6が3である。
この数値は、そのページが、幾つのアンカー情報を有しているか(そのページに、幾つのアンカーが打ち込まれているか)を示すものである。たとえは、Page1には1つのアンカーが打たれ、Page2には5つのアンカーが打たれていることが示されている。
PageTreeオブジェクトは、各Pageの前後関係や、まとまりを示す役割を有していることから、PageTreeオブジェクトによって束ねられている各ページが、いくつの仮想ページ(アンカーにより分断されるページ)を持っているかを管理させる(図38に示したようなアンカー打ち情報を管理させる)ようにする。このようにすることによって、複数のページを移動するような場合でも、リニアにページ移動することが出来る。
また、アンカーにより分断されるページ数を累積換算することにより、その電子書籍の仮想ページの総数を出すことができる。この仮想ページの総数とは、ユーザに、その電子書籍が何ページの本であるのかを認識させたいページ数であると換言することができる。例えば、図38に示した例では、アンカー打ち情報から、17ページ(=1+5+3+3+2+3)が、ユーザに認識させたいページ数であり、リニアにページ移動させるときのページ数である。
PageTreeオブジェクトは、図38に示したようなアンカー打ち情報を参照するが、PageTreeオブジェクトが参照するPageオブジェクトは、図39に示したようなアンカー打ち情報を参照する。まず、図39に示した例では、Page3(Pageオブジェクト)は、Block1乃至5を含む構成(Block乃至5に対応するBlockオブジェクトを参照する構成)とされている。
そのPage3が参照するアンカー打ち情報には、図39に示すように、3つのアンカー打ち情報が含まれている。このPage3に3つのアンカー打ち情報が存在していることは、図38に示したPageTreeオブジェクトが参照するアンカー打ち情報に記述されていることからも確認できる。
1つ目のアンカー打ち情報は、“Block2”のところに、アンカーが打たれていることを示している。この場合、Block2の先頭の部分にアンカーが打たれている。2つ目のアンカー打ち情報は、“Block3 0x200”のところにアンカーが打たれていることを示している。この場合、Block3内の“0x200”で示される位置にアンカーが打たれている。この“0x200”は、例えば、X−Y座標系で示される所定の座標を示す値とされても良いし、ページ内のどの文字のところで分断されるのをバイト数で表したものでも良い。
3つ目のアンカー打ち情報は、“Block5 0x120”のところにアンカーが打たれていることを示している。この場合、Block5内の“0x120”で示される位置にアンカーが打たれている。
このように、ページ内での分割位置を示すためのアンカー打ち情報も用意されている。Pageオブジェクトは、Page内にどのような情報が記述されるかを管理するところであることから、Page内のどのBlockのところで仮想ページが分断されるのかを管理させる(図39に示したようなアンカー打ち情報を管理させる)。また、Textを参照しているBlockで分断される場合は、Text内部のどの文字のところで分断されるのかをバイト数などで明示する。このような記述がされることにより、ページ内のどの位置から描画するかがわかるようになる。
このようなアンカーに関する情報は、出版社1(図1)からデータ作成装置2に供給されるデータには含まれていない。そのため、アンカー情報は、データ作成装置2において付加されるデータである。このような、出版社1から供給されるデータには含まれていないデータを付加することにより、課金がされるようにしても良い。また、データを付加することで、他の会社が発行する電子書籍との差別化をはかることができる。
アンカー情報が付加されるタイミングとしては、データコンバータ部22(図2)による処理が実行されるタイミングである。このように、アンカー情報は、ここでは、ユーザ側への配布用のデータが作成される際に、新たに付加される情報である。
ここでは、アンカー情報が、出版社1から供給されるソースデータには含まれていない情報であり、データ作成装置2により付加される情報の1例であるとして説明するが、アンカー情報以外の情報も、データ作成装置2により付加されるようにしても良いことは、言うまでもない。
次に、図40のフローチャートを参照し、ページ送りが指示されたときのユーザ端末7内で行われる処理について説明する。ページ送りが指示されたときには、上述したような特徴を有するアンカーという概念の情報が用いられる。図40に示したフローチャートの処理が開始されるのは、入力部106(図5)としての、送りボタン75(77)、または、戻りボタン76(78)(いずれも図4)が操作されたときであり、CPU101(図5)が、それらのボタンが操作されたと判断したときである。
ステップS111において、ボタンが操作された時点で、表示部71上に表示されているページが、何番目の仮想ページなのかの情報が取得される。図37を再度参照するに、ボタンが操作された時点で、表示部71上に表示されているページが、例えば、ブロック321乃至323が表示されているページであった場合、仮想ページの1ページ目(図37に示した状態においては、2ページの仮想ページから構成されるとし、上段が1ページ目、下段が2ページ目とする)が表示されていると判断され、その1ページ目の情報が取得される。
ステップS112において、その時点で表示されているPageTreeオブジェクトが取得される。この取得は、ステップS111において取得された情報を用いて行われる。このステップS112における処理で、PageTreeオブジェクトが取得されると、ステップS113において、PageTreeオブジェクトのアンカー情報から、現在位置が特定される。ステップS113までの処理により、図38で示した情報が取得されることになる。
すなわち、PageTreeオブジェクトが参照するアンカー打ち情報から、総ページ数が判断される。また、ステップS111の処理で、その時点でのページに関する情報が取得されているため、その時点でのページは、総ページ内のどの辺に位置するページであるかが判断可能となる。よって、現在位置を特定することができる。
ステップS114において、現在位置から仮想ページをNページ進んだ位置が求められる。ここで、Nページ進んだ位置とは、送りボタン75(77)が操作されている場合には、現在位置より先に位置するページ(番号的に大きなページ番号が付されているページ)であり、戻りボタン76(78)が操作されている場合には、現在位置より前に位置するページ(番号的に小さなページ番号が付されているページ)である。
また、ここで、Nページと表現したのは、必ずしも1ページずつ移動(ページ送りまたはページ戻り)(1アンカー情報毎に移動)すると設定されている必要がないためである。例えば、ページ数が少ない書籍であれば、1ページずつページが移動されても良いが、ページ数が多い書籍である場合、1ページずつページが移動されるよりも、複数ページ(Nページ)が一度に移動される方が使い勝手が良くなると考えられる。
そこで、ここでは、Nページ移動されるとして説明する。NページのNの設定の仕方であるが、その書籍の総ページ数を考慮して設定されるようにしても良い。例えば、総ページ数の5パーセントのページ数をNと設定するなどでも良い。また、さらに、総ページ数と現在位置を考慮し、現在位置から、指示されている方向に存在するページ数を算出し(例えば総ページ数が100ページで、現在位置が30ページ目で、指示されている方向が送りページ方向である場合、70ページと算出される)、その算出されたページ数の数パーセント(例えば、5パーセント)のページ数をNと設定しても良い。そのパーセント自体も、ページ数に依存し、変化されるようにしても良い。
もちろんNは、固定値でも良い。なお、Nページは、所定の秒数当たり、例えば、1秒当たりに移動されるページ数である。
どのような方式を用いてNが設定されても良いが、ステップS114において、現在位置から、指示された方向にNページだけ移動した位置が求められる。そして、ステップS115において、移動先として求められた位置に対応するPageオブジェクトにアクセスし、そのPageに対応するアンカー情報が取得される。例えば、図39を参照するに、移動先のPageオブジェクトが、Page3に対応するオブジェクトである場合、図39に示したようなアンカー打ち情報が取得されることになる。
ステップS116において、仮想ページ数の情報を基に、どの位置から描画するかを計算し、その計算された位置からの描画が、表示部71上で行われる。この描画は、簡便な表示である。ユーザが、紙書籍でページ送りしているとき、各ページをじっくり閲覧しているわけでなく、ページの一部分のみ(ページの端の部分(先頭部分)など)を閲覧しているだけである。そこで、電子書籍の場合も、例えば、表示されているコンテンツが小説などのときには、各ページの始めの数行だけが、表示されればよいと考えられる。
このようにすることで、描画にかかる処理能力を削減することができ、処理にかかる時間を少なくすることができる。そのため、連続的に、表示部71上の表示を切り換えていくことが可能となる。そのような簡易的な描画は、ボタンが操作されている間、すなわちページ送り(戻り)が指示されている間、繰り返し行われる。その為に、ステップS117において、続けて移動が指示されているか否かが判断される。
ステップS117において、ページの移動が継続的に指示されていると判断された場合、ステップS113に処理が戻され、それ以降の処理が繰り返し行われる。一方、ステップS117において、ページの移動は継続的に指示されていないと判断された場合、換言すれば、ページの移動の終了が指示された(ボタン操作は終了された)と判断された場合、ステップS118に処理が進められる。
ステップS118において、レイアウトなどが考慮された描画が行われる。これは、ページの移動が終了されたということは、ユーザは、その移動先のページを閲覧したいと所望しているためであると考えられる。そこで、そのようなときには、通常の表示が行われる方が好ましいので、そのようにされる。すなわち、ステップS118における処理は、移動先のページの通常の状態で表示されるべき表示がされるための処理である。
このように、ページ送り、または、ページ戻りの処理が行われる。ユーザは、紙書籍と同じような感覚で、ページ数の多い書籍であれば、早めにページをめくる(一度に多くのページをめくる)ことができ、ページ数の少ない書籍であれば、比較的ゆっくりページをめくる(1ページづつめくる)ことができる。また、ユーザは、ボタンを操作してる時間で、どのくらいのページの移動ができるのかという感覚的なことを、拡大率に関係なく、常に同じ感覚で行うことができる。
このように、本発明によれば、電子書籍のコンテンツデータのフォーマットをオブジェクト化し、かつ、レイアウト形式にブロックという概念を導入することで、フォーマットの拡張性を高めることが可能となる。
また、フォーマットをオブジェクト化したことにより、すでにある内容をほとんど変えずに、新たな内容を付け足すことが簡単になる。これによって、購入した電子書籍と同じフォーマットで、スクラップブックを作成できるという機能を実現することが可能となる。
さらに、文字拡大になどによるレイアウトの崩れがあることも予め想定し、アンカー情報を利用することによって、線形にページを移動することができるようなる。
上述した一連の処理は、それぞれの機能を有するハードウェアにより実行させることもできるが、ソフトウェアにより実行させることもできる。一連の処理をソフトウェアにより実行させる場合には、そのソフトウェアを構成するプログラムが専用のハードウェアに組み込まれているコンピュータ、または、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどに、記録媒体からインストールされる。
記録媒体は、図3に示すように、パーソナルコンピュータ(データ作成装置2)とは別に、ユーザにプログラムを提供するために配布される、プログラムが記録されている磁気ディスク61(フレキシブルディスクを含む)、光ディスク62(CD-ROM(Compact Disc-Read Only Memory),DVD(Digital Versatile Disc)を含む)、光磁気ディスク63(MD(Mini-Disc)(登録商標)を含む)、若しくは半導体メモリ64などよりなるパッケージメディアにより構成されるだけでなく、コンピュータに予め組み込まれた状態でユーザに提供される、プログラムが記憶されているROM42や記憶部48が含まれるハードディスクなどで構成される。
なお、本明細書において、媒体により提供されるプログラムを記述するステップは、記載された順序に従って、時系列的に行われる処理は勿論、必ずしも時系列的に処理されなくとも、並列的あるいは個別に実行される処理をも含むものである。
また、本明細書において、システムとは、複数の装置により構成される装置全体を表すものである。
1 出版社, 2 データ作成装置, 3 市場, 4 ネットワーク, 5 パッケージメディア, 6 PC, 7 ユーザ端末, 21 XMLコンバータ部, 22 データコンバータ部, 23 著作権保護処理部, 24 配信部, 25 パッケージメディア作成部, 71 表示部, 72 USBインタフェース, 73 イーサネットインタフェース, 74 ドライブ, 75 送りボタン, 76 戻りボタン, 79 ジョグダイヤル, 80 拡大ボタン, 81 決定ボタン, 131 書誌情報部, 132 ストリームデータ部, 133 オブジェクトデータ部, 151 表示可能領域, 152 仮想描画領域, 171 連続ページ群, 172 独立ページ群, 181 ヘッダー情報部, 182 オブジェクト情報部, 183 オブジェクトテーブル情報部, 301 アンカー