JP2007259121A - Closed caption data processing method, closed caption data processing program and closed caption data processor - Google Patents
Closed caption data processing method, closed caption data processing program and closed caption data processor Download PDFInfo
- Publication number
- JP2007259121A JP2007259121A JP2006081438A JP2006081438A JP2007259121A JP 2007259121 A JP2007259121 A JP 2007259121A JP 2006081438 A JP2006081438 A JP 2006081438A JP 2006081438 A JP2006081438 A JP 2006081438A JP 2007259121 A JP2007259121 A JP 2007259121A
- Authority
- JP
- Japan
- Prior art keywords
- segment
- data
- subtitle
- line
- segments
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Abstract
Description
本発明は、放送信号に含まれる字幕情報を利用して、放送の検索を可能とするための字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置に関する。 The present invention relates to a caption data processing method, a caption data processing program, and a caption data processing apparatus for enabling search of a broadcast by using caption information included in a broadcast signal.
通常、テレビジョン放送として放送される番組のデータには、映像データと音声データが含まれている。そして、放送される番組データには、表示させるか否かをユーザ側で選択可能な字幕データが含まれている場合がある。このような選択可能な字幕データは、一般にクローズドキャプション(closed caption)と称され、主に、聴覚障害者用に開発されたものである。この字幕の中には、出演者の会話だけではなく、例えば、BGMや効果音などの説明も含まれる。 Usually, the data of a program broadcast as a television broadcast includes video data and audio data. The broadcast program data may include subtitle data that allows the user to select whether to display the program data. Such selectable caption data is generally referred to as closed caption, and is mainly developed for the hearing impaired. This subtitle includes not only the performer's conversation but also explanations such as BGM and sound effects.
このクローズドキャプションは、テレビジョン信号の21番目の水平走査線に、画面に関する音声等を文字コード化したものを挿入する。クローズドキャプションのデータは、専用のデコーダによってテレビジョン信号から分離することができる。 In this closed caption, a voice-coded audio code or the like is inserted into the 21st horizontal scanning line of the television signal. The closed caption data can be separated from the television signal by a dedicated decoder.
このようなクローズドキャプションのデータに基づき映像を検索する映像検索装置に関する技術が開示されている(例えば、特許文献1を参照。)。この特許文献1に記載の映像検索装置では、入力部から「検索準備」の指示を受けると、映像再生部が媒体の再生を開始し、デコーダがテレビジョン信号をデコードしてクローズドキャプションデータを取得し、メモリに格納する。そして、入力部から「検索要求設定」を受けると、文章検索部においてメモリ内のクローズドキャプションデータを検索し、この検索結果をメモリに保存する。更に、メモリに記録された検索結果を読み出してデコーダへ送り、デコーダでテレビジョン信号に変換して、映像表示部に表示する。これにより、クローズドキャプションの文字情報を利用して映像の内容を容易に検索することができる。
A technique relating to a video search device that searches for video based on such closed caption data is disclosed (see, for example, Patent Document 1). In the video search device described in
また、表示するか否かをユーザが選択することが可能なテキストデータを用いてメタデータを生成する技術も開示されている(例えば、特許文献2を参照。)。この特許文献2に記載の情報処理装置においては、放送信号を取得し、この放送信号から番組を固有に区別可能な区別情報を取得する。そして、放送信号に、時刻情報と区別情報とを付加する。これにより、テキストデータに対応する時刻情報と番組を区別する区別情報を有するメタデータを用いて検索することができる。
ところで、対話の画面などでは、各話者の近くに、その発言の字幕を表示させることがある。このとき、発言が長い場合には、それらの発言を分割して複数行に亘って段組表示することがある。この場合、映像データの走査方向に字幕データを抽出してテキストデータを生成すると、段組が考慮されず複数の話者の発言が入れ子状態になってしなうことがある。これでは、このテキストデータからメタデータを生成しても、的確なデータを生成することができず、このようなメタデータでは正確な検索を行なうことが難しくなる。 By the way, on a dialogue screen or the like, a caption of the utterance may be displayed near each speaker. At this time, when the utterances are long, the utterances may be divided and displayed in multiple columns. In this case, when subtitle data is extracted in the scanning direction of the video data to generate text data, the utterances of a plurality of speakers may not be nested without considering the columns. Thus, even if metadata is generated from the text data, accurate data cannot be generated, and it is difficult to perform an accurate search with such metadata.
本発明は、上記課題を解決するためになされたものであり、その目的は、一連の文字群が複数行に亘って表示される場合であっても、より的確なテキストデータを生成することができる字幕データ処理方法、字幕データ処理プログラム及び字幕データ処理装置を提供
することにある。
The present invention has been made to solve the above-described problems, and an object of the present invention is to generate more accurate text data even when a series of character groups are displayed over a plurality of lines. A subtitle data processing method, a subtitle data processing program, and a subtitle data processing apparatus are provided.
上記問題点を解決するために、請求項1に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理方法であって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう段階と、この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更段階と、前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを要旨とする。
In order to solve the above problem, the invention described in
請求項2に記載の発明は、請求項1に記載の字幕データ処理方法において、前記セグメント判定条件は、前記字幕データに含まれる動作位置指定であることを要旨とする。
請求項3に記載の発明は、請求項1又は2に記載の字幕データ処理方法において、前記セグメント判定条件は、前記字幕データに含まれる配色指定であることを要旨とする。
The invention according to
The invention according to
請求項4に記載の発明は、請求項1〜3のいずれか1項に記載の字幕データ処理方法において、前記接続判定条件は、第1のセグメントが、これを含む行の直前の行に含まれる第2のセグメントに対して隣接されており、前記第1のセグメントの開始位置が前記第2のセグメントの開始位置に対して字下げされているか又は同じであり、かつ前記第1のセグメントの配色が、前記第2のセグメントの配色と同じであることであり、前記配置変更段階は、前記第1及び前記第2のセグメントの位置に基づいて、前記接続判定条件が満たされた場合には、前記第1のセグメントの次に前記第2のセグメントが配置するように並び替えることを要旨とする。 According to a fourth aspect of the present invention, in the subtitle data processing method according to any one of the first to third aspects, the connection determination condition is included in a line immediately before a line including the first segment. The start position of the first segment is indented or the same as the start position of the second segment, and The color arrangement is the same as the color arrangement of the second segment, and the arrangement changing step is performed when the connection determination condition is satisfied based on the positions of the first and second segments. The gist is to rearrange the second segment after the first segment.
請求項5に記載の発明は、請求項1〜4のいずれか1項に記載の字幕データ処理方法において、前記複数行判定処理の前に、前記一画面に異なる文字サイズの字幕データの有無を判定する文字サイズ判定段階と、異なる文字サイズの字幕データがあった場合には、小さい文字サイズの文字を含むセグメント毎にルビ条件を判定し、前記ルビ条件に一致するセグメントを削除する削除段階とを更に実行することを要旨とする。 According to a fifth aspect of the present invention, in the caption data processing method according to any one of the first to fourth aspects, before the multi-line determination process, presence / absence of caption data having a different character size is displayed on the one screen. A character size determination step for determining, and when there is subtitle data having a different character size, a deletion step for determining a ruby condition for each segment including a character with a small character size and deleting a segment that matches the ruby condition; Is further executed.
請求項6に記載の発明は、請求項5に記載の字幕データ処理方法において、前記ルビ条件として、セグメントの文字列が、ひらがな、カタカナ又は空白から構成され、同じ行において隣接する文字のサイズが異ならず、次行において、より大きなサイズの文字に隣接していることを条件として用いることを要旨とする。 According to a sixth aspect of the present invention, in the caption data processing method according to the fifth aspect, as the ruby condition, a character string of a segment is composed of hiragana, katakana, or a blank, and the size of adjacent characters in the same line is The gist is that the next line is used on the condition that it is adjacent to a character of a larger size.
請求項7に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理方法であって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう段階と、このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する段階と、このグループ内の個々のセグメントを前記順番で並ぶように並び替える段階と、前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを要旨とする。 The invention according to claim 7 is a caption data processing method for processing caption data extracted from a video signal, wherein the number of lines of caption data included in one screen is acquired, and a plurality of determinations are made as to whether or not there are two or more lines. A step of performing a row determination process, and a step of specifying the position of each segment included in each row of the caption data in each row based on a segment determination condition when the caption data includes two or more rows. Performing a group determination process for determining whether or not a group relationship condition is satisfied based on the identified position, and assigning an order to the segments determined to have a group relationship in the group determination process Grouping the segments, rearranging the individual segments in the group to line up in the order, and And summarized in that to perform a generating step of generating the text subtitle data in accordance with the turn.
請求項8に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理プログラムであって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段として機能させることを要旨とする。 The invention according to claim 8 is a caption data processing program for processing caption data extracted from a video signal, wherein the number of lines of caption data included in one screen is acquired and a plurality of judgments are made to determine whether or not there are two or more lines. A means for performing line determination processing; a specification means for specifying a position in each line of each segment included in each line of the caption data based on a segment determination condition when the caption data includes two or more lines; Means for performing a connection determination process for determining whether or not a connection determination condition for determining that the segment is connected to a segment in another row from which the segment is different is determined in the connection determination process. The arrangement changing means for rearranging the segments determined to be adjacent to each other, and the subtitle text data according to the order of the rearranged segments. And summarized in that to function as a generating means for generating data.
請求項9に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理プログラムであって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段として機能させることを要旨とする。 The invention according to claim 9 is a caption data processing program for processing caption data extracted from a video signal, wherein the number of lines of caption data included in one screen is acquired and a plurality of judgments are made to determine whether or not there are two or more lines. A means for performing line determination processing; a specification means for specifying a position in each line of each segment included in each line of the caption data based on a segment determination condition when the caption data includes two or more lines; Means for performing a group determination process for determining whether or not a group relation condition is satisfied based on the determined position, and assigning an order to the segments determined to be in a group relation in the group determination process Means for grouping, means for rearranging the individual segments in the group in order, and And summarized in that to function as a generating means for generating text data of the caption in accordance with the turn.
請求項10に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理装置であって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段を備えたことを要旨とする。
The invention according to
請求項11に記載の発明は、映像信号から抽出した字幕データを処理する字幕データ処理装置であって、一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段を備えたことを要旨とする。 The invention according to claim 11 is a caption data processing device for processing caption data extracted from a video signal, and obtains the number of lines of caption data included in one screen and determines whether or not there are two or more lines. A means for performing line determination processing; a specification means for specifying a position in each line of each segment included in each line of the caption data based on a segment determination condition when the caption data includes two or more lines; Means for performing a group determination process for determining whether or not a group relation condition is satisfied based on the determined position, and assigning an order to the segments determined to be in a group relation in the group determination process Means for grouping, means for rearranging the individual segments in the group so as to line up in the order, and order of the rearranged segments Depending the gist further comprising generating means for generating text data of subtitles.
(作用)
請求項1、8又は10に記載の発明によれば、一画面に含まれる字幕データが2行以上ある場合には、字幕データの個々のセグメントの各行内での位置からセグメントが異なる他の行のセグメントに対して接続関係であると判定するための接続判定条件を満たすか否かを判定する。そして、接続関係にあると判定されたセグメント同士が隣り合うように並び替え、並び替えたセグメントの順番に応じて字幕のテキストデータを生成する。通常、表示の関係により、複数行に亘って一連の文字群が表示される場合には、それらが所定の
接続関係にある。このため、各行内の位置から、所定の接続関係にあるセグメント同士であるか否かを判定し、接続関係にあると判定した場合には、一連の文字群であるとしてセグメント同士が隣り合うように並び替える。これにより、一連の文字群が複数行に亘って表示される場合であっても、より正確に、一連の文字群を取得することができる。従って、より有益なデータを効率よく生成することができる。
(Function)
According to the invention described in
請求項2に記載の発明によれば、字幕データに含まれる動作位置指定から、セグメントであるか否かを判定することができる。
請求項3に記載の発明によれば、字幕データに含まれる配色指定から、セグメントであるか否かを判定することができる。
According to the second aspect of the present invention, it is possible to determine whether or not the segment is based on the operation position designation included in the caption data.
According to the third aspect of the present invention, it is possible to determine whether or not the segment is based on the color scheme designation included in the caption data.
請求項4に記載の発明によれば、接続判定条件は、第1のセグメントが、これを含む行の直前の行に含まれる第2のセグメントに対して隣接されており、第1のセグメントの開始位置が第2のセグメントの開始位置に対して字下げされているか又は同じであり、かつ第1のセグメントの配色が第2のセグメントの配色と同じであることである。この接続判定条件が満たされた場合には、第1のセグメントの次に第2のセグメントが配置するように並び替える。一連の文字群であれば、続く行に別のセグメントが同色で表示され、見易くなるように直後のセグメントは「字下げ」又は「左揃え」されていることが多い。これらの条件を用いることにより、近接しているが一連の文字群と一連でない文字群とを区別し、より確実に、接続関係を判定することができる。
According to the invention of
請求項5に記載の発明によれば、一画面に異なる文字サイズの字幕データがあった場合には、小さい文字サイズの文字を含むセグメント毎にルビ条件を判定し、ルビ条件に一致するセグメントを削除する。これにより、テキストデータとしては重複して不要なルビを除去するので、必要なテキストデータのみを抽出して、より有益なデータを生成することができる。 According to the fifth aspect of the present invention, when there is subtitle data having a different character size on one screen, the ruby condition is determined for each segment including a character having a small character size, and a segment matching the ruby condition is determined. delete. Thereby, since unnecessary ruby is removed as text data, only necessary text data can be extracted and more useful data can be generated.
請求項6に記載の発明によれば、ルビ条件として、セグメントの文字列が、ひらがな、カタカナ又は空白から構成され、同じ行において隣接する文字のサイズが異ならず、次行において、より大きなサイズの文字に隣接していることを条件とする。ルビは、漢字などの読み方を示すものであるため、ルビ以外の文字に比べて小さく表示され、ひらがな又はカタカナで表示されることが普通である。また、ルビの位置調整のために空白を含んでルビが構成されることがある。従って、他のセグメントの文字サイズや位置から、ルビのセグメントであるか否かを判定することができる。よって、不要なルビをより確実に除去することができる。
According to the invention of
請求項7、9又は11に記載の発明によれば、一画面に含まれる字幕データが2行以上ある場合には、字幕データの個々のセグメントの各行内での位置からグループ関係を満たすか否かを判定する。そして、グループ関係にあると判定されたセグメントを、順番どおりに並び替え、並び替えたセグメントの順番に応じて字幕のテキストデータを生成する。通常、表示の関係により、複数行に亘って一連の文字群が表示される場合には、それらが所定のグループ関係にある。このため、各セグメントの位置から一連の文字群であるか否か、すなわち所定のグループ関係にあるセグメント同士であるか否かを判定し、グループ関係にあると判定した場合には、一連の文字群であるとして複数のセグメントに対して順番を付けてグループ化して、この順番に並び替える。これにより、一連の文字群が複数の領域に亘って表示される場合であっても、より正確に、一連の文字群を取得することができる。従って、より的確なテキストデータを効率よく生成することができる。 According to the invention described in claim 7, 9 or 11, when there are two or more subtitle data included in one screen, whether or not the group relationship is satisfied from the position in each row of the individual segments of the subtitle data. Determine whether. Then, the segments determined to have the group relationship are rearranged in order, and subtitle text data is generated according to the rearranged segment order. Usually, when a series of character groups are displayed over a plurality of lines due to the display relationship, they are in a predetermined group relationship. Therefore, from the position of each segment, it is determined whether or not it is a series of characters, that is, whether or not the segments are in a predetermined group relationship. As a group, a plurality of segments are grouped in order and rearranged in this order. Thereby, even if it is a case where a series of character groups are displayed over a some area | region, a series of character groups can be acquired more correctly. Therefore, more accurate text data can be generated efficiently.
本発明によれば、一連の文字群が複数の領域に亘って表示される場合であっても、一連
の文字群を一行としてより正確に取得し、より的確なテキストデータを生成することができる。
According to the present invention, even when a series of character groups is displayed over a plurality of areas, the series of character groups can be more accurately acquired as one line, and more accurate text data can be generated. .
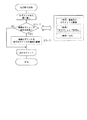
以下、本発明を具体化した一実施形態を、図1〜図9を用いて説明する。図1は、本発明を適用した字幕データ処理装置の構成について説明するための説明図である。本実施形態では、図1に示すように、放送局からの放送信号を、テレビジョン受像機30を用いて受信する。このテレビジョン受像機30には表示選択字幕デコーダ40が接続され、この表示選択字幕デコーダ40にはホームサーバ50が接続される。このホームサーバ50は、ネットワークとしてのインターネットIを介して、字幕データ処理装置としてのメタデータ作成サーバ70に接続される。このメタデータ作成サーバ70には、文字データ入力手段としてのオペレータ端末(図示せず)に接続されている。
Hereinafter, an embodiment embodying the present invention will be described with reference to FIGS. FIG. 1 is an explanatory diagram for explaining a configuration of a caption data processing apparatus to which the present invention is applied. In this embodiment, as shown in FIG. 1, a broadcast signal from a broadcast station is received using a
放送局10は、地上波や衛星波などを用いて番組を放送する施設である。放送される番組の放送信号には、映像データと音声データが含まれる。この映像データは、動画像データであり、音声データは、映像データと同期して再生される音声に関するデータである。
The
また、この放送信号の中には、映像として常に表示される字幕と、選択により表示される字幕とが含まれる。前者には、番組の題名やキャストなどの紹介、海外の作品における日本語字幕等がある。一方、後者のように表示選択の可能な字幕データ(いわゆるクローズドキャプション)には、出演者の会話に対応するテキストデータや、例えばBGMや効果音など、放送コンテンツに関する説明が含まれている場合もある。このように、表示と非表示を選択可能な字幕データを「表示選択字幕データ」と呼ぶ。 Also, the broadcast signal includes subtitles that are always displayed as video and subtitles that are displayed by selection. The former includes introductions of program titles and casts, Japanese subtitles in overseas works, etc. On the other hand, subtitle data (so-called closed caption) that can be displayed and selected as in the latter case may include text data corresponding to a performer's conversation, and explanations about broadcast content such as BGM and sound effects. is there. In this way, caption data that can be selected to be displayed or not is referred to as “display selected caption data”.
次に、この表示選択字幕データについて説明する。例えばNTSC方式のアナログの地上波放送では、映像信号に525本の走査線が用いられている。この525本のうち、各フィールド(2フィールドで1フレームを構成)の最初の21本相当は、VBI(Vertical Blanking Interval:垂直帰線消去期間)と呼ばれ、走査を開始するためのインターバル用に割り当てられている。クローズドキャプションは、各フィールドのVBIのうち、VBIの21本目に7bitの文字コードを多重化することによって伝送されるように構成されている。そして、各フィールドを使って2種類の文字セットを約60文字/秒で伝送することができる。この表示選択字幕データは、再生時に映像データからデコードされて、映像と同時に表示させることができる。 Next, the display selection subtitle data will be described. For example, in NTSC analog terrestrial broadcasting, 525 scanning lines are used for video signals. Of these 525 lines, the first 21 lines of each field (one field is composed of 2 fields) is called VBI (Vertical Blanking Interval), and is used as an interval for starting scanning. Assigned. The closed caption is configured to be transmitted by multiplexing a 7-bit character code in the 21st VBI of the VBI of each field. Each field can be used to transmit two types of character sets at about 60 characters / second. This display selection subtitle data is decoded from the video data at the time of reproduction, and can be displayed simultaneously with the video.
ユーザ側では、テレビジョン受像機30を用いて、表示選択字幕データを含む映像データ及び音声データで構成される放送信号が受信される。このテレビジョン受像機30は、チューナ31、信号処理部32、ディスプレイやスピーカからなる出力部33を備える。表示選択字幕データを表示させない場合には、テレビジョン受像機30は、チューナ31によって選局された放送信号を信号処理部32において復調する。そして、出力部33において、復調した放送信号のうち、映像信号はディスプレイに出力し、音声信号はスピーカに出力する。これにより、ユーザは番組を視聴することができる。
On the user side, the
表示選択字幕デコーダ40は、テレビジョン受像機30のチューナ31によって選局された放送信号を取得し、映像信号及び音声信号をデコードする。そして、表示選択字幕デコーダ40は、ユーザの操作入力に基づいて、表示選択字幕データを抽出し、更にデコードし、出力部33への出力を行なう。更に、表示選択字幕デコーダ40は、ホームサーバ50がインターネットIを介してメタデータ作成サーバ70から取得したメタデータを用いて検索や要約処理を実行する。
The display
図3は、この表示選択字幕デコーダ40の構成ブロック図である。映像信号デコーダ4
01は、供給された映像信号をデコードし、デコードされた映像データをメモリ403に供給する。メモリ403は、供給された映像信号を一時保持するフレームメモリである。音声信号デコーダ402は、供給された音声信号をデコードし、デコードされた音声データを出力する。
FIG. 3 is a configuration block diagram of the display
01 decodes the supplied video signal and supplies the decoded video data to the memory 403. The memory 403 is a frame memory that temporarily holds the supplied video signal. The
表示選択字幕データデコーダ405は、受信された放送信号をリアルタイムに出力する場合、メモリ403から映像データを取得する。そして、表示選択字幕データの表示が指示された場合、表示選択字幕データデコーダ405は、取得した映像データに含まれる表示選択字幕データをデコードして、対応するテキストデータをOSD(On Screen Display )406に供給するとともに、映像データを合成処理部407に供給する。
The display selection subtitle data decoder 405 acquires video data from the memory 403 when outputting the received broadcast signal in real time. When the display selection subtitle data is instructed to be displayed, the display selection subtitle data decoder 405 decodes the display selection subtitle data included in the acquired video data and converts the corresponding text data into an OSD (On Screen Display) 406. And the video data to the
OSD406は、供給されたテキストデータを、表示画面に重畳して表示させるための画像データであるOSDデータに変換して、合成処理部407に供給する。合成処理部407は、供給された映像データに、供給されたOSDデータを重畳して、出力端子からテレビジョン受像機30の出力部33のディスプレイに出力する。一方、音声処理部408は、音声信号デコーダ402によりデコードされた音声データを取得して、テレビジョン受像機30の出力部33のスピーカに出力する。
The OSD 406 converts the supplied text data into OSD data that is image data to be displayed superimposed on the display screen, and supplies the OSD data to the
また、映像信号及び音声信号をホームサーバ50に出力して録画させる場合、出力信号生成部409は、番組ID抽出部410に、メモリ403に保持されている映像データから番組管理データに含まれる番組IDを抽出させる。出力信号生成部409は、タイマ411を参照して、録画が開始された時刻(絶対時刻)を取得し、メモリ403から供給される映像データ、又は音声信号デコーダ402から供給される音声データのうちの少なくともいずれか一方に、取得した時刻情報を付加する。更に、映像データ及び音声データに対して、番組ID抽出部410から供給された番組IDを付加して、録画のための出力信号を生成してホームサーバ50に供給する。ここで付加された時刻情報は、タイムスタンプとして、後述する検索や抽出処理において用いられる。
When the video signal and the audio signal are output to the
このような処理により、表示選択字幕デコーダ40は、ユーザの操作入力に基づいて、表示選択字幕をデコードして映像に重畳させて表示させたり、録画データを生成し、ホームサーバ50に供給して録画させたりすることが可能となる。また、表示選択字幕デコーダ40は、映像データ及び音声データに付加された時刻情報や番組IDを用いて検索や要略処理が実行できるようになる。
Through such processing, the display
一方、ホームサーバ50は、ユーザの操作入力に基づいて、表示選択字幕デコーダ40により生成されたタイムスタンプつき録画データの供給を受けて、内部のデータ記憶手段に記録する。このホームサーバ50は、インターネットIを介して、メタデータ作成サーバ70から、表示選択字幕データに対応するテキストデータと、テキストデータに対応するタイムコードにより構成される暗号化メタデータの供給を受ける。更に、ホームサーバ50は、暗号化メタデータを、鍵データを利用して復号化し、このメタデータを用いてユーザが入力したテキストとメタデータとのマッチング処理を実行する。そして、マッチング処理の結果、ユーザが入力したテキストに対応するタイムコードを検出した場合には、タイムコードに基づいて録画データを検索し、表示選択字幕デコーダ40に供給する。
On the other hand, the
図4は、このホームサーバ50のブロック構成図である。操作入力部501は、例えば、ボタン、キー、タッチパネル、タッチパッド、レバーなどの入力デバイスで構成され、ユーザの操作入力を受ける。録画制御部502は、操作入力部501から放送番組の録画指示が入力された場合、表示選択字幕デコーダ40に対して映像信号や音声信号の出力を指示する。表示部504は、例えば、LCD(Liquid Crystal Display)又はCRT(Cathode Ray Tube)などで構成され、各種情報を表示する。
FIG. 4 is a block diagram of the
録画データ記憶部52には、表示選択字幕デコーダ40から供給される番組ID及びタイムスタンプが付加された映像データ及び音声データが記憶される。録画データ記憶部52は、例えば、ハードディスクなどの大容量記録媒体により構成されるようにしても、DVD(Digital Versatile Disk)や磁気テープなどのリムーバブルな記録媒体を用いることも可能である。
The recorded data storage unit 52 stores video data and audio data to which the program ID and time stamp supplied from the display
ネットワークIF部503は、インターネットIを介して通信を行なうインターフェースである。ここでは、メタデータ作成サーバ70との間でデータの送受信を行なう。暗号化メタデータ記憶部53は、ネットワークIF部503を介して、メタデータ作成サーバ70から取得した暗号化メタデータを記憶する。鍵データ記憶部54は、暗号化メタデータを復号化するために、予め復号化鍵を記憶する。この復号化鍵は、メタデータ作成サーバ70から番組ID毎に、ネットワークIF部503を介して提供され、記録される。復号処理部505は、暗号化メタデータ記憶部53に記録されている暗号化メタデータを、鍵データ記憶部54に記憶されている復号化鍵を用いて復号し、メタデータ記憶部55に記録する。
The network IF unit 503 is an interface that performs communication via the Internet I. Here, data is transmitted to and received from the
マッチング処理部506は、操作入力部501に、検索対象の番組IDと、検索キーとなるテキストが入力された場合、メタデータ記憶部55に記録されているメタデータを参照して、マッチング処理を実行する。そして、マッチング処理部506は、検索キーを含むテキストを特定した場合、このテキストに関連付けられたタイムコードを録画データ検索処理部507に供給する。
When the search target program ID and the text as the search key are input to the operation input unit 501, the matching
ここで、操作入力部501において番組IDのみが指定されている場合、マッチング処理部506は、この番組IDに関連付けられて記録されたメタデータをメタデータ記憶部55から抽出する。そして、このメタデータに含まれるタイムコードと番組IDは、録画データ記憶部52を検索するために用いられる。このため、抽出したタイムコードを録画データ検索処理部507に供給する。
Here, when only the program ID is specified in the operation input unit 501, the matching
録画データ検索処理部507は、マッチング処理部506から供給されたマッチング結果(番組IDとタイムコード)に基づいて録画データ記憶部52を検索する。そして、この番組IDの付与された録画において、タイムコードにより特定された画像を表示選択字幕デコーダ40に供給する。
The recorded data search processing unit 507 searches the recorded data storage unit 52 based on the matching result (program ID and time code) supplied from the matching
一方、メタデータ作成サーバ70は、各種ネットワークや電波を介して受信することにより、放送局10が作成した表示選択字幕データ付きの放送信号を取得する。そして、メタデータ作成サーバ70は、この放送信号を用いてメタデータを作成し、作成したメタデータを暗号化する。また、メタデータ作成サーバ70は、暗号化されたメタデータを、インターネットIを介してユーザに配布する。このメタデータ作成サーバ70は、制御手段としてのCPU(Central Processing Unit )からなる制御手段、ROM(Read Only Memory)やRAM(Random Access Memory )、HDD(Hard Disk Drive )等のデータ記
憶手段を備える。
On the other hand, the
次に、メタデータ作成サーバ70の構成について詳述する。図5にはメタデータ作成サーバ70のブロック構成を示す。メタデータ作成サーバ70のCPUは、字幕データ処理プログラムを実行することによって、複数行判定処理を行なう段階、特定段階、接続判定処理を行なう段階、配置変更段階、生成段階、文字サイズ判定段階及び削除段階等を実行する。この結果、メタデータ作成サーバ70は、以下の機能ブロック図に示す機能を実現する。
Next, the configuration of the
放送信号取得部701は、ネットワークや放送電波を介して放送信号を取得してデコーダ702に供給する。デコーダ702は、放送信号取得部701から供給された放送信号をデコードする。ここで、デコーダ702は、放送信号のうち、メタデータの作成に必要となる番組ID情報を含む番組管理情報や表示選択字幕データが含まれている映像信号のみをデコードする。
The broadcast
番組ID情報抽出部703は、デコーダ702によりデコードされた映像データに含まれる番組管理データから、放送番組を特定することができる番組ID情報を抽出し、メタデータ生成部708に供給する。更に、番組ID情報抽出部703は、この映像データを、表示選択字幕データ処理部705に供給する。この表示選択字幕データ処理部705は、複数行判定処理を行なう手段、特定手段、接続判定処理を行なう手段、配置変更手段、生成手段、文字サイズ判定手段及び削除手段として機能し、取得した映像データに含まれる表示選択字幕データをデコードし、字幕メタデータを生成する。
The program ID
次に、表示選択字幕データ処理部705における本発明に係わる字幕処理方法について、図6〜図9を用いて説明する。ここで、表示選択字幕データ処理部705は、画面毎に字幕処理を繰り返して行なう。
Next, a caption processing method according to the present invention in the display selection caption
表示選択字幕データ処理部705は、まず、デコーダ702においてデコードされた映像データに含まれる8単位符号からなる字幕データをデコードする。この字幕データには、文字の表示位置や大きさ等の制御符号や、文字のテキストデータなどの情報が含まれる。表示選択字幕データ処理部705は、デコードした字幕データを用いて、まず放送字幕ルビ処理を行なう(ステップS1−1)。この放送字幕ルビ処理は、テキストデータから放送字幕のルビを削除するための処理である。
The display selection subtitle
この放送字幕ルビ処理について、図7を用いて詳述する。この放送字幕ルビ処理において、表示選択字幕データ処理部705は、まず、画面内の文字のサイズがすべて同じか否かを判定する(ステップS2−1)。画面内の文字のサイズがすべて同じ場合(ステップS2−1において「YES」の場合)には、画面にはルビが含まれておらず、この放送字幕ルビ処理を終了する。
This broadcast subtitle ruby process will be described in detail with reference to FIG. In this broadcast subtitle ruby process, the display selection subtitle
画面内の文字のサイズがすべて同じでない場合(ステップS2−1において「NO」の場合)には、表示選択字幕データ処理部705は、セグメント毎に、セグメントがルビ特定条件に一致しているか否かを判定する(ステップS2−2)。ここで、表示選択字幕データ処理部705は、文字列中に含まれる動作位置の指定や文字列の文字の色や背景色などの配色指定など制御符号から、一連の文字群からなるセグメントを特定する。これら字幕データに含まれる動作位置指定や配色指定により、セグメントか否かを判定することができる。
If the sizes of the characters in the screen are not all the same (in the case of “NO” in step S2-1), the display selection subtitle
そして、このセグメントがルビかどうかを判定する。この場合、ルビは、漢字などの読み方を示すものであるため、ルビ以外の文字に比べて小さく表示され、ひらがな又はカタカナで表示されることが普通である。また、ルビの位置調整のために空白を含んでルビが構成されることがある。そこで、本実施形態では、ルビであると特定するためのルビ特定条件として、(1)異なる文字の文字サイズが小型サイズであり、(2)セグメントが「ひらがな」、「カタカナ」又は「空白」から構成されており、(3)標準サイズ文字に同じ行で隣接しておらず、かつ、(4)次の行において標準サイズ文字と隣接していることを用いる。例えば、(1)については文字サイズ指定の制御符号等を用いて判定する。また、(2)については、文字コード等を用いて判定する。更に、(3)、(4)については、位置指定の制御符号や文字サイズ指定の制御符号等を用いて判定する。 Then, it is determined whether this segment is ruby. In this case, since ruby indicates how to read kanji and the like, it is usually displayed smaller than characters other than ruby and is displayed in hiragana or katakana. In addition, a ruby may be configured including a blank for adjusting the position of the ruby. Therefore, in this embodiment, as ruby specifying conditions for specifying ruby, (1) the character size of different characters is a small size, and (2) the segment is “Hiragana”, “Katakana”, or “blank”. (3) The standard size character is not adjacent on the same line, and (4) the next line is adjacent to the standard size character. For example, (1) is determined using a character size designation control code or the like. Further, (2) is determined using a character code or the like. Further, (3) and (4) are determined using a position designation control code, a character size designation control code, and the like.
そして、セグメントが、上述した4つのルビ特定条件のすべてとは一致しない場合(ステップS2−2において「NO」の場合)には、表示選択字幕データ処理部705は、次のセグメントについての判定を行なう。
If the segment does not match all the above four ruby identification conditions (“NO” in step S2-2), the display selection subtitle
一方、セグメントが、上述した4つのルビ特定条件のすべてを充足する場合(ステップS2−2において「YES」の場合)には、表示選択字幕データ処理部705はルビであると判定して、このセグメントを削除する(ステップS2−3)。
On the other hand, if the segment satisfies all of the four ruby identification conditions described above (“YES” in step S2-2), the display selection subtitle
そして、セグメントを削除した行に、他のセグメントが残っている場合には、表示選択字幕データ処理部705は、同じ行の他のセグメントについて上記ステップS2−2以降の処理を行なう(ステップS2−4において「YES」)。ここで、同じ行に他のセグメントが残っているか否かは、位置指定の制御符号や文字サイズ指定の制御符号等を用いて判定する。一方、セグメントが残っていない場合(ステップS2−4において「NO」の場合)には、その行の削除を行なう(ステップS2−5)。
If another segment remains in the line from which the segment is deleted, the display selection subtitle
以上のステップS2−2〜S2−5の処理をセグメント毎に行なう放送字幕ルビ処理を、表示選択字幕データ処理部705は画面毎に実行し(ステップS1−1)、ルビと判定したデータ以外の字幕データを抽出する。
The display selection subtitle
次に、放送字幕ルビ処理以降の処理を、図6に戻って説明する。表示選択字幕データ処理部705は、1つの画面に2行以上の字幕があるか否かを判定する(ステップS1−2)。ここで、画面に2以上の字幕がない場合(ステップS1−2において「NO」の場合)には、その画面における字幕処理を終了し、次の画面について字幕処理を行なう。
Next, processing after the broadcast subtitle ruby processing will be described with reference to FIG. The display selection subtitle
一方、画面に2行以上の字幕がある場合(ステップS1−2において「YES」の場合)には、この画面に2つ以上のセグメントを含む行があるか否かを判断する(ステップS1−3)。具体的には、2行以上の字幕がある各行について、位置指定の制御符号や文字サイズ指定の制御符号等から、2以上のセグメントが含まれているか否かを判定する。ここで、2以上のセグメントを含む行がない場合(ステップS1−3において「NO」の場合)には、その画面における字幕処理を終了し、次の画面について字幕処理を行なう。 On the other hand, when there are two or more lines of subtitles on the screen (in the case of “YES” in step S1-2), it is determined whether or not there is a line including two or more segments on this screen (step S1- 3). Specifically, for each line having two or more subtitles, it is determined whether or not two or more segments are included from a position designation control code, a character size designation control code, or the like. Here, when there is no row including two or more segments (in the case of “NO” in step S1-3), the caption processing on the screen is terminated and caption processing is performed on the next screen.
そして、画面に2行以上の字幕があり、かつ2以上のセグメントを含む行がある場合(ステップS1−3において「YES」の場合)には、並び替え処理を行なう(ステップS1−4)。この並び替え処理において、図8に示す連続セグメント条件の充足性を、セグメント毎に判定する(ステップS3−1)。本実施形態では、連続セグメント条件として、「直前行のセグメントと隣接」し、「字下げ」又は「左揃え」が行なわれており、かつ「同色で表示されている」ことを用いる。 If there are two or more subtitles on the screen and there are two or more segments (“YES” in step S1-3), rearrangement processing is performed (step S1-4). In this rearrangement process, the sufficiency of the continuous segment condition shown in FIG. 8 is determined for each segment (step S3-1). In this embodiment, as the continuous segment condition, “adjacent to the segment in the previous line”, “indentation” or “left alignment”, and “displayed in the same color” are used.
具体的には、表示選択字幕データ処理部705は、まず、位置指定の制御符号や文字サイズ指定の制御符号等を用いて、連続セグメント条件の充足性の判定対象のセグメントの表示位置と、その直前の行にある各セグメントの位置とを比較する。この結果、判定対象のセグメントと、直前行にあるいずれかのセグメントとが隣接し、このセグメントに対して「字下げ」又は「左揃え」が行なわれていると判定されたとする。この場合には、配色についての制御符号を用いて、判定対象のセグメントの文字色と、隣接し、かつ「字下げ」又は「左揃え」が行なわれていると判定された直前行のセグメントの文字色とを比較する。この比較により、文字色が同色と判定された場合には、連続セグメント条件のすべてを充足することになる。なお、直前行のセグメントと隣接していなかったり、直前行のセグメントよりも左に位置していたり、異なる色で表示されていたりするような場合には、連続セグメント条件のすべての要素を充足しないので(ステップS3−1において「NO」)、このセグメントについての処理を終了し、次のセグメントについて処理を行なう。
Specifically, the display selection caption
一方、連続セグメント条件を充足する場合(ステップS3−1において「YES」の場合)には、このセグメントを先行セグメントの直後に配置するように、このセグメントのテキストデータの移動を行なう(ステップS3−2)。これにより、このセグメントについての処理を終了し、次のセグメントについて処理を行なう。そして、画面に含まれるセグメントのすべてについて処理を行なうと、並び替え処理が完了する(ステップS1−4)。 On the other hand, when the continuous segment condition is satisfied (in the case of “YES” in step S3-1), the text data of this segment is moved so that this segment is arranged immediately after the preceding segment (step S3- 2). As a result, the process for this segment is completed, and the process for the next segment is performed. Then, when the process is performed for all the segments included in the screen, the rearrangement process is completed (step S1-4).
並び替え処理が完了すると、表示選択字幕データ処理部705は、オペレータ端末に並び替え検知を通知する(ステップS1−5)。これにより、オペレータ端末で並び替え処理(ステップS1−4)が行なわれて生成された字幕メタデータをオペレータが確認する。そして、オペレータ端末では、必要に応じて手動修正を行なう(ステップS1−6)。ここで、オペレータは、一連の文字群でないにも係わらず連続セグメント条件を充足した場合には、それらが一連の文字群として並び替えが行なわれることになる。具体的には、1つの画面において各話者が2度以上発言し、それらが連続セグメント条件を充足する表示となっている場合がある。このままの形態でテキストデータを生成すると、同一話者の別の発言を繋げた字幕メタデータとなる。このような場合には、オペレータ端末では、一連の文字群として移動されたセグメントのテキストデータを元の順番に戻すように手動で、テキストデータの移動が行なわれる。
When the rearrangement process is completed, the display selection subtitle
そして、上述したステップS1−1〜S1−6の処理を画面毎に繰り返し、すべての画面についての処理が完了すると、字幕データ検知処理が完了し、字幕データが生成される。 And the process of step S1-1-S1-6 mentioned above is repeated for every screen, and if the process about all the screens is completed, a caption data detection process will be completed and caption data will be produced | generated.
次に、上述した字幕データ検知処理について、具体例を示しながら説明する。図9で示すように、この表示データには3行の字幕データが含まれる。第1行目にセグメントAが含まれ、この次の第2行目に2つのセグメント(B、C)が含まれる。更に、第3行目にはセグメントDが含まれている。また、ここでは、各セグメント(A,B,C,D)を構成する文字は同じ大きさであると想定する。更に、各話者が話している一連の文字群は同じ色、すなわちセグメントAとセグメントCは同じ色、セグメントBとセグメントDは同じ色で表示されるような制御符号が含まれているものとする。 Next, the caption data detection process described above will be described with a specific example. As shown in FIG. 9, the display data includes three lines of caption data. Segment A is included in the first row, and two segments (B, C) are included in the next second row. Furthermore, segment D is included in the third row. Here, it is assumed that the characters constituting each segment (A, B, C, D) have the same size. In addition, a series of characters spoken by each speaker includes control codes that are displayed in the same color, that is, segment A and segment C are displayed in the same color, and segment B and segment D are displayed in the same color. To do.
まず、字幕データ処理において、放送字幕ルビ処理(ステップS1−1)が行なわれる。この場合、各セグメント(A,B,C,D)を構成する文字はすべて同じ大きさで構成されているため、画面内の文字のサイズがすべて同じと判定されて(ステップS2−1において「YES」)、放送字幕ルビ処理は、データの削除を行なわない。 First, in the caption data processing, broadcast caption ruby processing (step S1-1) is performed. In this case, since the characters constituting each segment (A, B, C, D) are all configured to have the same size, it is determined that the sizes of the characters in the screen are all the same (in step S2-1, “ YES ”), broadcast subtitle ruby processing does not delete data.
図9に示す字幕データでは、1つの画面に2行以上の字幕がある(ステップS1−2において「YES」)。そして、この画面には、2つ以上のセグメント(B,C)を含む行がある(S1−3において「YES」)。このため、並び替え処理を実行する(ステップS1−4)。 In the caption data shown in FIG. 9, there are two or more lines of captions on one screen (“YES” in step S1-2). This screen includes a line including two or more segments (B, C) (“YES” in S1-3). For this reason, a rearrangement process is performed (step S1-4).
ここで、まず、この画面の字幕の最初の行に含まれているセグメントAについて、表示選択字幕データ処理部705は、連続セグメント条件の充足性を判定する(ステップS3−1)。このセグメントAの直前行にはセグメントがなく、連続セグメント条件を充足しないので、次のセグメントが連続セグメント条件を充足性するか否かを判定する(ステップS3−1)。
Here, first, for the segment A included in the first line of the caption on this screen, the display selection caption
ここで、次のセグメントは、セグメントAの次の行に含まれる最初のセグメントのセグメントBである。そこで、表示選択字幕データ処理部705は、セグメントBについて、
連続セグメント条件の充足性を判定する(ステップS3−1)。この場合、図9に示すように、セグメントBについては直前行に隣接する文字がないため、「直前行の文字と隣接」の条件に該当せず、連続セグメント条件を充足しない。従って、表示選択字幕データ処理部705は、ステップS3−1において「NO」と判定して、次のセグメントCについて、連続セグメント条件の充足性を判定する(ステップS3−1)。
Here, the next segment is the segment B of the first segment included in the next row of the segment A. Therefore, the display selection subtitle
Satisfaction of the continuous segment condition is determined (step S3-1). In this case, as shown in FIG. 9, since there is no character adjacent to the previous line for segment B, the condition “adjacent to the character on the previous line” is not met, and the continuous segment condition is not satisfied. Therefore, the display selection subtitle
ここで、セグメントCは、直前行のセグメントAと隣接しており、このセグメントAに対して字下げが行なわれており、セグメントAと同じ色で表示されている。このため、表示選択字幕データ処理部705は、連続セグメント条件を充足するとして(ステップS3−1において「YES」)、先行するセグメントAの直後にセグメントCが配置されるように、セグメントCのテキストデータの移動を行なう(ステップS3−2)。この結果、セグメントCは、セグメントBの後に続かずに、セグメントAの後に続くようになる。
Here, the segment C is adjacent to the segment A in the immediately preceding row, and the segment A is indented and displayed in the same color as the segment A. Therefore, the display selection subtitle
そして、表示選択字幕データ処理部705は、次のセグメント、すなわちセグメントB,Cを含む行の直後の行のセグメントDについて連続セグメント条件の充足性を判定する(ステップS3−1)。ここで、セグメントDは、直前行のセグメントBと隣接しており、このセグメントBに対して字下げが行なわれており、セグメントBと同じ色で表示されている。このため、表示選択字幕データ処理部705は、連続セグメント条件を充足するとして(ステップS3−1において「YES」)、先行するセグメントBの直後にセグメントDのテキストが配置されるように、テキストデータの移動を行なう(ステップS3−2)。この場合、セグメントAの後ろになるようにセグメントCが既に移動しているため、セグメントBの後ろにセグメントDが続く状態となっている。従って、表示選択字幕データ処理部705は、テキストデータの移動が行なわれていることを確認して処理を終了する。
Then, the display selection subtitle
以上により、最後のセグメントDについての処理を終了すると、図9に示す画面表示を行なう字幕放送信号に含まれる字幕データから構成される画面についての並び替え処理(ステップS1−4)が終了する。そして、これにより、字幕データ中で分離されていた言葉が一連の文字群となったテキストデータ(字幕メタデータ)が生成できる。そして、表示選択字幕データ処理部705は、オペレータ端末に並び替え位置の検知を通知し(ステップS1−5)、必要に応じて手動で修正する(ステップS1−6)。以上により、表示選択字幕データ処理部705における字幕データ検知処理が完了する。そして、表示選択字幕データ処理部705は、この字幕データ検知処理により生成した字幕メタデータをタイムコード付加処理部707に供給する。
As described above, when the process for the last segment D is finished, the rearrangement process (step S1-4) for the screen composed of the caption data included in the caption broadcast signal for screen display shown in FIG. 9 is finished. Thereby, text data (caption metadata) in which words separated in the caption data become a series of character groups can be generated. Then, the display selection subtitle
図5に示すように、タイムコード付加処理部707は、表示選択字幕データ処理部705において生成された字幕メタデータの登録指示を受けると、タイマ706を用いて、登録指示を受けた時刻をタイムコードとして付加する。例えば、表示選択字幕に対応するテキストの場合には、表示選択字幕の開始時刻に対応するタイムコードが付加される。放送信号取得部701が、放送に対してリアルタイムで放送信号を取得した場合、タイムコード付加処理部707はタイマ706が示す現在時刻に基づいて、タイムコードをテキストデータに付加するものとする。また、番組放送時刻に対してタイムコード付加時刻に遅れがある場合には、タイムコード付加処理部707は、この遅延時間とタイマ706が示す現在時刻とに基づいて、番組の放送時刻に対応するタイムコードを算出し、テキストデータに付加する。
As shown in FIG. 5, when receiving a registration instruction for subtitle metadata generated by the display selection subtitle
メタデータ生成部708は、タイムコード付加処理部707から供給されたタイムコードが付加されたテキストデータに、番組ID情報抽出部703から供給された番組ID情報を付加してメタデータを生成する。このメタデータは、図2に示すように、テキストデータに対して、テキスト群の開始時刻が記載されたタイムコードが付加される。そして、
番組ID情報抽出部703から供給された番組ID情報が付加されたメタデータは、暗号化処理部709に供給される。
The
The metadata to which the program ID information supplied from the program ID
暗号化処理部709は、番組ID毎に暗号化鍵を記憶している鍵データ記憶部72に接続されている。暗号化処理部709は、メタデータ生成部708から供給されたメタデータに含まれる番組IDに基づいて、鍵データ記憶部72から暗号化鍵を抽出し、この暗号化鍵を用いてメタデータの暗号化を行ない、暗号化メタデータ記憶部73に記録する。暗号化メタデータ記憶部73は、検索を行なった文字に基づいて映像情報ファイルを記録する。この暗号化メタデータは、ユーザからの要求に応じて、番組毎に、送信手段としての通信部710からインターネットIを介してホームサーバ50に提供される。
The
本実施形態によれば、以下のような効果を得ることができる。
○ 本実施形態では、表示選択字幕データ処理部705は、1つの画面に2行以上の字幕があり、かつ2つ以上のセグメントを含む行がある場合(ステップS1−3において「YES」の場合)には、並び替え処理を行なう(ステップS1−4)。この処理において、直前行のセグメントと隣接し、「字下げ」又は「左揃え」が行なわれており、かつ、同色で表示されている場合には、連続セグメントの条件を充足すると判定する(ステップS3−1において「YES」)。そして、表示選択字幕データ処理部705は、このセグメントを先行セグメントの直後に配置するように、セグメントに対応するテキストデータの移動を行なう(ステップS3−2)。そして、すべてのセグメントについて並び替え処理(ステップS1−4)を画面毎に行なうことにより、字幕放送信号に含まれる字幕データ中で分離された文字群が一連の文字群となったテキストデータ(字幕メタデータ)が生成できる。通常、表示の関係により、複数行に亘って一連の文字群が表示される場合には、それらの位置が隣接している。このため、各行内の位置から、隣接するセグメント同士であるか否かを判定し、隣接すると判定した場合には、一連の文字群であるとしてセグメント同士が隣り合うように、自動的に並び替えることができる。更に、このように生成したテキストデータから字幕メタデータを生成するので、一連の文字群が複数行に亘って表示される場合であっても、一連の文字群を一行としてより正確に取得し、より的確なテキストデータを生成することができる。
According to this embodiment, the following effects can be obtained.
○ In the present embodiment, the display selection subtitle
○ 本実施形態では、並び替え処理(ステップS1−4)の前に、放送字幕ルビ処理(ステップS1−1)を行なう。この放送字幕ルビ処理において、表示選択字幕データ処理部705は、画面内の文字のサイズがすべて同じでなかった場合(ステップS2−1において「NO」の場合)には、セグメント毎に、セグメントがルビ特定の条件に一致しているか否かを判定する(ステップS2−2)。そして、これらルビ特定の条件のすべてと一致する場合(ステップS2−2において「YES」の場合)には、表示選択字幕データ処理部705は、次行のルビであると判定して、このセグメントを削除する(ステップS2−3)。そして、セグメントを削除した行に、他のセグメントが残っている場合には、表示選択字幕データ処理部705は、同じ行の他のセグメントについて上記ステップS2−2以降の処理を行ない、セグメントが残っていない場合(ステップS2−4において「NO」の場合)には、その行の削除を行なう(ステップS2−5)。このようにルビ条件に一致するセグメントを削除することにより、テキストデータとしては重複して不要なルビを除去することができるので、必要なテキストデータのみを抽出してテキストデータを生成することができる。
In the present embodiment, broadcast subtitle ruby processing (step S1-1) is performed before the rearrangement processing (step S1-4). In this broadcast subtitle ruby process, the display selection subtitle
○ 本実施形態では、(1)異なる文字の文字サイズが小型サイズであり、(2)セグメントが「ひらがな」、「カタカナ」又は「空白」のみで構成されており、(3)標準サイズ文字に同じ行で隣接しておらず、かつ、(4)次の行において標準サイズ文字と隣接している場合には、ルビであると特定する。このため、これら4つのルビ特定条件を用いることにより、他のセグメントの文字サイズや位置から、ルビのセグメントであるか否か
を自動的に判定することができる。
○ In this embodiment, (1) the character size of different characters is a small size, (2) the segment is composed only of “Hiragana”, “Katakana” or “blank”, and (3) If it is not adjacent in the same line and (4) is adjacent to a standard size character in the next line, it is specified as ruby. Therefore, by using these four ruby specifying conditions, it is possible to automatically determine whether or not the segment is a ruby segment from the character size and position of the other segment.
○ 本実施形態の放送字幕ルビ処理では、表示選択字幕データ処理部705は、画面内の文字のサイズがすべて同じであった場合(ステップS2−1において「NO」の場合)には、ルビ特定条件を一致するか否かの判定(ステップS2−2)は行なわない。従って、ルビの存在がある画面についてのみ放送字幕ルビ処理(ステップS1−1)を行なうので、効率よく、より的確なテキストデータを生成することができる。
○ In the broadcast subtitle ruby process of the present embodiment, the display selection subtitle
○ 本実施形態では、表示選択字幕データ処理部705は、ルビを削除しても2行以上の字幕があり、かつ2つ以上のセグメントを含む行がある場合には、並び替え処理(ステップS1−4)を行ない、オペレータ端末に並び替え検知を通知する(ステップS1−5)。並び替え処理(ステップS1−4)の実行により、ルビを削除してもこの場合に、一連の文字群でないにも係わらず連続セグメント条件を充足し、一連の文字群としてテキストデータの移動が行なわれる(ステップS3−2)可能性がある。従って、並び替え処理(ステップS1−4)を行なった画面をオペレータ端末に通知し修正を行なうことができるので、より的確なテキストデータを生成することができる。また、ルビを削除すると字幕が1行となる場合には並び替え処理が行なわれないので、この場合にはオペレータ端末に通知されない。よって、間違いの可能性のある画面についてのみ、オペレータが確認するだけで、より正確な字幕メタデータを生成することができる。
In the present embodiment, the display selection subtitle
また、上記実施形態は、以下のように変更してもよい。
・ 上記実施形態では、ルビ判定条件として、(1)異なる文字の文字サイズが小型サイズであり、(2)セグメントが「ひらがな」、「カタカナ」又は「空白」のみで構成されており、(3)標準サイズ文字に同じ行で隣接しておらず、かつ、(4)次の行において標準サイズ文字と隣接しているという4つの条件を用いた。これに限らず、ルビ判定条件として、他の判定条件を用いてもよい。例えば、同じ画面において、「ひらがな」、「カタカナ」又は「空白」のみで構成されるセグメントの直下の位置に同じ読み方ができる漢字や外国文字がある場合には、ルビと判定してもよい。
Moreover, you may change the said embodiment as follows.
In the above embodiment, as the ruby determination condition, (1) the character size of different characters is a small size, (2) the segment is composed only of “Hiragana”, “Katakana”, or “blank”, and (3 Four conditions were used: a) not adjacent to a standard size character on the same line, and (4) adjacent to a standard size character on the next line. Not limited to this, other determination conditions may be used as ruby determination conditions. For example, if there is a kanji or foreign character that can be read in the same screen at a position immediately below a segment composed of only “Hiragana”, “Katakana”, or “Blank”, it may be determined as ruby.
・ 上記実施形態では、連続セグメントの条件として、「直前行のセグメントと隣接」し、「字下げ」又は「左揃え」が行なわれており、かつ「同色で表示されている」という3つの条件を用いた。これに限らず、他の条件でセグメントが連続しているか否かを判定してもよい。例えば、直前行のセグメントと隣接しかつ同色である場合、又は直前行のセグメントに対して「字下げ」又は「左揃え」が行なわれておりかつ同色である場合などをセグメントが連続していると判定してもよい。 In the above embodiment, as the condition for the continuous segment, three conditions are “adjacent to the segment in the previous line”, “indentation” or “left alignment”, and “displayed in the same color”. Was used. However, the present invention is not limited to this, and it may be determined whether or not segments are continuous under other conditions. For example, the segment is continuous if it is adjacent to the segment in the previous line and is the same color, or if the segment in the previous line is “indented” or “left-justified” and is the same color May be determined.
・ 上記実施形態では、並び替え処理(ステップS1−4)において、連続セグメントの条件を充足するか否かを判定する判定対象セグメントは、直前行のセグメントとの関係で条件を充足するか否かを判定した(ステップS3−1)。これに代えて、判定対象セグメントを、直後の行のセグメントの関係で条件を充足するか否かを判定してもよい。この場合には、連続セグメントの条件として、例えば、直後の行のセグメントと隣接するか否か、直後の行のセグメントが判定対象セグメントに対して「字下げ」又は「左揃え」を行なっているか、同色であるかの3つの条件を用いる。 In the above embodiment, in the rearrangement process (step S1-4), whether the determination target segment for determining whether or not the continuous segment condition is satisfied satisfies the condition in relation to the segment in the immediately preceding row. Was determined (step S3-1). Instead of this, it may be determined whether or not the determination target segment satisfies the condition in relation to the segment in the immediately following row. In this case, as a condition of the continuous segment, for example, whether or not it is adjacent to the segment of the immediately following line, whether the segment of the immediately following line is “indented” or “left aligned” with respect to the determination target segment , Three conditions of the same color are used.
・ 上記実施形態では、行毎に行なう並び替え処理(ステップS1−4)において、セグメント毎に、そのセグメントが連続セグメントの条件を充足するか否かを判定した(ステップS3−1)。この代わりに、他の方法によって、並び替えを行なうようにしてもよい。具体的には、表示選択字幕データ処理部705を、複数行判定処理を行なう手段、特定手段、グループ判定処理を行なう手段、グループ化する手段、並び替える手段及び生成手段として機能させる。例えば、連続条件を満たすセグメントに対して、一連の文字群で
あると認識できるグループ番号と、そのグループにおける順番(何番目のセグメントであるか)を一時的に記録する。そして、1画面における全セグメントに対して、グループ番号及び順番を付した場合には、そのグループ番号毎及びそのグループ内の順番に各セグメントを並び替える。更に、各グループの最初のセグメントの表示位置に応じて、画面におけるグループの順番でテキストデータを生成する。この場合であっても、各セグメントの表示位置から、複数行に亘って一連の文字群が隣接するセグメント同士であるか否かを判定して、より正確に、一連の文字群を取得することができる。従って、より的確なテキストデータを効率よく生成することができる。
In the above-described embodiment, in the rearrangement process (step S1-4) performed for each row, it is determined for each segment whether or not the segment satisfies the continuous segment condition (step S3-1). Instead, rearrangement may be performed by other methods. Specifically, the display selection subtitle
・ 上記実施形態では、2行以上の字幕があり、かつ2つ以上のセグメントを含む行がある場合(ステップS1−3において「YES」の場合)、オペレータ端末に並び替え位置の検知を通知した(ステップS1−5)。これに代えて、ステップS1−3の並び替え処理において、実際に連続セグメントを先行セグメントの直後に配置するようにテキストデータの移動を行なった場合(ステップS3−2)にのみ、オペレータ端末に並び替えの検知を通知してもよい。具体的には、ステップS3−2を実行した場合には、並び替えを行なったことを示す通知フラグを記録する。そして、画面に含まれるすべてのセグメントについて並び替え処理(ステップS1−4)を完了した場合には、表示選択字幕データ処理部705は、通知フラグが記録されているかを判定し、記録されている場合にのみオペレータ端末に並び替え位置の検知を通知する(ステップS1−5)。これにより、2行以上の字幕が含まれる画面においても並び替え処理(ステップS1−4)が行なわれなかった場合には、オペレータ端末への通知を省略でき、オペレータの負荷を軽減することができる。
In the above embodiment, when there are two or more subtitles and there is a line including two or more segments (in the case of “YES” in step S1-3), the operator terminal is notified of the detection of the rearrangement position. (Step S1-5). Instead, in the sorting process in step S1-3, the text data is moved so that the continuous segment is actually arranged immediately after the preceding segment (step S3-2). You may notify the detection of replacement. Specifically, when step S3-2 is executed, a notification flag indicating that rearrangement has been performed is recorded. When the rearrangement process (step S1-4) is completed for all segments included in the screen, the display selection subtitle
・ 上記実施形態では、メタデータ作成サーバ70の表示選択字幕データ処理部705が放送字幕ルビ処理や並び替え処理を行なった。これら処理を実行するハードウエアはこれに限定されるものではなく、放送受信者側、例えばホームサーバ50に、外字処理を行なう解析処理部を設けてもよい。
In the above embodiment, the display selection caption
・ 上記実施形態では、メタデータに基づいて画像を特定するポインタ情報としてタイムコードを用いたが、これに限られるものはではなく、画面毎に割り振られたフレームデータを用いることも可能である。この場合、字幕データ処理装置はフレームカウンタを備え、メタデータを記録する場合には、ポインタ情報としてフレームデータを用いる。そして、ダイジェストを作成したり、録画を再生したりする場合には、このフレームデータを用いて、画像や再生開始位置を特定することができる。この場合には、タイムコードにおける時刻のずれの影響をなくすことができる。 In the above embodiment, the time code is used as the pointer information for specifying the image based on the metadata. However, the time code is not limited to this, and it is also possible to use the frame data allocated for each screen. In this case, the caption data processing apparatus includes a frame counter, and uses frame data as pointer information when recording metadata. Then, when creating a digest or playing back a recording, this frame data can be used to specify an image and a playback start position. In this case, the influence of the time shift in the time code can be eliminated.
・ 上記実施形態では、表示選択字幕データ処理部705は、並び替え処理により生成したテキストデータを含む字幕メタデータを提供したが、テキスト変換した検索用ファイルやテキスト変換した表示ファイルを、利用者の要求に応じて組み合わせて提供してもよい。
In the above embodiment, the display selection subtitle
A,B,C,D…セグメント、10…放送局、30…録画装置、40…表示字幕デコーダ、50…ホームサーバ、70…字幕データ処理装置としてのメタデータ作成サーバ、705…複数行判定処理を行なう手段、特定手段、接続判定処理を行なう手段、配置変更手段、生成手段、文字サイズ判定手段及び削除手段としての表示選択字幕データ処理部。 A, B, C, D ... segment, 10 ... broadcasting station, 30 ... recording device, 40 ... display subtitle decoder, 50 ... home server, 70 ... metadata creation server as subtitle data processing device, 705 ... multiple line determination processing A display selection subtitle data processing unit as a means for performing, a specifying means, a means for performing connection determination processing, an arrangement changing means, a generation means, a character size determination means and a deletion means
Claims (11)
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう段階と、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更段階と、
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを特徴とする字幕データ処理方法。 A caption data processing method for processing caption data extracted from a video signal,
Obtaining a number of lines of subtitle data included in one screen and performing a multiple line determination process for determining whether or not there are two or more lines;
When the caption data has two or more lines, a specific stage for identifying the position of each segment included in each line of the caption data in each line based on a segment determination condition;
Performing connection determination processing for determining whether or not a connection determination condition is determined to be a connection relationship with respect to a segment in another row from which the segment is different from the identified position;
An arrangement change stage in which the segments determined to be connected in the connection determination process are rearranged to be adjacent to each other;
A subtitle data processing method, comprising: generating a subtitle text data in accordance with the rearranged segment order.
第1のセグメントが、これを含む行の直前の行に含まれる第2のセグメントに対して隣接されており、
前記第1のセグメントの開始位置が前記第2のセグメントの開始位置に対して字下げされているか又は同じであり、かつ
前記第1のセグメントの配色が、前記第2のセグメントの配色と同じであることであり、
前記配置変更段階は、前記第1及び前記第2のセグメントの位置に基づいて、前記接続判定条件が満たされた場合には、前記第1のセグメントの次に前記第2のセグメントが配置するように並び替えることを特徴とする請求項1〜3のいずれか1項に記載の字幕データ処理方法。 The connection determination condition is:
The first segment is adjacent to the second segment contained in the row immediately preceding the containing row;
The start position of the first segment is indented or the same as the start position of the second segment, and the color scheme of the first segment is the same as the color scheme of the second segment There is,
In the arrangement changing step, the second segment is arranged after the first segment when the connection determination condition is satisfied based on the positions of the first and second segments. The subtitle data processing method according to any one of claims 1 to 3, wherein the subtitle data is rearranged into the subtitle data.
前記一画面に異なる文字サイズの字幕データの有無を判定する文字サイズ判定段階と、
異なる文字サイズの字幕データがあった場合には、小さい文字サイズの文字を含むセグメント毎にルビ条件を判定し、前記ルビ条件に一致するセグメントを削除する削除段階とを更に実行することを特徴とする請求項1〜4のいずれか1項に記載の字幕データ処理方法。 Before the multi-line determination process,
A character size determination step for determining the presence or absence of subtitle data having a different character size on the one screen;
When there is subtitle data having a different character size, a ruby condition is determined for each segment including a character having a small character size, and a deletion step of deleting a segment that matches the ruby condition is further performed. The subtitle data processing method according to any one of claims 1 to 4.
セグメントの文字列が、ひらがな、カタカナ又は空白から構成され、
同じ行において隣接する文字のサイズが異ならず、
次行において、より大きなサイズの文字に隣接していることを条件として用いることを特徴とする請求項5に記載の字幕データ処理方法。 As the ruby condition,
The segment string consists of hiragana, katakana, or white space,
The size of adjacent characters on the same line is not different,
6. The caption data processing method according to claim 5, wherein the next line is used on condition that the character is adjacent to a character of a larger size.
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう段階と、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕デ
ータの各行に含まれる個々のセグメントの各行内での位置を特定する特定段階と、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう段階と、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する段階と、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える段階と、
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成段階とを実行することを特徴とする字幕データ処理方法。 A caption data processing method for processing caption data extracted from a video signal,
Obtaining a number of lines of subtitle data included in one screen and performing a multiple line determination process for determining whether or not there are two or more lines;
When the caption data has two or more lines, a specific stage for identifying the position of each segment included in each line of the caption data in each line based on a segment determination condition;
Performing a group determination process for determining whether or not a group relation condition is satisfied based on the identified position;
A step of grouping the segments by assigning an order to the segments determined to be in a group relationship in the group determination process;
Rearranging the individual segments in this group in the order described above;
A subtitle data processing method, comprising: generating a subtitle text data in accordance with the rearranged segment order.
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
として機能させることを特徴とする字幕データ処理プログラム。 A caption data processing program for processing caption data extracted from a video signal,
Means for obtaining a number of lines of subtitle data included in one screen and performing a multi-line determination process for determining whether or not there are two or more lines;
When the subtitle data has two or more lines, based on a segment determination condition, specifying means for specifying the position of each segment included in each line of the subtitle data in each line;
Means for performing connection determination processing for determining whether or not a connection determination condition for determining that the segment is connected to a segment in another row from which the segment is different is satisfied.
It is made to function as an arrangement changing means for rearranging the segments determined to be in a connection relationship in the connection determination processing so as to be adjacent to each other, and a generating means for generating subtitle text data according to the order of the rearranged segments. A subtitle data processing program characterized by the above.
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
として機能させることを特徴とする字幕データ処理プログラム。 A caption data processing program for processing caption data extracted from a video signal,
Means for obtaining a number of lines of subtitle data included in one screen and performing a multi-line determination process for determining whether or not there are two or more lines;
When the subtitle data has two or more lines, based on a segment determination condition, specifying means for specifying the position of each segment included in each line of the subtitle data in each line;
Means for performing group determination processing for determining whether or not a group relation condition is satisfied based on the specified position;
Means for grouping the segments by assigning an order to the segments determined to be in a group relationship in the group determination processing;
A subtitle data processing program that functions as means for rearranging the individual segments in the group so as to be arranged in the order, and generating means for generating subtitle text data in accordance with the order of the rearranged segments. .
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕データの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置から前記セグメントが異なる他の行のセグメントに対して接続関係であると判定される接続判定条件を満たすか否かを判定する接続判定処理を行なう手段、
この接続判定処理において接続関係にあると判定された前記セグメント同士が隣り合うように並び替える配置変更手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
を備えたことを特徴とする字幕データ処理装置。 A caption data processing device for processing caption data extracted from a video signal,
Means for obtaining a number of lines of subtitle data included in one screen and performing a multi-line determination process for determining whether or not there are two or more lines;
When the subtitle data has two or more lines, based on a segment determination condition, specifying means for specifying the position of each segment included in each line of the subtitle data in each line;
Means for performing connection determination processing for determining whether or not a connection determination condition for determining that the segment is connected to a segment in another row from which the segment is different is satisfied.
Arrangement changing means for rearranging the segments determined to be in the connection relation in the connection determination processing so as to be adjacent to each other, and generation means for generating subtitle text data according to the order of the rearranged segments A closed caption data processing apparatus.
一画面に含まれる字幕データの行数を取得し、2行以上の有無を判定する複数行判定処理を行なう手段、
前記字幕データが2行以上ある場合には、セグメント判定条件に基づいて、前記字幕デ
ータの各行に含まれる個々のセグメントの各行内での位置を特定する特定手段、
特定された前記位置に基づきグループ関係条件を満たすか否かを判定するグループ判定処理を行なう手段、
このグループ判定処理においてグループ関係にあると判定された前記セグメントに対して順番を付して前記セグメントをグループ化する手段、
このグループ内の個々のセグメントを前記順番で並ぶように並び替える手段、及び
前記並び替えたセグメントの順番に応じて字幕のテキストデータを生成する生成手段
を備えたことを特徴とする字幕データ処理装置。 A caption data processing device for processing caption data extracted from a video signal,
Means for obtaining a number of lines of subtitle data included in one screen and performing a multi-line determination process for determining whether or not there are two or more lines;
When the subtitle data has two or more lines, based on a segment determination condition, specifying means for specifying the position of each segment included in each line of the subtitle data in each line;
Means for performing group determination processing for determining whether or not a group relation condition is satisfied based on the specified position;
Means for grouping the segments by assigning an order to the segments determined to be in a group relationship in the group determination processing;
Subtitle data processing apparatus comprising: means for rearranging individual segments in this group so as to be arranged in the order; and generation means for generating subtitle text data in accordance with the order of the rearranged segments .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006081438A JP4353198B2 (en) | 2006-03-23 | 2006-03-23 | Subtitle data processing method, subtitle data processing program, and subtitle data processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006081438A JP4353198B2 (en) | 2006-03-23 | 2006-03-23 | Subtitle data processing method, subtitle data processing program, and subtitle data processing apparatus |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007259121A true JP2007259121A (en) | 2007-10-04 |
| JP4353198B2 JP4353198B2 (en) | 2009-10-28 |
Family
ID=38632896
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006081438A Expired - Fee Related JP4353198B2 (en) | 2006-03-23 | 2006-03-23 | Subtitle data processing method, subtitle data processing program, and subtitle data processing apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4353198B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010199711A (en) * | 2009-02-23 | 2010-09-09 | Sony Corp | Apparatus and method for processing content |
| JP5140687B2 (en) * | 2008-02-14 | 2013-02-06 | パナソニック株式会社 | REPRODUCTION DEVICE, INTEGRATED CIRCUIT, REPRODUCTION METHOD, PROGRAM, COMPUTER-READABLE RECORDING MEDIUM |
-
2006
- 2006-03-23 JP JP2006081438A patent/JP4353198B2/en not_active Expired - Fee Related
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5140687B2 (en) * | 2008-02-14 | 2013-02-06 | パナソニック株式会社 | REPRODUCTION DEVICE, INTEGRATED CIRCUIT, REPRODUCTION METHOD, PROGRAM, COMPUTER-READABLE RECORDING MEDIUM |
| CN101904169B (en) * | 2008-02-14 | 2013-03-20 | 松下电器产业株式会社 | Reproduction device, integrated circuit, reproduction method |
| US8428437B2 (en) | 2008-02-14 | 2013-04-23 | Panasonic Corporation | Reproduction device, integrated circuit, reproduction method, program, and computer-readable recording medium |
| JP2010199711A (en) * | 2009-02-23 | 2010-09-09 | Sony Corp | Apparatus and method for processing content |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4353198B2 (en) | 2009-10-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10991394B2 (en) | In-band data recognition and synchronization system | |
| CN1984291B (en) | Method for performing time-shift function and television receiver using the same | |
| CN1984275B (en) | Method of displaying progress bar and television receiver using the same | |
| US9106949B2 (en) | Creating and viewing customized multimedia segments | |
| US8453169B2 (en) | Video output device and video output method | |
| KR101360316B1 (en) | System and method for closed captioning | |
| JP4458832B2 (en) | Program extracting apparatus and control method thereof | |
| JP4019085B2 (en) | Program recording apparatus, program recording method, and program recording program | |
| JP2009239729A (en) | Device, method and program for informing content scene appearance | |
| US8315384B2 (en) | Information processing apparatus, information processing method, and program | |
| JP2009033234A (en) | Unit and method for processing program information | |
| JP4353198B2 (en) | Subtitle data processing method, subtitle data processing program, and subtitle data processing apparatus | |
| JP2008098793A (en) | Receiving device | |
| JP2010147640A (en) | Broadcast receiving apparatus | |
| JP2007174246A (en) | Video information processing method, program, and apparatus | |
| JP5156527B2 (en) | Program playback device | |
| JP2007060222A (en) | Apparatus, method and program for processing video | |
| KR100776196B1 (en) | Method for displaying program list in digital broadcasting receiver | |
| JP2013098742A (en) | Content output device and content output method | |
| JP2005303741A (en) | Information processing apparatus and information processing method, program, and information processing system | |
| EP3588968A1 (en) | Method and device for launching an action related to an upcoming audio visual program | |
| JP2007251743A (en) | Method, system and program for managing broadcast information | |
| JP2008211318A (en) | Program reservation device | |
| KR20050056443A (en) | Picture detecting method using closed caption data | |
| JP2013062600A (en) | Program recorder and past program list display method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090407 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090414 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090612 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090707 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090720 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120807 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |