JP2007259121A - 字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 - Google Patents
字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 Download PDFInfo
- Publication number
- JP2007259121A JP2007259121A JP2006081438A JP2006081438A JP2007259121A JP 2007259121 A JP2007259121 A JP 2007259121A JP 2006081438 A JP2006081438 A JP 2006081438A JP 2006081438 A JP2006081438 A JP 2006081438A JP 2007259121 A JP2007259121 A JP 2007259121A
- Authority
- JP
- Japan
- Prior art keywords
- segment
- data
- subtitle
- line
- subtitle data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Landscapes
- Television Systems (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
Abstract
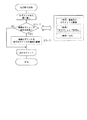
【解決手段】表示選択字幕データ処理部705は、ルビ特定条件に一致するルビのセグメントを削除する放送字幕ルビ処理を行なった後、1つの画面に2行以上の字幕があり、かつ2つ以上のセグメントを含む行がある場合には、セグメント毎に並び替え処理を行なう。この並び替え処理において、連続セグメントの条件を充足する場合には、このセグメントを先行セグメントの直後に配置するように、セグメントのテキストデータの移動を行なう。これにより、字幕データ中で分離された話し言葉が一連の文字群となったテキストデータ(字幕メタデータ)を生成して、タイムコード付加処理部707に供給する。
【選択図】図5
Description
することにある。
請求項3に記載の発明は、請求項1又は2に記載の字幕データ処理方法において、前記セグメント判定条件は、前記字幕データに含まれる配色指定であることを要旨とする。
請求項1、8又は10に記載の発明によれば、一画面に含まれる字幕データが2行以上ある場合には、字幕データの個々のセグメントの各行内での位置からセグメントが異なる他の行のセグメントに対して接続関係であると判定するための接続判定条件を満たすか否かを判定する。そして、接続関係にあると判定されたセグメント同士が隣り合うように並び替え、並び替えたセグメントの順番に応じて字幕のテキストデータを生成する。通常、表示の関係により、複数行に亘って一連の文字群が表示される場合には、それらが所定の
接続関係にある。このため、各行内の位置から、所定の接続関係にあるセグメント同士であるか否かを判定し、接続関係にあると判定した場合には、一連の文字群であるとしてセグメント同士が隣り合うように並び替える。これにより、一連の文字群が複数行に亘って表示される場合であっても、より正確に、一連の文字群を取得することができる。従って、より有益なデータを効率よく生成することができる。
請求項3に記載の発明によれば、字幕データに含まれる配色指定から、セグメントであるか否かを判定することができる。
の文字群を一行としてより正確に取得し、より的確なテキストデータを生成することができる。
01は、供給された映像信号をデコードし、デコードされた映像データをメモリ403に供給する。メモリ403は、供給された映像信号を一時保持するフレームメモリである。音声信号デコーダ402は、供給された音声信号をデコードし、デコードされた音声データを出力する。
憶手段を備える。
連続セグメント条件の充足性を判定する(ステップS3−1)。この場合、図9に示すように、セグメントBについては直前行に隣接する文字がないため、「直前行の文字と隣接」の条件に該当せず、連続セグメント条件を充足しない。従って、表示選択字幕データ処理部705は、ステップS3−1において「NO」と判定して、次のセグメントCについて、連続セグメント条件の充足性を判定する(ステップS3−1)。
番組ID情報抽出部703から供給された番組ID情報が付加されたメタデータは、暗号化処理部709に供給される。
○ 本実施形態では、表示選択字幕データ処理部705は、1つの画面に2行以上の字幕があり、かつ2つ以上のセグメントを含む行がある場合(ステップS1−3において「YES」の場合)には、並び替え処理を行なう(ステップS1−4)。この処理において、直前行のセグメントと隣接し、「字下げ」又は「左揃え」が行なわれており、かつ、同色で表示されている場合には、連続セグメントの条件を充足すると判定する(ステップS3−1において「YES」)。そして、表示選択字幕データ処理部705は、このセグメントを先行セグメントの直後に配置するように、セグメントに対応するテキストデータの移動を行なう(ステップS3−2)。そして、すべてのセグメントについて並び替え処理(ステップS1−4)を画面毎に行なうことにより、字幕放送信号に含まれる字幕データ中で分離された文字群が一連の文字群となったテキストデータ(字幕メタデータ)が生成できる。通常、表示の関係により、複数行に亘って一連の文字群が表示される場合には、それらの位置が隣接している。このため、各行内の位置から、隣接するセグメント同士であるか否かを判定し、隣接すると判定した場合には、一連の文字群であるとしてセグメント同士が隣り合うように、自動的に並び替えることができる。更に、このように生成したテキストデータから字幕メタデータを生成するので、一連の文字群が複数行に亘って表示される場合であっても、一連の文字群を一行としてより正確に取得し、より的確なテキストデータを生成することができる。
を自動的に判定することができる。
・ 上記実施形態では、ルビ判定条件として、(1)異なる文字の文字サイズが小型サイズであり、(2)セグメントが「ひらがな」、「カタカナ」又は「空白」のみで構成されており、(3)標準サイズ文字に同じ行で隣接しておらず、かつ、(4)次の行において標準サイズ文字と隣接しているという4つの条件を用いた。これに限らず、ルビ判定条件として、他の判定条件を用いてもよい。例えば、同じ画面において、「ひらがな」、「カタカナ」又は「空白」のみで構成されるセグメントの直下の位置に同じ読み方ができる漢字や外国文字がある場合には、ルビと判定してもよい。
あると認識できるグループ番号と、そのグループにおける順番(何番目のセグメントであるか)を一時的に記録する。そして、1画面における全セグメントに対して、グループ番号及び順番を付した場合には、そのグループ番号毎及びそのグループ内の順番に各セグメントを並び替える。更に、各グループの最初のセグメントの表示位置に応じて、画面におけるグループの順番でテキストデータを生成する。この場合であっても、各セグメントの表示位置から、複数行に亘って一連の文字群が隣接するセグメント同士であるか否かを判定して、より正確に、一連の文字群を取得することができる。従って、より的確なテキストデータを効率よく生成することができる。
Claims (11)
- 映像信号から抽出した字幕データを処理する字幕データ処理方法であって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう段階と、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更段階と、
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを特徴とする字幕データ処理方法。 - 前記セグメント判定条件は、前記字幕データに含まれる動作位置指定であることを特徴とする請求項1に記載の字幕データ処理方法。
- 前記セグメント判定条件は、前記字幕データに含まれる配色指定であることを特徴とする請求項1又は2に記載の字幕データ処理方法。
- 前記接続判定条件は、
第1のセグメントが、これを含む行の直前の行に含まれる第2のセグメントに対して隣接されており、
前記第1のセグメントの開始位置が前記第2のセグメントの開始位置に対して字下げされているか又は同じであり、かつ
前記第1のセグメントの配色が、前記第2のセグメントの配色と同じであることであり、
前記配置変更段階は、前記第1及び前記第2のセグメントの位置に基づいて、前記接続判定条件が満たされた場合には、前記第1のセグメントの次に前記第2のセグメントが配置するように並び替えることを特徴とする請求項1〜3のいずれか1項に記載の字幕データ処理方法。 - 前記複数行判定処理の前に、
前記一画面に異なる文字サイズの字幕データの有無を判定する文字サイズ判定段階と、
異なる文字サイズの字幕データがあった場合には、小さい文字サイズの文字を含むセグメント毎にルビ条件を判定し、前記ルビ条件に一致するセグメントを削除する削除段階とを更に実行することを特徴とする請求項1〜4のいずれか1項に記載の字幕データ処理方法。 - 前記ルビ条件として、
セグメントの文字列が、ひらがな、カタカナ又は空白から構成され、
同じ行において隣接する文字のサイズが異ならず、
次行において、より大きなサイズの文字に隣接していることを条件として用いることを特徴とする請求項5に記載の字幕データ処理方法。 - 映像信号から抽出した字幕データを処理する字幕データ処理方法であって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕デ
ータの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう段階と、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する段階と、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える段階と、
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを特徴とする字幕データ処理方法。 - 映像信号から抽出した字幕データを処理する字幕データ処理プログラムであって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
として機能させることを特徴とする字幕データ処理プログラム。 - 映像信号から抽出した字幕データを処理する字幕データ処理プログラムであって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
として機能させることを特徴とする字幕データ処理プログラム。 - 映像信号から抽出した字幕データを処理する字幕データ処理装置であって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
を備えたことを特徴とする字幕データ処理装置。 - 映像信号から抽出した字幕データを処理する字幕データ処理装置であって、
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕デ
ータの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
を備えたことを特徴とする字幕データ処理装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006081438A JP4353198B2 (ja) | 2006-03-23 | 2006-03-23 | 字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006081438A JP4353198B2 (ja) | 2006-03-23 | 2006-03-23 | 字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007259121A true JP2007259121A (ja) | 2007-10-04 |
| JP4353198B2 JP4353198B2 (ja) | 2009-10-28 |
Family
ID=38632896
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006081438A Expired - Fee Related JP4353198B2 (ja) | 2006-03-23 | 2006-03-23 | 字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4353198B2 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010199711A (ja) * | 2009-02-23 | 2010-09-09 | Sony Corp | コンテンツ処理装置および方法 |
| JP5140687B2 (ja) * | 2008-02-14 | 2013-02-06 | パナソニック株式会社 | 再生装置、集積回路、再生方法、プログラム、コンピュータ読取可能な記録媒体 |
-
2006
- 2006-03-23 JP JP2006081438A patent/JP4353198B2/ja not_active Expired - Fee Related
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5140687B2 (ja) * | 2008-02-14 | 2013-02-06 | パナソニック株式会社 | 再生装置、集積回路、再生方法、プログラム、コンピュータ読取可能な記録媒体 |
| CN101904169B (zh) * | 2008-02-14 | 2013-03-20 | 松下电器产业株式会社 | 再生装置、集成电路、再生方法 |
| US8428437B2 (en) | 2008-02-14 | 2013-04-23 | Panasonic Corporation | Reproduction device, integrated circuit, reproduction method, program, and computer-readable recording medium |
| JP2010199711A (ja) * | 2009-02-23 | 2010-09-09 | Sony Corp | コンテンツ処理装置および方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4353198B2 (ja) | 2009-10-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240276050A1 (en) | In-band data recognition and synchronization system | |
| EP2549771B1 (en) | Method and apparatus for viewing customized multimedia segments | |
| US8453169B2 (en) | Video output device and video output method | |
| CN1984275B (zh) | 显示进度条的方法以及使用该方法的电视接收器 | |
| CN1984291B (zh) | 执行时移功能的方法及使用该方法的电视接收机 | |
| CN101461241B (zh) | 隐藏式字幕的系统和方法 | |
| JP5135024B2 (ja) | コンテンツのシーン出現を通知する装置、方法およびプログラム | |
| US8315384B2 (en) | Information processing apparatus, information processing method, and program | |
| JP4019085B2 (ja) | 番組録画装置、番組録画方法および番組録画プログラム | |
| JP5405096B2 (ja) | 放送受信装置 | |
| JP4353198B2 (ja) | 字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置 | |
| KR100776196B1 (ko) | 디지털 방송 수신기에서 방송 프로그램 목록 출력 방법 | |
| JP5143269B1 (ja) | コンテンツ出力装置、及びコンテンツ出力方法 | |
| JP5156527B2 (ja) | 番組再生装置 | |
| JP2007174246A (ja) | 映像情報処理方法、映像情報処理プログラム及び映像情報処理装置 | |
| JP2007060222A (ja) | 映像処理装置、映像処理方法及び映像処理プログラム | |
| JP5197835B1 (ja) | 番組表制御装置及び番組表制御方法 | |
| EP3588968A1 (en) | Method and device for launching an action related to an upcoming audio visual program | |
| JP2007251743A (ja) | 放送情報管理方法、放送情報管理システム及び放送情報管理プログラム | |
| JP2013062600A (ja) | 番組記録装置および過去番組表の表示方法 | |
| JP2013098996A (ja) | コンテンツ出力装置、コンテンツ出力方法、及びコンテンツ出力プログラム | |
| KR20070083328A (ko) | 디지털 티브이의 채널 정보 표시 방법 및 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090407 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090414 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090612 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090707 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090720 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120807 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |